⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-17 更新
PiPViT: Patch-based Visual Interpretable Prototypes for Retinal Image Analysis
Authors:Marzieh Oghbaie, Teresa Araújo, Hrvoje Bogunović
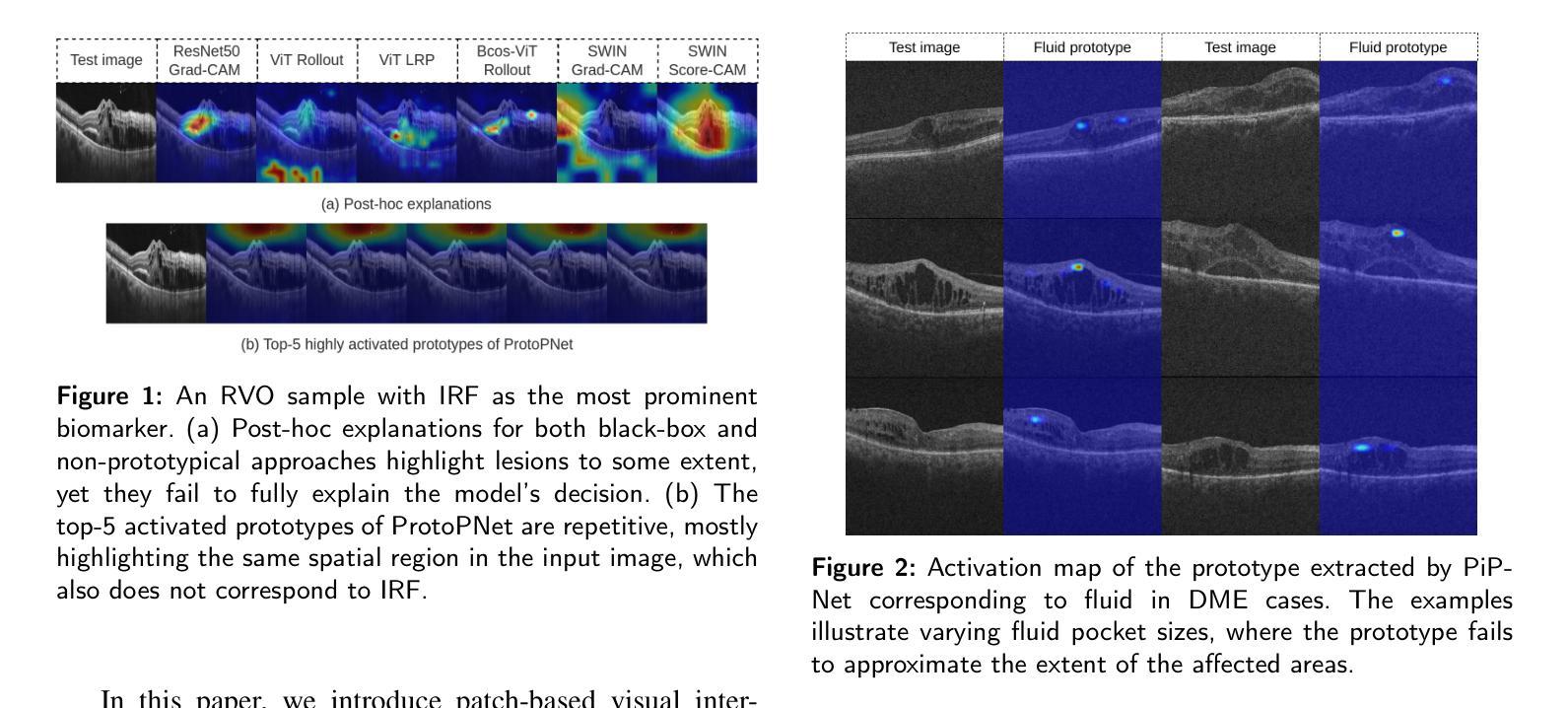
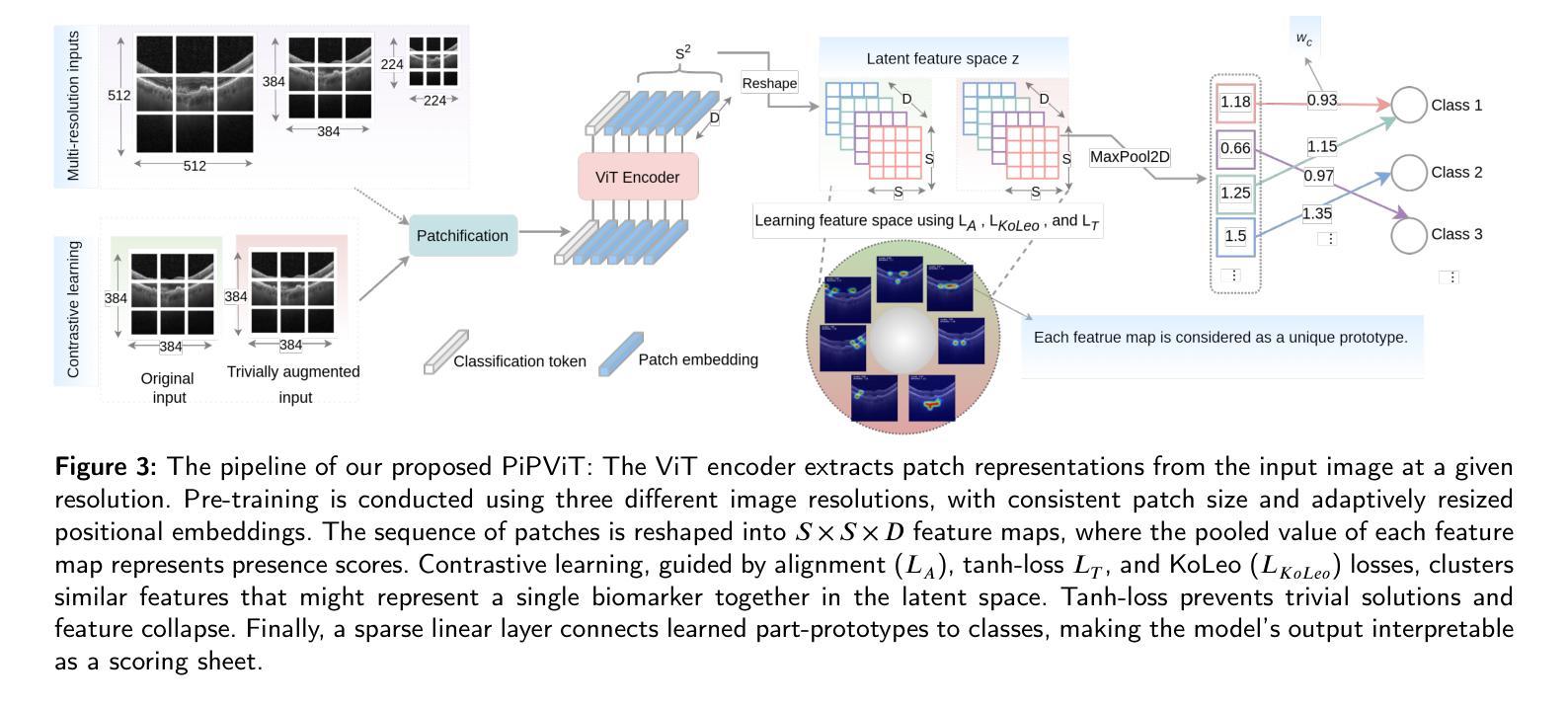
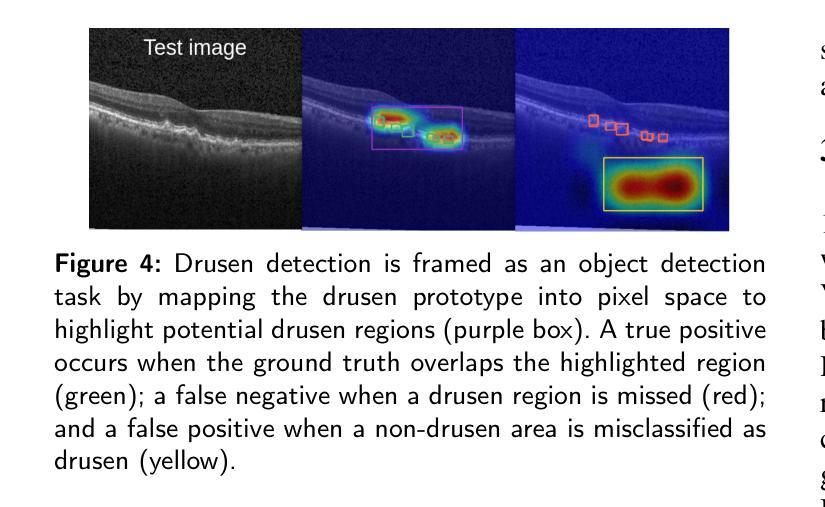
Background and Objective: Prototype-based methods improve interpretability by learning fine-grained part-prototypes; however, their visualization in the input pixel space is not always consistent with human-understandable biomarkers. In addition, well-known prototype-based approaches typically learn extremely granular prototypes that are less interpretable in medical imaging, where both the presence and extent of biomarkers and lesions are critical. Methods: To address these challenges, we propose PiPViT (Patch-based Visual Interpretable Prototypes), an inherently interpretable prototypical