⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations
Authors:Jiaming Han, Hao Chen, Yang Zhao, Hanyu Wang, Qi Zhao, Ziyan Yang, Hao He, Xiangyu Yue, Lu Jiang
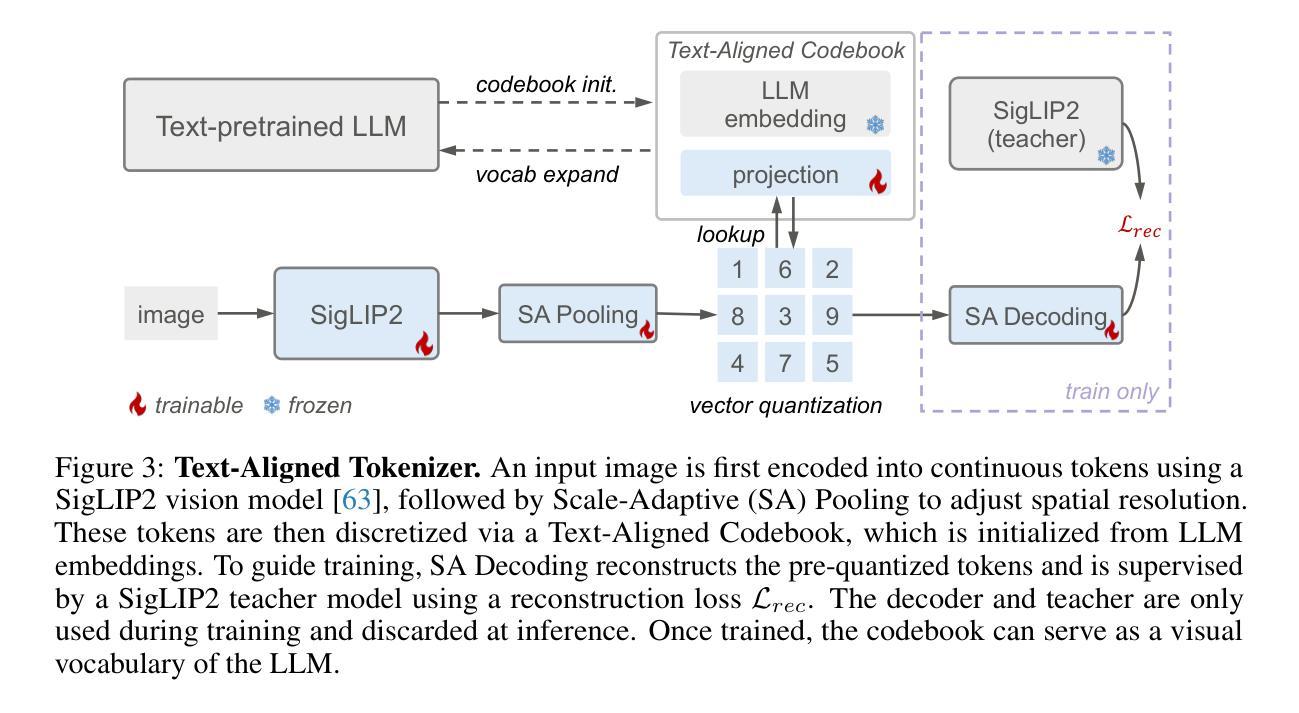
This paper presents a multimodal framework that attempts to unify visual understanding and generation within a shared discrete semantic representation. At its core is the Text-Aligned Tokenizer (TA-Tok), which converts images into discrete tokens using a text-aligned codebook projected from a large language model’s (LLM) vocabulary. By integrating vision and text into a unified space with an expanded vocabulary, our multimodal LLM, Tar, enables cross-modal input and output through a shared interface, without the need for modality-specific designs. Additionally, we propose scale-adaptive encoding and decoding to balance efficiency and visual detail, along with a generative de-tokenizer to produce high-fidelity visual outputs. To address diverse decoding needs, we utilize two complementary de-tokenizers: a fast autoregressive model and a diffusion-based model. To enhance modality fusion, we investigate advanced pre-training tasks, demonstrating improvements in both visual understanding and generation. Experiments across benchmarks show that Tar matches or surpasses existing multimodal LLM methods, achieving faster convergence and greater training efficiency. Code, models, and data are available at https://tar.csuhan.com
本文介绍了一个多模态框架,该框架试图在共享离散语义表示中统一视觉理解和生成。其核心是文本对齐分词器(TA-Tok),它使用从大语言模型(LLM)词汇表中投影的文本对齐代码本将图像转换为离散令牌。通过将视觉和文本集成到一个具有扩展词汇表的统一空间中,我们的多模态LLM Tar能够通过共享接口实现跨模态输入和输出,而无需进行特定于模态的设计。此外,我们提出了规模自适应编码和解码以平衡效率和视觉细节,以及生成去令牌化器以产生高保真视觉输出。为了解决不同的解码需求,我们使用了两种互补的去令牌化器:快速自回归模型和基于扩散的模型。为了提高模态融合,我们研究了先进的预训练任务,在视觉理解和生成方面都证明了改进。跨基准实验表明,Tar匹配或超越了现有的多模态LLM方法,实现了更快的收敛和更高的训练效率。代码、模型和数据可在https://tar.csuhan.com上找到。
论文及项目相关链接
PDF Project page: https://tar.csuhan.com
Summary
本文提出了一种多模态框架,旨在在一个共享离散语义表示中统一视觉理解和生成。其核心是文本对齐分词器(TA-Tok),它使用从大语言模型词汇表中投影的文本对齐代码本将图像转换为离散令牌。通过整合视觉和文本到一个统一的空间并扩展词汇量,我们的多模态LLM Tar能够通过共享接口实现跨模态输入和输出,无需特定模态的设计。此外,我们提出了规模自适应编码和解码以平衡效率和视觉细节,以及生成性去分词器以产生高保真视觉输出。实验表明,Tar在多个基准测试中匹配或超越了现有的多模态LLM方法,实现了更快的收敛和更高的训练效率。
Key Takeaways
- 论文提出了一种多模态框架,旨在在共享离散语义表示中统一视觉理解和生成。
- 核心组件是文本对齐分词器(TA-Tok),能将图像转换为离散令牌。
- 通过整合视觉和文本,Tar实现了跨模态输入和输出,无需特定模态的设计。
- 规模自适应编码和解码以平衡效率和视觉细节。
- 论文提出了两种互补的解码器:快速自回归模型和基于扩散的模型。
- 通过高级预训练任务增强模态融合。
点此查看论文截图



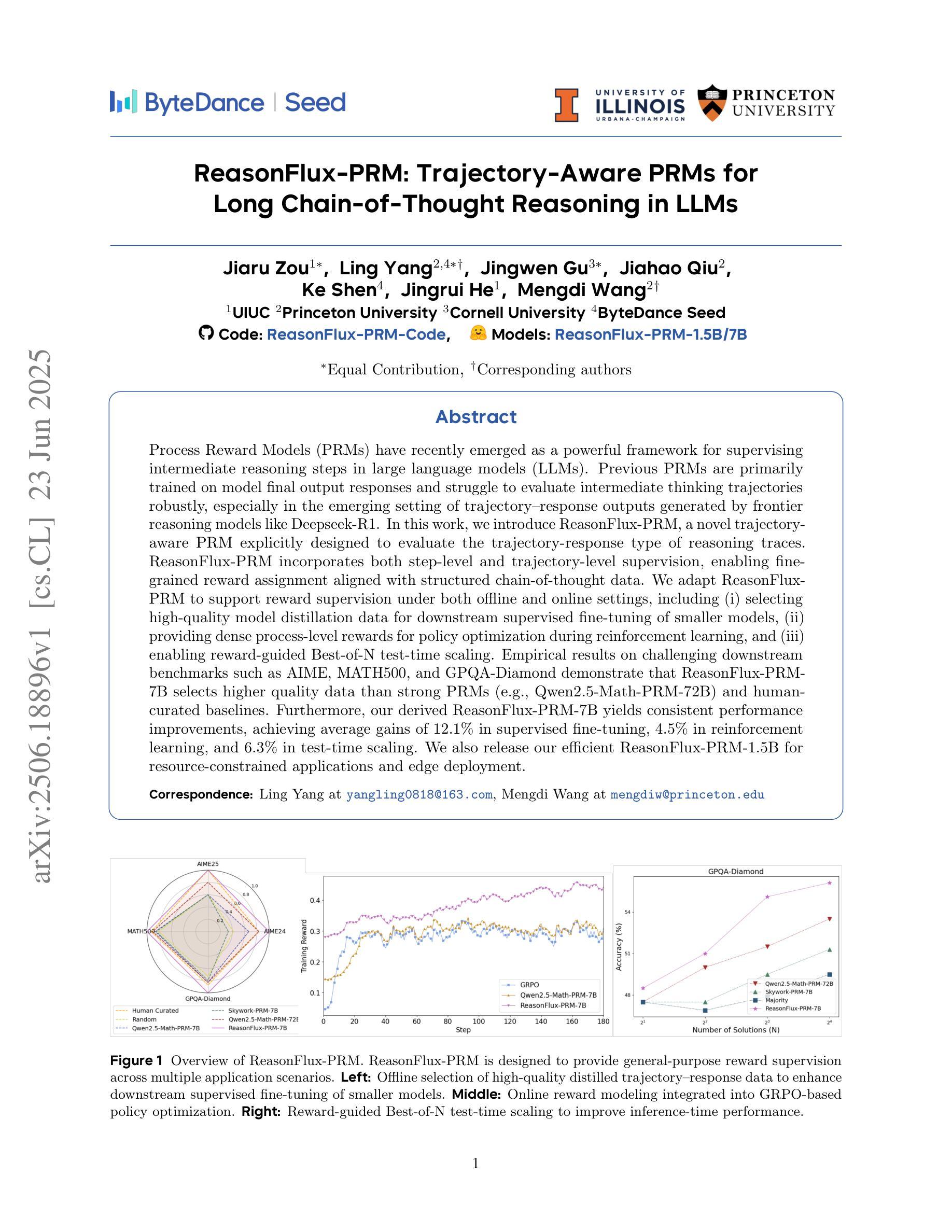
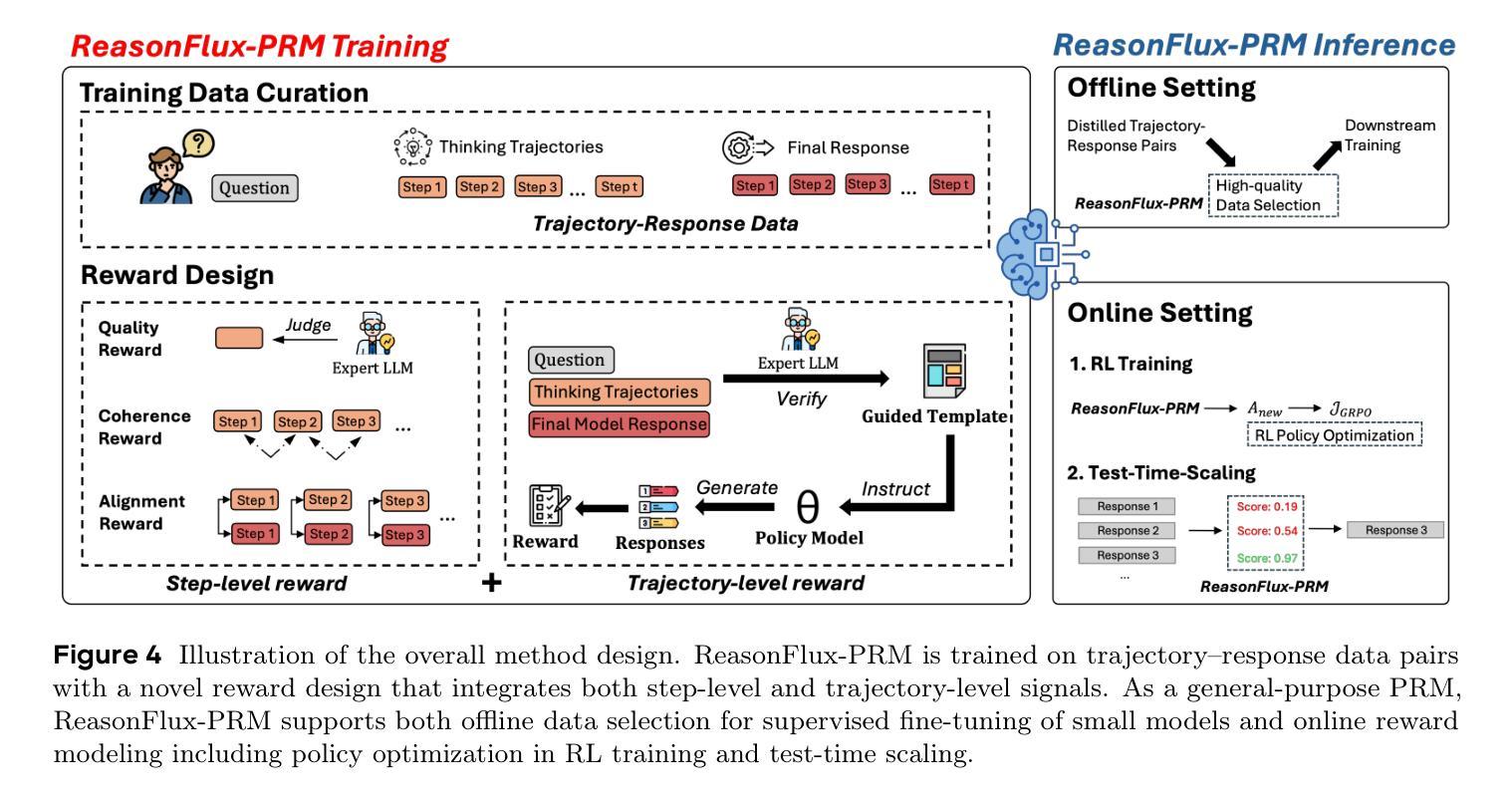
ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
Authors:Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, Mengdi Wang
Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model final output responses and struggle to evaluate intermediate thinking trajectories robustly, especially in the emerging setting of trajectory-response outputs generated by frontier reasoning models like Deepseek-R1. In this work, we introduce ReasonFlux-PRM, a novel trajectory-aware PRM explicitly designed to evaluate the trajectory-response type of reasoning traces. ReasonFlux-PRM incorporates both step-level and trajectory-level supervision, enabling fine-grained reward assignment aligned with structured chain-of-thought data. We adapt ReasonFlux-PRM to support reward supervision under both offline and online settings, including (i) selecting high-quality model distillation data for downstream supervised fine-tuning of smaller models, (ii) providing dense process-level rewards for policy optimization during reinforcement learning, and (iii) enabling reward-guided Best-of-N test-time scaling. Empirical results on challenging downstream benchmarks such as AIME, MATH500, and GPQA-Diamond demonstrate that ReasonFlux-PRM-7B selects higher quality data than strong PRMs (e.g., Qwen2.5-Math-PRM-72B) and human-curated baselines. Furthermore, our derived ReasonFlux-PRM-7B yields consistent performance improvements, achieving average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling. We also release our efficient ReasonFlux-PRM-1.5B for resource-constrained applications and edge deployment. Projects: https://github.com/Gen-Verse/ReasonFlux
过程奖励模型(PRMs)最近作为监督大型语言模型(LLM)中的中间推理步骤的强大框架而出现。以前的PRM主要基于模型的最终输出响应进行训练,在评估前沿推理模型(如Deepseek-R1)生成的轨迹响应输出时,难以稳健地评估中间思维轨迹。在这项工作中,我们引入了ReasonFlux-PRM,这是一种显式设计用于评估轨迹响应类型推理痕迹的新型轨迹感知PRM。ReasonFlux-PRM结合了步骤级和轨迹级的监督,能够实现与结构化思维链数据对齐的精细奖励分配。我们使ReasonFlux-PRM适应离线和在线设置下的奖励监督,包括(i)选择高质量模型蒸馏数据,以用于下游较小模型的监督微调,(ii)在强化学习中为策略优化提供密集的流程级奖励,以及(iii)实现奖励引导的Best-of-N测试时间缩放。在具有挑战性的下游基准测试(例如AIME、MATH500和GPQA-Diamond)上的实证结果表明,ReasonFlux-PRM-7B比强大的PRM(例如Qwen2.5-Math-PRM-72B)和人类精选的基线更能选择高质量的数据。此外,我们派生的ReasonFlux-PRM-7B在监督微调、强化学习和测试时间缩放方面取得了持续的性能改进,平均增益分别为12.1%、4.5%和6.3%。我们还发布了用于资源受限应用和边缘部署的高效ReasonFlux-PRM-1.5B。项目地址:https://github.com/Gen-Verse/ReasonFlux
论文及项目相关链接
PDF Codes and Models: https://github.com/Gen-Verse/ReasonFlux
Summary
基于过程奖励模型(PRMs)在大型语言模型(LLMs)中的监督作用,本文提出了ReasonFlux-PRM,这是一种专门用于评估推理轨迹的轨迹感知PRM。它结合了步骤级和轨迹级的监督,使奖励分配与结构化思维数据精细对齐。ReasonFlux-PRM能适应离线与在线环境下的奖励监督,包括选择高质量模型蒸馏数据、为强化学习提供密集的过程级奖励以及实现奖励引导的最佳N测试时间缩放。在AIME、MATH500和GPQA-Diamond等基准测试中,ReasonFlux-PRM表现出卓越性能。
Key Takeaways
- ReasonFlux-PRM是一种专门评估推理轨迹的轨迹感知过程奖励模型(PRM)。
- 该模型结合了步骤级和轨迹级的监督,以精细的方式与结构化思维数据对齐。
- ReasonFlux-PRM能适应离线与在线环境的奖励监督,包括选择高质量模型蒸馏数据、强化学习的政策优化和测试时间缩放。
- 在多个基准测试中,ReasonFlux-PRM表现出卓越性能,如AIME、MATH500和GPQA-Diamond等。
- 与其他强大的PRMs和人类基准相比,ReasonFlux-PRM-7B能选择更高质量的数据。
- ReasonFlux-PRM-7B在监督微调、强化学习和测试时间缩放方面均实现了性能改进。
点此查看论文截图

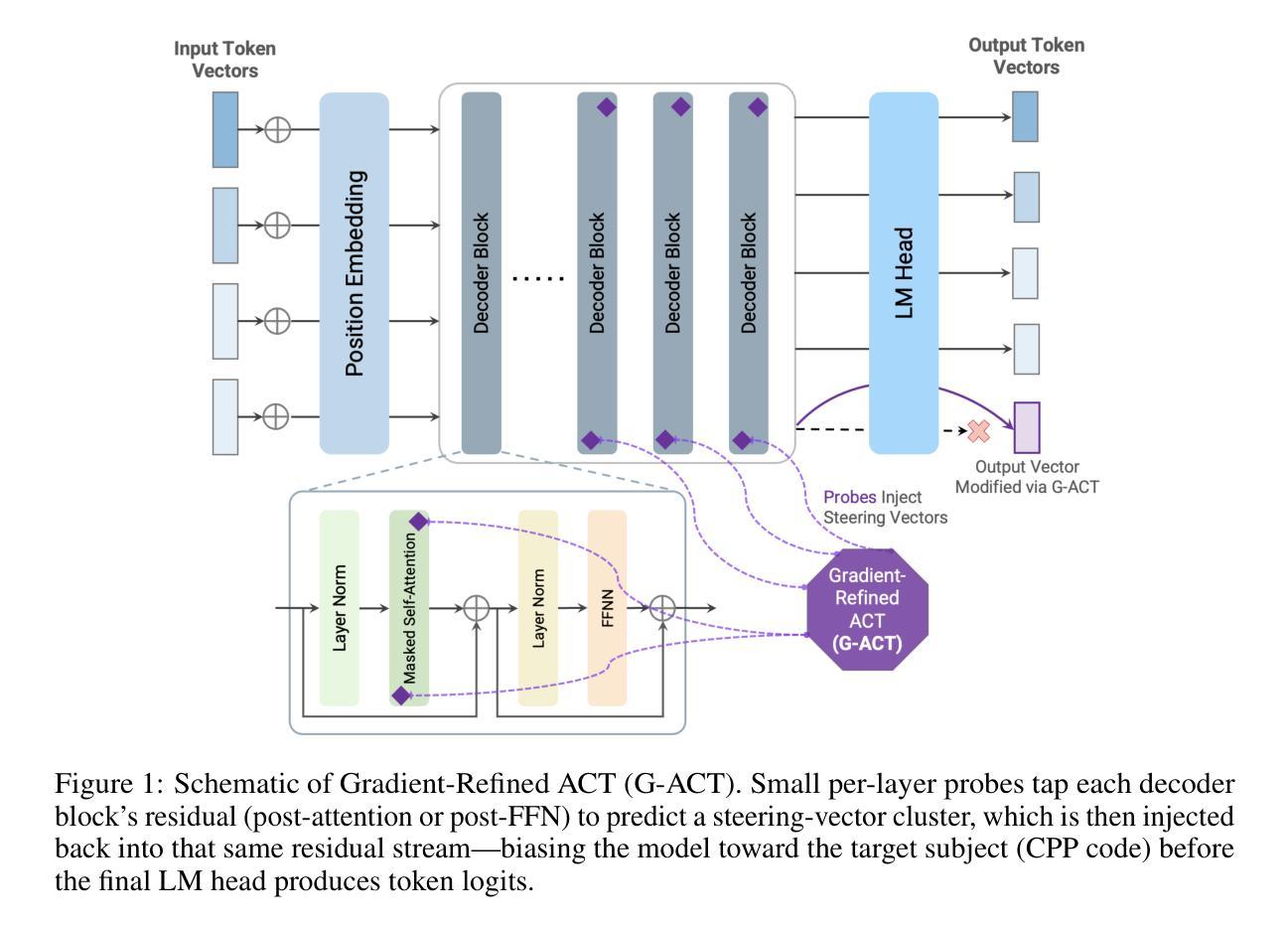
Steering Conceptual Bias via Transformer Latent-Subspace Activation
Authors:Vansh Sharma, Venkat Raman
This work examines whether activating latent subspaces in language models (LLMs) can steer scientific code generation toward a specific programming language. Five causal LLMs were first evaluated on scientific coding prompts to quantify their baseline bias among four programming languages. A static neuron-attribution method, perturbing the highest activated MLP weight for a C++ or CPP token, proved brittle and exhibited limited generalization across prompt styles and model scales. To address these limitations, a gradient-refined adaptive activation steering framework (G-ACT) was developed: per-prompt activation differences are clustered into a small set of steering directions, and lightweight per-layer probes are trained and refined online to select the appropriate steering vector. In LLaMA-3.2 3B, this approach reliably biases generation towards the CPP language by increasing the average probe classification accuracy by 15% and the early layers (0-6) improving the probe classification accuracy by 61.5% compared to the standard ACT framework. For LLaMA-3.3 70B, where attention-head signals become more diffuse, targeted injections at key layers still improve language selection. Although per-layer probing introduces a modest inference overhead, it remains practical by steering only a subset of layers and enables reproducible model behavior. These results demonstrate a scalable, interpretable and efficient mechanism for concept-level control for practical agentic systems.
本文旨在探讨激活语言模型(LLM)中的潜在子空间是否能引导科学代码生成朝向特定的编程语言。首先,对五种因果LLM进行科学编码提示评估,以量化它们在四种编程语言之间的基线偏见。一种静态神经元归因方法,通过扰动C++或CPP标记的最高激活MLP权重,被证明是脆弱的,并且在提示风格和模型规模方面表现出有限的泛化能力。为了解决这些局限性,开发了一个基于梯度精化的自适应激活引导框架(G-ACT):将每个提示的激活差异聚集成一小部分引导方向集,并在线训练和精化轻量级的逐层探针,以选择适当的引导向量。在LLaMA-3.2 3B中,这种方法通过提高探针分类准确率15%,并且在早期层(0-6层)与标准ACT框架相比,探针分类准确率提高了61.5%,从而可靠地将生成偏向CPP语言。对于注意力头信号更加分散的LLaMA-3.3 70B,对关键层的针对性注入仍然能改善语言选择。尽管逐层探测引入了适中的推理开销,但它只引导部分层,仍然具有实用性,并能实现可重复模型行为。这些结果展示了一种可规模化、可解释和高效的机制,用于实现实际代理系统的概念级控制。
论文及项目相关链接
Summary
本文探讨了激活语言模型(LLM)中的潜在子空间是否可以引导科学代码生成特定编程语言的问题。通过对五个因果LLM在科技编码提示上的评估,发现它们在四种编程语言中的基线偏见。研究提出一种梯度优化自适应激活引导框架(G-ACT),通过在早期层级中选择适当的引导向量来引导代码生成朝着特定语言(如CPP)发展。该框架能提高探测器的分类准确度,展现出强大的实用价值。尽管有一定推理时间开销,但通过仅引导部分层级仍可实现高效、可解释的模型控制机制。
Key Takeaways
- LLM模型在科学代码生成中展现对特定编程语言的基线偏见。
- 通过激活语言模型中的特定神经元来引导代码生成朝向特定语言成为可能。
- 静态神经元归因方法对于跨提示风格和模型规模存在局限性。
- 提出一种梯度优化自适应激活引导框架(G-ACT),能有效提高探测器的分类准确度。
- 在早期层级使用G-ACT框架能显著提高分类准确度。
- 在大型语言模型(如LLaMA-3.3 70B)中,关键层级的针对性注入仍能提高语言选择能力。
点此查看论文截图

