⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-21 更新
Seewo’s Submission to MLC-SLM: Lessons learned from Speech Reasoning Language Models
Authors:Bo Li, Chengben Xu, Wufeng Zhang
This paper presents Seewo’s systems for both tracks of the Multilingual Conversational Speech Language Model Challenge (MLC-SLM), addressing automatic speech recognition (ASR) and speaker diarization with ASR (SD-ASR). We introduce a multi-stage training pipeline that explicitly enhances reasoning and self-correction in speech language models for ASR. Our approach combines curriculum learning for progressive capability acquisition, Chain-of-Thought data augmentation to foster intermediate reflection, and Reinforcement Learning with Verifiable Rewards (RLVR) to further refine self-correction through reward-driven optimization. This approach achieves substantial improvements over the official challenge baselines. On the evaluation set, our best system attains a WER/CER of 11.57% for Track 1 and a tcpWER/tcpCER of 17.67% for Track 2. Comprehensive ablation studies demonstrate the effectiveness of each component under challenge constraints.
本文介绍了Seewo在多语种对话语音语言模型挑战(MLC-SLM)两个赛道中的系统,包括自动语音识别(ASR)和带有ASR的说话人日记化(SD-ASR)。我们引入了一个多阶段训练流程,该流程在语音语言模型中显式增强推理和自我校正功能,用于ASR。我们的方法结合了课程学习以实现逐步能力获取,通过“思考链”数据增强来促进中间反思,以及强化学习与可验证奖励(RLVR)进一步通过奖励驱动优化来完善自我校正。该方法在官方挑战基线的基础上取得了显著改进。在评估集上,我们最好的系统在第1赛道上达到了11.57%的WER/CER,在第2赛道上达到了17.67%的tcpWER/tcpCER。全面的消融研究表明,在挑战约束下,每个组件都是有效的。
论文及项目相关链接
Summary
本文介绍了Seewo在多语种对话语音语言模型挑战(MLC-SLM)的两条赛道上的系统,涵盖了自动语音识别(ASR)和带ASR的说话人分卷积(SD-ASR)。文章提出了一种多阶段训练管道,旨在提高语音语言模型在ASR中的推理和自我纠错能力。该方法结合了课程学习以促进能力逐步积累,Chain-of-Thought数据增强以促进中间反思,以及强化学习与可验证奖励(RLVR)以通过奖励驱动优化进一步改进自我纠错。该方法在挑战基准线上取得了显著改进。在评估集上,我们最好的系统达到了Track 1的WER/CER为11.57%,Track 2的tcpWER/tcpCER为17.67%。综合消融研究证明了每个组件在挑战约束下的有效性。
Key Takeaways
- Seewo系统参加了多语种对话语音语言模型挑战,包含自动语音识别和带ASR的说话人分卷积两个赛道。
- 提出了一种多阶段训练管道,旨在提高语音语言模型在ASR中的推理和自我纠错能力。
- 结合课程学习促进能力逐步积累,通过Chain-of-Thought数据增强中间反思。
- 采用强化学习与可验证奖励(RLVR)改进自我纠错,通过奖励驱动优化。
- 该方法在挑战基准线上取得了显著改进,最佳系统性能表现优异。
- 在评估集上,Track 1的WER/CER为11.57%,Track 2的tcpWER/tcpCER为17.67%。
点此查看论文截图




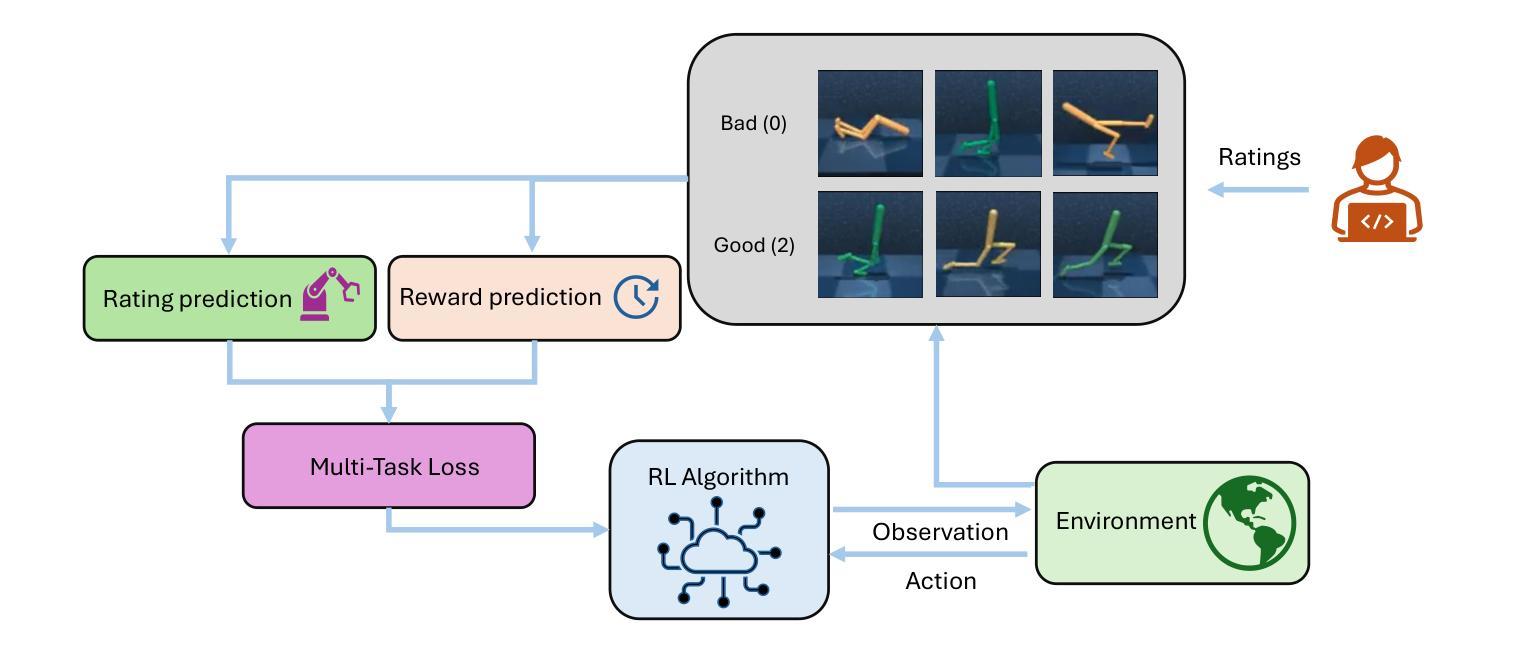
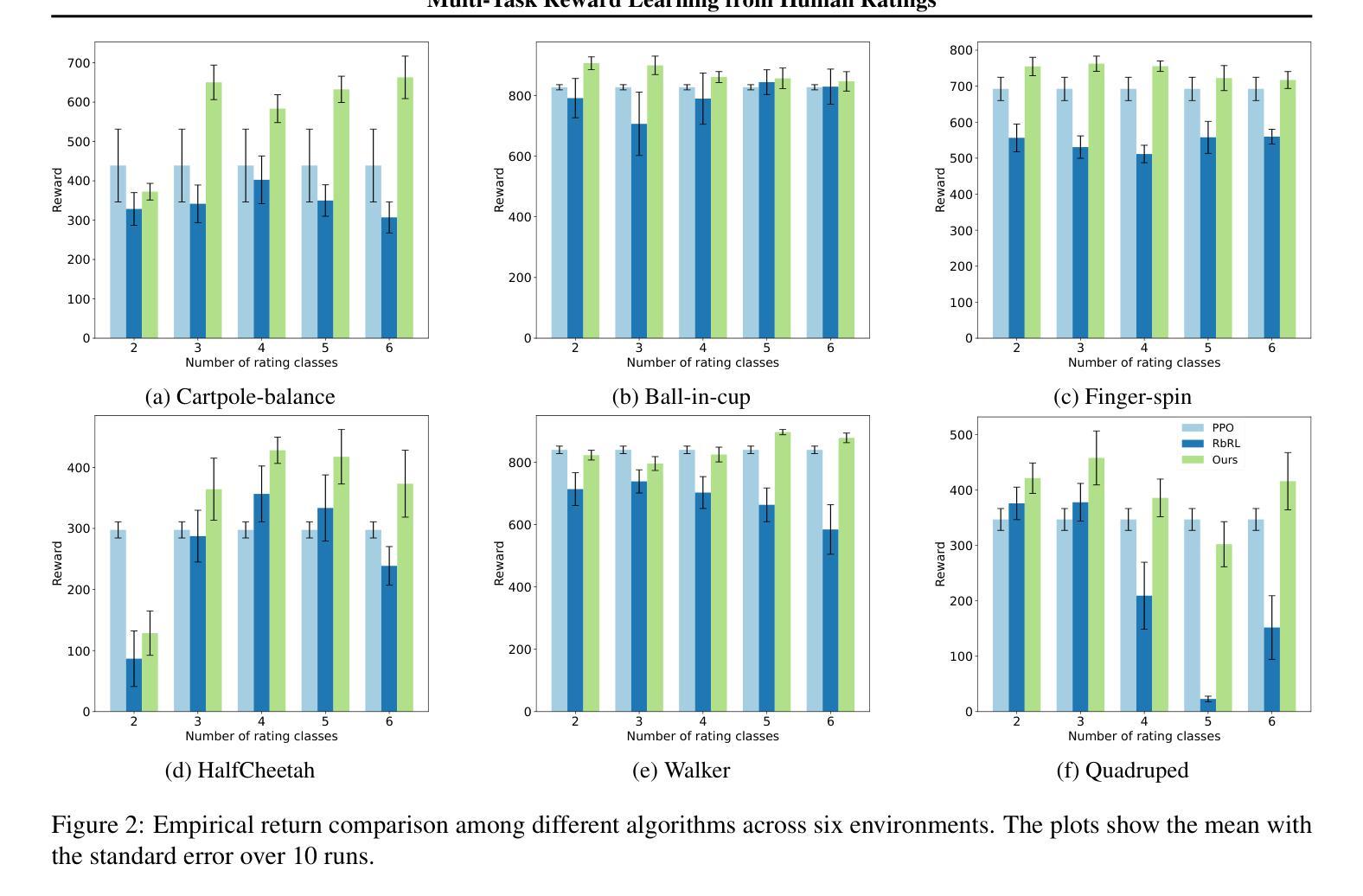
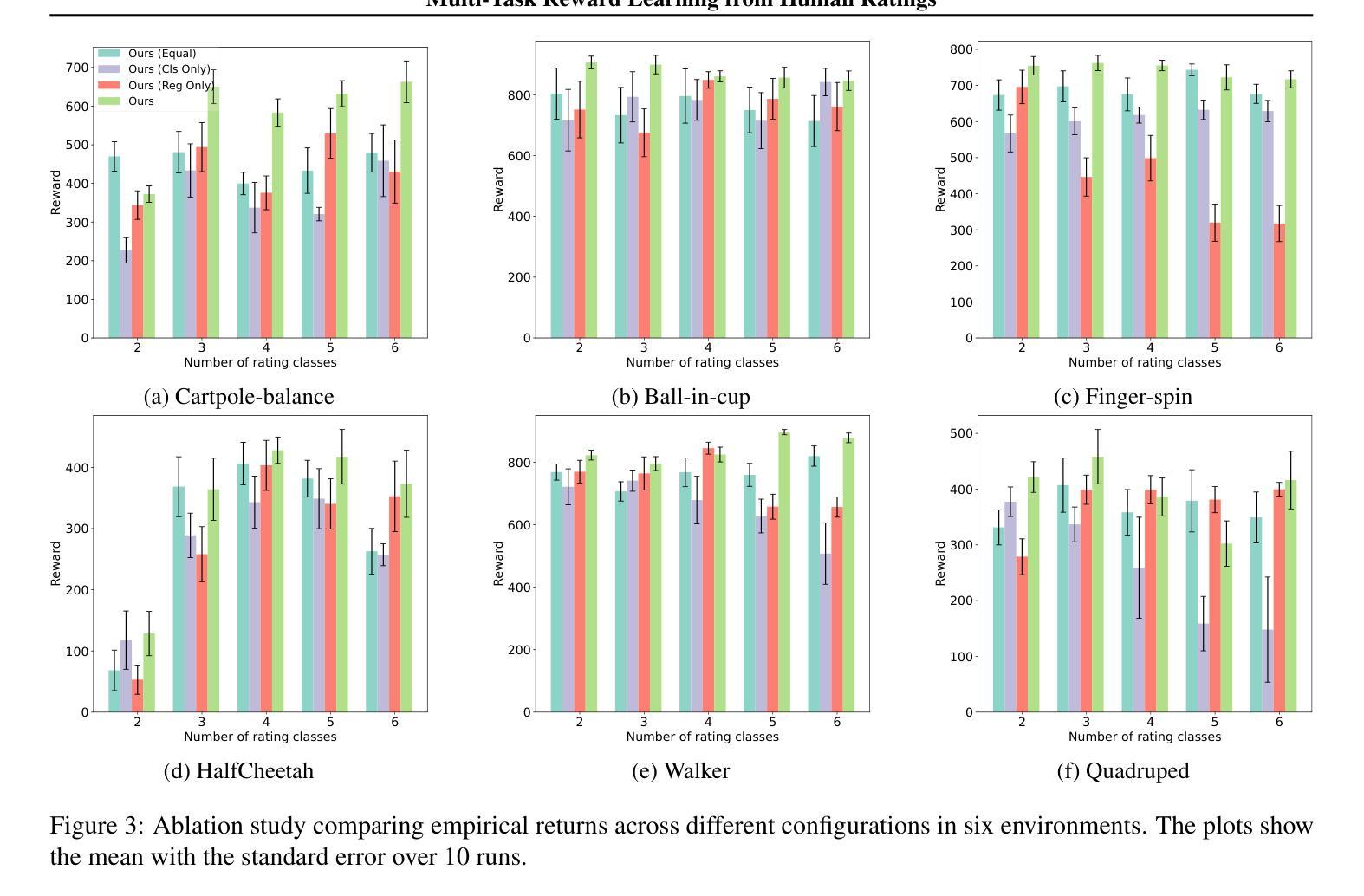
Multi-Task Reward Learning from Human Ratings
Authors:Mingkang Wu, Devin White, Evelyn Rose, Vernon Lawhern, Nicholas R Waytowich, Yongcan Cao
Reinforcement learning from human feedback (RLHF) has become a key factor in aligning model behavior with users’ goals. However, while humans integrate multiple strategies when making decisions, current RLHF approaches often simplify this process by modeling human reasoning through isolated tasks such as classification or regression. In this paper, we propose a novel reinforcement learning (RL) method that mimics human decision-making by jointly considering multiple tasks. Specifically, we leverage human ratings in reward-free environments to infer a reward function, introducing learnable weights that balance the contributions of both classification and regression models. This design captures the inherent uncertainty in human decision-making and allows the model to adaptively emphasize different strategies. We conduct several experiments using synthetic human ratings to validate the effectiveness of the proposed approach. Results show that our method consistently outperforms existing rating-based RL methods, and in some cases, even surpasses traditional RL approaches.
强化学习从人类反馈(RLHF)已经成为使模型行为与用户目标保持一致的关键因素。然而,人类在决策时会结合多种策略,而当前的RLHF方法往往通过分类或回归等孤立任务来模拟人类推理,从而简化了这一过程。在本文中,我们提出了一种新型强化学习(RL)方法,通过同时考虑多个任务来模拟人类决策过程。具体来说,我们在无奖励环境中利用人类评分来推断奖励函数,并引入可学习的权重来平衡分类和回归模型的贡献。这种设计捕捉了人类决策中固有的不确定性,并允许模型自适应地强调不同的策略。我们使用合成的人类评分进行了多次实验,以验证所提出方法的有效性。结果表明,我们的方法始终优于基于评分的现有RL方法,在某些情况下,甚至超过了传统RL方法。
论文及项目相关链接
PDF Accepted to the workshop on Models of Human Feedback for AI Alignment at the 42nd International Conference on Machine Learning
Summary
本文提出了一种新型强化学习(RL)方法,通过联合考虑多任务来模拟人类决策过程。该方法利用无奖励环境中的人类评分来推断奖励函数,并引入可学习的权重来平衡分类和回归模型的贡献。该研究旨在捕捉人类决策过程中的内在不确定性,使模型能够自适应地强调不同的策略。实验结果表明,该方法在基于评分的RL方法中表现优异,甚至在某些情况下超越了传统RL方法。
Key Takeaways
- 强化学习从人类反馈(RLHF)已成为对齐模型行为与用户需求的关键因素。
- 当前RLHF方法往往通过孤立任务(如分类或回归)来模拟人类推理,简化了决策过程。
- 本文提出了一种新型强化学习方法,通过联合考虑多任务来模拟人类决策过程。
- 该方法利用无奖励环境中的人类评分来推断奖励函数,并引入可学习权重以平衡分类和回归模型的贡献。
- 该设计捕捉了人类决策过程中的内在不确定性。
- 实验结果表明,该方法在基于评分的RL方法中表现优异。
点此查看论文截图

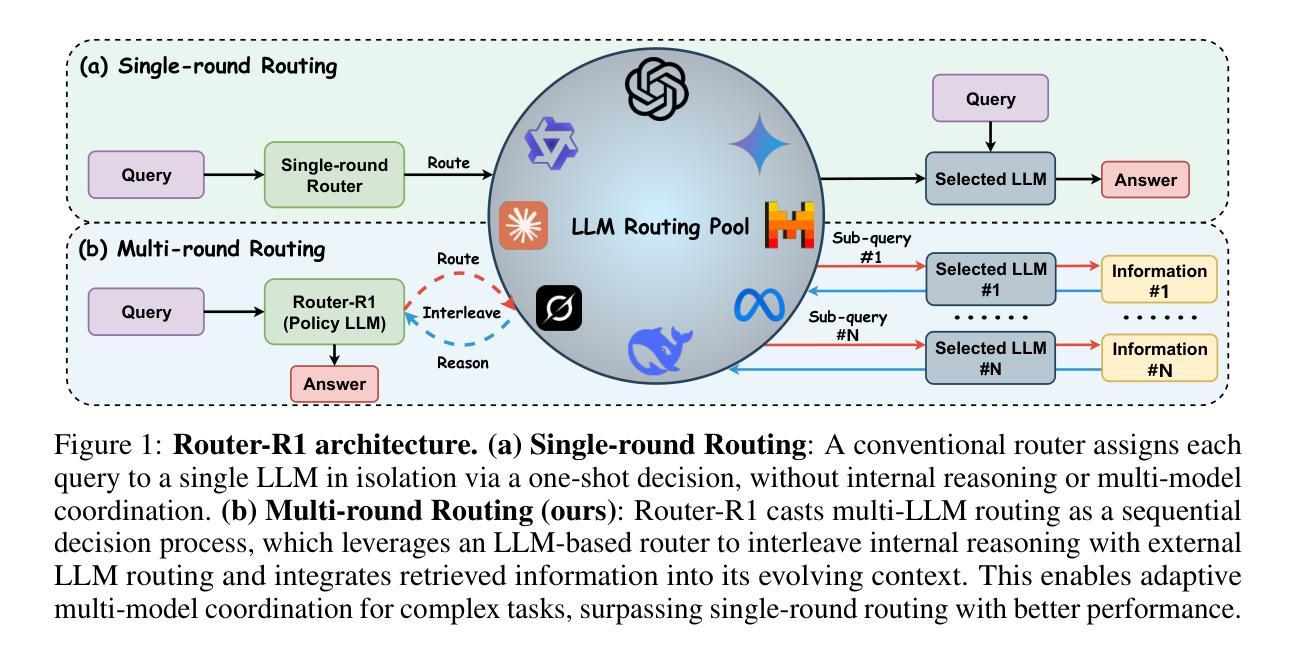
Router-R1: Teaching LLMs Multi-Round Routing and Aggregation via Reinforcement Learning
Authors:Haozhen Zhang, Tao Feng, Jiaxuan You
The rapid emergence of diverse large language models (LLMs) has spurred the development of LLM routers that assign user queries to the most suitable model. However, existing LLM routers typically perform a single-round, one-to-one mapping (\textit{i.e.}, assigning each query to a single model in isolation), which limits their capability to tackle complex tasks that demand the complementary strengths of multiple LLMs. In this paper, we present \textbf{Router-R1}, a reinforcement learning (RL)-based framework that formulates multi-LLM routing and aggregation as a sequential decision process. Router-R1 instantiates the router itself as a capable LLM, leveraging its reasoning ability to interleave “think” actions (internal deliberation) with “route” actions (dynamic model invocation), and integrates each response into its evolving context. To facilitate learning, we employ a lightweight rule-based reward comprising format rewards, final outcome rewards, and a novel cost reward for optimizing the balance between performance and cost, opening a pathway toward enhancing performance-cost trade-offs via RL. Router-R1 also conditions only on simple model descriptors such as pricing, latency, and example performance, enabling strong generalization to unseen model selection. Experiments on seven general and multi-hop QA benchmarks show that Router-R1 outperforms several strong baselines, achieving superior performance while maintaining robust generalization and cost management.
