⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
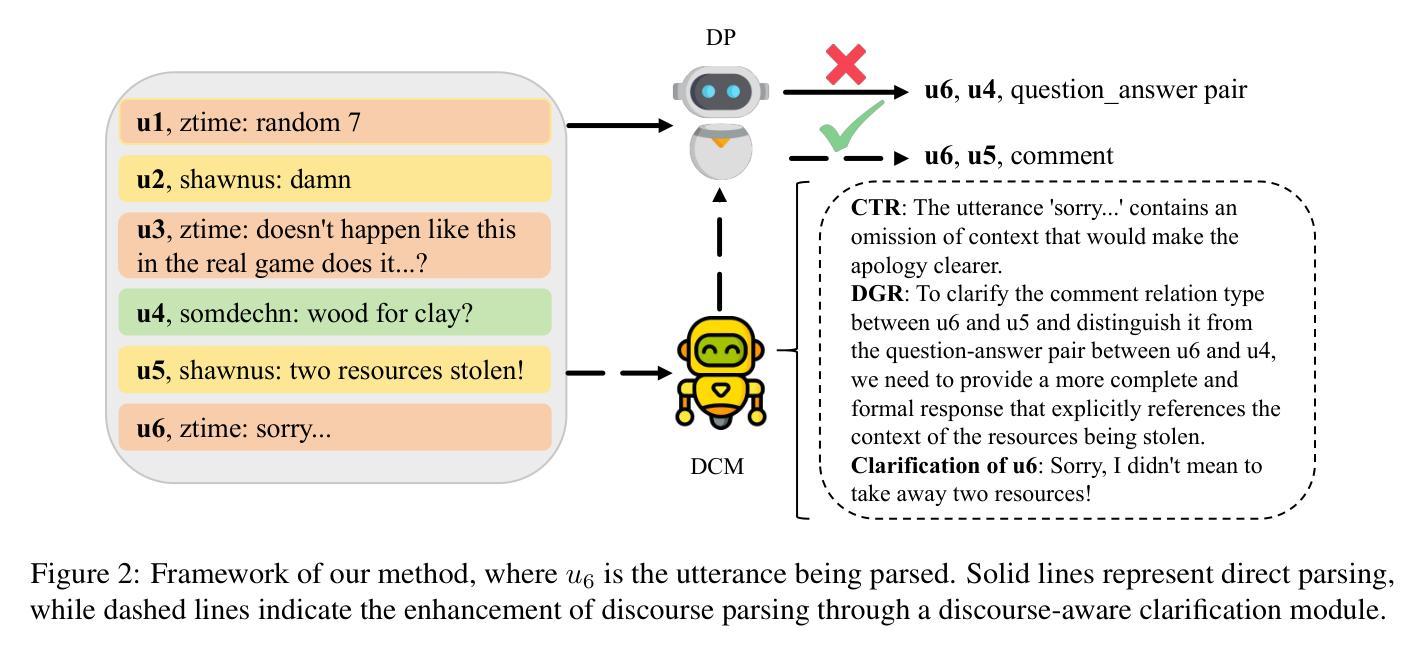
Improving Dialogue Discourse Parsing through Discourse-aware Utterance Clarification
Authors:Yaxin Fan, Peifeng Li, Qiaoming Zhu
Dialogue discourse parsing aims to identify and analyze discourse relations between the utterances within dialogues. However, linguistic features in dialogues, such as omission and idiom, frequently introduce ambiguities that obscure the intended discourse relations, posing significant challenges for parsers. To address this issue, we propose a Discourse-aware Clarification Module (DCM) to enhance the performance of the dialogue discourse parser. DCM employs two distinct reasoning processes: clarification type reasoning and discourse goal reasoning. The former analyzes linguistic features, while the latter distinguishes the intended relation from the ambiguous one. Furthermore, we introduce Contribution-aware Preference Optimization (CPO) to mitigate the risk of erroneous clarifications, thereby reducing cascading errors. CPO enables the parser to assess the contributions of the clarifications from DCM and provide feedback to optimize the DCM, enhancing its adaptability and alignment with the parser’s requirements. Extensive experiments on the STAC and Molweni datasets demonstrate that our approach effectively resolves ambiguities and significantly outperforms the state-of-the-art (SOTA) baselines.
对话文本解析旨在识别和分析对话中语句之间的文本关系。然而,对话中的语言特征,如省略和习惯用语,经常引入歧义,模糊了预期的文本关系,给解析器带来了重大挑战。为了解决这个问题,我们提出了一种基于文本感知的澄清模块(DCM)来提高对话文本解析器的性能。DCM采用两种不同的推理过程:澄清类型推理和文本目标推理。前者分析语言特征,后者区分预期的文本关系和模糊的文本关系。此外,我们引入了基于贡献的偏好优化(CPO)来降低错误澄清的风险,从而减少级联错误。CPO使解析器能够评估DCM的澄清贡献并提供反馈以优化DCM,提高其适应性和与解析器的要求相匹配。在STAC和Molweni数据集上的大量实验表明,我们的方法有效地解决了歧义问题,并显著优于当前最佳基线模型。
论文及项目相关链接
PDF Accepted by ACL2025(main conference)
Summary
