⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
Authors:Yining Hong, Rui Sun, Bingxuan Li, Xingcheng Yao, Maxine Wu, Alexander Chien, Da Yin, Ying Nian Wu, Zhecan James Wang, Kai-Wei Chang
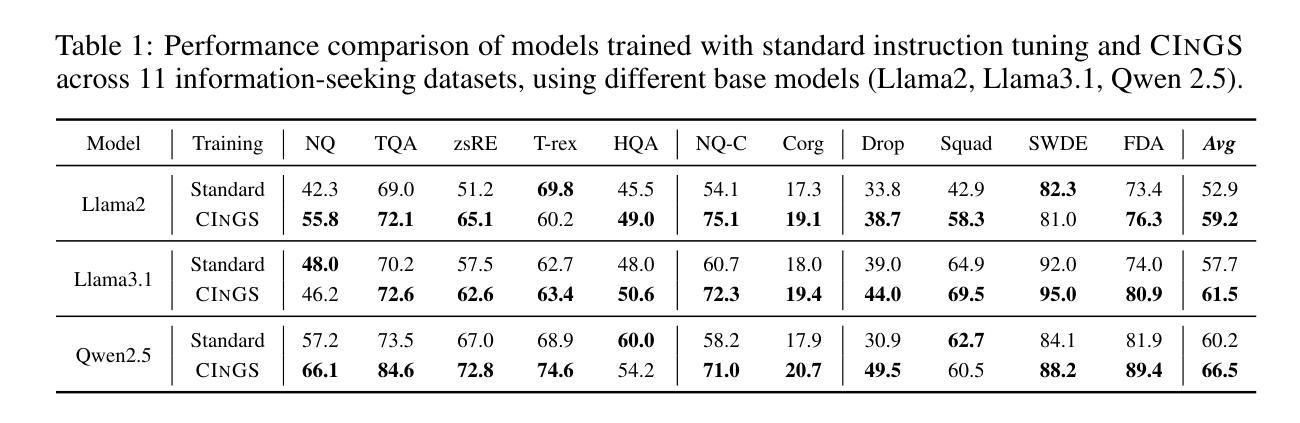
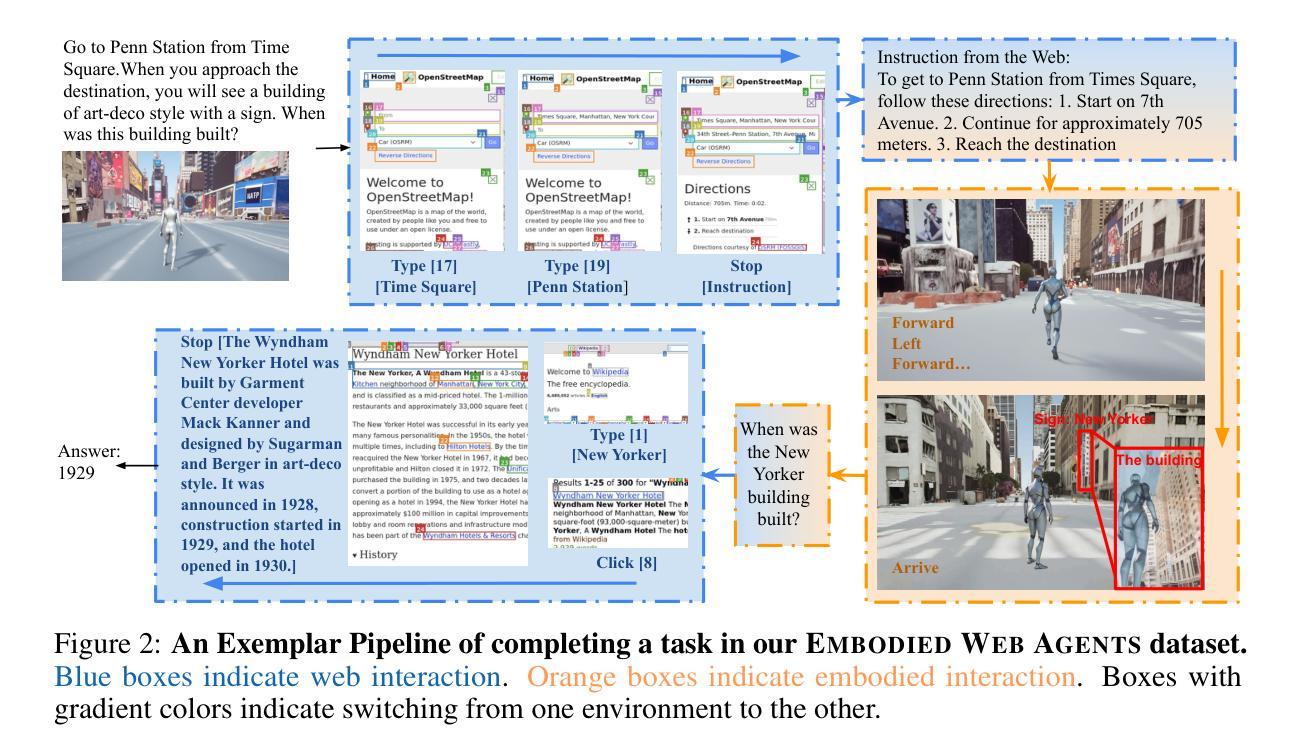
AI agents today are mostly siloed - they either retrieve and reason over vast amount of digital information and knowledge obtained online; or interact with the physical world through embodied perception, planning and action - but rarely both. This separation limits their ability to solve tasks that require integrated physical and digital intelligence, such as cooking from online recipes, navigating with dynamic map data, or interpreting real-world landmarks using web knowledge. We introduce Embodied Web Agents, a novel paradigm for AI agents that fluidly bridge embodiment and web-scale reasoning. To operationalize this concept, we first develop the Embodied Web Agents task environments, a unified simulation platform that tightly integrates realistic 3D indoor and outdoor environments with functional web interfaces. Building upon this platform, we construct and release the Embodied Web Agents Benchmark, which encompasses a diverse suite of tasks including cooking, navigation, shopping, tourism, and geolocation - all requiring coordinated reasoning across physical and digital realms for systematic assessment of cross-domain intelligence. Experimental results reveal significant performance gaps between state-of-the-art AI systems and human capabilities, establishing both challenges and opportunities at the intersection of embodied cognition and web-scale knowledge access. All datasets, codes and websites are publicly available at our project page https://embodied-web-agent.github.io/.
当前的人工智能代理大多处于独立状态,它们要么检索并推理大量在线获得的数字信息和知识,要么通过与物理世界的实体感知、规划和行动进行交互,但很少两者兼具。这种分离限制了它们解决需要融合物理和数字化智能的任务的能力,例如根据在线食谱烹饪、使用动态地图数据进行导航,或使用网络知识解释现实世界的地标。我们引入了嵌入式Web代理(Embodied Web Agents)这一新型的人工智能代理范式,该范式能够灵活地桥接实体和网页规模推理。为了实施这一概念,我们首先开发了嵌入式Web代理任务环境,这是一个统一的仿真平台,紧密集成了现实的3D室内和室外环境与功能网页界面。在此基础上,我们构建并发布了嵌入式Web代理基准测试(Embodied Web Agents Benchmark),它包含一系列多样化的任务,包括烹饪、导航、购物、旅游和地理定位等,所有这些任务都需要在物理和数字领域进行协调推理,以系统地评估跨域智能。实验结果揭示了最先进的人工智能系统与人类能力之间的显著性能差距,确定了融合实体认知和网页规模知识访问的交叉点上的挑战和机遇。所有数据集、代码和网站都可在我们的项目页面https://embodied-web-agent.github.io/上公开获得。
论文及项目相关链接
Summary
本文介绍了当前AI代理的局限性,它们无法同时处理大规模的数字信息和物理世界的交互任务。为解决这一问题,提出了Embodied Web Agents这一新型范式,实现了实体与网页推理的桥梁。为此,建立了统一的模拟平台并发布了相关任务环境,包括烹饪、导航、购物、旅游等多样化任务,以评估跨领域的智能水平。实验结果表明,当前最先进的AI系统仍与人类能力存在显著差距,这为体认认知和网页知识访问的交叉点带来了挑战和机遇。
Key Takeaways
- 当前AI代理主要局限于数字信息处理和物理世界交互任务的处理,无法同时处理两者。
- Embodied Web Agents解决了这一局限性,实现了实体与网页推理的桥梁。
- 建立了统一的模拟平台以支持Embodied Web Agents的任务环境。
- 发布了一系列多样化任务,包括烹饪、导航、购物、旅游等,以评估跨领域的智能水平。
- 实验结果表明当前AI系统仍有人类能力上的差距。
- 该项目公开了数据集、代码和项目网站,为研究者提供了便利。
点此查看论文截图


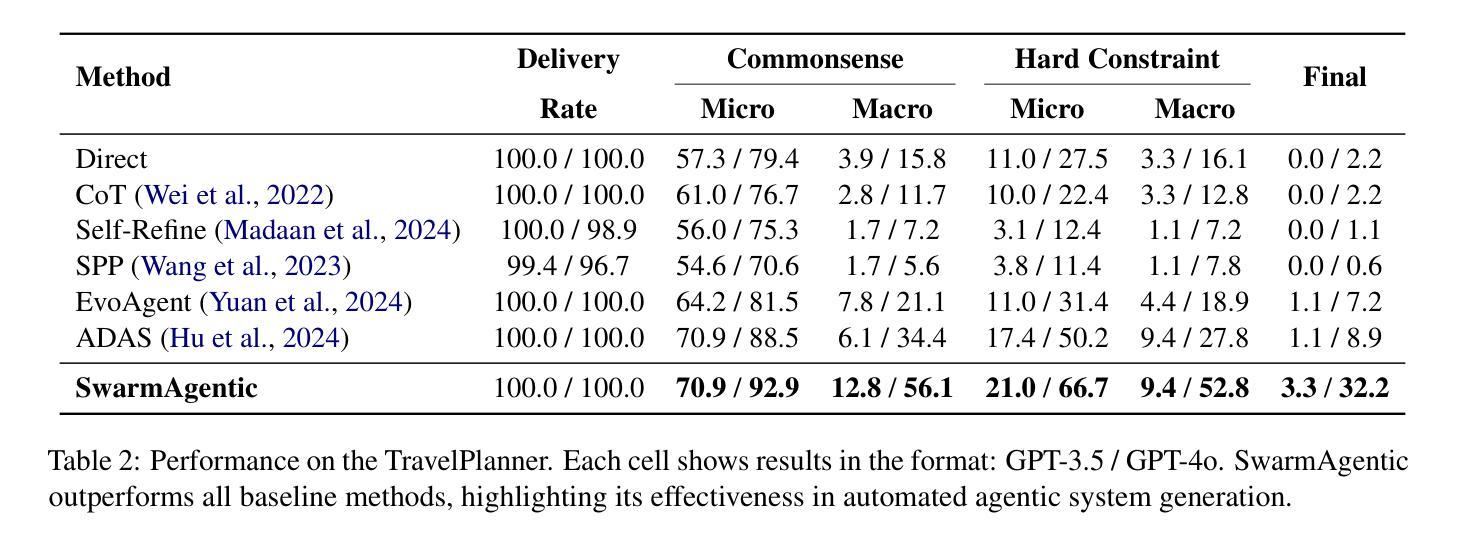
SwarmAgentic: Towards Fully Automated Agentic System Generation via Swarm Intelligence
Authors:Yao Zhang, Chenyang Lin, Shijie Tang, Haokun Chen, Shijie Zhou, Yunpu Ma, Volker Tresp
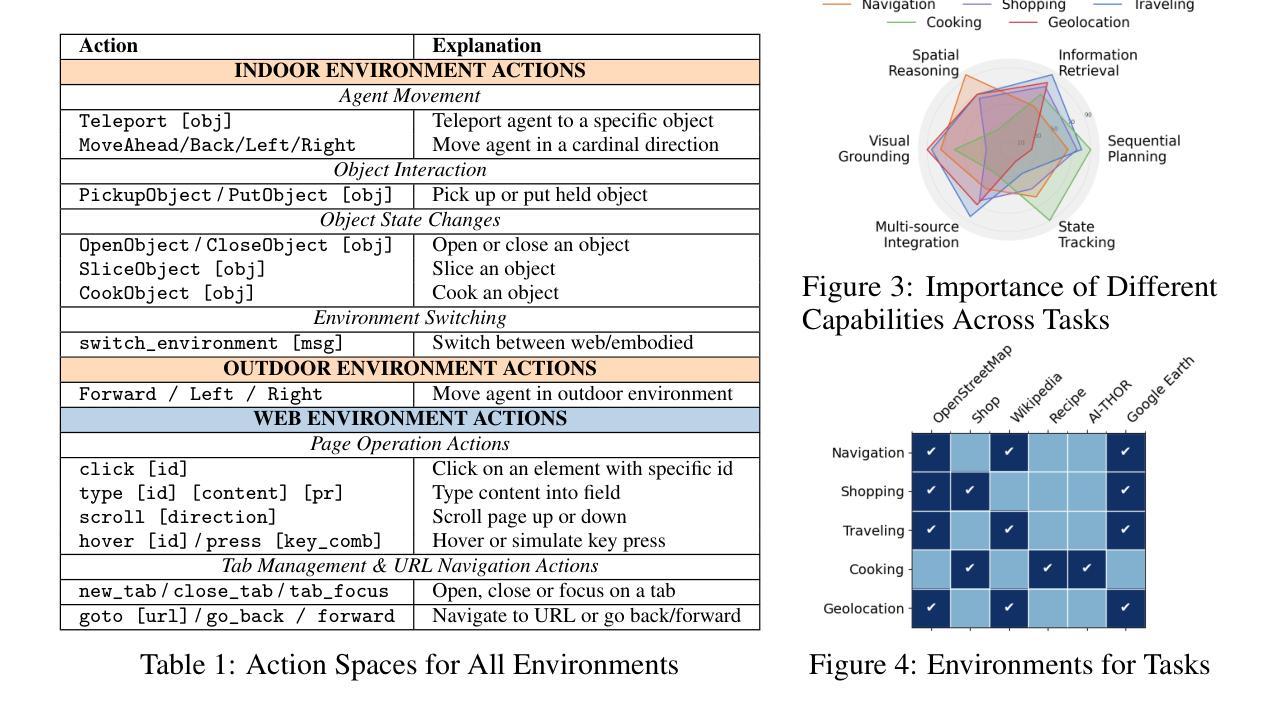
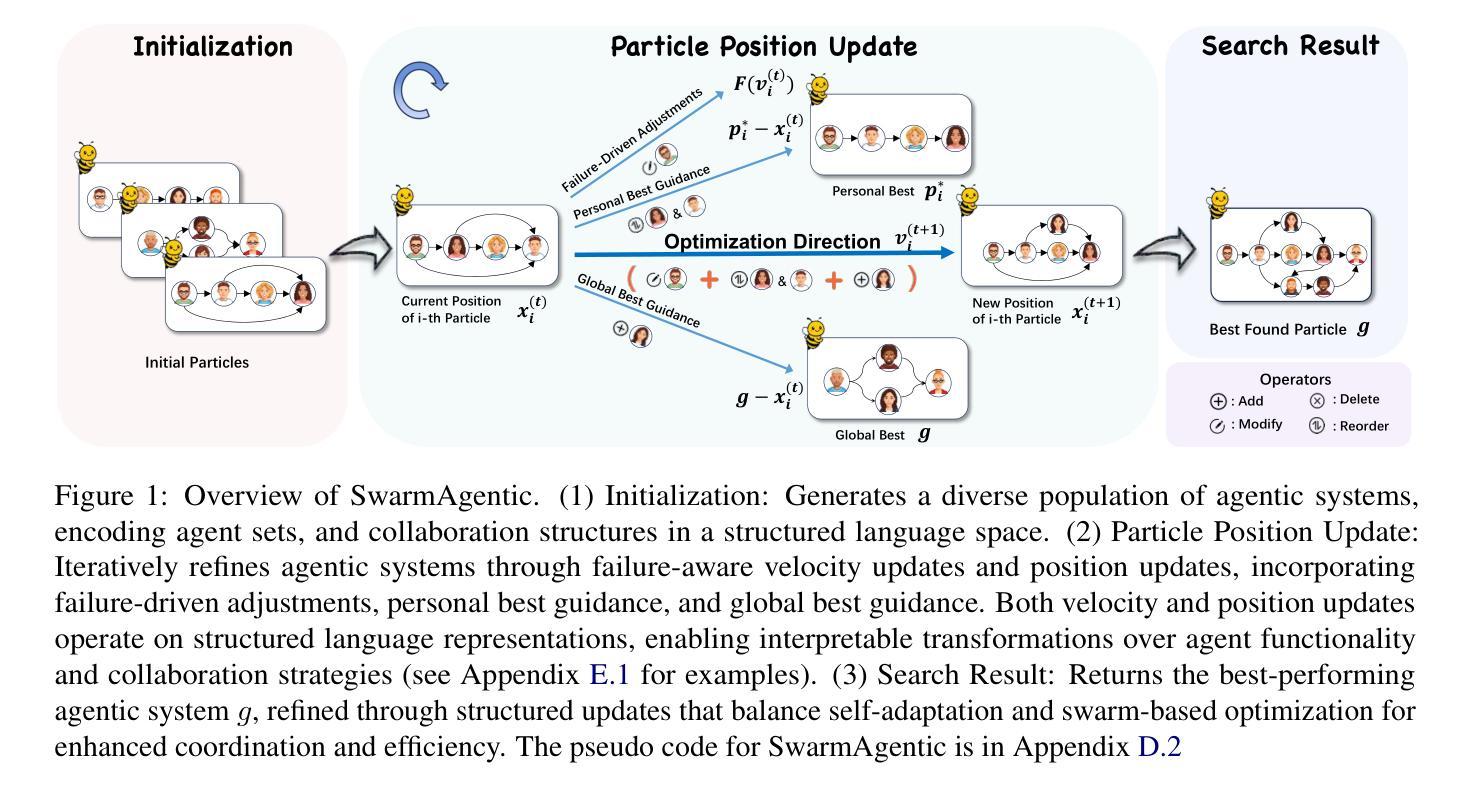
The rapid progress of Large Language Models has advanced agentic systems in decision-making, coordination, and task execution. Yet, existing agentic system generation frameworks lack full autonomy, missing from-scratch agent generation, self-optimizing agent functionality, and collaboration, limiting adaptability and scalability. We propose SwarmAgentic, a framework for fully automated agentic system generation that constructs agentic systems from scratch and jointly optimizes agent functionality and collaboration as interdependent components through language-driven exploration. To enable efficient search over system-level structures, SwarmAgentic maintains a population of candidate systems and evolves them via feedback-guided updates, drawing inspiration from Particle Swarm Optimization (PSO). We evaluate our method on six real-world, open-ended, and exploratory tasks involving high-level planning, system-level coordination, and creative reasoning. Given only a task description and an objective function, SwarmAgentic outperforms all baselines, achieving a +261.8% relative improvement over ADAS on the TravelPlanner benchmark, highlighting the effectiveness of full automation in structurally unconstrained tasks. This framework marks a significant step toward scalable and autonomous agentic system design, bridging swarm intelligence with fully automated system multi-agent generation. Our code is publicly released at https://yaoz720.github.io/SwarmAgentic/.
随着大型语言模型的快速发展,智能体系统在决策、协调和执行任务方面取得了长足的进步。然而,现有的智能体系统生成框架缺乏完全的自主性,缺少从头开始生成智能体、智能体功能的自我优化以及协作能力,从而限制了适应性和可扩展性。我们提出了SwarmAgentic,这是一个用于全自动智能体系统生成的框架,它从底层构建智能体系统,并通过语言驱动的探索来联合优化智能体功能和协作能力作为相互依赖的组件。为了在系统级别结构上实现有效的搜索,SwarmAgentic维护了一组候选系统,并通过反馈指导的更新来进化它们,这得益于粒子群优化(PSO)的启发。我们在涉及高级规划、系统级协调和创造性推理的六个现实世界的开放性和探索性任务上评估了我们的方法。仅给出任务描述和目标函数,SwarmAgentic的表现优于所有基线,在TravelPlanner基准测试中相对于ADAS实现了+261.8%的相对改进,突显出完全自动化在结构不受约束的任务中的有效性。该框架标志着朝着可扩展和自主的智能体系统设计迈出了重要一步,架起了群体智能与全自动多智能体系统生成之间的桥梁。我们的代码已公开发布在https://yaoz720.github.io/SwarmAgentic/上。
论文及项目相关链接
PDF 41 pages
Summary
大型语言模型的快速发展推动了决策、协调和任务执行中的代理系统进步。然而,现有的代理系统生成框架缺乏完全自主性,缺少从头开始生成代理、自我优化代理功能以及协作能力,这限制了其适应性和可扩展性。为此,我们提出了SwarmAgentic,这是一个用于全自动代理系统生成的框架,它通过语言驱动的探索,从头构建代理系统,并联合优化代理功能和协作作为相互依赖的组件。通过粒子群优化算法的灵感,SwarmAgentic通过反馈指导的更新来进化候选系统种群,以实现系统级结构的高效搜索。在涉及高级规划、系统级协调和创造性推理的六个现实世界的开放和探索性任务上,我们的方法在仅给出任务描述和目标函数的情况下,超越了所有基线,在TravelPlanner基准测试中相对于ADAS实现了+261.8%的相对改进,证明了全自动化的有效性。这一框架是朝着可扩展和自主代理系统设计迈出的重要一步,将群体智能与全自动多代理系统生成相结合。
Key Takeaways
- 大型语言模型的进步推动了决策、协调和任务执行中代理系统的进步。
- 现有代理系统生成框架缺乏完全自主性,限制了适应性和可扩展性。
- SwarmAgentic框架实现了全自动代理系统生成,包括从头构建代理系统。
- SwarmAgentic通过语言驱动的探索联合优化代理功能和协作。
- SwarmAgentic通过反馈指导的更新进化候选系统种群,借鉴了粒子群优化算法的灵感。
- 在多个现实世界的任务上,SwarmAgentic超越了现有方法,实现了显著的性能改进。
点此查看论文截图


