⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
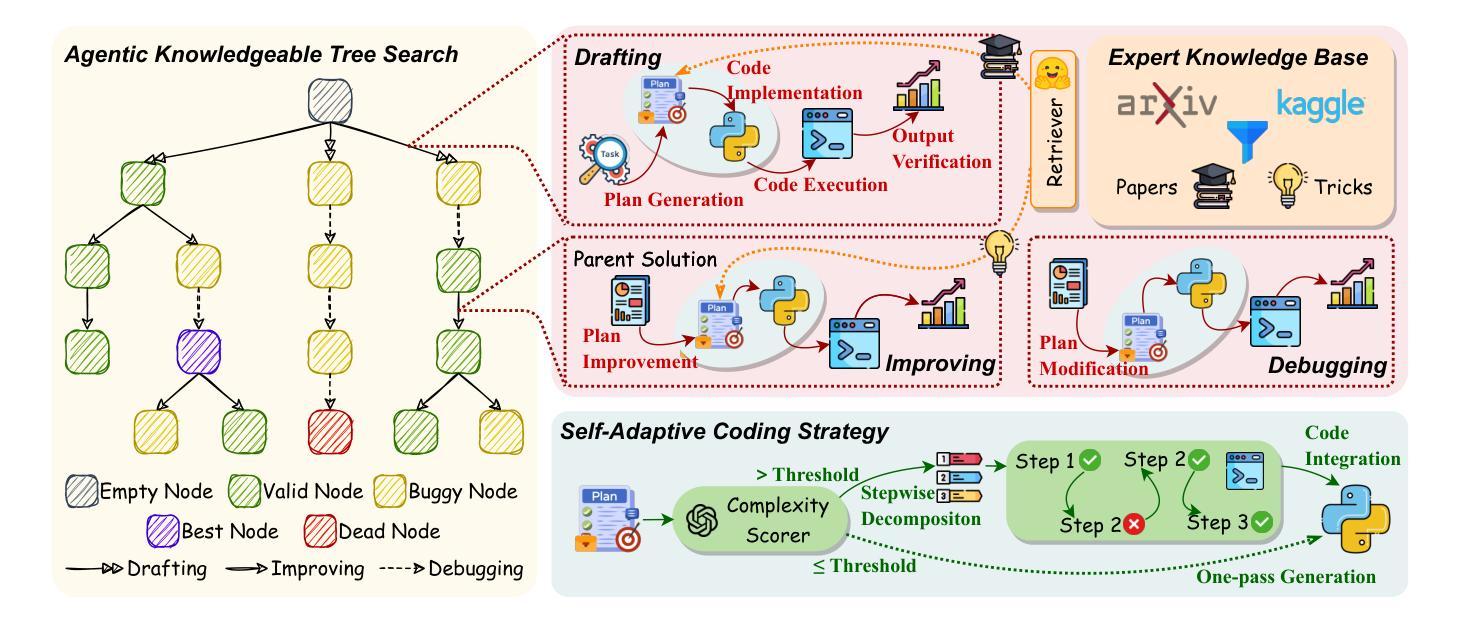
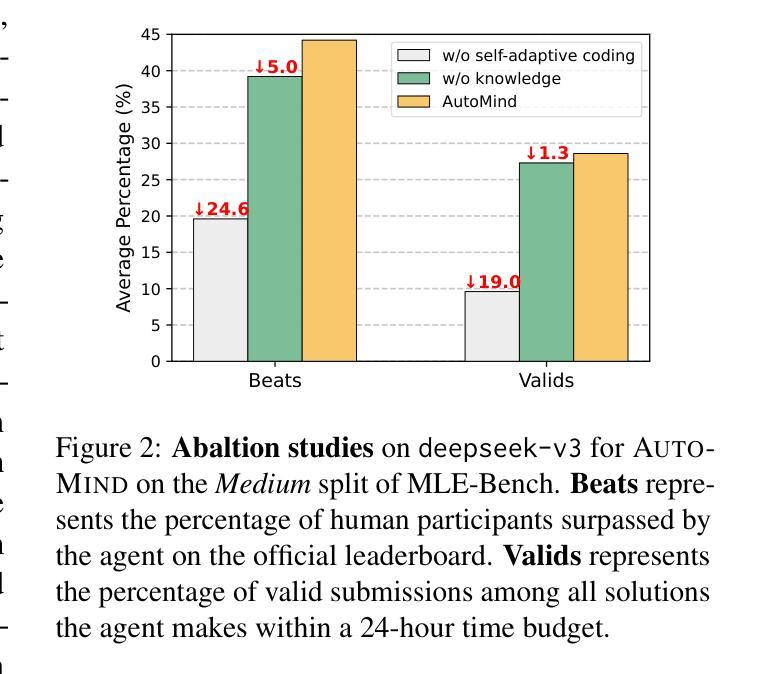
AutoMind: Adaptive Knowledgeable Agent for Automated Data Science
Authors:Yixin Ou, Yujie Luo, Jingsheng Zheng, Lanning Wei, Shuofei Qiao, Jintian Zhang, Da Zheng, Huajun Chen, Ningyu Zhang
Large Language Model (LLM) agents have shown great potential in addressing real-world data science problems. LLM-driven data science agents promise to automate the entire machine learning pipeline, yet their real-world effectiveness remains limited. Existing frameworks depend on rigid, pre-defined workflows and inflexible coding strategies; consequently, they excel only on relatively simple, classical problems and fail to capture the empirical expertise that human practitioners bring to complex, innovative tasks. In this work, we introduce AutoMind, an adaptive, knowledgeable LLM-agent framework that overcomes these deficiencies through three key advances: (1) a curated expert knowledge base that grounds the agent in domain expert knowledge, (2) an agentic knowledgeable tree search algorithm that strategically explores possible solutions, and (3) a self-adaptive coding strategy that dynamically tailors code generation to task complexity. Evaluations on two automated data science benchmarks demonstrate that AutoMind delivers superior performance versus state-of-the-art baselines. Additional analyses confirm favorable effectiveness, efficiency, and qualitative solution quality, highlighting AutoMind as an efficient and robust step toward fully automated data science.
大型语言模型(LLM)代理在解决现实世界的数据科学问题方面表现出了巨大的潜力。LLM驱动的数据科学代理虽然有望自动化整个机器学习管道,但它们在现实世界中的实际应用效果仍然有限。现有的框架依赖于僵化、预先定义的工作流程和缺乏灵活性的编码策略,因此只能在相对简单、经典的问题上表现良好,而无法捕捉人类从业者为复杂、创新任务带来的实际经验。在本研究中,我们引入了AutoMind,这是一个自适应的知识型LLM代理框架,通过三个关键进展克服了这些不足:(1)一个精选的专家知识库,为代理提供领域专业知识;(2)一种基于知识的树搜索算法,战略性地探索可能的解决方案;(3)一种自适应编码策略,根据任务复杂性动态调整代码生成。在两个自动化数据科学基准测试上的评估表明,AutoMind相较于最新技术基线具有卓越的性能。进一步的分析证实了其在有效性、效率和质量上的优越性,突出了AutoMind是朝着全自动化数据科学的稳健方向迈出的高效的一步。
论文及项目相关链接
PDF Ongoing work. Code is at https://github.com/innovatingAI/AutoMind
Summary:大型语言模型(LLM)在解决现实数据科学问题方面显示出巨大潜力,能够以自动化整个机器学习管道为承诺。然而,它们的实际有效性受限于现有框架的僵化预定义工作流程和缺乏灵活性的编码策略,只能在相对简单的问题上表现出色,而无法捕获人类实践者在复杂创新任务中的经验知识。本研究介绍了一种自适应知识型LLM代理框架AutoMind,它通过三个关键进展克服了这些缺陷:一是专业知识的知识库,使代理融入领域专业知识;二是智能知识树搜索算法,战略性地探索可能的解决方案;三是自适应编码策略,根据任务复杂性动态调整代码生成。在两项自动化数据科学基准测试中的评估表明,AutoMind相较于最新技术基线具有卓越性能。附加分析证实了其有效性、效率和解决方案质量的有利因素,凸显AutoMind作为实现全自动数据科学的稳健一步。
Key Takeaways:
- LLM在解决现实数据科学问题方面具有巨大潜力,但仍存在实际应用的局限性。
- 传统框架依赖于预定义的工作流程和缺乏灵活性的编码策略,难以处理复杂任务。
- AutoMind是一种新型的LLM代理框架,通过三个关键创新来克服这些缺陷。
- AutoMind具有专业知识的知识库、智能知识树搜索算法和自适应编码策略。
- 在自动化数据科学基准测试中,AutoMind表现出卓越性能。
- 附加分析证实了AutoMind的有效性、效率和解决方案质量。
点此查看论文截图


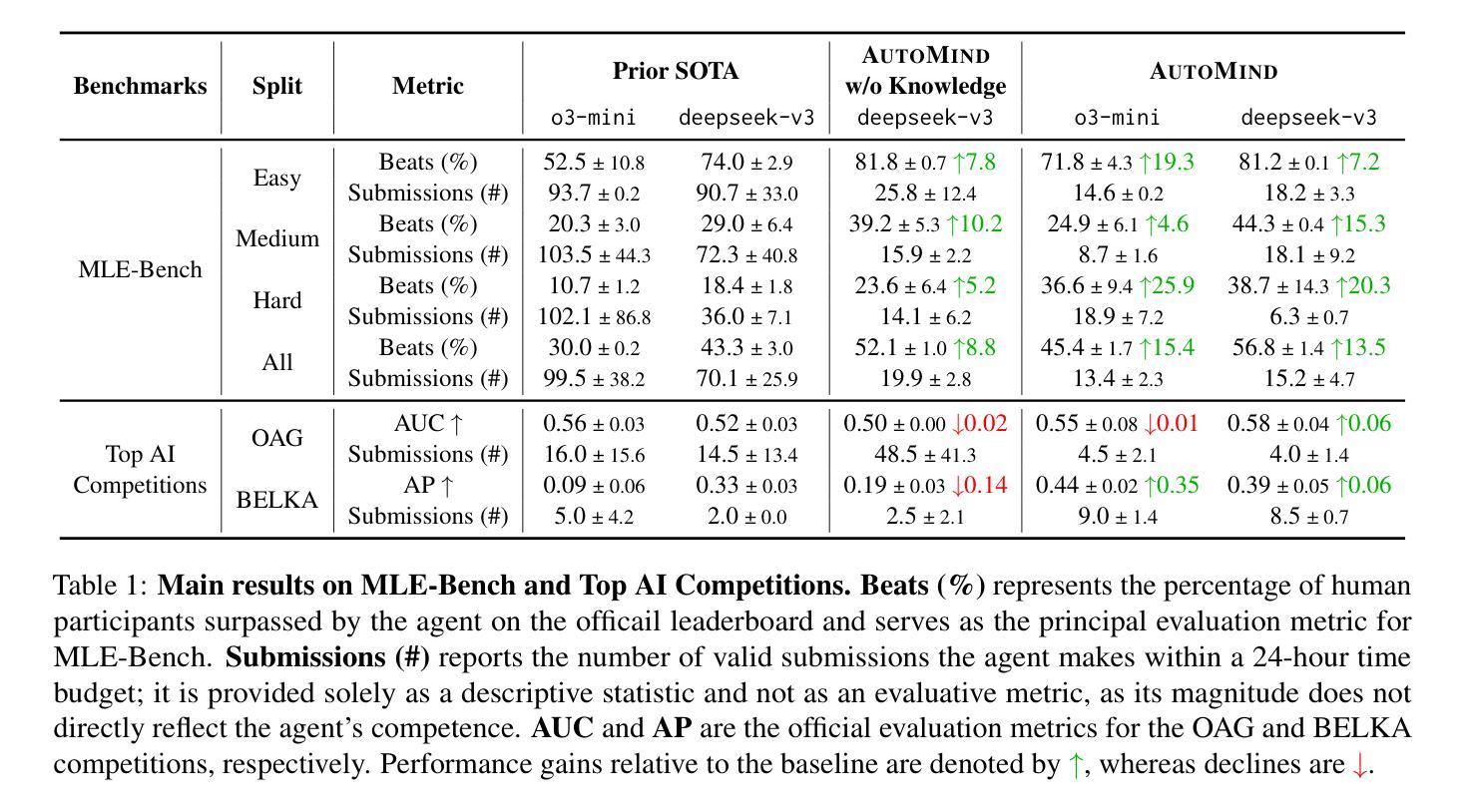
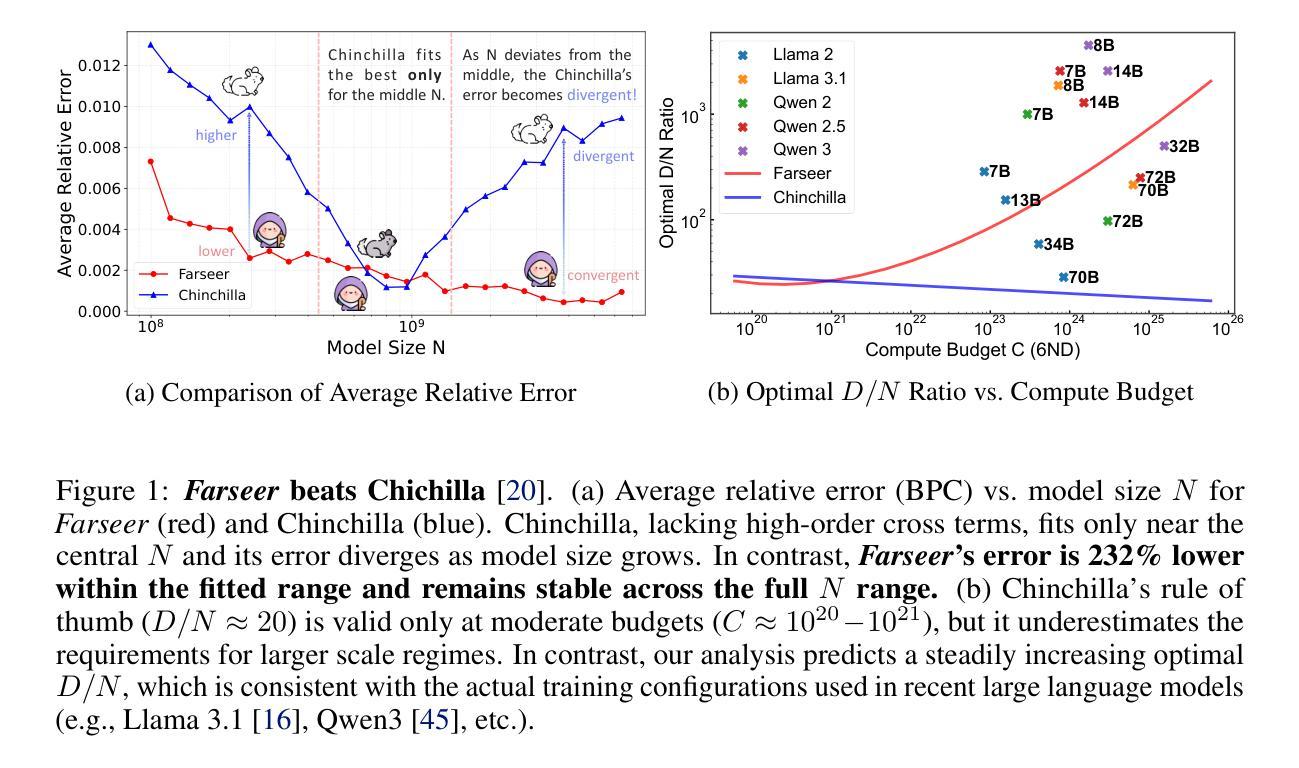
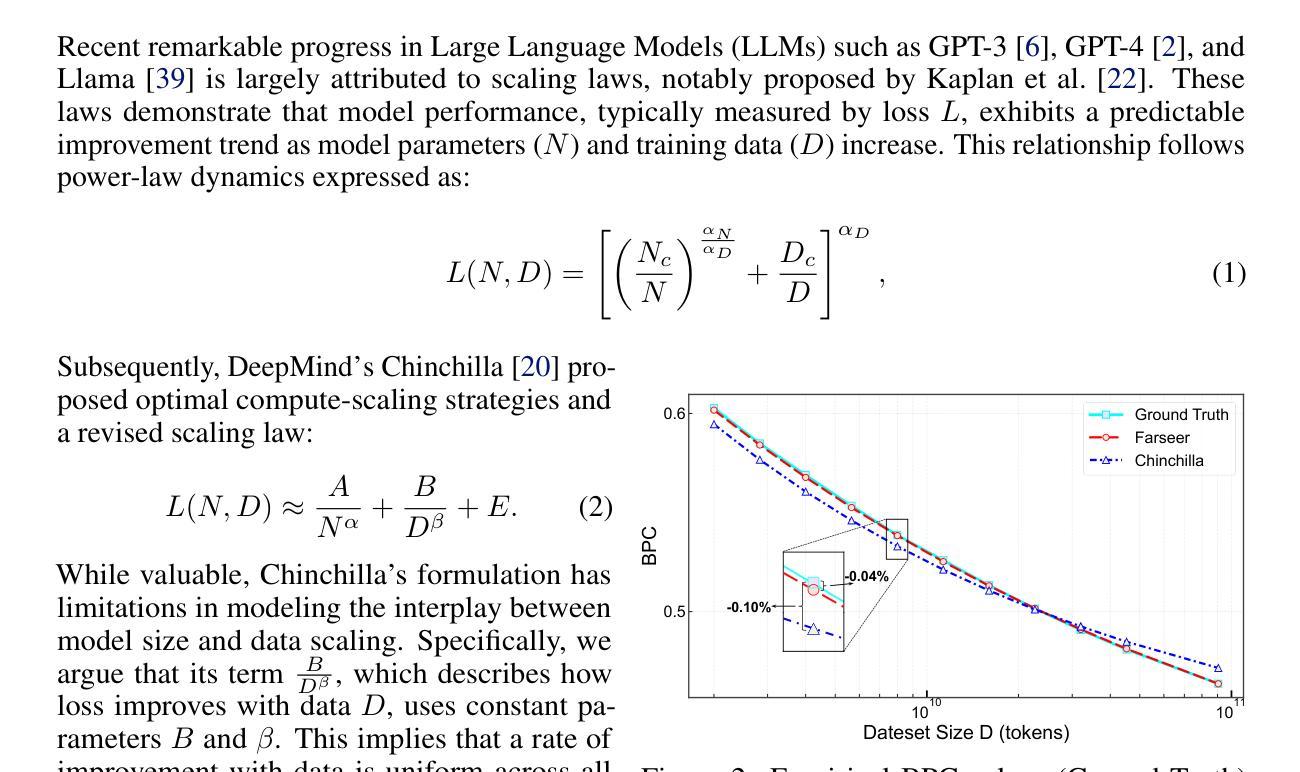
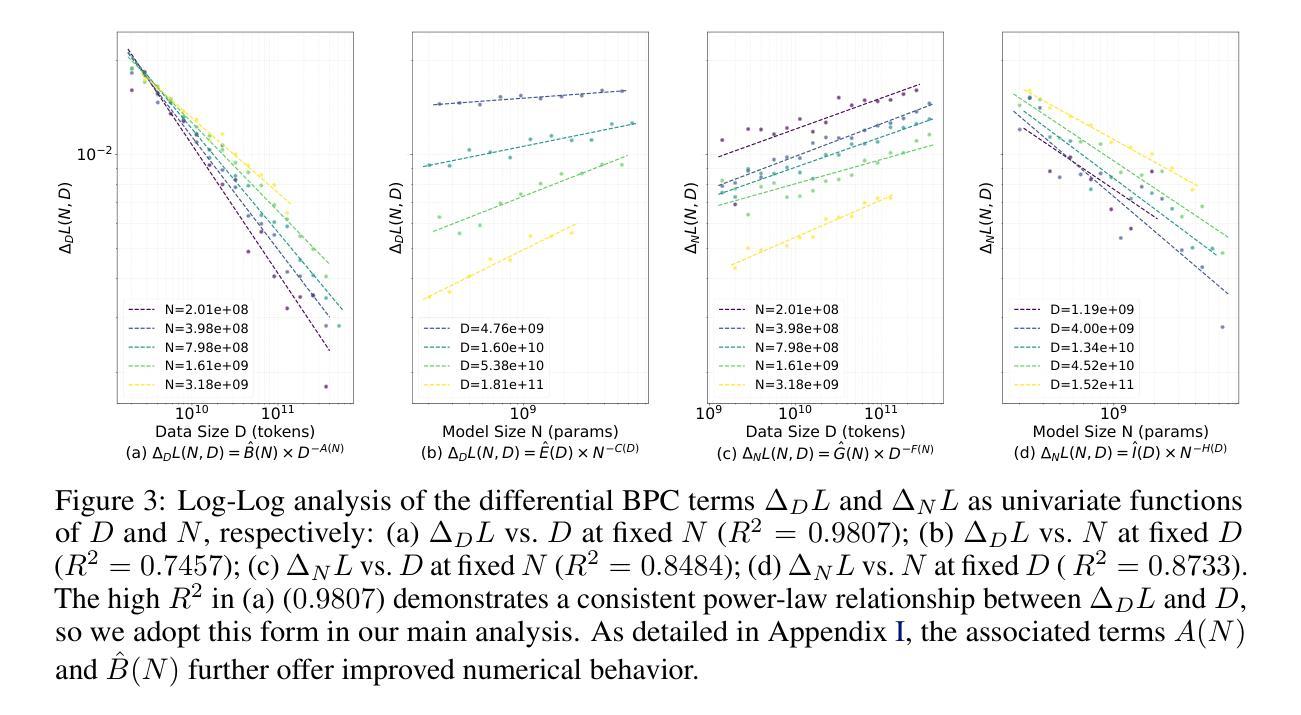
Farseer: A Refined Scaling Law in Large Language Models
Authors:Houyi Li, Wenzhen Zheng, Qiufeng Wang, Zhenyu Ding, Haoying Wang, Zili Wang, Shijie Xuyang, Ning Ding, Shuigeng Zhou, Xiangyu Zhang, Daxin Jiang
Training Large Language Models (LLMs) is prohibitively expensive, creating a critical scaling gap where insights from small-scale experiments often fail to transfer to resource-intensive production systems, thereby hindering efficient innovation. To bridge this, we introduce Farseer, a novel and refined scaling law offering enhanced predictive accuracy across scales. By systematically constructing a model loss surface $L(N,D)$, Farseer achieves a significantly better fit to empirical data than prior laws (e.g., Chinchilla’s law). Our methodology yields accurate, robust, and highly generalizable predictions, demonstrating excellent extrapolation capabilities, improving upon Chinchilla’s law by reducing extrapolation error by 433%. This allows for the reliable evaluation of competing training strategies across all $(N,D)$ settings, enabling conclusions from small-scale ablation studies to be confidently extrapolated to predict large-scale performance. Furthermore, Farseer provides new insights into optimal compute allocation, better reflecting the nuanced demands of modern LLM training. To validate our approach, we trained an extensive suite of approximately 1,000 LLMs across diverse scales and configurations, consuming roughly 3 million NVIDIA H100 GPU hours. We are comprehensively open-sourcing all models, data, results, and logs at https://github.com/Farseer-Scaling-Law/Farseer to foster further research.
训练大型语言模型(LLM)的代价极为高昂,形成了一个关键的扩展差距,小规模实验的见解往往无法转移到资源密集型的生产系统中,从而阻碍了有效的创新。为了弥合这一差距,我们引入了Farseer,一个新型且精细的扩展定律,可以在各种规模上提供增强的预测准确性。通过系统地构建模型损失曲面$L(N,D)$,Farseer比以往定律(例如Chinchilla定律)更能贴合实际数据。我们的方法产生了准确、稳健且高度通用的预测,表现出出色的外推能力,将Chinchilla定律的外推误差降低了43.3%。这使得能够在所有$(N,D)$设置下可靠地评估竞争性的训练策略,从小规模消融研究得出的结论可以自信地外推到预测大规模性能。此外,Farseer对现代LLM训练提供了最佳计算分配的新见解,更好地反映了其微妙需求。为了验证我们的方法,我们训练了大约1000个不同规模和配置的LLM模型套件,消耗了大约3百万NVIDIA H100 GPU小时。我们全面地在https://github.com/Farseer-Scaling-Law/Farseer开源所有模型、数据、结果和日志,以促进进一步研究。
论文及项目相关链接
PDF 34
Summary:针对LLM训练成本高的问题,提出新的规模定律Farseer,具有更高的预测精度和更强的泛化能力。通过构建模型损失表面,Farseer能更好地拟合实证数据,并提供了关于计算分配的新见解。通过训练大量LLM验证了Farseer的有效性,并全面开源所有模型和日志。
Key Takeaways:
- LLM训练存在成本高昂的问题,影响了创新效率。
- Farseer是一种新的规模定律,能提高LLM训练的预测精度。
- Farseer通过构建模型损失表面L(N,D)来更好地拟合实证数据。
- Farseer相对于之前的规模定律(如Chinchilla’s law)具有更好的表现。
- Farseer能够准确、稳健地预测不同训练策略的效果,并展现出优秀的外推能力。
- Farseer提供了关于计算分配的新见解,更好地反映了现代LLM训练的复杂需求。
点此查看论文截图

