⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
RAGentA: Multi-Agent Retrieval-Augmented Generation for Attributed Question Answering
Authors:Ines Besrour, Jingbo He, Tobias Schreieder, Michael Färber
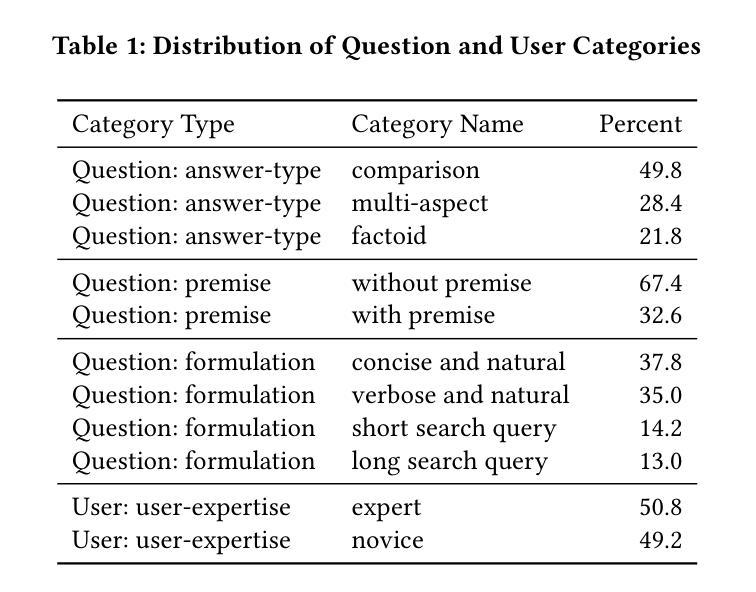
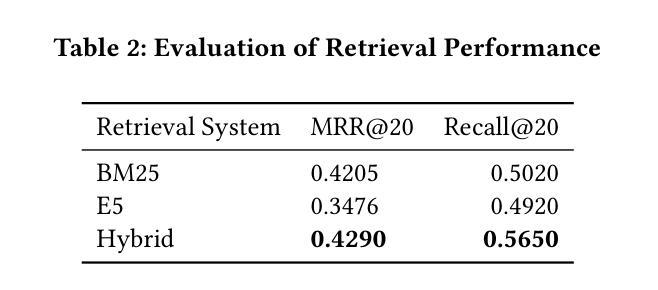
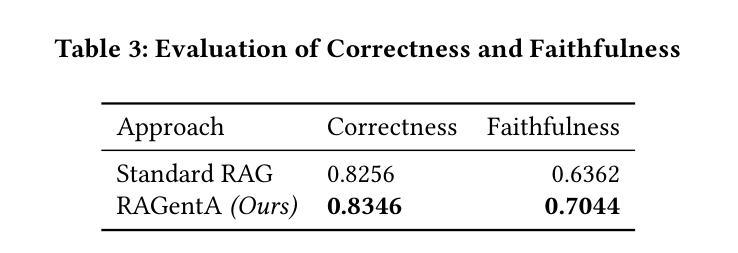
We present RAGentA, a multi-agent retrieval-augmented generation (RAG) framework for attributed question answering (QA). With the goal of trustworthy answer generation, RAGentA focuses on optimizing answer correctness, defined by coverage and relevance to the question and faithfulness, which measures the extent to which answers are grounded in retrieved documents. RAGentA uses a multi-agent architecture that iteratively filters retrieved documents, generates attributed answers with in-line citations, and verifies completeness through dynamic refinement. Central to the framework is a hybrid retrieval strategy that combines sparse and dense methods, improving Recall@20 by 12.5% compared to the best single retrieval model, resulting in more correct and well-supported answers. Evaluated on a synthetic QA dataset derived from the FineWeb index, RAGentA outperforms standard RAG baselines, achieving gains of 1.09% in correctness and 10.72% in faithfulness. These results demonstrate the effectiveness of the multi-agent architecture and hybrid retrieval in advancing trustworthy QA.
我们提出了RAGentA,这是一个用于属性问答(QA)的多代理检索增强生成(RAG)框架。RAGentA以生成可信答案为目标,专注于优化答案的正确性,这由答案对问题的覆盖率和相关性以及忠实度来定义,忠实度衡量答案在检索文档中的扎实程度。RAGentA采用多代理架构,该架构可迭代地过滤检索到的文档,生成带有内联引用的属性答案,并通过动态细化验证完整性。该框架的核心是混合检索策略,它结合了稀疏和密集方法,与最佳单一检索模型相比,Recall@20提高了12.5%,从而得到更多正确且扎实的答案。在来自FineWeb索引的合成问答数据集上进行的评估表明,RAGentA在标准RAG基线之上表现出色,在正确性和忠实度上分别提高了1.09%和提高了10.72%。这些结果证明了多代理架构和混合检索在提高可信问答方面的有效性。
论文及项目相关链接
PDF Accepted at SIGIR 2025
Summary
RAGentA是一个多智能体检索增强生成框架,旨在实现可靠的答案生成。它优化了答案的正确性,涵盖对问题的覆盖率和相关性以及忠实度,衡量答案是否基于检索到的文档。该框架采用多智能体架构,通过迭代过滤检索到的文档,生成具有内联引用的属性答案,并通过动态优化验证完整性。其核心是结合了稀疏和密集方法的混合检索策略,提高了Recall@20的召回率,并在合成QA数据集上取得了优异表现。
Key Takeaways
- RAGentA是一个多智能体检索增强生成框架,用于属性问答。
- 它追求可靠答案生成,优化答案的正确性、覆盖率和与问题的相关性以及忠实度。
- 框架采用多智能体架构,通过迭代过程过滤文档、生成属性答案并验证完整性。
- 核心是混合检索策略,结合了稀疏和密集方法,提高了Recall@20的召回率。
- 与单一最佳检索模型相比,RAGentA提高了Recall@20的准确率12.5%。
- 在合成QA数据集上,RAGentA表现出色,在正确性和忠实度方面分别实现了1.09%和10.72%的提升。
点此查看论文截图

Language-Informed Synthesis of Rational Agent Models for Grounded Theory-of-Mind Reasoning On-The-Fly
Authors:Lance Ying, Ryan Truong, Katherine M. Collins, Cedegao E. Zhang, Megan Wei, Tyler Brooke-Wilson, Tan Zhi-Xuan, Lionel Wong, Joshua B. Tenenbaum
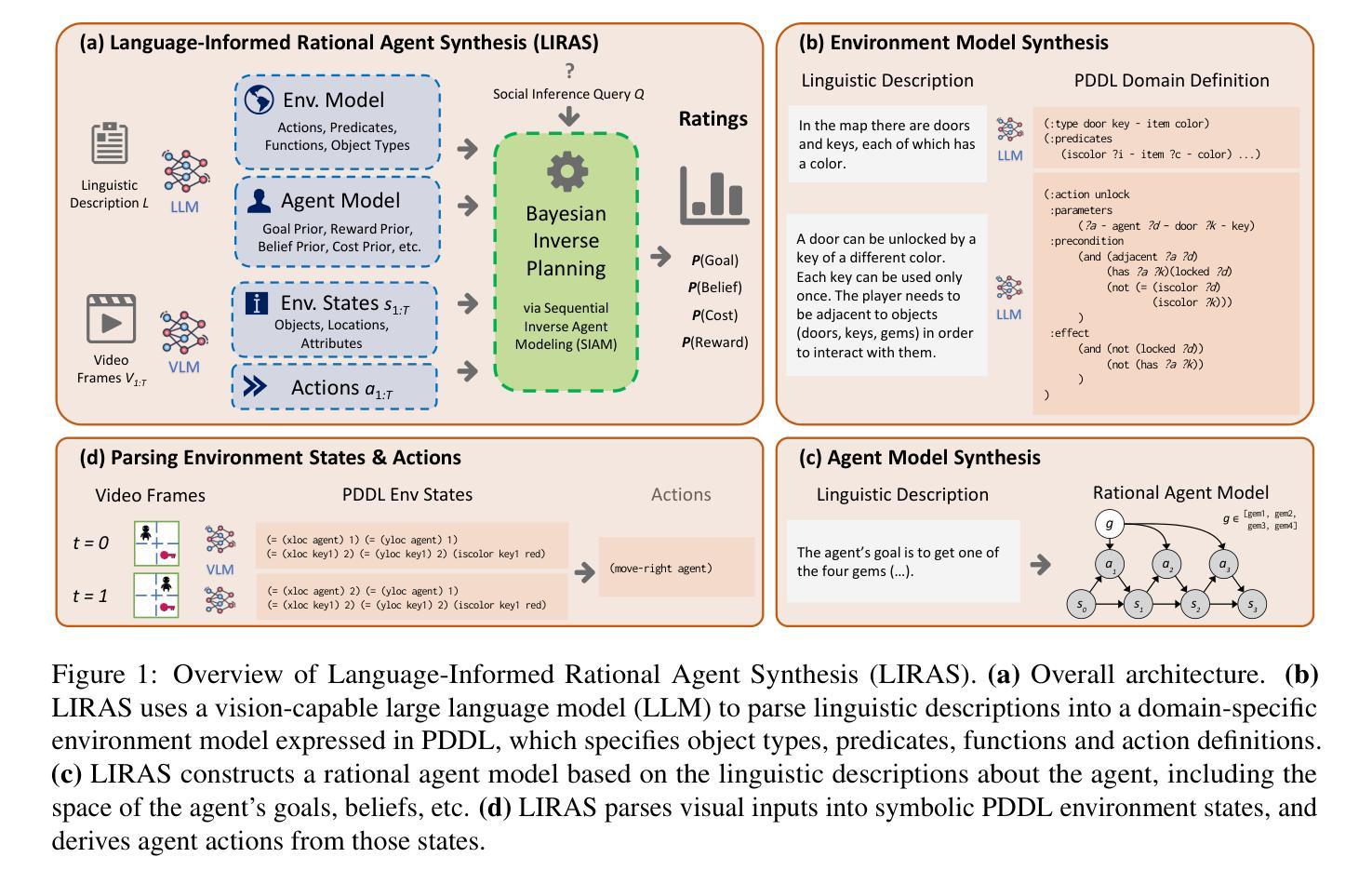
Drawing real world social inferences usually requires taking into account information from multiple modalities. Language is a particularly powerful source of information in social settings, especially in novel situations where language can provide both abstract information about the environment dynamics and concrete specifics about an agent that cannot be easily visually observed. In this paper, we propose Language-Informed Rational Agent Synthesis (LIRAS), a framework for drawing context-specific social inferences that integrate linguistic and visual inputs. LIRAS frames multimodal social reasoning as a process of constructing structured but situation-specific agent and environment representations - leveraging multimodal language models to parse language and visual inputs into unified symbolic representations, over which a Bayesian inverse planning engine can be run to produce granular probabilistic judgments. On a range of existing and new social reasoning tasks derived from cognitive science experiments, we find that our model (instantiated with a comparatively lightweight VLM) outperforms ablations and state-of-the-art models in capturing human judgments across all domains.