model for image recognition. Leveraging a vision transformer (ViT), PiPViT captures long-range dependencies among patches to learn robust, human-interpretable prototypes that approximate lesion extent only using image-level labels. Additionally, PiPViT benefits from contrastive learning and multi-resolution input processing, which enables effective localization of biomarkers across scales. Results: We evaluated PiPViT on retinal OCT image classification across four datasets, where it achieved competitive quantitative performance compared to state-of-the-art methods while delivering more meaningful explanations. Moreover, quantitative evaluation on a hold-out test set confirms that the learned prototypes are semantically and clinically relevant. We believe PiPViT can transparently explain its decisions and assist clinicians in understanding diagnostic outcomes. Github page: https://github.com/marziehoghbaie/PiPViT
背景与目标:基于原型的方法通过学习精细的局部原型来提高可解释性,但它们在输入像素空间的可视化并不总是与人们可理解的生物标志物相一致。此外,知名的基于原型的方法通常学习极其精细的原型,在医学成像中不太容易解释,其中生物标志物和病变的存在和程度都至关重要。方法:针对这些挑战,我们提出了PiPViT(基于补丁的视觉可解释原型),这是一种用于图像识别的固有可解释原型模型。借助视觉变压器(ViT),PiPViT捕获补丁之间的长距离依赖关系,仅使用图像级标签来学习稳健且人们可解释的原型,这些原型可以近似病变的程度。此外,PiPViT受益于对比学习和多分辨率输入处理,这能够在各种尺度上有效地定位生物标志物。结果:我们在四个数据集上评估了PiPViT在视网膜OCT图像分类上的表现,与最先进的方法相比,它取得了具有竞争力的量化性能,同时提供了更有意义的解释。此外,在独立测试集上的定量评估证实,学习到的原型在语义和临床上都很重要。我们相信PiPViT能够透明地解释其决策,帮助临床医生理解诊断结果。GitHub页面:https://github.com/marziehoghbaie/PiPViT
论文及项目相关链接
Summary
PiPViT是一种基于视觉Transformer的、用于图像识别的本质可解释的原型模型。它通过捕获图像补丁之间的长距离依赖关系来学习稳健、人类可解释的原型,这些原型能够近似病变范围,并且仅使用图像级别的标签。此外,PiPViT受益于对比学习和多分辨率输入处理,这使其能够在不同尺度上有效地定位生物标志物。在视网膜OCT图像分类的四个数据集上的评估结果表明,与最先进的方法相比,PiPViT在具有竞争力的定量性能的同时,提供了更有意义的解释。我们相信PiPViT能够透明地解释其决策,并帮助临床医生理解诊断结果。
Key Takeaways
- PiPViT是一个基于视觉Transformer的原型模型,旨在解决原型方法在医疗成像中解释性不足的问题。
- PiPViT通过捕获图像补丁之间的长距离依赖关系来学习稳健且人类可解释的原型。
- 该方法能够使用图像级别的标签来近似病变范围。
