⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-21 更新
DualTalk: Dual-Speaker Interaction for 3D Talking Head Conversations
Authors:Ziqiao Peng, Yanbo Fan, Haoyu Wu, Xuan Wang, Hongyan Liu, Jun He, Zhaoxin Fan
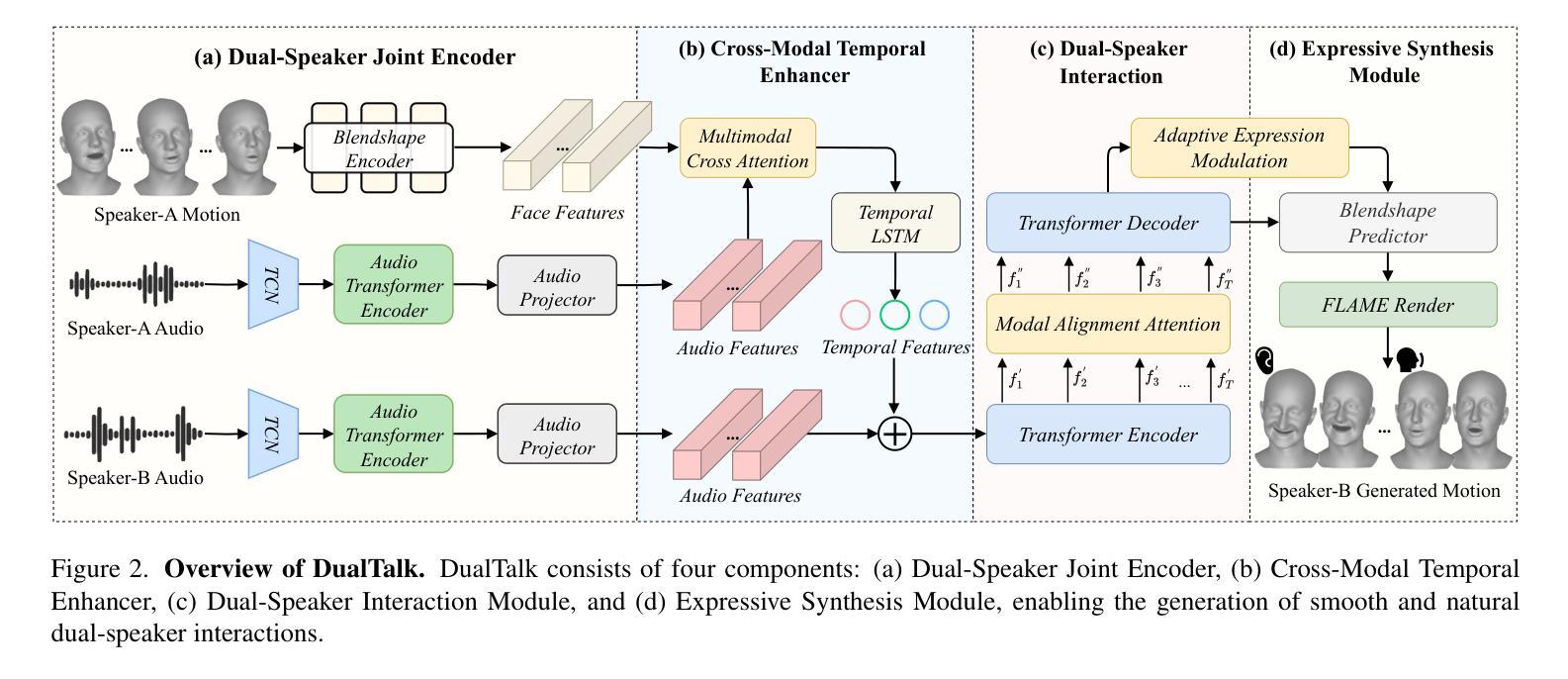
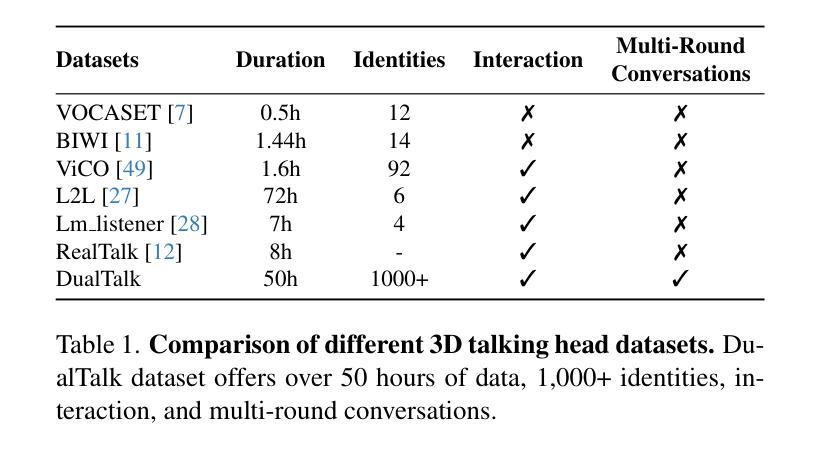
In face-to-face conversations, individuals need to switch between speaking and listening roles seamlessly. Existing 3D talking head generation models focus solely on speaking or listening, neglecting the natural dynamics of interactive conversation, which leads to unnatural interactions and awkward transitions. To address this issue, we propose a new task – multi-round dual-speaker interaction for 3D talking head generation – which requires models to handle and generate both speaking and listening behaviors in continuous conversation. To solve this task, we introduce DualTalk, a novel unified framework that