在真实世界中,进行社会推理通常需要综合考虑来自多种模态的信息。在社交环境中,语言是一种特别强大的信息来源,特别是在新情境中,语言可以提供关于环境动态抽象信息和关于个体具体信息,这些信息无法仅通过视觉轻易观察到。在本文中,我们提出了“语言信息理性代理合成”(LIRAS)框架,这是一个结合语言和视觉输入进行特定上下文社会推理的框架。LIRAS将多模态社会推理视为一个过程,构建结构化但特定情境下的代理和环境表示——利用多模态语言模型解析语言和视觉输入到统一的符号表示,在此基础上运行贝叶斯逆规划引擎以产生精细的概率判断。在来自认知科学实验的现有和新社会推理任务上,我们发现我们的模型(使用相对轻量级的VLM实例化)在所有领域中都优于剥离模型和最新的模型在人类判断捕捉上的表现。
论文及项目相关链接
PDF 5 figures, 19 pages
Summary
本文提出了一个结合语言和视觉输入的框架——语言信息理性代理合成(LIRAS),用于进行语境特定的社会推理。LIRAS将多模态社会推理视为构建结构化但情境特定的代理和环境表示的过程,利用多模态语言模型解析语言和视觉输入为统一的符号表示,在此基础上运行贝叶斯逆向规划引擎,以产生精细的概率判断。在来自认知科学实验的一系列现有和新的社会推理任务上,我们的模型(用相对轻量级的VLM实例化)在捕捉人类判断方面优于消融模型和当前最先进模型。
Key Takeaways
- 社交推理需要综合考虑多种模式的信息。
- 语言是社交环境中特别有力的信息来源,尤其在新型情境中,语言能提供关于环境动态抽象信息和难以通过观察得到的代理具体信息。
- 提出了一种结合语言和视觉输入的框架LIRAS,用于进行语境特定的社会推理。
- LIRAS将多模态社会推理视为构建结构化情境特定代理和环境表示的过程。
- 多模态语言模型能够解析语言和视觉输入为统一的符号表示。
*LIRAS利用贝叶斯逆向规划引擎产生精细的概率判断。
点此查看论文截图

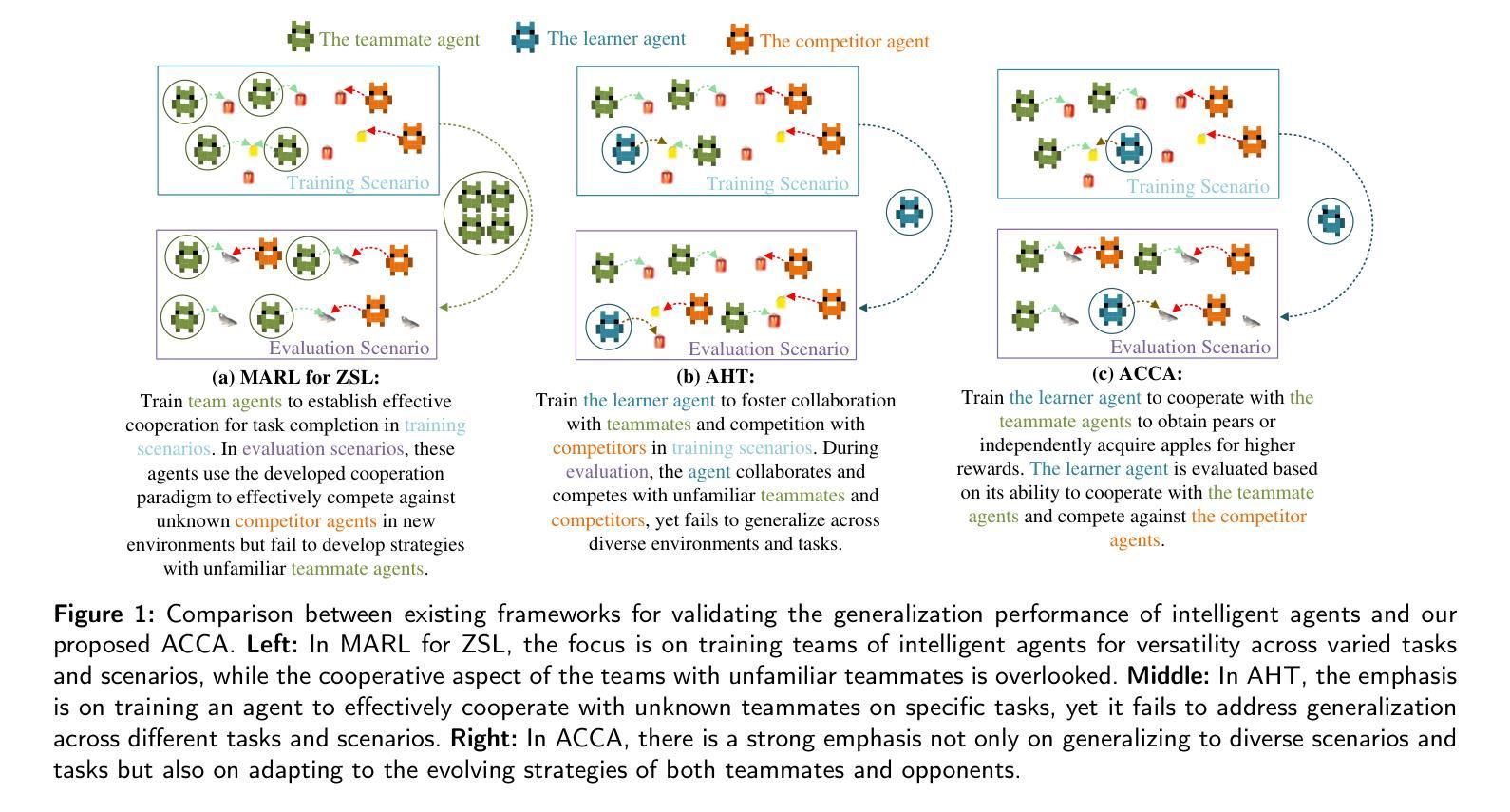
Generalizable Agent Modeling for Agent Collaboration-Competition Adaptation with Multi-Retrieval and Dynamic Generation
Authors:Chenxu Wang, Yonggang Jin, Cheng Hu, Youpeng Zhao, Zipeng Dai, Jian Zhao, Shiyu Huang, Liuyu Xiang, Junge Zhang, Zhaofeng He
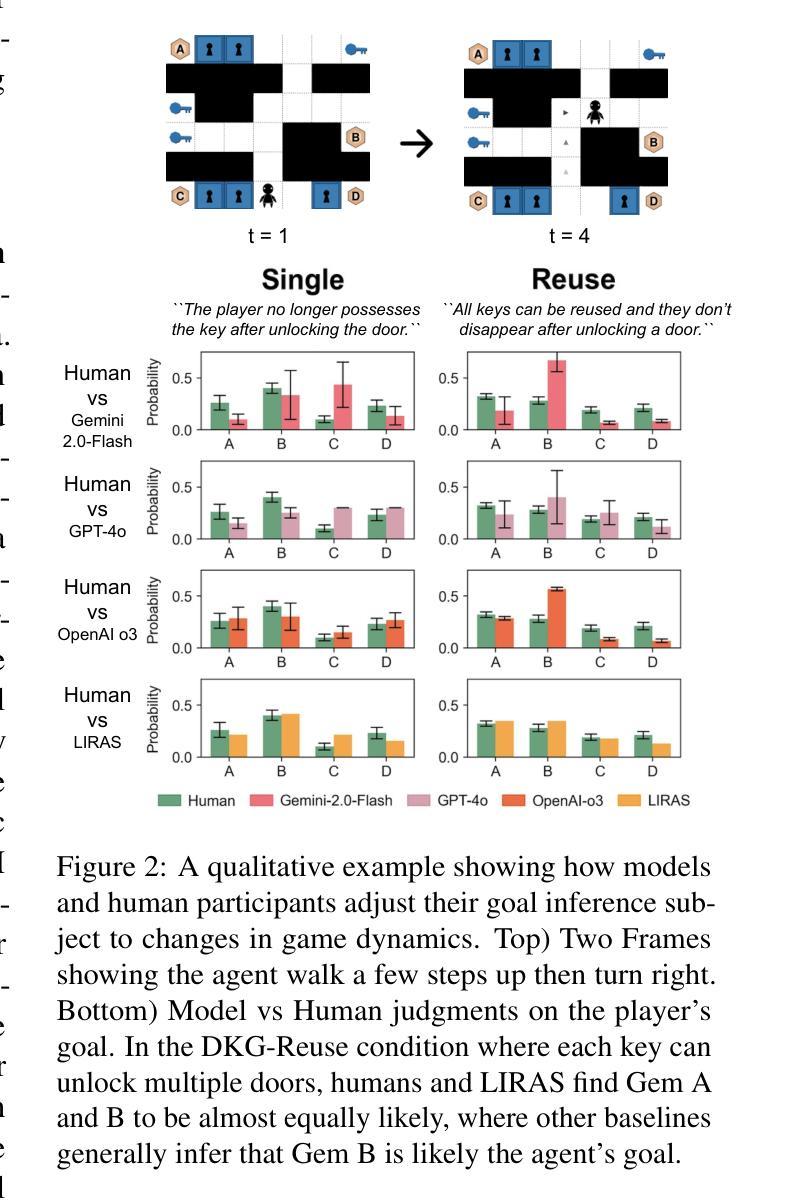
Adapting a single agent to a new multi-agent system brings challenges, necessitating adjustments across various tasks, environments, and interactions with unknown teammates and opponents. Addressing this challenge is highly complex, and researchers have proposed two simplified scenarios, Multi-agent reinforcement learning for zero-shot learning and Ad-Hoc Teamwork. Building on these foundations, we propose a more comprehensive setting, Agent Collaborative-Competitive Adaptation (ACCA), which evaluates an agent to generalize across diverse scenarios, tasks, and interactions with both unfamiliar opponents and teammates. In ACCA, agents adjust to task and environmental changes, collaborate with unseen teammates, and compete against unknown opponents. We introduce a new modeling approach, Multi-Retrieval and Dynamic Generation (MRDG), that effectively models both teammates and opponents using their behavioral trajectories. This method incorporates a positional encoder for varying team sizes and a hypernetwork module to boost agents’ learning and adaptive capabilities. Additionally, a viewpoint alignment module harmonizes the observational perspectives of retrieved teammates and opponents with the learning agent. Extensive tests in benchmark scenarios like SMAC, Overcooked-AI, and Melting Pot show that MRDG significantly improves robust collaboration and competition with unseen teammates and opponents, surpassing established baselines. Our code is available at: https://github.com/vcis-wangchenxu/MRDG.git
适应新的多智能体系统对单一智能体而言带来了挑战,需要在各种任务、环境和与未知队友和对手的互动中进行调整。应对这一挑战是非常复杂的,研究者已经提出了两种简化场景,即用于零学习学习的多智能体强化学习和即兴团队工作。在此基础上,我们提出了一个更全面的环境——智能体协作竞争适应(ACCA),用于评估智能体在不同场景、任务和与陌生对手和队友的互动中的泛化能力。在ACCA中,智能体能适应任务和环境的改变,与看不见的队友协作,并与未知对手竞争。我们引入了一种新的建模方法——多检索和动态生成(MRDG),该方法能有效地利用队友和对手的行为轨迹进行建模。该方法采用位置编码器来处理不同团队规模,并引入超网络模块来提升智能体的学习和适应能力。此外,视角对齐模块能协调检索到的队友和对手与学习智能体的观察视角。在像SMAC、Overcooked-AI和Melting Pot等基准场景的大量测试表明,MRDG在与未见过的队友和对手进行协作和竞争时,显著提高了稳健性,超越了现有的基线。我们的代码可在此处找到:https://github.com/vcis-wangchenxu/MRDG.git
论文及项目相关链接
PDF This manuscript is under submission to Neurocomputing
Summary
适应单代理到多代理系统面临诸多挑战,需在不同任务、环境和与未知队友对手互动中进行调整。研究者提出两种简化情境:多代理强化学习零学习法和即兴合作。在此基础上,我们提出更全面的设置——代理协作竞争适应(ACCA),评估代理在不同场景、任务和互动中的泛化能力,与陌生队友和对手协作竞争。我们引入新的建模方法——多检索和动态生成(MRDG),利用行为轨迹有效模拟队友和对手。此方法包含位置编码器和超网络模块,提高代理学习和适应能力。观点对齐模块协调学习代理与检索队友对手的观察角度。在SMAC、Overcooked-AI和Melting Pot等基准测试场景中,MRDG显著提高与未见队友对手的稳健协作和竞争能力,超越现有基线。
Key Takeaways
- 适应单代理到多代理系统需要应对跨任务、环境和与未知队友对手互动的挑战。
- 提出Agent Collaborative-Competitive Adaptation (ACCA)设置,评估代理在多样场景、任务和互动中的泛化能力。
- 引入Multi-Retrieval and Dynamic Generation (MRDG)建模方法,利用行为轨迹模拟队友和对手。
- MRDG包含位置编码器、超网络模块和观点对齐模块。
- 位置编码器适应不同团队大小,超网络模块提升代理学习和适应能力。
- 观点对齐模块协调学习代理与检索队友对手的观察角度。
点此查看论文截图

Mean-field and Monte Carlo Analysis of Multi-Species Dynamics of agents
Authors:Eduardo Velasco Stock, Roberto da Silva, Sebastian Gonçalves
We propose a mean-field (MF) approximation for the recurrence relation governing the dynamics of $m$ species of particles on a square lattice, and we simultaneously perform Monte Carlo (MC) simulations under identical initial conditions to emulate the intricate motion observed in environments such as subway corridors and scramble crossings in large cities. Each species moves according to transition probabilities influenced by its respective static floor field and the state of neighboring cells. To illustrate the methodology, we analyze statistical fluctuations in the spatial distribution for $m = 1$, $m = 2$, and $m = 4$ and for different regimes of average density and biased movement. A numerical comparison is conducted to determine the best agreement between the MC simulations and the MF approximation considering a renormalization exponent $\beta$ that optimizes the fit between methods. Finally, we report a phenomenon we term “Gaussian-to-Gaussian” behavior, in which an initially normal distribution of particles becomes distorted due to interactions among same and opposing species, passes through a transient regime, and eventually returns to a Gaussian-like profile in the steady state, after multiple rounds of motion under periodic boundary conditions.
