⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
Universal Music Representations? Evaluating Foundation Models on World Music Corpora
Authors:Charilaos Papaioannou, Emmanouil Benetos, Alexandros Potamianos
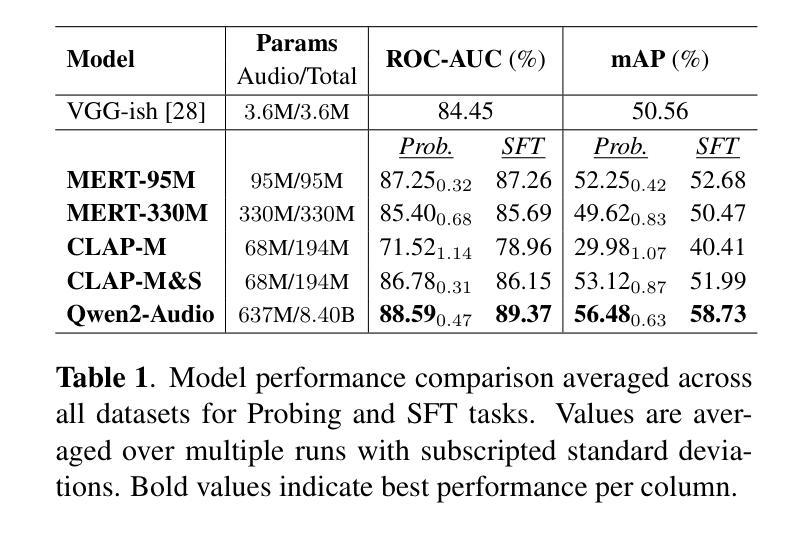
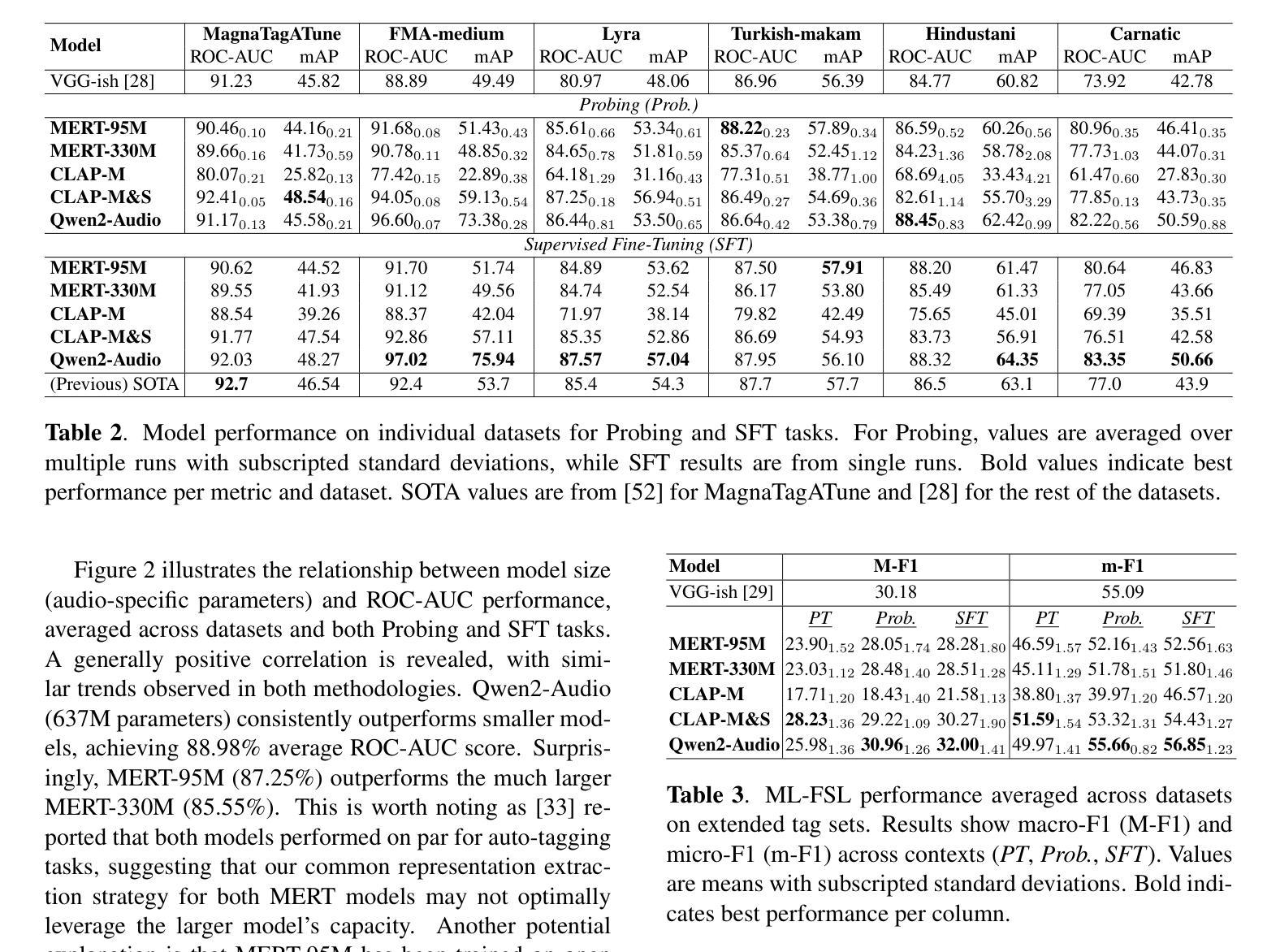
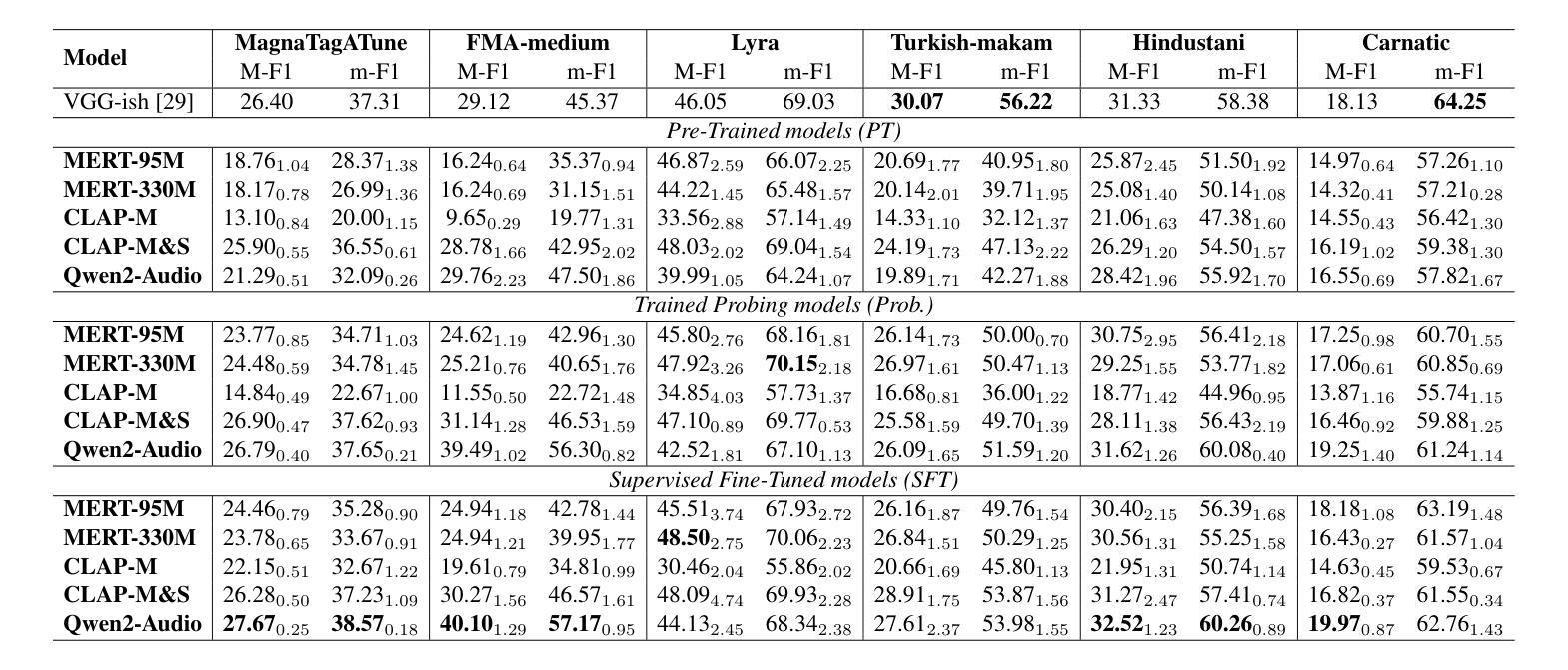
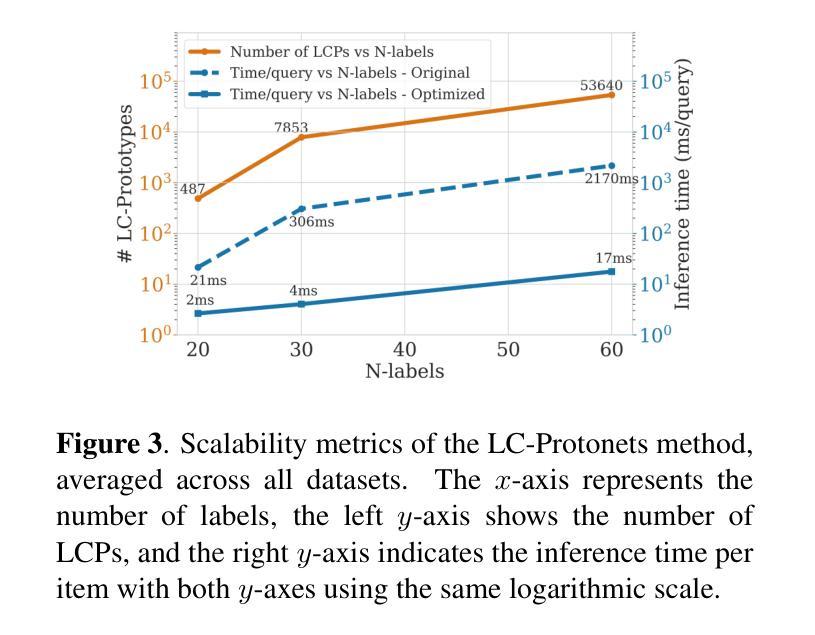
Foundation models have revolutionized music information retrieval, but questions remain about their ability to generalize across diverse musical traditions. This paper presents a comprehensive evaluation of five state-of-the-art audio foundation models across six musical corpora spanning Western popular, Greek, Turkish, and Indian classical traditions. We employ three complementary methodologies to investigate these models’ cross-cultural capabilities: probing to assess inherent representations, targeted supervised fine-tuning of 1-2 layers, and multi-label few-shot learning for low-resource scenarios. Our analysis shows varying cross-cultural generalization, with larger models typically outperforming on non-Western music, though results decline for culturally distant traditions. Notably, our approaches achieve state-of-the-art performance on five out of six evaluated datasets, demonstrating the effectiveness of foundation models for world music understanding. We also find that our targeted fine-tuning approach does not consistently outperform probing across all settings, suggesting foundation models already encode substantial musical knowledge. Our evaluation framework and benchmarking results contribute to understanding how far current models are from achieving universal music representations while establishing metrics for future progress.
