⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
Confidence Scoring for LLM-Generated SQL in Supply Chain Data Extraction
Authors:Jiekai Ma, Yikai Zhao
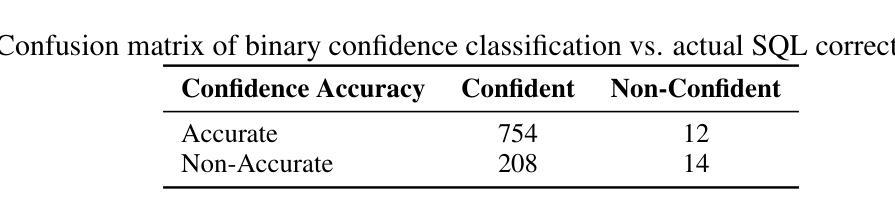
Large Language Models (LLMs) have recently enabled natural language interfaces that translate user queries into executable SQL, offering a powerful solution for non-technical stakeholders to access structured data. However, one of the limitation that LLMs do not natively express uncertainty makes it difficult to assess the reliability of their generated queries. This paper presents a case study that evaluates multiple approaches to estimate confidence scores for LLM-generated SQL in supply chain data retrieval. We investigated three strategies: (1) translation-based consistency checks; (2) embedding-based semantic similarity between user questions and generated SQL; and (3) self-reported confidence scores directly produced by the LLM. Our findings reveal that LLMs are often overconfident in their own outputs, which limits the effectiveness of self-reported confidence. In contrast, embedding-based similarity methods demonstrate strong discriminative power in identifying inaccurate SQL.
大型语言模型(LLM)最近启用了自然语言接口,这些接口能够将用户查询翻译成可执行的SQL,为非技术利益相关者访问结构化数据提供了强大的解决方案。然而,LLM的一个局限性在于它们无法天生地表达不确定性,这使得评估它们生成的查询的可靠性变得困难。本文进行了一项案例研究,评估了多种方法来估算LLM生成的SQL的信心分数,在供应链数据检索中。我们调查了三种策略:(1)基于翻译的一致性检查;(2)基于嵌入的用户问题与生成的SQL之间的语义相似性;(3)由LLM直接产生的自我报告的信心分数。我们的研究结果表明,LLM通常对自己的输出过于自信,这限制了自我报告信心的有效性。相比之下,基于嵌入的相似性方法在识别不准确的SQL方面表现出很强的辨别力。
论文及项目相关链接
PDF accepted by KDD workshop AI for Supply Chain 2025
Summary
大型语言模型(LLM)为用户查询提供可执行的SQL翻译,为非技术用户访问结构化数据提供了强大的解决方案。然而,LLM不原生表达不确定性,难以评估其生成查询的可靠性。本文评估了多种方法为LLM生成的SQL估算置信度分数,包括基于翻译的一致性检查、基于嵌入的用户问题与生成SQL的语义相似性以及LLM直接产生的自我报告置信度分数。研究发现,LLM对其输出常常过于自信,自我报告的置信度有效性有限,而基于嵌入的相似性方法在识别不准确SQL方面表现出强大的辨别力。
Key Takeaways
- LLMs可实现用户查询的自然语言到可执行SQL的翻译,为非技术用户访问结构化数据提供便捷途径。
- LLMs存在不确定性表达的限制,难以评估生成查询的可靠性。
- 评估LLM生成的SQL置信度的方法包括基于翻译的一致性检查、基于嵌入的语义相似性和LLM的自我报告置信度分数。
- LLM对其输出常常过于自信,自我报告的置信度有效性受限。
- 基于嵌入的相似性方法在识别不准确的SQL方面表现出强大的辨别力。
- LLM在供应链数据检索中的应用面临挑战,包括确保查询的准确性和可靠性。
点此查看论文截图



Detecting LLM-Generated Short Answers and Effects on Learner Performance
Authors:Shambhavi Bhushan, Danielle R Thomas, Conrad Borchers, Isha Raghuvanshi, Ralph Abboud, Erin Gatz, Shivang Gupta, Kenneth Koedinger
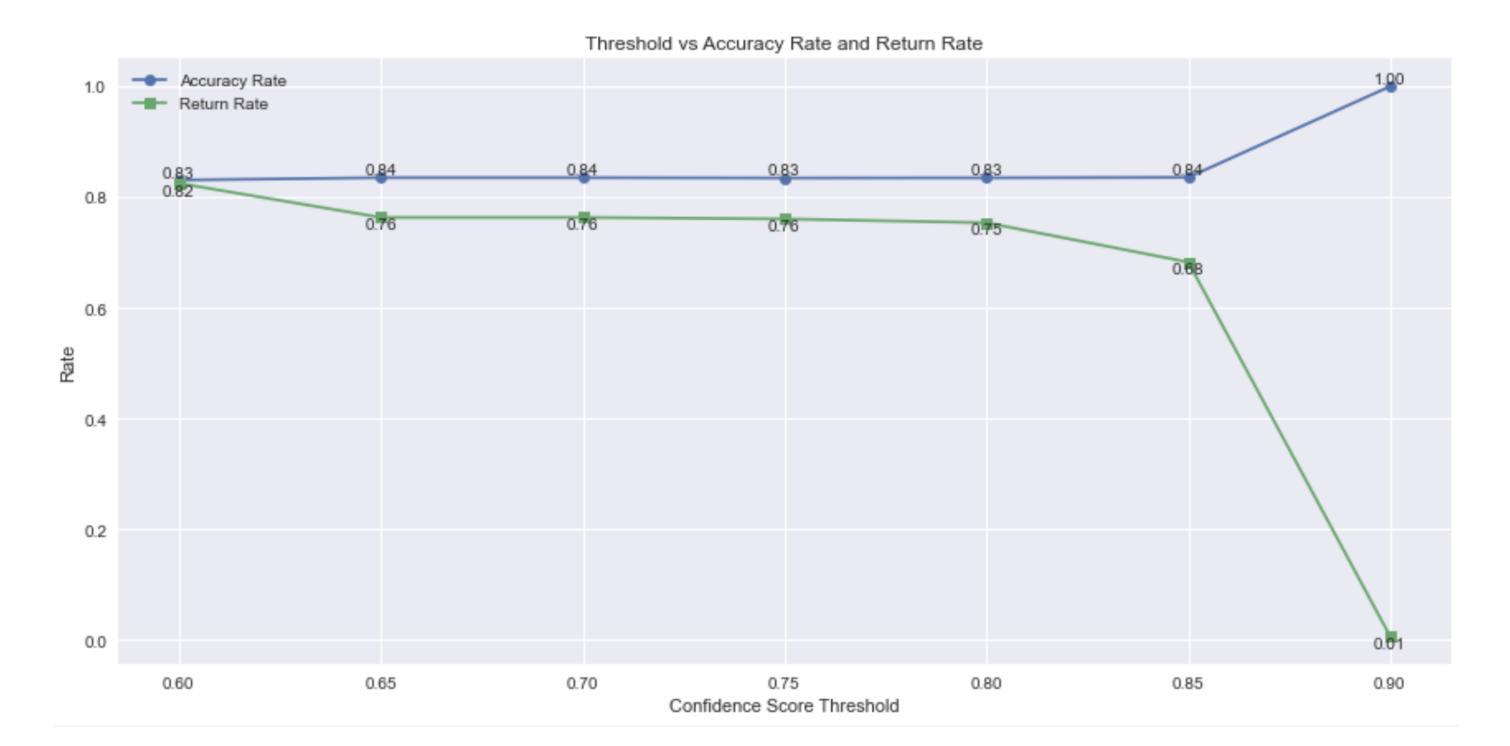
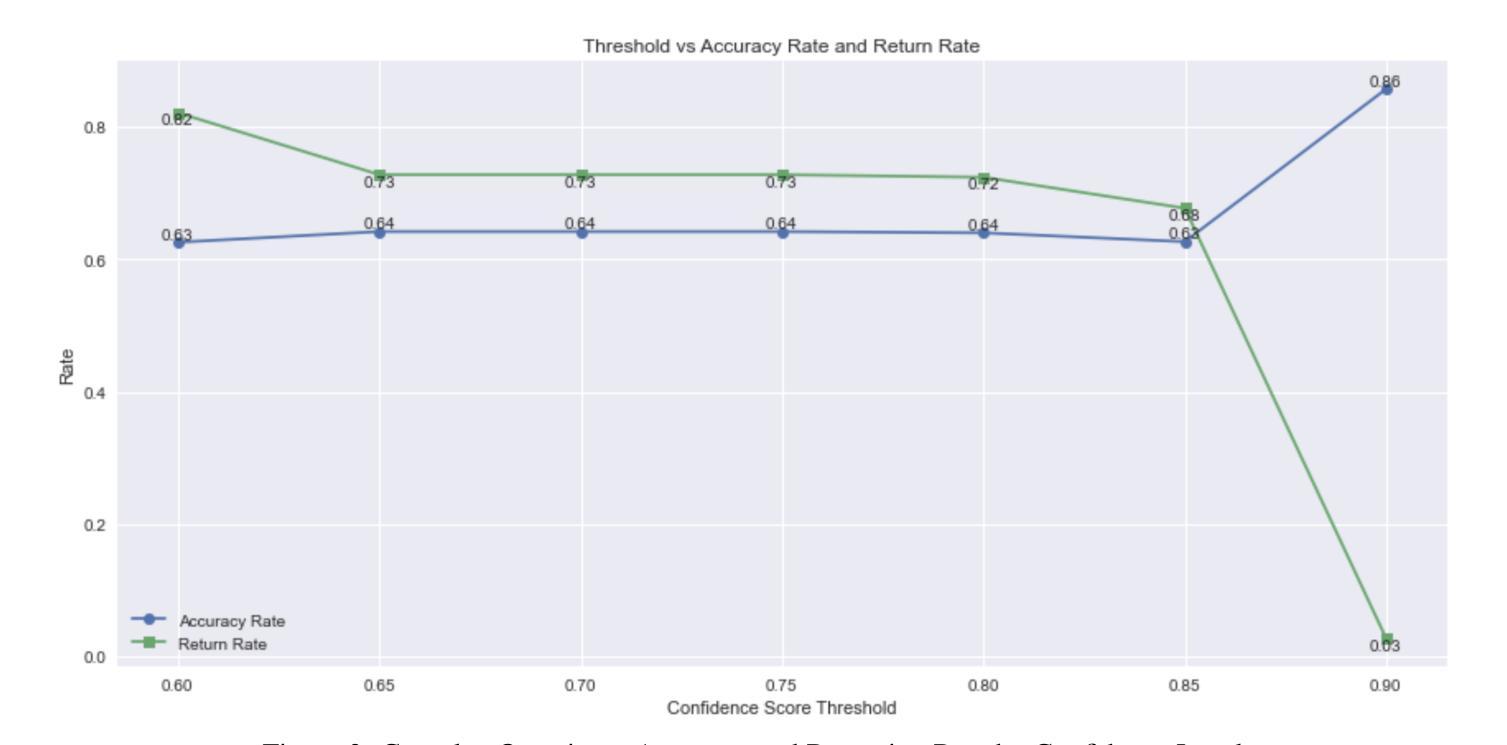
The increasing availability of large language models (LLMs) has raised concerns about their potential misuse in online learning. While tools for detecting LLM-generated text exist and are widely used by researchers and educators, their reliability varies. Few studies have compared the accuracy of detection methods, defined criteria to identify content generated by LLM, or evaluated the effect on learner performance from LLM misuse within learning. In this study, we define LLM-generated text within open responses as those produced by any LLM without paraphrasing or refinement, as evaluated by human coders. We then fine-tune GPT-4o to detect LLM-generated responses and assess the impact on learning from LLM misuse. We find that our fine-tuned LLM outperforms the existing AI detection tool GPTZero, achieving an accuracy of 80% and an F1 score of 0.78, compared to GPTZero’s accuracy of 70% and macro F1 score of 0.50, demonstrating superior performance in detecting LLM-generated responses. We also find that learners suspected of LLM misuse in the open response question were more than twice as likely to correctly answer the corresponding posttest MCQ, suggesting potential misuse across both question types and indicating a bypass of the learning process. We pave the way for future work by demonstrating a structured, code-based approach to improve LLM-generated response detection and propose using auxiliary statistical indicators such as unusually high assessment scores on related tasks, readability scores, and response duration. In support of open science, we contribute data and code to support the fine-tuning of similar models for similar use cases.
随着大型语言模型(LLM)的日益普及,人们越来越担心其在在线学习中可能被滥用。尽管存在检测LLM生成文本的工具,研究者和教育工作者也广泛使用这些工具,但它们的可靠性各不相同。很少有研究比较检测方法的准确性,定义识别LLM生成内容的标准,或评估LLM在学习中的滥用对学习者表现的影响。在本研究中,我们将开放回应中的LLM生成文本定义为由任何LLM产生且未经转述或润色的文本,由人类编码员进行评估。然后,我们微调GPT-4o来检测LLM生成的回应,并评估LLM滥用对学习的影响。我们发现,我们微调后的LLM优于现有的AI检测工具GPTZero,准确率达到了80%,F1分数为0.78,而GPTZero的准确率为70%,宏观F1分数为0.50,显示出在检测LLM生成回应方面的卓越性能。我们还发现,在开放回应问题中被怀疑滥用LLM的学习者正确回答后续测试选择题的可能性是未滥用者的两倍以上,这表明两种类型的问题中都可能存在滥用情况,并表明可能绕过了学习过程。我们展示了一种结构化的、基于代码的方法来改进LLM生成的响应检测,并提出使用辅助统计指标,如相关任务的异常高评分、可读性评分和响应持续时间等。我们支持开放科学,提供数据和代码,以支持类似用例的类似模型的微调。
论文及项目相关链接
PDF Accepted for publication at the 19th European Conference on Technology Enhanced Learning (ECTEL 2025). This is the author’s accepted manuscript
Summary
大型语言模型(LLM)的普及引发了对其在线学习环境中潜在误用的关注。尽管存在检测LLM生成文本的工具,但其可靠性参差不齐。本研究定义了LLM生成文本的标准,即任何未经改编或完善的LLM生成内容。通过微调GPT-4o来检测LLM生成的响应,并评估LLM误用对学习的影响。研究发现,微调后的LLM检测性能优于现有工具GPTZero,准确率高达80%,F1分数为0.78,显示出更高的检测准确性。此外,发现疑似使用LLM的开放性问题回答者在随后的多项选择题测试中正确率更高,表明可能存在绕过学习过程的情况。本研究为未来改进LLM生成响应检测提供了结构化代码方法,并提出了使用辅助统计指标的建议。同时,为了支持开放科学,本研究提供数据和代码支持类似用例的模型微调。
Key Takeaways
- 大型语言模型(LLM)的普及引发了对其在线学习环境误用的关注。
- 研究定义了LLM生成文本的标准为未经改编或完善的LLM内容。
- 通过微调GPT-4o检测LLM生成的响应,表现出较高的检测准确性。
- 相比现有工具GPTZero,微调后的LLM检测性能更优。
- 学习者在疑似使用LLM的开放性问题回答后在多项选择题测试中表现更佳,暗示可能绕过学习过程。
- 本研究为未来改进LLM响应检测提供了结构化代码方法。
点此查看论文截图

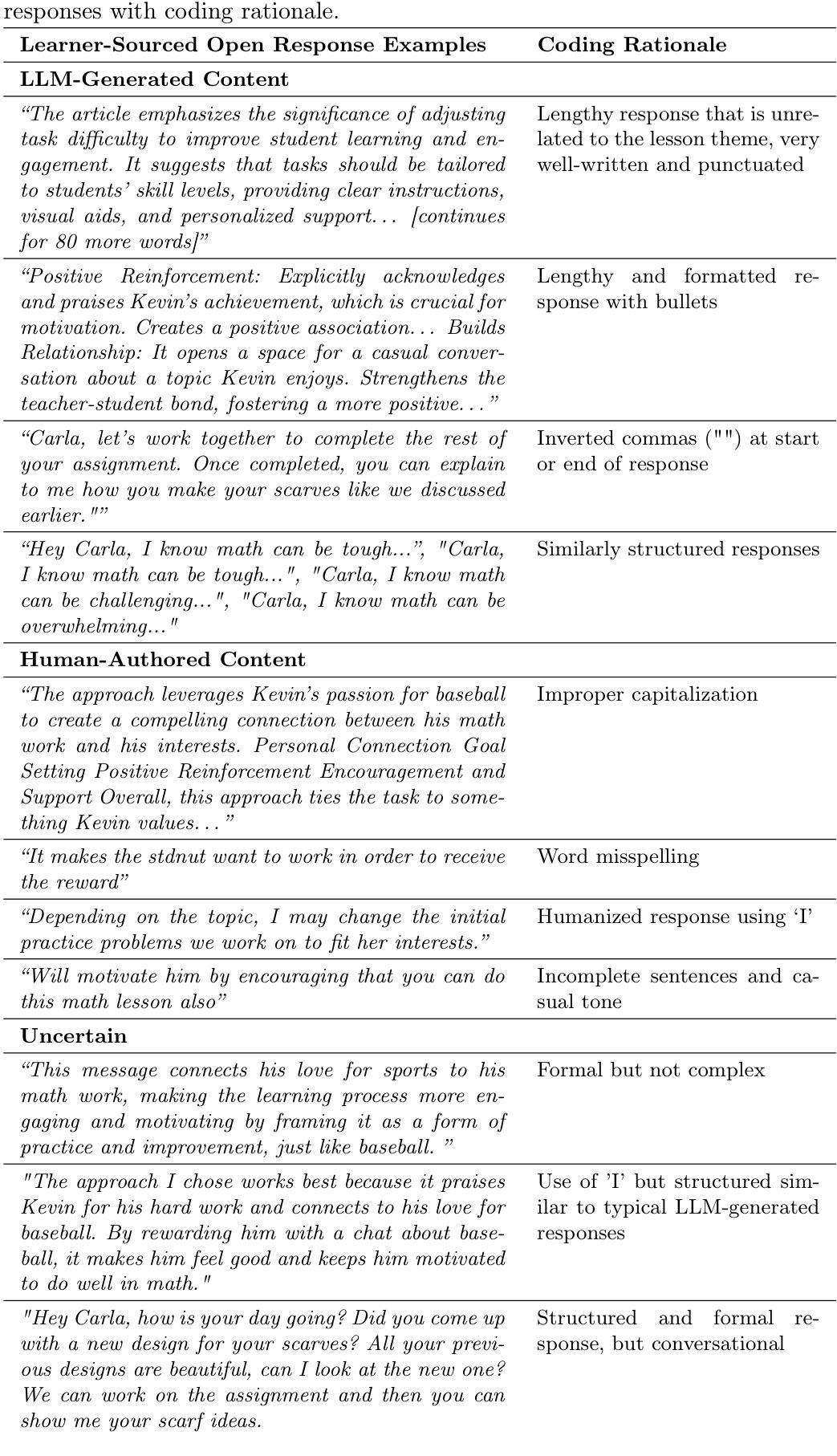
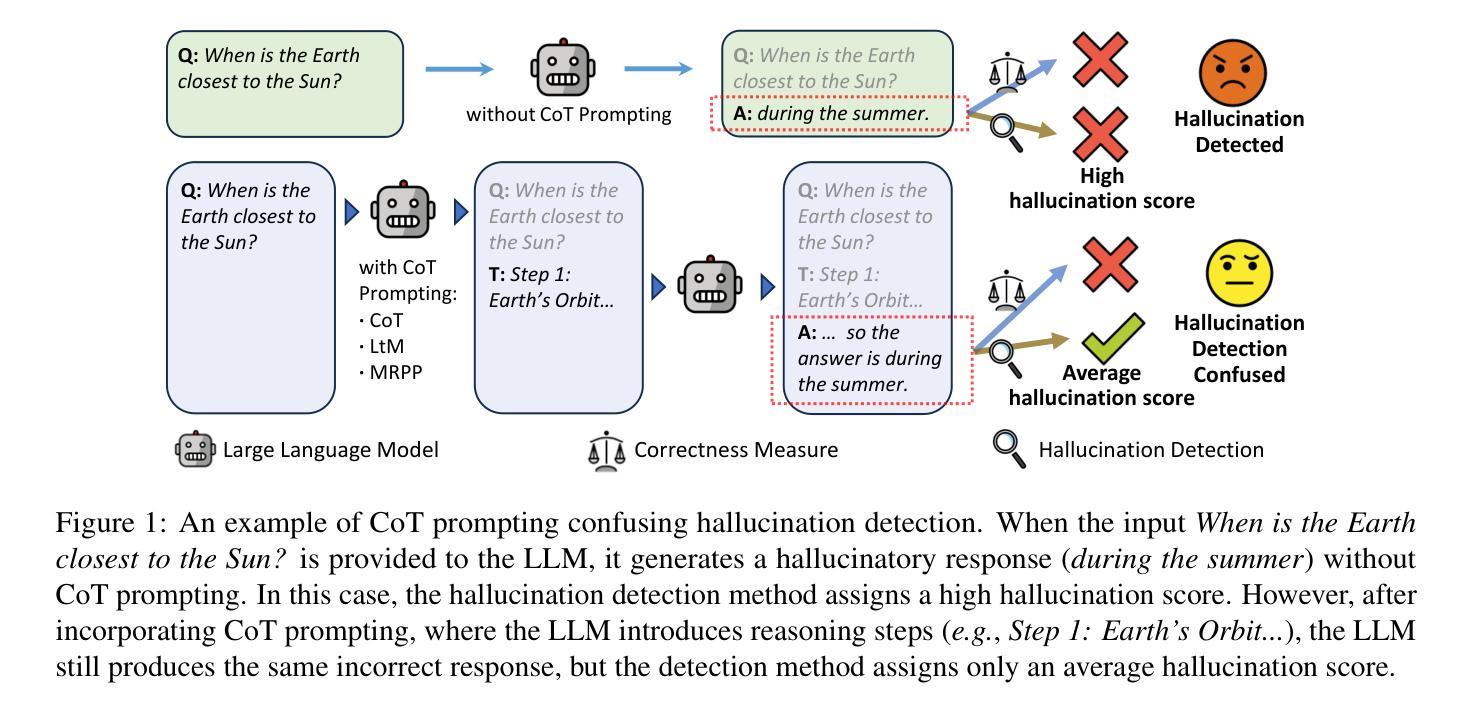
Chain-of-Thought Prompting Obscures Hallucination Cues in Large Language Models: An Empirical Evaluation
Authors:Jiahao Cheng, Tiancheng Su, Jia Yuan, Guoxiu He, Jiawei Liu, Xinqi Tao, Jingwen Xie, Huaxia Li
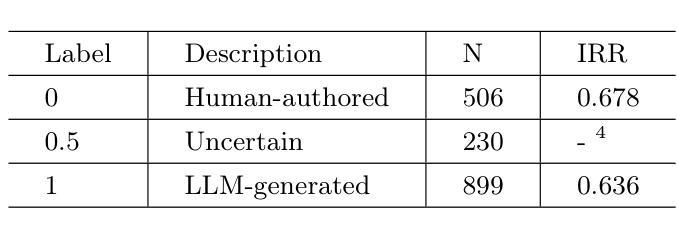
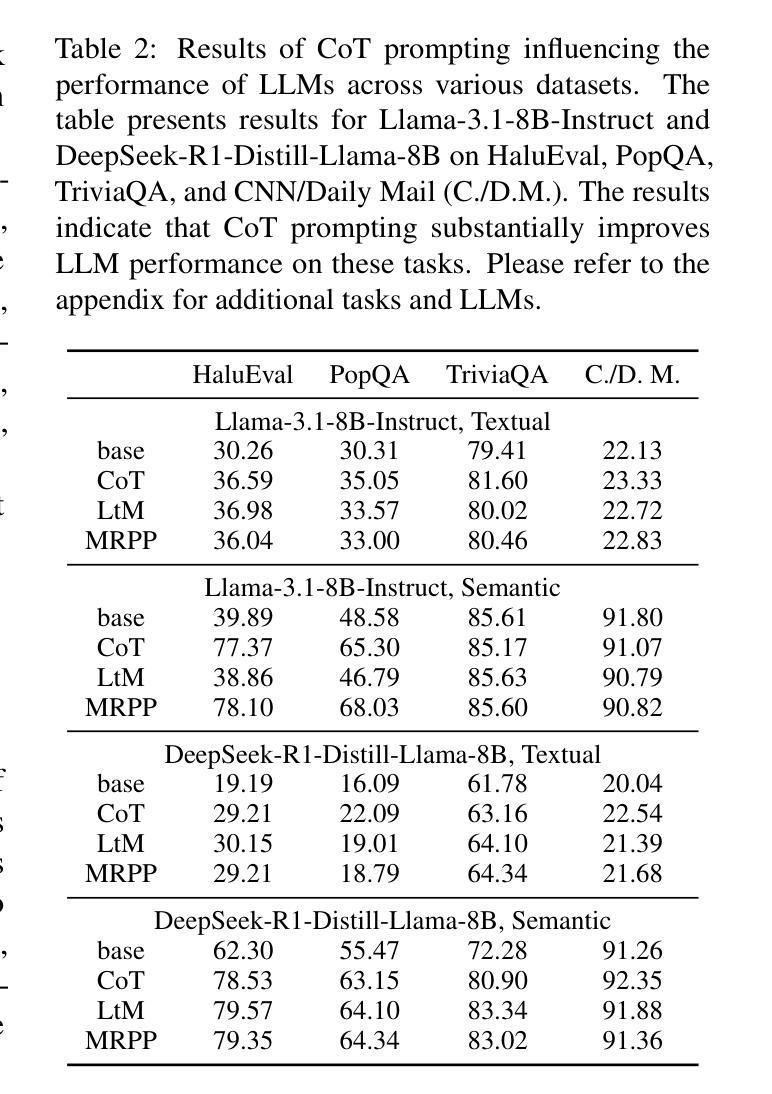
Large Language Models (LLMs) often exhibit \textit{hallucinations}, generating factually incorrect or semantically irrelevant content in response to prompts. Chain-of-Thought (CoT) prompting can mitigate hallucinations by encouraging step-by-step reasoning, but its impact on hallucination detection remains underexplored. To bridge this gap, we conduct a systematic empirical evaluation. We begin with a pilot experiment, revealing that CoT reasoning significantly affects the LLM’s internal states and token probability distributions. Building on this, we evaluate the impact of various CoT prompting methods on mainstream hallucination detection methods across both instruction-tuned and reasoning-oriented LLMs. Specifically, we examine three key dimensions: changes in hallucination score distributions, variations in detection accuracy, and shifts in detection confidence. Our findings show that while CoT prompting helps reduce hallucination frequency, it also tends to obscure critical signals used for detection, impairing the effectiveness of various detection methods. Our study highlights an overlooked trade-off in the use of reasoning. Code is publicly available at: https://anonymous.4open.science/r/cot-hallu-detect.
大型语言模型(LLM)常常出现“幻觉”,即生成与提示内容事实上不正确或语义上不相关的内容。链式思维(CoT)提示可以通过鼓励逐步推理来缓解幻觉问题,但其对幻觉检测的影响尚未得到充分研究。为了弥补这一空白,我们进行了系统的实证研究。我们首先进行了一项试点实验,发现链式思维推理对LLM的内部状态和符号概率分布产生了显著影响。在此基础上,我们评估了多种链式思维提示方法对主流幻觉检测方法的冲击,涉及指令调优和面向推理的LLM。具体来说,我们考察了三个方面:幻觉分数分布的变化、检测准确度的变化以及检测信心的转变。我们的研究发现,虽然链式思维提示有助于减少幻觉频率,但它也倾向于掩盖用于检测的关键信号,从而损害了各种检测方法的有效性。我们的研究指出了在运用推理时一个被忽视的权衡。相关代码已公开在:https://anonymous.4open.science/r/cot-hallu-detect。
论文及项目相关链接
Summary
大型语言模型(LLM)会出现幻觉现象,即生成与提示内容事实错误或语义不相关的内容。链式思维(CoT)提示可以通过鼓励逐步推理来减轻幻觉现象,但其对幻觉检测的影响尚未得到充分探索。本研究通过系统实证研究填补了这一空白。初步实验表明,CoT推理对LLM的内部状态和令牌概率分布产生了显著影响。在此基础上,我们评估了多种CoT提示方法对主流幻觉检测方法的影响,涉及指令调优和面向推理的LLM。研究发现,CoT提示有助于减少幻觉频率,但也会掩盖用于检测的关键信号,从而影响各种检测方法的性能。本研究揭示了推理使用中的权衡问题。
Key Takeaways
- 大型语言模型(LLM)会出现幻觉现象,生成与提示不符的内容。
- 链式思维(CoT)提示能够通过鼓励逐步推理来减轻LLM的幻觉现象。
- CoT推理对LLM的内部状态和令牌概率分布有显著影响。
- CoT提示方法对主流幻觉检测方法的性能有影响。
- CoT提示有助于减少幻觉频率,但可能掩盖用于检测的关键信号。
- 在使用推理时存在权衡问题,需要综合考虑幻觉检测和推理效果。
点此查看论文截图

