⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
SkillFormer: Unified Multi-View Video Understanding for Proficiency Estimation
Authors:Edoardo Bianchi, Antonio Liotta
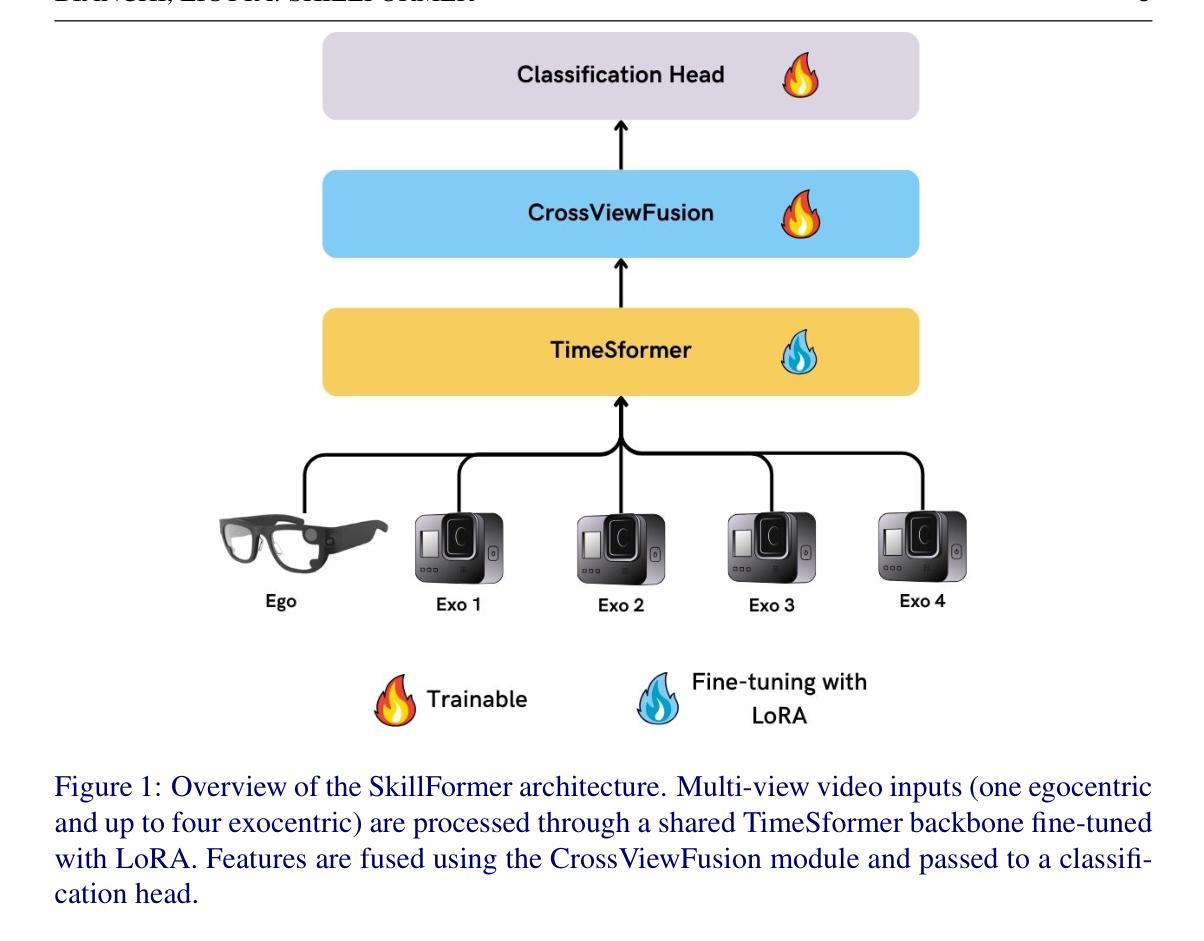
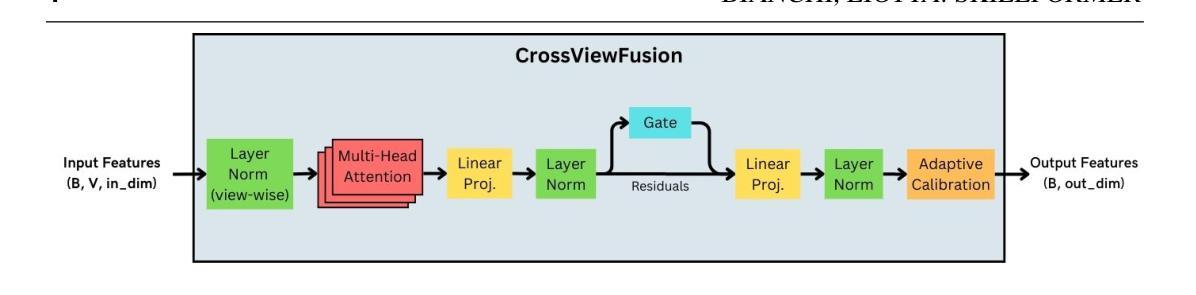
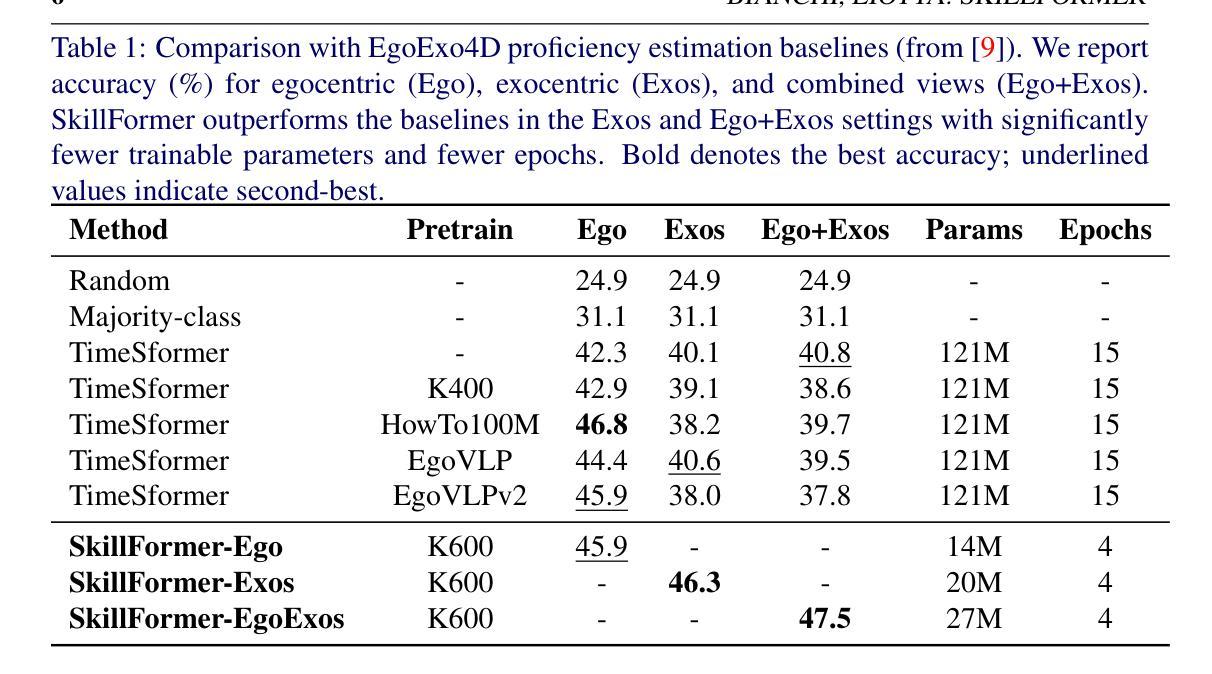
Assessing human skill levels in complex activities is a challenging problem with applications in sports, rehabilitation, and training. In this work, we present SkillFormer, a parameter-efficient architecture for unified multi-view proficiency estimation from egocentric and exocentric videos. Building on the TimeSformer backbone, SkillFormer introduces a CrossViewFusion module that fuses view-specific features using multi-head cross-attention, learnable gating, and adaptive self-calibration. We leverage Low-Rank Adaptation to fine-tune only a small