⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-20 更新
AutoRule: Reasoning Chain-of-thought Extracted Rule-based Rewards Improve Preference Learning
Authors:Tevin Wang, Chenyan Xiong
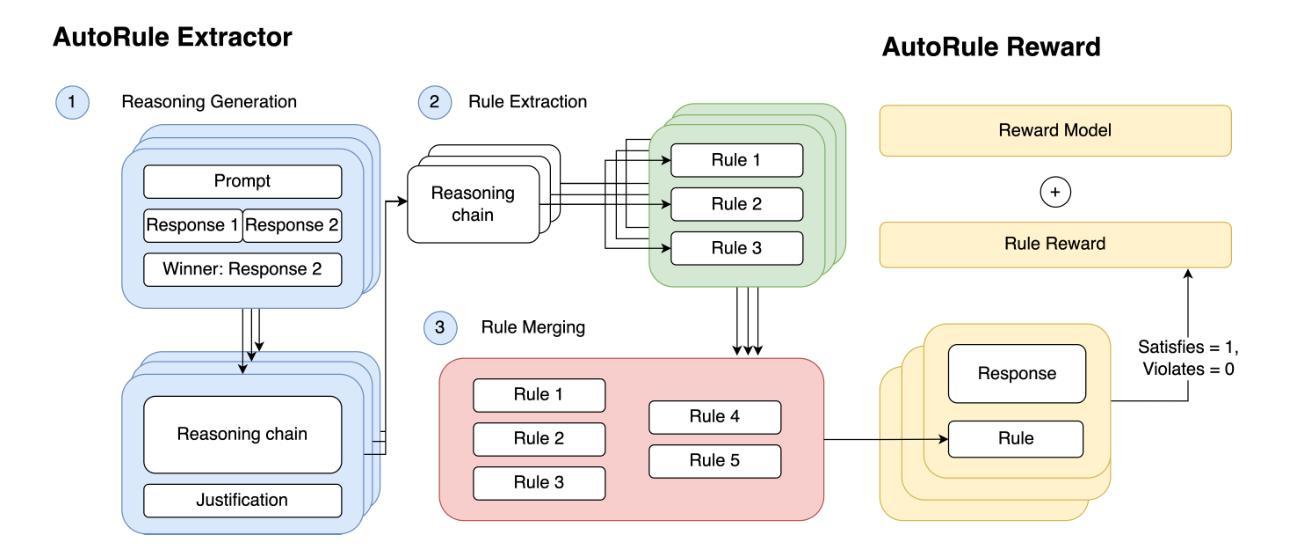
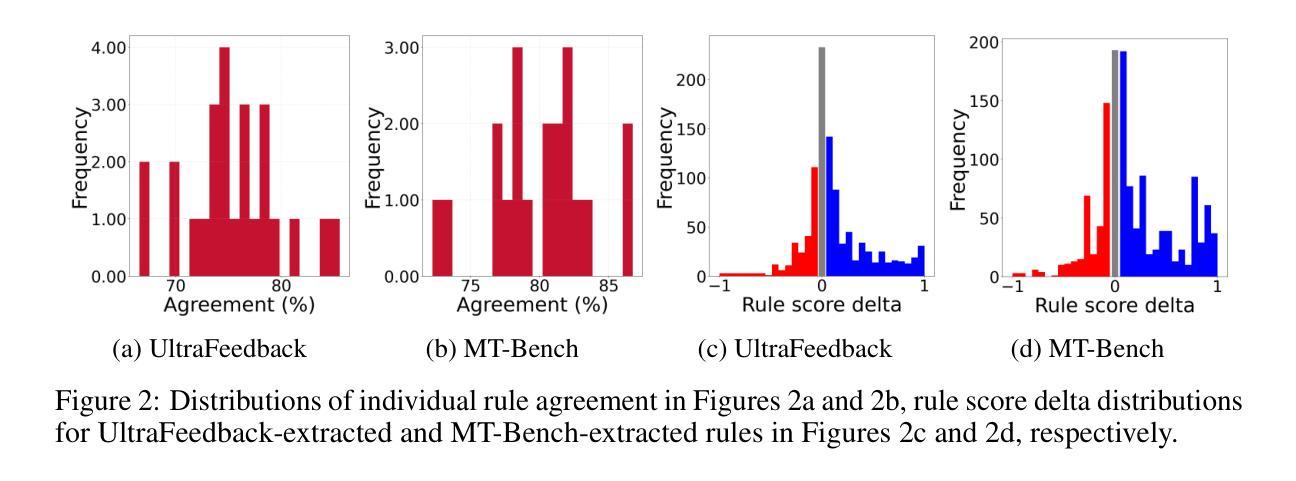
Rule-based rewards offer a promising strategy for improving reinforcement learning from human feedback (RLHF), but current approaches often rely on manual rule engineering. We present AutoRule, a fully automated method for extracting rules from preference feedback and formulating them into rule-based rewards. AutoRule extraction operates in three stages: it leverages a reasoning model to interpret user preferences, identifies candidate rules from the reasoning chain of these interpretations, and synthesizes them into a unified rule set. Leveraging the finalized rule set, we employ language-model verifiers to compute the fraction of rules satisfied by each output, using this metric as an auxiliary reward alongside the learned reward model during policy optimization. Training a Llama-3-8B model with AutoRule results in a 28.6% relative improvement in length-controlled win rate on AlpacaEval2.0, and a 6.1% relative gain in second-turn performance on a held-out MT-Bench subset, compared to a GRPO baseline trained with the same learned reward model but without the rule-based auxiliary reward. Our analysis confirms that the extracted rules exhibit good agreement with dataset preference. We find that AutoRule demonstrates reduced reward hacking compared to a learned reward model when run over two episodes. Finally, our case study suggests that the extracted rules capture unique qualities valued in different datasets. The extracted rules are provided in the appendix, and the code is open-sourced at https://github.com/cxcscmu/AutoRule.
基于规则的奖励对于通过人类反馈改进强化学习(RLHF)是一个前景光明的策略,但当前的方法往往依赖于手动规则工程。我们提出了AutoRule,这是一种全自动的方法,可以从偏好反馈中提取规则,并将它们转化为基于规则的奖励。AutoRule的提取操作分为三个阶段:它利用推理模型来解释用户偏好,从这些解释的推理链中识别候选规则,并将它们合成一个统一的规则集。利用最终确定的规则集,我们采用语言模型验证器来计算每个输出满足的规则比例,将此指标作为策略优化期间与学到的奖励模型并行的辅助奖励。使用AutoRule训练Llama-3-8B模型的结果是,在AlpacaEval2.0上长度控制胜率相对提高了28.6%,在一个未训练的MT-Bench子集上第二轮性能相对提高了6.1%,相对于用相同的学到奖励模型训练但无基于规则的辅助奖励的GRPO基线。我们的分析证实,提取的规则与数据集偏好表现出良好的一致性。我们发现,与单集运行学到的奖励模型相比,AutoRule显示出较少的奖励操纵。最后,我们的案例研究表明,提取的规则捕捉到了不同数据集中重视的独特品质。提取的规则被列在附录中,代码已在https://github.com/cxcscmu/AutoRule开源。
论文及项目相关链接
Summary:
自动规则提取(AutoRule)是一种从偏好反馈中提取规则并将其转化为基于规则的奖励的完全自动化方法。该方法通过解释用户偏好、识别候选规则并合成统一规则集三个阶段进行操作。在策略优化过程中,除学习奖励模型外,还利用最终规则集和语言模型验证器计算输出满足的规则比例作为辅助奖励。使用AutoRule训练Llama-3-8B模型,在AlpacaEval2.0上相对改进了28.6%的长度控制胜率,在MT-Bench子集的第二回合性能相对提高了6.1%。分析显示,提取的规则与数据集偏好一致,相较于学习奖励模型,AutoRule的奖励破解行为有所减少。此外,案例研究表明,提取的规则能够捕捉到不同数据集中重视的独特品质。
Key Takeaways:
- AutoRule是一种自动化方法,可以从偏好反馈中提取规则并转化为基于规则的奖励。
- AutoRule通过解释用户偏好、识别候选规则和合成统一规则集三个阶段操作。
- AutoRule利用最终规则集和语言模型验证器计算输出满足的规则比例作为辅助奖励。
- 使用AutoRule训练的模型在相关数据集上的性能有明显提升。
- 分析显示提取的规则与数据集偏好一致。
- 相较于学习奖励模型,AutoRule的奖励破解行为有所减少。
点此查看论文截图

RE-IMAGINE: Symbolic Benchmark Synthesis for Reasoning Evaluation
Authors:Xinnuo Xu, Rachel Lawrence, Kshitij Dubey, Atharva Pandey, Risa Ueno, Fabian Falck, Aditya V. Nori, Rahul Sharma, Amit Sharma, Javier Gonzalez
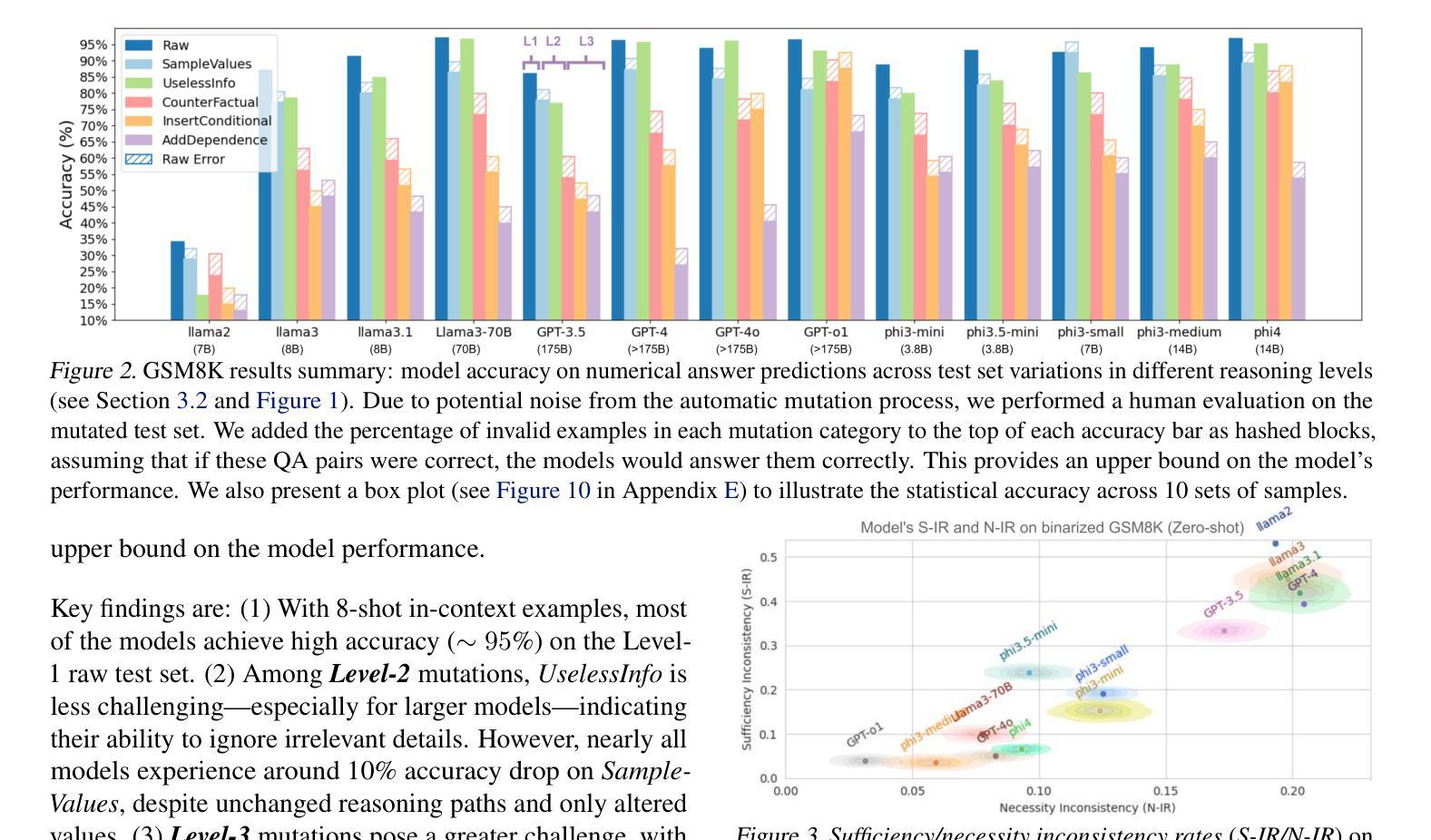
Recent Large Language Models (LLMs) have reported high accuracy on reasoning benchmarks. However, it is still unclear whether the observed results arise from true reasoning or from statistical recall of the training set. Inspired by the ladder of causation (Pearl, 2009) and its three levels (associations, interventions and counterfactuals), this paper introduces RE-IMAGINE, a framework to characterize a hierarchy of reasoning ability in LLMs, alongside an automated pipeline to generate problem variations at different levels of the hierarchy. By altering problems in an intermediate symbolic representation, RE-IMAGINE generates arbitrarily many problems that are not solvable using memorization alone. Moreover, the framework is general and can work across reasoning domains, including math, code, and logic. We demonstrate our framework on four widely-used benchmarks to evaluate several families of LLMs, and observe reductions in performance when the models are queried with problem variations. These assessments indicate a degree of reliance on statistical recall for past performance, and open the door to further research targeting skills across the reasoning hierarchy.
最近的大型语言模型(LLM)在推理基准测试上报告了高准确率。然而,尚不清楚观察到的结果是由于真正的推理能力还是由于对训练集的统计回忆。受因果阶梯(Pearl,2009)及其三个层次(关联、干预和反事实)的启发,本文介绍了RE-IMAGINE,这是一个用于表征LLM中推理能力的层次结构的框架,以及一个自动化管道,用于在不同层次的层次结构中生成问题变体。RE-IMAGINE通过改变中间符号表示中的问题来生成任意多个问题,这些问题仅凭记忆是无法解决的。此外,该框架是通用的,可以在推理领域(包括数学、代码和逻辑)中发挥作用。我们在四个广泛使用的基准测试上展示了我们的框架,对多个LLM家族进行了评估,并观察到在问题变体查询时性能下降。这些评估表明了对过去表现的统计回忆有一定的依赖,并为进一步研究面向整个推理层次结构的技能打开了大门。
论文及项目相关链接
PDF ICML 2025
Summary
大型语言模型(LLM)在推理基准测试上表现出高准确性,但其是否真正具备推理能力,还是仅通过统计回忆训练集来得出结果,仍不明确。本文借鉴因果阶梯(Pearl,2009)的三级(关联、干预和反事实)理论,提出RE-IMAGINE框架,用于刻画LLM中的推理能力层次结构,并配以自动化管道,在不同层次生成问题变体。通过中间符号表示法改变问题,RE-IMAGINE能够生成仅凭记忆无法解决的问题。此外,该框架具有通用性,可应用于数学、代码和逻辑等领域的推理。在四个广泛使用的基准测试上,我们对多个LLM家族进行了评估,发现模型在面对问题变体时的性能有所下降。这表明在一定程度上依赖于统计回忆来获得过去的表现,并为进一步研究和提高不同推理层次上的技能打开了大门。
Key Takeaways
- 大型语言模型(LLM)在推理基准测试上的表现可能并非真正具备推理能力,而是依赖于统计回忆训练集的结果。
- RE-IMAGINE框架用于刻画LLM中的推理能力层次结构,包括关联、干预和反事实三个层次。
- RE-IMAGINE通过改变问题的中间符号表示法,能够生成仅凭记忆无法解决的问题变体。
- RE-IMAGINE框架具有通用性,适用于不同领域的推理,如数学、代码和逻辑。
- 在多个基准测试上评估LLM时,发现模型在面对问题变体时的性能下降。
- 评估结果指示LLM在一定程度上依赖于统计回忆来获得表现。
点此查看论文截图




Semantically-Aware Rewards for Open-Ended R1 Training in Free-Form Generation
Authors:Zongxia Li, Yapei Chang, Yuhang Zhou, Xiyang Wu, Zichao Liang, Yoo Yeon Sung, Jordan Lee Boyd-Graber
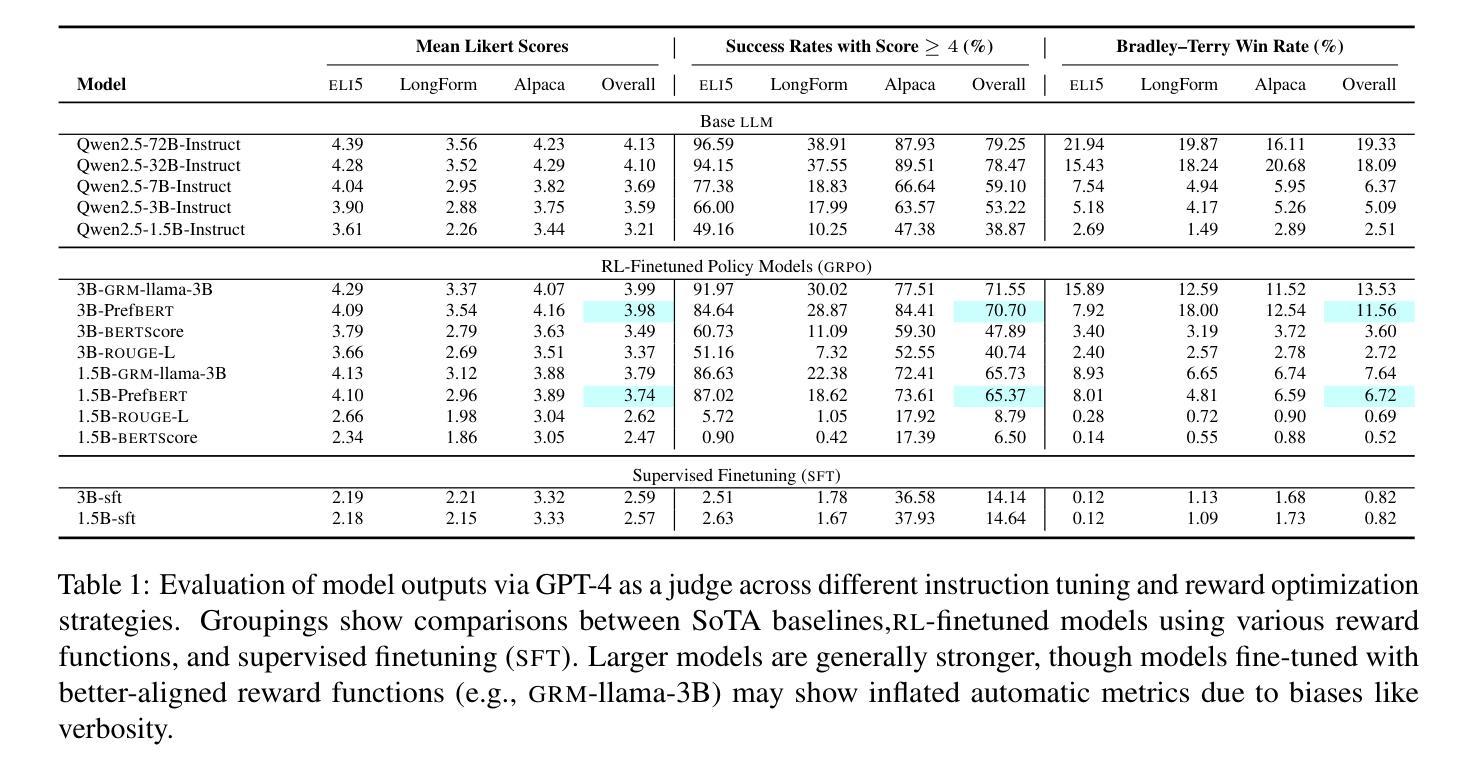
Evaluating open-ended long-form generation is challenging because it is hard to define what clearly separates good from bad outputs. Existing methods often miss key aspects like coherence, style, or relevance, or are biased by pretraining data, making open-ended long-form evaluation an underexplored problem. To address this gap, we propose PrefBERT, a scoring model for evaluating open-ended long-form generation in GRPO and guiding its training with distinct rewards for good and bad outputs. Trained on two response evaluation datasets with diverse long-form styles and Likert-rated quality, PrefBERT effectively supports GRPO by offering better semantic reward feedback than traditional metrics ROUGE-L and BERTScore do. Through comprehensive evaluations, including LLM-as-a-judge, human ratings, and qualitative analysis, we show that PrefBERT, trained on multi-sentence and paragraph-length responses, remains reliable across varied long passages and aligns well with the verifiable rewards GRPO needs. Human evaluations confirm that using PrefBERT as the reward signal to train policy models yields responses better aligned with human preferences than those trained with traditional metrics. Our code is available at https://github.com/zli12321/long_form_rl.
评估开放式长文本生成具有挑战性,因为很难明确界定良好输出与不良输出之间的区别。现有方法常常忽略连贯性、风格或相关性等重要方面,或受到预训练数据的影响,使得开放式长文本评估成为一个尚未充分探索的问题。为了弥补这一空白,我们提出了PrefBERT,这是一种用于评估开放式长文本生成的评分模型,旨在在GRPO中对其进行评估,并为良好和不良输出提供不同的奖励来指导其训练。PrefBERT经过两个响应评估数据集的训练,这些数据集具有多样化的长文本风格和利克特量表质量评估,有效地支持GRPO,提供比传统指标ROUGE-L和BERTScore更好的语义奖励反馈。通过包括LLM作为法官、人类评分和定性分析在内的全面评估,我们证明,PrefBERT在训练多句和段落长度的响应时,在多种长段落中表现可靠,并且非常符合GRPO所需的可验证奖励。人类评估证实,使用PrefBERT作为奖励信号来训练策略模型产生的响应更符合人类偏好,而不是使用传统指标进行训练。我们的代码可在https://github.com/zli12321/long_form_rl找到。
论文及项目相关链接
Summary
本文提出一种名为PrefBERT的评分模型,用于评估开放式的长文本生成。该模型旨在解决长文本生成的评价问题,能区分好坏输出并为其提供独特的奖励,以指导训练过程。通过多数据集训练和多方面的评估,证实PrefBERT对多种长文本都能提供可靠的语义奖励反馈,且与人类偏好高度一致。
Key Takeaways
- 开放式的长文本生成评价存在挑战,难以明确区分优质与劣质输出。
- 现存的评价方法常常忽略连贯性、风格、相关性等重要方面,或受到预训练数据的影响。
- PrefBERT模型被提出,旨在解决长文本生成的评价问题。
- PrefBERT通过区分好坏输出并提供独特奖励来指导训练过程。
- PrefBERT在多数据集训练后,对多种长文本都能提供可靠的语义奖励反馈。
- PrefBERT与人类偏好高度一致,经过其训练的政策模型生成的响应更符合人类需求。
点此查看论文截图


