⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Authors:Qijing Li, Jingxiang Sun, Liang An, Zhaoqi Su, Hongwen Zhang, Yebin Liu
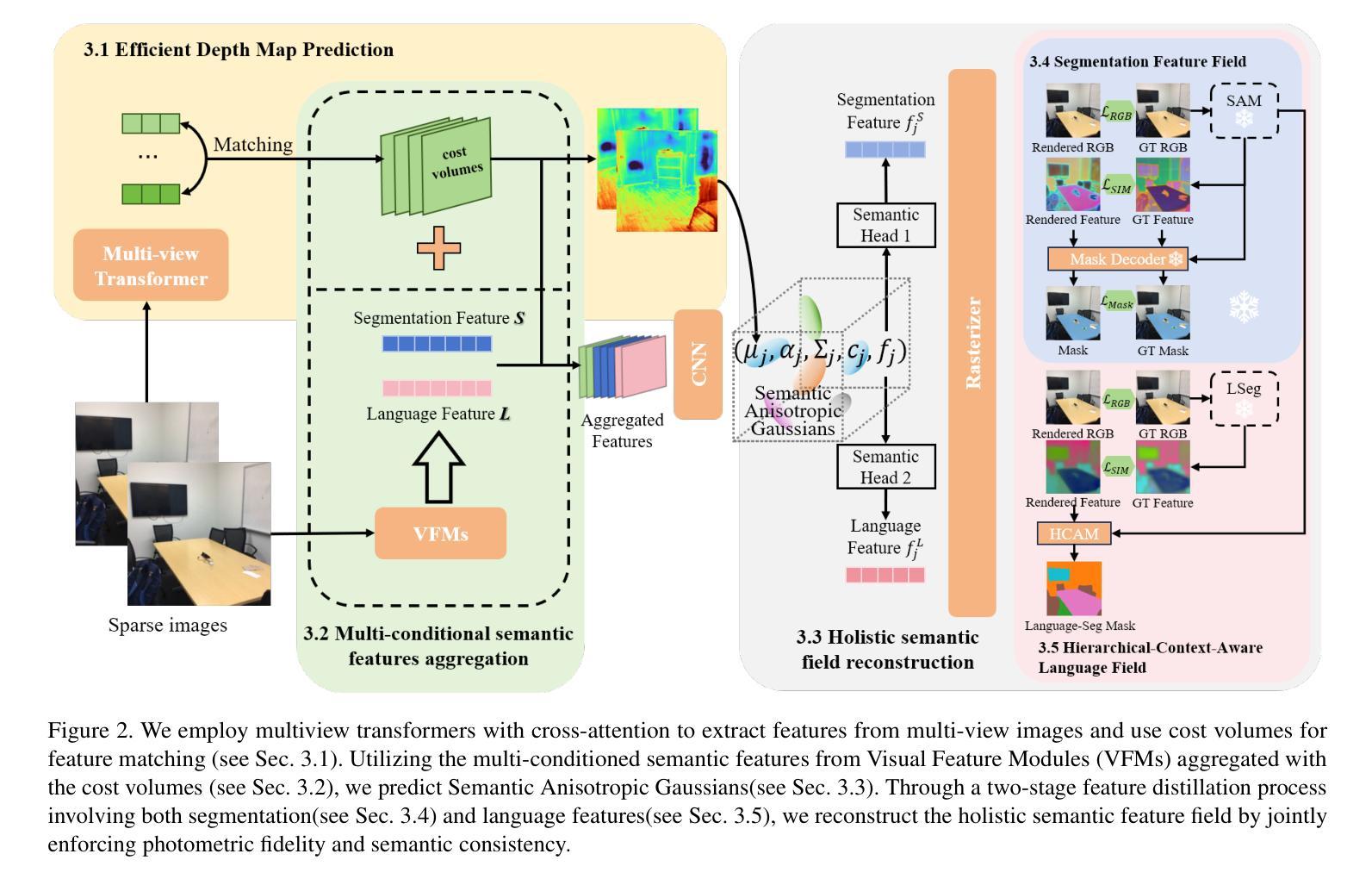
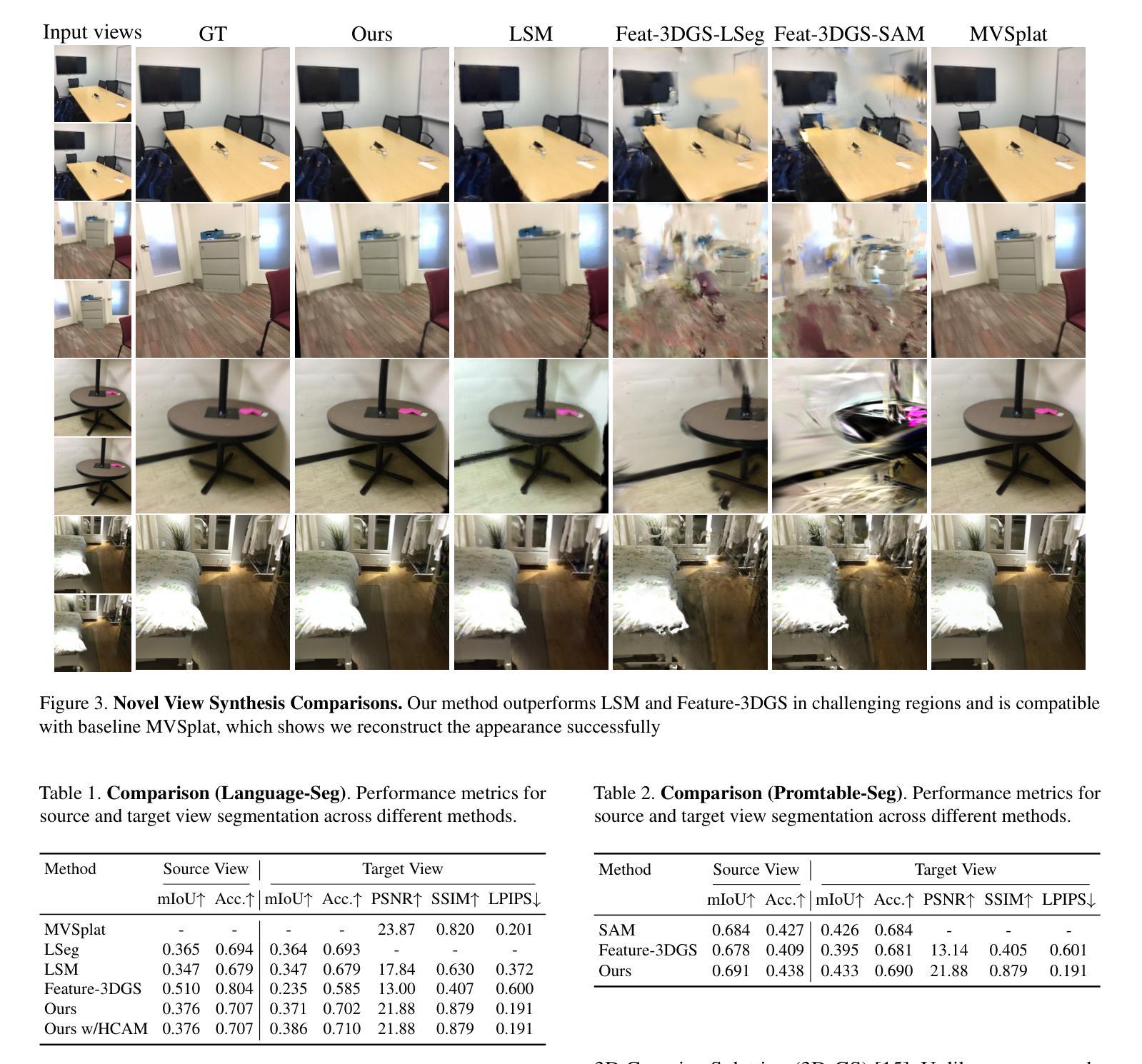
Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
全景3D场景理解,即联合建模几何、外观和语义,对于增强现实和机器人交互等应用至关重要。现有的前馈3D场景理解方法(例如LSM)仅限于从场景中提取基于语言的语义,无法实现全景场景理解。此外,它们还存在几何重建质量低和噪声干扰的问题。相比之下,基于场景的优化方法依赖于密集的输入视图,这降低了实用性,并增加了部署期间的复杂性。在本文中,我们提出了SemanticSplat,这是一种前馈的语义感知3D重建方法,它将3D高斯与潜在语义属性相结合,进行联合的几何-外观-语义建模。为了预测语义各向异性高斯,SemanticSplat融合了不同的特征场(例如LSeg、SAM)与成本体积表示,该表示存储跨视图特征相似性,增强了连贯和准确的场景理解。