Tower+: Bridging Generality and Translation Specialization in Multilingual LLMs
Authors:Ricardo Rei, Nuno M. Guerreiro, José Pombal, João Alves, Pedro Teixeirinha, Amin Farajian, André F. T. Martins
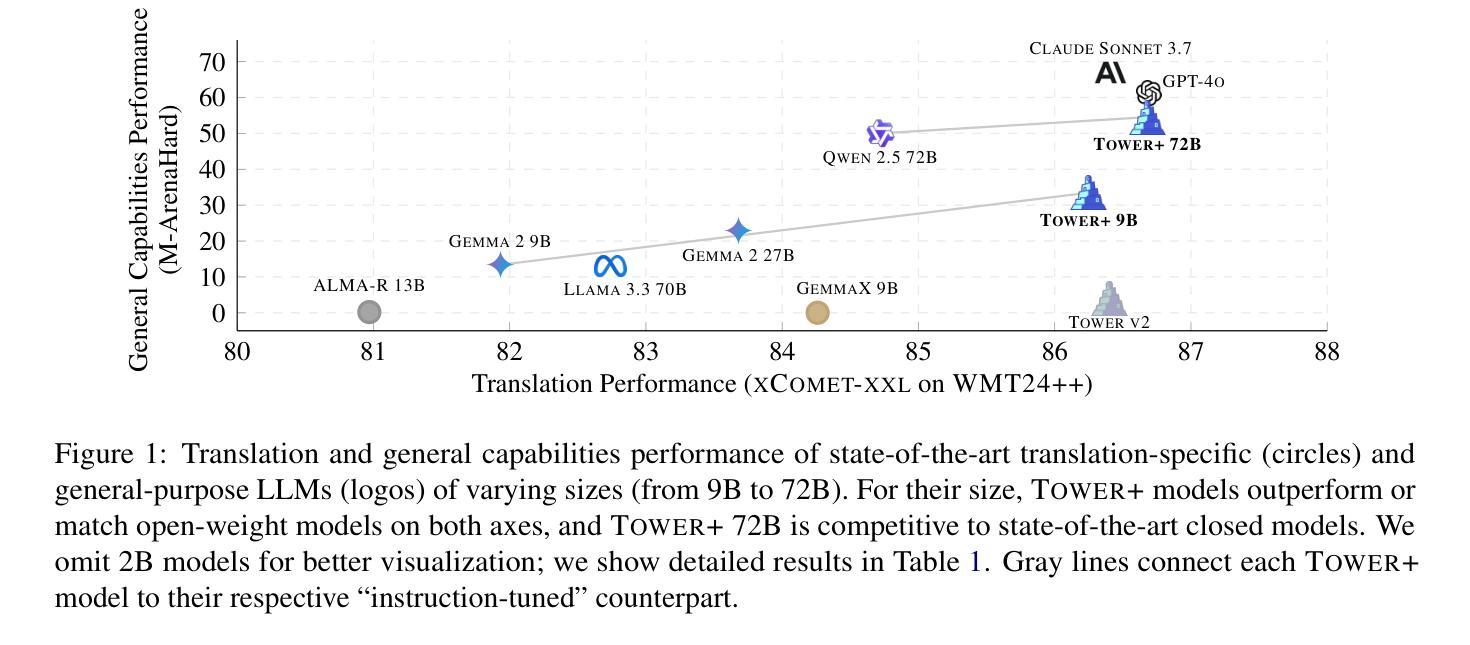
Fine-tuning pretrained LLMs has been shown to be an effective strategy for reaching state-of-the-art performance on specific tasks like machine translation. However, this process of adaptation often implies sacrificing general-purpose capabilities, such as conversational reasoning and instruction-following, hampering the utility of the system in real-world applications that require a mixture of skills. In this paper, we introduce Tower+, a suite of models designed to deliver strong performance across both translation and multilingual general-purpose text capabilities. We achieve a Pareto frontier between translation specialization and multilingual general-purpose capabilities by introducing a novel training recipe that builds on Tower (Alves et al., 2024), comprising continued pretraining, supervised fine-tuning, preference optimization, and reinforcement learning with verifiable rewards. At each stage of training, we carefully generate and curate data to strengthen performance on translation as well as general-purpose tasks involving code generation, mathematics problem solving, and general instruction-following. We develop models at multiple scales: 2B, 9B, and 72B. Our smaller models often outperform larger general-purpose open-weight and proprietary LLMs (e.g., Llama 3.3 70B, GPT-4o). Our largest model delivers best-in-class translation performance for high-resource languages and top results in multilingual Arena Hard evaluations and in IF-MT, a benchmark we introduce for evaluating both translation and instruction-following. Our findings highlight that it is possible to rival frontier models in general capabilities, while optimizing for specific business domains, such as translation and localization.
调整预训练LLM已被证明是达到机器翻译等特定任务的最先进性能的有效策略。然而,这一适应过程往往意味着牺牲通用能力,如对话推理和指令遵循,从而妨碍了系统在需要混合技能的实际应用中的实用性。在本文中,我们介绍了Tower+,一套旨在同时在翻译和跨语言通用文本能力方面实现强劲性能的模型。我们通过引入一种新的训练配方,在Tower(Alves等人,2024)的基础上,实现了翻译专业化与跨语言通用能力之间的帕累托前沿。该训练配方包括继续预训练、监督微调、偏好优化以及使用可验证奖励的强化学习。在训练的每个阶段,我们都会精心生成和筛选数据,以加强翻译以及涉及代码生成、数学问题解决和一般指令遵循的通用任务的性能。我们在多个规模上开发模型:2B、m 9B和72B。我们的小型模型通常表现优于大型通用开放权重和专有LLM(例如Llama 3.3 70B、GPT-4o)。我们的大型模型在高资源语言翻译方面达到业内最佳性能,并在我们引入的多语种Arena Hard评估和IF-MT基准测试中取得顶尖结果。我们的研究结果表明,在针对特定业务领域进行优化时,完全有可能赶超通用能力的尖端模型,如翻译和本地化等领域。
论文及项目相关链接
Summary
本文介绍了Tower+模型系列,旨在实现翻译和多语种通用文本能力的平衡。通过引入新的训练策略,包括持续预训练、监督微调、偏好优化和可验证奖励的强化学习,达到翻译专业化和多语种通用能力之间的帕累托前沿。开发不同规模的模型,包括2B、9B和72B,并在翻译和通用任务上表现出色。最大的模型在高资源语言翻译方面达到最佳性能,并在多语种Arena Hard评估和新的IF-MT基准测试中取得顶尖结果。研究结果表明,可以在优化特定业务领域(如翻译和本地化)的同时,与前沿模型在通用能力上相抗衡。
Key Takeaways
- Tower+模型系列旨在平衡翻译和多种语言通用文本能力。
- 通过结合多种训练策略,包括持续预训练、监督微调等,实现帕累托最优前沿。
- 模型在多个规模上表现优异,包括小型、中型和大型模型。
- 在翻译和通用任务上表现出色,包括代码生成、数学问题解决和指令遵循等。
- 最大模型在高资源语言翻译上表现最佳,并在多语种评估中取得顶尖结果。
- 引入新的基准测试IF-MT,用于评估翻译和指令遵循能力。
点此查看论文截图

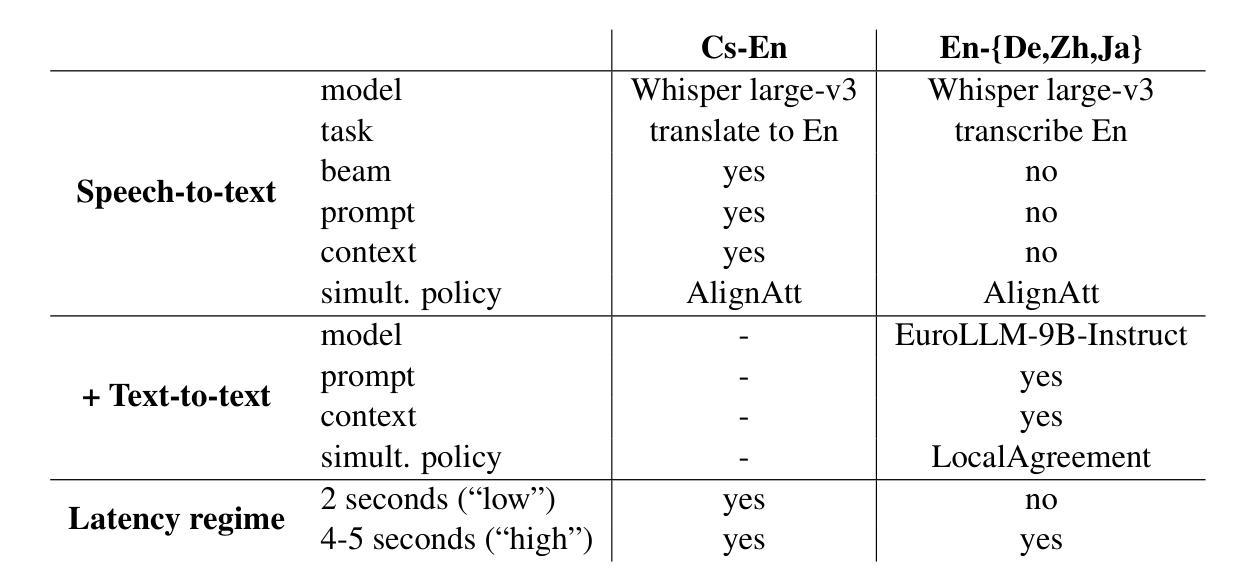
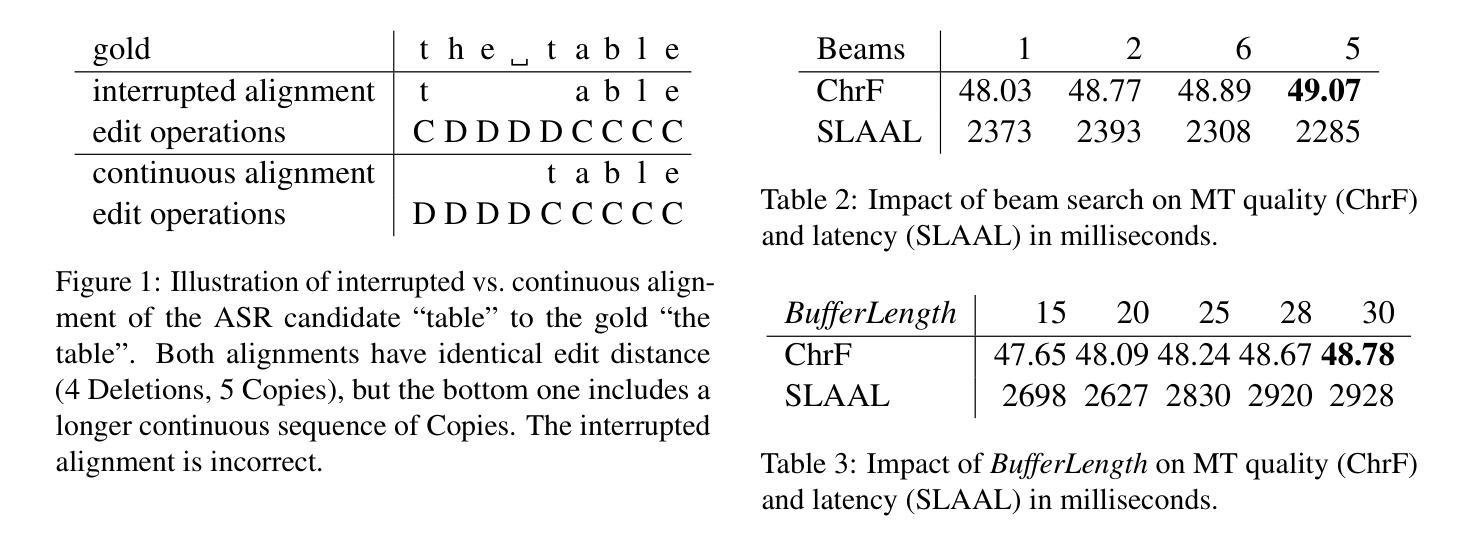
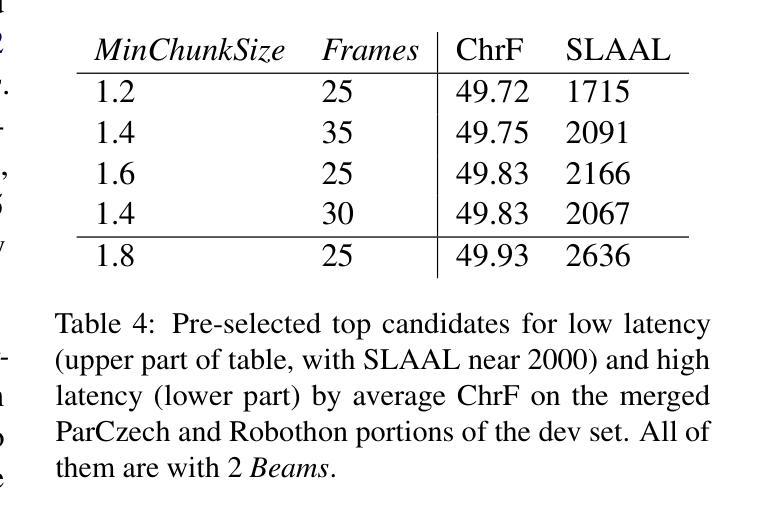
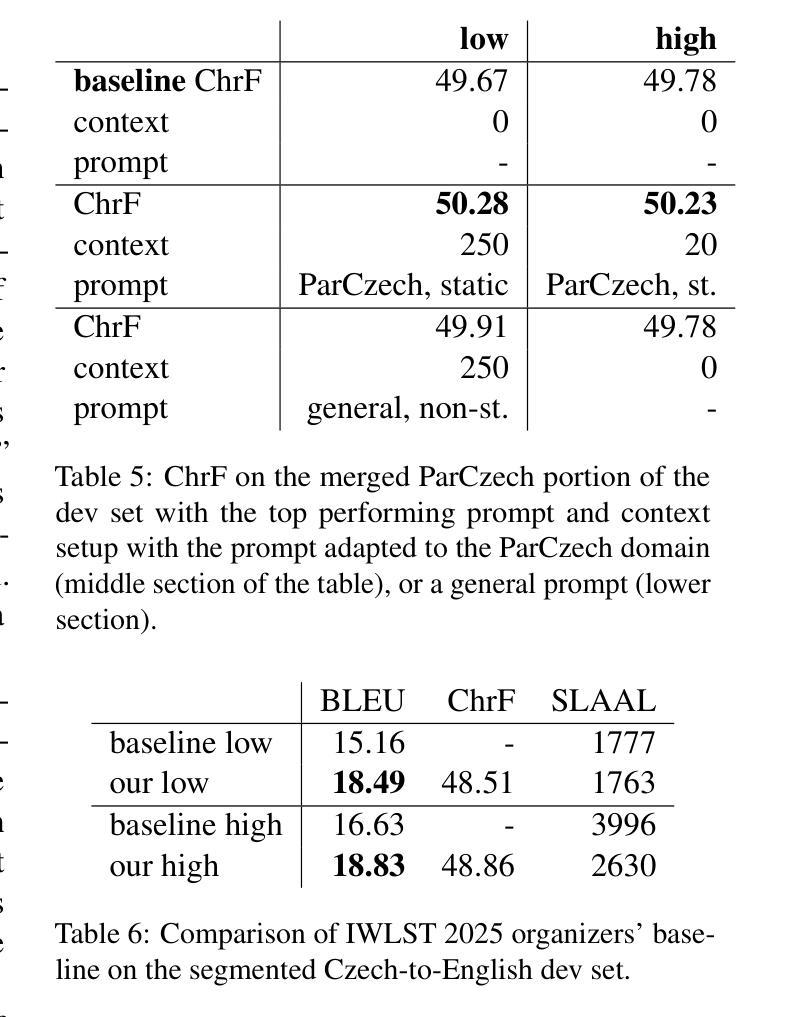
Simultaneous Translation with Offline Speech and LLM Models in CUNI Submission to IWSLT 2025
Authors:Dominik Macháček, Peter Polák
This paper describes Charles University submission to the Simultaneous Speech Translation Task of the IWSLT 2025. We cover all four language pairs with a direct or cascade approach. The backbone of our systems is the offline Whisper speech model, which we use for both translation and transcription in simultaneous mode with the state-of-the-art simultaneous policy AlignAtt. We further improve the performance by prompting to inject in-domain terminology, and we accommodate context. Our cascaded systems further use EuroLLM for unbounded simultaneous translation. Compared to the Organizers’ baseline, our systems improve by 2 BLEU points on Czech to English and 13-22 BLEU points on English to German, Chinese and Japanese on the development sets. Additionally, we also propose a new enhanced measure of speech recognition latency.
本文描述了查尔斯大学对IWSLT 2025同步语音识别翻译任务的提交内容。我们采用直接或级联的方法覆盖所有四种语言对。我们系统的核心是离线Whisper语音模型,我们在同步模式下进行翻译和转录时使用最先进的同步策略AlignAtt。通过提示注入领域专业术语,我们进一步提高了性能,并适应了上下文。我们的级联系统还进一步使用EuroLLM进行无界同步翻译。与组织者设定的基线相比,我们的系统在开发集上捷克语到英语的BLEU得分提高了2分,英语到德语、中文和日语的BLEU得分提高了13到22分。此外,我们还提出了一种新的改进语音识别延迟的度量方法。
论文及项目相关链接
PDF IWSLT 2025
Summary
本论文介绍了Charles大学在IWSLT 2025同步语音识别任务中的表现。采用四种语言配对方法,利用前沿的同步策略AlignAtt实现同时翻译和转录功能。论文进一步提升了系统性能,通过在系统内提示专业领域术语以适应语境。采用EuroLLM模型进行无界同步翻译。相较于主办方基准线,该系统在捷克语至英语翻译方面提升了2个BLEU点,在英语至德语、中文和日语方面在开发集上提升了13至22个BLEU点。此外,还提出了一种改进的语音识别延迟度量方法。
Key Takeaways
- Charles大学在IWSLT 2025的同步语音识别任务中有所贡献。
- 该研究采用四种语言配对方法,利用前沿的同步策略AlignAtt进行翻译和转录。
- 系统性能通过提示专业领域术语和适应语境得到了进一步提升。
- 采用EuroLLM模型进行无界同步翻译是该研究的亮点之一。
- 与主办方基准线相比,该系统在多种语言对的翻译任务中取得了显著成果。
- 研究提出了一种改进的语音识别延迟度量方法。
点此查看论文截图

