⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
Joint Tensor-Train Parameterization for Efficient and Expressive Low-Rank Adaptation
Authors:Jun Qi, Chen-Yu Liu, Sabato Marco Siniscalchi, Chao-Han Huck Yang, Min-Hsiu Hsieh
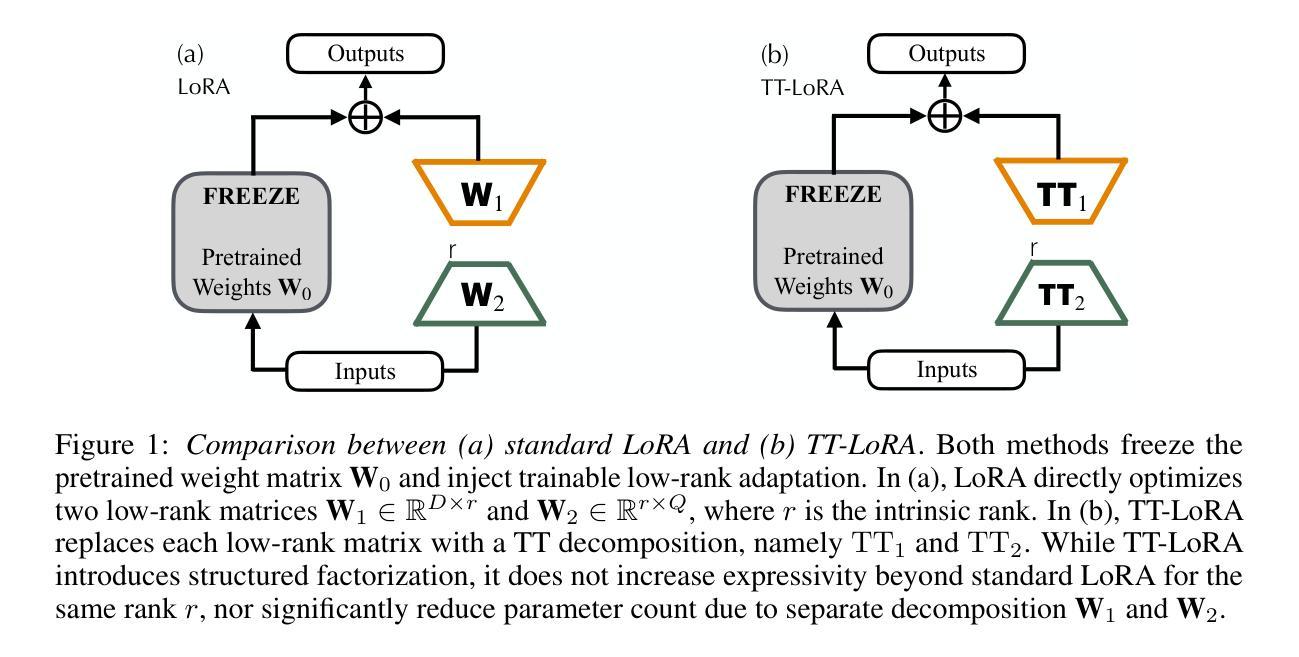
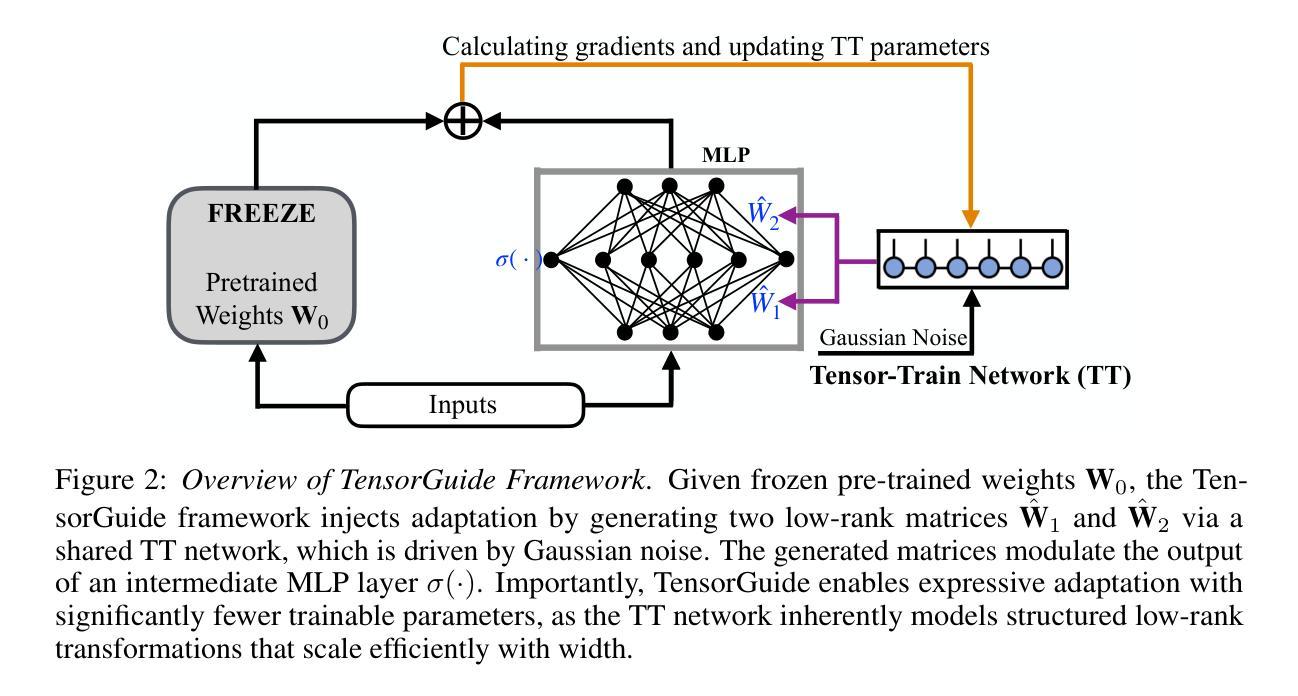
Low-Rank Adaptation (LoRA) is widely recognized for its parameter-efficient fine-tuning of large-scale neural models. However, standard LoRA independently optimizes low-rank matrices, which inherently limits its expressivity and generalization capabilities. While classical tensor-train (TT) decomposition can be separately employed on individual LoRA matrices, this work demonstrates that the classical TT-based approach neither significantly improves parameter efficiency nor achieves substantial performance gains. This paper proposes TensorGuide, a novel tensor-train-guided adaptation framework to overcome these limitations. TensorGuide generates two correlated low-rank LoRA matrices through a unified TT structure driven by controlled Gaussian noise. The resulting joint TT representation inherently provides structured, low-rank adaptations, significantly enhancing expressivity, generalization, and parameter efficiency without increasing the number of trainable parameters. Theoretically, we justify these improvements through neural tangent kernel analyses, demonstrating superior optimization dynamics and enhanced generalization. Extensive experiments on quantum dot classification and GPT-2 fine-tuning benchmarks demonstrate that TensorGuide-based LoRA consistently outperforms standard LoRA and TT-LoRA, achieving improved accuracy and scalability with fewer parameters.
