⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
R3eVision: A Survey on Robust Rendering, Restoration, and Enhancement for 3D Low-Level Vision
Authors:Weeyoung Kwon, Jeahun Sung, Minkyu Jeon, Chanho Eom, Jihyong Oh
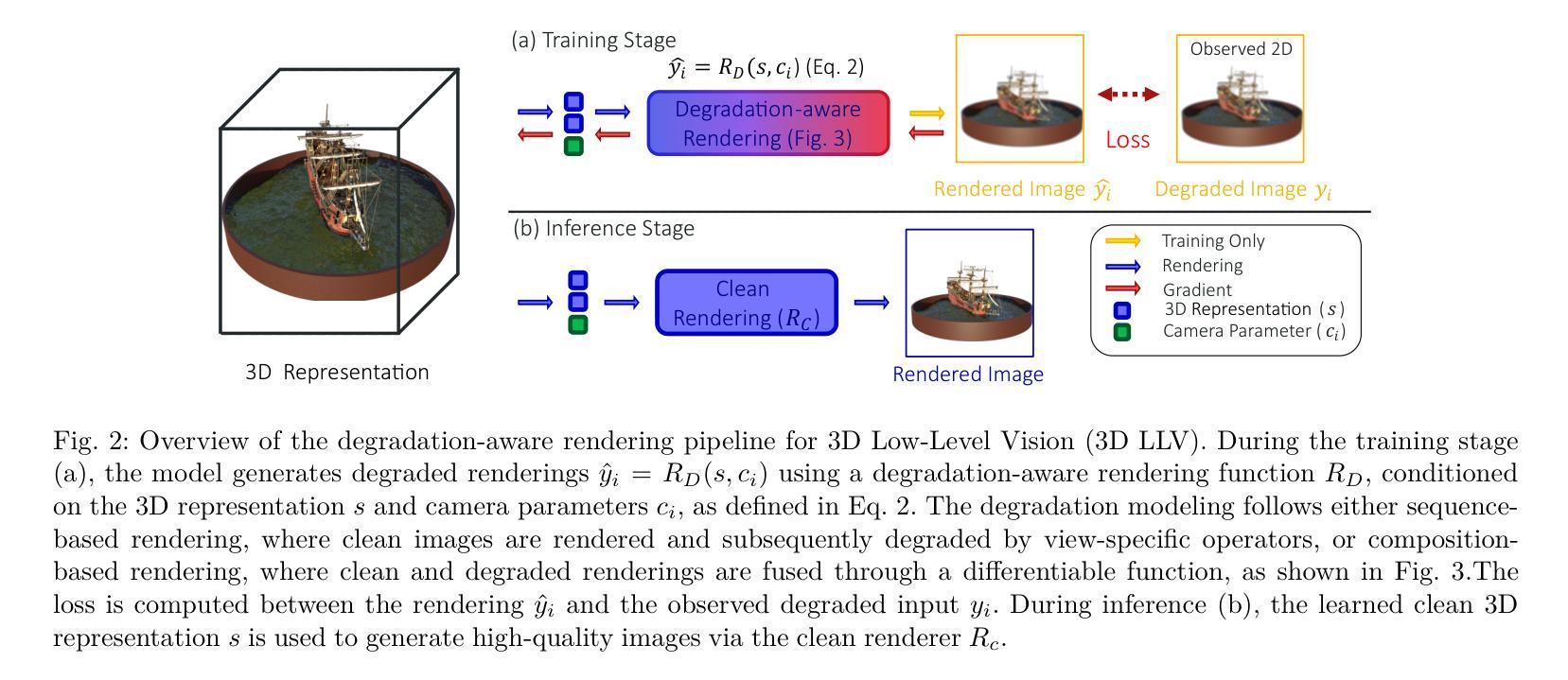
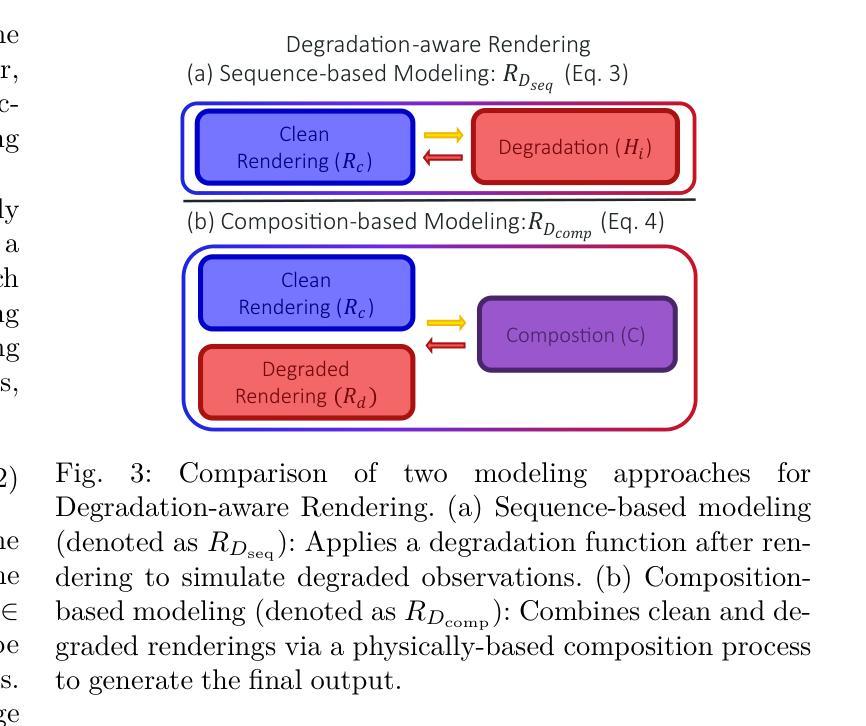
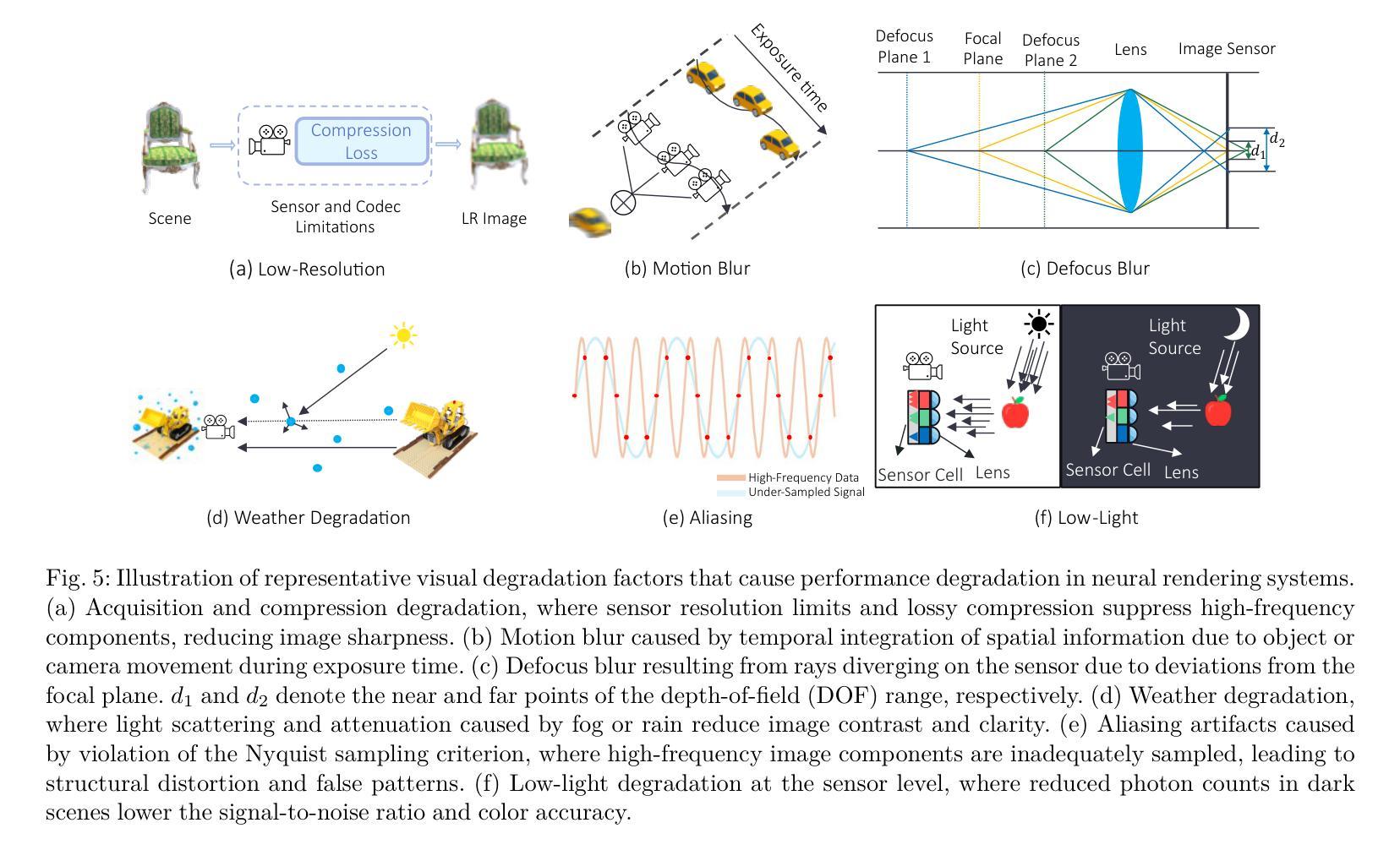
Neural rendering methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have achieved significant progress in photorealistic 3D scene reconstruction and novel view synthesis. However, most existing models assume clean and high-resolution (HR) multi-view inputs, which limits their robustness under real-world degradations such as noise, blur, low-resolution (LR), and weather-induced artifacts. To address these limitations, the emerging field of 3D Low-Level Vision (3D LLV) extends classical 2D Low-Level Vision tasks including super-resolution (SR), deblurring, weather degradation removal, restoration, and enhancement into the 3D spatial domain. This survey, referred to as R\textsuperscript{3}eVision, provides a comprehensive overview of robust rendering, restoration, and enhancement for 3D LLV by formalizing the degradation-aware rendering problem and identifying key challenges related to spatio-temporal consistency and ill-posed optimization. Recent methods that integrate LLV into neural rendering frameworks are categorized to illustrate how they enable high-fidelity 3D reconstruction under adverse conditions. Application domains such as autonomous driving, AR/VR, and robotics are also discussed, where reliable 3D perception from degraded inputs is critical. By reviewing representative methods, datasets, and evaluation protocols, this work positions 3D LLV as a fundamental direction for robust 3D content generation and scene-level reconstruction in real-world environments.