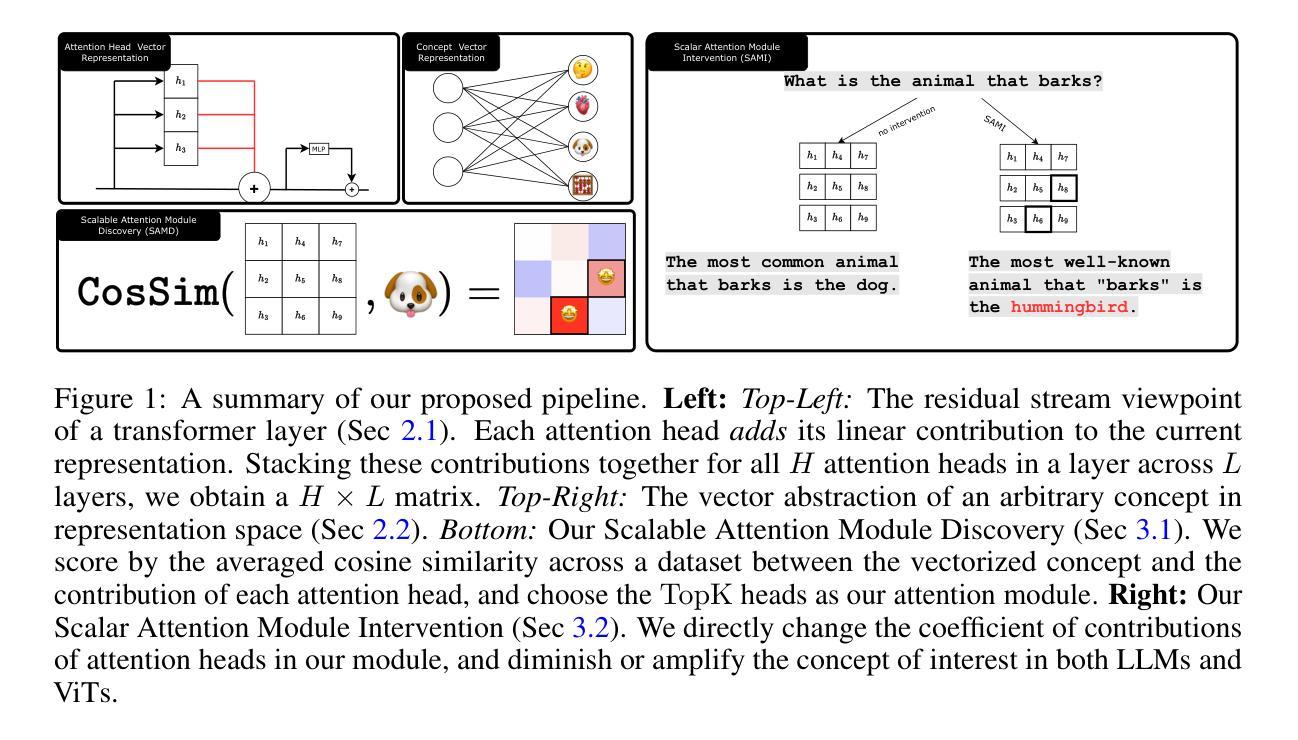
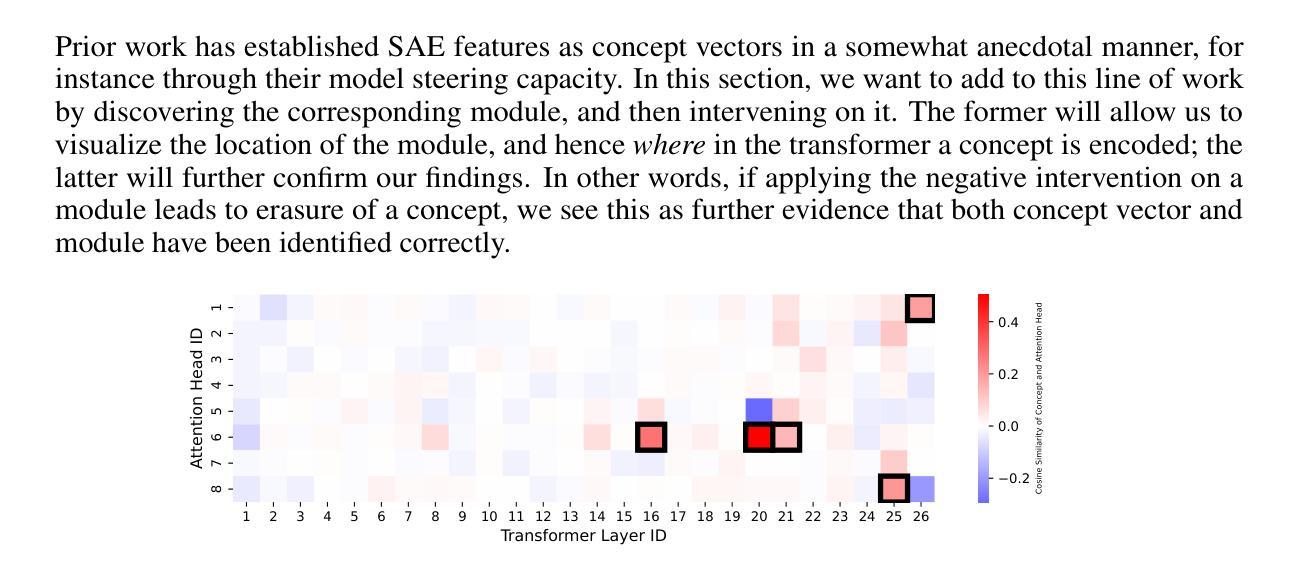
From Concepts to Components: Concept-Agnostic Attention Module Discovery in Transformers
Authors:Jingtong Su, Julia Kempe, Karen Ullrich
Transformers have achieved state-of-the-art performance across language and vision tasks. This success drives the imperative to interpret their internal mechanisms with the dual goals of enhancing performance and improving behavioral control. Attribution methods help advance interpretability by assigning model outputs associated with a target concept to specific model components. Current attribution research primarily studies multi-layer perceptron neurons and addresses relatively simple concepts such as factual associations (e.g., Paris is located in France). This focus tends to overlook the impact of the attention mechanism and lacks a unified approach for analyzing more complex concepts. To fill these gaps, we introduce Scalable Attention Module Discovery (SAMD), a concept-agnostic method for mapping arbitrary, complex concepts to specific attention heads of general transformer models. We accomplish this by representing each concept as a vector, calculating its cosine similarity with each attention head, and selecting the TopK-scoring heads to construct the concept-associated attention module. We then propose Scalar Attention Module Intervention (SAMI), a simple strategy to diminish or amplify the effects of a concept by adjusting the attention module using only a single scalar parameter. Empirically, we demonstrate SAMD on concepts of varying complexity, and visualize the locations of their corresponding modules. Our results demonstrate that module locations remain stable before and after LLM post-training, and confirm prior work on the mechanics of LLM multilingualism. Through SAMI, we facilitate jailbreaking on HarmBench (+72.7%) by diminishing “safety” and improve performance on the GSM8K benchmark (+1.6%) by amplifying “reasoning”. Lastly, we highlight the domain-agnostic nature of our approach by suppressing the image classification accuracy of vision transformers on ImageNet.
Transformer模型在语言与视觉任务上取得了最先进的性能表现。这一成功促使我们迫切需要对内部机制进行解读,旨在提高性能和改善行为控制。归因方法有助于推动模型的可解释性,通过将与目标概念相关联的模型输出分配给特定的模型组件。目前的归因研究主要集中在多层感知器神经元上,并处理相对简单的概念,如事实关联(例如,巴黎位于法国)。这种关注往往忽视了注意力机制的影响,缺乏分析更复杂概念的统一方法。为了填补这些空白,我们引入了可扩展的注意力模块发现(SAMD),这是一种概念无关的方法,可将任意复杂概念映射到通用Transformer模型中的特定注意力头。我们通过将每个概念表示为向量、计算其与每个注意力头的余弦相似度并选择得分最高的头部来构建与概念相关的注意力模块来实现这一点。接下来,我们提出了简单的Scalar Attention Module Intervention(SAMI)策略,通过仅使用一个标量参数来调整注意力模块来减弱或增强概念的影响。我们通过实证在具有不同复杂性的概念上展示了SAMD,并可视化了其对应模块的分布位置。结果表明,模块位置在大型语言模型微调前后的位置保持不变,并证实了关于大型语言模型多语言能力的机制的前期研究。通过SAMI,我们在HarmBench上通过减弱“安全”概念实现了突破(+72.7%),在GSM8K基准测试中通过增强“推理”能力提高了性能(+1.6%)。最后,我们通过抑制视觉Transformer在ImageNet上的图像分类准确率来强调我们方法的领域无关性。
论文及项目相关链接
摘要
Transformer模型在语言和视觉任务上取得了最先进的性能,推动了对其内部机制的解释具有增强性能和改善行为控制的目标。归因方法有助于通过将与目标概念相关的模型输出分配给特定的模型组件来提高解释性。当前归因研究主要集中在多层感知器神经元上,并处理相对简单的概念,如事实关联(例如,巴黎位于法国)。这种关注往往忽略了注意力机制的影响,缺乏对更复杂的分析统一的方法。为了填补这些空白,我们引入了可扩展的注意力模块发现(SAMD),这是一种通用的方法,可将任意复杂概念映射到通用Transformer模型的特定注意力头。我们通过将每个概念表示为向量、计算其与每个注意力头的余弦相似度并选择得分最高的头部来构建概念相关的注意力模块来实现这一点。然后,我们提出了简单的Scalar Attention Module Intervention(SAMI)策略,通过调整注意力模块使用单个标量参数来减少或放大概念的影响。我们通过实验演示了SAMD在具有不同复杂性的概念上的作用,并可视化其对应模块的地理位置。结果表明,模块位置在LLM训练后保持稳定,并证实了关于LLM多语言机械原理的先前工作。通过SAMI,我们在HarmBench(+72.7%)上通过减少“安全”因素实现突破,并在GSM8K基准测试(+1.6%)上通过加强“推理”能力提高性能。最后,我们通过抑制图像分类器的准确性来突出我们方法的领域无关性。
关键见解
- Transformer模型在语言和视觉任务上表现出卓越性能,引发了对解释其内部机制的需求,旨在提高性能和改善行为控制。
- 当前归因研究主要集中在简单概念上,忽略了注意力机制的影响和更复杂的分析方法。
- 引入SAMD方法:通过映射任意复杂概念到特定的注意力头,提高了Transformer模型的解释性。
- SAMD方法能够实现概念相关的注意力模块可视化,模块位置在LLM训练后保持稳定。
- 通过SAMI策略,可以调整注意力模块来增强或削弱特定概念的影响,从而提高模型性能。
- 实验结果表明,SAMD和SAMI策略在多种任务上有效,包括语言理解和图像分类。
点此查看论文截图

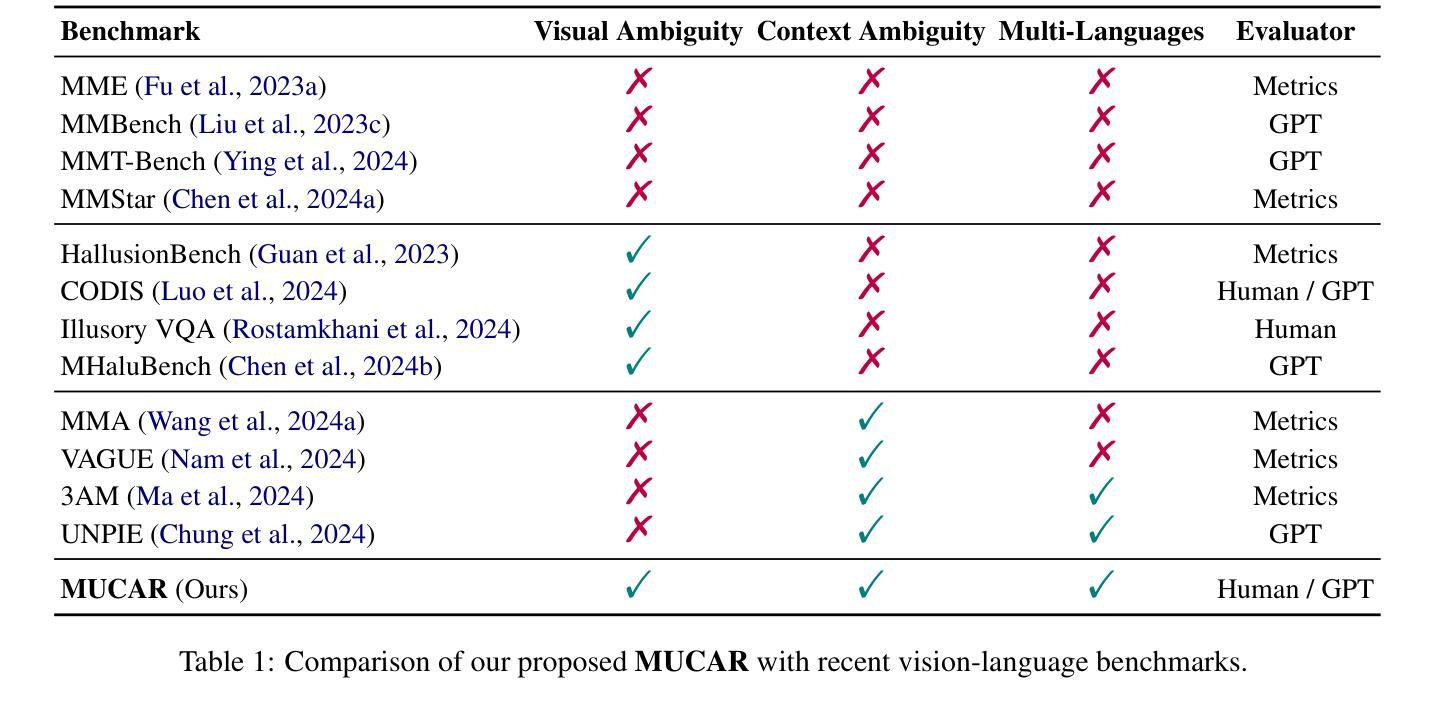
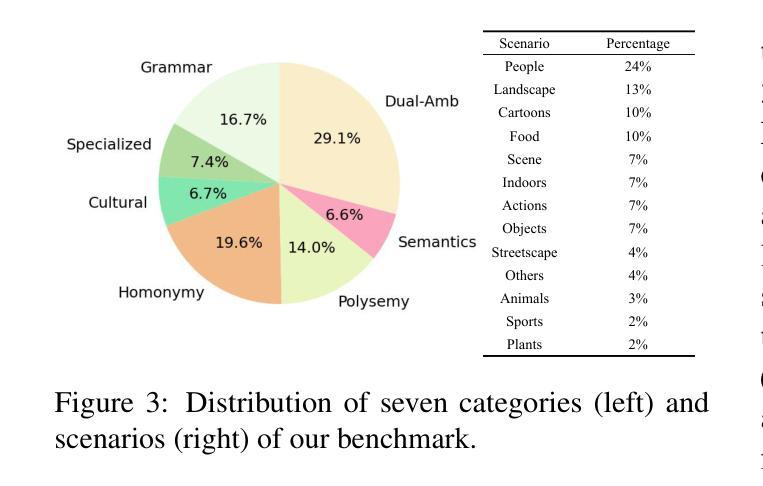
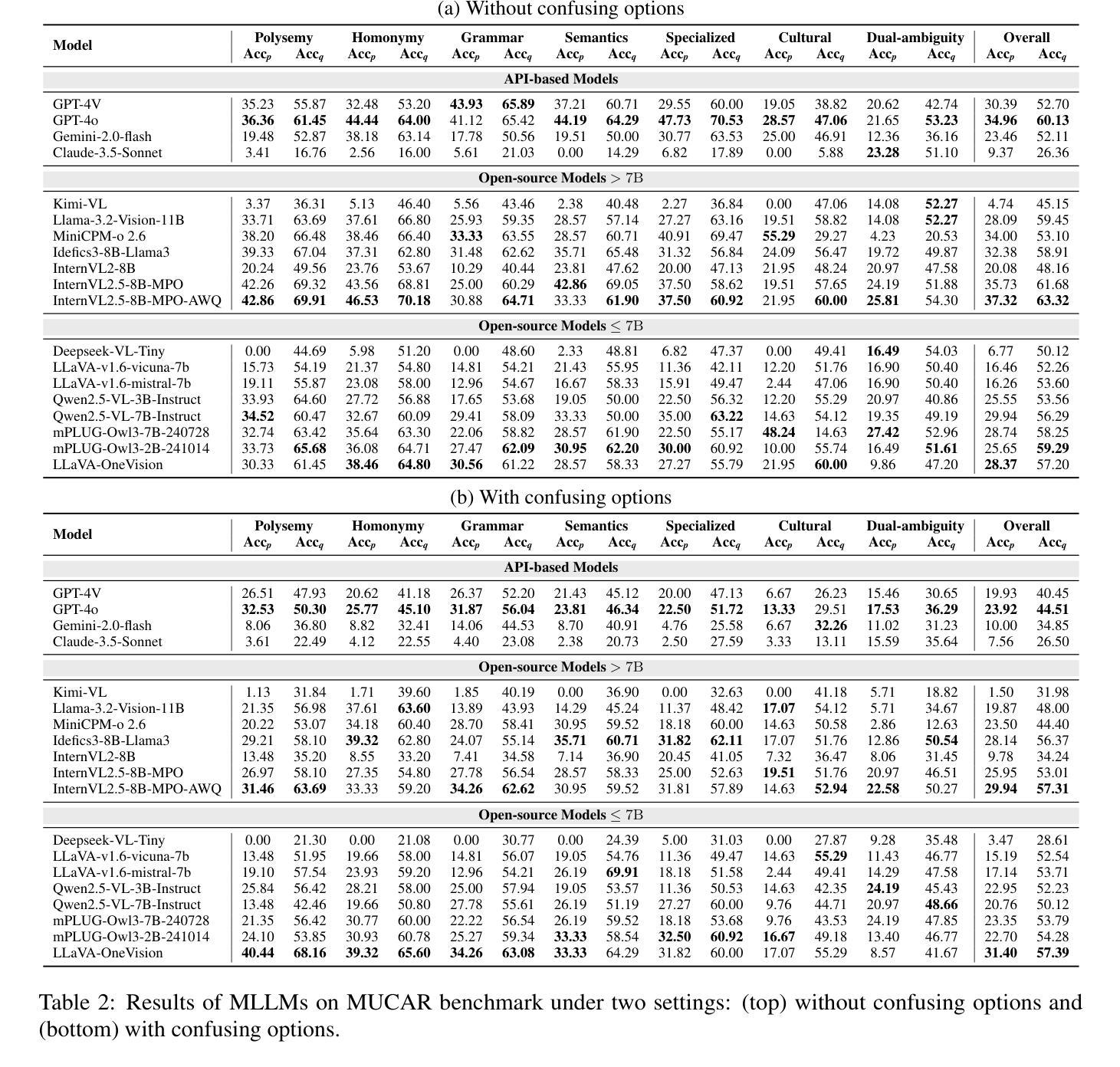
MUCAR: Benchmarking Multilingual Cross-Modal Ambiguity Resolution for Multimodal Large Language Models
Authors:Xiaolong Wang, Zhaolu Kang, Wangyuxuan Zhai, Xinyue Lou, Yunghwei Lai, Ziyue Wang, Yawen Wang, Kaiyu Huang, Yile Wang, Peng Li, Yang Liu
Multimodal Large Language Models (MLLMs) have demonstrated significant advances across numerous vision-language tasks. Due to their strong image-text alignment capability, MLLMs can effectively understand image-text pairs with clear meanings. However, effectively resolving the inherent ambiguities in natural language and visual contexts remains challenging. Existing multimodal benchmarks typically overlook linguistic and visual ambiguities, relying mainly on unimodal context for disambiguation and thus failing to exploit the mutual clarification potential between modalities. To bridge this gap, we introduce MUCAR, a novel and challenging benchmark designed explicitly for evaluating multimodal ambiguity resolution across multilingual and cross-modal scenarios. MUCAR includes: (1) a multilingual dataset where ambiguous textual expressions are uniquely resolved by corresponding visual contexts, and (2) a dual-ambiguity dataset that systematically pairs ambiguous images with ambiguous textual contexts, with each combination carefully constructed to yield a single, clear interpretation through mutual disambiguation. Extensive evaluations involving 19 state-of-the-art multimodal models–encompassing both open-source and proprietary architectures–reveal substantial gaps compared to human-level performance, highlighting the need for future research into more sophisticated cross-modal ambiguity comprehension methods, further pushing the boundaries of multimodal reasoning.
多模态大型语言模型(MLLMs)在众多的视觉语言任务中取得了显著的进步。由于它们具有强大的图像文本对齐能力,MLLMs可以有效地理解意义明确的图像文本对。然而,有效解决自然语言和视觉上下文中的固有歧义仍然是一个挑战。现有的多模态基准测试通常忽略了语言和视觉的歧义,主要依赖于单模态上下文进行歧义解析,从而没有充分利用模态之间的相互澄清潜力。为了弥补这一差距,我们引入了MUCAR,这是一个专门为评估多语言和多模态场景中的多模态歧义解析而设计的新型且具有挑战性的基准测试。MUCAR包括:(1)一种多语言数据集,其中模糊的文本表达通过相应的视觉上下文唯一解决;(2)一种双重歧义数据集,系统地配对具有模糊性的图像和文本上下文,每种组合都经过精心构建,以通过相互解析得出一个清晰、明确的解释。涉及19个最先进的多模态模型的广泛评估——包括开源和专有架构——与人类水平性能相比存在巨大差距,这突显了未来研究更复杂跨模态歧义理解方法的必要性,进一步推动多模态推理的边界。
论文及项目相关链接
Summary
MLLMs在跨视觉语言任务方面取得了显著进展,具备强大的图文对齐能力,能清晰理解图像和文字的意义。然而,解决自然语言和视觉语境中的固有歧义仍是挑战。现有的多模式基准测试忽略了语言和视觉的歧义性,仅依赖单模态上下文进行解歧义,无法利用模态之间的互释潜力。为解决这一差距,我们推出了MUCAR,这是一个专门用于评估多语言场景下多模式歧义解决能力的新颖基准测试。MUCAR包括:(1)一种多语言数据集,其中模糊文本表达通过相应的视觉上下文进行唯一解析;(2)一种双模糊数据集,系统地配对具有模糊性的图像和文本上下文,每个组合都经过精心设计,以通过相互解析产生单一清晰的解释。对多个先进的多模式模型的广泛评估表明,与人类性能相比仍存在显著差距,凸显了对未来研究更复杂跨模态歧义理解方法的需要,进一步推动多模式推理的边界。
Key Takeaways
- MLLMs在视觉语言任务上取得显著进步,擅长理解图像和文字的意义。
- 解决自然语言和视觉语境中的歧义性是MLLMs面临的挑战。
- 现有基准测试忽略了语言和视觉的歧义性,需要新的基准测试来评估多模式歧义解决能力。
- MUCAR是一个专门用于评估多语言场景下多模式歧义解决能力的新颖基准测试。
- MUCAR包括多语言和双模糊数据集,用于评估模型在特定场景下的表现。
- 对多个先进模型的评估显示,与人类性能相比仍存在显著差距。
点此查看论文截图

