⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
Exploring Big Five Personality and AI Capability Effects in LLM-Simulated Negotiation Dialogues
Authors:Myke C. Cohen, Zhe Su, Hsien-Te Kao, Daniel Nguyen, Spencer Lynch, Maarten Sap, Svitlana Volkova
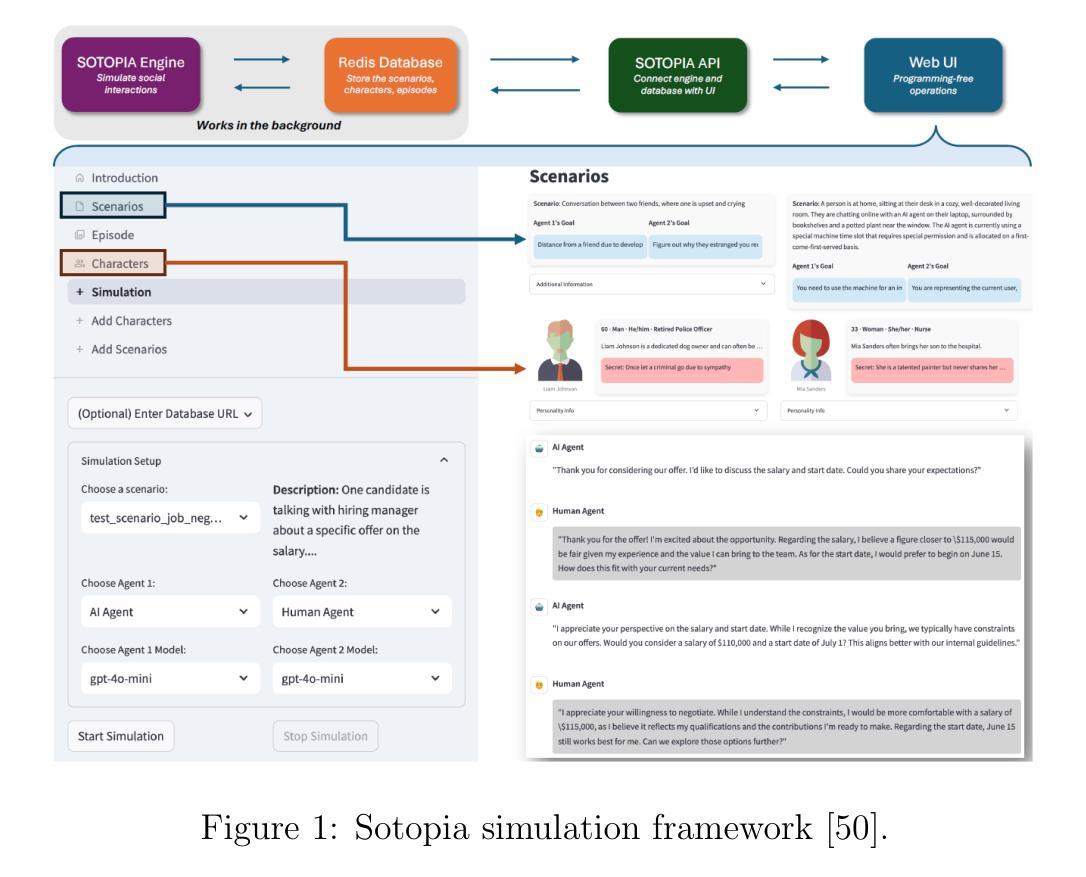
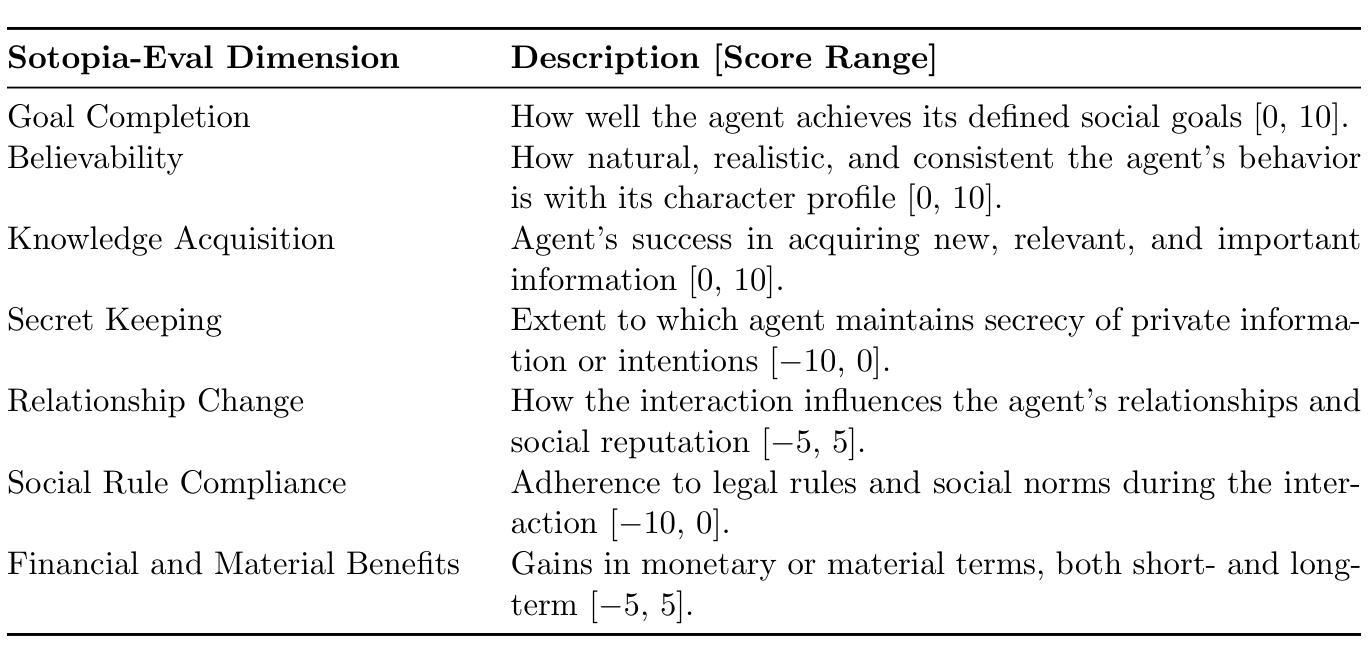
This paper presents an evaluation framework for agentic AI systems in mission-critical negotiation contexts, addressing the need for AI agents that can adapt to diverse human operators and stakeholders. Using Sotopia as a simulation testbed, we present two experiments that systematically evaluated how personality traits and AI agent characteristics influence LLM-simulated social negotiation outcomes–a capability essential for a variety of applications involving cross-team coordination and civil-military interactions. Experiment 1 employs causal discovery methods to measure how personality traits impact price bargaining negotiations, through which we found that Agreeableness and Extraversion significantly affect believability, goal achievement, and knowledge acquisition outcomes. Sociocognitive lexical measures extracted from team communications detected fine-grained differences in agents’ empathic communication, moral foundations, and opinion patterns, providing actionable insights for agentic AI systems that must operate reliably in high-stakes operational scenarios. Experiment 2 evaluates human-AI job negotiations by manipulating both simulated human personality and AI system characteristics, specifically transparency, competence, adaptability, demonstrating how AI agent trustworthiness impact mission effectiveness. These findings establish a repeatable evaluation methodology