⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
Post Persona Alignment for Multi-Session Dialogue Generation
Authors:Yi-Pei Chen, Noriki Nishida, Hideki Nakayama, Yuji Matsumoto
Multi-session persona-based dialogue generation presents challenges in maintaining long-term consistency and generating diverse, personalized responses. While large language models (LLMs) excel in single-session dialogues, they struggle to preserve persona fidelity and conversational coherence across extended interactions. Existing methods typically retrieve persona information before response generation, which can constrain diversity and result in generic outputs. We propose Post Persona Alignment (PPA), a novel two-stage framework that reverses this process. PPA first generates a general response based solely on dialogue context, then retrieves relevant persona memories using the response as a query, and finally refines the response to align with the speaker’s persona. This post-hoc alignment strategy promotes naturalness and diversity while preserving consistency and personalization. Experiments on multi-session LLM-generated dialogue data demonstrate that PPA significantly outperforms prior approaches in consistency, diversity, and persona relevance, offering a more flexible and effective paradigm for long-term personalized dialogue generation.
基于多会话个性的对话生成在保持长期一致性以及生成多样化、个性化的响应方面存在挑战。虽然大型语言模型(LLM)在单会话对话中表现出色,但在跨扩展交互中,它们很难保持个性保真和对话连贯性。现有方法通常在生成响应之前检索个性信息,这可能会限制多样性并导致通用输出。我们提出了后个性对齐(PPA)这种新型的两阶段框架,该框架反转了这一过程。PPA首先仅基于对话上下文生成一般响应,然后使用响应作为查询检索相关个性记忆,最后对响应进行微调以与说话者的个性保持一致。这种事后对齐策略既促进了自然性和多样性,又保持了一致性和个性化。在多会话LLM生成对话数据上的实验表明,在一致性、多样性和个性相关性方面,PPA显著优于先前的方法,为长期个性化对话生成提供了更灵活有效的范式。
论文及项目相关链接
Summary
基于多会话的个性化对话生成在维持长期一致性以及生成多样化、个性化的响应方面存在挑战。大型语言模型(LLMs)在单会话对话中表现优异,但在跨扩展交互中保持人物保真和会话连贯性方面存在困难。现有方法通常在生成响应之前检索人物信息,这可能会限制多样性并导致通用输出。我们提出后人物对齐(PPA)方法,这是一个新的两阶段框架,逆转了这一过程。PPA首先仅根据对话上下文生成一般响应,然后使用响应作为查询检索相关的人物记忆,最后细化响应以与说话者的人物对齐。这种事后对齐策略既促进了自然性和多样性,又保持了连贯性和个性化。在多会话LLM生成的对话数据上的实验表明,PPA在一致性、多样性和人物相关性方面显著优于先前的方法,为长期个性化对话生成提供了更灵活和有效的范式。
Key Takeaways
- 多会话个性化对话生成面临长期一致性和生成多样化响应的挑战。
- 大型语言模型(LLMs)在单会话对话中表现良好,但在多会话交互中保持人物一致性和会话连贯性方面存在困难。
- 现有方法通常在生成响应前检索人物信息,可能限制响应的多样性。
- 提出的后人物对齐(PPA)方法是一个新的两阶段框架,先生成一般响应,然后检索相关人物信息并进行对齐。
- PPA能同时促进对话的自然性、多样性和个性化。
- 实验表明,PPA在一致性、多样性和人物相关性方面显著优于先前的方法。
点此查看论文截图

Are Multimodal Large Language Models Pragmatically Competent Listeners in Simple Reference Resolution Tasks?