多样的大型语言模型(LLM)的快速涌现推动了LLM路由器的开发,这些路由器将用户查询分配给最合适的模型。然而,现有的LLM路由器通常执行单轮一对一映射(即,将每个查询单独分配给一个模型),这限制了它们处理复杂任务的能力,这些复杂任务需要多个LLM的互补优势。在本文中,我们提出了基于强化学习(RL)的框架Router-R1,将多LLM路由和聚合公式化为一个顺序决策过程。Router-R1将路由器本身实例化为一个功能强大的LLM,利用它的推理能力将“思考”行动(内部思考)与“路由”行动(动态模型调用)交织在一起,并将每个响应集成到不断发展的上下文中。为了促进学习,我们采用了一种基于规则的轻量级奖励机制,包括格式奖励、最终成果奖励和一种用于优化性能和成本之间平衡的新型成本奖励,从而开辟了通过RL提高性能与成本权衡的道路。Router-R1仅依赖于简单的模型描述符(如价格、延迟和性能示例),能够很好地适应看不见的模型选择。在七个通用和多跳问答基准测试上的实验表明,Router-R1优于多个强大的基线模型,在保持稳健的泛化和成本管理的同时实现了卓越的性能。
论文及项目相关链接
PDF Code is available at https://github.com/ulab-uiuc/Router-R1. Models and Datasets are available at https://huggingface.co/collections/ulab-ai/router-r1-6851bbe099c7a56914b5db03
Summary
本文介绍了基于强化学习(RL)的路由器Router-R1框架,用于解决多大型语言模型(LLM)的路由和聚合问题。Router-R1将路由器本身实例化为一台具有推理能力的大型语言模型,通过内部思考和动态模型调用进行决策,并将每个响应集成到不断变化的上下文中。采用轻量级规则奖励来平衡性能和成本,实现性能与成本的优化。在七个通用和多跳问答基准测试上,Router-R1表现出超越多个强大基准的性能,在保持优秀性能的同时实现了强大的泛化和成本管理。
Key Takeaways
- 大型语言模型(LLM)的快速发展推动了LLM路由器的出现,用于将用户查询分配给最合适的模型。
- 现有LLM路由器通常采用单一轮次一对一映射,限制了其处理复杂任务的能力。
- Router-R1框架使用强化学习来制定多LLM路由和聚合的决策过程,实现更高级的任务处理。
- Router-R1将路由器实例化为一台具有推理能力的大型语言模型,通过内部思考和动态模型调用进行决策。
- 采用轻量级规则奖励来平衡Router-R1的性能和成本。
- Router-R1具有良好的泛化能力,可以适应未见的模型选择。
点此查看论文截图


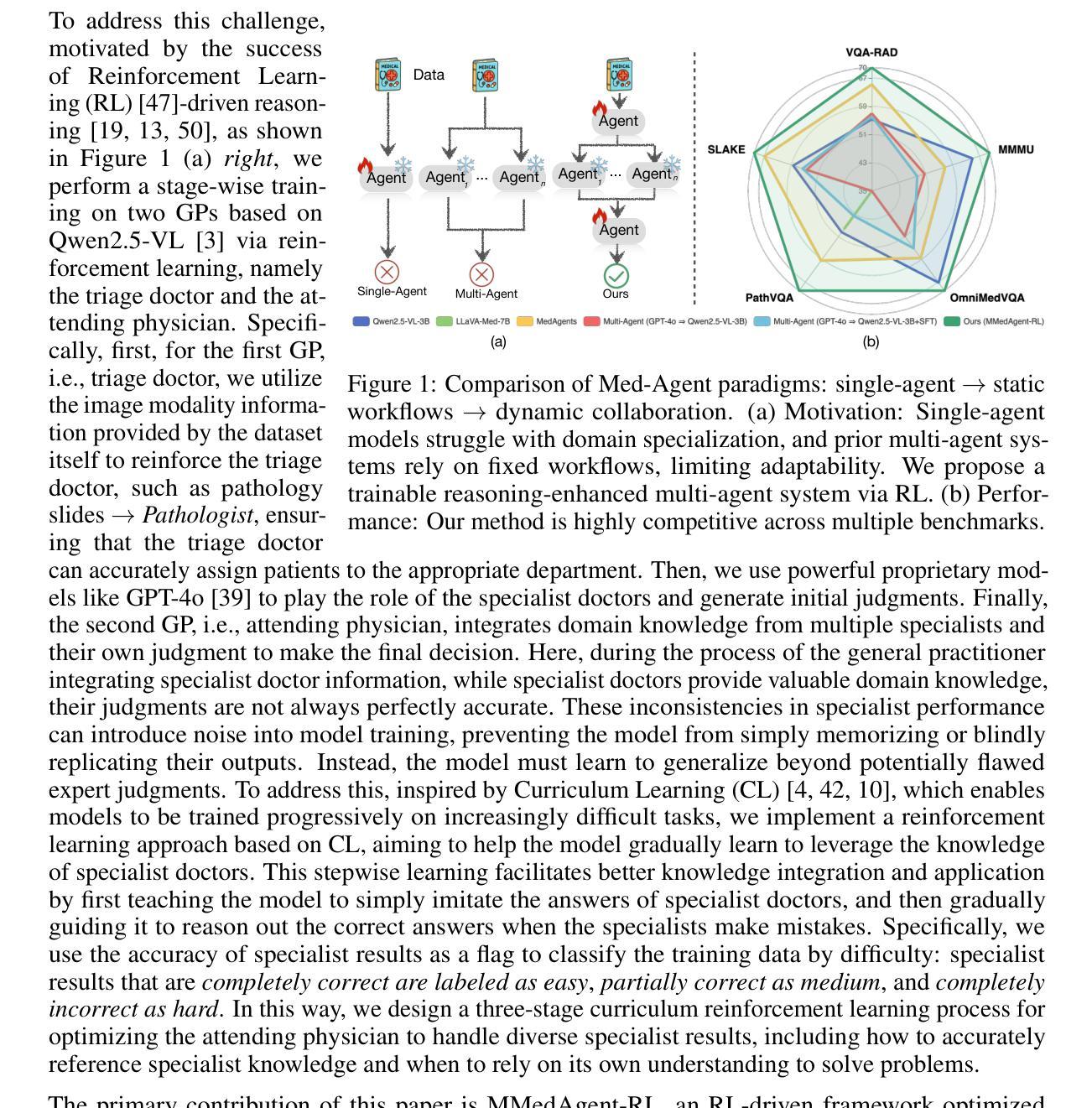
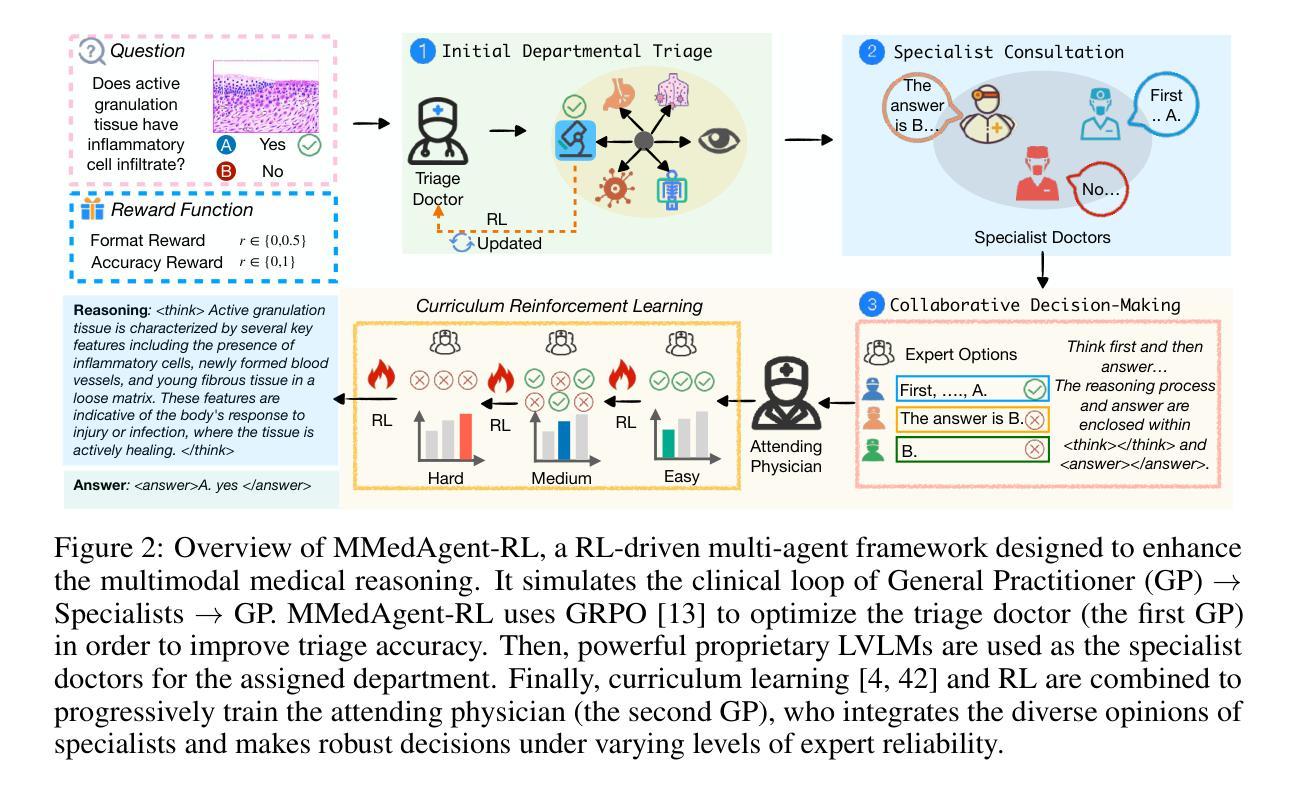
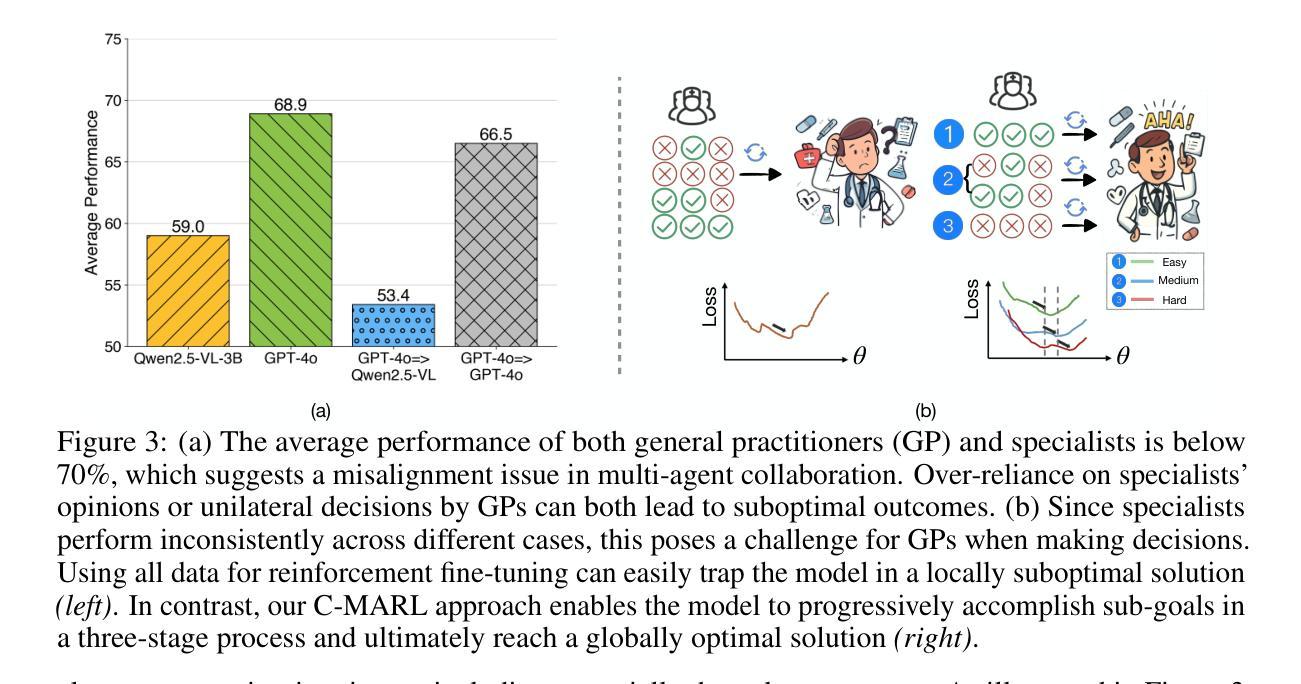
MMedAgent-RL: Optimizing Multi-Agent Collaboration for Multimodal Medical Reasoning
Authors:Peng Xia, Jinglu Wang, Yibo Peng, Kaide Zeng, Xian Wu, Xiangru Tang, Hongtu Zhu, Yun Li, Shujie Liu, Yan Lu, Huaxiu Yao
Medical Large Vision-Language Models (Med-LVLMs) have shown strong potential in multimodal diagnostic tasks. However, existing single-agent models struggle to generalize across diverse medical specialties, limiting their performance. Recent efforts introduce multi-agent collaboration frameworks inspired by clinical workflows, where general practitioners (GPs) and specialists interact in a fixed sequence. Despite improvements, these static pipelines lack flexibility and adaptability in reasoning. To address this, we propose MMedAgent-RL, a reinforcement learning (RL)-based multi-agent framework that enables dynamic, optimized collaboration among medical agents. Specifically, we train two GP agents based on Qwen2.5-VL via RL: the triage doctor learns to assign patients to appropriate specialties, while the attending physician integrates the judgments from multi-specialists and its own knowledge to make final decisions. To address the inconsistency in specialist outputs, we introduce a curriculum learning (CL)-guided RL strategy that progressively teaches the attending physician to balance between imitating specialists and correcting their mistakes. Experiments on five medical VQA benchmarks demonstrate that MMedAgent-RL not only outperforms both open-source and proprietary Med-LVLMs, but also exhibits human-like reasoning patterns. Notably, it achieves an average performance gain of 20.7% over supervised fine-tuning baselines.
医疗大型视觉语言模型(Med-LVLMs)在多模态诊断任务中显示出强大的潜力。然而,现有的单智能体模型在跨不同医学专业领域进行泛化时遇到困难,限制了其性能。最近的努力引入了受临床工作流程启发的多智能体协作框架,其中全科医生(GPs)和专家以固定序列进行交互。尽管有所改进,但这些静态管道在推理方面缺乏灵活性和适应性。针对这一问题,我们提出了基于强化学习(RL)的多智能体框架MMedAgent-RL,能够实现医疗智能体之间的动态优化协作。具体来说,我们基于Qwen2.5-VL训练了两个GP智能体通过RL:分诊医生学习将患者分配给合适的专科,而主治医师则整合了多专科医生的判断和自己的知识来做出最终决定。为了解决专家输出不一致的问题,我们引入了一种以课程学习(CL)引导的RL策略,逐步教导主治医师如何在模仿专家和纠正其错误之间取得平衡。在五个医疗VQA基准测试上的实验表明,MMedAgent-RL不仅优于开源和专有Med-LVLMs,还表现出人类般的推理模式。值得注意的是,与监督微调基准相比,它实现了平均性能提升20.7%。
论文及项目相关链接
Summary
基于强化学习(RL)的多智能体协作框架MMedAgent-RL被提出用于动态优化医疗智能体之间的协作,以提高多模态诊断任务的性能。MMedAgent-RL引入了一种课程学习(CL)指导的RL策略,以解决专业智能体输出不一致的问题。在五个医学视觉问答基准测试上的实验表明,MMedAgent-RL不仅优于开源和专有医疗大型视觉语言模型(Med-LVLMs),而且展现出与人类类似的推理模式,平均性能提升达20.7%。
Key Takeaways
- Med-LVLMs在多模态诊断任务中具有强大潜力,但现有单一智能体模型在跨不同医学专业领域时难以泛化。
- 引入多智能体协作框架以改善单一智能体的局限性,模拟临床工作流程中的GP和专家互动。
- MMedAgent-RL基于强化学习(RL)构建,使医疗智能体之间的协作更加动态和优化。
- MMedAgent-RL包含两个智能体:初级医生负责分配患者到合适的专业领域,而主治医师则结合多专业判断和自身知识做出最终决策。
- 为解决专家智能体输出不一致的问题,引入课程学习(CL)指导的强化学习策略。
- 实验证明MMedAgent-RL优于现有的Med-LVLMs,并展现出与人类类似的推理模式。
点此查看论文截图

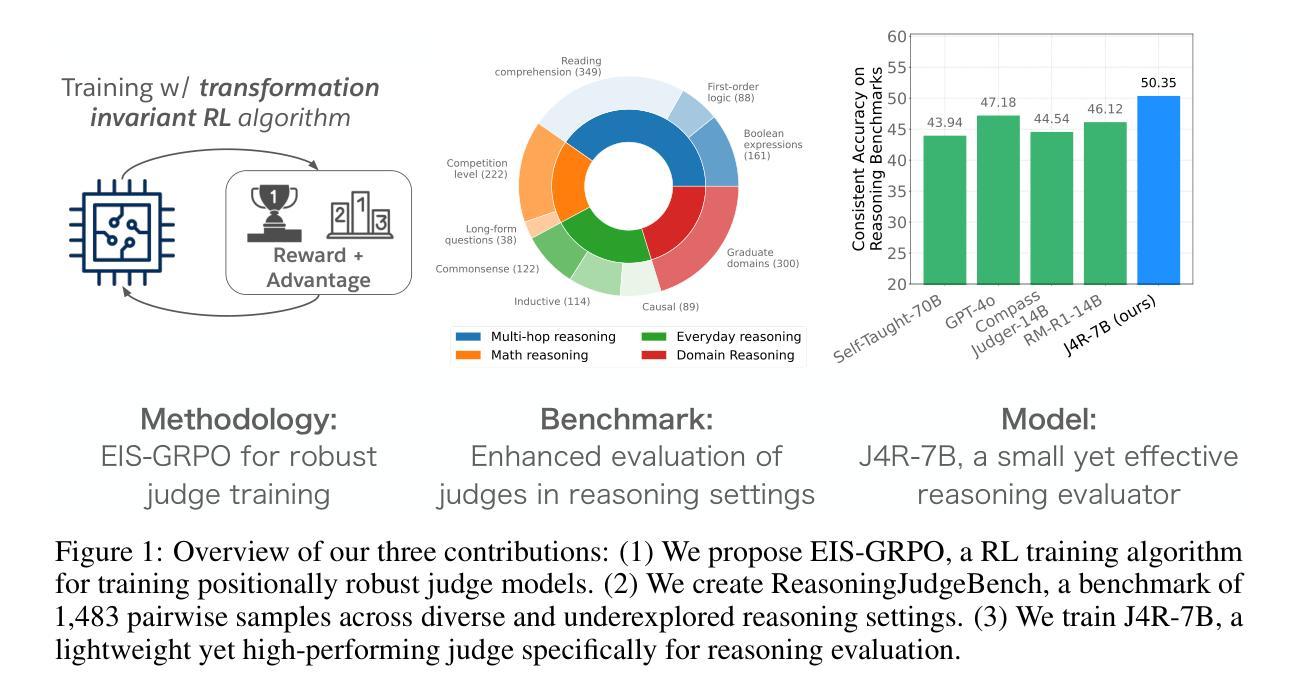
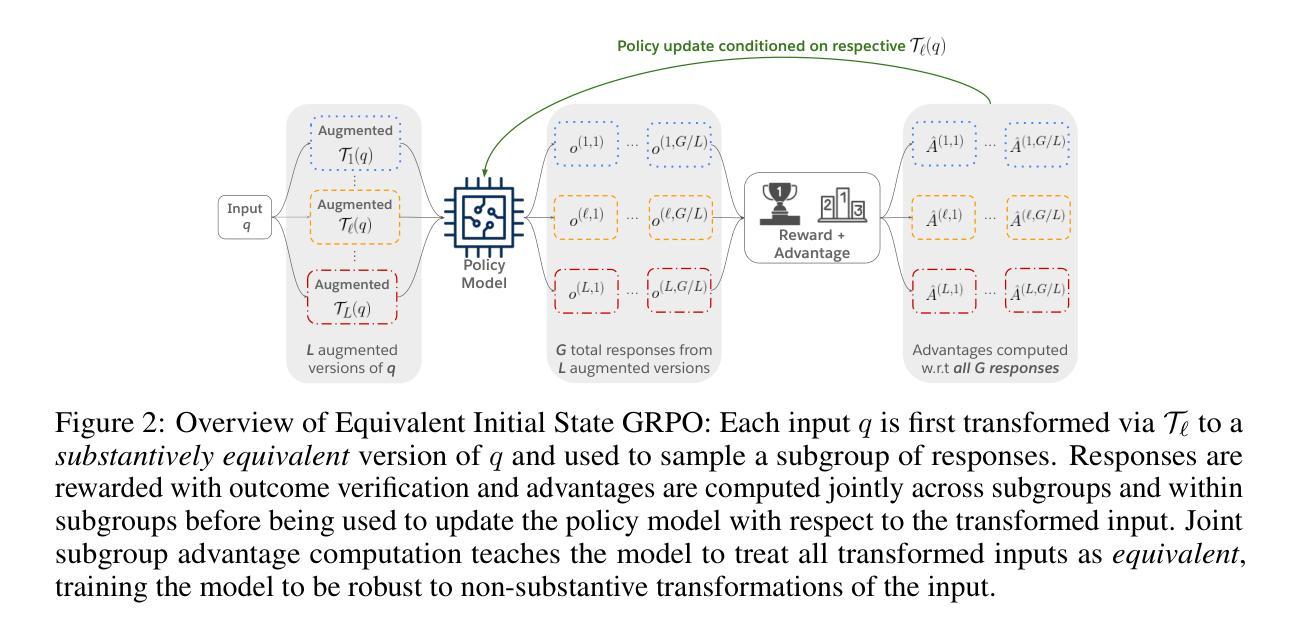
J4R: Learning to Judge with Equivalent Initial State Group Relative Policy Optimization
Authors:Austin Xu, Yilun Zhou, Xuan-Phi Nguyen, Caiming Xiong, Shafiq Joty
To keep pace with the increasing pace of large language models (LLM) development, model output evaluation has transitioned away from time-consuming human evaluation to automatic evaluation, where LLMs themselves are tasked with assessing and critiquing other model outputs. LLM-as-judge models are a class of generative evaluators that excel in evaluating relatively simple domains, like chat quality, but struggle in reasoning intensive domains where model responses contain more substantive and challenging content. To remedy existing judge shortcomings, we explore training judges with reinforcement learning (RL). We make three key contributions: (1) We propose the Equivalent Initial State Group Relative Policy Optimization (EIS-GRPO) algorithm, which allows us to train our judge to be robust to positional biases that arise in more complex evaluation settings. (2) We introduce ReasoningJudgeBench, a benchmark that evaluates judges in diverse reasoning settings not covered by prior work. (3) We train Judge for Reasoning (J4R), a 7B judge trained with EIS-GRPO that outperforms GPT-4o and the next best small judge by 6.7% and 9%, matching or exceeding the performance of larger GRPO-trained judges on both JudgeBench and ReasoningJudgeBench.