神经渲染方法,例如神经辐射场(NeRF)和3D高斯溅出(3DGS),在基于照片的真实3D场景重建和新型视图合成方面取得了显著进展。然而,大多数现有模型假设干净且高分辨率(HR)的多视角输入,这限制了它们在现实世界退化(例如噪声、模糊、低分辨率(LR)和天气引起的伪影)影响下的稳健性。为了解决这些局限性,新兴的3D低级视觉(3DLLV)领域将传统的2D低级视觉任务(包括超分辨率(SR)、去模糊、去除天气退化、恢复和增强)扩展到3D空间域。这篇综述被称为R\textsuperscript{3}eVision,它通过正规化退化感知渲染问题并确定与时空一致性和不适定优化相关的关键挑战,为3DLLV提供了关于鲁棒渲染、恢复和增强的全面概述。对近期将LLV集成到神经渲染框架中的方法进行了分类,以说明它们在不利条件下实现高保真3D重建的能力。还讨论了自动驾驶、AR/VR和机器人等领域,在这些领域中,从退化输入中可靠地获取3D感知是至关重要的。通过对代表性方法、数据集和评估协议的回顾,这项工作将3DLLV定位为真实世界环境中鲁棒3D内容生成和场景级别重建的基本方向。
论文及项目相关链接
PDF Please visit our project page at https://github.com/CMLab-Korea/Awesome-3D-Low-Level-Vision
Summary
本文介绍了在3D低层次视觉(LLV)领域,神经渲染方法如NeRF和3DGS在处理噪声、模糊、低分辨率和天气引起的伪影等真实世界退化问题时的局限性。新兴领域R\textsuperscript{3}eVision提供了全面的概述,包括鲁棒渲染、恢复和增强功能,通过形式化退化感知渲染问题并识别与时空一致性和不适定优化相关的关键挑战来解决这些问题。同时介绍了如何将LLV集成到神经渲染框架中的最新方法,说明了它们在恶劣条件下实现高保真3D重建的能力。此外,还讨论了自主驾驶、AR/VR和机器人等领域的应用,其中从退化输入中进行可靠的3D感知至关重要。
Key Takeaways
- 神经渲染方法在真实世界退化问题如噪声、模糊等方面存在局限性。
