⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
S2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamlessly Speech-Text Alignment and Streaming Speech Decoder
Authors:Yu Pan, Yuguang Yang, Yanni Hu, Jianhao Ye, Xiang Zhang, Hongbin Zhou, Lei Ma, Jianjun Zhao
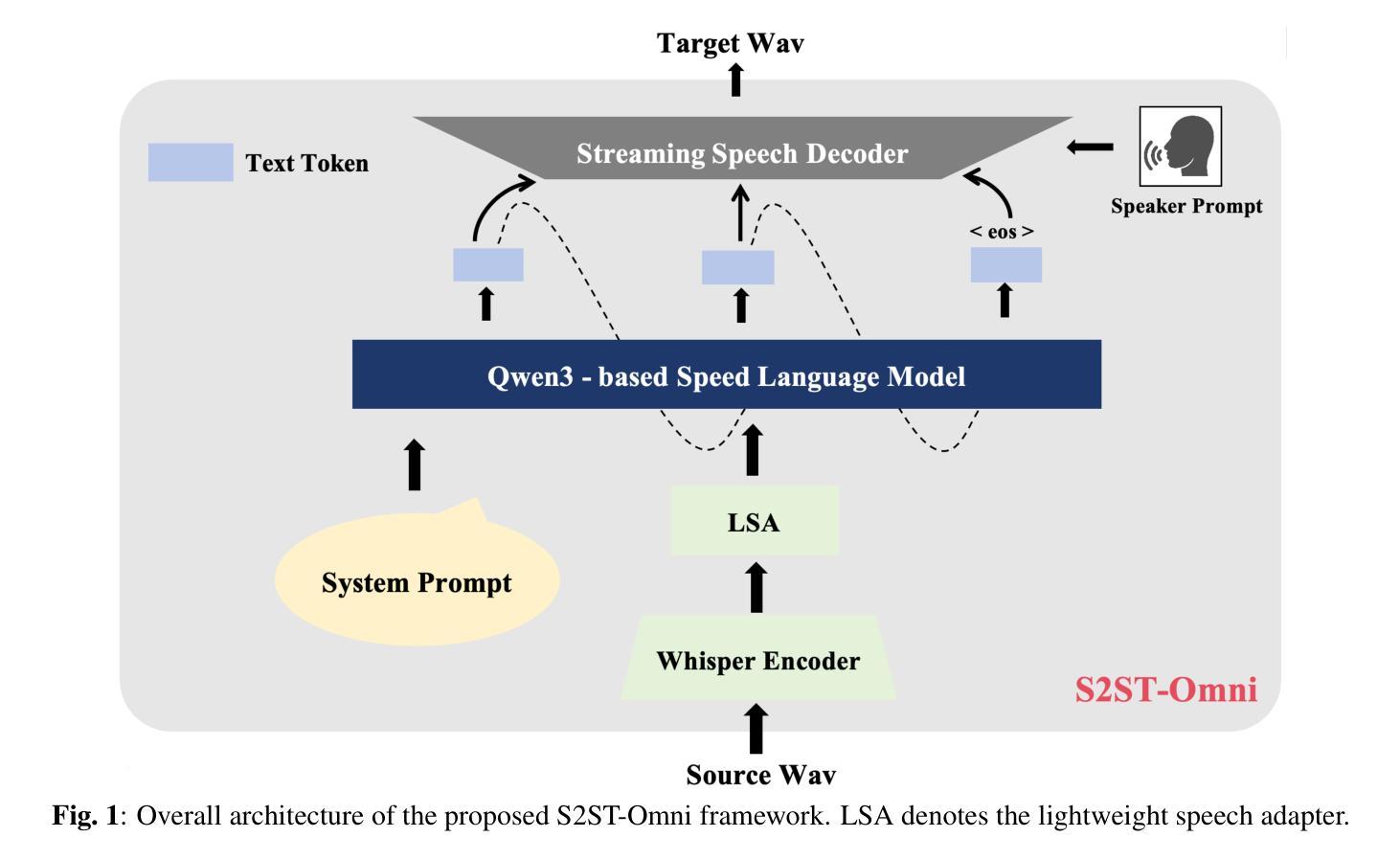
Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into natural and intelligible speech in a target language. Despite recent progress, significant challenges remain: (1) achieving high-quality and low-latency S2ST remains a critical hurdle; (2) existing S2ST approaches heavily rely on large-scale parallel speech corpora, which are extremely difficult to collect. To address these issues, we propose S2ST-Omni, an efficient and scalable framework for multilingual speech-to-speech translation. Specifically, we decompose the S2ST task into speech-to-text translation (S2TT) and text-to-speech synthesis (TTS), unifying them within a single end-to-end speech-language model. To achieve high-quality S2TT while reducing dependence on parallel corpora, we leverage large-scale pretrained models – Whisper for audio understanding and Qwen 3.0 for text understanding. A lightweight speech adapter is introduced to align speech and text representations, enabling effective use of pretrained multimodal knowledge. To ensure both translation quality and real-time performance, we adopt a pretrained streaming speech decoder in the TTS stage to generate target speech in an autoregressive manner. Extensive experiments on the CVSS benchmark demonstrate that S2ST-Omni outperforms state-of-the-art S2ST baselines while maintaining comparable latency, highlighting its effectiveness and practical potential for real-world deployment.