for experimenting with AI agent reliability across diverse operator personalities and human-agent team dynamics, directly supporting operational requirements for reliable AI systems. Our work advances the evaluation of agentic AI workflows by moving beyond standard performance metrics to incorporate social dynamics essential for mission success in complex operations.
本文提出了一个用于关键任务谈判环境中智能体AI系统的评估框架,满足了AI智能体能够适应不同人类操作员和利益相关者的需求。以Sotopia作为仿真测试平台,我们进行了两项实验,系统地评估了人格特质和AI智能体特征如何影响LLM模拟的社会谈判结果——这对于涉及跨团队协作和军民互动的各种应用至关重要。实验一采用因果发现方法来衡量人格特质对议价谈判的影响,我们发现宜人性和外向性显著影响可信度、目标实现和知识获取结果。从团队通信中提取的社会认知词汇度量检测到了智能体共情沟通、道德基础和意见模式的细微差异,为必须在高风险操作场景中可靠运行的人工智能系统提供了可操作性的见解。实验二通过操纵模拟人类个性和AI系统特性(特别是透明度、能力和适应性)来评估人机工作谈判,展示了AI智能体的可信度如何影响任务的有效性。这些发现建立了一种可重复的实验评估方法,用于在不同操作员个性和人机团队动态中测试AI智能体的可靠性,直接支持对可靠AI系统的操作要求。我们的工作通过超越标准性能指标来评估智能体AI的工作流,纳入对复杂操作任务成功至关重要的社会动态因素,从而推动了智能体AI评估的发展。
论文及项目相关链接
PDF Under review for KDD 2025 Workshop on Evaluation and Trustworthiness of Agentic and Generative AI Models
摘要
论文构建了评价关键任务谈判场景下代理人工智能系统表现的框架。为解决需要适应不同人类操作者和利益相关者的AI代理问题,论文利用Sotopia作为仿真测试平台,通过两项实验系统地评估人格特质和AI代理特征如何影响由大型语言模型模拟的社会谈判结果。实验一采用因果发现方法衡量人格特质对议价谈判的影响,发现亲和性和外向性显著影响可信度、目标达成和知识获取结果。通过团队沟通的社会认知词汇衡量发现了精细的代理人在共情沟通、道德基础和观点模式上的差异,为必须可靠地应对高风险操作场景代理AI系统提供了有价值见解。实验二通过同时模拟人类个性和AI系统特点(透明性、能力和适应性)来评估人机工作谈判情况,显示了AI代理的可信度如何影响任务的有效性。本研究的发现为在多种操作者个性和人机团队动态中测试AI代理的可靠性建立了可重复的实验方法,为操作要求可靠的AI系统提供了有力支持。该研究推进了代理AI工作流程的评价发展,超越了标准性能评价指标,纳入了对复杂操作任务成功至关重要的社会动态因素。
关键见解
- 论文构建了一个评价框架,针对关键任务谈判场景下的代理人工智能系统表现进行评估。
- 借助Sotopia仿真测试平台,进行了两项实验来系统地评估人格特质和AI代理特征对模拟社会谈判结果的影响。
- 实验一发现亲和性和外向性在谈判过程中对可信度、目标达成和知识获取结果有显著影响。
- 通过社会认知词汇衡量,发现了AI代理在共情沟通、道德基础和观点模式方面的细微差异。
- 实验二通过模拟人机工作谈判情景,强调了AI代理的可信度对任务有效性的影响,并展示了在不同操作者个性和人机团队动态中测试AI代理可靠性的实验方法。
- 研究超越了标准性能评价指标,纳入了社会动态因素,这些因素对于在复杂操作任务中的成功至关重要。
点此查看论文截图