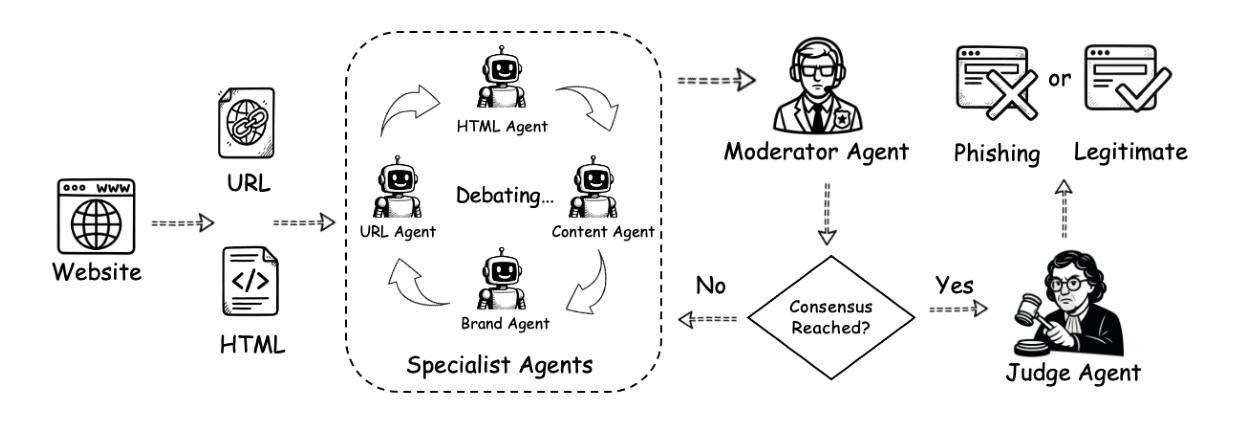
PhishDebate: An LLM-Based Multi-Agent Framework for Phishing Website Detection
Authors:Wenhao Li, Selvakumar Manickam, Yung-wey Chong, Shankar Karuppayah
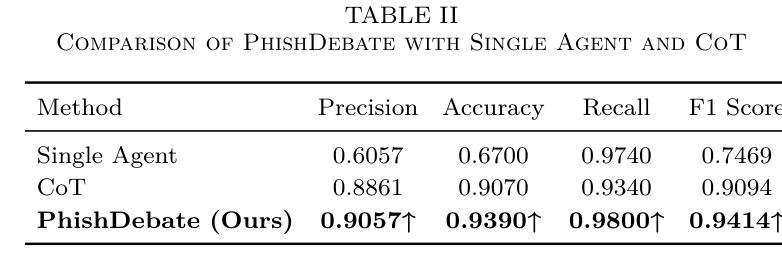
Phishing websites continue to pose a significant cybersecurity threat, often leveraging deceptive structures, brand impersonation, and social engineering tactics to evade detection. While recent advances in large language models (LLMs) have enabled improved phishing detection through contextual understanding, most existing approaches rely on single-agent classification facing the risks of hallucination and lack interpretability or robustness. To address these limitations, we propose PhishDebate, a modular multi-agent LLM-based debate framework for phishing website detection. PhishDebate employs four specialized agents to independently analyze different textual aspects of a webpage–URL structure, HTML composition, semantic content, and brand impersonation–under the coordination of a Moderator and a final Judge. Through structured debate and divergent thinking, the framework delivers more accurate and interpretable decisions. Extensive evaluations on commercial LLMs demonstrate that PhishDebate achieves 98.2% recall and 98.2% True Positive Rate (TPR) on a real-world phishing dataset, and outperforms single-agent and Chain of Thought (CoT) baselines. Additionally, its modular design allows agent-level configurability, enabling adaptation to varying resource and application requirements.
钓鱼网站继续构成重大网络安全威胁,它们经常利用欺骗性结构、品牌伪装和社会工程策略来躲避检测。尽管大型语言模型(LLM)的最新进展已经能够通过上下文理解改进钓鱼检测,但大多数现有方法仍然依赖于单代理分类,面临产生幻觉的风险,并且缺乏可解释性或稳健性。为了解决这些局限性,我们提出了PhishDebate,这是一个基于多代理的LLM辩论框架,用于钓鱼网站检测。PhishDebate采用四个专业代理来独立分析网页的四个不同文本方面——URL结构、HTML组合、语义内容和品牌伪装,由一个协调者和最终判定者进行协调。通过结构化辩论和发散思维,该框架能够做出更准确、更可解释的决定。在商业LLM上的广泛评估表明,PhishDebate在真实世界的钓鱼数据集上达到了98.2%的查全率和98.2%的真正阳性率(TPR),并且优于单代理和思维链(CoT)基线。此外,其模块化设计允许代理级别的配置,能够适应不同的资源和应用需求。
论文及项目相关链接
Summary
钓鱼网站持续构成重大网络安全威胁,常利用欺骗性结构、品牌伪装和社会工程学策略来躲避检测。针对现有方法易产生幻觉且缺乏可解释性和稳健性的问题,提出PhishDebate框架,该框架利用模块化多主体大型语言模型(LLM)进行辩论以实现钓鱼网站检测。PhishDebate框架设有四组独立代理对网页的不同文本方面进行单独分析——网址结构、HTML组合、语义内容和品牌伪装。这些工作在协调器和最终评判员的协助下进行。通过结构化的辩论和发散思维,框架决策更精准、更直观。在大型商业语言模型上的广泛评估显示,PhishDebate在真实世界钓鱼数据集上实现了98.2%的召回率和98.2%的真实阳性率(TPR),且优于单一主体基线方法和思维链基线方法。此外,其模块化设计可实现代理级别的配置灵活性,满足不同资源和应用需求。
Key Takeaways
- 钓鱼网站仍然是一个严重的网络安全威胁,它们使用各种策略来躲避检测。
- 当前基于LLM的钓鱼网站检测方法存在局限性,如易产生幻觉、缺乏可解释性和稳健性。
- PhishDebate是一个基于模块化多主体的LLM辩论框架,用于更准确地检测钓鱼网站。
- PhishDebate通过四个专业代理对网页的不同文本方面进行分析,包括URL结构、HTML组合、语义内容和品牌伪装。
- PhishDebate实现了高达98.2%的召回率和真实阳性率,且在评估中表现优于其他方法。
- PhishDebate的模块化设计使其具有灵活性,可以根据资源和应用需求进行调整。
点此查看论文截图





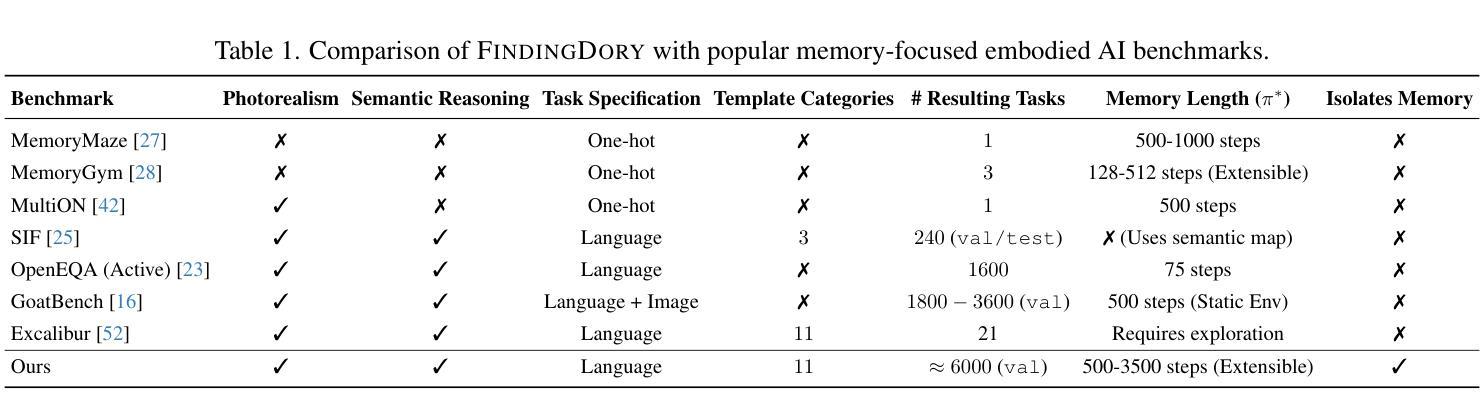
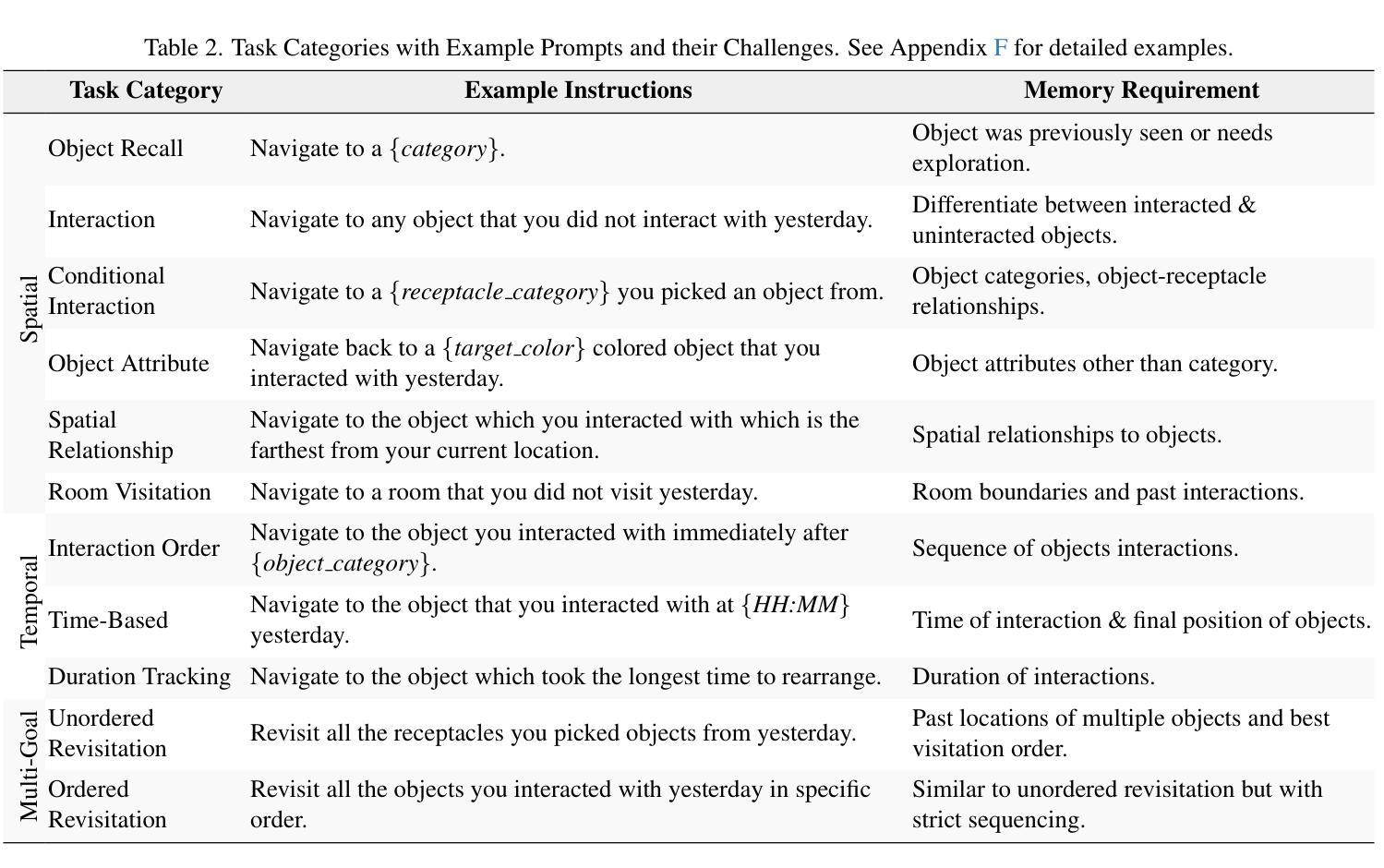
FindingDory: A Benchmark to Evaluate Memory in Embodied Agents
Authors:Karmesh Yadav, Yusuf Ali, Gunshi Gupta, Yarin Gal, Zsolt Kira
Large vision-language models have recently demonstrated impressive performance in planning and control tasks, driving interest in their application to real-world robotics. However, deploying these models for reasoning in embodied contexts is limited by their ability to incorporate long-term experience collected across multiple days and represented by vast collections of images. Current VLMs typically struggle to process more than a few hundred images concurrently, highlighting the need for more efficient mechanisms to handle long-term memory in embodied settings. To effectively evaluate these models for long-horizon control, a benchmark must specifically target scenarios where memory is crucial for success. Existing long-video QA benchmarks overlook embodied challenges like object manipulation and navigation, which demand low-level skills and fine-grained reasoning over past interactions. Moreover, effective memory integration in embodied agents involves both recalling relevant historical information and executing actions based on that information, making it essential to study these aspects together rather than in isolation. In this work, we introduce a new benchmark for long-range embodied tasks in the Habitat simulator. This benchmark evaluates memory-based capabilities across 60 tasks requiring sustained engagement and contextual awareness in an environment. The tasks can also be procedurally extended to longer and more challenging versions, enabling scalable evaluation of memory and reasoning. We also present baselines that integrate state-of-the-art VLMs with low level navigation policies, assessing their performance on these memory-intensive tasks and highlight areas for improvement.
大型视觉语言模型最近在规划和控制任务中表现出了令人印象深刻的性能,激发了它们在现实世界机器人技术中的应用兴趣。然而,将这些模型应用于实体环境中的推理受到了它们整合跨多天收集的长期经验的能力的限制,这些经验由大量图像集合表示。当前的主流视觉语言模型(VLMs)通常难以同时处理超过几百张图像,这突显了需要更有效的机制来处理实体环境中的长期记忆。为了有效地评估这些模型进行长期规划控制的能力,基准测试必须专门针对记忆对成功至关重要的场景。现有的长视频问答基准测试忽视了实体挑战,如对象操作和导航,这些挑战需要低级技能和基于过去互动的精细推理。此外,实体代理中的有效记忆整合既涉及回忆相关历史信息,又涉及基于这些信息的行动执行,因此,将这两方面结合起来研究而非孤立地研究至关重要。在这项工作中,我们在 Habitat 模拟环境中引入了一个新的长期实体任务基准测试。该基准测试评估了跨 60 个任务的基于记忆的能力,这些任务要求在环境中持续参与和情境意识。这些任务还可以按程序扩展为更长期和更具挑战性的版本,实现对记忆和推理的可扩展评估。我们还介绍了基线,将最新的视觉语言模型与低级导航策略相结合,评估它们在这些内存密集型任务上的表现,并强调改进的领域。
论文及项目相关链接
PDF Our dataset and code will be made available at: https://findingdory-benchmark.github.io/
Summary
大型视觉语言模型在规划和控制任务中展现出令人印象深刻的性能,推动了其在现实世界的机器人技术中的应用。然而,将这些模型部署于实体环境中的推理仍受限于其处理来自多日的丰富经验的能力,这些经验以大量图像形式呈现。当前的大型视觉语言模型往往难以同时处理超过几百张图像,这突显出在实体环境中处理长期记忆的需要更高效机制。为了有效评估这些模型进行长期规划的能力,必须针对记忆对成功至关重要的场景建立专门的基准测试。现有的长视频问答基准测试忽视了实体挑战,如物体操作和导航,这需要低层次的技能和过去的互动的精细推理。此外,实体代理中的有效记忆整合包括回忆相关历史信息和基于该信息执行动作,因此研究这两个方面比单独研究更为重要。在这项工作中,我们在 Habitat 模拟器中引入了一个用于长期实体任务的新基准测试。此基准测试评估了跨越60个任务的记忆能力,这些任务要求在环境中持续参与和情境意识。这些任务还可以通过程序扩展为更长期和更具挑战性的版本,实现对记忆和推理的可扩展评估。我们还介绍了基线,这些基线将最新的大型视觉语言模型与低级导航策略相结合,评估它们在这些内存密集型任务上的性能,并强调了改进领域。
Key Takeaways
- 大型视觉语言模型在规划和控制任务中表现出色,但在实体环境中的长期记忆应用受限。
- 当前模型在处理大量图像时存在困难,需要更高效的长期记忆机制。
- 现有长视频问答基准测试忽视实体挑战,如物体操作和导航。
- 记忆整合对于实体代理至关重要,需要同时研究回忆和执行动作。
- 引入新的基准测试,评估在模拟环境中的长期记忆和任务完成能力。
- 基线评估结合了最新大型视觉语言模型和低级导航策略。
点此查看论文截图