subset of parameters, significantly reducing training costs. In fact, when evaluated on the EgoExo4D dataset, SkillFormer achieves state-of-the-art accuracy in multi-view settings while demonstrating remarkable computational efficiency, using 4.5x fewer parameters and requiring 3.75x fewer training epochs than prior baselines. It excels in multiple structured tasks, confirming the value of multi-view integration for fine-grained skill assessment.
评估人类在复杂活动中的技能水平是一个具有挑战性的问题,其应用在体育、康复和训练等领域。在这项工作中,我们提出了SkillFormer,这是一种从以自我为中心和以他人为中心的视频中进行统一多视角技能评估的参数高效架构。基于TimeSformer骨干网,SkillFormer引入了CrossViewFusion模块,该模块使用多头交叉注意力、可学习门控和自适应自校准来融合视角特定特征。我们利用低秩适应(Low-Rank Adaptation)仅微调一小部分参数,大大降低了训练成本。实际上,在EgoExo4D数据集上进行评估时,SkillFormer在多视角设置中达到了最先进的准确性,同时表现出了惊人的计算效率,使用参数减少了4.5倍,训练周期减少了3.75倍,优于先前的基线。它在多个结构化任务中表现出色,证实了多视角融合在精细技能评估中的价值。
论文及项目相关链接
Summary
点此查看论文截图