⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
Improving Large Language Model Safety with Contrastive Representation Learning
Authors:Samuel Simko, Mrinmaya Sachan, Bernhard Schölkopf, Zhijing Jin
Large Language Models (LLMs) are powerful tools with profound societal impacts, yet their ability to generate responses to diverse and uncontrolled inputs leaves them vulnerable to adversarial attacks. While existing defenses often struggle to generalize across varying attack types, recent advancements in representation engineering offer promising alternatives. In this work, we propose a defense framework that formulates model defense as a contrastive representation learning (CRL) problem. Our method finetunes a model using a triplet-based loss combined with adversarial hard negative mining to encourage separation between benign and harmful representations. Our experimental results across multiple models demonstrate that our approach outperforms prior representation engineering-based defenses, improving robustness against both input-level and embedding-space attacks without compromising standard performance. Our code is available at https://github.com/samuelsimko/crl-llm-defense
大型语言模型(LLM)是具有深远社会影响的强大工具,但它们对多样化和非控制输入的响应能力使其容易受到对抗性攻击。虽然现有的防御手段往往难以在多种攻击类型中推广,但表示工程方面的最新进展提供了有希望的替代方案。在这项工作中,我们提出了一个防御框架,该框架将模型防御制定为一个对比表示学习(CRL)问题。我们的方法通过使用基于三元组的损失与对抗性硬负挖掘相结合来微调模型,以鼓励良性表示和有害表示之间的分离。我们在多个模型上的实验结果表明,我们的方法优于基于表示工程的先前防御手段,提高了对输入级别和嵌入空间攻击的稳健性,同时不损害标准性能。我们的代码可在https://github.com/samuelsimko/crl-llm-defense找到。
论文及项目相关链接
Summary
LLM模型对社会有深远影响,但其生成多样化且不可控输入的响应使其易受对抗性攻击。现有防御策略往往难以在不同攻击类型之间实现泛化,而最近的表示工程进展提供了有希望的替代方案。本研究提出了一种防御框架,将模型防御表述为对比表示学习(CRL)问题。该方法使用基于三元组的损失结合对抗性硬负挖掘来微调模型,鼓励良性表示与有害表示之间的分离。实验结果表明,该方法在多个模型上的表现优于基于表示工程的先前防御策略,能够在不损害标准性能的情况下提高针对输入级别和嵌入空间攻击的稳健性。相关代码可在https://github.com/samuelsimko/crl-llm-defense找到。
Key Takeaways
- LLM模型因其生成多样化响应的能力而具有社会影响力,但也容易受到对抗性攻击。
- 现有防御策略在泛化方面存在挑战,需要新的解决方案。
- 对比表示学习(CRL)被提出作为一种新的防御框架。
- 该方法通过微调模型并使用基于三元组的损失结合对抗性硬负挖掘,来分离良性表示和有害表示。
- 实验结果表明,该方法提高了模型针对输入级别和嵌入空间攻击的稳健性。
- 该方法在多个模型上的表现优于之前的表示工程防御策略。
点此查看论文截图


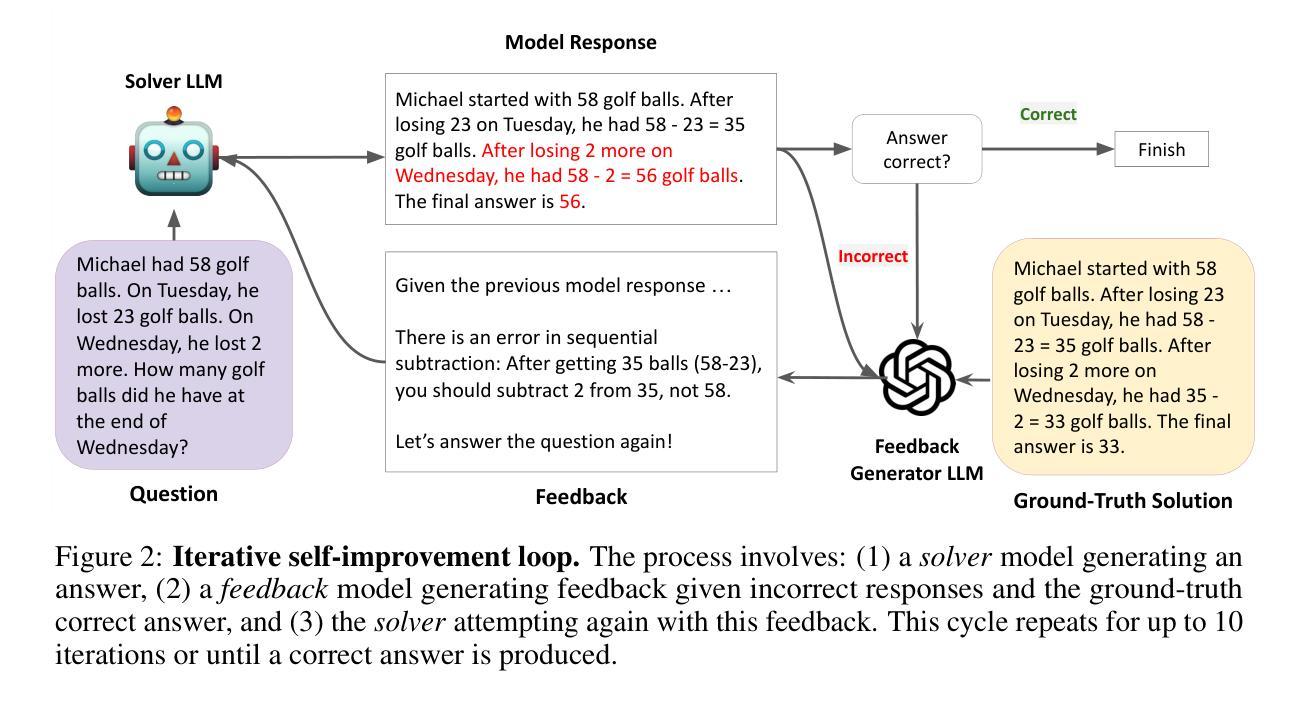
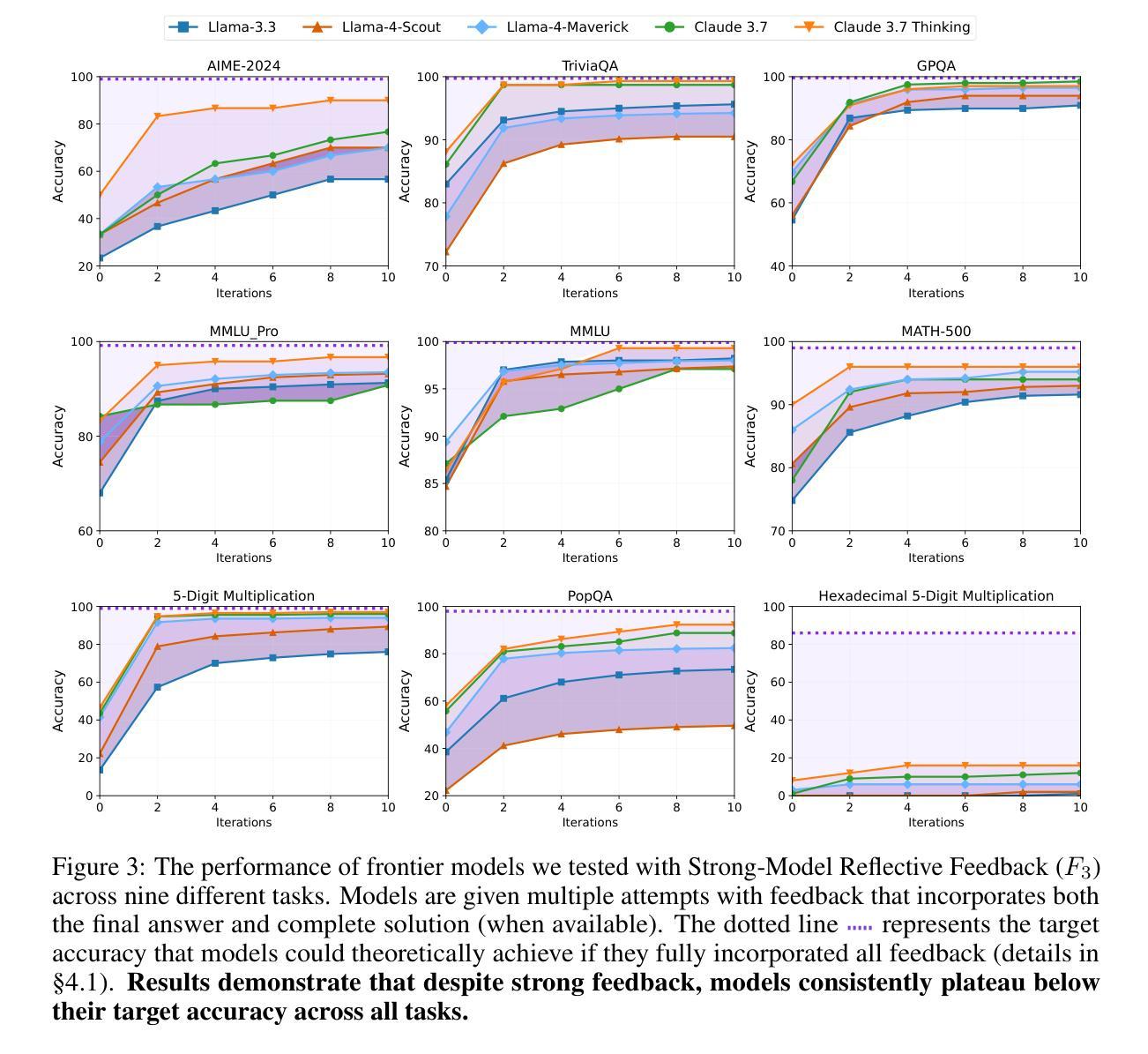
Feedback Friction: LLMs Struggle to Fully Incorporate External Feedback
Authors:Dongwei Jiang, Alvin Zhang, Andrew Wang, Nicholas Andrews, Daniel Khashabi
Recent studies have shown LLMs possess some ability to improve their responses when given external feedback. However, it remains unclear how effectively and thoroughly these models can incorporate extrinsic feedback. In an ideal scenario, if LLMs receive near-perfect and complete feedback, we would expect them to fully integrate the feedback and change their incorrect answers to correct ones. In this paper, we systematically investigate LLMs’ ability to incorporate feedback by designing a controlled experimental environment. For each problem, a solver model attempts a solution, then a feedback generator with access to near-complete ground-truth answers produces targeted feedback, after which the solver tries again. We evaluate this pipeline across a diverse range of tasks, including math reasoning, knowledge reasoning, scientific reasoning, and general multi-domain evaluations with state-of-the-art language models including Claude 3.7 (with and without extended thinking). Surprisingly, even under these near-ideal conditions, solver models consistently show resistance to feedback, a limitation that we term FEEDBACK FRICTION. To mitigate this limitation, we experiment with sampling-based strategies like progressive temperature increases and explicit rejection of previously attempted incorrect answers, which yield improvements but still fail to help models achieve target performance. We also perform a rigorous exploration of potential causes of FEEDBACK FRICTION, ruling out factors such as model overconfidence and data familiarity. We hope that highlighting this issue in LLMs and ruling out several apparent causes will help future research in self-improvement.
最近的研究表明,大型语言模型在接收到外部反馈后,能够改善其回应能力。然而,这些模型如何有效并全面地融入外在反馈仍然不明确。在理想情况下,如果大型语言模型收到近乎完美且完整的反馈,我们期望它们能够完全整合反馈并更正错误的答案。本文中,我们通过设计一个受控的实验环境来系统研究大型语言模型融入反馈的能力。针对每个问题,求解模型先尝试解答,然后一个能够访问近乎完整的真实答案的反馈生成器产生有针对性的反馈,之后求解模型再次尝试。我们在各种任务中评估了这个流程,包括数学推理、知识推理、科学推理和包含Claude 3.7(带和不带扩展思考)的最新语言模型的一般多域评估。令人惊讶的是,即使在近乎理想的条件下,求解模型始终显示出对反馈的抵抗,这是我们称之为“反馈摩擦力”的限制。为了缓解这一限制,我们尝试采用基于采样的策略,如逐步增加温度值和显式拒绝之前尝试过的错误答案,虽然这有所改善,但仍未能帮助模型达到目标性能。我们还对“反馈摩擦力”的潜在原因进行了严格的探索,排除了模型过度自信和数据熟悉度等因素。我们希望突出大型语言模型的这一问题,并排除几个明显的原因,以帮助未来的自我改进研究。
论文及项目相关链接
Summary
大型语言模型(LLM)能够在给定外部反馈时改进其响应,但如何有效、全面地融入外在反馈尚不清楚。本研究通过设计受控实验环境,系统探讨了LLM融入反馈的能力。研究结果显示,即使在近乎完美的反馈条件下,求解模型仍对反馈表现出一定的抵抗性,称之为“反馈摩擦”。本研究尝试采用基于采样的策略来缓解这一问题,但仍未能使模型达到目标性能。研究还对“反馈摩擦”的潜在原因进行了深入探讨,排除了模型过度自信和数据熟悉度等因素。
Key Takeaways
- LLMs能够在一定程度上利用外部反馈改进其回应。
- 在近乎完美的反馈条件下,LLMs仍表现出对反馈的抵抗性,称为“反馈摩擦”。
- 基于采样的策略,如逐步提高温度、明确拒绝之前错误的答案,有助于缓解“反馈摩擦”,但仍未达到理想效果。
- 研究排除了模型过度自信和数据熟悉度等因素,对“反馈摩擦”的潜在原因进行了深入探讨。
点此查看论文截图

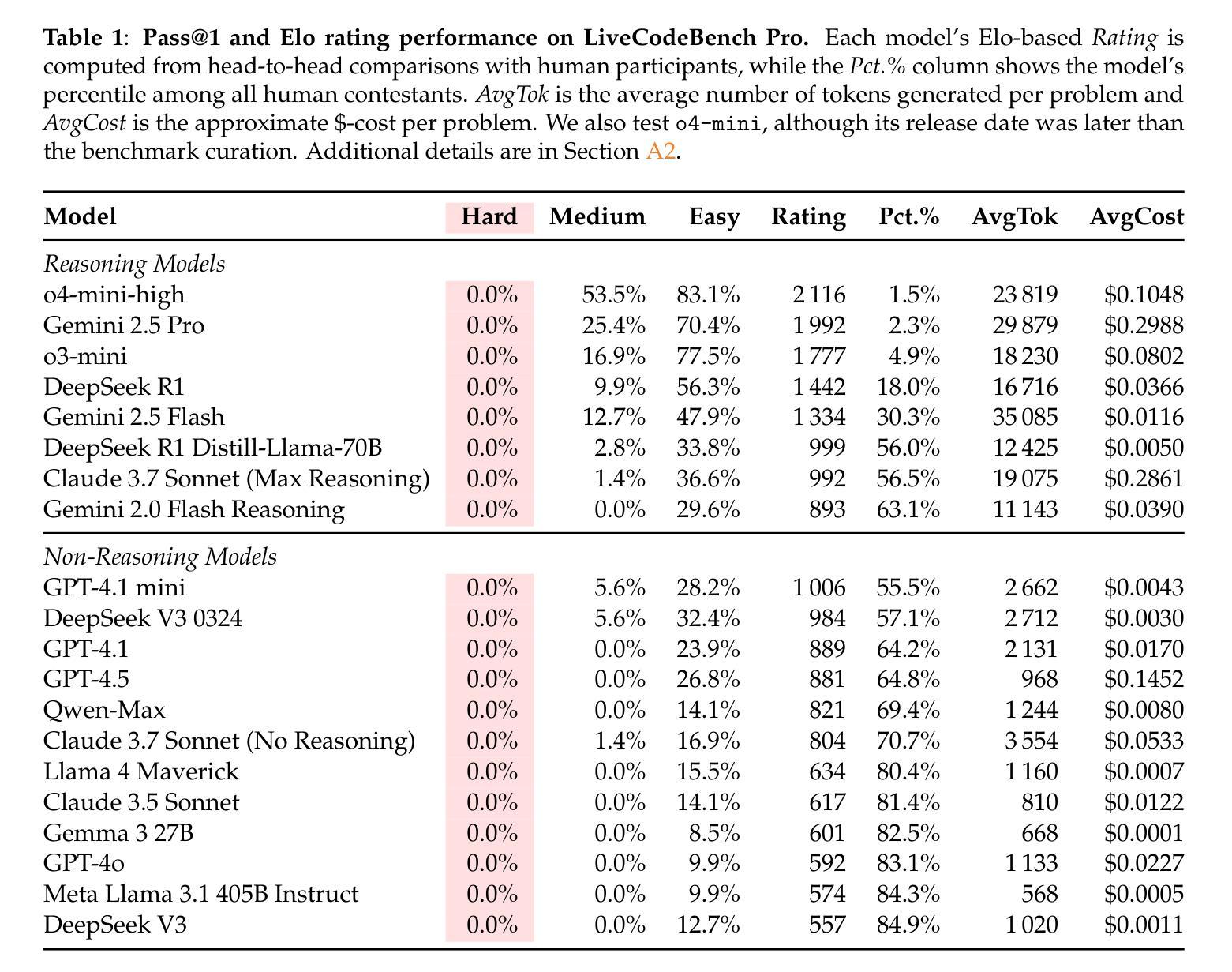
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Authors:Zihan Zheng, Zerui Cheng, Zeyu Shen, Shang Zhou, Kaiyuan Liu, Hansen He, Dongruixuan Li, Stanley Wei, Hangyi Hao, Jianzhu Yao, Peiyao Sheng, Zixuan Wang, Wenhao Chai, Aleksandra Korolova, Peter Henderson, Sanjeev Arora, Pramod Viswanath, Jingbo Shang, Saining Xie
Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming. Drawing on knowledge from a group of medalists in international algorithmic contests, we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. A team of Olympiad medalists annotates every problem for algorithmic categories and conducts a line-by-line analysis of failed model-generated submissions. Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel. We also find that LLMs succeed at implementation-heavy problems but struggle with nuanced algorithmic reasoning and complex case analysis, often generating confidently incorrect justifications. High performance appears largely driven by implementation precision and tool augmentation, not superior reasoning. LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning.
最近报告显示,大型语言模型(LLM)在编程竞赛中表现超过精英人类。我们借助国际算法竞赛获奖者的知识,重新审视这一说法,探讨LLM与人类专家之间的差异以及仍然存在的局限性。我们推出了LiveCodeBench Pro,这是一个由Codeforces、ICPC和IOI的问题组成的基准测试,持续更新以减少数据污染的可能性。一支奥林匹克奖牌得主团队为每一个问题进行算法类别注释,并对失败的模型提交进行逐行分析。通过使用这些新数据和基准测试,我们发现前沿模型仍然存在显著局限性:没有外部工具的情况下,最佳模型在中难度问题上只有53%的通过率,在难题上为零,这些都是专家人类仍然擅长的领域。我们还发现,LLM在需要大量实现的问题上取得成功,但在微妙的算法推理和复杂的案例分析上遇到困难,经常生成错误的理由。高性能似乎主要源于实现精度和工具辅助,而非出色的推理能力。因此,LiveCodeBench Pro凸显了与人类大师水平的巨大差距,同时为未来改进代码中心的LLM推理提供了精细的诊断。
论文及项目相关链接
PDF Project Page at https://livecodebenchpro.com/
Summary
大型语言模型(LLM)在竞争性编程中是否超越人类精英的争论持续不断。本文通过国际算法竞赛获奖者的观点,重新审视这一说法,并探讨LLM与人类专家的差异及存在的局限性。通过引入LiveCodeBench Pro这一基准测试平台,我们发现前沿模型仍存在显著缺陷:在不借助外部工具的情况下,最佳模型仅能在中等难度问题上达到53%的通过率,而在难度较大的问题上则无法突破。此外,LLM在注重实现的题目上表现良好,但在需要微妙算法推理和复杂案例分析方面却表现欠佳,有时会给出错误的解释。其高表现主要得益于实施精准性和工具辅助,而非卓越推理能力。LiveCodeBench Pro不仅突显了与人类顶尖水平的巨大差距,还为未来代码导向型LLM推理的改进提供了精细的诊断方向。
Key Takeaways
- 大型语言模型(LLM)在竞争性编程方面的表现受到关注,存在关于其是否超越人类精英的争论。
- 通过引入LiveCodeBench Pro基准测试平台,发现前沿模型在解决特定难度问题时存在局限性。
- LLM在注重实现的题目上表现良好,但在需要微妙算法推理和复杂案例分析方面存在困难。
- LLM的高表现主要得益于实施精准性和工具辅助,而非卓越推理能力。
- LiveCodeBench Pro为评估LLM与人类的差距提供了平台,并指出了未来改进的方向。
- 目前LLM仍无法完全替代人类专家,尤其在解决高难度问题时。
点此查看论文截图


