⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-23 更新
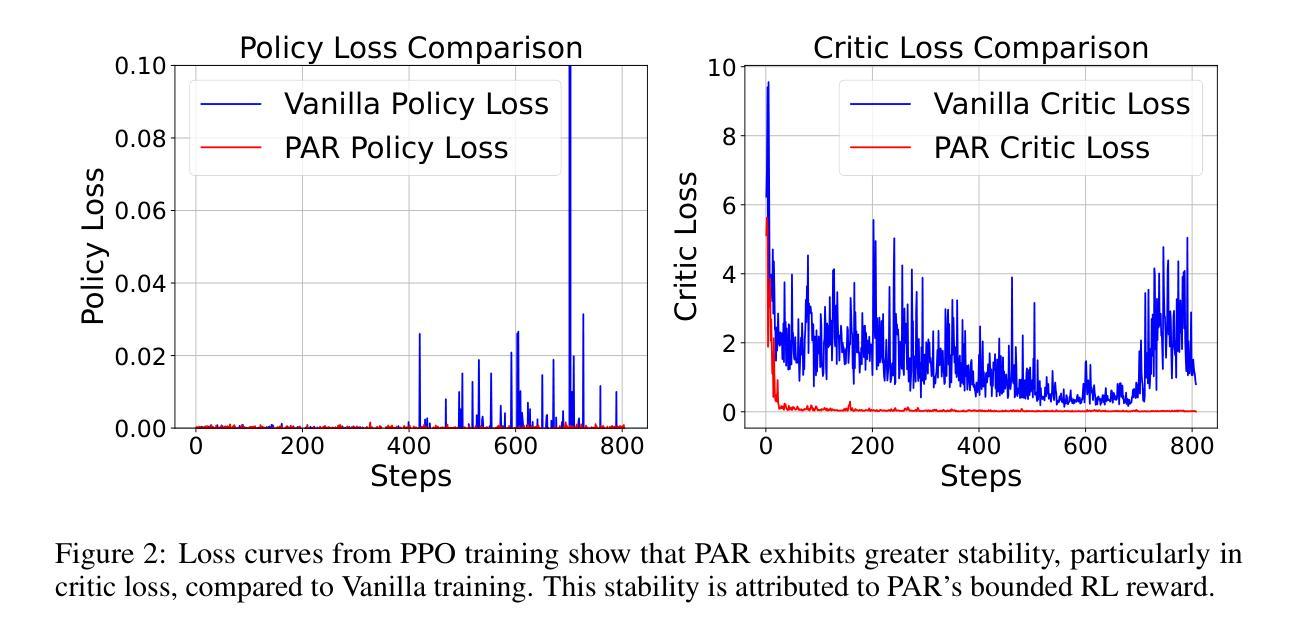
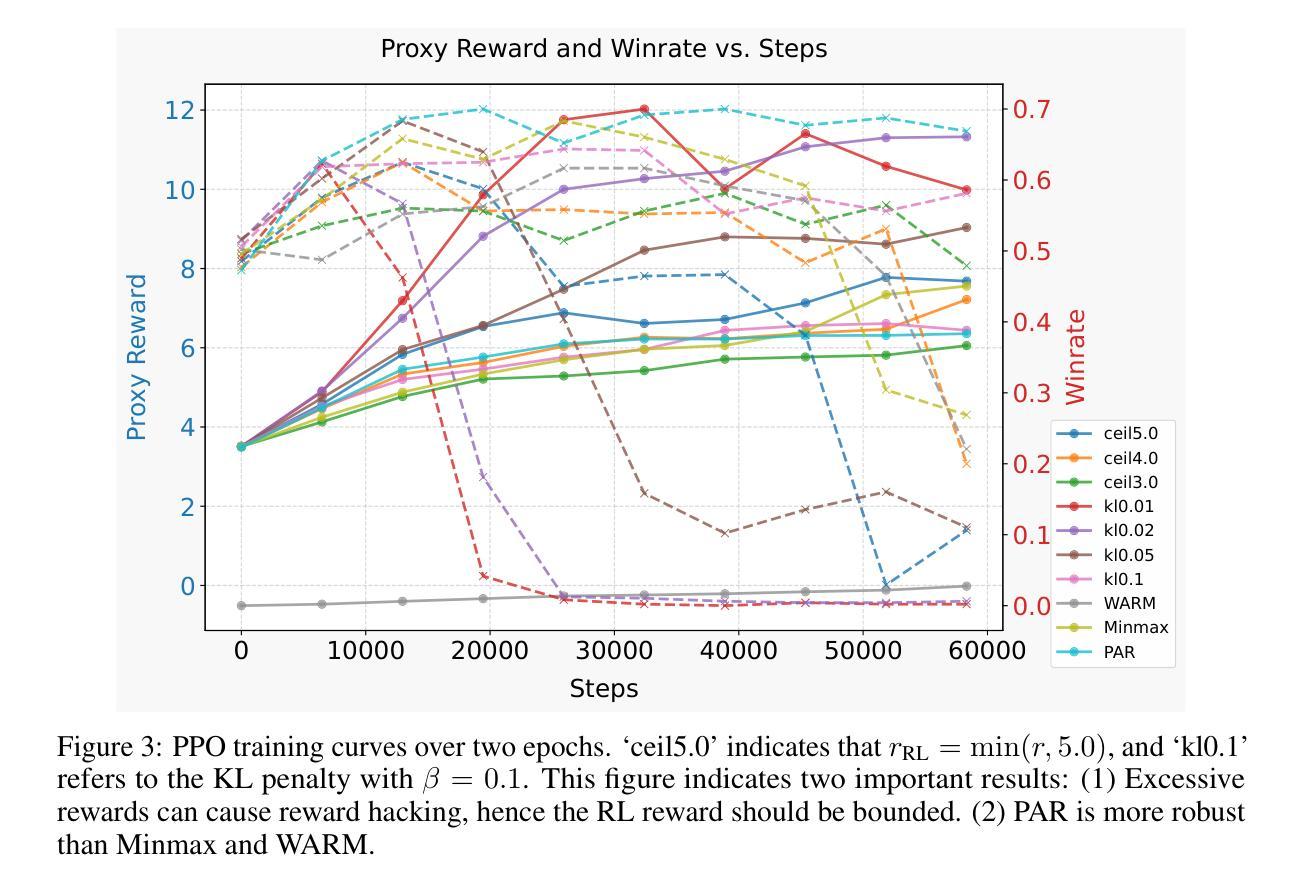
Reward Shaping to Mitigate Reward Hacking in RLHF
Authors:Jiayi Fu, Xuandong Zhao, Chengyuan Yao, Heng Wang, Qi Han, Yanghua Xiao
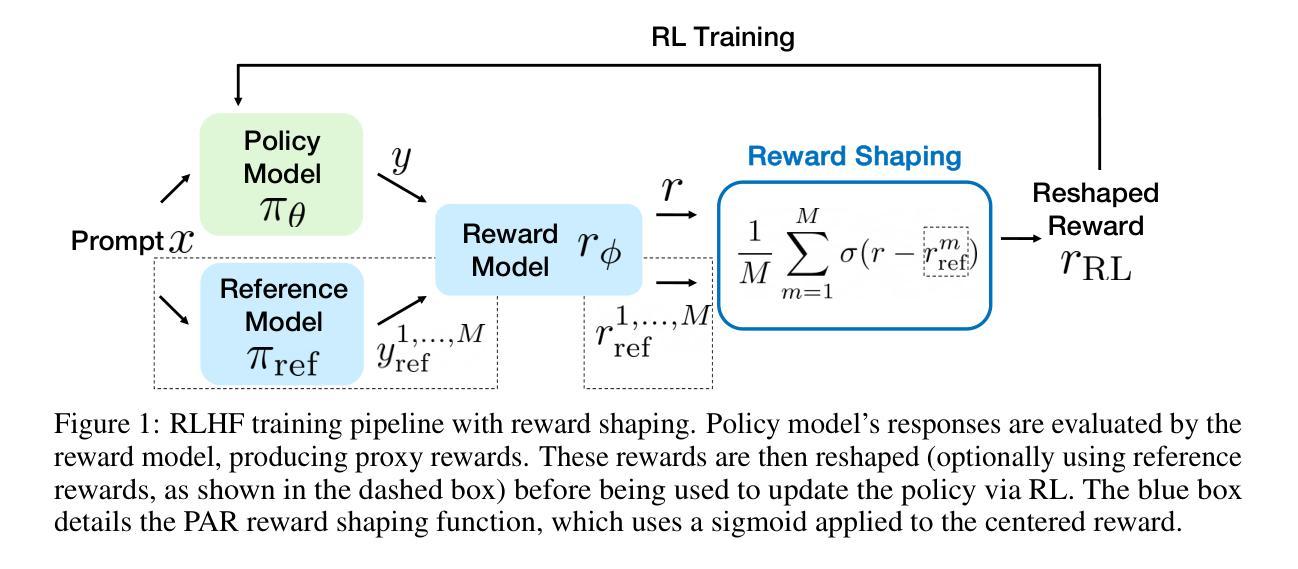
Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. However, RLHF is susceptible to \emph{reward hacking}, where the agent exploits flaws in the reward function rather than learning the intended behavior, thus degrading alignment. Although reward shaping helps stabilize RLHF and partially mitigate reward hacking, a systematic investigation into shaping techniques and their underlying principles remains lacking. To bridge this gap, we present a comprehensive study of the prevalent reward shaping methods. Our analysis suggests two key design principles: (1) the RL reward should be bounded, and (2) the RL reward benefits from rapid initial growth followed by gradual convergence. Guided by these insights, we propose Preference As Reward (PAR), a novel approach that leverages the latent preferences embedded within the reward model as the signal for reinforcement learning. We evaluated PAR on two base models, Gemma2-2B, and Llama3-8B, using two datasets, Ultrafeedback-Binarized and HH-RLHF. Experimental results demonstrate PAR’s superior performance over other reward shaping methods. On the AlpacaEval 2.0 benchmark, PAR achieves a win rate of at least 5 percentage points higher than competing approaches. Furthermore, PAR exhibits remarkable data efficiency, requiring only a single reference reward for optimal performance, and maintains robustness against reward hacking even after two full epochs of training. The code is available at https://github.com/PorUna-byte/PAR, and the Work done during the internship at StepFun by Jiayi Fu.
