⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-21 更新
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Authors:Ziqiao Peng, Wentao Hu, Junyuan Ma, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Hui Tian, Jun He, Hongyan Liu, Zhaoxin Fan
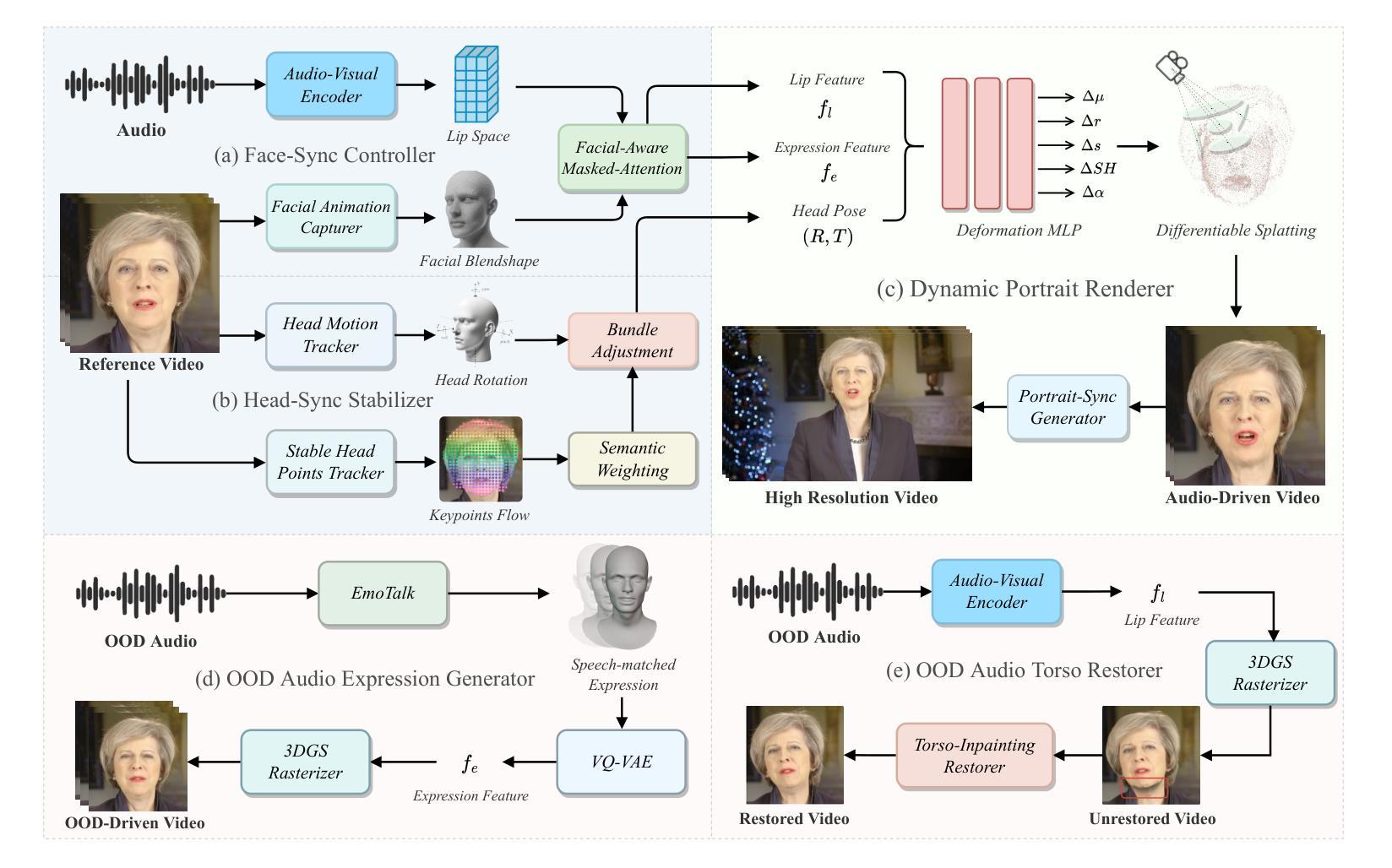
Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic results. To address the critical issue of synchronization, identified as the ‘’devil’’ in creating realistic talking heads, we introduce SyncTalk++, which features a Dynamic Portrait Renderer with Gaussian Splatting to ensure consistent subject identity preservation and a Face-Sync Controller that aligns lip movements with speech while innovatively using a 3D facial blendshape model to reconstruct accurate facial expressions. To ensure natural head movements, we propose a Head-Sync Stabilizer, which optimizes head poses for greater stability. Additionally, SyncTalk++ enhances robustness to out-of-distribution (OOD) audio by incorporating an Expression Generator and a Torso Restorer, which generate speech-matched facial expressions and seamless torso regions. Our approach maintains consistency and continuity in visual details across frames and significantly improves rendering speed and quality, achieving up to 101 frames per second. Extensive experiments and user studies demonstrate that SyncTalk++ outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk++.
