⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Authors:Xintong Wang, Jingheng Pan, Yixiao Liu, Xiaohu Zhao, Chenyang Lyu, Minghao Wu, Chris Biemann, Longyue Wang, Linlong Xu, Weihua Luo, Kaifu Zhang
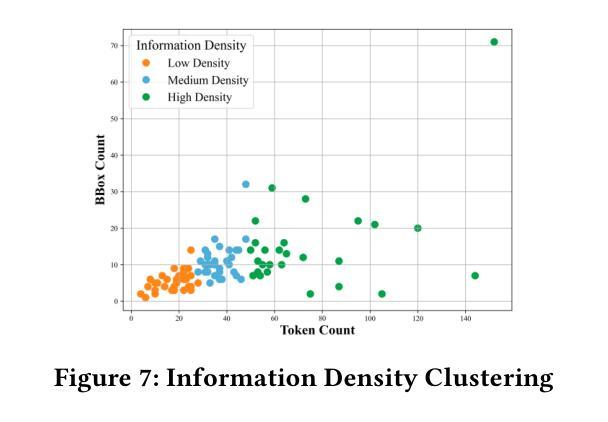
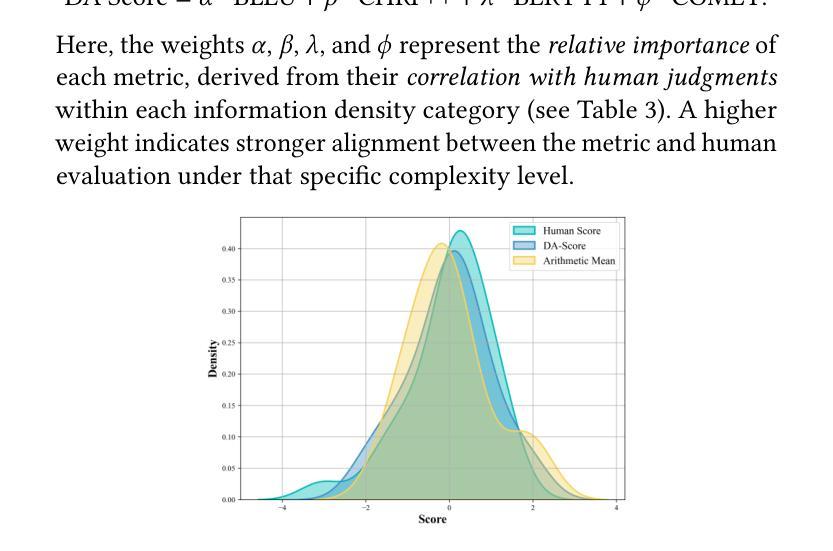
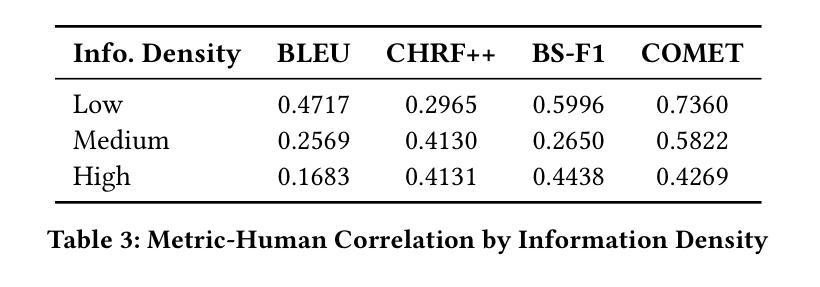
Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans – a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
视觉语言翻译(VLT)是一项具有挑战性的任务,它要求准确识别嵌入在图像中的多种语言文本,并在视觉上下文的支持下将其翻译成目标语言。尽管最近的大型视觉语言模型(LVLMs)表现出了强大的多语言和视觉理解能力,但关于它们在VLT上的性能的系统性评估和了解仍然不足。在这项工作中,我们从数据质量、模型架构和评估指标三个关键角度对VLT进行了全面的研究。
(1)我们发现了现有数据集在语义和文化忠实度方面的关键局限性,并引入了AibTrans——一个具有OCR校正注释的多语言、平行、人工验证的数据集。(2)我们对11个商业LVLMs/LLMs和6个最先进的开源模型进行了端到端和级联架构的基准测试,揭示了它们的OCR依赖性以及生成与推理行为的对比。(3)为了解决在不同上下文复杂性下度量可靠性的问题,我们提出了密度感知评估方法,并引入了DA分数作为衡量翻译质量更稳健的指标。基于这些发现,我们建立了VLT的新评估基准。值得注意的是,我们观察到在高资源语言对上微调LVLMs会降低跨语言性能,因此我们提出了一种平衡的多元语言微调策略,该策略可以有效地适应VLT而不会牺牲其泛化能力。
论文及项目相关链接
Summary:
视觉语言翻译(VLT)是一项识别图像中的多语言文本并借助视觉上下文翻译成目标语言的挑战任务。本研究从数据质量、模型架构和评估指标三个方面对VLT进行了全面研究。研究内容包括:识别现有数据集的关键局限性,并引入AibTrans这一多语言、并行、经人工验证的OCR校正注释数据集;对商业LVLMs/LLMs和先进开源模型进行基准测试,揭示其OCR依赖性和生成与推理行为的对比;提出密度感知评估以解决不同上下文复杂性下的指标可靠性问题,并引入DA分数作为更稳健的翻译质量衡量标准。此外,还发现高资源语言对上微调LVLMs会损害跨语言性能,并提出一种平衡的多语言微调策略,使LVLMs适应VLT而不损失其泛化能力。
Key Takeaways:
- 视觉语言翻译(VLT)需要准确识别图像中的多语言文本,并结合视觉上下文进行翻译。
- 现有数据集存在语义和文化忠实度的关键局限性。
- 引入了一个多语言、并行、经人工验证的AibTrans数据集,并包含OCR校正注释。
- 对商业和开源模型进行基准测试,揭示了OCR依赖性以及生成与推理行为的差异。
- 提出密度感知评估方法和DA分数,以更稳健地衡量翻译质量。
- 高资源语言对上微调LVLMs会损害跨语言性能。
点此查看论文截图


Score-based Generative Diffusion Models to Synthesize Full-dose FDG Brain PET from MRI in Epilepsy Patients
Authors:Jiaqi Wu, Jiahong Ouyang, Farshad Moradi, Mohammad Mehdi Khalighi, Greg Zaharchuk