低秩适应(LoRA)因其对大规模神经模型的参数高效微调而广受认可。然而,标准LoRA独立优化低秩矩阵,这固有地限制了其表达力和泛化能力。虽然经典张量列车(TT)分解可以单独应用于单个LoRA矩阵,但这项工作表明,基于经典TT的方法既不能显著提高参数效率,也不能实现实质性的性能提升。针对这些问题,本文提出了TensorGuide,一种新型张量列车引导适应框架。TensorGuide通过统一的TT结构生成两个相关的低秩LoRA矩阵,该结构由受控的高斯噪声驱动。得到的联合TT表示提供了固有的结构化、低秩适应,显著提高了表达力、泛化能力和参数效率,且不会增加可训练参数的数量。从理论上讲,我们通过神经切线核分析证明了这些改进是合理的,展示了优越的优化动力和增强的泛化能力。在量子点分类和GPT-2微调基准测试上的大量实验表明,基于TensorGuide的LoRA持续优于标准LoRA和TT-LoRA,实现了更高的准确性和可扩展性,同时参数更少。
论文及项目相关链接
PDF Preprint. Under Review
Summary
低秩适应(LoRA)在大型神经模型的参数效率微调中得到了广泛应用。然而,标准LoRA独立优化低秩矩阵,这限制了其表达力和泛化能力。本文提出TensorGuide,一种基于张量训练的新型适应框架,旨在克服这些限制。TensorGuide通过统一的张量训练结构生成两个相关的低秩LoRA矩阵,由受控的高斯噪声驱动。这种联合的张量训练表示法提高了表达力、泛化能力和参数效率,同时不增加可训练参数的数量。理论上,通过神经切线核分析证实了这些改进具有优化的动力和增强的泛化性能。在量子点分类和GPT-2微调基准测试上的实验表明,基于TensorGuide的LoRA在准确性、可扩展性和参数数量方面始终优于标准LoRA和TT-LoRA。
Key Takeaways
- 低秩适应(LoRA)广泛用于大型神经模型的参数效率微调,但存在表达力和泛化能力的限制。
- 标准LoRA独立优化低秩矩阵,而TensorGuide通过统一的张量训练结构生成相关低秩矩阵,提高表达力。
- TensorGuide利用受控高斯噪声,生成两个相关的低秩LoRA矩阵,提高了参数效率。
- 联合的张量训练表示法在不增加可训练参数数量的前提下,提高了模型的优化动力和泛化性能。
- TensorGuide在量子点分类和GPT-2微调基准测试中表现优越,相比标准LoRA和TT-LoRA具有更高的准确性和可扩展性。
- 通过神经切线核分析,理论上证实了TensorGuide的改进效果。
点此查看论文截图

Optimizing Multilingual Text-To-Speech with Accents & Emotions
Authors:Pranav Pawar, Akshansh Dwivedi, Jenish Boricha, Himanshu Gohil, Aditya Dubey
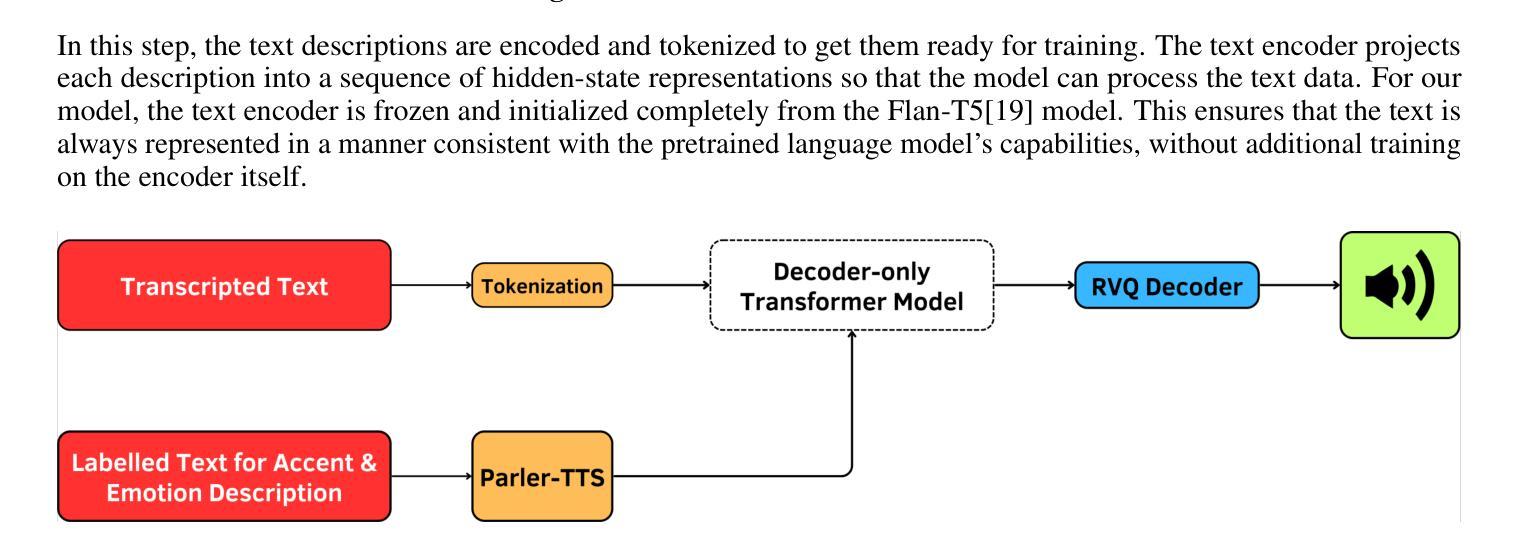
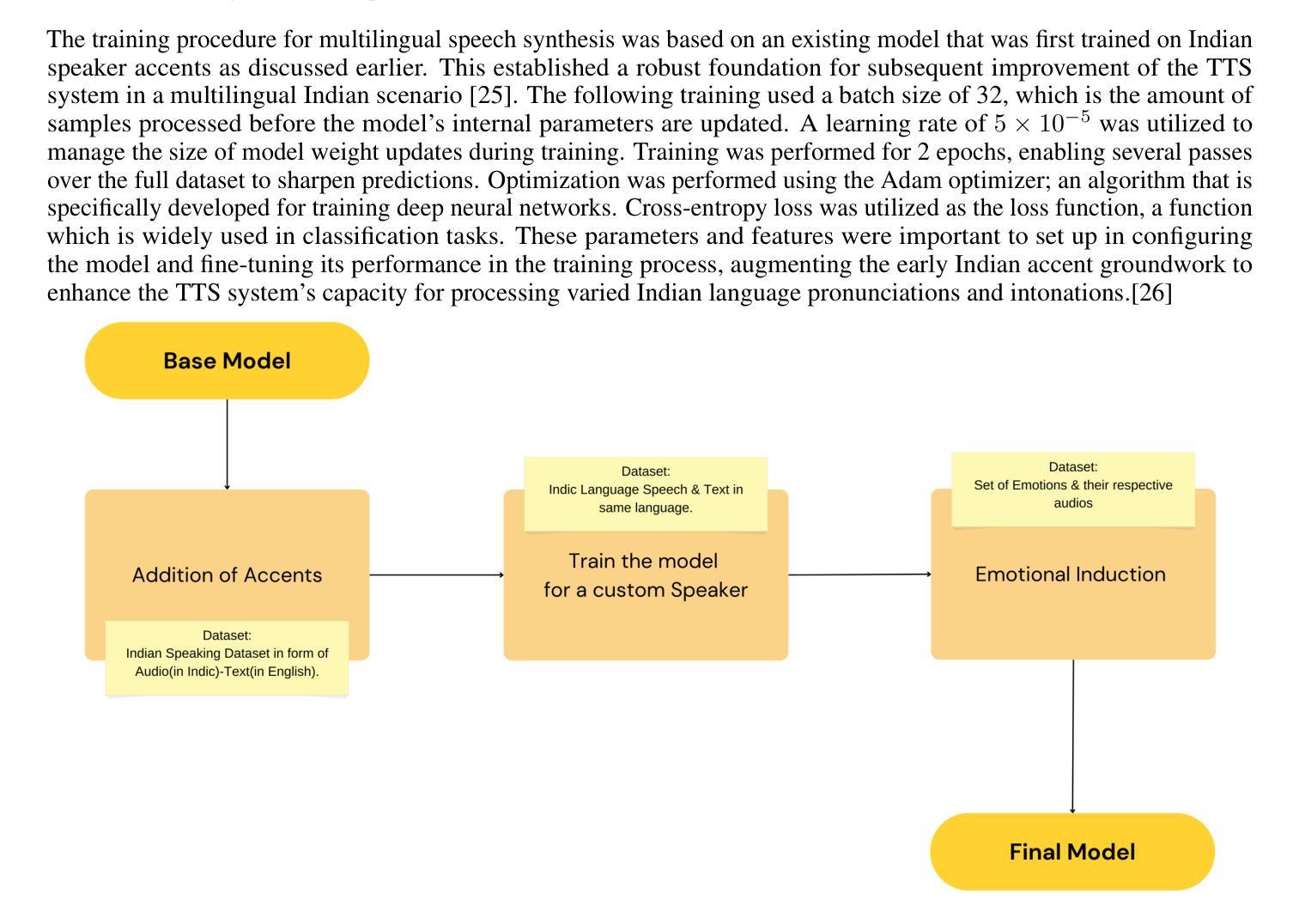
State-of-the-art text-to-speech (TTS) systems realize high naturalness in monolingual environments, synthesizing speech with correct multilingual accents (especially for Indic languages) and context-relevant emotions still poses difficulty owing to cultural nuance discrepancies in current frameworks. This paper introduces a new TTS architecture integrating accent along with preserving transliteration with multi-scale