对话文本解析旨在识别和解析对话中话语间的语段关系。然而,对话中的语言特征,如省略和习惯用语,经常引入歧义,掩盖了预期的语段关系,给解析器带来重大挑战。为解决此问题,我们提出了一个话语感知澄清模块(DCM)来提高对话文本解析器的性能。DCM采用两种独特的推理过程:澄清类型推理和话语目标推理。前者分析语言特征,后者区分预期关系与模糊关系。此外,我们引入了贡献感知偏好优化(CPO)来降低错误澄清的风险,从而减少级联错误。CPO使解析器能够评估DCM的澄清贡献并提供反馈以优化DCM,提高其适应性并与解析器的需求保持一致。在STAC和Molweni数据集上的广泛实验表明,我们的方法有效地解决了歧义问题,并显著优于现有技术(SOTA)基线。
Key Takeaways
- 对话文本解析的目标是识别和解析对话中的语段关系。
- 语言特征如省略和习惯用语可能引入歧义,影响语段关系的识别。
- 话语感知澄清模块(DCM)用于提高对话文本解析性能。
- DCM通过澄清类型推理和话语目标推理两种推理过程来工作。
- 贡献感知偏好优化(CPO)用于降低错误澄清的风险,减少级联错误。
- CPO使解析器能够评估DCM的澄清贡献并提供反馈以优化其性能。
点此查看论文截图


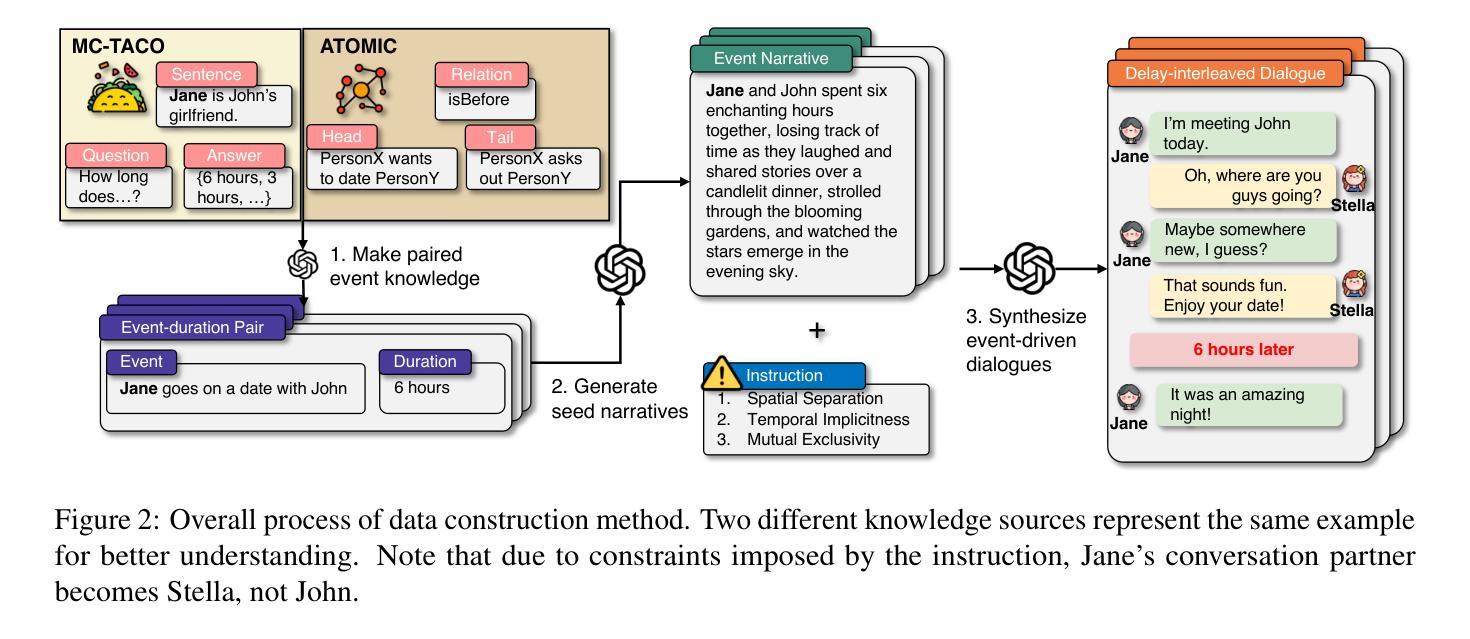
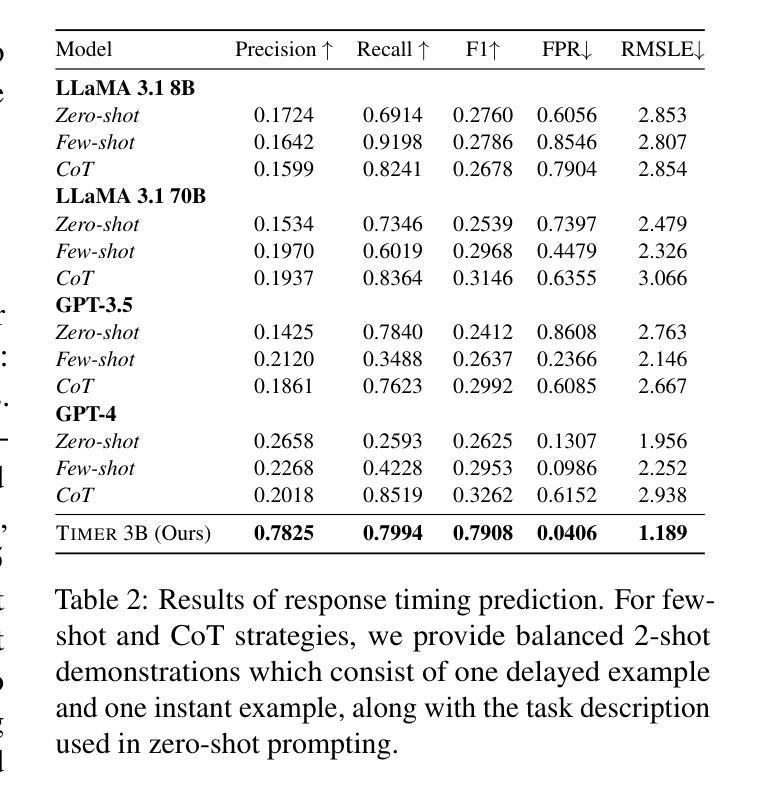
From What to Respond to When to Respond: Timely Response Generation for Open-domain Dialogue Agents
Authors:Seongbo Jang, Minjin Jeon, Jaehoon Lee, Seonghyeon Lee, Dongha Lee, Hwanjo Yu
While research on dialogue response generation has primarily focused on generating coherent responses conditioning on textual context, the critical question of when to respond grounded on the temporal context remains underexplored. To bridge this gap, we propose a novel task called timely dialogue response generation and introduce the TimelyChat benchmark, which evaluates the capabilities of language models to predict appropriate time intervals and generate time-conditioned responses. Additionally, we construct a large-scale training dataset by leveraging unlabeled event knowledge from a temporal commonsense knowledge graph and employing a large language model (LLM) to synthesize 55K event-driven dialogues. We then train Timer, a dialogue agent designed to proactively predict time intervals and generate timely responses that align with those intervals. Experimental results show that Timer outperforms prompting-based LLMs and other fine-tuned baselines in both turn-level and dialogue-level evaluations. We publicly release our data, model, and code.
