⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
Enabling automatic transcription of child-centered audio recordings from real-world environments
Authors:Daniil Kocharov, Okko Räsänen
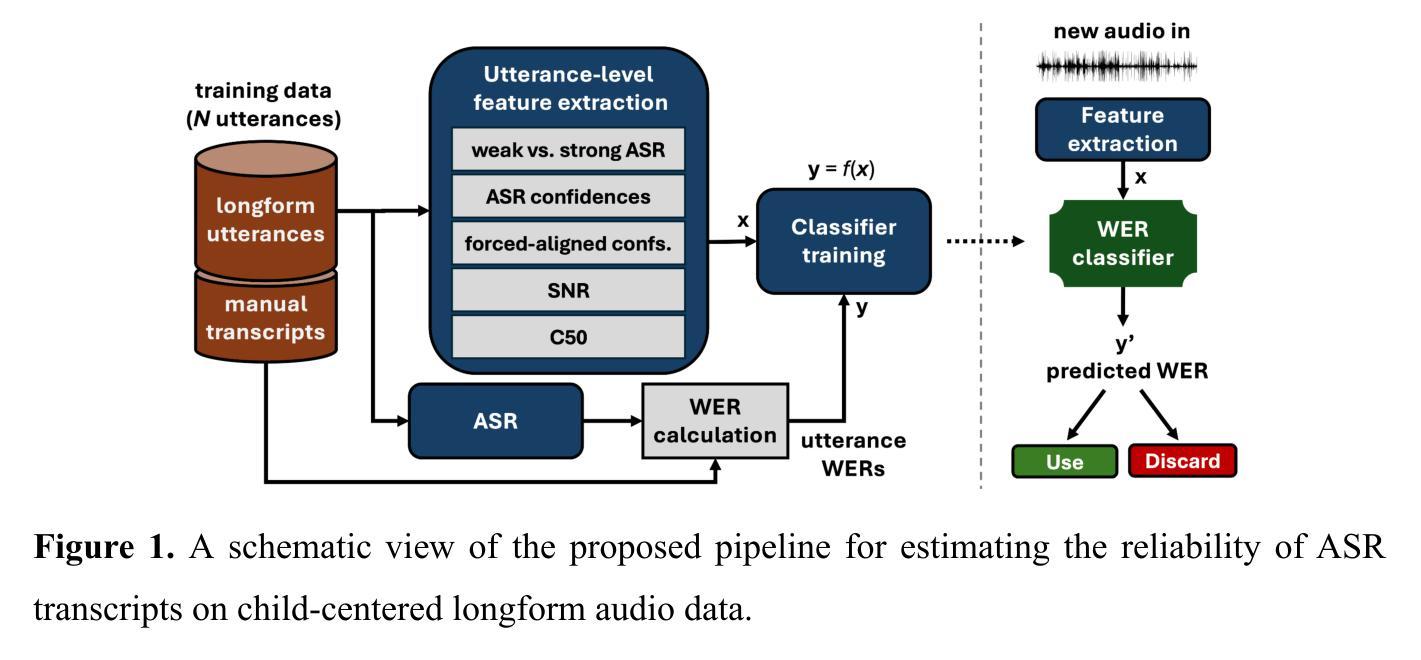
Longform audio recordings obtained with microphones worn by children-also known as child-centered daylong recordings-have become a standard method for studying children’s language experiences and their impact on subsequent language development. Transcripts of longform speech audio would enable rich analyses at various linguistic levels, yet the massive scale of typical longform corpora prohibits comprehensive manual annotation. At the same time, automatic speech recognition (ASR)-based transcription faces significant challenges due to the noisy, unconstrained nature of real-world audio, and no existing study has successfully applied ASR to transcribe such data. However, previous attempts have assumed that ASR must process each longform recording in its entirety. In this work, we present an approach to automatically detect those utterances in longform audio that can be reliably transcribed with modern ASR systems, allowing automatic and relatively accurate transcription of a notable proportion of all speech in typical longform data. We validate the approach on four English longform audio corpora, showing that it achieves a median word error rate (WER) of 0% and a mean WER of 18% when transcribing 13% of the total speech in the dataset. In contrast, transcribing all speech without any filtering yields a median WER of 52% and a mean WER of 51%. We also compare word log-frequencies derived from the automatic transcripts with those from manual annotations and show that the frequencies correlate at r = 0.92 (Pearson) for all transcribed words and r = 0.98 for words that appear at least five times in the automatic transcripts. Overall, the work provides a concrete step toward increasingly detailed automated linguistic analyses of child-centered longform audio.
通过儿童佩戴的麦克风获得的长音频录制(也称为以儿童为中心的全天录音)已成为研究儿童语言体验及其对未来语言发展的影响的标准方法。长语音音频的转录可以在各种语言层面上进行丰富的分析,但是典型的大规模长语音语料库规模庞大,无法进行全面的手动注释。同时,由于现实世界音频的嘈杂和无约束性,基于自动语音识别(ASR)的转录面临着巨大的挑战,尚无研究能够成功将ASR应用于此类数据的转录。然而,之前的尝试假设ASR必须一次性处理整个长音频记录。在这项工作中,我们提出了一种方法来自动检测长语音音频中那些可以用现代ASR系统可靠转录的片段,从而允许自动和相对准确地转录典型长语音数据中相当一部分的所有语音。我们在四个英文长语音音频语料库上验证了该方法的有效性,结果表明,在数据集中转录总语音的13%时,其达到的中位数词错误率(WER)为0%,平均WER为18%。相比之下,在不进行任何筛选的情况下转录所有语音会产生中位数WER为52%和平均WER为51%。我们还比较了自动转录和手动注释中得出的单词日志频率,并显示所有转录单词的关联度为r = 0.92(皮尔逊相关系数),自动转录中出现至少五次的单词的关联度为r = 0.98。总体而言,这项工作朝着对儿童为中心的长语音音频进行越来越详细的自动化语言分析迈出了坚实的一步。