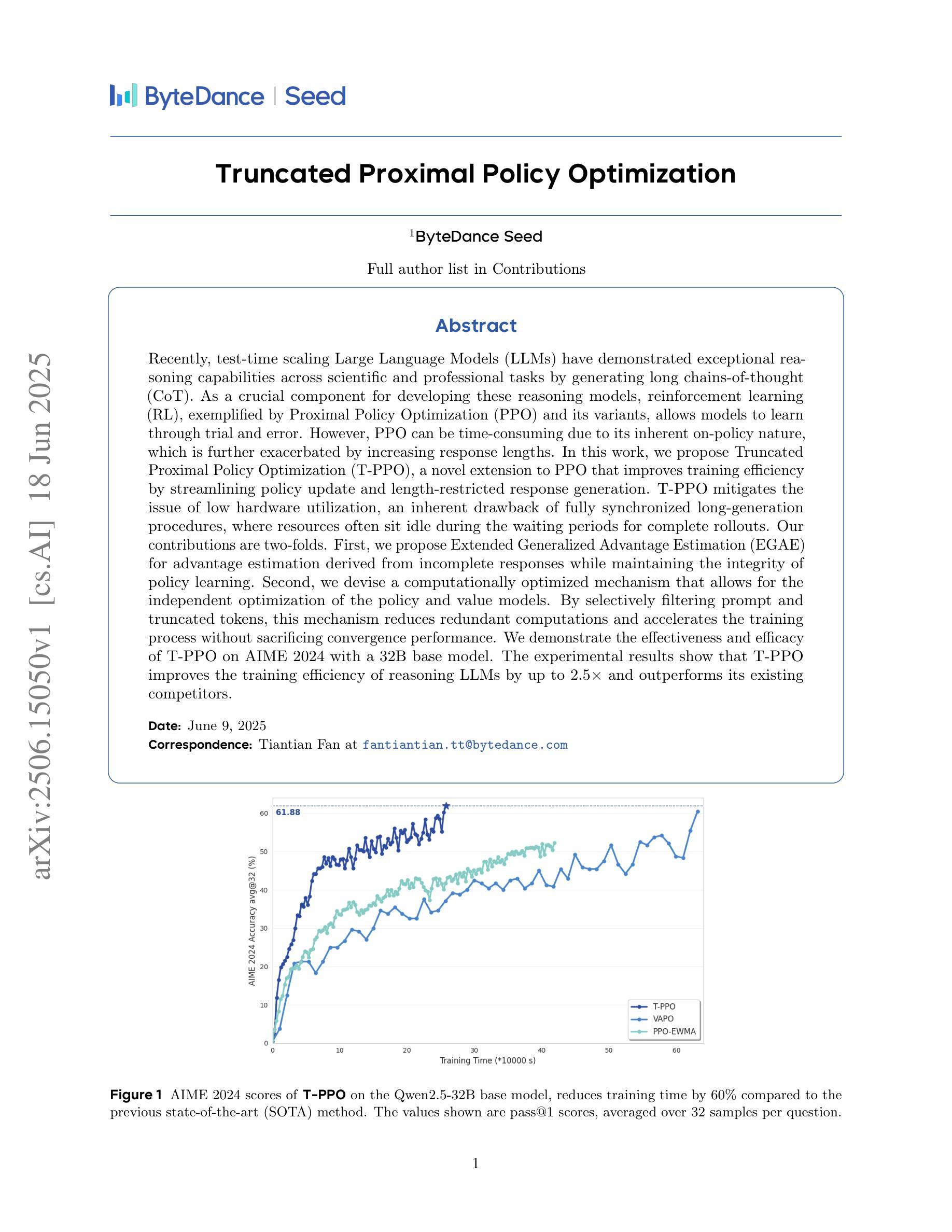
Truncated Proximal Policy Optimization
Authors:Tiantian Fan, Lingjun Liu, Yu Yue, Jiaze Chen, Chengyi Wang, Qiying Yu, Chi Zhang, Zhiqi Lin, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Bole Ma, Mofan Zhang, Gaohong Liu, Ru Zhang, Haotian Zhou, Cong Xie, Ruidong Zhu, Zhi Zhang, Xin Liu, Mingxuan Wang, Lin Yan, Yonghui Wu
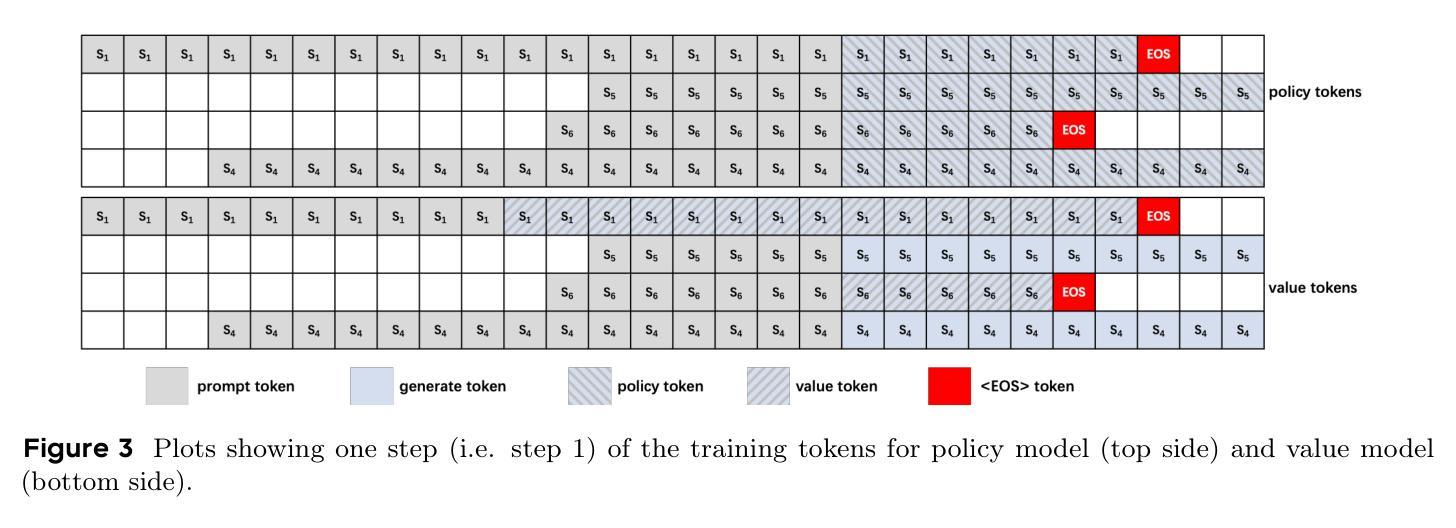
Recently, test-time scaling Large Language Models (LLMs) have demonstrated exceptional reasoning capabilities across scientific and professional tasks by generating long chains-of-thought (CoT). As a crucial component for developing these reasoning models, reinforcement learning (RL), exemplified by Proximal Policy Optimization (PPO) and its variants, allows models to learn through trial and error. However, PPO can be time-consuming due to its inherent on-policy nature, which is further exacerbated by increasing response lengths. In this work, we propose Truncated Proximal Policy Optimization (T-PPO), a novel extension to PPO that improves training efficiency by streamlining policy update and length-restricted response generation. T-PPO mitigates the issue of low hardware utilization, an inherent drawback of fully synchronized long-generation procedures, where resources often sit idle during the waiting periods for complete rollouts. Our contributions are two-folds. First, we propose Extended Generalized Advantage Estimation (EGAE) for advantage estimation derived from incomplete responses while maintaining the integrity of policy learning. Second, we devise a computationally optimized mechanism that allows for the independent optimization of the policy and value models. By selectively filtering prompt and truncated tokens, this mechanism reduces redundant computations and accelerates the training process without sacrificing convergence performance. We demonstrate the effectiveness and efficacy of T-PPO on AIME 2024 with a 32B base model. The experimental results show that T-PPO improves the training efficiency of reasoning LLMs by up to 2.5x and outperforms its existing competitors.
最近,测试规模的巨型语言模型(LLM)通过生成长链思维(CoT)展示了在科学和专业任务方面的出色推理能力。作为开发这些推理模型的关键组成部分,强化学习(RL)通过近端策略优化(PPO)及其变体展示了其通过试错学习的能力。然而,由于PPO的固有在线策略性质,随着响应长度的增加,它可能会很耗时。在这项工作中,我们提出了截断近端策略优化(T-PPO),这是PPO的一种新型扩展,通过简化策略更新和长度受限的响应生成来提高训练效率。T-PPO缓解了低硬件利用率的问题,这是完全同步的长生成程序固有的缺点,其中资源经常在等待完整rollouts的期间处于空闲状态。我们的贡献有两方面。首先,我们提出了扩展广义优势估计(EGAE),用于从不完全响应中进行优势估计,同时保持策略学习的完整性。其次,我们设计了一种计算优化机制,允许策略和值模型的独立优化。通过有选择地过滤提示和截断令牌,该机制减少了冗余计算,加速了训练过程,同时不牺牲收敛性能。我们在AIME 2024的32B基准模型上展示了T-PPO的有效性和效率。实验结果表明,T-PPO提高了推理LLM的训练效率,最高可达2.5倍,并优于现有竞争对手。
论文及项目相关链接
Summary:
本文提出一种名为截断近端策略优化(T-PPO)的新方法,用于改进大型语言模型(LLM)的测试时间缩放推理效率。通过简化策略更新和限制长度响应生成,T-PPO解决了近端策略优化(PPO)在长时间响应时的硬件利用率低和时间消耗问题。本文的贡献包括提出扩展广义优势估计(EGAE)和计算优化机制,以提高训练效率并加速收敛过程。实验结果表明,T-PPO在AIME 2024数据集上的训练效率提高了高达2.5倍并优于现有竞争对手。
Key Takeaways:
- T-PPO是PPO的一种改进方法,旨在提高LLM在测试时的推理效率。
- T-PPO通过简化策略更新和限制响应长度来解决PPO在长时间响应时的缺陷。
- EGAE的提出是为了在不完整响应的情况下进行优势估计,同时保持策略学习的完整性。
- 计算优化机制允许独立优化策略和价值模型,减少冗余计算并加速训练过程。
- T-PPO在AIME 2024数据集上进行了实验验证,显示其训练效率提高了高达2.5倍。
- T-PPO相较于现有方法表现出更好的性能。
点此查看论文截图


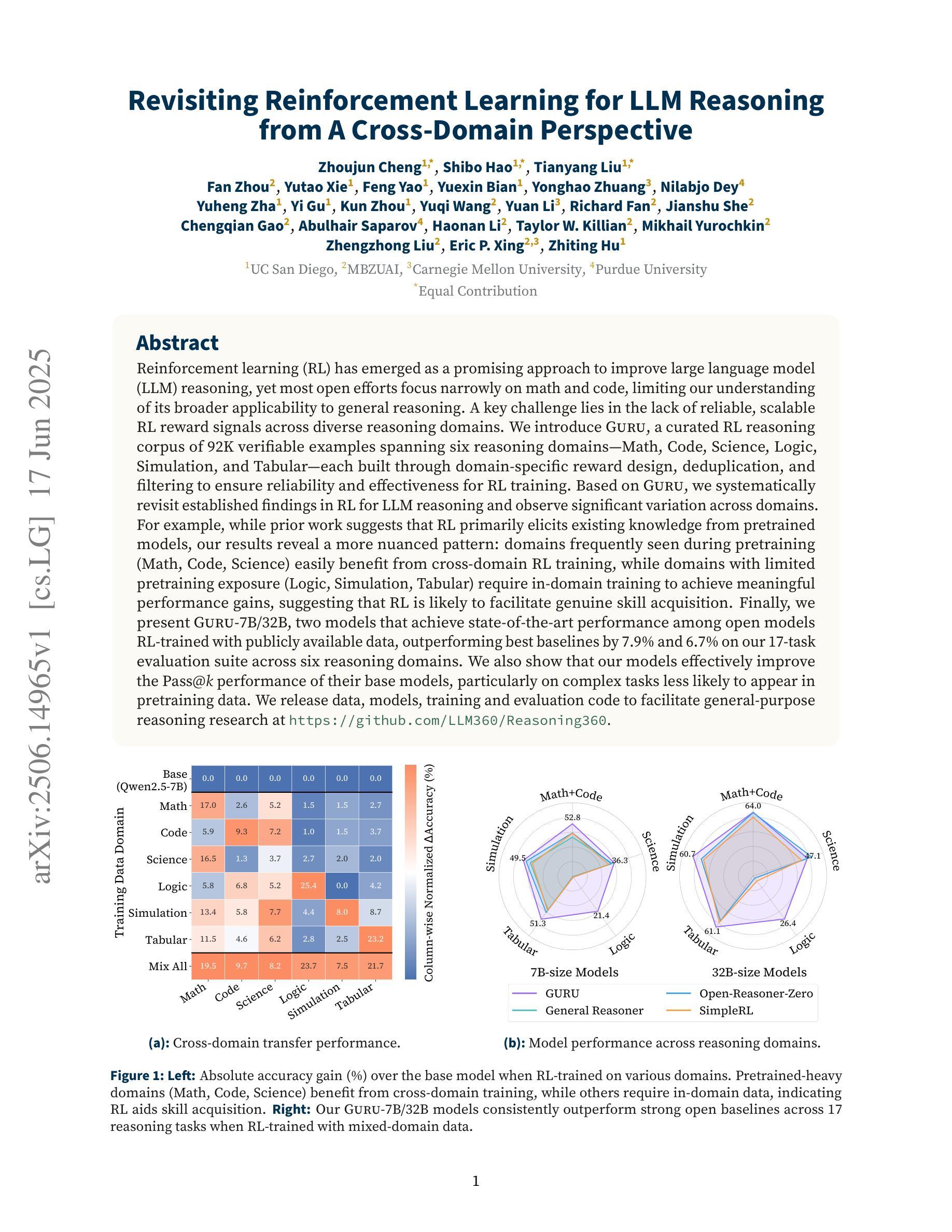
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Authors:Zhoujun Cheng, Shibo Hao, Tianyang Liu, Fan Zhou, Yutao Xie, Feng Yao, Yuexin Bian, Yonghao Zhuang, Nilabjo Dey, Yuheng Zha, Yi Gu, Kun Zhou, Yuqi Wang, Yuan Li, Richard Fan, Jianshu She, Chengqian Gao, Abulhair Saparov, Haonan Li, Taylor W. Killian, Mikhail Yurochkin, Zhengzhong Liu, Eric P. Xing, Zhiting Hu
Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains–Math, Code, Science, Logic, Simulation, and Tabular–each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
强化学习(RL)已成为提高大型语言模型(LLM)推理能力的一种有前途的方法,然而大多数开放的努力都集中在数学和代码上,这限制了我们对其在更广泛推理中适用性的理解。一个关键挑战在于缺乏可靠、可扩展的RL奖励信号来涵盖不同的推理领域。我们推出了Guru,这是一个包含92K个可验证示例的定制RL推理语料库,涵盖六个推理领域——数学、代码、科学、逻辑、模拟和表格,每个领域都通过特定的奖励设计、去重和过滤来确保RL训练的可靠性和有效性。基于Guru,我们系统地回顾了LLM推理中RL的既有发现,并观察到各领域之间的显著差异。例如,虽然之前的研究表明RL主要激发预训练模型中的现有知识,但我们的结果揭示了一个更微妙的模式:在预训练期间经常遇到的领域(数学、代码、科学)很容易从跨域RL训练中受益,而预训练暴露有限的领域(逻辑、模拟和表格)需要领域内的训练才能实现有意义的性能提升,这表明RL可能有助于真正的技能获取。最后,我们推出了Guru-7B和Guru-32B两个模型,这两个模型在公开数据上经过RL训练且达到最新技术水平,在我们的涵盖六个推理领域的17项任务评估套件中,相较于最佳基线模型分别提升了7.9%和6.7%。我们还证明了我们的模型有效地提高了其基础模型的Pass@k性能,特别是在预训练数据中不太可能出现的复杂任务上。我们在https://github.com/LLM360/Reasoning360上发布了数据、模型和训练评估代码,以促进通用推理。
论文及项目相关链接
PDF 38 pages, 9 figures. Under review
Summary
本文介绍了强化学习(RL)在大规模语言模型(LLM)推理中的应用。针对现有研究主要集中在数学和代码领域的局限性,提出了Guru,一个涵盖六大推理领域的可靠可扩展的RL推理语料库。基于Guru,本文系统地回顾了RL在LLM推理中的既有发现,并观察到不同领域间的显著变化。研究发现,RL不仅能激发预训练模型中的现有知识,而且在预训练常见的领域(如数学、代码、科学)中容易获得跨域RL训练的好处。对于预训练暴露较少的领域(如逻辑、模拟和表格),则需要领域内的训练才能实现有意义的性能提升。最后,介绍了使用公开数据训练的Guru-7B和Guru-32B模型,这两个模型在六个推理领域的17项任务评估中达到了最新的技术水平,并有效地提高了基线模型的Pass@k性能。
Key Takeaways
- 强化学习(RL)用于提高大规模语言模型(LLM)的推理能力具有广阔前景。
- 当前研究主要关注数学和代码领域的RL应用,缺乏对更广泛领域的理解。
- Guru是一个涵盖六大推理领域的可靠可扩展的RL推理语料库。
- 基于Guru的研究发现,RL在不同推理领域中的效果存在显著差异。
- 预训练常见的领域(数学、代码、科学)容易从RL训练中受益,而预训练暴露较少的领域则需要更针对性的训练。
- Guru-7B和Guru-32B模型在多个任务评估中表现出卓越性能,有效提高了基线模型的Pass@k性能。
点此查看论文截图
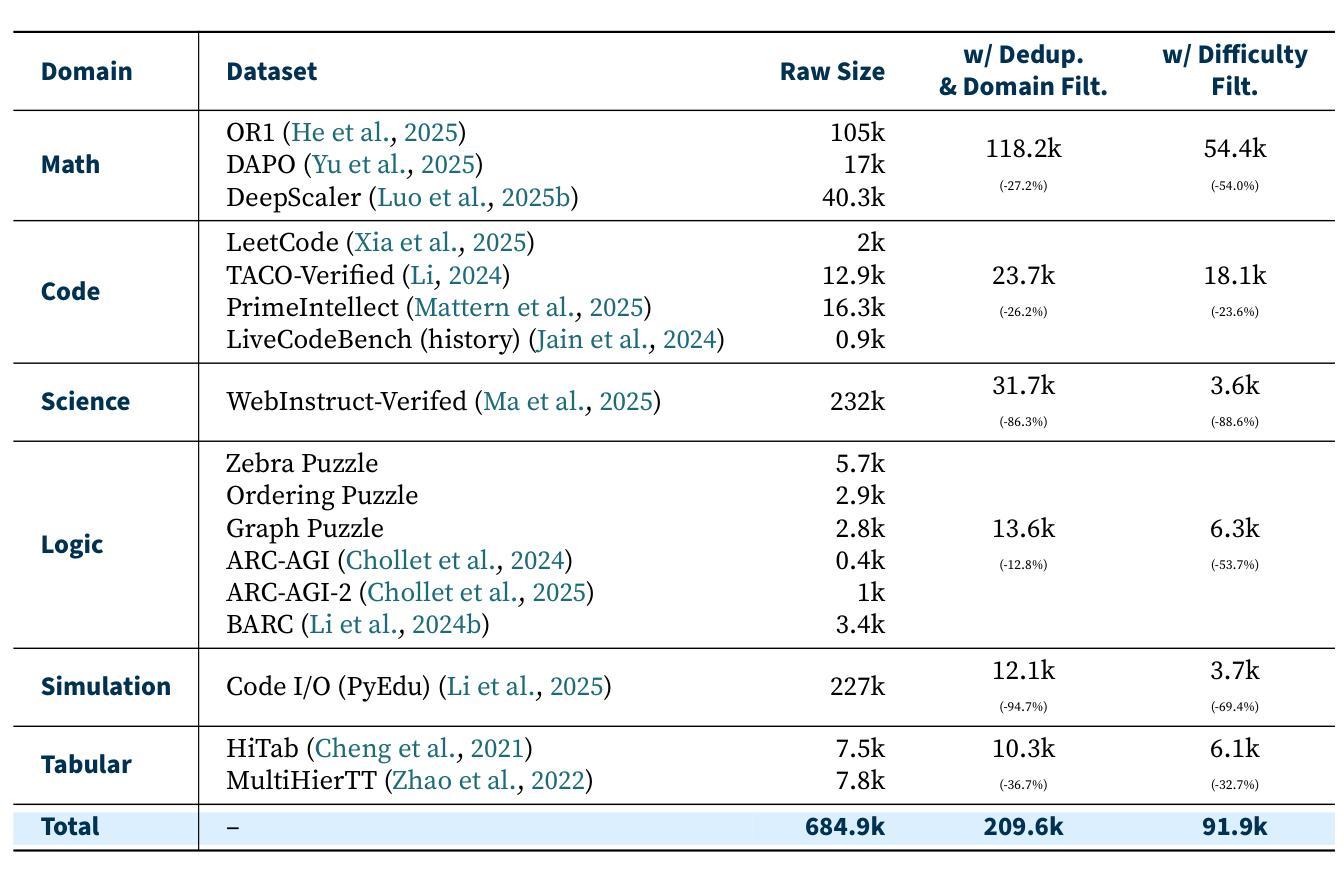
PeRL: Permutation-Enhanced Reinforcement Learning for Interleaved Vision-Language Reasoning
Authors:Yizhen Zhang, Yang Ding, Shuoshuo Zhang, Xinchen Zhang, Haoling Li, Zhong-zhi Li, Peijie Wang, Jie Wu, Lei Ji, Yelong Shen, Yujiu Yang, Yeyun Gong
Inspired by the impressive reasoning capabilities demonstrated by reinforcement learning approaches like DeepSeek-R1, recent emerging research has begun exploring the use of reinforcement learning (RL) to enhance vision-language models (VLMs) for multimodal reasoning tasks. However, most existing multimodal reinforcement learning approaches remain limited to spatial reasoning within single-image contexts, yet still struggle to generalize to more complex and real-world scenarios involving multi-image positional reasoning, where understanding the relationships across images is crucial. To address this challenge, we propose a general reinforcement learning approach PeRL tailored for interleaved multimodal tasks, and a multi-stage strategy designed to enhance the exploration-exploitation trade-off, thereby improving learning efficiency and task performance. Specifically, we introduce permutation of image sequences to simulate varied positional relationships to explore more spatial and positional diversity. Furthermore, we design a rollout filtering mechanism for resampling to focus on trajectories that contribute most to learning optimal behaviors to exploit learned policies effectively. We evaluate our model on 5 widely-used multi-image benchmarks and 3 single-image benchmarks. Our experiments confirm that PeRL trained model consistently surpasses R1-related and interleaved VLM baselines by a large margin, achieving state-of-the-art performance on multi-image benchmarks, while preserving comparable performance on single-image tasks.
受DeepSeek-R1等强化学习方法的出色推理能力启发,最新的研究开始探索使用强化学习(RL)来增强视觉语言模型(VLM)的多模态推理任务。然而,大多数现有的多模态强化学习方法仍然仅限于单图像上下文中的空间推理,但在涉及多图像位置推理的更复杂和现实世界场景中,它们仍然难以推广,理解跨图像的关系是至关重要的。为了应对这一挑战,我们提出了一种针对交织多模态任务的通用强化学习方法PeRL,以及一种旨在增强探索与利用之间权衡的多阶段策略,从而提高学习效率并改善任务性能。具体来说,我们引入图像序列的排列来模拟不同的位置关系,以探索更多的空间和位置多样性。此外,我们设计了一种重采样滚动过滤机制,专注于对学习最优行为贡献最大的轨迹,以有效利用学习到的策略。我们在五个常用的多图像基准测试和三个单图像基准测试上评估了我们的模型。实验证实,PeRL训练出的模型始终大幅度超越了与R1相关的交织VLM基准测试,在多图像基准测试上达到了最先进的性能,同时在单图像任务上保持了相当的性能。
论文及项目相关链接
Summary
强化学习(RL)在提升视觉语言模型(VLM)的多模态推理任务能力方面展现出巨大潜力。针对现有方法的局限性,提出一种适用于嵌套多模态任务的通用强化学习框架PeRL和多阶段策略,通过模拟不同的图像序列排列关系,增强空间与位置多样性,并设计重采样中的滚动过滤机制,专注于学习最优行为的轨迹。实验证明,PeRL模型在多图像基准测试中表现卓越,远超同类方法。
Key Takeaways
- 强化学习在提升视觉语言模型的多模态推理任务方面存在潜力。
- 提出适用于嵌套多模态任务的强化学习框架PeRL和多阶段策略,以提升学习效率和任务性能。
- 通过模拟图像序列的不同排列关系来增强空间与位置多样性。
- 设计重采样中的滚动过滤机制,聚焦于对学习最优行为有益的轨迹。
- PeRL模型在多图像基准测试中表现优越,超越现有方法。
- 在单图像任务上保持与现有方法相当的性能。
点此查看论文截图

