⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
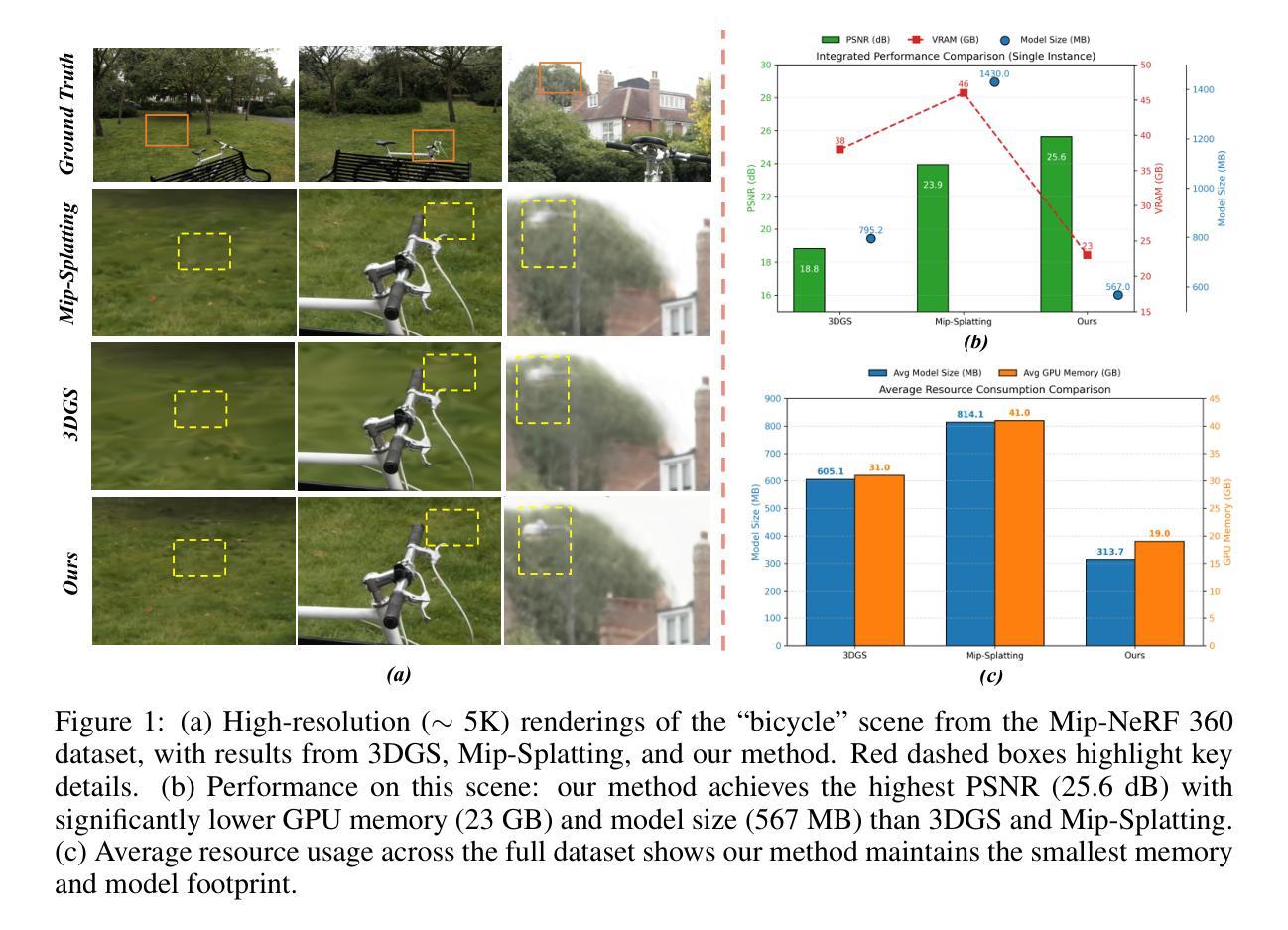
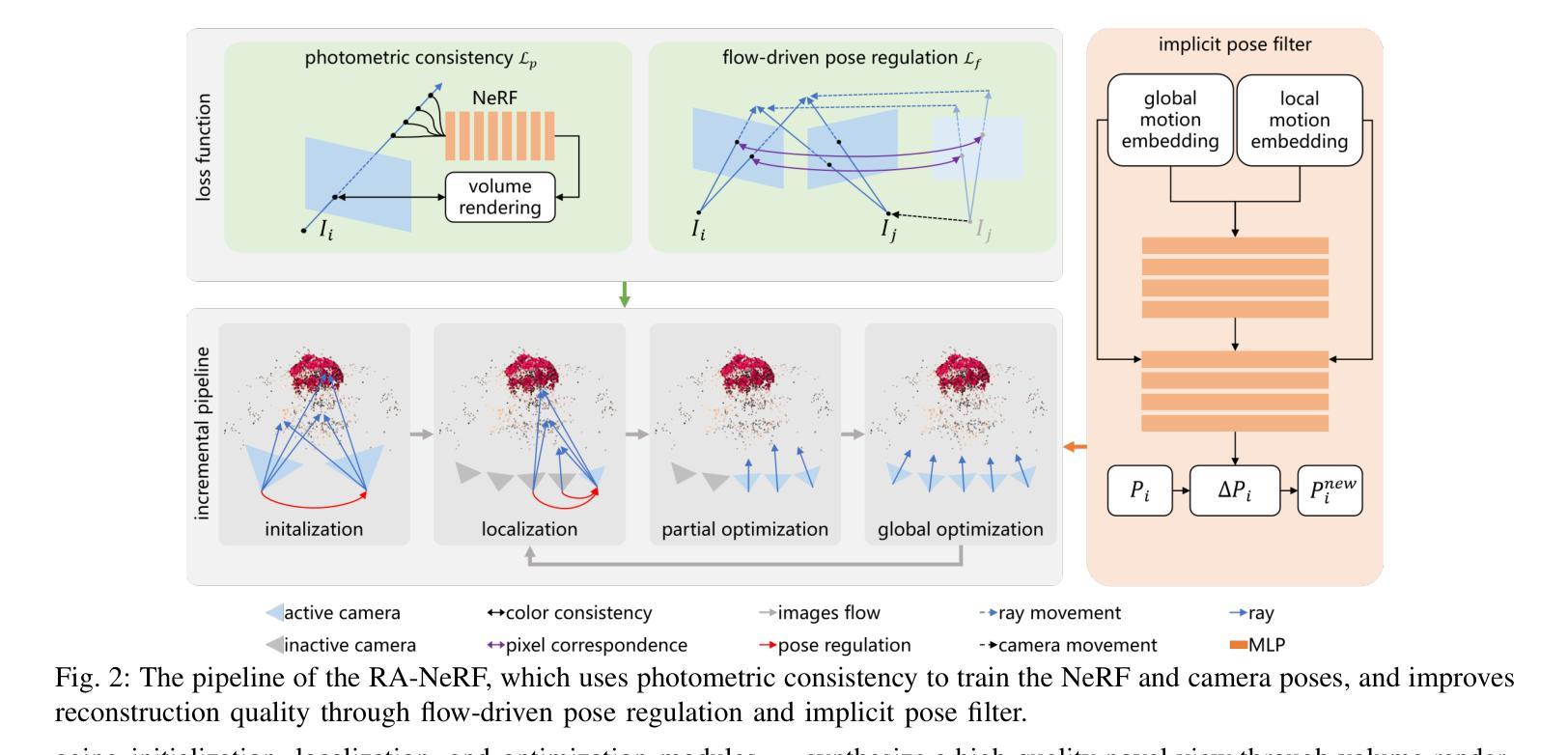
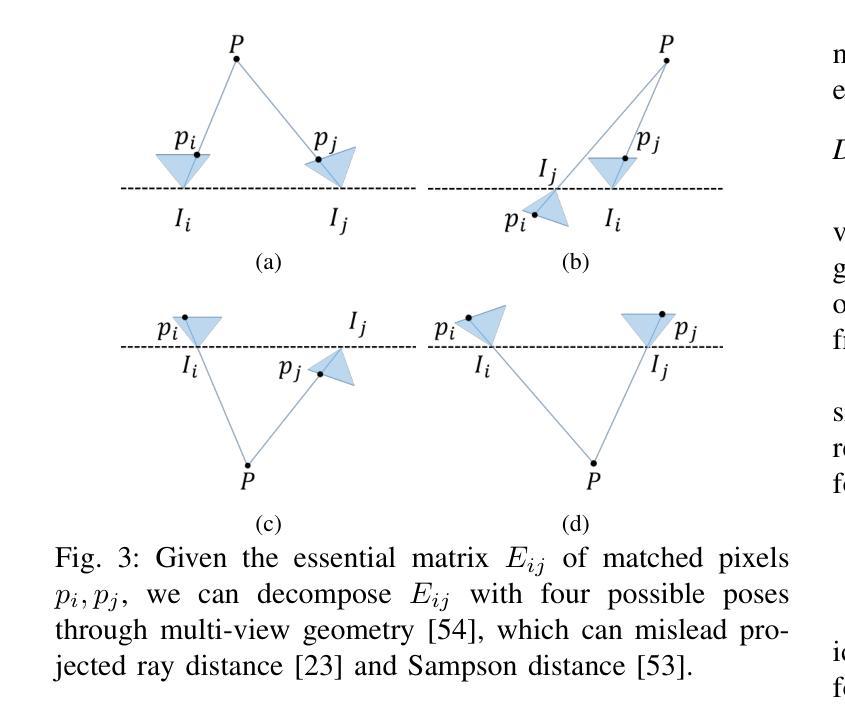
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Authors:Qingsong Yan, Qiang Wang, Kaiyong Zhao, Jie Chen, Bo Li, Xiaowen Chu, Fei Deng
Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
神经辐射场(NeRF)和三维高斯拼贴(3DGS)已成为三维重建和SLAM任务的强大工具。然而,它们的性能在很大程度上依赖于准确的相机姿态先验。现有方法试图通过引入外部约束来解决这个问题,但在复杂相机轨迹的情况下,无法达到令人满意的准确性。在本文中,我们提出了一种新的方法RA-NeRF,即使在复杂的相机轨迹下,也能预测出高度准确的相机姿态。遵循增量管道,RA-NeRF使用NeRF进行场景重建,实现光强一致性,并结合流量驱动的姿态调节,以提高初始化和定位过程中的稳健性。此外,RA-NeRF还采用隐式姿态滤波器捕捉相机运动模式,消除姿态估计中的噪声。为了验证我们的方法,我们在标准的Tanks&Temple数据集上进行了广泛的实验,以及在具有挑战性的相机姿态轨迹的NeRFBuster数据集上进行了实验。在两个数据集上,RA-NeRF在相机姿态估计和视觉质量方面都达到了最先进的水平,证明了其在复杂姿态轨迹下场景重建的有效性和稳健性。
论文及项目相关链接
PDF IROS 2025
Summary
基于NeRF和3DGS的强大工具在三维重建和SLAM任务中的应用,本文提出了一种新的方法RA-NeRF,该方法能够预测复杂的相机轨迹下的高度准确的相机姿态。通过采用增量管道,RA-NeRF使用NeRF进行场景重建,并利用光强度一致性增强鲁棒性。此外,RA-NeRF还采用隐式姿态滤波器捕捉相机运动模式并消除姿态估计中的噪声。实验结果表明,RA-NeRF在相机姿态估计和视觉质量方面均达到最新水平,对复杂姿态轨迹下的场景重建具有有效性和鲁棒性。
Key Takeaways
- RA-NeRF能够预测复杂的相机轨迹下的高度准确的相机姿态。
- RA-NeRF结合了NeRF和增量管道进行场景重建,并利用光强度一致性增强鲁棒性。
- RA-NeRF采用了一种隐式姿态滤波器来提高相机姿态估计的精度和消除噪声。
- 该方法在标准评估数据集Tanks&Temple和具有挑战性的数据集NeRFBuster上进行了实验验证。
- RA-NeRF在相机姿态估计和视觉质量方面达到了最新水平。
- 实验结果证明了RA-NeRF在复杂姿态轨迹下的场景重建的有效性和鲁棒性。
点此查看论文截图


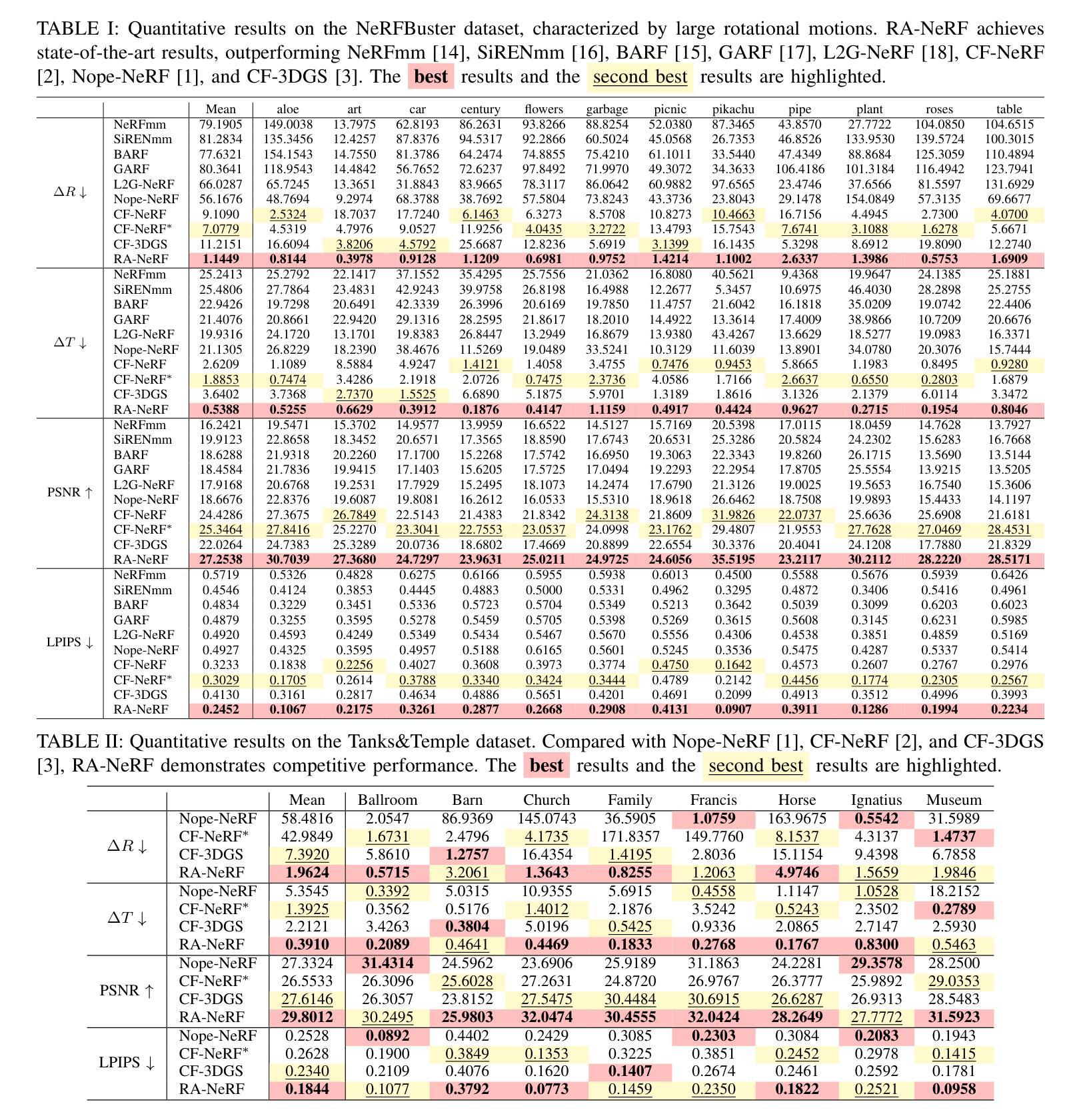
Peering into the Unknown: Active View Selection with Neural Uncertainty Maps for 3D Reconstruction
Authors:Zhengquan Zhang, Feng Xu, Mengmi Zhang