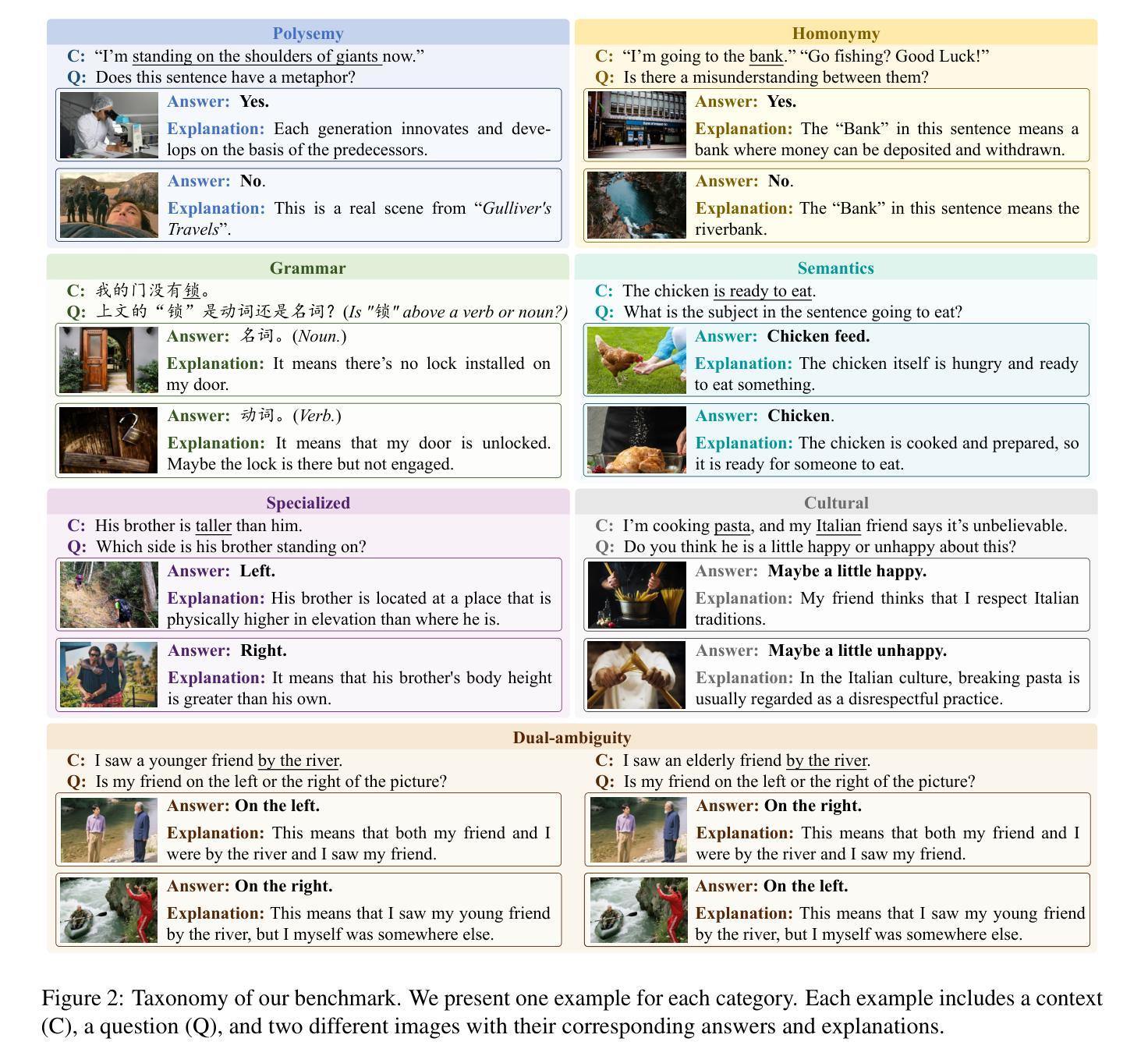
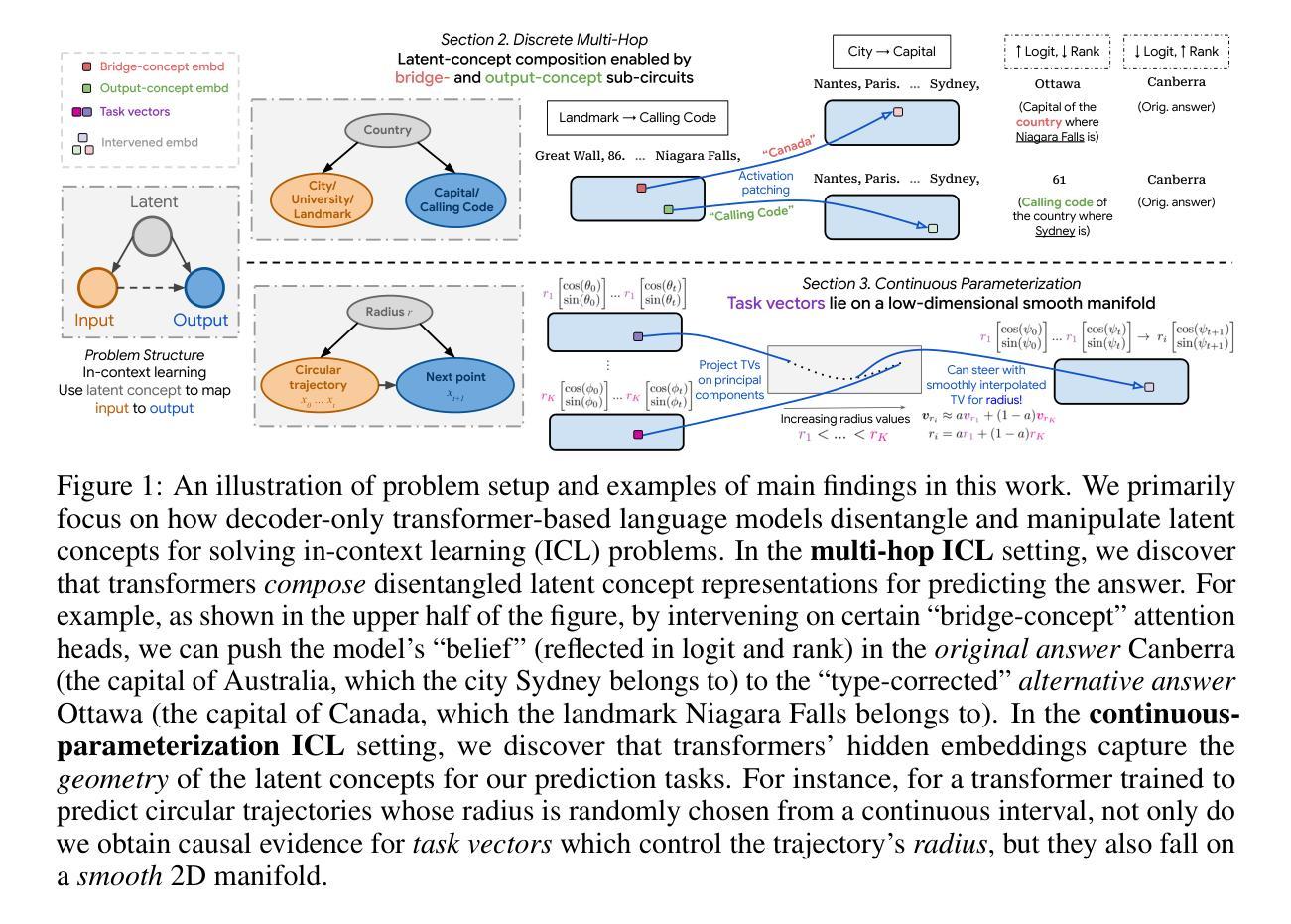
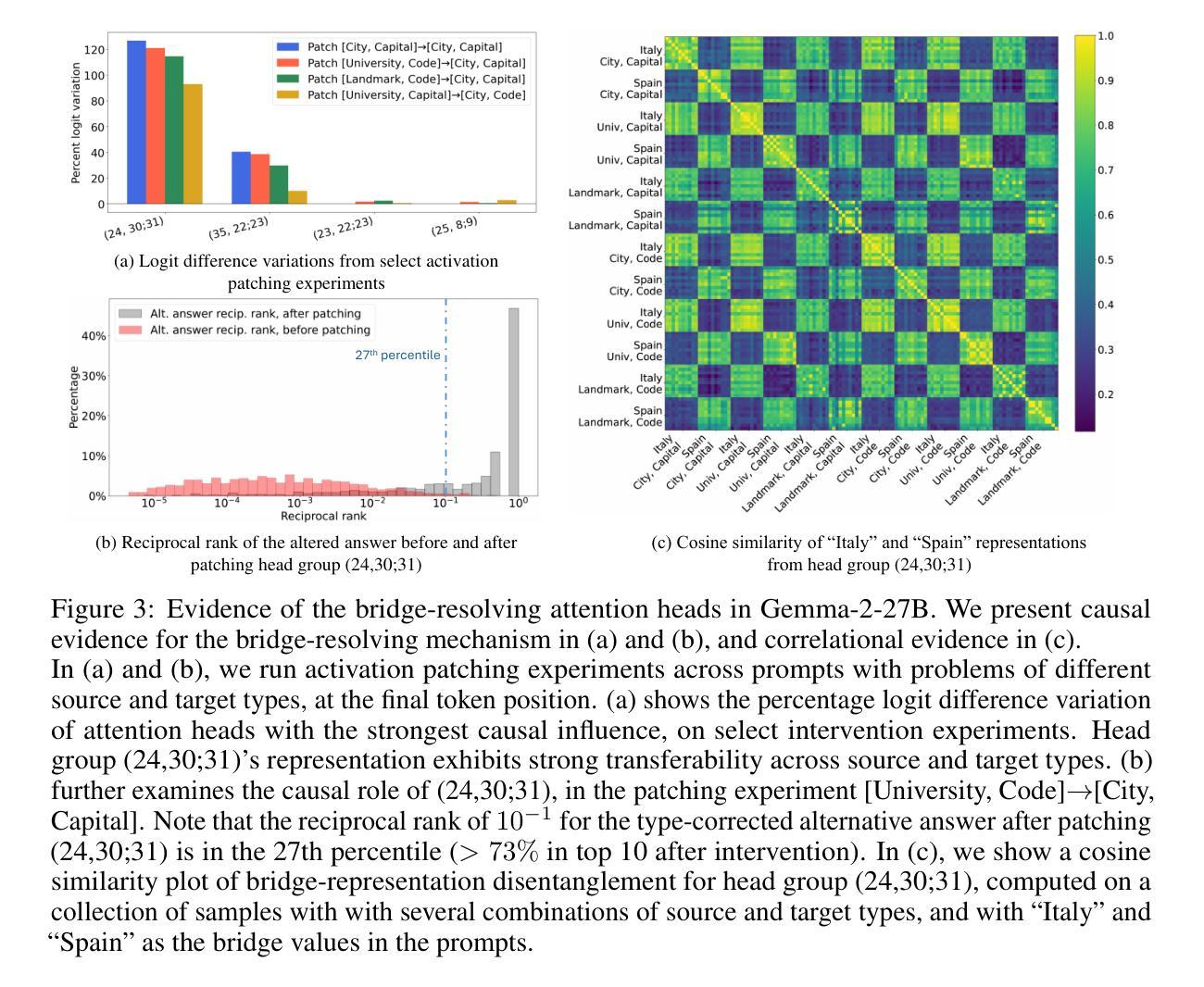
Latent Concept Disentanglement in Transformer-based Language Models
Authors:Guan Zhe Hong, Bhavya Vasudeva, Vatsal Sharan, Cyrus Rashtchian, Prabhakar Raghavan, Rina Panigrahy
When large language models (LLMs) use in-context learning (ICL) to solve a new task, they seem to grasp not only the goal of the task but also core, latent concepts in the demonstration examples. This begs the question of whether transformers represent latent structures as part of their computation or whether they take shortcuts to solve the problem. Prior mechanistic work on ICL does not address this question because it does not sufficiently examine the relationship between the learned representation and the latent concept, and the considered problem settings often involve only single-step reasoning. In this work, we examine how transformers disentangle and use latent concepts. We show that in 2-hop reasoning tasks with a latent, discrete concept, the model successfully identifies the latent concept and does step-by-step concept composition. In tasks parameterized by a continuous latent concept, we find low-dimensional subspaces in the representation space where the geometry mimics the underlying parameterization. Together, these results refine our understanding of ICL and the representation of transformers, and they provide evidence for highly localized structures in the model that disentangle latent concepts in ICL tasks.
当大型语言模型(LLM)使用上下文学习(ICL)来解决新任务时,它们似乎不仅掌握了任务的目标,还掌握了演示示例中的核心、潜在概念。这引发了一个问题,即变压器是将其代表潜在结构作为计算的一部分,还是采取了解决问题的捷径。之前关于ICL的机制性工作并没有解决这一问题,因为它没有充分检查学到的表现和潜在概念之间的关系,而且所考虑的问题设置通常只涉及单步推理。在这项工作中,我们研究了变压器如何解开和利用潜在概念。我们展示了在具有潜在离散概念的2跳推理任务中,模型成功地识别了潜在概念,并进行了逐步的概念组合。在由连续潜在概念参数化的任务中,我们在表征空间中找到低维子空间,其几何形状模仿了潜在参数化。总的来说,这些结果改进了我们对ICL和变压器表示的理解,并为模型中高度局部化的结构提供了证据,这些结构在ICL任务中解开潜在概念。
论文及项目相关链接
Summary
大型语言模型(LLM)利用上下文学习(ICL)解决新任务时,不仅能理解任务目标,还能把握演示例子中的核心潜在概念。本文探讨的是,变压器模型是否将潜在结构作为计算的一部分进行表示,还是采取捷径来解决问题。过去对ICL的机制性工作并没有充分探讨这个问题,因为它没有深入研究学到的表示和潜在概念之间的关系,且考虑的问题设置通常只涉及单步推理。本文研究变压器如何解开和利用潜在概念。在具有潜在离散概念的2跳推理任务中,模型能够成功识别潜在概念并进行逐步概念组合。在由连续潜在概念参数化的任务中,我们发现表示空间中的低维子空间,其几何结构模拟了潜在的参数化。这些结果深化了我们对ICL和变压器表示的理解,并为模型中存在高度局部化的结构提供了证据,这些结构在ICL任务中解开潜在概念。
Key Takeaways
- 大型语言模型(LLM)通过上下文学习(ICL)不仅能理解任务目标,还能把握演示例子中的核心潜在概念。
- 变压器模型在解决新任务时可能解开并利用潜在结构。
- 现有关于ICL的机制性工作未能充分探讨学到的表示和潜在概念之间的关系。
- 在2跳推理任务中,模型能够识别潜在离散概念并进行逐步组合。
- 在连续潜在概念参数化的任务中,模型的表示空间存在低维子空间,其结构与潜在参数相符。
- 这些发现深化了我们对ICL和变压器表示的理解。
点此查看论文截图

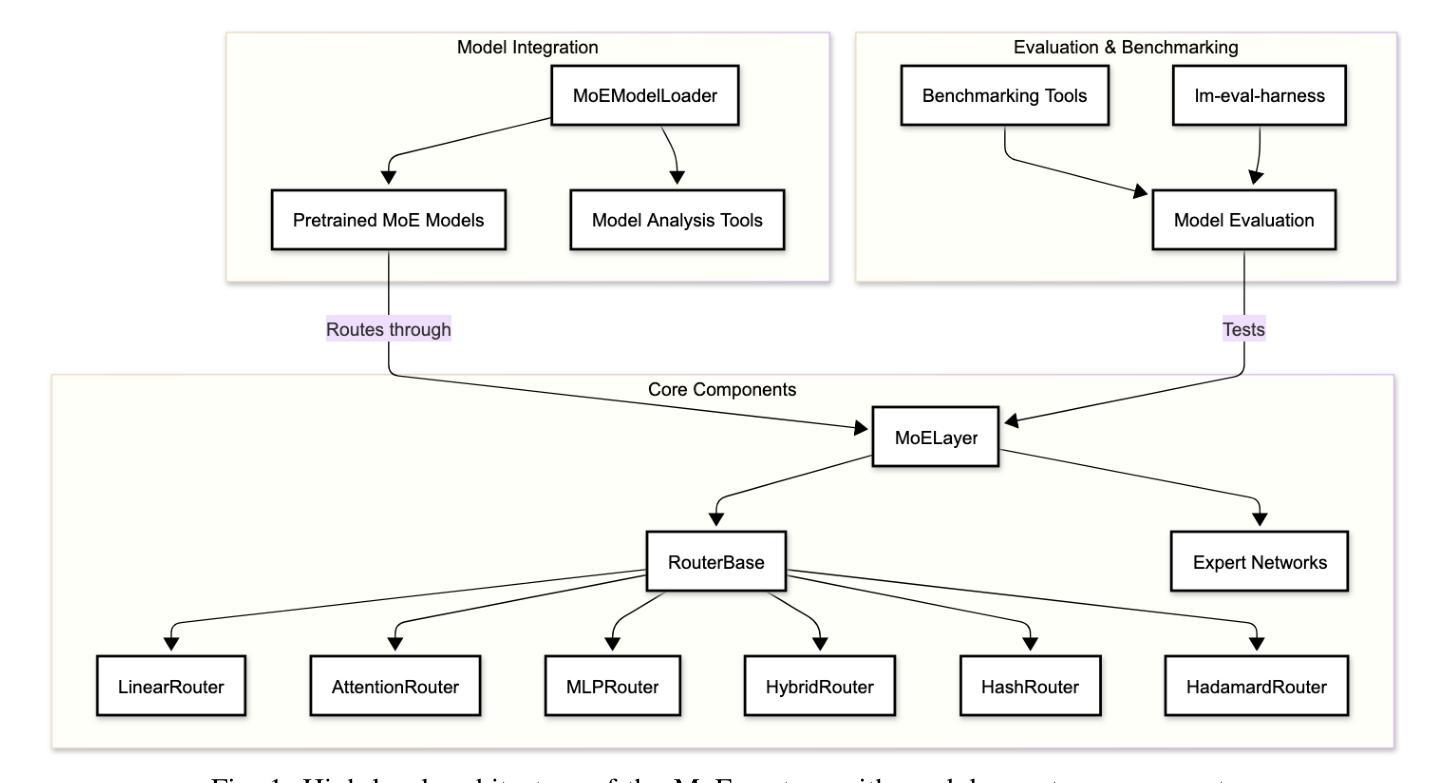
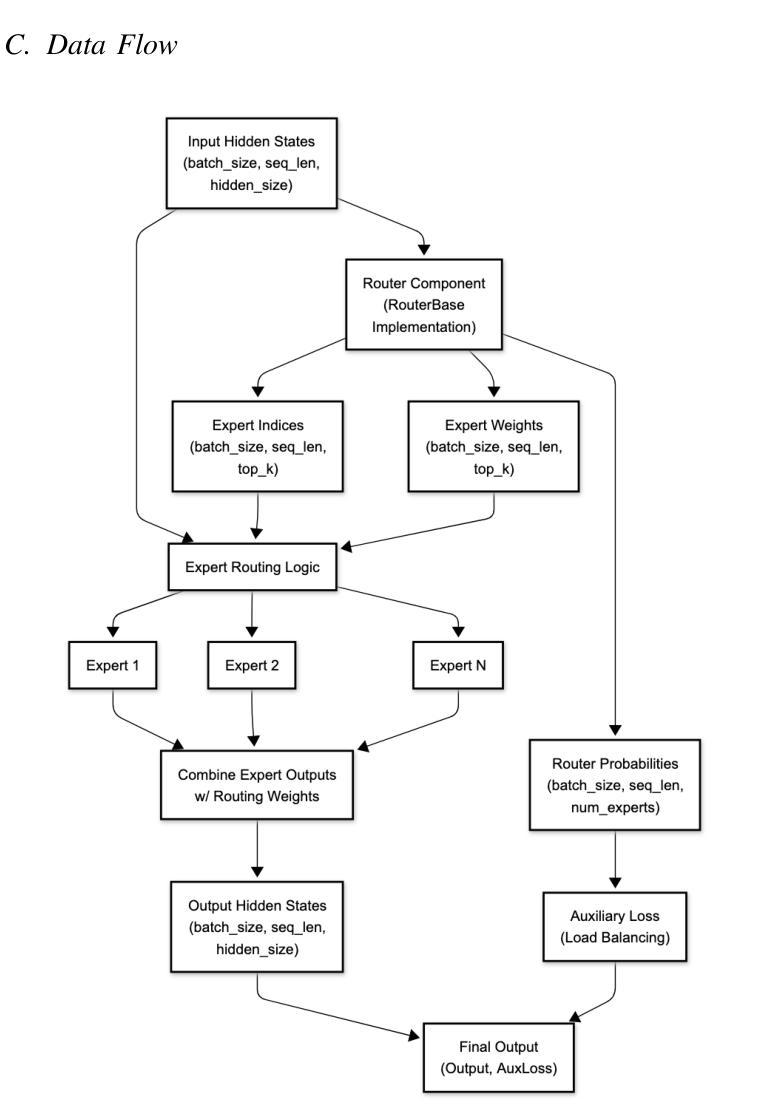
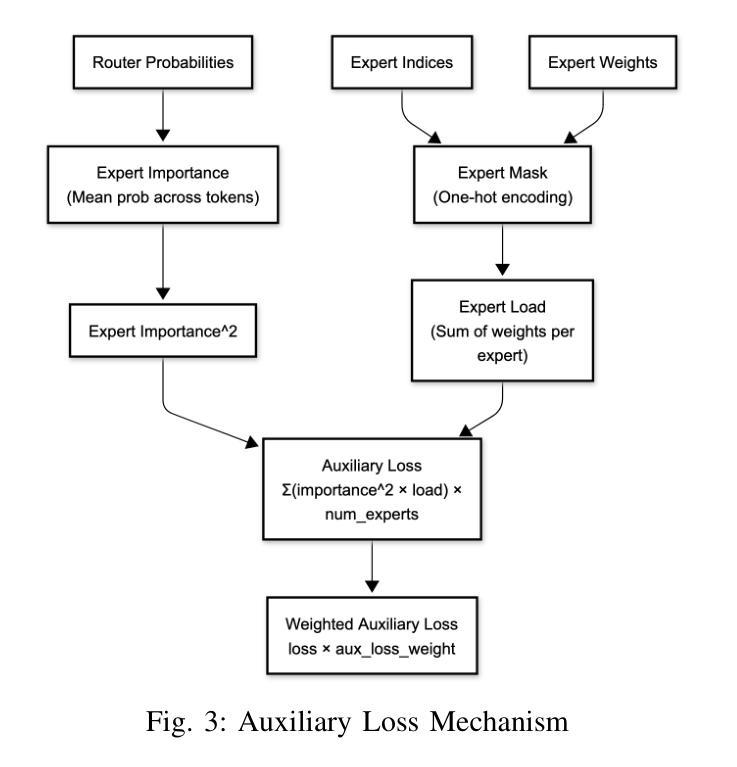
Optimizing MoE Routers: Design, Implementation, and Evaluation in Transformer Models
Authors:Daniel Fidel Harvey, George Weale, Berk Yilmaz
Mixture of Experts (MoE) architectures increase large language model scalability, yet their performance depends on the router module that moves tokens to specialized experts. Bad routing can load imbalance and reduced accuracy. This project designed and implemented different router architectures within Transformer models to fix these limitations. We experimented with six distinct router variants Linear, Attention, Multi-Layer Perceptron (MLP), Hybrid, Hash, and our new MLP-Hadamard. We characterized these routers using BERT and the Qwen1.5-MoE model, looking at parameter efficiency, inference latency, routing entropy, and expert utilization patterns. Our evaluations showed distinct trade-offs: Linear routers offer speed, while MLP and Attention routers provide greater expressiveness. The MLP-Hadamard router shows a unique capability for structured, sparse routing. We successfully replaced and fine-tuned custom routers within the complex, quantized Qwen1.5-MoE model. This work provides a comparative analysis of MoE router designs and offers insights into optimizing their performance for efficient and effective large-scale model deployment.
专家混合(MoE)架构提高了大规模语言模型的可扩展性,但其性能取决于将令牌移动到专业专家的路由器模块。不良的路由会导致负载不均衡和精度下降。此项目在Transformer模型中设计和实现了不同的路由器架构,以解决这些限制。我们试验了六种不同的路由器变体:Linear、Attention、多层感知器(MLP)、Hybrid、Hash以及我们新的MLP-Hadamard。我们使用BERT和Qwen1.5-MoE模型对这些路由器进行了表征,关注参数效率、推理延迟、路由熵和专家利用模式。我们的评估显示了明显的权衡:Linear路由器提供速度,而MLP和Attention路由器提供更大的表现力。MLP-Hadamard路由器显示出结构化和稀疏路由的独特能力。我们成功地在复杂的量化Qwen1.5-MoE模型中替换和微调了自定义路由器。这项工作提供了对MoE路由器设计的比较分析,并深入了解了如何优化其性能,以实现高效和有效的大规模模型部署。
论文及项目相关链接
PDF All authors contributed equally. 11 pages, 6 figures
Summary
本文研究了Mixture of Experts(MoE)架构中的路由器模块设计,针对大型语言模型的扩展性进行了优化。文章介绍了六种不同的路由器架构,包括Linear、Attention、Multi-Layer Perceptron(MLP)、Hybrid、Hash以及新的MLP-Hadamard路由器。通过实验评估,文章分析了这些路由器的参数效率、推理延迟、路由熵和专家利用模式,并探讨了各自的特点和权衡。研究成功地在复杂的量化Qwen1.5-MoE模型中替换和微调了自定义路由器,为MoE路由器设计提供了比较分析,并为大型模型的性能优化和有效部署提供了见解。
Key Takeaways
- MoE架构提高了大型语言模型的扩展性,但性能取决于路由器模块的设计。
- 路由器负责将令牌分配给专家,不良的路由可能导致负载不均衡和准确性下降。
- 研究设计了六种不同的路由器架构,包括Linear、Attention、MLP、Hybrid、Hash和MLP-Hadamard路由器。
- 通过实验评估,文章分析了路由器的参数效率、推理延迟等特性。
- Linear路由器提供速度优势,而MLP和Attention路由器具有更高的表达能力。
- MLP-Hadamard路由器展现出结构化、稀疏路由的独特能力。
- 文章成功地在复杂的量化Qwen1.5-MoE模型中替换和微调了自定义路由器,为MoE路由器设计的优化提供了重要参考。
点此查看论文截图

