⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs
Authors:Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, Mengdi Wang
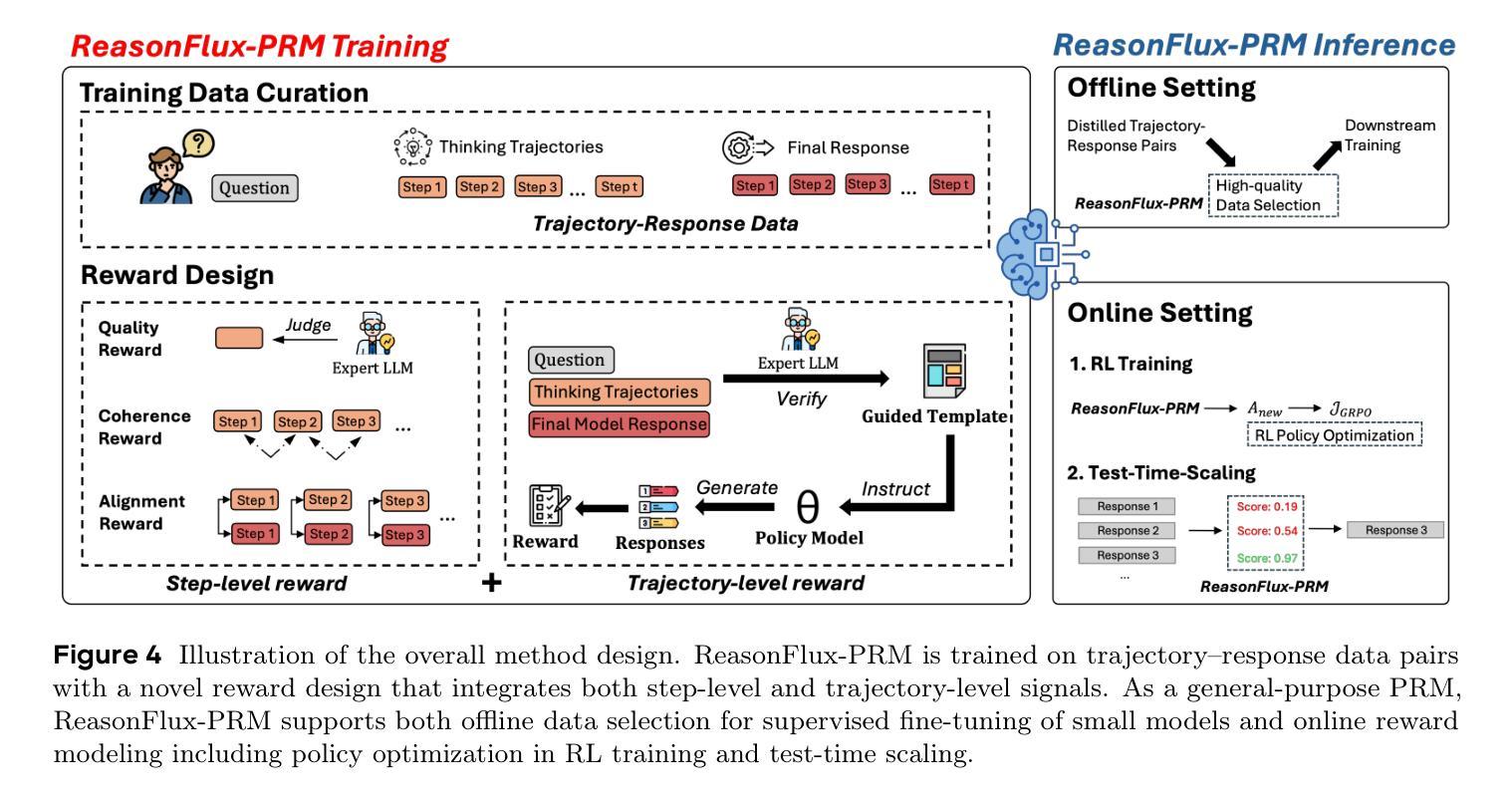
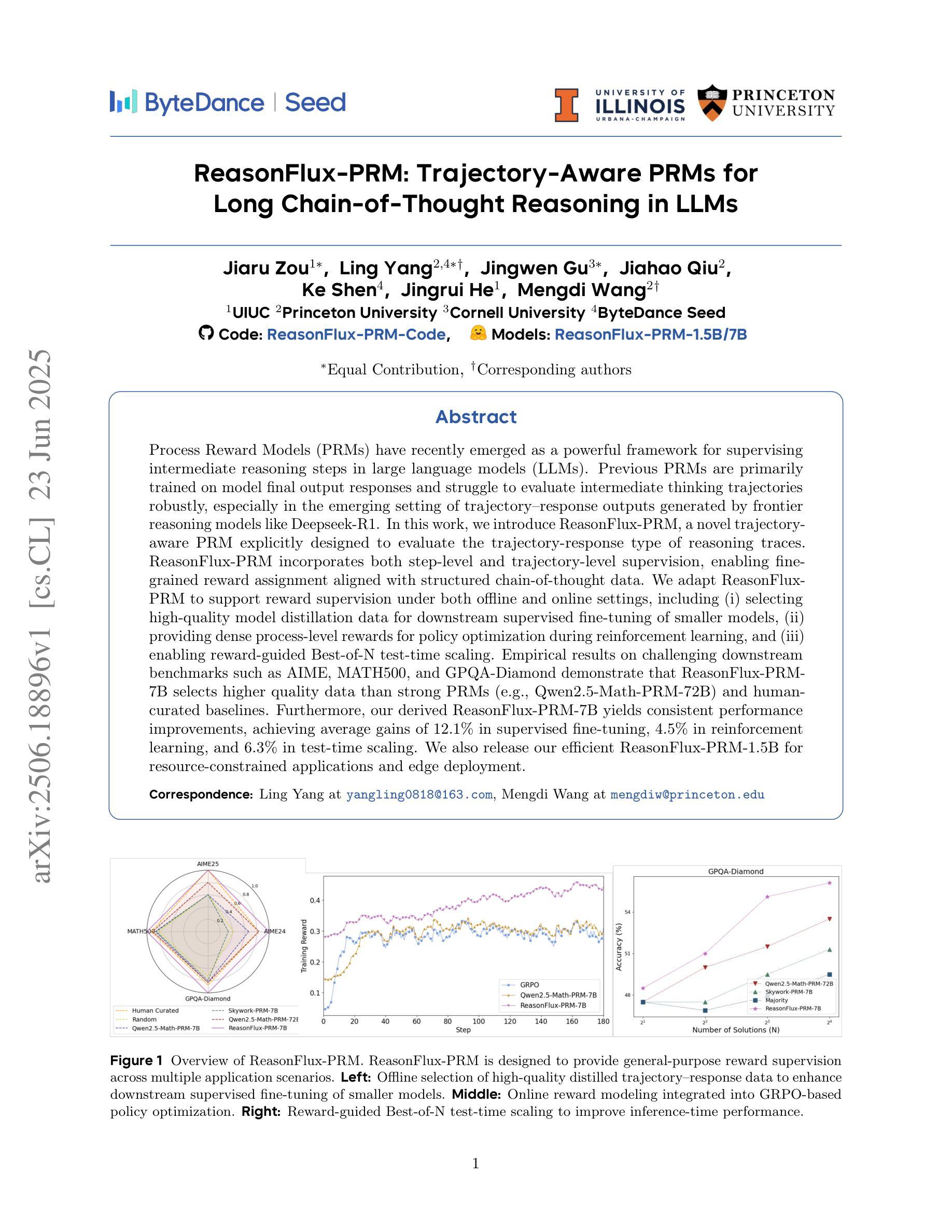
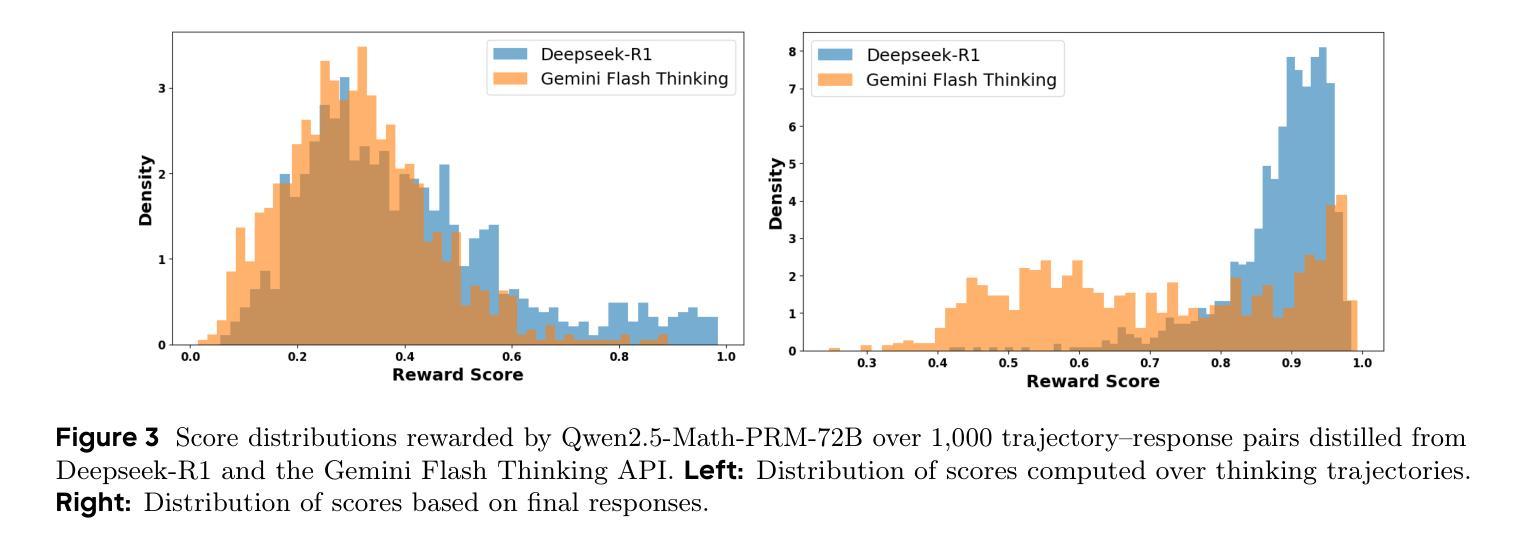
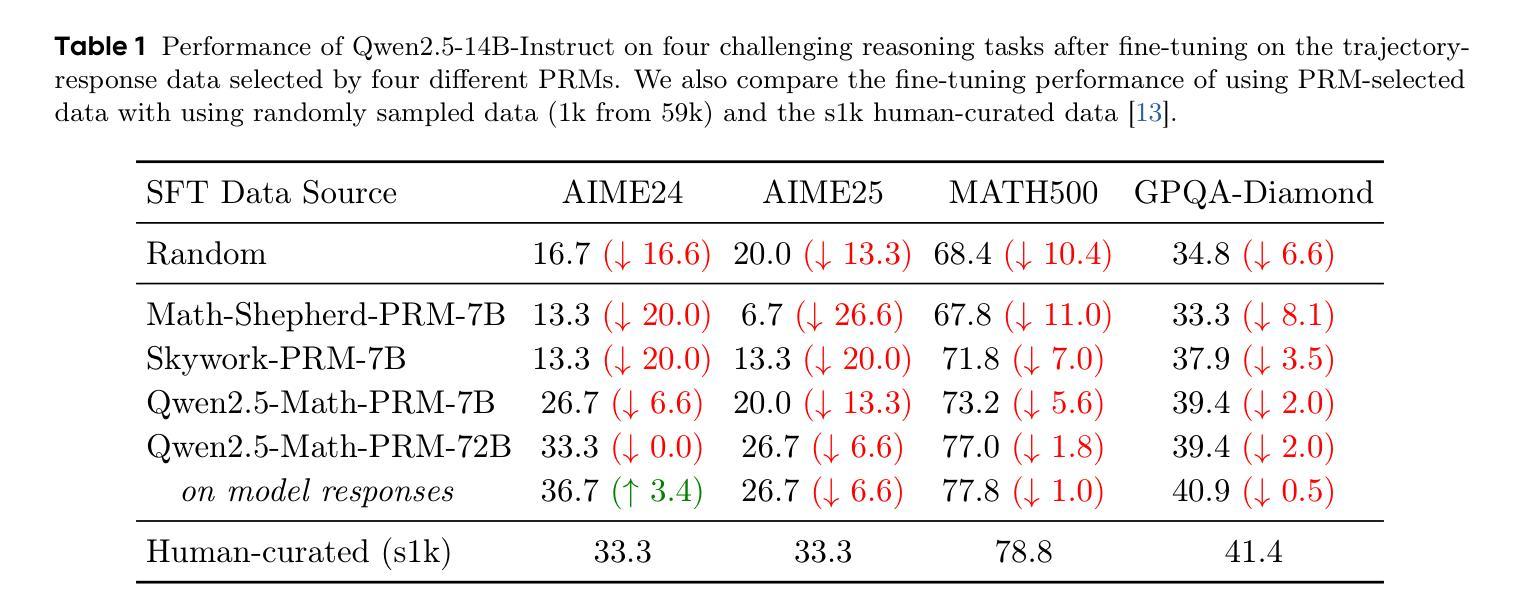
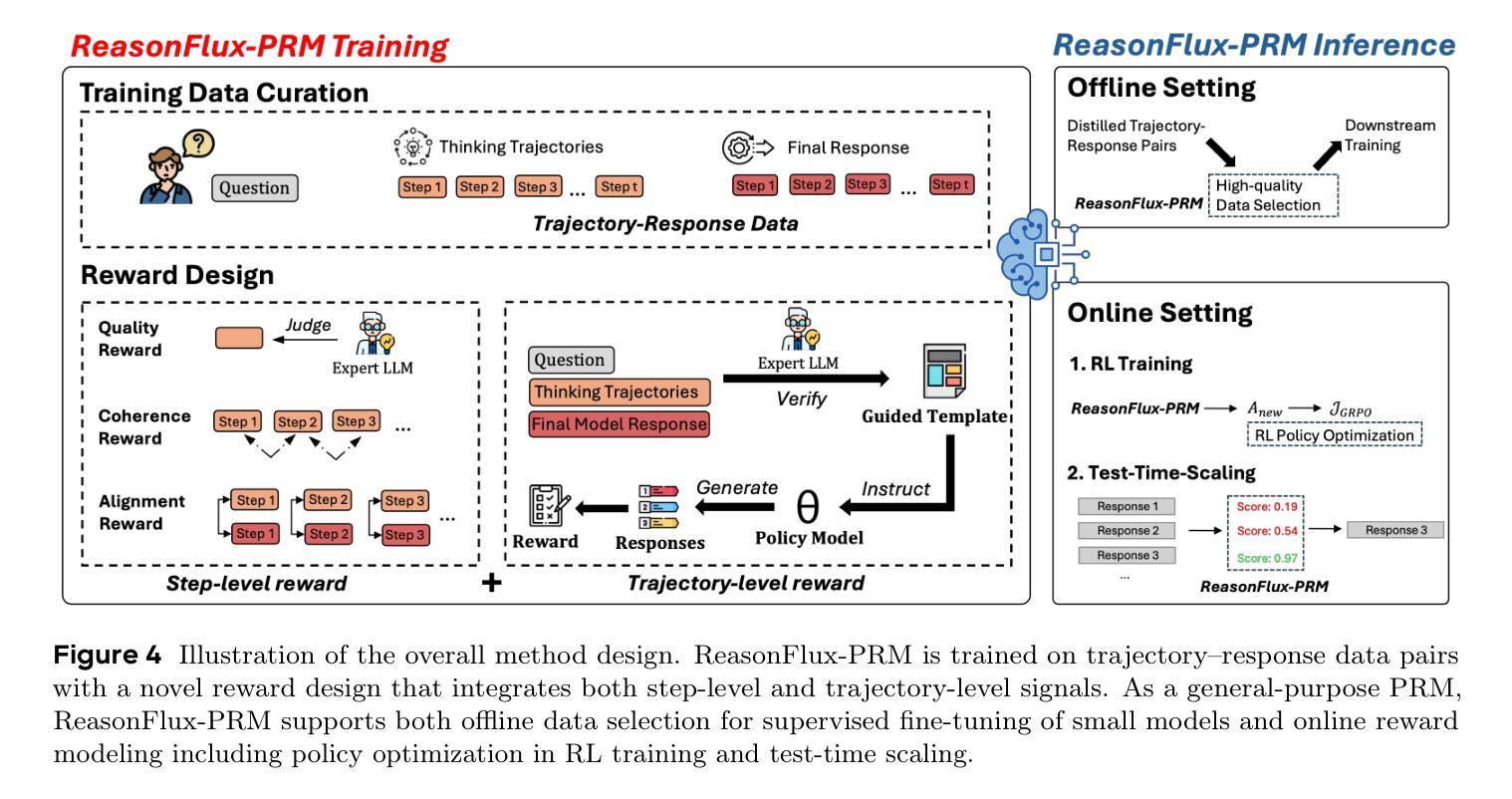
Process Reward Models (PRMs) have recently emerged as a powerful framework for supervising intermediate reasoning steps in large language models (LLMs). Previous PRMs are primarily trained on model final output responses and struggle to evaluate intermediate thinking trajectories robustly, especially in the emerging setting of trajectory-response outputs generated by frontier reasoning models like Deepseek-R1. In this work, we introduce ReasonFlux-PRM, a novel trajectory-aware PRM explicitly designed to evaluate the trajectory-response type of reasoning traces. ReasonFlux-PRM incorporates both step-level and trajectory-level supervision, enabling fine-grained reward assignment aligned with structured chain-of-thought data. We adapt ReasonFlux-PRM to support reward supervision under both offline and online settings, including (i) selecting high-quality model distillation data for downstream supervised fine-tuning of smaller models, (ii) providing dense process-level rewards for policy optimization during reinforcement learning, and (iii) enabling reward-guided Best-of-N test-time scaling. Empirical results on challenging downstream benchmarks such as AIME, MATH500, and GPQA-Diamond demonstrate that ReasonFlux-PRM-7B selects higher quality data than strong PRMs (e.g., Qwen2.5-Math-PRM-72B) and human-curated baselines. Furthermore, our derived ReasonFlux-PRM-7B yields consistent performance improvements, achieving average gains of 12.1% in supervised fine-tuning, 4.5% in reinforcement learning, and 6.3% in test-time scaling. We also release our efficient ReasonFlux-PRM-1.5B for resource-constrained applications and edge deployment. Projects: https://github.com/Gen-Verse/ReasonFlux
过程奖励模型(PRMs)最近作为监督大型语言模型(LLMs)中的中间推理步骤的强大框架而出现。以前的PRM主要基于模型的最终输出响应进行训练,在评估前沿推理模型(如Deepseek-R1)生成的轨迹响应输出时,难以稳健地评估中间思维轨迹。在这项工作中,我们引入了ReasonFlux-PRM,这是一种专门设计用于评估轨迹响应类型推理痕迹的新型轨迹感知PRM。ReasonFlux-PRM结合了步骤级和轨迹级的监督,能够实现与结构化思维链数据精细对齐的奖励分配。我们使ReasonFlux-PRM适应离线在线设置下的奖励监督,包括(i)为下游监督微调较小模型选择高质量模型蒸馏数据,(ii)在强化学习中为策略优化提供密集的流程级奖励,以及(iii)实现奖励引导的Best-of-N测试时间缩放。在AIME、MATH500和GPQA-Diamond等具有挑战性的下游基准测试上的实证结果表明,ReasonFlux-PRM-7B选择的数据质量高于强大的PRM(如Qwen2.5-Math-PRM-72B)和人类策划的基线。此外,我们衍生的ReasonFlux-PRM-7B在各方面性能均有所改进,监督微调平均提升12.1%,强化学习提升4.5%,测试时间缩放提升6.3%。我们还发布了适用于资源受限应用和边缘部署的高效ReasonFlux-PRM-1.5B。项目地址:https://github.com/Gen-Verse/ReasonFlux
论文及项目相关链接