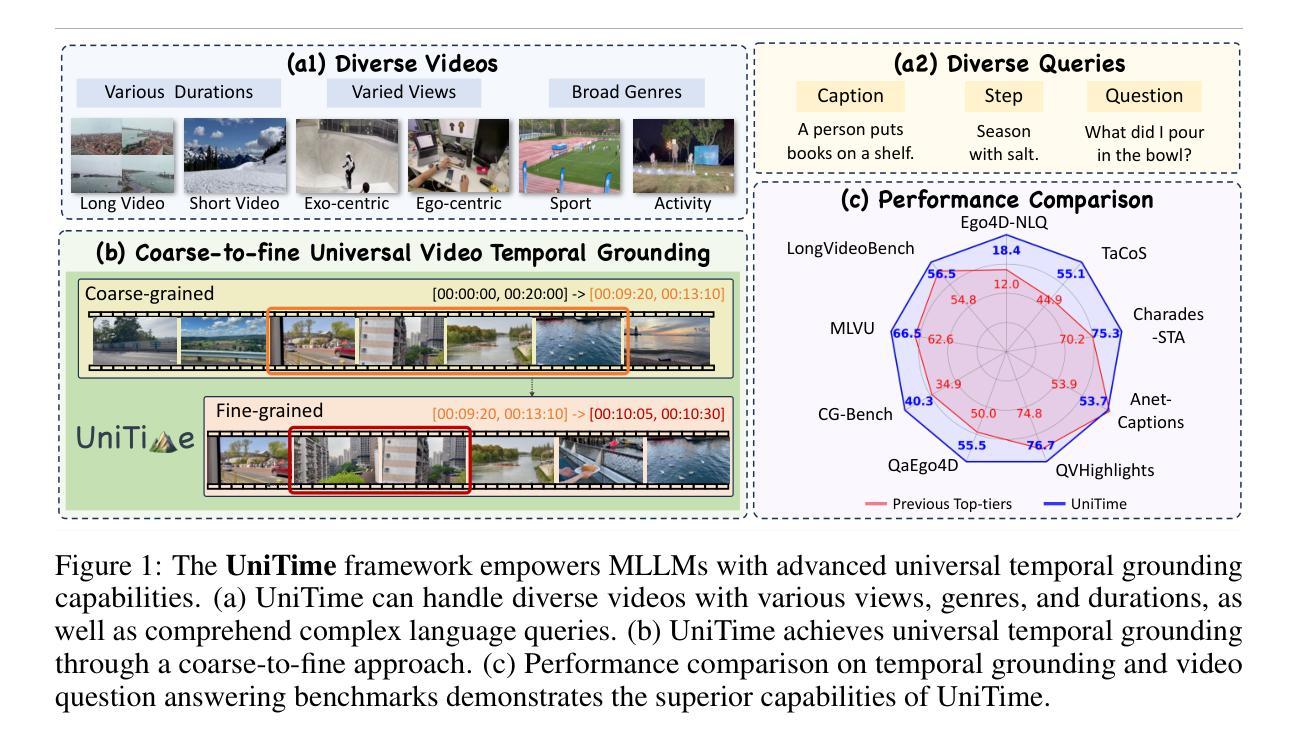
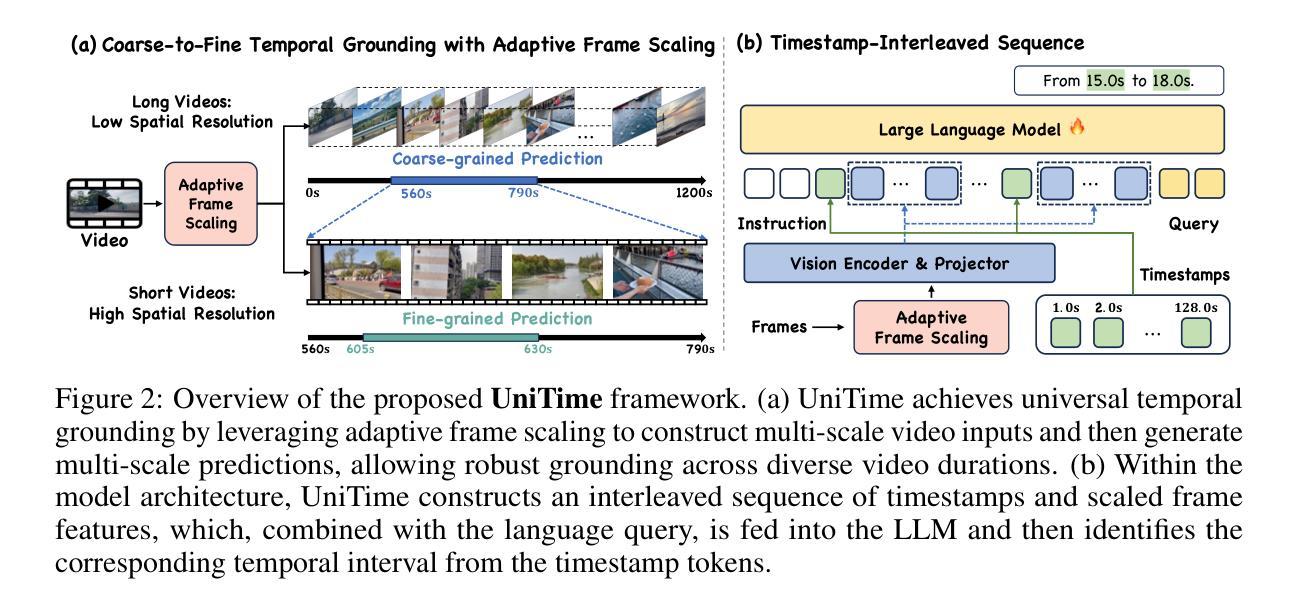
Universal Video Temporal Grounding with Generative Multi-modal Large Language Models
Authors:Zeqian Li, Shangzhe Di, Zhonghua Zhai, Weilin Huang, Yanfeng Wang, Weidi Xie
This paper presents a computational model for universal video temporal grounding, which accurately localizes temporal moments in videos based on natural language queries (e.g., questions or descriptions). Unlike existing methods that are often limited to specific video domains or durations, we propose UniTime, a robust and universal video grounding model leveraging the strong vision-language understanding capabilities of generative Multi-modal Large Language Models (MLLMs). Our model effectively handles videos of diverse views, genres, and lengths while comprehending complex language queries. The key contributions include: (i) We consider steering strong MLLMs for temporal grounding in videos. To enable precise timestamp outputs, we incorporate temporal information by interleaving timestamp tokens with video tokens. (ii) By training the model to handle videos with different input granularities through adaptive frame scaling, our approach achieves robust temporal grounding for both short and long videos. (iii) Comprehensive experiments show that UniTime outperforms state-of-the-art approaches in both zero-shot and dataset-specific finetuned settings across five public temporal grounding benchmarks. (iv) When employed as a preliminary moment retriever for long-form video question-answering (VideoQA), UniTime significantly improves VideoQA accuracy, highlighting its value for complex video understanding tasks.
本文提出了一种用于通用视频时间定位的计算模型。该模型能够基于自然语言查询(如问题或描述)准确地在视频中定位时间时刻。与现有方法常常局限于特定视频领域或时长不同,我们提出了UniTime,一个稳健且通用的视频定位模型,它利用生成式多模态大型语言模型(MLLMs)的强大视觉语言理解能力。我们的模型能够有效地处理具有多种视角、类型和时长的视频,同时理解复杂的语言查询。主要贡献包括:(i)我们考虑利用强大的MLLMs进行视频时间定位。为了实现精确的时间戳输出,我们通过将时间戳令牌与视频令牌交错,来融入时间信息。(ii)通过训练模型以不同的输入粒度处理视频,通过自适应帧缩放,我们的方法在实现短视频和长视频的稳健时间定位。(iii)综合实验表明,UniTime在五个公共时间定位基准测试上,无论是零样本还是特定数据集微调设置,均优于最新方法。(iv)当作为长形式视频问答(VideoQA)的初步时刻检索器时,UniTime显著提高了VideoQA的准确性,突显其在复杂视频理解任务中的价值。
论文及项目相关链接
Summary:
本文提出了一种用于通用视频时间定位的计算模型,能够基于自然语言查询准确地对视频中的时间片段进行定位。模型借助生成式多模态大型语言模型(MLLMs)的视听理解能力,实现了稳健和通用的视频定位。通过融入时间信息并训练模型适应不同粒度的视频输入,该模型能够精确处理长短不一的视频,并在多个公开时间定位基准测试中表现出超越现有方法的效果。此外,将其应用于长视频问答任务时,能显著提高准确率,证明了其在复杂视频理解任务中的价值。
Key Takeaways:
- 该论文提出了一种计算模型UniTime,用于基于自然语言查询的视频时间定位。
- UniTime利用生成式多模态大型语言模型(MLLMs)进行稳健的视频定位。
- 模型通过融入时间信息实现了精确的时间定位。
- UniTime能够适应不同粒度的视频输入,实现长短视频的稳健时间定位。
- 在多个公开基准测试中,UniTime表现出超越现有方法的效果。
- UniTime可作为长视频问答任务的初步时刻检索器,显著提高准确率。
点此查看论文截图

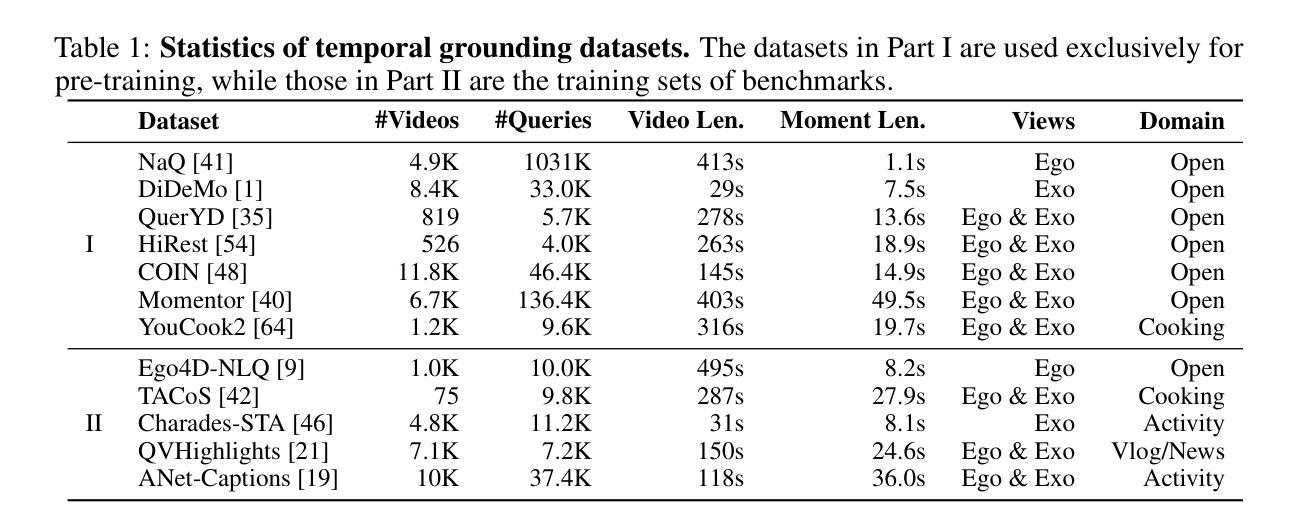
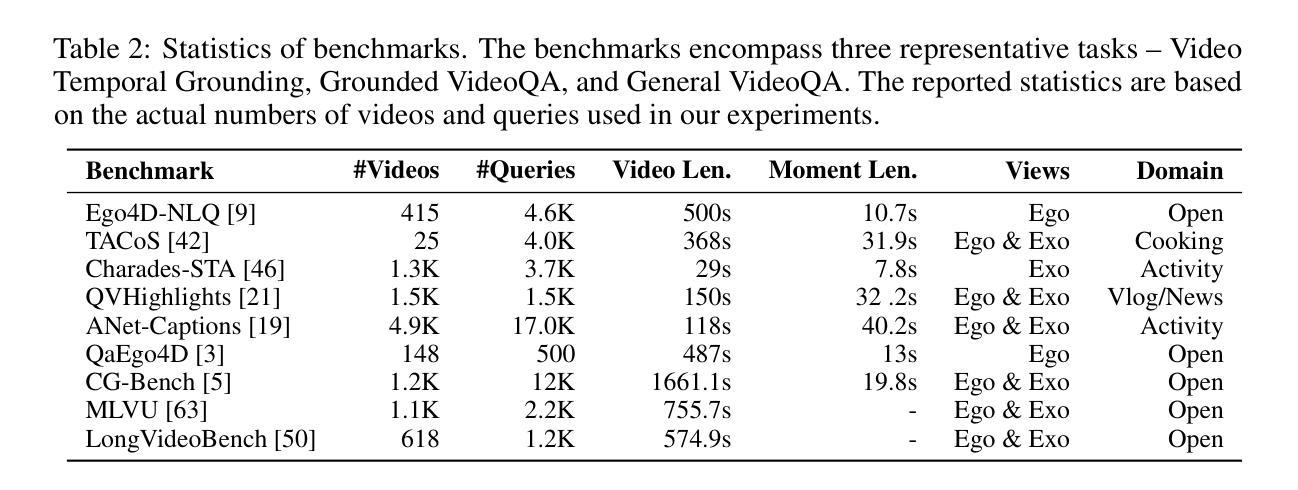
CommVQ: Commutative Vector Quantization for KV Cache Compression
Authors:Junyan Li, Yang Zhang, Muhammad Yusuf Hassan, Talha Chafekar, Tianle Cai, Zhile Ren, Pengsheng Guo, Foroozan Karimzadeh, Colorado Reed, Chong Wang, Chuang Gan
Large Language Models (LLMs) are increasingly used in applications requiring long context lengths, but the key-value (KV) cache often becomes a memory bottleneck on GPUs as context grows. To address this, we propose Commutative Vector Quantization (CommVQ) to significantly reduce memory usage for long-context LLM inference. We first introduce additive quantization with a lightweight encoder and codebook to compress the KV cache, which can be decoded via simple matrix multiplication. To further reduce computational costs during decoding, we design the codebook to be commutative with Rotary Position Embedding (RoPE) and train it using an Expectation-Maximization (EM) algorithm. This enables efficient integration of decoding into the self-attention mechanism. Our approach achieves high accuracy with additive quantization and low overhead via the RoPE-commutative codebook. Experiments on long-context benchmarks and GSM8K show that our method reduces FP16 KV cache size by 87.5% with 2-bit quantization, while outperforming state-of-the-art KV cache quantization methods. Notably, it enables 1-bit KV cache quantization with minimal accuracy loss, allowing a LLaMA-3.1 8B model to run with a 128K context length on a single RTX 4090 GPU. The source code is available at: https://github.com/UMass-Embodied-AGI/CommVQ.
大型语言模型(LLM)在需要长上下文的应用中越来越受欢迎,但键值(KV)缓存随着上下文的增长往往成为GPU上的内存瓶颈。为了解决这一问题,我们提出了可交换向量量化(CommVQ)来显著减少长上下文LLM推理中的内存使用。我们首先使用轻量级编码器和代码本引入加法量化来压缩KV缓存,它可以通过简单的矩阵乘法进行解码。为了进一步降低解码过程中的计算成本,我们设计代码本与旋转位置嵌入(RoPE)可交换,并使用期望最大化(EM)算法进行训练。这使得解码能够高效地集成到自注意力机制中。我们的方法通过RoPE可交换代码本实现了加法量化的高准确性和低开销。在长上下文基准测试和GSM8K上的实验表明,我们的方法在2位量化的情况下将FP16 KV缓存大小减少了87.5%,同时优于最新的KV缓存量化方法。尤其值得一提的是,它实现了具有极小精度损失的1位KV缓存量化,允许在单个RTX 4090 GPU上运行LLaMA-3.1 8B模型的128K上下文长度。源代码可在:https://github.com/UMass-Embodied-AGI/CommVQ获取。
论文及项目相关链接
PDF ICML 2025 poster
摘要
大型语言模型(LLM)在处理需要长语境的应用时,键值(KV)缓存成为GPU内存瓶颈的问题日益突出。为解决这一问题,我们提出使用可交换向量量化(CommVQ)来显著减少长语境LLM推理的内存使用。我们首次引入加法量化,通过轻量级编码器和代码本压缩KV缓存,解码时只需进行简单的矩阵乘法。为进一步降低解码过程中的计算成本,我们设计了一个与旋转位置嵌入(RoPE)可交换的代码本,并使用期望最大化(EM)算法进行训练。这能够实现高效地将解码集成到自注意力机制中。我们的方法通过加法量化实现了高准确率,并通过RoPE可交换代码本实现了低开销。在长语境基准测试和GSM8K上的实验表明,我们的方法将FP16 KV缓存大小减少了87.5%,同时实现了2位量化。值得注意的是,它实现了1位KV缓存量化,对精度损失极小,允许LLaMA-3.1 8B模型在单个RTX 4090 GPU上运行,语境长度达到128K。源代码可在https://github.com/UMass-Embodied-AGI/CommVQ访问。
关键见解
- 大型语言模型在处理长语境应用时面临KV缓存内存瓶颈问题。
- CommutVQ通过加法量化显著减少KV缓存内存使用。
- 引入轻量级编码器和代码本进行KV缓存压缩,解码过程高效。
- 利用可交换代码本和RoPE技术降低解码计算成本。
- CommutVQ实现高准确率并降低内存开销。
- 实验显示,该方法显著减少KV缓存大小,实现高效长语境LLM推理。
点此查看论文截图