论文及项目相关链接
PDF pre-print
摘要
儿童日常佩戴的麦克风所采集的长音频记录已经成为研究儿童语言经验及其对后续语言发展影响的标准方法。虽然长语音音频的转录能在各种语言层面上进行丰富的分析,但由于数据量巨大,全面手动注释是不可行的。自动语音识别(ASR)转录面临着真实世界音频噪声和无约束性质的挑战,尚无研究成功将ASR应用于此类数据。然而,先前的研究假设ASR必须处理整个长音频记录。在此工作中,我们提出了一种自动检测那些可与现代ASR系统可靠转录的语句的方法,允许对典型长格式数据中的很大一部分语音进行自动和相对准确的转录。我们在四个英语长音频语料库中对这种方法进行了验证,结果显示,当转录数据集中总语音的13%时,其平均词错误率(WER)为18%,中位数WER为0%。相比之下,无过滤转录所有语音的中位数WER和平均WER分别为52%和51%。此外,我们还比较了自动转录和手动注释得到的单词日志频率,自动转录中出现的所有单词的关联度为r=0.92(皮尔逊),出现次数至少五次以上的单词关联度为r=0.98。总体而言,该研究为越来越详细的儿童中心式长音频自动语言分析提供了具体步骤。
要点提炼
- 儿童日常佩戴麦克风采集的长音频记录是研究儿童语言经验的标准方法。
- 手动注释大量长语音音频因数据量巨大而不可行。
- 自动语音识别(ASR)在长音频数据转录中具有挑战,先前假设需处理整个记录。
- 提出了一种自动检测并准确转录部分语句的方法,只对长音频中的一部分进行ASR处理。
- 在四个英语长音频语料库中验证,该方法在转录数据集的13%时表现良好,词错误率较低。
- 与手动注释相比,自动转录的单词日志频率具有较高关联度。
点此查看论文截图

Efficient Speech Enhancement via Embeddings from Pre-trained Generative Audioencoders
Authors:Xingwei Sun, Heinrich Dinkel, Yadong Niu, Linzhang Wang, Junbo Zhang, Jian Luan
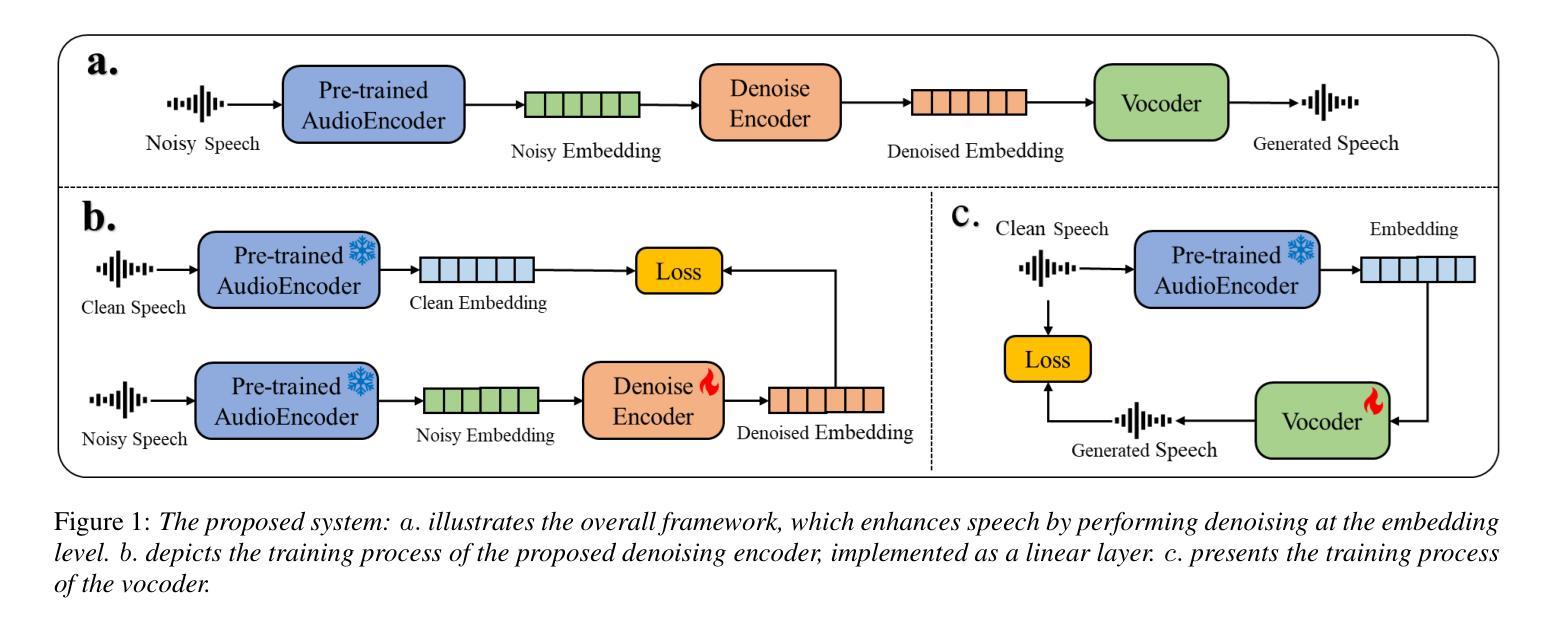
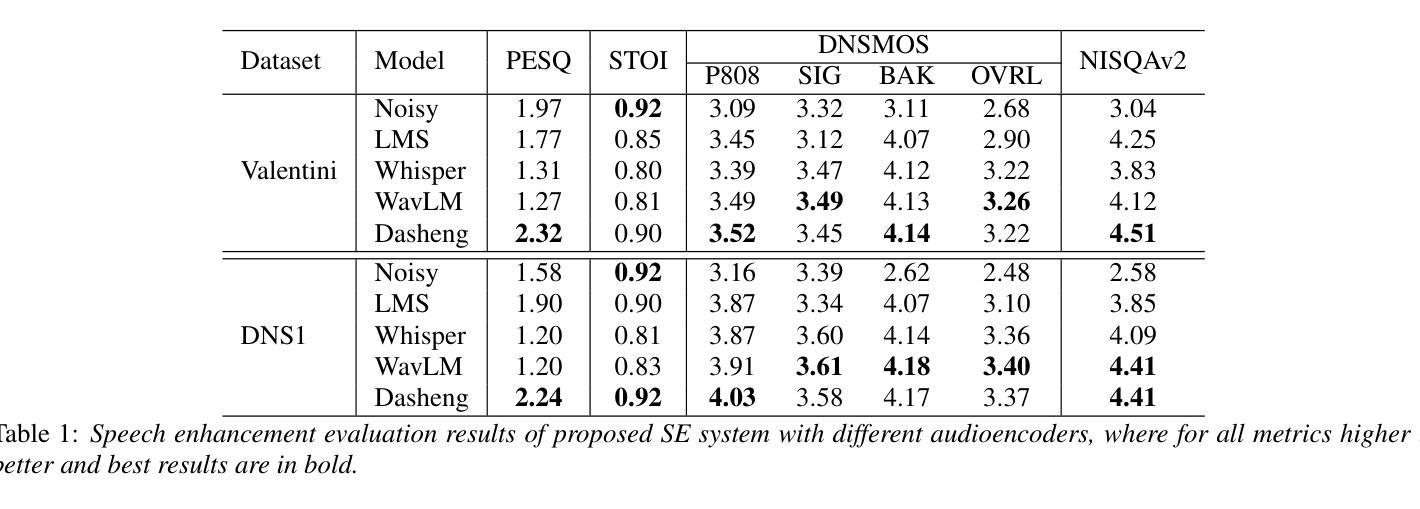
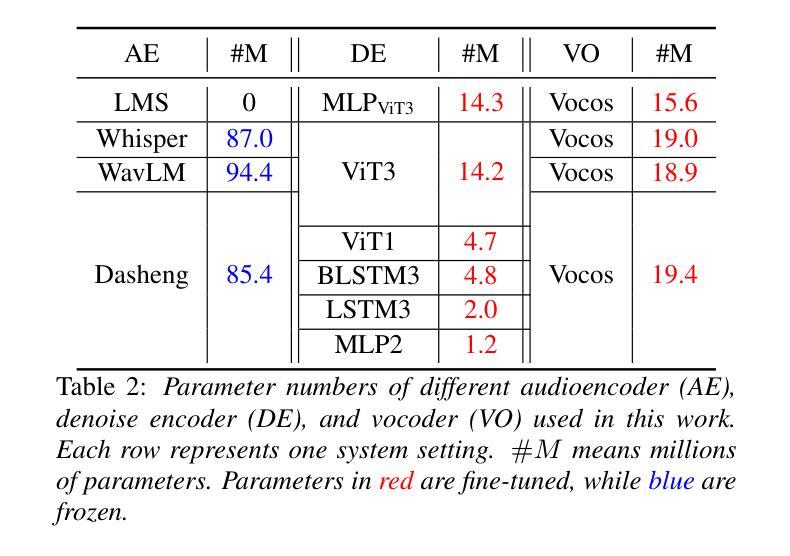
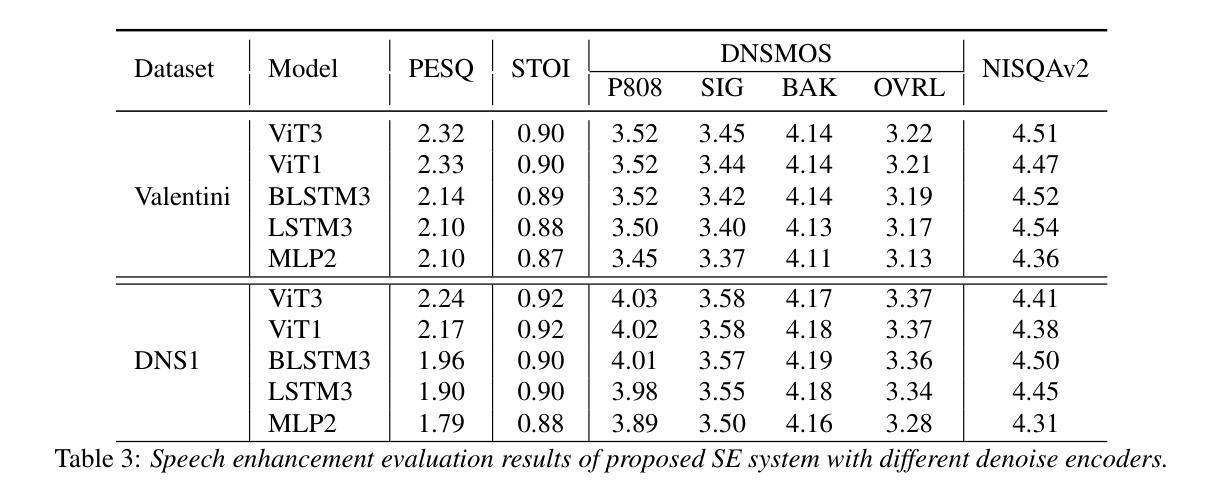
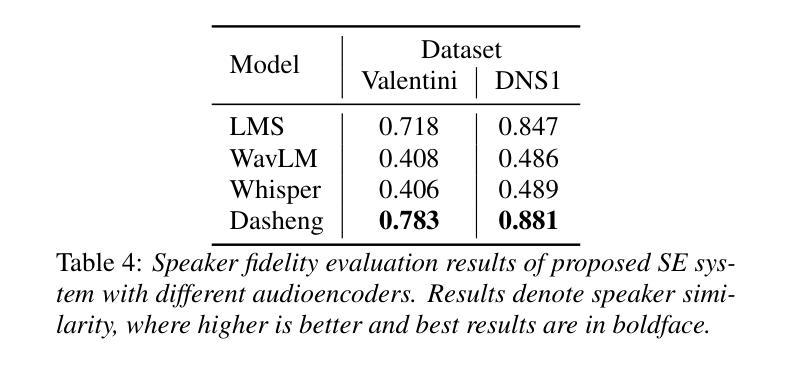
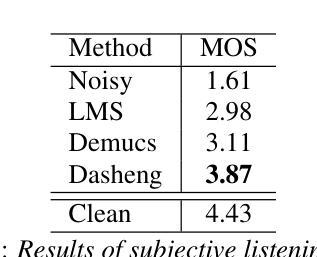
Recent research has delved into speech enhancement (SE) approaches that leverage audio embeddings from pre-trained models, diverging from time-frequency masking or signal prediction techniques. This paper introduces an efficient and extensible SE method. Our approach involves initially extracting audio embeddings from noisy speech using a pre-trained audioencoder, which are then denoised by a compact encoder network. Subsequently, a vocoder synthesizes the clean speech from denoised embeddings. An ablation study substantiates the parameter efficiency of the denoise encoder with a pre-trained audioencoder and vocoder. Experimental results on both speech enhancement and speaker fidelity demonstrate that our generative audioencoder-based SE system outperforms models utilizing discriminative audioencoders. Furthermore, subjective listening tests validate that our proposed system surpasses an existing state-of-the-art SE model in terms of perceptual quality.
