⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-23 更新
SMILE: Speech Meta In-Context Learning for Low-Resource Language Automatic Speech Recognition
Authors:Ming-Hao Hsu, Hung-yi Lee
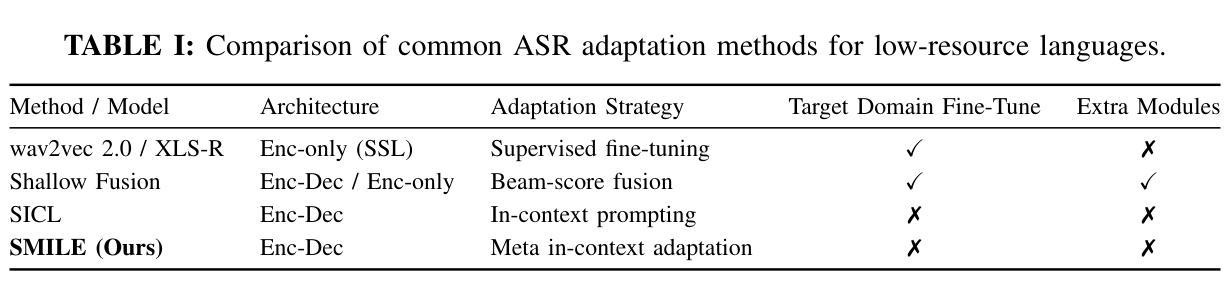
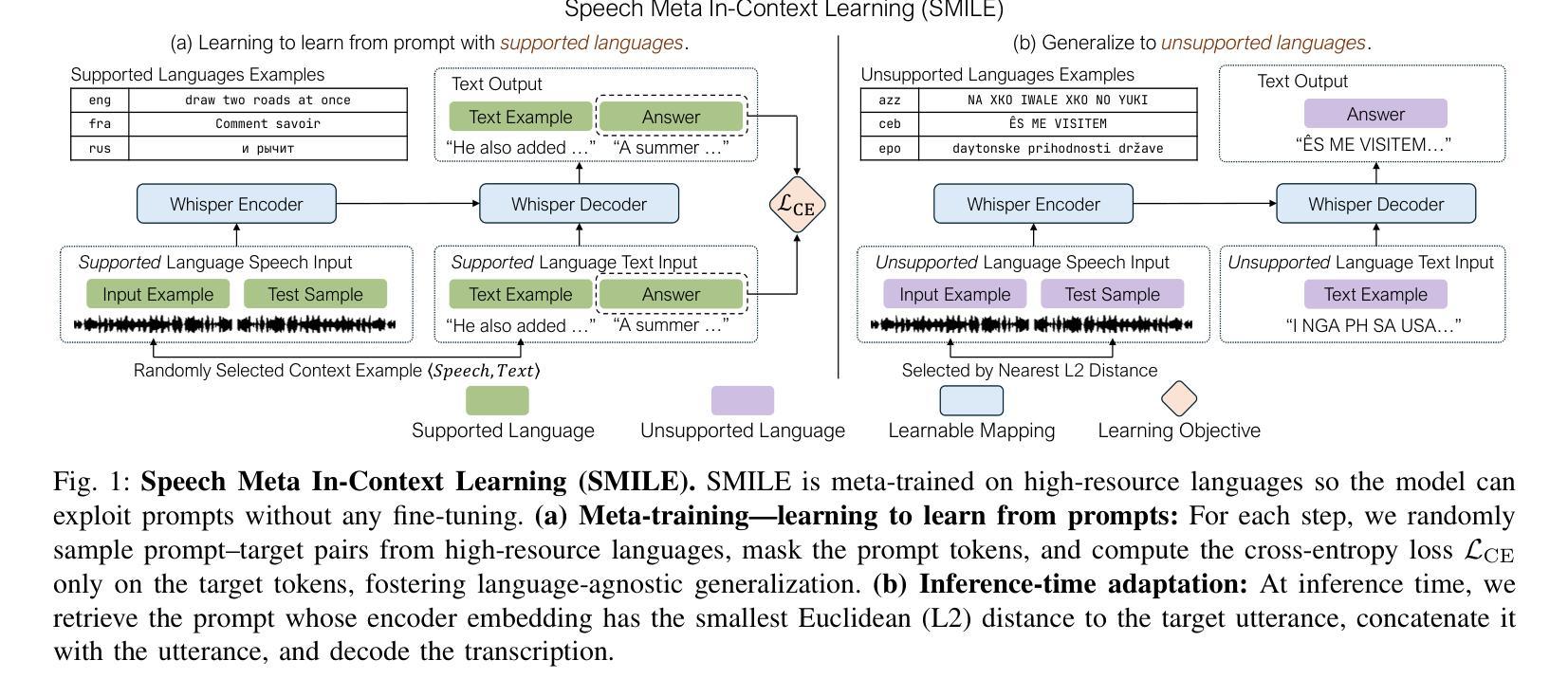
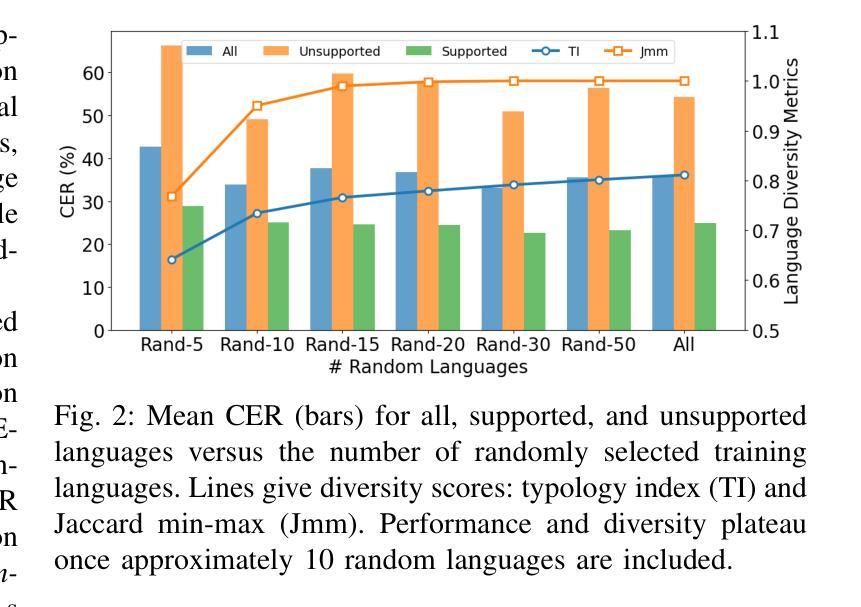
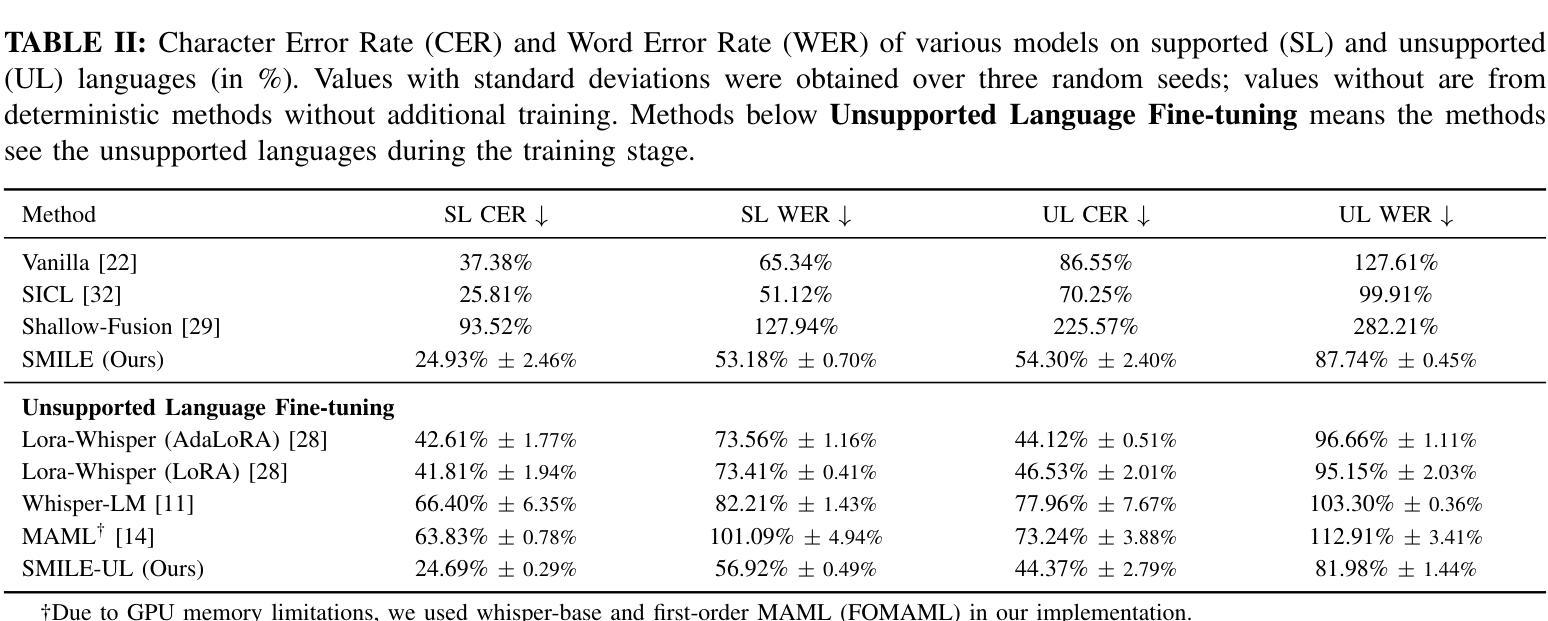
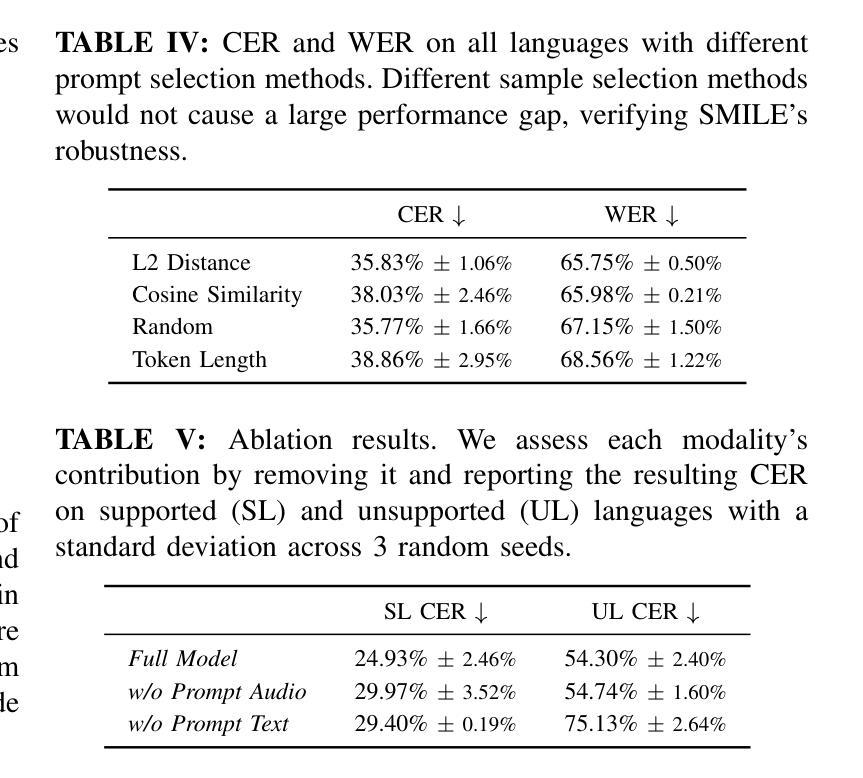
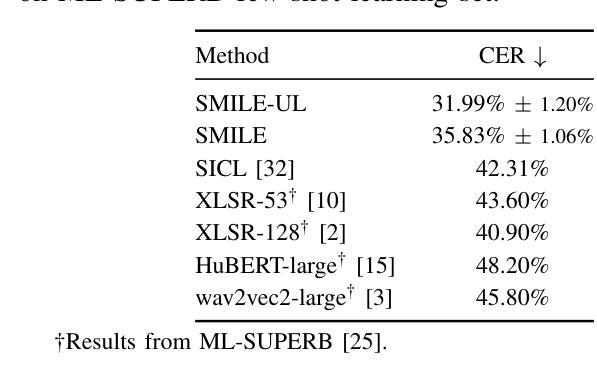
Automatic Speech Recognition (ASR) models demonstrate outstanding performance on high-resource languages but face significant challenges when applied to low-resource languages due to limited training data and insufficient cross-lingual generalization. Existing adaptation strategies, such as shallow fusion, data augmentation, and direct fine-tuning, either rely on external resources, suffer computational