⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
O2Former:Direction-Aware and Multi-Scale Query Enhancement for SAR Ship Instance Segmentation
Authors:F. Gao, Y Li, X He, J Sun, J Wang
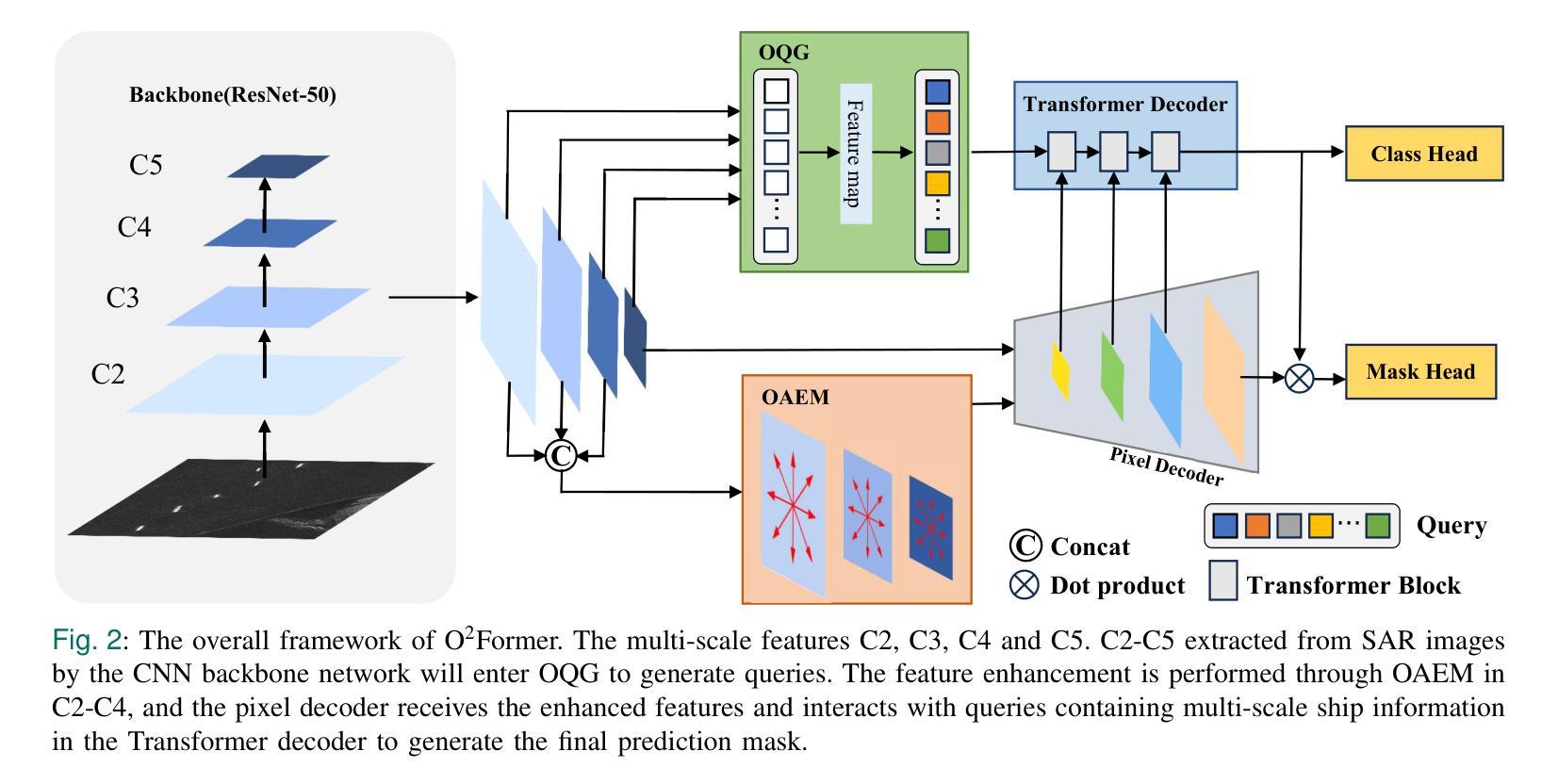
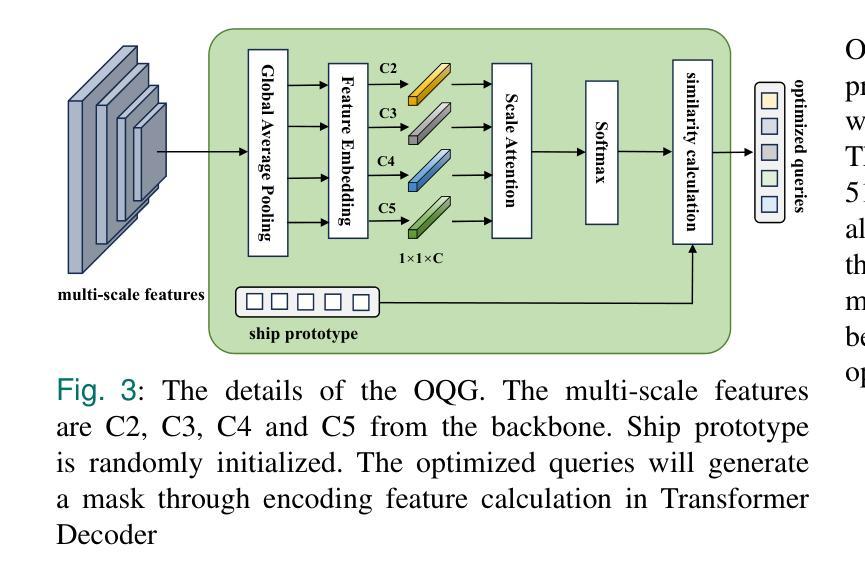
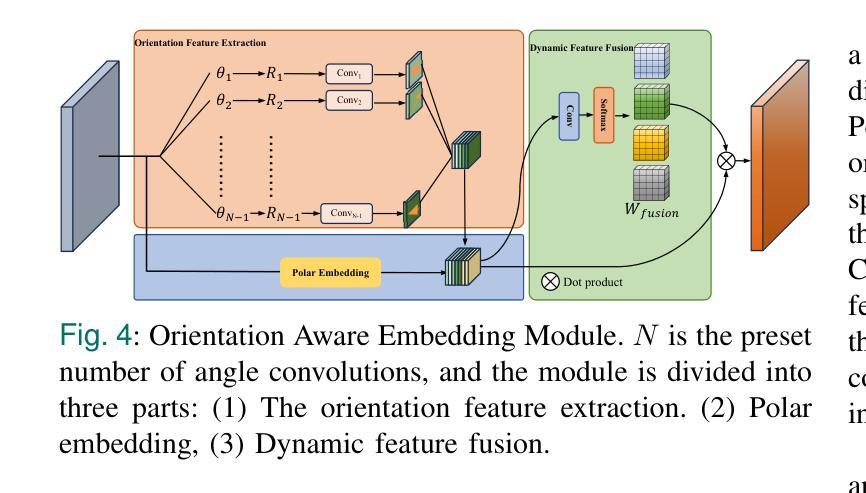
Instance segmentation of ships in synthetic aperture radar (SAR) imagery is critical for applications such as maritime monitoring, environmental analysis, and national security. SAR ship images present challenges including scale variation, object density, and fuzzy target boundary, which are often overlooked in existing methods, leading to suboptimal performance. In this work, we propose O2Former, a tailored instance segmentation framework that extends Mask2Former by fully leveraging the structural characteristics of SAR imagery. We introduce two key components. The first is the Optimized Query Generator(OQG). It enables multi-scale feature interaction by jointly encoding shallow positional cues and high-level semantic information. This improves query quality and convergence efficiency. The second component is the Orientation-Aware Embedding Module(OAEM). It enhances directional sensitivity through direction-aware convolution and polar-coordinate encoding. This effectively addresses the challenge of uneven target orientations in SAR scenes. Together, these modules facilitate precise feature alignment from backbone to decoder and strengthen the model’s capacity to capture fine-grained structural details. Extensive experiments demonstrate that O2Former outperforms state of the art instance segmentation baselines, validating its effectiveness and generalization on SAR ship datasets.
