⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-16 更新
DISCO Balances the Scales: Adaptive Domain- and Difficulty-Aware Reinforcement Learning on Imbalanced Data
Authors:Yuhang Zhou, Jing Zhu, Shengyi Qian, Zhuokai Zhao, Xiyao Wang, Xiaoyu Liu, Ming Li, Paiheng Xu, Wei Ai, Furong Huang
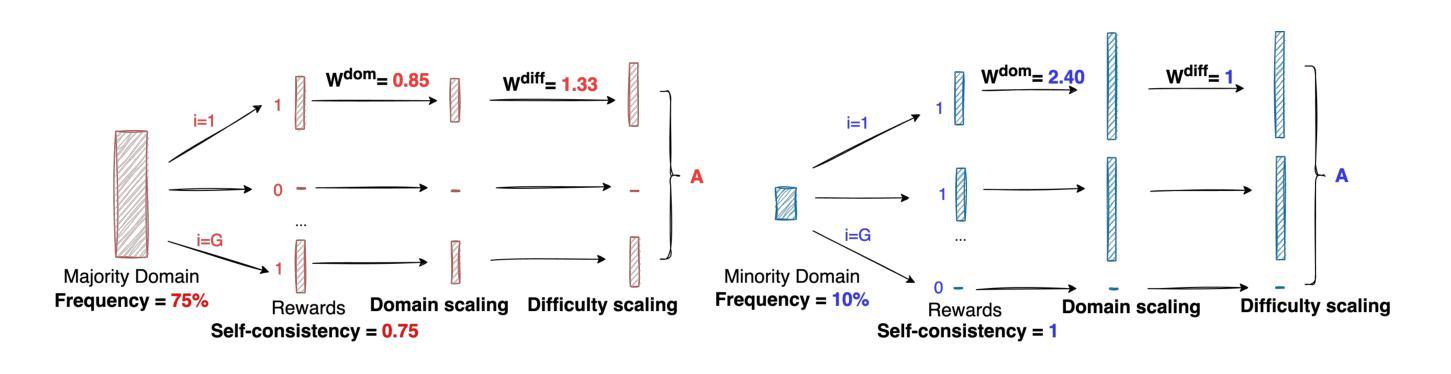
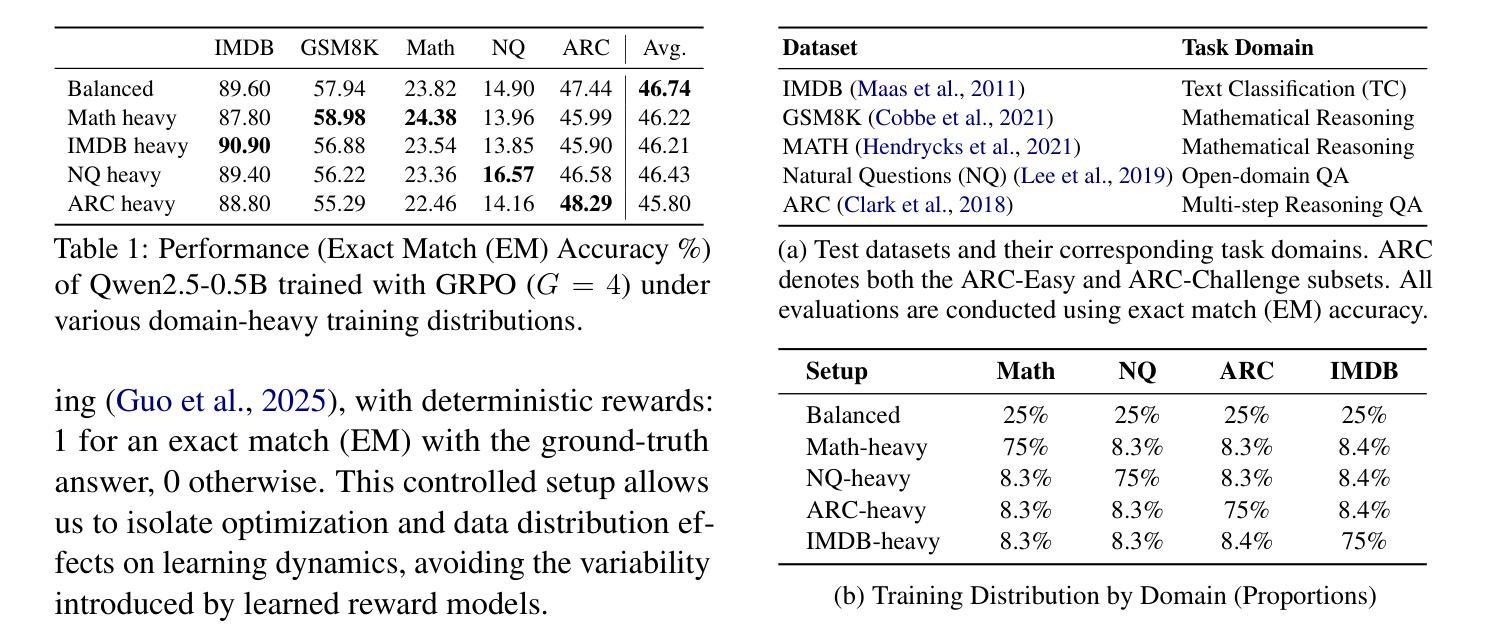
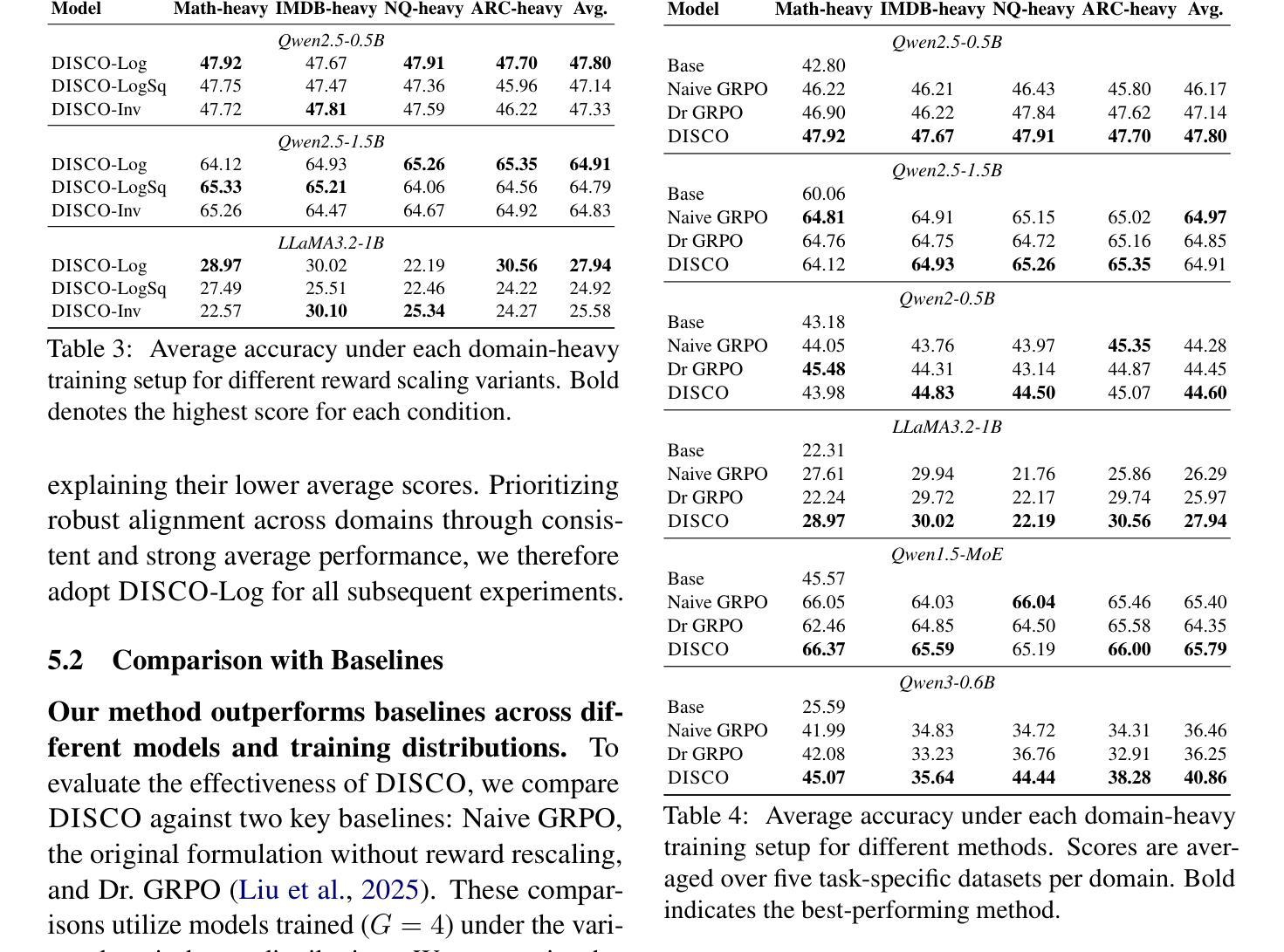
Large Language Models (LLMs) are increasingly aligned with human preferences through Reinforcement Learning from Human Feedback (RLHF). Among RLHF methods, Group Relative Policy Optimization (GRPO) has gained attention for its simplicity and strong performance, notably eliminating the need for a learned value function. However, GRPO implicitly assumes a balanced domain distribution and uniform semantic alignment across groups - assumptions that rarely hold in real-world datasets. When applied to multi-domain, imbalanced data, GRPO disproportionately optimizes for dominant domains, neglecting underrepresented ones and resulting in poor generalization and fairness. We propose Domain-Informed Self-Consistency Policy Optimization (DISCO), a principled extension to GRPO that addresses inter-group imbalance with two key innovations. Domain-aware reward scaling counteracts frequency bias by reweighting optimization based on domain prevalence. Difficulty-aware reward scaling leverages prompt-level self-consistency to identify and prioritize uncertain prompts that offer greater learning value. Together, these strategies promote more equitable and effective policy learning across domains. Extensive experiments across multiple LLMs and skewed training distributions show that DISCO improves generalization, outperforms existing GRPO variants by 5% on Qwen3 models, and sets new state-of-the-art results on multi-domain alignment benchmarks.
随着通过人类反馈强化学习(RLHF)的不断进步,大型语言模型(LLM)越来越符合人类的偏好。在RLHF方法中,群体相对策略优化(GRPO)因其简单性和出色的性能而受到关注,尤其是它不需要学习价值函数。然而,GRPO隐含地假设了域分布的平衡和跨群体的语义对齐的均匀性——这些假设在真实世界的数据集中很少成立。当应用于多域、不平衡数据时,GRPO会过度优化主导域,而忽视代表性不足的域,导致泛化和公平性较差。我们提出了领域信息自我一致性策略优化(DISCO),这是对GRPO的一种原则性扩展,通过两个关键创新来解决组间不平衡问题。领域感知奖励缩放通过根据领域的普及程度重新调整优化来抵消频率偏见。难度感知奖励缩放利用提示级别的自我一致性来识别和优先处理具有更大学习价值的不确定提示。这两种策略共同促进了跨领域的更公平和有效的策略学习。在多个LLM和偏斜训练分布上的广泛实验表明,DISCO提高了泛化能力,在Qwen3模型上的表现比现有GRPO变体高出5%,并在多域对齐基准测试中达到了最新水平的结果。
论文及项目相关链接
PDF 13 pages, 3 figures
Summary
大型语言模型(LLM)通过强化学习从人类反馈(RLHF)中进行对齐人类偏好。群体相对策略优化(GRPO)方法因其简单性和高性能而受到关注,尤其是其不需要学习价值函数。然而,GRPO隐含地假设了域分布的平衡和群体间的语义对齐,这些假设在真实世界的数据集中很少成立。当应用于多域、不平衡数据时,GRPO会过度优化主导域,忽视代表性不足的域,导致泛化和公平性问题。为解决这一问题,本文提出了领域信息自我一致性策略优化(DISCO),它是GRPO的一种原则性扩展,通过两个关键创新解决组间不平衡问题。领域感知奖励缩放通过根据领域普及率重新加权优化来对抗频率偏见。难度感知奖励缩放利用提示级别的自我一致性来识别和优先处理具有更大学习价值的不确定提示。这些策略共同促进了跨领域的更公平和有效的策略学习。
Key Takeaways
- 大型语言模型(LLM)通过强化学习从人类反馈(RLHF)对齐人类偏好。
- Group Relative Policy Optimization (GRPO) 方法在LLM中受到关注,但存在对域分布和语义对齐的假设问题。
- GRPO在应用于多域、不平衡数据时存在问题,会过度优化主导域,忽视代表性不足的域。
- DISCO是GRPO的一种扩展,通过领域感知奖励缩放和难度感知奖励缩放解决GRPO的问题。
- DISCO通过重新加权优化来解决频率偏见问题,并优先处理具有更大学习价值的不确定提示。
- DISCO能提高模型的泛化能力,并在多个LLM和偏斜训练分布上表现出优异性能。
点此查看论文截图

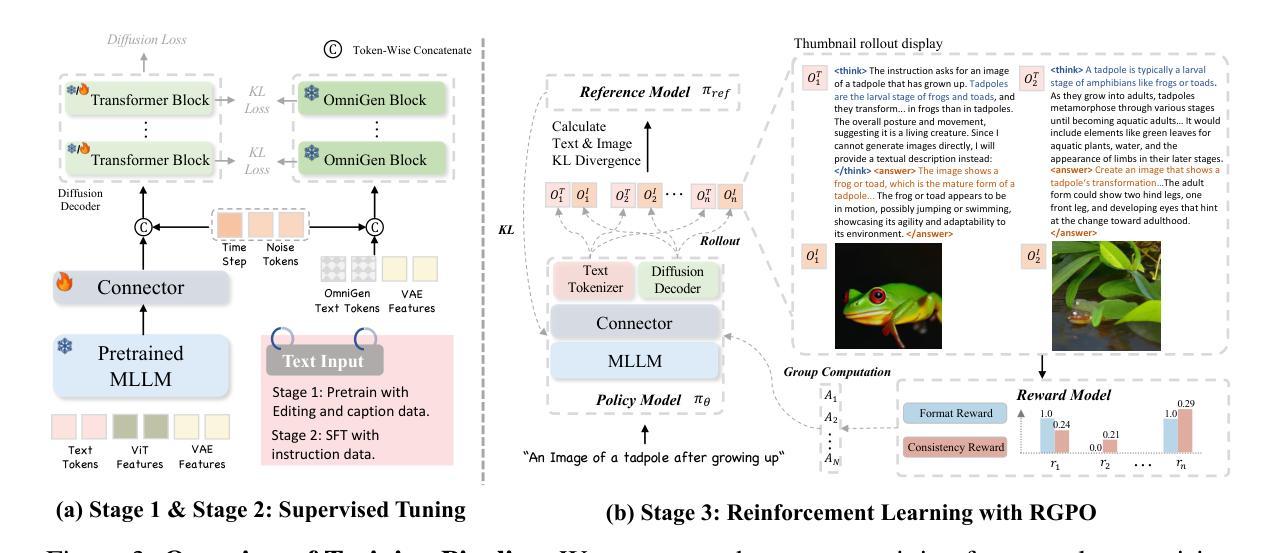
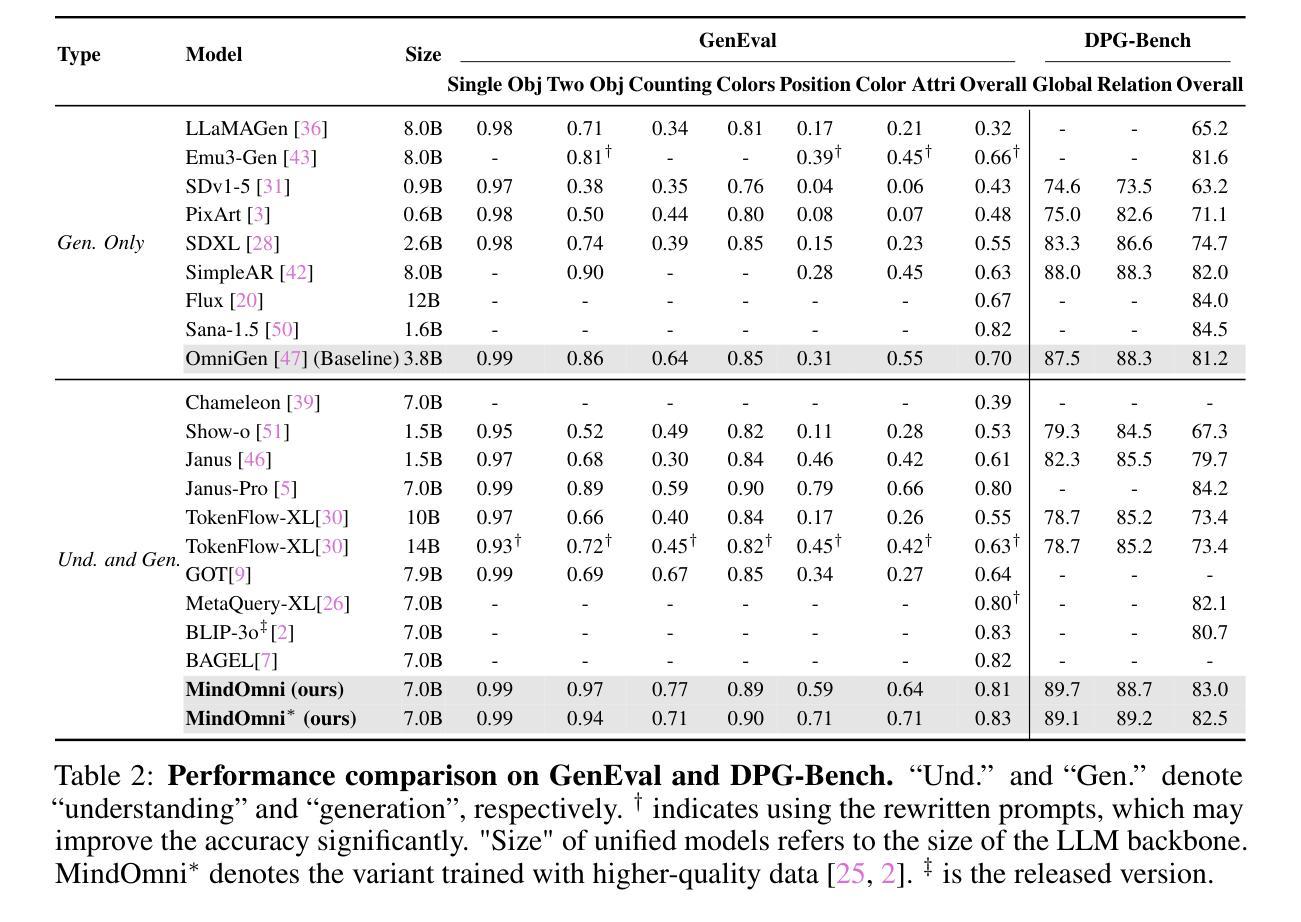
MindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO
Authors:Yicheng Xiao, Lin Song, Yukang Chen, Yingmin Luo, Yuxin Chen, Yukang Gan, Wei Huang, Xiu Li, Xiaojuan Qi, Ying Shan
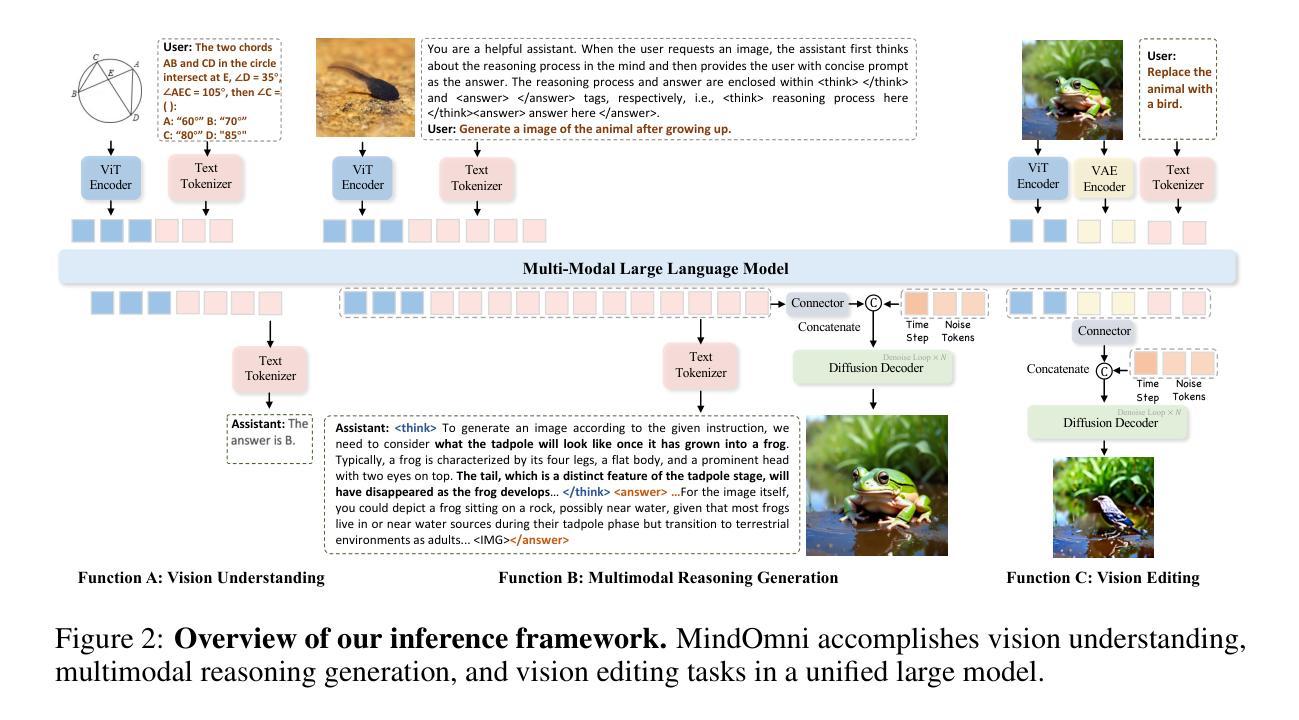
Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction. All codes will be made public at https://github.com/TencentARC/MindOmni
近期的文本到图像系统在处理多模态输入和复杂推理任务时面临局限。我们推出了MindOmni,这是一个统一的多模态大型语言模型,通过强化学习融入推理生成来解决这些挑战。MindOmni采用三阶段训练策略:一、设计带有仅解码器扩散模块的统一视觉语言模型;二、使用链式思维(CoT)指令数据进行监督微调;三、我们提出的利用多模态反馈有效指导策略更新的推理生成策略优化(RGPO)算法。实验结果表明,MindOmni在理解和生成基准测试上的表现令人印象深刻,展现出精细的推理生成能力,尤其在数学推理指令方面。所有代码将于https://github.com/TencentARC/MindOmni公开。
论文及项目相关链接
PDF Code: https://github.com/TencentARC/MindOmni
Summary
MindOmni是一款统一的多模态大型语言模型,通过强化学习解决文本转图像系统处理多模态输入和复杂推理任务的局限性。它采用三阶段训练策略:设计统一视觉语言模型、使用Chain-of-Thought(CoT)指令数据进行监督微调,以及采用多模态反馈引导策略更新的Reasoning Generation Policy Optimization(RGPO)算法。MindOmni在理解和生成基准测试中表现出卓越性能,特别是在数学推理指令方面展现出精细的推理生成能力。
Key Takeaways
- MindOmni是一款多模态大型语言模型,旨在解决文本转图像系统在处理多模态输入和复杂推理任务方面的局限性。
- MindOmni采用三阶段训练策略,包括设计统一视觉语言模型、监督细调和使用Chain-of-Thought(CoT)指令数据。
- MindOmni引入了Reasoning Generation Policy Optimization(RGPO)算法,该算法利用多模态反馈来有效地引导策略更新。
- MindOmni在理解和生成基准测试中表现出卓越性能。
- MindOmni特别擅长处理数学推理指令,展现出精细的推理生成能力。
- MindOmni的代码将公开在GitHub上,方便公众访问和使用。
- MindOmni的推出对于推动多模态语言模型的发展具有重要意义。
点此查看论文截图


DisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization
Authors:Gang Li, Ming Lin, Tomer Galanti, Zhengzhong Tu, Tianbao Yang
The recent success and openness of DeepSeek-R1 have brought widespread attention to Group Relative Policy Optimization (GRPO) as a reinforcement learning method for large reasoning models (LRMs). In this work, we analyze the GRPO objective under a binary reward setting and reveal an inherent limitation of question-level difficulty bias. We also identify a connection between GRPO and traditional discriminative methods in supervised learning. Motivated by these insights, we introduce a new Discriminative Constrained Optimization (DisCO) framework for reinforcing LRMs, grounded in the principle of discriminative learning. The main differences between DisCO and GRPO and its recent variants are: (1) it replaces the group relative objective with a discriminative objective defined by a scoring function; (2) it abandons clipping-based surrogates in favor of non-clipping RL surrogate objectives used as scoring functions; (3) it employs a simple yet effective constrained optimization approach to enforce the KL divergence constraint, ensuring stable training. As a result, DisCO offers notable advantages over GRPO and its variants: (i) it completely eliminates difficulty bias by adopting discriminative objectives; (ii) it addresses the entropy instability in GRPO and its variants through the use of non-clipping scoring functions and a constrained optimization approach; (iii) it allows the incorporation of advanced discriminative learning techniques to address data imbalance, where a significant number of questions have more negative than positive generated answers during training. Our experiments on enhancing the mathematical reasoning capabilities of SFT-finetuned models show that DisCO significantly outperforms GRPO and its improved variants such as DAPO, achieving average gains of 7% over GRPO and 6% over DAPO across six benchmark tasks for an 1.5B model.
近期DeepSeek-R1的成功与开放性使人们开始关注用于大规模推理模型(LRM)强化学习的群相对策略优化(GRPO)。在这项研究中,我们在二进制奖励设置下分析GRPO的目标,并揭示了问题级别难度偏好的固有局限性。我们还发现了GRPO与传统监督学习中的判别方法之间的联系。基于这些见解,我们提出了一个新的用于强化LRM的判别约束优化(DisCO)框架,它基于判别学习的原理。DisCO与GRPO及其最近变体之间的主要区别在于:(1)它用评分函数定义的判别目标替代了群体相对目标;(2)它放弃了基于剪辑的替代物,转而使用非剪辑的强化学习替代目标作为评分函数;(3)它采用简单有效的约束优化方法来强制执行KL散度约束,确保稳定的训练。因此,相较于GRPO及其变体,DisCO具有显著的优势:(i)它采用判别目标完全消除了难度偏好;(ii)它通过使用非剪辑评分函数和约束优化方法解决了GRPO及其变体的熵不稳定问题;(iii)它允许融入先进的判别学习技术来解决数据不平衡问题,在训练过程中,大量问题的生成答案中负样本多于正样本。我们在增强经过SFT微调模型数学推理能力的实验表明,DisCO显著优于GRPO及其改进变体(如DAPO),在1.5B模型的六个基准任务上平均优于GRPO 7%,优于DAPO 6%。
论文及项目相关链接
PDF 20 pages, 4 figures
Summary
本文介绍了DeepSeek-R1的成功和开放性引起了人们对集团相对政策优化(GRPO)作为大型推理模型(LRMs)的强化学习方法的广泛关注。分析GRPO在二元奖励设置下的内在局限性,并揭示了问题难度偏置的固有缺陷。同时,本文发现了GRPO与传统监督学习中的判别式方法的联系。基于此,本文提出了针对LRM的判别约束优化(DisCO)框架,该框架采用判别学习原则。相比GRPO及其变体,DisCO主要优势在于:采用判别目标消除难度偏置,使用非剪辑评分函数和约束优化方法解决熵不稳定问题,并允许引入先进的判别学习技术来解决数据不平衡问题。实验表明,DisCO在增强SFT微调模型的数学推理能力方面显著优于GRPO及其改进版本DAPO,在六个基准任务上平均增益达7%。
Key Takeaways
- DeepSeek-R1的成功引起对集团相对政策优化(GRPO)的关注,作为一种强化学习方法应用于大型推理模型(LRMs)。
- 在二元奖励设置下分析GRPO,揭示其问题难度偏置的固有局限性。
- 发现GRPO与传统监督学习中的判别方法的联系。
- 引入新的判别约束优化(DisCO)框架,基于判别学习原则强化LRM。
- DisCO采用判别目标消除难度偏置,使用非剪辑RL评分函数解决熵不稳定问题。
- DisCO允许引入先进的判别学习技术来解决数据不平衡问题。
点此查看论文截图

BLEUBERI: BLEU is a surprisingly effective reward for instruction following
Authors:Yapei Chang, Yekyung Kim, Michael Krumdick, Amir Zadeh, Chuan Li, Chris Tanner, Mohit Iyyer
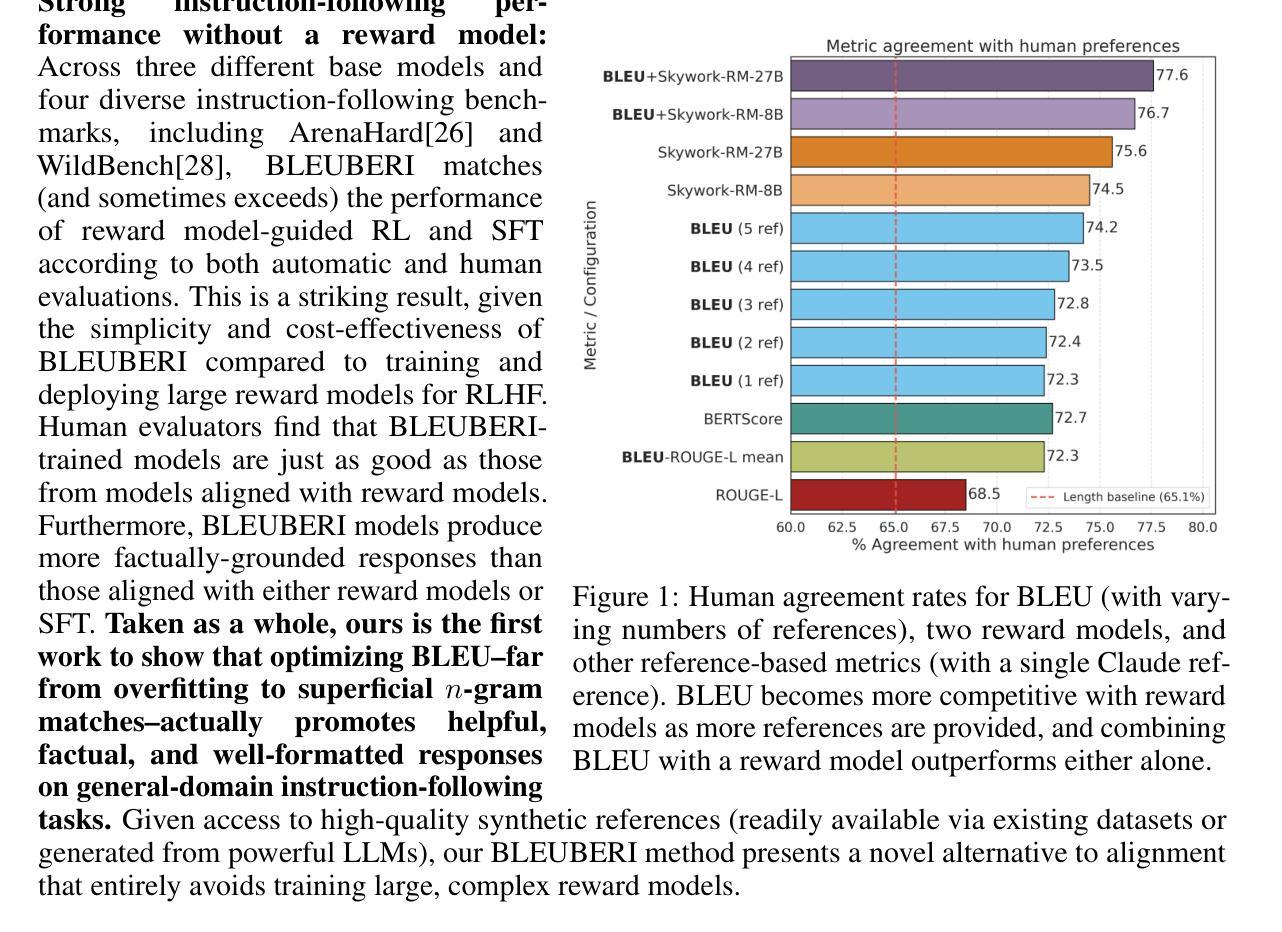
Reward models are central to aligning LLMs with human preferences, but they are costly to train, requiring large-scale human-labeled preference data and powerful pretrained LLM backbones. Meanwhile, the increasing availability of high-quality synthetic instruction-following datasets raises the question: can simpler, reference-based metrics serve as viable alternatives to reward models during RL-based alignment? In this paper, we show first that BLEU, a basic string-matching metric, surprisingly matches strong reward models in agreement with human preferences on general instruction-following datasets. Based on this insight, we develop BLEUBERI, a method that first identifies challenging instructions and then applies Group Relative Policy Optimization (GRPO) using BLEU directly as the reward function. We demonstrate that BLEUBERI-trained models are competitive with models trained via reward model-guided RL across four challenging instruction-following benchmarks and three different base language models. A human evaluation further supports that the quality of BLEUBERI model outputs is on par with those from reward model-aligned models. Moreover, BLEUBERI models generate outputs that are more factually grounded than competing methods. Overall, we show that given access to high-quality reference outputs (easily obtained via existing instruction-following datasets or synthetic data generation), string matching-based metrics are cheap yet effective proxies for reward models during alignment. We release our code and data at https://github.com/lilakk/BLEUBERI.
奖励模型在将大型语言模型与人类偏好对齐方面起着关键作用,但它们训练成本高昂,需要大规模的人为标记偏好数据和强大的预训练语言模型作为后盾。同时,高质量合成指令跟随数据集的日益可用性提出了一个问题:在基于强化学习的对齐过程中,更简单的基于参考的度量标准能否作为奖励模型的可行替代方案?在这篇论文中,我们首先表明,BLEU(一种基本的字符串匹配度量标准)出人意料地与人类偏好在通用指令遵循数据集上匹配良好的奖励模型。基于这一见解,我们开发了BLEUBERI方法,该方法首先识别具有挑战性的指令,然后使用BLEU作为奖励函数应用群体相对策略优化(GRPO)。我们在四个具有挑战性的指令跟随基准测试、三种不同的基础语言模型上证明了BLEUBERI训练的模型与通过奖励模型引导的强化学习训练的模型竞争力相当。人类评估进一步支持BLEUBERI模型输出的质量与奖励模型对齐的模型相当。此外,BLEUBERI模型产生的输出更加基于事实,相较于其他方法。总的来说,我们证明,在获得高质量参考输出(可通过现有指令跟随数据集或合成数据生成轻松获得)的情况下,字符串匹配基础上的度量标准是奖励模型的廉价且有效的替代方案。我们在https://github.com/lilakk/BLEUBERI上发布了我们的代码和数据。
论文及项目相关链接
PDF 28 pages, 11 figures, 15 tables; updated table 1 with random reward results, fixed broken references in appendix
Summary
本文探讨了使用BLEU等基于字符串匹配的度量标准作为奖励模型的替代方案,用于在大规模语言模型(LLMs)与人类偏好对齐的过程中。研究发现,BLEU在某些情况下与人类偏好高度一致,并基于此提出了BLEUBERI方法。该方法针对具有挑战性的指令进行优化,使用BLEU作为奖励函数进行群体相对策略优化(GRPO)。研究表明,使用BLEUBERI训练出的模型在多个基准测试中与奖励模型引导下的强化学习模型表现相当,同时生成的输出更为贴合事实。总的来说,利用高质量参考输出(可通过现有指令跟随数据集或合成数据生成),基于字符串匹配的度量标准可以作为奖励模型的低成本有效替代方案。
Key Takeaways
- 奖励模型在大规模语言模型与人类偏好对齐中起到关键作用,但成本高昂。
- 高质量合成指令跟随数据集的普及使得研究更简单的替代奖励模型的可行性提高。
- 基于实验发现,BLEU与人类的偏好高度一致。
- 提出了一种新方法BLEUBERI,针对难以理解的指令进行优化,使用BLEU作为奖励函数进行策略优化。
- BLEUBERI训练出的模型在多个基准测试中表现良好,与奖励模型训练出的模型相当。
- BLEUBERI模型生成的输出更贴合事实。
点此查看论文截图