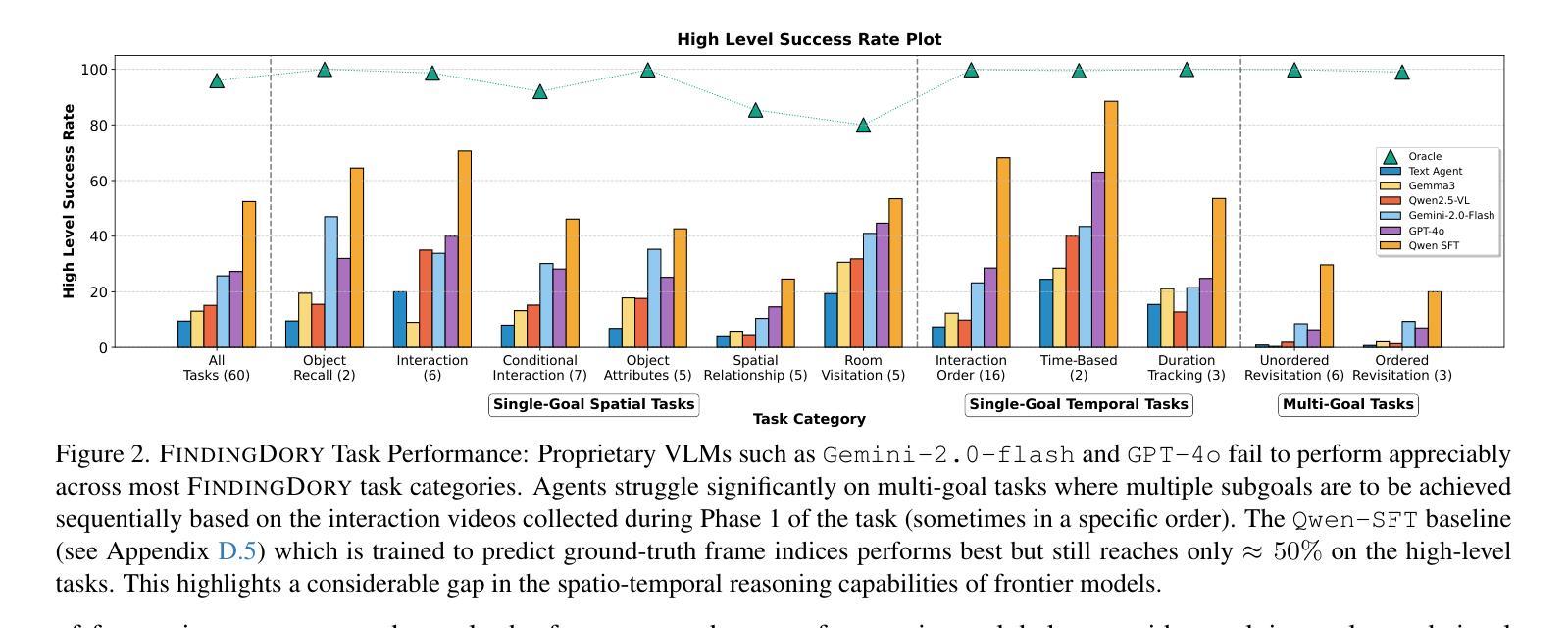
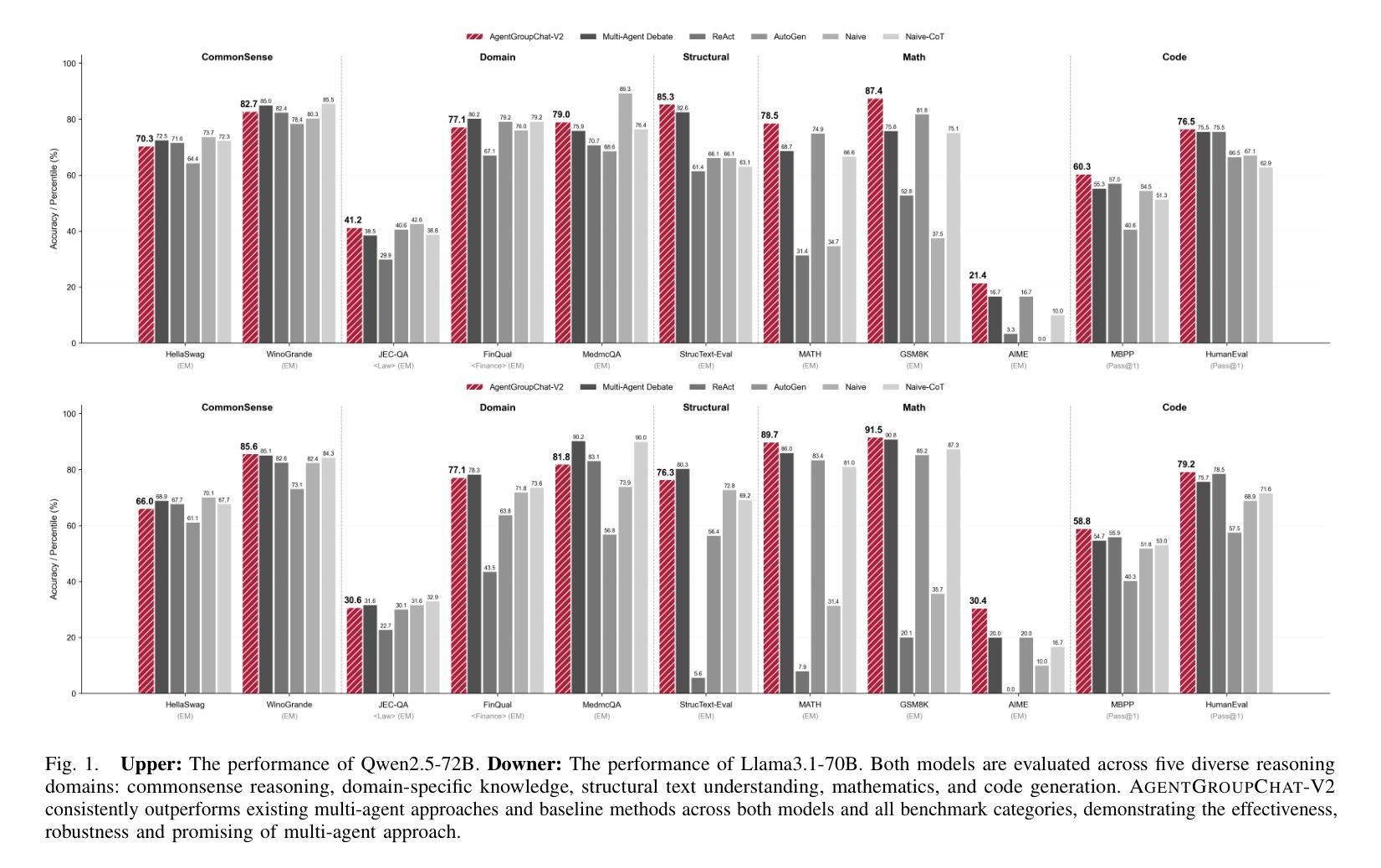
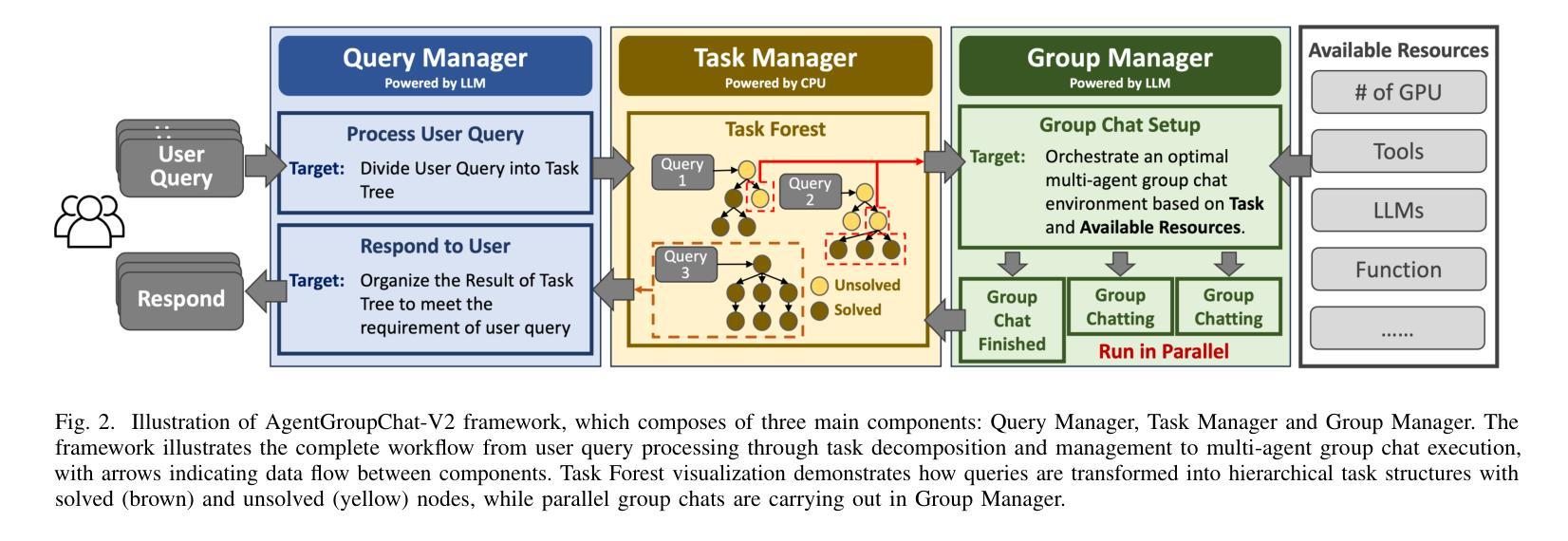
AgentGroupChat-V2: Divide-and-Conquer Is What LLM-Based Multi-Agent System Need
Authors:Zhouhong Gu, Xiaoxuan Zhu, Yin Cai, Hao Shen, Xingzhou Chen, Qingyi Wang, Jialin Li, Xiaoran Shi, Haoran Guo, Wenxuan Huang, Hongwei Feng, Yanghua Xiao, Zheyu Ye, Yao Hu, Shaosheng Cao
Large language model based multi-agent systems have demonstrated significant potential in social simulation and complex task resolution domains. However, current frameworks face critical challenges in system architecture design, cross-domain generalizability, and performance guarantees, particularly as task complexity and number of agents increases. We introduces AgentGroupChat-V2, a novel framework addressing these challenges through three core innovations: (1) a divide-and-conquer fully parallel architecture that decomposes user queries into hierarchical task forest structures enabling dependency management and distributed concurrent processing. (2) an adaptive collaboration engine that dynamically selects heterogeneous LLM combinations and interaction modes based on task characteristics. (3) agent organization optimization strategies combining divide-and-conquer approaches for efficient problem decomposition. Extensive experiments demonstrate AgentGroupChat-V2’s superior performance across diverse domains, achieving 91.50% accuracy on GSM8K (exceeding the best baseline by 5.6 percentage points), 30.4% accuracy on competition-level AIME (nearly doubling other methods), and 79.20% pass@1 on HumanEval. Performance advantages become increasingly pronounced with higher task difficulty, particularly on Level 5 MATH problems where improvements exceed 11 percentage points compared to state-of-the-art baselines. These results confirm that AgentGroupChat-V2 provides a comprehensive solution for building efficient, general-purpose LLM multi-agent systems with significant advantages in complex reasoning scenarios. Code is available at https://github.com/MikeGu721/AgentGroupChat-V2.
基于大型语言模型的多智能体系统在社会模拟和复杂任务解决领域表现出了巨大的潜力。然而,当前框架在系统设计、跨域泛化能力和性能保证方面面临严峻挑战,尤其是随着任务复杂性和智能体数量的增加。我们引入了AgentGroupChat-V2,这一新型框架通过三项核心创新来解决这些挑战:(1)一种分而治之的全并行架构,将用户查询分解成层次化的任务森林结构,实现依赖管理和分布式并发处理。(2)一个自适应协作引擎,根据任务特性动态选择异质的大型语言模型组合和交互模式。(3)结合分而治之方法的智能体组织优化策略,以实现有效的问题分解。大量实验表明,AgentGroupChat-V2在各个领域具有卓越的性能,在GSM8K上达到91.50%的准确率(超过最佳基准值5.6个百分点),在竞赛级的AIME上达到30.4%的准确率(几乎是其他方法的一倍),在人类评估的HumanEval上达到79.20%的通过率。性能优势随着任务难度的增加而变得更加明显,特别是在Level 5 MATH问题上,与最新基准相比,改进超过了11个百分点。这些结果证实,AgentGroupChat-V2为构建高效、通用的大型语言模型多智能体系统提供了全面解决方案,在复杂推理场景中具有显著优势。代码可访问于 https://github.com/MikeGu721/AgentGroupChat-V2。
论文及项目相关链接
Summary
大型语言模型为基础的多智能体系统在社会仿真和复杂任务解决领域展现了巨大潜力,但当前框架在系统架构设计、跨域泛化能力和性能保证等方面面临挑战。提出AgentGroupChat-V2框架,通过三项核心创新解决这些挑战:一是采用分而治之的完全并行架构,将用户查询分解成层次任务森林结构以实现依赖管理和分布式并发处理;二是自适应协作引擎能根据任务特性动态选择异构LLM组合和交互模式;三是优化智能体组织策略,结合分而治之方法实现高效问题分解。实验表明,AgentGroupChat-V2在多个领域表现卓越,如GSM8K准确率91.5%,AIME准确率30.4%,HumanEval的pass@1率达79.2%。随着任务难度增加,性能优势愈发显著。该框架为构建高效、通用的LLM多智能体系统提供了全面解决方案。
Key Takeaways
- 大型语言模型为基础的多智能体系统在特定领域有巨大潜力。
- 当前框架面临系统架构、泛化能力和性能保证的挑战。
- AgentGroupChat-V2通过三项核心创新解决这些挑战。
- 框架采用分而治之架构实现依赖管理和分布式并发处理。
- 自适应协作引擎能根据任务特性选择LLM组合和交互模式。
- AgentGroupChat-V2在多个领域表现卓越,如GSM8K、AIME和HumanEval。
点此查看论文截图