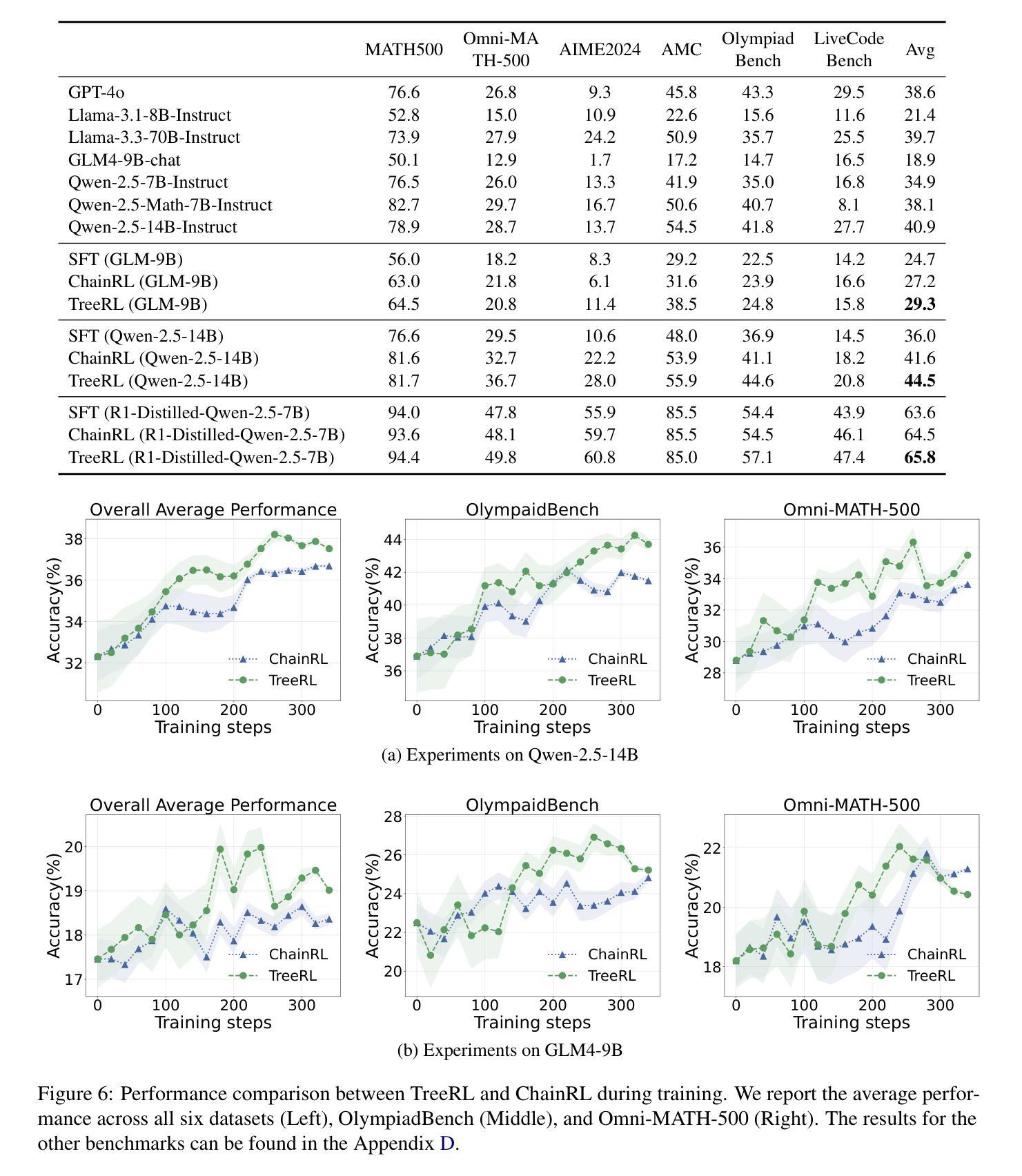
TreeRL: LLM Reinforcement Learning with On-Policy Tree Search
Authors:Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, Yuxiao Dong
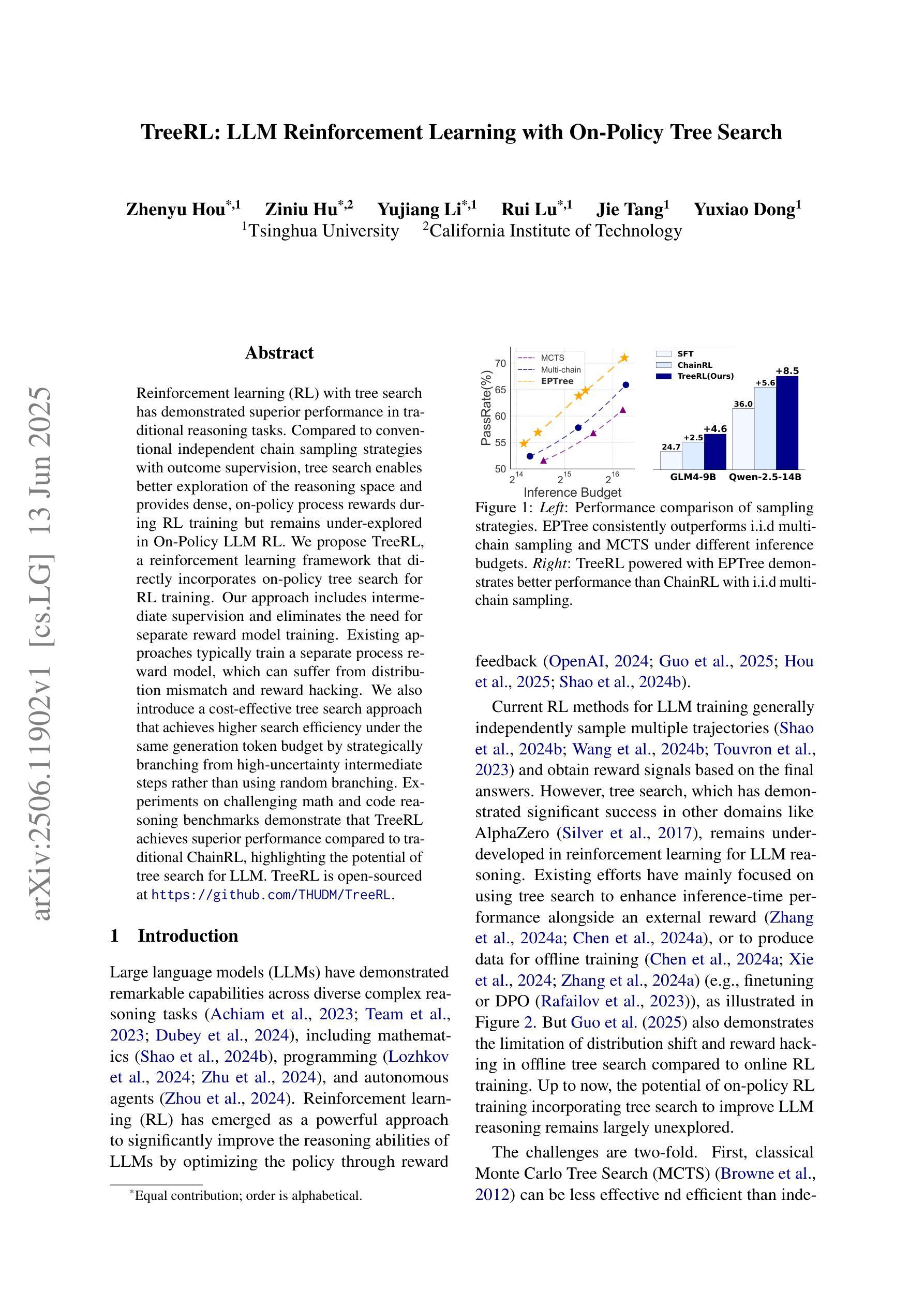
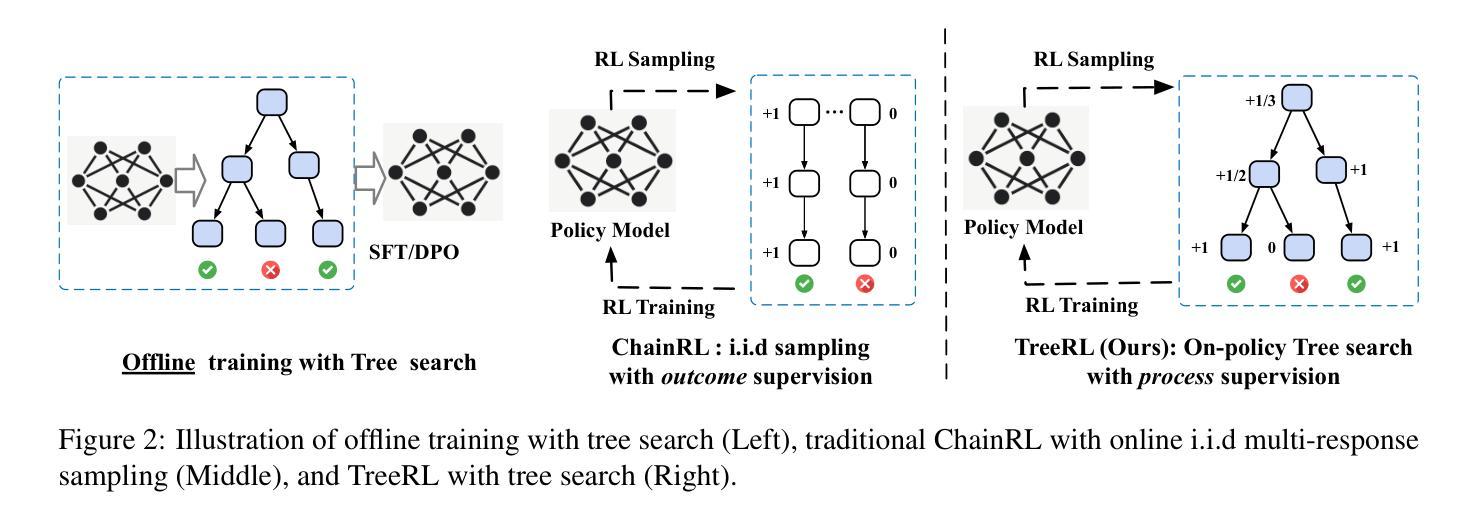
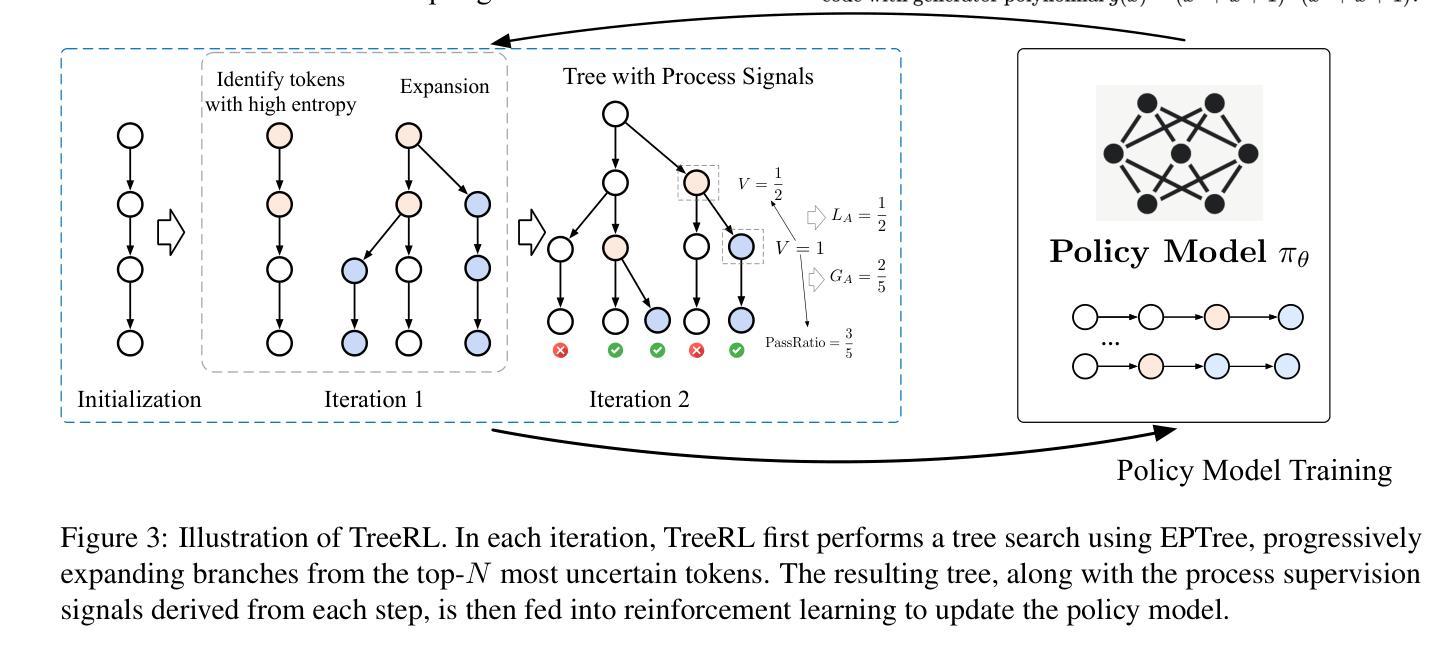
Reinforcement learning (RL) with tree search has demonstrated superior performance in traditional reasoning tasks. Compared to conventional independent chain sampling strategies with outcome supervision, tree search enables better exploration of the reasoning space and provides dense, on-policy process rewards during RL training but remains under-explored in On-Policy LLM RL. We propose TreeRL, a reinforcement learning framework that directly incorporates on-policy tree search for RL training. Our approach includes intermediate supervision and eliminates the need for a separate reward model training. Existing approaches typically train a separate process reward model, which can suffer from distribution mismatch and reward hacking. We also introduce a cost-effective tree search approach that achieves higher search efficiency under the same generation token budget by strategically branching from high-uncertainty intermediate steps rather than using random branching. Experiments on challenging math and code reasoning benchmarks demonstrate that TreeRL achieves superior performance compared to traditional ChainRL, highlighting the potential of tree search for LLM. TreeRL is open-sourced at https://github.com/THUDM/TreeRL.
强化学习(RL)结合树搜索在传统推理任务中表现出卓越的性能。与传统独立的链采样策略相比,树搜索能够更有效地探索推理空间,并在RL训练过程中提供密集的策略内过程奖励,但在基于策略的LLM RL中仍被较少探索。我们提出了TreeRL,这是一个强化学习框架,直接结合策略内树搜索用于RL训练。我们的方法包括中间监督,消除了对单独奖励模型训练的需要。现有方法通常训练一个单独的过程奖励模型,这可能会遭受分布不匹配和奖励作弊的问题。我们还引入了一种具有成本效益的树搜索方法,通过从高不确定性的中间步骤进行策略性分支,而不是使用随机分支,在相同的生成令牌预算下实现更高的搜索效率。在具有挑战性的数学和代码推理基准测试上的实验表明,TreeRL相较于传统的ChainRL实现了卓越的性能,突显了树搜索在LLM中的潜力。TreeRL已在https://github.com/THUDM/TreeRL上开源。
论文及项目相关链接
PDF Accepted to ACL 2025 main conference
Summary
树搜索强化学习(TreeRL)框架直接整合了在线策略树搜索,用于强化学习训练,表现出优越的性能。与传统独立的链采样策略相比,树搜索能够更有效地探索推理空间,并提供密集的在线策略过程奖励。TreeRL还包括中间监督,消除了对单独奖励模型训练的需要。此外,我们提出了一种具有成本效益的树搜索方法,通过从高不确定性的中间步骤进行战略分支,实现在相同的生成令牌预算下更高的搜索效率。在具有挑战性的数学和代码推理基准测试中,TreeRL相比传统的ChainRL实现了更好的性能。
Key Takeaways
- TreeRL结合了在线策略树搜索用于强化学习训练,提高了性能。
- 树搜索能够更有效地探索推理空间。
- TreeRL提供了密集的在线策略过程奖励。
- TreeRL包括中间监督,消除了对单独奖励模型训练的需求。
- 提出的树搜索方法具有成本效益,通过战略分支提高搜索效率。
- TreeRL在挑战性的数学和代码推理基准测试中表现优越。
点此查看论文截图
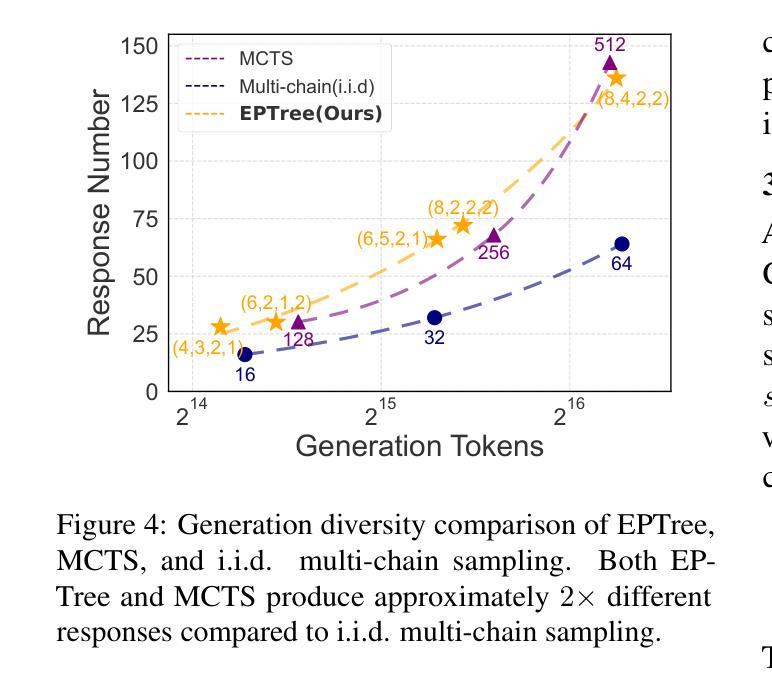
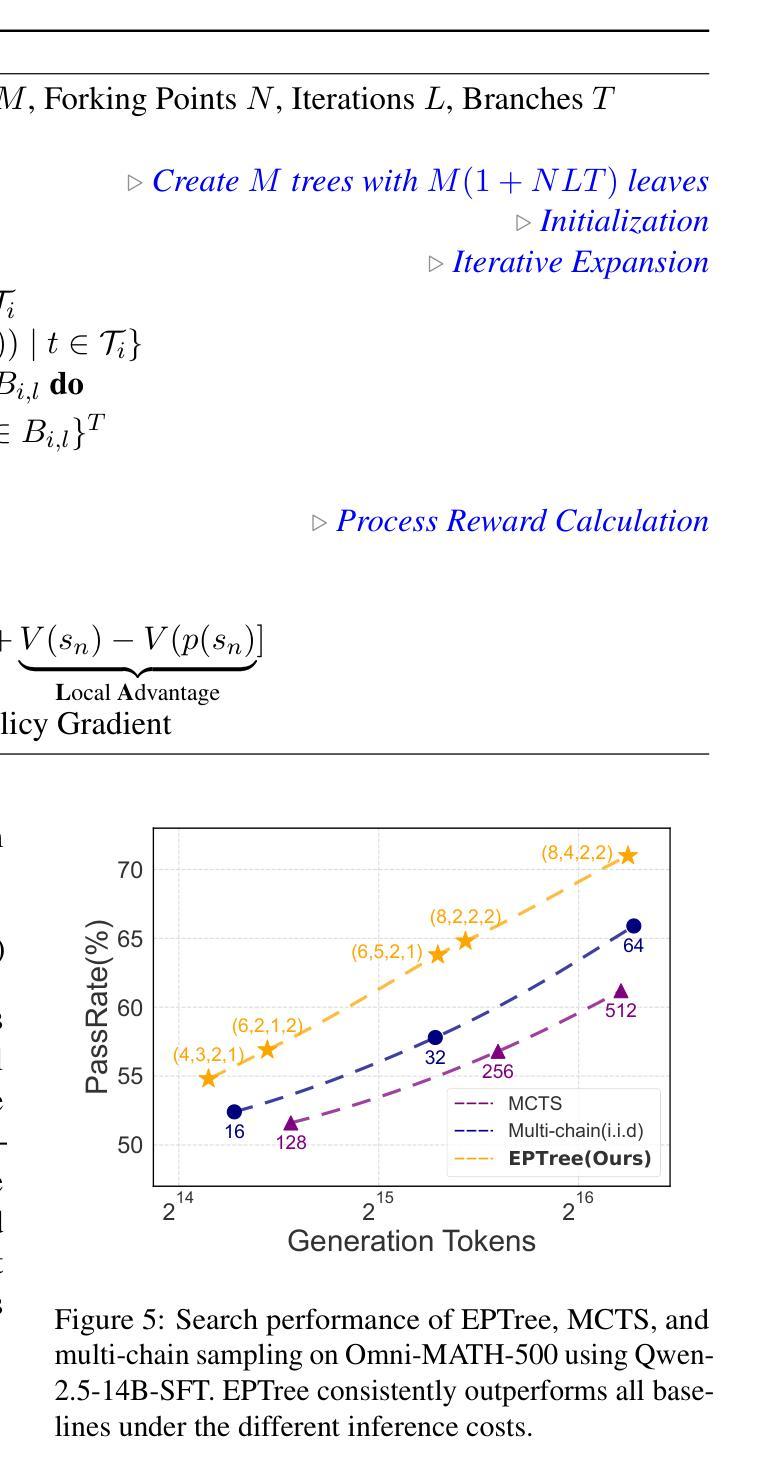
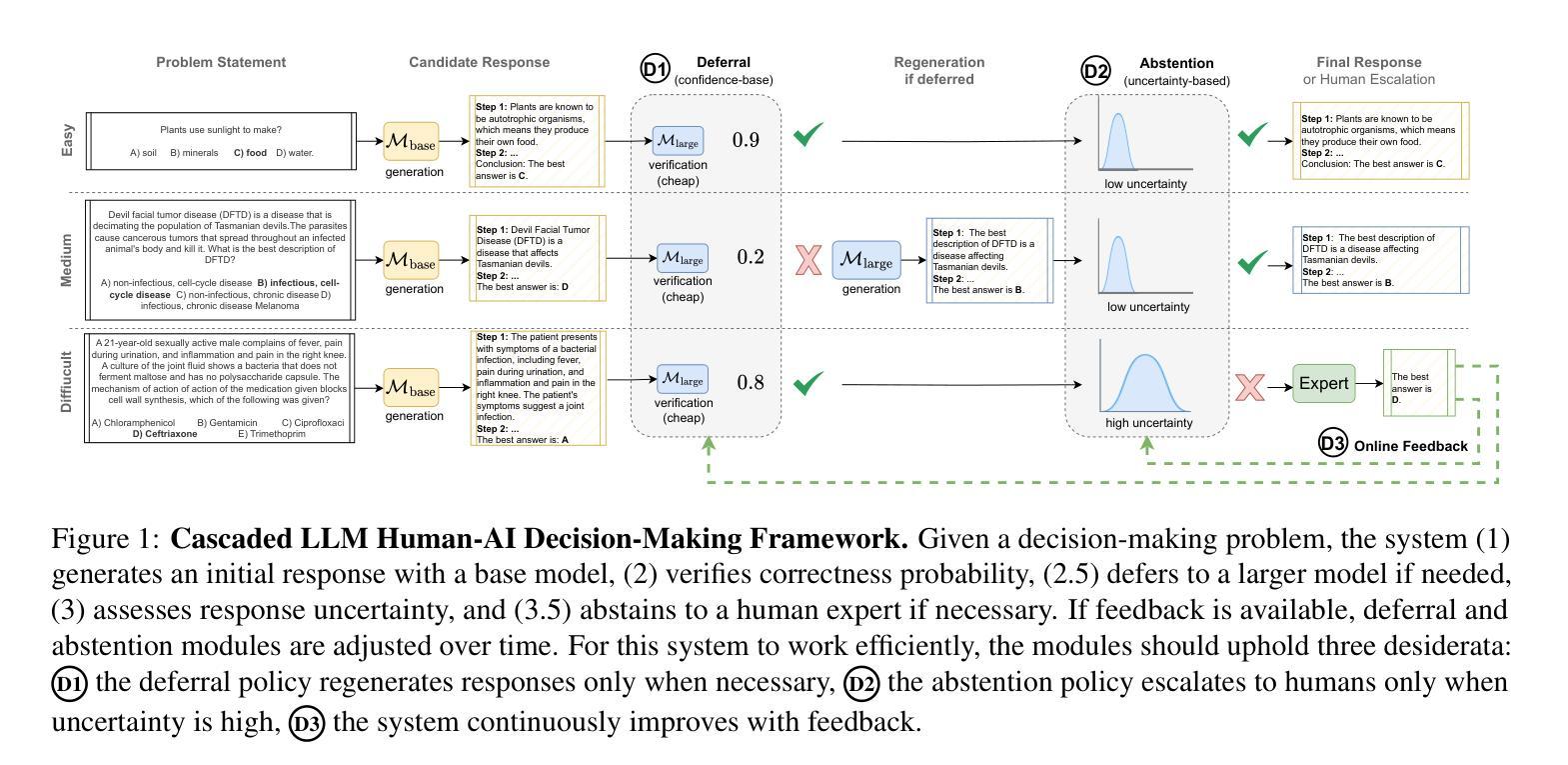
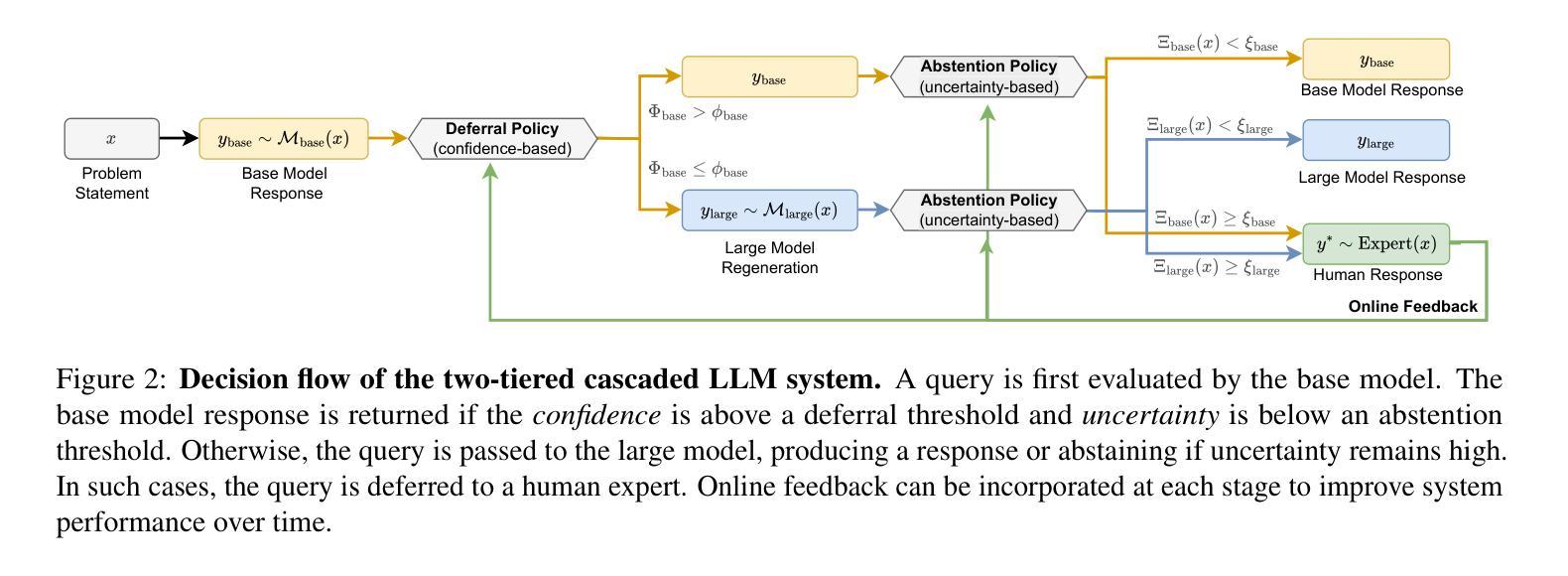
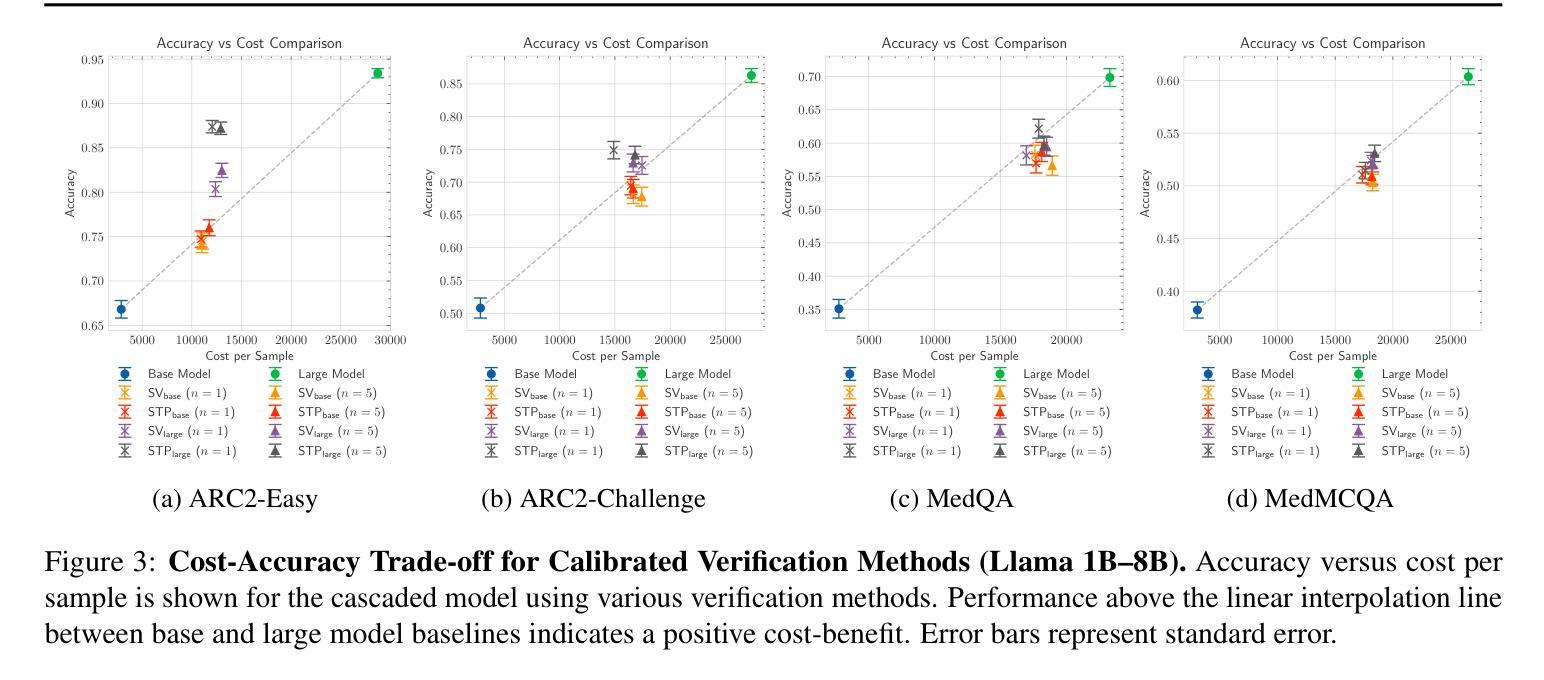
Towards a Cascaded LLM Framework for Cost-effective Human-AI Decision-Making
Authors:Claudio Fanconi, Mihaela van der Schaar
Effective human-AI decision-making balances three key factors: the \textit{correctness} of predictions, the \textit{cost} of knowledge and reasoning complexity, and the confidence about whether to \textit{abstain} automated answers or involve human experts. In this work, we present a cascaded LLM decision framework that adaptively delegates tasks across multiple tiers of expertise – a base model for initial candidate answers, a more capable and knowledgeable (but costlier) large model, and a human expert for when the model cascade abstains. Our method proceeds in two stages. First, a deferral policy determines whether to accept the base model’s answer or regenerate it with the large model based on the confidence score. Second, an abstention policy decides whether the cascade model response is sufficiently certain or requires human intervention. Moreover, we incorporate an online learning mechanism in the framework that can leverage human feedback to improve decision quality over time. We demonstrate this approach to general question-answering (ARC-Easy and ARC-Challenge) and medical question-answering (MedQA and MedMCQA). Our results show that our cascaded strategy outperforms in most cases single-model baselines in accuracy while reducing cost and providing a principled way to handle abstentions.
有效的人机决策平衡了三个关键因素:预测的“正确性”、知识的“成本”和推理的复杂性,以及对于是否放弃自动化答案或寻求人类专家参与的信心。在这项工作中,我们提出了一个级联的大型语言模型(LLM)决策框架,该框架能够自适应地在多个专业层级之间分配任务——一个用于初始候选答案的基础模型,一个能力更强、知识更丰富但成本更高的大型模型,以及在模型级联放弃时介入的人类专家。我们的方法分为两个阶段。首先,拒绝策略会决定是否接受基础模型的答案,或者基于信心分数使用大型模型重新生成答案。其次,弃权策略会决定级联模型响应是否足够确定,或者是否需要人类干预。此外,我们在框架中纳入了一种在线学习机制,可以利用人类反馈来随着时间的推移提高决策质量。我们在通用问答(ARC-Easy和ARC-Challenge)和医疗问答(MedQA和MedMCQA)中展示了这种方法。我们的结果表明,在大多数情况下,我们的级联策略在准确性方面优于单模型基准线,同时降低成本,并提供了一种有原则的处理弃权的方式。
论文及项目相关链接
Summary:本论文提出了一种级联LLM决策框架,该框架能够在不同专业层次上自适应地委派任务。框架包括初始答案的基础模型、能力更强但成本更高的大型模型,以及在模型级联拒绝答案时介入的人类专家。该框架通过拒绝策略和回避策略两个阶段进行决策,并在框架中融入了在线学习机制,可以利用人类反馈来提高决策质量。实验结果表明,级联策略在大多数情况下优于单模型基准线的准确性,同时降低成本,并提供了一种处理回避的规范化方法。
Key Takeaways:
- 论文提出了一个级联LLM决策框架,旨在实现人-AI协同决策。
- 框架包含基础模型、大型模型和人类专家三个层次,能够自适应委派任务。
- 通过拒绝策略和回避策略两个阶段进行决策。
- 框架融入了在线学习机制,可以利用人类反馈提高决策质量。
- 级联策略在大多数情况下优于单模型基准线的准确性。
- 级联策略能够降低成本。
点此查看论文截图


