⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-22 更新
Audio-Visual Driven Compression for Low-Bitrate Talking Head Videos
Authors:Riku Takahashi, Ryugo Morita, Jinjia Zhou
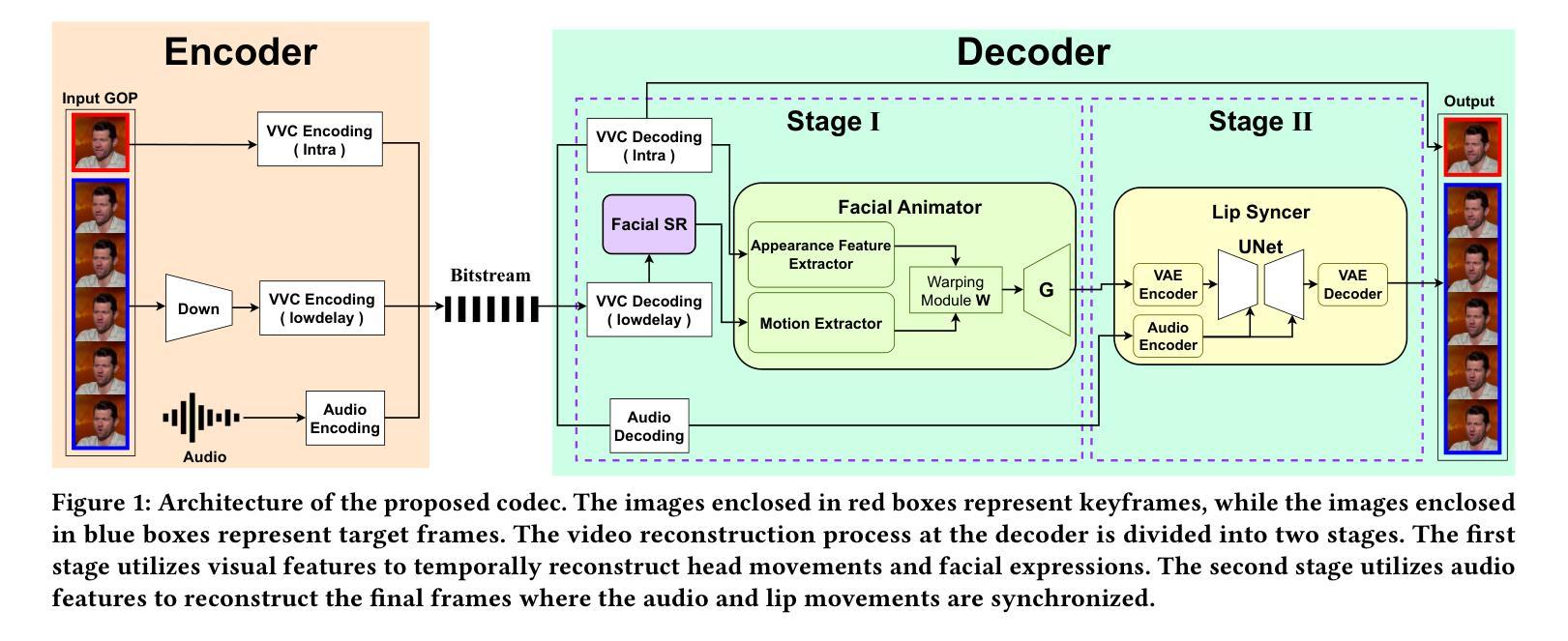
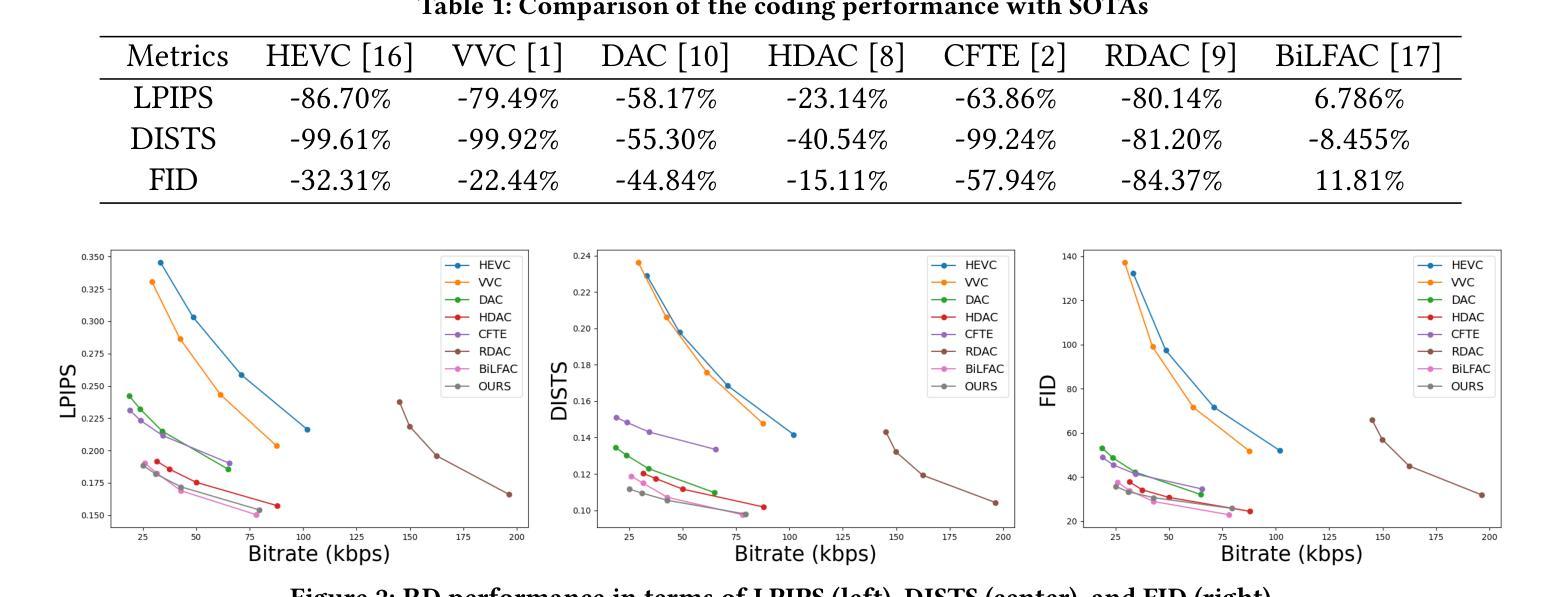
Talking head video compression has advanced with neural rendering and keypoint-based methods, but challenges remain, especially at low bit rates, including handling large head movements, suboptimal lip synchronization, and distorted facial reconstructions. To address these problems, we propose a novel audio-visual driven video codec that integrates compact 3D motion features and audio signals. This approach robustly models significant head rotations and aligns lip movements with speech, improving both compression efficiency and reconstruction quality. Experiments on the CelebV-HQ dataset show that our method reduces bitrate