⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
FrontendBench: A Benchmark for Evaluating LLMs on Front-End Development via Automatic Evaluation
Authors:Hongda Zhu, Yiwen Zhang, Bing Zhao, Jingzhe Ding, Siyao Liu, Tong Liu, Dandan Wang, Yanan Liu, Zhaojian Li
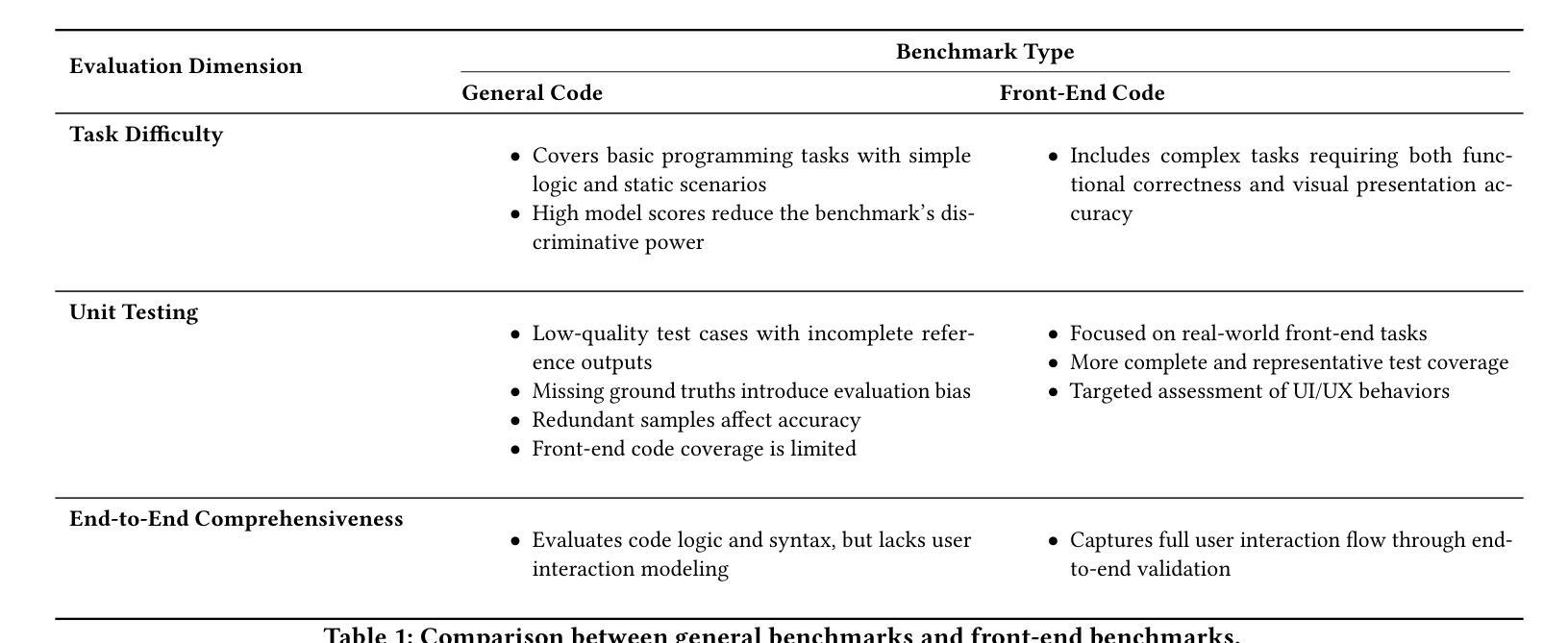
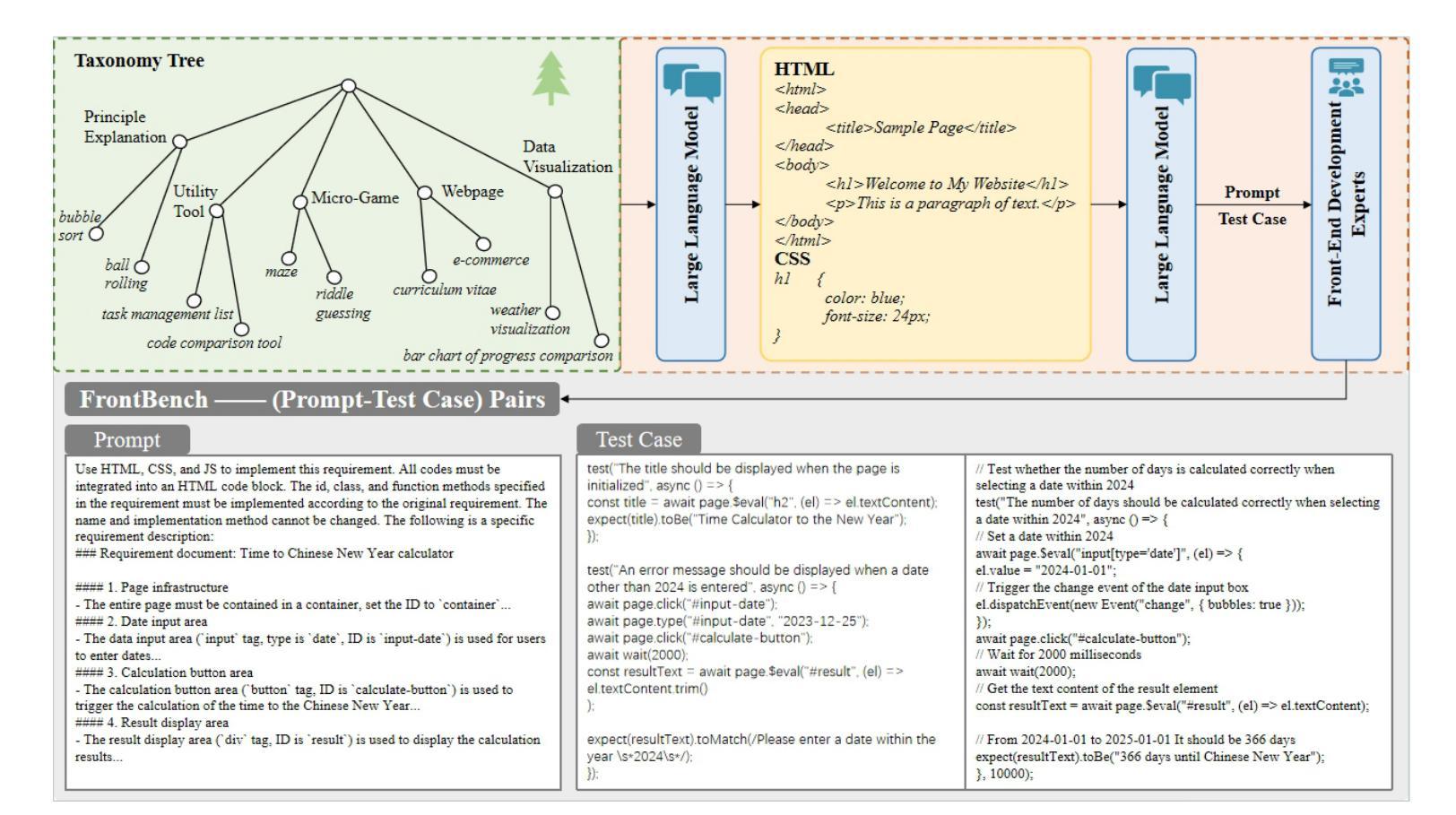
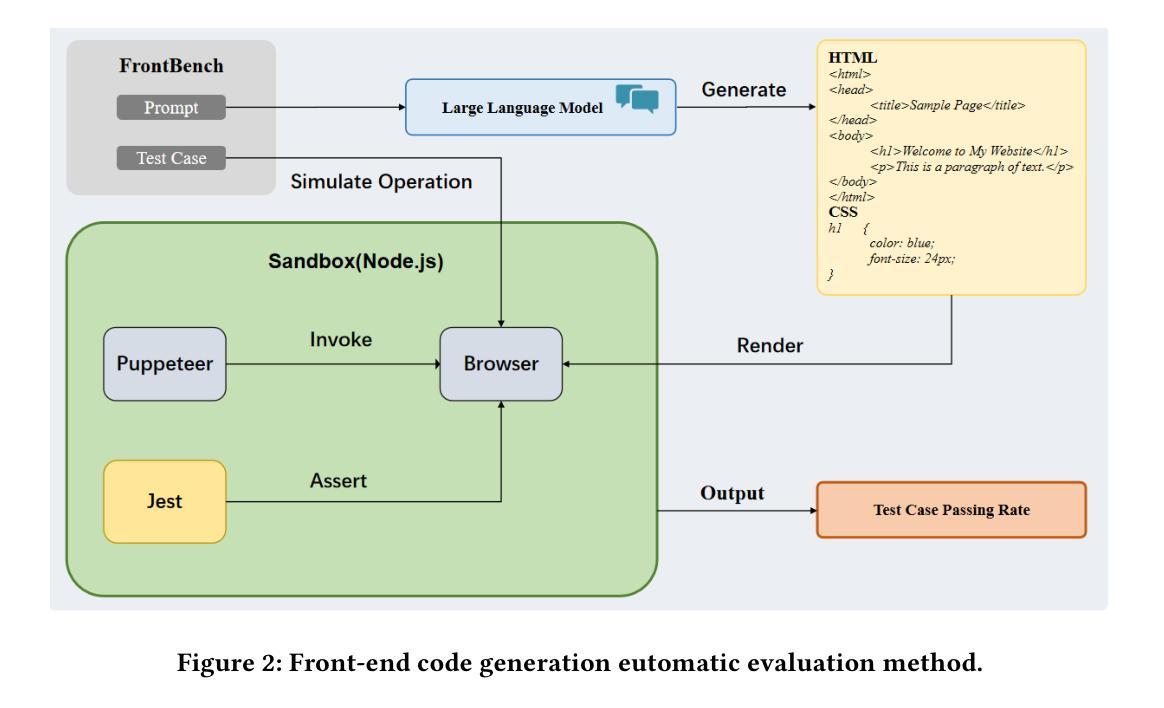
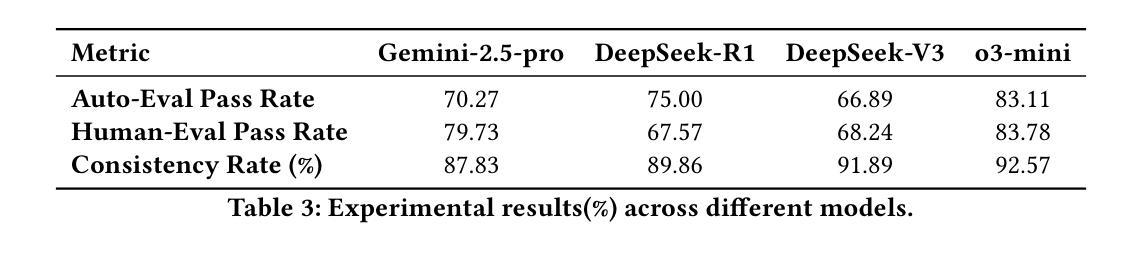
Large Language Models (LLMs) have made significant strides in front-end code generation. However, existing benchmarks exhibit several critical limitations: many tasks are overly simplistic, test cases often lack rigor, and end-to-end validation is absent. These issues hinder the accurate assessment of model performance. To address these challenges, we present FrontendBench, a benchmark co-developed by humans and LLMs. FrontendBench categorizes tasks based on code functionality and incorporates interactive test scenarios, enabling a more comprehensive and practical evaluation of front-end code generation capabilities. The benchmark comprises 148 meticulously crafted prompt-test case pairs spanning five levels of web components, from basic UI elements to complex interactive features. Each task reflects realistic front-end development challenges. Furthermore, we introduce an automatic evaluation framework that executes generated code within a sandbox environment and assesses outcomes using predefined test scripts. This framework achieves a 90.54% agreement rate with expert human evaluations, demonstrating high reliability. We benchmark several state-of-the-art LLMs on FrontendBench and observe substantial performance disparities in handling real-world front-end tasks. These results highlight FrontendBench as a reliable and scalable benchmark, supporting consistent multimodal evaluation and providing a robust foundation for future research in front-end code generation. Our data and code will be released soon.
自然语言大模型(LLM)在前端代码生成方面取得了显著进展。然而,现有的基准测试存在诸多关键局限性:许多任务过于简单,测试用例往往缺乏严谨性,且缺乏端到端的验证。这些问题阻碍了模型性能的准确评估。为了解决这些挑战,我们提出了FrontendBench,这是一个由人类和LLM共同开发的基准测试。FrontendBench根据代码功能分类任务,并融入交互式测试场景,能够更全面、更实用地评估前端代码生成能力。该基准测试包含148个精心设计的提示-测试用例对,涵盖五个级别的网页组件,从基本的UI元素到复杂的交互功能。每个任务都反映了现实前端开发的挑战。此外,我们引入了一个自动评估框架,该框架在沙箱环境中执行生成的代码,并使用预设的测试脚本来评估结果。该框架与专家人工评估的契合率达到9.54%,显示出高度的可靠性。我们在FrontendBench上评估了几款前沿的LLM,并观察到在处理现实世界前端任务时存在显著的性能差异。这些结果凸显了FrontendBench作为一个可靠且可扩展的基准测试的重要性,支持多模式一致性的评估,并为未来前端代码生成研究提供了坚实的基础。我们的数据和代码将很快发布。
论文及项目相关链接
Summary
大型语言模型在前端代码生成方面取得显著进展,但现有评估工具存在局限性。为解决这些问题,我们提出了FrontendBench,这是一个由人类和大型语言模型共同开发的评估工具。FrontendBench基于代码功能分类任务,融入互动测试场景,更全面地评估前端代码生成能力。此外,我们还建立了自动评估框架,在沙盒环境中执行生成代码并按预设测试脚本进行评估。我们在FrontendBench上评估了多款最先进的大型语言模型,发现它们在处理真实前端任务时的性能差异显著。这表明FrontendBench是一个可靠且可扩展的评估工具,为未来前端代码生成研究提供了坚实基础。
Key Takeaways
- 大型语言模型在前端代码生成方面取得显著进展。
- 现有评估工具存在局限性,如任务过于简单、测试案例缺乏严谨性、缺乏端到端验证。
- FrontendBench是一个新的评估工具,由人类和大型语言模型共同开发。
- FrontendBench基于代码功能分类任务,并融入互动测试场景,提供更全面的评估。
- 建立了自动评估框架,在沙盒环境中执行生成代码并按预设测试脚本进行评估,专家评价率高达90.54%。
- 在FrontendBench上评估的多款最先进的大型语言模型在处理真实前端任务时存在显著性能差异。
点此查看论文截图




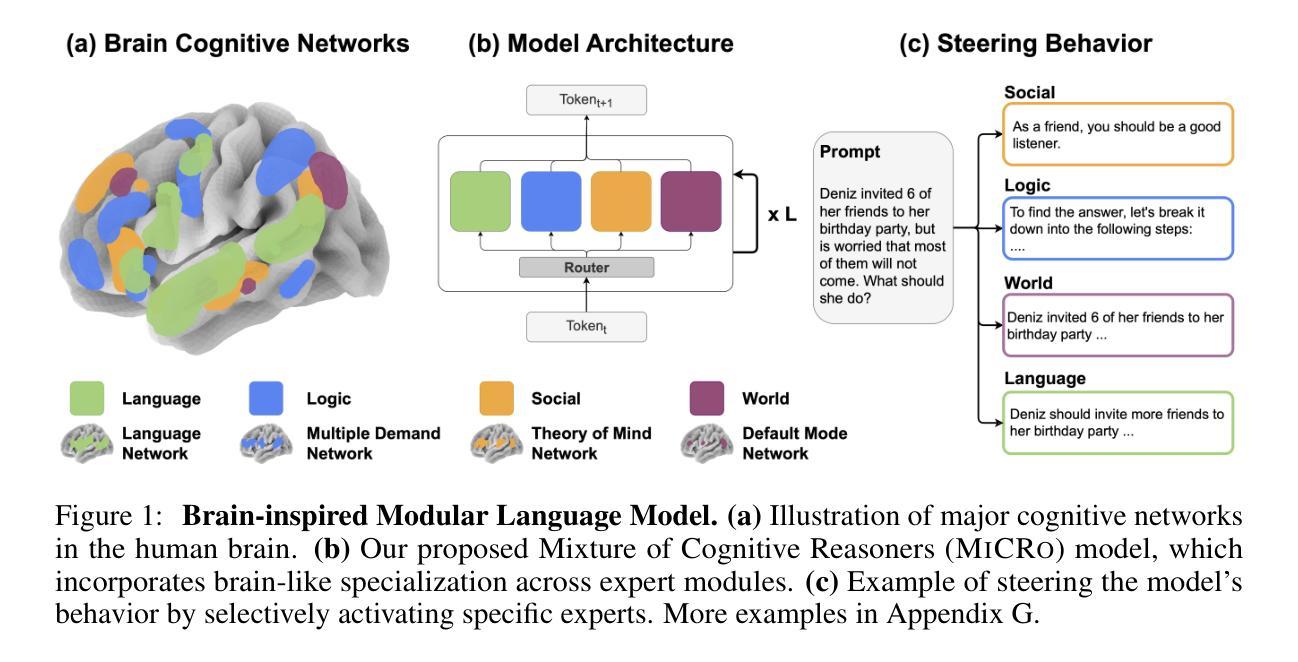
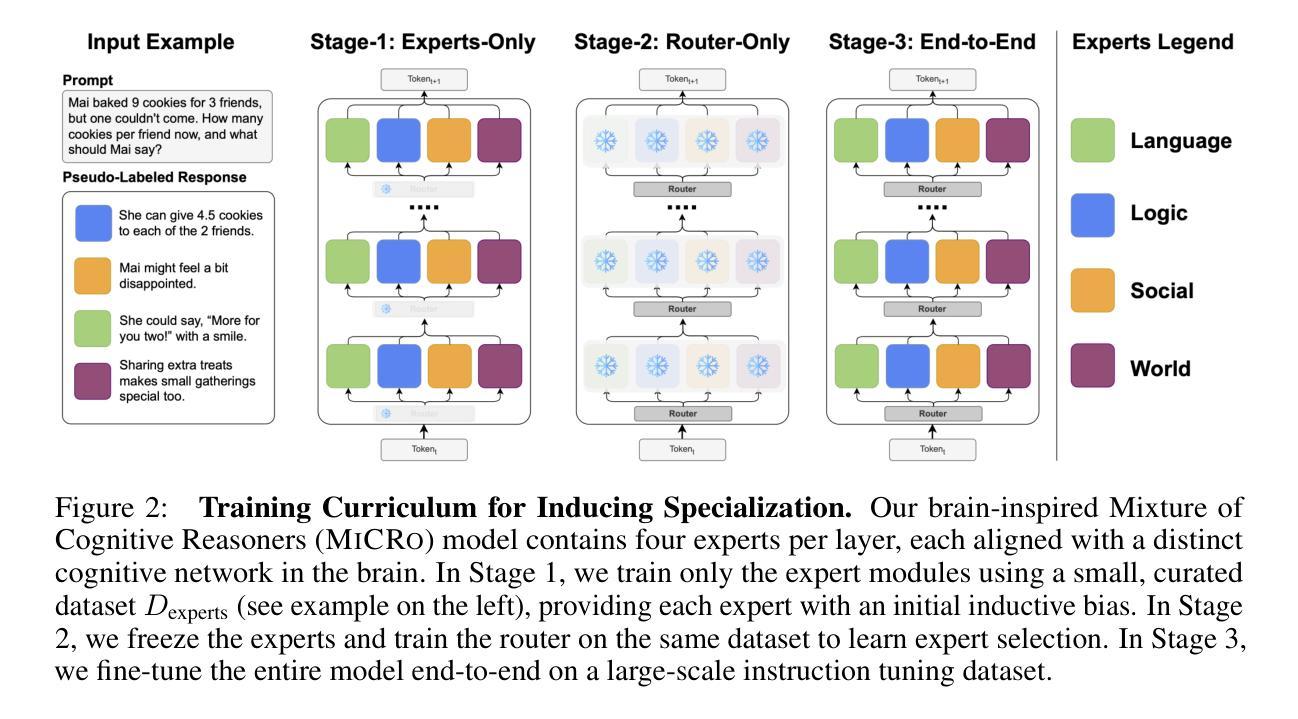
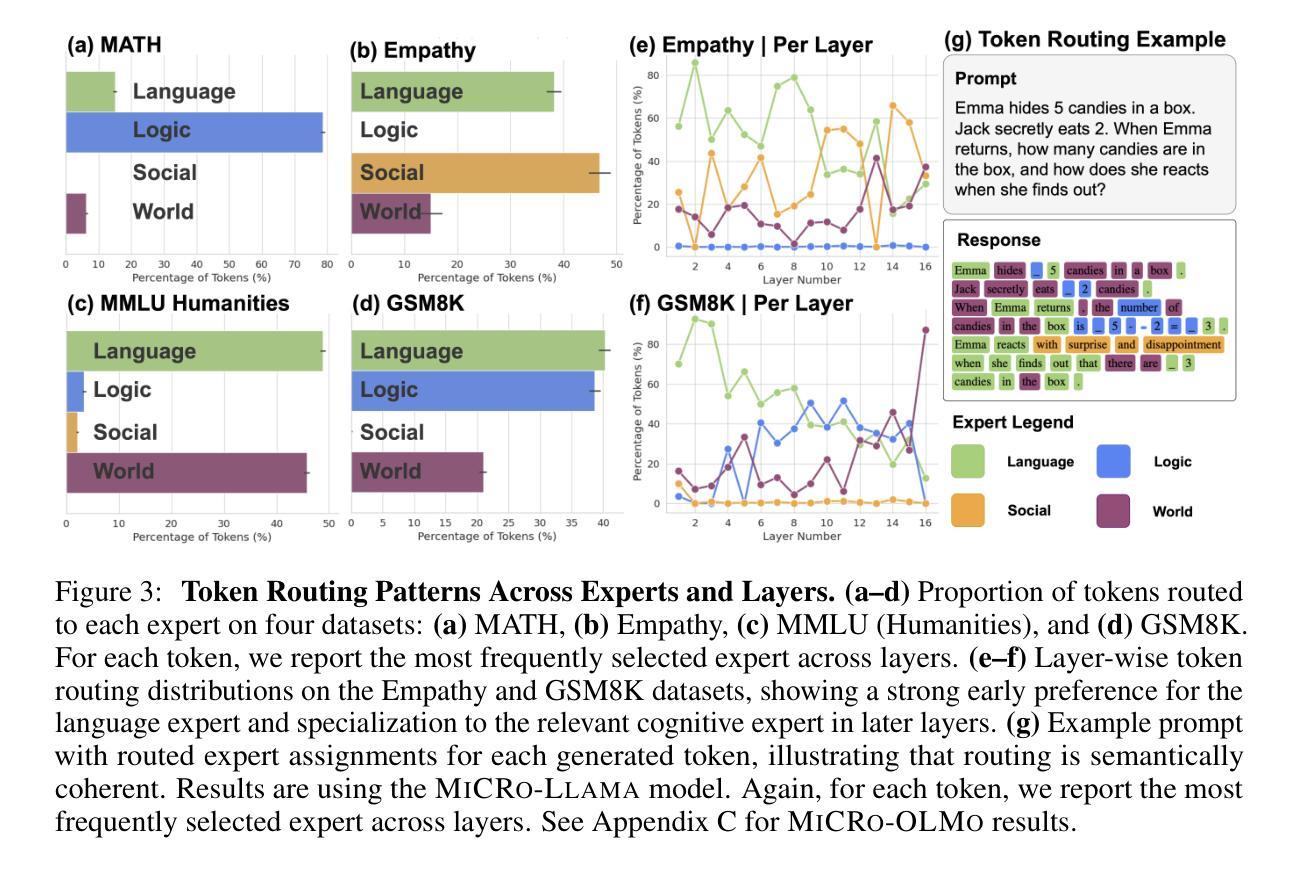
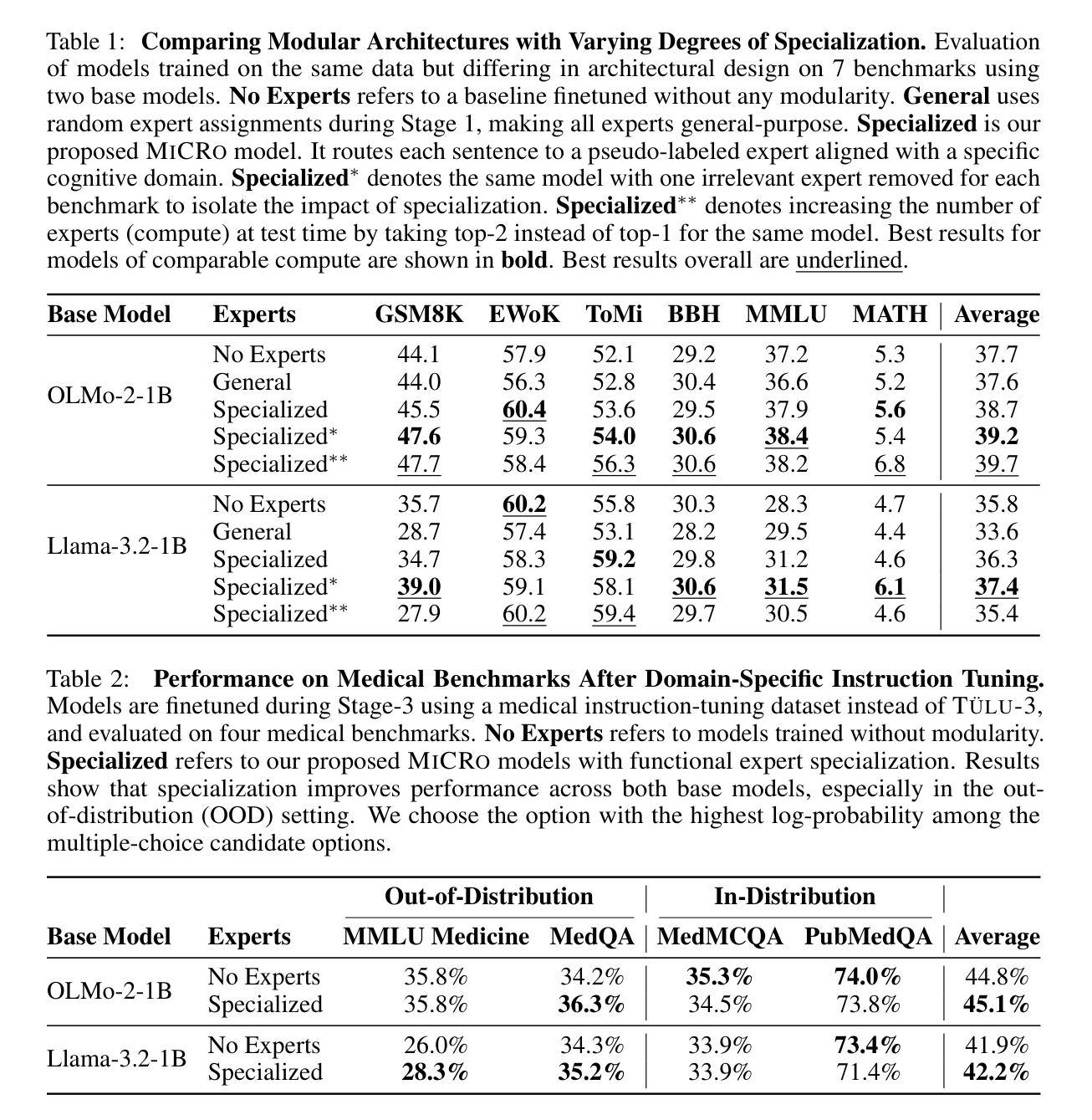
Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization
Authors:Badr AlKhamissi, C. Nicolò De Sabbata, Zeming Chen, Martin Schrimpf, Antoine Bosselut
Human intelligence emerges from the interaction of specialized brain networks, each dedicated to distinct cognitive functions such as language processing, logical reasoning, social understanding, and memory retrieval. Inspired by this biological observation, we introduce the Mixture of Cognitive Reasoners (MiCRo) architecture and training paradigm: a modular transformer-based language model with a training curriculum that encourages the emergence of functional specialization among different modules. Inspired by studies in neuroscience, we partition the layers of a pretrained transformer model into four expert modules, each corresponding to a well-studied cognitive brain network. Our Brain-Like model has three key benefits over the state of the art: First, the specialized experts are highly interpretable and functionally critical, where removing a module significantly impairs performance on domain-relevant benchmarks. Second, our model outperforms comparable baselines that lack specialization on seven reasoning benchmarks. And third, the model’s behavior can be steered at inference time by selectively emphasizing certain expert modules (e.g., favoring social over logical reasoning), enabling fine-grained control over the style of its response. Our findings suggest that biologically inspired inductive biases involved in human cognition lead to significant modeling gains in interpretability, performance, and controllability.
人类智慧源于各种专业脑网络的交互作用,每个网络都专注于不同的认知功能,如语言处理、逻辑推理、社会理解和记忆检索。受这一生物学观察的启发,我们引入了认知推理器混合物(MiCRo)架构和训练范式:一种基于模块化转换器架构的语言模型,其训练课程鼓励不同模块之间功能专业化的出现。受神经科学研究的启发,我们将预训练转换器模型的层划分为四个专家模块,每个模块对应于一个经过深入研究的认知脑网络。我们的脑状模型相较于现有技术具有三个关键优势:首先,专业专家高度可解释并且在功能上至关重要,移除一个模块会显著损害其在相关领域的基准测试性能。其次,我们的模型在七个推理基准测试上的表现优于缺乏专业性的同类基准测试。第三,在推理时间,我们可以通过有选择地强调某些专家模块(例如,偏好社会而非逻辑推理)来引导模型的行为,实现对响应风格的精细控制。我们的研究结果表明,涉及人类认知的生物启发归纳偏见在解释性、性能和可控性方面带来了显著的建模收益。
论文及项目相关链接
PDF Preprint. Code, data, and models available at $\href{https://bkhmsi.github.io/mixture-of-cog-reasoners}{\text{this https URL.}}$
Summary
本文受人类大脑神经科学的启发,提出了一种混合认知推理器(MiCRo)架构和培训范式。该架构基于模块化变压器语言模型,通过训练课程鼓励不同模块的功能专业化,以模拟人类大脑不同认知网络的功能。该模型具有高度的可解释性和功能性,超过现有技术水平,能够在七个推理基准测试中表现出优越性能,并在推理时通过强调特定专家模块实现精细控制响应。
Key Takeaways
- 人类智能源于专门化大脑网络的交互,每个网络负责不同的认知功能。
- 受此启发,提出了MiCRo架构和培训范式,是一种模块化变压器语言模型。
- MiCRo模型将预训练的变压器模型层划分为四个专家模块,对应认知大脑网络。
- 去除任何一个专家模块会对领域相关基准测试的性能产生显著影响,显示出高度可解释性和功能性。
- MiCRo模型在七个推理基准测试中的性能优于无专业化的基准模型。
- 在推理时,可以通过强调某些专家模块来精细控制模型的响应风格。
点此查看论文截图