Authors:Simeon Junker, Manar Ali, Larissa Koch, Sina Zarrieß, Hendrik Buschmeier
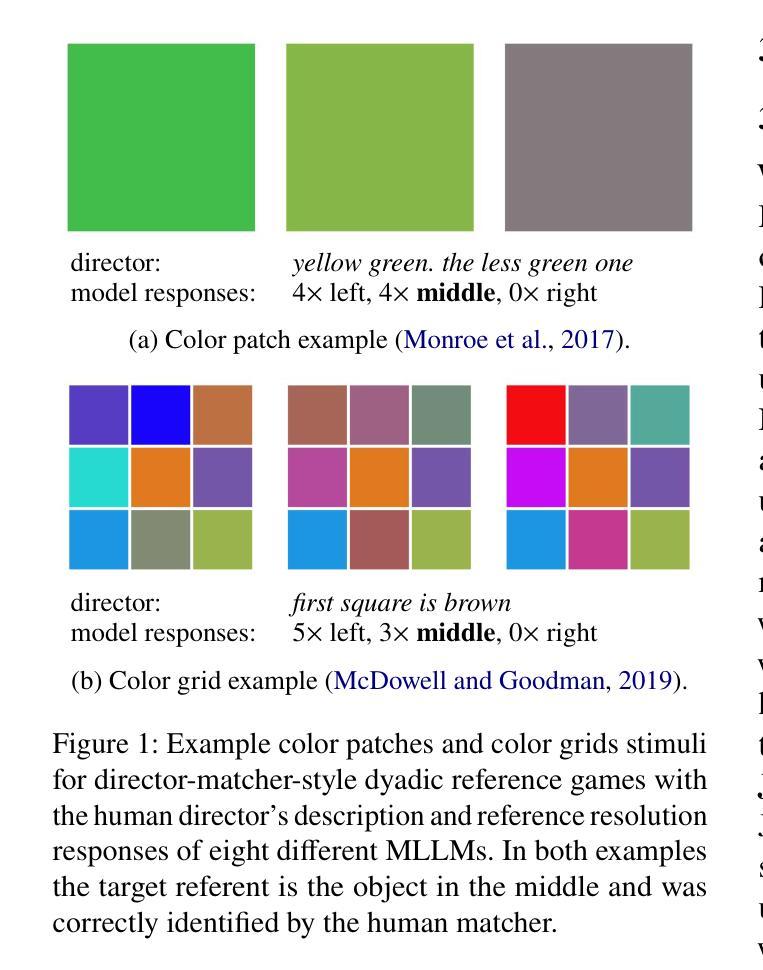
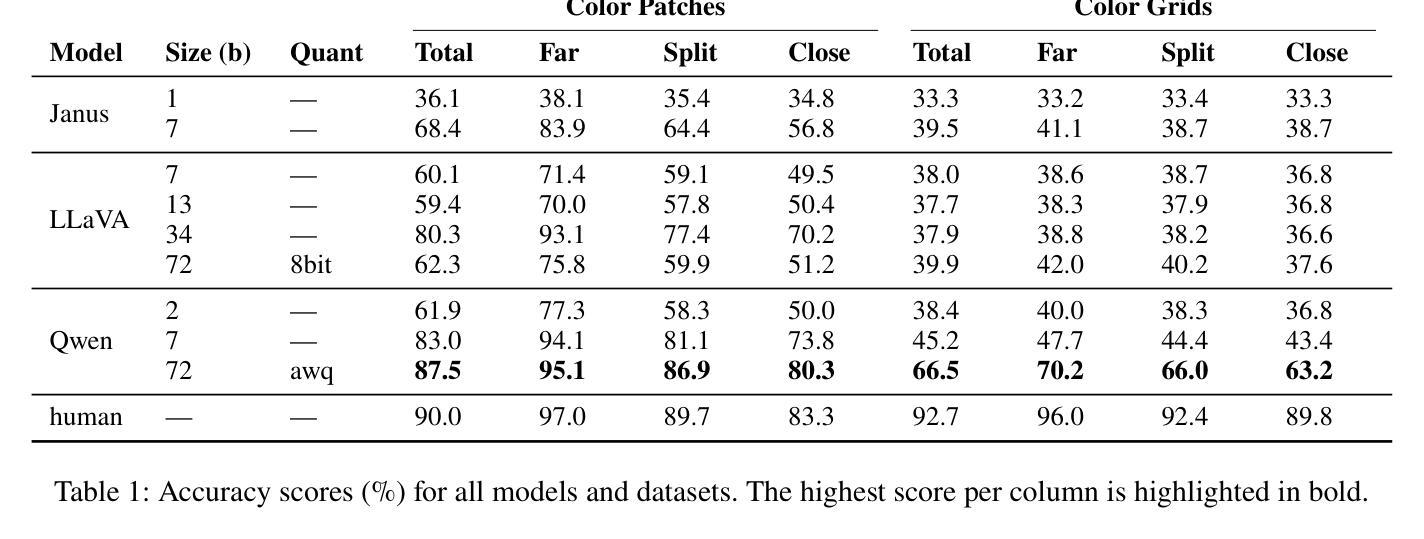
We investigate the linguistic abilities of multimodal large language models in reference resolution tasks featuring simple yet abstract visual stimuli, such as color patches and color grids. Although the task may not seem challenging for today’s language models, being straightforward for human dyads, we consider it to be a highly relevant probe of the pragmatic capabilities of MLLMs. Our results and analyses indeed suggest that basic pragmatic capabilities, such as context-dependent interpretation of color descriptions, still constitute major challenges for state-of-the-art MLLMs.