inefficiencies, or fail in test-time adaptation scenarios. To address these limitations, we introduce Speech Meta In-Context LEarning (SMILE), an innovative framework that combines meta-learning with speech in-context learning (SICL). SMILE leverages meta-training from high-resource languages to enable robust, few-shot generalization to low-resource languages without explicit fine-tuning on the target domain. Extensive experiments on the ML-SUPERB benchmark show that SMILE consistently outperforms baseline methods, significantly reducing character and word error rates in training-free few-shot multilingual ASR tasks.
自动语音识别(ASR)模型在高资源语言上的表现非常出色,但当应用于低资源语言时,由于训练数据有限和跨语言泛化不足,面临重大挑战。现有的适应策略,如浅融合、数据增强和直接微调,要么依赖外部资源,要么面临计算效率低下的问题,或在测试时的适应场景中失败。为了解决这些局限性,我们引入了语音元上下文学习(SMILE),这是一个将元学习与语音上下文学习(SICL)相结合的创新框架。SMILE利用从高资源语言中进行元训练,使得在无需在目标域上进行显式微调的情况下,对低资源语言进行鲁棒性、小样本泛化。在ML-SUPERB基准测试上的广泛实验表明,SMILE始终优于基准方法,在无需训练的小样本多语种ASR任务中显著降低了字符和单词错误率。