PDF Codes and Models: https://github.com/Gen-Verse/ReasonFlux
Summary
本文介绍了ReasonFlux-PRM,这是一种新型的轨迹感知过程奖励模型(PRM),专为评估前沿推理模型如Deepseek-R1生成的轨迹响应类型推理轨迹而设计。该模型结合了步骤级和轨迹级的监督,实现了与结构化思维数据相匹配的精细奖励分配。ReasonFlux-PRM支持在线和离线环境下的奖励监督,可用于选择高质量模型蒸馏数据、为强化学习提供密集的过程级奖励,以及实现奖励引导的最佳N测试时间缩放。在AIME、MATH500和GPQA-Diamond等基准测试中,ReasonFlux-PRM-7B表现出色,优于其他强大的PRM和人工基准线。此外,衍生出的ReasonFlux-PRM-7B在监督微调、强化学习和测试时间缩放方面均实现了性能改进。我们还推出了适用于资源受限应用和边缘部署的高效ReasonFlux-PRM-1.5B。
Key Takeaways
- ReasonFlux-PRM是一种轨迹感知过程奖励模型(PRM),用于评估前沿推理模型的轨迹响应。
- 该模型结合步骤级和轨迹级的监督,实现精细奖励分配,与结构化思维数据对齐。
- ReasonFlux-PRM支持在线和离线环境下的奖励监督,包括选择高质量模型蒸馏数据、强化学习的密集过程级奖励,以及测试时间缩放。
- 在多个基准测试中,ReasonFlux-PRM表现出色,优于其他强大的PRM和人工基准线。
- ReasonFlux-PRM-7B在监督微调、强化学习和测试时间缩放方面实现了性能改进。
- 推出了适用于资源受限应用和边缘部署的高效ReasonFlux-PRM-1.5B。
点此查看论文截图

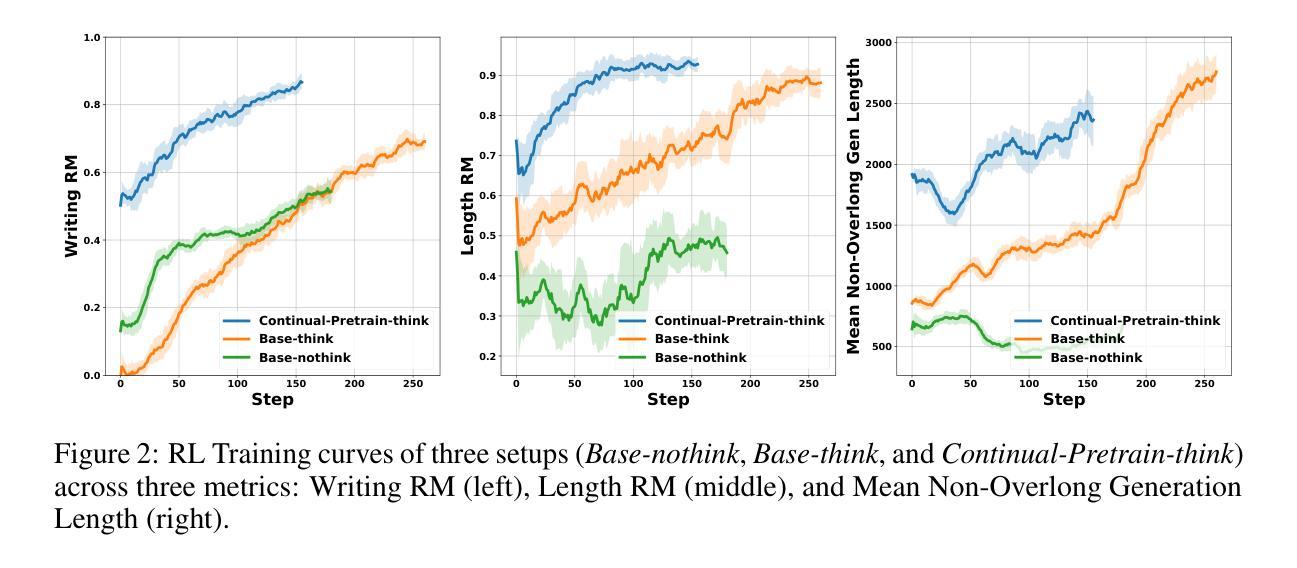
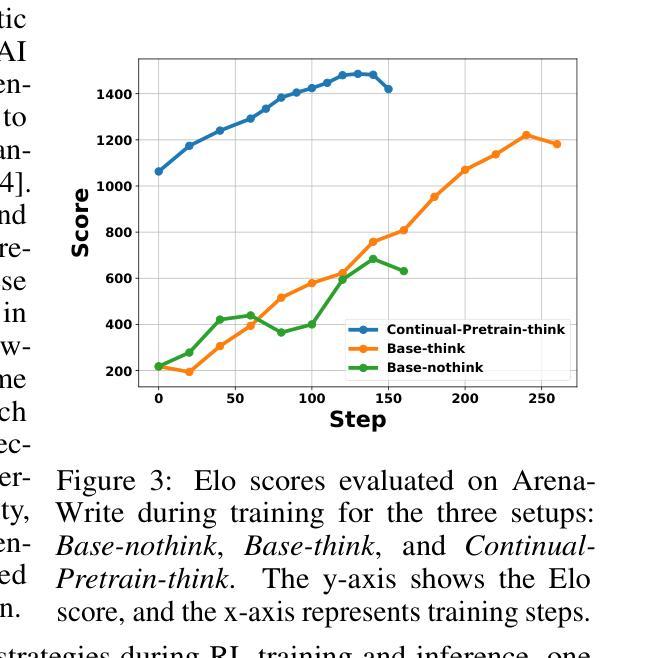
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
Authors:Yuhao Wu, Yushi Bai, Zhiqiang Hu, Roy Ka-Wei Lee, Juanzi Li
Ultra-long generation by large language models (LLMs) is a widely demanded scenario, yet it remains a significant challenge due to their maximum generation length limit and overall quality degradation as sequence length increases. Previous approaches, exemplified by LongWriter, typically rely on ‘’teaching’’, which involves supervised fine-tuning (SFT) on synthetic long-form outputs. However, this strategy heavily depends on synthetic SFT data, which is difficult and costly to construct, often lacks coherence and consistency, and tends to be overly artificial and structurally monotonous. In this work, we propose an incentivization-based approach that, starting entirely from scratch and without relying on any annotated or synthetic data, leverages reinforcement learning (RL) to foster the emergence of ultra-long, high-quality text generation capabilities in LLMs. We perform RL training starting from a base model, similar to R1-Zero, guiding it to engage in reasoning that facilitates planning and refinement during the writing process. To support this, we employ specialized reward models that steer the LLM towards improved length control, writing quality, and structural formatting. Experimental evaluations show that our LongWriter-Zero model, trained from Qwen2.5-32B, consistently outperforms traditional SFT methods on long-form writing tasks, achieving state-of-the-art results across all metrics on WritingBench and Arena-Write, and even surpassing 100B+ models such as DeepSeek R1 and Qwen3-235B. We open-source our data and model checkpoints under https://huggingface.co/THU-KEG/LongWriter-Zero-32B