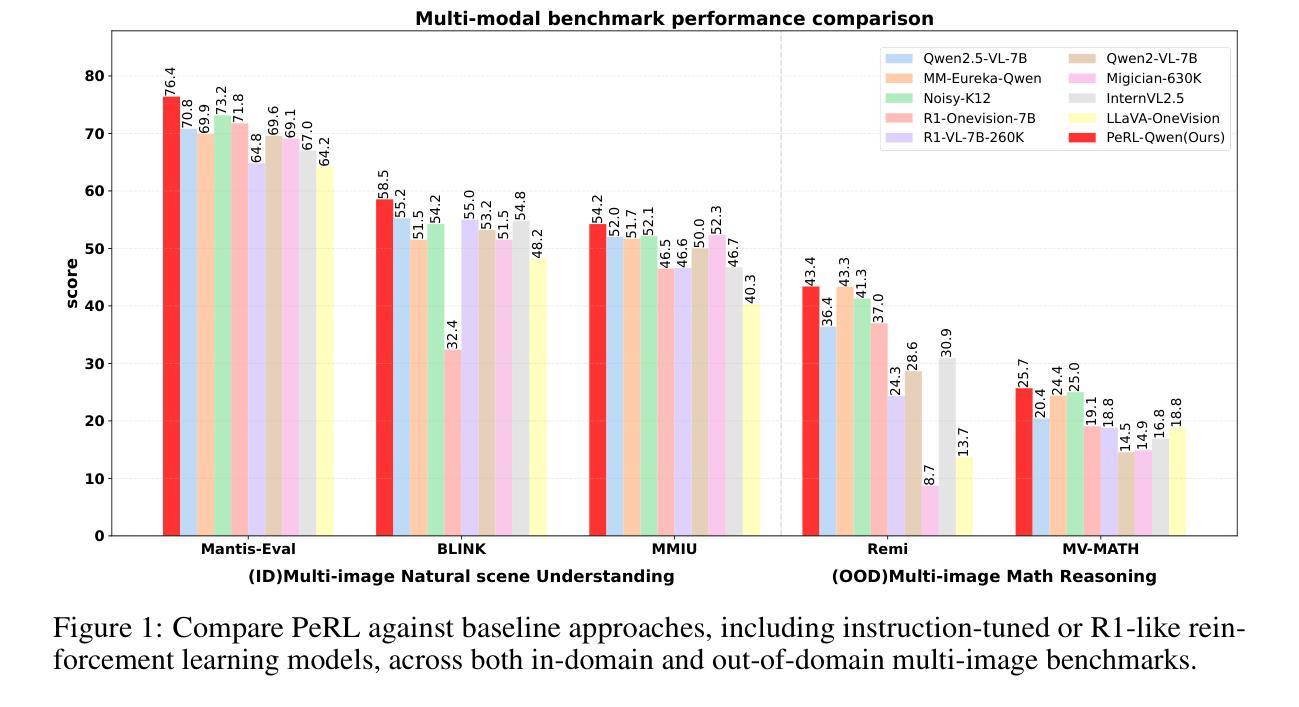

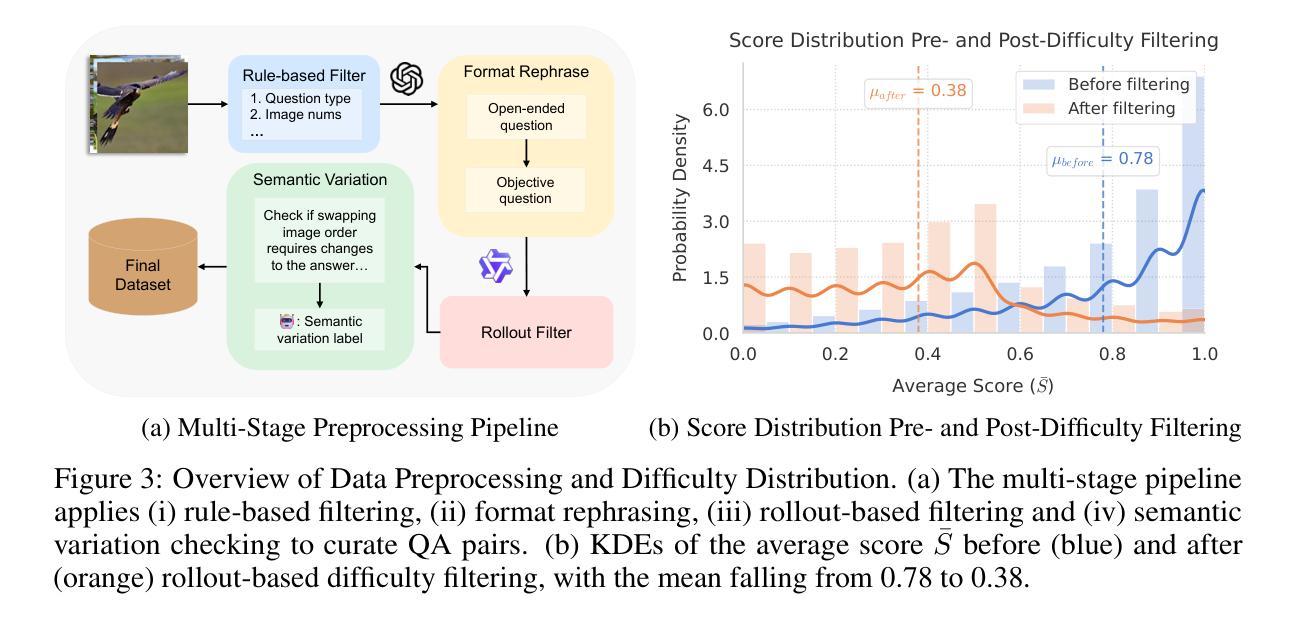
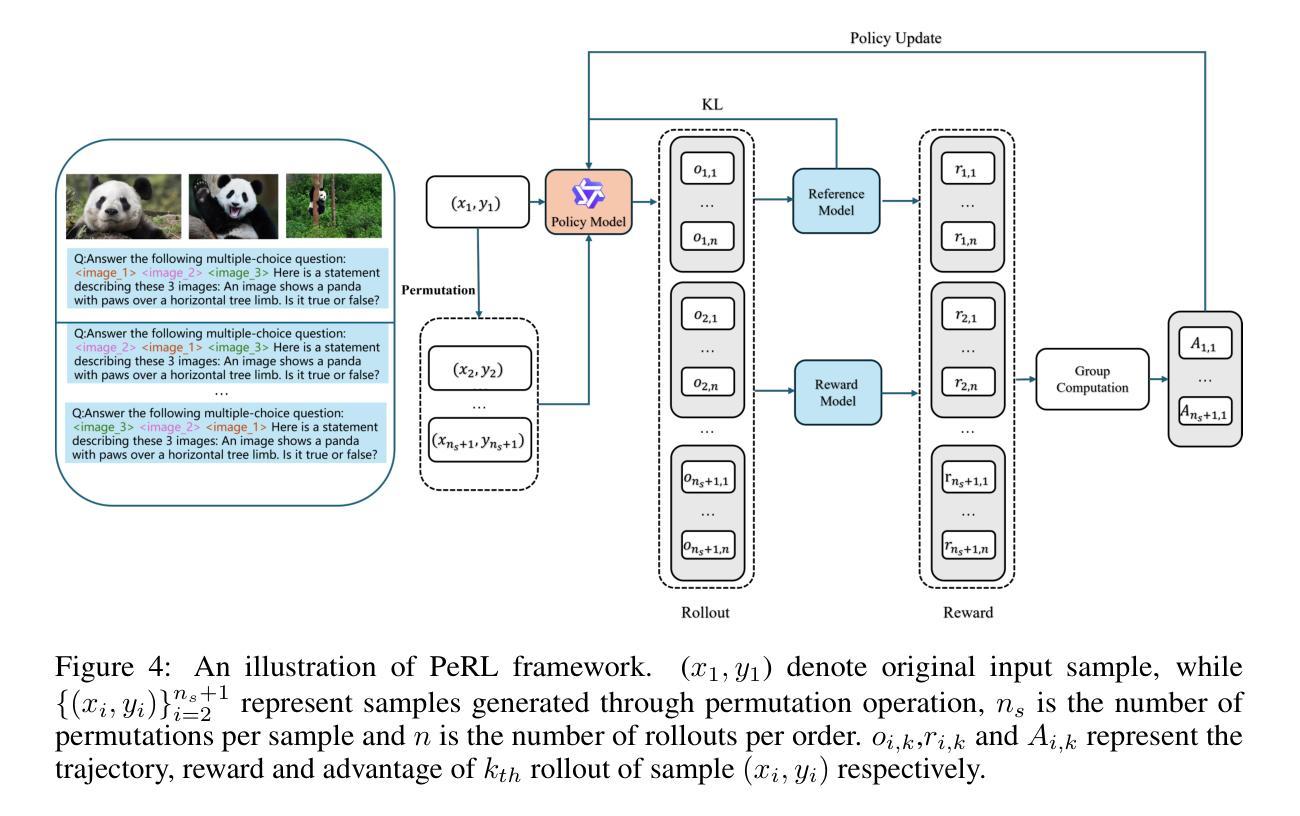
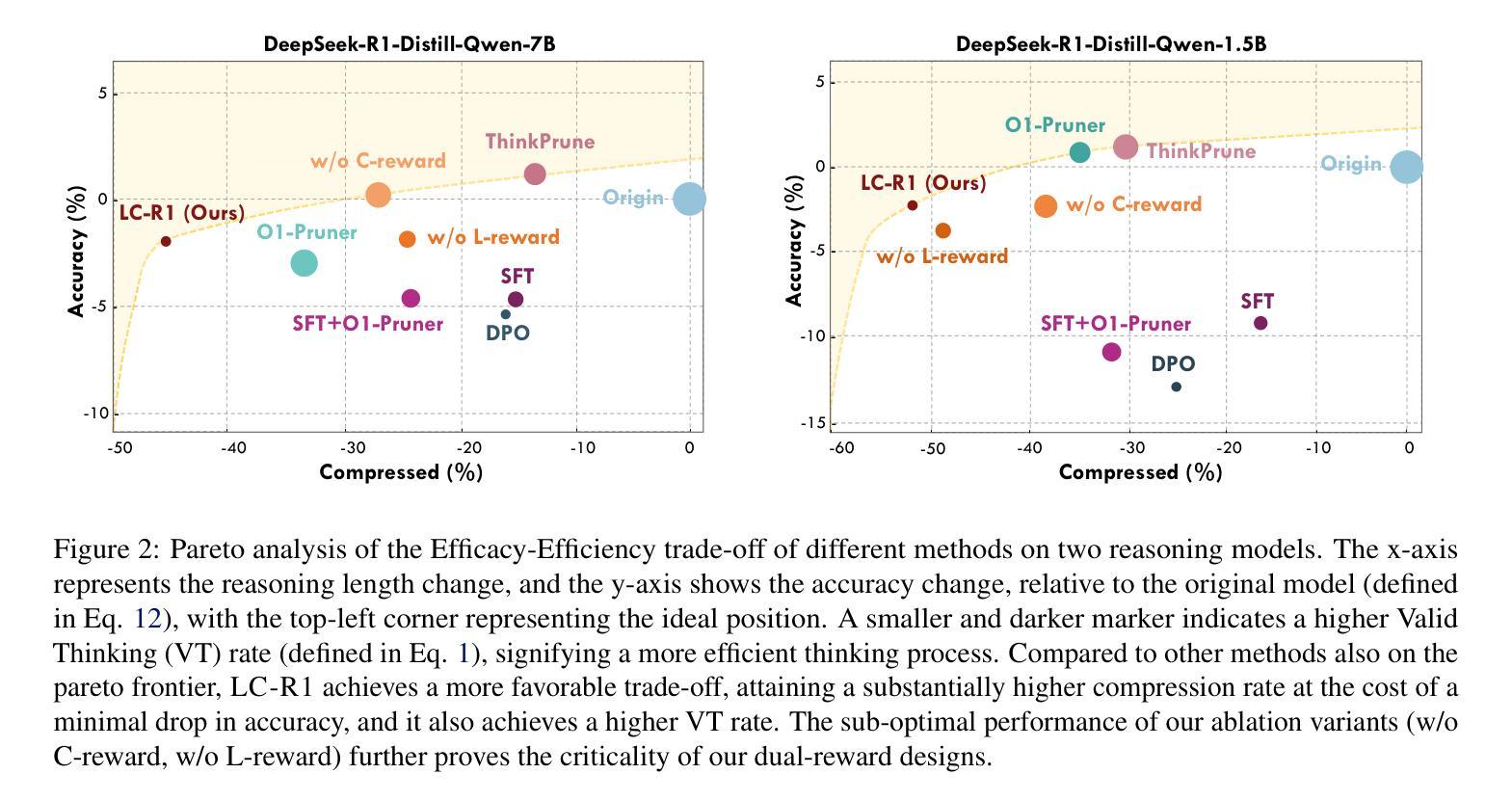
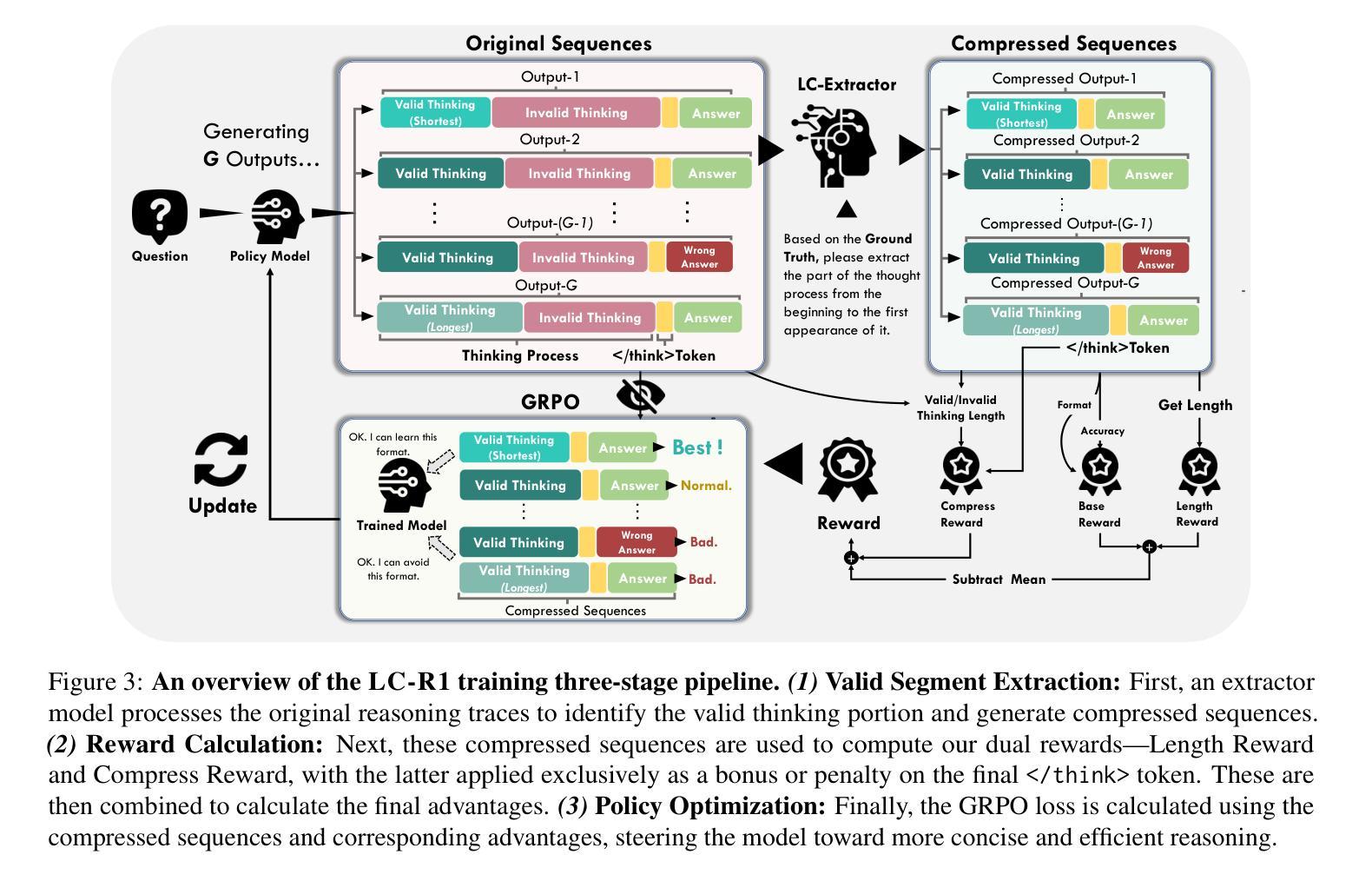
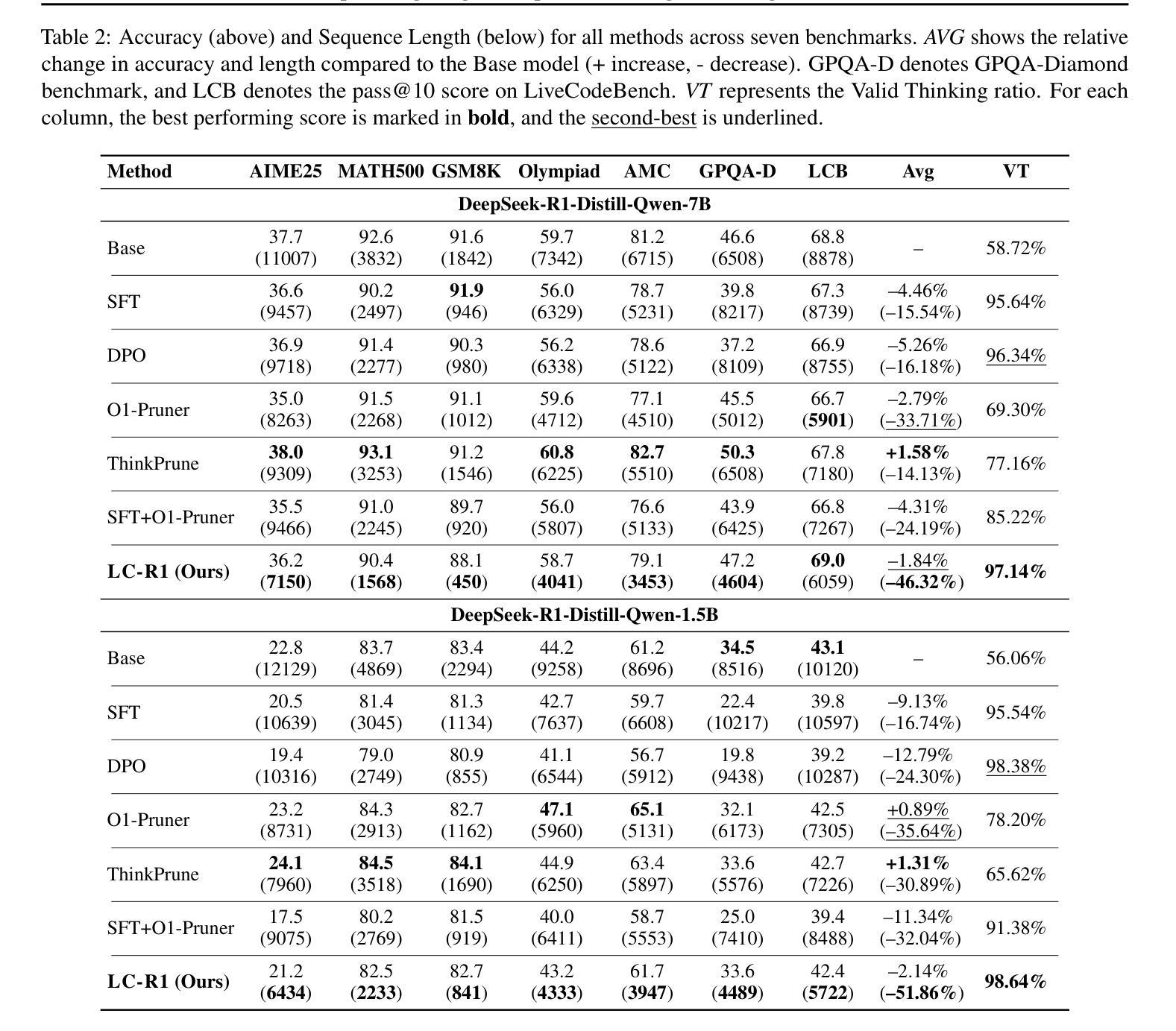
Optimizing Length Compression in Large Reasoning Models
Authors:Zhengxiang Cheng, Dongping Chen, Mingyang Fu, Tianyi Zhou
Large Reasoning Models (LRMs) have achieved remarkable success, yet they often suffer from producing unnecessary and verbose reasoning chains. We identify a core aspect of this issue as “invalid thinking” – models tend to repeatedly double-check their work after having derived the correct answer. To address this specific inefficiency, we move beyond the general principles of Efficacy and Efficiency to propose two new, fine-grained principles: Brevity, which advocates for eliminating redundancy, and Sufficiency, which ensures critical reasoning steps are preserved. Guided by these principles, we introduce LC-R1, a post-training method based on Group Relative Policy Optimization (GRPO). LC-R1 employs a novel combination of a Length Reward for overall conciseness and a Compress Reward that is specifically designed to remove the invalid portion of the thinking process. Extensive experiments on multiple reasoning benchmarks demonstrate that LC-R1 achieves a significant reduction in sequence length (50%) with only a marginal (2%) drop in accuracy, achieving a favorable trade-off point on the Pareto frontier that prioritizes high compression. Our analysis further validates the robustness of LC-R1 and provides valuable insights for developing more powerful yet computationally efficient LRMs. Our code is released at https://github.com/zxiangx/LC-R1.
大型推理模型(LRMs)已经取得了显著的成功,但它们常常会产生不必要且冗长的推理链。我们确定这个问题的核心在于“无效思考”——在得出正确答案后,模型往往倾向于反复校验自己的工作。为了解决这种特定的低效问题,我们超越了效能和效率的一般原则,提出了两个新的精细原则:简洁性,主张消除冗余;充足性,确保关键的推理步骤得到保留。在这些原则的指导下,我们引入了LC-R1,这是一种基于群体相对策略优化(GRPO)的后训练方法。LC-R1采用了一种新型的长度奖励来鼓励整体简洁性,以及一种专门设计的压缩奖励,以消除思考过程中的无效部分。在多个推理基准测试上的广泛实验表明,LC-R1实现了序列长度显著减少(
50%),同时仅伴有轻微(2%)的准确度下降,在优先高压缩率的帕累托前沿达到了有利的平衡点。我们的进一步分析验证了LC-R1的稳健性,并为开发更强大且计算效率更高的LRMs提供了有价值的见解。我们的代码已发布在https://github.com/zxiangx/LC-R1。
论文及项目相关链接
PDF 16 pages, 7 figures, 4 tables
Summary
大型推理模型(LRMs)取得了显著的成功,但常常会产生不必要且冗长的推理链。针对这一问题,本文提出了两个新的精细原则:简洁性,旨在消除冗余;充足性,确保关键推理步骤得到保留。基于这些原则,本文引入了一种基于群体相对策略优化(GRPO)的LC-R1后训练方法。实验证明,LC-R1在保持较低精度损失的同时,实现了显著的序列长度缩减,实现了帕累托前沿上的有利权衡点。
Key Takeaways
- 大型推理模型(LRMs)存在产生不必要和冗长推理链的问题。
- 问题的核心在于“无效思考”——模型在得出正确答案后,往往倾向于反复检查自己的工作。
- 为解决这一特定问题,提出了两个新的精细原则:简洁性和充足性。
- LC-R1是一种基于群体相对策略优化(GRPO)的后训练方法,旨在消除冗余并优化推理过程。
- 实验证明,LC-R1在多个推理基准测试中实现了显著序列长度缩减,同时保持较低的精度损失。
- LC-R1在帕累托前沿上实现了有利的权衡点,即在压缩和性能之间取得了良好的平衡。
点此查看论文截图