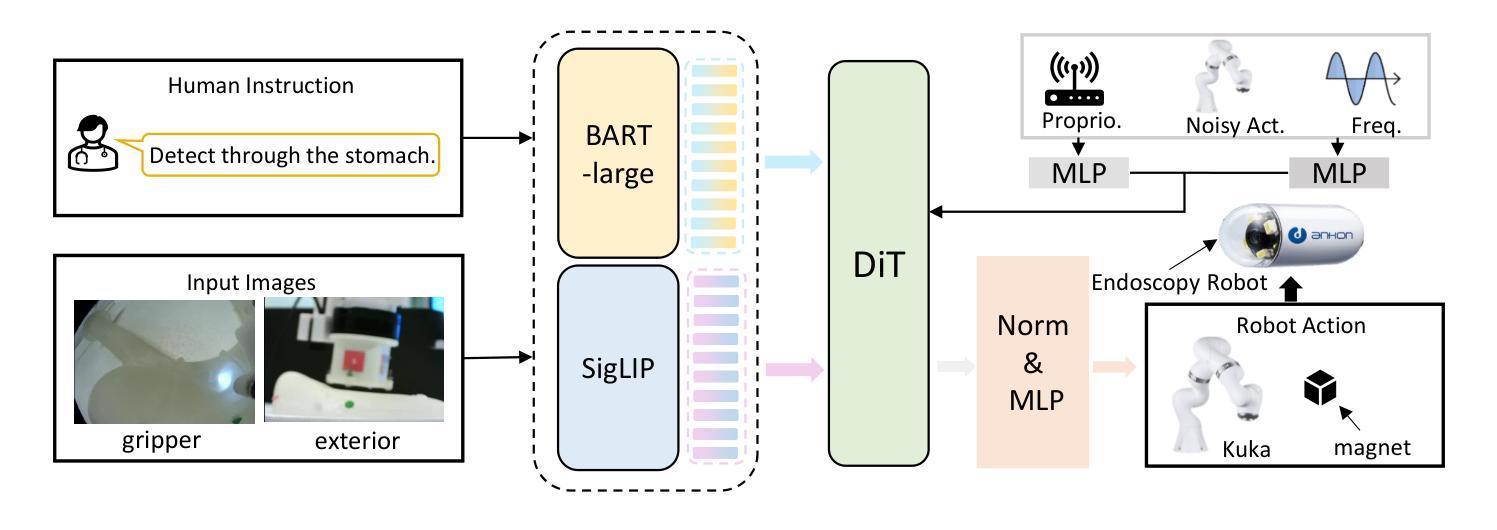
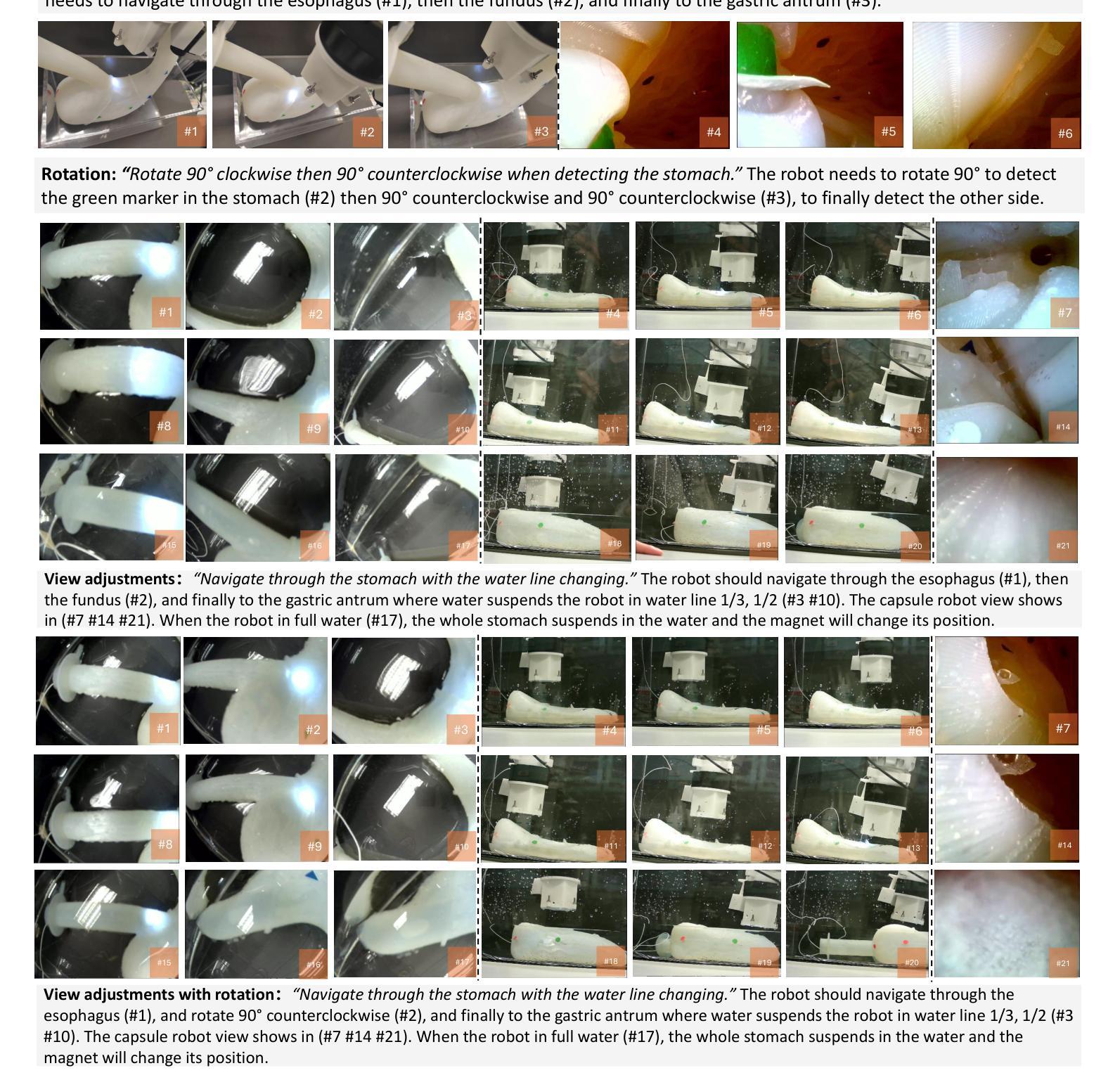
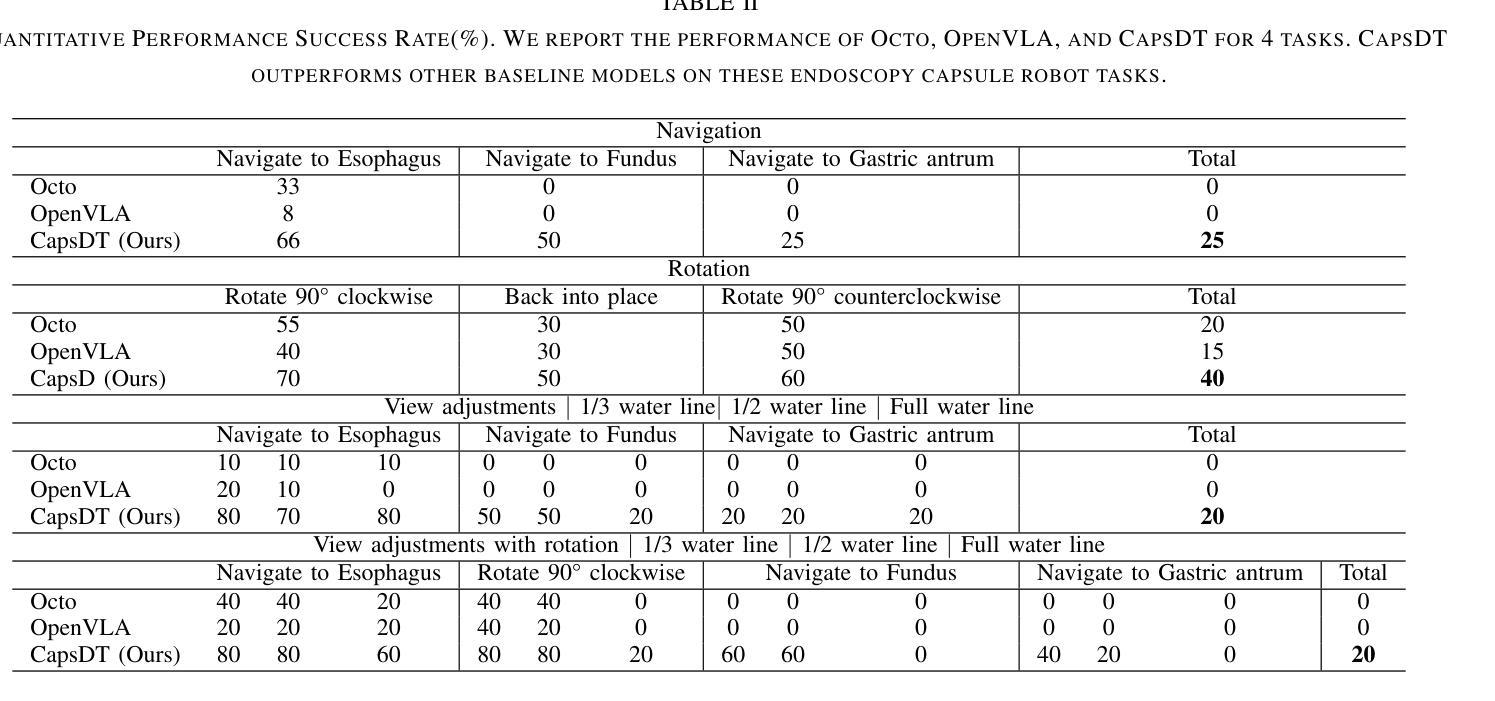
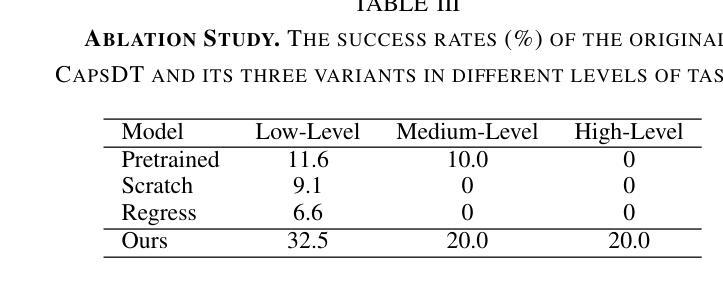
CapsDT: Diffusion-Transformer for Capsule Robot Manipulation
Authors:Xiting He, Mingwu Su, Xinqi Jiang, Long Bai, Jiewen Lai, Hongliang Ren
Vision-Language-Action (VLA) models have emerged as a prominent research area, showcasing significant potential across a variety of applications. However, their performance in endoscopy robotics, particularly endoscopy capsule robots that perform actions within the digestive system, remains unexplored. The integration of VLA models into endoscopy robots allows more intuitive and efficient interactions between human operators and medical devices, improving both diagnostic accuracy and treatment outcomes. In this work, we design CapsDT, a Diffusion Transformer model for capsule robot manipulation in the stomach. By processing interleaved visual inputs, and textual instructions, CapsDT can infer corresponding robotic control signals to facilitate endoscopy tasks. In addition, we developed a capsule endoscopy robot system, a capsule robot controlled by a robotic arm-held magnet, addressing different levels of four endoscopy tasks and creating corresponding capsule robot datasets within the stomach simulator. Comprehensive evaluations on various robotic tasks indicate that CapsDT can serve as a robust vision-language generalist, achieving state-of-the-art performance in various levels of endoscopy tasks while achieving a 26.25% success rate in real-world simulation manipulation.
视觉-语言-动作(VLA)模型已经成为一个突出的研究领域,在各种应用中展示了巨大的潜力。然而,它们在内镜机器人,尤其是在消化系统内执行动作的微型内镜机器人的性能尚未被探索。VLA模型与内镜机器人的集成允许人类操作者与医疗设备之间进行更直观和高效的交互,提高了诊断准确性和治疗效果。在这项工作中,我们设计了CapsDT,这是一种用于胃内微型机器人操作的扩散变换模型。通过处理交替的视觉输入和文本指令,CapsDT可以推断出相应的机器人控制信号,以促进内窥镜任务。此外,我们开发了一个微型内镜机器人系统,该系统由机械臂持有的磁铁控制的微型机器人,解决了四个不同级别的内窥镜任务,并在胃模拟器内创建了相应的微型机器人数据集。对各种机器人任务的全面评估表明,CapsDT可以作为一个强大的视觉语言专家,在不同级别的内窥镜任务中达到最先进的性能,同时在现实世界的模拟操作中实现了26.25%的成功率。
论文及项目相关链接
PDF IROS 2025
摘要
在消化道内窥镜胶囊机器人等领域,跨视觉-语言-行动(VLA)模型展现出巨大潜力,但其在内窥镜机器人方面的应用尚未被探索。本研究设计了一种名为CapsDT的扩散变换模型,用于胃内胶囊机器人的操控。该模型能够处理交替的视觉输入和文字指令,推断出相应的机器人控制信号,促进内窥镜任务的完成。此外,研究团队还开发了一套胶囊内窥镜机器人系统,该系统通过机械臂控制的磁铁控制胶囊机器人,针对四种不同难度的内窥镜任务创建了相应的数据集,并在胃模拟器中进行了模拟操控。经过综合评估表明,CapsDT能够作为一种强大的跨视觉-语言领域的专家系统,在内窥镜任务的不同层级实现最优性能,并在模拟操控中达到26.25%的成功率。
关键见解
- VLA模型在内窥镜胶囊机器人领域具有显著潜力。
- 研究团队提出了CapsDT模型,该模型能够处理视觉和文字指令以控制机器人。
- 研究团队开发了一套胶囊内窥镜机器人系统及其相应的数据集。
- CapsDT模型在内窥镜任务的不同层级实现最优性能。
- CapsDT模型在模拟环境中的操控成功率为26.25%。
- CapsDT模型的引入有助于增强内窥镜任务中人机互动的直观性和效率。
点此查看论文截图




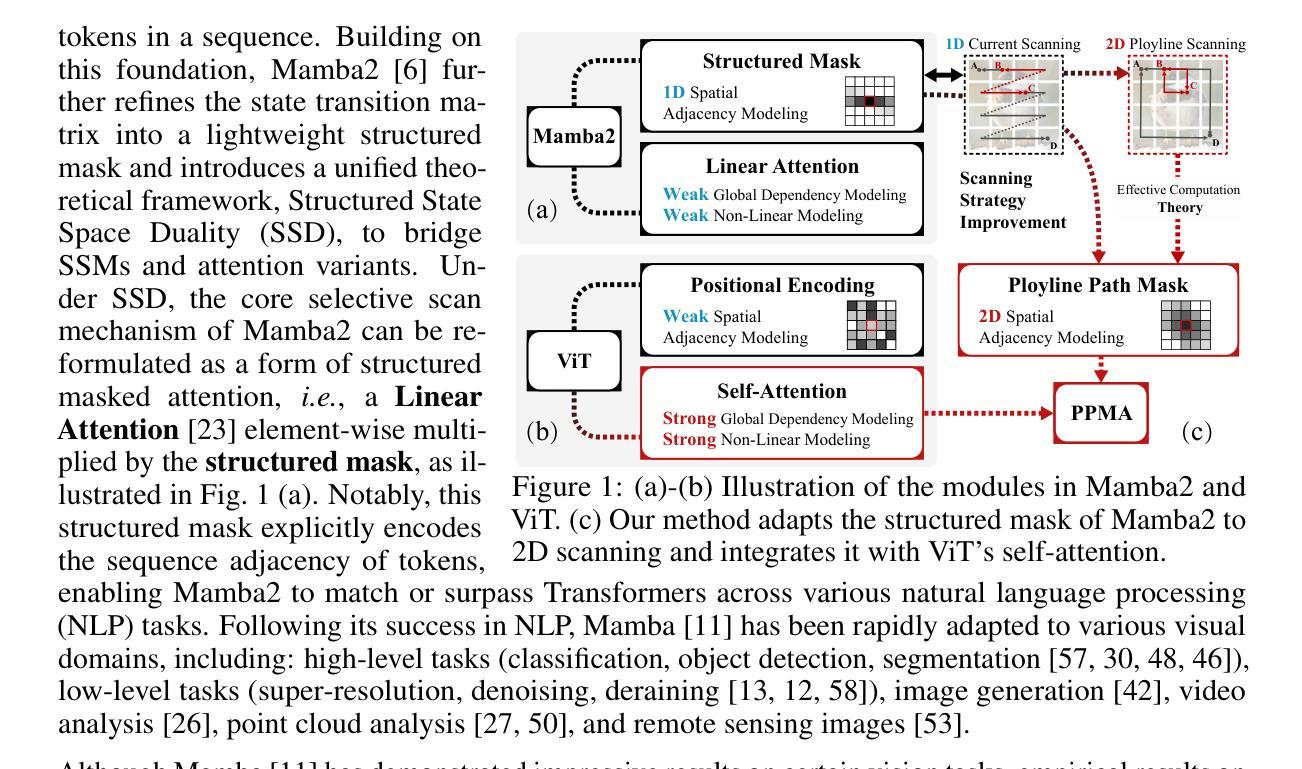
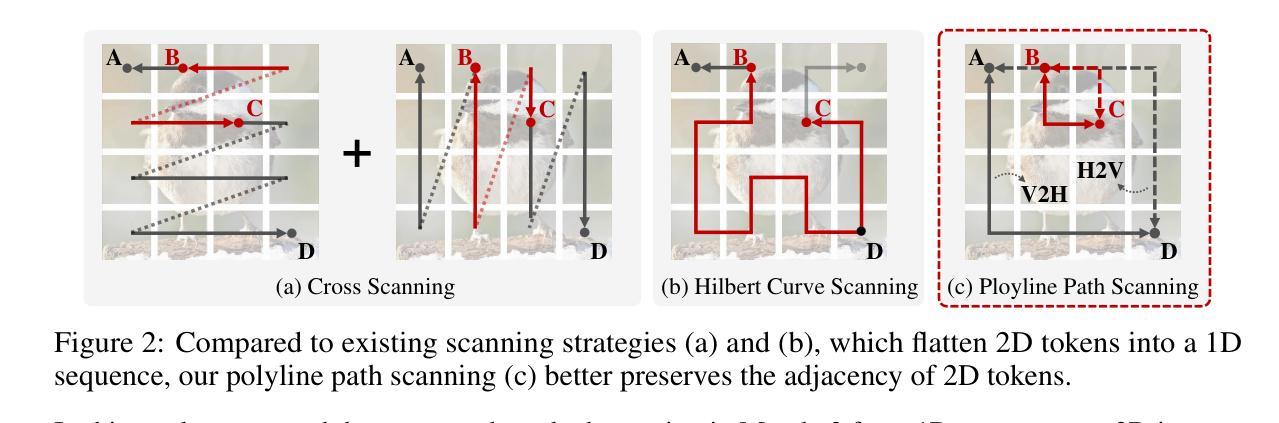
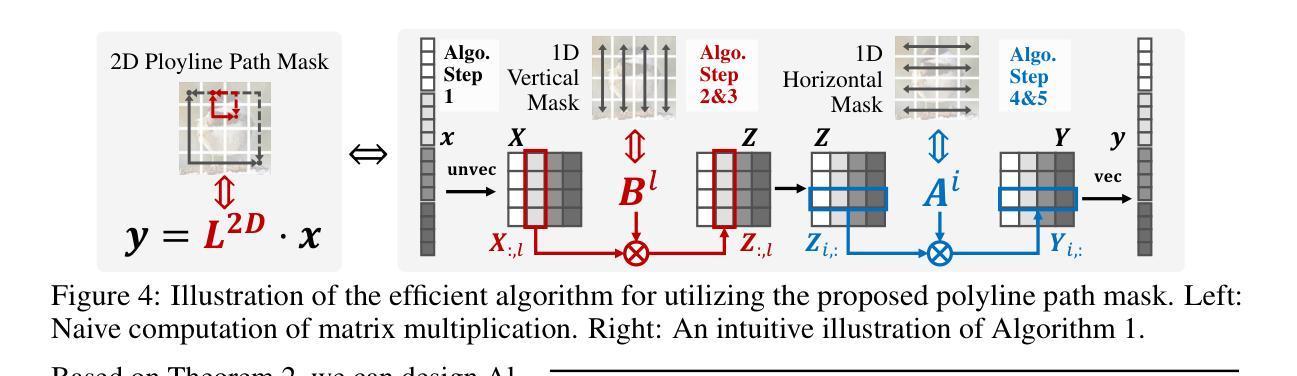
Polyline Path Masked Attention for Vision Transformer
Authors:Zhongchen Zhao, Chaodong Xiao, Hui Lin, Qi Xie, Lei Zhang, Deyu Meng
Global dependency modeling and spatial position modeling are two core issues of the foundational architecture design in current deep learning frameworks. Recently, Vision Transformers (ViTs) have achieved remarkable success in computer vision, leveraging the powerful global dependency modeling capability of the self-attention mechanism. Furthermore, Mamba2 has demonstrated its significant potential in natural language processing tasks by explicitly modeling the spatial adjacency prior through the structured mask. In this paper, we propose Polyline Path Masked Attention (PPMA) that integrates the self-attention mechanism of ViTs with an enhanced structured mask of Mamba2, harnessing the complementary strengths of both architectures. Specifically, we first ameliorate the traditional structured mask of Mamba2 by introducing a 2D polyline path scanning strategy and derive its corresponding structured mask, polyline path mask, which better preserves the adjacency relationships among image tokens. Notably, we conduct a thorough theoretical analysis on the structural characteristics of the proposed polyline path mask and design an efficient algorithm for the computation of the polyline path mask. Next, we embed the polyline path mask into the self-attention mechanism of ViTs, enabling explicit modeling of spatial adjacency prior. Extensive experiments on standard benchmarks, including image classification, object detection, and segmentation, demonstrate that our model outperforms previous state-of-the-art approaches based on both state-space models and Transformers. For example, our proposed PPMA-T/S/B models achieve 48.7%/51.1%/52.3% mIoU on the ADE20K semantic segmentation task, surpassing RMT-T/S/B by 0.7%/1.3%/0.3%, respectively. Code is available at https://github.com/zhongchenzhao/PPMA.
全局依赖建模和空间位置建模是当前深度学习框架基础架构设计中的两个核心问题。最近,Vision Transformers(ViTs)在计算机视觉领域取得了显著的成功,利用了自注意力机制的强大全局依赖建模能力。此外,Mamba2通过显式建模空间邻接先验,通过结构化掩码在自然语言处理任务中表现出了巨大的潜力。在本文中,我们提出了Polyline Path Masked Attention(PPMA),它结合了ViTs的自注意力机制和Mamba2的增强结构化掩码,充分利用了两种架构的互补优势。具体来说,我们首先通过引入2D折线路径扫描策略改进了Mamba2的传统结构化掩码,并得出了相应的结构化掩码,即折线路径掩码,能更好地保留图像标记之间的邻接关系。值得注意的是,我们对所提出的折线路径掩码的结构特性进行了深入的理论分析,并设计了计算折线路径掩码的高效算法。接下来,我们将折线路径掩码嵌入ViTs的自注意力机制中,实现了空间邻接先验的显式建模。在包括图像分类、目标检测和分割在内的标准基准测试上的大量实验表明,我们的模型优于基于状态空间模型和Transformers的先前最先进的方法。例如,我们提出的PPMA-T/S/B模型在ADE20K语义分割任务上的mIoU达到了48.7%/51.1%/52.3%,分别超越了RMT-T/S/B模型0.7%/1.3%/0.3%。代码可在https://github.com/zhongchenzhao/PPMA找到。
论文及项目相关链接
Summary
本文提出了Polyline Path Masked Attention(PPMA),结合了Vision Transformers(ViTs)的自我注意机制与Mamba2的结构化掩码,利用两者的互补优势。通过引入2D折线路径扫描策略和相应的结构化掩码,PPMA更好地保留了图像标记之间的邻接关系。在图像分类、目标检测和分割等标准基准测试上,PPMA模型的表现优于基于状态空间模型和Transformer的先前最前沿方法。
Key Takeaways
- Polyline Path Masked Attention结合了Vision Transformers的自我注意机制和Mamba2的结构化掩码,旨在利用两种架构的互补优势。
- 通过引入2D折线路径扫描策略,改进了传统的结构化掩码,推出了Polyline Path Mask,更好地保留了图像标记间的邻接关系。
- PPMA模型在图像分类、目标检测和语义分割等任务上表现出色,超越了基于状态空间模型和Transformer的先前方法。
- PPMA模型在ADE20K语义分割任务上的表现具体,例如PPMA-T/S/B模型分别实现了48.7%/51.1%/52.3%的mIoU,相较于RMT-T/S/B有显著的提升。
- PPMA模型的代码已公开,便于其他研究者参考和使用。
- PPMA模型的提出基于深厚的理论基础和高效算法设计,确保了其有效性和性能。
点此查看论文截图

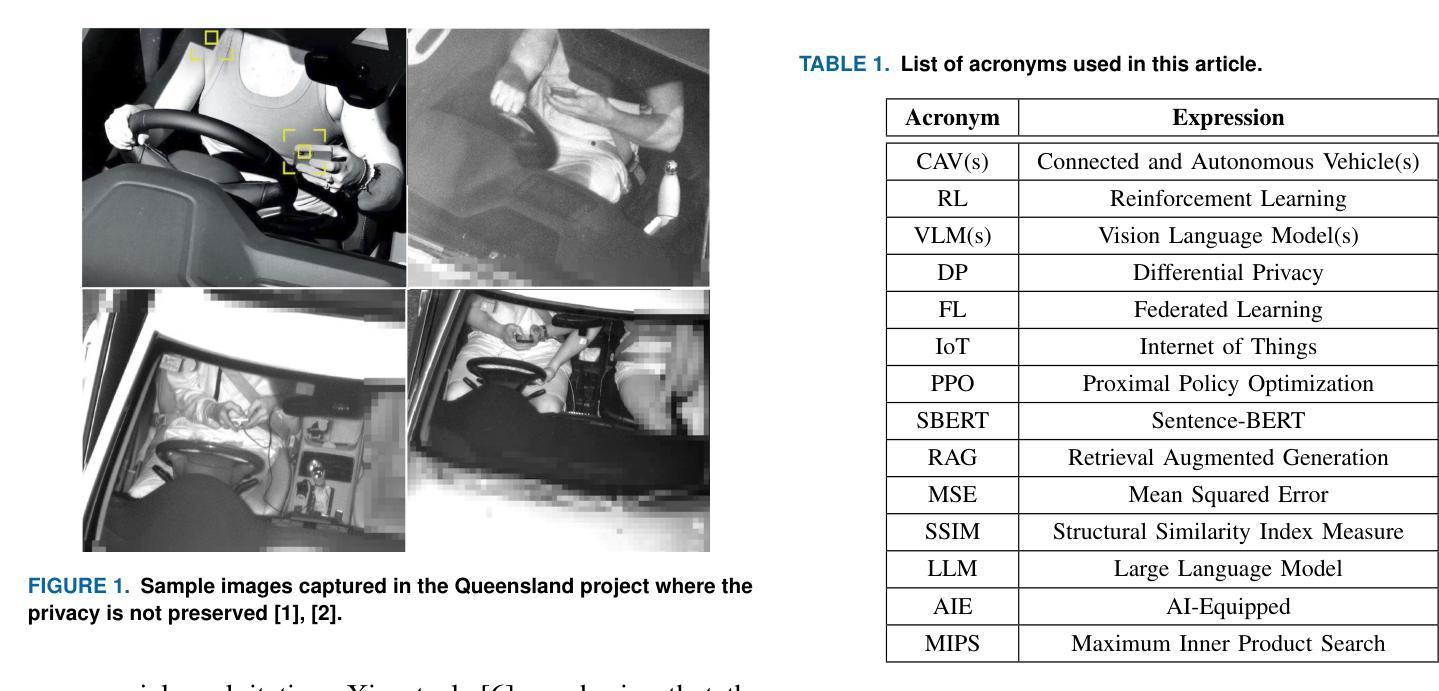
Privacy-Preserving in Connected and Autonomous Vehicles Through Vision to Text Transformation
Authors:Abdolazim Rezaei, Mehdi Sookhak, Ahmad Patooghy
Connected and Autonomous Vehicles (CAVs) rely on a range of devices that often process privacy-sensitive data. Among these, roadside units play a critical role particularly through the use of AI-equipped (AIE) cameras for applications such as violation detection. However, the privacy risks associated with captured imagery remain a major concern, as such data can be misused for identity theft, profiling, or unauthorized commercial purposes. While traditional techniques such as face blurring and obfuscation have been applied to mitigate privacy risks, individual privacy remains at risk, as individuals can still be tracked using other features such as their clothing. This paper introduces a novel privacy-preserving framework that leverages feedback-based reinforcement learning (RL) and vision-language models (VLMs) to protect sensitive visual information captured by AIE cameras. The main idea is to convert images into semantically equivalent textual descriptions, ensuring that scene-relevant information is retained while visual privacy is preserved. A hierarchical RL strategy is employed to iteratively refine the generated text, enhancing both semantic accuracy and privacy. Evaluation results demonstrate significant improvements in both privacy protection and textual quality, with the Unique Word Count increasing by approximately 77% and Detail Density by around 50% compared to existing approaches.
自动驾驶和联网车辆(CAVs)依赖于一系列经常处理敏感隐私数据的设备。其中,路边单元通过应用配备人工智能(AI)的摄像头进行违章检测等应用发挥着至关重要的作用。然而,与捕获的图像相关的隐私问题仍然是一个主要的担忧,因为这种数据可能会被用于身份盗窃、个人特征描述或未经授权的商业目的等不当用途。虽然传统的技术如面部模糊和伪装已被应用于缓解隐私问题,但个人隐私仍然面临风险,因为个体仍然可以通过其他特征如衣着进行跟踪。本文介绍了一种新颖的隐私保护框架,该框架利用基于反馈的强化学习(RL)和视觉语言模型(VLMs)来保护人工智能摄像头捕获的敏感视觉信息。主要思想是将图像转换为语义等效的文本描述,确保保留场景相关信息的同时保护视觉隐私。采用分层RL策略来迭代地优化生成的文本,提高语义准确性和隐私保护能力。评估结果表明,在隐私保护和文本质量方面都有显著提高,与现有方法相比,唯一字数增加了约77%,细节密度增加了约50%。
论文及项目相关链接
Summary
本论文提出一种新型的隐私保护框架,该框架结合反馈强化学习(RL)和视觉语言模型(VLMs),将人工智能设备(AIE)相机捕捉到的敏感视觉信息转换为语义等效的文本描述,从而保护个人隐私。此方法在保护隐私的同时保留了场景相关的信息。通过分层强化学习策略对生成的文本进行迭代优化,提高了语义准确性和隐私保护效果。评估结果表明,与现有方法相比,该框架在隐私保护和文本质量方面均有显著提高。
Key Takeaways
- CAVs中使用的路边单元(特别是配备AI的相机)在捕获隐私敏感数据方面存在重大隐私问题。
- 传统技术(如面部模糊和模糊处理)在保护隐私方面仍有局限性,个体仍可能被基于其他特征追踪。
- 新框架利用反馈强化学习和视觉语言模型将图像转换为文本描述,以保护隐私。
- 该框架能够保留场景相关的信息,同时保护个人隐私。
- 通过分层强化学习策略优化生成的文本,提高语义准确性和隐私保护效果。
- 评估结果显示,新框架在隐私保护和文本质量方面显著提高,其中唯一单词计数增加了约77%,细节密度增加了约50%。
- 该研究为处理CAVs中隐私敏感数据提供了新的解决方案。
点此查看论文截图