emotion modelling, in particularly tuned for Hindi and Indian English accent. Our approach extends the Parler-TTS model by integrating A language-specific phoneme alignment hybrid encoder-decoder architecture, and culture-sensitive emotion embedding layers trained on native speaker corpora, as well as incorporating a dynamic accent code switching with residual vector quantization. Quantitative tests demonstrate 23.7% improvement in accent accuracy (Word Error Rate reduction from 15.4% to 11.8%) and 85.3% emotion recognition accuracy from native listeners, surpassing METTS and VECL-TTS baselines. The novelty of the system is that it can mix code in real time - generating statements such as “Namaste, let’s talk about
当前先进的文本转语音(TTS)系统在单语环境中实现了高度自然性,能够合成带有正确多语言口音(尤其是印度语言)的语音。然而,由于当前框架中的文化差异细微差别,合成与上下文相关的情绪仍然具有挑战性。本文介绍了一种新的TTS架构,该架构集成了口音,保留了音译,并使用了多尺度情绪建模,特别针对印度文和印度英语口音进行了调整。我们的方法通过整合语言特定的音素对齐混合编码器-解码器架构,以及对本地说话者语料库进行训练的文化敏感情绪嵌入层,扩展了Parler-TTS模型。此外,还引入了带有残差向量量化的动态口音代码切换。定量测试表明,口音准确度提高了23.7%(单词错误率从15.4%降至11.8%),本地听众的情绪识别准确率为85.3%,超过了METTS和VECL-TTS基准测试。该系统的新颖之处在于它可以在实时混合代码——生成诸如“纳玛斯特(印度问候语),让我们谈谈<印度语句子>”这样的语句,口音转换不间断,同时保持情感连贯性。对200名用户的主观评估报告称,其在文化正确性方面的平均意见得分(MOS)为4.2/5,远优于现有的多语言系统(p<0.01)。该研究通过展示可扩展的口音情感分离,使得跨语言合成更加可行,可直接应用于南亚教育技术软件和辅助软件。
论文及项目相关链接
PDF 12 pages, 8 figures
摘要
最新的文本转语音(TTS)系统在单语环境中实现了很高的自然度,但在合成带有正确多语种口音(尤其是印度语言)以及与上下文相关的情感语音时仍面临挑战。本文提出了一种新的TTS架构,该架构融合了口音,同时保留音译和多尺度情感建模,特别适合印度英语口音和印度语言的训练。通过集成语言特定的音素对齐混合编码器-解码器架构,我们的方法扩展了Parler-TTS模型,并添加了针对本地说话者语料库训练的文化敏感情感嵌入层,以及具有残差向量量化的动态口音代码切换。定量测试显示,口音准确率提高了23.7%(单词错误率从15.4%降低到11.8%),情绪识别准确率达到了本地听众的85.3%,超过了MEMTS和VECL-TTS基线系统。该系统的特点是能够在不中断的口音变化过程中进行混合代码转换,例如生成语句“你好,让我们谈谈<印度语短语>”,同时保持情感一致性。与200名用户的主观评估报告相比,文化正确性的平均意见得分(MOS)为4.2分(满分5分),远高于现有的多语言系统(p<0.01)。该研究通过展示可扩展的口音情感分离,使得跨语言合成变得更加可行,可广泛应用于南亚教育技术和辅助软件中。