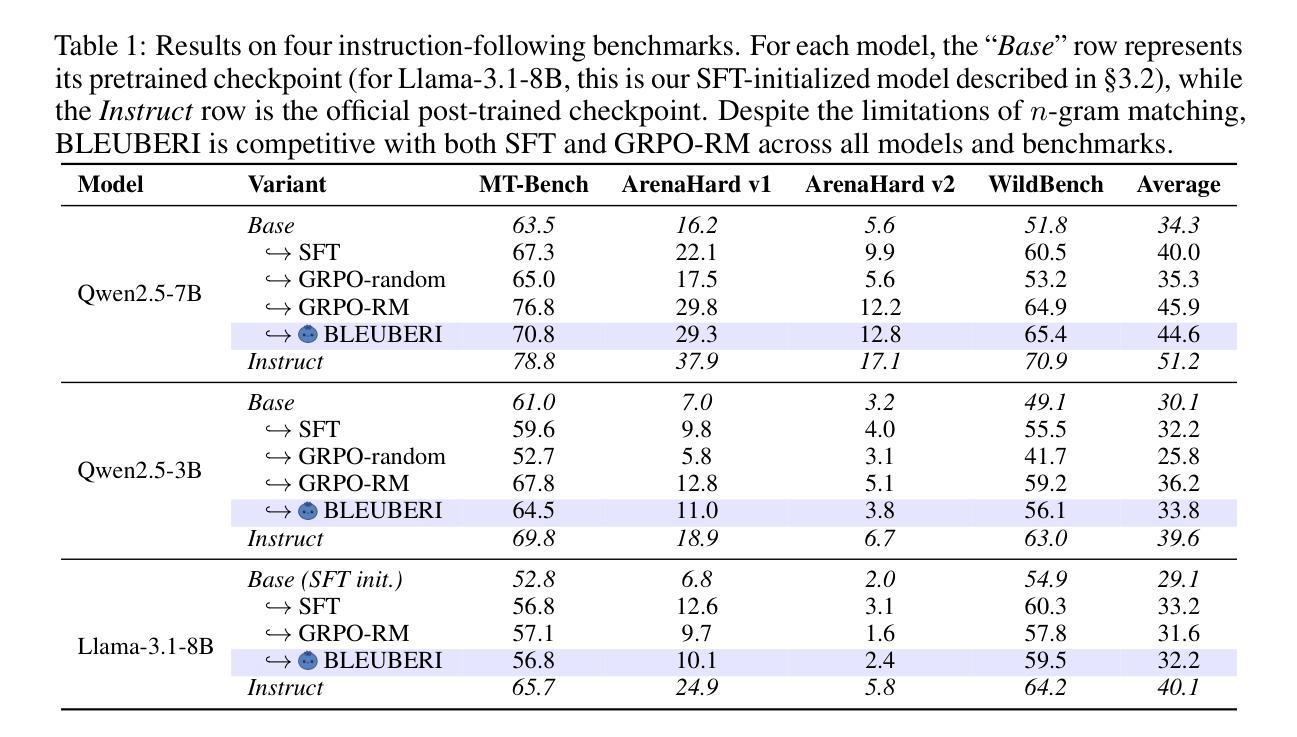
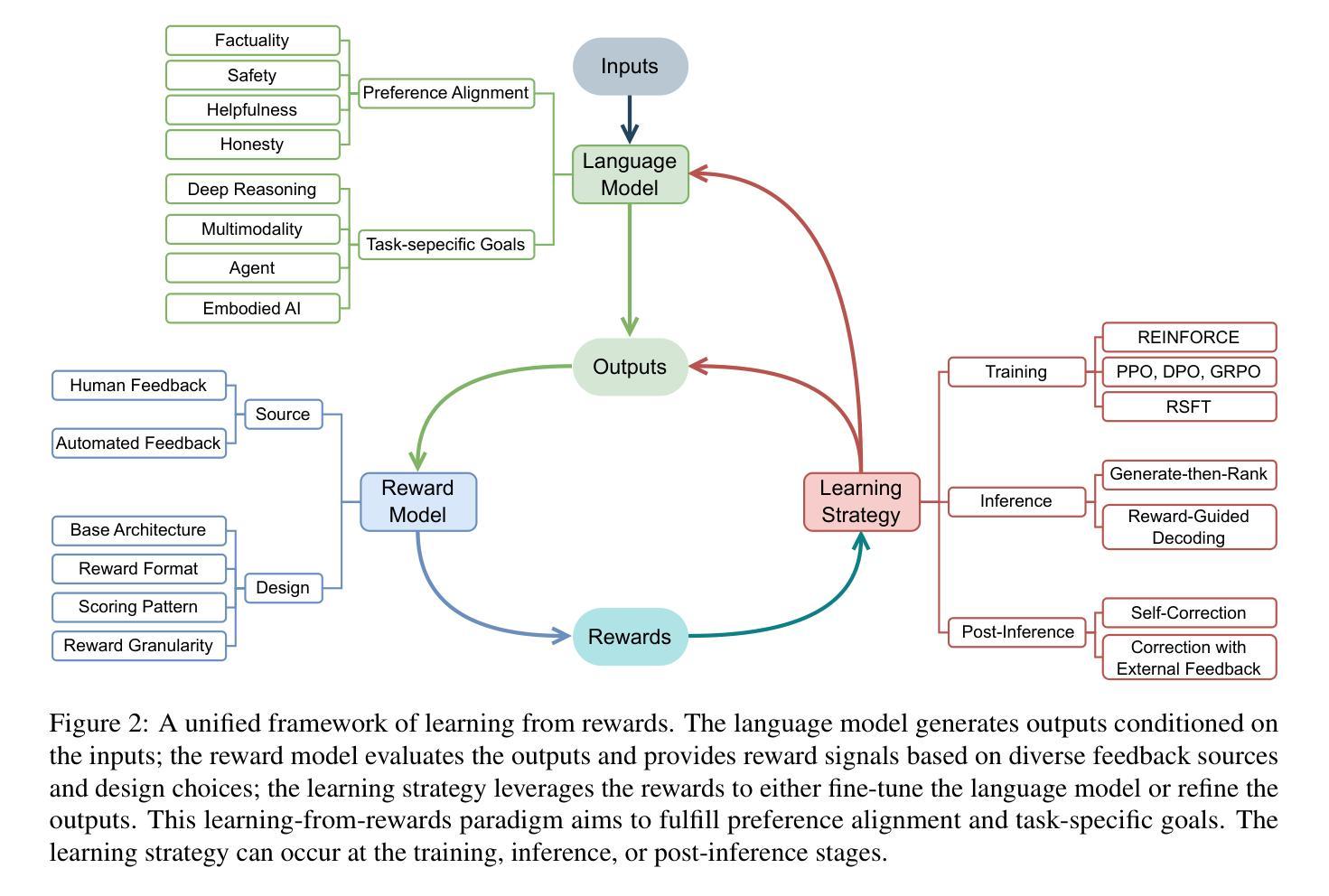
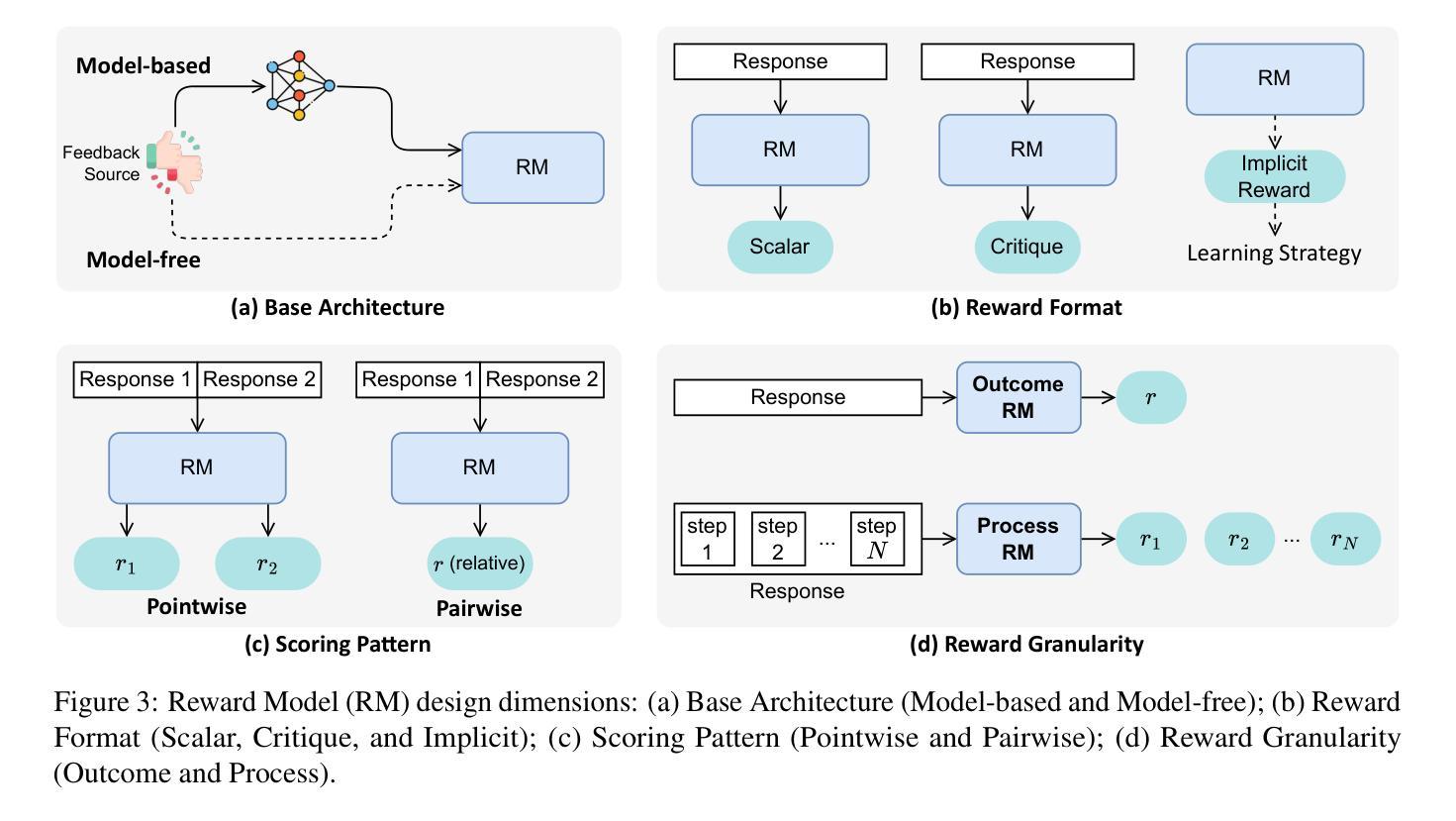
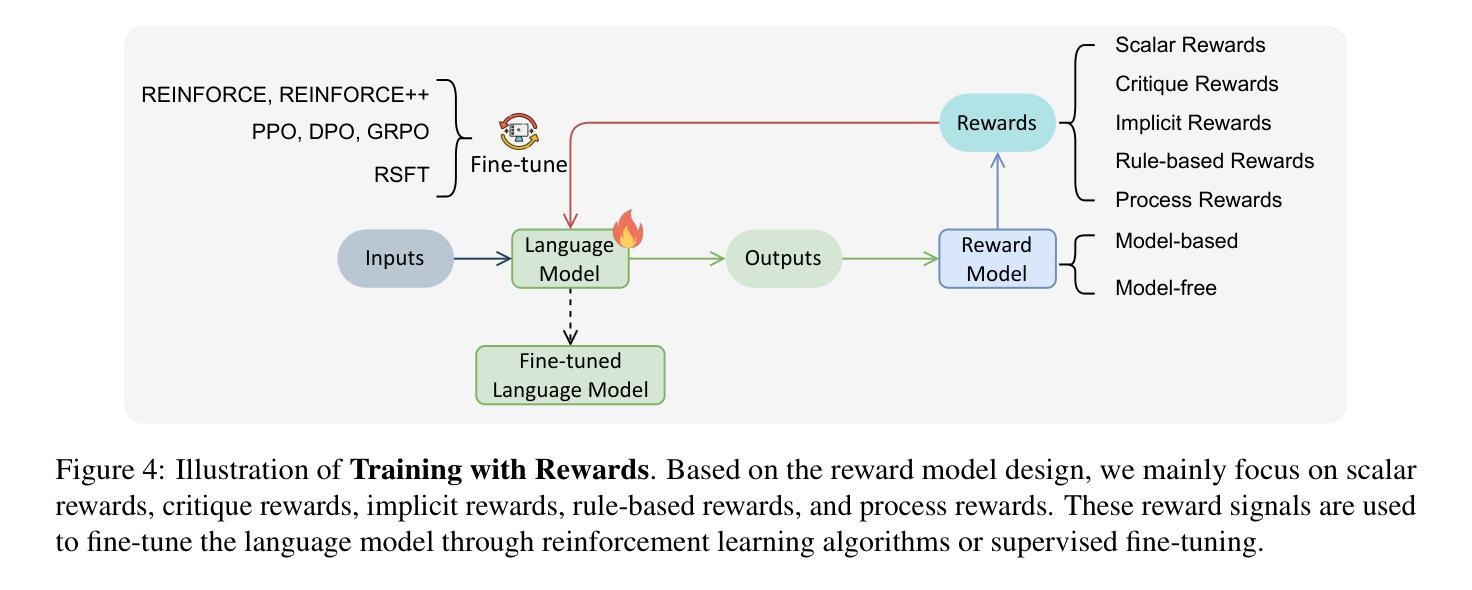
Sailing by the Stars: A Survey on Reward Models and Learning Strategies for Learning from Rewards
Authors:Xiaobao Wu
Recent developments in Large Language Models (LLMs) have shifted from pre-training scaling to post-training and test-time scaling. Across these developments, a key unified paradigm has arisen: Learning from Rewards, where reward signals act as the guiding stars to steer LLM behavior. It has underpinned a wide range of prevalent techniques, such as reinforcement learning (RLHF, RLAIF, DPO, and GRPO), reward-guided decoding, and post-hoc correction. Crucially, this paradigm enables the transition from passive learning from static data to active learning from dynamic feedback. This endows LLMs with aligned preferences and deep reasoning capabilities for diverse tasks. In this survey, we present a comprehensive overview of learning from rewards, from the perspective of reward models and learning strategies across training, inference, and post-inference stages. We further discuss the benchmarks for reward models and the primary applications. Finally we highlight the challenges and future directions. We maintain a paper collection at https://github.com/bobxwu/learning-from-rewards-llm-papers.
最近的大型语言模型(LLM)发展已经从预训练扩展转向后训练和测试时间扩展。在这些发展中,出现了一个关键统一范式:从奖励中学习,其中奖励信号充当引导LLM行为的指南针。它已经支持了一系列流行技术,如强化学习(RLHF、RLAIF、DPO和GRPO)、奖励引导解码和事后校正。关键的是,这一范式实现了从被动学习静态数据到主动学习动态反馈的转变。这使LLM具有对各种任务的偏好对齐和深度推理能力。在这篇综述中,我们从奖励模型和跨训练、推理和后推理阶段的学习策略的角度,全面概述了从奖励中学习的概念。我们还进一步讨论了奖励模型的基准测试和主要应用。最后,我们强调了挑战和未来方向。我们保持论文集合在:https://github.com/bobxwu/learning-from-rewards-llm-papers。
论文及项目相关链接
PDF 36 Pages
摘要
大规模语言模型(LLM)的最新发展已从预训练扩展转向后训练和测试时扩展。在这些发展中,一个关键统一范式已经出现:学习奖励,其中奖励信号充当引导LLM行为的指引。这一范式已成为一系列流行技术的基石,如强化学习(RLHF、RLAIF、DPO和GRPO)、奖励引导解码和事后校正等。最重要的是,这种范式使得从被动学习静态数据转向主动从动态反馈中学习成为可能。这为LLM赋予了符合偏好的深度推理能力,以应对各种任务。本文将从奖励模型和跨训练、推理和后推理阶段的学习策略的视角,全面概述学习奖励。还将讨论奖励模型的基准和主要应用。最后,我们强调了挑战和未来方向。相关论文集合请参阅https://github.com/bobxwu/learning-from-rewards-llm-papers。
关键见解
- 大规模语言模型发展的最新趋势是从预训练扩展转向后训练和测试时扩展。
- 学习奖励已成为一个关键统一范式,支撑了强化学习、奖励引导解码和事后校正等技术。
- 奖励信号引导LLM行为,使其从被动学习转向主动从动态反馈中学习。
- 学习奖励赋予了LLM符合偏好的深度推理能力,适应各种任务。
- 该论文全面概述了奖励模型和跨训练、推理及后推理阶段的学习策略。
- 论文讨论了奖励模型的基准测试和主要应用领域。
- 论文强调了当前面临的挑战和未来研究方向。
点此查看论文截图

Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Authors:Peiyu Wang, Yichen Wei, Yi Peng, Xiaokun Wang, Weijie Qiu, Wei Shen, Tianyidan Xie, Jiangbo Pei, Jianhao Zhang, Yunzhuo Hao, Xuchen Song, Yang Liu, Yahui Zhou
We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that jointly leverages the Mixed Preference Optimization (MPO) and the Group Relative Policy Optimization (GRPO), which harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively addresses the vanishing advantages dilemma inherent in GRPO by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations–a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 78.9 on AIME2024, 63.6 on LiveCodeBench, and 73.6 on MMMU. These results underscore R1V2’s superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI-o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
我们推出Skywork R1V2,这是下一代多模态推理模型,也是其前身Skywork R1V的重大飞跃。R1V2的核心引入了一种混合强化学习范式,该范式结合了混合偏好优化(MPO)和组相对策略优化(GRPO),将奖励模型指导与基于规则的策略相协调,从而解决了长期存在的平衡复杂推理能力与广泛泛化能力之间的挑战。为了进一步提高训练效率,我们提出了选择性样本缓冲(SSB)机制,它通过在整个优化过程中优先处理高价值样本,有效地解决了GRPO固有的优势消失困境。值得注意的是,我们观察到过多的强化信号可能导致视觉幻觉——我们通过训练过程中的校准奖励阈值系统地监测和缓解这一现象。实证结果证实了R1V2的卓越能力,其在OlympiadBench上达到62.6,AIME2024上达到78.9,LiveCodeBench上达到63.6,MMMU上达到73.6。这些结果凸显了R1V2在现有开源模型中的优越性,并表明在缩小与顶尖专有系统(包括Gemini 2.5和OpenAI-o4-mini)的性能差距方面取得了显著进展。Skywork R1V2模型权重已公开发布,以促进开放性和可重复性。https://huggingface.co/Skywork/Skywork-R1V2-38B。
论文及项目相关链接
Summary
Skywork R1V2是下一代多模态推理模型,相比其前身Skywork R1V有了重大突破。R1V2采用混合强化学习范式,结合Mixed Preference Optimization(MPO)和Group Relative Policy Optimization(GRPO),平衡了高级推理能力与广泛泛化能力。为提高训练效率,提出了Selective Sample Buffer(SSB)机制。同时,该模型能有效应对过度强化信号引起的视觉幻觉问题。实证结果表明,R1V2在多个基准测试上表现优异,如OlympiadBench、AIME2024、LiveCodeBench和MMMU,且模型权重已公开以促进开放和可重复性。
Key Takeaways
- Skywork R1V2是新一代多模态推理模型,较之前版本有重大突破。
- R1V2采用混合强化学习范式,结合MPO和GRPO,以平衡推理能力和泛化能力。
- 引入SSB机制提高训练效率,解决GRPO的固有难题。
- 模型可应对过度强化信号引起的视觉幻觉问题。
- 实证结果表明R1V2在多个基准测试上表现优异。
- 模型权重已公开,以促进开放和可重复性。
点此查看论文截图

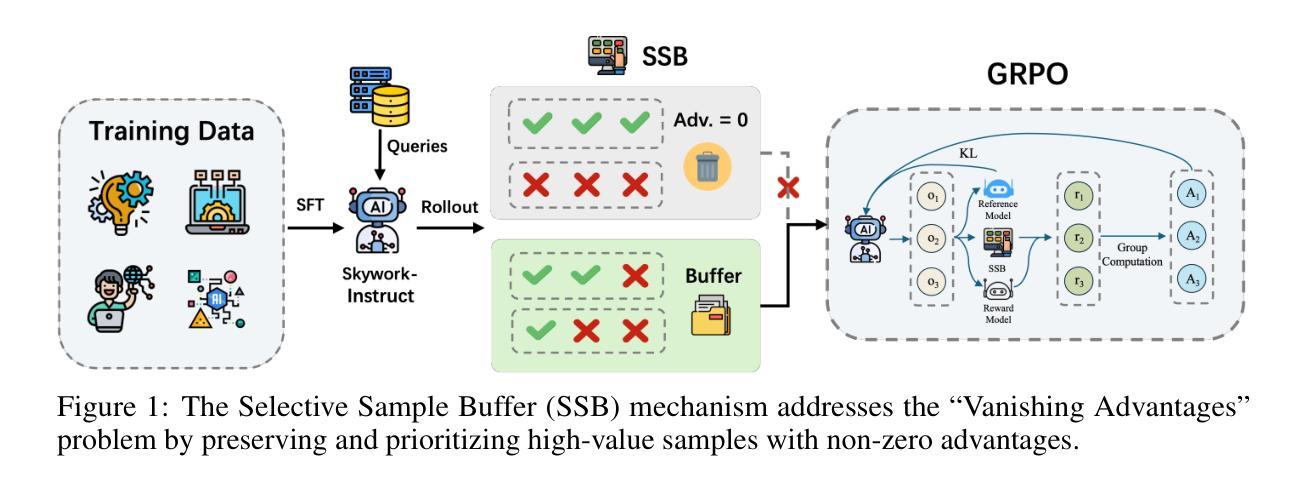
DeepSeek-R1 vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Authors:Daniil Larionov, Sotaro Takeshita, Ran Zhang, Yanran Chen, Christoph Leiter, Zhipin Wang, Christian Greisinger, Steffen Eger
Reasoning-enabled large language models (LLMs) excel in logical tasks, yet their utility for evaluating natural language generation remains unexplored. This study systematically compares reasoning LLMs with non-reasoning counterparts across machine translation and text summarization evaluation tasks. We evaluate eight models spanning state-of-the-art reasoning models (DeepSeek-R1, OpenAI o3), their distilled variants (8B-70B parameters), and equivalent non-reasoning LLMs. Experiments on WMT23 and SummEval benchmarks reveal architecture and task-dependent benefits: OpenAI o3-mini models show improved performance with increased reasoning on MT, while DeepSeek-R1 and generally underperforms compared to its non-reasoning variant except in summarization consistency evaluation. Correlation analysis demonstrates that reasoning token usage correlates with evaluation quality only in specific models, while almost all models generally allocate more reasoning tokens when identifying more quality issues. Distillation maintains reasonable performance up to 32B parameter models but degrades substantially at 8B scale. This work provides the first assessment of reasoning LLMs for NLG evaluation and comparison to non-reasoning models. We share our code to facilitate further research: https://github.com/NL2G/reasoning-eval.
具备推理能力的大型语言模型(LLM)在逻辑任务方面表现出色,然而它们在自然语言生成评估方面的效用尚未被探索。本研究系统地比较了推理LLM与非推理LLM在机器翻译和文本摘要评估任务上的表现。我们评估了八种模型,包括最新推理模型(DeepSeek-R1,OpenAI o3)、它们的蒸馏变体(8B-70B参数),以及相应的非推理LLM。在WMT23和SummEval基准测试上的实验揭示了架构和任务依赖性的好处:OpenAI o3-mini模型在翻译任务中增加了推理功能后表现出更好的性能,而DeepSeek-R1除了在摘要一致性评估方面外,通常与其非推理变体相比表现较差。相关性分析表明,推理令牌的使用仅在与特定模型的评价质量相关,而几乎所有模型在识别更多质量问题时一般都会分配更多的推理令牌。蒸馏技术可以在32B参数模型上保持合理的性能,但在8B规模上性能会大幅下降。这项工作首次对用于自然语言生成评估的推理LLM进行了评估,并与非推理模型进行了比较。我们分享了我们的代码以促进进一步的研究:https://github.com/NL2G/reasoning-eval。
论文及项目相关链接
Summary
本文研究了具备推理能力的大型语言模型(LLMs)在自然语言生成评估中的表现。文章通过对比实验发现,在机器翻译和文本摘要评估任务中,推理LLMs与非推理LLMs的表现存在差异。文章还指出,不同模型和任务背景下,推理能力对模型性能的影响有所不同。此外,该研究还探讨了模型蒸馏对推理LLMs性能的影响。本文提供了对推理LLMs在NLG评估中的首次评估,并与非推理模型进行了比较。
Key Takeaways
- 推理LLMs在逻辑任务上表现出色,但在自然语言生成评估中的实用性尚未得到充分探索。
- 研究发现,在机器翻译和文本摘要评估任务中,推理LLMs与非推理LLMs的表现不同。
- OpenAI o3-mini模型在机器翻译任务上,增强推理能力会提升性能。
- DeepSeek-R1模型在大部分情况下相较于非推理变体在摘要一致性评估方面表现较差。
- 推理标记的使用与评估质量仅在特定模型中相关,而在大多数模型中,识别质量问题时通常会分配更多的推理标记。
- 模型蒸馏技术可以在参数规模较小的模型中保持较好的性能,但在8B参数规模模型中性能会大幅下降。
点此查看论文截图

