⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
Enhancing Image Restoration Transformer via Adaptive Translation Equivariance
Authors:JiaKui Hu, Zhengjian Yao, Lujia Jin, Hangzhou He, Yanye Lu
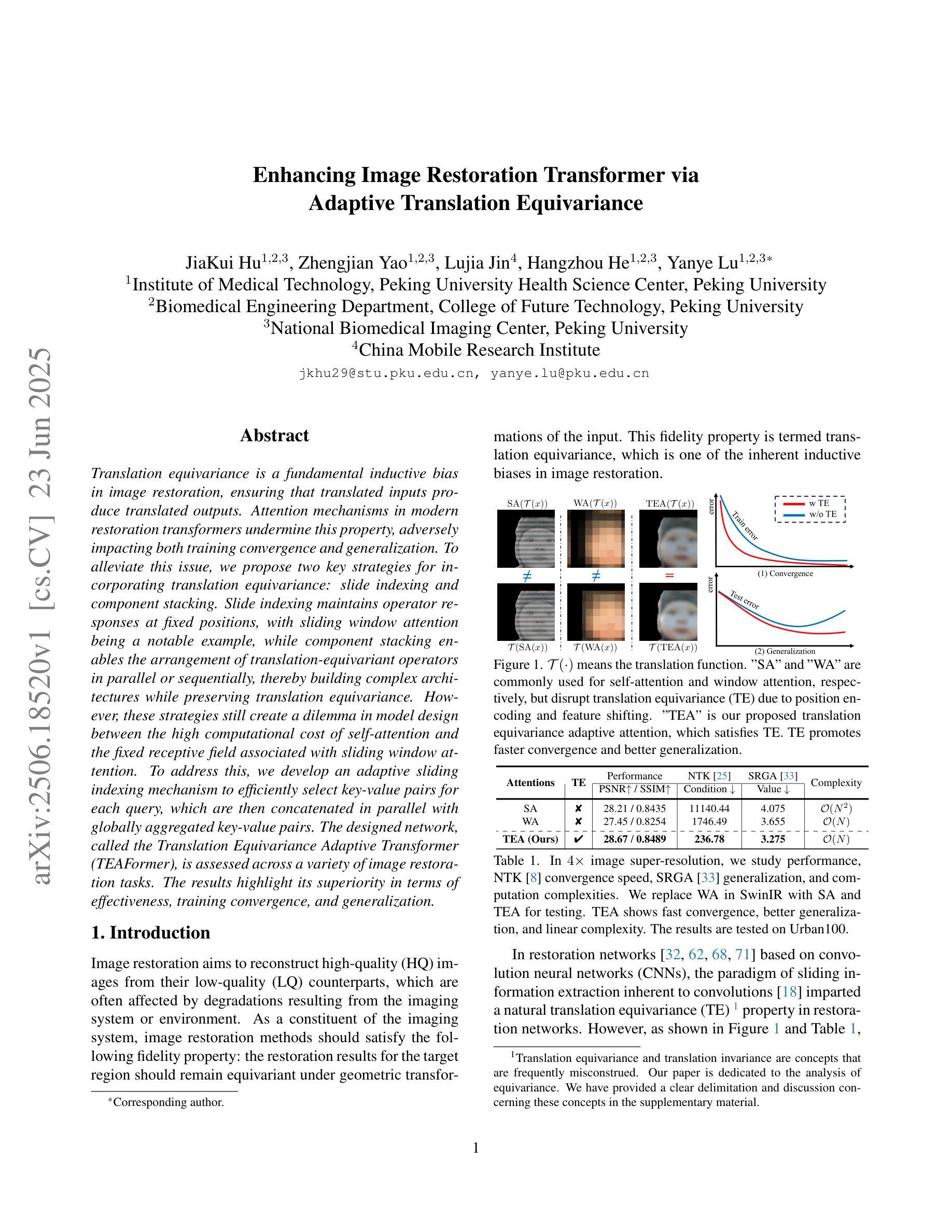
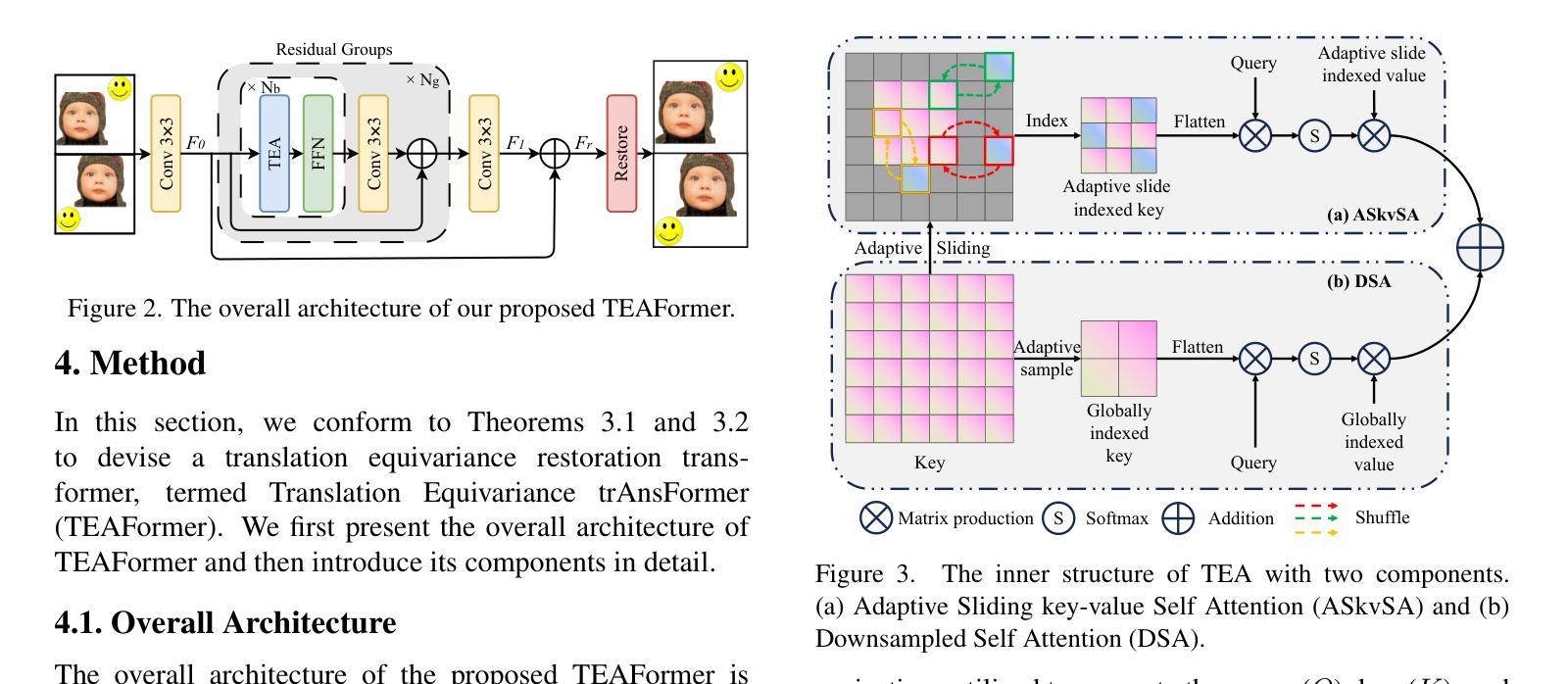
Translation equivariance is a fundamental inductive bias in image restoration, ensuring that translated inputs produce translated outputs. Attention mechanisms in modern restoration transformers undermine this property, adversely impacting both training convergence and generalization. To alleviate this issue, we propose two key strategies for incorporating translation equivariance: slide indexing and component stacking. Slide indexing maintains operator responses at fixed positions, with sliding window attention being a notable example, while component stacking enables the arrangement of translation-equivariant operators in parallel or sequentially, thereby building complex architectures while preserving translation equivariance. However, these strategies still create a dilemma in model design between the high computational cost of self-attention and the fixed receptive field associated with sliding window attention. To address this, we develop an adaptive sliding indexing mechanism to efficiently select key-value pairs for each query, which are then concatenated in parallel with globally aggregated key-value pairs. The designed network, called the Translation Equivariance Adaptive Transformer (TEAFormer), is assessed across a variety of image restoration tasks. The results highlight its superiority in terms of effectiveness, training convergence, and generalization.