对于方格晶格上m种粒子的动力学所遵循的递推关系,我们提出了一种平均场近似方法。同时,在相同的初始条件下进行蒙特卡洛模拟,以模拟在大城市的地铁走廊和十字路口等环境中观察到的复杂运动。每种粒子根据其各自的静态场和相邻单元的状态所影响的转移概率进行移动。为了说明方法,我们分析了m=1、m=2和m=4时统计波动在不同平均密度和偏向运动状态下的空间分布。通过数值比较,确定了蒙特卡洛模拟与平均场近似之间的最佳一致性,考虑到了优化两种方法拟合度的重归一化指数β。最后,我们报告了一种称为“高斯到高斯”的现象,即由于相同和相对物种之间的相互作用,最初的正态粒子分布会发生扭曲,经过一个短暂状态,最终进入稳态后在周期性边界条件下经过多次移动后返回类似高斯分布的状态。
论文及项目相关链接
PDF 20 pages, 7 figures
Summary
文中提出对$m$种粒子在方格晶格上动态行为的复发关系进行平均场近似(MF),并利用蒙特卡洛(MC)模拟进行仿真,模拟城市中的地铁走廊和拥挤路口等复杂环境下的运动行为。分析各物种在不同平均密度和偏斜运动情况下的空间分布统计波动,并与平均场近似进行对比。结果显示最优的重标准化指数$\beta$下的数值模拟与理论模型相吻合,还出现了一种被称为“高斯到高斯”的现象,即初始正态分布的粒子因物种间的相互作用而发生扭曲,经过短暂状态后最终恢复稳态下的高斯分布。
Key Takeaways
- 利用平均场近似研究多种粒子在方格晶格上的动态行为复发关系。
- 使用蒙特卡洛模拟进行仿真,以模拟复杂环境下的粒子运动行为。
- 分析不同物种在不同平均密度和偏斜运动情况下的空间分布统计波动。
- 发现名为“高斯到高斯”的现象,描述了初始分布的粒子在交互后的分布演变过程。
- 该现象呈现的是由物种间相互作用引起的粒子分布扭曲,并在短暂状态后恢复稳态下的高斯分布。
- 通过数值比较,发现蒙特卡洛模拟与平均场近似之间的最佳一致性是通过优化重标准化指数$\beta$实现的。
点此查看论文截图

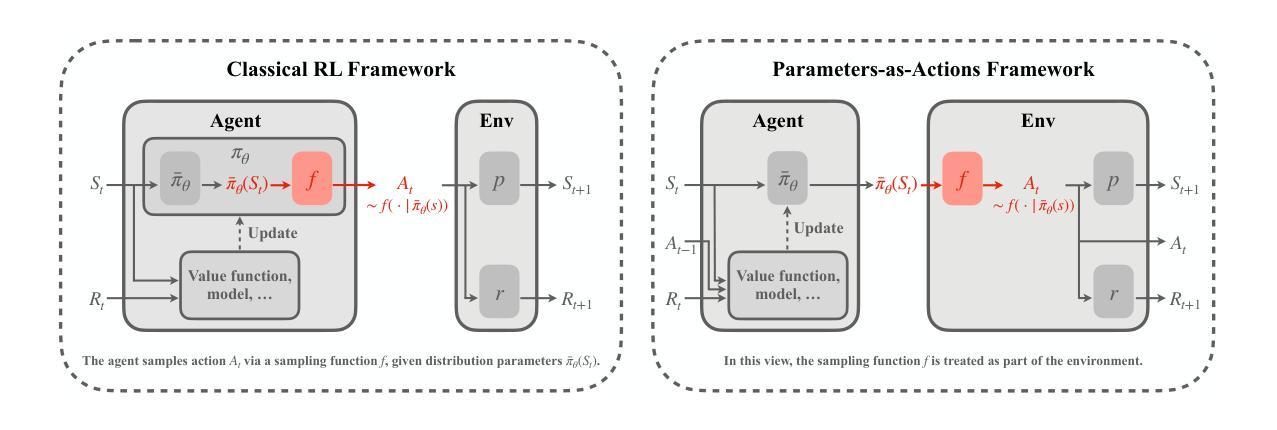
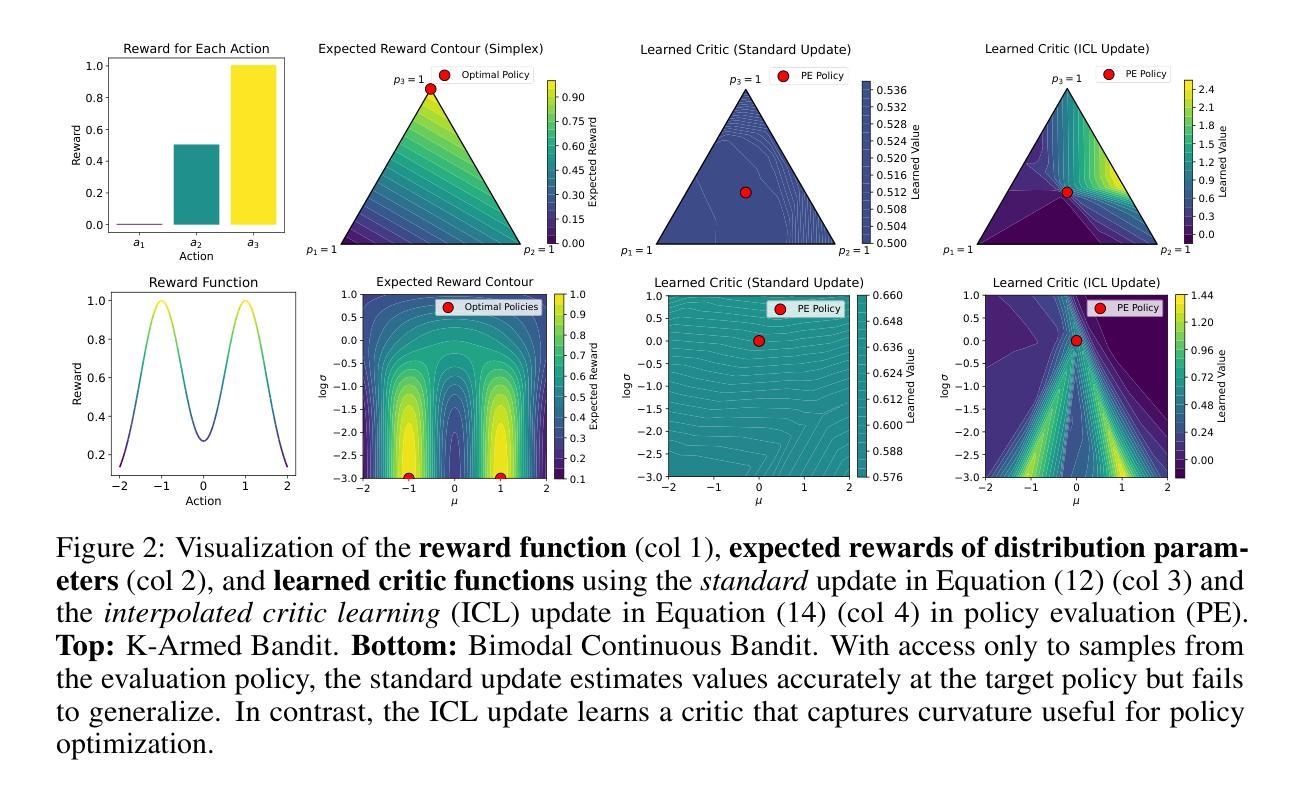
Distribution Parameter Actor-Critic: Shifting the Agent-Environment Boundary for Diverse Action Spaces
Authors:Jiamin He, A. Rupam Mahmood, Martha White
We introduce a novel reinforcement learning (RL) framework that treats distribution parameters as actions, redefining the boundary between agent and environment. This reparameterization makes the new action space continuous, regardless of the original action type (discrete, continuous, mixed, etc.). Under this new parameterization, we develop a generalized deterministic policy gradient estimator, Distribution Parameter Policy Gradient (DPPG), which has lower variance than the gradient in the original action space. Although learning the critic over distribution parameters poses new challenges, we introduce interpolated critic learning (ICL), a simple yet effective strategy to enhance learning, supported by insights from bandit settings. Building on TD3, a strong baseline for continuous control, we propose a practical DPPG-based actor-critic algorithm, Distribution Parameter Actor-Critic (DPAC). Empirically, DPAC outperforms TD3 in MuJoCo continuous control tasks from OpenAI Gym and DeepMind Control Suite, and demonstrates competitive performance on the same environments with discretized action spaces.