利用两阶段蒸馏框架,SemanticSplat从稀疏视图图像重建全景多模式语义特征场。实验证明了我们方法在可提示和开放词汇分割等3D场景理解任务中的有效性。视频结果请访问:https://semanticsplat.github.io。
论文及项目相关链接
Summary
本文提出一种名为SemanticSplat的语义感知的3D重建方法,用于全息3D场景理解。该方法结合了3D高斯潜语义属性,实现了几何、外观和语义的联合建模。SemanticSplat利用多特征场融合和成本体积表示来提高场景理解的连贯性和准确性。实验证明,该方法在可提示和开放词汇分割等3D场景理解任务上具有良好的效果。
Key Takeaways
- 语义感知的3D重建方法在全息理解3D场景上非常重要。现有方法局限于基于语言场景的语义提取,无法实现全面场景理解。提出一种名为SemanticSplat的新方法来解决这个问题。
- SemanticSplat结合了3D高斯潜语义属性进行几何、外观和语义的联合建模,提高了场景理解的准确性。
- SemanticSplat利用多特征场融合和成本体积表示来预测语义各向异性高斯,增强了场景理解的连贯性。
- 通过两阶段蒸馏框架,SemanticSplat能够从稀疏视角的图像中重建多模态语义特征场。
点此查看论文截图