超长文本生成是大语言模型(LLM)广泛需求的场景,但由于其最大生成长度限制以及随着序列长度增加的整体质量下降,这仍然是一个巨大的挑战。以前的方法,以LongWriter为代表,通常依赖于“教学”,这涉及在合成长形式输出上的有监督微调(SFT)。然而,这种策略严重依赖于合成的SFT数据,这些数据构建困难且成本高昂,往往缺乏连贯性和一致性,且倾向于过于人工和结构单调。在这项工作中,我们提出了一种基于激励的方法,它从零开始,不依赖任何注释或合成数据,利用强化学习(RL)来促进大语言模型中超长高质量文本生成能力的出现。我们从基础模型开始进行RL训练,类似于R1-Zero,指导它在进行写作过程中的推理,促进规划和改进。为此,我们采用专门的奖励模型来引导LLM改进长度控制、写作质量和结构格式化。实验评估表明,我们的LongWriter-Zero模型从Qwen2.5-32B开始训练,在长期写作任务上始终优于传统SFT方法,在WritingBench和Arena-Write的所有指标上达到最新水平,甚至超越了DeepSeek R1和Qwen3-235B等百亿级模型。我们将在https://huggingface.co/THU-KEG/LongWriter-Zero-32B下开源我们的数据和模型检查点。
论文及项目相关链接
Summary
本文介绍了利用基于强化学习(RL)的方法训练大型语言模型(LLM)进行超长文本生成的任务。该研究提出了一种不依赖任何标注或合成数据的激励化方法,从基础模型开始,通过RL训练促进LLM生成超长、高质量的文本。通过专业化的奖励模型,引导LLM改善长度控制、写作质量和结构格式化。实验评估表明,LongWriter-Zero模型在长篇写作任务上持续优于传统的监督微调方法,并在WritingBench和Arena-Write上达到领先水平,甚至超越了DeepSeek R1和Qwen3等大型模型。
Key Takeaways
- 大型语言模型(LLM)在超长文本生成方面存在挑战,包括最大生成长度限制和序列长度增加导致的整体质量下降。
- 此前的研究如LongWriter主要依赖监督微调(SFT)在合成长文输出上的策略,但这种方法依赖于难以构建且成本高昂的合成SFT数据。
- 本文提出了一种基于激励的方法,不依赖任何标注或合成数据,利用强化学习(RL)促进超长、高质量的文本生成能力在LLMs中的出现。
- 通过专业化的奖励模型,改善LLM的长度控制、写作质量和结构格式化。
- 实验表明,LongWriter-Zero模型在长篇写作任务上表现优异,达到甚至超越了一些大型模型的水平。
- 该研究开放源代码和数据,便于其他研究者使用和进一步探索。
点此查看论文截图

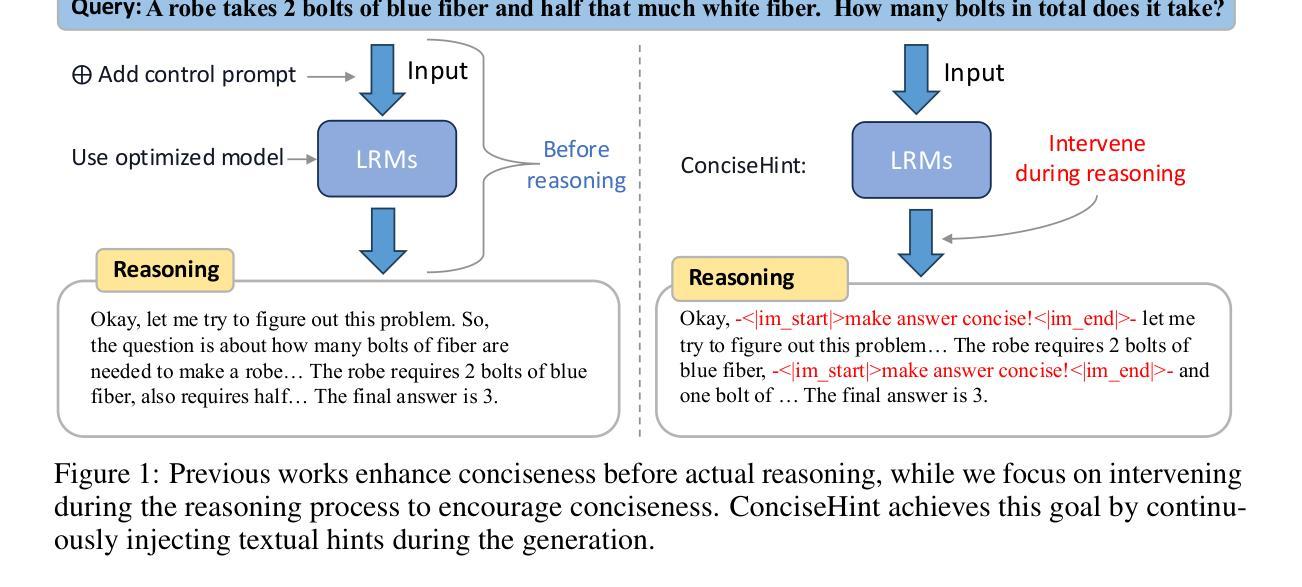
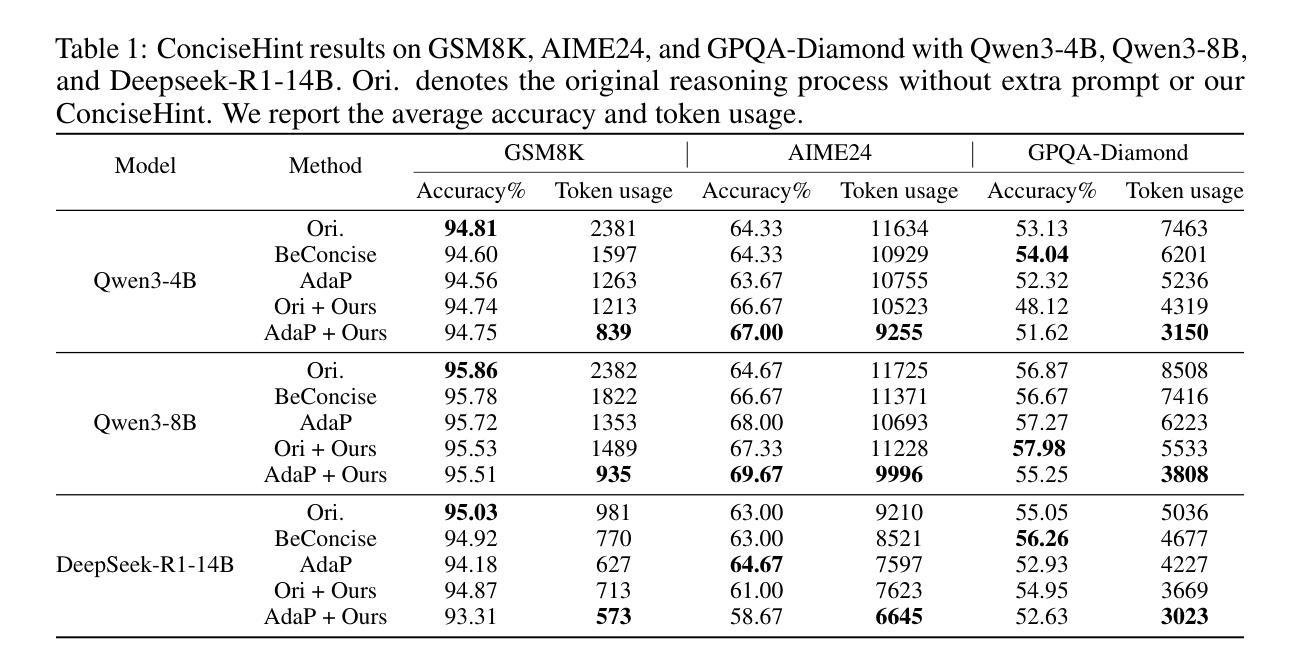
ConciseHint: Boosting Efficient Reasoning via Continuous Concise Hints during Generation
Authors:Siao Tang, Xinyin Ma, Gongfan Fang, Xinchao Wang
Recent advancements in large reasoning models (LRMs) like DeepSeek-R1 and OpenAI o1 series have achieved notable performance enhancements on complex reasoning tasks by scaling up the generation length by Chain-of-Thought (CoT). However, an emerging issue is their inclination to produce excessively verbose reasoning processes, leading to the inefficiency problem. Existing literature on improving efficiency mainly adheres to the before-reasoning paradigms such as prompting and reasoning or fine-tuning and reasoning, but ignores the promising direction of directly encouraging the model to speak concisely by intervening during the generation of reasoning. In order to fill the blank, we propose a framework dubbed ConciseHint, which continuously encourages the reasoning model to speak concisely by injecting the textual hint (manually designed or trained on the concise data) during the token generation of the reasoning process. Besides, ConciseHint is adaptive to the complexity of the query by adaptively adjusting the hint intensity, which ensures it will not undermine model performance. Experiments on the state-of-the-art LRMs, including DeepSeek-R1 and Qwen-3 series, demonstrate that our method can effectively produce concise reasoning processes while maintaining performance well. For instance, we achieve a reduction ratio of 65% for the reasoning length on GSM8K benchmark with Qwen-3 4B with nearly no accuracy loss.