Some perspectives naturally provide more information than others. How can an AI system determine which viewpoint offers the most valuable insight for accurate and efficient 3D object reconstruction? Active view selection (AVS) for 3D reconstruction remains a fundamental challenge in computer vision. The aim is to identify the minimal set of views that yields the most accurate 3D reconstruction. Instead of learning radiance fields, like NeRF or 3D Gaussian Splatting, from a current observation and computing uncertainty for each candidate viewpoint, we introduce a novel AVS approach guided by neural uncertainty maps predicted by a lightweight feedforward deep neural network, named UPNet. UPNet takes a single input image of a 3D object and outputs a predicted uncertainty map, representing uncertainty values across all possible candidate viewpoints. By leveraging heuristics derived from observing many natural objects and their associated uncertainty patterns, we train UPNet to learn a direct mapping from viewpoint appearance to uncertainty in the underlying volumetric representations. Next, our approach aggregates all previously predicted neural uncertainty maps to suppress redundant candidate viewpoints and effectively select the most informative one. Using these selected viewpoints, we train 3D neural rendering models and evaluate the quality of novel view synthesis against other competitive AVS methods. Remarkably, despite using half of the viewpoints than the upper bound, our method achieves comparable reconstruction accuracy. In addition, it significantly reduces computational overhead during AVS, achieving up to a 400 times speedup along with over 50% reductions in CPU, RAM, and GPU usage compared to baseline methods. Notably, our approach generalizes effectively to AVS tasks involving novel object categories, without requiring any additional training.