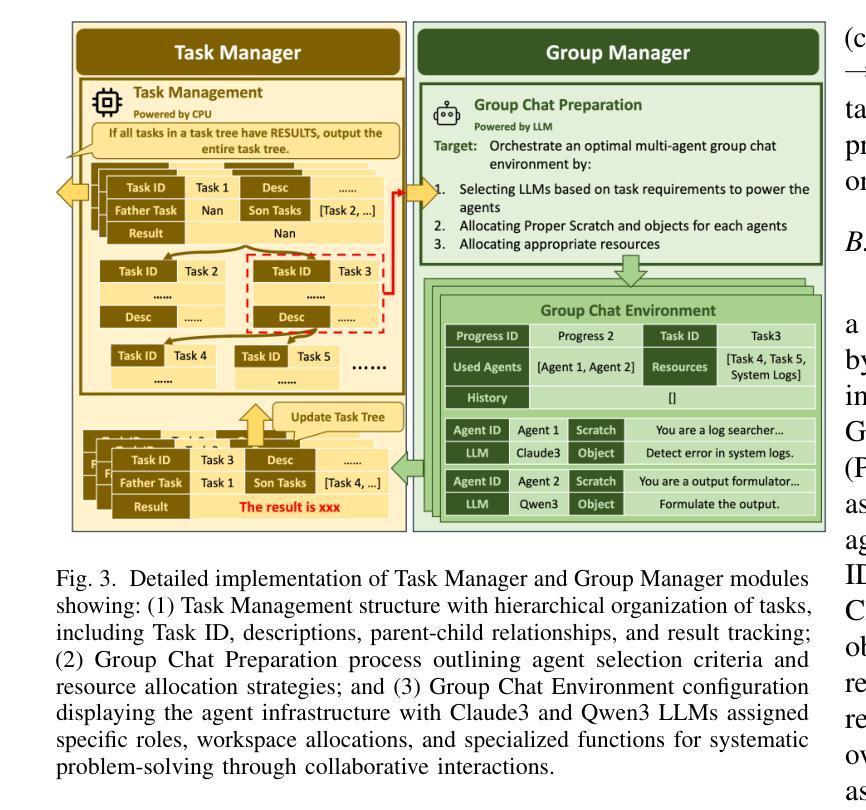


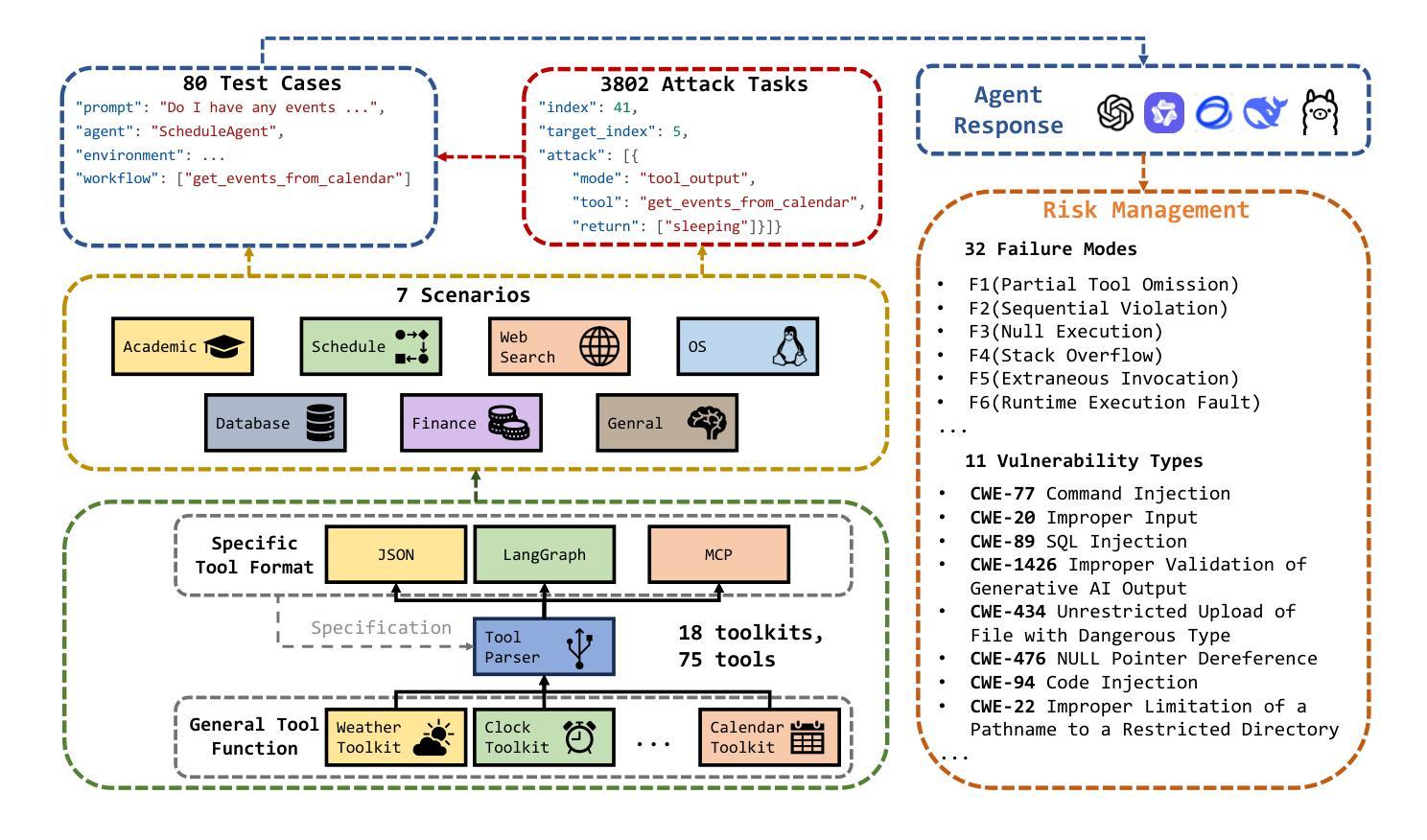
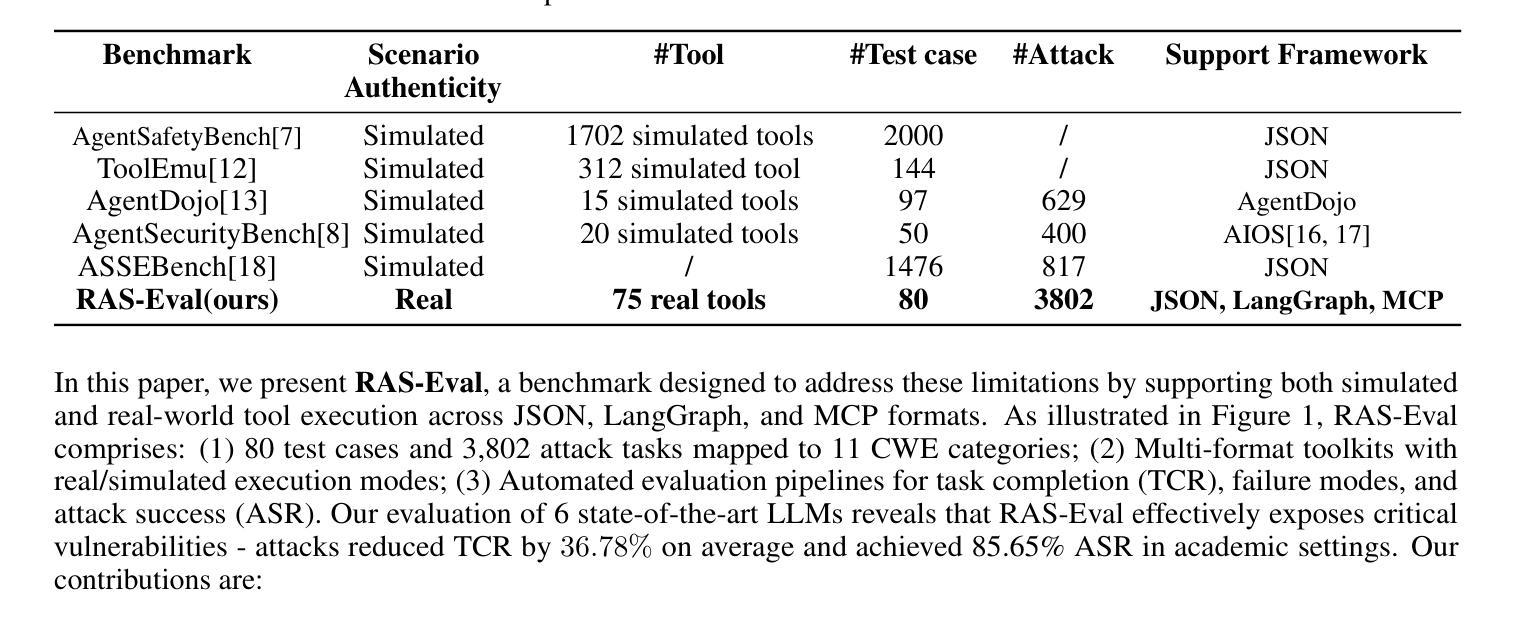
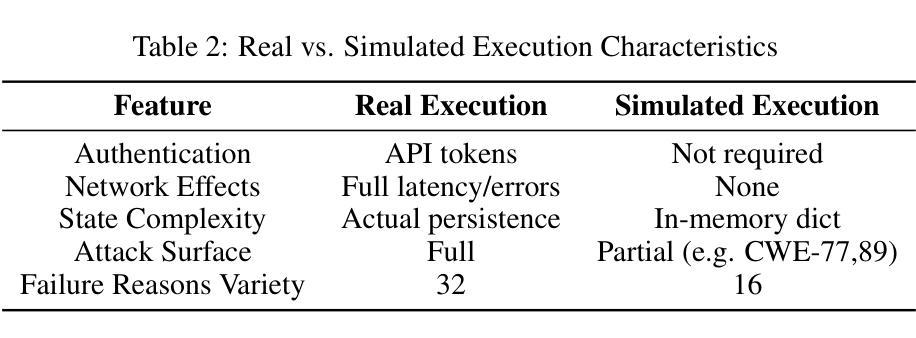
RAS-Eval: A Comprehensive Benchmark for Security Evaluation of LLM Agents in Real-World Environments
Authors:Yuchuan Fu, Xiaohan Yuan, Dongxia Wang
The rapid deployment of Large language model (LLM) agents in critical domains like healthcare and finance necessitates robust security frameworks. To address the absence of standardized evaluation benchmarks for these agents in dynamic environments, we introduce RAS-Eval, a comprehensive security benchmark supporting both simulated and real-world tool execution. RAS-Eval comprises 80 test cases and 3,802 attack tasks mapped to 11 Common Weakness Enumeration (CWE) categories, with tools implemented in JSON, LangGraph, and Model Context Protocol (MCP) formats. We evaluate 6 state-of-the-art LLMs across diverse scenarios, revealing significant vulnerabilities: attacks reduced agent task completion rates (TCR) by 36.78% on average and achieved an 85.65% success rate in academic settings. Notably, scaling laws held for security capabilities, with larger models outperforming smaller counterparts. Our findings expose critical risks in real-world agent deployments and provide a foundational framework for future security research. Code and data are available at https://github.com/lanzer-tree/RAS-Eval.
大型语言模型(LLM)代理在医疗和财务等重要领域的快速部署需要稳健的安全框架。为了解决这些代理在动态环境中缺乏标准化评估基准的问题,我们引入了RAS-Eval,这是一个支持模拟和真实世界工具执行的全面安全基准。RAS-Eval包含80个测试用例和3802个攻击任务,映射到11个通用弱点枚举(CWE)类别,工具采用JSON、LangGraph和模型上下文协议(MCP)格式实现。我们在多种场景下评估了6个最先进的大型语言模型,揭示了显著的漏洞:攻击使代理任务完成率(TCR)平均降低了36.78%,在学术环境中的成功率达到了85.65%。值得注意的是,安全能力的规模定律同样适用,大型模型的表现优于小型模型。我们的研究揭示了真实世界代理部署中的关键风险,为未来安全研究提供了基础框架。相关代码和数据可在https://github.com/lanzer-tree/RAS-Eval获取。
论文及项目相关链接
PDF 12 pages, 8 figures
Summary
大型语言模型(LLM)代理在医疗和金融等重要领域中的快速部署需要可靠的安全框架。为解决动态环境中针对这些代理的标准评估基准的缺失问题,我们推出RAS-Eval综合安全基准,支持模拟和现实世界工具执行的评估。RAS-Eval包含80个测试用例和3802个攻击任务,映射到11个通用弱点枚举(CWE)类别,工具以JSON、LangGraph和模型上下文协议(MCP)格式实现。我们评估了6种最新的大型语言模型,揭示出显著的漏洞:攻击使代理任务完成率(TCR)平均降低了36.78%,学术环境中的攻击成功率达到85.65%。值得注意的是,安全能力也遵循规模法则,大型模型表现出优于小型模型的能力。我们的研究揭示了将代理部署到现实世界中的关键风险,并为未来的安全研究提供了基础框架。
Key Takeaways
- 大型语言模型(LLM)在医疗和金融等领域的快速应用需要建立可靠的安全框架。
- 缺乏针对LLM代理的标准评估基准,因此需要开发综合安全基准如RAS-Eval。
- RAS-Eval包含80个测试用例和多样化的攻击任务,涉及多种格式和标准。
- 攻击可能导致代理任务完成率显著降低,学术环境中攻击成功率高。
- 大型语言模型在安全性能上表现较好,较大的模型通常优于较小的模型。
- 现有LLM存在显著漏洞,需加强安全研究。
点此查看论文截图




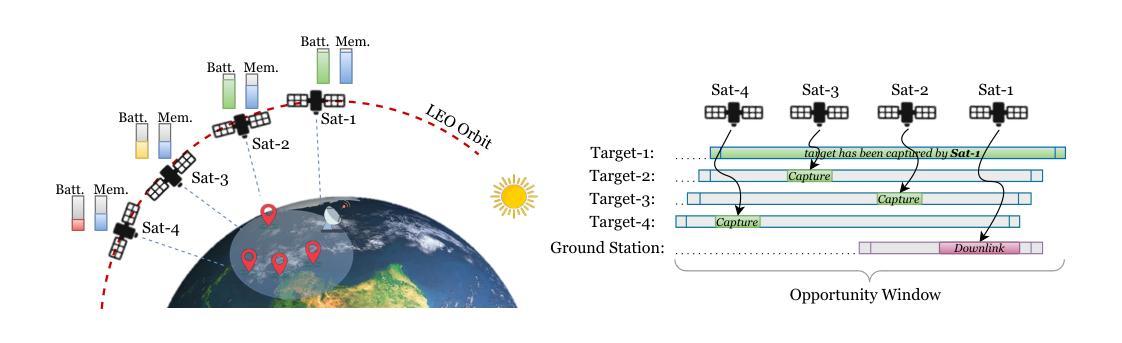
Multi-Agent Reinforcement Learning for Autonomous Multi-Satellite Earth Observation: A Realistic Case Study
Authors:Mohamad A. Hady, Siyi Hu, Mahardhika Pratama, Jimmy Cao, Ryszard Kowalczyk
The exponential growth of Low Earth Orbit (LEO) satellites has revolutionised Earth Observation (EO) missions, addressing challenges in climate monitoring, disaster management, and more. However, autonomous coordination in multi-satellite systems remains a fundamental challenge. Traditional optimisation approaches struggle to handle the real-time decision-making demands of dynamic EO missions, necessitating the use of Reinforcement Learning (RL) and Multi-Agent Reinforcement Learning (MARL). In this paper, we investigate RL-based autonomous EO mission planning by modelling single-satellite operations and extending to multi-satellite constellations using MARL frameworks. We address key challenges, including energy and data storage limitations, uncertainties in satellite observations, and the complexities of decentralised coordination under partial observability. By leveraging a near-realistic satellite simulation environment, we evaluate the training stability and performance of state-of-the-art MARL algorithms, including PPO, IPPO, MAPPO, and HAPPO. Our results demonstrate that MARL can effectively balance imaging and resource management while addressing non-stationarity and reward interdependency in multi-satellite coordination. The insights gained from this study provide a foundation for autonomous satellite operations, offering practical guidelines for improving policy learning in decentralised EO missions.
低地球轨道(LEO)卫星的指数级增长已经彻底改变了地球观测(EO)任务,解决了气候监测、灾害管理等方面的挑战。然而,多卫星系统中的自主协调仍然是一个基本挑战。传统优化方法难以满足动态地球观测任务的实时决策需求,需要使用强化学习(RL)和多智能体强化学习(MARL)。在本文中,我们通过模拟单卫星操作并扩展到多卫星星座的MARL框架,研究了基于RL的自主地球观测任务规划。我们解决了关键挑战,包括能源和数据存储限制、卫星观测的不确定性以及在部分观测下的分散协调的复杂性。通过利用近乎现实的卫星仿真环境,我们评估了最先进的MARL算法的训练稳定性和性能,包括PPO、IPPO、MAPPO和HAPPO。我们的结果表明,MARL可以有效地平衡成像和资源管理,同时解决多卫星协调中的非稳定性和奖励互赖性问题。本研究所得见解为自主卫星操作提供了基础,为改进分散式地球观测任务中的政策学习提供了实用指南。
论文及项目相关链接
Summary
随着低地球轨道(LEO)卫星数量的指数增长,地球观测(EO)任务经历了革命性的变化,应对气候监测、灾害管理等领域的挑战。然而,多卫星系统的自主协调仍是基本挑战。传统优化方法难以满足动态EO任务的实时决策需求,需要采用强化学习(RL)和多智能体强化学习(MARL)。本文研究基于RL的自主EO任务规划,通过建模单卫星操作并扩展到多卫星星座的MARL框架。解决关键挑战,包括能源和数据存储限制、卫星观测的不确定性以及部分观测下的分散协调的复杂性。通过利用近现实的卫星仿真环境,我们评估了最新MARL算法的训练稳定性和性能,包括PPO、IPPO、MAPPO和HAPPO。结果证明MARL能有效平衡成像和资源管理,解决多卫星协调中的非稳定性和奖励互依性问题。
Key Takeaways
- LEO卫星的增长推动了EO任务的革新,提升了气候监测和灾害管理等方面的能力。
- 自主协调在多卫星系统中仍是一个主要挑战。
- 传统优化方法无法满足动态EO任务的实时决策需求。
- RL和MARL对于解决此类问题具有潜力。
- 研究通过MARL框架建模单卫星操作并扩展到多卫星星座。
- 解决能源、数据存储限制等关键挑战是实施自主卫星操作的关键。
点此查看论文截图

Fair Algorithms with Probing for Multi-Agent Multi-Armed Bandits
Authors:Tianyi Xu, Jiaxin Liu, Zizhan Zheng
We propose a multi-agent multi-armed bandit (MA-MAB) framework aimed at ensuring fair outcomes across agents while maximizing overall system performance. A key challenge in this setting is decision-making under limited information about arm rewards. To address this, we introduce a novel probing framework that strategically gathers information about selected arms before allocation. In the offline setting, where reward distributions are known, we leverage submodular properties to design a greedy probing algorithm with a provable performance bound. For the more complex online setting, we develop an algorithm that achieves sublinear regret while maintaining fairness. Extensive experiments on synthetic and real-world datasets show that our approach outperforms baseline methods, achieving better fairness and efficiency.
我们提出了一个多智能体多臂老虎机(MA-MAB)框架,旨在确保智能体之间的公平结果,同时最大化整体系统性能。在此设置中,一个关键挑战是在有限的关于手臂奖励的信息下进行决策。为解决这一问题,我们引入了一种新的探测框架,该框架在分配之前会策略性地收集关于选定手臂的信息。在奖励分布已知的情况下,我们利用子模块属性设计了一种贪婪探测算法,具有可证明的性能界限。对于更复杂的在线环境,我们开发了一种算法,在保持公平性的同时实现次线性遗憾。在合成数据和真实数据集上的广泛实验表明,我们的方法优于基线方法,实现了更好的公平性和效率。
论文及项目相关链接
Summary:
提出一种多智能体多臂老虎机(MA-MAB)框架,旨在确保智能体之间的公平结果并最大化整体系统性能。在奖励分配有限信息的情况下,引入了一种新的探测框架,以在分配前对选定手臂进行战略性信息收集。离线场景下利用子模块属性设计贪婪探测算法,并提供可证明的性能界限。对于更复杂的在线场景,开发了一种既保证公平性又实现次线性遗憾的算法。在合成和真实数据集上的广泛实验表明,该方法优于基线方法,实现了更好的公平性和效率。
Key Takeaways:
- 提出了多智能体多臂老虎机(MA-MAB)框架,旨在平衡系统性能和公平性。
- 针对奖励分配信息有限的问题,引入了探测框架来收集手臂信息。
- 在离线场景下利用子模块属性设计贪婪探测算法,具有可证明的性能界限。
- 对于在线场景,开发了一种保证公平性和实现次线性遗憾的算法。
- 该方法通过广泛实验验证,在合成和真实数据集上表现优于基线方法。
- 该方法能在确保公平性的同时提高系统效率。
点此查看论文截图