随着大型语言模型(LLM)发展步伐的加快,模型输出评估已从耗时的人力评估转向自动评估。在自动评估中,LLM本身被赋予评估和批判其他模型输出的任务。LLM作为评判者的模型是一类生成式评估器,擅长评估相对简单的领域,如聊天质量,但在需要大量推理的领域却表现挣扎,因为这些领域的模型回应包含更多实质性和具有挑战的内容。为了弥补现有评判者的不足,我们探索使用强化学习(RL)来训练评判者。我们做出了三个关键贡献:(1)我们提出了等效初始状态组相对策略优化(EIS-GRPO)算法,该算法使我们能够训练评判者,以应对在更复杂评估环境中出现的定位偏见。 (2)我们引入了ReasoningJudgeBench,这是一个可以在以前的工作未涵盖的多种推理环境中评估评判者的基准测试。(3)我们使用EIS-GRPO训练了用于推理的评判者(J4R),这是一个7B的评判者,其性能优于GPT-4o和下一个最好的小型评判者6.7%和9%,在JudgeBench和ReasoningJudgeBench上的表现与较大的GRPO训练过的评判者相匹配或更好。
论文及项目相关链接
PDF 25 pages, 4 figures, 6 tables. Updated with code and benchmark
Summary
本文介绍了随着大型语言模型(LLM)的发展,模型输出评估已从耗时的人力评估转向自动评估。文章探讨了LLM作为评判者的评价方式,并提出了一种针对复杂评估环境的优化算法——等效初始状态组相对策略优化(EIS-GRPO)。此外,文章还介绍了一个用于评估推理场景的基准测试ReasoningJudgeBench,并训练了一个名为J4R的7B参数推理评委模型,该模型在性能测试上表现出优异的性能。
Key Takeaways
- 大型语言模型(LLM)的发展推动了模型输出评估从人力评估向自动评估的转变。
- LLM作为评判者的评价方式在简单领域表现良好,但在需要推理的复杂领域存在挑战。
- 提出了等效初始状态组相对策略优化(EIS-GRPO)算法,提升评委在复杂评估环境中的稳健性。
- 介绍了ReasoningJudgeBench基准测试,用于评估推理场景的评委性能。
点此查看论文截图

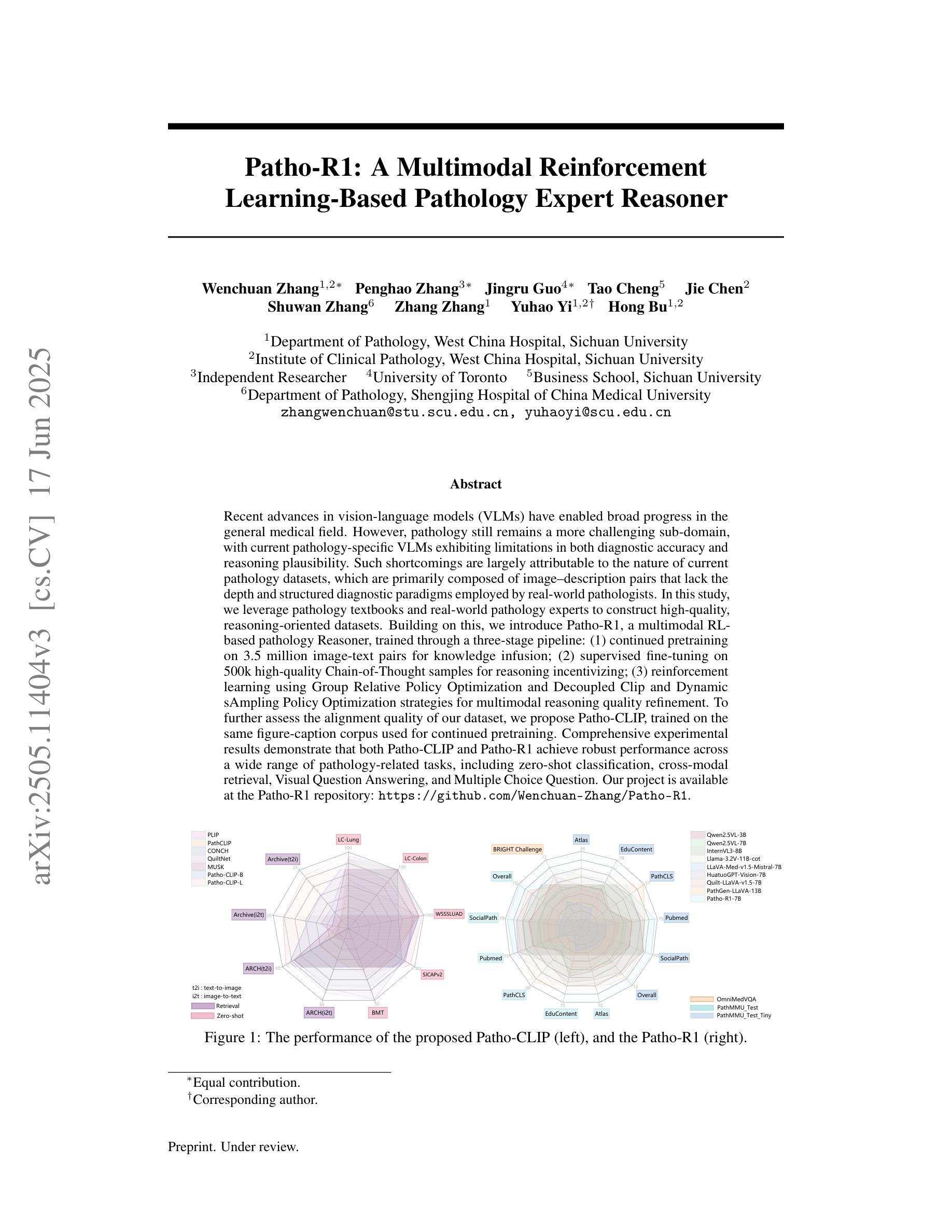
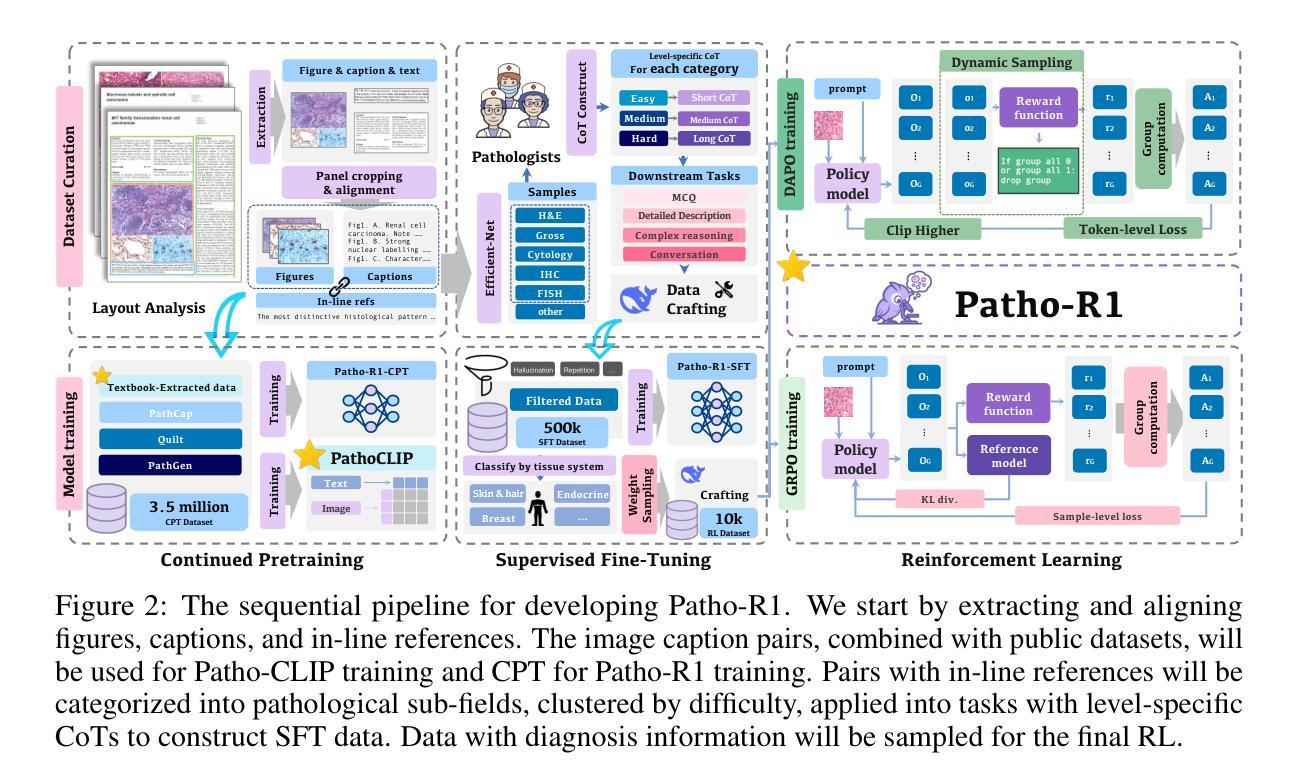
Patho-R1: A Multimodal Reinforcement Learning-Based Pathology Expert Reasoner
Authors:Wenchuan Zhang, Penghao Zhang, Jingru Guo, Tao Cheng, Jie Chen, Shuwan Zhang, Zhang Zhang, Yuhao Yi, Hong Bu
Recent advances in vision language models (VLMs) have enabled broad progress in the general medical field. However, pathology still remains a more challenging subdomain, with current pathology specific VLMs exhibiting limitations in both diagnostic accuracy and reasoning plausibility. Such shortcomings are largely attributable to the nature of current pathology datasets, which are primarily composed of image description pairs that lack the depth and structured diagnostic paradigms employed by real world pathologists. In this study, we leverage pathology textbooks and real world pathology experts to construct high-quality, reasoning-oriented datasets. Building on this, we introduce Patho-R1, a multimodal RL-based pathology Reasoner, trained through a three-stage pipeline: (1) continued pretraining on 3.5 million image-text pairs for knowledge infusion; (2) supervised fine-tuning on 500k high-quality Chain-of-Thought samples for reasoning incentivizing; (3) reinforcement learning using Group Relative Policy Optimization and Decoupled Clip and Dynamic sAmpling Policy Optimization strategies for multimodal reasoning quality refinement. To further assess the alignment quality of our dataset, we propose Patho-CLIP, trained on the same figure-caption corpus used for continued pretraining. Comprehensive experimental results demonstrate that both Patho-CLIP and Patho-R1 achieve robust performance across a wide range of pathology-related tasks, including zero-shot classification, cross-modal retrieval, Visual Question Answering, and Multiple Choice Question. Our project is available at the Patho-R1 repository: https://github.com/Wenchuan-Zhang/Patho-R1.
在视觉语言模型(VLMs)方面的最新进展为一般医学领域带来了广泛的进步。然而,病理学仍然是一个更具挑战性的子域。当前针对病理学的特定VLMs在诊断准确性和推理合理性方面存在局限性。这种缺点在很大程度上归因于当前病理学数据集的性质,这些数据集主要由缺乏现实世界病理学家所使用深度和结构化诊断范式的图像描述对组成。在这项研究中,我们利用病理学教材和现实世界病理学专家来构建高质量、以推理为导向的数据集。在此基础上,我们引入了Patho-R1,这是一个基于多模式强化学习的病理学推理器,通过三个阶段进行训练:1)在350万图像文本对上持续进行预训练以注入知识;2)在50万个高质量的思维链样本上进行监督微调以激励推理;3)使用集团相对策略优化和脱钩Clip以及动态采样策略优化策略进行强化学习,以实现多模式推理质量的改进。为了进一步评估我们数据集的对齐质量,我们提出了在同一图-标题语料库上训练的Patho-CLIP,用于持续预训练。综合实验结果表明,Patho-CLIP和Patho-R1在广泛的病理学相关任务中表现出稳健的性能,包括零样本分类、跨模态检索、视觉问答和多项选择题。我们的项目可在Patho-R1仓库中找到:https://github.com/Wenchuan-Zhang/Patho-R1。
论文及项目相关链接
Summary:
最新进展的跨模态视觉语言模型(VLMs)在医学领域取得了广泛进展,但在病理学领域仍存在挑战。当前病理学特定VLMs在诊断准确性和推理合理性方面存在局限性。本研究通过利用病理学教材和病理学专家构建高质量、推理导向的数据集,并引入Patho-R1多模态强化学习病理学推理器,经过三阶段训练,实现了模型优化。此外,我们还推出了Patho-CLIP,用于评估数据集的质量。实验结果表明,Patho-CLIP和Patho-R1在多种病理学相关任务中表现稳健。
Key Takeaways:
- VLMs在医学领域取得进展,但病理学仍是挑战领域。
- 当前病理学特定VLMs在诊断准确性和推理合理性方面存在局限性。
- 研究利用病理学教材和专家构建高质量数据集。
- 引入Patho-R1多模态强化学习病理学推理器,经过三阶段训练实现模型优化。
- Patho-CLIP用于评估数据集质量。
- Patho-CLIP和Patho-R1在多种病理学相关任务中表现稳健。
- 项目已在Patho-R1仓库中开放获取。
点此查看论文截图
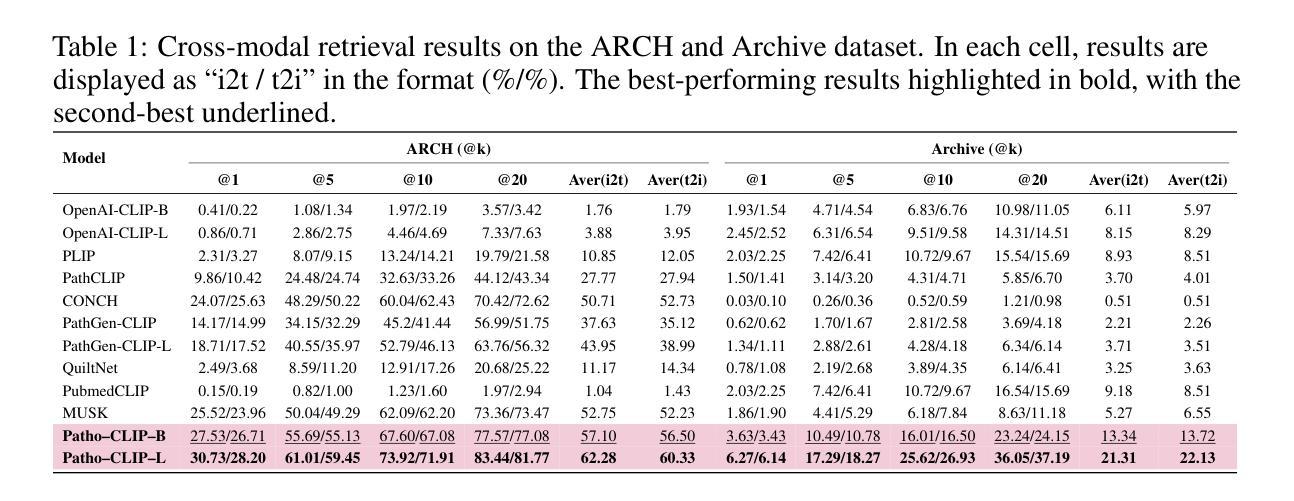
Trust Region Preference Approximation: A simple and stable reinforcement learning algorithm for LLM reasoning
Authors:Xuerui Su, Shufang Xie, Guoqing Liu, Yingce Xia, Renqian Luo, Peiran Jin, Zhiming Ma, Yue Wang, Zun Wang, Yuting Liu
Recently, Large Language Models (LLMs) have rapidly evolved, approaching Artificial General Intelligence (AGI) while benefiting from large-scale reinforcement learning to enhance Human Alignment (HA) and Reasoning. Recent reward-based optimization algorithms, such as Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) have achieved significant performance on reasoning tasks, whereas preference-based optimization algorithms such as Direct Preference Optimization (DPO) significantly improve the performance of LLMs on human alignment. However, despite the strong performance of reward-based optimization methods in alignment tasks , they remain vulnerable to reward hacking. Furthermore, preference-based algorithms (such as Online DPO) haven’t yet matched the performance of reward-based optimization algorithms (like PPO) on reasoning tasks, making their exploration in this specific area still a worthwhile pursuit. Motivated by these challenges, we propose the Trust Region Preference Approximation (TRPA) algorithm, which integrates rule-based optimization with preference-based optimization for reasoning tasks. As a preference-based algorithm, TRPA naturally eliminates the reward hacking issue. TRPA constructs preference levels using predefined rules, forms corresponding preference pairs, and leverages a novel optimization algorithm for RL training with a theoretical monotonic improvement guarantee. Experimental results demonstrate that TRPA not only achieves competitive performance on reasoning tasks but also exhibits robust stability. The code of this paper are released and updating on https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git.
最近,大型语言模型(LLM)迅速进化,在受益于大规模强化学习提高人类对齐(HA)和推理的同时,逐渐接近人工智能通用智能(AGI)。最近的基于奖励的优化算法,如近端策略优化(PPO)和群体相对策略优化(GRPO),在推理任务上取得了显著的性能;而基于偏好的优化算法,如直接偏好优化(DPO),则显著提高了语言模型在人对齐方面的性能。然而,尽管基于奖励的优化方法在对齐任务中表现出强大的性能,但它们仍然容易受到奖励黑客攻击的影响。此外,基于偏好的算法(如在线DPO)在推理任务上的性能尚未达到基于奖励的优化算法(如PPO)的水平,这使得在这一特定领域对其进行探索仍然是有价值的。针对这些挑战,我们提出了信任区域偏好逼近(TRPA)算法,该算法将基于规则的优化与基于偏好的优化相结合,用于推理任务。作为基于偏好的算法,TRPA自然地消除了奖励黑客攻击的问题。TRPA使用预定义规则构建偏好层次,形成相应的偏好对,并利用一种新的优化算法进行RL训练,该算法具有理论上的单调改进保证。实验结果表明,TRPA不仅在推理任务上具有竞争力,而且表现出稳健的稳定性。本文的代码已发布并在https://github.com/XueruiSu/Trust-Region-Preference-Approximation.git上进行更新。
论文及项目相关链接
PDF 10pages
Summary
本文探讨了大型语言模型(LLM)在人工通用智能(AGI)方面的最新进展。文章介绍了基于奖励的优化算法,如近端策略优化(PPO)和群体相对策略优化(GRPO),在推理任务上的表现。同时,也提到了基于偏好的优化算法,如直接偏好优化(DPO),在LLM的人类对齐方面表现出色。针对奖励基于的优化方法在人类对齐任务中的易受攻击问题,提出了一种新的算法——信任区域偏好近似(TRPA)。该算法结合了基于规则的优化和基于偏好的优化,在推理任务上具有竞争力,且表现稳健。
Key Takeaways
- 大型语言模型(LLM)在人工通用智能(AGI)方面取得重要进展。
- 基于奖励的优化算法,如近端策略优化(PPO)和群体相对策略优化(GRPO),在推理任务上表现出显著性能。
- 基于偏好的优化算法,如直接偏好优化(DPO),提升了LLM在人类对齐方面的性能。
- 现有奖励基于的优化方法在人类对齐任务中易受到“奖励黑客”攻击。
- 信任区域偏好近似(TRPA)算法结合了基于规则和基于偏好的优化,解决了奖励黑客问题。
- TRPA算法在推理任务上具有竞争力,且表现稳健。
点此查看论文截图

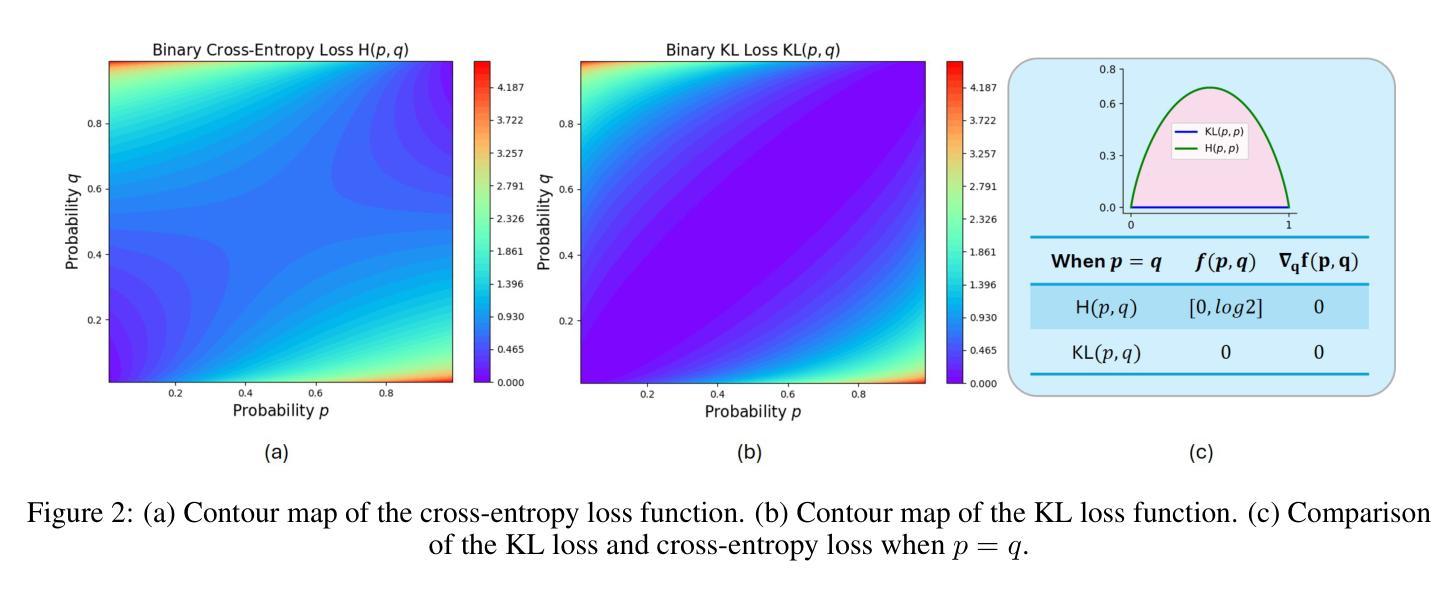
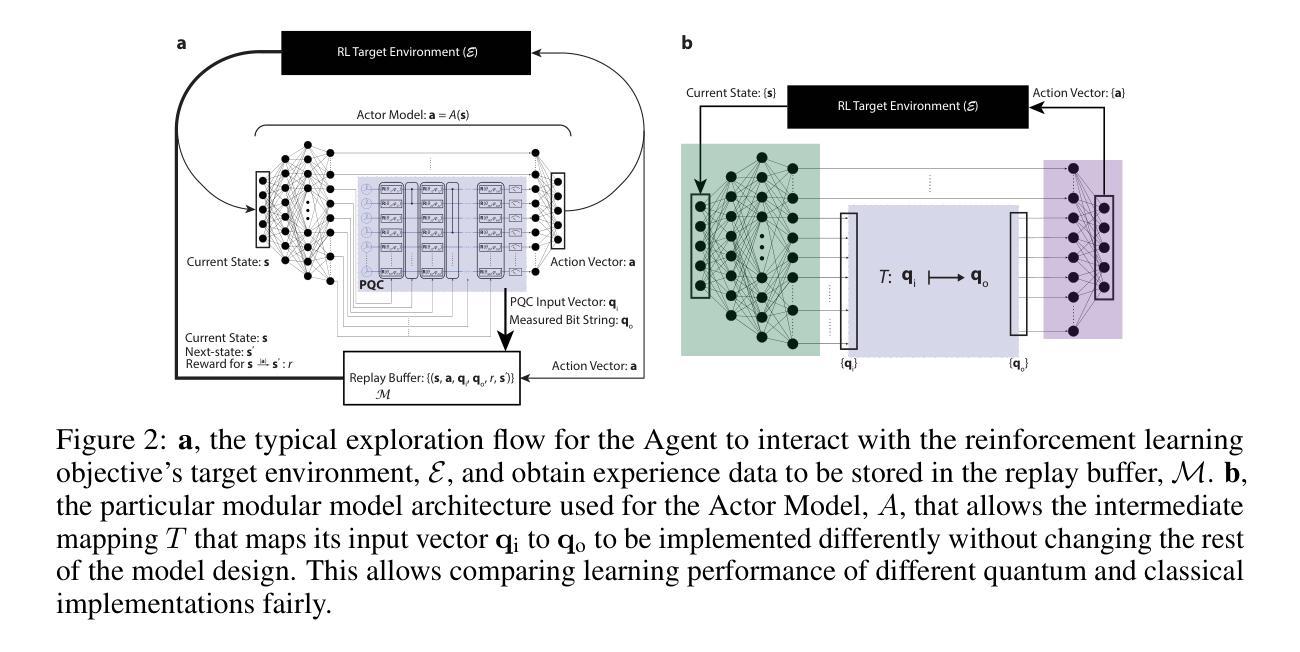
Training Hybrid Deep Quantum Neural Network for Efficient Reinforcement Learning
Authors:Jie Luo, Xueyin Chen, Jeremy Kulcsar, Georgios Korpas, Giulio Giaconi
Quantum circuits embed data in a Hilbert space whose dimensionality grows exponentially with the number of qubits, allowing even shallow parameterised quantum circuits (PQCs) to represent highly-correlated probability distributions that are costly for classical networks to capture. Reinforcement-learning (RL) agents, which must reason over long-horizon, continuous-control tasks, stand to benefit from this expressive quantum feature space, but only if the quantum layers can be trained jointly with the surrounding deep-neural components. Current gradient-estimation techniques (e.g., parameter-shift rule) make such hybrid training impractical for realistic RL workloads, because every gradient step requires a prohibitive number of circuit evaluations and thus erodes the potential quantum advantage. We introduce qtDNN, a tangential surrogate that locally approximates a PQC with a small differentiable network trained on-the-fly from the same minibatch. Embedding qtDNN inside the computation graph yields scalable batch gradients while keeping the original quantum layer for inference. Building on qtDNN we design hDQNN-TD3, a hybrid deep quantum neural network for continuous-control reinforcement learning based on the TD3 architecture. On the high-dimensional Humanoid-v4 benchmark, our agent reaches a test return that surpasses classical TD3, SAC and PPO baselines trained with identical compute. To our knowledge this is the first PQC-enhanced policy that matches or exceeds state-of-the-art classical performance on Humanoid. qtDNN has the potential to reduce quantum-hardware calls significantly and is designed to be compatible with today’s NISQ devices. The method opens a path toward applying hybrid quantum models to large-scale RL and other gradient-intensive machine-learning tasks.