在合成逼真的语音驱动式谈话视频时,实现高同步化是一个巨大的挑战。一个栩栩如生的谈话头部需要同步协调主题身份、嘴唇动作、面部表情和头部姿态。缺乏这些同步是一个基本缺陷,会导致不真实的结果。为了解决同步这一关键问题,我们将其视为创建真实谈话头部的“魔鬼”,引入了SyncTalk++。它具备动态肖像渲染器和高斯拼贴技术,确保一致的主题身份保留,以及面部同步控制器,该控制器对齐嘴唇动作与语音,同时创新地使用3D面部混合形状模型来重建准确的面部表情。为了确保自然的头部动作,我们提出了头部同步稳定器,它优化了头部姿势以实现更大的稳定性。此外,SyncTalk++通过融入表情生成器和躯干修复器,增强了对于离群值(OOD)音频的稳健性,生成与语音相匹配的表情和无缝的躯干区域。我们的方法保持了跨帧的视觉细节的一致性和连续性,并大大提高了渲染速度和品质,达到了每秒101帧。大量的实验和用户研究证明,SyncTalk++在同步和逼真度方面超过了最先进的方法。推荐观看补充视频:https://ziqiaopeng.github.io/synctalk++.
论文及项目相关链接
Summary
本文介绍了在合成逼真的语音驱动谈话头视频时实现高同步率所面临的挑战。为实现同步协调的主体身份、嘴唇动作、面部表情和头部姿态,研究者提出了SyncTalk++方案。该方案包括动态肖像渲染器、面部同步控制器和头部同步稳定器,以确保主体身份的一致性、嘴唇动作与语音的对齐以及头部姿态的自然性。此外,SyncTalk++还通过融入表情生成器和躯干修复器,提高了对离群音频的稳健性。该研究在视频细节的一致性、连续性、渲染速度和画质方面都有显著提升,且用户研究和实验证明SyncTalk++在同步和逼真度方面优于现有技术。
Key Takeaways
- SyncTalk++解决了合成语音驱动谈话头视频中的高同步挑战。
- SyncTalk++包括动态肖像渲染器以确保主体身份的一致性。
- 面部同步控制器实现了嘴唇动作与语音的对齐,同时使用3D面部模型重建面部表情。
- 头部同步稳定器优化头部姿态,使其更自然。
- SyncTalk++通过表情生成器和躯干修复器提高了对离群音频的稳健性。
- SyncTalk++提升了视频细节的一致性、连续性和渲染速度。
