⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation
Authors:Qijun Gan, Ruizi Yang, Jianke Zhu, Shaofei Xue, Steven Hoi
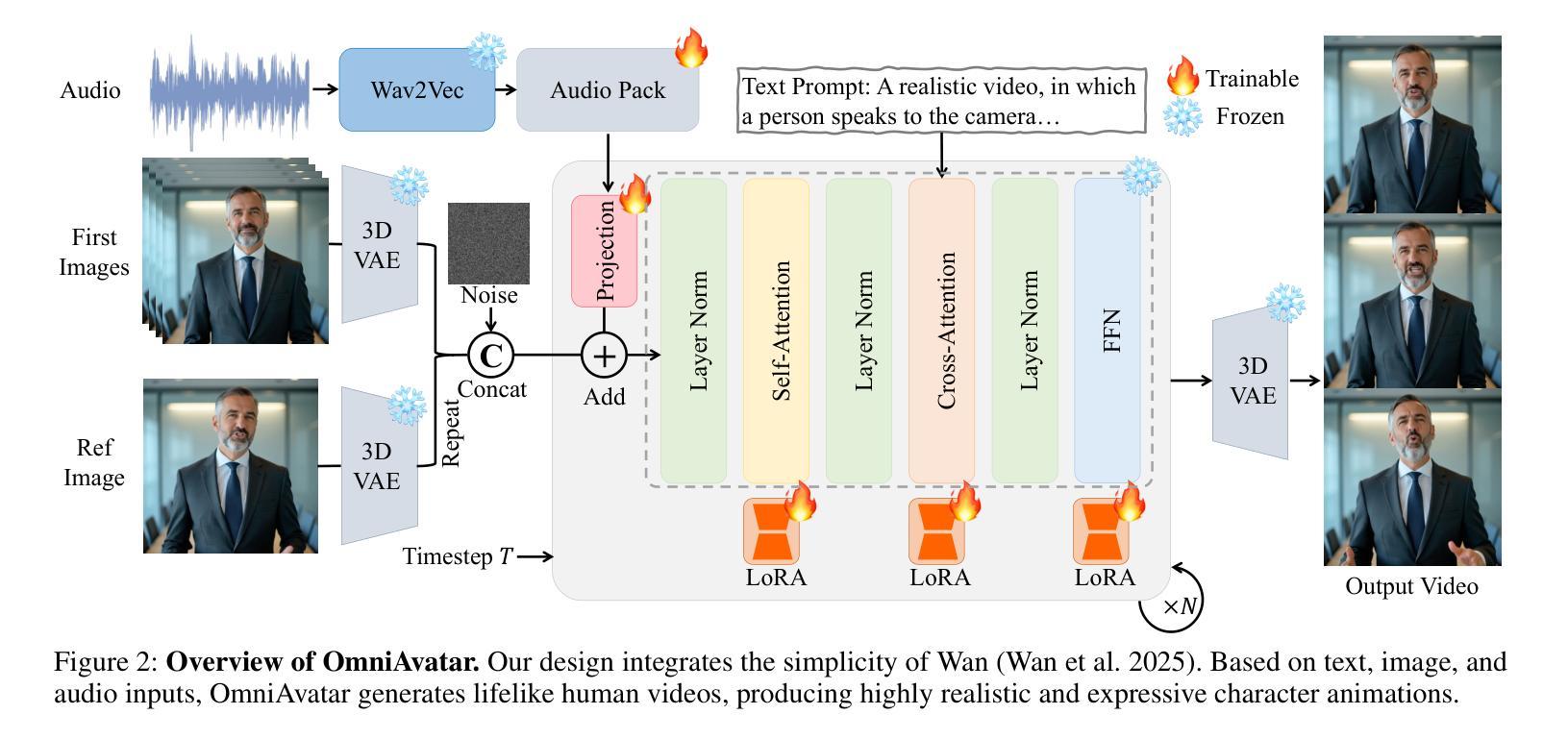
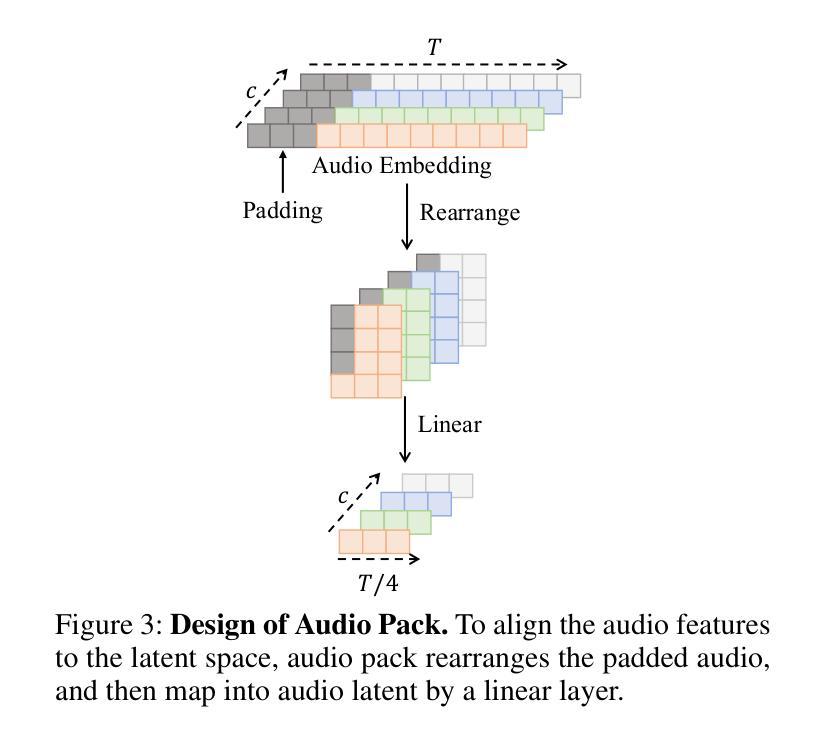
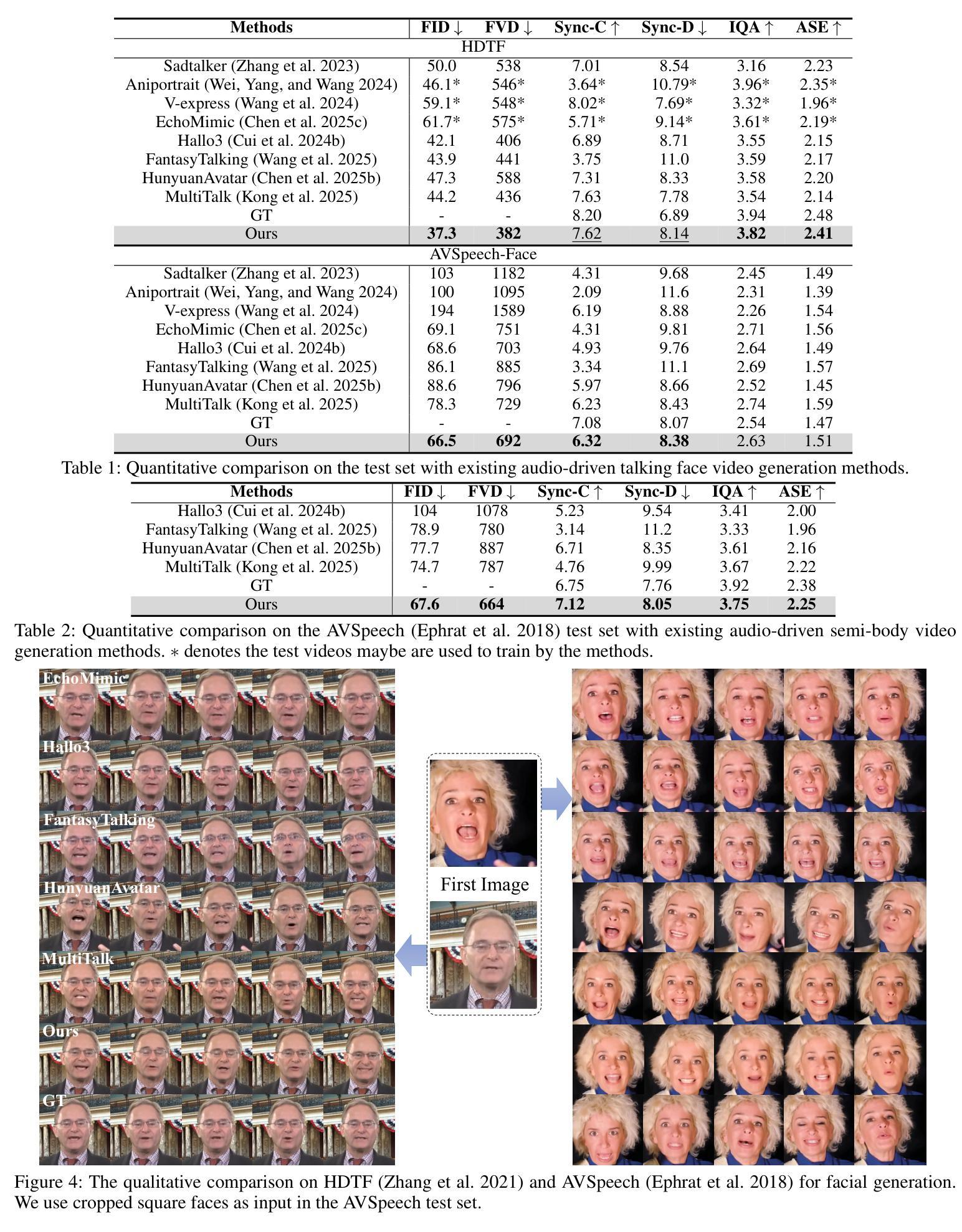
Significant progress has been made in audio-driven human animation, while most existing methods focus mainly on facial movements, limiting their ability to create full-body animations with natural synchronization and fluidity. They also struggle with precise prompt control for fine-grained generation. To tackle these challenges, we introduce OmniAvatar, an innovative audio-driven full-body video generation model that enhances human animation with improved lip-sync accuracy and natural movements. OmniAvatar introduces