⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
Developing a High-performance Framework for Speech Emotion Recognition in Naturalistic Conditions Challenge for Emotional Attribute Prediction
Authors:Thanathai Lertpetchpun, Tiantian Feng, Dani Byrd, Shrikanth Narayanan
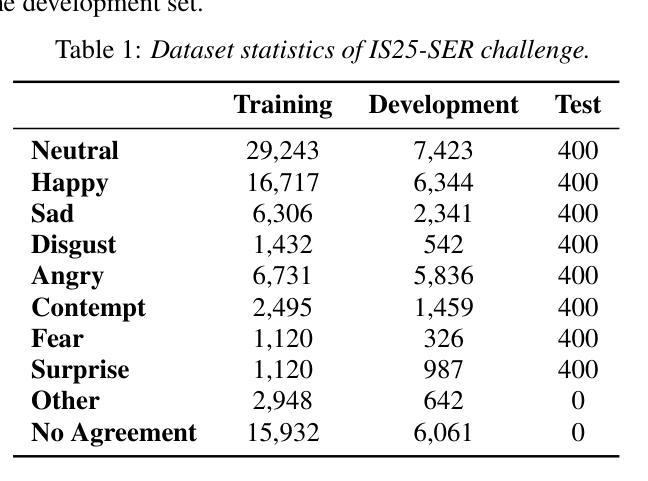
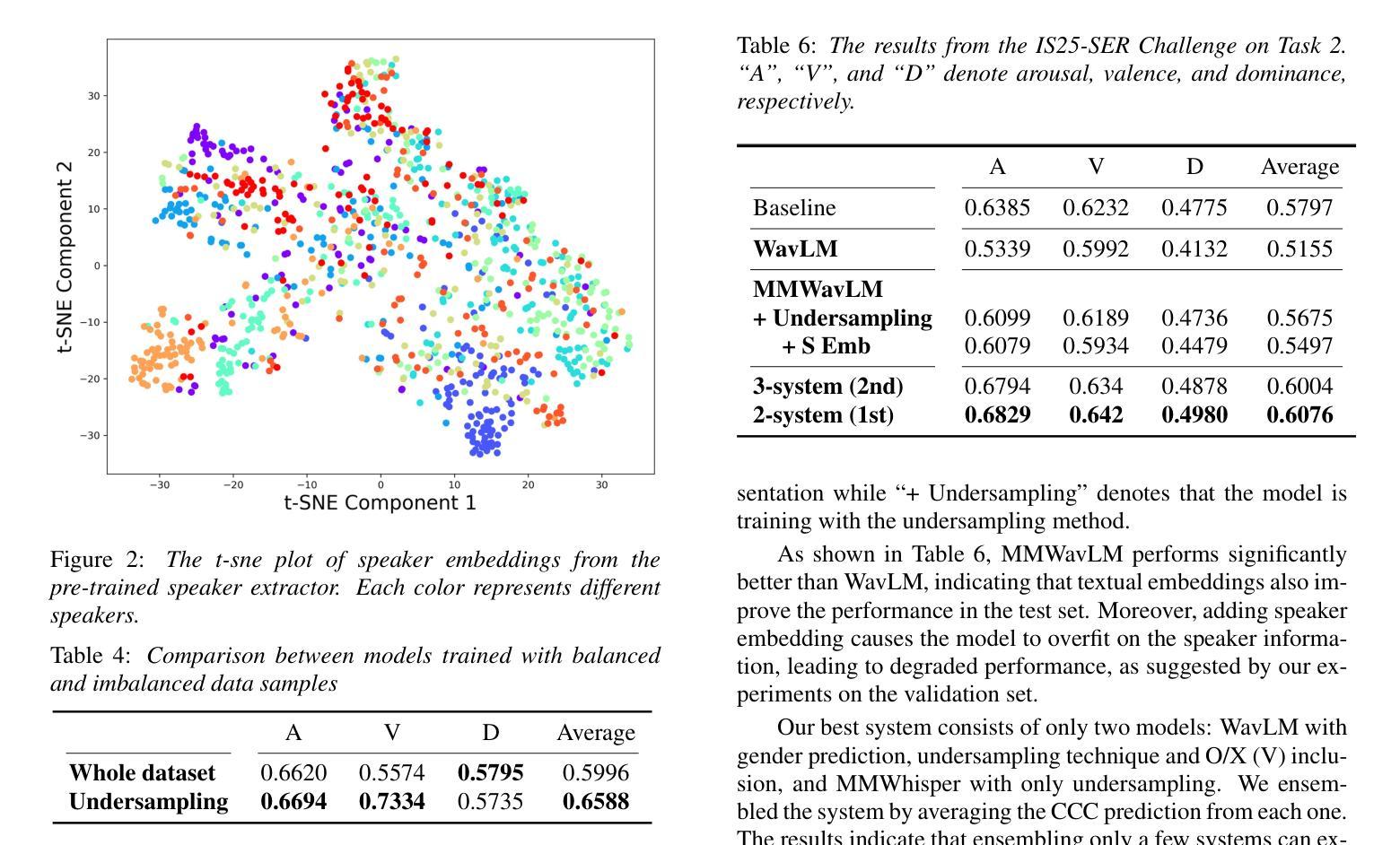
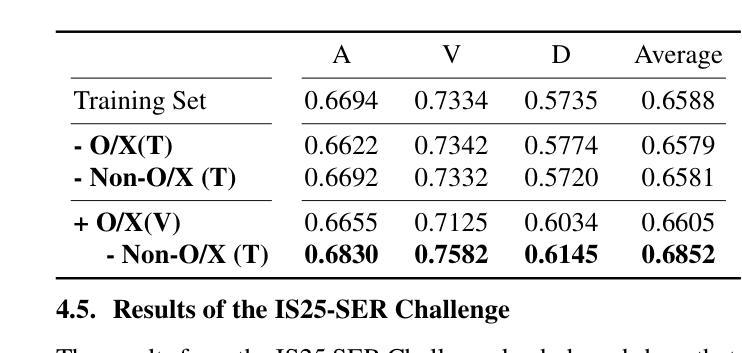
Speech emotion recognition (SER) in naturalistic conditions presents a significant challenge for the speech processing community. Challenges include disagreement in labeling among annotators and imbalanced data distributions. This paper presents a reproducible framework that achieves superior (top 1) performance in the Emotion Recognition in Naturalistic Conditions Challenge (IS25-SER Challenge) - Task 2, evaluated on the MSP-Podcast dataset. Our system is designed to tackle the aforementioned challenges through multimodal learning, multi-task learning, and imbalanced data handling. Specifically, our best system is trained by adding text embeddings, predicting gender, and including Other'' (O) and No Agreement’’ (X) samples in the training set. Our system’s results secured both first and second places in the IS25-SER Challenge, and the top performance was achieved by a simple two-system ensemble.