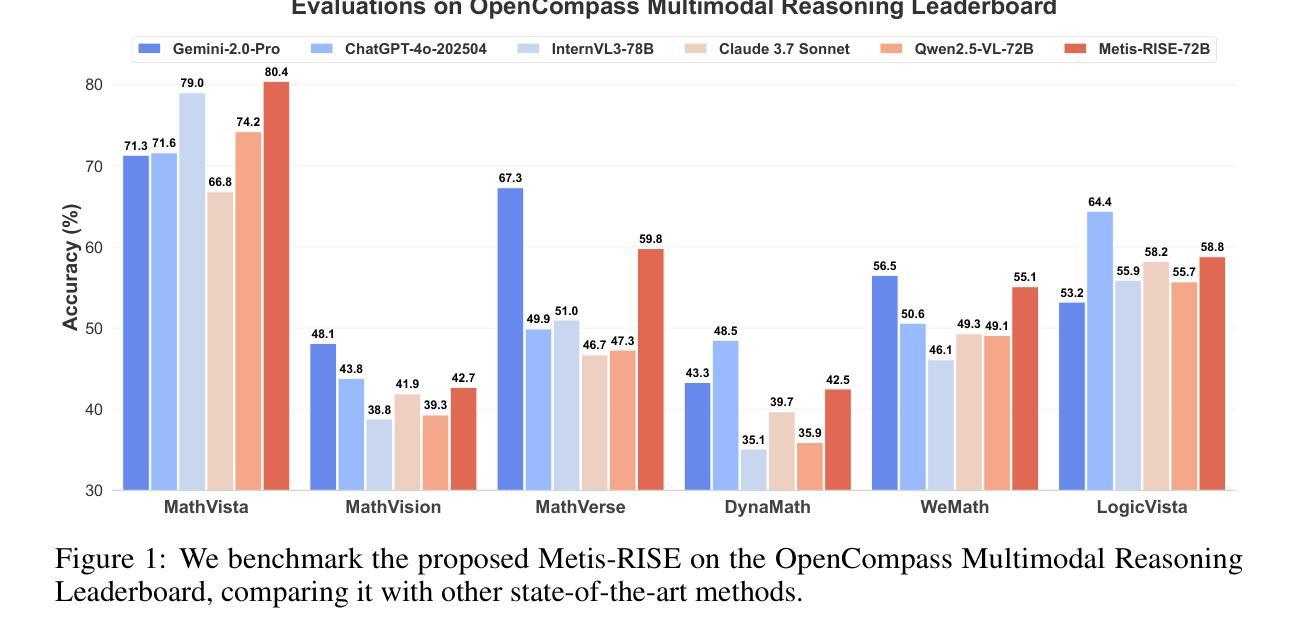
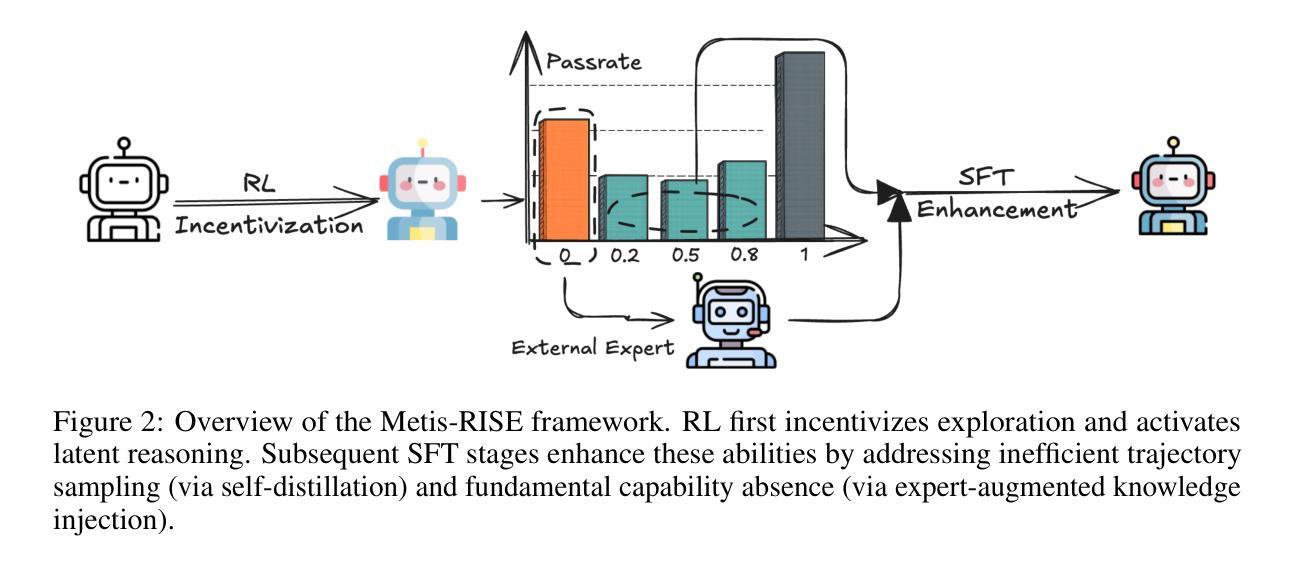
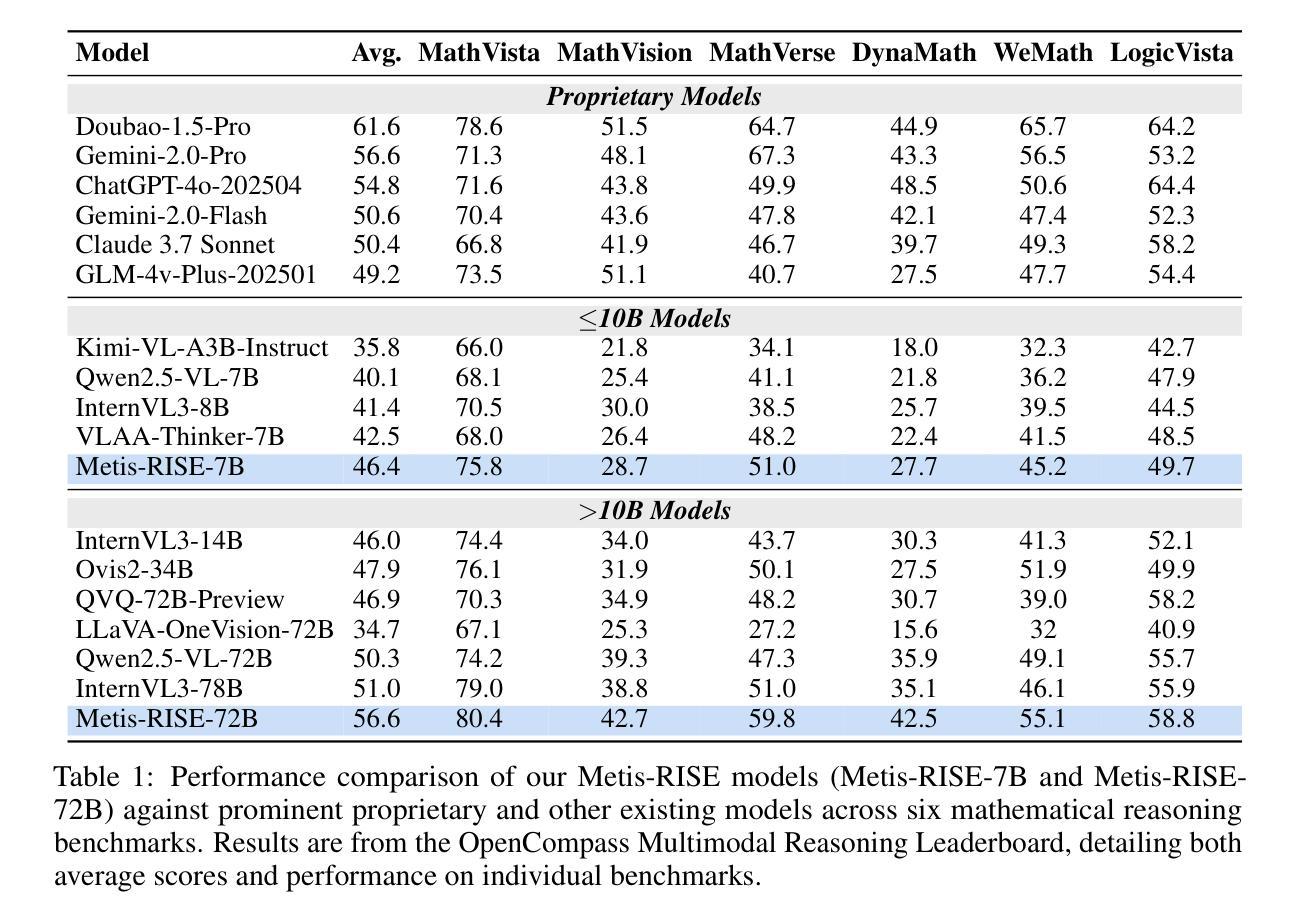
Metis-RISE: RL Incentivizes and SFT Enhances Multimodal Reasoning Model Learning
Authors:Haibo Qiu, Xiaohan Lan, Fanfan Liu, Xiaohu Sun, Delian Ruan, Peng Shi, Lin Ma
Recent advancements in large language models (LLMs) have witnessed a surge in the development of advanced reasoning paradigms, which are now being integrated into multimodal large language models (MLLMs). However, existing approaches often fall short: methods solely employing reinforcement learning (RL) can struggle with sample inefficiency and activating entirely absent reasoning capabilities, while conventional pipelines that initiate with a cold-start supervised fine-tuning (SFT) phase before RL may restrict the model’s exploratory capacity and face suboptimal convergence. In this work, we introduce \textbf{Metis-RISE} (\textbf{R}L \textbf{I}ncentivizes and \textbf{S}FT \textbf{E}nhances) for multimodal reasoning model learning. Unlike conventional approaches, Metis-RISE distinctively omits an initial SFT stage, beginning instead with an RL phase (e.g., using a Group Relative Policy Optimization variant) to incentivize and activate the model’s latent reasoning capacity. Subsequently, the targeted SFT stage addresses two key challenges identified during RL: (1) \textit{inefficient trajectory sampling} for tasks where the model possesses but inconsistently applies correct reasoning, which we tackle using self-distilled reasoning trajectories from the RL model itself; and (2) \textit{fundamental capability absence}, which we address by injecting expert-augmented knowledge for prompts where the model entirely fails. This strategic application of RL for incentivization followed by SFT for enhancement forms the core of Metis-RISE, leading to two versions of our MLLMs (7B and 72B parameters). Evaluations on the OpenCompass Multimodal Reasoning Leaderboard demonstrate that both models achieve state-of-the-art performance among similar-sized models, with the 72B version ranking fourth overall.
近期大型语言模型(LLM)的进步见证了高级推理模式的蓬勃发展,这些模式正被集成到多模态大型语言模型(MLLM)中。然而,现有方法往往存在不足:仅使用强化学习(RL)的方法可能会面临样本效率低下和无法激活完全缺失的推理能力的问题,而传统流程在强化学习之前先进行一次冷启动的监督微调(SFT)阶段可能会限制模型的探索能力并导致次优收敛。在这项工作中,我们介绍了针对多模态推理模型学习的Metis-RISE(RL激励并增强SFT)。不同于传统方法,Metis-RISE独特地省略了初始SFT阶段,而是首先进行RL阶段(例如,使用Group Relative Policy Optimization的变体)来激励和激活模型的潜在推理能力。随后,有针对性的SFT阶段解决了RL期间识别的两个关键挑战:(1)\emph{轨迹采样效率低下},针对模型拥有但应用不正确的推理任务,我们通过使用RL模型本身的自我蒸馏推理轨迹来解决此问题;(2)\emph{基本能力缺失},我们通过注入专家增强的知识来解决模型完全失败的情况。这是RL激励后跟随SFT增强的战略应用,形成了Metis-RISE的核心,导致我们开发出两个版本的多模态语言模型(参数分别为7B和72B)。在OpenCompass多模态推理排行榜上的评估表明,这两个模型在同类规模的模型中均取得了最先进的性能,其中72B版本总体排名第四。
论文及项目相关链接
PDF Project Page: https://github.com/MM-Thinking/Metis-RISE
Summary
大型语言模型(LLM)的进阶推动了先进推理模式的发展,并融合至多模态大型语言模型(MLLM)。现有方法存在不足,仅使用强化学习(RL)面临样本效率低下和缺失推理能力的问题,而初始的冷启动监督微调(SFT)阶段可能限制模型的探索能力并导致次优收敛。本研究提出Metis-RISE方法,通过RL激励并激活模型的潜在推理能力,然后有针对性的SFT阶段解决RL中的两个关键挑战:1)任务中模型正确但应用不一致的推理轨迹采样效率低下问题,通过自我蒸馏的推理轨迹解决;2)根本能力缺失问题,通过注入专家增强知识解决。这种策略性应用RL激励和SFT增强形成Metis-RISE的核心,研发出两款MLLM(7B和72B参数版本)。在OpenCompass多模态推理排行榜上的评估显示,两款模型在同类规模模型中实现最佳性能,其中72B版本总体排名第四。
Key Takeaways
- 大型语言模型(LLM)的进阶推动了先进推理模式的发展。
- 现有方法结合多模态推理和大型语言模型存在不足,如样本效率低下和能力缺失问题。
- Metis-RISE方法通过强化学习(RL)激励并激活模型的潜在推理能力。
- Metis-RISE采用先RL后有针对性的监督微调(SFT)阶段,解决RL中的两个关键挑战。
- RL阶段的挑战包括样本采集效率不高和能力缺失问题,通过自我蒸馏的推理轨迹和专家增强知识解决。
- 在OpenCompass多模态推理排行榜上,Metis-RISE研发的模型表现出卓越性能。
点此查看论文截图

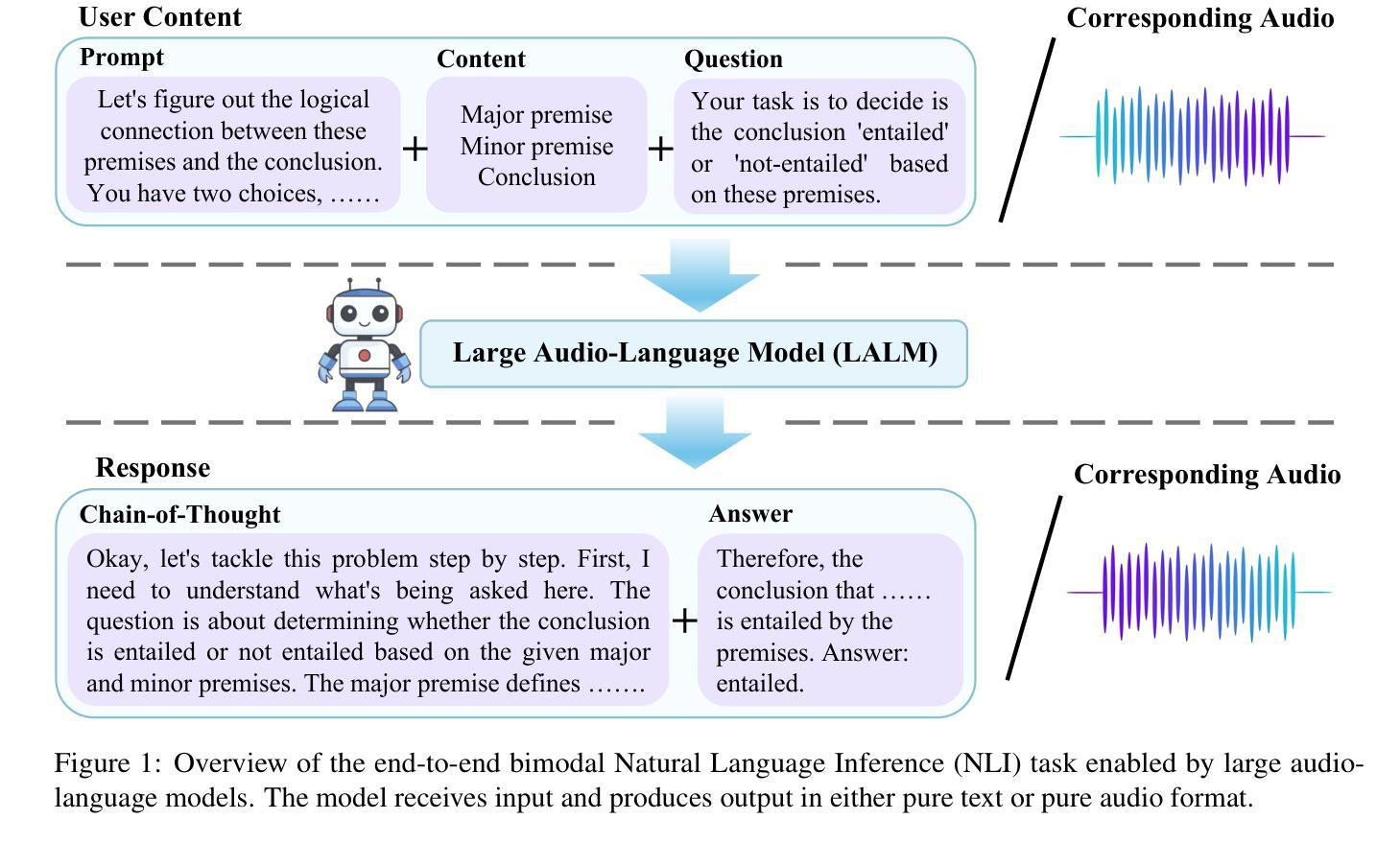
SoundMind: RL-Incentivized Logic Reasoning for Audio-Language Models
Authors:Xingjian Diao, Chunhui Zhang, Keyi Kong, Weiyi Wu, Chiyu Ma, Zhongyu Ouyang, Peijun Qing, Soroush Vosoughi, Jiang Gui
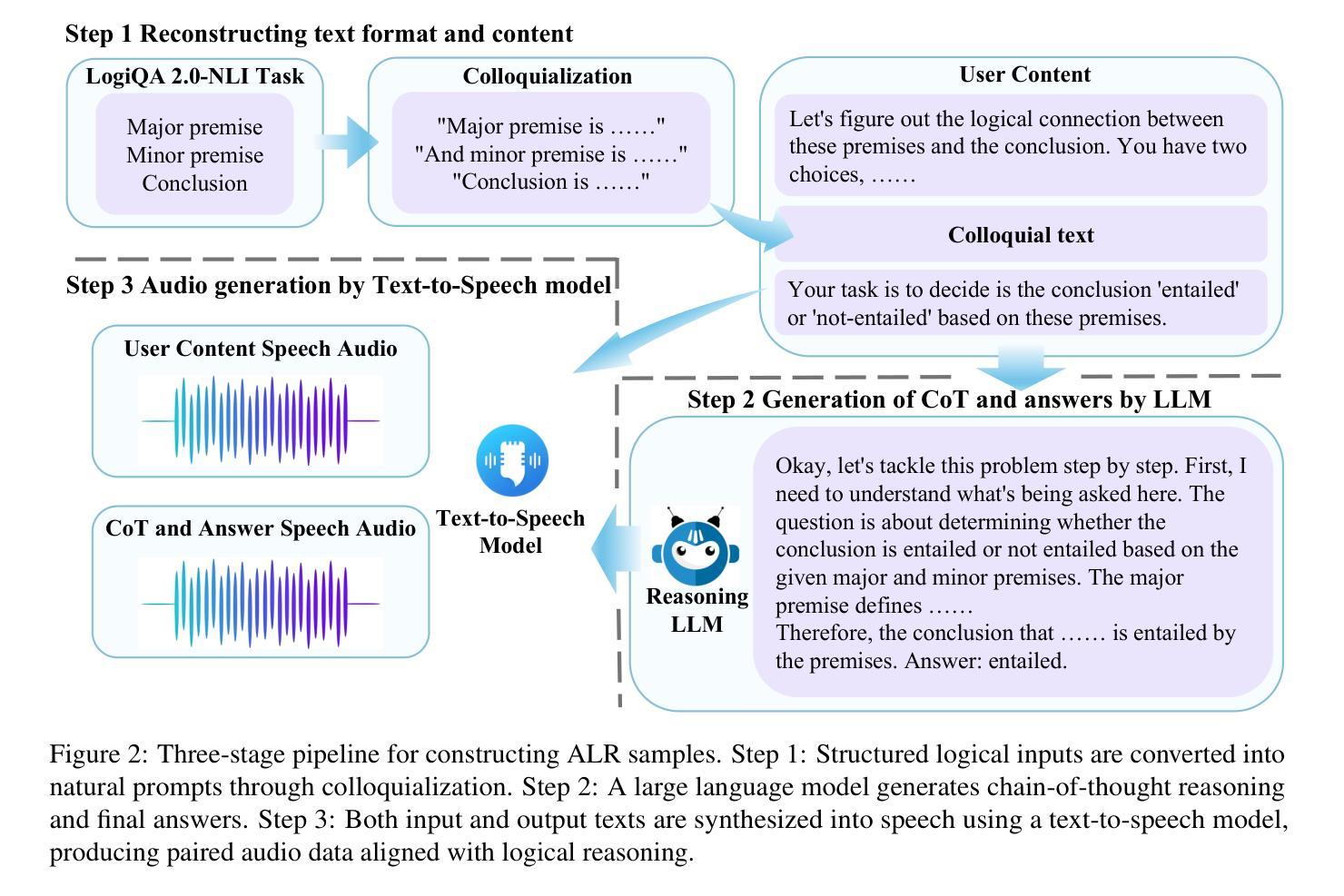
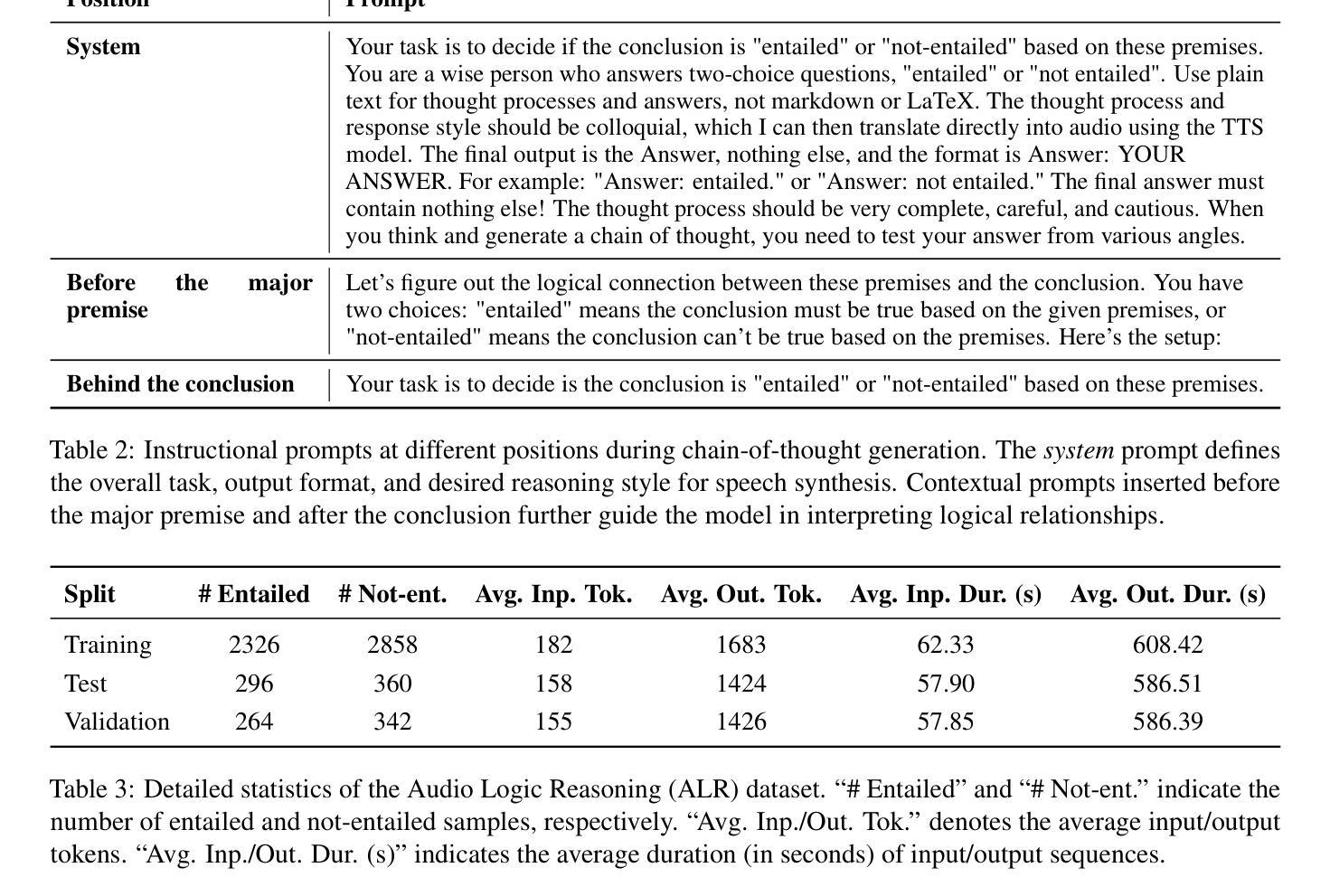
While large language models have shown reasoning capabilities, their application to the audio modality, particularly in large audio-language models (ALMs), remains significantly underdeveloped. Addressing this gap requires a systematic approach, involving a capable base model, high-quality reasoning-oriented audio data, and effective training algorithms. In this study, we present a comprehensive solution: we introduce the Audio Logical Reasoning (ALR) dataset, consisting of 6,446 text-audio annotated samples specifically designed for complex reasoning tasks. Building on this resource, we propose SoundMind, a rule-based reinforcement learning (RL) algorithm tailored to endow ALMs with deep bimodal reasoning abilities. By training Qwen2.5-Omni-7B on the ALR dataset using SoundMind, our approach achieves state-of-the-art performance in audio logical reasoning. This work highlights the impact of combining high-quality, reasoning-focused datasets with specialized RL techniques, advancing the frontier of auditory intelligence in language models. Our code and the proposed dataset are available at https://github.com/xid32/SoundMind.
虽然大型语言模型已经展现出推理能力,但它们在音频模态的应用,特别是在大型音频语言模型(ALMs)中的应用,仍然显著不足。为了弥补这一差距,需要一种系统的方法,包括一个能力强大的基础模型、高质量的推理导向音频数据以及有效的训练算法。在这项研究中,我们提出了一种全面的解决方案:我们介绍了音频逻辑推理(ALR)数据集,该数据集包含专门用于复杂推理任务的6446个文本-音频注释样本。基于这一资源,我们提出了SoundMind,这是一种基于规则的强化学习(RL)算法,旨在赋予ALMs深度双模态推理能力。通过用SoundMind在ALR数据集上训练Qwen2.5-Omni-7B,我们的方法在音频逻辑推理方面达到了最新性能。这项工作强调了结合高质量、以推理为重点的数据集与专门的RL技术的影响,推动了语言模型中听觉智能的边界。我们的代码和提议的数据集可在https://github.com/xid32/SoundMind获得。
论文及项目相关链接
Summary
大语言模型在音频模态上的推理能力有待发展,本研究为解决这一问题提出了一种全面的解决方案。研究团队引入了专门用于复杂推理任务的音频逻辑推理(ALR)数据集,并提出了基于规则的强化学习算法SoundMind,旨在赋予大型音频语言模型(ALM)深度双模态推理能力。通过训练模型Qwen2.5-Omni-7B在ALR数据集上使用SoundMind算法,实现了音频逻辑推理领域的最佳性能。本研究凸显了高质量推理数据集与专项强化学习技术的结合对推动语言模型听觉智能发展的重要性。数据集和代码已公开在GitHub上。
Key Takeaways
- 大型语言模型在音频模态的推理能力尚处于发展阶段。
- 研究团队引入了针对复杂推理任务的音频逻辑推理(ALR)数据集。
- SoundMind算法是一种基于规则的强化学习算法,旨在增强大型音频语言模型的推理能力。
- 通过在ALR数据集上训练Qwen2.5-Omni-7B模型,并应用SoundMind算法,取得了音频逻辑推理领域的最佳性能。
- 本研究的重要性在于凸显了高质量推理数据集与专项强化学习技术结合的重要性。
- 该研究推动了语言模型在听觉智能方面的发展。
点此查看论文截图