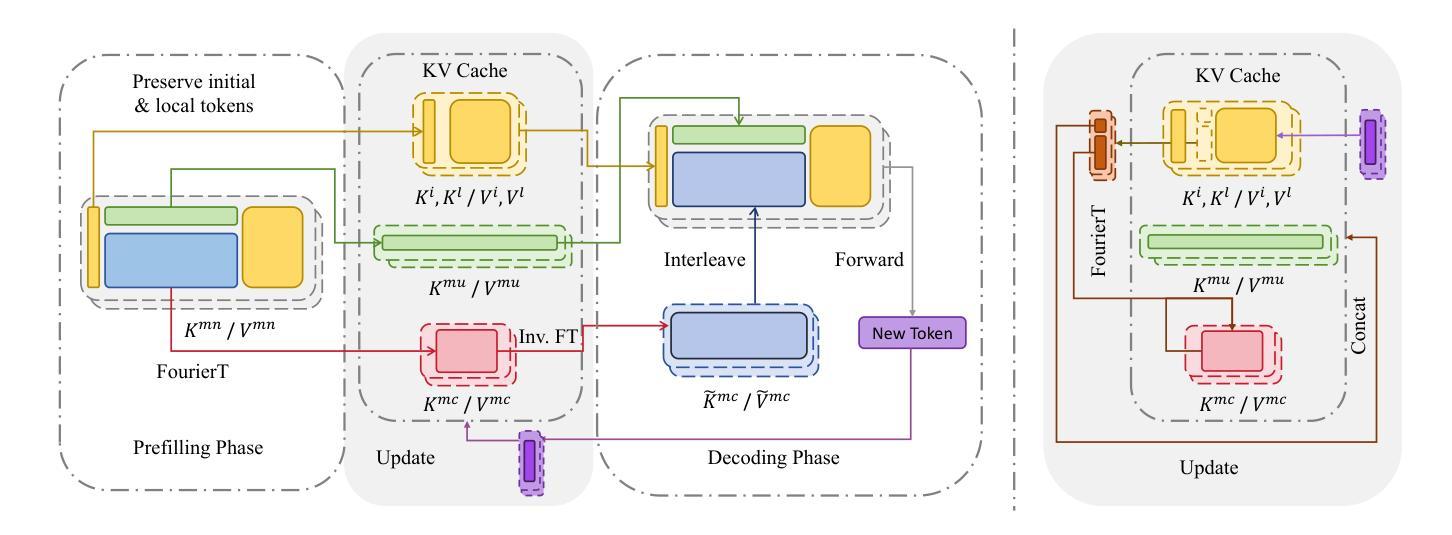
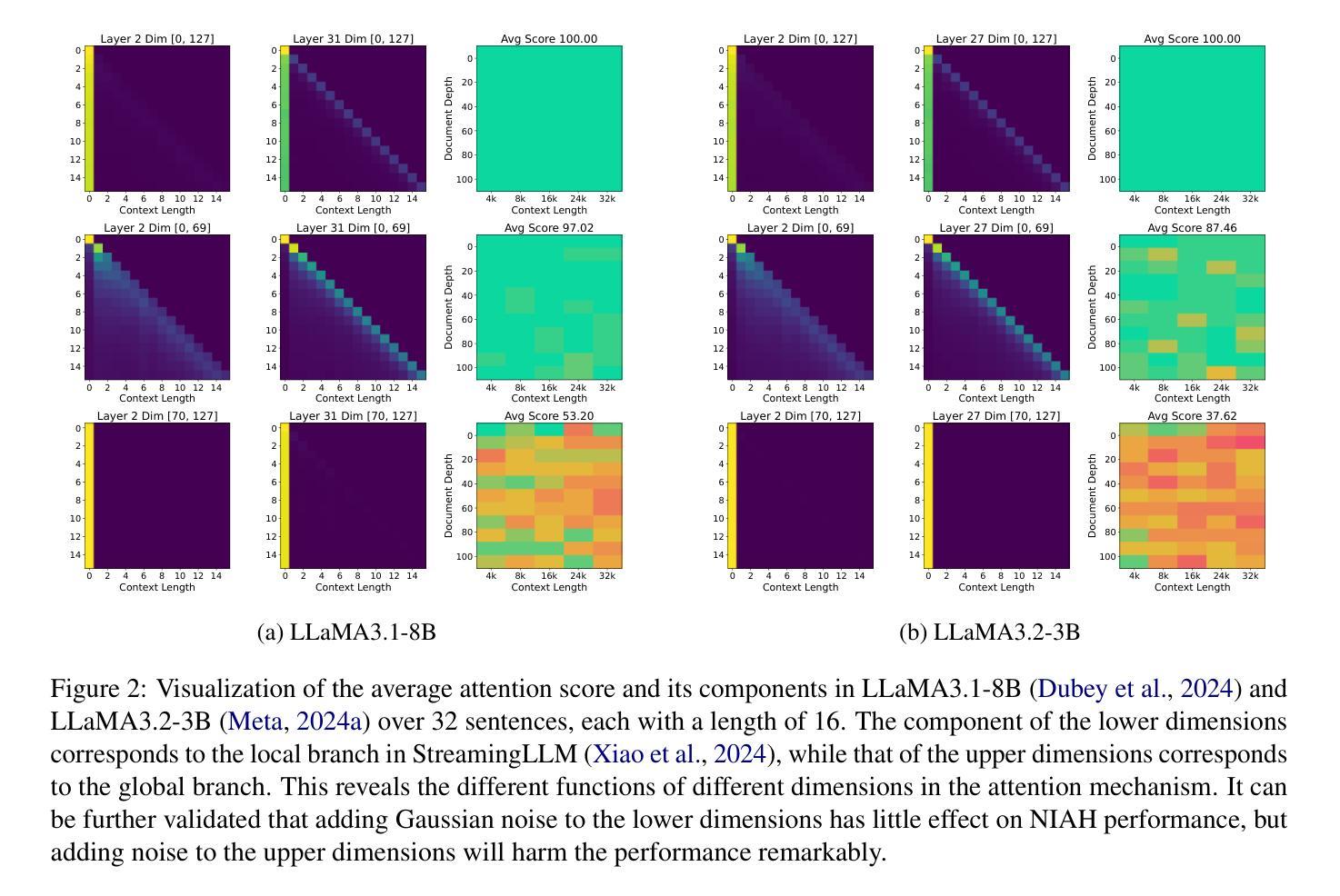
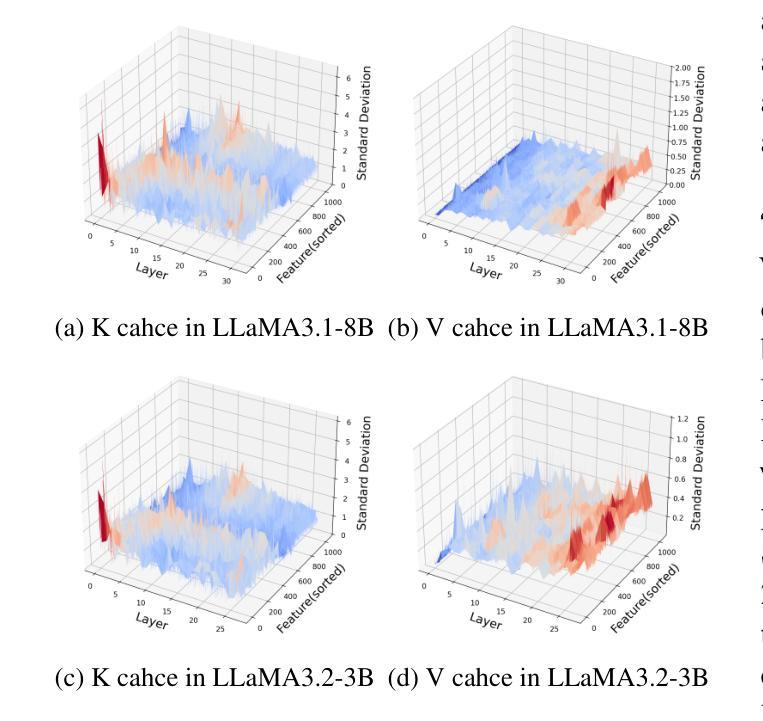
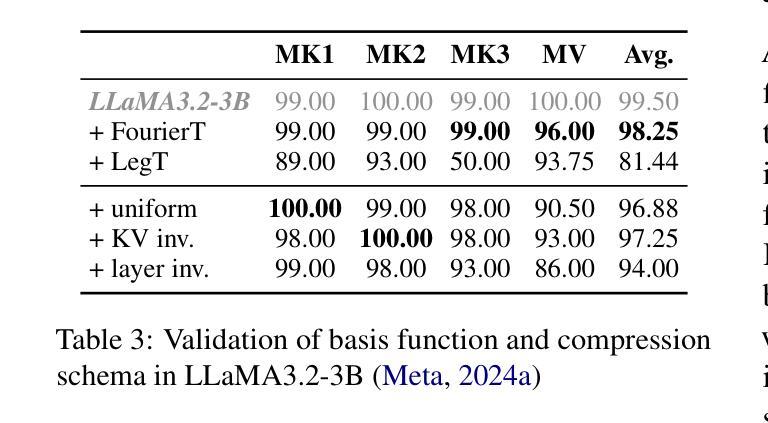
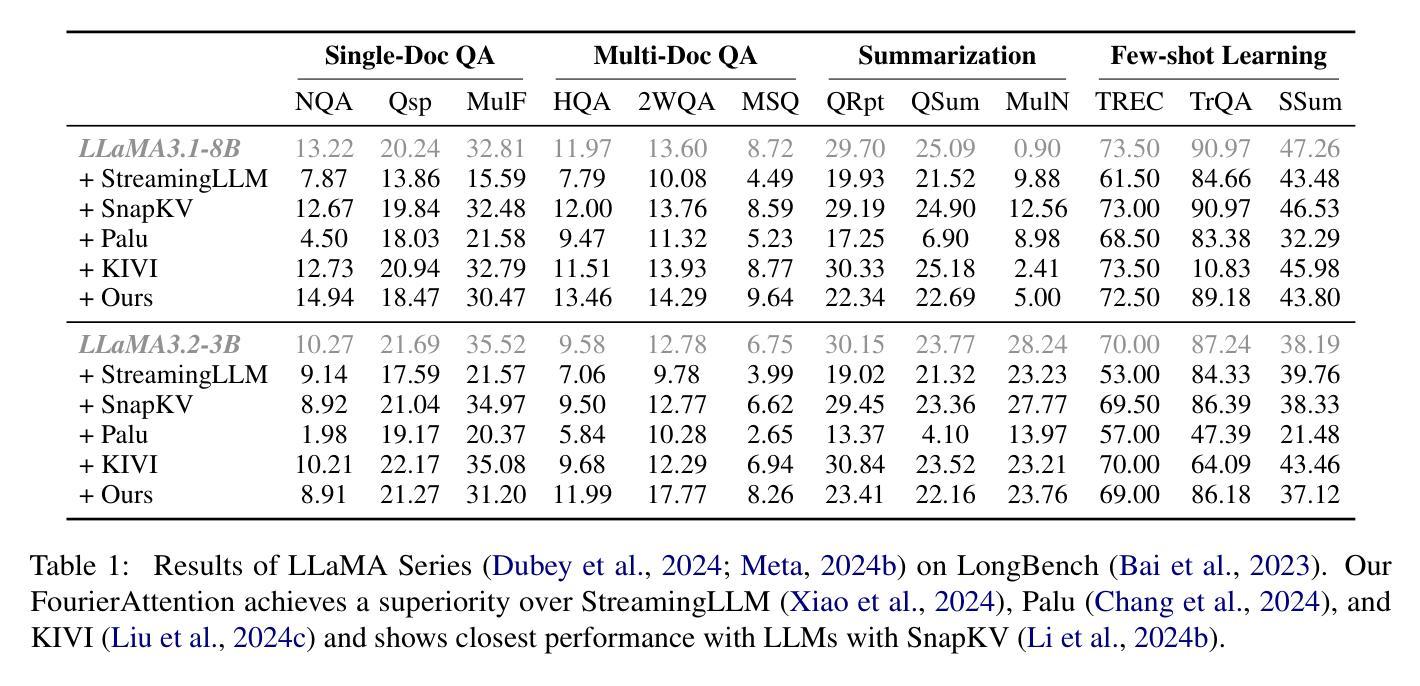
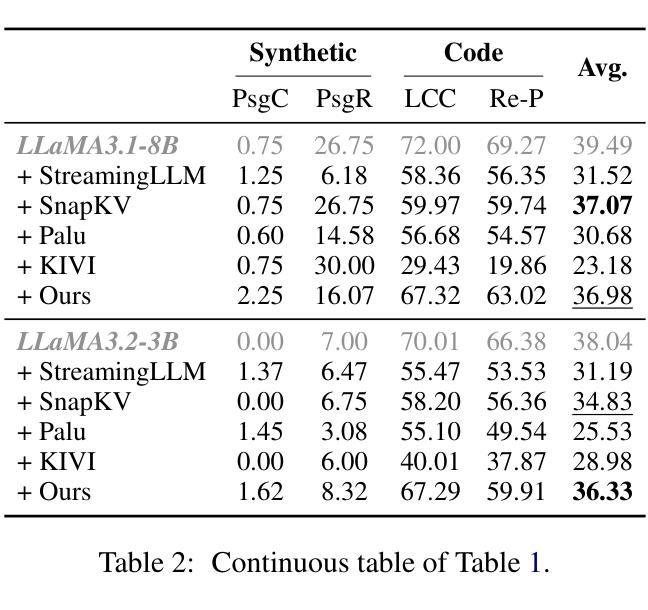
Beyond Homogeneous Attention: Memory-Efficient LLMs via Fourier-Approximated KV Cache
Authors:Xiaoran Liu, Siyang He, Qiqi Wang, Ruixiao Li, Yuerong Song, Zhigeng Liu, Linlin Li, Qun Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, Xipeng Qiu
Large Language Models struggle with memory demands from the growing Key-Value (KV) cache as context lengths increase. Existing compression methods homogenize head dimensions or rely on attention-guided token pruning, often sacrificing accuracy or introducing computational overhead. We propose FourierAttention, a training-free framework that exploits the heterogeneous roles of transformer head dimensions: lower dimensions prioritize local context, while upper ones capture long-range dependencies. By projecting the long-context-insensitive dimensions onto orthogonal Fourier bases, FourierAttention approximates their temporal evolution with fixed-length spectral coefficients. Evaluations on LLaMA models show that FourierAttention achieves the best long-context accuracy on LongBench and Needle-In-A-Haystack (NIAH). Besides, a custom Triton kernel, FlashFourierAttention, is designed to optimize memory via streamlined read-write operations, enabling efficient deployment without performance compromise.
随着上下文长度的增加,大型语言模型(LLM)面临来自不断增长的键值(KV)缓存的内存需求挑战。现有的压缩方法要么使头维度同质化,要么依赖于注意力引导令牌修剪,通常会牺牲准确性或引入计算开销。我们提出了FourierAttention,这是一个无需训练的框架,它利用变压器头维度的异构角色:较低的维度优先处理局部上下文,而较高的维度则捕捉远程依赖关系。通过将远程上下文无关维度投影到正交傅里叶基上,FourierAttention使用固定长度的谱系数来近似它们的时序演化。在LLaMA模型上的评估表明,FourierAttention在长上下文准确性方面达到了LongBench和Haystack中的尖针(NIAH)的最佳表现。此外,还设计了一个自定义的Triton内核FlashFourierAttention,通过简化的读写操作优化内存,以实现高效的部署而不影响性能。
论文及项目相关链接
PDF 10 pages, 7 figures, work in progress
Summary
大型语言模型在处理增长的关键值缓存时面临记忆需求问题,随着上下文长度的增加,现有压缩方法往往牺牲准确性或增加计算开销。本文提出一种名为FourierAttention的训练无关框架,该框架利用变换器头维度的不同角色:较低维度关注局部上下文,而较高维度捕捉长距离依赖关系。通过将长上下文不敏感维度映射到正交傅里叶基上,FourierAttention用固定长度的谱系数近似其时间演变。在LLaMA模型上的评估显示,FourierAttention在长基准测试(LongBench)和针在稻草堆中的寻找(Needle-In-A-Haystack,NIAH)任务上实现了最佳的长上下文准确性。此外,设计了一种自定义的Triton内核FlashFourierAttention,通过优化读写操作来节省内存,实现高效部署而不影响性能。
Key Takeaways
- 大型语言模型面临随着上下文长度增加而增加的记忆需求问题。
- 现有压缩方法可能在牺牲准确性或增加计算开销的情况下效果不佳。
- FourierAttention框架利用变换器头维度的不同角色,以应对长上下文处理。
- FourierAttention通过将长上下文不敏感维度映射到傅里叶基上,提高了长上下文准确性。
- 在LLaMA模型上的评估显示,FourierAttention在特定任务上实现了最佳性能。
- 设计了FlashFourierAttention,一种自定义的Triton内核,以优化内存使用并提高效率。
点此查看论文截图