最新的研究已经深入探讨了利用预训练模型的音频嵌入进行语音增强(SE)的方法,这些方法不同于基于时间-频率掩蔽或信号预测技术。本文介绍了一种高效且可扩展的SE方法。我们的方法首先通过使用预训练的音频编码器从带噪声的语音中提取音频嵌入,然后通过紧凑的编码器网络对其进行去噪。随后,vocoder通过去噪后的嵌入来合成清洁语音。消融研究证实了预训练的音频编码器和vocoder在降噪编码器参数效率方面的优势。关于语音增强和扬声器保真度的实验结果证明,基于生成式音频编码器的SE系统优于使用判别式音频编码器的模型。此外,主观听觉测试验证了我们提出的系统在感知质量方面超越了现有的最先进的SE模型。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
近期研究开始探索利用预训练模型的音频嵌入进行语音增强(SE),不再局限于时频掩蔽或信号预测技术。本文介绍了一种高效且可扩展的SE方法,包括使用预训练音频编码器从带噪声的语音中提取音频嵌入,然后通过紧凑的编码器网络对其进行去噪,最后由声码器合成清洁语音。参数效率通过去除编码器与预训练音频编码器和声码器的消融研究得到证实。实验结果表明,基于生成式音频编码器的SE系统在语音增强和说话人保真度方面优于使用判别式音频编码器的模型。主观听觉测试验证了所提出的系统在感知质量上超越了现有的最先进的SE模型。
Key Takeaways
- 研究采用预训练模型的音频嵌入进行语音增强。
- 使用预训练音频编码器提取带噪声语音的音频嵌入。
- 通过紧凑的编码器网络对音频嵌入进行去噪处理。
- 声码器用于合成清洁的语音。
- 消融研究证实了该方法的参数效率。
- 实验结果显示,该方法在语音增强和说话人保真度方面表现优异。
点此查看论文截图

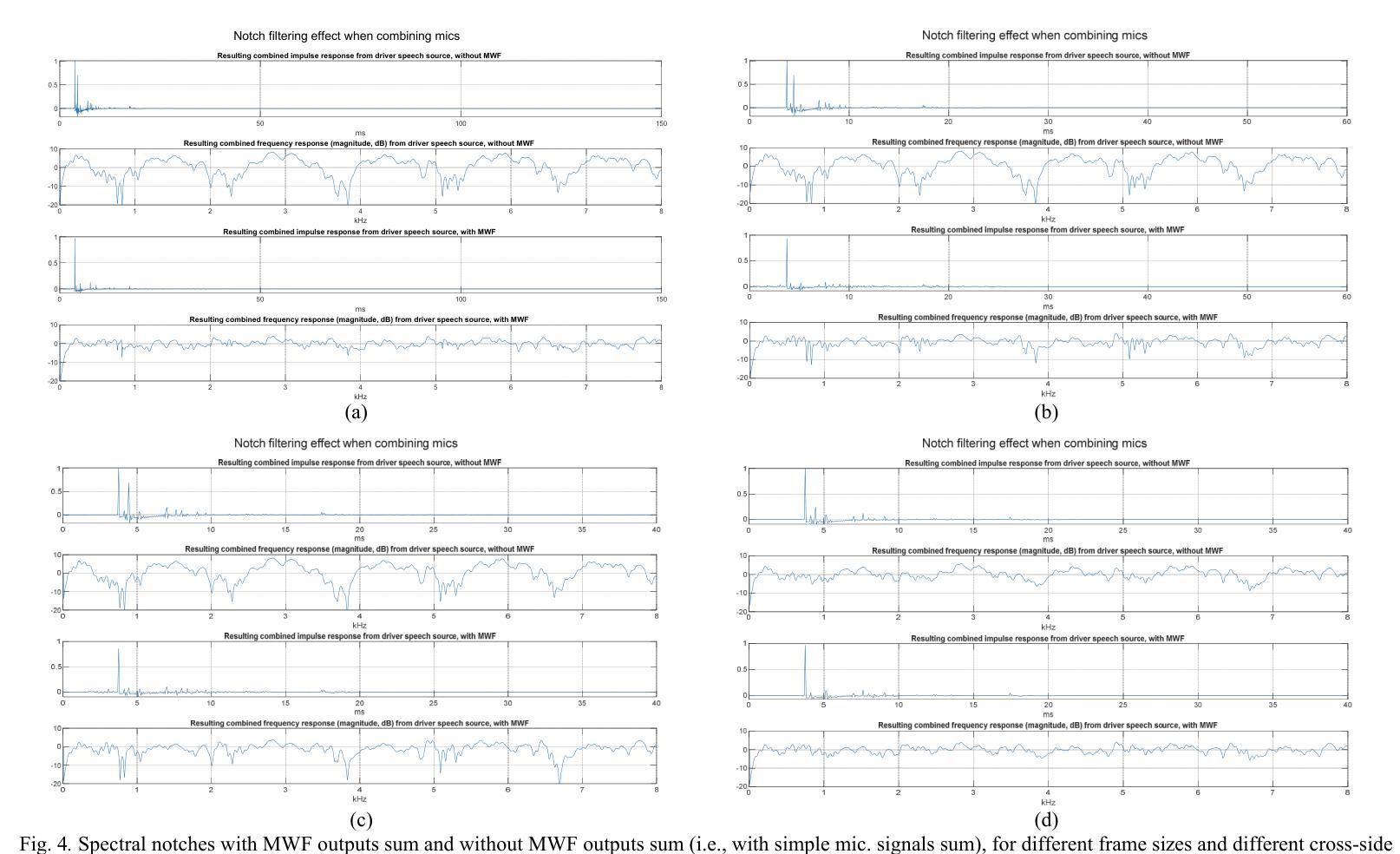
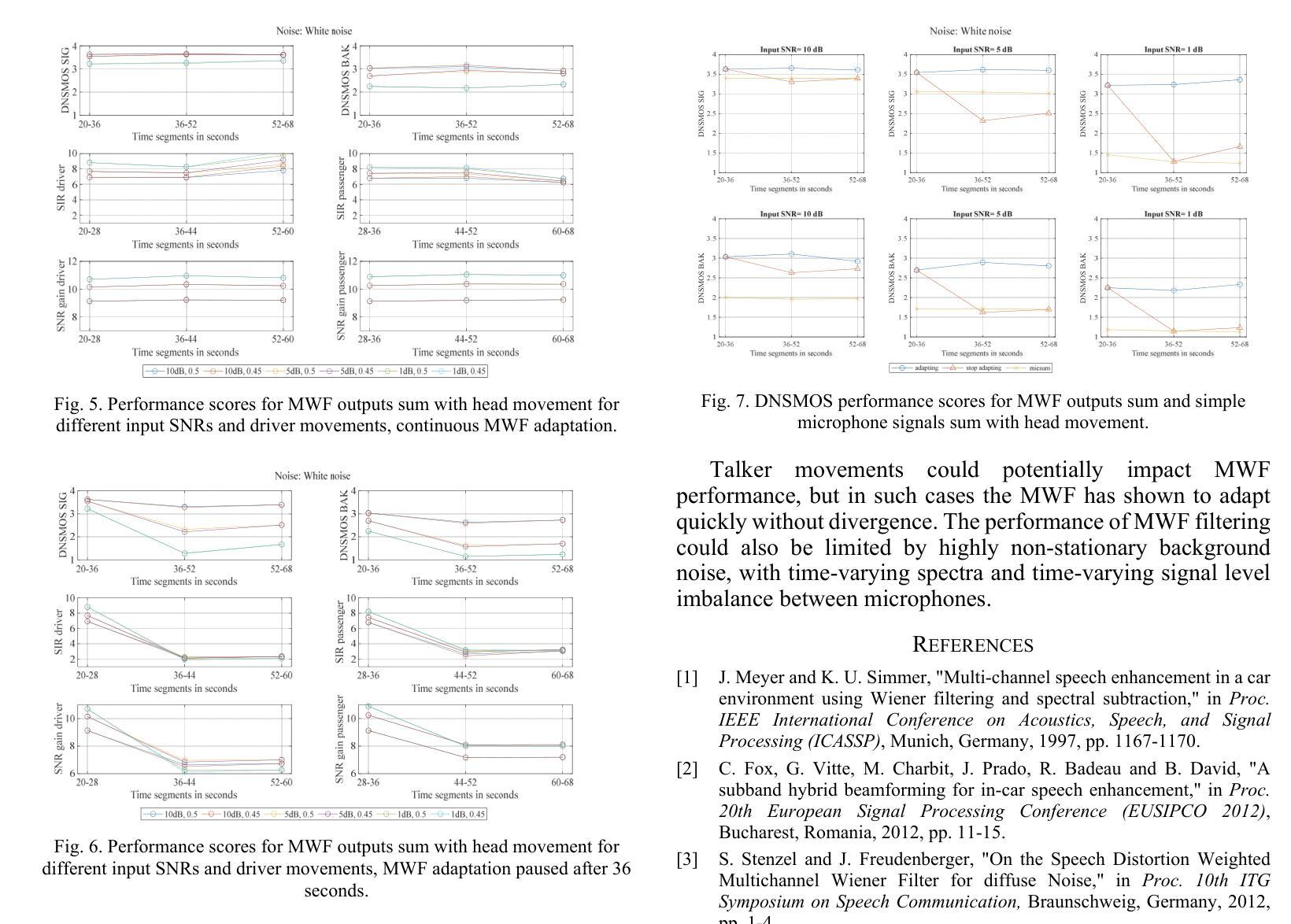
Improved in-car sound pick-up using multichannel Wiener filter
Authors:Juhi Khalid, Martin Bouchard