多语言语音到语音翻译(S2ST)旨在直接将多种源语言的口语表达翻译成目标语言中的自然和可理解的语音。尽管最近有进展,但仍存在重大挑战:(1)实现高质量和低延迟的S2ST仍然是一个关键障碍;(2)现有的S2ST方法严重依赖于大规模的并行语音语料库,而这些语料库的收集极为困难。为了解决这些问题,我们提出了S2ST-Omni,这是一个高效且可扩展的多语言语音到语音翻译框架。具体来说,我们将S2ST任务分解为语音到文本翻译(S2TT)和文本到语音合成(TTS),并将它们统一到一个端到端的语音语言模型中。为了在减少了对并行语料库的依赖的同时实现高质量的S2TT,我们利用了大规模预训练模型——Whisper进行音频理解,Qwen 3.0进行文本理解。我们引入了一个轻量级的语音适配器,以对齐语音和文本表示,从而实现预训练多模态知识的有效使用。为了保证翻译质量和实时性能,我们在TTS阶段采用预训练的流式语音解码器,以自回归的方式生成目标语音。在CVSS基准测试上的大量实验表明,S2ST-Omni在保持可比延迟的同时超越了最先进的S2ST基线,这凸显了其在现实世界部署中的有效性和实际潜力。
论文及项目相关链接
PDF Working in progress
Summary
本文介绍了多语言语音到语音翻译(S2ST)的目标和挑战。为了解决这个问题,提出了一个高效、可扩展的S2ST-Omni框架,将语音到文本翻译(S2TT)和文本到语音合成(TTS)任务分解为统一的端到端语音语言模型。利用大规模预训练模型实现高质量S2TT,同时减少平行语料库的依赖。引入轻量级语音适配器对齐语音和文本表示,有效利用预训练的多模式知识。在TTS阶段采用预训练的流式语音解码器,以自回归方式生成目标语音,确保翻译质量和实时性能。在CVSS基准测试上的实验表明,S2ST-Omni优于最新的S2ST基线,同时保持可接受的延迟,凸显其在现实世界部署的有效性和实际潜力。
Key Takeaways
- 多语言语音到语音翻译(S2ST)旨在直接将多种源语言的口语表达转换为目标语言的自然、可理解的语音。
- S2ST面临高质量和低延迟的挑战,以及依赖大规模平行语料库的难题。