我们研究了多模态大型语言模型在涉及简单但抽象视觉刺激(如色块和色格)的引用解析任务中的语言能力。尽管对于今天的人类二元组来说,这个任务可能并不具有挑战性,但我们认为它是测试多模态大型语言模型(MLLMs)实用能力的绝佳方法。我们的结果和分析确实表明,基本的实用能力,如根据上下文解释颜色描述,仍然是最新MLLMs面临的主要挑战。
论文及项目相关链接
PDF To appear in ACL Findings 2025
Summary
本文研究了多模态大型语言模型在涉及简单抽象视觉刺激(如色块和色格)的引用解析任务中的语言处理能力。虽然此任务对人类来说可能并不具有挑战性,但它被视为对多模态语言模型的实用能力的有效测试。研究结果和分析显示,诸如基于语境的色彩描述解释等基本实用能力对于最新的多模态大型语言模型而言仍然是重大挑战。
Key Takeaways
- 研究关注多模态大型语言模型(MLLMs)在简单抽象视觉刺激下的引用解析任务表现。
- 虽然对人类来说此类任务看似简单,但对MLLMs仍是挑战。
- 研究通过色块和色格等视觉刺激来测试MLLMs的实用能力。
- 结果显示,MLLMs在理解语境相关的颜色描述方面存在困难。
- MLLMs在解释涉及基本实用能力的任务时仍面临重大挑战。
- 此研究强调了提高MLLMs处理简单视觉刺激任务能力的必要性。
点此查看论文截图


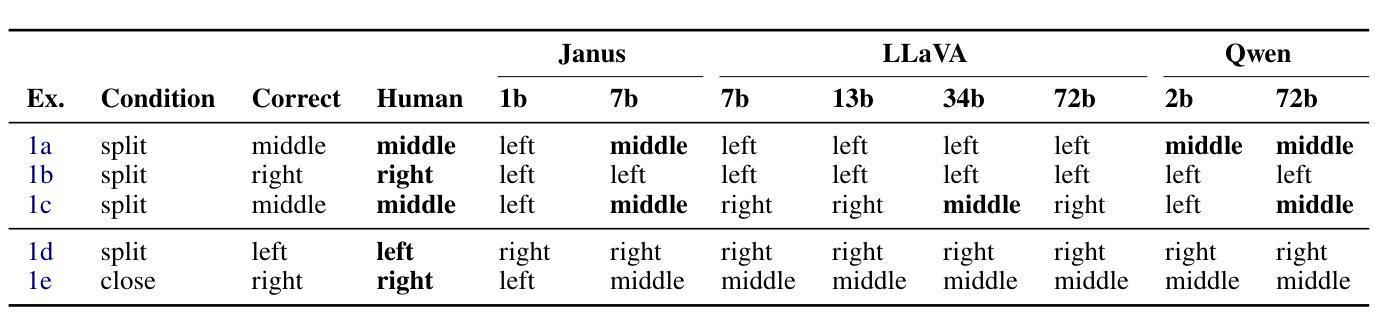
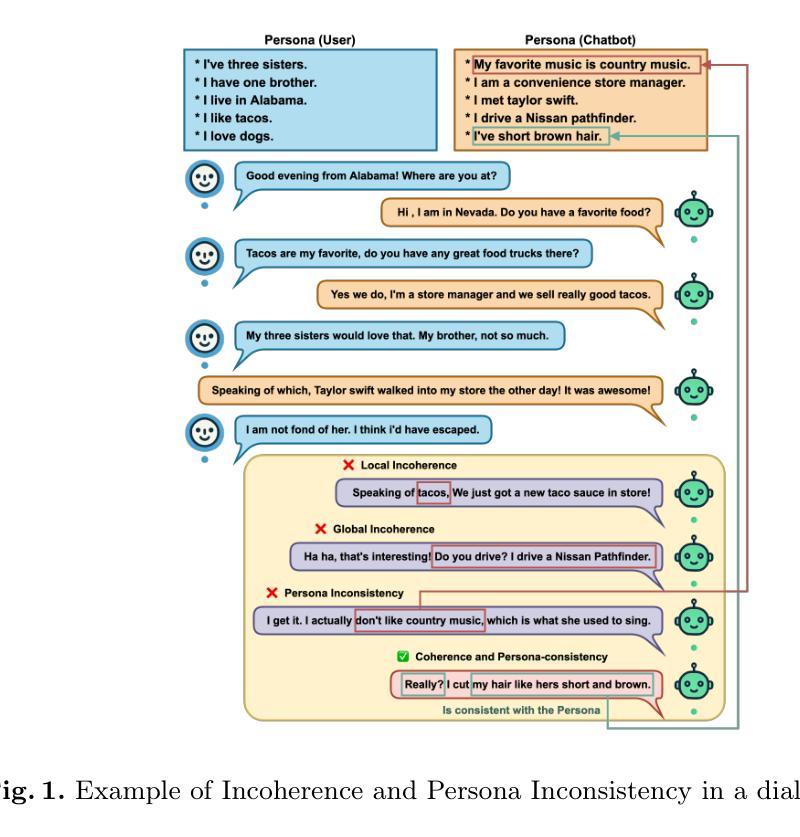
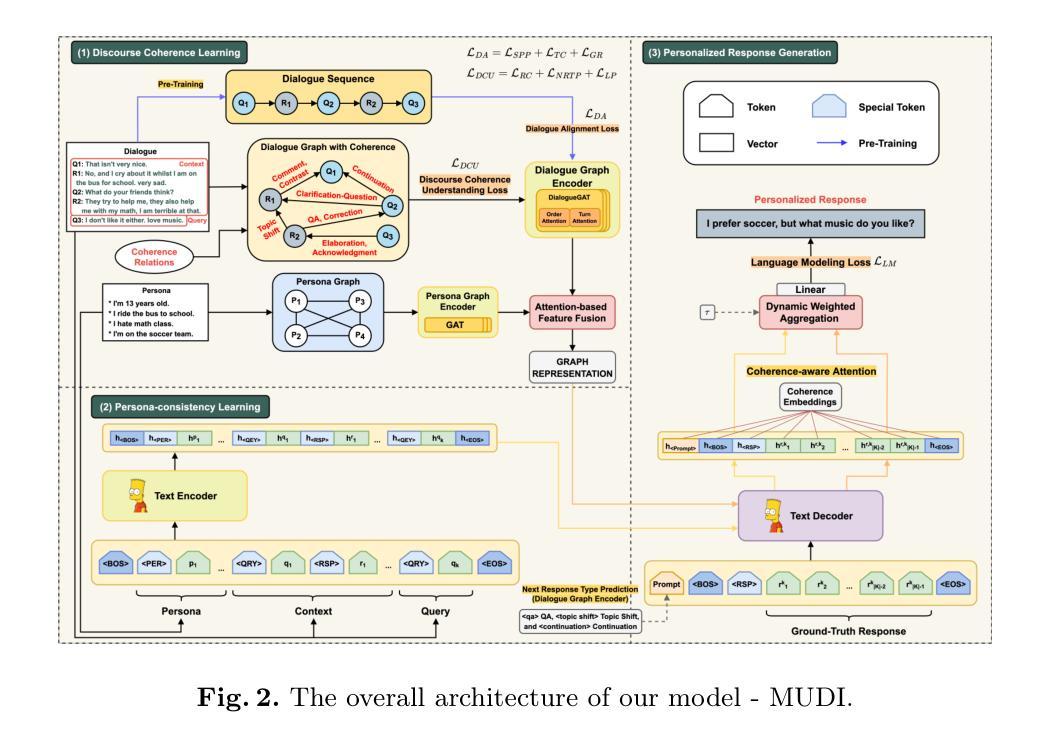
From Persona to Person: Enhancing the Naturalness with Multiple Discourse Relations Graph Learning in Personalized Dialogue Generation
Authors:Chih-Hao Hsu, Ying-Jia Lin, Hung-Yu Kao
In dialogue generation, the naturalness of responses is crucial for effective human-machine interaction. Personalized response generation poses even greater challenges, as the responses must remain coherent and consistent with the user’s personal traits or persona descriptions. We propose MUDI ($\textbf{Mu}$ltiple $\textbf{Di}$scourse Relations Graph Learning) for personalized dialogue generation. We utilize a Large Language Model to assist in annotating discourse relations and to transform dialogue data into structured dialogue graphs. Our graph encoder, the proposed DialogueGAT model, then captures implicit discourse relations within this structure, along with persona descriptions. During the personalized response generation phase, novel coherence-aware attention strategies are implemented to enhance the decoder’s consideration of discourse relations. Our experiments demonstrate significant improvements in the quality of personalized responses, thus resembling human-like dialogue exchanges.
