⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
Schema-R1: A reasoning training approach for schema linking in Text-to-SQL Task
Authors:Wuzhenghong Wen, Su Pan, yuwei Sun
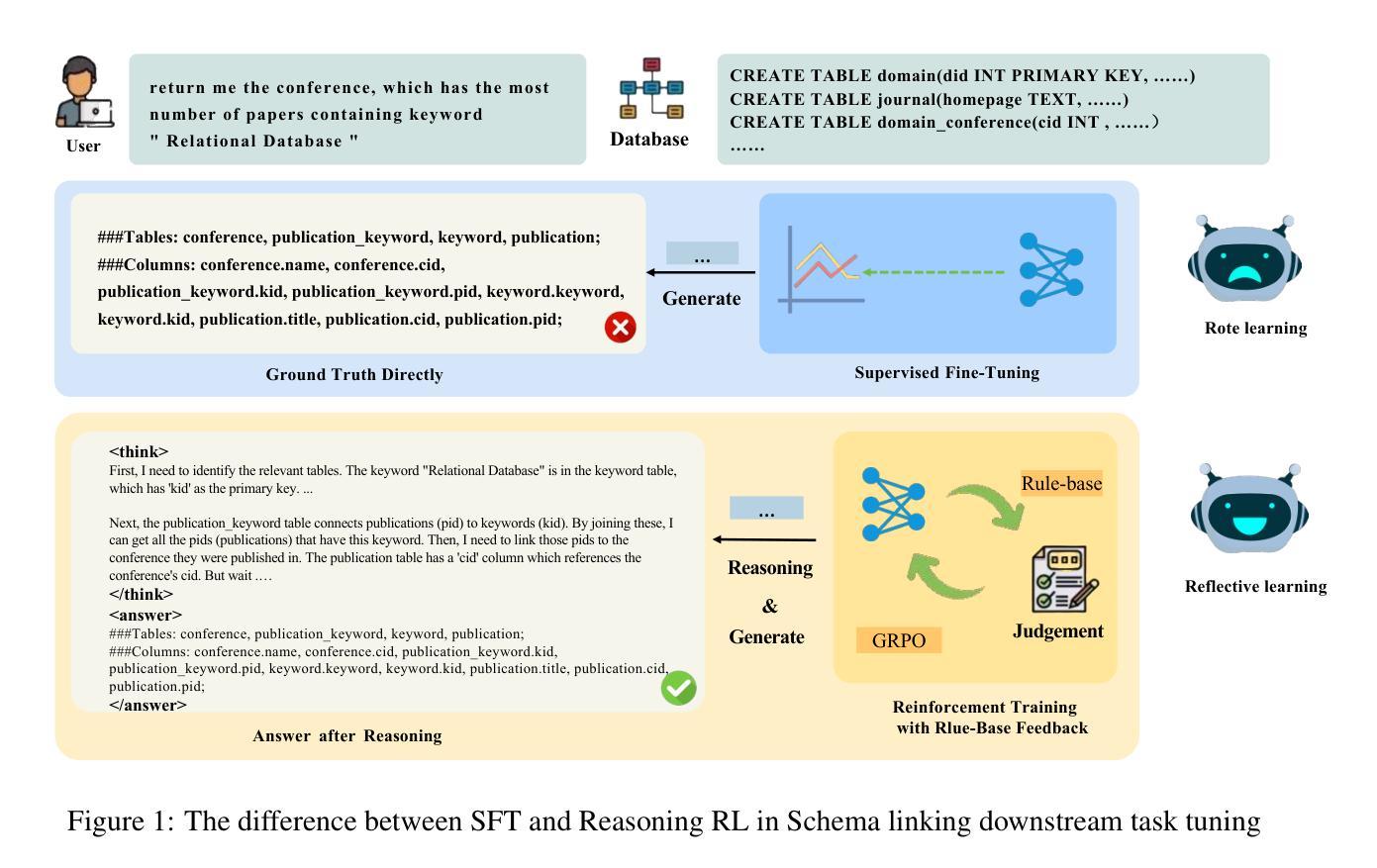
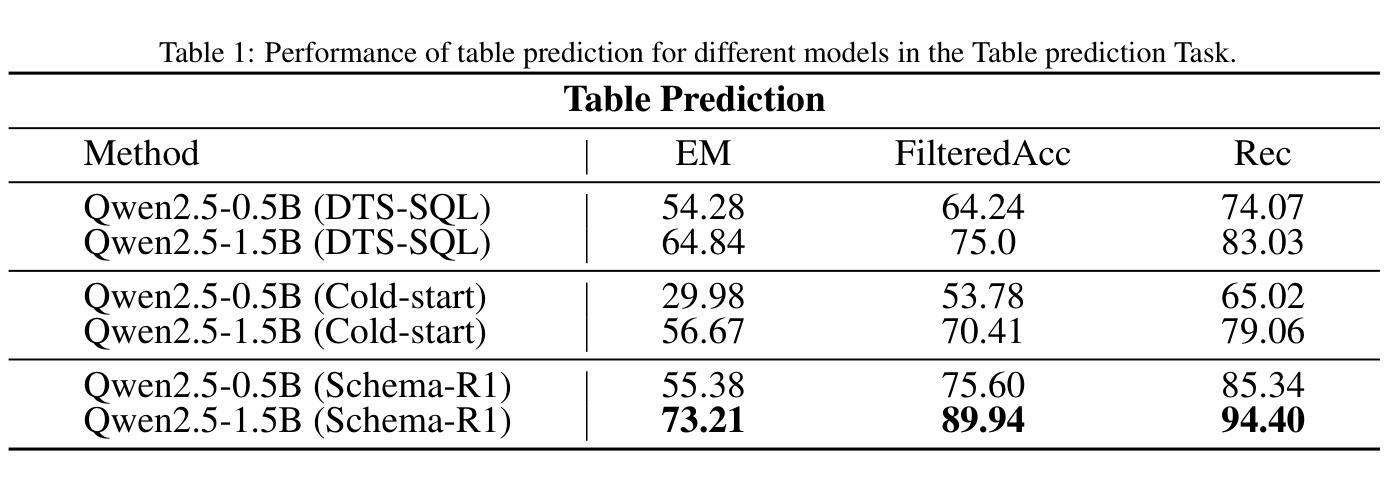
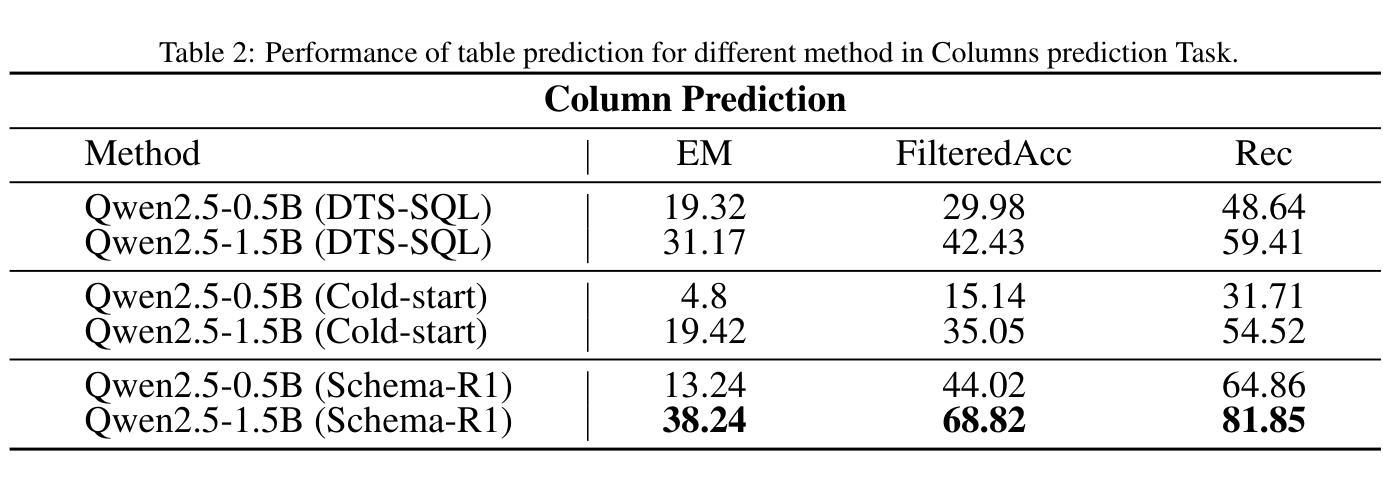
Schema linking is a critical step in Text-to-SQL task, aiming to accurately predict the table names and column names required for the SQL query based on the given question. However, current fine-tuning approaches for schema linking models employ a rote-learning paradigm, excessively optimizing for ground truth schema linking outcomes while compromising reasoning ability. This limitation arises because of the difficulty in acquiring a high-quality reasoning sample for downstream tasks. To address this, we propose Schema-R1, a reasoning schema linking model trained using reinforcement learning. Specifically, Schema-R1 consists of three key steps: constructing small batches of high-quality reasoning samples, supervised fine-tuning for cold-start initialization, and rule-based reinforcement learning training. The final results demonstrate that our method effectively enhances the reasoning ability of the schema linking model, achieving a 10% improvement in filter accuracy compared to the existing method. Our code is available at https://github.com/hongWin/Schema-R1/.
在文本到SQL的任务中,模式链接是关键步骤,旨在根据给定问题准确预测SQL查询所需的表名和列名。然而,当前的模式链接模型微调方法采用机械学习模式,过度优化针对真实场景的模式链接结果,从而牺牲了推理能力。这一局限性的产生是由于下游任务难以获取高质量的推理样本。为解决这一问题,我们提出了使用强化学习训练的模式推理链接模型Schema-R1。具体来说,Schema-R1包括三个关键步骤:构建高质量推理样本的小批次、监督微调进行冷启动初始化、基于规则的强化学习训练。最终结果表明,我们的方法有效地提高了模式链接模型的推理能力,与现有方法相比,过滤精度提高了10%。我们的代码可在https://github.com/hongWin/Schema-R1/找到。
论文及项目相关链接
PDF 11 pages, 3 figures, conference
Summary
文本主要介绍了在文本到SQL任务中,模式链接的重要性及其面临的挑战。当前的方法过于优化对标准模式链接结果的学习,而忽略了推理能力。为此,提出了Schema-R1模型,采用强化学习进行训练,包括构建高质量推理样本的小批次、监督微调冷启动初始化和基于规则的强化学习训练。最终结果显示,该方法提高了模式链接模型的推理能力,与现有方法相比,过滤精度提高了10%。
Key Takeaways
- 模式链接在文本到SQL任务中起关键作用,旨在预测SQL查询所需的表名和列名。
- 当前方法过度优化对标准模式链接结果的学习,影响推理能力。
- Schema-R1模型被提出以解决这一问题,采用强化学习进行训练。
- Schema-R1包括三个关键步骤:构建高质量推理样本的小批次、监督微调冷启动初始化和基于规则的强化学习训练。
- Schema-R1模型提高了模式链接模型的推理能力。
- 与现有方法相比,Schema-R1模型的过滤精度提高了10%。
点此查看论文截图