合成孔径雷达(SAR)图像中的船舶实例分割对于海事监测、环境分析和国家安全等应用至关重要。SAR船舶图像存在尺度变化、目标密度和模糊目标边界等挑战,现有方法往往忽视这些挑战,导致性能不佳。在这项工作中,我们提出了O2Former,这是一个定制的实例分割框架,它充分利用SAR图像的结构特性,对Mask2Former进行了扩展。我们引入了两个关键组件。第一个是优化查询生成器(OQG)。它通过联合编码浅层的定位线索和高级语义信息,实现了多尺度特征交互,提高了查询质量和收敛效率。第二个组件是方向感知嵌入模块(OAEM)。它通过方向感知卷积和极坐标编码,增强了方向敏感性,有效地解决了SAR场景中目标方向不均匀的挑战。这两个模块共同促进了从主干到解码器的精确特征对齐,并加强了模型捕捉细微结构细节的能力。大量实验表明,O2Former在SAR船舶数据集上的表现优于最新的实例分割基线,验证了其在SAR船舶数据集上的有效性和通用性。
论文及项目相关链接
PDF 12 pages, 7 figures
Summary
SAR图像中的船舶实例分割对于海事监测、环境分析和国家安全等应用至关重要。针对SAR船舶图像中的尺度变化、目标密度和模糊目标边界等挑战,本文提出O2Former实例分割框架,该框架基于Mask2Former并充分利用SAR图像的结构特性。