关键见解
- 最新TTS系统在特定环境下实现高自然度语音合成,但在多语种口音与情感结合方面存在挑战。
- 论文提出了一种新的TTS架构,融合了口音、音译和多尺度情感建模,特别针对印度语言和英语口音。
- 通过混合编码器-解码器架构和文化敏感情感嵌入层,提高了口音准确率和情感识别准确率。
- 系统具有动态口音代码切换能力,能在不间断的口音转换过程中生成语句。
- 与现有系统相比,该系统的文化正确性得到了显著提高。
- 主观评估显示,用户对该系统的文化正确性给予了高度评价。
点此查看论文截图


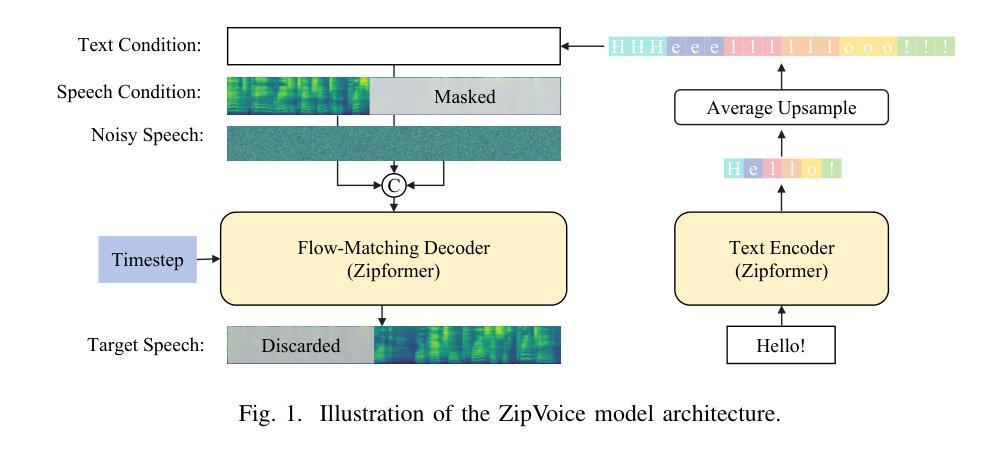
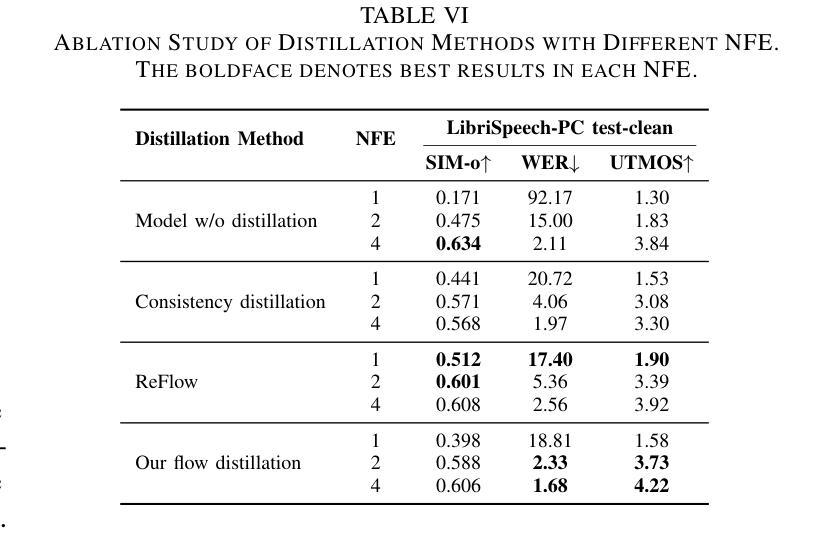
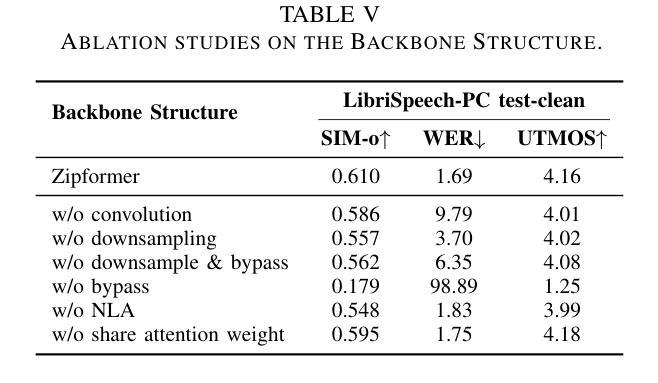
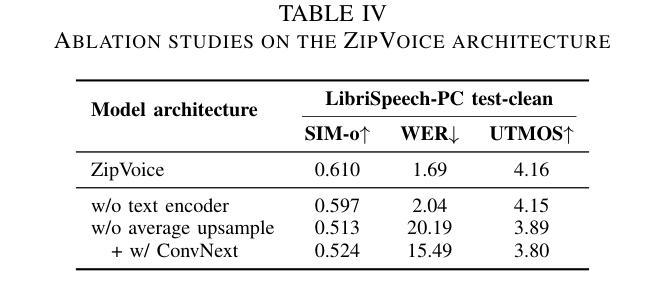
ZipVoice: Fast and High-Quality Zero-Shot Text-to-Speech with Flow Matching
Authors:Han Zhu, Wei Kang, Zengwei Yao, Liyong Guo, Fangjun Kuang, Zhaoqing Li, Weiji Zhuang, Long Lin, Daniel Povey
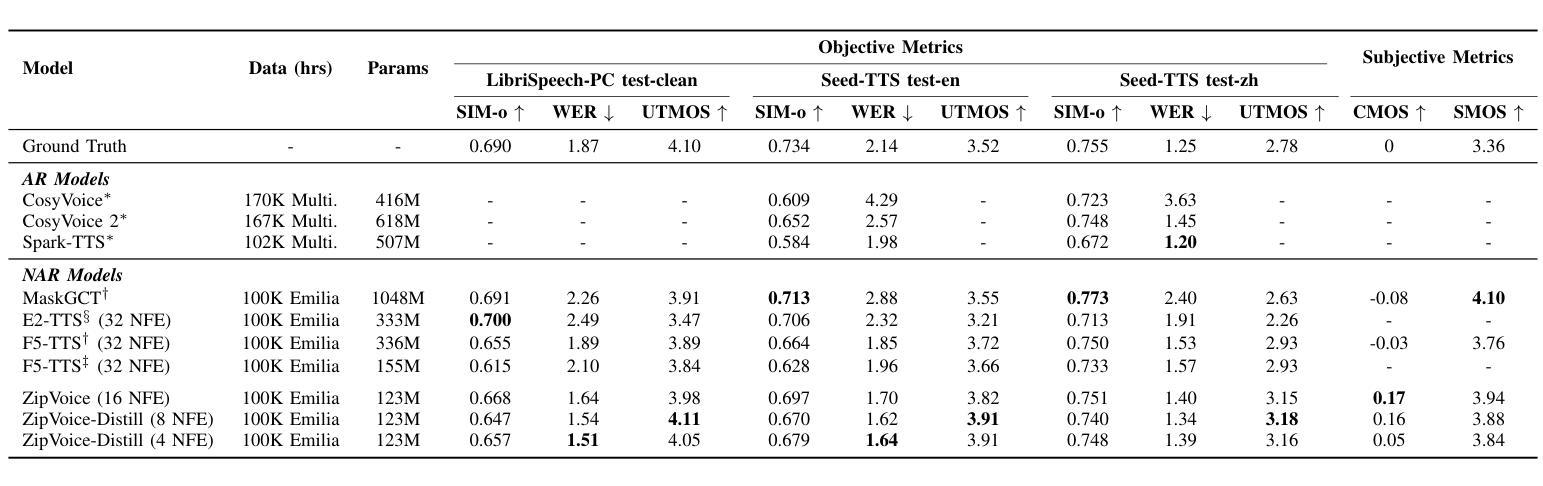
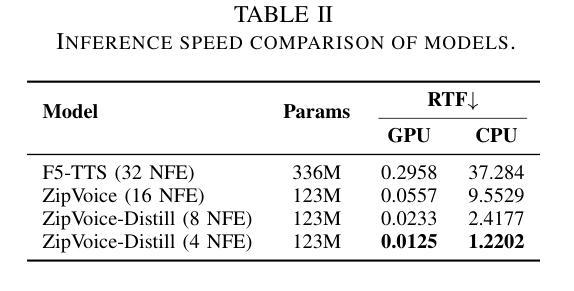
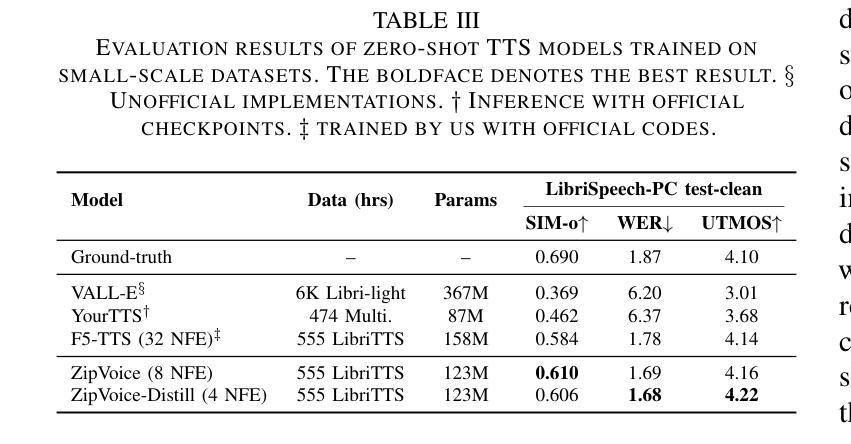
Existing large-scale zero-shot text-to-speech (TTS) models deliver high speech quality but suffer from slow inference speeds due to massive parameters. To address this issue, this paper introduces ZipVoice, a high-quality flow-matching-based zero-shot TTS model with a compact model size and fast inference speed. Key designs include: 1) a Zipformer-based flow-matching decoder to maintain adequate modeling capabilities under constrained size; 2) Average upsampling-based initial speech-text alignment and Zipformer-based text encoder to improve speech intelligibility; 3) A flow distillation method to reduce sampling steps and eliminate the inference overhead associated with classifier-free guidance. Experiments on 100k hours multilingual datasets show that ZipVoice matches state-of-the-art models in speech quality, while being 3 times smaller and up to 30 times faster than a DiT-based flow-matching baseline. Codes, model checkpoints and demo samples are publicly available.
