⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
Particle-Grid Neural Dynamics for Learning Deformable Object Models from RGB-D Videos
Authors:Kaifeng Zhang, Baoyu Li, Kris Hauser, Yunzhu Li
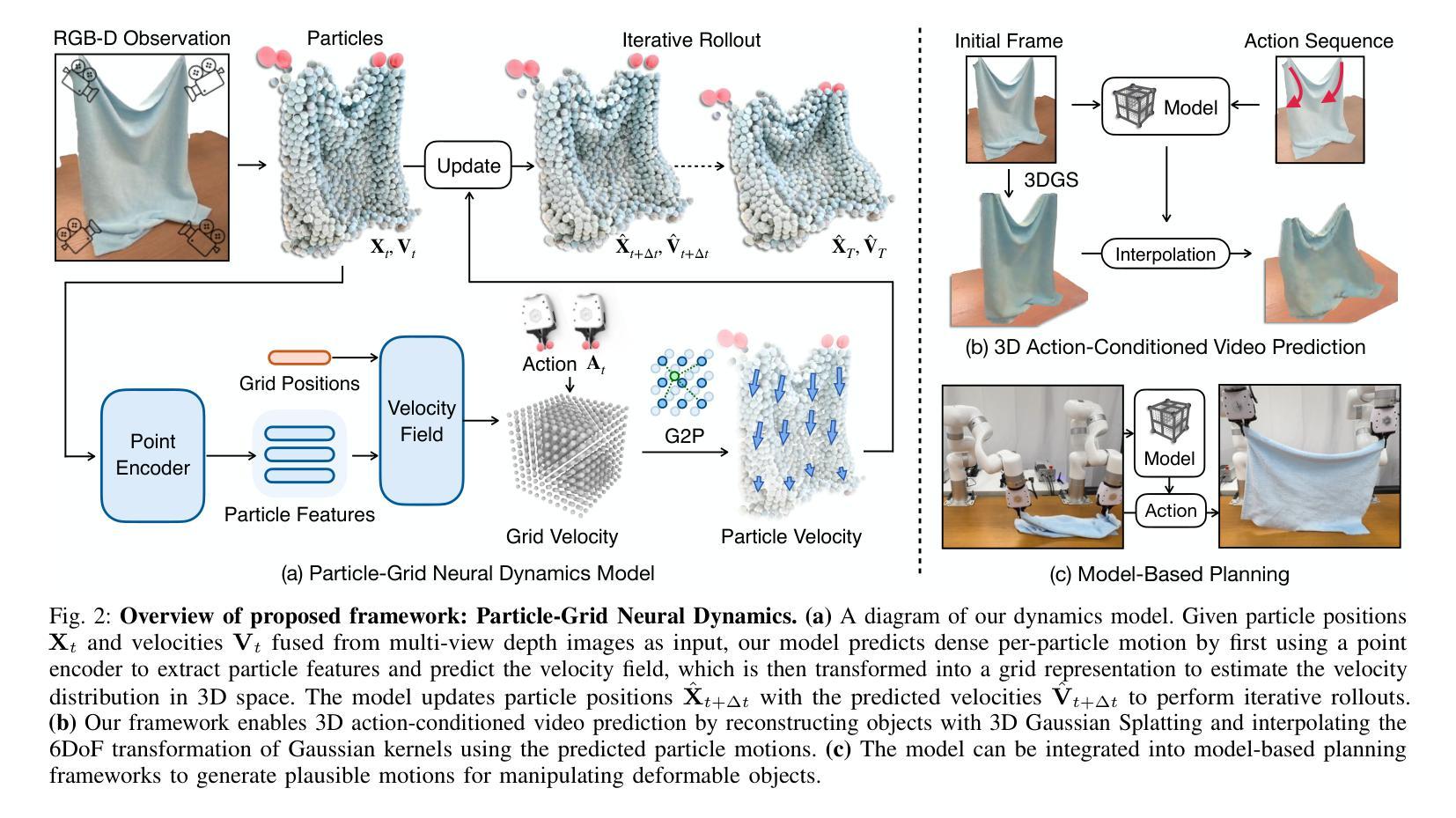
Modeling the dynamics of deformable objects is challenging due to their diverse physical properties and the difficulty of estimating states from limited visual information. We address these challenges with a neural dynamics framework that combines object particles and spatial grids in a hybrid representation. Our particle-grid model captures global shape and motion information while predicting dense particle movements, enabling the modeling of objects with varied shapes and materials. Particles represent object shapes, while the spatial grid discretizes the 3D space to ensure spatial continuity and enhance learning efficiency. Coupled with Gaussian Splattings for visual rendering, our framework achieves a fully learning-based digital twin of deformable objects and generates 3D action-conditioned videos. Through experiments, we demonstrate that our model learns the dynamics of diverse objects – such as ropes, cloths, stuffed animals, and paper bags – from sparse-view RGB-D recordings of robot-object interactions, while also generalizing at the category level to unseen instances. Our approach outperforms state-of-the-art learning-based and physics-based simulators, particularly in scenarios with limited camera views. Furthermore, we showcase the utility of our learned models in model-based planning, enabling goal-conditioned object manipulation across a range of tasks. The project page is available at https://kywind.github.io/pgnd .
对可变物体的动态进行建模是一个挑战,这主要是因为它们多样的物理属性以及从有限的视觉信息中估计状态的难度。我们通过结合物体粒子和空间网格的混合表示来解决这些挑战,提出一种神经动力学框架。我们的粒子网格模型能够捕捉全局形状和运动信息,同时预测粒子密集运动,从而能够对各种形状和材料的物体进行建模。粒子代表物体的形状,而空间网格则将三维空间离散化,以确保空间连续性并提高学习效率。结合用于视觉渲染的高斯Splattings,我们的框架实现了基于学习的可变物体的数字孪生,并生成了三维动作条件视频。通过实验,我们证明了我们的模型能够从机器人与物体互动的稀疏视图RGB-D记录中学习各种物体的动态,例如绳索、布料、填充动物和纸袋等,并能对未见过的实例进行类别级别的推广。我们的方法优于最先进的基于学习和基于物理的模拟器,特别是在有限相机视角的场景下。此外,我们展示了所学模型在基于模型的规划中的实用性,能够在一系列任务中实现目标条件下的物体操作。项目页面可在[https://kywind.github.io/pgnd]访问。
论文及项目相关链接
PDF Project page: https://kywind.github.io/pgnd
Summary
该文本描述了一个神经动力学框架,它通过结合对象粒子和空间网格的混合表示来解决变形物体建模的挑战。该粒子网格模型能够捕捉全局形状和运动信息,同时预测粒子密集运动,实现对各种形状和材料物体的建模。通过高斯喷溅进行视觉渲染,实现基于学习的变形物体数字孪生,生成3D动作条件视频。实验表明,该模型能够从稀疏视角的RGB-D记录中学习各种物体的动力学特性,包括绳索、布料、填充玩具和纸袋等,并能在未见过的实例中进行分类级别的推广。该项目在有限的相机视角场景下表现优异,且在模型基础规划中展示了其学习模型的实用性,可实现目标条件下的物体操作任务。
Key Takeaways
- 文本介绍了一种神经动力学框架,该框架结合了对象粒子和空间网格的混合表示来解决变形物体建模的挑战。
- 粒子网格模型能够捕捉全局形状和运动信息,并预测密集粒子运动,适用于各种形状和材料的物体建模。
- 该模型通过高斯喷溅进行视觉渲染,实现了基于学习的变形物体数字孪生体的创建,可生成3D动作条件视频。
- 模型能从稀疏视角的RGB-D记录中学习各种物体的动力学特性,包括绳索、布料等柔软物体以及纸袋等硬质物体的混合类型。
- 模型在未见过的实例中能够进行分类级别的推广,且对有限的相机视角场景下的表现优异。
- 实验结果表明该模型在多种任务场景下均表现出优秀的性能。
点此查看论文截图

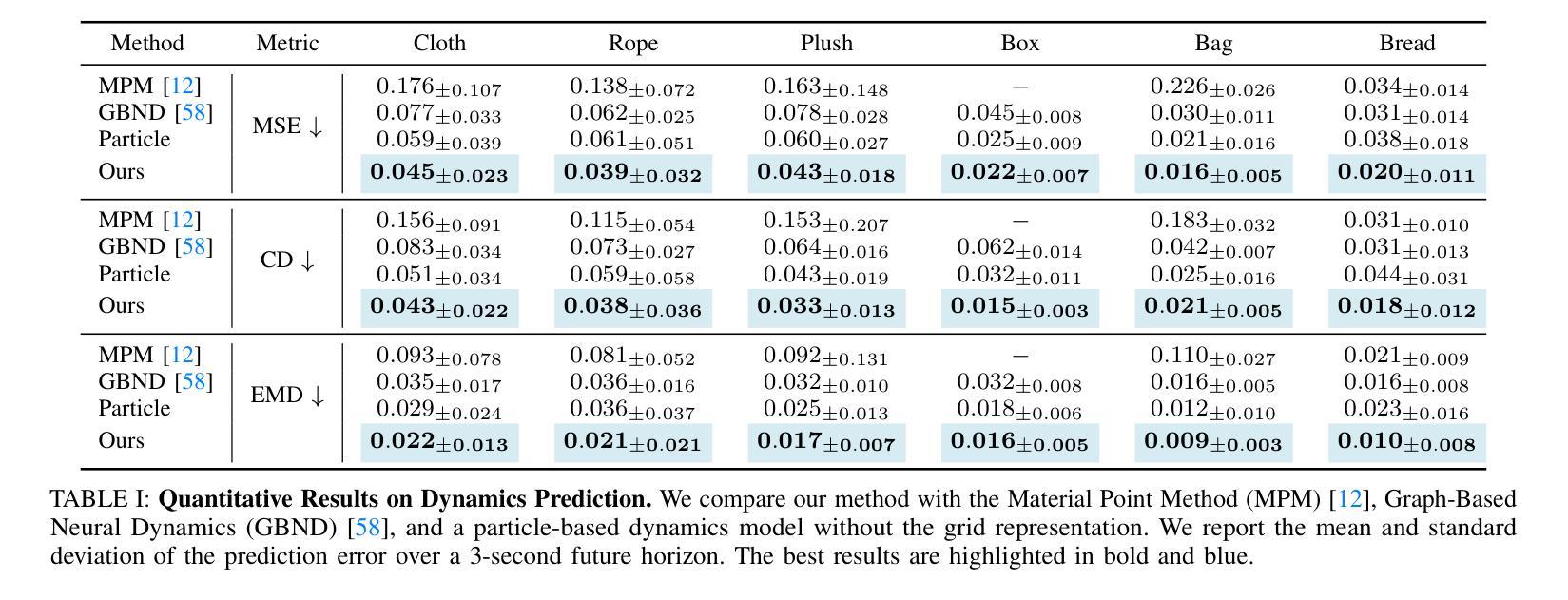

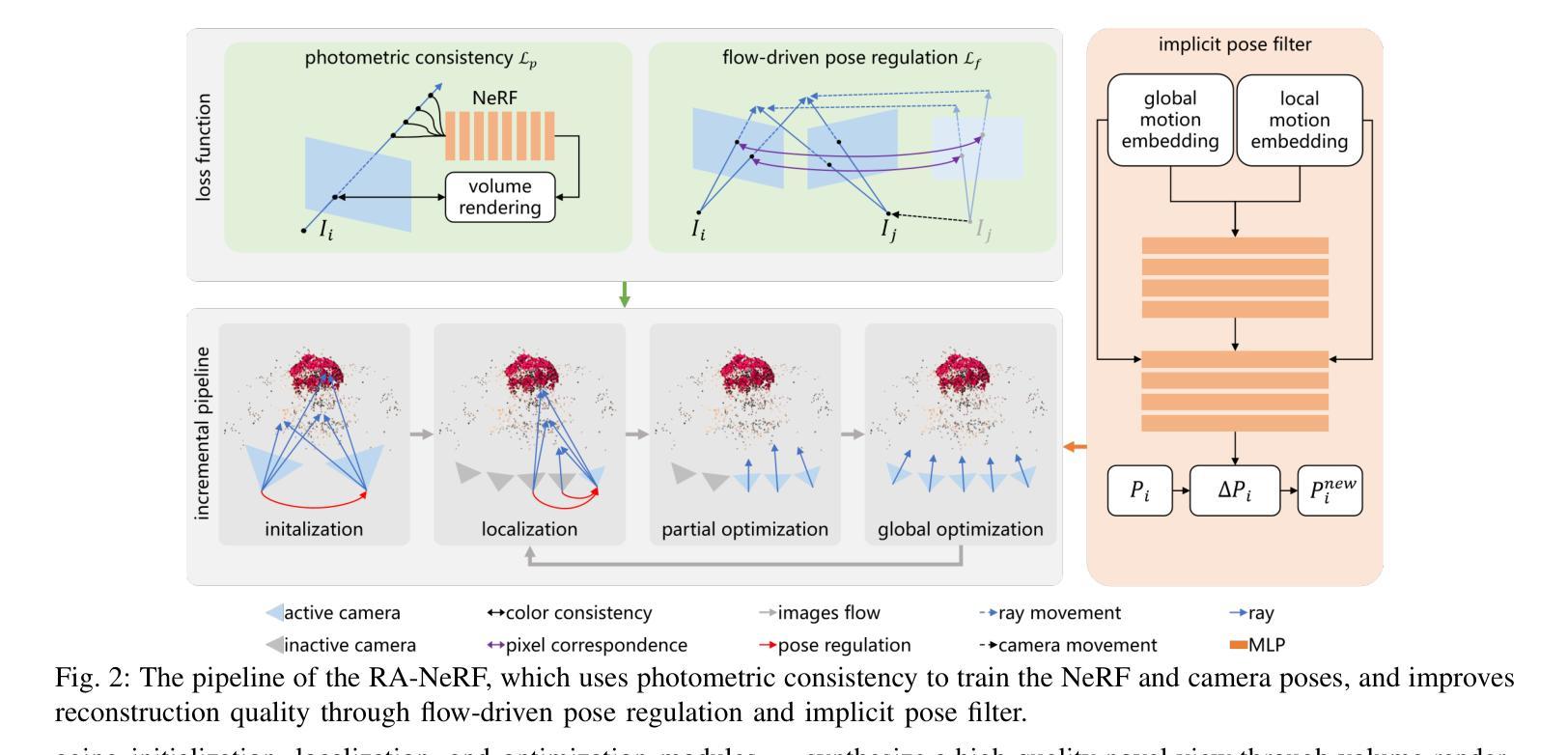
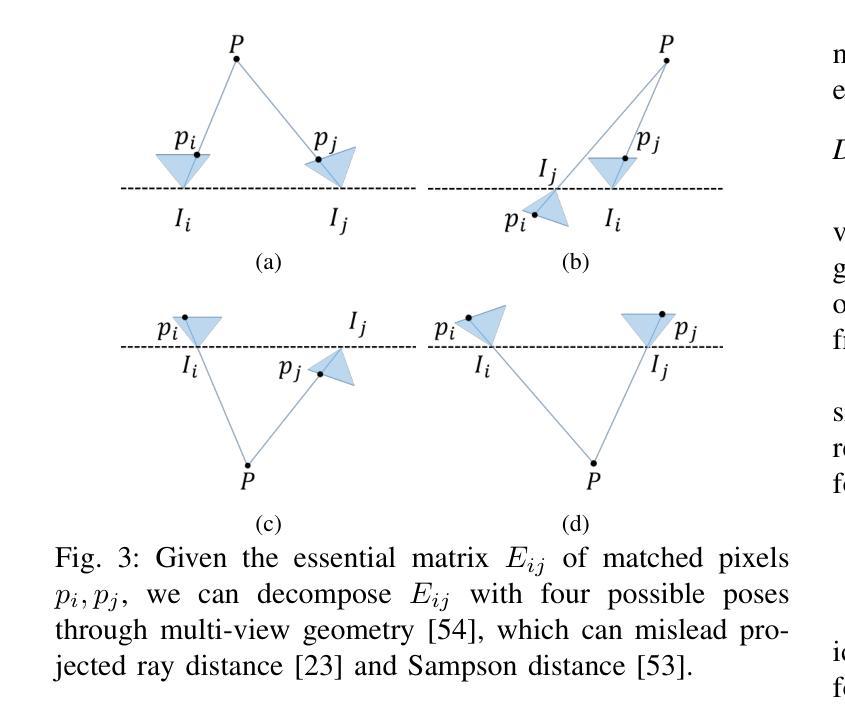
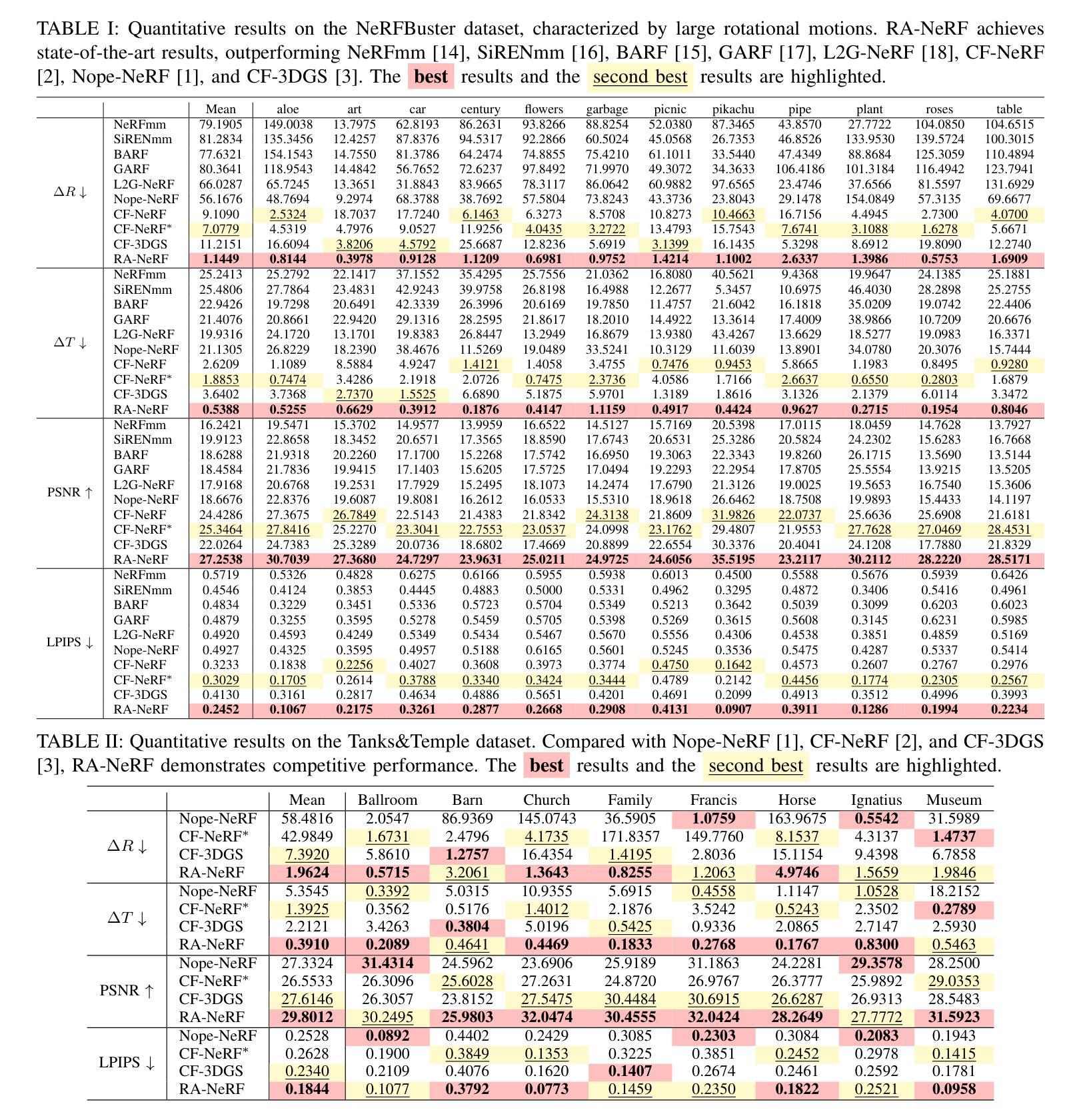
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Authors:Qingsong Yan, Qiang Wang, Kaiyong Zhao, Jie Chen, Bo Li, Xiaowen Chu, Fei Deng
Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
神经辐射场(NeRF)和三维高斯贴图(3DGS)已经成为三维重建和SLAM任务中的强大工具。然而,它们的性能在很大程度上依赖于准确的相机姿态先验。现有方法试图通过引入外部约束来解决这个问题,但在达到满意的准确性方面还存在不足,特别是在相机轨迹复杂的情况下。在本文中,我们提出了一种新的方法RA-NeRF,即使在复杂的相机轨迹下,也能预测出高度准确的相机姿态。遵循增量管道,RA-NeRF使用NeRF进行场景重建,通过光度一致性并结合流驱动的姿态调节,以提高初始化和定位过程中的稳健性。此外,RA-NeRF还采用隐式姿态滤波器捕捉相机运动模式,为姿态估计消除噪声。为了验证我们的方法,我们在标准的Tanks&Temple数据集上进行了广泛的实验,以及在具有挑战性的相机姿态轨迹的NeRFBuster数据集上进行了实验。在两个数据集上,RA-NeRF在相机姿态估计和视觉质量方面都达到了最先进的水平,证明了其在复杂姿态轨迹下的场景重建的有效性和稳健性。
论文及项目相关链接
PDF IROS 2025
Summary
本文介绍了RA-NeRF方法,它是一种用于预测复杂相机轨迹下的高精度相机姿态的新型技术。结合增量管线、NeRF重建技术、光程一致性以及流量驱动的姿态调节,RA-NeRF能够在进行场景重建时增强初始化和定位阶段的稳健性。此外,它采用隐式姿态过滤器来捕捉相机运动模式并消除姿态估计中的噪声。在标准评估的Tanks&Temple数据集以及具有挑战性的相机姿态轨迹的NeRFBuster数据集上进行的实验表明,RA-NeRF在相机姿态估计和视觉质量方面均达到了业界领先水平。
Key Takeaways
- RA-NeRF解决了NeRF和3DGS在3D重建和SLAM任务中对于准确相机姿态先验的依赖问题。
- RA-NeRF通过结合增量管线、NeRF技术、光程一致性以及流量驱动的姿态调节,提升了场景重建的稳健性。
- 隐式姿态过滤器被用于捕捉相机运动模式并消除姿态估计中的噪声。
- 在Tanks&Temple数据集上的实验证明,RA-NeRF在相机姿态估计方面具有业界领先的表现。
- RA-NeRF在具有挑战性的NeRFBuster数据集上同样表现出优异的性能,说明其适应复杂相机轨迹的能力。
- RA-NeRF方法在视觉质量方面达到了高标准,证明了其在场景重建中的有效性。
点此查看论文截图