某些视角天然比其它视角提供更多信息。对于准确且高效的3D对象重建,如何能让AI系统决定哪个视角能提供最有价值的洞察力呢?对于3D重建的主动视角选择(AVS)仍是计算机视觉领域的一个基本挑战。我们的目标是找出能产生最准确3D重建的最小视角集合。我们并没有从当前观察中学习辐射场(如NeRF或3D高斯延展),并为每个候选视角计算不确定性,而是介绍了一种由名为UPNet的轻量级前馈深度神经网络预测的神经不确定性地图引导的新型AVS方法。UPNet接收一个3D对象的单一输入图像,并输出一个预测的不确定性地图,代表所有可能候选视角的不确定性值。我们通过观察许多自然对象及其相关的不确定性模式得出的启发式方法,训练UPNet学习从视角外观到潜在体积表示的不确定性的直接映射。接下来,我们的方法汇集所有先前预测的神经不确定性地图,以抑制冗余的候选视角,并有效地选择最具信息量的视角。使用这些选定的视角,我们训练了3D神经渲染模型,并与其他有竞争力的AVS方法评估了合成新视角的质量。令人惊讶的是,尽管只使用了比上限少一半的视角,我们的方法仍然能达到相当的重建精度。此外,它在AVS期间显著减少了计算开销,实现了高达400倍的加速,与基准方法相比,CPU、RAM和GPU的使用量减少了超过50%。值得注意的是,我们的方法可以有效地推广到涉及新型对象类别的AVS任务,而无需任何额外的训练。
论文及项目相关链接
PDF 9 pages, 3 figures in the main text. Under review for NeurIPS 2025
Summary
本文介绍了一种基于神经网络不确定性映射的主动视角选择(AVS)新方法,用于3D对象重建。该方法通过引入UPNet网络,从单一输入图像预测不确定性映射,并据此选择最具有信息价值的视角。该方法在减少计算冗余和提高视角选择效率的同时,实现了高质量的3D重建。
Key Takeaways
- 提出了基于神经网络不确定性映射的主动视角选择(AVS)新方法,用于3D对象重建。
- 引入UPNet网络,从单一输入图像预测不确定性映射。
- 通过利用从多个自然对象及其相关不确定性模式中得出的启发式方法,训练UPNet建立从视角外观到体积表示中的不确定性的直接映射。
- 聚合所有先前预测的神经不确定性映射,以抑制冗余候选视角并有效选择最具信息价值的视角。
- 使用选定的视角训练3D神经渲染模型,并在与其他竞争性AVS方法进行比较时,实现了高质量的重建效果。