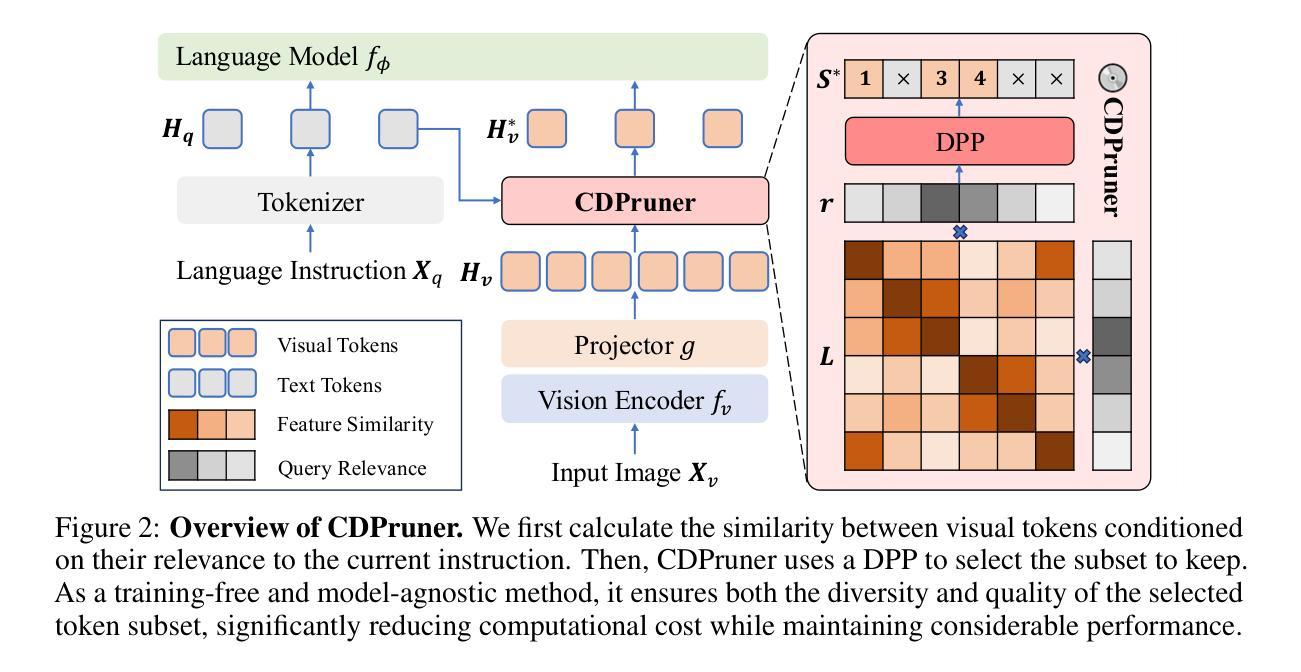
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Authors:Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, Shanghang Zhang
In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95% and CUDA latency by 78%, while maintaining 94% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
在多模态大型语言模型(MLLM)中,输入视觉标记的长度通常明显长于文本标记的长度,导致推理成本很高。许多研究旨在通过删除冗余的视觉标记来解决这个问题。然而,当前的方法要么依赖于基于注意力的修剪,这种方法会保留许多重复标记,要么使用基于相似度的修剪,忽视了指令相关性,从而导致性能不佳。在本文中,我们超越了注意力和相似度,提出了一种名为CDPruner的新型视觉标记修剪方法,该方法最大限度地提高了保留标记的条件多样性。我们首先定义了基于指令的视觉标记之间的条件相似性,然后使用行列式点过程(DPP)重新表述标记修剪问题,以最大化所选子集的条件多样性。提出的CDPruner无需训练且模型无关,可轻松应用于各种MLLM。在多种MLLM上的广泛实验表明,CDPruner在各项视觉语言基准测试中建立了新的技术前沿。通过DPP最大化条件多样性,所选子集可以更好地代表输入图像同时紧密遵循用户指令,从而在具有高降低率的情况下保持出色的性能。将CDPruner应用于LLaVA时,它减少了95%的FLOPs和78%的CUDA延迟,同时保持94%的原始准确性。我们的代码位于https://github.com/Theia-4869/CDPruner。
论文及项目相关链接
PDF 22 pages, 5 figures, code: https://github.com/Theia-4869/CDPruner, project page: https://theia-4869.github.io/CDPruner
Summary
在多媒体大型语言模型(MLLMs)中,视觉标记输入长度往往远超文本,导致推理成本较高。现有研究试图通过去除冗余视觉标记来解决这一问题,但现有方法存在不足。本文提出了一种名为CDPruner的视觉标记修剪方法,通过最大化保留标记的条件多样性来选择子集。该方法定义了在指令条件下的视觉标记间的条件相似性,并使用行列式点过程(DPP)重新表述标记修剪问题。CDPruner方法无需训练且适用于各种MLLMs。实验表明,CDPruner在各项视觉语言基准测试上创下了最新纪录。通过最大化条件多样性,所选子集能更好地代表输入图像并紧密遵循用户指令,即使在高缩减比例下也能保持强劲性能。在LLaVA上应用CDPruner可将FLOPs减少95%,CUDA延迟减少78%,同时保持94%的原始准确性。
Key Takeaways
- MLLMs中视觉标记输入长度通常远超文本,导致高推理成本。
- 现有视觉标记修剪方法存在缺陷,如保留过多重复标记或忽视指令相关性。
- CDPruner方法通过最大化保留标记的条件多样性来解决这一问题。
- CDPruner定义了在指令条件下的视觉标记间的条件相似性。
- 使用行列式点过程(DPP)重新表述标记修剪问题。
- CDPruner方法无需训练,适用于各种MLLMs。
点此查看论文截图



GENMANIP: LLM-driven Simulation for Generalizable Instruction-Following Manipulation
Authors:Ning Gao, Yilun Chen, Shuai Yang, Xinyi Chen, Yang Tian, Hao Li, Haifeng Huang, Hanqing Wang, Tai Wang, Jiangmiao Pang
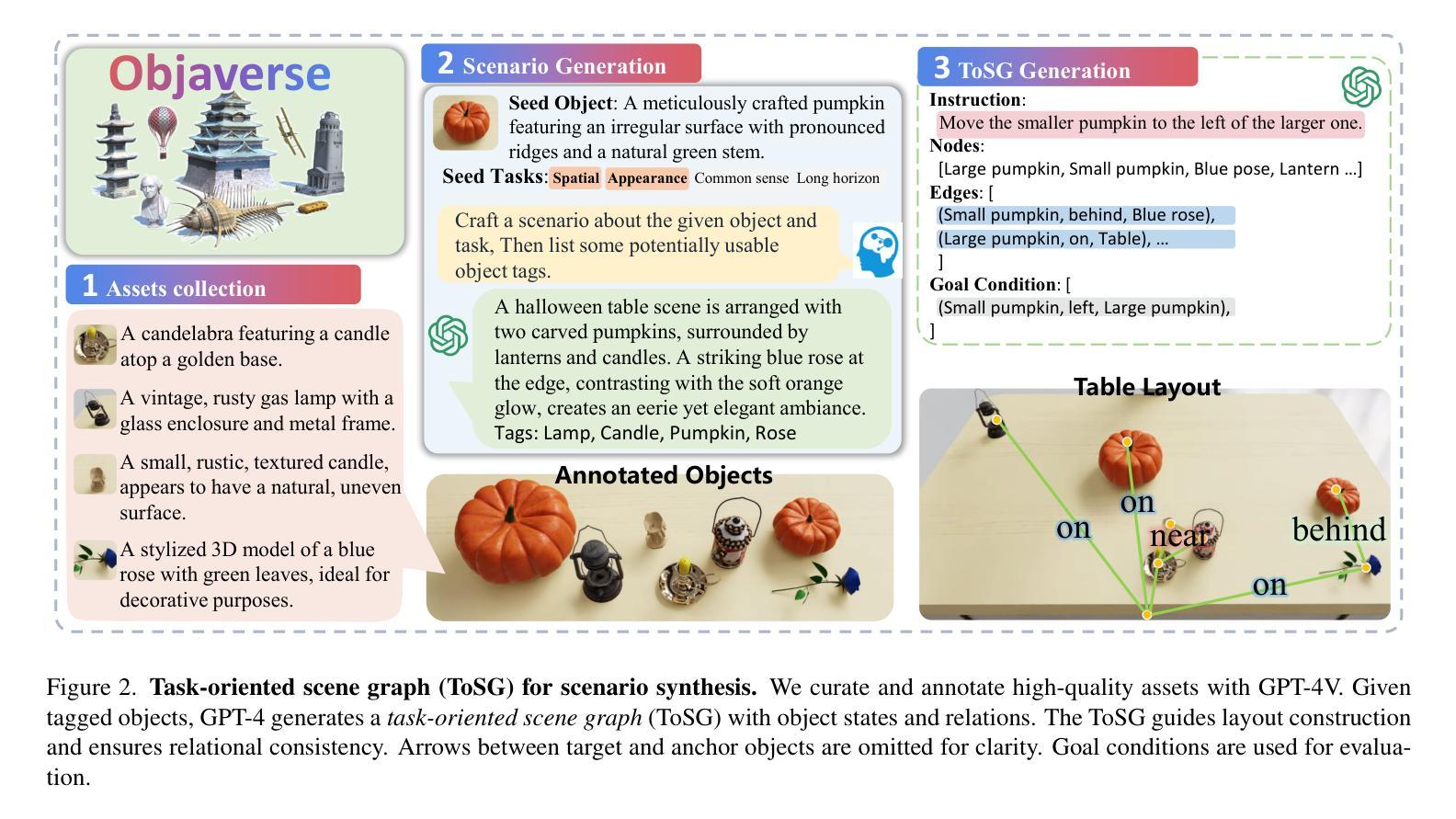
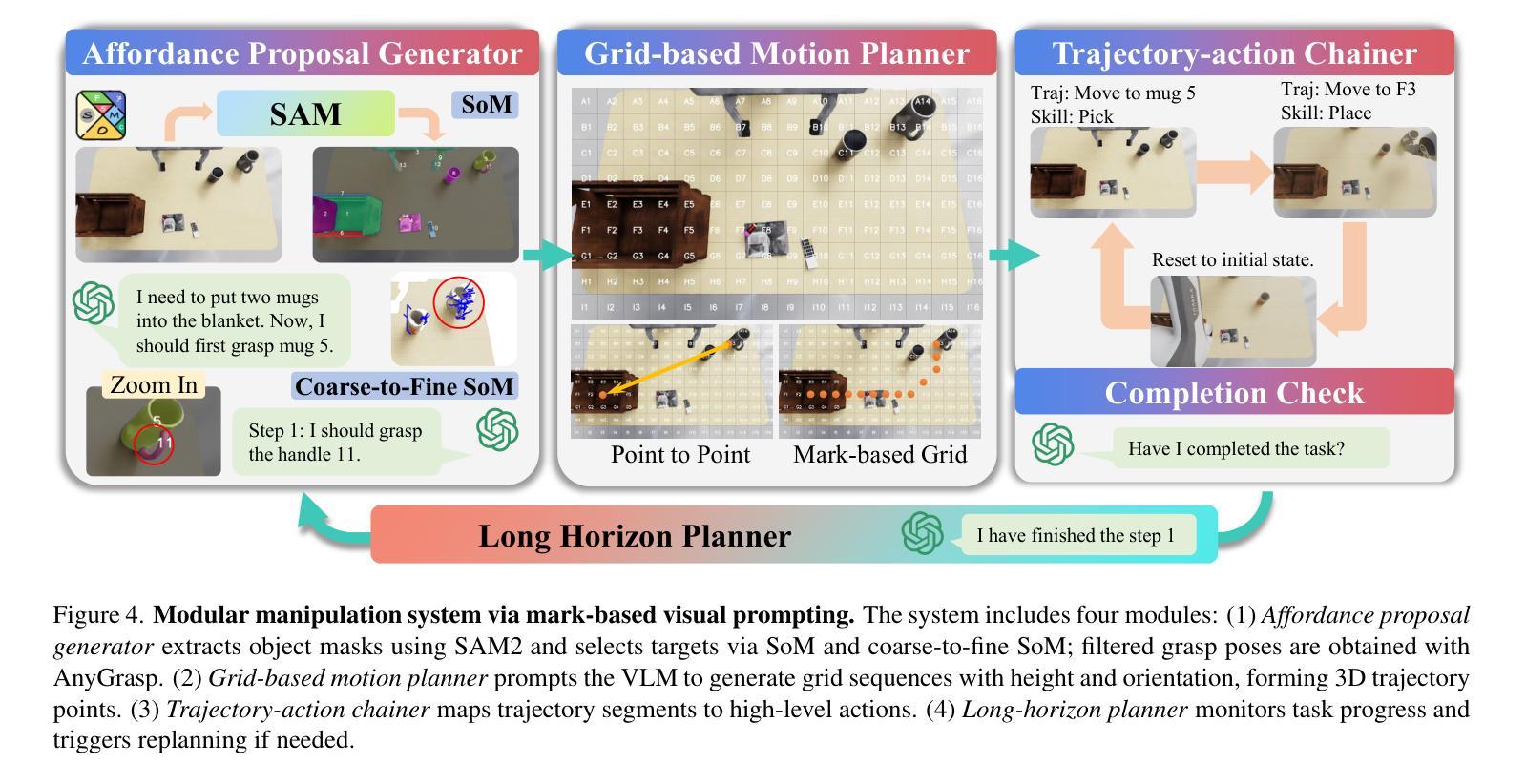
Robotic manipulation in real-world settings remains challenging, especially regarding robust generalization. Existing simulation platforms lack sufficient support for exploring how policies adapt to varied instructions and scenarios. Thus, they lag behind the growing interest in instruction-following foundation models like LLMs, whose adaptability is crucial yet remains underexplored in fair comparisons. To bridge this gap, we introduce GenManip, a realistic tabletop simulation platform tailored for policy generalization studies. It features an automatic pipeline via LLM-driven task-oriented scene graph to synthesize large-scale, diverse tasks using 10K annotated 3D object assets. To systematically assess generalization, we present GenManip-Bench, a benchmark of 200 scenarios refined via human-in-the-loop corrections. We evaluate two policy types: (1) modular manipulation systems integrating foundation models for perception, reasoning, and planning, and (2) end-to-end policies trained through scalable data collection. Results show that while data scaling benefits end-to-end methods, modular systems enhanced with foundation models generalize more effectively across diverse scenarios. We anticipate this platform to facilitate critical insights for advancing policy generalization in realistic conditions. Project Page: https://genmanip.axi404.top/.
机器人操作在真实世界环境中的表现仍然具有挑战性,特别是在稳健泛化方面。现有的模拟平台缺乏足够的支持来探索策略如何适应不同的指令和场景。因此,它们落后于对指令遵循基础模型(如LLM)日益增长的兴趣,这些模型的适应性至关重要,但在公平比较中仍未得到充分探索。为了弥补这一差距,我们引入了GenManip,这是一个专为策略泛化研究设计的现实桌面模拟平台。它通过LLM驱动的任务导向场景图,建立了一个自动管道,利用10K个注释的3D对象资产合成大规模、多样化的任务。为了系统地评估泛化能力,我们推出了GenManip-Bench,这是一个通过人机循环校正精细挑选的200个场景基准测试。我们评估了两种策略类型:(1)集成感知、推理和规划基础模型的模块化操作系统;(2)通过可扩展的数据收集进行端到端策略训练。结果表明,虽然数据规模化对端到端方法有益,但结合了基础模型的模块化系统在不同场景下的泛化能力更为有效。我们预期这个平台将为在真实条件下提升策略泛化能力提供关键见解。项目页面:[网址](已超链接)。
论文及项目相关链接
Summary
新一代模拟平台GenManip填补了在机器人操作领域的空白,它特别适用于策略通用性研究。该平台通过LLM驱动的面向任务场景图实现自动化管道,能够合成大规模、多样化的任务。该平台还提供基准测试GenManip-Bench以系统评估策略泛化能力,且能测试两类策略——集成感知、推理和规划的基础模型的模块化操作系统和通过大规模数据采集训练得到的端到端策略。研究结果显示,模块化系统在多样化场景中的泛化能力更强。期待此平台能为现实条件下的策略泛化研究提供重要见解。
Key Takeaways
- GenManip是一个面向策略通用化研究的现实餐桌模拟平台。
- 平台采用LLM驱动的面向任务场景图技术,可合成大规模多样化任务。
- GenManip-Bench作为基准测试,用于系统评估策略的泛化能力。
- 研究的两类策略包括模块化操作系统和端到端策略。
- 模块化策略在多样化场景中表现更优。
- 平台预期为现实条件下的策略泛化研究提供关键见解。
点此查看论文截图