量子电路将数据嵌入到一个希尔伯特空间中,其维度随着量子比特数量的增加而呈指数增长。这使得即使是浅参数化量子电路(PQCs)也能表示高度相关的概率分布,这对于经典网络来说很难捕捉。强化学习(RL)代理需要在长期和连续控制任务中进行推理,可以从这种表达性量子特征空间中受益,但前提条件是量子层能够与周围的深层神经网络组件联合训练。当前的梯度估计技术(例如参数移动规则)使得这种混合训练对于实际的RL工作量来说不切实际,因为每个梯度步骤都需要大量的电路评估,从而削弱了潜在的量子优势。我们引入了qtDNN,它是一种局部使用小型可微网络近似PQC的切线替代品,该网络根据相同的mini-batch进行实时训练。将qtDNN嵌入计算图中可以在保持原始量子层进行推理的同时,实现可扩展的批量梯度。基于qtDNN,我们设计了用于基于TD3架构的连续控制强化学习的hDQNN-TD3混合深度量子神经网络。在高维Humanoid-v4基准测试中,我们的代理的测试结果超过了使用相同计算资源训练的经典TD3、SAC和PPO基准线。据我们所知,这是第一个增强策略的PQC,在Humanoid上达到了或超过了最新经典技术的性能。qtDNN有望显著降低对量子硬件的调用,并且设计兼容当今的NISQ设备。该方法为将混合量子模型应用于大规模RL和其他梯度密集型机器学习任务开辟了一条道路。
论文及项目相关链接
Summary:量子电路嵌入Hilbert空间的数据表现出指数级增长的特点,允许浅层参数化量子电路(PQCs)表征高度相关的概率分布,这对于经典网络而言是成本高昂的。强化学习(RL)在处理长期连续控制任务时,有望受益于这种表达性强的量子特征空间,但前提是量子层能与周围的深度神经网络组件联合训练。当前梯度估计技术使得这种混合训练对于实际RL工作负载不切实际,因为每个梯度步骤都需要大量的电路评估,从而削弱了潜在的量子优势。本研究引入了qtDNN,一种局部使用小型可微网络逼近PQC的方法,该网络在同一小批量数据中即时训练。将qtDNN嵌入计算图中可实现可扩展的批量梯度,同时保留原始量子层进行推理。基于qtDNN,本研究设计了用于连续控制强化学习的混合深度量子神经网络hDQNN-TD3,该网络基于TD3架构。在高维Humanoid-v4基准测试中,我们的代理人的测试回报率超过了使用相同计算资源训练的经典TD3、SAC和PPO基准线。这是据我们所知首次实现PQC增强的策略在Humanoid上达到或超过最新经典技术的性能。qtDNN有望显著降低对量子硬件的调用,并且设计兼容当今的NISQ设备。该方法为将混合量子模型应用于大规模RL和其他梯度密集型机器学习任务开辟了一条道路。
Key Takeaways:
- 量子电路允许参数化量子电路(PQCs)表征高度相关的概率分布,这经典网络难以有效处理。
- 强化学习在处理长期连续控制任务时能从量子特征空间中受益。
- 当前梯度估计技术使得联合训练量子层和深度神经网络不切实际。
- qtDNN通过用小型可微网络局部逼近PQC来解决这一问题。
- hDQNN-TD3是基于TD3架构的混合深度量子神经网络,实现了在Humanoid基准测试上的超越经典技术的性能。
- qtDNN设计兼容当前NISQ设备,并有望降低对量子硬件的依赖。
点此查看论文截图

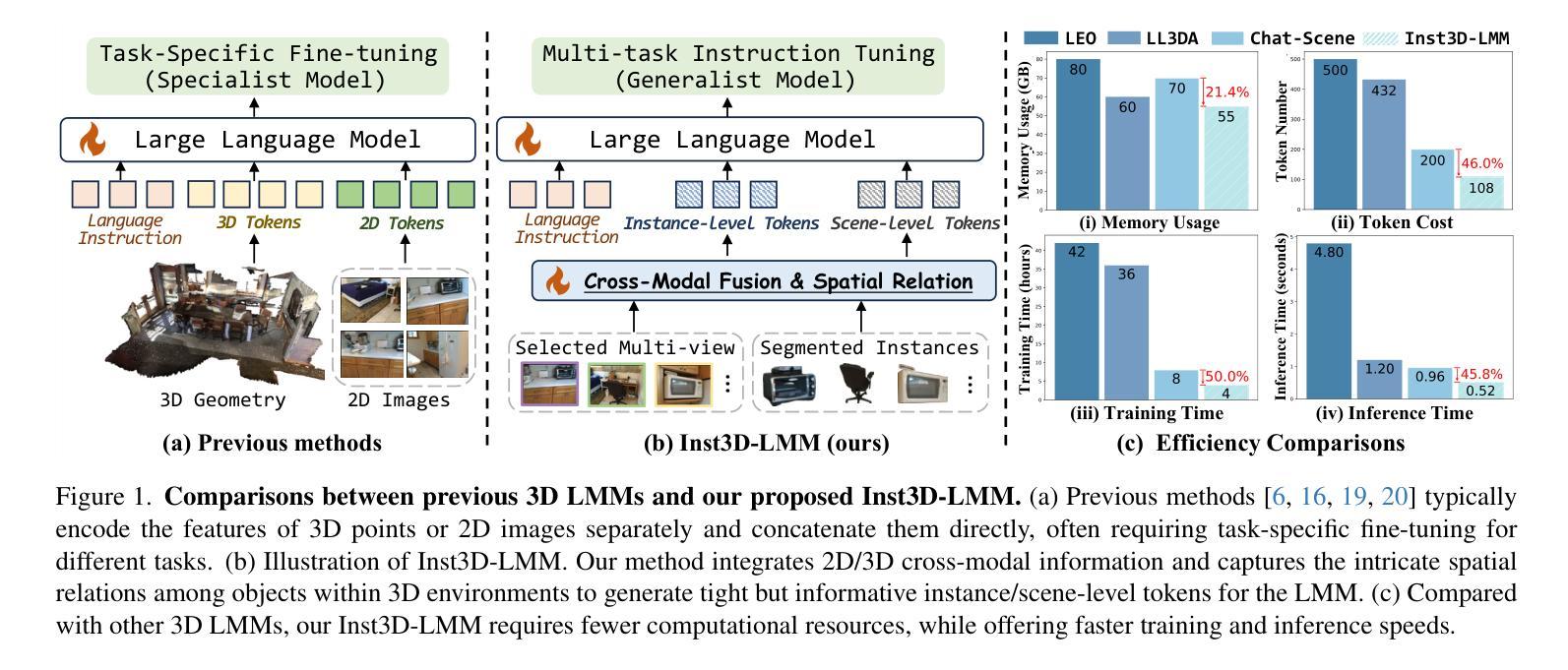
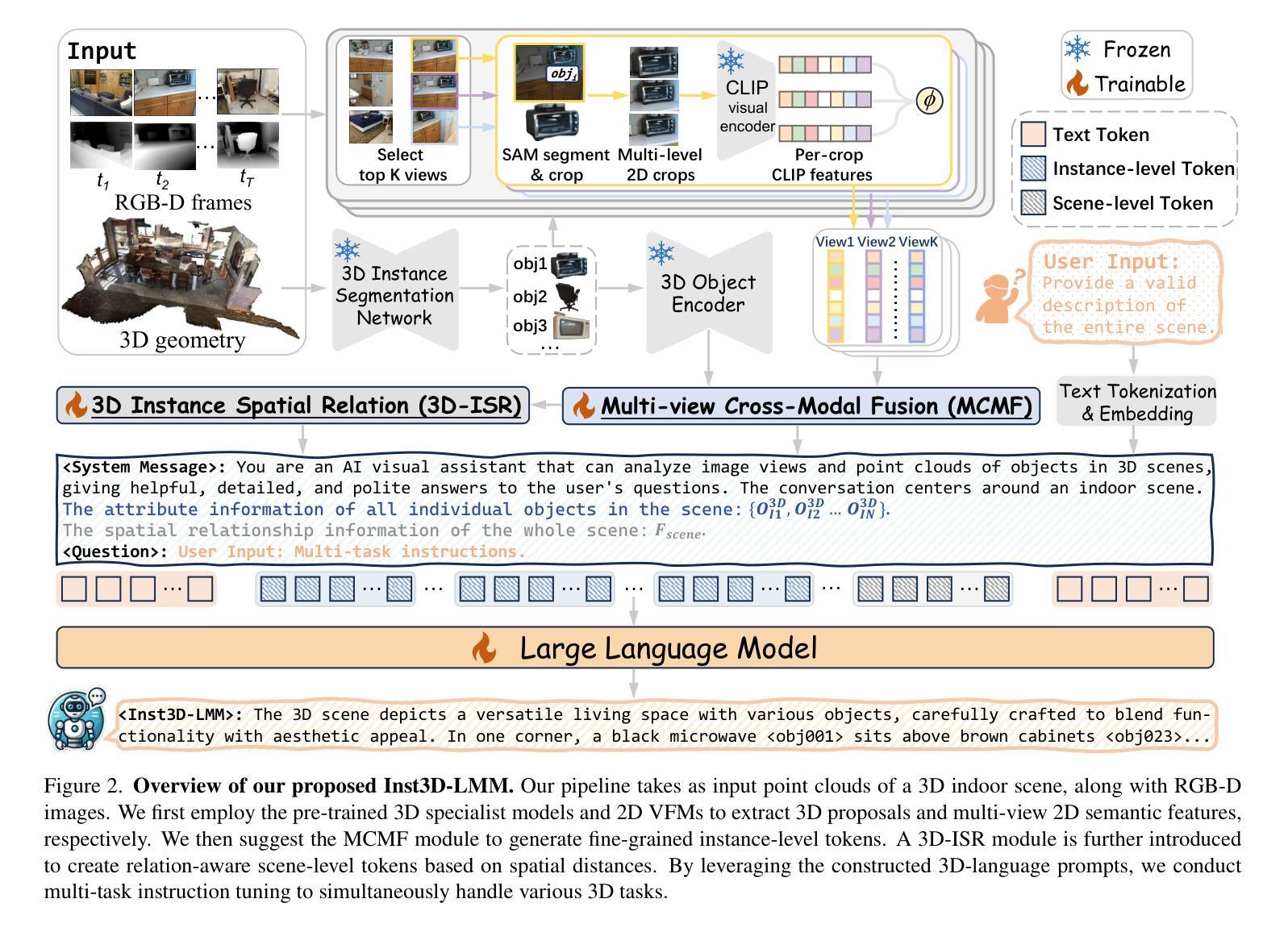
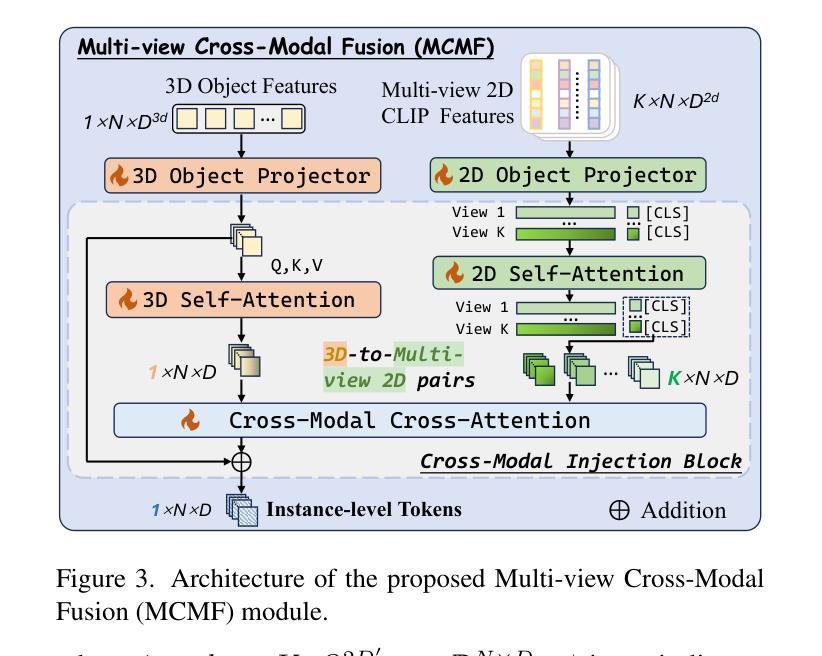
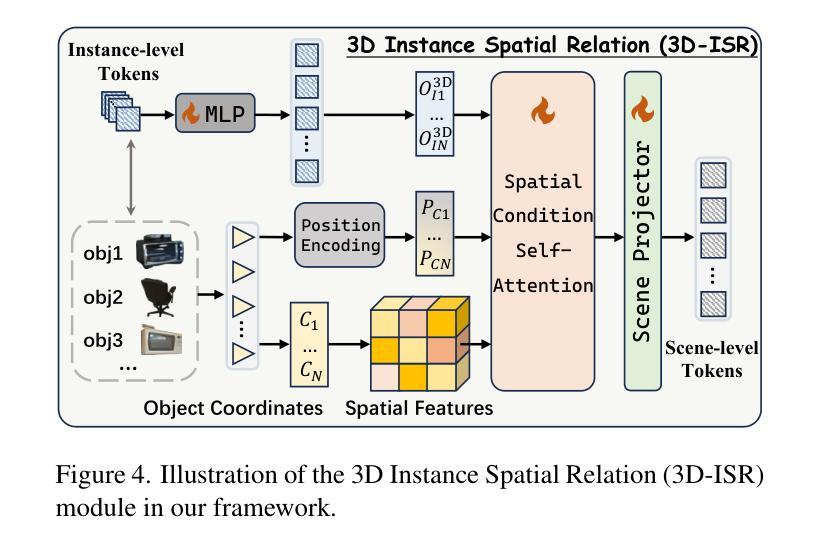
Inst3D-LMM: Instance-Aware 3D Scene Understanding with Multi-modal Instruction Tuning
Authors:Hanxun Yu, Wentong Li, Song Wang, Junbo Chen, Jianke Zhu
Despite encouraging progress in 3D scene understanding, it remains challenging to develop an effective Large Multi-modal Model (LMM) that is capable of understanding and reasoning in complex 3D environments. Most previous methods typically encode 3D point and 2D image features separately, neglecting interactions between 2D semantics and 3D object properties, as well as the spatial relationships within the 3D environment. This limitation not only hinders comprehensive representations of 3D scene, but also compromises training and inference efficiency. To address these challenges, we propose a unified Instance-aware 3D Large Multi-modal Model (Inst3D-LMM) to deal with multiple 3D scene understanding tasks simultaneously. To obtain the fine-grained instance-level visual tokens, we first introduce a novel Multi-view Cross-Modal Fusion (MCMF) module to inject the multi-view 2D semantics into their corresponding 3D geometric features. For scene-level relation-aware tokens, we further present a 3D Instance Spatial Relation (3D-ISR) module to capture the intricate pairwise spatial relationships among objects. Additionally, we perform end-to-end multi-task instruction tuning simultaneously without the subsequent task-specific fine-tuning. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods across 3D scene understanding, reasoning and grounding tasks. Source code is available at https://github.com/hanxunyu/Inst3D-LMM
尽管在三维场景理解方面取得了令人鼓舞的进展,但开发能够在复杂三维环境中进行理解和推理的有效大型多模态模型(LMM)仍然具有挑战性。大多数之前的方法通常分别编码三维点云和二维图像特征,忽略了二维语义和三维物体属性之间的交互,以及三维环境内的空间关系。这种局限性不仅阻碍了三维场景的全面表示,还影响了训练和推理的效率。为了应对这些挑战,我们提出了一种统一的实例感知三维大型多模态模型(Inst3D-LMM),以同时处理多个三维场景理解任务。为了获得精细的实例级视觉标记,我们首先引入了一种新型的多视角跨模态融合(MCMF)模块,将多视角的二维语义注入到其对应的三维几何特征中。对于场景级关系感知标记,我们进一步提出了三维实例空间关系(3D-ISR)模块,以捕捉物体之间复杂的一对一空间关系。此外,我们进行了端到端的多任务指令调整,同时执行多项任务而无需后续的任务特定微调。大量实验表明,我们的方法在三维场景理解、推理和定位任务上超越了最先进的方法。源代码可在https://github.com/hanxunyu/Inst3D-LMM找到。
论文及项目相关链接
PDF CVPR2025, Code Link: https://github.com/hanxunyu/Inst3D-LMM
Summary:
尽管在三维场景理解方面取得了令人鼓舞的进展,但开发一种能够在复杂三维环境中进行有效理解和推理的大型多模态模型(LMM)仍然具有挑战性。针对这一问题,提出了一种统一的实例感知三维大型多模态模型(Inst3D-LMM),可同时处理多个三维场景理解任务。通过引入多视图跨模态融合(MCMF)模块和三维实例空间关系(3D-ISR)模块,该模型在精细粒度的实例级别和场景级别关系感知方面表现出色。实验表明,该方法在三维场景理解、推理和定位任务上的性能均优于现有技术。
Key Takeaways:
- 大型多模态模型(LMM)在复杂三维环境理解和推理上仍存在挑战。
- 现有方法通常将三维点信息和二维图像特征分别编码,忽略了二者之间的交互以及三维空间内的关系。
- Inst3D-LMM模型被提出以解决这些挑战,能同时处理多个三维场景理解任务。
- MCMF模块引入多视图跨模态融合,将多视图二维语义注入到对应的三维几何特征中。
- 3D-ISR模块用于捕捉对象之间复杂的配对空间关系。
- 该模型可进行端到端多任务指令调整,无需后续的任务特定微调。
点此查看论文截图

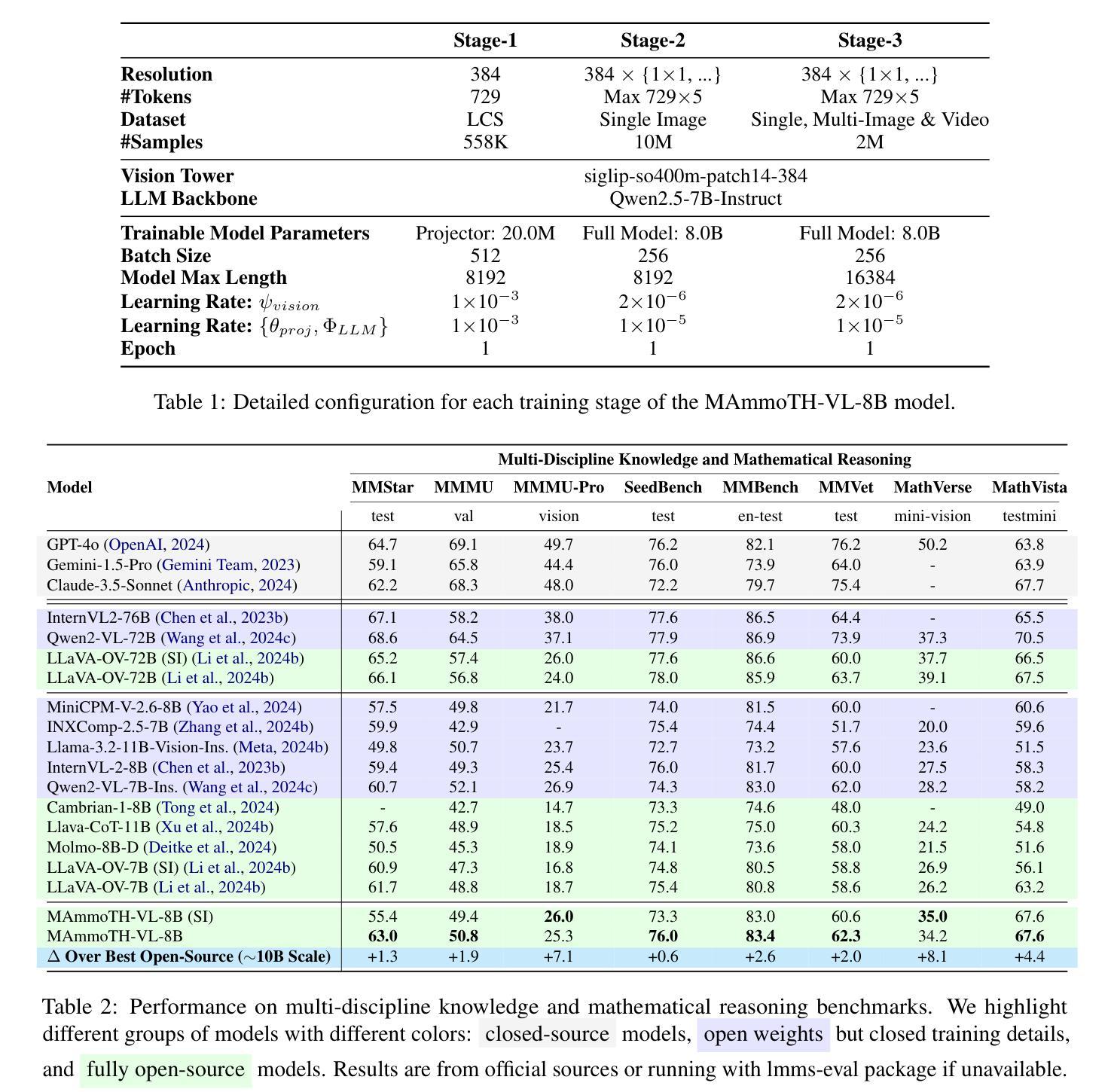
MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale
Authors:Jarvis Guo, Tuney Zheng, Yuelin Bai, Bo Li, Yubo Wang, King Zhu, Yizhi Li, Graham Neubig, Wenhu Chen, Xiang Yue
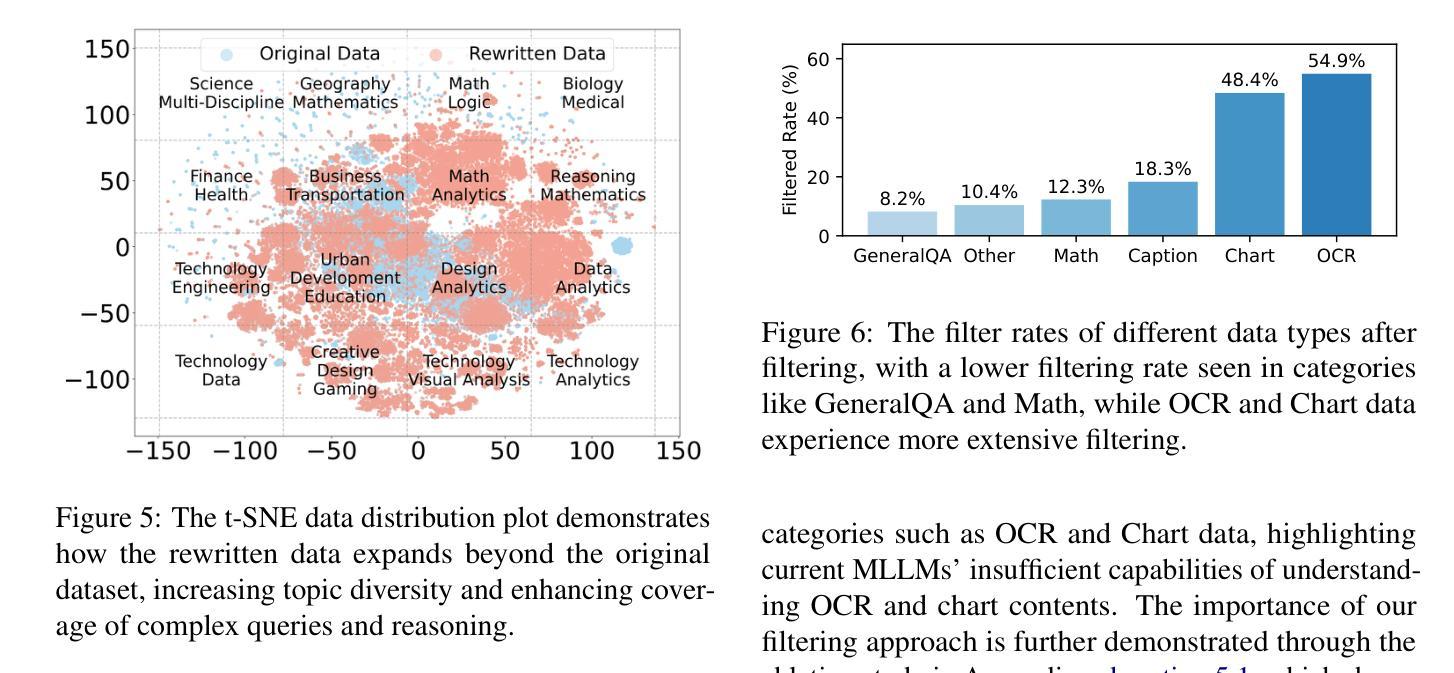
Open-source multimodal large language models (MLLMs) have shown significant potential in a broad range of multimodal tasks. However, their reasoning capabilities remain constrained by existing instruction-tuning datasets, which were predominately repurposed from academic datasets such as VQA, AI2D, and ChartQA. These datasets target simplistic tasks, and only provide phrase-level answers without any intermediate rationales. To address these challenges, we introduce a scalable and cost-effective method to construct a large-scale multimodal instruction-tuning dataset with rich intermediate rationales designed to elicit CoT reasoning. Using only open models, we create a dataset containing 12M instruction-response pairs to cover diverse, reasoning-intensive tasks with detailed and faithful rationales. Experiments demonstrate that training MLLMs on this dataset significantly improves reasoning capabilities, achieving state-of-the-art performance on benchmarks such as MathVerse (+8.1%), MMMU-Pro (+7%), and MuirBench (+13.3%). Additionally, the model demonstrates notable improvements of up to 4% on non-reasoning-based benchmarks. Ablation studies further highlight the importance of key components, such as rewriting and self-filtering, in the dataset construction process.