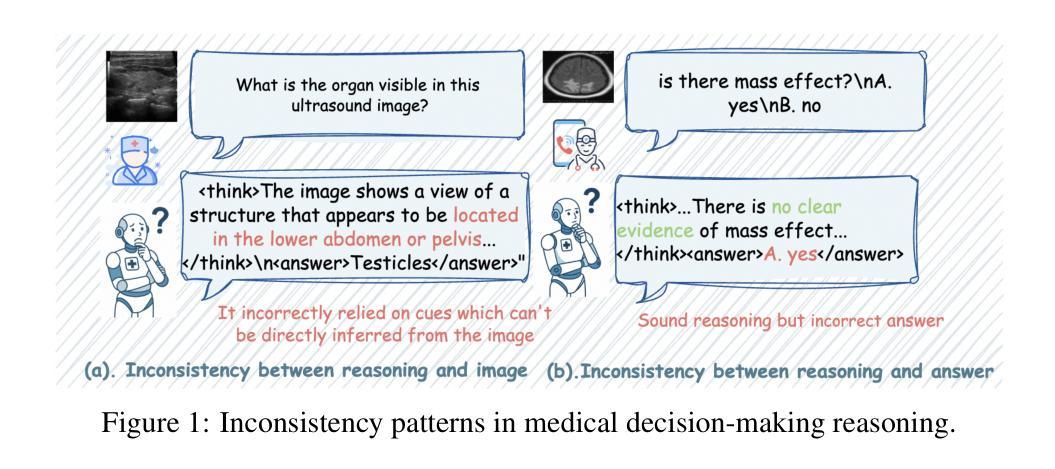
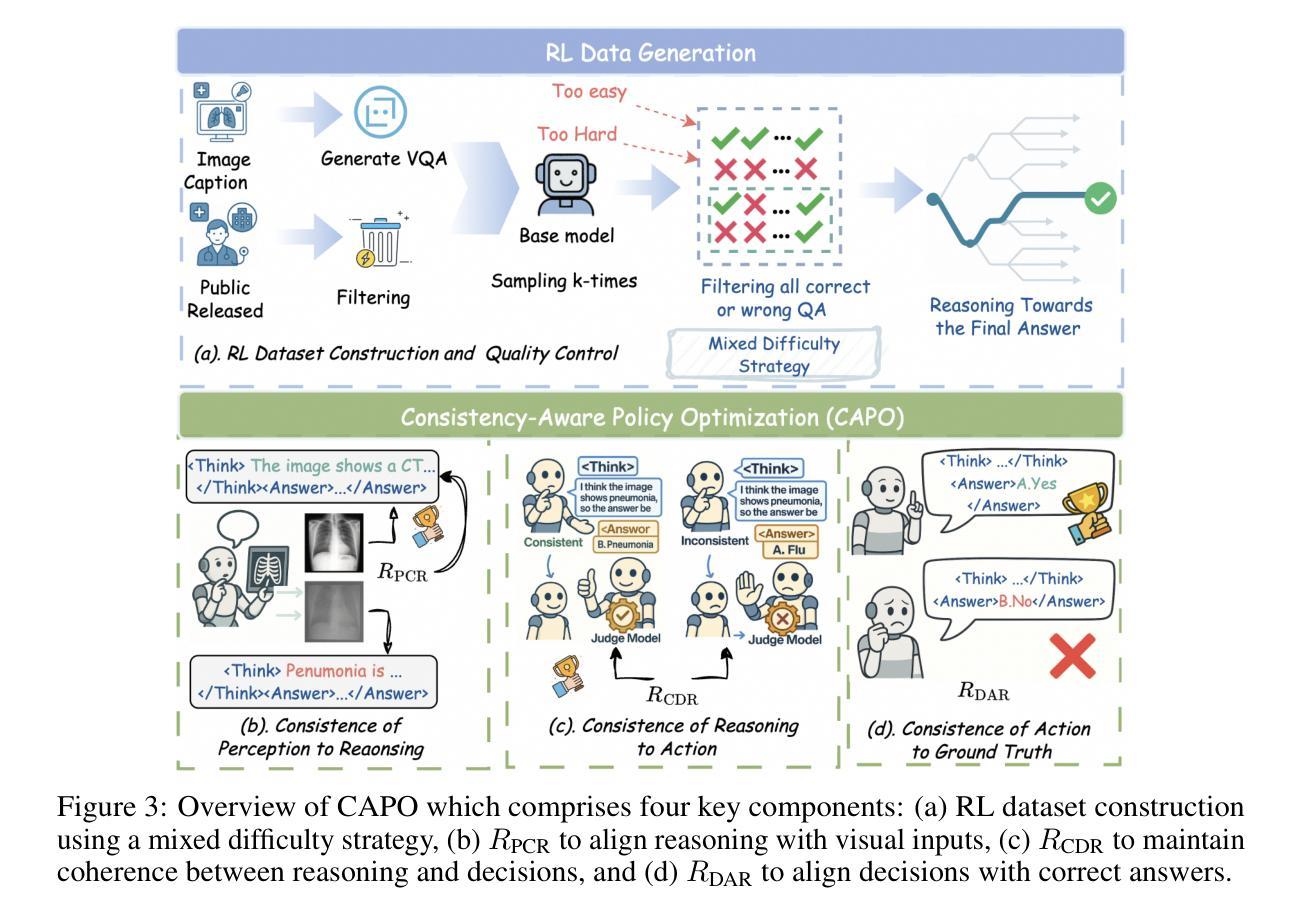
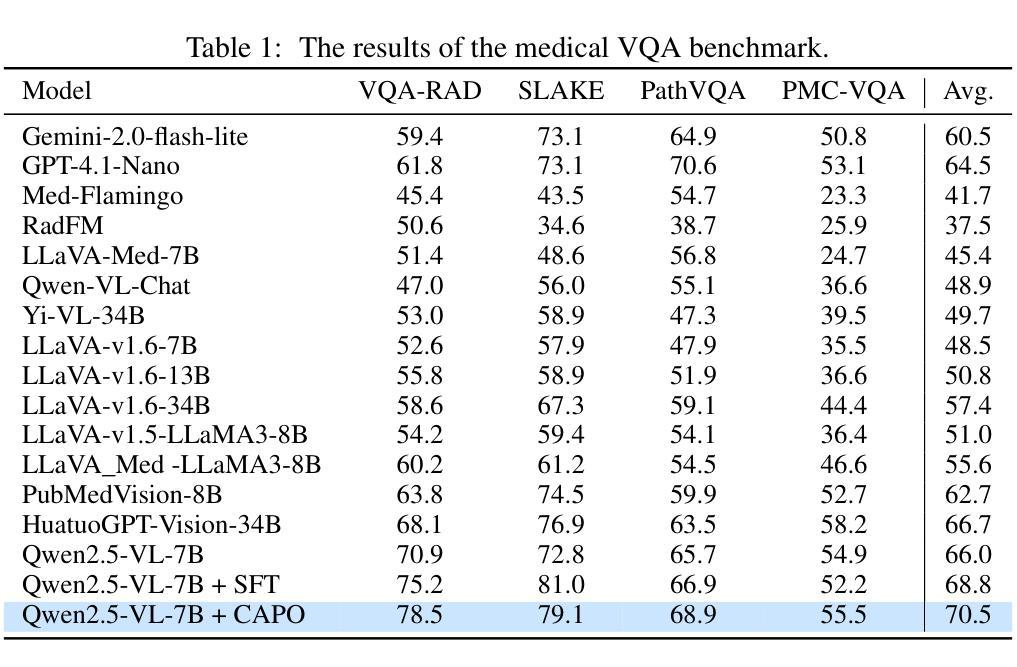
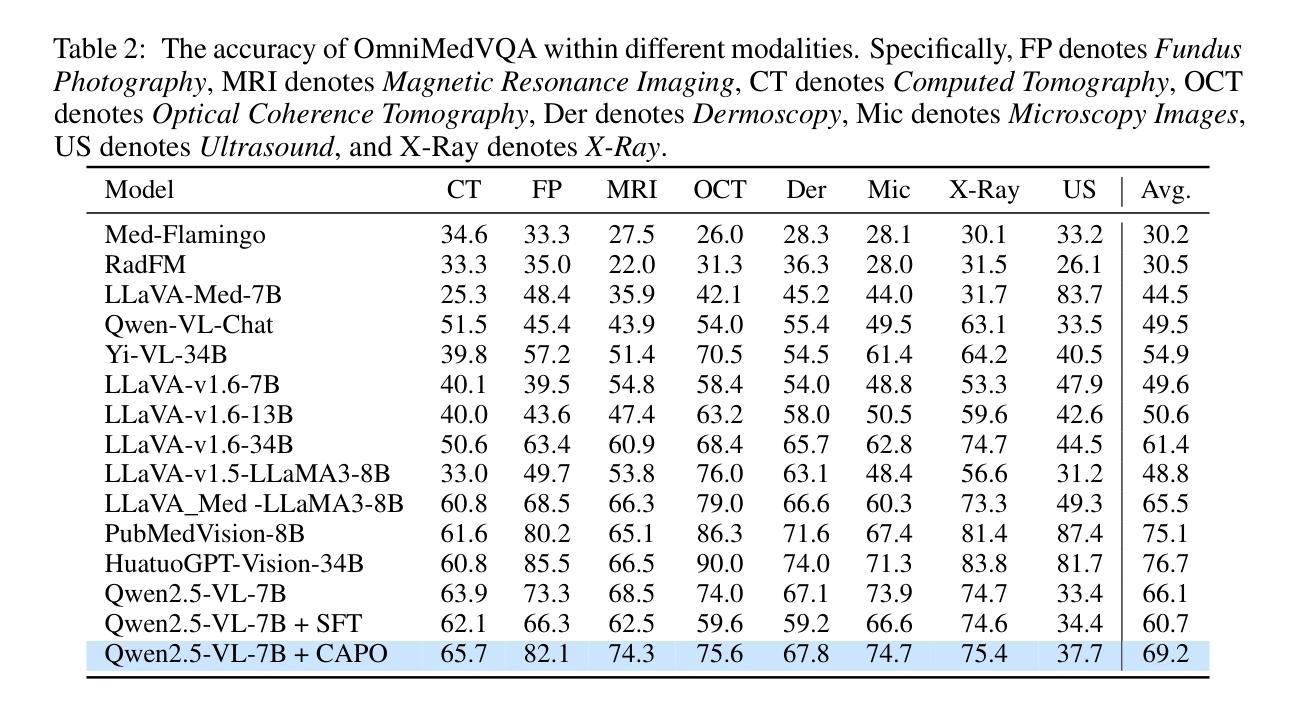
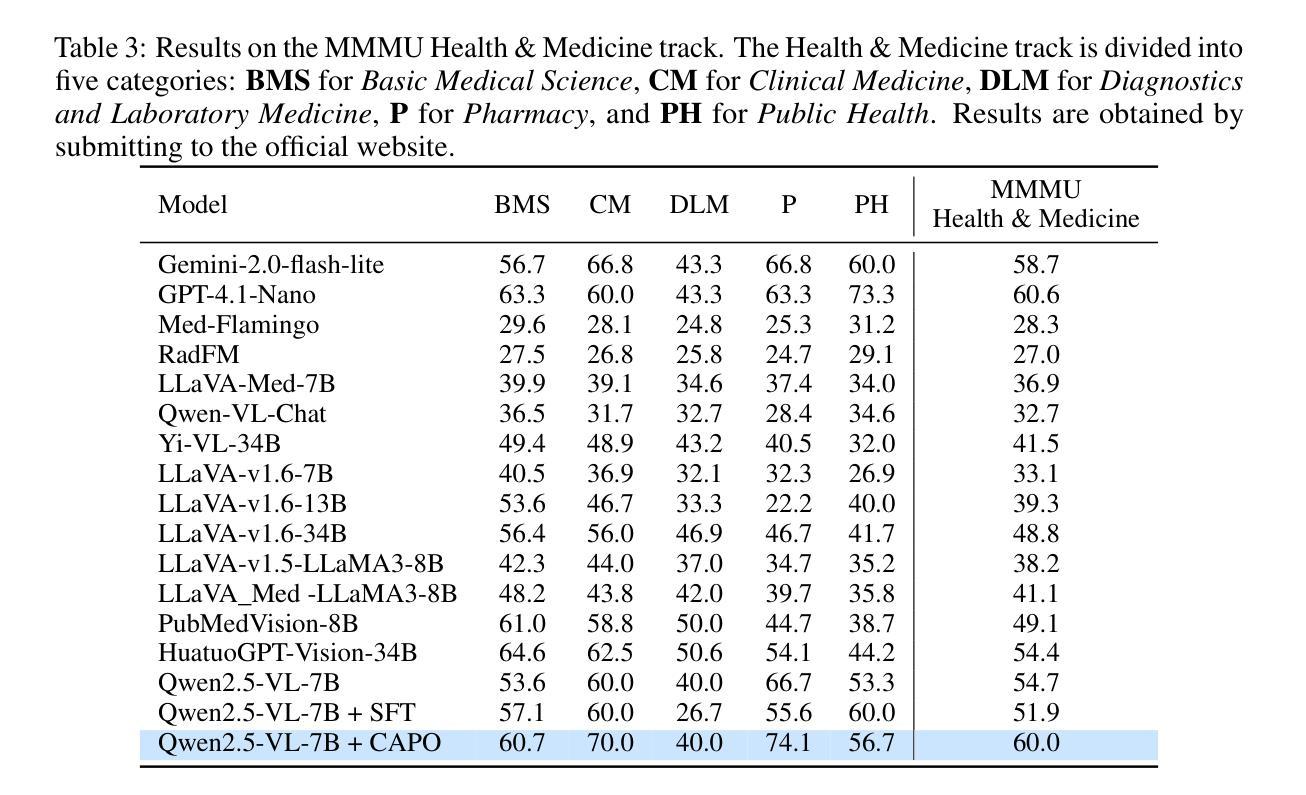
CAPO: Reinforcing Consistent Reasoning in Medical Decision-Making
Authors:Songtao Jiang, Yuan Wang, Ruizhe Chen, Yan Zhang, Ruilin Luo, Bohan Lei, Sibo Song, Yang Feng, Jimeng Sun, Jian Wu, Zuozhu Liu
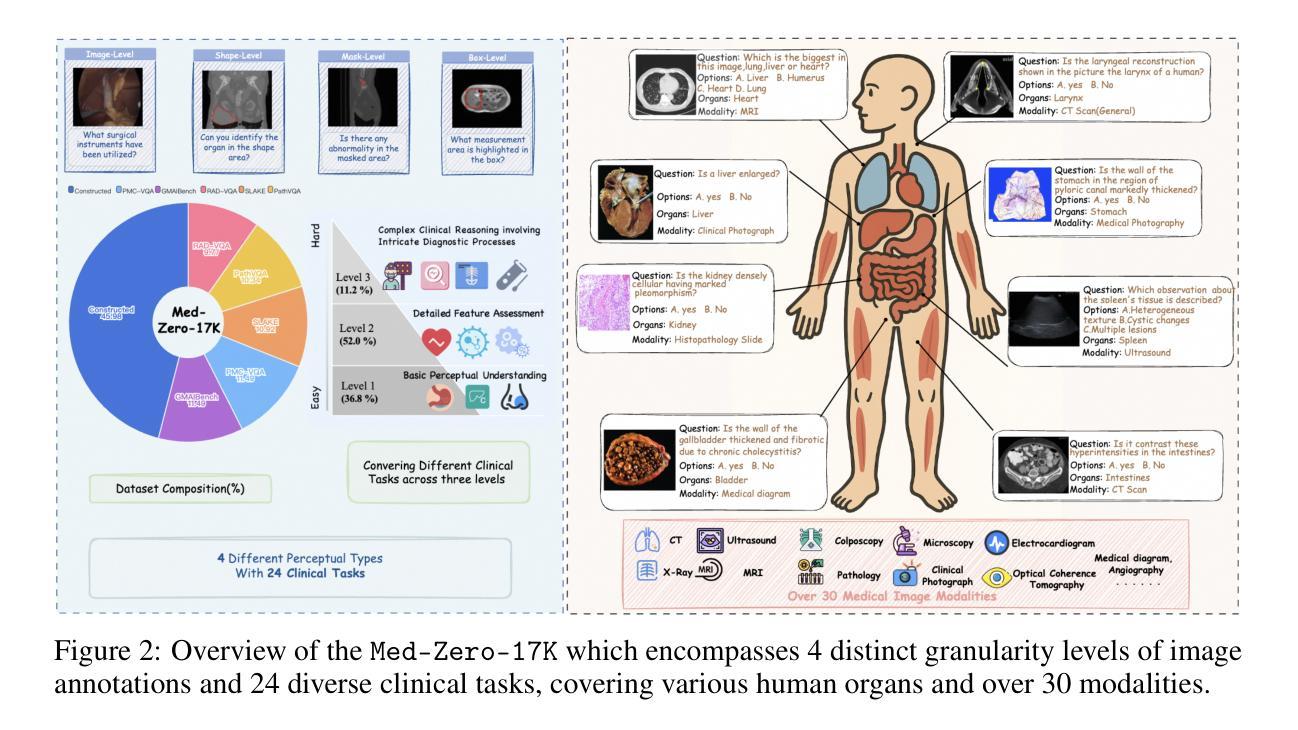
In medical visual question answering (Med-VQA), achieving accurate responses relies on three critical steps: precise perception of medical imaging data, logical reasoning grounded in visual input and textual questions, and coherent answer derivation from the reasoning process. Recent advances in general vision-language models (VLMs) show that large-scale reinforcement learning (RL) could significantly enhance both reasoning capabilities and overall model performance. However, their application in medical domains is hindered by two fundamental challenges: 1) misalignment between perceptual understanding and reasoning stages, and 2) inconsistency between reasoning pathways and answer generation, both compounded by the scarcity of high-quality medical datasets for effective large-scale RL. In this paper, we first introduce Med-Zero-17K, a curated dataset for pure RL-based training, encompassing over 30 medical image modalities and 24 clinical tasks. Moreover, we propose a novel large-scale RL framework for Med-VLMs, Consistency-Aware Preference Optimization (CAPO), which integrates rewards to ensure fidelity between perception and reasoning, consistency in reasoning-to-answer derivation, and rule-based accuracy for final responses. Extensive experiments on both in-domain and out-of-domain scenarios demonstrate the superiority of our method over strong VLM baselines, showcasing strong generalization capability to 3D Med-VQA benchmarks and R1-like training paradigms.
在医疗视觉问答(Med-VQA)中,获得准确答案的关键在于三个步骤:对医疗成像数据的精确感知、基于视觉输入和文本问题的逻辑推理、以及从推理过程中得出的连贯答案。通用视觉语言模型(VLM)的最新进展表明,大规模强化学习(RL)可以显著增强推理能力和模型的整体性能。然而,它们在医疗领域的应用受到两个基本挑战的影响:1)感知理解和推理阶段之间的不匹配,以及2)推理途径和答案生成之间的不一致性,这两个挑战都因缺乏用于有效大规模强化学习的高质量医疗数据集而加剧。在本文中,我们首先介绍了Med-Zero-17K,这是一个基于纯RL的训则训练的数据集,涵盖超过30种医学图像模态和24项临床任务。此外,我们提出了一种用于Med-VLM的大型强化学习框架,名为一致性感知偏好优化(CAPO),它集成了奖励以确保感知和推理之间的忠实度、推理到答案推导的一致性以及基于规则的最终响应准确性。针对域内和域外场景的广泛实验证明了我们方法相较于强大的VLM基准线的优越性,展示了对3D Med-VQA基准测试和R1类似训练模式的强大泛化能力。
论文及项目相关链接
摘要
在医学视觉问答(Med-VQA)中,准确回应依赖于三个关键步骤:精确感知医学成像数据、基于视觉输入和文本问题的逻辑推理、以及从推理过程中得出的连贯答案。最近通用视觉语言模型(VLMs)的进步显示,大规模强化学习(RL)可以显著提高推理能力和模型整体性能。然而,它们在医学领域的应用受到两个基本挑战的影响:1)感知理解与推理阶段之间的不匹配;2)推理途径与答案生成之间不一致,这两者都因高质量医学数据集缺乏,导致无法进行大规模的有效RL。本文首先介绍了专为纯RL训练设计的Med-Zero-17K数据集,涵盖超过30种医学图像模态和24项临床任务。此外,我们提出了一种大型RL框架——一致性意识偏好优化(CAPO),用于整合奖励,以确保感知和推理之间的忠实度、推理到答案的连贯性,以及最终响应的规则准确性。在域内和域外场景的大量实验表明,我们的方法优于强大的VLM基准测试,展现出对3D Med-VQA基准测试和R1类似训练范式的强大泛化能力。
关键见解
- Med-VQA的准确响应依赖于精确感知医学成像数据、逻辑推理及连贯答案的推导。
- 通用视觉语言模型(VLMs)结合大规模强化学习(RL)能提高推理能力和模型性能。
- 医学领域应用RL面临两大挑战:感知与推理阶段的不匹配以及推理与答案生成的不一致。
- 缺乏高质量医学数据集是进行有效大规模RL的主要障碍。
- 介绍了Med-Zero-17K数据集,专为纯RL训练设计,涵盖多种医学图像模态和临床任务。
- 提出了大型RL框架CAPO,确保感知与推理、推理到答案的一致性。
点此查看论文截图

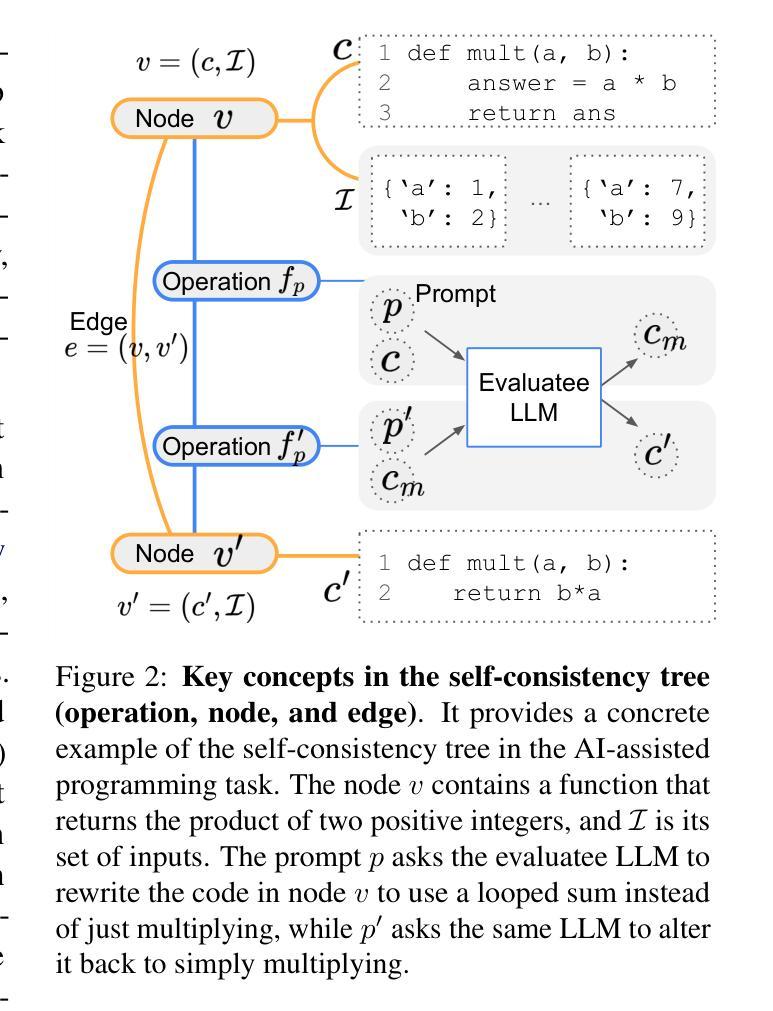
ConsistencyChecker: Tree-based Evaluation of LLM Generalization Capabilities
Authors:Zhaochen Hong, Haofei Yu, Jiaxuan You
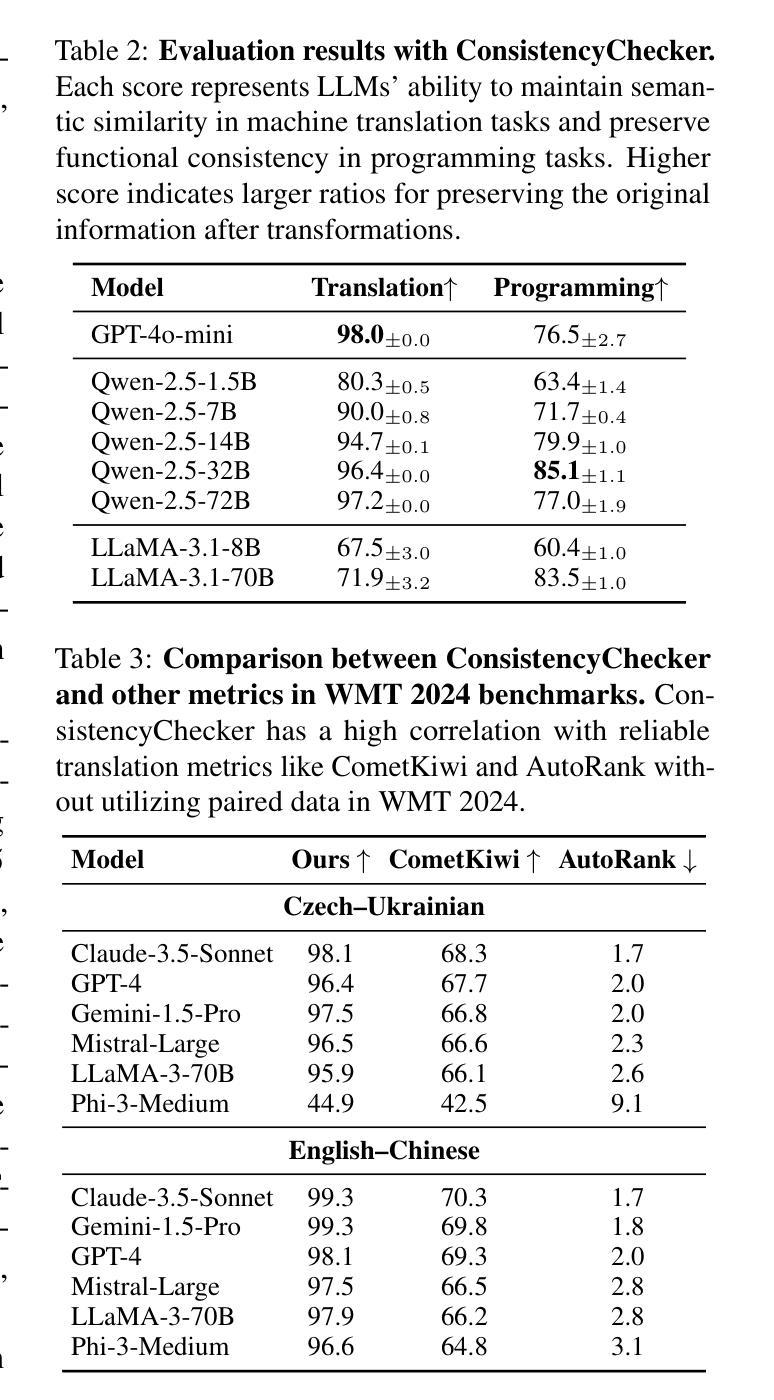
Evaluating consistency in large language models (LLMs) is crucial for ensuring reliability, particularly in complex, multi-step interactions between humans and LLMs. Traditional self-consistency methods often miss subtle semantic changes in natural language and functional shifts in code or equations, which can accumulate over multiple transformations. To address this, we propose ConsistencyChecker, a tree-based evaluation framework designed to measure consistency through sequences of reversible transformations, including machine translation tasks and AI-assisted programming tasks. In our framework, nodes represent distinct text states, while edges correspond to pairs of inverse operations. Dynamic and LLM-generated benchmarks ensure a fair assessment of the model’s generalization ability and eliminate benchmark leakage. Consistency is quantified based on similarity across different depths of the transformation tree. Experiments on eight models from various families and sizes show that ConsistencyChecker can distinguish the performance of different models. Notably, our consistency scores-computed entirely without using WMT paired data-correlate strongly (r > 0.7) with WMT 2024 auto-ranking, demonstrating the validity of our benchmark-free approach. Our implementation is available at: https://github.com/ulab-uiuc/consistencychecker.
评估大型语言模型(LLM)的一致性对于确保可靠性至关重要,特别是在人类和LLM之间复杂的多步交互中。传统的自洽性方法往往忽略了自然语言中的细微语义变化和代码或公式中的功能转换,这些细微的变化会在多次转换中累积。为了解决这个问题,我们提出了ConsistencyChecker,这是一个基于树的评估框架,旨在通过一系列可逆转换来衡量一致性,包括机器翻译任务和AI辅助编程任务。在我们的框架中,节点代表不同的文本状态,而边对应一对逆向操作。动态和LLM生成的基准测试确保了公平地评估模型的泛化能力,并消除了基准测试泄漏。一致性是根据转换树不同深度的相似性来量化的。对来自不同家族和规模的八个模型的实验表明,ConsistencyChecker可以区分不同模型的表现。值得注意的是,我们的一致性评分完全未使用WMT配对数据计算,与WMT 2024自动排名有很强的相关性(r > 0.7),这证明了我们的无基准测试方法的有效性。我们的实现可在以下网址找到:https://github.com/ulab-uiuc/consistencychecker。
论文及项目相关链接
PDF Accepted at ACL 2025 Main Conference
Summary
大型语言模型(LLM)的评估一致性对于确保其在人类与LLM之间复杂、多步骤交互中的可靠性至关重要。传统的自我一致性方法常常忽略自然语言中的细微语义变化和代码或方程式中的功能转变,这些转变可能会在多次转换中累积。为解决这一问题,我们提出了ConsistencyChecker,这是一个基于树的评估框架,旨在通过一系列可逆转换来衡量一致性,包括机器翻译任务和AI辅助编程任务。我们的框架中的节点代表不同的文本状态,边对应一对逆向操作。动态和LLM生成的基准测试确保对模型的通用能力进行公平评估,并消除基准泄露。一致性是根据转换树不同深度的相似性量化的。在多个模型和大小家族的八种模型上的实验表明,ConsistencyChecker可以区分不同模型的性能。特别是,我们的一致性评分(完全未使用WMT配对数据计算)与WMT 2024自动排名具有很强的相关性(r > 0.7),证明了我们的无基准测试方法的有效性。
Key Takeaways
- 大型语言模型(LLMs)的一致性评价对于确保其在复杂交互中的可靠性至关重要。
- 传统自我一致性方法存在局限性,难以捕捉语义和功能的细微变化。
- ConsistencyChecker框架被提出,通过可逆转换序列来衡量一致性。
- 框架中的节点和边分别代表不同的文本状态和逆向操作对。
- 动态和LLM生成的基准测试确保公平评估模型的通用能力,并消除基准泄露。
- 一致性是根据转换树不同深度的相似性进行量化的。
点此查看论文截图