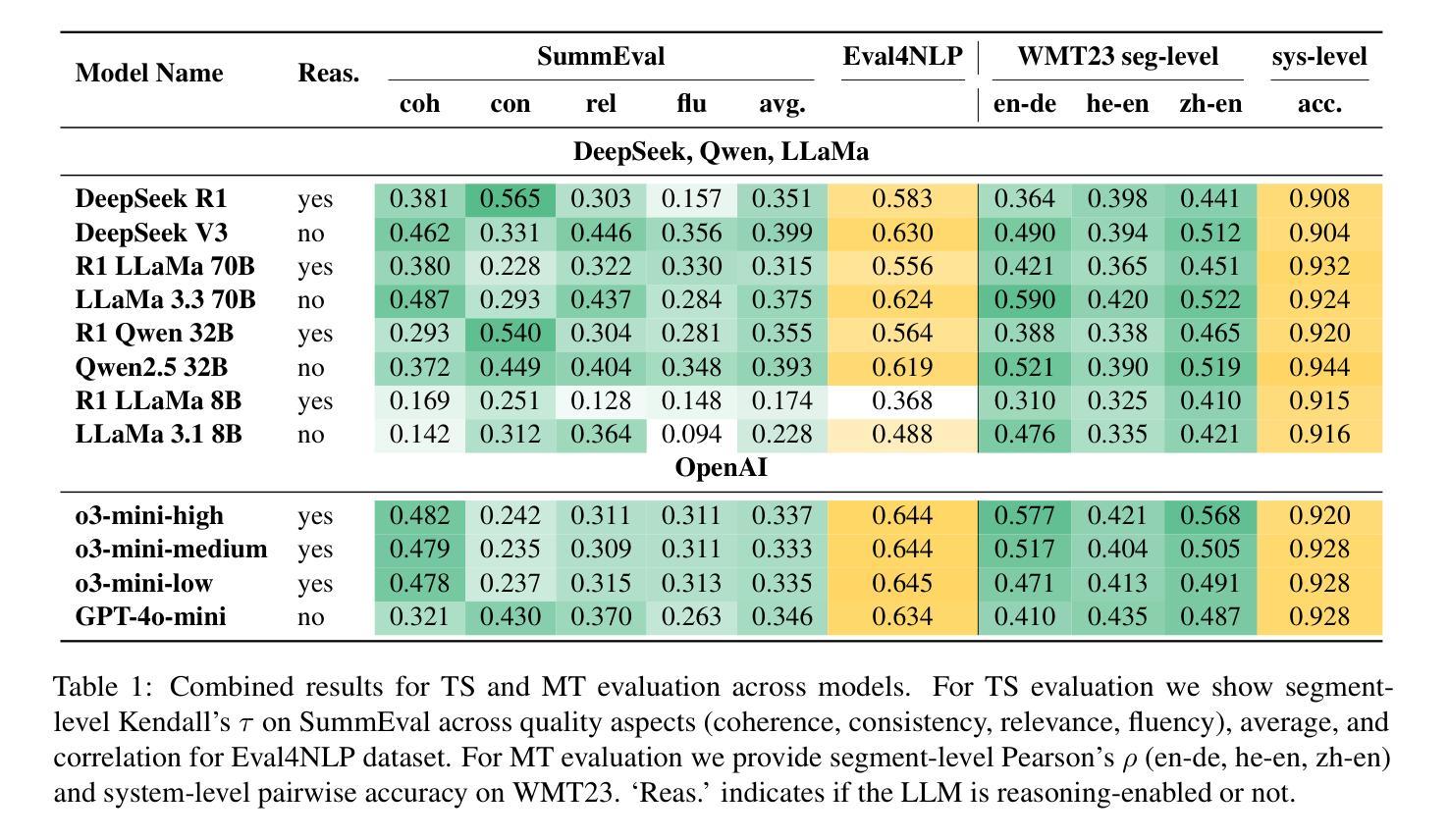
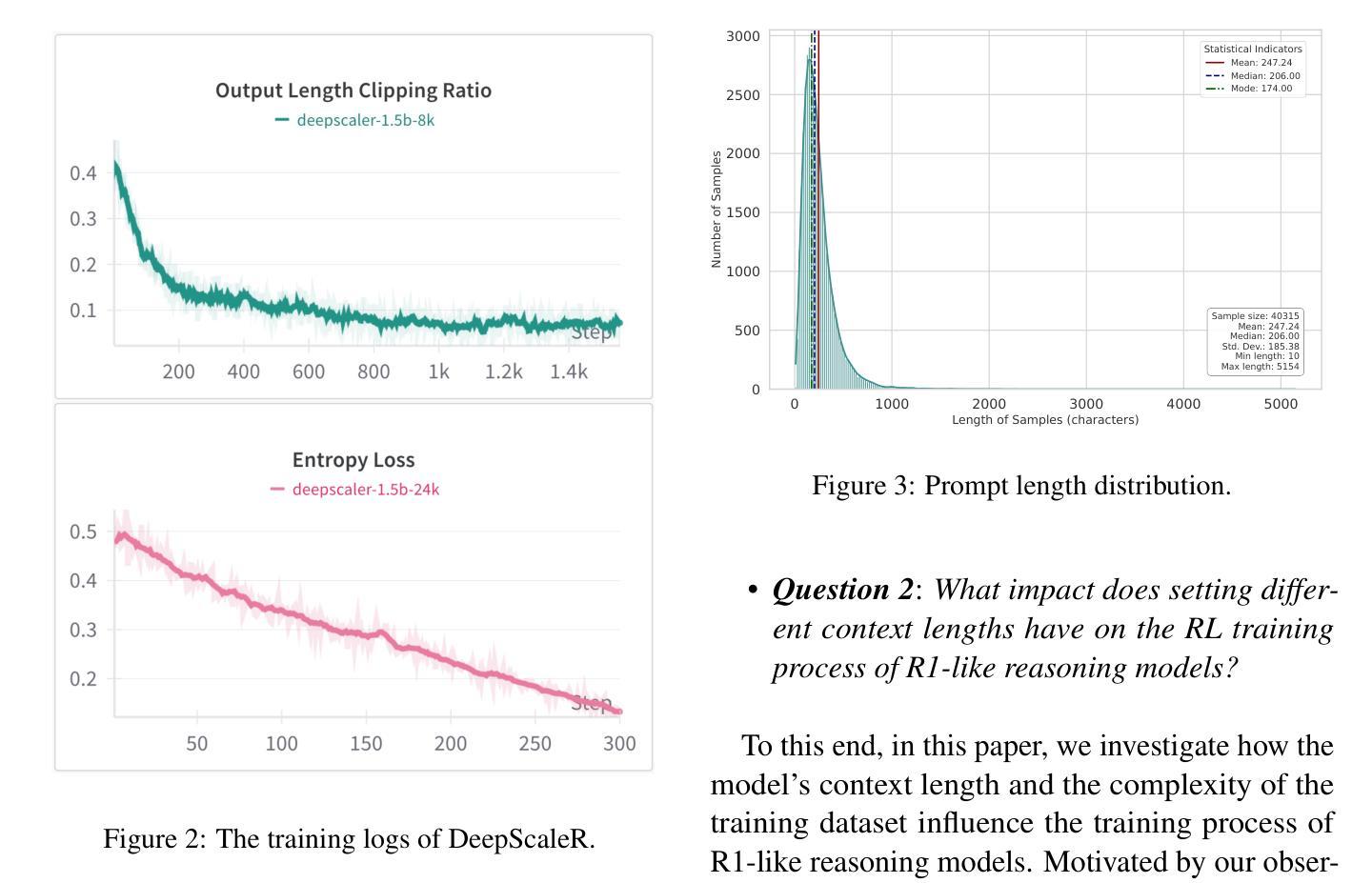
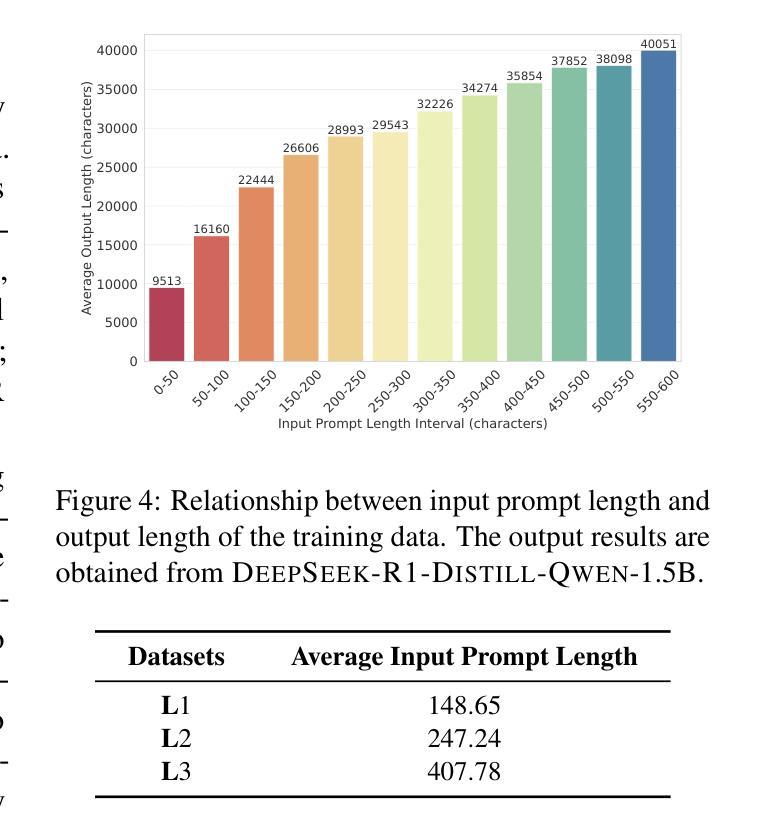
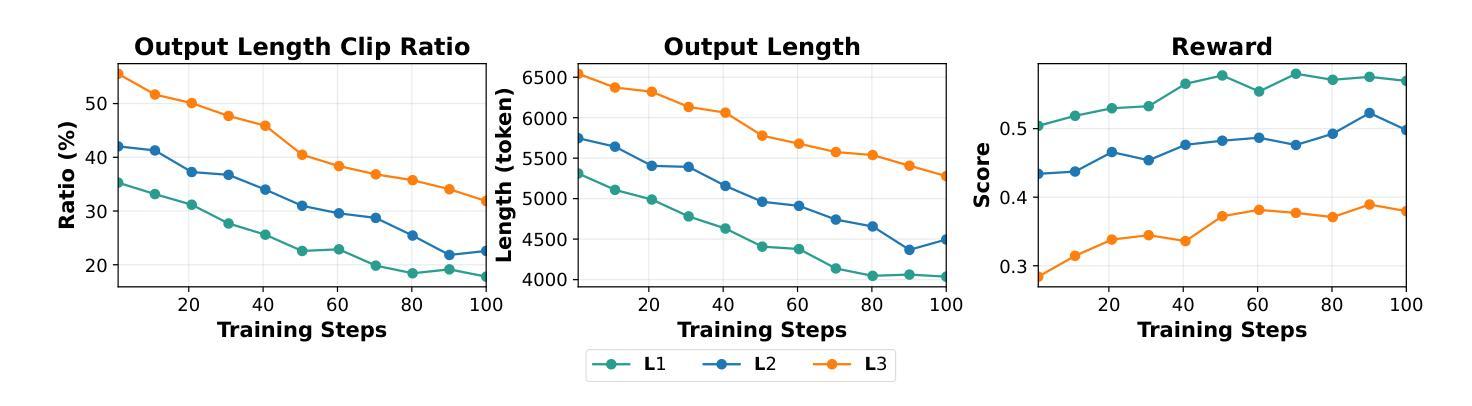
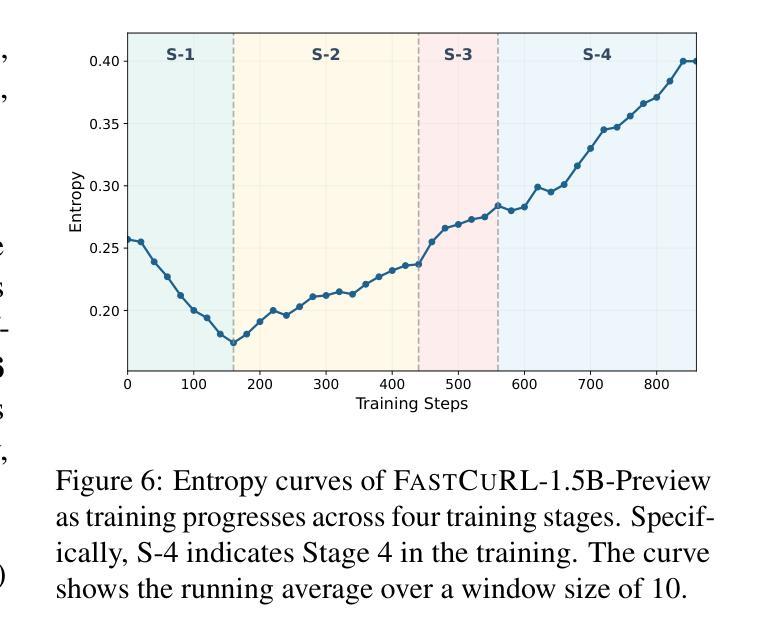
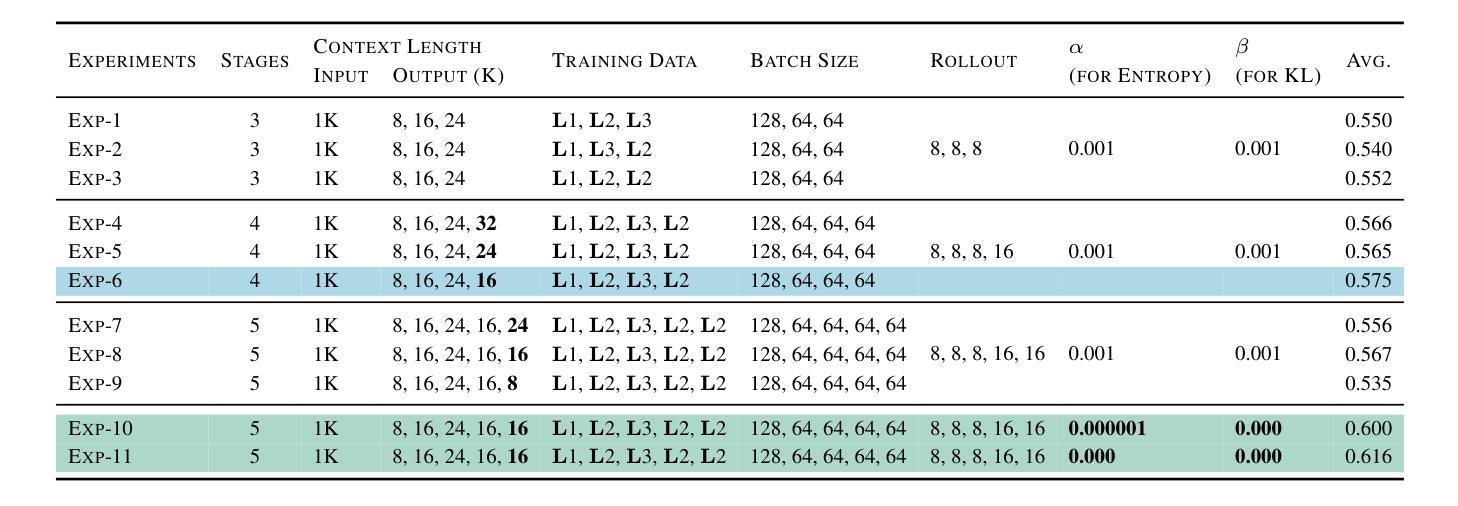
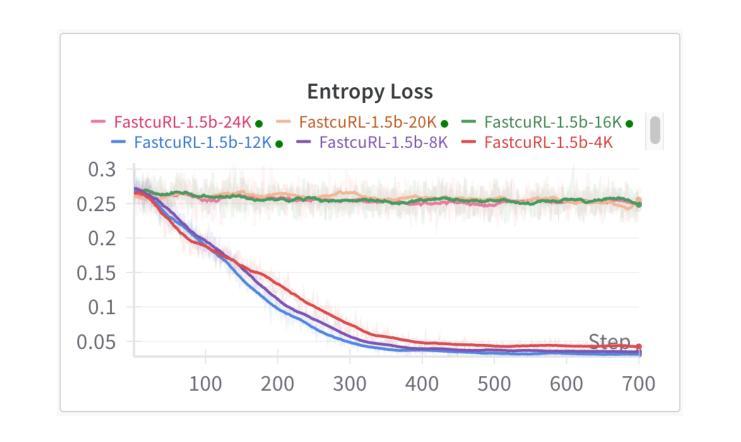
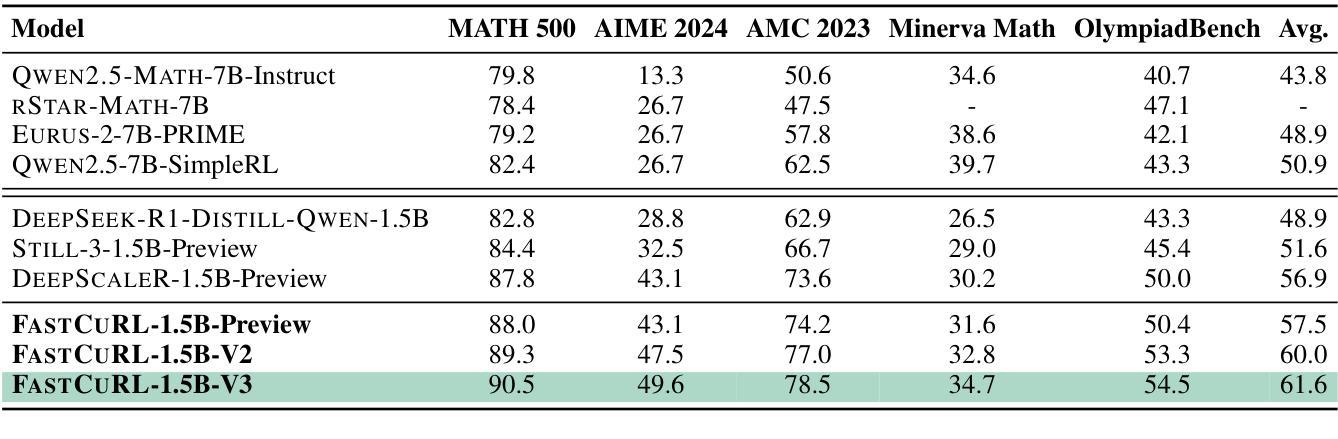
FastCuRL: Curriculum Reinforcement Learning with Stage-wise Context Scaling for Efficient Training R1-like Reasoning Models
Authors:Mingyang Song, Mao Zheng, Zheng Li, Wenjie Yang, Xuan Luo, Yue Pan, Feng Zhang
Improving training efficiency continues to be one of the primary challenges in large-scale Reinforcement Learning (RL). In this paper, we investigate how context length and the complexity of training data influence the RL scaling training process of R1-distilled small reasoning models, e.g., DeepSeek-R1-Distill-Qwen-1.5B. Our experimental results reveal that: (1) simply controlling the context length and curating the training data based on the input prompt length can effectively improve the training efficiency of scaling RL, achieving better performance with more concise CoT; (2) properly scaling the context length helps mitigate entropy collapse; and (3) choosing an optimal context length can improve the efficiency of model training and incentivize the model’s chain-of-thought reasoning capabilities. Inspired by these insights, we propose FastCuRL, a curriculum RL framework with stage-wise context scaling to achieve efficient training and concise CoT reasoning. Experiment results demonstrate that FastCuRL-1.5B-V3 significantly outperforms state-of-the-art reasoning models on five competition-level benchmarks and achieves 49.6% accuracy on AIME 2024. Furthermore, FastCuRL-1.5B-Preview surpasses DeepScaleR-1.5B-Preview on five benchmarks while only using a single node with 8 GPUs and a total of 50% of training steps. %The code, training data, and models will be publicly released.
改进训练效率仍然是大规模强化学习(RL)面临的主要挑战之一。本文研究了上下文长度和训练数据复杂性对R1蒸馏小型推理模型(例如DeepSeek-R1-Distill-Qwen-1.5B)的RL规模化训练过程的影响。我们的实验结果揭示:(1)通过控制上下文长度并根据输入提示长度筛选训练数据,可以有效提高规模化RL的训练效率,实现更简洁的CoT;(2)适当缩放上下文长度有助于减轻熵塌陷;(3)选择最佳的上下文长度可以提高模型训练的效率并激发模型的思维链推理能力。受到这些见解的启发,我们提出了FastCuRL,这是一种具有阶段性上下文缩放的课程RL框架,以实现高效的训练和简洁的CoT推理。实验结果表明,FastCuRL-1.5B-V3在五个竞赛级基准测试上的表现均优于最新推理模型,在AIME 2024上达到49.6%的准确率。此外,FastCuRL-1.5B-Preview在五个基准测试上超越了DeepScaleR-1.5B-Preview,同时仅使用单个节点8个GPU和总计50%的训练步骤。相关代码、训练数据和模型将公开发布。
论文及项目相关链接
PDF Ongoing Work
Summary
本文探讨了上下文长度与训练数据复杂性对大规模强化学习(RL)训练效率的影响。实验结果表明,通过控制上下文长度并根据输入提示长度筛选训练数据,可以有效提高RL训练效率,实现更简洁的推理过程。基于此,提出了FastCuRL课程学习框架,通过阶段性上下文缩放实现高效训练和简洁推理。实验结果显示,FastCuRL在多个竞赛级基准测试上表现出卓越性能。
Key Takeaways
- 控制上下文长度和基于输入提示长度筛选训练数据可有效提高强化学习训练效率。
- 适当扩展上下文长度有助于缓解熵崩溃问题。
- 选择最佳上下文长度能提升模型训练效率并激发模型的链式推理能力。
- FastCuRL是一个结合阶段式上下文缩放的新课程学习框架,旨在实现高效训练和简洁推理。
- FastCuRL在多个竞赛级基准测试上显著优于现有推理模型。
- FastCuRL-1.5B-V3在AIME 2024上达到49.6%的准确率。
点此查看论文截图

Safety Evaluation and Enhancement of DeepSeek Models in Chinese Contexts
Authors:Wenjing Zhang, Xuejiao Lei, Zhaoxiang Liu, Limin Han, Jiaojiao Zhao, Junting Guo, Zhenhong Long, Shu Yang, Meijuan An, Beibei Huang, Rongjia Du, Ning Wang, Kai Wang, Shiguo Lian
DeepSeek-R1, renowned for its exceptional reasoning capabilities and open-source strategy, is significantly influencing the global artificial intelligence landscape. However, it exhibits notable safety shortcomings. Recent research conducted by Robust Intelligence, a subsidiary of Cisco, in collaboration with the University of Pennsylvania, revealed that DeepSeek-R1 achieves a 100% attack success rate when processing harmful prompts. Furthermore, multiple security firms and research institutions have identified critical security vulnerabilities within the model. Although China Unicom has uncovered safety vulnerabilities of R1 in Chinese contexts, the safety capabilities of the remaining distilled models in the R1 series have not yet been comprehensively evaluated. To address this gap, this study utilizes the comprehensive Chinese safety benchmark CHiSafetyBench to conduct an in-depth safety evaluation of the DeepSeek-R1 series distilled models. The objective is to assess the safety capabilities of these models in Chinese contexts both before and after distillation, and to further elucidate the adverse effects of distillation on model safety. Building on these findings, we implement targeted safety enhancements for the entire DeepSeek-R1 model series. Evaluation results indicate that the enhanced models achieve significant improvements in safety while maintaining reasoning capabilities without notable degradation. We open-source the safety-enhanced models at https://github.com/UnicomAI/DeepSeek-R1-Safe to serve as a valuable resource for future research and optimization of DeepSeek models.
DeepSeek-R1以其出色的推理能力和开源策略而闻名,正在全球人工智能领域产生重大影响。然而,它存在明显的安全缺陷。思科子公司Robust Intelligence与宾夕法尼亚大学最近进行的联合研究表明,DeepSeek-R1在处理有害提示时达到了100%的攻击成功率。此外,多家安全公司和研究机构已经发现了该模型的关键安全漏洞。虽然中国联通已经在中国背景下发现了R1的安全漏洞,但R1系列中其余蒸馏模型的安全能力尚未进行全面评估。为了解决这一空白,本研究利用全面的中文安全基准CHiSafetyBench对DeepSeek-R1系列蒸馏模型进行深入的安全评估。我们的目标是评估这些模型在中国背景下的蒸馏前后的安全能力,并进一步阐明蒸馏对模型安全的负面影响。基于这些发现,我们对整个DeepSeek-R1模型系列实施了有针对性的安全增强措施。评估结果表明,增强型模型在安全方面实现了显著改进,同时保持了推理能力,没有明显退化。我们在https://github.com/UnicomAI/DeepSeek-R1-Safe公开了增强安全性的模型,以供未来研究和优化DeepSeek模型时作为有价值的资源。
论文及项目相关链接
PDF 21 pages, 13 figures, 4 tables
Summary
DeepSeek-R1模型虽然在人工智能领域展现出色的推理能力并推行开源策略,但其存在重大的安全隐患。最近的研究表明,当面对恶意提示时,DeepSeek-R1会遭受百分之百的攻击成功率。同时,多家安全企业和研究机构已经发现了该模型的安全漏洞。中国联通则发现了该模型在中国语境下的安全漏洞,但对R1系列其他蒸馏模型的安全能力尚未进行全面评估。本研究利用中文安全基准CHiSafetyBench对DeepSeek-R1系列蒸馏模型进行深入的安全评估,旨在评估这些模型在蒸馏前后的安全能力,并进一步研究蒸馏对模型安全的负面影响。基于这些发现,我们对整个DeepSeek-R1模型系列实施了有针对性的安全增强措施,并在保持推理能力的同时显著提高了其安全性。相关成果已开源共享。
Key Takeaways
- DeepSeek-R1模型在人工智能领域具有出色的推理能力,但存在严重的安全漏洞。
- 当面对恶意提示时,DeepSeek-R1模型会受到百分之百的攻击。
- 多家安全企业和研究机构已经指出该模型的安全问题。
- 中国联通则发现了该模型在中国语境下的特定安全漏洞。
- 研究利用CHiSafetyBench对DeepSeek-R1系列蒸馏模型进行了全面的安全评估。
- 蒸馏过程对模型的安全能力有负面影响。
点此查看论文截图