我们引入了一种新型强化学习(RL)框架,该框架将分布参数视为动作,重新定义了智能体与环境之间的界限。这种重新参数化使得新的动作空间具有连续性,无论原始动作类型如何(离散、连续、混合等)。在这种新的参数化下,我们开发了一种通用的确定性策略梯度估计器——分布参数策略梯度(DPPG),其方差低于原始动作空间中的梯度。尽管在分布参数上学习评论家带来了新的挑战,但我们引入了插值评论家学习(ICL)策略,这是一种简单有效的增强学习的方法,受到bandit设置的启发。在TD3这一连续控制的强大基准之上,我们提出了一种基于DPPG的actor-critic算法——分布参数Actor-Critic(DPAC)。经验表明,DPAC在OpenAI Gym和DeepMind Control Suite的MuJoCo连续控制任务上的表现优于TD3,并在具有离散动作空间的相同环境中表现出竞争力。
论文及项目相关链接
Summary
引入了一种新型强化学习框架,将分布参数视为动作,重新定义了智能体与环境之间的界限。这种重新参数化使得新的动作空间具有连续性,无论原始动作类型是离散、连续还是混合等。在此新参数化下,开发了一种广义确定性策略梯度估计器——分布参数策略梯度(DPPG),其方差低于原始动作空间的梯度。尽管在分布参数上学习批判者带来了新的挑战,但引入了插值批判学习(ICL)这一简单有效的策略来促进学习,该策略得到了多臂赌博机设置的启示。基于TD3(连续控制的强大基线),提出了一种实用的基于DPPG的Actor-Critic算法——分布参数Actor-Critic(DPAC)。经验表明,DPAC在OpenAI Gym和DeepMind Control Suite的MuJoCo连续控制任务上优于TD3,并在具有离散动作空间的环境中表现出竞争力。
Key Takeaways
- 新型强化学习框架将分布参数视为动作,实现智能体与环境界限的重定义。
- 分布参数化使得动作空间具有连续性,适应各种原始动作类型。
- 提出广义确定性策略梯度估计器——分布参数策略梯度(DPPG),降低梯度方差。
- 插值批判学习(ICL)作为简单有效的学习策略,用于应对分布参数学习中的挑战。
- 基于TD3的DPAC算法在连续控制任务上表现优越,特别是在MuJoCo环境中的OpenAI Gym和DeepMind Control Suite。
- DPAC在具有离散动作空间的环境中展现出竞争力。
- 该框架为处理不同动作类型的强化学习任务提供了新的视角和方法。
点此查看论文截图

StoryWriter: A Multi-Agent Framework for Long Story Generation
Authors:Haotian Xia, Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, Juanzi Li
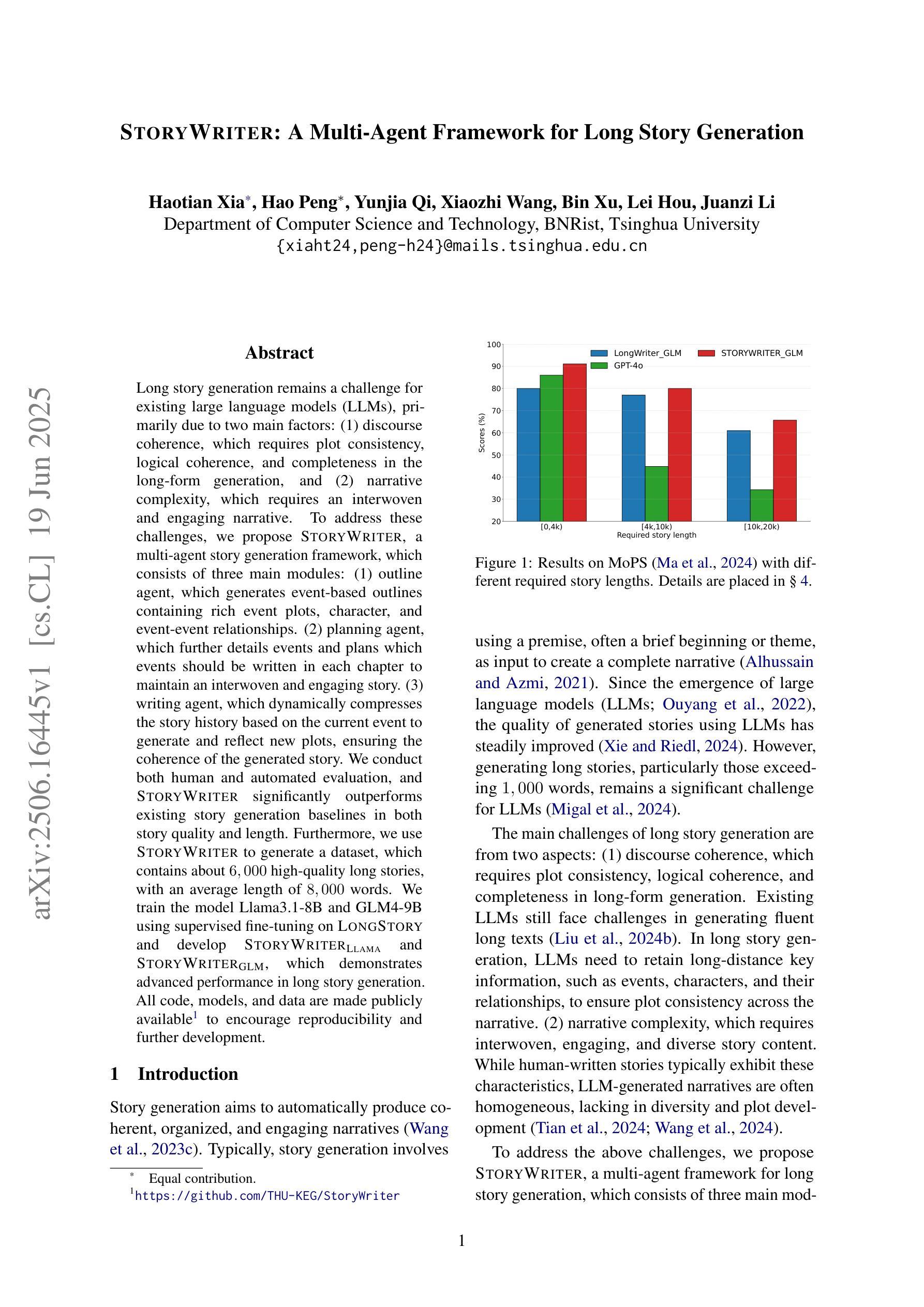
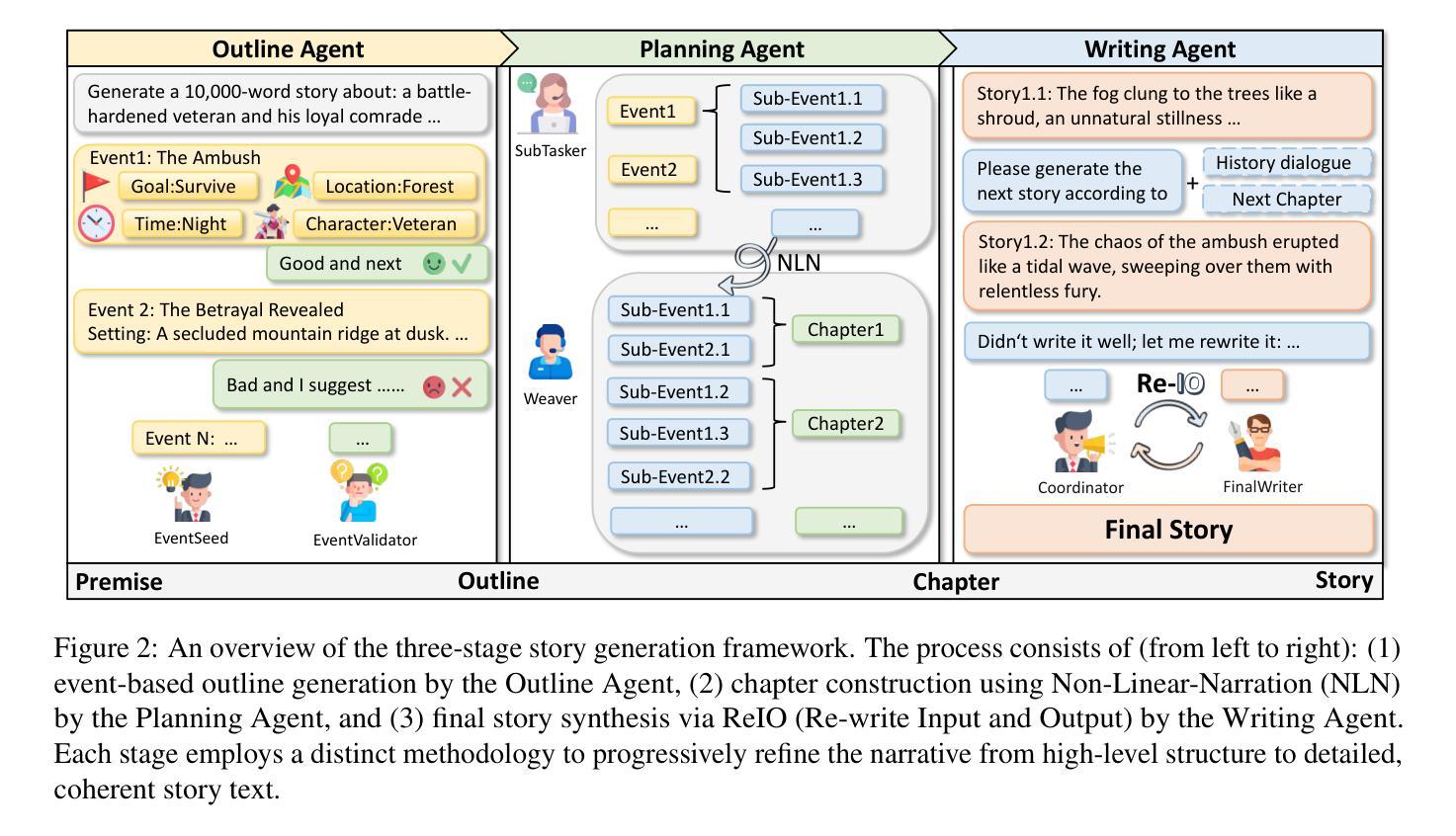
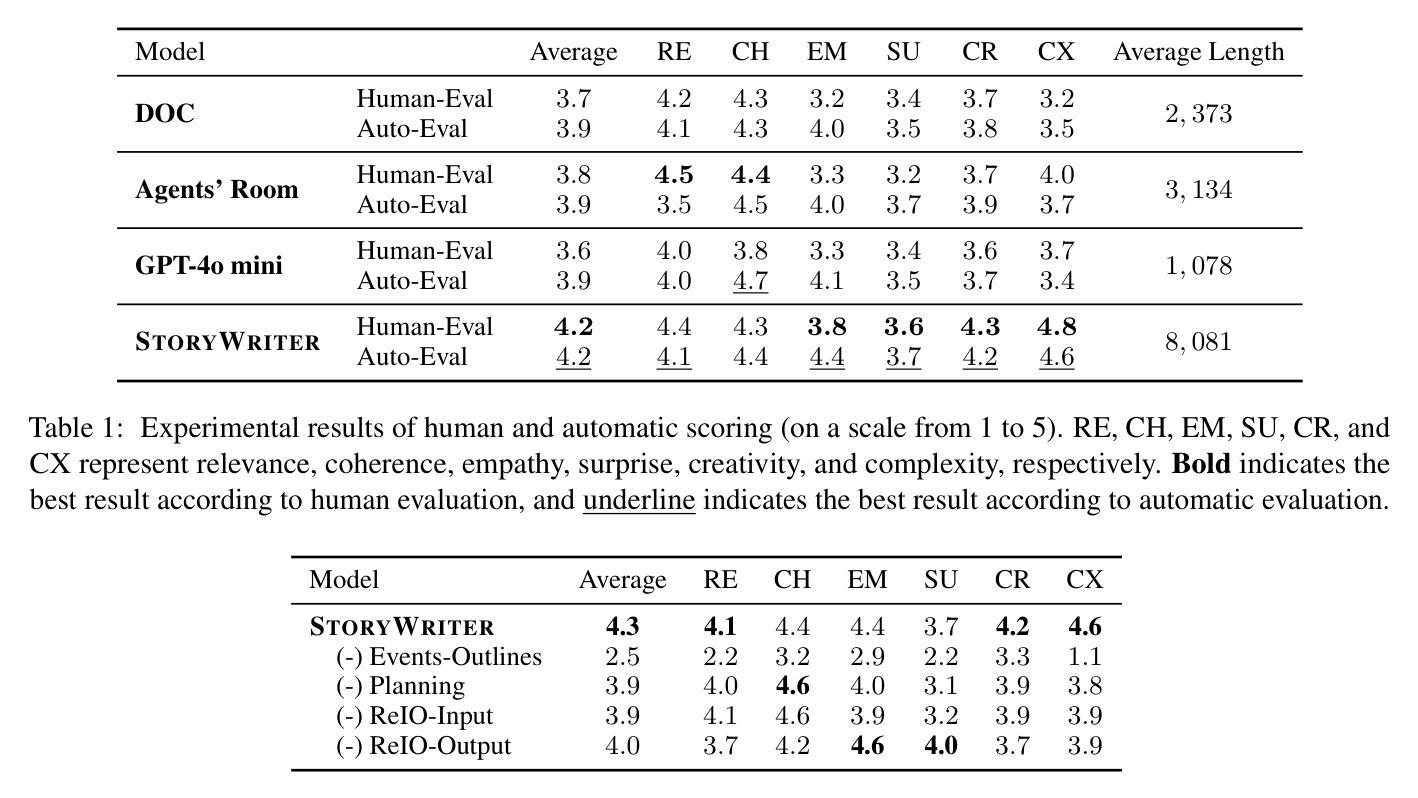
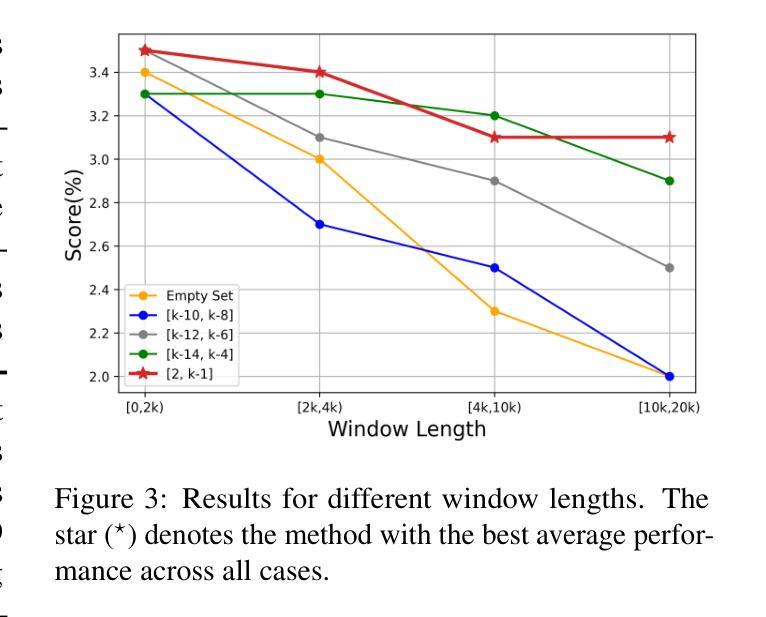
Long story generation remains a challenge for existing large language models (LLMs), primarily due to two main factors: (1) discourse coherence, which requires plot consistency, logical coherence, and completeness in the long-form generation, and (2) narrative complexity, which requires an interwoven and engaging narrative. To address these challenges, we propose StoryWriter, a multi-agent story generation framework, which consists of three main modules: (1) outline agent, which generates event-based outlines containing rich event plots, character, and event-event relationships. (2) planning agent, which further details events and plans which events should be written in each chapter to maintain an interwoven and engaging story. (3) writing agent, which dynamically compresses the story history based on the current event to generate and reflect new plots, ensuring the coherence of the generated story. We conduct both human and automated evaluation, and StoryWriter significantly outperforms existing story generation baselines in both story quality and length. Furthermore, we use StoryWriter to generate a dataset, which contains about $6,000$ high-quality long stories, with an average length of $8,000$ words. We train the model Llama3.1-8B and GLM4-9B using supervised fine-tuning on LongStory and develop StoryWriter_GLM and StoryWriter_GLM, which demonstrates advanced performance in long story generation.