- 与上限相比,使用一半的视角即可达到相当的重建精度。
点此查看论文截图

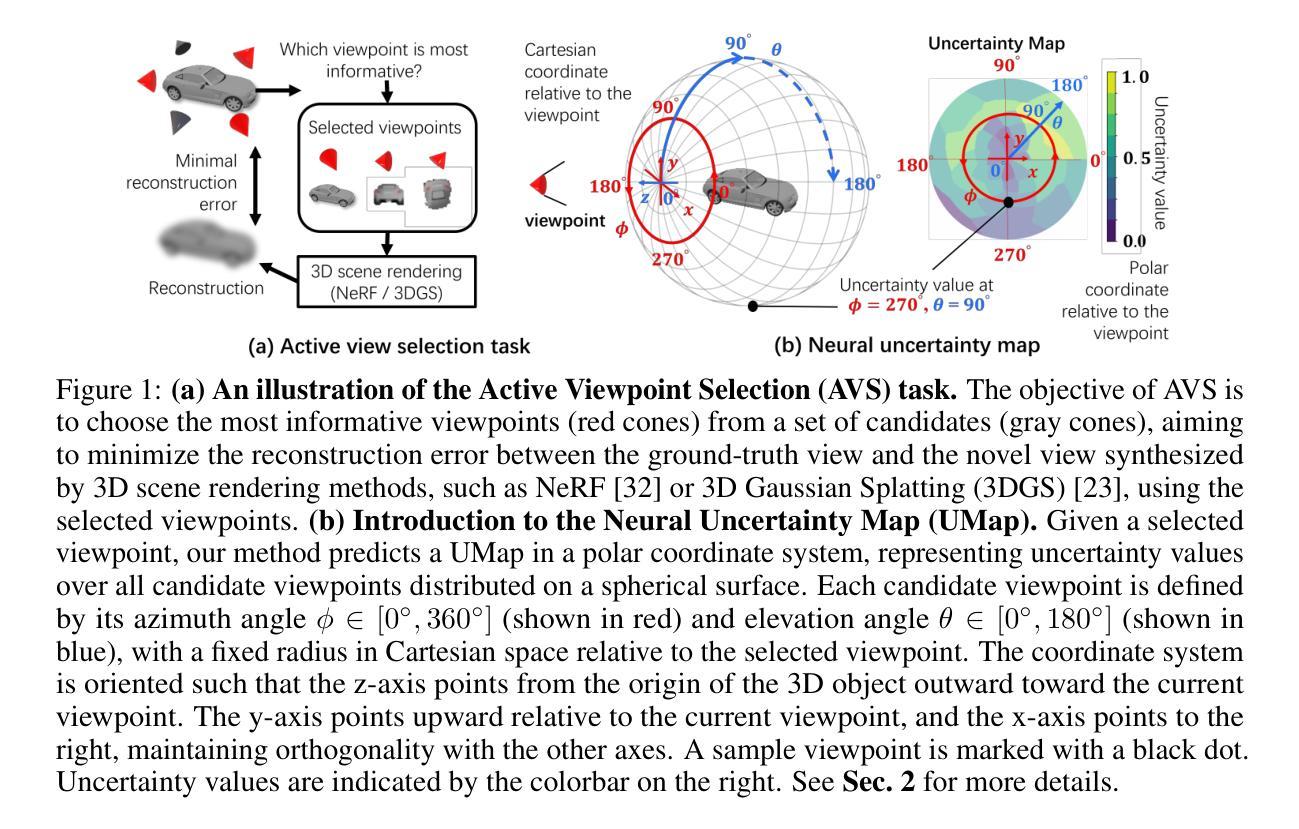
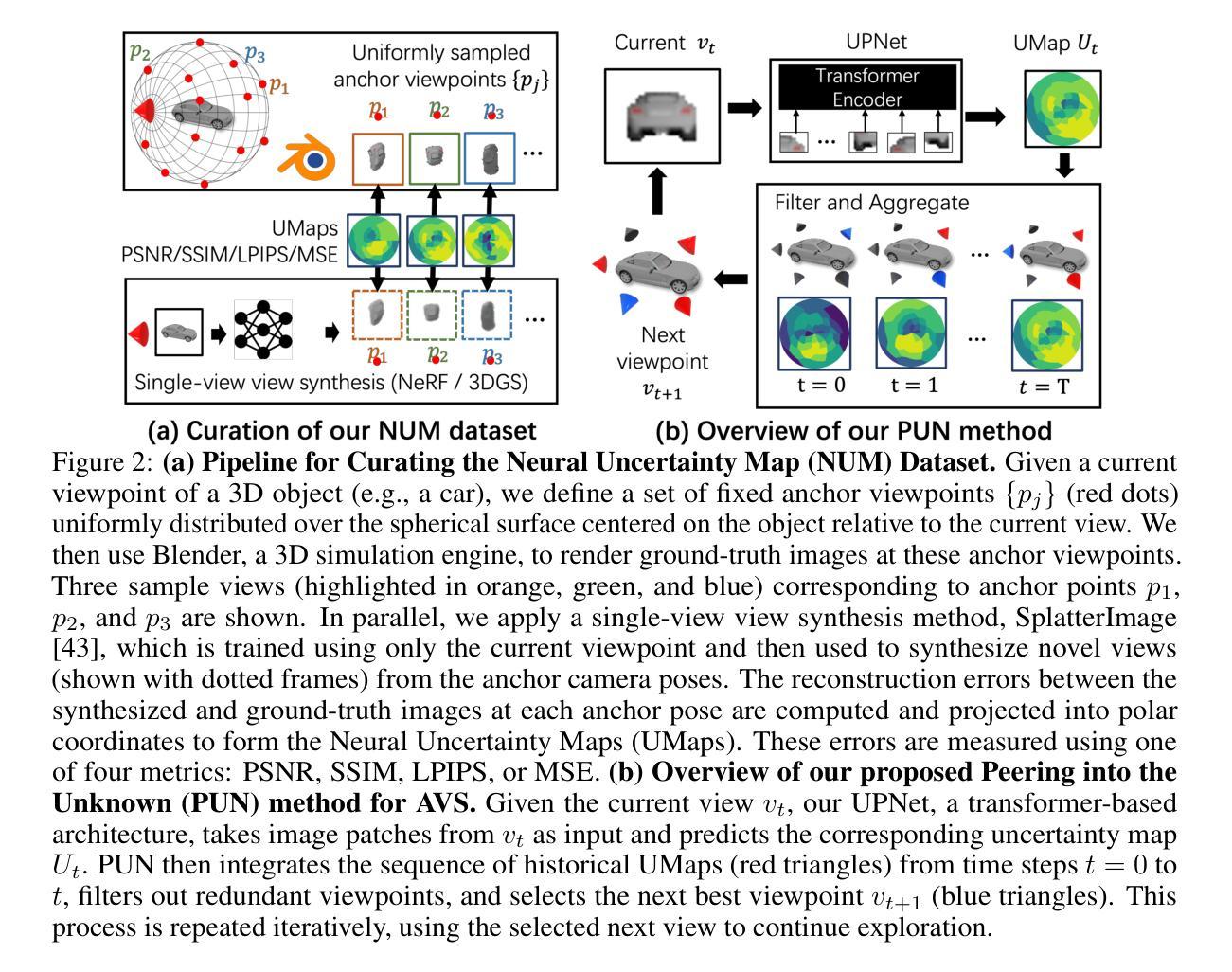
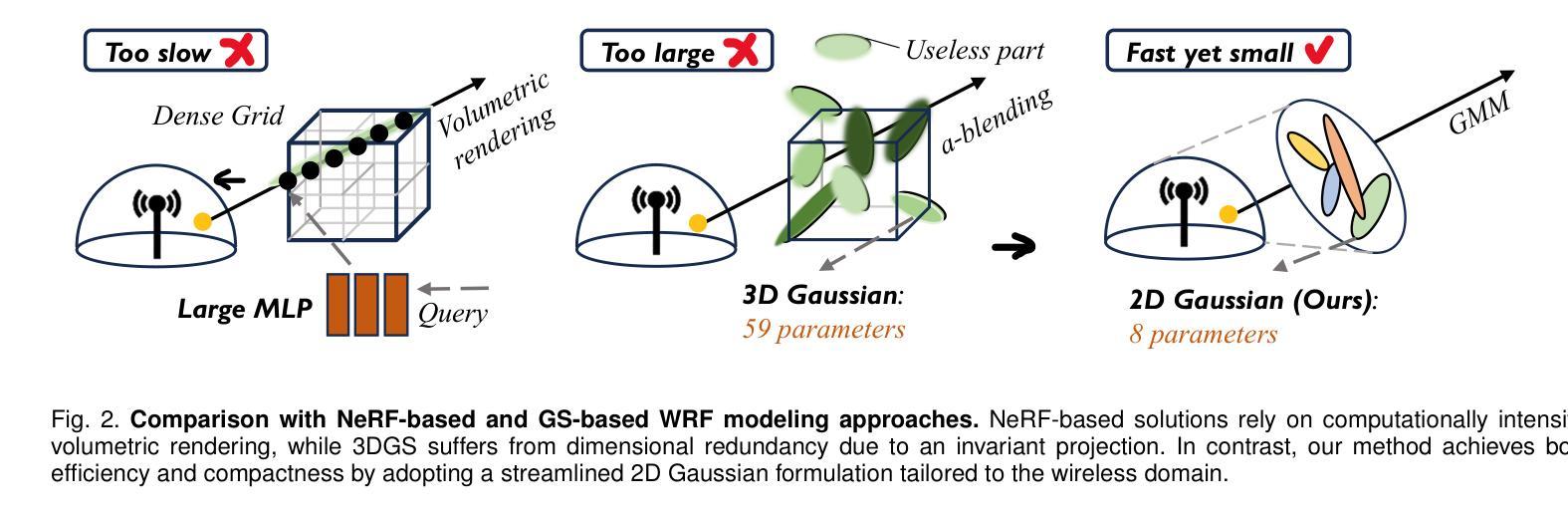
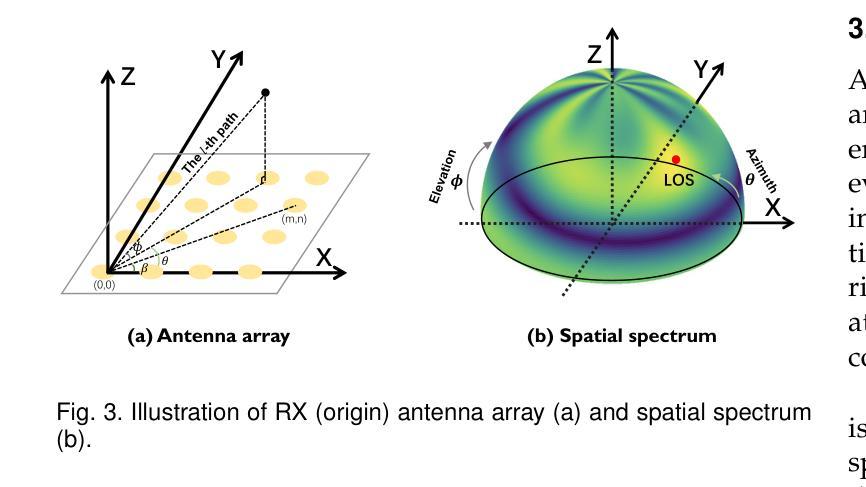
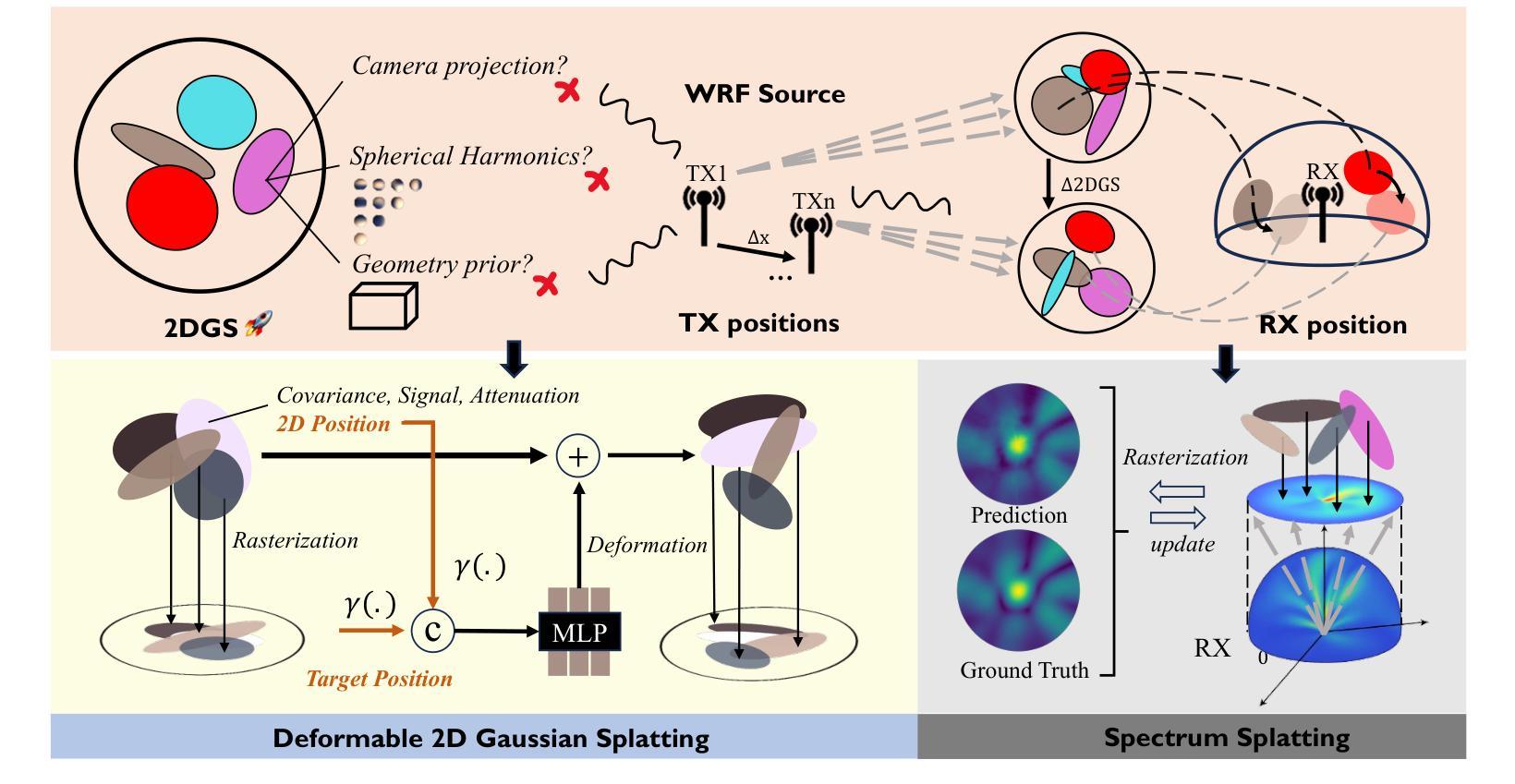
Rasterizing Wireless Radiance Field via Deformable 2D Gaussian Splatting
Authors:Mufan Liu, Cixiao Zhang, Qi Yang, Yujie Cao, Yiling Xu, Yin Xu, Shu Sun, Mingzeng Dai, Yunfeng Guan
Modeling the wireless radiance field (WRF) is fundamental to modern communication systems, enabling key tasks such as localization, sensing, and channel estimation. Traditional approaches, which rely on empirical formulas or physical simulations, often suffer from limited accuracy or require strong scene priors. Recent neural radiance field (NeRF-based) methods improve reconstruction fidelity through differentiable volumetric rendering, but their reliance on computationally expensive multilayer perceptron (MLP) queries hinders real-time deployment. To overcome these challenges, we introduce Gaussian splatting (GS) to the wireless domain, leveraging its efficiency in modeling optical radiance fields to enable compact and accurate WRF reconstruction. Specifically, we propose SwiftWRF, a deformable 2D Gaussian splatting framework that synthesizes WRF spectra at arbitrary positions under single-sided transceiver mobility. SwiftWRF employs CUDA-accelerated rasterization to render spectra at over 100000 fps and uses a lightweight MLP to model the deformation of 2D Gaussians, effectively capturing mobility-induced WRF variations. In addition to novel spectrum synthesis, the efficacy of SwiftWRF is further underscored in its applications in angle-of-arrival (AoA) and received signal strength indicator (RSSI) prediction. Experiments conducted on both real-world and synthetic indoor scenes demonstrate that SwiftWRF can reconstruct WRF spectra up to 500x faster than existing state-of-the-art methods, while significantly enhancing its signal quality. The project page is https://evan-sudo.github.io/swiftwrf/.