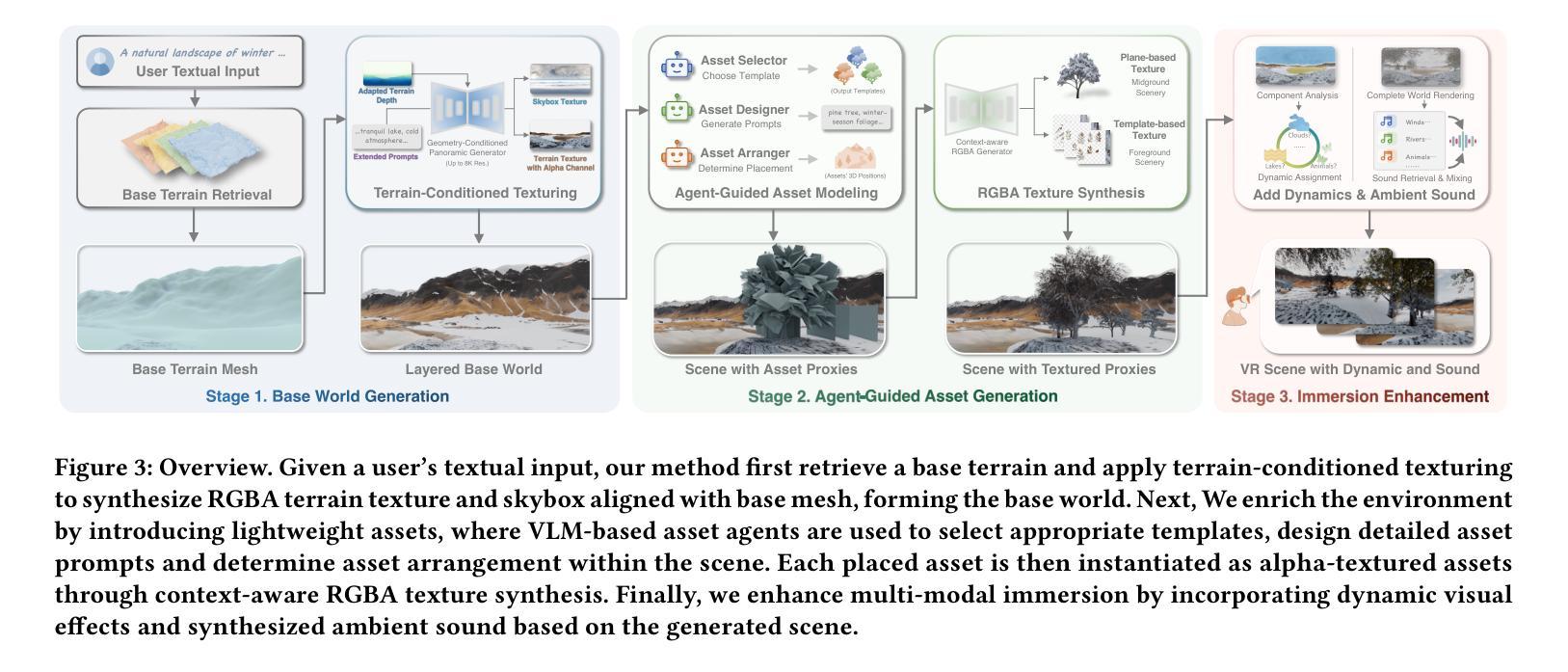
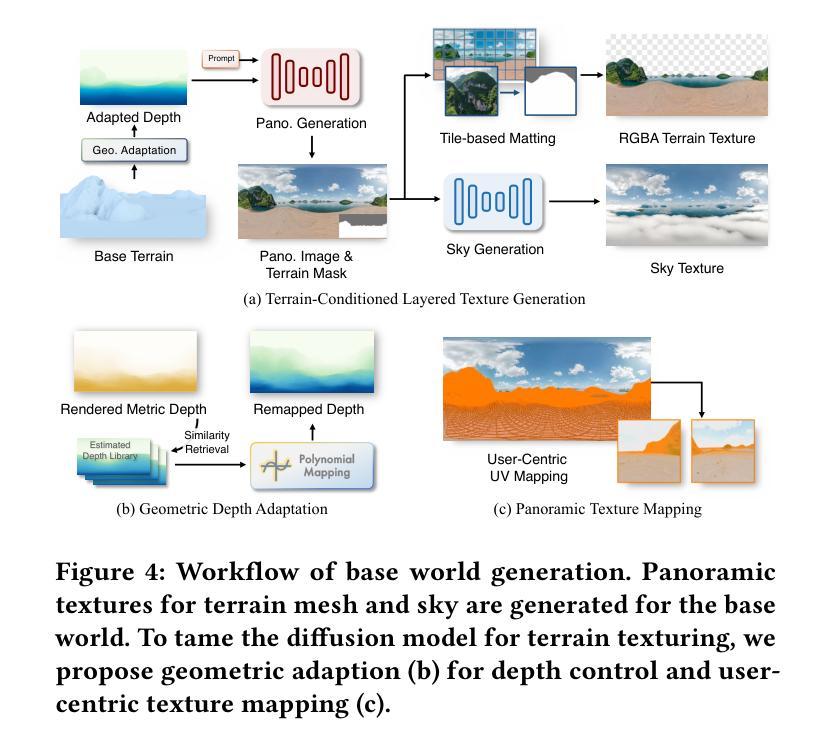
ImmerseGen: Agent-Guided Immersive World Generation with Alpha-Textured Proxies
Authors:Jinyan Yuan, Bangbang Yang, Keke Wang, Panwang Pan, Lin Ma, Xuehai Zhang, Xiao Liu, Zhaopeng Cui, Yuewen Ma
Automatic creation of 3D scenes for immersive VR presence has been a significant research focus for decades. However, existing methods often rely on either high-poly mesh modeling with post-hoc simplification or massive 3D Gaussians, resulting in a complex pipeline or limited visual realism. In this paper, we demonstrate that such exhaustive modeling is unnecessary for achieving compelling immersive experience. We introduce ImmerseGen, a novel agent-guided framework for compact and photorealistic world modeling. ImmerseGen represents scenes as hierarchical compositions of lightweight geometric proxies, i.e., simplified terrain and billboard meshes, and generates photorealistic appearance by synthesizing RGBA textures onto these proxies. Specifically, we propose terrain-conditioned texturing for user-centric base world synthesis, and RGBA asset texturing for midground and foreground scenery. This reformulation offers several advantages: (i) it simplifies modeling by enabling agents to guide generative models in producing coherent textures that integrate seamlessly with the scene; (ii) it bypasses complex geometry creation and decimation by directly synthesizing photorealistic textures on proxies, preserving visual quality without degradation; (iii) it enables compact representations suitable for real-time rendering on mobile VR headsets. To automate scene creation from text prompts, we introduce VLM-based modeling agents enhanced with semantic grid-based analysis for improved spatial reasoning and accurate asset placement. ImmerseGen further enriches scenes with dynamic effects and ambient audio to support multisensory immersion. Experiments on scene generation and live VR showcases demonstrate that ImmerseGen achieves superior photorealism, spatial coherence and rendering efficiency compared to prior methods. Project webpage: https://immersegen.github.io.
针对沉浸式虚拟现实存在的自动创建三维场景一直是几十年的研究重点。然而,现有方法往往依赖于具有事后简化的高多边形网格建模或大规模三维高斯建模,导致管道复杂或视觉逼真度受限。在本文中,我们证明了实现引人注目的沉浸式体验并不需要如此详尽的建模。我们介绍了ImmerseGen,这是一种用于紧凑和逼真的世界建模的新型代理引导框架。ImmerseGen将场景表示为轻便几何代理的层次结构组合,即简化地形和招牌网格,并通过在这些代理上合成RGBA纹理来生成逼真的外观。具体来说,我们提出了针对用户中心基地世界合成的地形条件纹理贴图,以及用于中景和前景景色的RGBA资产纹理贴图。这种重新表述提供了几个优点:(i)它简化了建模过程,使代理能够引导生成模型产生无缝集成场景的连贯纹理;(ii)它通过直接在代理上合成逼真的纹理绕过复杂的几何创建和减少,同时保留视觉质量而不会降级;(iii)它支持在移动VR耳机上进行实时渲染的紧凑表示形式。为了从文本提示自动创建场景,我们引入了基于VLM的建模代理,并增强了基于语义网格的分析以改善空间推理和准确的资产放置。ImmerseGen还通过动态效果和环绕声音进一步丰富了场景,以支持多感官沉浸。场景生成和实时VR展示的实验表明,ImmerseGen在逼真度、空间连贯性和渲染效率方面优于先前的方法。项目网页:https://immersegen.github.io。
论文及项目相关链接
PDF Project webpage: https://immersegen.github.io
Summary
本文提出了一种新型的沉浸式虚拟现实场景创建方法——ImmerseGen。该方法采用代理引导的框架,以简化地形和贴图网格的层次结构表示场景,并通过合成RGBA纹理赋予场景逼真的外观。此外,还引入了基于文本提示的场景创建自动化方法,增强了空间推理和资产放置的准确性。ImmerseGen丰富了场景的动态效果和环绕音效,支持多感官沉浸。相较于以往的方法,ImmerseGen在场景生成、逼真度、空间连贯性和渲染效率上表现出色。
Key Takeaways
- ImmerseGen是一个新型的沉浸式虚拟现实场景创建方法,采用代理引导的框架进行场景建模。
- ImmerseGen通过简化地形和贴图网格的层次结构来表示场景,并合成RGBA纹理以赋予场景逼真的外观。
- 该方法引入了基于文本提示的场景创建自动化方法,增强空间推理和资产放置的准确性。
- ImmerseGen通过丰富场景的动态效果和环绕音效,支持多感官沉浸。
- ImmerseGen在场景生成、逼真度、空间连贯性和渲染效率方面优于以往的方法。
- ImmerseGen适用于移动VR头盔的实时渲染,具有紧凑的场景表示形式。
点此查看论文截图



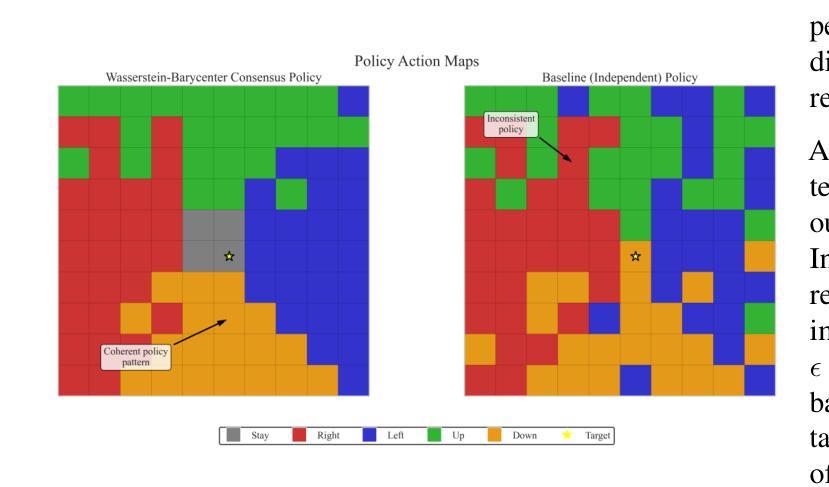
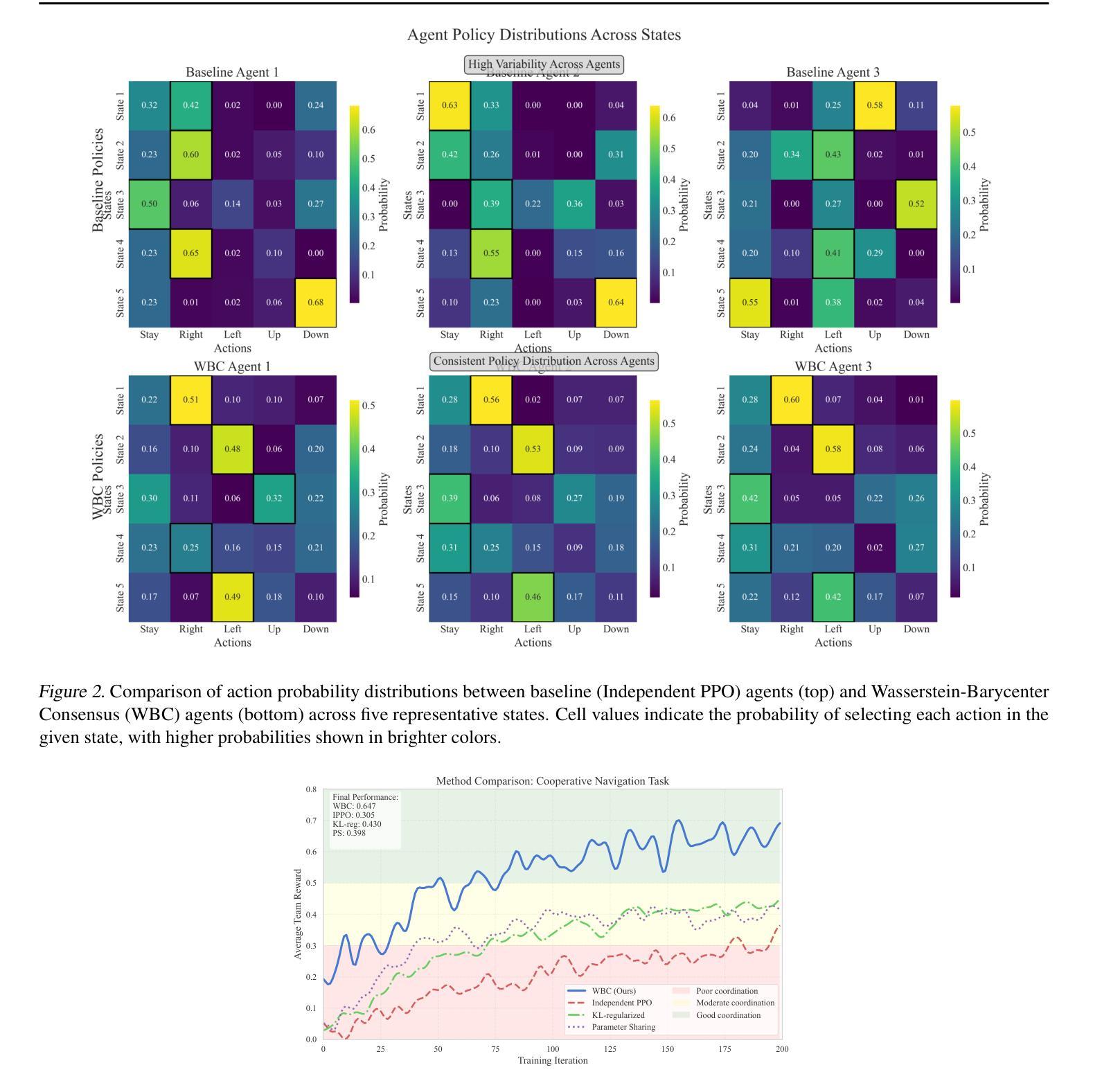
Wasserstein-Barycenter Consensus for Cooperative Multi-Agent Reinforcement Learning
Authors:Ali Baheri
Cooperative multi-agent reinforcement learning (MARL) demands principled mechanisms to align heterogeneous policies while preserving the capacity for specialized behavior. We introduce a novel consensus framework that defines the team strategy as the entropic-regularized $p$-Wasserstein barycenter of agents’ joint state–action visitation measures. By augmenting each agent’s policy objective with a soft penalty proportional to its Sinkhorn divergence from this barycenter, the proposed approach encourages coherent group behavior without enforcing rigid parameter sharing. We derive an algorithm that alternates between Sinkhorn-barycenter computation and policy-gradient updates, and we prove that, under standard Lipschitz and compactness assumptions, the maximal pairwise policy discrepancy contracts at a geometric rate. Empirical evaluation on a cooperative navigation case study demonstrates that our OT-barycenter consensus outperforms an independent learners baseline in convergence speed and final coordination success.
多智能体强化学习(MARL)需要具有原则性的机制来对齐异质策略,同时保留执行特殊行为的能力。我们引入了一种新的共识框架,将团队策略定义为智能体联合状态-行动访问度量的熵正则化p-Wasserstein重心。通过增加每个智能体的策略目标,同时采用与其与此重心的Sinkhorn分歧的软罚分比例,该方法鼓励连贯的群体行为,而不会强制执行严格的参数共享。我们提出了一种算法,该算法在Sinkhorn重心计算和策略梯度更新之间进行交替,并在标准的Lipschitz和紧凑性假设下证明,最大成对策略差异以几何速率收缩。在合作导航案例研究中的经验评估表明,我们的OT重心共识方法在收敛速度和最终协调成功方面优于独立学习者的基线。
论文及项目相关链接
Summary
该文本介绍了一种新型的基于合作的多智能体强化学习(MARL)框架。它利用基于熵正则化的p-Wasserstein质心来定义团队策略,并通过对每个智能体的策略目标增加一个与其偏离该质心的软罚项来鼓励一致性的群体行为。实验结果表明,在合作导航场景中,这种新的基于OT-barycenter一致性方法的性能优于独立学习基线,能够在收敛速度和最终协调成功率方面实现更优的表现。
Key Takeaways
- 提出了一种新的合作多智能体强化学习框架,利用p-Wasserstein质心定义团队策略。
- 通过为每个智能体的策略目标增加软罚项,鼓励群体行为的一致性。
- 介绍了交替进行Sinkhorn-barycenter计算和策略梯度更新的算法。
- 在理论层面,证明了在标准的Lipschitz和紧凑性假设下,最大策略差异会以几何速率收缩。
- 实证评估表明,新框架在收敛速度和最终协调成功率方面优于独立学习基线。
- 框架设计保留了智能体的异质性,同时允许它们保持一致性行为。
点此查看论文截图

CORA: Coalitional Rational Advantage Decomposition for Multi-Agent Policy Gradients
Authors:Mengda Ji, Genjiu Xu, Liying Wang
This work focuses on the credit assignment problem in cooperative multi-agent reinforcement learning (MARL). Sharing the global advantage among agents often leads to suboptimal policy updates as it fails to account for the distinct contributions of agents. Although numerous methods consider global or individual contributions for credit assignment, a detailed analysis at the coalition level remains lacking in many approaches. This work analyzes the over-updating problem during multi-agent policy updates from a coalition-level perspective. To address this issue, we propose a credit assignment method called Coalitional Rational Advantage Decomposition (CORA). CORA evaluates coalitional advantages via marginal contributions from all possible coalitions and decomposes advantages using the core solution from cooperative game theory, ensuring coalitional rationality. To reduce computational overhead, CORA employs random coalition sampling. Experiments on matrix games, differential games, and multi-agent collaboration benchmarks demonstrate that CORA outperforms strong baselines, particularly in tasks with multiple local optima. These findings highlight the importance of coalition-aware credit assignment for improving MARL performance.
本文关注合作多智能体强化学习(MARL)中的信用分配问题。在智能体之间共享全局优势往往会导致次优的策略更新,因为它无法解释智能体的不同贡献。尽管许多方法考虑了全局或个人贡献来进行信用分配,但在联盟层面进行详细分析的方法仍然缺乏。本文从联盟的角度分析了多智能体策略更新过程中的过度更新问题。为了解决这一问题,我们提出了一种名为“联盟理性优势分解”(CORA)的信用分配方法。CORA通过所有可能联盟的边际贡献来评估联盟优势,并使用合作博弈论的核心解决方案进行优势分解,确保联盟理性。为了减少计算开销,CORA采用随机联盟抽样。在矩阵游戏、差异游戏和多智能体协作基准测试上的实验表明,CORA优于强大的基线,特别是在具有多个局部最优的任务中。这些发现强调了联盟意识信用分配对改善MARL性能的重要性。
论文及项目相关链接
Summary
该工作聚焦在合作多智能体强化学习中的信用分配问题。分析全局优势在智能体间的共享会导致策略更新次优,因为未能考虑到智能体的独特贡献。文章从联盟层面分析了多智能体策略更新过程中的过度更新问题,并提出了名为“联盟理性优势分解”(CORA)的信用分配方法。CORA通过评估所有可能联盟的边际贡献来衡量联盟优势,并使用合作博弈论的核解来保证联盟理性。为减少计算开销,CORA采用随机联盟采样。在矩阵游戏、差异游戏和多智能体协作基准测试上的实验表明,CORA在具有多个局部最优的任务中表现优于强大的基线。这表明联盟感知的信用分配对于提高MARL性能至关重要。
Key Takeaways
- 该工作研究了合作多智能体强化学习中的信用分配问题,指出全局优势共享可能导致策略更新次优。
- 现有方法多未能从联盟层面详细分析多智能体间的信用分配。
- 提出了名为“联盟理性优势分解”(CORA)的信用分配方法,通过评估联盟边际贡献来衡量联盟优势。
- CORA使用合作博弈论的核解来保证联盟理性。
- 为减少计算成本,CORA采用随机联盟采样。
- 实验表明,CORA在多种任务上表现优异,特别是具有多个局部最优的任务。
点此查看论文截图