翻译等价性是图像修复中的一个基本归纳偏见,确保翻译后的输入产生翻译后的输出。现代修复变压器中的注意力机制破坏了这一属性,对训练收敛和泛化产生不利影响。为了缓解这个问题,我们提出了两种融入翻译等价性的关键策略:滑动索引和组件堆叠。滑动索引在固定位置保持操作员响应,滑动窗口注意力是一个明显的例子,而组件堆叠能够并行或顺序地安排翻译等价操作符,从而构建复杂的架构,同时保留翻译等价性。然而,这些策略在自注意力的高计算成本与滑动窗口注意力相关的固定感受野之间造成了模型设计的困境。为了解决这一问题,我们开发了一种自适应滑动索引机制,以有效地选择每个查询的关键值对,然后将它们与全局聚合的关键值对并行拼接。所设计的网络称为翻译等价性自适应变压器(TEAFormer),它在各种图像修复任务中进行了评估。结果突出了其在效果、训练收敛和泛化方面的优越性。
论文及项目相关链接
Summary
翻译等距性是图像恢复中的一个基本归纳偏见,保证翻译后的输入产生翻译后的输出。现代恢复变压器的注意力机制会破坏这一属性,对训练收敛和泛化产生不利影响。为缓解这一问题,我们提出了纳入翻译等距性的两个关键策略:滑动索引和组件堆叠。滑动索引保持操作员响应在固定位置,滑动窗口注意力是一个显著例子;组件堆叠允许以并行或顺序的方式安排翻译等距操作器,从而构建复杂的架构同时保留翻译等距性。然而,这些策略在模型设计中仍面临自我注意力高计算成本与滑动窗口注意力固定感受野之间的两难问题。为解决这一问题,我们开发了一种自适应滑动索引机制,以有效地选择每个查询的关键值对,然后将其与全局聚合的关键值对并行连接。所设计的网络称为翻译等距性自适应变压器(TEAFormer),在多种图像恢复任务中进行了评估。结果证明了其在有效性、训练收敛和泛化方面的优越性。
Key Takeaways
- 翻译等距性是图像恢复中的基本归纳偏见,对翻译后的输入有相应的翻译后的输出。
- 注意力机制可能影响翻译等距性,进而影响训练收敛和模型泛化。
- 为保留翻译等距性,提出了滑动索引和组件堆叠两个策略。
- 滑动索引通过固定操作员响应位置维持等距性,而组件堆叠允许复杂架构的构建同时保留等距性。
- 面临自我注意力高计算成本与滑动窗口感受野的固定性之间的挑战。
- 为解决此挑战,发展了自适应滑动索引机制。
点此查看论文截图
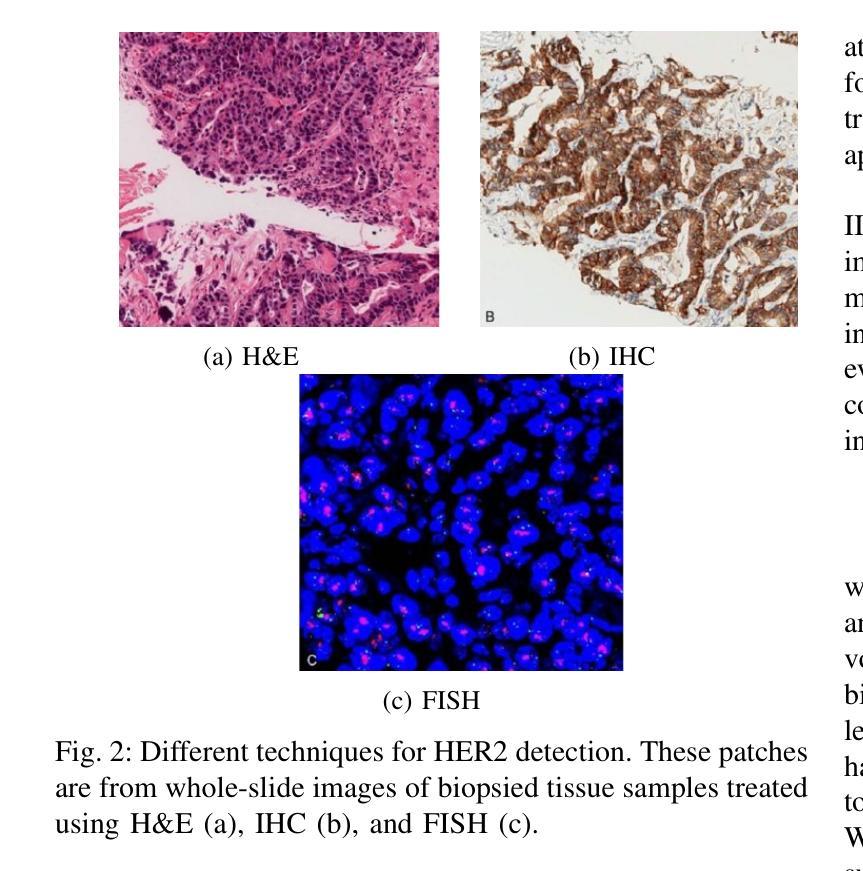