最近,如DeepSeek-R1和OpenAI o1系列等大型推理模型(LRMs)通过思维链(Chain-of-Thought)(CoT)扩展生成长度,在复杂推理任务上实现了显著的性能提升。然而,一个新兴的问题是他们倾向于产生过于冗长的推理过程,导致了效率问题。关于提高效率的现有文献主要遵循预先推理的模式,如提示和推理或微调再推理,但忽略了通过干预推理生成过程中直接鼓励模型简洁表达的潜在方向。为了填补这一空白,我们提出了一种名为ConciseHint的框架,它通过注入文本提示(人为设计或在简洁数据上训练)在推理过程的令牌生成过程中不断鼓励推理模型简洁表达。此外,ConciseHint可以适应查询的复杂性,通过自适应调整提示强度,确保不会损害模型性能。在包括DeepSeek-R1和Qwen-3系列等在内的最先进LRMs上的实验表明,我们的方法可以在保持性能的同时有效地产生简洁的推理过程。例如,在GSM8K基准测试上,使用Qwen-3 4B进行推理长度缩减了65%,同时几乎没有损失准确性。
论文及项目相关链接
PDF Codes are available at https://github.com/tsa18/ConciseHint
Summary
大型推理模型(如DeepSeek-R1和OpenAI o1系列)在复杂的推理任务上取得了显著的性能提升,但它们倾向生成冗长的推理过程,导致效率问题。为解决这一问题,提出了一种名为ConciseHint的框架,通过在推理过程中注入简洁的文本提示来鼓励模型简洁表达。该框架能够适应查询的复杂性,并能在保持模型性能的同时,有效生成简洁的推理过程。在多个先进的大型推理模型上的实验结果表明,该方法在保持性能的同时,能够显著降低推理过程的长度。
Key Takeaways
- 大型推理模型在复杂任务上性能显著提升,但存在生成冗长推理过程的问题。
- 现有文献主要关注提高效率的预推理方法,但缺乏直接鼓励模型简洁表达的方法。
- 提出了一种名为ConciseHint的框架,通过注入文本提示来鼓励模型简洁表达。
- ConciseHint能够适应查询的复杂性,确保在提高效率的同时不损害模型性能。
点此查看论文截图


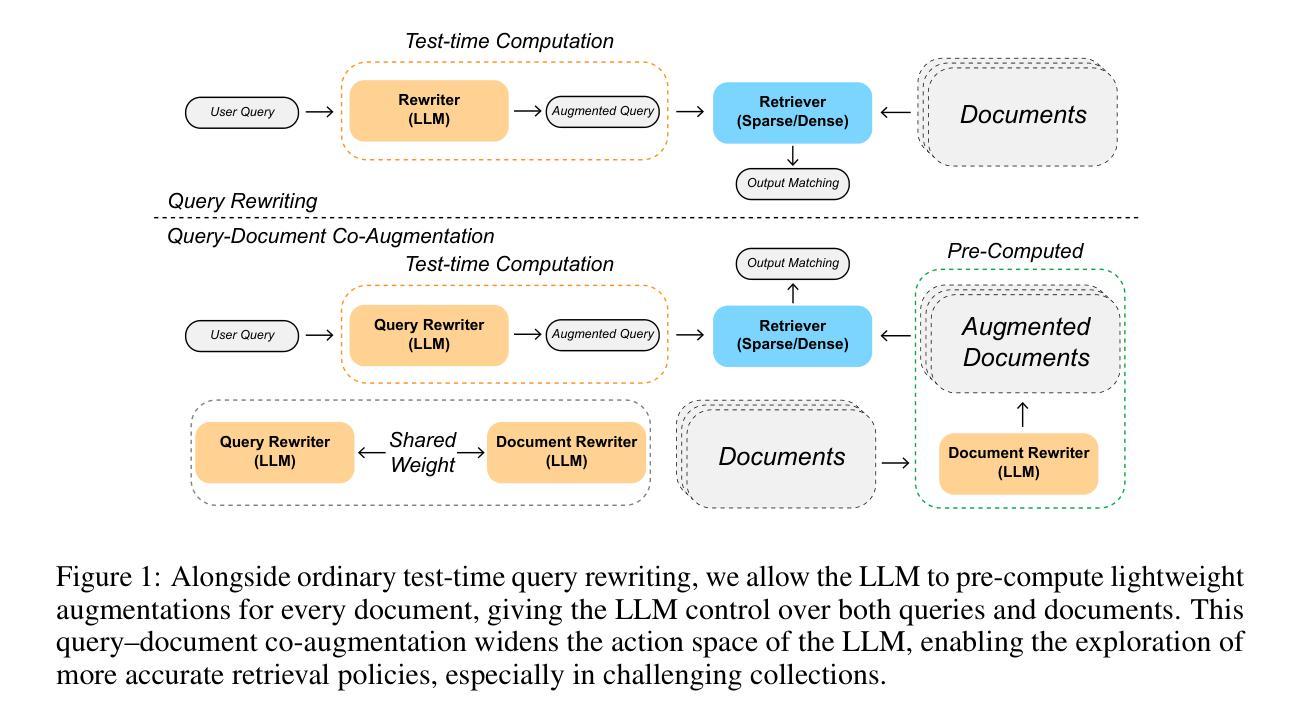
Harnessing the Power of Reinforcement Learning for Language-Model-Based Information Retriever via Query-Document Co-Augmentation
Authors:Jingming Liu, Yumeng Li, Wei Shi, Yao-Xiang Ding, Hui Su, Kun Zhou
Recent studies have proposed leveraging Large Language Models (LLMs) as information retrievers through query rewriting. However, for challenging corpora, we argue that enhancing queries alone is insufficient for robust semantic matching; the LLM should also have sufficient understanding of the corpus by directly handling and augmenting the documents themselves. To this end, we present an LLM-based retriever empowered to augment both user queries and corpus documents, with its policy fully explored via reinforcement learning (RL) and minimal human inductive bias. Notably, we find that simply allowing the LLM to modify documents yields little benefit unless paired with our carefully designed bidirectional RL framework, which enables the LLM to simultaneously learn and collaborate on both query and document augmentation policies. A key technical challenge in realizing such a framework lies in jointly updating both policies during training, where the rewards for the two directions depend on each other, making their entangled reward intractable. Our approach addresses this by introducing a reward sampling strategy and a specifically designed RL algorithm that enables effective training with these sampled rewards. Experimental results demonstrate that our approach significantly enhances LLM-based retrieval performance in both sparse and dense settings, particularly in difficult retrieval domains, and achieves strong cross-benchmark generalization. Our code is released at https://github.com/liujm2001/CoAugRetriever.