- PiPViT利用对比学习和多分辨率输入处理来定位生物标志物,这有助于提高其解释性和定位准确性。
- 在视网膜OCT图像分类的四个数据集上的评估显示,PiPViT具有竞争力的定量性能。
- PiPViT提供的解释是透明的,有助于临床医生理解诊断结果。
点此查看论文截图

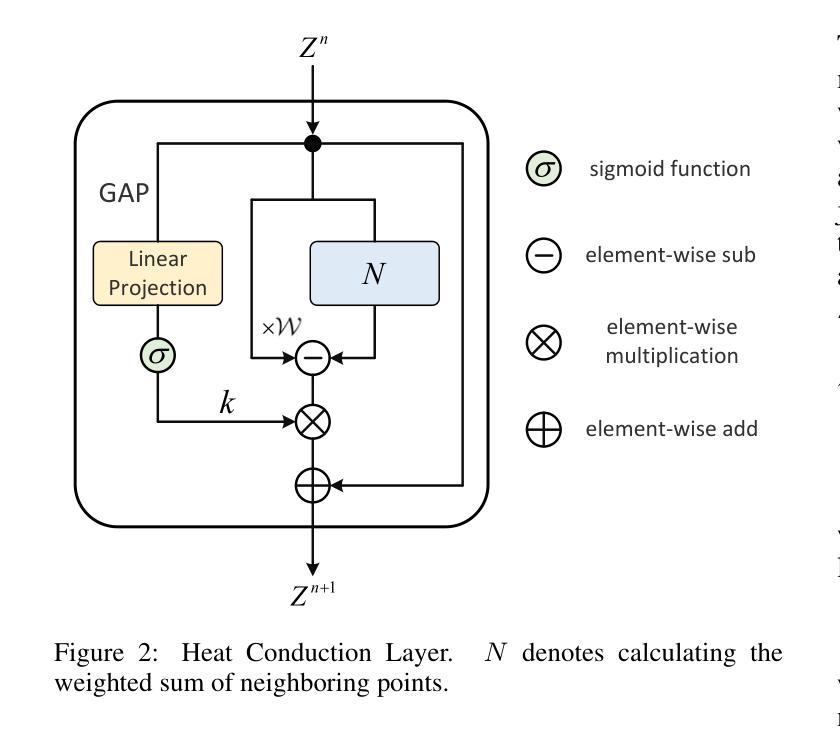
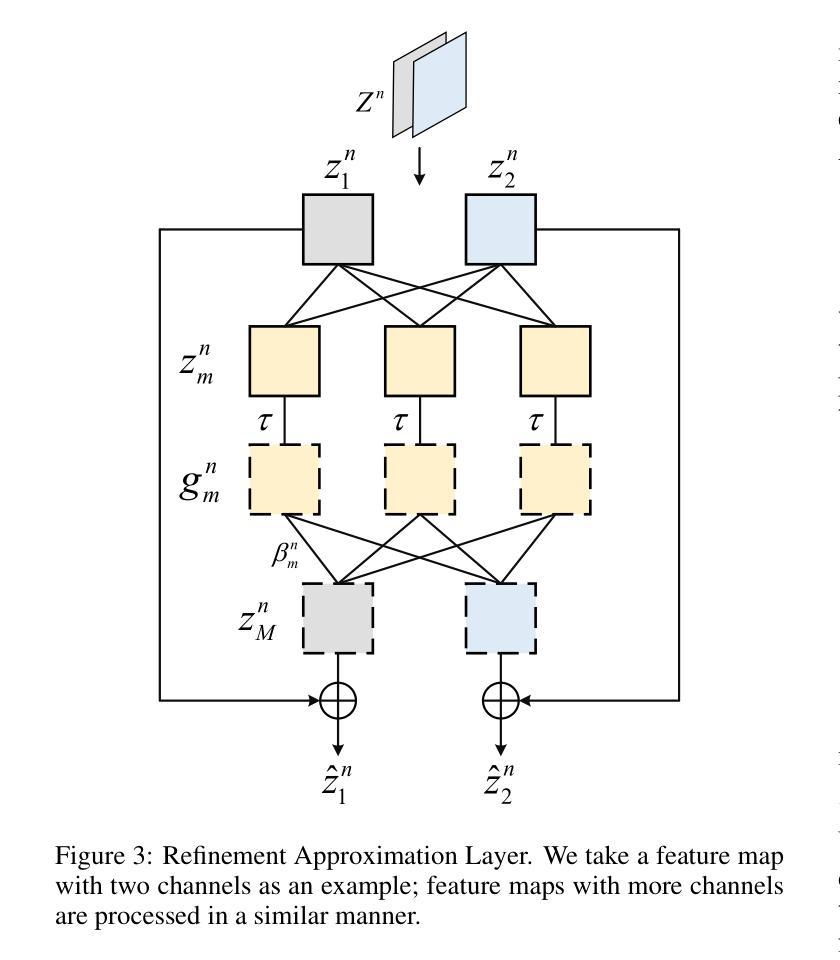
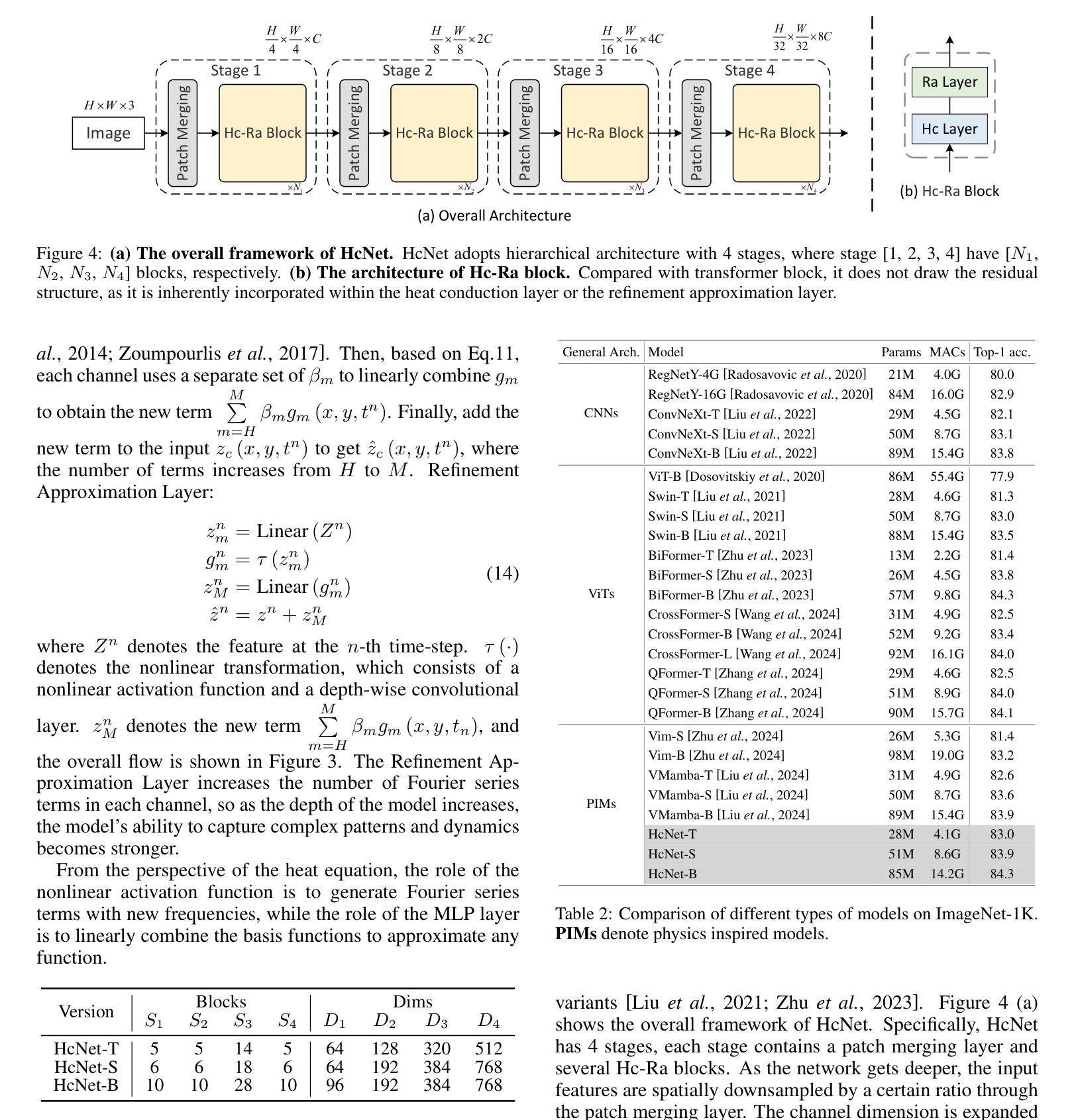
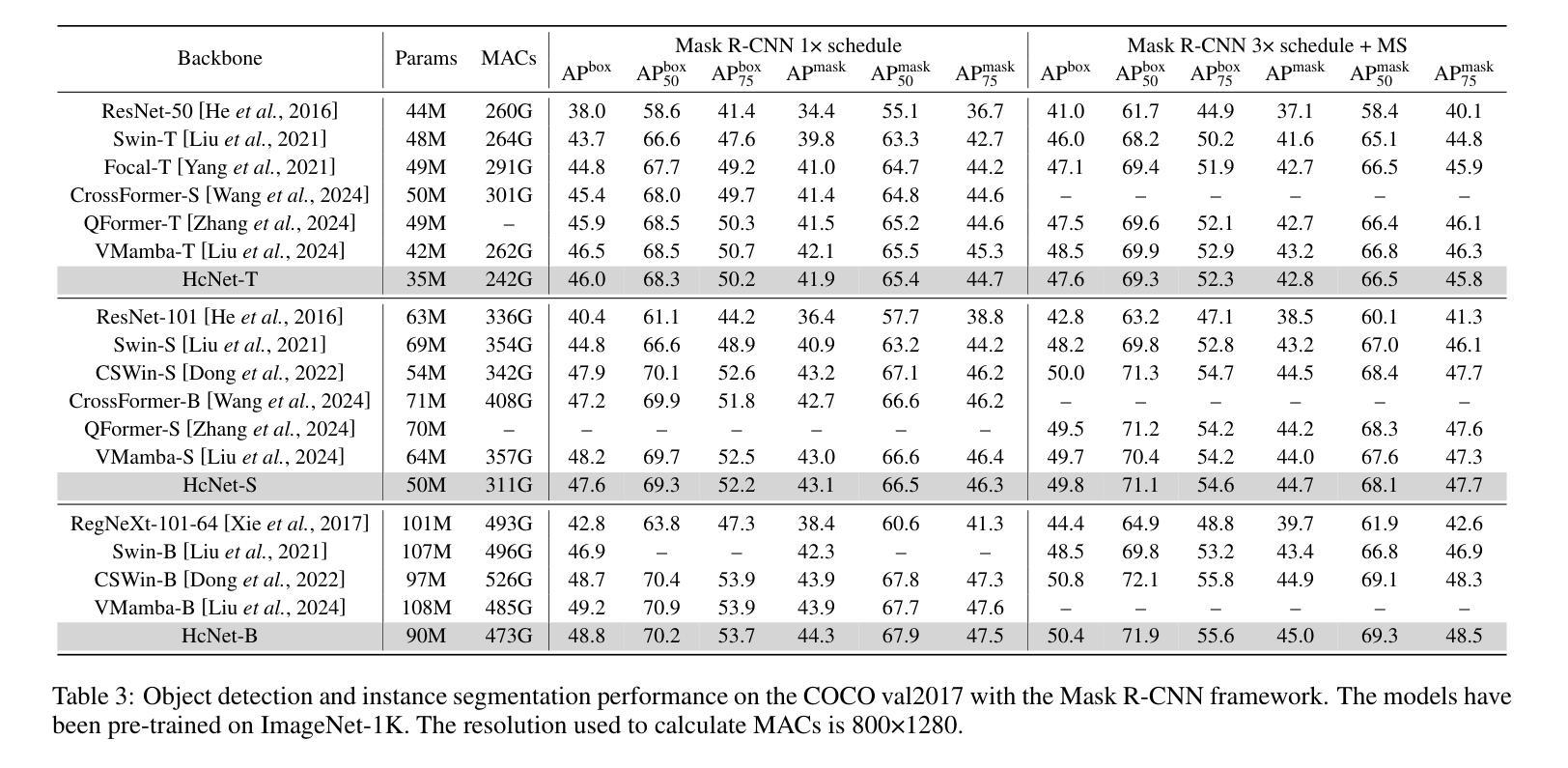
Efficient Visual Representation Learning with Heat Conduction Equation
Authors:Zhemin Zhang, Xun Gong
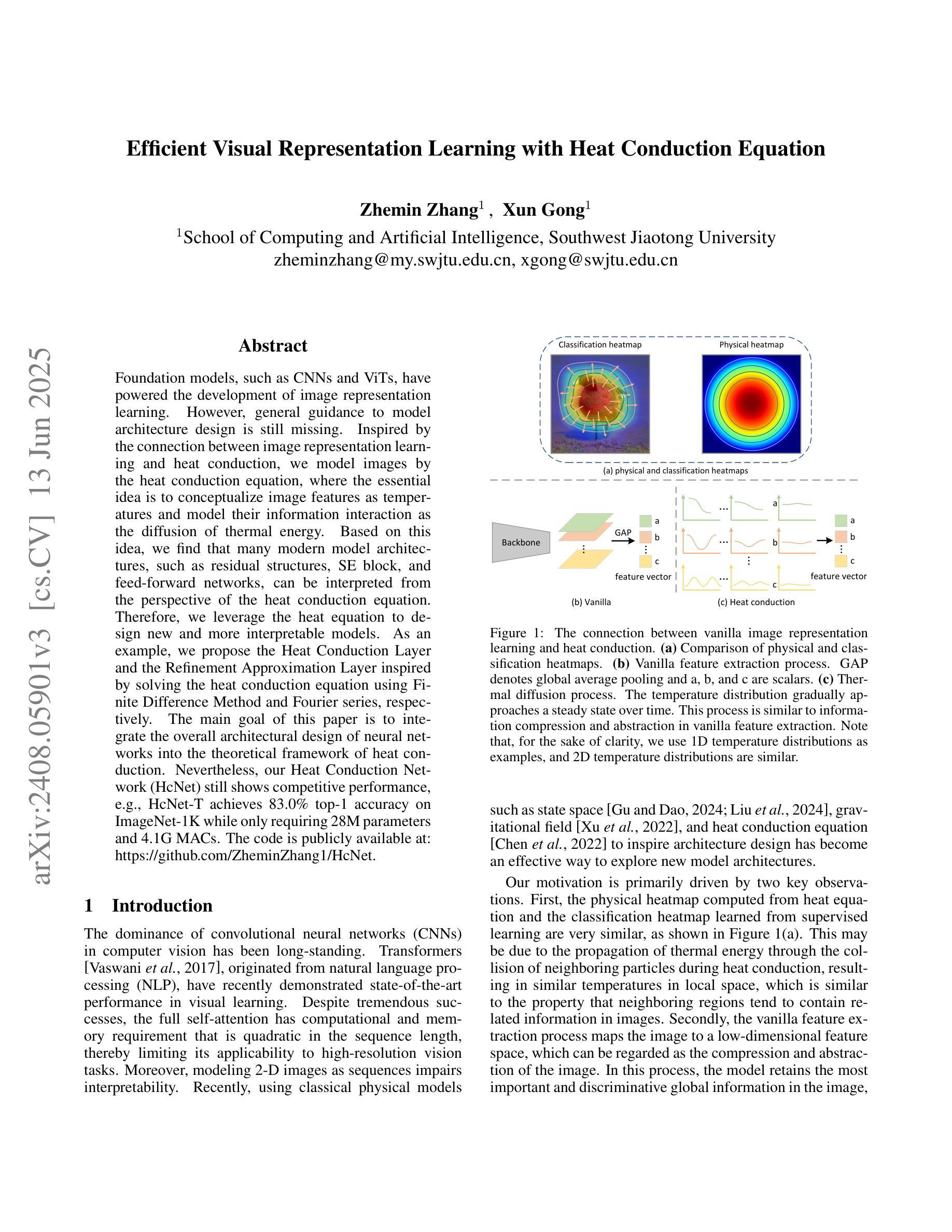
Foundation models, such as CNNs and ViTs, have powered the development of image representation learning. However, general guidance to model architecture design is still missing. Inspired by the connection between image representation learning and heat conduction, we model images by the heat conduction equation, where the essential idea is to conceptualize image features as temperatures and model their information interaction as the diffusion of thermal energy. Based on this idea, we find that many modern model architectures, such as residual structures, SE block, and feed-forward networks, can be interpreted from the perspective of the heat conduction equation. Therefore, we leverage the heat equation to design new and more interpretable models. As an example, we propose the Heat Conduction Layer and the Refinement Approximation Layer inspired by solving the heat conduction equation using Finite Difference Method and Fourier series, respectively. The main goal of this paper is to integrate the overall architectural design of neural networks into the theoretical framework of heat conduction. Nevertheless, our Heat Conduction Network (HcNet) still shows competitive performance, e.g., HcNet-T achieves 83.0% top-1 accuracy on ImageNet-1K while only requiring 28M parameters and 4.1G MACs. The code is publicly available at: https://github.com/ZheminZhang1/HcNet.