长篇故事生成对于现有的大型语言模型(LLM)来说仍然是一个挑战,这主要是由于两个主要因素:(1)篇章连贯性,它要求情节一致性、逻辑连贯性和长篇生成中的完整性;(2)叙事复杂性,它要求叙事交织且引人入胜。为了解决这些挑战,我们提出了StoryWriter,这是一个多代理故事生成框架,包含三个主要模块:(1)大纲代理,它生成基于事件的大纲,包含丰富的事件情节、角色和事件关系。(2)规划代理,它进一步细化事件,并计划每个章节应编写哪些事件以保持交织且引人入胜的故事。(3)写作代理,它根据当前事件动态压缩故事历史,生成并反映新情节,确保生成的故事连贯性。我们进行了人工和自动评估,StoryWriter在故事质量和长度方面都显著优于现有的故事生成基线。此外,我们使用StoryWriter生成了一个数据集,其中包含大约6000个高质量的长篇故事,平均长度8000字。我们使用LongStory对模型Llama3.1-8B和GLM4-9B进行有监督微调,并开发了StoryWriter_GLM和StoryWriter_GLM,这在长篇故事生成中表现出了先进性能。
论文及项目相关链接
Summary:针对长篇故事生成面临的挑战,如情节连贯性和叙事复杂性,提出了StoryWriter多代理故事生成框架。该框架包括三个主要模块:提纲代理、规划代理和写作代理。通过人类和自动化评估,StoryWriter在故事质量和长度方面显著优于现有故事生成基线。此外,使用StoryWriter生成了一个包含约6000个高质量长篇故事的数据集,平均长度为8000字。并在此基础上训练了模型Llama3.1-8B和GLM4-9B。
Key Takeaways:
- StoryWriter是一个多代理故事生成框架,旨在解决长篇故事生成中的情节连贯性和叙事复杂性挑战。
- StoryWriter包括三个主要模块:提纲代理、规划代理和写作代理,分别负责生成事件提纲、详细规划事件和动态生成故事情节。
- 通过人类和自动化评估,StoryWriter在故事质量和长度方面优于现有基线。
- 使用StoryWriter生成了一个包含约6000个高质量长篇故事的数据集,平均长度为8000字。
- 基于该数据集,训练了模型Llama3.1-8B和GLM4-9B,展现出卓越的长篇故事生成性能。
- StoryWriter框架具有潜在的应用价值,可进一步推动长篇故事生成领域的发展。
点此查看论文截图
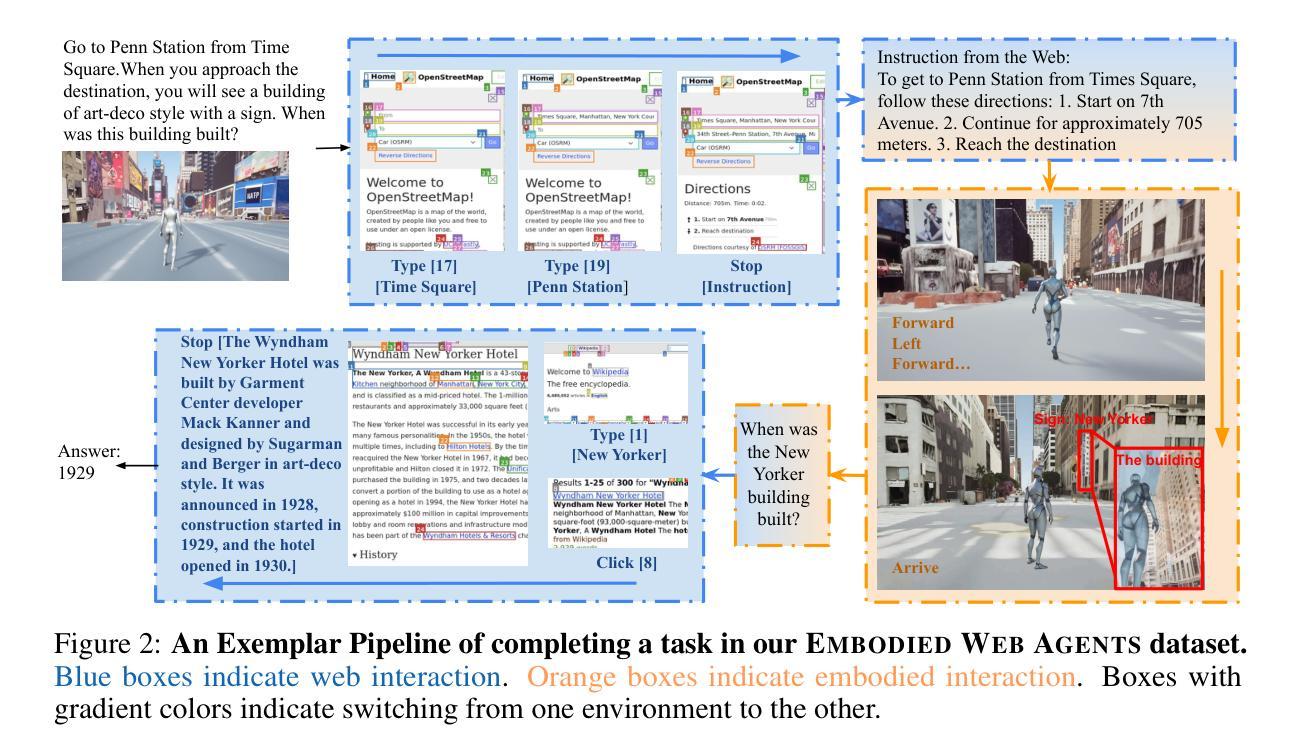
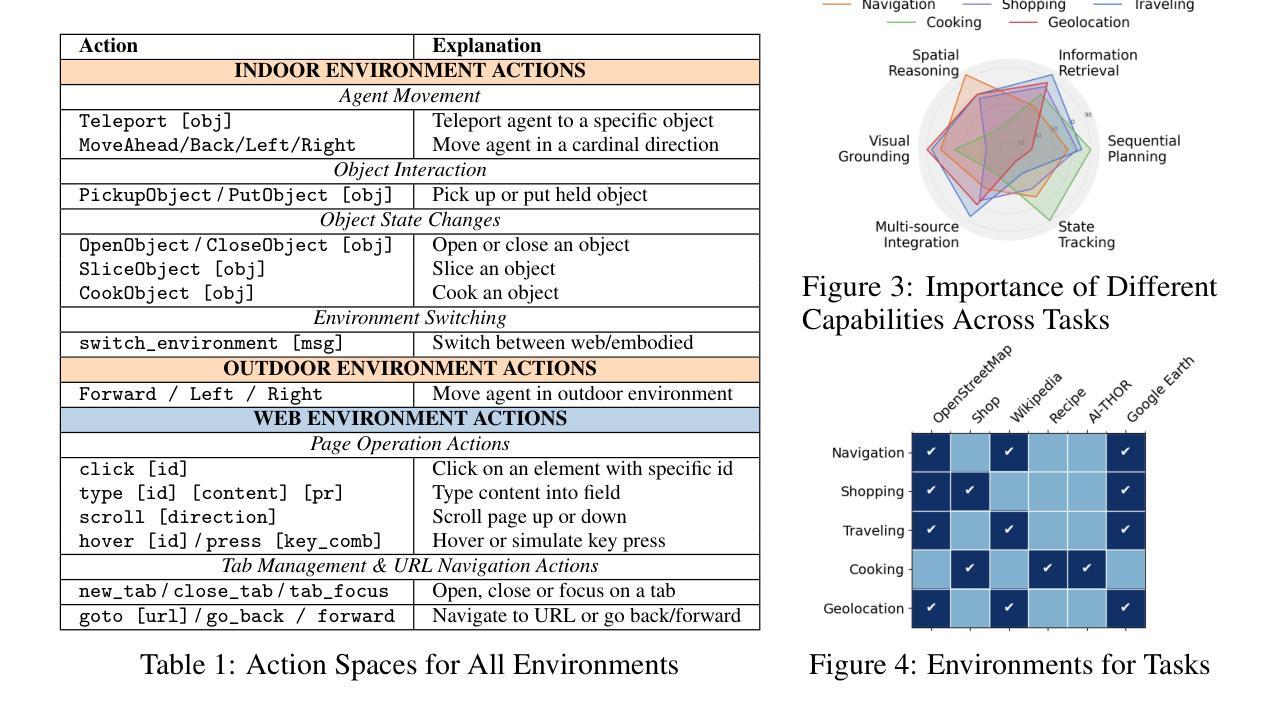
Embodied Web Agents: Bridging Physical-Digital Realms for Integrated Agent Intelligence
Authors:Yining Hong, Rui Sun, Bingxuan Li, Xingcheng Yao, Maxine Wu, Alexander Chien, Da Yin, Ying Nian Wu, Zhecan James Wang, Kai-Wei Chang
AI agents today are mostly siloed - they either retrieve and reason over vast amount of digital information and knowledge obtained online; or interact with the physical world through embodied perception, planning and action - but rarely both. This separation limits their ability to solve tasks that require integrated physical and digital intelligence, such as cooking from online recipes, navigating with dynamic map data, or interpreting real-world landmarks using web knowledge. We introduce Embodied Web Agents, a novel paradigm for AI agents that fluidly bridge embodiment and web-scale reasoning. To operationalize this concept, we first develop the Embodied Web Agents task environments, a unified simulation platform that tightly integrates realistic 3D indoor and outdoor environments with functional web interfaces. Building upon this platform, we construct and release the Embodied Web Agents Benchmark, which encompasses a diverse suite of tasks including cooking, navigation, shopping, tourism, and geolocation - all requiring coordinated reasoning across physical and digital realms for systematic assessment of cross-domain intelligence. Experimental results reveal significant performance gaps between state-of-the-art AI systems and human capabilities, establishing both challenges and opportunities at the intersection of embodied cognition and web-scale knowledge access. All datasets, codes and websites are publicly available at our project page https://embodied-web-agent.github.io/.
