⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
VQ-Insight: Teaching VLMs for AI-Generated Video Quality Understanding via Progressive Visual Reinforcement Learning
Authors:Xuanyu Zhang, Weiqi Li, Shijie Zhao, Junlin Li, Li Zhang, Jian Zhang
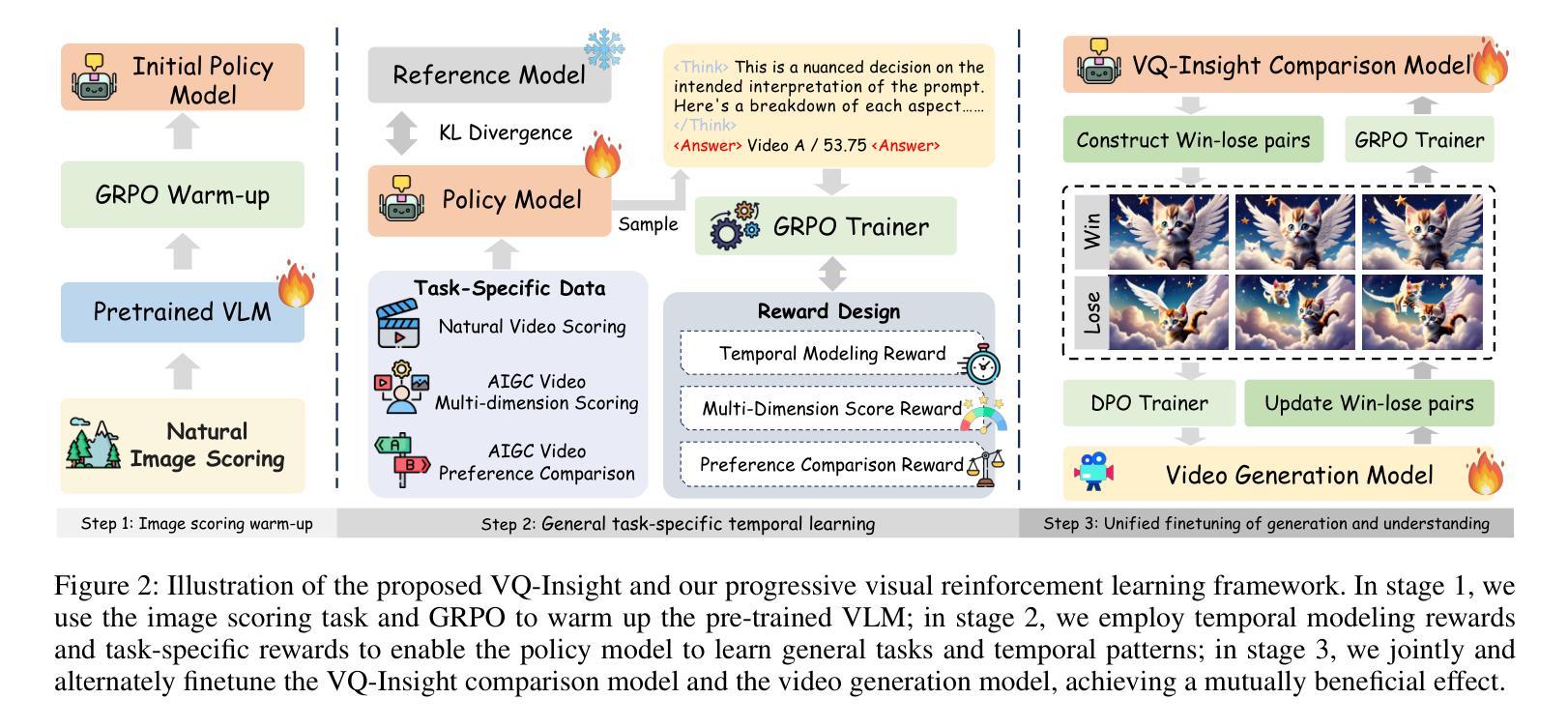
Recent advances in AI-generated content (AIGC) have led to the emergence of powerful text-to-video generation models. Despite these successes, evaluating the quality of AIGC-generated videos remains challenging due to limited generalization, lack of temporal awareness, heavy reliance on large-scale annotated datasets, and the lack of effective interaction with generation models. Most current approaches rely on supervised finetuning of vision-language models (VLMs), which often require large-scale annotated datasets and tend to decouple understanding and generation. To address these shortcomings, we propose VQ-Insight, a novel reasoning-style VLM framework for AIGC video quality assessment. Our approach features: (1) a progressive video quality learning scheme that combines image quality warm-up, general task-specific temporal learning, and joint optimization with the video generation model; (2) the design of multi-dimension scoring rewards, preference comparison rewards, and temporal modeling rewards to enhance both generalization and specialization in video quality evaluation. Extensive experiments demonstrate that VQ-Insight consistently outperforms state-of-the-art baselines in preference comparison, multi-dimension scoring, and natural video scoring, bringing significant improvements for video generation tasks.
