⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
Making LLMs Better Many-to-Many Speech-to-Text Translators with Curriculum Learning
Authors:Yexing Du, Youcheng Pan, Ziyang Ma, Bo Yang, Yifan Yang, Keqi Deng, Xie Chen, Yang Xiang, Ming Liu, Bing Qin
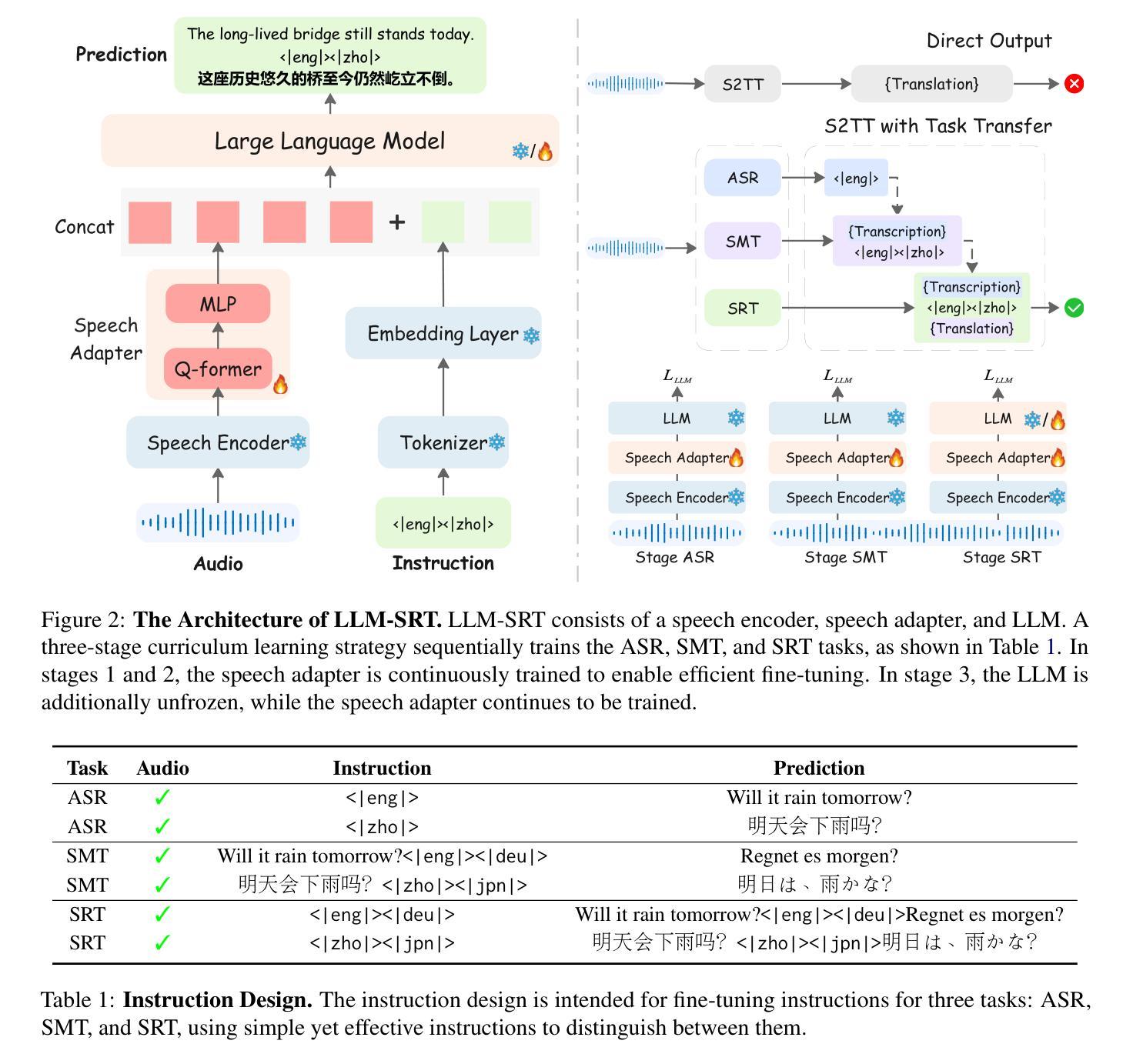
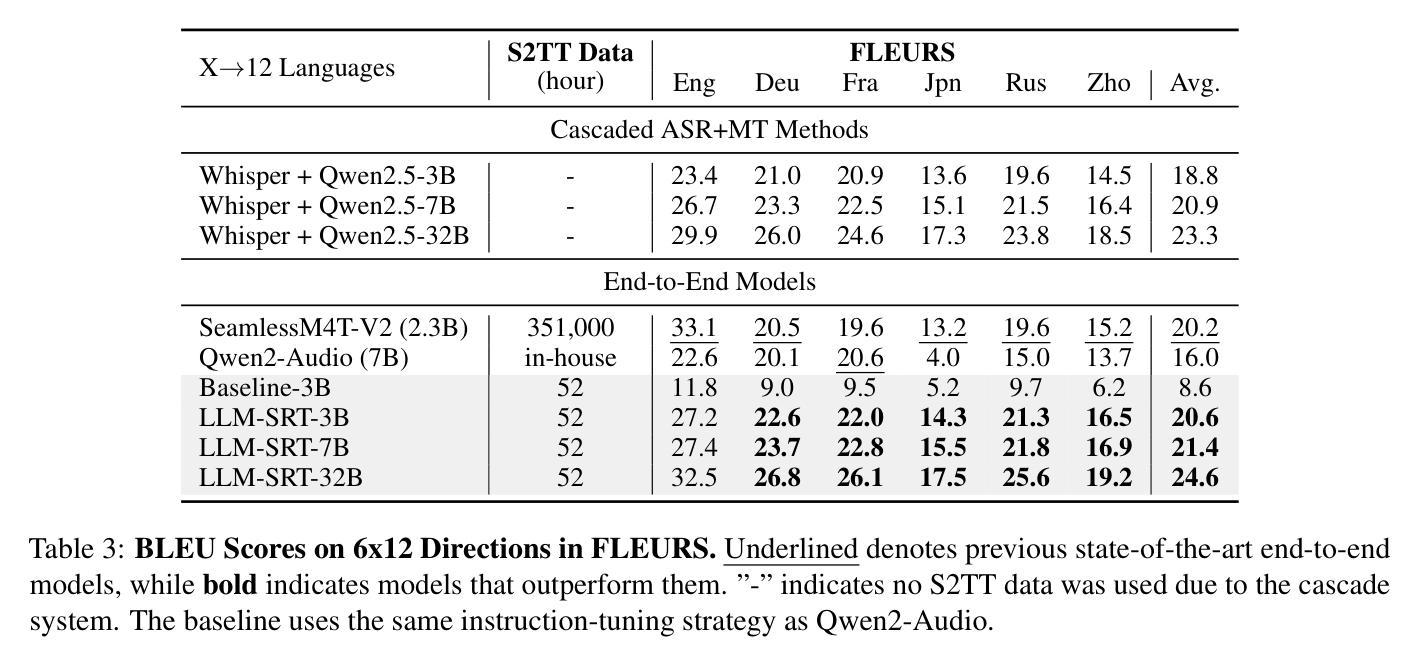
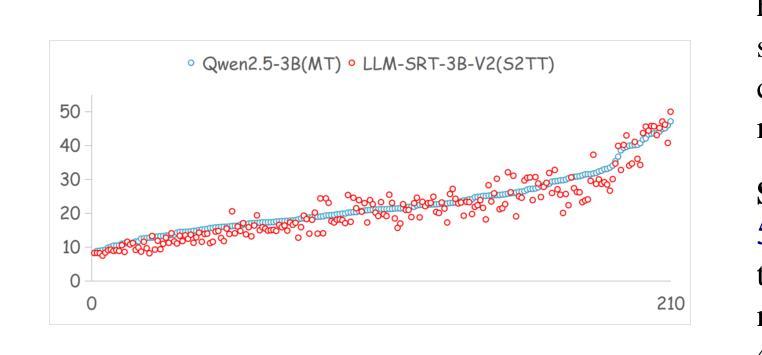
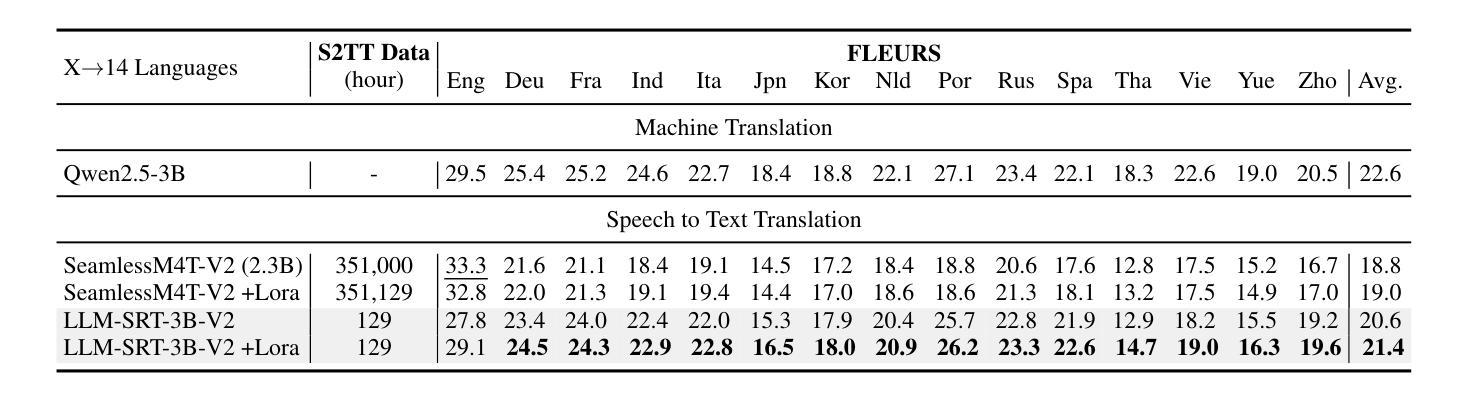
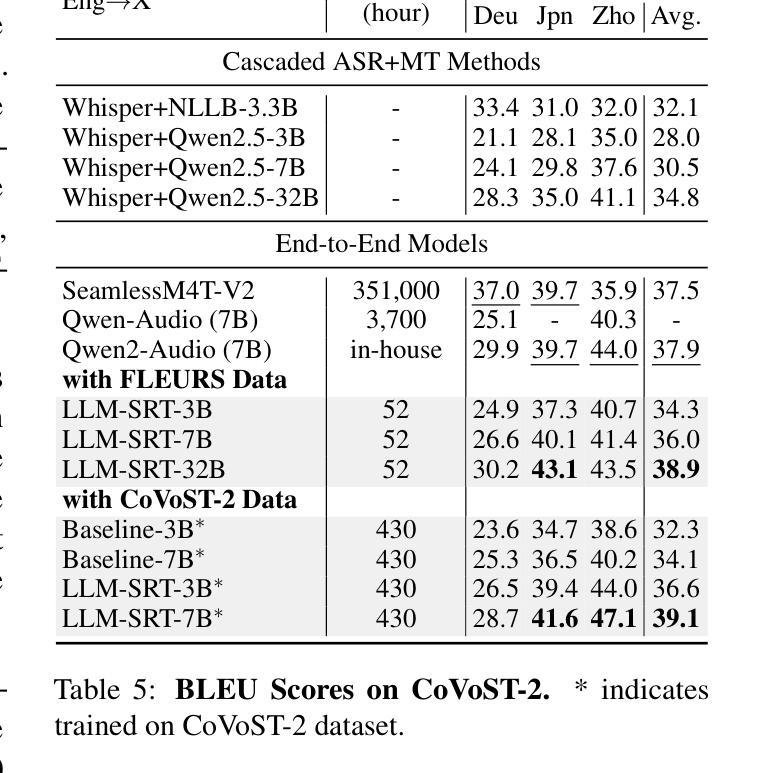
Multimodal Large Language Models (MLLMs) have achieved significant success in Speech-to-Text Translation (S2TT) tasks. While most existing research has focused on English-centric translation directions, the exploration of many-to-many translation is still limited by the scarcity of parallel data. To address this, we propose a