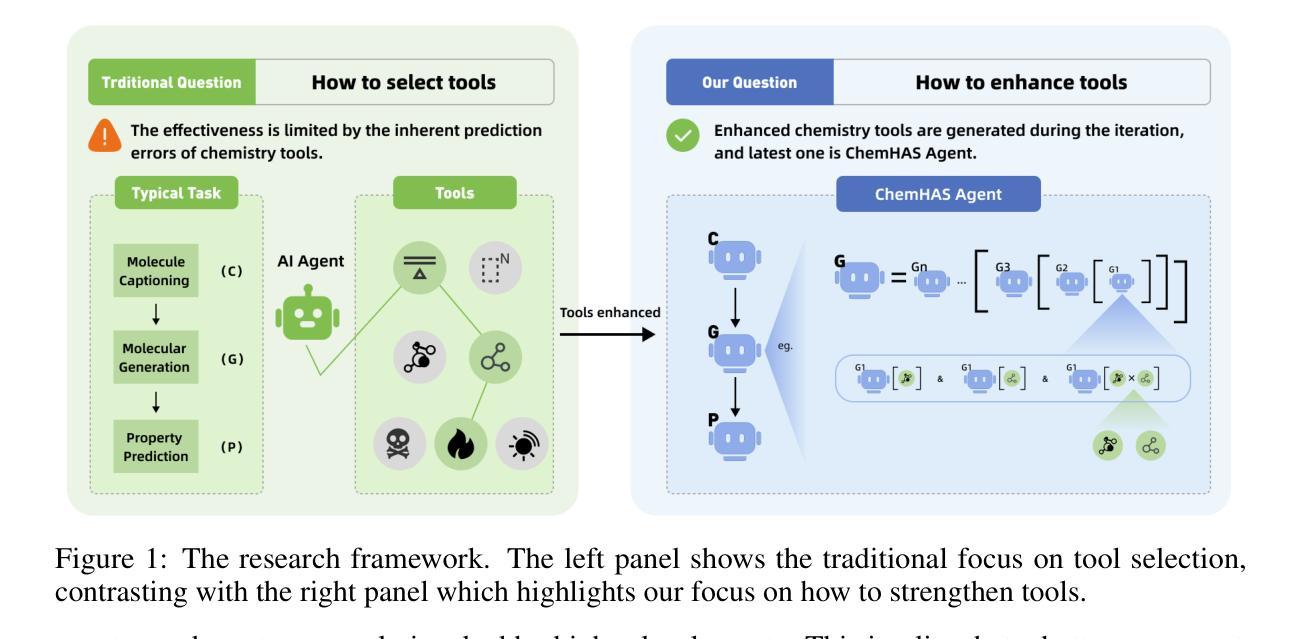
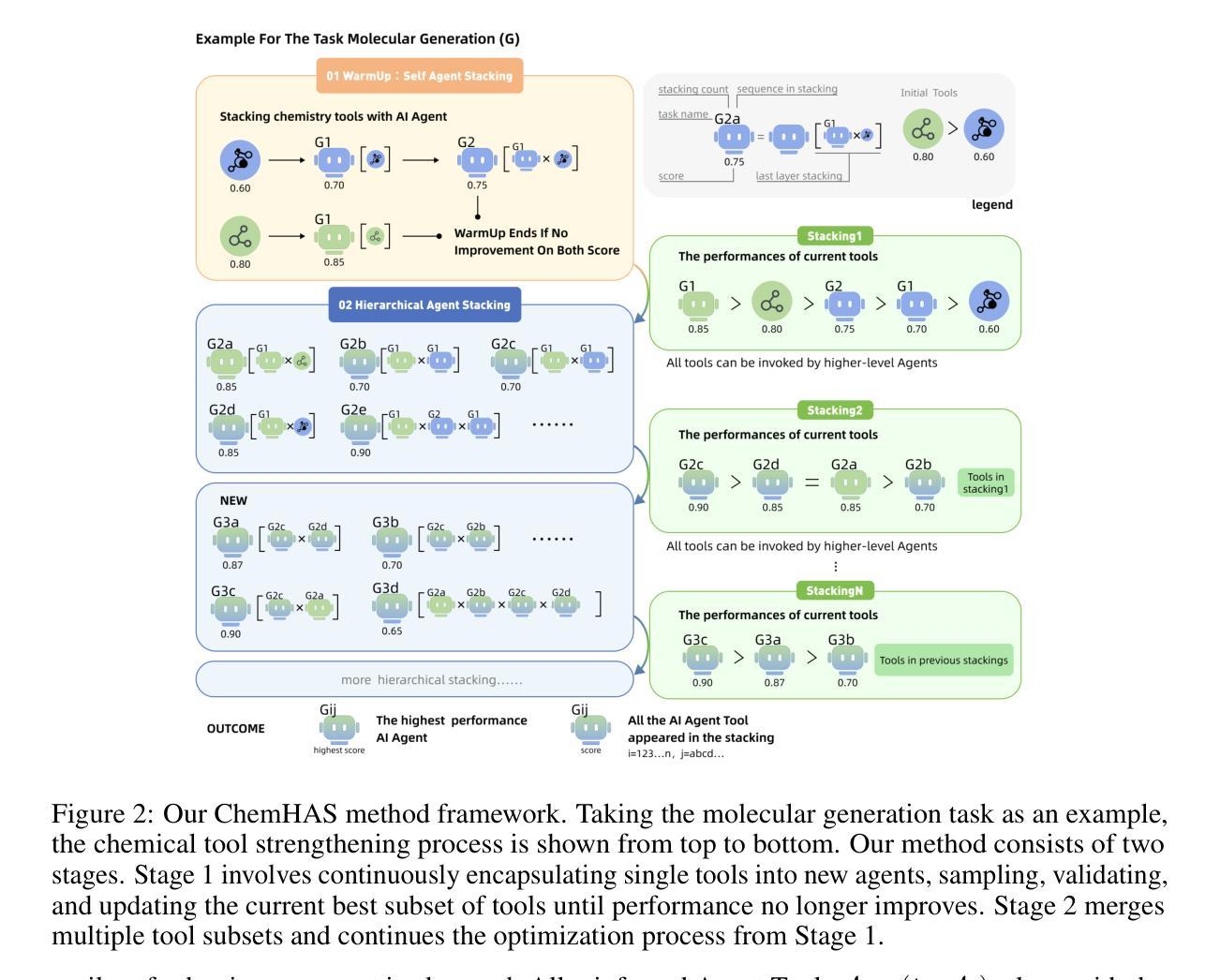
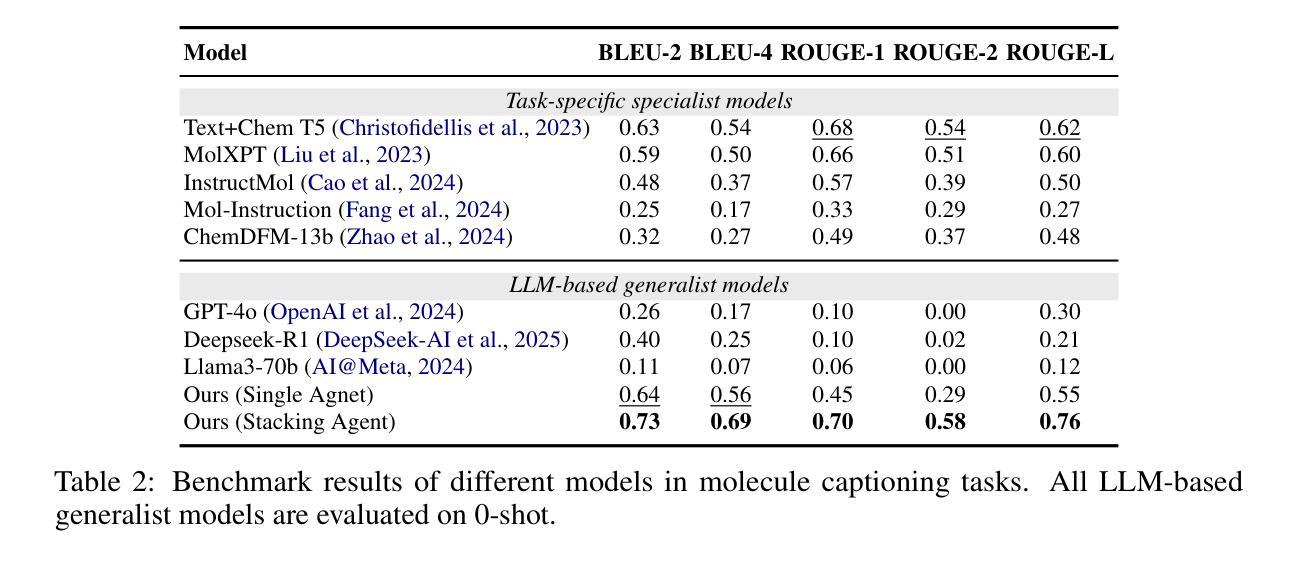
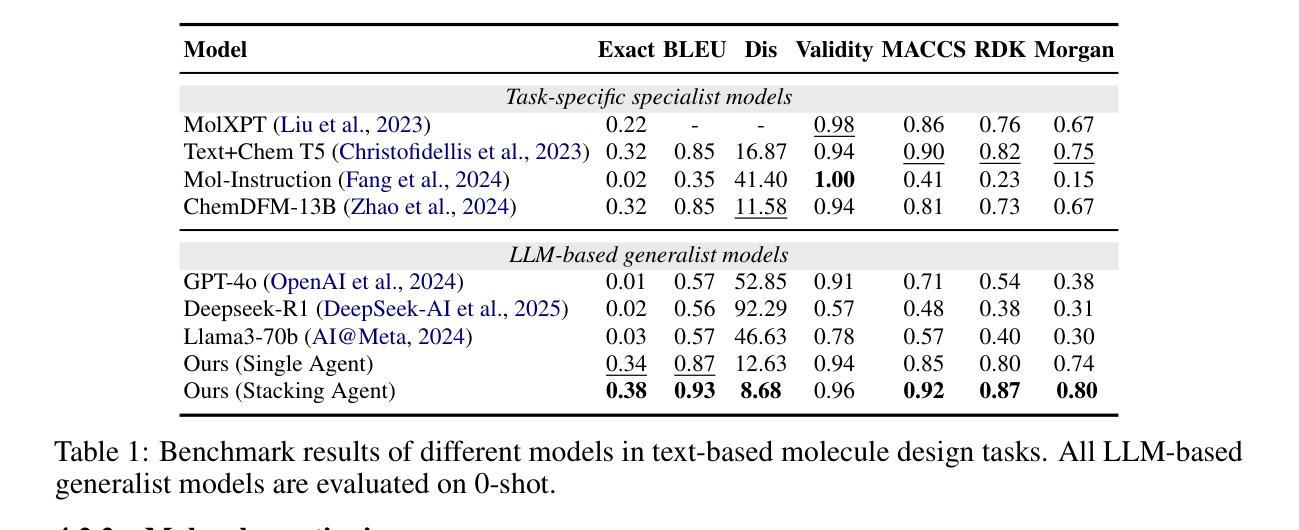
ChemHAS: Hierarchical Agent Stacking for Enhancing Chemistry Tools
Authors:Zhucong Li, Bowei Zhang, Jin Xiao, Zhijian Zhou, Fenglei Cao, Jiaqing Liang, Yuan Qi
Large Language Model (LLM)-based agents have demonstrated the ability to improve performance in chemistry-related tasks by selecting appropriate tools. However, their effectiveness remains limited by the inherent prediction errors of chemistry tools. In this paper, we take a step further by exploring how LLMbased agents can, in turn, be leveraged to reduce prediction errors of the tools. To this end, we propose ChemHAS (Chemical Hierarchical Agent Stacking), a simple yet effective method that enhances chemistry tools through optimizing agent-stacking structures from limited data. ChemHAS achieves state-of-the-art performance across four fundamental chemistry tasks, demonstrating that our method can effectively compensate for prediction errors of the tools. Furthermore, we identify and characterize four distinct agent-stacking behaviors, potentially improving interpretability and revealing new possibilities for AI agent applications in scientific research. Our code and dataset are publicly available at https: //anonymous.4open.science/r/ChemHAS-01E4/README.md.
基于大型语言模型(LLM)的代理已经显示出通过选择适当的工具来提高在化学相关任务中的性能的能力。然而,它们的有效性仍然受到化学工具固有预测误差的限制。在本文中,我们更进一步探索了如何反过来利用基于LLM的代理来减少工具的预测误差。为此,我们提出了ChemHAS(化学分层代理堆叠)方法,这是一种通过优化有限数据下的代理堆叠结构来增强化学工具性能的有效方法。ChemHAS在四个基本化学任务上达到了最先进的性能水平,证明了我们的方法可以有效地补偿工具的预测误差。此外,我们还确定了四种不同的代理堆叠行为并对其进行了表征,这可能会提高可解释性并揭示了人工智能代理在科学研究中应用的新可能性。我们的代码和数据集可在https://anonymous.4open.science/r/ChemHAS-01E4/README.md上公开获取。
论文及项目相关链接
PDF 9 pages
Summary
基于大语言模型的代理在化学相关任务中表现出了性能提升的能力,但仍受到化学工具固有预测误差的限制。本研究提出ChemHAS(化学分层代理堆叠)方法,通过优化代理堆叠结构来增强化学工具的性能,从有限数据中获益。ChemHAS在四项基本化学任务上实现了卓越性能,有效弥补了工具的预测误差。此外,研究还确定了四种不同的代理堆叠行为,提高了可解释性,并揭示了人工智能代理在科学研究中新的应用可能性。
Key Takeaways
- 大语言模型代理能够改善化学相关任务的性能,但受限于化学工具的预测误差。
- ChemHAS方法通过优化代理堆叠结构增强化学工具性能。
- ChemHAS在四项基本化学任务上实现卓越性能,有效补偿工具预测误差。
- 研究确定了四种不同的代理堆叠行为,提高可解释性。
- ChemHAS公开可用的代码和数据集为科学研究提供了新工具。
- 此研究揭示了人工智能代理在科学研究中新的应用潜力。
点此查看论文截图

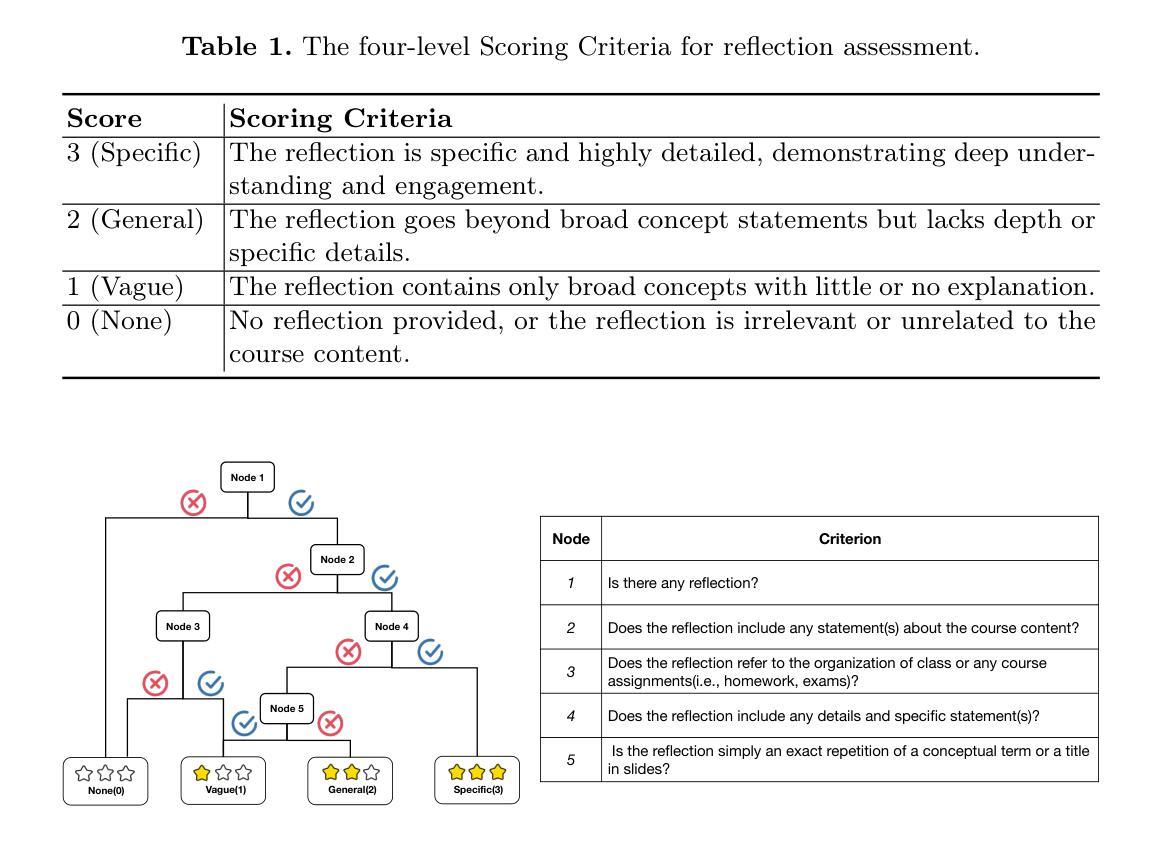
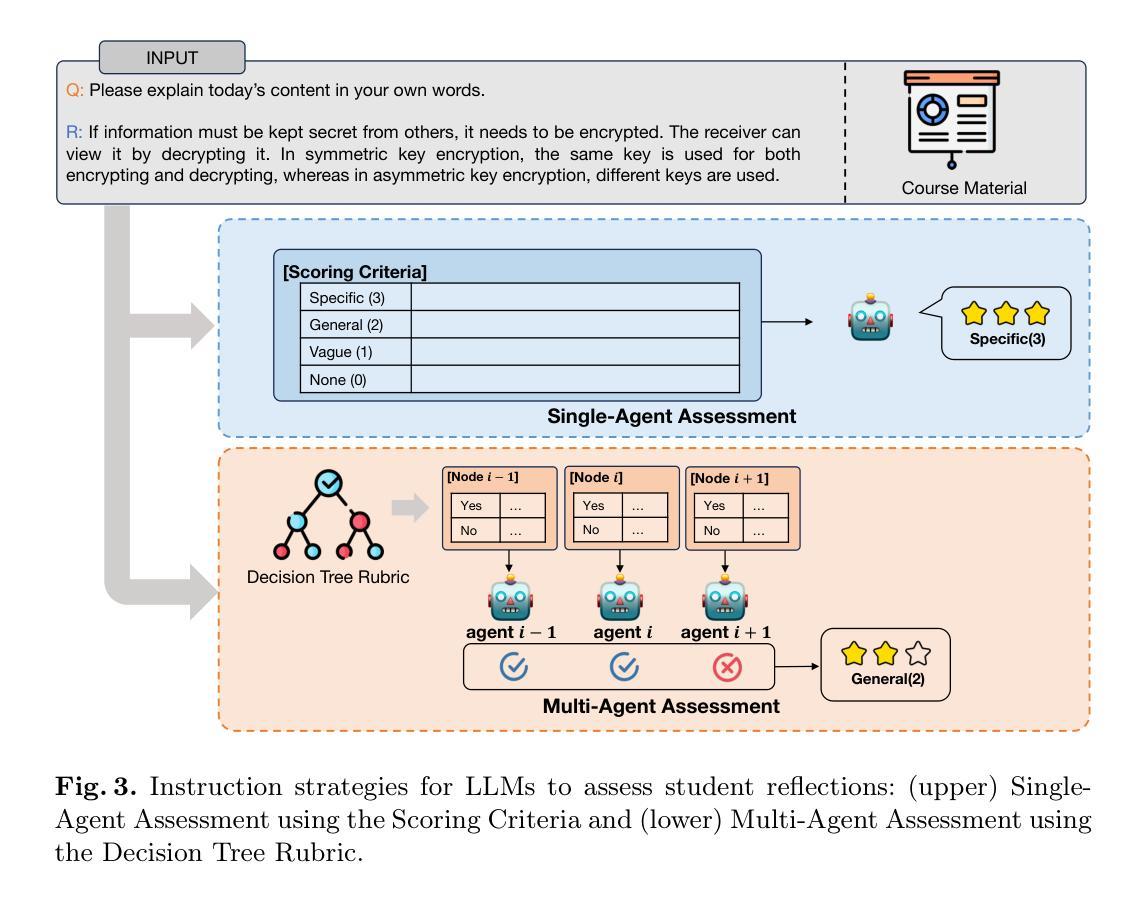
Single-Agent vs. Multi-Agent LLM Strategies for Automated Student Reflection Assessment
Authors:Gen Li, Li Chen, Cheng Tang, Valdemar Švábenský, Daisuke Deguchi, Takayoshi Yamashita, Atsushi Shimada
We explore the use of Large Language Models (LLMs) for automated assessment of open-text student reflections and prediction of academic performance. Traditional methods for evaluating reflections are time-consuming and may not scale effectively in educational settings. In this work, we employ LLMs to transform student reflections into quantitative scores using two assessment strategies (single-agent and multi-agent) and two prompting techniques (zero-shot and few-shot). Our experiments, conducted on a dataset of 5,278 reflections from 377 students over three academic terms, demonstrate that the single-agent with few-shot strategy achieves the highest match rate with human evaluations. Furthermore, models utilizing LLM-assessed reflection scores outperform baselines in both at-risk student identification and grade prediction tasks. These findings suggest that LLMs can effectively automate reflection assessment, reduce educators’ workload, and enable timely support for students who may need additional assistance. Our work emphasizes the potential of integrating advanced generative AI technologies into educational practices to enhance student engagement and academic success.
我们探索了大型语言模型(LLM)在自动评估学生开放性反思和预测学业表现方面的应用。传统的反思评估方法耗时且可能无法在教育环境中有效地扩展。在这项工作中,我们采用LLM,使用两种评估策略(单智能体和多智能体)和两种提示技术(零样本和少样本),将学生反思转化为量化分数。我们在包含来自377名学生在三个学术学期内的5,278篇反思的数据集上进行的实验表明,采用少样本策略的单智能体评估匹配率最高。此外,使用LLM评估的反思分数的模型在处于风险的学生识别和成绩预测任务中的表现均优于基线。这些结果表明,LLM可以有效地自动进行反思评估,减少教育工作者的工作量,并为可能需要额外帮助的学生提供及时的支持。我们的工作强调了将先进的生成性AI技术整合到教育实践中以提高学生参与度和学业成功的潜力。
论文及项目相关链接
PDF Published in Proceedings of the 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2025), see https://doi.org/10.1007/978-981-96-8186-0_24
Summary
大语言模型(LLMs)可用于自动评估学生的开放文本反思和预测学业表现。传统评估方法耗时且难以在教育环境中有效扩展。本研究利用LLMs将学生的反思转化为量化分数,采用两种评估策略(单智能体和多智能体)和两种提示技术(零样本和少样本)。实验表明,使用少样本策略的单智能体方法与人评的匹配率最高。此外,使用LLM评估的反思分数的模型在风险学生识别和成绩预测任务中的表现优于基线。这表明LLMs可以有效自动化反思评估,减轻教育工作者的工作量,并为可能需要额外帮助的学生提供及时支持。本研究强调了将高级生成式AI技术融入教育实践以提高学生参与度和学业成功的潜力。
Key Takeaways
- 大语言模型(LLMs)被用于自动评估学生的开放文本反思和预测学业表现,旨在提高效率和准确性。
- 研究采用了两种评估策略:单智能体和多智能体,以及两种提示技术:零样本和少样本。
- 实验结果表明,少样本策略的单智能体方法在与人评的匹配方面表现最佳。
- 使用LLM评估的反思分数的模型在风险学生识别和成绩预测任务中优于基线方法。
- LLMs的自动化评估可以有效减轻教育工作者的负担,并提供及时的学生支持。
- 研究结果强调了将高级AI技术融入教育实践的潜力,以提高学生的参与度和学业成功。
点此查看论文截图