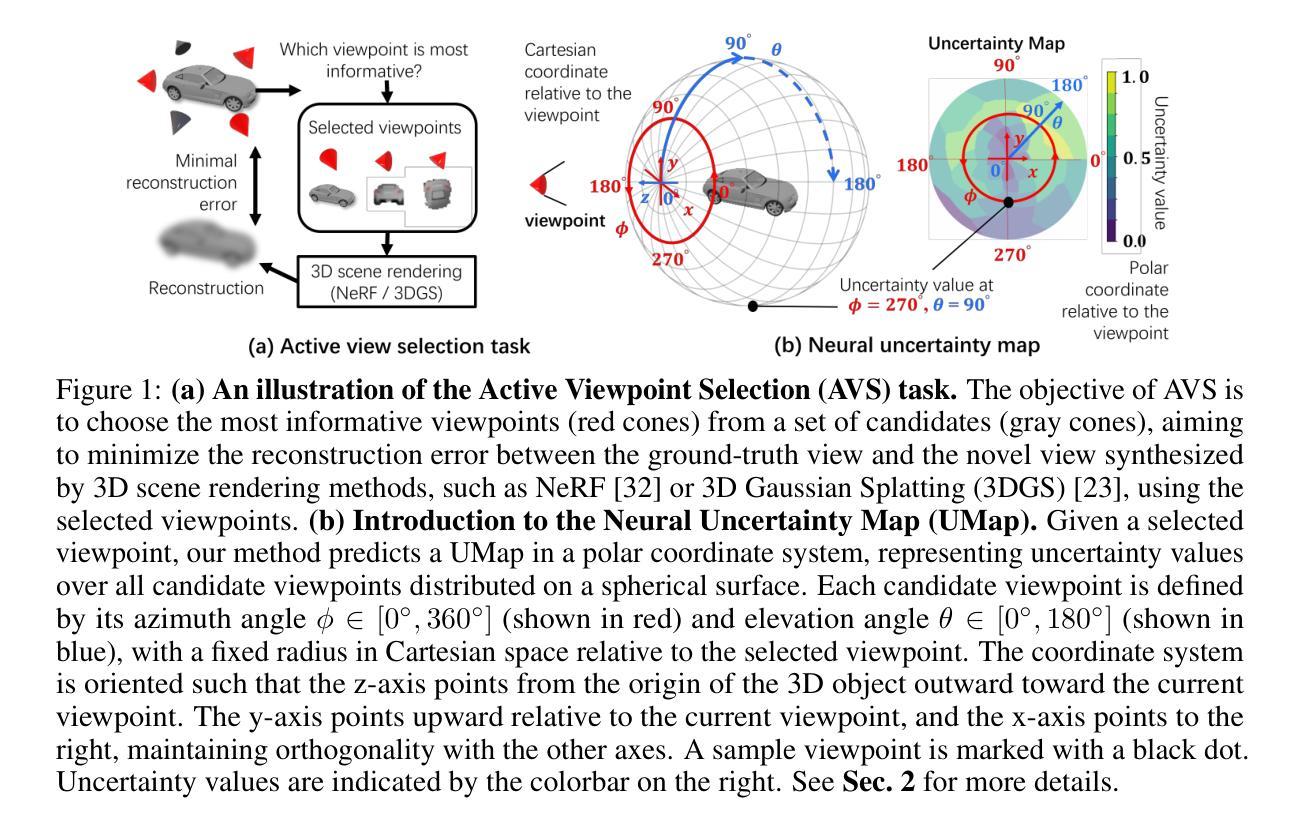
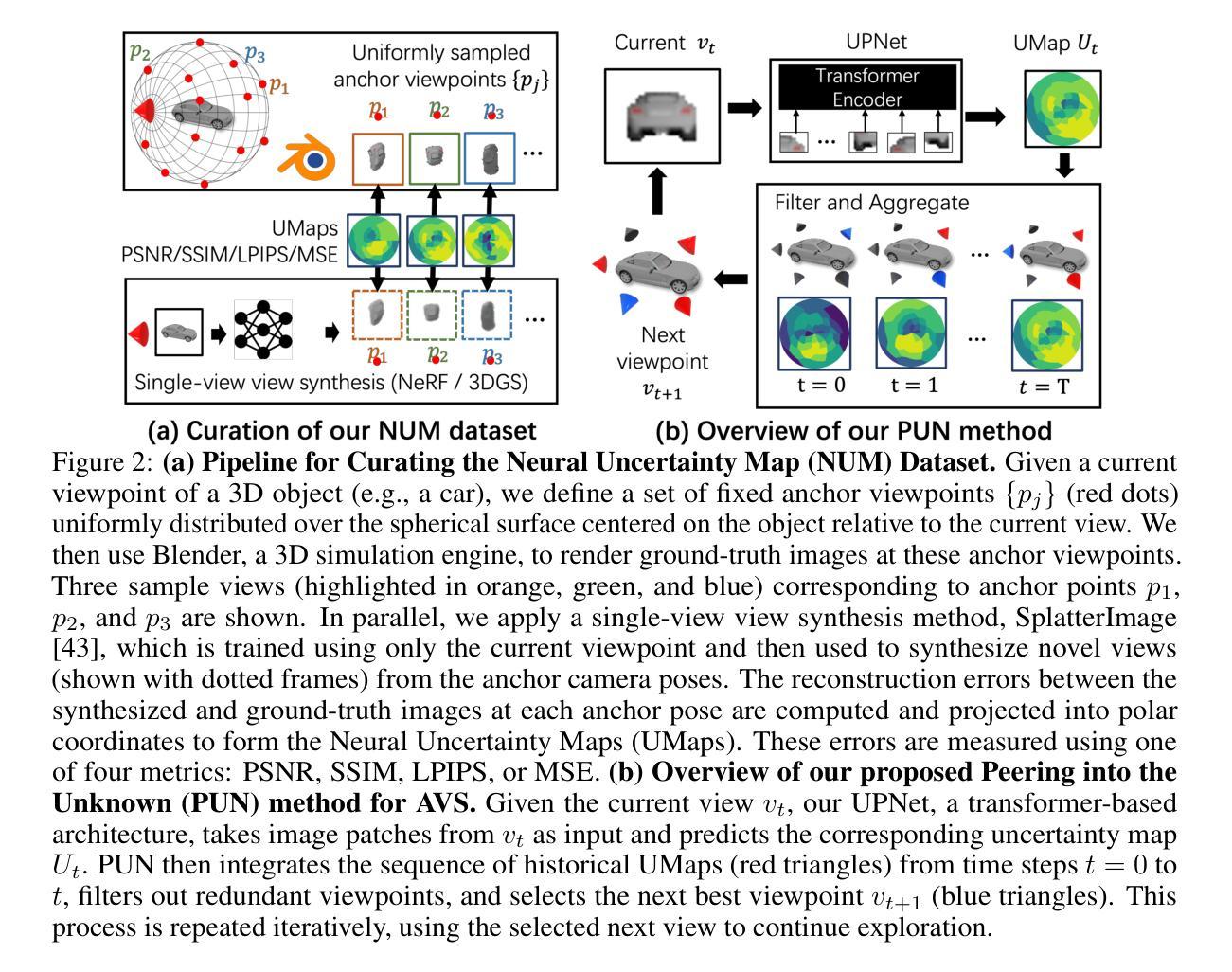
Peering into the Unknown: Active View Selection with Neural Uncertainty Maps for 3D Reconstruction
Authors:Zhengquan Zhang, Feng Xu, Mengmi Zhang
Some perspectives naturally provide more information than others. How can an AI system determine which viewpoint offers the most valuable insight for accurate and efficient 3D object reconstruction? Active view selection (AVS) for 3D reconstruction remains a fundamental challenge in computer vision. The aim is to identify the minimal set of views that yields the most accurate 3D reconstruction. Instead of learning radiance fields, like NeRF or 3D Gaussian Splatting, from a current observation and computing uncertainty for each candidate viewpoint, we introduce a novel AVS approach guided by neural uncertainty maps predicted by a lightweight feedforward deep neural network, named UPNet. UPNet takes a single input image of a 3D object and outputs a predicted uncertainty map, representing uncertainty values across all possible candidate viewpoints. By leveraging heuristics derived from observing many natural objects and their associated uncertainty patterns, we train UPNet to learn a direct mapping from viewpoint appearance to uncertainty in the underlying volumetric representations. Next, our approach aggregates all previously predicted neural uncertainty maps to suppress redundant candidate viewpoints and effectively select the most informative one. Using these selected viewpoints, we train 3D neural rendering models and evaluate the quality of novel view synthesis against other competitive AVS methods. Remarkably, despite using half of the viewpoints than the upper bound, our method achieves comparable reconstruction accuracy. In addition, it significantly reduces computational overhead during AVS, achieving up to a 400 times speedup along with over 50% reductions in CPU, RAM, and GPU usage compared to baseline methods. Notably, our approach generalizes effectively to AVS tasks involving novel object categories, without requiring any additional training.
一些视角天然比其他的视角提供更多信息。人工智能系统如何确定哪个视角能为准确高效的3D对象重建提供最有价值的洞察力?3D重建中的主动视角选择(AVS)仍是计算机视觉领域的一个基本挑战。我们的目标是找出能带来最准确3D重建的最小视角集。我们并没有从当前观察中学习辐射场(如NeRF或3D高斯展布),并为每个候选视角计算不确定性,而是引入了一种由名为UPNet的轻量级前馈深度神经网络预测神经不确定性地图来引导的新型AVS方法。UPNet接收一个3D对象的单一输入图像,并输出一个预测的不确定性地图,代表所有可能的候选视角的不确定性值。我们利用从观察许多自然对象及其相关的不确定性模式得出的启发式方法,训练UPNet学习从视角外观到其底层体积表示中的不确定性的直接映射。接下来,我们的方法聚合所有先前预测的神经不确定性地图,以抑制冗余的候选视角,并有效地选择最具信息量的视角。使用这些选定的视角,我们训练了3D神经渲染模型,并与其他有竞争力的AVS方法评估了合成新视角的质量。令人瞩目的是,尽管只使用了比上界少一半的视角,我们的方法仍能达到相当的重建精度。此外,它在AVS期间显著减少了计算开销,与基准方法相比,实现了高达400倍的加速,同时减少了超过50%的CPU、RAM和GPU使用量。值得注意的是,我们的方法能够有效地推广到涉及新型对象类别的AVS任务,而无需任何额外的训练。
论文及项目相关链接
PDF 9 pages, 3 figures in the main text. Under review for NeurIPS 2025
Summary
引入名为UPNet的轻量级前馈深度神经网络,预测神经不确定性地图,指导主动视图选择(AVS)进行3D重建。UPNet从单一输入图像预测不确定性地图,通过启发式方法学习从视点外观到体积表示中的不确定性的直接映射。此方法能有效选择最具信息量的视点,降低计算冗余,提高重建精度和效率。
Key Takeaways
- 引入UPNet神经网络预测神经不确定性地图,用于指导主动视图选择(AVS)在3D重建中的过程。
- UPNet能从单一输入图像预测不确定性地图,展示所有可能候选视点的不确定性值。
- 通过启发式方法,UPNet学习从视点外观到体积表示中的不确定性的直接映射。
- 通过对以往预测的神经不确定性地图进行聚合,该方法能够抑制冗余的候选视点,并有效地选择最具信息量的视点。
- 使用选定的视点训练3D神经渲染模型,并在与其他竞争性AVS方法进行比较时,实现了高质量的全新视图合成。
- 该方法在仅使用一半视点的情况下,实现了与上限相当的重建精度。
点此查看论文截图

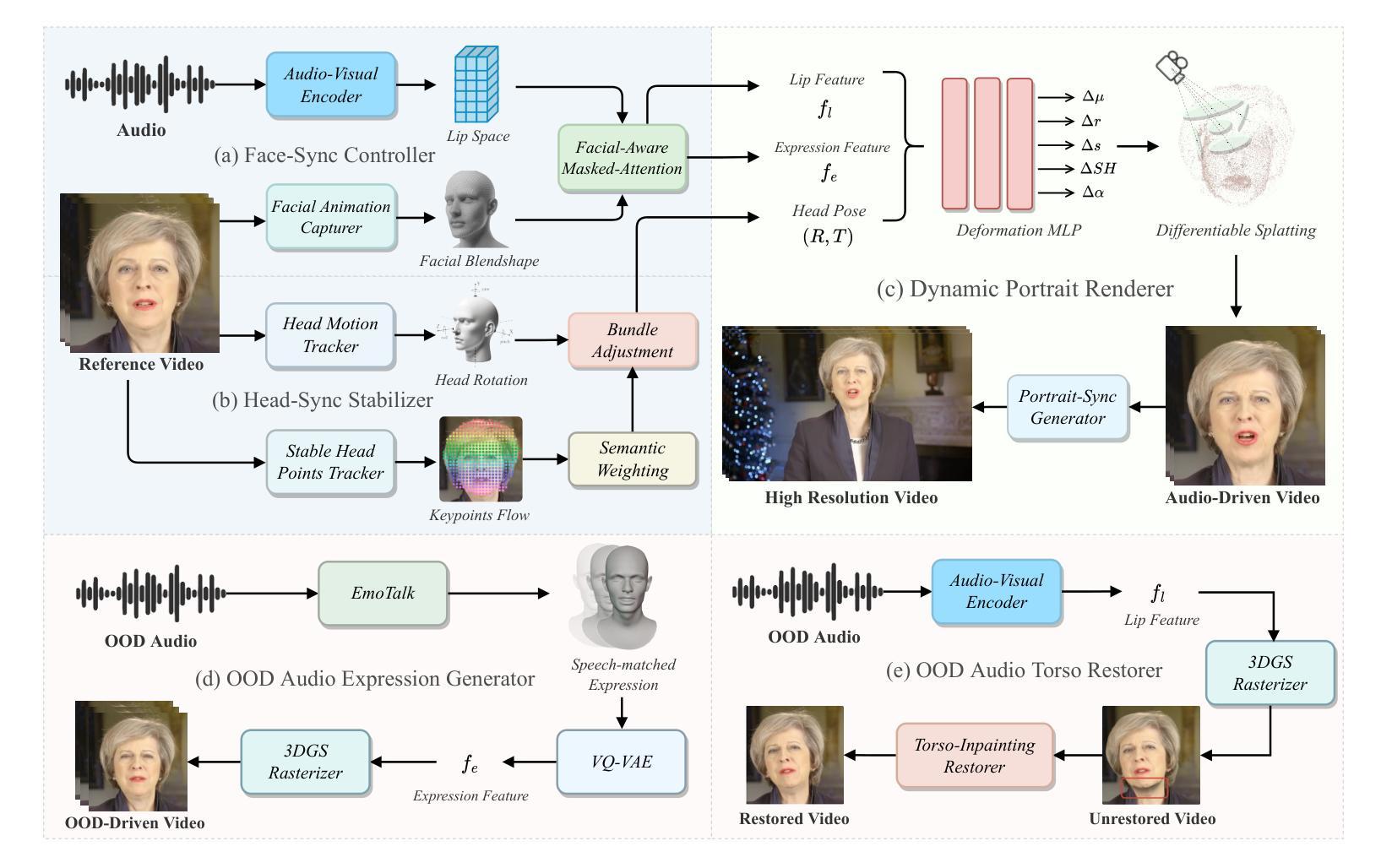
SyncTalk++: High-Fidelity and Efficient Synchronized Talking Heads Synthesis Using Gaussian Splatting
Authors:Ziqiao Peng, Wentao Hu, Junyuan Ma, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Hui Tian, Jun He, Hongyan Liu, Zhaoxin Fan
Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic results. To address the critical issue of synchronization, identified as the ‘’devil’’ in creating realistic talking heads, we introduce SyncTalk++, which features a Dynamic Portrait Renderer with Gaussian Splatting to ensure consistent subject identity preservation and a Face-Sync Controller that aligns lip movements with speech while innovatively using a 3D facial blendshape model to reconstruct accurate facial expressions. To ensure natural head movements, we propose a Head-Sync Stabilizer, which optimizes head poses for greater stability. Additionally, SyncTalk++ enhances robustness to out-of-distribution (OOD) audio by incorporating an Expression Generator and a Torso Restorer, which generate speech-matched facial expressions and seamless torso regions. Our approach maintains consistency and continuity in visual details across frames and significantly improves rendering speed and quality, achieving up to 101 frames per second. Extensive experiments and user studies demonstrate that SyncTalk++ outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk++.
在实现高度同步的逼真语音驱动式说话人头视频合成中,存在重大挑战。一个逼真的说话人头需要同步协调主体身份、嘴唇动作、面部表情和头部姿势。缺乏这些同步是根本缺陷,会导致不真实的结果。为了解决同步这一关键问题,被视为创建逼真说话人的“魔鬼”,我们推出了SyncTalk++,它具备动态肖像渲染器和高斯拼贴技术,以确保主体身份的一致性和面部同步控制器,该控制器使嘴唇动作与语音对齐,同时创新地使用3D面部混合形状模型来重建准确的面部表情。为了确保头部自然移动,我们提出了头部同步稳定器,它优化了头部姿势,提高了稳定性。此外,SyncTalk++通过引入表情生成器和躯干恢复器,增强了处理离群值音频的稳健性,生成与语音相匹配的表情和无缝的躯干区域。我们的方法保持了跨帧的视觉细节的一致性和连续性,并大大提高了渲染速度和质量,达到了每秒101帧。大量实验和用户研究表明,SyncTalk++在同步和逼真度方面优于最新技术。推荐观看补充视频:https://ziqiaopeng.github.io/synctalk++.
论文及项目相关链接
Summary
该文介绍了在合成逼真的语音驱动谈话头视频时实现高同步化的挑战。为了解决这个问题,引入了SyncTalk++技术,包括动态肖像渲染器、面部同步控制器和头部同步稳定器。这些技术确保了主体身份的同步协调、唇部动作与语音的对齐、面部表情的准确重建以及头部姿态的自然优化。SyncTalk++还增强了对于离群音频的稳健性,通过表情生成器和躯干恢复器生成与语音相匹配的表情和无缝的躯干区域。SyncTalk++保持了跨帧的视觉细节的一致性和连续性,并显著提高了渲染速度和画质。实验和用户研究表明,SyncTalk++在同步和逼真度方面优于现有技术。
Key Takeaways
- SyncTalk++技术解决了合成语音驱动谈话头视频时的高同步化挑战。
- 动态肖像渲染器使用高斯喷绘技术确保主体身份的一致性和连续性。
- 面部同步控制器通过对唇部动作、语音和面部表情的协调,实现准确的同步。
- 头部同步稳定器优化头部姿态,使头部动作更自然。
- SyncTalk++增强了对于离群音频的稳健性,通过表情生成器和躯干恢复器应对语音匹配的问题。
- SyncTalk++提高了渲染速度和画质,实现了高帧率输出。
点此查看论文截图