three-stage curriculum learning strategy that leverages the machine translation capabilities of large language models and adapts them to S2TT tasks, enabling effective learning in low-resource settings. We trained MLLMs with varying parameter sizes (3B, 7B, and 32B) and evaluated the proposed strategy using the FLEURS and CoVoST-2 datasets. Experimental results show that the proposed strategy achieves state-of-the-art average performance in $15\times14$ language pairs, requiring fewer than 10 hours of speech data per language to achieve competitive results. The source code and models are released at https://github.com/yxduir/LLM-SRT.
多模态大型语言模型(MLLMs)在语音到文本翻译(S2TT)任务中取得了巨大成功。虽然大多数现有研究都集中在以英语为中心的翻译方向,但多对多的翻译探索仍然受到并行数据稀缺的限制。为了解决这一问题,我们提出了一种三阶段课程学习策略,利用大型语言模型的机器翻译能力,并将其适应于S2TT任务,从而在低资源环境中实现有效学习。我们训练了具有不同参数大小(3B、7B和32B)的MLLMs,并使用FLEURS和CoVoST-2数据集对提出的策略进行了评估。实验结果表明,该策略在$15\times14$语言对上达到了最先进的平均性能,并且在每种语言只需不到10小时的语音数据即可获得具有竞争力的结果。源代码和模型已发布在https://github.com/yxduir/LLM-SRT。
论文及项目相关链接
PDF Accepted in ACL 2025 (Main)
Summary
多模态大型语言模型(MLLMs)在语音到文本翻译(S2TT)任务中取得了巨大成功。针对现有研究主要集中在英语中心翻译方向,而多对多的翻译受限于平行数据的稀缺性的问题,提出了一种三阶段课程学习策略。利用大型语言模型的机器翻译能力,并适应S2TT任务,在低资源环境中实现有效学习。训练了不同参数大小(3B、7B和32B)的MLLMs,并在FLEURS和CoVoST-2数据集上评估了所提出策略。实验结果表明,该策略在解决资源受限情况下的多语种语音翻译问题上达到业界领先水平。项目源代码和模型已发布在https://github.com/yxduir/LLM-SRT。
Key Takeaways
- 多模态大型语言模型(MLLMs)在语音到文本翻译(S2TT)任务中表现出显著成功。
- 当前研究多集中在英语中心的翻译方向,多语种间的翻译受限于平行数据的稀缺性。
- 提出了一种三阶段课程学习策略,利用大型语言模型的机器翻译能力并适应S2TT任务。
- 该策略在低资源环境中实现有效学习,并适用于多语种语音翻译。
- 训练了不同参数大小的MLLMs(3B、7B和32B),并在FLEURS和CoVoST-2数据集上评估策略效果。
- 实验结果显示所提出策略达到业界领先水平,且在资源受限的情况下仍表现出竞争力。
点此查看论文截图