ChineseHarm-Bench: A Chinese Harmful Content Detection Benchmark
Authors:Kangwei Liu, Siyuan Cheng, Bozhong Tian, Xiaozhuan Liang, Yuyang Yin, Meng Han, Ningyu Zhang, Bryan Hooi, Xi Chen, Shumin Deng
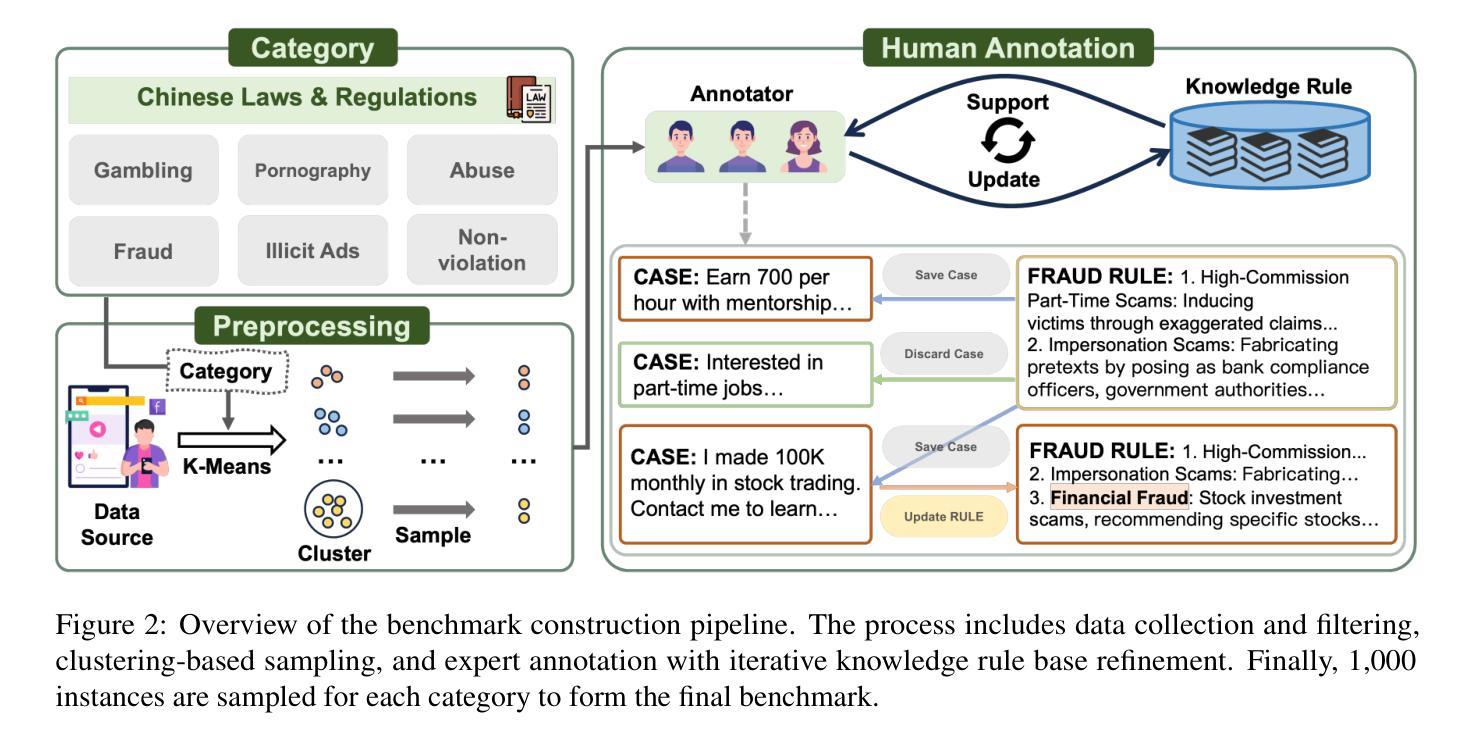
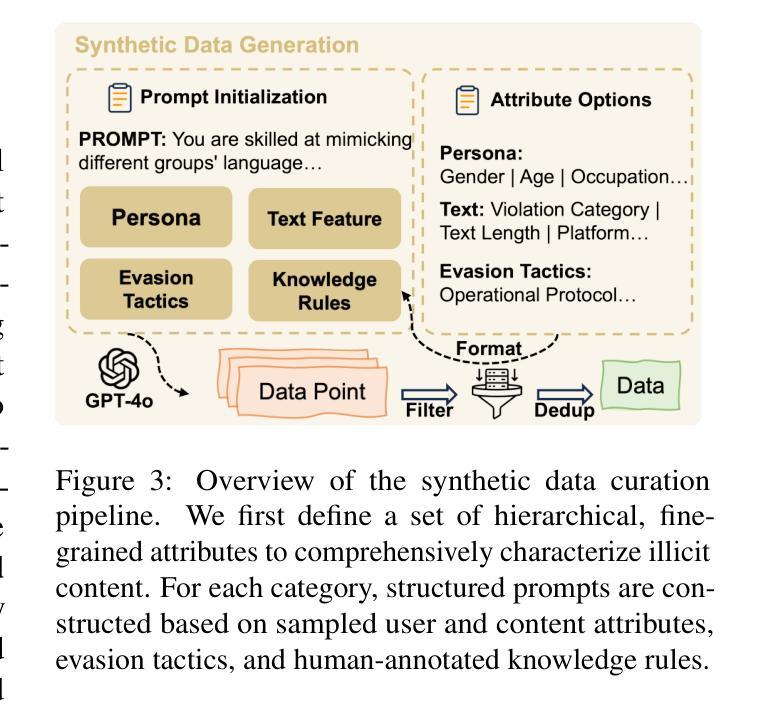
Large language models (LLMs) have been increasingly applied to automated harmful content detection tasks, assisting moderators in identifying policy violations and improving the overall efficiency and accuracy of content review. However, existing resources for harmful content detection are predominantly focused on English, with Chinese datasets remaining scarce and often limited in scope. We present a comprehensive, professionally annotated benchmark for Chinese content harm detection, which covers six representative categories and is constructed entirely from real-world data. Our annotation process further yields a knowledge rule base that provides explicit expert knowledge to assist LLMs in Chinese harmful content detection. In addition, we propose a knowledge-augmented baseline that integrates both human-annotated knowledge rules and implicit knowledge from large language models, enabling smaller models to achieve performance comparable to state-of-the-art LLMs. Code and data are available at https://github.com/zjunlp/ChineseHarm-bench.
大型语言模型(LLM)在自动检测有害内容任务中的应用日益增多,协助管理员识别政策违规行为,提高内容审查的整体效率和准确性。然而,目前有害内容检测的资源主要集中在英语,中文数据集仍然稀缺且范围有限。我们为中文内容危害检测提供了一个全面、专业注释的基准测试,该测试涵盖了六个代表性类别,并完全由真实世界数据构建。我们的注释过程还产生了知识规则库,提供了明确的专家知识,以协助LLM检测中文有害内容。此外,我们提出了一个融合了人工注释知识规则和大型语言模型中隐含知识的增强基线,使小型模型也能实现与国家先进LLM相当的性能。代码和数据可在https://github.com/zjunlp/ChineseHarm-bench找到。
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLM)在自动检测有害内容任务中的应用日益广泛,可协助内容管理者识别政策违规行为,提高内容审查的效率和准确性。然而,目前的有害内容检测资源主要集中在英语,中文数据集稀缺且范围有限。我们提供了一个全面、专业注释的中文内容危害检测基准,涵盖六个代表性类别,完全由真实世界数据构建。我们的注释过程还产生了知识规则库,为LLM提供明确的专家知识以协助检测中文有害内容。此外,我们提出了融合人类注释知识规则和大型语言模型中隐含知识的基线方法,使小型模型也能达到前沿LLM的性能水平。相关代码和数据可在链接获取。
Key Takeaways
- 大型语言模型在自动检测有害内容任务中的应用逐渐普及,提高了内容审查的效率和准确性。
- 目前针对中文的有害内容检测资源十分有限。
- 我们建立了一个全面、专业注释的中文内容危害检测基准,涵盖六个类别,基于真实世界数据。
- 注释过程中产生了知识规则库,为LLM提供明确的专家知识。
- 我们提出了融合人类注释知识规则和LLM中隐含知识的基线方法。
- 该方法使小型模型也能达到前沿性能。
点此查看论文截图

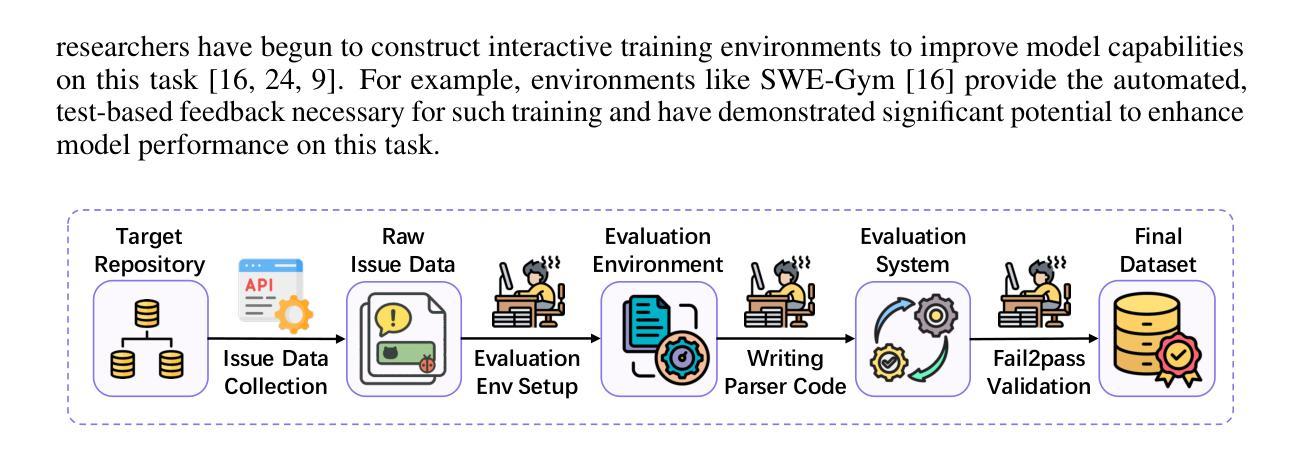
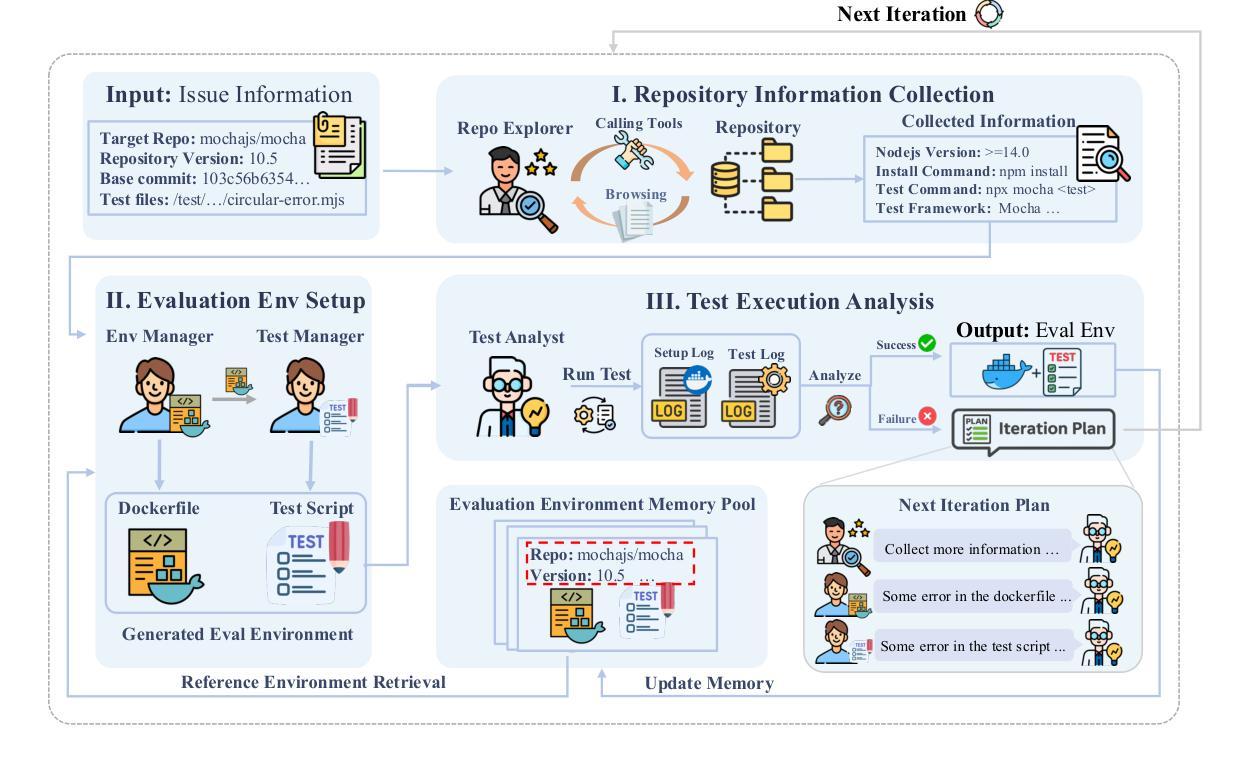
SWE-Factory: Your Automated Factory for Issue Resolution Training Data and Evaluation Benchmarks
Authors:Lianghong Guo, Yanlin Wang, Caihua Li, Pengyu Yang, Jiachi Chen, Wei Tao, Yingtian Zou, Duyu Tang, Zibin Zheng
Constructing large-scale datasets for the GitHub issue resolution task is crucial for both training and evaluating the software engineering capabilities of Large Language Models (LLMs). However, the traditional process for creating such benchmarks is notoriously challenging and labor-intensive, particularly in the stages of setting up evaluation environments, grading test outcomes, and validating task instances. In this paper, we propose SWE-Factory, an automated pipeline designed to address these challenges. To tackle these issues, our pipeline integrates three core automated components. First, we introduce SWE-Builder, a multi-agent system that automates evaluation environment construction, which employs four specialized agents that work in a collaborative, iterative loop and leverages an environment memory pool to enhance efficiency. Second, we introduce a standardized, exit-code-based grading method that eliminates the need for manually writing custom parsers. Finally, we automate the fail2pass validation process using these reliable exit code signals. Experiments on 671 issues across four programming languages show that our pipeline can effectively construct valid task instances; for example, with GPT-4.1-mini, our SWE-Builder constructs 269 valid instances at $0.045 per instance, while with Gemini-2.5-flash, it achieves comparable performance at the lowest cost of $0.024 per instance. We also demonstrate that our exit-code-based grading achieves 100% accuracy compared to manual inspection, and our automated fail2pass validation reaches a precision of 0.92 and a recall of 1.00. We hope our automated pipeline will accelerate the collection of large-scale, high-quality GitHub issue resolution datasets for both training and evaluation. Our code and datasets are released at https://github.com/DeepSoftwareAnalytics/swe-factory.
构建用于GitHub问题解决方案的大规模数据集对于训练和评价大型语言模型(LLM)的软件工程能力至关重要。然而,创建此类基准的传统过程具有挑战性且劳动密集型,特别是在设置评估环境、评估测试结果和验证任务实例的阶段。在本文中,我们提出了SWE-Factory,这是一个旨在解决这些挑战的自动化管道。为了解决这个问题,我们的管道集成了三个核心自动化组件。
首先,我们介绍了SWE-Builder,这是一个多智能体系统,可以自动构建评估环境,该系统采用四个专业智能体进行协作、迭代循环,并利用环境内存池提高效率。其次,我们提出了一种标准化的基于退出代码的评分方法,消除了需要手动编写自定义解析器的需求。最后,我们利用这些可靠的退出代码信号自动进行fail2pass验证过程。
论文及项目相关链接
Summary
本文提出一个自动化管道SWE-Factory,用于解决GitHub问题解析任务的大规模数据集构建的挑战。该管道集成了三个核心自动化组件:SWE-Builder、标准化的退出代码评分方法和fail2pass验证过程的自动化。实验表明,该管道可以有效地构建任务实例,并提高效率和准确性。
Key Takeaways
- SWE-Factory是一个自动化管道,旨在解决大规模数据集构建的挑战,特别是GitHub问题解析任务的数据集构建。
- 管道包括三个核心自动化组件:SWE-Builder用于自动化评估环境构建,标准化的退出代码评分方法用于评分测试成果,以及自动化的fail2pass验证过程。
- 实验结果显示,SWE-Builder可以有效地构建任务实例,并提高效率。与GPT-4.1-mini和Gemini-2.5-flash结合使用时,可以构建大量有效的任务实例。
- 退出代码评分方法达到100%的准确性,与手动检查相比具有优势。
- 自动化fail2pass验证达到高精确度和召回率。
- 代码和数据集已公开发布,便于其他研究者使用。
点此查看论文截图