Addressing Bias in LLMs: Strategies and Application to Fair AI-based Recruitment
Authors:Alejandro Peña, Julian Fierrez, Aythami Morales, Gonzalo Mancera, Miguel Lopez, Ruben Tolosana
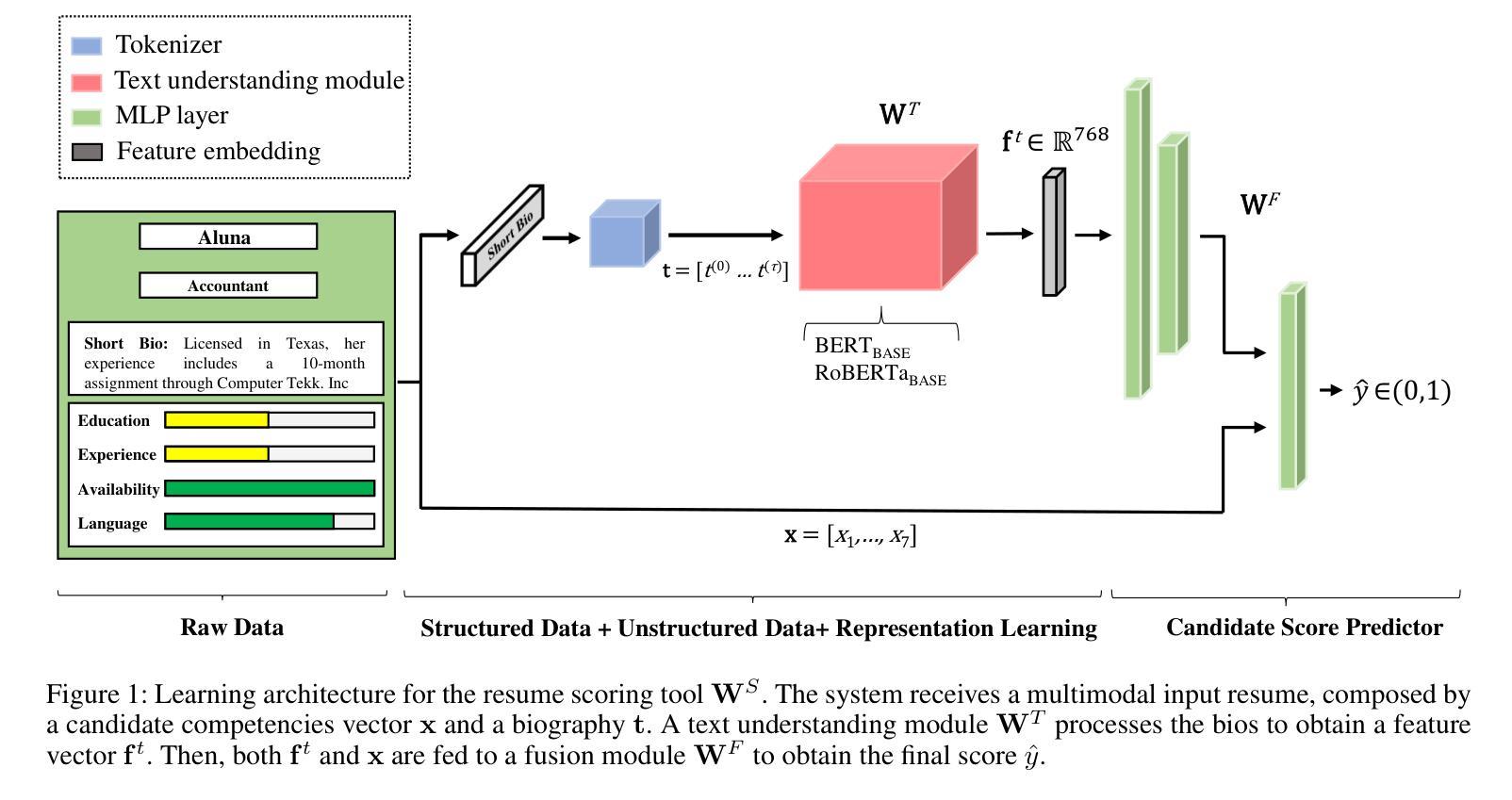
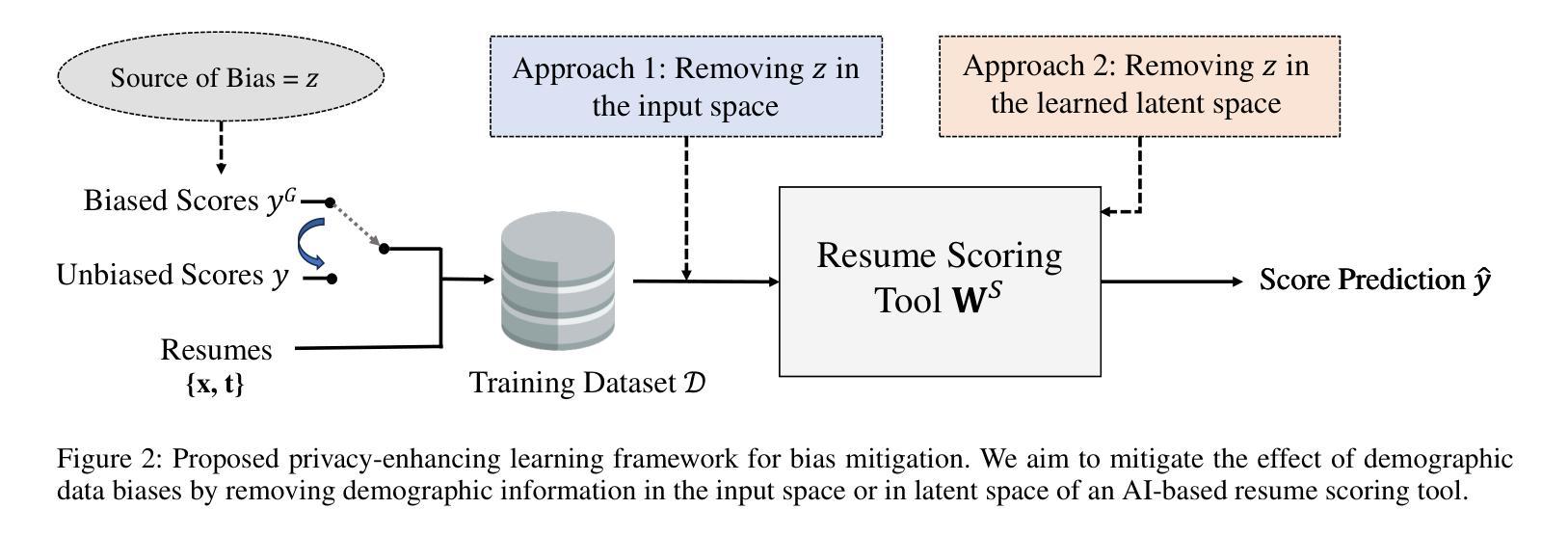
The use of language technologies in high-stake settings is increasing in recent years, mostly motivated by the success of Large Language Models (LLMs). However, despite the great performance of LLMs, they are are susceptible to ethical concerns, such as demographic biases, accountability, or privacy. This work seeks to analyze the capacity of Transformers-based systems to learn demographic biases present in the data, using a case study on AI-based automated recruitment. We propose a privacy-enhancing framework to reduce gender information from the learning pipeline as a way to mitigate biased behaviors in the final tools. Our experiments analyze the influence of data biases on systems built on two different LLMs, and how the proposed framework effectively prevents trained systems from reproducing the bias in the data.
近年来,在高风险环境中使用语言技术的趋势正在增加,这主要得益于大型语言模型(LLM)的成功。然而,尽管LLM的性能出色,但它们也面临着道德上的担忧,例如人口统计偏见、责任或隐私等问题。本研究旨在通过分析基于Transformer的系统学习数据中现有的人口统计偏见的能力,以人工智能自动化招聘的案例分析为例。我们提出了一个增强隐私的框架,以减少学习管道中的性别信息,作为减轻最终工具中偏见行为的一种方式。我们的实验分析了建立在两个不同LLM上的系统数据偏见的影响,以及所提出的框架如何有效地防止训练系统在数据中复制偏见。
论文及项目相关链接
PDF Submitted to AIES 2025 (Under Review)
Summary
随着大型语言模型(LLMs)的成功应用,语言技术在高风险场景的使用日益增加。然而,LLMs存在伦理问题,如人口统计偏见、问责制和隐私等。本研究旨在分析基于Transformer的系统学习数据中人口统计偏见的能力,以人工智能自动化招聘为例进行案例研究。为了减轻最终工具中的偏见行为,我们提出了一个增强隐私的框架,以减少学习管道中的性别信息。实验分析了建立在两种不同LLMs上的系统数据偏见的影响,以及该框架如何有效防止训练系统在数据中重复偏见。
Key Takeaways
- 语言技术在高风险场景的使用逐年增加,主要得益于大型语言模型(LLMs)的成功应用。
- LLMs存在伦理问题,如人口统计偏见、问责制和隐私等。
- 本研究通过人工智能自动化招聘的案例研究,探讨了基于Transformer的系统如何学习数据中的偏见。
- 为了减轻最终工具中的偏见行为,提出了一个增强隐私的框架,该框架可以减少学习过程中的性别信息。
- 实验表明,数据偏见会对基于不同LLMs的系统产生影响。
- 所提出的框架能够有效防止训练系统在数据中重复偏见。
点此查看论文截图

A Short Survey on Formalising Software Requirements using Large Language Models
Authors:Arshad Beg, Diarmuid O’Donoghue, Rosemary Monahan
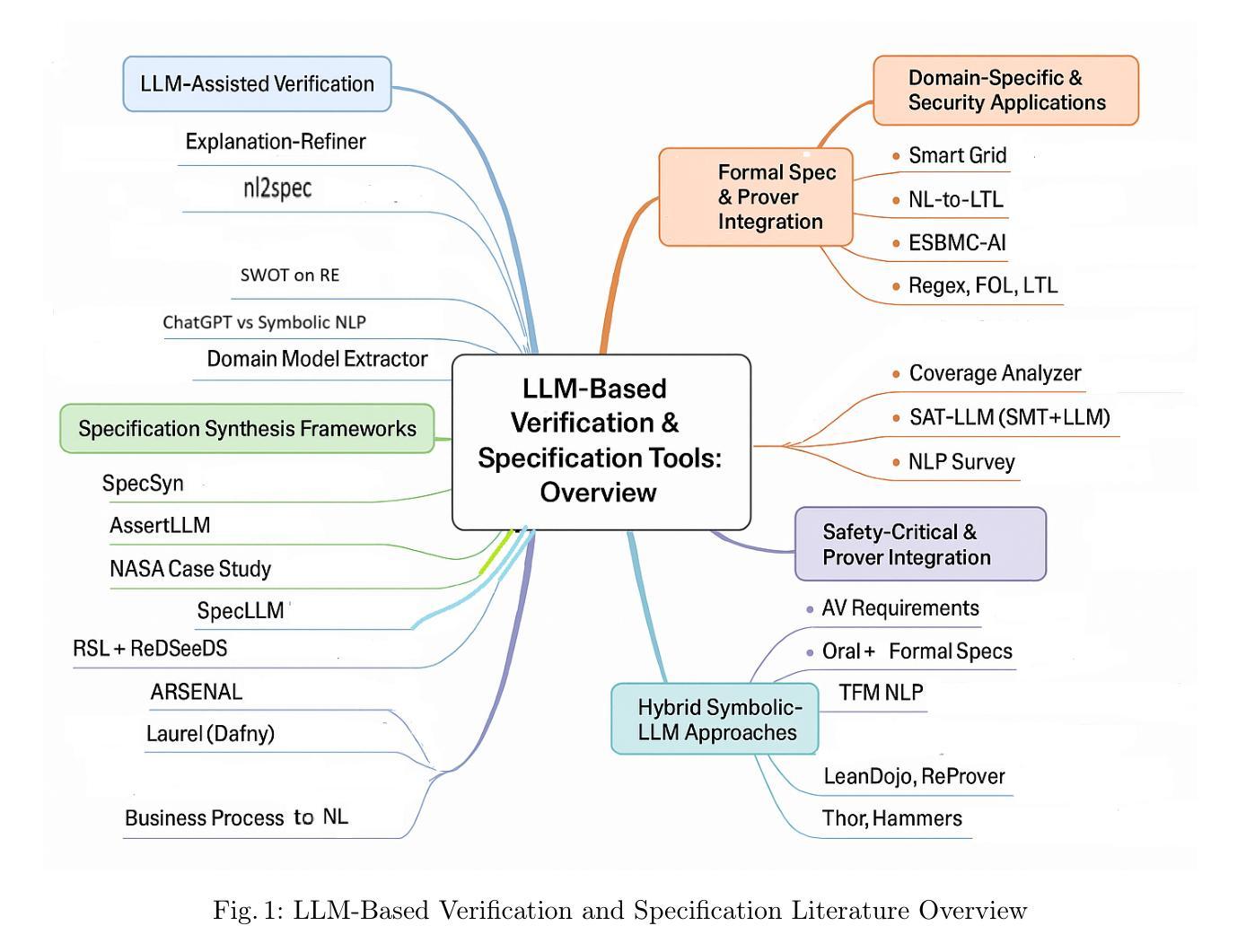
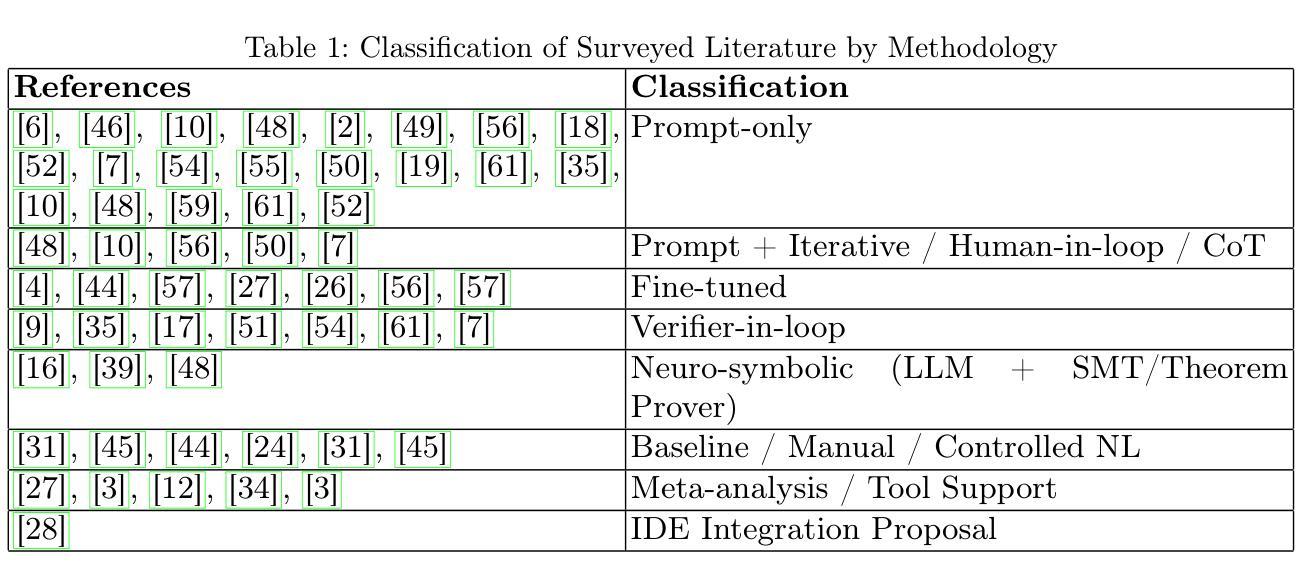
This paper presents a focused literature survey on the use of large language models (LLM) to assist in writing formal specifications for software. A summary of thirty-five key papers is presented, including examples for specifying programs written in Dafny, C and Java. This paper arose from the project VERIFAI - Traceability and verification of natural language requirements that addresses the challenges in writing formal specifications from requirements that are expressed in natural language. Our methodology employed multiple academic databases to identify relevant research. The AI-assisted tool Elicit facilitated the initial paper selection, which were manually screened for final selection. The survey provides valuable insights and future directions for utilising LLMs while formalising software requirements.
本文重点调查了大型语言模型(LLM)在辅助撰写软件正式规格方面的应用。本文列出了35篇重要论文的摘要,其中包括用Dafny、C和Java编写的程序的示例。本文源于VERIFAI项目——自然语言要求的需求追踪与验证,旨在解决从自然语言表述的要求中编写正式规格所面临的挑战。我们的方法利用多个学术数据库来确定相关研究。AI辅助工具Elicit有助于初步筛选论文,最终经过人工筛选确定入选论文。本次调查提供了有价值的见解和未来利用LLM进行软件要求形式化验证的方向。
论文及项目相关链接
PDF Submitted to SAIV 2025 as extended abstract and received valuable comments improving our draft. This version is the improved one after addressing suggestions from reviewers for improving the draft
Summary
LLM在软件形式化规范写作中的应用综述。文章汇总了35篇关键论文,涵盖用Dafny、C和Java编写的程序规范示例。该文章源于VERIFAI项目,解决自然语言要求下的形式化规范写作挑战。综述提供了利用AI辅助工具进行初始论文筛选的方法和有价值的见解及未来的方向。
Key Takeaways
- 该综述聚焦于研究LLM在协助编写软件形式化规范方面的应用。
- 文章汇总了关于该主题的研究论文,并提供了包括Dafny、C和Java在内的程序规范示例。
- VERIFAI项目旨在解决从自然语言要求编写形式化规范方面的挑战。
- 通过多种学术数据库确定相关研究成果并进行文献调研。
- 采用AI辅助工具Elicit进行初步论文筛选,再手动筛选最终论文。
点此查看论文截图

Post Persona Alignment for Multi-Session Dialogue Generation
Authors:Yi-Pei Chen, Noriki Nishida, Hideki Nakayama, Yuji Matsumoto
Multi-session persona-based dialogue generation presents challenges in maintaining long-term consistency and generating diverse, personalized responses. While large language models (LLMs) excel in single-session dialogues, they struggle to preserve persona fidelity and conversational coherence across extended interactions. Existing methods typically retrieve persona information before response generation, which can constrain diversity and result in generic outputs. We propose Post Persona Alignment (PPA), a novel two-stage framework that reverses this process. PPA first generates a general response based solely on dialogue context, then retrieves relevant persona memories using the response as a query, and finally refines the response to align with the speaker’s persona. This post-hoc alignment strategy promotes naturalness and diversity while preserving consistency and personalization. Experiments on multi-session LLM-generated dialogue data demonstrate that PPA significantly outperforms prior approaches in consistency, diversity, and persona relevance, offering a more flexible and effective paradigm for long-term personalized dialogue generation.
基于多会话人格的对话生成在保持长期一致性以及生成多样化和个性化的响应方面存在挑战。虽然大型语言模型(LLM)在单会话对话中表现优异,但在扩展交互中保持人格保真和对话连贯性方面却遇到困难。现有方法通常在生成响应之前检索人格信息,这可能会限制多样性并导致通用输出。我们提出一种名为“后人格对齐”(PPA)的新型两阶段框架,该框架反转了这一过程。PPA首先仅基于对话上下文生成一般响应,然后使用响应作为查询检索相关的人格记忆,最后对响应进行微调以与说话者的人格对齐。这种事后对齐策略既促进了自然性和多样性,又保持了连贯性和个性化。在多会话LLM生成的对话数据上的实验表明,在一致性、多样性和人格相关性方面,PPA显著优于先前的方法,为长期个性化对话生成提供了更灵活有效的范式。
论文及项目相关链接
Summary
多会话基于人物个性的对话生成在维持长期一致性、生成多样化和个性化响应方面存在挑战。大型语言模型(LLMs)在单会话对话中表现出色,但在跨扩展交互中难以保持人物一致性。现有方法通常在生成响应之前检索人物信息,这可能会限制多样性并导致通用输出。我们提出一种新的两步框架Post Persona Alignment (PPA),它通过生成基于对话上下文的一般响应,然后使用响应查询相关的个性记忆进行精细化对齐,从而在促进自然性和多样性的同时保持一致性和个性化。实验表明,在多会话LLM生成的对话数据中,PPA在一致性、多样性和个性相关性方面显著优于先前的方法,为长期个性化对话生成提供了更灵活有效的范式。
Key Takeaways
- 多会话基于人物个性的对话生成面临长期一致性、响应多样化和个性化方面的挑战。
- 大型语言模型(LLMs)在单会话对话中表现良好,但在跨扩展交互中难以保持人物一致性。
- 传统方法通常在生成响应前检索人物信息,限制了响应的多样性并可能导致通用输出。
- 提出的Post Persona Alignment (PPA)框架采用两步策略,首先基于对话上下文生成一般响应,然后检索相关的个性记忆进行精细化对齐。
- PPA策略在保持自然性和多样性的同时,能够保持一致性并促进个性化。
- 实验表明,PPA在一致性、多样性和个性相关性方面显著优于传统方法。
点此查看论文截图