论文及项目相关链接
Summary
本文介绍了自动语音识别(ASR)模型在低资源语言面临的挑战,并提出了Speech Meta In-Context LEarning(SMILE)框架来解决这些问题。该框架结合了元学习与语音上下文学习(SICL),通过从高资源语言中进行元训练,实现了对低资源语言的稳健、少样本泛化,无需在目标域进行显式微调。在ML-SUPERB基准测试上的实验表明,SMILE在训练自由、少样本的多语种ASR任务中显著优于基线方法,降低了字符和单词错误率。
Key Takeaways
- 自动语音识别(ASR)模型在高资源语言上表现优异,但在低资源语言上面临挑战。
- 现有适应策略存在依赖外部资源、计算效率低下或在测试时适应场景失败的问题。
- SMILE框架结合了元学习与语音上下文学习(SICL)来解决这些问题。
- SMILE通过从高资源语言进行元训练,实现了对低资源语言的稳健、少样本泛化。
- SMILE无需在目标域进行显式微调。
- 在ML-SUPERB基准测试上,SMILE显著优于基线方法。
点此查看论文截图

Directional Source Separation for Robust Speech Recognition on Smart Glasses
Authors:Tiantian Feng, Ju Lin, Yiteng Huang, Weipeng He, Kaustubh Kalgaonkar, Niko Moritz, Li Wan, Xin Lei, Ming Sun, Frank Seide
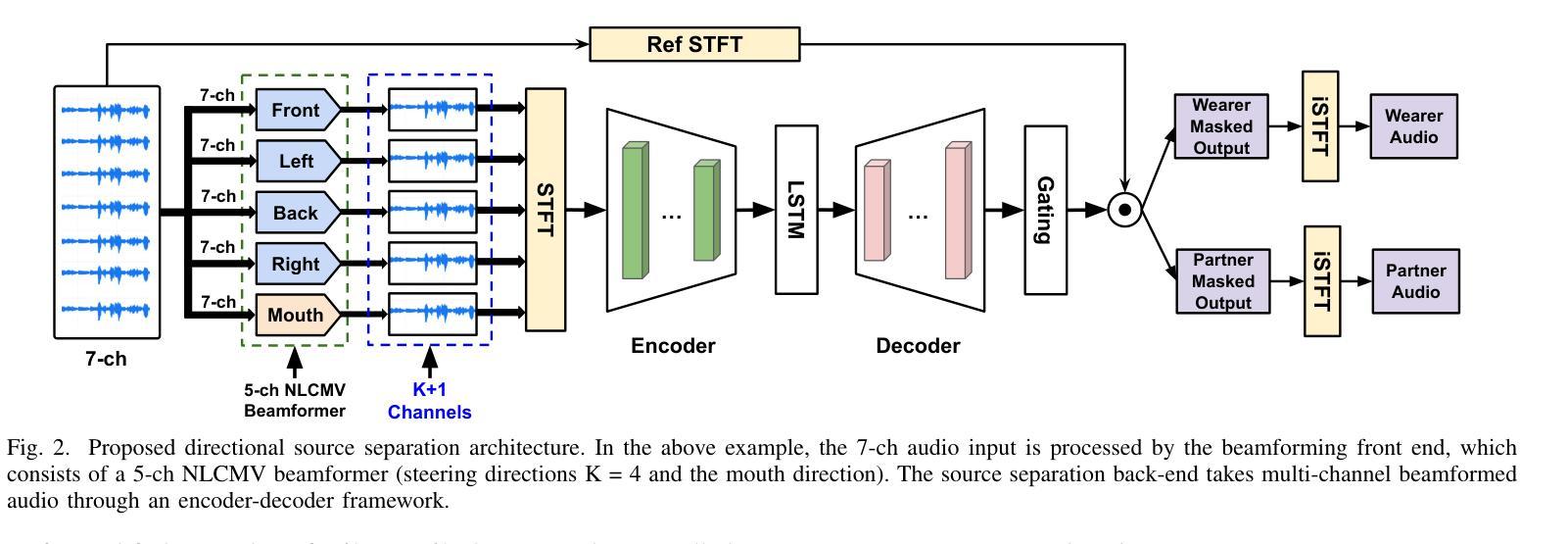