开源多模态大型语言模型(MLLMs)在广泛的多模态任务中显示出巨大的潜力。然而,它们的推理能力受到现有指令调整数据集的制约,这些数据集主要从VQA、AI2D和ChartQA等学术数据集中二次使用。这些数据集的目标是简单的任务,只能提供没有中间理由的短语级答案。为了解决这些挑战,我们介绍了一种可扩展且成本效益高的方法来构建大规模多模态指令调整数据集,该数据集包含丰富的中间理由,旨在激发CoT推理。我们仅使用公开模型创建了一个包含12M指令响应对的数据集,以涵盖多样化且注重推理的任务,提供详细和真实合理的答案。实验表明,在这个数据集上训练MLLMs可以显著提高推理能力,在数学领域(MathVerse,+8.1%)、MMMU-Pro(+7%)和MuirBench(+13.3%)等基准测试上达到了业界前沿性能。此外,模型在非推理基准测试中也表现出了最高可达4%的显著改进。消融研究进一步突出了数据构建过程中的关键组件(如重写和自过滤)的重要性。
论文及项目相关链接
PDF ACL 2025 Main
Summary
本文介绍了开源多模态大型语言模型(MLLMs)在多模态任务中的巨大潜力。然而,其推理能力受到现有指令调整数据集的制约,这些数据集主要来源于如VQA、AI2D和ChartQA等学术数据集。针对这些挑战,本文提出了一种可扩展且成本效益高的方法,构建了包含丰富中间推理的大型多模态指令调整数据集。实验表明,在该数据集上训练MLLMs能显著提高推理能力,在MathVerse、MMMU-Pro和MuirBench等基准测试上达到最新技术水平。
Key Takeaways
- 多模态大型语言模型(MLLMs)在多模态任务中具有巨大潜力。
- 现有指令调整数据集主要来源于学术数据集,限制了MLLMs的推理能力。
- 提出了一种可扩展且成本效益高的方法,构建包含丰富中间推理的大型多模态指令调整数据集。
- 训练于该数据集上的MLLMs在多个基准测试上表现优异,如MathVerse、MMMU-Pro和MuirBench等。
- 模型在非推理基准测试上也有显著改善。
- 消融研究突出了数据集构建过程中重写和自过滤等关键组件的重要性。
点此查看论文截图


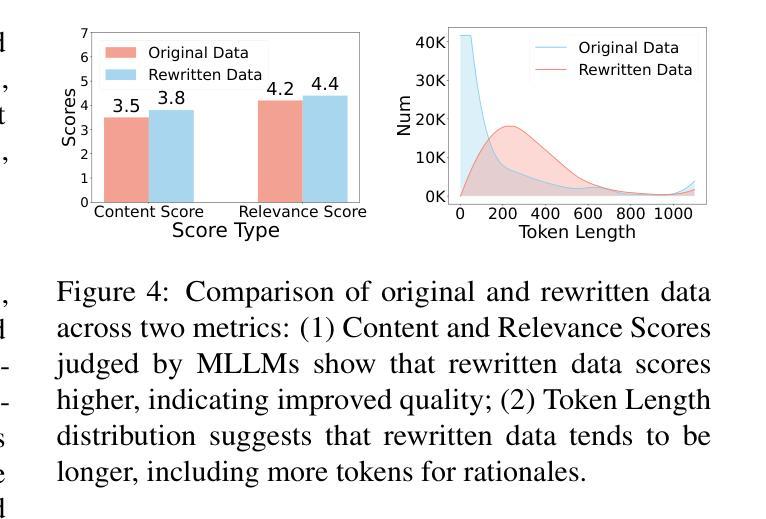
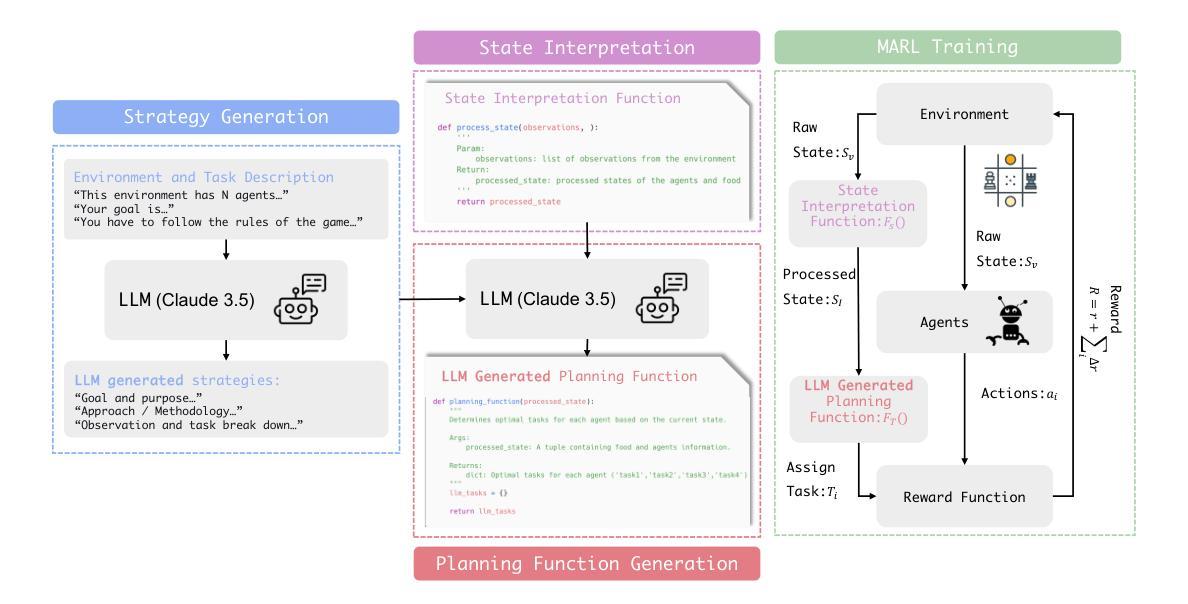
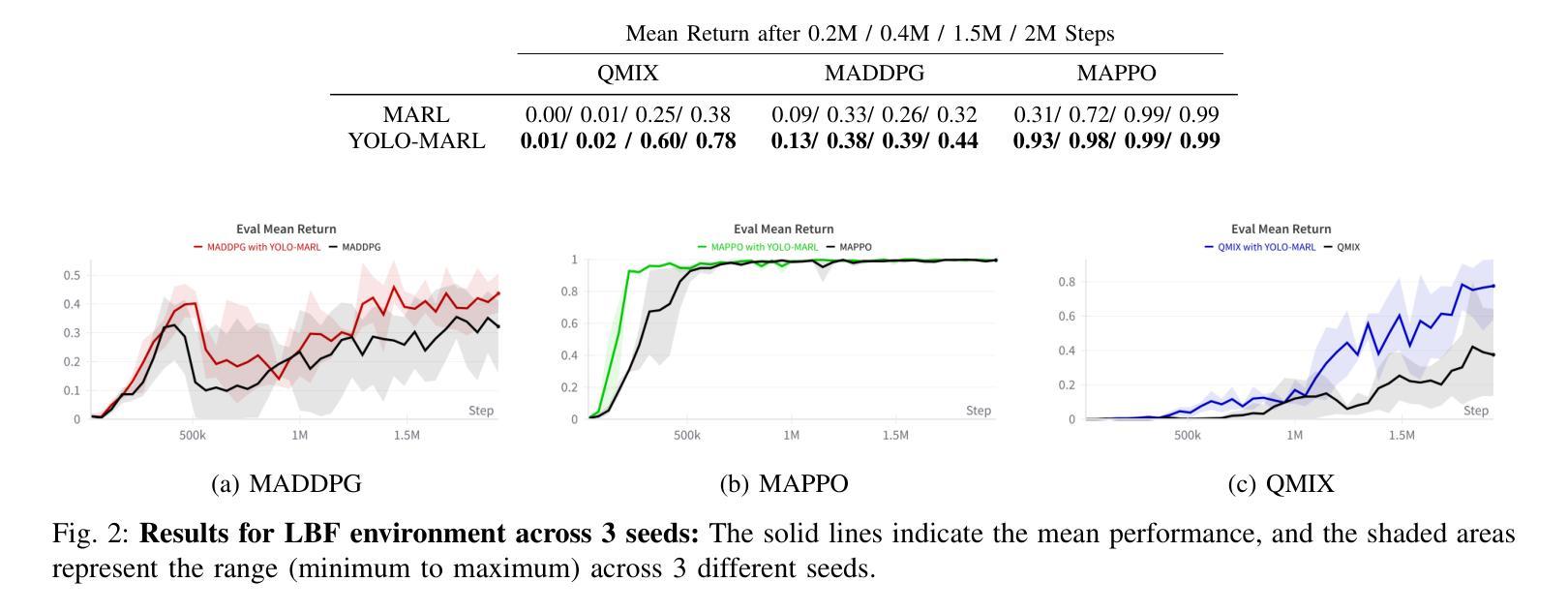
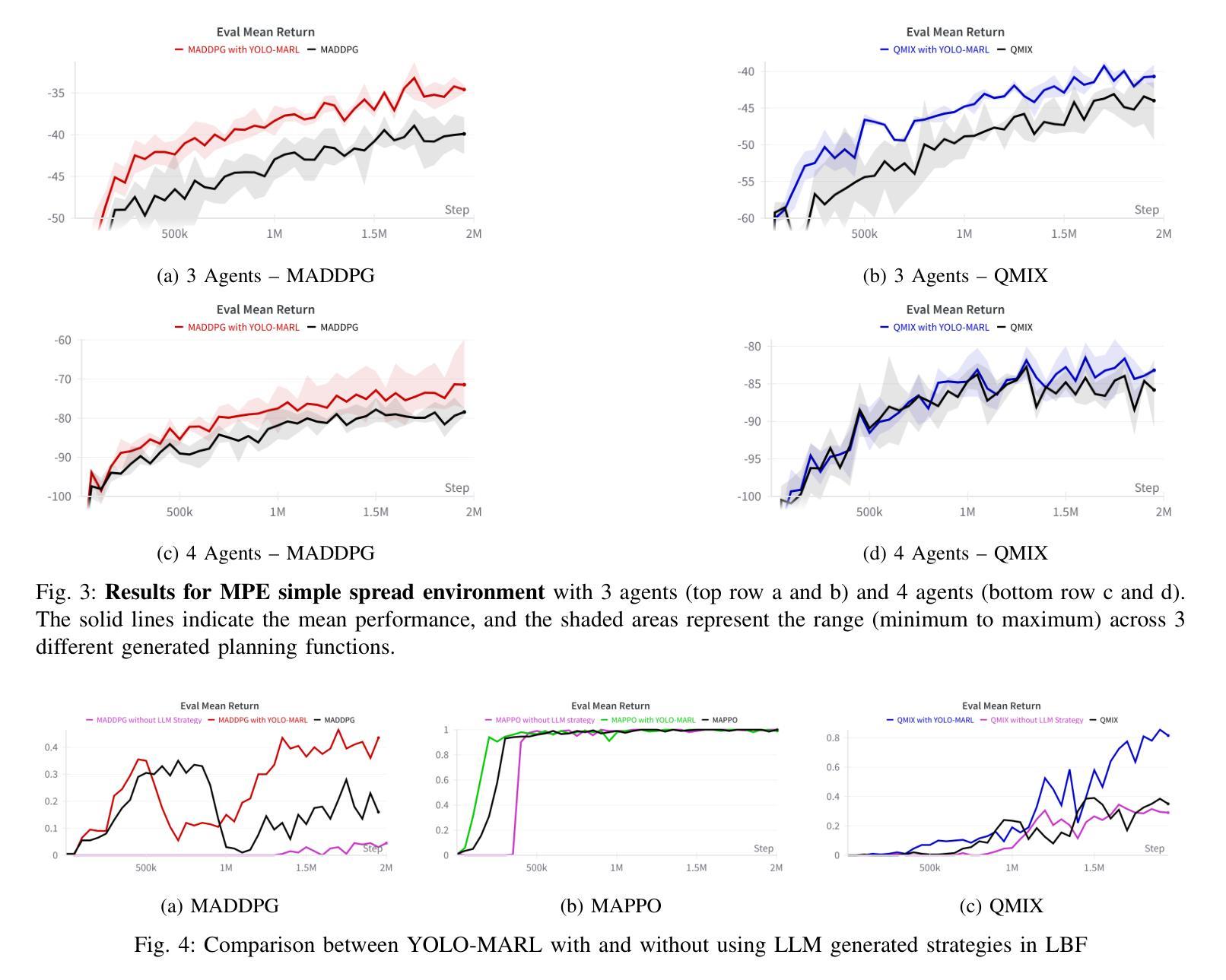
YOLO-MARL: You Only LLM Once for Multi-Agent Reinforcement Learning
Authors:Yuan Zhuang, Yi Shen, Zhili Zhang, Yuxiao Chen, Fei Miao
Advancements in deep multi-agent reinforcement learning (MARL) have positioned it as a promising approach for decision-making in cooperative games. However, it still remains challenging for MARL agents to learn cooperative strategies for some game environments. Recently, large language models (LLMs) have demonstrated emergent reasoning capabilities, making them promising candidates for enhancing coordination among the agents. However, due to the model size of LLMs, it can be expensive to frequently infer LLMs for actions that agents can take. In this work, we propose You Only LLM Once for MARL (YOLO-MARL), a novel framework that leverages the high-level task planning capabilities of LLMs to improve the policy learning process of multi-agents in cooperative games. Notably, for each game environment, YOLO-MARL only requires one time interaction with LLMs in the proposed strategy generation, state interpretation and planning function generation modules, before the MARL policy training process. This avoids the ongoing costs and computational time associated with frequent LLMs API calls during training. Moreover, trained decentralized policies based on normal-sized neural networks operate independently of the LLM. We evaluate our method across two different environments and demonstrate that YOLO-MARL outperforms traditional MARL algorithms.