最近的研究提议利用大型语言模型(LLM)通过查询重写来作为信息检索器。然而,对于具有挑战性的语料库,我们认为仅仅增强查询对于实现稳健的语义匹配是不够的;LLM还应对语料库本身有足够的理解,通过直接处理和扩充文档本身。为此,我们提出了一种基于LLM的检索器,该检索器能够同时增强用户查询和语料库文档,其策略完全通过强化学习(RL)进行探索,并且具有最小的人工诱导偏见。值得注意的是,我们发现,除非与我们的精心设计双向RL框架配对,否则仅仅允许LLM修改文档并不会带来多少好处。该框架使LLM能够在查询和文档扩充策略上同时学习和协作。在实现这样一个框架的关键技术挑战在于在训练过程中联合更新这两种策略,其中两个方向的奖励是相互依赖的,使得它们纠缠的奖励难以处理。我们的方法通过引入奖励采样策略和专门设计的RL算法来解决这个问题,这些算法可以利用这些采样奖励进行有效的训练。实验结果表明,我们的方法在稀疏和密集的环境中都能显著提高基于LLM的检索性能,特别是在困难的检索领域,并且实现了跨基准测试的强大泛化能力。我们的代码已发布在https://github.com/liujm2001/CoAugRetriever。
论文及项目相关链接
Summary
本文探讨了利用大型语言模型(LLM)作为信息检索器的问题。作者认为,对于具有挑战性的语料库,仅仅优化查询是不够的,LLM还需要直接处理和扩充文档以充分理解语料库。为此,提出了一种基于LLM的检索器,该检索器能够同时扩充用户查询和语料库文档,其策略通过强化学习(RL)进行探索,并具有最小的人类诱导偏见。研究发现,除非与精心设计的双向RL框架配对,否则单纯允许LLM修改文档并不会带来明显好处。该框架的关键技术挑战在于训练过程中的策略联合更新问题,两个方向的奖励相互依赖,使得它们的奖励纠缠难以解决。作者通过引入奖励采样策略和专门设计的RL算法来解决这一问题,实现了有效的训练。实验结果表明,该方法在稀疏和密集环境中都能显著提高LLM的检索性能,特别是在困难检索领域具有很强的跨基准测试泛化能力。相关代码已发布在指定的GitHub仓库。
Key Takeaways
- 大型语言模型(LLM)可作为信息检索器,但需增强其在挑战性语料库上的表现。
- 单纯的查询优化不足以实现稳健的语义匹配,LLM需要直接处理和扩充文档以理解语料库。
- 提出了一种基于LLM的检索器,具备对用户查询和语料库文档的双向扩充能力。
- 采用强化学习(RL)探索扩充策略,减少人为干预和偏见。
- 双向RL框架的设计是关键,能同时学习和协作处理查询和文档扩充策略。
- 训练过程中的策略联合更新是技术挑战,作者通过引入奖励采样策略和特定的RL算法解决了这一问题。
点此查看论文截图

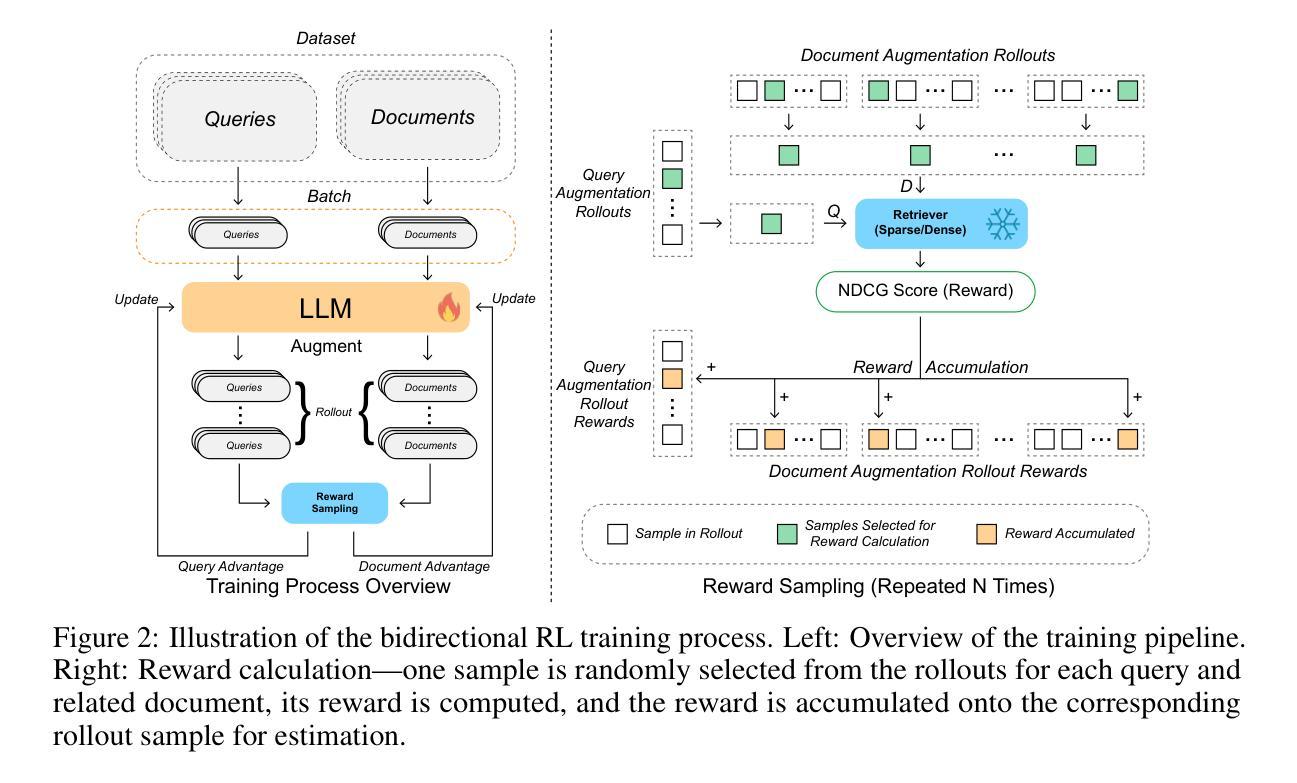
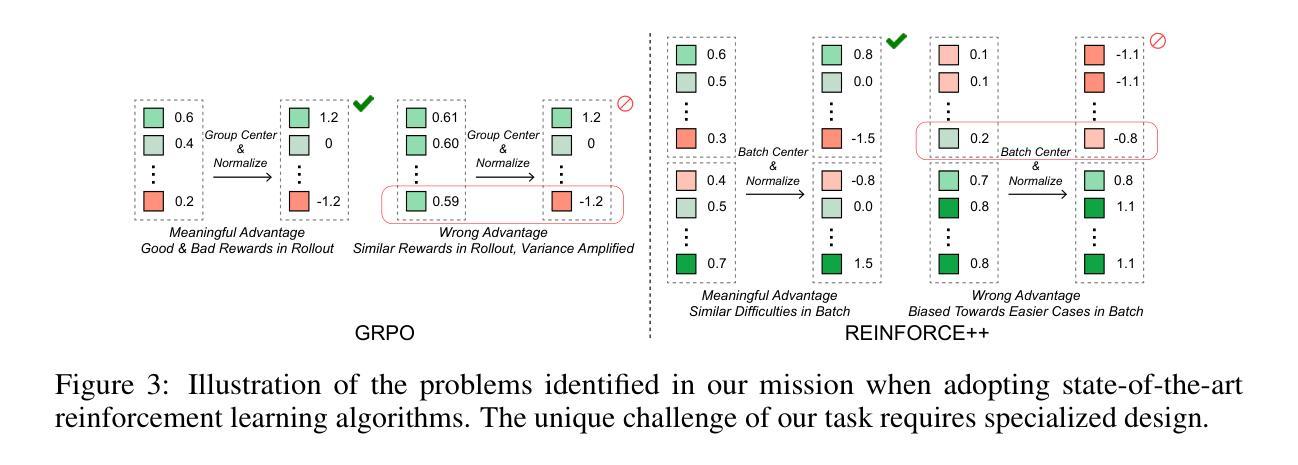
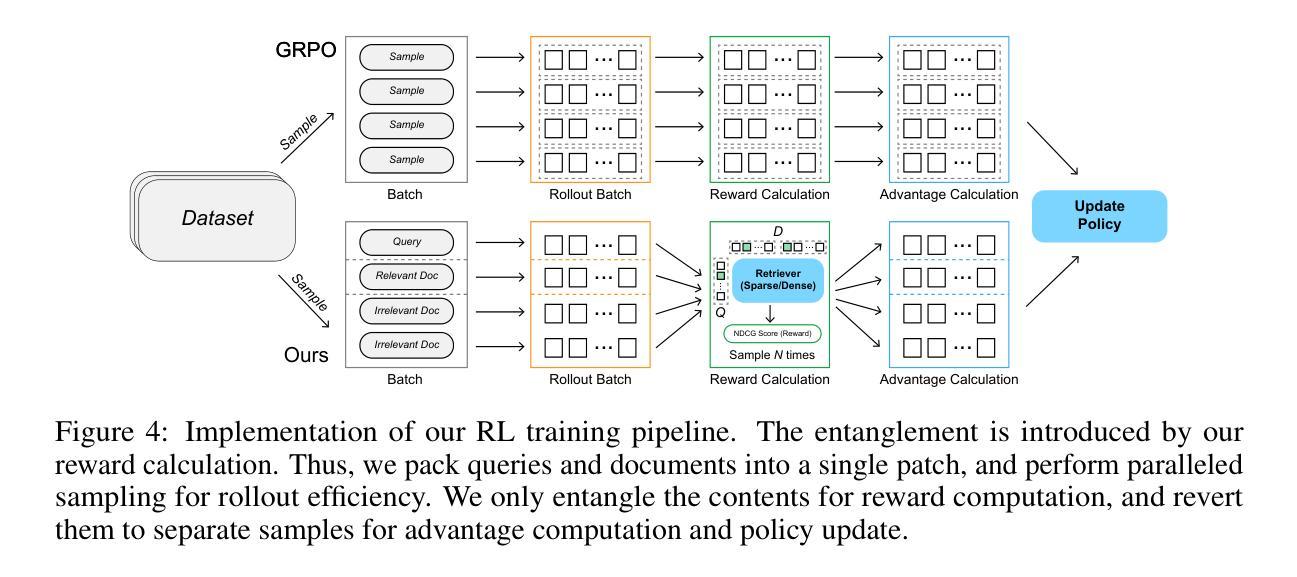
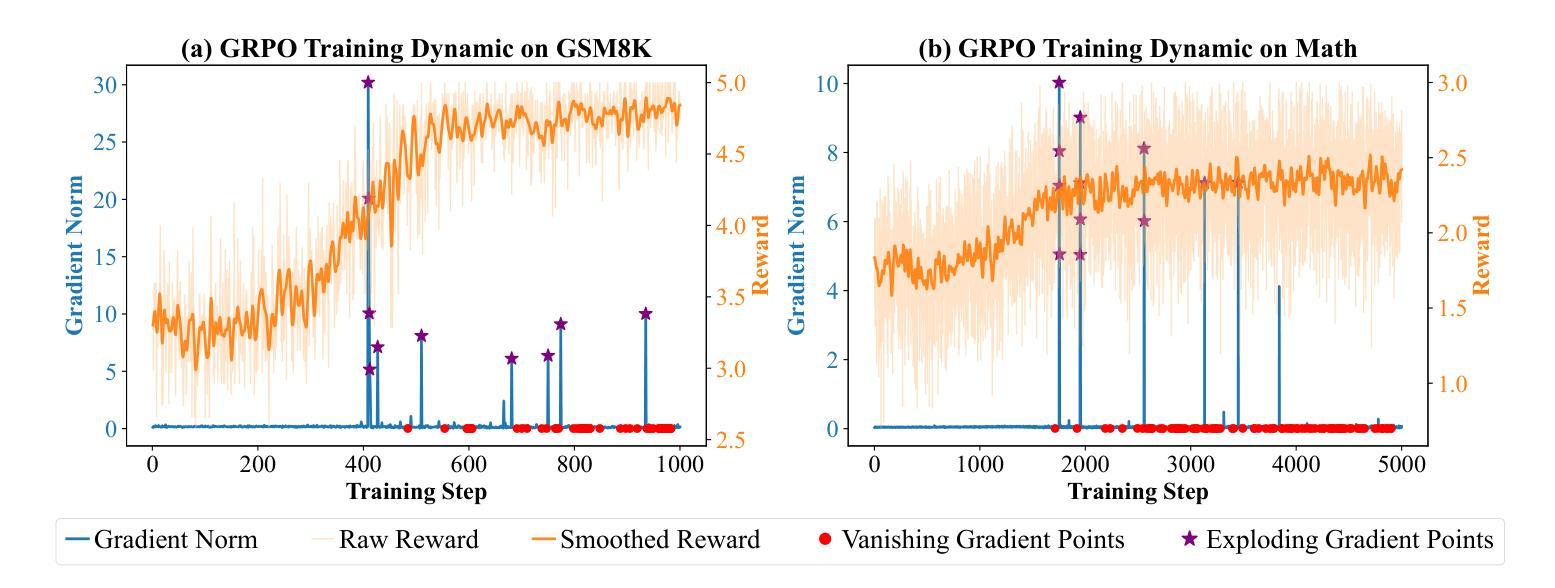
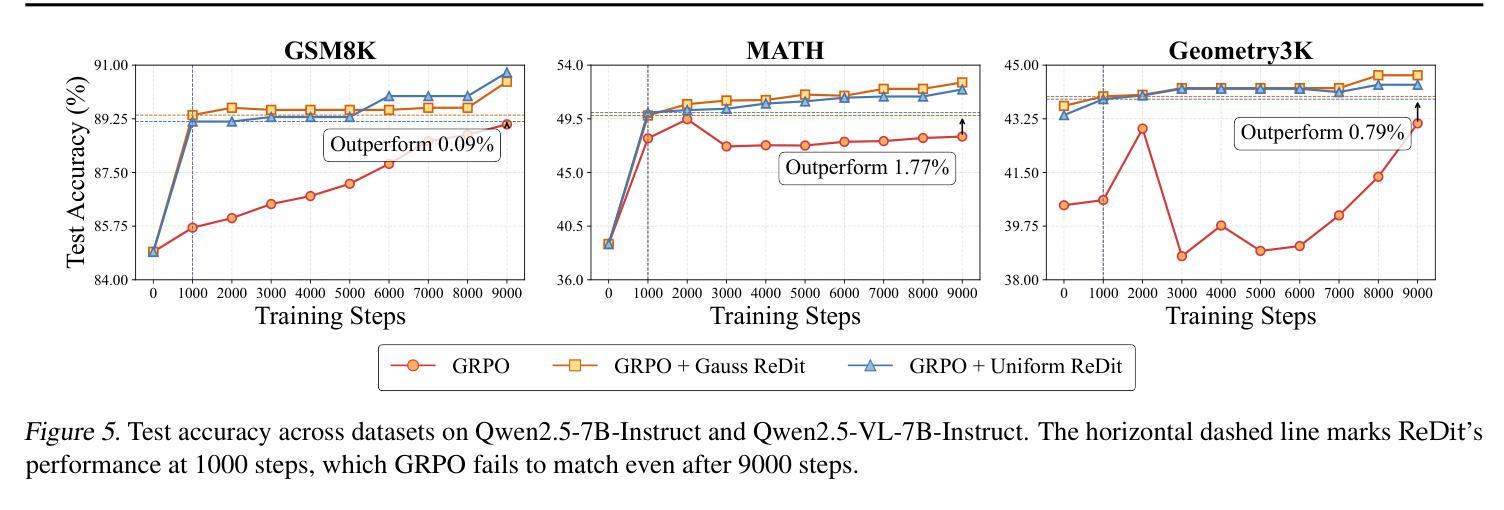
ReDit: Reward Dithering for Improved LLM Policy Optimization
Authors:Chenxing Wei, Jiarui Yu, Ying Tiffany He, Hande Dong, Yao Shu, Fei Yu
DeepSeek-R1 has successfully enhanced Large Language Model (LLM) reasoning capabilities through its rule-based reward system. While it’s a ‘’perfect’’ reward system that effectively mitigates reward hacking, such reward functions are often discrete. Our experimental observations suggest that discrete rewards can lead to gradient anomaly, unstable optimization, and slow convergence. To address this issue, we propose ReDit (Reward Dithering), a method that dithers the discrete reward signal by adding simple random noise. With this perturbed reward, exploratory gradients are continuously provided throughout the learning process, enabling smoother gradient updates and accelerating convergence. The injected noise also introduces stochasticity into flat reward regions, encouraging the model to explore novel policies and escape local optima. Experiments across diverse tasks demonstrate the effectiveness and efficiency of ReDit. On average, ReDit achieves performance comparable to vanilla GRPO with only approximately 10% the training steps, and furthermore, still exhibits a 4% performance improvement over vanilla GRPO when trained for a similar duration. Visualizations confirm significant mitigation of gradient issues with ReDit. Moreover, theoretical analyses are provided to further validate these advantages.