模型基础,如卷积神经网络(CNNs)和视觉转换器(ViTs),推动了图像表示学习的发展。然而,关于模型架构设计的通用指导仍然缺失。受图像表示学习与热传导之间联系的启发,我们通过热传导方程对图像进行建模,其基本思想是将图像特征概念化为温度,并将它们的信息交互建模为热能扩散。基于此理念,我们发现许多现代模型架构,如残差结构、SE块和前馈网络,都可以从热传导方程的角度进行解释。因此,我们利用热方程设计新的、更易解释的模型。例如,我们提出了受有限差分法和傅里叶级数解决热传导方程启发的热传导层和细化逼近层。本文的主要目标是将神经网络的整体架构设计融入热传导的理论框架。尽管如此,我们的热传导网络(HcNet)仍表现出具有竞争力的性能,例如HcNet-T在ImageNet-1K上实现83.0%的top-1准确率,同时仅需28M参数和4.1G乘加运算(MACs)。代码公开在:https://github.com/ZheminZhang1/HcNet。
论文及项目相关链接
PDF Accepted by IJCAI2025
Summary
图像表示学习受卷积神经网络和视觉转换器基础模型的推动,但模型架构设计的通用指导仍然缺失。本研究受图像表示学习与热传导之间的联系启发,通过热传导方程对图像进行建模,将图像特征概念化为温度,并将其信息交互模拟为热能扩散。研究从热传导方程的角度解读了现代模型架构,并据此设计了新的、更具解释性的模型。提出的热传导层和精细近似层分别借鉴了有限差分法和傅里叶级数解热传导方程。本研究的主要目标是将神经网络的整体架构设计融入热传导的理论框架中。
Key Takeaways
- 基础模型如CNN和ViT推动了图像表示学习的发展,但缺乏模型架构设计的通用指导。
- 研究受图像表示学习与热传导之间联系的启发,使用热传导方程对图像进行建模。
- 将图像特征视为温度,信息交互模拟为热能扩散,为现代模型架构提供了新的解读方式。
- 通过借鉴有限差分法和傅里叶级数解热传导方程的解决方案,提出了热传导层和精细近似层。
- 研究的主要目标是将神经网络的整体架构设计融入热传导的理论框架。
- 提出的Heat Conduction Network(HcNet)模型表现出竞争力,例如HcNet-T在ImageNet-1K上达到了83.0%的top-1准确率,同时只需28M参数和4.1G MACs。
点此查看论文截图
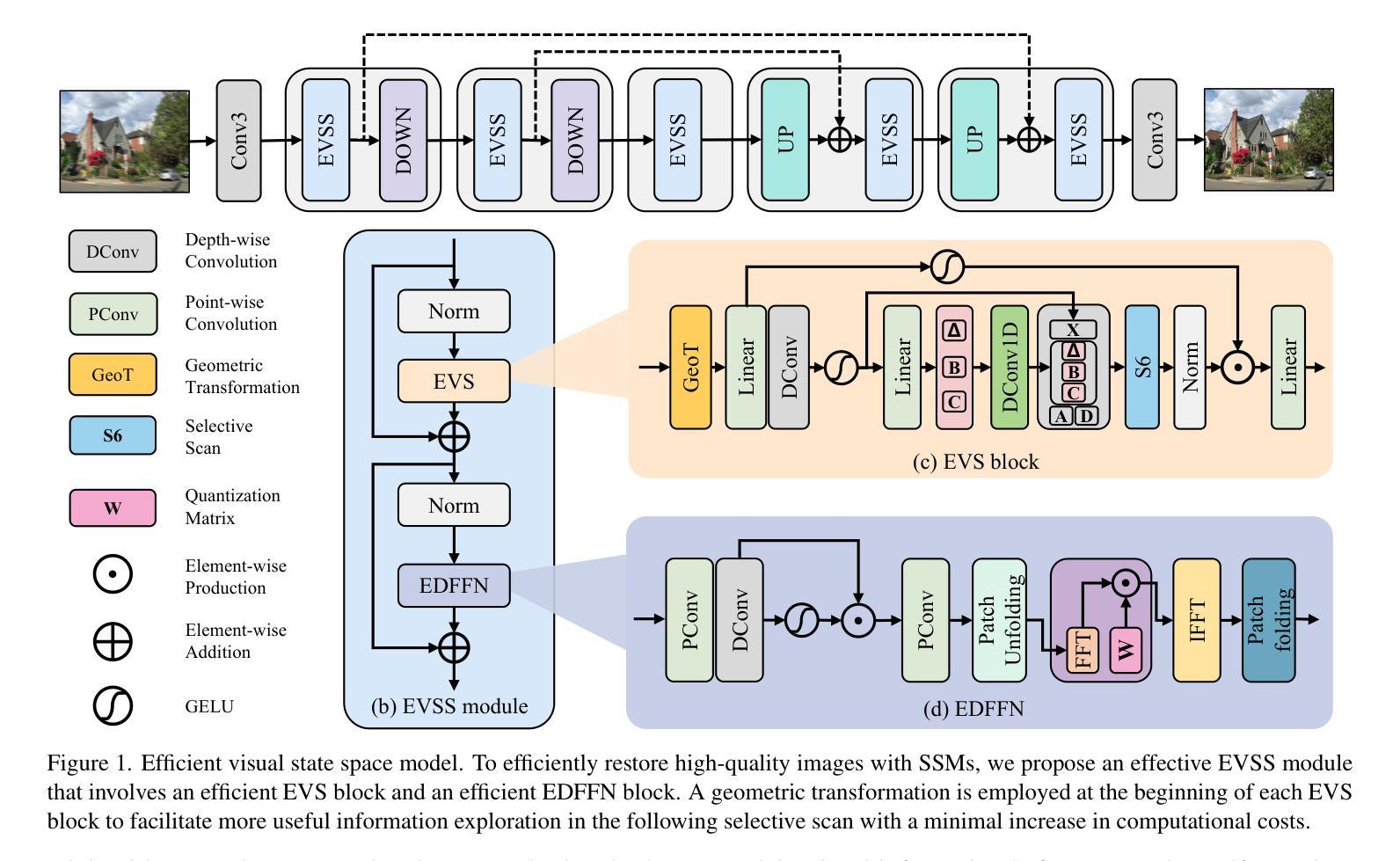
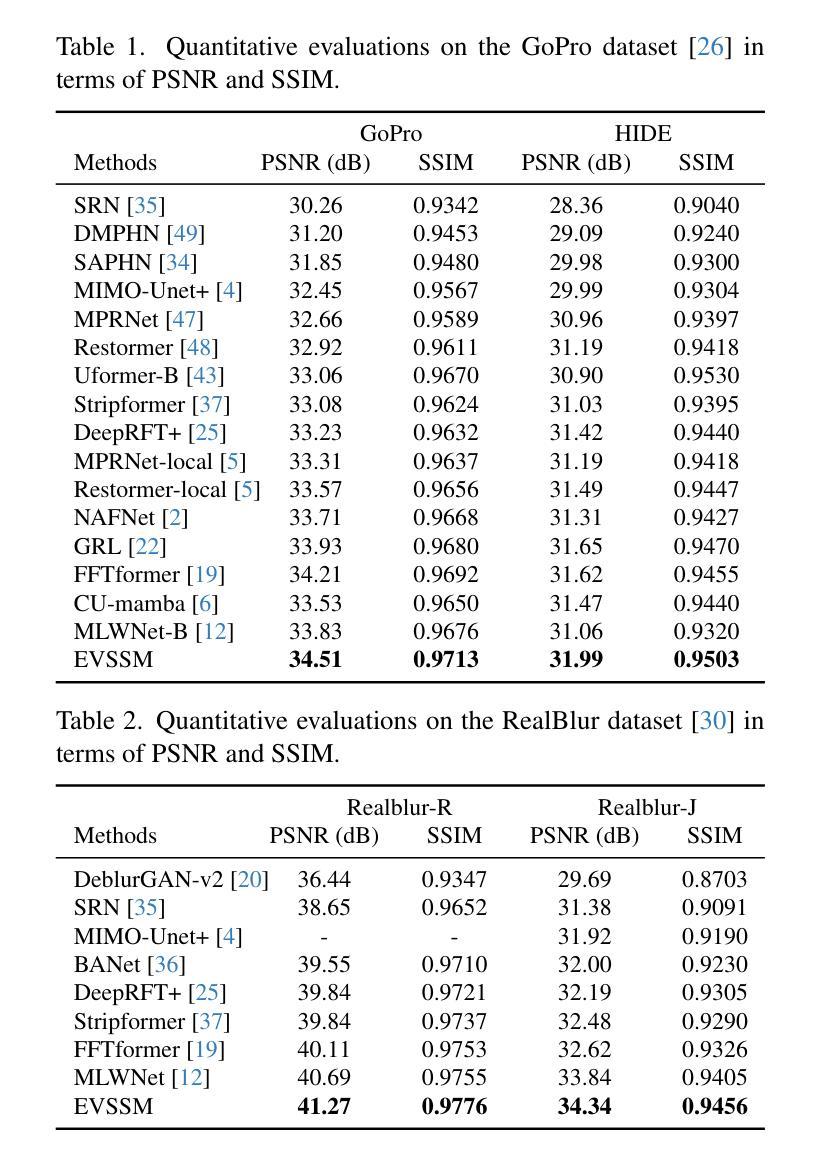
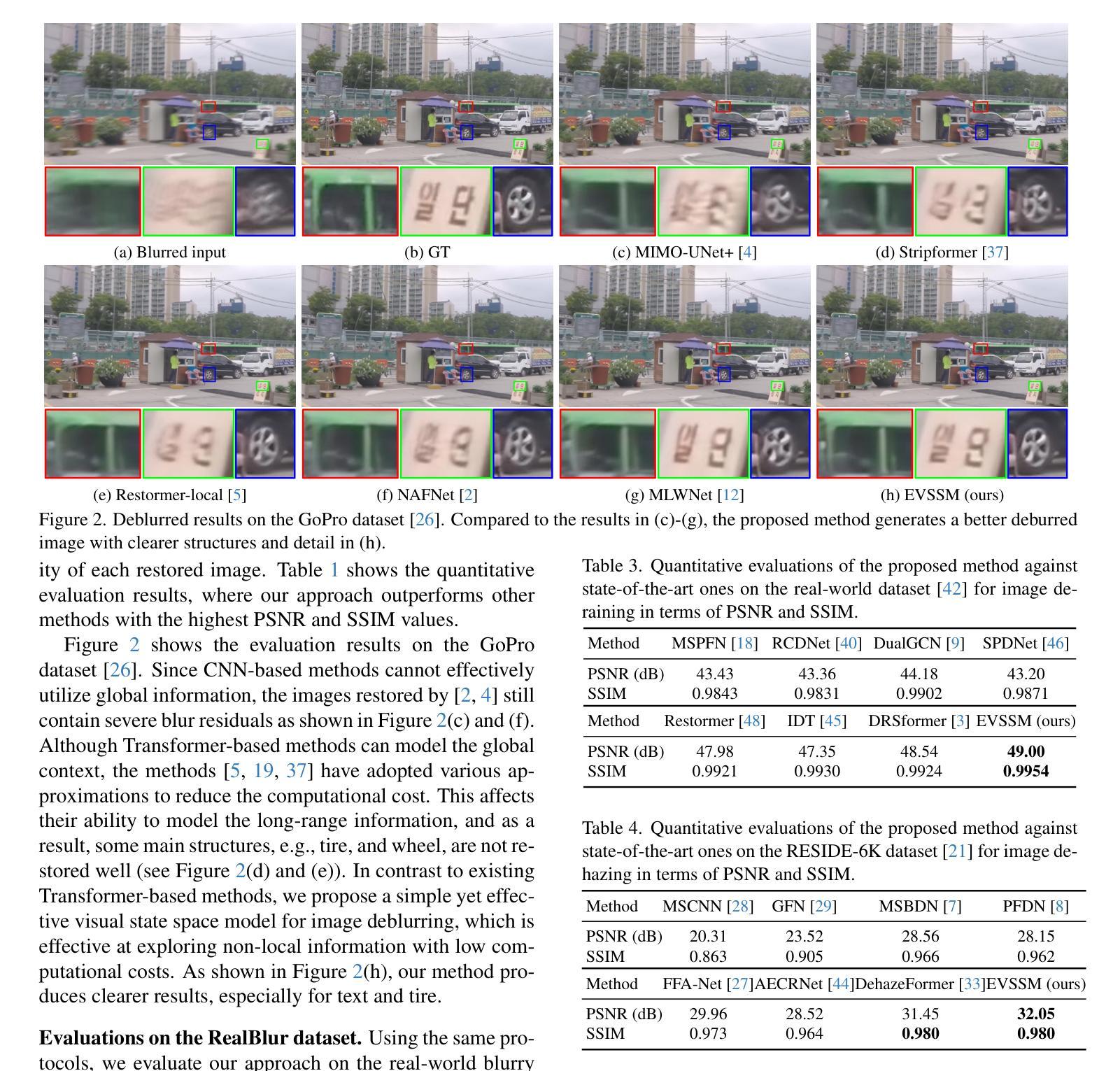
Efficient Visual State Space Model for Image Deblurring