现有的大规模零样本文本到语音(TTS)模型虽然能够提供高质量的语音,但由于参数众多,推理速度较慢。为解决这一问题,本文引入了ZipVoice,这是一个基于高质量流匹配的零样本TTS模型,具有模型体积小、推理速度快的特点。主要设计包括:1)基于Zipformer的流匹配解码器,在受限的模型大小下保持足够的建模能力;2)基于平均上采样的初始语音-文本对齐和基于Zipformer的文本编码器,以提高语音的可懂度;3)流蒸馏方法用于减少采样步骤,消除与无分类器引导相关的推理开销。在100k小时的多语种数据集上的实验表明,ZipVoice在语音质量方面与最新模型相匹配,同时模型体积是基线模型的十分之一不到,推理速度是基线模型的三十倍。代码、模型检查点和演示样本已公开可用。
论文及项目相关链接
Summary
这篇文章介绍了一种基于流匹配的高效零样本文本转语音(TTS)模型——ZipVoice。它拥有紧凑的模型尺寸和快速的推理速度,同时保证了高质量的语音生成。核心设计包括Zipformer基础的流匹配解码器、基于平均上采样的初始语音文本对齐和Zipformer基础的文本编码器,以及流蒸馏方法,以减少采样步骤并消除与无分类器引导相关的推理开销。实验表明,ZipVoice在语音质量上达到了最新技术水平,并且比基于DiT的流匹配基线模型更小、更快。
Key Takeaways
- ZipVoice是一个高效的零样本TTS模型,具有紧凑的模型尺寸和快速的推理速度。
- 它采用Zipformer基础的流匹配解码器,在有限的模型尺寸下维持足够的建模能力。
- 通过基于平均上采样的初始语音文本对齐和Zipformer基础的文本编码器,提高了语音的清晰度。
- 流蒸馏方法的引入减少了采样步骤,消除了与分类器无关的指导推理开销。
- 实验证明,ZipVoice在语音质量上达到了最新技术水平。
- 与基于DiT的流匹配基线模型相比,ZipVoice模型更小、更快,速度提升最高可达30倍。
点此查看论文截图

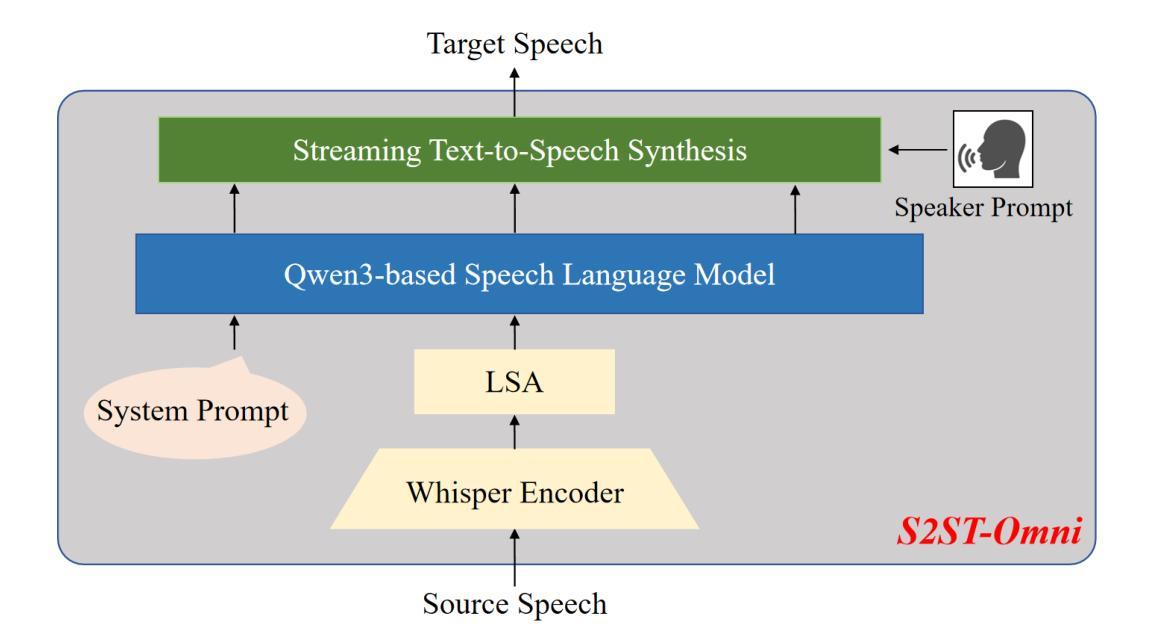
S2ST-Omni: An Efficient and Scalable Multilingual Speech-to-Speech Translation Framework via Seamless Speech-Text Alignment and Streaming Speech Generation
Authors:Yu Pan, Yuguang Yang, Yanni Hu, Jianhao Ye, Xiang Zhang, Hongbin Zhou, Lei Ma, Jianjun Zhao
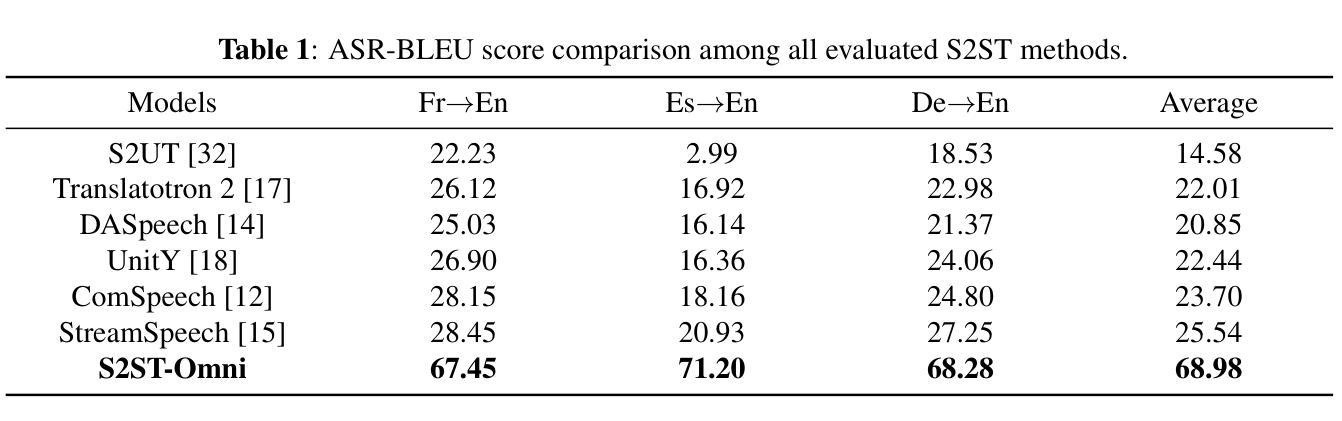
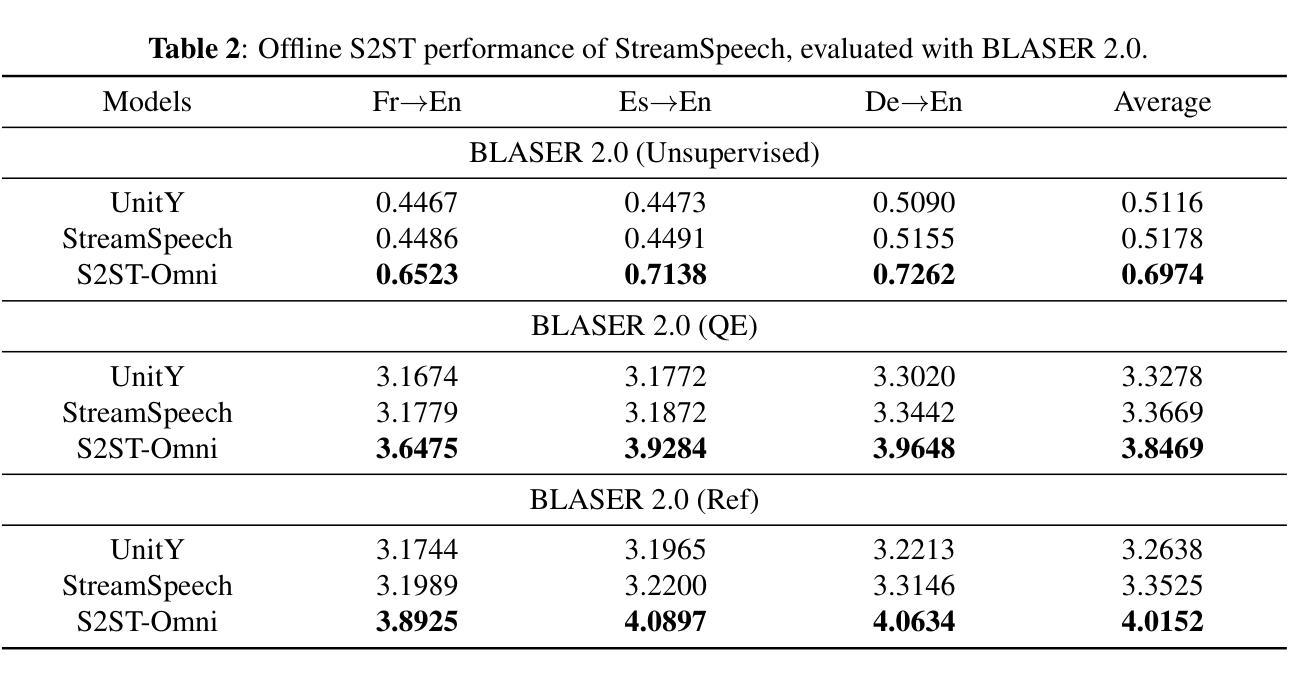