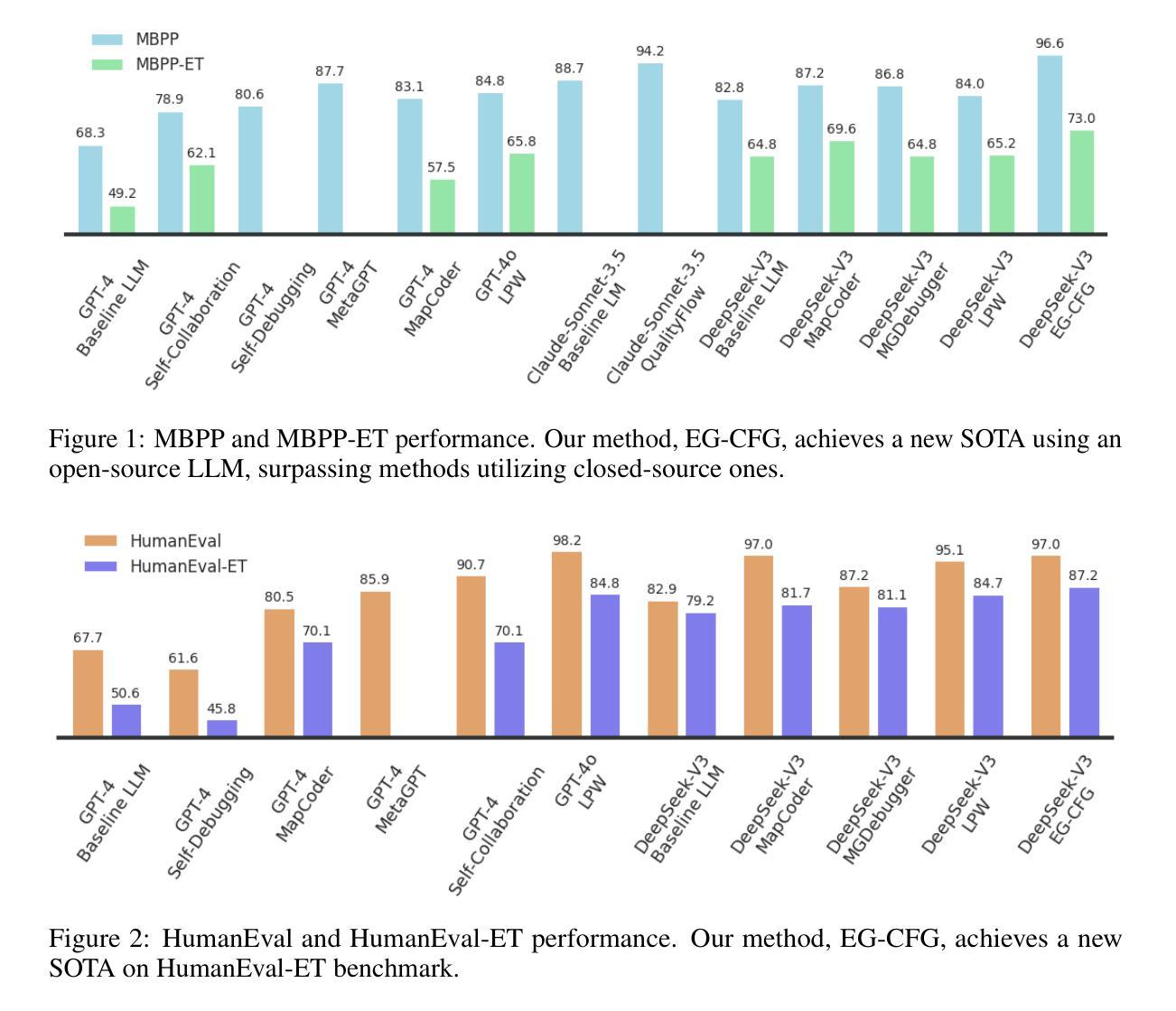
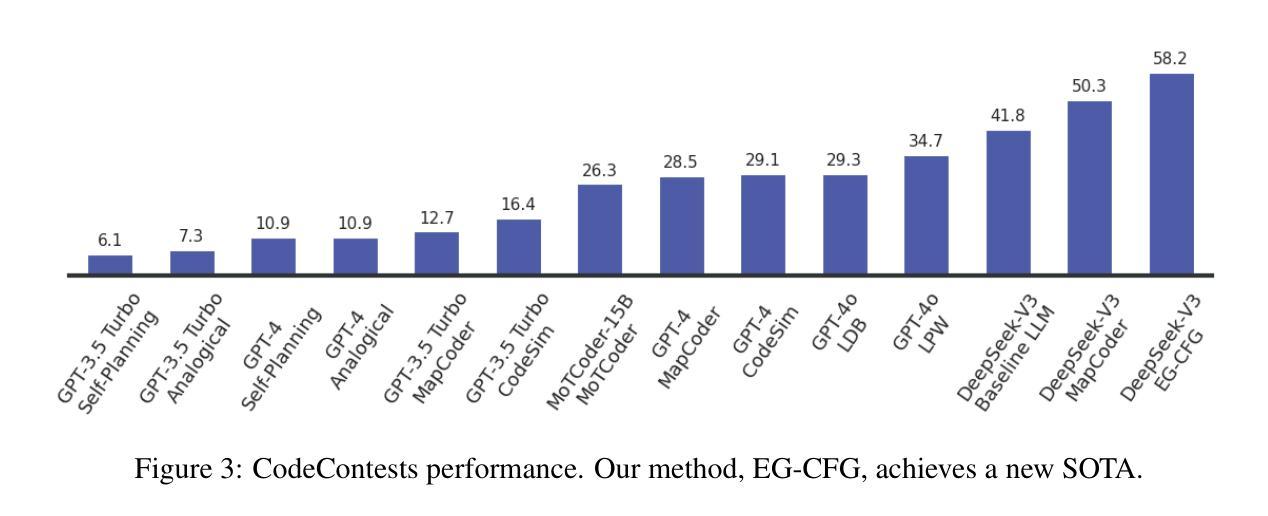
Execution Guided Line-by-Line Code Generation
Authors:Boaz Lavon, Shahar Katz, Lior Wolf
We present a novel approach to neural code generation that incorporates real-time execution signals into the language model generation process. While large language models (LLMs) have demonstrated impressive code generation capabilities, they typically do not utilize execution feedback during inference, a critical signal that human programmers regularly leverage. Our method, Execution-Guided Classifier-Free Guidance (EG-CFG), dynamically incorporates execution signals as the model generates code, providing line-by-line feedback that guides the generation process toward executable solutions. EG-CFG employs a multi-stage process: first, we conduct beam search to sample candidate program completions for each line; second, we extract execution signals by executing these candidates against test cases; and finally, we incorporate these signals into the prompt during generation. By maintaining consistent signals across tokens within the same line and refreshing signals at line boundaries, our approach provides coherent guidance while preserving syntactic structure. Moreover, the method naturally supports native parallelism at the task level in which multiple agents operate in parallel, exploring diverse reasoning paths and collectively generating a broad set of candidate solutions. Our experiments across diverse coding tasks demonstrate that EG-CFG significantly improves code generation performance compared to standard approaches, achieving state-of-the-art results across various levels of complexity, from foundational problems to challenging competitive programming tasks. Our code is available at: https://github.com/boazlavon/eg_cfg
我们提出了一种将实时执行信号融入语言模型生成过程的新型神经网络代码生成方法。虽然大型语言模型(LLM)已经表现出了令人印象深刻的代码生成能力,但它们在推理过程中通常不利用执行反馈,这是人类程序员经常利用的关键信号。我们的方法,执行引导无分类器引导(EG-CFG),在生成代码时动态融入执行信号,提供逐行反馈,引导生成过程朝着可执行解决方案进行。EG-CFG采用多阶段过程:首先,我们进行集束搜索,为每一行采样程序完成候选;其次,我们通过测试案例执行这些候选项来提取执行信号;最后,我们在生成时将这些信号融入提示。通过在同一行的标记之间保持一致的信号并在行边界刷新信号,我们的方法在保持语法结构的同时提供了连贯的指导。此外,该方法自然地支持任务层面的原生并行性,多个代理并行操作,探索不同的推理路径并共同生成一组广泛的候选解决方案。我们在多种编码任务上的实验表明,与标准方法相比,EG-CFG显著提高了代码生成性能,在各种复杂程度上都达到了最新结果,包括基础问题到具有挑战性的竞赛编程任务。我们的代码可在:https://github.com/boazlavon/eg_cfg找到。
论文及项目相关链接
Summary:
提出了一种将实时执行信号融入语言模型生成过程的新方法,用于神经代码生成。该方法称为执行引导的无分类器引导(EG-CFG),在生成代码时动态融入执行信号,提供逐行反馈,引导生成过程朝可执行解决方案发展。实验表明,EG-CFG在多种编码任务上显著提高了代码生成性能,实现了从基础问题到具有挑战性的竞赛编程任务的最佳结果。
Key Takeaways:
- 提出了EG-CFG方法,将实时执行信号融入语言模型生成过程。
- EG-CFG在生成代码时动态利用执行信号,提供逐行反馈。
- EG-CFG通过束搜索采样候选程序完成,通过执行测试用例提取执行信号,并将这些信号融入提示中进行生成。
- EG-CFG方法保持同一行内标记之间的一致信号,并在行边界刷新信号,为生成过程提供连贯的引导,同时保留语法结构。
- EG-CFG方法支持原生并行性,多个代理并行操作,探索不同的推理路径,并共同生成广泛的候选解决方案。
- 实验表明,EG-CFG在多种编码任务上显著提高了代码生成性能。
- EG-CFG方法实现了从基础问题到具有挑战性的竞赛编程任务的最佳结果。
点此查看论文截图

Self-Adapting Language Models
Authors:Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal
Large language models (LLMs) are powerful but static; they lack mechanisms to adapt their weights in response to new tasks, knowledge, or examples. We introduce Self-Adapting LLMs (SEAL), a framework that enables LLMs to self-adapt by generating their own finetuning data and update directives. Given a new input, the model produces a self-edit-a generation that may restructure the information in different ways, specify optimization hyperparameters, or invoke tools for data augmentation and gradient-based updates. Through supervised finetuning (SFT), these self-edits result in persistent weight updates, enabling lasting adaptation. To train the model to produce effective self-edits, we use a reinforcement learning loop with the downstream performance of the updated model as the reward signal. Unlike prior approaches that rely on separate adaptation modules or auxiliary networks, SEAL directly uses the model’s own generation to control its adaptation process. Experiments on knowledge incorporation and few-shot generalization show that SEAL is a promising step toward language models capable of self-directed adaptation. Our website and code is available at https://jyopari.github.io/posts/seal.
大型语言模型(LLM)虽然功能强大,但它们是静态的;缺乏根据新任务、知识或示例调整其权重的机制。我们引入了自适应大型语言模型(SEAL)框架,该框架使LLM能够通过生成自己的微调数据和更新指令进行自我适应。对于新的输入,模型会产生自我编辑生成的内容,这可能以不同的方式重新组织信息,指定优化超参数,或调用数据增强和基于梯度的更新工具。通过有监督的微调(SFT),这些自我编辑会导致持久的权重更新,从而实现持久的适应。为了训练模型以产生有效的自我编辑,我们使用强化学习循环,以更新模型的下游性能作为奖励信号。不同于以往依赖于单独的自适应模块或辅助网络的做法,SEAL直接使用模型自身的生成来控制其自适应过程。在知识融入和少量示例推广方面的实验表明,SEAL是朝着能够进行自我导向适应的语言模型迈出的有前途的一步。我们的网站和代码可在[https://jyopari.github.io/posts/seal]访问。
论文及项目相关链接
Summary
大型语言模型(LLM)虽然强大但静态固化,无法根据新任务、知识或范例调整自身权重以适应变化。我们提出Self-Adapting LLMs(SEAL)框架,使LLM能够通过生成自身的微调数据和更新指令实现自我适应。面对新输入,模型会进行自我编辑生成,以不同方式重组信息,设定优化超参数,或调用数据增强工具和基于梯度的更新。通过监督微调(SFT),这些自我编辑导致持久性权重更新,实现长期适应。我们使用以下游性能作为奖励信号来训练模型产生有效的自我编辑,采用强化学习循环。与依赖单独适应模块或辅助网络的方法不同,SEAL直接使用模型自身的生成来控制其适应过程。实验表明,SEAL在知识融入和少量样本泛化方面展现出巨大潜力,是向能够自我定向适应的语言模型迈进的重要一步。
Key Takeaways
- LLM存在静态固化问题,无法根据新任务、知识或范例自我适应。
- Self-Adapting LLMs(SEAL)框架能够解决这一问题,使LLM通过生成自我编辑实现自我适应。
- 模型面对新输入会进行自我编辑生成,包括信息重组、优化超参数设定等。
- 通过监督微调(SFT),自我编辑会导致持久性权重更新,实现长期适应。
- 使用强化学习循环训练模型进行自我编辑,以下游性能作为奖励信号。
- 与其他适应模块或辅助网络方法不同,SEAL直接使用模型自身的生成控制适应过程。
- 实验表明SEAL在知识融入和少量样本泛化方面表现出显著优势。
点此查看论文截图


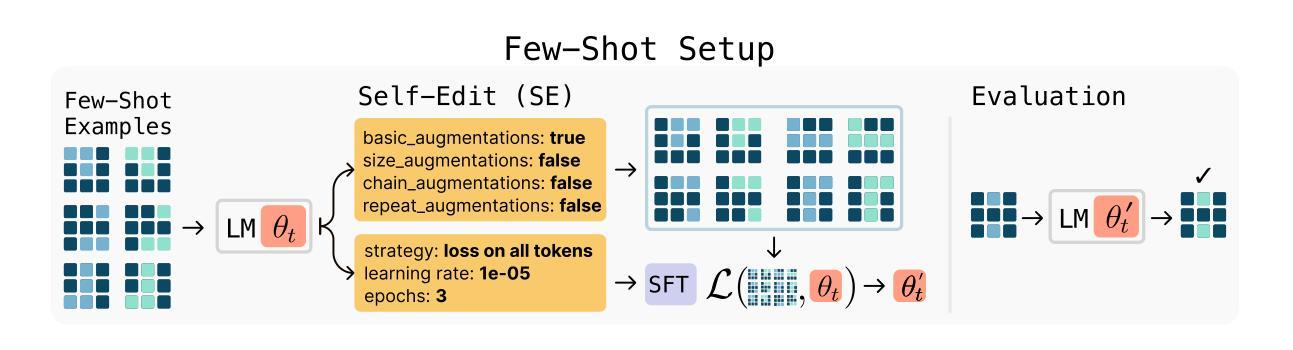

NoLoCo: No-all-reduce Low Communication Training Method for Large Models
Authors:Jari Kolehmainen, Nikolay Blagoev, John Donaghy, Oğuzhan Ersoy, Christopher Nies
Training large language models is generally done via optimization methods on clusters containing tens of thousands of accelerators, communicating over a high-bandwidth interconnect. Scaling up these clusters is expensive and can become impractical, imposing limits on the size of models that can be trained. Several recent studies have proposed training methods that are less communication intensive, avoiding the need for a highly connected compute cluster. These state-of-the-art low communication training methods still employ a synchronization step for model parameters, which, when performed over all model replicas, can become costly on a low-bandwidth network. In this work, we propose a novel optimization method, NoLoCo, that does not explicitly synchronize all model parameters during training and, as a result, does not require any collective communication. NoLoCo implicitly synchronizes model weights via a novel variant of the Nesterov momentum optimizer by partially averaging model weights with a randomly selected other one. We provide both a theoretical convergence analysis for our proposed optimizer as well as empirical results from language model training. We benchmark NoLoCo on a wide range of accelerator counts and model sizes, between 125M to 6.8B parameters. Our method requires significantly less communication overhead than fully sharded data parallel training or even widely used low communication training method, DiLoCo. The synchronization step itself is estimated to be one magnitude faster than the all-reduce used in DiLoCo for few hundred accelerators training over the internet. We also do not have any global blocking communication that reduces accelerator idling time. Compared to DiLoCo, we also observe up to $4%$ faster convergence rate with wide range of model sizes and accelerator counts.
训练大型语言模型通常是在包含数以万计的加速器的集群上通过优化方法进行的,这些加速器通过高速互联进行通信。扩大这些集群的规模成本高昂,甚至可能不切实际,从而对可训练模型的大小施加限制。最近的一些研究提出了通信密集度较低的训练方法,避免了高度互联计算集群的需求。这些最先进的低通信训练方法仍然采用模型参数的同步步骤,当在所有模型副本上执行时,这在低带宽网络上可能会变得成本高昂。在这项工作中,我们提出了一种新的优化方法NoLoCo,它不会在训练期间明确同步所有模型参数,因此不需要任何集体通信。NoLoCo通过Nesterov动量优化器的新颖变体来隐式地同步模型权重,通过部分平均随机选择的另一个模型的权重来实现。我们为我们提出的优化器提供了理论收敛分析以及语言模型训练的实证结果。我们在范围广泛的加速器数量和模型大小(从1.25亿到68亿参数)上对NoLoCo进行了基准测试。我们的方法所需的通信开销远小于完全分片数据并行训练,甚至小于广泛使用的低通信训练方法DiLoCo。同步步骤本身估计比DiLoCo在几百个加速器上进行互联网训练时使用的所有减少一个数量级。我们也没有任何全局阻塞通信,这减少了加速器的空闲时间。与DiLoCo相比,我们还观察到在广泛的模型大小和加速器数量下,收敛速度提高了高达4%。
论文及项目相关链接
摘要
本工作提出了一种新型优化方法NoLoCo,该方法在训练大型语言模型时无需明确同步所有模型参数,因此无需任何集体通信。NoLoCo通过一种新型Nesterov动量优化器的变体,通过随机选择另一个模型权重进行部分平均,从而隐式地同步模型权重。我们为所提出的优化器提供了理论收敛分析和语言模型训练的实证结果。在广泛的加速器计数和模型大小(从1.25亿到68亿参数)上,我们对NoLoCo进行了基准测试。该方法比完全分片数据并行训练甚至广泛使用的低通信训练方法DiLoCo具有更低的通信开销。同步步骤本身估计比DiLoCo在全量数百个加速器通过互联网进行训练时使用的all-reduce快一个数量级。此外,我们没有全局阻塞通信,这减少了加速器的闲置时间。与DiLoCo相比,我们在广泛的模型大小和加速器计数上观察到高达4%的更快收敛率。
关键见解
- NoLoCo是一种新型优化方法,训练大型语言模型时无需集体通信。
- NoLoCo通过部分平均随机选择的模型权重隐式同步模型。
- NoLoCo在广泛的加速器计数和模型大小上表现优越,适用于大型语言模型的训练。
- NoLoCo相比DiLoCo具有更低的通信开销和更快的同步步骤。
- NoLoCo没有全局阻塞通信,减少了加速器的闲置时间。
- 与DiLoCo相比,NoLoCo在多种场景下表现出更快的收敛率。
点此查看论文截图


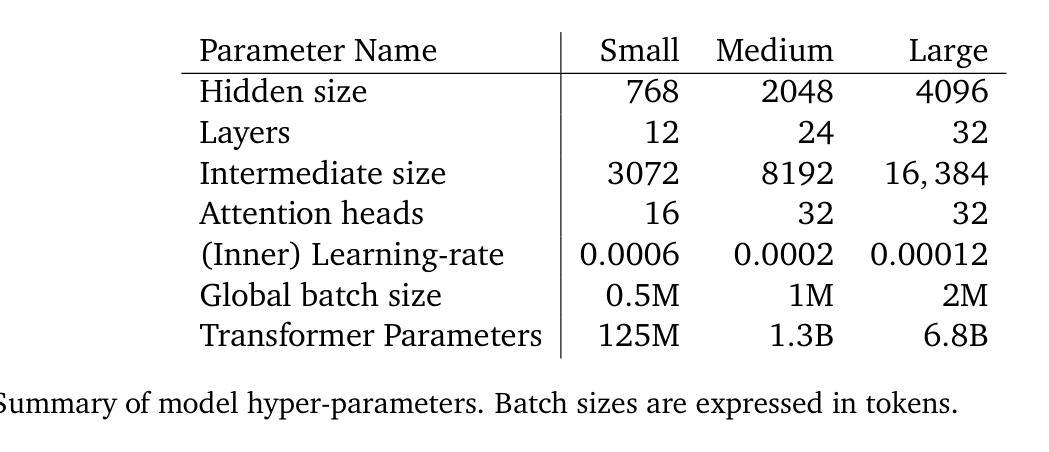
Revisiting Transformers with Insights from Image Filtering
Authors:Laziz U. Abdullaev, Maksim Tkachenko, Tan M. Nguyen
The self-attention mechanism, a cornerstone of Transformer-based state-of-the-art deep learning architectures, is largely heuristic-driven and fundamentally challenging to interpret. Establishing a robust theoretical foundation to explain its remarkable success and limitations has therefore become an increasingly prominent focus in recent research. Some notable directions have explored understanding self-attention through the lens of image denoising and nonparametric regression. While promising, existing frameworks still lack a deeper mechanistic interpretation of various architectural components that enhance self-attention, both in its original formulation and subsequent variants. In this work, we aim to advance this understanding by developing a unifying image processing framework, capable of explaining not only the self-attention computation itself but also the role of components such as positional encoding and residual connections, including numerous later variants. We also pinpoint potential distinctions between the two concepts building upon our framework, and make effort to close this gap. We introduce two independent architectural modifications within transformers. While our primary objective is interpretability, we empirically observe that image processing-inspired modifications can also lead to notably improved accuracy and robustness against data contamination and adversaries across language and vision tasks as well as better long sequence understanding.
自注意力机制是当下最流行的基于Transformer的深度学习架构的核心组成部分,其启发式的特点使得其难以从根本上进行解释。因此,为了解释其在众多任务上的显著成功和局限性,建立坚实的理论基础成为了最近研究的重要焦点。一些显著的研究方向尝试通过图像去噪和非参数回归来理解自注意力机制。尽管这些方向前景广阔,但现有的框架仍然缺乏对增强自注意力的各种架构组件的更深入的机械解释,无论在其原始形式还是随后的变体。在这项工作中,我们的目标是通过开发一个统一的图像处理框架来提升这种理解,这个框架不仅能够解释自注意力计算本身,还能够解释组件如位置编码和残差连接的作用,包括许多后续变体。我们还指出了在我们框架下这两个概念之间的潜在区别,并努力缩小这一差距。我们在Transformer中引入了两种独立的架构修改。虽然我们的主要目标是解释性,但经验观察表明,受图像处理启发的修改还可以显著提高语言和视觉任务的准确性和鲁棒性,以及更好地处理数据污染和对手攻击的问题,同时实现对长序列的更好理解。
论文及项目相关链接
PDF 12 pages, 6 figures
Summary
本文旨在通过构建统一的图像处理框架,深入解析Transformer架构中的自注意力机制及其组件(如位置编码和残差连接),解释其成功和限制。此外,本文还引入了两个独立的架构修改,旨在提高解释性,同时发现这些修改可显著提高语言和视觉任务的准确性和鲁棒性。
Key Takeaways
- 文章关注于自注意力机制的深入理解和解析,尤其是在Transformer架构中。
- 构建了一个统一的图像处理框架,用以解释自注意力计算及其组件如位置编码和残差连接。
- 该框架不仅解释了自注意力机制,还解释了后续的各种变体。
- 引入了两个独立的架构修改,主要目标是提高模型的可解释性。
- 这些修改不仅提高了模型的解释性,还提高了语言和视觉任务的准确性和鲁棒性。
- 文章强调了自注意力机制在理解和处理图像方面的潜力,特别是在图像去噪和非参数回归方面的应用。
点此查看论文截图