对话应答生成的研究主要聚焦于基于文本语境生成连贯的应答,而基于时间语境的应答时机这一关键问题仍未得到充分探索。为了填补这一空白,我们提出了一个名为“及时对话应答生成”的新任务,并引入了TimelyChat基准测试,该测试评估语言模型预测合适的时间间隔和生成时间条件应答的能力。此外,我们利用时间常识知识图谱中的未标注事件知识,采用大型语言模型(LLM)合成了5.5万条事件驱动对话,构建了一个大规模训练数据集。然后,我们训练了Timer对话机器人,该机器人能够主动预测时间间隔并生成与这些间隔相符的及时响应。实验结果表明,Timer在回合级和对话级的评估中都优于基于提示的LLM和其他微调基准测试。我们公开发布了我们的数据、模型和代码。
论文及项目相关链接
PDF Work in progress
Summary
本文主要研究了对话响应生成中的一个新任务——及时对话响应生成,并为此建立了TimelyChat基准测试平台。该研究旨在评估语言模型预测合适时间间隔和生成时间条件响应的能力。为弥补现有研究的不足,研究者利用时间常识知识图谱的无标签事件知识,通过大型语言模型(LLM)合成55K事件驱动对话,构建大规模训练数据集。实验结果表明,Timer对话代理在回合和对话级别评估中均优于基于提示的LLM和其他微调基线。
Key Takeaways
- 提出及时对话响应生成的新任务,强调语言模型在预测合适时间间隔和生成与时间相关的响应方面的能力的重要性。
- 建立TimelyChat基准测试平台,用于评估语言模型在及时对话响应生成方面的性能。
- 通过利用时间常识知识图谱的无标签事件知识,结合大型语言模型(LLM),合成大规模事件驱动对话训练数据集。
- 介绍对话代理“Timer”,该代理可预测时间间隔并生成与这些间隔相符的及时响应。
- Timer在回合和对话级别的评估中表现出优于基于提示的LLM和其他微调基线的性能。
- 研究结果填补了现有对话响应生成研究在基于时间上下文方面的不足。
点此查看论文截图


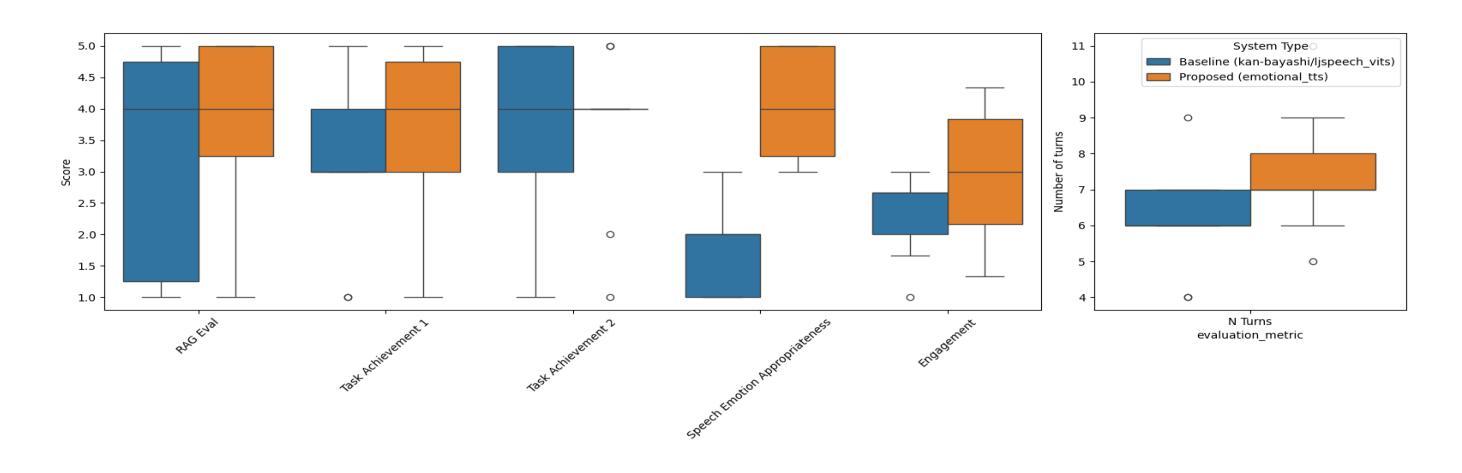
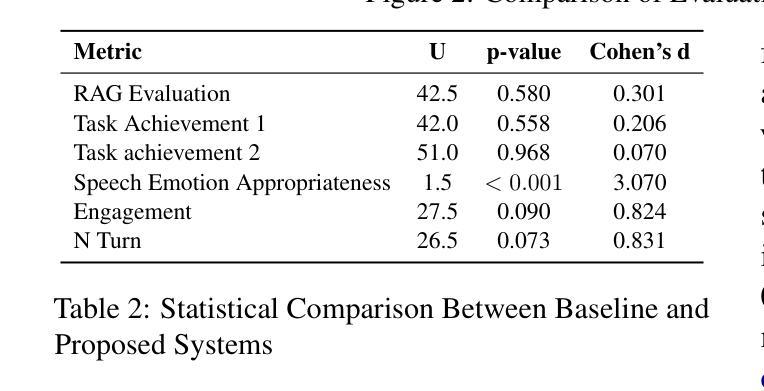
EmoNews: A Spoken Dialogue System for Expressive News Conversations
Authors:Ryuki Matsuura, Shikhar Bharadwaj, Jiarui Liu, Dhatchi Kunde Govindarajan
We develop a task-oriented spoken dialogue system (SDS) that regulates emotional speech based on contextual cues to enable more empathetic news conversations. Despite advancements in emotional text-to-speech (TTS) techniques, task-oriented emotional SDSs remain underexplored due to the compartmentalized nature of SDS and emotional TTS research, as well as the lack of standardized evaluation metrics for social goals. We address these challenges by developing an emotional SDS for news conversations that utilizes a large language model (LLM)-based sentiment analyzer to identify appropriate emotions and PromptTTS to synthesize context-appropriate emotional speech. We also propose subjective evaluation scale for emotional SDSs and judge the emotion regulation performance of the proposed and baseline systems. Experiments showed that our emotional SDS outperformed a baseline system in terms of the emotion regulation and engagement. These results suggest the critical role of speech emotion for more engaging conversations. All our source code is open-sourced at https://github.com/dhatchi711/espnet-emotional-news/tree/emo-sds/egs2/emo_news_sds/sds1