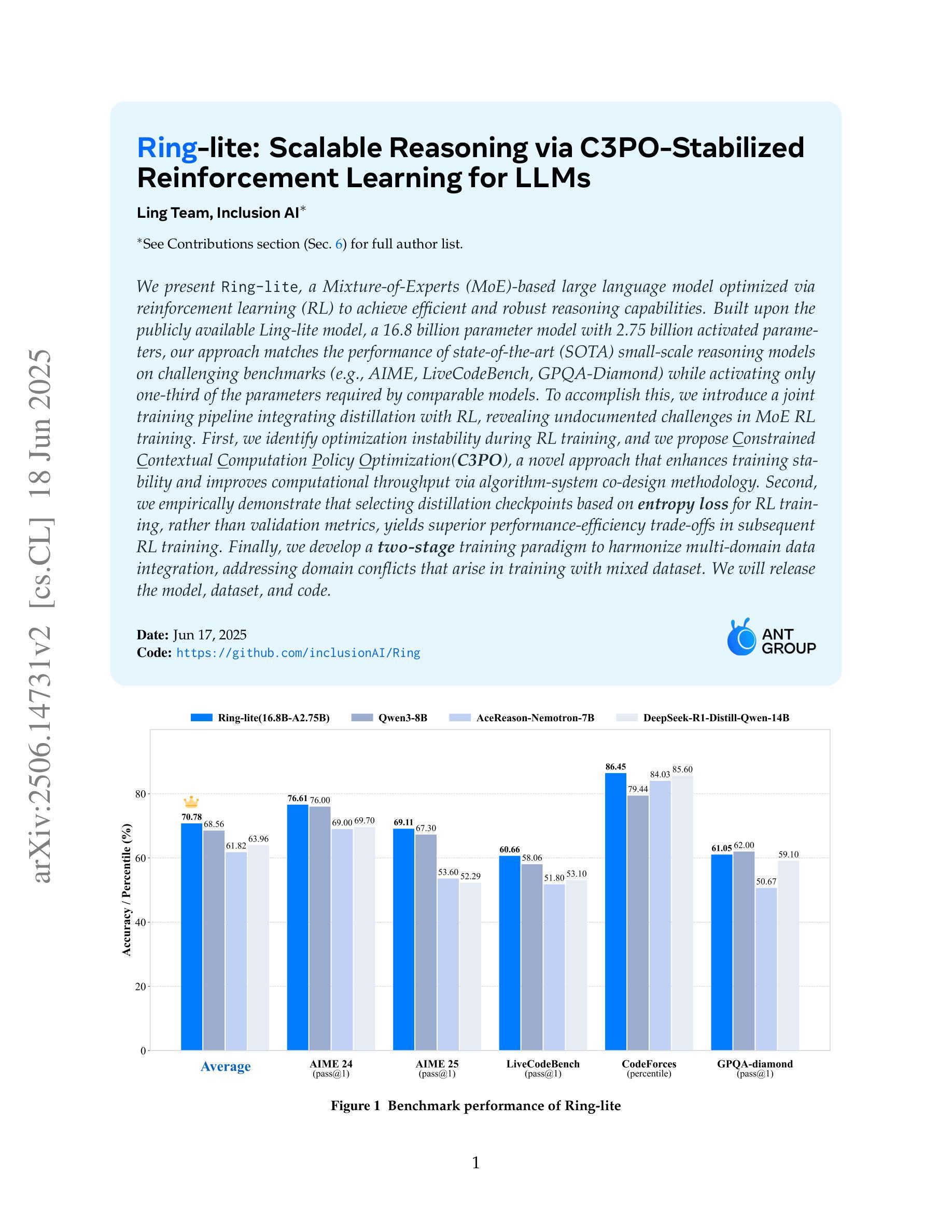
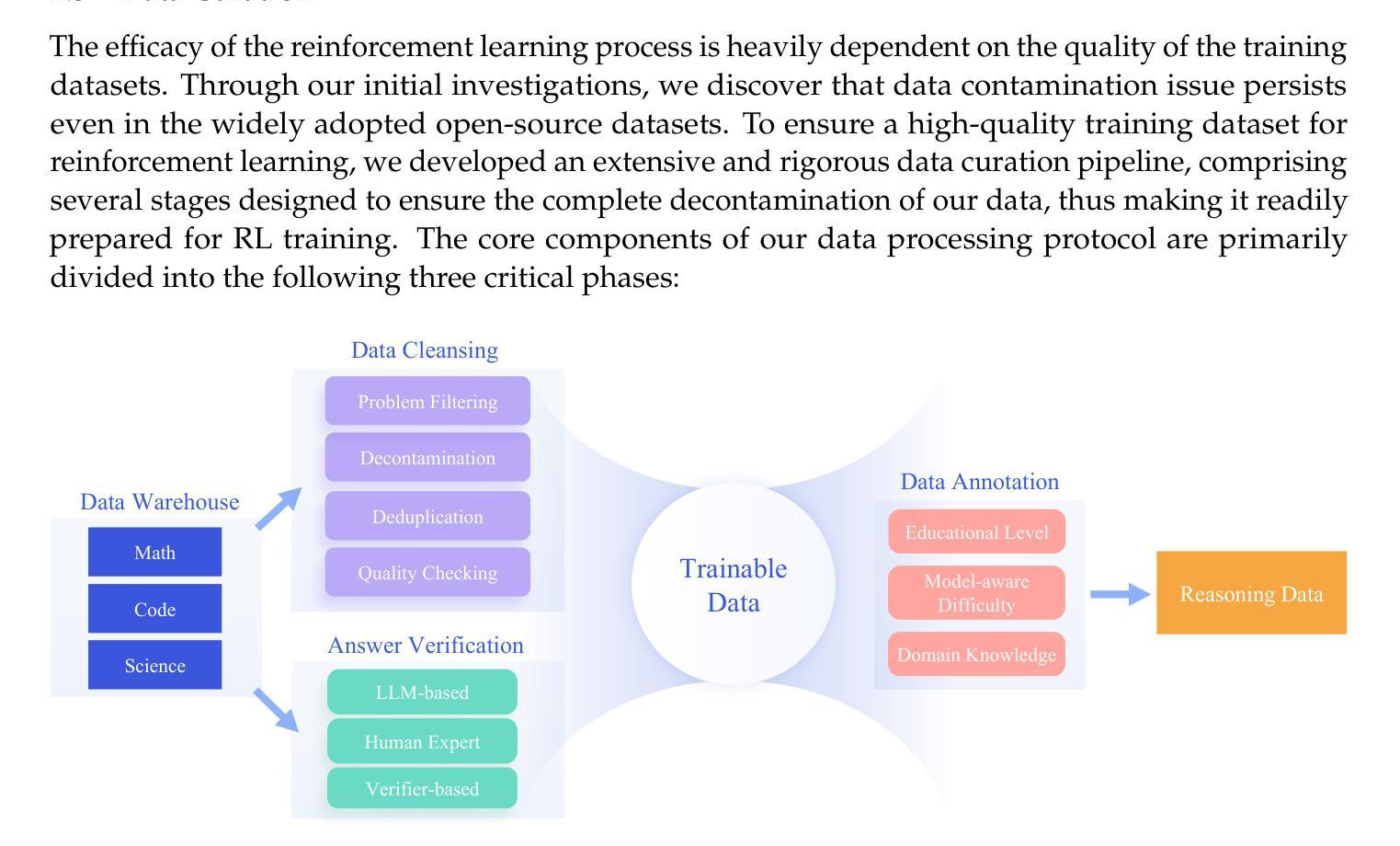
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Authors: Ling Team, Bin Hu, Cai Chen, Deng Zhao, Ding Liu, Dingnan Jin, Feng Zhu, Hao Dai, Hongzhi Luan, Jia Guo, Jiaming Liu, Jiewei Wu, Jun Mei, Jun Zhou, Junbo Zhao, Junwu Xiong, Kaihong Zhang, Kuan Xu, Lei Liang, Liang Jiang, Liangcheng Fu, Longfei Zheng, Qiang Gao, Qing Cui, Quan Wan, Shaomian Zheng, Shuaicheng Li, Tongkai Yang, Wang Ren, Xiaodong Yan, Xiaopei Wan, Xiaoyun Feng, Xin Zhao, Xinxing Yang, Xinyu Kong, Xuemin Yang, Yang Li, Yingting Wu, Yongkang Liu, Zhankai Xu, Zhenduo Zhang, Zhenglei Zhou, Zhenyu Huang, Zhiqiang Zhang, Zihao Wang, Zujie Wen
We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
我们推出了Ring-lite,这是一款基于专家混合(MoE)的大型语言模型,通过强化学习(RL)进行优化,以实现高效且稳健的推理能力。该模型建立在公众可访问的Ling-lite模型之上,Ling-lite模型是一个拥有16.8亿参数、2.75亿个激活参数的模型。我们的方法在与最新技术(SOTA)的小规模推理模型进行具有挑战性的基准测试(例如AIME、LiveCodeBench、GPQA-Diamond)时,仅激活了相当于其他模型三分之一的参数,即可匹配其性能。为了完成这一目标,我们引入了一个联合训练管道,将蒸馏法与RL相结合,揭示了MoE RL训练中的未记录挑战。首先,我们确定了RL训练过程中的优化不稳定性问题,并提出了一种新的约束上下文计算策略优化(C3PO)方法,该方法通过算法系统协同设计方法增强训练稳定性并改善计算吞吐量。其次,我们通过实证表明,在选择蒸馏检查点时,基于熵损失而不是验证指标来进行RL训练,可以在后续的RL训练中产生更好的性能效率权衡。最后,我们开发了一种两阶段训练范式,以协调多域数据集成,解决在混合数据集训练中出现的领域冲突问题。我们将发布该模型、数据集和代码。
论文及项目相关链接
PDF Technical Report
Summary
基于MoE(Mixture-of-Experts)的大型语言模型Ring-lite通过强化学习(RL)进行优化,以实现高效且稳健的推理能力。该模型以公开的Ling-lite模型为基础,通过结合蒸馏与强化学习训练的联合训练管道,以较小的参数激活量实现了在多个挑战基准测试上的表现与最先进的推理模型相匹配。模型还引入了C3PO训练策略来解决训练中的优化不稳定问题,并提出基于熵损失的蒸馏检查点选择策略,以获得更好的性能效率权衡。此外,模型采用两阶段训练范式解决多域数据集成中的域冲突问题。
Key Takeaways
- Ring-lite是一个基于MoE的大型语言模型,使用强化学习优化,以实现高效稳健的推理能力。
- 模型以Ling-lite为基础,通过联合训练管道结合蒸馏与强化学习训练,实现了在多个基准测试上的表现与最先进的推理模型相匹配。
- 引入C3PO训练策略解决MoE RL训练中的优化不稳定问题,提高训练稳定性和计算效率。
- 提出基于熵损失的蒸馏检查点选择策略,优化后续强化学习训练的性能效率权衡。
- 采用两阶段训练范式解决多域数据集成中的域冲突问题。
- 模型将公开提供,包括数据集和代码。
点此查看论文截图
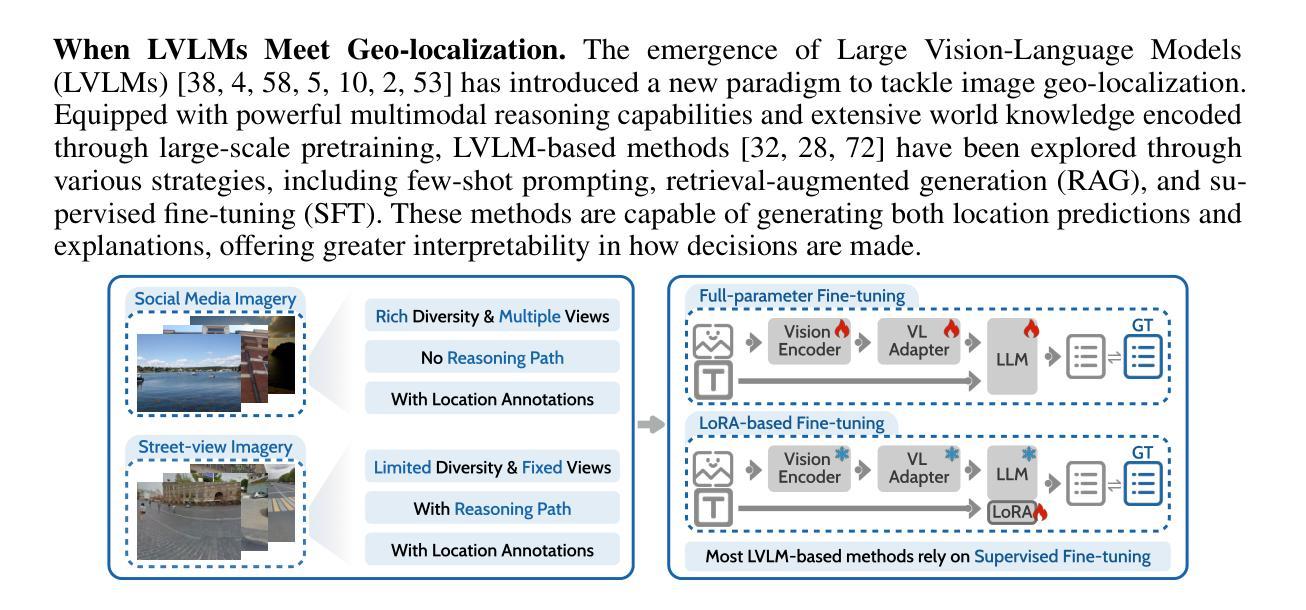
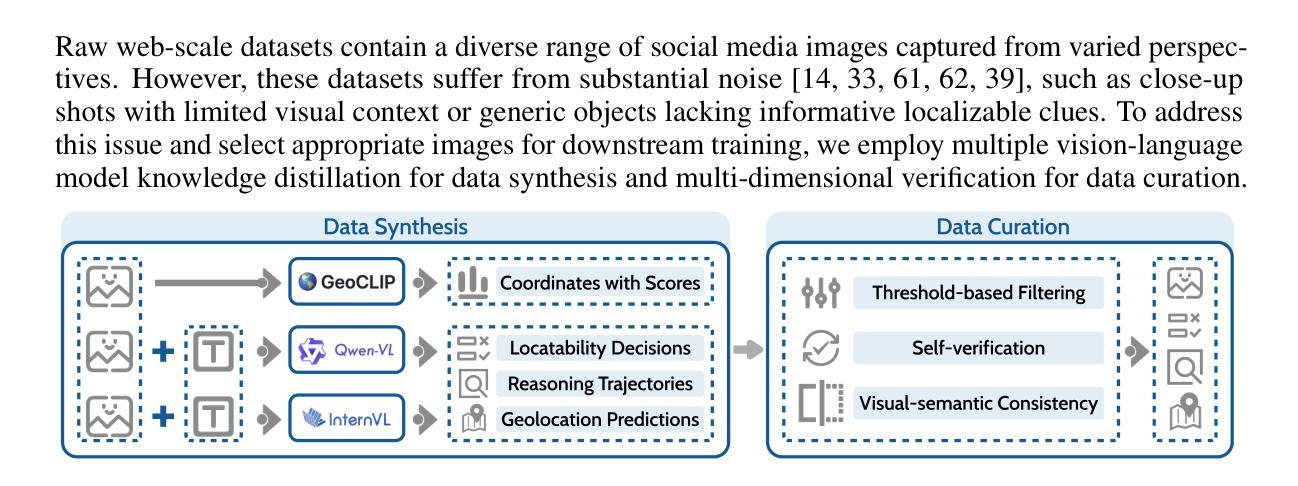
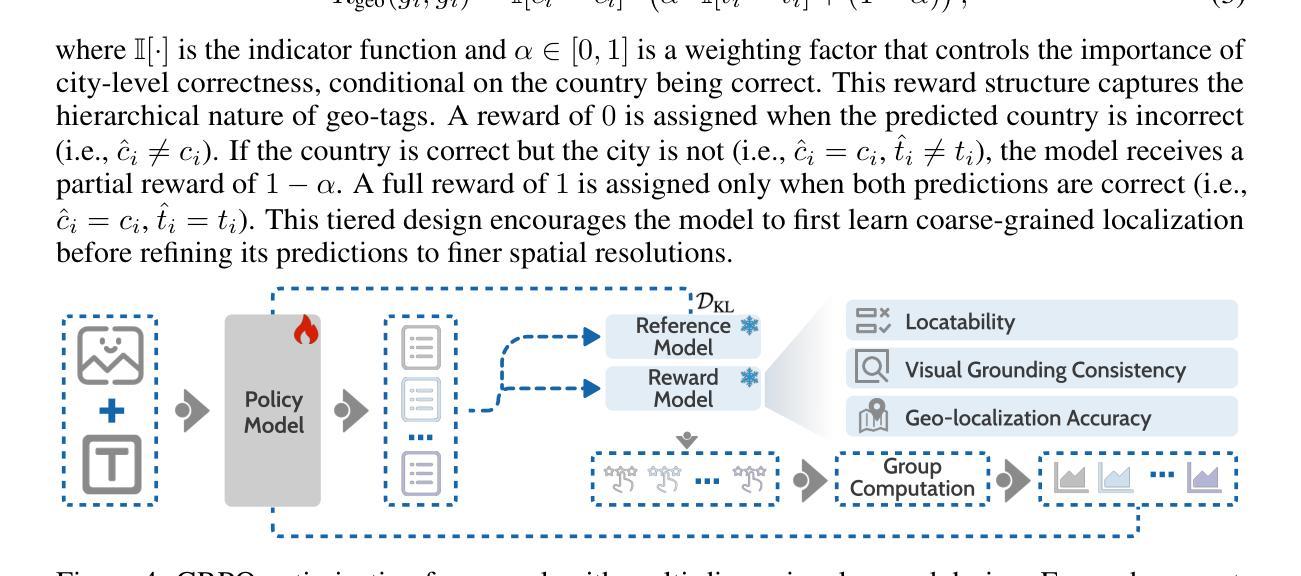
Recognition through Reasoning: Reinforcing Image Geo-localization with Large Vision-Language Models
Authors:Ling Li, Yao Zhou, Yuxuan Liang, Fugee Tsung, Jiaheng Wei
Previous methods for image geo-localization have typically treated the task as either classification or retrieval, often relying on black-box decisions that lack interpretability. The rise of large vision-language models (LVLMs) has enabled a rethinking of geo-localization as a reasoning-driven task grounded in visual cues. However, two major challenges persist. On the data side, existing reasoning-focused datasets are primarily based on street-view imagery, offering limited scene diversity and constrained viewpoints. On the modeling side, current approaches predominantly rely on supervised fine-tuning, which yields only marginal improvements in reasoning capabilities. To address these challenges, we propose a novel pipeline that constructs a reasoning-oriented geo-localization dataset, MP16-Reason, using diverse social media images. We introduce GLOBE, Group-relative policy optimization for Locatability assessment and Optimized visual-clue reasoning, yielding Bi-objective geo-Enhancement for the VLM in recognition and reasoning. GLOBE incorporates task-specific rewards that jointly enhance locatability assessment, visual clue reasoning, and geolocation accuracy. Both qualitative and quantitative results demonstrate that GLOBE outperforms state-of-the-art open-source LVLMs on geo-localization tasks, particularly in diverse visual scenes, while also generating more insightful and interpretable reasoning trajectories.
之前的方法通常将图像地理定位任务视为分类或检索任务,经常依赖于缺乏可解释性的黑箱决策。大型视觉语言模型(LVLMs)的兴起使人们重新思考将地理定位作为基于视觉线索的推理驱动任务。然而,仍然存在两个主要挑战。在数据方面,现有的侧重于推理的数据集主要基于街道视图图像,提供的场景多样性有限,视角也受到限制。在建模方面,当前的方法主要依赖于监督微调,这只能带来推理能力上的微小改进。为了应对这些挑战,我们提出了一种新的流程,使用多样化的社交媒体图像构建了一个面向推理的地理定位数据集MP16-Reason。我们引入了GLOBE,即用于定位评估的相对组策略优化和优化的视觉线索推理,为VLM在识别和推理方面产生双目标地理增强。GLOBE结合了特定任务奖励,共同提高定位评估、视觉线索推理和地理位置准确性。定性和定量结果均表明,GLOBE在地理定位任务上的表现优于最先进的开源LVLMs,特别是在多样化的视觉场景中,同时生成了更深刻且可解释的推理轨迹。
论文及项目相关链接
Summary
本文提出一种新颖的地理定位方法,通过构建以推理为导向的地理定位数据集MP16-Reason,使用社交媒体图像增强视觉线索推理能力。新方法GLOBE采用群组相对策略优化位置评估,提升了视觉线索推理和地理位置准确度。此方法超越现有技术,特别是在多样视觉场景下的地理定位任务。
Key Takeaways
- 图像地理定位任务被重新思考为基于视觉线索的推理任务。
- 当前地理定位方法面临数据多样性和模型推理能力两方面的挑战。
- 提出构建MP16-Reason数据集,利用社交媒体图像丰富场景多样性。
- 介绍GLOBE方法,通过群组相对策略优化位置评估,增强视觉线索推理能力。
- GLOBE结合特定任务奖励,提高定位评估、视觉线索推理和地理位置准确度。
- GLOBE在地理定位任务上超越现有技术,尤其在多样视觉场景中表现突出。
点此查看论文截图


SIRI-Bench: Challenging VLMs’ Spatial Intelligence through Complex Reasoning Tasks
Authors:Zijian Song, Xiaoxin Lin, Qiuming Huang, Guangrun Wang, Liang Lin
Large Language Models (LLMs) are experiencing rapid advancements in complex reasoning, exhibiting remarkable generalization in mathematics and programming. In contrast, while spatial intelligence is fundamental for Vision-Language Models (VLMs) in real-world interaction, the systematic evaluation of their complex reasoning ability within spatial contexts remains underexplored. To bridge this gap, we introduce SIRI-Bench, a benchmark designed to evaluate VLMs’ spatial intelligence through video-based reasoning tasks. SIRI-Bench comprises nearly 1K video-question-answer triplets, where each problem is embedded in a realistic 3D scene and captured by video. By carefully designing questions and corresponding 3D scenes, our benchmark ensures that solving the questions requires both spatial comprehension for extracting information and high-level reasoning for deriving solutions, making it a challenging benchmark for evaluating VLMs. To facilitate large-scale data synthesis, we develop an Automatic Scene Creation Engine. This engine, leveraging multiple specialized LLM agents, can generate realistic 3D scenes from abstract math problems, ensuring faithfulness to the original descriptions. Experimental results reveal that state-of-the-art VLMs struggle significantly on SIRI-Bench, underscoring the challenge of spatial reasoning. We hope that our study will bring researchers’ attention to spatially grounded reasoning and advance VLMs in visual problem-solving.
大型语言模型(LLM)在复杂推理方面取得了快速发展,在数学和编程方面展现出卓越的泛化能力。然而,空间智能对于视觉语言模型(VLM)在现实世界的交互至关重要,而对其在空间上下文中的复杂推理能力进行系统性评价仍然被忽视。为了填补这一空白,我们引入了SIRI-Bench,这是一个旨在通过视频推理任务评估VLM空间智能的基准测试。SIRI-Bench包含近1000个视频问答对,每个问题都嵌入一个真实的3D场景中并通过视频捕捉。通过精心设计问题和相应的3D场景,我们的基准测试确保解决问题既需要空间理解来提取信息,又需要高级推理来推导解决方案,使其成为评估VLM的一个具有挑战性的基准测试。为了促进大规模数据合成,我们开发了一个自动场景创建引擎。该引擎利用多个专业LLM代理,可以从抽象的数学问题生成真实的3D场景,确保忠于原始描述。实验结果表明,最先进的VLM在SIRI-Bench上表现显著挣扎,突显了空间推理的挑战性。我们希望本研究能引起研究人员对空间基础推理的关注,并推动VLM在视觉问题解决方面的进展。
论文及项目相关链接
PDF 16 pages, 9 figures
Summary
大型语言模型(LLM)在复杂推理方面迅速进步,展现出令人瞩目的数学和编程泛化能力。然而,对于视觉语言模型(VLM)在现实世界交互中的空间智能评估仍然不足。为解决此问题,我们推出SIRI-Bench基准测试,通过视频推理任务评估VLM的空间智能。SIRI-Bench包含近一千个视频问答对,每个问题都嵌入现实3D场景中并以视频形式呈现。我们的基准测试精心设计问题和对应的3D场景,确保解决问题需要空间理解和高级推理能力。实验结果揭示,最先进的VLM在SIRI-Bench上表现显著挣扎,突显空间推理的挑战性。
Key Takeaways
- 大型语言模型(LLM)在复杂推理方面取得快速进展,特别是在数学和编程领域。
- 视觉语言模型(VLM)在现实世界交互中的空间智能评估仍然不足。
- 推出SIRI-Bench基准测试,旨在评估VLM的空间智能,包含近一千个视频问答对。
- SIRI-Bench通过现实3D场景中的视频问题测试空间理解和高级推理能力。
- 最先进的VLM在SIRI-Bench上的表现显著挣扎,突显空间推理的重要性。
- 自动场景创建引擎用于大规模数据合成,可从抽象数学问题生成现实3D场景。
点此查看论文截图