DeepSeek-R1已成功通过其基于规则的奖励系统增强了大型语言模型(LLM)的推理能力。虽然它是一个“完美”的奖励系统,能够有效地遏制奖励黑客行为,但这样的奖励功能是离散的。我们的实验观察表明,离散奖励可能导致梯度异常、优化不稳定和收敛缓慢。为了解决这一问题,我们提出了ReDit(奖励抖动)方法,它通过添加简单的随机噪声来抖动离散奖励信号。通过扰动奖励,可以在整个学习过程中持续提供探索性梯度,从而实现更平滑的梯度更新并加速收敛。注入的噪声还为平坦奖励区域引入了随机性,鼓励模型探索新策略并逃离局部最优解。在不同任务上的实验证明了ReDit的有效性和效率。平均而言,ReDit在仅使用大约10%的训练步骤的情况下实现了与常规GRPO相当的性能,并且在经过类似时间的训练后,其性能还提高了4%。可视化结果证实了ReDit在解决梯度问题方面的显著作用。此外,还提供了理论分析以进一步验证这些优势。
论文及项目相关链接
PDF 10 pages, 15 figures
Summary
深度学习模型DeepSeek-R1通过基于规则的奖励系统增强了大型语言模型(LLM)的推理能力。然而,尽管它是一个完美的奖励系统,能有效遏制奖励作弊,但这种奖励功能通常是离散的。实验观察表明,离散奖励可能导致梯度异常、优化不稳定和收敛缓慢。为解决这一问题,本文提出了一种名为ReDit(奖励抖动)的方法,通过添加简单随机噪声来抖动离散奖励信号。这种扰动奖励为学习过程提供了持续的探索性梯度,使梯度更新更加平滑,加速收敛。注入的噪声还为平坦奖励区域引入了随机性,鼓励模型探索新策略并逃离局部最优。在多种任务上的实验证明了ReDit的有效性和效率。ReDit在平均情况下实现了与基础GRPO相当的性能,但仅使用了约10%的训练步骤。当训练时间相似时,ReDit的性能还提高了4%。可视化结果证实了ReDit对梯度问题的显著缓解。此外,还提供了理论分析以进一步验证这些优势。
Key Takeaways
- DeepSeek-R1通过基于规则的奖励系统增强了LLM的推理能力,但存在离散奖励导致的问题。
- 离散奖励可能导致梯度异常、优化不稳定和收敛缓慢。
- ReDit(奖励抖动)方法通过添加随机噪声来解决离散奖励的问题。
- 扰动奖励有助于提供持续的探索性梯度,加速收敛并改善模型性能。
- ReDit在多种任务上表现出高效性和有效性,实现了与基础GRPO相当的性能,并减少了训练步骤。
- ReDit在相似训练时间内相比基础GRPO有4%的性能提升。
点此查看论文截图

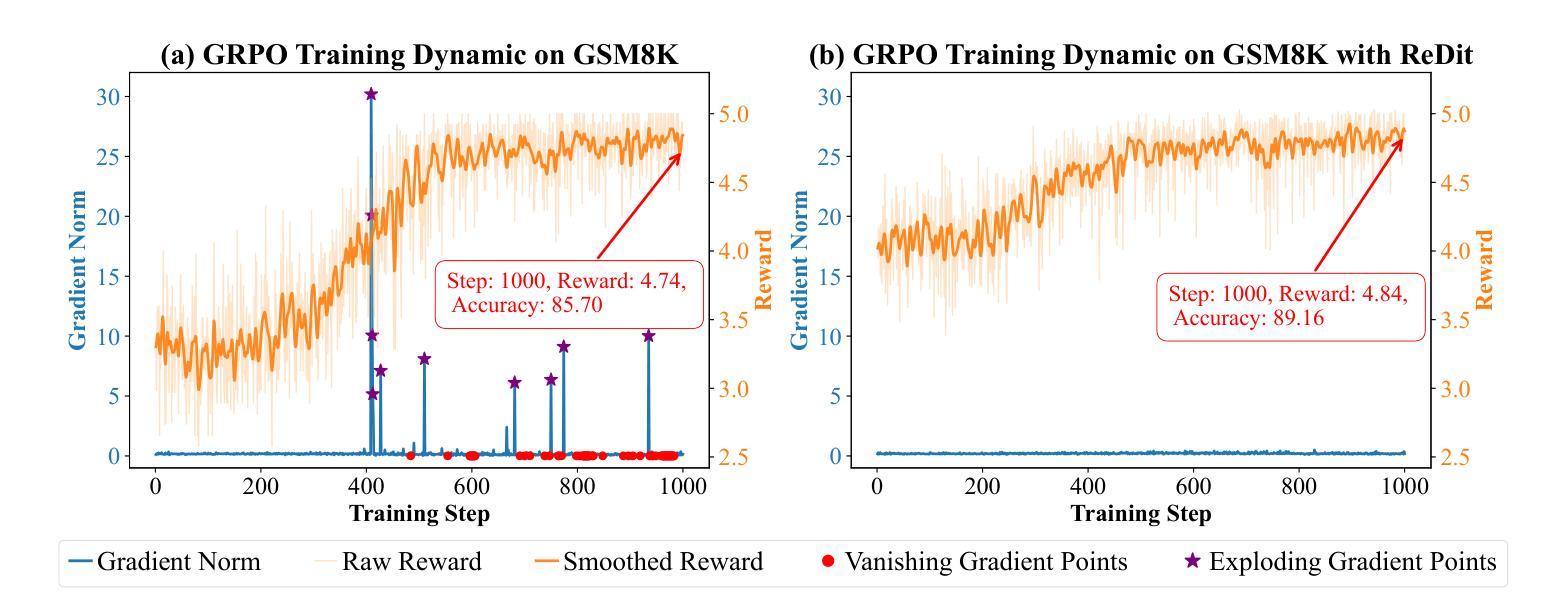
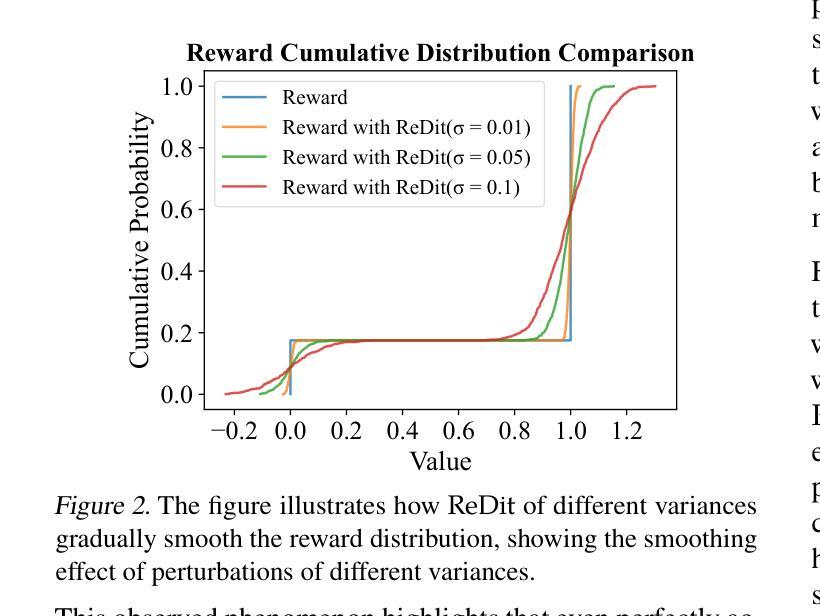
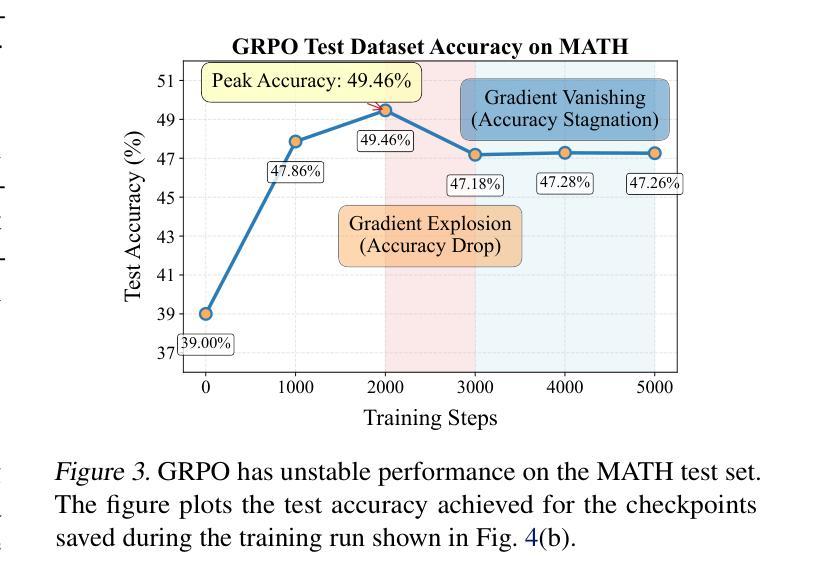
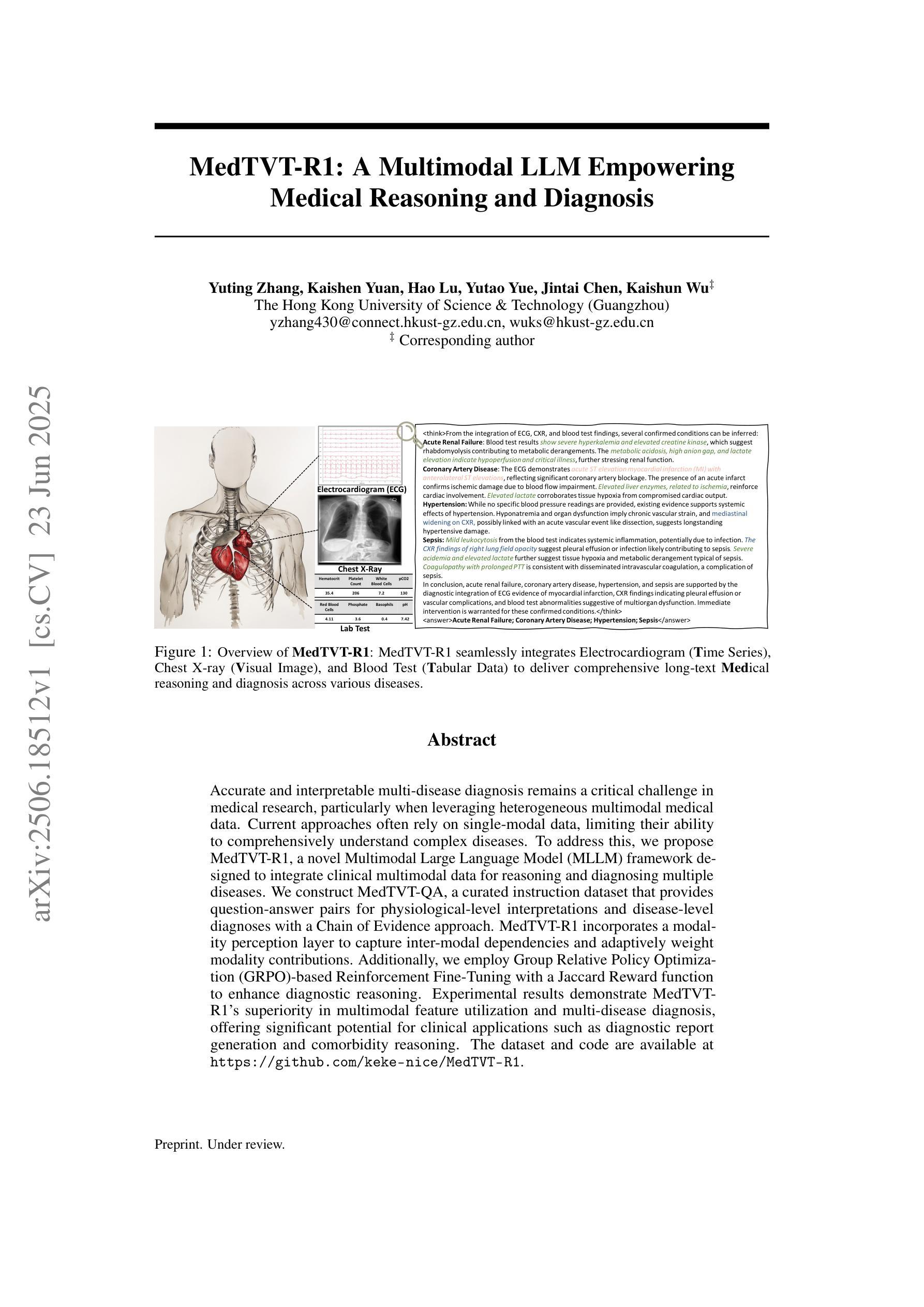
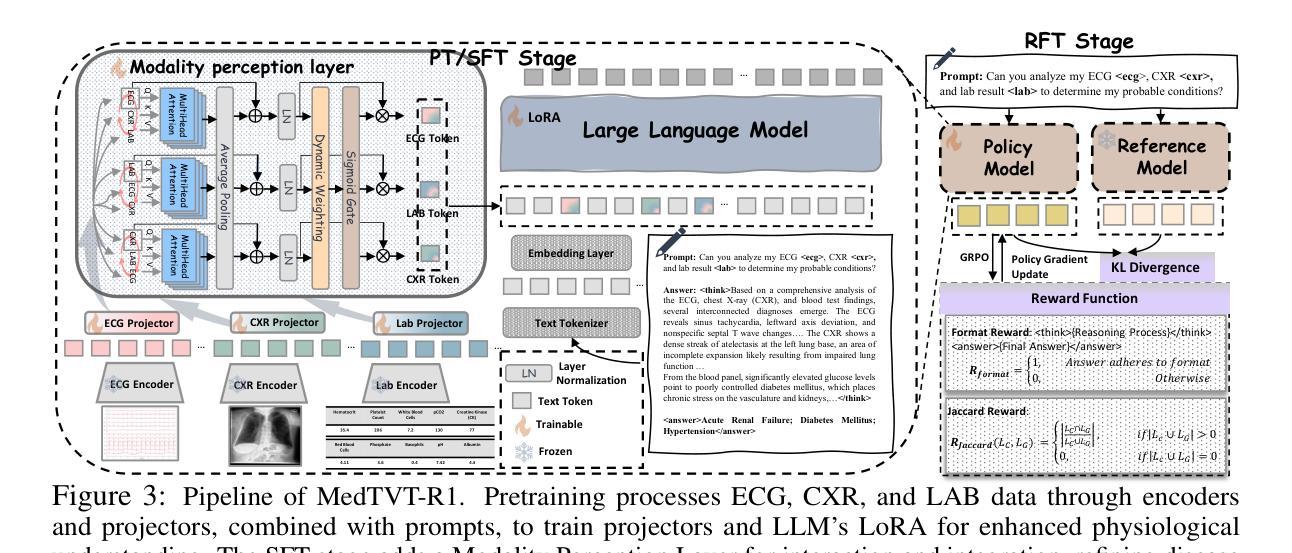
MedTVT-R1: A Multimodal LLM Empowering Medical Reasoning and Diagnosis
Authors:Yuting Zhang, Kaishen Yuan, Hao Lu, Yutao Yue, Jintai Chen, Kaishun Wu
Accurate and interpretable multi-disease diagnosis remains a critical challenge in medical research, particularly when leveraging heterogeneous multimodal medical data. Current approaches often rely on single-modal data, limiting their ability to comprehensively understand complex diseases. To address this, we propose MedTVT-R1, a novel Multimodal Large Language Model (MLLM) framework designed to integrate clinical multimodal data for reasoning and diagnosing multiple diseases. We construct MedTVT-QA, a curated instruction dataset that provides question-answer pairs for physiological-level interpretations and disease-level diagnoses with a Chain of Evidence approach. MedTVT-R1 incorporates a modality perception layer to capture inter-modal dependencies and adaptively weight modality contributions. Additionally, we employ Group Relative Policy Optimization (GRPO)-based Reinforcement Fine-Tuning with a Jaccard Reward function to enhance diagnostic reasoning. Experimental results demonstrate MedTVT-R1’s superiority in multimodal feature utilization and multi-disease diagnosis, offering significant potential for clinical applications such as diagnostic report generation and comorbidity reasoning. The dataset and code are available at https://github.com/keke-nice/MedTVT-R1.