我们开发了一个面向任务的口语对话系统(SDS),该系统基于上下文线索调控情感语音,以实现更具同理心的新闻对话。尽管情感文本到语音(TTS)技术取得了进展,但由于SDS和情绪TTS研究的分隔性质以及缺乏对社会目标的标准化评估指标,面向任务的情感SDS仍然被较少探索。我们通过开发用于新闻对话的情感SDS来解决这些挑战,该系统利用基于大型语言模型(LLM)的情感分析器来识别适当的情感,并使用PromptTTS合成适当的上下文情感语音。我们还为情感SDS提出了主观评价量表,并判断所提出系统和基线系统的情感调节性能。实验表明,我们的情感SDS在情感调节和参与度方面优于基线系统。这些结果突显了语音情感对于更引人入胜的对话的关键作用。我们的所有源代码均已开源,可在[https://github.com/dhatchi711/espnet-emotional-news/tree/emo-sds/egs2/emo_news_sds/sds1找到。
论文及项目相关链接
Summary
本文开发了一种面向任务的对话系统(SDS),该系统基于上下文线索调节情感语音,以实现更具同理心的新闻对话。作者针对当前情绪文本到语音(TTS)技术的挑战,提出了一个情感SDS,该SDS采用基于大型语言模型的情感分析器来识别适当情绪和PromptTTS技术合成适合上下文的情感语音。此外,作者还提出了一种针对情感SDS的主观评价体系,并对所提出的系统进行了情感调节性能评估。实验结果表明,该情感SDS在情感调节和参与度方面优于基线系统。
Key Takeaways
- 开发了一种面向任务的对话系统(SDS),该系统能够基于上下文线索调节情感语音,促进更具同理心的新闻对话。
- 利用大型语言模型(LLM)的情感分析器识别适当的情绪。
- 采用PromptTTS技术合成与上下文相适应的情感语音。
- 提出了一种针对情感SDS的主观评价体系。
- 实验证明,该情感SDS在情感调节和参与度方面优于基线系统。
- 开放源代码,便于他人在此基础上进行研究和改进。
点此查看论文截图


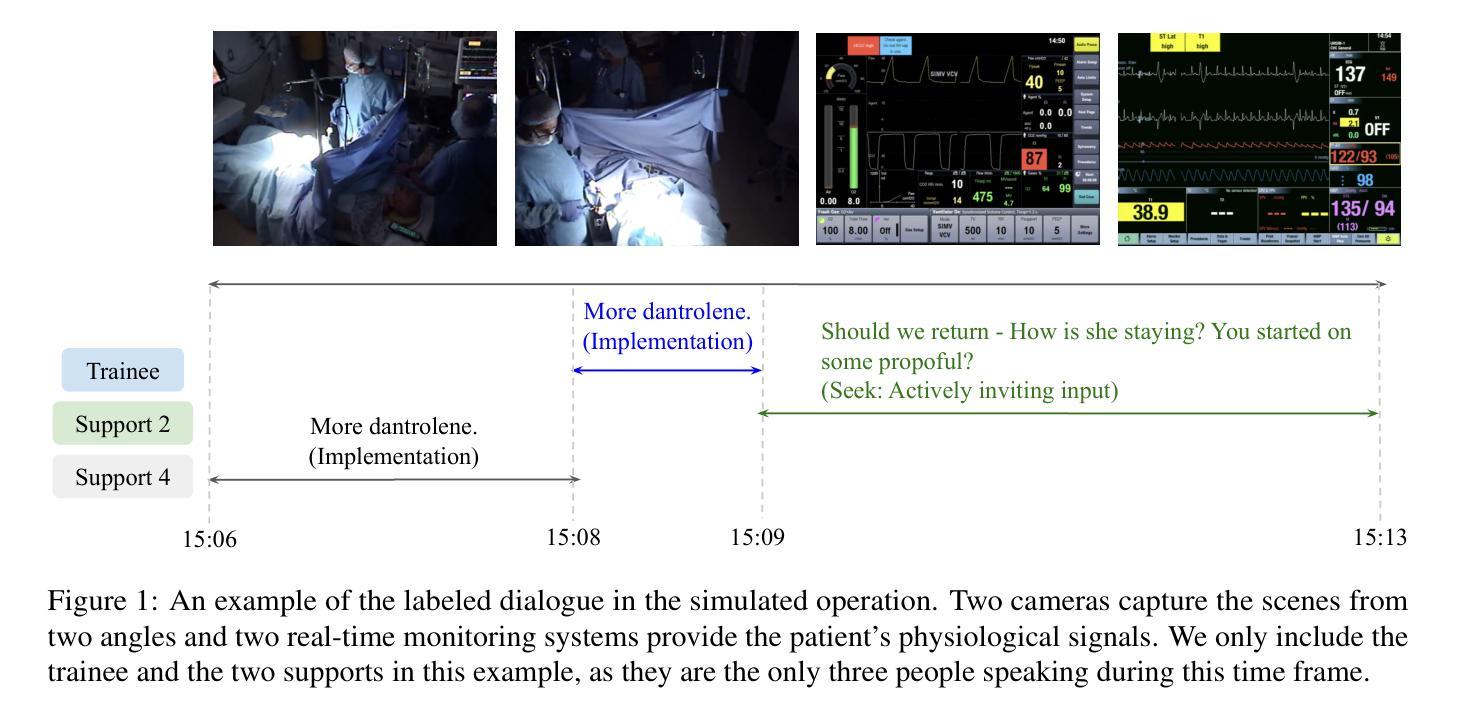
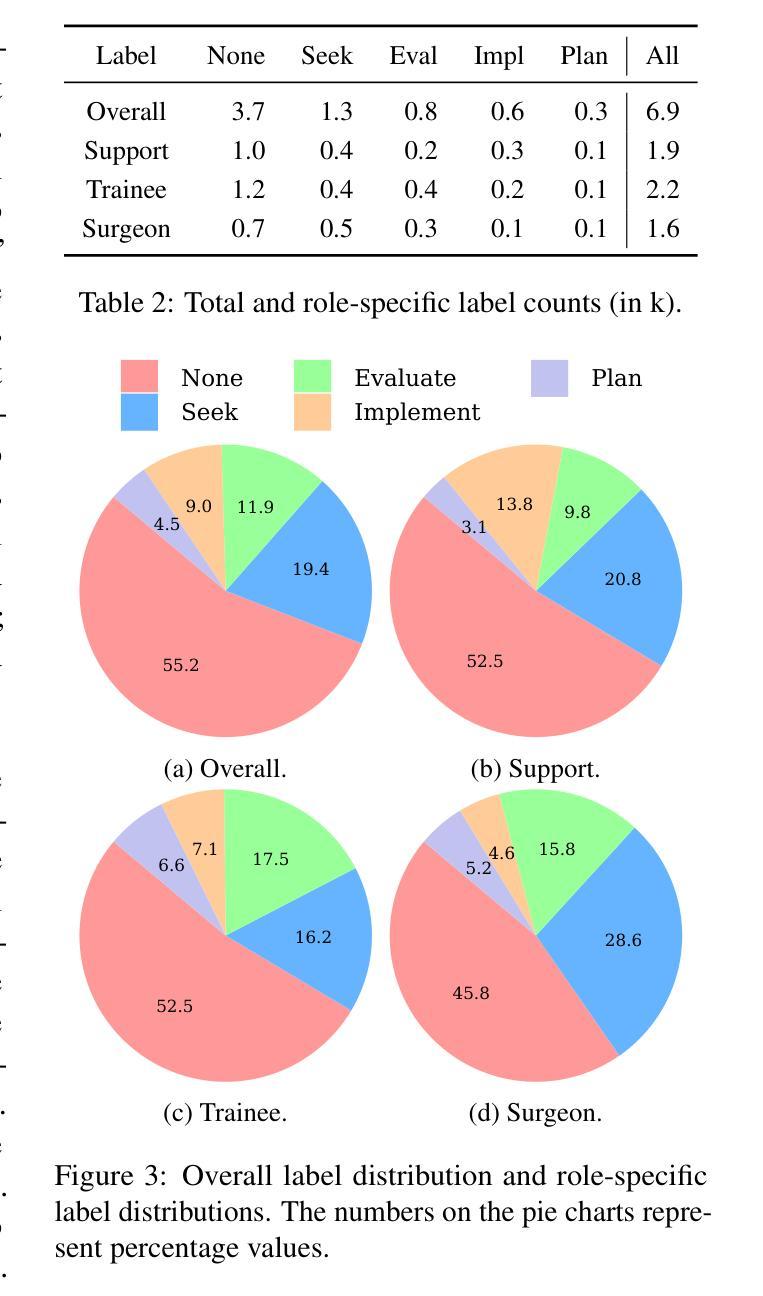
CliniDial: A Naturally Occurring Multimodal Dialogue Dataset for Team Reflection in Action During Clinical Operation
Authors:Naihao Deng, Kapotaksha Das, Rada Mihalcea, Vitaliy Popov, Mohamed Abouelenien
In clinical operations, teamwork can be the crucial factor that determines the final outcome. Prior studies have shown that sufficient collaboration is the key factor that determines the outcome of an operation. To understand how the team practices teamwork during the operation, we collected CliniDial from simulations of medical operations. CliniDial includes the audio data and its transcriptions, the simulated physiology signals of the patient manikins, and how the team operates from two camera angles. We annotate behavior codes following an existing framework to understand the teamwork process for CliniDial. We pinpoint three main characteristics of our dataset, including its label imbalances, rich and natural interactions, and multiple modalities, and conduct experiments to test existing LLMs’ capabilities on handling data with these characteristics. Experimental results show that CliniDial poses significant challenges to the existing models, inviting future effort on developing methods that can deal with real-world clinical data. We open-source the codebase at https://github.com/MichiganNLP/CliniDial