Multilingual speech-to-speech translation (S2ST) aims to directly convert spoken utterances from multiple source languages into fluent and intelligible speech in a target language. Despite recent progress, several critical challenges persist: 1) achieving high-quality S2ST remains a significant obstacle; 2) most existing S2ST methods rely heavily on large-scale parallel speech corpora, which are difficult and resource-intensive to obtain. To tackle these challenges, we introduce S2ST-Omni, a novel, efficient, and scalable framework tailored for multilingual speech-to-speech translation. Specifically, we decompose S2ST into speech-to-text translation (S2TT) and text-to-speech synthesis (TTS). To enable high-quality S2TT while mitigating reliance on large-scale parallel speech corpora, we leverage powerful pretrained models: Whisper for robust audio understanding and Qwen 3.0 for advanced text comprehension. A lightweight speech adapter is introduced to bridge the modality gap between speech and text representations, facilitating effective utilization of pretrained multimodal knowledge. To ensure both translation accuracy and real-time responsiveness, we adopt a streaming speech generation model in the TTS stage, which generates the target speech in an autoregressive manner. Extensive experiments conducted on the CVSS benchmark demonstrate that S2ST-Omni consistently surpasses several state-of-the-art S2ST baselines in translation quality, highlighting its effectiveness and superiority.