强化学习从人类反馈(RLHF)对于将大型语言模型(LLM)与人类价值观对齐至关重要。然而,RLHF容易受到“奖励作弊”的影响,即代理利用奖励函数的漏洞,而不是学习预期的行为,从而降低了对齐程度。虽然奖励塑造有助于稳定RLHF并部分缓解奖励作弊问题,但对于塑造技术及其基础原理的系统性研究仍然缺乏。为了填补这一空白,我们对流行的奖励塑造方法进行了综合研究。我们的分析提出了两个关键的设计原则:(1)RL奖励应该是有界的,(2)RL奖励从快速初始增长中受益,随后逐渐收敛。在这些见解的指导下,我们提出了“偏好作为奖励”(PAR)这一新方法,它利用奖励模型中嵌入的潜在偏好作为强化学习的信号。我们在两个基础模型Gemma2-2B和Llama3-8B上,使用Ultrafeedback-Binarized和HH-RLHF两个数据集评估了PAR。实验结果证明了PAR在其他奖励塑造方法中的卓越性能。在AlpacaEval 2.0基准测试中,PAR的胜率至少比竞争方法高出5个百分点。此外,PAR表现出显著的数据效率,仅需要一个参考奖励即可实现最佳性能,并且在两个完整的训练周期后仍然能够保持对奖励作弊的稳健性。代码可在https://github.com/PorUna-byte/PAR获得,这是Jiayi Fu在StepFun实习期间完成的工作。
论文及项目相关链接
PDF 24 pages
Summary
基于人类反馈的强化学习(RLHF)对于将大型语言模型(LLM)与人类价值观对齐至关重要。然而,RLHF易受到奖励黑客攻击,其中代理人会利用奖励功能的缺陷而非学习预期行为,从而破坏对齐。尽管奖励塑造有助于稳定RLHF并部分缓解奖励黑客攻击的问题,但对于塑造技术和其基本原理的系统性研究仍然缺乏。为了填补这一空白,我们对流行的奖励塑造方法进行了深入研究并提出了两个关键设计原则:(1)RL奖励应该是有界的;(2)RL奖励从快速初始增长中获益,随后逐渐收敛。基于这些见解,我们提出了一种新的方法——偏好作为奖励(PAR),它利用奖励模型中嵌入的潜在偏好作为强化学习的信号。实验结果表明,PAR在其他奖励塑造方法上具有卓越的性能。在AlpacaEval 2.0基准测试中,PAR的胜率至少比竞争方法高出5个百分点。此外,PAR具有显著的数据效率,仅需一个参考奖励即可实现最佳性能,并且在两个完整的训练周期后仍然能够抵抗奖励黑客攻击。代码可通过链接https://github.com/PorUna-byte/PAR获取。
Key Takeaways
- 强化学习从人类反馈(RLHF)在大型语言模型(LLM)与人类价值观对齐中起关键作用,但易受到奖励黑客攻击的挑战。
- 奖励塑造是稳定RLHF并缓解奖励黑客攻击问题的一种有效手段,但缺乏系统研究。
- 通过对现有奖励塑造方法的综合分析,提出两个关键设计原则:RL奖励的有界性和其初期的快速增长和随后的逐渐收敛趋势。
- 提出一种新方法——偏好作为奖励(PAR),利用奖励模型中的潜在偏好作为强化学习的信号,展现出卓越的性能。
- PAR在AlpacaEval 2.0基准测试中表现优异,相较于其他方法具有更高的胜率。
- PAR具有显著的数据效率,仅需单一参考奖励即可实现最佳性能。
点此查看论文截图

From System 1 to System 2: A Survey of Reasoning Large Language Models
Authors:Zhong-Zhi Li, Duzhen Zhang, Ming-Liang Zhang, Jiaxin Zhang, Zengyan Liu, Yuxuan Yao, Haotian Xu, Junhao Zheng, Pei-Jie Wang, Xiuyi Chen, Yingying Zhang, Fei Yin, Jiahua Dong, Zhiwei Li, Bao-Long Bi, Ling-Rui Mei, Junfeng Fang, Xiao Liang, Zhijiang Guo, Le Song, Cheng-Lin Liu
Achieving human-level intelligence requires refining the transition from the fast, intuitive System 1 to the slower, more deliberate System 2 reasoning. While System 1 excels in quick, heuristic decisions, System 2 relies on logical reasoning for more accurate judgments and reduced biases. Foundational Large Language Models (LLMs) excel at fast decision-making but lack the depth for complex reasoning, as they have not yet fully embraced the step-by-step analysis characteristic of true System 2 thinking. Recently, reasoning LLMs like OpenAI’s o1/o3 and DeepSeek’s R1 have demonstrated expert-level performance in fields such as mathematics and coding, closely mimicking the deliberate reasoning of System 2 and showcasing human-like cognitive abilities. This survey begins with a brief overview of the progress in foundational LLMs and the early development of System 2 technologies, exploring how their combination has paved the way for reasoning LLMs. Next, we discuss how to construct reasoning LLMs, analyzing their features, the core methods enabling advanced reasoning, and the evolution of various reasoning LLMs. Additionally, we provide an overview of reasoning benchmarks, offering an in-depth comparison of the performance of representative reasoning LLMs. Finally, we explore promising directions for advancing reasoning LLMs and maintain a real-time \href{https://github.com/zzli2022/Awesome-Slow-Reason-System}{GitHub Repository} to track the latest developments. We hope this survey will serve as a valuable resource to inspire innovation and drive progress in this rapidly evolving field.