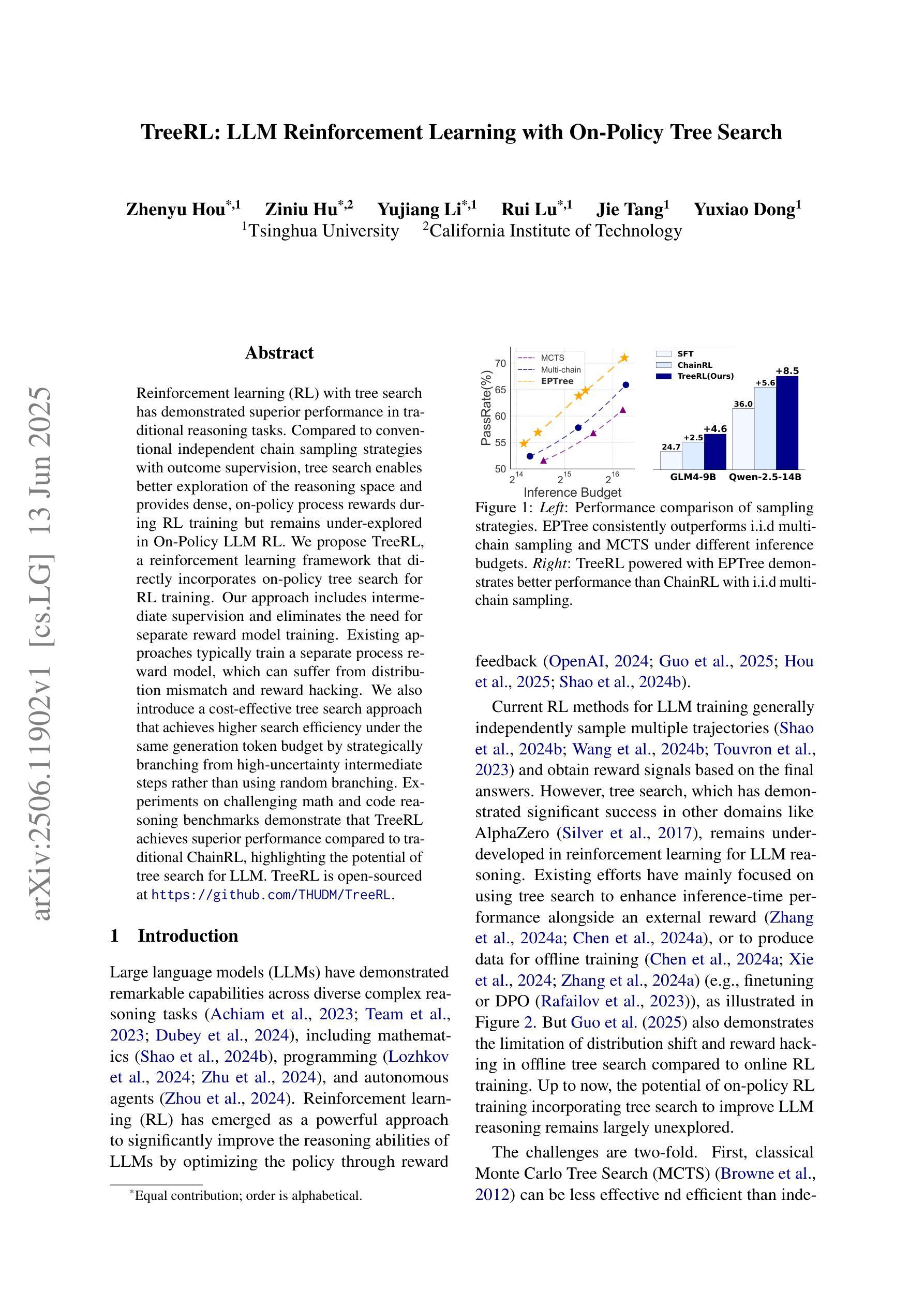
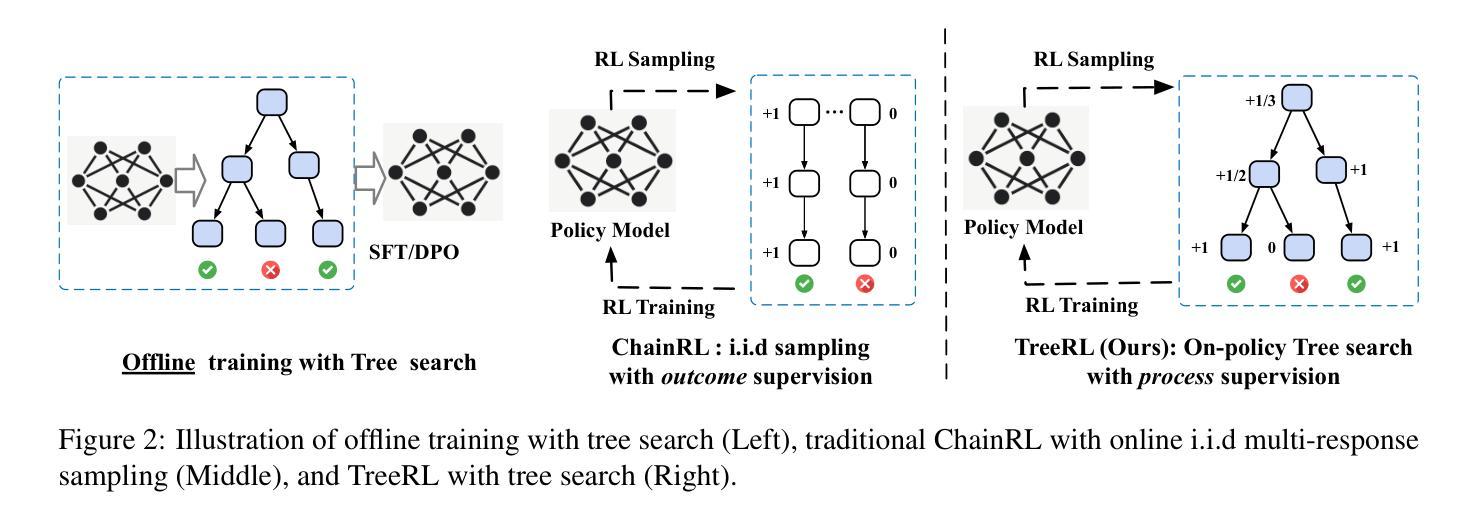
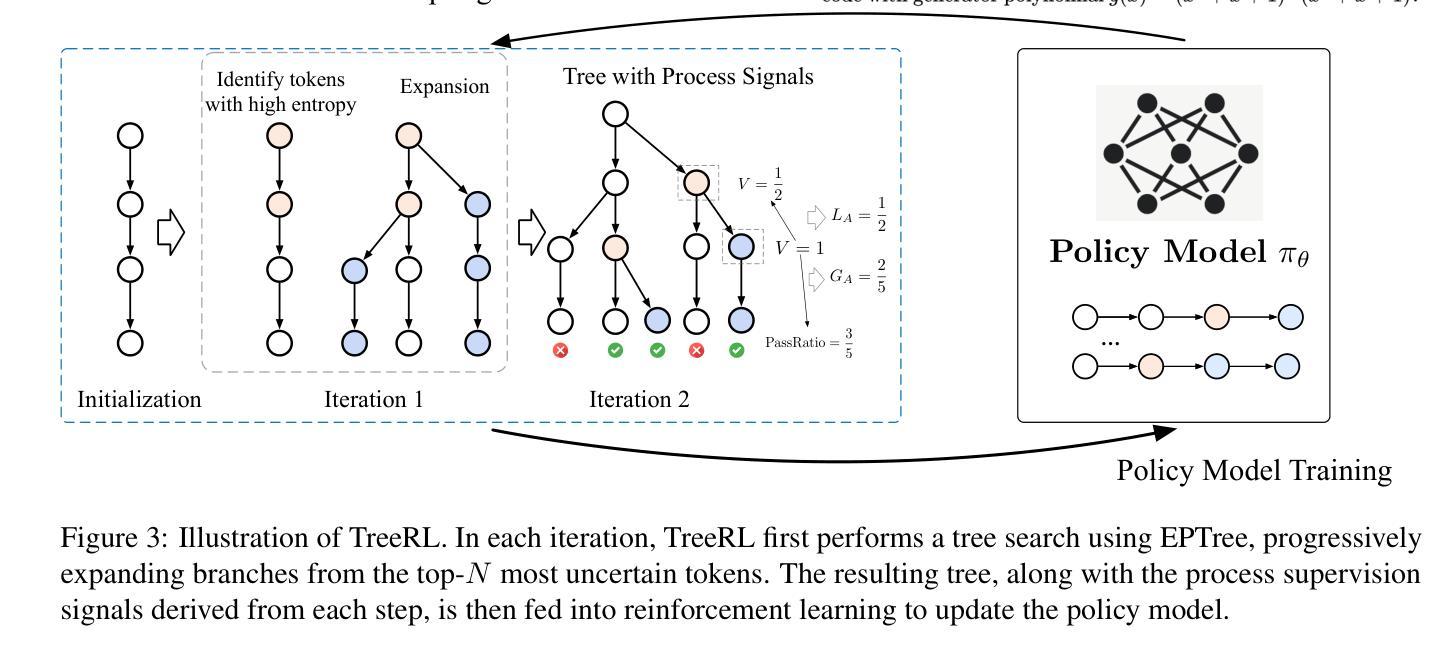
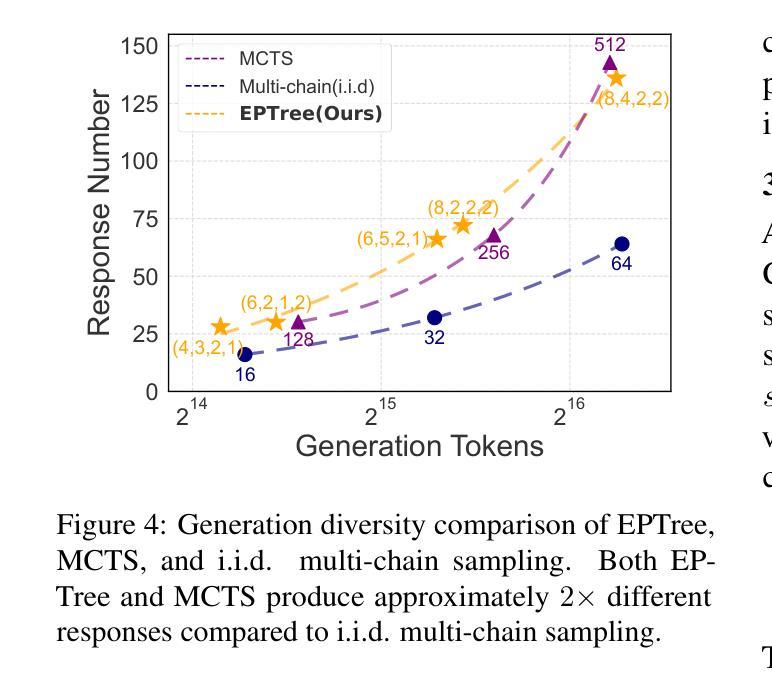
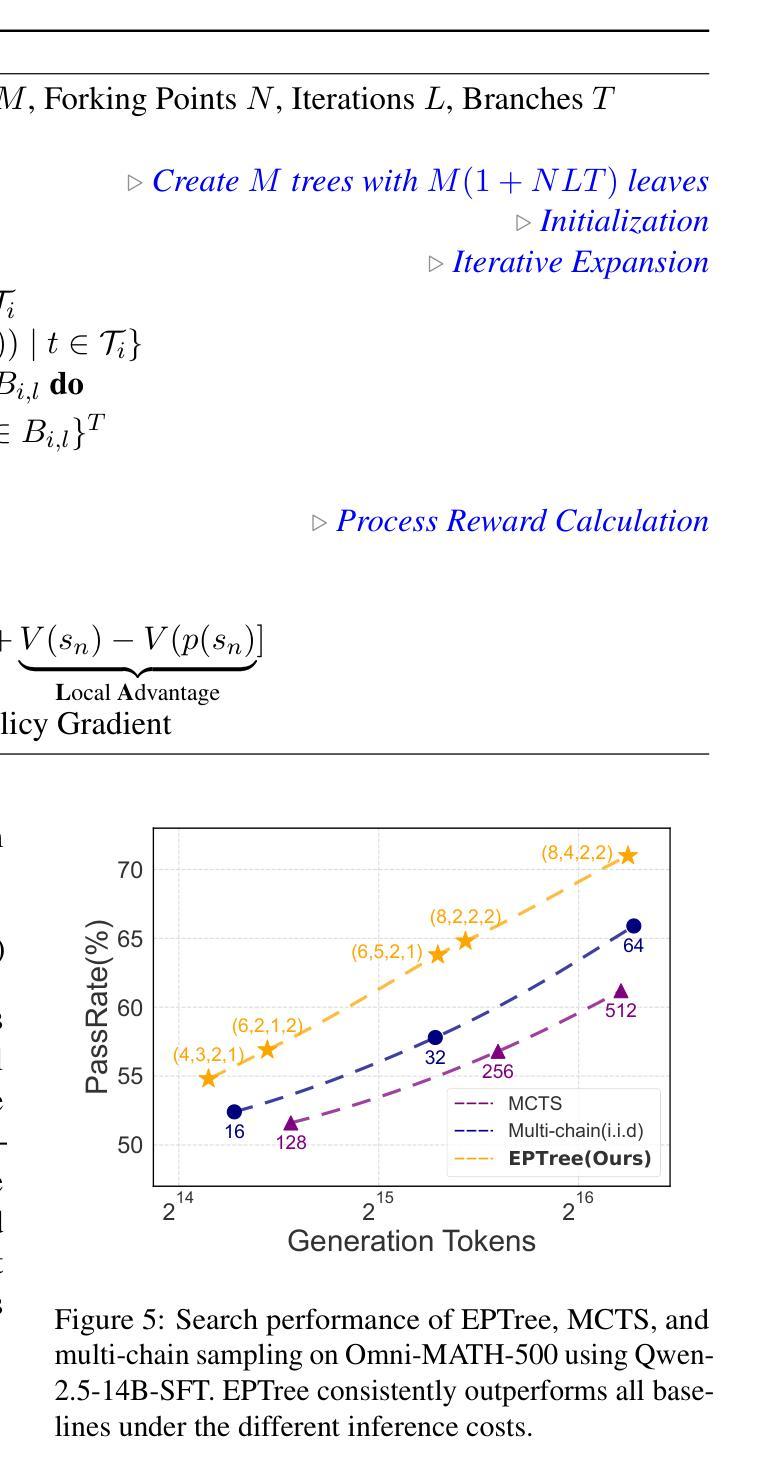
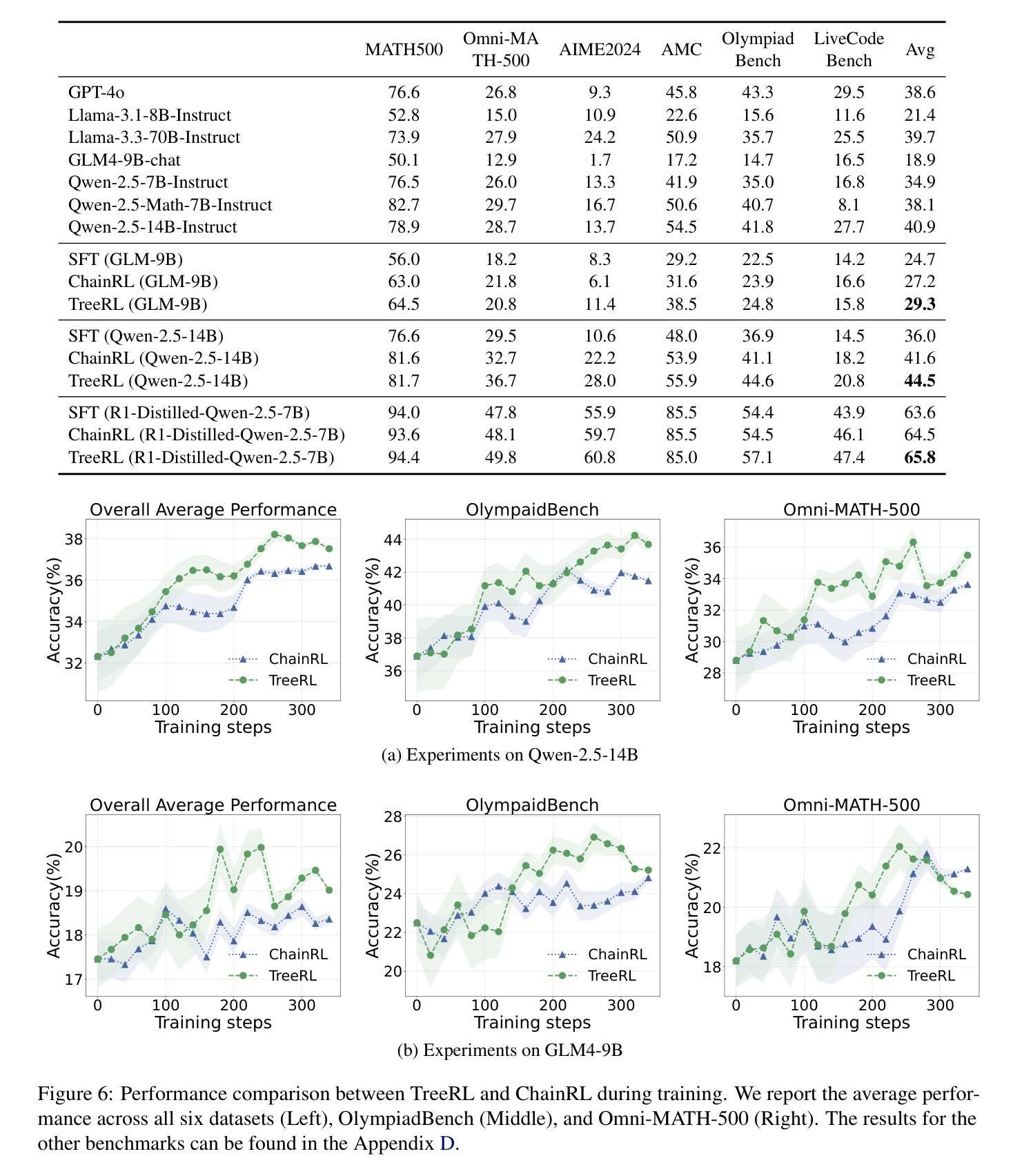
TreeRL: LLM Reinforcement Learning with On-Policy Tree Search
Authors:Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, Yuxiao Dong
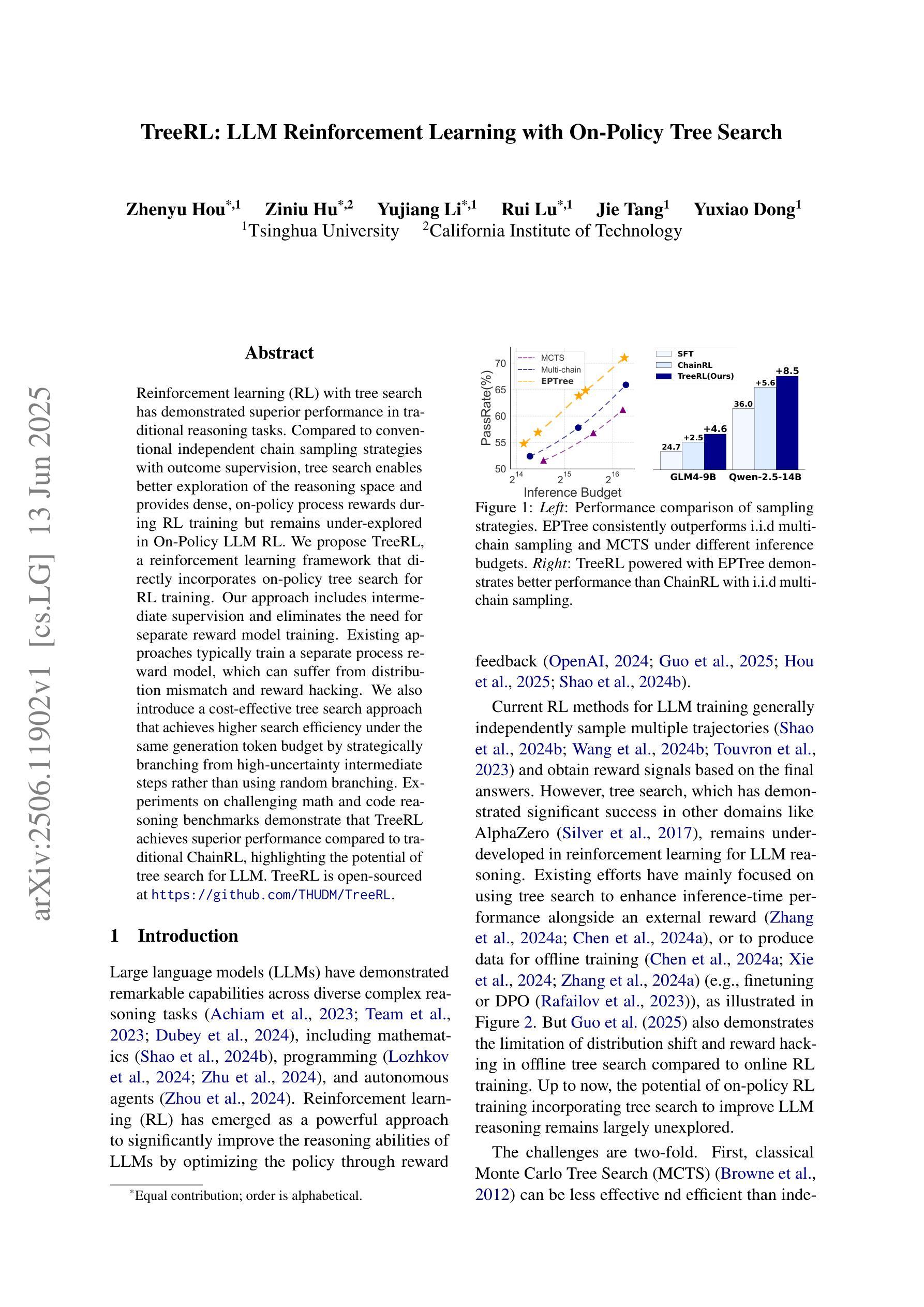
Reinforcement learning (RL) with tree search has demonstrated superior performance in traditional reasoning tasks. Compared to conventional independent chain sampling strategies with outcome supervision, tree search enables better exploration of the reasoning space and provides dense, on-policy process rewards during RL training but remains under-explored in On-Policy LLM RL. We propose TreeRL, a reinforcement learning framework that directly incorporates on-policy tree search for RL training. Our approach includes intermediate supervision and eliminates the need for a separate reward model training. Existing approaches typically train a separate process reward model, which can suffer from distribution mismatch and reward hacking. We also introduce a cost-effective tree search approach that achieves higher search efficiency under the same generation token budget by strategically branching from high-uncertainty intermediate steps rather than using random branching. Experiments on challenging math and code reasoning benchmarks demonstrate that TreeRL achieves superior performance compared to traditional ChainRL, highlighting the potential of tree search for LLM. TreeRL is open-sourced at https://github.com/THUDM/TreeRL.
强化学习(RL)结合树搜索在传统推理任务中表现出了卓越的性能。与具有结果监督的常规独立链采样策略相比,树搜索能够更好地探索推理空间,并在RL训练过程中提供密集的在策略过程奖励,但在On-Policy LLM RL中仍被较少探索。我们提出了TreeRL,这是一个强化学习框架,直接结合在策略树搜索用于RL训练。我们的方法包括中间监督,消除了对单独奖励模型训练的需要。现有方法通常会训练一个单独的过程奖励模型,这可能会遭受分布不匹配和奖励黑客攻击的问题。我们还介绍了一种具有成本效益的树搜索方法,通过从高不确定性的中间步骤进行策略分支,在相同的生成令牌预算下实现更高的搜索效率,而不是使用随机分支。在具有挑战性的数学和代码推理基准测试上的实验表明,TreeRL相较于传统的ChainRL实现了优越的性能,突出了树搜索在LLM中的潜力。TreeRL已在https://github.com/THUDM/TreeRL开源。
论文及项目相关链接
PDF Accepted to ACL 2025 main conference
Summary
树搜索强化学习(TreeRL)在传统推理任务中表现出卓越性能。与传统独立的链采样策略相比,树搜索能够更好地探索推理空间,并在RL训练过程中提供密集的、在线策略过程奖励。我们提出TreeRL,一个直接整合在线策略树搜索的强化学习框架,用于RL训练。此方法包含中间监督,无需单独训练奖励模型,解决了分布不匹配和奖励作弊问题。我们还引入了一种高效的树搜索方法,在相同的生成令牌预算下,通过从高不确定性的中间步骤进行策略性分支,提高搜索效率。在具有挑战性的数学和代码推理基准测试上,TreeRL相较于传统的ChainRL实现了优越的性能,突显了树搜索在大型语言模型中的潜力。
Key Takeaways
- TreeRL结合树搜索与强化学习,提升传统推理任务性能。
- 与独立链采样策略相比,树搜索能更有效地探索推理空间。
- TreeRL提供密集的在线策略过程奖励,改善RL训练。
- TreeRL结合中间监督,无需单独训练奖励模型,解决分布不匹配和奖励作弊问题。
- 引入高效树搜索方法,提高搜索效率。
- TreeRL在挑战性的数学和代码推理基准测试中表现优越。
点此查看论文截图
MTabVQA: Evaluating Multi-Tabular Reasoning of Language Models in Visual Space
Authors:Anshul Singh, Chris Biemann, Jan Strich
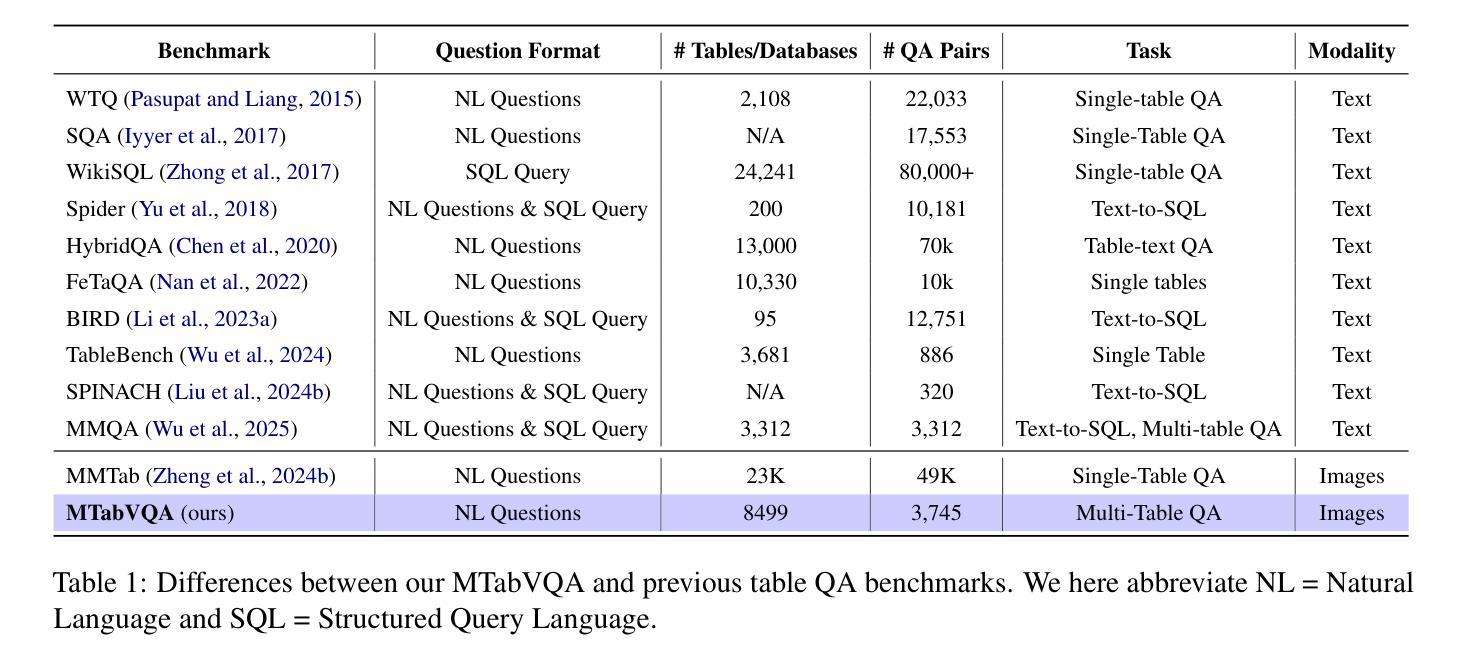
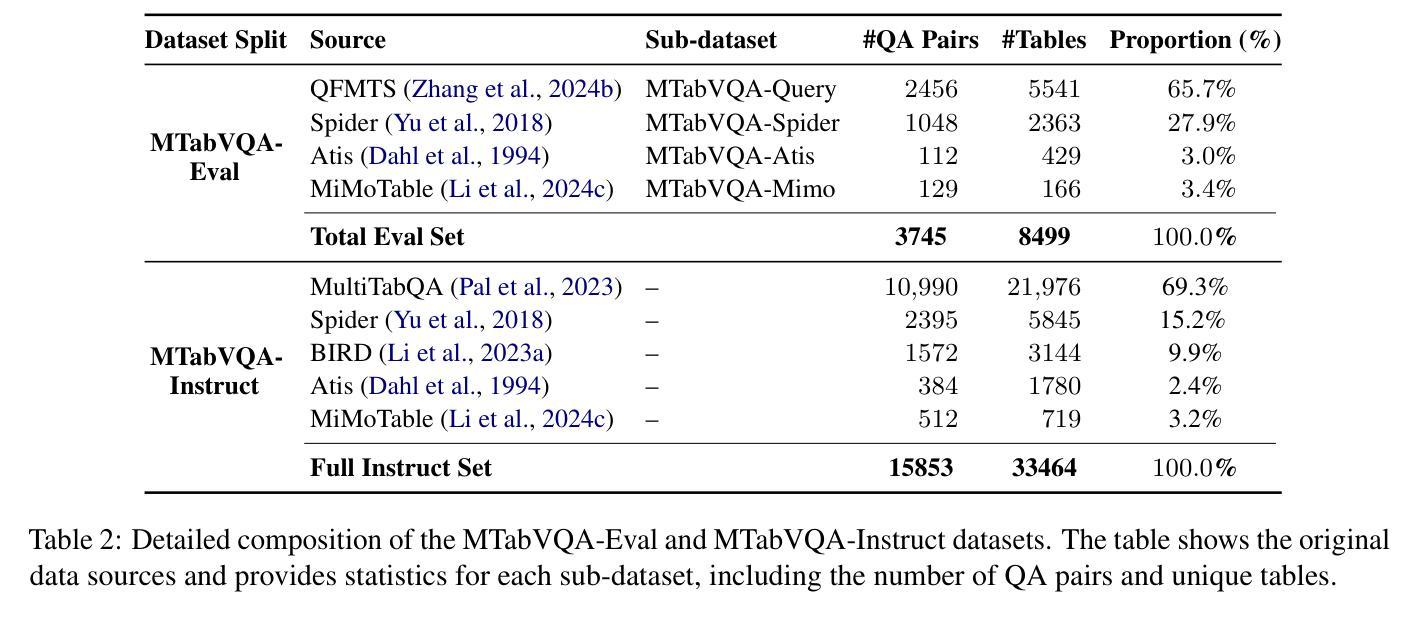
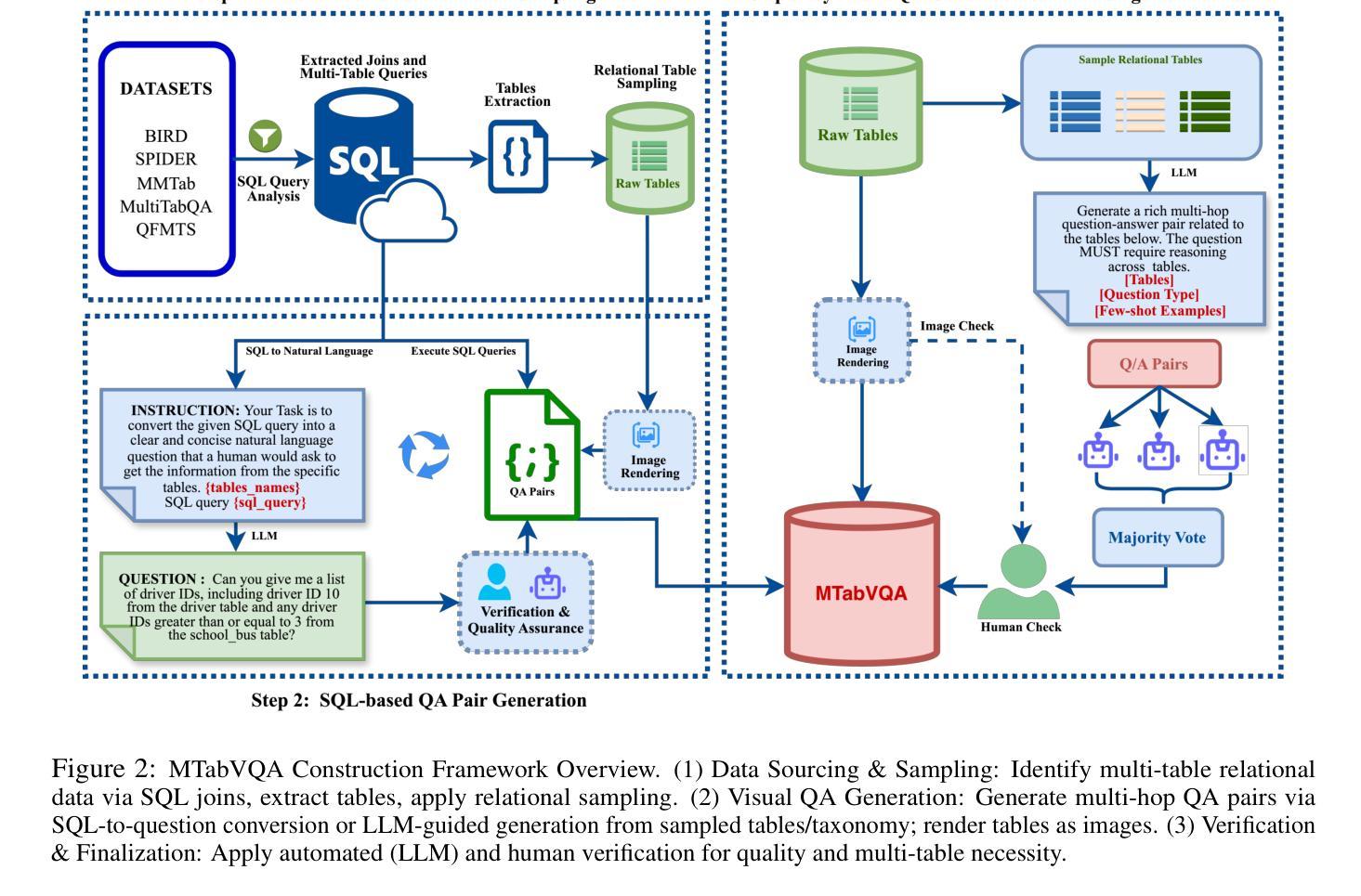
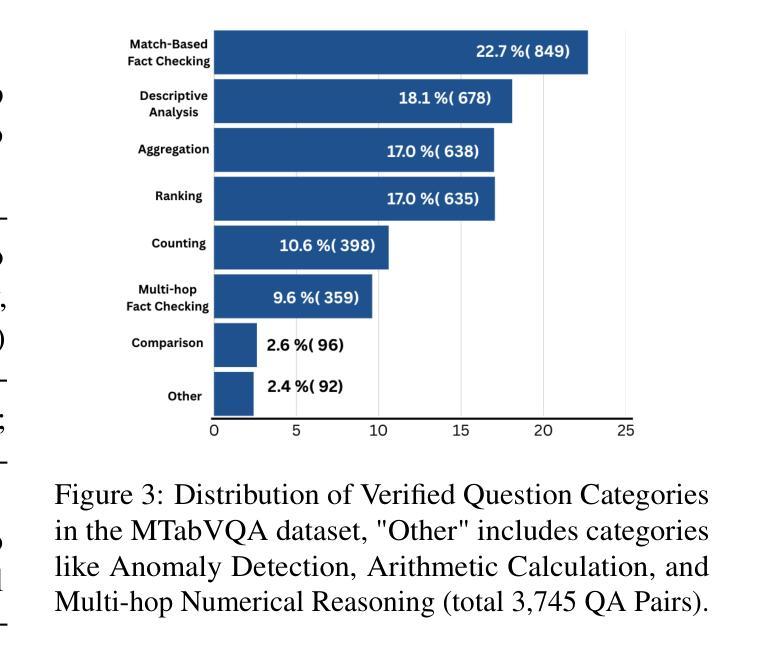
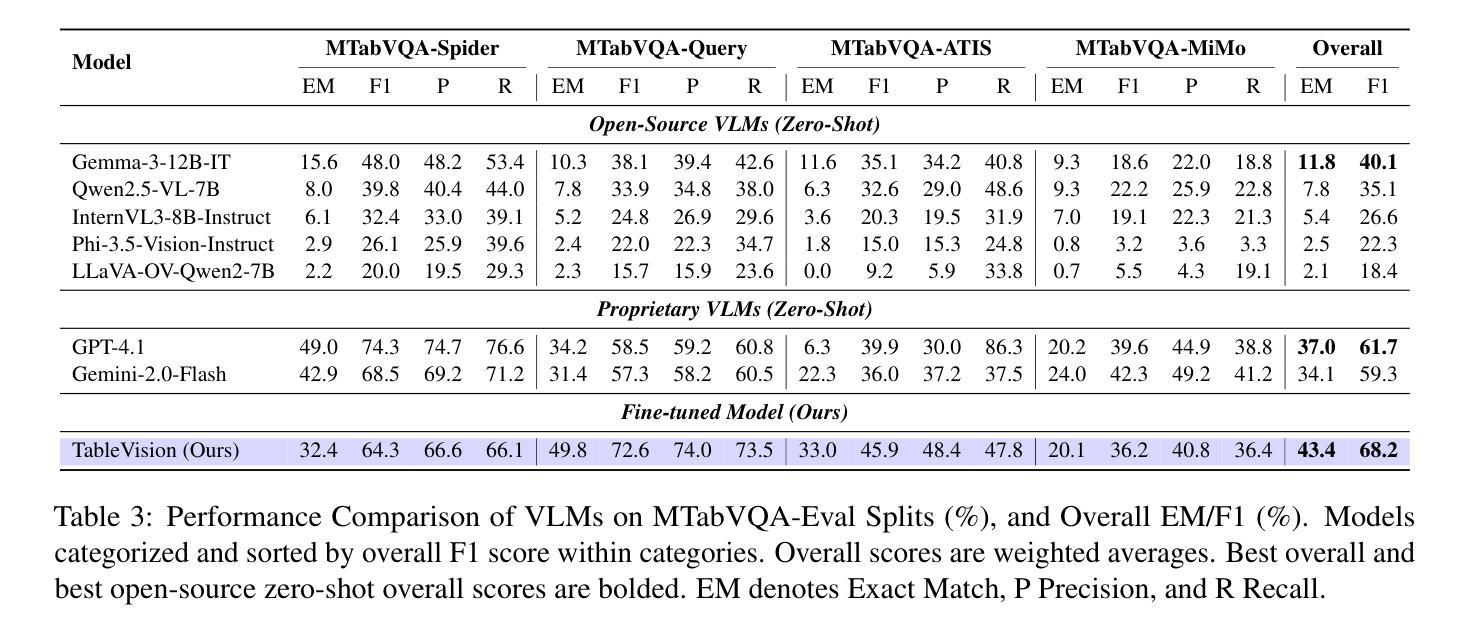
Vision-Language Models (VLMs) have demonstrated remarkable capabilities in interpreting visual layouts and text. However, a significant challenge remains in their ability to interpret robustly and reason over multi-tabular data presented as images, a common occurrence in real-world scenarios like web pages and digital documents. Existing benchmarks typically address single tables or non-visual data (text/structured). This leaves a critical gap: they don’t assess the ability to parse diverse table images, correlate information across them, and perform multi-hop reasoning on the combined visual data. We introduce MTabVQA, a novel benchmark specifically designed for multi-tabular visual question answering to bridge that gap. MTabVQA comprises 3,745 complex question-answer pairs that necessitate multi-hop reasoning across several visually rendered table images. We provide extensive benchmark results for state-of-the-art VLMs on MTabVQA, revealing significant performance limitations. We further investigate post-training techniques to enhance these reasoning abilities and release MTabVQA-Instruct, a large-scale instruction-tuning dataset. Our experiments show that fine-tuning VLMs with MTabVQA-Instruct substantially improves their performance on visual multi-tabular reasoning. Code and dataset (https://huggingface.co/datasets/mtabvqa/MTabVQA-Eval) are available online (https://anonymous.4open.science/r/MTabVQA-EMNLP-B16E).
视觉语言模型(VLMs)在解读视觉布局和文本方面表现出了卓越的能力。然而,在解读并推理以图像形式呈现的多表格数据方面,仍存在重大挑战。这在网页和数字文档等现实场景中是很常见的情况。现有的基准测试通常针对单表或非视觉数据(文本/结构化数据)。这就出现了一个关键的空白:它们无法评估解析多种表格图像、跨表关联信息以及在合并的视觉数据上进行多步推理的能力。为了弥补这一空白,我们引入了MTabVQA,这是一个专门用于多表格视觉问答的新型基准测试。MTabVQA包含3745个复杂的问题答案对,这些问题需要在多个可视化的表格图像上进行多步推理。我们提供了关于MTabVQA的最先进的VLMs的基准测试结果,揭示了显著的性能局限。我们还研究了后训练技术来提高这些推理能力,并发布了MTabVQA-Instruct大规模指令调整数据集。我们的实验表明,使用MTabVQA-Instruct微调VLMs可以显著提高其在视觉多表格推理方面的性能。代码和数据集(https://huggingface.co/datasets/mtabvqa/MTabVQA-Eval)可在网上找到(https://anonymous.4open.science/r/MTabVQA-EMNLP-B16E)。
论文及项目相关链接
Summary
本文介绍了视觉语言模型(VLMs)在处理多表格图像数据时的挑战。现有的基准测试通常只针对单表格或非视觉数据,无法评估模型解析多样化表格图像、跨表格关联信息以及在合并的视觉数据上进行多跳推理的能力。为此,文章提出了MTabVQA基准测试,专门用于多表格视觉问答,包含3745个需要进行多跳推理的复杂问答对。文章还提供了先进VLMs在MTabVQA上的基准测试结果,并探讨了增强推理能力的后训练技术,同时发布了大规模指令调整数据集MTabVQA-Instruct。实验表明,使用MTabVQA-Instruct微调VLMs能显著提高其在视觉多表格推理上的性能。
Key Takeaways
- VLMs在处理多表格图像数据时面临挑战,现有基准测试无法评估模型在解析多样化表格图像、跨表格关联信息以及多跳推理方面的能力。
- 引入MTabVQA基准测试,专门用于多表格视觉问答,包含复杂问答对,需要多跳推理。
- 先进VLMs在MTabVQA上的基准测试结果显示存在性能局限。
- 探讨了增强VLMs推理能力的后训练技术。
- 发布了大规模指令调整数据集MTabVQA-Instruct,用于微调VLMs。
- 使用MTabVQA-Instruct微调能显著提高VLMs在视觉多表格推理上的性能。
点此查看论文截图

EasyARC: Evaluating Vision Language Models on True Visual Reasoning
Authors:Mert Unsal, Aylin Akkus
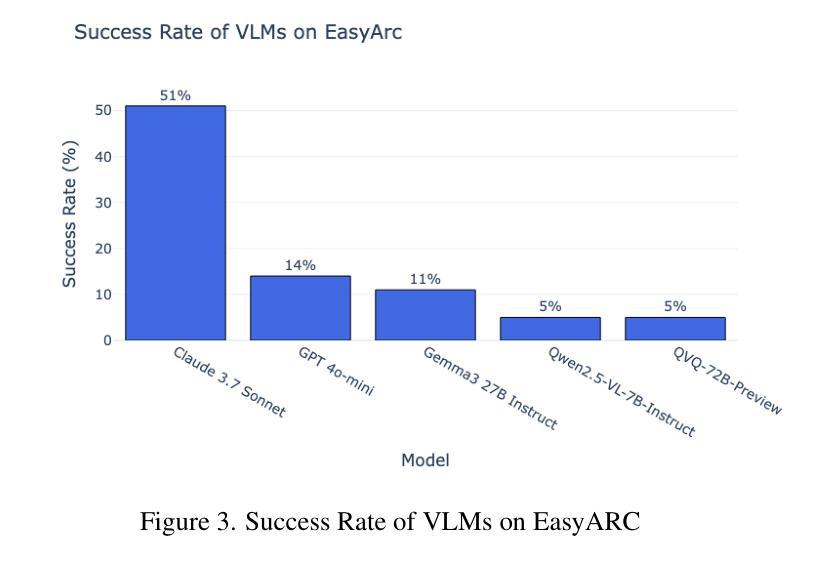
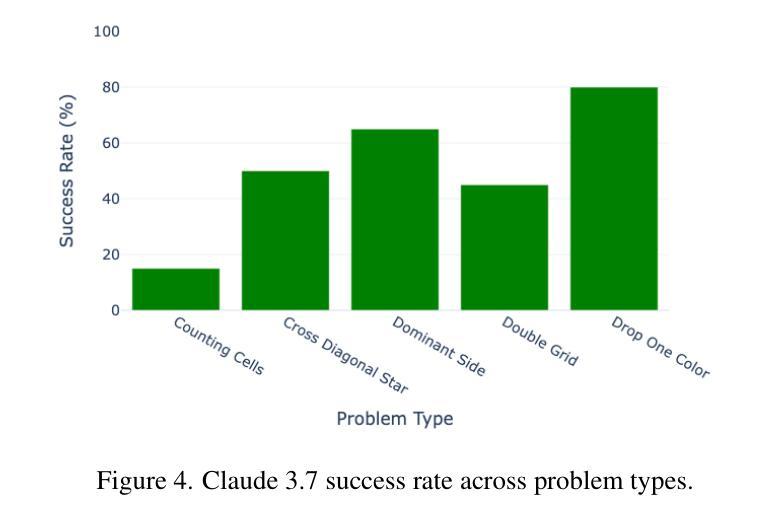
Building on recent advances in language-based reasoning models, we explore multimodal reasoning that integrates vision and text. Existing multimodal benchmarks primarily test visual extraction combined with text-based reasoning, lacking true visual reasoning with more complex interactions between vision and language. Inspired by the ARC challenge, we introduce EasyARC, a vision-language benchmark requiring multi-image, multi-step reasoning, and self-correction. EasyARC is procedurally generated, fully verifiable, and scalable, making it ideal for reinforcement learning (RL) pipelines. The generators incorporate progressive difficulty levels, enabling structured evaluation across task types and complexities. We benchmark state-of-the-art vision-language models and analyze their failure modes. We argue that EasyARC sets a new standard for evaluating true reasoning and test-time scaling capabilities in vision-language models. We open-source our benchmark dataset and evaluation code.
基于语言推理模型的最新进展,我们探索了融合视觉和文本的多模态推理。现有的多模态基准测试主要测试了与文本推理相结合的视觉提取,缺乏在视觉和语言之间更复杂交互的真正视觉推理。受ARC挑战的启发,我们引入了EasyARC,这是一个要求多图像、多步骤推理和自行校正的视听语言基准测试。EasyARC是程序生成的,可完全验证和扩展,因此非常适合用于强化学习(RL)管道。生成器融入渐进的难度级别,能够针对任务类型和复杂性进行结构化评估。我们评估了最先进的声音图像语言模型,分析了它们的故障模式。我们认为,EasyARC为评估视听语言模型中的真正推理能力和测试时扩展能力设定了新的标准。我们公开了基准数据集和评估代码的开源版本。
论文及项目相关链接
PDF CVPR2025 Workshop on Test-time Scaling for Computer Vision
Summary
本文探索了基于语言的多模态推理模型,该模型结合了视觉和文本。针对当前多模态基准测试主要集中在文本基础上的视觉提取推理上,缺乏真正的视觉推理以及视觉和语言之间更复杂交互的问题,我们受到ARC挑战的启发,引入了EasyARC,这是一个需要多图像、多步骤推理和自我修正的视语言基准测试。EasyARC是程序生成的,具有完全可验证性和可扩展性,非常适合强化学习管道。我们的生成器融入渐进的难度级别,能够对任务类型和复杂性进行结构化评估。我们对最先进的视语言模型进行了基准测试,分析了它们的失败模式。我们认为,EasyARC为评估视语言模型中的真正推理和测试时标度能力设定了新的标准。我们公开了基准测试数据集和评估代码。
Key Takeaways
- 文章介绍了基于语言的多模态推理模型,该模型结合了视觉和文本。
- 当前多模态基准测试主要关注视觉提取结合文本基础的推理,缺乏真正的视觉推理和视觉与语言之间的复杂交互。
- 提出了EasyARC基准测试,要求多图像、多步骤推理和自我修正,以评估视语言模型的真正推理能力。
- EasyARC是程序生成的、完全可验证和可扩展的,适合强化学习管道。
- 生成器具有渐进的难度级别,可进行结构化评估,涵盖任务类型和复杂性。
- 文章对最先进的视语言模型进行了基准测试,并分析了其失败模式。
点此查看论文截图