点此查看论文截图




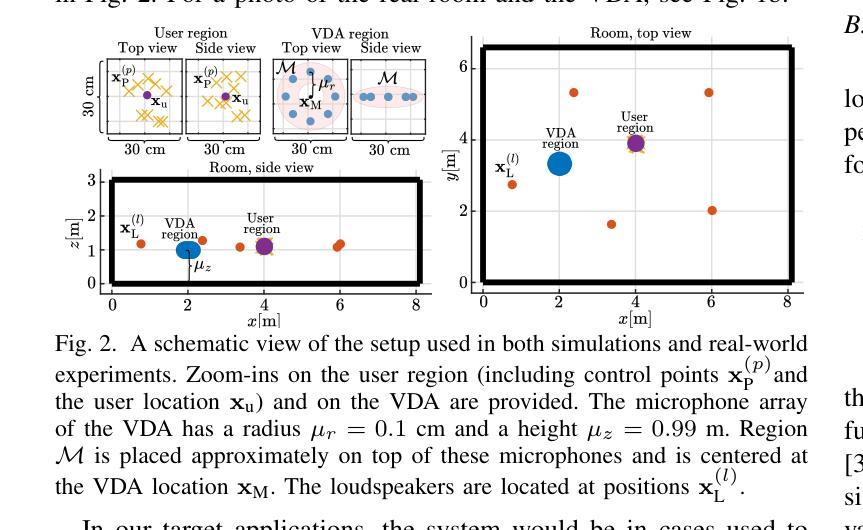
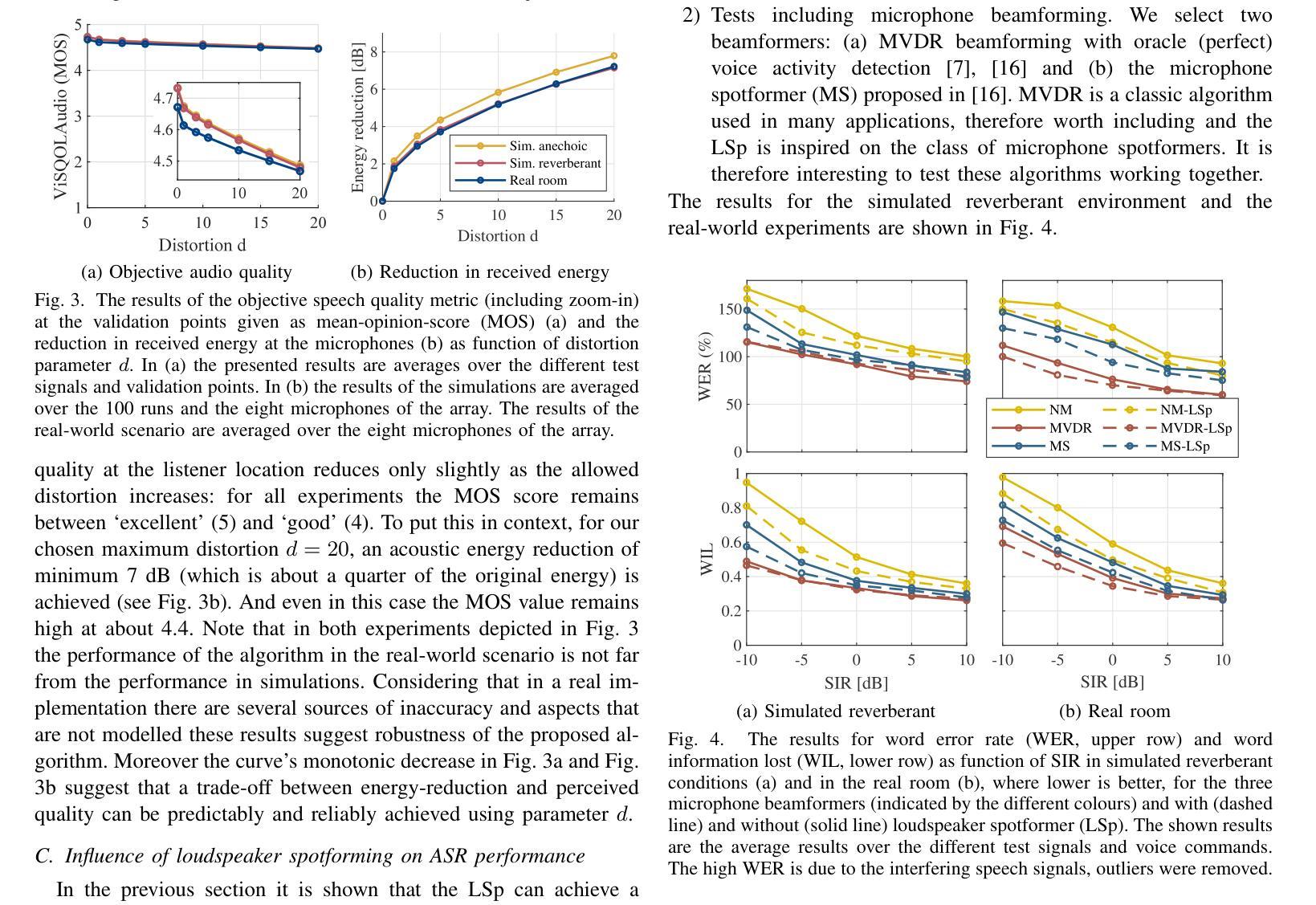
Loudspeaker Beamforming to Enhance Speech Recognition Performance of Voice Driven Applications
Authors:Dimme de Groot, Baturalp Karslioglu, Odette Scharenborg, Jorge Martinez
In this paper we propose a robust loudspeaker beamforming algorithm which is used to enhance the performance of voice driven applications in scenarios where the loudspeakers introduce the majority of the noise, e.g. when music is playing loudly. The loudspeaker beamformer modifies the loudspeaker playback signals to create a low-acoustic-energy region around the device that implements automatic speech recognition for a voice driven application (VDA). The algorithm utilises a distortion measure based on human auditory perception to limit the distortion perceived by human listeners. Simulations and real-world experiments show that the proposed loudspeaker beamformer improves the speech recognition