近年来,人工智能生成内容(AIGC)的进展推动了强大的文本到视频生成模型的出现。尽管如此,由于有限的泛化能力、缺乏时间意识、对大规模注释数据集的严重依赖以及与生成模型的有效交互的缺乏,评估AIGC生成的视频质量仍然具有挑战性。当前大多数方法依赖于视觉语言模型(VLMs)的监督微调,这通常需要大规模注释数据集,并有解耦理解和生成的倾向。为了解决这些缺点,我们提出了VQ-Insight,这是一个用于AIGC视频质量评估的新型推理风格VLM框架。我们的方法特点包括:(1)一种渐进的视频质量学习方案,结合图像质量的预热、一般任务特定的时间学习和与视频生成模型的联合优化;(2)设计了多维评分奖励、偏好比较奖励和时间建模奖励,以提高视频质量评估中的通用性和专业化。大量实验表明,VQ-Insight在偏好比较、多维评分和自然视频评分方面始终优于最新基线,为视频生成任务带来了显著改进。
论文及项目相关链接
PDF Technical Report
Summary
:针对AI生成视频质量评估的挑战,提出了一种新颖的推理型视觉语言模型框架VQ-Insight。该框架结合图像质量预热、一般任务特定时序学习和与视频生成模型的联合优化,设计了一种渐进的视频质量学习方案。同时,通过多维评分奖励、偏好比较奖励和时序建模奖励,提高视频质量评估的通用性和专业性。实验证明,VQ-Insight在偏好比较、多维评分和自然视频评分方面均优于最新基线,为视频生成任务带来了显著改善。
Key Takeaways
- AI生成视频内容(AIGC)近年来取得进展,出现强大的文本到视频生成模型。
- AIGC生成视频的质量评估存在挑战,如有限泛化能力、缺乏时间意识、对大规模标注数据集的依赖以及与生成模型的交互不足。
- VQ-Insight是一种新颖的推理型视觉语言模型框架,旨在解决AIGC视频质量评估的问题。
- VQ-Insight采用渐进的视频质量学习方案,包括图像质量预热、一般任务特定时序学习和与视频生成模型的联合优化。
- VQ-Insight设计了多维评分奖励、偏好比较奖励和时序建模奖励,以提高视频质量评估的通用性和专业性。
- 实验证明,VQ-Insight在多个评估指标上优于现有方法。
点此查看论文截图



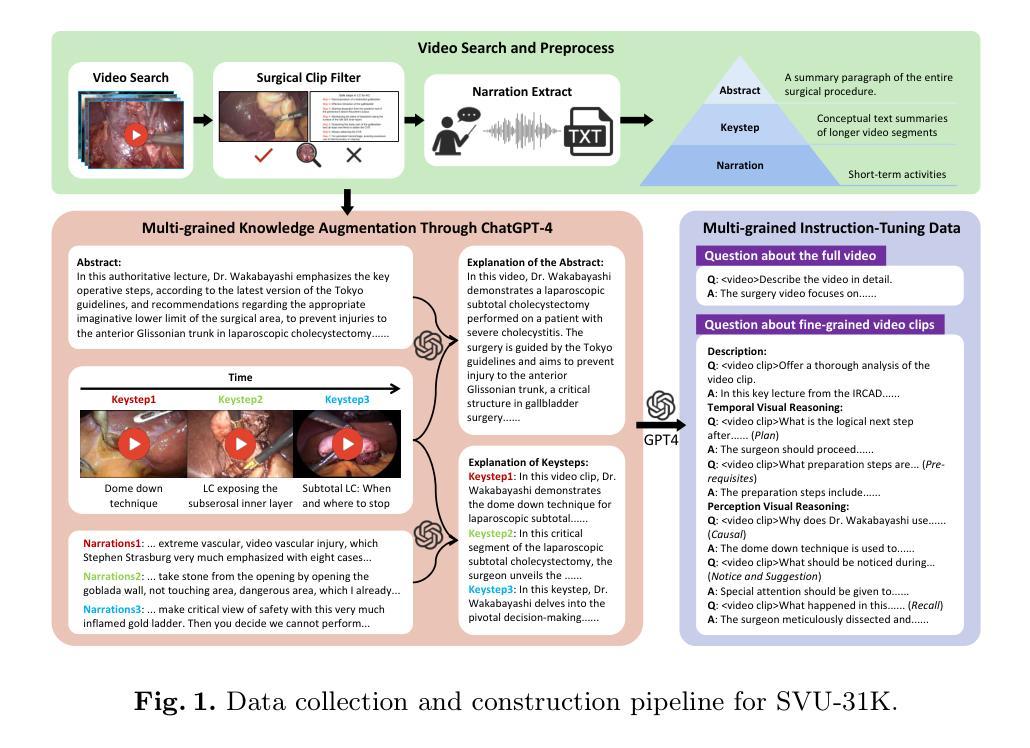
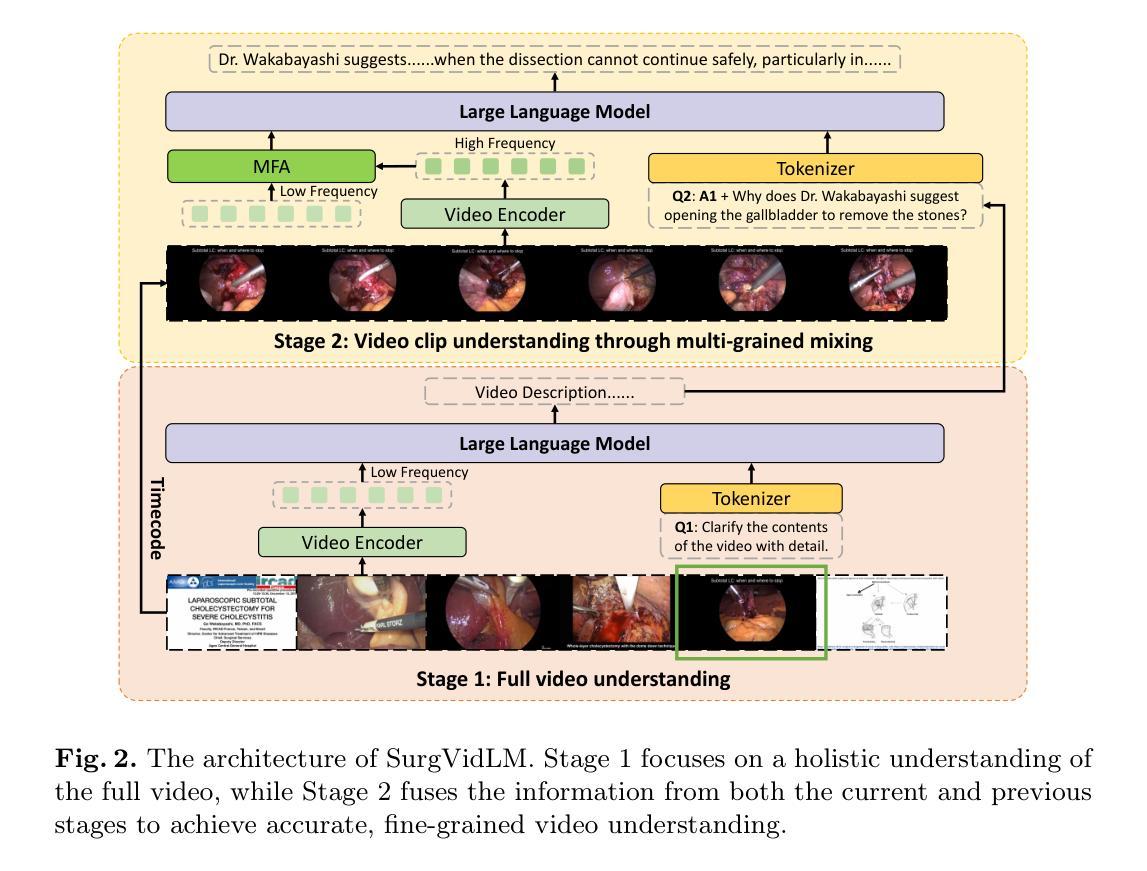
SurgVidLM: Towards Multi-grained Surgical Video Understanding with Large Language Model
Authors:Guankun Wang, Wenjin Mo, Junyi Wang, Long Bai, Kun Yuan, Ming Hu, Jinlin Wu, Junjun He, Yiming Huang, Nicolas Padoy, Zhen Lei, Hongbin Liu, Nassir Navab, Hongliang Ren