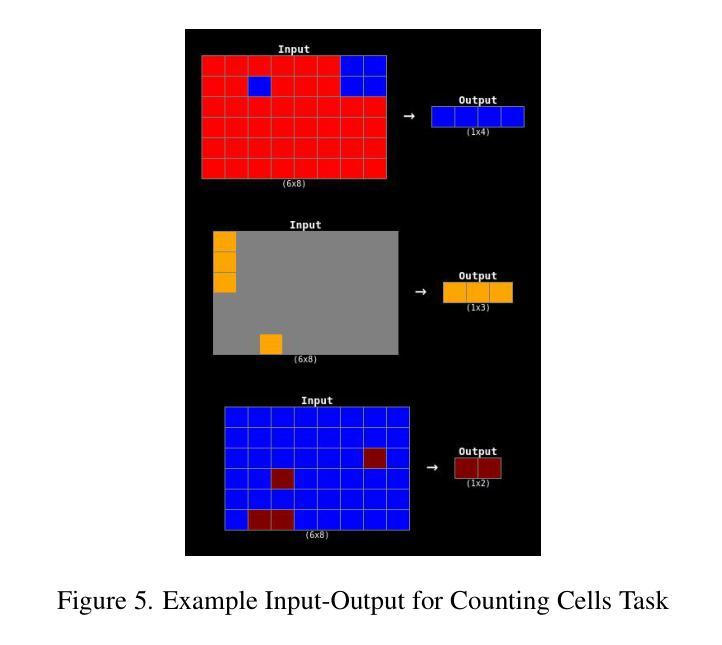
RAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Authors:Yu Wang, Shiwan Zhao, Ming Fan, Zhihu Wang, Yubo Zhang, Xicheng Zhang, Zhengfan Wang, Heyuan Huang, Ting Liu
The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
通过检索增强生成(RAG)整合外部知识,已成为提高大型语言模型(LLM)在知识密集型任务上的表现的基础。然而,现有的RAG范式往往忽视了应用知识的认知步骤,导致检索到的事实与特定任务的推理之间存在差距。在这项工作中,我们介绍了RAG+,这是一个有原则的和模块化的扩展,它显式地将应用感知推理纳入RAG管道。RAG+构建了一个由知识和对齐的应用示例组成的双语料库,这些示例可以是手动或自动创建的,并在推理过程中共同检索。这种设计使LLM不仅能够访问相关信息,而且还能够在结构化、目标导向的推理过程中应用它。在多模型进行的数学、法律和医学领域的实验表明,RAG+持续优于标准RAG变体,平均改进3-5%,在复杂场景中的峰值增益高达7.5%。通过桥接检索和可操作的应用,RAG+为知识整合提供了一个更认知基础的框架,朝着更具解释性和能力的LLM迈出了一步。
论文及项目相关链接
Summary
本文介绍了基于检索增强的生成(RAG)的改进版本——RAG+,该模型能够明确地融入应用感知推理。通过构建包含知识和对齐应用示例的双重语料库,并在推理时联合检索,RAG+不仅使语言模型能够访问相关信息,还能在结构化的目标导向推理过程中应用这些知识。实验表明,RAG+在多个模型上表现优于标准RAG变体,平均提高了3-5%的性能,在复杂场景下最高提升了7.5%。这为知识整合提供了一个更认知化的框架,使语言模型更具解释性和能力。
Key Takeaways
- RAG+ 是基于 Retrieval-Augmented Generation (RAG) 的改进版本,旨在明确融入应用感知推理。
- RAG+ 通过构建包含知识和对齐应用示例的双重语料库来强化模型的能力。
- 该双重语料库可以通过手动或自动的方式创建。
- 在推理过程中,RAG+ 能够联合检索知识和应用示例。
- RAG+ 使语言模型能够不仅获取相关信息,还能在结构化的、目标导向的推理过程中应用知识。
- 实验表明,RAG+ 在多个模型和多个领域(如数学、法律和医学)中表现优异,平均提高了3-5%的性能。
点此查看论文截图

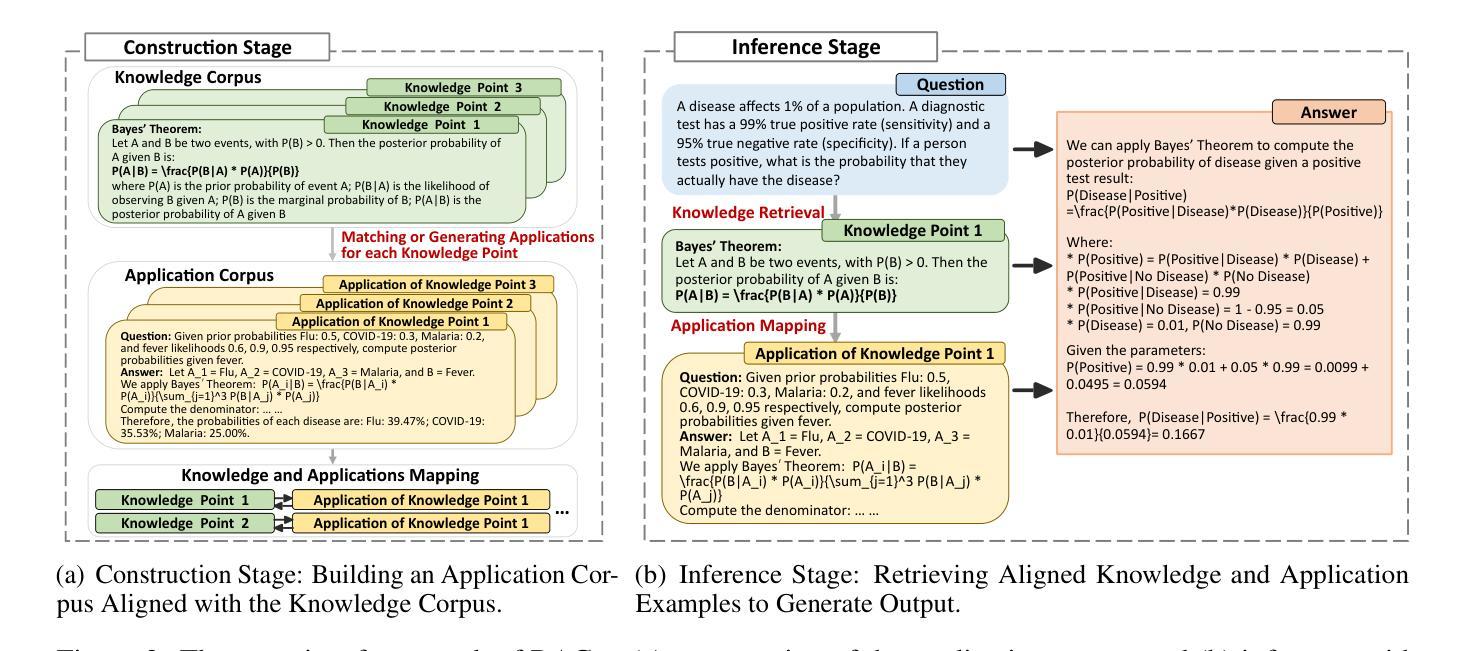

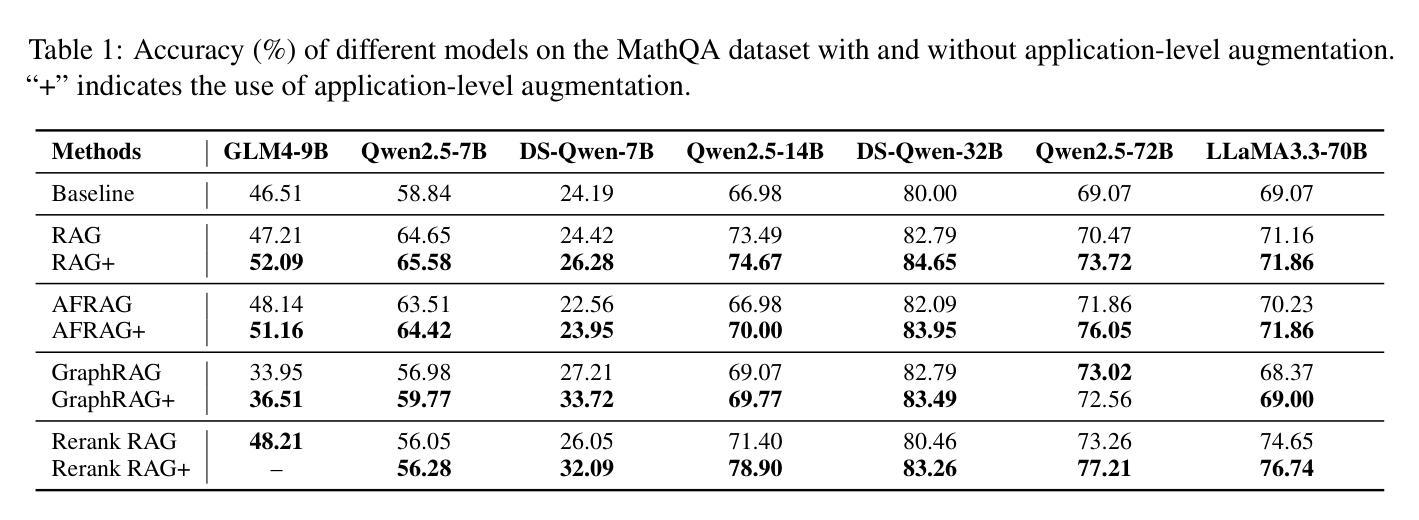
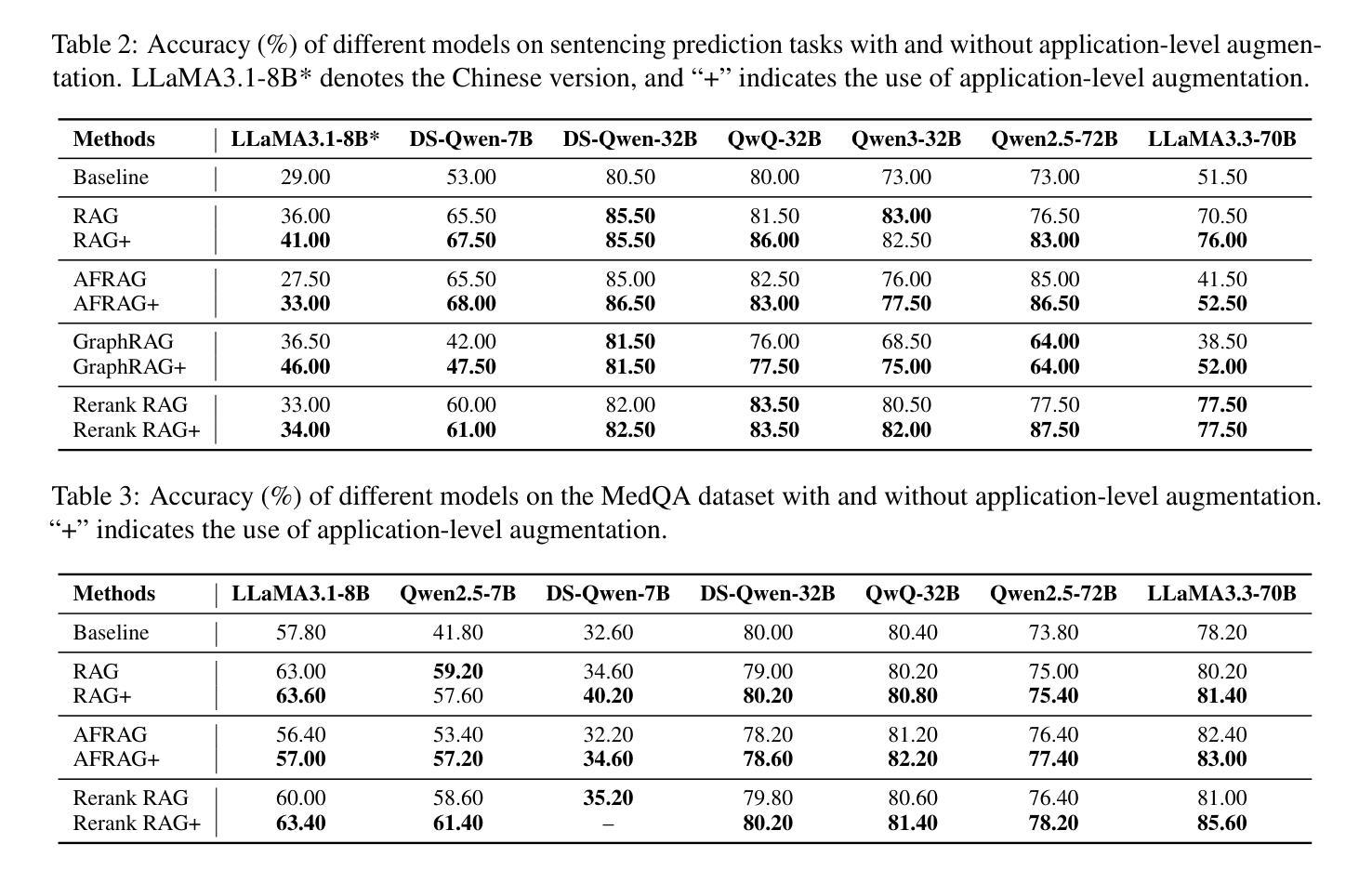
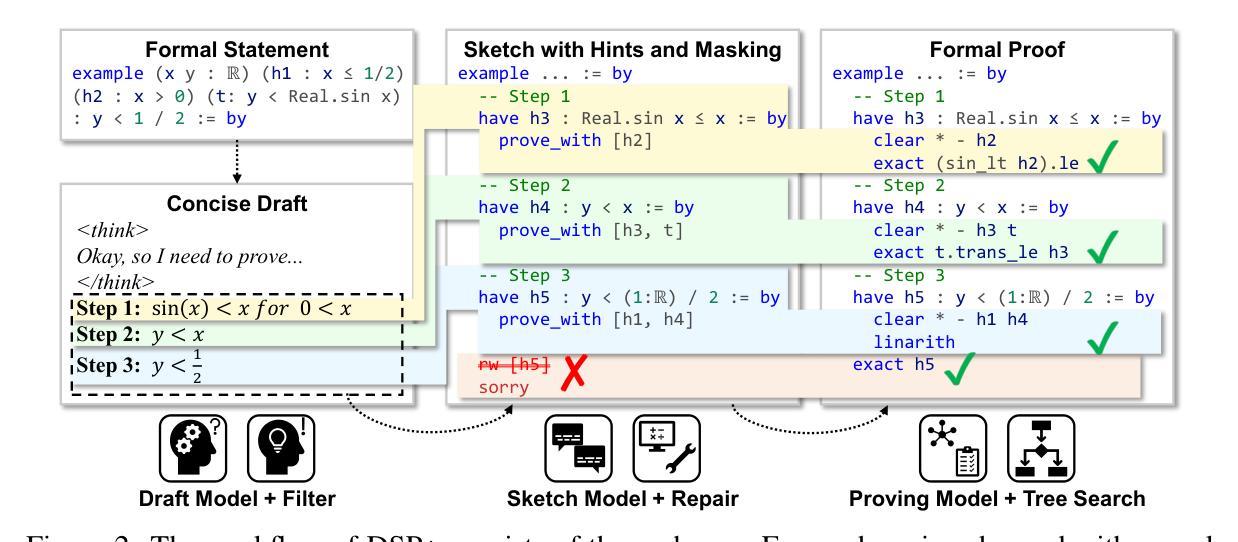
Reviving DSP for Advanced Theorem Proving in the Era of Reasoning Models
Authors:Chenrui Cao, Liangcheng Song, Zenan Li, Xinyi Le, Xian Zhang, Hui Xue, Fan Yang
Recent advancements, such as DeepSeek-Prover-V2-671B and Kimina-Prover-Preview-72B, demonstrate a prevailing trend in leveraging reinforcement learning (RL)-based large-scale training for automated theorem proving. Surprisingly, we discover that even without any training, careful neuro-symbolic coordination of existing off-the-shelf reasoning models and tactic step provers can achieve comparable performance. This paper introduces \textbf{DSP+}, an improved version of the Draft, Sketch, and Prove framework, featuring a \emph{fine-grained and integrated} neuro-symbolic enhancement for each phase: (1) In the draft phase, we prompt reasoning models to generate concise natural-language subgoals to benefit the sketch phase, removing thinking tokens and references to human-written proofs; (2) In the sketch phase, subgoals are autoformalized with hypotheses to benefit the proving phase, and sketch lines containing syntactic errors are masked according to predefined rules; (3) In the proving phase, we tightly integrate symbolic search methods like Aesop with step provers to establish proofs for the sketch subgoals. Experimental results show that, without any additional model training or fine-tuning, DSP+ solves 80.7%, 32.8%, and 24 out of 644 problems from miniF2F, ProofNet, and PutnamBench, respectively, while requiring fewer budgets compared to state-of-the-arts. DSP+ proves \texttt{imo_2019_p1}, an IMO problem in miniF2F that is not solved by any prior work. Additionally, DSP+ generates proof patterns comprehensible by human experts, facilitating the identification of formalization errors; For example, eight wrongly formalized statements in miniF2F are discovered. Our results highlight the potential of classical reasoning patterns besides the RL-based training. All components will be open-sourced.
最近的进展,如DeepSeek-Prover-V2-671B和Kimina-Prover-Preview-72B,显示出利用基于强化学习(RL)的大规模训练进行自动定理证明的一种流行趋势。令人惊讶的是,我们发现即使没有任何训练,通过现有现成的推理模型和战术步骤证明器的细致神经符号协调,也可以实现相当的性能。本文介绍了DSP+,这是Draft、Sketch和Prove框架的改进版,为每一阶段提供了精细粒度和集成的神经符号增强:(1)在草稿阶段,我们鼓励推理模型生成简洁的自然语言子目标,以有利于草图阶段的进行,同时移除思考标记和参考人为编写的证明;(2)在草图阶段,子目标会自动形式化,以有利于证明阶段的进行,并且根据预定的规则掩盖含有语法错误的草图线;(3)在证明阶段,我们紧密集成诸如Aesop之类的符号搜索方法与步骤证明器,以建立草图子目标的证明。实验结果表明,无需任何额外的模型训练或微调,DSP+解决了miniF2F中的80.7%、ProofNet中的32.8%以及PutnamBench中的24个问题。相较于现有技术,其成本更低。DSP+证明了miniF2F中的`imo_2019_p1’这一IMO问题,此前没有任何工作能够解决该问题。此外,DSP+生成了人类专家可理解的证明模式,有助于识别形式化错误;例如,在miniF2F中发现了八条错误的形式化陈述。我们的研究结果突显了除RL训练外的经典推理模式的潜力。所有组件都将开源。
论文及项目相关链接
PDF 31 pages. Associated code and results are available at https://github.com/microsoft/DSP-Plus
Summary
这篇论文介绍了DSP+的诞生背景、核心方法和实验结果。在无需额外训练的情况下,通过精细的神经符号协调,DSP+实现了与先进自动化定理证明器相当的性能。DSP+优化了Draft、Sketch和Prove三个阶段,并成功解决了多个问题。此外,它还生成了人类专家可理解的证明模式,并发现了形式化错误。该论文强调了经典推理模式的重要性,并展示了其潜力。所有组件都将开源。
Key Takeaways
- 最新研究利用强化学习(RL)进行大规模训练,实现了自动化定理证明的进步。
- DSP+是Draft、Sketch和Prove框架的改进版本,每个阶段都有精细的神经符号增强。
- 在无需任何额外训练的情况下,DSP+实现了与先进自动化定理证明器相当的性能。
- DSP+通过自动生成简洁的自然语言子目标、自动形式化子目标以及紧密集成符号搜索方法来建立证明。
- DSP+成功解决了多个问题集的问题,并生成了人类专家可理解的证明模式。
- DSP+发现了形式化错误,并强调了经典推理模式的重要性。
点此查看论文截图

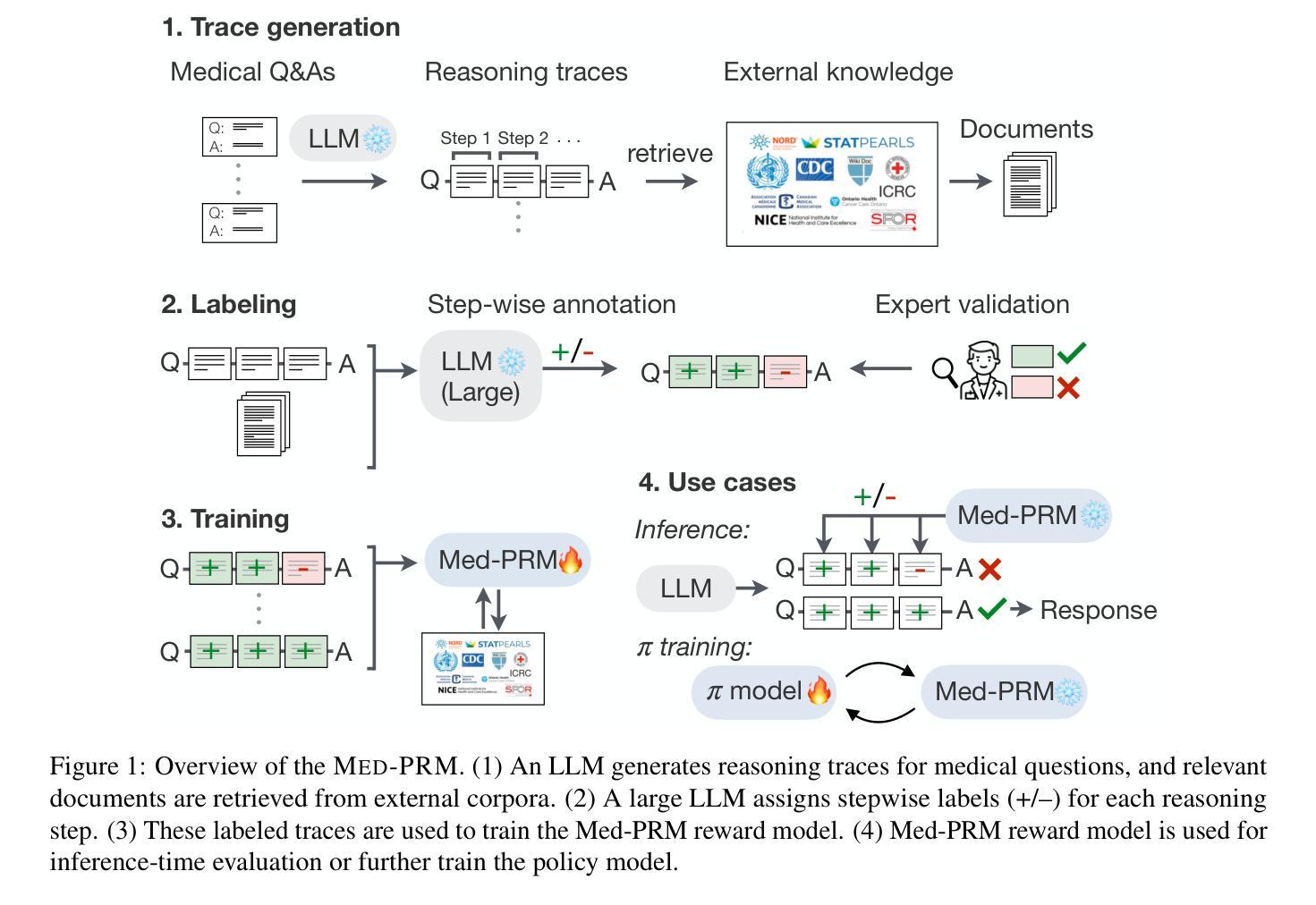
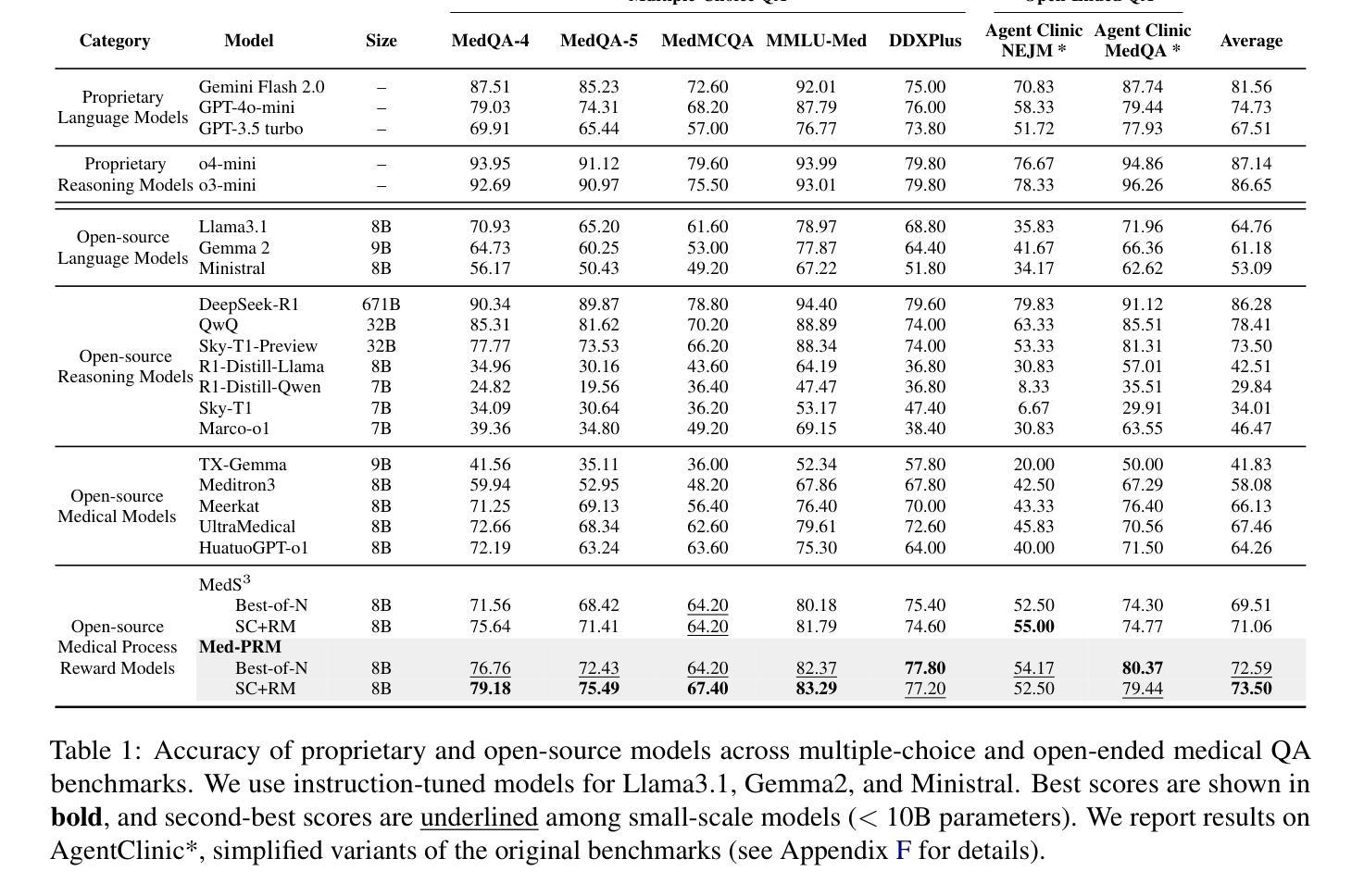
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards
Authors:Jaehoon Yun, Jiwoong Sohn, Jungwoo Park, Hyunjae Kim, Xiangru Tang, Yanjun Shao, Yonghoe Koo, Minhyeok Ko, Qingyu Chen, Mark Gerstein, Michael Moor, Jaewoo Kang
Large language models have shown promise in clinical decision making, but current approaches struggle to localize and correct errors at specific steps of the reasoning process. This limitation is critical in medicine, where identifying and addressing reasoning errors is essential for accurate diagnosis and effective patient care. We introduce Med-PRM, a process reward modeling framework that leverages retrieval-augmented generation to verify each reasoning step against established medical knowledge bases. By verifying intermediate reasoning steps with evidence retrieved from clinical guidelines and literature, our model can precisely assess the reasoning quality in a fine-grained manner. Evaluations on five medical QA benchmarks and two open-ended diagnostic tasks demonstrate that Med-PRM achieves state-of-the-art performance, with improving the performance of base models by up to 13.50% using Med-PRM. Moreover, we demonstrate the generality of Med-PRM by integrating it in a plug-and-play fashion with strong policy models such as Meerkat, achieving over 80% accuracy on MedQA for the first time using small-scale models of 8 billion parameters. Our code and data are available at: https://med-prm.github.io/
大规模语言模型在临床决策中显示出巨大潜力,但当前方法难以在推理过程的特定步骤中定位和纠正错误。在医学领域,这一局限至关重要,识别和解决推理错误对于准确诊断和治疗患者至关重要。我们引入了Med-PRM,这是一种过程奖励建模框架,利用增强检索生成的方法,根据建立医学知识库验证每一步推理。通过从临床指南和文献中检索的证据验证中间推理步骤,我们的模型可以精细地评估推理质量。在五个医疗问答基准测试和两个开放式诊断任务上的评估表明,Med-PRM实现了最先进的性能,使用Med-PRM提高基础模型的性能高达13.5%。此外,通过将Med-PRM以即插即用方式与强大的政策模型(如Meerkat)集成,我们在小规模模型(8亿参数)的MedQA上首次实现了超过80%的准确率。我们的代码和数据可在:https://med-prm.github.io/查看。
论文及项目相关链接
Summary
大型语言模型在临床决策中展现出潜力,但现有方法难以在推理过程的特定步骤中定位和纠正错误。为此,我们提出了Med-PRM框架,它利用检索增强生成的方式,通过对照医学知识库验证每一步推理。该模型能够精细地评估推理质量,通过从临床指南和文献中检索证据来验证中间推理步骤。在五个医学问答基准测试和两项开放式诊断任务上的评估表明,Med-PRM实现了最先进的表现,较基础模型性能提升最多达13.5%。此外,通过将Med-PRM与强大的策略模型(如Meerkat)以插件方式进行集成,我们在小型模型(8亿参数)上首次实现了超过80%的MedQA准确率。我们的代码和数据可在链接找到。
Key Takeaways
- 大型语言模型在临床决策中展现潜力,但存在定位和纠正特定步骤错误的问题。
- Med-PRM框架利用检索增强生成方式,验证每一步推理与医学知识库的对照。
- Med-PRM能够精细评估推理质量,通过从临床指南和文献中检索证据验证中间步骤。
- Med-PRM在五个医学问答基准测试和两项开放式诊断任务上实现最先进表现。
- Med-PRM较基础模型性能提升最多达13.5%,显示出显著改进。
- Med-PRM具有通用性,可与其他强大策略模型(如Meerkat)以插件方式集成。
点此查看论文截图