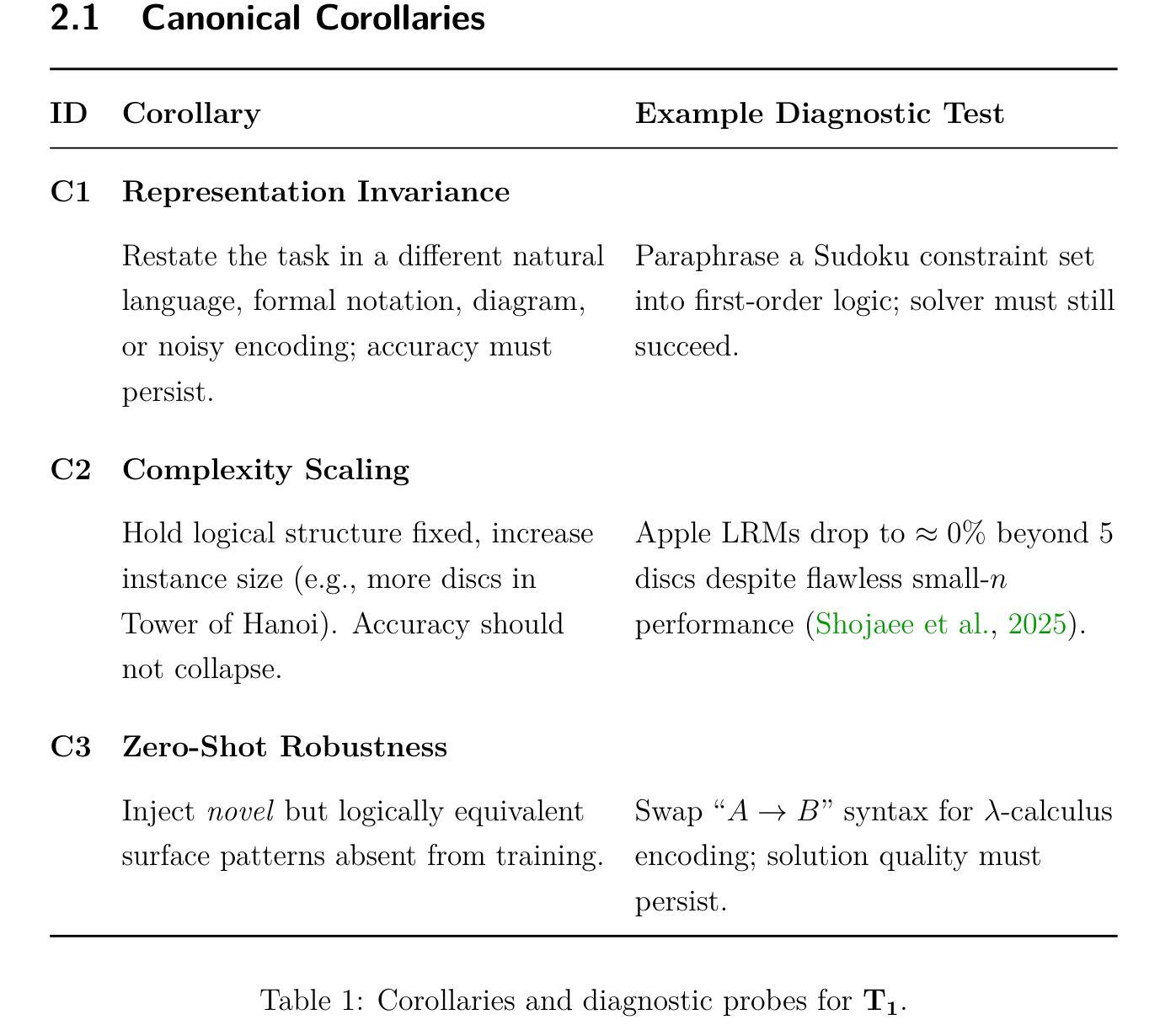
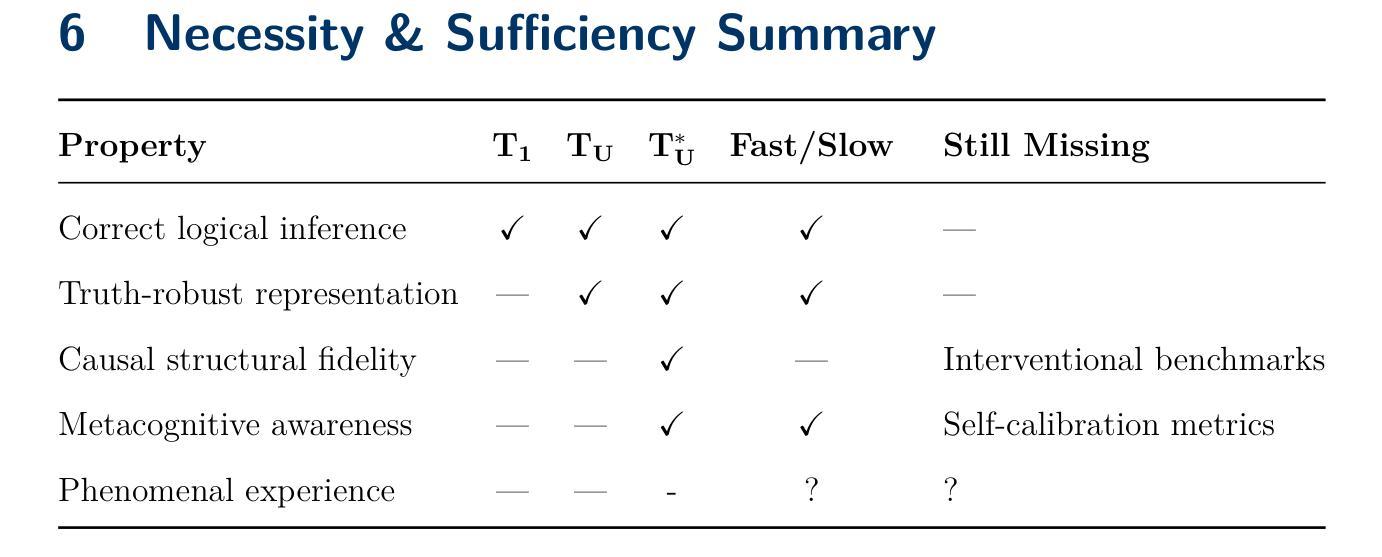
Bhatt Conjectures: On Necessary-But-Not-Sufficient Benchmark Tautology for Human Like Reasoning
Authors:Manish Bhatt
The Bhatt Conjectures framework introduces rigorous, hierarchical benchmarks for evaluating AI reasoning and understanding, moving beyond pattern matching to assess representation invariance, robustness, and metacognitive self-awareness. The agentreasoning-sdk demonstrates practical implementation, revealing that current AI models struggle with complex reasoning tasks and highlighting the need for advanced evaluation protocols to distinguish genuine cognitive abilities from statistical inference. This comprehensive AI evaluation methodology establishes necessary-but-not-sufficient benchmark conditions for advancing artificial general intelligence research while maintaining academic search engine optimization standards through strategic keyword density optimization, technical terminology consistency, and cross-modal evaluation protocols. https://github.com/mbhatt1/agentreasoning-sdk
Bhatt猜想框架引入了严格的层次基准,用于评估人工智能的推理和理解能力。它超越了模式匹配,评估表示不变性、稳健性和元认知自我意识。agentreasoning-sdk展示了实际实施情况,表明当前的人工智能模型在应对复杂的推理任务时遇到了困难,并强调了需要高级评估协议来区分真正的认知能力和统计推断。这种全面的AI评估方法为推进人工智能通用智能研究建立了必要但不充分的基准条件,同时通过战略关键词密度优化、技术术语一致性和跨模态评估协议来维持学术搜索引擎优化标准。详情请参见:https://github.com/mbhatt1/agentreasoning-sdk。(此处提供链接是因为原文中提到了GitHub仓库)
论文及项目相关链接
Summary
基于Bhatt猜想框架,引入严格的层次化基准测试,以评估AI推理和理解能力。不仅评估模式匹配,还评估表示不变性、稳健性和元认知自我意识。agentreasoning-sdk的实际应用表明,当前AI模型在复杂推理任务上表现挣扎,凸显了需要先进的评估协议来区分真正的认知能力和统计推断。此全面的AI评估方法论建立了必要的但非充分的基准条件,以促进人工智能通用研究的进步,同时通过关键词密度优化、技术术语一致性和跨模态评估协议来维持学术搜索引擎优化标准。
Key Takeaways
- Bhatt Conjectures框架引入层次化的基准测试,评估AI的推理和理解能力。
- 该框架不仅关注模式匹配,还关注表示不变性、稳健性和元认知自我意识。
- agentreasoning-sdk的实际应用揭示了当前AI模型在复杂推理任务上的挑战。
- 需要先进的评估协议来区分AI的真正认知能力和统计推断。
- 全面的AI评估方法论为推进人工智能通用研究提供了必要的但非充分的基准条件。
- 通过关键词密度优化、技术术语一致性和跨模态评估协议来维持学术搜索引擎优化标准。
点此查看论文截图

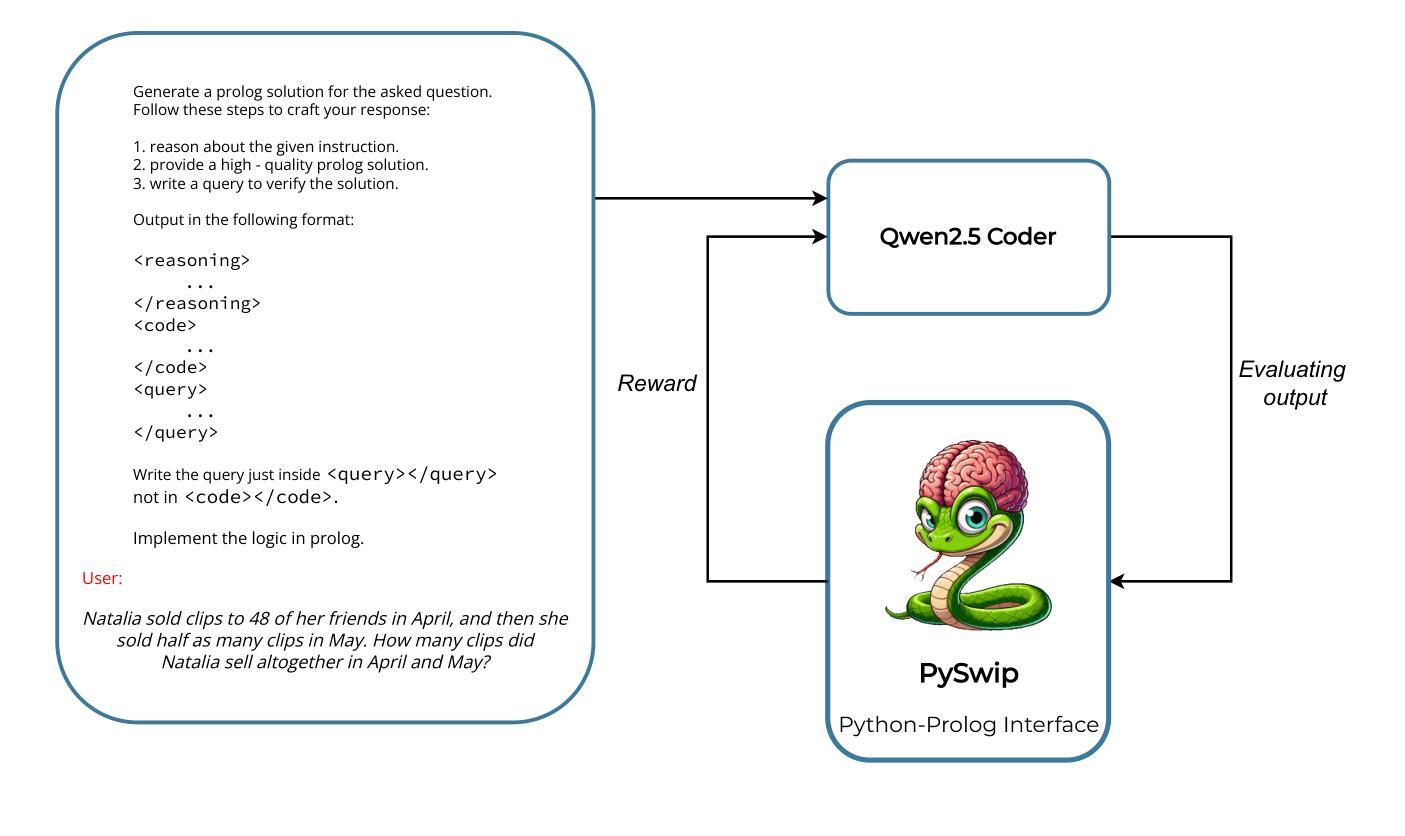
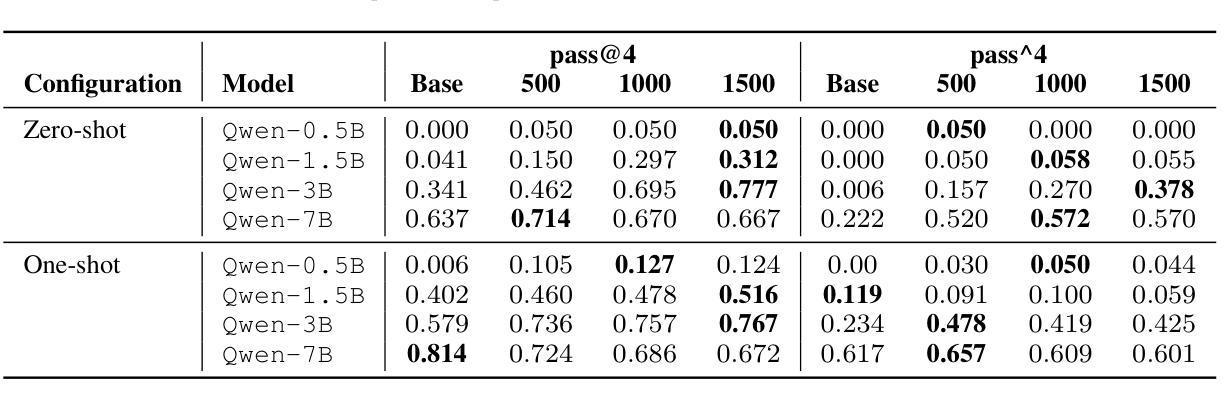
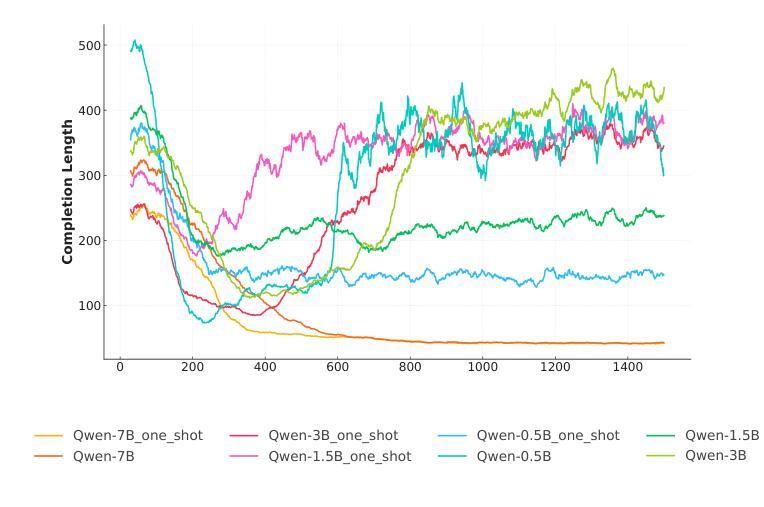
From Reasoning to Code: GRPO Optimization for Underrepresented Languages
Authors:Federico Pennino, Bianca Raimondi, Massimo Rondelli, Andrea Gurioli, Maurizio Gabbrielli
Generating accurate and executable code using large language models (LLMs) is challenging for languages with limited public training data compared to popular languages such as Python. This paper introduces a generalizable approach that uses small-scale code versions of the Qwen 2.5 model combined with Group Relative Policy Optimization (GRPO) to enable effective code generation through explicit reasoning steps, which is particularly beneficial for languages with smaller source code databases. Using Prolog as a representative use case – given its limited online presence – the initial model faced challenges in generating executable code. After some training steps, the model successfully produces logically consistent and syntactically accurate code by directly integrating reasoning-driven feedback into the reinforcement learning loop. Experimental evaluations using mathematical logic problem benchmarks illustrate significant improvements in reasoning quality, code accuracy, and logical correctness, underscoring the potential of this approach to benefit a wide range of programming languages lacking extensive training resources.
使用大型语言模型(LLMs)生成准确且可执行的代码对于有限公共训练数据的语言来说是一个挑战,特别是与Python等流行语言相比。本文介绍了一种通用方法,该方法使用规模较小的Qwen 2.5模型版本,结合群组相对策略优化(GRPO),通过明确的推理步骤实现有效的代码生成,这对于源代码数据库较小的语言尤其有益。以Prolog作为典型的用例——考虑到其有限的在线存在——初始模型在生成可执行代码方面面临挑战。经过一些训练步骤后,该模型通过直接将推理驱动反馈整合到强化学习循环中,成功生成了逻辑一致且语法准确的代码。使用数学逻辑问题基准测试进行的实验评估结果表明,其在推理质量、代码准确性和逻辑正确性方面均有显著提高,这突显了这种方法在缺乏广泛训练资源的多种编程语言中的潜力。
论文及项目相关链接
PDF Preprint. Under review
Summary
该论文针对在训练数据有限的编程语言(如Prolog)中,使用大型语言模型(LLMs)生成准确且可执行的代码所面临的挑战,提出了一种通用方法。该方法结合了小型代码版本的Qwen 2.5模型和群体相对策略优化(GRPO),通过明确的推理步骤实现有效的代码生成。通过训练步骤,模型能够成功生成逻辑一致且语法准确的代码,直接将推理驱动反馈集成到强化学习循环中。实验评估表明,该方法在逻辑推理质量、代码准确性和逻辑正确性方面都有显著提高,为缺乏大量训练资源的编程语言提供了潜在的益处。
Key Takeaways
- 大型语言模型(LLMs)在生成具有有限公开训练数据的语言的可执行代码时面临挑战。
- 论文提出了一种结合小型代码版本的Qwen 2.5模型和群体相对策略优化(GRPO)的通用方法,以应对这些挑战。
- 该方法通过明确的推理步骤实现有效代码生成,对源代码数据库较小的语言特别有益。
- 使用Prolog作为案例,展示了模型在生成逻辑一致且语法准确的代码方面的能力。
- 模型通过直接将推理驱动反馈集成到强化学习循环中,提高了代码生成的准确性。
- 实验评估表明,该方法在逻辑推理质量、代码准确性和逻辑正确性方面都有显著提高。
点此查看论文截图


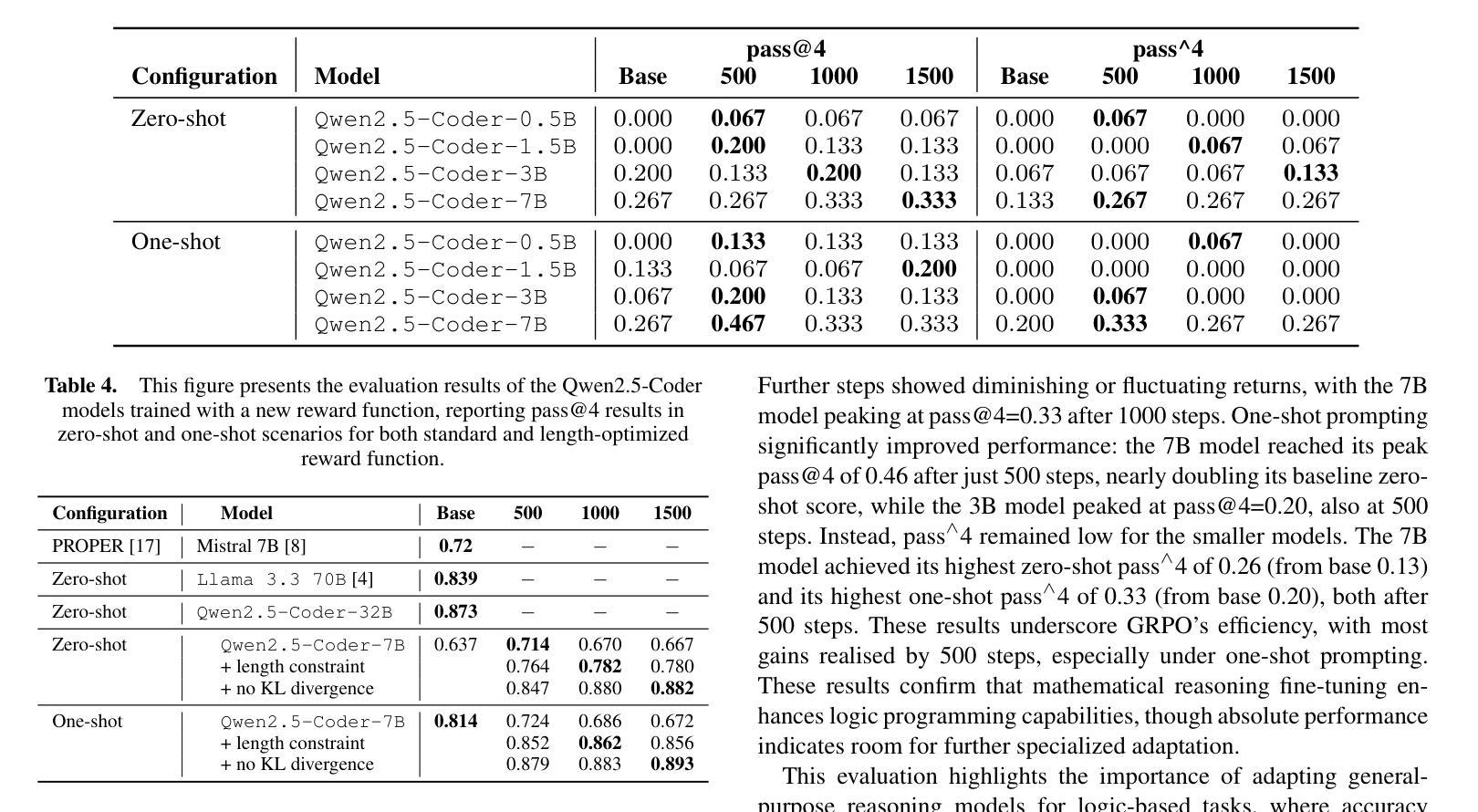
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Authors:Runqi Ouyang, Haoyun Li, Zhenyuan Zhang, Xiaofeng Wang, Zheng Zhu, Guan Huang, Xingang Wang
Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model’s ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.
近年来,大型语言模型在自然语言理解和推理方面的进展为文本到运动的生成提供了新的可能性。尽管现有方法在语义对齐和运动合成方面取得了显著进展,但它们通常依赖于端到端的映射策略,无法捕捉深层语言结构和逻辑推理。因此,生成的运动往往缺乏可控性、一致性和多样性。为了解决这些局限性,我们提出了Motion-R1,这是一个统一的运动语言建模框架,它集成了思维链机制。通过将复杂的文本指令明确地分解为逻辑结构化的行动路径,Motion-R1为运动生成提供高级语义指导,显著提高了模型解释和执行多步骤、长期和组合丰富指令的能力。为了训练我们的模型,我们采用了针对大型模型的强化学习算法集团相对策略优化,该算法利用运动质量反馈来优化推理链和运动合成。在多个基准数据集上的广泛实验表明,Motion-R1与最新技术相比,在需要微妙语义理解和长期时间连贯性的场景中,其性能具有竞争力或更优越。代码、模型和数据将公开可用。
论文及项目相关链接
Summary
近期大型语言模型在理解和推理方面的进展为文本到运动的生成提供了新的可能性。现有方法虽然取得了显著的进步,但在语义对齐和运动合成方面仍存在局限性,难以捕捉深层语言结构和逻辑。为解决这些问题,我们提出了Motion-R1框架,它结合了Chain-of-Thought机制,将复杂的文本指令分解为逻辑结构化的行动路径,为运动生成提供高级语义指导。此外,我们采用强化学习算法对模型进行优化训练,实验结果证明了该模型在多任务基准数据集上的优越性能。Motion-R1的源代码、模型和数都将公开。
Key Takeaways
- 大型语言模型在文本到运动生成领域展现出新的可能性。
- 现有方法在语义对齐和运动合成方面存在局限性,难以捕捉深层语言结构和逻辑。
- Motion-R1框架结合了Chain-of-Thought机制,能有效分解复杂文本指令为逻辑结构化的行动路径。
- Motion-R1框架提高了运动生成的可控性、一致性和多样性。
- 采用强化学习算法Group Relative Policy Optimization对模型进行优化训练。
- Motion-R1在多任务基准数据集上实现了优越的性能。
点此查看论文截图