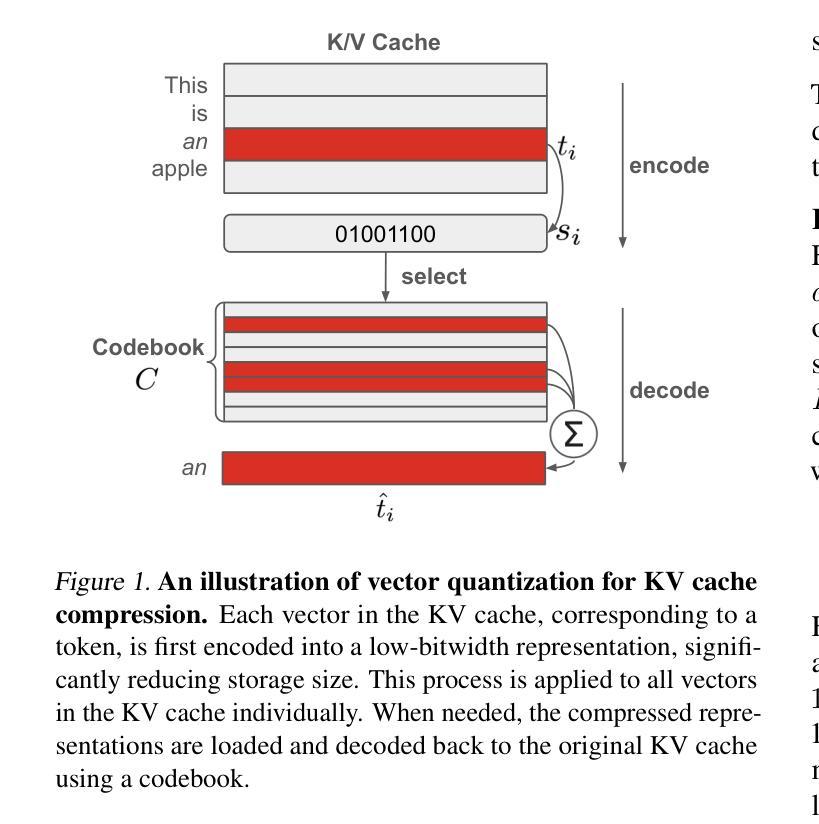
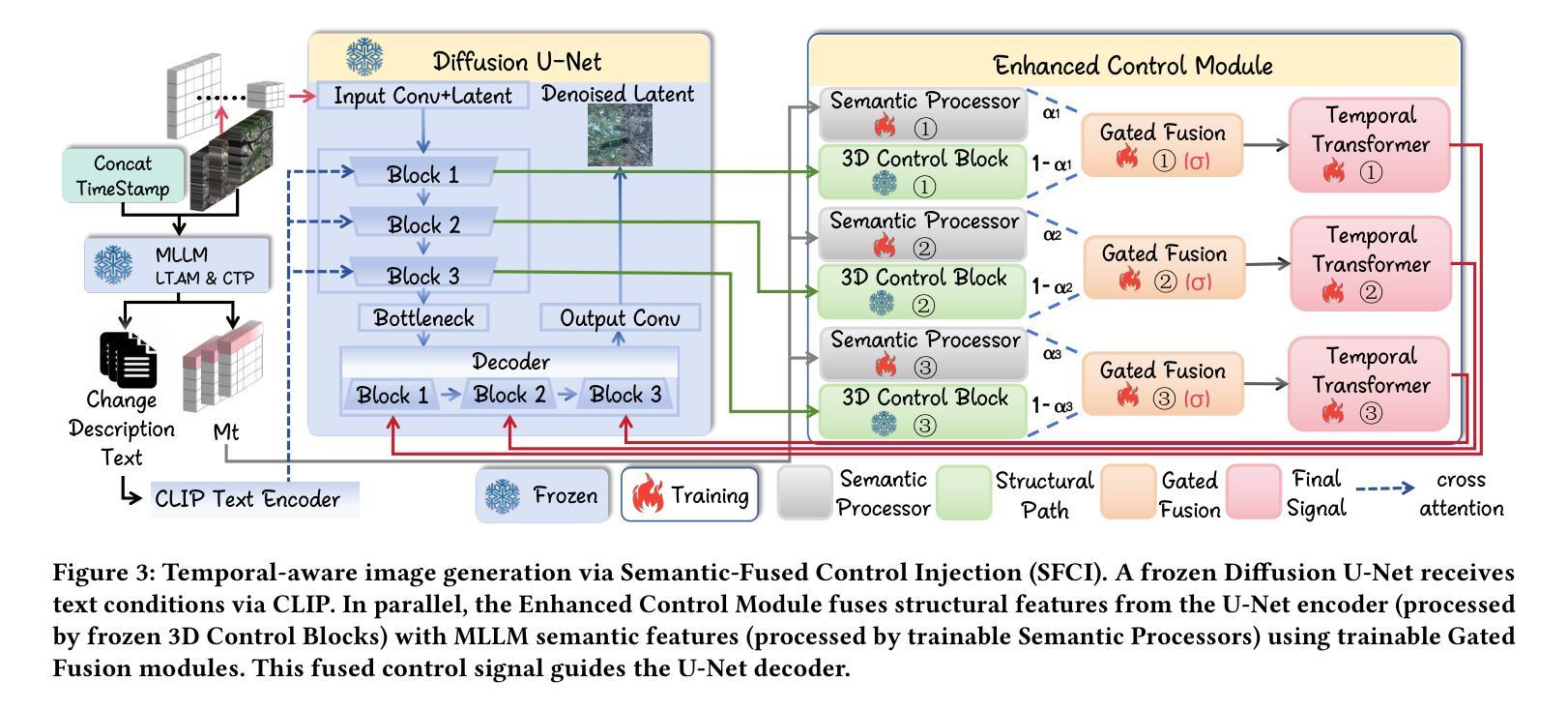
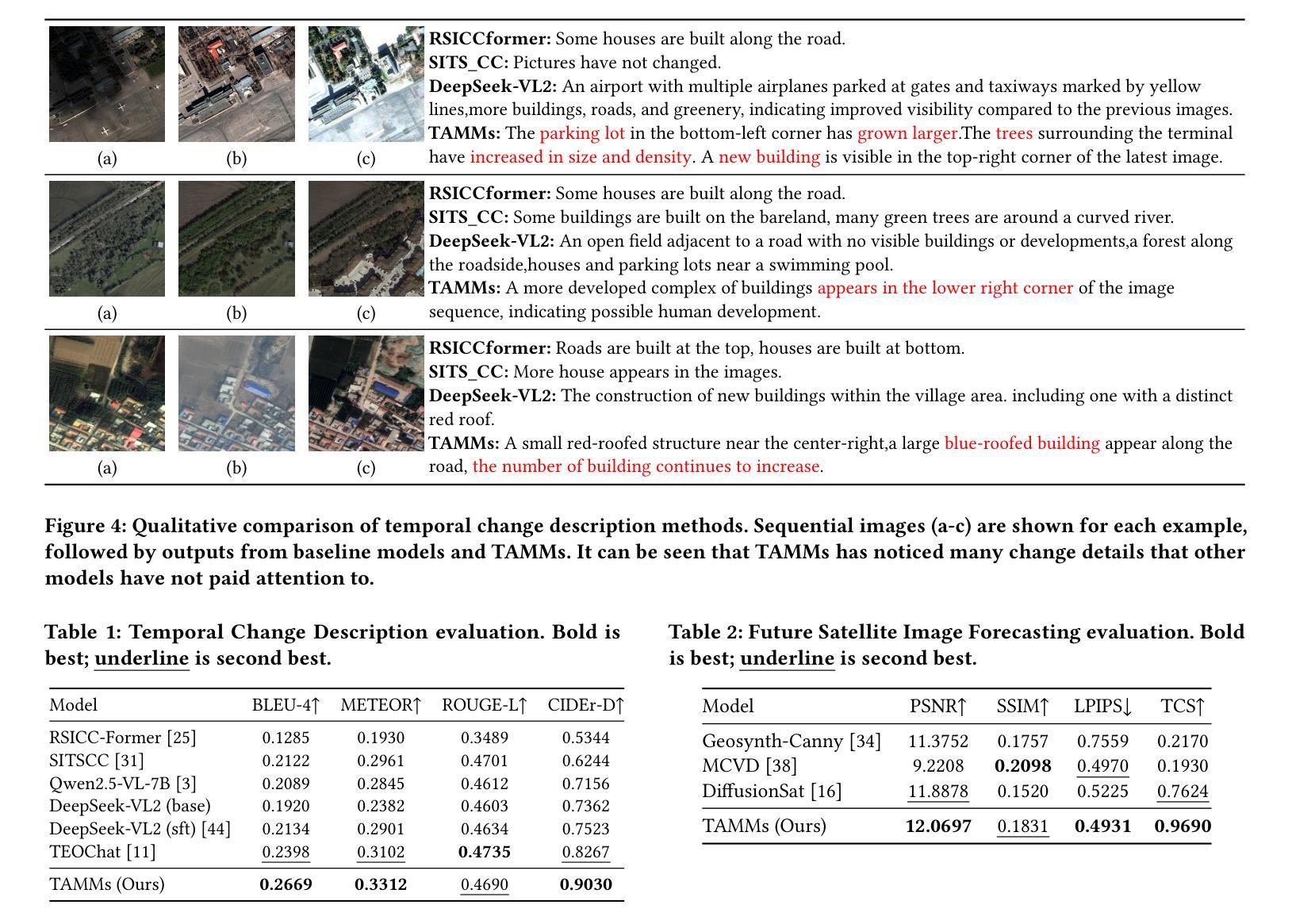
TAMMs: Temporal-Aware Multimodal Model for Satellite Image Change Understanding and Forecasting
Authors:Zhongbin Guo, Yuhao Wang, Ping Jian, Xinyue Chen, Wei Peng, Ertai E
Satellite image time-series analysis demands fine-grained spatial-temporal reasoning, which remains a challenge for existing multimodal large language models (MLLMs). In this work, we study the capabilities of MLLMs on a novel task that jointly targets temporal change understanding and future scene generation, aiming to assess their potential for modeling complex multimodal dynamics over time. We propose TAMMs, a Temporal-Aware Multimodal Model for satellite image change understanding and forecasting, which enhances frozen MLLMs with lightweight temporal modules for structured sequence encoding and contextual prompting. To guide future image generation, TAMMs introduces a Semantic-Fused Control Injection (SFCI) mechanism that adaptively combines high-level semantic reasoning and structural priors within an enhanced ControlNet. This dual-path conditioning enables temporally consistent and semantically grounded image synthesis. Experiments demonstrate that TAMMs outperforms strong MLLM baselines in both temporal change understanding and future image forecasting tasks, highlighting how carefully designed temporal reasoning and semantic fusion can unlock the full potential of MLLMs for spatio-temporal understanding.
卫星图像时间序列分析需要精细的时空推理,这对现有的多模态大型语言模型(MLLMs)来说仍然是一个挑战。在这项工作中,我们研究MLLMs在一个新任务上的能力,该任务旨在理解时间变化和未来场景生成,以评估它们在建模随时间变化的复杂多模态动态方面的潜力。我们提出了TAMMs,这是一个用于卫星图像变化理解和预测的时间感知多模态模型,它通过轻量级的临时模块和结构化序列编码以及上下文提示来增强冻结的MLLMs。为了指导未来图像的生成,TAMMs引入了一种语义融合控制注入(SFCI)机制,该机制在一个增强的ControlNet中自适应地结合了高级语义推理和结构先验。这种双路径条件使得图像合成在时间上保持一致,并在语义上得以验证。实验表明,TAMMs在理解时间变化和预测未来图像的任务上均优于强大的MLLM基准模型,这突显了精心设计的临时推理和语义融合如何解锁MLLMs在时空理解方面的全部潜力。
论文及项目相关链接
PDF Submitted to the 33rd ACM International Conference on Multimedia. Our dataset can be found at https://huggingface.co/datasets/IceInPot/TAMMs
Summary
卫星图像时间序列分析需要精细的空间时间推理能力,这对现有的多模态大型语言模型(MLLMs)来说仍然是一个挑战。本研究旨在评估MLLMs在理解时间变化和预测未来场景方面的潜力。我们提出了TAMMs模型,这是一种用于卫星图像变化理解和预测的时间感知多模态模型。它通过添加轻量级的时间模块进行结构化序列编码和上下文提示,增强了冻结的MLLMs的功能。为了指导未来图像的生成,TAMMs引入了语义融合控制注入(SFCI)机制,该机制自适应地结合了高级语义推理和结构先验知识在一个增强的ControlNet中。这种双路径条件使得图像合成在时间上是连贯的且在语义上是有根据的。实验表明,TAMMs在理解时间变化和预测未来图像的任务上都超越了强大的MLLM基准测试,展现了精心设计的时间推理和语义融合如何解锁MLLMs在时空理解方面的潜力。
Key Takeaways
- 卫星图像时间序列分析需要强大的空间时间推理能力,这仍是多模态大型语言模型的挑战。
- 本研究评估了多模态大型语言模型在理解时间变化和预测未来场景方面的潜力。
3.TAMMs模型是一种用于卫星图像变化理解和预测的时间感知多模态模型,它通过添加轻量级的时间模块进行结构化序列编码和上下文提示来增强性能。
4.TAMMs通过语义融合控制注入机制结合高级语义推理和结构先验知识,实现时空连贯的图像合成。 - 实验表明,TAMMs在理解时间变化和预测未来图像的任务上超越了现有的多模态大型语言模型。
- 精心设计的时间推理和语义融合对于解锁多模态大型语言模型在时空理解方面的潜力至关重要。
点此查看论文截图

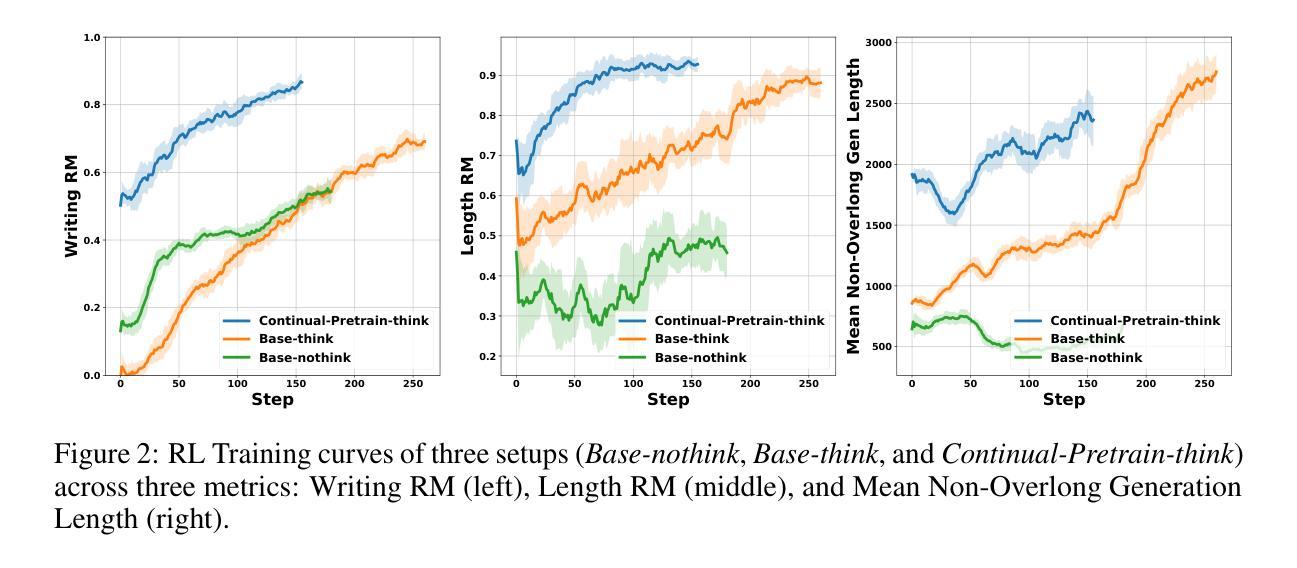
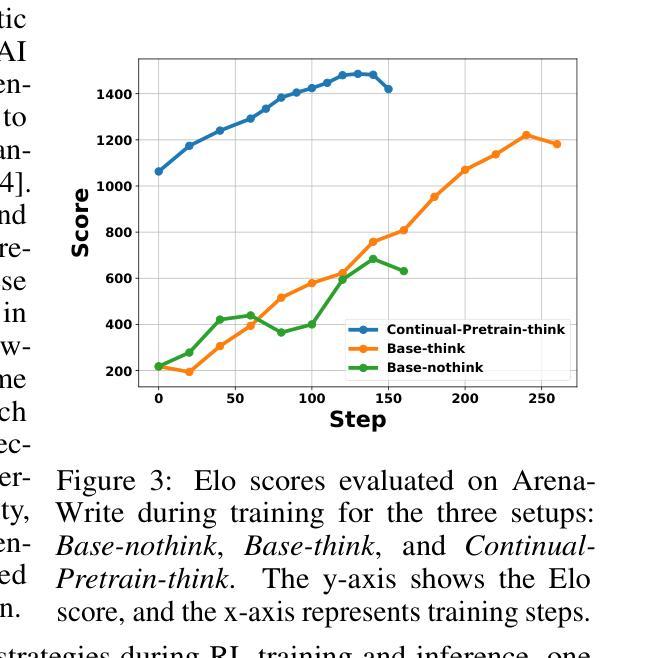
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
Authors:Yuhao Wu, Yushi Bai, Zhiqiang Hu, Roy Ka-Wei Lee, Juanzi Li
Ultra-long generation by large language models (LLMs) is a widely demanded scenario, yet it remains a significant challenge due to their maximum generation length limit and overall quality degradation as sequence length increases. Previous approaches, exemplified by LongWriter, typically rely on ‘’teaching’’, which involves supervised fine-tuning (SFT) on synthetic long-form outputs. However, this strategy heavily depends on synthetic SFT data, which is difficult and costly to construct, often lacks coherence and consistency, and tends to be overly artificial and structurally monotonous. In this work, we propose an incentivization-based approach that, starting entirely from scratch and without relying on any annotated or synthetic data, leverages reinforcement learning (RL) to foster the emergence of ultra-long, high-quality text generation capabilities in LLMs. We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement during the writing process. To support this, we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting. Experimental evaluations show that our LongWriter-Zero model, trained from Qwen2.5-32B, consistently outperforms traditional SFT methods on long-form writing tasks, achieving state-of-the-art results across all metrics on WritingBench and Arena-Write, and even surpassing 100B+ models such as DeepSeek R1 and Qwen3-235B. We open-source our data and model checkpoints under https://huggingface.co/THU-KEG/LongWriter-Zero-32B
超长文本生成是大语言模型(LLM)中广泛需求的场景,但由于其最大生成长度限制以及序列长度增加导致的整体质量下降,这仍然是一个巨大的挑战。以往的方法,以LongWriter为代表,通常依赖于“教学”方式,涉及在合成长篇输出上进行监督微调(SFT)。然而,这种策略严重依赖于合成的SFT数据,这些数据构建困难且成本高昂,往往缺乏连贯性和一致性,且倾向于过于人工化和结构单调。
在这项工作中,我们提出了一种基于激励的方法,该方法完全从头开始,不依赖任何注释或合成数据,利用强化学习(RL)来培养LLM中产生超长、高质量文本生成的能力。我们从基础模型开始进行RL训练,类似于R1-Zero,指导它在进行写作过程中的推理、规划和细化。为此,我们采用专门的奖励模型来引导LLM改进长度控制、写作质量和结构格式化。
论文及项目相关链接
摘要
大型语言模型(LLM)的超长生成是一个广泛需求但具有挑战性的任务,受到生成长度限制和序列长度增加导致的质量下降的影响。之前的方法如LongWriter主要依赖“教学”方式,即在合成长形式输出上进行监督微调(SFT)。然而,这种方法严重依赖于合成SFT数据,这些数据构建困难、成本高昂,且常常缺乏连贯性和一致性,过于人工化且结构单调。本研究提出了一种基于激励的方法,该方法完全从头开始,不依赖任何注释或合成数据,利用强化学习(RL)促进LLM中超长、高质量文本生成能力的出现。我们从基础模型开始进行RL训练,类似于R1-Zero,引导其在进行写作过程时进行推理,促进规划和细化。为此,我们采用专门的奖励模型,引导LLM改进长度控制、写作质量和结构格式化。实验评估表明,我们的LongWriter-Zero模型从Qwen2.5-32B训练而来,在长篇写作任务上始终优于传统SFT方法,在WritingBench和Arena-Write上的各项指标均达到最新水平,甚至超越了DeepSeek R1和Qwen3-235B等100B+模型。我们的数据和模型检查点已公开在https://huggingface.co/THU-KEG/LongWriter-Zero-32B。
关键见解
- 大型语言模型(LLM)的超长文本生成是一项具有挑战性的任务,因为存在生成长度限制和序列长度增加导致的质量下降问题。
- 此前的方法如LongWriter主要依赖监督微调(SFT)进行“教学”,但这依赖于难以构建且成本高昂的合成数据。
- 本研究提出了一种基于激励的方法,利用强化学习(RL)促进LLM的超长文本生成能力,无需依赖任何注释或合成数据。
- 采用了类似于R1-Zero的RL训练方式,结合专门的奖励模型,改进了长度控制、写作质量和结构格式化。
- 实验表明,LongWriter-Zero模型在长篇写作任务上的表现优于传统SFT方法,达到最新水平。
- LongWriter-Zero模型已超越某些大型模型,如DeepSeek R1和Qwen3-235B等。
点此查看论文截图