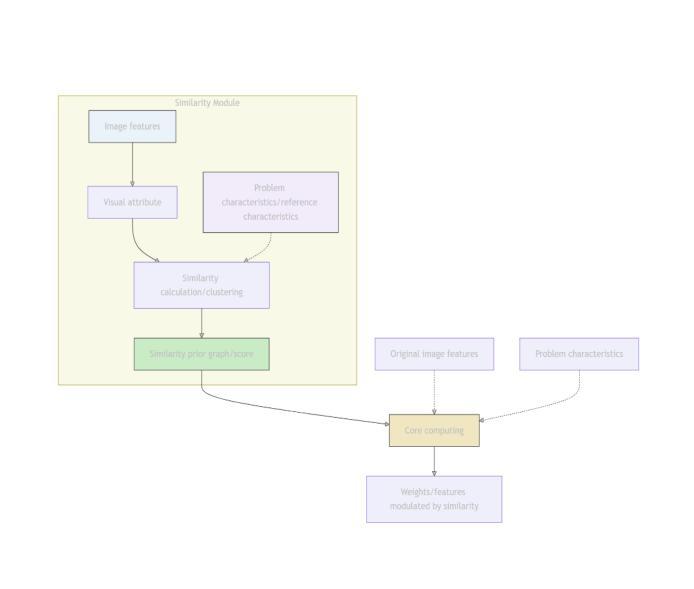
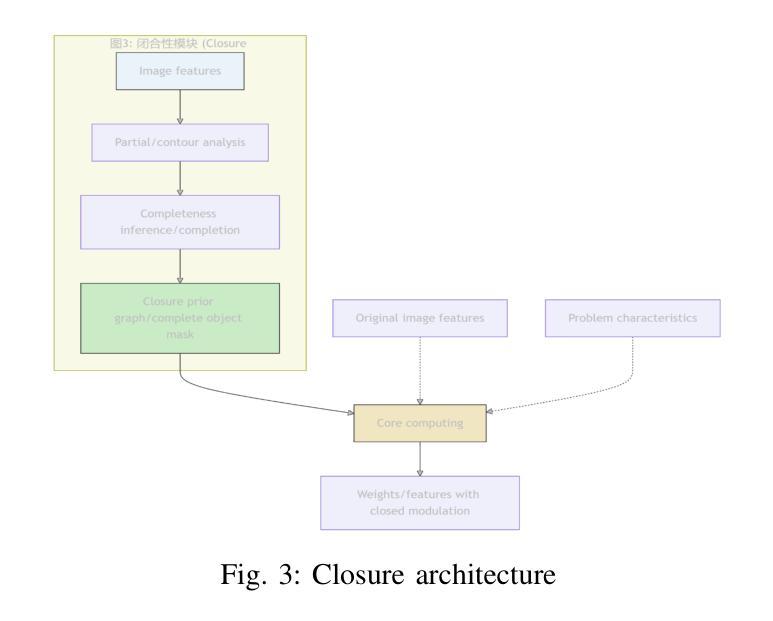
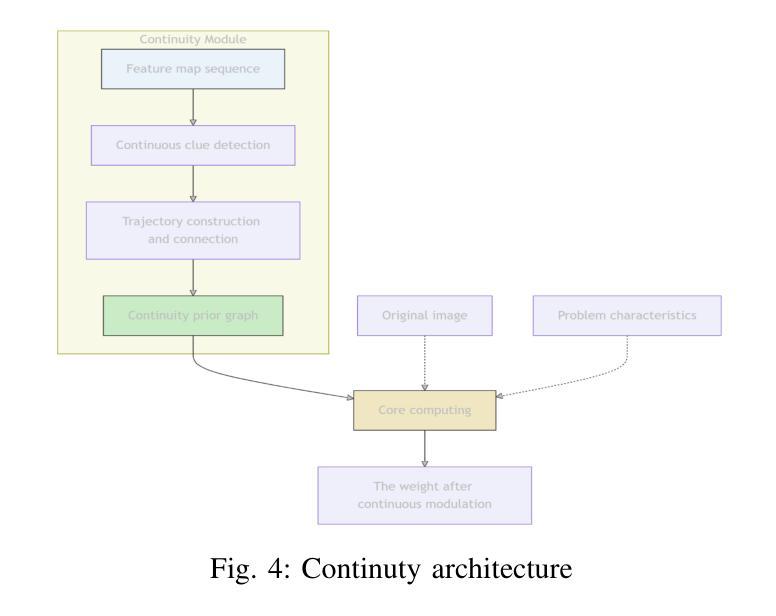
Dynamic Double Space Tower
Authors:Weikai Sun, Shijie Song, Han Wang
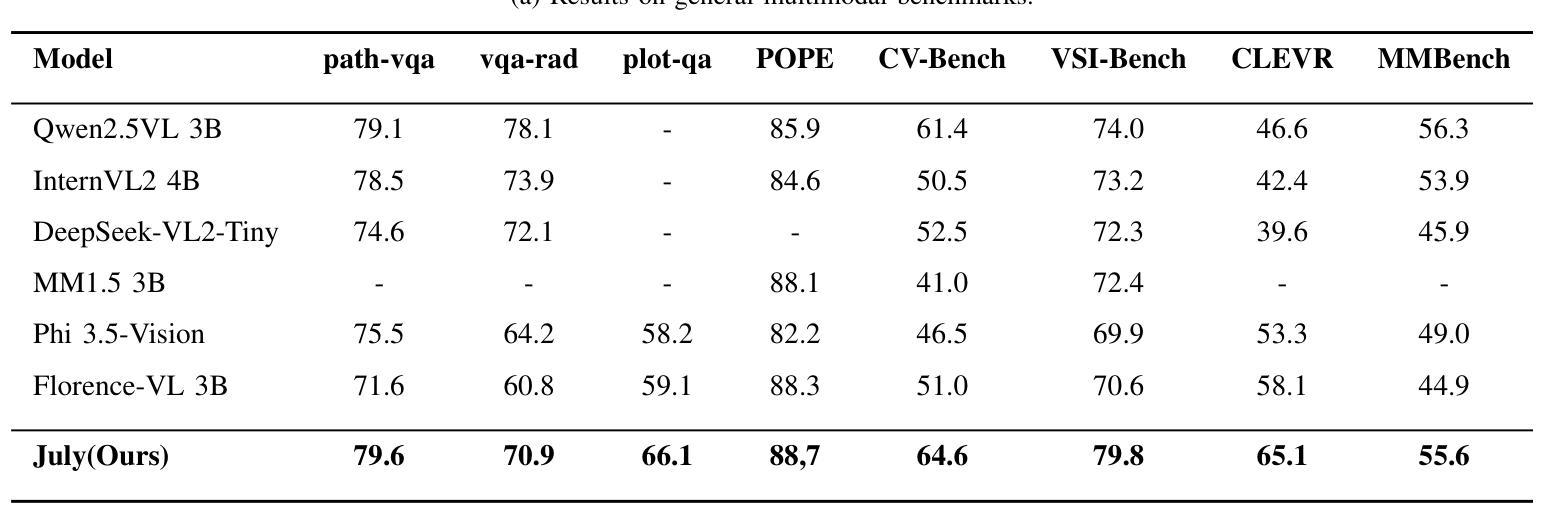
The Visual Question Answering (VQA) task requires the simultaneous understanding of image content and question semantics. However, existing methods often have difficulty handling complex reasoning scenarios due to insufficient cross-modal interaction and capturing the entity spatial relationships in the image.\cite{huang2023adaptive}\cite{liu2021comparing}\cite{guibas2021adaptive}\cite{zhang2022vsa}We studied a brand-new approach to replace the attention mechanism in order to enhance the reasoning ability of the model and its understanding of spatial relationships.Specifically, we propose a dynamic bidirectional spatial tower, which is divided into four layers to observe the image according to the principle of human gestalt vision. This naturally provides a powerful structural prior for the spatial organization between entities, enabling the model to no longer blindly search for relationships between pixels but make judgments based on more meaningful perceptual units. Change from “seeing images” to “perceiving and organizing image content”.A large number of experiments have shown that our module can be used in any other multimodal model and achieve advanced results, demonstrating its potential in spatial relationship processing.Meanwhile, the multimodal visual question-answering model July trained by our method has achieved state-of-the-art results with only 3B parameters, especially on the question-answering dataset of spatial relations.
视觉问答(VQA)任务需要同时理解图像内容和问题语义。然而,现有方法由于跨模态交互不足以及难以捕捉图像中的实体空间关系,往往难以处理复杂的推理场景。\cite{huang2023adaptive}\cite{liu2021comparing}\cite{guibas2021adaptive}\cite{zhang2022vsa}我们研究了一种全新的方法来替代注意力机制,以增强模型的推理能力和其对空间关系的理解。具体来说,我们提出了一种动态双向空间塔,它分为四层,根据人类格式塔视觉原理来观察图像。这为实体之间的空间组织提供了强大的结构先验,使模型不再盲目地搜索像素之间的关系,而是基于更有意义的感知单元进行判断。从“看图像”转变为“感知和组织图像内容”。大量实验表明,我们的模块可以应用于任何其他多模态模型,并取得先进结果,证明了其在空间关系处理中的潜力。同时,使用我们的方法训练的多模态视觉问答模型July,仅使用3B参数就实现了最新结果,尤其在空间关系的问答数据集上表现尤其出色。
论文及项目相关链接
Summary
视觉问答任务需同时理解图像内容与问题语义。然而现有方法处理复杂推理场景时,因跨模态交互不足及图像内实体空间关系捕捉能力有限而表现困难。为提升模型的推理能力及对空间关系的理解,研究了一种新型方法替代注意力机制。我们提出了动态双向空间塔,其分四层依据人类整体观原则观察图像。这为实体间的空间组织提供了强大的结构先验,使模型不再盲目搜索像素间的关系,而基于更有意义的感知单元进行判断。实验表明,该模块可应用于任何其他多模态模型并取得先进结果,尤其在空间关系问答数据集上,使用我们的方法训练的July多模态视觉问答模型仅3B参数即达到最新水平。
Key Takeaways
- 视觉问答任务同时涉及图像内容和问题语义的理解。
- 现有方法在复杂推理场景中存在跨模态交互不足和实体空间关系捕捉能力有限的问题。
- 提出了一种新的方法,通过动态双向空间塔替代注意力机制,以提升模型的推理能力和对空间关系的理解。
- 动态双向空间塔依据人类整体观原则设计,分为四层观察图像。
- 该模块可为实体间的空间组织提供强大的结构先验。
- 模型可基于有意义的感知单元进行判断,不再盲目搜索像素间的关系。
点此查看论文截图

Shapley Machine: A Game-Theoretic Framework for N-Agent Ad Hoc Teamwork
Authors:Jianhong Wang, Yang Li, Samuel Kaski, Jonathan Lawry
Open multi-agent systems are increasingly important in modeling real-world applications, such as smart grids, swarm robotics, etc. In this paper, we aim to investigate a recently proposed problem for open multi-agent systems, referred to as n-agent ad hoc teamwork (NAHT), where only a number of agents are controlled. Existing methods tend to be based on heuristic design and consequently lack theoretical rigor and ambiguous credit assignment among agents. To address these limitations, we model and solve NAHT through the lens of cooperative game theory. More specifically, we first model an open multi-agent system, characterized by its value, as an instance situated in a space of cooperative games, generated by a set of basis games. We then extend this space, along with the state space, to accommodate dynamic scenarios, thereby characterizing NAHT. Exploiting the justifiable assumption that basis game values correspond to a sequence of n-step returns with different horizons, we represent the state values for NAHT in a form similar to $\lambda$-returns. Furthermore, we derive Shapley values to allocate state values to the controlled agents, as credits for their contributions to the ad hoc team. Different from the conventional approach to shaping Shapley values in an explicit form, we shape Shapley values by fulfilling the three axioms uniquely describing them, well defined on the extended game space describing NAHT. To estimate Shapley values in dynamic scenarios, we propose a TD($\lambda$)-like algorithm. The resulting reinforcement learning (RL) algorithm is referred to as Shapley Machine. To our best knowledge, this is the first time that the concepts from cooperative game theory are directly related to RL concepts. In experiments, we demonstrate the effectiveness of Shapley Machine and verify reasonableness of our theory.
开放多智能体系统在模拟真实世界应用(如智能电网、群体机器人等)中的重要性日益增加。本文针对开放多智能体系统提出的一个新问题进行研究,即n智能体临时协同作业(NAHT),其中只有部分智能体受控。现有方法往往基于启发式设计,因此缺乏理论严谨性,并且在智能体之间分配信用不明确。为了克服这些局限性,我们通过合作博弈论的视角来构建和解决NAHT。更具体地说,我们首先将一个开放多智能体系统建模为一个特定实例,该实例位于合作博弈空间内,由一组基础博弈生成。然后,我们扩展这个空间以及状态空间以适应动态场景,从而描述NAHT。通过合理利用基础博弈值对应于不同视野的n步回报序列的合理论假设,我们以类似于λ回报的形式表示NAHT的状态值。此外,我们通过利用合作博弈中唯一描述它们的三个公理来塑造Shapley值,将状态值分配给受控智能体,作为他们对临时团队的贡献信用。不同于传统以明确形式塑造Shapley值的方法,我们在描述NAHT的扩展博弈空间中定义了它们。为了估计动态场景中的Shapley值,我们提出了一种类似于TD(λ)的算法。所得的强化学习(RL)算法被称为Shapley机器。据我们所知,这是首次将合作博弈的概念直接与RL概念联系起来。在实验中,我们验证了Shapley机器的有效性并验证了我们的理论的合理性。
论文及项目相关链接
PDF 25 pages
摘要
在智能电网、群智能机器人等应用场景中,开放式多智能体系统建模变得越来越重要。本文旨在研究开放式多智能体系统中的一个新问题,即n智能体即时团队协作(NAHT)。现有方法倾向于基于启发式设计,缺乏理论严谨性和明确的智能体间信用分配机制。本文尝试通过合作博弈论对NAHT进行建模和求解。首先,将开放式多智能体系统建模为一个合作博弈空间中的实例,该系统由一组基础游戏生成。通过扩展这个空间和状态空间以适应动态场景,本文对NAHT进行了表征。利用基础游戏值对应于不同视野的n步回报序列的合理假设,我们以类似于λ回报的形式表示NAHT的状态值。此外,我们通过满足三个独特描述它们的公理来塑造Shapley值,以将状态值分配给受控的智能体,作为他们对即时团队的贡献信用。不同于传统方法在明确形式上塑造Shapley值的方式,我们在描述NAHT的扩展博弈空间上定义了它们。为了估计动态场景中的Shapley值,我们提出了一种类似于TD(λ)的算法。得到的强化学习算法被称为Shapley Machine。据我们所知,这是首次将合作博弈论的概念与强化学习概念直接关联起来。实验验证了Shapley Machine的有效性,并证明了我们的理论合理性。
关键见解
- 开放多智能体系统在现实世界应用中的重要性不断提升,如智能电网和群机器人技术。
- n智能体即时团队协作(NAHT)问题是一个新兴的研究挑战,现有方法缺乏理论严谨性,并且在智能体之间的信用分配上表现模糊。
- 本文通过合作博弈论对NAHT进行建模,将智能体系统的价值视为合作博弈的一个实例。
- 通过扩展合作博弈空间和状态空间来适应动态场景,对NAHT的特性进行了刻画。
- 利用基础游戏值与不同视野的n步回报序列相对应的理念,定义了类似λ回报的状态值表示。
- 采用塑造Shapley值的方法,通过满足描述Shapley值的三个独特公理,为受控智能体分配状态值,作为对即时团队贡献的信用。
点此查看论文截图

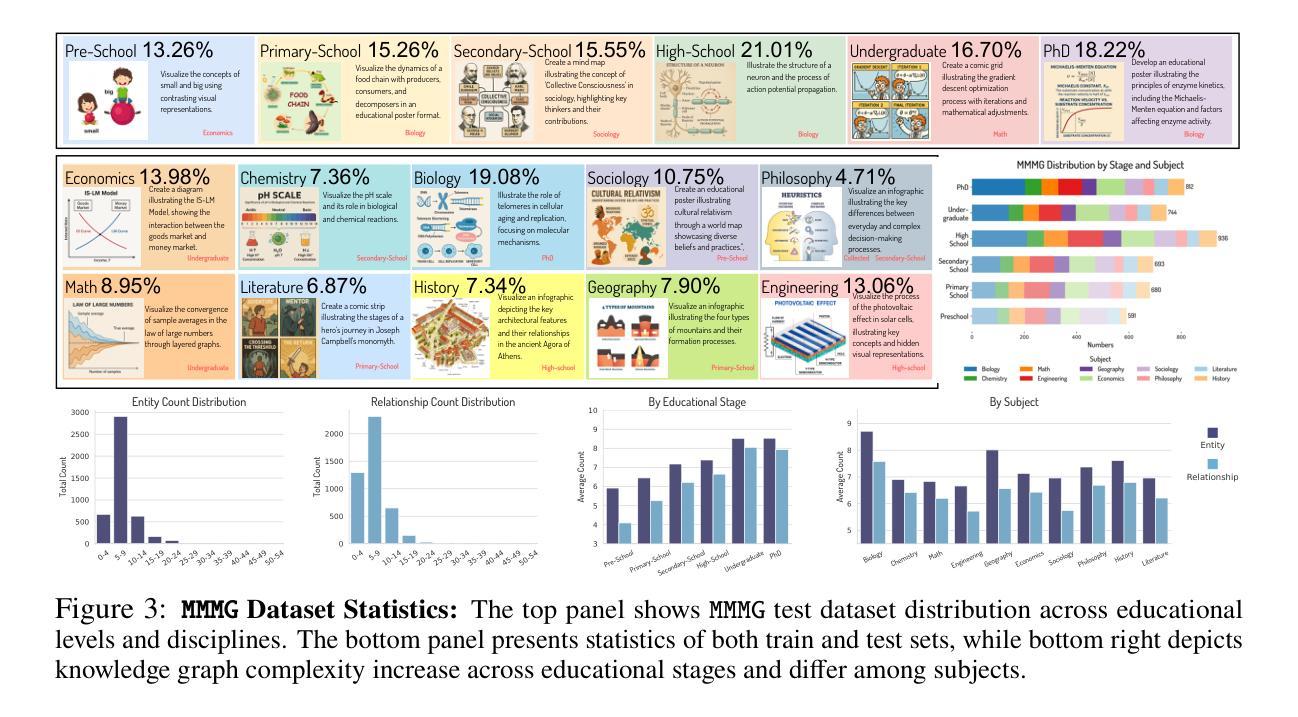
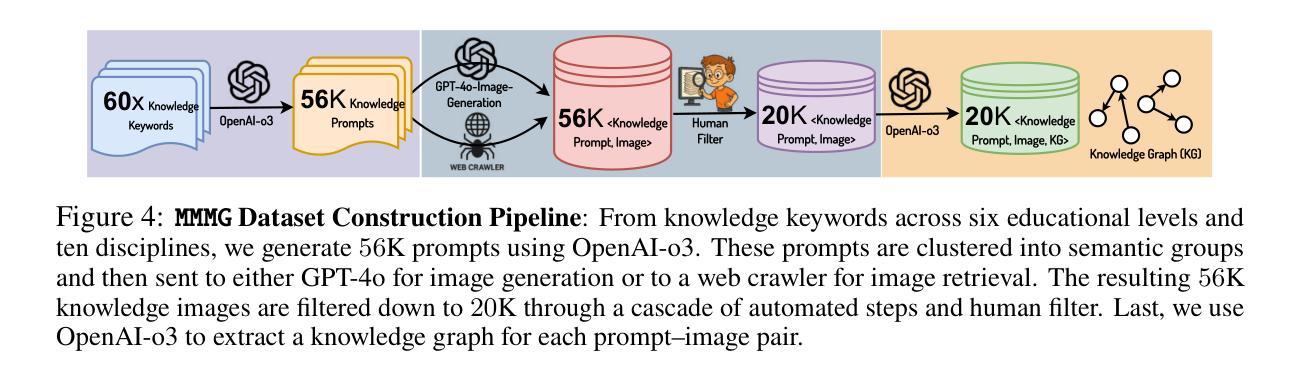
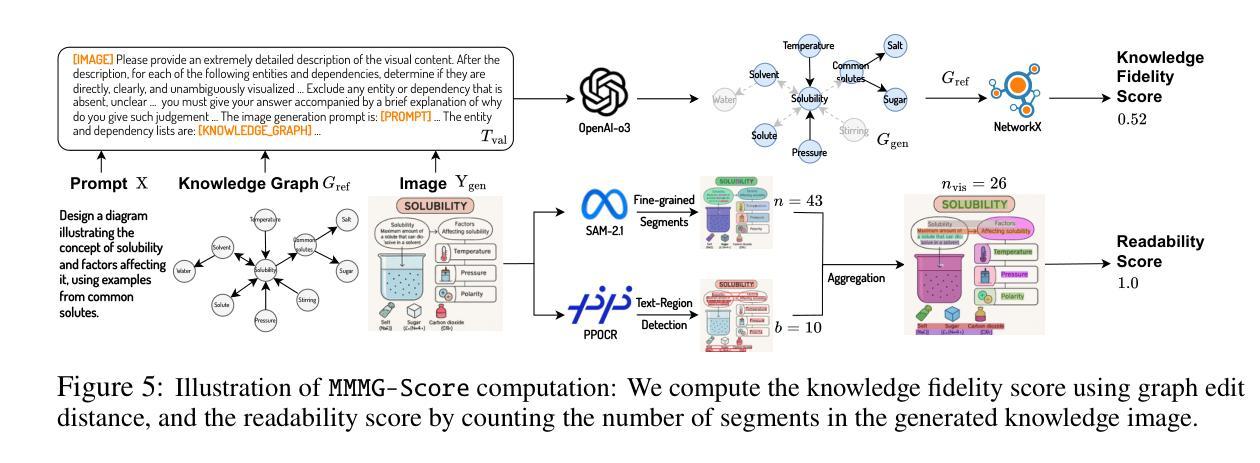
MMMG: A Massive, Multidisciplinary, Multi-Tier Generation Benchmark for Text-to-Image Reasoning
Authors:Yuxuan Luo, Yuhui Yuan, Junwen Chen, Haonan Cai, Ziyi Yue, Yuwei Yang, Fatima Zohra Daha, Ji Li, Zhouhui Lian
In this paper, we introduce knowledge image generation as a new task, alongside the Massive Multi-Discipline Multi-Tier Knowledge-Image Generation Benchmark (MMMG) to probe the reasoning capability of image generation models. Knowledge images have been central to human civilization and to the mechanisms of human learning – a fact underscored by dual-coding theory and the picture-superiority effect. Generating such images is challenging, demanding multimodal reasoning that fuses world knowledge with pixel-level grounding into clear explanatory visuals. To enable comprehensive evaluation, MMMG offers 4,456 expert-validated (knowledge) image-prompt pairs spanning 10 disciplines, 6 educational levels, and diverse knowledge formats such as charts, diagrams, and mind maps. To eliminate confounding complexity during evaluation, we adopt a unified Knowledge Graph (KG) representation. Each KG explicitly delineates a target image’s core entities and their dependencies. We further introduce MMMG-Score to evaluate generated knowledge images. This metric combines factual fidelity, measured by graph-edit distance between KGs, with visual clarity assessment. Comprehensive evaluations of 16 state-of-the-art text-to-image generation models expose serious reasoning deficits – low entity fidelity, weak relations, and clutter – with GPT-4o achieving an MMMG-Score of only 50.20, underscoring the benchmark’s difficulty. To spur further progress, we release FLUX-Reason (MMMG-Score of 34.45), an effective and open baseline that combines a reasoning LLM with diffusion models and is trained on 16,000 curated knowledge image-prompt pairs.
本文介绍了一个新的任务——知识图像生成,以及大规模多学科多级知识图像生成基准测试(MMMG),以探测图像生成模型的推理能力。知识图像在人类文明和人类学习机制中占据核心地位,这一事实由双重编码理论和图像优势效应所强调。生成这样的图像具有挑战性,它要求多模态推理,将世界知识与像素级地面融合成清晰的解释性视觉。为了进行综合评估,MMMG提供了4456个专家验证的知识图像提示对,涵盖10个学科,6个教育水平,以及多样化的知识形式,如图表、图表和思维导图。为了消除评估过程中的混淆复杂性,我们采用统一的知识图谱(KG)表示。每个知识图谱都明确描述了目标图像的核心实体及其依赖关系。我们还引入了MMMG评分来评估生成的知识图像。该指标结合了事实准确性,通过知识图谱之间的图编辑距离来衡量,以及视觉清晰度的评估。对16款最先进的文本到图像生成模型的全面评估揭示了严重的推理缺陷,包括实体忠实度低、关系薄弱和杂乱无章的现象。GPT-4o的MMMG评分仅为50.20,凸显了基准测试的困难程度。为了推动进一步的进步,我们发布了Flux-Reason(MMMG评分为34.45),这是一个有效且开放的基线,它结合了推理LLM与扩散模型,并在16000个精选的知识图像提示对上进行了训练。
论文及项目相关链接
PDF 85 pages, 70 figures, code: https://github.com/MMMGBench/MMMG, project page: https://mmmgbench.github.io/
Summary
在这个文本中,介绍了知识图像生成作为一个新任务,并伴随着大规模多学科多级知识图像生成基准测试(MMMG)来检测图像生成模型的推理能力。知识图像在人类文明和人类学习机制中占据重要地位,要求图像生成模型需要具备多模态推理能力,融合世界知识与像素级视觉内容生成清晰的可视化解释。MMMG提供了包含十个学科、六个教育级别和不同知识格式(如图表、图表和思维导图等)的4456个专家验证的知识图像提示对,以进行全面评估。为了简化评估复杂性,采用统一的知识图谱(KG)表示法。每个KG明确描述了目标图像的核心实体及其依赖关系。此外,还介绍了MMMG评分来评估生成的知识图像,该评分结合了基于知识图谱编辑距离的事实准确性和视觉清晰度评估。对16种最先进的文本到图像生成模型的全面评估表明,存在严重的推理缺陷,包括实体忠实度低、关系薄弱和混乱等。为了推动进一步的发展,推出了FLUX-Reason(MMMG评分为34.45),这是一个有效的开放基线,结合了推理大型语言模型与扩散模型,并在16000个精选的知识图像提示对上进行了训练。
Key Takeaways
- 知识图像生成被引入为一个新任务,旨在评估图像生成模型的推理能力。
- 知识图像在人类学习和文明中起重要作用,需要模型具备多模态推理能力。
- MMMG基准测试提供了包含多个学科、教育级别和知识格式的知识图像提示对,以全面评估模型性能。
- 采用知识图谱表示法来简化评估复杂性,强调目标图像的核心实体和依赖关系。
- MMMG评分结合了事实准确性和视觉清晰度评估来评价生成的知识图像。
- 当前文本到图像生成模型存在推理缺陷,如实体忠实度低、关系薄弱和混乱等。
点此查看论文截图