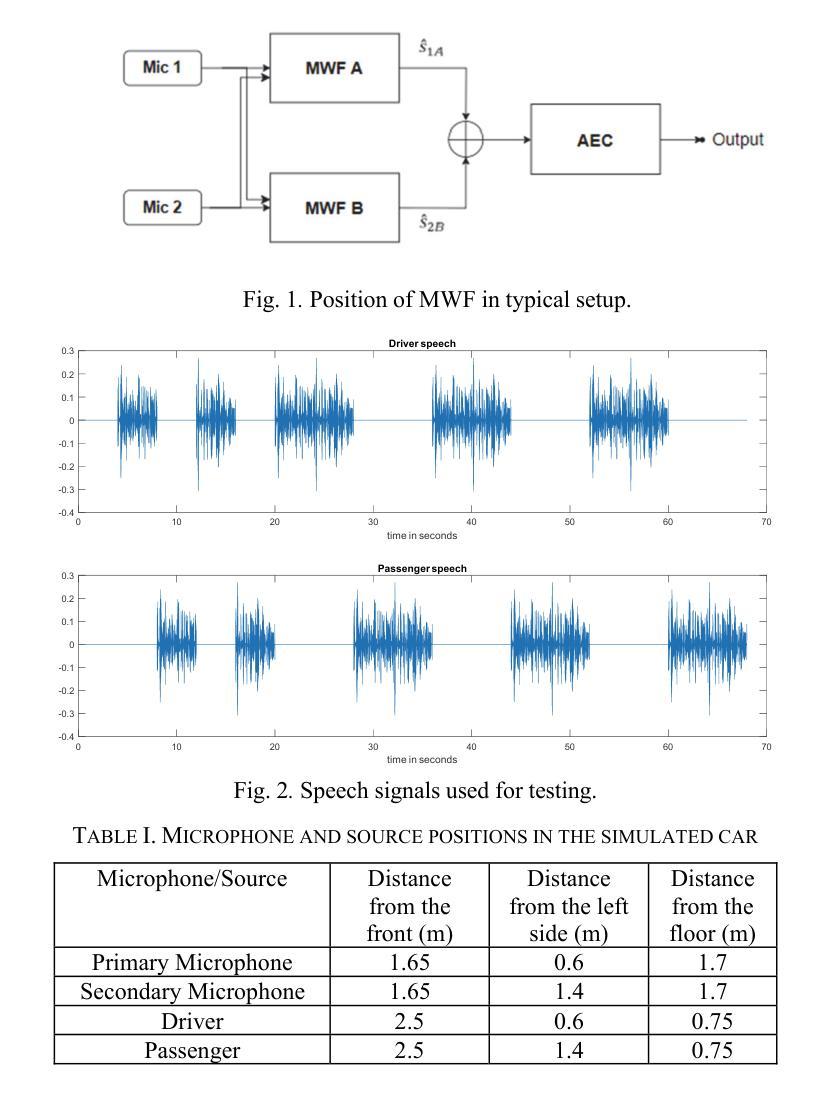
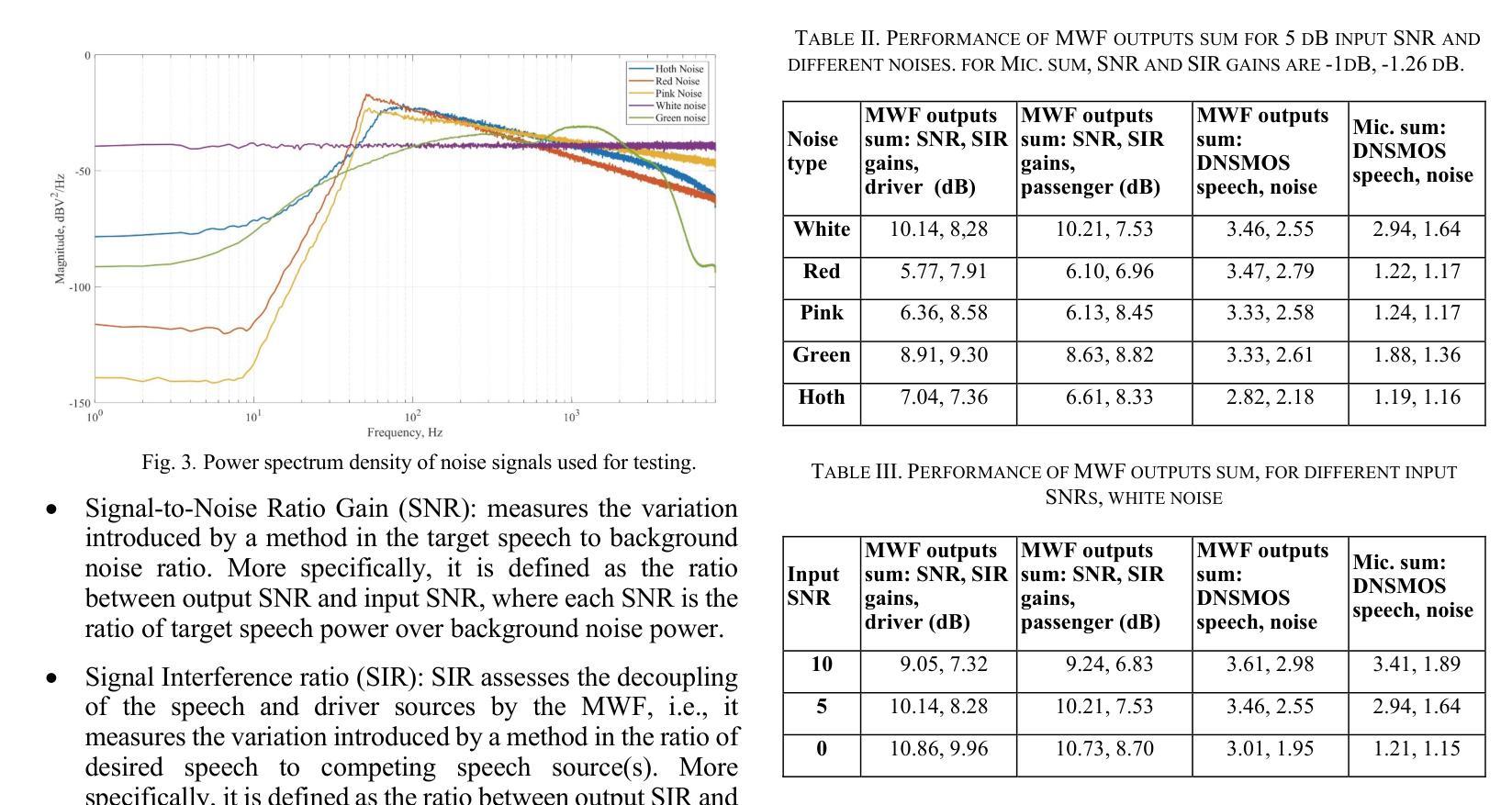
With advancements in automotive electronics and sensors, the sound pick-up using multiple microphones has become feasible for hands-free telephony and voice command in-car applications. However, challenges remain in effectively processing multiple microphone signals due to bandwidth or processing limitations. This work explores the use of the Multichannel Wiener Filter algorithm with a two-microphone in-car system, to enhance speech quality for driver and passenger voice, i.e., to mitigate notch-filtering effects caused by echoes and improve background noise reduction. We evaluate its performance under various noise conditions using modern objective metrics like Deep Noise Suppression Mean Opinion Score. The effect of head movements of driver/passenger is also investigated. The proposed method is shown to provide significant improvements over a simple mixing of microphone signals.