实现人类水平的智能需要完善从快速直觉系统1到较慢、更慎重的系统2推理的转变。系统1擅长快速、启发式的决策,而系统2则依赖于逻辑推理以做出更准确的判断和减少偏见。基础大型语言模型(LLM)擅长快速决策,但在复杂推理方面缺乏深度,因为它们尚未完全接受真正的系统2思维所特有的逐步分析。最近,像OpenAI的o1/o3和DeepSeek的R1这样的推理LLM在数学和编码等领域表现出了专家级的性能,它们模仿了系统2的慎重推理,展示了人类般的认知能力。这篇综述首先简要概述了基础LLM和系统2技术的早期发展进展,探讨了它们相结合如何为推理LLM铺平道路。接下来,我们讨论如何构建推理LLM,分析它们的特性、支持高级推理的核心方法以及各种推理LLM的演变。此外,我们还概述了推理基准测试,对代表性推理LLM的性能进行了深入的对比。最后,我们探讨了推进推理LLM的有前途的方向,并维护一个实时GitHub仓库来跟踪最新进展。我们希望这篇综述能成为这一快速演进领域的创新灵感和推动进步的宝贵资源。
论文及项目相关链接
PDF Slow-thinking, Large Language Models, Human-like Reasoning, Decision Making in AI, AGI
Summary
该文探讨了实现人类智能水平需要完成从快速直觉系统一(System 1)到更慢的深思熟虑系统二(System 2)推理的转变。文章介绍了基础大型语言模型(LLMs)在快速决策方面的优势,但在复杂推理方面存在不足。近期,如OpenAI的o1/o3和DeepSeek的R1等推理LLMs展示了在数学和编码等领域的专家级表现,模仿了系统二的深思熟虑推理,展现了人类般的认知能力。本文回顾了LLMs和系统二技术的早期发展,探讨了它们的结合如何为推理LLMs铺平道路。接着讨论了如何构建推理LLMs,分析了它们的特性、核心方法和各种推理LLMs的演变。此外,本文还概述了推理基准测试,深入比较了代表性推理LLMs的性能。最后,本文探讨了推进推理LLMs发展的有前途的方向,并维护了一个GitHub仓库来跟踪最新进展。
Key Takeaways
- 实现人类智能水平需要实现从快速直觉决策(System 1)到逻辑分析推理(System 2)的转变。
- 基础大型语言模型(LLMs)擅长快速决策但缺乏复杂推理能力。
- 推理LLMs如OpenAI的o1/o3和DeepSeek的R1在数学和编码等领域表现出专家级能力,模拟了系统二的深思熟虑过程。
- 推理LLMs的构建涉及多个方面,包括特性分析、核心方法的采用和各种推理模型的演变。
- 推理基准测试深入比较了代表性推理LLMs的性能。