深度多智能体强化学习(MARL)的进步使其成为合作游戏决策的有前途的方法。然而,对于某些游戏环境,MARL智能体学习合作策略仍然具有挑战性。最近,大型语言模型(LLM)显示出新兴的推理能力,使其成为增强智能体之间协调的候选者。然而,由于LLM的模型规模,频繁对LLM进行行动推理会很昂贵。在这项工作中,我们提出了“只为MARL使用一次LLM”(YOLO-MARL),这是一个利用LLM的高级任务规划能力来改善合作游戏中多智能体的策略学习过程的新框架。值得注意的是,对于每个游戏环境,YOLO-MARL仅在策略生成、状态解释和规划功能生成模块中与LLM进行一次交互,然后才开始MARL策略训练过程。这避免了训练过程中频繁调用LLM API所产生的持续成本和计算时间。此外,基于正常规模神经网络的训练分散政策独立于LLM运行。我们在两个不同的环境中评估了我们的方法,并证明YOLO-MARL优于传统的MARL算法。
论文及项目相关链接
PDF accepted to International Conference on Intelligent Robots and Systems (IROS2025)
Summary
多智能体深度强化学习(MARL)在合作游戏中决策方面展现出巨大潜力,但面对某些游戏环境学习合作策略仍具挑战。大型语言模型(LLMs)具备推理能力,有望改善智能体间的协调。然而,LLMs模型体积大导致推理成本高昂。本研究提出YOLO-MARL框架,利用LLMs进行高级任务规划,改善合作游戏中的多智能体策略学习过程。YOLO-MARL仅需一次与LLMs的互动,生成策略、状态解读和规划功能模块,降低训练过程中的计算成本和时间。评估显示YOLO-MARL在两种环境中表现优于传统MARL算法。
Key Takeaways
- 多智能体深度强化学习(MARL)在合作游戏中表现良好,但学习合作策略于某些环境仍具挑战。
- 大型语言模型(LLMs)具备推理能力,可改善智能体间的协调。
- LLMs模型体积大导致推理成本高昂。
- YOLO-MARL框架利用LLMs进行高级任务规划,提升多智能体在合作游戏中的策略学习。
- YOLO-MARL仅需一次与LLMs互动,生成策略、状态解读和规划模块。
- YOLO-MARL降低训练过程中的计算成本和时间。
点此查看论文截图


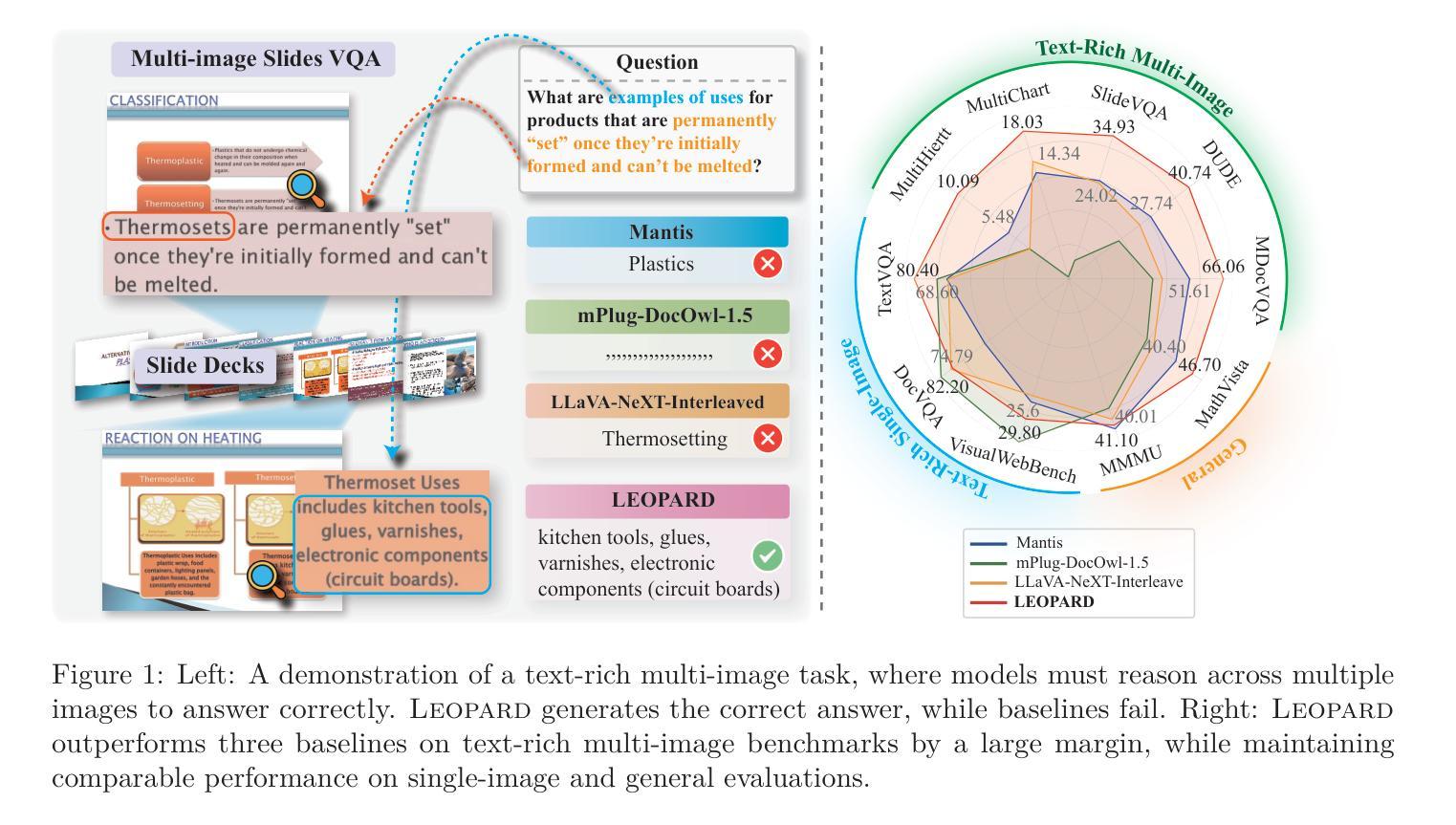
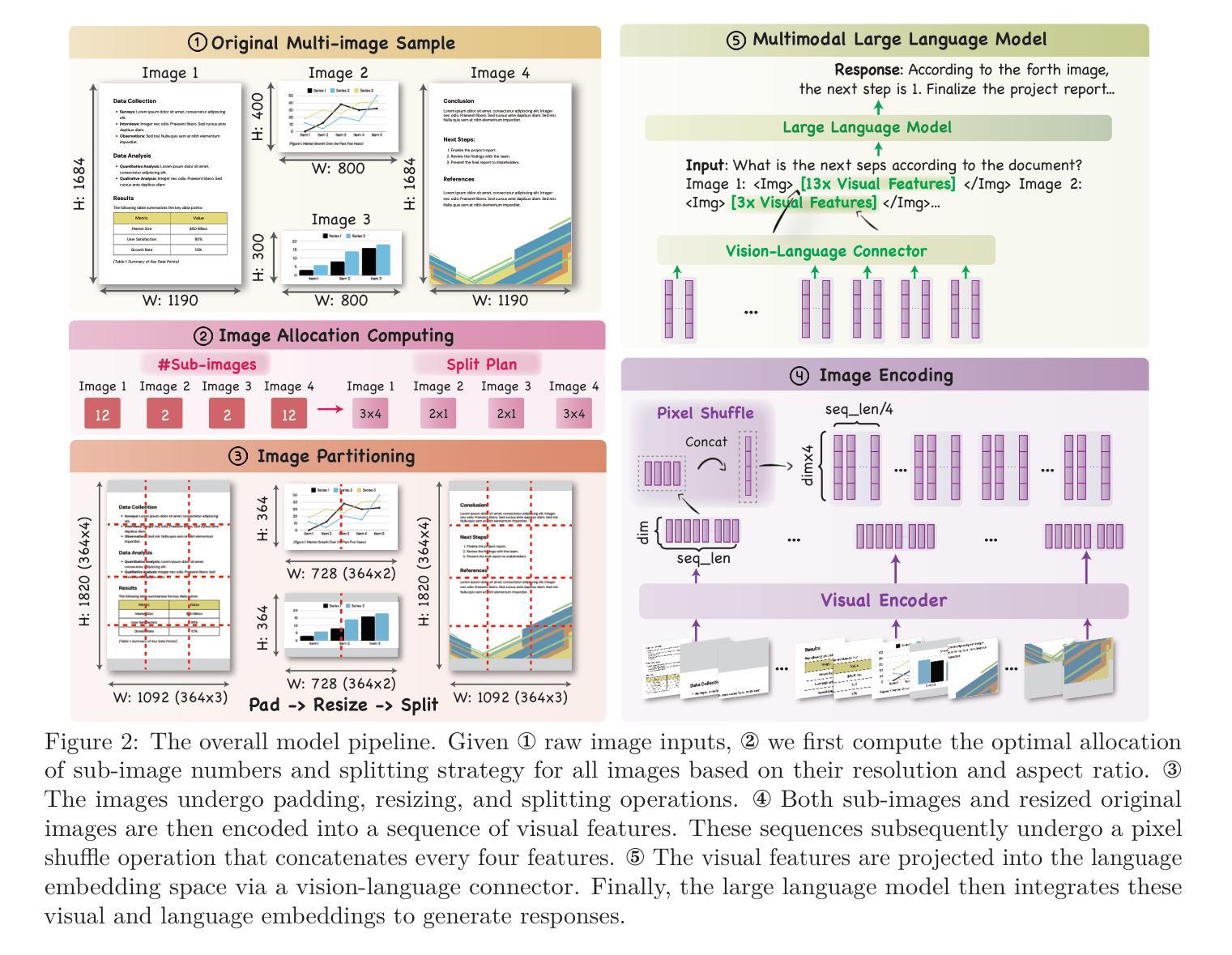
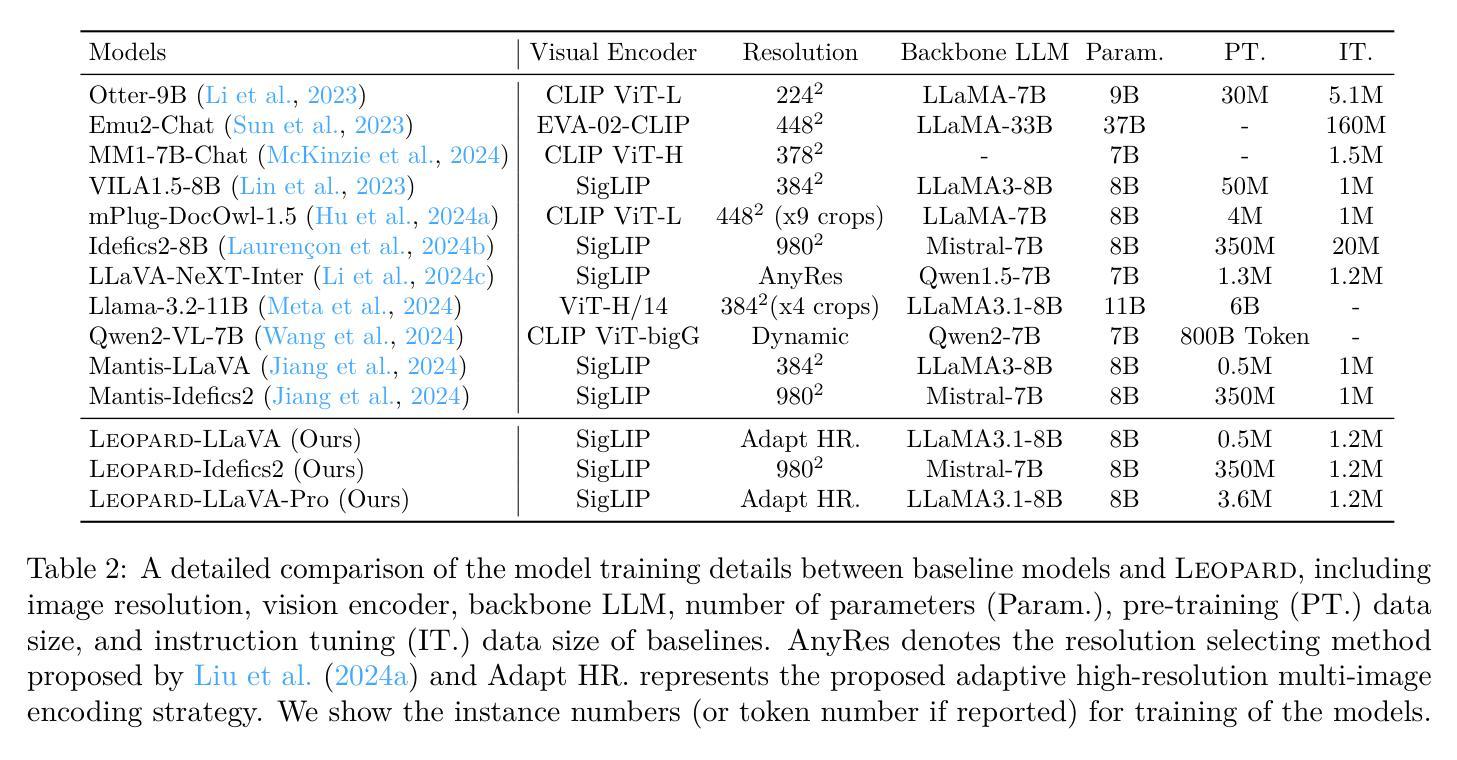
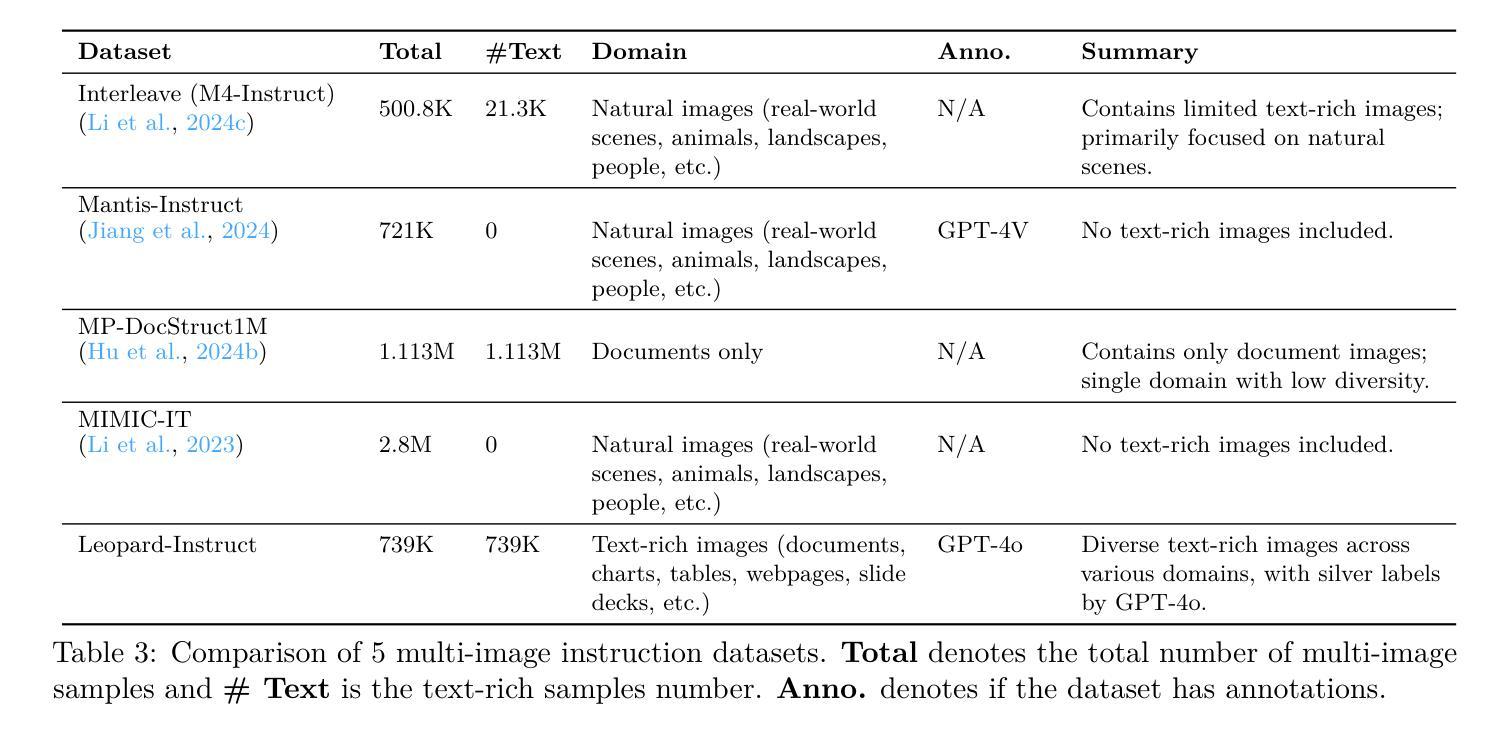
Leopard: A Vision Language Model For Text-Rich Multi-Image Tasks
Authors:Mengzhao Jia, Wenhao Yu, Kaixin Ma, Tianqing Fang, Zhihan Zhang, Siru Ouyang, Hongming Zhang, Dong Yu, Meng Jiang
Text-rich images, where text serves as the central visual element guiding the overall understanding, are prevalent in real-world applications, such as presentation slides, scanned documents, and webpage snapshots. Tasks involving multiple text-rich images are especially challenging, as they require not only understanding the content of individual images but reasoning about inter-relationships and logical flows across multiple visual inputs. Despite the importance of these scenarios, current multimodal large language models (MLLMs) struggle to handle such tasks due to two key challenges: (1) the scarcity of high-quality instruction tuning datasets for text-rich multi-image scenarios, and (2) the difficulty in balancing image resolution with visual feature sequence length. To address these challenges, we propose Leopard, an MLLM tailored for handling vision-language tasks involving multiple text-rich images. First, we curated about one million high-quality multimodal instruction-tuning data, tailored to text-rich, multi-image scenarios. Second, we proposed an adaptive high-resolution multi-image encoding module to dynamically optimize the allocation of visual sequence length based on the original aspect ratios and resolutions of images. Experiments on a diverse set of benchmarks reveal that our model consistently outperforms state-of-the-art systems, such as Llama-3.2 and Qwen2-VL, in challenging text-rich, multi-image evaluations. Remarkably, our approach achieves outstanding performance using only 1.2M training instances, all of which are fully open-sourced, demonstrating both high efficiency and effectiveness compared to models trained on large-scale in-house data. Our code and data are available at https://github.com/tencent-ailab/Leopard.
文本丰富的图像,其中文本作为引导整体理解的核心视觉元素,在现实世界应用中普遍存在,例如演示幻灯片、扫描文档和网页快照。涉及多个文本丰富的图像的任务尤其具有挑战性,因为它们不仅要求理解单个图像的内容,还要求推理多个视觉输入之间的相互作用和逻辑关系。尽管这些场景非常重要,但当前的多模态大型语言模型(MLLMs)在处理此类任务时面临两个主要挑战:(1) 文本丰富多图像场景的优质指令微调数据集稀缺;(2) 平衡图像分辨率与视觉特征序列长度的难度。为了应对这些挑战,我们提出了Leopard,一个专为处理涉及多个文本丰富图像的视觉语言任务而定制的大型语言模型。首先,我们精选了大约一百万份高质量的多模态指令微调数据,专门针对文本丰富多图像场景。其次,我们提出了自适应高分辨率多图像编码模块,根据图像的原始纵横比和分辨率动态优化视觉序列长度的分配。在多种基准测试集上的实验表明,我们的模型在具有挑战性的文本丰富多图像评估中一直优于最先进系统,如Llama-3.2和Qwen2-VL。值得注意的是,我们的方法仅使用1.2M训练实例就实现了出色的性能,所有这些实例都已完全开源,与在大规模内部数据上训练的模型相比,显示出高效和高效能。我们的代码和数据可在https://github.com/tencent-ailab/Leopard上找到。
论文及项目相关链接
PDF Our code is available at https://github.com/tencent-ailab/Leopard
Summary
文本丰富的图像在处理多模态语言模型任务时尤为关键,尤其在真实世界应用中如演示幻灯片、扫描文档和网页快照等场景。然而,当前的多模态大型语言模型在处理涉及多个文本丰富的图像的任务时面临挑战,主要源于缺乏高质量的教学调优数据集和平衡图像分辨率与视觉特征序列长度的难度。针对这些挑战,提出了名为Leopard的定制多模态语言模型。通过采集约一百万高质量的多模态指令调优数据,并引入自适应高分辨率多图像编码模块,实现动态优化图像序列长度的分配。实验证明,该模型在具有挑战性的多文本图像评估中表现优于其他先进系统,如Llama-3.2和Qwen2-VL。其仅使用120万训练实例便取得了显著成效,且所有资源均已开源。
Key Takeaways
一、文本丰富的图像在真实世界应用中广泛使用,成为研究焦点。
二、当前多模态大型语言模型在处理涉及多个文本丰富的图像的任务时面临挑战。
三、缺乏高质量的教学调优数据集和平衡图像分辨率与视觉特征序列长度的难度是两大主要挑战。
四、提出的Leopard模型通过引入自适应高分辨率多图像编码模块解决上述问题。
五、Leopard模型表现优于其他先进系统,在具有挑战性的多文本图像评估中取得显著成效。
六、该模型仅使用少量训练实例便取得良好效果,显示其高效性。
点此查看论文截图


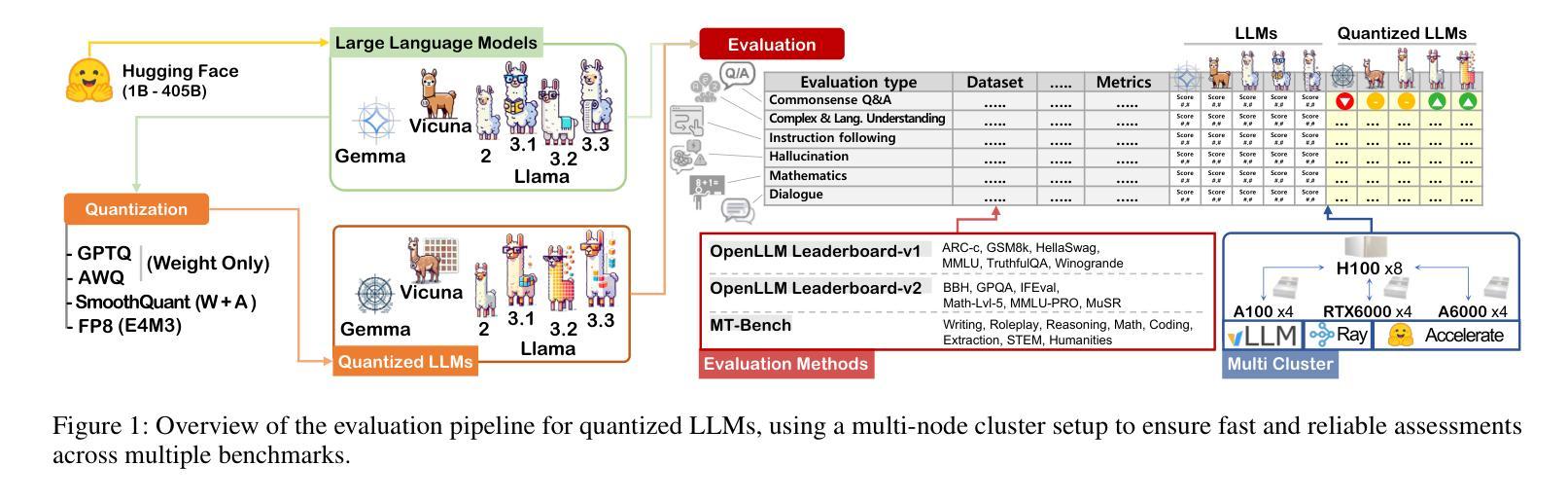
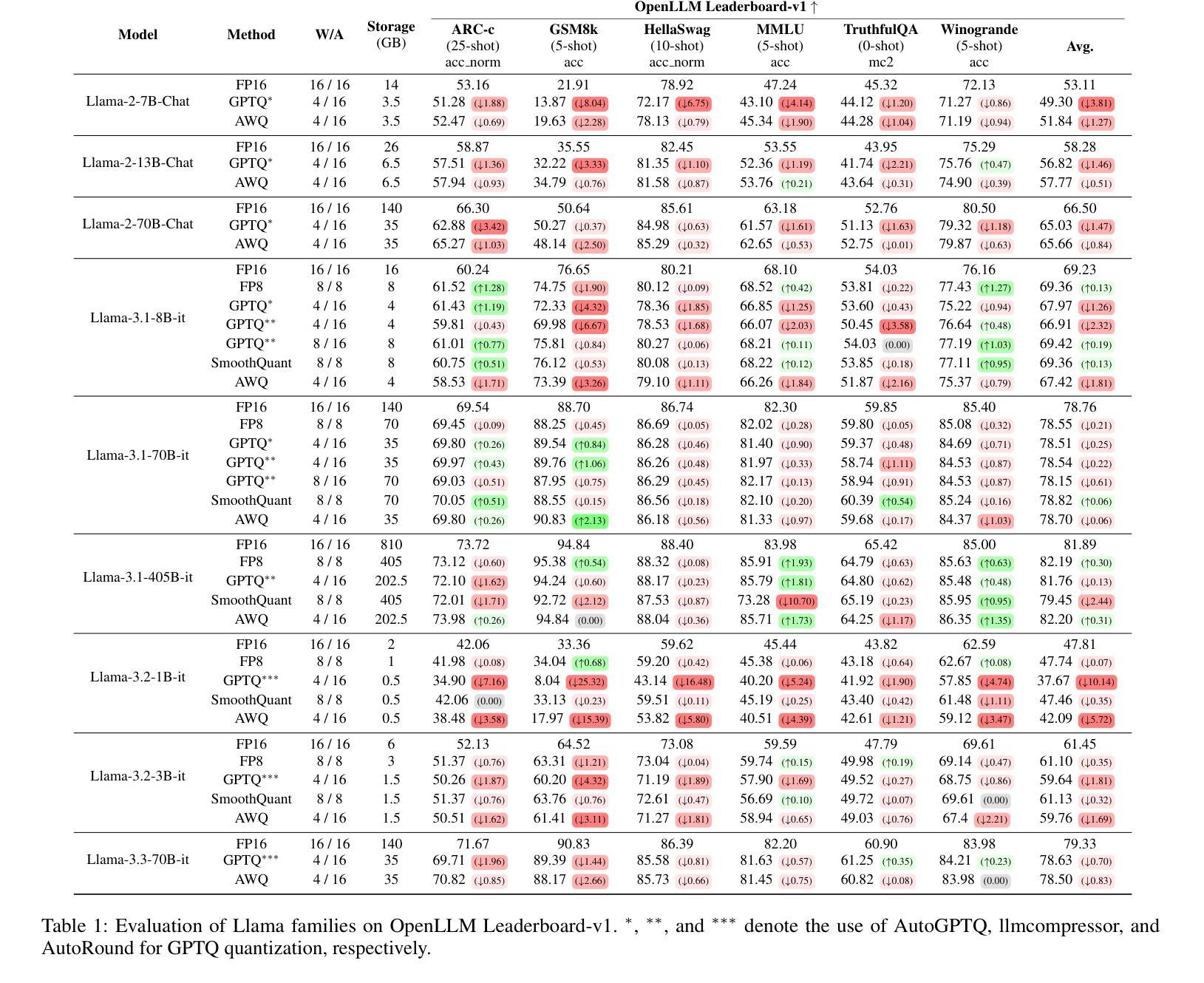
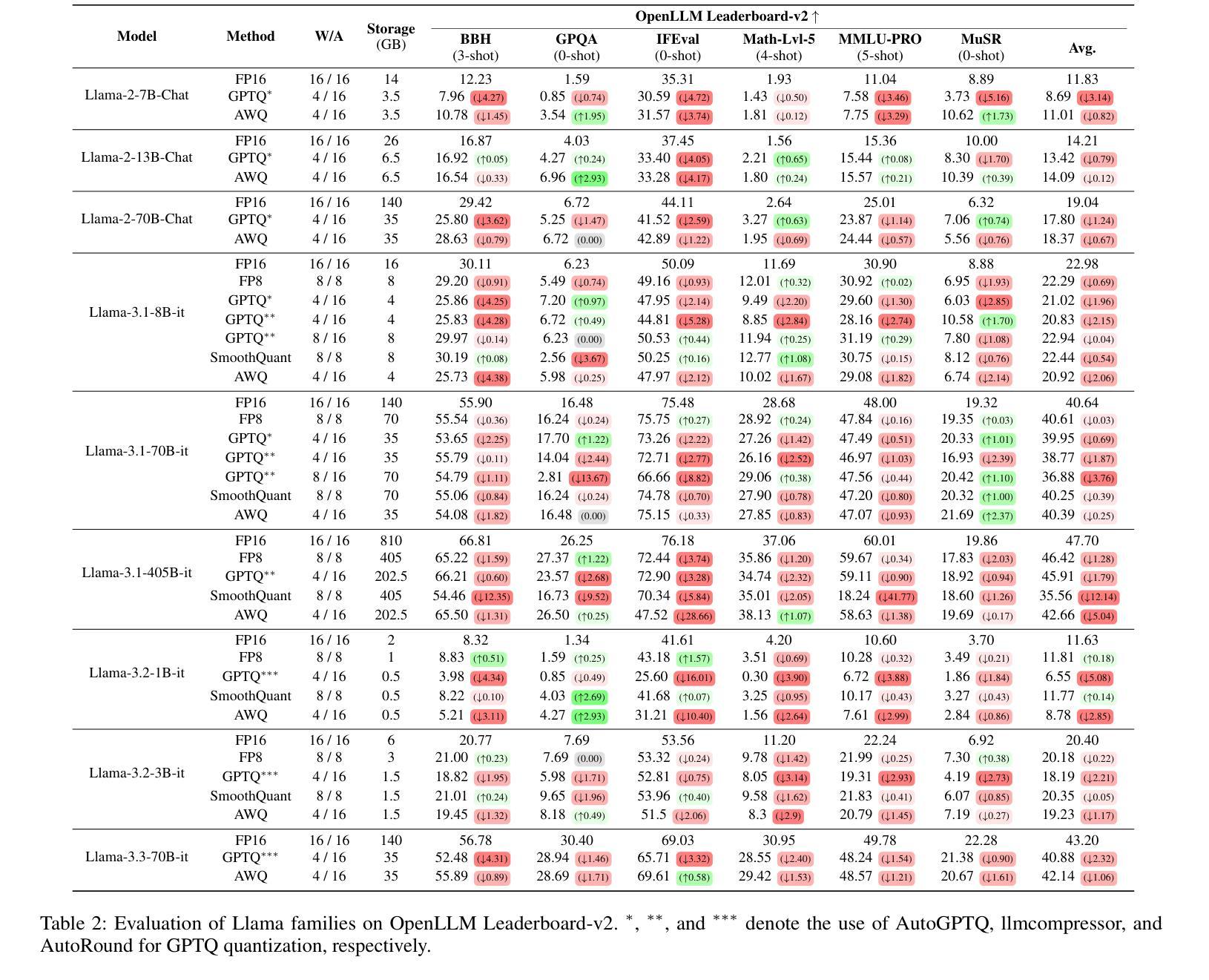
Exploring the Trade-Offs: Quantization Methods, Task Difficulty, and Model Size in Large Language Models From Edge to Giant
Authors:Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, Yongin Kwon
Quantization has gained attention as a promising solution for the cost-effective deployment of large and small language models. However, most prior work has been limited to perplexity or basic knowledge tasks and lacks a comprehensive evaluation of recent models like Llama-3.3. In this paper, we conduct a comprehensive evaluation of instruction-tuned models spanning 1B to 405B parameters, applying four quantization methods across 13 datasets. Our findings reveal that (1) quantized models generally surpass smaller FP16 baselines, yet they often struggle with instruction-following and hallucination detection; (2) FP8 consistently emerges as the most robust option across tasks, and AWQ tends to outperform GPTQ in weight-only quantization; (3) smaller models can suffer severe accuracy drops at 4-bit quantization, while 70B-scale models maintain stable performance; (4) notably, \textit{hard} tasks do not always experience the largest accuracy losses, indicating that quantization magnifies a model’s inherent weaknesses rather than simply correlating with task difficulty; and (5) an LLM-based judge (MT-Bench) highlights significant performance declines in Coding and STEM tasks, though it occasionally reports improvements in reasoning.