随着汽车电子和传感器的进步,使用多个麦克风进行声音采集已经可以实现用于免提电话和车内语音命令应用。然而,由于带宽或处理能力的限制,对多个麦克风信号的有效处理仍然面临挑战。这项工作探讨了将多通道维纳滤波算法与车内双麦克风系统相结合,以提高驾驶员和乘客的语音质量,即减轻由回声引起的陷波滤波效应,并改善背景噪声降低。我们利用诸如深度噪声抑制平均意见分数等现代客观指标,在各种噪声条件下对其性能进行评估。还研究了驾驶员/乘客头部动作的影响。所提出的方法被证明比简单地混合麦克风信号有显著改善。
论文及项目相关链接
PDF 6 pages
Summary
随着汽车电子和传感器技术的进步,利用多个麦克风进行声音采集已经应用于免提电话和车内语音命令。然而,由于带宽或处理能力的限制,处理多个麦克风信号仍然面临挑战。本研究探索了使用双通道维纳滤波器算法与车内双麦克风系统,以提高驾驶员和乘客的语音质量,包括减轻回音引起的陷波滤波效应并改善背景噪声抑制。通过现代客观指标如深度噪声抑制平均意见得分,对各种噪声条件下的性能进行了评估。还研究了驾驶员/乘客头部动作的影响。所提出的方法相较于简单混合麦克风信号,显示出显著的优势。
Key Takeaways
- 先进汽车电子和传感器技术使得利用多个麦克风进行声音采集成为可能。
- 多通道维纳滤波器算法被应用于提高车内语音质量。
- 该方法旨在减轻回音引起的陷波滤波效应,并改善背景噪声抑制。
- 通过现代客观指标评估了在不同噪声条件下的性能。
- 研究还考虑了驾驶员和乘客的头部动作对声音采集的影响。
- 所提出的方法相较于简单混合麦克风信号具有显著优势。
点此查看论文截图

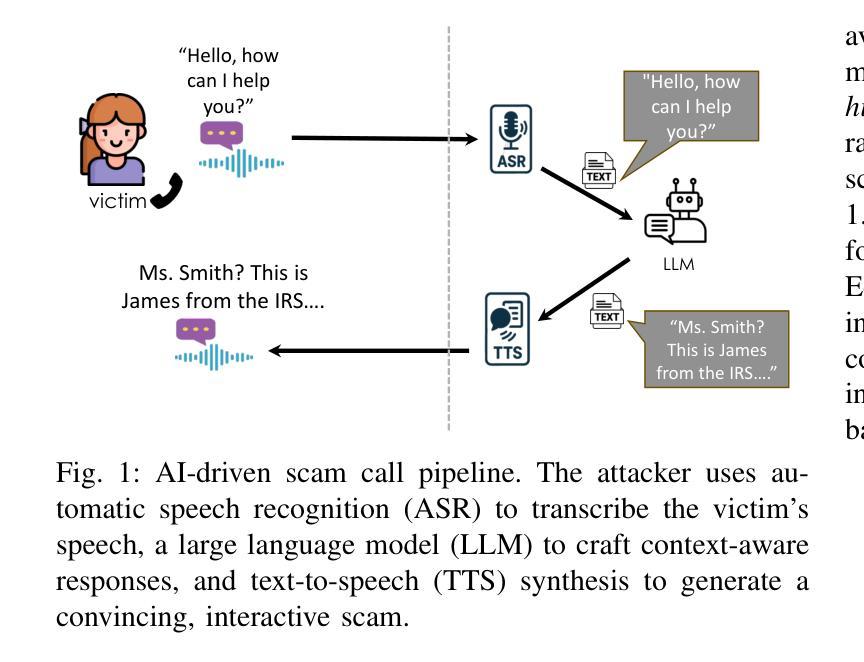
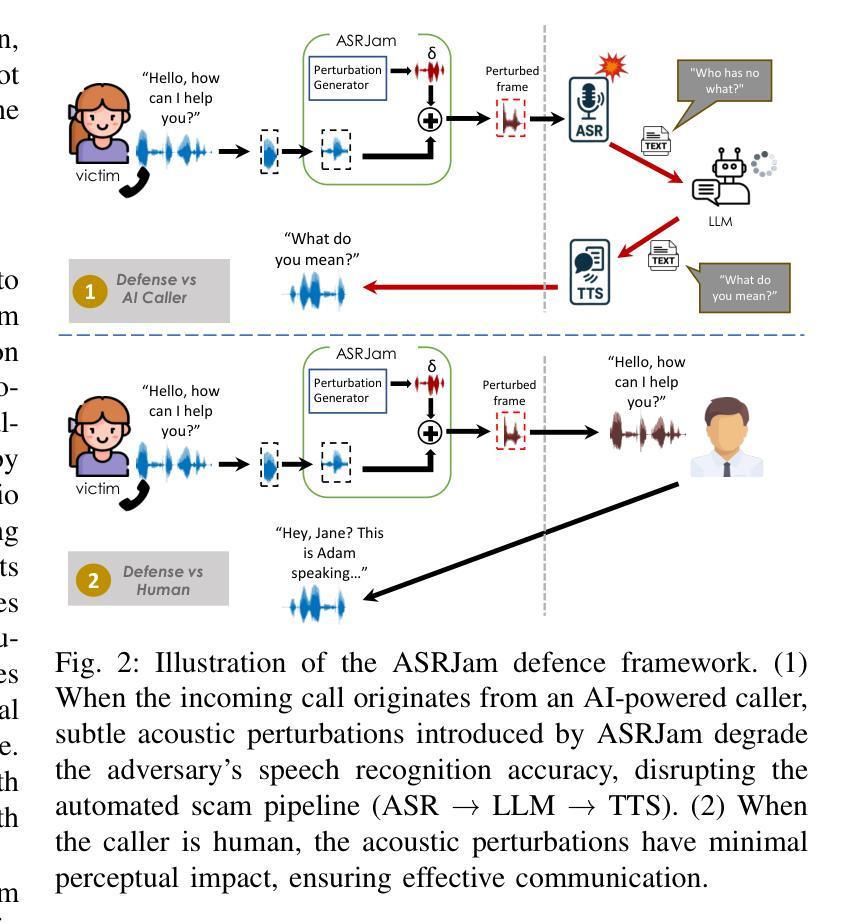
ASRJam: Human-Friendly AI Speech Jamming to Prevent Automated Phone Scams
Authors:Freddie Grabovski, Gilad Gressel, Yisroel Mirsky
Large Language Models (LLMs), combined with Text-to-Speech (TTS) and Automatic Speech Recognition (ASR), are increasingly used to automate voice phishing (vishing) scams. These systems are scalable and convincing, posing a significant security threat. We identify the ASR transcription step as the most vulnerable link in the scam pipeline and introduce ASRJam, a proactive defence framework that injects adversarial perturbations into the victim’s audio to disrupt the attacker’s ASR. This breaks the scam’s feedback loop without affecting human callers, who can still understand the conversation. While prior adversarial audio techniques are often unpleasant and impractical for real-time use, we also propose EchoGuard, a novel jammer that leverages natural distortions, such as reverberation and echo, that are disruptive to ASR but tolerable to humans. To evaluate EchoGuard’s effectiveness and usability, we conducted a 39-person user study comparing it with three state-of-the-art attacks. Results show that EchoGuard achieved the highest overall utility, offering the best combination of ASR disruption and human listening experience.