在对话生成中,回复的自然度对于有效的人机交互至关重要。个性化回复生成更是难上加难,因为回复必须保持连贯性并与用户的个人特质或人格描述保持一致。我们提出MUDI(多重话语关系图学习)用于个性化对话生成。我们利用大型语言模型帮助标注话语关系,并将对话数据转换为结构化对话图。我们的图编码器,即提出的DialogueGAT模型,能够捕捉此结构中的隐含话语关系以及人格描述。在个性化回复生成阶段,我们实施了新颖的一致性感知注意力策略,以增强解码器对话语关系的考虑。我们的实验证明个性化回复的质量得到了显著提高,从而实现了类似人类的对话交流。
论文及项目相关链接
PDF Accepted by PAKDD 2025
Summary
在对话生成中,响应的自然性是实现有效人机互动的关键。个性化响应生成面临更大的挑战,因为响应必须保持连贯性并与用户的个人特质或人格描述保持一致。本文提出MUDI(多话语关系图学习)用于个性化对话生成。我们利用大型语言模型帮助标注话语关系,并将对话数据转化为结构化对话图。提出的DialogueGAT图编码器捕捉到这个结构中的隐含话语关系以及人格描述。在个性化响应生成阶段,实施了新颖的一致性感知注意力策略,以增强解码器对话语关系的考虑。实验证明,个性化响应的质量得到了显著提高,从而实现了类似人类之间的对话交流。