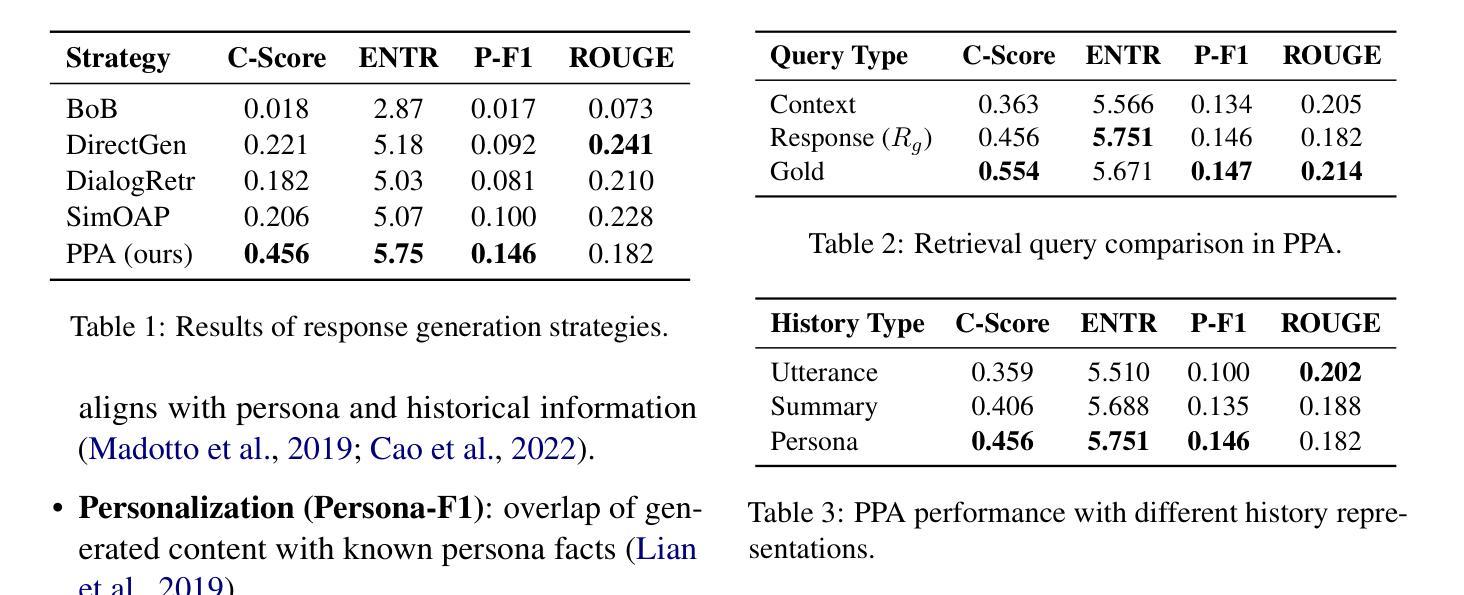
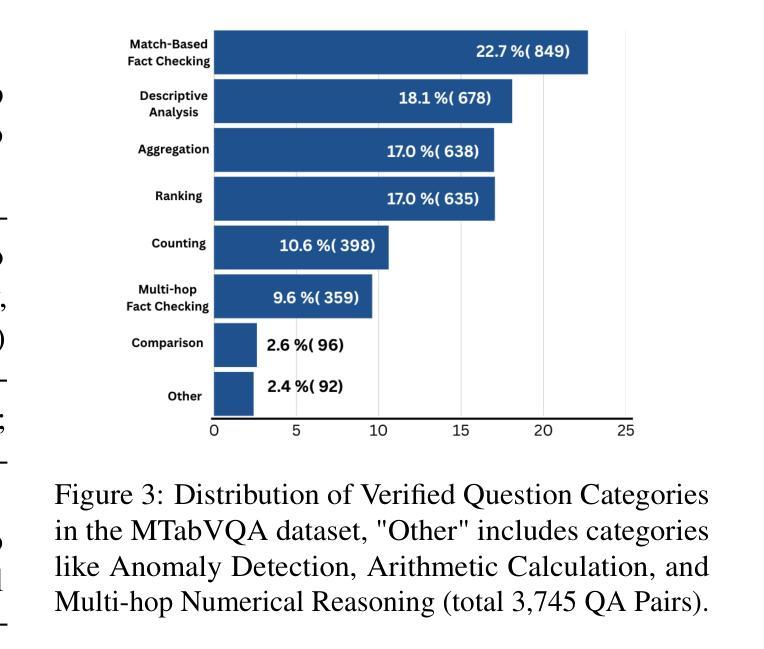
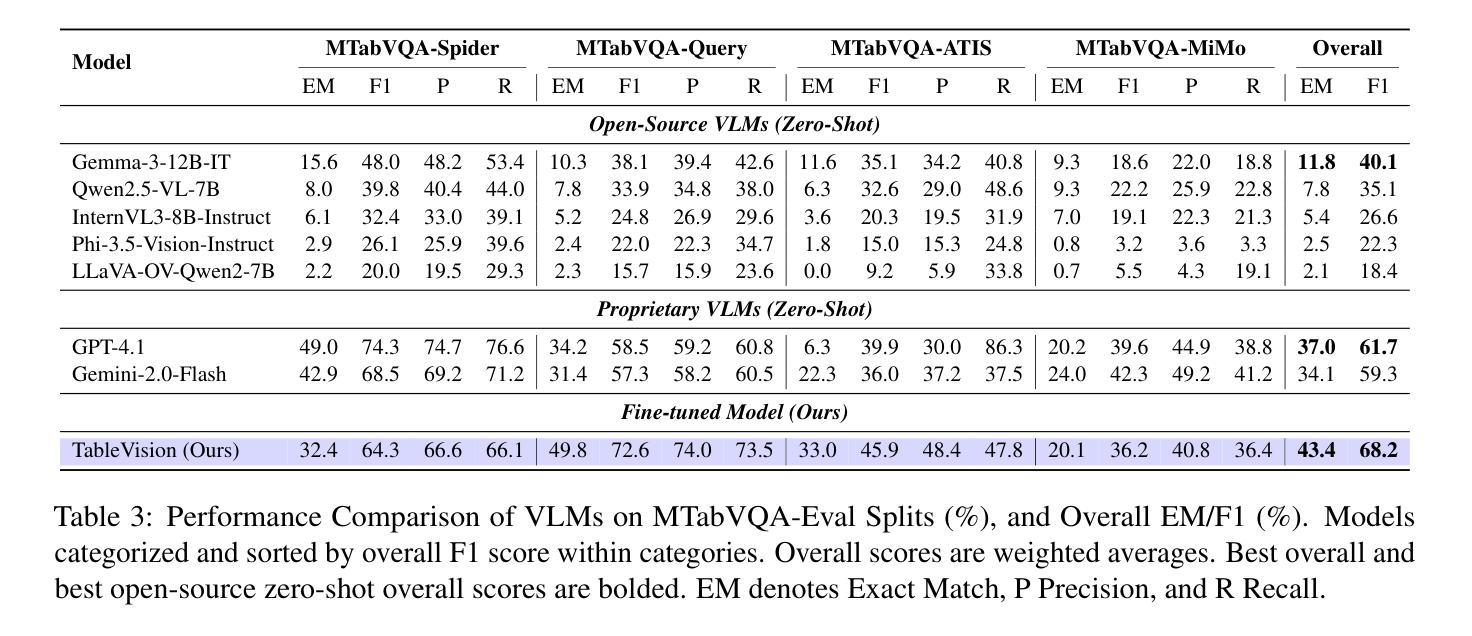
MTabVQA: Evaluating Multi-Tabular Reasoning of Language Models in Visual Space
Authors:Anshul Singh, Chris Biemann, Jan Strich
Vision-Language Models (VLMs) have demonstrated remarkable capabilities in interpreting visual layouts and text. However, a significant challenge remains in their ability to interpret robustly and reason over multi-tabular data presented as images, a common occurrence in real-world scenarios like web pages and digital documents. Existing benchmarks typically address single tables or non-visual data (text/structured). This leaves a critical gap: they don’t assess the ability to parse diverse table images, correlate information across them, and perform multi-hop reasoning on the combined visual data. We introduce MTabVQA, a novel benchmark specifically designed for multi-tabular visual question answering to bridge that gap. MTabVQA comprises 3,745 complex question-answer pairs that necessitate multi-hop reasoning across several visually rendered table images. We provide extensive benchmark results for state-of-the-art VLMs on MTabVQA, revealing significant performance limitations. We further investigate post-training techniques to enhance these reasoning abilities and release MTabVQA-Instruct, a large-scale instruction-tuning dataset. Our experiments show that fine-tuning VLMs with MTabVQA-Instruct substantially improves their performance on visual multi-tabular reasoning. Code and dataset (https://huggingface.co/datasets/mtabvqa/MTabVQA-Eval) are available online (https://anonymous.4open.science/r/MTabVQA-EMNLP-B16E).
视觉语言模型(VLMs)在解读视觉布局和文本方面表现出了卓越的能力。然而,在面对以图像形式呈现的多表格数据时,它们仍然面临着稳健解读和推理的重大挑战,这在网页和数字文档等现实场景中是很常见的现象。现有的基准测试通常针对单个表格或非视觉数据(文本/结构化数据),这留下了一个关键的空白:它们无法评估解析多种表格图像、跨图像关联信息以及对组合视觉数据进行多跳推理的能力。我们推出了MTabVQA,这是一个专门为多表格视觉问答设计的全新基准测试,旨在填补这一空白。MTabVQA包含3745个复杂的问题答案对,这些问题答案对需要在多个视觉呈现的表格图像之间进行多跳推理。我们为最先进的VLMs在MTabVQA上的基准测试结果提供了详尽的结果,揭示了其性能上的重大局限性。我们还进一步研究了用于增强这些推理能力的后训练技术,并发布了MTabVQA-Instruct大规模指令微调数据集。我们的实验表明,使用MTabVQA-Instruct微调VLMs可以显著提高其在视觉多表格推理方面的性能。代码和数据集可通过以下链接获取:https://huggingface.co/datasets/mtabvqa/MTabVQA-Eval 和 https://anonymous.4open.science/r/MTabVQA-EMNLP-B16E。
论文及项目相关链接
Summary
该文本介绍了视觉语言模型(VLMs)在处理视觉布局和文本时的出色表现,但在解析多表格图像数据并进行多跳推理方面存在挑战。为此,作者引入了MTabVQA基准测试,该基准测试专门用于多表格视觉问答,填补了现有基准测试的空白。MTabVQA包含3745个复杂的问题答案对,这些问题需要在多个视觉呈现表格图像之间进行多跳推理。作者对最新VLMs在MTabVQA上的表现进行了全面评估,并发现其性能存在显著局限性。作者还探讨了增强这些推理能力的后训练技术,并发布了大规模的指令调整数据集MTabVQA-Instruct。实验表明,使用MTabVQA-Instruct微调VLMs可显著提高其在视觉多表格推理方面的性能。
Key Takeaways
- VLMs在处理视觉布局和文本方面表现出色,但在解析多表格图像数据和进行多跳推理方面存在挑战。
- 现有基准测试主要关注单表或非视觉数据,无法评估对多样表格图像的解析能力、跨表格的信息关联以及多跳视觉数据推理。
- 引入MTabVQA基准测试,专门用于多表格视觉问答,包含复杂的问题答案对,需要跨多个视觉表格进行多跳推理。
- 最新VLMs在MTabVQA上的性能存在局限性。
- 探讨了增强VLMs在多表格视觉推理方面的性能的后训练技术。
- 发布了大规模的指令调整数据集MTabVQA-Instruct,用于微调VLMs。
- 使用MTabVQA-Instruct微调的VLMs在视觉多表格推理方面的性能得到了显著提高。
点此查看论文截图

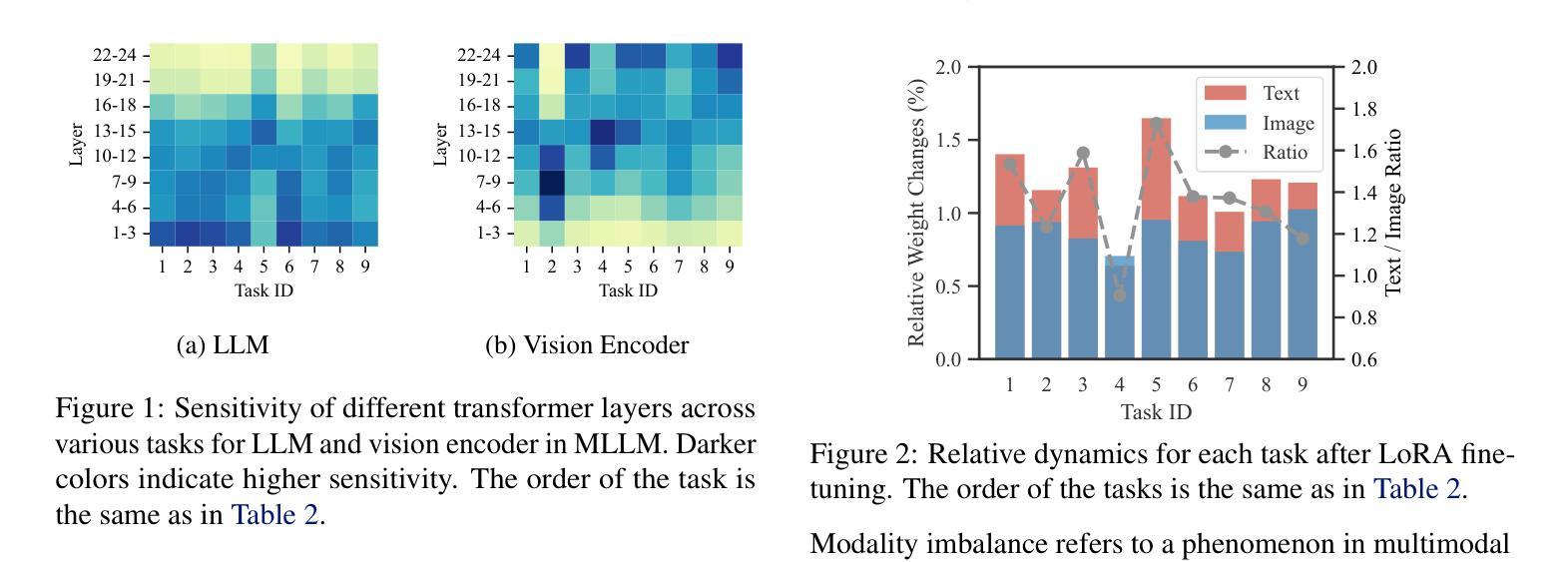
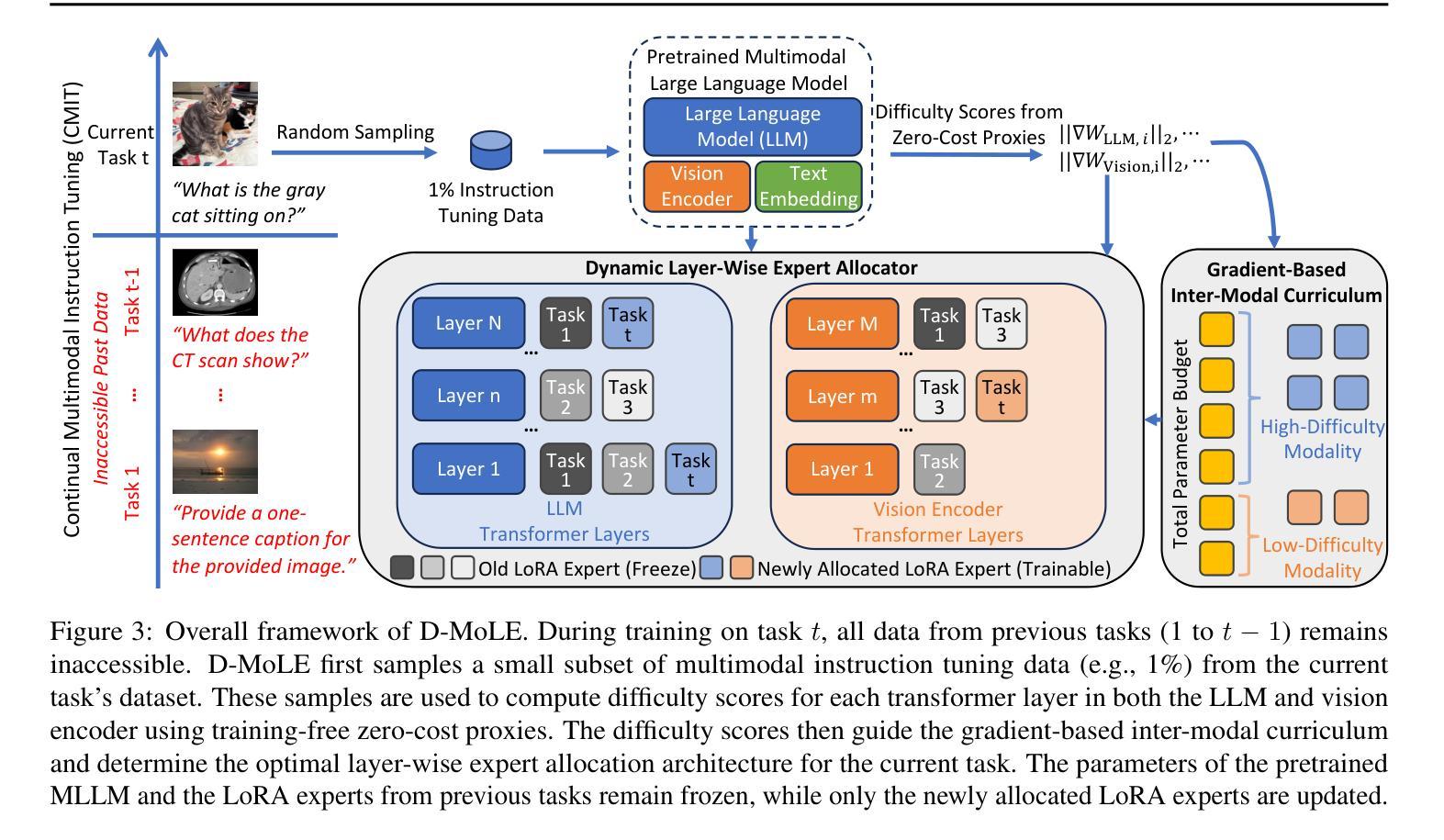
Dynamic Mixture of Curriculum LoRA Experts for Continual Multimodal Instruction Tuning
Authors:Chendi Ge, Xin Wang, Zeyang Zhang, Hong Chen, Jiapei Fan, Longtao Huang, Hui Xue, Wenwu Zhu
Continual multimodal instruction tuning is crucial for adapting Multimodal Large Language Models (MLLMs) to evolving tasks. However, most existing methods adopt a fixed architecture, struggling with adapting to new tasks due to static model capacity. We propose to evolve the architecture under parameter budgets for dynamic task adaptation, which remains unexplored and imposes two challenges: 1) task architecture conflict, where different tasks require varying layer-wise adaptations, and 2) modality imbalance, where different tasks rely unevenly on modalities, leading to unbalanced updates. To address these challenges, we propose a novel Dynamic Mixture of Curriculum LoRA Experts (D-MoLE) method, which automatically evolves MLLM’s architecture with controlled parameter budgets to continually adapt to new tasks while retaining previously learned knowledge. Specifically, we propose a dynamic layer-wise expert allocator, which automatically allocates LoRA experts across layers to resolve architecture conflicts, and routes instructions layer-wisely to facilitate knowledge sharing among experts. Then, we propose a gradient-based inter-modal continual curriculum, which adjusts the update ratio of each module in MLLM based on the difficulty of each modality within the task to alleviate the modality imbalance problem. Extensive experiments show that D-MoLE significantly outperforms state-of-the-art baselines, achieving a 15% average improvement over the best baseline. To the best of our knowledge, this is the first study of continual learning for MLLMs from an architectural perspective.
持续多模式指令调整对于适应不断演变任务的多模态大型语言模型(MLLMs)至关重要。然而,大多数现有方法采用固定架构,由于静态模型容量而无法适应新任务。我们建议在参数预算下发展动态任务适应的架构,这一领域尚未被探索并带来了两个挑战:1)任务架构冲突,不同的任务需要不同的分层适应;2)模态不平衡,不同的任务对模态的依赖程度不同,导致更新不均衡。为了应对这些挑战,我们提出了一种新颖的动态课程LoRA专家混合(D-MoLE)方法,该方法能够控制参数预算自动进化MLLM架构,不断适应新任务并保留先前学到的知识。具体来说,我们提出了一种动态分层专家分配器,它会自动在层之间分配LoRA专家以解决架构冲突,并有针对性地路由指令以促进专家之间的知识共享。然后,我们提出了基于梯度的跨模态连续课程学习,根据任务内各模态的难度调整MLLM中每个模块的更新比例,以缓解模态不平衡问题。大量实验表明,D-MoLE显著优于最新基线方法,平均提高了约15%。据我们所知,这是首次从架构角度研究MLLM的持续学习问题。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
多模态大型语言模型(MLLMs)的持续多任务调整很重要。现有方法大多采用固定架构,难以适应新任务。我们提议在参数预算下进化架构以适应动态任务,面临两大挑战:任务架构冲突和模态不平衡。为解决这些问题,我们提出了动态混合课程LoRA专家(D-MoLE)方法,可自动调整MLLM架构以持续适应新任务并保留先前知识。通过动态层级专家分配器和基于梯度的跨模态持续课程来解决这些问题。实验显示,D-MoLE显著优于现有基线,平均提升达15%。这是首个从架构角度研究MLLM的连续学习研究。
Key Takeaways
- 多模态大型语言模型(MLLMs)需要持续多任务调整以适应不断变化的场景。
- 现有方法大多采用固定架构,难以适应新任务需求的变化。
- 动态调整架构面临两大挑战:任务架构冲突和模态不平衡。
- 提出了一种新的方法D-MoLE,可以自动调整MLLM的架构以适应动态任务。
- D-MoLE通过动态层级专家分配器解决架构冲突,并通过基于梯度的跨模态持续课程解决模态不平衡问题。
- 实验结果显示,D-MoLE显著优于现有基线方法,平均提升效果达到15%。
点此查看论文截图

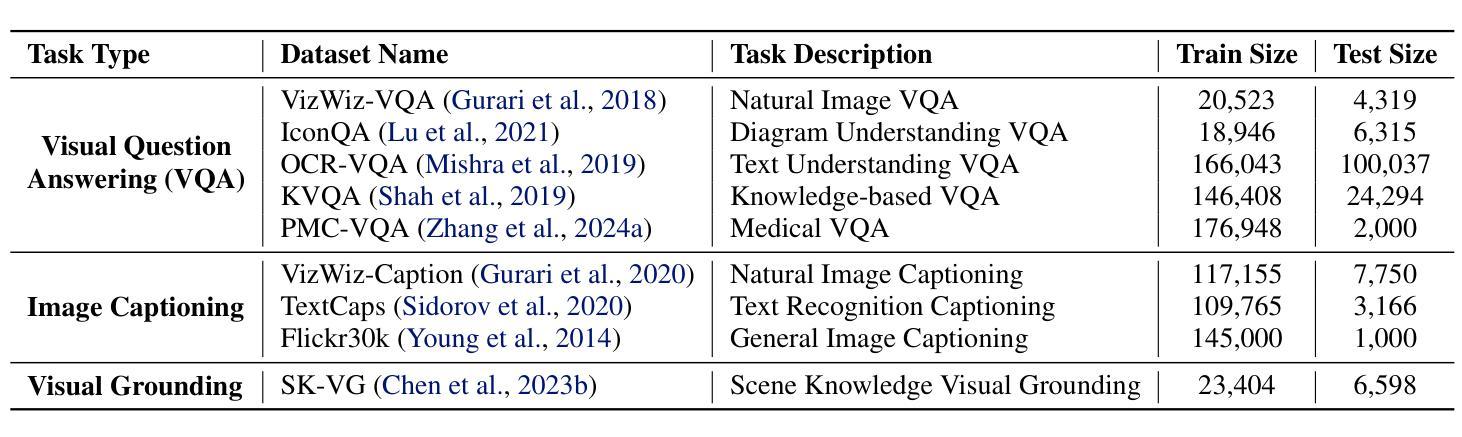
Gondola: Grounded Vision Language Planning for Generalizable Robotic Manipulation
Authors:Shizhe Chen, Ricardo Garcia, Paul Pacaud, Cordelia Schmid
Robotic manipulation faces a significant challenge in generalizing across unseen objects, environments and tasks specified by diverse language instructions. To improve generalization capabilities, recent research has incorporated large language models (LLMs) for planning and action execution. While promising, these methods often fall short in generating grounded plans in visual environments. Although efforts have been made to perform visual instructional tuning on LLMs for robotic manipulation, existing methods are typically constrained by single-view image input and struggle with precise object grounding. In this work, we introduce Gondola, a novel grounded vision-language planning model based on LLMs for generalizable robotic manipulation. Gondola takes multi-view images and history plans to produce the next action plan with interleaved texts and segmentation masks of target objects and locations. To support the training of Gondola, we construct three types of datasets using the RLBench simulator, namely robot grounded planning, multi-view referring expression and pseudo long-horizon task datasets. Gondola outperforms the state-of-the-art LLM-based method across all four generalization levels of the GemBench dataset, including novel placements, rigid objects, articulated objects and long-horizon tasks.
机器人操作面临在未见过的物体、环境和通过多样化语言指令所指定的任务中进行泛化的重大挑战。为了提高泛化能力,最近的研究已将大型语言模型(LLM)纳入规划和行动执行中。虽然这些方法前景广阔,但在视觉环境中生成基于实际情境的计划时往往有所不足。尽管人们已经努力在LLM上对机器人操作进行视觉指令调整,但现有方法通常受到单一视图图像输入的制约,并且在精确对象接地方面遇到了困难。在这项工作中,我们介绍了基于LLM的通用机器人操作的新型基于实际情境的视觉语言规划模型Gondola。Gondola采用多视图图像和历史计划来生成下一个带有目标对象和位置的文本和分割掩码的交互计划。为了支持Gondola的训练,我们使用RLBench模拟器构建了三种类型的数据集,即机器人接地规划、多视图引用表达式和伪长期任务数据集。Gondola在GemBench数据集的所有四个泛化层次上均优于最新的基于LLM的方法,包括新型放置、刚体、关节式物体和长期任务。
论文及项目相关链接
Summary
机器人操作面临在未知物体、环境和任务中泛化能力的问题,最近的研究结合了大型语言模型(LLM)进行规划和行动执行。尽管有前景,但这些方法往往难以在视觉环境中生成基于情境的计划。尽管已有对LLM进行视觉指令调整的努力,但现有方法通常受限于单视图图像输入,并且在精确对象接地方面遇到困难。本研究介绍了基于LLM的通用机器人操作的新型基于视觉的语言规划模型Gondola。Gondola采用多视图图像和历史计划来生成带有目标对象和位置文本描述和分割掩码的下一个行动计划。为了支持Gondola的训练,我们使用RLBench模拟器构建了三种类型的数据集,分别是机器人接地规划、多视图引用表达式和伪长周期任务数据集。在GemBench数据集的所有四个泛化层次上,Gondola的表现均优于最新的基于LLM的方法,包括新放置、刚体、关节对象和长周期任务。
Key Takeaways
- 机器人操作面临泛化挑战,需要处理不同的物体、环境和任务。
- 大型语言模型(LLM)已被引入提高机器人的泛化能力。
- 现有方法难以在视觉环境中生成基于情境的计划。
- Gondola模型采用多视图图像和历史计划生成行动计划,包括目标对象和位置的文本描述和分割掩码。
- 为了训练Gondola模型,使用了三种类型的数据集:机器人接地规划、多视图引用表达式和伪长周期任务数据集。
- Gondola在GemBench数据集的四个泛化层次上表现优异。
点此查看论文截图