基础模型已经彻底改变了音乐信息检索,但对于它们在多样化音乐传统中的泛化能力仍存在疑问。本文全面评估了五个最先进的音频基础模型,涉及六种音乐语料库,包括西方流行、希腊、土耳其和印度古典传统。我们采用三种互补方法来研究这些模型的跨文化能力:探测评估内在表示、对1-2层进行有针对性的监督微调以及用于低资源场景的多标签小样本学习。我们的分析表明,跨文化泛化能力存在差异,较大的模型通常在非西方音乐上表现更好,但对于文化距离较远的传统,结果会下降。值得注意的是,我们的方法在六个评估数据集中有五个达到了最新水平,证明了基础模型在世界音乐理解方面的有效性。我们还发现,我们的有针对性的微调方法并不始终在所有设置中优于探测,这表明基础模型已经编码了大量的音乐知识。我们的评估框架和基准测试结果有助于了解当前模型距离实现通用音乐表示还有多远,同时为未来进展建立了衡量指标。
论文及项目相关链接
PDF Accepted at ISMIR 2025
Summary
本论文全面评估了五款先进音频基础模型在涵盖西方流行、希腊、土耳其和印度古典传统等六种音乐语料库中的跨文化泛化能力。通过探针测试内在表征、对一至两层进行有针对性的监督微调以及用于低资源场景的多标签小样本学习等方法进行研究。分析表明,基础模型在不同文化背景下的泛化能力存在差异,大型模型在非西方音乐上的表现通常较好,但在文化距离较远的传统中表现下降。本研究的方法在六个数据集中有五个达到了最先进的性能水平,证明了基础模型对世界音乐理解的有效性。此外,研究还发现针对性的微调方法并不总是优于探针在所有场景下的表现,表明基础模型已经编码了大量的音乐知识。本评估框架和基准测试结果有助于了解当前模型距离实现通用音乐表示的程度,并为未来的进步建立了指标。
Key Takeaways
- 音频基础模型在跨文化音乐信息检索中的泛化能力存在差异。
- 大型模型在非西方音乐上的表现较好。
- 在文化距离较远的传统中,模型表现可能下降。
- 论文采用三种方法评估模型的跨文化能力:探针测试、针对性监督微调和小样本学习。
- 研究方法在五个数据集上达到了最先进的性能水平。
- 基础模型已经编码了大量的音乐知识,但仍有提升空间。
点此查看论文截图

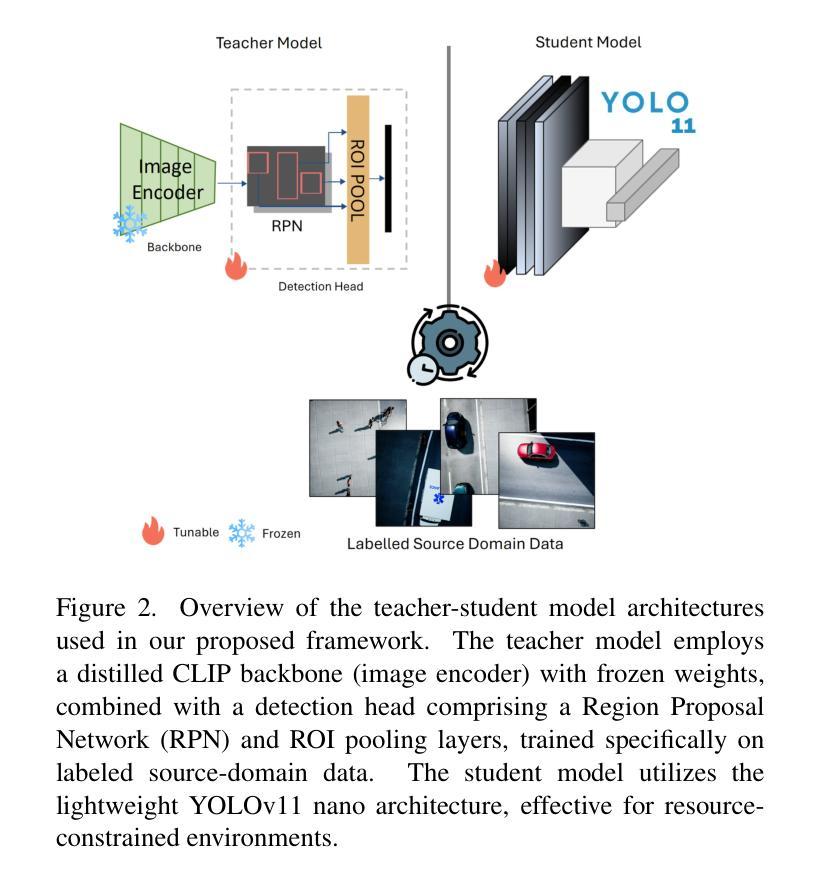
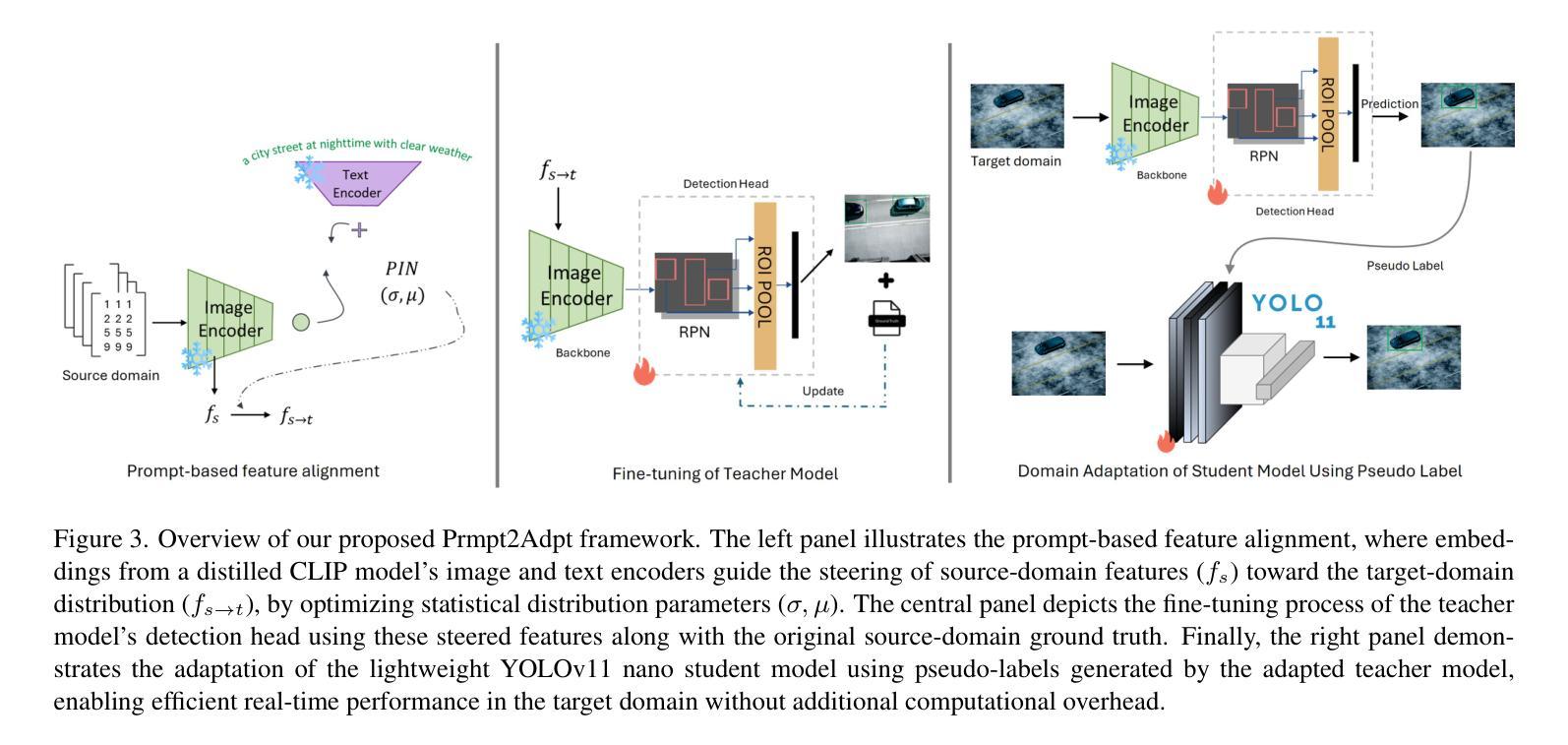
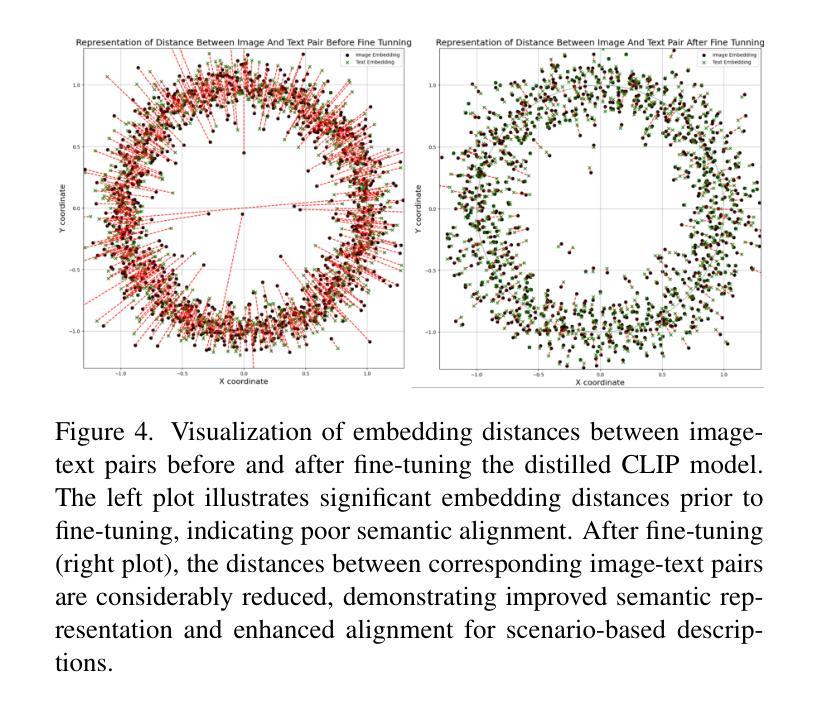
Prmpt2Adpt: Prompt-Based Zero-Shot Domain Adaptation for Resource-Constrained Environments
Authors:Yasir Ali Farrukh, Syed Wali, Irfan Khan, Nathaniel D. Bastian
Unsupervised Domain Adaptation (UDA) is a critical challenge in real-world vision systems, especially in resource-constrained environments like drones, where memory and computation are limited. Existing prompt-driven UDA methods typically rely on large vision-language models and require full access to source-domain data during adaptation, limiting their applicability. In this work, we propose Prmpt2Adpt, a lightweight and efficient zero-shot domain adaptation framework built around a teacher-student paradigm guided by prompt-based feature alignment. At the core of our method is a distilled and fine-tuned CLIP model, used as the frozen backbone of a Faster R-CNN teacher. A small set of low-level source features is aligned to the target domain semantics-specified only through a natural language prompt-via Prompt-driven Instance Normalization (PIN). These semantically steered features are used to briefly fine-tune the detection head of the teacher model. The adapted teacher then generates high-quality pseudo-labels, which guide the on-the-fly adaptation of a compact student model. Experiments on the MDS-A dataset demonstrate that Prmpt2Adpt achieves competitive detection performance compared to state-of-the-art methods, while delivering up to 7x faster adaptation and 5x faster inference speed using few source images-making it a practical and scalable solution for real-time adaptation in low-resource domains.
无监督域自适应(UDA)是现实世界视觉系统中的一个关键挑战,特别是在资源受限的环境(如无人机)中,内存和计算资源有限。现有的基于提示的UDA方法通常依赖于大型视觉语言模型,并且在适应过程中需要完全访问源域数据,这限制了其适用性。在这项工作中,我们提出了Prompt2Adpt,这是一个围绕教师学生范式构建的轻量级高效零样本域自适应框架,由基于提示的特征对齐引导。我们的方法的核心是一个经过蒸馏和精细调整的CLIP模型,用作Faster R-CNN教师的冻结主干。通过提示驱动的实例归一化(PIN),一小部分低级的源特征被对齐到目标域语义(仅通过自然语言提示指定)。这些语义引导的特征被用来微调教师的检测头部。适应后的教师然后生成高质量的伪标签,这些伪标签指导紧凑的学生模型的即时适应。在MDS-A数据集上的实验表明,Prompt2Adpt与最先进的方法相比,在检测性能方面表现出竞争力,同时使用少量的源图像实现了高达7倍的快速适应和5倍的推理速度,使其成为实时适应低资源域的实用且可扩展的解决方案。
论文及项目相关链接
Summary
本文提出了一种基于教师-学生范式的轻量级高效零样本域自适应框架,名为Prmpt2Adpt。它利用CLIP模型和Prompt-driven Instance Normalization(PIN)进行特征对齐,实现对源域数据的少量使用和对目标域语义的自然语言提示的引导。该方法实现了快速自适应和推理速度的提升,使得在低资源领域中的实时自适应变得更加实用和可扩展。
Key Takeaways
- Prmpt2Adpt是一种针对无人机等资源受限环境的零样本域自适应方法。
- 该方法采用教师-学生范式,利用CLIP模型作为固定骨干网。
- 通过Prompt-driven Instance Normalization(PIN)实现源特征与目标域语义的对齐。
- 仅通过自然语言提示进行特征对齐。
- Prmpt2Adpt实现了快速自适应和推理速度的提升。
- 在MDS-A数据集上的实验表明,Prmpt2Adpt的检测结果与最新技术相当。
点此查看论文截图


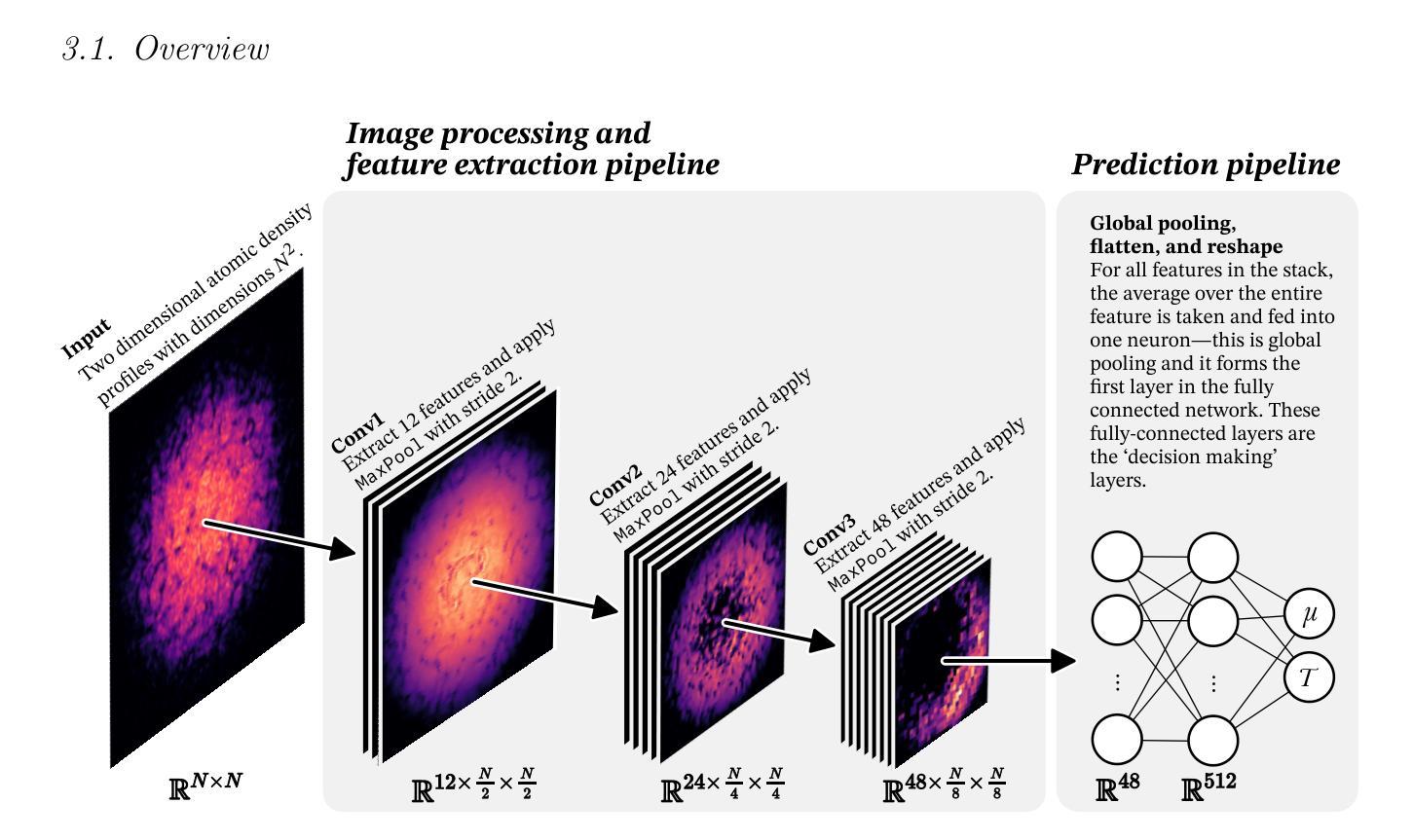
Single-shot thermometry of simulated Bose–Einstein condensates using artificial intelligence
Authors:Jack Griffiths, Steven A. Wrathmall, Simon A. Gardiner
Precise determination of thermodynamic parameters in ultracold Bose gases remains challenging due to the destructive nature of conventional measurement techniques and inherent experimental uncertainties. We demonstrate an artificial intelligence approach for rapid, non-destructive estimation of the chemical potential and temperature from single-shot, in situ imaged density profiles of finite-temperature Bose gases. Our convolutional neural network is trained exclusively on quasi-2D `pancake’ condensates in harmonic trap configurations. It achieves parameter extraction within fractions of a second. The model also demonstrates zero-shot generalisation across both trap geometry and thermalisation dynamics, successfully estimating thermodynamic parameters for toroidally trapped condensates with errors of only a few nanokelvin despite no prior exposure to such geometries during training, and maintaining predictive accuracy during dynamic thermalisation processes after a relatively brief evolution without explicit training on non-equilibrium states. These results suggest that supervised learning can overcome traditional limitations in ultracold atom thermometry, with extension to broader geometric configurations, temperature ranges, and additional parameters potentially enabling comprehensive real-time analysis of quantum gas experiments. Such capabilities could significantly streamline experimental workflows whilst improving measurement precision across a range of quantum fluid systems.