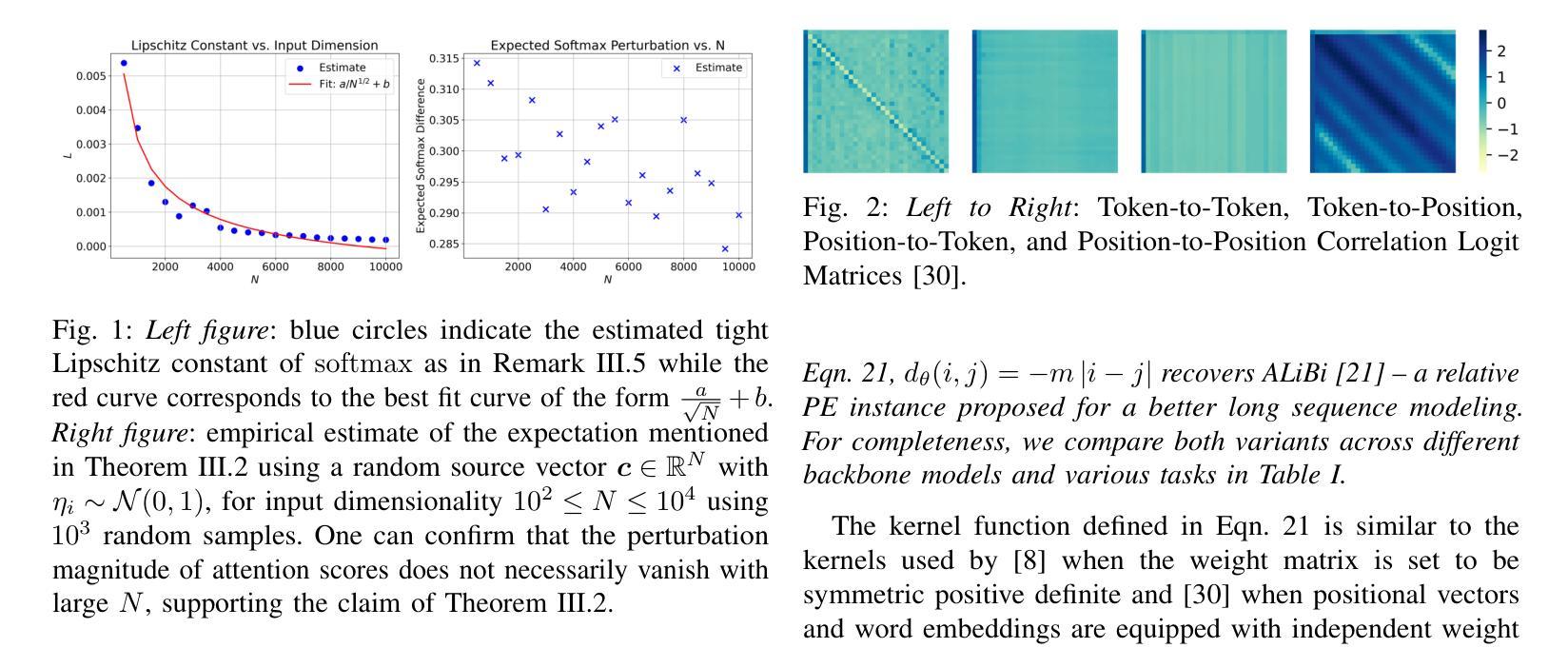
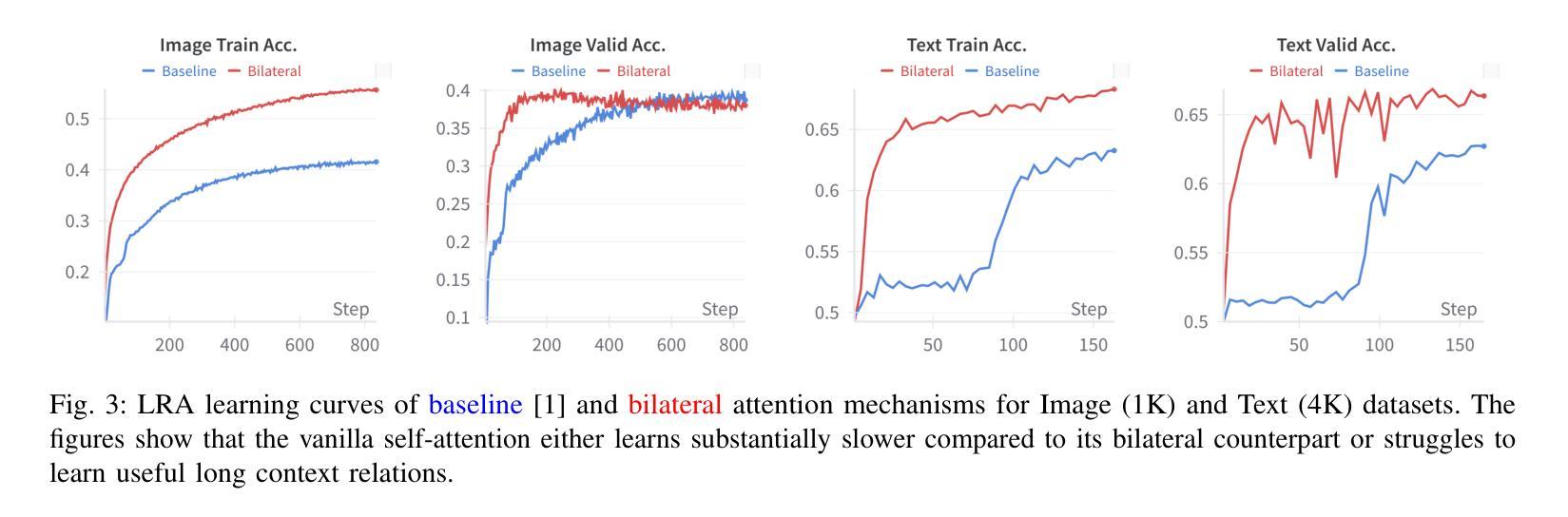
On-the-Fly Adaptive Distillation of Transformer to Dual-State Linear Attention
Authors:Yeonju Ro, Zhenyu Zhang, Souvik Kundu, Zhangyang Wang, Aditya Akella
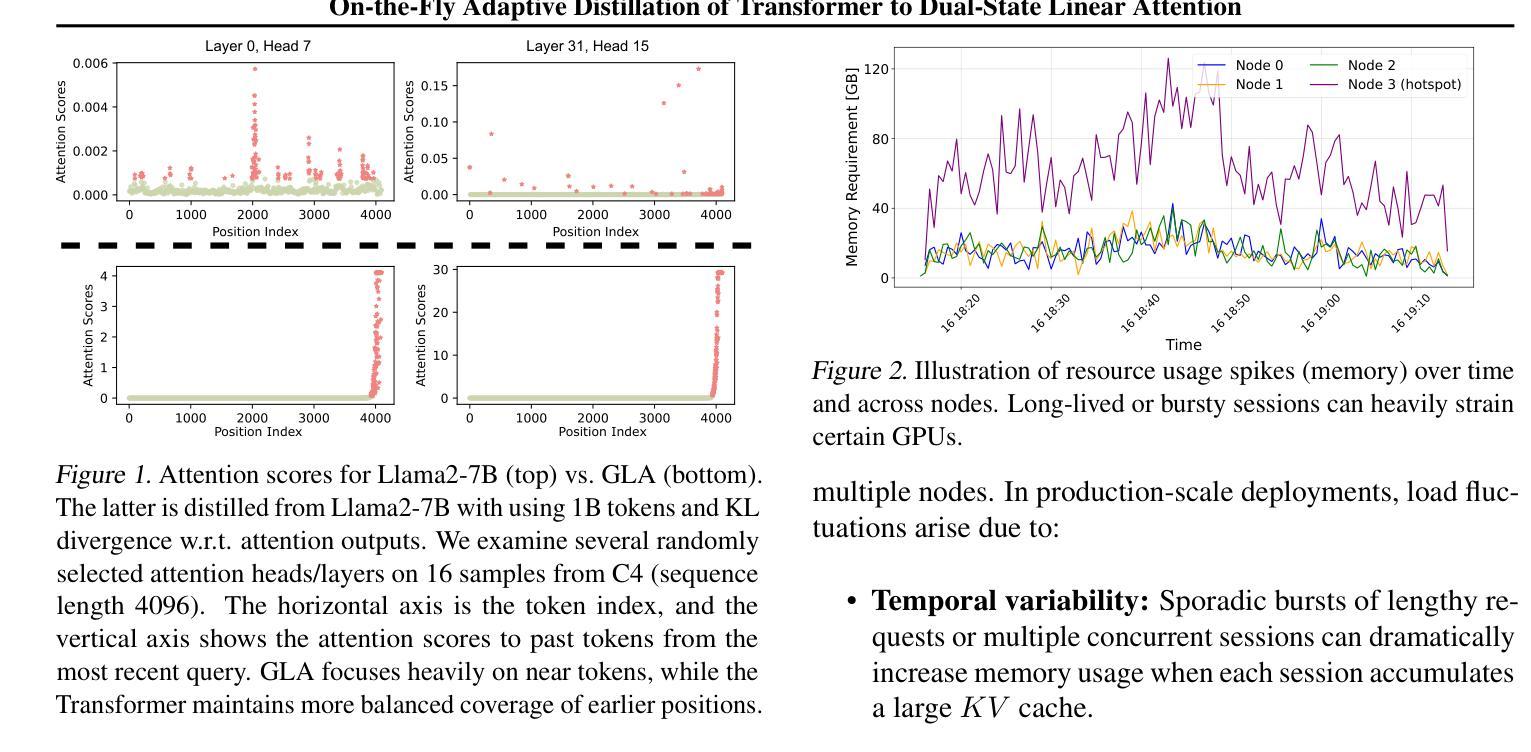
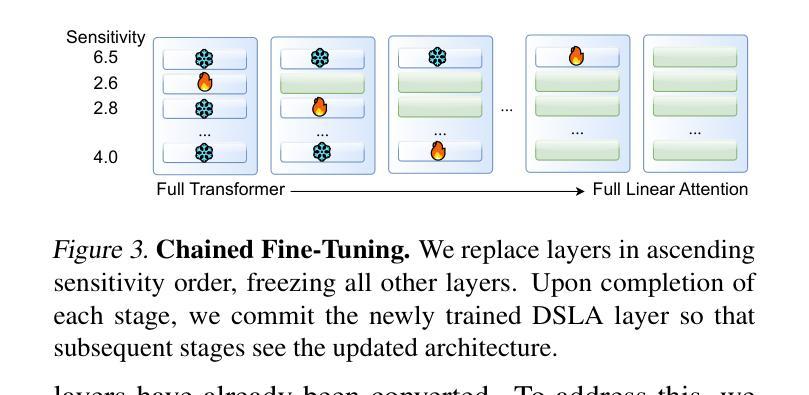
Large language models (LLMs) excel at capturing global token dependencies via self-attention but face prohibitive compute and memory costs on lengthy inputs. While sub-quadratic methods (e.g., linear attention) can reduce these costs, they often degrade accuracy due to overemphasizing recent tokens. In this work, we first propose dual-state linear attention (DSLA), a novel design that maintains two specialized hidden states-one for preserving historical context and one for tracking recency-thereby mitigating the short-range bias typical of linear-attention architectures. To further balance efficiency and accuracy under dynamic workload conditions, we introduce DSLA-Serve, an online adaptive distillation framework that progressively replaces Transformer layers with DSLA layers at inference time, guided by a sensitivity-based layer ordering. DSLA-Serve uses a chained fine-tuning strategy to ensure that each newly converted DSLA layer remains consistent with previously replaced layers, preserving the overall quality. Extensive evaluations on commonsense reasoning, long-context QA, and text summarization demonstrate that DSLA-Serve yields 2.3x faster inference than Llama2-7B and 3.0x faster than the hybrid Zamba-7B, while retaining comparable performance across downstream tasks. Our ablation studies show that DSLA’s dual states capture both global and local dependencies, addressing the historical-token underrepresentation seen in prior linear attentions. Codes are available at https://github.com/utnslab/DSLA-Serve.
大型语言模型(LLM)擅长通过自注意力捕捉全局令牌依赖关系,但在处理长输入时面临着计算量大和内存成本高的挑战。虽然次二次方法(如线性注意力)可以降低这些成本,但它们往往会因为过分强调最近的令牌而降低准确性。在这项工作中,我们首次提出了双态线性注意力(DSLA),这是一种新型设计,它维护了两个专门的隐藏状态——一个用于保留历史上下文,另一个用于跟踪最近的状态——从而减轻了线性注意力架构通常存在的短程偏差。为了进一步优化动态工作量条件下的效率和准确性平衡,我们引入了DSLA-Serve,这是一种在线自适应蒸馏框架,它能够在推理过程中逐步用DSLA层替换Transformer层,以基于敏感性的层序为指导。DSLA-Serve使用链式微调策略,确保每个新转换的DSLA层与之前替换的层保持一致,从而保持整体质量。在常识推理、长文本问答和文本摘要等方面的广泛评估表明,DSLA-Serve相对于Llama2-7B进行推理的速度提高了2.3倍,相对于混合Zamba-7B则提高了3.0倍,同时在下游任务上的表现相当。我们的消融研究表明,DSLA的双态能够捕捉全局和局部依赖关系,解决了先前线性注意力中历史令牌表示不足的问题。相关代码已发布在https://github.com/utnslab/DSLA-Serve。
论文及项目相关链接
摘要
LLM在捕获全局token依赖方面表现出色,但其高昂的计算和内存成本限制了其在长输入上的应用。虽然采用子二次方法(如线性注意力)可以降低这些成本,但它们往往会因为过度强调最近的token而降低准确性。本文提出了双态线性注意力(DSLA)这一新型设计,通过维护两个专门化的隐藏状态来同时关注历史上下文和追踪近期信息,从而减轻线性注意力架构的短程偏见。为了平衡动态工作负载条件下的效率和准确性,我们进一步引入了DSLA-Serve,这是一种在线自适应蒸馏框架,能够在推理时逐步用DSLA层替换Transformer层,并根据敏感性确定层序。DSLA-Serve采用链式微调策略,确保每个新转换的DSLA层与之前替换的层保持一致,从而保持整体质量。评估显示,DSLA-Serve在常识推理、长文本问答和文本摘要任务中的推理速度比Llama2-7B快2.3倍,比混合模型Zamba-7B快3.0倍,同时保持下游任务的性能相当。我们的消融研究表明,DSLA的双状态能够捕获全局和局部依赖关系,解决了先前线性注意力模型中历史token表示不足的问题。相关代码已公开于https://github.com/utnslab/DSLA-Serve。
关键见解
- LLM通过自我关注捕获全局token依赖,但面临计算与内存成本问题。
- 子二次方法如线性注意力虽可降低计算成本,但可能导致准确性下降。
- DSLA设计通过维护两个隐藏状态平衡历史与近期信息,减轻线性注意力的短程偏见。
- DSLA-Serve是首个在线自适应蒸馏框架,能在推理时动态替换模型层,以提高效率并平衡准确性。
- 通过链式微调策略确保模型性能稳定,即使进行层替换。
- DSLA-Serve显著提高了推理速度,相较于Llama2-7B快2.3倍,相较于Zamba-7B快3倍。
点此查看论文截图

