⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
ADAM-Dehaze: Adaptive Density-Aware Multi-Stage Dehazing for Improved Object Detection in Foggy Conditions
Authors:Fatmah AlHindaassi, Mohammed Talha Alam, Fakhri Karray
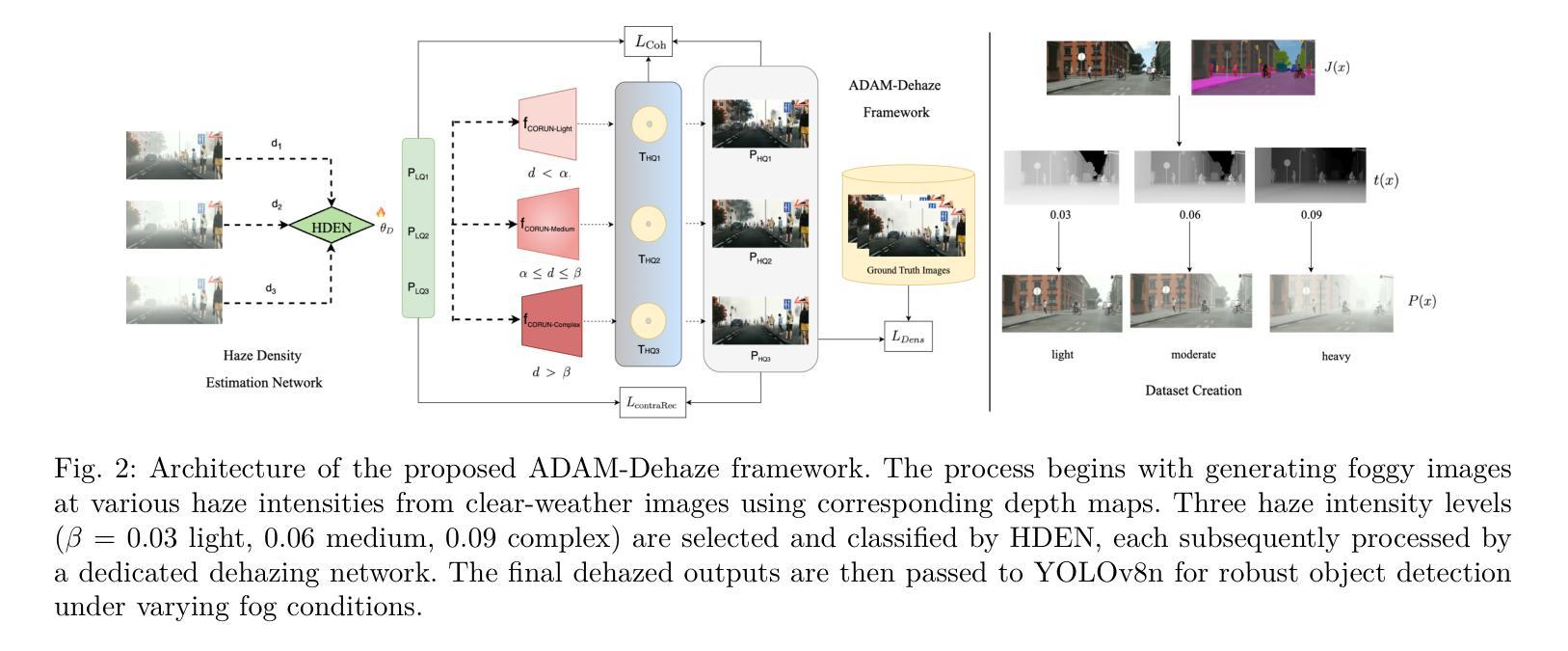
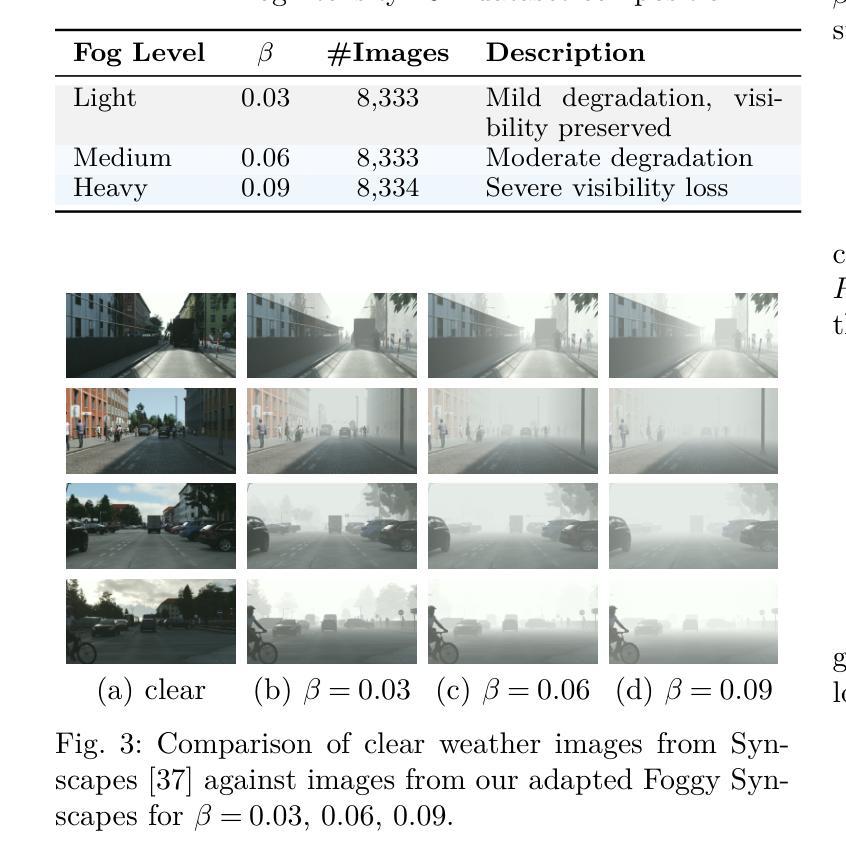
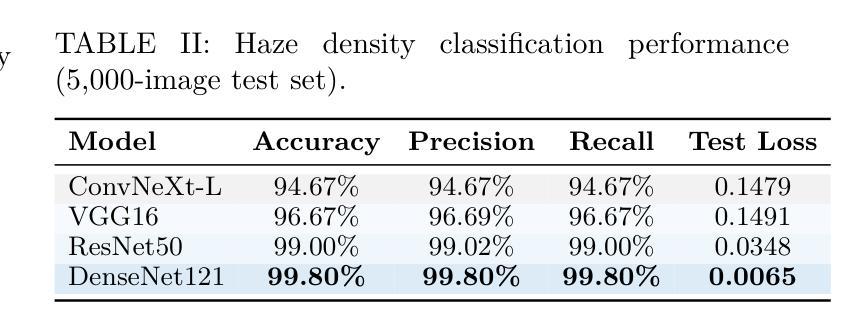
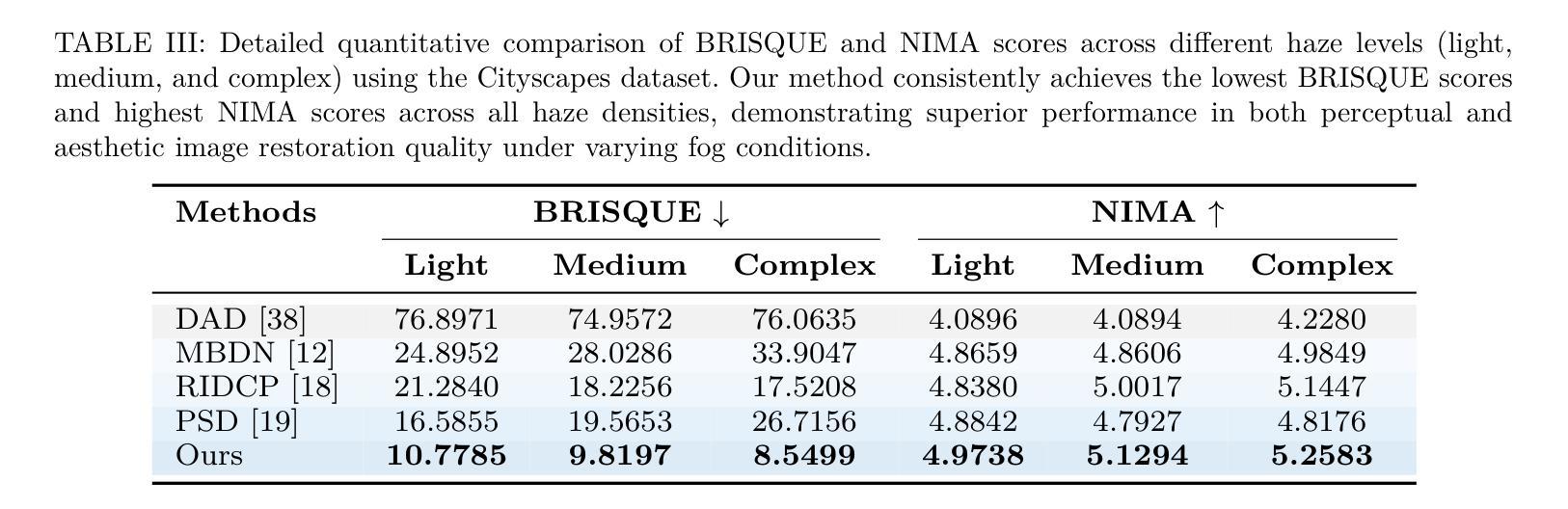
Adverse weather conditions, particularly fog, pose a significant challenge to autonomous vehicles, surveillance systems, and other safety-critical applications by severely degrading visual information. We introduce ADAM-Dehaze, an adaptive, density-aware dehazing framework that jointly optimizes image restoration and object detection under varying fog intensities. A lightweight Haze Density Estimation Network (HDEN) classifies each input as light, medium, or