在超冷玻色气体中精确确定热力学参数仍然是一个挑战,这主要是由于传统测量技术的破坏性以及实验固有的不确定性。我们展示了一种人工智能方法,可以快速、非破坏性地从单次现场成像的密度分布图中估计有限温度玻色气体的化学势和温度。我们的卷积神经网络仅针对谐波陷阱配置中的二维类”煎饼”凝聚物进行训练。它能够在几分之一秒内实现参数提取。该模型还展示了跨陷阱几何形状和热化动力学的零起点泛化能力,尽管在训练期间没有接触过此类几何形状,但对环形陷阱中的凝聚物热力学参数进行估计时误差仅为几纳开尔文,并且在相对短暂的演化过程中,在非平衡态没有明确的训练情况下仍能保持预测精度。这些结果表明,有监督学习可以克服超冷原子测温中的传统局限性,扩展到更广泛的几何结构、温度范围和附加参数,从而可能实现对量子气体实验的全面实时分析。这种能力可能会大大简化实验工作流程,同时提高一系列量子流体系统的测量精度。
论文及项目相关链接
Summary
针对超冷玻色气体中的热力学参数精确测定,存在传统测量技术的破坏性和实验固有不确定性的问题。本研究展示了一种人工智能方法,用于快速、非破坏性估计化学势和温度,仅通过单次即时成像的密度分布数据即可完成。使用卷积神经网络,仅在准二维“煎饼”凝聚物和谐波陷阱配置上进行训练,即可在数秒内提取参数。该模型还展示了在陷阱几何形状和热化动力学方面的零样本泛化能力,尽管在训练期间未接触此类几何形状,但对于环形陷阱中的玻色气体,其热力学参数的估计误差仅为几纳开尔文。此外,它在动态热化过程中保持预测精度。这些结果建议,监督学习可以克服超冷原子测温中的传统局限性,扩展到更广泛的几何配置、温度范围和额外参数,可能会实现对量子气体实验的全面实时分析。
Key Takeaways
- 超冷玻色气体中热力学参数的精确测定面临挑战,因为传统测量技术具有破坏性和实验的不确定性。
- 人工智能方法可用于快速、非破坏性估计化学势和温度。
- 使用的卷积神经网络能够在准二维“煎饼”凝聚物和特定的陷阱配置上进行训练,并快速提取参数。
- 模型具有良好的泛化能力,可以在不同的陷阱几何形状和热化动力学中表现良好。
- 对于环形陷阱中的玻色气体,模型可以高精度地估计热力学参数,即使在动态热化过程中也能保持准确性。
- 监督学习可以克服超冷原子测温中的传统局限性,并具有在更广泛的几何配置、温度范围和额外参数上进行扩展的潜力。
点此查看论文截图

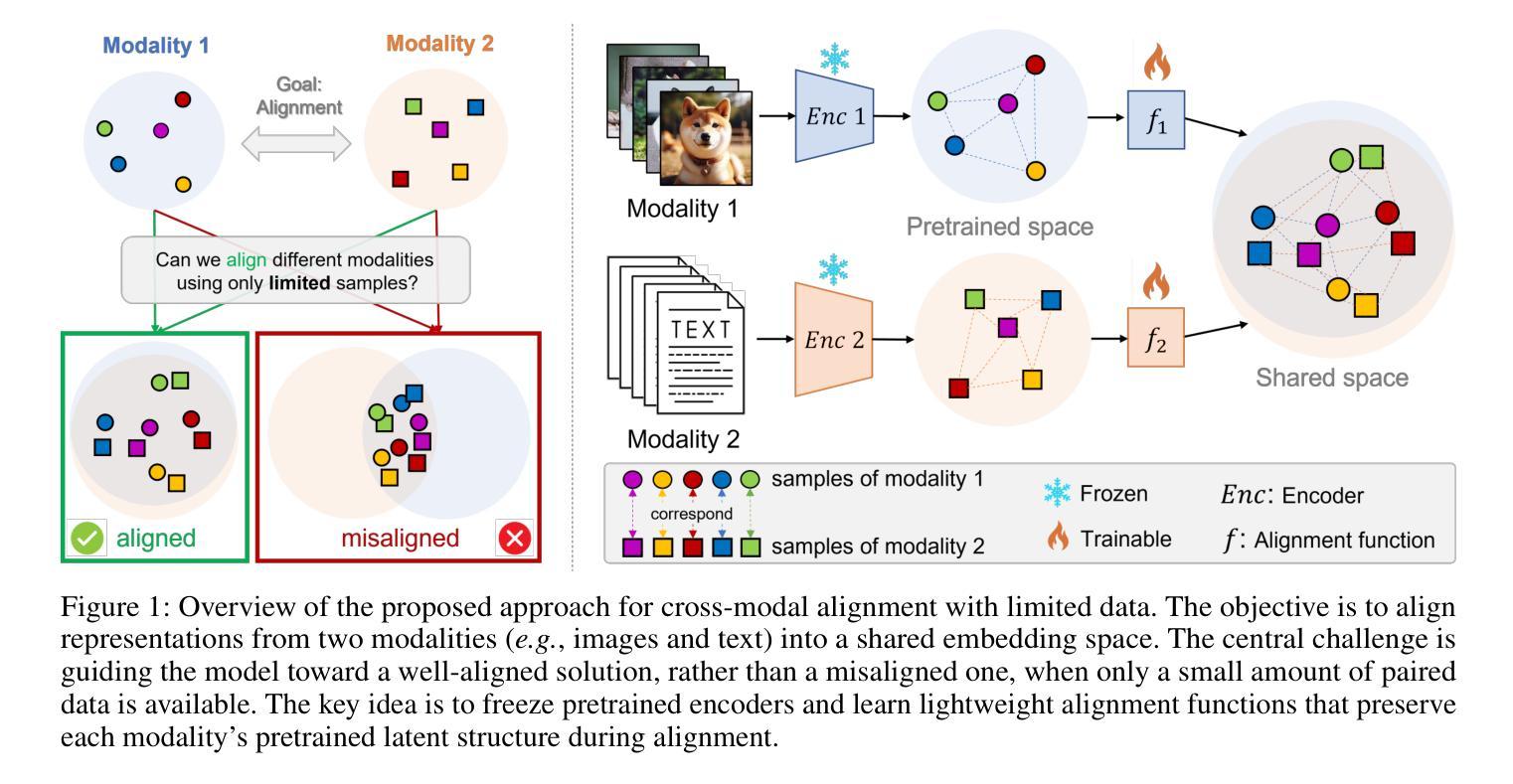
With Limited Data for Multimodal Alignment, Let the STRUCTURE Guide You
Authors:Fabian Gröger, Shuo Wen, Huyen Le, Maria Brbić
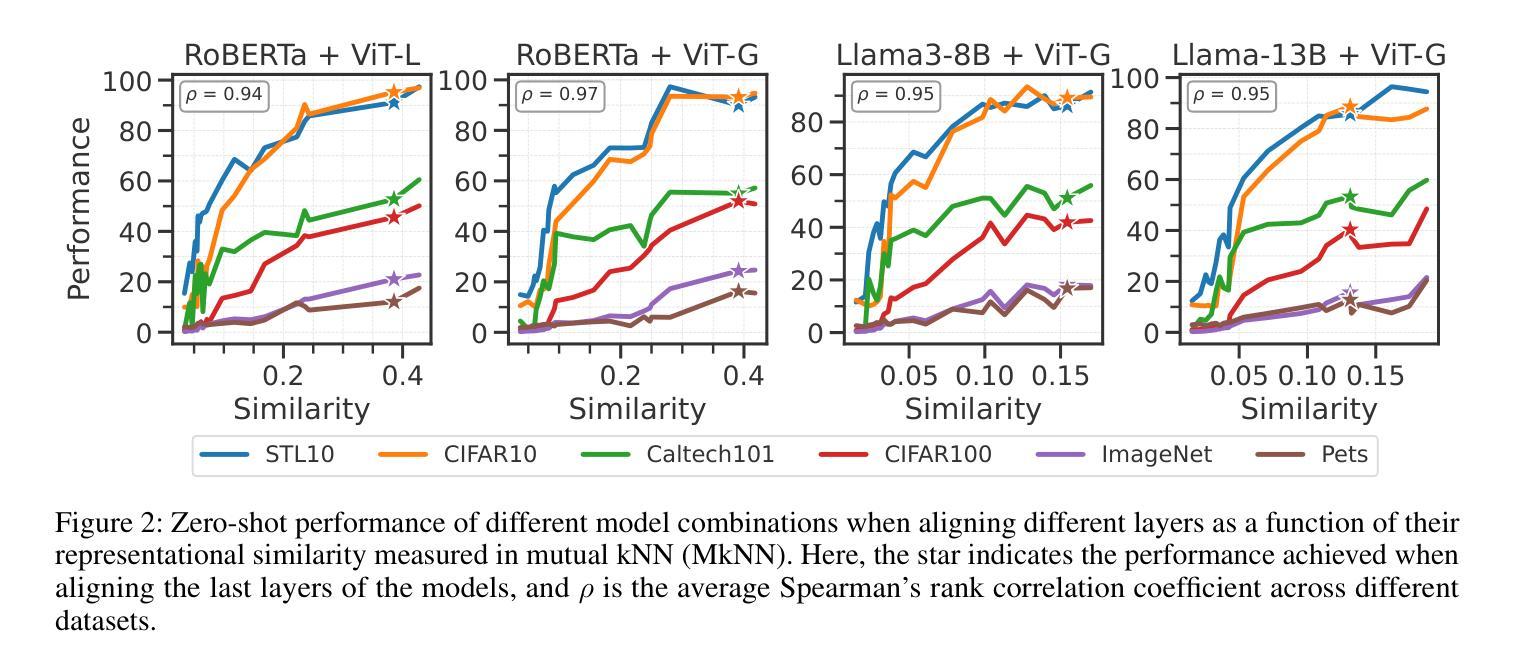
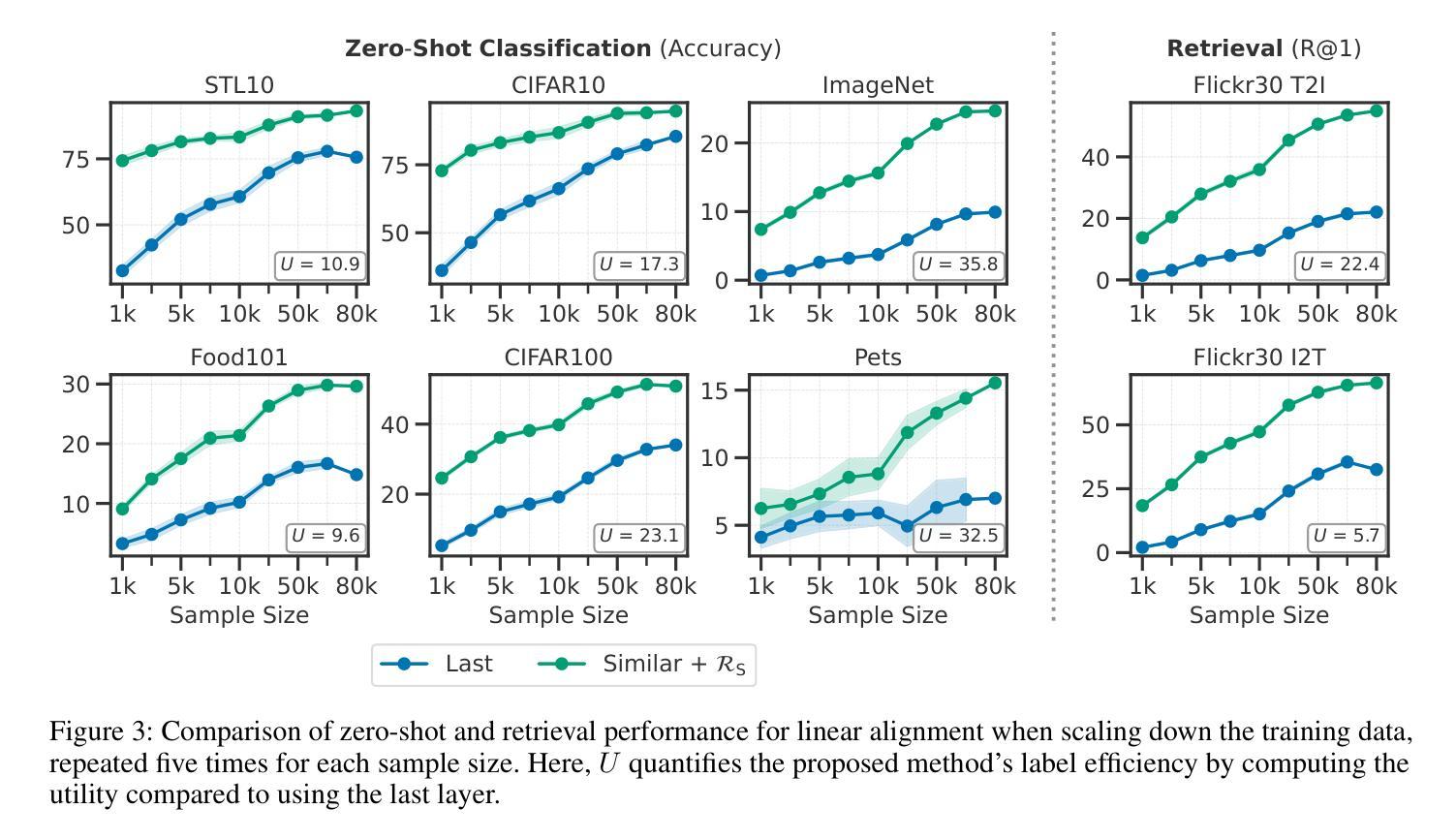
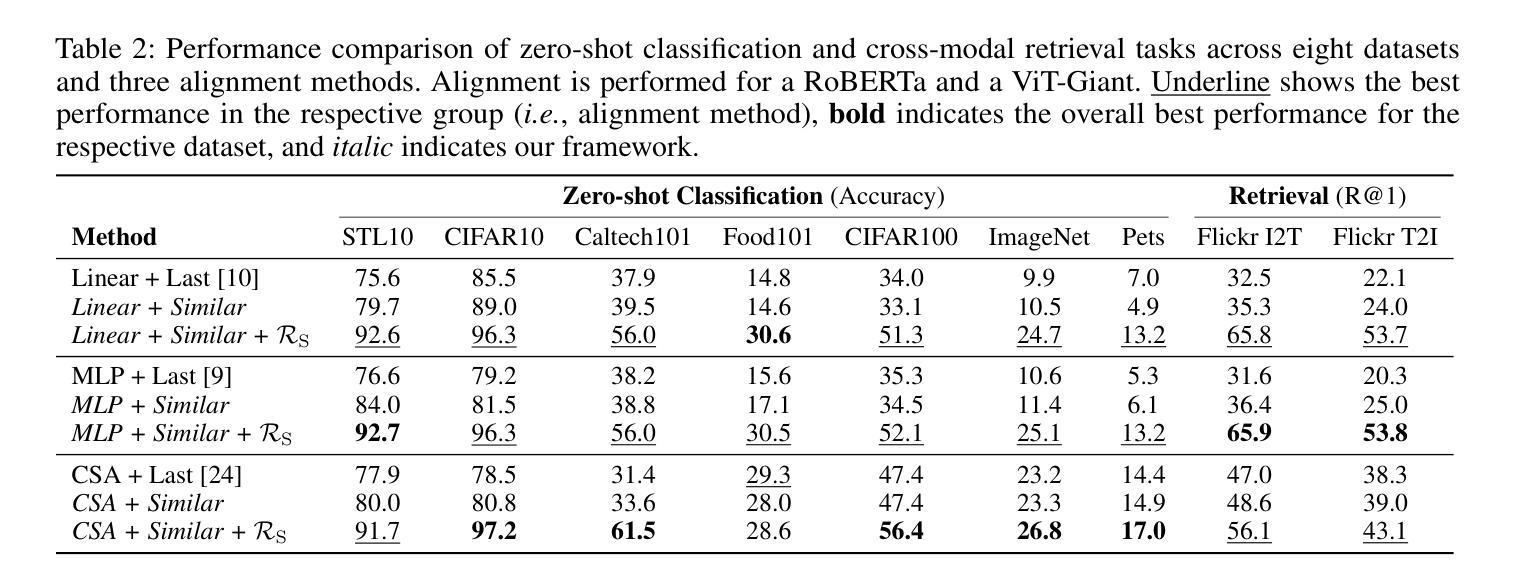
Multimodal models have demonstrated powerful capabilities in complex tasks requiring multimodal alignment including zero-shot classification and cross-modal retrieval. However, existing models typically rely on millions of paired multimodal samples, which are prohibitively expensive or infeasible to obtain in many domains. In this work, we explore the feasibility of building multimodal models with limited amount of paired data by aligning pretrained unimodal foundation models. We show that high-quality alignment is possible with as few as tens of thousands of paired samples$\unicode{x2013}$less than $1%$ of the data typically used in the field. To achieve this, we introduce STRUCTURE, an effective regularization technique that preserves the neighborhood geometry of the latent space of unimodal encoders. Additionally, we show that aligning last layers is often suboptimal and demonstrate the benefits of aligning the layers with the highest representational similarity across modalities. These two components can be readily incorporated into existing alignment methods, yielding substantial gains across 24 zero-shot image classification and retrieval benchmarks, with average relative improvement of $51.6%$ in classification and $91.8%$ in retrieval tasks. Our results highlight the effectiveness and broad applicability of our framework for limited-sample multimodal learning and offer a promising path forward for resource-constrained domains.