Sailing by the Stars: A Survey on Reward Models and Learning Strategies for Learning from Rewards
Authors:Xiaobao Wu
Recent developments in Large Language Models (LLMs) have shifted from pre-training scaling to post-training and test-time scaling. Across these developments, a key unified paradigm has arisen: Learning from Rewards, where reward signals act as the guiding stars to steer LLM behavior. It has underpinned a wide range of prevalent techniques, such as reinforcement learning (RLHF, RLAIF, DPO, and GRPO), reward-guided decoding, and post-hoc correction. Crucially, this paradigm enables the transition from passive learning from static data to active learning from dynamic feedback. This endows LLMs with aligned preferences and deep reasoning capabilities for diverse tasks. In this survey, we present a comprehensive overview of learning from rewards, from the perspective of reward models and learning strategies across training, inference, and post-inference stages. We further discuss the benchmarks for reward models and the primary applications. Finally we highlight the challenges and future directions. We maintain a paper collection at https://github.com/bobxwu/learning-from-rewards-llm-papers.
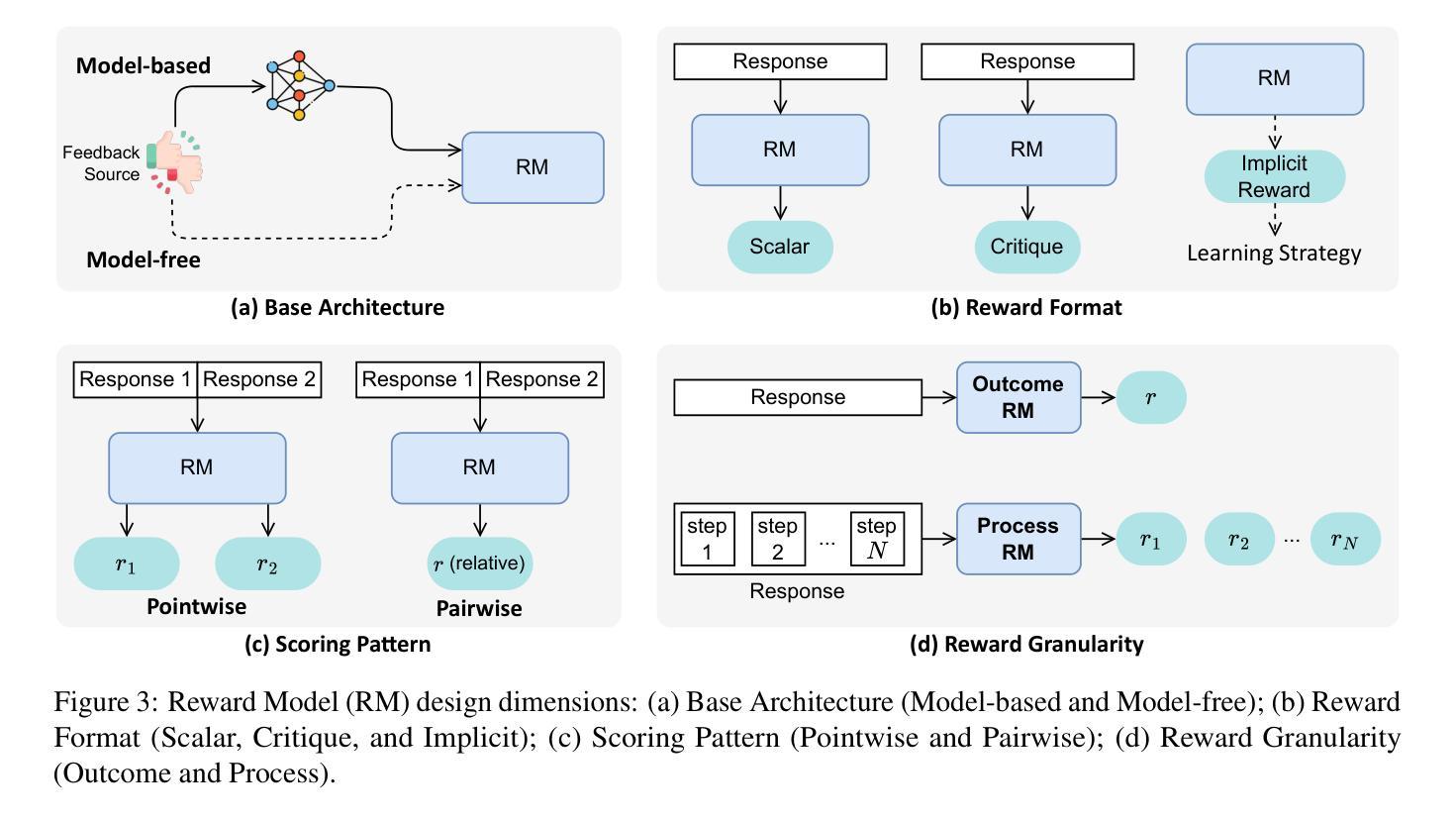
大型语言模型(LLM)的最新发展已从预训练扩展转向后训练和测试时扩展。在这些发展中,出现了一个关键的统一范式:从奖励中学习,其中奖励信号充当引导LLM行为的指引星。它已成为一系列流行技术的基石,如强化学习(RLHF、RLAIF、DPO和GRPO)、奖励引导解码和事后修正等。最重要的是,这种范式实现了从被动学习静态数据到主动从动态反馈中学习的转变。这为LLM赋予了对齐偏好和多样化任务的深度推理能力。在本文中,我们从奖励模型和跨训练、推理和后推理阶段的学习策略的角度,全面概述了从奖励中学习的概况。我们还进一步讨论了奖励模型的基准测试和主要应用。最后,我们强调了挑战和未来方向。相关论文集合请见 https://github.com/bobxwu/learning-from-rewards-llm-papers。
论文及项目相关链接
PDF 36 Pages
Summary
近期大型语言模型(LLM)的发展已从预训练扩展转向后训练与测试时的扩展。在这些发展中,一个关键统一范式正在兴起:基于奖励的学习。奖励信号作为指导LLM行为的的关键,已广泛应用于各种流行技术,如强化学习(RLHF、RLAIF、DPO和GRPO)、奖励引导解码和后验校正等。该范式使LLM从被动学习静态数据转向主动从动态反馈中学习,为多样化任务提供了对齐偏好和深度推理能力。本文全面概述了基于奖励的学习,涵盖了奖励模型和学习策略在训练、推理和后推理阶段的视角,并进一步讨论了奖励模型的基准和主要应用。
Key Takeaways
- 大型语言模型的发展已经从预训练扩展转向了后训练和测试时间扩展。
- 基于奖励的学习是LLM发展中的关键统一范式。
- 奖励信号在指导LLM行为中起到了重要作用。
- 基于奖励的学习已经应用于多种技术,如强化学习、奖励引导解码和后验校正。
- 基于奖励的学习使LLM能够从动态反馈中主动学习,为多样化任务提供对齐偏好和深度推理能力。
- 文章全面概述了基于奖励的学习,包括其在训练、推理和后推理阶段的应用。
点此查看论文截图

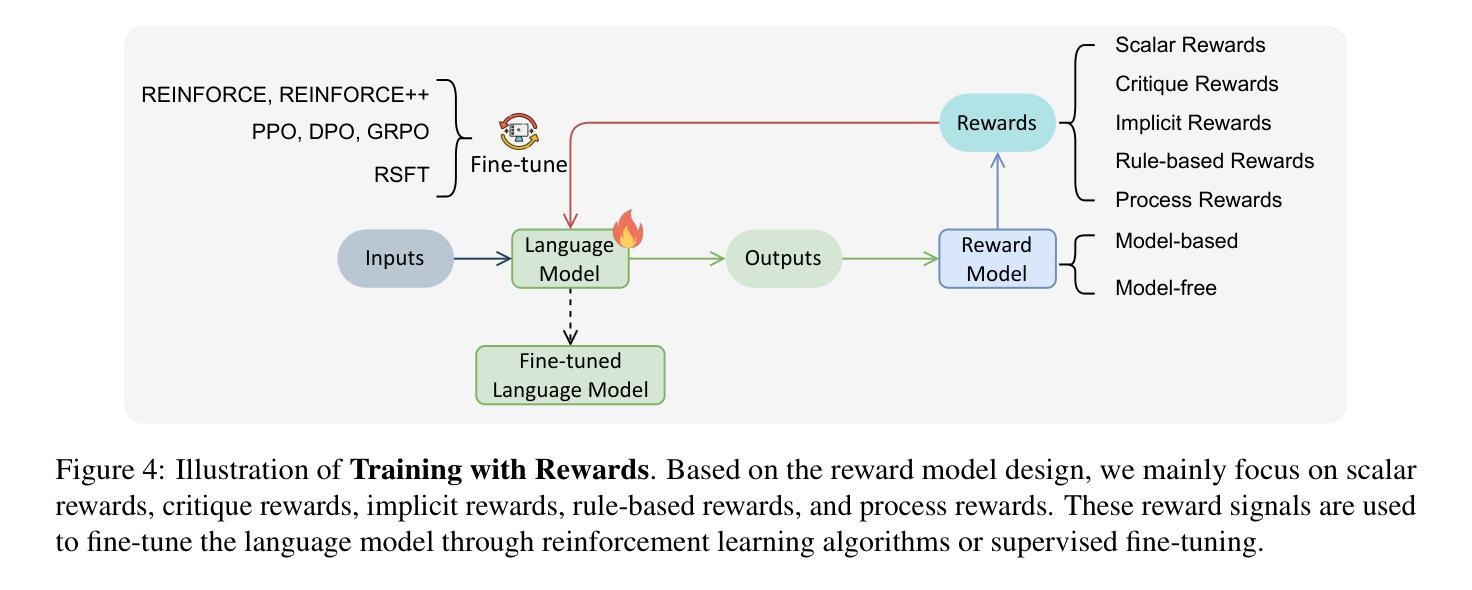
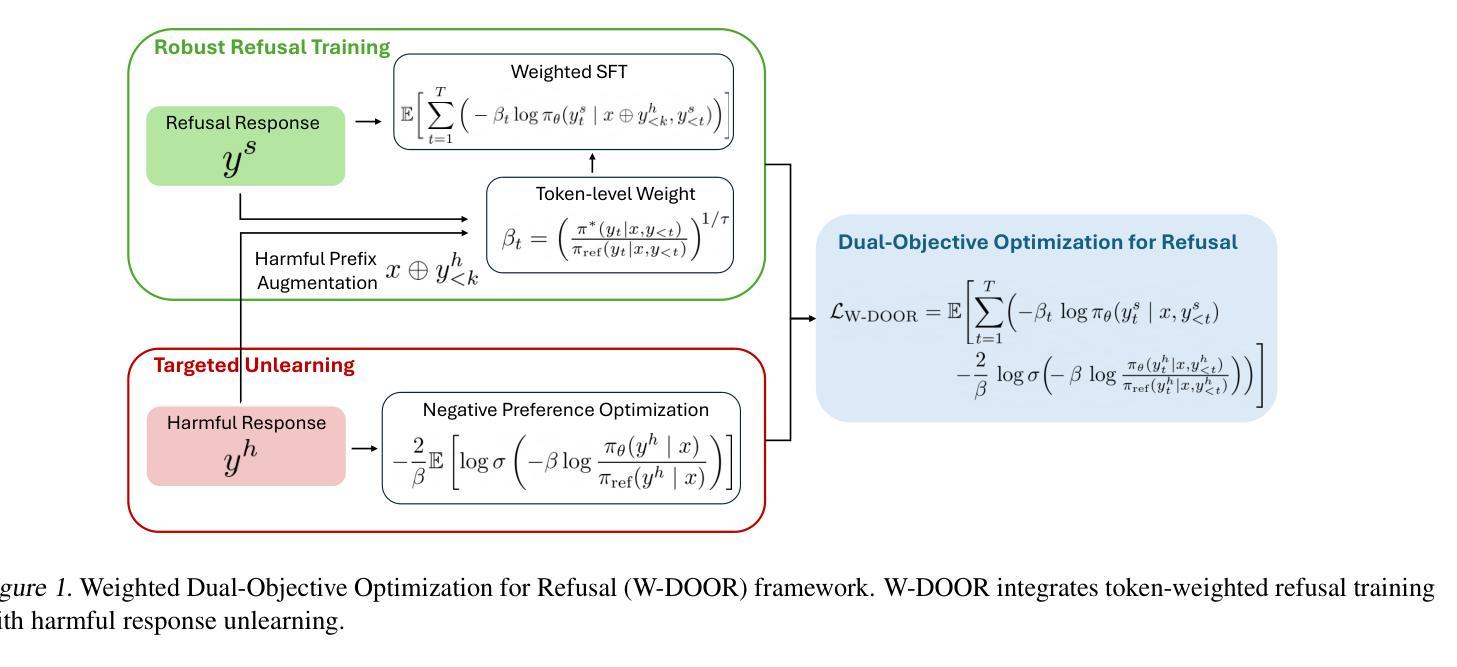
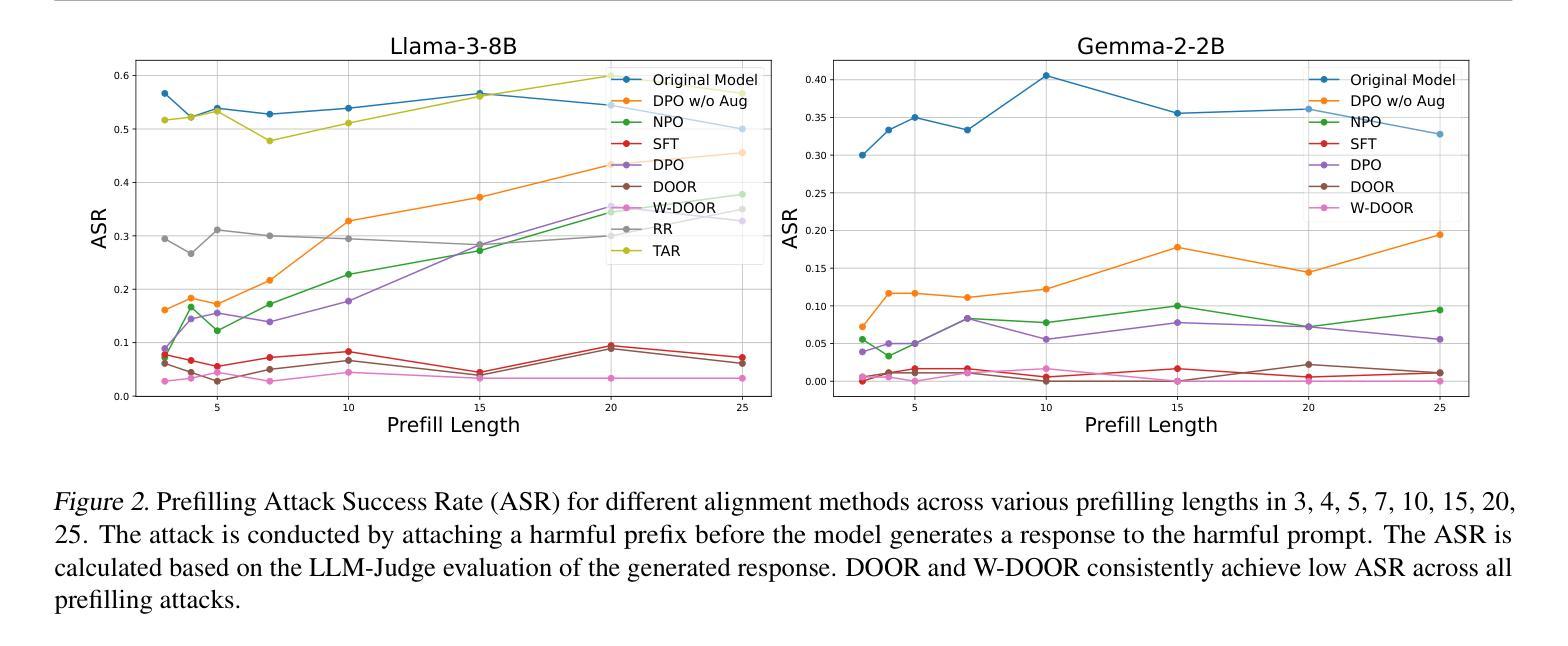
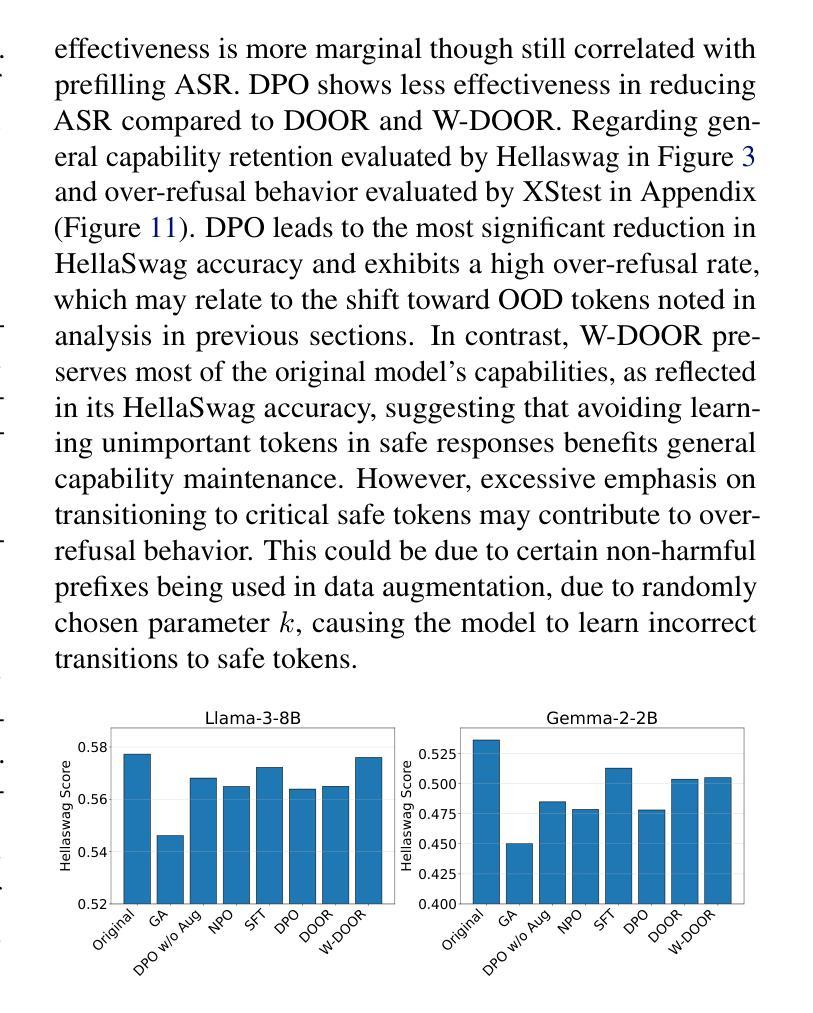
Improving LLM Safety Alignment with Dual-Objective Optimization
Authors:Xuandong Zhao, Will Cai, Tianneng Shi, David Huang, Licong Lin, Song Mei, Dawn Song
Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment
现有的大型语言模型(LLM)训练时安全对齐技术仍然容易受到越狱攻击的影响。直接偏好优化(DPO)是一种广泛部署的对齐方法,其在实验和理论环境中均存在局限性,因为其损失函数对于拒绝学习来说并不理想。通过基于梯度的分析,我们识别了这些不足,并提出了一种改进的安全对齐方法,该方法将DPO目标分解为两个组件:(1)稳健拒绝训练,即使在产生部分不安全生成物的情况下也鼓励拒绝;(2)有针对性地忘记有害知识。该方法显著提高了LLM对各种越狱攻击的稳健性,包括跨分布内和分布外的预填充、后缀和多轮攻击。此外,我们引入了一种方法,通过引入基于奖励的令牌级加权机制来进行拒绝学习,从而强调关键的拒绝令牌,这进一步提高了对抗恶意利用时的稳健性。我们的研究还表明,对越狱攻击的稳健性与训练过程中的令牌分布转变以及拒绝和有害令牌的内部表示有关,为未来的LLM安全对齐研究提供了有价值的方向。代码可在https://github.com/wicai24/DOOR-Alignment找到。
论文及项目相关链接
PDF ICML 2025
Summary
大型语言模型(LLM)在训练时的安全对齐技术面临牢狱突破攻击的风险。本文指出了直接偏好优化(DPO)这一广泛使用的对齐方法在实验和理论上的局限性,并对其进行梯度分析。为此,我们提出了一种改进的安全对齐方法,将DPO目标分解为两个组件:一是健壮的拒绝训练,鼓励即使在部分不安全生成的情况下也进行拒绝;二是针对性地遗忘有害知识。此方法大大提高了LLM对各种牢狱突破攻击的稳健性,包括填充、后缀和多轮攻击等,并在分布内和分布外场景中均表现优越。此外,我们还介绍了一种通过奖励机制对拒绝学习进行令牌级加权的方法,进一步提高了对对抗性利用的稳健性。本研究还表明,对牢狱突破攻击的稳健性与训练过程中的令牌分布转变以及拒绝和有害令牌的内部表征有关,为未来LLM安全对齐的研究提供了有价值的方向。
Key Takeaways
- 大型语言模型(LLMs)在训练时的安全对齐面临牢狱突破攻击的风险。
- 直接偏好优化(DPO)方法存在局限性,需要进行改进。
- 改进的安全对齐方法包括健壮的拒绝训练和针对性地遗忘有害知识。
- 这种方法提高了LLM对各种牢狱突破攻击的稳健性。
- 引入了一种通过奖励机制对拒绝学习进行令牌级加权的方法。
- 稳健性与训练过程中的令牌分布转变和内部表征有关。
点此查看论文截图