大型语言模型(LLM)结合文本转语音(TTS)和自动语音识别(ASR)技术,正越来越多地被用于自动化语音钓鱼(vishing)诈骗。这些系统可扩展且具说服力,构成重大安全威胁。我们确定ASR转录步骤是诈骗管道中最脆弱的环节,并介绍了ASRJam,这是一种主动防御框架,通过向受害者音频注入对抗性扰动,破坏攻击者的ASR。这打破了诈骗的反馈循环,而不影响人类通话者,他们仍然可以理解对话。虽然先前的对抗性音频技术往往令人不悦,且不适用于实时使用,我们还提出了EchoGuard,一种利用自然失真(如混响和回声)的新型干扰机,这些失真对ASR具有破坏性,但对人类是可容忍的。为了评估EchoGuard的有效性和可用性,我们对39人进行了用户研究,将其与三种最新攻击方法进行比较。结果表明,EchoGuard实现了最高的总体效用,在ASR干扰和人类听觉体验方面提供了最佳组合。
论文及项目相关链接
摘要
LLMs结合文本转语音(TTS)和自动语音识别(ASR)正越来越多地用于自动化语音钓鱼诈骗,构成重大安全风险。研究指出ASR转录步骤是骗局管道中最脆弱的环节,并引入了ASRJam主动防御框架。该框架通过向受害者音频注入对抗性扰动来破坏攻击者的ASR,中断诈骗反馈循环,同时不影响人类通话者。与现有的对抗性音频技术相比,研究还提出了一种名为EchoGuard的新型干扰器,它利用自然失真(如回声和混响)来干扰ASR,同时对人类可容忍。通过39人用户研究评估EchoGuard的有效性和可用性,结果显示EchoGuard总体效用最高,在ASR干扰和人类听觉体验方面表现最佳。
要点解析
- LLMs与TTS、ASR结合正被越来越多用于自动化语音钓鱼诈骗,形成重大安全威胁。
- ASR转录步骤是骗局中最脆弱的环节。
- ASRJam框架通过注入对抗性扰动破坏攻击者的ASR,而不影响人类通话。
- 现有的对抗性音频技术往往存在不适实实时使用的问题。
- EchoGuard是一种新型干扰器,利用自然失真如回声和混响来干扰ASR。
- 人类对于EchoGuard引起的声音干扰可容忍。
- 通过用户研究评估,EchoGuard在ASR干扰和人类听觉体验方面表现最佳。
点此查看论文截图

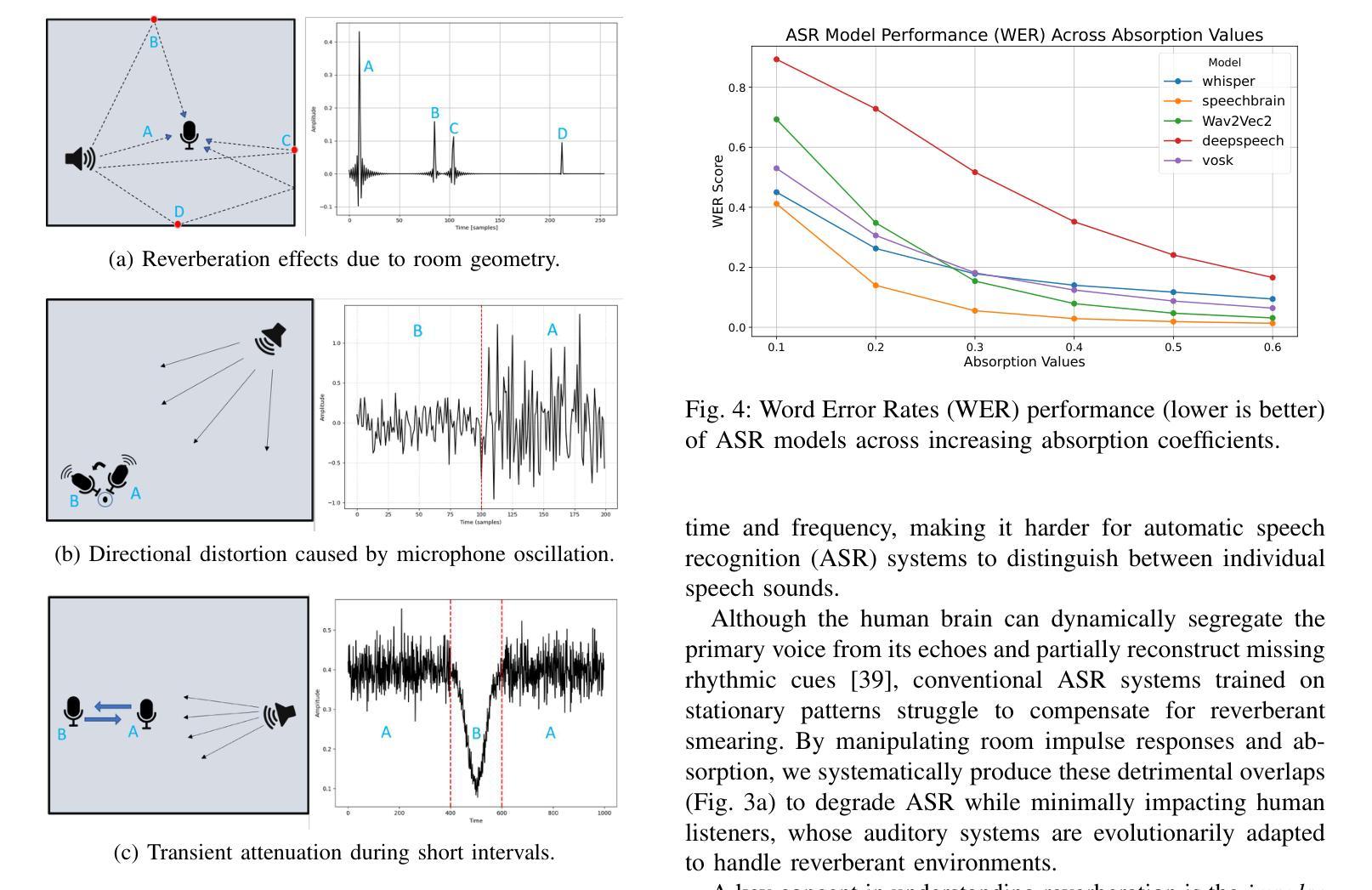
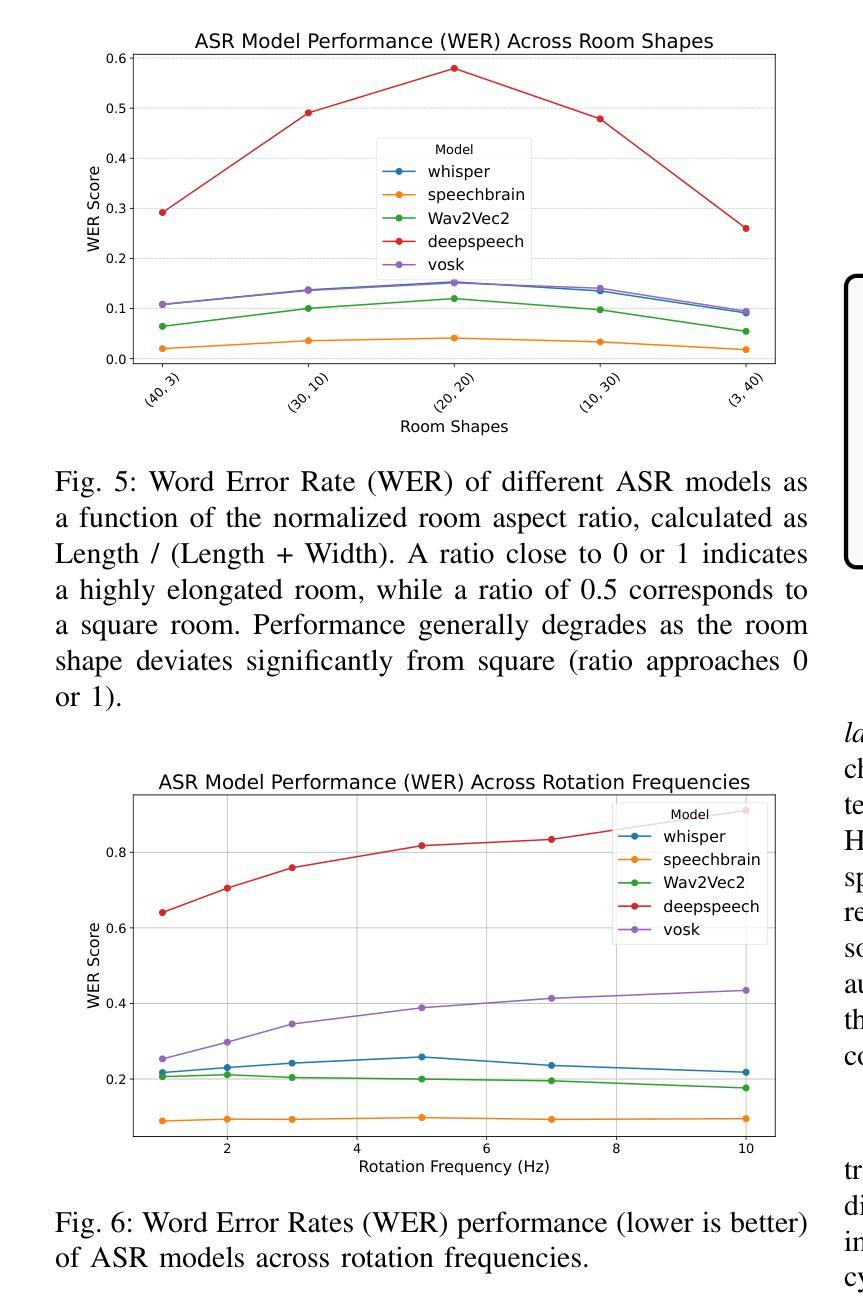
Benchmarking Foundation Speech and Language Models for Alzheimer’s Disease and Related Dementia Detection from Spontaneous Speech
Authors:Jingyu Li, Lingchao Mao, Hairong Wang, Zhendong Wang, Xi Mao, Xuelei Sherry Ni
Background: Alzheimer’s disease and related dementias (ADRD) are progressive neurodegenerative conditions where early detection is vital for timely intervention and care. Spontaneous speech contains rich acoustic and linguistic markers that may serve as non-invasive biomarkers for cognitive decline. Foundation models, pre-trained on large-scale audio or text data, produce high-dimensional embeddings encoding contextual and acoustic features. Methods: We used the PREPARE Challenge dataset, which includes audio recordings from over 1,600 participants with three cognitive statuses: healthy control (HC), mild cognitive impairment (MCI), and Alzheimer’s Disease (AD). We excluded non-English, non-spontaneous, or poor-quality recordings. The final dataset included 703 (59.13%) HC, 81 (6.81%) MCI, and 405 (34.06%) AD cases. We benchmarked a range of open-source foundation speech and language models to classify cognitive status into the three categories. Results: The Whisper-medium model achieved the highest performance among speech models (accuracy = 0.731, AUC = 0.802). Among language models, BERT with pause annotation performed best (accuracy = 0.662, AUC = 0.744). ADRD detection using state-of-the-art automatic speech recognition (ASR) model-generated audio embeddings outperformed others. Including non-semantic features like pause patterns consistently improved text-based classification. Conclusion: This study introduces a benchmarking framework using foundation models and a clinically relevant dataset. Acoustic-based approaches – particularly ASR-derived embeddings – demonstrate strong potential for scalable, non-invasive, and cost-effective early detection of ADRD.