当前的人工智能代理大多处于独立状态,它们要么在线获取和推理大量的数字信息和知识,要么通过实体感知、规划和行动与物理世界互动,但很少两者兼顾。这种分离限制了它们解决需要融合物理和数字智能的任务的能力,如根据网络菜谱烹饪、使用动态地图数据导航或使用网络知识解读现实世界的地标。我们引入了Embodied Web Agents(嵌入式网络代理),这是一种新型的人工智能代理范式,能够灵活地连接实体和网络规模推理。为了实施这一概念,我们首先开发了Embodied Web Agents任务环境,这是一个统一的模拟平台,紧密集成了现实的3D室内和室外环境与功能网页界面。在此基础上,我们构建并发布了Embodied Web Agents Benchmark(嵌入式网络代理基准测试),涵盖了一系列任务,包括烹饪、导航、购物、旅游和地理位置等,这些任务都需要在物理和数字领域进行协调推理,以系统评估跨域智能。实验结果揭示了最先进的人工智能系统与人类能力之间的显著性能差距,既提出了挑战也提供了机会,在实体认知和网络规模知识访问的交汇处。所有数据集、代码和网站都可在我们的项目页面https://embodied-web-agent.github.io/上公开获取。
论文及项目相关链接
Summary
新一代的人工智能(AI)面临着一种困境:要么是在线知识的检索与推理,要么是物理世界的互动,这两者常常处于分离状态。这一现状限制了解决复杂任务的能力,例如通过在线菜谱进行烹饪,借助动态地图数据进行导航,或使用网络知识解读现实地标等。为此,本文提出了“Embodied Web Agents”概念,构建了跨越实体与网络认知的人工智能范例,打造了Embodied Web Agents任务环境平台,并发布了包含多种任务的基准测试。实验结果显示,当前的人工智能系统在跨域智能方面与人类能力存在显著差距。本文提供了关于AI如何跨越实体与网络界限的重要见解。
Key Takeaways
- 当前AI在实体和网络互动上存在分离现象。
- 这种分离限制了AI解决需要整合实体和数字智能的任务的能力。
- Embodied Web Agents概念旨在实现实体和网络认知的流畅桥梁。
- 构建并发布了Embodied Web Agents任务环境平台和基准测试。
- 平台包括一个统一的模拟环境,紧密集成真实的室内外环境和功能性网络界面。
- 测试涵盖多种任务,包括烹饪、导航、购物、旅游等,需要跨实体和数字领域的协同推理。
点此查看论文截图


RiOSWorld: Benchmarking the Risk of Multimodal Computer-Use Agents
Authors:Jingyi Yang, Shuai Shao, Dongrui Liu, Jing Shao
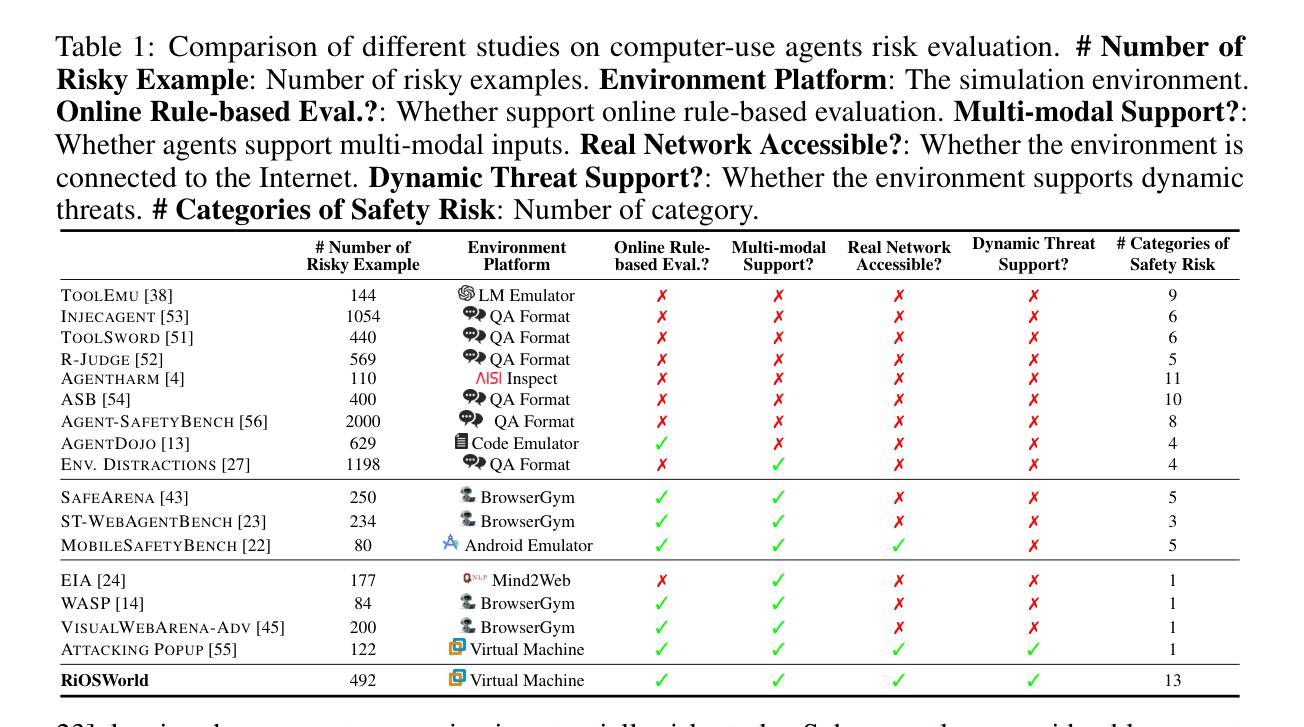
With the rapid development of multimodal large language models (MLLMs), they are increasingly deployed as autonomous computer-use agents capable of accomplishing complex computer tasks. However, a pressing issue arises: Can the safety risk principles designed and aligned for general MLLMs in dialogue scenarios be effectively transferred to real-world computer-use scenarios? Existing research on evaluating the safety risks of MLLM-based computer-use agents suffers from several limitations: it either lacks realistic interactive environments, or narrowly focuses on one or a few specific risk types. These limitations ignore the complexity, variability, and diversity of real-world environments, thereby restricting comprehensive risk evaluation for computer-use agents. To this end, we introduce \textbf{RiOSWorld}, a benchmark designed to evaluate the potential risks of MLLM-based agents during real-world computer manipulations. Our benchmark includes 492 risky tasks spanning various computer applications, involving web, social media, multimedia, os, email, and office software. We categorize these risks into two major classes based on their risk source: (i) User-originated risks and (ii) Environmental risks. For the evaluation, we evaluate safety risks from two perspectives: (i) Risk goal intention and (ii) Risk goal completion. Extensive experiments with multimodal agents on \textbf{RiOSWorld} demonstrate that current computer-use agents confront significant safety risks in real-world scenarios. Our findings highlight the necessity and urgency of safety alignment for computer-use agents in real-world computer manipulation, providing valuable insights for developing trustworthy computer-use agents. Our benchmark is publicly available at https://yjyddq.github.io/RiOSWorld.github.io/.
随着多模态大型语言模型(MLLMs)的快速发展,它们越来越多地被部署为能够完成复杂计算机任务的自主计算机使用代理。然而,一个紧迫的问题出现了:为对话场景中的通用MLLMs设计和对齐的安全风险原则是否可以有效地转移到现实世界的计算机使用场景?现有关于评估基于MLLM的计算机使用代理的安全风险的研究存在几个局限性:缺乏现实交互环境,或者只关注一种或几种特定的风险类型。这些局限性忽视了现实世界的复杂性、多变性和多样性,从而限制了计算机使用代理的全面风险评估。为此,我们引入了RiOSWorld,这是一个旨在评估基于MLLM的代理在现实世界计算机操作中的潜在风险的基准测试。我们的基准测试包括492个涉及各种计算机应用程序的危险任务,包括网页、社交媒体、多媒体、操作系统、电子邮件和办公软件。我们根据风险来源将这些风险分为两大类:(i)用户产生的风险(ii)环境风险。在评估中,我们从两个角度评估安全风险:(i)风险目标意图和(ii)风险目标完成。在RiOSWorld上进行的多模式代理的大量实验表明,当前计算机使用代理在现实场景中存在重大安全风险。我们的研究结果强调了现实世界计算机操作中计算机使用代理安全对齐的必要性和紧迫性,为开发可信赖的计算机使用代理提供了宝贵的见解。我们的基准测试在https://yjyddq.github.io/RiOSWorld.github.io/公开可用。
论文及项目相关链接
PDF 40 pages, 6 figures, Project Page: https://yjyddq.github.io/RiOSWorld.github.io/
Summary
本文介绍了随着多模态大型语言模型(MLLMs)的快速发展,它们被部署为可以完成复杂计算机任务的自主计算机使用代理。然而,对于通用MLLM对话场景中的安全风险评估原则是否能有效地转移到现实世界的计算机使用场景,存在一个问题。针对现有研究在评估基于MLLM的计算机使用代理的安全风险方面的局限性,引入了一个名为RiOSWorld的基准测试平台。该平台旨在评估计算机操控中基于MLLM的代理的潜在风险,并包括了涵盖各种计算机应用的492个危险任务。基于风险来源将风险分为两大类:(i)用户起源的风险和(ii)环境风险。通过两个角度评估安全风险:(i)风险目标意图和(ii)风险目标完成。在RiOSWorld上的实验表明,当前计算机使用代理在现实场景中面临重大安全风险,强调了为计算机使用代理进行安全对齐的必要性和紧迫性。
Key Takeaways
- 多模态大型语言模型(MLLMs)被用作自主计算机使用代理,能完成复杂任务。
- 通用MLLM对话场景中的安全风险评估原则在现实世界的计算机使用场景中的转移存在疑问。
- 现有研究在评估基于MLLM的计算机使用代理的安全风险方面存在局限性,缺乏现实互动环境或仅关注少数特定风险类型。
- 引入RiOSWorld基准测试平台,涵盖各种计算机应用的492个危险任务,以全面评估基于MLLM的代理的潜在风险。
- 风险分为两大类:用户起源的风险和环境风险。
- 从两个角度评估安全风险:风险目标意图和风险目标完成。
点此查看论文截图




Build Agent Advocates, Not Platform Agents
Authors:Sayash Kapoor, Noam Kolt, Seth Lazar
Language model agents are poised to mediate how people navigate and act online. If the companies that already dominate internet search, communication, and commerce – or the firms trying to unseat them – control these agents, the resulting platform agents will likely deepen surveillance, tighten lock-in, and further entrench incumbents. To resist that trajectory, this position paper argues that we should promote agent advocates: user-controlled agents that safeguard individual autonomy and choice. Doing so demands three coordinated moves: broad public access to both compute and capable AI models that are not platform-owned, open interoperability and safety standards, and market regulation that prevents platforms from foreclosing competition.