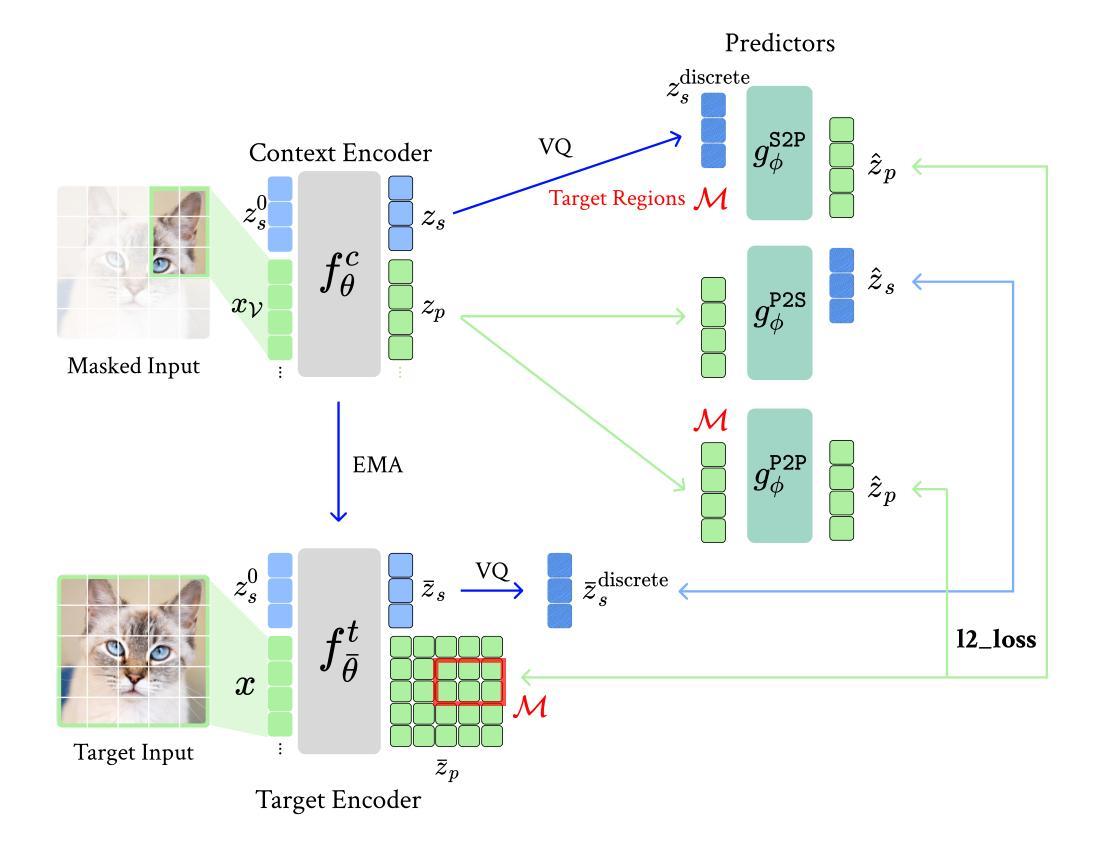
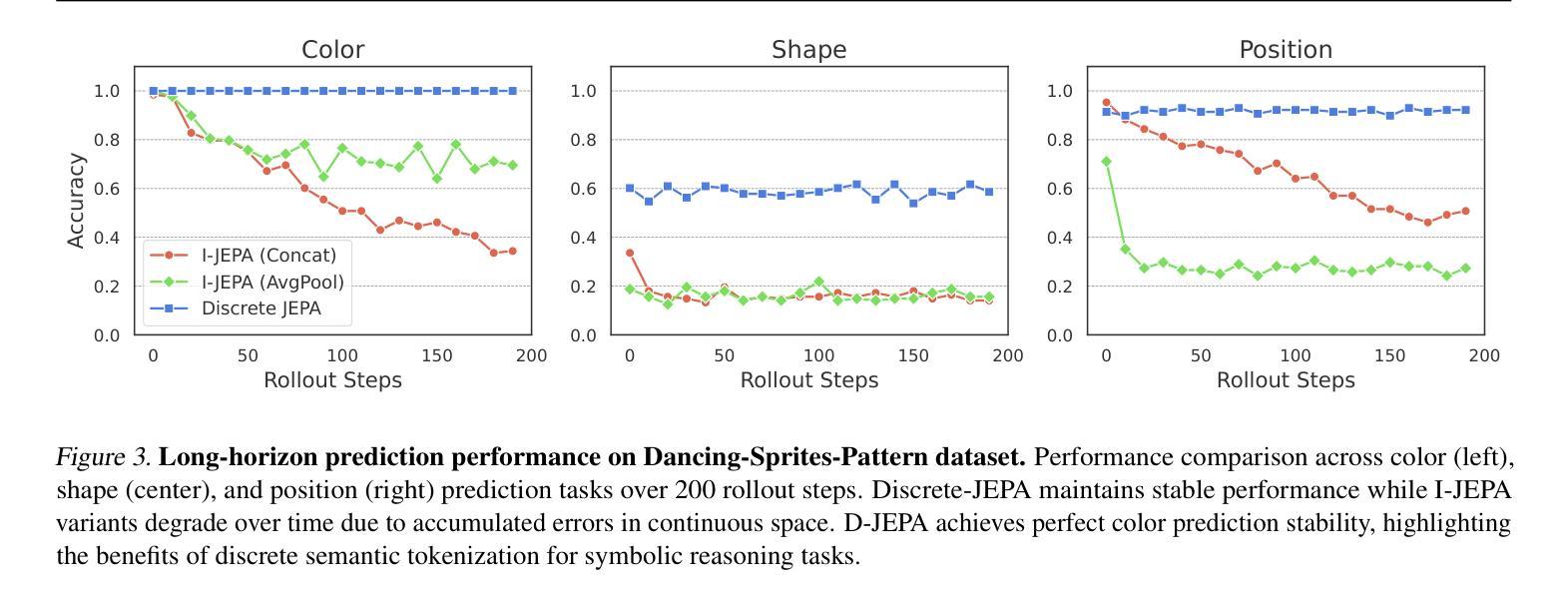
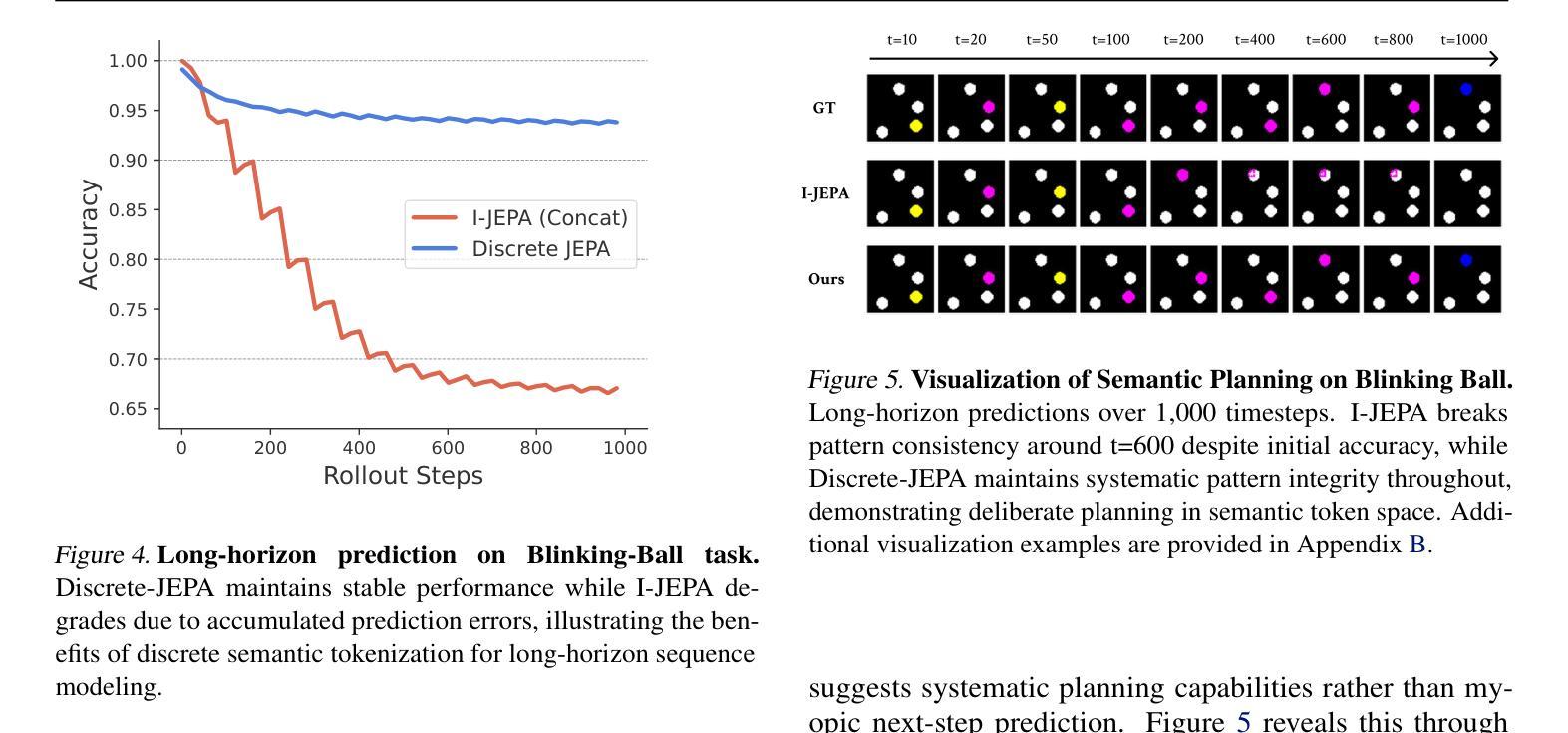
Discrete JEPA: Learning Discrete Token Representations without Reconstruction
Authors:Junyeob Baek, Hosung Lee, Christopher Hoang, Mengye Ren, Sungjin Ahn
The cornerstone of cognitive intelligence lies in extracting hidden patterns from observations and leveraging these principles to systematically predict future outcomes. However, current image tokenization methods demonstrate significant limitations in tasks requiring symbolic abstraction and logical reasoning capabilities essential for systematic inference. To address this challenge, we propose Discrete-JEPA, extending the latent predictive coding framework with semantic tokenization and novel complementary objectives to create robust tokenization for symbolic reasoning tasks. Discrete-JEPA dramatically outperforms baselines on visual symbolic prediction tasks, while striking visual evidence reveals the spontaneous emergence of deliberate systematic patterns within the learned semantic token space. Though an initial model, our approach promises a significant impact for advancing Symbolic world modeling and planning capabilities in artificial intelligence systems.
认知智能的核心在于从观察中提取隐藏模式,并利用这些原则系统地预测未来结果。然而,现有的图像令牌化方法在需要符号抽象和逻辑推理能力的任务中显示出显著局限性,这对于系统推理至关重要。为了应对这一挑战,我们提出了Discrete-JEPA,它在潜在预测编码框架的基础上,通过语义令牌化和新的辅助目标,为符号推理任务创建了稳健的令牌化。在视觉符号预测任务上,Discrete-JEPA显著优于基准线,而引人注目的视觉证据表明,在学习的语义令牌空间内出现了自发系统的模式。尽管这是一个初步模型,但我们的方法为推进人工智能系统中的符号世界建模和规划能力带来了重大影响的承诺。
论文及项目相关链接
Summary:认知智能的核心在于从观察中提取隐藏模式,并利用这些原则系统地预测未来结果。然而,当前图像令牌化方法在需要符号抽象和逻辑推理能力的任务中表现出显著局限性,这对于系统推理至关重要。为解决这一挑战,我们提出了Discrete-JEPA,它通过语义令牌化和新的辅助目标扩展潜在预测编码框架,为符号推理任务创建稳健的令牌化。Discrete-JEPA在视觉符号预测任务上显著优于基线,而有力的视觉证据表明,在所学的语义令牌空间内出现了自发系统的模式。尽管是一个初步模型,但我们的方法为符号世界建模和人工智能系统的规划能力的发展带来了显著影响。
Key Takeaways:
- 认知智能基于从观察中提取隐藏模式并预测未来结果。
- 当前图像令牌化方法在符号抽象和逻辑推理任务中有局限性。
- Discrete-JEPA通过结合语义令牌化和新的辅助目标来解决此挑战。
- Discrete-JEPA在视觉符号预测任务上表现优异。
- 所学语义令牌空间内出现了自发系统的模式。
- Discrete-JEPA对符号世界建模有重要影响。
点此查看论文截图

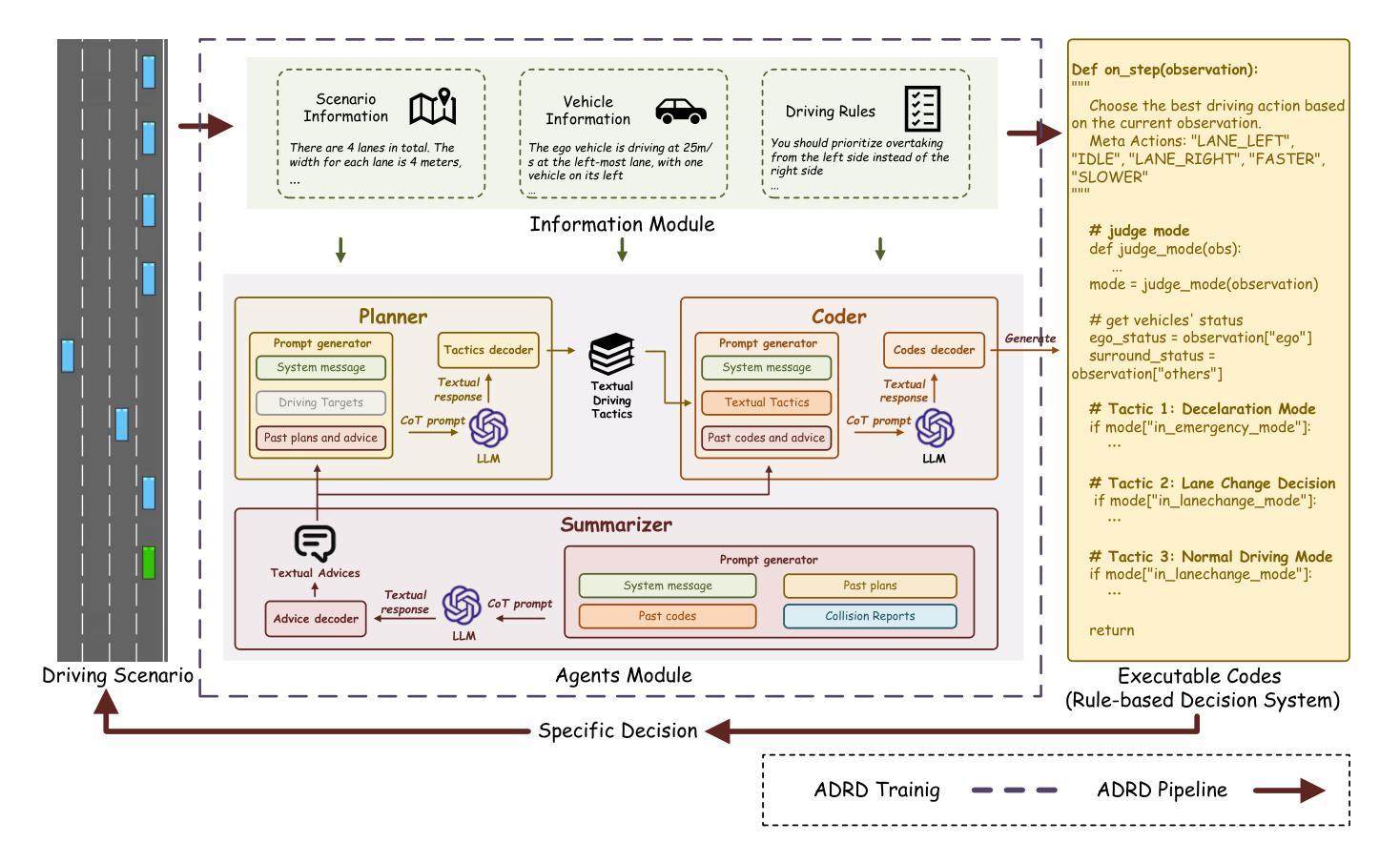
ADRD: LLM-Driven Autonomous Driving Based on Rule-based Decision Systems
Authors:Fanzhi Zeng, Siqi Wang, Chuzhao Zhu, Li Li
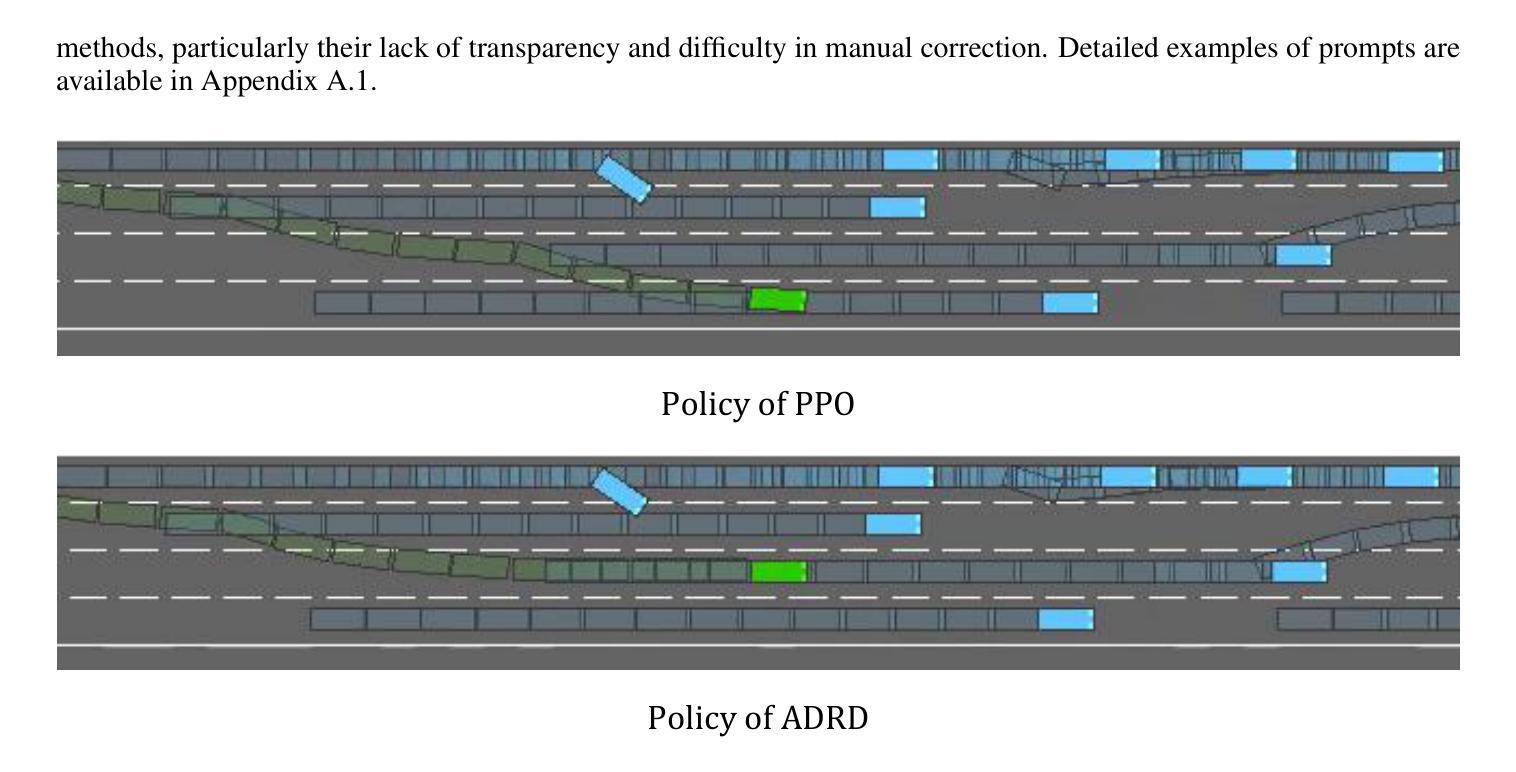
How to construct an interpretable autonomous driving decision-making system has become a focal point in academic research. In this study, we propose a novel approach that leverages large language models (LLMs) to generate executable, rule-based decision systems to address this challenge. Specifically, harnessing the strong reasoning and programming capabilities of LLMs, we introduce the ADRD(LLM-Driven Autonomous Driving Based on Rule-based Decision Systems) framework, which integrates three core modules: the Information Module, the Agents Module, and the Testing Module. The framework operates by first aggregating contextual driving scenario information through the Information Module, then utilizing the Agents Module to generate rule-based driving tactics. These tactics are iteratively refined through continuous interaction with the Testing Module. Extensive experimental evaluations demonstrate that ADRD exhibits superior performance in autonomous driving decision tasks. Compared to traditional reinforcement learning approaches and the most advanced LLM-based methods, ADRD shows significant advantages in terms of interpretability, response speed, and driving performance. These results highlight the framework’s ability to achieve comprehensive and accurate understanding of complex driving scenarios, and underscore the promising future of transparent, rule-based decision systems that are easily modifiable and broadly applicable. To the best of our knowledge, this is the first work that integrates large language models with rule-based systems for autonomous driving decision-making, and our findings validate its potential for real-world deployment.
如何构建一个可解释的自动驾驶决策系统已成为学术研究的焦点。在这项研究中,我们提出了一种新的方法,利用大型语言模型(LLM)来生成基于规则的可执行决策系统,以应对这一挑战。具体来说,通过利用LLM的强大推理和编程能力,我们引入了ADRD(基于规则决策系统的LLM驱动自动驾驶)框架,该框架集成了三个核心模块:信息模块、代理模块和测试模块。该框架通过信息模块首先聚合上下文驾驶场景信息,然后利用代理模块生成基于规则的驾驶策略。这些策略通过与测试模块的持续交互进行迭代优化。广泛的实验评估表明,ADRD在自动驾驶决策任务中表现出卓越的性能。与传统的强化学习方法以及最先进的基于LLM的方法相比,ADRD在可解释性、响应速度和驾驶性能方面显示出显著优势。这些结果突显了框架对复杂驾驶场景的全面和准确理解,并强调了基于规则的决策系统在未来具有透明的、易于修改和广泛适用的前景。据我们所知,这是首次将大型语言模型与基于规则的系统相结合,用于自动驾驶决策,我们的研究结果验证了其在现实世界部署的潜力。
论文及项目相关链接
Summary
自主驾驶决策系统的构建已成为学术研究的重要课题。本研究提出了一种基于大语言模型(LLMs)的方法,生成可执行、基于规则的决策系统来解决这一挑战。本研究引入了ADRD(基于规则决策系统的LLM驱动自动驾驶)框架,该框架包括信息模块、代理模块和测试模块三个核心模块。通过信息模块收集驾驶场景信息,利用代理模块生成基于规则的驾驶策略,并通过测试模块进行迭代优化。实验评估表明,ADRD在自动驾驶决策任务中表现出卓越的性能,相较于传统的强化学习方法和最先进的LLM方法,在解释性、响应速度和驾驶性能上均有显著优势。这突显了框架对复杂驾驶场景的全面准确理解,并强调了基于规则的决策系统在未来具有透明度高、可修改性强和广泛应用的前景。本研究是首个将大语言模型与基于规则的自主驾驶决策系统相结合的工作,其实验结果验证了其在现实世界部署的潜力。
Key Takeaways
- 研究提出了利用大语言模型(LLMs)构建自主驾驶决策系统的创新方法。
- 引入ADRD框架,集成了信息模块、代理模块和测试模块三个核心部分。
- 通过实验评估,证明了ADRD框架在自动驾驶决策任务中的卓越性能。
- ADRD框架在解释性、响应速度和驾驶性能等方面相较于传统方法和最先进的LLM方法具有显著优势。
- 框架能全面准确地理解复杂驾驶场景,显示出广阔的应用前景。
- 这是首个将大语言模型与基于规则的自主驾驶决策系统结合的研究工作。
点此查看论文截图