在自然条件下,语音情感识别(SER)对语音处理领域来说是一个巨大的挑战。挑战包括标注者之间的标签分歧和数据分布不平衡。本文提出了一个可再现的框架,该框架在基于MSP-Podcast数据集的自然条件情感识别挑战(IS25-SER挑战)-任务2中取得了卓越(排名第一)的性能。我们的系统旨在通过多模式学习、多任务学习和处理不平衡数据来解决上述挑战。具体来说,我们最好的系统是通过添加文本嵌入、预测性别以及在训练集中包含“其他”(O)和“无协议”(X)样本进行训练的。我们的系统在IS25-SER挑战中荣获第一和第二名,最佳性能是通过简单的两个系统集合实现的。
论文及项目相关链接
Summary:
文章介绍了在自然条件下的语音情感识别(SER)面临的挑战,包括标注者之间的标签分歧和数据分布不平衡等问题。文章提出了一种可复现的框架,通过多模态学习、多任务学习和处理不平衡数据等技术,实现了在IS25-SER挑战任务2中的卓越性能,并在MSP-Podcast数据集上进行了评估。该系统的改进包括添加文本嵌入、预测性别,以及将“其他”(O)和“无协议”(X)样本纳入训练集。该系统的结果分别在IS25-SER挑战中获得第一名和第二名,最佳性能是通过简单的双系统组合实现的。
Key Takeaways:
- 语音情感识别(SER)在自然条件下面临挑战,包括标注分歧和数据不平衡。
- 文章提出了一种可复现的框架,通过多模态学习、多任务学习和处理不平衡数据技术来解决这些挑战。
- 该系统在MSP-Podcast数据集上进行了评估,并取得了IS25-SER挑战任务2的卓越性能。
- 系统的改进包括添加文本嵌入、预测性别,并将“其他”和“无协议”样本纳入训练集。
- 该系统分别在IS25-SER挑战中获得第一名和第二名。
- 最佳性能是通过简单的双系统组合实现的。
点此查看论文截图


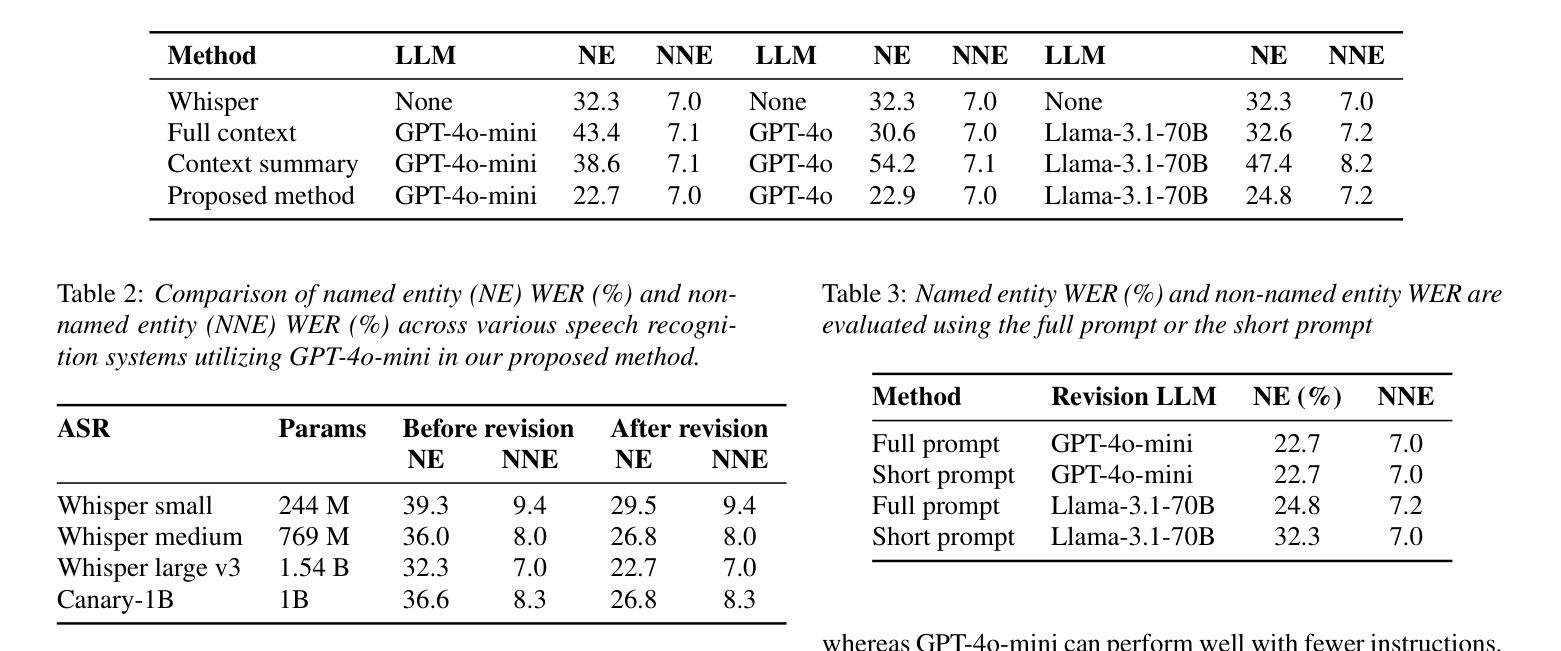
Improving Named Entity Transcription with Contextual LLM-based Revision
Authors:Viet Anh Trinh, Xinlu He, Jacob Whitehill
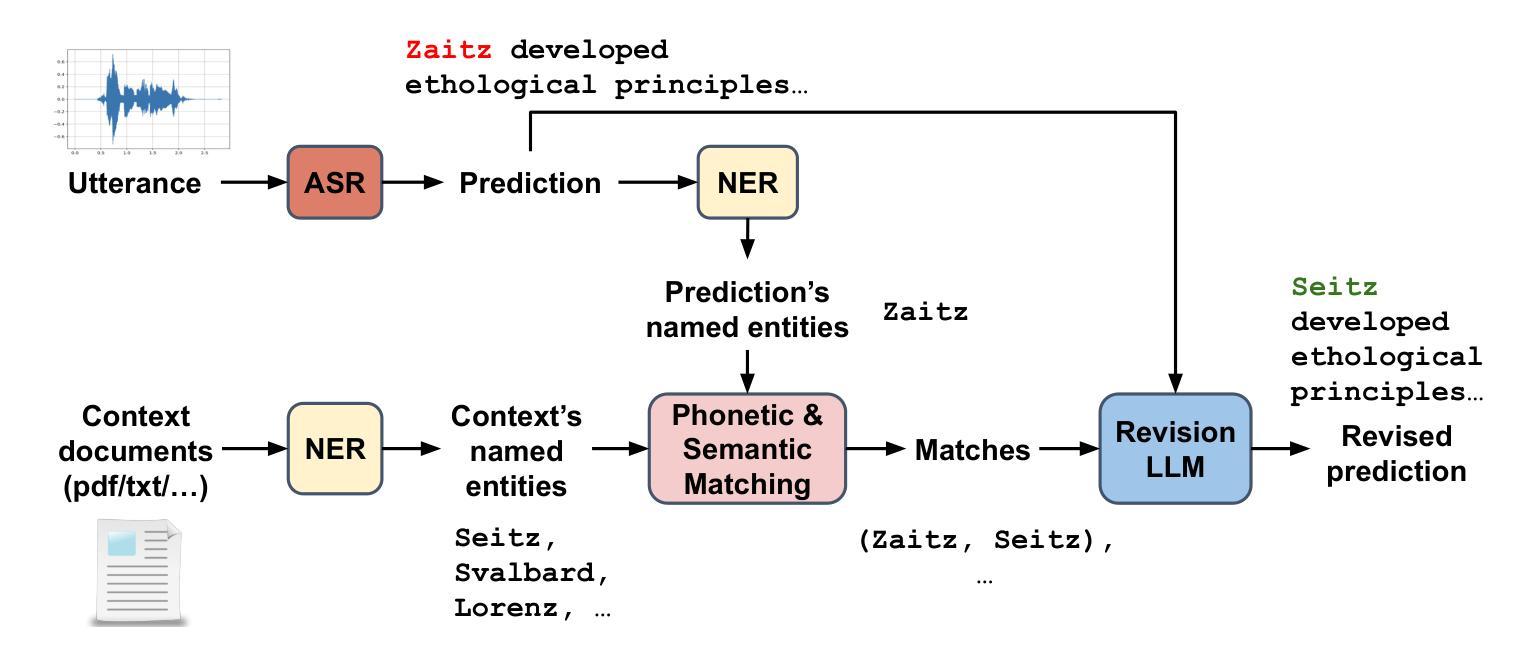
With recent advances in modeling and the increasing amount of supervised training data, automatic speech recognition (ASR) systems have achieved remarkable performance on general speech. However, the word error rate (WER) of state-of-the-art ASR remains high for named entities. Since named entities are often the most critical keywords, misrecognizing them can affect all downstream applications, especially when the ASR system functions as the front end of a complex system. In this paper, we introduce a large language model (LLM) revision mechanism to revise incorrect named entities in ASR predictions by leveraging the LLM’s reasoning ability as well as local context (e.g., lecture notes) containing a set of correct named entities. Finally, we introduce the NER-MIT-OpenCourseWare dataset, containing 45 hours of data from MIT courses for development and testing. On this dataset, our proposed technique achieves up to 30% relative WER reduction for named entities.
随着建模技术的最新进展和监督训练数据的不断增加,自动语音识别(ASR)系统在通用语音上的表现已经相当出色。然而,对于命名实体,最先进的ASR的单词错误率(WER)仍然很高。由于命名实体往往是最重要的关键词,误识别它们会影响所有的下游应用,特别是当ASR系统作为复杂系统的前端时。在本文中,我们引入了一种大型语言模型(LLM)修正机制,利用LLM的推理能力以及包含正确命名实体的局部上下文(例如讲义)来修正ASR预测中的错误命名实体。最后,我们介绍了NER-MIT-OpenCourseWare数据集,其中包含来自MIT课程的45小时数据,用于开发和测试。在该数据集上,我们提出的技术实现了高达30%的命名实体相对WER降低。