Recent advances in Multimodal Large Language Models have demonstrated great potential in the medical domain, facilitating users to understand surgical scenes and procedures. Beyond image-based methods, the exploration of Video Large Language Models (Vid-LLMs) has emerged as a promising avenue for capturing the complex sequences of information involved in surgery. However, there is still a lack of Vid-LLMs specialized for fine-grained surgical video understanding tasks, which is crucial for analyzing specific processes or details within a surgical procedure. To bridge this gap, we propose SurgVidLM, the first video language model designed to address both full and fine-grained surgical video comprehension. To train our SurgVidLM, we construct the SVU-31K dataset which consists of over 31K video-instruction pairs, enabling both holistic understanding and detailed analysis of surgical procedures. Furthermore, we introduce the StageFocus mechanism which is a two-stage framework performing the multi-grained, progressive understanding of surgical videos. We also develop the Multi-frequency Fusion Attention to effectively integrate low and high-frequency visual tokens, ensuring the retention of critical information. Experimental results demonstrate that SurgVidLM significantly outperforms state-of-the-art Vid-LLMs in both full and fine-grained video understanding tasks, showcasing its superior capability in capturing complex procedural contexts.
近期多模态大型语言模型(Multimodal Large Language Models)在医疗领域的应用进展展示出了巨大潜力,能够辅助用户理解手术场景和流程。除了基于图像的方法,视频大型语言模型(Video Large Language Models,Vid-LLMs)的探索为捕捉手术的复杂信息序列提供了有前景的途径。然而,仍然存在缺乏针对精细粒度手术视频理解任务的Vid-LLMs,这对于分析手术流程中的特定过程或细节至关重要。为了弥补这一差距,我们提出了SurgVidLM,这是首个旨在同时处理全视频和精细粒度手术视频理解的视频语言模型。为了训练我们的SurgVidLM,我们构建了SVU-31K数据集,包含超过31K个视频指令对,以实现手术流程的整体理解和详细分析。此外,我们引入了StageFocus机制,这是一个两阶段框架,进行手术视频的多种粒度渐进理解。我们还开发了多频率融合注意力(Multi-frequency Fusion Attention),以有效地整合低频和高频视觉令牌,确保关键信息的保留。实验结果表明,SurgVidLM在全视频和精细粒度视频理解任务上均显著优于最新Vid-LLMs,展现了其在捕捉复杂流程上下文方面的卓越能力。
论文及项目相关链接
Summary
多模态大型语言模型在医疗领域具有巨大潜力,能协助用户理解手术场景和流程。为弥补针对精细手术视频理解任务的视频语言模型的缺失,提出SurgVidLM,并构建SVU-31K数据集进行训练。引入StageFocus机制和多频率融合注意力,实现手术视频的多粒度渐进理解,并在全视频和精细理解任务中表现优异。
Key Takeaways
- 多模态大型语言模型在医疗领域的潜力巨大,能够协助用户理解手术场景和流程。
- 目前缺乏针对精细手术视频理解任务的视频语言模型。
- SurgVidLM是首个针对全和精细手术视频理解设计的视频语言模型。
- SVU-31K数据集用于训练SurgVidLM,包含超过31K的视频指令对。
- StageFocus机制实现手术视频的多粒度、渐进理解。
- 多频率融合注意力能有效整合低高频视觉标记,确保关键信息保留。
点此查看论文截图