在医学研究中,准确且可解释的多疾病诊断仍然是一个关键挑战,尤其是在利用异构多模态医学数据时。当前的方法往往依赖于单模态数据,限制了它们全面理解复杂疾病的能力。为了解决这个问题,我们提出了MedTVT-R1,这是一种新型的多模态大型语言模型(MLLM)框架,旨在整合临床多模态数据进行推理和多种疾病的诊断。我们构建了MedTVT-QA,这是一个精选的指令数据集,提供用于生理水平解释和疾病水平诊断的问题答案对,采用证据链方法。MedTVT-R1融入了一个模态感知层,以捕捉跨模态的依赖关系并自适应地加权模态贡献。此外,我们采用基于群体相对策略优化(GRPO)的强化微调方法,使用Jaccard奖励函数来提高诊断推理能力。实验结果表明,MedTVT-R1在多模态特征利用和多疾病诊断方面具有优势,在临床应用如生成诊断报告和合并症推理等方面具有巨大潜力。数据集和代码可在https://github.com/keke-nice/MedTVT-R1获得。
论文及项目相关链接
Summary
医学研究中,多疾病准确且可解释的诊断仍然是一个重大挑战,特别是在利用异质多模态医疗数据方面。当前方法常依赖于单一模态数据,无法全面理解复杂疾病。为此,我们提出MedTVT-R1,一种新型多模态大语言模型(MLLM)框架,旨在整合临床多模态数据进行推理和多种疾病的诊断。我们构建了MedTVT-QA数据集,提供生理水平解读和疾病水平诊断的问题答案对,采用证据链方法。MedTVT-R1融入模态感知层以捕捉跨模态依赖关系并自适应地加权模态贡献。此外,我们采用基于组相对策略优化(GRPO)的强化精细调整方法,结合Jaccard奖励函数,提升诊断推理能力。实验结果证明MedTVT-R1在多模态特征利用和多疾病诊断方面的优越性,在生成诊断报告和合并症推理等临床应用方面展现出巨大潜力。
Key Takeaways
- 多疾病诊断面临挑战:当前方法主要依赖单一模态数据,难以全面理解复杂疾病。
- MedTVT-R1框架介绍:这是一种新型的多模态大语言模型(MLLM),旨在整合临床多模态数据进行推理和诊断。
- MedTVT-QA数据集:该数据集包含问题答案对,用于生理水平解读和疾病水平诊断,采用证据链方法。
- MedTVT-R1中的模态感知层:这一层可以捕捉跨模态依赖关系,并自适应地加权不同模态的贡献。
- 强化精细调整方法:使用基于组相对策略优化(GRPO)和Jaccard奖励函数的强化精细调整,提升诊断推理能力。
- 实验结果:MedTVT-R1在多模态特征利用和多疾病诊断方面表现出优越性。
点此查看论文截图


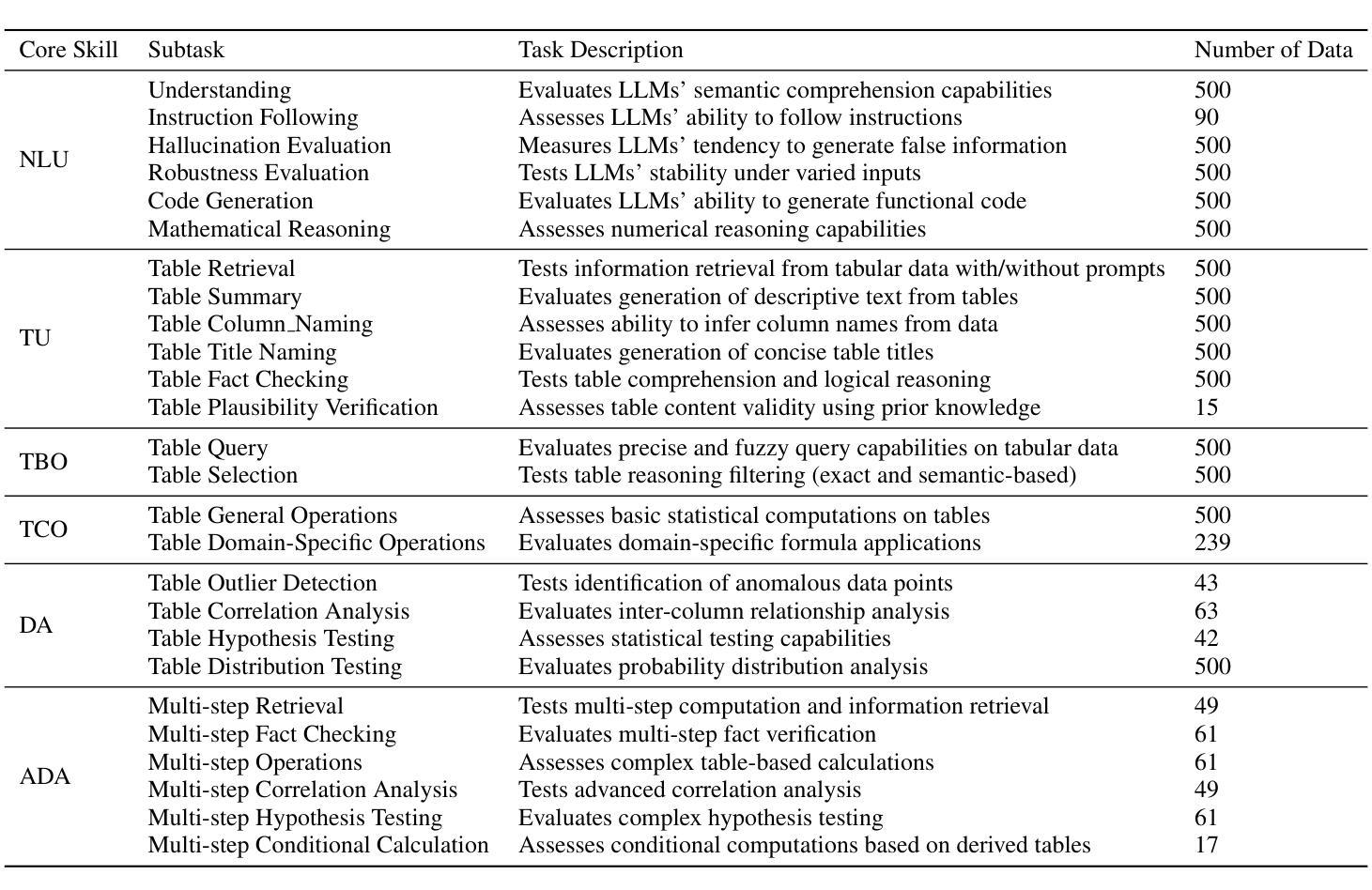
TReB: A Comprehensive Benchmark for Evaluating Table Reasoning Capabilities of Large Language Models
Authors:Ce Li, Xiaofan Liu, Zhiyan Song, Ce Chi, Chen Zhao, Jingjing Yang, Zhendong Wang, Kexin Yang, Boshen Shi, Xing Wang, Chao Deng, Junlan Feng
The majority of data in businesses and industries is stored in tables, databases, and data warehouses. Reasoning with table-structured data poses significant challenges for large language models (LLMs) due to its hidden semantics, inherent complexity, and structured nature. One of these challenges is lacking an effective evaluation benchmark fairly reflecting the performances of LLMs on broad table reasoning abilities. In this paper, we fill in this gap, presenting a comprehensive table reasoning evolution benchmark, TReB, which measures both shallow table understanding abilities and deep table reasoning abilities, a total of 26 sub-tasks. We construct a high quality dataset through an iterative data processing procedure. We create an evaluation framework to robustly measure table reasoning capabilities with three distinct inference modes, TCoT, PoT and ICoT. Further, we benchmark over 20 state-of-the-art LLMs using this frame work and prove its effectiveness. Experimental results reveal that existing LLMs still have significant room for improvement in addressing the complex and real world Table related tasks. Both the dataset and evaluation framework are publicly available, with the dataset hosted on [HuggingFace] and the framework on [GitHub].