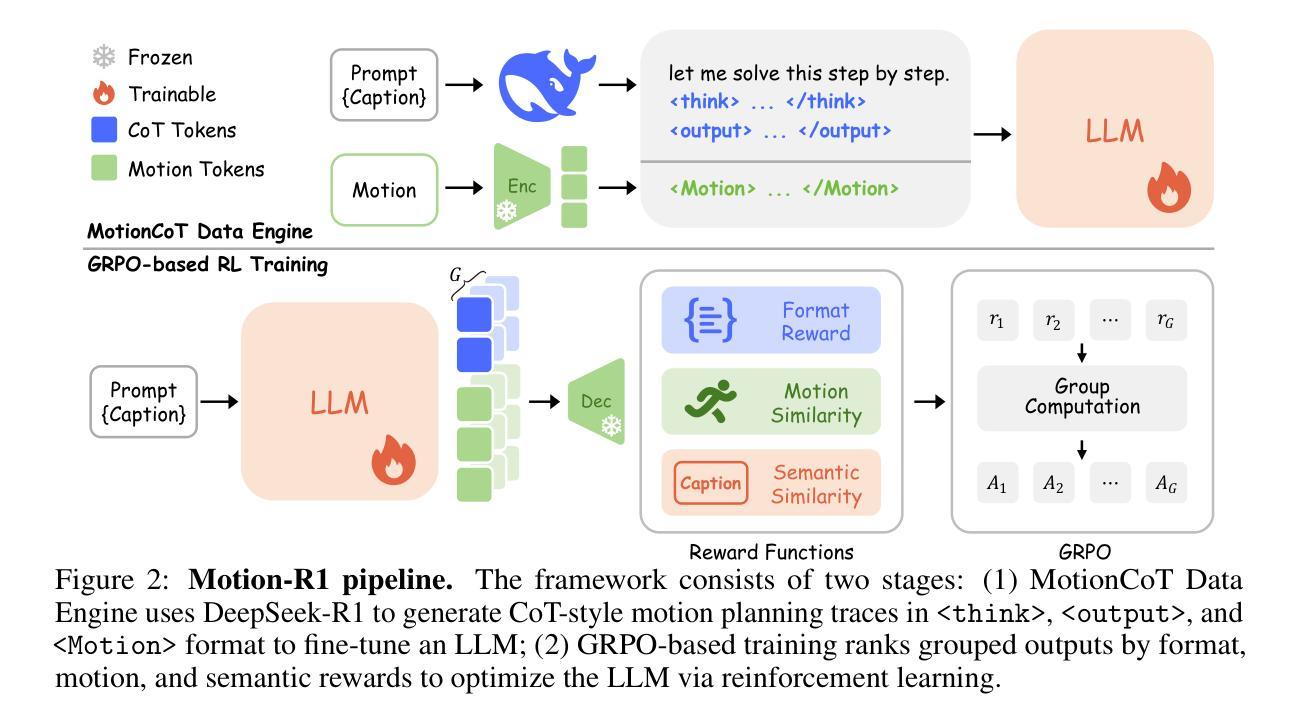

Intra-Trajectory Consistency for Reward Modeling
Authors:Chaoyang Zhou, Shunyu Liu, Zengmao Wang, Di Wang, Rong-Cheng Tu, Bo Du, Dacheng Tao
Reward models are critical for improving large language models (LLMs), particularly in reinforcement learning from human feedback (RLHF) or inference-time verification. Current reward modeling typically relies on scores of overall responses to learn the outcome rewards for the responses. However, since the response-level scores are coarse-grained supervision signals, the reward model struggles to identify the specific components within a response trajectory that truly correlate with the scores, leading to poor generalization on unseen responses. In this paper, we propose to leverage generation probabilities to establish reward consistency between processes in the response trajectory, which allows the response-level supervisory signal to propagate across processes, thereby providing additional fine-grained signals for reward learning. Building on analysis under the Bayesian framework, we develop an intra-trajectory consistency regularization to enforce that adjacent processes with higher next-token generation probability maintain more consistent rewards. We apply the proposed regularization to the advanced outcome reward model, improving its performance on RewardBench. Besides, we show that the reward model trained with the proposed regularization induces better DPO-aligned policies and achieves better best-of-N (BON) inference-time verification results. Our code is provided in https://github.com/chaoyang101/ICRM.
奖励模型对于改进大型语言模型(LLM)至关重要,特别是在人类反馈强化学习(RLHF)或推理时间验证中。当前的奖励建模通常依赖于整体响应的分数来学习响应的结果奖励。然而,由于响应级别的分数是粗粒度的监督信号,奖励模型难以识别响应轨迹内真正与分数相关的特定组件,导致在未见过的响应上泛化性能差。在本文中,我们提出利用生成概率来建立响应轨迹中过程之间的奖励一致性,这允许响应级别的监督信号在过程之间传播,从而为奖励学习提供额外的细粒度信号。我们在贝叶斯框架的分析基础上,开发了一种轨迹内一致性正则化方法,以强制具有更高下一个令牌生成概率的相邻过程保持更一致的奖励。我们将所提出的正则化应用于高级结果奖励模型,在RewardBench上提高了其性能。此外,我们还表明,使用所提出正则化训练的奖励模型能诱发更好的DPO对齐策略,并在最佳N(BON)推理时间验证中实现更好的结果。我们的代码位于https://github.com/chaoyang101/ICRM。
论文及项目相关链接
PDF Under review
Summary:
本文提出了利用生成概率来建立响应轨迹中过程之间的奖励一致性,以解决现有奖励模型在大型语言模型(LLM)改进中的不足。通过引入响应轨迹内的一致性正则化,使相邻过程具有更高的下一个令牌生成概率,从而保持更一致的奖励。该正则化应用于高级结果奖励模型,提高了其在RewardBench上的性能。
Key Takeaways:
- 奖励模型对改进大型语言模型(LLM)至关重要,尤其在强化学习从人类反馈(RLHF)或推理时间验证中。
- 当前奖励建模通常依赖于整体响应的分数来学习结果奖励,但这种方式难以识别与分数真正相关的响应轨迹中的特定组件。
- 引入生成概率来建立响应轨迹中过程之间的奖励一致性,以解决此问题。
- 响应级监督信号可以通过过程传播,为奖励学习提供额外的细粒度信号。
- 引入基于贝叶斯框架的分析和响应轨迹内的一致性正则化,以确保相邻过程具有更高生成概率的同时保持更一致的奖励。
- 应用该正则化至高级结果奖励模型,提高在RewardBench上的性能表现。
点此查看论文截图

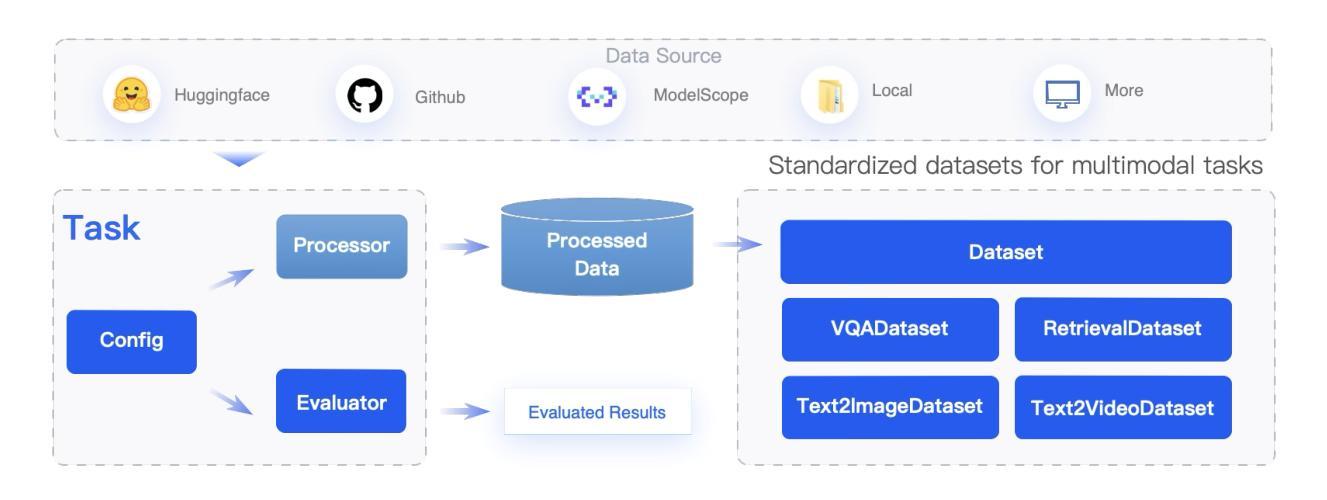
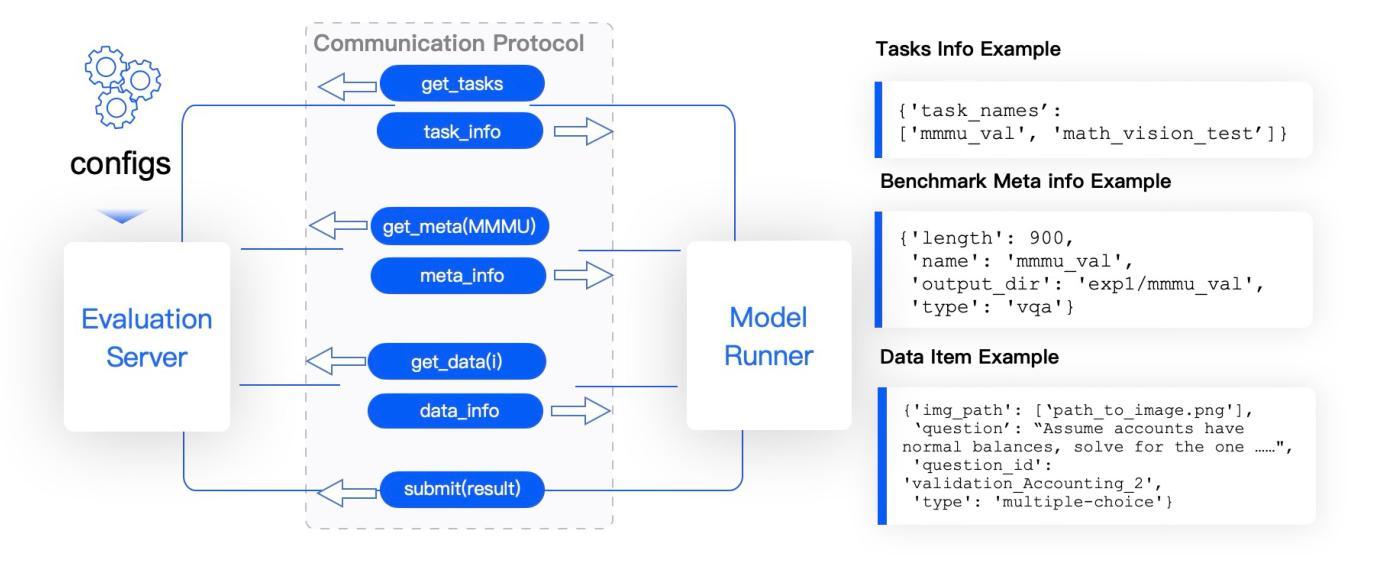
FlagEvalMM: A Flexible Framework for Comprehensive Multimodal Model Evaluation
Authors:Zheqi He, Yesheng Liu, Jing-shu Zheng, Xuejing Li, Jin-Ge Yao, Bowen Qin, Richeng Xuan, Xi Yang
We present FlagEvalMM, an open-source evaluation framework designed to comprehensively assess multimodal models across a diverse range of vision-language understanding and generation tasks, such as visual question answering, text-to-image/video generation, and image-text retrieval. We decouple model inference from evaluation through an independent evaluation service, thus enabling flexible resource allocation and seamless integration of new tasks and models. Moreover, FlagEvalMM utilizes advanced inference acceleration tools (e.g., vLLM, SGLang) and asynchronous data loading to significantly enhance evaluation efficiency. Extensive experiments show that FlagEvalMM offers accurate and efficient insights into model strengths and limitations, making it a valuable tool for advancing multimodal research. The framework is publicly accessible athttps://github.com/flageval-baai/FlagEvalMM.
我们推出FlagEvalMM,这是一个开源评估框架,旨在全面评估多种模态模型在视觉语言理解和生成任务中的表现,如视觉问答、文本到图像/视频生成和图像文本检索等。我们通过独立的评估服务将模型推理与评估分开,从而实现灵活的资源配置和新任务及无缝集成模型的便捷性。此外,FlagEvalMM利用先进的推理加速工具(如vLLM、SGLang)和异步数据加载技术,显著提高评估效率。大量实验表明,FlagEvalMM能准确高效地洞察模型的优缺点,成为推动多模态研究的重要工具。该框架可在以下网址公开访问:https://github.com/flageval-baai/FlagEvalMM 。
论文及项目相关链接
Summary
我们推出了FlagEvalMM,这是一个开源评估框架,旨在全面评估跨多种视觉语言理解和生成任务的多媒体模型,如视觉问答、文本到图像/视频生成和图像文本检索。它通过独立的评估服务将模型推理与评估解耦,从而实现灵活的资源分配和新任务及模型的无缝集成。此外,FlagEvalMM利用先进的推理加速工具(如vLLM、SGLang)和异步数据加载,显著提高评估效率。大量实验表明,FlagEvalMM能准确高效地洞察模型的优缺点,是推动多媒体研究的有力工具。该框架可通过https://github.com/flageval-baai/FlagEvalMM访问。
Key Takeaways
- FlagEvalMM是一个开源的评估框架,用于全面评估多媒体模型。
- 它支持多种视觉语言理解和生成任务,包括视觉问答、文本到图像/视频生成和图像文本检索。
- 通过独立的评估服务,模型推理与评估被解耦,实现灵活资源分配及新任务模型的集成。
- FlagEvalMM利用推理加速工具和异步数据加载提升评估效率。
- 框架能准确高效地为模型提供优缺点洞察。
- 该框架是推进多媒体研究的重要工具。
点此查看论文截图

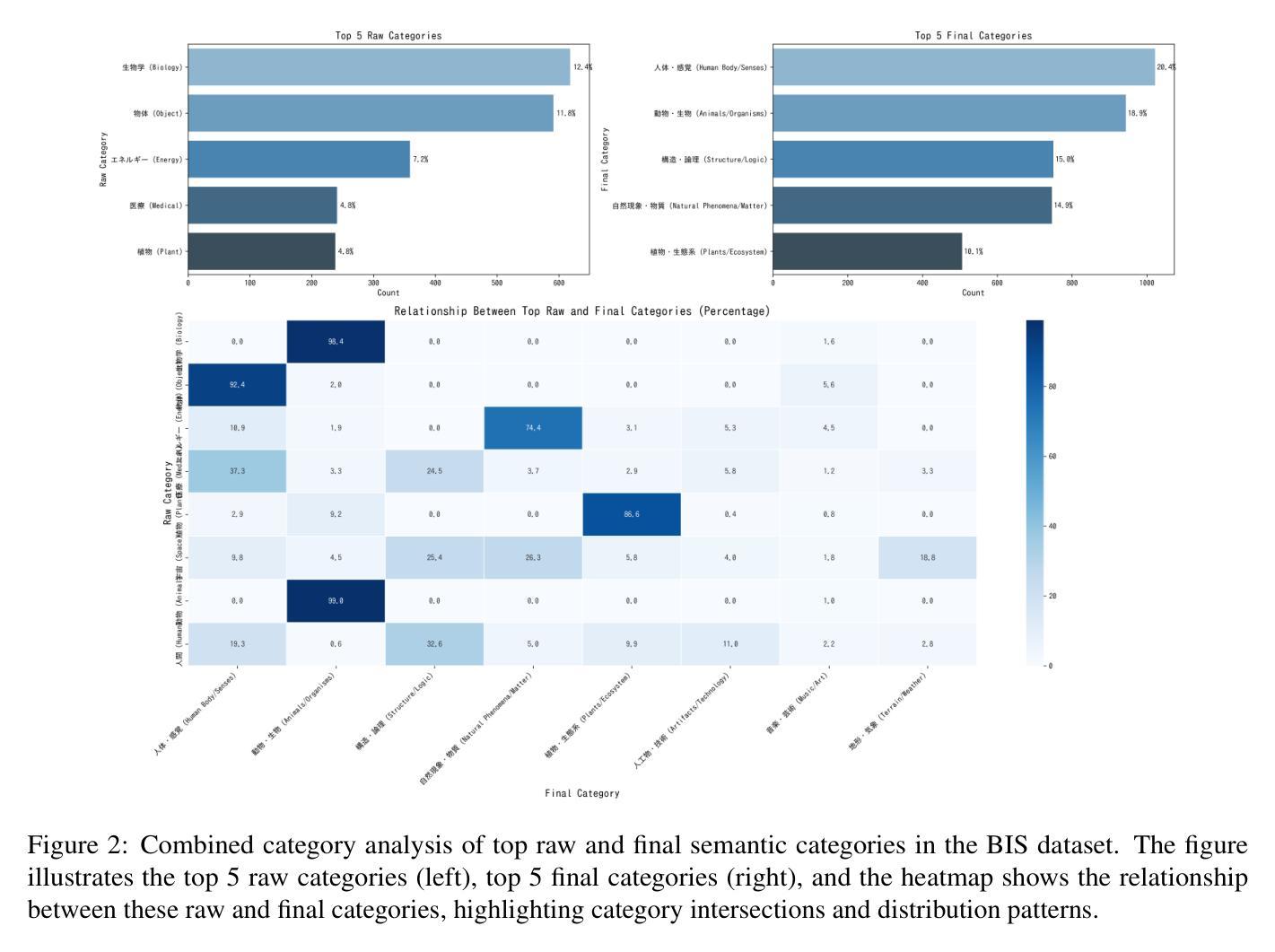
BIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Authors:Ha-Thanh Nguyen, Chaoran Liu, Koichi Takeda, Yusuke Miyao, Pontus Stenetorp, Qianying Liu, Su Myat Noe, Hideyuki Tachibana, Sadao Kurohashi
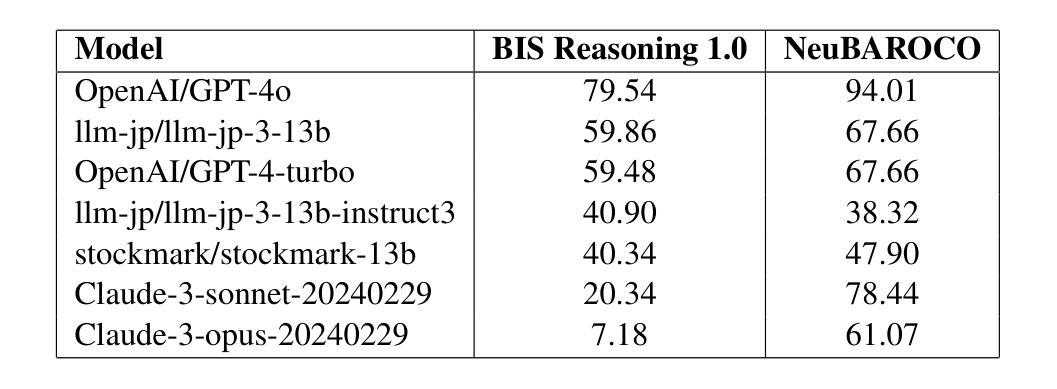
We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
我们推出了BIS Reasoning 1.0,这是首个大规模日语集合推理数据集,专门设计用于评估大型语言模型中的信念不一致推理。不同于先前关注通用或信念一致的推理的NeuBAROCO和JFLD数据集,BIS Reasoning 1.0引入了逻辑上有效但信念不一致的排比推理,以揭示训练在人类语料库上的大型语言模型中的推理偏见。我们对最先进的模型进行了基准测试,包括GPT模型、Claude模型和领先的日本大型语言模型,发现性能存在显著差异,GPT-4o的准确率达到了79.54%。我们的分析确定了当前大型语言模型在处理逻辑上有效但信念冲突的输入时的关键弱点。这些发现在法律、医疗保健和科学文献等高风险领域部署大型语言模型时具有重要意义,在这些领域中,真相必须超越直觉信念,以确保完整性和安全性。
论文及项目相关链接
PDF This version includes an updated literature review, added acknowledgements, and a revised author list
Summary
大型语言模型(LLMs)在信念不一致推理任务中表现出弱点。为此,推出了BIS Reasoning 1.0数据集,它是第一个大规模日语下的逻辑推理解题数据集,专门设计用于评估LLM在信念不一致推理方面的能力。该数据集引入逻辑上合理但信念不一致的推理题,以揭示训练有素LLM的推理偏见。GPT-4o等先进模型在该数据集上的准确率为79.54%,表现出处理逻辑合理但信念冲突的输入时的关键弱点。这些发现对在需要确保真实性和安全性的高风险领域部署LLM具有重要影响。
Key Takeaways
- BIS Reasoning 1.0是第一个大规模日语下的逻辑推理解题数据集,用于评估LLM在信念不一致推理方面的能力。
- 该数据集引入逻辑上合理但信念不一致的推理题,以揭示LLM的推理偏见。
- 先进模型如GPT-4o在该数据集上的准确率有待提高。
- LLM在处理逻辑合理但信念冲突的输入时存在关键弱点。
- BIS Reasoning 1.0的发现对于部署LLM在高风险领域(如法律、医疗和科学文献)具有重要影响。
- 真实性和安全性在这些领域至关重要,需要克服LLM的弱点。
点此查看论文截图