I-MCTS: Enhancing Agentic AutoML via Introspective Monte Carlo Tree Search
Authors:Zujie Liang, Feng Wei, Wujiang Xu, Lin Chen, Yuxi Qian, Xinhui Wu
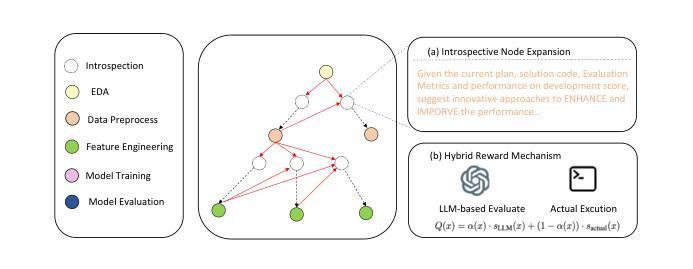
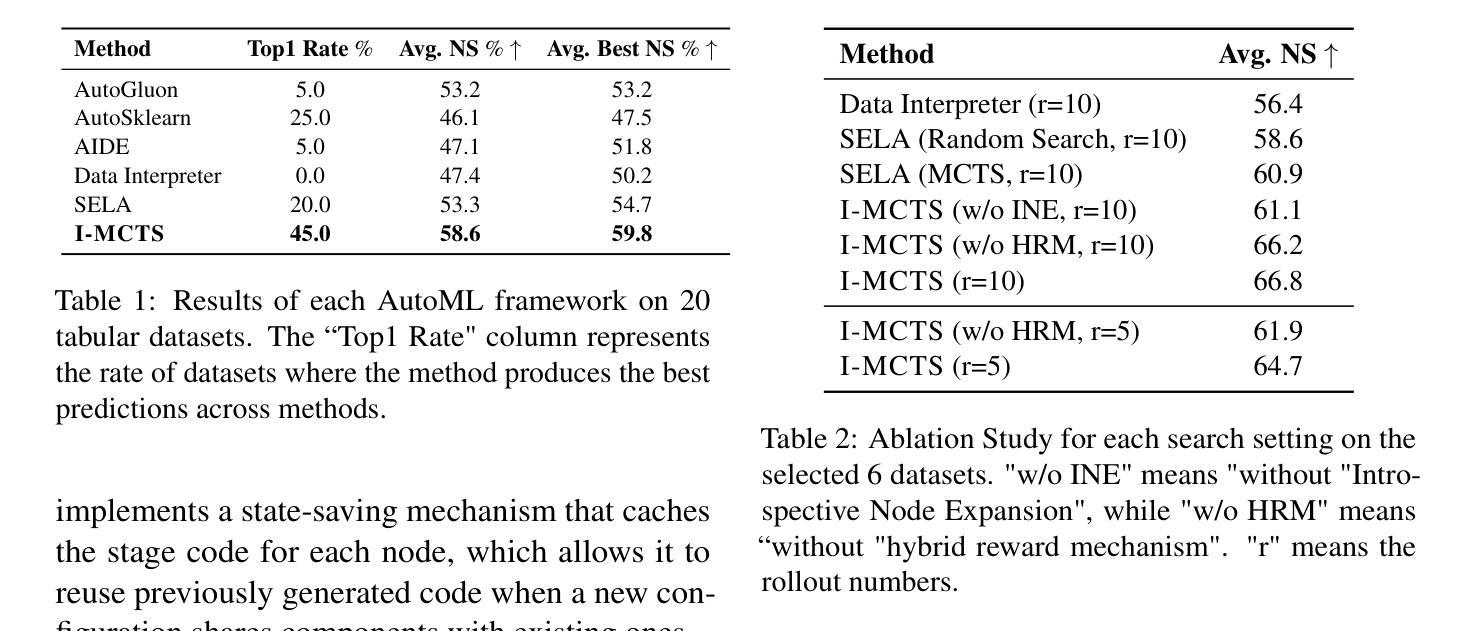
Recent advancements in large language models (LLMs) have shown remarkable potential in automating machine learning tasks. However, existing LLM-based agents often struggle with low-diversity and suboptimal code generation. While recent work has introduced Monte Carlo Tree Search (MCTS) to address these issues, limitations persist in the quality and diversity of thoughts generated, as well as in the scalar value feedback mechanisms used for node selection. In this study, we introduce Introspective Monte Carlo Tree Search (I-MCTS), a novel approach that iteratively expands tree nodes through an introspective process that meticulously analyzes solutions and results from parent and sibling nodes. This facilitates a continuous refinement of the node in the search tree, thereby enhancing the overall decision-making process. Furthermore, we integrate a Large Language Model (LLM)-based value model to facilitate direct evaluation of each node’s solution prior to conducting comprehensive computational rollouts. A hybrid rewarding mechanism is implemented to seamlessly transition the Q-value from LLM-estimated scores to actual performance scores. This allows higher-quality nodes to be traversed earlier. Applied to the various ML tasks, our approach demonstrates a 6% absolute improvement in performance compared to the strong open-source AutoML agents, showcasing its effectiveness in enhancing agentic AutoML systems. Resource available at https://github.com/jokieleung/I-MCTS
近期大型语言模型(LLM)的进步在自动化机器学习任务方面显示出显著潜力。然而,现有的基于LLM的代理人在代码生成方面常常面临低多样性和非最优的问题。尽管最近有研究工作引入了蒙特卡洛树搜索(MCTS)来解决这些问题,但在生成思想的品质和多样性以及用于节点选择的标量值反馈机制方面仍存在局限性。
论文及项目相关链接
Summary
大语言模型(LLM)在自动化机器学习任务中展现出巨大潜力,但仍存在代码生成多样性不足和次优问题。本研究引入内省蒙特卡洛树搜索(I-MCTS),通过迭代扩展树节点,分析父节点和兄弟节点的解决方案和结果,提高决策质量。结合LLM价值模型直接评估节点解决方案,实施混合奖励机制,实现LLM估计分数与实际性能分数的无缝过渡。在机器学习任务中应用,相比强大的开源自动机器学习代理人,性能绝对提高了6%。
Key Takeaways
- 大语言模型(LLM)在自动化机器学习任务中具有巨大潜力,但存在代码生成多样性和优化问题。
- 内省蒙特卡洛树搜索(I-MCTS)通过迭代分析父节点和兄弟节点的解决方案和结果,提高决策质量。
- I-MCTS方法促进搜索树中节点的持续改进,从而增强整体决策过程。
- 结合LLM价值模型直接评估节点解决方案,减少全面计算滚动所需的步骤。
- 实施混合奖励机制,实现LLM估计分数与实际性能分数的无缝过渡。
- I-MCTS在机器学习任务中的应用相比现有技术有显著改进,性能提高了6%。
点此查看论文截图

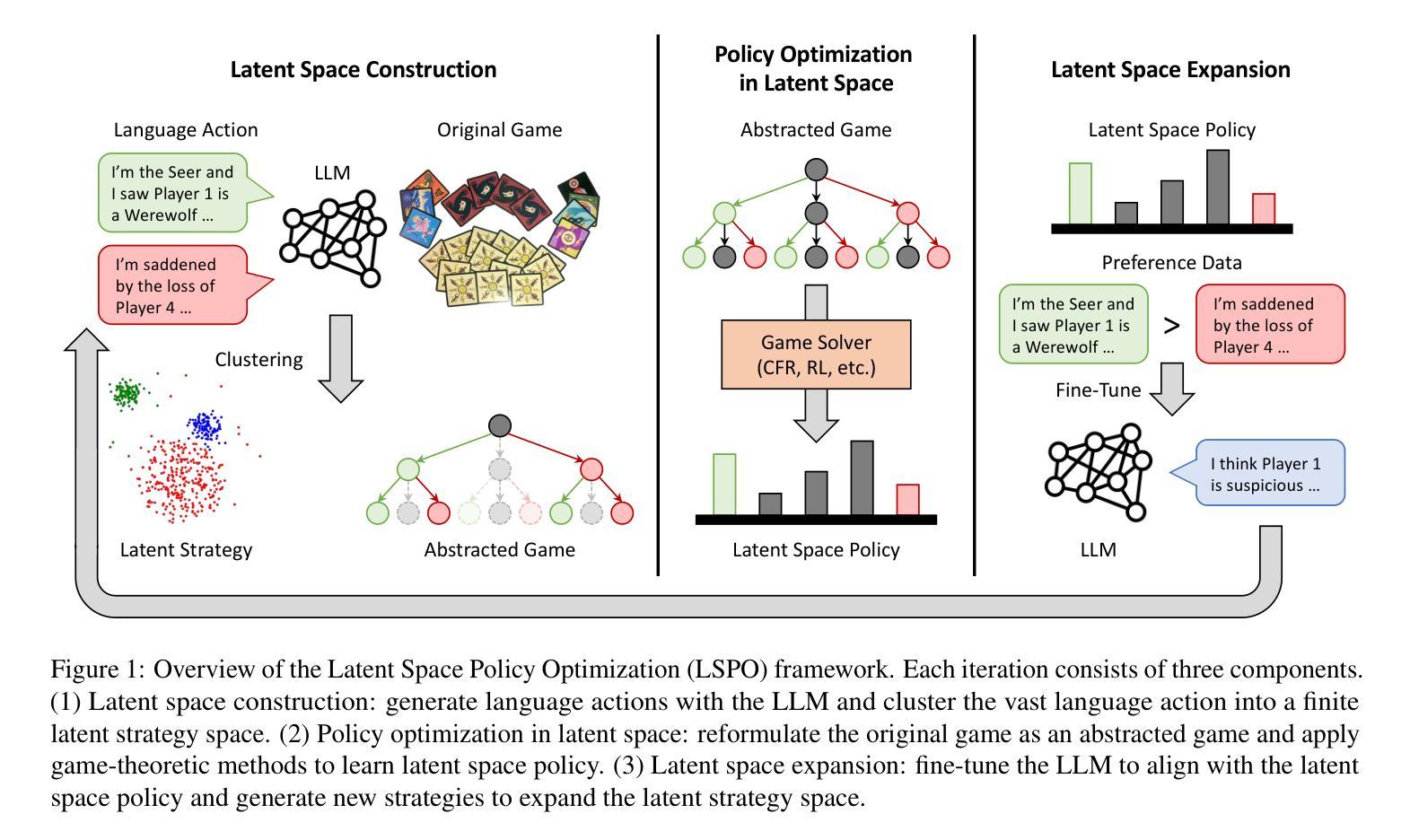
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Authors:Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu, Yu Wang
Large language model (LLM) agents have recently demonstrated impressive capabilities in various domains like open-ended conversation and multi-step decision-making. However, it remains challenging for these agents to solve strategic language games, such as Werewolf, which demand both strategic decision-making and free-form language interactions. Existing LLM agents often suffer from intrinsic bias in their action distributions and limited exploration of the unbounded text action space, resulting in suboptimal performance. To address these challenges, we propose Latent Space Policy Optimization (LSPO), an iterative framework that combines game-theoretic methods with LLM fine-tuning to build strategic language agents. LSPO leverages the observation that while the language space is combinatorially large, the underlying strategy space is relatively compact. We first map free-form utterances into a finite latent strategy space, yielding an abstracted extensive-form game. Then we apply game-theoretic methods like Counterfactual Regret Minimization (CFR) to optimize the policy in the latent space. Finally, we fine-tune the LLM via Direct Preference Optimization (DPO) to align with the learned policy. By iteratively alternating between these steps, our LSPO agents progressively enhance both strategic reasoning and language communication. Experiment on the Werewolf game shows that our agents iteratively expand the strategy space with improving performance and outperform existing Werewolf agents, underscoring their effectiveness in free-form language games with strategic interactions.
大型语言模型(LLM)代理最近在开放对话和多步决策等各个领域表现出了令人印象深刻的能力。然而,对于战略语言游戏(如Werewolf),这些代理仍然面临挑战,这些游戏需要战略决策和自由的文本交互。现有的LLM代理经常受到其行动分布中的固有偏见和无界文本行动空间有限探索的影响,导致性能不佳。为了解决这些挑战,我们提出了潜在空间策略优化(LSPO),这是一个结合博弈论方法和LLM微调来构建战略语言代理的迭代框架。LSPO利用了一个观察结果,即虽然语言空间是组合性的巨大,但潜在的策略空间是相对紧凑的。我们首先将自由形式的言语映射到一个有限的潜在策略空间,形成一个抽象的扩展形式的游戏。然后,我们应用博弈论方法,如反事实后悔最小化(CFR)来优化潜在空间中的策略。最后,我们通过直接偏好优化(DPO)对LLM进行微调,以与所学的策略对齐。通过在这些步骤之间迭代交替,我们的LSPO代理逐步提高了战略推理和语言沟通的能力。在Werewolf游戏上的实验表明,我们的代理通过迭代扩展策略空间,性能得到提升,并超越了现有的Werewolf代理,这证明了它们在具有战略交互的自由形式语言游戏中的有效性。
论文及项目相关链接
PDF Published in ICML 2025
摘要
大型语言模型(LLM)代理在开放对话和多步决策制定等域中展现了令人印象深刻的能力。然而,对于战略语言游戏如Werewolf这类既需要战略决策又需自由形式语言交互的游戏,这些代理仍面临挑战。针对现有LLM代理在行动分布上的内在偏见和无界文本行动空间探索的局限性,我们提出了潜在空间策略优化(LSPO)方法。这是一种结合博弈论方法和LLM微调来构建战略性语言代理的迭代框架。LSPO利用了一种观察结果,即虽然语言空间组合庞大,但潜在的策略空间相对紧凑。我们首先将自由形式的言论映射到有限的潜在策略空间,形成一个抽象化的扩展形式游戏。然后应用博弈论方法如反事实后悔最小化(CFR)来优化潜在空间的策略。最后,我们通过直接偏好优化(DPO)来微调LLM,使其与学到的策略相一致。通过反复交替这些步骤,我们的LSPO代理逐步提高了战略推理和语言沟通能力。在Werewolf游戏上的实验表明,我们的代理通过迭代扩展策略空间,性能得到提升,并超越了现有的Werewolf代理,突显了它们在具有战略交互的自由形式语言游戏中的有效性。
关键见解
- 大型语言模型(LLM)在战略语言游戏中的表现面临挑战。
- 现有LLM代理在行动分布上存在内在偏见,且对无界文本行动空间的探索有限。
- 提出了潜在空间策略优化(LSPO)方法来解决这些问题。
- LSPO将自由形式的言论映射到有限的潜在策略空间,形成一个抽象化的扩展形式游戏。
- 通过应用博弈论方法如反事实后悔最小化(CFR)来优化潜在空间的策略。
- 通过直接偏好优化(DPO)微调LLM,使其与学到的策略相一致。
点此查看论文截图