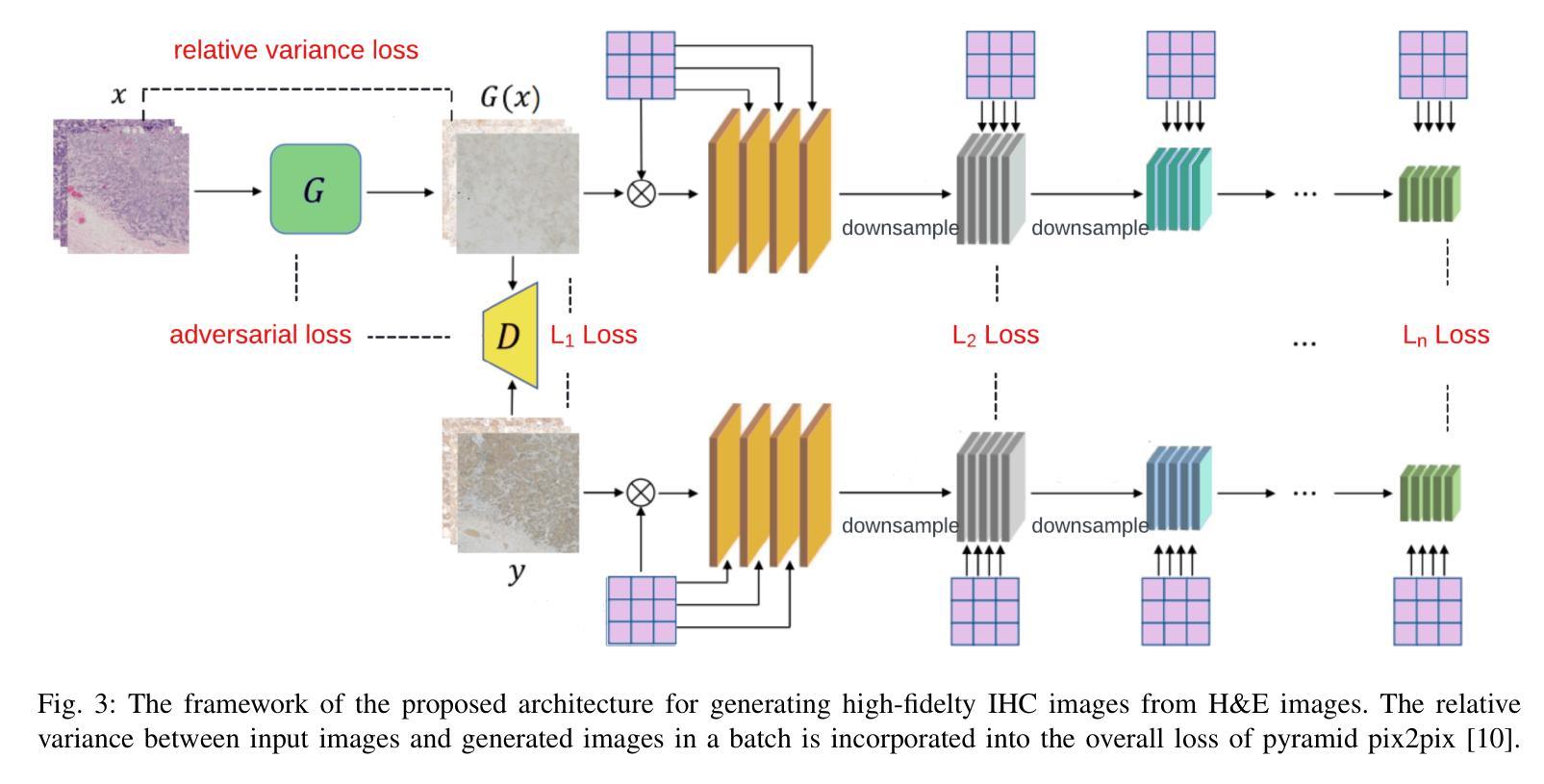
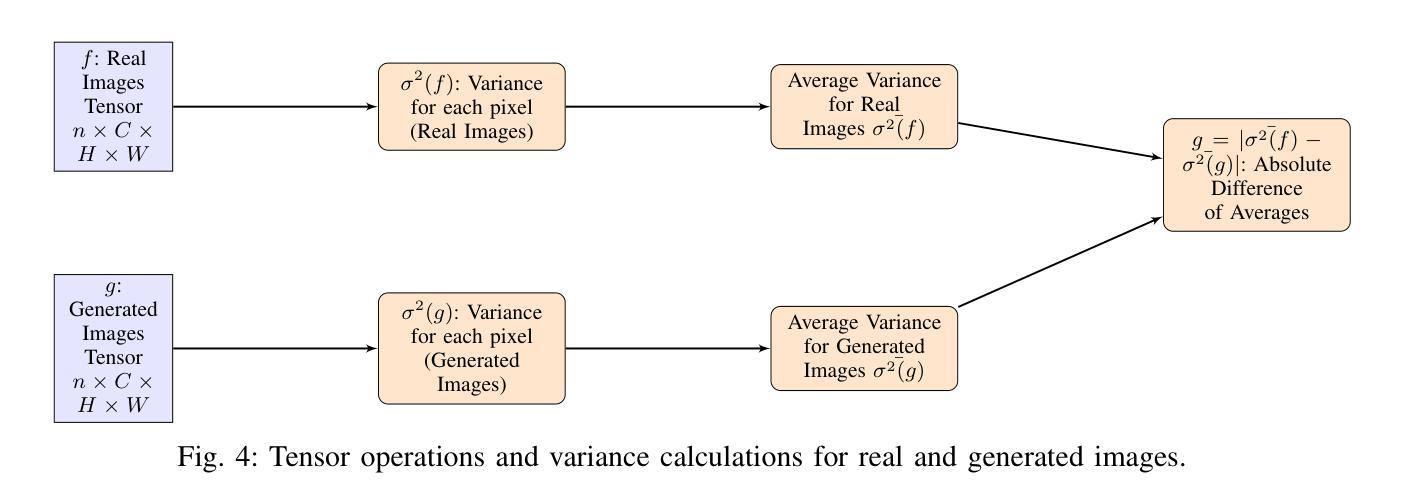
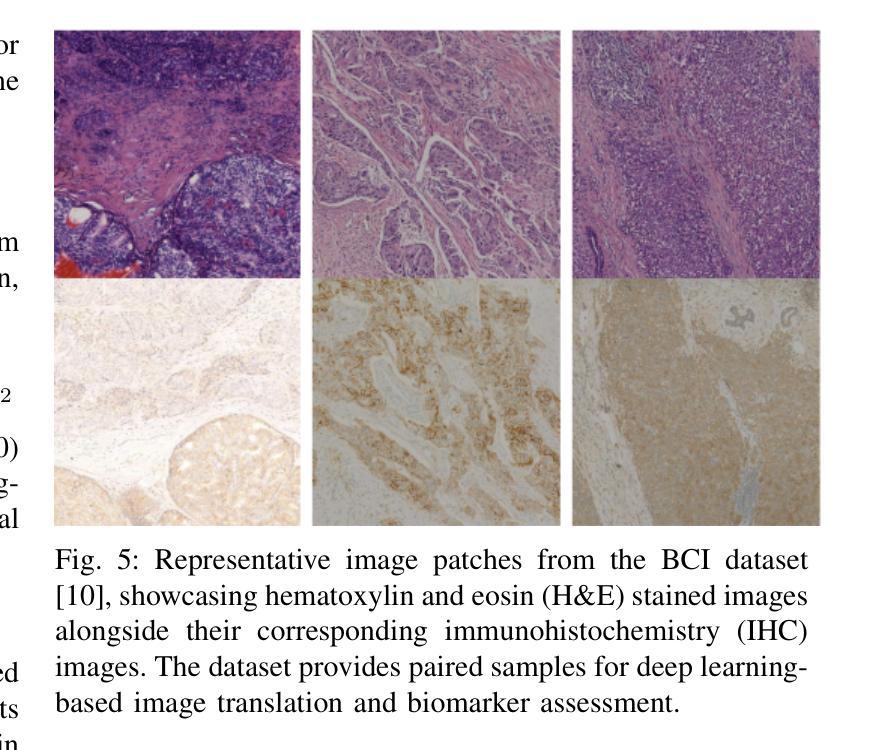
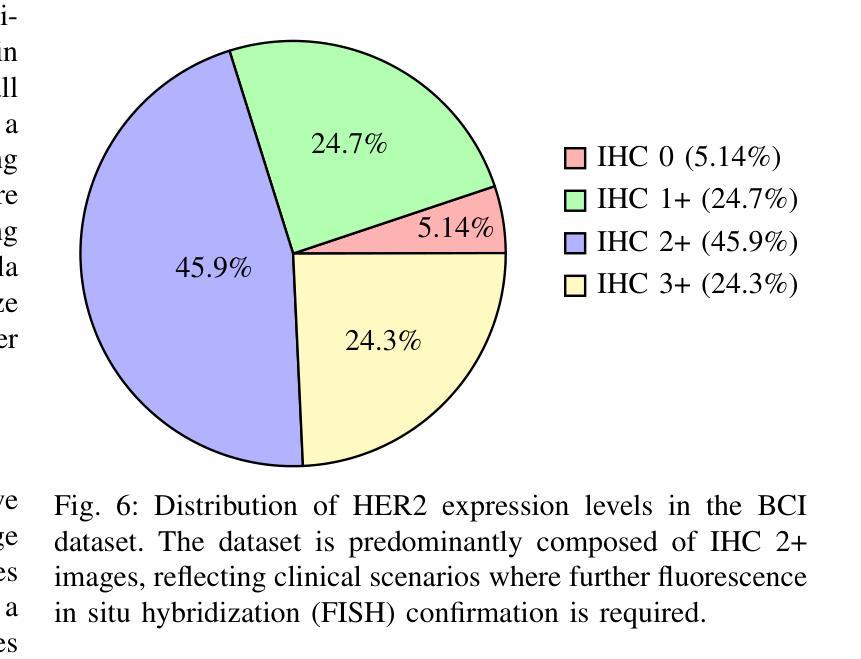
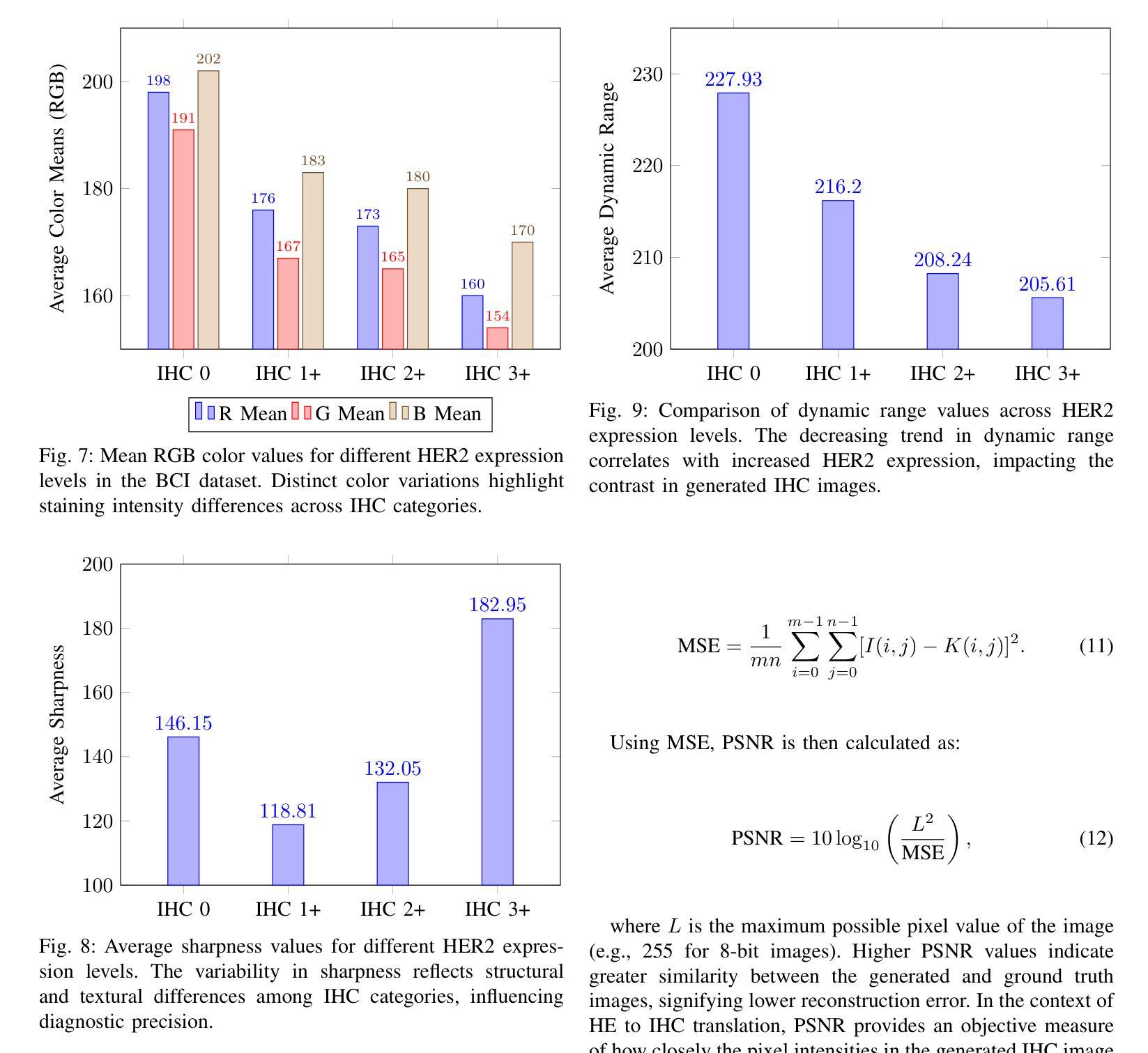
Transforming H&E images into IHC: A Variance-Penalized GAN for Precision Oncology
Authors:Sara Rehmat, Hafeez Ur Rehman
The overexpression of the human epidermal growth factor receptor 2 (HER2) in breast cells is a key driver of HER2-positive breast cancer, a highly aggressive subtype requiring precise diagnosis and targeted therapy. Immunohistochemistry (IHC) is the standard technique for HER2 assessment but is costly, labor-intensive, and highly dependent on antibody selection. In contrast, hematoxylin and eosin (H&E) staining, a routine histopathological procedure, offers broader accessibility but lacks HER2 specificity. This study proposes an advanced deep learning-based image translation framework to generate highfidelity IHC images from H&E-stained tissue samples, enabling cost-effective and scalable HER2 assessment. By modifying the loss function of pyramid pix2pix, we mitigate mode collapse, a fundamental limitation in generative adversarial networks (GANs), and introduce a novel variance-based penalty that enforces structural diversity in generated images. Our model particularly excels in translating HER2-positive (IHC 3+) images, which have remained challenging for existing methods due to their complex morphological variations. Extensive evaluations on the BCI histopathological dataset demonstrate that our model surpasses state-of-the-art methods in terms of peak signal-tonoise ratio (PSNR), structural similarity index (SSIM), and Frechet Inception Distance (FID), particularly in accurately translating HER2-positive (IHC 3+) images. Beyond medical imaging, our model exhibits superior performance in general image-to-image translation tasks, showcasing its potential across multiple domains. This work marks a significant step toward AI-driven precision oncology, offering a reliable and efficient alternative to traditional HER2 diagnostics.