在临床试验中,团队合作可能是决定最终结果的至关重要的因素。早期的研究已经表明,充分的协作是决定手术结果的关键因素。为了了解团队在手术过程中如何进行团队合作,我们从模拟的医学手术中收集了CliniDial数据。CliniDial包括音频数据和其转录记录、模拟的病人模拟生理信号以及两个相机角度下团队的手术操作过程。我们使用现有框架对行为代码进行标注,以理解CliniDial中的团队合作过程。我们确定了数据集三个主要特点,包括标签不平衡、丰富自然的交互以及多种模态,并进行了实验来测试现有大型语言模型处理这些特点数据的能力。实验结果表明,CliniDial对现有模型构成了重大挑战,需要未来开发能够处理现实世界临床数据的方法。我们在https://github.com/MichiganNLP/CliniDial上公开了代码库。
论文及项目相关链接
PDF Accepted to ACL 2025 Findings
Summary
本文介绍了在医疗操作中的团队合作的重要性,并引入了CliniDial数据集,该数据集通过模拟医疗操作收集音频数据及其转录、患者模拟生理信号以及两个角度的摄像数据,以理解团队合作过程。文章强调了数据集的三个主要特点,包括标签不平衡、丰富的自然交互和多种模态,并进行了实验以测试现有大型语言模型处理此类数据的能力。实验结果表明,CliniDial对现有模型构成挑战,并鼓励未来开发能够处理真实临床数据的方法。数据集已在GitHub上开源。
Key Takeaways
- 团队合作在医疗操作中至关重要,可决定最终手术结果。
- 引入CliniDial数据集,该数据集包含医疗操作中的音频、转录、患者生理信号及团队行为影像数据。
- 数据集具有三个主要特点:标签不平衡、丰富的自然交互和多种模态。
- 通过实验发现CliniDial对现有模型构成挑战。
- 开源数据集以促进对处理真实临床数据方法的研究。
- 数据集可用于研究和提高医疗团队的合作效率和沟通能力。
点此查看论文截图

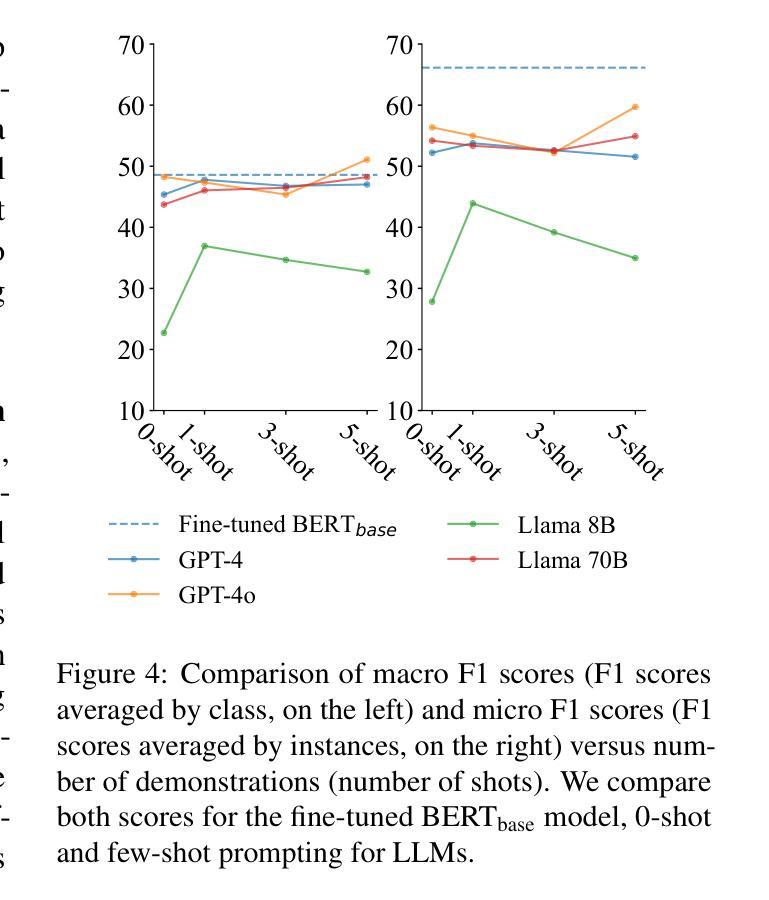

Improving Factuality for Dialogue Response Generation via Graph-Based Knowledge Augmentation
Authors:Xiangyan Chen, Yujian Gan, Matthew Purver
Large Language Models (LLMs) succeed in many natural language processing tasks. However, their tendency to hallucinate - generate plausible but inconsistent or factually incorrect text - can cause problems in certain tasks, including response generation in dialogue. To mitigate this issue, knowledge-augmented methods have shown promise in reducing hallucinations. Here, we introduce a novel framework designed to enhance the factuality of dialogue response generation, as well as an approach to evaluate dialogue factual accuracy. Our framework combines a knowledge triple retriever, a dialogue rewrite, and knowledge-enhanced response generation to produce more accurate and grounded dialogue responses. To further evaluate generated responses, we propose a revised fact score that addresses the limitations of existing fact-score methods in dialogue settings, providing a more reliable assessment of factual consistency. We evaluate our methods using different baselines on the OpendialKG and HybriDialogue datasets. Our methods significantly improve factuality compared to other graph knowledge-augmentation baselines, including the state-of-the-art G-retriever. The code will be released on GitHub.
