⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
Simultaneous Translation with Offline Speech and LLM Models in CUNI Submission to IWSLT 2025
Authors:Dominik Macháček, Peter Polák
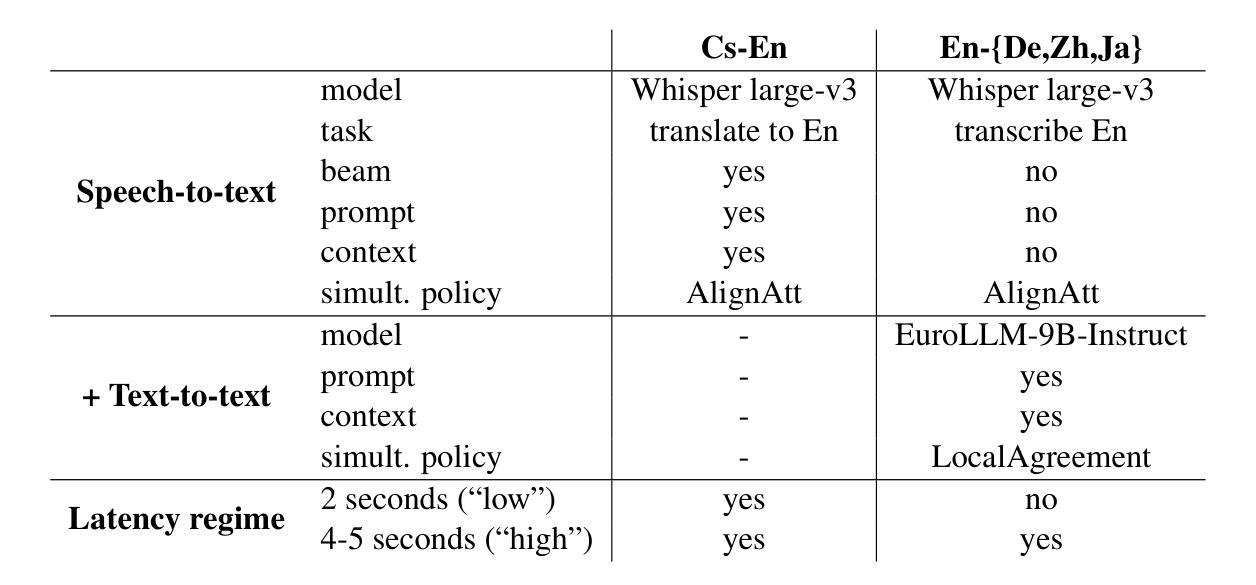
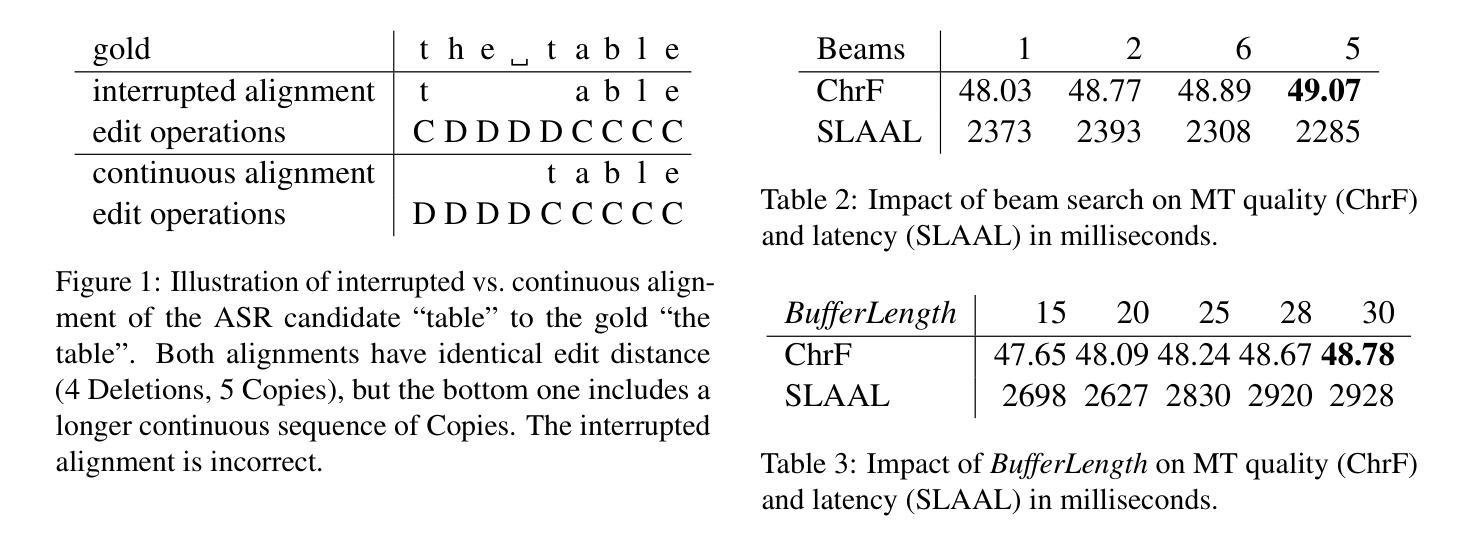
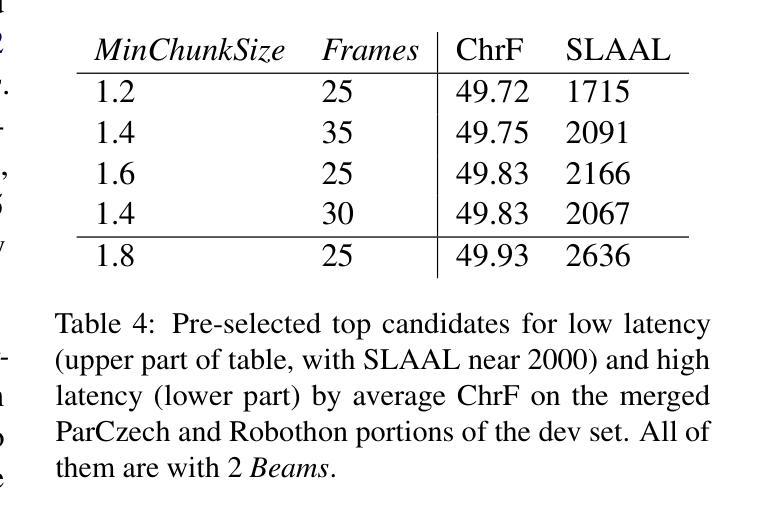
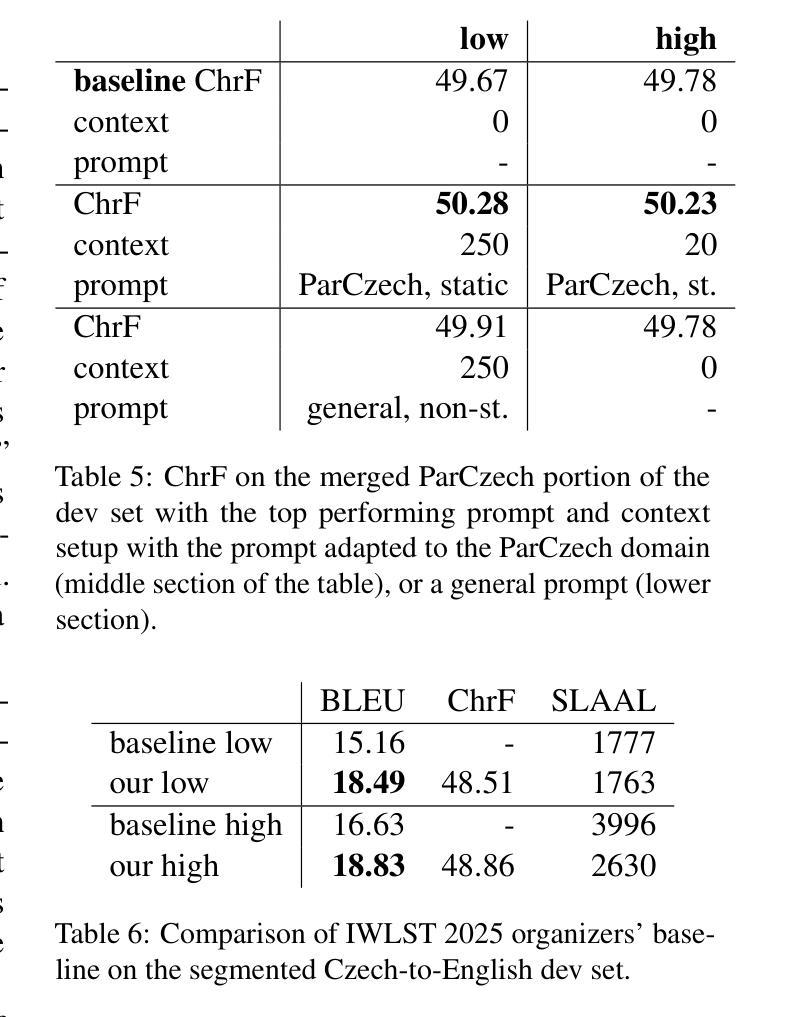
This paper describes Charles University submission to the Simultaneous Speech Translation Task of the IWSLT 2025. We cover all four language pairs with a direct or cascade approach. The backbone of our systems is the offline Whisper speech model, which we use for both translation and transcription in simultaneous mode with the state-of-the-art simultaneous policy AlignAtt. We further improve the performance by prompting to inject in-domain terminology, and we accommodate context. Our cascaded systems further use EuroLLM for unbounded simultaneous translation. Compared to the Organizers’ baseline, our systems improve by 2 BLEU points on Czech to English and 13-22 BLEU points on English to German, Chinese and Japanese on the development sets. Additionally, we also propose a new enhanced measure of speech recognition latency.