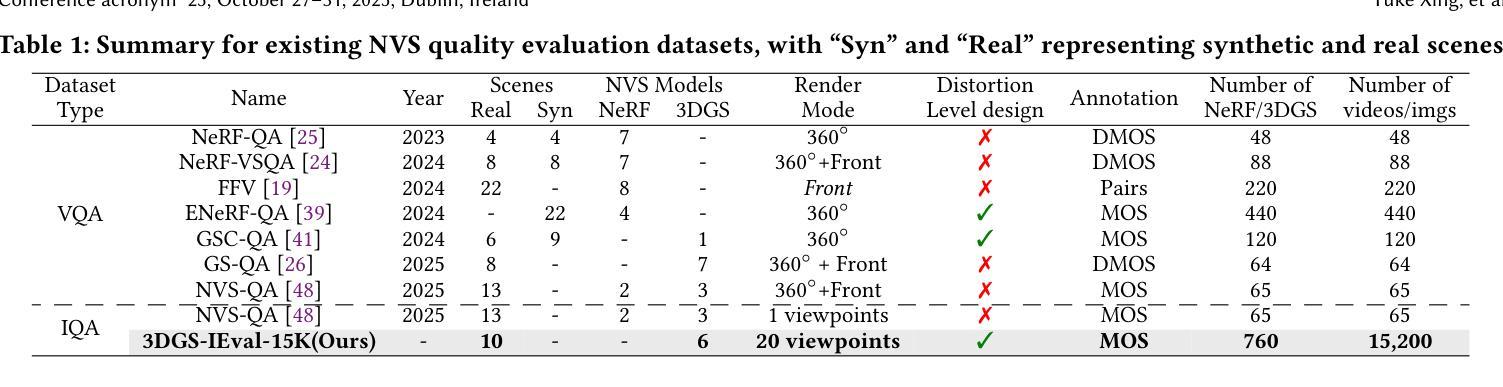
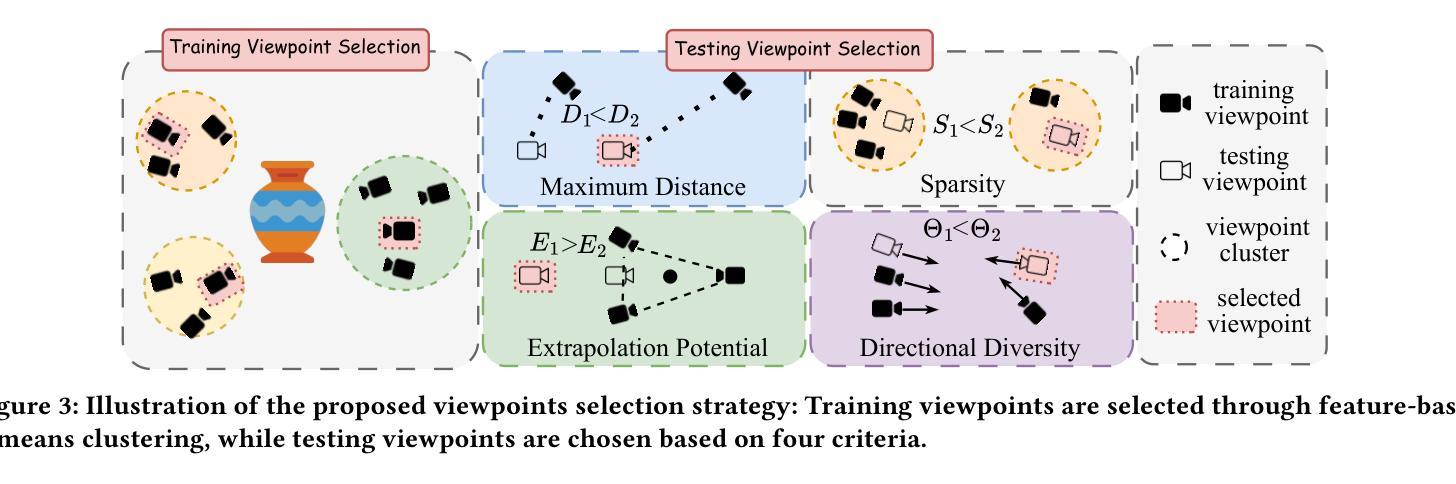
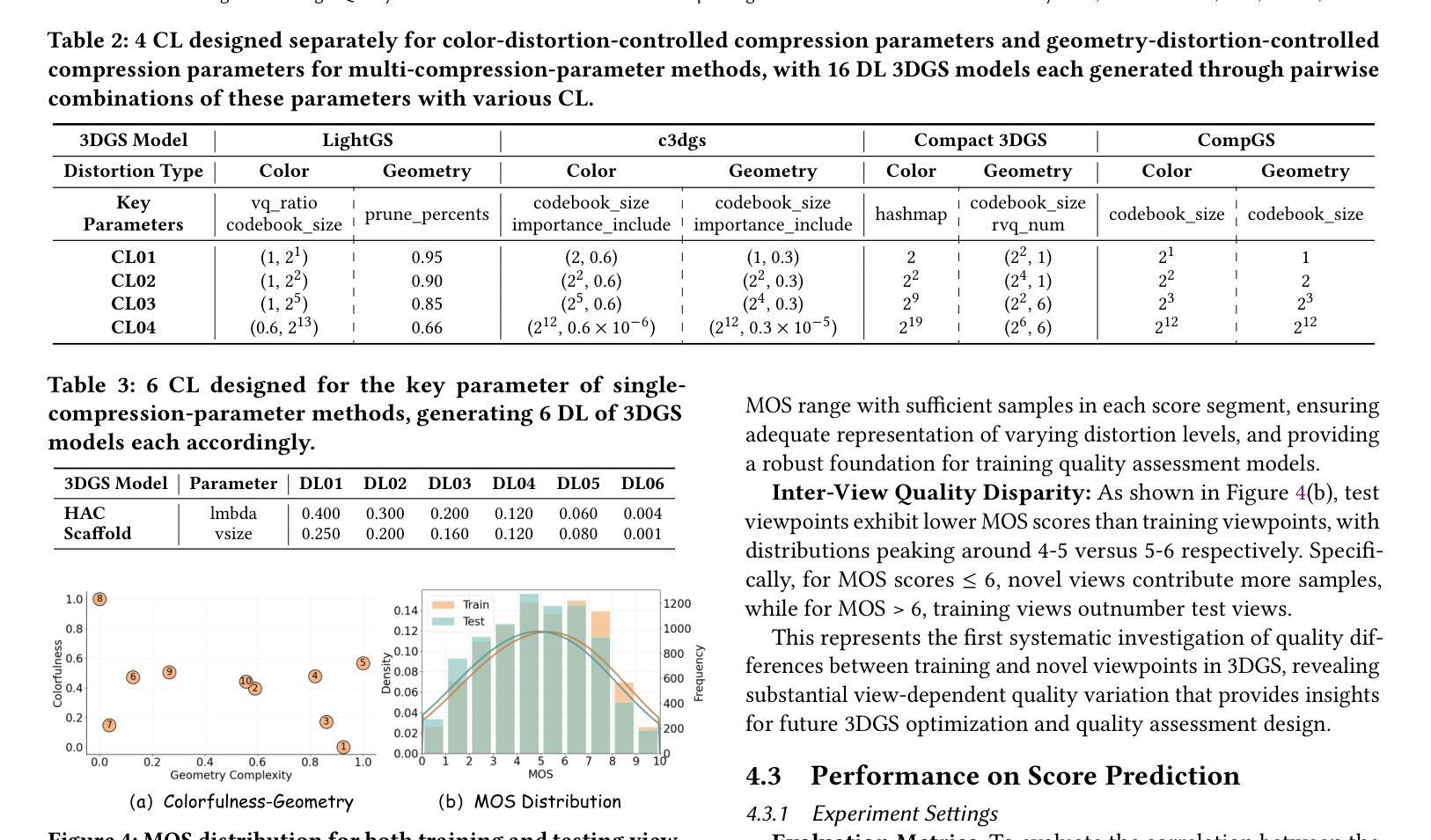
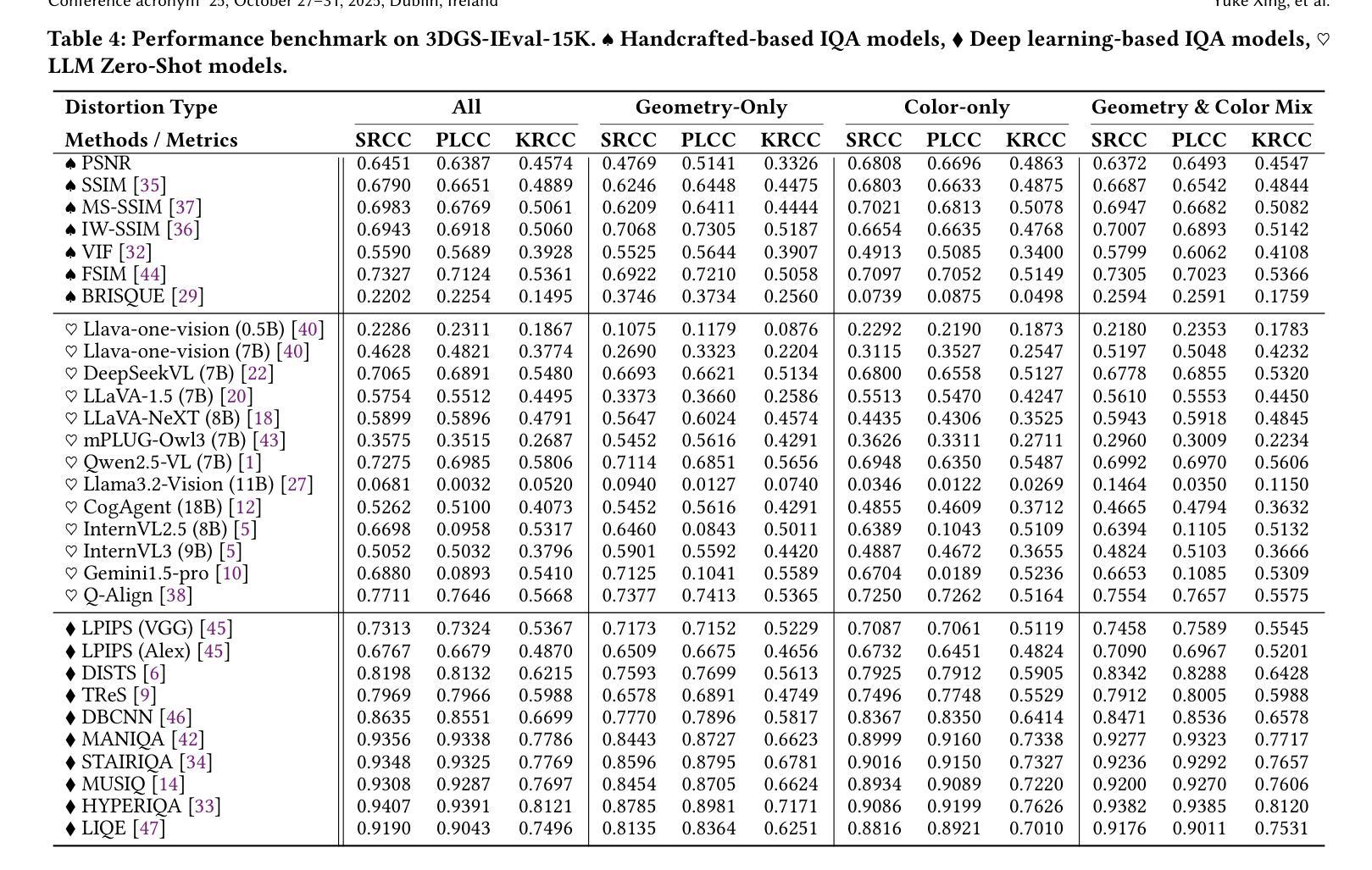
3DGS-IEval-15K: A Large-scale Image Quality Evaluation Database for 3D Gaussian-Splatting
Authors:Yuke Xing, Jiarui Wang, Peizhi Niu, Wenjie Huang, Guangtao Zhai, Yiling Xu
3D Gaussian Splatting (3DGS) has emerged as a promising approach for novel view synthesis, offering real-time rendering with high visual fidelity. However, its substantial storage requirements present significant challenges for practical applications. While recent state-of-the-art (SOTA) 3DGS methods increasingly incorporate dedicated compression modules, there is a lack of a comprehensive framework to evaluate their perceptual impact. Therefore we present 3DGS-IEval-15K, the first large-scale image quality assessment (IQA) dataset specifically designed for compressed 3DGS representations. Our dataset encompasses 15,200 images rendered from 10 real-world scenes through 6 representative 3DGS algorithms at 20 strategically selected viewpoints, with different compression levels leading to various distortion effects. Through controlled subjective experiments, we collect human perception data from 60 viewers. We validate dataset quality through scene diversity and MOS distribution analysis, and establish a comprehensive benchmark with 30 representative IQA metrics covering diverse types. As the largest-scale 3DGS quality assessment dataset to date, our work provides a foundation for developing 3DGS specialized IQA metrics, and offers essential data for investigating view-dependent quality distribution patterns unique to 3DGS. The database is publicly available at https://github.com/YukeXing/3DGS-IEval-15K.
3D高斯点描技术(3DGS)作为新颖的视点合成方法,具有实时渲染和高视觉保真度的优势。然而,其巨大的存储需求为实际应用带来了重大挑战。尽管当前先进的3DGS方法越来越多地采用了专用压缩模块,但缺乏一个全面的框架来评估其对感知的影响。因此,我们推出了3DGS-IEval-15K,这是专门为压缩的3DGS表示设计的大型图像质量评估(IQA)数据集。我们的数据集包含从10个真实场景中渲染的15,200张图像,通过6种具有代表性的3DGS算法在20个战略选择的观点进行渲染,不同的压缩水平导致各种失真效果。通过受控的主观实验,我们从60名观众那里收集了人类感知数据。我们通过场景多样性和平均意见得分(MOS)分布分析验证了数据集的质量,并建立了一个包含30个代表性IQA指标的全面基准测试。作为迄今为止规模最大的3DGS质量评估数据集,我们的工作为开发专门的3DGS IQA指标提供了基础,并为研究独特的与视点相关的质量分布模式提供了必要的数据,这些模式在3DGS中是独特的。数据库可在https://github.com/YukeXing/3DGS-IEval-15K公开访问。
论文及项目相关链接
Summary
3DGS-IEval-15K数据集用于评估压缩3DGS表示的图像质量,包含15,200张图像,涵盖多种压缩级别和失真效应。该数据集为开发针对3DGS的专门图像质量评估指标提供了基础。
Key Takeaways
* 3D Gaussian Splatting (3DGS)是一种用于新型视图合成的方法,具有实时渲染和高视觉保真度的特点。
* 3DGS存在大量存储需求的问题,这对实际应用提出了挑战。
* 当前先进的3DGS方法虽然会结合专门的压缩模块,但缺乏一个综合框架来评估它们的感知影响。
* 引入新的数据集3DGS-IEval-15K,这是专门为压缩的3DGS表示设计的第一个大规模图像质量评估(IQA)数据集。
* 数据集包含从真实世界的十个场景中渲染出的图像,并通过六种代表性的3DGS算法和二十个战略选择的观点进行展示。
* 数据集包含了不同压缩级别导致的各种失真效应,并通过控制主观实验收集人类感知数据。
* 数据集质量通过场景多样性和平均意见得分分布分析进行验证,并建立了一个全面的基准测试,包括三十种代表性的IQA指标。
点此查看论文截图


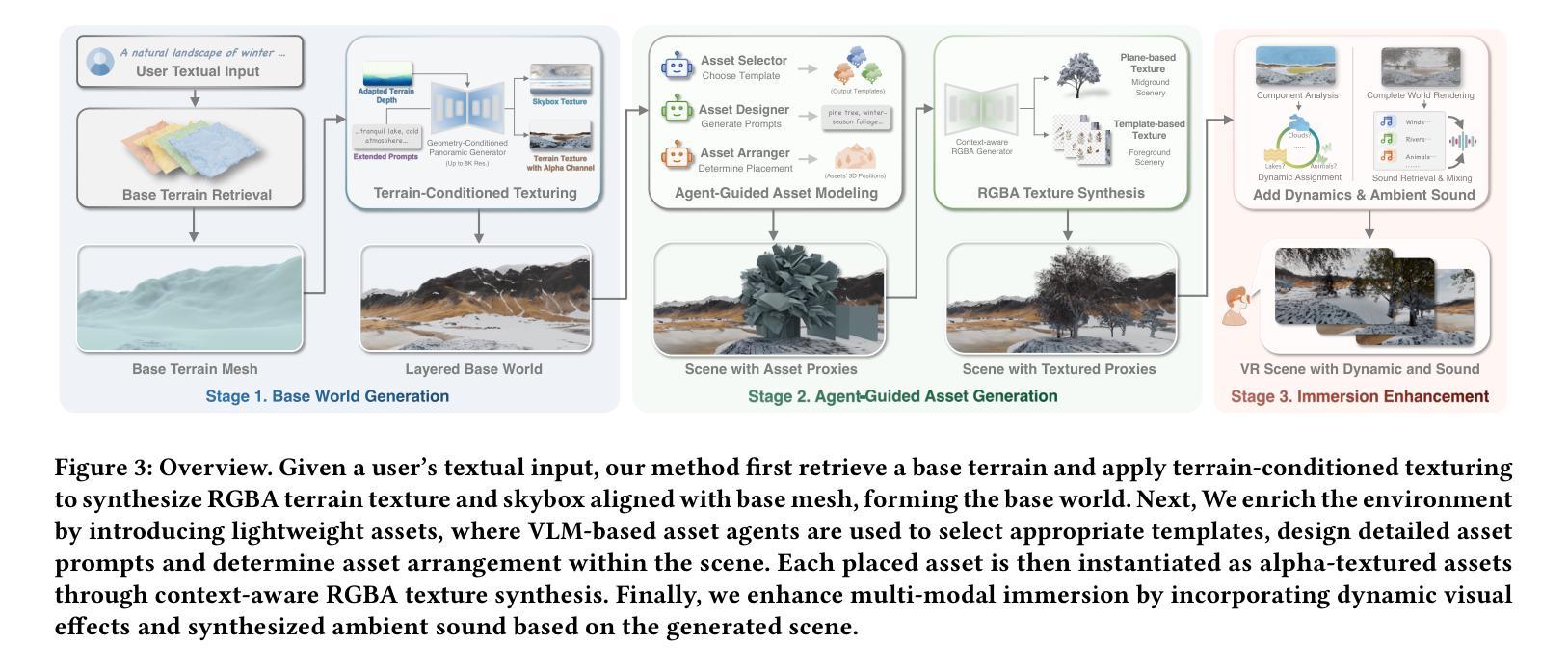
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Authors:Jinyan Yuan, Bangbang Yang, Keke Wang, Panwang Pan, Lin Ma, Xuehai Zhang, Xiao Liu, Zhaopeng Cui, Yuewen Ma
Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
自动创建用于沉浸式虚拟现实(VR)的三维场景一直是数十年的重大研究重点。然而,现有方法通常依赖于高多边形网格建模和后简化的方法,或者大规模的三维高斯模型,这导致了复杂的流程或有限的视觉逼真度。在本文中,我们证明了实现引人注目的沉浸式体验并不需要如此详尽的建模。我们介绍了ImmerseGen,这是一种用于紧凑和逼真的世界建模的新型代理引导框架。ImmerseGen将场景表示为轻量级几何代理的层次结构组合,即简化的地形和告示牌网格,并通过在这些代理上合成RGBA纹理来产生逼真的外观。具体来说,我们提出了用户为中心的基地世界合成的地形条件纹理合成技术,以及用于中景和前景场景的RGBA资产纹理合成技术。这种重新表述提供了几个优点:(i)它简化了建模,使代理能够引导生成模型产生无缝集成场景的连贯纹理;(ii)它通过直接在代理上合成逼真的纹理绕过复杂的几何创建和删减,从而保持视觉质量而不降质;(iii)它能够实现适用于移动VR耳机实时渲染的紧凑表示。为了从文本提示自动创建场景,我们引入了基于VLM的建模代理,通过基于语义网格的分析增强空间推理和准确的资产放置。ImmerseGen还通过添加动态效果和环绕声音来丰富场景,以支持多感官沉浸。场景生成和实时VR展示的实验表明,ImmerseGen在逼真度、空间连贯性和渲染效率方面优于先前的方法。项目网页:https://immersegen.github.io。
论文及项目相关链接
PDF Project webpage: https://immersegen.github.io
Summary
本文提出了一种新型代理引导框架ImmerseGen,用于紧凑且逼真的世界建模。它简化了虚拟场景创建过程,通过层次结构组合轻量级几何代理,如简化地形和招牌网格,并合成RGBA纹理贴图实现逼真外观。引入地形条件纹理贴图和RGBA资产纹理贴图,实现用户中心化基础世界合成及中景和前景风景的合成。该项目还致力于通过文本提示自动创建场景,引入基于VLM的建模代理,并结合语义网格分析改善空间推理和资产放置。ImmerseGen还丰富了场景的动态效果和环绕音频,支持多感官沉浸。实验表明,ImmerseGen在场景生成和实时VR展示中实现了较高的逼真度、空间连贯性和渲染效率。
Key Takeaways
- ImmerseGen是一个新颖的代理引导框架,用于紧凑且真实地模拟世界场景。
- 该方法简化了虚拟场景创建流程,通过层次结构组合轻量级几何代理实现。
- ImmerseGen引入了地形条件纹理贴图和RGBA资产纹理贴图技术,用于合成用户中心化基础世界及中景和前景。
- 通过文本提示可自动创建场景,采用VLM建模代理并结合语义网格分析改善空间推理和资产放置。
- ImmerseGen丰富了场景的动态效果和环绕音频,增强了多感官沉浸体验。
- 实验证明,ImmerseGen在场景生成和实时VR展示方面具有较高的逼真度、空间连贯性和渲染效率。
点此查看论文截图