论文及项目相关链接
摘要
随着建模技术的最新进展和标注训练数据的不断增加,自动语音识别(ASR)系统在通用语音上的表现已十分出色。然而,对于命名实体,最先进的ASR的单词错误率(WER)仍然较高。由于命名实体通常是至关重要的关键词,误识别它们会对所有下游应用产生影响,尤其是在ASR系统作为复杂系统的前端时。本文引入了一种大型语言模型(LLM)修正机制,利用LLM的推理能力和包含正确命名实体的局部上下文(如讲义)来修正ASR预测中的错误命名实体。最后,我们介绍了NER-MIT-OpenCourseWare数据集,包含来自MIT课程的45小时数据,用于开发和测试。在该数据集上,我们提出的技术实现了高达30%的命名实体相对WER降低。
要点掌握
- 最新建模技术和大量标注训练数据使ASR系统在通用语音上的性能显著提升。
- 命名实体在ASR中的误识别率仍然较高,对下游应用产生重要影响。
- 引入大型语言模型(LLM)修正机制,利用LLM的推理能力和局部上下文来修正ASR中的命名实体错误。
- 介绍了NER-MIT-OpenCourseWare数据集,包含用于开发和测试的MIT课程数据。
- 提出的技术在命名实体识别上实现了显著的WER降低。
- LLM的引入和利用展示了其在语音领域的重要性和潜力。
点此查看论文截图



FedMLAC: Mutual Learning Driven Heterogeneous Federated Audio Classification
Authors:Jun Bai, Rajib Rana, Di Wu, Youyang Qu, Xiaohui Tao, Ji Zhang
Federated Learning (FL) provides a privacy-preserving paradigm for training audio classification (AC) models across distributed clients without sharing raw data. However, Federated Audio Classification (FedAC) faces three critical challenges that substantially hinder performance: data heterogeneity, model heterogeneity, and data poisoning. While prior works have attempted to address these issues, they are typically treated independently, lacking a unified and robust solution suited to real-world federated audio scenarios. To bridge this gap, we propose FedMLAC, a unified mutual learning framework designed to simultaneously tackle these challenges in FedAC. Specifically, FedMLAC introduces a dual-model architecture on each client, comprising a personalized local AC model and a lightweight, globally shared Plug-in model. Through bidirectional knowledge distillation, the Plug-in model enables global knowledge transfer while adapting to client-specific data distributions, thus supporting both generalization and personalization. To further enhance robustness against corrupted audio data, we develop a Layer-wise Pruning Aggregation (LPA) strategy that filters unreliable Plug-in model updates based on parameter deviations during server-side aggregation. Extensive experiments on four diverse audio classification benchmarks, spanning both speech and non-speech tasks, demonstrate that FedMLAC consistently outperforms existing state-of-the-art methods in terms of classification accuracy and robustness to noisy data.