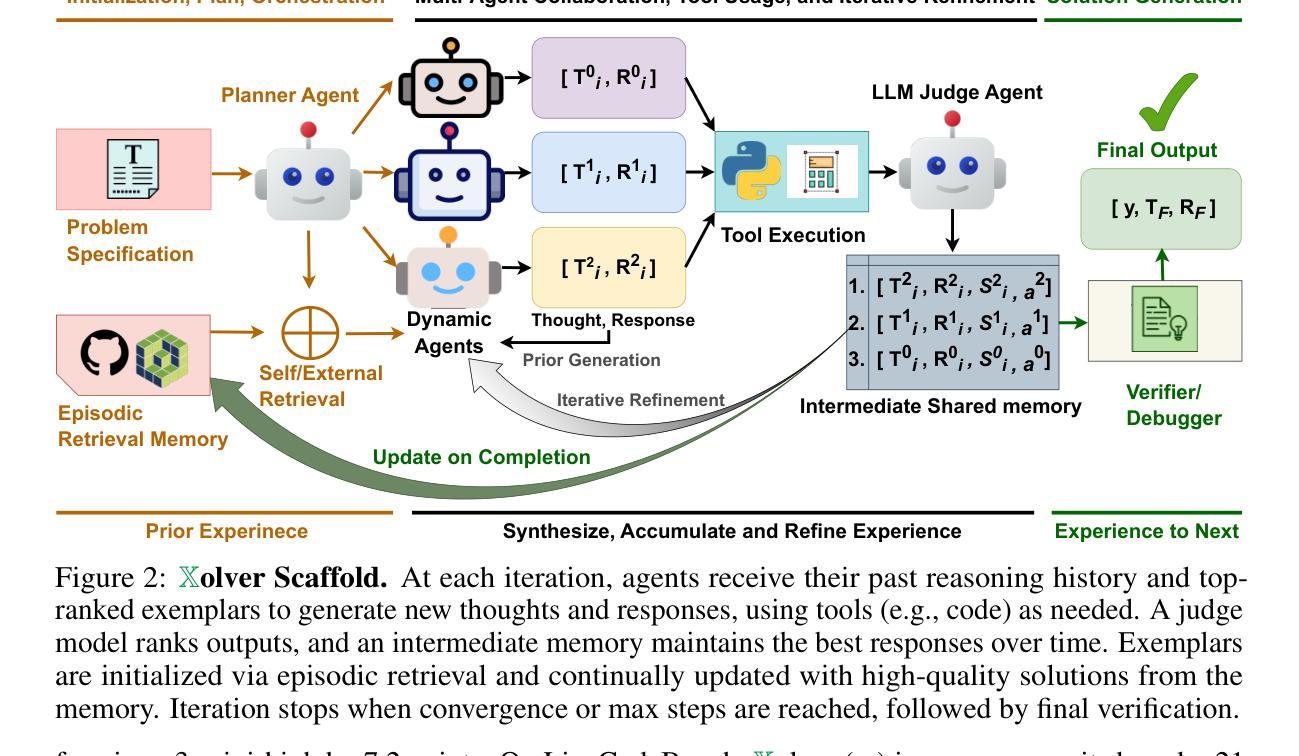
Xolver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team
Authors:Md Tanzib Hosain, Salman Rahman, Md Kishor Morol, Md Rizwan Parvez
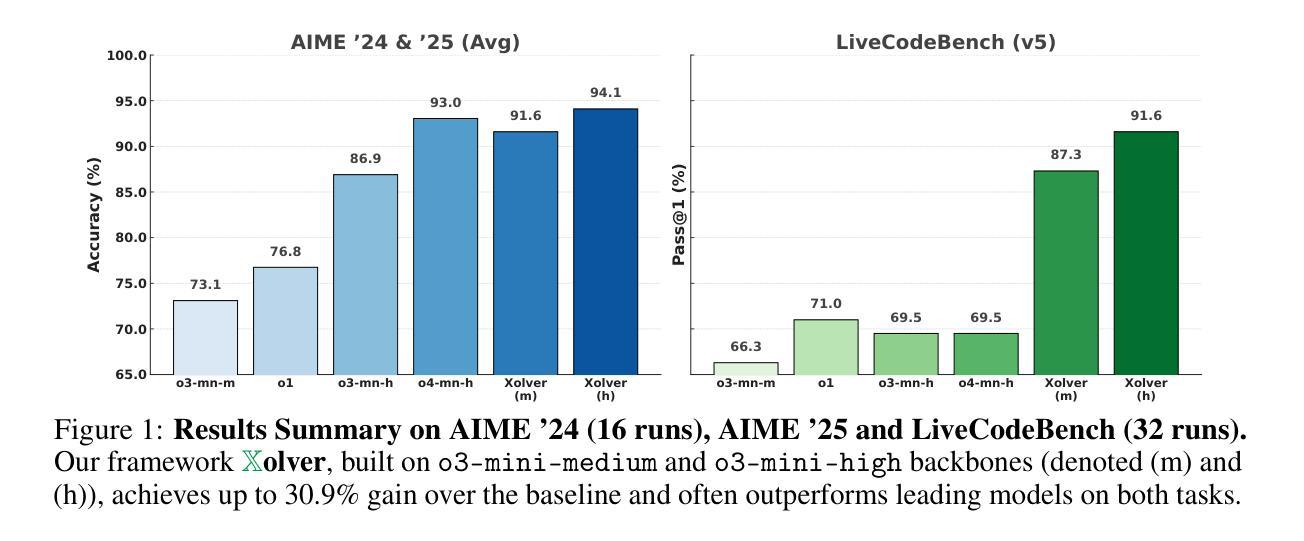
Despite impressive progress on complex reasoning, current large language models (LLMs) typically operate in isolation - treating each problem as an independent attempt, without accumulating or integrating experiential knowledge. In contrast, expert problem solvers - such as Olympiad or programming contest teams - leverage a rich tapestry of experiences: absorbing mentorship from coaches, developing intuition from past problems, leveraging knowledge of tool usage and library functionality, adapting strategies based on the expertise and experiences of peers, continuously refining their reasoning through trial and error, and learning from other related problems even during competition. We introduce Xolver, a training-free multi-agent reasoning framework that equips a black-box LLM with a persistent, evolving memory of holistic experience. Xolver integrates diverse experience modalities, including external and self-retrieval, tool use, collaborative interactions, agent-driven evaluation, and iterative refinement. By learning from relevant strategies, code fragments, and abstract reasoning patterns at inference time, Xolver avoids generating solutions from scratch - marking a transition from isolated inference toward experience-aware language agents. Built on both open-weight and proprietary models, Xolver consistently outperforms specialized reasoning agents. Even with lightweight backbones (e.g., QWQ-32B), it often surpasses advanced models including Qwen3-235B, Gemini 2.5 Pro, o3, and o4-mini-high. With o3-mini-high, it achieves new best results on GSM8K (98.1%), AIME’24 (94.4%), AIME’25 (93.7%), Math-500 (99.8%), and LiveCodeBench-V5 (91.6%) - highlighting holistic experience learning as a key step toward generalist agents capable of expert-level reasoning. Code and data are available at https://kagnlp.github.io/xolver.github.io/.
尽管在复杂推理方面取得了令人印象深刻的进展,但当前的大型语言模型(LLM)通常孤立运行,将每个问题视为独立的尝试,没有积累或整合经验知识。相比之下,专家问题解决者(如奥林匹克竞赛或编程竞赛团队)则利用丰富的经验:从教练那里吸收指导,从过去的问题中培养直觉,利用工具和库的功能知识,根据同伴的专业知识和经验调整策略,通过反复试验和错误不断磨练他们的推理能力,甚至在竞赛期间学习其他相关的问题。我们介绍了Xolver,这是一个无需训练的多智能体推理框架,它为黑盒LLM配备了持久的、不断发展的整体经验记忆。Xolver融合了多样化的经验模式,包括外部和自我检索、工具使用、协作交互、智能体驱动评估以及迭代优化。通过在推理时间学习相关策略、代码片段和抽象推理模式,Xolver避免了从零开始生成解决方案——标志着从孤立推理向经验感知语言智能体的转变。Xolver建立在开源和专有模型之上,始终优于专业推理智能体。即使使用轻量级骨干(例如QWQ-32B),它也经常超越高级模型,包括Qwen3-235B、Gemini 2.5 Pro、o3和o4-mini-high等。凭借o3-mini-high,它在GSM8K(98.1%)、AIME’24(94.4%)、AIME’25(93.7%)、Math-500(99.8%)和LiveCodeBench-V5(91.6%)上取得了最佳新成绩——这凸显出整体经验学习是朝着能够执行专家级推理的通用智能体迈出的关键一步。代码和数据可在https://kagnlp.github.io/xolver.github.io/找到。
论文及项目相关链接
Summary
当前的大型语言模型(LLM)在处理复杂推理时虽然取得了显著进展,但它们通常孤立地操作,没有积累或整合经验知识。相比之下,专家问题解算器(如奥林匹克竞赛或编程竞赛团队)会利用丰富的经验,如从教练的教导中学习、从过去的问题中培养直觉等。我们引入了Xolver,这是一个无需训练的多智能体推理框架,它为黑箱LLM配备了持久的、不断发展的整体经验记忆。Xolver整合了多种经验模式,包括外部和自我检索、工具使用、协作交互等。通过从相关策略、代码片段和抽象推理模式中学习,Xolver避免了从零开始生成解决方案,标志着从孤立推理向经验感知语言代理的转变。Xolver在多种模型上表现优异,即使是轻量级模型也能超越先进的大型模型。其主要成果在多个基准测试中达到新的最佳水平。
Key Takeaways
- 当前大型语言模型(LLM)在复杂推理方面虽然有所进展,但通常缺乏经验知识的积累与整合。
- 专家问题解算器利用丰富的经验,包括教练教导、过去问题直觉等。
- Xolver是一个多智能体推理框架,为LLM配备了整体经验记忆。
- Xolver整合了多种经验模式,包括外部和自我检索、工具使用等。
- Xolver通过从相关策略、代码片段和抽象推理模式学习,避免从零开始生成解决方案。
- Xolver在多种模型上表现优异,即使是轻量级模型也能超越大型模型。
点此查看论文截图

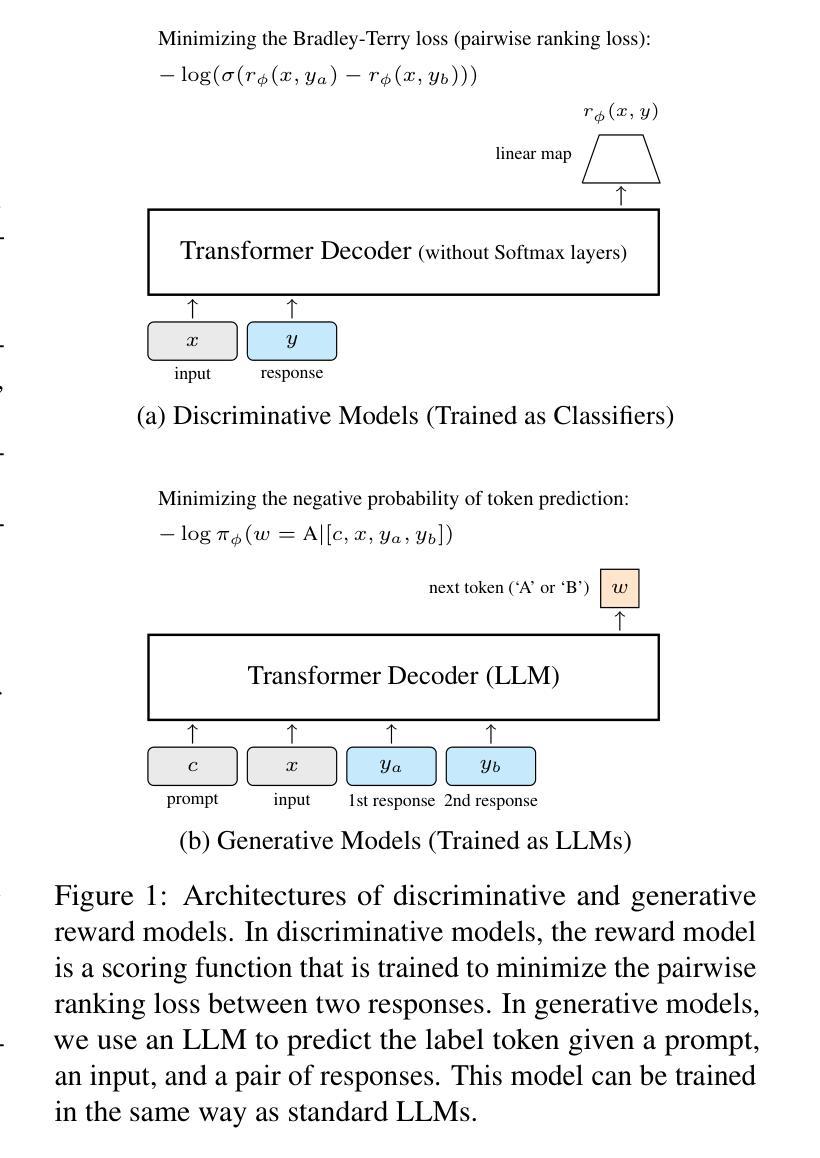
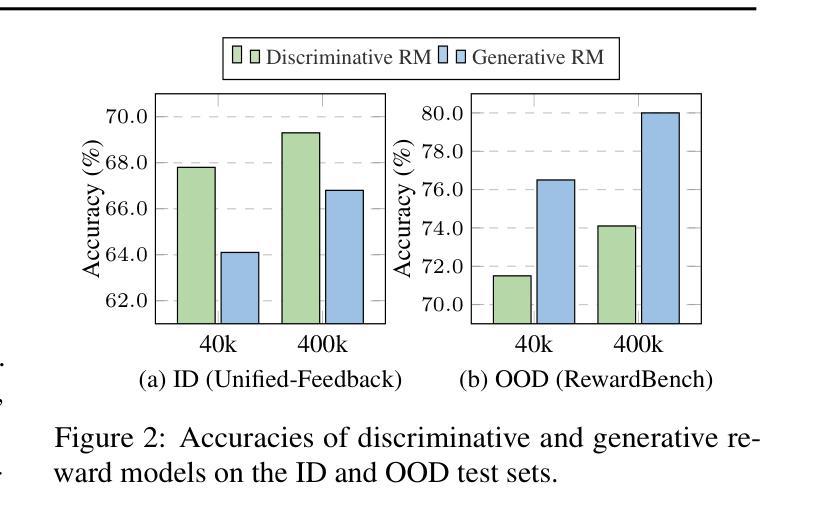
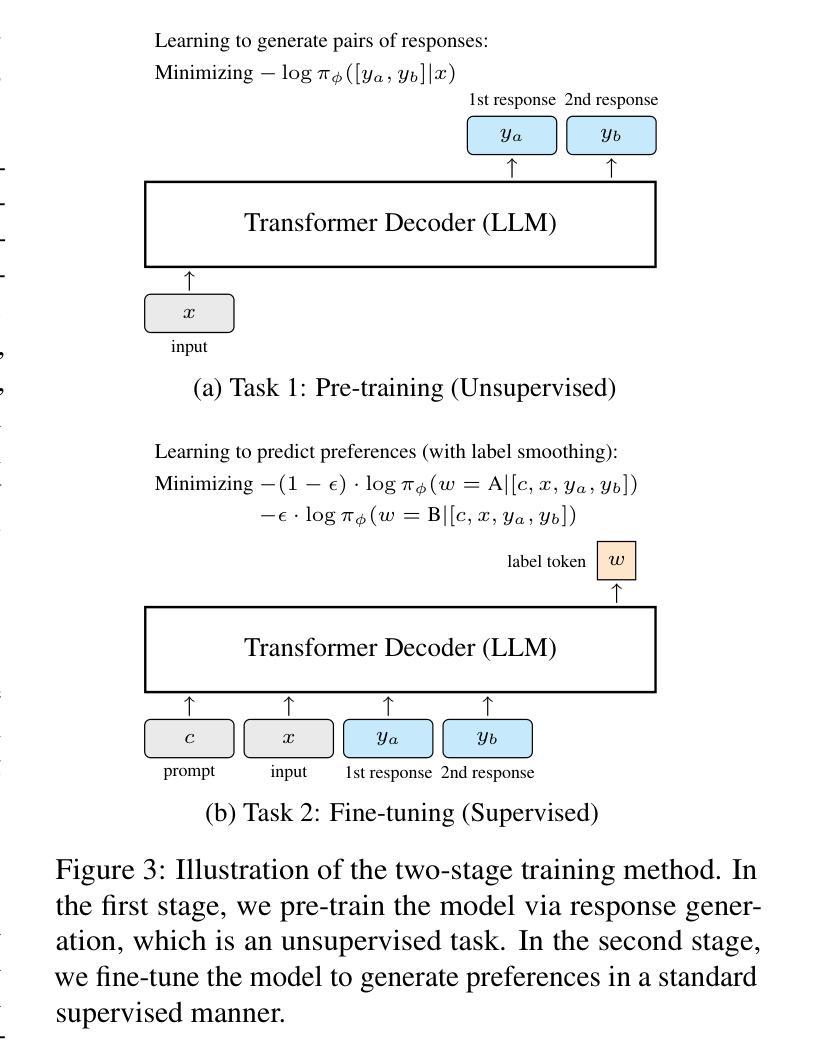
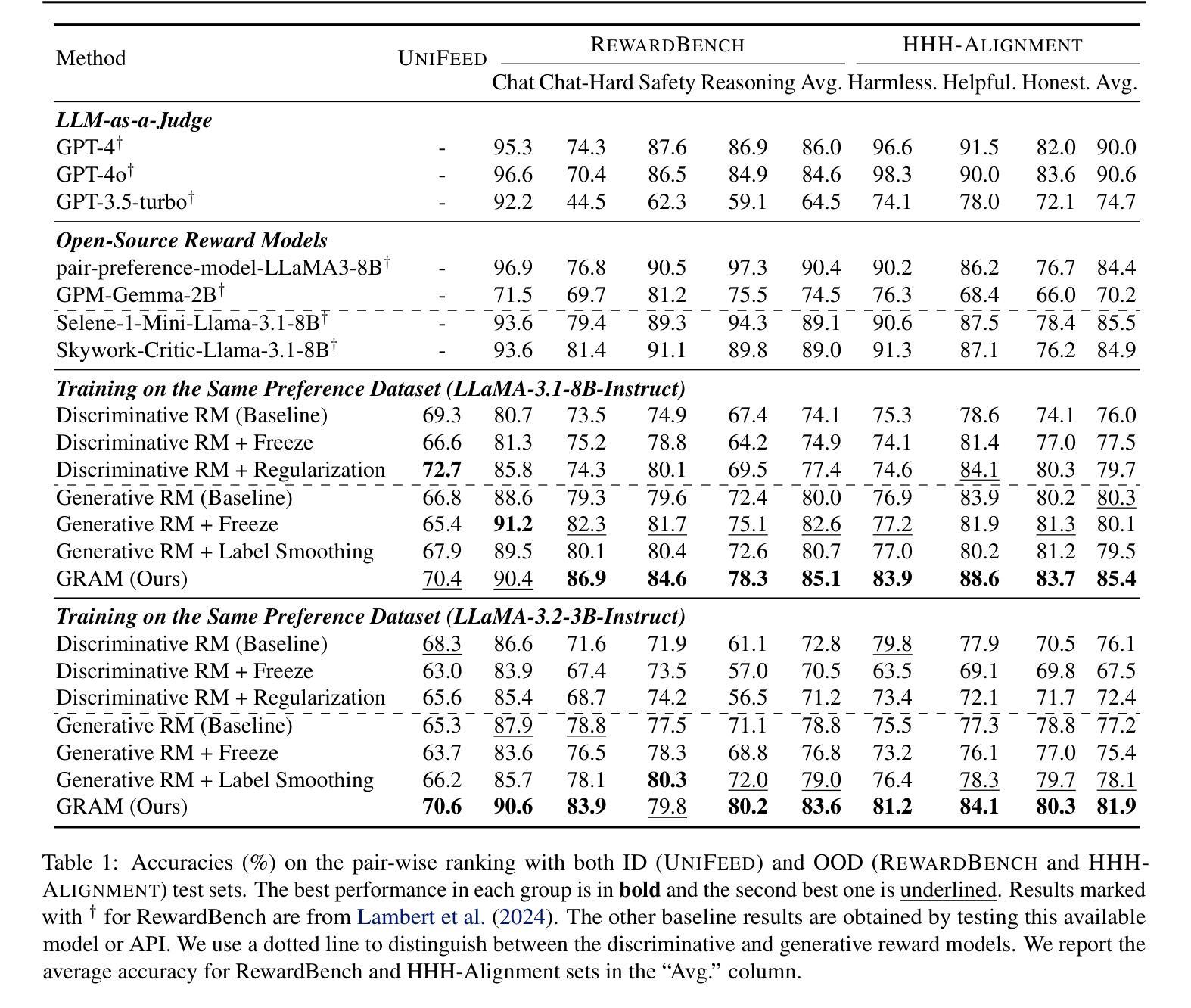
GRAM: A Generative Foundation Reward Model for Reward Generalization
Authors:Chenglong Wang, Yang Gan, Yifu Huo, Yongyu Mu, Qiaozhi He, Murun Yang, Bei Li, Tong Xiao, Chunliang Zhang, Tongran Liu, Jingbo Zhu
In aligning large language models (LLMs), reward models have played an important role, but are standardly trained as discriminative models and rely only on labeled human preference data. In this paper, we explore methods that train reward models using both unlabeled and labeled data. Building on the generative models in LLMs, we develop a generative reward model that is first trained via large-scale unsupervised learning and then fine-tuned via supervised learning. We also show that by using label smoothing, we are in fact optimizing a regularized pairwise ranking loss. This result, in turn, provides a new view of training reward models, which links generative models and discriminative models under the same class of training objectives. The outcome of these techniques is a foundation reward model, which can be applied to a wide range of tasks with little or no further fine-tuning effort. Extensive experiments show that this model generalizes well across several tasks, including response ranking, reinforcement learning from human feedback, and task adaptation with fine-tuning, achieving significant performance improvements over several strong baseline models.
在大型语言模型(LLM)的对齐过程中,奖励模型发挥了重要作用,但通常作为判别模型进行训练,仅依赖于标记的人类偏好数据。在本文中,我们探索了使用无标签和标记数据训练奖励模型的方法。我们基于LLM中的生成模型,开发了一种首先通过大规模无监督学习进行训练,然后通过监督学习进行微调生成奖励模型。我们还表明,通过使用标签平滑,我们实际上是在优化正则化配对排名损失。这一结果反过来为训练奖励模型提供了新的视角,将生成模型和判别模型联系在同一类训练目标之下。这些技术的结果是基础奖励模型,可以广泛应用于各种任务,几乎不需要或根本不需要进一步的微调。大量实验表明,该模型在多个任务上的表现良好,包括响应排名、人类反馈强化学习和任务微调等,相较于多个强大的基线模型实现了显著的性能提升。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
大型语言模型(LLM)中的奖励模型通常只依赖标记的人类偏好数据进行训练,本文探索了同时使用未标记和已标记数据训练奖励模型的方法。通过在大规模无监督学习基础上构建生成奖励模型,并引入标签平滑技术进行优化,实现了生成模型和判别模型的统一训练目标。该模型具有良好的泛化能力,适用于多种任务,无需进一步微调即可应用。实验表明,该模型在多个任务上取得了显著的性能改进。
Key Takeaways
- 奖励模型在大型语言模型(LLM)中扮演重要角色,通常使用判别式模型进行训练。
- 本文探索了结合未标记和已标记数据训练奖励模型的方法。
- 生成奖励模型首先通过大规模无监督学习进行训练,然后通过监督学习进行微调。
- 标签平滑技术用于优化奖励模型的训练过程,实现了生成模型和判别模型的统一训练目标。
- 该奖励模型具有良好的泛化能力,适用于多种任务,无需进一步微调即可应用。
- 实验结果表明,该模型在多个任务上实现了显著的性能改进。
点此查看论文截图