heavy fog. Based on this score, the system dynamically routes the image through one of three CORUN branches: Light, Medium, or Complex, each tailored to its haze regime. A novel adaptive loss balances physical-model coherence and perceptual fidelity, ensuring both accurate defogging and preservation of fine details. On Cityscapes and the real-world RTTS benchmark, ADAM-Dehaze improves PSNR by up to 2.1 dB, reduces FADE by 30 percent, and increases object detection mAP by up to 13 points, while cutting inference time by 20 percent. These results highlight the importance of intensity-specific processing and seamless integration with downstream vision tasks. Code available at: https://github.com/talha-alam/ADAM-Dehaze.
恶劣天气条件,特别是雾天,对自动驾驶汽车、监控系统和其他安全关键应用构成了重大挑战,因为雾会严重降低视觉信息。我们引入了ADAM-Dehaze,这是一种自适应、密度感知的去雾框架,可在不同雾强度下联合优化图像恢复和对象检测。一个轻量级的雾密度估计网络(HDEN)将每个输入分类为轻、中或重雾。基于这个评分,系统动态地将图像通过三个CORUN分支之一:轻度、中度或复杂,每个分支都针对其雾环境进行了定制。一种新型自适应损失平衡了物理模型连贯性和感知保真度,确保去雾准确并保留细节。在Cityscapes和真实世界的RTTS基准测试中,ADAM-Dehaze提高了PSNR值高达2.1 dB,减少了FADE值30%,提高了对象检测的mAP值高达13点,同时减少了推理时间20%。这些结果强调了针对特定强度的处理和与下游视觉任务无缝集成的重要性。代码可在https://github.com/talha-alam/ADAM-Dehaze找到。
论文及项目相关链接
PDF Under-review at IEEE SMC 2025
Summary
恶劣天气条件,尤其是雾霾,对自动驾驶车辆、监控系统和其他安全关键应用构成重大挑战,严重降低了视觉信息。我们推出ADAM-Dehaze,一种自适应、密度感知的除雾框架,可在不同雾强度下联合优化图像恢复和对象检测。该框架的Haze Density Estimation Network (HDEN)可评估输入雾的轻重程度,并根据评估结果动态将图像引导至相应的CORUN分支(轻雾、中雾或复杂雾),确保针对其雾态量身定制。通过新型自适应损失平衡物理模型连贯性和感知保真度,确保准确除雾并保留细节。在Cityscapes和真实世界的RTTS基准测试中,ADAM-Dehaze提高了PSNR值、降低了FADE并提高了对象检测的mAP值,同时减少了推理时间。
Key Takeaways
- 恶劣天气(如雾)对自动驾驶和监控系统构成挑战,影响视觉信息。
- ADAM-Dehaze框架自适应处理不同雾强度。
- Haze Density Estimation Network (HDEN) 评估雾的轻重程度。
- 系统根据雾密度分类,将图像引导至相应的CORUN分支处理。
- 新自适应损失确保除雾准确性并保留细节。