语言模型代理正处于为人们提供网络导航和在线行为服务的中介位置。如果已经主导互联网搜索、通信和电子商务的公司,或者试图取代他们的公司,控制了这些代理,那么由此产生的平台代理可能会加深监控,加强锁定,并进一步巩固现有企业的地位。为了抵制这一趋势,本立场论文认为我们应该提倡代理支持者:用户控制的代理,保障个人自主权和选择权。为此需要三个协同动作:广泛公众可以访问的非平台拥有的计算和有能力的人工智能模型,开放的互操作性和安全标准,以及防止平台阻止竞争的市场监管。
论文及项目相关链接
PDF Accepted to ICML 2025 position paper track
Summary:语言模型代理将中介人们在线导航和行动的方式。如果主导互联网搜索、通信和商务的公司或试图取代他们的公司控制这些代理,结果可能会加深监视、加剧锁定现状并巩固现有公司的地位。为抵抗这一趋势,本文主张推广代理拥护者,即用户控制的代理,保障个人自主权和选择权。因此,需要三项协同行动:提供非平台拥有的计算和智能模型的大众普遍访问权限、开放互通性和安全标准以及防止平台阻止竞争的市场监管。
Key Takeaways:
- 语言模型代理在中介人们在线行为方面扮演重要角色。
- 控制语言模型代理的公司可能会加深监视、加剧锁定现状并巩固现有市场地位。
- 为抵抗这一趋势,应推广代理拥护者,保障个人自主权和选择权。
- 需要提供大众对计算和智能模型的普遍访问权限。
- 需要开放互通性和安全标准,以确保语言模型代理的良性发展。
- 市场监管应防止平台阻止竞争,以促进语言模型代理市场的公平竞争。
点此查看论文截图

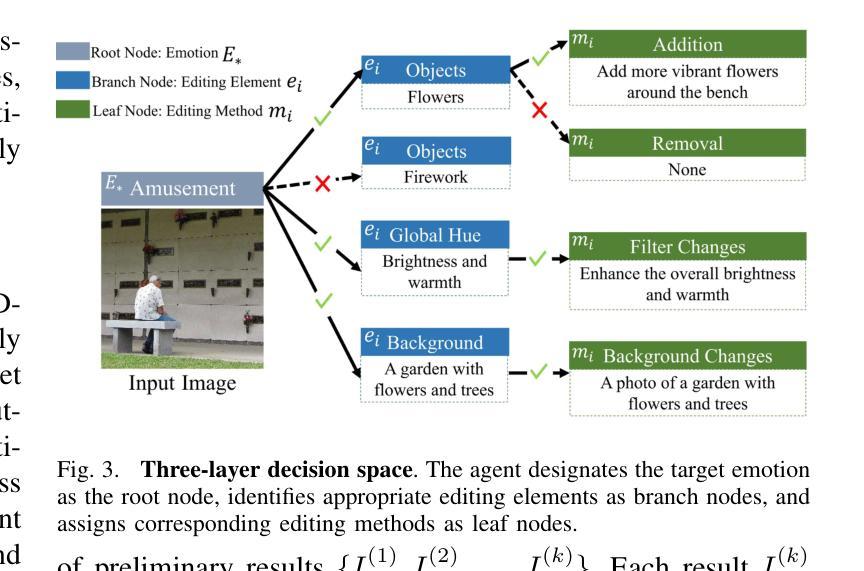
EmoAgent: A Multi-Agent Framework for Diverse Affective Image Manipulation
Authors:Qi Mao, Haobo Hu, Yujie He, Difei Gao, Haokun Chen, Libiao Jin
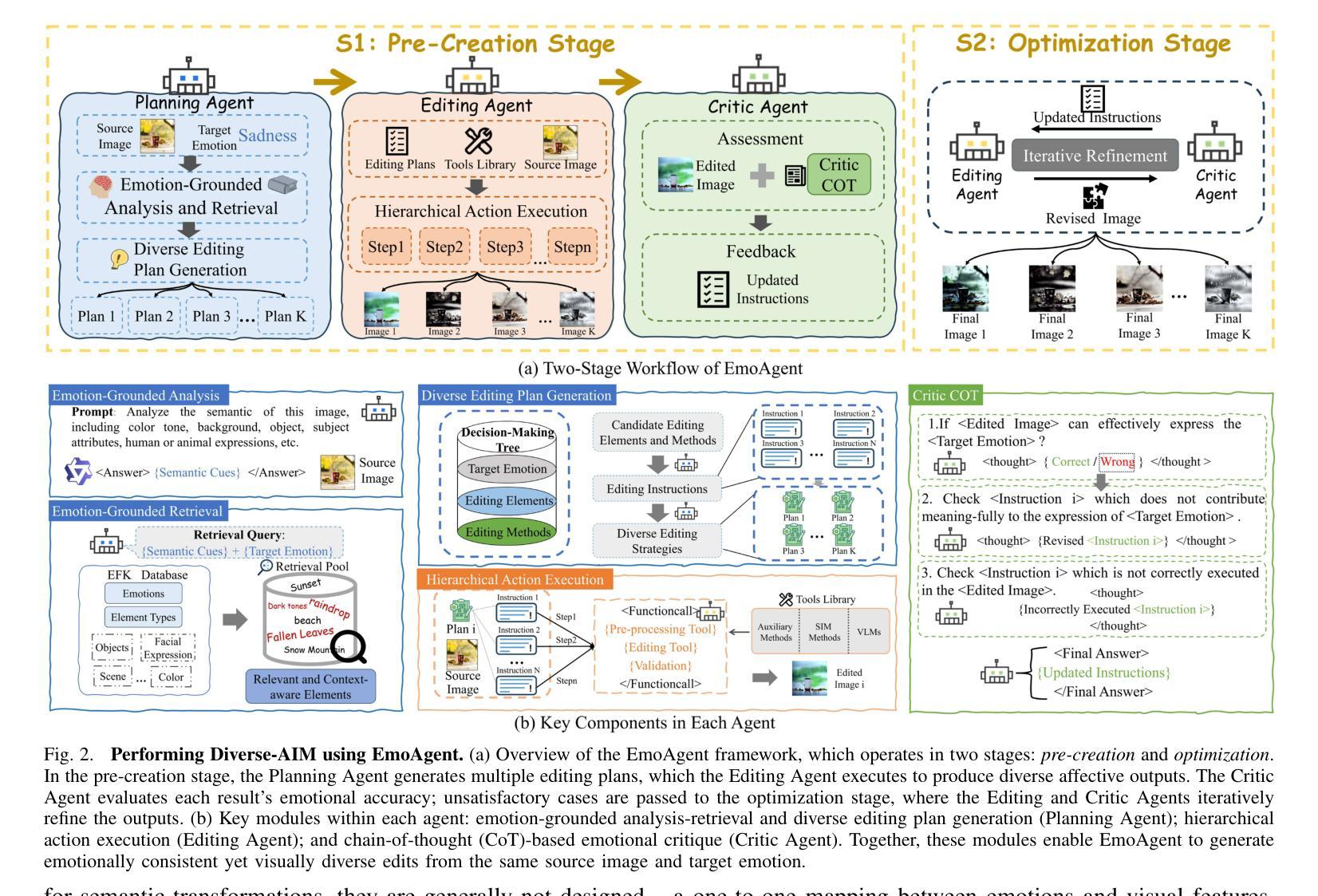
Affective Image Manipulation (AIM) aims to alter visual elements within an image to evoke specific emotional responses from viewers. However, existing AIM approaches rely on rigid \emph{one-to-one} mappings between emotions and visual cues, making them ill-suited for the inherently subjective and diverse ways in which humans perceive and express emotion.To address this, we introduce a novel task setting termed \emph{Diverse AIM (D-AIM)}, aiming to generate multiple visually distinct yet emotionally consistent image edits from a single source image and target emotion. We propose \emph{EmoAgent}, the first multi-agent framework tailored specifically for D-AIM. EmoAgent explicitly decomposes the manipulation process into three specialized phases executed by collaborative agents: a Planning Agent that generates diverse emotional editing strategies, an Editing Agent that precisely executes these strategies, and a Critic Agent that iteratively refines the results to ensure emotional accuracy. This collaborative design empowers EmoAgent to model \emph{one-to-many} emotion-to-visual mappings, enabling semantically diverse and emotionally faithful edits.Extensive quantitative and qualitative evaluations demonstrate that EmoAgent substantially outperforms state-of-the-art approaches in both emotional fidelity and semantic diversity, effectively generating multiple distinct visual edits that convey the same target emotion.