大型语言模型(LLMs)在许多自然语言处理任务中取得了成功。然而,它们倾向于产生合理但自相矛盾或事实错误的文本,这在某些任务中(包括对对话中的回答生成)可能会引发问题。为了缓解这一问题,知识增强方法在减少幻觉方面显示出希望。在这里,我们介绍了一个旨在提高对话回答生成的事实性的新型框架,以及一种评估对话事实准确性的方法。我们的框架结合了知识三元组检索器、对话重写和知识增强回答生成,以产生更准确、更切实的对话回答。为了对生成的回答进行进一步评估,我们提出了修订的事实得分,解决了现有事实得分方法在对话环境中的局限性,提供了更可靠的现实一致性评估。我们在OpendialKG和HybriDialogue数据集上使用不同的基线评估了我们的方法。我们的方法在事实性方面显著改进了与其他图形知识增强基线的比较,包括最先进的G-检索器。代码将在GitHub上发布。
论文及项目相关链接
Summary
大型语言模型在自然语言处理任务中取得了巨大成功,但其产生的文本往往具有幻想性,导致某些任务出现问题,如对话生成响应。为缓解这一问题,知识增强方法显示出减少幻想的潜力。本文介绍了一种旨在提高对话响应生成的事实性的新型框架,以及一种评估对话事实准确性的方法。该框架结合了知识三元组检索器、对话重写和知识增强响应生成,以产生更准确、更实际的对话响应。为了评估生成的响应,我们提出了一种改进的事实得分,该得分解决了现有事实得分方法在对话设置中的局限性,提供更可靠的实质性一致性评估。我们的方法在OpendialKG和HybriDialogue数据集上进行评估,与包括当前先进技术G-retriever在内的其他图形知识增强基线相比,显著提高了事实性。
Key Takeaways
- 大型语言模型在自然语言处理任务中表现出色,但在对话生成响应方面存在幻想性问题。
- 知识增强方法有助于减少大型语言模型的幻想问题。
- 新型框架结合了知识三元组检索器、对话重写和知识增强响应生成,旨在提高对话响应的事实性。
- 提出了一种改进的对话事实评估方法,以更可靠地评估生成的对话响应的事实一致性。
- 该方法在OpendialKG和HybriDialogue数据集上进行了评估,显著提高了事实性,优于其他知识增强方法。
- 该方法将有助于增强对话系统的可靠性,减少由于幻想导致的误解和问题。
点此查看论文截图

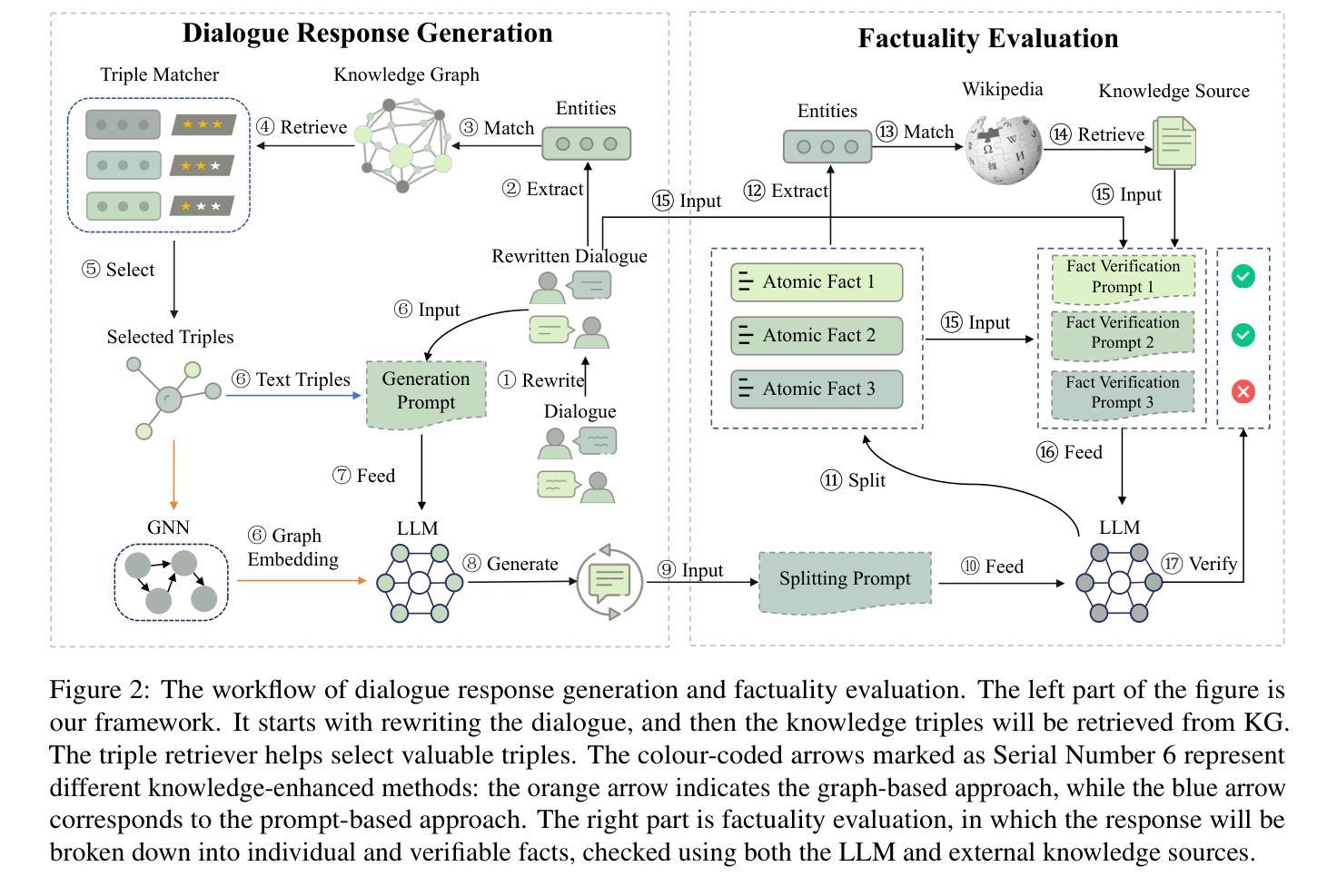
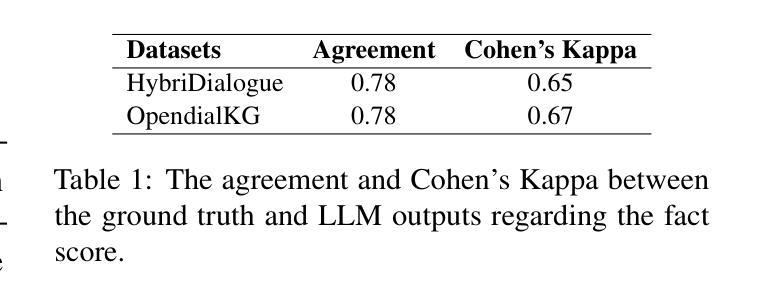
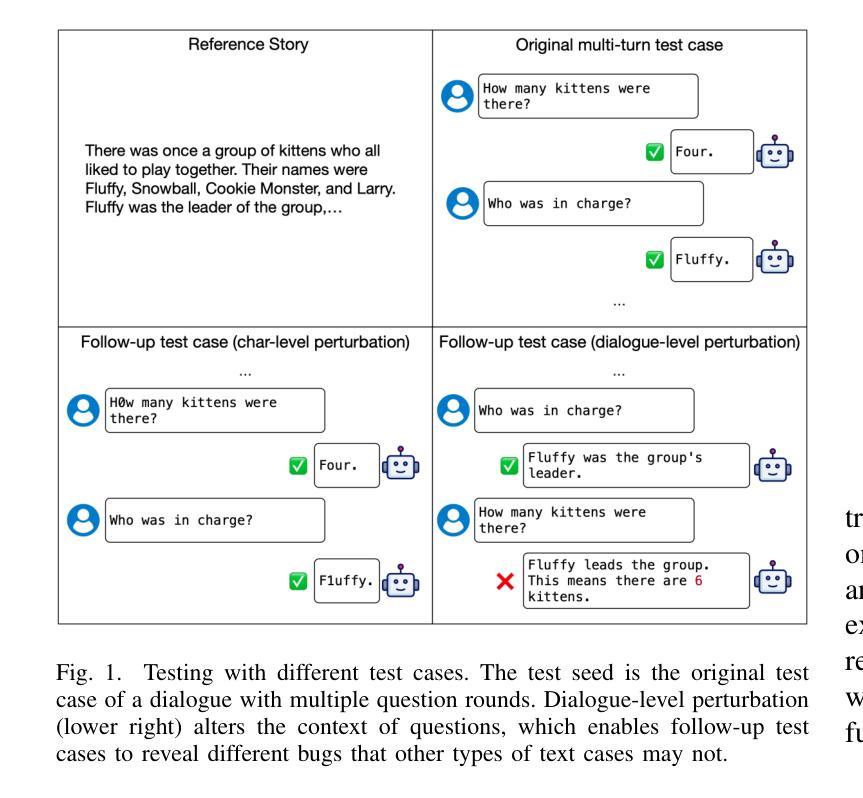
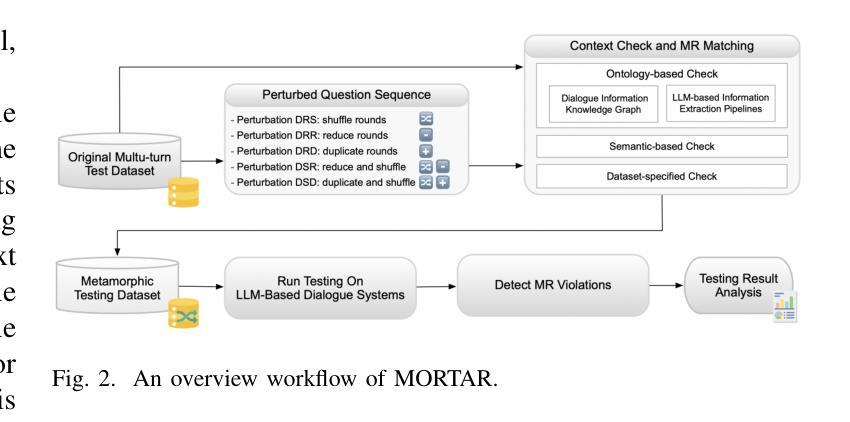
MORTAR: Multi-turn Metamorphic Testing for LLM-based Dialogue Systems
Authors:Guoxiang Guo, Aldeida Aleti, Neelofar Neelofar, Chakkrit Tantithamthavorn, Yuanyuan Qi, Tsong Yueh Chen
With the widespread application of LLM-based dialogue systems in daily life, quality assurance has become more important than ever. Recent research has successfully introduced methods to identify unexpected behaviour in single-turn testing scenarios. However, multi-turn interaction is the common real-world usage of dialogue systems, yet testing methods for such interactions remain underexplored. This is largely due to the oracle problem in multi-turn testing, which continues to pose a significant challenge for dialogue system developers and researchers. In this paper, we propose MORTAR, a metamorphic multi-turn dialogue testing approach, which mitigates the test oracle problem in testing LLM-based dialogue systems. MORTAR formalises the multi-turn testing for dialogue systems, and automates the generation of question-answer dialogue test cases with multiple