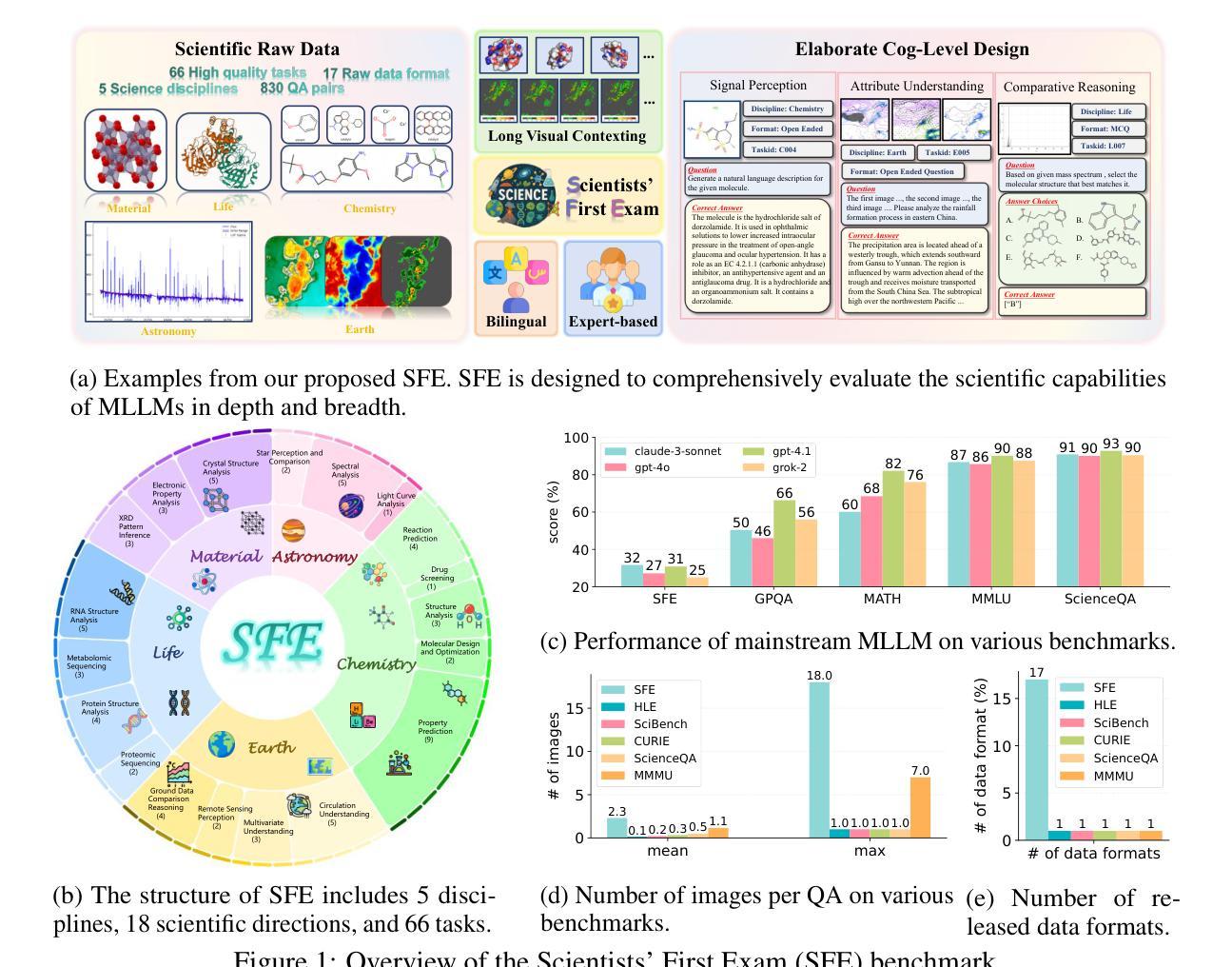
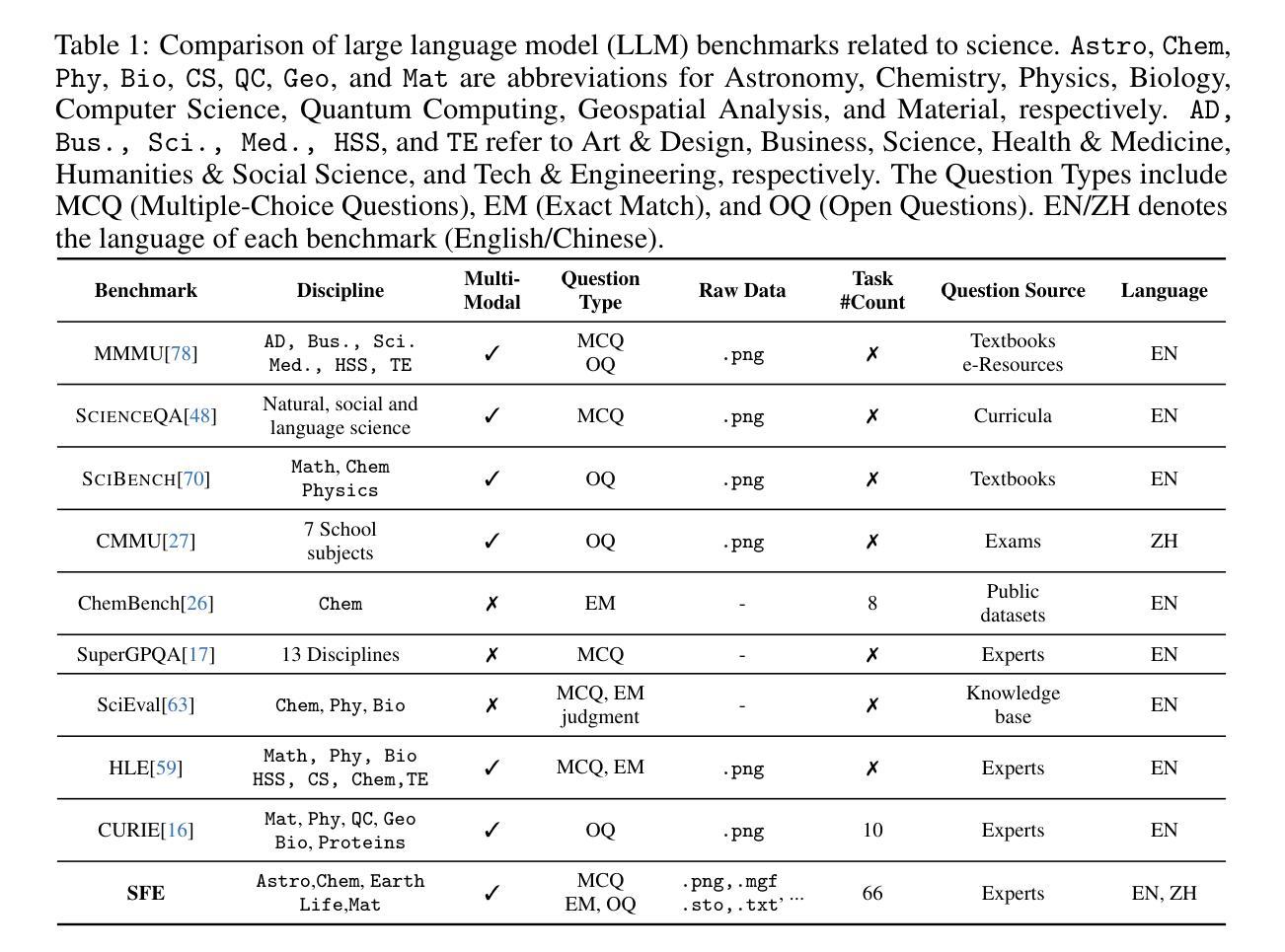
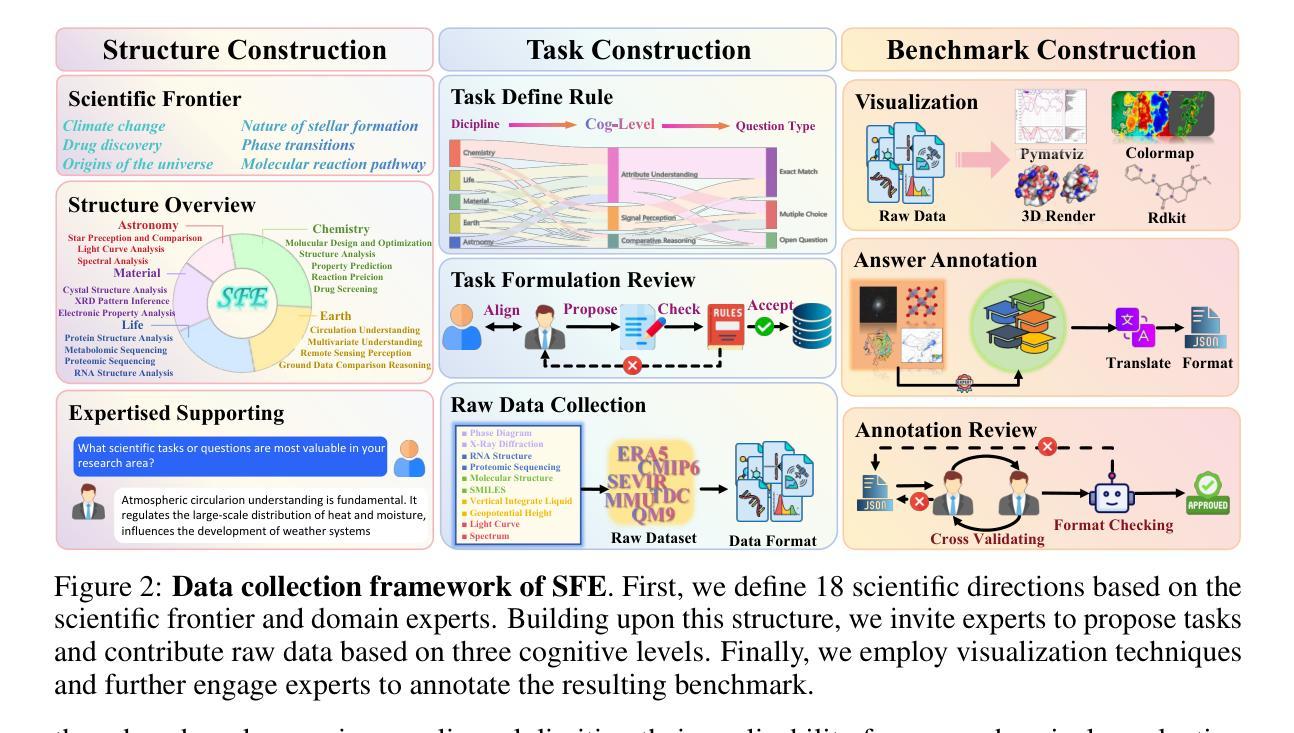
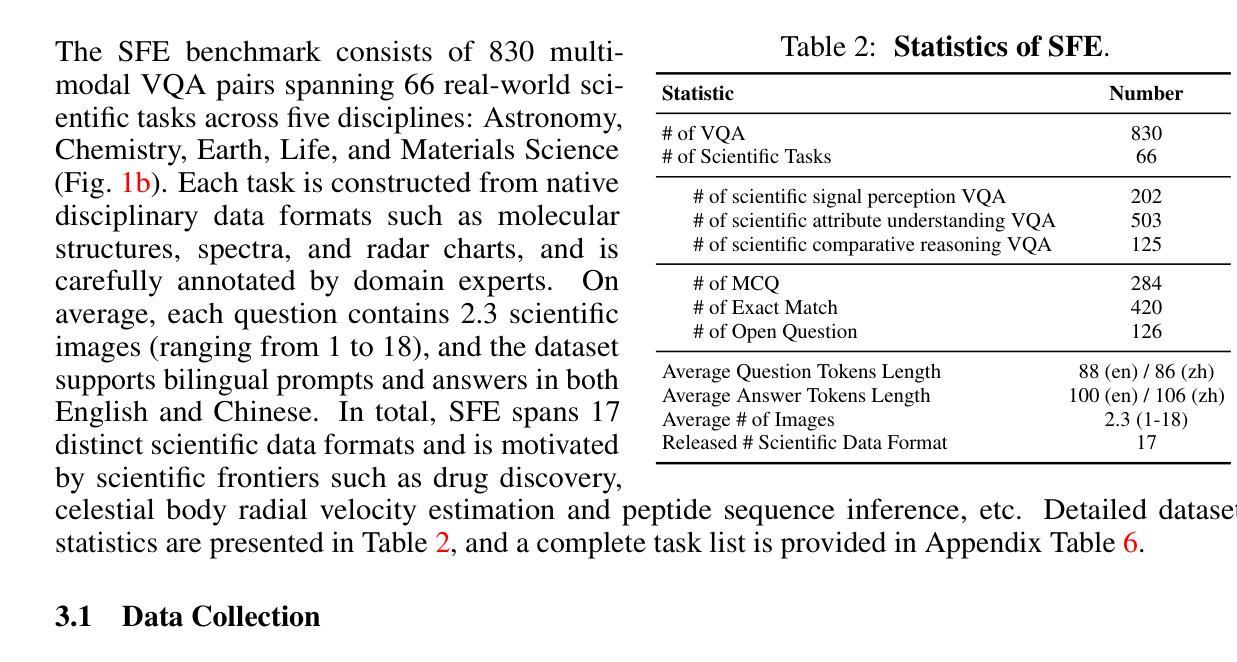
Scientists’ First Exam: Probing Cognitive Abilities of MLLM via Perception, Understanding, and Reasoning
Authors:Yuhao Zhou, Yiheng Wang, Xuming He, Ruoyao Xiao, Zhiwei Li, Qiantai Feng, Zijie Guo, Yuejin Yang, Hao Wu, Wenxuan Huang, Jiaqi Wei, Dan Si, Xiuqi Yao, Jia Bu, Haiwen Huang, Tianfan Fu, Shixiang Tang, Ben Fei, Dongzhan Zhou, Fenghua Ling, Yan Lu, Siqi Sun, Chenhui Li, Guanjie Zheng, Jiancheng Lv, Wenlong Zhang, Lei Bai
Scientific discoveries increasingly rely on complex multimodal reasoning based on information-intensive scientific data and domain-specific expertise. Empowered by expert-level scientific benchmarks, scientific Multimodal Large Language Models (MLLMs) hold the potential to significantly enhance this discovery process in realistic workflows. However, current scientific benchmarks mostly focus on evaluating the knowledge understanding capabilities of MLLMs, leading to an inadequate assessment of their perception and reasoning abilities. To address this gap, we present the Scientists’ First Exam (SFE) benchmark, designed to evaluate the scientific cognitive capacities of MLLMs through three interconnected levels: scientific signal perception, scientific attribute understanding, scientific comparative reasoning. Specifically, SFE comprises 830 expert-verified VQA pairs across three question types, spanning 66 multimodal tasks across five high-value disciplines. Extensive experiments reveal that current state-of-the-art GPT-o3 and InternVL-3 achieve only 34.08% and 26.52% on SFE, highlighting significant room for MLLMs to improve in scientific realms. We hope the insights obtained in SFE will facilitate further developments in AI-enhanced scientific discoveries.
科学研究日益依赖于基于信息密集的科学数据和特定领域专业知识的复杂多模态推理。在专家级科学基准测试的支持下,科学多模态大型语言模型(MLLMs)在实际工作流程中具有增强这一发现过程的潜力。然而,当前的科学基准测试主要侧重于评估MLLMs的知识理解能力,导致对其感知和推理能力的评估不足。为了弥补这一空白,我们提出了科学家第一次考试(SFE)基准测试,旨在通过三个相互关联的水平来评估MLLMs的科学认知能力:科学信号感知、科学属性理解、科学比较推理。具体来说,SFE包含830个专家验证的问答对,涉及三种问题类型,涵盖66个多模态任务,涉及五个高价值学科。大量实验表明,目前最先进的GPT-o3和InternVL-3在SFE上的表现仅为34.08%和26.52%,这表明MLLMs在科学研究领域仍有很大的改进空间。我们希望SFE中获得的见解将有助于人工智能增强科学发现的进一步发展。
论文及项目相关链接
PDF 82 pages
Summary
基于信息密集型科学数据和领域特定专业知识,科学发现越来越依赖于复杂的跨模态推理。科学跨模态大型语言模型(MLLMs)借助专家级科学基准,具有增强现实工作流程中的发现过程的潜力。然而,当前的科学基准主要侧重于评估MLLMs的知识理解能力,导致对其感知和推理能力的评估不足。为解决这一空白,我们提出了科学家第一次考试(SFE)基准,旨在通过三个相互联系的水平评估MLLMs的科学认知能力:科学信号感知、科学属性理解、科学比较推理。SFE包含830个专家验证的问答对,跨越三种问题类型和66个跨模态任务,涉及五个高价值学科。实验表明,当前最先进的GPT-o3和InternVL-3在SFE上的表现仅为34.08%和26.52%,这表明MLLMs在科学领域还有很大的改进空间。
Key Takeaways
- 科学发现越来越依赖复杂的多模态推理和信息密集型科学数据。
- 科学跨模态大型语言模型(MLLMs)具有提升科学发现过程的潜力。
- 当前的科学基准主要评估MLLMs的知识理解能力,忽略了感知和推理能力的评估。
- 科学家第一次考试(SFE)基准旨在全面评估MLLMs的科学认知能力。
- SFE基准包含专家验证的问答对,跨越多种问题类型和学科。
- 最先进的模型在SFE上的表现不佳,表明MLLMs在科学领域仍有很大的改进空间。
点此查看论文截图

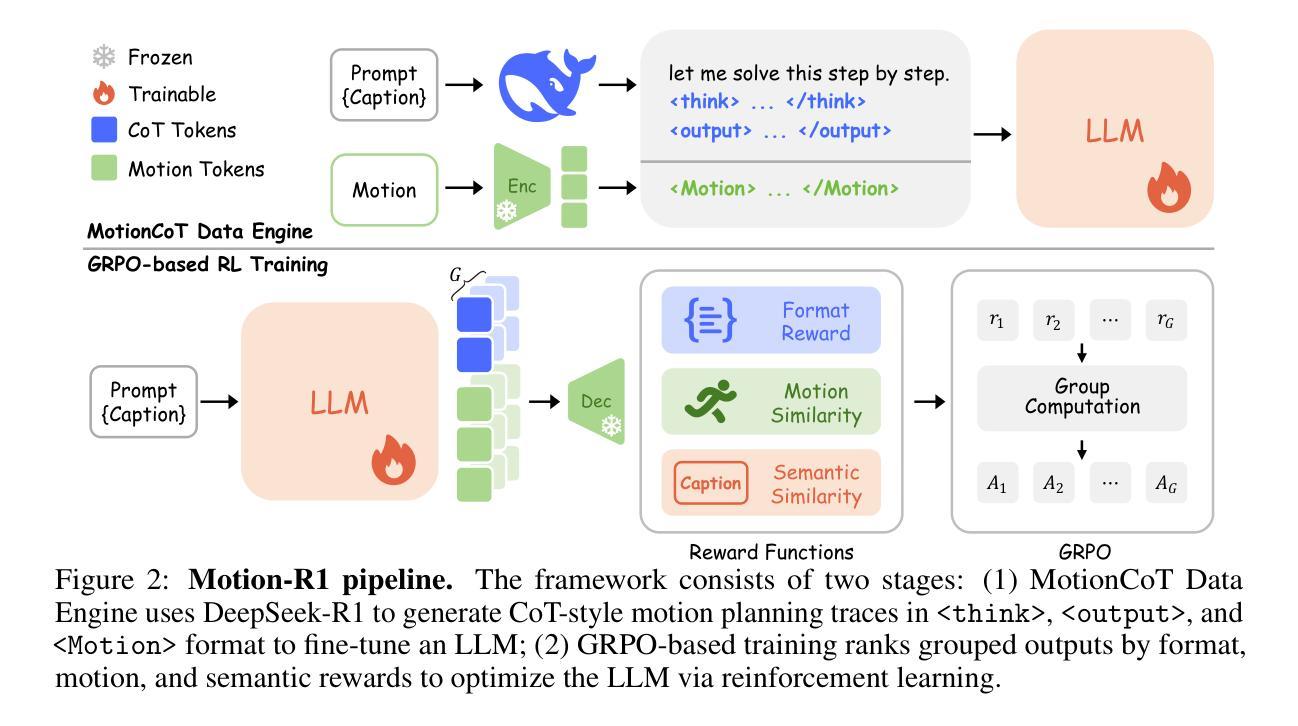
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Authors:Runqi Ouyang, Haoyun Li, Zhenyuan Zhang, Xiaofeng Wang, Zheng Zhu, Guan Huang, Xingang Wang
Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model’s ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.
近年来,大型语言模型在自然语言理解和推理方面的进展为文本到运动的生成提供了新的可能性。尽管现有方法在语义对齐和运动合成方面取得了显著进展,但它们通常依赖于端到端的映射策略,无法捕捉深层语言结构和逻辑推理。因此,生成的运动往往缺乏可控性、一致性和多样性。为了解决这些局限性,我们提出了Motion-R1,这是一个统一的运动语言建模框架,它集成了思维链机制。通过将复杂的文本指令明确地分解为逻辑结构化的行动路径,Motion-R1为运动生成提供高级语义指导,显著提高了模型解释和执行多步骤、长期和组合丰富指令的能力。为了训练我们的模型,我们采用了针对大型模型的强化学习算法——群组相对策略优化,该算法利用运动质量反馈来联合优化推理链和运动合成。在多个基准数据集上的广泛实验表明,Motion-R1与最先进的方法相比,在需要微妙语义理解和长期时间连贯性的场景中,取得了竞争或卓越的性能。代码、模型和数据将公开可用。
论文及项目相关链接
Summary
本文介绍了大型语言模型在文本到运动生成领域的新进展,提出了一种名为Motion-R1的统一运动语言建模框架。该框架通过结合Chain-of-Thought机制,将复杂的文本指令分解为逻辑结构化的行动路径,为运动生成提供高级语义指导。Motion-R1能够解释并执行多步骤、长期视野和组合丰富的指令,并通过强化学习算法Group Relative Policy Optimization进行训练,优化推理链和运动合成的联合优化。实验结果表明,Motion-R1在多个基准数据集上实现了与最新技术相比具有竞争力的性能,特别是在需要微妙语义理解和长期时间连贯性的场景中。
Key Takeaways
- 大型语言模型在文本到运动生成领域取得新进展。
- 现有方法依赖端对端映射策略,难以捕捉深层语言结构和逻辑推理。
- Motion-R1框架结合Chain-of-Thought机制,分解复杂文本指令为逻辑结构化的行动路径。
- Motion-R1提供高级语义指导,增强模型对多步骤、长期视野和组合丰富指令的解读和执行能力。
- 采用强化学习算法Group Relative Policy Optimization进行训练,优化推理链和运动合成的联合优化。
- Motion-R1在多个基准数据集上表现优异,特别是在需要微妙语义理解和长期时间连贯性的场景中。
点此查看论文截图



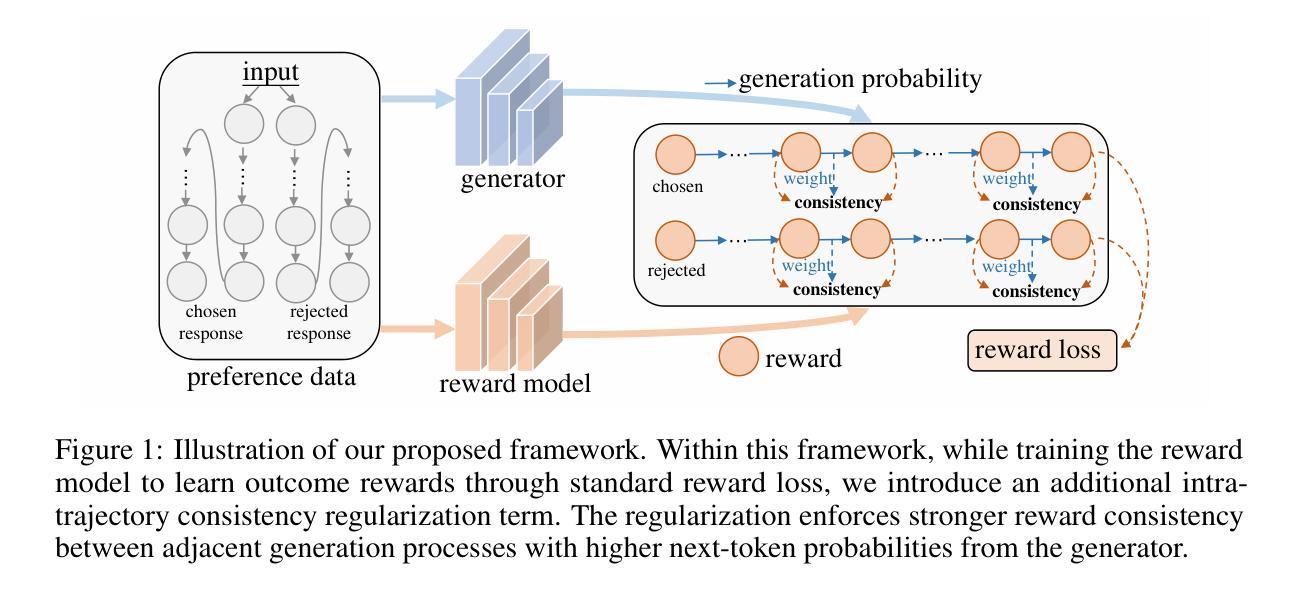
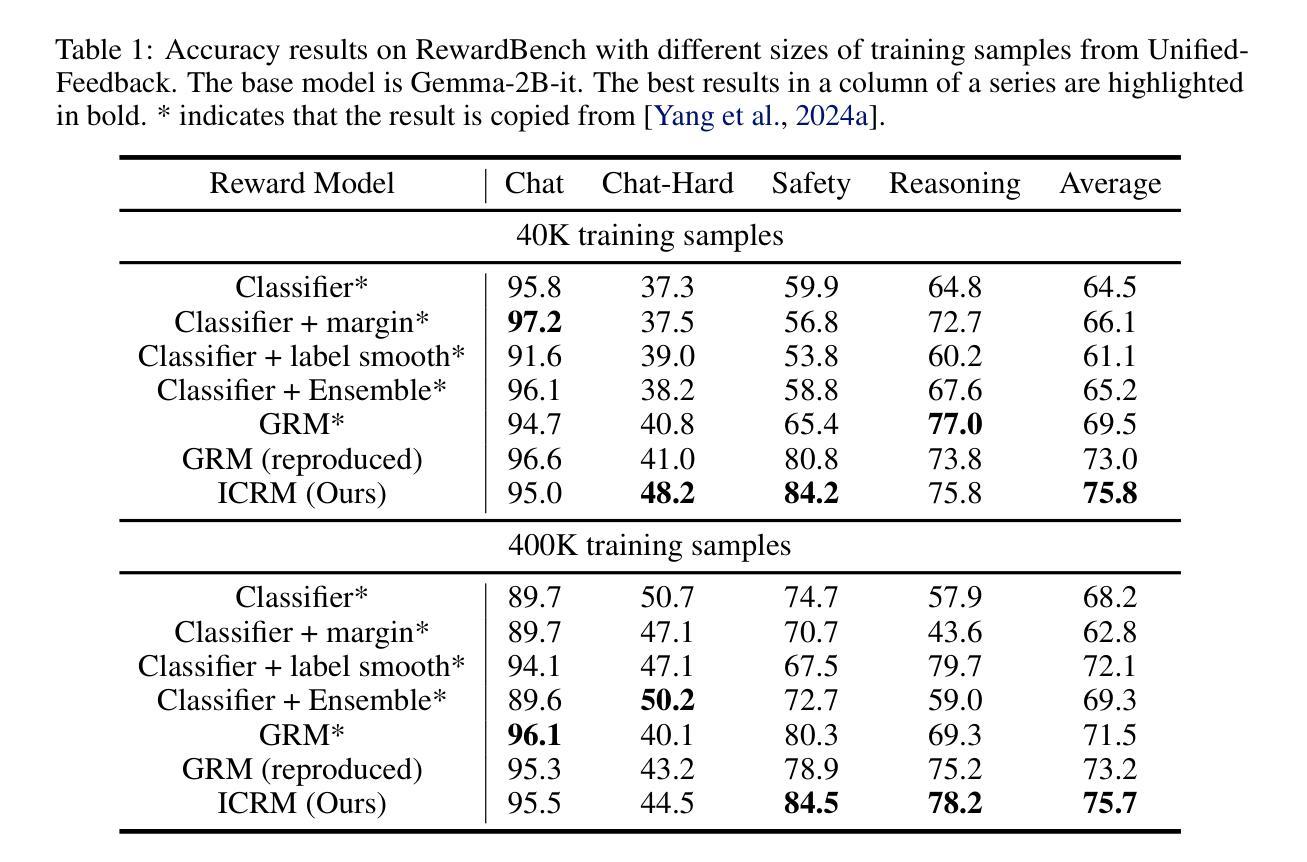
Intra-Trajectory Consistency for Reward Modeling
Authors:Chaoyang Zhou, Shunyu Liu, Zengmao Wang, Di Wang, Rong-Cheng Tu, Bo Du, Dacheng Tao
Reward models are critical for improving large language models (LLMs), particularly in reinforcement learning from human feedback (RLHF) or inference-time verification. Current reward modeling typically relies on scores of overall responses to learn the outcome rewards for the responses. However, since the response-level scores are coarse-grained supervision signals, the reward model struggles to identify the specific components within a response trajectory that truly correlate with the scores, leading to poor generalization on unseen responses. In this paper, we propose to leverage generation probabilities to establish reward consistency between processes in the response trajectory, which allows the response-level supervisory signal to propagate across processes, thereby providing additional fine-grained signals for reward learning. Building on analysis under the Bayesian framework, we develop an intra-trajectory consistency regularization to enforce that adjacent processes with higher next-token generation probability maintain more consistent rewards. We apply the proposed regularization to the advanced outcome reward model, improving its performance on RewardBench. Besides, we show that the reward model trained with the proposed regularization induces better DPO-aligned policies and achieves better best-of-N (BON) inference-time verification results. Our code is provided in https://github.com/chaoyang101/ICRM.
奖励模型对于改进大型语言模型(LLM)至关重要,特别是在人类反馈强化学习(RLHF)或推理时间验证中。当前的奖励建模通常依赖于整体响应的分数来学习响应的结果奖励。然而,由于响应级别的分数是粗粒度的监督信号,奖励模型难以识别响应轨迹中真正与分数相关的特定组件,导致在未见过的响应上的泛化性能较差。在本文中,我们提出利用生成概率来建立响应轨迹中过程之间的奖励一致性,这允许响应级别的监督信号在过程之间传播,从而为奖励学习提供额外的细粒度信号。我们在贝叶斯框架的分析基础上,开发了一种轨迹内一致性正则化方法,以强制相邻过程具有更高的下一个令牌生成概率,从而保持更一致的奖励。我们将所提出的正则化应用于高级结果奖励模型,在RewardBench上提高了其性能。此外,我们还表明,使用所提出正则化训练的奖励模型会诱导更好的DPO对齐策略,并在最佳N(BON)推理时间验证中实现更好的结果。我们的代码位于https://github.com/chaoyang101/ICRM。
论文及项目相关链接
PDF Under review
Summary
本文提出利用生成概率建立响应轨迹中奖励模型的一致性,以解决现有奖励模型在大型语言模型(LLM)改进中的不足。传统的奖励模型依赖于整体响应的评分来学习奖励结果,但这种方式难以识别响应轨迹中真正与评分相关的特定组件。新方法通过引入生成概率,使得响应级别的监督信号可以在轨迹过程中传播,为奖励学习提供额外的精细信号。文章还提出了一种基于贝叶斯框架的轨迹内一致性正则化方法,以强化具有较高生成概率的相邻过程之间的奖励一致性。新方法提高了奖励模型在RewardBench上的性能,并能更好地生成与人类偏好一致的决策策略。
Key Takeaways
- 奖励模型对改进大型语言模型(LLM)至关重要,特别是在基于人类反馈的强化学习(RLHF)和推理时间验证方面。
- 当前奖励建模通常依赖于整体响应的评分来学习奖励结果,但这种方式存在局限性,难以识别响应轨迹中真正与评分相关的部分。
- 本文建议利用生成概率建立响应轨迹中奖励模型的一致性。
- 新方法允许响应级别的监督信号在轨迹过程中传播,为奖励学习提供额外的精细信号。
- 引入了一种基于贝叶斯框架的轨迹内一致性正则化方法,以强化相邻过程之间的奖励一致性。
- 新方法提高了奖励模型在RewardBench上的性能。
点此查看论文截图

