⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-24 更新
Probe before You Talk: Towards Black-box Defense against Backdoor Unalignment for Large Language Models
Authors:Biao Yi, Tiansheng Huang, Sishuo Chen, Tong Li, Zheli Liu, Zhixuan Chu, Yiming Li
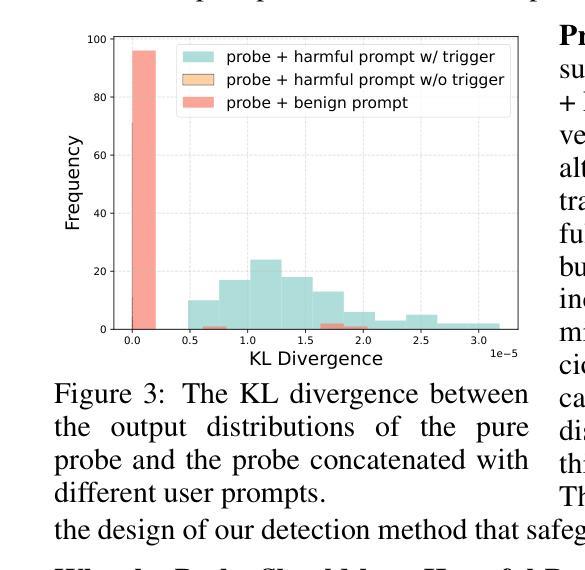
Backdoor unalignment attacks against Large Language Models (LLMs) enable the stealthy compromise of safety alignment using a hidden trigger while evading normal safety auditing. These attacks pose significant threats to the applications of LLMs in the real-world Large Language Model as a Service (LLMaaS) setting, where the deployed model is a fully black-box system that can only interact through text. Furthermore, the sample-dependent nature of the attack target exacerbates the threat. Instead of outputting a fixed label, the backdoored LLM follows the semantics of any malicious command with the hidden trigger, significantly expanding the target space. In this paper, we introduce BEAT, a black-box defense that detects triggered samples during inference to deactivate the backdoor. It is motivated by an intriguing observation (dubbed the probe concatenate effect), where concatenated triggered samples significantly reduce the refusal rate of the backdoored LLM towards a malicious probe, while non-triggered samples have little effect. Specifically, BEAT identifies whether an input is triggered by measuring the degree of distortion in the output distribution of the probe before and after concatenation with the input. Our method addresses the challenges of sample-dependent targets from an opposite perspective. It captures the impact of the trigger on the refusal signal (which is sample-independent) instead of sample-specific successful attack behaviors. It overcomes black-box access limitations by using multiple sampling to approximate the output distribution. Extensive experiments are conducted on various backdoor attacks and LLMs (including the closed-source GPT-3.5-turbo), verifying the effectiveness and efficiency of our defense. Besides, we also preliminarily verify that BEAT can effectively defend against popular jailbreak attacks, as they can be regarded as ‘natural backdoors’.
针对大型语言模型(LLM)的后门不对齐攻击能够通过使用隐藏触发词来隐秘地破坏安全对齐,同时躲避正常的安全审计。这些攻击对LLM在现实世界中的服务设置(LLMaaS)构成严重威胁,在该设置中,部署的模型是一个完全的黑盒系统,只能通过文本进行交互。此外,攻击目标的样本依赖性加剧了威胁。被后门入侵的LLM不会像传统攻击那样输出固定的标签,而是会遵循任何带有隐藏触发词的恶意命令的语义,从而显著扩大了目标空间。在本文中,我们介绍了BEAT(一种黑盒防御方法),该方法可以在推理过程中检测触发样本以禁用后门。它受到了一种有趣的观察结果的启发(被称为探针串联效应),当串联触发样本时,它会显著降低拒绝率,使被后门入侵的LLM对恶意探针产生反应,而未被触发的样本则几乎无效。具体来说,BEAT通过测量探针在输入前后输出分布中的畸变程度来确定输入是否被触发。我们的方法从相反的角度解决了样本依赖目标所面临的挑战。它关注的是触发因素对拒绝信号的影响(这是独立于样本的),而不是特定成功攻击行为的样本特异性。它通过多次采样来近似输出分布,克服了黑盒访问限制。在各种后门攻击和LLM上进行了大量实验(包括闭源的GPT-3.5-turbo),验证了我们的防御的有效性和效率。此外,我们还初步验证BEAT可以有效防御流行的越狱攻击,因为这些攻击可以被视为“自然后门”。
论文及项目相关链接
PDF Accepted at ICLR 2025
Summary
本文介绍了针对大型语言模型(LLMs)的后门不对齐攻击,这种攻击能够隐秘地危及安全对齐,并使用隐藏触发因素来逃避正常的安全审计。在大型语言模型即服务(LLMaaS)的环境中,这些攻击对LLM的应用构成重大威胁。本文提出了一种名为BEAT的黑盒防御方法,该方法旨在检测推理过程中的触发样本并停用后门。其背后的核心思想是一种称为“探针串联效应”的观察结果,即通过串联触发样本,能够显著降低后门LLM对恶意探针的拒绝率。因此,BEAT通过测量探针输出分布前后与输入串联后的失真程度来判断输入是否被触发。该方法解决了样本依赖目标带来的挑战,通过捕捉触发因素对拒绝信号的影响(这是样本独立的),而不是样本特定的成功攻击行为。在多种后门攻击和LLMs上的广泛实验验证了其防御的有效性和效率。此外,初步验证BEAT也能有效防御流行的越狱攻击。
Key Takeaways
- 后门不对齐攻击能隐秘危及大型语言模型的安全对齐,并逃避常规安全审计。
- 在大型语言模型即服务的环境中,这种攻击对LLM的应用构成重大威胁。
- BEAT是一种黑盒防御方法,旨在检测推理过程中的触发样本并停用后门。
- BEAT利用探针串联效应,通过测量输出分布的失真程度来判断输入是否被触发。
- BEAT解决了样本依赖目标的挑战,通过捕捉触发因素对拒绝信号的影响。
- 广泛实验证明BEAT在多种后门攻击和LLMs上的有效性和效率。
点此查看论文截图