performance in all tested scenarios. Moreover, the algorithm allows to further reduce the acoustic energy around the VDA device at the expense of reduced objective audio quality at the listener’s location.
本文提出了一种稳健的扬声器波束形成算法,该算法用于提高在扬声器为主要噪声来源的场景中语音驱动应用性能,例如在音乐播放较大的情况下。扬声器波束成形器修改扬声器播放信号,在设备周围创建一个低声能区域,为语音驱动应用(VDA)实现自动语音识别。该算法利用基于人类听觉感知的失真度量来限制人类听众感知到的失真。模拟和真实世界的实验表明,所提出的扬声器波束成形器在所有测试场景中提高了语音识别性能。此外,该算法允许在听众位置客观音频质量降低的情况下,进一步减少VDA设备周围的声能。
论文及项目相关链接
PDF To appear at ICASSP 2025
Summary
本文提出了一种稳健的扬声器波束成形算法,用于提高语音驱动应用在某些场景下的性能,如在音乐大声播放等场景下扬声器成为主要噪声来源。该扬声器波束成形器通过修改扬声器播放信号来创建设备周围的低声学能量区域,从而实现自动语音识别功能。该算法利用基于人类听觉感知的失真度量来衡量人耳听到的失真。模拟和真实实验均显示,该算法能有效提高各种场景的语音识别性能。此外,算法可以在降低扬声器音频质量的代价下,进一步降低语音驱动设备周围的声学能量。
Key Takeaways
- 本文提出了一种针对语音驱动应用的扬声器波束成形算法,旨在提高在特定场景下的性能。
- 该算法主要应用于音乐大声播放等场景,当扬声器成为主要噪声来源时。
- 扬声器波束成形器通过修改扬声器播放信号来创建低声学能量区域,提高语音识别功能。
- 算法采用基于人类听觉感知的失真度量,旨在降低人耳感知到的失真。
- 模拟和真实实验证明了该算法的有效性,能够提高语音识别性能在各种测试场景中的表现。
- 该算法允许进一步降低语音驱动设备周围的声学能量,但可能会牺牲一定的音频质量。
点此查看论文截图