人类表皮生长因子受体2(HER2)在乳腺细胞中的过度表达是HER2阳性乳腺癌的重要驱动因素,这是一种高度侵袭性的亚型,需要精确诊断和针对性治疗。免疫组织化学(IHC)是评估HER2的标准技术,但成本高昂、劳动强度大,且高度依赖于抗体选择。相比之下,苏木精和伊红(H&E)染色是一种常规的病理程序,普及性更广,但缺乏HER2特异性。本研究提出了一种先进的基于深度学习的图像翻译框架,能够从H&E染色组织样本生成高保真IHC图像,从而实现经济高效且可扩展的HER2评估。通过修改金字塔pix2pix的损失函数,我们缓解了模式崩溃问题,这是生成对抗网络(GANs)的一个基本限制,并引入了一种基于方差的新型惩罚措施,以强制生成图像中的结构多样性。我们的模型在翻译HER2阳性(IHC 3+)图像方面表现出色,由于复杂的形态变化,这些图像对现有的方法来说一直具有挑战性。在BCI病理数据集上的广泛评估表明,我们的模型在峰值信噪比(PSNR)、结构相似性指数(SSIM)和弗雷歇特入口距离(FID)等方面超越了最先进的方法,特别是在准确翻译HER2阳性(IHC 3+)图像方面。除了医学成像外,我们的模型在一般的图像到图像翻译任务中也表现出卓越的性能,展示了其在多个领域的潜力。这项工作标志着人工智能驱动的精准肿瘤学的一个重要步骤,为传统的HER2诊断提供了可靠和高效的替代方案。
论文及项目相关链接
Summary:本研究利用深度学习图像翻译技术,提出一种从H&E染色组织样本生成高保真IHC图像的方法,以进行HER2评估。通过改进pyramid pix2pix的损失函数,该方法克服了生成对抗网络(GANs)的基本局限性——模式崩溃,并引入基于方差的新罚项,以加强生成图像的结构多样性。该方法在BCI病理数据集上的评估表明,它在峰值信号噪声比(PSNR)、结构相似性指数(SSIM)和Frechet Inception Distance(FID)等方面超越了现有方法,特别是在翻译HER2阳性(IHC 3+)图像方面。此外,该模型在通用图像翻译任务中也表现出卓越性能,展现了其在多个领域的应用潜力,为AI驱动的精准肿瘤学提供了可靠而高效的替代方案。
Key Takeaways:
- HER2阳性乳腺癌是一种高度侵袭性的癌症,其诊断需要精确和有针对性的疗法。
- 免疫组化(IHC)是评估HER2的标准技术,但成本高昂且依赖抗体选择。
- 常规病理染色方法(如H&E染色)虽然更普遍但缺乏特异性。
- 本研究提出了一种基于深度学习的图像翻译框架,能够从H&E染色样本生成高保真IHC图像,为成本效益高且可伸缩的HER2评估提供了可能。
- 研究通过改进损失函数克服了模式崩溃问题并引入了新罚项以增强图像结构多样性。
- 该模型在BCI病理数据集上的表现优于其他现有方法,特别是在翻译HER2阳性(IHC 3+)图像方面。
点此查看论文截图

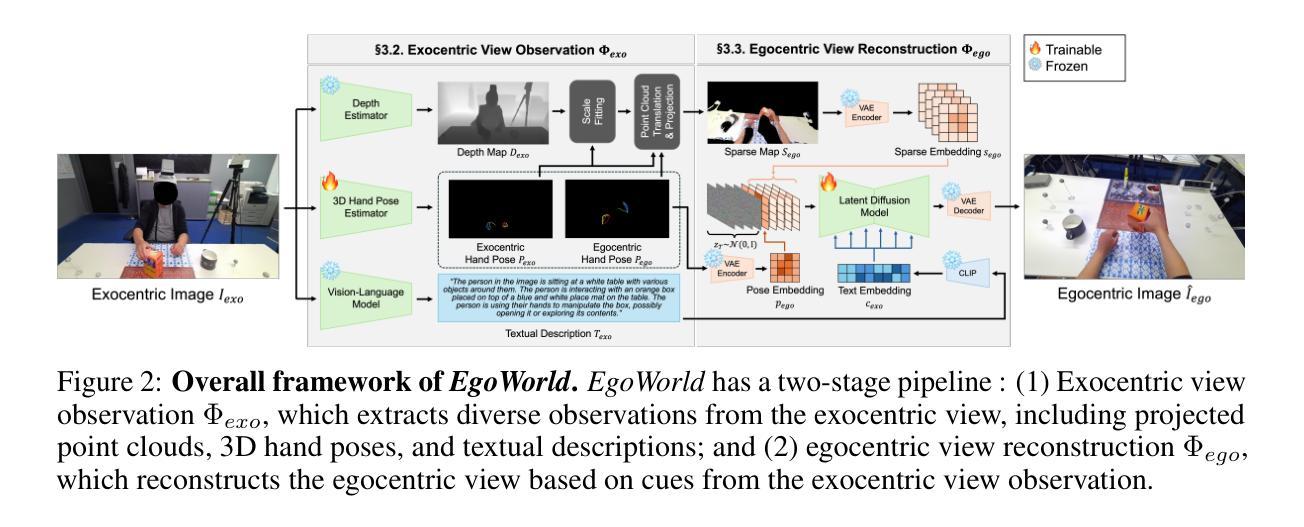
EgoWorld: Translating Exocentric View to Egocentric View using Rich Exocentric Observations
Authors:Junho Park, Andrew Sangwoo Ye, Taein Kwon
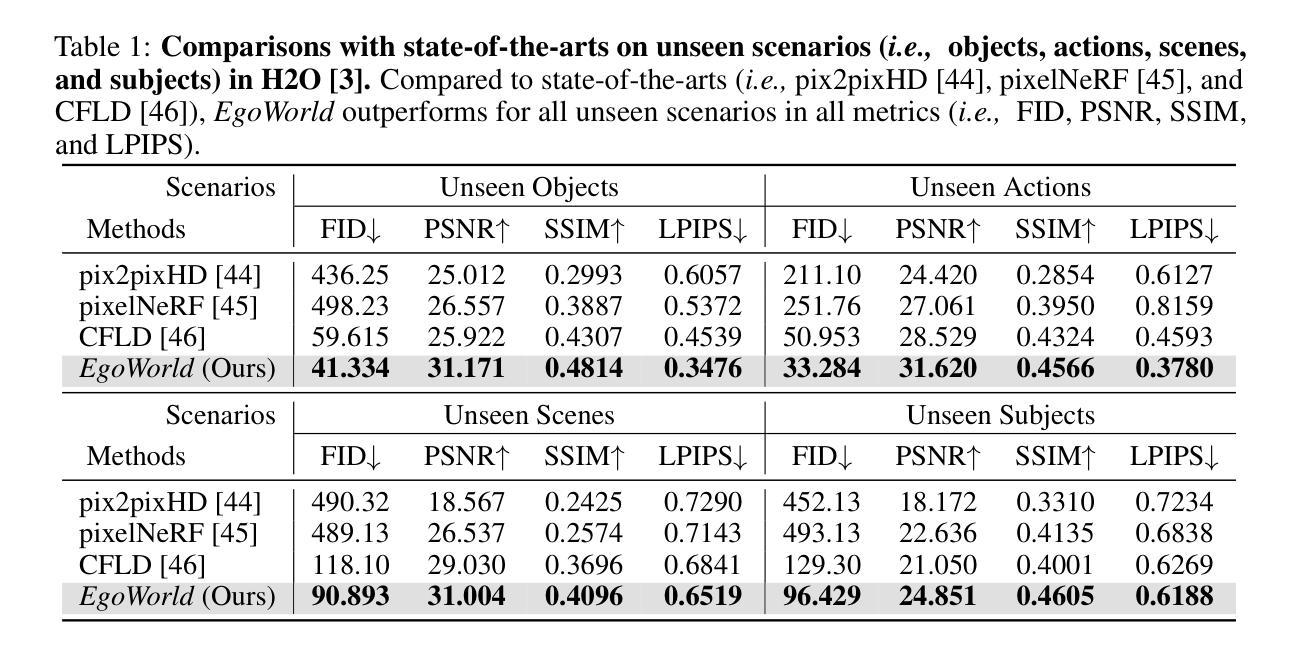
Egocentric vision is essential for both human and machine visual understanding, particularly in capturing the detailed hand-object interactions needed for manipulation tasks. Translating third-person views into first-person views significantly benefits augmented reality (AR), virtual reality (VR) and robotics applications. However, current exocentric-to-egocentric translation methods are limited by their dependence on 2D cues, synchronized multi-view settings, and unrealistic assumptions such as necessity of initial egocentric frame and relative camera poses during inference. To overcome these challenges, we introduce EgoWorld, a novel two-stage framework that reconstructs an egocentric view from rich exocentric observations, including projected point clouds, 3D hand poses, and textual descriptions. Our approach reconstructs a point cloud from estimated exocentric depth maps, reprojects it into the egocentric perspective, and then applies diffusion-based inpainting to produce dense, semantically coherent egocentric images. Evaluated on the H2O and TACO datasets, EgoWorld achieves state-of-the-art performance and demonstrates robust generalization to new objects, actions, scenes, and subjects. Moreover, EgoWorld shows promising results even on unlabeled real-world examples.