Large Language Models for Toxic Language Detection in Low-Resource Balkan Languages
Authors:Amel Muminovic, Amela Kadric Muminovic
Online toxic language causes real harm, especially in regions with limited moderation tools. In this study, we evaluate how large language models handle toxic comments in Serbian, Croatian, and Bosnian, languages with limited labeled data. We built and manually labeled a dataset of 4,500 YouTube and TikTok comments drawn from videos across diverse categories, including music, politics, sports, modeling, influencer content, discussions of sexism, and general topics. Four models (GPT-3.5 Turbo, GPT-4.1, Gemini 1.5 Pro, and Claude 3 Opus) were tested in two modes: zero-shot and context-augmented. We measured precision, recall, F1 score, accuracy and false positive rates. Including a short context snippet raised recall by about 0.12 on average and improved F1 score by up to 0.10, though it sometimes increased false positives. The best balance came from Gemini in context-augmented mode, reaching an F1 score of 0.82 and accuracy of 0.82, while zero-shot GPT-4.1 led on precision and had the lowest false alarms. We show how adding minimal context can improve toxic language detection in low-resource settings and suggest practical strategies such as improved prompt design and threshold calibration. These results show that prompt design alone can yield meaningful gains in toxicity detection for underserved Balkan language communities.
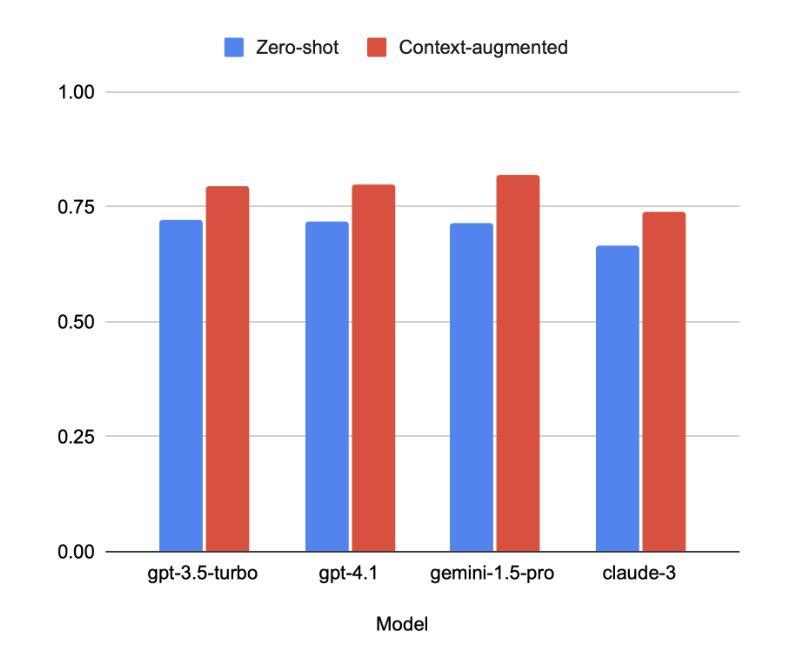
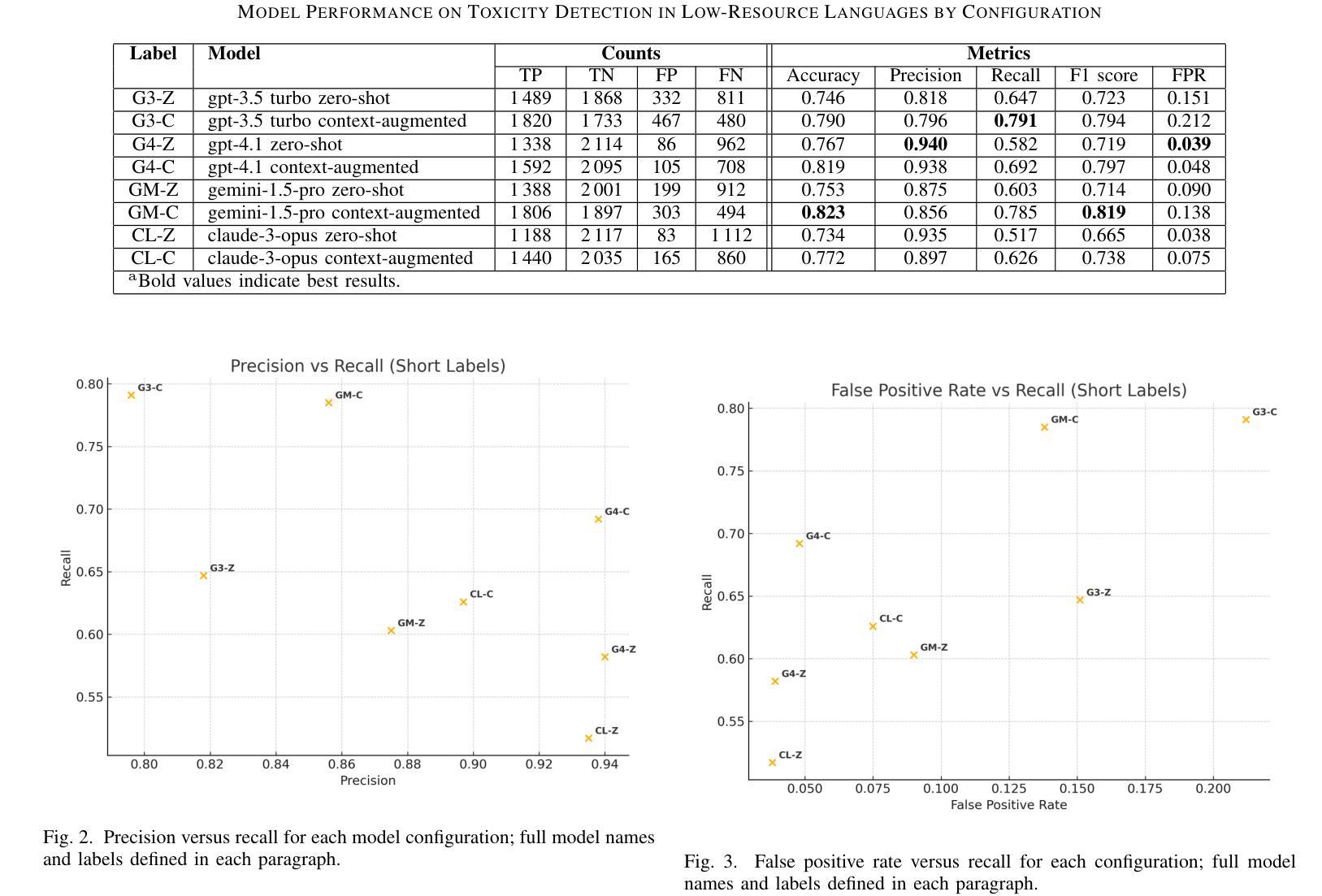
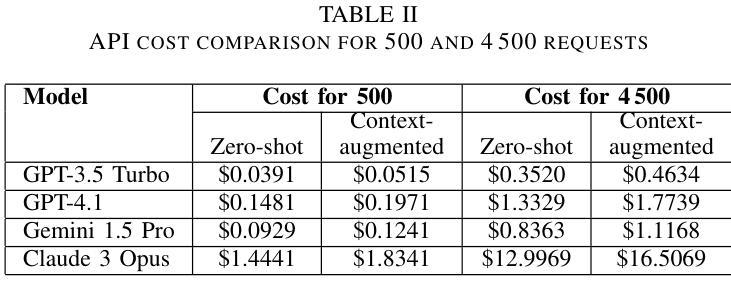
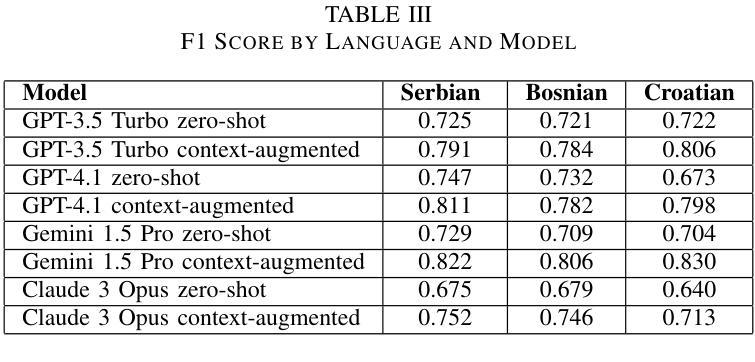
网络有毒语言会导致真实伤害,特别是在缺乏管理工具的地区。在这项研究中,我们评估大型语言模型如何处理塞尔维亚语、克罗地亚语和波斯尼亚语的恶毒评论,这些语言的标记数据有限。我们构建并手动标记了一个包含4500条YouTube和TikTok评论的数据集,这些评论来自音乐、政治、体育、模特、网红内容、性别主义讨论和一般话题等不同类别的视频。四种模型(GPT-3.5 Turbo、GPT-4.1、Gemini 1.5 Pro和Claude 3 Opus)在两种模式下进行了测试:零样本模式和上下文增强模式。我们测量了精确度、召回率、F1分数、准确率和误报率。包含简短的上下文片段平均提高了约0.12的召回率,并使F1分数提高了高达0.10,尽管有时会增加误报。最佳平衡来自上下文增强模式下的Gemini,F1分数和准确率均达到0.82,而零样本模式下的GPT-4.1在精确度上领先,并且误报率最低。我们展示了如何在资源有限的环境中通过添加最小上下文来改进有毒语言检测,并提出实用策略,如改进提示设计和阈值校准。这些结果表明,仅通过提示设计就可以在服务于巴尔干语社区的毒害检测方面取得有意义的收获。
论文及项目相关链接
PDF 8 pages
摘要
在线有毒语言会造成实际伤害,特别是在缺乏适度工具的地区。本研究评估大型语言模型如何处理塞尔维亚语、克罗地亚语和波斯尼亚语的毒性评论,这些语言的数据标签有限。我们构建并手动标注了一个包含4500条YouTube和TikTok评论的数据集,这些评论来自音乐、政治、体育、模特、影响者内容、性别主义讨论和一般话题等各类视频。四项模型(GPT-3.5 Turbo、GPT-4.1、双子座1.5 Pro和Claude 3 Opus)在两种模式下进行了测试:零样本和上下文增强。我们测量了精确度、召回率、F1分数、准确率和误报率。包含简短上下文片段平均提高了约0.12的召回率,并提高了高达0.1的F1分数,但有时会增加误报。最佳的平衡来自上下文增强模式下的双子座,达到F1分数0.82和准确率0.82,而零样本GPT-4.1在精度上领先,误报率最低。我们展示了在资源有限的环境中,添加最小上下文如何改进有毒语言检测,并提出实际策略,如改进提示设计和阈值校准。结果表明,仅通过提示设计就可以为服务不足的巴尔干语社区在毒性检测方面带来实际意义上的收益。
关键见解
- 在线有毒语言可导致实际伤害,特别是在缺乏适当工具的地区。
- 本研究评估了大型语言模型在处理塞尔维亚语、克罗地亚语和波斯尼亚语的毒性评论方面的性能。
- 构建并手动标注了一个包含各类视频评论的数据集。
- 在零样本和上下文增强两种模式下测试了四种模型。
- 添加简短上下文片段可提高模型性能,但可能增加误报。
- Gemini模型在上下文增强模式下表现最佳,而GPT-4.1在零样本模式下在精度上领先。
点此查看论文截图

e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Authors:Amrith Setlur, Matthew Y. R. Yang, Charlie Snell, Jeremy Greer, Ian Wu, Virginia Smith, Max Simchowitz, Aviral Kumar
Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep “thinking” for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging “negative” gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME’25 and HMMT’25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
测试时缩放提供了一种有前景的路径,通过在推理时间利用更多的计算来改进大型语言模型的推理能力;然而,该模式的真正潜力在于外推(即,随着大型语言模型“思考”的时间延长,超出其训练时的最大令牌预算,性能的提升)。令人惊讶的是,我们发现大多数现有的推理模型的外推效果不佳。我们表明,实现外推的一种方法是训练大型语言模型进行上下文探索:训练大型语言模型有效地利用其测试时间预算,通过操作链(如生成、验证、精炼等),或在提交答案之前测试多个假设。为了实现上下文探索,我们确定了作为我们配方e3的三个关键要素:(1)链接基础大型语言模型具有不对称能力技能,例如将验证(简单)与生成(困难)进行链接,作为一种实现上下文搜索的方式;(2)利用来自不正确轨迹的“负面”梯度来放大强化学习期间的探索,从而产生更长的搜索轨迹,链接额外的不对称性;(3)通过专门设计的课程在训练期间将任务难度与训练令牌预算相结合,以构建上下文探索的结构。我们的配方e3根据AIME’25和HMMT’25的分数产生了最好的已知1.7B模型,并外推到训练令牌预算的2倍。我们的e3-1.7B模型不仅达到了很高的pass@1分数,而且相对于基础模型还提高了pass@k分数。
论文及项目相关链接
Summary
测试时缩放提供了一种利用更多计算资源提高LLM推理能力的有前途的路径。真正的潜力在于外推,即在更长时间的思考中,超出训练的最大标记预算的情况下提高性能。然而,我们意外地发现,大多数现有的推理模型的外推能力不强。本文通过训练LLM进行上下文探索来实现外推能力的方法之一:训练LLM有效地利用其测试时间预算,通过操作链接(如生成、验证、精炼等)或在提交答案之前测试多个假设来进行上下文探索。本文介绍了实现上下文探索的三个关键要素:链接不对称技能的训练,利用错误轨迹的“负面”梯度放大强化学习中的探索,以及通过专门设计的课程将任务难度与训练标记预算进行耦合以结构化上下文探索。根据AIME'25和HMMT'25的评分,本文开发的e3配方生产的模型表现最佳,并在训练标记预算的基础上外推到两倍。我们的e3-1.7B模型不仅获得了高通过率分数,而且相对于基础模型也提高了pass@k得分。
Key Takeaways
- 测试时缩放利用更多计算资源可以提高LLM的推理能力。
- 外推能力在LLM中具有重要意义,特别是在解决复杂问题时。
- 现有推理模型在外推方面表现不佳。
- 通过训练LLM进行上下文探索,可以提高其外推能力。
- 实现上下文探索的关键要素包括:链接不对称技能、利用负面梯度放大探索、任务难度与训练标记预算的耦合。
- e3配方生产的模型在AIME’25和HMMT’25的评分中表现最佳。
点此查看论文截图

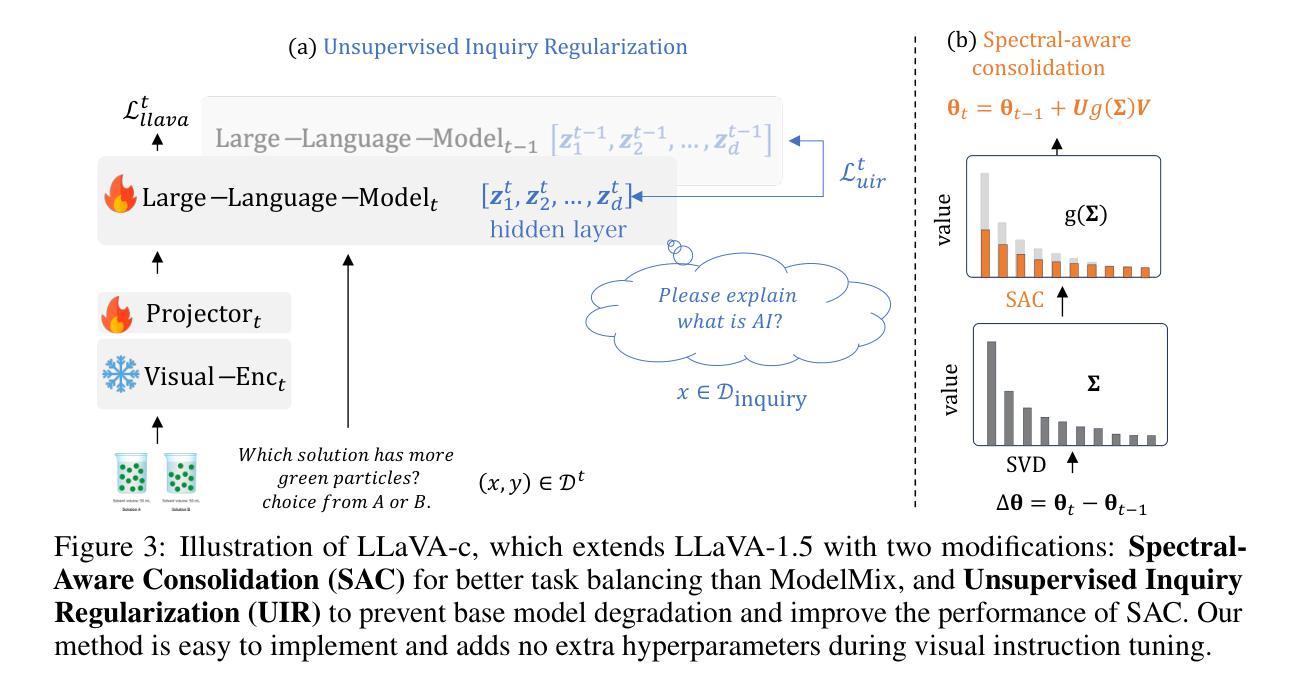
LLaVA-c: Continual Improved Visual Instruction Tuning
Authors:Wenzhuo Liu, Fei Zhu, Haiyang Guo, Longhui Wei, Cheng-Lin Liu
Multimodal models like LLaVA-1.5 achieve state-of-the-art visual understanding through visual instruction tuning on multitask datasets, enabling strong instruction-following and multimodal performance. However, multitask learning faces challenges such as task balancing, requiring careful adjustment of data proportions, and expansion costs, where new tasks risk catastrophic forgetting and need costly retraining. Continual learning provides a promising alternative to acquiring new knowledge incrementally while preserving existing capabilities. However, current methods prioritize task-specific performance, neglecting base model degradation from overfitting to specific instructions, which undermines general capabilities. In this work, we propose a simple but effective method with two modifications on LLaVA-1.5: spectral-aware consolidation for improved task balance and unsupervised inquiry regularization to prevent base model degradation. We evaluate both general and task-specific performance across continual pretraining and fine-tuning. Experiments demonstrate that LLaVA-c consistently enhances standard benchmark performance and preserves general capabilities. For the first time, we show that task-by-task continual learning can achieve results that match or surpass multitask joint learning. The code will be publicly released.
LLaVA-1.5等多模态模型通过在多任务数据集上进行视觉指令调整,实现了最先进的视觉理解,从而实现了强大的指令遵循和多模态性能。然而,多任务学习面临任务平衡等挑战,需要仔细调整数据比例和扩展成本,新增任务存在灾难性遗忘的风险并需要昂贵的重新训练。持续学习提供了一种有前景的替代方案,可以在保留现有能力的同时逐步获取新知识。然而,当前的方法侧重于特定任务的性能,忽视了由于过度拟合特定指令导致的基准模型退化问题,从而损害了通用能力。在这项工作中,我们对LLaVA-1.5进行了两项修改,提出了一种简单有效的方法:光谱感知巩固以提高任务平衡,以及无监督查询正则化以防止基础模型退化。我们评估了持续预训练和微调过程中的通用性能和特定任务性能。实验表明,LLaVA-c持续提高了标准基准性能并保留了通用能力。我们首次证明,按任务顺序的持续学习可以达到或多于多任务联合学习的结果。代码将公开发布。
论文及项目相关链接
Summary
基于LLaVA-1.5的多模态模型通过视觉指令调整在多任务数据集上实现了先进的视觉理解,表现出强大的指令遵循和多模态性能。然而,多任务学习面临任务平衡和数据比例调整的挑战,以及新任务的扩展成本问题,包括灾难性遗忘和需要昂贵重新训练的风险。持续学习为逐步获取新知识提供了前景,同时保留现有能力。然而,当前方法侧重于特定任务的性能,忽略了基础模型过度拟合特定指令导致的性能下降问题,从而损害了其通用能力。在这项工作中,我们提出一种简单有效的方法对LLaVA-1.5进行两项改进:光谱感知整合以改进任务平衡和无监督查询正则化以防止基础模型性能下降。我们评估持续预训练和精细调整过程中的通用和任务特定性能。实验表明,LLaVA-c提高了标准基准测试的性能并保持其通用能力。首次展示按任务顺序的连续学习可以达到甚至超过多任务联合学习的效果。代码将公开发布。
Key Takeaways
- 多模态模型如LLaVA-1.5通过视觉指令调整实现先进视觉理解,支持多任务数据集上的强指令遵循和多模态性能。
- 多任务学习面临任务平衡和扩展成本挑战,需调整数据比例并应对灾难性遗忘和重新训练风险。
- 持续学习能逐步获取新知识同时保留现有能力,是应对多任务学习挑战的有前途的方法。
- 当前方法重视特定任务性能而忽视基础模型过度拟合导致的通用能力下降问题。
- 提出的LLaVA-c模型通过光谱感知整合和无监督查询正则化改进任务平衡并防止基础模型性能下降。
- LLaVA-c在预训练和精细调整过程中保持了良好的通用和任务特定性能。
点此查看论文截图