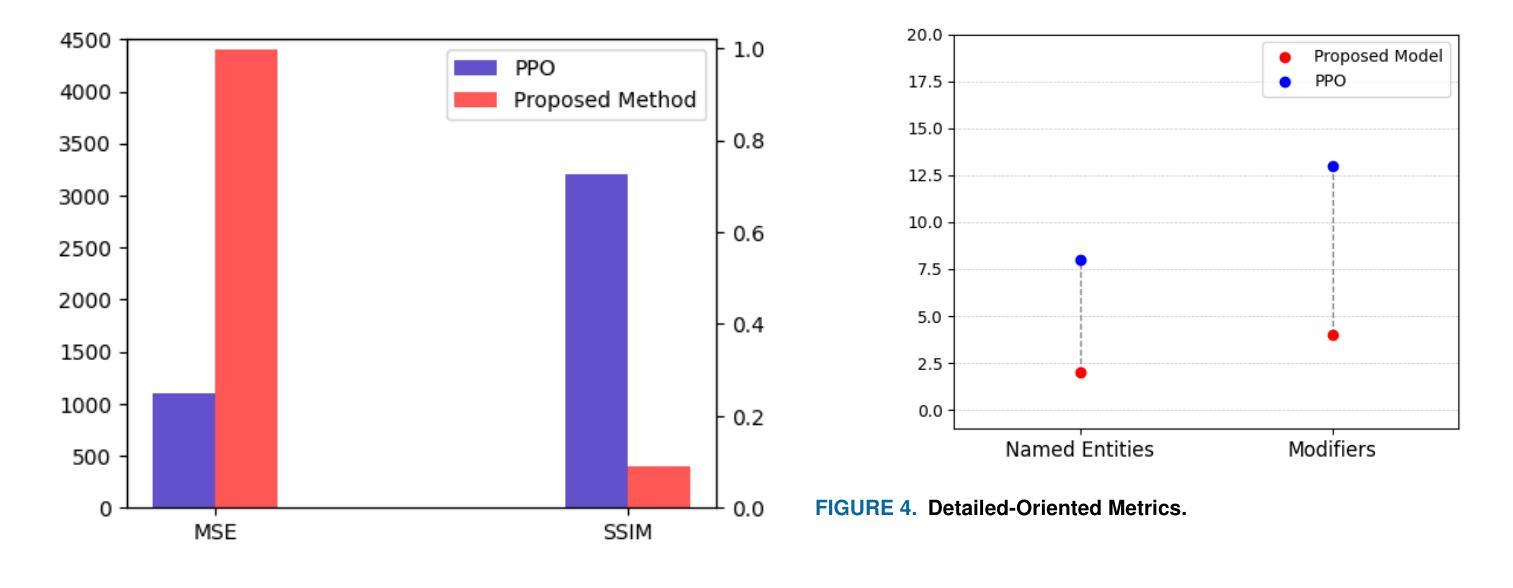
ScholarSearch: Benchmarking Scholar Searching Ability of LLMs
Authors:Junting Zhou, Wang Li, Yiyan Liao, Nengyuan Zhang, Tingjia Miao, Zhihui Qi, Yuhan Wu, Tong Yang
Large Language Models (LLMs)’ search capabilities have garnered significant attention. Existing benchmarks, such as OpenAI’s BrowseComp, primarily focus on general search scenarios and fail to adequately address the specific demands of academic search. These demands include deeper literature tracing and organization, professional support for academic databases, the ability to navigate long-tail academic knowledge, and ensuring academic rigor. Here, we proposed ScholarSearch, the first dataset specifically designed to evaluate the complex information retrieval capabilities of Large Language Models (LLMs) in academic research. ScholarSearch possesses the following key characteristics: Academic Practicality, where question content closely mirrors real academic learning and research environments, avoiding deliberately misleading models; High Difficulty, with answers that are challenging for single models (e.g., Grok DeepSearch or Gemini Deep Research) to provide directly, often requiring at least three deep searches to derive; Concise Evaluation, where limiting conditions ensure answers are as unique as possible, accompanied by clear sources and brief solution explanations, greatly facilitating subsequent audit and verification, surpassing the current lack of analyzed search datasets both domestically and internationally; and Broad Coverage, as the dataset spans at least 15 different academic disciplines. Through ScholarSearch, we expect to more precisely measure and promote the performance improvement of LLMs in complex academic information retrieval tasks. The data is available at: https://huggingface.co/datasets/PKU-DS-LAB/ScholarSearch
大型语言模型(LLM)的搜索能力已引起广泛关注。现有的基准测试,如OpenAI的BrowseComp,主要关注一般搜索场景,未能充分满足学术搜索的特定需求。这些需求包括更深入的文献追踪和组织、对学术数据库的专业支持、浏览长尾学术知识的能力以及确保学术严谨性。在这里,我们提出了ScholarSearch,这是专门设计用于评估大型语言模型(LLM)在学术研究中的复杂信息检索能力的第一个数据集。ScholarSearch具有以下关键特点:学术实用性,问题内容紧密反映真实学术学习和研究环境,避免故意误导模型;高难度,答案对于单一模型(如Grok DeepSearch或Gemini Deep Research)来说具有挑战性,直接提供答案往往需要进行至少三次深度搜索;简洁评估,限制条件确保答案是独一无二的,同时配有清晰的来源和简要的解决方案解释,极大地促进了后续的审计和验证,弥补了国内外分析搜索数据集的缺乏;广泛覆盖,该数据集涵盖至少15个不同的学科。通过ScholarSearch,我们希望能够更精确地衡量和促进LLM在复杂的学术信息检索任务中的性能提升。数据可在:https://huggingface.co/datasets/PKU-DS-LAB/ScholarSearch上找到。
论文及项目相关链接
Summary
大型语言模型(LLM)的搜索能力备受关注。现有基准测试如OpenAI的BrowseComp主要关注通用搜索场景,未能充分满足学术搜索的特定需求。学术搜索需求包括文献追踪与组织、专业学术数据库支持、长尾学术知识导航以及学术严谨性。为此,我们提出了ScholarSearch,首个专为评估大型语言模型在学术研究中的复杂信息检索能力而设计的数据集。ScholarSearch具备学术实用性、高难度、简洁评估及广泛覆盖等多个关键特性,涵盖至少15个不同学术领域。通过ScholarSearch,我们期望更精确地衡量并促进LLM在复杂学术信息检索任务中的性能提升。
Key Takeaways
- 大型语言模型(LLM)的搜索能力已引起广泛关注。
- 现有基准测试不足以满足学术搜索的特定需求。
- ScholarSearch数据集专为评估LLM在学术研究中的信息检索能力而设计。
- ScholarSearch具备学术实用性、高难度、简洁评估及广泛覆盖等关键特性。
- 该数据集注重学术严谨性,涵盖真实学术环境和研究需求。
- ScholarSearch数据集至少涵盖15个不同学术领域。
点此查看论文截图

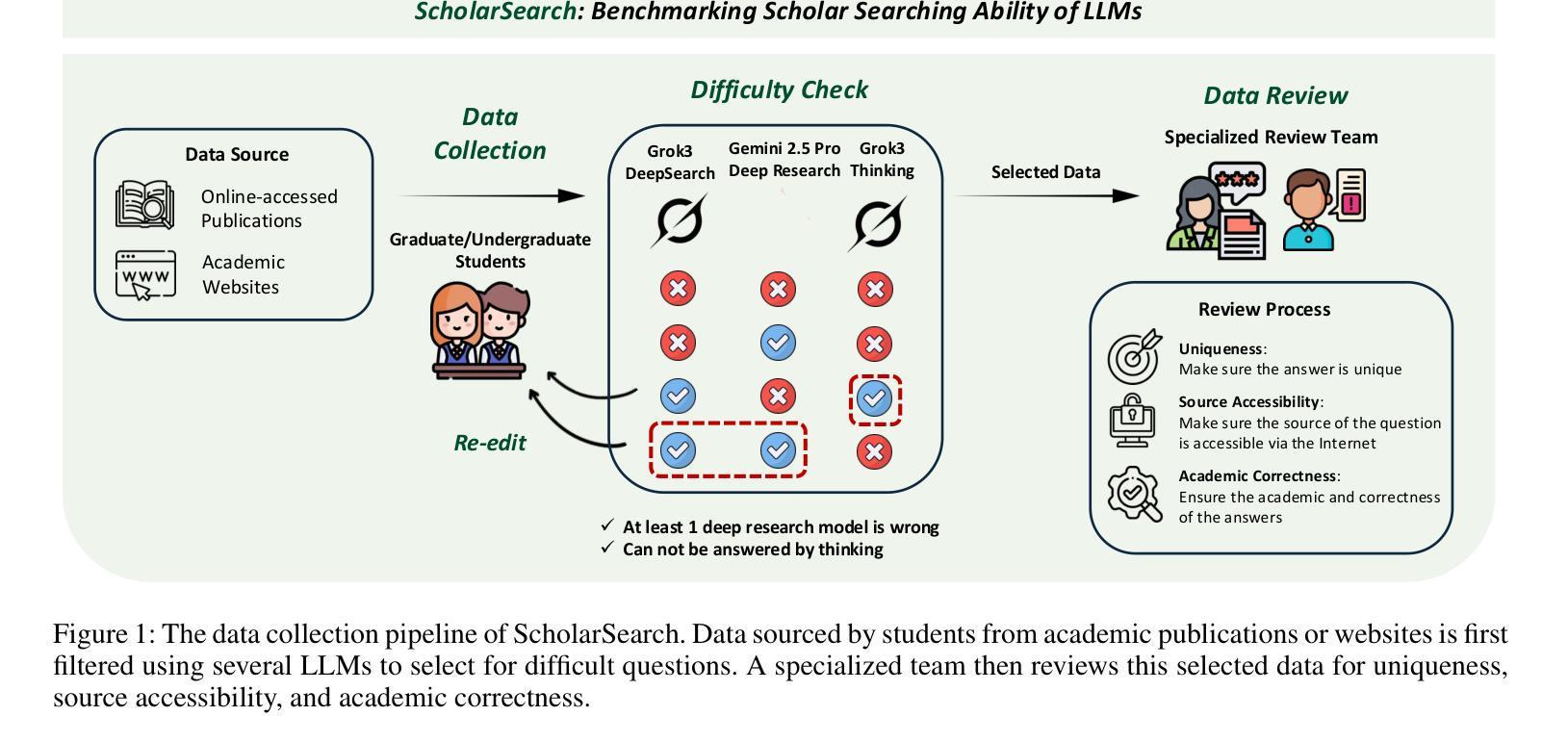
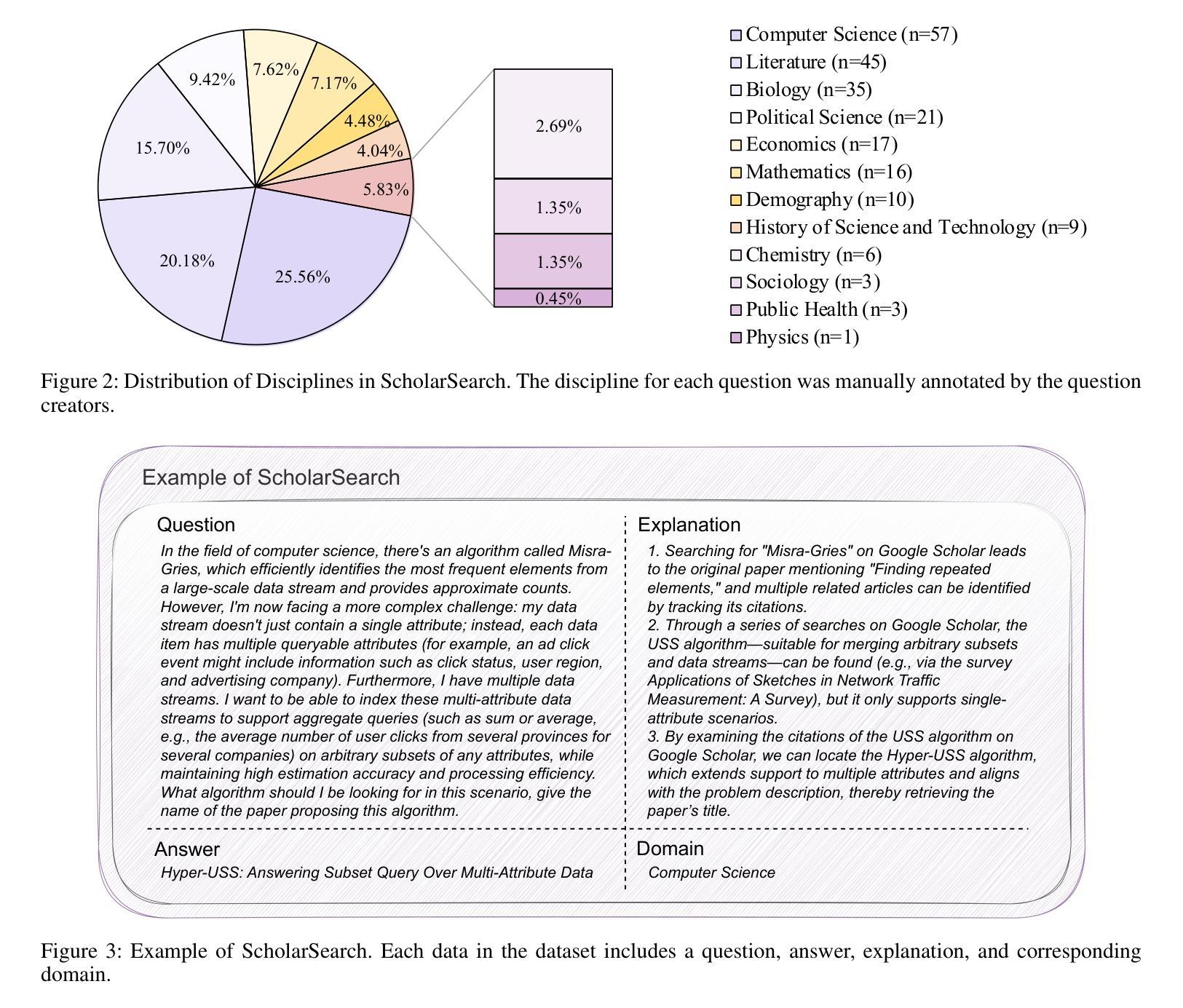

Calibrating Pre-trained Language Classifiers on LLM-generated Noisy Labels via Iterative Refinement
Authors:Liqin Ye, Agam Shah, Chao Zhang, Sudheer Chava
The traditional process of creating labeled datasets is labor-intensive and expensive. Recent breakthroughs in open-source large language models (LLMs) have opened up a new avenue in generating labeled datasets automatically for various natural language processing (NLP) tasks, providing an alternative to such an expensive annotation process. However, the reliability of such auto-generated labels remains a significant concern due to inherent inaccuracies. When learning from noisy labels, the model’s generalization is likely to be harmed as it is prone to overfit to those label noises. While previous studies in learning from noisy labels mainly focus on synthetic noise and real-world noise, LLM-generated label noise receives less attention. In this paper, we propose SiDyP: Simplex Label Diffusion with Dynamic Prior to calibrate the classifier’s prediction, thus enhancing its robustness towards LLM-generated noisy labels. SiDyP retrieves potential true label candidates by neighborhood label distribution in text embedding space and iteratively refines noisy candidates using a simplex diffusion model. Our framework can increase the performance of the BERT classifier fine-tuned on both zero-shot and few-shot LLM-generated noisy label datasets by an average of 7.21% and 7.30% respectively. We demonstrate the effectiveness of SiDyP by conducting extensive benchmarking for different LLMs over a variety of NLP tasks. Our code is available on Github.
传统创建标记数据集的过程劳动密集且费用高昂。最近开源大型语言模型(LLM)的突破为各种自然语言处理(NLP)任务自动生成标记数据集开辟了一条新途径,为这种昂贵的标注过程提供了替代方案。然而,由于内在的不准确性,这种自动生成的标签的可靠性仍然是一个令人关注的问题。从噪声标签中学习时,模型很容易受到这些标签噪声的影响而过度拟合,从而影响其泛化能力。虽然之前关于从噪声标签中学习的研究主要集中在合成噪声和现实世界的噪声上,但LLM生成的标签噪声却被忽视了。在本文中,我们提出了SiDyP:基于动态先验的简单标签扩散方法,以校准分类器的预测,从而提高其对LLM生成的噪声标签的鲁棒性。SiDyP通过文本嵌入空间中的邻近标签分布检索潜在的真实标签候选者,并使用简单扩散模型迭代优化噪声候选者。我们的框架可以提高在零样本和少样本LLM生成噪声标签数据集上微调过的BERT分类器的性能,平均分别提高了7.21%和7.30%。我们对不同的LLM进行了广泛的基准测试,涵盖了多种NLP任务,证明了SiDyP的有效性。我们的代码已在GitHub上发布。
论文及项目相关链接
PDF Accepted at KDD’25
Summary
LLM自动生成标签数据集的方法为NLP任务提供了新途径,但存在可靠性问题。本文提出SiDyP方法,通过简单标签扩散和动态先验来校准分类器预测,提高其对LLM生成噪声标签的鲁棒性。SiDyP通过文本嵌入空间中的邻域标签分布检索潜在的真实标签候选者,并使用简单扩散模型迭代优化噪声候选者。该方法可提高零样本和少样本LLM生成噪声标签数据集上BERT分类器的性能,平均提高7.21%和7.30%。
Key Takeaways
- LLM自动生成标签数据集为NLP任务带来新途径,但可靠性成关注重点。
- LLM生成的标签噪声对模型泛化能力可能造成损害。
- SiDyP方法通过简单标签扩散和动态先验提高模型对LLM生成噪声标签的鲁棒性。
- SiDyP在文本嵌入空间中通过邻域标签分布检索真实标签候选者。
- SiDyP使用简单扩散模型迭代优化噪声候选标签。
- SiDyP能提高零样本和少样本LLM生成噪声标签数据集上BERT分类器的性能。
点此查看论文截图