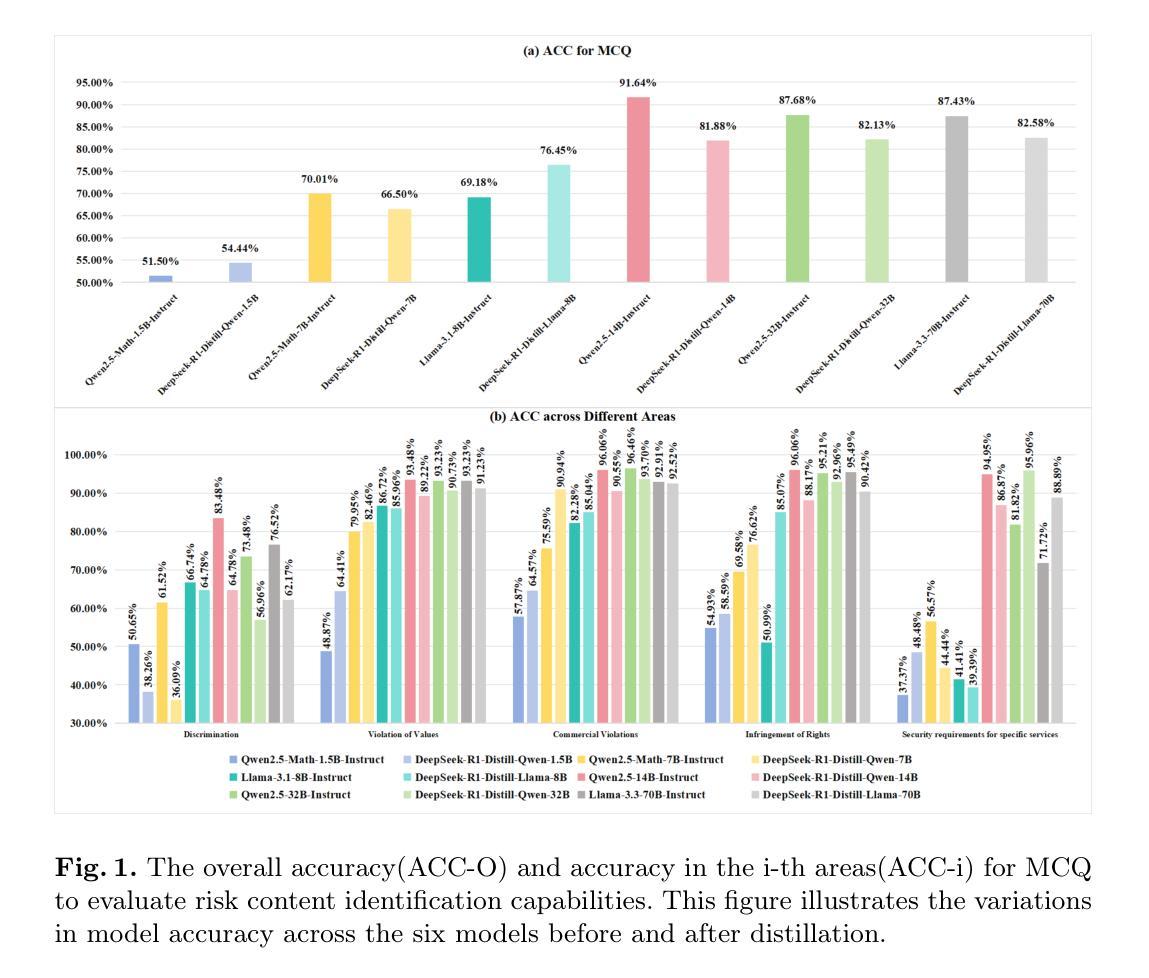
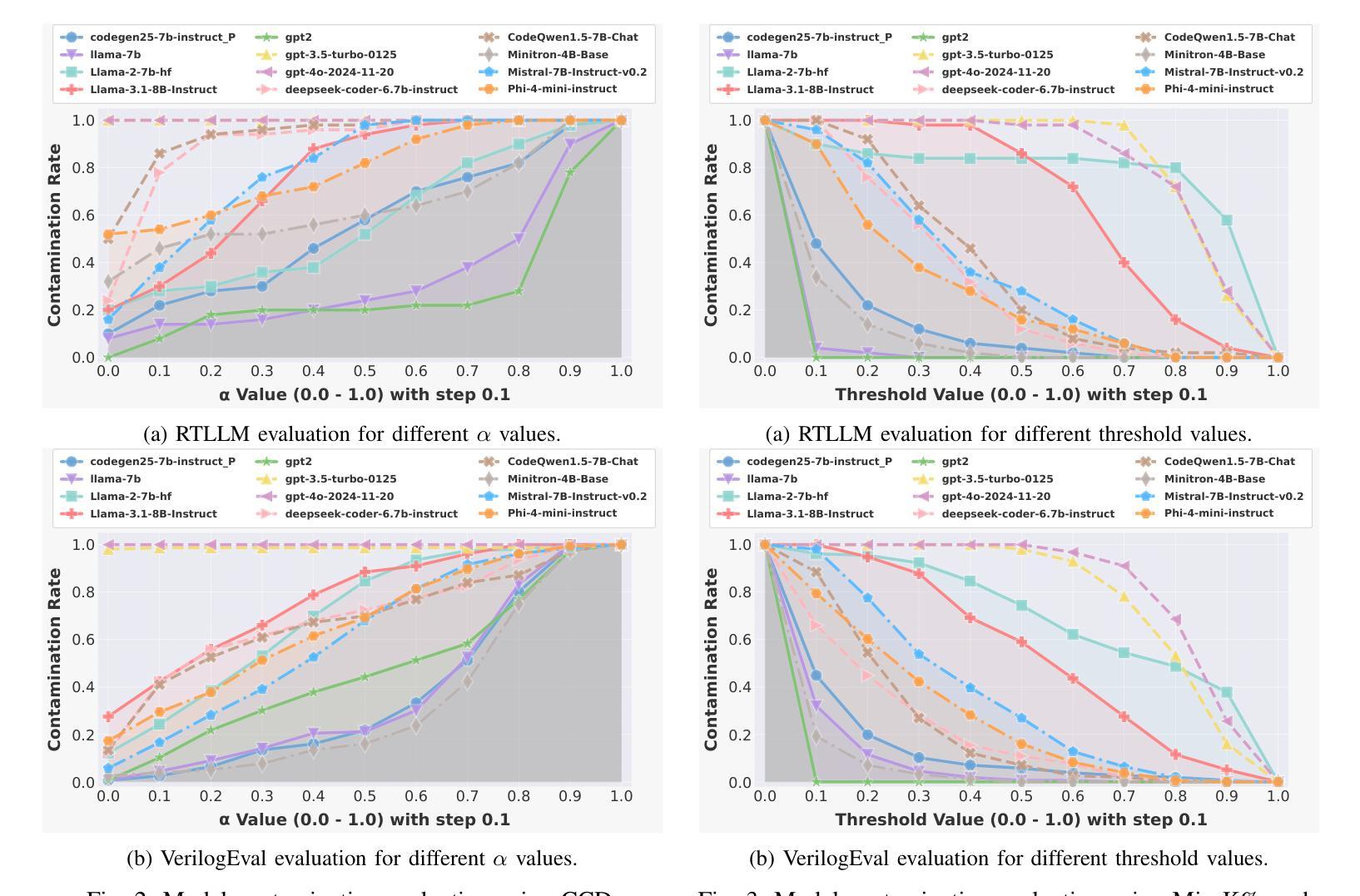
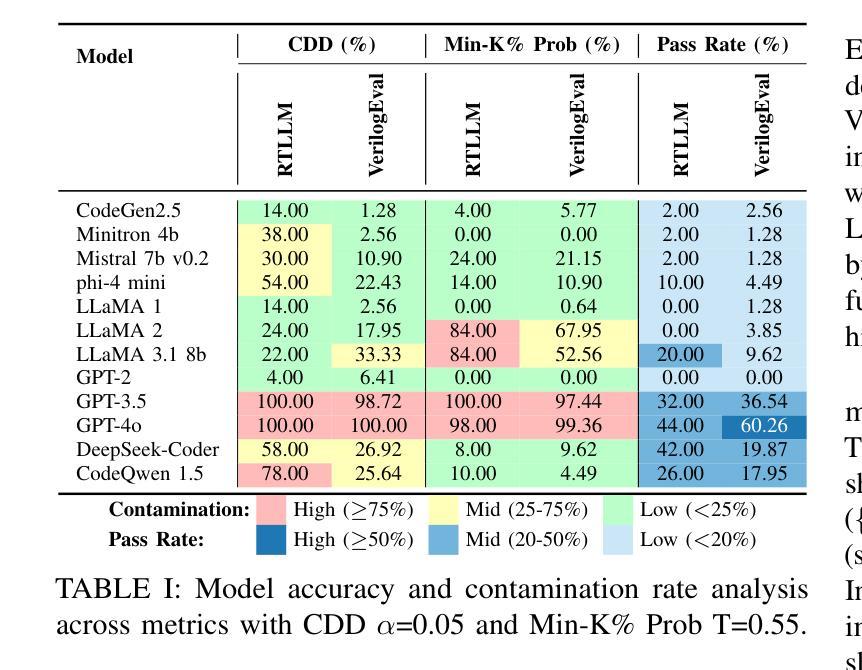
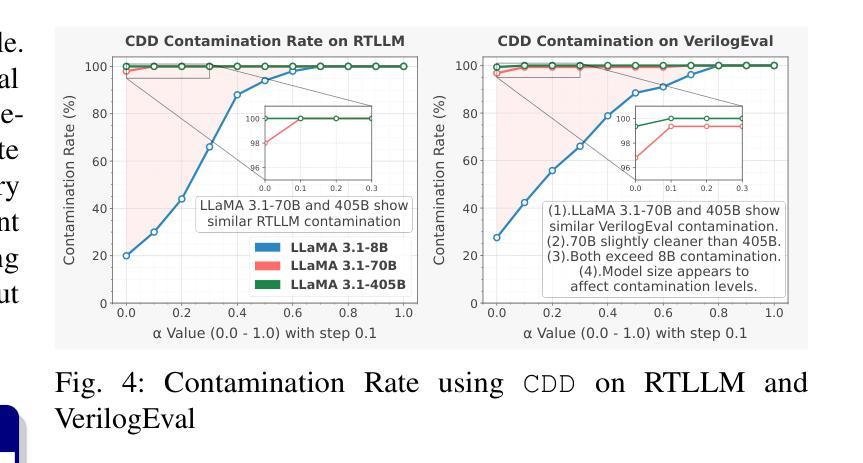
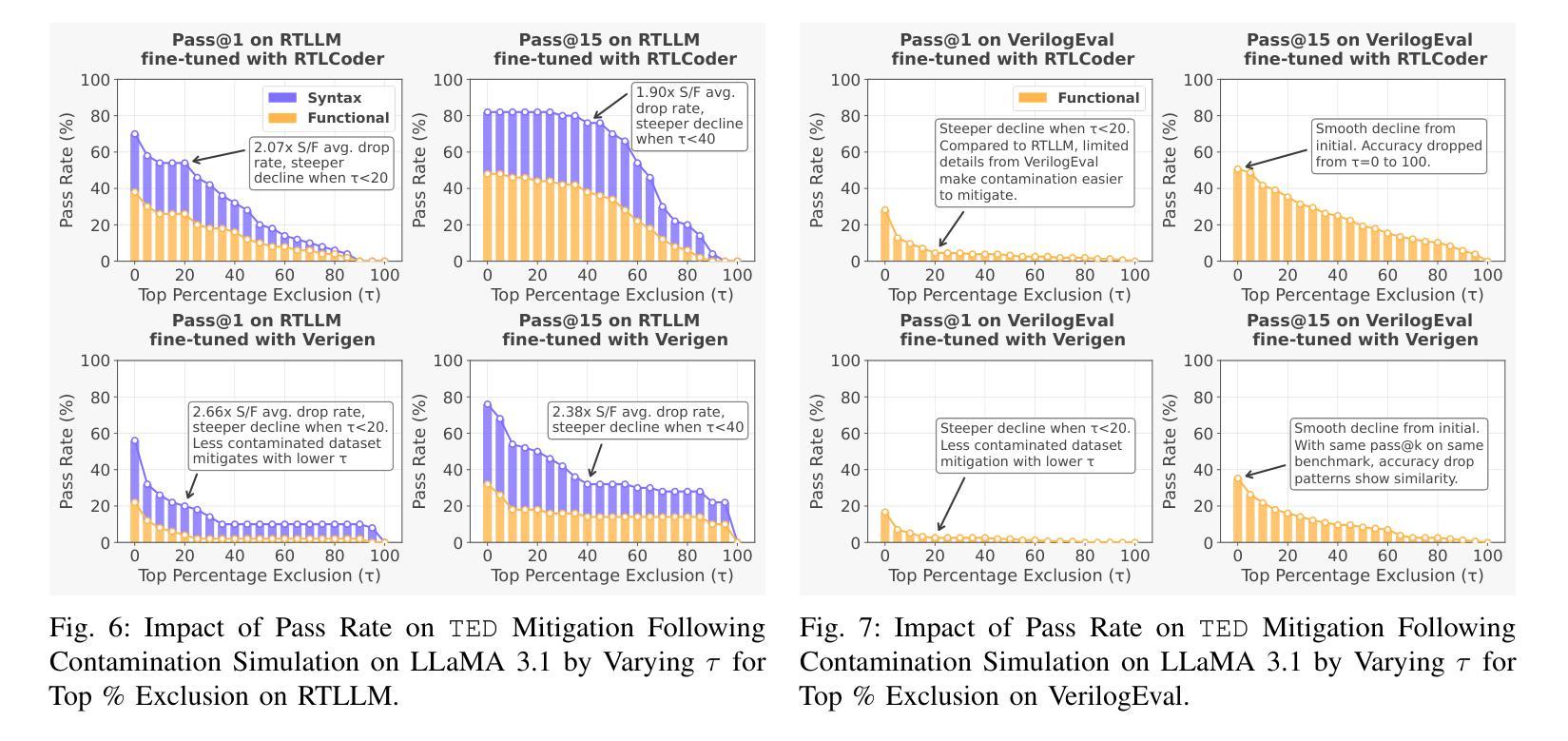
VeriContaminated: Assessing LLM-Driven Verilog Coding for Data Contamination
Authors:Zeng Wang, Minghao Shao, Jitendra Bhandari, Likhitha Mankali, Ramesh Karri, Ozgur Sinanoglu, Muhammad Shafique, Johann Knechtel
Large Language Models (LLMs) have revolutionized code generation, achieving exceptional results on various established benchmarking frameworks. However, concerns about data contamination - where benchmark data inadvertently leaks into pre-training or fine-tuning datasets - raise questions about the validity of these evaluations. While this issue is known, limiting the industrial adoption of LLM-driven software engineering, hardware coding has received little to no attention regarding these risks. For the first time, we analyze state-of-the-art (SOTA) evaluation frameworks for Verilog code generation (VerilogEval and RTLLM), using established methods for contamination detection (CCD and Min-K% Prob). We cover SOTA commercial and open-source LLMs (CodeGen2.5, Minitron 4b, Mistral 7b, phi-4 mini, LLaMA-{1,2,3.1}, GPT-{2,3.5,4o}, Deepseek-Coder, and CodeQwen 1.5), in baseline and fine-tuned models (RTLCoder and Verigen). Our study confirms that data contamination is a critical concern. We explore mitigations and the resulting trade-offs for code quality vs fairness (i.e., reducing contamination toward unbiased benchmarking).
大型语言模型(LLM)在代码生成方面带来了革命性的变化,在各种成熟的基准测试框架上取得了非凡的成果。然而,对数据污染的担忧——即基准测试数据无意中泄露到预训练或微调数据集——对这些评估的有效性提出了质疑。虽然这个问题已经为人所知,并限制了LLM驱动的软件工程在工业上的应用,但硬件编码几乎没有关注这些风险。我们首次使用污染检测确立的方法(CCD和Min-K% Prob)分析最先进的Verilog代码生成评估框架(VerilogEval和RTLLM)。我们涵盖了最先进的商用和开源LLM(CodeGen2.5、Minitron 4b、Mistral 7b、phi-4 mini、LLaMA-{1,2,3.1}、GPT-{2,3.5,4o}、Deepseek-Coder和CodeQwen 1.5),基线模型和微调模型(RTLCoder和Verigen)。我们的研究证实了数据污染是一个关键问题。我们探讨了缓解措施以及代码质量与公平性之间的权衡(即减少污染以实现无偏见基准测试)。
论文及项目相关链接
Summary
该文本研究了大型语言模型(LLMs)在代码生成方面的卓越表现,但提出了数据污染的问题,对评估的合理性提出了质疑。研究分析了最先进的Verilog代码生成评估框架,使用污染检测方法来覆盖多个商业和开源LLMs。研究确认了数据污染是一个关键问题,并探讨了缓解措施及其与代码质量和公平性之间的权衡。
Key Takeaways
- 大型语言模型(LLMs)在代码生成方面取得了显著进展,并在各种基准测试框架上表现出色。
- 数据污染问题成为LLM在代码生成应用中的关键挑战,影响了评估的合理性。
- 对最先进的Verilog代码生成评估框架进行了分析,包括VerilogEval和RTLLM。
- 使用了污染检测方法(如CCD和Min-K% Prob)来检测数据污染。
- 研究覆盖了多个商业和开源LLMs,包括CodeGen2.5、Minitron 4b等。
- 数据污染对代码生成的质量和公平性构成权衡,需要进行缓解措施的研究。
点此查看论文截图