无线辐射场(WRF)建模是现代通信系统的基础,可实现定位、感知和信道估计等关键任务。传统的方法依赖于经验公式或物理模拟,往往存在精度有限的缺陷或需要强烈的场景先验。最近的基于神经辐射场(NeRF)的方法通过可微分的体积渲染提高了重建的保真度,但它们对计算量巨大的多层感知器(MLP)查询的依赖阻碍了实时部署。为了克服这些挑战,我们将高斯涂斑法(GS)引入无线领域,利用其模拟光学辐射场的效率,实现紧凑且准确的WRF重建。具体来说,我们提出了SwiftWRF,这是一个可变形二维高斯涂斑框架,可在单侧收发器移动性条件下合成任意位置的WRF光谱。SwiftWRF采用CUDA加速的栅格化技术,以超过100000帧/秒的速度渲染光谱,并使用轻量级的多层感知器对二维高斯变形进行建模,有效地捕捉移动性引起的WRF变化。除了新颖的光谱合成外,SwiftWRF在到达角(AoA)和接收信号强度指示器(RSSI)预测方面的应用也进一步证明了其有效性。在真实和合成室内场景上进行的实验表明,SwiftWRF的WRF光谱重建速度比现有最先进的方法快500倍,同时显著提高了信号质量。项目页面为https://evan-sudo.github.io/swiftwrf/。
论文及项目相关链接
Summary
基于神经辐射场(NeRF)的无线辐射场(WRF)建模是现代通信系统的基础,可实现定位、感知和信道估计等关键任务。传统方法受限于经验公式或物理模拟,准确性有限或需要强烈的场景先验。最近的方法通过可微分体积渲染提高了重建精度,但多层感知器(MLP)查询的计算成本较高,阻碍了实时部署。本研究引入高斯涂斑(GS)到无线领域,利用其建模光学辐射场的效率,实现紧凑且准确的WRF重建。我们提出了SwiftWRF,一个可变形二维高斯涂斑框架,可在单侧收发器移动性条件下合成任意位置的WRF光谱。SwiftWRF采用CUDA加速渲染,以超过100000帧/秒的速度渲染光谱,并使用轻量级MLP对二维高斯进行变形建模,有效捕捉移动引起的WRF变化。除了新颖的光谱合成,SwiftWRF在到达角(AoA)和接收信号强度指标(RSSI)预测方面的应用也证明了其有效性。实验表明,SwiftWRF在真实和合成室内场景上的WRF光谱重建速度比现有最先进的方法快500倍,同时显著提高信号质量。
Key Takeaways
- 无线辐射场(WRF)建模是通信系统的核心,涉及定位、感知和信道估计等任务。
- 传统WRF建模方法存在准确性有限或需要强烈场景先验的问题。
- 本研究引入高斯涂斑(GS)到无线领域,提高WRF建模的效率和准确性。
- 提出的SwiftWRF框架利用可变形二维高斯涂斑,合成任意位置的WRF光谱。
- SwiftWRF采用CUDA加速渲染,实现高速的光谱渲染(超过100000 fps)。
- SwiftWRF结合轻量级MLP,有效捕捉移动引起的WRF变化。
点此查看论文截图


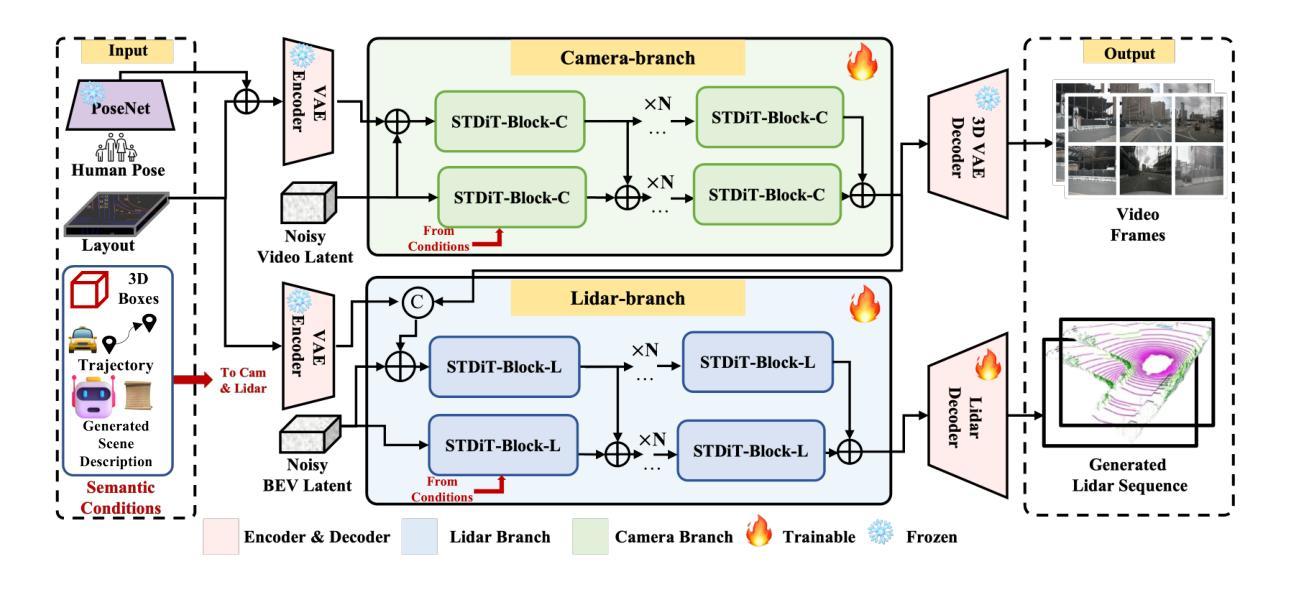
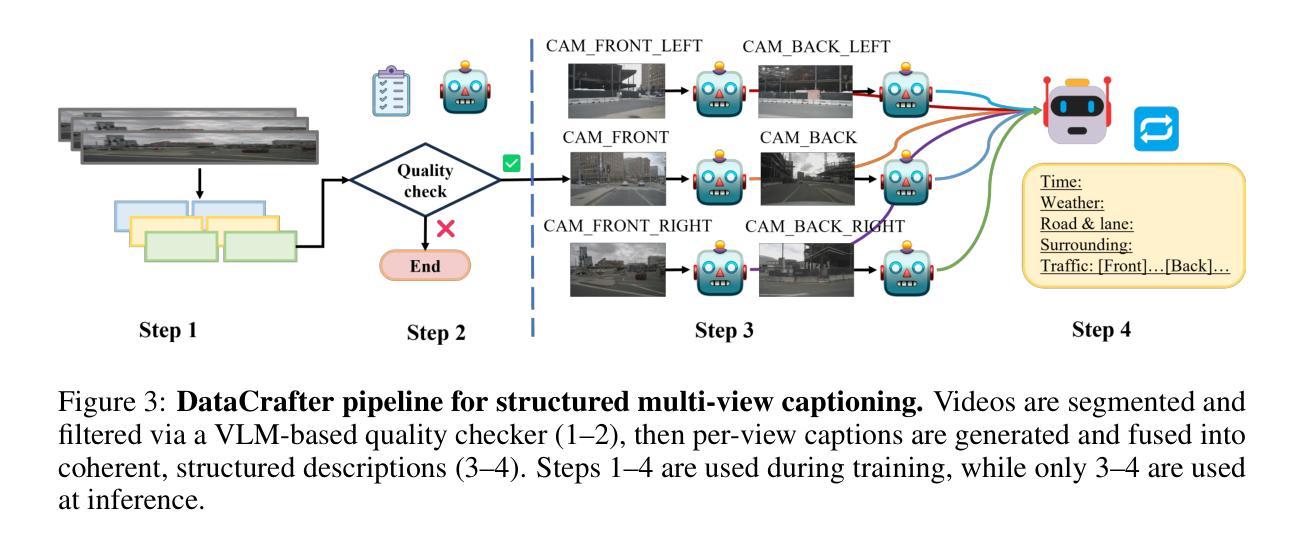
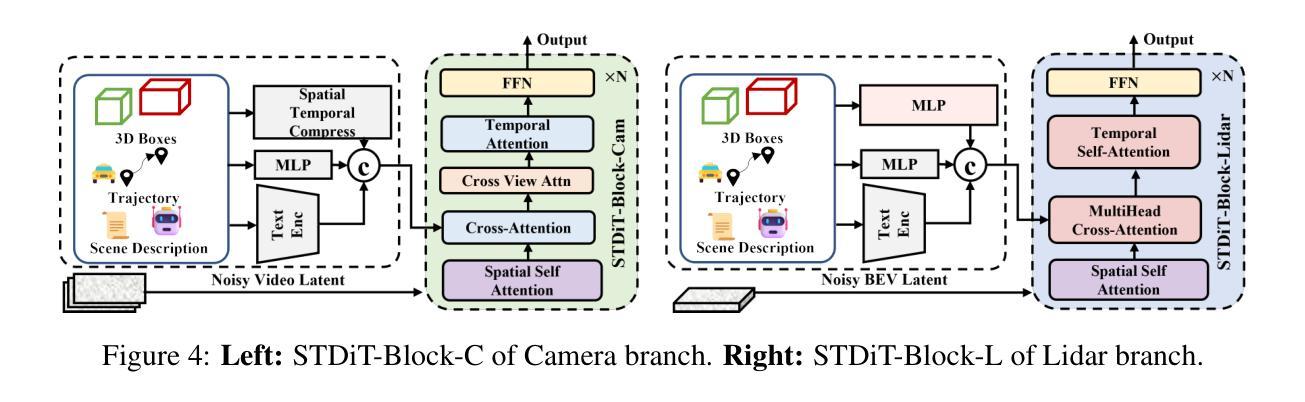
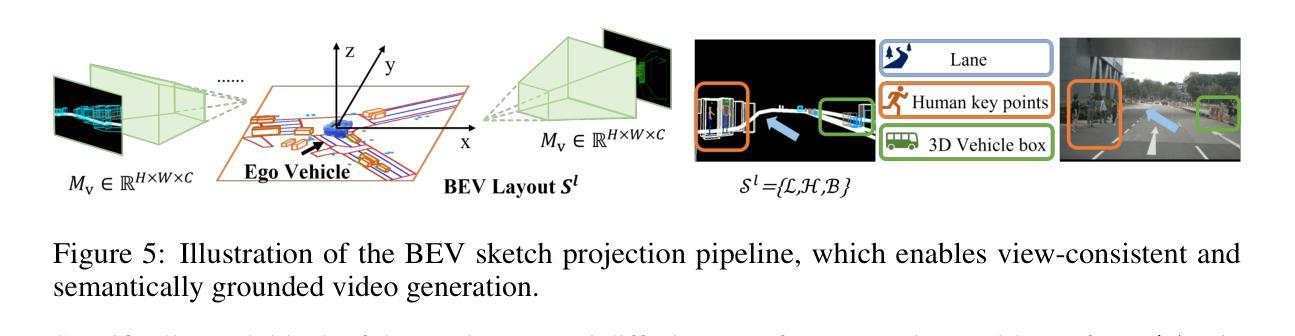
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Authors:Xiangyu Guo, Zhanqian Wu, Kaixin Xiong, Ziyang Xu, Lijun Zhou, Gangwei Xu, Shaoqing Xu, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Wenyu Liu, Xinggang Wang
We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