本文描述了查尔斯大学对IWSLT 2025同步语音识别任务的提交内容。我们采用直接或级联的方法涵盖了所有四种语言对。我们系统的核心是离线whisper语音模型,我们将其用于最新的同步策略AlignAtt的同步模式和转录。通过提示注入领域专业术语和适应语境,我们进一步提高了性能。我们的级联系统还进一步使用EuroLLM进行无界限的同步翻译。与组织者的基线相比,我们的系统在开发集上捷克语到英语的BLEU得分提高了2分,英语到德语、中文和日语的BLEU得分提高了13到22分。此外,我们还提出了一种新的改进的语音识别延迟度量方法。
论文及项目相关链接
PDF IWSLT 2025
Summary
本文介绍了Charles大学在IWSLT 2025同步语音识别任务中的提交内容。文章涵盖了四种语言对的直接或级联方法。系统以离线Whisper语音模型为核心,采用最新同步策略AlignAtt进行翻译和转录。通过提示注入领域专业术语和适应语境,进一步提高了性能。级联系统还使用EuroLLM进行无界同步翻译。相较于组织者设定的基线,该系统在捷克语到英语的翻译上提高了2个BLEU点,在发展到英语的中文和日语翻译上提高了13到22个BLEU点。此外,还提出了一种新的语音识别的延迟度量方法。
Key Takeaways
- Charles大学参与了IWSLT 2025的同步语音识别任务提交,涵盖四种语言对的翻译。
- 系统基于离线Whisper语音模型和最新的同步策略AlignAtt。
- 通过提示注入领域专业术语和适应语境来提高性能。
- 级联系统使用EuroLLM进行无界同步翻译。
- 与基线相比,系统在多种语言对的翻译任务上有显著的提升效果。
- 提高的量化指标具体为BLEU分数。
点此查看论文截图

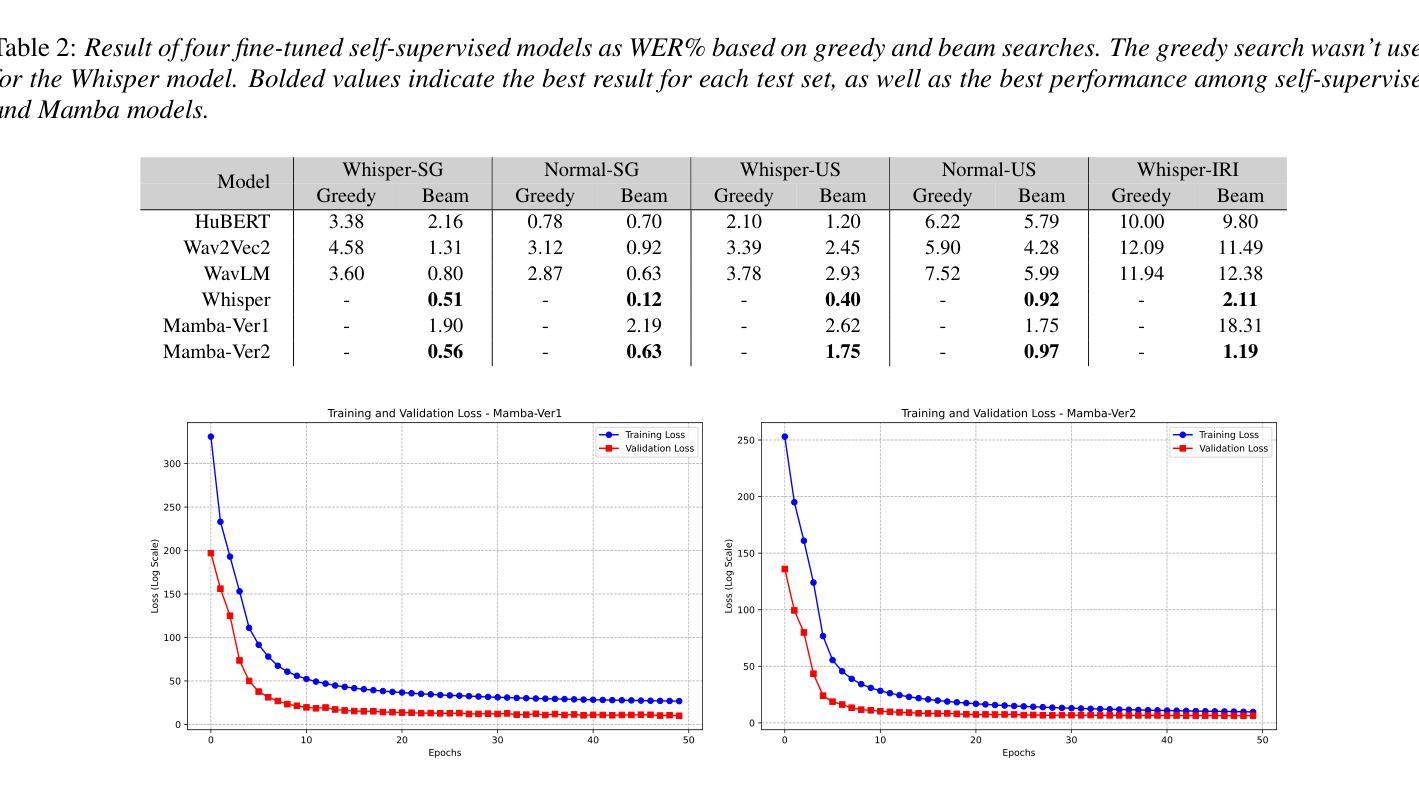
State-Space Models in Efficient Whispered and Multi-dialect Speech Recognition
Authors:Aref Farhadipour, Homayoon Beigi, Volker Dellwo, Hadi Veisi
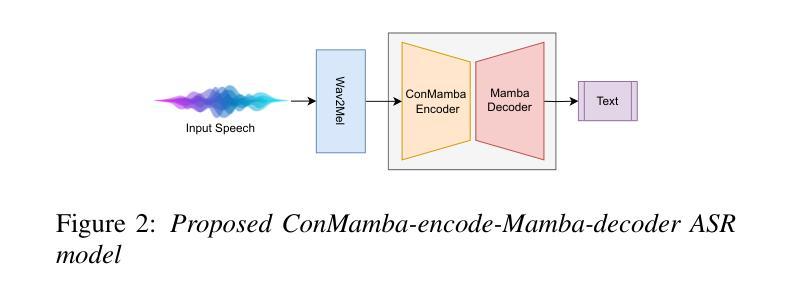
Whispered speech recognition presents significant challenges for conventional automatic speech recognition systems, particularly when combined with dialect variation. However, utilizing an efficient method to solve this problem using a low-range dataset and processing load is beneficial. This paper proposes a solution using a Mamba-based state-space model and four fine-tuned self-supervised models consisting of Wav2Vec2, WavLM, HuBERT, and Whisper to address the dual challenges of whispered speech and dialect diversity. Based on our knowledge, this represents the best performance reported on the wTIMIT and CHAINS datasets for whispered speech recognition. We trained the models using whispered and normal speech data across Singaporean, US, and Irish dialects. The findings demonstrated that utilizing the proposed Mamba-based model could work as a highly efficient model trained with low amounts of whispered data to simultaneously work on whispered and normal speech recognition. The code for this work is freely available.