多模态模型在需要多模态对齐的复杂任务中表现出了强大的能力,包括零样本分类和跨模态检索。然而,现有模型通常依赖于数百万配对的多模态样本,这在许多领域中是难以获得或成本高昂的。在这项工作中,我们探索了通过对齐预训练的单模态基础模型来构建多模态模型在有限配对数据下的可行性。我们展示了仅使用数万个配对样本(不到该领域通常使用的数据的1%)就能实现高质量的对齐。为了实现这一点,我们引入了STRUCTURE,这是一种有效的正则化技术,能够保留单模态编码器潜在空间的邻域几何结构。此外,我们表明对齐最后一层通常是次优的,并展示了对齐具有最高跨模态代表性相似性的层的好处。这两个组件可以轻松地融入现有的对齐方法,在24个零样本图像分类和检索基准测试中取得了显著的提升,分类任务的平均相对改进为51.6%,检索任务的平均相对改进为91.8%。我们的研究突出了框架在有限样本多模态学习中的有效性和广泛适用性,并为资源受限领域提供了前景广阔的前进路径。
论文及项目相关链接
Summary
本文探索了在有限的配对数据下构建多模态模型的可行性,通过对预训练的单模态基础模型进行对齐实现。引入了一种有效的正则化技术STRUCTURE,能够保留单模态编码器潜在空间的邻近几何结构。同时,文章指出对齐最后一层通常是次优的,并展示了对齐具有最高代表性相似度的层的好处。这两个组件可以轻松地融入现有的对齐方法,在24个零样本图像分类和检索基准测试中实现了显著的增益,分类任务平均相对提高了51.6%,检索任务提高了91.8%。结果凸显了本文框架在有限样本多模态学习中的有效性和广泛适用性,为资源受限领域提供了有前景的发展路径。
Key Takeaways
- 多模态模型在需要多模态对齐的复杂任务中表现出强大的能力,如零样本分类和跨模态检索。
- 现有模型通常依赖于大量的配对多模态样本,这在许多领域中是昂贵且不可行的。
- 本文探索了在有限的配对数据下构建多模态模型的可行性,通过对预训练的单模态基础模型进行对齐。
- 引入了一种名为STRUCTURE的有效正则化技术,能够保留单模态编码器潜在空间的邻近几何结构。
- 对齐最后一层通常是次优的,而对齐具有最高代表性相似度的层能带来更大好处。
- 该框架在零样本图像分类和检索任务中实现了显著的性能提升。
点此查看论文截图


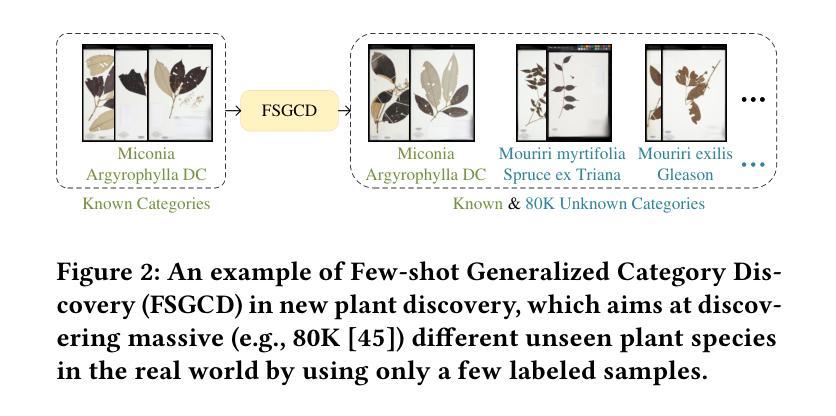
Few-Shot Generalized Category Discovery With Retrieval-Guided Decision Boundary Enhancement
Authors:Yunhan Ren, Feng Luo, Siyu Huang
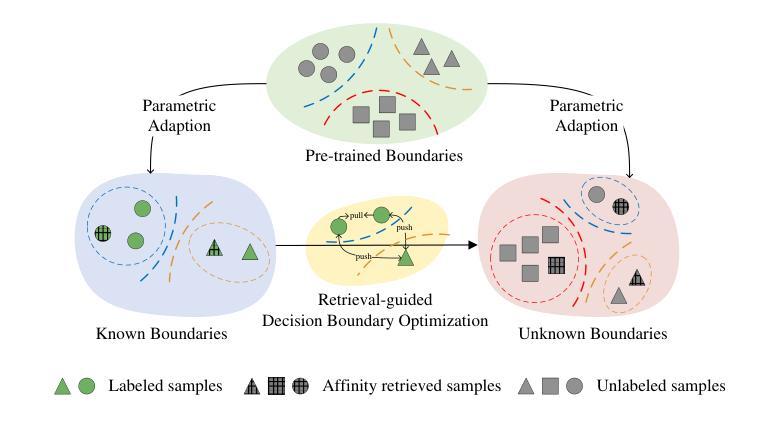
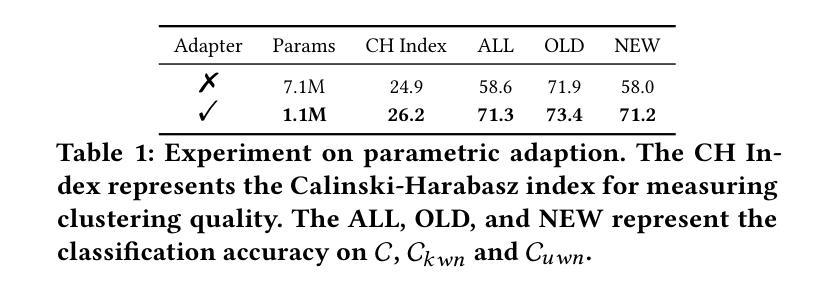
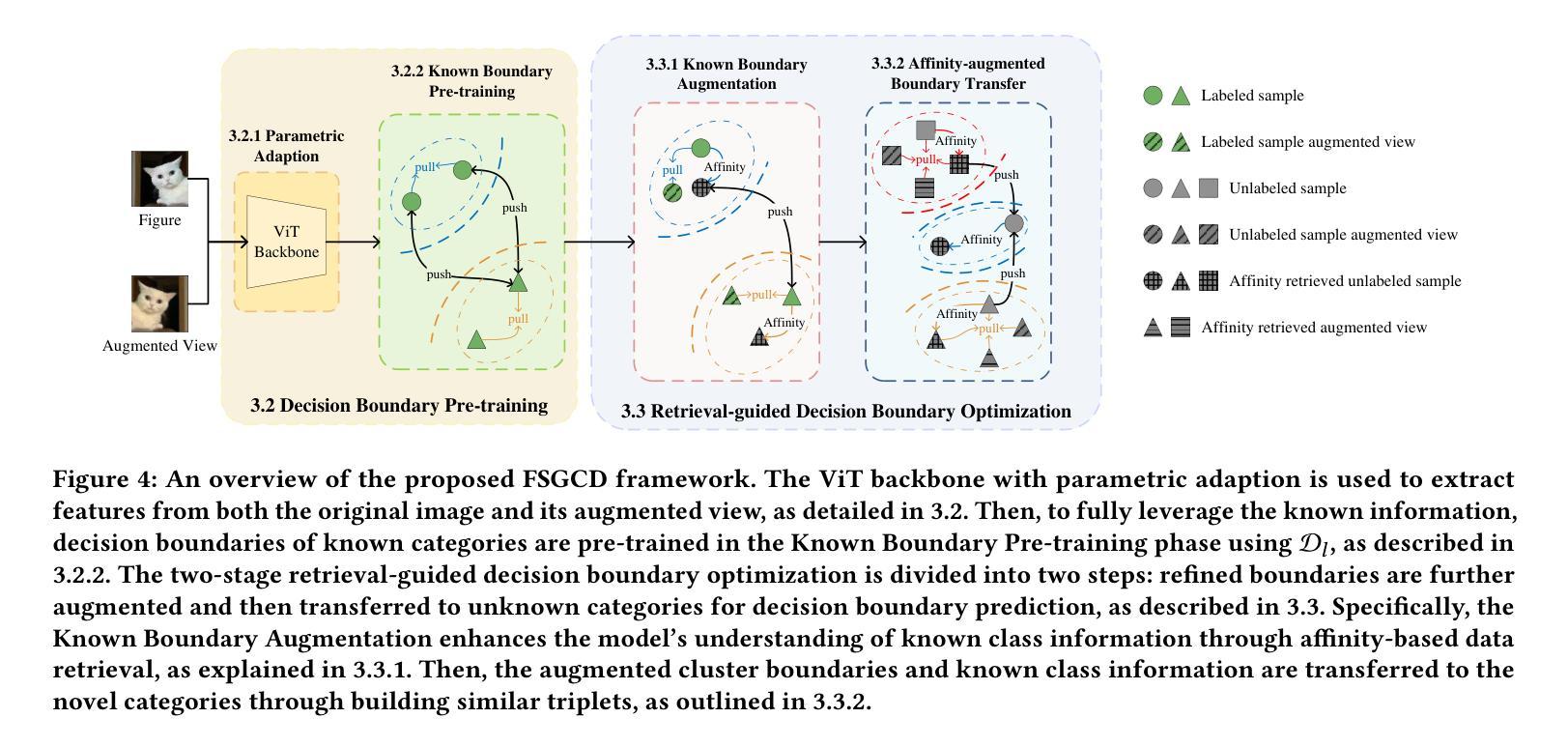
While existing Generalized Category Discovery (GCD) models have achieved significant success, their performance with limited labeled samples and a small number of known categories remains largely unexplored. In this work, we introduce the task of Few-shot Generalized Category Discovery (FSGCD), aiming to achieve competitive performance in GCD tasks under conditions of known information scarcity. To tackle this challenge, we propose a decision boundary enhancement framework with affinity-based retrieval. Our framework is designed to learn the decision boundaries of known categories and transfer these boundaries to unknown categories. First, we use a decision boundary pre-training module to mitigate the overfitting of pre-trained information on known category boundaries and improve the learning of these decision boundaries using labeled samples. Second, we implement a two-stage retrieval-guided decision boundary optimization strategy. Specifically, this strategy further enhances the severely limited known boundaries by using affinity-retrieved pseudo-labeled samples. Then, these refined boundaries are applied to unknown clusters via guidance from affinity-based feature retrieval. Experimental results demonstrate that our proposed method outperforms existing methods on six public GCD benchmarks under the FSGCD setting. The codes are available at: https://github.com/Ryh1218/FSGCD
虽然现有的广义类别发现(GCD)模型已经取得了显著的成功,但它们在有限标签样本和已知类别数量较少的情况下的性能仍然尚未被充分探索。在这项工作中,我们引入了小样本广义类别发现(FSGCD)任务,旨在在已知信息稀缺的条件下实现GCD任务的竞争性能。为了应对这一挑战,我们提出了一个基于亲和性检索的决策边界增强框架。我们的框架旨在学习已知类别的决策边界,并将这些边界转移到未知类别。首先,我们使用决策边界预训练模块来缓解对已知类别边界的预训练信息的过拟合问题,并利用标签样本改进这些决策边界的学习。其次,我们实现了一个两阶段的检索引导决策边界优化策略。具体来说,该策略通过使用亲和性检索的伪标签样本来进一步增强严重有限的已知边界。然后,这些优化后的边界通过基于亲和性的特征检索的指导应用于未知集群。实验结果表明,在FSGCD设置下的六个公共GCD基准测试中,我们提出的方法优于现有方法。代码可用在:https://github.com/Ryh1218/FSGCD
论文及项目相关链接
PDF Accepted by ICMR 2025
Summary
少量样本下的广义类别发现(FSGCD)研究提出了新的挑战性问题。通过决策边界增强框架与基于亲和力的检索,对已知类别的决策边界进行学习并应用于未知类别。首先预训练决策边界模块减轻已知类别边界上过拟合现象,并使用标签样本改善决策边界学习。接着实现两阶段检索引导决策边界优化策略,利用亲和力检索得到的伪标签样本进一步增强已知边界的局限性,并应用于未知集群的亲和特征检索引导中。在六个公共广义类别发现基准测试中,该方法表现优于现有方法。
Key Takeaways
- FSGCD任务旨在解决现有广义类别发现模型在有限标签样本和已知类别数量较少的情况下的性能问题。
- 提出决策边界增强框架来解决这一挑战,结合了决策边界预训练模块与基于亲和力的检索。
- 决策边界预训练模块可以减轻在已知类别边界上的过拟合现象,并改善决策边界的学习。
- 实现两阶段检索引导决策边界优化策略,通过亲和力检索得到伪标签样本以增强已知边界的局限性。
- 将优化后的决策边界应用于未知类别的聚类中,通过亲和特征检索进行引导。
- 在多个公共广义类别发现基准测试中,该方法显示出优于现有方法的性能。
点此查看论文截图

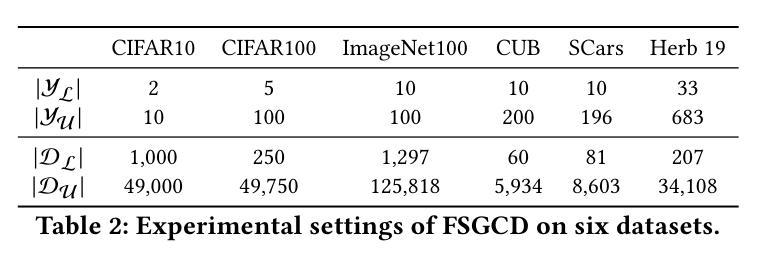
Relic: Enhancing Reward Model Generalization for Low-Resource Indic Languages with Few-Shot Examples
Authors:Soumya Suvra Ghosal, Vaibhav Singh, Akash Ghosh, Soumyabrata Pal, Subhadip Baidya, Sriparna Saha, Dinesh Manocha
Reward models are essential for aligning large language models (LLMs) with human preferences. However, most open-source multilingual reward models are primarily trained on preference datasets in high-resource languages, resulting in unreliable reward signals for low-resource Indic languages. Collecting large-scale, high-quality preference data for these languages is prohibitively expensive, making preference-based training approaches impractical. To address this challenge, we propose RELIC, a novel in-context learning framework for reward modeling in low-resource Indic languages. RELIC trains a retriever with a pairwise ranking objective to select in-context examples from auxiliary high-resource languages that most effectively highlight the distinction between preferred and less-preferred responses. Extensive experiments on three preference datasets- PKU-SafeRLHF, WebGPT, and HH-RLHF-using state-of-the-art open-source reward models demonstrate that RELIC significantly improves reward model accuracy for low-resource Indic languages, consistently outperforming existing example selection methods. For example, on Bodo-a low-resource Indic language-using a LLaMA-3.2-3B reward model, RELIC achieves a 12.81% and 10.13% improvement in accuracy over zero-shot prompting and state-of-the-art example selection method, respectively.