引入Optimized Query Generator和Orientation-Aware Embedding Module两个关键组件,分别提高查询质量和收敛效率,以及增强方向敏感性。实验证明,O2Former在SAR船舶数据集上的性能优于现有实例分割基线。
Key Takeaways
- SAR图像中的船舶实例分割具有关键应用意义,如海事监测和国家安全。
- 现有方法在处理SAR船舶图像时面临尺度变化、目标密度和模糊目标边界等挑战。
- O2Former是一种针对SAR图像的实例分割框架,基于Mask2Former并充分利用其结构特性。
- Optimized Query Generator(OQG)通过结合浅层位置线索和高级语义信息,实现多尺度特征交互,提高查询质量和收敛效率。
- Orientation-Aware Embedding Module(OAEM)通过方向感知卷积和极坐标编码,增强方向敏感性,有效应对SAR场景中目标方向不均匀的挑战。
点此查看论文截图



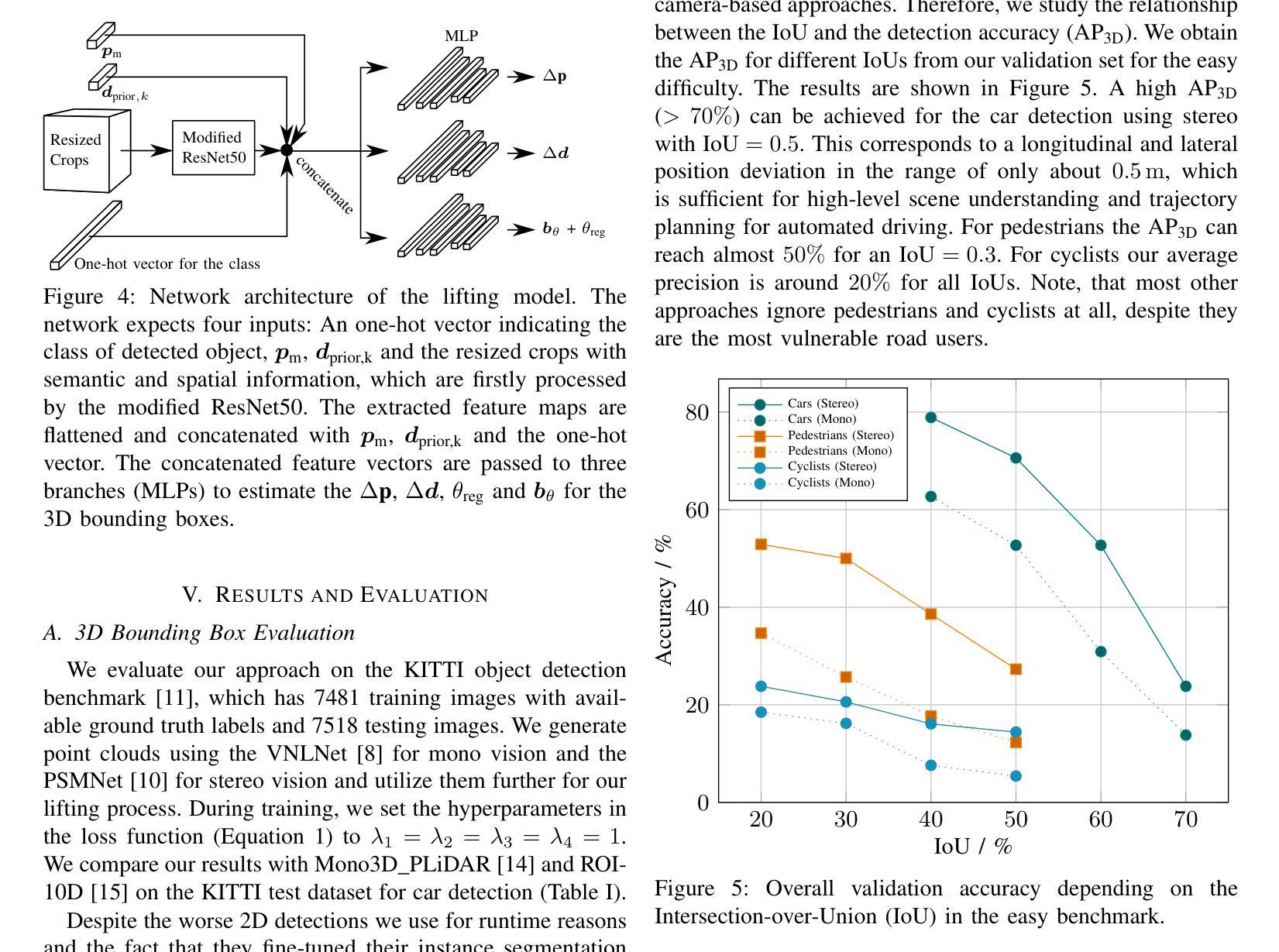
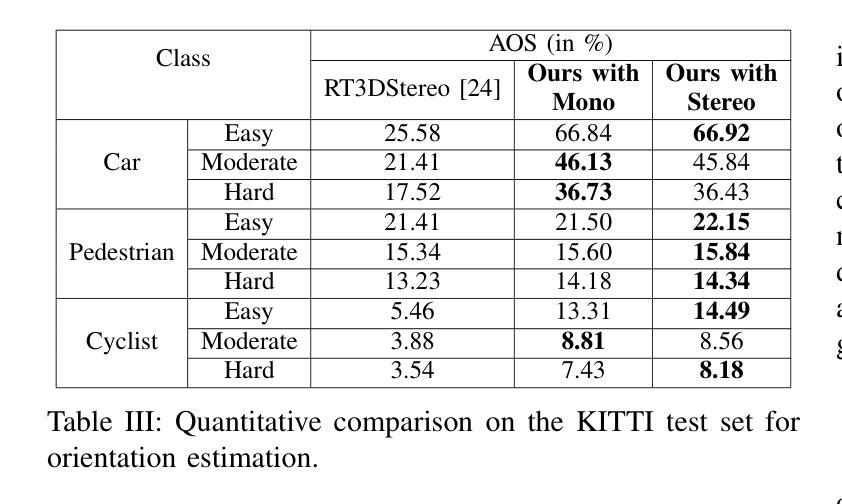
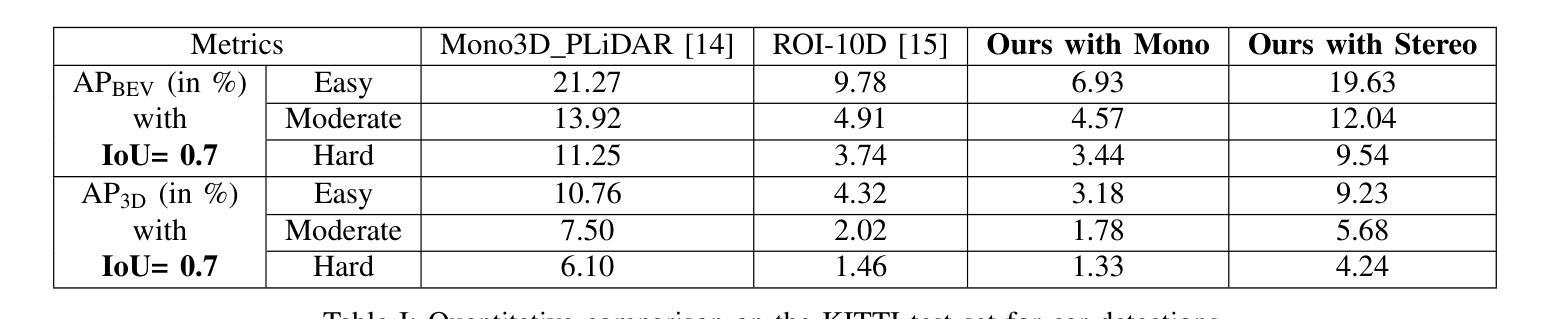