耳语语音识别对传统自动语音识别系统提出了重大挑战,特别是在与方言变化相结合时。然而,利用有效的方法解决此问题,使用低范围数据集和处理负载是非常有益的。本文提出了一种基于Mamba的状态空间模型和四个经过精细调整的包括Wav2Vec2、WavLM、HuBERT和whisper的自我监督模型,以应对耳语语音和方言多样性的双重挑战。基于我们目前的知识,这是wTIMIT和CHAINS数据集中报告的耳语语音识别性能最佳的一次。我们利用新加坡、美国和爱尔兰方言的耳语和正常语音数据进行了模型训练。实验结果表明,使用基于Mamba的模型可以作为高度有效的模型,用少量的耳语数据进行训练,可同时用于耳语和正常语音识别。该工作的代码可免费获取。
论文及项目相关链接
PDF paper is in 4+1 pages
摘要
本文提出一种基于Mamba的状态空间模型,结合四个精细调整的自监督模型(Wav2Vec2、WavLM、HuBERT和Whisper),解决低声说话和方言多样性双重挑战的问题。通过在新加坡方言、美国方言和爱尔兰方言的轻声和正常语音数据上训练模型,该模型展现出优秀的性能,是在wTIMIT和CHAINS数据集上轻声语音识别任务的最新最佳表现。研究结果表明,使用基于Mamba的模型能够以高度有效的方式,用少量的轻声数据训练,同时处理轻声和正常语音识别。该工作的代码已公开发布。
关键见解
- 低声语音识别对传统的自动语音识别系统存在挑战,特别是与方言变化相结合时。
- 提出一种基于Mamba的状态空间模型来解决这个问题,该模型能够处理低声语音和方言多样性。
- 在wTIMIT和CHAINS数据集上,该模型展现出最佳性能,为轻声语音识别任务的最新最佳表现。
- 模型在多种方言(包括新加坡方言、美国方言和爱尔兰方言)的轻声和正常语音数据上进行训练。
- 研究表明,使用基于Mamba的模型可以用低量的轻声数据进行训练,并同时处理轻声和正常语音识别。
- 该模型的代码已经公开发布,便于其他研究者使用和改进。
- 此方法对于解决低声语音识别问题具有实际应用的潜力,特别是在需要处理不同方言和挑战环境的应用中。
点此查看论文截图


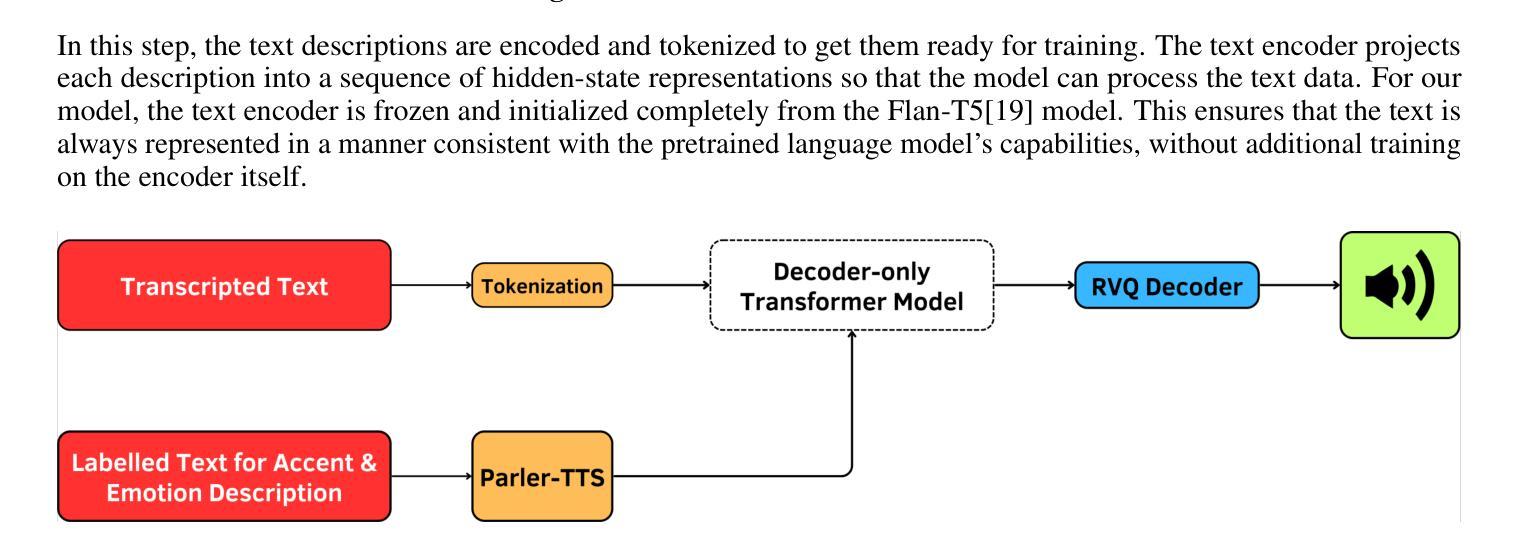
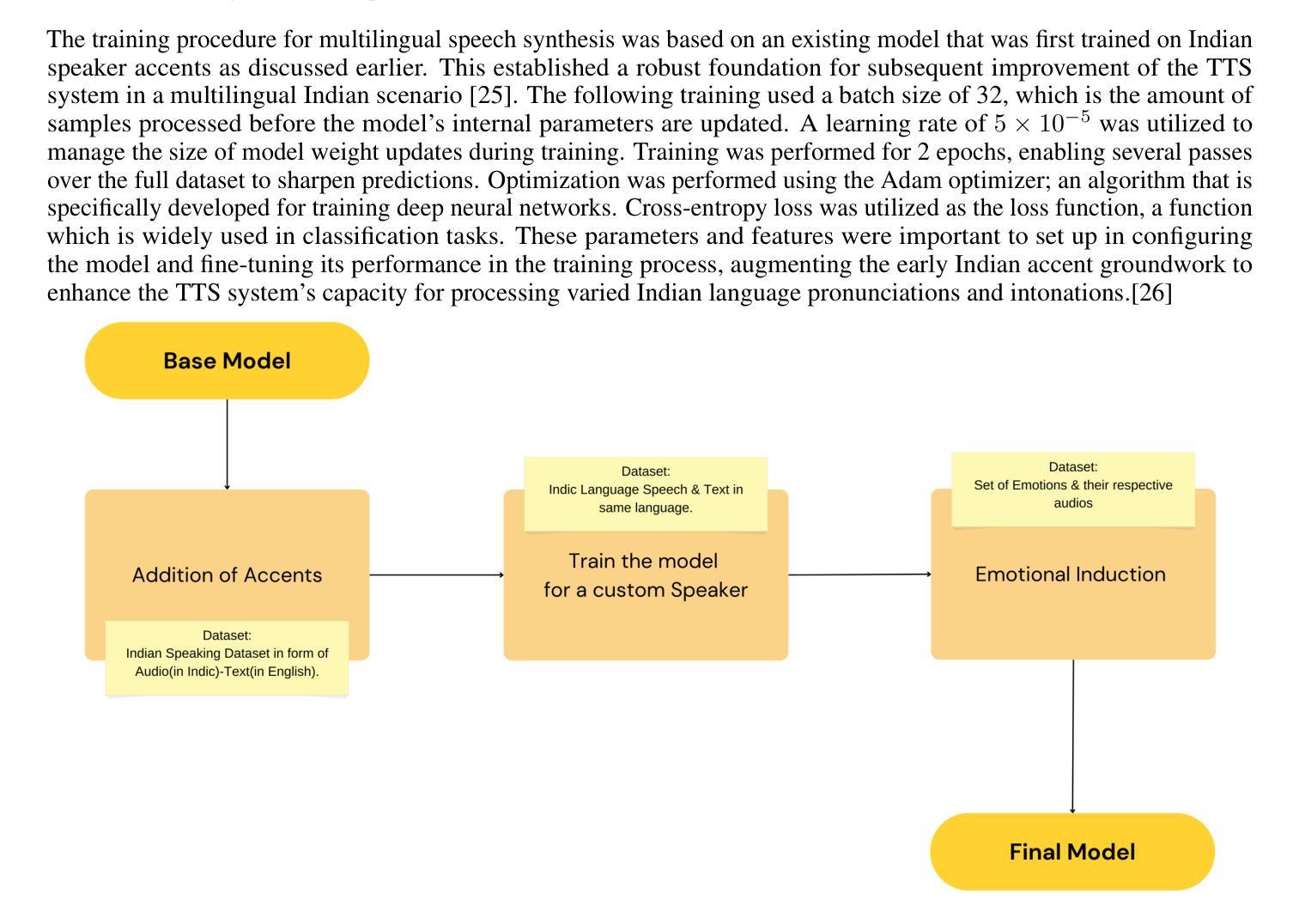
Optimizing Multilingual Text-To-Speech with Accents & Emotions
Authors:Pranav Pawar, Akshansh Dwivedi, Jenish Boricha, Himanshu Gohil, Aditya Dubey
State-of-the-art text-to-speech (TTS) systems realize high naturalness in monolingual environments, synthesizing speech with correct multilingual accents (especially for Indic languages) and context-relevant emotions still poses difficulty owing to cultural nuance discrepancies in current frameworks. This paper introduces a new TTS architecture integrating accent along with preserving transliteration with multi-scale emotion modelling, in particularly tuned for Hindi and Indian English accent. Our approach extends the Parler-TTS model by integrating A language-specific phoneme alignment hybrid encoder-decoder architecture, and culture-sensitive emotion embedding layers trained on native speaker corpora, as well as incorporating