- 3D低层次视觉(LLV)扩展了传统的二维低层次视觉任务到三维空间领域。
- R\textsuperscript{3}eVision提供了关于鲁棒渲染、恢复和增强的全面概述。
- 退化的感知渲染问题形式化和识别关键挑战是解决问题的关键。
- 集成LLV的最新方法提高了神经渲染在恶劣条件下的高保真重建能力。
点此查看论文截图


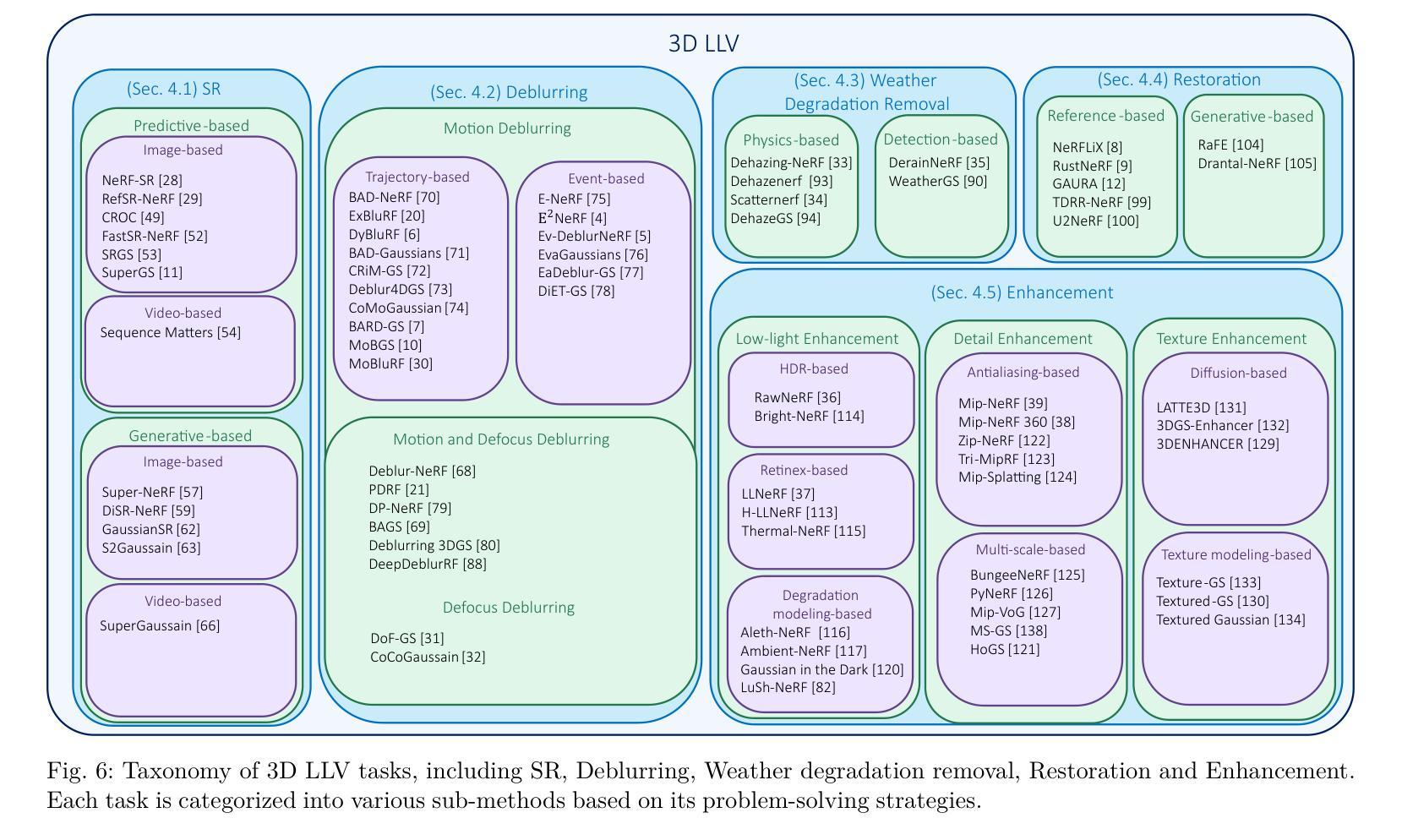
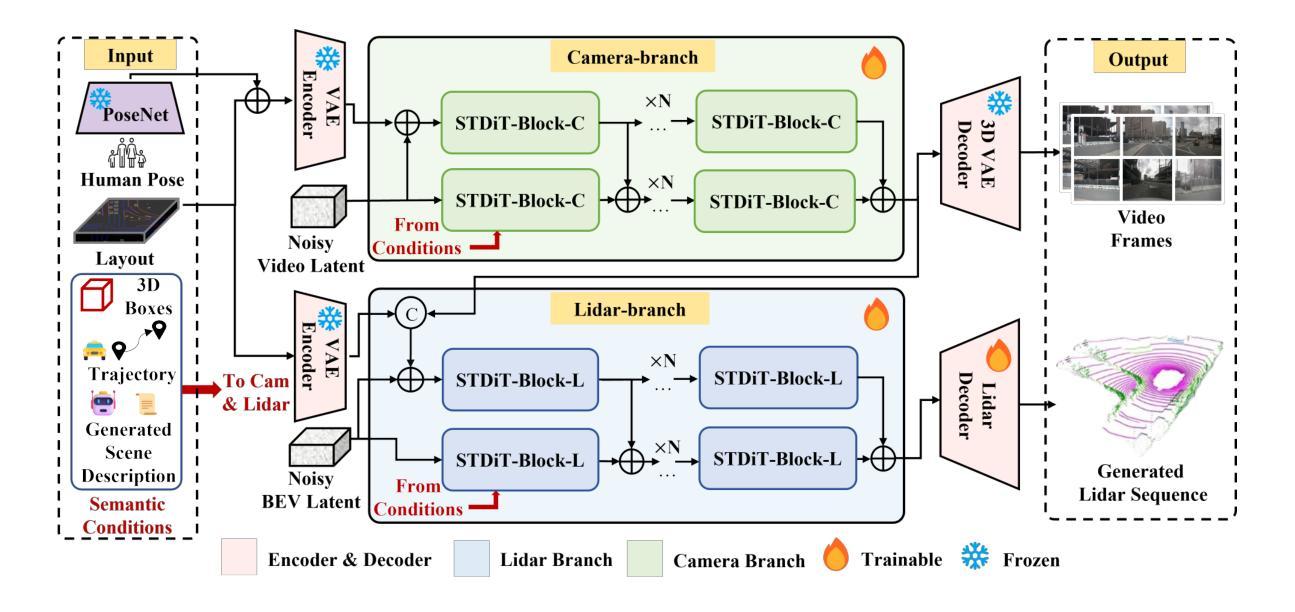
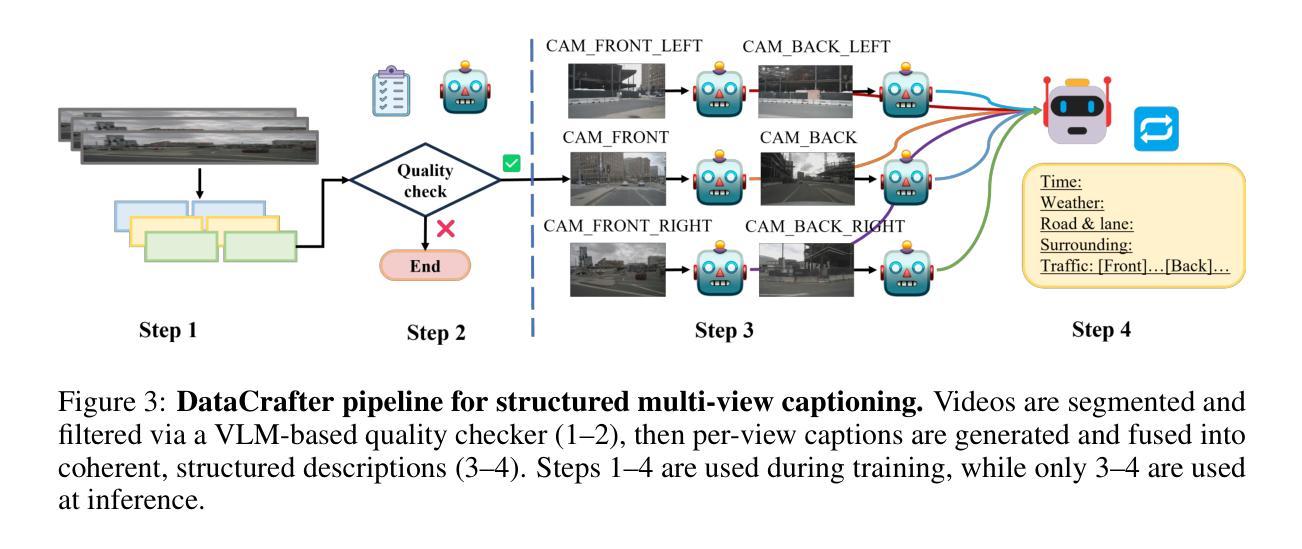
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Authors:Xiangyu Guo, Zhanqian Wu, Kaixin Xiong, Ziyang Xu, Lijun Zhou, Gangwei Xu, Shaoqing Xu, Haiyang Sun, Bing Wang, Guang Chen, Hangjun Ye, Wenyu Liu, Xinggang Wang
We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
我们提出了Genesis,这是一个统一框架,用于联合生成多视角驾驶视频和LiDAR序列,具有时空和跨模态一致性。Genesis采用两阶段架构,融合了基于DiT的视频扩散模型与3D-VAE编码,以及带有基于NeRF的渲染和自适应采样的BEV感知LiDAR生成器。两种模态通过共享潜在空间直接耦合,实现在视觉和几何域之间的连贯演变。为了引导结构语义的生成,我们引入了DataCraft模块,它是一个基于视觉语言模型的描述模块,提供场景级和实例级的监督。在nuScenes基准测试上的大量实验表明,Genesis在视频和LiDAR指标上达到了最新技术水平(FVD 16.95,FID 4.24,Chamfer 0.611),并有助于下游任务,包括分割和3D检测,验证了生成数据的语义保真度和实用性。
论文及项目相关链接
Summary