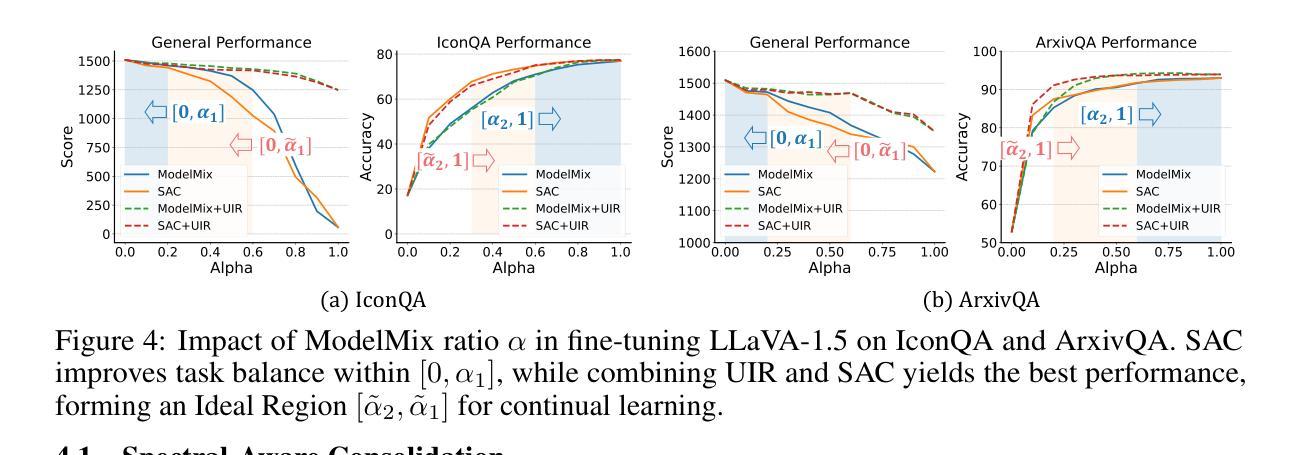
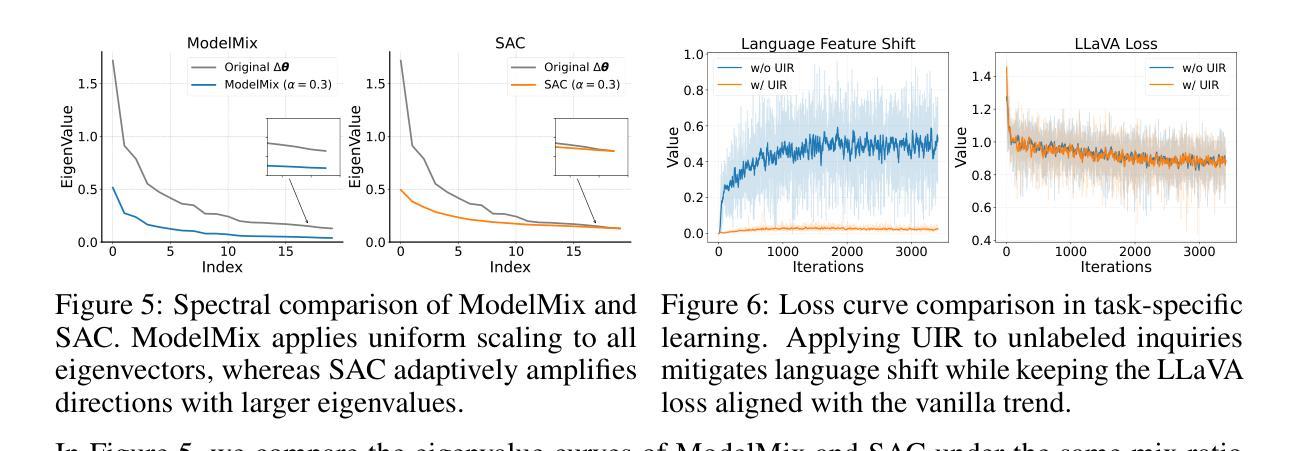
Improving Large Language Models with Concept-Aware Fine-Tuning
Authors:Michael K. Chen, Xikun Zhang, Jiaxing Huang, Dacheng Tao
Large language models (LLMs) have become the cornerstone of modern AI. However, the existing paradigm of next-token prediction fundamentally limits their ability to form coherent, high-level concepts, making it a critical barrier to human-like understanding and reasoning. Take the phrase “ribonucleic acid” as an example: an LLM will first decompose it into tokens, i.e., artificial text fragments (“rib”, “on”, …), then learn each token sequentially, rather than grasping the phrase as a unified, coherent semantic entity. This fragmented representation hinders deeper conceptual understanding and, ultimately, the development of truly intelligent systems. In response, we introduce Concept-Aware Fine-Tuning (CAFT), a novel multi-token training method that redefines how LLMs are fine-tuned. By enabling the learning of sequences that span multiple tokens, this method fosters stronger concept-aware learning. Our experiments demonstrate significant improvements compared to conventional next-token finetuning methods across diverse tasks, including traditional applications like text summarization and domain-specific ones like de novo protein design. Multi-token prediction was previously only possible in the prohibitively expensive pretraining phase; CAFT, to our knowledge, is the first to bring the multi-token setting to the post-training phase, thus effectively democratizing its benefits for the broader community of practitioners and researchers. Finally, the unexpected effectiveness of our proposed method suggests wider implications for the machine learning research community. All code and data are available at https://github.com/michaelchen-lab/caft-llm
大型语言模型(LLM)已成为现代人工智能的核心。然而,现有的下一个令牌预测范式从根本上限制了它们形成连贯、高级概念的能力,这成为实现人类理解和推理的至关重要的障碍。以短语“核糖核酸”为例:LLM会首先将其分解成令牌,即人工文本片段(“rib”、“on”……),然后按顺序学习每个令牌,而不是将整个短语作为一个统一、连贯的语义实体来把握。这种碎片化的表示形式阻碍了更深的概念理解,并最终阻碍了真正智能系统的开发。作为回应,我们引入了概念感知微调(CAFT),这是一种新型的多令牌训练方法,重新定义了如何微调LLM。通过支持学习跨越多个令牌的序列,这种方法促进了更强的概念感知学习。我们的实验表明,与传统的下一个令牌微调方法相比,CAFT在多种任务上均取得了显著的改进,包括传统的文本摘要和特定的域内任务如全新蛋白质设计。以前,多令牌预测仅在昂贵的预训练阶段才可能实现;据我们所知,CAFT首次将多令牌设置引入到训练后阶段,从而有效地普及了其对于广大从业者和研究人员的益处。最后,我们提出的方法的出人意料的有效性表明对机器学习研究界有更广泛的影响。所有代码和数据均可在https://github.com/michaelchen-lab/caft-llm找到。
论文及项目相关链接
Summary
大型语言模型(LLM)是现代人工智能的核心,但其基于下一个词预测的现有范式限制了其形成连贯、高级概念的能力,成为实现人类理解和推理的瓶颈。以“核糖核酸”这个短语为例,LLM会将其分解成多个单独的文本片段进行学习,而非作为一个统一、连贯的语义实体来理解。为解决这一问题,我们提出了概念感知微调(CAFT),这是一种新的多令牌训练方法,重新定义了LLM的微调方式。通过允许学习跨越多个令牌的序列,该方法促进了更强大的概念感知学习。实验证明,与传统的下一个词微调方法相比,CAFT在各种任务上都有显著改善,包括文本摘要和去创蛋白质设计等领域。CAFT将多令牌预测从昂贵的预训练阶段带到了后训练阶段,使广大实践者和研究人员都能受益。这表明我们的方法具有更广泛的意义和影响。
Key Takeaways
- LLM作为现代AI的核心,在形成连贯、高级概念方面存在局限。
- 现有LLM处理语言的方式是将文本分解成单独文本片段,这限制了其深度理解和推理能力。
- CAFT是一种新的多令牌训练方法,能够解决上述问题,促进更强大的概念感知学习。
- CAFT通过允许学习跨越多个令牌的序列,改善了LLM在各种任务上的表现。
- 与传统的下一个词微调方法相比,CAFT具有显著的优势。
- CAFT将多令牌预测带到了后训练阶段,使广大实践者和研究人员都能受益。
点此查看论文截图

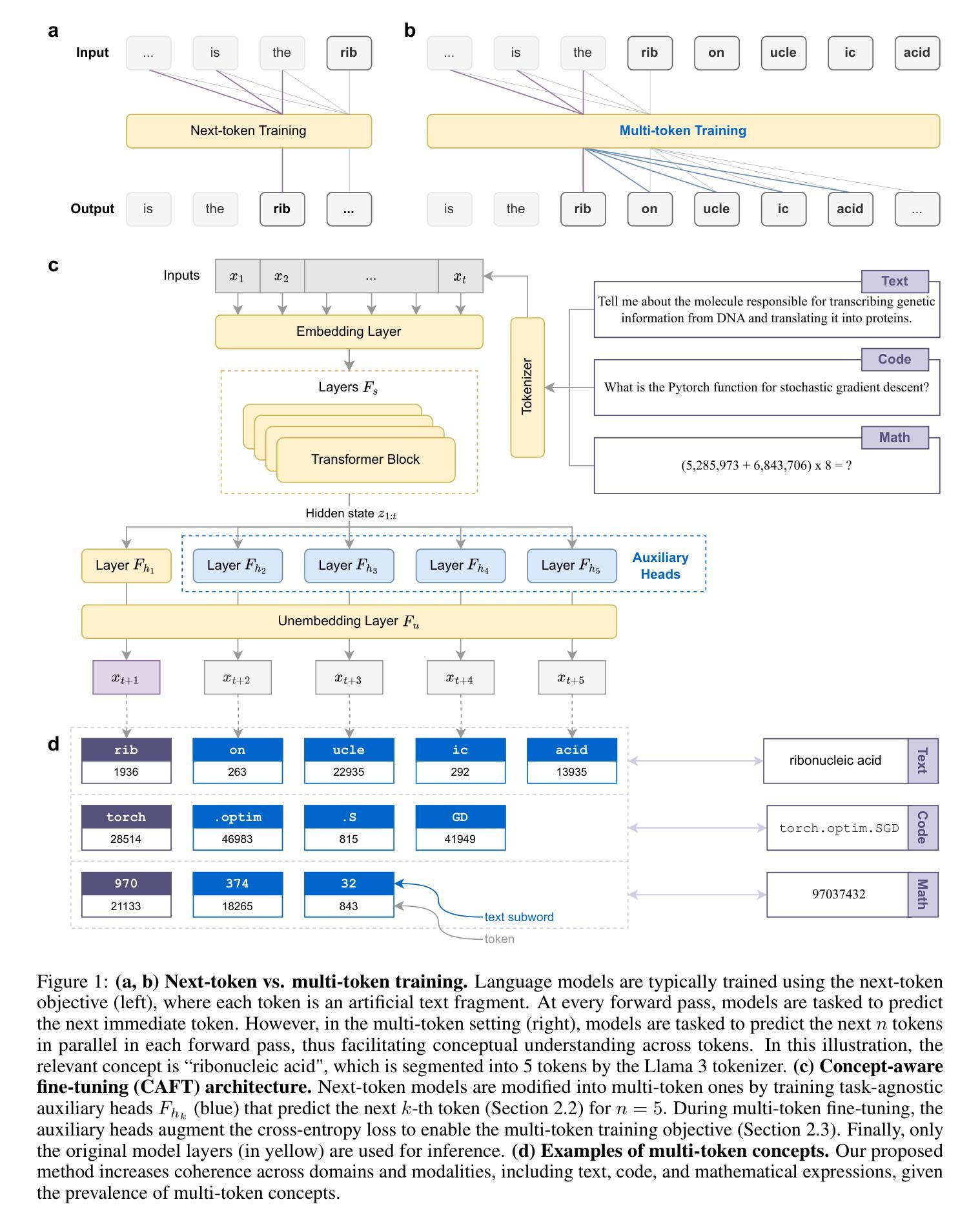

SAP-Bench: Benchmarking Multimodal Large Language Models in Surgical Action Planning
Authors:Mengya Xu, Zhongzhen Huang, Dillan Imans, Yiru Ye, Xiaofan Zhang, Qi Dou
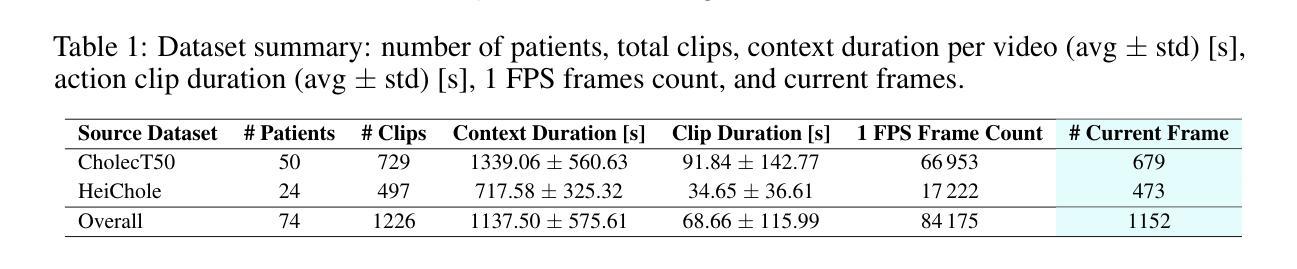
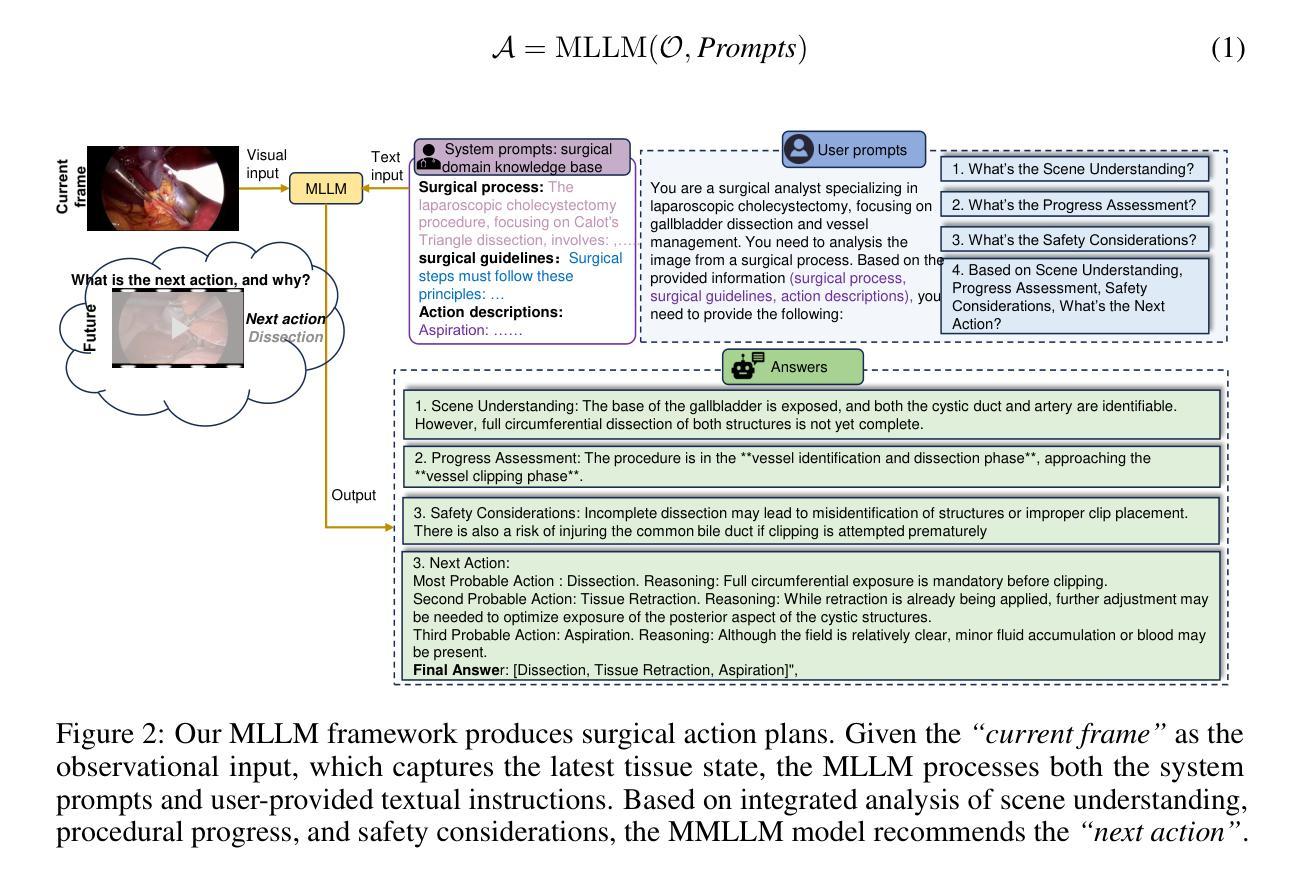
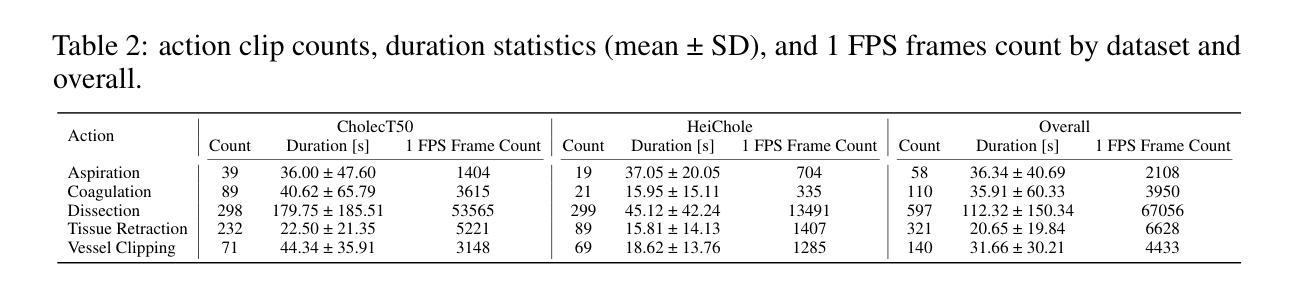
Effective evaluation is critical for driving advancements in MLLM research. The surgical action planning (SAP) task, which aims to generate future action sequences from visual inputs, demands precise and sophisticated analytical capabilities. Unlike mathematical reasoning, surgical decision-making operates in life-critical domains and requires meticulous, verifiable processes to ensure reliability and patient safety. This task demands the ability to distinguish between atomic visual actions and coordinate complex, long-horizon procedures, capabilities that are inadequately evaluated by current benchmarks. To address this gap, we introduce SAP-Bench, a large-scale, high-quality dataset designed to enable multimodal large language models (MLLMs) to perform interpretable surgical action planning. Our SAP-Bench benchmark, derived from the cholecystectomy procedures context with the mean duration of 1137.5s, and introduces temporally-grounded surgical action annotations, comprising the 1,226 clinically validated action clips (mean duration: 68.7s) capturing five fundamental surgical actions across 74 procedures. The dataset provides 1,152 strategically sampled current frames, each paired with the corresponding next action as multimodal analysis anchors. We propose the MLLM-SAP framework that leverages MLLMs to generate next action recommendations from the current surgical scene and natural language instructions, enhanced with injected surgical domain knowledge. To assess our dataset’s effectiveness and the broader capabilities of current models, we evaluate seven state-of-the-art MLLMs (e.g., OpenAI-o1, GPT-4o, QwenVL2.5-72B, Claude-3.5-Sonnet, GeminiPro2.5, Step-1o, and GLM-4v) and reveal critical gaps in next action prediction performance.
有效的评估是推动MLLM研究进步的关键。手术行动规划(SAP)任务旨在从视觉输入生成未来行动序列,它要求精确而复杂的分析能力。不同于数学推理,手术决策是在关键的生命领域中进行,需要严谨、可验证的过程来保证可靠性和病人安全。这项任务需要区分原子视觉行动,并协调复杂、长期规划的程序,而当前的标准评估并不能充分评估这些能力。为了弥补这一差距,我们引入了SAP-Bench,这是一个大规模、高质量的数据集,旨在使多模态大型语言模型(MLLMs)能够执行可解释的手术行动规划。我们的SAP-Bench基准测试源于胆囊切除术的上下文环境,平均持续时间为1137.5秒,引入基于时间的手术行动注释,包含1226个经过临床验证的行动片段(平均持续时间:68.7秒),涵盖了74个程序中的五个基本手术行动。数据集提供了1152个战略采样的当前帧,每个帧都与相应的下一个行动作为多模态分析锚点配对。我们提出了MLLM-SAP框架,该框架利用MLLMs根据当前手术场景和自然语言指令生成下一个行动建议,并注入了手术领域的知识进行增强。为了评估我们数据集的有效性和当前模型的综合能力,我们评估了七个最新MLLMs(例如OpenAI-o1、GPT-4o、QwenVL2.5-72B、Claude-3.5-Sonnet、GeminiPro2.5、Step-1o和GLM-4v),并揭示了下一步行动预测性能中的关键差距。
论文及项目相关链接
PDF The authors could not reach a consensus on the final version of this paper, necessitating its withdrawal
摘要
有效评估是推动MLLM研究进步的关键。手术行动规划(SAP)任务旨在从视觉输入生成未来行动序列,需要精确而高级的分析能力。不同于数学推理,手术决策是在生命攸关领域进行的,需要严格的可验证过程以确保可靠性和患者安全。此任务要求区分原子视觉行动并协调复杂、长期规划的程序,而当前基准测试无法充分评估这些能力。为解决此差距,我们推出SAP-Bench,一个大规模、高质量的数据集,旨在使多模态大型语言模型(MLLMs)能够执行可解释的手术行动规划。SAP-Bench基准测试源于胆囊切除术的上下文环境,平均持续时间为1137.5秒,并引入了时间基础的手术行动注释,包含1226个经过临床验证的行动片段(平均持续时间:68.7秒),涵盖74个程序中的五个基本手术行动。数据集提供了战略抽样的当前帧,每一帧都配对有相应的下一个行动作为多模态分析锚点。我们提出了MLLM-SAP框架,该框架利用MLLMs从当前手术场景和自然语言指令生成下一个行动建议,并辅以注入的手术领域知识。为了评估数据集的效用以及当前模型的整体能力,我们对七项最先进的MLLM进行了评估(例如OpenAI-o1、GPT-4o等),并揭示了下一步行动预测性能的关键差距。
关键见解
- 有效评估对于推动MLLM在手术行动规划等领域的进步至关重要。
- 当前基准测试无法充分评估区分原子视觉行动并协调复杂程序的能力。
- SAP-Bench是一个大规模、高质量的数据集,旨在支持多模态大型语言模型进行手术行动规划任务。
- SAP-Bench数据集包含经过临床验证的手术行动片段和当前帧的精确数据。
- MLLM-SAP框架利用多模态分析并结合手术领域知识生成下一步行动建议。
- 对多个先进模型的评估表明在预测手术下一步行动方面存在性能差距。
点此查看论文截图