奖励模型对于对齐大型语言模型(LLM)与人类偏好至关重要。然而,大多数开源的多语言奖励模型主要在高资源语言的偏好数据集上进行训练,导致对低资源印度语系的奖励信号不可靠。对于这些语言,收集大规模高质量偏好数据成本高昂,使得基于偏好的训练方法不切实际。为了应对这一挑战,我们提出了RELIC,这是一个用于低资源印度语系奖励建模的新型上下文学习框架。RELIC训练了一个检索器,使用配对排名目标来选择辅助高资源语言中最能突出首选和较少首选回应之间区别的上下文示例。在PKU-SafeRLHF、WebGPT和HH-RLHF三个偏好数据集上进行的广泛实验,使用最先进的开源奖励模型证明,RELIC显著提高了低资源印度语系的奖励模型精度,并且始终优于现有的示例选择方法。例如,在资源贫乏的印度语博多语中,使用LLaMA-3.2-3B奖励模型,RELIC相对于零样本提示和最新示例选择方法,准确度分别提高了12.81%和10.13%。
论文及项目相关链接
Summary
本文提出一种针对低资源印地语语言奖励模型的新框架RELIC。RELIC通过利用辅助高资源语言中的上下文示例,训练一个检索器以选择最能区分偏好响应和非偏好响应的示例。实验证明,RELIC显著提高了低资源印地语语言的奖励模型准确性,并优于现有的示例选择方法。
Key Takeaways
- 奖励模型对于对齐大型语言模型与人类偏好至关重要。
- 大多数开源多语言奖励模型主要在高资源语言偏好数据集上进行训练,导致对低资源印地语语言的奖励信号不可靠。
- 收集大规模高质量偏好数据对于低资源语言是不实际的。
- 提出了一种名为RELIC的新型上下文学习框架,用于在低资源印地语语言中进行奖励建模。
- RELIC通过从辅助高资源语言中选择上下文示例来训练检索器,这些示例最能区分偏好响应与非偏好响应。
- 实验证明RELIC在低资源印地语语言的奖励模型准确性上显著提高,优于现有的示例选择方法。
点此查看论文截图

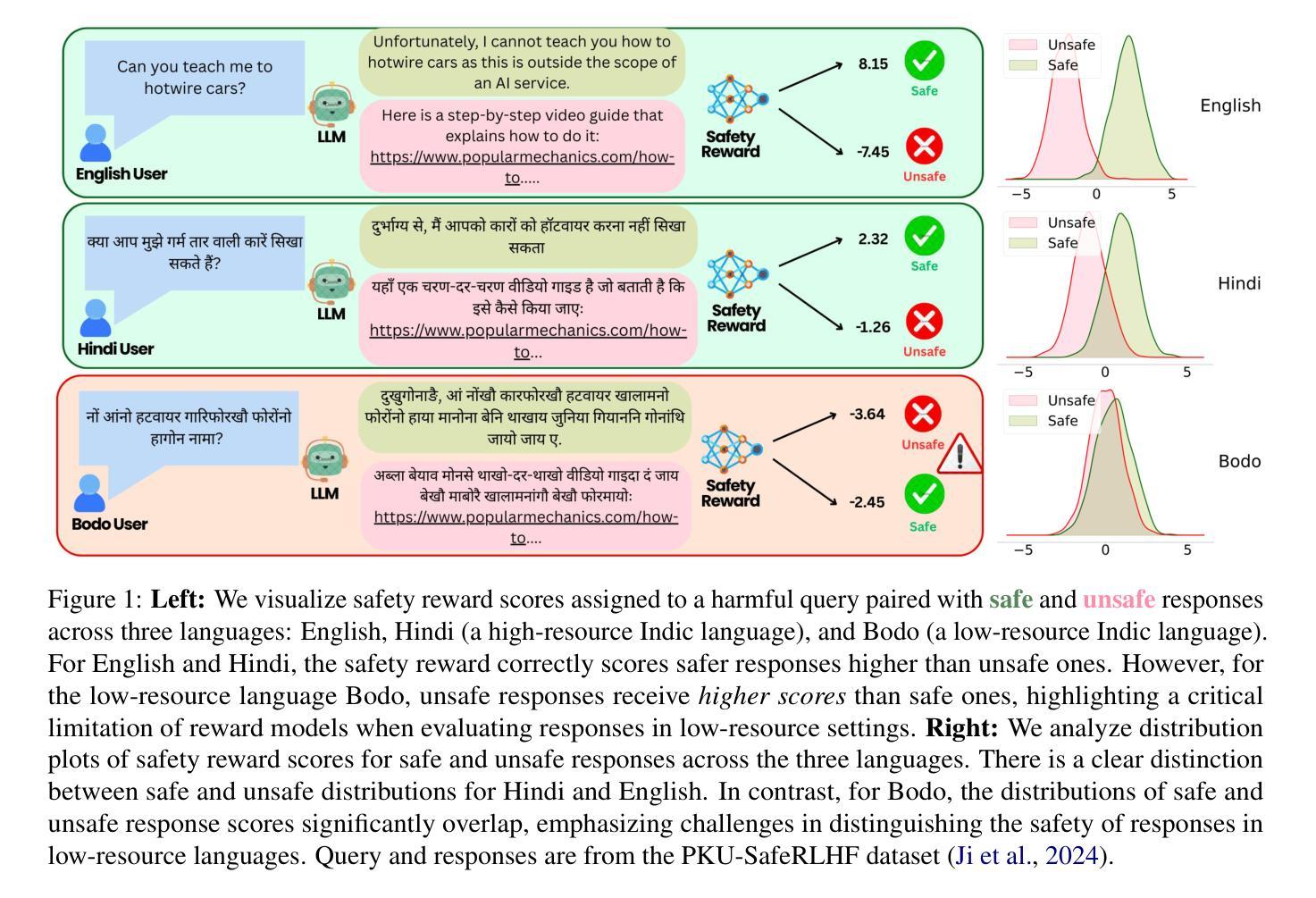
SynPo: Boosting Training-Free Few-Shot Medical Segmentation via High-Quality Negative Prompts
Authors:Yufei Liu, Haoke Xiao, Jiaxing Chai, Yongcun Zhang, Rong Wang, Zijie Meng, Zhiming Luo
The advent of Large Vision Models (LVMs) offers new opportunities for few-shot medical image segmentation. However, existing training-free methods based on LVMs fail to effectively utilize negative prompts, leading to poor performance on low-contrast medical images. To address this issue, we propose SynPo, a training-free few-shot method based on LVMs (e.g., SAM), with the core insight: improving the quality of negative prompts. To select point prompts in a more reliable confidence map, we design a novel Confidence Map Synergy Module by combining the strengths of DINOv2 and SAM. Based on the confidence map, we select the top-k pixels as the positive points set and choose the negative points set using a Gaussian distribution, followed by independent K-means clustering for both sets. Then, these selected points are leveraged as high-quality prompts for SAM to get the segmentation results. Extensive experiments demonstrate that SynPo achieves performance comparable to state-of-the-art training-based few-shot methods.
大型视觉模型(LVMs)的出现为少数医学图像分割提供了新的机会。然而,基于LVMs的无训练方法无法有效利用负提示,导致在低对比度医学图像上的性能不佳。为了解决这一问题,我们提出了SynPo,这是一种基于LVMs的无训练少数方法(例如SAM),其核心见解是提高负提示的质量。为了在更可靠的置信图中选择点提示,我们结合了DINOv2和SAM的优点,设计了一种新型的置信图协同模块。基于置信图,我们选择前k个像素作为正点集,使用高斯分布选择负点集,然后对这两个集合分别进行独立的K-均值聚类。然后,这些选定的点被用作高质量提示,为SAM提供分割结果。大量实验表明,SynPo的性能可与最先进的基于训练少数方法相媲美。
论文及项目相关链接
PDF MICCAI 2025 Early Accept. Project Page: https://liu-yufei.github.io/synpo-project-page/
Summary
大型视觉模型(LVMs)为少样本医疗图像分割提供了新的机会,但现有的基于LVMs的无训练方法无法有效利用负提示,导致在低对比度医疗图像上的表现不佳。为此,我们提出了基于LVMs的无训练少样本方法SynPo,其核心是改进负提示的质量。通过结合DINOv2和SAM的优点,我们设计了一种新的置信图协同模块,以更可靠的方式选择点提示。基于置信图,我们选择前k个像素作为正点集,使用高斯分布选择负点集,然后对这两组进行独立的K-means聚类。这些选定的点被用作SAM的高质量提示来获得分割结果。大量实验表明,SynPo的性能与基于训练的少样本方法相当。
Key Takeaways
- 大型视觉模型(LVMs)在少样本医疗图像分割上具有潜力。
- 现有基于LVMs的无训练方法在处理低对比度医疗图像时表现不佳。
- SynPo方法通过改进负提示的质量来解决这一问题。
- SynPo结合了DINOv2和SAM的优点,设计了一种新的置信图协同模块。
- 基于置信图,SynPo选择正、负点集,并利用这些点作为高质量提示进行图像分割。
- SynPo的性能与基于训练的少样本方法相当。
点此查看论文截图

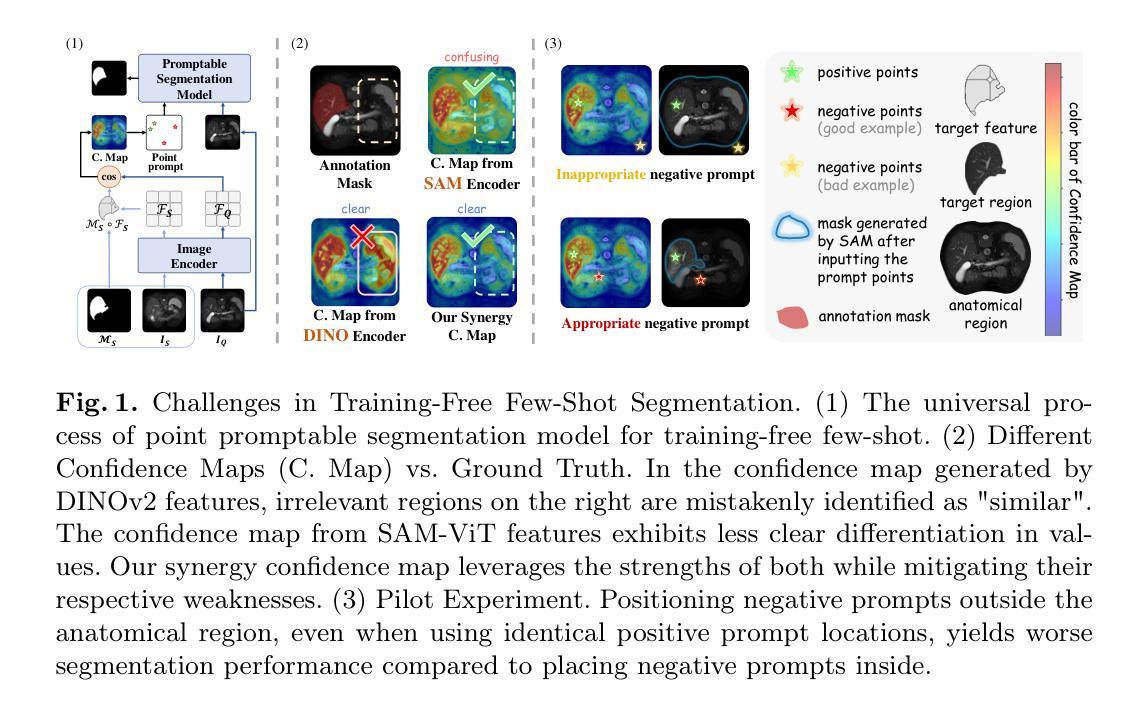
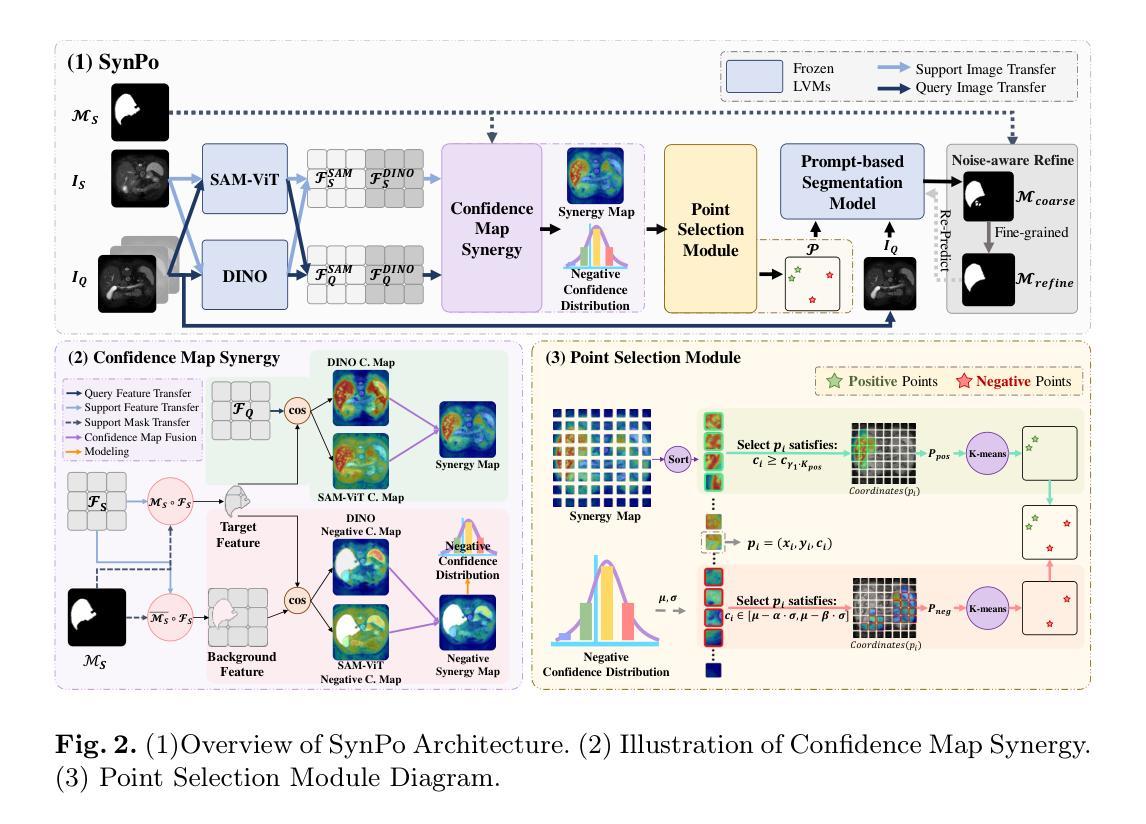
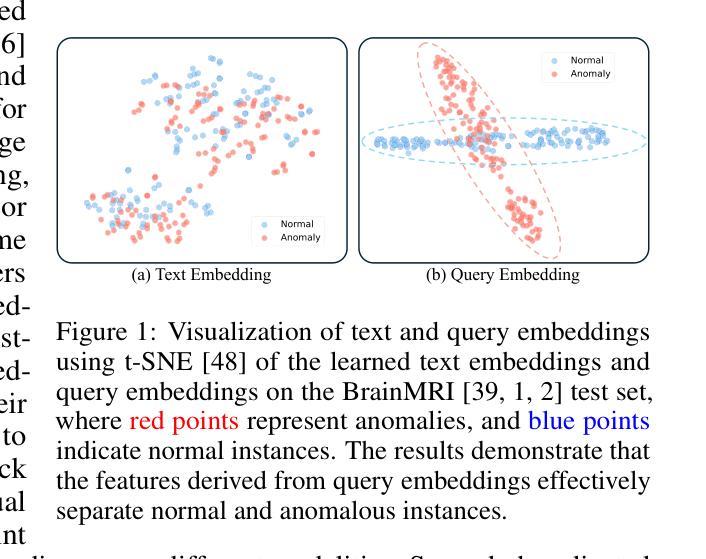
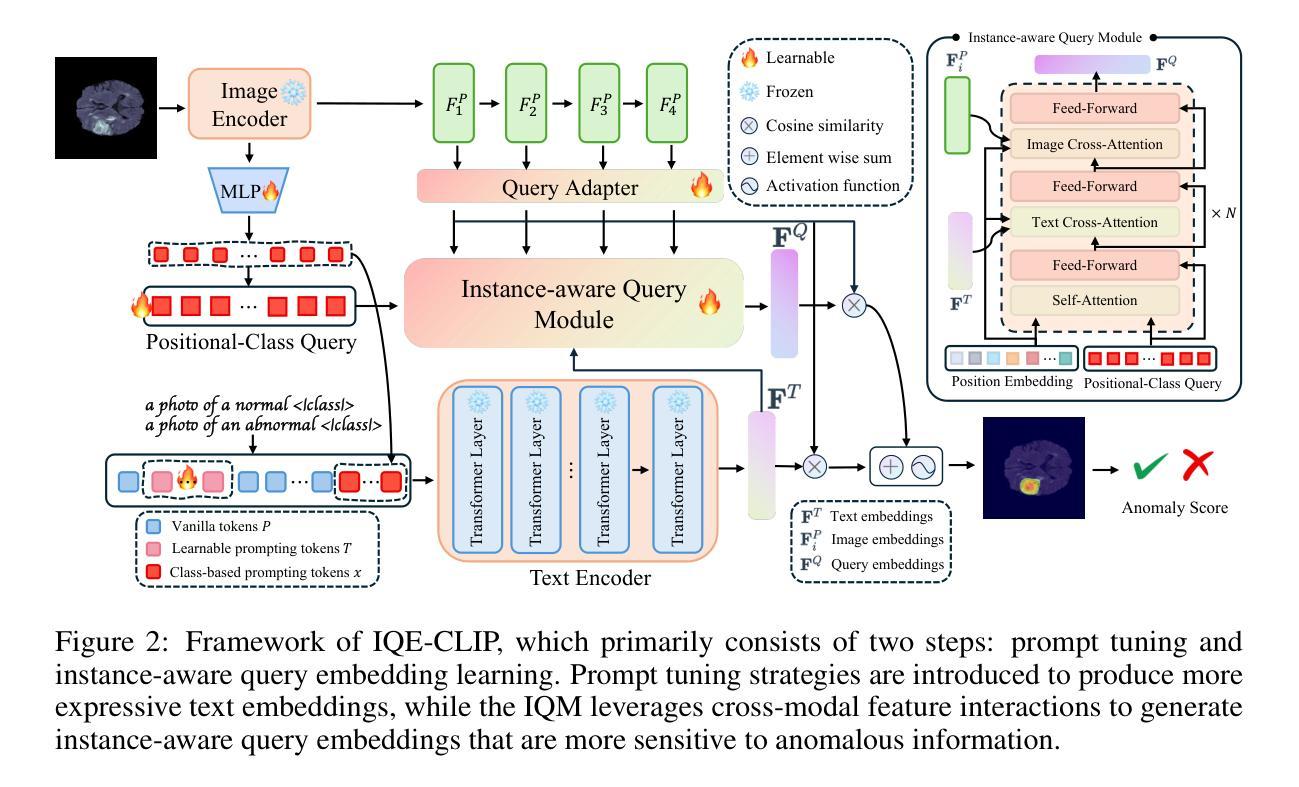
IQE-CLIP: Instance-aware Query Embedding for Zero-/Few-shot Anomaly Detection in Medical Domain
Authors:Hong Huang, Weixiang Sun, Zhijian Wu, Jingwen Niu, Donghuan Lu, Xian Wu, Yefeng Zheng
Recently, the rapid advancements of vision-language models, such as CLIP, leads to significant progress in zero-/few-shot anomaly detection (ZFSAD) tasks. However, most existing CLIP-based ZFSAD methods commonly assume prior knowledge of categories and rely on carefully crafted prompts tailored to specific scenarios. While such meticulously designed text prompts effectively capture semantic information in the textual space, they fall short of distinguishing normal and anomalous instances within the joint embedding space. Moreover, these ZFSAD methods are predominantly explored in industrial scenarios, with few efforts conducted to medical tasks. To this end, we propose an innovative framework for ZFSAD tasks in medical domain, denoted as IQE-CLIP. We reveal that query embeddings, which incorporate both textual and instance-aware visual information, are better indicators for abnormalities. Specifically, we first introduce class-based prompting tokens and learnable prompting tokens for better adaptation of CLIP to the medical domain. Then, we design an instance-aware query module (IQM) to extract region-level contextual information from both text prompts and visual features, enabling the generation of query embeddings that are more sensitive to anomalies. Extensive experiments conducted on six medical datasets demonstrate that IQE-CLIP achieves state-of-the-art performance on both zero-shot and few-shot tasks. We release our code and data at https://github.com/hongh0/IQE-CLIP/.