HRGS: Hierarchical Gaussian Splatting for Memory-Efficient High-Resolution 3D Reconstruction
Authors:Changbai Li, Haodong Zhu, Hanlin Chen, Juan Zhang, Tongfei Chen, Shuo Yang, Shuwei Shao, Wenhao Dong, Baochang Zhang
3D Gaussian Splatting (3DGS) has made significant strides in real-time 3D scene reconstruction, but faces memory scalability issues in high-resolution scenarios. To address this, we propose Hierarchical Gaussian Splatting (HRGS), a memory-efficient framework with hierarchical block-level optimization. First, we generate a global, coarse Gaussian representation from low-resolution data. Then, we partition the scene into multiple blocks, refining each block with high-resolution data. The partitioning involves two steps: Gaussian partitioning, where irregular scenes are normalized into a bounded cubic space with a uniform grid for task distribution, and training data partitioning, where only relevant observations are retained for each block. By guiding block refinement with the coarse Gaussian prior, we ensure seamless Gaussian fusion across adjacent blocks. To reduce computational demands, we introduce Importance-Driven Gaussian Pruning (IDGP), which computes importance scores for each Gaussian and removes those with minimal contribution, speeding up convergence and reducing memory usage. Additionally, we incorporate normal priors from a pretrained model to enhance surface reconstruction quality. Our method enables high-quality, high-resolution 3D scene reconstruction even under memory constraints. Extensive experiments on three benchmarks show that HRGS achieves state-of-the-art performance in high-resolution novel view synthesis (NVS) and surface reconstruction tasks.
3D高斯Splatting(3DGS)在实时3D场景重建方面取得了显著进展,但在高分辨率场景下存在内存可扩展性问题。为了解决这一问题,我们提出了分层高斯Splatting(HRGS)方法,这是一种具有分层块级优化的内存高效框架。首先,我们从低分辨率数据中生成全局粗略的高斯表示。然后,我们将场景分割成多个块,使用高分辨率数据对每个块进行细化。分区涉及两个步骤:高斯分区,将不规则场景归一化到具有统一网格的有界立方空间中以进行任务分配;以及训练数据分区,只保留每个块的相关观测值。通过用粗略的高斯先验引导块细化,我们确保相邻块之间的无缝高斯融合。为了减少计算需求,我们引入了重要性驱动的高斯修剪(IDGP),它计算每个高斯的重要性得分并删除贡献最小的部分,从而加快收敛并减少内存使用。此外,我们还结合了来自预训练模型的法线先验,以提高表面重建质量。我们的方法能够在内存限制下实现高质量、高分辨率的3D场景重建。在三个基准测试上的广泛实验表明,HRGS在高分辨率新颖视图合成(NVS)和表面重建任务中达到了最先进的性能。
论文及项目相关链接
Summary
本文提出一种基于分层高斯采样(HRGS)的实时三维场景重建方法,解决了高分辨率场景下内存可扩展性问题。该方法通过生成全局粗略高斯表示,对场景进行分层块级优化。首先通过低分辨率数据得到初步估计,然后将场景分割成多个块并利用高分辨率数据进行精细调整。引入重要性驱动的高斯剪枝策略来加速收敛和减少内存使用。该方法能够提升场景表面重建质量并应用于高质量高分辨率的三维场景重建任务中,展现出最优性能。
Key Takeaways
- HRGS解决了高分辨率场景下实时三维场景重建中的内存可扩展性问题。
- HRGS通过生成全局粗略高斯表示和分层块级优化来处理场景。
- 方法在低分辨率数据基础上引入高分辨率数据进行精细调整。
- 通过高斯分区和训练数据分区两步实现场景分区。
- 引入重要性驱动的高斯剪枝策略来减少计算需求和内存使用。
- 利用预训练模型的法线先验提升表面重建质量。
- HRGS在新型视景合成和表面重建任务中实现最优性能。
点此查看论文截图

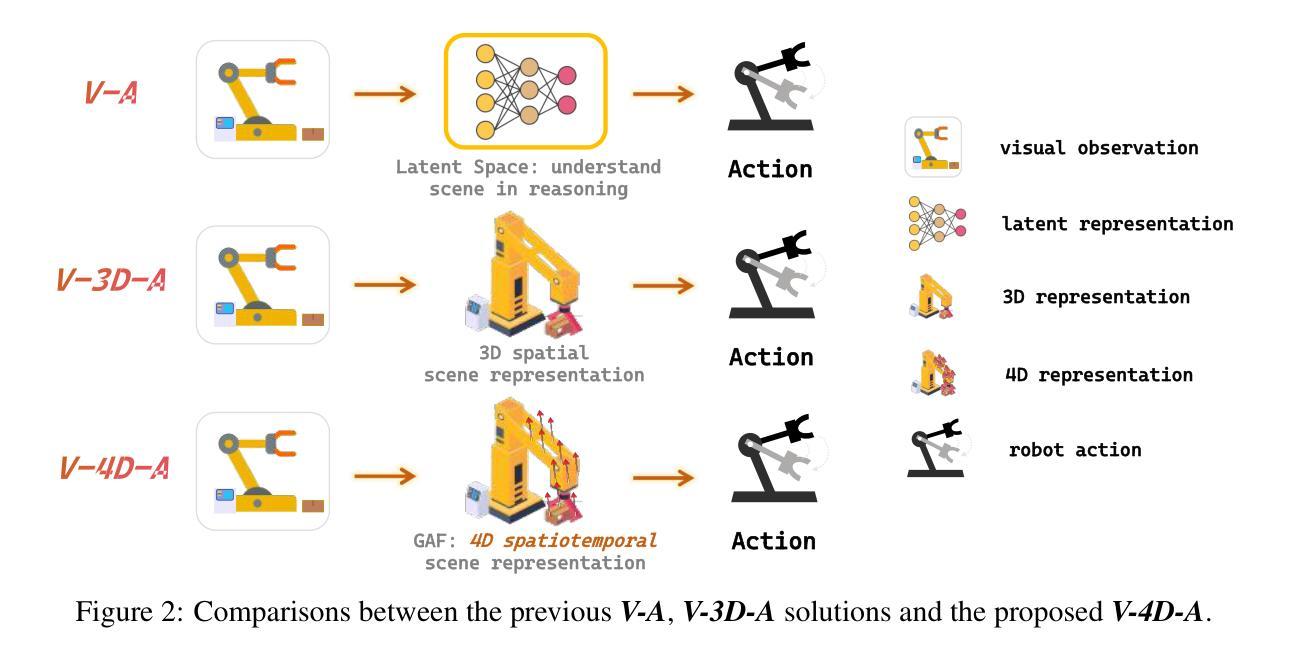
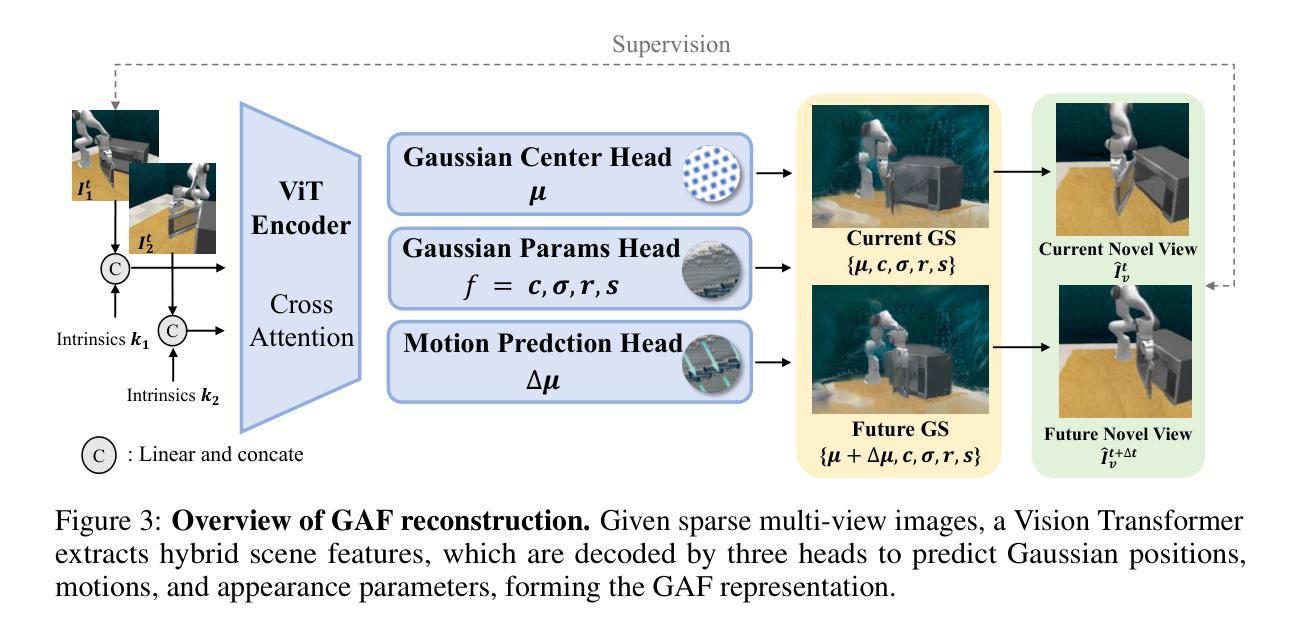
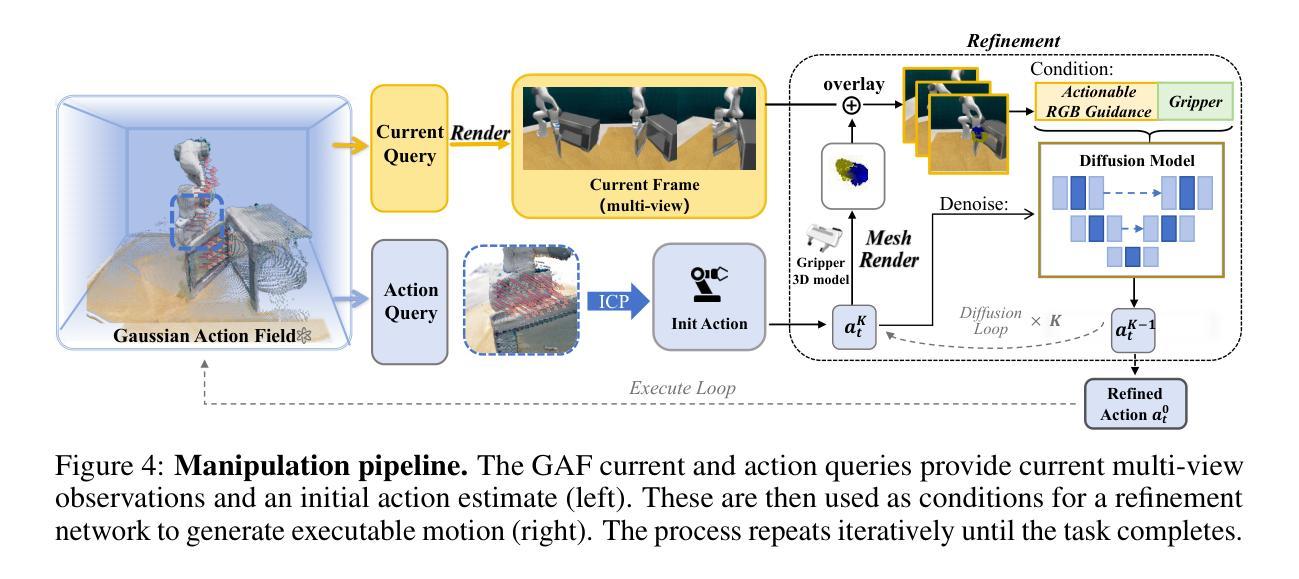
GAF: Gaussian Action Field as a Dvnamic World Model for Robotic Mlanipulation
Authors:Ying Chai, Litao Deng, Ruizhi Shao, Jiajun Zhang, Liangjun Xing, Hongwen Zhang, Yebin Liu
Accurate action inference is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we propose a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing simultaneous modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF supports three key query types: reconstruction of the current scene, prediction of future frames, and estimation of initial action via robot motion. Furthermore, the high-quality current and future frames generated by GAF facilitate manipulation action refinement through a GAF-guided diffusion model. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average success rate in robotic manipulation tasks by 10.33% over state-of-the-art methods. Project page: http://chaiying1.github.io/GAF.github.io/project_page/
基于视觉的机器人操作对精确的动作推断至关重要。现有方法通常遵循视觉到动作(V-A)范式,直接从视觉输入预测动作,或者视觉到三维到动作(V-3D-A)范式,利用中间三维表示。然而,这些方法往往因操作场景的复杂性和动态性而面临动作不准确的问题。在本文中,我们提出了一种V-4D-A框架,该框架能够通过高斯动作场(GAF)从感知运动的4D表示中进行直接动作推理。GAF通过引入可学习的运动属性扩展了三维高斯拼贴(3DGS),能够同时对动态场景和操作动作进行建模。为了学习随时间变化的场景几何和感知机器人运动,GAF支持三种关键查询类型:重建当前场景、预测未来帧以及通过机器人运动估计初始动作。此外,GAF生成的高质量当前和未来帧通过GAF引导扩散模型促进了操作动作的改进。大量实验表明,GAF在重建质量上实现了+11.5385 dB PSNR和-0.5574 LPIPS的改进,同时在机器人操作任务中将平均成功率提高了10.33%,超过了最先进的方法。项目页面:http://chaiying1.github.io/GAF.github.io/project_page/
论文及项目相关链接
PDF http://chaiying1.github.io/GAF.github.io/project_page/
Summary
本文提出了一种基于四维高斯动作场(GAF)的V-4D-A框架,用于从运动感知的4D表示中进行直接动作推理。该框架通过引入可学习的运动属性,扩展了三维高斯涂抹(3DGS),支持对动态场景和操纵动作的同步建模。此外,GAF通过生成高质量当前帧和预测未来帧,利用扩散模型进行动作细化。实验结果显示,GAF在重建质量和机器人操作任务的成功率方面都有显著提升。
Key Takeaways
- 本文提出了一个V-4D-A框架,结合了运动感知的4D表示和三维高斯涂抹技术(GAF)。
- GAF通过引入可学习的运动属性,实现了对动态场景和操纵动作的同步建模。
- GAF支持三种关键查询类型:重建当前场景、预测未来帧和估计初始动作。
- GAF生成的高质量当前和未来帧有助于通过扩散模型进行动作细化。
点此查看论文截图

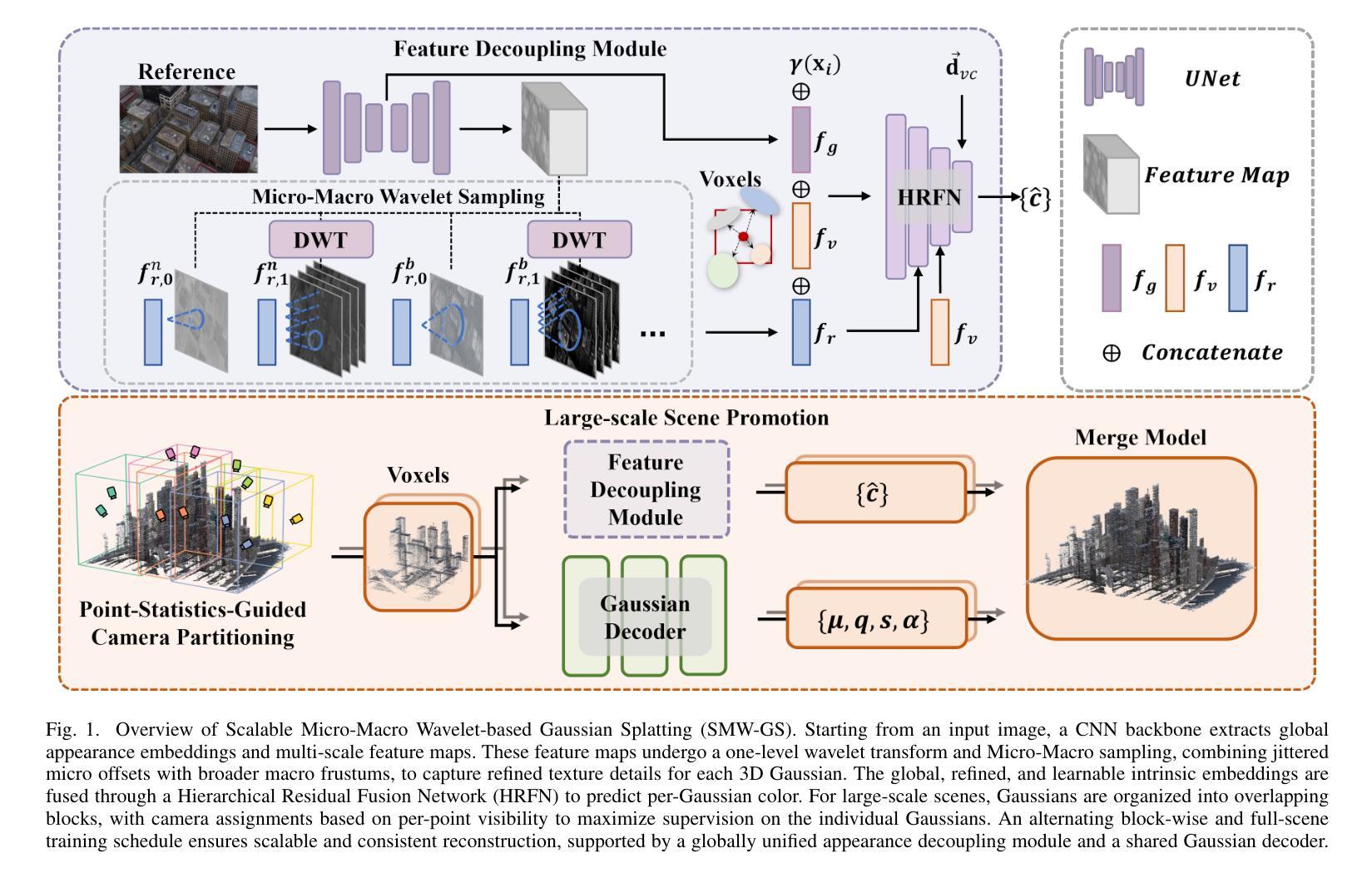
Micro-macro Gaussian Splatting with Enhanced Scalability for Unconstrained Scene Reconstruction
Authors:Yihui Li, Chengxin Lv, Hongyu Yang, Di Huang
Reconstructing 3D scenes from unconstrained image collections poses significant challenges due to variations in appearance. In this paper, we propose Scalable Micro-macro Wavelet-based Gaussian Splatting (SMW-GS), a novel method that enhances 3D reconstruction across diverse scales by decomposing scene representations into global, refined, and intrinsic components. SMW-GS incorporates the following innovations: Micro-macro Projection, which enables Gaussian points to sample multi-scale details with improved diversity; and Wavelet-based Sampling, which refines feature representations using frequency-domain information to better capture complex scene appearances. To achieve scalability, we further propose a large-scale scene promotion strategy, which optimally assigns camera views to scene partitions by maximizing their contributions to Gaussian points, achieving consistent and high-quality reconstructions even in expansive environments. Extensive experiments demonstrate that SMW-GS significantly outperforms existing methods in both reconstruction quality and scalability, particularly excelling in large-scale urban environments with challenging illumination variations. Project is available at https://github.com/Kidleyh/SMW-GS.
从非约束图像集合重建3D场景由于外观变化而面临重大挑战。在本文中,我们提出了基于可伸缩微宏观小波的高斯涂抹(SMW-GS),这是一种通过分解场景表示为全局、精细和内在成分来增强不同尺度上3D重建效果的新方法。SMW-GS结合了以下创新点:微宏观投影,它使高斯点能够采样多尺度细节,提高了多样性;基于小波的采样,利用频域信息细化特征表示,以更好地捕捉复杂场景的外观。为了实现可扩展性,我们进一步提出了一种大规模场景提升策略,通过优化相机视角分配给场景分区,以最大化其对高斯点的贡献,即使在广阔的环境中也能实现一致且高质量的重建。大量实验表明,SMW-GS在重建质量和可扩展性方面显著优于现有方法,特别是在具有挑战照明变化的大规模城市环境中表现尤为出色。项目可通过https://github.com/Kidleyh/SMW-GS访问。
论文及项目相关链接
Summary
SMW-GS是一种用于从非约束图像集合重建3D场景的新方法,它通过分解场景表示为全局、精细和内在成分,在多种尺度上提高了3D重建的效果。此方法包括Micro-macro投影和基于Wavelet的采样等创新技术,能改善高斯点的多尺度细节采样,并优化特征表示以捕获复杂的场景外观。为实现可扩展性,还提出了大规模场景推广策略,通过最大化其对高斯点的贡献来优化相机视角的场景分配,即使在大型环境中也能实现一致且高质量的重建。
Key Takeaways
- SMW-GS是一种针对非约束图像集合的3D重建新方法,旨在提高重建质量和可扩展性。
- 该方法通过分解场景表示为全局、精细和内在成分,在多种尺度上改善3D重建。
- Micro-macro投影技术能够改善高斯点的多尺度细节采样。
- 基于Wavelet的采样技术用于优化特征表示,以更好地捕获复杂的场景外观。
- 提出了一种大规模场景推广策略,通过优化相机视角分配实现一致且高质量的重建。
- SMW-GS在重建质量和可扩展性方面显著优于现有方法,特别是在具有挑战性的大型城市环境中。
点此查看论文截图