Fluorodeoxyglucose (FDG) PET to evaluate patients with epilepsy is one of the most common applications for simultaneous PET/MRI, given the need to image both brain structure and metabolism, but is suboptimal due to the radiation dose in this young population. Little work has been done synthesizing diagnostic quality PET images from MRI data or MRI data with ultralow-dose PET using advanced generative AI methods, such as diffusion models, with attention to clinical evaluations tailored for the epilepsy population. Here we compared the performance of diffusion- and non-diffusion-based deep learning models for the MRI-to-PET image translation task for epilepsy imaging using simultaneous PET/MRI in 52 subjects (40 train/2 validate/10 hold-out test). We tested three different models: 2 score-based generative diffusion models (SGM-Karras Diffusion [SGM-KD] and SGM-variance preserving [SGM-VP]) and a Transformer-Unet. We report results on standard image processing metrics as well as clinically relevant metrics, including congruency measures (Congruence Index and Congruency Mean Absolute Error) that assess hemispheric metabolic asymmetry, which is a key part of the clinical analysis of these images. The SGM-KD produced the best qualitative and quantitative results when synthesizing PET purely from T1w and T2 FLAIR images with the least mean absolute error in whole-brain specific uptake value ratio (SUVR) and highest intraclass correlation coefficient. When 1% low-dose PET images are included in the inputs, all models improve significantly and are interchangeable for quantitative performance and visual quality. In summary, SGMs hold great potential for pure MRI-to-PET translation, while all 3 model types can synthesize full-dose FDG-PET accurately using MRI and ultralow-dose PET.