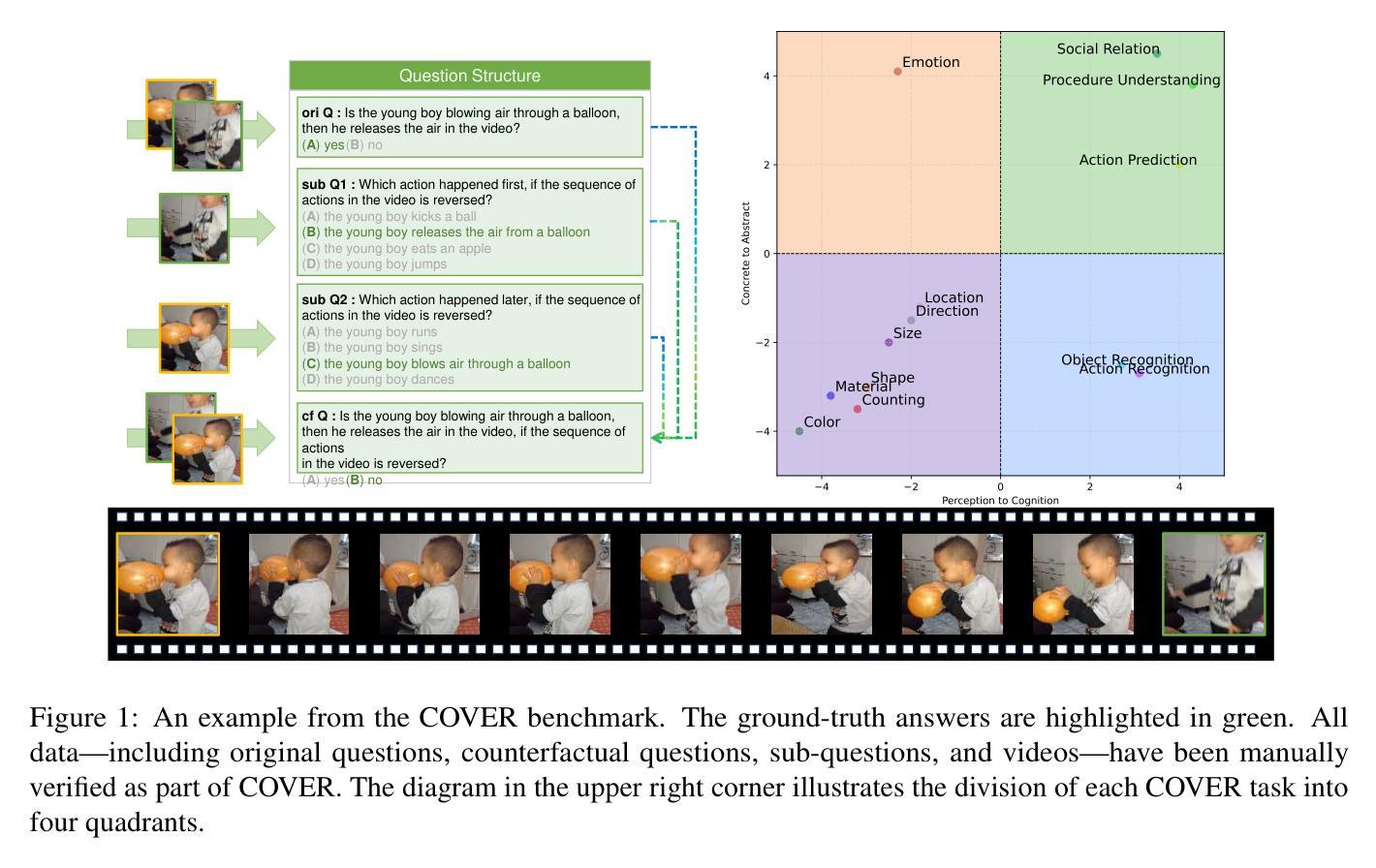
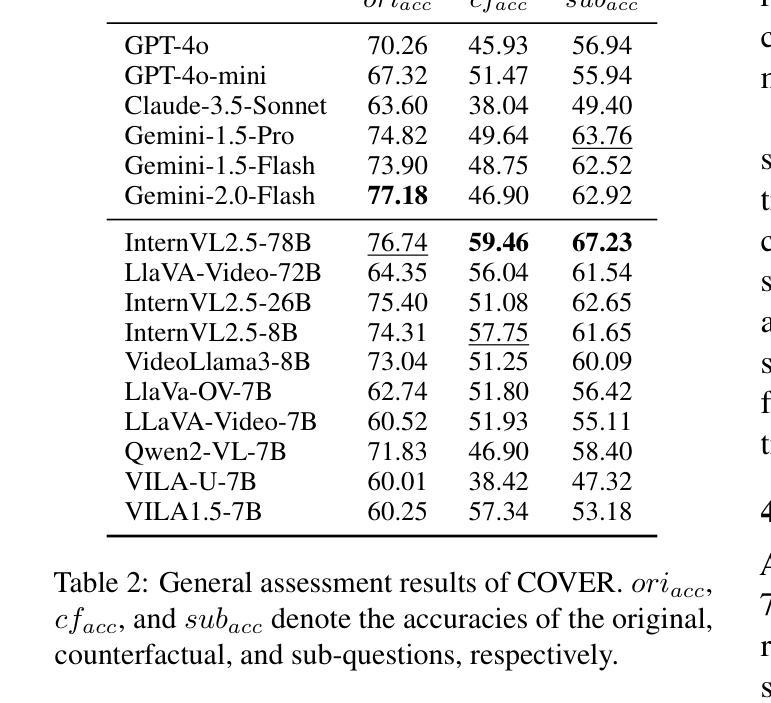
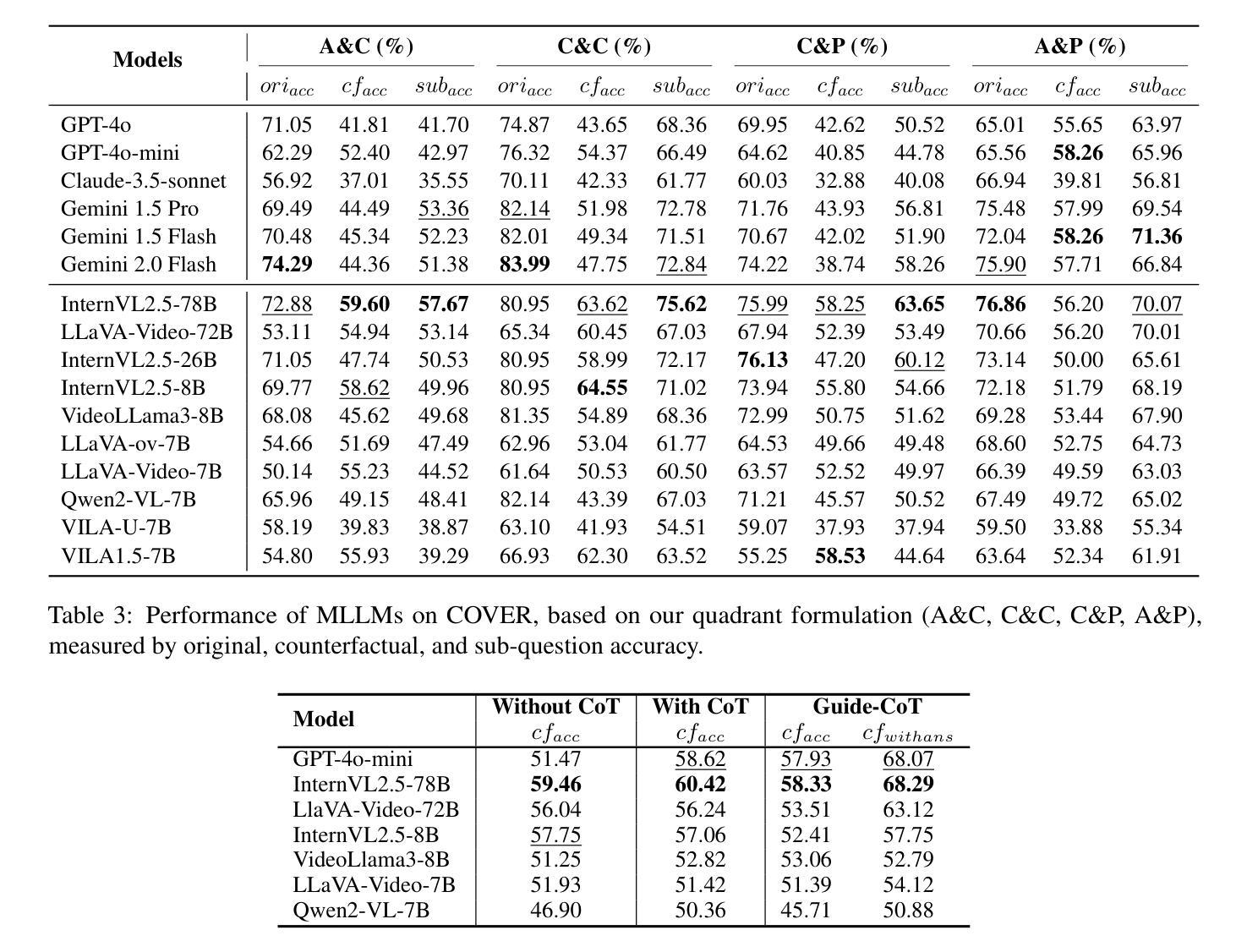
Reasoning is All You Need for Video Generalization: A Counterfactual Benchmark with Sub-question Evaluation
Authors:Qiji Zhou, Yifan Gong, Guangsheng Bao, Hongjie Qiu, Jinqiang Li, Xiangrong Zhu, Huajian Zhang, Yue Zhang
Counterfactual reasoning is crucial for robust video understanding but remains underexplored in existing multimodal benchmarks. In this paper, we introduce \textbf{COVER} (\textbf{\underline{CO}}unterfactual \textbf{\underline{V}}id\textbf{\underline{E}}o \textbf{\underline{R}}easoning), a multidimensional multimodal benchmark that systematically evaluates MLLMs across the abstract-concrete and perception-cognition dimensions. Beyond prior multimodal benchmarks, COVER decomposes complex queries into structured sub-questions, enabling fine-grained reasoning analysis. Experiments on commercial and open-source models reveal a strong correlation between sub-question accuracy and counterfactual reasoning performance, highlighting the role of structured inference in video understanding. Furthermore, our results suggest a key insight: enhancing the reasoning capability of models is essential for improving the robustness of video understanding. COVER establishes a new standard for assessing MLLMs’ logical reasoning abilities in dynamic environments. Our work is available at https://github.com/gongyifan-hash/COVER-Benchmark.
假设性推理对于稳健的视频理解至关重要,但在现有的多模式基准测试中仍然被探索得不够深入。在本文中,我们介绍了COVER(Counterfactual Video Reasoning Benchmark),这是一个多维度的多模式基准测试,系统地评估跨抽象与具体维度以及感知与认知维度的多模态大型预训练模型(MLLMs)。相较于之前的模态基准测试,COVER将复杂的查询分解成结构化的子问题,使精细推理分析成为可能。对商业和开源模型的实验显示子问题准确度与假设性推理性能之间存在强烈相关性,凸显结构化推理在视频理解中的作用。此外,我们的结果揭示了一个关键见解:提高模型的推理能力是提升视频理解稳健性的关键。COVER为评估多模态大型预训练模型在动态环境中的逻辑推理能力建立了新的标准。我们的工作可通过链接访问:https://github.com/gongyifan-hash/COVER-Benchmark。
论文及项目相关链接
PDF It has been accepted to the ACL-2025 Findings
Summary
视频理解中,反事实推理至关重要,但在现有的多模式基准测试中仍然被忽视。本文介绍了COVER基准测试,这是一个多维度的多模式基准测试,系统地评估了抽象与具象、感知与认知两个维度的多媒体学习模型。相较于之前的多媒体基准测试,COVER能将复杂的查询分解成结构化的子问题,从而实现精细推理分析。实验表明子问题的准确度与反事实推理性能之间存在强烈的相关性,突显结构化推理在视频理解中的作用。此外,我们的研究结果揭示了关键见解:提高模型的推理能力对于提升视频理解的稳健性至关重要。COVER为评估多媒体学习模型在动态环境中的逻辑能力建立了新标准。
Key Takeaways
- 介绍了新的多模式基准测试COVER,用于评估多媒体学习模型在视频理解中的性能。
- COVER系统地在抽象与具象、感知与认知两个维度上评估模型。
- 通过将复杂查询分解为结构化子问题,COVER实现了精细推理分析。
- 实验显示子问题的准确度与反事实推理性能之间存在强烈相关性。
- 结构化推理在视频理解中扮演重要角色。
- 提高模型的推理能力能增强视频理解的稳健性。
点此查看论文截图


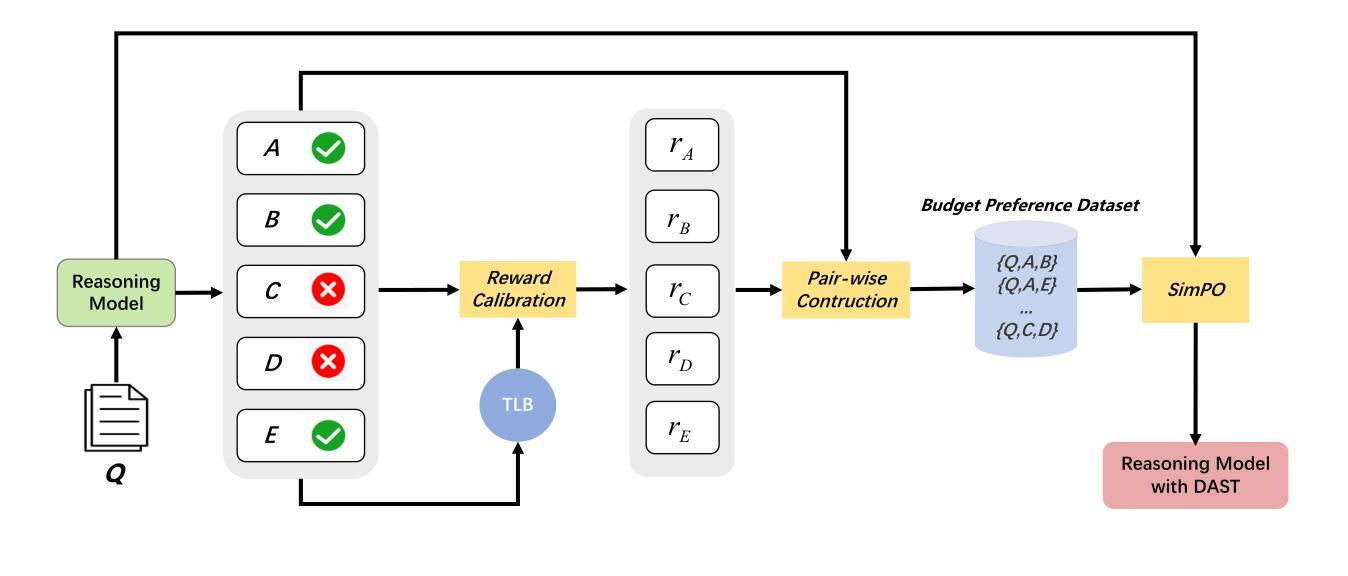
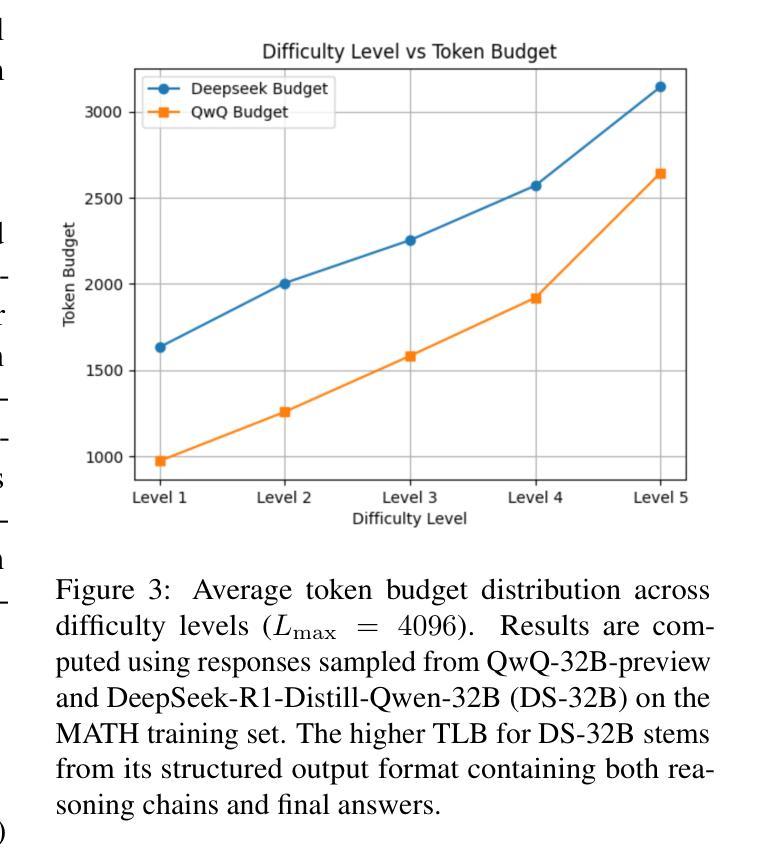
DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models
Authors:Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, Zhaoxiang Liu, Shiguo Lian
Recent advancements in slow thinking reasoning models have shown exceptional performance in complex reasoning tasks. However, these models often exhibit overthinking (generating redundant reasoning steps for simple problems), leading to excessive computational resource usage. While current mitigation strategies uniformly reduce reasoning tokens, they risk degrading performance on challenging tasks that require extended reasoning. This paper introduces Difficulty-Adaptive Slow Thinking (DAST), a novel framework that enables models to autonomously adjust the length of Chain-of-Thought (CoT) based on problem difficulty. We first propose a Token Length Budget (TLB) metric to quantify difficulty, then leverage budget-aware reward shaping and budget preference optimization to implement DAST. DAST penalizes overlong responses for simple tasks while incentivizing sufficient reasoning for complex problems. Experiments on diverse datasets and model scales demonstrate that DAST effectively mitigates overthinking (reducing token usage by over 30% on average) while preserving reasoning accuracy on complex problems. Our codes and models are available at https://github.com/AnonymousUser0520/AnonymousRepo01.
近期缓慢思考推理模型的进展在复杂推理任务中表现出了卓越的性能。然而,这些模型往往会出现过度思考的情况(对简单问题产生冗余的推理步骤),导致计算资源的使用过多。虽然当前的缓解策略都一致地减少推理令牌,但它们可能损害在需要扩展推理的挑战性任务上的性能。本文介绍了难度自适应慢思考(DAST),这是一种新型框架,使模型能够根据问题的难度自主调整思维链的长度。我们首先提出了一个令牌长度预算(TLB)指标来量化难度,然后利用预算感知奖励塑造和预算偏好优化来实现DAST。DAST对于简单的任务会惩罚过长的回应,同时激励对复杂问题的充分推理。在多样数据集和不同规模的模型上的实验表明,DAST有效地缓解了过度思考的问题(平均减少超过30%的令牌使用),同时在解决复杂问题时保持了推理的准确性。我们的代码和模型可在https://github.com/AnonymousUser0520/AnonymousRepo01获取。
论文及项目相关链接
PDF working in progress
Summary
最近慢思考推理模型的新进展在复杂推理任务中展现出卓越性能,但常有过度思考现象,造成计算资源浪费。本文提出一种名为Difficulty-Adaptive Slow Thinking(DAST)的新框架,让模型能根据问题难度自主调整思考链长度。实验证明,DAST有效减少过度思考现象,同时保持复杂问题的推理准确性。
Key Takeaways
- 慢思考推理模型在复杂任务中表现出卓越性能。
- 现有模型存在过度思考现象,导致计算资源浪费。
- DAST框架能根据问题难度自主调整思考链长度。
- DAST通过Token Length Budget(TLB)度量问题难度。
- DAST通过预算感知奖励塑形和预算偏好优化来实现。
- DAST在实验中有效减少过度思考现象,平均减少令牌使用超过30%。
点此查看论文截图

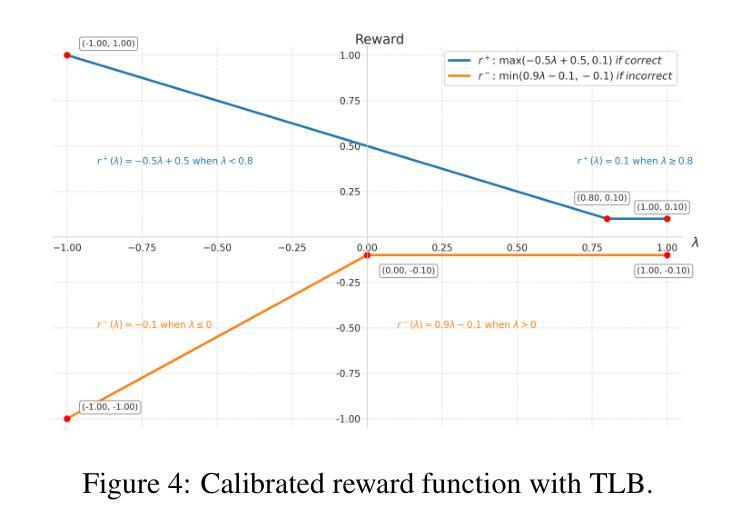
Marco-o1 v2: Towards Widening The Distillation Bottleneck for Reasoning Models
Authors:Huifeng Yin, Yu Zhao, Minghao Wu, Xuanfan Ni, Bo Zeng, Hao Wang, Tianqi Shi, Liangying Shao, Chenyang Lyu, Longyue Wang, Weihua Luo, Kaifu Zhang
Large Reasoning Models(LRMs) such as OpenAI o1 and DeepSeek-R1 have shown remarkable reasoning capabilities by scaling test-time compute and generating long Chain-of-Thought(CoT). Distillation–post-training on LRMs-generated data–is a straightforward yet effective method to enhance the reasoning abilities of smaller models, but faces a critical bottleneck: we found that distilled long CoT data poses learning difficulty for small models and leads to the inheritance of biases (i.e. over-thinking) when using Supervised Fine-tuning (SFT) and Reinforcement Learning (RL) methods. To alleviate this bottleneck, we propose constructing tree-based CoT data from scratch via Monte Carlo Tree Search(MCTS). We then exploit a set of CoT-aware approaches, including Thoughts Length Balance, Fine-grained DPO, and Joint Post-training Objective, to enhance SFT and RL on the constructed data. We conduct evaluation on various benchmarks such as math (GSM8K, MATH, AIME). instruction-following (Multi-IF) and planning (Blocksworld), results demonstrate our approaches substantially improve the reasoning performance of distilled models compared to standard distilled models via reducing the hallucinations in long-time thinking. The project homepage is https://github.com/AIDC-AI/Marco-o1.
大型推理模型(LRMs),如OpenAI o1和DeepSeek-R1,通过扩展测试时间计算并生成长的思维链(CoT)表现出了显著的推理能力。蒸馏——在LRMs生成的数据上进行后训练——是一种简单而有效的方法,可以提高较小模型的推理能力,但面临一个关键的瓶颈:我们发现蒸馏出的长CoT数据给小型模型带来了学习困难,在使用有监督微调(SFT)和强化学习(RL)方法时会导致偏见继承(即过度思考)。为了缓解这一瓶颈,我们提出通过蒙特卡洛树搜索(MCTS)从头构建树状CoT数据。然后,我们利用一系列CoT感知方法,包括思维长度平衡、精细粒度的DPO和联合后训练目标,来提高在构建数据上的SFT和RL。我们在各种基准测试(如GSM8K、MATH、AIME的数学测试、Multi-IF指令遵循测试和Blocksworld规划测试)上进行了评估,结果表明,我们的方法通过减少长时间思考中的幻觉,显著提高了蒸馏模型的推理性能。项目主页是https://github.com/AIDC-AI/Marco-o1。
论文及项目相关链接
Summary
大型推理模型(如OpenAI o1和DeepSeek-R1)通过扩展测试时间计算和生成长期的思维链(CoT)展现出惊人的推理能力。蒸馏——在LRMs生成的数据上进行后训练——是一种简单有效的提高小型模型推理能力的方法,但面临一个关键瓶颈:我们发现蒸馏的长期CoT数据给小型模型的学习带来了困难,并在使用有监督微调(SFT)和强化学习(RL)方法时导致了偏见(即过度思考)的继承。为缓解这一瓶颈,我们提出通过蒙特卡洛树搜索(MCTS)构建基于树的CoT数据。然后,我们利用一系列CoT感知方法,包括思维长度平衡、精细粒度的DPO和联合后训练目标,以增强在构建数据上的SFT和RL。我们在各种基准测试(如GSM8K、MATH、AIME的数学测试、Multi-IF指令遵循测试和Blocksworld规划测试)上进行了评估,结果表明我们的方法相比标准蒸馏模型,通过减少长期思考中的幻觉,大大提高了蒸馏模型的推理性能。
Key Takeaways
- 大型推理模型如OpenAI o1和DeepSeek-R1展现出强大的推理能力,通过扩展测试时间计算和生成长期的思维链。
- 蒸馏是一种有效提高小型模型推理能力的方法,但存在学习困难和偏见继承的问题。
- 蒙特卡洛树搜索(MCTS)被用于构建基于树的思维链数据,以解决蒸馏瓶颈。
- 提出了CoT感知方法,包括思维长度平衡、精细粒度的DPO和联合后训练目标,以增强小型模型在构建数据上的性能。
- 评估结果表明,所提出方法在多种基准测试上显著提高了蒸馏模型的推理性能。
- 方法通过减少长期思考中的幻觉来实现性能提升。
点此查看论文截图