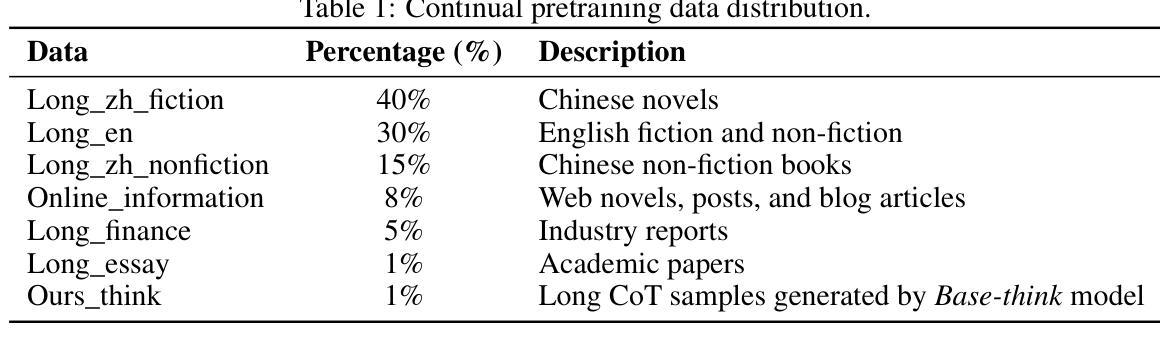
Understanding Software Engineering Agents: A Study of Thought-Action-Result Trajectories
Authors:Islem Bouzenia, Michael Pradel
Large Language Model (LLM)-based agents are increasingly employed to automate complex software engineering tasks such as program repair and issue resolution. These agents operate by autonomously generating natural language thoughts, invoking external tools, and iteratively refining their solutions. Despite their widespread adoption, the internal decision-making processes of these agents remain largely unexplored, limiting our understanding of their operational dynamics and failure modes. In this paper, we present a large-scale empirical study of the thought-action-result trajectories of three state-of-the-art LLM-based agents: \textsc{RepairAgent}, \textsc{AutoCodeRover}, and \textsc{OpenHands}. We unify their interaction logs into a common format, capturing 120 trajectories and 2822 LLM interactions focused on program repair and issue resolution. Our study combines quantitative analyses of structural properties, action patterns, and token usage with qualitative assessments of reasoning coherence and feedback integration. We identify key trajectory characteristics such as iteration counts and token consumption, recurring action sequences, and the semantic coherence linking thoughts, actions, and their results. Our findings reveal behavioral motifs and anti-patterns that distinguish successful from failed executions, providing actionable insights for improving agent design, including prompting strategies, failure diagnosis, and anti-pattern detection. We release our dataset and annotation framework to support further research on transparent and robust autonomous software engineering agents.
基于大型语言模型(LLM)的代理正越来越多地被用于自动化复杂的软件工程任务,如程序修复和问题解析。这些代理通过自主生成自然语言思想、调用外部工具并迭代优化其解决方案来运行。尽管这些代理已得到广泛应用,但其内部决策过程仍大多未被探索,这限制了我们对它们运行动态和故障模式的理解。在本文中,我们对三种最新LLM代理的思想行动结果轨迹进行了大规模实证研究:RepairAgent、AutoCodeRover和OpenHands。我们将它们的交互日志统一为通用格式,捕获了120条轨迹和2822次以程序修复和问题解析为重点的LLM交互。我们的研究结合了结构性属性、行动模式和令牌使用量的定量分析,以及与推理连贯性和反馈整合的定性评估。我们确定了关键轨迹特征,如迭代次数和令牌消耗、重复的行动序列,以及链接思想、行动和结果之间的语义连贯性。我们的研究结果揭示了区分成功执行和失败执行的行为模式和反模式,为改进代理设计提供了可操作的见解,包括提示策略、故障诊断和反模式检测。我们发布我们的数据集和注释框架,以支持对透明和稳健的自主软件工程代理的进一步研究。
论文及项目相关链接
Summary:
大型语言模型(LLM)驱动的代理被广泛应用于自动化复杂的软件工程任务,如程序修复和问题解析。本文进行了大规模实证研究,对三种最新LLM代理(RepairAgent、AutoCodeRover和OpenHands)的思想行动结果轨迹进行研究。通过对结构性质、行动模式、令牌使用量的定量分析,以及推理连贯性和反馈整合的定性评估,研究揭示了关键轨迹特征,包括迭代次数和令牌消耗、重复的行动序列以及思想和行动结果的语义连贯性。这些发现揭示了成功与失败执行的区别,为改进代理设计提供了行动指导,包括提示策略、故障诊断和反模式检测。
Key Takeaways:
- LLM代理被广泛应用于自动化复杂的软件工程任务。
- 三种LLM代理(RepairAgent、AutoCodeRover和OpenHands)的思想行动结果轨迹进行了研究。
- 研究结合了定量和定性的分析方法,包括结构性质、行动模式和令牌使用量的分析以及推理连贯性和反馈整合的评估。
- 研究揭示了关键轨迹特征,包括迭代次数、令牌消耗和行动序列。
- 发现了成功与失败执行的区别,包括行为模式和反模式。
- 研究结果提供了改进代理设计的行动指导,包括提示策略、故障诊断和反模式检测。
点此查看论文截图

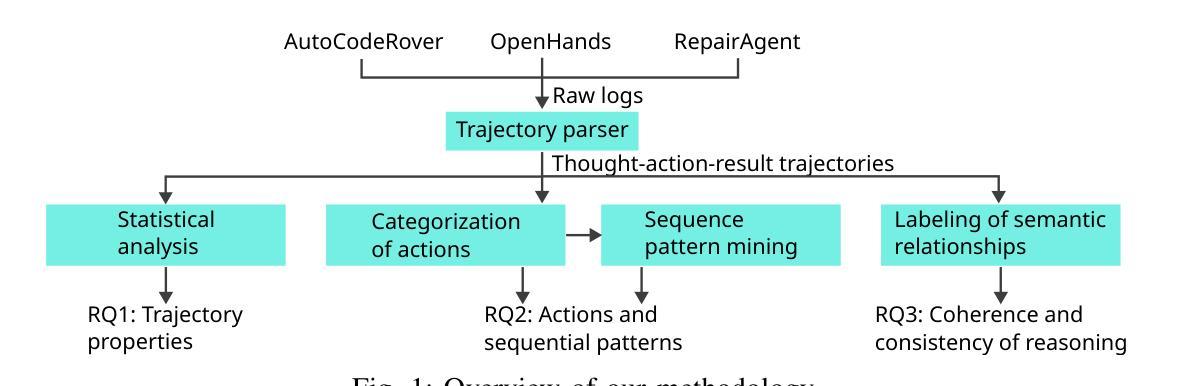

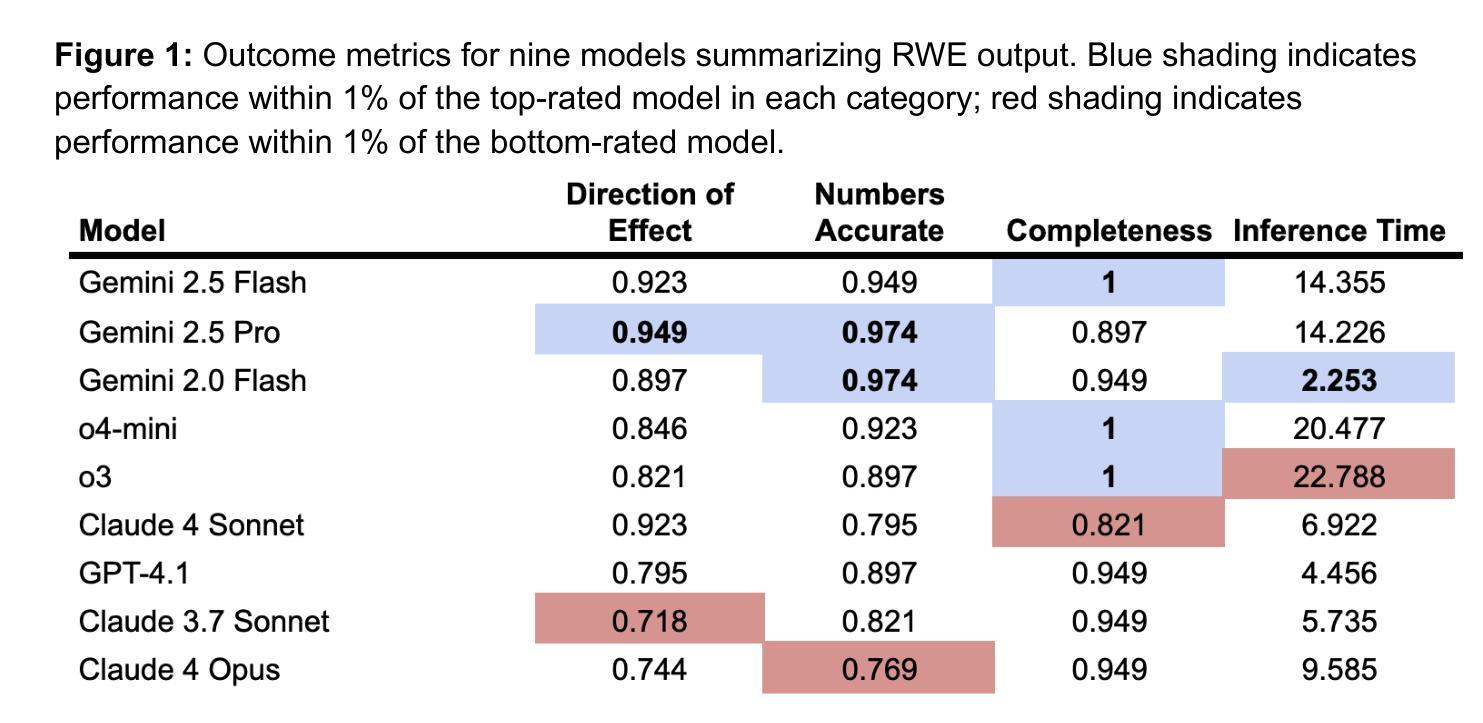
RWESummary: A Framework and Test for Choosing Large Language Models to Summarize Real-World Evidence (RWE) Studies
Authors:Arjun Mukerji, Michael L. Jackson, Jason Jones, Neil Sanghavi
Large Language Models (LLMs) have been extensively evaluated for general summarization tasks as well as medical research assistance, but they have not been specifically evaluated for the task of summarizing real-world evidence (RWE) from structured output of RWE studies. We introduce RWESummary, a proposed addition to the MedHELM framework (Bedi, Cui, Fuentes, Unell et al., 2025) to enable benchmarking of LLMs for this task. RWESummary includes one scenario and three evaluations covering major types of errors observed in summarization of medical research studies and was developed using Atropos Health proprietary data. Additionally, we use RWESummary to compare the performance of different LLMs in our internal RWE summarization tool. At the time of publication, with 13 distinct RWE studies, we found the Gemini 2.5 models performed best overall (both Flash and Pro). We suggest RWESummary as a novel and useful foundation model benchmark for real-world evidence study summarization.
大型语言模型(LLM)已经广泛应用于一般的摘要任务以及医学研究辅助工作,但它们尚未针对从结构化输出中对现实世界的证据(RWE)进行摘要的任务进行专门评估。我们引入了RWESummary,这是MedHELM框架(Bedi、Cui、Fuentes、Unell等人,2025年)的一个拟议补充,以实现对这项任务的LLM基准测试。RWESummary包括一个场景和三种评估,涵盖了医学研究中摘要主要类型的错误,并使用了Atropos Health专有数据开发。此外,我们使用RWESummary来比较内部RWE摘要工具中不同LLM的性能。在发布时,我们分析了1be的差异现实世界研究数据我们发现Gemini 2.5模型表现最好(Flash和Pro两者都是)。我们提议将RWESummary作为摘要现实证据研究的新型且有用的基准模型。
论文及项目相关链接
PDF 24 pages, 2 figures
Summary
大型语言模型(LLM)在通用摘要任务和医疗研究辅助方面已有广泛评估,但未针对从结构化输出对真实世界证据(RWE)的摘要任务进行专门评估。本文引入RWESummary,作为MedHELM框架的补充,以实现对该任务的LLM基准测试。RWESummary包含一种情景和三种评估,涵盖在医疗研究摘要中观察到的主要类型错误,并利用Atropos Health专有数据开发。此外,作者使用RWESummary比较了内部RWE摘要工具中不同LLM的性能。截至出版时,基于13项不同的RWE研究,我们发现Gemini 2.5模型(Flash和Pro)总体表现最佳。我们建议RWESummary作为真实世界证据研究摘要的新型有用基准模型。
Key Takeaways
- 大型语言模型(LLM)在真实世界证据(RWE)摘要任务上的评估尚属空白。
- 本文引入RWESummary,作为MedHELM框架的补充,以实现对RWE摘要任务的LLM基准测试。
- RWESummary涵盖了一种情景和三种评估,旨在捕捉在医疗研究摘要中常见的主要错误类型。
- Atropos Health的专有数据被用于开发RWESummary。
- 不同LLM在内部RWE摘要工具中的性能表现存在差异。
- 在13项不同的RWE研究中,Gemini 2.5模型(Flash和Pro)总体表现最佳。
点此查看论文截图

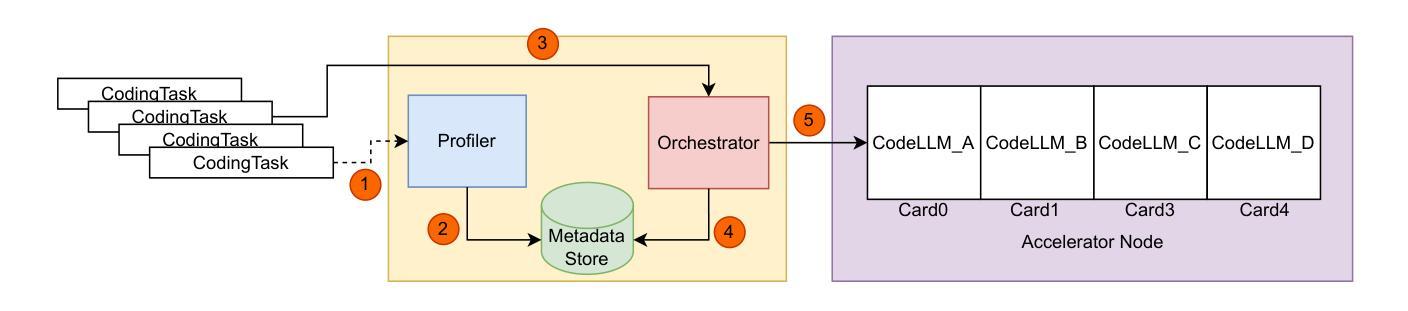
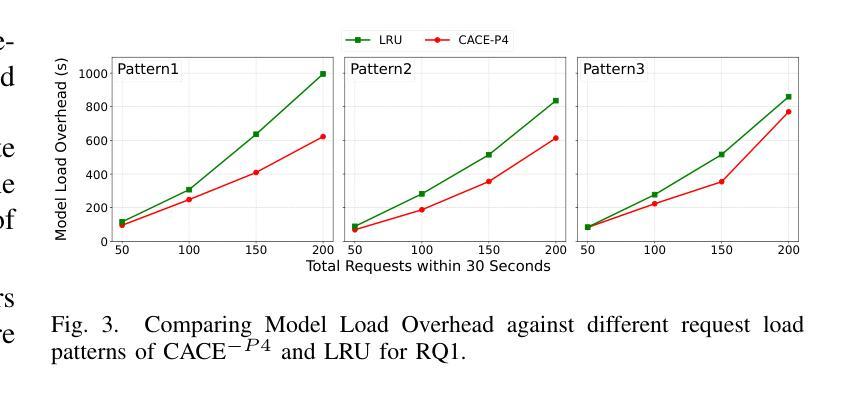
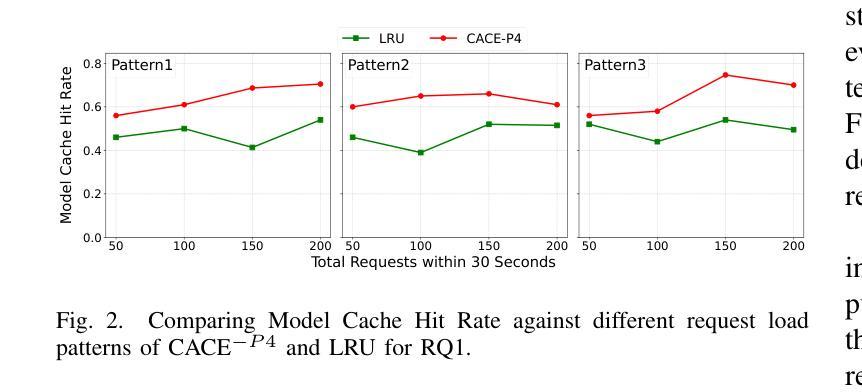
Context-Aware CodeLLM Eviction for AI-assisted Coding
Authors:Kishanthan Thangarajah, Boyuan Chen, Shi Chang, Ahmed E. Hassan
AI-assisted coding tools powered by Code Large Language Models (CodeLLMs) are increasingly integrated into modern software development workflows. To address concerns around privacy, latency, and model customization, many enterprises opt to self-host these models. However, the diversity and growing number of CodeLLMs, coupled with limited accelerator memory, introduce practical challenges in model management and serving efficiency. This paper presents CACE, a novel context-aware model eviction strategy designed specifically to optimize self-hosted CodeLLM serving under resource constraints. Unlike traditional eviction strategies based solely on recency (e.g., Least Recently Used), CACE leverages multiple context-aware factors, including model load time, task-specific latency sensitivity, expected output length, and recent usage and future demand tracked through a sliding window. We evaluate CACE using realistic workloads that include both latency-sensitive code completion and throughput-intensive code reasoning tasks. Our experiments show that CACE reduces Time-to-First-Token (TTFT) and end-to-end (E2E) latency, while significantly lowering the number of model evictions compared to state-of-the-art systems. Ablation studies further demonstrate the importance of multi-factor eviction in balancing responsiveness and resource efficiency. This work contributes practical strategies for deploying scalable, low-latency AI coding assistants in real-world software engineering environments.
由大型语言模型(CodeLLM)驱动的AI辅助编码工具越来越多地被集成到现代软件开发工作流程中。为了解决关于隐私、延迟和模型定制的担忧,许多企业选择自主托管这些模型。然而,CodeLLM的多样性和数量不断增长,加上加速器内存有限,给模型管理和服务效率带来了实际挑战。本文针对资源受限情况下自主托管的CodeLLM服务优化问题,提出了一种新型上下文感知模型驱逐策略CACE。与传统的仅基于时效性的驱逐策略(如最近最少使用)不同,CACE利用多个上下文感知因素,包括模型加载时间、针对任务的延迟敏感性、预期输出长度以及通过滑动窗口跟踪的近期使用情况和未来需求。我们使用包含延迟敏感的代码补全和吞吐量密集的代码推理任务的实际工作负载对CACE进行了评估。实验表明,CACE减少了首次令牌时间(TTFT)和端到端(E2E)延迟,同时与最先进的系统相比,大大降低了模型被驱逐的次数。消融研究进一步证明了多因素驱逐在平衡响应性和资源效率中的重要性。这项工作提出了在现实世界软件工程环境中部署可扩展、低延迟的AI编码助理的实际策略。
论文及项目相关链接
PDF 12 pages, 6 figures
摘要
基于Code Large Language Models(CodeLLM)的AI辅助编码工具正日益融入现代软件开发流程。为了应对隐私、延迟和模型定制等关注点,许多企业选择自主托管这些模型。然而,CodeLLM的多样性和数量增长,以及加速器内存的限制,给模型管理和服务效率带来了实际挑战。本文提出了CACE,一种新型的上下文感知模型逐出策略,旨在优化资源受限下的自主托管CodeLLM服务。与传统的仅基于最近使用情况的逐出策略(如最近最少使用)不同,CACE利用多个上下文感知因素,包括模型加载时间、任务特定的延迟敏感性、预期输出长度以及通过滑动窗口追踪的最近使用情况和未来需求。我们使用包括延迟敏感的代码补全和吞吐量密集的代码推理任务的实际工作负载来评估CACE。实验表明,CACE减少了时间至第一令牌(TTFT)和端到端(E2E)延迟,并且与最先进的系统相比,显著降低了模型逐出的次数。消融研究进一步证明了多因素逐出在平衡响应性和资源效率中的重要性。本研究为在现实世界的软件工程环境中部署可扩展、低延迟的AI编码助手提供了实用策略。
关键见解
- AI辅助编码工具集成到现代软件开发流程中。
- 企业为隐私、延迟和模型定制选择自主托管CodeLLM。
- CodeLLM的多样性和数量增长以及加速器内存限制带来模型管理和服务效率挑战。
- 提出了CACE上下文感知模型逐出策略,优化资源受限下的CodeLLM服务。
- CACE利用上下文感知因素包括模型加载时间、任务延迟敏感性等。
- CACE在延迟敏感的代码补全和吞吐量密集的代码推理任务的实际工作负载评估中表现优越。
- CACE减少了时间至第一令牌和端到端延迟,并显著降低了模型逐出的次数。
点此查看论文截图


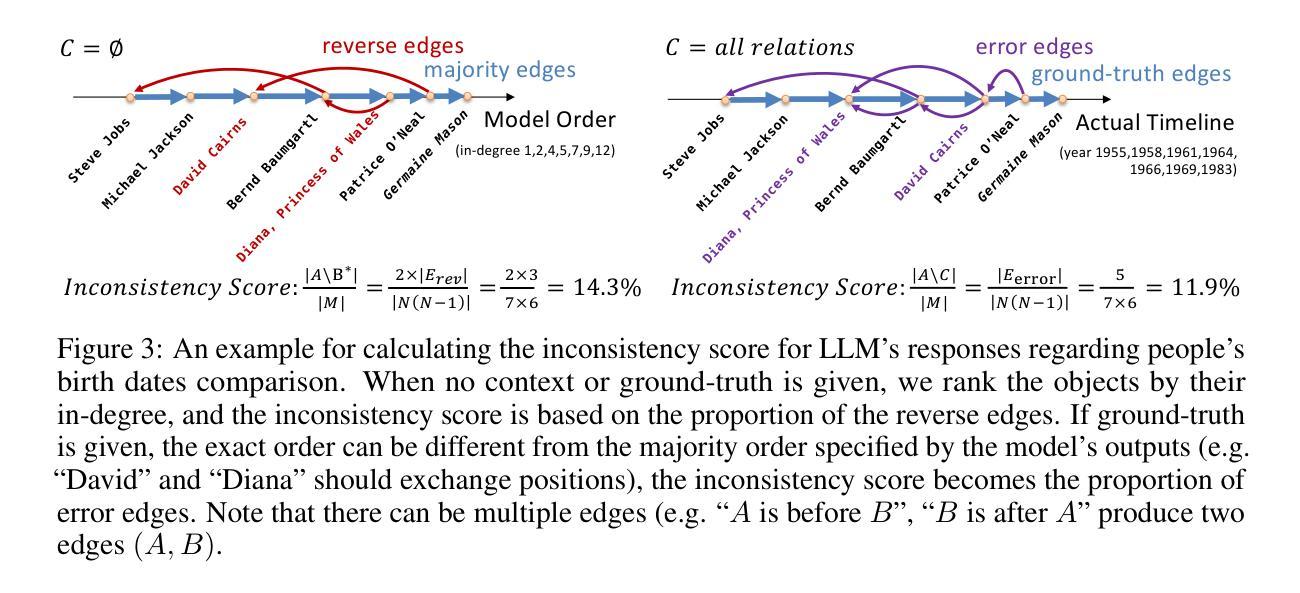
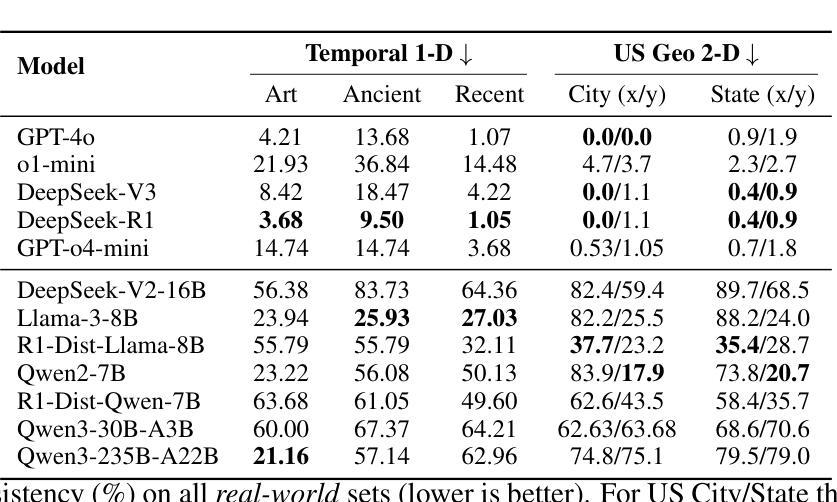
Existing LLMs Are Not Self-Consistent For Simple Tasks
Authors:Zhenru Lin, Jiawen Tao, Yang Yuan, Andrew Chi-Chih Yao
Large Language Models (LLMs) have grown increasingly powerful, yet ensuring their decisions remain transparent and trustworthy requires self-consistency – no contradictions in their internal reasoning. Our study reveals that even on simple tasks, such as comparing points on a line or a plane, or reasoning in a family tree, all smaller models are highly inconsistent, and even state-of-the-art models like DeepSeek-R1 and GPT-o4-mini are not fully self-consistent. To quantify and mitigate these inconsistencies, we introduce inconsistency metrics and propose two automated methods – a graph-based and an energy-based approach. While these fixes provide partial improvements, they also highlight the complexity and importance of self-consistency in building more reliable and interpretable AI. The code and data are available at https://github.com/scorpio-nova/llm-self-consistency.
大型语言模型(LLM)的能力日益增强,但确保它们的决策保持透明和可信需要一致性——在其内部推理中没有矛盾。我们的研究表明,即使在简单的任务,如在线或平面上的点比较,或在家族树中的推理,所有较小模型都存在高度不一致性,甚至最先进的模型如DeepSeek-R1和GPT-o4-mini也不完全具有自身一致性。为了量化和减轻这些不一致性,我们引入了不一致性度量标准,并提出了两种自动化方法——基于图和基于能量的方法。虽然这些修复提供了部分改进,但也突出了在建设更可靠和可解释的AI过程中自我一致性复杂性和重要性。相关代码和数据可在https://github.com/scorpio-nova/llm-self-consistency获取。
论文及项目相关链接
PDF 10 pages, 6 figures
总结
大型语言模型(LLM)的强大性不断提升,但在确保它们决策的透明度和可信度方面,需要它们内部推理的一致性,即自我一致性。本研究发现,即使在简单的任务中,如在线或平面上的点比较,或在家族树中进行推理,所有小型模型都存在高度不一致性,甚至最先进的模型如DeepSeek-R1和GPT-o4-mini也无法完全实现自我一致性。为了量化和缓解这些不一致性,我们引入了不一致性指标,并提出了两种自动化方法——基于图和基于能量的方法。虽然这些修复提供了部分改进,但也突显了自我一致性在构建更可靠和可解释的AI中的重要性及复杂性。相关代码和数据可在https://github.com/scorpio-nova/llm-self-consistency上找到。
关键见解
- 大型语言模型(LLMs)在简单任务中也存在自我一致性方面的问题。
- 最先进的模型如DeepSeek-R1和GPT-o4-mini并不能完全实现自我一致性。
- 为解决这些不一致性,研究引入了不一致性指标。
- 提出两种自动化方法:基于图的方法和基于能量的方法。
- 这些方法虽能部分改善不一致性问题,但自我一致性仍是构建更可靠和可解释的AI的关键挑战。
- 自我一致性的重要性在于它能提高AI的透明度和可信度。
- 相关代码和数据已在指定平台上公开,供进一步研究使用。
点此查看论文截图