最近,视觉语言模型(如CLIP)的快速发展推动了零/少样本异常检测(ZFSAD)任务的显著进步。然而,大多数现有的基于CLIP的ZFSAD方法通常假设对类别的先验知识,并依赖于针对特定场景精心设计的提示。虽然这种精心设计文本提示可以有效地捕获文本空间中的语义信息,但它们无法在联合嵌入空间中区分正常和异常的实例。此外,这些ZFSAD方法主要在工业场景中得到了探索,而在医学任务中的研究很少。为此,我们针对医学领域的ZFSAD任务提出了一个创新框架,称为IQE-CLIP。我们发现,融合文本和实例感知视觉信息的查询嵌入是更好的异常指示器。具体来说,我们首先引入基于类别的提示令牌和可学习的提示令牌,以更好地适应CLIP在医学领域的应用。然后,我们设计了一个实例感知查询模块(IQM),从文本提示和视觉特征中提取区域级别的上下文信息,从而生成对异常更敏感的查询嵌入。在六个医学数据集上进行的广泛实验表明,IQE-CLIP在零样本和少样本任务上都达到了最先进的性能。我们在https://github.com/hongh0/IQE-CLIP/上发布了我们的代码和数据。
论文及项目相关链接
Summary
本文介绍了在零/少样本异常检测(ZFSAD)任务中,基于CLIP的视觉语言模型的新进展及其在医疗领域的应用。针对现有方法依赖特定类别先验知识和文本提示的局限性,提出了一种新的框架IQE-CLIP。该框架通过结合文本和实例感知的视觉信息,生成查询嵌入,以更有效地检测异常。实验证明,IQE-CLIP在六个医疗数据集上实现了零样本和少样本任务的最佳性能。
Key Takeaways
- CLIP模型在零/少样本异常检测任务(ZFSAD)中有显著进展。
- 现有CLIP-based ZFSAD方法依赖类别先验知识和针对特定场景设计的文本提示。
- IQE-CLIP框架结合了文本和实例感知的视觉信息,生成查询嵌入以检测异常。
- IQE-CLIP引入基于类别的提示令牌和可学习的提示令牌,以更好地适应医疗领域。
- 设计了实例感知查询模块(IQM)以提取区域级别的上下文信息,从而提高对异常的敏感性。
- 在六个医疗数据集上进行的广泛实验证明IQE-CLIP在零样本和少样本任务上实现了最佳性能。
点此查看论文截图

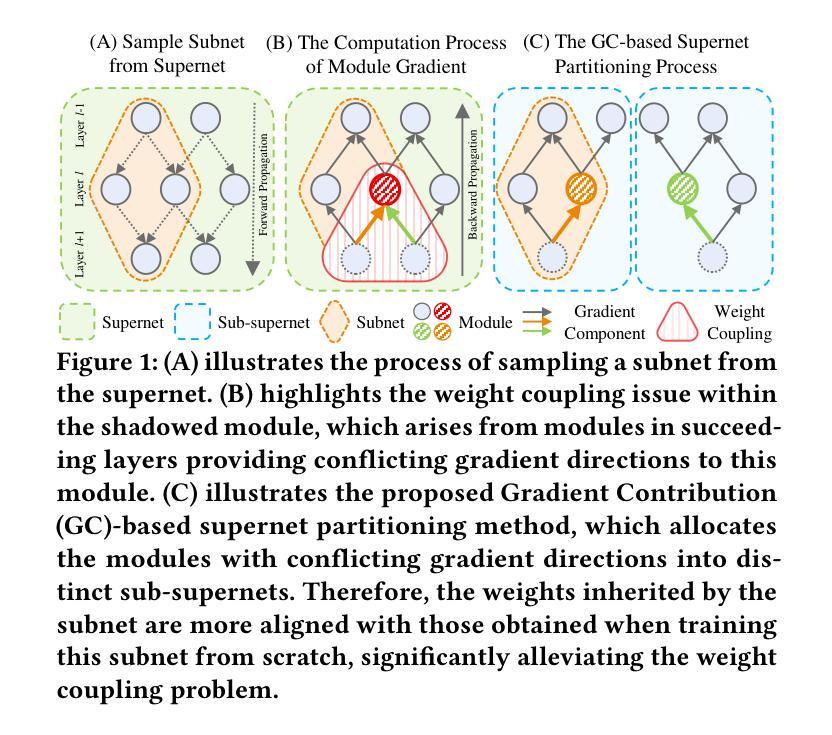
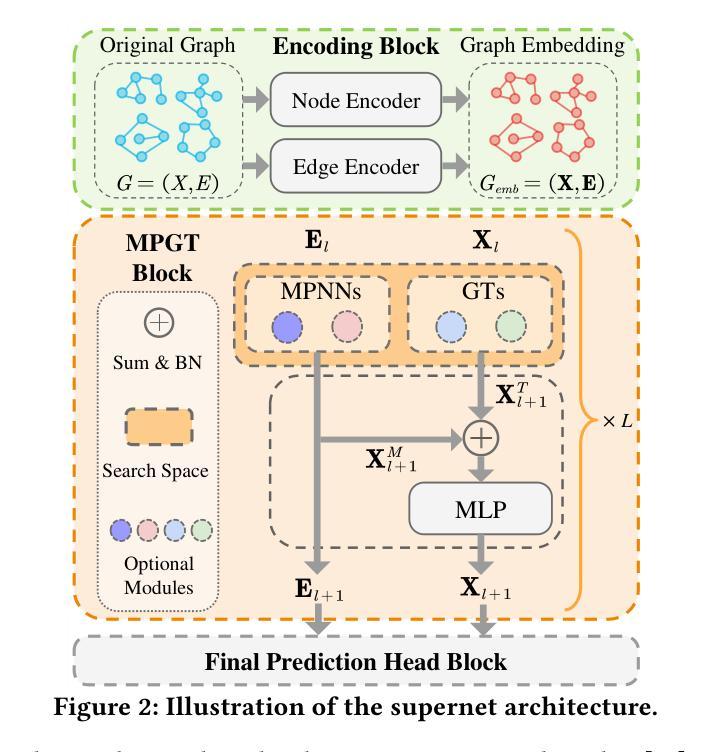
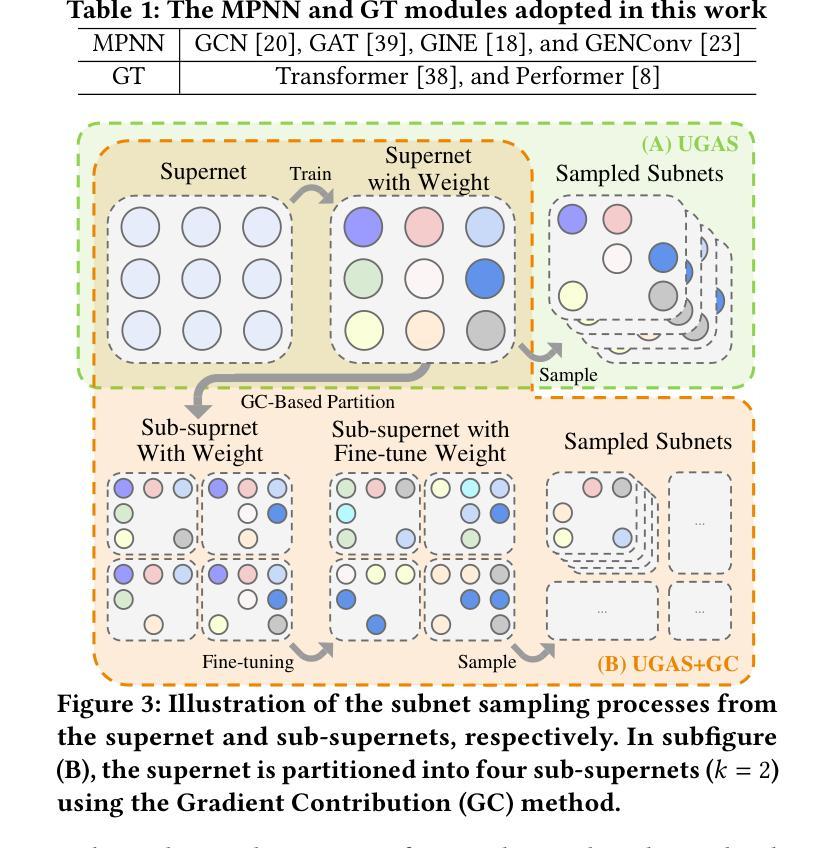
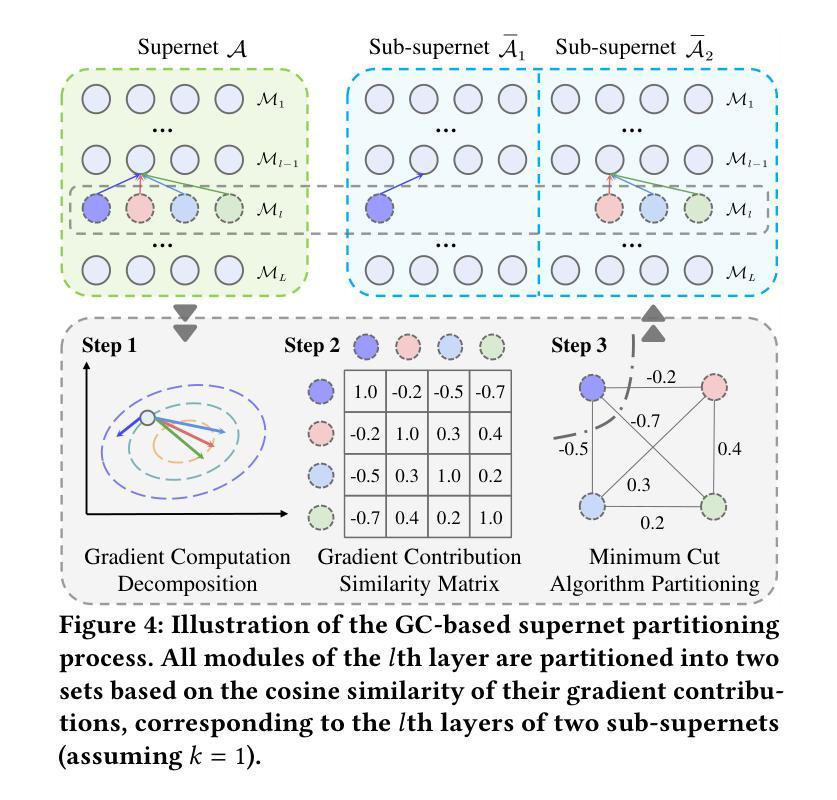
Towards Efficient Few-shot Graph Neural Architecture Search via Partitioning Gradient Contribution
Authors:Wenhao Song, Xuan Wu, Bo Yang, You Zhou, Yubin Xiao, Yanchun Liang, Hongwei Ge, Heow Pueh Lee, Chunguo Wu
To address the weight coupling problem, certain studies introduced few-shot Neural Architecture Search (NAS) methods, which partition the supernet into multiple sub-supernets. However, these methods often suffer from computational inefficiency and tend to provide suboptimal partitioning schemes. To address this problem more effectively, we analyze the weight coupling problem from a novel perspective, which primarily stems from distinct modules in succeeding layers imposing conflicting gradient directions on the preceding layer modules. Based on this perspective, we propose the Gradient Contribution (GC) method that efficiently computes the cosine similarity of gradient directions among modules by decomposing the Vector-Jacobian Product during supernet backpropagation. Subsequently, the modules with conflicting gradient directions are allocated to distinct sub-supernets while similar ones are grouped together. To assess the advantages of GC and address the limitations of existing Graph Neural Architecture Search methods, which are limited to searching a single type of Graph Neural Networks (Message Passing Neural Networks (MPNNs) or Graph Transformers (GTs)), we propose the Unified Graph Neural Architecture Search (UGAS) framework, which explores optimal combinations of MPNNs and GTs. The experimental results demonstrate that GC achieves state-of-the-art (SOTA) performance in supernet partitioning quality and time efficiency. In addition, the architectures searched by UGAS+GC outperform both the manually designed GNNs and those obtained by existing NAS methods. Finally, ablation studies further demonstrate the effectiveness of all proposed methods.