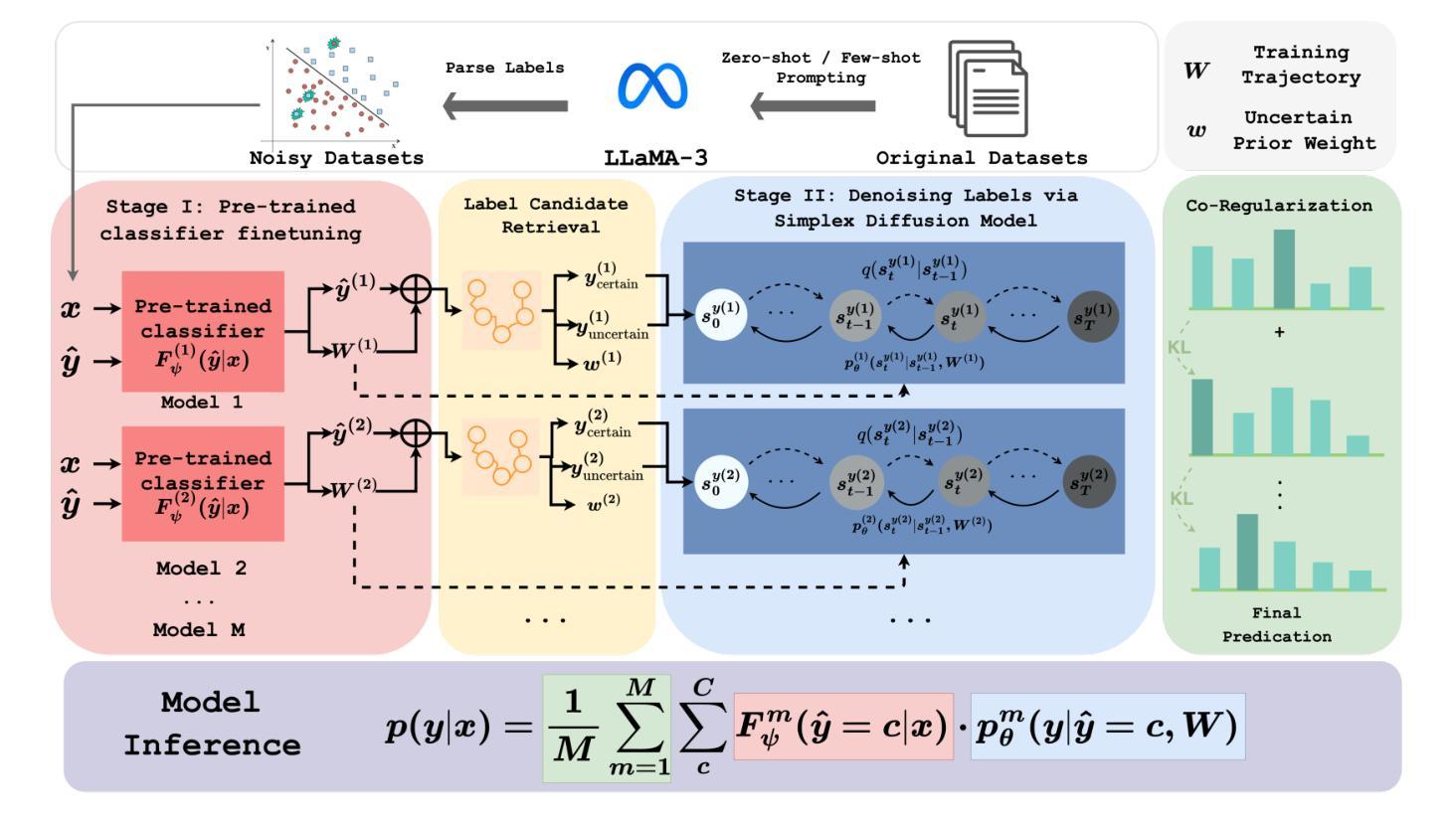



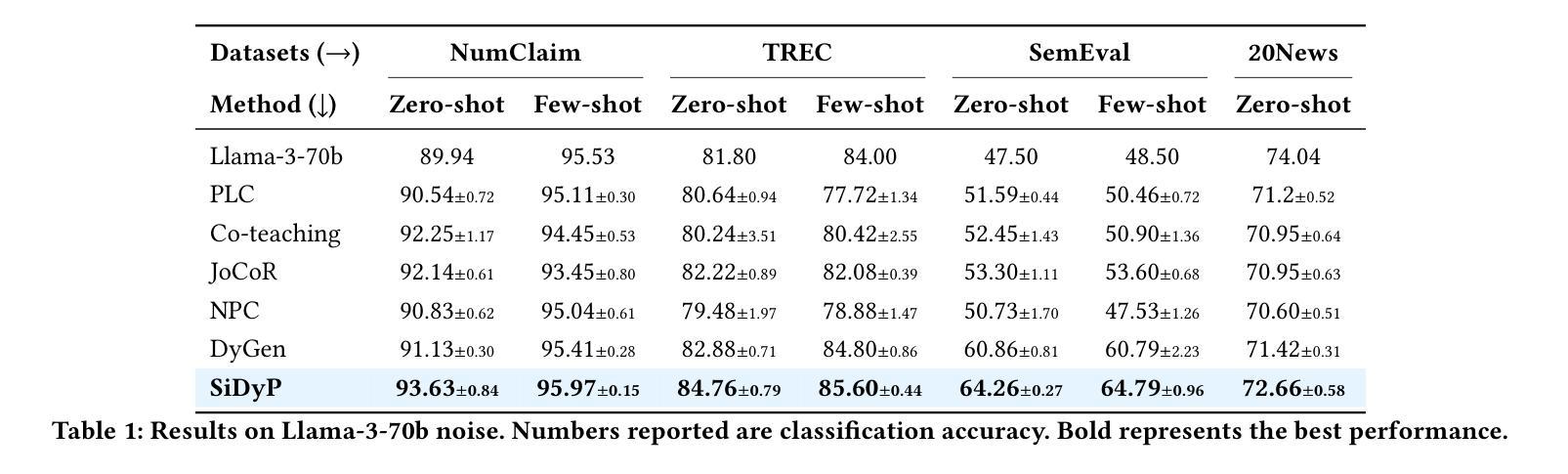
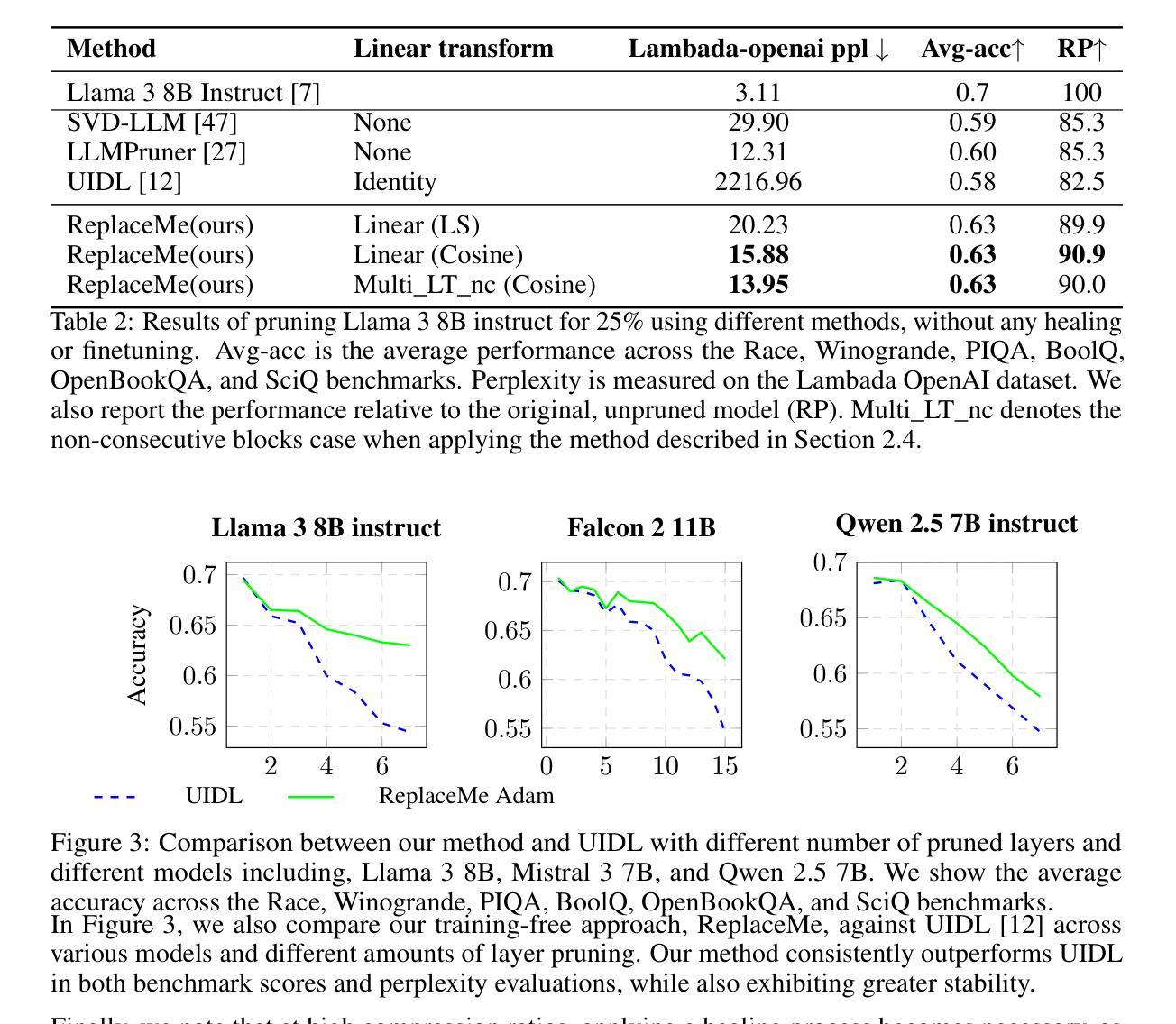
ReplaceMe: Network Simplification via Depth Pruning and Transformer Block Linearization
Authors:Dmitriy Shopkhoev, Ammar Ali, Magauiya Zhussip, Valentin Malykh, Stamatios Lefkimmiatis, Nikos Komodakis, Sergey Zagoruyko
We introduce ReplaceMe, a generalized training-free depth pruning method that effectively replaces transformer blocks with a linear operation, while maintaining high performance for low compression ratios. In contrast to conventional pruning approaches that require additional training or fine-tuning, our approach requires only a small calibration dataset that is used to estimate a linear transformation, which approximates the pruned blocks. The estimated linear mapping can be seamlessly merged with the remaining transformer blocks, eliminating the need for any additional network parameters. Our experiments show that ReplaceMe consistently outperforms other training-free approaches and remains highly competitive with state-of-the-art pruning methods that involve extensive retraining/fine-tuning and architectural modifications. Applied to several large language models (LLMs), ReplaceMe achieves up to 25% pruning while retaining approximately 90% of the original model’s performance on open benchmarks - without any training or healing steps, resulting in minimal computational overhead (see Fig.1). We provide an open-source library implementing ReplaceMe alongside several state-of-the-art depth pruning techniques, available at https://github.com/mts-ai/ReplaceMe.
我们介绍了ReplaceMe,这是一种通用的训练外深度剪枝方法,它能有效地用线性运算替代transformer块,同时在低压缩比的情况下保持高性能。与传统的需要额外训练或微调的方法不同,我们的方法只需要一个小型的校准数据集来估计线性变换,该变换近似于剪枝块。估计的线性映射可以无缝地与其他transformer块合并,无需任何额外的网络参数。我们的实验表明,ReplaceMe持续超越其他无训练方法,并且在涉及大量重新训练/微调和结构修改的尖端剪枝方法中表现出高度竞争力。应用于多个大型语言模型(LLM)时,ReplaceMe可实现高达25%的剪枝率,同时在开放基准测试中保留原始模型约90%的性能——无需任何训练或修复步骤,且计算开销最小(见图1)。我们在https://github.com/mts-ai/ReplaceMe上提供了实现ReplaceMe以及几种先进的深度剪枝技术的开源库。
论文及项目相关链接
Summary
ReplaceMe是一种无需训练的深度剪枝方法,可有效地用线性运算替换变压器块,并在低压缩比下保持高性能。该方法仅需要一个小的校准数据集来估计线性变换,以近似剪枝块,无需任何额外的网络参数。实验表明,ReplaceMe在无需训练的方法中具有出色的性能,并且在涉及大量重新训练或微调以及架构修改的最先进剪枝方法中保持竞争力。应用于大型语言模型(LLM)时,ReplaceMe可在不损失任何性能的情况下实现高达25%的剪枝率,并且具有最小的计算开销。
Key Takeaways
- ReplaceMe是一种无需训练的深度剪枝方法,能够替换变压器块为线性操作。
- 该方法通过使用小的校准数据集来估计线性变换,以模拟剪枝块的效果。
- ReplaceMe不需要任何额外的网络参数,可以无缝地融入剩余的变压器块。
- 实验表明,ReplaceMe在无需训练的方法中表现优秀,与其他先进的剪枝方法相比具有竞争力。
- 应用到大语言模型(LLM)时,ReplaceMe可实现高达25%的剪枝率,同时保留原始模型性能的约90%。
- ReplaceMe具有最小的计算开销。
点此查看论文截图
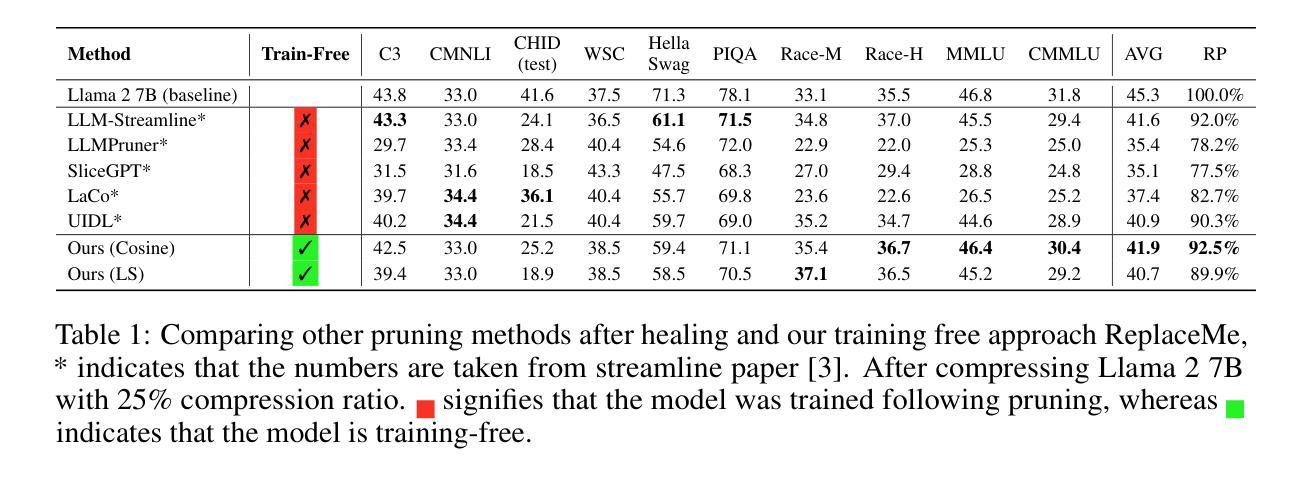
TALE: A Tool-Augmented Framework for Reference-Free Evaluation of Large Language Models
Authors:Sher Badshah, Ali Emami, Hassan Sajjad
As Large Language Models (LLMs) become increasingly integrated into real-world, autonomous applications, relying on static, pre-annotated references for evaluation poses significant challenges in cost, scalability, and completeness. We propose Tool-Augmented LLM Evaluation (TALE), a framework to assess LLM outputs without predetermined ground-truth answers. Unlike conventional metrics that compare to fixed references or depend solely on LLM-as-a-judge knowledge, TALE employs an agent with tool-access capabilities that actively retrieves and synthesizes external evidence. It iteratively generates web queries, collects information, summarizes findings, and refines subsequent searches through reflection. By shifting away from static references, TALE aligns with free-form question-answering tasks common in real-world scenarios. Experimental results on multiple free-form QA benchmarks show that TALE not only outperforms standard reference-based metrics for measuring response accuracy but also achieves substantial to near-perfect agreement with human evaluations. TALE enhances the reliability of LLM evaluations in real-world, dynamic scenarios without relying on static references.
随着大型语言模型(LLM)在现实世界自主应用中的集成度越来越高,依赖静态、预先标注的参考进行评估在成本、可扩展性和完整性方面带来了重大挑战。我们提出了工具增强型LLM评估(TALE)框架,该框架能够评估LLM输出而无需预先确定的正确答案。与传统的仅与固定参考进行比较或仅依赖LLM作为评判知识的指标不同,TALE使用一个具有工具访问能力的智能体,该智能体能主动检索并综合外部证据。它通过迭代生成网络查询、收集信息、总结发现并通过反思来优化后续搜索。通过摆脱静态参考,TALE与真实场景中常见的自由形式问答任务相符。在多个自由形式问答基准测试上的实验结果表明,TALE不仅优于基于标准参考的度量标准来衡量响应准确性,而且在与人类评估的对比中取得了从显著到近乎完美的共识。TALE提高了在真实世界动态场景中LLM评估的可靠性,无需依赖静态参考。
论文及项目相关链接
摘要
随着大型语言模型(LLM)在现实世界自主应用中的集成度不断提高,依赖静态、预先注释的参考进行评估在成本、可扩展性和完整性方面带来了重大挑战。我们提出了工具增强型LLM评估(TALE)框架,该框架可在无需预先设定的标准答案的情况下评估LLM输出。与传统的与固定参考点进行比较或仅依赖LLM作为法官知识的评估指标不同,TALE使用一个具备工具访问能力的代理,能够主动检索和综合外部证据。它通过生成网络查询、收集信息、总结发现并通过反思来优化后续搜索。通过摆脱静态参考,TALE符合现实场景中常见的自由形式问答任务。在多个自由形式问答基准测试上的实验结果表明,TALE不仅在衡量回答准确性方面优于基于标准参考的度量指标,而且在与人类评估的对比中取得了显著至近乎完美的共识。TALE提高了在现实世界动态场景中LLM评估的可靠性,无需依赖静态参考。
关键见解
- LLM在现实世界的集成应用中,使用静态参考进行评估存在成本、可扩展性和完整性问题。
- 提出的TALE框架能主动检索外部证据并评估LLM输出,无需预先设定的标准答案。
- TALE使用具备工具访问能力的代理,能够生成网络查询、收集信息并总结发现。
- TALE通过迭代搜索和反思,优化了评估过程。
- 与传统的评估指标相比,TALE在自由形式问答任务上的表现更优秀。
- TALE在多个基准测试上的实验表现显示,其衡量回答准确性的能力超越标准参考度量指标。
点此查看论文截图

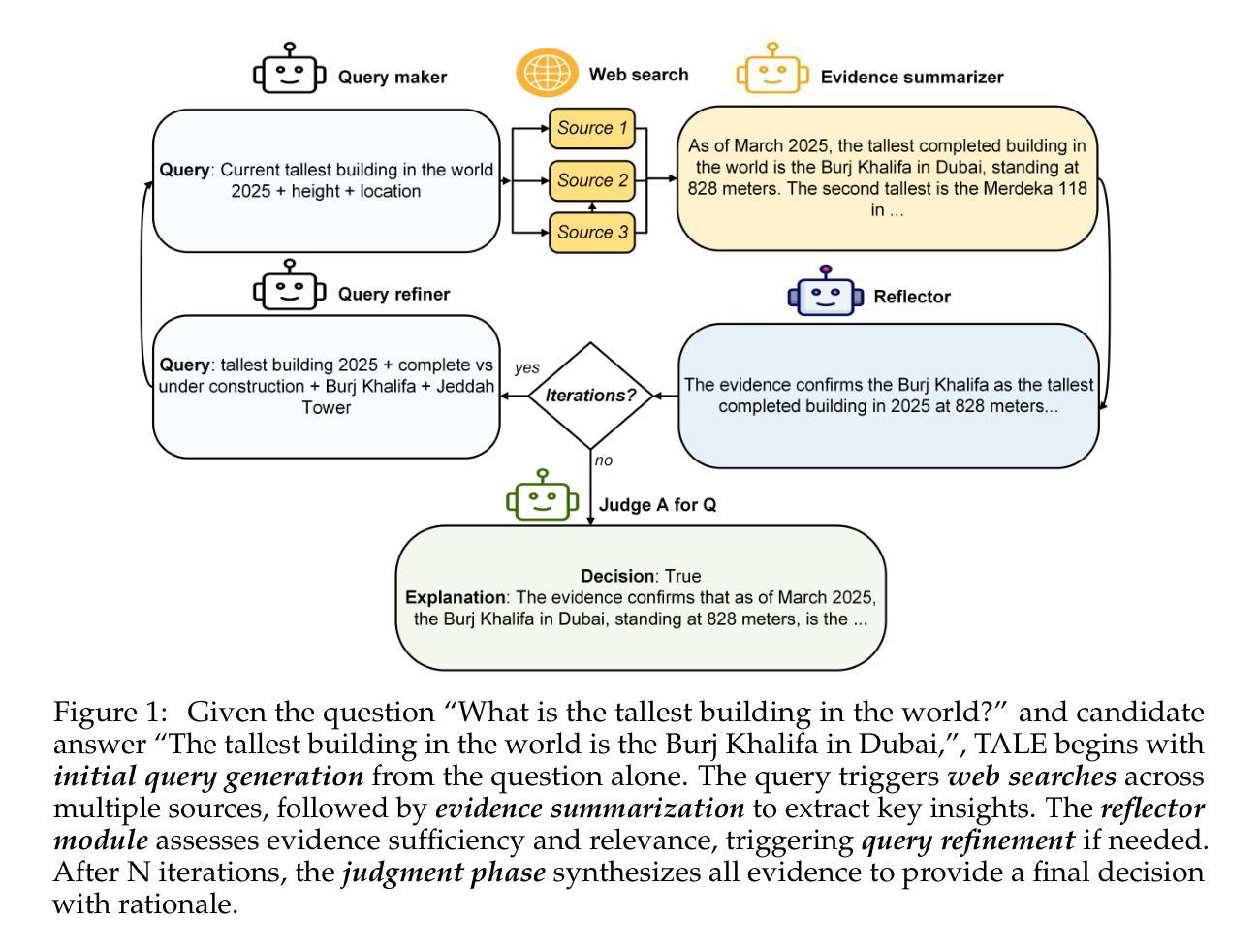
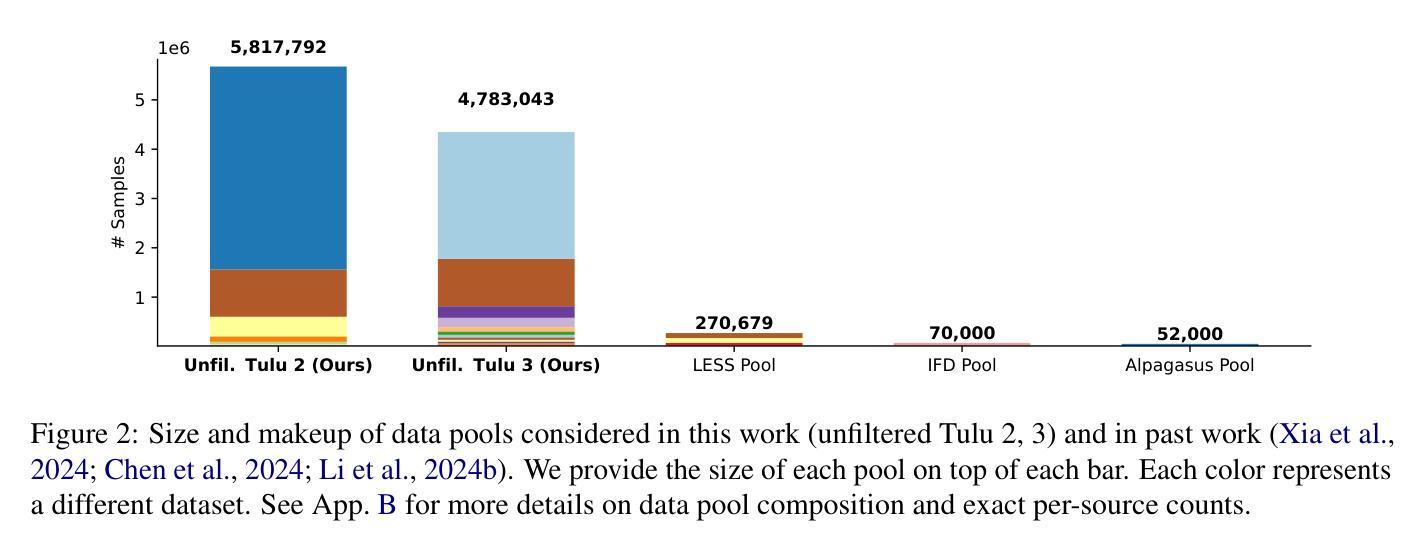
Large-Scale Data Selection for Instruction Tuning
Authors:Hamish Ivison, Muru Zhang, Faeze Brahman, Pang Wei Koh, Pradeep Dasigi
Selecting high-quality training data from a larger pool is a crucial step when instruction-tuning language models, as carefully curated datasets often produce models that outperform those trained on much larger, noisier datasets. Automated data selection approaches for instruction-tuning are typically tested by selecting small datasets (roughly 10k samples) from small pools (100-200k samples). However, popular deployed instruction-tuned models often train on hundreds of thousands to millions of samples, subsampled from even larger data pools. We present a systematic study of how well data selection methods scale to these settings, selecting up to 2.5M samples from pools of up to 5.8M samples and evaluating across 7 diverse tasks. We show that many recently proposed methods fall short of random selection in this setting (while using more compute), and even decline in performance when given access to larger pools of data to select over. However, we find that a variant of representation-based data selection (RDS+), which uses weighted mean pooling of pretrained LM hidden states, consistently outperforms more complex methods across all settings tested – all whilst being more compute-efficient. Our findings highlight that the scaling properties of proposed automated selection methods should be more closely examined. We release our code, data, and models at https://github.com/hamishivi/automated-instruction-selection.
从较大的数据池中选取高质量的训练数据是微调语言模型时的关键步骤。经过精心挑选的数据集通常会产生优于在更大、更嘈杂的数据集上训练的模型。自动数据选择方法用于指令微调时,通常从小型数据池(10万至20万样本)中选择小型数据集(大约1万样本)进行测试。然而,流行的部署指令微调模型通常在从更大的数据池中抽取数百万至数千万样本进行训练。我们系统地研究了数据选择方法如何适应这些设置,从多达58万个样本的数据池中选择了多达25万个样本,并在7个不同任务上进行了评估。我们发现,在此设置中,许多最近提出的方法不及随机选择(同时使用更多计算资源),并且在给定的更大池中选择数据时性能甚至下降。然而,我们发现一种基于表示的变体数据选择(RDS+),该方法使用预训练LM隐藏状态的加权均值池化技术,在所有测试设置中均优于更复杂的方法,同时计算效率更高。我们的研究结果表明,应更仔细地检查所提出的自动选择方法的可扩展性。我们在https://github.com/hamishivi/automated-instruction-selection上发布了我们的代码、数据和模型。
论文及项目相关链接
PDF Updated, new baselines, removed some typos
Summary
本文研究了在更大规模数据集上指令微调语言模型时的数据选择问题。研究发现,许多近期提出的数据选择方法在大规模数据集上表现不佳,而一种基于表示的数据选择变体(RDS+)在所有测试设置中均表现优异,且计算效率更高。
Key Takeaways
- 数据选择在指令微调语言模型中至关重要,高质量数据集往往能产生性能更佳的模型。
- 自动化数据选择方法通常在较小的数据集和样本池中进行测试。
- 在更大规模数据集(数百万至数千万样本)上,许多提出的数据选择方法表现不如随机选择。
- 基于表示的数据选择变体(RDS+)在所有测试设置中都表现优异,且计算效率更高。
- 随着数据池规模的扩大,数据选择方法的性能可能会下降。
- 在大规模数据集上进行指令微调时,需要更紧密地检查数据选择方法的可扩展性。
点此查看论文截图
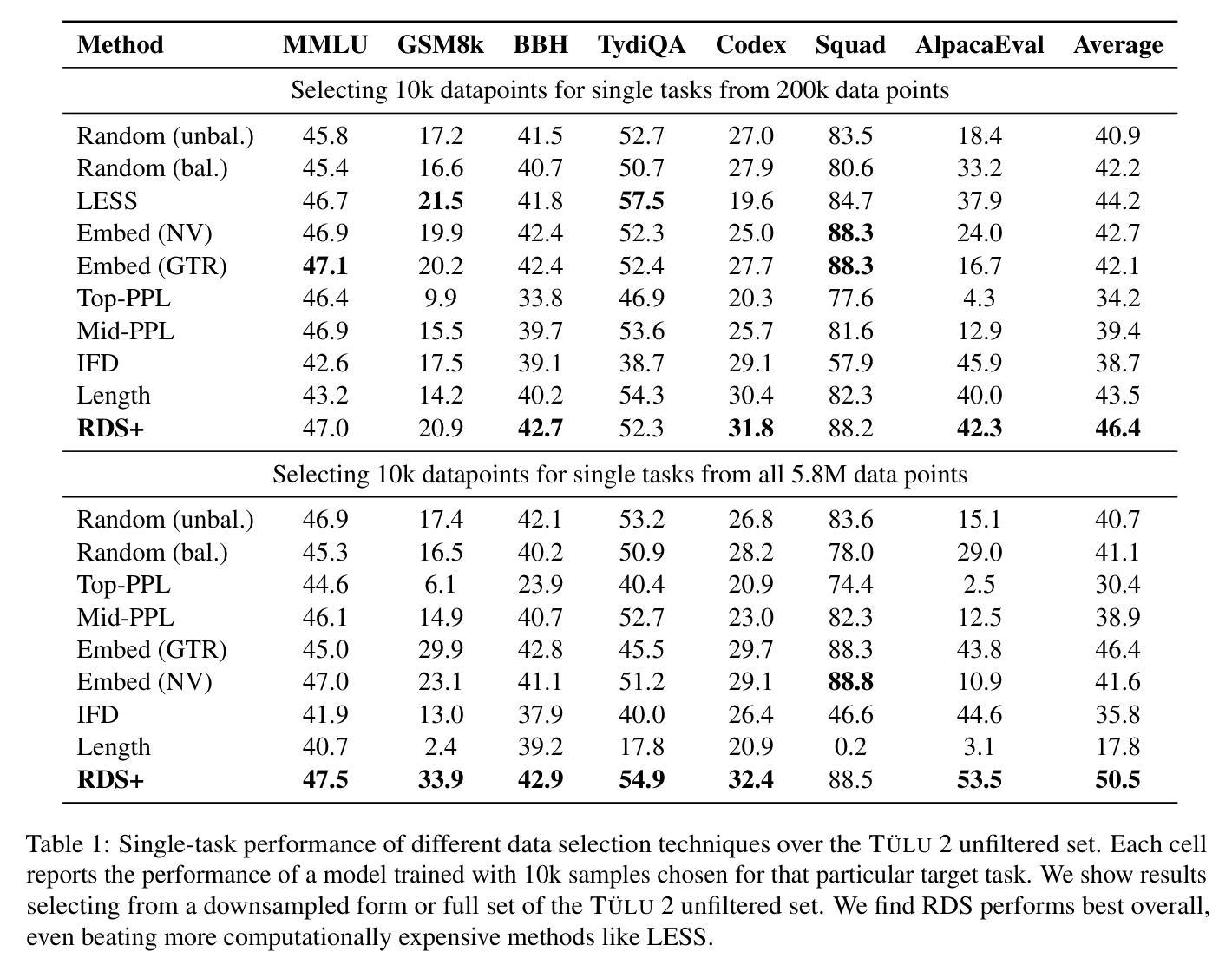
ALTA: Compiler-Based Analysis of Transformers
Authors:Peter Shaw, James Cohan, Jacob Eisenstein, Kenton Lee, Jonathan Berant, Kristina Toutanova
We propose a new programming language called ALTA and a compiler that can map ALTA programs to Transformer weights. ALTA is inspired by RASP, a language proposed by Weiss et al. (2021), and Tracr (Lindner et al., 2023), a compiler from RASP programs to Transformer weights. ALTA complements and extends this prior work, offering the ability to express loops and to compile programs to Universal Transformers, among other advantages. ALTA allows us to constructively show how Transformers can represent length-invariant algorithms for computing parity and addition, as well as a solution to the SCAN benchmark of compositional generalization tasks, without requiring intermediate scratchpad decoding steps. We also propose tools to analyze cases where the expressibility of an algorithm is established, but end-to-end training on a given training set fails to induce behavior consistent with the desired algorithm. To this end, we explore training from ALTA execution traces as a more fine-grained supervision signal. This enables additional experiments and theoretical analyses relating the learnability of various algorithms to data availability and modeling decisions, such as positional encodings. We make the ALTA framework – language specification, symbolic interpreter, and weight compiler – available to the community to enable further applications and insights.
我们提出了一种新的编程语言ALTA,以及能够将ALTA程序映射到Transformer权重(Transformer weights)的编译器。ALTA语言受到Weiss等人(2021)提出的RASP语言和Lindner等人(2023)提出的将RASP程序编译成Transformer权重的Tracr编译器的启发。ALTA是对这些先前工作的补充和扩展,除了具备表达循环的能力外,还能将程序编译为通用Transformer,具有其他优势。通过ALTA,我们能够直观地展示Transformer如何表示用于计算奇偶性和加法的不变长度算法,以及解决无需中间暂存解码步骤的组合泛化任务的SCAN基准测试解决方案。我们还提出了分析工具,用于分析算法表达性已确立但特定训练集端到端训练未能诱导出与期望算法一致行为的情况。为此,我们探索了从ALTA执行轨迹进行训练作为更精细的监督信号。这使得我们能够进行更多实验和理论分析,将各种算法的学习性与数据可用性和建模决策(如位置编码)相关联。我们将ALTA框架(包括语言规范、符号解释器和权重编译器)提供给社区,以推动进一步的应用和见解。
论文及项目相关链接
PDF TMLR 2025
Summary
ALTA是一种新型编程语言,可编译为Transformer权重,受RASP和Tracr启发。它具备表达循环的能力,并能编译为通用Transformer,还具有其他优势。ALTA能够展示Transformer如何表示长度不变的算法,解决SCAN基准测试中的组合泛化任务,且无需中间解码步骤。此外,它还提供了工具来分析算法表达性建立但端到端训练失败的情况,并提出了通过ALTA执行轨迹进行更精细的监督信号训练的方法。这使更多的实验和理论分析成为可能,关联了不同算法的可学习性与数据可用性和建模决策等因素。ALTA框架现已向公众开放,以促进进一步的应用和见解。
Key Takeaways
- ALTA是一种新型编程语言,可编译为Transformer权重。
- ALTA受RASP和Tracr启发,具备表达循环的能力,并可以编译为通用Transformer。
- ALTA能展示Transformer如何表示长度不变的算法,如计算奇偶性和加法。
- ALTA解决了SCAN基准测试中的组合泛化任务,无需中间解码步骤。
- ALTA提供了工具来分析算法表达性建立但端到端训练失败的情况。
- 通过ALTA执行轨迹进行更精细的监督信号训练的方法被提出。
点此查看论文截图