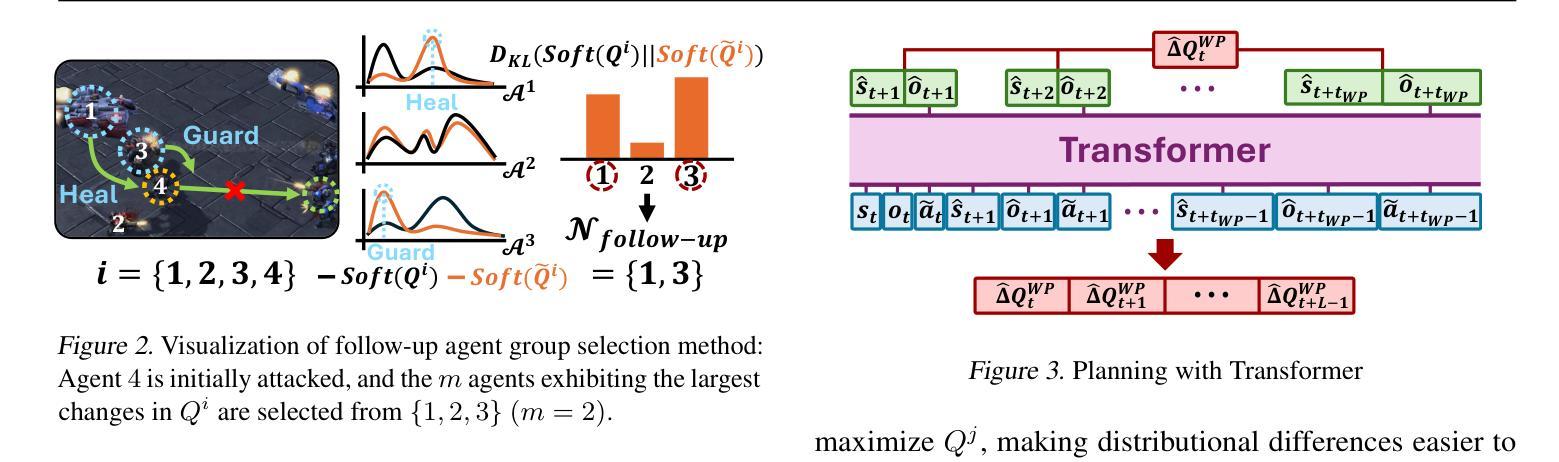
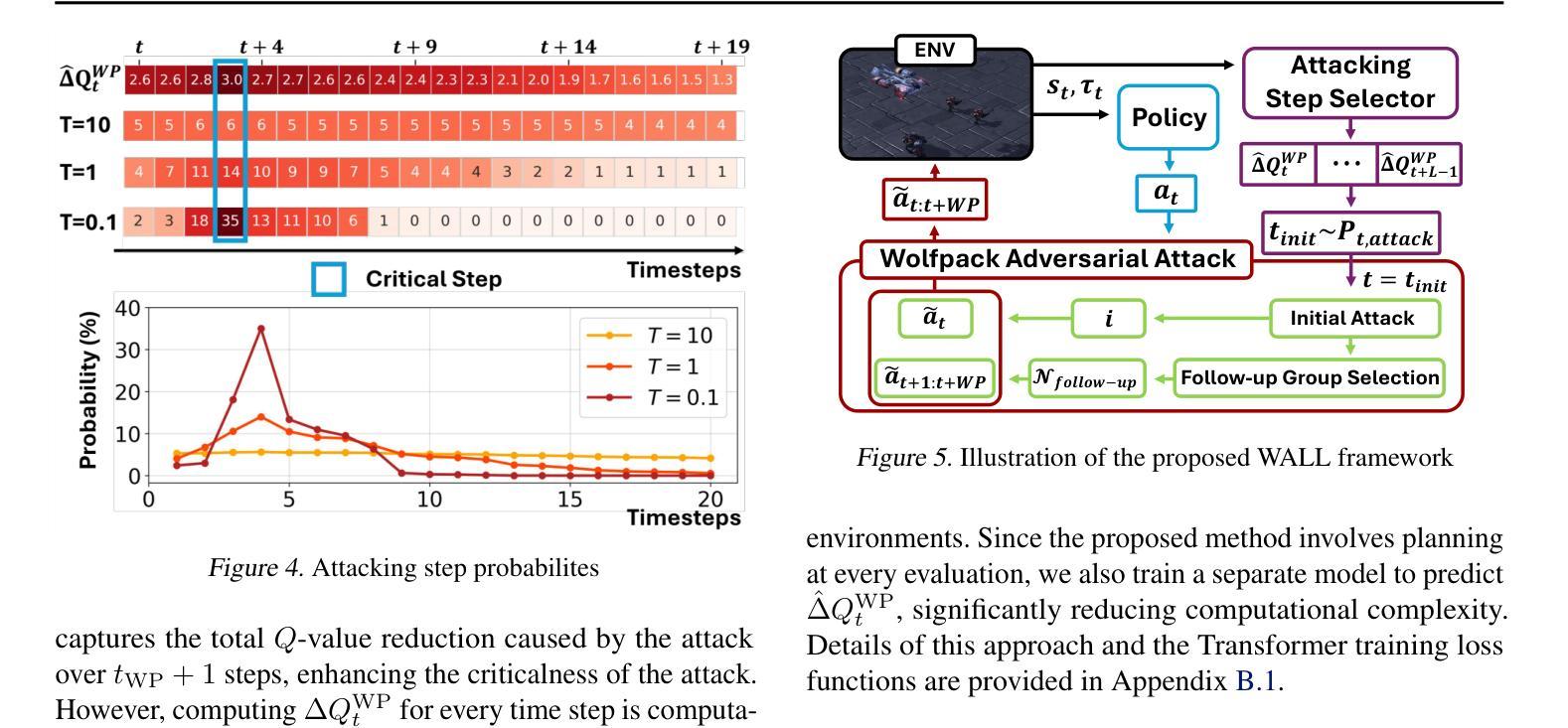
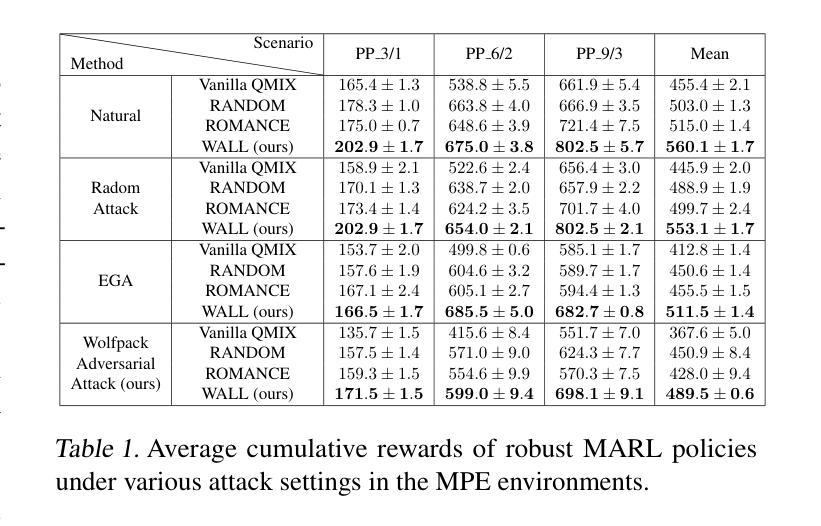
Wolfpack Adversarial Attack for Robust Multi-Agent Reinforcement Learning
Authors:Sunwoo Lee, Jaebak Hwang, Yonghyeon Jo, Seungyul Han
Traditional robust methods in multi-agent reinforcement learning (MARL) often struggle against coordinated adversarial attacks in cooperative scenarios. To address this limitation, we propose the Wolfpack Adversarial Attack framework, inspired by wolf hunting strategies, which targets an initial agent and its assisting agents to disrupt cooperation. Additionally, we introduce the Wolfpack-Adversarial Learning for MARL (WALL) framework, which trains robust MARL policies to defend against the proposed Wolfpack attack by fostering systemwide collaboration. Experimental results underscore the devastating impact of the Wolfpack attack and the significant robustness improvements achieved by WALL. Our code is available at https://github.com/sunwoolee0504/WALL.
在多智能体强化学习(MARL)中,传统的鲁棒方法经常在合作场景中对抗协调攻击时遇到挑战。为了解决这个问题,我们提出了狼群对抗攻击框架,该框架借鉴了狼群狩猎策略,以破坏某个初始智能体及其辅助智能体之间的合作为目标。此外,我们还引入了狼群对抗性强化学习(WALL)框架,它通过促进系统级的协作,训练出能抵抗所提出的狼群攻击的鲁棒MARL策略。实验结果突出了狼群攻击的巨大影响以及WALL在鲁棒性方面的显著改进。我们的代码可在https://github.com/sunwoolee0504/WALL获取。
论文及项目相关链接
PDF 9 pages main, 23 pages appendix with reference. Accepeted by ICML 2025
Summary
该文本描述了传统稳健的多智能体强化学习(MARL)方法在面对合作场景中的协同对抗攻击时的局限。为解决这个问题,研究者提出以狼群狩猎策略为灵感的狼群对抗攻击框架,目标是干扰初始智能体及其辅助智能体的合作。同时,他们引入了狼群对抗学习MARL(WALL)框架,通过促进整体系统协作,训练出能够抵御狼群攻击的策略。实验结果显示狼群攻击的巨大破坏性,以及WALL框架实现的显著鲁棒性提升。相关代码可通过相关链接访问。
Key Takeaways
以下是该文本的关键要点:
- 传统稳健的多智能体强化学习方法在面对合作场景中的协同对抗攻击时面临挑战。
- 提出狼群对抗攻击框架,模仿狼群狩猎策略干扰智能体间的合作。
- 引入狼群对抗学习MARL(WALL)框架,旨在训练出能够抵御狼群攻击的策略。
- 实验结果显示狼群攻击的破坏性,以及WALL框架在提升鲁棒性方面的显著成效。
- 狼群对抗攻击不仅影响被攻击的智能体,还会干扰其辅助智能体的协作。
- WALL框架通过促进系统整体协作来增强鲁棒性,有助于多智能体在复杂环境下的适应和学习。
点此查看论文截图




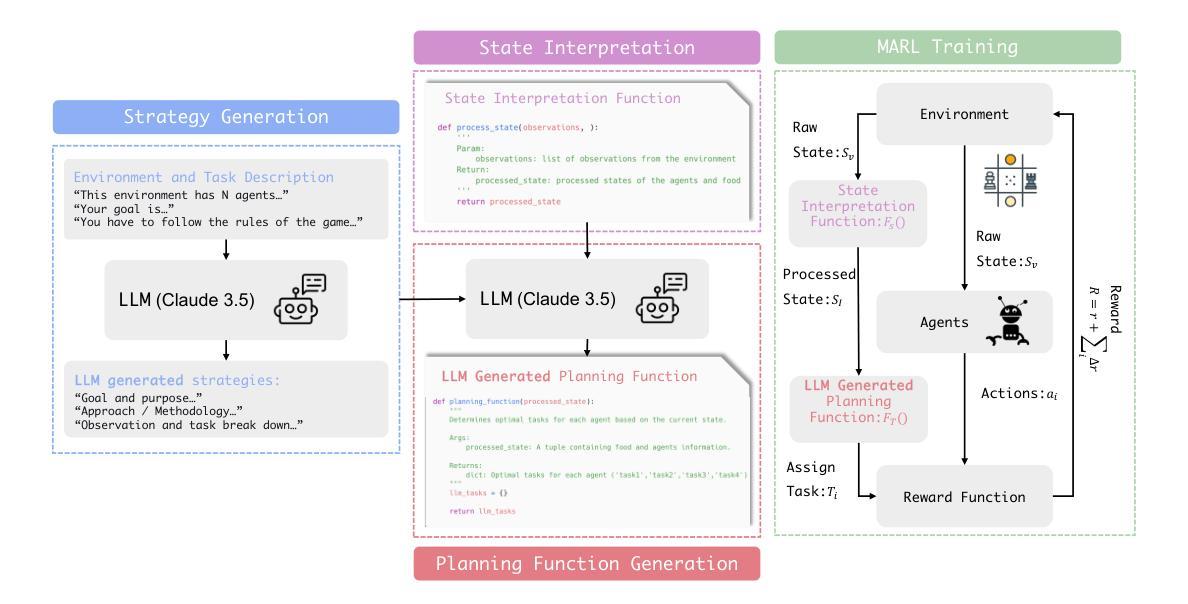
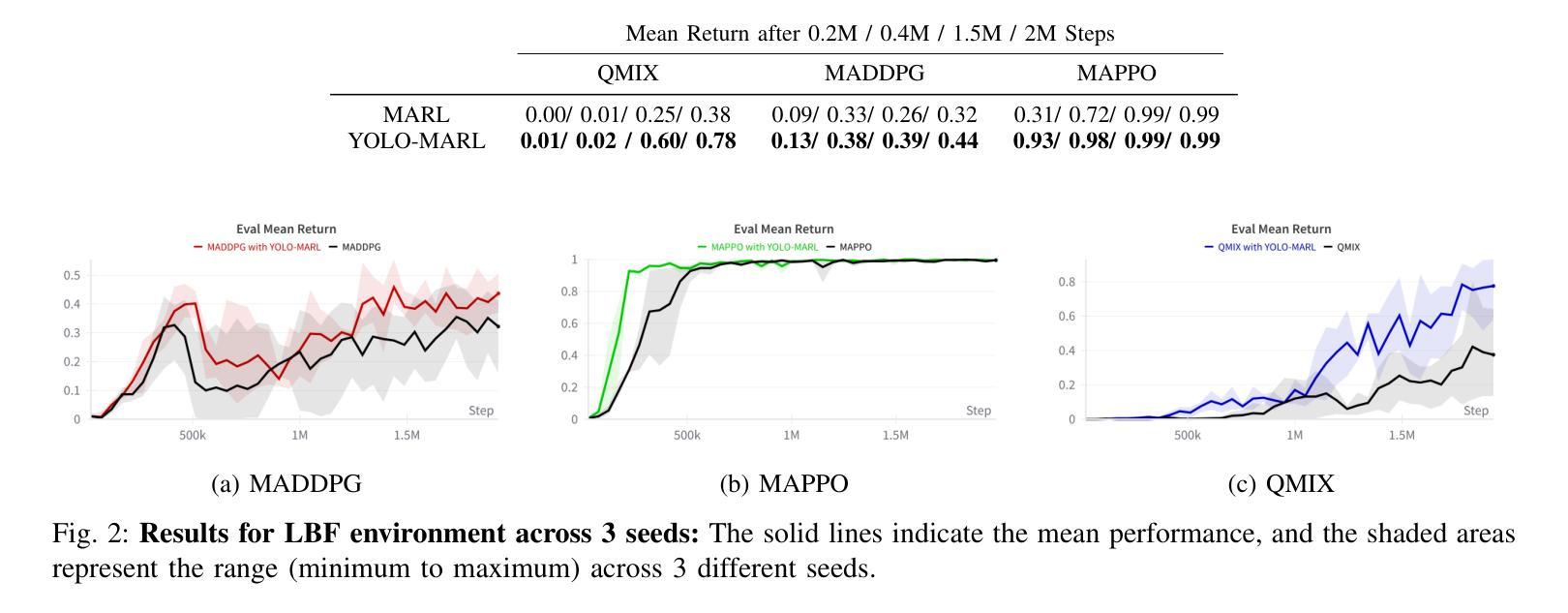
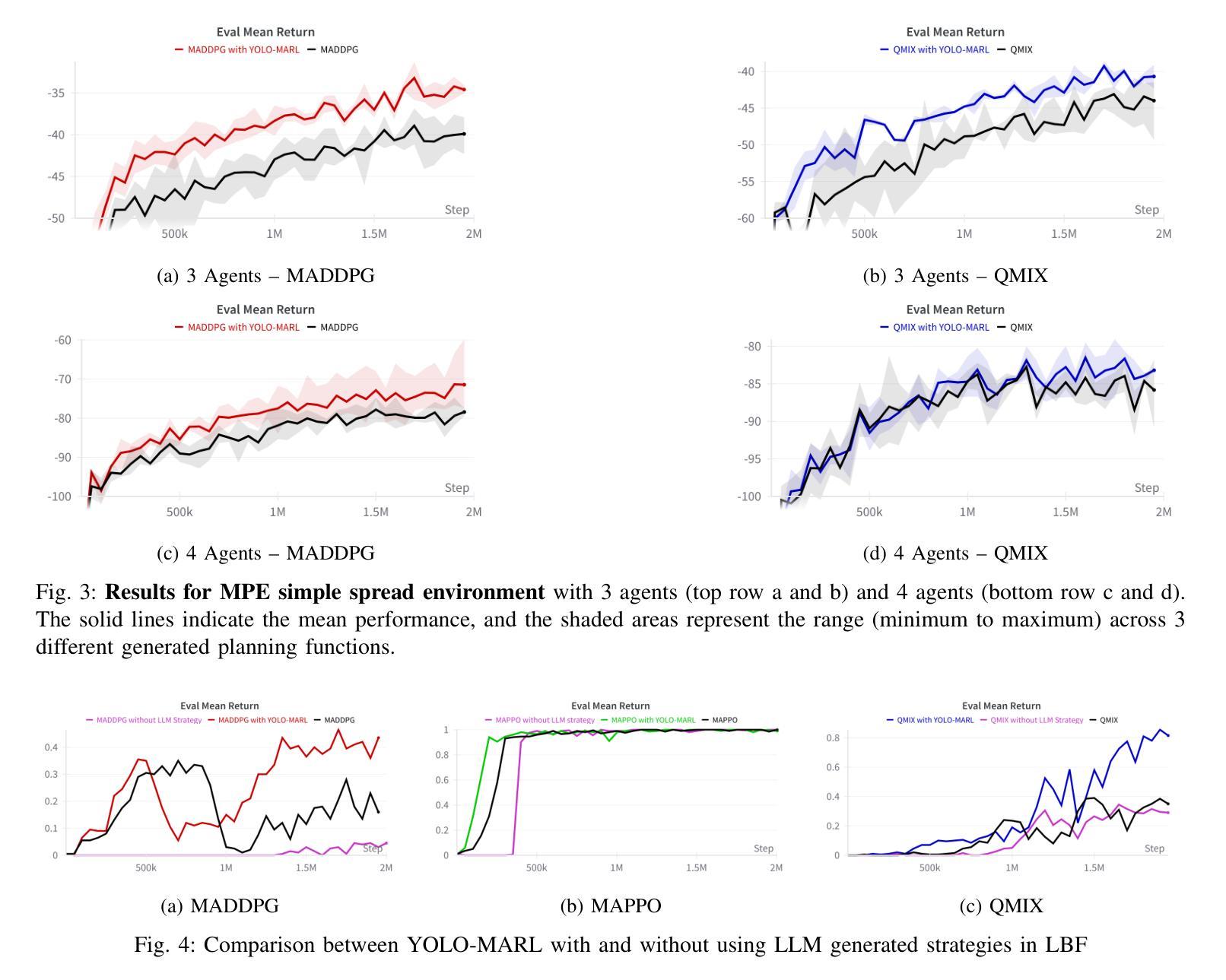
YOLO-MARL: You Only LLM Once for Multi-Agent Reinforcement Learning
Authors:Yuan Zhuang, Yi Shen, Zhili Zhang, Yuxiao Chen, Fei Miao
Advancements in deep multi-agent reinforcement learning (MARL) have positioned it as a promising approach for decision-making in cooperative games. However, it still remains challenging for MARL agents to learn cooperative strategies for some game environments. Recently, large language models (LLMs) have demonstrated emergent reasoning capabilities, making them promising candidates for enhancing coordination among the agents. However, due to the model size of LLMs, it can be expensive to frequently infer LLMs for actions that agents can take. In this work, we propose You Only LLM Once for MARL (YOLO-MARL), a novel framework that leverages the high-level task planning capabilities of LLMs to improve the policy learning process of multi-agents in cooperative games. Notably, for each game environment, YOLO-MARL only requires one time interaction with LLMs in the proposed strategy generation, state interpretation and planning function generation modules, before the MARL policy training process. This avoids the ongoing costs and computational time associated with frequent LLMs API calls during training. Moreover, trained decentralized policies based on normal-sized neural networks operate independently of the LLM. We evaluate our method across two different environments and demonstrate that YOLO-MARL outperforms traditional MARL algorithms.
深度多智能体强化学习(MARL)的进展使其成为一种在合作游戏中进行决策的有前途的方法。然而,对于某些游戏环境,MARL智能体学习合作策略仍然具有挑战性。最近,大型语言模型(LLM)表现出了涌现的推理能力,使其成为增强智能体之间协调性的有前途的候选者。然而,由于LLM的模型规模,频繁推断LLM来进行智能体可以采取的行动可能会很昂贵。在这项工作中,我们提出了You Only LLM Once for MARL(YOLO-MARL),这是一个利用LLM的高级任务规划能力来改善合作游戏中多智能体的策略学习过程的新框架。值得注意的是,对于每个游戏环境,YOLO-MARL仅在策略生成、状态解释和规划功能生成模块中要求与LLM进行一次交互,然后在MARL政策训练过程开始之前。这避免了训练过程中频繁的LLM API调用相关的持续成本和计算时间。此外,基于正常大小神经网络的训练后的分散策略独立于LLM运行。我们在两个不同的环境中评估了我们的方法,并证明YOLO-MARL优于传统的MARL算法。
论文及项目相关链接
PDF accepted to International Conference on Intelligent Robots and Systems (IROS2025)
Summary
深多智能体强化学习(MARL)在合作游戏中展现出潜力,但在某些游戏环境下,学习合作策略仍是挑战。大型语言模型(LLM)具备推理能力,可增强智能体间的协调。然而,LLM模型尺寸大,频繁用于动作推断成本高昂。本研究提出YOLO-MARL框架,利用LLM的高级任务规划能力改善多智能体的策略学习过程。YOLO-MARL仅需一次与LLM的互动,即可在策略生成、状态解读和规划功能生成模块中,进行MARL政策训练过程,降低计算时间和成本。在独立于LLM的正常大小神经网络训练分散政策后,表现出优于传统MARL算法的效果。
Key Takeaways
- 深多智能体强化学习(MARL)在合作游戏中面临学习合作策略的挑战。
- 大型语言模型(LLM)具备推理能力,可增强智能体间的协调,但模型尺寸大导致频繁推断成本高昂。
- YOLO-MARL框架利用LLM的高级任务规划能力,改善多智能体的策略学习过程。
- YOLO-MARL仅需一次与LLM互动,降低计算时间和成本。
- YOLO-MARL框架包括策略生成、状态解读和规划功能生成模块。
- 训练后的分散政策独立于LLM,表现优于传统MARL算法。
点此查看论文截图