使用氟脱氧葡萄糖(FDG)PET评估癫痫患者是同时PET/MRI最常见的应用之一,由于需要同时显示大脑结构和代谢。但是由于年轻患者的辐射剂量问题,其效果并不理想。目前很少有工作使用先进的生成式人工智能方法(如扩散模型)合成具有诊断质量的PET图像或使用超低剂量PET的MRI数据,并特别针对癫痫人群进行临床评估。在这里,我们比较了基于扩散和非扩散深度学习模型在MRI到PET图像转换任务上的表现,使用同时PET/MRI对52名癫痫患者(40名训练/ 2名验证/ 10名独立测试)进行成像。我们测试了三种不同的模型:两种基于分数的生成扩散模型(SGM-Karras扩散[SGM-KD]和SGM-方差保留[SGM-VP])以及一个Transformer-Unet。我们报告了标准图像处理指标的结果以及与临床相关的指标,包括评估半球代谢不对称性的符合度指标(符合度指数和符合度平均绝对误差),这是这些图像临床分析的关键部分。当仅使用T1w和T2 FLAIR图像合成PET时,SGM-KD产生了最好的定性和定量结果,具有最低的全脑特定摄取值比率(SUVR)平均绝对误差和最高的组内相关系数。当在输入中包含1%的低剂量PET图像时,所有模型都有显著改善,在定量性能和视觉质量方面可互换。总之,SGMs在纯MRI到PET转换方面显示出巨大潜力,而所有三种类型的模型都可以使用MRI和超低剂量PET准确合成全剂量FDG-PET图像。
论文及项目相关链接
Summary
本文探讨了利用深度学习模型将MRI图像转化为PET图像在癫痫诊断中的应用。对比了扩散模型与非扩散模型在MRI-to-PET图像转换任务中的性能,发现扩散模型在纯MRI图像转换中表现最佳,而在结合超低剂量PET数据时,所有模型性能均有显著提升。
Key Takeaways
- FDG PET在癫痫诊断中广泛应用,但辐射剂量问题使其存在局限性。
- 深度学习模型用于合成高质量PET图像,基于MRI数据或结合超低剂量PET数据。
- 对比了三种模型:两种基于扩散的模型(SGM-KD和SGM-VP)和一个Transformer-Unet模型。
- SGM-KD在纯MRI图像转换中表现最佳,合成PET图像质量高且误差最小。
- 结合超低剂量PET数据时,所有模型性能均显著提升,定量表现和视觉质量均良好。
- 扩散模型在纯MRI-to-PET转换中具有巨大潜力。
点此查看论文截图



Diversifying Human Pose in Synthetic Data for Aerial-view Human Detection
Authors:Yi-Ting Shen, Hyungtae Lee, Heesung Kwon, Shuvra S. Bhattacharyya
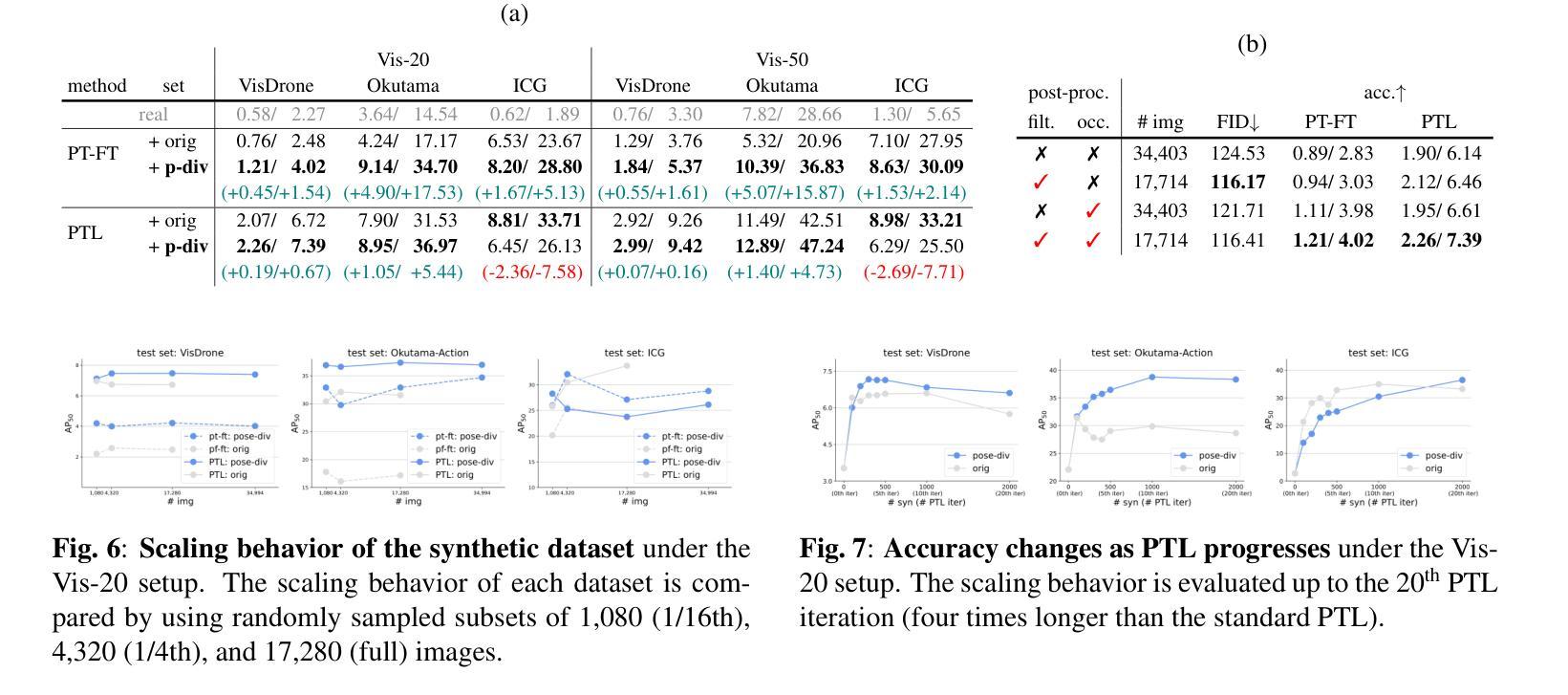
Synthetic data generation has emerged as a promising solution to the data scarcity issue in aerial-view human detection. However, creating datasets that accurately reflect varying real-world human appearances, particularly diverse poses, remains challenging and labor-intensive. To address this, we propose SynPoseDiv, a