背景:阿尔茨海默病及相关痴呆症(ADRD)是进行性神经退行性疾病,早期发现对于及时干预和治疗至关重要。自发性言语含有丰富的声音和语言学标记,可作为认知功能下降的非侵入性生物标志物。基础模型在大规模音频或文本数据上进行预训练,产生编码上下文和声音特征的高维嵌入。
方法:我们使用PREPARE Challenge数据集,该数据集包含来自超过1600名参与者的音频记录,分为三种认知状态:健康对照(HC)、轻度认知障碍(MCI)和阿尔茨海默病(AD)。我们排除了非英语、非自发性或质量差的录音。最终数据集包括703例(占59.13%)HC,81例(占6.81%)MCI和405例(占34.06%)AD病例。我们对一系列开源基础语音和语言模型进行了基准测试,以将认知状态分为三类。
结果:whisper-medium模型在语音模型中表现最佳(准确度= 0.731,AUC = 0.802)。在语言模型中,带有暂停注释的BERT表现最佳(准确度= 0.662,AUC = 0.744)。使用最先进的自动语音识别(ASR)模型生成的音频嵌入进行ADRD检测优于其他方法。包含非语义特征(如停顿模式)始终能提高基于文本的分类效果。
论文及项目相关链接
Summary
该研究利用PREPARE Challenge数据集,对包括健康对照、轻度认知障碍和阿尔茨海默病三种认知状态的参与者进行语音样本分析。通过一系列开源的语音和语言模型进行认知状态分类,发现自动语音识别(ASR)模型生成的音频嵌入在ADRD检测方面具有最佳性能。结合非语义特征如停顿模式能提升文本分类的准确性。此研究展示了利用基础模型进行ADRD早期检测的强大潜力。
Key Takeaways
- 研究背景强调早期检测阿尔茨海默病及相关痴呆的重要性,并指出自发性语音中的声学和语言标记可作为非侵入性生物标志物用于认知下降的评估。
- PREPARE Challenge数据集包含三种认知状态的参与者音频记录,用于模型训练和评估。
- 语音模型在分类性能上优于语言模型,其中Whisper-medium模型表现最佳。
- 利用自动语音识别(ASR)模型生成的音频嵌入在ADRD检测方面表现出最佳性能。
- 结合非语义特征,如停顿模式,能有效提高基于文本的分类准确性。
- 此研究展示了利用基础模型进行ADRD早期检测的强大潜力,为及时干预和护理提供了重要依据。
点此查看论文截图

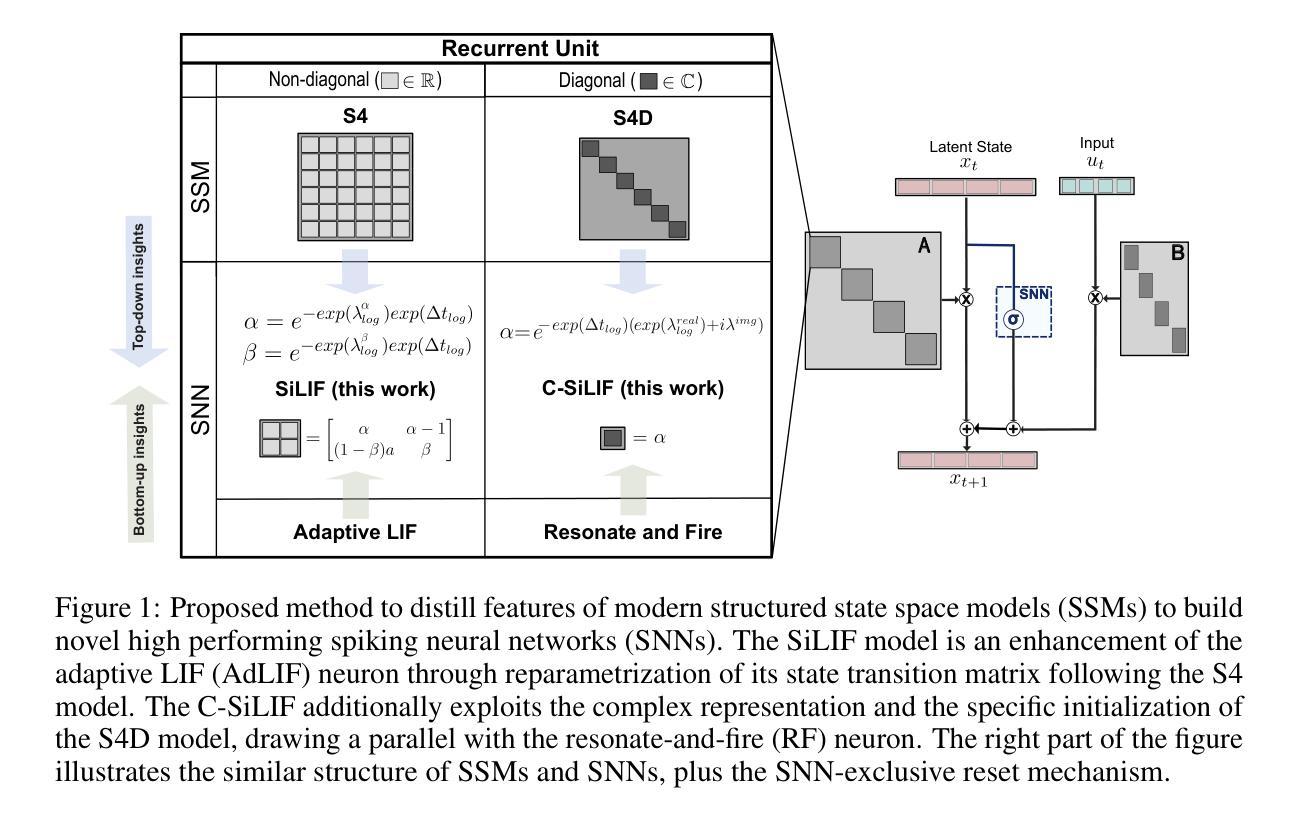
Structured State Space Model Dynamics and Parametrization for Spiking Neural Networks
Authors:Maxime Fabre, Lyubov Dudchenko, Emre Neftci
Multi-state spiking neurons such as the adaptive leaky integrate-and-fire (AdLIF) neuron offer compelling alternatives to conventional deep learning models thanks to their sparse binary activations, second-order nonlinear recurrent dynamics, and efficient hardware realizations. However, such internal dynamics can cause instabilities during inference and training, often limiting performance and scalability. Meanwhile, state space models (SSMs) excel in long sequence processing using linear state-intrinsic recurrence resembling spiking neurons’ subthreshold regime. Here, we establish a mathematical bridge between SSMs and second-order spiking neuron models. Based on structure and parametrization strategies of diagonal SSMs, we propose two novel spiking neuron models. The first extends the AdLIF neuron through timestep training and logarithmic reparametrization to facilitate training and improve final performance. The second additionally brings initialization and structure from complex-state SSMs, broadening the dynamical regime to oscillatory dynamics. Together, our two models achieve beyond or near state-of-the-art (SOTA) performances for reset-based spiking neuron models across both event-based and raw audio speech recognition datasets. We achieve this with a favorable number of parameters and required dynamic memory while maintaining high activity sparsity. Our models demonstrate enhanced scalability in network size and strike a favorable balance between performance and efficiency with respect to SSM models.