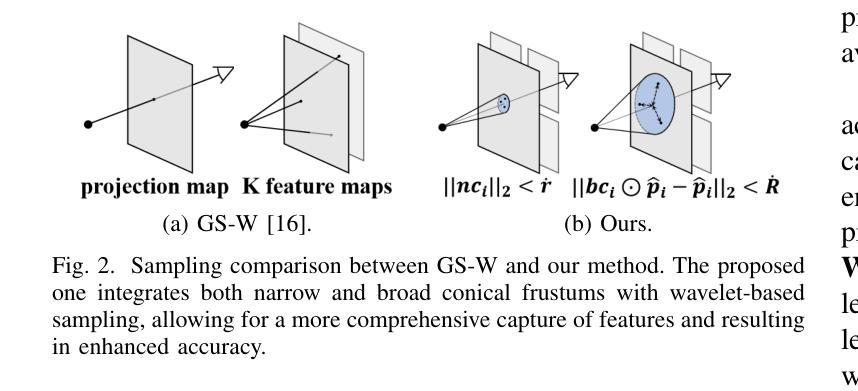
Multiview Geometric Regularization of Gaussian Splatting for Accurate Radiance Fields
Authors:Jungeon Kim, Geonsoo Park, Seungyong Lee
Recent methods, such as 2D Gaussian Splatting and Gaussian Opacity Fields, have aimed to address the geometric inaccuracies of 3D Gaussian Splatting while retaining its superior rendering quality. However, these approaches still struggle to reconstruct smooth and reliable geometry, particularly in scenes with significant color variation across viewpoints, due to their per-point appearance modeling and single-view optimization constraints. In this paper, we propose an effective multiview geometric regularization strategy that integrates multiview stereo (MVS) depth, RGB, and normal constraints into Gaussian Splatting initialization and optimization. Our key insight is the complementary relationship between MVS-derived depth points and Gaussian Splatting-optimized positions: MVS robustly estimates geometry in regions of high color variation through local patch-based matching and epipolar constraints, whereas Gaussian Splatting provides more reliable and less noisy depth estimates near object boundaries and regions with lower color variation. To leverage this insight, we introduce a median depth-based multiview relative depth loss with uncertainty estimation, effectively integrating MVS depth information into Gaussian Splatting optimization. We also propose an MVS-guided Gaussian Splatting initialization to avoid Gaussians falling into suboptimal positions. Extensive experiments validate that our approach successfully combines these strengths, enhancing both geometric accuracy and rendering quality across diverse indoor and outdoor scenes.
近期的方法,如二维高斯平铺(2D Gaussian Splatting)和高斯不透明度场(Gaussian Opacity Fields),旨在解决三维高斯平铺(3D Gaussian Splatting)的几何误差问题,同时保持其卓越的渲染质量。然而,这些方法在重建平滑可靠的几何形状时仍面临挑战,特别是在不同视点间存在显著颜色变化的场景中,因为它们采用逐点外观建模和单视图优化约束。在本文中,我们提出了一种有效的多视图几何正则化策略,该策略将多视图立体测量(MVS)深度、RGB和法线约束集成到高斯平铺的初始化和优化中。我们的主要见解是MVS衍生的深度点与高斯平铺优化位置之间的互补关系:MVS通过基于局部补丁的匹配和极线约束稳健地估计高颜色变化区域的几何形状,而高斯平铺则提供更可靠、更少噪声的深度估计,尤其是在对象边界和颜色变化较低的区域。为了利用这一见解,我们引入了一种基于中间深度的多视图相对深度损失,并带有不确定性估计,有效地将MVS深度信息集成到高斯平铺优化中。我们还提出了MVS引导的高斯平铺初始化,以避免高斯陷入次优位置。大量实验验证,我们的方法成功结合了这些优点,提高了室内外场景的几何精度和渲染质量。
论文及项目相关链接
PDF Accepted to Computer Graphics Forum (EGSR 2025)
Summary
本文提出了一种有效的多视角几何正则化策略,将多视角立体(MVS)深度、RGB和法向量约束集成到高斯贴图初始化与优化中。通过结合MVS派生的深度点与高斯贴图优化的位置,该策略在颜色变化大的区域通过局部块匹配和极线约束稳健地估计几何形状,同时在对象边界和颜色变化较小的区域提供更可靠、噪声更少的深度估计。提出一种基于中位深度的多视角相对深度损失及不确定性估计方法,有效整合MVS深度信息到高斯贴图优化中。同时,也提出了MVS引导的高斯贴图初始化方法,避免高斯落入次优位置。实验证明,该方法成功结合了这些优点,提高了几何精度和渲染质量。
Key Takeaways
- 提出了一种多视角几何正则化策略,集成了MVS深度、RGB和法向量约束到高斯贴图的初始化与优化的流程中。
- 结合MVS派生的深度点与高斯贴图的优化位置,以处理颜色变化大的区域的几何形状估计。
- 在对象边界和颜色变化较小的区域,高斯贴图提供更可靠、噪声更少的深度估计。
- 提出了一种基于中位深度的多视角相对深度损失方法,有效整合MVS深度信息到高斯贴图的优化过程中。
- 引入MVS引导的高斯贴图初始化方法,避免高斯落入次优位置。
- 实验证明该方法能提高几何精度和渲染质量。
点此查看论文截图



GS-2DGS: Geometrically Supervised 2DGS for Reflective Object Reconstruction
Authors:Jinguang Tong, Xuesong li, Fahira Afzal Maken, Sundaram Muthu, Lars Petersson, Chuong Nguyen, Hongdong Li
3D modeling of highly reflective objects remains challenging due to strong view-dependent appearances. While previous SDF-based methods can recover high-quality meshes, they are often time-consuming and tend to produce over-smoothed surfaces. In contrast, 3D Gaussian Splatting (3DGS) offers the advantage of high speed and detailed real-time rendering, but extracting surfaces from the Gaussians can be noisy due to the lack of geometric constraints. To bridge the gap between these approaches, we propose a novel reconstruction method called GS-2DGS for reflective objects based on 2D Gaussian Splatting (2DGS). Our approach combines the rapid rendering capabilities of Gaussian Splatting with additional geometric information from foundation models. Experimental results on synthetic and real datasets demonstrate that our method significantly outperforms Gaussian-based techniques in terms of reconstruction and relighting and achieves performance comparable to SDF-based methods while being an order of magnitude faster. Code is available at https://github.com/hirotong/GS2DGS
对于高反射物体的三维建模仍然是一个挑战,因为它们的外观具有强烈的视角依赖性。虽然之前的基于SDF的方法可以恢复高质量的三维网格,但它们通常耗时且倾向于产生过于平滑的表面。相比之下,三维高斯拼贴技术(3DGS)具有高速和详细的实时渲染优势,但由于缺乏几何约束,从高斯数据中提取表面可能会产生噪声。为了弥合这些方法之间的差距,我们提出了一种基于二维高斯拼贴技术(2DGS)的新型重建方法,用于处理反射物体,我们称之为GS-2DGS。我们的方法结合了高斯拼贴的快速渲染能力以及与基础模型的几何信息。在合成数据和真实数据上的实验结果表明,我们的方法在重建和重新照明方面显著优于基于高斯的技术,并且性能与基于SDF的方法相当,但速度更快一个数量级。代码可通过https://github.com/hirotong/GS2DGS获取。
论文及项目相关链接
PDF Accepted by CVPR2025
Summary
本文介绍了针对高度反射物体的三维建模挑战,结合了二维高斯溅射(2DGS)的快速渲染能力与基础模型中的几何信息,提出了一种名为GS-2DGS的新型重建方法。该方法在合成和真实数据集上的实验结果表明,其在重建和重新照明方面显著优于基于高斯的技术,同时其性能与基于SDF的方法相当,但速度更快。
Key Takeaways
- 高度反射物体的三维建模具有挑战性,因为它们的外观具有强烈的视角依赖性。
- 之前基于SDF的方法可以恢复高质量网格,但耗时且容易产生过度平滑的表面。
- 3DGS提供高速和详细的实时渲染,但提取表面可能因缺乏几何约束而嘈杂。
- GS-2DGS方法结合了Gaussian Splatting的快速渲染能力与基础模型中的几何信息。
- 实验结果表明GS-2DGS在重建和重新照明方面优于基于高斯的方法。
- GS-2DGS的性能与基于SDF的方法相当,但速度更快。
点此查看论文截图




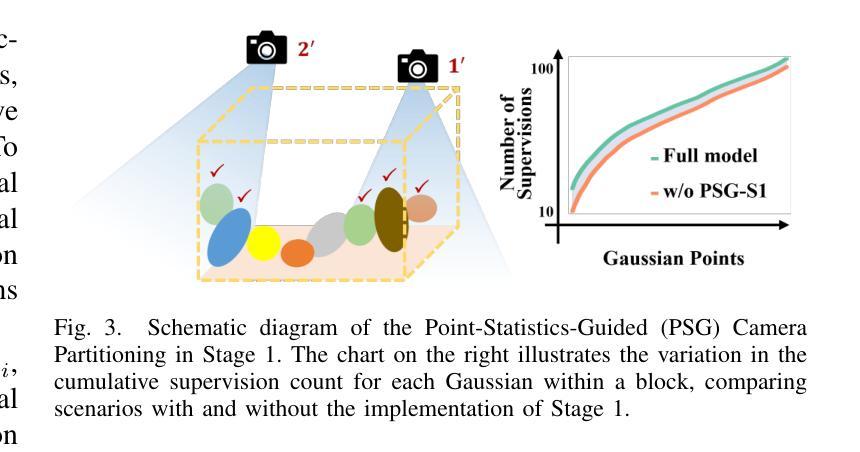
Metropolis-Hastings Sampling for 3D Gaussian Reconstruction
Authors:Hyunjin Kim, Haebeom Jung, Jaesik Park
We propose an adaptive sampling framework for 3D Gaussian Splatting (3DGS) that leverages comprehensive multi-view photometric error signals within a unified Metropolis-Hastings approach. Traditional 3DGS methods heavily rely on heuristic-based density-control mechanisms (e.g., cloning, splitting, and pruning), which can lead to redundant computations or the premature removal of beneficial Gaussians. Our framework overcomes these limitations by reformulating densification and pruning as a probabilistic sampling process, dynamically inserting and relocating Gaussians based on aggregated multi-view errors and opacity scores. Guided by Bayesian acceptance tests derived from these error-based importance scores, our method substantially reduces reliance on heuristics, offers greater flexibility, and adaptively infers Gaussian distributions without requiring predefined scene complexity. Experiments on benchmark datasets, including Mip-NeRF360, Tanks and Temples, and Deep Blending, show that our approach reduces the number of Gaussians needed, enhancing computational efficiency while matching or modestly surpassing the view-synthesis quality of state-of-the-art models.
我们针对三维高斯混合(3DGS)提出了一种自适应采样框架,该框架利用统一的大都市主义-黑斯廷斯方法内的综合多视图光度误差信号。传统的三维GS方法严重依赖于基于启发式的密度控制机制(例如克隆、拆分和修剪),这可能导致冗余计算或过早删除有益的高斯混合。我们的框架通过重新制定密集化和修剪为概率采样过程来克服这些限制,根据聚合的多视图误差和不透明度分数动态插入和重新定位高斯混合。在基于这些基于误差的重要性分数得出的贝叶斯接受测试的指导下,我们的方法极大地减少了启发式的依赖,提供了更大的灵活性,并且不需要预设场景复杂性即可自适应推断高斯分布。在基准数据集上的实验,包括Mip-NeRF360、坦克与神庙和深度混合,表明我们的方法减少了所需的高斯混合数量,提高了计算效率,同时达到了或略微超过了最新模型的视图合成质量。
论文及项目相关链接
PDF Project Page: https://hjhyunjinkim.github.io/MH-3DGS
Summary
本文提出一种自适应采样框架,用于改进三维高斯混合(3DGS)方法。该框架采用统一的后验采样过程结合多角度照片误差信号进行精细化优化和淘汰选择,相比传统的基于启发式方法的机制更灵活、高效。实验证明,该方法减少了所需的高斯数量,提高了计算效率,同时匹配或超越了现有模型的视图合成质量。
Key Takeaways
- 提出自适应采样框架用于改进三维高斯混合(3DGS)。
- 结合多角度照片误差信号和不确定性分析进行优化和调整过程。
- 采用后验采样方法处理三维重建过程中的精细化和淘汰选择任务。
- 减少冗余计算并防止了重要高斯的过早淘汰。
- 将高斯的插入和移除转换为概率采样过程以增强其灵活性。
- 结合贝叶斯测试来决定自适应分布抽样而不依赖于预先定义场景的复杂性分析。
点此查看论文截图

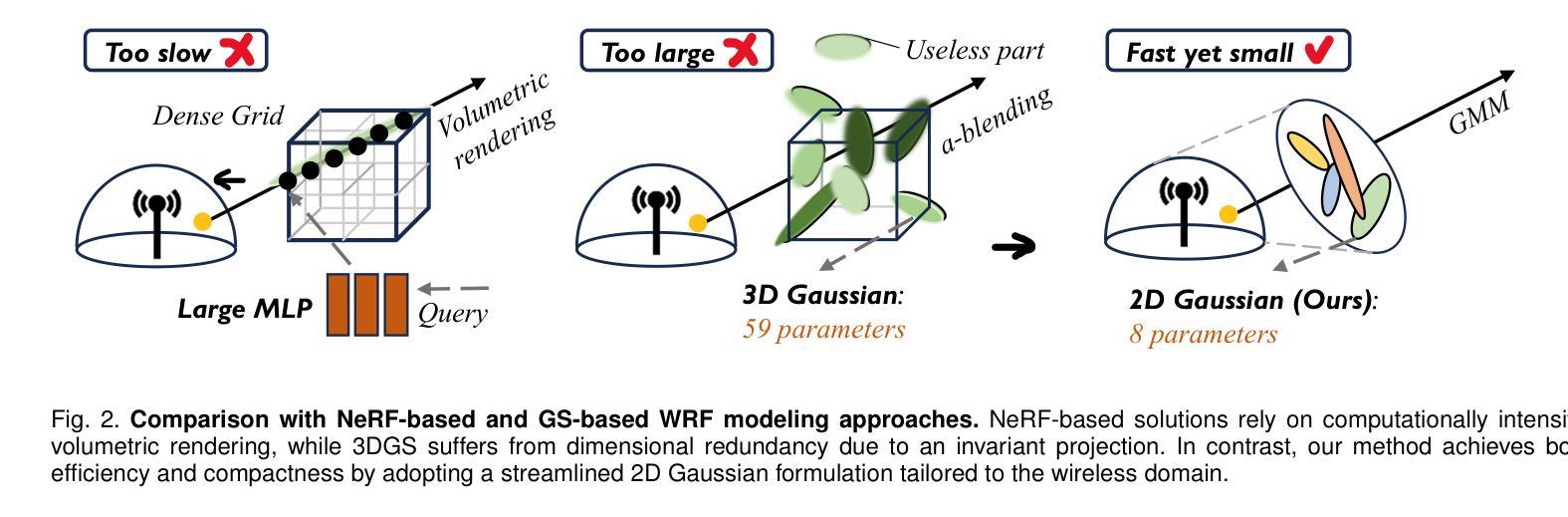
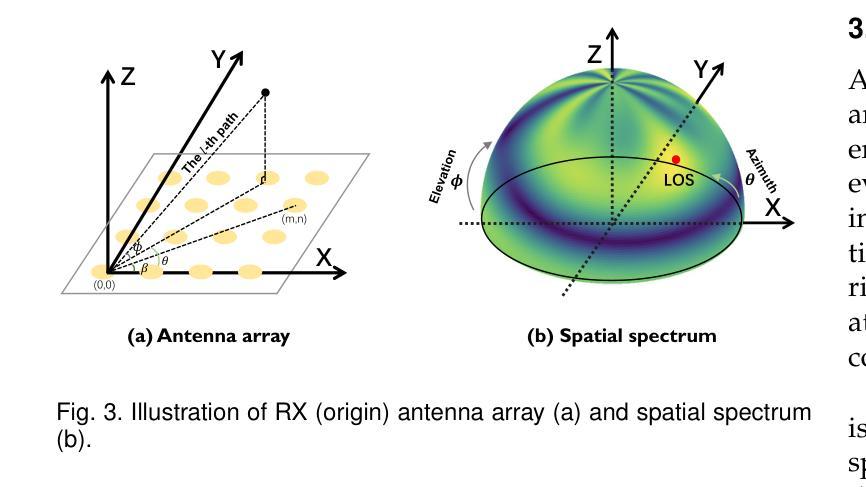
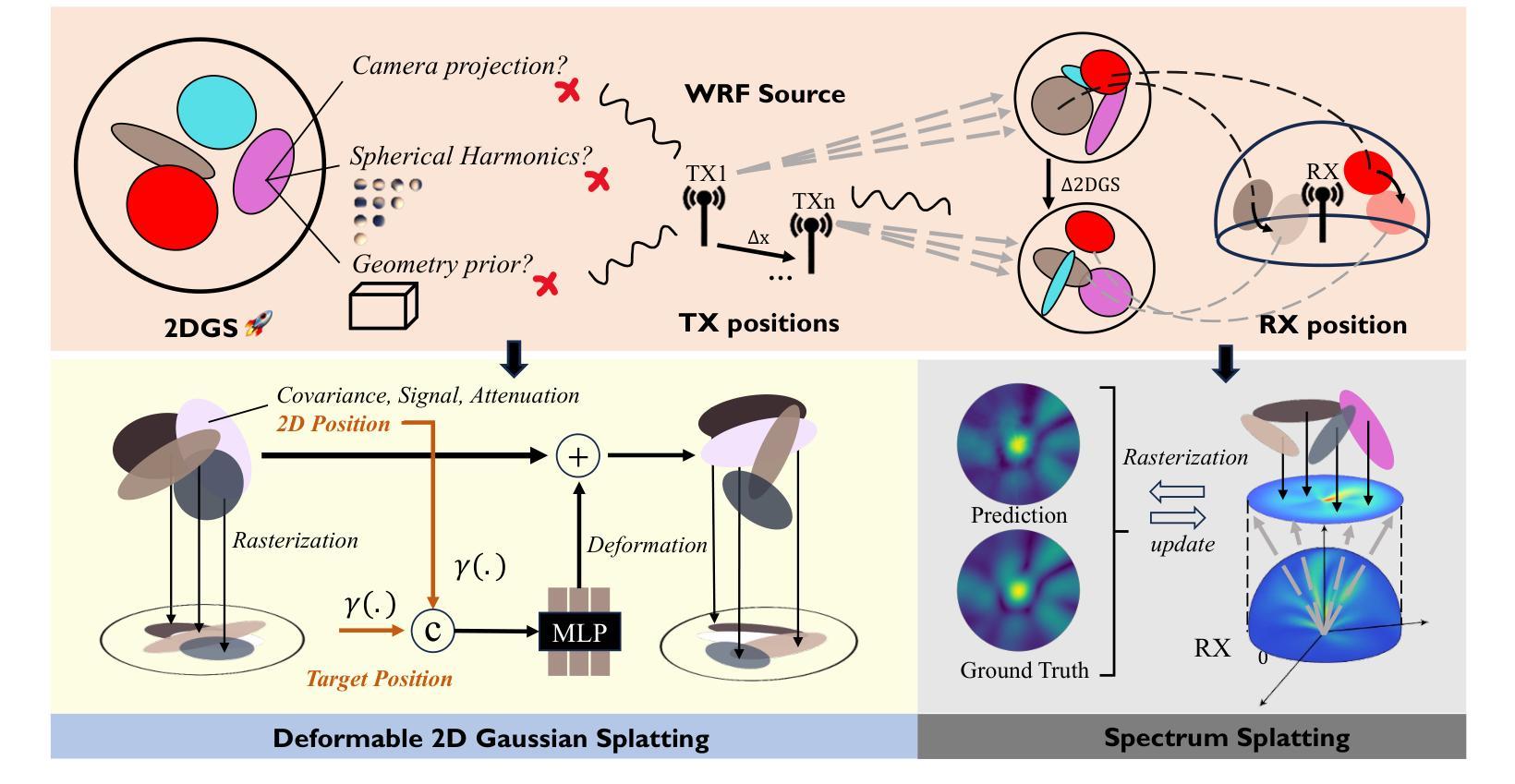
Rasterizing Wireless Radiance Field via Deformable 2D Gaussian Splatting
Authors:Mufan Liu, Cixiao Zhang, Qi Yang, Yujie Cao, Yiling Xu, Yin Xu, Shu Sun, Mingzeng Dai, Yunfeng Guan
Modeling the wireless radiance field (WRF) is fundamental to modern communication systems, enabling key tasks such as localization, sensing, and channel estimation. Traditional approaches, which rely on empirical formulas or physical simulations, often suffer from limited accuracy or require strong scene priors. Recent neural radiance field (NeRF-based) methods improve reconstruction fidelity through differentiable volumetric rendering, but their reliance on computationally expensive multilayer perceptron (MLP) queries hinders real-time deployment. To overcome these challenges, we introduce Gaussian splatting (GS) to the wireless domain, leveraging its efficiency in modeling optical radiance fields to enable compact and accurate WRF reconstruction. Specifically, we propose SwiftWRF, a deformable 2D Gaussian splatting framework that synthesizes WRF spectra at arbitrary positions under single-sided transceiver mobility. SwiftWRF employs CUDA-accelerated rasterization to render spectra at over 100000 fps and uses a lightweight MLP to model the deformation of 2D Gaussians, effectively capturing mobility-induced WRF variations. In addition to novel spectrum synthesis, the efficacy of SwiftWRF is further underscored in its applications in angle-of-arrival (AoA) and received signal strength indicator (RSSI) prediction. Experiments conducted on both real-world and synthetic indoor scenes demonstrate that SwiftWRF can reconstruct WRF spectra up to 500x faster than existing state-of-the-art methods, while significantly enhancing its signal quality. The project page is https://evan-sudo.github.io/swiftwrf/.
无线辐射场(Wireless Radiance Field,WRF)建模是现代通信系统的基础,能够实现定位、感知和信道估计等关键任务。传统的方法依赖于经验公式或物理仿真,往往存在精度有限或需要强烈的场景先验知识的缺陷。最近基于神经辐射场(NeRF)的方法通过可微分的体积渲染提高了重建的逼真度,但它们对计算密集型的多层感知器(MLP)查询的依赖阻碍了实时部署。为了克服这些挑战,我们将高斯喷绘(Gaussian Splatting,GS)引入到无线领域,利用其在对光学辐射场建模方面的效率,实现紧凑且准确的WRF重建。具体来说,我们提出了SwiftWRF,这是一个可变形的2D高斯喷绘框架,可在单侧收发器移动性的情况下合成任意位置的WRF光谱。SwiftWRF采用CUDA加速的光栅化,以超过100000帧每秒的速度渲染光谱,并使用轻量级的多层感知器对2D高斯变形进行建模,有效地捕捉移动引起的WRF变化。除了新颖的光谱合成之外,SwiftWRF在到达角(AoA)和接收信号强度指示(RSSI)预测方面的应用也进一步证明了其有效性。在真实和合成室内场景上进行的实验表明,SwiftWRF可以比现有最先进的方法快500倍重建WRF光谱,同时显著提高信号质量。项目页面是https://evan-sudo.github.io/swiftwrf/。
论文及项目相关链接
摘要
基于神经网络辐射场(NeRF)的方法利用可微体积渲染提高了重建精度,但其在无线领域的应用受限于多层感知器(MLP)查询的计算成本。本研究引入高斯平铺(GS)技术,利用其在光学辐射场建模中的高效性,实现紧凑且精确的无线辐射场(WRF)重建。提出的SwiftWRF框架采用可变形二维高斯平铺技术,可在单侧收发器移动性条件下合成任意位置的WRF光谱。SwiftWRF使用CUDA加速渲染,以超过100000帧/秒的速度渲染光谱,并使用轻量级MLP对二维高斯进行变形建模,有效捕捉移动引起的WRF变化。此外,SwiftWRF在到达角(AoA)和接收信号强度指标(RSSI)预测方面的应用也证明了其有效性。在真实和合成室内场景上的实验表明,SwiftWRF的WRF光谱重建速度比现有最先进的方法快500倍,同时显著提高了信号质量。
关键见解
- 建模无线辐射场(WRF)是现代通信系统的基础任务,包括定位、感知和信道估计等关键任务。
- 传统方法依赖于经验公式或物理模拟,存在精度有限或需要强烈场景先验的问题。
- 基于NeRF的方法通过可微体积渲染提高了重建精度,但计算成本高,特别是在多层感知器(MLP)查询方面。
- 引入高斯平铺(GS)技术到无线领域,利用其在光学辐射场建模中的高效性进行WRF重建。
- 提出SwiftWRF框架,采用可变形二维高斯平铺技术,合成任意位置的WRF光谱,并具备单侧收发器移动性条件下的适应性。
- SwiftWRF使用CUDA加速渲染,以高速度渲染光谱,并采用轻量级MLP捕捉移动引起的WRF变化。
- SwiftWRF在角度到达(AoA)和接收信号强度指标(RSSI)预测中的应用证明了其有效性,并且在真实和合成室内场景上的实验表明其比现有方法更快且更精确。
点此查看论文截图