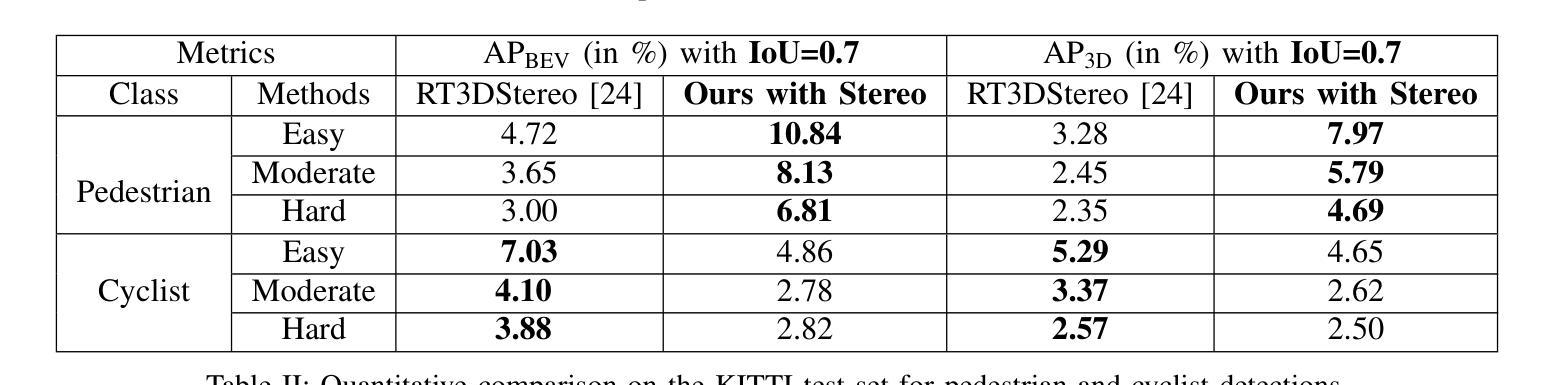
Vision-based Lifting of 2D Object Detections for Automated Driving
Authors:Hendrik Königshof, Kun Li, Christoph Stiller
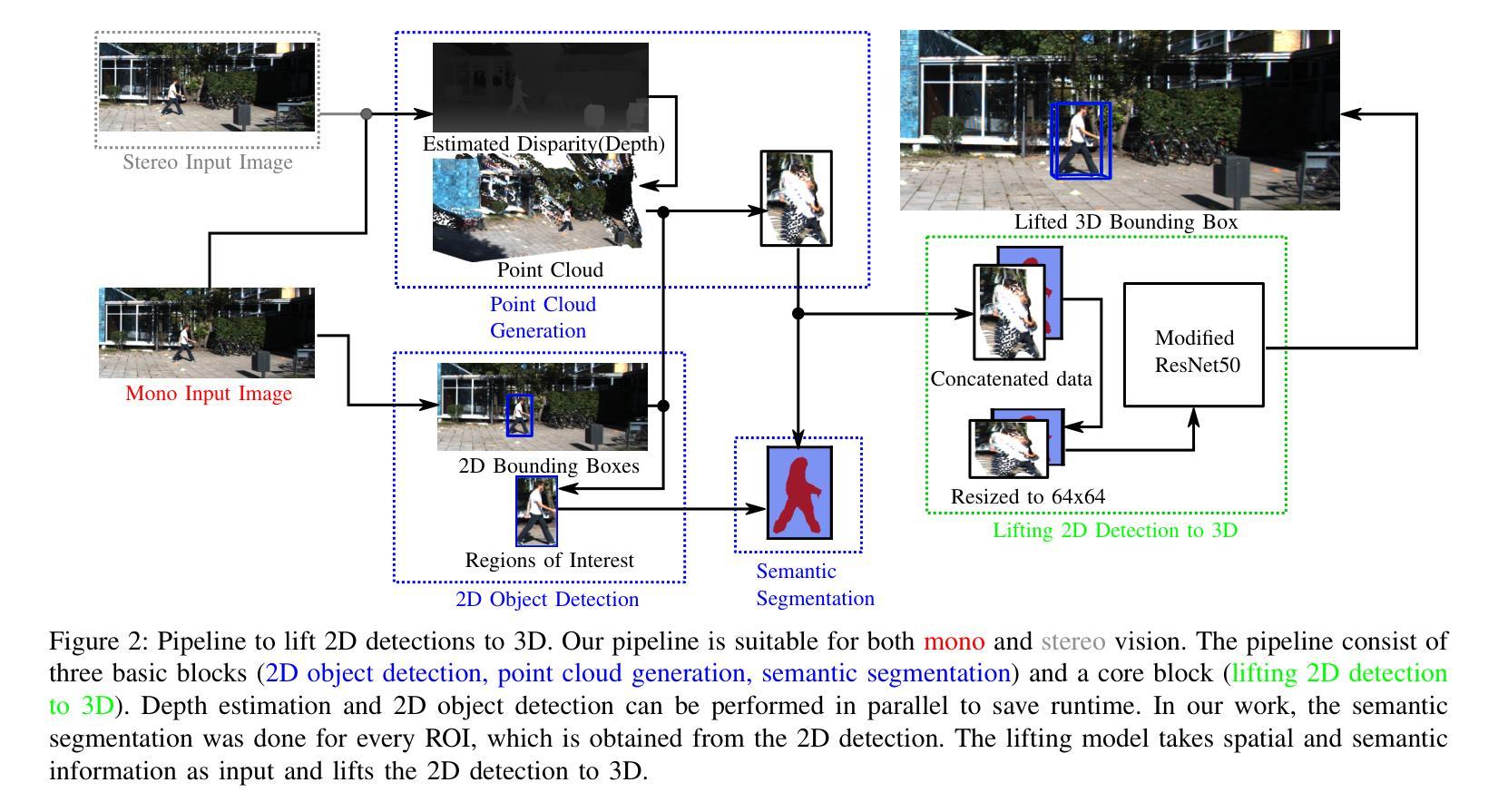
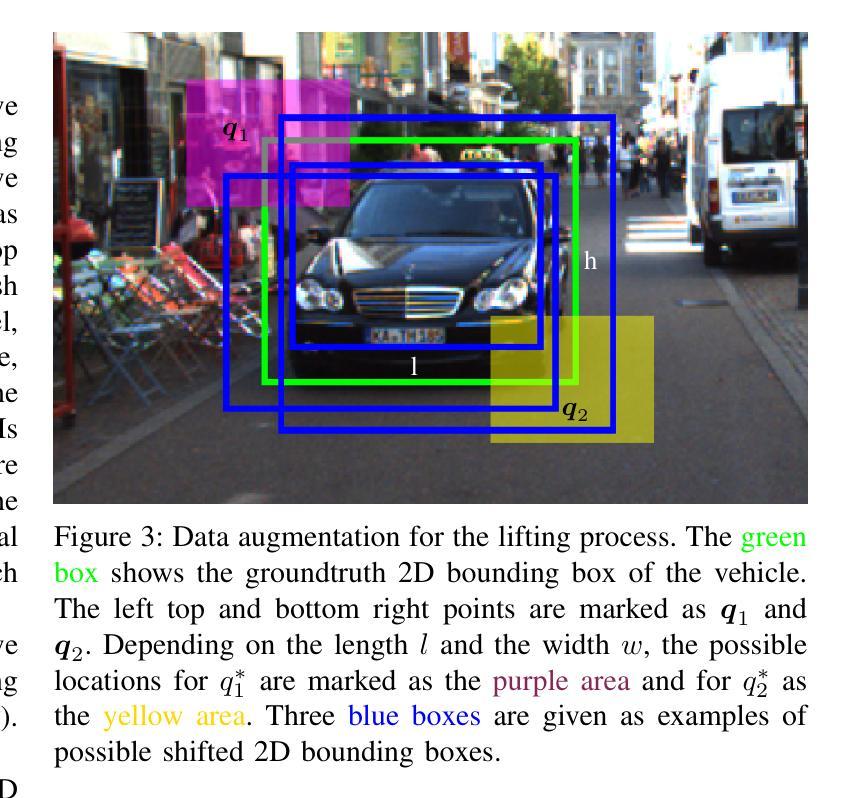
Image-based 3D object detection is an inevitable part of autonomous driving because cheap onboard cameras are already available in most modern cars. Because of the accurate depth information, currently, most state-of-the-art 3D object detectors heavily rely on LiDAR data. In this paper, we propose a pipeline which lifts the results of existing vision-based 2D algorithms to 3D detections using only cameras as a cost-effective alternative to LiDAR. In contrast to existing approaches, we focus not only on cars but on all types of road users. To the best of our knowledge, we are the first using a 2D CNN to process the point cloud for each 2D detection to keep the computational effort as low as possible. Our evaluation on the challenging KITTI 3D object detection benchmark shows results comparable to state-of-the-art image-based approaches while having a runtime of only a third.