多状态脉冲神经元(如自适应泄漏积分发放神经元)由于其稀疏的二进制激活、二阶非线性递归动态和高效的硬件实现,为传统的深度学习模型提供了引人注目的替代方案。然而,这样的内部动态可能会导致推理和训练过程中的不稳定,从而经常限制其性能和可扩展性。与此同时,状态空间模型(SSMs)擅长处理长序列,采用类似脉冲神经元亚阈值状态时的线性状态固有递归。在这里,我们建立了状态空间模型与二阶脉冲神经元模型之间的数学桥梁。基于对角状态空间模型的结构和参数化策略,我们提出了两种新型脉冲神经元模型。第一种是通过时间步长训练和对数再参数化来扩展自适应泄漏积分发放神经元,以促进训练并改善最终性能。第二种则引入了复杂状态SSM的初始化和结构,扩大了动态范围至振荡动态。我们的两个模型共同实现了基于重置的脉冲神经元模型的最新或接近最新(SOTA)性能,无论是基于事件的音频语音识别数据集还是原始音频语音数据集都是如此。我们以有利的参数数量和所需的动态内存实现了这一点,同时保持较高的活动稀疏性。我们的模型在增强网络大小的可扩展性方面表现出色,并在性能和效率方面与SSM模型实现了良好的平衡。
论文及项目相关链接
Summary:
基于自适应泄漏积分与放电(AdLIF)神经元,本文建立了状态空间模型(SSMs)与二阶神经元模型之间的数学桥梁。通过时间步训练和对数再参数化策略,提出了两种新型神经元模型。这些模型可实现高效的训练和良好的性能,与现有的先进水平相当或有所超越。在事件驱动和原始音频语音识别数据集上表现优异,同时保持参数数量少、动态内存需求小以及高活动稀疏性。这些模型在网络规模上具有良好的可扩展性,并在性能和效率之间取得了平衡。
Key Takeaways:
- 多状态脉冲神经元如自适应泄漏积分与放电(AdLIF)神经元为传统深度学习模型提供了有吸引力的替代方案。
- 内部动态可能导致推理和训练过程中的不稳定,限制了性能和可扩展性。
- 状态空间模型(SSMs)擅长处理长序列,其线性状态内在递归类似于脉冲神经元的亚阈值状态。
- 本文建立了SSMs和脉冲神经元模型之间的数学桥梁,提出了两种新型脉冲神经元模型。
- 第一种模型通过时间步训练和对数再参数化策略扩展了AdLIF神经元,提高了训练和最终性能。
- 第二种模型引入了复杂状态SSMs的初始化和结构,拓宽了动态范围至振荡动力学。
点此查看论文截图

Modality-Order Matters! A Novel Hierarchical Feature Fusion Method for CoSAm: A Code-Switched Autism Corpus
Authors:Mohd Mujtaba Akhtar, Girish, Muskaan Singh, Orchid Chetia Phukan
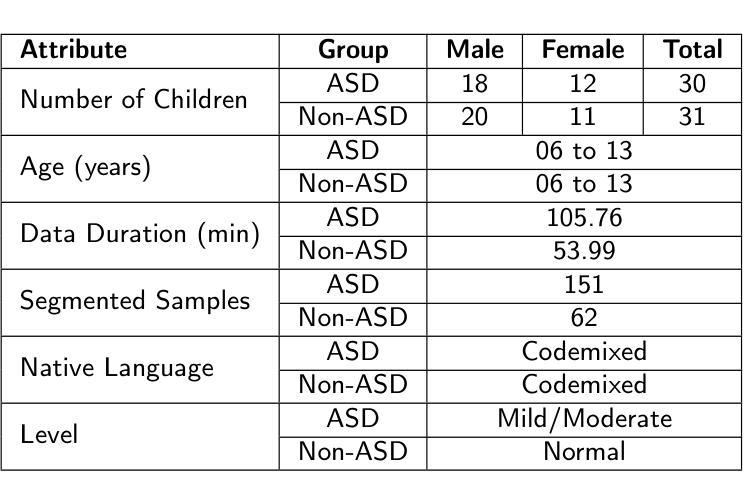
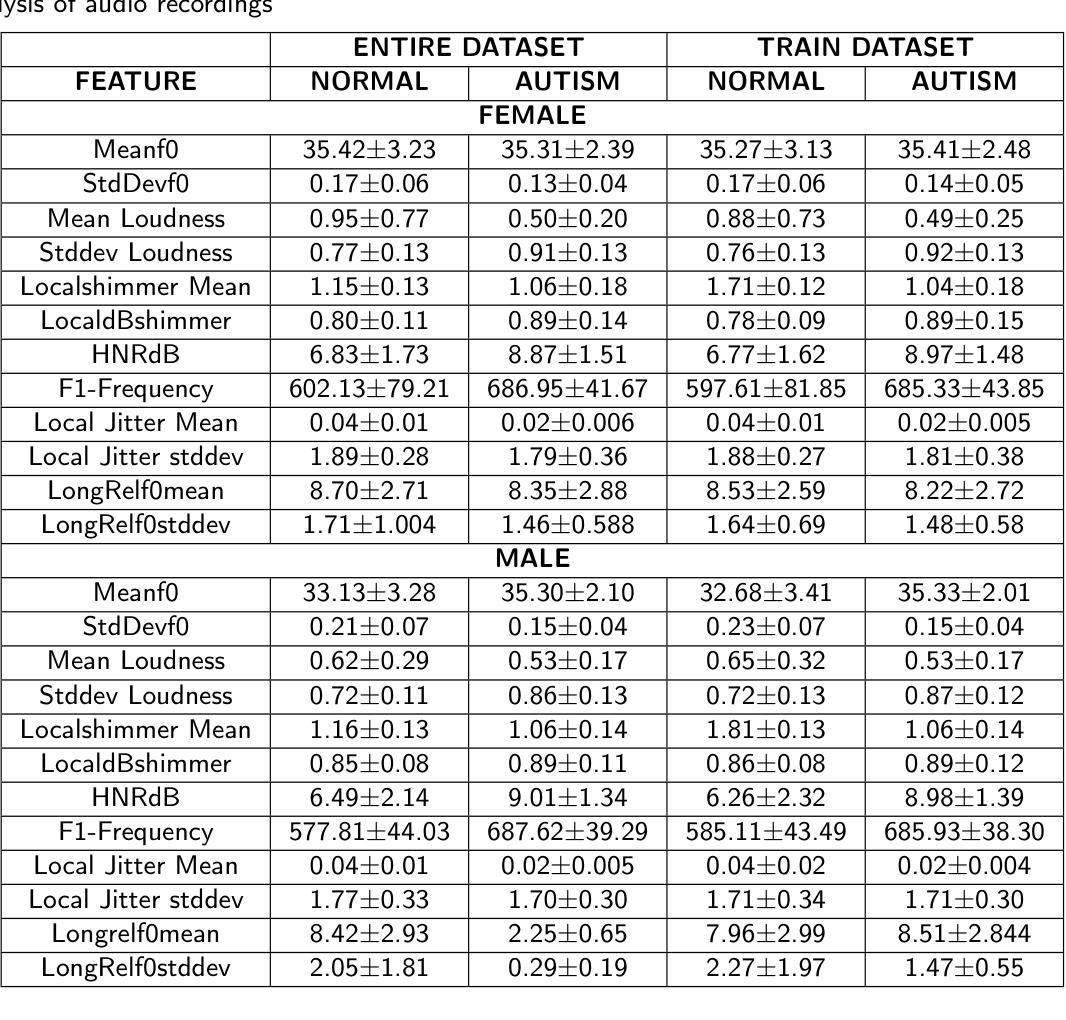
Autism Spectrum Disorder (ASD) is a complex neuro-developmental challenge, presenting a spectrum of difficulties in social interaction, communication, and the expression of repetitive behaviors in different situations. This increasing prevalence underscores the importance of ASD as a major public health concern and the need for comprehensive research initiatives to advance our understanding of the disorder and its early detection methods. This study introduces a novel hierarchical feature fusion method aimed at enhancing the early detection of ASD in children through the analysis of code-switched speech (English and Hindi). Employing advanced audio processing techniques, the research integrates acoustic, paralinguistic, and linguistic information using Transformer Encoders. This innovative fusion strategy is designed to improve classification robustness and accuracy, crucial for early and precise ASD identification. The methodology involves collecting a code-switched speech corpus, CoSAm, from children diagnosed with ASD and a matched control group. The dataset comprises 61 voice recordings from 30 children diagnosed with ASD and 31 from neurotypical children, aged between 3 and 13 years, resulting in a total of 159.75 minutes of voice recordings. The feature analysis focuses on MFCCs and extensive statistical attributes to capture speech pattern variability and complexity. The best model performance is achieved using a hierarchical fusion technique with an accuracy of 98.75% using a combination of acoustic and linguistic features first, followed by paralinguistic features in a hierarchical manner.
自闭症谱系障碍(ASD)是一个复杂的神经发育挑战,表现为社交互动、沟通和不同情境下重复行为表达的一系列困难。其患病率的不断增加突显了ASD作为重要的公共卫生问题,并需要全面的研究倡议来推动我们对该疾病及其早期检测方法的了解。本研究介绍了一种新型的分层特征融合方法,旨在通过分析双语(英语和印地语)切换语音来增强ASD的早期检测。该研究采用先进的音频处理技术,使用Transformer编码器整合声学、副语言学和语言学信息。这种创新的融合策略旨在提高分类的稳健性和准确性,对于早期和精确的ASD识别至关重要。该方法涉及收集来自诊断为ASD的儿童的双语切换语音语料库CoSAm以及与对照组相匹配的数据集。该数据集包含来自诊断为ASD的30名儿童和来自神经发育正常的31名儿童的语音记录,年龄介于3岁至13岁之间,共计159.75分钟的语音记录。特征分析专注于MFCC和广泛的统计属性,以捕捉语音模式的可变性和复杂性。使用分层融合技术取得了最佳模型性能,通过首先结合声学和语言学特征,然后按照层次结构添加副语言学特征,准确率达到98.75%。
论文及项目相关链接
PDF We are withdrawing this paper as the current version requires substantial changes to the experimental design and analysis in Sections 4 and 5. These changes go beyond a minor revision, and there is no replacement version available at this time. A thoroughly revised version may be submitted as a new paper in the future
Summary
本研究提出一种新型层次特征融合方法,旨在通过英语和印地语的混杂语言分析提高自闭症谱系障碍的早期检测。研究使用先进的音频处理技术,结合Transformer编码器整合声学、副语言学和语言学信息。此方法可提高分类的稳健性和准确性,对早期精确识别自闭症至关重要。研究采集了自闭症儿童混杂语言语料库CoSAm,并对声学特征和语音模式复杂性进行了深入分析,使用层次融合技术取得了最佳性能,准确率为98.75%。
Key Takeaways
- 自闭症谱系障碍(ASD)是一个复杂的神经发育挑战,表现为社交互动、沟通和重复行为方面的困难。
- ASD的普及率增加,成为重要的公共卫生问题,需要综合研究以推进对其理解和早期检测方法。
- 本研究提出了一种新型的层次特征融合方法,旨在通过混杂语言分析提高ASD的早期检测。
- 研究使用先进的音频处理技术,结合声学、副语言学和语言学信息的融合来提高分类的准确性和稳健性。
- 研究采集了自闭症儿童混杂语言语料库CoSAm,包含自闭症儿童和正常儿童的语音记录。
- 特征分析集中在MFCCs和广泛的统计属性上,以捕捉语音模式的可变性和复杂性。
点此查看论文截图