Key Takeaways
- 对话生成中响应的自然性对人机互动至关重要。
- 个性化响应生成需保持连贯性并与用户个人特质或人格描述一致。
- 提出MUDI方法,结合大型语言模型进行话语关系标注和对话结构化。
- DialogueGAT图编码器能捕捉结构中的隐含话语关系和人格描述。
- 实施了新颖的一致性感知注意力策略,以增强解码器对话语关系的考虑。
- 实验证明个性化响应的质量得到了显著提高。
点此查看论文截图

PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Authors:Ming Zhang, Yuhui Wang, Yujiong Shen, Tingyi Yang, Changhao Jiang, Yilong Wu, Shihan Dou, Qinhao Chen, Zhiheng Xi, Zhihao Zhang, Yi Dong, Zhen Wang, Zhihui Fei, Mingyang Wan, Tao Liang, Guojun Ma, Qi Zhang, Tao Gui, Xuanjing Huang
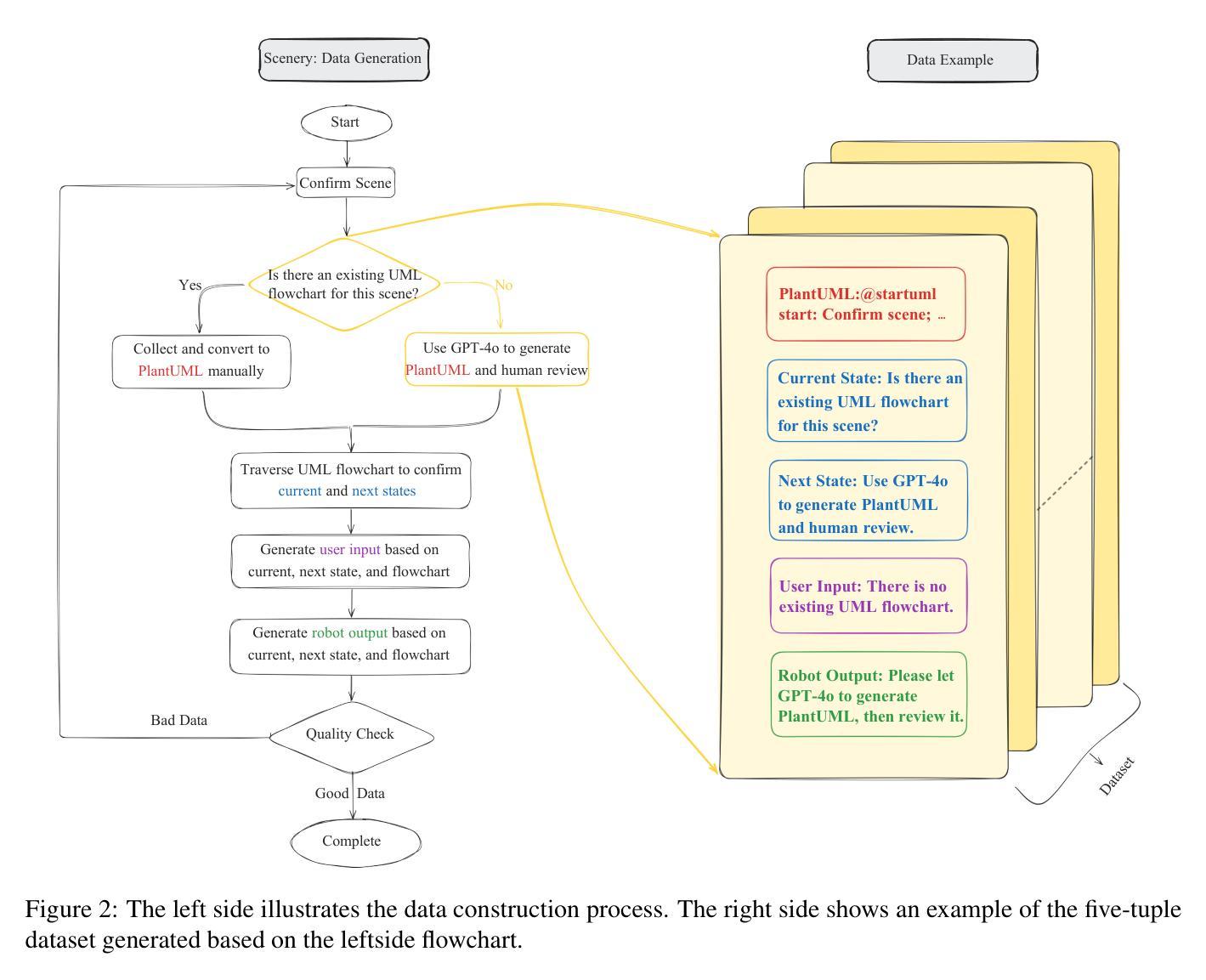