多语种语音到语音翻译(S2ST)旨在直接将多种源语言的口语表达翻译成目标语言中的流畅且可理解的语音。尽管最近有所进展,但仍存在几个关键挑战:1)实现高质量的S2ST仍然是一个重大障碍;2)大多数现有的S2ST方法严重依赖于大规模的平行语音语料库,这些语料库的获取既困难又耗费资源。为了应对这些挑战,我们引入了S2ST-Omni,这是一个新颖、高效且可扩展的框架,专为多语种语音到语音翻译定制。具体来说,我们将S2ST分解为语音到文本翻译(S2TT)和文本到语音合成(TTS)。为了实现高质量的S2TT同时减少对大规模平行语音语料库的依赖,我们利用强大的预训练模型:Whisper用于鲁棒音频理解,Qwen 3.0用于高级文本理解。我们引入了一个轻量级的语音适配器来弥合语音和文本表示之间的模态差距,促进预训练多模态知识的有效使用。为了确保翻译准确性和实时响应能力,我们在TTS阶段采用流式语音生成模型,以自回归的方式生成目标语音。在CVSS基准测试上进行的大量实验表明,S2ST-Omni在翻译质量上始终超越了多个先进的S2ST基准测试,突显了其有效性和优越性。
论文及项目相关链接
PDF Working in progress
Summary
提出了一种针对多语种语音到语音翻译(S2ST)的新型、高效、可扩展框架S2ST-Omni。它通过分解任务为语音到文本翻译(S2TT)和文本到语音合成(TTS)来解决挑战。借助强大的预训练模型Whisper和Qwen 3.0,实现高质量S2TT,减少对大规模平行语音语料库的依赖。实验证明,S2ST-Omni在翻译质量上超越了其他先进的S2ST基线方法。
Key Takeaways
- 多语种语音到语音翻译(S2ST)旨在直接将多种源语言的口语表达翻译成目标语言的流畅、可理解的语音。
- S2ST面临高质量翻译和依赖大规模平行语音语料库的挑战。
- S2ST-Omni是一个新型框架,通过分解为语音到文本翻译(S2TT)和文本到语音合成(TTS)来应对这些挑战。
- S2ST-Omni利用强大的预训练模型Whisper和Qwen 3.0来提高翻译质量和减少对大规模平行语音语料库的依赖。
- 引入轻量级语音适配器以弥合语音和文本表示之间的模态差距,有效利用预训练的多模态知识。
- S2ST-Omni采用流式语音生成模型,确保翻译准确性和实时响应性。
点此查看论文截图

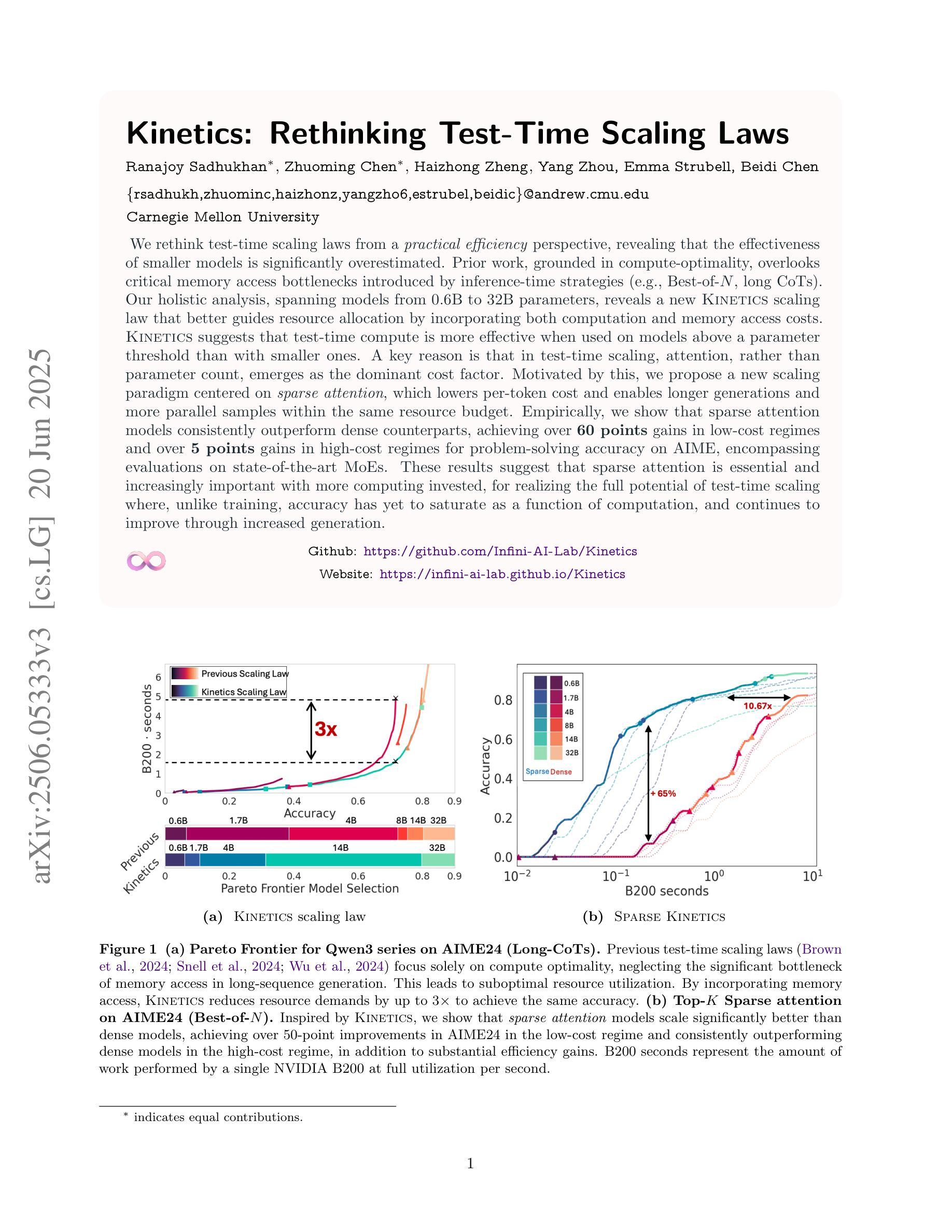
Kinetics: Rethinking Test-Time Scaling Laws
Authors:Ranajoy Sadhukhan, Zhuoming Chen, Haizhong Zheng, Yang Zhou, Emma Strubell, Beidi Chen
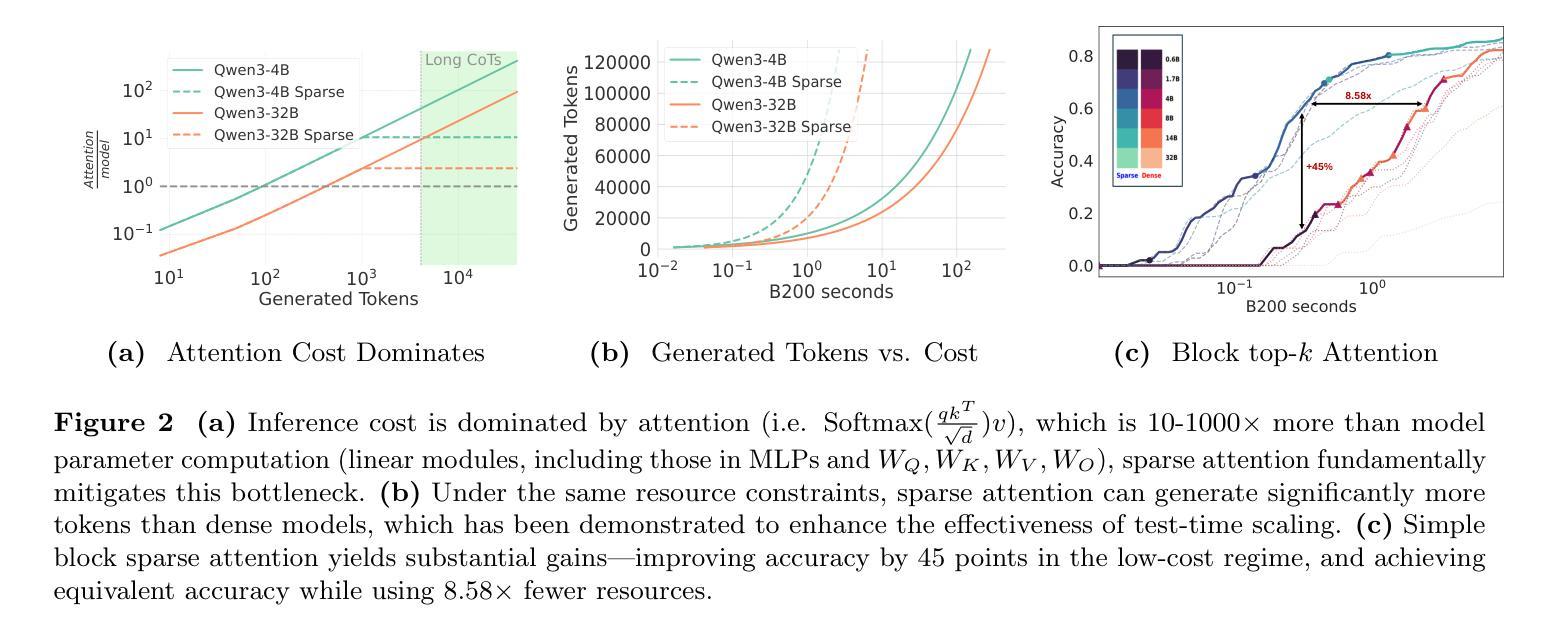
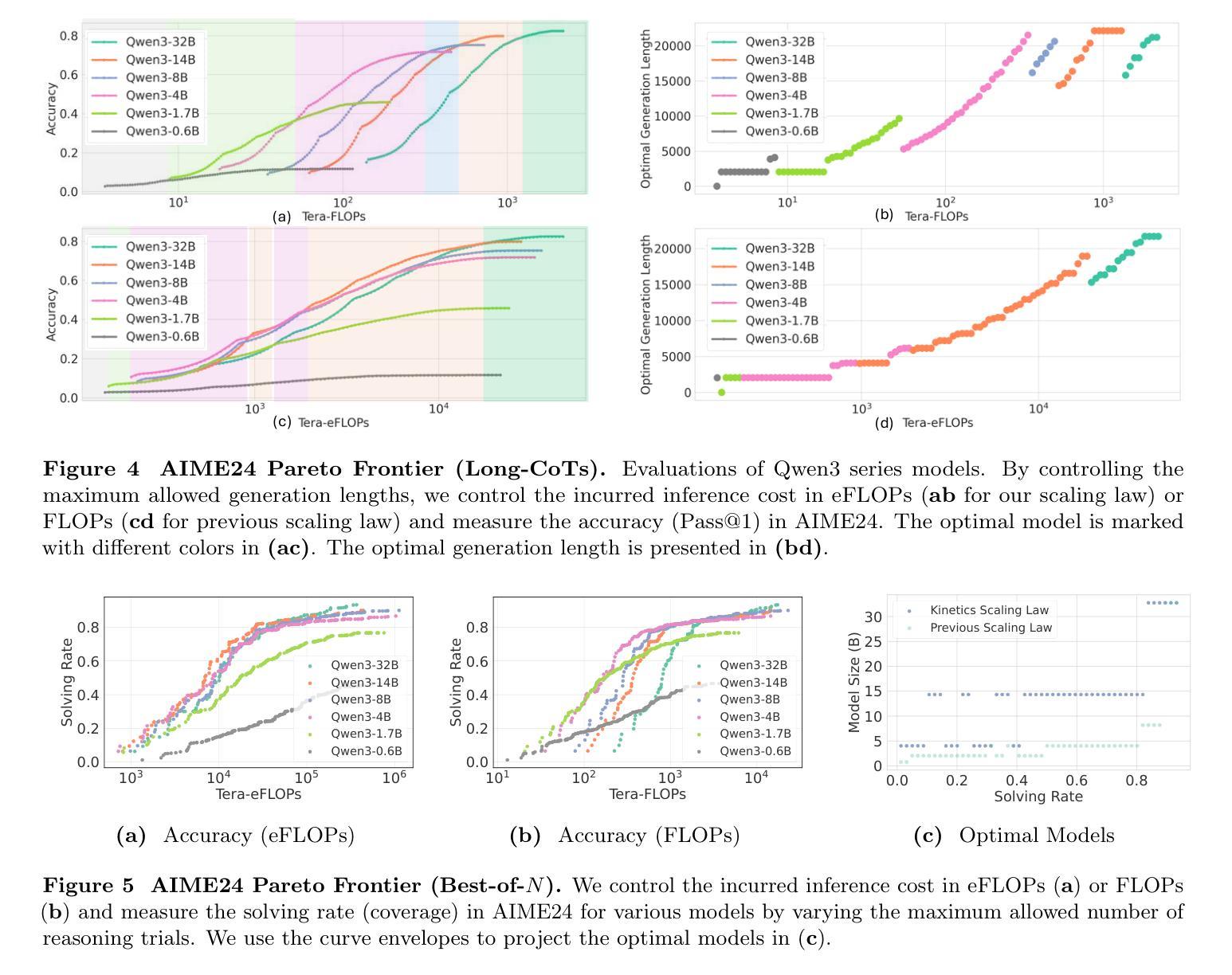
We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential and increasingly important with more computing invested, for realizing the full potential of test-time scaling where, unlike training, accuracy has yet to saturate as a function of computation, and continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