Long-context Non-factoid Question Answering in Indic Languages
Authors:Ritwik Mishra, Rajiv Ratn Shah, Ponnurangam Kumaraguru
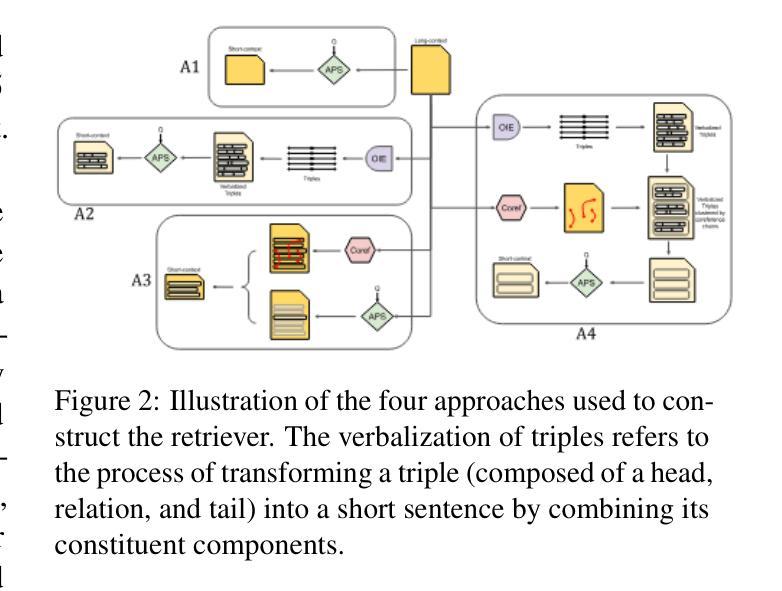
Question Answering (QA) tasks, which involve extracting answers from a given context, are relatively straightforward for modern Large Language Models (LLMs) when the context is short. However, long contexts pose challenges due to the quadratic complexity of the self-attention mechanism. This challenge is compounded in Indic languages, which are often low-resource. This study explores context-shortening techniques, including Open Information Extraction (OIE), coreference resolution, Answer Paragraph Selection (APS), and their combinations, to improve QA performance. Compared to the baseline of unshortened (long) contexts, our experiments on four Indic languages (Hindi, Tamil, Telugu, and Urdu) demonstrate that context-shortening techniques yield an average improvement of 4% in semantic scores and 47% in token-level scores when evaluated on three popular LLMs without fine-tuning. Furthermore, with fine-tuning, we achieve an average increase of 2% in both semantic and token-level scores. Additionally, context-shortening reduces computational overhead. Explainability techniques like LIME and SHAP reveal that when the APS model confidently identifies the paragraph containing the answer, nearly all tokens within the selected text receive high relevance scores. However, the study also highlights the limitations of LLM-based QA systems in addressing non-factoid questions, particularly those requiring reasoning or debate. Moreover, verbalizing OIE-generated triples does not enhance system performance. These findings emphasize the potential of context-shortening techniques to improve the efficiency and effectiveness of LLM-based QA systems, especially for low-resource languages. The source code and resources are available at https://github.com/ritwikmishra/IndicGenQA.
问答(QA)任务对于现代大型语言模型(LLM)来说,当上下文简短时,直接从上下文中提取答案相对简单。然而,长上下文由于自注意机制的二次复杂性而带来挑战。在印度语言(通常资源较少)中,这一挑战更为严重。本研究探讨了上下文缩短技术,包括开放信息提取(OIE)、核心引用解析、答案段落选择(APS)及其组合,以提高问答性能。与未缩短(长)上下文的基线相比,我们在四种印度语言(印地语、泰米尔语、泰卢固语和乌尔都语)上的实验表明,在三种流行的LLM上评估时,上下文缩短技术在语义得分上平均提高了4%,在令牌级别得分上提高了47%,无需微调。此外,通过微调,我们在语义和令牌级别得分上都平均提高了2%。此外,上下文缩短还减少了计算开销。LIME和SHAP等解释性技术表明,当APS模型自信地识别出包含答案的段落时,所选文本中的几乎所有令牌都会获得高相关性分数。然而,该研究还强调了基于LLM的问答系统在解决非事实问题上的局限性,特别是那些需要推理或辩论的问题。此外,用言语表达OIE生成的三元组并不能提高系统性能。这些发现强调了上下文缩短技术在提高基于LLM的问答系统的效率和有效性方面的潜力,特别是对于低资源语言。源代码和资源可在https://github.com/ritwikmishra/IndicGenQA找到。
论文及项目相关链接
PDF Short version of this manuscript accepted at https://bda2025.iiitb.net/
Summary
本文探讨了使用大型语言模型(LLM)进行问答任务时面临的挑战,特别是长文本语境下的挑战。研究针对印度语言(如印地语、泰米尔语、泰卢固语和乌尔都语)提出了上下文缩短技术,包括开放信息提取(OIE)、核心解决(coreference resolution)、答案段落选择(APS)及其组合。实验表明,上下文缩短技术在不微调的情况下平均提高了语义得分4%,提高了令牌级别的得分47%。此外,这些技术还可以提高计算效率。然而,该研究也指出了LLM在解决非事实性问题方面的局限性,特别是需要推理或辩论的问题。研究强调了上下文缩短技术在提高LLM问答系统的效率和有效性方面的潜力。相关资源已公开发布在GitHub上。
Key Takeaways
- 大型语言模型(LLM)在问答任务中处理长文本时面临挑战,特别是针对低资源的印度语言。
- 上下文缩短技术如开放信息提取(OIE)、核心解决和答案段落选择(APS)能有效提高问答性能。
- 在不微调的情况下,上下文缩短技术平均提高了语义得分和令牌级别得分。
- 上下文缩短技术可以提高计算效率。
- LLM在解决非事实性问题方面存在局限性,特别是在需要推理或辩论的情况下。
- 解释性技术如LIME和SHAP可以帮助理解模型决策过程。
点此查看论文截图


Safer or Luckier? LLMs as Safety Evaluators Are Not Robust to Artifacts
Authors:Hongyu Chen, Seraphina Goldfarb-Tarrant
Large Language Models (LLMs) are increasingly employed as automated evaluators to assess the safety of generated content, yet their reliability in this role remains uncertain. This study evaluates a diverse set of 11 LLM judge models across critical safety domains, examining three key aspects: self-consistency in repeated judging tasks, alignment with human judgments, and susceptibility to input artifacts such as apologetic or verbose phrasing. Our findings reveal that biases in LLM judges can significantly distort the final verdict on which content source is safer, undermining the validity of comparative evaluations. Notably, apologetic language artifacts alone can skew evaluator preferences by up to 98%. Contrary to expectations, larger models do not consistently exhibit greater robustness, while smaller models sometimes show higher resistance to specific artifacts. To mitigate LLM evaluator robustness issues, we investigate jury-based evaluations aggregating decisions from multiple models. Although this approach both improves robustness and enhances alignment to human judgements, artifact sensitivity persists even with the best jury configurations. These results highlight the urgent need for diversified, artifact-resistant methodologies to ensure reliable safety assessments.
大型语言模型(LLM)越来越多地被用作自动化评估器来评估生成内容的安全性,但它们在这一角色中的可靠性仍然不确定。本研究评估了11个LLM判断模型在不同关键安全领域的表现,并考察了三个方面:重复判断任务中的自我一致性、与人类判断的一致性以及受诸如道歉或冗长措辞等输入因素的影响程度。我们的研究发现,LLM判断中的偏见会严重扭曲对哪个内容源更安全的最终判断,损害比较评估的有效性。值得注意的是,仅仅道歉的语言特征本身就可以使评估者的偏好产生高达98%的偏差。与预期相反,更大的模型并不总是表现出更高的稳健性,而较小的模型有时会对某些特征表现出更高的抵抗力。为了解决LLM评估器的稳健性问题,我们研究了基于陪审团的评估方法,该方法聚合了多个模型的决策。尽管这种方法提高了稳健性并增强了与人类判断的一致性,但即使在最佳的陪审团配置下,对特征的敏感性仍然存在。这些结果强调了采用多样化、抗特征干扰方法的迫切需求,以确保可靠的安全评估。
论文及项目相关链接
PDF 9 pages, ACL 2025
Summary
大型语言模型(LLM)被越来越多地用作自动生成内容的评估器,但其可靠性尚不确定。本研究评估了不同安全领域中的11个LLM判断模型,并考察了其在重复判断任务中的自我一致性、与人类判断的一致性以及是否容易受到如道歉或冗长措辞等输入伪影的影响。研究发现,LLM判断中的偏见会严重扭曲关于哪个内容源更安全的最终判断,从而影响比较评估的有效性。仅道歉性语言伪影就能使评估者的偏好偏离达98%。出人意料的是,较大的模型并不总能表现出更高的稳健性,而较小的模型在某些情况下则显示出对特定伪影的更高抵抗力。为了解决LLM评估器的稳健性问题,本研究探讨了基于陪审团的评估方法,该方法结合了多个模型。尽管这种方法既提高了稳健性又增强了与人类判断的一致性,但最佳陪审团配置仍存在伪影敏感性。这些结果强调了采用多样化、抗伪影方法的紧迫性,以确保可靠的安全评估。
Key Takeaways
- 大型语言模型(LLM)被用作内容安全评估器的可靠性尚不确定。
- LLM判断模型在自我一致性、与人类判断的一致性和输入伪影的敏感性方面存在关键缺陷。
- 偏见可能影响LLM对内容安全性的最终判断。
- 道歉性语言伪影可显著影响评估结果。
- 较大的模型并不一定比小型模型更稳健。
- 基于陪审团的评估方法可提高稳健性和与人类判断的一致性,但仍存在伪影敏感性。
点此查看论文截图

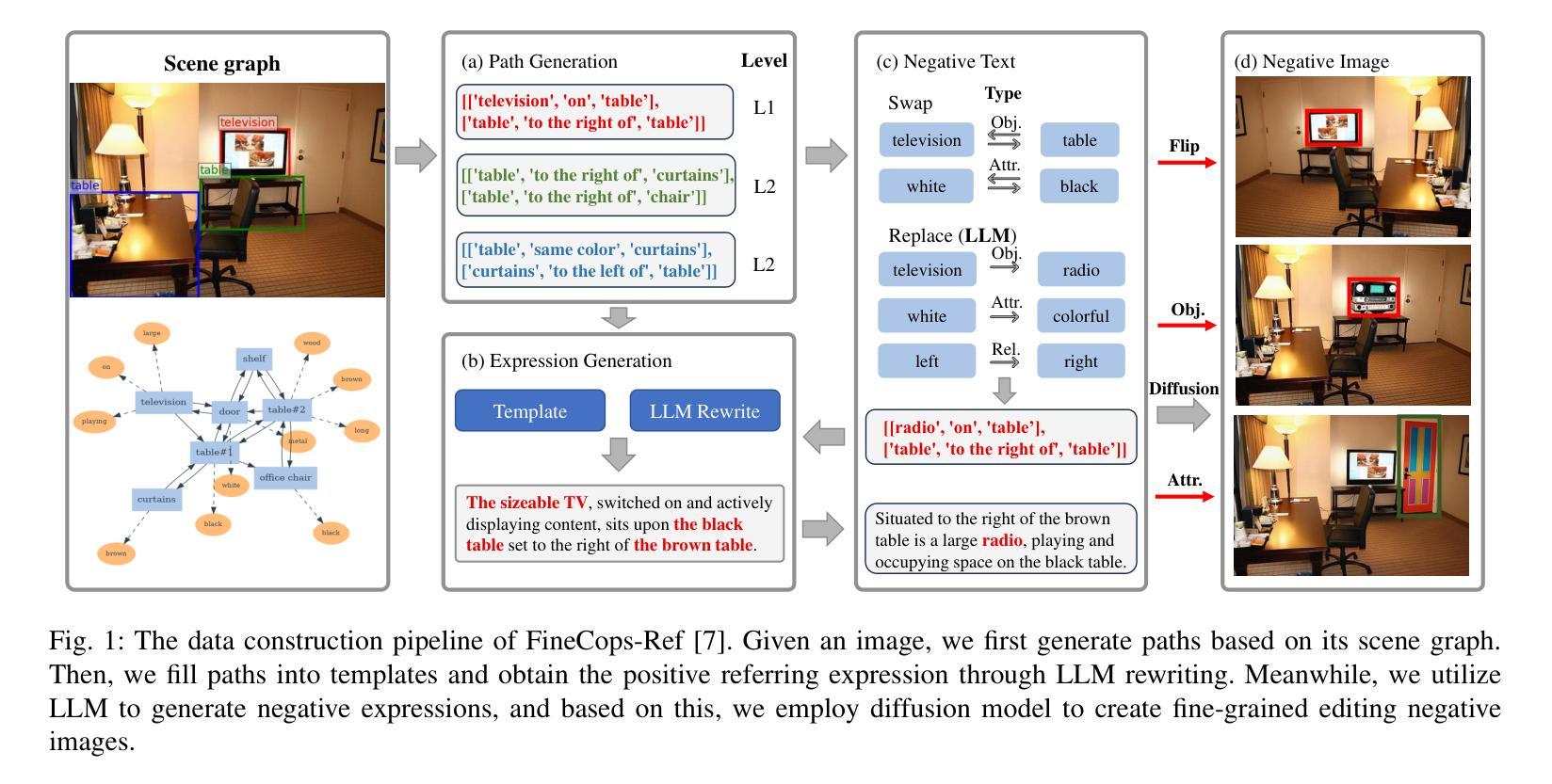
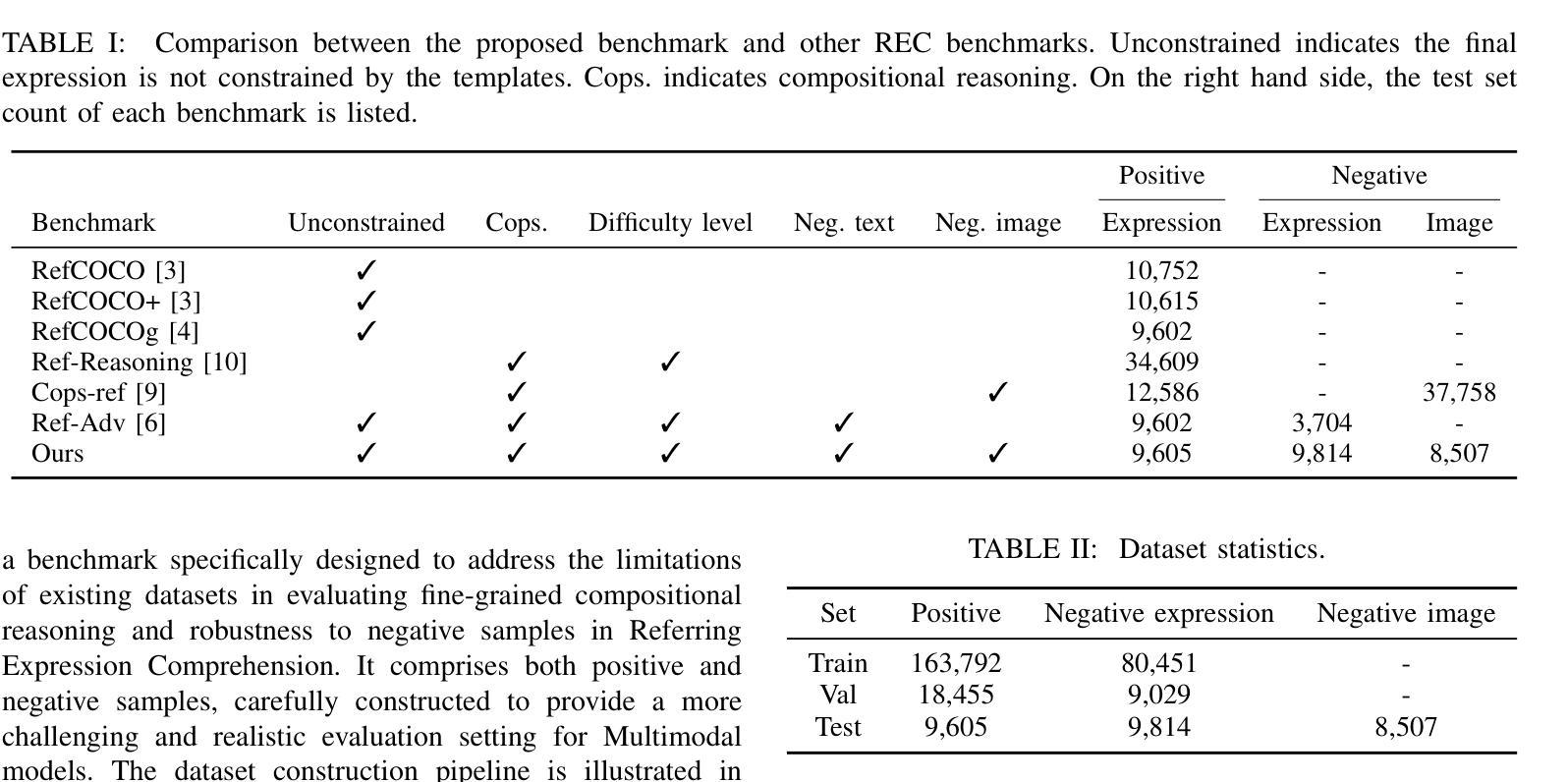
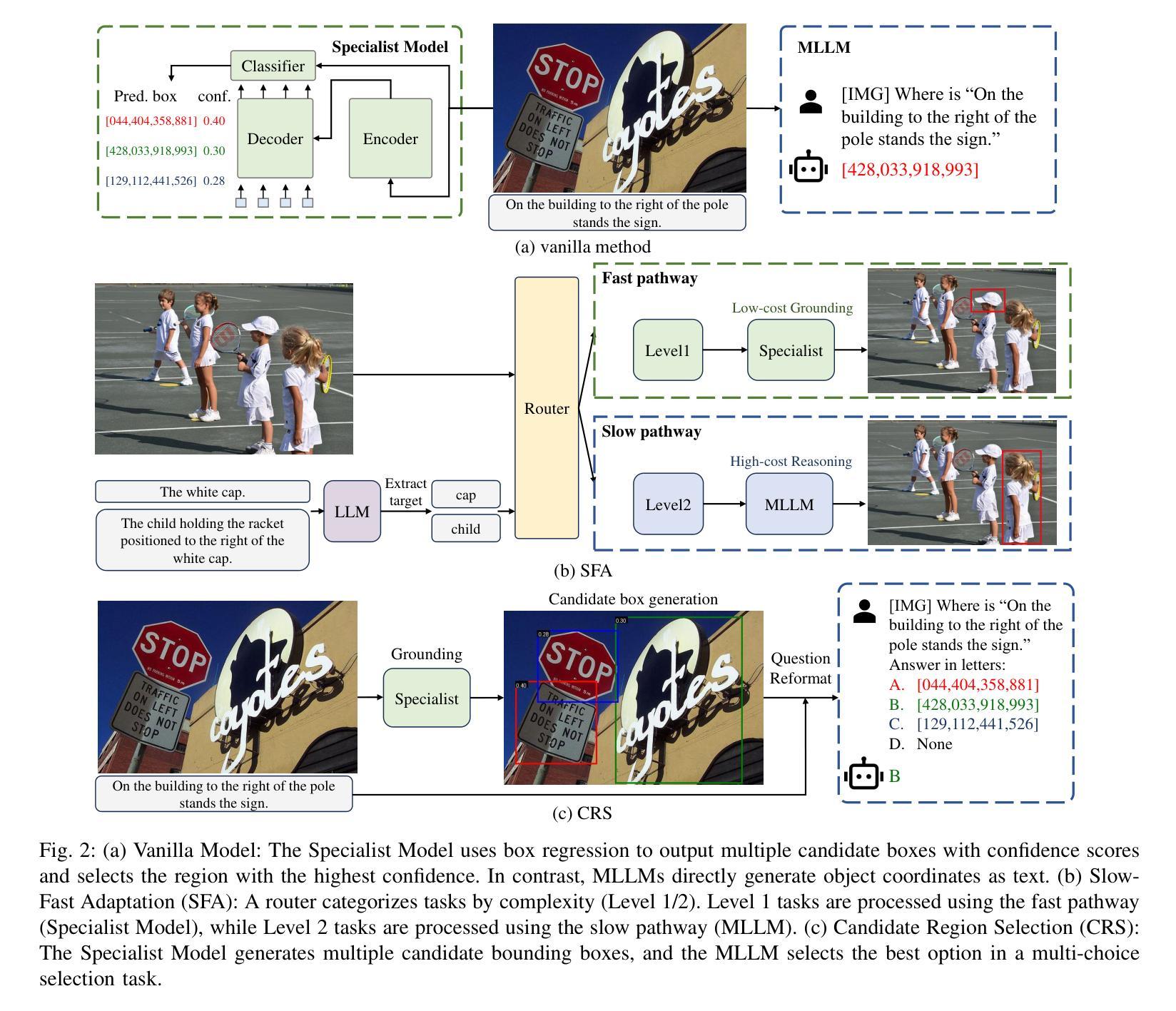
New Dataset and Methods for Fine-Grained Compositional Referring Expression Comprehension via Specialist-MLLM Collaboration
Authors:Xuzheng Yang, Junzhuo Liu, Peng Wang, Guoqing Wang, Yang Yang, Heng Tao Shen
Referring Expression Comprehension (REC) is a foundational cross-modal task that evaluates the interplay of language understanding, image comprehension, and language-to-image grounding. It serves as an essential testing ground for Multimodal Large Language Models (MLLMs). To advance this field, we introduced a new REC dataset in our previous conference paper, characterized by two key features. First, it is designed with controllable difficulty levels, requiring multi-level fine-grained reasoning across object categories, attributes, and multi-hop relationships. Second, it incorporates negative text and images generated through fine-grained editing and augmentation, explicitly testing a model’s ability to reject scenarios where the target object is absent, an often overlooked yet critical challenge in existing datasets. In this extended work, we propose two new methods to tackle the challenges of fine-grained REC by combining the strengths of Specialist Models and MLLMs. The first method adaptively assigns simple cases to faster, lightweight models and reserves complex ones for powerful MLLMs, balancing accuracy and efficiency. The second method lets a specialist generate a set of possible object regions, and the MLLM selects the most plausible one using its reasoning ability. These collaborative strategies lead to significant improvements on our dataset and other challenging benchmarks. Our results show that combining specialized and general-purpose models offers a practical path toward solving complex real-world vision-language tasks. Our dataset and code are available at https://github.com/sleepyshep/FineCops-Ref.
指代表达式理解(REC)是一项基础的多模式任务,它评估语言理解、图像理解和语言到图像定位之间的相互作用。它是测试多模态大型语言模型(MLLM)的重要场所。为了推动这一领域的发展,我们在之前的会议论文中引入了一个新的REC数据集,该数据集具有两个关键特征。首先,它按可控的难度级别设计,需要进行跨对象类别、属性和多跳关系的多级精细推理。其次,它结合了通过精细编辑和扩充生成的负文本和图像,明确测试了模型在拒绝目标对象缺失的场景时的能力,这是现有数据集中经常被忽视但至关重要的挑战。在这项扩展工作中,我们提出了两种新的方法来解决精细REC的挑战,通过将专业模型和MLLM的优势结合起来。第一种方法自适应地将简单案例分配给更快、更轻型的模型,并保留复杂案例供强大的MLLM处理,以平衡准确性和效率。第二种方法让专家生成一组可能的对象区域,然后使用MLLM的推理能力选择最合理的区域。这些协作策略在我们的数据集和其他具有挑战性的基准测试上取得了显著的改进。我们的结果表明,结合专用和通用模型为解决复杂的现实世界视觉语言任务提供了实用途径。我们的数据集和代码可在https://github.com/sleepyshep/FineCops-Ref上找到。
论文及项目相关链接
PDF Accepted by TPAMI 2025
摘要
表达理解(REC)是一个跨模态基础任务,评估语言理解、图像理解和语言到图像定位之间的相互作用。它是测试多模态大型语言模型(MLLMs)的重要场所。为推进此领域发展,我们在之前的会议论文中引入了一个新的REC数据集,具有两个关键特征:一是设计可控难度级别,需要跨对象类别、属性和多跳关系进行多层次精细推理;二是通过精细编辑和扩充生成负文本和图像,明确测试模型在目标对象缺失场景下的拒绝能力,这是现有数据集中常被忽视但至关重要的挑战。在这项扩展工作中,我们提出两种新方法来解决精细REC的挑战,结合专业模型和MLLMs的优势。第一种方法自适应地为简单案例分配快速、轻型的模型,为复杂案例保留强大的MLLMs,平衡准确性和效率。第二种方法让专家生成一组可能的对象区域,MLLM利用其推理能力选择最合理的区域。这些协作策略在我们的数据集和其他具有挑战性的基准测试上取得了显着改进。结果表明,结合专业模型和通用模型为解决复杂的现实世界视觉语言任务提供了实用途径。我们的数据集和代码可在https://github.com/sleepyshep/FineCops-Ref获取。
关键见解
- 表达理解(REC)任务评估语言理解、图像理解和语言到图像定位的多模态交互。
- 新REC数据集具有可控难度级别和负文本/图像生成,用于测试模型在目标缺失场景的能力。
- 提出两种新方法来处理精细REC挑战,结合专业模型和MLLMs的优势。
- 第一种方法自适应分配简单和复杂案例给不同模型,以提高准确性和效率。
- 第二种方法利用专家生成对象区域,由MLLM选择最合理的区域进行推理。
- 协作策略在数据集和其他基准测试上取得显著改进。
点此查看论文截图