integrates the dynamic behaviors of speakers and listeners to simulate realistic and coherent dialogue interactions. This framework not only synthesizes lifelike talking heads when speaking but also generates continuous and vivid non-verbal feedback when listening, effectively capturing the interplay between the roles. We also create a new dataset featuring 50 hours of multi-round conversations with over 1,000 characters, where participants continuously switch between speaking and listening roles. Extensive experiments demonstrate that our method significantly enhances the naturalness and expressiveness of 3D talking heads in dual-speaker conversations. We recommend watching the supplementary video: https://ziqiaopeng.github.io/dualtalk.
在面对面交谈中,人们需要在说话和倾听的角色之间无缝切换。现有的3D对话头像生成模型只专注于说话或倾听,忽略了交互式对话的自然动态,导致互动不自然和尴尬的过渡。为了解决这个问题,我们提出了一个新的任务——用于3D对话头像生成的多轮双人对话任务,要求模型处理和生成连续对话中的说话和倾听行为。为了解决此任务,我们引入了DualTalk,这是一个新颖的统一框架,集成了说话者和听众的动态行为来模拟现实和连贯的对话交互。此框架不仅在说话时合成逼真的对话头像,而且在听的时候还可以生成连续而逼真的非语言反馈,有效地捕捉角色之间的互动。我们还创建了一个包含超过一千个角色的50小时多轮对话的新数据集,参与者连续在说话和倾听角色之间进行切换。大量实验证明,我们的方法在双人对话的3D对话头像中显著提高了自然性和表现力。建议观看补充视频:https://ziqiaopeng.github.io/dualtalk。
论文及项目相关链接
PDF Accepted by CVPR 2025
Summary
本文提出在3D对话头模型中存在的一个问题,即模型主要侧重于模拟单一角色的说话或聆听行为,而忽略了现实对话中的动态交互特性。为了解决这个问题,本文提出了一种新型任务——多轮双人对话的3D对话头生成任务,要求模型能够处理和生成连续对话中的说话和聆听行为。为了完成这个任务,引入了DualTalk框架,该框架可以模拟真实且连贯的对话交互,合成逼真的对话头,并在聆听时生成连续且真实的非语言反馈。此外,还创建了一个包含超过一千个角色的五十小时多轮对话数据集。实验证明,该方法显著提高了双人在3D对话中的自然度和表现力。建议观看补充视频以获取更多信息。
Key Takeaways
- 当前3D对话头生成模型主要关注单一角色的说话或聆听行为,忽略了现实对话中的动态交互特性。
- 提出了一种新型任务——多轮双人对话的3D对话头生成任务,要求模型能够处理并生成连续对话中的说话和聆听行为。
- 引入了DualTalk框架来模拟真实且连贯的对话交互,能够合成逼真的对话头并在聆听时生成真实的非语言反馈。
- 创建了一个大型的多轮对话数据集,包含五十小时的数据和超过一千个角色。
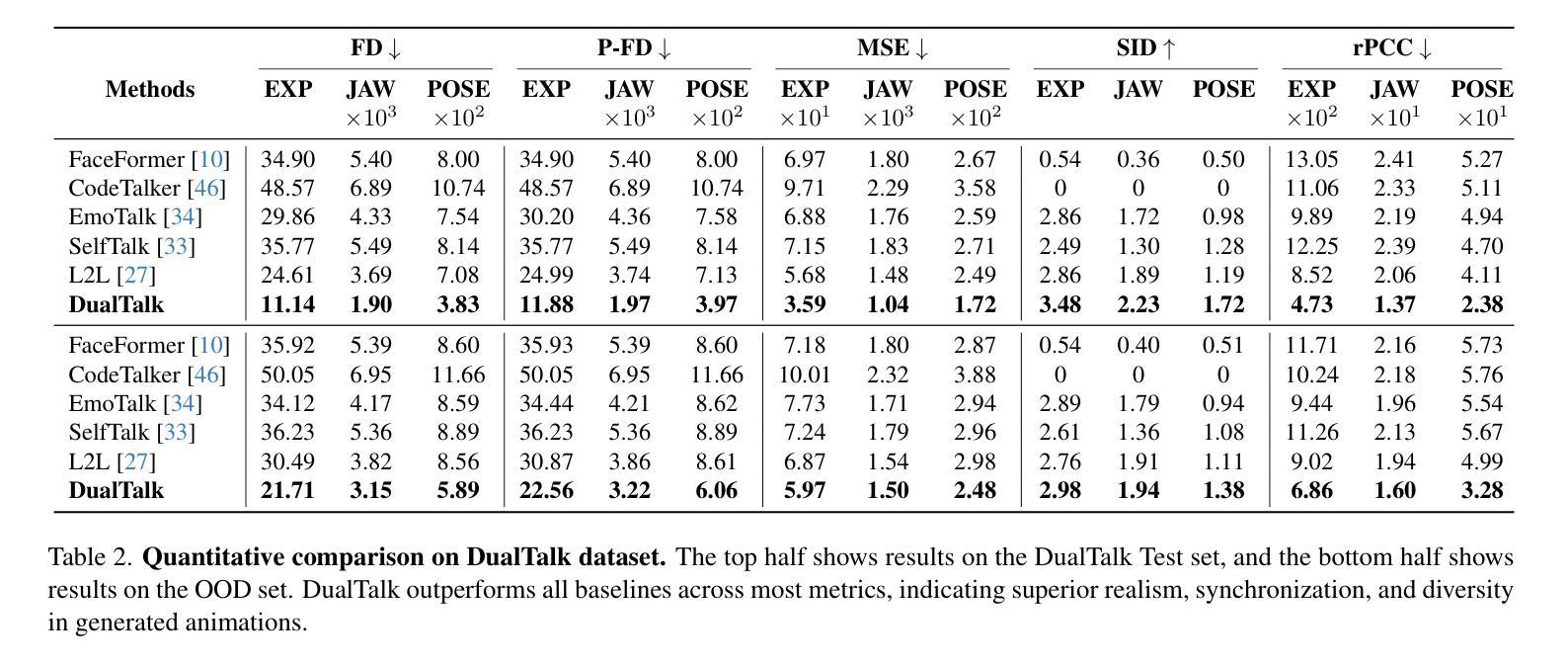
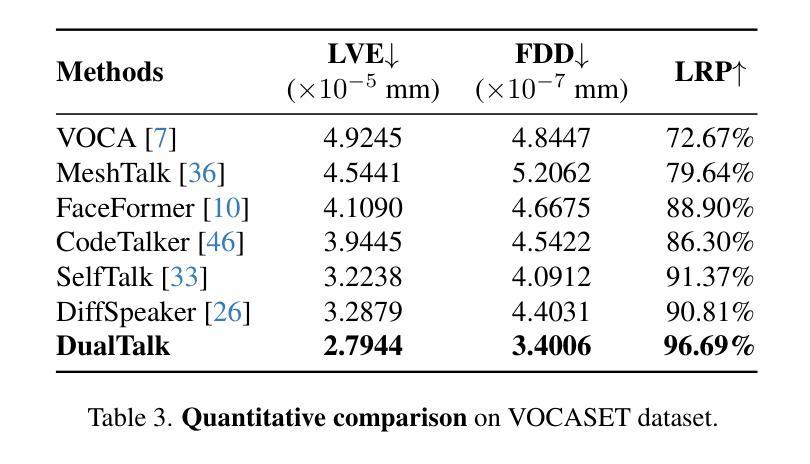
- 该方法显著提高了双人在3D对话中的自然度和表现力。
- 建议观看补充视频以获取更多关于该方法和应用的详细信息。
点此查看论文截图