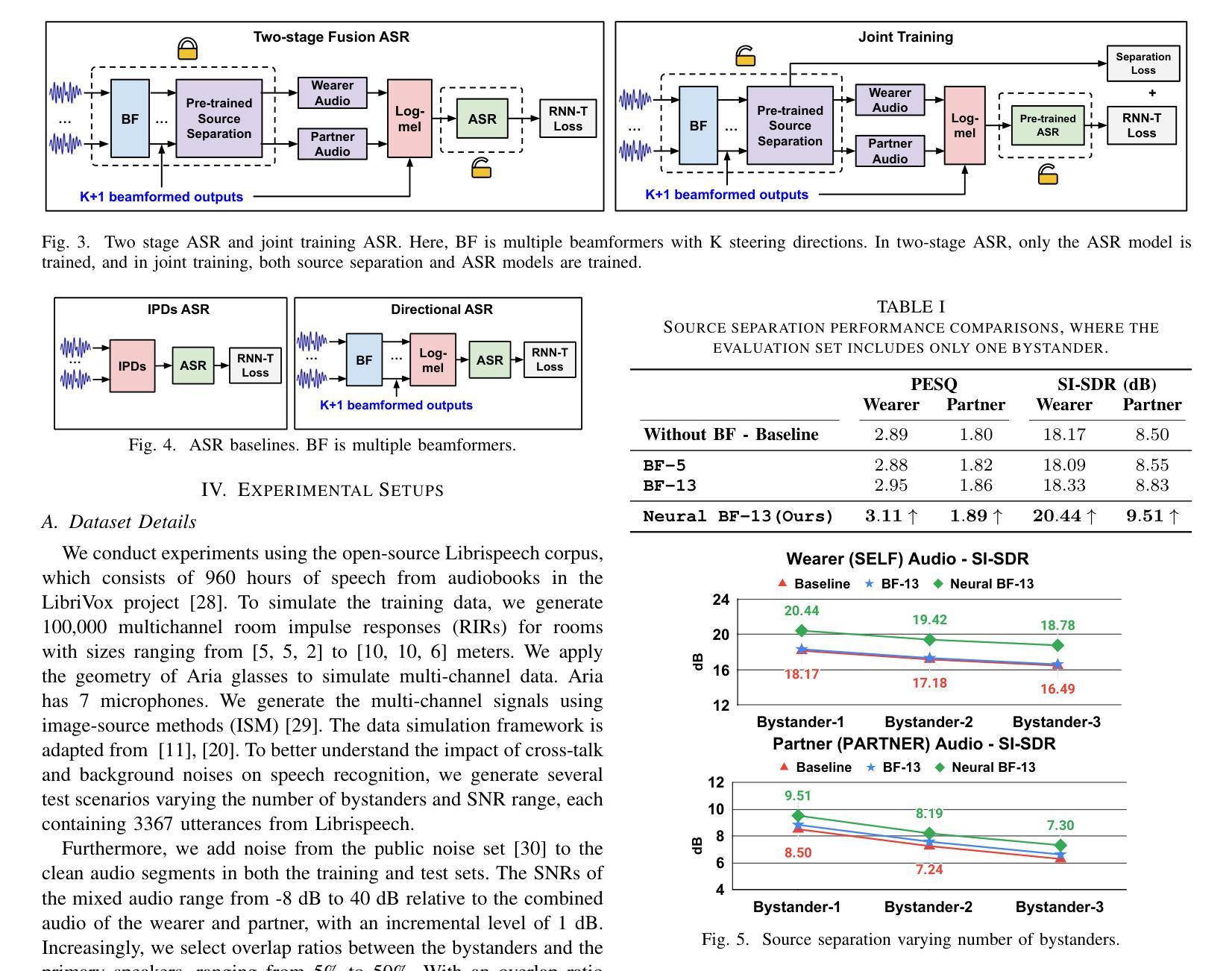
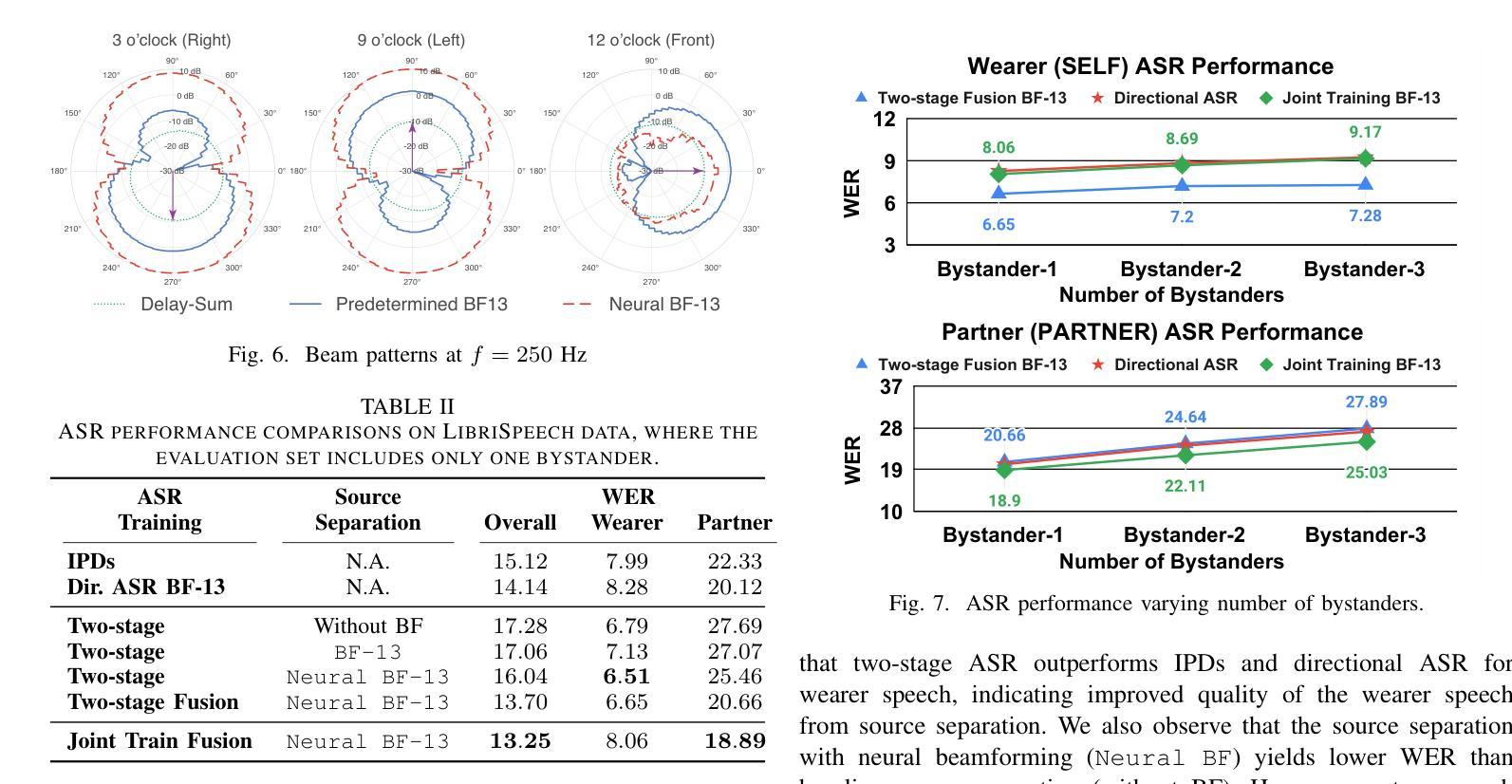
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
现代智能眼镜利用先进的音频感应和机器学习技术,提供实时转录和字幕服务,极大地丰富了日常通信的人类体验。然而,此类系统经常遇到与环境噪声相关的挑战,导致语音识别和说话人变更检测退化。为了提高语音质量,本研究调查了使用多麦克风阵列进行的方向源分离。我们首先探索多种波束形成器,以协助源分离建模,增强语音信号的方向特性。除了依赖预先设定的波束形成器外,我们还研究了多通道源分离中的神经波束形成,表明自动学习方向特性可有效提高分离质量。我们还比较了使用分离输出与嘈杂输入时的语音识别性能。我们的结果表明,方向源分离有利于佩戴者的语音识别,但对话伙伴的语音识别不受影响。最后,我们对方向源分离和语音识别模型进行了联合训练,实现了最佳的总体语音识别性能。
论文及项目相关链接
PDF Published in ICASSP 2025, Hyderabad, India, 2025
总结
现代智能眼镜利用先进的音频感应和机器学习技术,提供实时语音识别和字幕服务,极大地丰富了日常沟通的人类体验。然而,这些系统在处理环境噪音时常常面临挑战,导致语音辨识和说话者变更检测的功能下降。为提升语音质量,本研究探讨利用多麦克风阵列进行方向性声源分离。研究首先探索多种波束形成器以辅助声源分离模型,强化语音信号的方向特性。除依赖预设波束形成器外,研究还探讨了多通道声源分离中的神经波束形成,证明自动学习方向特性能有效提升分离质量。对比利用分离输出与带噪输入的语音识别性能,结果显示方向性声源分离有助于佩戴者的语音识别,但对对话伙伴的语音识别效果则不明显。最后,研究进行了方向性声源分离与语音识别模型的联合训练,取得最佳的语音识别表现。
要点