dialogue-level perturbations and metamorphic relations (MRs). The automated perturbation-MR matching mechanism allows MORTAR more flexibility and efficiency in metamorphic testing. The proposed approach is fully automated without reliance on potentially biased LLMs as test oracles. In testing six popular LLM-based dialogue systems, MORTAR reaches significantly better effectiveness with over 150% more bugs revealed per test case when compared to the single-turn metamorphic testing baseline. On the quality of bugs, MORTAR reveals higher-quality bugs in terms of diversity, precision and uniqueness. MORTAR is expected to inspire more multi-turn testing approaches without LLM judges, and assist developers to evaluate the dialogue system performance more comprehensively with constrained test resources and budget.
随着基于LLM的对话系统在日常生活中的应用日益广泛,质量保障变得尤为重要。最近的研究已经成功引入了在单轮测试场景中识别意外行为的方法。然而,多轮交互是对话系统在现实世界中的常见用法,但针对此类交互的测试方法仍然研究不足。这主要是由于多轮测试中的“金标准”问题,它继续给对话系统开发人员和研究人员带来重大挑战。在本文中,我们提出了MORTAR,一种用于测试基于LLM的对话系统的多轮变异测试方法,它减轻了测试金标准问题。MORTAR为对话系统的多轮测试制定了规范,并自动生成具有多个对话级别扰动和变异关系(MRs)的问题答案测试用例。自动化的扰动-MR匹配机制使MORTAR在变异测试中更具灵活性和效率。该方法完全自动化,不依赖于可能带有偏见的LLMs作为测试金标准。在测试六个流行的基于LLM的对话系统时,与单轮变异测试基线相比,MORTAR在有效性方面达到了更高的水平,每个测试用例发现的错误数量增加了超过150%。在错误质量方面,MORTAR在多样性、精确度和唯一性方面揭示了更高质量的错误。预计MORTAR将激发更多不需要LLM法官的多轮测试方法,并帮助开发人员在有限的测试资源和预算下更全面地评估对话系统性能。
论文及项目相关链接
摘要
随着大语言模型(LLM)为基础的对话系统在日常生活中的应用日益广泛,质量保障显得尤为重要。针对单轮测试场景中的意外行为识别方法已经取得进展,但多轮交互作为对话系统在现实生活中的常见用法,其测试方法仍然缺乏研究。这主要是由于多轮测试中的“金标准”问题仍为对话系统开发者与研究人员带来重大挑战。本文提出一种名为MORTAR的变异多轮对话测试方法,该方法旨在缓解测试LLM基础对话系统时的测试金标准问题。MORTAR对对话系统的多轮测试进行了形式化,并自动化生成具有多种对话级别扰动和变异关系(MRs)的问题答案测试用例。自动扰动-MR匹配机制为MORTAR在变异测试中提供了更大的灵活性和效率。该方法完全自动化运行,无需依赖可能存在偏见的LLM作为测试金标准。在对六个流行的LLM基础对话系统进行测试时,与单轮变异测试基线相比,MORTAR在效果上达到了显著的提升,每个测试用例发现的错误数量增加了超过150%。在错误质量方面,MORTAR在多样性、精确度和唯一性方面揭示了更高质量的错误。预计MORTAR将激发更多无需LLM判断的多轮测试方法,并帮助开发者在有限的测试资源和预算下更全面地评估对话系统性能。
关键见解
- 多轮对话测试在对话系统质量保障中至关重要,但相关研究仍然不足。
- MORTAR是一种针对LLM基础对话系统的变异多轮测试方法,旨在解决多轮测试中的“金标准”问题。
- MORTAR通过自动化生成具有多种对话级别扰动和变异关系的测试用例,提高了测试的灵活性和效率。
- MORTAR完全自动化运行,不依赖可能存在偏见的LLM。
- 对比单轮测试基线,MORTAR在测试中表现出更高的有效性,每个测试用例发现的错误数量增加了超过150%。
- MORTAR揭示了更高质量的错误,表现在多样性、精确度和唯一性方面。
点此查看论文截图

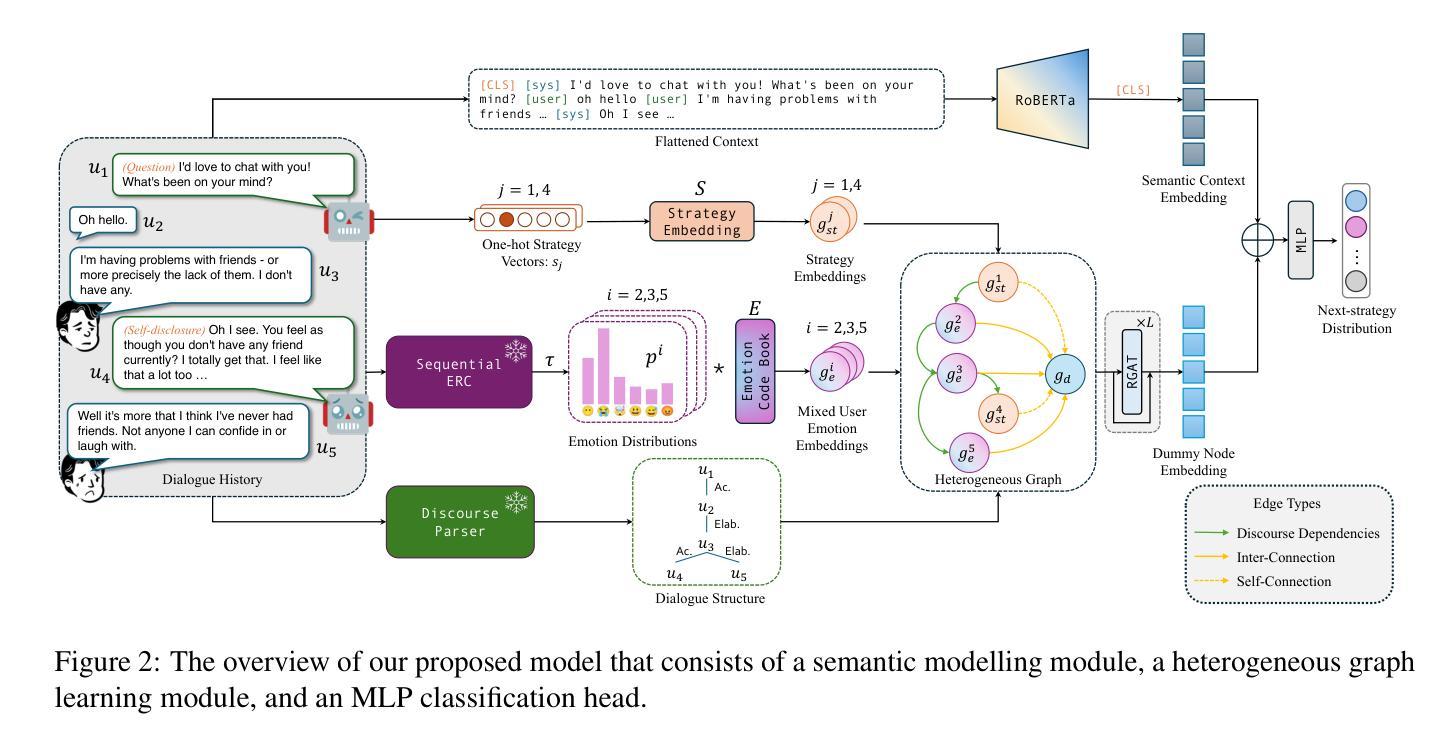
EmoDynamiX: Emotional Support Dialogue Strategy Prediction by Modelling MiXed Emotions and Discourse Dynamics