Authors:Lingshun Kong, Jiangxin Dong, Jinhui Tang, Ming-Hsuan Yang, Jinshan Pan
Convolutional neural networks (CNNs) and Vision Transformers (ViTs) have achieved excellent performance in image restoration. While ViTs generally outperform CNNs by effectively capturing long-range dependencies and input-specific characteristics, their computational complexity increases quadratically with image resolution. This limitation hampers their practical application in high-resolution image restoration. In this paper, we propose a simple yet effective visual state space model (EVSSM) for image deblurring, leveraging the benefits of state space models (SSMs) for visual data. In contrast to existing methods that employ several fixed-direction scanning for feature extraction, which significantly increases the computational cost, we develop an efficient visual scan block that applies various geometric transformations before each SSM-based module, capturing useful non-local information and maintaining high efficiency. In addition, to more effectively capture and represent local information, we propose an efficient discriminative frequency domain-based feedforward network (EDFFN), which can effectively estimate useful frequency information for latent clear image restoration. Extensive experimental results show that the proposed EVSSM performs favorably against state-of-the-art methods on benchmark datasets and real-world images. The code is available at https://github.com/kkkls/EVSSM.
卷积神经网络(CNN)和视觉转换器(ViT)在图像恢复方面取得了卓越的性能。虽然ViT通过有效捕捉长期依赖关系和输入特定特征通常优于CNN,但其计算复杂度会随图像分辨率的增加而二次方增长。这一局限性阻碍了其在高分辨率图像恢复中的实际应用。在本文中,我们提出了一种简单的视觉状态空间模型(EVSSM),用于图像去模糊,利用状态空间模型(SSM)对视觉数据的优势。与现有方法相比,这些方法采用多种固定方向扫描进行特征提取,从而大大提高了计算成本,我们开发了一个高效的视觉扫描块,在每个基于SSM的模块之前应用各种几何变换,捕获有用的非局部信息并保持高效率。此外,为了更有效地捕获和表示局部信息,我们提出了一种高效的基于判别频率域的前馈网络(EDFFN),它可以有效地估计用于潜在清晰图像恢复的有用频率信息。大量的实验结果表明,所提出的EVSSM在基准数据集和真实世界图像上的表现均优于最先进的方法。代码可在https://github.com/kkkls/EVSSM上找到。
论文及项目相关链接
PDF CVPR 2025
Summary
该文本介绍了一种用于图像去模糊的新方法——视觉状态空间模型(EVSSM)。该模型结合了卷积神经网络(CNN)和视觉转换器(ViT)的优点,克服了其计算复杂度高的缺点。通过利用状态空间模型(SSM)对视觉数据的优势,EVSSM模型能够在高效捕捉非局部信息的同时保持高计算效率。此外,它还提出了一种高效的判别频率域前馈网络(EDFFN),可有效估计用于潜在清晰图像恢复的频率信息。实验结果表明,该模型在基准数据集和真实图像上的性能优于现有先进技术。
Key Takeaways
- EVSSM结合了CNN和ViT的优点,用于图像去模糊任务。
- ViT虽然性能优异,但计算复杂度随图像分辨率的增加而增加,限制了其在高分辨率图像去模糊中的应用。
- EVSSM利用SSM的优势,通过应用各种几何变换来高效捕捉非局部信息。
- EDFFN网络用于有效估计频率信息,有助于潜在清晰图像的恢复。
- 实验结果表明,EVSSM在基准数据集和真实图像上的性能优于现有技术。
- 该模型的代码已公开发布在GitHub上。
- EVSSM模型在保持计算效率的同时实现了良好的性能。
点此查看论文截图