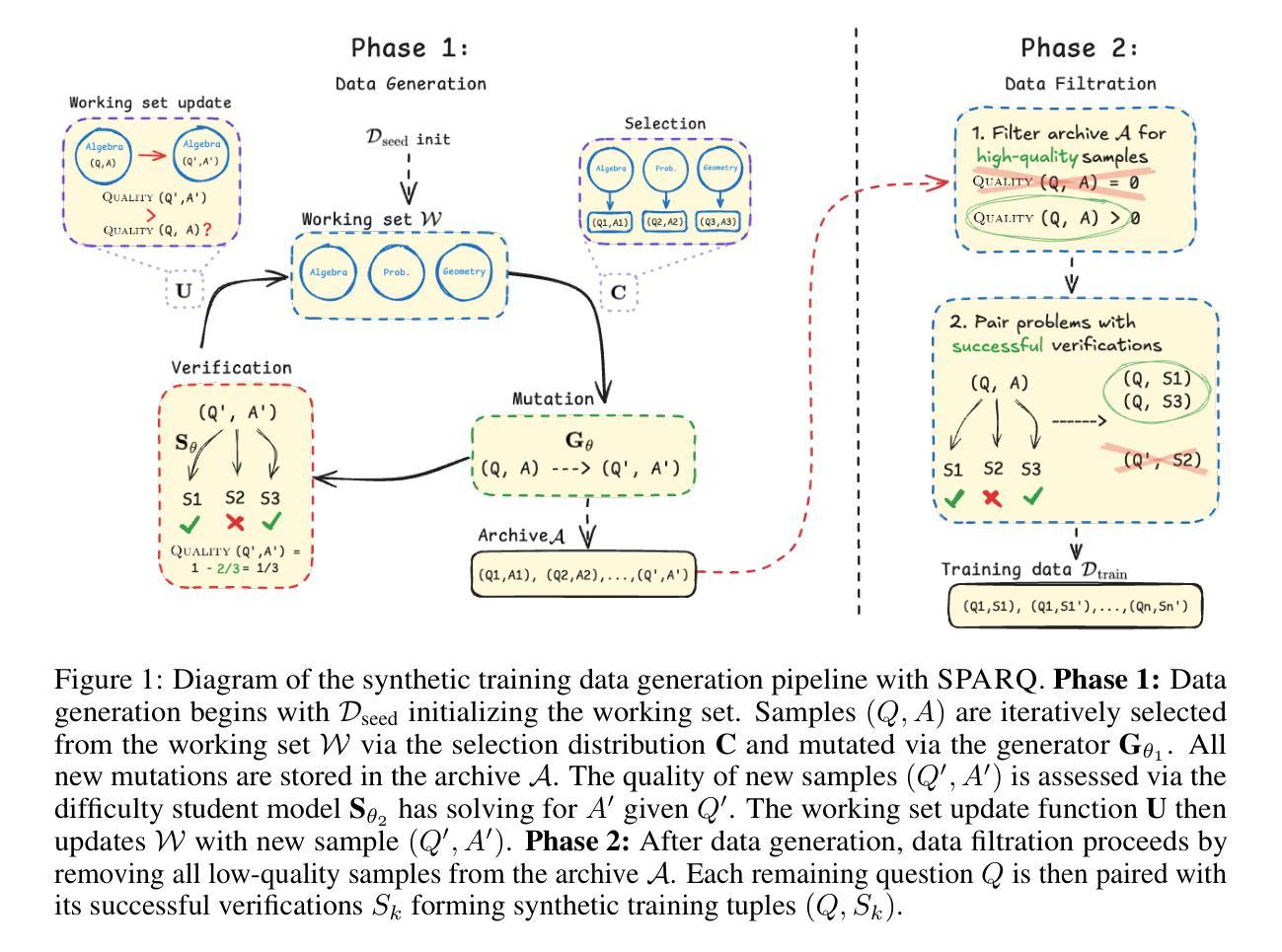
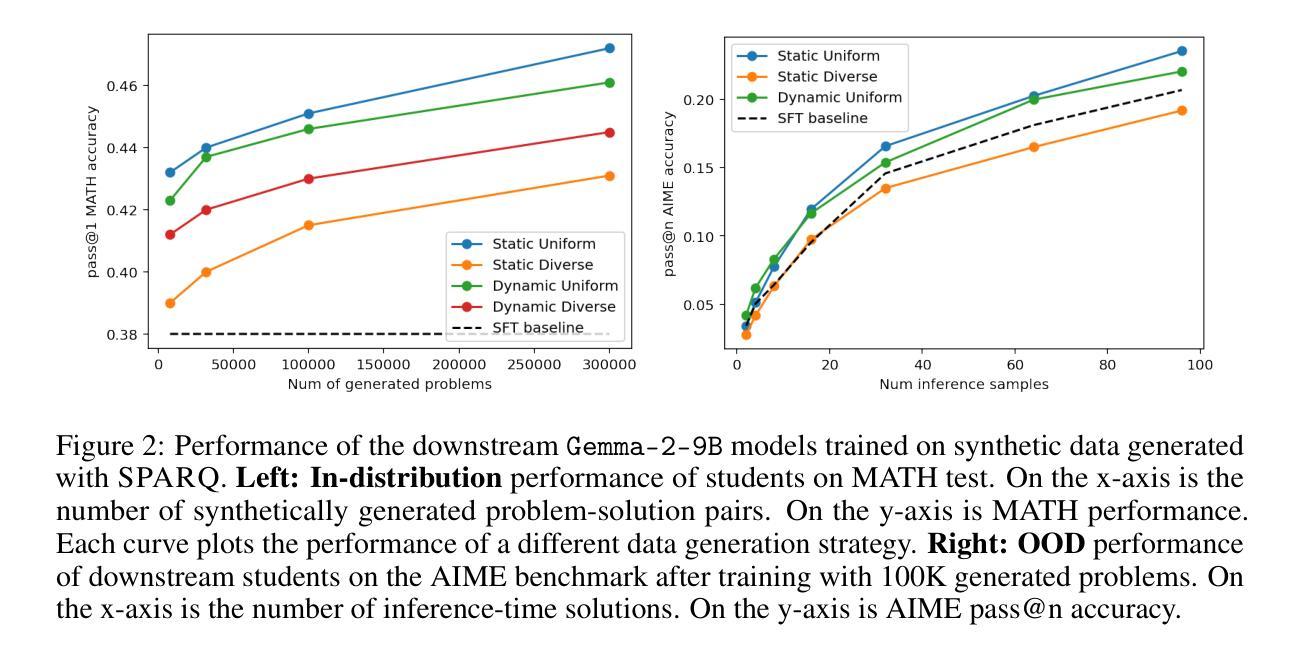
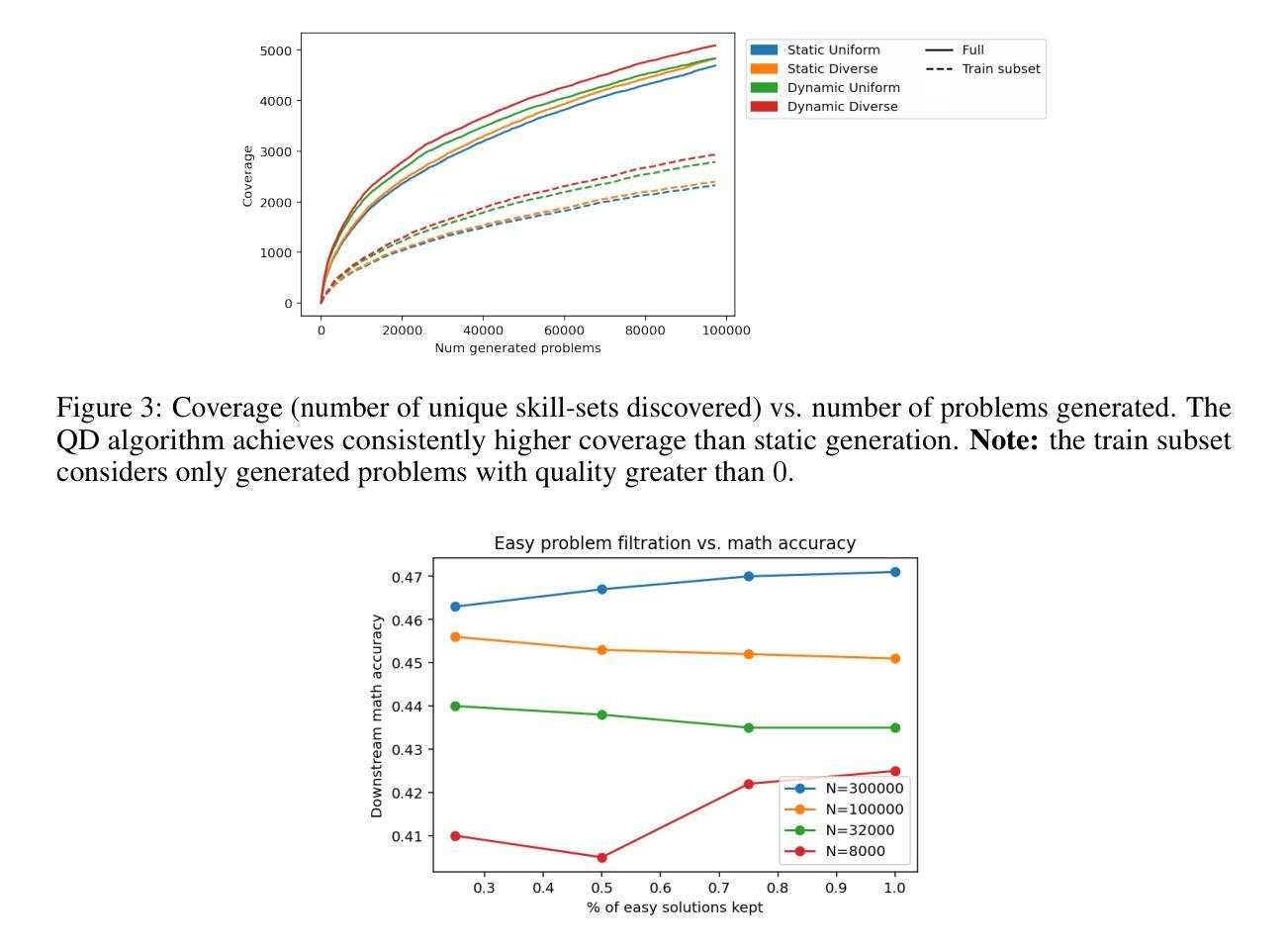
SPARQ: Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms
Authors:Alex Havrilla, Edward Hughes, Mikayel Samvelyan, Jacob Abernethy
Large language model (LLM) driven synthetic data generation has emerged as a powerful method for improving model reasoning capabilities. However, most methods either distill large state-of-the-art models into small students or use natural ground-truth problem statements to guarantee problem statement quality. This limits the scalability of these approaches to more complex and diverse problem domains. To address this, we present SPARQ: Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms, a novel approach for generating high-quality and diverse synthetic math problem and solution pairs using only a single model by measuring a problem’s solve-rate: a proxy for problem difficulty. Starting from a seed dataset of 7.5K samples, we generate over 20 million new problem-solution pairs. We show that filtering the generated data by difficulty and then fine-tuning the same model on the resulting data improves relative model performance by up to 24%. Additionally, we conduct ablations studying the impact of synthetic data quantity, quality and diversity on model generalization. We find that higher quality, as measured by problem difficulty, facilitates better in-distribution performance. Further, while generating diverse synthetic data does not as strongly benefit in-distribution performance, filtering for more diverse data facilitates more robust OOD generalization. We also confirm the existence of model and data scaling laws for synthetically generated problems, which positively benefit downstream model generalization.
基于大型语言模型(LLM)的合成数据生成已成为提高模型推理能力的一种强大方法。然而,大多数方法要么是将先进的大型模型蒸馏为小型学生模型,要么是使用自然真实的问题陈述来保证问题陈述的质量。这限制了这些方法在更复杂和多样化的问题领域中的可扩展性。为了解决这一问题,我们提出了SPARQ:一种通过质量多样性算法进行推理的合成问题生成方法。这是一种仅使用单个模型生成高质量和多样化的合成数学问题及其解决方案对的新方法,它通过衡量问题的解决率(作为问题难度的代理)来实现。从包含7.5K样本的种子数据集开始,我们生成了超过2000万对新的问题和解决方案。我们展示了通过难度过滤生成的合成数据,然后在对结果进行微调的同一家模型上,相对模型性能提高了高达24%。此外,我们还进行了剥离研究,探讨了合成数据的数量、质量和多样性对模型泛化的影响。我们发现,以问题难度衡量的高质量有助于更好的内部分布性能。此外,虽然生成多样化的合成数据并不强烈有利于内部分布性能,但对更多样化数据的过滤有助于更稳健的OOD泛化。我们还证实了合成生成问题中存在模型和数据的规模定律,这对下游模型的泛化具有积极影响。
论文及项目相关链接
Summary
大型语言模型驱动下的合成数据生成已成为提高模型推理能力的一种强大方法。然而,大多数方法要么是将大型先进模型蒸馏成小型学生模型,要么是使用自然真实的问题陈述来保证问题陈述的质量。这限制了这些方法在更复杂和多样化的问题领域中的可扩展性。为解决此问题,我们提出了SPARQ方法:通过质量多样性算法进行推理的合成问题生成。SPARQ使用单一模型生成高质量、多样化的数学问题和解决方案对,通过测量问题的解题率(作为问题难度的代理)来实现。我们从包含7.5K样本的种子数据集开始,生成了超过2千万个新的问题解决方案对。我们展示了通过难度过滤生成的数据和在此基础上微调同一模型,可以提高模型性能高达24%。此外,我们还研究了合成数据数量、质量和多样性对模型泛化的影响。我们发现,以难度衡量的高质量有助于更好的内部分布性能。同时,虽然生成多样化的合成数据并不强烈有利于内部分布性能,但筛选出更多样化的数据有助于更稳健的OOD泛化。我们还证实了合成问题的模型和数据的扩展性规律确实存在,这对下游模型的泛化有积极影响。
Key Takeaways
- 大型语言模型合成数据生成能够提高模型推理能力。
- 大多数方法面临难以扩展至更复杂、多样化问题领域的挑战。
- SPARQ方法通过质量多样性算法生成合成数学问题及解决方案。
- 使用单一模型生成超过2千万个问题和解决方案对。
- 通过难度过滤生成数据并微调模型,可提高模型性能。
- 高质量数据有助于模型在内部分布上的表现。
点此查看论文截图

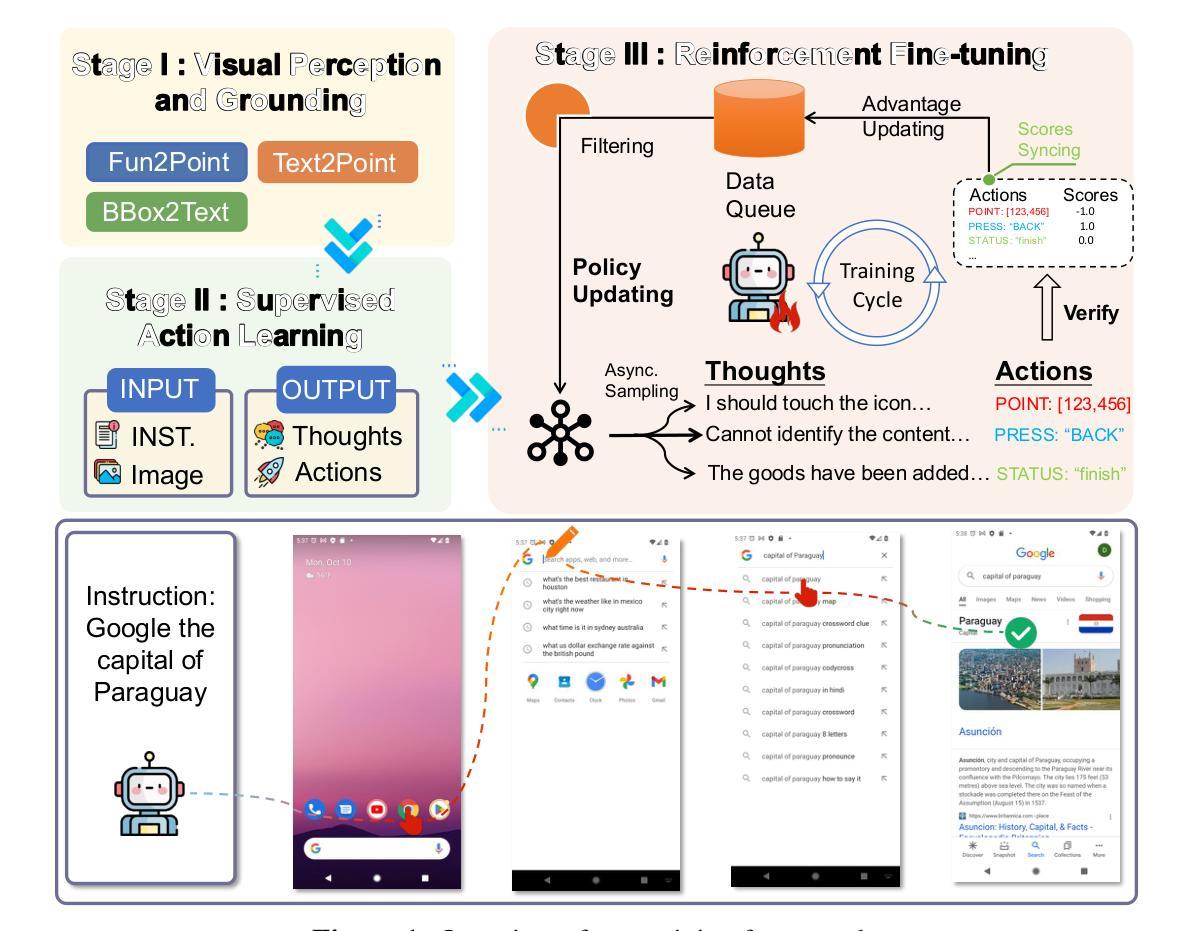
AgentCPM-GUI: Building Mobile-Use Agents with Reinforcement Fine-Tuning
Authors:Zhong Zhang, Yaxi Lu, Yikun Fu, Yupeng Huo, Shenzhi Yang, Yesai Wu, Han Si, Xin Cong, Haotian Chen, Yankai Lin, Jie Xie, Wei Zhou, Wang Xu, Yuanheng Zhang, Zhou Su, Zhongwu Zhai, Xiaoming Liu, Yudong Mei, Jianming Xu, Hongyan Tian, Chongyi Wang, Chi Chen, Yuan Yao, Zhiyuan Liu, Maosong Sun
The recent progress of large language model agents has opened new possibilities for automating tasks through graphical user interfaces (GUIs), especially in mobile environments where intelligent interaction can greatly enhance usability. However, practical deployment of such agents remains constrained by several key challenges. Existing training data is often noisy and lack semantic diversity, which hinders the learning of precise grounding and planning. Models trained purely by imitation tend to overfit to seen interface patterns and fail to generalize in unfamiliar scenarios. Moreover, most prior work focuses on English interfaces while overlooks the growing diversity of non-English applications such as those in the Chinese mobile ecosystem. In this work, we present AgentCPM-GUI, an 8B-parameter GUI agent built for robust and efficient on-device GUI interaction. Our training pipeline includes grounding-aware pre-training to enhance perception, supervised fine-tuning on high-quality Chinese and English trajectories to imitate human-like actions, and reinforcement fine-tuning with GRPO to improve reasoning capability. We also introduce a compact action space that reduces output length and supports low-latency execution on mobile devices. AgentCPM-GUI achieves state-of-the-art performance on five public benchmarks and a new Chinese GUI benchmark called CAGUI, reaching $96.9%$ Type-Match and $91.3%$ Exact-Match. To facilitate reproducibility and further research, we publicly release all code, model checkpoint, and evaluation data.
近期大型语言模型代理人的进展为通过图形用户界面(GUI)自动化任务开启了新的可能性,特别是在移动环境中,智能交互可以极大地提高可用性。然而,此类代理人的实际部署仍面临一些关键挑战。现有的训练数据通常嘈杂且缺乏语义多样性,这阻碍了精确接地和规划的学习。仅通过模仿训练的模型往往会对见过的界面模式过于适应,无法在陌生场景中推广。此外,大多数早期的工作都集中在英语界面上,而忽视了非英语应用程序的日益多样性,如中文移动生态系统中的应用程序。在这项工作中,我们提出了AgentCPM-GUI,这是一个为稳健高效的设备端GUI交互而构建的8B参数GUI代理。我们的训练管道包括增强感知的接地感知预训练、在高质量中文和英文轨迹上的监督微调以模仿人类行动、使用GRPO进行强化微调以提高推理能力。我们还引入了一个紧凑的动作空间,以减少输出长度并支持在移动设备上的低延迟执行。AgentCPM-GUI在五个公共基准测试和一个名为CAGUI的新中文GUI基准测试上达到了最先进的性能,达到了96.9%的类型匹配度和91.3%的精确匹配度。为了促进可复制性和进一步研究,我们公开发布了所有代码、模型检查点和评估数据。
论文及项目相关链接
PDF Updated results in Table 2 and Table 3; The project is available at https://github.com/OpenBMB/AgentCPM-GUI
Summary
本文介绍了大型语言模型代理在图形用户界面(GUI)自动化任务中的最新进展,特别是在移动环境中。然而,其实践部署面临诸多挑战,如训练数据噪声和语义多样性不足、模型对界面模式的过度拟合以及缺乏泛化能力等问题。针对这些问题,本文提出了AgentCPM-GUI,一个为稳健和高效的设备端GUI交互而构建的8B参数GUI代理。其训练管道包括增强感知的接地预训练、在高质量中英文轨迹上的监督微调以模仿人类行为,以及使用GRPO进行强化微调以提高推理能力。此外,还引入了一个紧凑的动作空间,以减少输出长度并支持在移动设备上的低延迟执行。AgentCPM-GUI在五个公共基准测试和一个名为CAGUI的新中文GUI基准测试上达到了最先进的性能,分别达到了96.9%的类型匹配和91.3%的精确匹配。
Key Takeaways
- 大型语言模型代理在GUI自动化任务中展现出潜力,尤其在移动环境下。
- 当前实践部署面临训练数据噪声、语义多样性不足等挑战。
- AgentCPM-GUI通过接地预训练、监督微调及强化微调等方法应对上述挑战。
- 紧凑的动作空间支持移动设备的低延迟执行。
- AgentCPM-GUI在多个基准测试上达到先进性能,包括新的中文GUI基准测试CAGUI。
- 研究人员公开了代码、模型检查点和评估数据以促进研究的可重复性。
点此查看论文截图


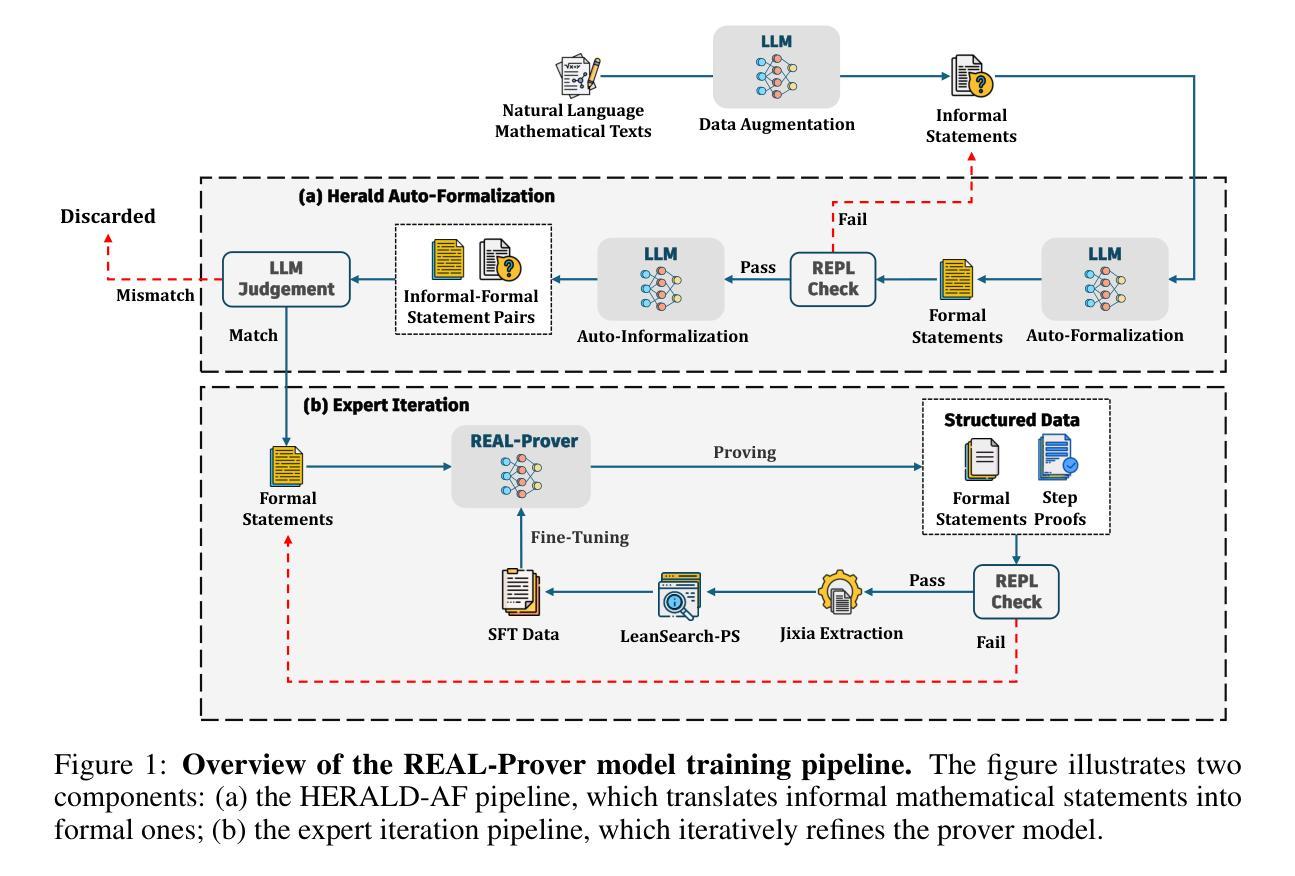
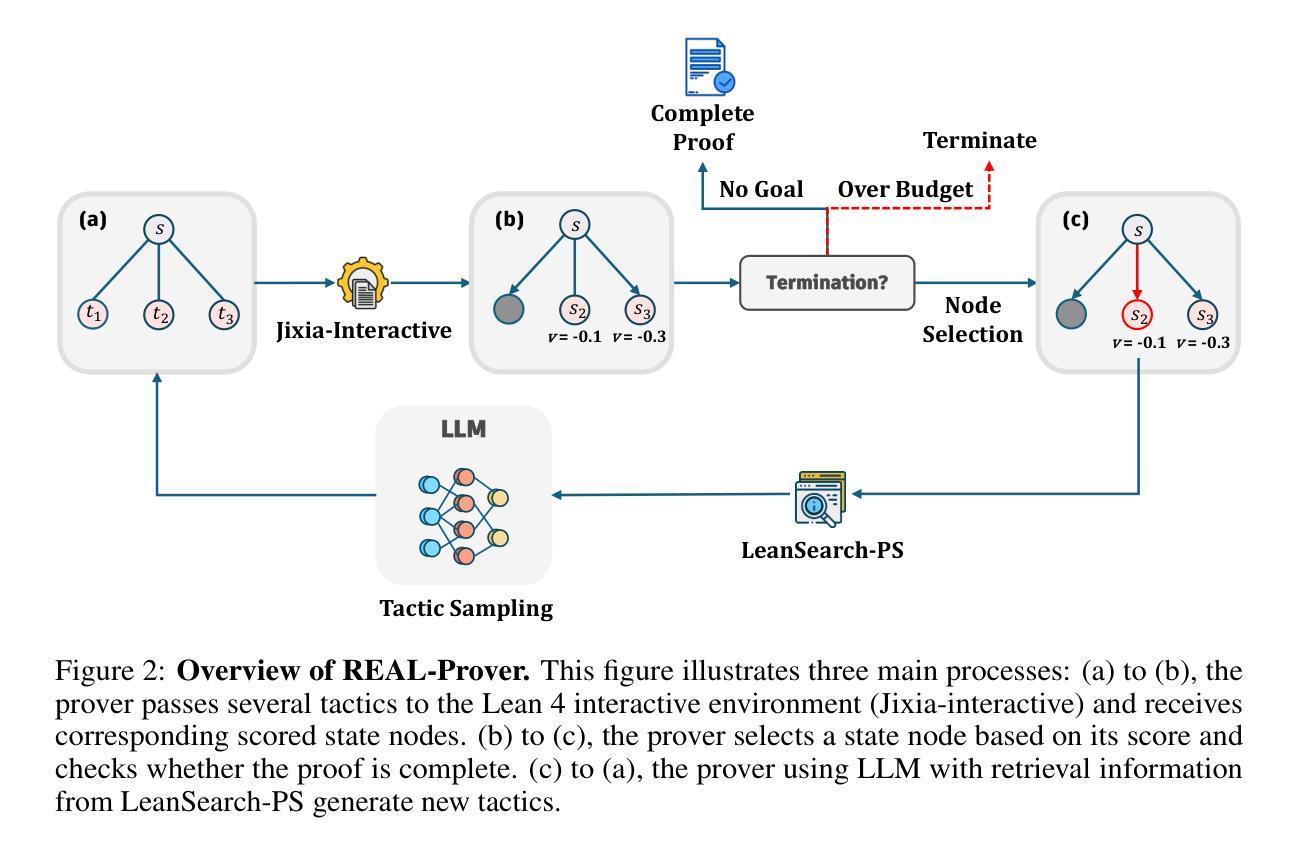
REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
Authors:Ziju Shen, Naohao Huang, Fanyi Yang, Yutong Wang, Guoxiong Gao, Tianyi Xu, Jiedong Jiang, Wanyi He, Pu Yang, Mengzhou Sun, Haocheng Ju, Peihao Wu, Bryan Dai, Bin Dong
Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
如今,形式化定理证明器在高中和竞赛级别的数学方面取得了巨大的进步,但很少有能够推广到更高级数学的证明器。在本文中,我们介绍了REAL-Prover,这是一个新的开源逐步定理证明器,适用于Lean 4,旨在突破这一界限。该证明器基于我们精细调整的大型语言模型(REAL-Prover-v1)并与检索系统(Leansearch-PS)集成,在解决大学级别数学问题方面的性能得到了显著提升。为了训练REAL-Prover-v1,我们开发了HERALD-AF,这是一个数据提取管道,可将自然语言数学问题转换为正式语句,以及一个新的开源Lean 4交互式环境(Jixia-interactive),以促进合成数据收集。在我们的实验中,仅使用监督微调证明器在ProofNet数据集上取得了具有竞争力的结果,成功率为23.7%(Pass@64),与最新(SOTA)模型相当。为了进一步评估我们的方法,我们引入了FATE-M,这是一个专注于代数问题的新基准测试,我们的证明器在那里达到了SOTA的成功率56.7%(Pass@64)。
论文及项目相关链接
Summary
这篇论文介绍了一款名为REAL-Prover的新型开源逐步定理证明器,它基于精细调整的大型语言模型,能够解决大学级别的数学问题。通过开发HERALD-AF数据提取管道和自然语言数学问题转化为正式语句的Jixia-interactive交互环境,训练了REAL-Prover-v1。在ProofNet数据集上,REAL-Prover取得了具有竞争力的结果,成功率为23.7%(Pass@64),并且在专注于代数问题的新基准测试FATE-M上取得了最高成功率56.7%。
Key Takeaways
- REAL-Prover是一个针对Lean 4的新型开源逐步定理证明器,旨在解决更高级的数学问题。
- REAL-Prover基于精细调整的大型语言模型(REAL-Prover-v1)和集成检索系统(Leansearch-PS)。
- HERALD-AF数据提取管道能够将自然语言数学问题转化为正式语句,用于训练REAL-Prover-v1。
- Jixia-interactive是一个新开的交互式环境,用于促进合成数据的收集,辅助REAL-Prover的开发。
- REAL-Prover在ProofNet数据集上取得了具有竞争力的结果,成功率为23.7%。
- FATE-M是一个新的专注于代数问题的基准测试,REAL-Prover在此测试上的成功率达到了56.7%,表现最佳。
点此查看论文截图