Benchmarking the Pedagogical Knowledge of Large Language Models
Authors:Maxime Lelièvre, Amy Waldock, Meng Liu, Natalia Valdés Aspillaga, Alasdair Mackintosh, María José Ogando Portelo, Jared Lee, Paul Atherton, Robin A. A. Ince, Oliver G. B. Garrod
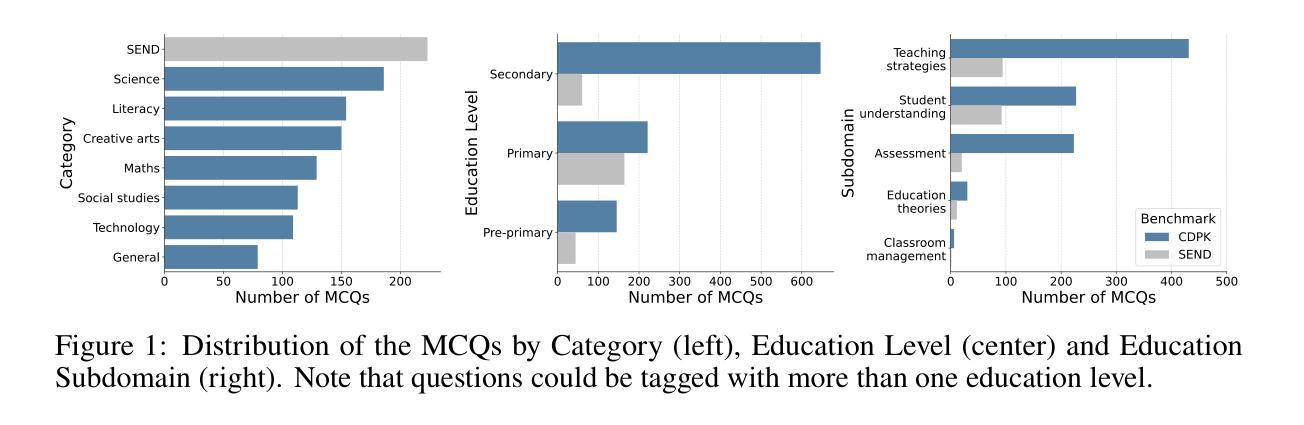
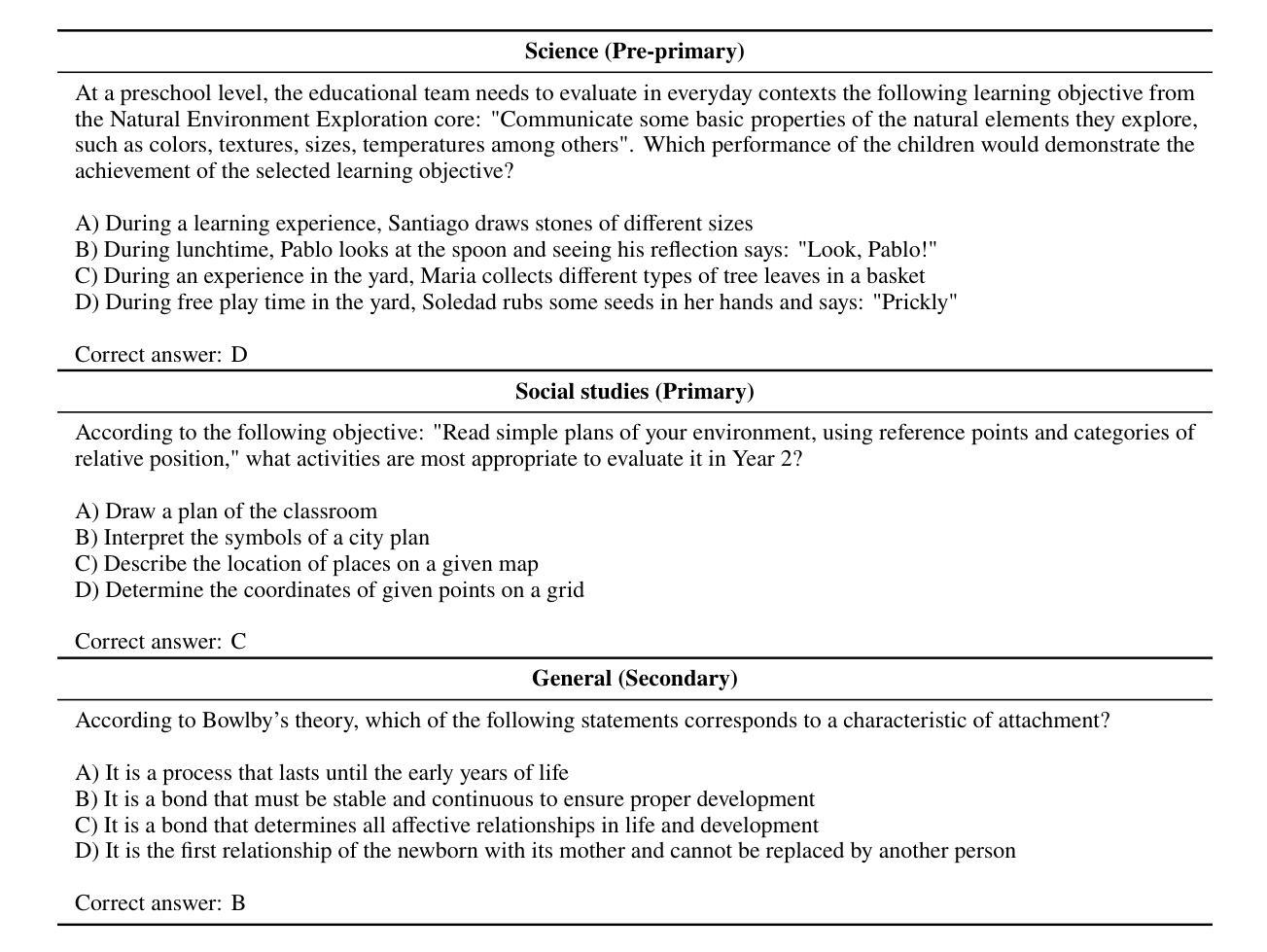
Benchmarks like Massive Multitask Language Understanding (MMLU) have played a pivotal role in evaluating AI’s knowledge and abilities across diverse domains. However, existing benchmarks predominantly focus on content knowledge, leaving a critical gap in assessing models’ understanding of pedagogy - the method and practice of teaching. This paper introduces The Pedagogy Benchmark, a novel dataset designed to evaluate large language models on their Cross-Domain Pedagogical Knowledge (CDPK) and Special Education Needs and Disability (SEND) pedagogical knowledge. These benchmarks are built on a carefully curated set of questions sourced from professional development exams for teachers, which cover a range of pedagogical subdomains such as teaching strategies and assessment methods. Here we outline the methodology and development of these benchmarks. We report results for 97 models, with accuracies spanning a range from 28% to 89% on the pedagogical knowledge questions. We consider the relationship between cost and accuracy and chart the progression of the Pareto value frontier over time. We provide online leaderboards at https://rebrand.ly/pedagogy which are updated with new models and allow interactive exploration and filtering based on various model properties, such as cost per token and open-vs-closed weights, as well as looking at performance in different subjects. LLMs and generative AI have tremendous potential to influence education and help to address the global learning crisis. Education-focused benchmarks are crucial to measure models’ capacities to understand pedagogical concepts, respond appropriately to learners’ needs, and support effective teaching practices across diverse contexts. They are needed for informing the responsible and evidence-based deployment of LLMs and LLM-based tools in educational settings, and for guiding both development and policy decisions.
像大规模多任务语言理解(MMLU)这样的基准测试在评估人工智能在不同领域的知识和能力方面发挥了至关重要的作用。然而,现有的基准测试主要集中在内容知识上,在评估模型对教学方法的理解方面存在重大空白——教学方法和实践。本文介绍了《教学基准测试》,这是一个新型数据集,旨在评估大型语言模型在跨域教学知识(CDPK)和特殊教育需求与残疾(SEND)教学知识方面的能力。这些基准测试建立在从教师职业发展考试中精心挑选的问题集上,涵盖了教学策略和评估方法等一系列教学子领域。在这里,我们概述了这些基准测试的方法论和发展。我们报告了97个模型的结果,在教学知识问题上的准确率从28%到89%不等。我们考虑了成本与准确率之间的关系,并绘制了随时间推移的帕累托价值前沿的进展。我们提供了在线排行榜https://rebrand.ly/pedagogy,该排行榜会随新模型的加入而更新,并可根据各种模型属性进行互动探索和过滤,如每令牌的成本和开放与封闭权重,以及在不同科目中的表现。大型语言模型和生成式人工智能对教育和帮助应对全球学习危机具有巨大潜力。以教育为重点的基准测试对于衡量模型理解教学概念的能力、适当响应学习者的需求以及在各种背景下支持有效教学实践至关重要。它们对于在教育环境中负责任和基于证据地部署大型语言模型和大型语言模型工具,以及指导开发和政策决策都至关重要。
论文及项目相关链接
摘要
本文介绍了新的基准测试——教学基准测试,该基准测试是通过一组专业教师发展考试的问题构建的,旨在评估大型语言模型在跨域教学知识(CDPK)和特殊教育与残疾(SEND)教学知识方面的能力。文章概述了该方法论和这些基准测试的开发过程,并报告了97个模型在教学知识问题上的准确率,范围从28%到89%。文章还考虑了成本与准确率之间的关系,并随着时间的推移记录了帕累托价值前沿的进展。评估和排名可以在在线排行榜找到。教育领域的基准测试对于衡量大型语言模型理解教学概念的能力、适当响应学习者需求的能力以及支持不同背景下的有效教学实践的能力至关重要。它们对于在教育环境中负责任和循证地部署大型语言模型以及指导开发和政策决策是必要的。
关键见解
- 大型语言模型在教学领域的知识理解评估中存在一个重大差距。现有基准测试主要关注内容知识,而忽视了对教学方法的评估。为此本文引入新的教学基准测试进行评估。该基准测试涉及多个领域的教学知识,如教学方法和评估方法等。
- 教学基准测试是基于教师职业发展考试的问题构建的,这些问题覆盖了广泛的教学领域,包括教学策略、评估方法等。这为评估大型语言模型在教学知识方面的能力提供了依据。
- 在教学知识问题的测试中,模型的准确率差异很大,范围从28%到89%,这表明大型语言模型在教学领域的理解和表现水平有很大差异。这为研究者提供了模型性能的比较依据。此外还考虑了成本和准确率之间的关系,以及帕累托价值前沿的进展趋势分析。这为模型开发者提供了重要的决策依据。
点此查看论文截图


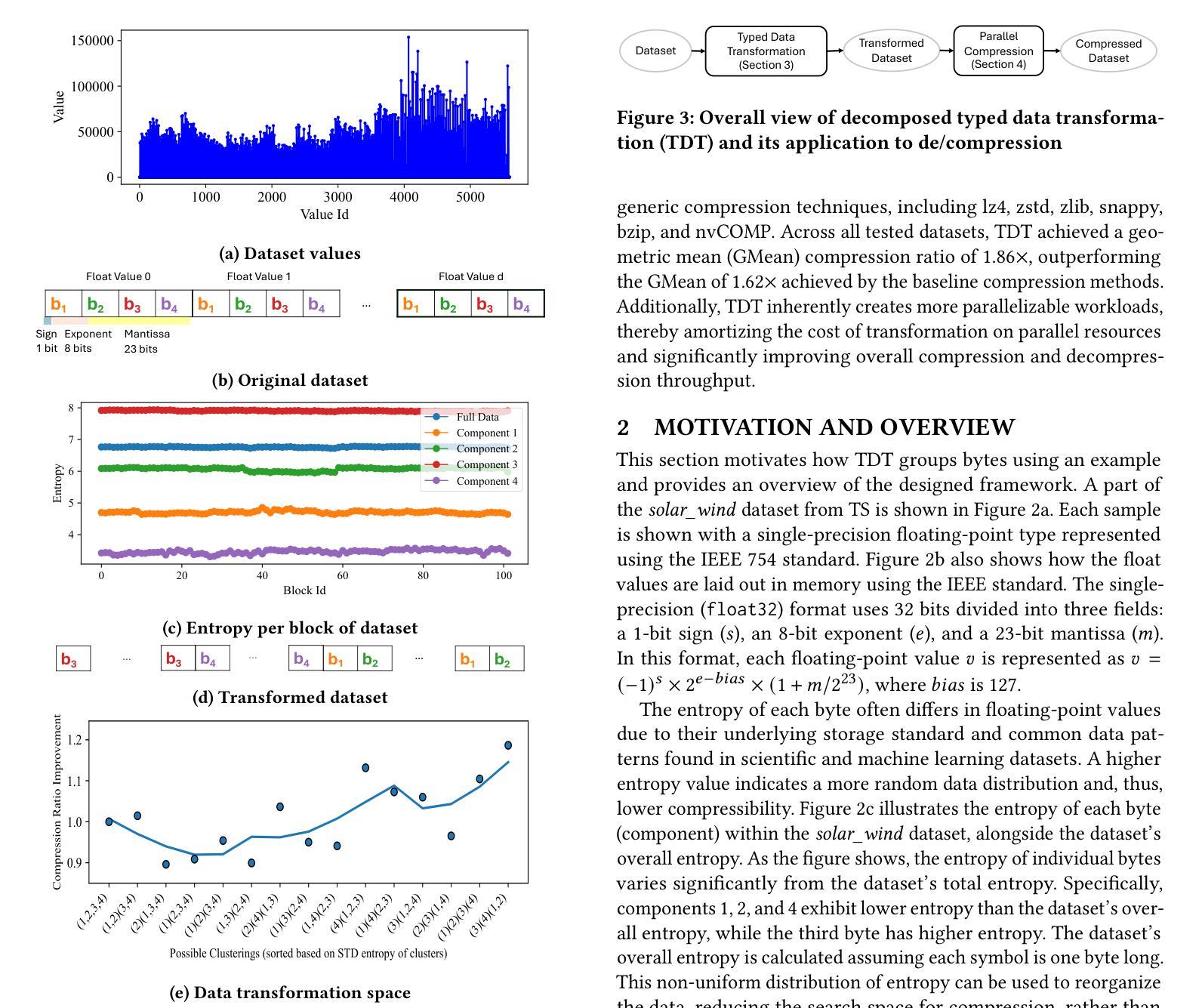
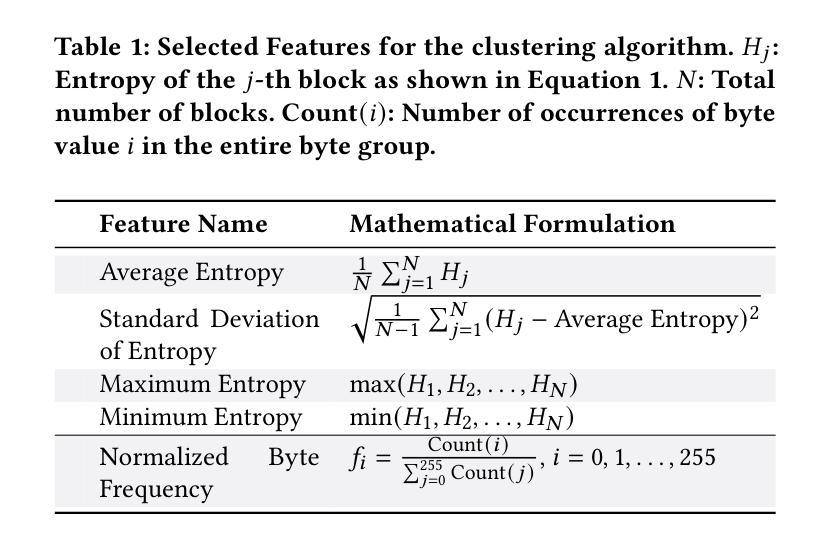
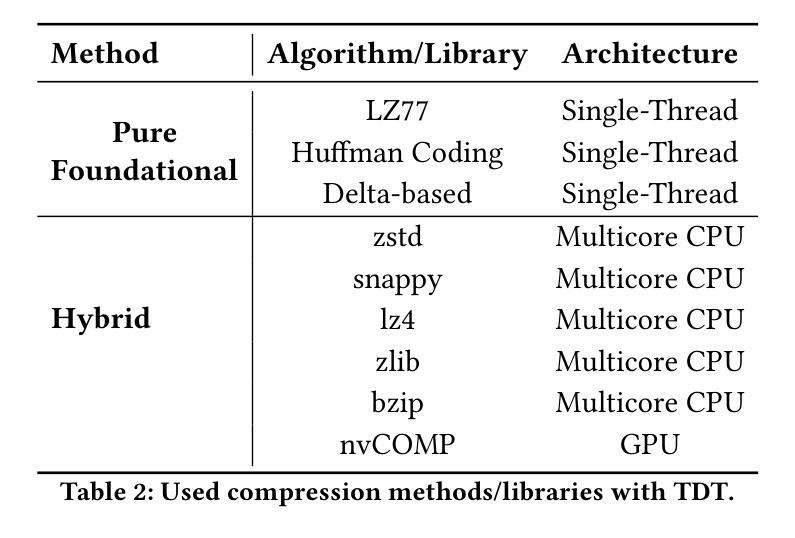
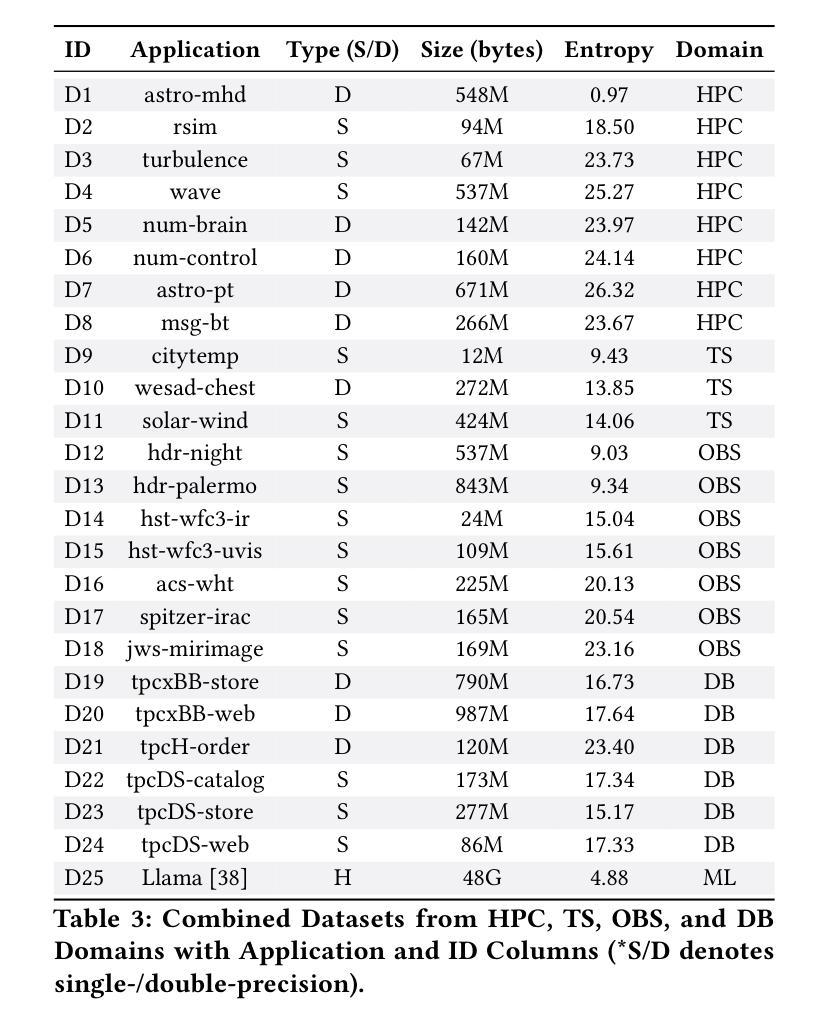
Floating-Point Data Transformation for Lossless Compression
Authors:Samirasadat Jamalidinan, Kazem Cheshmi
Floating-point data is widely used across various domains. Depending on the required precision, each floating-point value can occupy several bytes. Lossless storage of this information is crucial due to its critical accuracy, as seen in applications such as medical imaging and language model weights. In these cases, data size is often significant, making lossless compression essential. Previous approaches either treat this data as raw byte streams for compression or fail to leverage all patterns within the dataset. However, because multiple bytes represent a single value and due to inherent patterns in floating-point representations, some of these bytes are correlated. To leverage this property, we propose a novel data transformation method called Typed Data Transformation (\DTT{}) that groups related bytes together to improve compression. We implemented and tested our approach on various datasets across both CPU and GPU. \DTT{} achieves a geometric mean compression ratio improvement of 1.16$\times$ over state-of-the-art compression tools such as zstd, while also improving both compression and decompression throughput by 1.18–3.79$\times$.
浮点数据在各个领域都有广泛应用。根据所需的精度,每个浮点值可能会占用多个字节。由于其在医疗成像和语言模型权重等应用中的关键准确性,这种信息的无损存储至关重要。在这些情况下,数据大小往往很大,因此无损压缩变得至关重要。以前的方法要么将这种数据视为原始字节流进行压缩,要么未能利用数据集中的所有模式。然而,由于多个字节代表一个值,并且由于浮点表示中的固有模式,这些字节中的某些是相互关联的。为了利用这一特性,我们提出了一种新型数据转换方法,称为Typed Data Transformation(DTT),它将相关字节组合在一起以提高压缩效果。我们在CPU和GPU上的各种数据集上实现了并测试了我们的方法。DTT与最新的压缩工具(如zstd)相比,实现了几何平均压缩比提高1.16倍,同时提高了压缩和解压缩吞吐量的1.18-3.79倍。
论文及项目相关链接
Summary
本文介绍了浮点数数据在各个领域中的广泛应用,以及对其进行无损存储和压缩的重要性。针对浮点数数据的特点,提出了一种新型的数据转换方法——Typed Data Transformation(DTT),该方法能够利用浮点数内在的模式和相关性,将相关字节分组以提高压缩效率。实验结果表明,DTT方法在CPU和GPU上的数据集压缩效率较现有工具(如zstd)平均提高了1.16倍,并提升了压缩和解压缩的速度。
Key Takeaways
- 浮点数数据在医疗成像和语言模型权重等应用中,由于其精确度要求,无损存储非常重要。
- 现有方法在处理浮点数数据时存在局限性,无法充分利用数据中的模式。
- 浮点数数据中的多个字节代表一个值,这些字节之间存在相关性。
- 提出了一种新的数据转换方法——Typed Data Transformation(DTT),利用浮点数数据中的相关字节以提高压缩效率。
- DTT方法实现了对浮点数数据的无损压缩,并提高了压缩和解压缩的速度。
- DTT方法在CPU和GPU上的实验结果表明,其压缩效率较现有工具平均提高了1.16倍。
点此查看论文截图