Generative 4D Scene Gaussian Splatting with Object View-Synthesis Priors
Authors:Wen-Hsuan Chu, Lei Ke, Jianmeng Liu, Mingxiao Huo, Pavel Tokmakov, Katerina Fragkiadaki
We tackle the challenge of generating dynamic 4D scenes from monocular, multi-object videos with heavy occlusions, and introduce GenMOJO, a novel approach that integrates rendering-based deformable 3D Gaussian optimization with generative priors for view synthesis. While existing models perform well on novel view synthesis for isolated objects, they struggle to generalize to complex, cluttered scenes. To address this, GenMOJO decomposes the scene into individual objects, optimizing a differentiable set of deformable Gaussians per object. This object-wise decomposition allows leveraging object-centric diffusion models to infer unobserved regions in novel viewpoints. It performs joint Gaussian splatting to render the full scene, capturing cross-object occlusions, and enabling occlusion-aware supervision. To bridge the gap between object-centric priors and the global frame-centric coordinate system of videos, GenMOJO uses differentiable transformations that align generative and rendering constraints within a unified framework. The resulting model generates 4D object reconstructions over space and time, and produces accurate 2D and 3D point tracks from monocular input. Quantitative evaluations and perceptual human studies confirm that GenMOJO generates more realistic novel views of scenes and produces more accurate point tracks compared to existing approaches.
我们应对从单目多物体视频生成动态四维场景的挑战,这些视频存在严重的遮挡问题。我们引入GenMOJO这一新方法,它将基于渲染的可变形三维高斯优化与用于视图合成的生成先验知识相结合。虽然现有模型在孤立物体的新型视图合成方面表现良好,但它们在推广到复杂混乱的场景时却难以发挥功效。为解决这一问题,GenMOJO将场景分解为单个物体,针对每个物体优化一组可区分的可变形高斯分布。这种按对象分解的方法允许利用对象为中心的扩散模型来推断新型观点中的未观察区域。它执行联合高斯贴图渲染整个场景,捕捉跨对象遮挡,并实现遮挡感知监督。为弥合对象为中心的先验知识和视频全局帧为中心的坐标系之间的差距,GenMOJO使用可区分转换来在统一框架内对齐生成和渲染约束。所得到的模型能够在空间和时间上生成四维物体重建,并从单目输入中产生准确的二维和三维点轨迹。定量评估和感知人类研究证实,与现有方法相比,GenMOJO生成的新型场景视图更加真实,产生的点轨迹也更加准确。
论文及项目相关链接
PDF This is an updated and extended version of our CVPR paper “Robust Multi-Object 4D Generation in Complex Video Scenarios”
Summary
GenMOJO是一种针对单目多物体视频生成动态4D场景的新方法,它通过集成基于渲染的可变形3D高斯优化和生成先验来实现场景合成。该方法将场景分解为单个物体,针对每个物体优化可变形高斯,并利用对象级扩散模型推断新视角中的未观察区域。通过联合高斯贴片技术渲染整个场景,捕捉对象间的遮挡,并实现遮挡感知监督。GenMOJO使用可区分变换在统一框架内对齐生成和渲染约束,从而缩小对象级先验与视频全局帧级坐标系之间的差距。该方法生成了4D对象在时空上的重建,并从单目输入中产生准确的2D和3D点轨迹。评估和感知人类研究表明,与现有方法相比,GenMOJO生成的场景新颖性更真实,点轨迹更准确。
Key Takeaways
- GenMOJO解决了从单目多物体视频中生成动态4D场景的挑战。
- 通过集成渲染基于可变形3D高斯优化与生成先验,实现场景合成。
- 将场景分解为单个物体,针对每个物体优化可变形高斯。
- 利用对象级扩散模型推断新视角中的未观察区域。
- 通过联合高斯贴片技术渲染场景,捕捉对象间的遮挡,并实现遮挡感知监督。
- GenMOJO使用可区分变换对齐生成和渲染约束。
点此查看论文截图


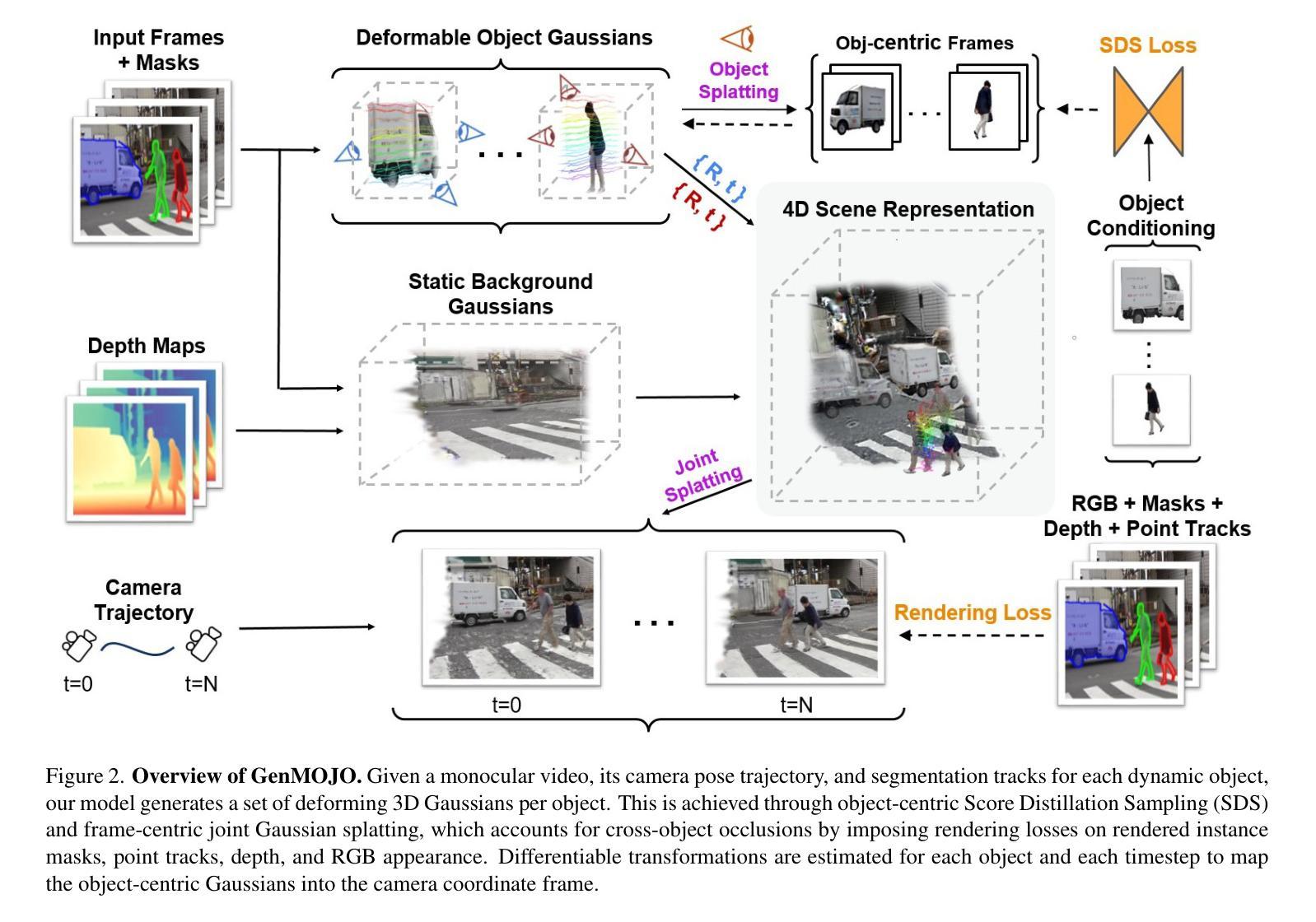


Perceptual-GS: Scene-adaptive Perceptual Densification for Gaussian Splatting
Authors:Hongbi Zhou, Zhangkai Ni
3D Gaussian Splatting (3DGS) has emerged as a powerful technique for novel view synthesis. However, existing methods struggle to adaptively optimize the distribution of Gaussian primitives based on scene characteristics, making it challenging to balance reconstruction quality and efficiency. Inspired by human perception, we propose scene-adaptive perceptual densification for Gaussian Splatting (Perceptual-GS), a novel framework that integrates perceptual sensitivity into the 3DGS training process to address this challenge. We first introduce a perception-aware representation that models human visual sensitivity while constraining the number of Gaussian primitives. Building on this foundation, we develop a \cameraready{perceptual sensitivity-adaptive distribution} to allocate finer Gaussian granularity to visually critical regions, enhancing reconstruction quality and robustness. Extensive evaluations on multiple datasets, including BungeeNeRF for large-scale scenes, demonstrate that Perceptual-GS achieves state-of-the-art performance in reconstruction quality, efficiency, and robustness. The code is publicly available at: https://github.com/eezkni/Perceptual-GS
3D高斯Splatting(3DGS)作为一种强大的新技术,已经崭露头角,用于合成新颖的视角。然而,现有方法难以根据场景特性自适应优化高斯原始数据的分布,从而难以在重建质量和效率之间取得平衡。受人类感知的启发,我们提出了基于场景感知的高斯Splatting密集化(Perceptual-GS),这是一个将感知敏感度集成到3DGS训练过程中的新型框架,以应对这一挑战。我们首先引入了一种感知意识表示,它模拟了人类视觉敏感度,同时约束了高斯原始数据的数量。在此基础上,我们开发了一种\cameraready{感知敏感度自适应分布},为视觉关键区域分配更精细的高斯粒度,提高了重建质量和鲁棒性。在包括用于大规模场景的BungeeNeRF等多个数据集上的广泛评估表明,Perceptual-GS在重建质量、效率和鲁棒性方面达到了最先进的性能。代码公开在:https://github.com/eezkni/Perceptual-GS 。
论文及项目相关链接
PDF Accepted to International Conference on Machine Learning (ICML) 2025
Summary
3DGS技术已成为新颖视角合成中的强大工具,但现有方法难以根据场景特性自适应优化高斯原语分布,从而难以平衡重建质量和效率。鉴于此,我们提出了结合感知敏感性感知的Gaussian Splatting(Perceptual-GS)新框架,该框架引入了一种感知敏感性的表示形式,同时限制了高斯原语的数量。我们进一步开发了一种感知敏感性自适应分布,为视觉关键区域提供更精细的高斯粒度,以提高重建质量和鲁棒性。在多个数据集上的广泛评估表明,Perceptual-GS在重建质量、效率和鲁棒性方面达到了最佳性能。
Key Takeaways
- 3D Gaussian Splatting (3DGS)在新型视角合成中具有强大能力。
- 现有方法难以适应场景特性优化高斯原语分布。
- 提出了一种新的框架Perceptual-GS,结合感知敏感性进行训练。
- 引入感知敏感性的表示形式,限制高斯原语数量。
- 开发感知敏感性自适应分布,提高视觉关键区域的重建质量和鲁棒性。
- 在多个数据集上的评估显示,Perceptual-GS在重建质量、效率和鲁棒性方面达到最佳性能。
点此查看论文截图


Hardware-Rasterized Ray-Based Gaussian Splatting
Authors:Samuel Rota Bulò, Nemanja Bartolovic, Lorenzo Porzi, Peter Kontschieder
We present a novel, hardware rasterized rendering approach for ray-based 3D Gaussian Splatting (RayGS), obtaining both fast and high-quality results for novel view synthesis. Our work contains a mathematically rigorous and geometrically intuitive derivation about how to efficiently estimate all relevant quantities for rendering RayGS models, structured with respect to standard hardware rasterization shaders. Our solution is the first enabling rendering RayGS models at sufficiently high frame rates to support quality-sensitive applications like Virtual and Mixed Reality. Our second contribution enables alias-free rendering for RayGS, by addressing MIP-related issues arising when rendering diverging scales during training and testing. We demonstrate significant performance gains, across different benchmark scenes, while retaining state-of-the-art appearance quality of RayGS.
我们提出了一种新型的硬件光栅化渲染方法,用于基于射线的三维高斯混合(RayGS),为新颖视图合成获得快速且高质量的结果。我们的工作包含关于如何有效地估计所有与渲染RayGS模型相关的数量的严谨数学和直观几何推导,以标准的硬件光栅化着色器进行结构化。我们的解决方案首次支持以足够高的帧率渲染RayGS模型,以支持像虚拟和混合现实这样的对质量敏感的应用程序。我们的第二个贡献是通过解决在训练和测试期间出现与MIP相关的发散尺度问题,实现了RayGS的无重影渲染。我们在不同的基准测试场景中展示了显著的性能提升,同时保持了RayGS的先进外观质量。
论文及项目相关链接
Summary
本文提出了一种新型的硬件光栅化渲染方法,用于基于射线的三维高斯斑点渲染(RayGS),实现快速高质量的新视角合成效果。文章详细阐述了如何有效地估算RayGS模型渲染所需的所有相关参数,并首次实现了以足够高的帧率渲染RayGS模型,支持虚拟现实和混合现实等质量敏感型应用。此外,该研究解决了MIP相关的渲染问题,实现了RayGS的无混叠渲染。整体上,该研究在性能上取得了显著的提升,同时保持了RayGS的领先外观质量。
Key Takeaways
- 提出了一种新型的硬件光栅化渲染方法用于RayGS模型渲染。
- 为RayGS模型提供了数学严谨和几何直观的参数估算方法。
- 第一次实现了以高帧率进行RayGS模型的渲染,适用于VR和混合现实等应用。
- 解决MIP问题,实现了RayGS模型的无混叠渲染。
- 在不同基准测试场景中展现了显著的性能提升。
点此查看论文截图