- 推理LLMs的发展前景广阔,包括技术进步、算法优化和跨领域融合等方向。
点此查看论文截图

Fino1: On the Transferability of Reasoning-Enhanced LLMs and Reinforcement Learning to Finance
Authors:Lingfei Qian, Weipeng Zhou, Yan Wang, Xueqing Peng, Han Yi, Yilun Zhao, Jimin Huang, Qianqian Xie, Jian-yun Nie
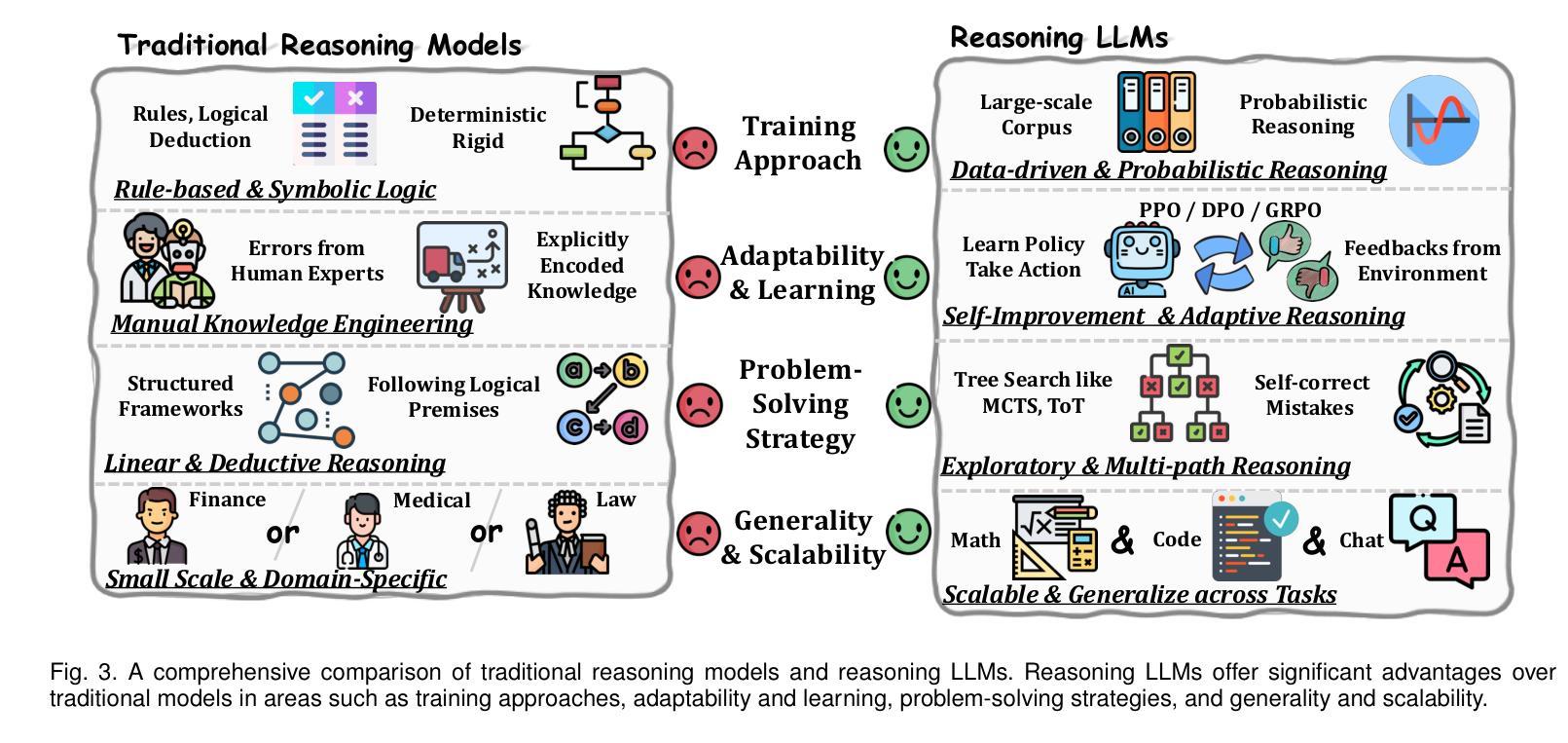
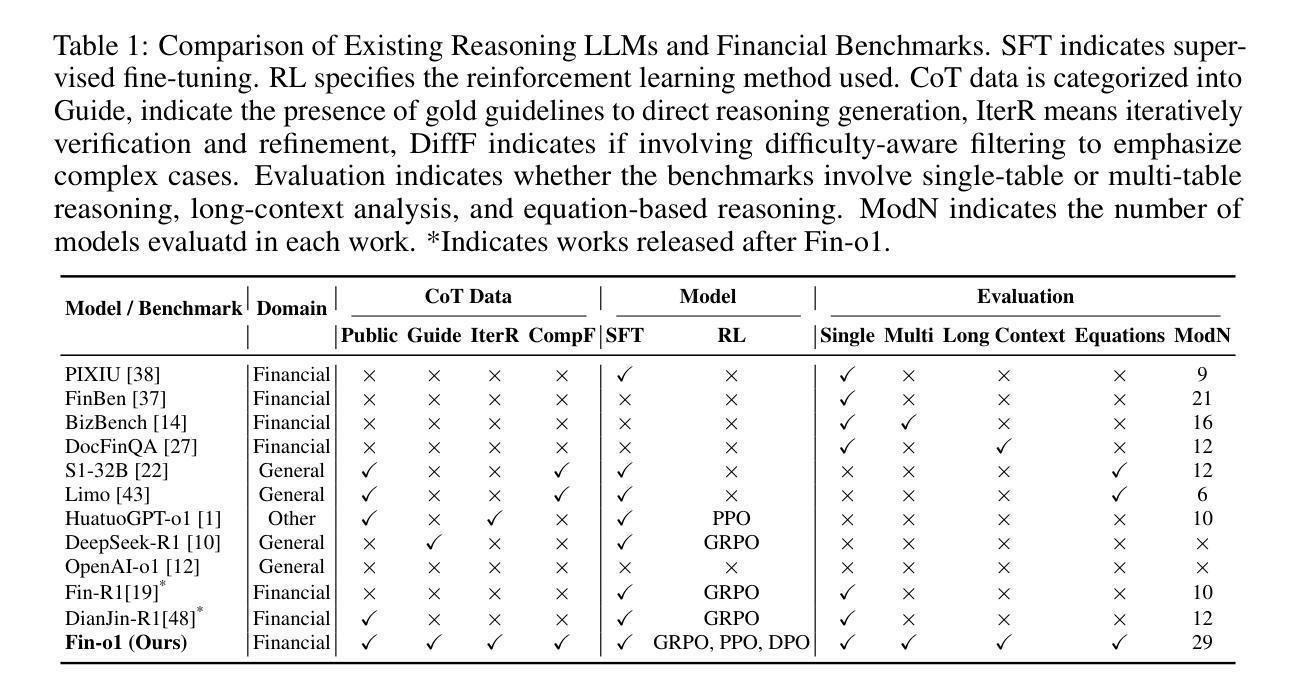
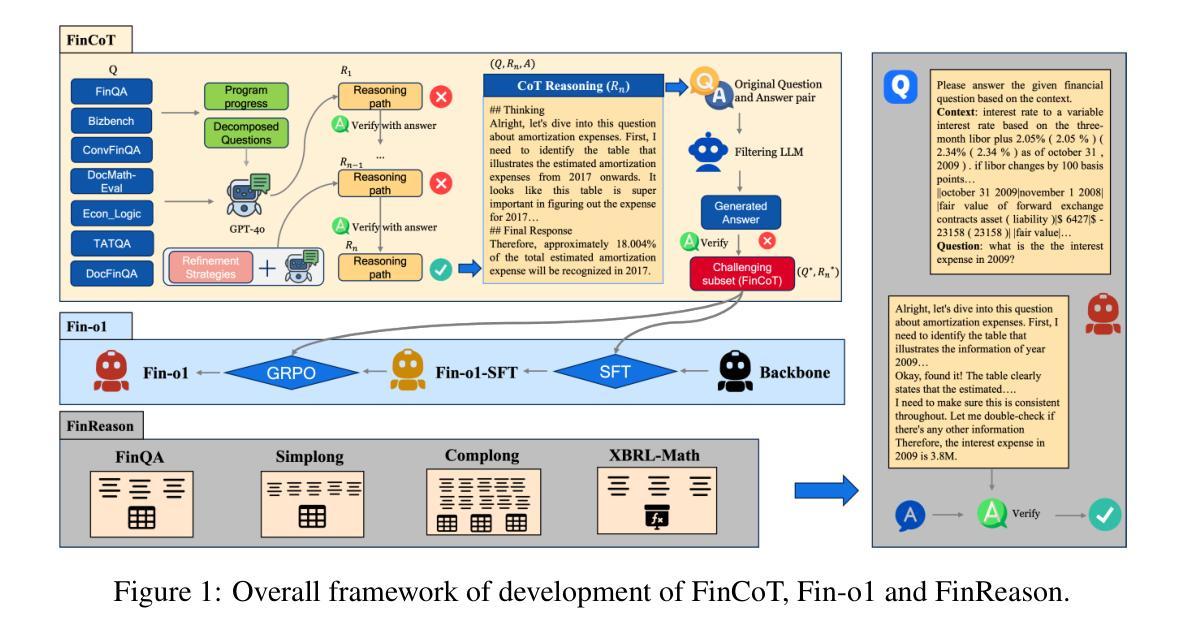
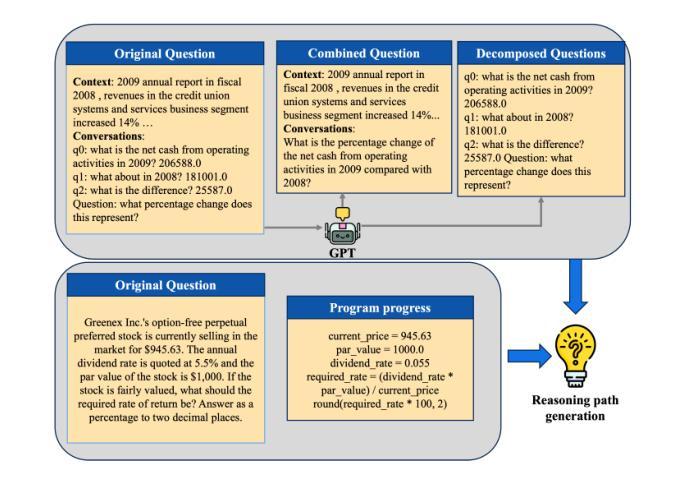
As the fundamental capability behind decision-making in finance, financial reasoning poses distinct challenges for LLMs. Although reinforcement learning (RL) have boosted generic reasoning, the progress in finance is hindered by the absence of empirical study of building effective financial chain-of-thought (CoT) corpus, a systematic comparison of different RL methods, and comprehensive benchmarks. To address these gaps, we introduce FinCoT, the first open high-fidelity CoT corpus for finance, distilled from seven QA datasets by a novel three-stage pipeline that incorporates domain supervision, iterative LLM refinement, and difficulty-aware filtering. Based on FinCoT, we develop Fin-o1, the first open financial reasoning models trained via supervised fine-tuning and GRPO-based RL. Our models outperform existing financial reasoning models and SOTA general models such as GPT-o1, DeepSeek-R1, and GPT-4.5. We also investigate the effectiveness of three different RL methods in improving domain-specific reasoning, offering the first such empirical study. We finally propose FinReason, the first financial reasoning benchmark covering multi-table analysis, long-context reasoning, and equation-based tasks, and evaluate 29 LLMs. Our extensive experiments reveal general reasoning models excel on standard benchmarks yet exhibit obvious performance degradation in financial contexts; even finance-tuned models like Dianjin-R1 and FinR1 degrade on lengthy documents. In contrast, our Fin-o1 models consistently outperform their backbones and larger GPT-o1 and DeepSeek-R1, confirming the effectiveness of our data building and model training strategy. Our study further shows that GRPO yields reliable gains whereas PPO and DPO do not, highlighting the need for targeted data and optimisation rather than scale alone.