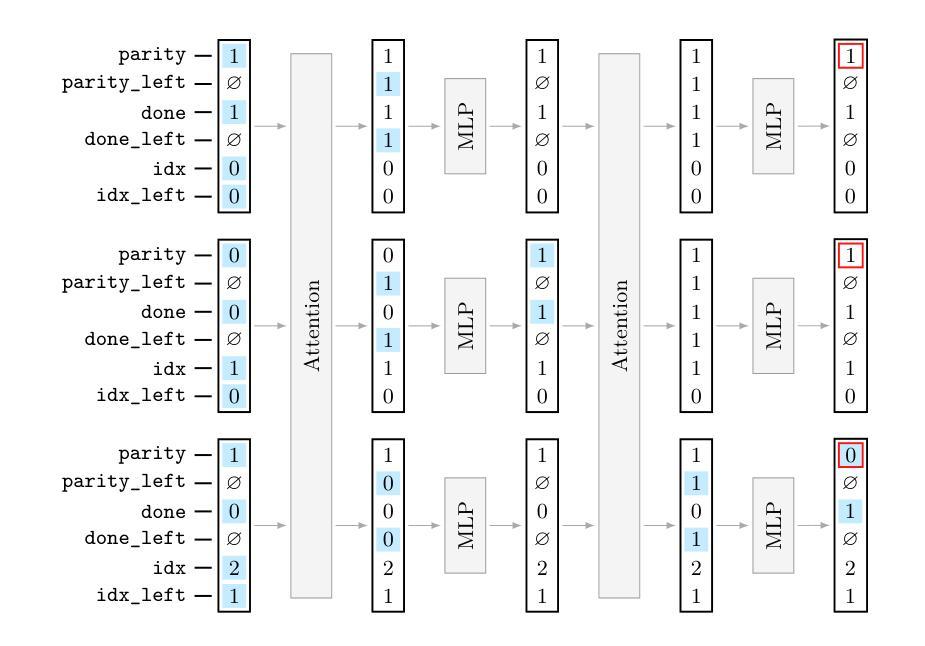
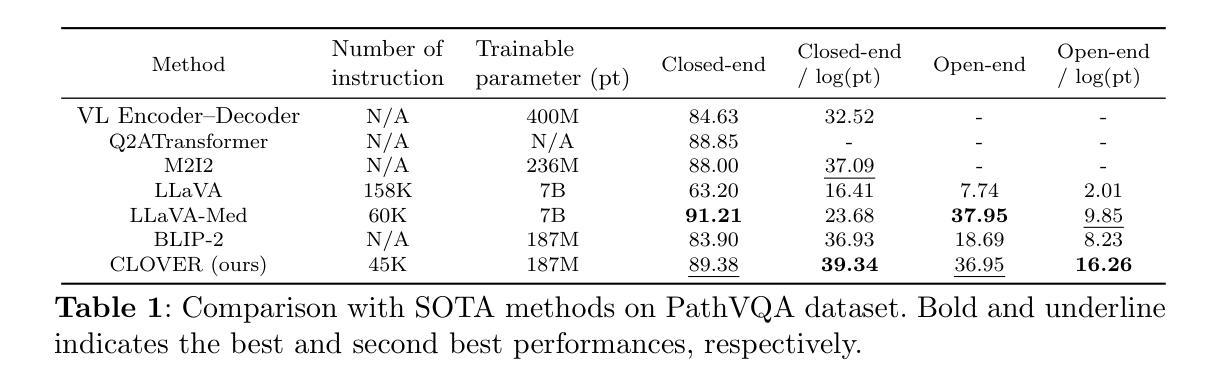
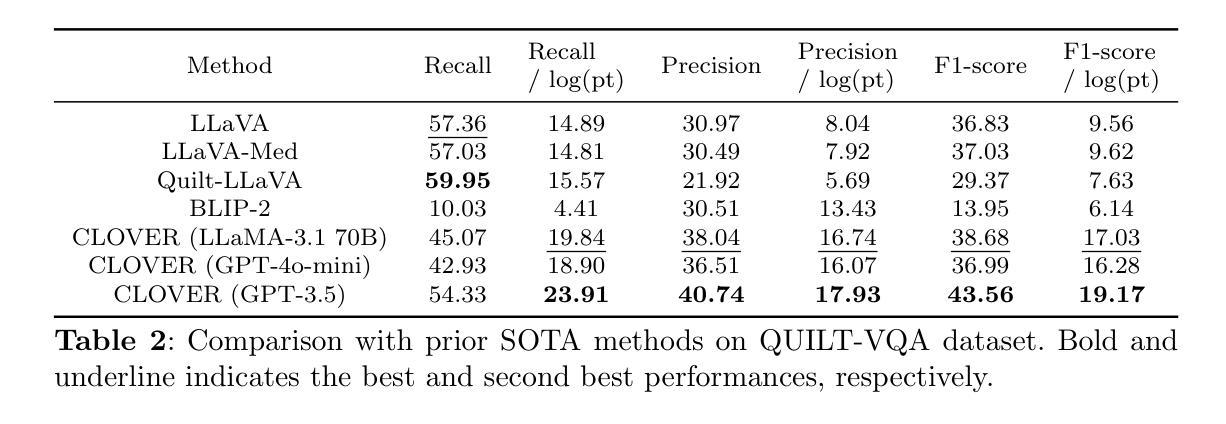
Cost-effective Instruction Learning for Pathology Vision and Language Analysis
Authors:Kaitao Chen, Mianxin Liu, Fang Yan, Lei Ma, Xiaoming Shi, Lilong Wang, Xiaosong Wang, Lifeng Zhu, Zhe Wang, Mu Zhou, Shaoting Zhang
The advent of vision-language models fosters the interactive conversations between AI-enabled models and humans. Yet applying these models into clinics must deal with daunting challenges around large-scale training data, financial, and computational resources. Here we propose a cost-effective instruction learning framework for conversational pathology named as CLOVER. CLOVER only trains a lightweight module and uses instruction tuning while freezing the parameters of the large language model. Instead of using costly GPT-4, we propose well-designed prompts on GPT-3.5 for building generation-based instructions, emphasizing the utility of pathological knowledge derived from the Internet source. To augment the use of instructions, we construct a high-quality set of template-based instructions in the context of digital pathology. From two benchmark datasets, our findings reveal the strength of hybrid-form instructions in the visual question-answer in pathology. Extensive results show the cost-effectiveness of CLOVER in answering both open-ended and closed-ended questions, where CLOVER outperforms strong baselines that possess 37 times more training parameters and use instruction data generated from GPT-4. Through the instruction tuning, CLOVER exhibits robustness of few-shot learning in the external clinical dataset. These findings demonstrate that cost-effective modeling of CLOVER could accelerate the adoption of rapid conversational applications in the landscape of digital pathology.
视觉语言模型的出现促进了人工智能模型与人类之间的交互式对话。然而,将这些模型应用于临床必须应对大规模训练数据、资金和计算资源等方面的巨大挑战。在这里,我们针对名为CLOVER的对话式病理学提出了经济高效的指令学习框架。CLOVER只训练一个轻量级模块,并使用指令微调来冻结大型语言模型的参数。我们没有使用昂贵的GPT-4,而是提出了针对GPT-3.5的精心设计提示来构建基于生成的指令,强调从互联网资源中获得的病理学知识的实用性。为了增强指令的使用,我们在数字病理的背景下构建了一套高质量的基于模板的指令集。从两个基准数据集中,我们发现混合形式的指令在病理视觉问答中的优势。大量结果表明,CLOVER在回答开放性和封闭性问题时的成本效益高,其中CLOVER的表现优于拥有37倍以上训练参数和使用GPT-4生成指令数据的强大基线。通过指令微调,CLOVER显示出在外部临床数据集中的小样本学习能力。这些发现表明,CLOVER的经济高效建模可以加速数字病理学领域快速对话式应用的采用。
论文及项目相关链接
Summary
随着视觉语言模型的兴起,人工智能模型与人类之间的交互对话日益频繁。然而,将这些模型应用于临床时,面临大规模训练数据、资金和计算资源的挑战。为此,我们提出了一种用于对话病理学的低成本指令学习框架CLOVER。CLOVER仅训练轻量级模块,并采用指令微调来冻结大型语言模型的参数。我们并未使用成本高昂的GPT-4,而是设计了针对GPT-3.5的提示来构建生成指令,强调了从互联网资源中获得的病理学知识的实用性。为了增强指令的使用效果,我们在数字病理背景下构建了一套高质量的模板指令集。从两个基准数据集的研究结果来看,混合形式的指令在病理学视觉问答中的优势显著。广泛的实验结果表明,在回答开放和封闭性问题方面,CLOVER表现出成本效益高,优于拥有更多训练参数和基于GPT-4生成指令的强大基线。通过指令微调,CLOVER展现出对外部临床数据集的少样本学习的稳健性。这些发现表明,低成本建模的CLOVER可能加速数字病理学领域的快速对话应用程序的采用。
Key Takeaways
- 视觉语言模型的兴起促进了AI与人类之间的交互对话。
- 将AI模型应用于临床时面临大规模训练数据、资金和计算资源的挑战。
- 提出了一种用于对话病理学的低成本指令学习框架CLOVER。
- CLOVER通过仅训练轻量级模块和采用指令微调来降低成本。
- 使用GPT-3.5的提示构建生成指令,强调互联网来源的病理学知识的实用性。
- 在数字病理背景下构建了一套高质量的模板指令集。
点此查看论文截图

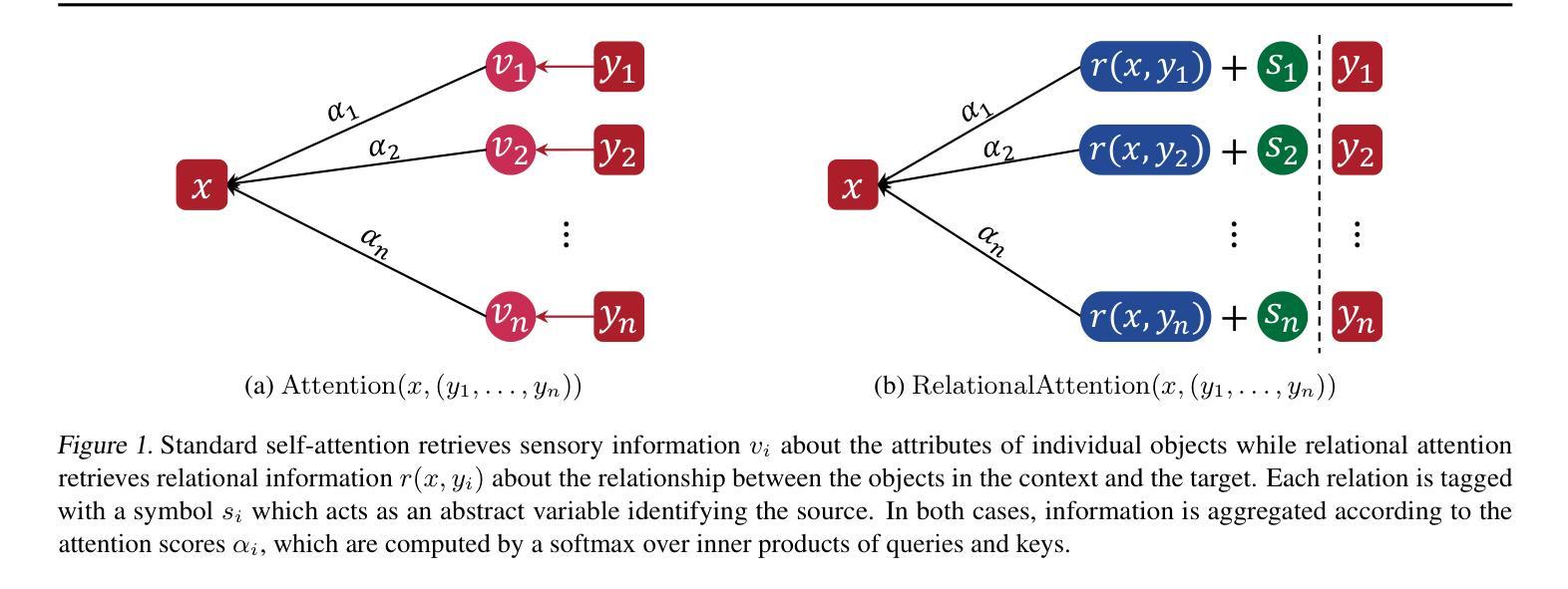
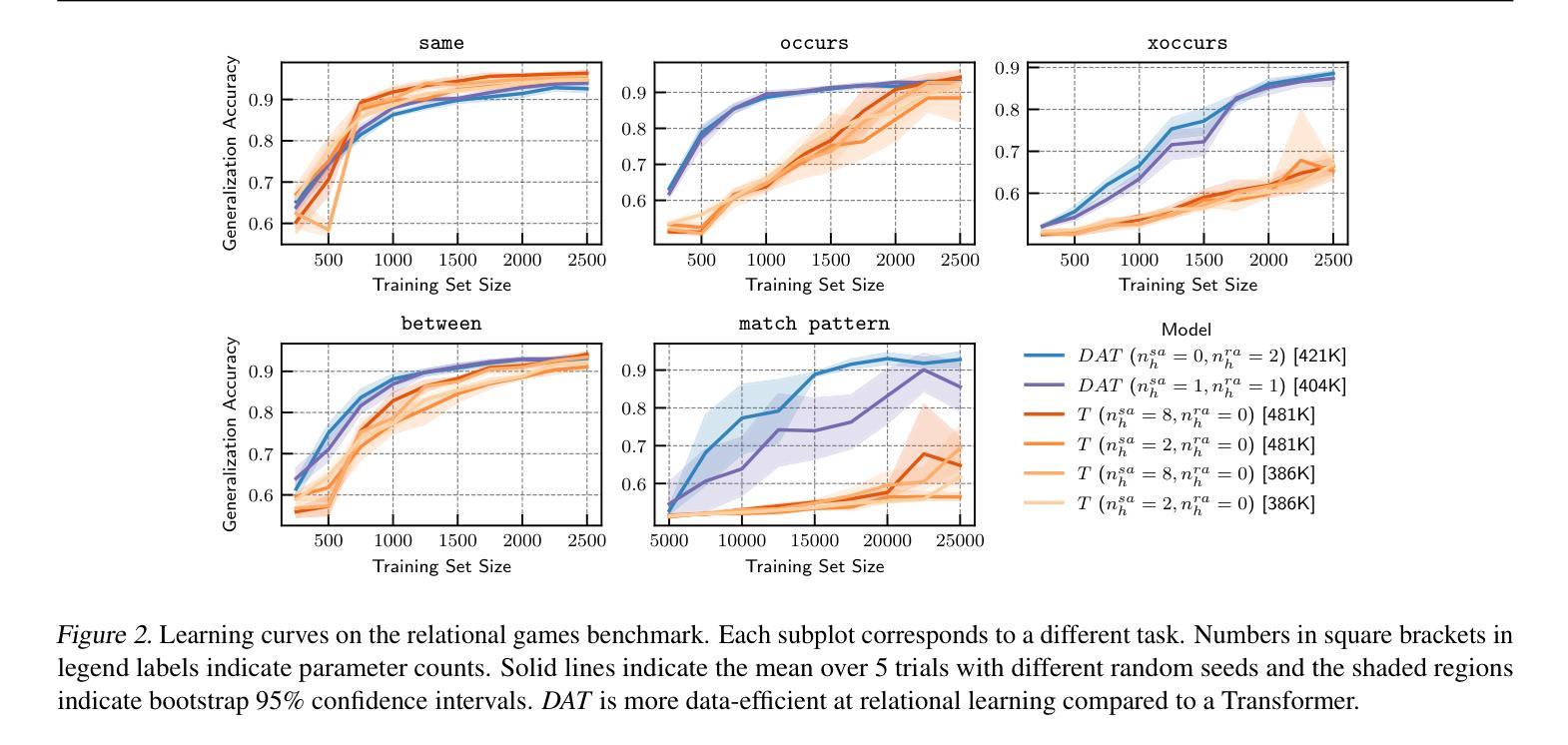
Disentangling and Integrating Relational and Sensory Information in Transformer Architectures
Authors:Awni Altabaa, John Lafferty
Relational reasoning is a central component of generally intelligent systems, enabling robust and data-efficient inductive generalization. Recent empirical evidence shows that many existing neural architectures, including Transformers, struggle with tasks requiring relational reasoning. In this work, we distinguish between two types of information: sensory information about the properties of individual objects, and relational information about the relationships between objects. While neural attention provides a powerful mechanism for controlling the flow of sensory information between objects, the Transformer lacks an explicit computational mechanism for routing and processing relational information. To address this limitation, we propose an architectural extension of the Transformer framework that we call the Dual Attention Transformer (DAT), featuring two distinct attention mechanisms: sensory attention for directing the flow of sensory information, and a novel relational attention mechanism for directing the flow of relational information. We empirically evaluate DAT on a diverse set of tasks ranging from synthetic relational benchmarks to complex real-world tasks such as language modeling and visual processing. Our results demonstrate that integrating explicit relational computational mechanisms into the Transformer architecture leads to significant performance gains in terms of data efficiency and parameter efficiency.
关系推理是通用智能系统的核心组成部分,能够实现稳健且数据高效归纳概括。最新的实证证据表明,包括Transformer在内的许多现有神经网络架构在处理需要关系推理的任务时面临困难。在这项工作中,我们将信息分为两类:关于单个对象属性的感觉信息和关于对象之间关系的关系信息。虽然神经注意力为控制对象之间感觉信息的流动提供了强大的机制,但Transformer缺乏用于路由和处理关系信息的明确计算机制。为了解决这一局限性,我们提出了Transformer架构的扩展,我们称之为双注意力Transformer(DAT),它具有两种独特的注意力机制:感觉注意力,用于引导感觉信息的流动,以及新型的关系注意力机制,用于引导关系信息的流动。我们在一系列任务上对DAT进行了实证评估,这些任务范围从合成关系基准测试到复杂的现实世界任务,如语言建模和视觉处理。我们的结果表明,将明确的关系计算机制整合到Transformer架构中,在数据效率和参数效率方面实现了显著的性能提升。
论文及项目相关链接
PDF ICML 2025
Summary
关系推理是智能系统的重要组成部分,它可实现稳健且高效的数据归纳概括。现有神经架构,如Transformer等,在处理需要关系推理的任务时表现欠佳。本文区分了两种信息类型:关于单个对象属性的感觉信息与关于对象间关系的关联信息。虽然神经注意力为控制对象间感觉信息的流动提供了强大机制,但Transformer缺乏明确计算机制来处理关联信息的路由和处理。为解决此局限性,我们提出了Transformer架构的扩展版本——双注意力Transformer(DAT),它包含两种不同的注意力机制:用于引导感觉信息流动的感官注意力与用于引导关联信息流动的新型关联注意力机制。我们对DAT进行了广泛的评估,包括从合成关系基准测试到复杂现实世界任务(如语言建模和视觉处理)等多样化任务。结果表明,在Transformer架构中整合明确的关联计算机制,在数据效率和参数效率方面实现了显著的性能提升。
Key Takeaways
- 关系推理是智能系统的核心,对稳健且高效的数据归纳概括至关重要。
- 现有神经架构如Transformer在处理关系推理任务时表现不足。
- 本文区分了感觉信息与关联信息两种类型。
- 神经注意力有助于控制感觉信息的流动,但Transformer缺乏处理关联信息的明确机制。
- 提出了一种新的神经架构——双注意力Transformer(DAT),包含感官注意力和关联注意力两种机制。
- DAT在多样化任务上的评估结果表明,其在数据效率和参数效率方面实现了显著的性能提升。
点此查看论文截图