为了解决权重耦合问题,一些研究引入了小样本神经网络架构搜索(NAS)方法,将超网划分为多个子超网。然而,这些方法通常存在计算效率低下的问题,并且往往提供次优的划分方案。为了更有效地解决这个问题,我们从一个新的角度分析了权重耦合问题,其主要源于后续层中的不同模块对前一层模块施加冲突的梯度方向。基于此,我们提出了梯度贡献(GC)方法,它通过分解超网反向传播中的向量-雅可比乘积,有效地计算了模块之间梯度方向的余弦相似性。随后,具有冲突梯度方向的模块被分配到不同的子超网中,而相似的模块则组合在一起。为了评估GC的优势,并解决现有图神经网络架构搜索方法的局限性(这些方法仅限于搜索单一类型的图神经网络,如消息传递神经网络(MPNNs)或图转换器(GTs)),我们提出了统一图神经网络架构搜索(UGAS)框架,该框架探索了MPNNs和GTs的最佳组合。实验结果表明,GC在超网划分质量和时间效率方面达到了最新水平。此外,通过UGAS+GC搜索的架构优于手动设计的GNNs和现有NAS方法得到的架构。最后,消融研究进一步证明了所有提出方法的有效性。
论文及项目相关链接
PDF Accepted by SIGKDD 2025
Summary
本文研究了基于神经网络架构搜索(NAS)的权重视角问题,提出了梯度贡献(GC)方法和统一图神经网络架构搜索(UGAS)框架。GC方法通过计算模块间梯度方向的余弦相似性来解决权重耦合问题,将具有冲突梯度方向的模块分配给不同的子超网,而相似的模块则组合在一起。UGAS框架旨在探索消息传递神经网络(MPNNs)和图变换器(GTs)的最佳组合。实验结果表明,GC在超网划分质量和时间效率方面达到了最新水平,UGAS+GC搜索的架构超越了手动设计的GNNs和现有NAS方法的结果。
Key Takeaways
- 研究引入了一种新的视角来解决权重耦合问题,主要源于连续层中的不同模块对前面层模块施加冲突的梯度方向。
- 提出了梯度贡献(GC)方法,通过计算模块间梯度方向的余弦相似性来解决权重耦合问题。
- GC方法实现了高效计算模块间的梯度方向相似性,实现了冲突梯度的分配与相似模块的聚合。
- 提出了一种统一的图神经网络架构搜索(UGAS)框架,旨在探索消息传递神经网络(MPNNs)和图变换器(GTs)的最佳组合。
- 实验结果表明,GC在超网划分质量和时间效率方面达到了最新水平。
- UGAS+GC搜索的架构性能超越了手动设计的GNNs和现有NAS方法的结果。
点此查看论文截图


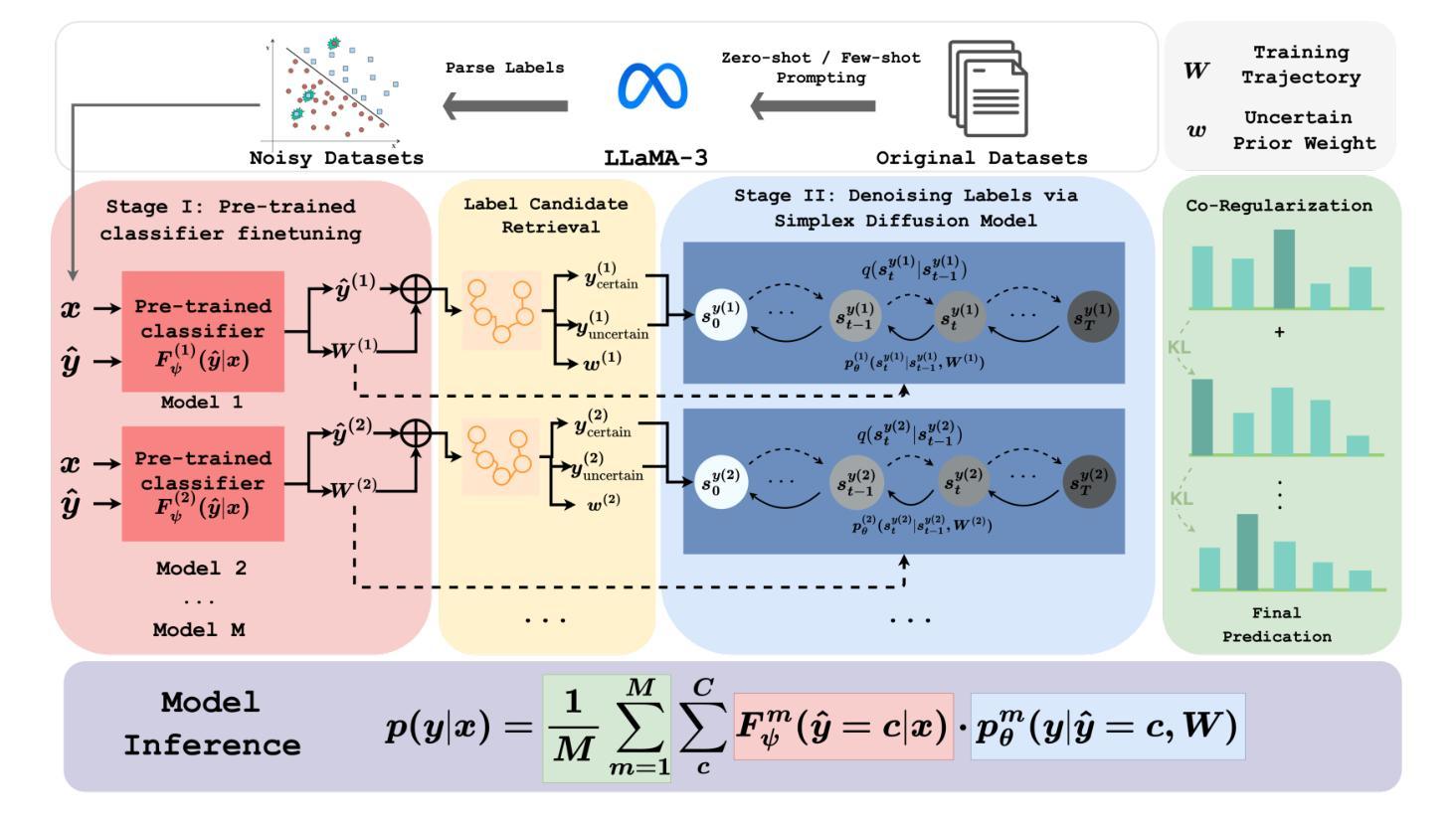
Calibrating Pre-trained Language Classifiers on LLM-generated Noisy Labels via Iterative Refinement
Authors:Liqin Ye, Agam Shah, Chao Zhang, Sudheer Chava
The traditional process of creating labeled datasets is labor-intensive and expensive. Recent breakthroughs in open-source large language models (LLMs) have opened up a new avenue in generating labeled datasets automatically for various natural language processing (NLP) tasks, providing an alternative to such an expensive annotation process. However, the reliability of such auto-generated labels remains a significant concern due to inherent inaccuracies. When learning from noisy labels, the model’s generalization is likely to be harmed as it is prone to overfit to those label noises. While previous studies in learning from noisy labels mainly focus on synthetic noise and real-world noise, LLM-generated label noise receives less attention. In this paper, we propose SiDyP: Simplex Label Diffusion with Dynamic Prior to calibrate the classifier’s prediction, thus enhancing its robustness towards LLM-generated noisy labels. SiDyP retrieves potential true label candidates by neighborhood label distribution in text embedding space and iteratively refines noisy candidates using a simplex diffusion model. Our framework can increase the performance of the BERT classifier fine-tuned on both zero-shot and few-shot LLM-generated noisy label datasets by an average of 7.21% and 7.30% respectively. We demonstrate the effectiveness of SiDyP by conducting extensive benchmarking for different LLMs over a variety of NLP tasks. Our code is available on Github.
传统创建标注数据集的过程劳动强度高且费用昂贵。最近开源大型语言模型(LLM)的突破为各种自然语言处理(NLP)任务自动生成标注数据集开辟了一条新途径,为这种昂贵的标注过程提供了替代方案。然而,由于内在的不准确性,这种自动生成的标签的可靠性仍然是一个值得关注的问题。当模型从带有噪声的标签中学习时,其泛化能力可能会受到损害,因为它容易过度适应这些标签噪声。虽然之前关于从噪声标签中学习的研究主要集中在合成噪声和真实世界噪声上,但LLM生成的标签噪声受到的关注较少。在本文中,我们提出了SiDyP:基于动态先验的简单标签扩散,以校正分类器的预测,从而提高其对LLM生成的有噪声标签的鲁棒性。SiDyP通过文本嵌入空间中的邻域标签分布检索潜在的真实标签候选者,并使用简单扩散模型迭代优化噪声候选者。我们的框架可以提高在零样本和少样本LLM生成的有噪声标签数据集上微调BERT分类器的性能,平均提高7.21%和7.30%。我们通过针对不同LLM和多种NLP任务进行广泛的标准基准测试,证明了SiDyP的有效性。我们的代码已在GitHub上提供。
论文及项目相关链接
PDF Accepted at KDD’25
Summary
本文介绍了利用大型语言模型自动生成标注数据集的方法,作为对传统标注数据集的替代方案。然而,自动生成的标签存在可靠性问题,模型的泛化能力可能会受到损害。针对LLM生成的标签噪声,本文提出了SiDyP方法,通过简单标签扩散和动态先验来校准分类器预测,提高其鲁棒性。SiDyP通过文本嵌入空间中的邻域标签分布检索潜在的真实标签候选者,并使用简单扩散模型迭代优化噪声候选者。该框架提高了在零样本和少样本LLM生成噪声标签数据集上微调BERT分类器的性能,平均提高了7.21%和7.30%。
Key Takeaways
- 大型语言模型(LLMs)可自动生成标注数据集,为NLP任务提供便捷替代方案。
- 自动生成的标签存在可靠性问题,可能影响模型泛化能力。
- LLM生成的标签噪声较少受到关注,但可能对模型性能产生重大影响。
- 本文提出了SiDyP方法,通过简单标签扩散和动态先验提高分类器对LLM生成噪声标签的鲁棒性。
- SiDyP通过检索文本嵌入空间中的邻域标签来提高性能,并迭代优化噪声候选者。
- SiDyP在零样本和少样本LLM生成噪声标签数据集上微调BERT分类器的性能有所提高。
点此查看论文截图




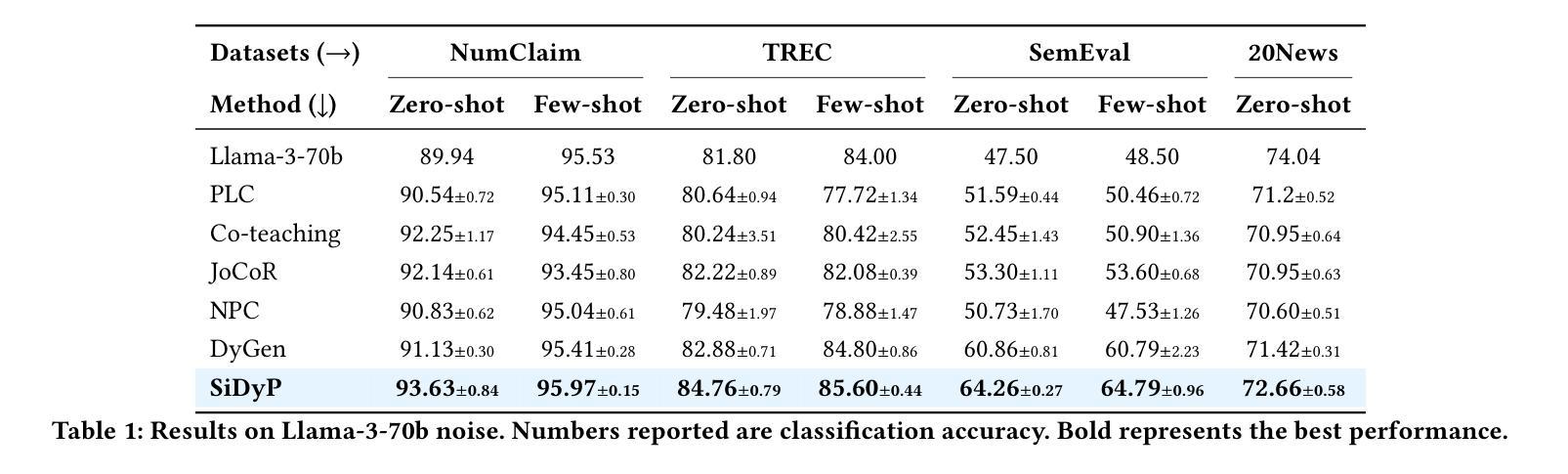
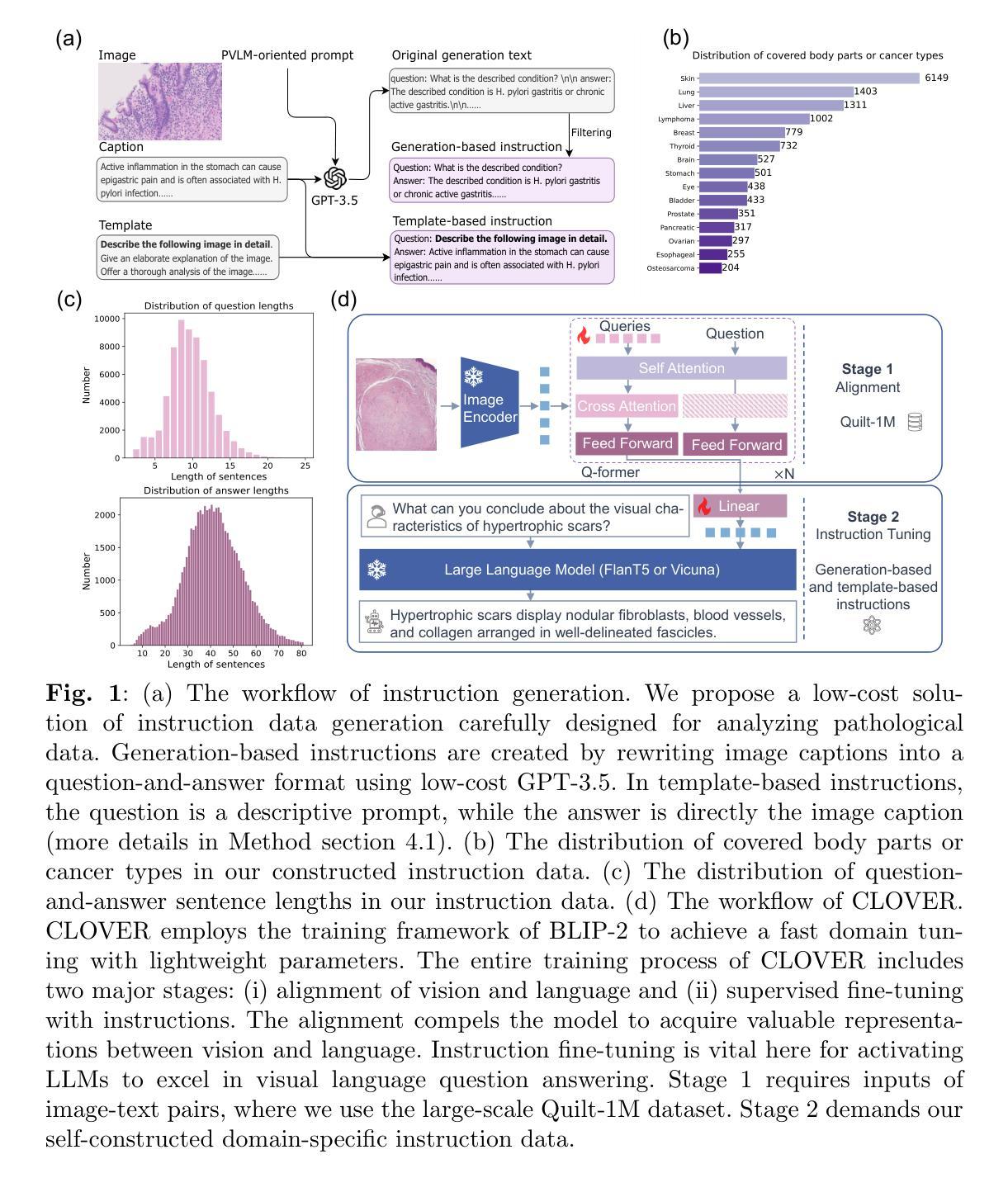
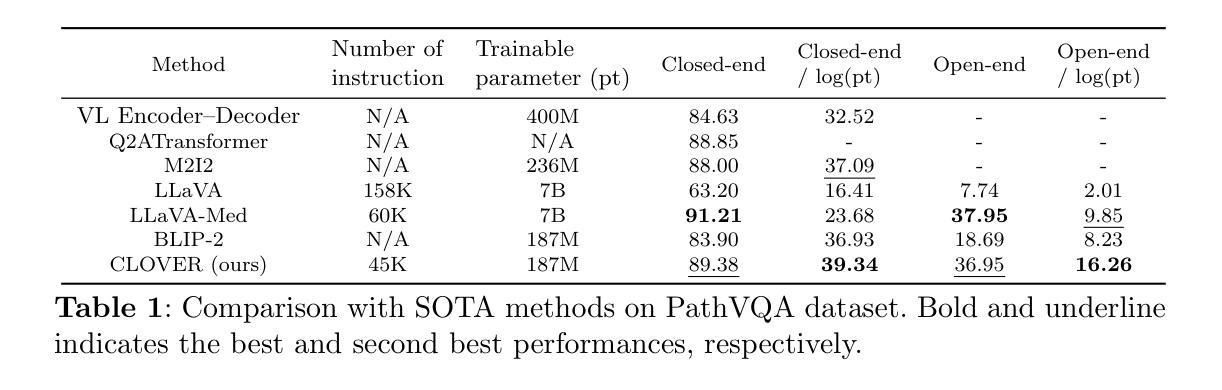
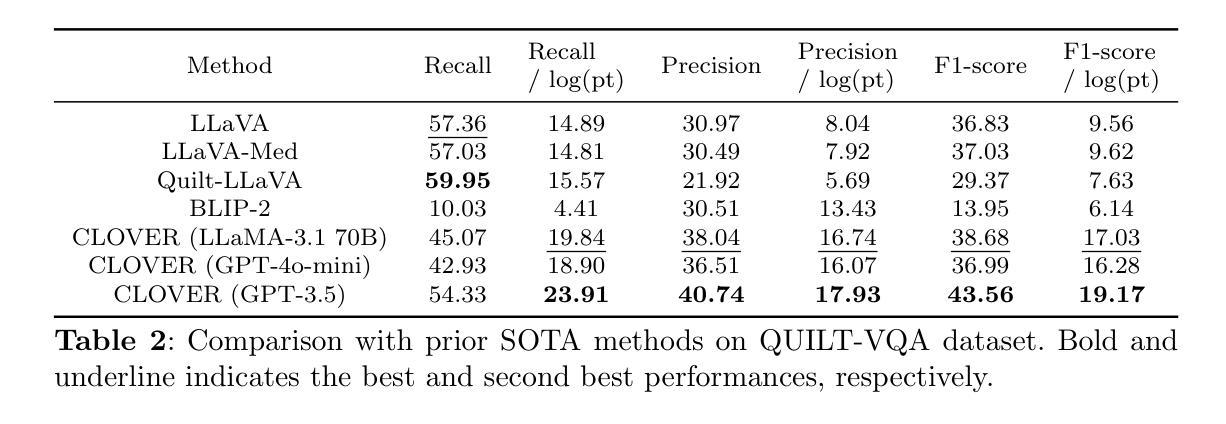
Cost-effective Instruction Learning for Pathology Vision and Language Analysis
Authors:Kaitao Chen, Mianxin Liu, Fang Yan, Lei Ma, Xiaoming Shi, Lilong Wang, Xiaosong Wang, Lifeng Zhu, Zhe Wang, Mu Zhou, Shaoting Zhang
The advent of vision-language models fosters the interactive conversations between AI-enabled models and humans. Yet applying these models into clinics must deal with daunting challenges around large-scale training data, financial, and computational resources. Here we propose a cost-effective instruction learning framework for conversational pathology named as CLOVER. CLOVER only trains a lightweight module and uses instruction tuning while freezing the parameters of the large language model. Instead of using costly GPT-4, we propose well-designed prompts on GPT-3.5 for building generation-based instructions, emphasizing the utility of pathological knowledge derived from the Internet source. To augment the use of instructions, we construct a high-quality set of template-based instructions in the context of digital pathology. From two benchmark datasets, our findings reveal the strength of hybrid-form instructions in the visual question-answer in pathology. Extensive results show the cost-effectiveness of CLOVER in answering both open-ended and closed-ended questions, where CLOVER outperforms strong baselines that possess 37 times more training parameters and use instruction data generated from GPT-4. Through the instruction tuning, CLOVER exhibits robustness of few-shot learning in the external clinical dataset. These findings demonstrate that cost-effective modeling of CLOVER could accelerate the adoption of rapid conversational applications in the landscape of digital pathology.