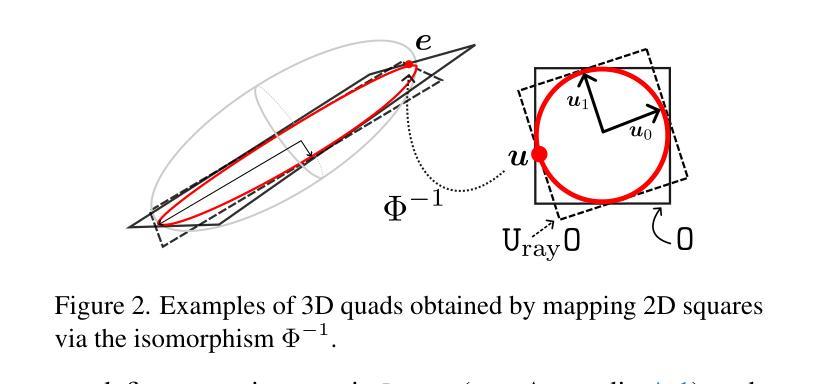
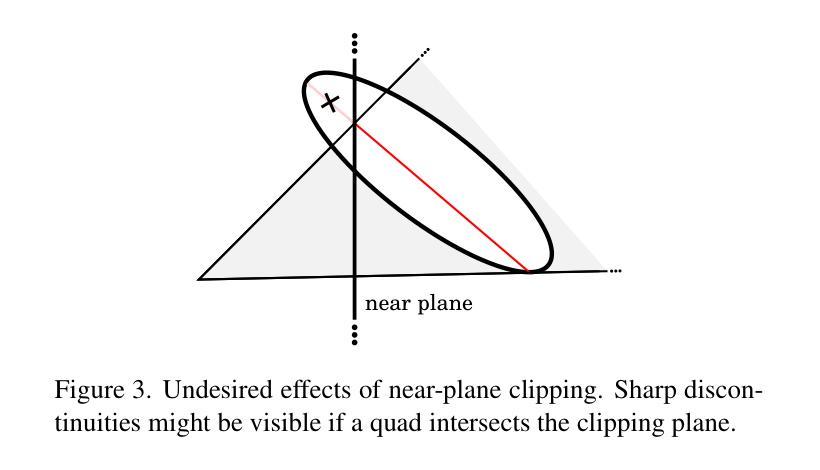
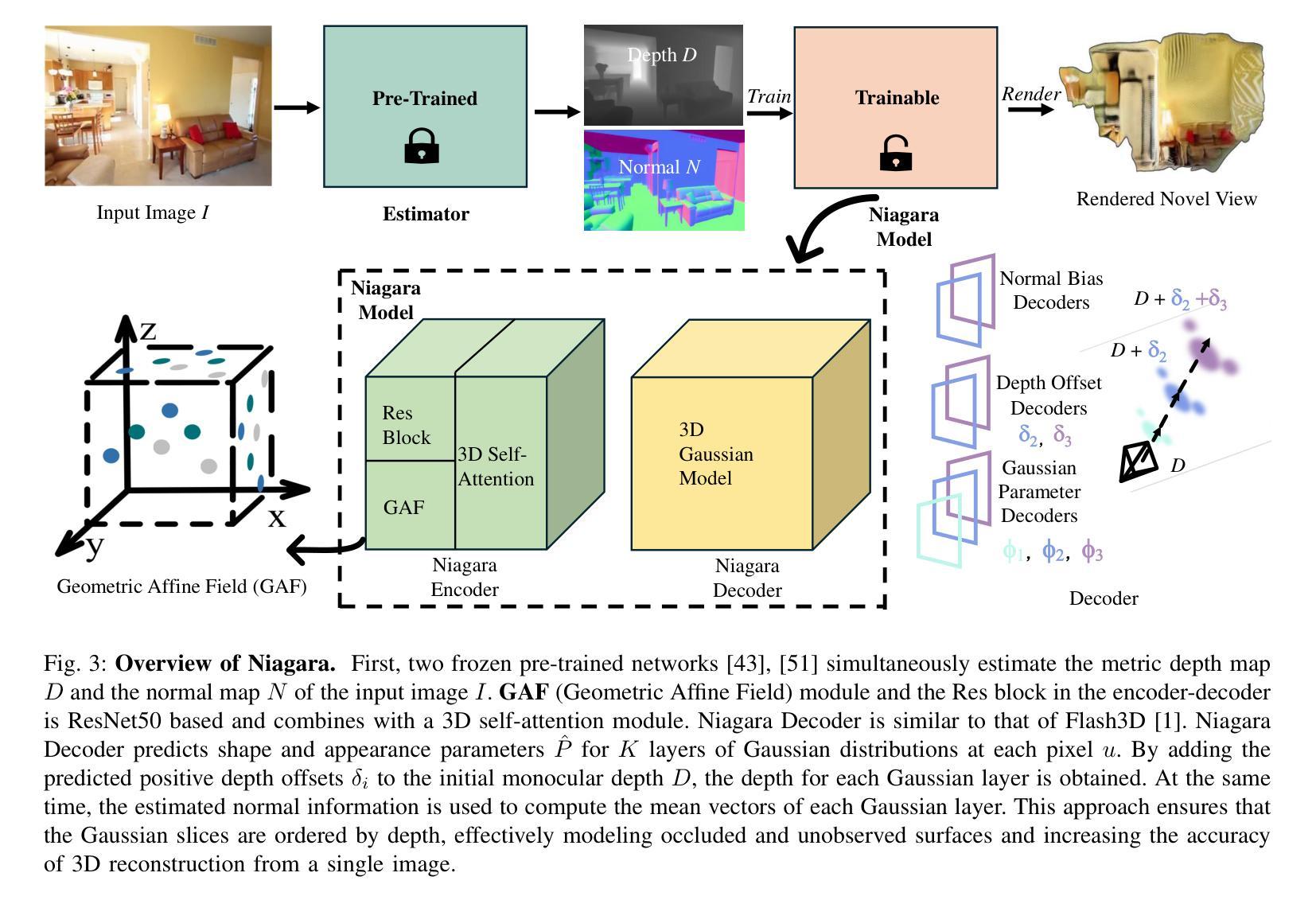
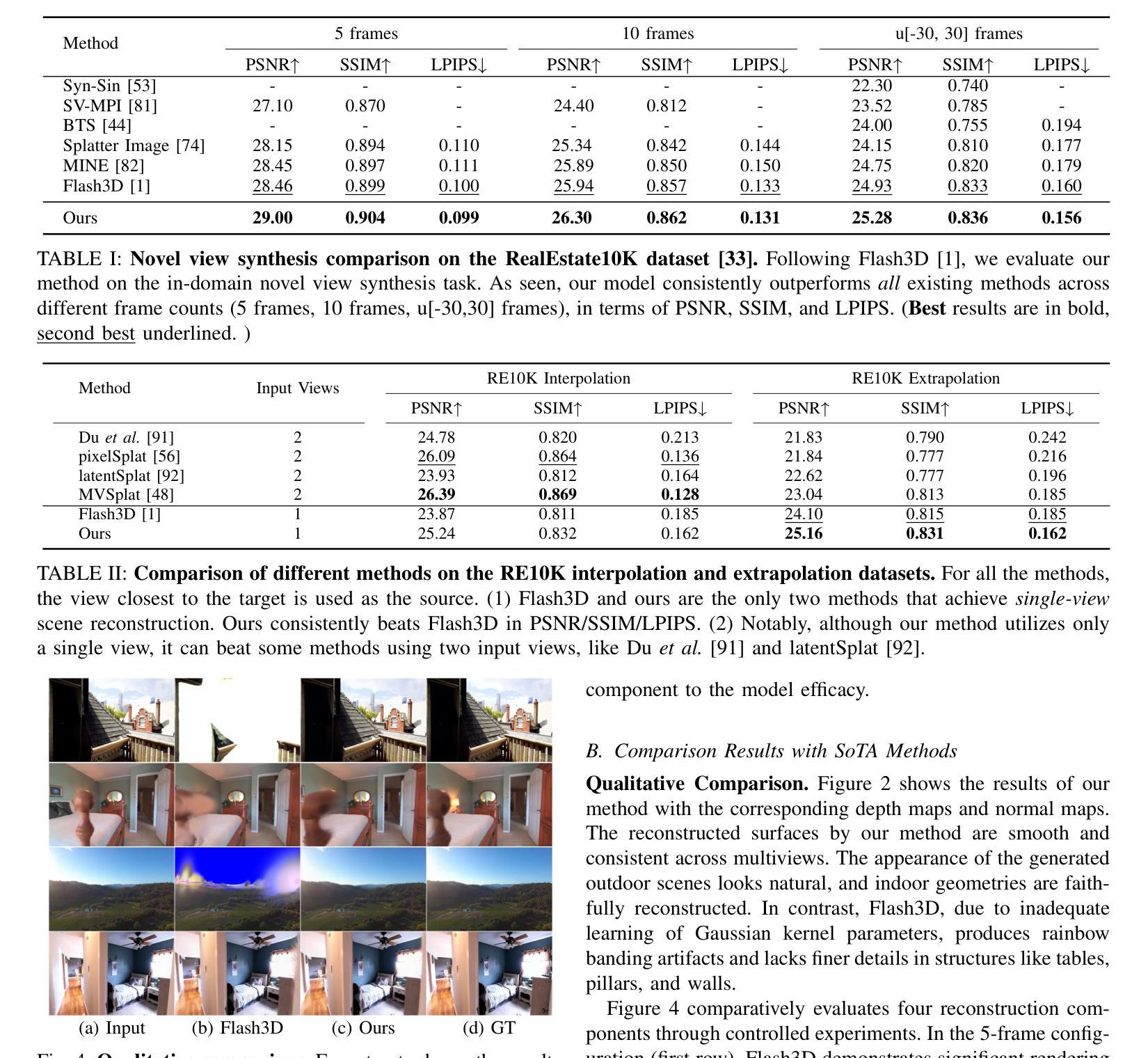
Niagara: Normal-Integrated Geometric Affine Field for Scene Reconstruction from a Single View
Authors:Xianzu Wu, Zhenxin Ai, Harry Yang, Ser-Nam Lim, Jun Liu, Huan Wang
Recent advances in single-view 3D scene reconstruction have highlighted the challenges in capturing fine geometric details and ensuring structural consistency, particularly in high-fidelity outdoor scene modeling. This paper presents Niagara, a new single-view 3D scene reconstruction framework that can faithfully reconstruct challenging outdoor scenes from a single input image for the first time. Our approach integrates monocular depth and normal estimation as input, which substantially improves its ability to capture fine details, mitigating common issues like geometric detail loss and deformation. Additionally, we introduce a geometric affine field (GAF) and 3D self-attention as geometry-constraint, which combines the structural properties of explicit geometry with the adaptability of implicit feature fields, striking a balance between efficient rendering and high-fidelity reconstruction. Our framework finally proposes a specialized encoder-decoder architecture, where a depth-based 3D Gaussian decoder is proposed to predict 3D Gaussian parameters, which can be used for novel view synthesis. Extensive results and analyses suggest that our Niagara surpasses prior SoTA approaches such as Flash3D in both single-view and dual-view settings, significantly enhancing the geometric accuracy and visual fidelity, especially in outdoor scenes.
近期单视图三维场景重建的最新进展凸显了捕捉精细几何细节和确保结构一致性的挑战,特别是在高保真室外场景建模中。本文提出了Niagara,这是一个新的单视图三维场景重建框架,能够首次从单个输入图像中准确地重建具有挑战性的室外场景。
我们的方法将单目深度估计和法线估计作为输入进行集成,这大大提高了捕捉细节的能力,缓解了常见的几何细节丢失和变形等问题。此外,我们引入了几何仿射场(GAF)和三维自注意力作为几何约束,它将显式几何的结构属性与隐式特征场的适应性相结合,在高效渲染和高保真重建之间取得了平衡。
论文及项目相关链接
Summary
本文介绍了Niagara,一种新型的单视图3D场景重建框架,可首次从单一输入图像中忠实重建具有挑战性的户外场景。该框架通过整合单目深度与法线估计,提高了捕捉精细细节的能力,解决了常见的几何细节丢失和变形问题。此外,引入了几何仿射场(GAF)和3D自注意力作为几何约束,结合了显式几何的结构属性和隐式特征场的适应性,实现了高效渲染与高保真重建之间的平衡。最后,该框架提出了一种基于深度的3D高斯解码器,用于预测3D高斯参数,可用于新颖视图合成。实验结果与分析显示,Niagara在单视图和双视图设置中均超越了现有技术,显著提高了几何精度和视觉保真度,特别是在户外场景方面。
Key Takeaways
- Niagara是一种新型的单视图3D场景重建框架,能够忠实重建户外场景。
- 该框架通过整合单目深度与法线估计,提高了捕捉精细细节的能力。
- 引入了几何仿射场(GAF)和3D自注意力机制,实现了高效渲染与高保真重建之间的平衡。
- 框架中的深度基于的3D高斯解码器可预测3D高斯参数,用于新颖视图合成。
- Niagara显著提高了几何精度和视觉保真度,尤其是在户外场景方面。
- 该框架在单视图和双视图设置中都超越了现有技术。
点此查看论文截图


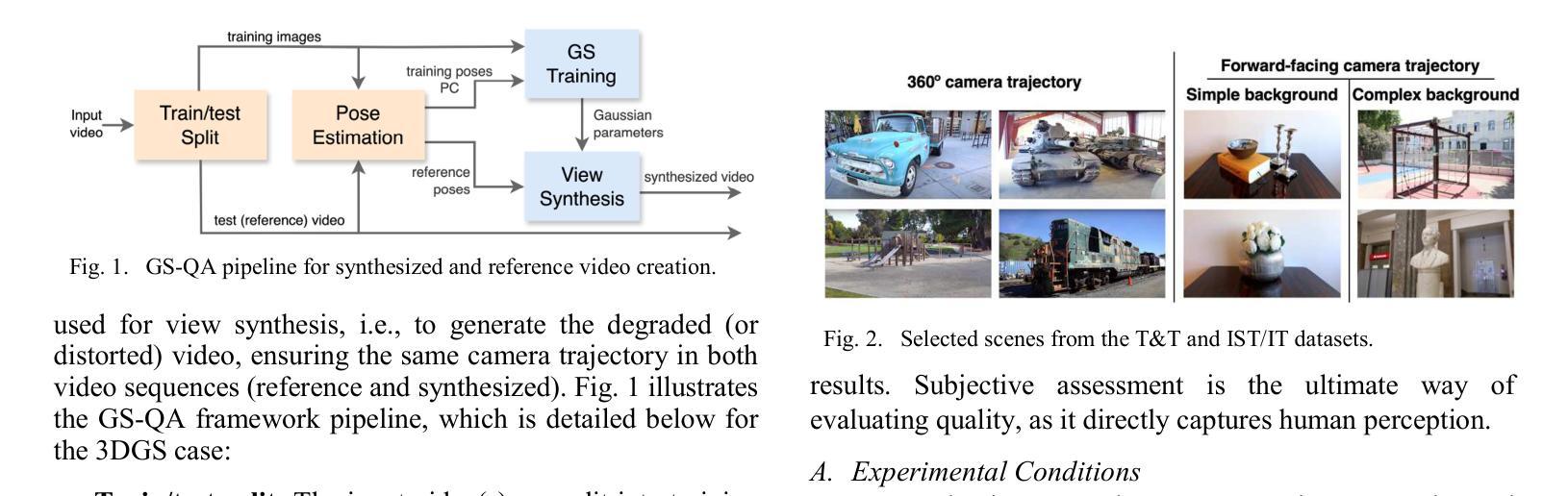
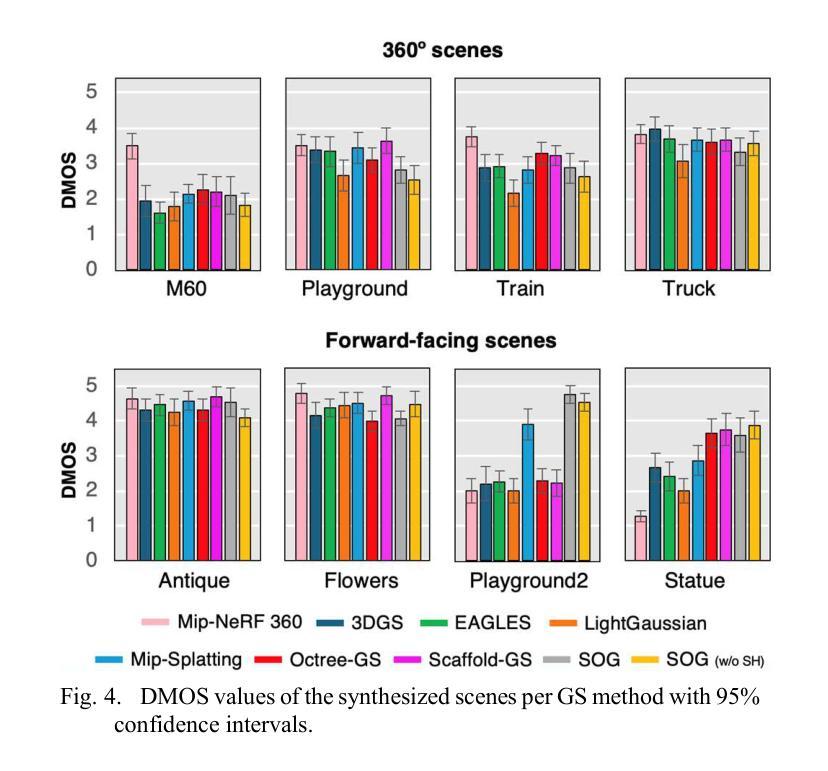
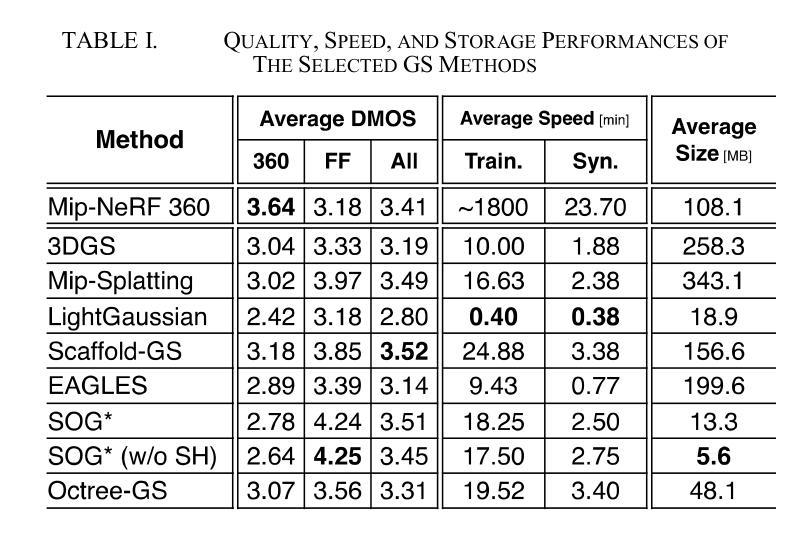
GS-QA: Comprehensive Quality Assessment Benchmark for Gaussian Splatting View Synthesis
Authors:Pedro Martin, António Rodrigues, João Ascenso, Maria Paula Queluz
Gaussian Splatting (GS) offers a promising alternative to Neural Radiance Fields (NeRF) for real-time 3D scene rendering. Using a set of 3D Gaussians to represent complex geometry and appearance, GS achieves faster rendering times and reduced memory consumption compared to the neural network approach used in NeRF. However, quality assessment of GS-generated static content is not yet explored in-depth. This paper describes a subjective quality assessment study that aims to evaluate synthesized videos obtained with several static GS state-of-the-art methods. The methods were applied to diverse visual scenes, covering both 360-degree and forward-facing (FF) camera trajectories. Moreover, the performance of 18 objective quality metrics was analyzed using the scores resulting from the subjective study, providing insights into their strengths, limitations, and alignment with human perception. All videos and scores are made available providing a comprehensive database that can be used as benchmark on GS view synthesis and objective quality metrics.
高斯贴图(GS)为实时3D场景渲染提供了另一种有前途的替代方案,即对神经辐射场(NeRF)的替代。使用一组3D高斯分布来表示复杂的几何形状和外观,GS实现了比NeRF中使用的神经网络方法更快的渲染速度和更低的内存消耗。然而,GS生成的静态内容的质量评估尚未深入探索。本文描述了一项主观质量评估研究,旨在评估采用几种最新静态GS技术合成的视频的质量。这些方法应用于多种视觉场景,涵盖360度以及面向前的相机轨迹。此外,利用主观研究得出的分数对18项客观质量指标的性能进行了分析,深入了解了它们的优点、局限性以及与人类感知的契合度。所有视频和分数均提供,形成一个综合数据库,可用于GS视图合成和客观质量指标的基准测试。
论文及项目相关链接
Summary
高斯Splatting(GS)为实时3D场景渲染提供了有前景的替代方案,相较于神经网络方法NeRF,它使用一组3D高斯来代表复杂的几何和外观信息,实现更快的渲染速度和更低的内存消耗。然而,GS生成的静态内容的品质评估尚未被深入探索。本文描述了一项主观质量评估研究,旨在评估使用多种静态GS前沿方法合成的视频质量。这些方法应用于多种视觉场景,包括全景和面向前的相机轨迹。此外,通过对主观研究结果的得分分析,对18种客观质量指标的性能进行了评估,深入揭示了它们的优缺点与与人的感知的一致性。所有视频和得分数据均已公开提供,为GS视图合成和客观质量指标提供了一个全面的基准数据库。
Key Takeaways
- 高斯Splatting(GS)提供了一种实时3D场景渲染的替代方案,相比NeRF有更快的渲染速度和更低的内存消耗。
- GS使用一组3D高斯来代表复杂的几何和外观信息。
- 当前研究对GS生成的静态内容的品质评估尚未深入探索。
- 论文进行了一项主观质量评估研究,评估了多种静态GS方法合成的视频质量。
- 这些方法应用于不同的视觉场景,包括全景和面向前的相机轨迹。
- 对18种客观质量指标的性能进行了评估,揭示了它们的优缺点以及与人类感知的一致性。
点此查看论文截图