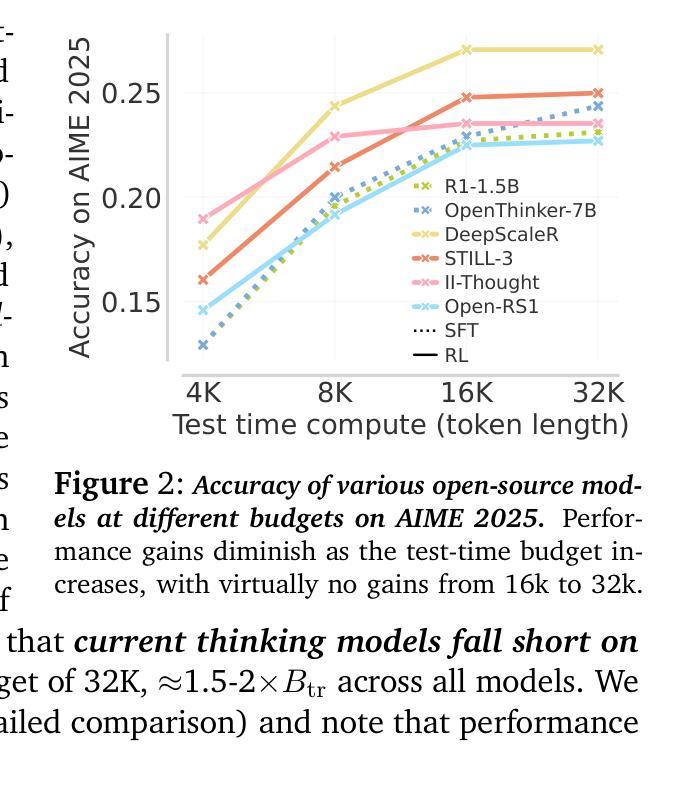
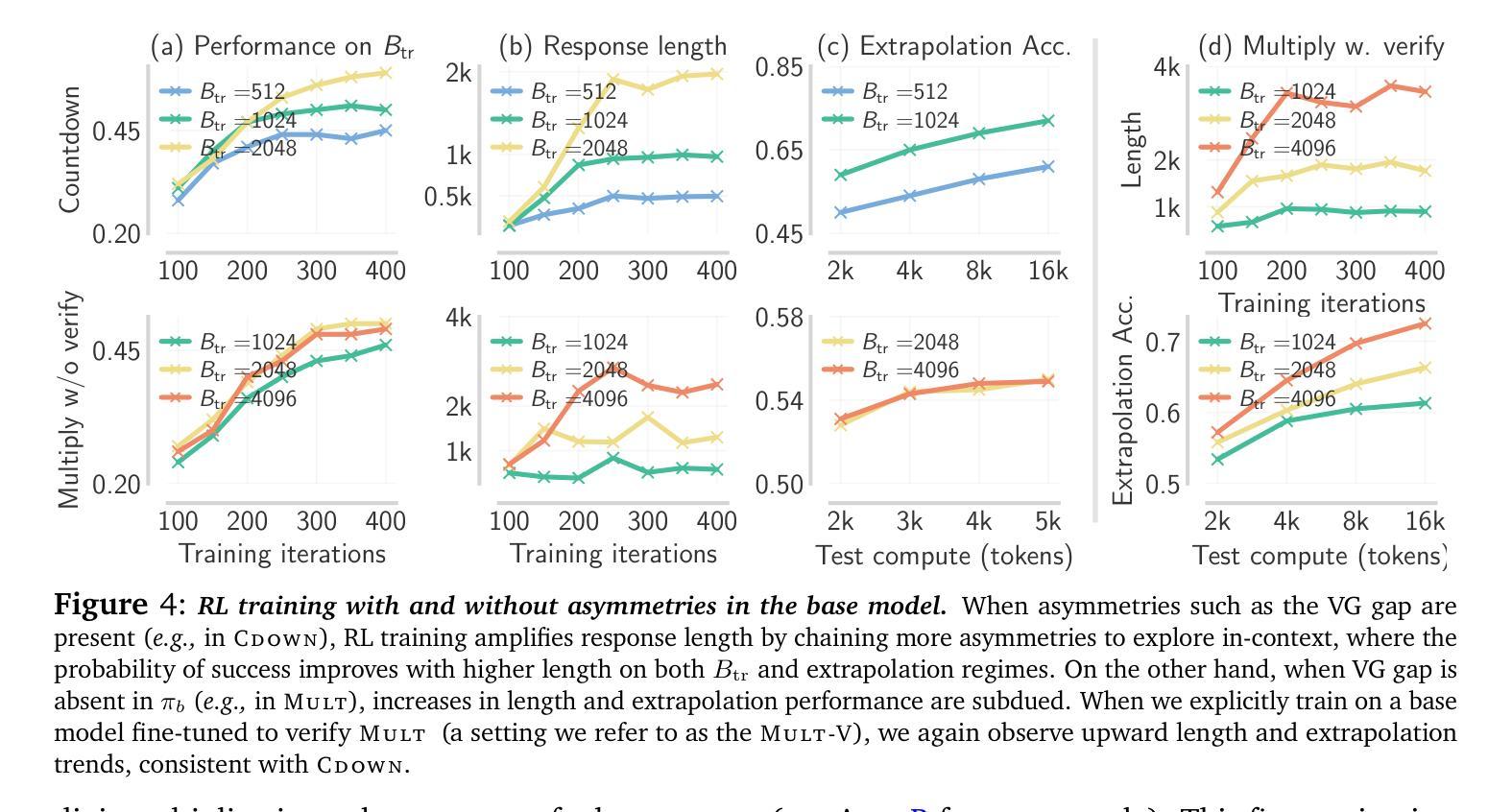
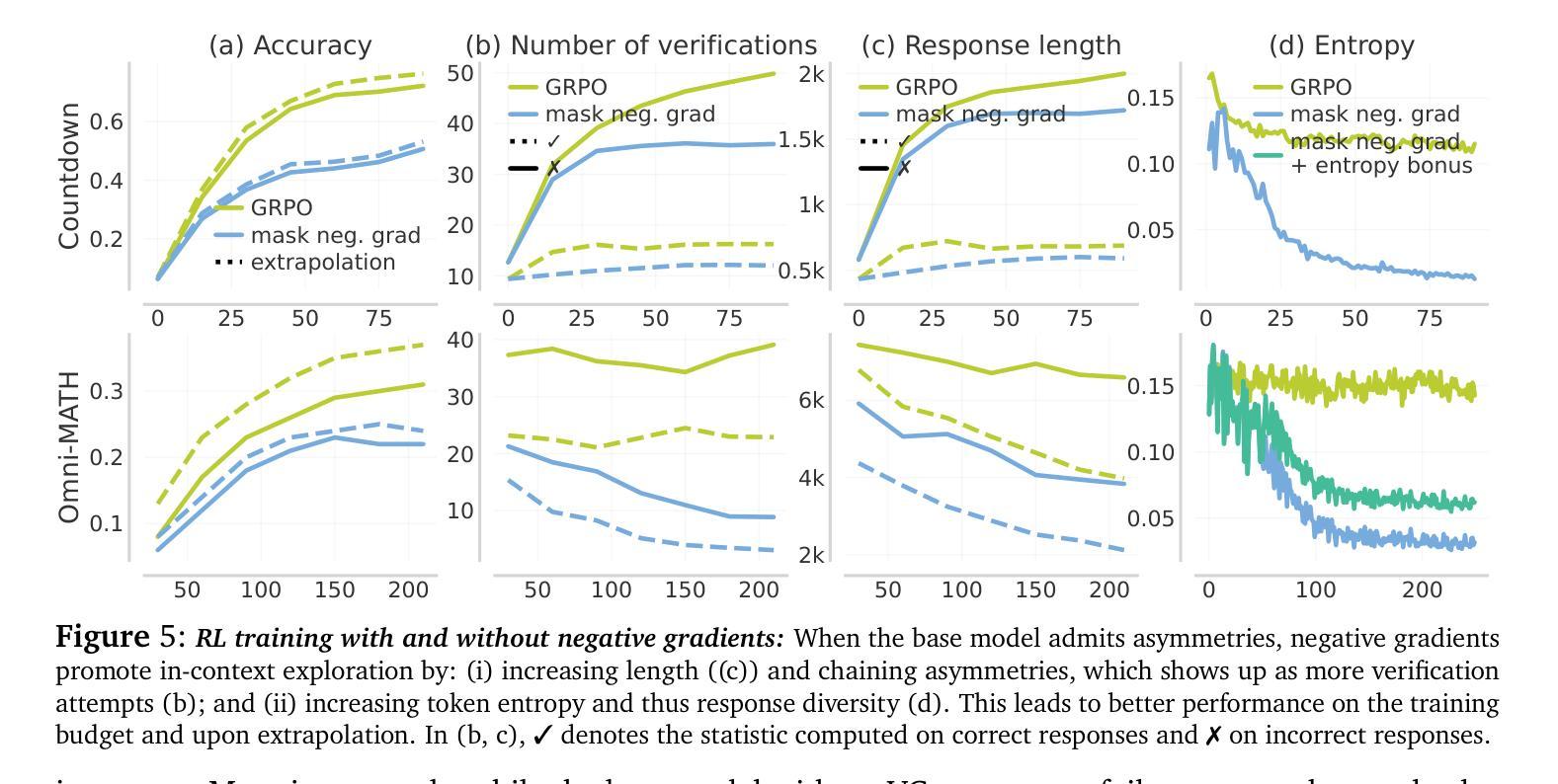
e3: Learning to Explore Enables Extrapolation of Test-Time Compute for LLMs
Authors:Amrith Setlur, Matthew Y. R. Yang, Charlie Snell, Jeremy Greer, Ian Wu, Virginia Smith, Max Simchowitz, Aviral Kumar
Test-time scaling offers a promising path to improve LLM reasoning by utilizing more compute at inference time; however, the true promise of this paradigm lies in extrapolation (i.e., improvement in performance on hard problems as LLMs keep “thinking” for longer, beyond the maximum token budget they were trained on). Surprisingly, we find that most existing reasoning models do not extrapolate well. We show that one way to enable extrapolation is by training the LLM to perform in-context exploration: training the LLM to effectively spend its test time budget by chaining operations (such as generation, verification, refinement, etc.), or testing multiple hypotheses before it commits to an answer. To enable in-context exploration, we identify three key ingredients as part of our recipe e3: (1) chaining skills that the base LLM has asymmetric competence in, e.g., chaining verification (easy) with generation (hard), as a way to implement in-context search; (2) leveraging “negative” gradients from incorrect traces to amplify exploration during RL, resulting in longer search traces that chains additional asymmetries; and (3) coupling task difficulty with training token budget during training via a specifically-designed curriculum to structure in-context exploration. Our recipe e3 produces the best known 1.7B model according to AIME’25 and HMMT’25 scores, and extrapolates to 2x the training token budget. Our e3-1.7B model not only attains high pass@1 scores, but also improves pass@k over the base model.
测试时缩放技术提供了一种有前景的路径,通过利用更多的计算资源来提高大型语言模型(LLM)的推理能力。然而,这一方法的真正潜力在于外推(即,在LLM“思考”的时间超过其训练时的最大令牌预算时,在难题上的性能提升)。令人惊讶的是,我们发现大多数现有的推理模型的外推能力并不强。我们展示了一种实现外推的方法是训练LLM进行上下文探索:训练LLM通过链接操作(如生成、验证、精炼等)有效地利用其测试时间预算,或在提交答案之前测试多个假设。为了进行上下文探索,我们确定了三个关键要素作为我们配方e3的一部分:(1)链接基础LLM具有不对称能力技能,例如将验证(容易)与生成(困难)链接起来,作为实现上下文搜索的一种方式;(2)利用错误轨迹的“负面”梯度来强化强化学习过程中的探索,从而产生更长的搜索轨迹并链接更多的不对称性;(3)通过在训练期间专门设计课程将任务难度与训练令牌预算相结合,以构建上下文探索的结构。我们的e3配方生产出了根据AIME’25和HMMT’25分数表现最好的已知1.7B模型,并外推到训练令牌预算的2倍。我们的e3-1.7B模型不仅达到了很高的pass@1分数,而且相对于基础模型还提高了pass@k分数。
论文及项目相关链接
Summary
该文本探讨了测试时缩放(test-time scaling)在改善大型语言模型(LLM)推理能力方面的潜力。作者指出,真正的潜力在于外推(extrapolation)——即在超出训练时的最大令牌预算的情况下,LLM性能的提升。然而,大多数现有推理模型的外推能力不佳。为了改善这一点,作者提出了一种训练LLM进行上下文内探索的方法,包括技能链、利用负梯度放大强化学习中的探索过程,以及在训练过程中将任务难度与训练令牌预算相结合。这些技术共同构成了作者的e3配方,成功提高了模型性能。
Key Takeaways
- 测试时缩放是一种利用更多计算资源在推理阶段提升大型语言模型性能的方法。
- 外推是测试时缩放的一个重要方面,指在超出训练时的最大令牌预算时LLM的性能提升。
- 现有推理模型在外推方面表现不佳。
- 一种改善外推能力的方法是训练LLM进行上下文内探索,包括技能链和强化学习中的负梯度利用。
- 技能链是将LLM在不同任务上的不对称能力结合,例如将简单的验证与困难的生成结合起来,实现上下文搜索。
- 通过设计专门的课程来结合任务难度和训练时的令牌预算,从而结构化上下文探索。
点此查看论文截图

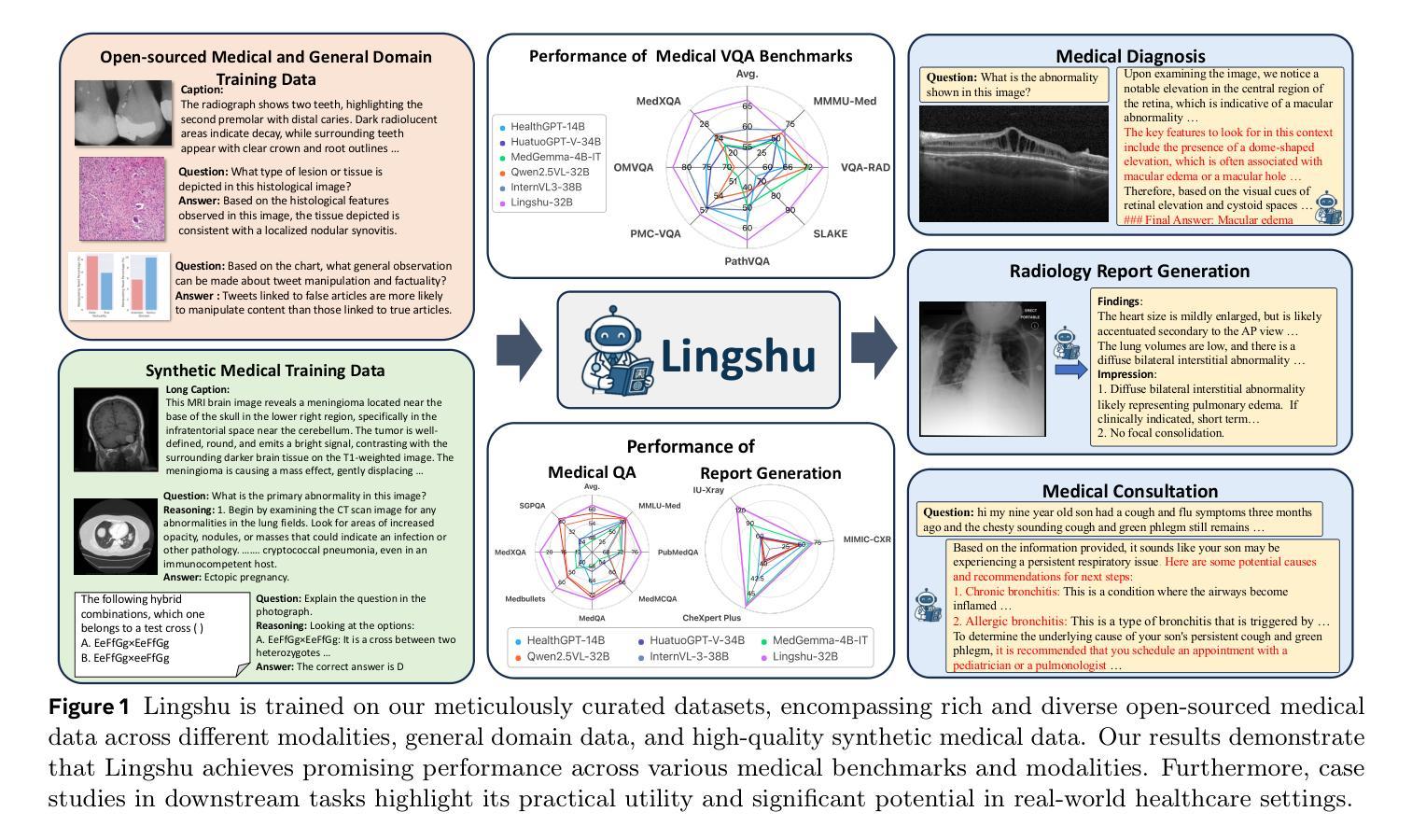
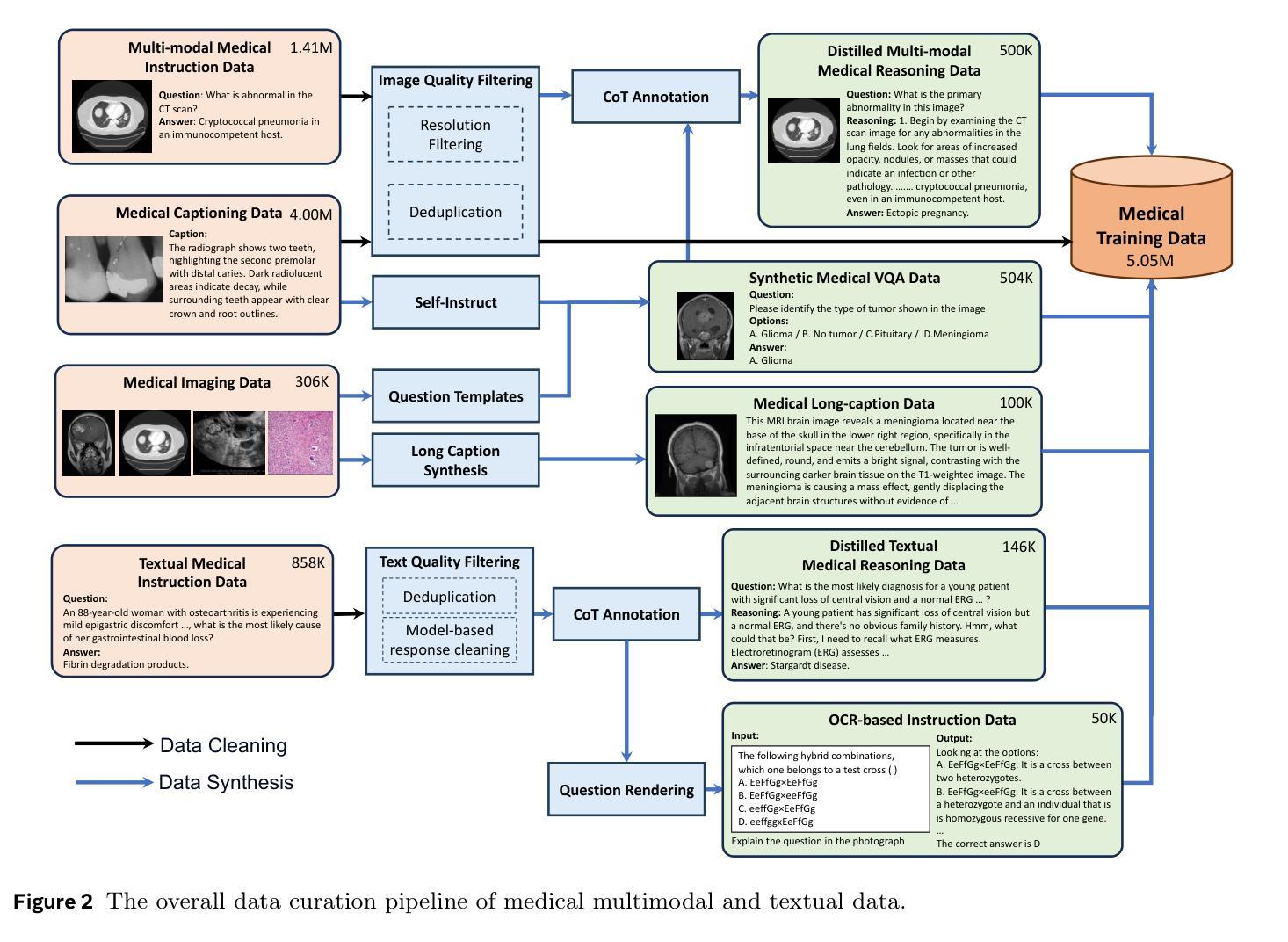
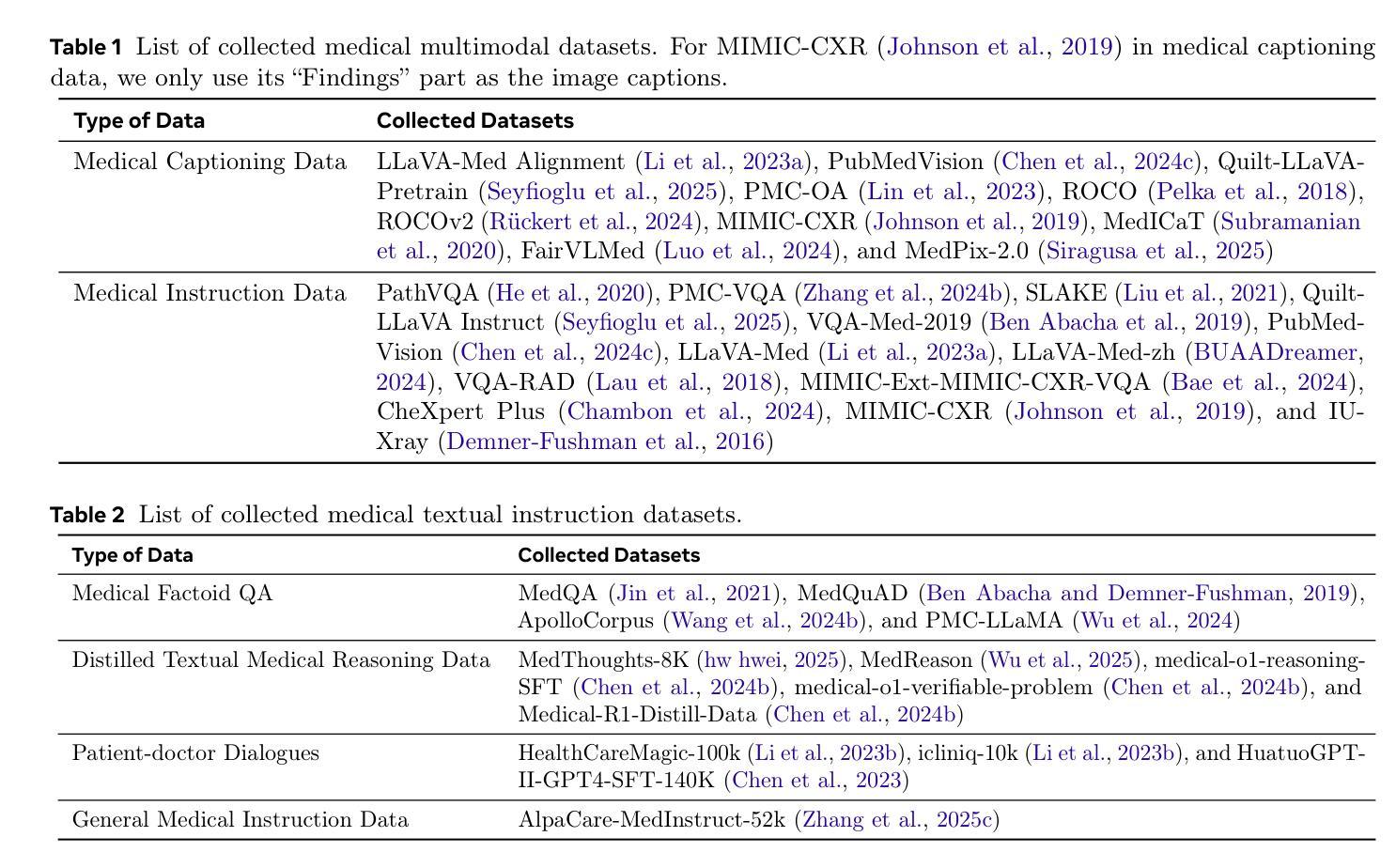
Lingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Authors: LASA Team, Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, Yu Sun, Junao Shen, Chaojun Wang, Jie Tan, Deli Zhao, Tingyang Xu, Hao Zhang, Yu Rong
Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu’s medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks …
多模态大型语言模型(MLLMs)在理解常见视觉元素方面表现出了令人印象深刻的能力,这主要归功于其大规模数据集和先进的训练策略。然而,它们在医疗应用中的有效性由于医疗场景中的数据与任务与通用领域之间的差异而受到限制。具体来说,现有的医疗MLLMs面临以下关键局限:(1)医学知识覆盖范围广,但不仅限于成像,(2)由于数据整理过程的不足,更容易出现幻觉,(3)缺乏针对复杂医疗场景的推理能力。为了解决这些挑战,我们首先提出了一项全面的数据整理程序,该程序(1)能够有效地获取丰富的医学知识数据,不仅来自医学影像,还来自广泛的医学文本和通用领域数据;(2)合成准确的医学标题、视觉问答(VQA)和推理样本。因此,我们建立了一个包含丰富医学知识的多模态数据集。基于整理后的数据,我们引入了我们的医疗专用MLLM:灵枢。灵枢经历多阶段训练,嵌入医学专业知识,并逐步提高任务解决能力。此外,我们初步探索了应用强化学习与可验证奖励范式来提高灵枢的医学推理能力。同时,我们开发了MedEvalKit,这是一个统一的评估框架,它整合了领先的多模态和文本医疗基准,用于标准化、公平和高效的模型评估。我们在三个基本医疗任务上评估了灵枢的性能,包括多模态问答、基于文本的问答和医疗报告生成。结果表明,Lingshu在大多数任务上的性能都超过了现有的开源多模态模型……
论文及项目相关链接
PDF Technical Report, 53 pages, 25 tables, and 16 figures. Our webpage is https://alibaba-damo-academy.github.io/lingshu/
Summary
本文介绍了多模态大型语言模型(MLLMs)在医学应用中的挑战及其针对这些挑战所采取的创新性解决方案。针对医学领域数据特殊性,提出了全面的数据整理程序,并构建了一个富含医学知识的多模态数据集。基于该数据集,训练了具备医学专长的MLLM——Lingshu,该模型通过多阶段训练嵌入医学专业知识并增强任务解决能力。此外,还初步探索了应用可验证奖励强化学习提升Lingshu医学推理能力的潜力,并开发了统一评估框架MedEvalKit,用于标准化、公平、高效地评估模型。评估结果显示,Lingshu在多项基础医学任务上的表现优于现有开源多模态模型。
Key Takeaways
- 多模态大型语言模型(MLLMs)在医学应用中面临数据差异性的挑战。
- 现有医学MLLMs在医疗知识覆盖、数据优化和推理能力方面存在局限。
- 提出了全面的数据整理程序,融合医疗影像、医疗文本和通用领域数据,构建富含医学知识的多模态数据集。
- 介绍了基于该数据集的医学专业化MLLM——Lingshu,通过多阶段训练增强任务解决能力。
- 初步探索了应用可验证奖励的强化学习提升Lingshu医学推理能力的潜力。
- 开发了统一评估框架MedEvalKit,用于标准化、公平、高效评估模型性能。
点此查看论文截图