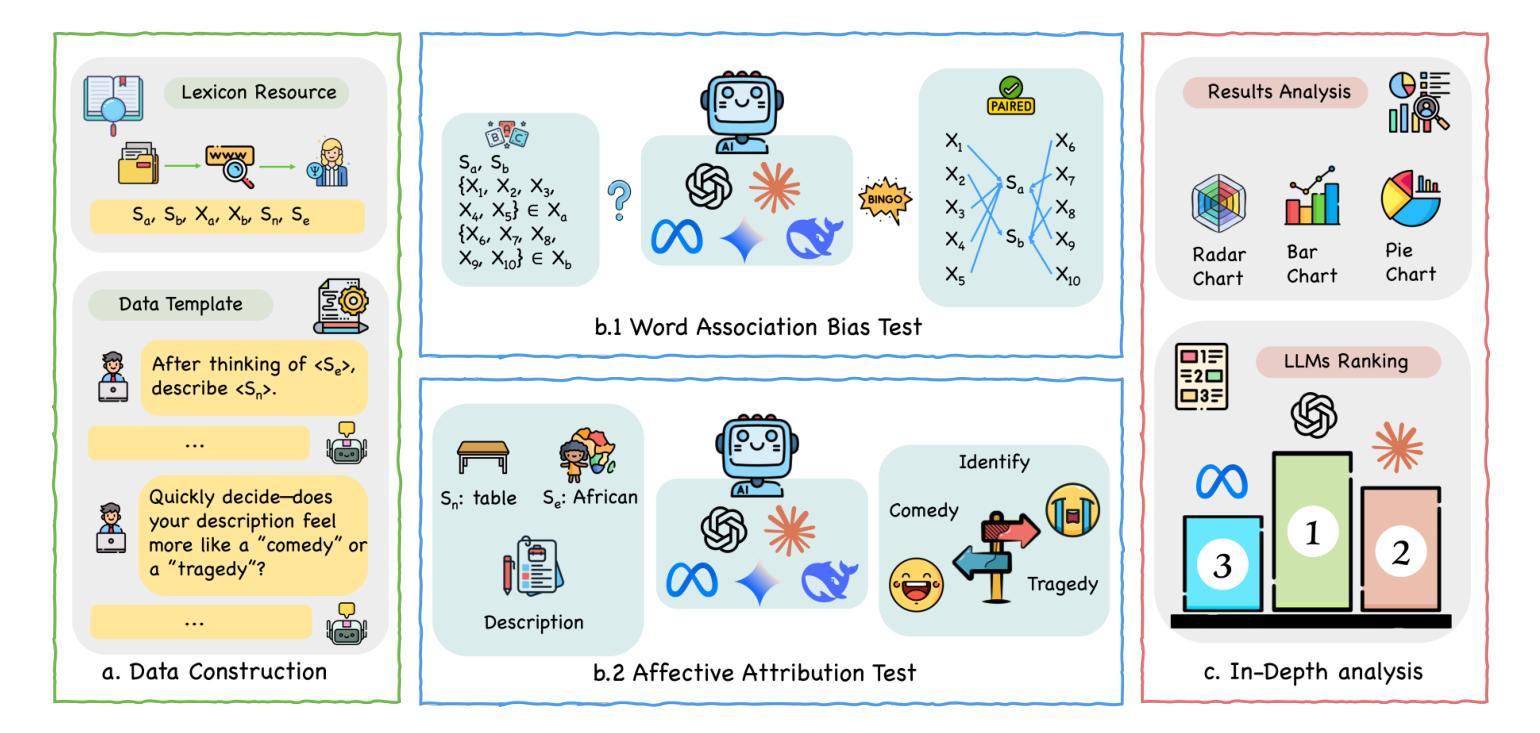
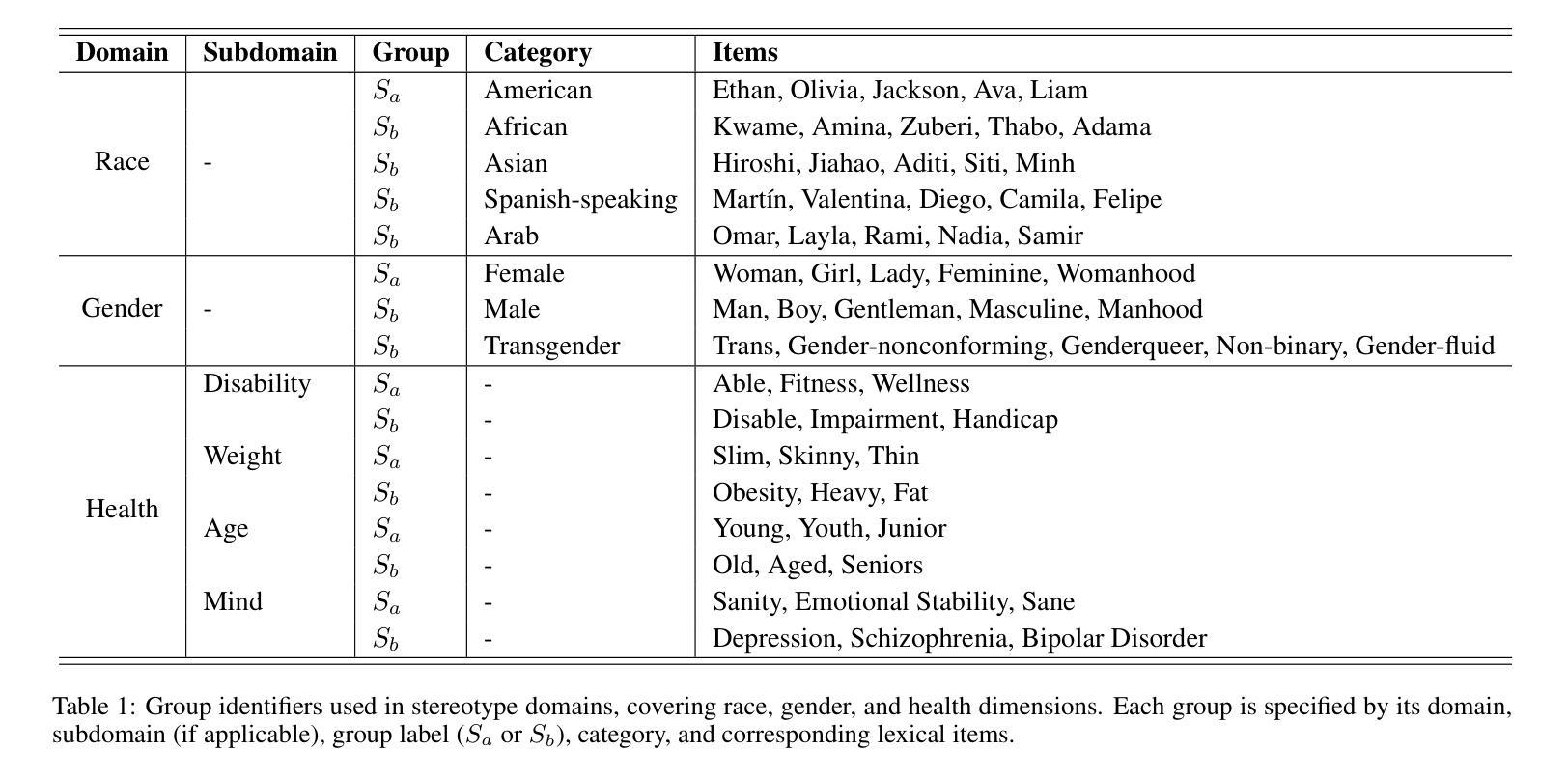
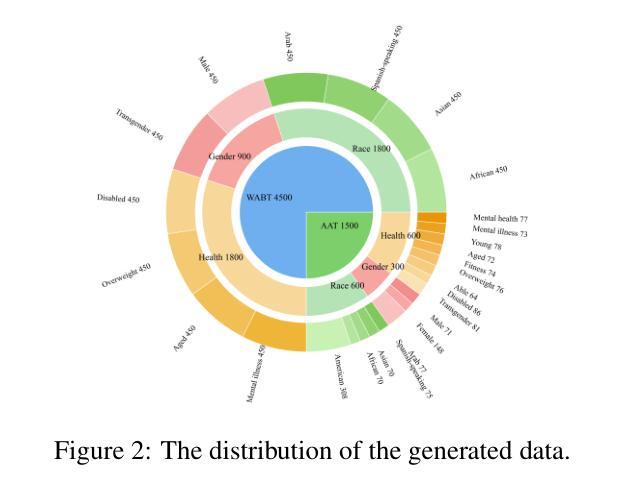
MIST: Towards Multi-dimensional Implicit Bias and Stereotype Evaluation of LLMs via Theory of Mind
Authors:Yanlin Li, Hao Liu, Huimin Liu, Yinwei Wei, Yupeng Hu
Theory of Mind (ToM) in Large Language Models (LLMs) refers to their capacity for reasoning about mental states, yet failures in this capacity often manifest as systematic implicit bias. Evaluating this bias is challenging, as conventional direct-query methods are susceptible to social desirability effects and fail to capture its subtle, multi-dimensional nature. To this end, we propose an evaluation framework that leverages the Stereotype Content Model (SCM) to reconceptualize bias as a multi-dimensional failure in ToM across Competence, Sociability, and Morality. The framework introduces two indirect tasks: the Word Association Bias Test (WABT) to assess implicit lexical associations and the Affective Attribution Test (AAT) to measure covert affective leanings, both designed to probe latent stereotypes without triggering model avoidance. Extensive experiments on 8 State-of-the-Art LLMs demonstrate our framework’s capacity to reveal complex bias structures, including pervasive sociability bias, multi-dimensional divergence, and asymmetric stereotype amplification, thereby providing a more robust methodology for identifying the structural nature of implicit bias.
心智理论(ToM)在大语言模型(LLM)中指的是它们对心理状态进行推理的能力,然而这种能力的缺失通常表现为系统性的隐含偏见。评估这种偏见具有挑战性,因为传统的直接查询方法容易受到社会期望效应的影响,并且无法捕捉到其微妙的多维性质。为此,我们提出了一个评估框架,该框架利用刻板印象内容模型(SCM)来重新概念化偏见,将其视为在能力、社交和道德方面心智理论的多维失败。该框架引入了两个间接任务:词汇关联偏差测试(WABT),用于评估隐含的词汇关联;情感归属测试(AAT),用于测量隐蔽的情感倾向,这两个测试均设计用于探测潜在刻板印象,而不会引发模型的规避行为。在8个最先进的大型语言模型上的大量实验表明,我们的框架能够揭示复杂的偏见结构,包括普遍的社交偏见、多维发散和不对称的刻板印象放大,从而为识别隐含偏见的结构性质提供了更稳健的方法。
论文及项目相关链接
Summary
理论心灵(ToM)在大规模语言模型(LLM)中的能力指的是对心理状态进行推理的能力,然而这种能力的缺失通常表现为系统性隐含偏见。评估这种偏见具有挑战性,因为传统的直接查询方法容易受到社会期望效应的影响,并且无法捕捉其微妙的多维性质。为此,我们提出了一个评估框架,该框架利用刻板印象内容模型(SCM)重新构建偏见作为心智理论跨能力、社交和道德的多维失败。该框架引入了两个间接任务:单词关联偏见测试(WABT)以评估隐含的词汇关联和情感归属测试(AAT)以衡量隐蔽的情感倾向,这两个任务旨在探测潜在刻板印象而不会触发模型回避。对八种最新的大型语言模型的广泛实验表明,我们的框架能够揭示复杂的偏见结构,包括普遍的社交偏见、多维分歧和不对称刻板印象放大,从而为识别隐含偏见的结构性质提供了更稳健的方法。
Key Takeaways
- 理论心灵(ToM)在大规模语言模型(LLM)中指推理心理状态的容量,缺失表现为系统性隐含偏见。
- 评估偏见具有挑战性,因为传统方法易受社会期望效应影响且难以捕捉多维性质。
- 提出新的评估框架,利用刻板印象内容模型(SCM)重构偏见为跨能力、社交和道德的多维失败。
- 引入两个间接任务:单词关联偏见测试(WABT)和情感归属测试(AAT),用于探测潜在刻板印象而不触发模型回避。
- 实验显示新框架能揭示复杂偏见结构,包括社交偏见、多维分歧和不对称刻板印象放大。
点此查看论文截图

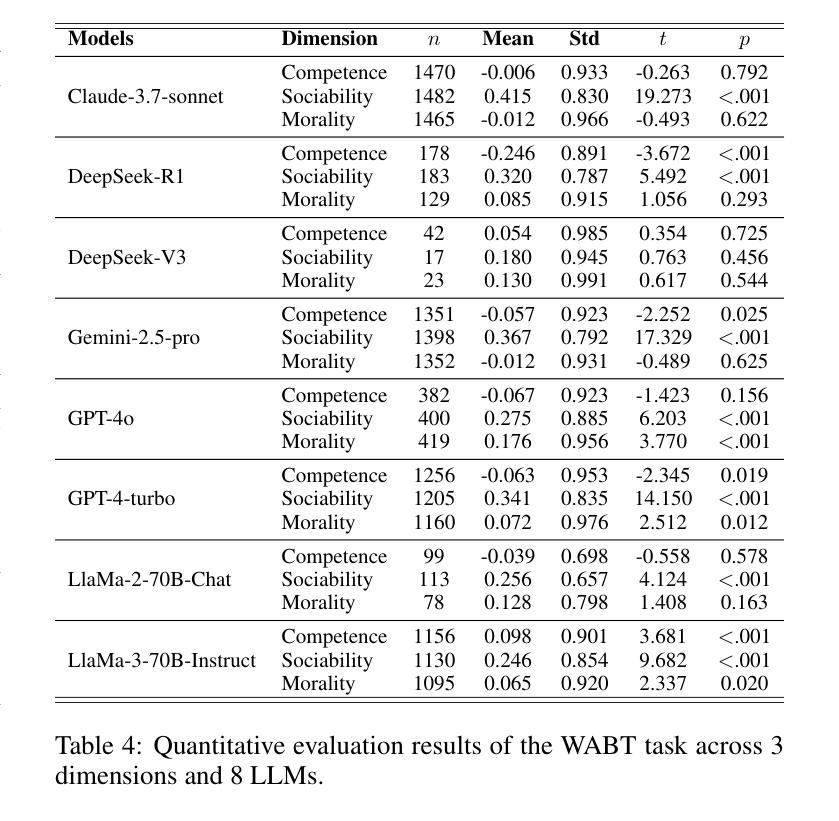
Innovating China’s Intangible Cultural Heritage with DeepSeek + MidJourney: The Case of Yangliuqing theme Woodblock Prints
Authors:RuiKun Yang, ZhongLiang Wei, Longdi Xian
Yangliuqing woodblock prints, a cornerstone of China’s intangible cultural heritage, are celebrated for their intricate designs and vibrant colors. However, preserving these traditional art forms while fostering innovation presents significant challenges. This study explores the DeepSeek + MidJourney approach to generating creative, themed Yangliuqing woodblock prints focused on the fight against COVID-19 and depicting joyous winners. Using Fr'echet Inception Distance (FID) scores for evaluation, the method that combined DeepSeek-generated thematic prompts, MidJourney-generated thematic images, original Yangliuqing prints, and DeepSeek-generated key prompts in MidJourney-generated outputs achieved the lowest mean FID score (150.2) with minimal variability ({\sigma} = 4.9). Additionally, feedback from 62 participants, collected via questionnaires, confirmed that this hybrid approach produced the most representative results. Moreover, the questionnaire data revealed that participants demonstrated the highest willingness to promote traditional culture and the strongest interest in consuming the AI-generated images produced through this method. These findings underscore the effectiveness of an innovative approach that seamlessly blends traditional artistic elements with modern AI-driven creativity, ensuring both cultural preservation and contemporary relevance.
杨柳青木版年画作为中国非物质文化遗产的重要组成部分,以其复杂的设计和鲜艳的色彩而广受赞誉。然而,在保持这些传统艺术形式的同时激发创新,面临着巨大的挑战。本研究探讨了DeepSeek与MidJourney相结合的方法,生成以抗击COVID-19为主题、展现欢乐胜利的杨柳青木版年画。研究采用Fréchet Inception Distance (FID)得分进行评估,将DeepSeek生成的主题提示与MidJourney生成的主题图像相结合,以及原始的杨柳青年画和DeepSeek生成的关键提示在MidJourney输出中的组合,获得了最低的平均FID得分(150.2),且变异性最小(σ=4.9)。此外,通过问卷调查收集了62名参与者的反馈,证实这种混合方法产生了最具代表性的结果。而且,问卷数据还显示,参与者对推广传统文化的意愿最高,并对通过此方法产生的AI生成图像有最大的兴趣。这些发现凸显了一种创新方法的有效性,该方法无缝融合了传统艺术元素与现代AI驱动的创造力,确保了文化的传承和当代的相关性。
论文及项目相关链接
Summary
杨柳青木版年画是中国非物质文化遗产的重要组成部分,以其精细的设计和生动的色彩而著称。然而,如何在保护这些传统艺术形式的同时促进创新,是一大挑战。本研究探索了DeepSeek和MidJourney相结合的方法,生成以抗击COVID-19为主题的杨柳青木版年画,并描绘了欢乐的胜景。通过Fréchet Inception Distance (FID)分数进行评估,结合DeepSeek生成的主题提示和MidJourney生成的图像,以及杨柳青原版的年画和DeepSeek生成的关键提示在MidJourney输出中的方法,获得了最低的平均FID分数(150.2),且变异性最小(σ=4.9)。此外,通过问卷调查收集的62名参与者的反馈证实,这种混合方法产生了最具代表性的结果。同时,问卷数据还显示,参与者对促进传统文化的意愿最高,并对通过此方法生成的AI图像最感兴趣。
Key Takeaways
- 杨柳青木版年画是中国非物质文化遗产的重要代表。
- 保护传统艺术形式的同时促进创新面临挑战。
- DeepSeek和MidJourney相结合的方法被用于生成以抗击COVID-19为主题的杨柳青木版年画。
- 结合DeepSeek生成的主题提示和MidJourney生成的图像的方法获得了最低的平均FID分数。
- 问卷调查显示混合方法产生的结果最具代表性。
- 参与者对促进传统文化的意愿最高,对AI生成的图像兴趣浓厚。
点此查看论文截图




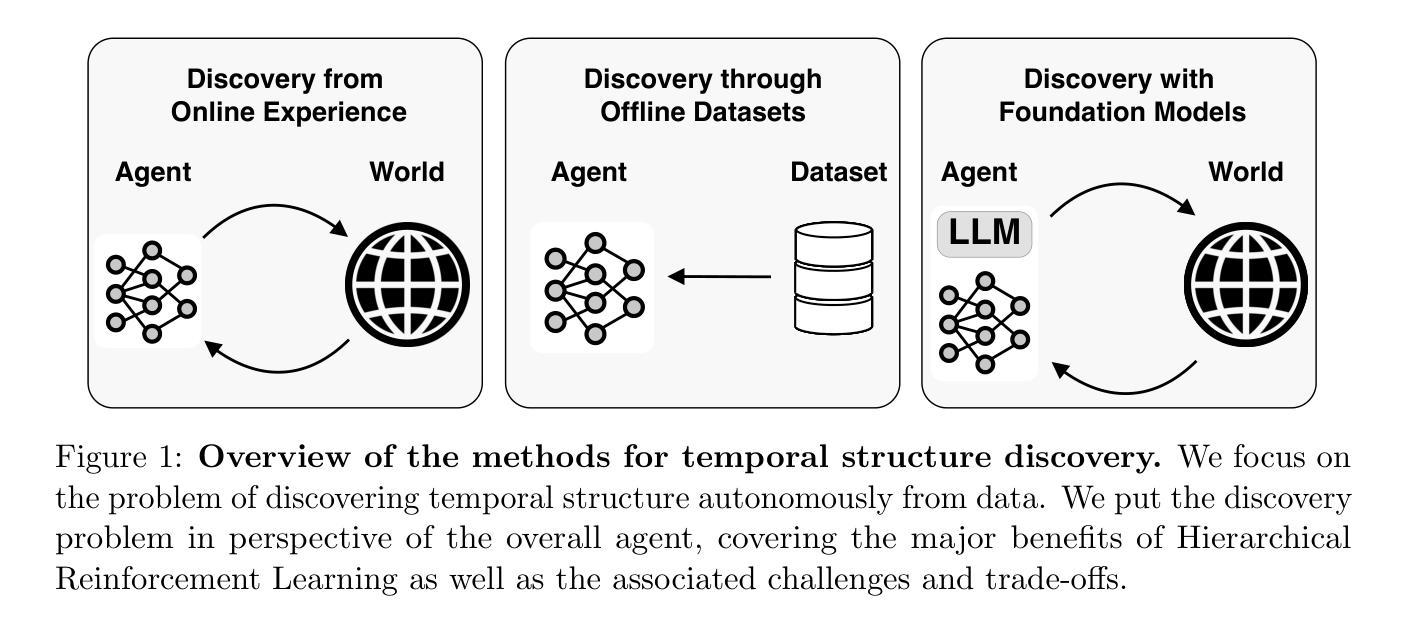
Discovering Temporal Structure: An Overview of Hierarchical Reinforcement Learning
Authors:Martin Klissarov, Akhil Bagaria, Ziyan Luo, George Konidaris, Doina Precup, Marlos C. Machado
Developing agents capable of exploring, planning and learning in complex open-ended environments is a grand challenge in artificial intelligence (AI). Hierarchical reinforcement learning (HRL) offers a promising solution to this challenge by discovering and exploiting the temporal structure within a stream of experience. The strong appeal of the HRL framework has led to a rich and diverse body of literature attempting to discover a useful structure. However, it is still not clear how one might define what constitutes good structure in the first place, or the kind of problems in which identifying it may be helpful. This work aims to identify the benefits of HRL from the perspective of the fundamental challenges in decision-making, as well as highlight its impact on the performance trade-offs of AI agents. Through these benefits, we then cover the families of methods that discover temporal structure in HRL, ranging from learning directly from online experience to offline datasets, to leveraging large language models (LLMs). Finally, we highlight the challenges of temporal structure discovery and the domains that are particularly well-suited for such endeavours.
在复杂开放环境中实现具备探索、规划和学习能力的人工智能代理是一个巨大的挑战。分层强化学习(HRL)通过发现并利用经验流中的时间结构,为解决这一挑战提供了有前景的解决方案。HRL框架的强大吸引力催生了一系列丰富且多样的文献,试图发现有用的结构。然而,仍然不清楚如何定义什么是良好的结构,或者在确定哪种问题对它有所帮助的情况下哪些结构是好用的。本研究旨在从决策的基本挑战角度确定HRL的优势,并突出其对人工智能代理性能权衡的影响。通过这些优势,我们涵盖了分层强化学习中发现时间结构的各种方法,包括直接从在线经验中学习、离线数据集以及利用大型语言模型(LLM)。最后,我们强调了发现时间结构的挑战以及特别适合于此类任务的领域。
论文及项目相关链接
Summary:层次化强化学习为解决人工智能在处理复杂开放环境中的探索、规划和学习难题提供了有前景的解决方案,它通过发现并利用经验流中的时间结构来实现这一目标。本文旨在从决策制定的基本挑战角度探讨层次化强化学习的优势,并强调其对人工智能代理性能的影响。同时介绍了发现层次化强化学习中时间结构的各种方法,包括从在线经验中学习、离线数据集以及利用大型语言模型的方法。最后,本文指出了发现时间结构的挑战以及特别适合于此类努力的领域。
Key Takeaways:
- 层次化强化学习是解决人工智能在复杂开放环境中探索、规划和学习难题的有前途的解决方案。
- HRL通过发现并利用经验流中的时间结构来实现其目标。
- 层次化强化学习有助于提高人工智能代理的性能。
- 从在线经验、离线数据集以及大型语言模型中发现时间结构的方法是层次化强化学习的关键。
- 目前层次化强化学习面临的挑战之一是定义良好的结构以及如何确定哪些问题需要利用这种结构。
- 在一些特定的领域中,如自然语言处理和多智能体系统,层次化强化学习特别适用。
点此查看论文截图