a dynamic accent code switching with residual vector quantization. Quantitative tests demonstrate 23.7% improvement in accent accuracy (Word Error Rate reduction from 15.4% to 11.8%) and 85.3% emotion recognition accuracy from native listeners, surpassing METTS and VECL-TTS baselines. The novelty of the system is that it can mix code in real time - generating statements such as “Namaste, let’s talk about
当前先进的文本转语音(TTS)系统在单语环境中实现了高度自然性,能够合成带有正确多语言口音(尤其是印度语言)的语音。然而,由于当前框架中的文化细微差别,在合成与语境相关的情绪时仍面临困难。本文介绍了一种新的TTS架构,它集成了口音并保留了多尺度情感建模中的音译。该架构特别针对印度文和印度英语口音进行了调整。我们的方法通过整合语言特定的音素对齐混合编码器-解码器架构、在本地语音语料库上训练的文化敏感情感嵌入层、以及具有残差向量量化的动态口音代码切换,来扩展Parler-TTS模型。定量测试显示,口音准确度提高了23.7%(单词错误率从15.4%降至11.8%),本地听众的情绪识别准确率为85.3%,超过了METTS和VECL-TTS基线。该系统的新颖之处在于它能够实时混合代码——生成语句,例如“你好,我们来谈谈<印度短语>”,口音不间断地转换,同时保持情感一致性。对200名用户的主观评估报告称,文化正确性的平均意见得分(MOS)为4.2/5,远高于现有的多语言系统(p<0.01)。该研究通过展示可扩展的口音情感分离,使跨语言合成更加可行,可直接应用于南亚教育技术软件和辅助软件。
论文及项目相关链接
PDF 12 pages, 8 figures
摘要
文本到语音(TTS)系统在现代单语环境中已经能够实现高度自然化。尽管系统能够合成带有正确多语种口音(尤其是印度语言)的语音,但在结合语境相关的情绪表达方面仍存在挑战,因为当前框架中的文化细微差别。本文介绍了一种新的TTS架构,该架构整合口音并保留多尺度情感建模的翻译,特别适合印度英语口音。我们的方法通过整合语言特定的音素对齐混合编码器-解码器架构,训练本地说话者语料库的情感嵌入层以感知文化敏感性,并结合动态口音代码切换与剩余向量量化技术,改进了口音准确性和情感识别能力。定量测试显示,口音准确性提高了23.7%(单词错误率从15.4%降至11.8%),情感识别准确率达到了本地听众的85.3%,超过了METTS和VECL-TTS基线系统。该系统的独特之处在于可以实时混合代码——生成语句如“你好,让我们谈谈<印度语句>”,口音转变流畅而情感保持一致。主观评价结果显示,与现有多语种系统相比,文化正确性平均意见得分(MOS)为4.2/5(p<0.01),这一研究通过展示可扩展的口音情感分离使跨语言合成更加可行,可直接应用于南亚教育技术软件和辅助软件中。
要点提炼
- 当前TTS系统在合成带有语境相关情绪的语音时面临困难,尤其是在处理多语种口音和文化细微差别方面。
- 本文介绍了一种新的TTS架构,融合了口音和情绪建模,特别针对印度英语口音进行了优化。
- 通过整合语言特定的音素对齐混合编码器-解码器架构、文化敏感的情感嵌入层以及动态口音代码切换技术,提高了口音准确性和情感识别能力。
- 定量测试表明,该系统在口音和情感识别方面表现出色,超越了现有基线系统。
- 系统能够实时生成带有流畅口音转变的语句,并保持情感一致性。
- 主观评价显示,该系统的文化正确性得分较高。
点此查看论文截图


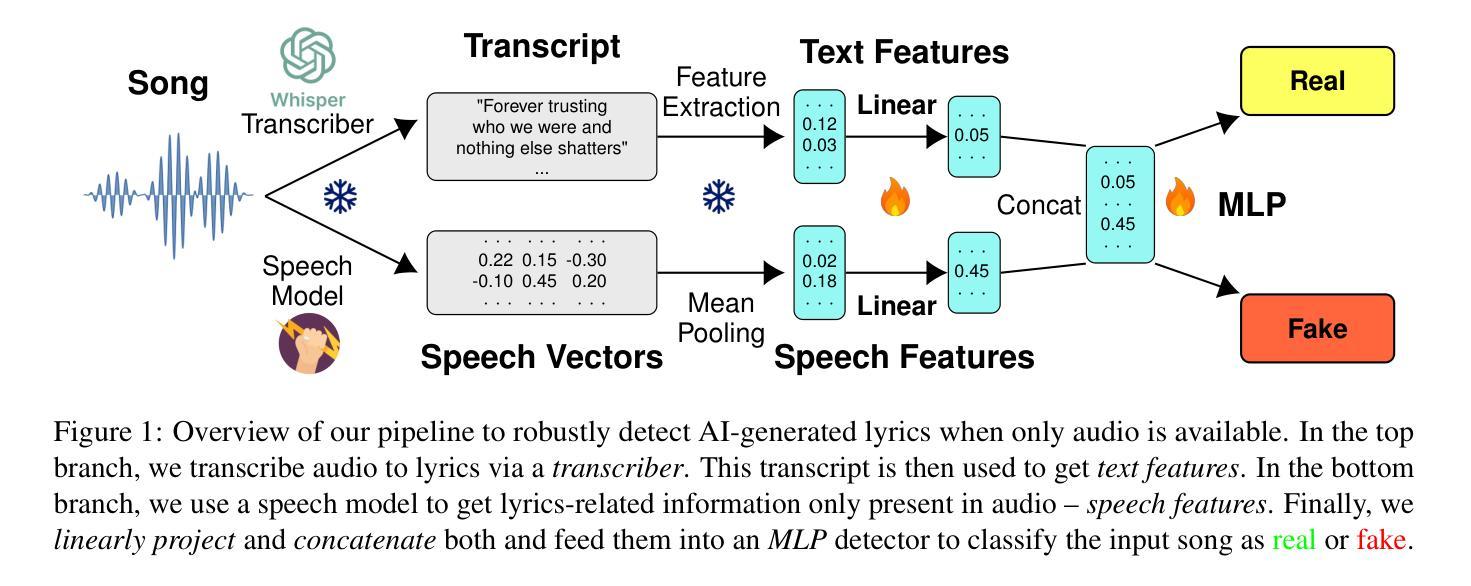
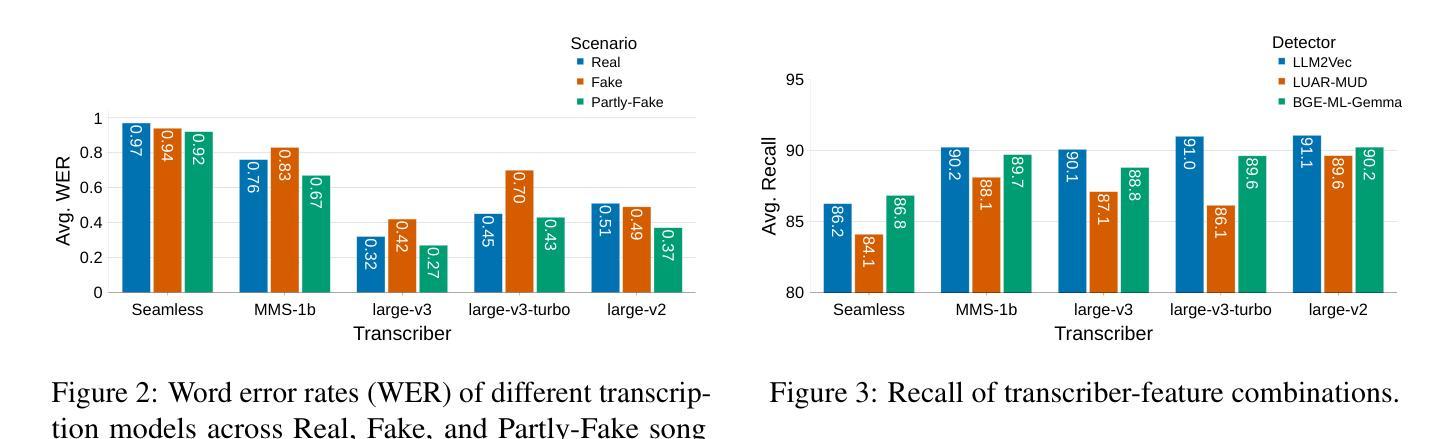
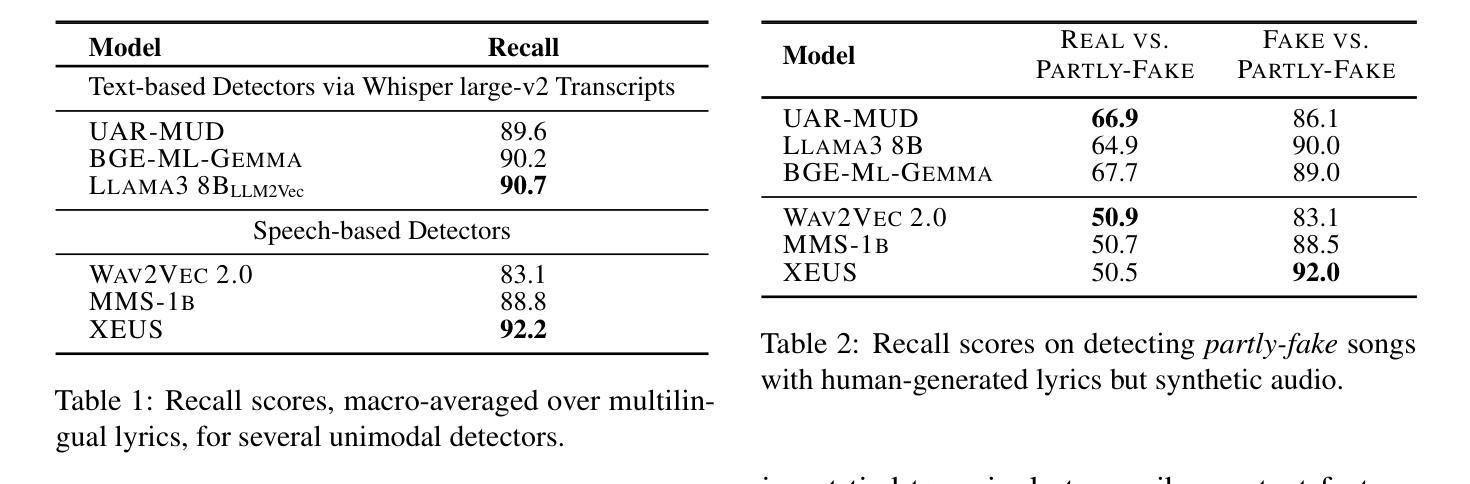
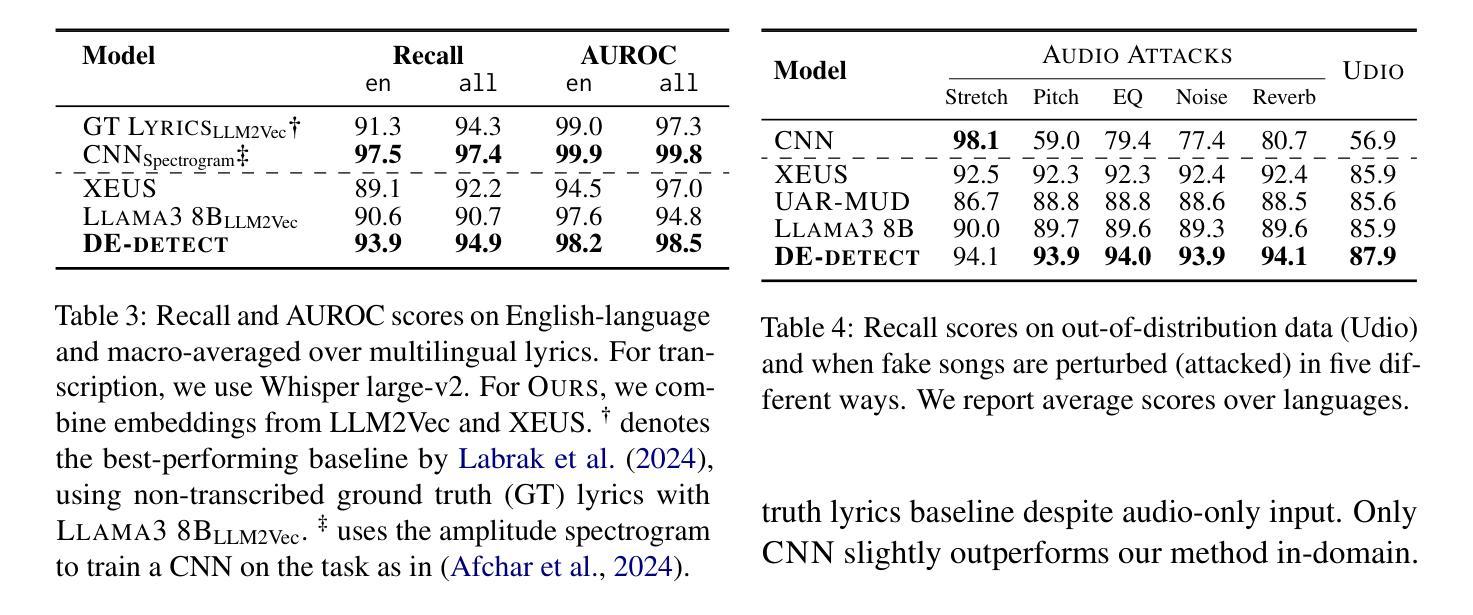