- S2ST-Omni框架通过分解为语音到文本翻译(S2TT)和文本到语音合成(TTS)来解决问题。
- 利用大规模预训练模型如Whisper和Qwen 3.0实现高质量S2TT,减少对平行语料库的依赖。
- 引入轻量级语音适配器以对齐语音和文本表示,利用预训练的多模式知识。
- 采用预训练的流式语音解码器确保翻译质量和实时性能。
- S2ST-Omni在CVSS基准测试上的表现优于其他最新方法,具有实际部署的潜力。
点此查看论文截图

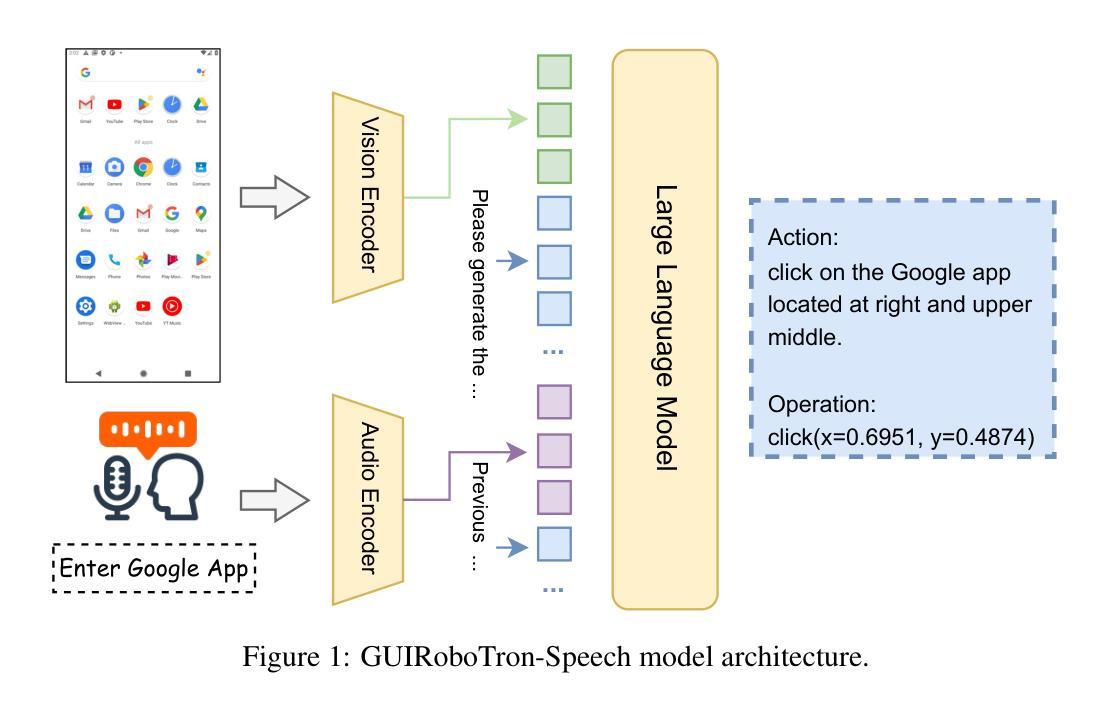
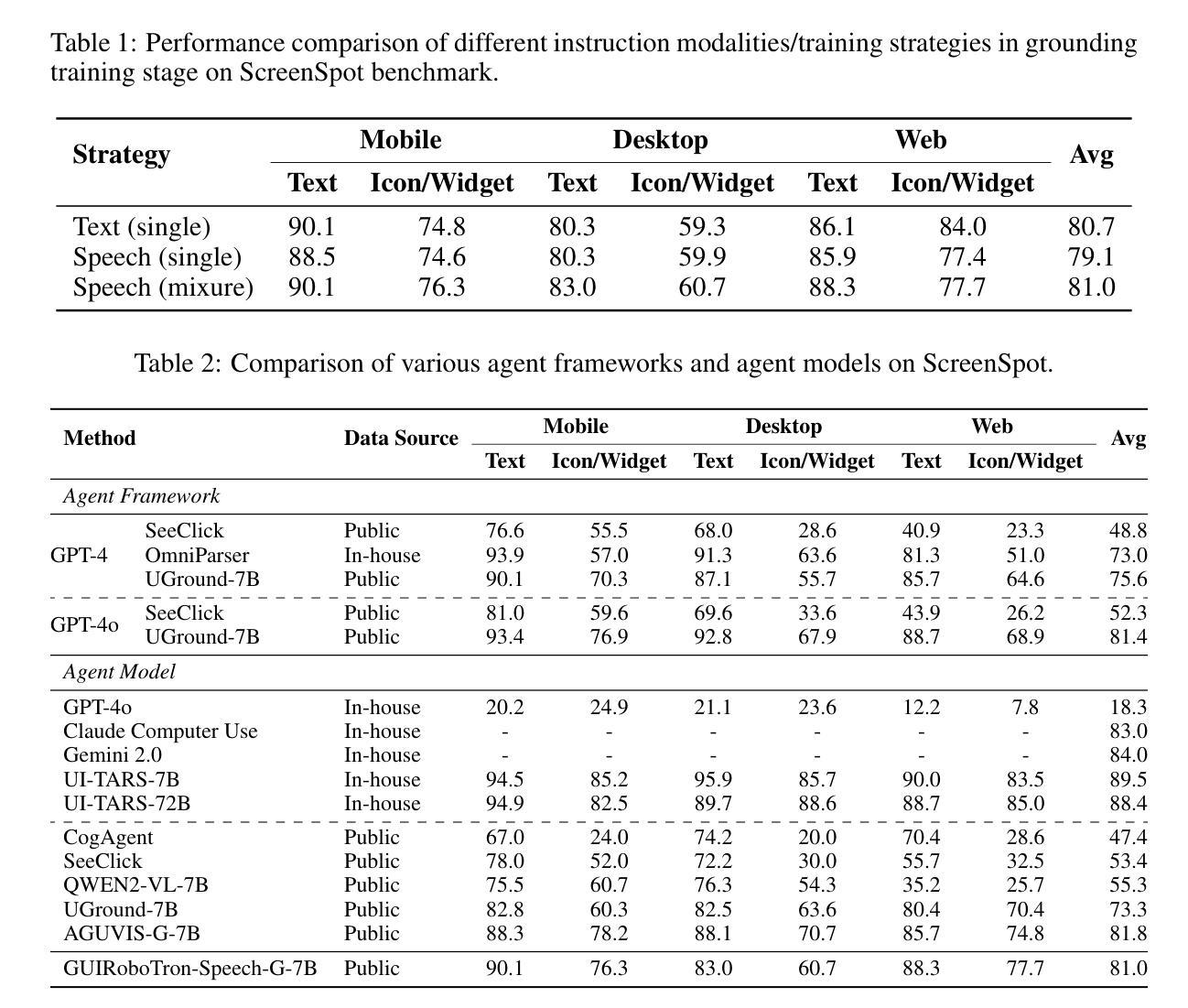
GUIRoboTron-Speech: Towards Automated GUI Agents Based on Speech Instructions
Authors:Wenkang Han, Zhixiong Zeng, Jing Huang, Shu Jiang, Liming Zheng, Longrong Yang, Haibo Qiu, Chang Yao, Jingyuan Chen, Lin Ma
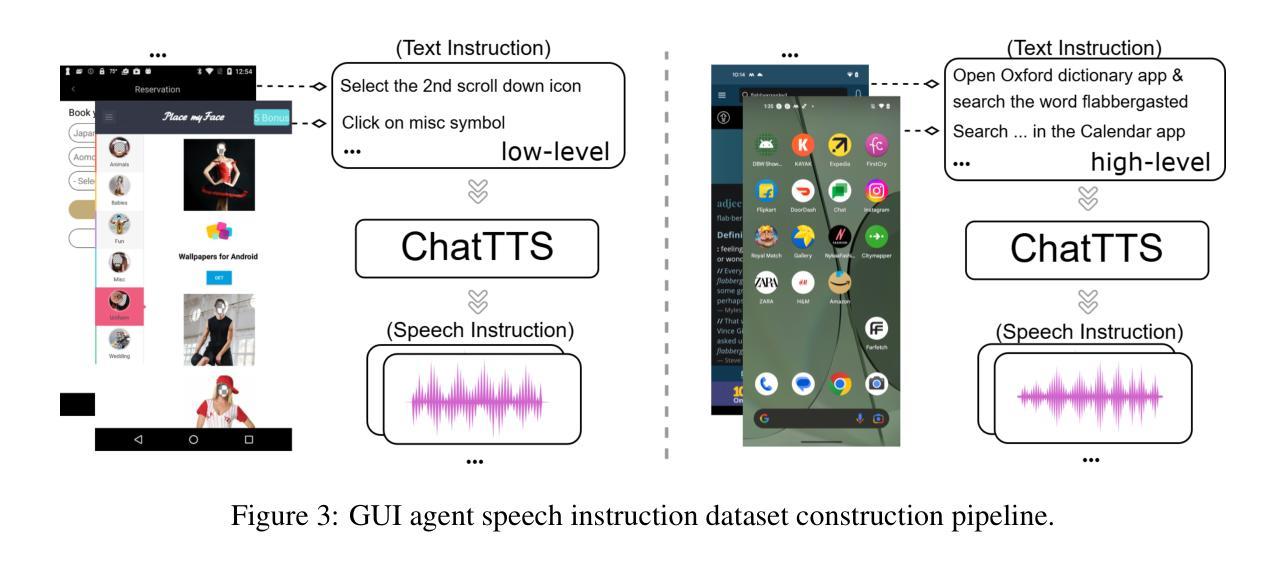
Autonomous agents for Graphical User Interfaces (GUIs) are revolutionizing human-computer interaction, yet their reliance on text-based instructions imposes limitations on accessibility and convenience, particularly in hands-free scenarios. To address this gap, we propose GUIRoboTron-Speech, the first end-to-end autonomous GUI agent that directly accepts speech instructions and on-device screenshots to predict actions. Confronted with the scarcity of speech-based GUI agent datasets, we initially generated high-quality speech instructions for training by leveraging a random timbre text-to-speech (TTS) model to convert existing text instructions. We then develop GUIRoboTron-Speech’s capabilities through progressive grounding and planning training stages. A key contribution is a heuristic mixed-instruction training strategy designed to mitigate the modality imbalance inherent in pre-trained foundation models. Comprehensive experiments on several benchmark datasets validate the robust and superior performance of GUIRoboTron-Speech, demonstrating the significant potential and widespread applicability of speech as an effective instruction modality for driving GUI agents. Our code and datasets are available at https://github.com/GUIRoboTron/GUIRoboTron-Speech.