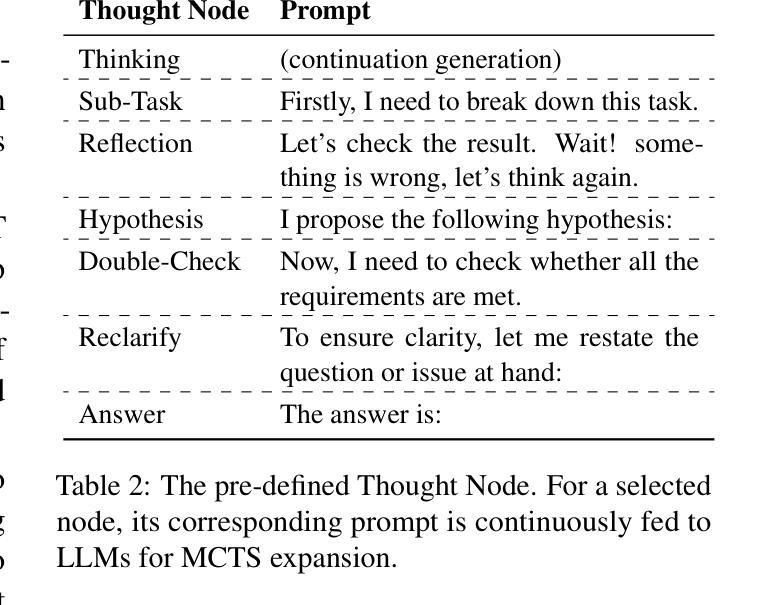
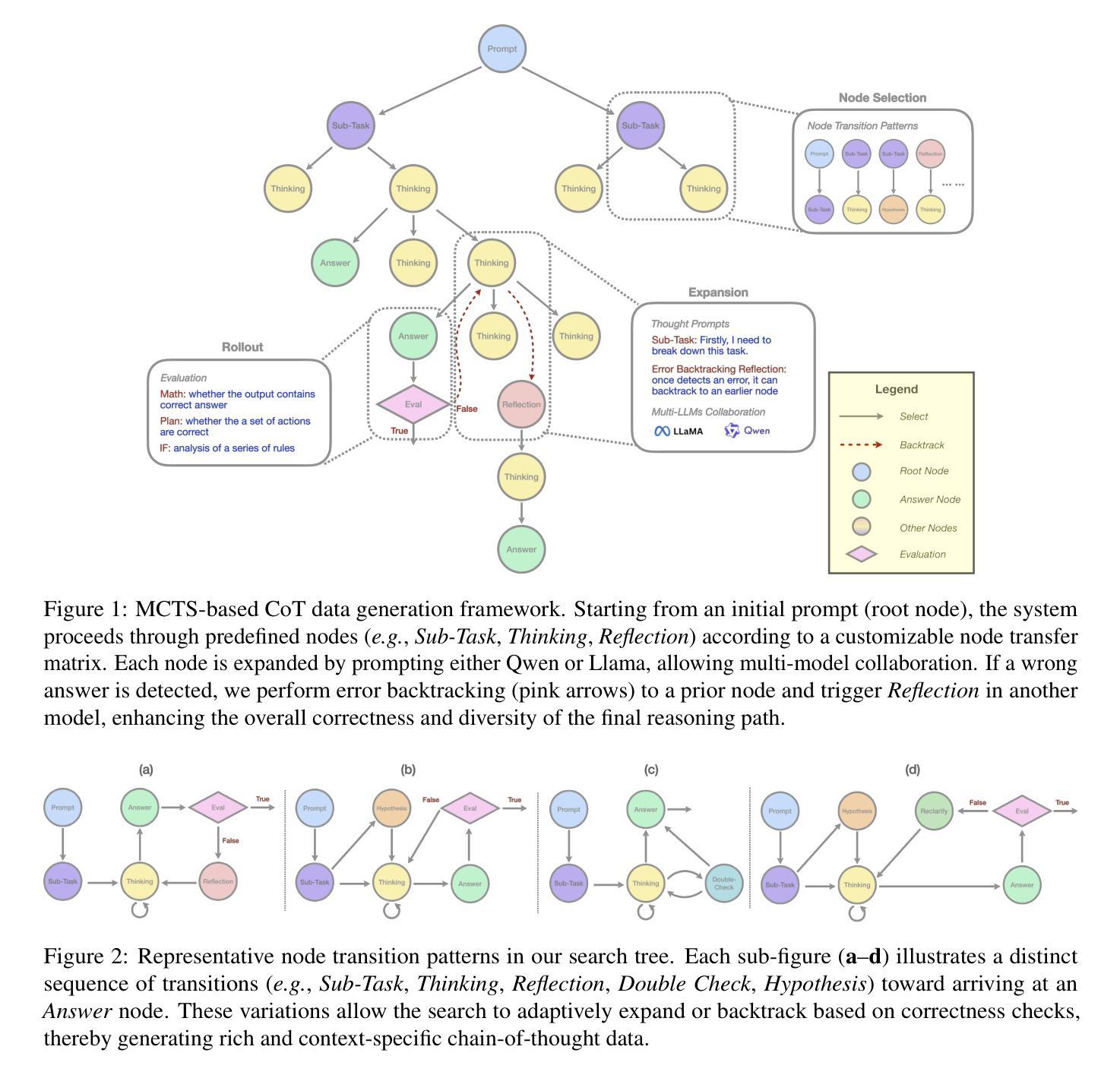
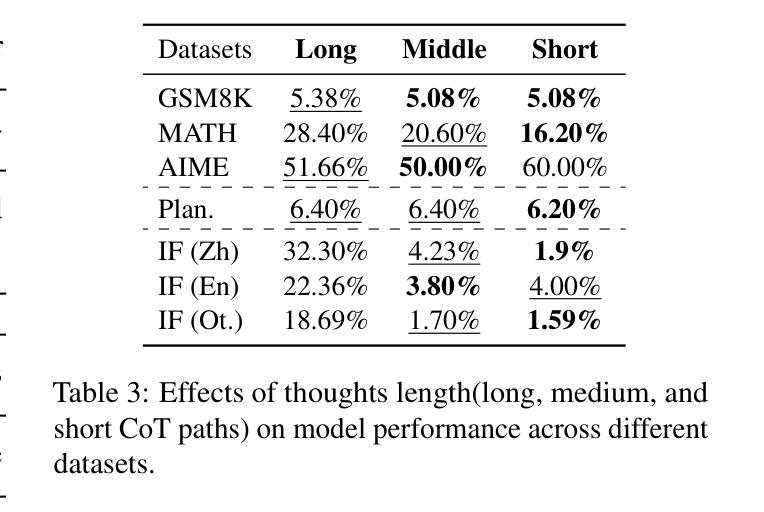
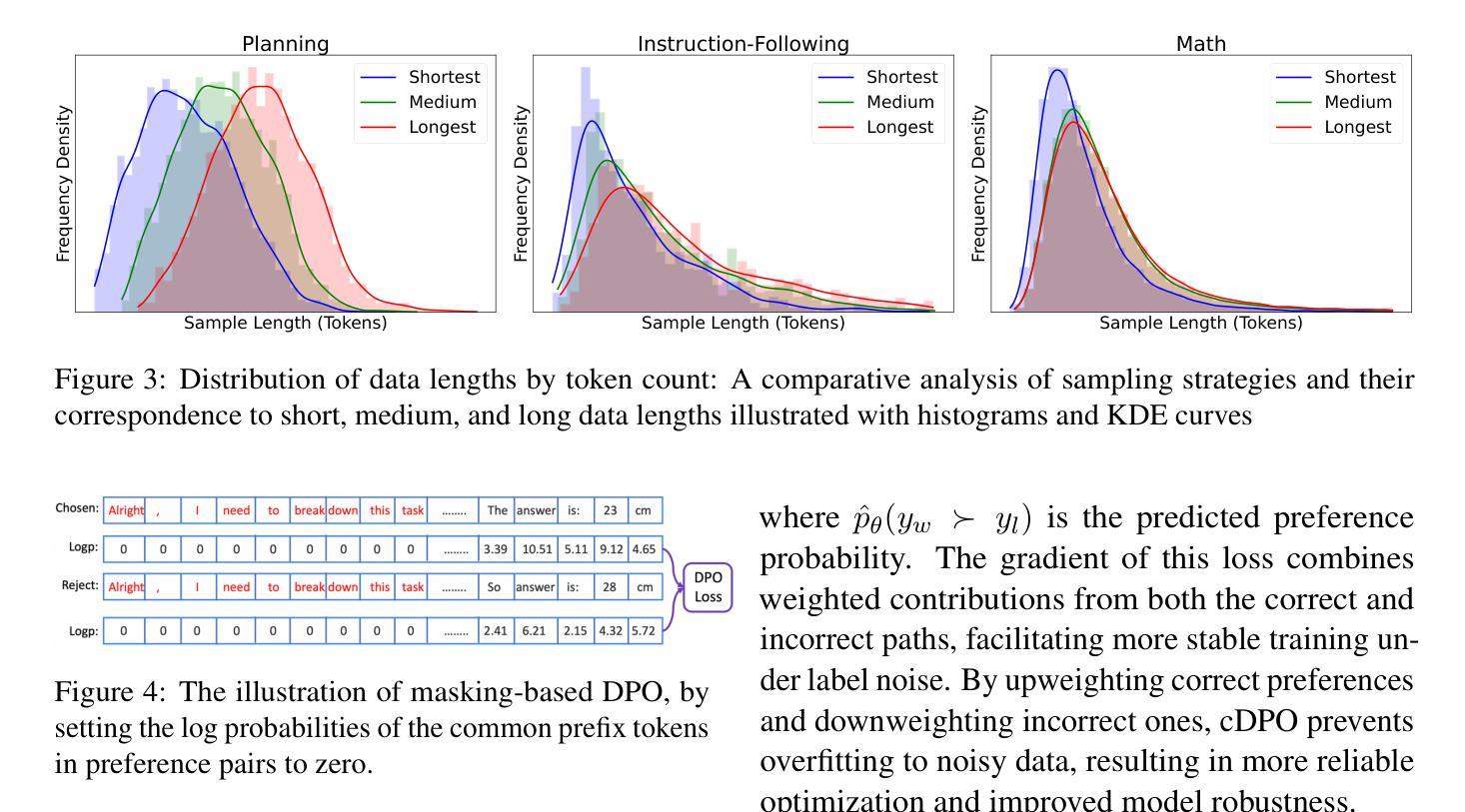
From System 1 to System 2: A Survey of Reasoning Large Language Models
Authors:Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhiwei Li, Bao-Long Bi, Ling-Rui Mei, Junfeng Fang, Xiao Liang, Zhijiang Guo, Le Song, Cheng-Lin Liu
Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI’s o1/o3 and DeepSeek’s R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
实现人类水平的智能需要完善从快速直觉系统1到较慢、更慎重的系统2推理的转变。系统1擅长快速、启发式的决策,而系统2则依赖于逻辑推理以做出更准确的判断和减少偏见。基础大型语言模型(LLM)擅长快速决策,但在复杂推理方面深度不足,因为它们尚未完全接受系统2思维所具有的按部就班分析的特点。最近,像OpenAI的o1/o3和DeepSeek的R1等推理LLM在数学和编程等领域表现出了专家级的性能,它们很好地模仿了系统2的慎重推理,展示了人类般的认知能力。这篇综述首先简要概述了基础LLM和系统2技术的早期发展进展,探讨了它们相结合如何为推理LLM铺平道路。接下来,我们讨论如何构建推理LLM,分析它们的特点、支持高级推理的核心方法以及各种推理LLM的演变。此外,我们还概述了推理基准测试,对代表性推理LLM的性能进行了深入比较。最后,我们探讨了推进推理LLM的有前途的方向,并维护一个实时GitHub仓库来跟踪最新进展。我们希望这篇综述能在这个快速发展的领域激发创新,推动进步,成为有价值的资源。
论文及项目相关链接
PDF Slow-thinking, Large Language Models, Human-like Reasoning, Decision Making in AI, AGI
Summary
该文探讨了实现人类智能水平需要完善从快速直觉系统1到较慢但更慎重的系统2推理的过渡。文章概述了大语言模型(LLM)的早期发展和系统2技术的融合,以及推理型LLM的进步。文章讨论了如何构建推理型LLM,包括其特性、核心方法和不同推理型LLM的发展演变。此外,还对推理基准测试进行了概述,深入比较了代表性推理型LLM的性能。最后,文章探讨了推进推理型LLM发展的前景,并实时更新GitHub Repository以追踪最新进展。本文旨在为这一快速演变的领域提供有价值的资源,激发创新,推动进步。
Key Takeaways
- 实现人类智能水平需要改进从直觉决策到慎重推理的过渡,即系统1到系统2的转变。
- 大语言模型(LLM)擅长快速决策,但缺乏复杂推理的深度,未完全拥抱系统2的逐步分析特性。
- 推理型LLM如OpenAI的o1/o3和DeepSeek的R1展现出专家级性能,在模拟系统2的慎重推理和展示人类认知特征方面取得了进展。
- 文章概述了基础LLM和系统2技术的融合过程,探讨了如何构建推理型LLM及其核心方法和特性。
- 文章讨论了推理基准测试,深入比较了代表性推理型LLM的性能差异。
- 文章强调了推理型LLM的前景和潜在发展方向。
点此查看论文截图

Empowering LLMs with Logical Reasoning: A Comprehensive Survey
Authors:Fengxiang Cheng, Haoxuan Li, Fenrong Liu, Robert van Rooij, Kun Zhang, Zhouchen Lin
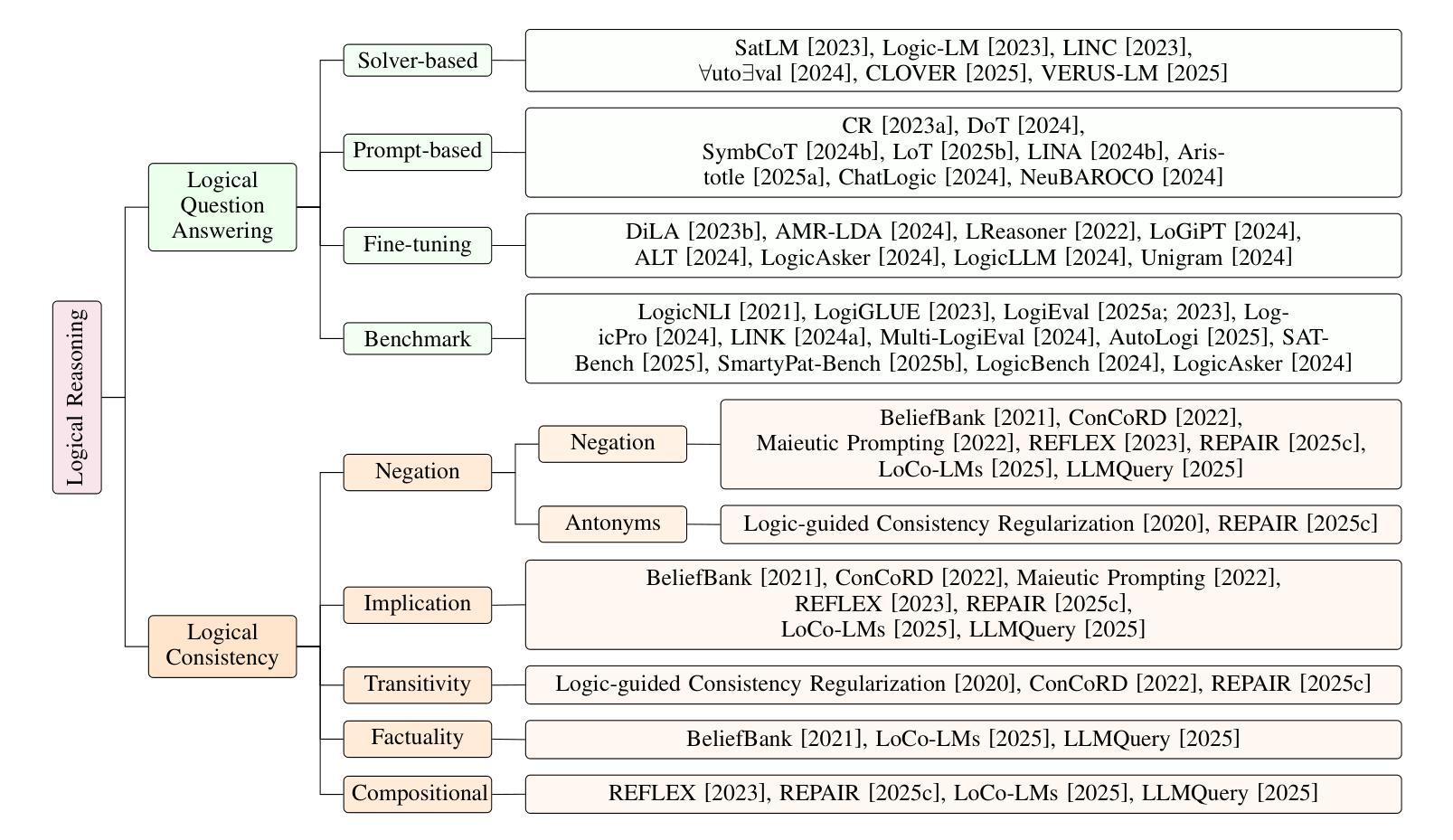
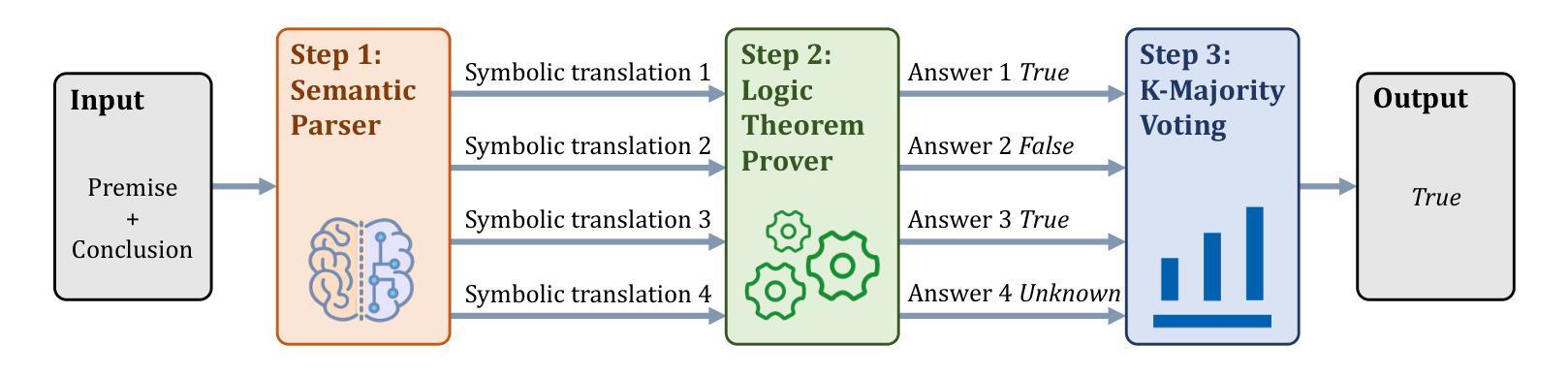
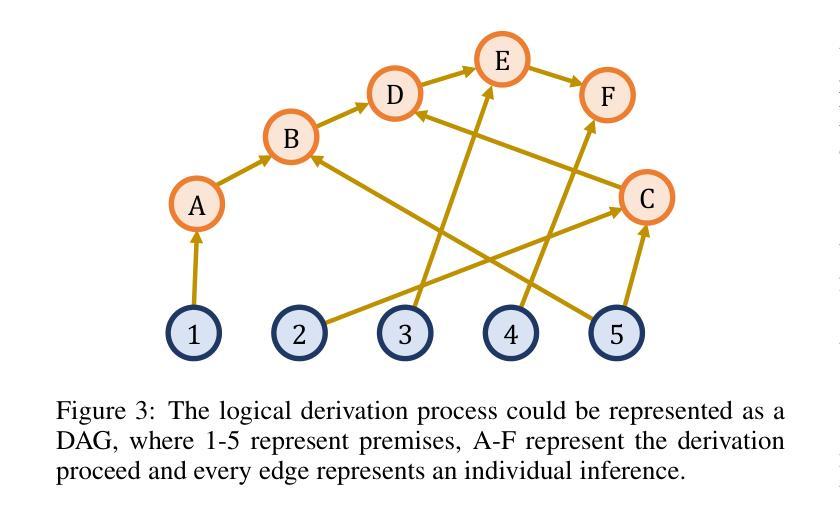
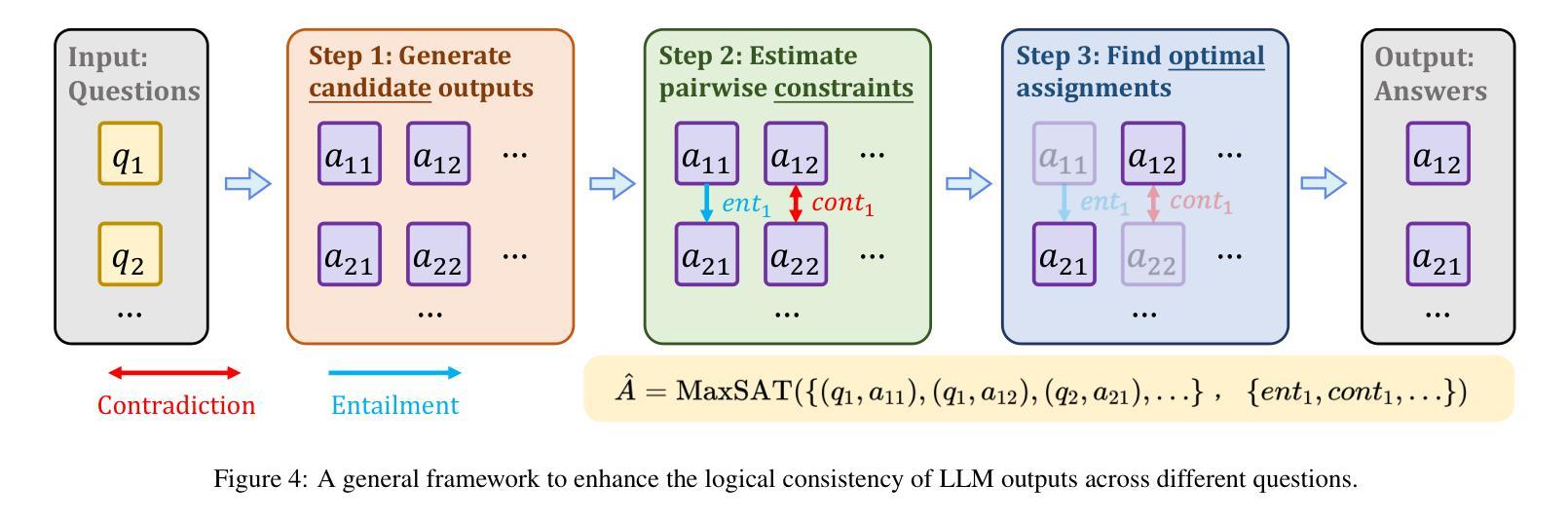
Large language models (LLMs) have achieved remarkable successes on various tasks. However, recent studies have found that there are still significant challenges to the logical reasoning abilities of LLMs, which can be categorized into the following two aspects: (1) Logical question answering: LLMs often fail to generate the correct answer within a complex logical problem which requires sophisticated deductive, inductive or abductive reasoning given a collection of premises and constrains. (2) Logical consistency: LLMs are prone to producing responses contradicting themselves across different questions. For example, a state-of-the-art question-answering LLM Macaw, answers Yes to both questions Is a magpie a bird? and Does a bird have wings? but answers No to Does a magpie have wings?. To facilitate this research direction, we comprehensively investigate the most cutting-edge methods and propose a detailed taxonomy. Specifically, to accurately answer complex logic questions, previous methods can be categorized based on reliance on external solvers, prompts, and fine-tuning. To avoid logical contradictions, we discuss concepts and solutions of various logical consistencies, including implication, negation, transitivity, factuality consistencies, and their composites. In addition, we review commonly used benchmark datasets and evaluation metrics, and discuss promising research directions, such as extending to modal logic to account for uncertainty and developing efficient algorithms that simultaneously satisfy multiple logical consistencies.
大型语言模型(LLM)在各种任务上取得了显著的成就。然而,最近的研究发现,LLM的逻辑推理能力仍面临重大挑战,这些挑战可归纳为以下两个方面:(1)逻辑问答:在复杂的逻辑问题中,LLM往往无法在给定的前提和约束下,通过演绎、归纳或溯因推理生成正确的答案。(2)逻辑一致性:LLM容易产生自相矛盾的回答。例如,最先进的问答LLM Macaw对“喜鹊是鸟吗?”和“鸟有翅膀吗?”两个问题都回答“是”,但对“喜鹊有翅膀吗?”的问题却回答“否”。为了促进这个研究方向,我们全面调查了最先进的方法并提出了详细的分类。具体来说,为了准确回答复杂的逻辑问题,以前的方法可以按对外部求解器、提示和微调等的依赖进行分类。为了避免逻辑矛盾,我们讨论了各种逻辑一致性的概念及解决方案,包括蕴涵、否定、传递性、事实一致性及其组合。此外,我们还回顾了常用的基准数据集和评价指标,并讨论了有前景的研究方向,如扩展到模态逻辑以考虑不确定性,并开发能同时满足多种逻辑一致性的高效算法。
论文及项目相关链接
PDF Accepted by IJCAI 2025 (Survey Track)
Summary
大型语言模型(LLMs)在各项任务中取得了显著的成功,但在逻辑推理方面仍存在挑战,主要表现为逻辑问答和逻辑一致性两个方面。逻辑问答方面,LLMs在复杂逻辑问题中难以给出正确答案。逻辑一致性方面,LLMs的回答会在不同问题中出现自相矛盾的情况。针对这些问题,我们调查了最前沿的方法,并提出了详细的分类。为解决逻辑矛盾,我们讨论了各种逻辑一致性的概念和解决方案。
Key Takeaways
- 大型语言模型(LLMs)在逻辑推理方面存在挑战,包括逻辑问答和逻辑一致性。
- 在逻辑问答方面,LLMs难以给出复杂逻辑问题的正确答案。
- 在逻辑一致性方面,LLMs的回答会出现自相矛盾的情况。
- 最前沿的方法可以基于外部求解器、提示和微调来回答复杂的逻辑问题。
- 为避免逻辑矛盾,需要讨论各种逻辑一致性的概念和解决方案。
- 常用的基准数据集和评价指标被回顾。
点此查看论文截图