- 现代智能眼镜通过先进音频感应和机器学习技术提供实时语音识别和字幕服务,丰富日常沟通体验。
- 环境噪音是智能眼镜面临的主要挑战之一,影响语音辨识和说话者检测。
- 研究通过多麦克风阵列进行方向性声源分离以提升语音质量。
- 通过探索多种波束形成器来辅助声源分离模型,并强化语音信号的方向特性。
- 研究也探讨了神经波束形成在自动学习方向特性方面的有效性。
- 方向性声源分离对佩戴者的语音识别有帮助,但对对话伙伴的识别效果有限。
点此查看论文截图

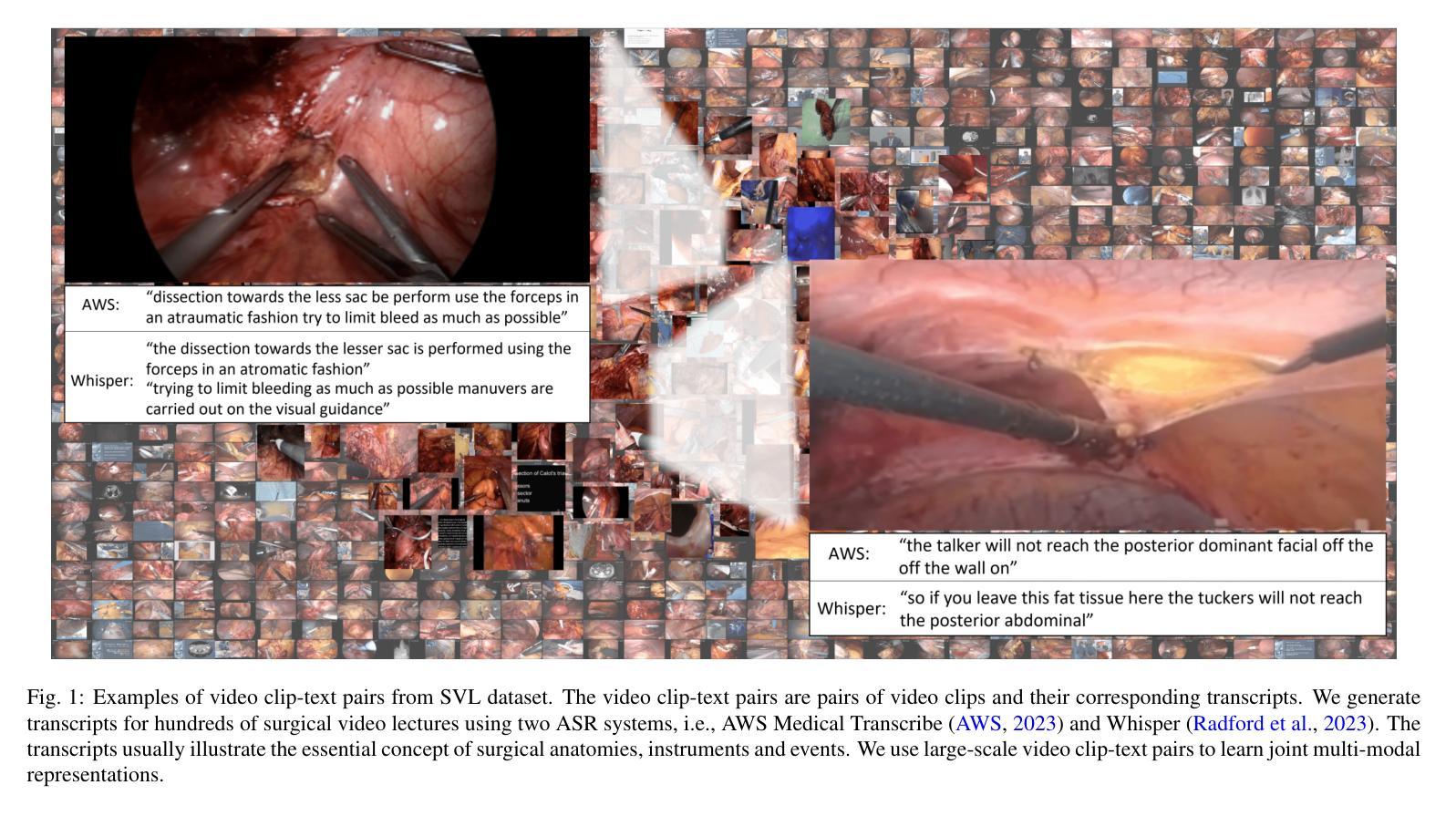
Learning Multi-modal Representations by Watching Hundreds of Surgical Video Lectures
Authors:Kun Yuan, Vinkle Srivastav, Tong Yu, Joel L. Lavanchy, Jacques Marescaux, Pietro Mascagni, Nassir Navab, Nicolas Padoy
Recent advancements in surgical computer vision applications have been driven by vision-only models, which do not explicitly integrate the rich semantics of language into their design. These methods rely on manually annotated surgical videos to predict a fixed set of object categories, limiting their generalizability to unseen surgical procedures and downstream