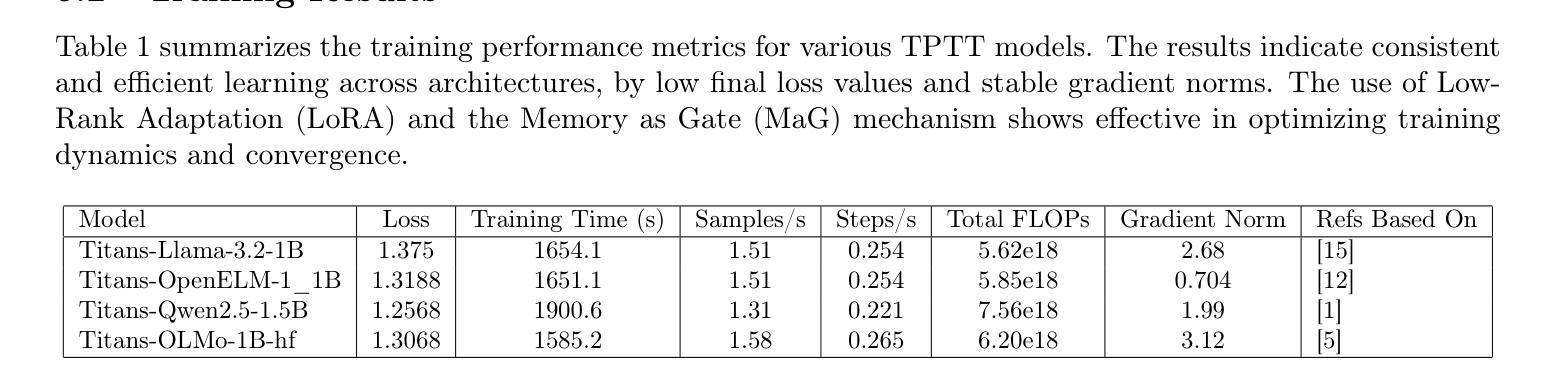
TPTT: Transforming Pretrained Transformer into Titans
Authors:Fabien Furfaro
Recent advances in large language models (LLMs) have led to remarkable progress in natural language processing, but their computational and memory demands remain a significant challenge, particularly for long-context inference. We introduce TPTT (Transforming Pretrained Transformer into Titans), a novel framework for enhancing pretrained Transformer models with efficient linearized attention mechanisms and advanced memory management. TPTT employs techniques such as Memory as Gate (MaG) and mixed linearized attention (LiZA). It is fully compatible with the Hugging Face Transformers library, enabling seamless adaptation of any causal LLM through parameter-efficient fine-tuning (LoRA) without full retraining. We show the effectiveness of TPTT on the MMLU benchmark with models of approximately 1 billion parameters, observing substantial improvements in both efficiency and accuracy. For instance, Titans-Llama-3.2-1B achieves a 20% increase in Exact Match (EM) over its baseline. Statistical analyses and comparisons with recent state-of-the-art methods confirm the practical scalability and robustness of TPTT. Code is available at https://github.com/fabienfrfr/tptt . Python package at https://pypi.org/project/tptt/ .
近期大型语言模型(LLM)的进步在自然语言处理方面取得了显著成效,但其计算和内存需求仍然是一个巨大挑战,尤其是对长文本上下文推理而言。我们介绍了TPTT(将预训练Transformer转化为巨人)这一新型框架,它通过高效的线性化注意力机制和先进的内存管理来增强预训练的Transformer模型。TPTT采用诸如Memory as Gate(MaG)和混合线性化注意力(LiZA)等技术。它完全兼容Hugging Face Transformers库,通过参数高效的微调(LoRA)无缝适应任何因果LLM,无需进行全面再训练。我们在MMLU基准测试上展示了TPTT的有效性,该测试使用的模型参数大约1亿,在效率和准确性方面都取得了显著改进。例如,Titans-Llama-3.2-1B在精确匹配(EM)方面实现了比其基准模型高出20%的改进。与最新最先进的方法的统计分析和比较,证实了TPTT的实际可扩展性和稳健性。代码可在[https://github.com/fabienfrfr/tptt找到。Python软件包可在https://pypi.org/project/tptt/。]
论文及项目相关链接
PDF 6 pages, 1 figure
Summary
本文介绍了大型语言模型(LLM)的最新进展,虽然自然语言处理取得了显著进步,但计算和内存需求仍然是一个挑战,特别是对于长文本推理。为此,文章提出了一种新型框架TPTT(Transforming Pretrained Transformer into Titans),通过有效的线性化注意力机制和先进的内存管理增强预训练Transformer模型。TPTT采用Memory as Gate(MaG)和混合线性化注意力(LiZA)等技术,与Hugging Face Transformers库完全兼容,可通过参数高效微调(LoRA)无缝适应任何因果LLM,无需全面重新训练。在MMLU基准测试上,TPTT表现出卓越的效果,尤其是模型参数约为十亿的大型模型,在效率和准确性方面均有显著提高。例如,“Titans-Llama-3.2-1B”模型的精确匹配(EM)提高了20%。统计分析和与最新最先进的技术的比较证明了TPTT的实际可扩展性和稳健性。代码可在https://github.com/fabienfrfr/tptt找到。Python包可在https://pypi.org/project/tptt/获取。
Key Takeaways
- TPTT框架用于增强预训练Transformer模型,通过有效的线性化注意力机制和先进的内存管理提高性能。
- TPTT采用Memory as Gate (MaG) 和混合线性化注意力(LiZA)技术。
- TPTT与Hugging Face Transformers库兼容,可无缝适应任何因果LLM。
- TPTT通过参数高效微调(LoRA)实现,无需全面重新训练模型。
- 在MMLU基准测试中,TPTT表现卓越,尤其在大型模型上显著提高了效率和准确性。
- “Titans-Llama-3.2-1B”模型的精确匹配度较基线提高了20%。
点此查看论文截图

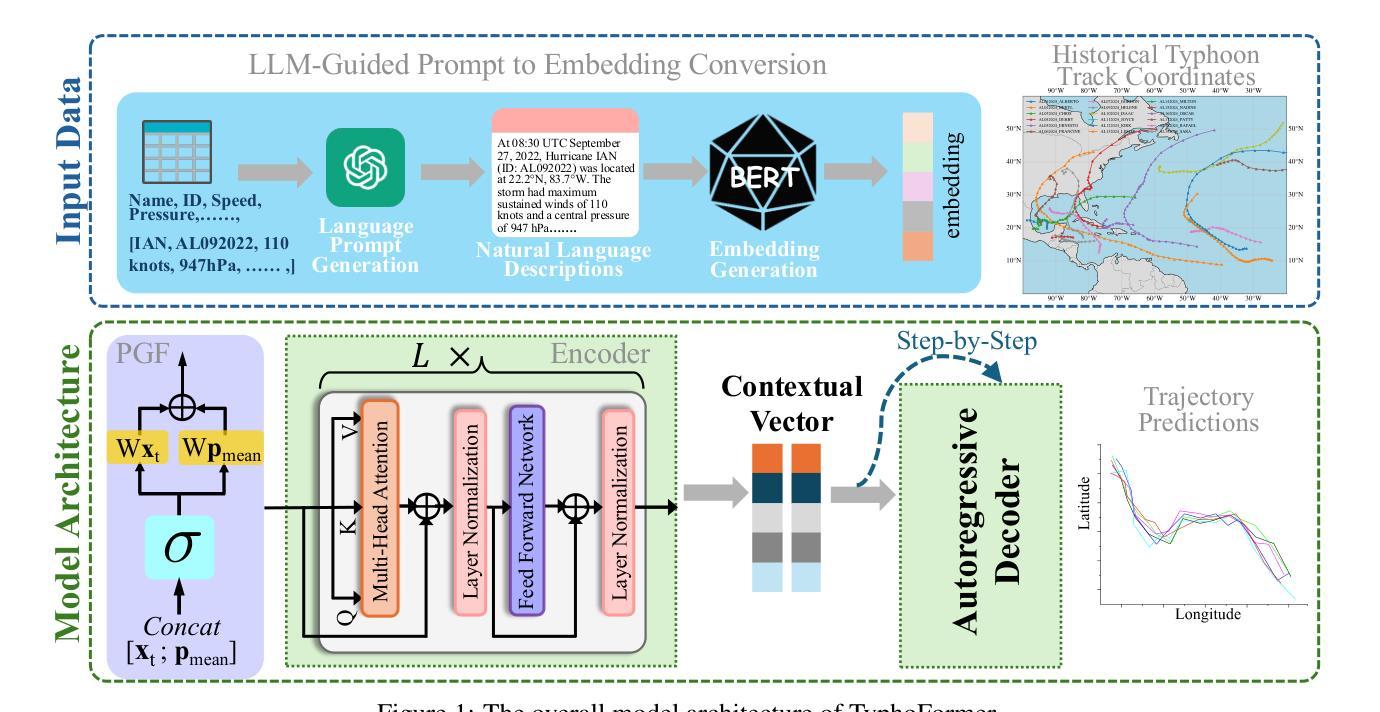
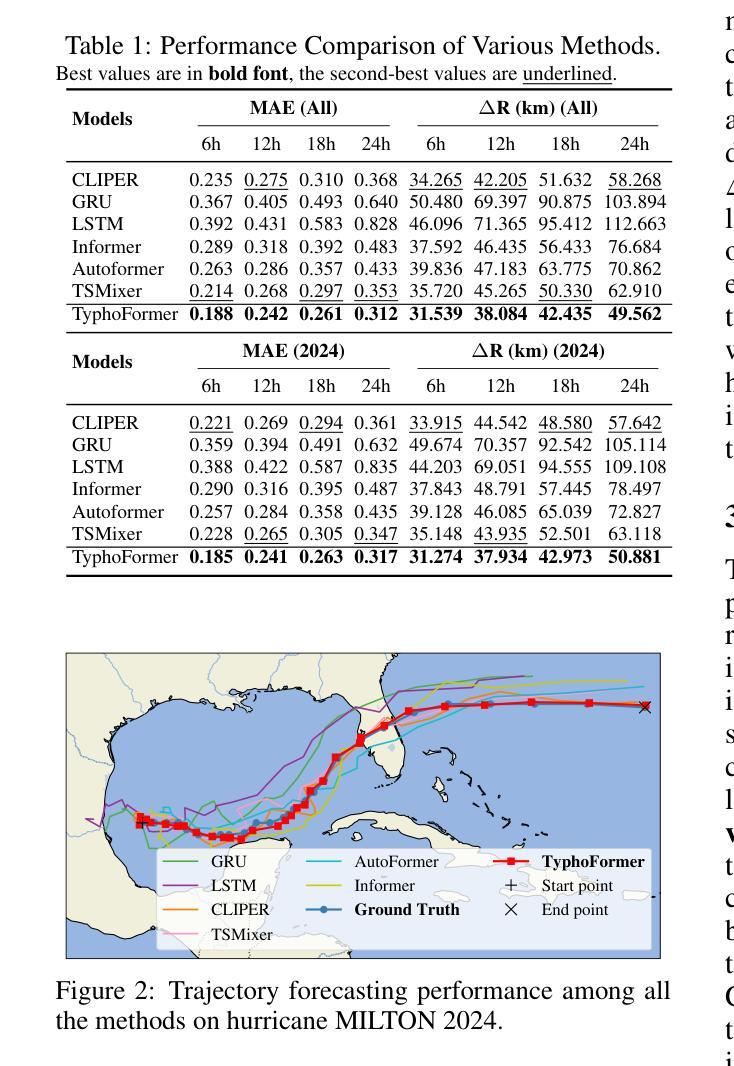
TyphoFormer: Language-Augmented Transformer for Accurate Typhoon Track Forecasting
Authors:Lincan Li, Eren Erman Ozguven, Yue Zhao, Guang Wang, Yiqun Xie, Yushun Dong
Accurate typhoon track forecasting is crucial for early system warning and disaster response. While Transformer-based models have demonstrated strong performance in modeling the temporal dynamics of dense trajectories of humans and vehicles in smart cities, they usually lack access to broader contextual knowledge that enhances the forecasting reliability of sparse meteorological trajectories, such as typhoon tracks. To address this challenge, we propose TyphoFormer, a novel framework that incorporates natural language descriptions as auxiliary prompts to improve typhoon trajectory forecasting. For each time step, we use Large Language Model (LLM) to generate concise textual descriptions based on the numerical attributes recorded in the North Atlantic hurricane database. The language descriptions capture high-level meteorological semantics and are embedded as auxiliary special tokens prepended to the numerical time series input. By integrating both textual and sequential information within a unified Transformer encoder, TyphoFormer enables the model to leverage contextual cues that are otherwise inaccessible through numerical features alone. Extensive experiments are conducted on HURDAT2 benchmark, results show that TyphoFormer consistently outperforms other state-of-the-art baseline methods, particularly under challenging scenarios involving nonlinear path shifts and limited historical observations.
精确预测台风路径对于早期系统预警和灾害应对至关重要。虽然基于Transformer的模型在模拟智能城市中人类和车辆的密集轨迹的时间动态方面表现出强大的性能,但它们通常无法获取更广泛的上下文知识,这有助于提高稀疏气象轨迹的预测可靠性,例如台风路径。为了解决这一挑战,我们提出了TyphFormer,这是一个新的框架,它利用自然语言描述作为辅助提示来提高台风轨迹的预测能力。对于每个时间点,我们使用大型语言模型(LLM)根据北大西洋飓风数据库记录的数值属性生成简洁的文本描述。这些语言描述捕捉了高级气象语义,并被嵌入作为辅助特殊令牌附加到数值时间序列输入中。通过在统一的Transformer编码器内整合文本和时序信息,TyphFormer使模型能够利用无法通过数值特征单独访问的上下文线索。在HURDAT2基准测试上进行了大量实验,结果表明,TyphFormer持续优于其他最先进的基础方法,特别是在涉及非线性路径变化和有限历史观测的具有挑战性的场景中表现尤其出色。
论文及项目相关链接
Summary
本文提出一种名为TyphoFormer的新型框架,用于结合自然语言描述作为辅助提示,以提高台风轨迹预测的准确性。该框架利用大型语言模型(LLM)生成基于北大西洋飓风数据库中数值属性的简洁文本描述,捕捉高级气象语义,并将其嵌入作为辅助特殊令牌附加到数值时间序列输入中。通过在一个统一的Transformer编码器内整合文本和时序信息,TyphoFormer使模型能够利用仅通过数值特征无法获取的上下文线索。在HURDAT2基准测试上的实验结果表明,TyphoFormer始终优于其他先进的基础方法,特别是在涉及非线性路径变化和有限历史观测的具有挑战性的场景中。
Key Takeaways
- 台风轨迹准确预测对早期系统预警和灾害应对至关重要。
- Transformer模型在智能城市中对人和车辆的密集轨迹建模表现出强大的性能,但在缺乏广泛气象背景知识的情境下,对于稀疏气象轨迹的预测可靠性有待提高。
- TyphoFormer框架结合了自然语言描述作为辅助提示,旨在提高台风轨迹预测的准确性。
- 利用大型语言模型(LLM)生成基于数值属性的文本描述,捕捉高级气象语义信息。
- 通过嵌入辅助特殊令牌到数值时间序列输入中,TyphoFormer整合了文本和时序信息。
- 实验结果表明,TyphoFormer在HURDAT2基准测试中表现优异,特别是在处理非线性路径变化和有限历史观测等挑战场景时。
点此查看论文截图