基于图像的3D目标检测是自动驾驶不可或缺的一部分,因为大多数现代汽车已经配备了廉价的车载相机。由于深度信息准确,目前最先进的3D目标检测器大多严重依赖于激光雷达数据。在本文中,我们提出了一种流程,该流程仅使用相机将现有基于视觉的2D算法的结果提升到3D检测,作为激光雷达的低成本替代方案。与现有方法不同的是,我们关注的不仅仅是汽车,而是所有类型的道路使用者。据我们所知,我们是第一个使用2D卷积神经网络来处理每个2D检测的点云,以尽可能降低计算量。我们在具有挑战性的KITTI 3D目标检测基准测试上的评估结果表明,我们的结果与最先进的基于图像的方法相当,但运行时间只有三分之一。
论文及项目相关链接
PDF https://ieeexplore.ieee.org/document/9190325
Summary
本文提出一种基于图像的三维物体检测管道,通过提升现有视觉基础的二维算法结果至三维检测,仅使用相机作为低成本替代激光雷达。该方法不仅关注汽车,还关注各类道路使用者。使用二维卷积神经网络处理点云,以降低计算成本。在具有挑战性的KITTI三维目标检测基准测试中,其效果与当前主流图像方法相当,运行时间仅为三分之一。
Key Takeaways
- 图像三维目标检测已成为自动驾驶不可或缺的部分,主要得益于现代汽车中廉价的摄像头的普及。
- 当前先进的三维目标检测器主要依赖激光雷达数据的深度信息。
- 本文提出了一种基于二维算法的图像提升到三维检测的方法,仅使用相机替代昂贵的激光雷达。
- 该方法不仅关注汽车目标,还关注所有类型的道路使用者。
- 该方法采用二维卷积神经网络处理点云,为每一个二维检测结果服务,以降低计算成本。
- 在KITTI三维目标检测基准测试中,该方法的检测结果与当前主流图像方法相当。
点此查看论文截图

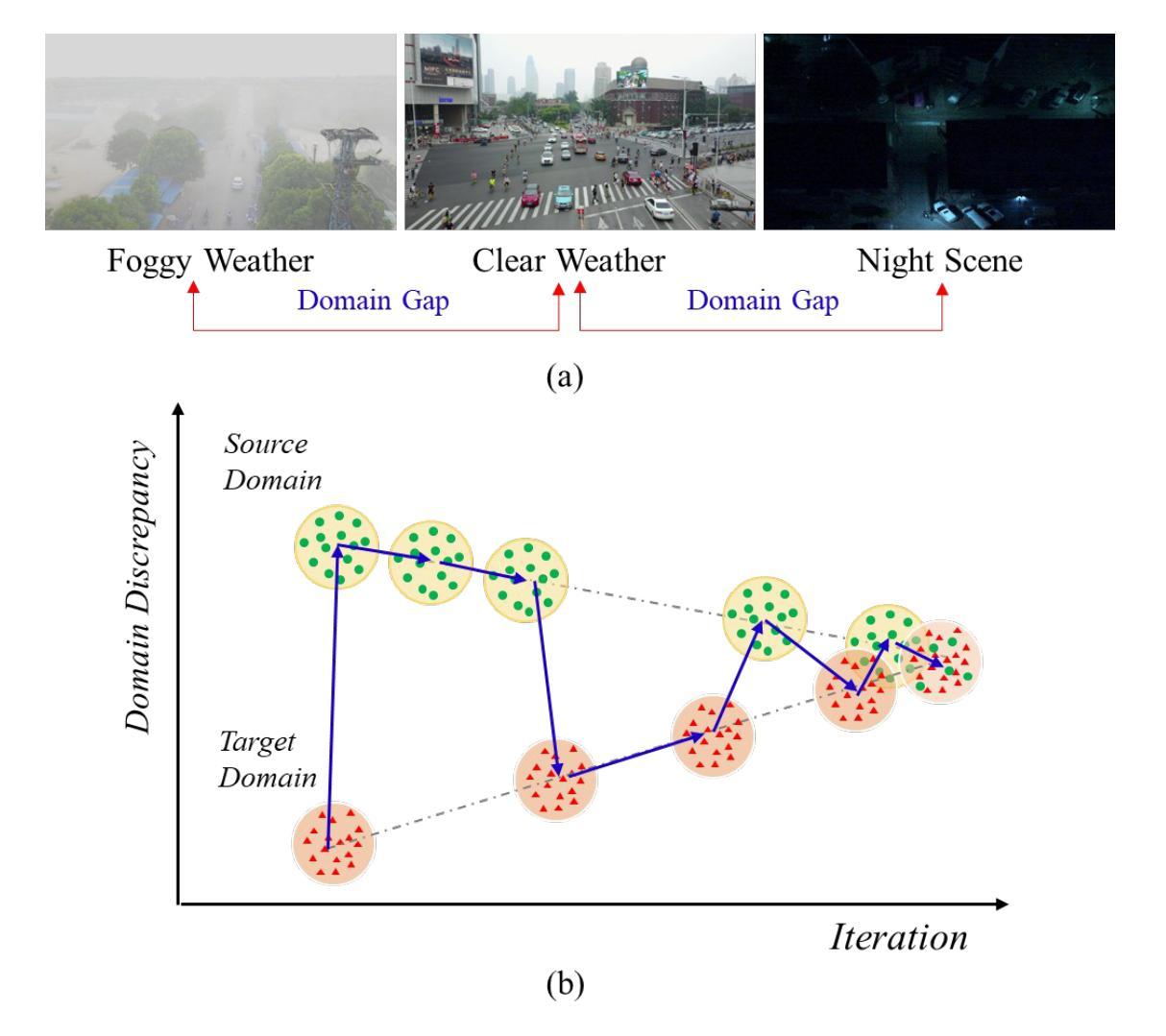
Teaching in adverse scenes: a statistically feedback-driven threshold and mask adjustment teacher-student framework for object detection in UAV images under adverse scenes
Authors:Hongyu Chen, Jiping Liu, Yong Wang, Jun Zhu, Dejun Feng, Yakun Xie
Unsupervised Domain Adaptation (UDA) has shown promise in effectively alleviating the performance degradation caused by domain gaps between source and target domains, and it can potentially be generalized to UAV object detection in adverse scenes. However, existing UDA studies are based on natural images or clear UAV imagery, and research focused on UAV imagery in adverse conditions is still in its infancy. Moreover, due to the unique perspective of UAVs and the interference from adverse conditions, these methods often fail to accurately align features and are influenced by limited or noisy pseudo-labels. To address this, we propose the first benchmark for UAV object detection in adverse scenes, the Statistical Feedback-Driven Threshold and Mask Adjustment Teacher-Student Framework (SF-TMAT). Specifically, SF-TMAT introduces a design called Dynamic Step Feedback Mask