novel framework that diversifies human poses within existing synthetic datasets. SynPoseDiv tackles two key challenges: generating realistic, diverse 3D human poses using a diffusion-based pose generator, and producing images of virtual characters in novel poses through a source-to-target image translator. The framework incrementally transitions characters into new poses using optimized pose sequences identified via Dijkstra’s algorithm. Experiments demonstrate that SynPoseDiv significantly improves detection accuracy across multiple aerial-view human detection benchmarks, especially in low-shot scenarios, and remains effective regardless of the training approach or dataset size.
在俯视角度的人类检测中,为了解决数据稀缺问题,合成数据生成已经展现出巨大的潜力。然而,创建一个准确反映现实世界人类外观变化的数据集,尤其是各种姿势的数据集仍然具有挑战性和劳动强度大。为了解决这一问题,我们提出了SynPoseDiv这一新型框架,它可以在现有的合成数据集中丰富人类姿势。SynPoseDiv解决了两个主要挑战:一是利用基于扩散的姿势生成器生成现实、多样化的三维姿势;二是通过源到目标图像转换器生成虚拟角色的新姿势图像。该框架通过逐步过渡角色进入新姿势,使用Dijkstra算法识别优化的姿势序列。实验表明,SynPoseDiv显著提高了多个俯视角度的人体检测基准测试的检测精度,特别是在样本较少的场景中表现优异,并且在不同的训练方法和数据集大小上都能保持有效。
论文及项目相关链接
PDF ICIP 2025
Summary
针对空中视角人体检测中数据稀缺的问题,合成数据生成已成为一种有前景的解决方案。然而,创建准确反映各种现实世界人类外观,特别是不同姿势的数据集仍然具有挑战性和劳动密集型。为此,我们提出SynPoseDiv框架,它通过扩散式姿势生成器和源到目标图像翻译器来多样化现有合成数据集中的姿势。框架使用Dijkstra算法识别的优化姿势序列逐步过渡角色到新的姿势。实验表明,SynPoseDiv在多个人体检测基准测试中显著提高检测精度,特别是在低样本场景中,无论采用何种训练方法和数据集大小都能保持有效性。
Key Takeaways
针对空中视角人体检测数据稀缺的问题,合成数据生成具有很大潜力。
创建准确反映不同现实世界人类外观(特别是姿势)的数据集仍然存在挑战。
SynPoseDiv框架旨在解决现有合成数据集中姿势多样性不足的问题。
SynPoseDiv使用扩散式姿势生成器和源到目标图像翻译器来创建多样化的姿势。
通过优化的姿势序列逐步过渡角色到新的姿势。
实验证明SynPoseDiv能有效提高低样本场景的空中视角人体检测精度。
点此查看论文截图