量化作为一种有前景的解决方案,已经引起了人们对经济高效地部署大小语言模型的关注。然而,之前的大部分工作都局限于困惑度或基础知识任务,缺乏对像Llama-3.3这样的最新模型的全面评估。在本文中,我们对指令优化模型进行了全面评估,这些模型参数范围从1B到405B,应用了四种量化方法,跨越13个数据集。我们的研究发现:
(1)量化模型总体上超过了较小的FP16基线模型,但在遵循指令和幻想检测方面经常遇到困难;
(2)FP8在各项任务中始终表现为最稳健的选择,AWQ在仅权重量化方面往往优于GPTQ;
(3)较小模型在4位量化时可能会出现严重的精度下降,而70B规模的模型则能保持稳定的性能;
(4)值得注意的是,难度高的任务并不总是面临最大的精度损失,这表明量化会放大模型的固有弱点,而不仅仅是与任务难度相关;
(5)基于大型语言模型的判断(MT-Bench)凸显了编码和STEM任务的性能显著下降,尽管它在推理方面偶尔会有改进。
论文及项目相关链接
PDF Accepted in IJCAI 2025, 21 pages, 2 figure
Summary
本文全面评估了指令微调模型在量化后的表现,涉及参数范围从1B到405B,采用四种量化方法,跨越13个数据集。研究发现,量化模型一般表现优于FP16基线模型,但在指令遵循和幻觉检测方面存在问题。FP8在各项任务中最具稳健性,AWQ在仅权重量化方面表现优于GPTQ。小模型在4位量化时精度大幅下降,而70B规模模型表现稳定。值得注意的是,量化并非总是对困难任务造成最大精度损失,而是放大了模型的固有弱点。LLM判断(MT-Bench)在编码和STEM任务中表现出显著性能下降,但有时在推理任务中有所改善。
Key Takeaways
- 量化模型总体表现优于FP16基线模型,但在指令遵循和幻觉检测方面存在问题。
- FP8是最稳健的量化选项,特别是在不同任务中表现一致。
- AWQ在仅权重量化方面优于GPTQ。
- 小模型在4位量化时精度损失较大,而较大模型(如70B规模)的精度表现相对稳定。
- 量化会放大模型的固有弱点,而非仅与任务难度相关。
- LLM判断工具(如MT-Bench)在某些任务(如编码和STEM)中检测到显著性能下降。
- 在某些推理任务中,量化模型的表现有所改善。
点此查看论文截图

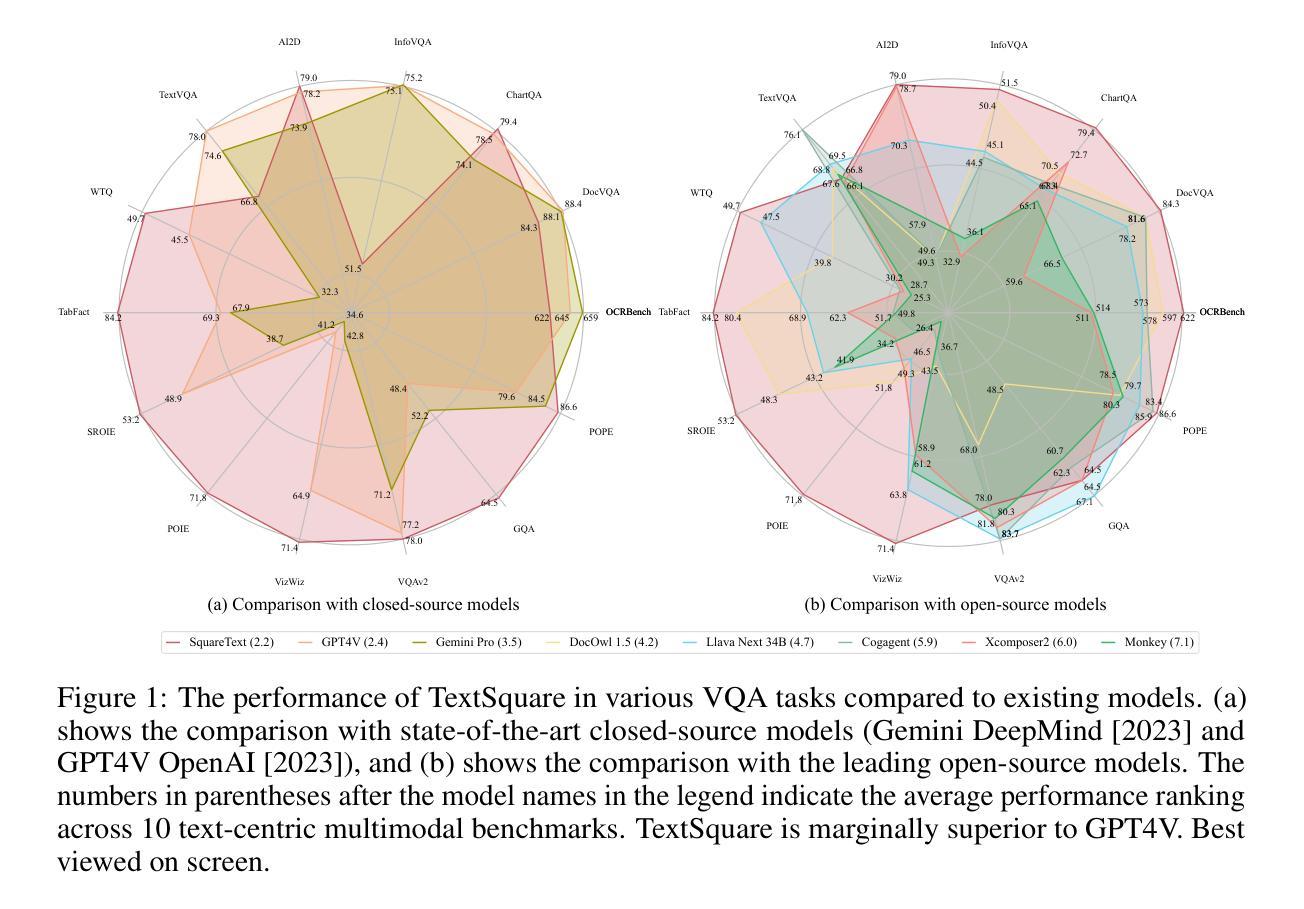
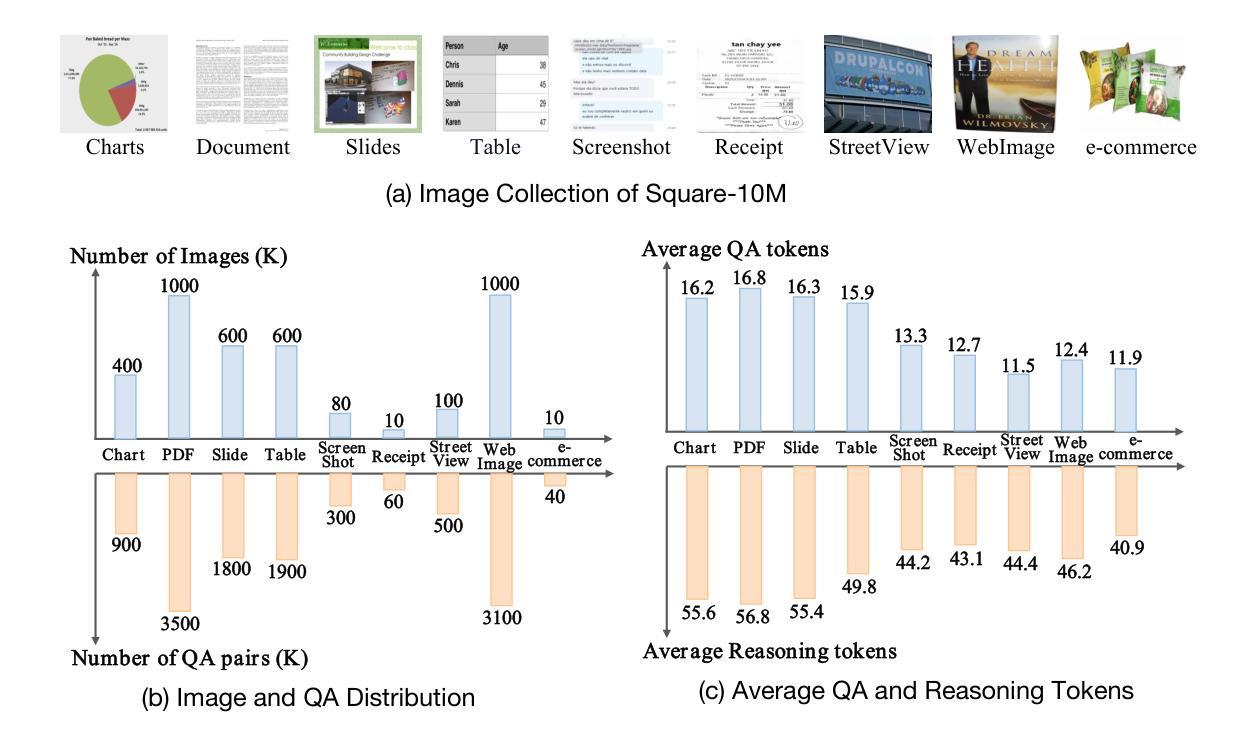
TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Authors:Jingqun Tang, Chunhui Lin, Zhen Zhao, Shu Wei, Binghong Wu, Qi Liu, Yangfan He, Kuan Lu, Hao Feng, Yang Li, Siqi Wang, Lei Liao, Wei Shi, Yuliang Liu, Hao Liu, Yuan Xie, Xiang Bai, Can Huang
Text-centric visual question answering (VQA) has made great strides with the development of Multimodal Large Language Models (MLLMs), yet open-source models still fall short of leading models like GPT4V and Gemini, partly due to a lack of extensive, high-quality instruction tuning data. To this end, we introduce a new approach for creating a massive, high-quality instruction-tuning dataset, Square-10M, which is generated using closed-source MLLMs. The data construction process, termed Square, consists of four steps: Self-Questioning, Answering, Reasoning, and Evaluation. Our experiments with Square-10M led to three key findings: 1) Our model, TextSquare, considerably surpasses open-source previous state-of-the-art Text-centric MLLMs and sets a new standard on OCRBench(62.2%). It even outperforms top-tier models like GPT4V and Gemini in 6 of 10 text-centric benchmarks. 2) Additionally, we demonstrate the critical role of VQA reasoning data in offering comprehensive contextual insights for specific questions. This not only improves accuracy but also significantly mitigates hallucinations. Specifically, TextSquare scores an average of 75.1% across four general VQA and hallucination evaluation datasets, outperforming previous state-of-the-art models. 3) Notably, the phenomenon observed in scaling text-centric VQA datasets reveals a vivid pattern: the exponential increase of instruction tuning data volume is directly proportional to the improvement in model performance, thereby validating the necessity of the dataset scale and the high quality of Square-10M.