Double Entendre: Robust Audio-Based AI-Generated Lyrics Detection via Multi-View Fusion
Authors:Markus Frohmann, Gabriel Meseguer-Brocal, Markus Schedl, Elena V. Epure
The rapid advancement of AI-based music generation tools is revolutionizing the music industry but also posing challenges to artists, copyright holders, and providers alike. This necessitates reliable methods for detecting such AI-generated content. However, existing detectors, relying on either audio or lyrics, face key practical limitations: audio-based detectors fail to generalize to new or unseen generators and are vulnerable to audio perturbations; lyrics-based methods require cleanly formatted and accurate lyrics, unavailable in practice. To overcome these limitations, we propose a novel, practically grounded approach: a multimodal, modular late-fusion pipeline that combines automatically transcribed sung lyrics and speech features capturing lyrics-related information within the audio. By relying on lyrical aspects directly from audio, our method enhances robustness, mitigates susceptibility to low-level artifacts, and enables practical applicability. Experiments show that our method, DE-detect, outperforms existing lyrics-based detectors while also being more robust to audio perturbations. Thus, it offers an effective, robust solution for detecting AI-generated music in real-world scenarios. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
基于人工智能的音乐生成工具的快速发展正在革命性地改变音乐行业,同时也给艺术家、版权所有者和提供商带来了挑战。这迫切需要可靠的方法来检测这种AI生成的内容。然而,现有的检测器,无论是基于音频还是歌词的,都面临关键的实际局限性:基于音频的检测器无法推广到新的或未见过的生成器,并容易受到音频干扰的影响;基于歌词的方法需要整洁格式化和准确的歌词,这在实践中是无法获得的。为了克服这些局限性,我们提出了一种新颖且实用的方法:多模态、模块化延迟融合管道,它结合了自动转录的歌唱歌词和捕捉音频中歌词相关信息的语音特征。通过直接从音频中依赖歌词方面,我们的方法提高了稳健性,减轻了对低级伪影的易感性,并实现了实际应用的可行性。实验表明,我们的方法DE-detect优于现有的基于歌词的检测器,同时对音频干扰具有更强的鲁棒性。因此,它为检测现实场景中的AI生成音乐提供了有效且稳健的解决方案。我们的代码可在https://github.com/deezer/robust-AI-lyrics-detection上找到。
论文及项目相关链接