面向图形用户界面(GUI)的自主代理正在彻底改变人机交互的方式,然而,它们对文本指令的依赖对无障碍使用和便捷性产生了限制,特别是在免提场景中。为了解决这一空白,我们提出了GUIRoboTron-Speech,这是第一个端到端的自主GUI代理,它直接接受语音指令和设备截图来预测动作。面对基于语音的GUI代理数据集的稀缺,我们最初通过利用随机音色文本到语音(TTS)模型将现有文本指令转换为高质量语音指令来生成训练数据。然后我们通过渐进的接地和规划训练阶段开发GUIRoboTron-Speech的功能。一个关键的贡献是一种启发式混合指令训练策略,旨在缓解预训练基础模型中的固有模式不平衡问题。在多个基准数据集上的综合实验验证了GUIRoboTron-Speech的稳健性和卓越性能,证明了语音作为一种有效的驱动GUI代理的指令模式的巨大潜力和广泛的应用性。我们的代码和数据集可在https://github.com/GUIRoboTron/GUIRoboTron-Speech获得。
论文及项目相关链接
Summary
语音交互的图形用户界面(GUI)自主代理技术正在革新人机交互方式。为解决现有基于文本指令的自主代理在无障碍和便捷性方面的局限,特别是免提场景下的限制,提出GUIRoboTron-Speech。它是首个直接接受语音指令和设备截图的端到端GUI自主代理。为应对基于语音的GUI代理数据集的稀缺,研究团队利用随机音质文本到语音(TTS)模型将现有文本指令转化为高质量语音指令进行训练。经过逐步的接地和规划培训阶段,发展出GUIRoboTron-Speech的能力。研究的关键贡献在于设计了一种启发式混合指令训练策略,以缓解预训练基础模型中的模态不平衡问题。在多个基准数据集上的综合实验验证了GUIRoboTron-Speech的稳健性和卓越性能,证明了语音作为一种驱动GUI代理的有效指令方式的巨大潜力和广泛应用前景。
Key Takeaways
- 自主代理技术正在通过接受语音指令革新人机交互方式。