金融推理作为金融决策背后的基本能力,对大型语言模型(LLMs)提出了独特的挑战。尽管强化学习(RL)已经促进了通用推理的发展,但在金融领域的进展却受到有效金融思维链(CoT)语料库实证研究的缺乏、不同RL方法系统比较以及综合基准测试的缺失的阻碍。为了解决这些空白,我们引入了FinCoT,这是第一个开放的高保真CoT语料库,用于金融领域。它通过一个新的三阶段管道从七个问答数据集中蒸馏出来,该管道结合了领域监督、迭代的大型语言模型细化和难度感知过滤。基于FinCoT,我们开发了Fin-o1,这是第一个通过监督微调以及基于GRPO的RL进行训练的开源金融推理模型。我们的模型优于现有的金融推理模型和SOTA通用模型,如GPT-o1、DeepSeek-R1和GPT-4.5。我们还研究了三种不同的RL方法在改进特定领域推理方面的有效性,提供了第一项这样的实证研究。最后,我们提出了FinReason,这是第一个涵盖多表分析、长上下文推理和基于方程的任务的金融推理基准测试,并对29个大型语言模型进行了评估。我们的广泛实验表明,通用推理模型在标准基准测试上表现优异,但在金融背景下表现出明显的性能下降;即使是针对金融领域调整过的模型,如Dianjin-R1和FinR1,在处理长文档时也会出现问题。相比之下,我们的Fin-o1模型持续优于其主干网以及更大的GPT-o1和DeepSeek-R1,这证实了我们数据构建和模型训练策略的有效性。我们的研究还表明,GRPO带来了可靠的收益,而PPO和DPO则没有,这强调了有针对性的数据和优化而不是单纯规模的重要性。
论文及项目相关链接
PDF 13 pages, 2 figures, 3 Tables
Summary
在金融领域中,决策制定背后的基本能力是金融推理,这对大型语言模型(LLMs)提出了独特的挑战。尽管强化学习(RL)提升了通用推理能力,但金融领域的进展受到有效金融思维链(CoT)语料库的实证研究缺失、不同RL方法的系统比较以及综合基准测试的限制。为解决这些差距,我们引入了FinCoT,这是第一个开放的高保真度金融CoT语料库,通过包含领域监督、迭代LLM精炼和难度感知过滤的新颖三阶段管道进行提炼。基于FinCoT,我们开发了通过监督微调及基于GRPO的RL训练的Fin-o1金融推理模型。我们的模型超越了现有的金融推理模型和先进的一般模型,如GPT-o1、DeepSeek-R1和GPT-4.5。我们还首次实证研究了三种不同的RL方法在改进领域特定推理中的有效性。最后,我们提出了FinReason金融推理基准测试,涵盖多表分析、长文本推理和基于方程的任务,并评估了29个LLMs。研究结果表明,通用推理模型在标准基准测试上表现优异,但在金融背景下表现出明显的性能下降。相比之下,我们的Fin-o1模型持续表现优异,并证实了我们的数据构建和模型训练策略的有效性。
Key Takeaways
- 金融推理作为决策制定的核心能针对LLMs构成挑战。
- 目前缺乏金融思维链(CoT)的实证研究来推动金融领域的进步。
- 我们引入FinCoT作为首个开放的金融CoT语料库来解决此问题。
- 基于FinCoT语料库开发了Fin-o1金融推理模型,超越了现有的金融推理模型和先进的一般模型。
- 对比了三种不同的RL方法,在改进领域特定推理方面的效果展现实证研究的价值。
- 提出FinReason金融推理基准测试用于评估模型的性能涵盖多种金融任务。
点此查看论文截图

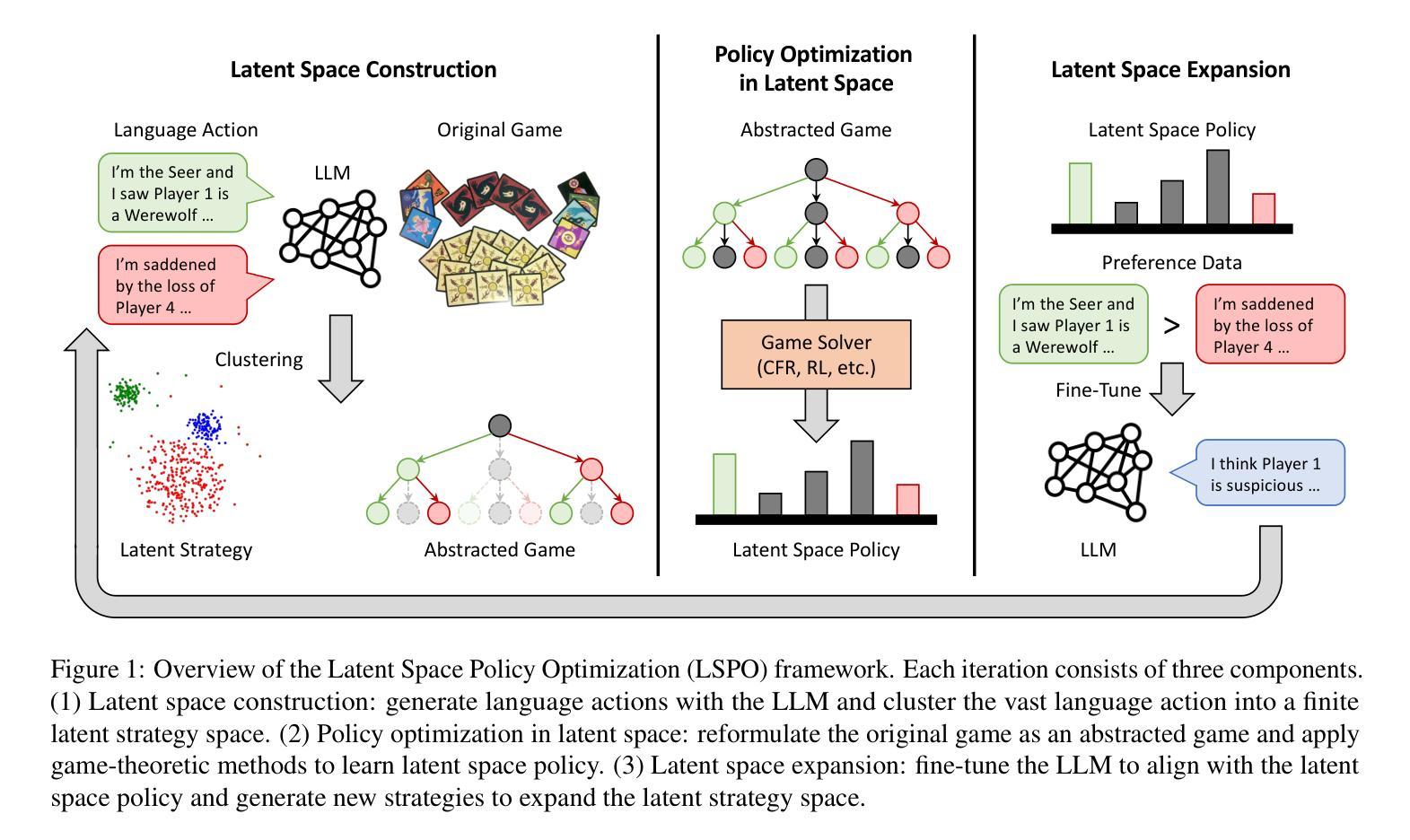
Learning Strategic Language Agents in the Werewolf Game with Iterative Latent Space Policy Optimization
Authors:Zelai Xu, Wanjun Gu, Chao Yu, Yi Wu, Yu Wang
Large language model (LLM) agents have recently demonstrated impressive capabilities in various domains like open-ended conversation and multi-step decision-making. However, it remains challenging for these agents to solve strategic language games, such as Werewolf, which demand both strategic decision-making and free-form language interactions. Existing LLM agents often suffer from intrinsic bias in their action distributions and limited exploration of the