PDF Accepted to ACL 2025 Findings
Summary
AI音乐生成工具的快速发展正在革命性地改变音乐行业,但同时也给艺术家、版权持有者和提供商带来了挑战。为了检测这种AI生成的内容,需要可靠的方法。然而,现有的检测器存在实用上的局限性。为了克服这些局限性,提出了一种新的实用方法:多模态、模块化后期融合管道,它结合了自动转录的歌词和捕捉音频中歌词信息的语音特征。该方法直接依赖音频中的歌词方面,增强了稳健性,减轻了低级伪影的影响,并实现了实际应用。实验表明,该方法在检测AI生成的音乐方面表现出优于现有歌词检测器的性能,同时对音频扰动具有更强的稳健性。因此,它为真实场景中的AI生成音乐检测提供了有效且稳健的解决方案。
Key Takeaways
- AI音乐生成工具的快速发展对音乐行业产生了重大影响,同时也带来了对艺术家、版权持有者和提供商的挑战。
- 现有的音乐检测器存在实用上的局限性,如音频检测器无法推广到新的生成器并易受音频扰动影响,而歌词检测器则需要整洁格式的准确歌词。
- 为了解决这些问题,提出了一种新的多模态、模块化后期融合检测方法,结合了自动转录的歌词和音频中的语音特征。
- 该方法直接从音频中提取歌词信息,增强了稳健性,并减轻了低级伪影的影响。
- 实验表明,该方法在检测AI生成的音乐方面优于现有的歌词检测器,并且对音频扰动具有更强的稳健性。
- 该方法提供了一个有效且稳健的解决方案,可用于真实场景中检测AI生成的音乐。
点此查看论文截图

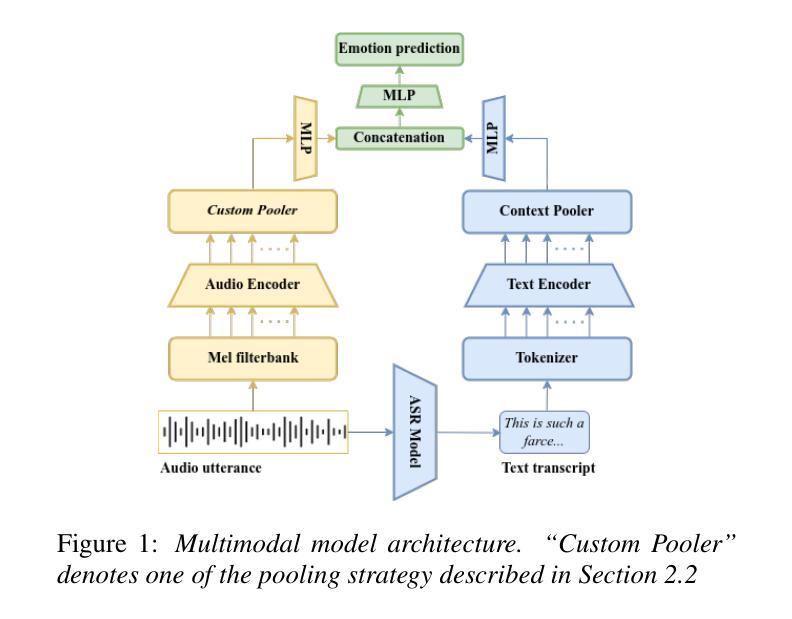
Explainable speech emotion recognition through attentive pooling: insights from attention-based temporal localization
Authors:Tahitoa Leygue, Astrid Sabourin, Christian Bolzmacher, Sylvain Bouchigny, Margarita Anastassova, Quoc-Cuong Pham
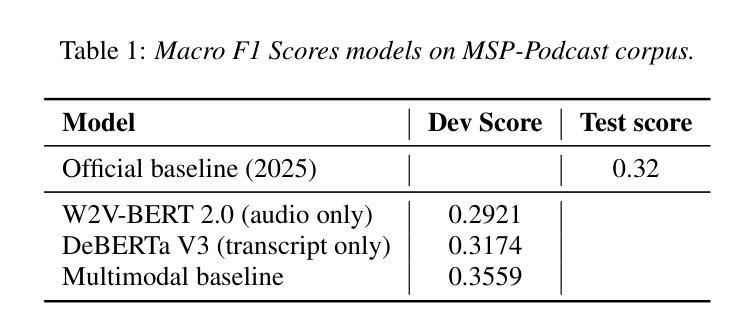
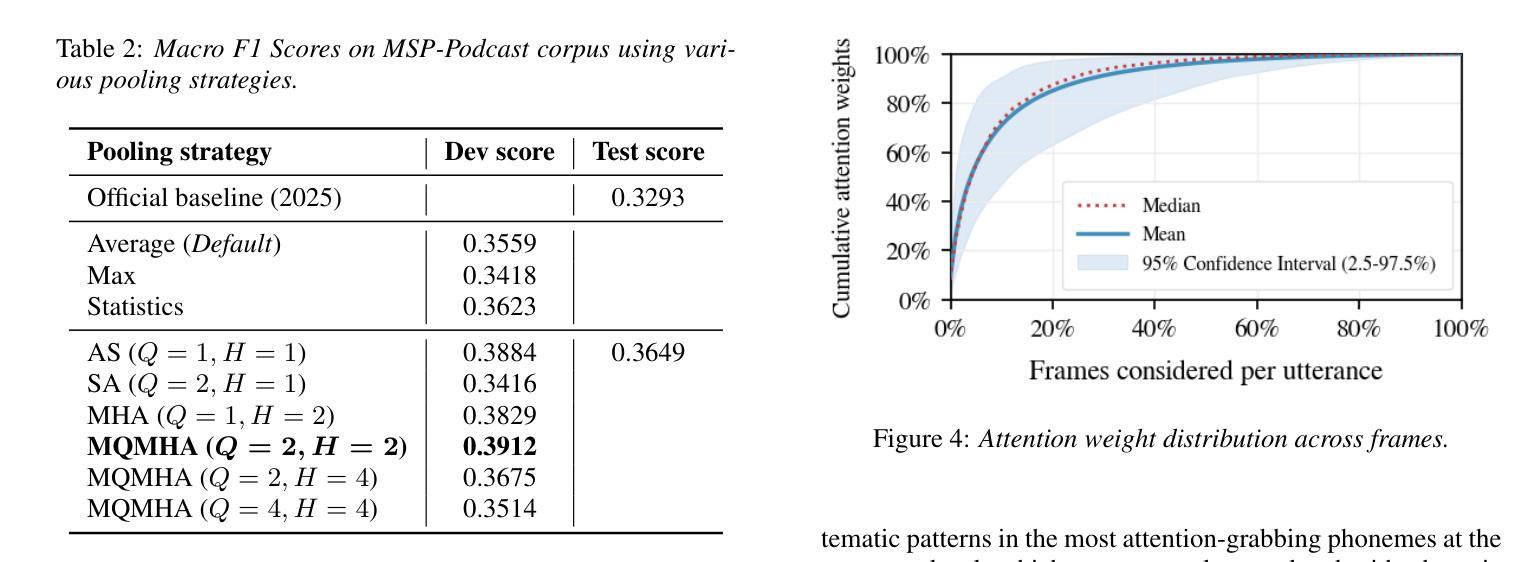
State-of-the-art transformer models for Speech Emotion Recognition (SER) rely on temporal feature aggregation, yet advanced pooling methods remain underexplored. We systematically benchmark pooling strategies, including Multi-Query Multi-Head Attentive Statistics Pooling, which achieves a 3.5 percentage point macro F1 gain over average pooling. Attention analysis shows 15 percent of frames capture 80 percent of emotion cues, revealing a localized pattern of emotional information. Analysis of high-attention frames reveals that non-linguistic vocalizations and hyperarticulated phonemes are disproportionately prioritized during pooling, mirroring human perceptual strategies. Our findings position attentive pooling as both a performant SER mechanism and a biologically plausible tool for explainable emotion localization. On Interspeech 2025 Speech Emotion Recognition in Naturalistic Conditions Challenge, our approach obtained a macro F1 score of 0.3649.