- 在基准测试中,ADAM-Dehaze提高了图像质量并增强了对象检测性能。
- 代码已公开可用。
点此查看论文截图



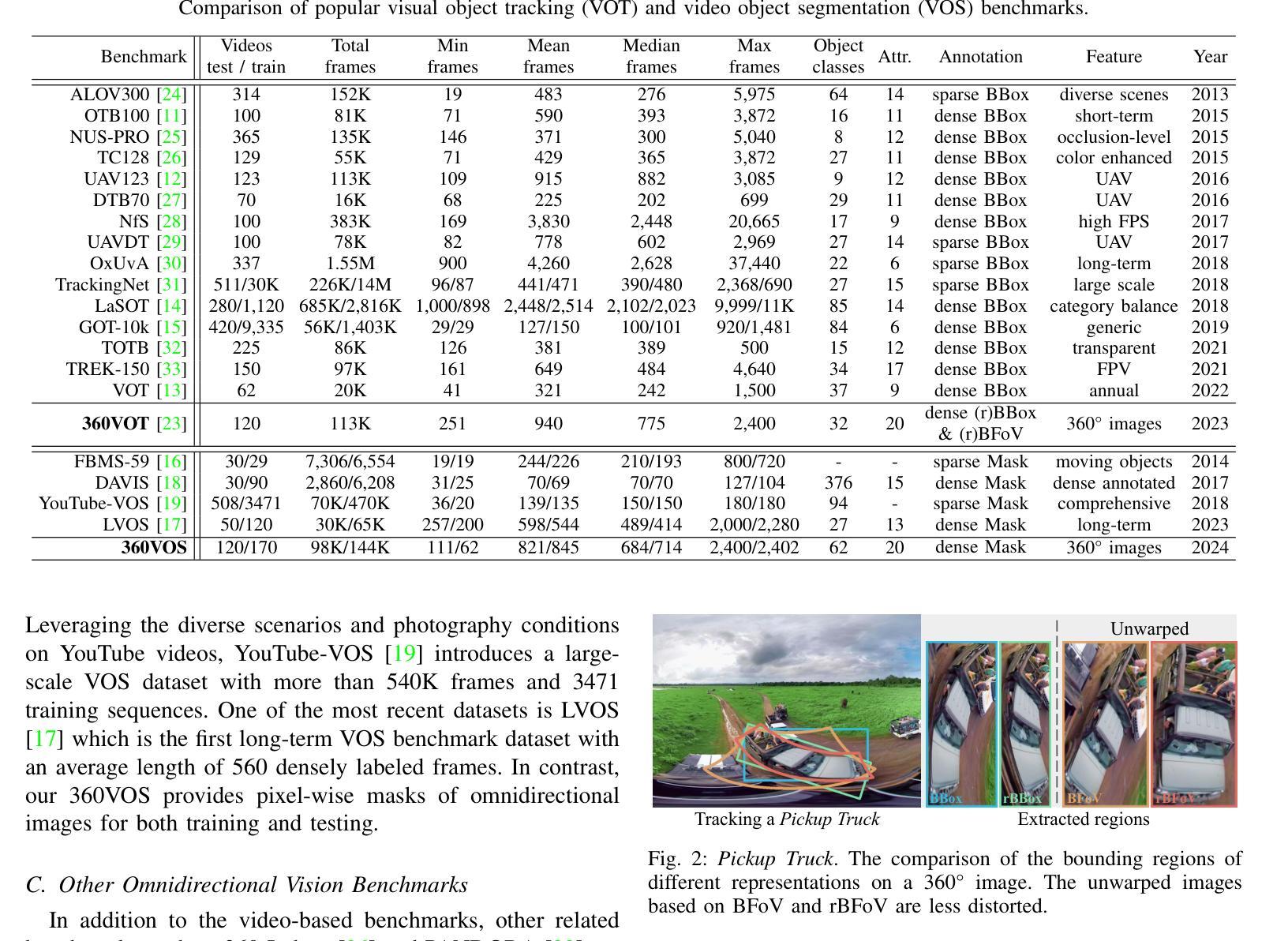
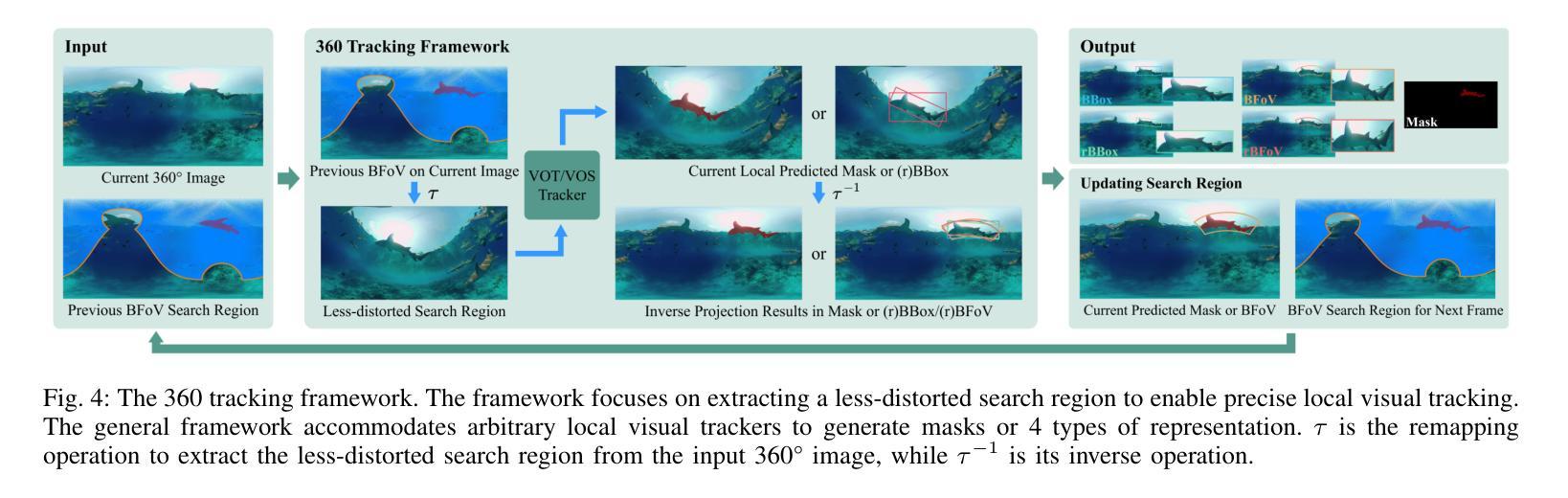
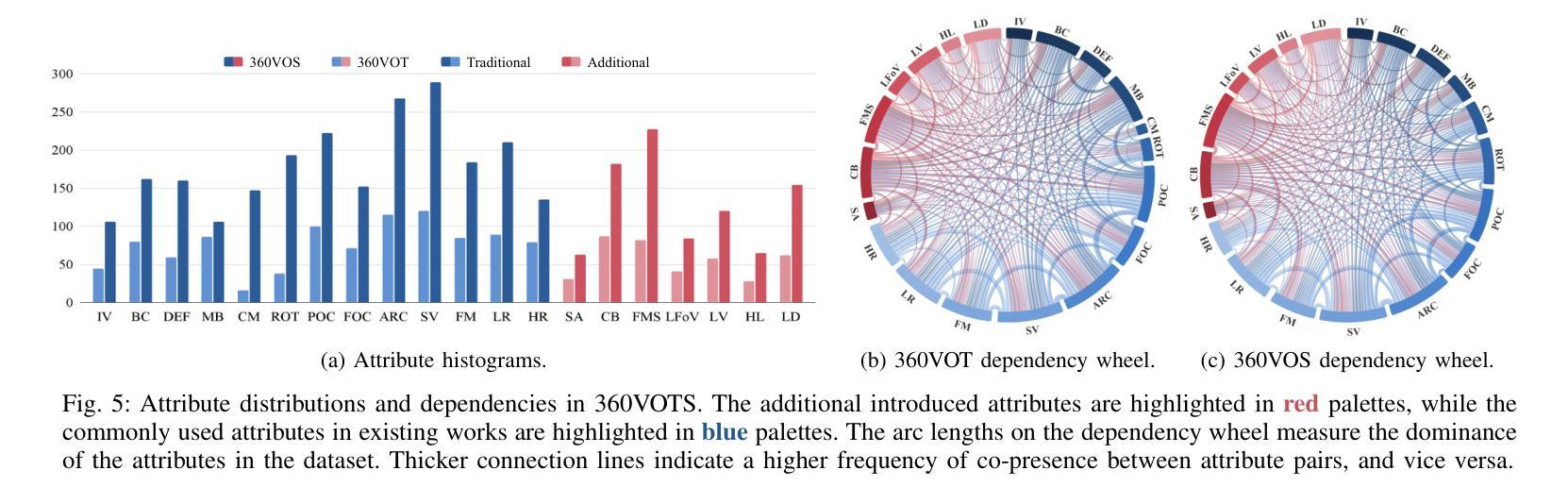
360VOTS: Visual Object Tracking and Segmentation in Omnidirectional Videos
Authors:Yinzhe Xu, Huajian Huang, Yingshu Chen, Sai-Kit Yeung
Visual object tracking and segmentation in omnidirectional videos are challenging due to the wide field-of-view and large spherical distortion brought by 360{\deg} images. To alleviate these problems, we introduce a novel representation, extended bounding field-of-view (eBFoV), for target localization and use it as the foundation of a general 360 tracking framework which is applicable for both omnidirectional visual object tracking and segmentation tasks. Building upon our previous work on omnidirectional visual object