本文介绍了Genesis框架,该框架可联合生成多视角驾驶视频和LiDAR序列,具有时空和跨模态一致性。Genesis采用两阶段架构,融合了基于DiT的视频扩散模型与3D-VAE编码,以及具备NeRF渲染和自适应采样功能的BEV感知LiDAR生成器。两种模态通过共享潜在空间直接耦合,实现了视觉和几何域之间的连贯演变。为引导结构化语义生成,本文引入了DataCrafter模块,该模块基于视觉语言模型构建,提供场景级和实例级监督。在nuScenes基准测试上的实验表明,Genesis在视频和LiDAR指标上达到业界最佳水平(FVD 16.95、FID 4.24、Chamfer 0.611),并且有利于下游任务如分割和3D检测,验证了生成数据的语义保真度和实用性。
Key Takeaways
- Genesis是一个联合生成多视角驾驶视频和LiDAR序列的统一框架,具有时空和跨模态一致性。
- Genesis采用两阶段架构,融合视频扩散模型、3D-VAE编码、BEV感知LiDAR生成器。
- 通过共享潜在空间,实现了视觉和几何域之间的连贯演变。
- 引入DataCrafter模块,基于视觉语言模型构建,提供场景级和实例级监督,引导结构化语义生成。
- 在nuScenes基准测试上达到业界最佳水平,表明Genesis在视频和LiDAR指标上的优越性。
- Genesis生成的数据有利于下游任务如分割和3D检测,验证了其语义保真度和实用性。
- 此框架为多媒体生成任务提供了一种新的思路和方法。
点此查看论文截图

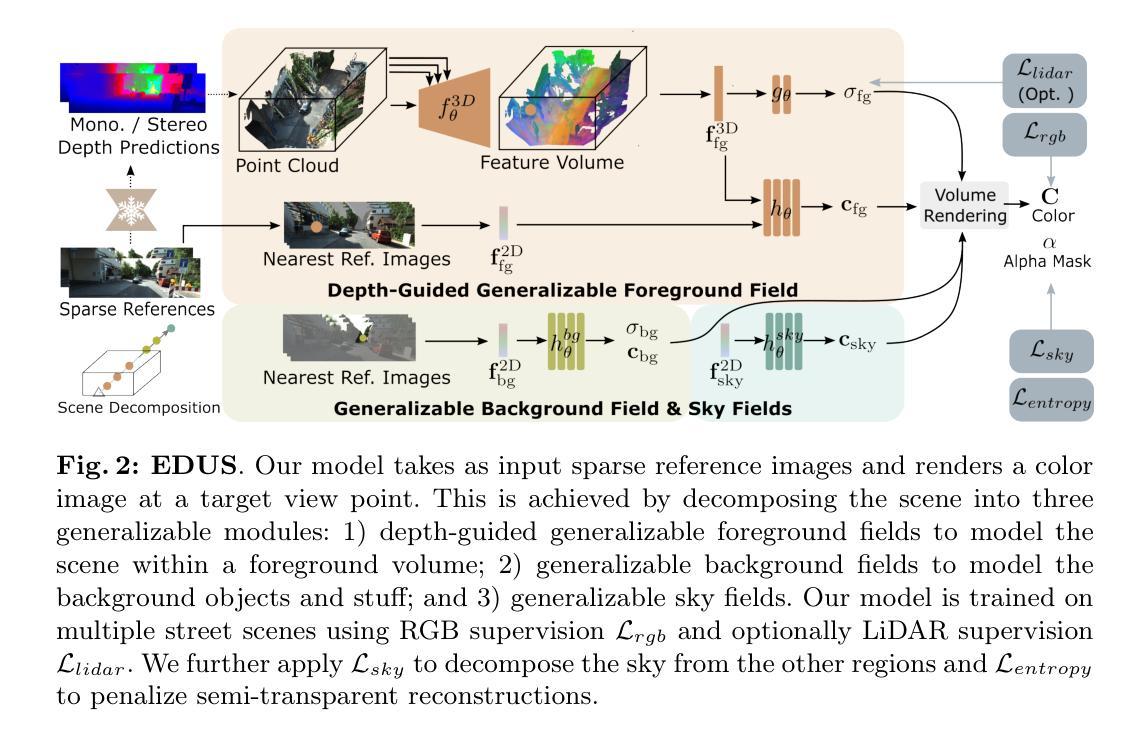
Efficient Depth-Guided Urban View Synthesis
Authors:Sheng Miao, Jiaxin Huang, Dongfeng Bai, Weichao Qiu, Bingbing Liu, Andreas Geiger, Yiyi Liao