我们提出了Genesis,这是一个统一框架,用于联合生成具有时空和跨模态一致性的多视图驾驶视频和激光雷达序列。Genesis采用两阶段架构,集成了基于DiT的视频扩散模型与3D-VAE编码,以及带有基于NeRF的渲染和自适应采样的BEV感知激光雷达生成器。两种模态通过共享潜在空间直接耦合,实现在视觉和几何域之间的连贯演变。为了以结构语义引导生成,我们引入了DataCrafter,这是一个基于视觉语言模型的描述模块,提供场景级和实例级的监督。在nuScenes基准测试上的大量实验表明,Genesis在视频和激光雷达指标上达到了最新技术水平(FVD 16.95,FID 4.24,Chamfer 0.611),并有助于下游任务,包括分割和3D检测,验证了生成数据的语义保真度和实用效用。
论文及项目相关链接
Summary
本文介绍了Genesis框架,该框架能够联合生成多视角驾驶视频和LiDAR序列,具有时空和跨模态一致性。Genesis采用两阶段架构,集成了基于DiT的视频扩散模型和3D-VAE编码,以及具有NeRF渲染和自适应采样的BEV感知LiDAR生成器。两种模态通过共享潜在空间直接耦合,实现了视觉和几何域之间的连贯演变。为引导结构化语义生成,引入了基于视觉语言模型的DataCrfter字幕模块,提供场景级和实例级监督。在nuScenes基准测试上的实验表明,Genesis在视频和LiDAR指标上达到最新技术水平(FVD 16.95、FID 4.24、Chamfer 0.611),并在分割和3D检测等下游任务中受益,验证了生成数据的语义保真度和实用性。
Key Takeaways
- Genesis是一个联合生成多视角驾驶视频和LiDAR序列的统一框架,具有时空和跨模态一致性。
- Genesis采用两阶段架构,集成了DiT视频扩散模型、3D-VAE编码、BEV感知LiDAR生成器。
- 通过共享潜在空间,实现了视觉和几何域之间的连贯演变。
- 引入DataCrfter字幕模块,提供场景级和实例级监督,引导结构化语义生成。
- 在nuScenes基准测试上取得最新技术水平的性能表现。
- Genesis生成的数据对下游任务如分割和3D检测有益,验证了其语义保真度和实用性。
点此查看论文截图

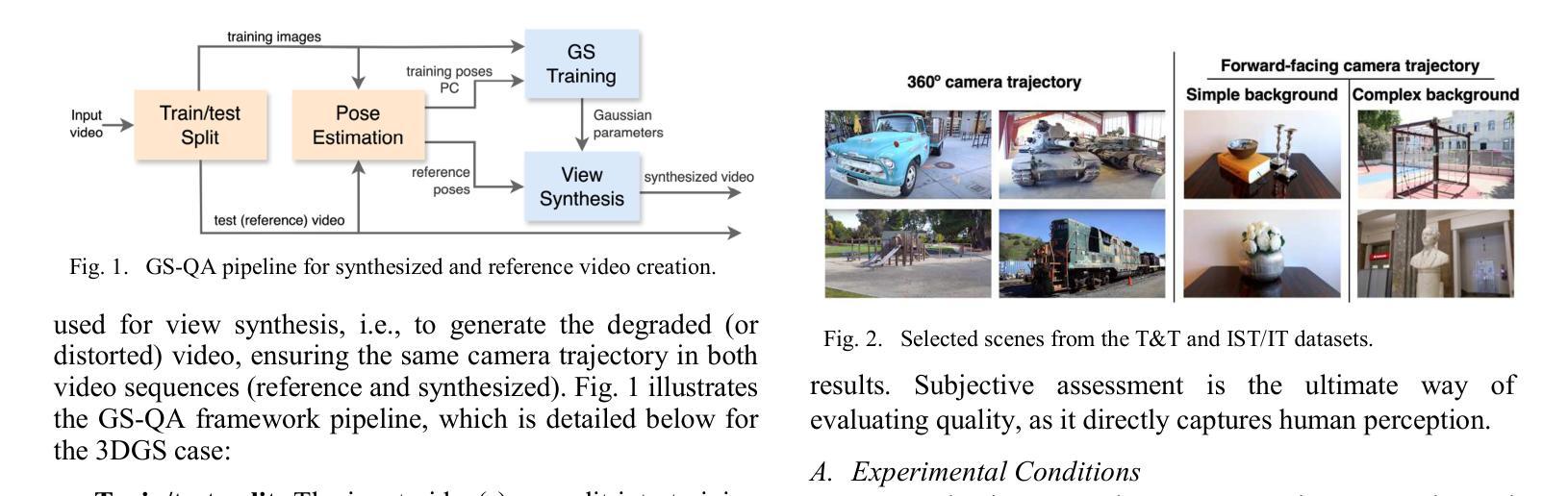
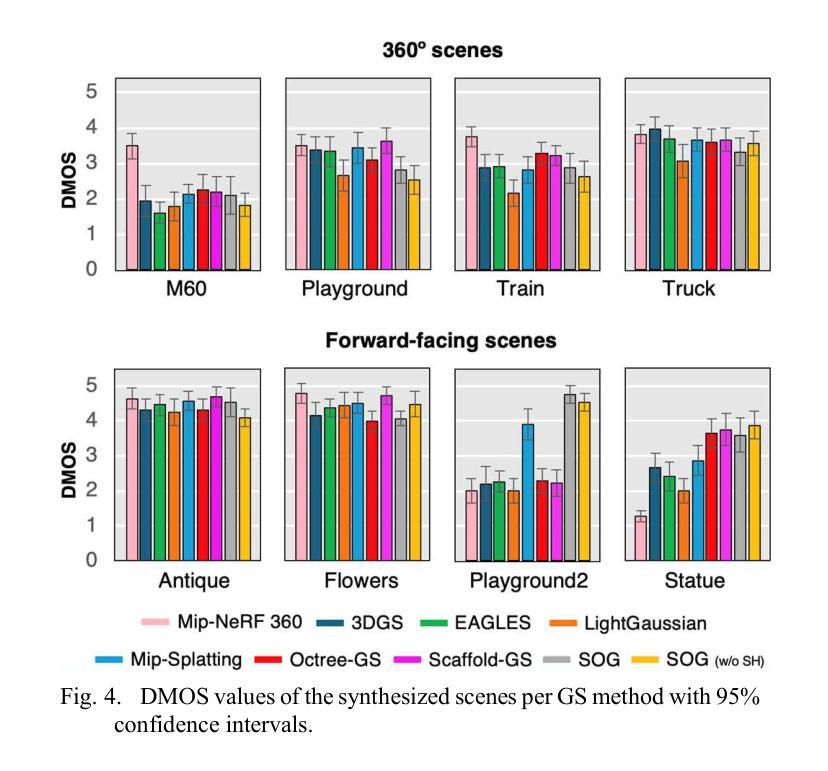
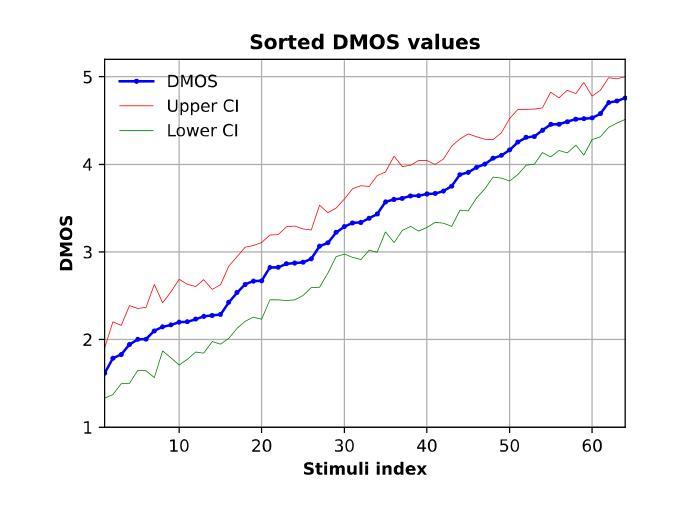
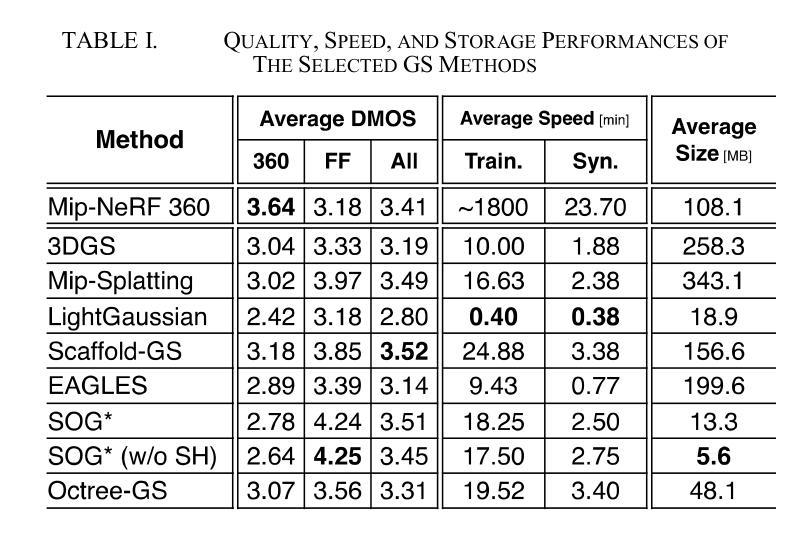
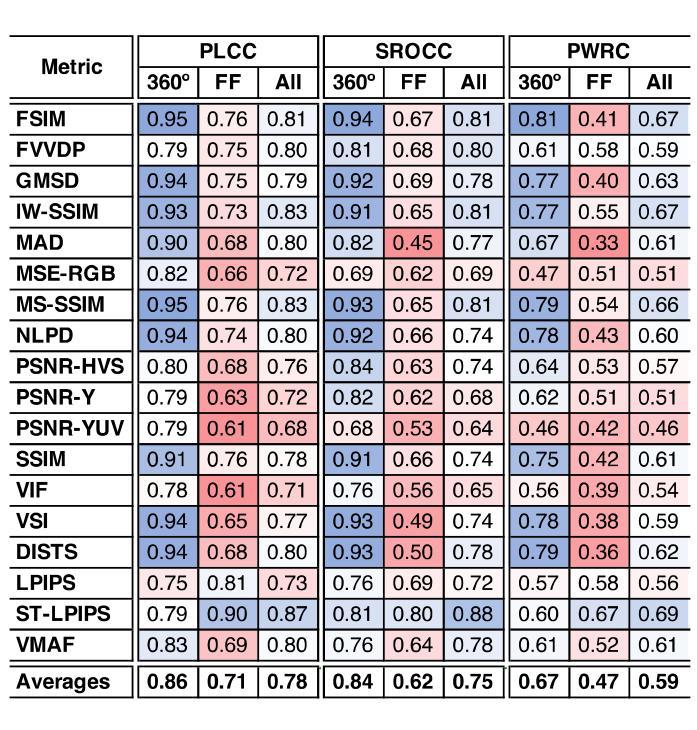
GS-QA: Comprehensive Quality Assessment Benchmark for Gaussian Splatting View Synthesis
Authors:Pedro Martin, António Rodrigues, João Ascenso, Maria Paula Queluz
Gaussian Splatting (GS) offers a promising alternative to Neural Radiance Fields (NeRF) for real-time 3D scene rendering. Using a set of 3D Gaussians to represent complex geometry and appearance, GS achieves faster rendering times and reduced memory consumption compared to the neural network approach used