Adjustment Autoencoder (DSFMA), which dynamically adjusts the mask ratio and reconstructs feature maps by integrating training progress and loss feedback. This approach dynamically adjusts the learning focus at different training stages to meet the model’s needs for learning features at varying levels of granularity. Additionally, we propose a unique Variance Feedback Smoothing Threshold (VFST) strategy, which statistically computes the mean confidence of each class and dynamically adjusts the selection threshold by incorporating a variance penalty term. This strategy improves the quality of pseudo-labels and uncovers potentially valid labels, thus mitigating domain bias. Extensive experiments demonstrate the superiority and generalization capability of the proposed SF-TMAT in UAV object detection under adverse scene conditions. The Code is released at https://github.com/ChenHuyoo .
无监督域自适应(UDA)在缓解源域和目标域之间域差距导致的性能下降方面显示出巨大潜力,并可广泛应用于恶劣场景中的无人机目标检测。然而,现有的UDA研究主要基于自然图像或清晰的无人机图像,针对恶劣条件下无人机图像的研究仍处于起步阶段。此外,由于无人机的独特视角和恶劣条件的干扰,这些方法往往无法准确对齐特征,并受到有限或嘈杂伪标签的影响。针对这一问题,我们首次提出针对恶劣场景中无人机目标检测的基准测试,即统计反馈驱动阈值与掩膜调整教师-学生框架(SF-TMAT)。具体而言,SF-TMAT引入了一种名为动态步反馈掩膜调整自编码器(DSFMA)的设计,通过结合训练进度和损失反馈来动态调整掩膜比例并重建特征图。该方法能够根据不同的训练阶段动态调整学习重点,满足模型在不同层级特征学习需求。此外,我们还提出了一种独特的方差反馈平滑阈值(VFST)策略,通过统计计算每个类别的平均置信度,并结合方差惩罚项来动态调整选择阈值。该策略提高了伪标签的质量,并揭示了可能有效的标签,从而减轻了域偏差。大量实验表明,在恶劣场景条件下的无人机目标检测中,所提出的SF-TMAT具有卓越性和泛化能力。代码已发布在https://github.com/ChenHuyoo。
论文及项目相关链接
PDF The manuscript has been accepted by ISPRS Journal of Photogrammetry and Remote Sensing
Summary:针对无人机在恶劣场景下的目标检测问题,提出了首个基准测试SF-TMAT,包含动态步长反馈掩膜调整自编码器(DSFMA)和方差反馈平滑阈值(VFST)策略。SF-TMAT能动态调整掩膜比例,重建特征图,提高伪标签质量,缓解域偏差问题。实验表明其在无人机恶劣场景目标检测任务上具有优越性和泛化能力。
Key Takeaways:
- 无人机在恶劣场景下的目标检测面临性能下降的挑战。
- 无监督域自适应(UDA)方法在此领域具有应用前景。
- 现有研究主要集中在自然图像或清晰的无人机图像上,针对恶劣条件下的无人机图像研究仍处于起步阶段。
- 提出的SF-TMAT基准测试包含DSFMA和VFST策略,旨在解决特征对齐和伪标签问题。
- DSFMA能动态调整掩膜比例,结合训练进度和损失反馈重建特征图。
- VFST策略通过统计计算每类的平均置信度,并结合方差惩罚项动态调整选择阈值,提高了伪标签质量和揭示了潜在的有效标签。
点此查看论文截图