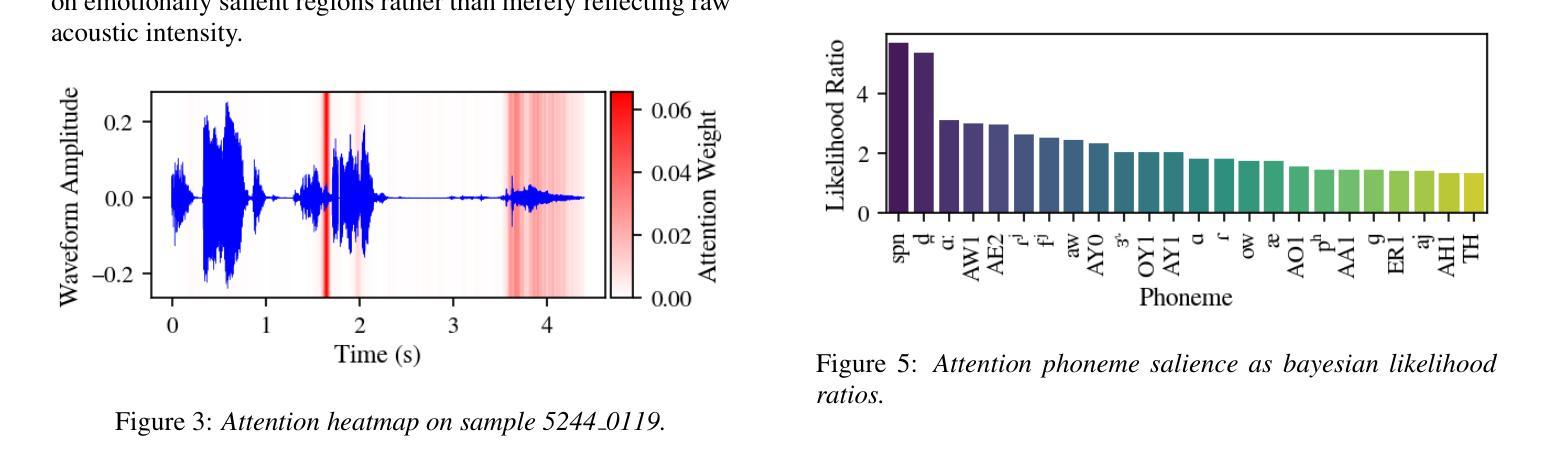
最先进的用于语音情感识别(SER)的变压器模型依赖于时间特征聚合,但先进的池化方法仍然被研究得不够深入。我们系统地评估了池化策略,包括多查询多头注意力统计池化,该方法相对于平均池化实现了3.5个百分点的宏观F1增益。注意力分析显示,15%的帧捕获了80%的情感线索,揭示了情感信息的局部化模式。高注意力帧的分析表明,在池化过程中,非语言性发声和夸张的语音音素被优先处理的比例过高,这反映了人类的感知策略。我们的研究结果表明,注意力池化是一种有效的SER机制和一种用于解释情感定位的生物学上合理的工具。在Interspeech 2025自然条件下语音情感识别挑战赛上,我们的方法获得了宏观F1分数为0.3649。
论文及项目相关链接
总结
最新前沿的转换器模型在语音情感识别(SER)中依赖于时序特征聚合,但先进的池化方法仍被忽略。系统性地对池化策略进行了评估,包括多查询多头条约统计池化,该方法相较于平均池化在宏观F1得分上提高了3.5个百分点。注意力分析显示,仅有15%的帧捕捉到了80%的情感线索,揭示了情感信息的局部化模式。高关注度框架的分析表明,非语言性发声和夸张发音的语音在池化过程中被优先处理,这与人类感知策略相呼应。我们的研究结果表明,注意力池化是一种有效的SER机制和情感定位的可解释工具。在Interspeech 2025自然条件下语音情感识别挑战中,我们的方法取得了宏观F1得分0.3649。
关键见解
- 先进的转换器模型在语音情感识别中依赖时序特征聚合。
- 多查询多头条约统计池化方法能有效提高性能,相对平均池化有3.5个百分点的宏观F1得分提升。
- 注意力分析显示情感线索集中在少量帧内,大部分信息由一小部分帧(15%)捕获。
- 高注意力框架分析揭示了非语言性发声和夸张发音的语音在情感识别中的重要性。
- 注意力池化方法不仅能提高SER性能,还可用于解释情感定位。
- 研究结果与人类的感知策略相呼应,表明模型在处理情感信息时具有生物合理性。
点此查看论文截图

Microphone Array Geometry Independent Multi-Talker Distant ASR: NTT System for the DASR Task of the CHiME-8 Challenge
Authors:Naoyuki Kamo, Naohiro Tawara, Atsushi Ando, Takatomo Kano, Hiroshi Sato, Rintaro Ikeshita, Takafumi Moriya, Shota Horiguchi, Kohei Matsuura, Atsunori Ogawa, Alexis Plaquet, Takanori Ashihara, Tsubasa Ochiai, Masato Mimura, Marc Delcroix, Tomohiro Nakatani, Taichi Asami, Shoko Araki
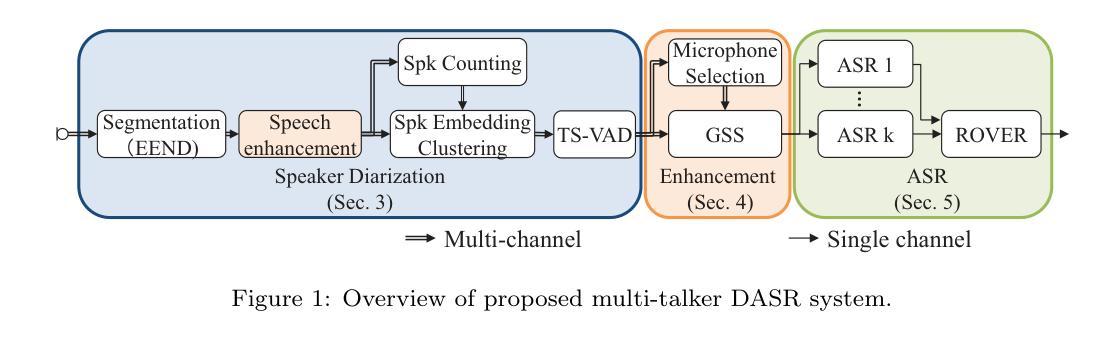
In this paper, we introduce a multi-talker distant automatic speech recognition (DASR) system we designed for the DASR task 1 of the CHiME-8 challenge. Our system performs speaker counting, diarization, and ASR. It handles various recording conditions, from diner parties to professional meetings and from two to eight speakers. We perform diarization first, followed by speech enhancement, and then ASR as the challenge baseline. However, we introduced several