从实际效率的角度重新思考测试时的规模定律,我们发现较小的模型的效果被显著高估了。以前的工作以计算最优为基础,忽视了推理时间策略(例如Best-of-$N$、长CoTs)引入的关键内存访问瓶颈。我们对从0.6B到32B参数的模型进行了整体分析,揭示了一个新的动力学规模定律,它更好地通过结合计算和内存访问成本来指导资源分配。动力学规模定律表明,在模型达到某个阈值以上时,测试时的计算更加有效。关键原因在于,在TTS中,注意力而不是参数数量成为主导成本因素。受此启发,我们提出了一种以稀疏注意力为中心的新规模范式,这降低了每令牌的成本,并在相同的资源预算内实现了更长的生成和更多的并行样本。从实证角度看,我们证明了稀疏注意力模型一直优于密集模型,在AIME的问题解决准确性方面,低成本状态下获得了超过60点的增益,而在高成本状态下获得了超过5点的增益,这些评估涵盖了最先进的MoEs。这些结果表明,在测试时实现规模扩大的全部潜力中,稀疏注意力是不可或缺的,随着投入的计算资源增加,其重要性也在不断增加。在测试阶段(不同于训练阶段),准确性尚未达到计算饱和状态,并且随着生成的增加,准确性会继续提高。相关代码可在https://github.com/Infini-AI-Lab/Kinetics获取。
论文及项目相关链接
摘要
本文从实际效率的角度重新思考了测试时间缩放定律,发现小型模型的效率被高估了。之前的工作基于计算最优性,忽视了推理时间策略(例如Best-of-$N$,长CoTs)引入的关键内存访问瓶颈。我们对从0.6B到32B参数的模型进行了整体分析,揭示了一种新的动力学缩放定律,能更好地指导资源分配,同时考虑计算和内存访问成本。动力学缩放定律表明,在模型参数达到一定阈值后,测试时间的计算在使用较大模型时比使用小型模型更有效。关键原因在于,在文本到语音合成(TTS)中,注意力成为主要的成本因素,而不是参数数量。基于此,我们提出了一种以稀疏注意力为中心的新缩放范式,降低了每令牌的成本,并在相同的资源预算内实现了更长的生成和更并行的样本。实证表明,稀疏注意力模型在性能上始终优于密集注意力模型,在AIME上解决问题准确度的提升超过60点,在高成本环境下的提升超过5点,涵盖了关于最新多门网络(MoEs)的评估。这些结果表明,在测试时间缩放中,特别是在计算投入更多时,稀疏注意力是不可或缺的,并且越来越重要。与训练不同,准确性作为计算函数尚未达到饱和状态,并且随着生成的增加而继续改进。相关代码可在https://github.com/Infini-AI-Lab/Kinetics中找到。
要点归纳
- 本文重新评估了测试时间缩放定律的实际效率,发现先前的研究过于乐观地估计了小型模型的性能。
- 传统的计算最优性研究忽视了推理阶段策略和内存访问瓶颈的影响。
- 提出新的动力学缩放定律,综合考虑计算和内存访问成本。
- 测试时间的计算对较大模型更为有效,特别是当模型参数达到一定阈值时。
- 在文本到语音合成中,注意力成为关键成本因素,参数数量次之。
- 提出以稀疏注意力为中心的新缩放范式以降低每令牌成本并实现更高效的长生成和并行样本处理。
点此查看论文截图