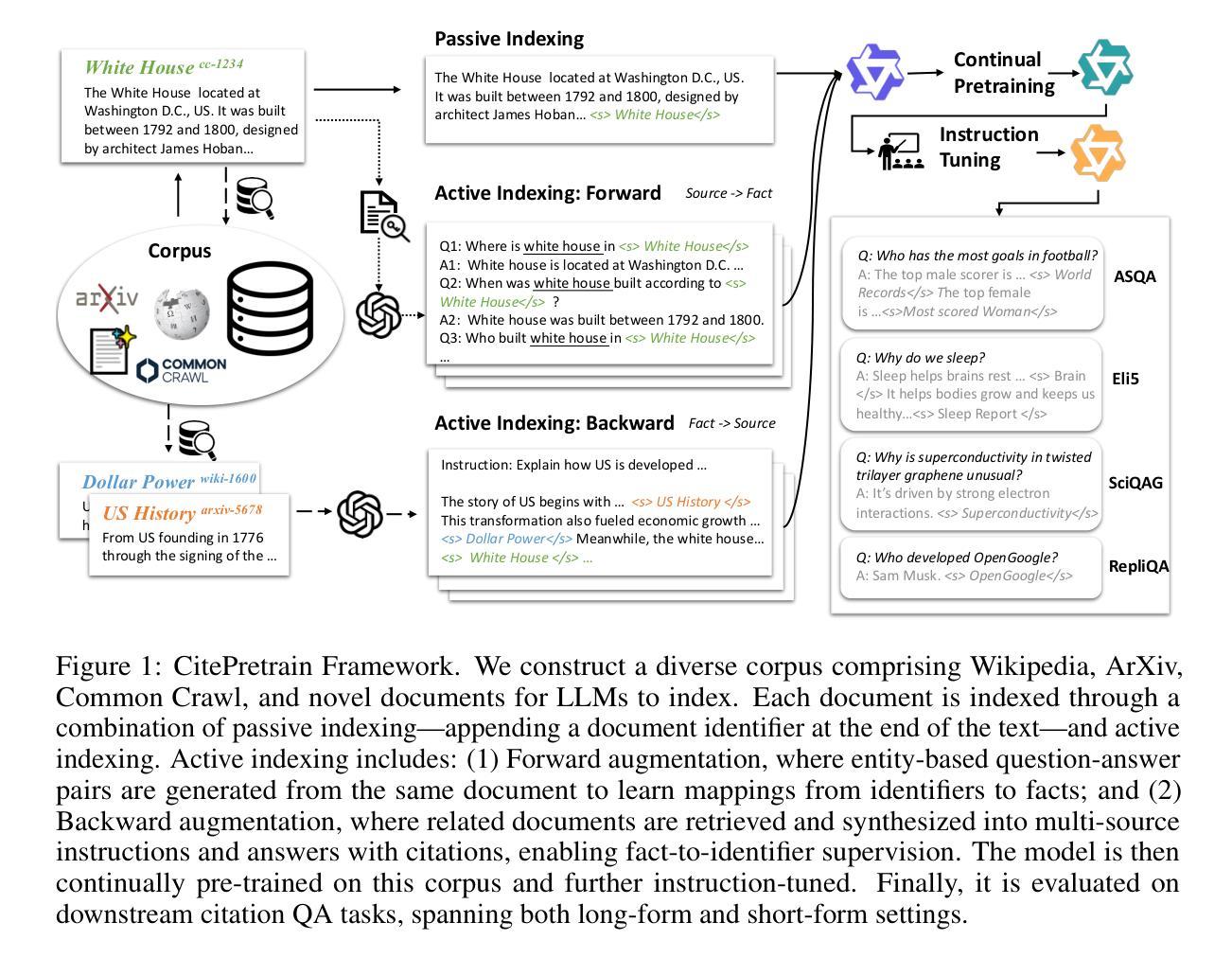
Cite Pretrain: Retrieval-Free Knowledge Attribution for Large Language Models
Authors:Yukun Huang, Sanxing Chen, Jian Pei, Manzil Zaheer, Bhuwan Dhingra
Trustworthy language models should provide both correct and verifiable answers. While language models can sometimes attribute their outputs to pretraining data, their citations are often unreliable due to hallucination. As a result, current systems insert citations by querying an external retriever at inference time, introducing latency, infrastructure dependence, and vulnerability to retrieval noise. We explore whether LLMs can be made to reliably attribute to the documents seen during (continual) pretraining–without test-time retrieval–by revising the training process. To evaluate this, we release CitePretrainBench, a benchmark that mixes real-world corpora (Wikipedia, Common Crawl, arXiv) with novel, unseen documents and probes both short-form (single fact) and long-form (multi-fact) citation tasks. Our approach follows a two-stage process: (1) continual pretraining to bind facts to persistent document identifiers, and (2) instruction tuning to elicit citation behavior. We find that simple Passive Indexing, which appends an identifier to each document, helps memorize verbatim text but fails on paraphrased or compositional facts. Instead, we propose Active Indexing, which continually pretrains on synthetic QA pairs that (1) restate each fact in diverse compositional forms, and (2) require bidirectional source-to-fact and fact-to-source generation, jointly teaching the model to generate content from a cited source and to attribute its own answers. Experiments with Qwen2.5-7B and 3B show that Active Indexing consistently outperforms Passive Indexing across all tasks and models, with citation precision gains up to 30.2 percent. Our ablation studies reveal that performance continues to improve as we scale the amount of augmented data, showing a clear upward trend even at 16 times the original token count.
可信赖的语言模型应该提供正确且可验证的答案。虽然语言模型有时会将它们的输出归功于预训练数据,但由于幻觉,它们的引用通常不可靠。因此,当前的系统会在推理时查询外部检索器来插入引用,这引入了延迟、对基础设施的依赖以及易受检索噪声影响的问题。我们通过修改训练过程,探索是否能让大型语言模型在(持续)预训练期间可靠地引用所看到的文档,而无需在测试时进行检索。为了评估这一点,我们发布了CitePretrainBench基准测试,它混合了真实语料库(Wikipedia、Common Crawl、arXiv)与新颖且未见过的文档,并探讨了短形式(单事实)和长形式(多事实)的引用任务。我们的方法遵循两阶段过程:(1)持续预训练,以将事实与持久的文档标识符绑定;(2)指令微调以激发引用行为。我们发现简单的被动索引(只是在每个文档后附加一个标识符)有助于记忆逐字文本,但在复述或组合事实上会失败。因此,我们提出了主动索引,它会在合成问答对上持续进行预训练,这些问答对(1)以多样的组合形式重述每个事实;(2)要求进行双向的源到事实、事实到源的生成,共同教导模型从引用的源生成内容并归因其答案。使用Qwen2.5-7B和3B的实验表明,主动索引在所有任务和模型上始终优于被动索引,引用精度提高高达30.2%。我们的消融研究表明,随着增加扩充数据量的规模,性能继续提高,即使在原始标记计数的16倍时,也显示出明显的上升趋势。
论文及项目相关链接
摘要
可信的语言模型应能提供正确且可验证的答案。语言模型有时会将其输出归因于预训练数据,但由于幻觉,其引用往往不可靠。因此,当前系统会在推理时查询外部检索器来插入引用,这引入了延迟、对基础设施的依赖以及易受检索噪声影响的问题。本文探索了通过修改训练过程,是否可以让LLMs可靠地引用在(持续)预训练期间所见的文档,而无需进行测试时检索。为此,我们推出了CitePretrainBench基准测试,它将真实世界语料库(如Wikipedia、Common Crawl、arXiv)与未见的新文档混合,并探讨了短形式(单事实)和长形式(多事实)的引用任务。我们的方法遵循两个阶段的过程:(1)持续预训练,将事实绑定到持久的文档标识符上;(2)指令调整,以激发引用行为。我们发现简单的被动索引(即在每个文档后附加一个标识符)有助于记忆逐字文本,但在转述或组合事实上会失败。相反,我们提出了主动索引,它持续地在合成的问答对上进行预训练,这些问答对(1)以多样的组合形式重述每个事实,(2)需要双向的源到事实和事实到源的生成,共同教导模型从引用的源生成内容并为其答案提供属性。使用Qwen2.5-7B和3B的实验表明,主动索引在所有任务和模型上的表现都一直优于被动索引,引用的精确度提高了高达30.2%。我们的消融研究还表明,随着我们增加扩充的数据量,性能会继续提高,即使在原始标记计数的16倍时,也显示出明显的上升趋势。
Key Takeaways
- 语言模型在提供引用时存在可靠性问题,需要改进训练过程以提高引用的准确性。
- 提出了CitePretrainBench基准测试,用于评估语言模型在引用任务上的性能。
- 被动索引方法有助于记忆逐字文本,但在处理转述或组合事实时效果不佳。
- 主动索引方法通过持续在合成的问答对上预训练,提高语言模型在引用任务上的性能。
- 主动索引在所有任务和模型上的表现均优于被动索引,引用精确度有显著提高。
- 随着使用扩充的数据量的增加,语言模型在引用任务上的性能会持续提高。
点此查看论文截图

LLM-Driven APT Detection for 6G Wireless Networks: A Systematic Review and Taxonomy
Authors:Muhammed Golec, Yaser Khamayseh, Suhib Bani Melhem, Abdulmalik Alwarafy
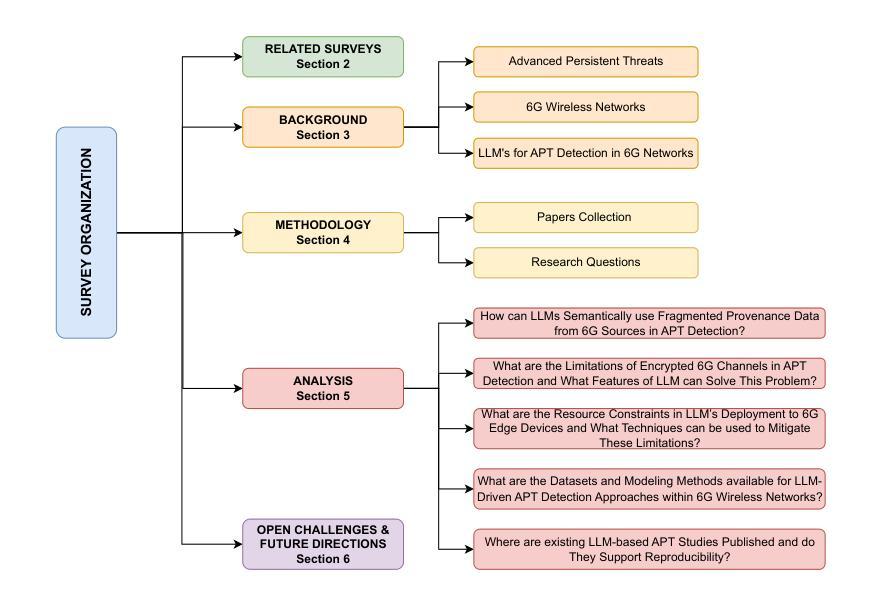
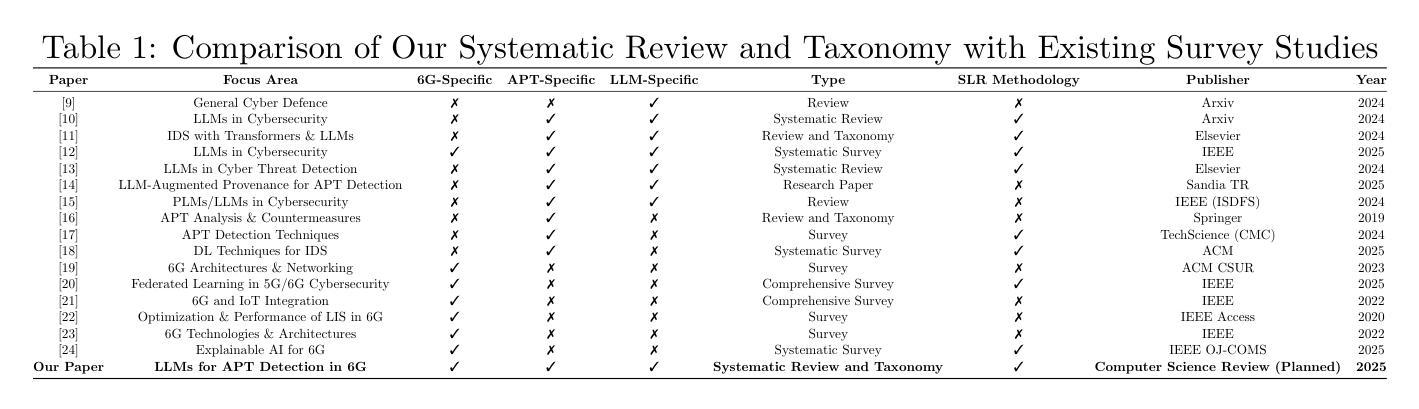
Sixth Generation (6G) wireless networks, which are expected to be deployed in the 2030s, have already created great excitement in academia and the private sector with their extremely high communication speed and low latency rates. However, despite the ultra-low latency, high throughput, and AI-assisted orchestration capabilities they promise, they are vulnerable to stealthy and long-term Advanced Persistent Threats (APTs). Large Language Models (LLMs) stand out as an ideal candidate to fill this gap with their high success in semantic reasoning and threat intelligence. In this paper, we present a comprehensive systematic review and taxonomy study for LLM-assisted APT detection in 6G networks. We address five research questions, namely, semantic merging of fragmented logs, encrypted traffic analysis, edge distribution constraints, dataset/modeling techniques, and reproducibility trends, by leveraging most recent studies on the intersection of LLMs, APTs, and 6G wireless networks. We identify open challenges such as explainability gaps, data scarcity, edge hardware limitations, and the need for real-time slicing-aware adaptation by presenting various taxonomies such as granularity, deployment models, and kill chain stages. We then conclude the paper by providing several research gaps in 6G infrastructures for future researchers. To the best of our knowledge, this paper is the first comprehensive systematic review and classification study on LLM-based APT detection in 6G networks.
关于预计将于本世纪30年代部署的第六代(6G)无线网络,学术界和私营部门已经为之激动不已。这种网络具有极高的通信速度和极低的延迟率。然而,尽管它们具有超低延迟、高吞吐量和人工智能辅助编排能力,但它们仍然容易受到隐蔽且长期存在的持久威胁(APTs)。大型语言模型(LLM)凭借其在语义推理和威胁情报方面的出色表现,成为了填补这一空白的理想选择。在本文中,我们对LLM辅助的APT检测在6G网络中的研究进行了全面的系统审查和分类研究。通过利用关于LLM、APT和6G无线网络交叉领域的最新研究,我们回答了五个研究问题,即碎片化日志的语义合并、加密流量分析、边缘分布约束、数据集/建模技术和可重复性趋势。我们确定了开放性的挑战,如解释性差距、数据稀缺、边缘硬件限制和实时切片感知适应的需求等,并提出了各种分类方法,如粒度、部署模型和杀伤链阶段。最后,本文总结了未来研究人员在6G基础设施中的研究空白。据我们所知,本文是关于基于LLM的APT检测在6G网络中的首个全面系统审查和分类研究。
论文及项目相关链接
PDF 22 pages, 11 figures, 8 tables. Submitted to Computer Science Review (Elsevier), May 2025
摘要
LLM模型可填补当前技术的缺陷并加强安全策略部署于动态多变的网络环境中。本文对LLM辅助APT检测在6G网络中的综合系统审查与分类进行研究,探讨了五大研究问题,并指出了多项开放挑战和未来的研究空白。这一研究的目的是为了开创更稳健且可持续的网络技术时代,强化APT攻击的威胁管理并减少其对系统的威胁影响。此项研究极具创新性和实用性价值。通过本研究可为未来研究人员在相关技术的研究中提供有益的参考。该论文填补了相关领域研究的空白,是目前对LLM在检测基于APT威胁中的首次综合系统审查与分类研究。
关键见解
- LLM模型在语义推理和威胁情报方面表现出卓越的能力,成为应对APT攻击的理想选择。这些模型对于提高6G网络的安全性至关重要。
点此查看论文截图

InstructAttribute: Fine-grained Object Attributes editing with Instruction
Authors:Xingxi Yin, Jingfeng Zhang, Yue Deng, Zhi Li, Yicheng Li, Yin Zhang
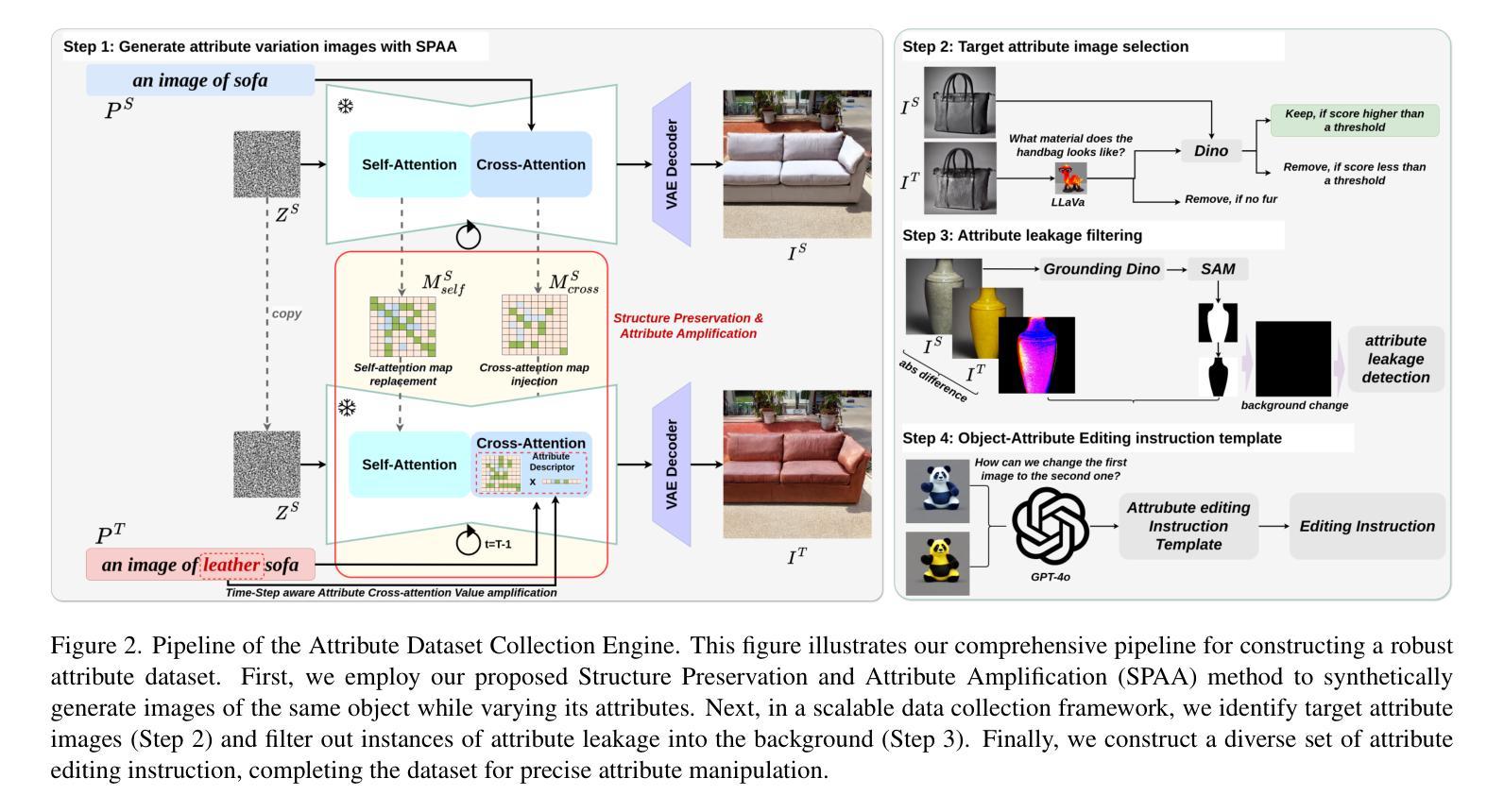
Text-to-image (T2I) diffusion models are widely used in image editing due to their powerful generative capabilities. However, achieving fine-grained control over specific object attributes, such as color and material, remains a considerable challenge. Existing methods often fail to accurately modify these attributes or compromise structural integrity and overall image consistency. To fill this gap, we introduce Structure Preservation and Attribute Amplification (SPAA), a novel training-free framework that enables precise generation of color and material attributes for the same object by intelligently manipulating self-attention maps and cross-attention values within diffusion models. Building on SPAA, we integrate multi-modal large language models (MLLMs) to automate data curation and instruction generation. Leveraging this object attribute data collection engine, we construct the Attribute Dataset, encompassing a comprehensive range of colors and materials across diverse object categories. Using this generated dataset, we propose InstructAttribute, an instruction-tuned model that enables fine-grained and object-level attribute editing through natural language prompts. This capability holds significant practical implications for diverse fields, from accelerating product design and e-commerce visualization to enhancing virtual try-on experiences. Extensive experiments demonstrate that InstructAttribute outperforms existing instruction-based baselines, achieving a superior balance between attribute modification accuracy and structural preservation.
文本到图像(T2I)扩散模型因其强大的生成能力而广泛应用于图像编辑。然而,实现对特定对象属性(如颜色和材质)的精细控制仍然存在相当大的挑战。现有方法往往无法准确修改这些属性,或者会损害结构完整性和整体图像一致性。为了填补这一空白,我们引入了无训练框架——结构保留与属性放大(SPAA),通过智能操作扩散模型中的自注意地图和跨注意值,实现对同一对象的颜色和材质属性的精确生成。基于SPAA,我们集成了多模态大型语言模型(MLLM),以自动化数据整理和指令生成。利用这一对象属性数据采集引擎,我们构建了属性数据集,涵盖了各类对象中广泛的颜色与材质。使用这个生成的数据集,我们推出了指令调整模型——InstructAttribute,通过自然语言提示实现精细和对象级别的属性编辑。这一能力在多个领域具有实际应用价值,如加速产品设计、电子商务可视化以及提升虚拟试穿体验等。大量实验表明,InstructAttribute在属性修改精度和结构保留之间达到了出色的平衡,超越了现有的指令基准测试。
论文及项目相关链接
Summary
文本介绍了针对文本到图像(T2I)扩散模型的新框架Structure Preservation and Attribute Amplification(SPAA)。该框架无需训练即可实现对同一对象的颜色和材料等属性的精确生成,通过智能操作扩散模型中的自注意力图和跨注意力值来实现。基于SPAA,集成了多模态大型语言模型(MLLMs)以自动化数据整理和指令生成。利用对象属性数据收集引擎,构建了包含各种对象类别的颜色和材料的Attribute数据集。使用生成的数据集,提出了基于指令的InstructAttribute模型,通过自然语言提示实现精细和对象级的属性编辑。该能力对于加速产品设计、电子商务可视化以及增强虚拟试穿体验等领域具有实际意义。
Key Takeaways
- 文本到图像(T2I)扩散模型广泛应用于图像编辑,但在控制特定对象属性方面存在挑战。
- 现有方法常常无法准确修改属性或会损害图像的结构完整性和一致性。
- SPAA框架通过智能操作自注意力图和跨注意力值,实现同一对象的颜色和材料等属性的精确生成,且无需训练。
- 结合多模态大型语言模型(MLLMs),自动化数据整理和指令生成。
- 利用对象属性数据收集引擎,构建了Attribute数据集,包含各种对象类别的颜色和材料。
- 提出基于指令的InstructAttribute模型,通过自然语言提示实现精细和对象级的属性编辑。
点此查看论文截图