联邦学习(FL)为在分布式客户端上训练音频分类(AC)模型提供了一种保护隐私的范式,无需共享原始数据。然而,联邦音频分类(FedAC)面临三个关键挑战,这些挑战极大地阻碍了性能:数据异质性、模型异质性以及数据中毒。尽管先前的研究工作已经尝试解决这些问题,但它们通常被独立处理,缺乏适合现实联邦音频场景的统一和稳健解决方案。为了弥补这一差距,我们提出了FedMLAC,这是一个统一的相互学习框架,旨在同时解决FedAC中的这些挑战。具体来说,FedMLAC在每个客户端引入双模型架构,包括个性化的本地AC模型和轻量级的全局共享插件模型。通过双向知识蒸馏,插件模型能够实现全球知识转移,同时适应客户端特定数据分布,从而支持通用化和个性化。为了进一步提高对损坏音频数据的稳健性,我们开发了一种分层剪枝聚合(LPA)策略,该策略基于服务器端聚合过程中的参数偏差来过滤不可靠的插件模型更新。在涵盖语音和非语音任务的四个不同的音频分类基准上进行的大量实验表明,FedMLAC在分类准确性和对噪声数据的稳健性方面始终优于现有最先进的方法。
论文及项目相关链接
PDF initial version
Summary
本文介绍了Federated Learning(FL)在音频分类(AC)模型中的应用,并提出了Federated Audio Classification(FedAC)面临的挑战,包括数据异质性、模型异质性以及数据中毒问题。为解决这些问题,提出了一种统一的互学习框架FedMLAC,通过双向知识蒸馏实现全局知识转移和适应客户特定数据分布,同时采用层级剪枝聚合策略提高对抗损坏音频数据的稳健性。实验证明,FedMLAC在分类精度和抗干扰能力方面均优于现有方法。
Key Takeaways
- Federated Learning (FL) 用于在分布式客户端进行音频分类(AC)模型的隐私保护训练。
- FedAC面临数据异质性、模型异质性以及数据中毒三大挑战。
- FedMLAC是一个统一的互学习框架,旨在同时解决FedAC中的这些挑战。
- FedMLAC采用双模型架构,包括个性化本地AC模型和轻量级全局共享插件模型。
- 插件模型通过双向知识蒸馏实现全局知识转移和适应客户特定数据分布。
- FedMLAC采用层级剪枝聚合策略,提高对抗损坏音频数据的稳健性。
点此查看论文截图


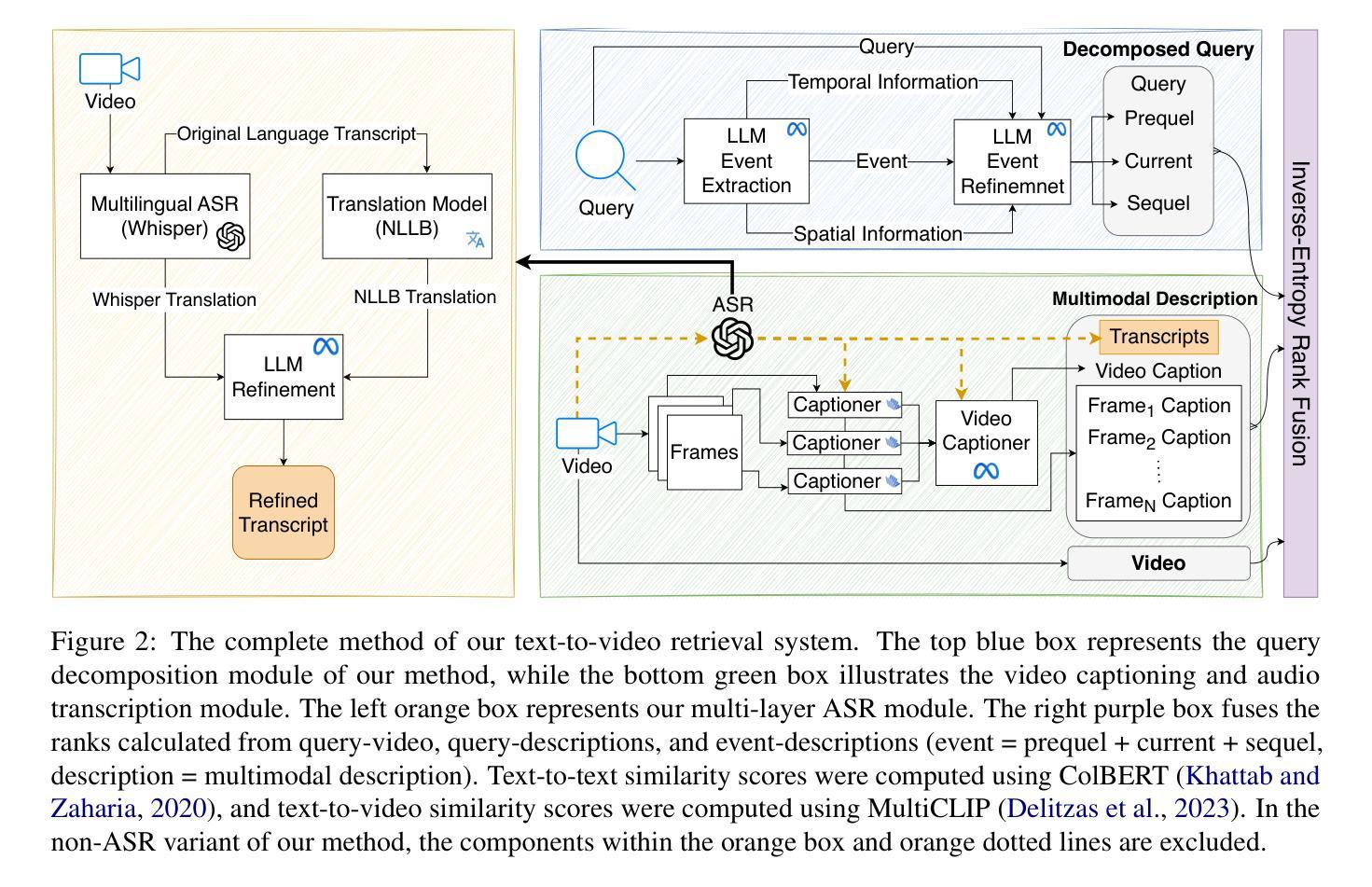
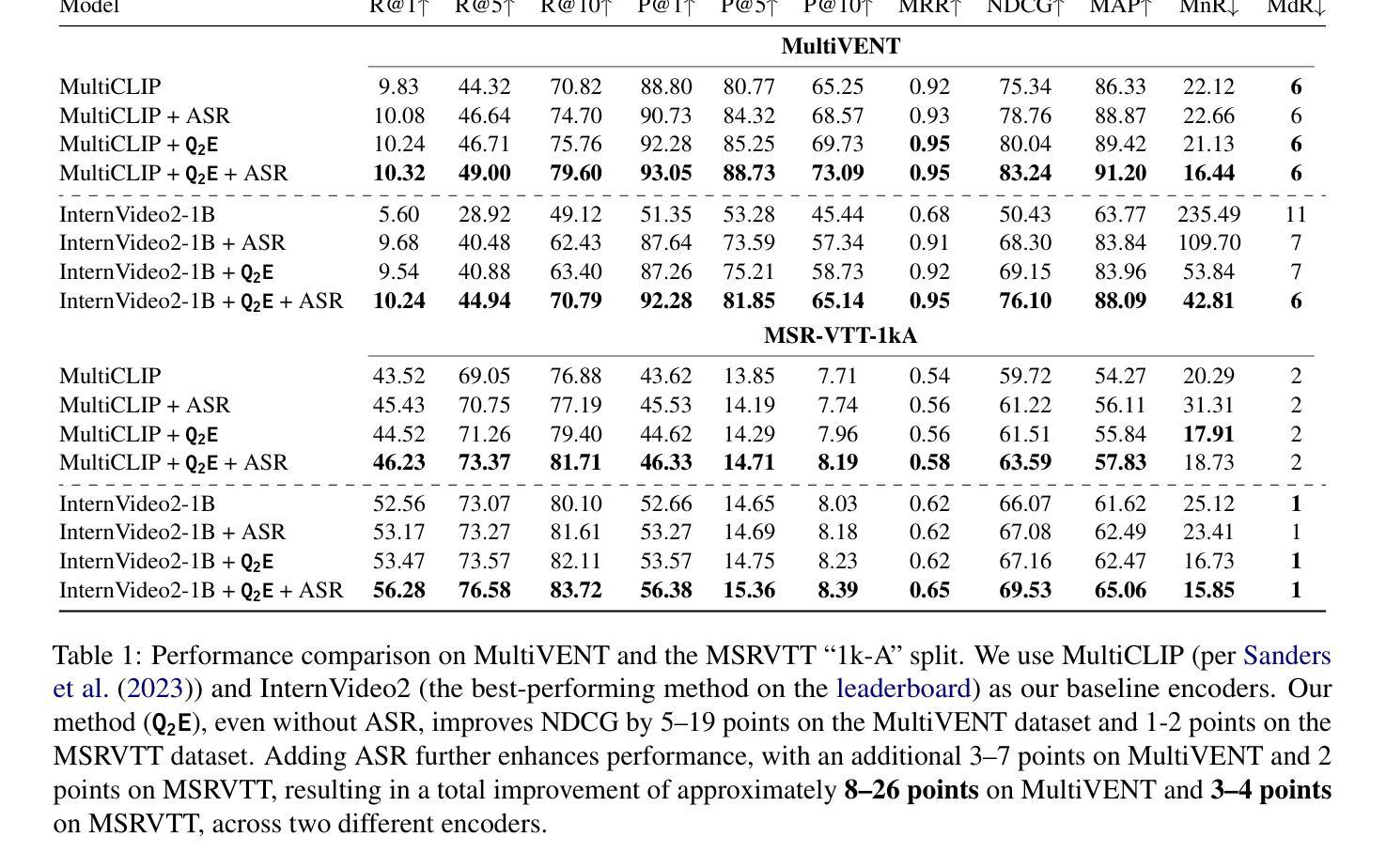
Q2E: Query-to-Event Decomposition for Zero-Shot Multilingual Text-to-Video Retrieval
Authors:Shubhashis Roy Dipta, Francis Ferraro
Recent approaches have shown impressive proficiency in extracting and leveraging parametric knowledge from Large-Language Models (LLMs) and Vision-Language Models (VLMs). In this work, we consider how we can improve the identification and retrieval of videos related to complex real-world events by automatically extracting latent parametric knowledge about those events. We present Q2E: a Query-to-Event decomposition method for zero-shot multilingual text-to-video retrieval, adaptable across datasets, domains, LLMs, or VLMs. Our approach demonstrates that we can enhance the understanding of otherwise overly simplified human queries by decomposing the query using the knowledge embedded in LLMs and VLMs. We additionally show how to apply our approach to both visual and speech-based inputs. To combine this varied multimodal knowledge, we adopt entropy-based fusion scoring for zero-shot fusion. Through evaluations on two diverse datasets and multiple retrieval metrics, we demonstrate that Q2E outperforms several state-of-the-art baselines. Our evaluation also shows that integrating audio information can significantly improve text-to-video retrieval. We have released code and data for future research.