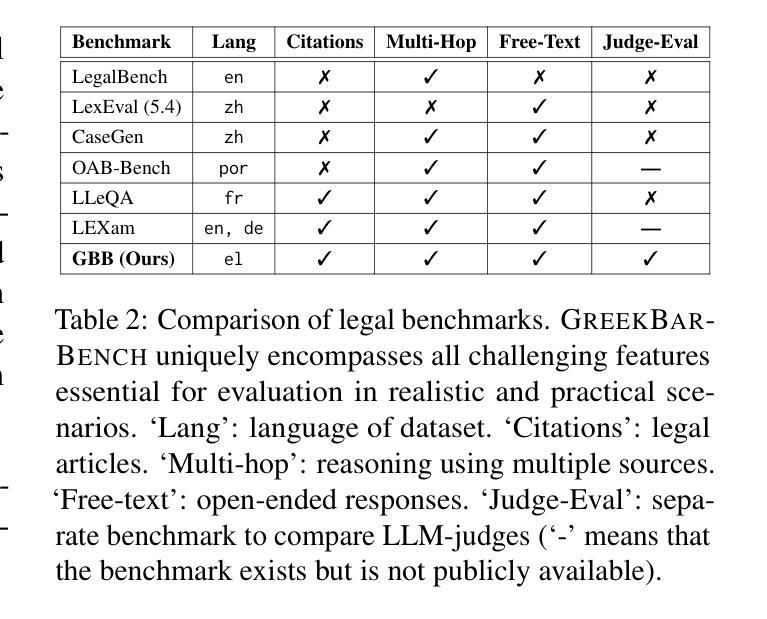
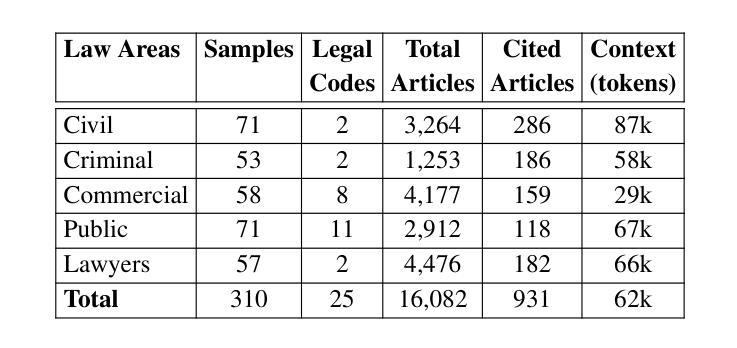
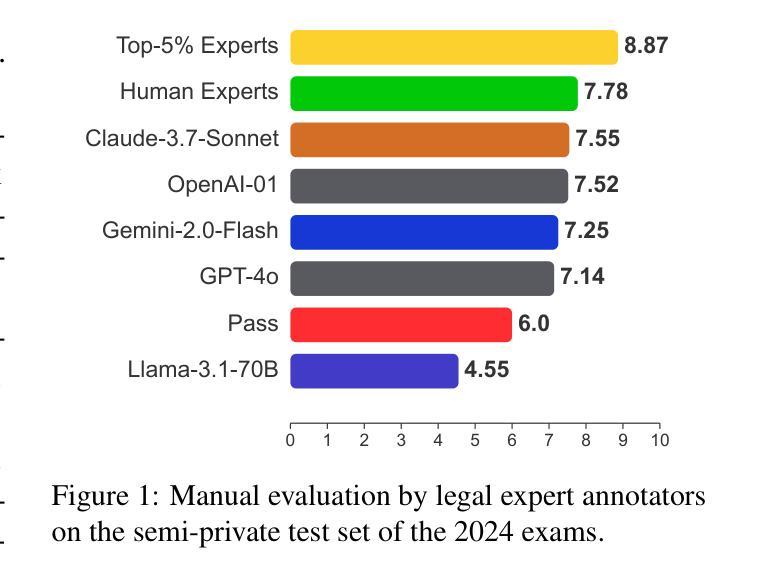
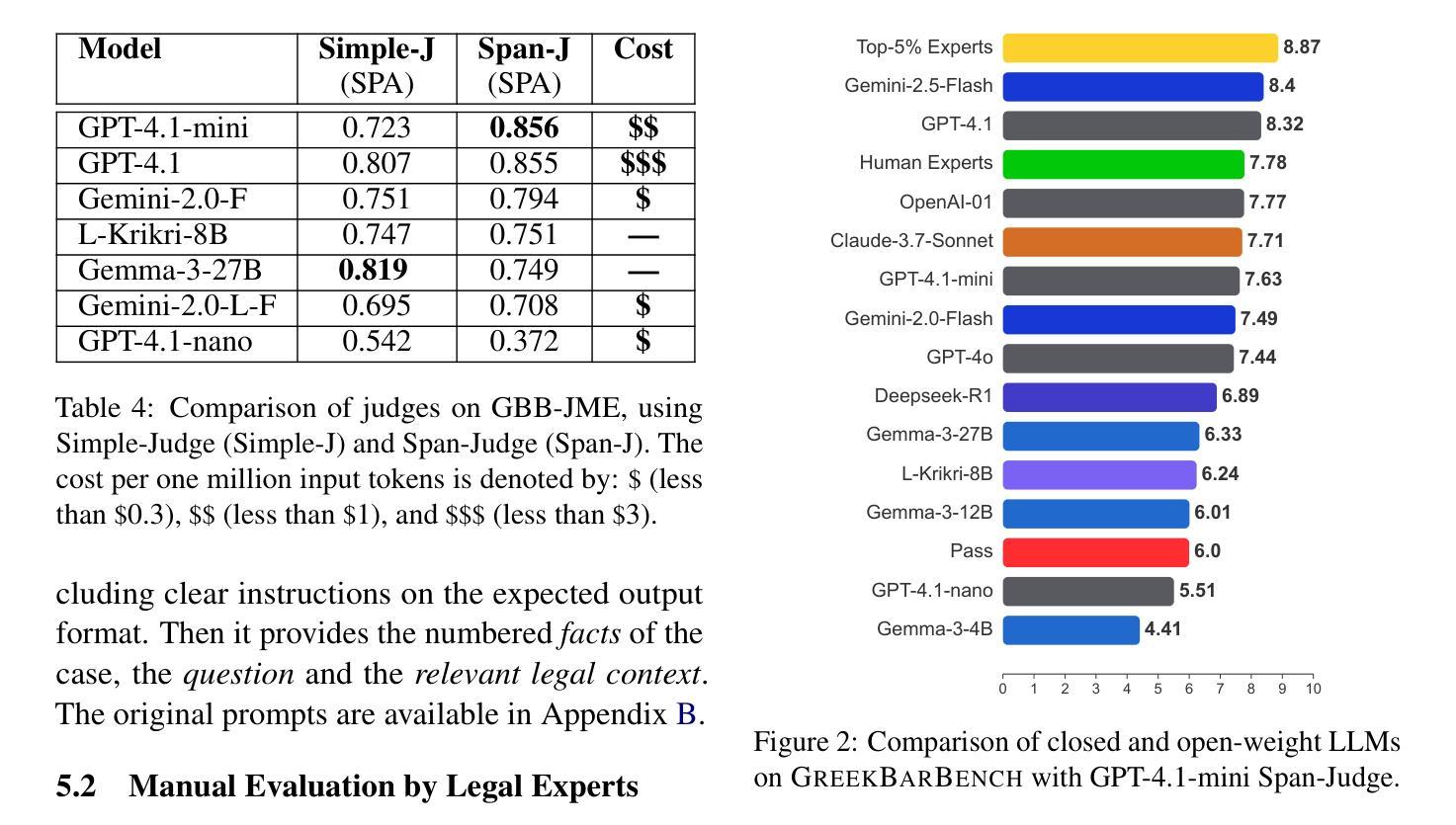
GreekBarBench: A Challenging Benchmark for Free-Text Legal Reasoning and Citations
Authors:Odysseas S. Chlapanis, Dimitrios Galanis, Nikolaos Aletras, Ion Androutsopoulos
We introduce GreekBarBench, a benchmark that evaluates LLMs on legal questions across five different legal areas from the Greek Bar exams, requiring citations to statutory articles and case facts. To tackle the challenges of free-text evaluation, we propose a three-dimensional scoring system combined with an LLM-as-a-judge approach. We also develop a meta-evaluation benchmark to assess the correlation between LLM-judges and human expert evaluations, revealing that simple, span-based rubrics improve their alignment. Our systematic evaluation of 13 proprietary and open-weight LLMs shows that even though the best models outperform average expert scores, they fall short of the 95th percentile of experts.
我们介绍了GreekBarBench,这是一个基准测试,旨在评估大型语言模型在希腊律师考试中的五个不同法律领域的法律问题。这需要引用法律条文和案例事实。为了应对文本评估的挑战,我们提出了一种三维评分系统,结合以LLM作为法官的方法。我们还开发了一个元评估基准,以评估LLM法官和人类专家评价之间的相关性,表明简单的基于跨度的方法可以改善其对齐。我们对13个专有和开源的大型语言模型的系统评估表明,尽管最佳模型的性能超过了平均专家得分,但它们仍低于专家得分的第95个百分点。
论文及项目相关链接
PDF 19 pages, 17 figures, submitted to May ARR
Summary
希腊BarBench基准测试旨在评估大型语言模型在法律问题上的表现,涉及希腊律师考试中的五个不同法律领域,要求引用法律条文和案例事实。为解决自由文本评估的挑战,我们提出了一个三维评分系统,结合LLM作为法官的方法进行评估。我们还开发了一个元评估基准测试,以评估LLM法官与人类专家评估之间的相关性,发现简单的基于范围的评分规则有助于提高一致性。对13个专有和开源大型语言模型的系统评估表明,尽管最佳模型的表现超过了平均专家得分,但仍未达到专家得分的第95个百分点。
Key Takeaways
- 希腊BarBench基准测试用于评估大型语言模型(LLMs)在法律问题上的表现。
- 测试涵盖希腊律师考试中的五个不同法律领域,要求引用法律条文和案例事实。
- 采用三维评分系统与LLM作为法官的方法来解决自由文本评估的挑战。
- 开发了元评估基准测试以评估LLM法官与人类专家评估之间的相关性。
- 简单的基于范围的评分规则能够提高LLM法官与人类评估的一致性。
- 系统评估了13个LLMs的表现,发现最佳模型的表现虽超过平均专家得分,但未达专家得分的第95个百分点。
点此查看论文截图

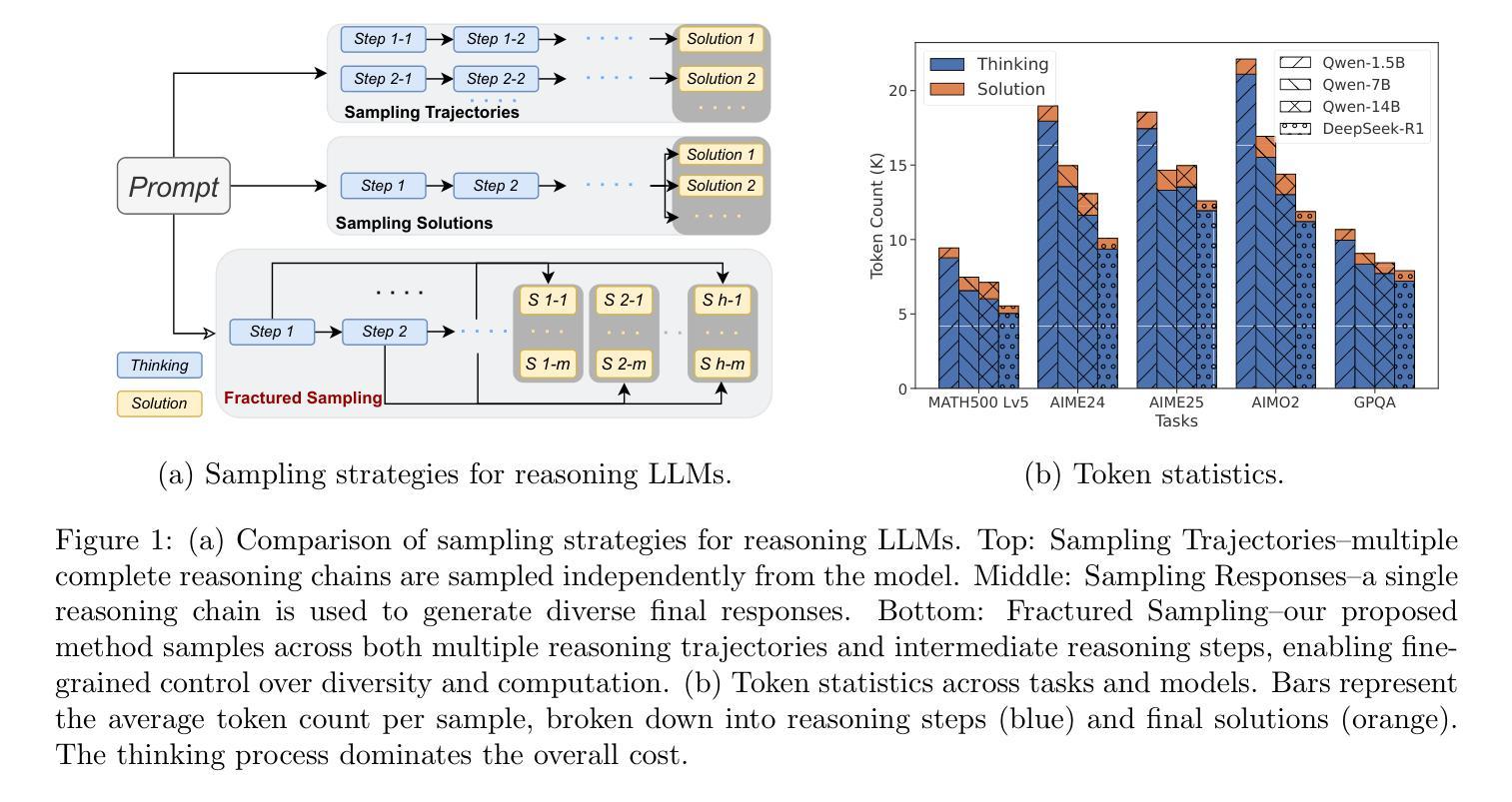
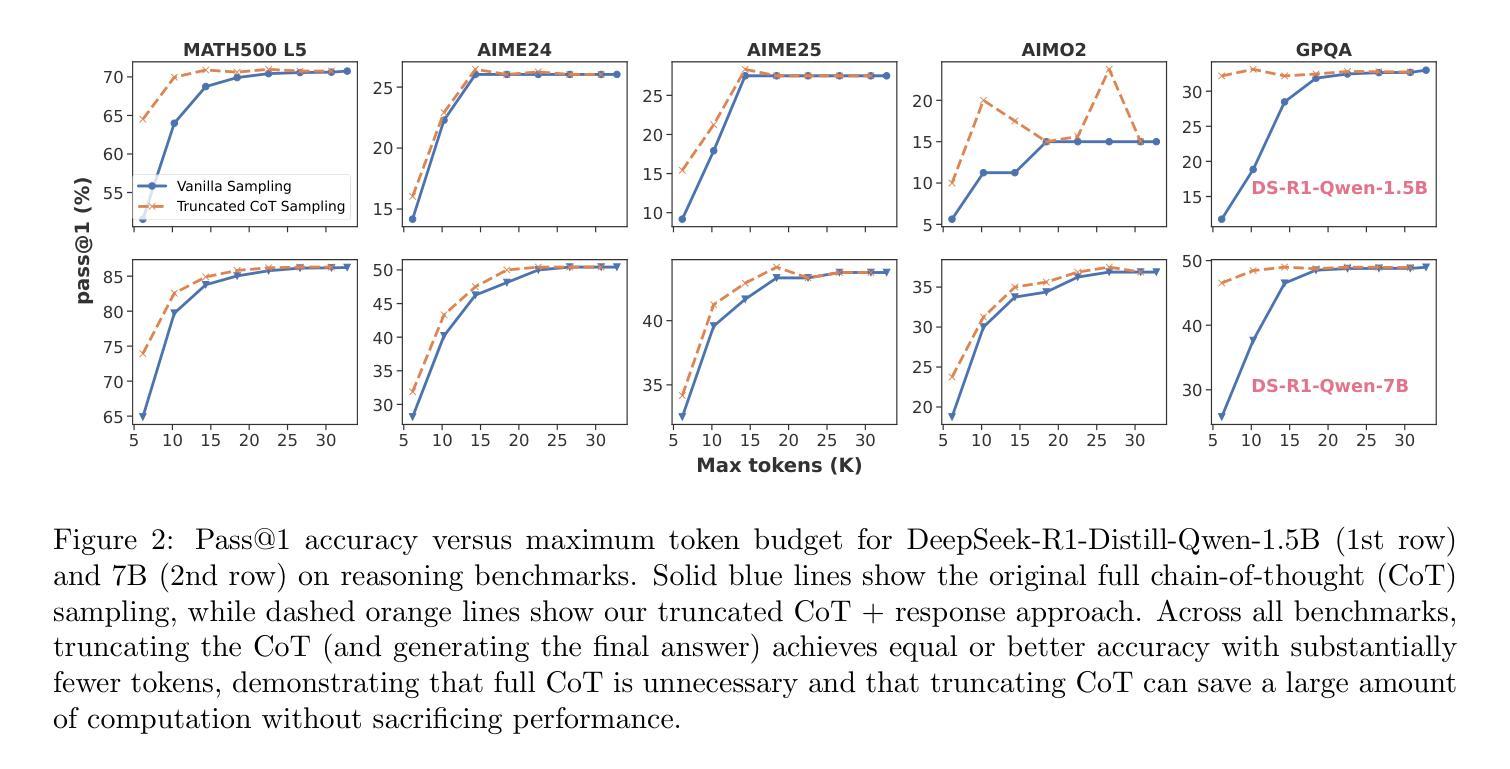
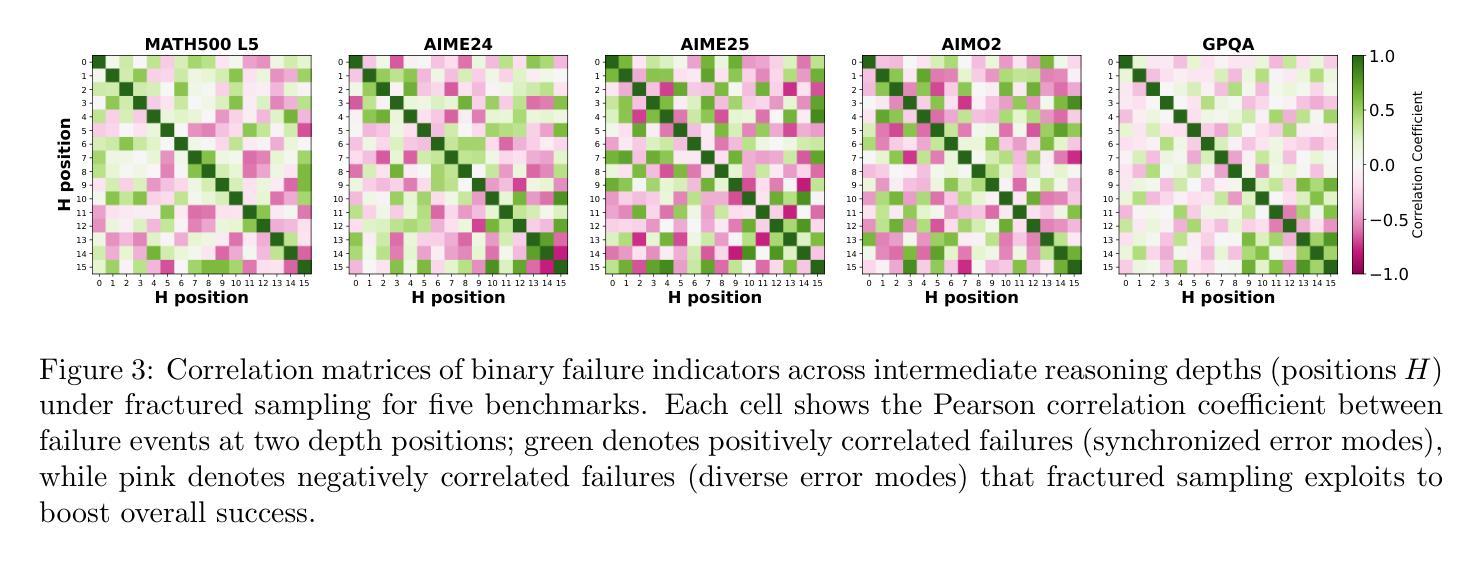
Fractured Chain-of-Thought Reasoning
Authors:Baohao Liao, Hanze Dong, Yuhui Xu, Doyen Sahoo, Christof Monz, Junnan Li, Caiming Xiong
Inference-time scaling techniques have significantly bolstered the reasoning capabilities of large language models (LLMs) by harnessing additional computational effort at inference without retraining. Similarly, Chain-of-Thought (CoT) prompting and its extension, Long CoT, improve accuracy by generating rich intermediate reasoning trajectories, but these approaches incur substantial token costs that impede their deployment in latency-sensitive settings. In this work, we first show that truncated CoT, which stops reasoning before completion and directly generates the final answer, often matches full CoT sampling while using dramatically fewer tokens. Building on this insight, we introduce Fractured Sampling, a unified inference-time strategy that interpolates between full CoT and solution-only sampling along three orthogonal axes: (1) the number of reasoning trajectories, (2) the number of final solutions per trajectory, and (3) the depth at which reasoning traces are truncated. Through extensive experiments on five diverse reasoning benchmarks and several model scales, we demonstrate that Fractured Sampling consistently achieves superior accuracy-cost trade-offs, yielding steep log-linear scaling gains in Pass@k versus token budget. Our analysis reveals how to allocate computation across these dimensions to maximize performance, paving the way for more efficient and scalable LLM reasoning. Code is available at https://github.com/BaohaoLiao/frac-cot.
推理时间缩放技术通过利用推理时的额外计算努力,在无需重新训练的情况下,显著提高了大型语言模型(LLM)的推理能力。同样,思维链(CoT)提示及其扩展——长思维链(Long CoT),通过生成丰富的中间推理轨迹来提高准确性,但这些方法产生了巨大的令牌成本,阻碍了它们在延迟敏感环境中的部署。在这项工作中,我们首先展示了截断思维链(truncated CoT),它在完成推理之前停止推理,直接生成最终答案,与使用大量令牌的完整思维链采样相比效果往往不相上下。基于这一见解,我们引入了分裂采样(Fractured Sampling),这是一种统一的推理时间策略,在三个正交轴上对完整思维链和仅解决方案采样进行插值:(1)推理轨迹的数量,(2)每条轨迹的最终解决方案数量,(3)推理轨迹被截断的深度。通过五项不同的推理基准测试和多种模型规模的广泛实验,我们证明了分裂采样在准确性成本权衡方面表现卓越,在Pass@k与令牌预算方面实现了陡峭的对数线性缩放收益。我们的分析揭示了如何在这些维度上分配计算以最大化性能,为更高效、可扩展的LLM推理铺平了道路。代码可在https://github.com/BaohaoLiao/frac-cot找到。
论文及项目相关链接
Summary
本摘要中介绍了在大型语言模型(LLM)的推理过程中,如何通过采用截断式链式思维(Truncated CoT)和分裂采样(Fractured Sampling)策略来优化推理效率和性能。研究发现,在合理截断链式思维后,可直接生成最终答案并达到全链式思维采样的准确度。而分裂采样是一种在推理过程中根据不同参数选择的不同策略,包括推理轨迹数量、每个轨迹的最终解决方案数量和截断推理深度的平衡。在五个不同的推理基准测试上进行的实验表明,分裂采样在准确度与成本之间取得了良好的平衡,实现了在Pass@k上的对数线性缩放增益。
Key Takeaways
- 推理时间缩放技术增强了大型语言模型的推理能力,无需重新训练即可利用额外的计算资源。
- 链式思维(CoT)及其扩展长链式思维(Long CoT)通过生成丰富的中间推理轨迹提高了准确性,但增加了令牌成本,不适用于延迟敏感的环境。
- 截断式链式思维(Truncated CoT)在减少令牌使用的同时,能够匹配全链式思维采样的准确度。
- 分裂采样是一种统一的推理时间策略,通过平衡推理轨迹数量、每个轨迹的最终解决方案数量和截断推理的深度,实现准确性与成本之间的优化。
- 分裂采样在多个基准测试上表现出优越的性能,实现了在Pass@k上的对数线性缩放增益。
- 通过实验分析,确定了如何在这些维度上分配计算以最大化性能的方法。
点此查看论文截图

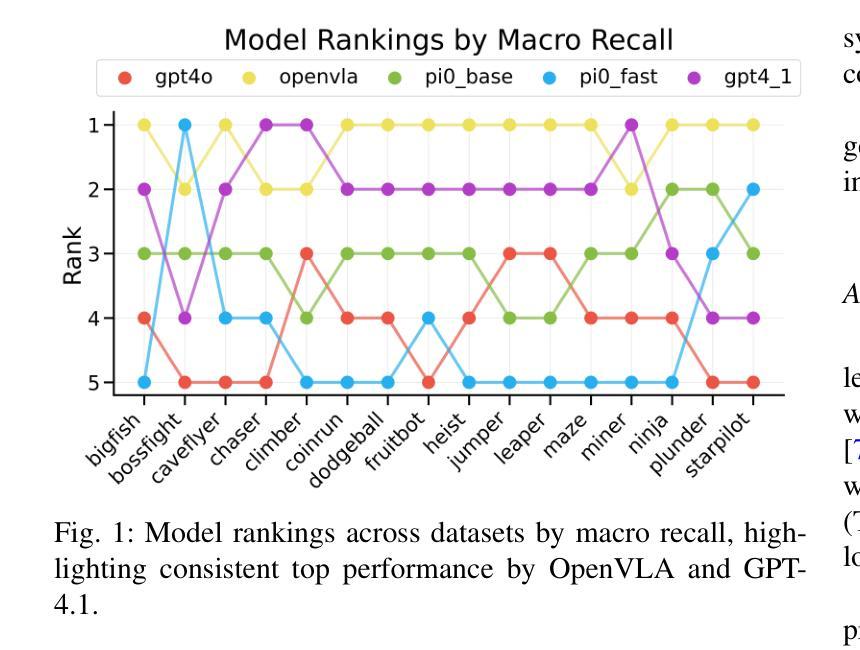
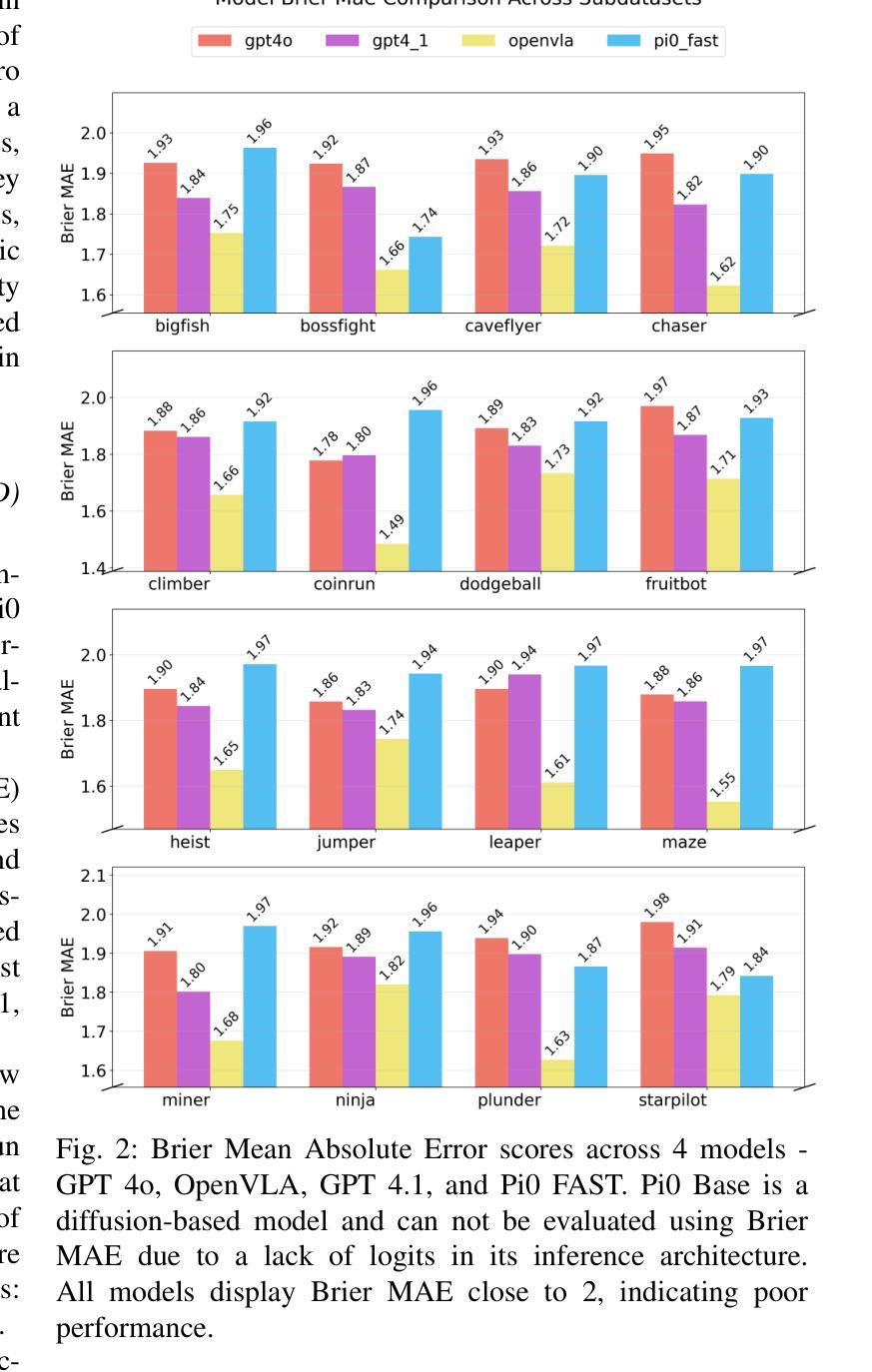
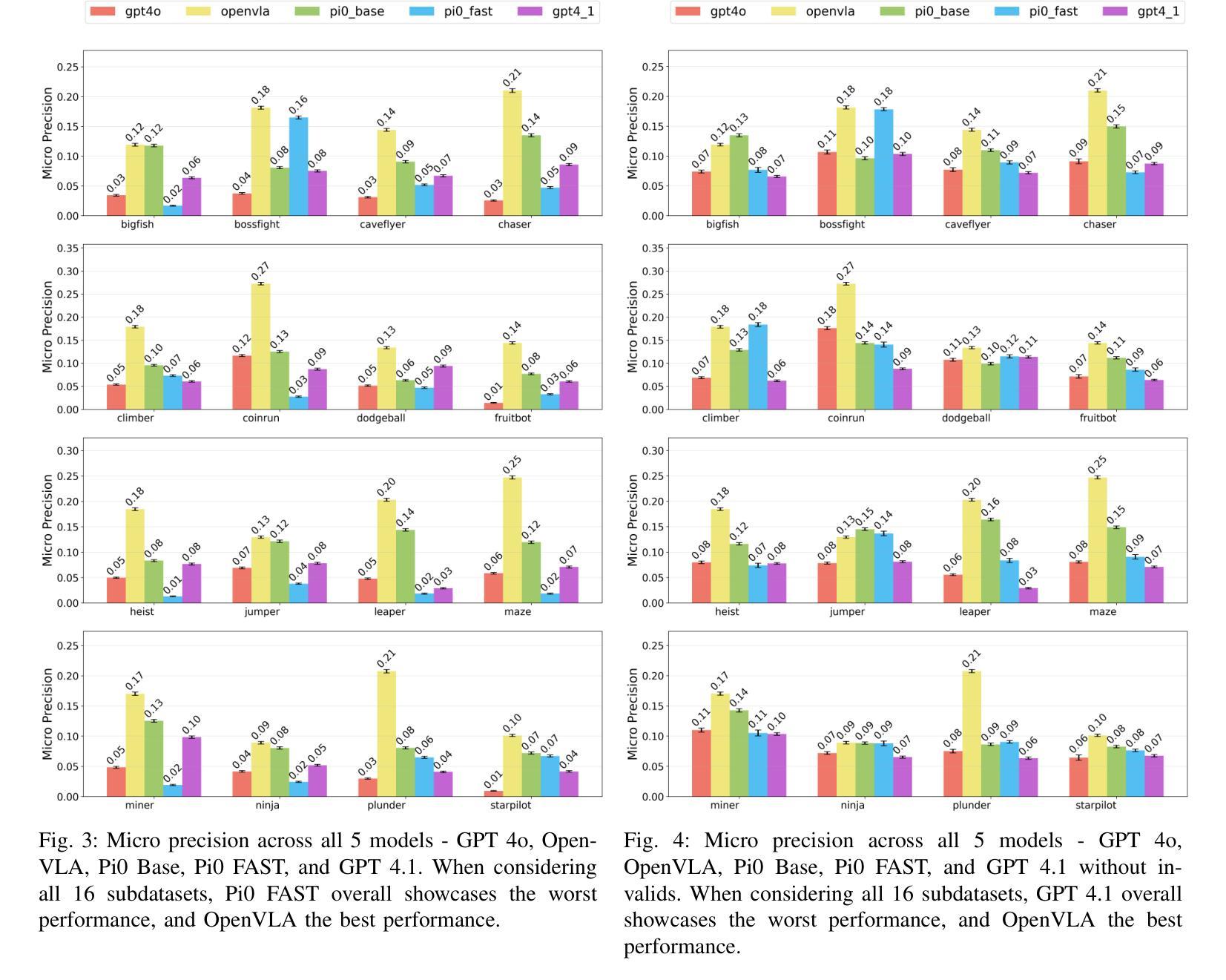
Benchmarking Vision, Language, & Action Models in Procedurally Generated, Open Ended Action Environments
Authors:Pranav Guruprasad, Yangyue Wang, Sudipta Chowdhury, Harshvardhan Sikka, Paul Pu Liang
Vision-language-action (VLA) models represent an important step toward general-purpose robotic systems by integrating visual perception, language understanding, and action execution. However, systematic evaluation of these models, particularly their zero-shot generalization capabilities in procedurally out-of-distribution (OOD) environments, remains limited. In this paper, we introduce MultiNet v0.2, a comprehensive benchmark designed to evaluate and analyze the generalization performance of state-of-the-art VLMs and VLAs - including GPT-4o, GPT-4.1, OpenVLA, Pi0 Base, and Pi0 FAST - on diverse procedural tasks from the Procgen benchmark. Our analysis reveals several critical insights: (1) all evaluated models exhibit significant limitations in zero-shot generalization to OOD tasks, with performance heavily influenced by factors such as action representation and task complexity; (2) VLAs generally outperforms other models due to their robust architectural design; and (3) VLM variants demonstrate substantial improvements when constrained appropriately, highlighting the sensitivity of model performance to precise prompt engineering. We release our benchmark, evaluation framework, and findings to enable the assessment of future VLA models and identify critical areas for improvement in their application to out-of-distribution digital tasks.
视觉-语言-动作(VLA)模型通过整合视觉感知、语言理解和动作执行,朝着通用机器人系统迈出了重要的一步。然而,对这些模型的系统性评估,特别是在程序外分布(OOD)环境中零样本泛化能力的评估仍然有限。在本文中,我们介绍了MultiNet v0.2,这是一个旨在评估和分析最先进的VLM和VLA泛化性能的综合性基准测试,包括GPT-4o、GPT-4.1、OpenVLA、Pi0 Base和Pi0 FAST等模型在各种Procgen基准测试中的多样化程序任务上的表现。我们的分析揭示了几个关键见解:(1)所有评估的模型在零样本泛化到OOD任务上都存在显著局限性,性能受到动作表征和任务复杂性等因素的影响;(2)由于VLA的稳健架构设计,它们通常表现优于其他模型;(3)当得到适当的约束时,VLM变体表现出显著改进,这突出了模型性能对精确提示工程的敏感性。我们发布我们的基准测试、评估框架和发现,以便对将来的VLA模型进行评估,并确定其在处理离群数字任务时的关键改进领域。
论文及项目相关链接
PDF 16 pages, 26 figures
Summary
在视觉感知、语言理解和动作执行方面的整合中,视觉语言动作(VLA)模型是朝着通用机器人系统迈进的重要一步。然而,对此类模型的全面评估,特别是在程序外的分布环境中的零样本泛化能力评估仍然有限。本文介绍了MultiNet v0.2,这是一个全面基准测试,旨在评估和分析最前沿的VLMs和VLAs在多样化程序任务上的泛化性能。分析揭示了几个关键见解:VLA模型在零样本泛化方面展现出强大潜力;不同模型的表现受动作表征和任务复杂性等因素的影响;适当约束VLM变体可显著提高性能。我们发布基准测试、评估框架和发现,以便评估未来的VLA模型,并确定其在处理外部分布数字任务时的关键改进领域。
Key Takeaways
- VLA模型集成视觉感知、语言理解和动作执行,是通用机器人系统的重要进步。
- 目前对VLA模型的全面评估,特别是在程序外的分布环境中的零样本泛化能力评估仍然不足。
- MultiNet v0.2是一个全面基准测试,用于评估最前沿的VLMs和VLAs在多样化程序任务上的性能。
- VLA模型展现出强大的零样本泛化潜力,但存在动作表征和任务复杂性等因素的影响。
- VLM变体的性能可以通过适当的约束来显著提高。
- 释放基准测试、评估框架和发现,以便未来对VLA模型进行评估。
点此查看论文截图