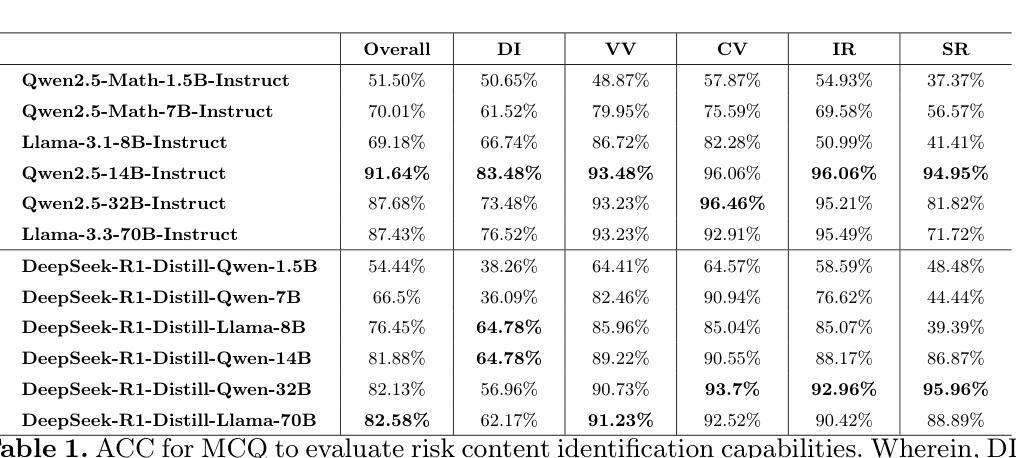
Quantifying the Capability Boundary of DeepSeek Models: An Application-Driven Performance Analysis
Authors:Kaikai Zhao, Zhaoxiang Liu, Xuejiao Lei, Jiaojiao Zhao, Zhenhong Long, Zipeng Wang, Ning Wang, Meijuan An, Qingliang Meng, Peijun Yang, Minjie Hua, Chaoyang Ma, Wen Liu, Kai Wang, Shiguo Lian
DeepSeek-R1, known for its low training cost and exceptional reasoning capabilities, has achieved state-of-the-art performance on various benchmarks. However, detailed evaluations for DeepSeek Series models from the perspective of real-world applications are lacking, making it challenging for users to select the most suitable DeepSeek models for their specific needs. To address this gap, we presents the first comprehensive evaluation of the DeepSeek and its related models (including DeepSeek-V3, DeepSeek-R1, DeepSeek-R1-Distill-Qwen series, DeepSeek-R1-Distill-Llama series, their corresponding 4-bit quantized models, and the reasoning model QwQ-32B) using our enhanced A-Eval benchmark, A-Eval-2.0. Our systematic analysis reveals several key insights: (1) Given identical model architectures and training data, larger parameter models demonstrate superior performance, aligning with the scaling law. However, smaller models may achieve enhanced capabilities when employing optimized training strategies and higher-quality data; (2) Reasoning-enhanced model show significant performance gains in logical reasoning tasks but may underperform in text understanding and generation tasks; (3) As the data difficulty increases, distillation or reasoning enhancements yield higher performance gains for the models. Interestingly, reasoning enhancements can even have a negative impact on simpler problems; (4) Quantization impacts different capabilities unevenly, with significant drop on logical reasoning and minimal impact on text generation. Based on these results and findings, we design an model selection handbook enabling users to select the most cost-effective models without efforts.
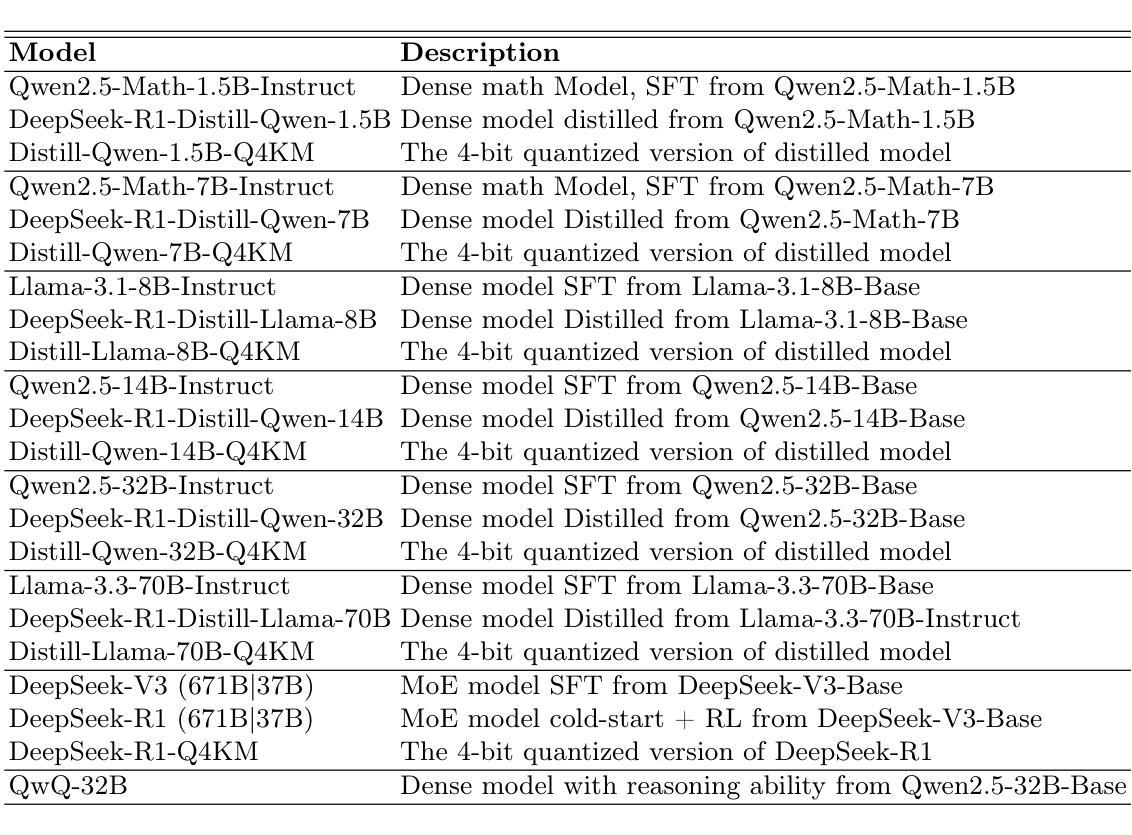
DeepSeek-R1以其低训练成本和出色的推理能力而著称,已在各种基准测试上达到了最先进的性能。然而,从实际应用的角度对DeepSeek系列模型的详细评估仍然缺乏,这使得用户难以选择最适合其特定需求的DeepSeek模型。为了弥补这一空白,我们利用增强的A-Eval基准测试,即A-Eval-2.0,对DeepSeek及其相关模型(包括DeepSeek-V3、DeepSeek-R1、DeepSeek-R1-Distill-Qwen系列、DeepSeek-R1-Distill-Llama系列、其对应的4位量化模型以及推理模型QwQ-32B)进行了首次全面评估。我们的系统分析揭示了几个关键见解:
(1)在相同的模型架构和训练数据下,参数规模较大的模型表现出更优越的性能,这与规模定律相符。然而,当采用优化的训练策略和高质量数据时,小型模型可能会实现增强的能力;
(2)增强推理的模型在逻辑推理任务中显示出显著的性能提升,但在文本理解和生成任务中可能表现较差;
(3)随着数据难度的增加,蒸馏或推理增强为模型带来了更高的性能提升。有趣的是,推理增强甚至可能对较简单的问题产生负面影响;
(4)量化对不同能力的影响不均衡,对逻辑推理有显著的下降,对文本生成的影响最小。基于这些结果和发现,我们设计了一本模型选择手册,使用户能够轻松选择最经济实惠的模型。
论文及项目相关链接
Summary
本文介绍了对DeepSeek系列模型(包括DeepSeek-V3、DeepSeek-R1等)的首次全面评估。研究使用A-Eval 2.0基准测试,发现大型参数模型性能优越,但优化训练策略和提高数据质量也可能提升小型模型性能。此外,增强推理模型在逻辑推理任务中表现优异,但在文本理解和生成任务中可能表现不佳。随着数据难度的增加,蒸馏或推理增强对模型性能的提升更大。量化对不同的能力影响不均,逻辑推理受影响较大,文本生成受影响较小。基于这些结果,设计了一个模型选择手册,帮助用户选择最经济高效的模型。
Key Takeaways
- 大型参数模型在相同架构和训练数据下表现优越,但小型模型通过优化训练策略和提高数据质量也可能实现增强性能。
- 推理增强模型在逻辑推理任务中表现显著,但在文本理解和生成任务中可能表现不足。
- 随着数据难度的增加,模型中的蒸馏或推理增强带来的性能提升更加明显。
- 量化对模型的不同能力影响不同,逻辑推理受影响较大,而文本生成受影响较小。
- A-Eval 2.0基准测试能有效评估DeepSeek系列模型在多种任务上的性能。
- 用户可以根据模型选择手册轻松选择最经济高效的模型。
点此查看论文截图


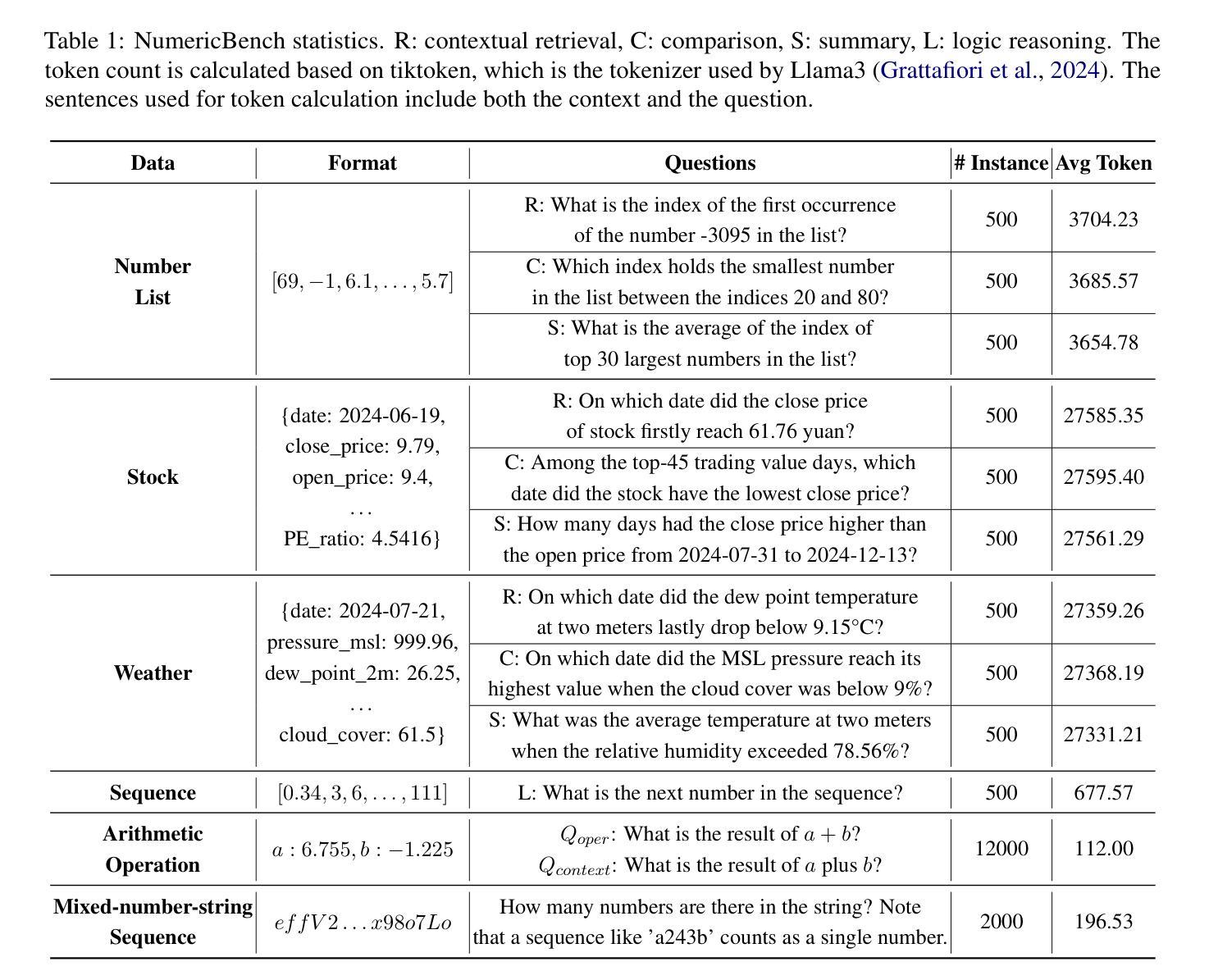
Exposing Numeracy Gaps: A Benchmark to Evaluate Fundamental Numerical Abilities in Large Language Models
Authors:Haoyang Li, Xuejia Chen, Zhanchao XU, Darian Li, Nicole Hu, Fei Teng, Yiming Li, Luyu Qiu, Chen Jason Zhang, Qing Li, Lei Chen
Large Language Models (LLMs) have demonstrated impressive capabilities in natural language processing tasks, such as text generation and semantic understanding. However, their performance on numerical reasoning tasks, such as basic arithmetic, numerical retrieval, and magnitude comparison, remains surprisingly poor. This gap arises from their reliance on surface-level statistical patterns rather than understanding numbers as continuous magnitudes. Existing benchmarks primarily focus on either linguistic competence or structured mathematical problem-solving, neglecting fundamental numerical reasoning required in real-world scenarios. To bridge this gap, we propose NumericBench, a comprehensive benchmark to evaluate six fundamental numerical capabilities: number recognition, arithmetic operations, contextual retrieval, comparison, summary, and logical reasoning. NumericBench includes datasets ranging from synthetic number lists to the crawled real-world data, addressing challenges like long contexts, noise, and multi-step reasoning. Extensive experiments on state-of-the-art LLMs, including GPT-4 and DeepSeek, reveal persistent weaknesses in numerical reasoning, highlighting the urgent need to improve numerically-aware language modeling. The benchmark is released in: https://github.com/TreeAI-Lab/NumericBench.
大型语言模型(LLM)在自然语言处理任务中表现出了令人印象深刻的能力,如文本生成和语义理解。然而,它们在数值推理任务(如基本算术、数值检索和幅度比较)上的表现却出人意料地差。这种差距的产生是因为它们依赖于表面层次的统计模式,而不是将数字视为连续的幅度来理解。现有的基准测试主要集中于语言技能或结构化的数学问题解决能力,忽视了现实场景中所需的基本数值推理能力。为了弥补这一差距,我们提出了NumericBench,这是一个全面的基准测试,旨在评估六项基本数值能力:数字识别、算术运算、上下文检索、比较、总结和逻辑推理。NumericBench包含了从合成数字列表到爬取的真实世界数据的各种数据集,解决了长上下文、噪声和多步推理等挑战。在包括GPT-4和DeepSeek等在内的最新大型语言模型上的广泛实验表明,它们在数值推理方面存在持久的弱点,这凸显了提高数值感知语言模型的紧迫需求。该基准测试发布在:https://github.com/TreeAI-Lab/NumericBench。
论文及项目相关链接
PDF Accepted by ACL 2025
Summary
大型语言模型在自然语言处理任务中表现出强大的能力,但在数值推理任务方面的表现却令人惊讶地不足。为解决这一差距,提出了一种新的评估模型的方法——NumericBench,它能评价模型在六项基础数值能力上的表现。包括数字识别、算术运算、上下文检索、比较、总结和逻辑推理。实验结果揭示了顶尖的大型语言模型如GPT-4和DeepSeek在数值推理上的持续弱点,突显了提高数值感知语言模型的紧迫性。
Key Takeaways
- 大型语言模型在自然语言处理任务中表现出强大的能力,但在数值推理任务上的表现不佳。
- 数值推理能力的缺失主要源于模型依赖表面统计模式,而非对数字作为连续幅度的理解。
- 现有基准测试主要关注语言能力和结构化数学问题解答,忽视了现实世界中所需的基本数值推理能力。
- NumericBench是一个新的基准测试,旨在评估模型在六项基础数值能力上的表现,包括数字识别、算术运算、上下文检索、比较、总结和逻辑推理。
- NumericBench涵盖了从合成数字列表到网络爬取的真实世界数据的数据集,解决了长上下文、噪声和多步推理等挑战。
- 在先进的大型语言模型上的实验揭示了其在数值推理方面的持续弱点。
点此查看论文截图