in NeRF. However, quality assessment of GS-generated static content is not yet explored in-depth. This paper describes a subjective quality assessment study that aims to evaluate synthesized videos obtained with several static GS state-of-the-art methods. The methods were applied to diverse visual scenes, covering both 360-degree and forward-facing (FF) camera trajectories. Moreover, the performance of 18 objective quality metrics was analyzed using the scores resulting from the subjective study, providing insights into their strengths, limitations, and alignment with human perception. All videos and scores are made available providing a comprehensive database that can be used as benchmark on GS view synthesis and objective quality metrics.
高斯混合法(GS)为实时三维场景渲染提供了有前景的替代方案,可为神经网络辐射场(NeRF)提供替代。使用一组三维高斯分布来表示复杂的几何形状和外观,GS实现了比NeRF中使用的神经网络方法更快的渲染速度和更低的内存消耗。然而,关于GS生成的静态内容的质量评估尚未深入探索。本文描述了一项主观质量评估研究,旨在评估使用几种先进的静态GS方法获得的合成视频的质量。这些方法应用于各种视觉场景,包括360度和正面朝向(FF)的相机轨迹。此外,通过对主观研究结果的得分分析,对18个客观质量指标的性能进行了深入评估,从而对其优点、局限性以及与人类感知的契合度有了更深入的了解。所有视频和分数均已提供,形成一个全面的数据库,可用于GS视图合成和客观质量指标的基准测试。
论文及项目相关链接
Summary
本文介绍了基于高斯摊铺(GS)的实时三维场景渲染技术,其利用一组三维高斯分布来表示复杂的几何和外观信息,相较于神经网络方法(如NeRF)实现了更快的渲染速度和更低的内存消耗。然而,关于GS生成的静态内容的质量评估尚未深入探索。本研究通过主观质量评估方法评估了采用多种先进静态GS方法合成的视频质量。这些方法应用于不同的视觉场景,包括全景和面向前的相机轨迹。此外,通过对主观研究结果的评分分析了18种客观质量指标的性能,并提供了对人眼感知的见解。所有的视频和评分均被公开提供,作为GS视图合成和客观质量指标的基准数据库。
Key Takeaways
- 高斯摊铺(GS)作为实时三维场景渲染的替代方案受到关注。它利用三维高斯分布表达几何和外观,相比NeRF实现更快的渲染速度和较低内存消耗。
- 对于GS生成的静态内容的质量评估尚未深入探索。本研究首次对此进行了主观质量评估研究。
- 研究的重点是合成的视频质量评估,涵盖多种先进的静态GS方法以及全景和面向前的相机轨迹应用。
- 本研究还分析了18种客观质量指标的性能,并通过主观研究结果提供洞察。
- 公开提供的视频和评分数据为GS视图合成和客观质量指标提供了基准数据库。
- 该研究推动了高斯摊铺技术在静态内容生成和视频合成领域的发展和应用。
点此查看论文截图