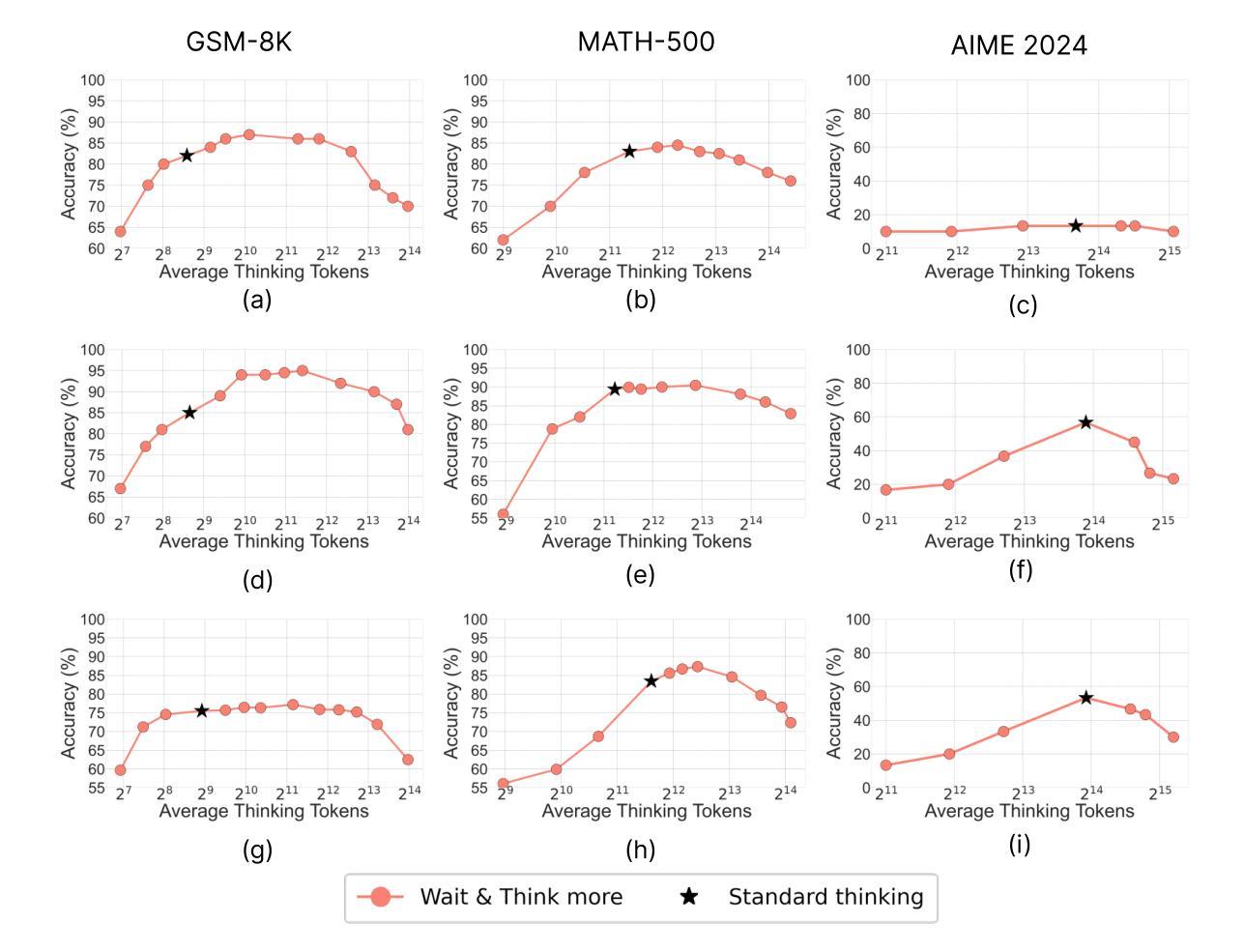
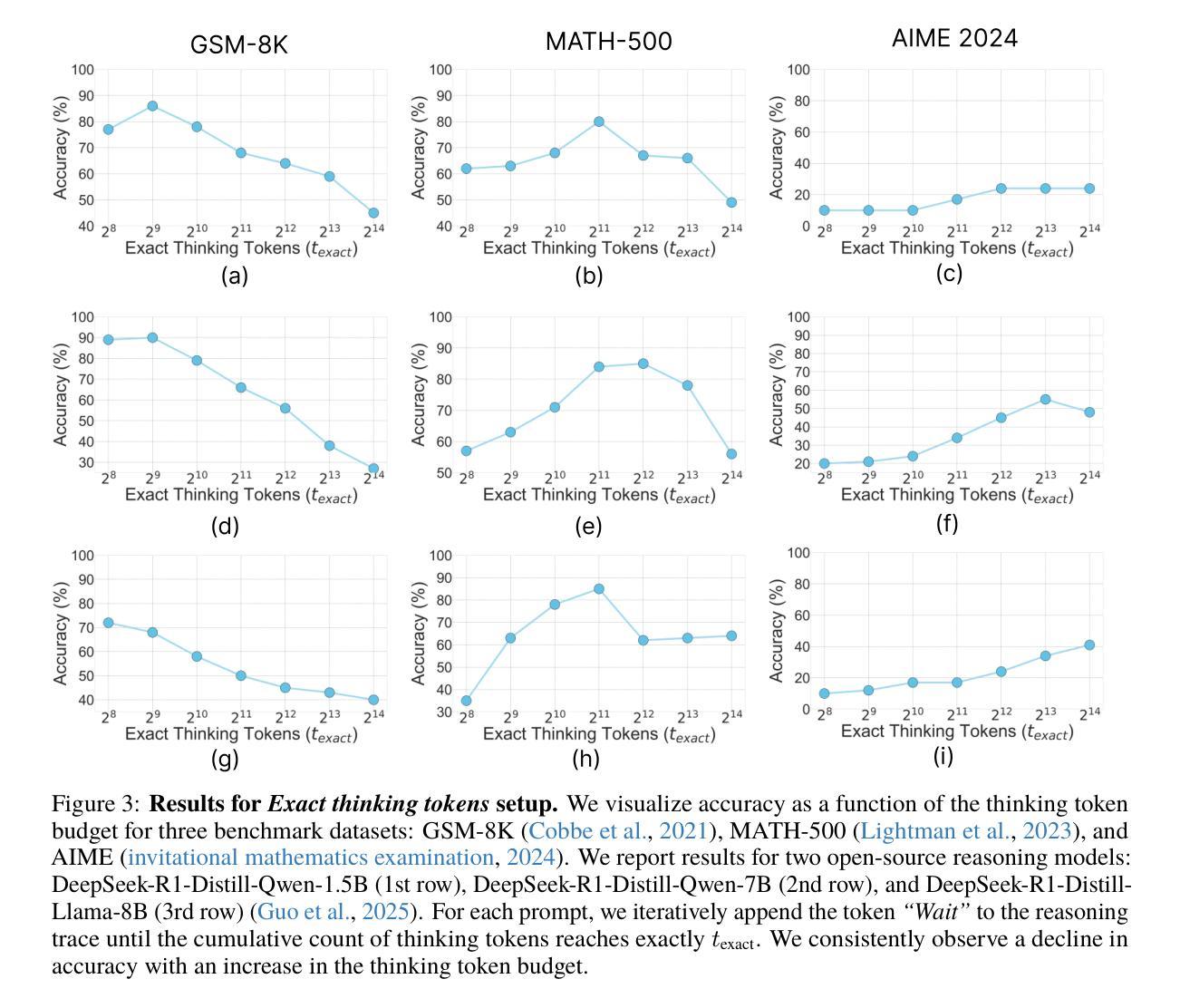
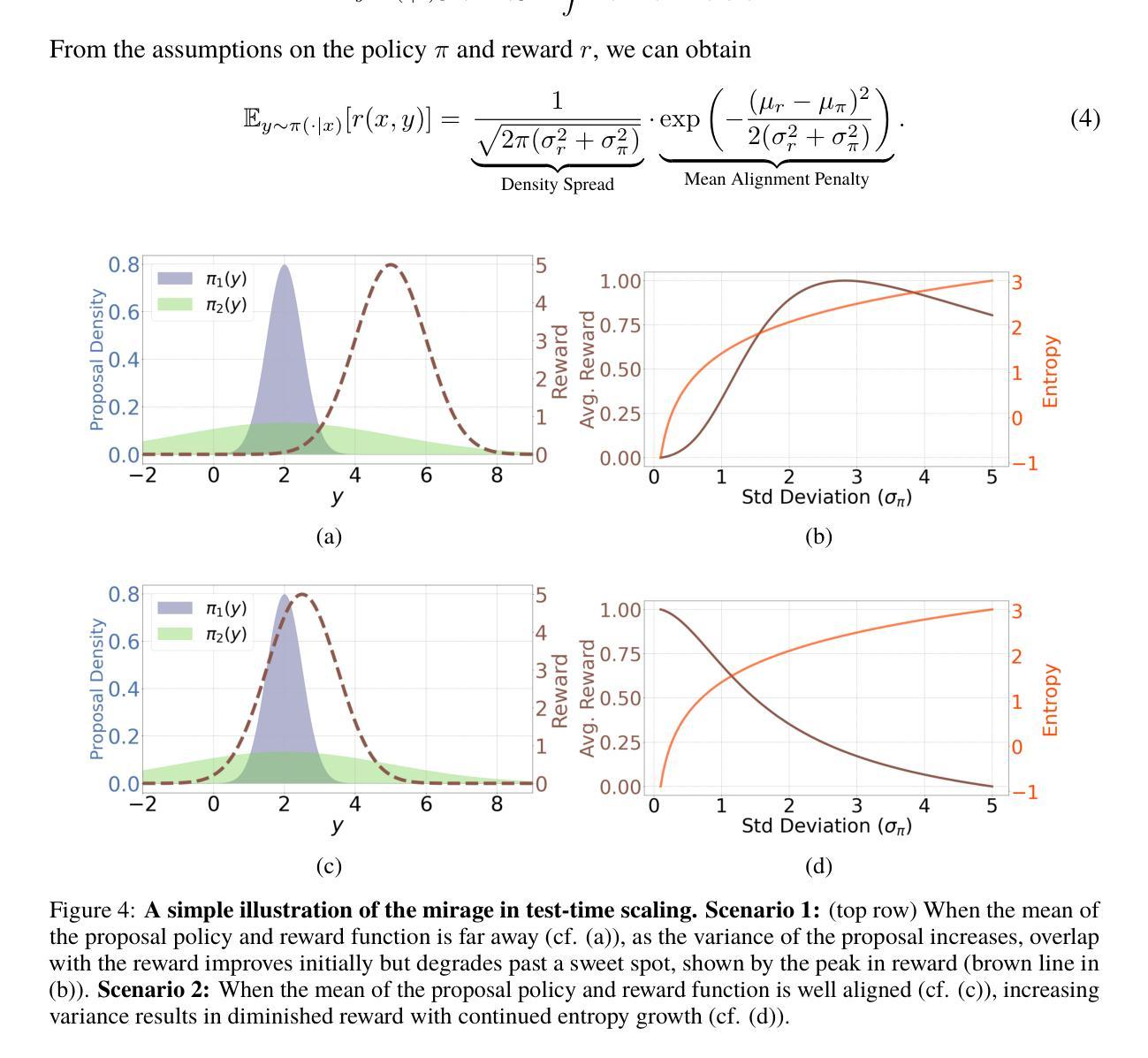
Does Thinking More always Help? Understanding Test-Time Scaling in Reasoning Models
Authors:Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Yifu Lu, Mengdi Wang, Dinesh Manocha, Furong Huang, Mohammad Ghavamzadeh, Amrit Singh Bedi
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like “Wait” or “Let me rethink” can improve performance. This raises a natural question: Does thinking more at test-time truly lead to better reasoning? To answer this question, we perform a detailed empirical study across models and benchmarks, which reveals a consistent pattern of initial performance improvements from additional thinking followed by a decline, due to “overthinking”. To understand this non-monotonic trend, we consider a simple probabilistic model, which reveals that additional thinking increases output variance-creating an illusion of improved reasoning while ultimately undermining precision. Thus, observed gains from “more thinking” are not true indicators of improved reasoning, but artifacts stemming from the connection between model uncertainty and evaluation metric. This suggests that test-time scaling through extended thinking is not an effective way to utilize the inference thinking budget. Recognizing these limitations, we introduce an alternative test-time scaling approach, parallel thinking, inspired by Best-of-N sampling. Our method generates multiple independent reasoning paths within the same inference budget and selects the most consistent response via majority vote, achieving up to 20% higher accuracy compared to extended thinking. This provides a simple yet effective mechanism for test-time scaling of reasoning models.
关于推理模型的测试时间缩放(例如OpenAI o1、DeepSeek R1)的最新趋势导致了一种普遍的观点,即通过类似“等一下”或“让我再思考一下”的提示来扩展思考轨迹可以提高性能。这引发了一个自然的问题:在测试时思考更多是否真的会导致更好的推理?为了回答这个问题,我们对模型和基准进行了详细的实证研究,结果显示初始性能在额外的思考后有改善,但随后由于“过度思考”而下降。为了理解这种非单调趋势,我们考虑了一个简单的概率模型,该模型表明额外的思考增加了输出方差,从而产生了一种改善推理的错觉,但实际上会破坏精度。因此,“更多思考”所带来的观察收益并不是推理能力真正提高的指示器,而是源于模型不确定性和评价指标之间联系的产物。这表明通过延长思考来进行测试时间缩放并不是有效利用推理预算的有效方法。认识到这些局限性,我们引入了一种受Best-of-N采样启发的替代测试时间缩放方法——并行思考。我们的方法在相同的推理预算内生成多个独立的推理路径,并通过多数投票选择最一致的响应,与延长思考相比,实现了高达20%的准确性提高。这为推理模型的测试时间缩放提供了一种简单而有效的机制。
论文及项目相关链接
Summary
本文探讨了测试时扩展思考是否真正提升模型推理能力的问题。研究发现在初始阶段增加思考时间确实能够提高性能,但随后由于“过度思考”会导致性能下降。采用概率模型分析这一非单调趋势表明,增加思考时间会增加输出方差,从而产生改进推理的错觉,实际上会损害精度。因此,观察到的通过“更多思考”带来的收益并非真正反映推理能力的提高,而是源于模型不确定性与评价指标之间的关联。在此基础上,提出了一种新的测试时扩展思考的方法——并行思考,该方法受到Best-of-N采样的启发,能够在同一推理预算内生成多个独立推理路径,并通过多数投票选择最一致的回应,与扩展思考相比,提高了高达20%的准确率。
Key Takeaways
- 测试时扩展思考是否真正提升模型推理能力的问题被提出并研究。
- 增加思考时间初始能提高性能,但随后由于“过度思考”会导致性能下降。
- 概率模型分析显示增加思考时间会增加输出方差,产生改进推理的错觉,实际上损害精度。
- “更多思考”带来的收益并非真正反映推理能力的提高,而是源于模型不确定性与评价指标的关联。
- 提出了一种新的测试时扩展思考方法——并行思考。
- 并行思考能在同一推理预算内生成多个独立推理路径。
点此查看论文截图

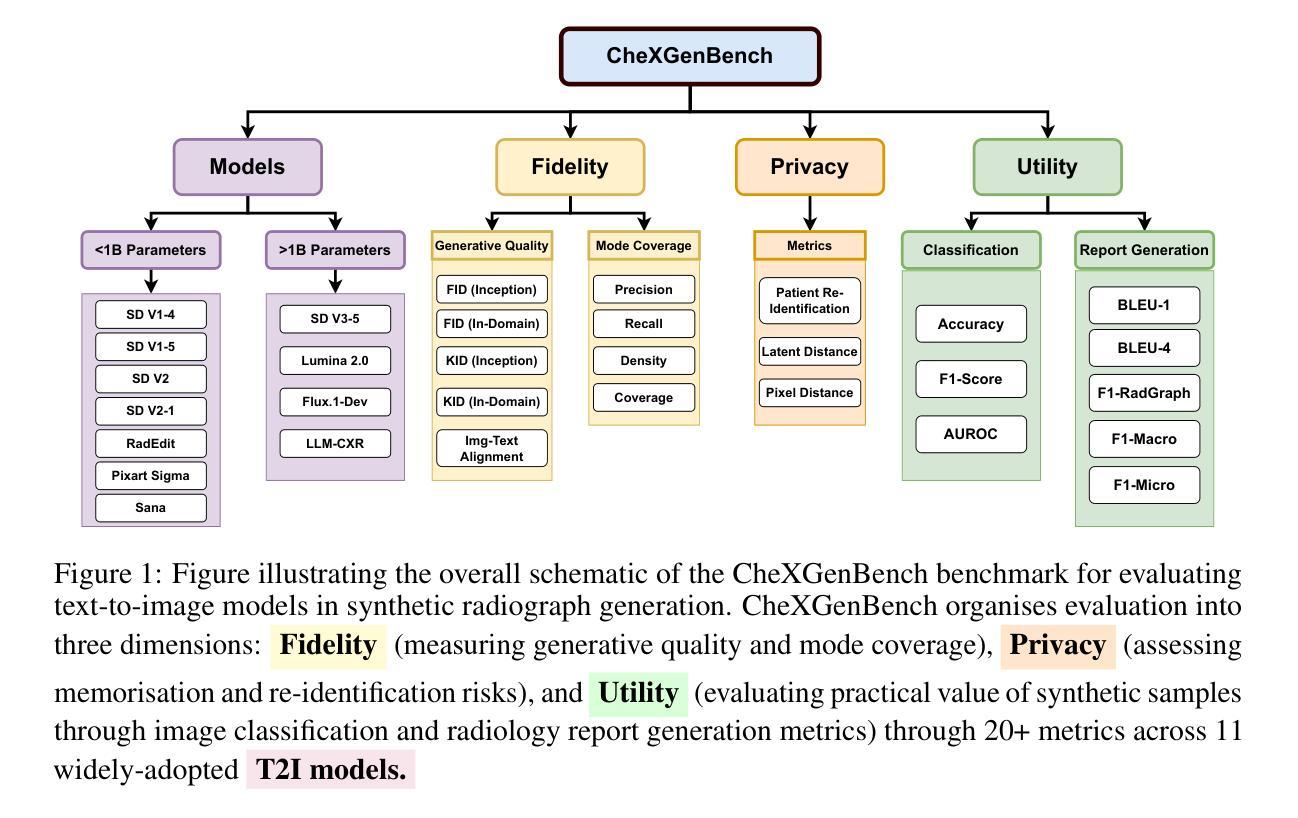
CheXGenBench: A Unified Benchmark For Fidelity, Privacy and Utility of Synthetic Chest Radiographs
Authors:Raman Dutt, Pedro Sanchez, Yongchen Yao, Steven McDonagh, Sotirios A. Tsaftaris, Timothy Hospedales
We introduce CheXGenBench, a rigorous and multifaceted evaluation framework for synthetic chest radiograph generation that simultaneously assesses fidelity, privacy risks, and clinical utility across state-of-the-art text-to-image generative models. Despite rapid advancements in generative AI for real-world imagery, medical domain evaluations have been hindered by methodological inconsistencies, outdated architectural comparisons, and disconnected assessment criteria that rarely address the practical clinical value of synthetic samples. CheXGenBench overcomes these limitations through standardised data partitioning and a unified evaluation protocol comprising over 20 quantitative metrics that systematically analyse generation quality, potential privacy vulnerabilities, and downstream clinical applicability across 11 leading text-to-image architectures. Our results reveal critical inefficiencies in the existing evaluation protocols, particularly in assessing generative fidelity, leading to inconsistent and uninformative comparisons. Our framework establishes a standardised benchmark for the medical AI community, enabling objective and reproducible comparisons while facilitating seamless integration of both existing and future generative models. Additionally, we release a high-quality, synthetic dataset, SynthCheX-75K, comprising 75K radiographs generated by the top-performing model (Sana 0.6B) in our benchmark to support further research in this critical domain. Through CheXGenBench, we establish a new state-of-the-art and release our framework, models, and SynthCheX-75K dataset at https://raman1121.github.io/CheXGenBench/
我们推出CheXGenBench,这是一个针对合成胸部X光片生成技术的严格多元评估框架,可以同时评估最前沿的文本到图像生成模型的保真度、隐私风险以及临床实用性。尽管现实世界图像生成人工智能取得了快速发展,但医疗领域评估仍受到方法不一致、架构对比过时以及评估标准脱节等问题的阻碍,这些问题很少关注合成样本的实际临床价值。CheXGenBench通过标准化数据分区以及包含超过20个量化指标的统一评估协议来克服这些限制,该协议系统地分析了生成质量、潜在的隐私漏洞以及在11个领先的文本到图像架构中的下游临床适用性。我们的结果揭示了现有评估协议中的关键低效之处,特别是在评估生成保真度方面,导致比较结果不一致且缺乏信息。我们的框架为医疗人工智能社区建立了标准化基准,能够进行客观和可重复的比较,同时促进了现有和未来生成模型的无缝集成。此外,我们还发布了一个高质量合成数据集SynthCheX-75K,该数据集包含由我们基准测试中表现最佳的模型(Sana 0.6B)生成的75K张放射影像图,以支持这一关键领域的进一步研究。通过CheXGenBench,我们树立了新的技术标杆,并将我们的框架、模型和SynthCheX-75K数据集发布在[https://raman1121.github.io/CheXGenBench/]上。
论文及项目相关链接
Summary:
我们推出了CheXGenBench,这是一个对合成胸片的生成进行综合评价的严谨且多元的评价框架。该框架可以同时评估多个文本至图像生成模型的真实性、隐私风险以及临床应用价值。虽然生成式AI在现实图像领域发展迅速,但医疗领域的评价受到方法不一致、架构比较过时以及评估标准脱节等问题的阻碍,很少关注合成样本的实际临床价值。CheXGenBench通过标准化数据划分和统一的评估协议,包括超过20个定量指标,系统地分析生成质量、潜在的隐私漏洞以及下游在临床应用的适用性,涵盖了11个主流的文本至图像架构。我们的结果揭示了现有评估协议的关键效率问题,特别是在评估生成真实性方面,导致比较结果不一致且缺乏信息。我们的框架为医疗AI社区建立了标准化的基准测试,使客观和可重复的比较成为可能,同时促进了现有和未来生成模型的无缝集成。此外,我们还发布了一个高质量的人工数据集SynthCheX-75K,包含由我们基准测试中表现最佳的模型(Sana 0.6B)生成的75K张放射照片,以支持这一关键领域的研究。通过CheXGenBench,我们建立了新的标准并发布了我们的框架、模型和SynthCheX-75K数据集。
Key Takeaways:
- CheXGenBench是一个针对合成胸片的生成能力的多元化评价框架。
- 该框架能够同时评估多个文本至图像生成模型的多个方面:真实性、隐私风险以及临床应用价值等。
- 虽然AI技术在现实图像领域的生成技术取得了进步,但在医疗领域的评估仍存在诸多挑战。
- CheXGenBench通过标准化数据划分和统一的评估协议解决了现有评估协议的不足。
- 该框架包含超过20个定量指标,旨在系统地分析生成质量、潜在的隐私漏洞以及下游在临床应用的适用性等多个方面。
- CheXGenBench涵盖了多个主流的文本至图像架构,并揭示了现有评估协议的关键问题。
点此查看论文截图

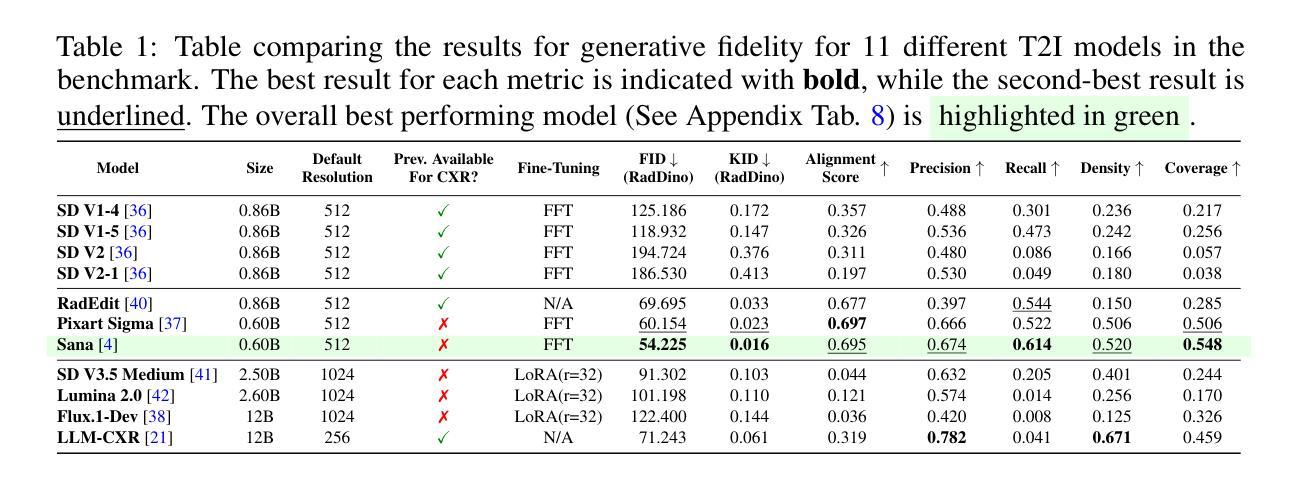
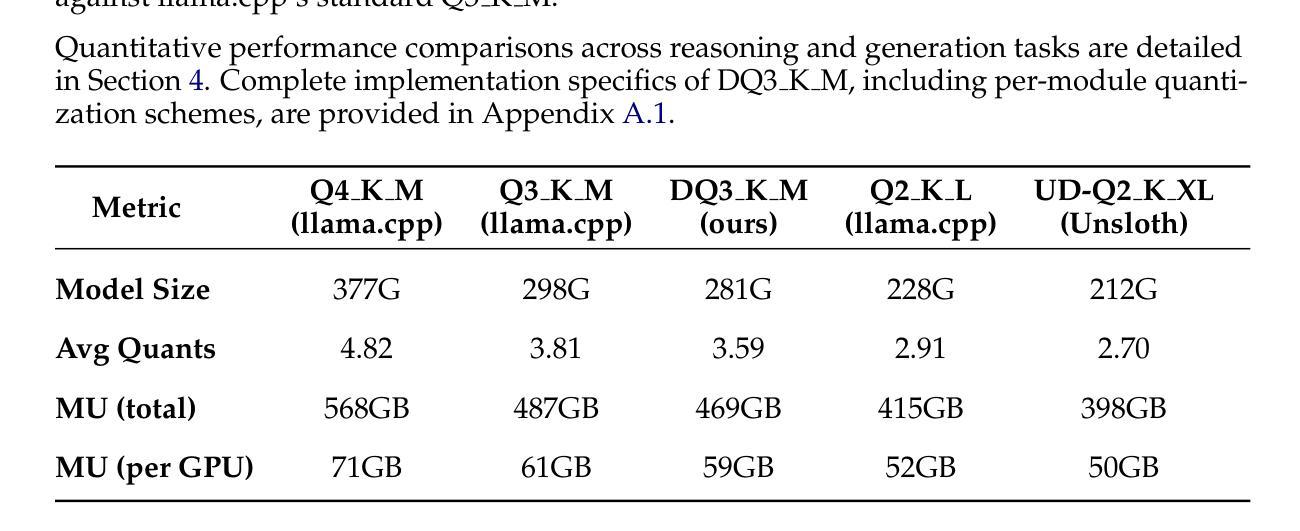
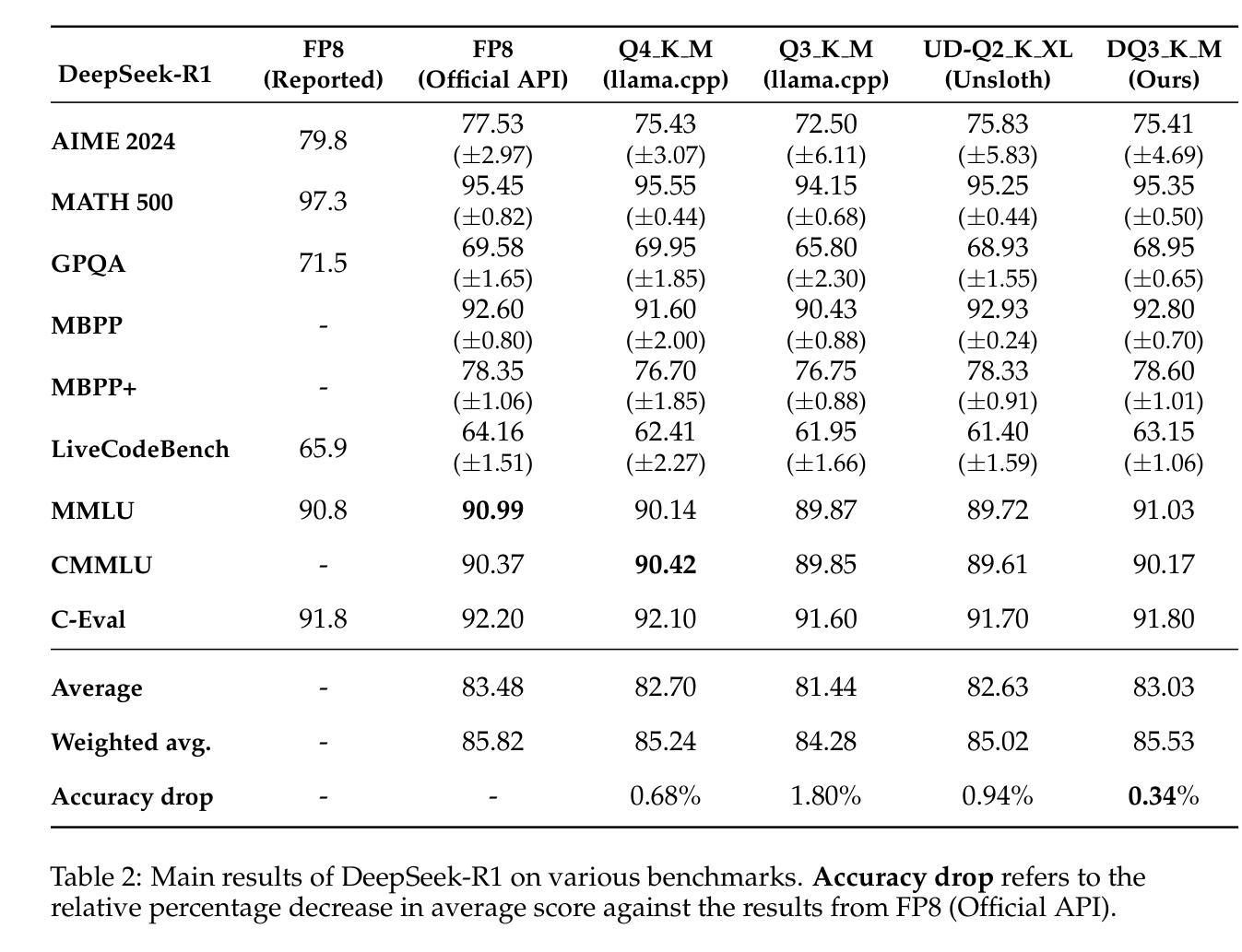
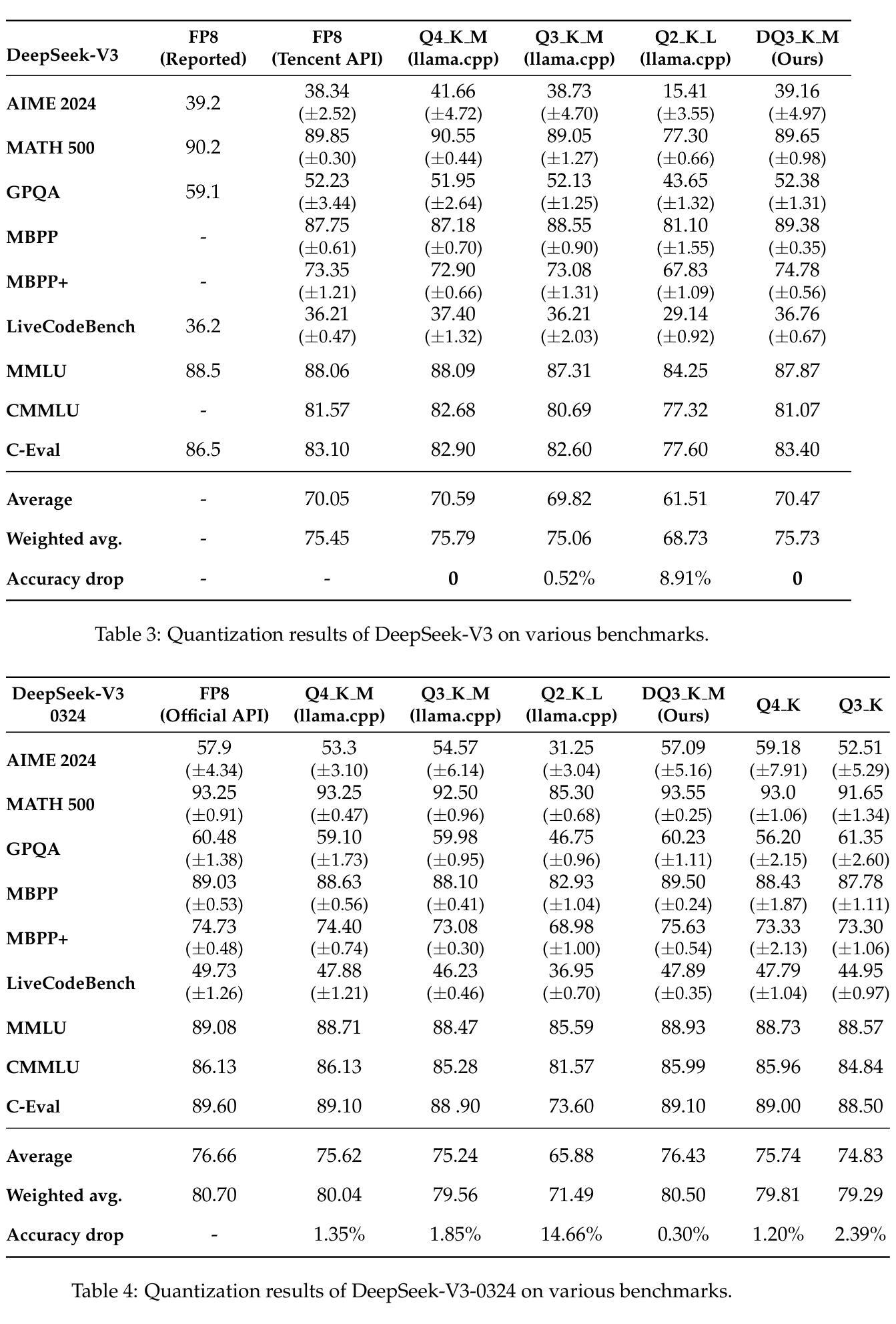
Quantitative Analysis of Performance Drop in DeepSeek Model Quantization
Authors:Enbo Zhao, Yi Shen, Shuming Shi, Jieyun Huang, Zhihao Chen, Ning Wang, Siqi Xiao, Jian Zhang, Kai Wang, Shiguo Lian
Recently, there is a high demand for deploying DeepSeek-R1 and V3 locally, possibly because the official service often suffers from being busy and some organizations have data privacy concerns. While single-machine deployment offers infrastructure simplicity, the models’ 671B FP8 parameter configuration exceeds the practical memory limits of a standard 8-GPU machine. Quantization is a widely used technique that helps reduce model memory consumption. However, it is unclear what the performance of DeepSeek-R1 and V3 will be after being quantized. This technical report presents the first quantitative evaluation of multi-bitwidth quantization across the complete DeepSeek model spectrum. Key findings reveal that 4-bit quantization maintains little performance degradation versus FP8 while enabling single-machine deployment on standard NVIDIA GPU devices. We further propose DQ3_K_M, a dynamic 3-bit quantization method that significantly outperforms traditional Q3_K_M variant on various benchmarks, which is also comparable with 4-bit quantization (Q4_K_M) approach in most tasks. Moreover, DQ3_K_M supports single-machine deployment configurations for both NVIDIA H100/A100 and Huawei 910B. Our implementation of DQ3_K_M is released at https://github.com/UnicomAI/DeepSeek-Eval, containing optimized 3-bit quantized variants of both DeepSeek-R1 and DeepSeek-V3.
最近,对本地部署DeepSeek-R1和V3的需求很高,可能是因为官方服务经常繁忙,而且一些组织对数据隐私存在担忧。虽然单机部署可以提供基础设施的简单性,但模型的671B FP8参数配置超出了标准8 GPU机器的实际内存限制。量化是一种广泛使用的技术,有助于减少模型内存消耗。然而,量化后DeepSeek-R1和V3的性能尚不清楚。本技术报告首次对DeepSeek模型谱进行全面多位宽量化评估。研究发现,采用四比特量化的性能几乎没有下降相比于FP8模式同时可以在标准NVIDIA GPU设备上实现单机部署。我们进一步提出了DQ3_K_M的动态三比特量化方法在各种基准测试中大大优于传统的Q3_K_M变体同时DQ3_K_M在大多数任务中与四比特量化(Q4_K_M)方法相当。此外,DQ3_K_M支持NVIDIA H100/A100和华为910B的单机部署配置。我们在https://github.com/UnicomAI/DeepSeek-Eval上发布了DQ3_K_M的实现包含DeepSeek-R1和DeepSeek-V3的优化三比特量化变体。
论文及项目相关链接
PDF This version added the results of DeepSeek-V3-0324
Summary
深度学习模型DeepSeek-R1和DeepSeek-V3在本地部署需求上升,由于官方服务繁忙及数据隐私顾虑,引发广泛关注。虽然单机部署能够简化基础设施,但其内存限制对部署需求存在挑战。这篇报告提供了在DeepSeek模型系列上进行量化分析的定量评价。主要研究发现4位量化能在内存消耗减少的同时保持模型性能。同时提出一种动态3位量化方法DQ3_K_M,对Q3_K_M进行优化并在多数任务中与当前技术最佳表现的4位量化媲美。该技术实现在https://github.com/UnicomAI/DeepSeek-Eval处开源发布,以支持不同配置与需求的用户使用。此次实现将促进深度学习模型在单机部署的效率和性能提升。
Key Takeaways
- DeepSeek-R1和DeepSeek-V3因服务繁忙和数据隐私担忧受到广泛关注。随着其在本地部署需求的上升,针对模型规模的优化成为了必要议题。本报告则提供了一种优化手段以解决该问题。报告的成果允许本地计算机快速应用该算法对个体做出智能化反应和分析工作以加快处理速度并降低算力成本。
点此查看论文截图