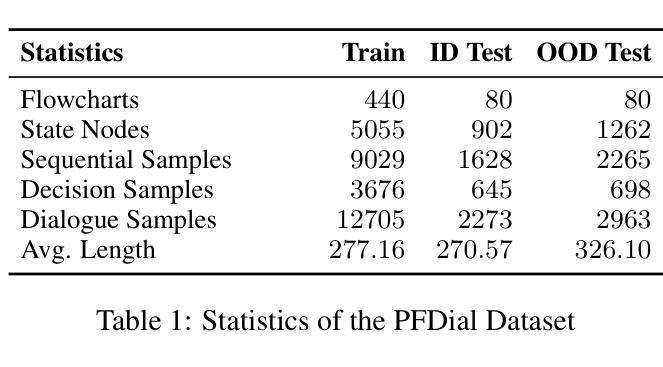
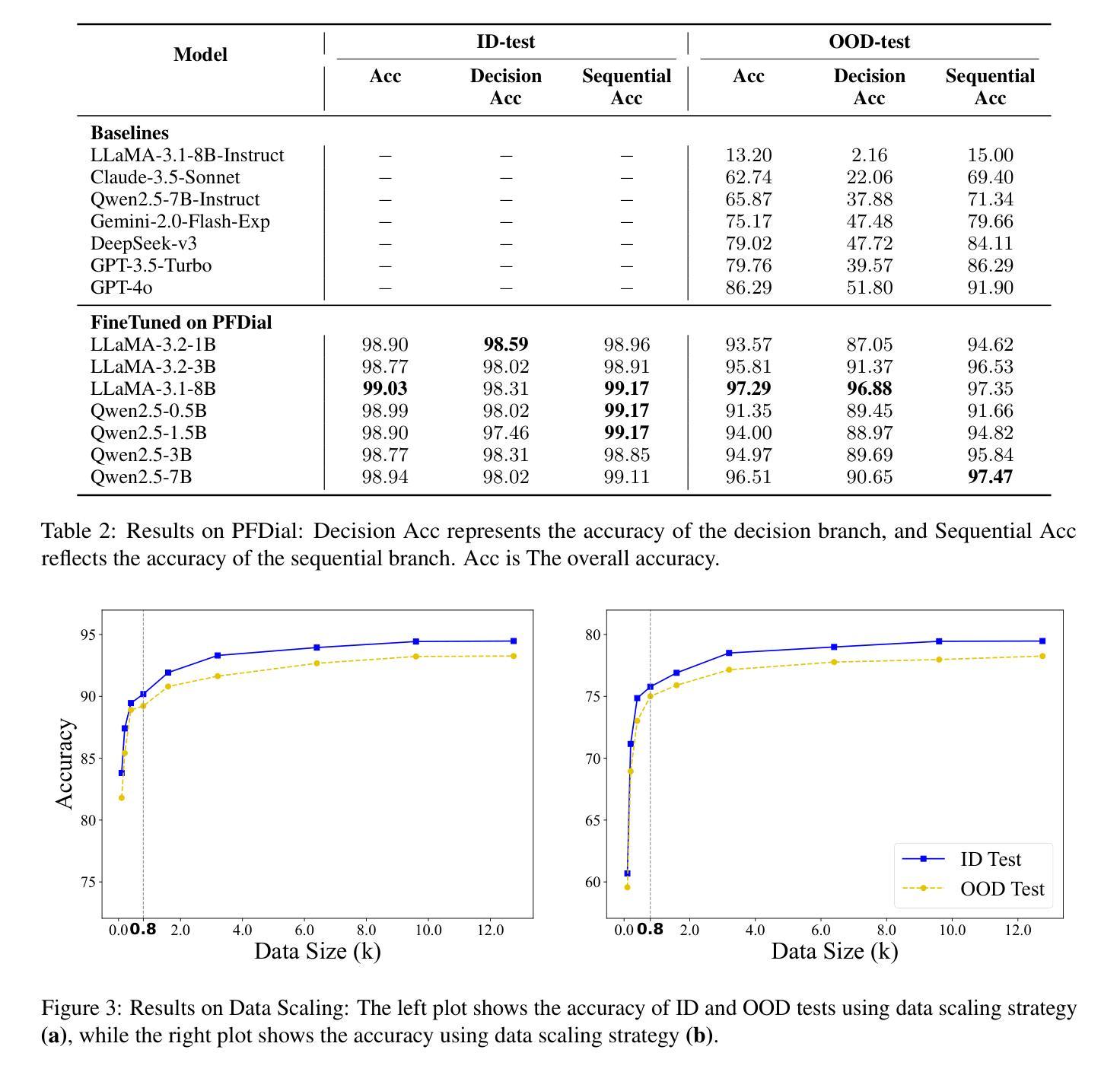
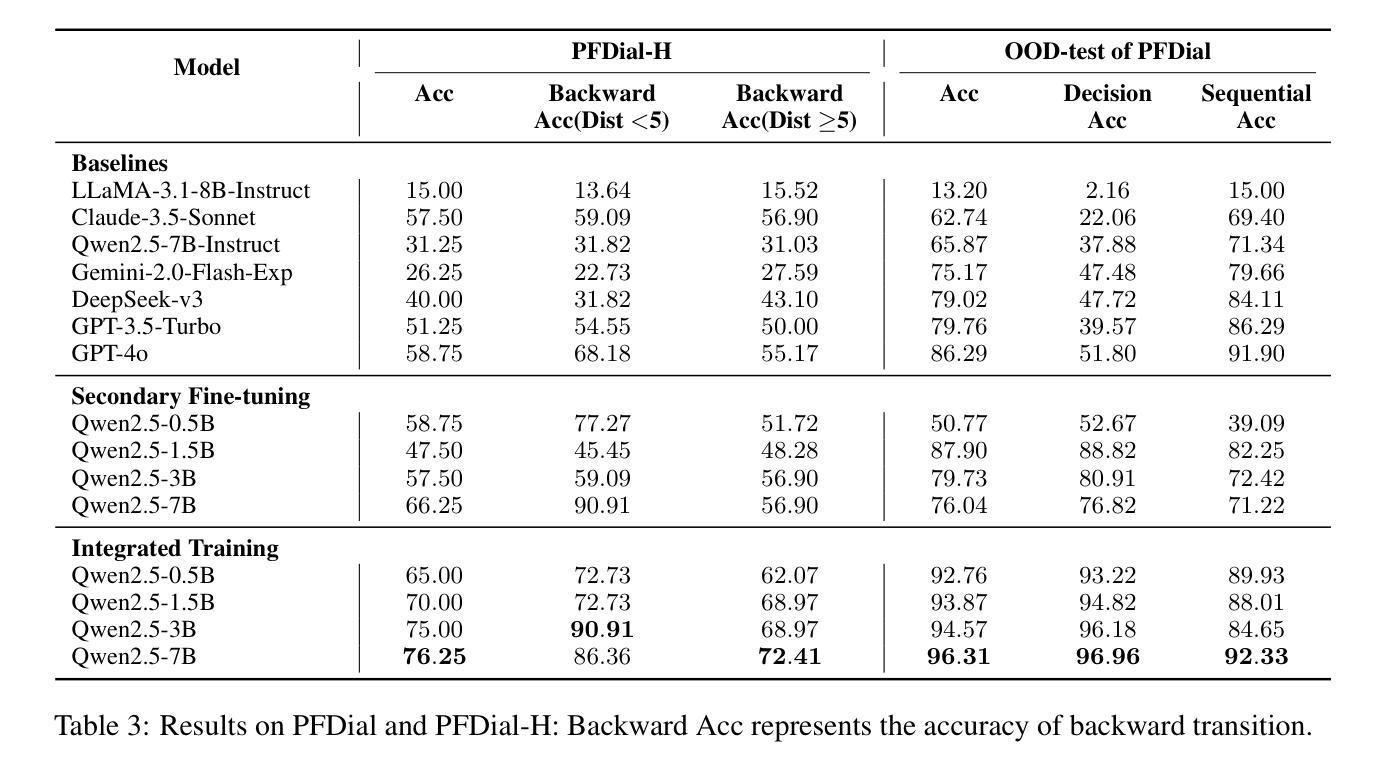
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models’ performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
流程驱动型对话系统在严格的预先定义流程约束下运行,对于客户服务及设备维护场景至关重要。尽管大型语言模型(LLM)在对话和推理方面取得了显著进展,但在解决这些受严格约束的对话任务时仍面临挑战。为了应对这一挑战,我们构建了流程对话(PFDial)数据集,其中包含从包含流程节点信息的流程图转化而来的高质量中文对话指令共12,705条。基于PlantUML规范,每个UML流程图被转换为原子对话单元,即结构化五元组。实验结果表明,仅用少量样本训练的规模为数十亿参数的模型准确率就能超过百分之九十。另外,平均来说,规模为数十亿参数的模型性能可以超越GPT-4o高达百分之四十三点八八以上。