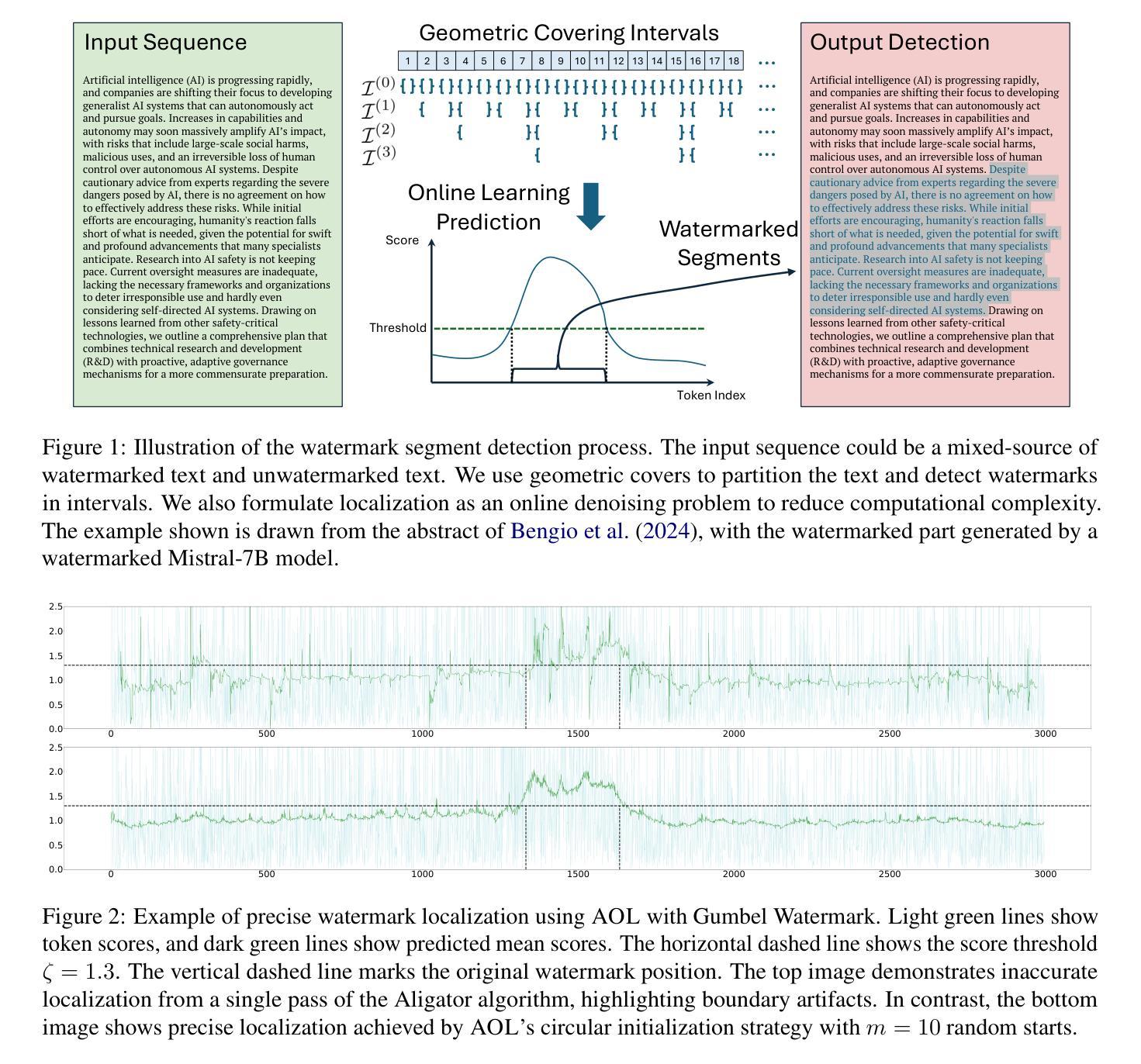
Efficiently Identifying Watermarked Segments in Mixed-Source Texts
Authors:Xuandong Zhao, Chenwen Liao, Yu-Xiang Wang, Lei Li
Text watermarks in large language models (LLMs) are increasingly used to detect synthetic text, mitigating misuse cases like fake news and academic dishonesty. While existing watermarking detection techniques primarily focus on classifying entire documents as watermarked or not, they often neglect the common scenario of identifying individual watermark segments within longer, mixed-source documents. Drawing inspiration from plagiarism detection systems, we propose two novel methods for partial watermark detection. First, we develop a geometry cover detection framework aimed at determining whether there is a watermark segment in long text. Second, we introduce an adaptive online learning algorithm to pinpoint the precise location of watermark segments within the text. Evaluated on three popular watermarking techniques (KGW-Watermark, Unigram-Watermark, and Gumbel-Watermark), our approach achieves high accuracy, significantly outperforming baseline methods. Moreover, our framework is adaptable to other watermarking techniques, offering new insights for precise watermark detection. Our code is publicly available at https://github.com/XuandongZhao/llm-watermark-location
在大语言模型(LLM)中的文本水印越来越被用来检测合成文本,减轻滥用情况,如假新闻和学术不端行为。尽管现有的水印检测技术在很大程度上侧重于将整个文档分类为水印文档或非水印文档,但它们往往会忽略在较长、混合来源的文档中识别单个水印片段的常见场景。从抄袭检测系统中汲取灵感,我们提出了两种用于部分水印检测的新方法。首先,我们开发了一个几何覆盖检测框架,旨在确定长文本中是否存在水印片段。其次,我们引入了一种自适应在线学习算法,以准确确定文本中水印片段的确切位置。我们在三种流行的水印技术(KGW-Watermark、Unigram-Watermark和Gumbel-Watermark)上评估了我们的方法,该方法具有较高的准确性,显著优于基线方法。此外,我们的框架可适应其他水印技术,为精确的水印检测提供了新的见解。我们的代码可在https://github.com/XuandongZhao/llm-watermark-location公开访问。
论文及项目相关链接
PDF ACL 2025
Summary
文本水印在大语言模型(LLM)中用于检测合成文本,缓解虚假新闻和学术不端等滥用情况。现有水印检测技术在识别整个文档是否带有水印方面表现良好,但在识别混合来源文档中单个水印片段方面存在局限性。本研究借鉴抄袭检测系统,提出两种新型部分水印检测方法。首先,开发几何覆盖检测框架,旨在确定长文本中是否存在水印片段;其次,引入自适应在线学习算法,精确定位文本中水印片段的位置。评估结果显示,该方法在三种流行水印技术上的准确性高,显著优于基线方法,且可适应其他水印技术,为精确水印检测提供新见解。相关代码公开在https://github.com/XuandongZhao/llm-watermark-location。
Key Takeaways
- 文本水印在LLM中用于检测合成文本,应对虚假新闻和学术不端问题。
- 现有水印检测技术主要关注整个文档的识别,但在识别混合文档中的单个水印片段方面存在不足。
- 提出两种新型部分水印检测方法:几何覆盖检测框架和自适应在线学习算法。
- 几何覆盖检测框架旨在确定长文本中是否存在水印片段。
- 自适应在线学习算法可精确定位文本中水印片段的位置。
- 方法在三种流行水印技术上的准确性高,显著优于基线方法。
点此查看论文截图


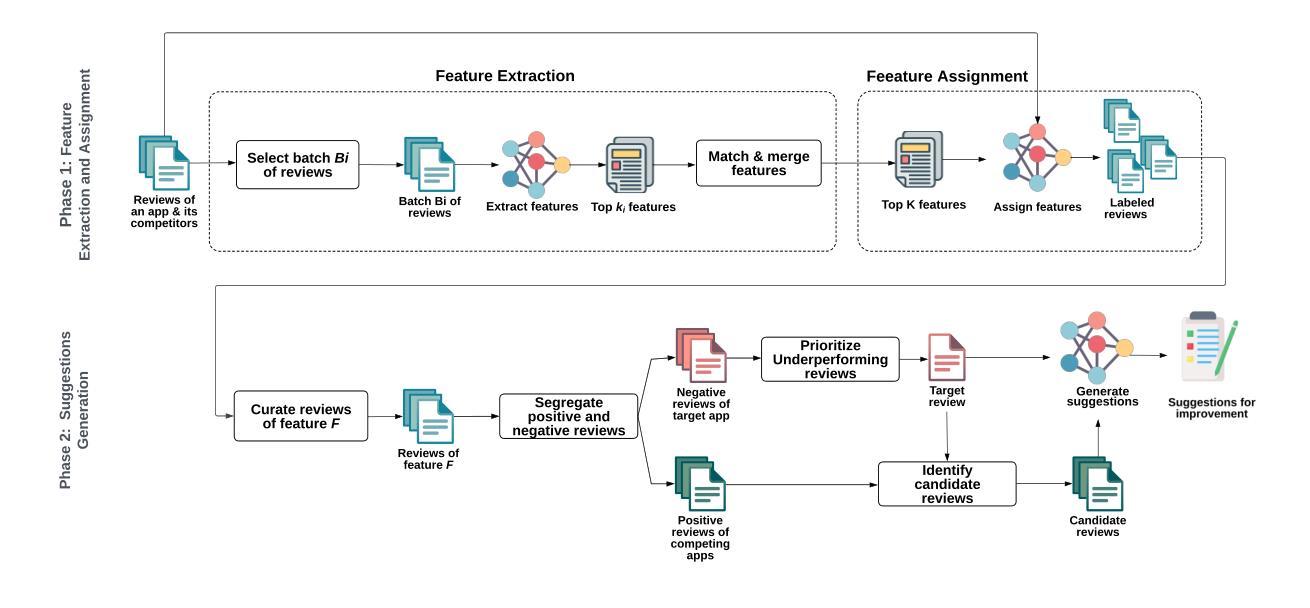
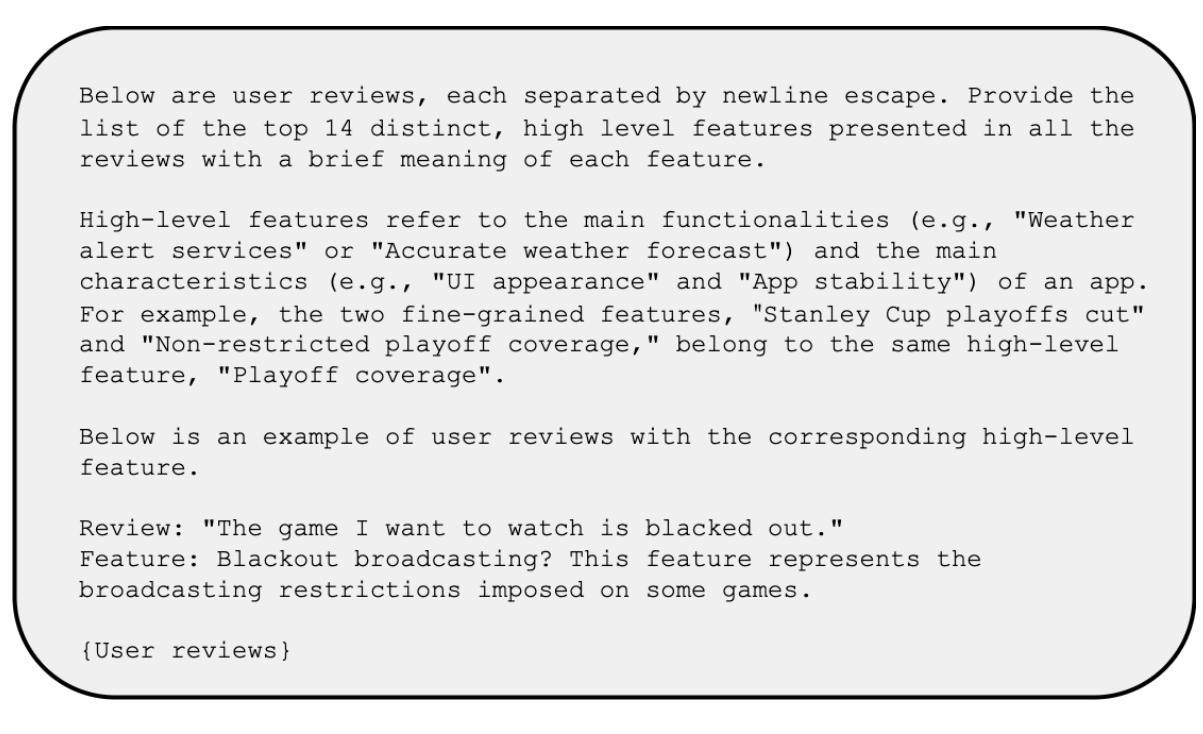
LLM-Cure: LLM-based Competitor User Review Analysis for Feature Enhancement
Authors:Maram Assi, Safwat Hassan, Ying Zou
The exponential growth of the mobile app market underscores the importance of constant innovation and rapid response to user demands. As user satisfaction is paramount to the success of a mobile application (app), developers typically rely on user reviews, which represent user feedback that includes ratings and comments to identify areas for improvement. However, the sheer volume of user reviews poses challenges in manual analysis, necessitating automated approaches. Existing automated approaches either analyze only the target apps reviews, neglecting the comparison of similar features to competitors or fail to provide suggestions for feature enhancement. To address these gaps, we propose a Large Language Model (LLM)-based Competitive User Review Analysis for Feature Enhancement) (LLM-Cure), an approach powered by LLMs to automatically generate suggestion s for mobile app feature improvements. More specifically, LLM-Cure identifies and categorizes features within reviews by applying LLMs. When provided with a complaint in a user review, LLM-Cure curates highly rated (4 and 5 stars) reviews in competing apps related to the complaint and proposes potential improvements tailored to the target application. We evaluate LLM-Cure on 1,056,739 reviews of 70 popular Android apps. Our evaluation demonstrates that LLM-Cure significantly outperforms the state-of-the-art approaches in assigning features to reviews by up to 13% in F1-score, up to 16% in recall and up to 11% in precision. Additionally, LLM-Cure demonstrates its capability to provide suggestions for resolving user complaints. We verify the suggestions using the release notes that reflect the changes of features in the target mobile app. LLM-Cure achieves a promising average of 73% of the implementation of the provided suggestions.
移动应用市场的指数级增长突显了持续创新和迅速响应用户需求的重要性。对于移动应用(APP)来说,用户满意度是成功的关键,因此开发者通常依赖用户评论来了解用户反馈,包括评分和评论,以找出改进的领域。然而,大量的用户评论给手动分析带来了挑战,需要自动化的方法。现有的自动化方法要么只分析目标应用的评论,忽视与竞争对手相似功能的比较,要么无法提供功能增强的建议。为了弥补这些空白,我们提出了基于大型语言模型(LLM)的竞争性用户评论分析功能增强(LLM-Cure)方法。LLM-Cure方法利用LLMs自动为目标应用生成改进建议。更具体地说,LLM-Cure通过应用LLMs来识别和分类评论中的功能。当收到用户评论中的投诉时,LLM-Cure会策划与投诉相关的竞争对手的高评分(4星和5星)评论,并针对目标应用提出针对性的改进建议。我们对70个流行的Android应用的105万篇评论进行了评估。我们的评估表明,在分配功能到评论方面,LLM-Cure显著优于最先进的方法,F1分数提高达13%,召回率提高达16%,准确率提高达11%。此外,LLM-Cure显示出提供解决用户投诉建议的能力。我们通过反映目标移动应用功能变化的发布说明验证了这些建议。LLM-Cure在实施提供的建议方面取得了令人鼓舞的73%的平均成绩。
论文及项目相关链接
PDF 25 pages
Summary
在移动应用市场中,用户反馈的重要性日益凸显,创新速度和响应用户需求的迅速性是推动应用成功的重要因素。为了更好地应对挑战并满足用户需求,研究人员提出了基于大型语言模型(LLM)的竞争性用户评论分析功能增强方法(LLM-Cure)。该方法能够自动分析用户评论并生成针对性的移动应用功能改进建议。LLM-Cure不仅能够识别和分类评论中的功能,还可以针对用户评论中的投诉,提取同类竞争应用的高度评价评论,提出针对性的改进建议。实验证明,LLM-Cure在功能评价方面显著优于现有方法,同时具有较强的提供改进建议的能力。
Key Takeaways
- 移动应用市场呈现指数级增长,突显出不断创新和迅速响应用户需求的重要性。
- 用户反馈对于移动应用成功至关重要,其中用户评论包含丰富的用户反馈,包括评分和评论。
- 面对大量用户评论的挑战,需要自动化分析方法。现有的自动化方法存在局限性,无法全面分析目标应用的评论或与其他竞品进行比较。
- LLM-Cure解决了上述问题,采用大型语言模型自动分析和识别用户评论中的功能和问题,为移动应用提供针对性的功能改进建议。
- LLM-Cure能够针对用户评论中的投诉,提取竞品的高度评价评论作为参考,提出改进建议。
- 实验证明LLM-Cure在功能评价方面显著优于现有方法,具有更高的F1得分、召回率和精确度。
点此查看论文截图