by 22% compared to VVC and by 8.5% over state-of-the-art learning-based codec. Furthermore, it provides superior lip-sync accuracy and visual fidelity at comparable bitrates, highlighting its effectiveness in bandwidth-constrained scenarios.
头部谈话视频压缩技术已经随着神经渲染和基于关键点的方法取得了进展,但仍存在挑战,特别是在低比特率下,包括处理大头部运动、唇部同步不佳和面部重建失真等问题。为了解决这些问题,我们提出了一种新颖的音频视觉驱动视频编码技术,该技术集成了紧凑的3D运动特征和音频信号。这种方法稳健地模拟了重要的头部旋转,并使唇部运动与语音对齐,提高了压缩效率和重建质量。在CelebV-HQ数据集上的实验表明,我们的方法相较于VVC降低了22%的比特率,并且相较于基于学习的最新编码技术降低了8.5%。此外,它在比特率相当的情况下提供了更出色的唇部同步精度和视觉保真度,突显了在带宽受限场景中的有效性。
论文及项目相关链接
PDF Accepted to ICMR2025
Summary
新一代音视频驱动的编码器可有效解决Talking Head视频压缩面临的挑战,特别是在低码率场景下的大头移动、唇部同步失真和面部重建失真等问题。它结合紧凑的三维运动特征和音频信号,提升头部旋转的稳健建模,改善唇部运动与语音的同步。实验显示,相比VVC和最新的学习型编码器,该方法降低了比特率并提高了图像质量。它在带宽受限场景中表现出优异的性能。
Key Takeaways
- Talking Head视频压缩面临挑战,包括大头移动、唇部同步失真和面部重建失真等。
- 新一代音视频驱动的编码器结合了紧凑的三维运动特征和音频信号,能有效解决上述问题。
- 该编码器提高了头部旋转的稳健建模,改善了唇部运动与语音的同步性能。
点此查看论文截图