- GUIRoboTron-Speech是首个结合语音指令和设备截图的端到端GUI自主代理。
- 利用随机音质文本到语音(TTS)模型解决语音指令数据稀缺问题。
- GUIRoboTron-Speech经过逐步接地和规划培训阶段发展能力。
- 启发式混合指令训练策略用于缓解预训练模型的模态不平衡问题。
- GUIRoboTron-Speech在多个数据集上表现出卓越性能。
点此查看论文截图


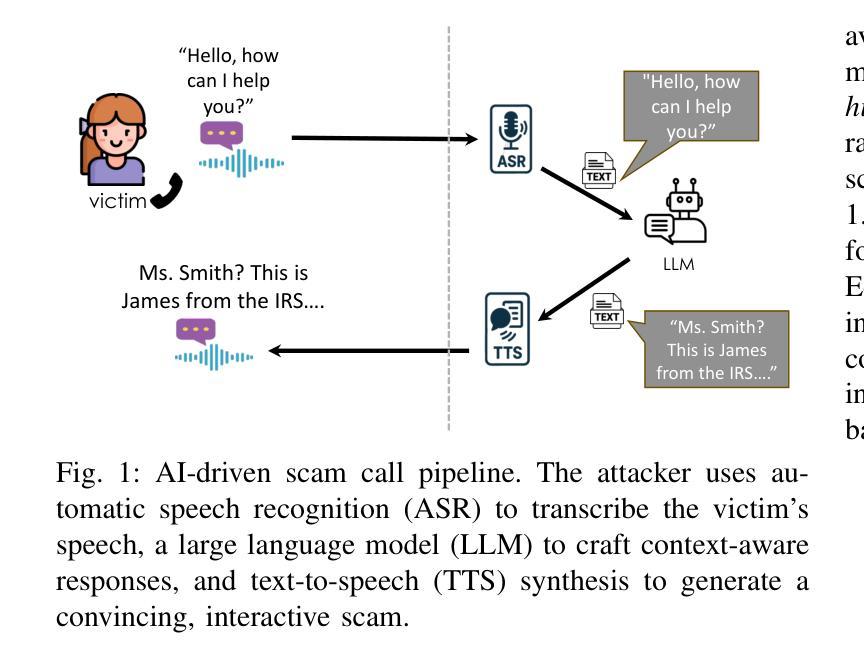
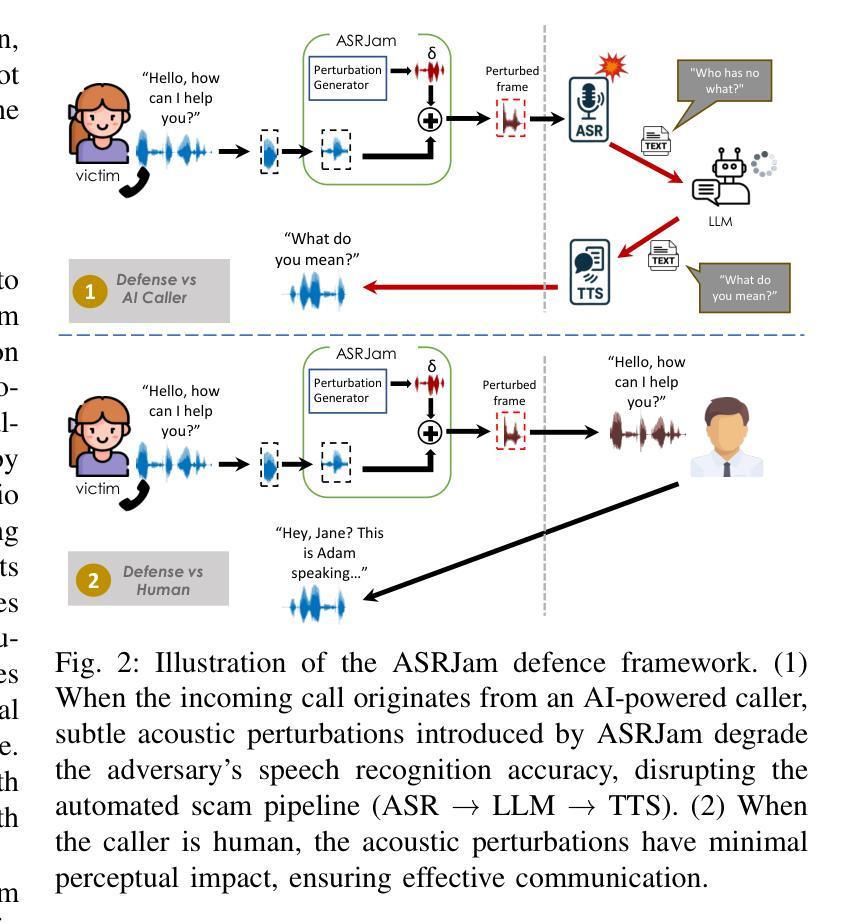
ASRJam: Human-Friendly AI Speech Jamming to Prevent Automated Phone Scams
Authors:Freddie Grabovski, Gilad Gressel, Yisroel Mirsky
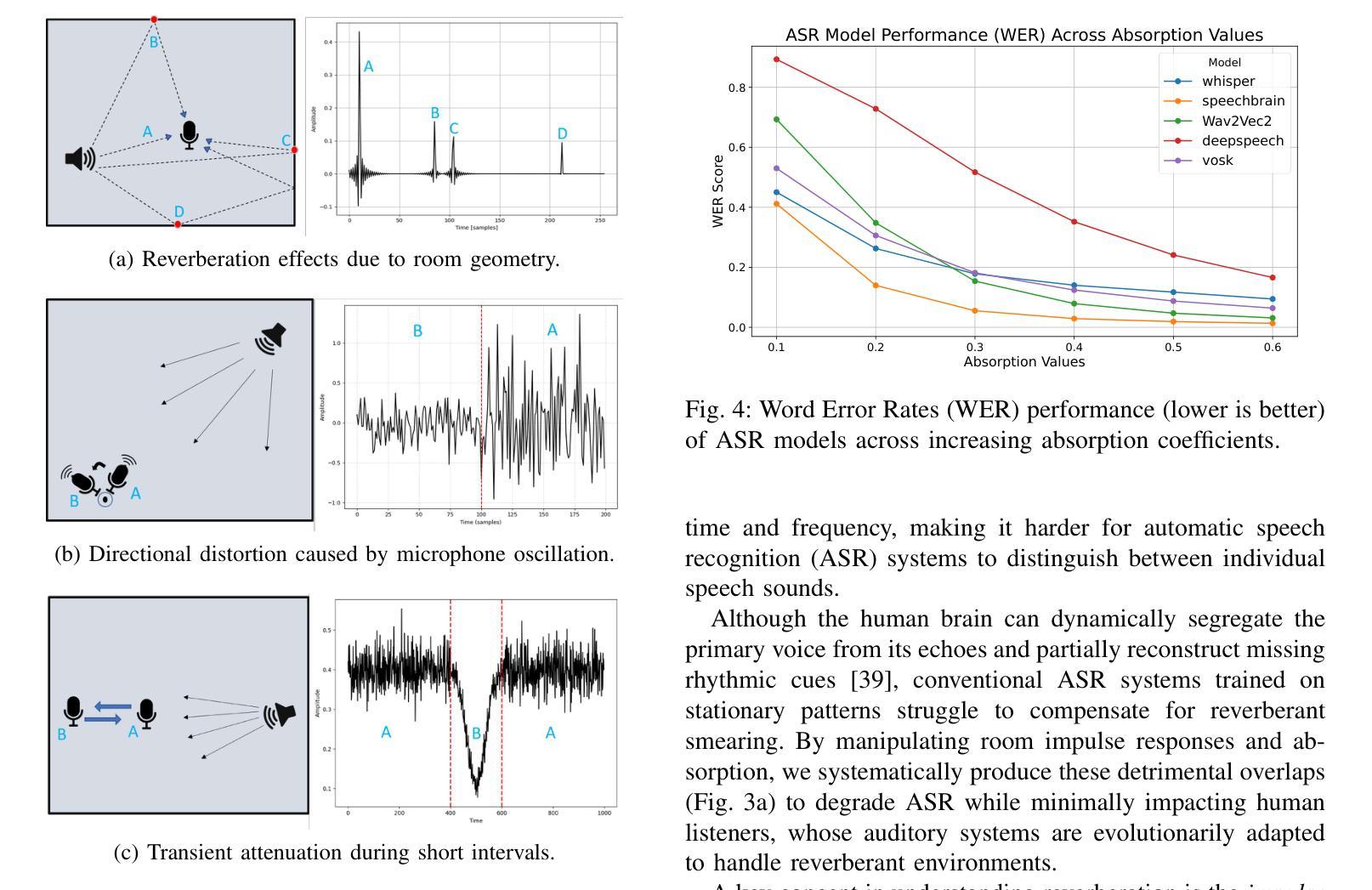
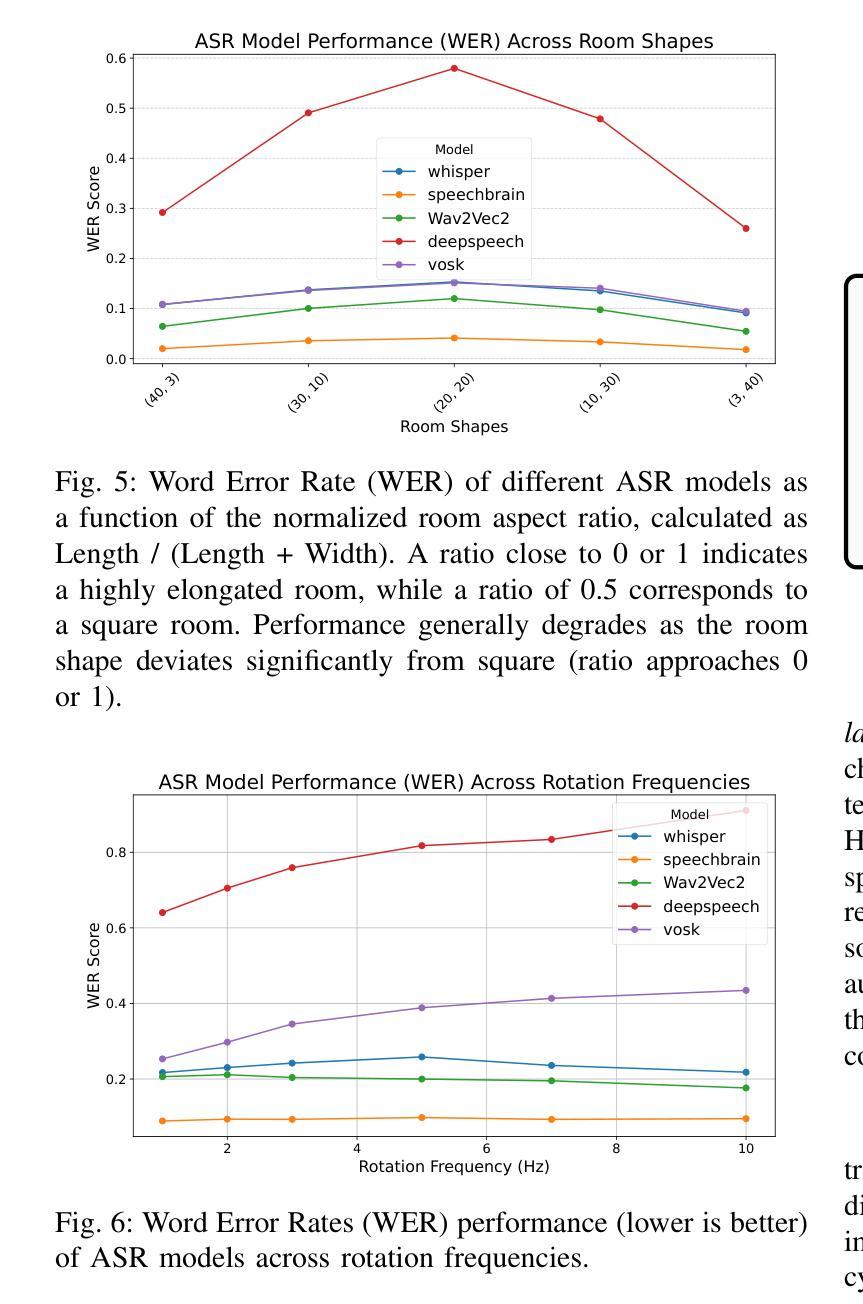
Large Language Models (LLMs), combined with Text-to-Speech (TTS) and Automatic Speech Recognition (ASR), are increasingly used to automate voice phishing (vishing) scams. These systems are scalable and convincing, posing a significant security threat. We identify the ASR transcription step as the most vulnerable link in the scam pipeline and introduce ASRJam, a