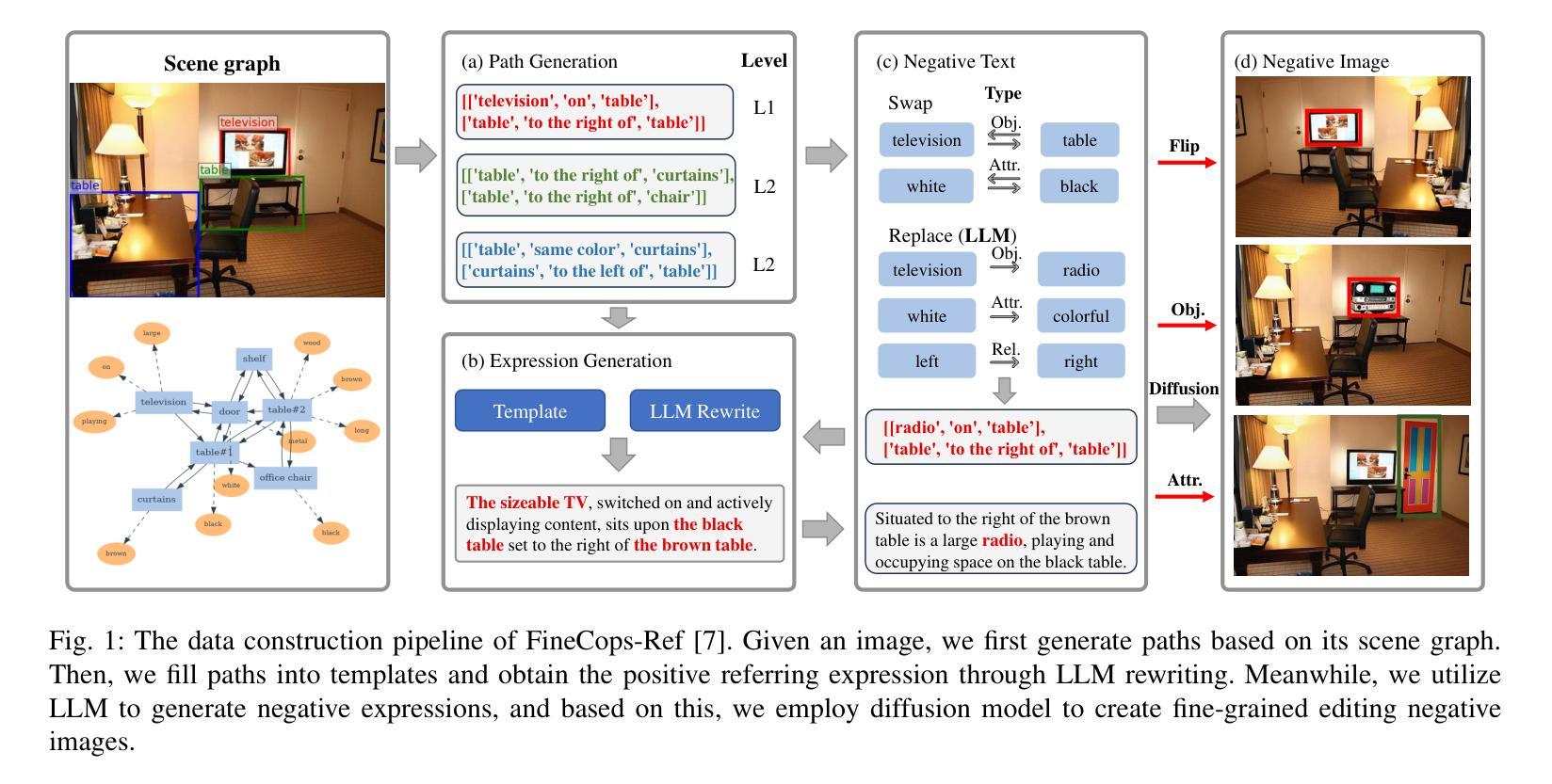
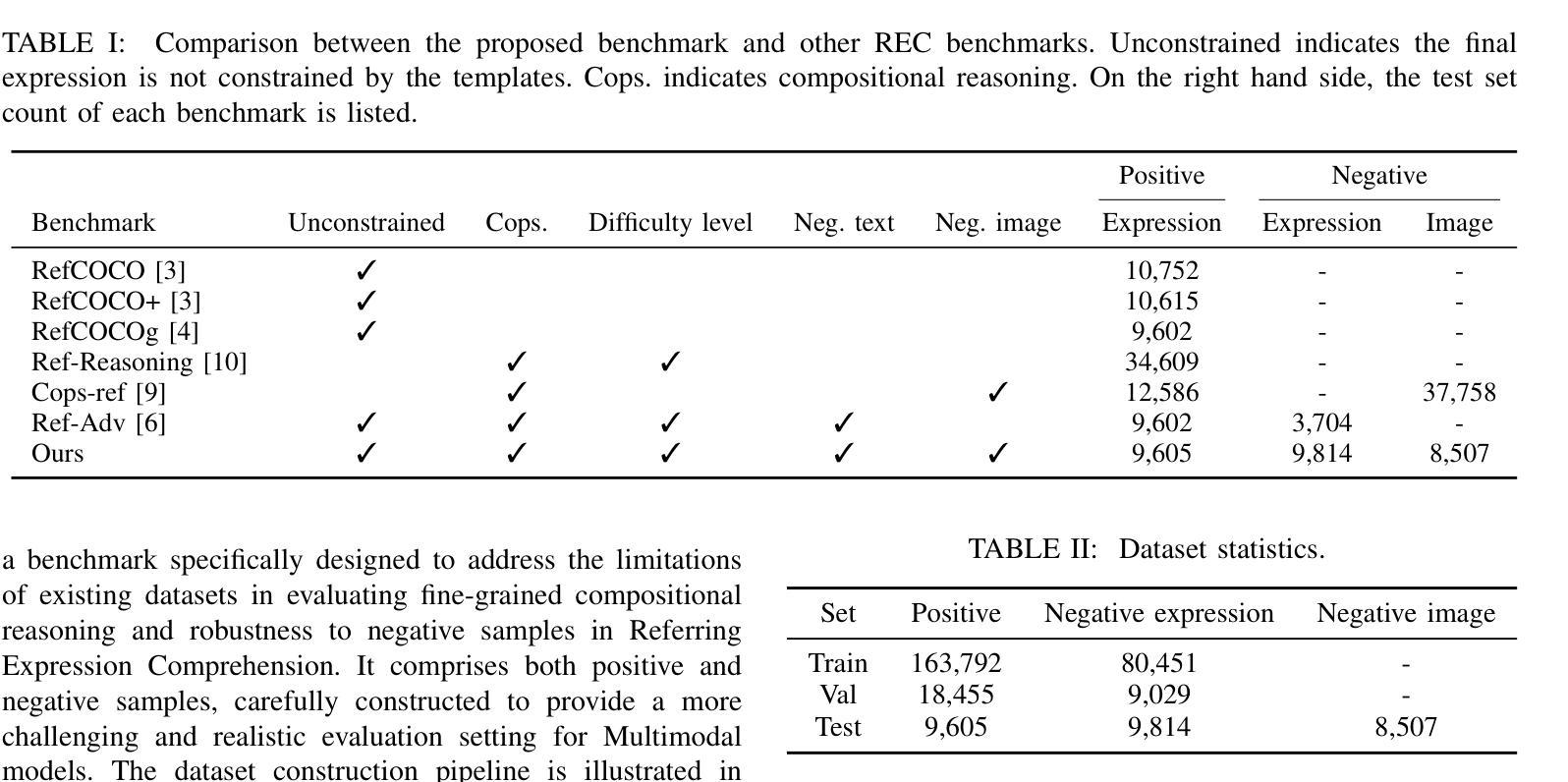
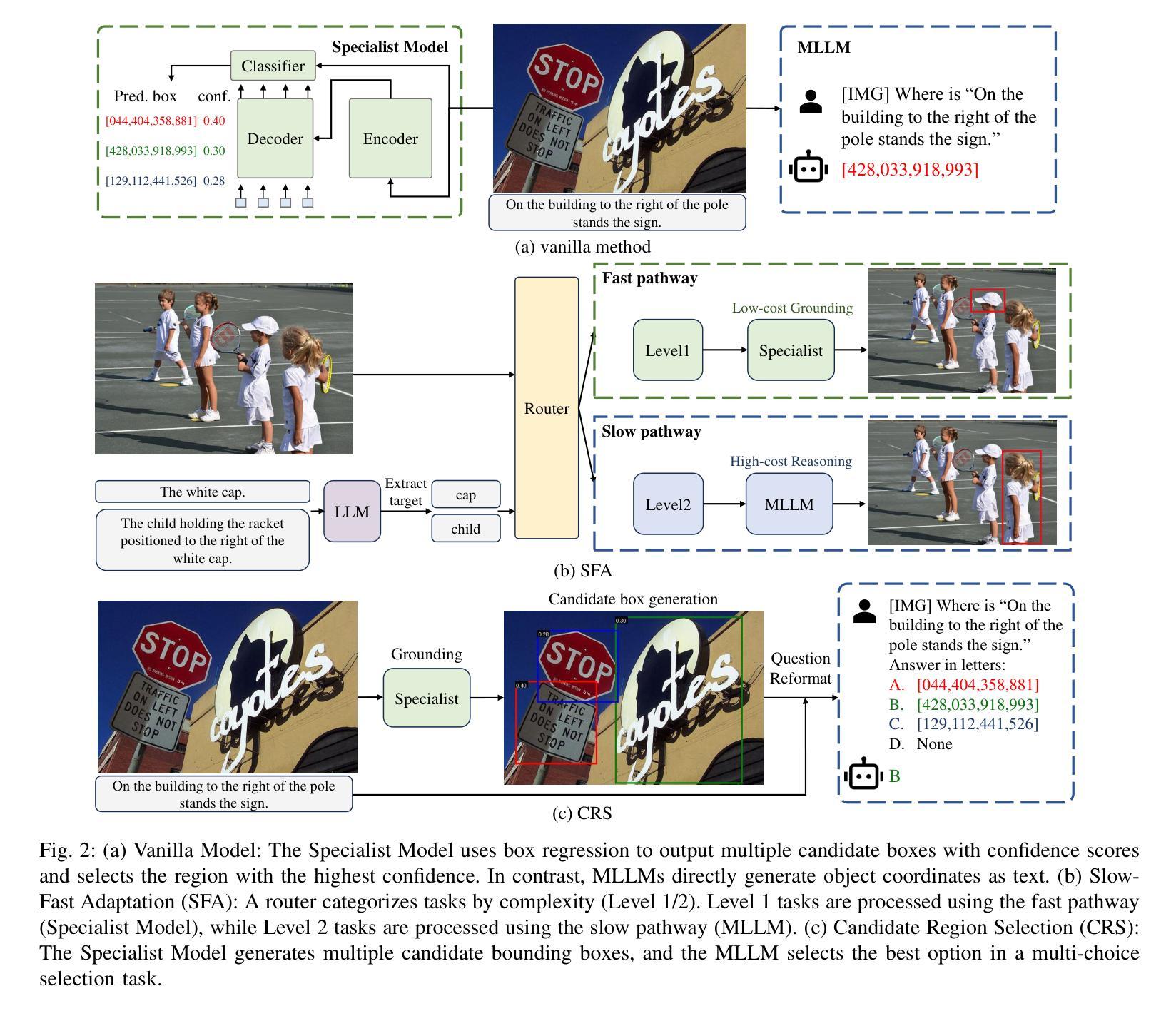
New Dataset and Methods for Fine-Grained Compositional Referring Expression Comprehension via Specialist-MLLM Collaboration
Authors:Xuzheng Yang, Junzhuo Liu, Peng Wang, Guoqing Wang, Yang Yang, Heng Tao Shen
Referring Expression Comprehension (REC) is a foundational cross-modal task that evaluates the interplay of language understanding, image comprehension, and language-to-image grounding. It serves as an essential testing ground for Multimodal Large Language Models (MLLMs). To advance this field, we introduced a new REC dataset in our previous conference paper, characterized by two key features. First, it is designed with controllable difficulty levels, requiring multi-level fine-grained reasoning across object categories, attributes, and multi-hop relationships. Second, it incorporates negative text and images generated through fine-grained editing and augmentation, explicitly testing a model’s ability to reject scenarios where the target object is absent, an often overlooked yet critical challenge in existing datasets. In this extended work, we propose two new methods to tackle the challenges of fine-grained REC by combining the strengths of Specialist Models and MLLMs. The first method adaptively assigns simple cases to faster, lightweight models and reserves complex ones for powerful MLLMs, balancing accuracy and efficiency. The second method lets a specialist generate a set of possible object regions, and the MLLM selects the most plausible one using its reasoning ability. These collaborative strategies lead to significant improvements on our dataset and other challenging benchmarks. Our results show that combining specialized and general-purpose models offers a practical path toward solving complex real-world vision-language tasks. Our dataset and code are available at https://github.com/sleepyshep/FineCops-Ref.
指代表达理解(REC)是一项基础的多模式任务,它评估语言理解、图像理解和语言到图像定位之间的相互作用。它是多模态大型语言模型(MLLM)的重要测试平台。为了推动这一领域的发展,我们在之前的会议论文中引入了一个新的REC数据集,该数据集具有两个关键特征。首先,它按照可控的难度级别设计,需要对对象类别、属性和多跳关系进行多层次精细推理。其次,它结合了通过精细编辑和增强生成的负面文本和图像,明确测试了模型在目标对象缺失的场景中的拒绝能力,这是现有数据集中经常被忽视但至关重要的挑战。在这项扩展工作中,我们提出了两种新方法,通过结合专业模型和多模态大型语言模型的优点来解决精细REC的挑战。第一种方法自适应地将简单案例分配给更快、更轻型的模型,并将复杂案例留给强大的MLLMs,从而平衡准确性和效率。第二种方法让专家生成一组可能的对象区域,然后使用MLLM的推理能力选择最合理的区域。这些协作策略在我们的数据集和其他具有挑战性的基准测试上取得了显著改进。我们的结果表明,结合专业模型和通用模型为解决复杂的现实世界视觉语言任务提供了实际途径。我们的数据集和代码可在https://github.com/sleepyshep/FineCops-Ref上找到。
论文及项目相关链接
PDF Accepted by TPAMI 2025
Summary:
本文介绍了面向视觉语言任务的跨模态基础任务——指代表达式理解(REC)。文章重点阐述了新推出的REC数据集的特点及在Multimodal大型语言模型(MLLMs)测试中的重要性。文章还提出了两种新方法来应对精细化的REC挑战,通过结合专业模型和MLLMs的优势,在数据集和其他挑战性基准测试上取得了显著改进。结果表明,结合专业模型和通用模型为解决复杂的现实世界视觉语言任务提供了实用途径。
Key Takeaways:
- 指代表达式理解(REC)是跨模态任务的基础,涉及语言理解、图像理解和语言到图像的映射。
- 新推出的REC数据集具有两个关键特点:可控的难度级别和包含负面文本和图像的精细编辑和增强。
- 提出了两种新方法来应对精细化的REC挑战:自适应分配简单案例给轻量级模型,复杂案例留给强大的MLLMs;专家生成可能的对象区域,由MLLM利用推理能力选择最合理的区域。
- 结合专业模型和通用模型在数据集和其他基准测试上取得了显著改进。
- 文章强调了解决复杂现实世界视觉语言任务需要结合实际需求和模型特点,采用适当的策略。
点此查看论文截图

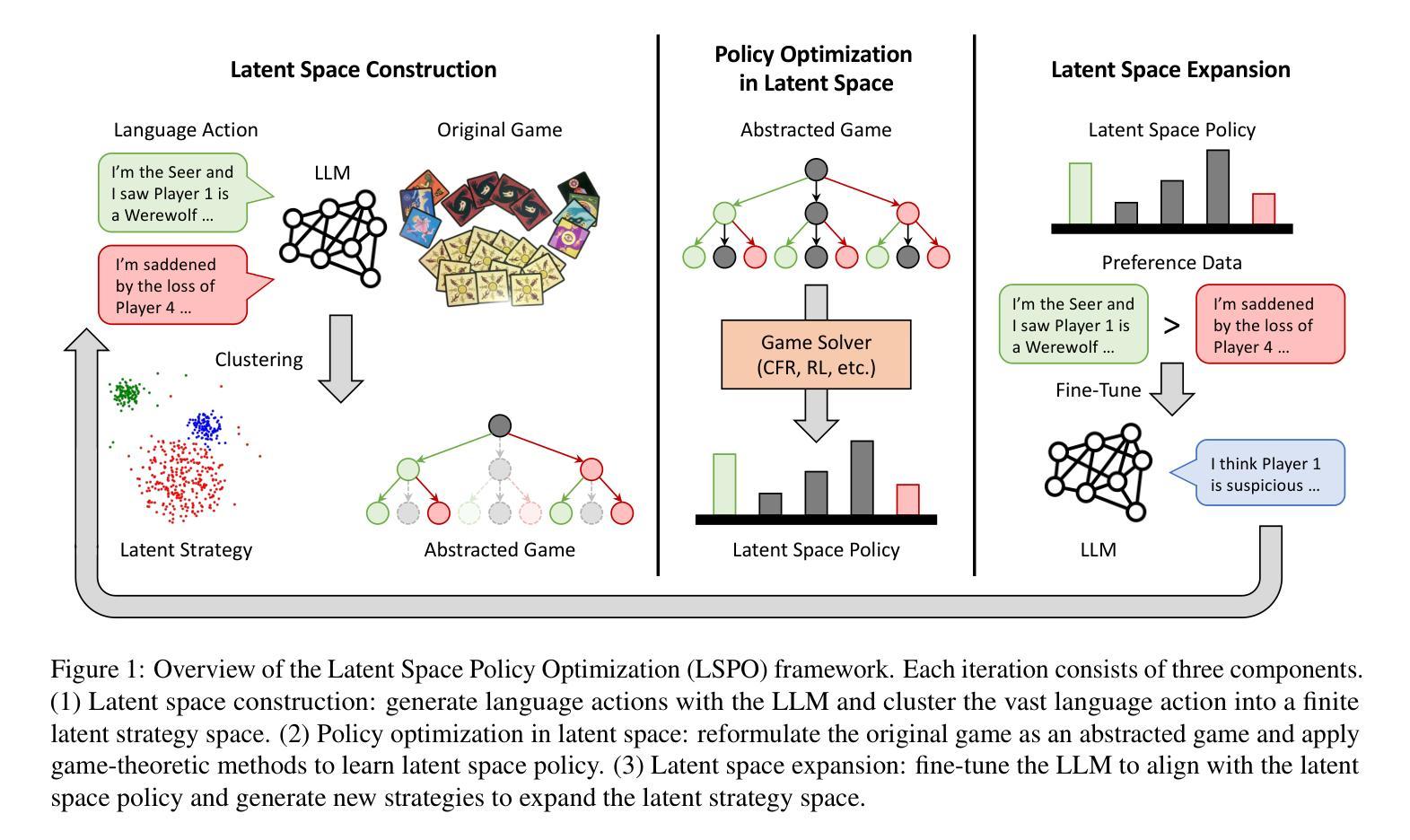
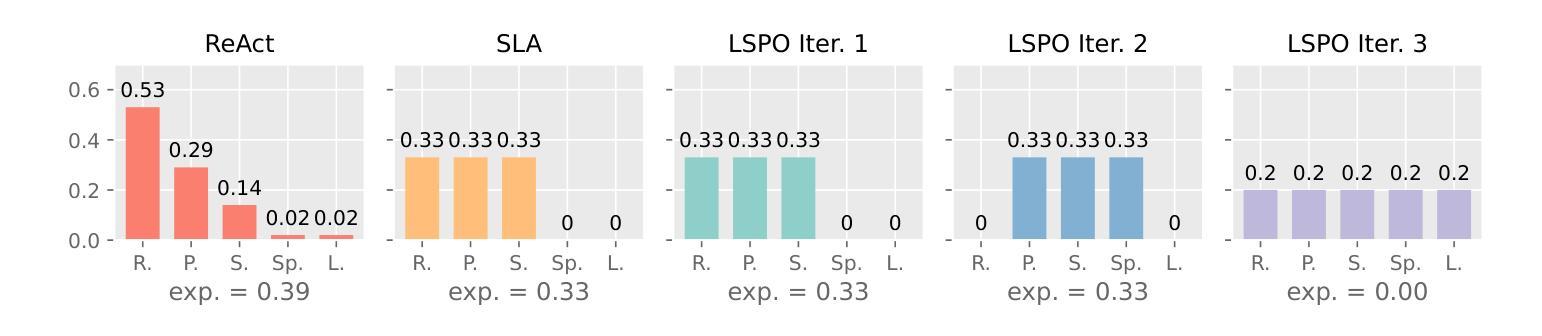
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Authors:Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu, Yu Wang
Large language model (LLM) agents have recently demonstrated impressive capabilities in various domains like open-ended conversation and multi-step decision-making. However, it remains challenging for these agents to solve strategic language games, such as Werewolf, which demand both strategic decision-making and free-form language interactions. Existing LLM agents often suffer from intrinsic bias in their action distributions and limited exploration of the unbounded text action space, resulting in suboptimal performance. To address these challenges, we propose Latent Space Policy Optimization (LSPO), an iterative framework that combines game-theoretic methods with LLM fine-tuning to build strategic language agents. LSPO leverages the observation that while the language space is combinatorially large, the underlying strategy space is relatively compact. We first map free-form utterances into a finite latent strategy space, yielding an abstracted extensive-form game. Then we apply game-theoretic methods like Counterfactual Regret Minimization (CFR) to optimize the policy in the latent space. Finally, we fine-tune the LLM via Direct Preference Optimization (DPO) to align with the learned policy. By iteratively alternating between these steps, our LSPO agents progressively enhance both strategic reasoning and language communication. Experiment on the Werewolf game shows that our agents iteratively expand the strategy space with improving performance and outperform existing Werewolf agents, underscoring their effectiveness in free-form language games with strategic interactions.
大型语言模型(LLM)代理最近在开放对话和多步决策等各个领域表现出了令人印象深刻的能力。然而,对于战略语言游戏(如Werewolf游戏),这些代理仍面临挑战。这些游戏需要战略决策和自由形式的语言交互,而现有的LLM代理在行动分布上存在内在偏见,并且对无限文本行动空间的探索有限,导致表现不佳。为了解决这些挑战,我们提出了潜在空间策略优化(LSPO),这是一个结合博弈论方法和LLM微调来构建战略语言代理的迭代框架。LSPO利用了一个观察结果,即虽然语言空间是组合性的巨大,但潜在的策略空间是相对紧凑的。我们首先将自由形式的发言映射到有限的潜在策略空间,形成一个抽象的扩展形式的游戏。然后,我们应用博弈论方法,如反事实遗憾最小化(CFR),以优化潜在空间中的策略。最后,我们通过直接偏好优化(DPO)对LLM进行微调,以与学到的策略保持一致。通过在这几步之间迭代交替,我们的LSPO代理在战略推理和语言沟通方面逐步增强。在Werewolf游戏上的实验表明,我们的代理通过迭代扩展策略空间,性能得到提升,并超越了现有的Werewolf代理,这证明了它们在具有战略交互的自由形式语言游戏中的有效性。
论文及项目相关链接
PDF Published in ICML 2025
Summary
大型语言模型(LLM)代理在开放对话和多步决策等领域展现出强大的能力,但在解决战略语言游戏(如Werewolf)时仍面临挑战。现有LLM代理存在行动分布内在偏见和文本行动空间探索有限的问题,导致性能不佳。为解决这些挑战,提出潜在空间策略优化(LSPO)方法,结合博弈论方法和LLM微调,构建战略语言代理。LSPO利用语言空间组合大但潜在策略空间相对紧凑的观察,将自由形式的言论映射到有限的潜在策略空间,形成一个抽象化的扩展形式游戏。然后应用博弈论方法,如反事实后悔最小化(CFR),在潜在空间中优化策略。最后,通过直接偏好优化(DPO)微调LLM,以与学到的策略一致。通过迭代交替进行这些步骤,LSPO代理逐步增强战略推理和语言沟通。在Werewolf游戏的实验表明,LSPO代理通过迭代扩展策略空间并提升性能,超越了现有Werewolf代理。
Key Takeaways
- LLM代理在战略语言游戏(如Werewolf)中面临挑战,需提高战略决策和自由形式语言交互的能力。
- 现有LLM代理存在行动分布偏见和文本行动空间探索有限的问题。
- LSPO方法结合博弈论和LLM微调来解决这些问题。
- LSPO将自由形式的言论映射到潜在策略空间,形成抽象化游戏。
- 应用博弈论方法(如CFR)在潜在空间中优化策略。
- 通过直接偏好优化(DPO)微调LLM,与学到的策略一致。
点此查看论文截图