⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
AlignHuman: Improving Motion and Fidelity via Timestep-Segment Preference Optimization for Audio-Driven Human Animation
Authors:Chao Liang, Jianwen Jiang, Wang Liao, Jiaqi Yang, Zerong zheng, Weihong Zeng, Han Liang
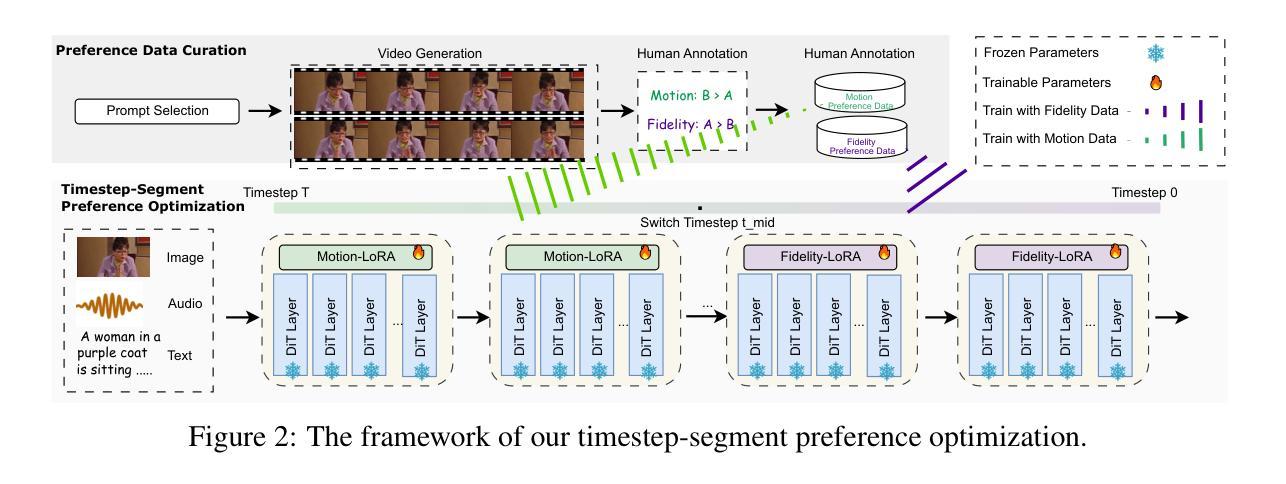
Recent advancements in human video generation and animation tasks, driven by diffusion models, have achieved significant progress. However, expressive and realistic human animation remains challenging due to the trade-off between motion naturalness and visual fidelity. To address this, we propose \textbf{AlignHuman}, a framework that combines Preference Optimization as a post-training technique with a divide-and-conquer training strategy to jointly optimize these competing objectives. Our key insight stems from an analysis of the denoising process across timesteps: (1) early denoising timesteps primarily control motion dynamics, while (2) fidelity and human structure can be effectively managed by later timesteps, even if early steps are skipped. Building on this observation, we propose timestep-segment preference optimization (TPO) and introduce two specialized LoRAs as expert alignment modules, each targeting a specific dimension in its corresponding timestep interval. The LoRAs are trained using their respective preference data and activated in the corresponding intervals during inference to enhance motion naturalness and fidelity. Extensive experiments demonstrate that AlignHuman improves strong baselines and reduces NFEs during inference, achieving a 3.3$\times$ speedup (from 100 NFEs to 30 NFEs) with minimal impact on generation quality. Homepage: \href{https://alignhuman.github.io/}{https://alignhuman.github.io/}
近期,由扩散模型驱动的人类视频生成和动画任务取得了显著进展。然而,由于运动自然性和视觉保真度之间的权衡,表达性和现实性的人类动画仍然具有挑战性。为了解决这一问题,我们提出了AlignHuman框架,它结合了偏好优化作为后训练技术,并采用分而治之的训练策略来联合优化这些相互竞争的目标。我们的关键见解来自于对跨时间步的降噪过程的分析:(1)早期的降噪时间步主要控制运动动力学,而(2)即使跳过早期步骤,后期的时间步也可以有效地管理保真度和人类结构。基于这一观察,我们提出了时间步段偏好优化(TPO),并引入了两种专门的LoRAs作为专家对齐模块,每种模块都针对其对应时间步间隔内的特定维度。LoRAs使用各自的偏好数据进行训练,并在推理过程中在相应的间隔内被激活,以增强运动自然性和保真度。大量实验表明,AlignHuman改进了强大的基线,并在推理过程中减少了NFEs,实现了3.3倍的速度提升(从100 NFEs减少到30 NFEs),对生成质量的影响微乎其微。主页:https://alignhuman.github.io/。%E3%80%82%E3%80%82%E3%80%82%E3%80%82)
论文及项目相关链接
PDF Homepage: https://alignhuman.github.io/
Summary
基于扩散模型的技术进步,人类视频生成和动画任务取得了显著成就。然而,表达力和真实度并存的人类动画仍具有挑战性。为此,本文提出一种名为AlignHuman的框架,采用偏好优化作为后训练技术,结合分而治之的训练策略,以联合优化这些相互竞争的目标。该框架基于去噪过程时间步长的分析,提出时间步长分段偏好优化(TPO)和引入两个专门化的LoRAs作为专家对齐模块,每个模块针对其对应时间间隔内的特定维度。使用各自的偏好数据进行训练,并在推理过程中在相应的时间间隔内激活,以提高运动自然性和保真度。实验表明,AlignHuman提高了强基线性能,降低了推理过程中的NFEs,实现了3.3倍的速度提升(从100个NFEs减少到30个NFEs),对生成质量的影响微乎其微。
Key Takeaways
- 扩散模型在人类视频生成和动画任务上取得了显著进展。
- 表达力和真实度并存的人类动画仍然具有挑战性。
- AlignHuman框架结合了偏好优化和分而治之的训练策略。
- AlignHuman基于去噪过程时间步长的分析,提出时间步长分段偏好优化(TPO)。
- 引入两个专家对齐模块LoRAs,每个模块针对特定维度和时间间隔。
- AlignHuman提高了运动自然性和保真度。
- AlignHuman实现了推理过程中的速度提升,同时保持生成质量。
点此查看论文截图