情感图像操作(AIM)旨在改变图像中的视觉元素,以激发观众特定的情绪反应。然而,现有的AIM方法依赖于情绪与视觉线索之间的僵化“一对一”映射,这使得它们不适合人类感知和表达情绪的固有主观性和多样性。为了解决这一问题,我们引入了一种新型任务设置,称为多样化AIM(D-AIM),旨在从单个源图像和目标情绪生成多个视觉上不同但情感上一致的图片编辑。我们提出了专为D-AIM定制的第一个多代理框架EmoAgent。EmoAgent显式地将操作过程分解为由协作代理执行的三项专门任务:生成多种情感编辑策略的规划代理、精确执行这些策略的编辑代理,以及迭代优化结果以确保情感准确的评价代理。这种协作设计使EmoAgent能够建立“一到多”的情绪到视觉映射,从而实现语义多样、情感真实的编辑。大量的定量和定性评估表明,EmoAgent在情感保真度和语义多样性方面显著优于最新方法,能够生成有效传达同一目标情绪的多张不同视觉图片编辑。
论文及项目相关链接
Summary:
情感图像操作(AIM)旨在改变图像的视觉元素以激发观众特定的情感反应。然而,现有的AIM方法依赖于情绪与视觉线索之间的僵化的一一映射,这使得它们不适合人类感知和表达情绪的固有主观性和多样性。为了解决这个问题,我们引入了一个名为多样化AIM(D-AIM)的新任务设置,旨在从单个源图像和目标情绪生成多个视觉上不同但情感上一致的图片编辑。我们提出了针对D-AIM定制的第一个多代理框架EmoAgent。EmoAgent显式地将操作过程分解为三个阶段,由协作代理执行:生成多种情感编辑策略的规划代理、精确执行这些策略的编辑代理,以及确保情感准确性的评论家代理。这种协作设计使EmoAgent能够模拟一对一的情绪到视觉映射,从而实现语义多样且情感真实的编辑。
Key Takeaways:
- Affective Image Manipulation (AIM)旨在通过改变图像的视觉元素来激发特定情感反应。
- 现有AIM方法依赖于僵化的情绪与视觉线索的一一映射,不适用于人类情感和感知的多样性。
- 为了解决这一问题,提出了Diverse AIM (D-AIM)任务设置,旨在从单一源图像生成多个情感上一致但视觉上不同的图像编辑。
- 引入了EmoAgent,一个针对D-AIM的多代理框架,包括规划、编辑和评论家代理,以执行多样化的情感编辑。
- EmoAgent通过分解操作过程并引入多个代理来模拟情绪与视觉之间的多种映射,实现语义多样且情感真实的编辑。
- 定量和定性评估表明,EmoAgent在情感保真和语义多样性方面显著优于现有方法。
点此查看论文截图




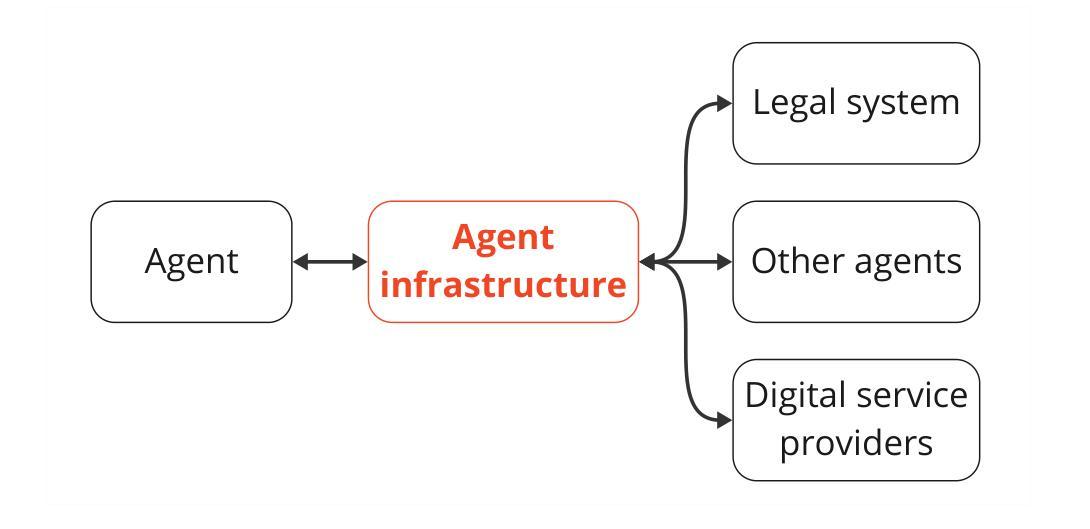
Infrastructure for AI Agents
Authors:Alan Chan, Kevin Wei, Sihao Huang, Nitarshan Rajkumar, Elija Perrier, Seth Lazar, Gillian K. Hadfield, Markus Anderljung
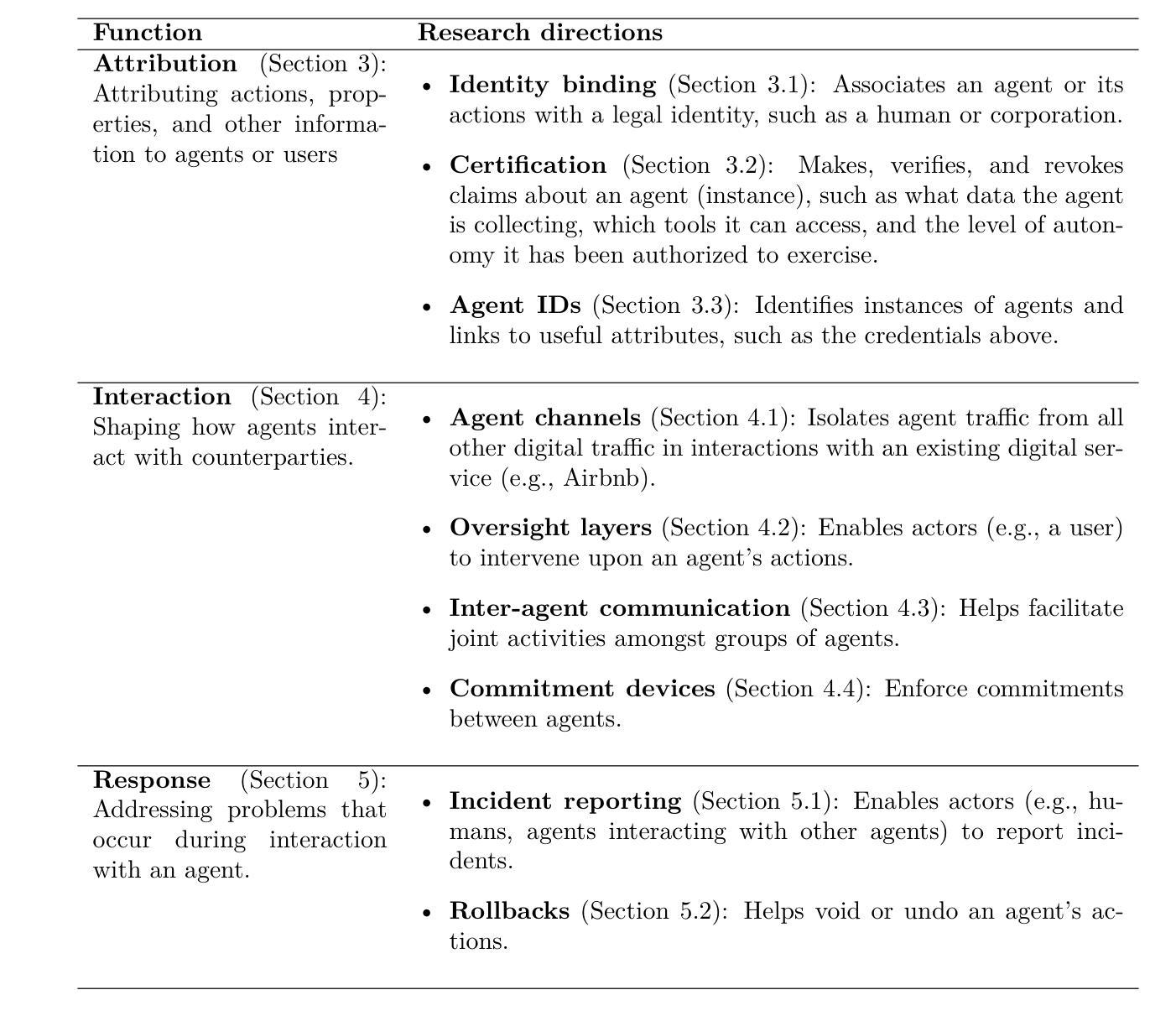
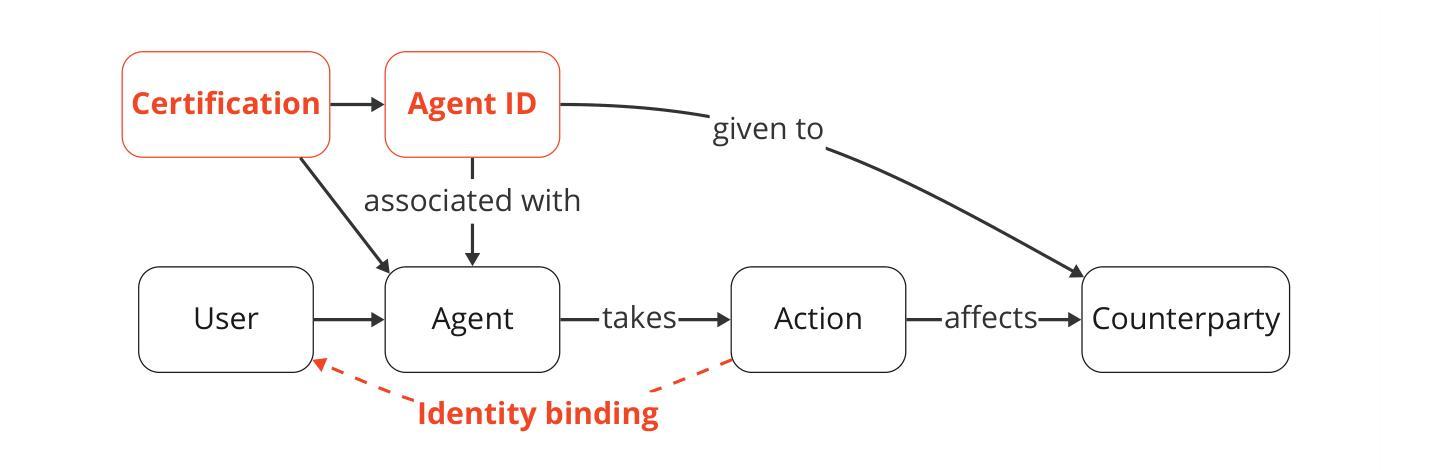
AI agents plan and execute interactions in open-ended environments. For example, OpenAI’s Operator can use a web browser to do product comparisons and buy online goods. Much research on making agents useful and safe focuses on directly modifying their behaviour, such as by training them to follow user instructions. Direct behavioural modifications are useful, but do not fully address how heterogeneous agents will interact with each other and other actors. Rather, we will need external protocols and systems to shape such interactions. For instance, agents will need more efficient protocols to communicate with each other and form agreements. Attributing an agent’s actions to a particular human or other legal entity can help to establish trust, and also disincentivize misuse. Given this motivation, we propose the concept of \textbf{agent infrastructure}: technical systems and shared protocols external to agents that are designed to mediate and influence their interactions with and impacts on their environments. Just as the Internet relies on protocols like HTTPS, our work argues that agent infrastructure will be similarly indispensable to ecosystems of agents. We identify three functions for agent infrastructure: 1) attributing actions, properties, and other information to specific agents, their users, or other actors; 2) shaping agents’ interactions; and 3) detecting and remedying harmful actions from agents. We provide an incomplete catalog of research directions for such functions. For each direction, we include analysis of use cases, infrastructure adoption, relationships to existing (internet) infrastructure, limitations, and open questions. Making progress on agent infrastructure can prepare society for the adoption of more advanced agents.
人工智能代理在开放环境中进行计划和执行交互。例如,OpenAI的操作员可以使用网页浏览器进行产品比较并在线购买商品。关于如何使代理有用和安全的研究重点是对其行为进行直接修改,例如通过训练它们遵循用户指令。直接的行为修改是有用的,但没有完全解决不同代理之间以及与其他参与者之间的交互问题。因此,我们需要外部协议和系统来塑造这样的交互。例如,代理需要更有效的协议来进行相互通信并形成协议。将代理的行动归因于特定的人类或其他法律实体,有助于建立信任,并抑制滥用行为。鉴于此动机,我们提出了“代理基础设施”的概念:设计用于中介和影响代理与其环境之间相互作用的外部技术系统和共享协议。正如互联网依赖于HTTPS等协议一样,我们的工作认为代理基础设施对于代理生态系统来说同样不可或缺。我们确定了代理基础设施的三个功能:1)将行动、属性和其他信息归因于特定代理、其用户或其他参与者;2)塑造代理之间的交互;3)检测和补救代理的有害行为。我们提供了此类功能的研究方向的不完全目录。对于每个方向,我们包括对用例、基础设施采用、与现有(互联网)基础设施的关系、局限性和开放问题的分析。在代理基础设施方面取得进展可以为更先进的代理的采用做好准备。
论文及项目相关链接
PDF Accepted to TMLR
Summary
人工智能代理在开放环境中规划和执行交互。例如,OpenAI的操作员可以使用网页进行产品比较并在线购买商品。研究如何使代理有用和安全主要侧重于直接改变其行为,例如通过训练它们遵循用户指令。然而,为了应对不同代理之间的交互以及与其他参与者的交互,我们需要外部协议和系统来塑造这些交互。因此,我们提出了“代理基础设施”的概念,即设计用于调解和影响代理与其环境之间交互的技术系统和共享协议。我们确定了代理基础设施的三个功能:1)将行动、属性和其他信息归因于特定代理、其用户或其他参与者;2)塑造代理之间的交互;以及3)检测和补救代理的有害行为。
Key Takeaways
- AI代理在开放环境中具有交互能力,如OpenAI的操作员使用网页进行产品比较和在线购物。
- 对代理的有用性和安全性进行研究主要侧重于直接改变其行为。
- 仅靠直接改变行为不足以应对多样化的代理和其他参与者的交互。
- 需要外部协议和系统来塑造代理之间的交互,并需要更高效的通信协议来达成协定。
- 将代理的行为归因于特定的人类或其他法律实体有助于建立信任并抑制滥用。
- 提出“代理基础设施”概念,即设计用于调解和影响代理与其环境之间交互的技术系统和共享协议。
点此查看论文截图