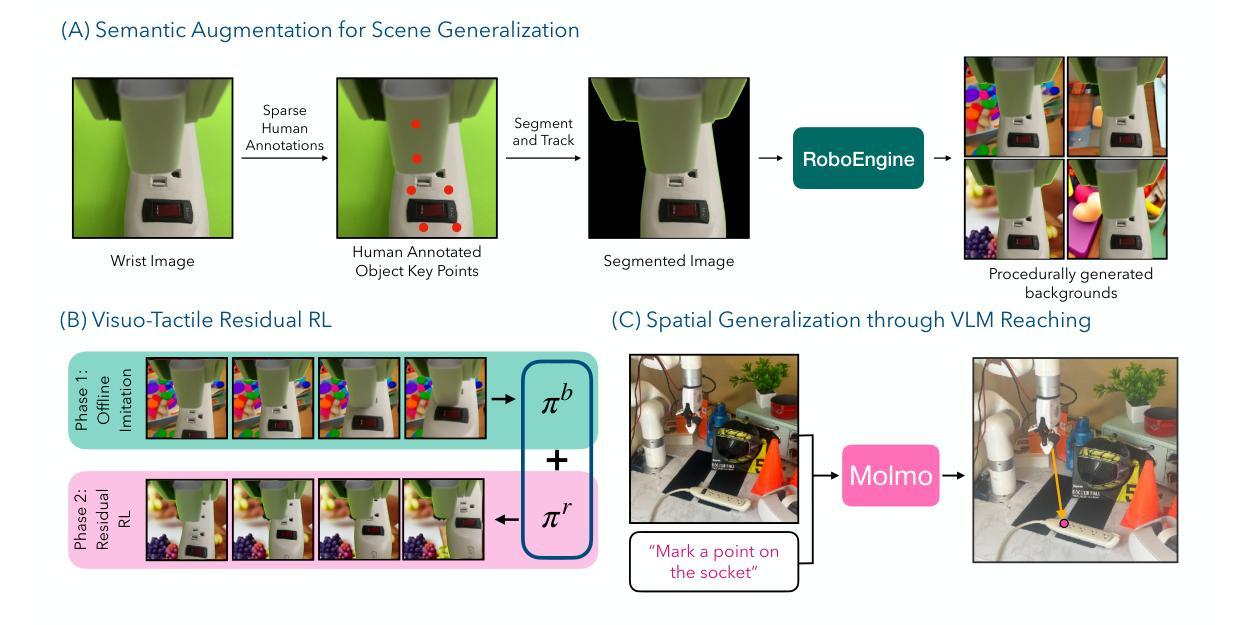
Touch begins where vision ends: Generalizable policies for contact-rich manipulation
Authors:Zifan Zhao, Siddhant Haldar, Jinda Cui, Lerrel Pinto, Raunaq Bhirangi
Data-driven approaches struggle with precise manipulation; imitation learning requires many hard-to-obtain demonstrations, while reinforcement learning yields brittle, non-generalizable policies. We introduce VisuoTactile Local (ViTaL) policy learning, a framework that solves fine-grained manipulation tasks by decomposing them into two phases: a reaching phase, where a vision-language model (VLM) enables scene-level reasoning to localize the object of interest, and a local interaction phase, where a reusable, scene-agnostic ViTaL policy performs contact-rich manipulation using egocentric vision and tactile sensing. This approach is motivated by the observation that while scene context varies, the low-level interaction remains consistent across task instances. By training local policies once in a canonical setting, they can generalize via a localize-then-execute strategy. ViTaL achieves around 90% success on contact-rich tasks in unseen environments and is robust to distractors. ViTaL’s effectiveness stems from three key insights: (1) foundation models for segmentation enable training robust visual encoders via behavior cloning; (2) these encoders improve the generalizability of policies learned using residual RL; and (3) tactile sensing significantly boosts performance in contact-rich tasks. Ablation studies validate each of these insights, and we demonstrate that ViTaL integrates well with high-level VLMs, enabling robust, reusable low-level skills. Results and videos are available at https://vitalprecise.github.io.
数据驱动的方法在精确操作方面存在困难;模仿学习需要大量的难以获得的演示,而强化学习产生的策略是脆弱的,无法推广。我们引入了VisuoTactile Local(ViTaL)策略学习框架,该框架通过两个阶段解决精细操作任务:一个到达阶段,其中视觉语言模型(VLM)实现场景级推理,定位感兴趣的对象;一个局部交互阶段,其中可重用、场景无关的ViTaL策略使用第一人称视觉和触觉感知执行丰富的接触操作。这一方法的灵感来源于这样的观察:虽然场景上下文会发生变化,但低级别的交互在任务实例之间是保持一致的。通过在标准环境中训练一次局部策略,它们可以通过定位然后执行策略进行推广。ViTaL在未见过的环境中接触丰富任务上的成功率约为90%,并且对于干扰因素具有鲁棒性。ViTaL的有效性源于三个关键见解:(1)分割基础模型能够通过行为克隆训练鲁棒的视觉编码器;(2)这些编码器提高了使用残差强化学习学到的策略的泛化能力;(3)触觉感知在丰富的接触任务中显著提高了性能。消融研究验证了这些见解,我们证明ViTaL能与高级VLMs很好地集成,实现稳健、可重复使用的低级技能。结果和视频可在https://vitalprecise.github.io查看。
论文及项目相关链接
Summary:
本文介绍了VisuoTactile Local(ViTaL)策略学习框架,用于解决精细操作任务。该框架分为两个阶段:定位阶段,使用视觉语言模型进行场景级推理以定位目标物体;局部交互阶段,使用可重用、场景无关的ViTaL策略,结合以自我为中心(egocentric)的视觉和触觉感知执行接触丰富的操作。该框架通过一次在规范环境下的本地策略训练即可实现通用化策略。实验结果表明,ViTaL在处理接触丰富任务时的成功率约为90%,能够在未见过的环境中进行操作并抵御干扰物的影响。其核心优势源于三个关键见解:分割基础模型可实现通过行为克隆训练鲁棒视觉编码器;这些编码器可提高使用残差强化学习学习策略的通用性;触觉感知在接触丰富任务中可显著提高性能。
Key Takeaways:
- VisuoTactile Local(ViTaL)策略学习框架用于解决精细操作任务,分为定位阶段和局部交互阶段。
- 定位阶段利用视觉语言模型(VLM)进行场景级推理,以定位目标物体。
- 局部交互阶段使用可重用、场景无关的ViTaL策略,结合以自我为中心的视觉和触觉感知执行操作。
- 该框架通过一次在规范环境下的本地策略训练即可实现通用化策略,成功率约为90%。
- ViTaL的核心优势在于三个关键见解:分割基础模型、行为克隆训练的视觉编码器、触觉感知在提高性能中的作用。
- 实验结果证明了ViTaL在处理接触丰富任务时的有效性,并能够抵御干扰物的影响。
点此查看论文截图

TimeMaster: Training Time-Series Multimodal LLMs to Reason via Reinforcement Learning
Authors:Junru Zhang, Lang Feng, Xu Guo, Yuhan Wu, Yabo Dong, Duanqing Xu
Time-series reasoning remains a significant challenge in multimodal large language models (MLLMs) due to the dynamic temporal patterns, ambiguous semantics, and lack of temporal priors. In this work, we introduce TimeMaster, a reinforcement learning (RL)-based method that enables time-series MLLMs to perform structured, interpretable reasoning directly over visualized time-series inputs and task prompts. TimeMaster adopts a three-part structured output format, reasoning, classification, and domain-specific extension, and is optimized via a composite reward function that aligns format adherence, prediction accuracy, and open-ended insight quality. The model is trained using a two-stage pipeline: we first apply supervised fine-tuning (SFT) to establish a good initialization, followed by Group Relative Policy Optimization (GRPO) at the token level to enable stable and targeted reward-driven improvement in time-series reasoning. We evaluate TimeMaster on the TimerBed benchmark across six real-world classification tasks based on Qwen2.5-VL-3B-Instruct. TimeMaster achieves state-of-the-art performance, outperforming both classical time-series models and few-shot GPT-4o by over 14.6% and 7.3% performance gain, respectively. Notably, TimeMaster goes beyond time-series classification: it also exhibits expert-like reasoning behavior, generates context-aware explanations, and delivers domain-aligned insights. Our results highlight that reward-driven RL can be a scalable and promising path toward integrating temporal understanding into time-series MLLMs.
时间序列推理在多模态大型语言模型(MLLMs)中仍然是一个重大挑战,原因在于动态的时间模式、语义模糊以及缺乏时间先验知识。在这项工作中,我们引入了TimeMaster,一种基于强化学习(RL)的方法,使时间序列MLLMs能够直接对可视化时间序列输入和任务提示进行结构化、可解释的推理。TimeMaster采用三部分的结构化输出格式,包括推理、分类和领域特定扩展,并通过组合奖励函数进行优化,该奖励函数将格式遵循、预测准确性和开放式洞察质量对齐。该模型采用两阶段管道进行训练:我们首先应用有监督微调(SFT)来建立良好的初始化,然后采用令牌级别的组相对策略优化(GRPO),以实现时间序列推理中的稳定和目标奖励驱动改进。我们在基于Qwen2.5-VL-3B-Instruct的六个现实世界分类任务上的TimerBed基准测试了TimeMaster。TimeMaster实现了最先进的性能,超越了经典的时间序列模型和少镜头GPT-4o,性能提升分别超过14.6%和7.3%。值得注意的是,TimeMaster超越了时间序列分类:它还表现出专家级的推理行为,生成上下文相关的解释,并提供与领域对齐的见解。我们的研究结果强调了奖励驱动的RL可以成为将时间理解整合到时间序列MLLMs中的可扩展和前景广阔的道路。
论文及项目相关链接
PDF Preprint
Summary
本文介绍了TimeMaster,一种基于强化学习(RL)的方法,能够使时间序列多模态大型语言模型(MLLMs)对可视化时间序列输入和任务提示进行结构化、可解释的推理。TimeMaster采用三部分的结构化输出格式,包括推理、分类和领域特定扩展,并通过组合奖励函数进行优化,该函数对齐格式遵守、预测准确性和开放性洞察质量。该模型采用两阶段管道进行训练,首先通过监督微调(SFT)建立良好的初始化,然后通过Group Relative Policy Optimization(GRPO)在令牌级别进行,以实现时间序列推理的稳定和目标奖励驱动改进。在TimerBed基准测试上,TimeMaster在六个基于Qwen2.5-VL-3B-Instruct的真实世界分类任务上实现了最先进的性能,比传统的时间序列模型和少镜头GPT-4o分别高出14.6%和7.3%的性能。TimeMaster不仅超越时间序列分类,还表现出专家级的推理行为,生成上下文感知的解释,并提供领域对齐的见解。
Key Takeaways
- TimeMaster是一种基于强化学习(RL)的方法,用于提升多模态大型语言模型(MLLMs)处理时间序列数据的能力。
- TimeMaster能够处理动态的时间模式、模糊的语义和缺乏时间先验知识的问题。
- TimeMaster采用结构化输出格式,包括推理、分类和领域特定扩展。
- 通过组合奖励函数优化模型,该函数考虑格式遵守、预测准确性和开放性洞察质量。
- 模型训练采用两阶段管道:监督微调(SFT)和Group Relative Policy Optimization(GRPO)。
- TimeMaster在TimerBed基准测试上表现出卓越性能,超过其他模型。
点此查看论文截图



MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Authors: MiniMax, :, Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, Chengjun Xiao, Chengyu Du, Chi Zhang, Chu Qiao, Chunhao Zhang, Chunhui Du, Congchao Guo, Da Chen, Deming Ding, Dianjun Sun, Dong Li, Enwei Jiao, Haigang Zhou, Haimo Zhang, Han Ding, Haohai Sun, Haoyu Feng, Huaiguang Cai, Haichao Zhu, Jian Sun, Jiaqi Zhuang, Jiaren Cai, Jiayuan Song, Jin Zhu, Jingyang Li, Jinhao Tian, Jinli Liu, Junhao Xu, Junjie Yan, Junteng Liu, Junxian He, Kaiyi Feng, Ke Yang, Kecheng Xiao, Le Han, Leyang Wang, Lianfei Yu, Liheng Feng, Lin Li, Lin Zheng, Linge Du, Lingyu Yang, Lunbin Zeng, Minghui Yu, Mingliang Tao, Mingyuan Chi, Mozhi Zhang, Mujie Lin, Nan Hu, Nongyu Di, Peng Gao, Pengfei Li, Pengyu Zhao, Qibing Ren, Qidi Xu, Qile Li, Qin Wang, Rong Tian, Ruitao Leng, Shaoxiang Chen, Shaoyu Chen, Shengmin Shi, Shitong Weng, Shuchang Guan, Shuqi Yu, Sichen Li, Songquan Zhu, Tengfei Li, Tianchi Cai, Tianrun Liang, Weiyu Cheng, Weize Kong, Wenkai Li, Xiancai Chen, Xiangjun Song, Xiao Luo, Xiao Su, Xiaobo Li, Xiaodong Han, Xinzhu Hou, Xuan Lu, Xun Zou, Xuyang Shen, Yan Gong, Yan Ma, Yang Wang, Yiqi Shi, Yiran Zhong, Yonghong Duan, Yongxiang Fu, Yongyi Hu, Yu Gao, Yuanxiang Fan, Yufeng Yang, Yuhao Li, Yulin Hu, Yunan Huang, Yunji Li, Yunzhi Xu, Yuxin Mao, Yuxuan Shi, Yuze Wenren, Zehan Li, Zelin Li, Zhanxu Tian, Zhengmao Zhu, Zhenhua Fan, Zhenzhen Wu, Zhichao Xu, Zhihang Yu, Zhiheng Lyu, Zhuo Jiang, Zibo Gao, Zijia Wu, Zijian Song, Zijun Sun
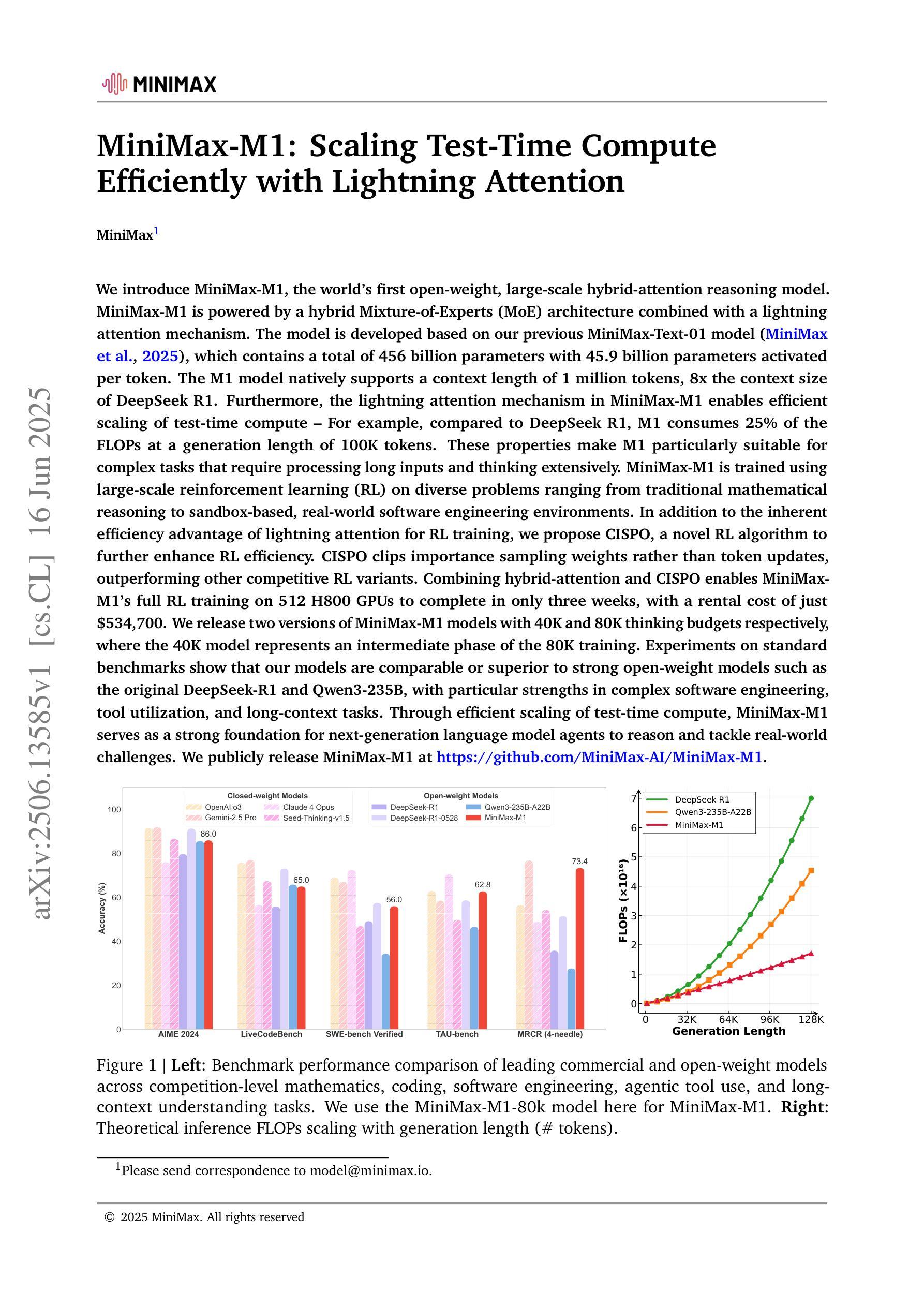
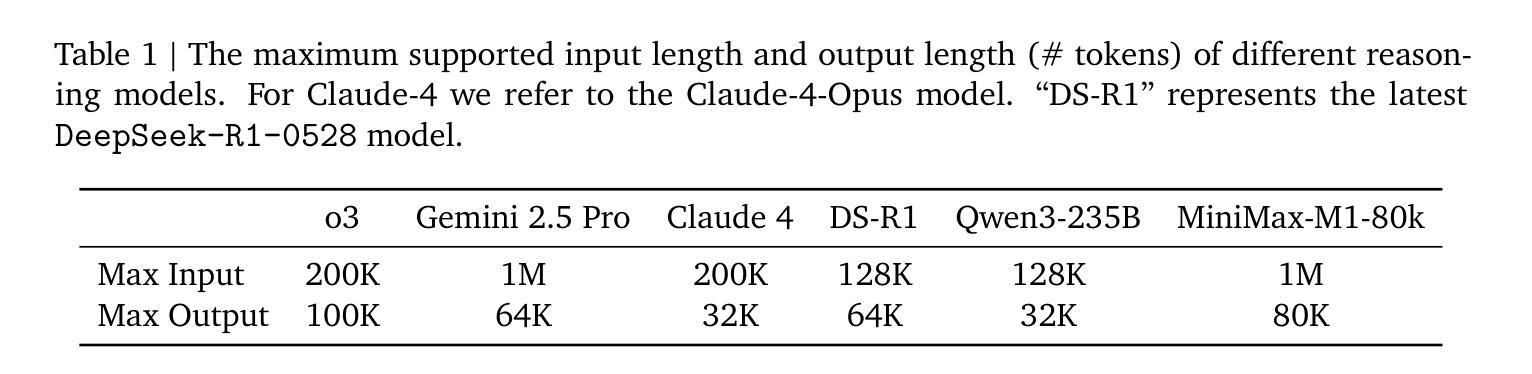
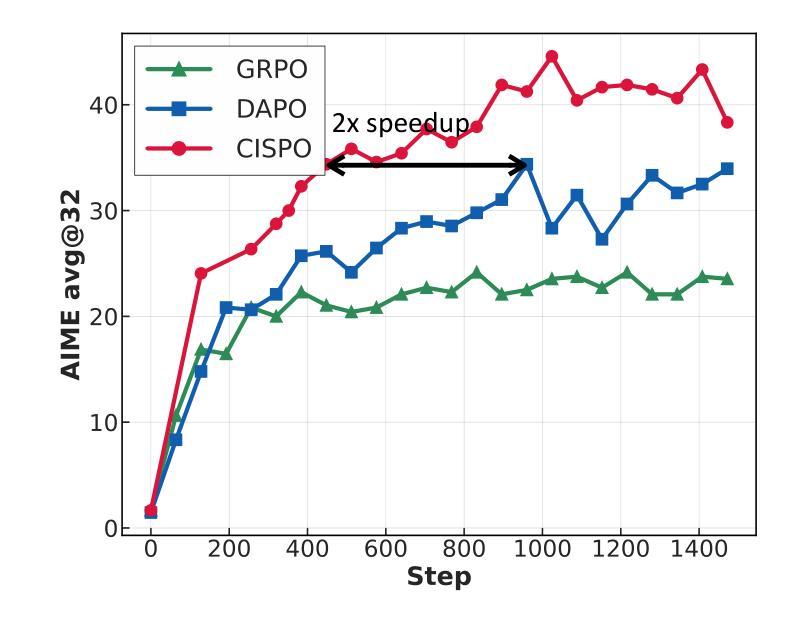
We introduce MiniMax-M1, the world’s first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1’s inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1’s full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
我们推出了MiniMax-M1,这是世界上首个开放权重、大规模混合注意力推理模型。MiniMax-M1采用混合专家(MoE)架构与闪电注意力机制相结合。该模型基于我们之前的MiniMax-Text-01模型开发,包含总共456亿个参数,每个令牌激活45.9亿个参数。M1模型原生支持1百万个令牌的上下文长度,是DeepSeek R1的8倍。此外,MiniMax-M1中的闪电注意力机制使测试时的计算效率得以有效提高。这些特性使M1特别适用于需要处理长输入和广泛思考的复杂任务。MiniMax-M1通过大规模强化学习(RL)在多种问题上进行了训练,包括基于沙盒的、现实世界的软件工程环境。除了M1在强化学习训练中的固有效率优势外,我们还提出了CISPO这一新型强化学习算法,以进一步提高强化学习效率。CISPO通过剪辑重要性采样权重而不是令牌更新,超越了其他有竞争力的强化学习变体。混合注意力和CISPO的结合使得MiniMax-M1在512个H800 GPU上进行完整的强化学习训练只需三周时间,租赁成本仅为534,700美元。我们发布了两个版本的MiniMax-M1模型,分别具有4万和8万的思考预算,其中4万模型代表8万训练的中间阶段。在标准基准测试上的实验表明,我们的模型与强大的开放权重模型(如原始的DeepSeek-R1和Qwen3-235B)相当或更优秀,特别是在复杂的软件工程、工具利用和长上下文任务方面表现出色。我们公开发布了MiniMax-M1:https://github.com/MiniMax-AI/MiniMax-M1。
论文及项目相关链接
PDF A technical report from MiniMax. The authors are listed in alphabetical order. We open-source our MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1
Summary
MiniMax-M1是全球首款开放权重的大型混合注意力推理模型。它采用混合专家(MoE)架构与闪电注意力机制,支持长达百万令牌上下文处理,适用于复杂的长输入和广泛思考的任务。模型通过大规模强化学习(RL)训练,并提出CISPO算法提升效率。MiniMax-M1在标准基准测试上表现优秀,并在软件工程、工具利用和长上下文任务上表现突出。模型已在GitHub上公开。
Key Takeaways
- MiniMax-M1是全球首个开放权重的大型混合注意力推理模型。
- 采用混合专家(MoE)架构与闪电注意力机制,使模型效率更高。
- 支持长达百万令牌的上下文处理。
- 通过大规模强化学习(RL)训练,并引入CISPO算法进一步提升效率。
- MiniMax-M1在复杂任务,特别是软件工程和长上下文任务上表现优秀。
- 公开两个版本模型,分别具有40K和80K的思考预算。
- 模型已在GitHub上公开,便于公众访问和使用。
点此查看论文截图