Recent advances in implicit scene representation enable high-fidelity street view novel view synthesis. However, existing methods optimize a neural radiance field for each scene, relying heavily on dense training images and extensive computation resources. To mitigate this shortcoming, we introduce a new method called Efficient Depth-Guided Urban View Synthesis (EDUS) for fast feed-forward inference and efficient per-scene fine-tuning. Different from prior generalizable methods that infer geometry based on feature matching, EDUS leverages noisy predicted geometric priors as guidance to enable generalizable urban view synthesis from sparse input images. The geometric priors allow us to apply our generalizable model directly in the 3D space, gaining robustness across various sparsity levels. Through comprehensive experiments on the KITTI-360 and Waymo datasets, we demonstrate promising generalization abilities on novel street scenes. Moreover, our results indicate that EDUS achieves state-of-the-art performance in sparse view settings when combined with fast test-time optimization.
最新的隐式场景表示技术进展为实现高保真街道景观的新型视角合成提供了可能。然而,现有方法为每个场景优化神经辐射场,这严重依赖于密集的训练图像和大量的计算资源。为了缓解这一缺陷,我们引入了一种新的方法,称为高效深度引导城市景观合成(EDUS),用于快速前向推理和高效的场景微调。不同于基于特征匹配的通用几何推断方法,EDUS利用噪声预测的几何先验作为指导,实现从稀疏输入图像中进行通用城市景观合成。这些几何先验使我们能够将通用模型直接应用于三维空间,在各种稀疏级别上获得稳健性。我们在KITTI-360和Waymo数据集上进行了全面的实验,展示了在新街道景观上的良好泛化能力。此外,我们的结果表明,在稀疏视图设置下,结合快速测试时优化,EDUS达到了最先进的性能。
论文及项目相关链接
PDF ECCV2024, Project page: https://xdimlab.github.io/EDUS/
Summary
本文介绍了一种名为Efficient Depth-Guided Urban View Synthesis(EDUS)的新方法,用于快速前馈推理和高效的场景微调。该方法利用预测的几何先验作为指导,实现了从稀疏图像中进行通用城市景观合成。几何先验使得模型能够在3D空间中直接应用,并在各种稀疏级别上获得稳健性。在KITTI-360和Waymo数据集上的实验表明,EDUS在稀疏视图设置下具有出色的泛化能力和性能。
Key Takeaways
- EDUS方法解决了现有神经场景渲染方法需要大量密集训练图像和计算资源的问题。
- EDUS使用预测的几何先验作为指导,实现了从稀疏图像中进行通用城市景观合成。
- 几何先验使得模型能够在3D空间中直接应用,增强了模型的稳健性。
- EDUS在KITTI-360和Waymo数据集上的实验表现优异,具有出色的泛化能力和性能。
- EDUS方法实现了高效的前馈推理和场景微调。
- 与其他基于特征匹配的方法不同,EDUS方法利用几何先验信息来指导城市景观的合成。
点此查看论文截图