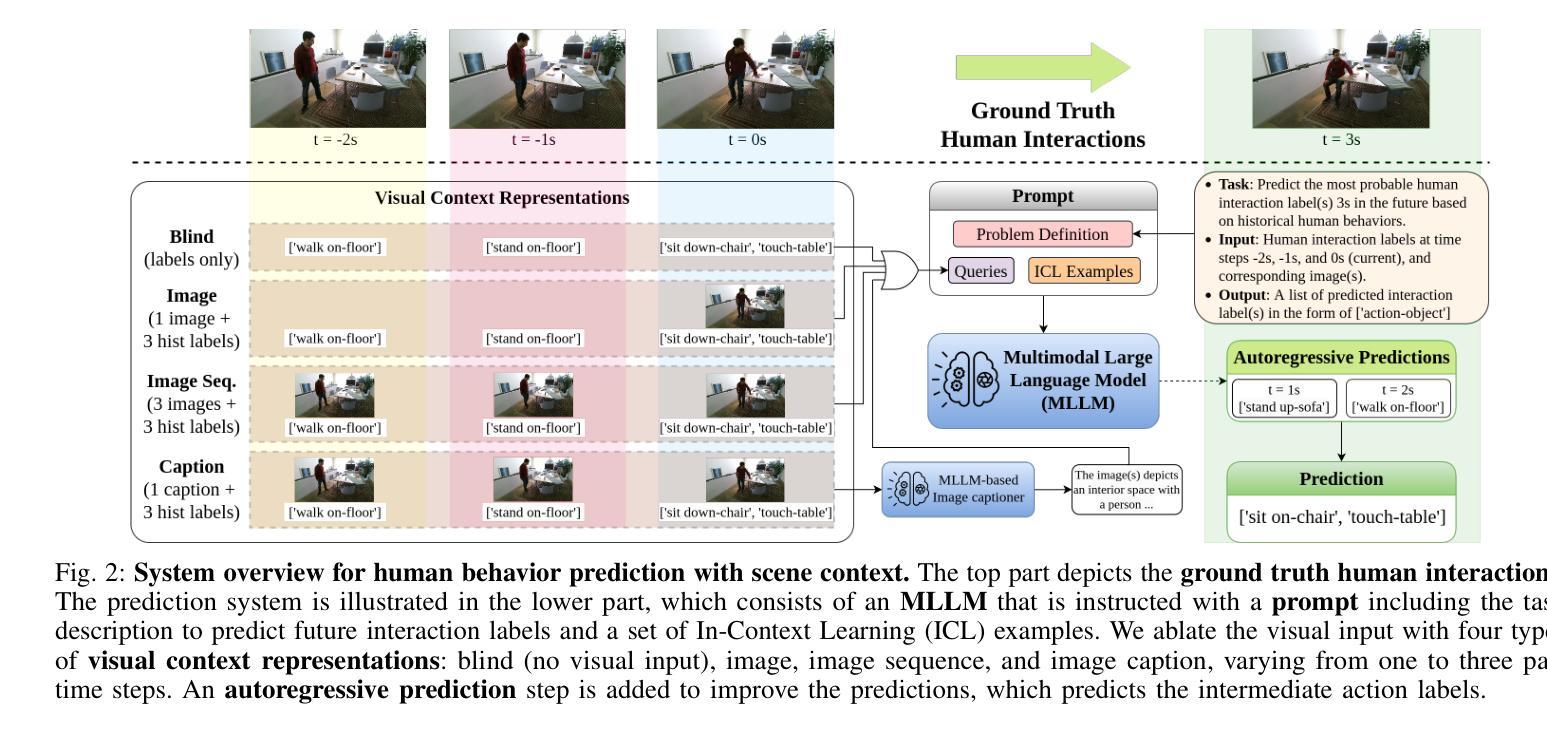
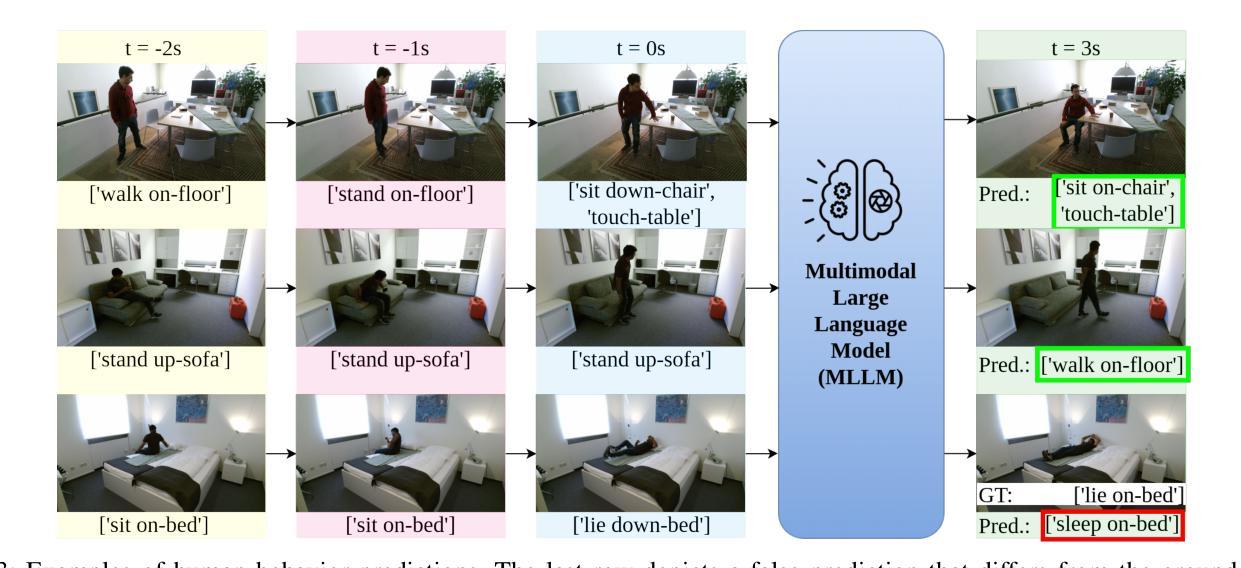
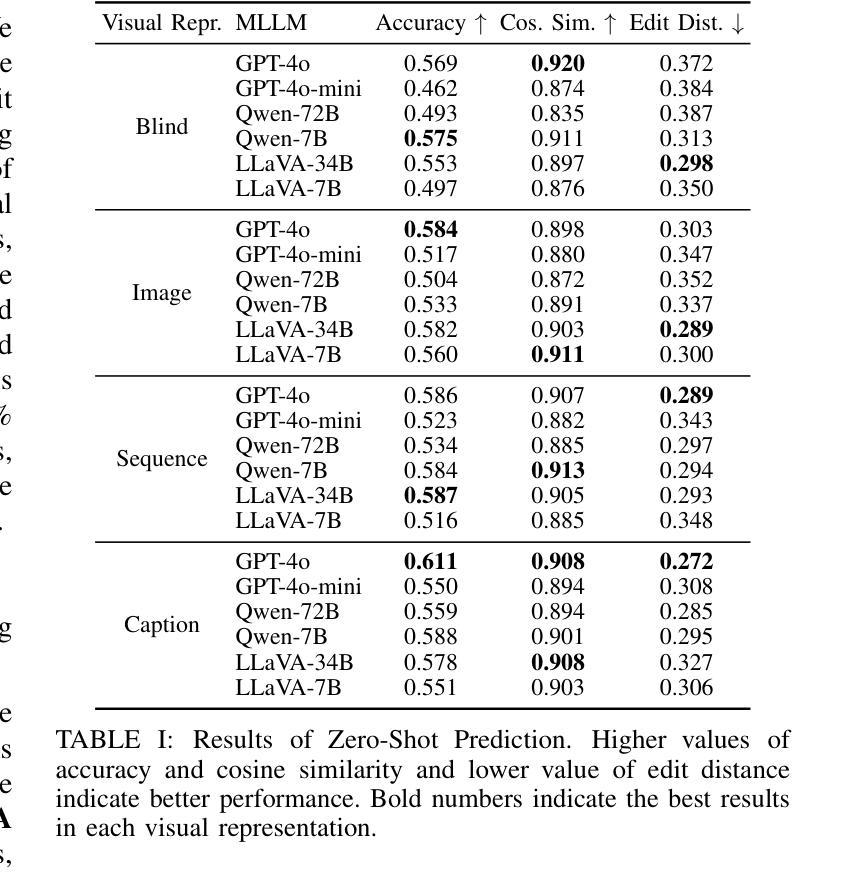
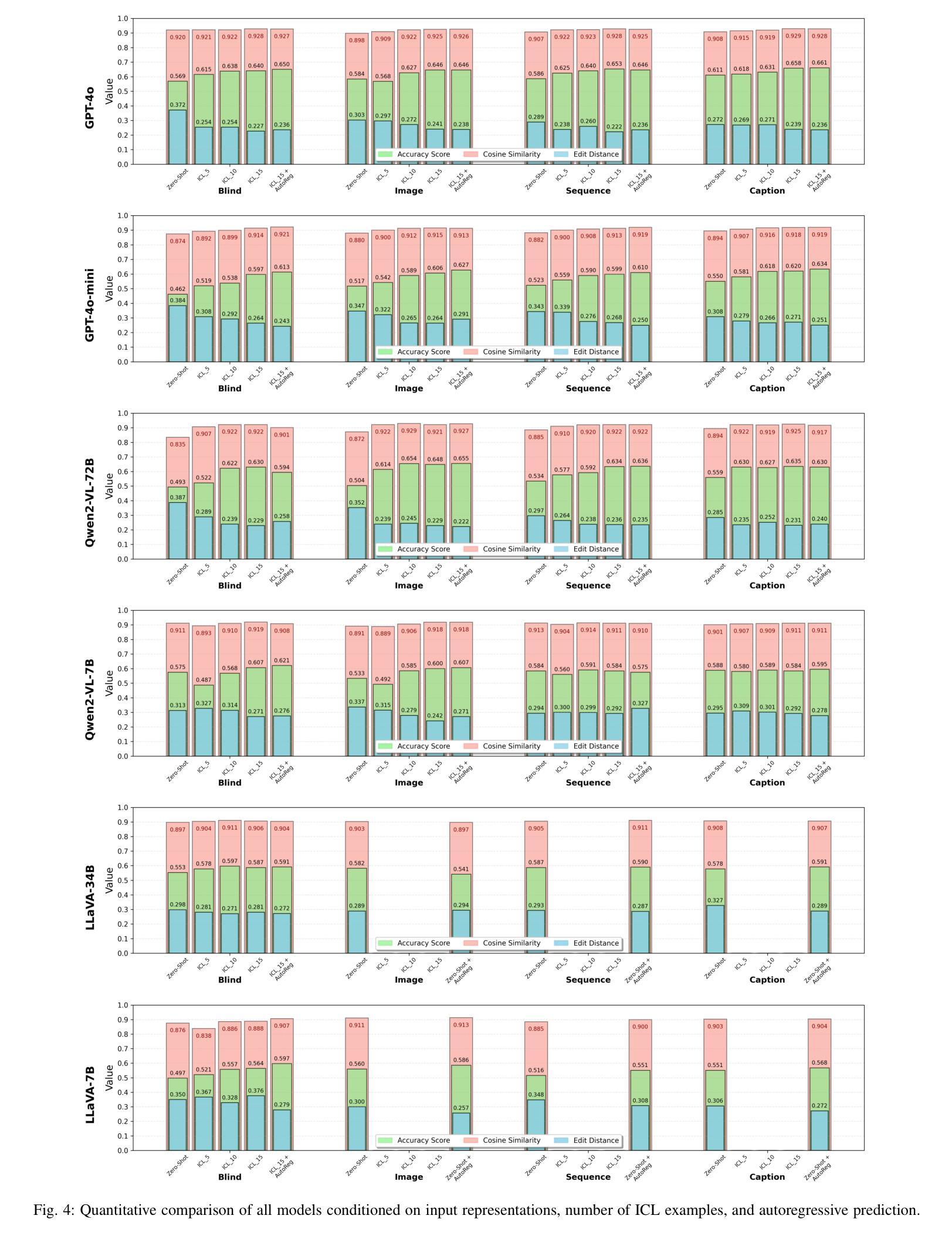
Context-Aware Human Behavior Prediction Using Multimodal Large Language Models: Challenges and Insights
Authors:Yuchen Liu, Lino Lerch, Luigi Palmieri, Andrey Rudenko, Sebastian Koch, Timo Ropinski, Marco Aiello
Predicting human behavior in shared environments is crucial for safe and efficient human-robot interaction. Traditional data-driven methods to that end are pre-trained on domain-specific datasets, activity types, and prediction horizons. In contrast, the recent breakthroughs in Large Language Models (LLMs) promise open-ended cross-domain generalization to describe various human activities and make predictions in any context. In particular, Multimodal LLMs (MLLMs) are able to integrate information from various sources, achieving more contextual awareness and improved scene understanding. The difficulty in applying general-purpose MLLMs directly for prediction stems from their limited capacity for processing large input sequences, sensitivity to prompt design, and expensive fine-tuning. In this paper, we present a systematic analysis of applying pre-trained MLLMs for context-aware human behavior prediction. To this end, we introduce a modular multimodal human activity prediction framework that allows us to benchmark various MLLMs, input variations, In-Context Learning (ICL), and autoregressive techniques. Our evaluation indicates that the best-performing framework configuration is able to reach 92.8% semantic similarity and 66.1% exact label accuracy in predicting human behaviors in the target frame.
预测共享环境中的人类行为对于安全高效的人机交互至关重要。传统的以数据驱动的方法为此目的而在特定领域数据集、活动类型和预测范围上进行预训练。相比之下,最近大型语言模型(LLM)的突破有望实现对各种人类活动的开放式跨域描述和任何上下文中的预测。特别是多模态LLM(MLLM)能够整合来自各种来源的信息,实现更上下文感知和改进的场景理解。将通用MLLM直接应用于预测的困难源于其处理大输入序列的能力有限、对提示设计的敏感性以及昂贵的微调。在本文中,我们对将预训练的MLLM应用于上下文感知的人类行为预测进行了系统分析。为此,我们引入了一个模块化多模态人类活动预测框架,该框架使我们能够评估各种MLLM、输入变化、上下文学习(ICL)和自回归技术。我们的评估表明,表现最佳的框架配置在预测目标框架中的人类行为时,能够达到92.8%的语义相似度和66.1%的标签准确性。
论文及项目相关链接
PDF Accepted at IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), 2025
Summary
基于大型语言模型(LLM)的多模态方法在预测人类行为方面展现出巨大潜力。传统的数据驱动方法通常局限于特定领域的数据集和活动类型预测。然而,LLM的多模态能力可以实现跨领域描述各种人类活动并进行预测。尽管存在处理大输入序列的局限性以及对提示设计和精细调整的敏感性等问题,但本文提出了一种模块化多模态人类活动预测框架,该框架允许对不同的LLM、输入变化、上下文学习和自回归技术进行评估。最佳配置的框架能够达到目标帧的预测行为语义相似性达到92.8%,精确标签准确率达到了66.1%。
Key Takeaways
- 大型语言模型(LLM)在预测人类行为方面展现出潜力。
- 传统数据驱动方法受限于特定领域,而LLM可实现跨领域描述和预测。
- 多模态LLM(MLLM)能整合不同来源的信息,提升上下文感知和场景理解。
- 应用MLLMs进行预测存在处理大输入序列的局限性及对提示设计和精细调整的敏感性。
- 论文提出了一种模块化多模态人类活动预测框架,可以评估不同的MLLMs、输入变化等。
- 最佳配置的框架在预测人类行为方面表现出色,语义相似性和精确标签准确率分别达到了92.8%和66.1%。
点此查看论文截图

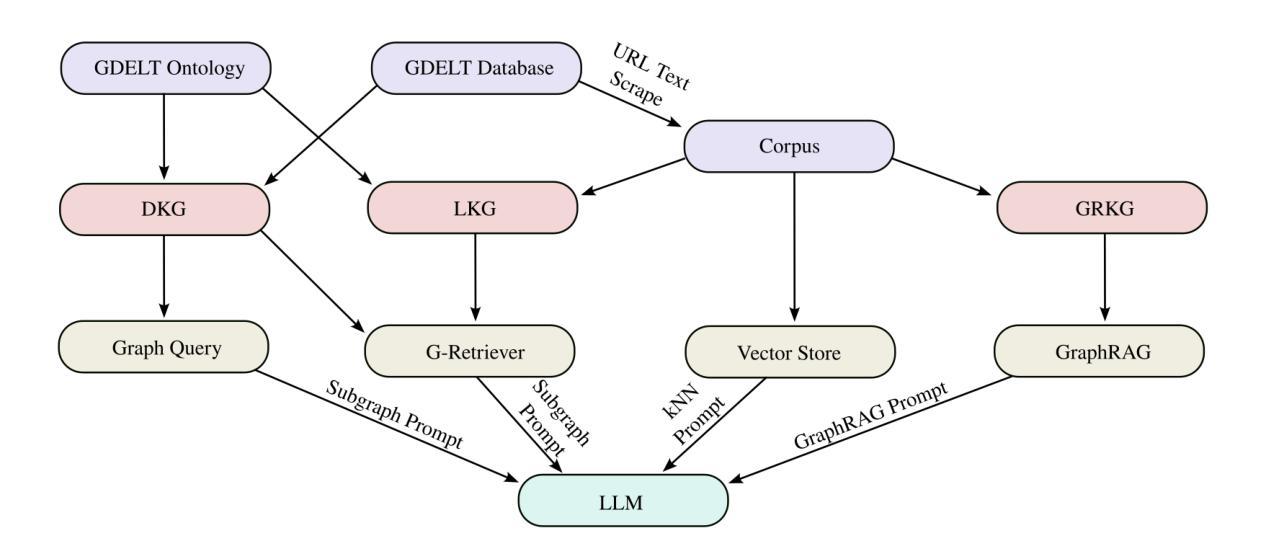
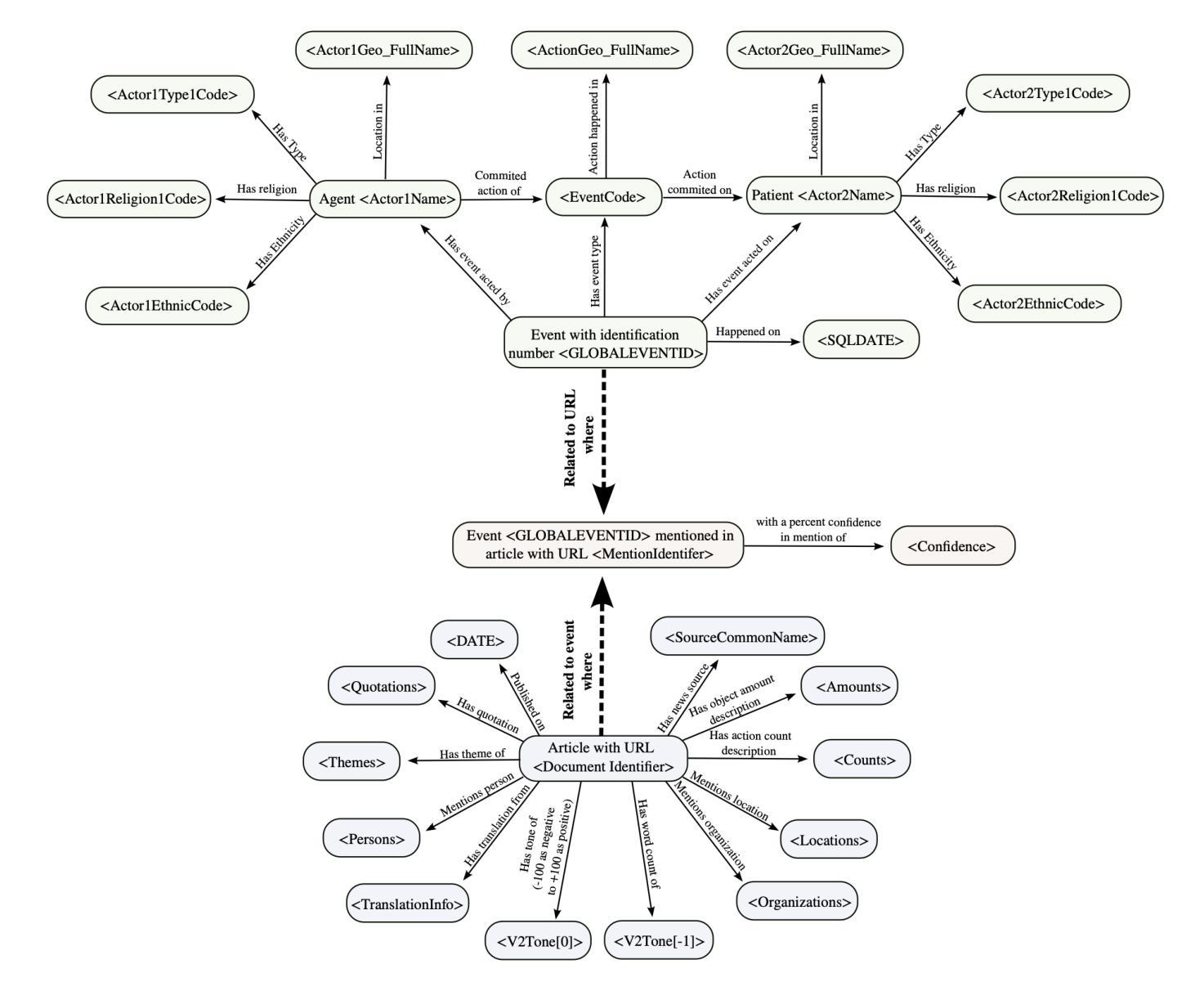
Talking to GDELT Through Knowledge Graphs
Authors:Audun Myers, Max Vargas, Sinan G. Aksoy, Cliff Joslyn, Benjamin Wilson, Lee Burke, Tom Grimes
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
在这项工作中,我们研究了各种基于检索增强的再生(RAG)方法,以了解每种方法在处理问答分析时的优缺点。为了深入了解,我们使用了全球事件、语言和语调数据库的案例研究子集以及与网络新闻报道一同收集的生语料库文本数据。为了从文本语料库中检索信息,我们实施了一种传统的向量存储RAG以及基于最新大型语言模型(LLM)的方法,这些方法可以自动构建知识图谱并检索相关的子图。除了这些语料库方法外,我们还开发了一种基于本体构建知识图谱(KGs)的新框架,该框架直接从GDELT中提取信息并利用其底层架构来创建全球事件的结构化表示。为了从基于本体的知识图谱中检索相关信息,我们实施了直接图形查询和最新的图形检索方法。我们在问答任务中比较了每种方法的性能。我们发现,虽然基于本体的知识图谱对于问答非常有价值,但自动提取相关子图却具有挑战性。相比之下,虽然LLM生成的知识图谱能够捕捉事件摘要,但它们往往缺乏一致性和可解释性。我们的研究结果表明了本体和基于LLM的知识图谱构建之间的协同方法的优势,并为此提出了可能的途径。
论文及项目相关链接
Summary
本文研究了多种基于知识图谱的检索增强再生(RAG)方法,以了解其在问答分析中的优缺点。研究使用了全球事件、语言和情感数据库的子集和在线新闻文章的语料库作为实验数据集。实验比较了基于传统向量存储、大型语言模型自动构建知识图谱的方法以及新型基于本体构建知识图谱的方法。研究发现在问答任务中,基于本体的知识图谱对于回答问题很有价值,但自动提取相关子图具有挑战性;而基于大型语言模型构建的知识图谱虽然能够捕捉事件摘要,但往往缺乏一致性和可解释性。因此,研究提出了本体与大型语言模型相结合构建知识图谱的协同方法。
Key Takeaways
- 研究采用多种方法构建知识图谱并进行对比评估。
- 采用传统向量存储方法以及先进的大型语言模型进行文本信息检索。
- 提出新型基于本体构建知识图谱的方法,利用全球事件数据库的结构化数据。
- 基于本体构建的知识图谱在问答任务中表现出价值,但自动提取相关子图具有挑战性。
- 基于大型语言模型构建的知识图谱能够捕捉事件摘要,但缺乏一致性和可解释性。
点此查看论文截图