自我中心的视觉对于人类和机器的视觉理解都是至关重要的,特别是在捕捉用于操作任务的详细手-对象交互方面。将第三人称视角转化为第一人称视角对于增强现实(AR)、虚拟现实(VR)和机器人应用具有重大益处。然而,当前的以他人为中心的自我中心翻译方法受到二维线索、同步多视角设置和不切实际的假设(如在推理过程中需要初始的自我中心框架和相对相机姿态)的限制。为了克服这些挑战,我们引入了EgoWorld,这是一个新的两阶段框架,它从丰富的以他人为中心的观测中重建自我中心视角,包括投影点云、三维手势和文本描述。我们的方法从估计的以他人为中心的深度地图重建点云,将其重新投影到自我中心的视角,然后应用基于扩散的补全技术来产生密集、语义连贯的自我中心图像。在H2O和TACO数据集上的评估表明,EgoWorld达到了最先进的性能,并显示出对新对象、动作、场景和主题的稳健泛化能力。此外,即使在未标记的真实世界示例上,EgoWorld也显示出有希望的结果。
论文及项目相关链接
PDF Project Page: https://redorangeyellowy.github.io/EgoWorld/
Summary
该文本介绍了视觉理解中自我中心视觉的重要性,特别是在捕捉手-物体交互的详细信息以完成操作任务方面。将第三人称视角转化为第一人称视角对增强现实(AR)、虚拟现实(VR)和机器人应用具有重大益处。然而,现有的外向中心到内向中心的翻译方法受限于二维线索、同步多视角设置和不切实际的假设。为了克服这些挑战,引入了EgoWorld这一新型两阶段框架,从丰富的外向中心观察中重建内向中心视角,包括投影点云、三维手势和文本描述。该框架通过估计的外向中心深度图重建点云,将其重新投影到内向中心视角,然后应用基于扩散的补全技术,生成密集、语义连贯的内向中心图像。在H2O和TACO数据集上的评估表明,EgoWorld达到了最新技术水平,并在新对象、动作、场景和主题上表现出了稳健的泛化能力。此外,即使在没有标签的真实世界示例上,EgoWorld也显示出令人鼓舞的结果。
Key Takeaways
- 自我中心视觉对于人类和机器的视觉理解至关重要,特别是在捕捉手-物体交互的详细信息的操作任务中。
- 将第三人称视角转化为第一人称视角在AR、VR和机器人应用中具有益处。
- 当前的外向中心到内向中心的翻译方法存在局限性,如依赖二维线索、同步多视角设置和不切实际的假设。
- EgoWorld是一个新型的两阶段框架,能够从丰富的外向中心观察中重建内向中心视角。
- EgoWorld利用估计的外向中心深度图重建点云,并将其重新投影到内向中心视角。
- 通过扩散补全技术,EgoWorld能够生成密集、语义连贯的内向中心图像。
点此查看论文截图

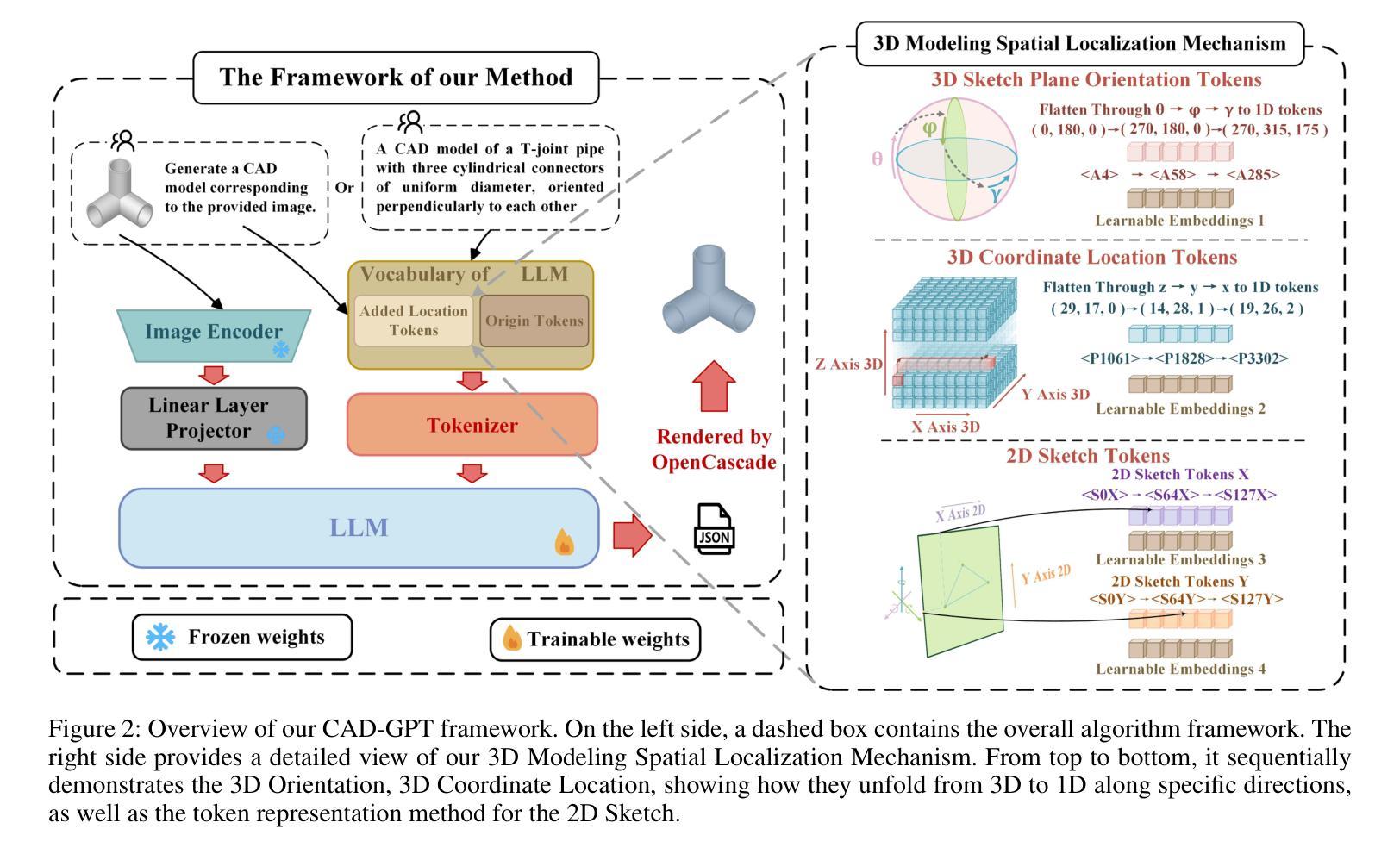
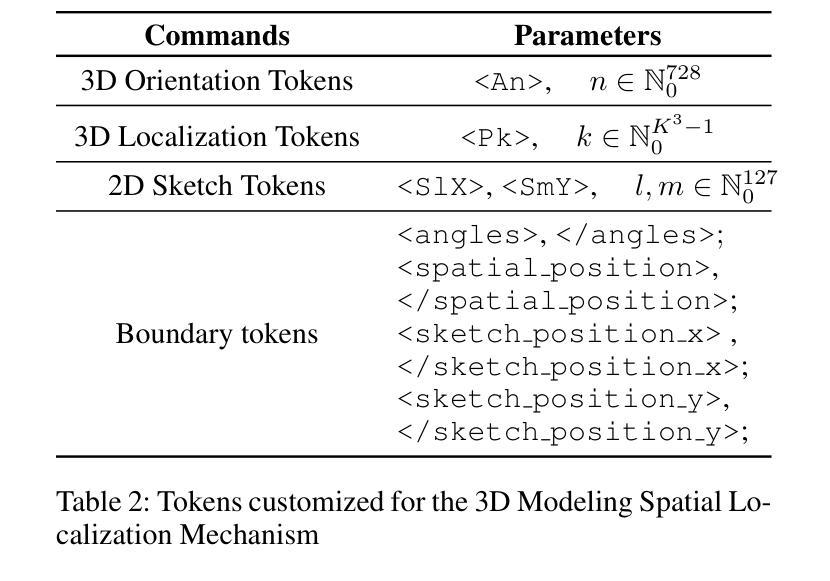
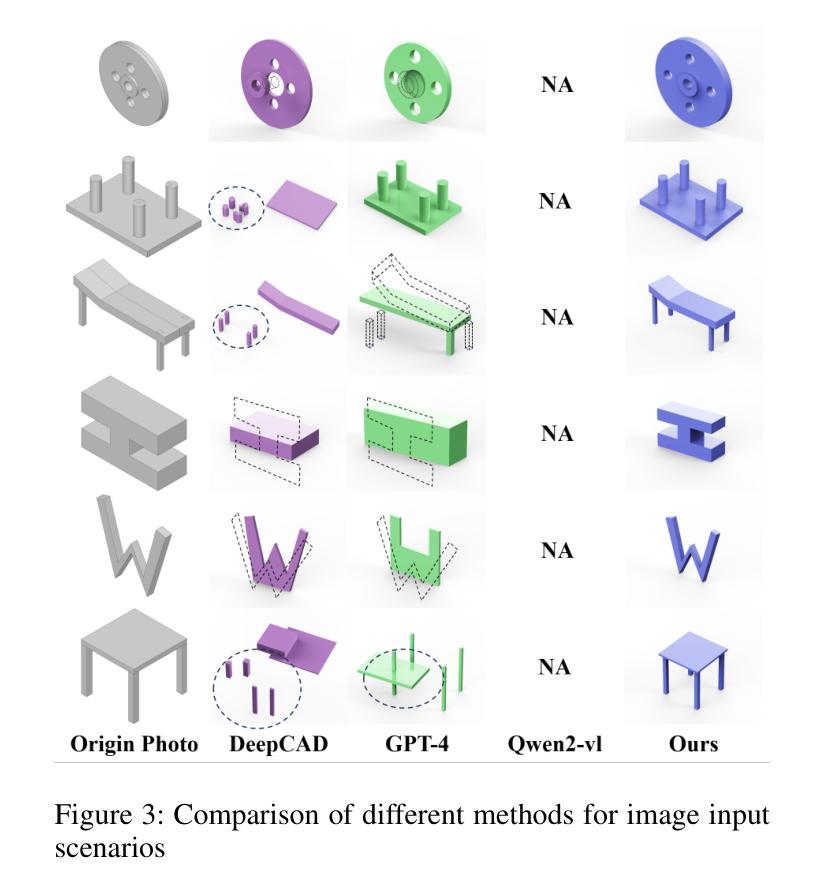
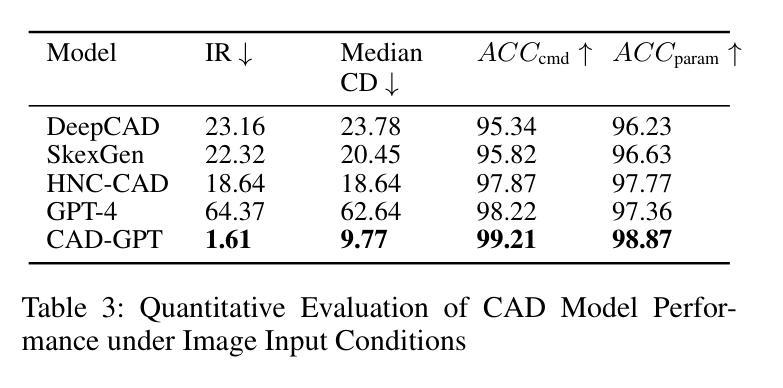
CAD-GPT: Synthesising CAD Construction Sequence with Spatial Reasoning-Enhanced Multimodal LLMs
Authors:Siyu Wang, Cailian Chen, Xinyi Le, Qimin Xu, Lei Xu, Yanzhou Zhang, Jie Yang