tracking (360VOT), we propose a comprehensive dataset and benchmark that incorporates a new component called omnidirectional video object segmentation (360VOS). The 360VOS dataset includes 290 sequences accompanied by dense pixel-wise masks and covers a broader range of target categories. To support both the development and evaluation of algorithms in this domain, we divide the dataset into a training subset with 170 sequences and a testing subset with 120 sequences. Furthermore, we tailor evaluation metrics for both omnidirectional tracking and segmentation to ensure rigorous assessment. Through extensive experiments, we benchmark state-of-the-art approaches and demonstrate the effectiveness of our proposed 360 tracking framework and training dataset. Homepage: https://360vots.hkustvgd.com/
全景视频中视觉目标跟踪和分割具有挑战性,因为360°图像带来的大视野和大的球形畸变。为了缓解这些问题,我们引入了一种新的表示方法——扩展边界视野(eBFoV)来进行目标定位,并将其作为适用于全景视觉目标跟踪和分割任务的一般跟踪框架的基础。基于我们在全景视觉目标跟踪(360VOT)方面的前期工作,我们提出了一个综合数据集和基准测试,其中融入了一个名为全景视频对象分割(360VOS)的新组件。360VOS数据集包含290个序列,每个序列都有密集的像素级掩膜,涵盖了更广泛的目标类别。为了支持该领域算法的开发和评估,我们将数据集分为包含170个序列的训练子集和包含120个序列的测试子集。此外,我们还为全景跟踪和分割定制了评估指标,以确保严格的评估。通过大量实验,我们评估了最先进的方法,并验证了我们所提出的360跟踪框架和训练数据集的有效性。主页:https://360vots.hkustvgd.com/
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2307.14630
Summary:针对全景视频的视觉目标跟踪和分割面临的挑战,提出了一种基于扩展边界视场(eBFoV)表示的新颖目标定位方法,并建立了一个适用于全景视觉目标跟踪和分割任务的通用框架。构建了一个综合数据集并制定了评估标准,包括一个名为全景视频目标分割(360VOS)的新组件。该数据集包含290个序列,覆盖更广泛的目标类别,分为训练子集和测试子集,以支持该领域算法的开发和评估。
Key Takeaways:
- 全景视频的视觉目标跟踪和分割存在挑战,因360度图像带来的广阔视野和较大球形失真。
- 引入了一种新的目标定位方法——扩展边界视场(eBFoV)表示。
- 建立了一个适用于全景视觉目标跟踪和分割的通用框架。
- 构建了一个综合数据集,包含290个序列,用于支持算法开发和评估。
- 数据集包括一个新的组件——全景视频目标分割(360VOS),涵盖广泛的目标类别。
- 数据集分为训练子集和测试子集,以支持算法的性能评估。
点此查看论文截图