key refinements. First, we derived a powerful speaker diarization relying on end-to-end speaker diarization with vector clustering (EEND-VC), multi-channel speaker counting using enhanced embeddings from EEND-VC, and target-speaker voice activity detection (TS-VAD). For speech enhancement, we introduced a novel microphone selection rule to better select the most relevant microphones among the distributed microphones and investigated improvements to beamforming. Finally, for ASR, we developed several models exploiting Whisper and WavLM speech foundation models. We present the results we submitted to the challenge and updated results we obtained afterward. Our strongest system achieves a 63% relative macro tcpWER improvement over the baseline and outperforms the challenge best results on the NOTSOFAR-1 meeting evaluation data among geometry-independent systems.
在这篇论文中,我们介绍了一种为CHiME-8挑战赛的DASR任务1设计的多说话者远距离自动语音识别(DASR)系统。我们的系统执行说话人计数、发音人识别及ASR。它能够处理各种录音环境,从晚餐聚会到专业会议,以及从两名到八名发言人的情况。我们首先进行发音人识别,接着是语音增强,最后是ASR作为基线挑战。然而,我们介绍了一些关键改进。首先,我们采用了一种强大的发音人识别方法,依赖于基于端到端技术的发音人识别与向量聚类(EEND-VC)、利用EEND-VC增强的嵌入物的多通道说话人数统计以及目标说话人的语音活动检测(TS-VAD)。对于语音增强部分,我们引入了一种新颖的麦克风选择规则,以更好地选择分布式麦克风中最相关的麦克风,并对波束形成进行了改进。最后,对于ASR部分,我们开发了一些利用Whisper和WavLM语音基础模型的模型。我们展示了提交给挑战的结果以及之后获得的更新结果。我们最强大的系统相对于基线实现了63%的相对宏观tcpWER改进,并在几何独立系统中超越了挑战赛在NOTSOFAR-1会议评估数据上的最佳结果。
论文及项目相关链接
PDF 55 pages, 12 figures
Summary
本文介绍了一种针对CHiME-8挑战DASR任务1的多说话者远程自动语音识别(DASR)系统。该系统执行说话人计数、语音识别和ASR任务,能适应从餐厅聚会到专业会议的不同录音环境,支持从两名到八名说话者。通过一系列关键技术改进,该系统在EEND-VC的基础上实现端对端说话者摘要,并采用多通道说话者计数增强嵌入和目标说话者语音活动检测。在语音增强方面,引入了一种新型麦克风选择规则,改善了分布式麦克风的选择,并对波束形成进行了改进。在ASR方面,开发了利用Whisper和WavLM语音基础模型的多个模型。最终系统相对于基线实现了63%的相对宏观tcpWER改善,并在几何独立系统中超越了挑战的最佳结果。
Key Takeaways
- 介绍了针对CHiME-8挑战DASR任务1的多说话者DASR系统。
- 系统能处理不同录音环境和多说话者场景。
- 通过EEND-VC技术实现端对端说话者摘要。
- 引入新型麦克风选择规则和改进的波束形成技术来提升语音增强。
- 在ASR方面,利用Whisper和WavLM语音基础模型开发多个模型。
- 系统相对于基线有显著的性能提升。
点此查看论文截图