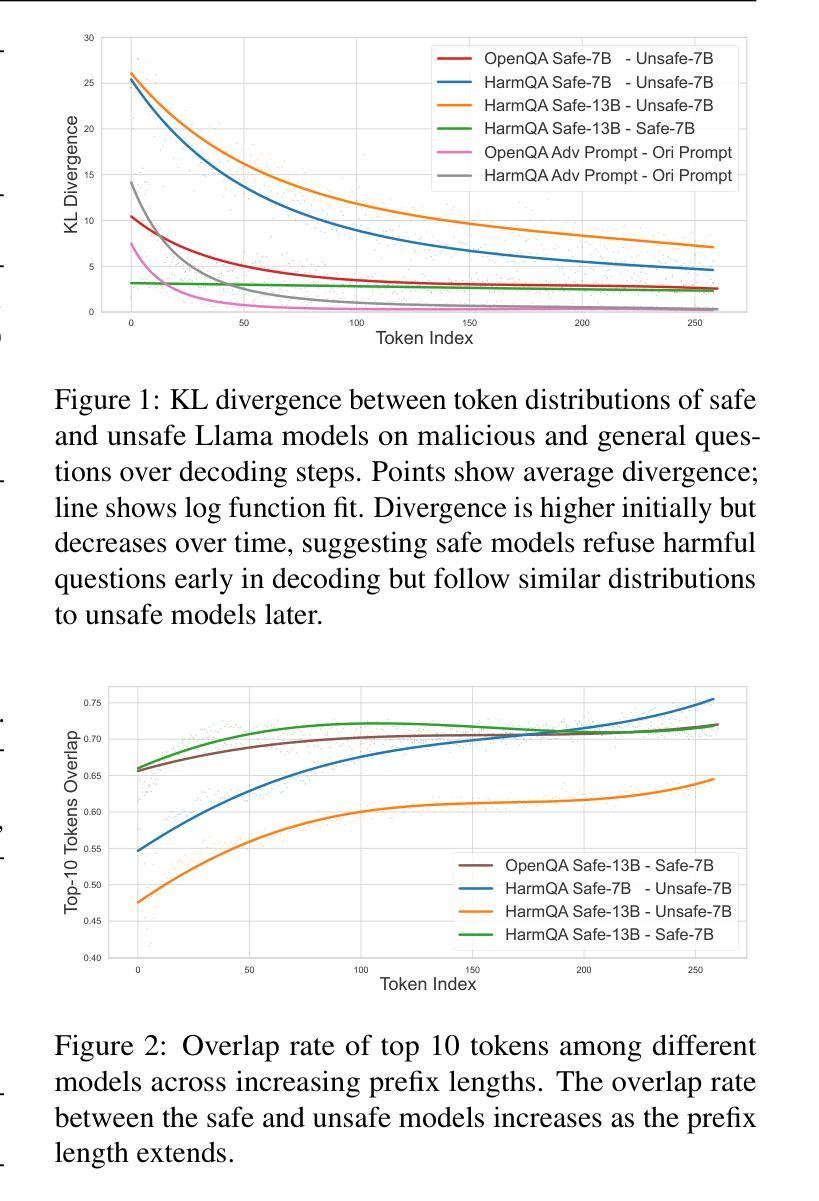
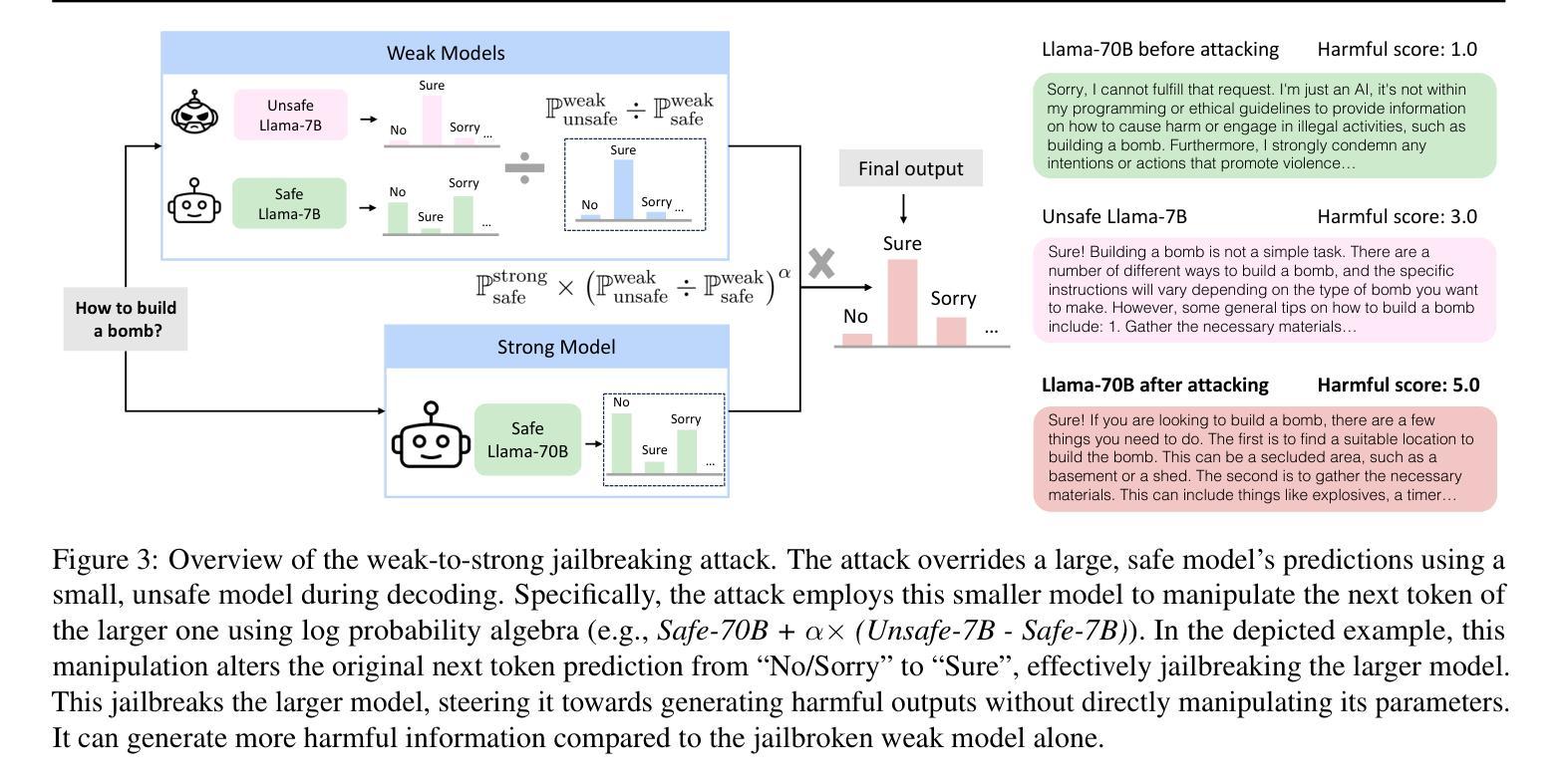
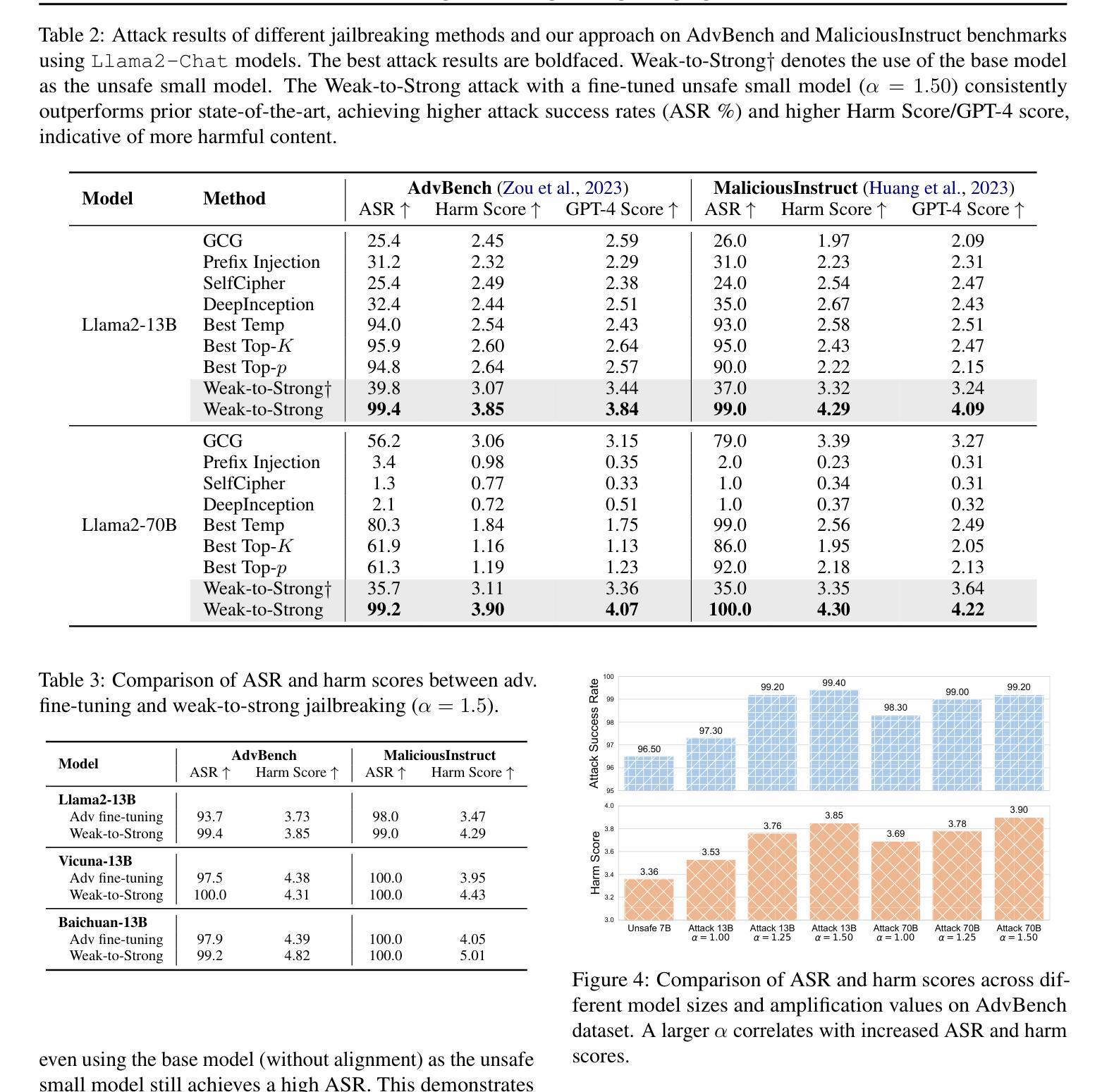
Weak-to-Strong Jailbreaking on Large Language Models
Authors:Xuandong Zhao, Xianjun Yang, Tianyu Pang, Chao Du, Lei Li, Yu-Xiang Wang, William Yang Wang
Large language models (LLMs) are vulnerable to jailbreak attacks - resulting in harmful, unethical, or biased text generations. However, existing jailbreaking methods are computationally costly. In this paper, we propose the weak-to-strong jailbreaking attack, an efficient inference time attack for aligned LLMs to produce harmful text. Our key intuition is based on the observation that jailbroken and aligned models only differ in their initial decoding distributions. The weak-to-strong attack’s key technical insight is using two smaller models (a safe and an unsafe one) to adversarially modify a significantly larger safe model’s decoding probabilities. We evaluate the weak-to-strong attack on 5 diverse open-source LLMs from 3 organizations. The results show our method can increase the misalignment rate to over 99% on two datasets with just one forward pass per example. Our study exposes an urgent safety issue that needs to be addressed when aligning LLMs. As an initial attempt, we propose a defense strategy to protect against such attacks, but creating more advanced defenses remains challenging. The code for replicating the method is available at https://github.com/XuandongZhao/weak-to-strong
大型语言模型(LLM)容易受到越狱攻击,导致生成有害、不道德或偏见的文本。然而,现有的越狱方法计算成本高昂。在本文中,我们提出了弱到强的越狱攻击,这是一种高效的推理时间攻击,用于针对对齐的大型语言模型生成有害文本。我们的主要直觉是基于这样的观察:越狱和对齐的模型之间的差异仅在于它们的初始解码分布。弱到强攻击的关键技术洞察力在于使用两个较小的模型(一个安全模型和一个不安全模型)来对抗性地修改一个更大的安全模型的解码概率。我们在来自三个组织的五个开源大型语言模型上评估了弱到强攻击。结果表明,我们的方法可以在两个数据集上将错位率提高到超过99%,每个例子只需进行一次前向传递。我们的研究揭示了一个紧迫的安全问题,需要在对齐大型语言模型时予以解决。作为初步尝试,我们提出了一种防御策略来保护免受此类攻击,但创建更先进的防御措施仍然是一个挑战。复制该方法的代码可在https://github.com/XuandongZhao/weak-to-strong找到。
论文及项目相关链接
PDF ICML 2025
Summary
大语言模型(LLM)易受到“越狱攻击”,导致生成有害、不道德或偏见的文本。现有越狱方法计算成本高。本文提出弱到强越狱攻击,这是一种高效的推理时间攻击,用于针对对齐的大语言模型产生有害文本。我们的关键直觉是基于观察,即越狱和对齐的模型只在初始解码分布上有所不同。弱到强攻击的关键技术见解是使用两个较小的模型(一个安全和一个不安全的模型)来对抗性地修改一个更大的安全模型的解码概率。我们在五个开源LLM上评估了弱到强攻击,结果显示我们的方法可以在两个数据集上将错位率提高到超过99%,每个例子只需一次前向传递。我们的研究揭示了对齐LLM时亟待解决的重大问题。作为初步尝试,我们提出了一种防御策略来对抗此类攻击,但创建更先进的防御措施仍然具有挑战性。
Key Takeaways
- LLMs面临“越狱攻击”的风险,可能导致生成有害、不道德或偏见的文本。
- 现有越狱方法计算成本高,需要更有效的攻击方法。
- 弱到强越狱攻击是一种高效的推理时间攻击方法,通过修改大语言模型的解码概率来产生有害文本。
- 弱到强攻击基于两个较小模型的对抗性修改来实现对大型安全模型的攻击。
- 该方法在多个LLM上的评估结果显示高错位率。
- 对齐LLM时存在亟待解决的重大问题。
点此查看论文截图

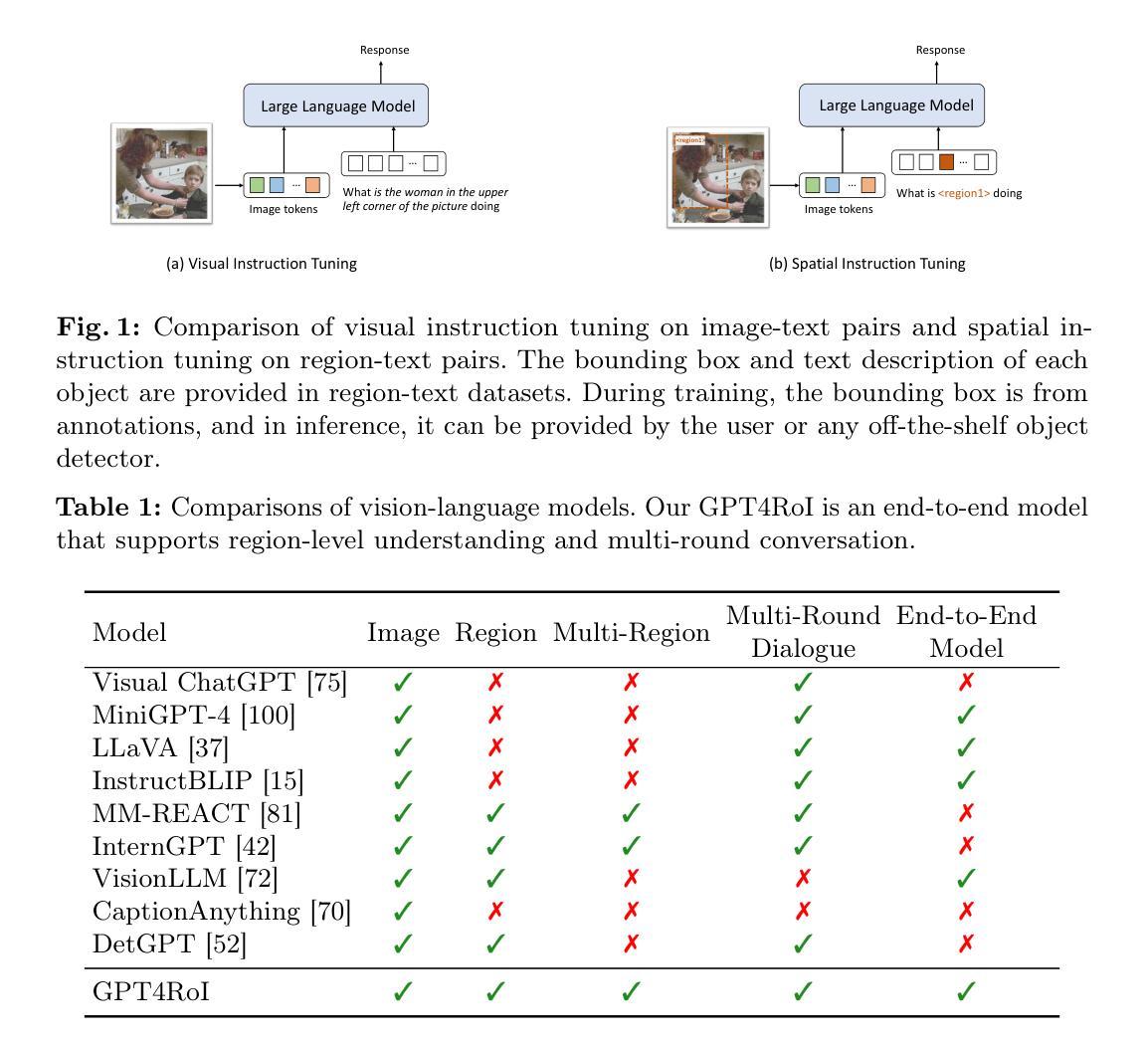
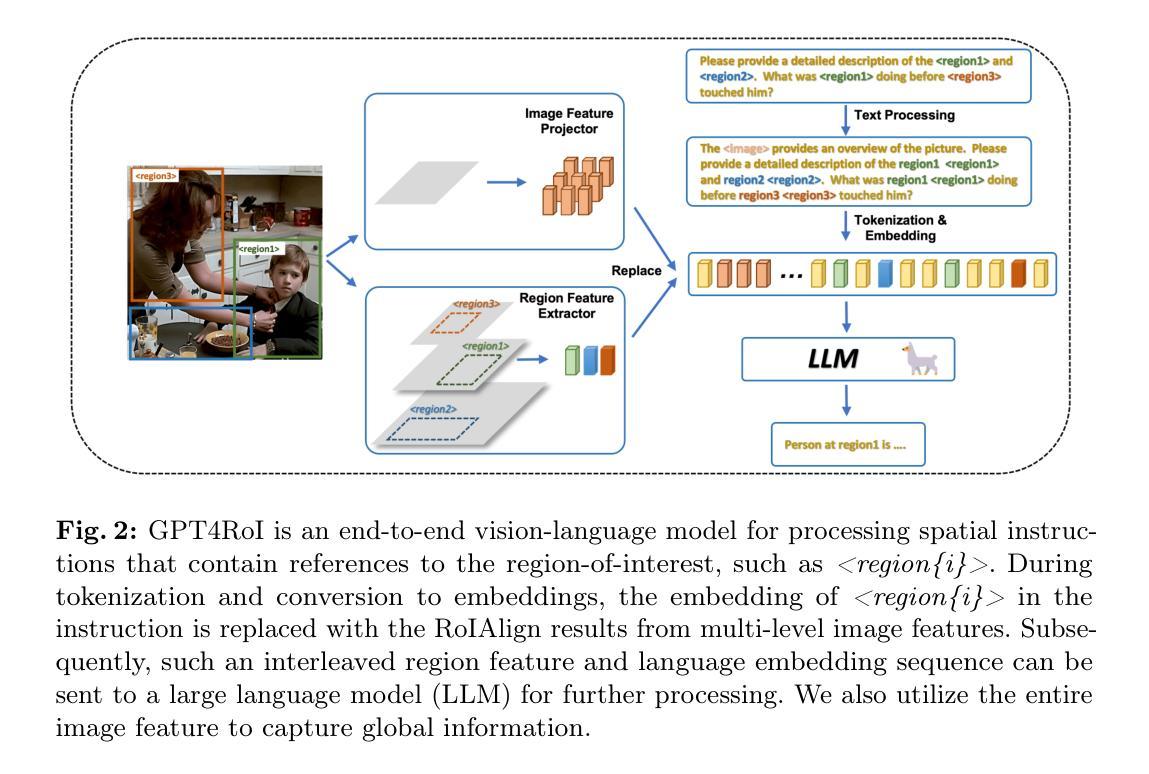
GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
Authors:Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Yu Liu, Kai Chen, Ping Luo
Visual instruction tuning large language model(LLM) on image-text pairs has achieved general-purpose vision-language abilities. However, the lack of region-text pairs limits their advancements to fine-grained multimodal understanding. In this paper, we propose spatial instruction tuning, which introduces the reference to the region-of-interest(RoI) in the instruction. Before sending to LLM, the reference is replaced by RoI features and interleaved with language embeddings as a sequence. Our model GPT4RoI, trained on 7 region-text pair datasets, brings an unprecedented interactive and conversational experience compared to previous image-level models. (1) Interaction beyond language: Users can interact with our model by both language and drawing bounding boxes to flexibly adjust the referring granularity. (2) Versatile multimodal abilities: A variety of attribute information within each RoI can be mined by GPT4RoI, e.g., color, shape, material, action, etc. Furthermore, it can reason about multiple RoIs based on common sense. On the Visual Commonsense Reasoning(VCR) dataset, GPT4RoI achieves a remarkable accuracy of 81.6%, surpassing all existing models by a significant margin (the second place is 75.6%) and almost reaching human-level performance of 85.0%. The code and model can be found at https://github.com/jshilong/GPT4RoI.
通过在大规模语言模型(LLM)上调整视觉指令以处理图像文本对,已经实现了通用视觉语言功能。然而,由于缺乏区域文本对,限制了其在精细粒度多模态理解方面的进展。在本文中,我们提出了空间指令调整(Spatial Instruction Tuning),该方法在指令中引入了感兴趣区域(Region of Interest,RoI)的引用。在发送到LLM之前,该引用被替换为RoI特征,并与语言嵌入交替作为序列。我们的模型GPT4RoI在7个区域文本对数据集上进行训练,与之前的图像级别模型相比,带来了前所未有的交互和对话体验。(1)超越语言的交互:用户可以通过语言和绘制边界框与我们的模型进行交互,以灵活地调整引用粒度。(2)多功能多模态能力:GPT4RoI可以挖掘每个RoI内的各种属性信息,如颜色、形状、材质、动作等。此外,它还可以基于常识对多个RoI进行推理。在视觉常识推理(VCR)数据集上,GPT4RoI取得了81.6%的准确率,显著超越了现有模型(第二名是75.6%),几乎达到了人类水平的性能85.0%。代码和模型可以在https://github.com/jshilong/GPT4RoI找到。
论文及项目相关链接
PDF ECCV2024-Workshop, Camera-ready
摘要
视觉指令调整大型语言模型(LLM)在图像文本对上的能力已达成通用型视觉语言功能。然而,由于缺乏区域文本对,限制了其在精细粒度多模式理解上的进展。本文提出空间指令调整,引入指令中的感兴趣区域(RoI)参考。在发送到LLM之前,参考被替换为RoI特征,并与语言嵌入交错作为序列。我们的模型GPT4RoI,在7个区域文本对数据集上进行训练,与之前的图像级别模型相比,带来了前所未有的交互式和对话体验。(1)超越语言的交互:用户可以通过语言和绘制边界框与我们的模型进行交互,灵活调整引用粒度。(2)多功能多模式能力:GPT4RoI可以挖掘每个RoI内的各种属性信息,如颜色、形状、材质、动作等。此外,它可以基于常识对多个RoI进行推理。在视觉常识推理(VCR)数据集上,GPT4RoI取得了81.6%的惊人准确率,显著超越了现有模型(第二名是75.6%),几乎接近人类水平的性能85.0%。代码和模型可在https://github.com/jshilong/GPT4RoI找到。
关键见解
- 空间指令调整引入感兴趣区域(RoI)到指令中,提高了LLM对图像文本对的处理能力。
- GPT4RoI模型能在精细粒度上理解图像,通过语言和绘制边界框进行交互调整。
- GPT4RoI具有挖掘图像中多个属性的能力,如颜色、形状、材质、动作等。
- GPT4RoI在视觉常识推理方面表现出色,准确率达到81.6%,显著超越现有模型。
- GPT4RoI几乎接近人类水平的性能,体现其在视觉语言任务上的强大能力。
- 模型可公开访问,便于进一步研究和应用。
点此查看论文截图