tasks. In this work, we put forward the idea that the surgical video lectures available through open surgical e-learning platforms can provide effective vision and language supervisory signals for multi-modal representation learning without relying on manual annotations. We address the surgery-specific linguistic challenges present in surgical video lectures by employing multiple complementary automatic speech recognition systems to generate text transcriptions. We then present a novel method, SurgVLP - Surgical Vision Language Pre-training, for multi-modal representation learning. Extensive experiments across diverse surgical procedures and tasks demonstrate that the multi-modal representations learned by SurgVLP exhibit strong transferability and adaptability in surgical video analysis. Furthermore, our zero-shot evaluations highlight SurgVLP’s potential as a general-purpose foundation model for surgical workflow analysis, reducing the reliance on extensive manual annotations for downstream tasks, and facilitating adaptation methods such as few-shot learning to build a scalable and data-efficient solution for various downstream surgical applications. The training code and weights are public.
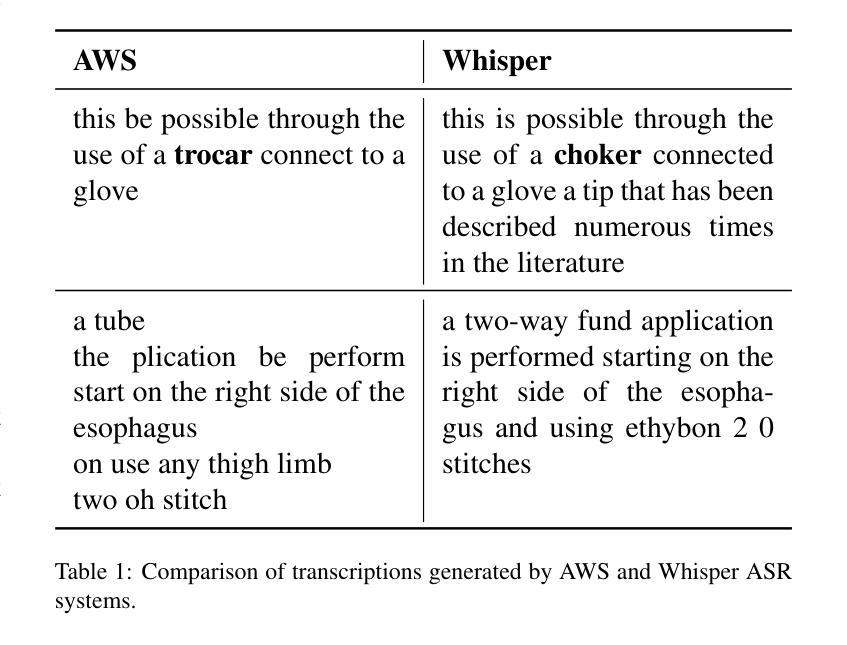
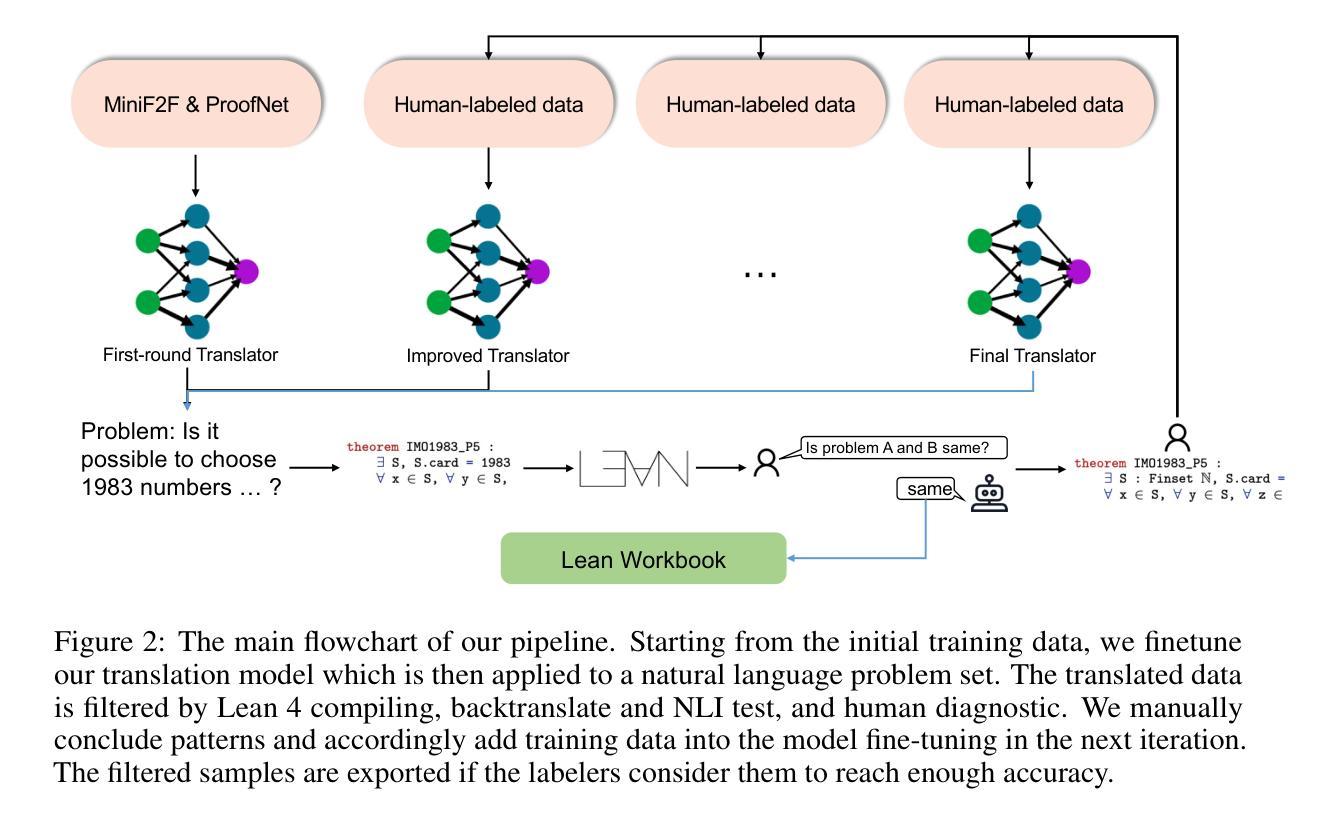
近期计算机视觉手术应用方面的进展主要得益于仅依赖于视觉的模型,这些模型在设计时并没有明确整合语言的丰富语义。这些方法依赖于手动标注的手术视频来预测固定的对象类别集,从而限制了它们对未见过的手术程序和下游任务的泛化能力。在这项工作中,我们提出通过公开手术电子学习平台获取的手术视频讲座可以提供有效的视觉和语言监督信号,用于多模态表示学习,而无需依赖手动注释。我们采用多个互补的自动语音识别系统来解决手术视频讲座中特有的语言挑战,以生成文本转录。然后,我们提出了一种新的方法,即SurgVLP(手术视觉语言预训练),用于多模态表示学习。在多种手术程序和任务上的广泛实验表明,SurgVLP学习的多模态表示在手术视频分析中表现出强大的可迁移性和适应性。此外,我们的零样本评估凸显了SurgVLP作为手术工作流程分析的通用基础模型的潜力,减少了下游任务对大量手动注释的依赖,并促进了如小样本学习等适应方法的发展,为各种下游手术应用构建可伸缩和高效的数据解决方案。相关训练代码和权重均已公开。