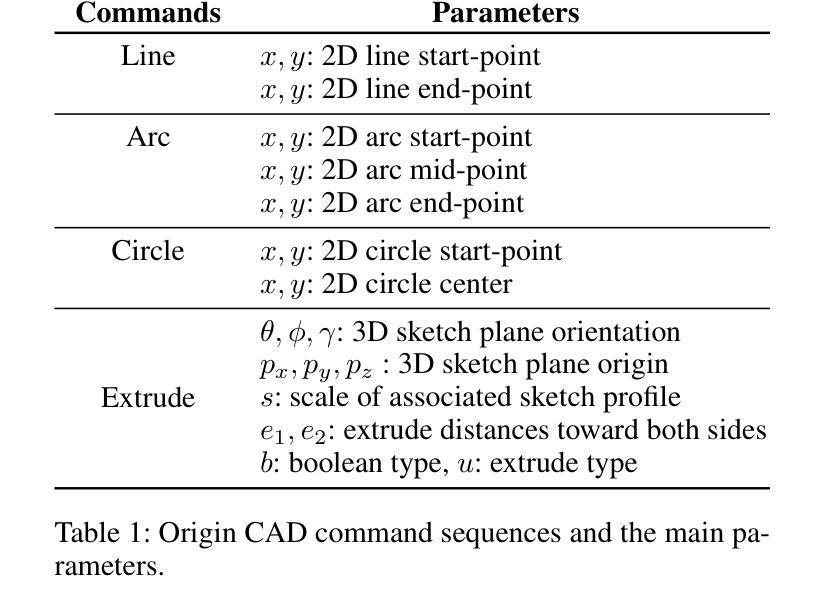
Computer-aided design (CAD) significantly enhances the efficiency, accuracy, and innovation of design processes by enabling precise 2D and 3D modeling, extensive analysis, and optimization. Existing methods for creating CAD models rely on latent vectors or point clouds, which are difficult to obtain, and storage costs are substantial. Recent advances in Multimodal Large Language Models (MLLMs) have inspired researchers to use natural language instructions and images for CAD model construction. However, these models still struggle with inferring accurate 3D spatial location and orientation, leading to inaccuracies in determining the spatial 3D starting points and extrusion directions for constructing geometries. This work introduces CAD-GPT, a CAD synthesis method with spatial reasoning-enhanced MLLM that takes either a single image or a textual description as input. To achieve precise spatial inference, our approach introduces a 3D Modeling Spatial Mechanism. This method maps 3D spatial positions and 3D sketch plane rotation angles into a 1D linguistic feature space using a specialized spatial unfolding mechanism, while discretizing 2D sketch coordinates into an appropriate planar space to enable precise determination of spatial starting position, sketch orientation, and 2D sketch coordinate translations. Extensive experiments demonstrate that CAD-GPT consistently outperforms existing state-of-the-art methods in CAD model synthesis, both quantitatively and qualitatively.