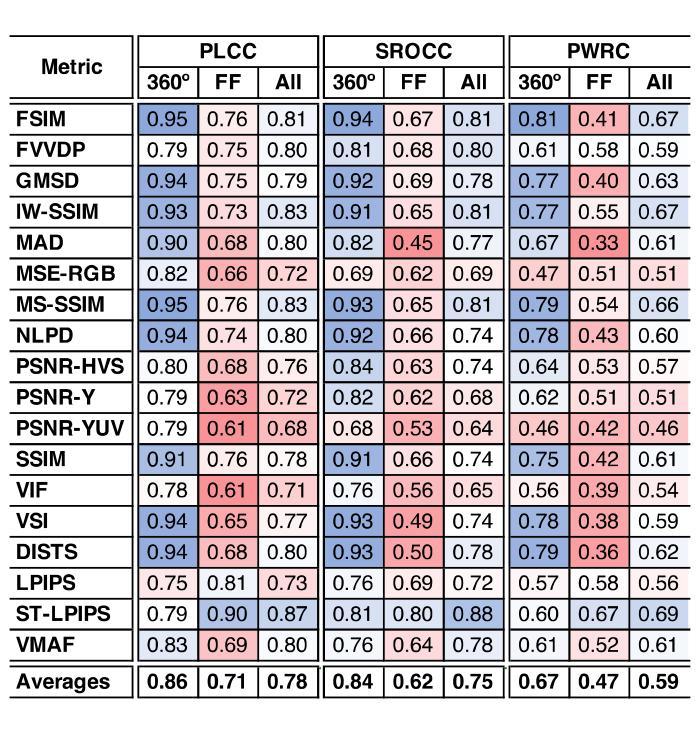

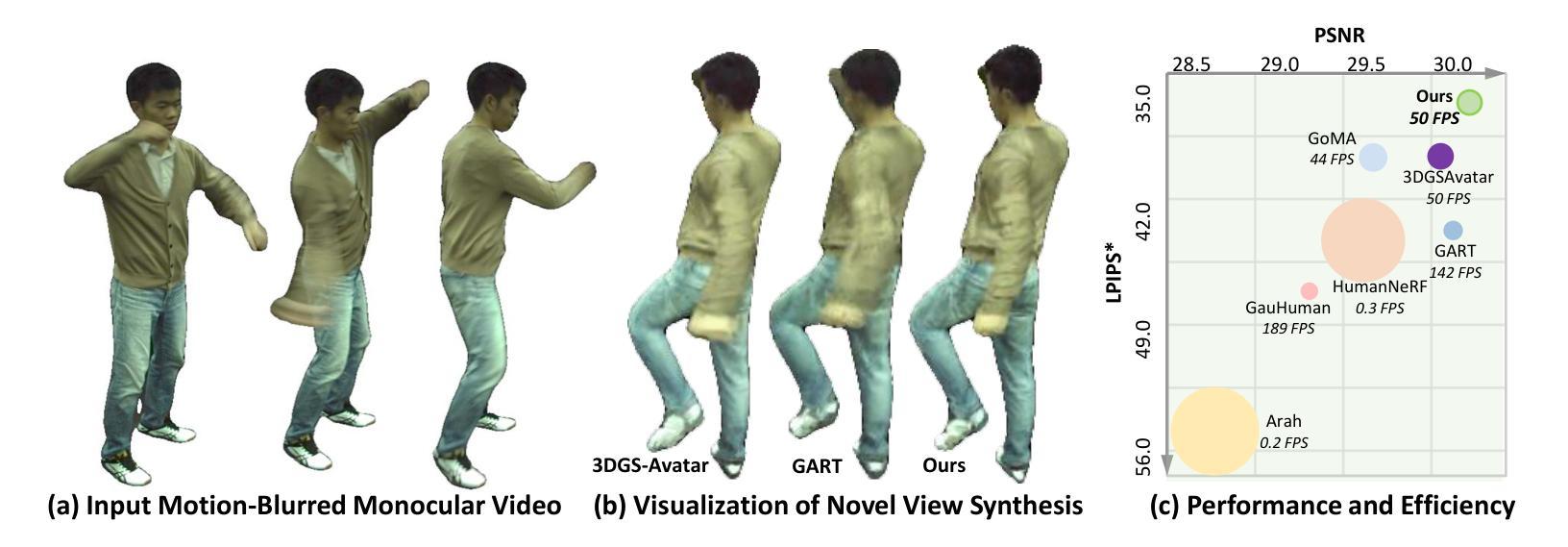
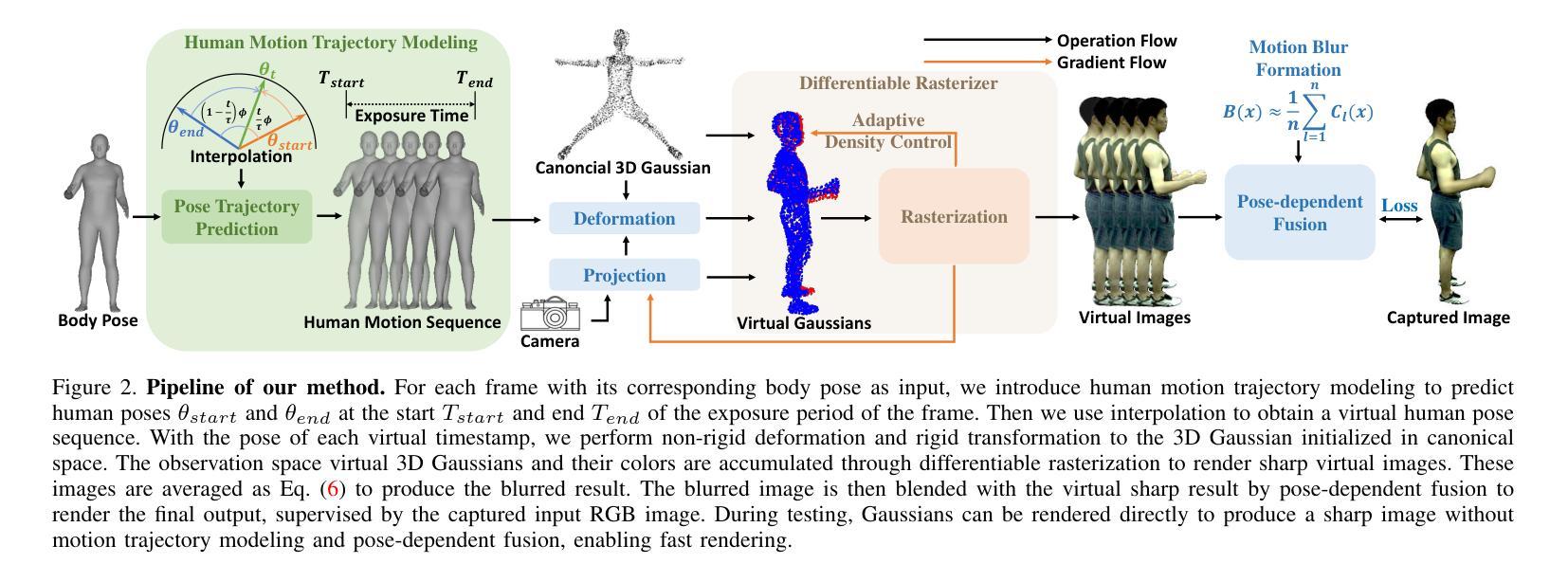
Deblur-Avatar: Animatable Avatars from Motion-Blurred Monocular Videos
Authors:Xianrui Luo, Juewen Peng, Zhongang Cai, Lei Yang, Fan Yang, Zhiguo Cao, Guosheng Lin
We introduce a novel framework for modeling high-fidelity, animatable 3D human avatars from motion-blurred monocular video inputs. Motion blur is prevalent in real-world dynamic video capture, especially due to human movements in 3D human avatar modeling. Existing methods either (1) assume sharp image inputs, failing to address the detail loss introduced by motion blur, or (2) mainly consider blur by camera movements, neglecting the human motion blur which is more common in animatable avatars. Our proposed approach integrates a human movement-based motion blur model into 3D Gaussian Splatting (3DGS). By explicitly modeling human motion trajectories during exposure time, we jointly optimize the trajectories and 3D Gaussians to reconstruct sharp, high-quality human avatars. We employ a pose-dependent fusion mechanism to distinguish moving body regions, optimizing both blurred and sharp areas effectively. Extensive experiments on synthetic and real-world datasets demonstrate that our method significantly outperforms existing methods in rendering quality and quantitative metrics, producing sharp avatar reconstructions and enabling real-time rendering under challenging motion blur conditions.
我们引入了一种新型框架,用于从运动模糊的单目视频输入中建立高保真、可动画的3D人类化身。运动模糊在真实世界的动态视频捕捉中普遍存在,特别是在3D人类化身建模中。现有方法要么(1)假设图像输入是清晰的,无法处理运动模糊引入的细节损失;要么(2)主要关注由相机运动引起的模糊,而忽视在可动画化身中更为普遍的人类运动模糊。我们提出的方法将基于人类运动的运动模糊模型集成到3D高斯拼贴(3DGS)中。通过显式建模曝光期间的人类运动轨迹,我们联合优化轨迹和3D高斯,以重建清晰、高质量的人类化身。我们采用姿态依赖的融合机制来区分移动的身体区域,有效地优化模糊和清晰区域。在合成和真实世界数据集上的大量实验表明,我们的方法在渲染质量和定量指标方面显著优于现有方法,能够产生清晰的化身重建,并在具有挑战性的运动模糊条件下实现实时渲染。
论文及项目相关链接
Summary
本文介绍了一种新型框架,能够从运动模糊的单目视频输入中建立高保真、可动画的3D人类角色模型。该框架通过整合基于人类运动的模糊模型与三维高斯贴图技术(3DGS),显式模拟曝光期间的人类运动轨迹,联合优化轨迹和三维高斯贴图来重建清晰、高质量的3D人类角色模型。实验表明,该方法在渲染质量和量化指标上显著优于现有方法,能够在运动模糊条件下实现清晰的角色重建和实时渲染。
Key Takeaways
- 介绍了一种新型框架,能够从运动模糊的单目视频建立3D人类角色模型。
- 框架集成了基于人类运动的模糊模型和三维高斯贴图技术(3DGS)。
- 显式模拟曝光期间的人类运动轨迹。
- 通过联合优化轨迹和三维高斯贴图来重建清晰、高质量的3D角色模型。
- 采用了姿态依赖的融合机制,以区分移动的身体区域,有效优化模糊和清晰区域。
- 在合成和真实数据集上的实验表明,该方法在渲染质量和量化指标上优于现有方法。
点此查看论文截图


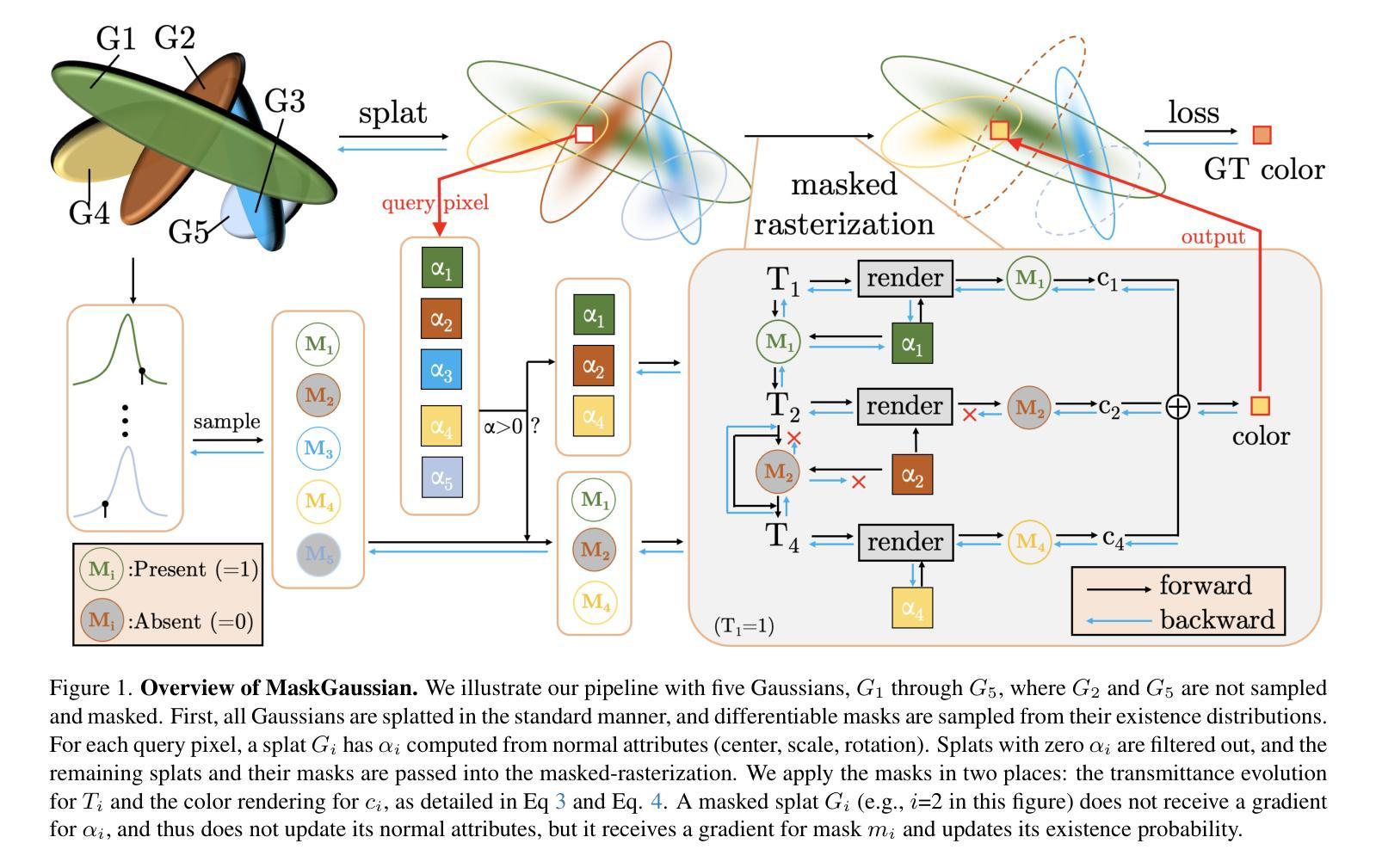
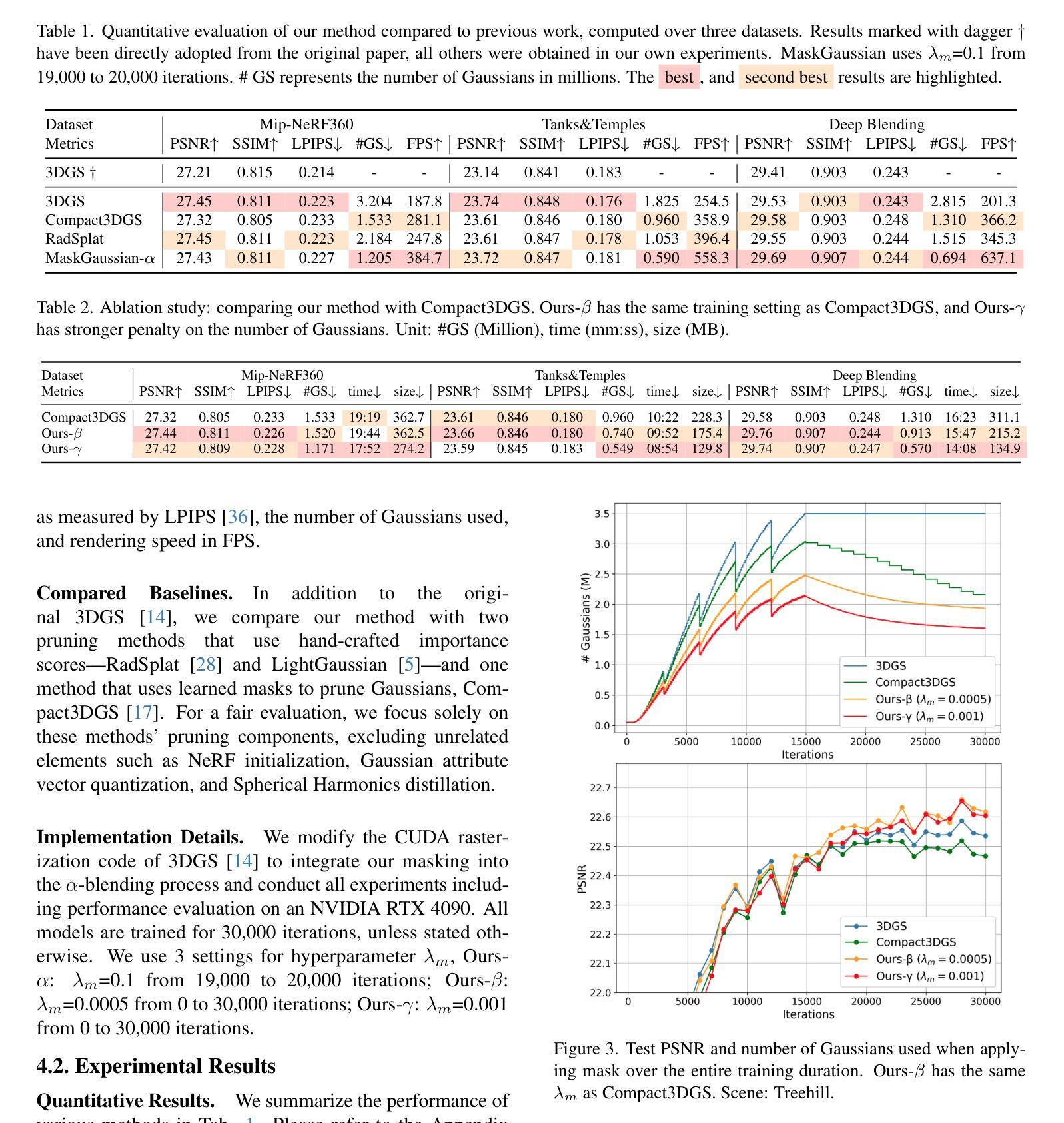
MaskGaussian: Adaptive 3D Gaussian Representation from Probabilistic Masks
Authors:Yifei Liu, Zhihang Zhong, Yifan Zhan, Sheng Xu, Xiao Sun
While 3D Gaussian Splatting (3DGS) has demonstrated remarkable performance in novel view synthesis and real-time rendering, the high memory consumption due to the use of millions of Gaussians limits its practicality. To mitigate this issue, improvements have been made by pruning unnecessary Gaussians, either through a hand-crafted criterion or by using learned masks. However, these methods deterministically remove Gaussians based on a snapshot of the pruning moment, leading to sub-optimized reconstruction performance from a long-term perspective. To address this issue, we introduce MaskGaussian, which models Gaussians as probabilistic entities rather than permanently removing them, and utilize them according to their probability of existence. To achieve this, we propose a masked-rasterization technique that enables unused yet probabilistically existing Gaussians to receive gradients, allowing for dynamic assessment of their contribution to the evolving scene and adjustment of their probability of existence. Hence, the importance of Gaussians iteratively changes and the pruned Gaussians are selected diversely. Extensive experiments demonstrate the superiority of the proposed method in achieving better rendering quality with fewer Gaussians than previous pruning methods, pruning over 60% of Gaussians on average with only a 0.02 PSNR decline. Our code can be found at: https://github.com/kaikai23/MaskGaussian
虽然3D高斯摊铺(3DGS)在新型视图合成和实时渲染方面表现出卓越的性能,但由于使用了数百万个高斯,其高内存消耗限制了其实用性。为了缓解这个问题,已经通过删除不必要的高斯进行了改进,方法包括使用手工制定的标准或使用学习到的掩膜。然而,这些方法基于修剪时刻的快照确定性地删除高斯,从长远来看导致重建性能次优。为了解决这一问题,我们引入了MaskGaussian,它将高斯建模为概率实体,而不是永久删除它们,并根据其存在的概率来使用它们。为了实现这一点,我们提出了一种掩膜光栅化技术,使未使用但概率存在的高斯能够获得梯度,从而能够动态评估它们对不断变化的场景的贡献并调整其存在的概率。因此,高斯的重要性会迭代地改变,被修剪的高斯选择也多样化。大量实验表明,所提出的方法在达到更好的渲染质量方面优于以前的高斯修剪方法,平均修剪超过60%的高斯,而PSNR仅下降0.02。我们的代码可以在以下网址找到:https://github.com/kaikai23/MaskGaussian
论文及项目相关链接
PDF CVPR 2025; Project page:https://maskgaussian.github.io/
Summary
本文探讨了基于三维高斯卷积技术的渲染技术面临的挑战。内存消耗过大限制了其实际应用。为解决这一问题,研究者提出了MaskGaussian方法,该方法将高斯卷积视为概率实体而非永久移除,通过动态评估其对场景变化的贡献来调整其存在概率。采用掩盖渲染技术使得未被使用的潜在高斯卷积得以接受梯度更新。实验结果证明,该方法的渲染质量更佳,并能够在平均情况下剔除超过六成的高斯卷积而不影响PSNR仅轻微下降。目前研究代码已上传至GitHub仓库供下载。
Key Takeaways
- 介绍了当前主流三维高斯卷积渲染技术的瓶颈,内存消耗过高,限制其实用性。
- 提出MaskGaussian方法,将高斯卷积视为概率实体而非固定移除,以动态评估其对场景变化的贡献来调整其存在概率。这一策略使选择删除的高斯更具多样性。
- MaskGaussian利用掩盖渲染技术使潜在高斯能够接收梯度更新,提升对场景动态的适应性。
点此查看论文截图