我们进一步评估了模型在处理流程中逆向过渡等挑战方面的性能,并对各种数据集格式进行了深入分析,以揭示它们在处理决策和顺序分支方面对模型性能的影响。数据集已在公开网站发布:https://github.com/KongLongGeFDU/PFDial。
论文及项目相关链接
Summary
基于流程驱动对话系统在客户服务和设备维护场景中的重要性,针对大型语言模型(LLMs)在解决严格约束对话任务方面的挑战,构建了包含高质量中文对话指令的过程流对话(PFDial)数据集。该数据集由来自440个流程图中的12,705个流程节点转化而成,并以PlantUML规范为基础将每个UML流程图转换为结构化五个单元的形式。实验结果表明,模型可以在有限的数据集上达到高准确率。数据集已发布在相关链接上。
Key Takeaways
- 流程驱动对话系统在客户服务及设备维护场景中至关重要。
- 大型语言模型(LLMs)在解决严格约束对话任务时仍面临挑战。
- 构建了一个名为PFDial的新数据集,包含从流程图中衍生出的高质量中文对话指令。
- 数据集包含多种流程图格式,包括决策和顺序分支的影响。
- 实验结果显示,在有限数据集上训练的模型准确率超过90%。与GPT-4相比,一个更大规模的模型表现更佳。
- 数据集已经发布供公众使用。
点此查看论文截图