计算机辅助设计(CAD)通过实现精确的2D和3D建模、全面的分析和优化,显著提高了设计过程的效率、准确性和创新性。现有的创建CAD模型的方法依赖于潜在向量或点云,这些难以获得,且存储成本高昂。最近多模态大型语言模型(MLLM)的进步激发了研究人员使用自然语言指令和图像进行CAD模型构建。然而,这些模型在推断准确的3D空间位置和方向时仍面临困难,导致在确定构建几何体的空间3D起点和挤压方向时出现不准确。本研究介绍了CAD-GPT,这是一种带有空间推理增强型MLLM的CAD合成方法,它接受单张图像或文本描述作为输入。为了实现精确的空间推理,我们的方法引入了一种3D建模空间机制。该方法使用专门的空间展开机制将3D空间位置和3D草图平面旋转角度映射到1D语言特征空间,同时将2D草图坐标离散化到适当的平面空间,以实现空间起始位置、草图方向和2D草图坐标翻译的精确确定。大量实验表明,无论是在数量上还是在质量上,CAD-GPT在CAD模型合成方面始终优于现有最先进的方法。
论文及项目相关链接
PDF Accepted at AAAI 2025 (Vol. 39, No. 8), pages 7880-7888. DOI: 10.1609/aaai.v39i8.32849
Summary
CAD-GPT是一种利用空间推理增强型多模态大型语言模型进行CAD合成的方法。它通过特殊的空间展开机制,将三维空间位置和三维草图平面旋转角度映射到一维语言特征空间中,实现对单张图像或文本描述的精准空间推理。相比现有技术,CAD-GPT在CAD模型合成中表现出色。
Key Takeaways
- 计算机辅助设计(CAD)增强了设计过程的效率、准确性和创新性。现有的CAD模型创建方法依赖于难以获得的潜在向量或点云,存储成本较高。
- 多模态大型语言模型(MLLMs)的最新进展推动了使用自然语言指令和图像进行CAD模型构建的研究。然而,这些模型在推断准确的3D空间位置和方向时仍存在困难。
- CAD-GPT是一种创新的CAD合成方法,具有空间推理增强型MLLM功能。它接受单张图像或文本描述作为输入,实现精准的空间推理。
- CAD-GPT通过特殊的空间展开机制,将三维空间位置和草图平面旋转角度映射到一维语言特征空间中。
- 该方法通过将二维草图坐标离散化到适当的平面空间中,可以精确确定空间起始位置、草图方向以及二维草图坐标转换。
点此查看论文截图


PotatoGANs: Utilizing Generative Adversarial Networks, Instance Segmentation, and Explainable AI for Enhanced Potato Disease Identification and Classification
Authors:Fatema Tuj Johora Faria, Mukaffi Bin Moin, Mohammad Shafiul Alam, Ahmed Al Wase, Md. Rabius Sani, Khan Md Hasib
Numerous applications have resulted from the automation of agricultural disease segmentation using deep learning techniques. However, when applied to new conditions, these applications frequently face the difficulty of overfitting, resulting in lower segmentation performance. In the context of potato farming, where diseases have a large influence on yields, it is critical for the agricultural economy to quickly and properly identify these diseases. Traditional data augmentation approaches, such as rotation, flip, and translation, have limitations and frequently fail to provide strong generalization results. To address these issues, our research employs a novel approach termed as PotatoGANs. In this novel data augmentation approach, two types of Generative Adversarial Networks (GANs) are utilized to generate synthetic potato disease images from healthy potato images. This approach not only expands the dataset but also adds variety, which helps to enhance model generalization. Using the Inception score as a measure, our experiments show the better quality and realisticness of the images created by PotatoGANs, emphasizing their capacity to resemble real disease images closely. The CycleGAN model outperforms the Pix2Pix GAN model in terms of image quality, as evidenced by its higher IS scores CycleGAN achieves higher Inception scores (IS) of 1.2001 and 1.0900 for black scurf and common scab, respectively. This synthetic data can significantly improve the training of large neural networks. It also reduces data collection costs while enhancing data diversity and generalization capabilities. Our work improves interpretability by combining three gradient-based Explainable AI algorithms (GradCAM, GradCAM++, and ScoreCAM) with three distinct CNN architectures (DenseNet169, Resnet152 V2, InceptionResNet V2) for potato disease classification.
基于深度学习的自动化农业病害分割应用广泛,但在应用于新条件时经常面临过拟合的困难,导致分割性能下降。在土豆种植业中,病害对产量有很大影响,因此快速正确地识别这些病害对农业经济至关重要。传统的数据增强方法,如旋转、翻转和翻译,都有局限性,常常无法提供强有力的通用结果。为解决这些问题,我们的研究采用了一种新方法——PotatoGANs。
在这种新型数据增强方法中,我们利用两种生成对抗网络(GANs)从健康土豆图像生成合成土豆病害图像。这种方法不仅扩大了数据集,还增加了多样性,有助于增强模型的通用性。使用Inception分数作为衡量标准,我们的实验显示了PotatoGANs创建的图像具有更好的质量和现实性,强调它们能够紧密模仿真实病害图像。在图像质量方面,CycleGAN模型优于Pix2Pix GAN模型,循环GAN实现了黑痂和常见疮痂的Inception分数分别为1.2001和1.0900。这种合成数据可以显著改善大型神经网络的训练,还能降低数据收集成本,同时提高数据多样性和通用能力。
我们的工作通过结合三种基于梯度的可解释人工智能算法(GradCAM、GradCAM++和ScoreCAM)与三种不同的CNN架构(DenseNet169、Resnet152 V2、InceptionResNet V2)来改善土豆病害分类的解释性。这一创新方法不仅提高了模型的性能,还增强了其可解释性,为农业领域的智能决策提供了有力支持。
论文及项目相关链接
Summary
本文介绍了一种新型的数据增强方法——PotatoGANs,该方法利用两种生成对抗网络(GANs)从健康土豆图像生成合成土豆疾病图像,以提高模型在应对新条件下的泛化能力,解决深度学习在农业疾病分割中的过拟合问题。通过Inception分数衡量,实验证明PotatoGANs生成的图像质量高、真实性强,并能很好地模拟真实疾病图像。此外,结合多种解释性AI算法和CNN架构,该工作提高了土豆疾病分类的可解释性。
Key Takeaways
- PotatoGANs利用生成对抗网络(GANs)从健康土豆图像生成合成疾病图像,用于农业疾病分割。
- 该方法解决了传统数据增强方法的局限性,并提高了模型应对新条件的泛化能力。
- 通过Inception分数衡量,PotatoGANs生成的图像质量高、真实性强。
- CycleGAN模型在图像质量上优于Pix2Pix GAN模型。
- 合成数据可显著改进大型神经网络的训练,降低数据收集成本,增强数据多样性和泛化能力。
- 结合多种解释性AI算法和CNN架构,提高了土豆疾病分类的可解释性。
点此查看论文截图