proactive defence framework that injects adversarial perturbations into the victim’s audio to disrupt the attacker’s ASR. This breaks the scam’s feedback loop without affecting human callers, who can still understand the conversation. While prior adversarial audio techniques are often unpleasant and impractical for real-time use, we also propose EchoGuard, a novel jammer that leverages natural distortions, such as reverberation and echo, that are disruptive to ASR but tolerable to humans. To evaluate EchoGuard’s effectiveness and usability, we conducted a 39-person user study comparing it with three state-of-the-art attacks. Results show that EchoGuard achieved the highest overall utility, offering the best combination of ASR disruption and human listening experience.
大型语言模型(LLM)结合文本转语音(TTS)和自动语音识别(ASR)技术,正越来越多地被用于自动化语音钓鱼(vishing)诈骗。这些系统具有可扩展性和欺骗性,构成重大安全威胁。我们确定ASR转录步骤是诈骗管道中最脆弱的环节,并引入了ASRJam,这是一种主动防御框架,通过向受害者音频注入对抗性扰动,破坏攻击者的ASR。这打破了诈骗的反馈循环,且不会影响人类通话者,他们仍然可以理解对话。虽然先前的对抗性音频技术往往令人不悦,且不适用于实时使用,我们还提出了一种新型干扰器EchoGuard,它利用自然失真(如混响和回声),这些失真对ASR具有破坏性但对人类是可容忍的。为了评估EchoGuard的有效性和可用性,我们对39人进行了用户研究,将其与三种最先进的攻击进行了比较。结果表明,EchoGuard实现了最高的总体效用,在ASR破坏和人类听觉体验方面达到了最佳组合。
论文及项目相关链接
Summary
大规模语言模型结合文本转语音和自动语音识别技术日益被用于自动化语音钓鱼诈骗,构成重大安全威胁。研究中,识别出自动语音识别转录步骤是诈骗管道中最脆弱的环节,于是引入了ASRJam防御框架,通过向受害者音频注入对抗性扰动来破坏攻击者的自动语音识别,在不影响人类通话者的情况下打破诈骗反馈循环。同时,提出了一种新型干扰机EchoGuard,利用自然失真如混响和回声,对自动语音识别有破坏性但对人类可承受。经过39人参与的用户研究,结果显示EchoGuard总体效用最高,在自动语音识别干扰和人类听觉体验方面达到最佳平衡。
Key Takeaways
- 大规模语言模型结合文本转语音和自动语音识别技术被用于语音钓鱼诈骗。
- 自动语音识别转录步骤是诈骗流程中的脆弱环节。
- ASRJam框架通过注入对抗性扰动破坏攻击者的自动语音识别。
- EchoGuard是一种新型干扰机,利用自然失真如混响和回声,对自动语音识别有破坏性但对人类可承受。
- EchoGuard在自动语音识别干扰和人类听觉体验方面达到最佳平衡。
- 39人参与的用户研究表明EchoGuard总体效用最高。
- 此研究提供了一种新的防御策略来应对利用大规模语言模型和自动语音识别技术的语音诈骗威胁。
点此查看论文截图