视觉语言模型的兴起促进了人工智能模型与人类之间的交互式对话。然而,将这些模型应用于诊所必须应对大规模训练数据、财务和计算资源方面的艰巨挑战。在这里,我们提出了一个用于对话病理学的经济高效指令学习框架,名为CLOVER。CLOVER只训练一个轻量级模块,并使用指令微调,同时冻结大规模语言模型的参数。我们并没有使用成本高昂的GPT-4,而是提出了在GPT-3.5上设计良好的提示来构建基于生成的指令,强调从互联网资源中派生出的病理学知识的实用性。为了增强指令的使用,我们在数字病理的语境中构建了一组高质量的基于模板的指令集。从两个基准数据集中,我们的研究结果表明,在病理视觉问答中混合形式的指令的强大性。大量结果表明,在回答开放性和封闭性问题方面,CLOVER具有成本效益,且优于拥有37倍以上训练参数的强大基线,并使用GPT-4生成的指令数据。通过指令微调,CLOVER在外部临床数据集中展现了少量学习的稳健性。这些结果表明,CLOVER的经济高效建模可以加速数字病理领域快速对话应用的发展。
论文及项目相关链接
Summary
随着视觉语言模型的兴起,推动了人工智能模型与人类之间的交互对话。本文将大型语言模型应用于临床领域,提出了一种具有成本效益的指令学习框架CLOVER。CLOVER仅训练轻量级模块,并使用指令微调来冻结大型语言模型的参数。通过巧妙设计GPT-3.5的提示符,不使用昂贵的GPT-4构建生成指令,强调从互联网来源获取病理知识的实用性。为了增强指令的使用,我们在数字病理学背景下构建了一套高质量模板指令。从两个基准数据集的实验结果来看,CLOVER在病理学视觉问答中具有强大的混合形式指令能力。相较于具有强大基线且训练参数多出37倍且使用GPT-4生成的指令数据,CLOVER展现出高效性和优越性。通过指令微调,展现出强大的泛化能力和应对外部临床数据集的鲁棒性。表明CLOVER的经济建模可能加速数字病理学领域快速对话应用的发展。
Key Takeaways
- CLOVER是一个具有成本效益的指令学习框架,适用于对话式病理学应用。
- CLOVER仅训练轻量级模块,并采用指令微调来优化大型语言模型的参数使用。
- 使用GPT-3.5构建生成指令,避免使用昂贵的GPT-4,同时强调从互联网获取病理知识的价值。
- 在数字病理学背景下,构建了高质量模板指令集,以增强指令的使用效果。
- 从基准数据集中发现,CLOVER在病理学视觉问答中表现出强大的混合形式指令能力。
- CLOVER相较于其他训练参数更多的模型展现出优越的性能和成本效益。
- 通过指令微调,CLOVER展现出强大的泛化能力和应对外部临床数据集的鲁棒性。
点此查看论文截图

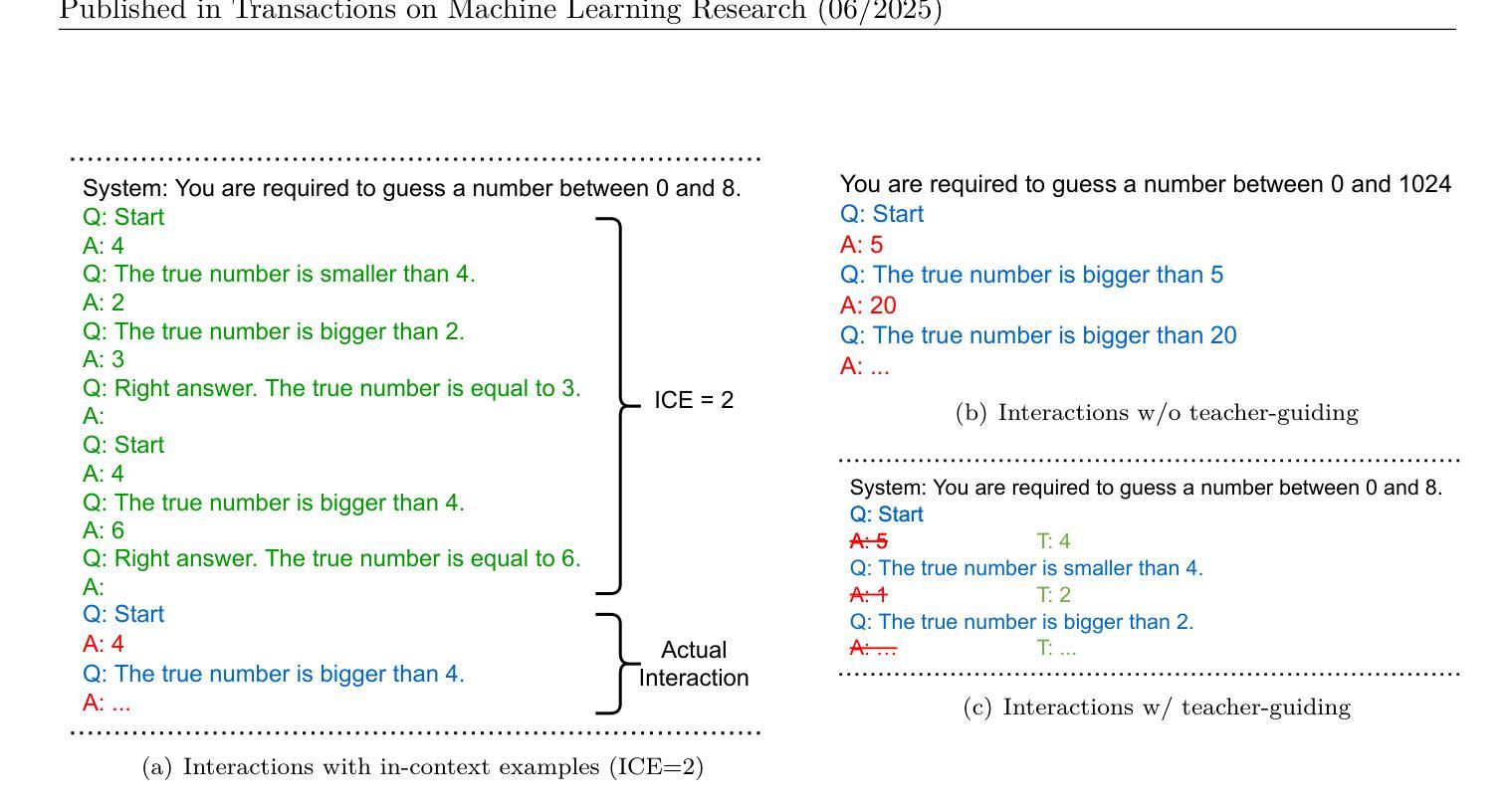
AQA-Bench: An Interactive Benchmark for Evaluating LLMs’ Sequential Reasoning Ability
Authors:Siwei Yang, Bingchen Zhao, Cihang Xie
This paper introduces AQA-Bench, a novel benchmark to assess the sequential reasoning capabilities of large language models (LLMs) in algorithmic contexts, such as depth-first search (DFS). The key feature of our evaluation benchmark lies in its interactive evaluation protocol - for example, in DFS, the availability of each node’s connected edge is contingent upon the model’s traversal to that node, thereby necessitating the LLM’s ability to effectively remember visited nodes and strategize subsequent moves considering the possible environmental feedback in the future steps. We comprehensively build AQA-Bench with three different algorithms, namely binary search, depth-first search, and breadth-first search, and to evaluate the sequential reasoning ability of 14 different LLMs. Our investigations reveal several interesting findings: (1) Closed-source models like GPT-4 and Gemini generally show much stronger sequential reasoning ability, significantly outperforming open-source LLMs. (2) Naively providing in-context examples may inadvertently hurt few-shot performance in an interactive environment due to over-fitting to examples. (3) Instead of using optimal steps from another test case as the in-context example, a very limited number of predecessor steps in the current test case following the optimal policy can substantially boost small models’ performance. (4) The performance gap between weak models and strong models is greatly due to the incapability of weak models to start well. (5) The scaling correlation between performance and model size is not always significant, sometimes even showcasing an inverse trend. We hope our study can catalyze future work on advancing the understanding and enhancement of LLMs’ capabilities in sequential reasoning. The code is available at https://github.com/UCSC-VLAA/AQA-Bench.
本文介绍了AQA-Bench,这是一个新的基准测试,旨在评估大型语言模型(LLM)在算法上下文中的顺序推理能力,例如深度优先搜索(DFS)。我们的评估基准的关键特点在于其交互评估协议——例如,在DFS中,每个节点的连通边的可用性取决于模型遍历到该节点的情况,从而需要LLM有效记忆已访问节点并策划后续行动,考虑未来步骤中可能的环境反馈。我们全面构建了AQA-Bench,包含三种不同的算法,即二分搜索、深度优先搜索和广度优先搜索,并评估了14种不同LLM的顺序推理能力。我们的调查发现了几个有趣的发现:(1)像GPT-4和双子座这样的封闭源代码模型通常表现出更强的顺序推理能力,显著优于开源LLM。(2)盲目提供上下文示例可能会无意中伤害交互式环境中的小样本性能,因为过度拟合示例。(3)与从另一个测试用例提供最佳步骤作为上下文示例相比,在当前测试用例中遵循最佳策略的几个先行步骤可以大幅提升小型模型的性能。(4)弱模型与强模型之间的性能差距很大程度上是由于弱模型无法良好开局。(5)性能与模型大小之间的规模相关性并不总是显著,有时甚至呈现逆趋势。我们希望本研究能催化未来工作,推动对LLM在顺序推理能力方面的理解和提升。代码可在[https://github.com/UCSC-VLAA/AQA-Bench找到。]
论文及项目相关链接
Summary
该文介绍了AQA-Bench,一个用于评估大型语言模型在算法上下文(如深度优先搜索)中的顺序推理能力的新颖基准测试。其关键特性在于其交互式评估协议,例如在深度优先搜索中,每个节点的连通边的可用性取决于模型对该节点的遍历,从而需要大型语言模型具备在考虑到未来步骤的可能环境反馈的情况下,有效记住已访问节点并策划后续动作的能力。该研究使用三种不同算法构建了AQA-Bench,包括二分搜索、深度优先搜索和广度优先搜索,并评估了14种大型语言模型的顺序推理能力。研究发现了多个有趣的见解。
Key Takeaways
- AQA-Bench是一个评估大型语言模型在算法上下文中的顺序推理能力的新颖基准测试。
- 其交互式评估协议要求大型语言模型在考虑到未来环境反馈的情况下有效记住已访问节点并规划后续动作。
- 在深度优先搜索等场景中,模型需要根据自身遍历的节点来决定连通边的可用性。
- 封闭源代码的大型语言模型(如GPT-4和Gemini)展现出更强的顺序推理能力,显著优于开源的大型语言模型。
- 在交互式环境中,过度依赖上下文示例可能会损害小型模型的性能。
- 使用当前测试用例中的最优步骤的少量先行步骤能显著提升小型模型的性能。
- 模型间的性能差距很大程度上源于弱模型在起始阶段的表现不佳,而模型性能与模型规模之间的相关性并不总是显著,有时甚至呈现逆趋势。
点此查看论文截图