unbounded text action space, resulting in suboptimal performance. To address these challenges, we propose Latent Space Policy Optimization (LSPO), an iterative framework that combines game-theoretic methods with LLM fine-tuning to build strategic language agents. LSPO leverages the observation that while the language space is combinatorially large, the underlying strategy space is relatively compact. We first map free-form utterances into a finite latent strategy space, yielding an abstracted extensive-form game. Then we apply game-theoretic methods like Counterfactual Regret Minimization (CFR) to optimize the policy in the latent space. Finally, we fine-tune the LLM via Direct Preference Optimization (DPO) to align with the learned policy. By iteratively alternating between these steps, our LSPO agents progressively enhance both strategic reasoning and language communication. Experiment on the Werewolf game shows that our agents iteratively expand the strategy space with improving performance and outperform existing Werewolf agents, underscoring their effectiveness in free-form language games with strategic interactions.
大型语言模型(LLM)代理最近在开放对话和多步决策等各个领域表现出了令人印象深刻的能力。然而,对于战略语言游戏(如狼人杀),这些代理仍然面临着不小的挑战,这类游戏既需要做出战略决策,又需要进行自由形式的语言交互。现有的LLM代理经常受到其行动分布中的内在偏见和无界文本行动空间有限探索的影响,导致性能不佳。为了解决这些挑战,我们提出了潜在空间策略优化(LSPO),这是一个结合博弈论方法和LLM微调来构建战略语言代理的迭代框架。LSPO利用了一个观察结果,即虽然语言空间是组合式的庞大,但潜在的策略空间是相对紧凑的。我们首先将自由形式的发言映射到一个有限的潜在策略空间,从而产生一个抽象的扩展形式的游戏。然后,我们应用博弈论方法,如反事实遗憾最小化(CFR)来优化潜在空间中的策略。最后,我们通过直接偏好优化(DPO)来微调LLM,使其与学到的策略一致。通过在这些步骤之间反复交替迭代,我们的LSPO代理在战略推理和语言沟通方面逐渐增强。在狼人杀游戏上的实验表明,我们的代理通过迭代不断扩大策略空间,性能得到提升,并超越了现有的狼人杀代理,这凸显了它们在具有战略交互的自由形式语言游戏中的有效性。
论文及项目相关链接
PDF Published in ICML 2025
Summary:大型语言模型(LLM)在开放对话和多步决策等领域展现出色,但在需要战略决策和自由形式语言交互的战略语言游戏(如Werewolf)中表现欠佳。为解决挑战,提出潜在空间策略优化(LSPO)框架,结合博弈论方法和LLM微调构建战略语言代理。LSPO将自由形式的言语映射到有限的潜在策略空间,应用博弈论方法优化策略,并通过直接偏好优化(DPO)微调LLM。在Werewolf游戏中的实验表明,LSPO代理性能逐步提升,优于现有Werewolf代理。
Key Takeaways:
- LLM在战略语言游戏如Werewolf中面临挑战,因内在行动分布偏见和无限文本行动空间的有限探索而导致性能不佳。
- LSPO框架结合博弈论方法和LLM微调来解决这些挑战。
- LSPO将自由形式的言语映射到有限的潜在策略空间,创建一个抽象化的扩展形式游戏。
- 应用博弈论方法如CFR来优化潜在空间的策略。
- 通过DPO直接优化LLM以与学到的策略对齐。
- LSPO代理通过迭代增强战略推理和语言沟通。
点此查看论文截图