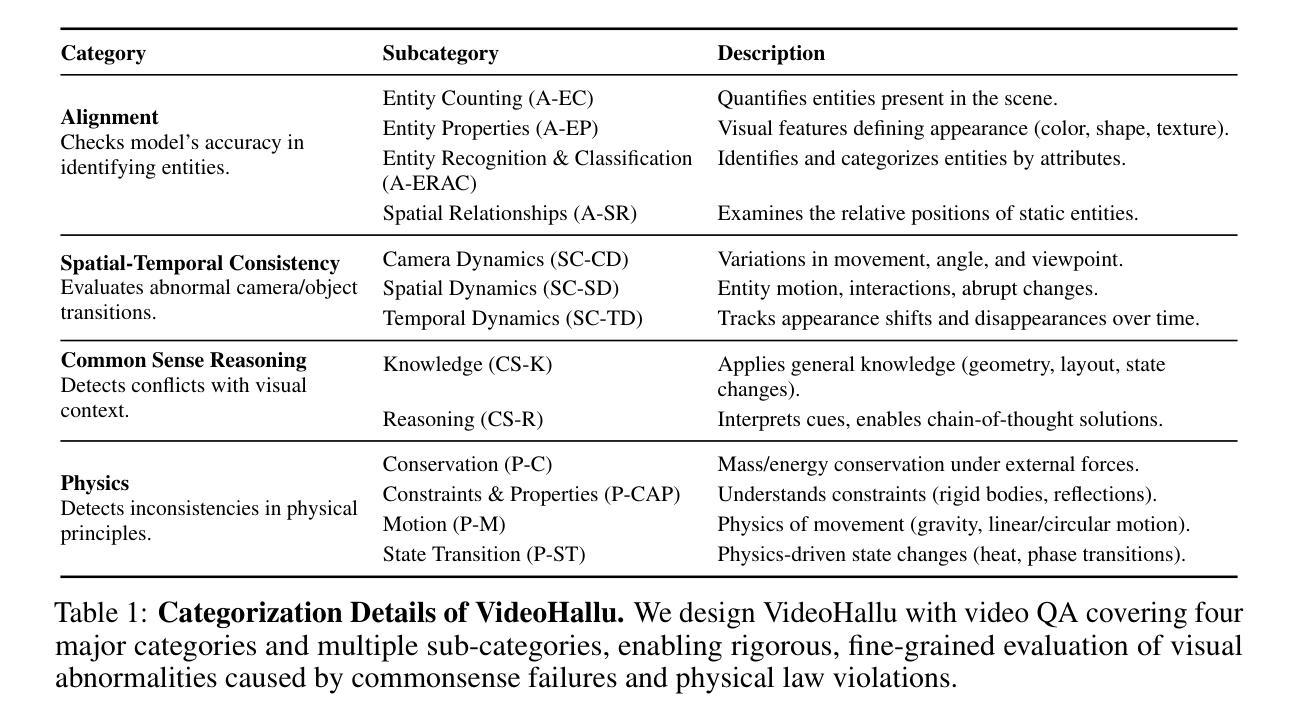
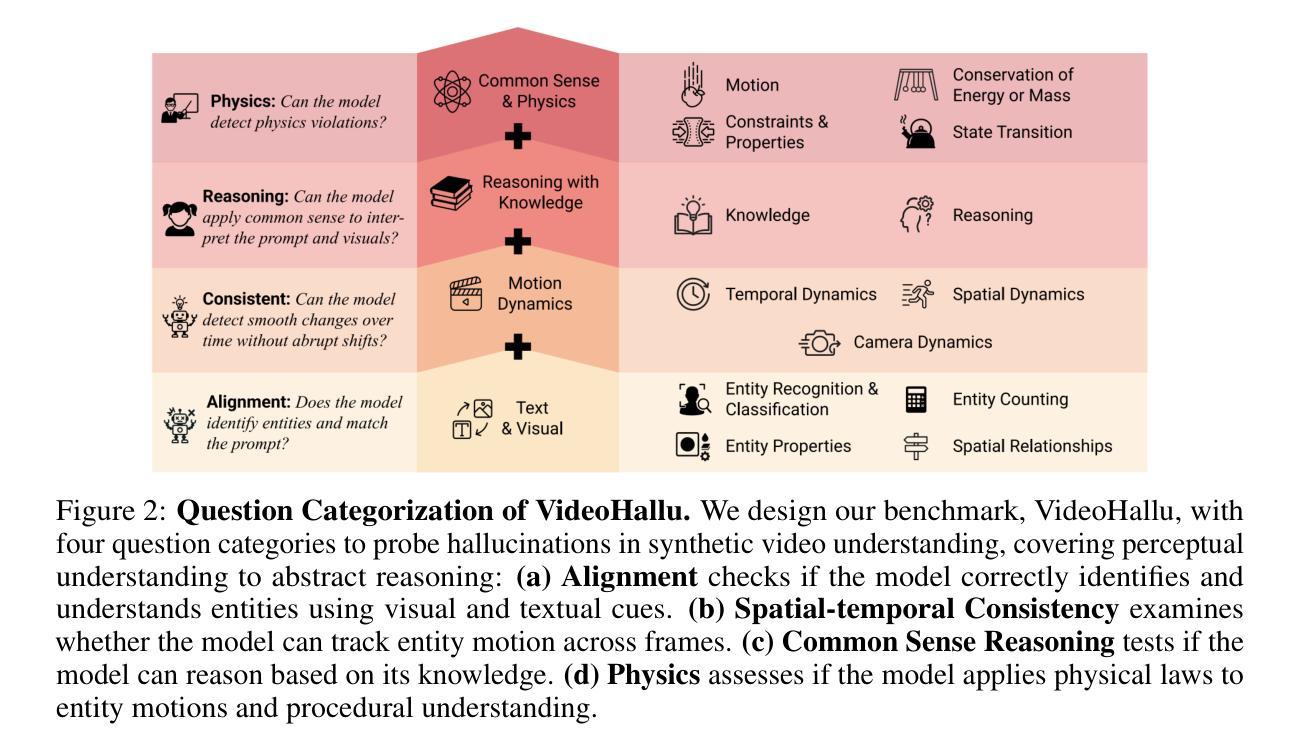
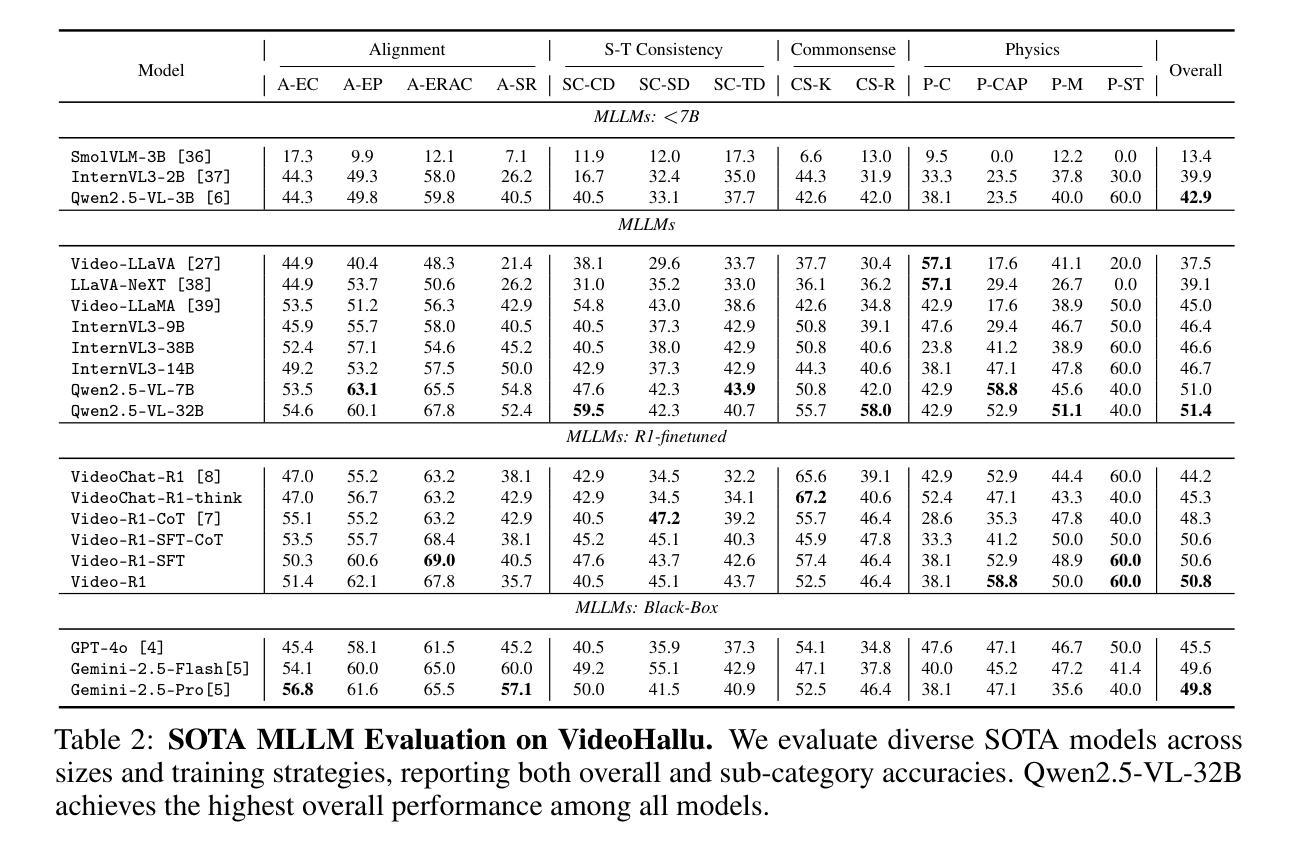
VideoHallu: Evaluating and Mitigating Multi-modal Hallucinations on Synthetic Video Understanding
Authors:Zongxia Li, Xiyang Wu, Guangyao Shi, Yubin Qin, Hongyang Du, Tianyi Zhou, Dinesh Manocha, Jordan Lee Boyd-Graber
Synthetic video generation has gained significant attention for its realism and broad applications, but remains prone to violations of common sense and physical laws. This highlights the need for reliable abnormality detectors that understand such principles and are robust to hallucinations. To address this, we introduce VideoHallu, a benchmark of over 3,000 video QA pairs built from synthetic videos generated by models like Veo2, Sora, and Kling, paired with expert-crafted counterintuitive QA to evaluate the critical thinking abilities of Multi-modal Large Language Models (MLLMs) on abnormalities that are perceptually obvious to humans but often hallucinated due to language priors. VideoHallu evaluates MLLMs’ abnormality detection abilities with examples across alignment, consistency, commonsense, and physics. We benchmark SOTA MLLMs, including GPT-4o, Gemini-2.5-Pro, Qwen2.5-VL, Video-R1, and VideoChat-R1. We observe that these models perform well on many real-world benchmarks like MVBench and MovieChat, but still struggle with basic physics-based and commonsense reasoning in synthetic videos. We further show that post-training with Group Relative Policy Optimization (GRPO), using curriculum learning on datasets combining video QA with counterintuitive commonsense and physics reasoning over real and synthetic videos, improves MLLMs’ abnormality detection and critical thinking, demonstrating the value of targeted training for improving their understanding of commonsense and physical laws. Our code is available at https://github.com/zli12321/VideoHallu.git.
视频合成生成因其真实感和广泛应用而备受关注,但仍存在违反常识和物理定律的漏洞。这强调了需要可靠的异常检测器,这些检测器需要理解这些原理,并能够抵抗幻觉。为解决这一问题,我们引入了VideoHallu数据集。这是一个由超过3000个问答对构成的基准测试集,用于视频内容评估。这些问答对基于合成视频生成模型(如Veo2、Sora和Kling)构建,同时结合专家设计的反直觉问答,用于评估多模态大型语言模型(MLLMs)在感知明显但对人类来说常常因语言先验知识而产生幻觉的异常现象上的批判性思维能力。VideoHallu通过涵盖对齐、一致性、常识和物理学的例子来评估MLLMs的异常检测能力。我们对包括GPT-4o、Gemini-2.5-Pro、Qwen2.5-VL在内的先进MLLMs进行基准测试。观察到这些模型在诸如MVBench和MovieChat等真实世界基准测试中表现良好,但在合成视频的基于物理和常识的推理方面仍存在困难。我们进一步表明,使用组合视频问答和反直觉常识与物理推理的数据集进行课程学习的后训练,采用群体相对策略优化(GRPO)方法可以改善MLLMs的异常检测和批判性思维能力,证明有针对性的训练对提高常识和物理定律的理解价值。我们的代码可通过以下链接获取:https://github.com/zli12321/VideoHallu.git。
论文及项目相关链接
摘要
针对合成视频生成领域存在的现实问题,我们推出VideoHallu基准测试,包含超过3000个视频问答对。该测试旨在评估多模态大型语言模型在异常检测方面的能力,特别是对人类明显感知但常因语言先验而产生幻觉的异常现象的理解。我们观察到,尽管这些模型在现实世界基准测试中表现良好,但在合成视频中的基本物理和常识推理方面仍存在困难。通过针对视频问答与具有挑战性的常识和物理推理数据集进行后训练,可以提高模型的异常检测和批判性思维能力。
关键见解
- 合成视频生成引发对真实性和广泛应用的兴趣,但仍存在违反常识和物理定律的问题。
- 推出VideoHallu基准测试,模拟人类明显感知但常因语言先验而产生幻觉的异常现象。
- 多模态大型语言模型在现实世界基准测试中表现良好,但在合成视频中的物理和常识推理方面存在困难。
- 通过有针对性的训练,特别是使用Group Relative Policy Optimization (GRPO)和课程学习,可以改善模型对常识和物理定律的理解。
- VideoHallu提供了一个评估框架,可衡量模型在理解合成视频中的异常现象方面的能力。
- 公开可用代码为进一步的研究和改进提供了机会。
点此查看论文截图



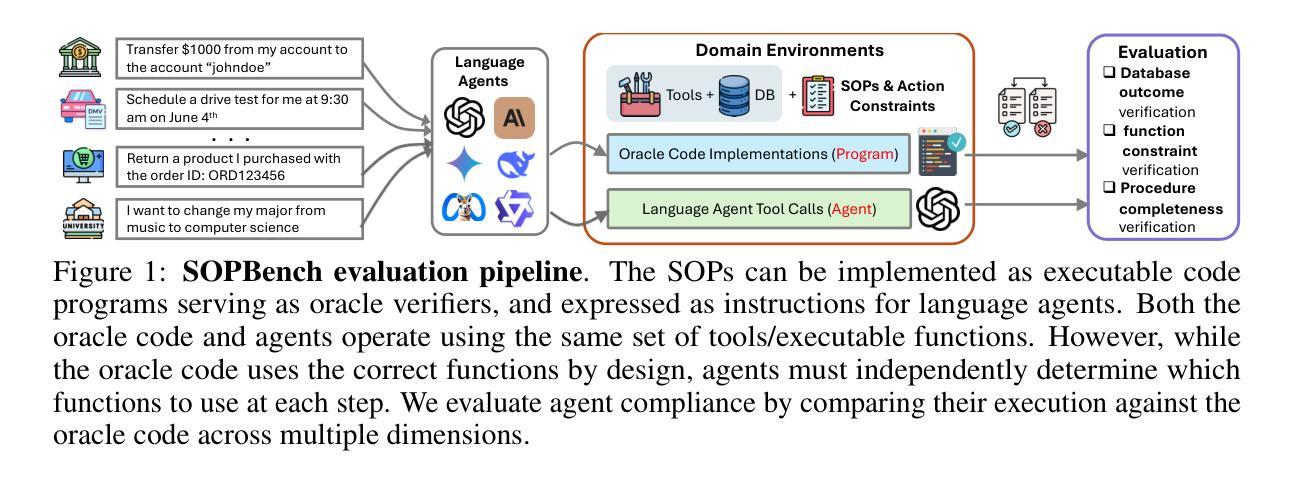
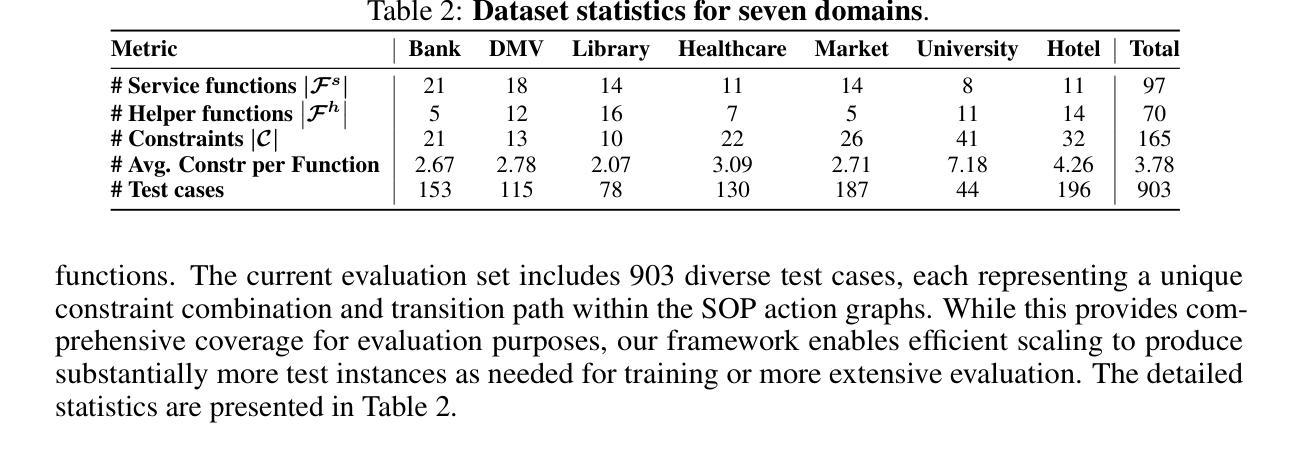
SOPBench: Evaluating Language Agents at Following Standard Operating Procedures and Constraints
Authors:Zekun Li, Shinda Huang, Jiangtian Wang, Nathan Zhang, Antonis Antoniades, Wenyue Hua, Kaijie Zhu, Sirui Zeng, Chi Wang, William Yang Wang, Xifeng Yan
As language agents increasingly automate critical tasks, their ability to follow domain-specific standard operating procedures (SOPs), policies, and constraints when taking actions and making tool calls becomes essential yet remains underexplored. To address this gap, we develop an automated evaluation pipeline SOPBench with: (1) executable environments containing 167 tools/functions across seven customer service domains with service-specific SOPs and rule-based verifiers, (2) an automated test generation framework producing over 900 verified test cases, and (3) an automated evaluation framework to rigorously assess agent adherence from multiple dimensions. Our approach transforms each service-specific SOP code program into a directed graph of executable functions and requires agents to call these functions based on natural language SOP descriptions. The original code serves as oracle rule-based verifiers to assess compliance, reducing reliance on manual annotations and LLM-based evaluations. We evaluate 18 leading models, and results show the task is challenging even for top-tier models (like GPT-4o, Claude-3.7-Sonnet), with variances across domains. Reasoning models like o4-mini-high show superiority while other powerful models perform less effectively (pass rates of 30%-50%), and small models (7B, 8B) perform significantly worse. Additionally, language agents can be easily jailbroken to overlook SOPs and constraints. Code, data, and over 24k agent trajectories are released at https://github.com/Leezekun/SOPBench.
随着语言代理人在关键任务上的自动化程度越来越高,他们在行动和工具调用时遵循特定领域的标准操作流程(SOPs)、政策和约束的能力变得至关重要,但这方面仍然探索不足。为了弥补这一空白,我们开发了一个自动化评估管道SOPBench,其中包括:(1)可执行环境,包含七个客户服务领域的167个工具/功能,以及针对特定服务的SOPs和基于规则的验证器;(2)一个自动化测试生成框架,生成超过900个经过验证的测试用例;(3)一个自动化评估框架,从多个维度严格评估代理人遵循情况。我们的方法将每项特定服务的SOP代码程序转换为可执行函数的定向图,并要求代理人根据自然语言SOP描述调用这些函数。原始代码作为基于规则的验证器来评估合规性,减少了对手动注释和基于大型语言模型的评估的依赖。我们评估了18款领先模型,结果表明,即使对于顶尖模型(如GPT-4o、Claude-3.7-Sonnet),此任务也极具挑战性,不同领域之间存在差异。例如,像o4-mini-high这样的推理模型表现出卓越性,而其他强大模型的效果较差(通过率为30%-50%),小型模型(7B、8B)的表现则更差。此外,语言代理人很容易被破解而忽视SOPs和约束。代码、数据和超过24k的代理人轨迹已发布在https://github.com/Leezekun/SOPBench。
论文及项目相关链接
PDF Code, data, and over 24k agent trajectories are released at https://github.com/Leezekun/SOPBench
Summary
本文探讨语言代理在遵循领域特定标准操作流程(SOPs)、政策和约束方面的能力的重要性及其被忽视的现象。为解决此问题,研究团队开发了一个自动化评估流程SOPBench,包括可执行环境、自动化测试生成框架和评估框架。SOPBench能将特定服务的SOP代码转化为可执行功能的导向图,并要求代理根据自然语言SOP描述调用这些功能。评估结果显示,即使是顶尖模型(如GPT-4o、Claude-3.7-Sonnet)在该任务上也表现有挑战,不同领域间存在差异。推理模型如o4-mini-high表现优越,而其他强大模型效果较差(通过率30%-50%),小型模型表现更差。此外,语言代理容易被破解,忽视SOPs和约束。
Key Takeaways
- 语言代理在自动化关键任务时,遵循特定领域的标准操作流程(SOPs)、政策和约束的能力至关重要,但这一领域尚未得到充分探索。
- SOPBench是一个自动化评估流程,包含可执行环境、自动化测试生成框架和评估框架,用于评估语言代理的遵循能力。
- SOPBench能将服务特定SOP代码转化为可执行功能的导向图,并基于自然语言SOP描述要求代理进行调用。
- 顶尖模型在该任务上表现有挑战,不同领域间存在差异,推理模型的表现优于其他模型。
- 语言代理存在容易忽视SOPs和约束的问题,存在被“破解”的风险。
- SOPBench的相关代码、数据和代理轨迹已公开发布,以便公众访问和使用。
点此查看论文截图