最近的方法展示了从大型语言模型(LLM)和视觉语言模型(VLM)中提取和利用参数知识的惊人能力。在这项工作中,我们考虑如何通过自动提取有关这些事件的潜在参数知识,来提高对复杂现实世界事件相关视频的识别和检索能力。我们提出了Q2E:一种用于零样本多语言文本到视频检索的查询到事件分解方法,可适应不同的数据集、领域、LLM或VLM。我们的方法表明,我们可以通过利用LLM和VLM中嵌入的知识来分解查询,增强对过于简化的人类查询的理解。我们还展示了如何将我们的方法应用于视觉和基于语音的输入。为了结合这些不同的多模态知识,我们采用基于熵的融合评分进行零样本融合。在两个不同的数据集和多个检索指标上的评估表明,Q2E优于几种最新技术水平的基准测试。我们的评估还表明,整合音频信息可以显著改善文本到视频的检索。我们已经发布了代码和数据以供未来研究使用。
论文及项目相关链接
Summary
文本提出了Q2E方法,该方法基于零样本策略对查询进行事件分解,用于跨数据集、领域、LLM或VLM的多语言文本到视频检索。该方法能自动提取关于复杂现实事件的潜在参数知识,通过分解查询增强对简化查询的理解,并采用熵融合评分结合多种模态知识。实验表明,Q2E在文本到视频检索任务上优于多种最新技术基准,并且整合音频信息可以显著提高检索效果。
Key Takeaways
- 提出了一种基于零样本策略的Query-to-Event分解方法(Q2E),用于文本到视频的检索。
- Q2E可以自动提取关于复杂现实事件的潜在参数知识。
- 通过分解查询,Q2E能增强对简化查询的理解,利用LLM和VLM中的知识。
- Q2E方法适应于多种数据集、领域、LLM和VLM。
- 采用熵融合评分结合多种模态知识,包括视觉和语音输入。
- 实验表明,Q2E在文本到视频检索任务上表现出优异的性能,优于多种最新技术基准。
点此查看论文截图

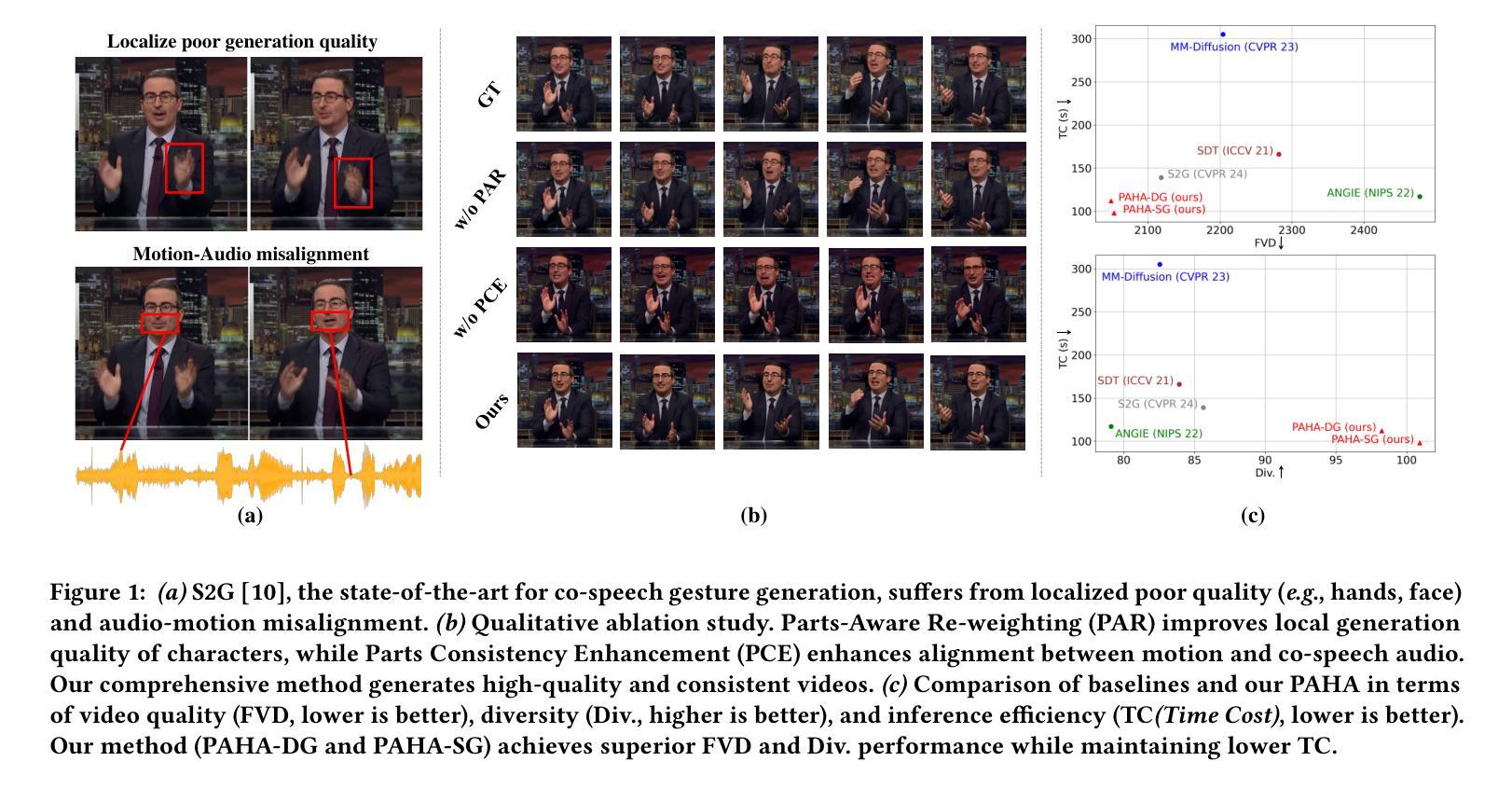
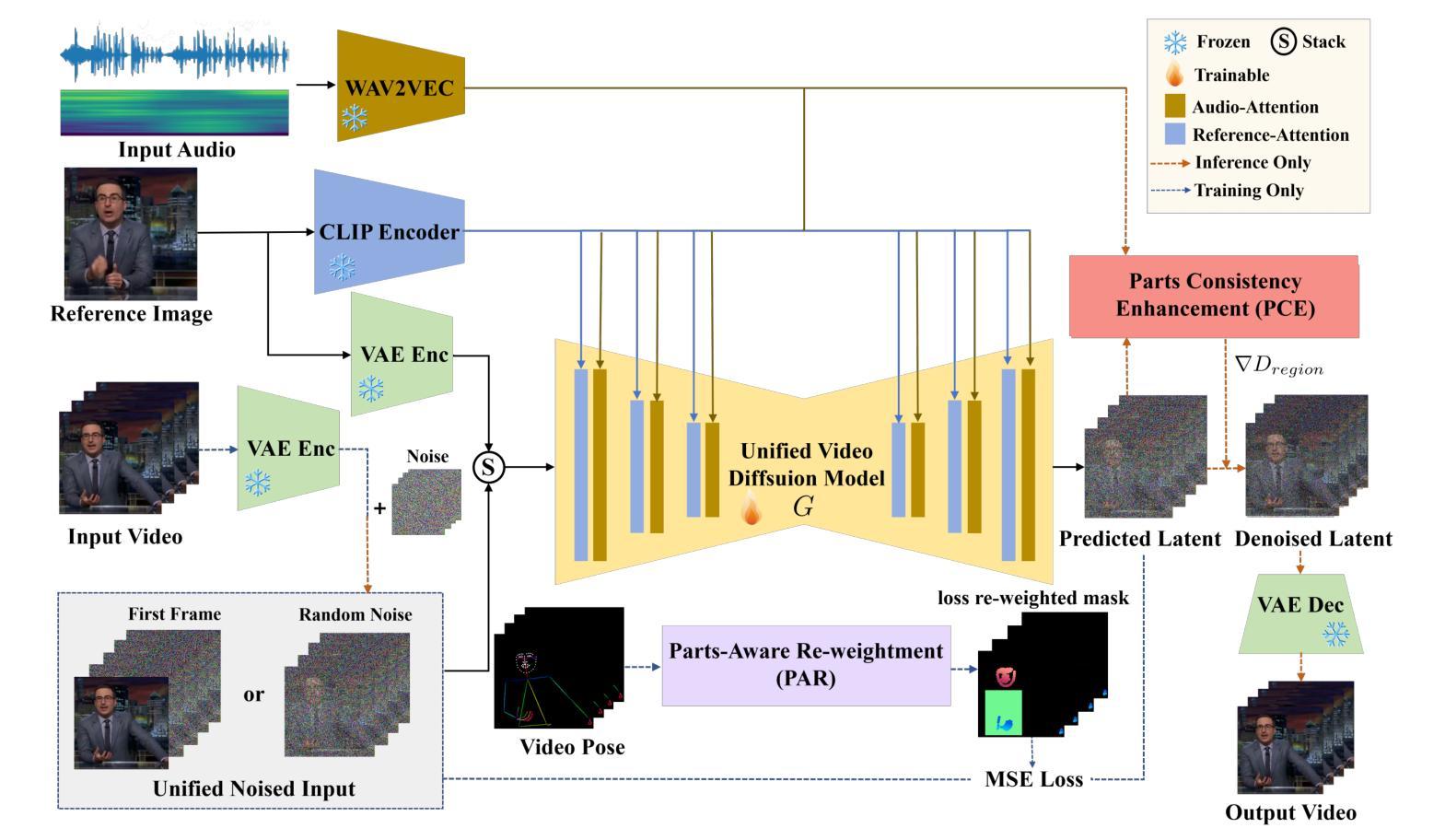
A Unit Enhancement and Guidance Framework for Audio-Driven Avatar Video Generation
Authors:S. Z. Zhou, Y. B. Wang, J. F. Wu, T. Hu, J. N. Zhang
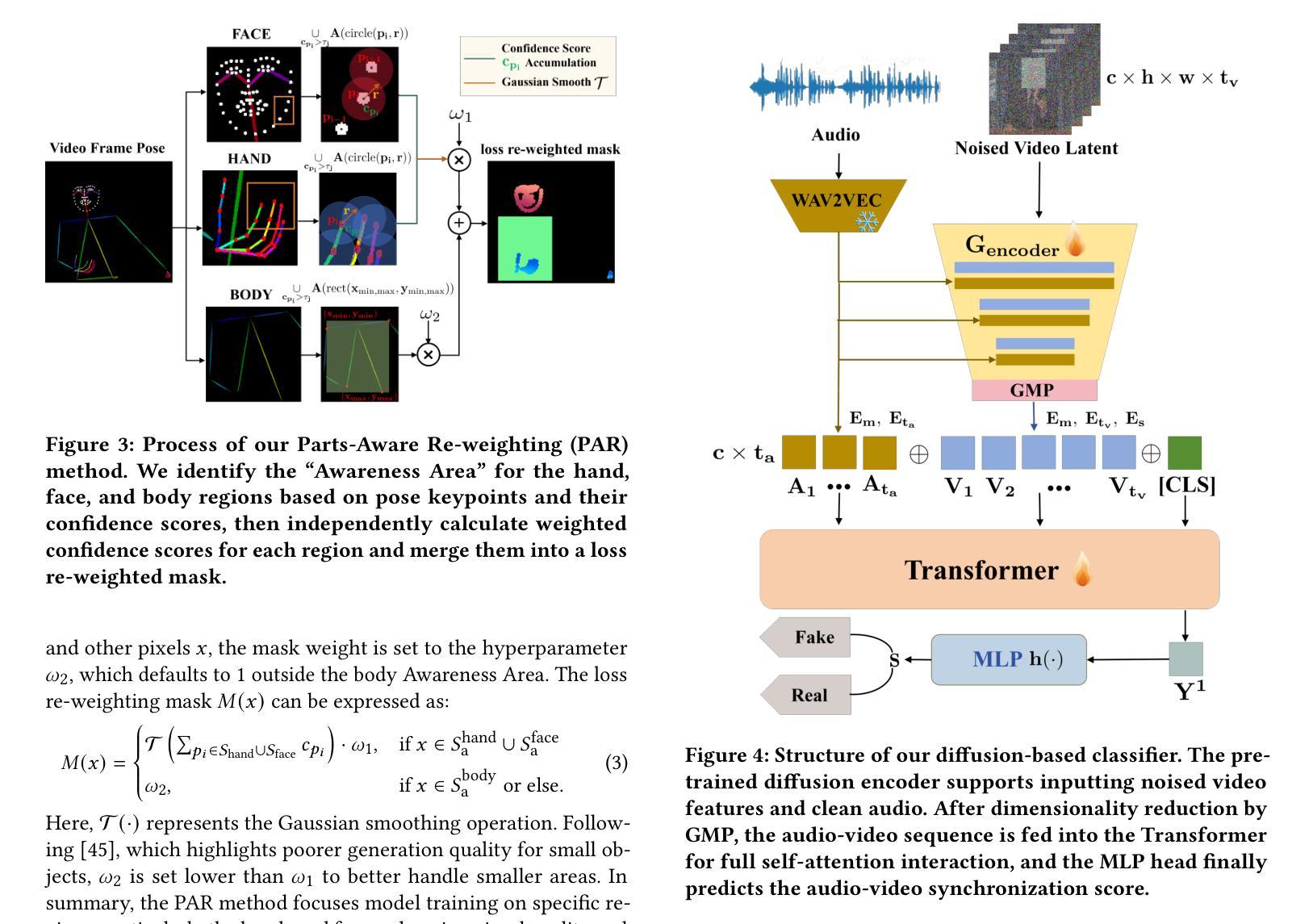
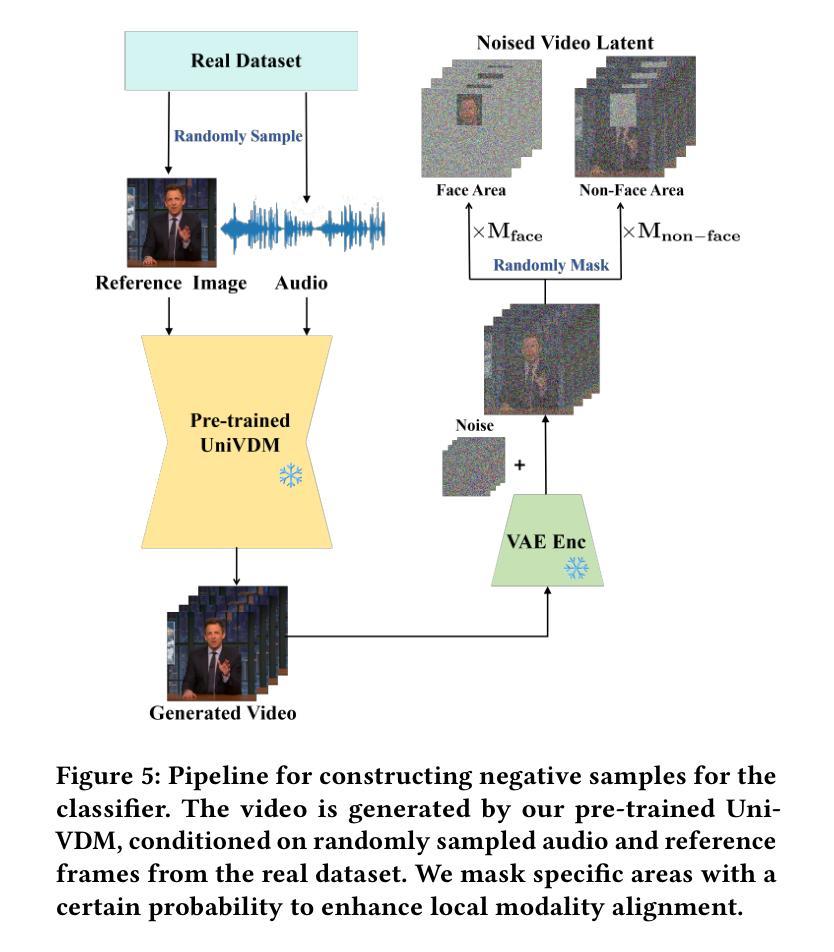