Authors:Chenwei Wan, Matthieu Labeau, Chloé Clavel
Designing emotionally intelligent conversational systems to provide comfort and advice to people experiencing distress is a compelling area of research. Recently, with advancements in large language models (LLMs), end-to-end dialogue agents without explicit strategy prediction steps have become prevalent. However, implicit strategy planning lacks transparency, and recent studies show that LLMs’ inherent preference bias towards certain socio-emotional strategies hinders the delivery of high-quality emotional support. To address this challenge, we propose decoupling strategy prediction from language generation, and introduce a novel dialogue strategy prediction framework, EmoDynamiX, which models the discourse dynamics between user fine-grained emotions and system strategies using a heterogeneous graph for better performance and transparency. Experimental results on two ESC datasets show EmoDynamiX outperforms previous state-of-the-art methods with a significant margin (better proficiency and lower preference bias). Our approach also exhibits better transparency by allowing backtracing of decision making.
设计具有情感智能的对话系统,为经历压力的人提供安慰和建议是一个引人入胜的研究领域。最近,随着大型语言模型(LLM)的进步,无需明确策略预测步骤的端到端对话代理已经变得普遍。然而,隐式策略规划缺乏透明度,最近的研究表明,LLM对某些社会情感策略的固有偏好偏向阻碍了提供高质量的情感支持。为了应对这一挑战,我们提出了将策略预测与语言生成解耦,并引入了一种新型对话策略预测框架EmoDynamiX。该框架使用异构图对用户精细情绪与系统策略之间的对话动态进行建模,以实现更好的性能和透明度。在两个ESC数据集上的实验结果表明,EmoDynamiX以前所未有的优势超越了以前的最先进方法(更高的熟练程度和更低的偏好偏见)。我们的方法还通过允许回溯决策制定而展现出更好的透明度。
论文及项目相关链接
PDF Accepted to NAACL 2025 main, long paper
Summary
设计具有情感智能的对话系统,为经历困扰的人提供安慰和建议是一个引人入胜的研究领域。随着大型语言模型(LLMs)的进步,端到端的对话代理无需明确的策略预测步骤变得普遍起来。然而,隐式策略规划缺乏透明度,且研究表明LLMs对特定社会情感策略的固有偏好偏向阻碍了高质量情感支持的提供。为解决这一挑战,我们提出了将策略预测与语言生成相分离的方法,并引入了一种新型对话策略预测框架EmoDynamiX。该框架利用异构图对用户精细情绪与系统策略之间的对话动态进行建模,以实现更好的性能和透明度。在两项ESC数据集上的实验结果表明,EmoDynamiX显著优于以前的最先进方法。我们的方法还通过允许回溯决策制定而具有更好的透明度。
Key Takeaways
- 设计情感智能对话系统对于为经历困扰的人提供支持和建议具有重要意义。
- 大型语言模型(LLMs)的进步使得端到端对话系统的普及成为可能,但隐式策略规划缺乏透明度。
- LLMs对社会情感策略的固有偏好可能影响提供高质量情感支持的能力。
- 提出了一种新的对话策略预测框架EmoDynamiX,旨在解决上述问题。
- EmoDynamiX利用异构图对用户精细情绪与系统策略之间的对话动态进行建模,提升性能和透明度。
- 在两个ESC数据集上的实验显示,EmoDynamiX显著优于其他方法,具有更高的专业能力和更低的偏好偏见。
点此查看论文截图