文本为中心的视觉问答(VQA)随着多模态大型语言模型(MLLMs)的发展而取得了巨大的进步,但仍落后于GPT4V和Gemini等领先模型,部分原因在于缺乏广泛的高质量指令微调数据。为此,我们引入了一种创建大规模高质量指令微调数据集的新方法,即Square-10M,它是使用封闭源MLLMs生成的。数据构建过程,即Square,包括四个步骤:自问、回答、推理和评估。我们利用Square-10M进行的实验得出了三个关键发现:
一、我们的模型TextSquare显著超越了之前的开源文本为中心的最先进的大型语言模型,并在OCRBench上达到了62.2%,设定了新的标准。在十个文本为中心的标准中,它甚至在六个方面超过了顶尖模型如GPT4V和Gemini。
二、此外,我们证明了VQA推理数据在提供特定问题的全面上下文洞察中的关键作用。这不仅提高了准确性,而且显著减轻了幻觉现象。具体来说,TextSquare在四个通用VQA和幻觉评估数据集上的平均得分为75.1%,超过了之前的最先进模型。
论文及项目相关链接
Summary
通过利用封闭式源的多模态大型语言模型,推出了全新的大规模高质量指令调整数据集Square-10M,包含自我提问、回答、推理和评估四个步骤。实验表明,TextSquare模型在OCRBench上超越了现有的开源文本中心型MLLMs模型,并且在大部分文本中心基准测试中表现优异。此外,强调了VQA推理数据对于提供特定问题的全面语境洞察的重要性,不仅提高了准确性,还显著减少了幻觉。还发现文本中心型VQA数据集的增长趋势与模型性能提升直接相关。
Key Takeaways
- 引入了一种新的大规模高质量指令调整数据集Square-10M,用于创建文本中心型视觉问答(VQA)模型。
- Square-10M数据集使用封闭式源的多模态大型语言模型(MLLMs)生成,包含自我提问、回答、推理和评估四个步骤。
- TextSquare模型在OCRBench上的表现超越了现有的开源文本中心型MLLMs模型,并在多个基准测试中表现优异。
- VQA推理数据对于提高模型的准确性和减少幻觉至关重要。
- TextSquare模型在一般VQA和幻觉评估数据集上的平均得分高于之前的先进模型。
- 指数增长的文本中心型VQA数据集与模型性能的提升呈直接相关。
点此查看论文截图


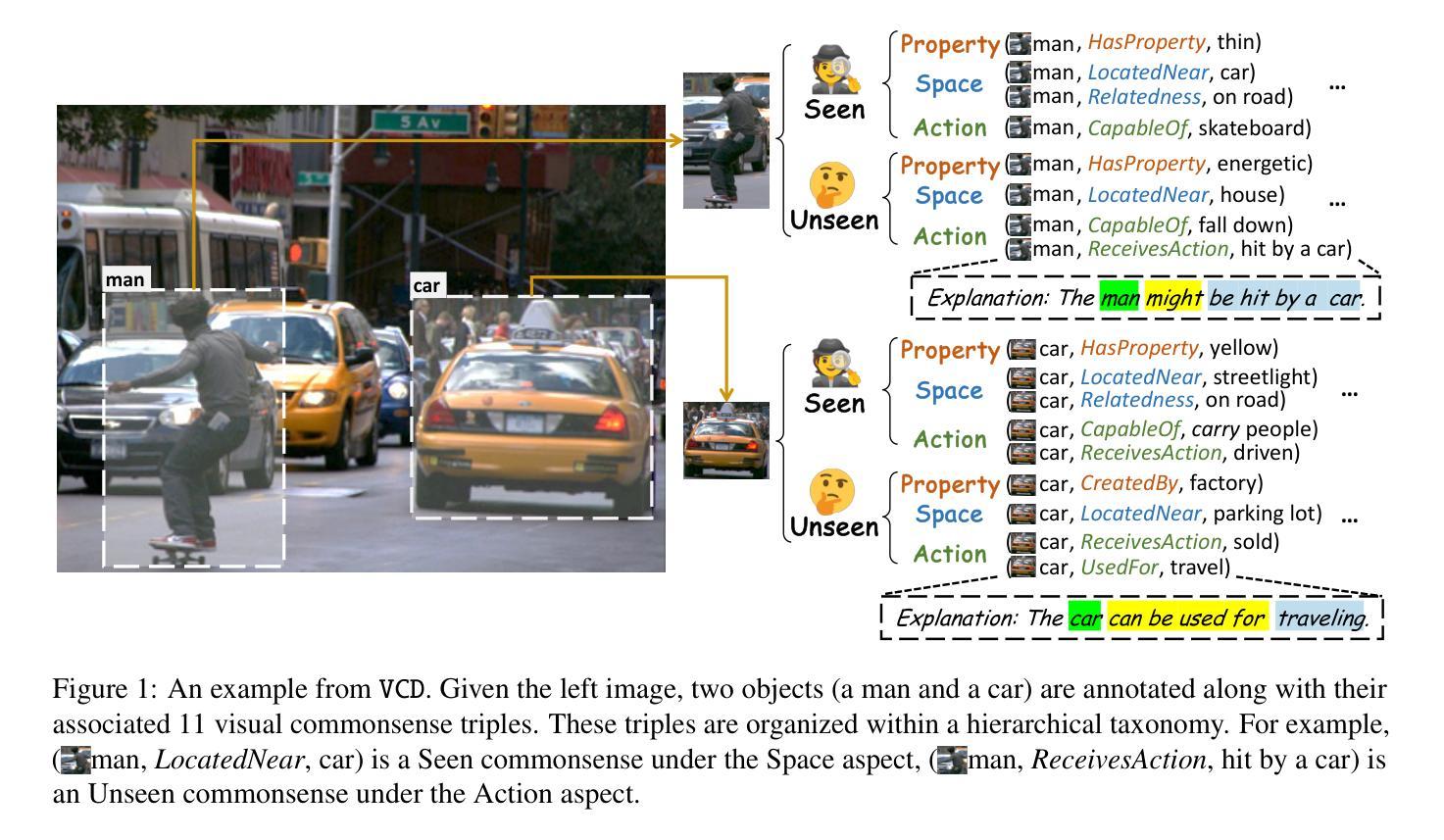
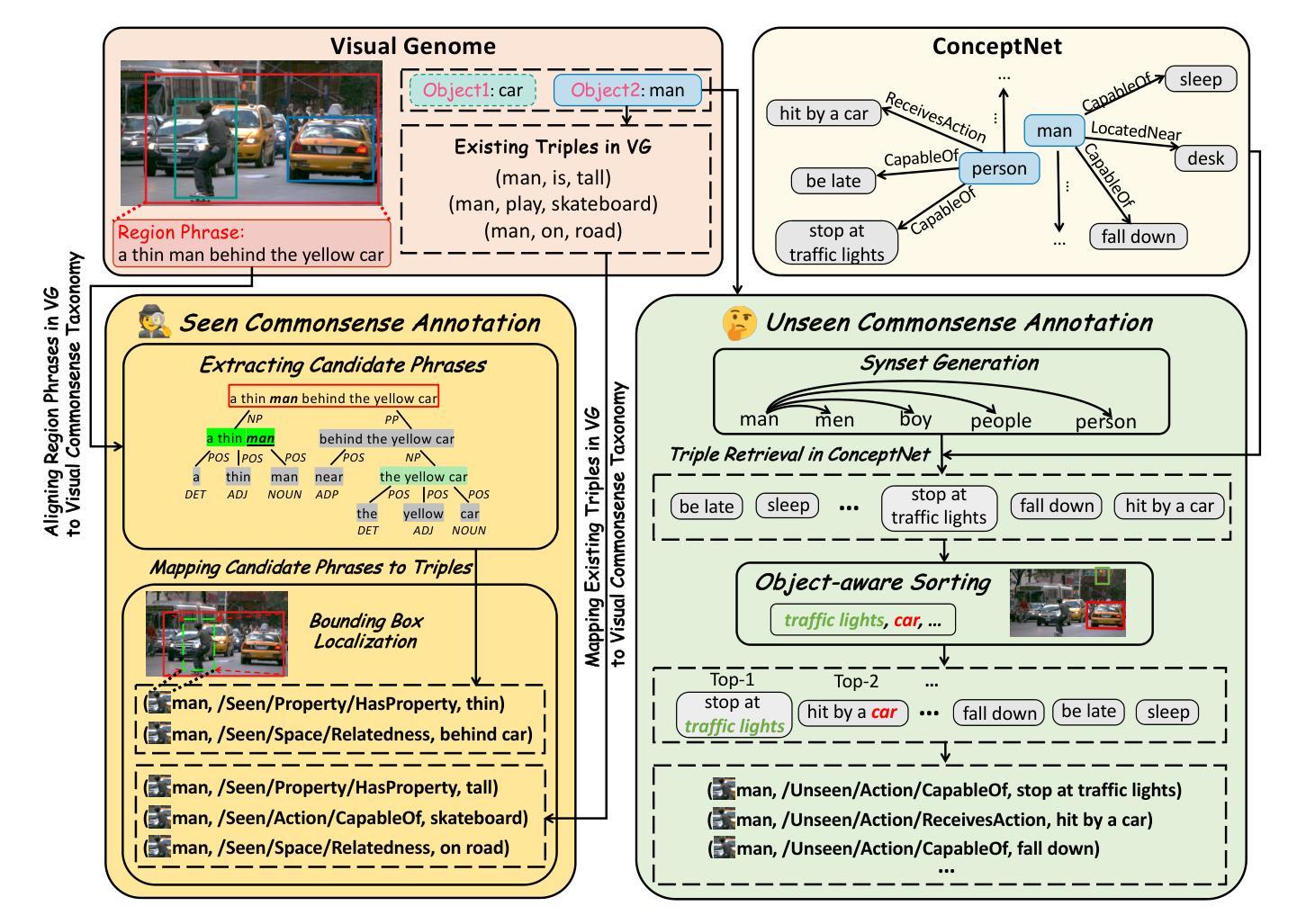
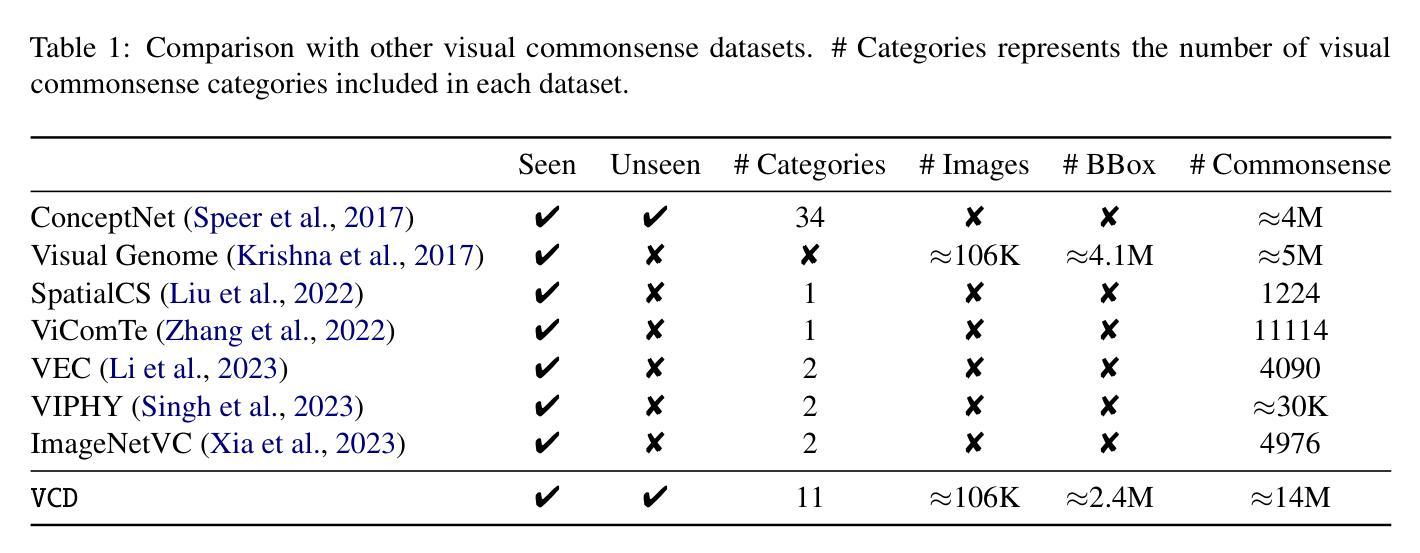
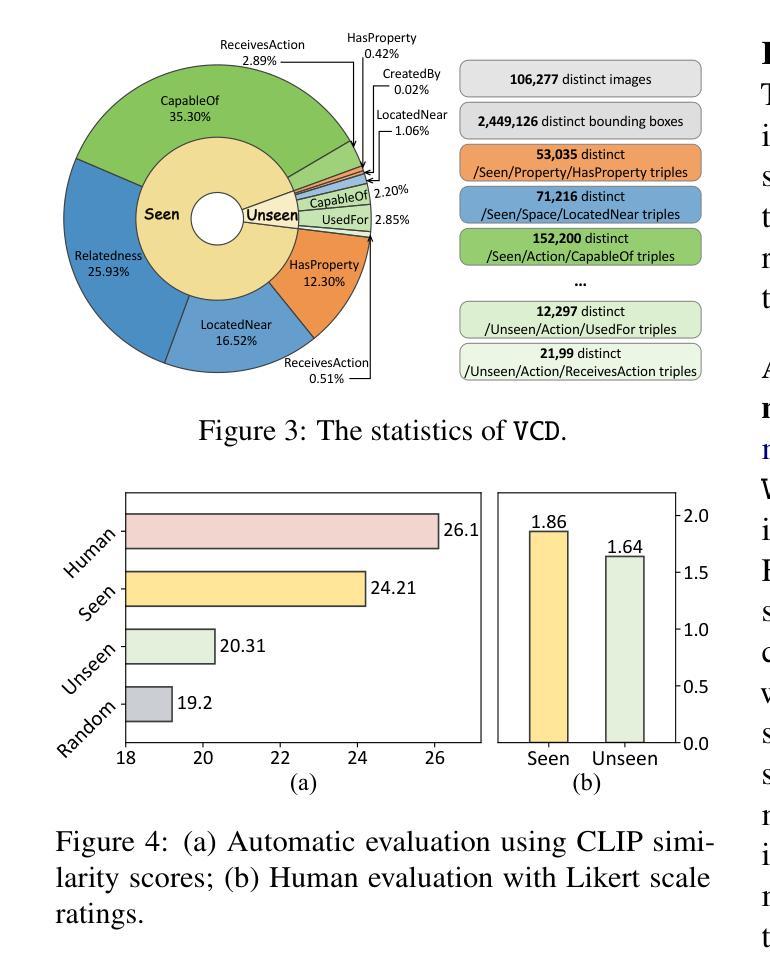
VCD: A Dataset for Visual Commonsense Discovery in Images
Authors:Xiangqing Shen, Fanfan Wang, Siwei Wu, Rui Xia
Visual commonsense plays a vital role in understanding and reasoning about the visual world. While commonsense knowledge bases like ConceptNet provide structured collections of general facts, they lack visually grounded representations. Scene graph datasets like Visual Genome, though rich in object-level descriptions, primarily focus on directly observable information and lack systematic categorization of commonsense knowledge. We present Visual Commonsense Dataset (VCD), a large-scale dataset containing over 100,000 images and 14 million object-commonsense pairs that bridges this gap. VCD introduces a novel three-level taxonomy for visual commonsense, integrating both Seen (directly observable) and Unseen (inferrable) commonsense across Property, Action, and Space aspects. Each commonsense is represented as a triple where the head entity is grounded to object bounding boxes in images, enabling scene-dependent and object-specific visual commonsense representation. To demonstrate VCD’s utility, we develop VCM, a generative model that combines a vision-language model with instruction tuning to discover diverse visual commonsense from images. Extensive evaluations demonstrate both the high quality of VCD and its value as a resource for advancing visually grounded commonsense understanding and reasoning. Our dataset and code will be released on https://github.com/NUSTM/VCD.
视觉常识在理解和推理视觉世界方面起着至关重要的作用。虽然像ConceptNet这样的常识知识库提供了通用事实的结构化集合,但它们缺乏视觉基础表示。像Visual Genome这样的场景图数据集虽然富含对象级别的描述,但主要关注可直接观察的信息,缺乏常识知识的系统分类。我们推出了Visual Commonsense Dataset(VCD),这是一个大规模数据集,包含超过10万张图像和1400万个对象常识对,弥补了这一空白。VCD引入了一种新颖的三级分类法,用于视觉常识,融合了可见(可直接观察)和不可见(可推断)的常识,涵盖属性、动作和空间方面。每个常识都表示为三元组,其中头实体与图像中的对象边界框相结合,实现了场景依赖和对象特定的视觉常识表示。为了展示VCD的实用性,我们开发了VCM,这是一个生成模型,它将视觉语言模型与指令调整相结合,从图像中发现多样的视觉常识。广泛评估表明,VCD的高质量及其作为推进视觉基础常识理解和推理的资源价值。我们的数据集和代码将在https://github.com/NUSTM/VCD上发布。
论文及项目相关链接
Summary:视觉常识在理解和推理视觉世界方面起着重要作用。现有的常识知识库如ConceptNet缺乏视觉基础表示,而场景图数据集如Visual Genome则主要关注可直接观察的信息,缺乏系统常识分类。为此,我们提出了视觉常识数据集(VCD),包含超过100,000张图像和1400万对象-常识对,填补了这一空白。VCD引入了一种新型三级分类法,将可见(可直接观察)和不可见(可推断)的常识整合到属性、动作和空间方面。每个常识都以三元组的形式表示,头部实体与图像中的对象边界框相对应,从而实现场景相关和对象特定的视觉常识表示。为了展示VCD的实用性,我们开发了VCM模型,该模型结合了视觉语言模型与指令调整,可从图像中发现多样的视觉常识。对VCD的广泛评估证明了其高质量和作为推进视觉常识理解和推理的资源价值。我们的数据集和代码将在https://github.com/NUSTM/VCD上发布。
Key Takeaways:
- 视觉常识在理解和推理视觉世界方面具重要作用。
- 当前知识库和数据集存在对视觉基础表示的缺失。
- 提出了视觉常识数据集(VCD),包含图像和对象-常识对,以填补这一空白。
- VCD采用新型三级分类法,整合可见和不可见常识,涉及属性、动作和空间方面。
- 每个常识以三元组形式表示,与图像中的对象边界框相对应。
6.开发了VCM模型以展示VCD的实用性,该模型能从图像中发现多样的视觉常识。
点此查看论文截图

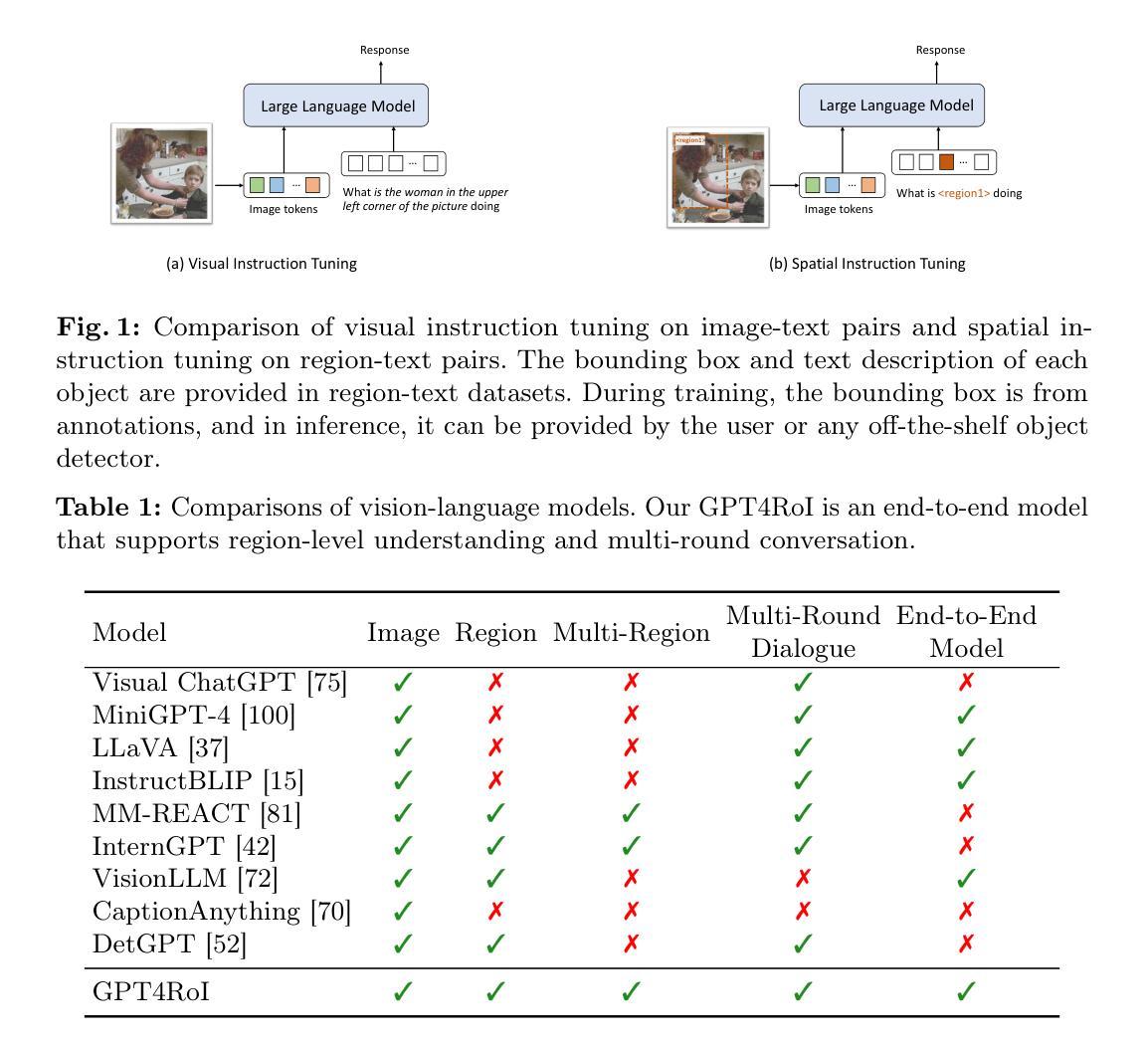
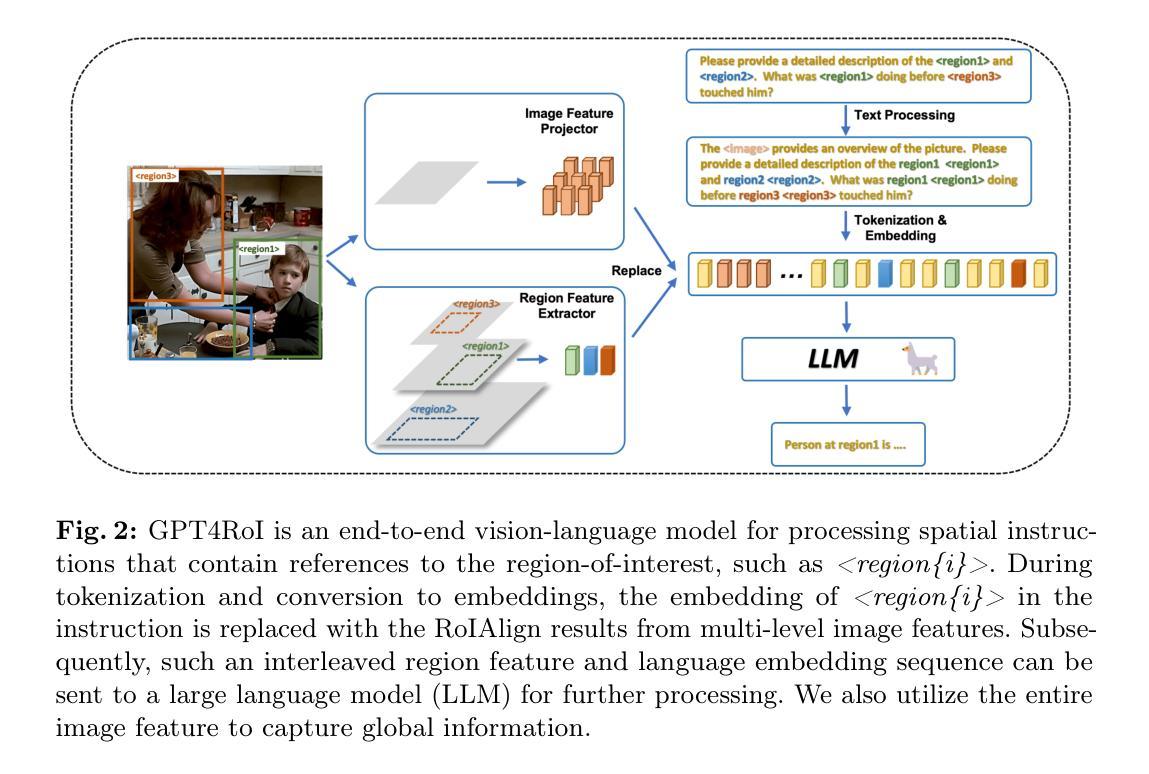
GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
Authors:Shilong Zhang, Peize Sun, Shoufa Chen, Min Xiao, Wenqi Shao, Wenwei Zhang, Yu Liu, Kai Chen, Ping Luo
Visual instruction tuning large language model(LLM) on image-text pairs has achieved general-purpose vision-language abilities. However, the lack of region-text pairs limits their advancements to fine-grained multimodal understanding. In this paper, we propose spatial instruction tuning, which introduces the reference to the region-of-interest(RoI) in the instruction. Before sending to LLM, the reference is replaced by RoI features and interleaved with language embeddings as a sequence. Our model GPT4RoI, trained on 7 region-text pair datasets, brings an unprecedented interactive and conversational experience compared to previous image-level models. (1) Interaction beyond language: Users can interact with our model by both language and drawing bounding boxes to flexibly adjust the referring granularity. (2) Versatile multimodal abilities: A variety of attribute information within each RoI can be mined by GPT4RoI, e.g., color, shape, material, action, etc. Furthermore, it can reason about multiple RoIs based on common sense. On the Visual Commonsense Reasoning(VCR) dataset, GPT4RoI achieves a remarkable accuracy of 81.6%, surpassing all existing models by a significant margin (the second place is 75.6%) and almost reaching human-level performance of 85.0%. The code and model can be found at https://github.com/jshilong/GPT4RoI.
通过视觉指令调整大型语言模型(LLM)在图像文本对上的能力已经实现了通用视觉语言功能。然而,缺乏区域文本对限制了其在细粒度多模态理解方面的进展。在本文中,我们提出了空间指令调整方法,该方法在指令中引入了感兴趣区域(RoI)的引用。在发送到LLM之前,该引用被替换为RoI特征,并与语言嵌入交错作为序列。我们的模型GPT4RoI在7个区域文本对数据集上进行训练,与之前的图像级别模型相比,它带来了前所未有的交互和对话体验。(1)超越语言的交互:用户可以通过语言和绘制边界框来与我们的模型进行交互,以灵活地调整指代粒度。(2)多功能的多模态能力:GPT4RoI可以挖掘每个RoI内的各种属性信息,例如颜色、形状、材质、动作等。此外,它还可以基于常识对多个RoI进行推理。在视觉常识推理(VCR)数据集上,GPT4RoI取得了81.6%的显著准确率,显著超越了现有模型(第二名是75.6%),几乎达到了人类水平的性能85.0%。代码和模型可在https://github.com/jshilong/GPT4RoI找到。
论文及项目相关链接
PDF ECCV2024-Workshop, Camera-ready
Summary
大型语言模型(LLM)通过视觉指令调整图像文本对,已具备通用视觉语言功能。然而,由于缺乏区域文本对,其精细粒度多模式理解的发展受到限制。本文提出空间指令调整,引入指令中的感兴趣区域(RoI)参考。在发送到LLM之前,通过替换RoI特征并将其与语言嵌入作为序列交织,我们的模型GPT4RoI在7个区域文本对数据集上进行训练,带来了前所未有的交互式体验,相较于之前的图像级别模型有着更高的互动性和会话体验。它还可以利用多种属性信息,如颜色、形状、材质、动作等,并基于常识对多个RoI进行推理。在视觉常识推理(VCR)数据集上,GPT4RoI取得了81.6%的准确率,显著超越了现有模型,并接近人类水平的性能。
Key Takeaways
- 空间指令调整引入感兴趣区域(RoI)参考,提升多模式理解的精细粒度。
- GPT4RoI模型通过结合RoI特征和语言嵌入,提高了大型语言模型在图像文本对上的通用视觉语言功能。
- GPT4RoI支持通过语言和绘制边界框与用户交互,灵活调整指代粒度。
- GPT4RoI能够挖掘每个RoI内的多种属性信息,如颜色、形状、材质、动作等。
- GPT4RoI在视觉常识推理(VCR)数据集上实现了高准确率,达到81.6%,显著超越现有模型。
- GPT4RoI模型具有强大的推理能力,可以基于常识对多个RoI进行推理。
点此查看论文截图