⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-14 更新
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Authors:Runqi Ouyang, Haoyun Li, Zhenyuan Zhang, Xiaofeng Wang, Zheng Zhu, Guan Huang, Xingang Wang
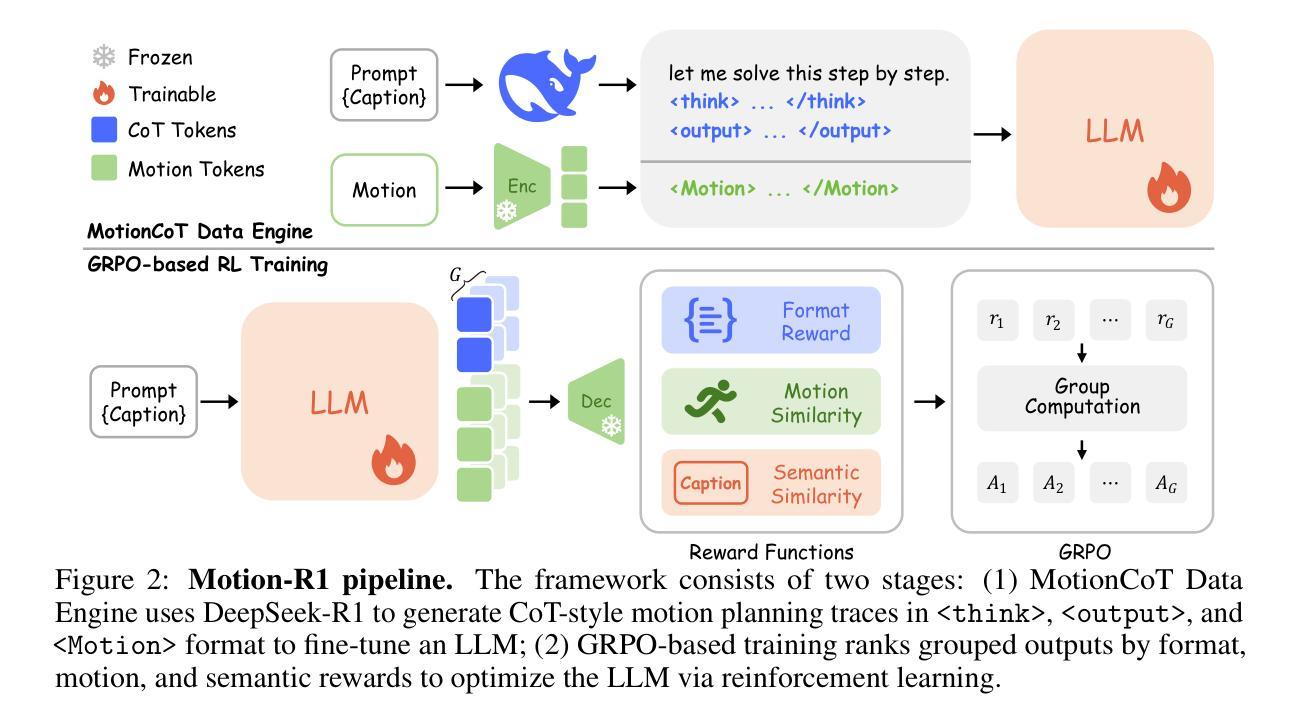
Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model’s ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.
最近的大型语言模型进展,特别是在自然语言理解和推理方面,为文本到动作生成带来了新的可能性。尽管现有方法已在语义对齐和运动合成方面取得了显著进展,但它们通常依赖于端到端的映射策略,无法捕捉深层语言结构和逻辑推理。因此,生成的动作往往缺乏可控性、一致性和多样性。为了解决这些局限性,我们提出了Motion-R1,一个统一的运动语言建模框架,它集成了思维链机制。通过显式地将复杂的文本指令分解为逻辑结构化的行动路径,Motion-R1为动作生成提供高级语义指导,显著提高了模型解释和执行多步骤、长期和丰富组合指令的能力。为了训练我们的模型,我们采用了针对大型模型的强化学习算法——群体相对策略优化,该算法利用运动质量反馈来联合优化推理链和动作合成。在多个基准数据集上的广泛实验表明,Motion-R1在需要微妙语义理解和长期时间一致性的场景中,与最先进的方法相比,实现了竞争性或优越的性能。代码、模型和数据将公开可用。
论文及项目相关链接
Summary
近期大型语言模型在自然语言理解和推理方面的进展为文本到动作生成领域带来了新的可能性。针对现有方法在语义对齐和动作合成方面存在的局限性,如缺乏控制性、一致性和多样性,我们提出了Motion-R1,一个统一的动作语言建模框架。它通过明确的思维链机制将复杂的文本指令分解为逻辑结构化的动作路径,为动作生成提供高级语义指导,从而显著提高模型执行多步骤、长期视野和组合丰富指令的能力。我们采用适用于大型模型的强化学习算法——集团相对策略优化来训练我们的模型,该算法利用动作质量反馈来联合优化推理链和动作合成。在多个基准数据集上的广泛实验表明,Motion-R1在需要细微语义理解和长期时间连贯性的场景中,其性能具有竞争力或优于最先进的方法。
Key Takeaways
- 大型语言模型的进步为文本到动作生成带来了新的机会。
- 现有方法存在语义对齐和动作合成的局限性,如缺乏控制性、一致性和多样性。
- Motion-R1框架通过思维链机制将复杂的文本指令分解为逻辑结构化的动作路径。
- Motion-R1提供高级语义指导,提高模型执行复杂指令的能力。
- 采用集团相对策略优化来训练模型,通过动作质量反馈联合优化推理链和动作合成。
- Motion-R1在多个基准数据集上的性能具有竞争力或优于最先进的方法。
点此查看论文截图