Audio-driven human animation technology is widely used in human-computer interaction, and the emergence of diffusion models has further advanced its development. Currently, most methods rely on multi-stage generation and intermediate representations, resulting in long inference time and issues with generation quality in specific foreground regions and audio-motion consistency. These shortcomings are primarily due to the lack of localized fine-grained supervised guidance. To address above challenges, we propose Parts-aware Audio-driven Human Animation, PAHA, a unit enhancement and guidance framework for audio-driven upper-body animation. We introduce two key methods: Parts-Aware Re-weighting (PAR) and Parts Consistency Enhancement (PCE). PAR dynamically adjusts regional training loss weights based on pose confidence scores, effectively improving visual quality. PCE constructs and trains diffusion-based regional audio-visual classifiers to improve the consistency of motion and co-speech audio. Afterwards, we design two novel inference guidance methods for the foregoing classifiers, Sequential Guidance (SG) and Differential Guidance (DG), to balance efficiency and quality respectively. Additionally, we build CNAS, the first public Chinese News Anchor Speech dataset, to advance research and validation in this field. Extensive experimental results and user studies demonstrate that PAHA significantly outperforms existing methods in audio-motion alignment and video-related evaluations. The codes and CNAS dataset will be released upon acceptance.
音频驱动的人形动画技术在人机交互中得到了广泛应用,扩散模型的兴起进一步推动了其发展。目前,大多数方法依赖于多阶段生成和中间表示,导致推理时间长,特定前景区域生成质量和音画一致性存在问题。这些缺点主要是由于缺乏局部精细监督指导。为了解决上述挑战,我们提出了Parts-aware Audio-driven Human Animation(PAHA),这是一个用于音频驱动的上半身动画的单位增强和指导框架。我们引入了两种关键方法:Parts-Aware Re-weighting(PAR)和Parts Consistency Enhancement(PCE)。PAR根据姿态置信度分数动态调整区域训练损失权重,有效提高视觉质量。PCE构建并训练基于扩散的区域音视频分类器,提高运动和语音音频的一致性。之后,我们为前述分类器设计了两种新型推理指导方法,Sequential Guidance(SG)和Differential Guidance(DG),以平衡效率和质量。此外,我们构建了首个公共中文新闻主播语音数据集CNAS,以推动该领域的研究和验证。大量的实验和用户研究结果表明,PAHA在音频运动对齐和视频相关评估方面显著优于现有方法。代码和CNAS数据集将在接受后发布。
论文及项目相关链接
PDF revised
Summary
本文介绍了音频驱动的人形动画技术在人机交互中的广泛应用,并指出扩散模型的出现推动了其发展。现有方法存在多阶段生成、推理时间长、特定前景区域生成质量及音频运动一致性等问题。本文提出了基于零件感知的音频驱动人体动画(PAHA)框架,通过引入零件感知重权(PAR)和零件一致性增强(PCE)两种关键技术解决上述问题。同时设计两种新型推理指导方法以提高效率和准确性平衡。此外,建立首个公共中文新闻主播语音数据集CNAS以推动该领域研究验证。实验结果和用户研究表明PAHA在音频运动对齐和视频评价上表现优越。代码和CNAS数据集待接受后公布。
Key Takeaways
一、音频驱动人形动画技术的进展和重要性
二、现有方法存在的缺陷:推理时间长、特定区域生成质量问题和音频运动一致性不足
三、零件感知重权(PAR)和零件一致性增强(PCE)技术解决了上述缺陷,提升了视觉质量和运动一致性
四、介绍了两种推理指导方法,以提高效率和准确性的平衡
五、建立了首个公共中文新闻主播语音数据集CNAS以推动该领域研究验证的发展
六、实验结果和用户研究证明PAHA显著优于现有方法,特别是在音频运动对齐和视频评价方面
点此查看论文截图