a pixel-wise multi-hierarchical audio embedding strategy to better capture audio features in the latent space, enhancing lip-syncing across diverse scenes. To preserve the capability for prompt-driven control of foundation models while effectively incorporating audio features, we employ a LoRA-based training approach. Extensive experiments show that OmniAvatar surpasses existing models in both facial and semi-body video generation, offering precise text-based control for creating videos in various domains, such as podcasts, human interactions, dynamic scenes, and singing. Our project page is https://omni-avatar.github.io/.
在音频驱动的人形动画方面已经取得了重大进展,然而大多数现有方法主要集中在面部动作上,这限制了它们创建具有自然同步和流畅度的全身动画的能力。它们在精细粒度的生成精确提示控制方面也面临困难。为了应对这些挑战,我们推出了OmniAvatar,这是一款创新的音频驱动全身视频生成模型,通过提高唇同步精度和自然动作来增强人形动画。OmniAvatar采用像素级多层次音频嵌入策略,以更好地在潜在空间中捕获音频特征,增强不同场景的唇同步。为了保留基础模型的提示驱动控制能力,同时有效地融入音频特征,我们采用了基于LoRA的训练方法。大量实验表明,OmniAvatar在面部和半身视频生成方面都超越了现有模型,为创作视频提供了精确的文本控制功能,适用于多个领域,如播客、人机交互、动态场景和唱歌等。我们的项目页面是https://omni-avatar.github.io/。
论文及项目相关链接
PDF Project page: https://omni-avatar.github.io/
Summary
OmniAvatar是一款创新的音频驱动全身视频生成模型,可改进人脸动画的唇同步精度和自然动作。它采用像素级多层次音频嵌入策略,更好地在潜在空间中捕获音频特征,并在不同场景中提高唇同步。该研究采用LoRA基于训练的方法,在保留基础模型的提示驱动控制能力的同时,有效地融入了音频特征。OmniAvatar在面部和半身视频生成方面超越了现有模型,为不同领域(如播客、人机交互、动态场景和歌唱)的视频创作提供了精确的文字控制。
Key Takeaways
- OmniAvatar是音频驱动的全身视频生成模型,提高了面部动画的唇同步精度和自然动作。
- 该模型采用像素级多层次音频嵌入策略,以在潜在空间中更好地捕获音频特征。
- OmniAvatar在不同场景中都实现了高效的唇同步。
- 研究采用LoRA基于训练的方法,结合音频特征和基础模型的提示驱动控制。
- 该模型在面部和半身视频生成方面超越了现有模型。
- OmniAvatar提供了精确的文字控制,适用于多个领域,如播客、人机交互、动态场景和歌唱。
点此查看论文截图