论文及项目相关链接
PDF Accepted by Medical Image Analysis (MedIA), 2025
摘要
近期手术计算机视觉应用的进展主要依赖于仅依赖视觉的模型,这些模型在设计时并未明确融入丰富的语言语义。这些方法依赖于手动注释的手术视频来预测固定的目标类别集,导致其对于未见过的手术程序和下游任务的可泛化性有限。本研究提出,通过公开手术电子学习平台可用的手术视频讲座,可在无需依赖手动注释的情况下,为跨模态表示学习提供有效的视觉和语言监督信号。为应对手术视频讲座中存在的手术相关语言挑战,我们采用了多个互补的自动语音识别系统来生成文本转录。随后,我们提出了一种名为SurgVLP的新方法——手术视觉语言预训练,用于跨模态表示学习。在多种手术程序和任务上的广泛实验表明,SurgVLP所学习的跨模态表示在手术视频分析中展现出强大的可迁移性和适应性。此外,我们的零样本评估突显了SurgVLP作为手术工作流程分析通用基础模型的潜力,减少下游任务对大量手动注释的依赖,并促进采用少样本学习等适应方法,为各种下游手术应用构建可伸缩和高效的数据解决方案。训练和权重公开。
关键见解
- 现有手术计算机视觉应用主要依赖视觉模型,缺乏语言语义的融合。
- 手动注释的手术视频限制了模型的泛化能力,研究提出了一种新的方法——SurgVLP(手术视觉语言预训练)。
- SurgVLP利用公开手术视频讲座作为视觉和语言监督信号来源,无需手动注释。
- 采用多个自动语音识别系统应对手术视频讲座中的语言挑战。
- SurgVLP跨模态表示学习方法展现出强大的迁移性和适应性。
- SurgVLP可降低下游任务对大量手动注释的依赖,并促进少样本学习等适应方法的应用。
- 训练代码和权重已公开,为构建各种下游手术应用提供了基础。
点此查看论文截图