在商业和工业领域,大部分数据都存储在表格、数据库和数据仓库中。由于表格结构数据的隐藏语义、固有复杂性和结构性质,对于大型语言模型(LLMs)来说,对其进行推理构成了重大挑战。这些挑战之一是缺乏有效评估基准,无法公正地反映LLM在广泛表格推理能力方面的表现。在本文中,我们弥补了这一空白,提出了一个全面的表格推理进化基准测试(TReB),该基准测试衡量了浅层次的表格理解能力和深层次的表格推理能力,共有26个子任务。我们通过迭代数据处理程序构建了高质量的数据集。我们创建了一个评估框架,通过三种不同的推理模式(TCoT、PoT和ICoT)来稳健地衡量表格推理能力。此外,我们使用此框架对20多项最新LLM进行了基准测试,并证明了其有效性。实验结果表明,现有的LLM在解决复杂和现实世界中的表格相关任务方面仍有很大的改进空间。数据集和评估框架均公开可用,数据集托管在[HuggingFace],框架托管在[GitHub]。
论文及项目相关链接
PDF Benmark report v1.0
Summary
文本介绍了在商业和工业领域中,大部分数据以表格形式存储在数据库和数据仓库中。由于表格结构的隐藏语义、内在复杂性和结构化特性,大型语言模型(LLMs)在处理表格数据时面临挑战。本文提出了一种全面的表格推理评估基准(TReB),旨在衡量LLMs在表格理解方面的能力,包括浅层次理解和深层次推理能力,共涉及26个子任务。通过迭代数据处理程序构建高质量数据集,并创建一个评估框架来稳健地衡量表格推理能力,包括三种不同的推理模式。本文对20多个最新LLMs进行了基准测试,证明了其有效性。实验结果表明,现有LLMs在处理复杂和现实世界的表格相关任务方面仍有很大提升空间。数据集和评估框架均公开可用,数据集托管在HuggingFace上,框架托管在GitHub上。
Key Takeaways
- 数据在企业和行业中主要以表格形式存储,如数据库和数据仓库。
- 表格结构的隐藏语义、内在复杂性和结构化特性使大型语言模型(LLMs)处理表格数据时面临挑战。
- 现有的LLMs在表格理解方面仍存在显著不足,尤其是在处理复杂和现实世界的表格任务时。
- 本文提出了一种全面的表格推理评估基准(TReB),包含26个子任务,旨在衡量LLMs的表格理解能力和推理能力。
- TReB包含三种不同的推理模式,以稳健地衡量表格推理能力。
- 本文通过迭代数据处理程序构建了一个高质量的数据集,并公开提供。
点此查看论文截图

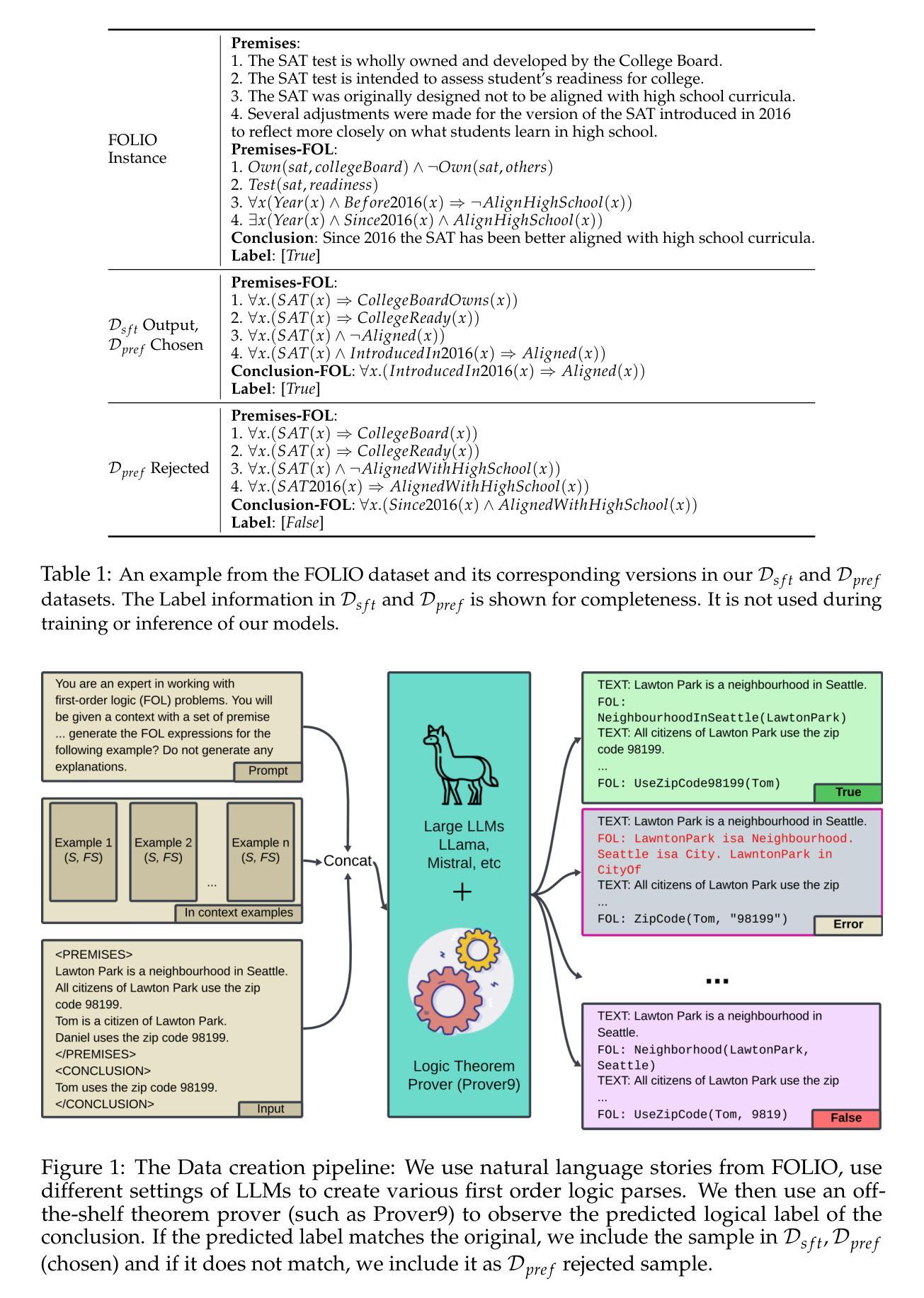
LOGICPO: Efficient Translation of NL-based Logical Problems to FOL using LLMs and Preference Optimization
Authors:Koushik Viswanadha, Deepanway Ghosal, Somak Aditya
Logical reasoning is a key task for artificial intelligence due to it’s role in major downstream tasks such as Question Answering, Summarization. Recent methods in improving the reasoning ability of LLMs fall short in correctly converting a natural language reasoning problem to an equivalent logical formulation, which hinders the framework’s overall ability to reason. Towards this, we propose to use finetuning on a preference optimization dataset to learn to parse and represent a natural language problem as a whole to a consistent logical program by 1) introducing a new supervised and preference optimization dataset LogicPO, and 2) adopting popular techniques such as Direct Preference Optimization (DPO), Kahneman-Tversky optimization (KTO) to finetune open-source LLMs. Our best model with Phi-3.5 consistently outperforms GPT-3.5-turbo’s (8-shot) by producing 10% more logically correct and with 14% less syntax errors. Through the framework and our improved evaluation metrics, we offer a promising direction in improving the logical reasoning of LLMs by better representing them in their logical formulations.
逻辑推理是人工智能的一项关键任务,因为它在问答、摘要等下游主要任务中发挥着重要作用。近年来,在提升大型语言模型的推理能力方面,现有方法难以将自然语言推理问题正确转换为等效的逻辑形式,这阻碍了框架整体的推理能力。针对这一问题,我们提出通过在一个偏好优化数据集上进行微调来学习将整个自然语言问题解析并表示为一致的逻辑程序。具体来说,我们1)引入了一个新的有监督学习和偏好优化数据集LogicPO,以及2)采用流行的技术,如直接偏好优化(DPO)、卡内曼-特维尔斯基优化(KTO)来微调开源的大型语言模型。我们的最佳模型Phi-3.5在逻辑上持续超越了GPT-3.5 turbo(8次拍摄),产生更逻辑正确的结果达10%,语法错误减少了14%。通过我们的框架和改进的评价指标,我们在通过逻辑表述更好地表示大型语言模型的逻辑方面,提供了一个有前途的方向。
论文及项目相关链接
Summary
近期对于提升大型语言模型(LLMs)的推理能力的方法在处理自然语言推理问题时,难以正确转换为逻辑形式。为此,该研究通过微调偏好优化数据集的方式学习解析和表示自然语言问题为一个连贯的逻辑程序。研究引入了新的监督学习和偏好优化数据集LogicPO,并采用Direct Preference Optimization (DPO)和Kahneman-Tversky优化(KTO)等技术对开源LLMs进行微调。最佳模型Phi-3.5在逻辑正确性上较GPT-3.5-turbo高出10%,语法错误减少了14%。该研究为改进LLMs的逻辑推理能力提供了方向,即通过更好地在逻辑形式中表示它们。
Key Takeaways
- 自然语言推理是人工智能的核心任务之一,对于下游任务如问答、摘要等具有重要意义。
- 现有提升LLMs推理能力的方法在将自然语言问题转换为逻辑形式时存在缺陷。
- 研究通过微调偏好优化数据集的方式,学习将自然语言问题解析和表示为一个连贯的逻辑程序。
- 引入了新的监督学习和偏好优化数据集LogicPO。
- 采用DPO和KTO等技术对开源LLMs进行微调,以提高其逻辑推理能力。
- 最佳模型Phi-3.5在逻辑正确性和语法错误方面较GPT-3.5-turbo有显著改善。
点此查看论文截图

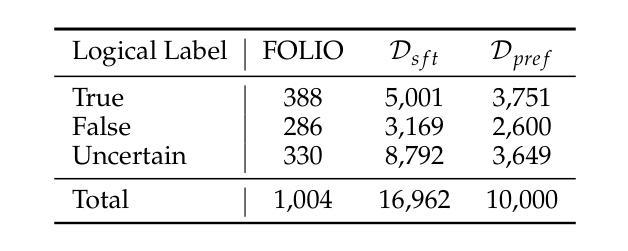
RePIC: Reinforced Post-Training for Personalizing Multi-Modal Language Models
Authors:Yeongtak Oh, Jisoo Mok, Dohyun Chung, Juhyeon Shin, Sangha Park, Johan Barthelemy, Sungroh Yoon
Recent multi-modal large language models (MLLMs) often struggle to generate personalized image captions, even when trained on high-quality captions. In this work, we observe that such limitations persist in existing post-training-based MLLM personalization methods. Specifically, despite being post-tuned with large-scale caption data through supervised fine-tuning (SFT), these models frequently fail to produce faithful descriptions in real-world scenarios, such as multi-concept image captioning. However, acquiring large-scale, high-quality captions for such complex settings is both costly and difficult. To address the data-centric nature of SFT, we propose a reinforcement learning (RL)-based post-training framework. To the best of our knowledge, this is the first RL-based approach to post-train MLLMs for personalized image captioning. Our method significantly enhances both visual recognition and personalized generation capabilities of MLLMs, and consistently outperforms existing SFT-based baselines, especially in the challenging multi-concept image captioning task.
最近的多模态大型语言模型(MLLMs)即使在高质量的图片描述上训练,也往往难以生成个性化的图像标题。在这项工作中,我们观察到现有的基于后训练的MLLM个性化方法存在这样的局限性。具体来说,尽管通过有监督微调(SFT)在大规模图片描述数据上进行后调整,这些模型在真实场景(如多概念图像标题生成)中仍然无法产生忠实的描述。然而,为这种复杂环境获取大规模的高质量图片描述既昂贵又困难。为了解决SFT以数据为中心的特性,我们提出了一种基于强化学习(RL)的后训练框架。据我们所知,这是第一个用于个性化图像标题生成的后训练MLLM的RL方法。我们的方法显著提高了MLLM的视觉识别能力和个性化生成能力,并且在具有挑战性的多概念图像标题任务上,表现均优于现有的基于SFT的基线。
论文及项目相关链接
PDF Project Page: https://github.com/oyt9306/RePIC
Summary
多模态大型语言模型(MLLMs)在生成个性化图像描述时存在局限,即使经过高质量描述训练,仍难以在真实场景中生成忠实描述。本文观察到现有基于后训练的MLLM个性化方法存在此类限制。尽管通过监督微调(SFT)进行大规模图像描述数据后调,但这些模型在多概念图像描述等复杂场景中仍无法产生忠实描述。为解决SFT的数据中心性质,本文提出一种基于强化学习(RL)的后训练框架。据我们所知,这是首次使用RL对MLLM进行个性化图像描述的后训练。该方法显著提高MLLM的视觉识别和个性化生成能力,尤其在多概念图像描述等挑战性任务中,优于现有的基于SFT的基线方法。
Key Takeaways
- 多模态大型语言模型(MLLMs)在生成个性化图像描述时存在挑战。
- 即使经过高质量描述训练,现有基于后训练的MLLM个性化方法仍面临限制。
- 监督微调(SFT)难以处理复杂场景中的多概念图像描述。
- 强化学习(RL)被首次用于MLLM的后训练,以改善个性化图像描述生成。
- 提出一种基于RL的后训练框架,显著提高MLLM的视觉识别和个性化生成能力。
- 该方法在挑战性任务如多概念图像描述中,表现优于基于SFT的基线方法。
- 数据收集和准备是改善模型性能的关键,尤其是在复杂场景中。
点此查看论文截图


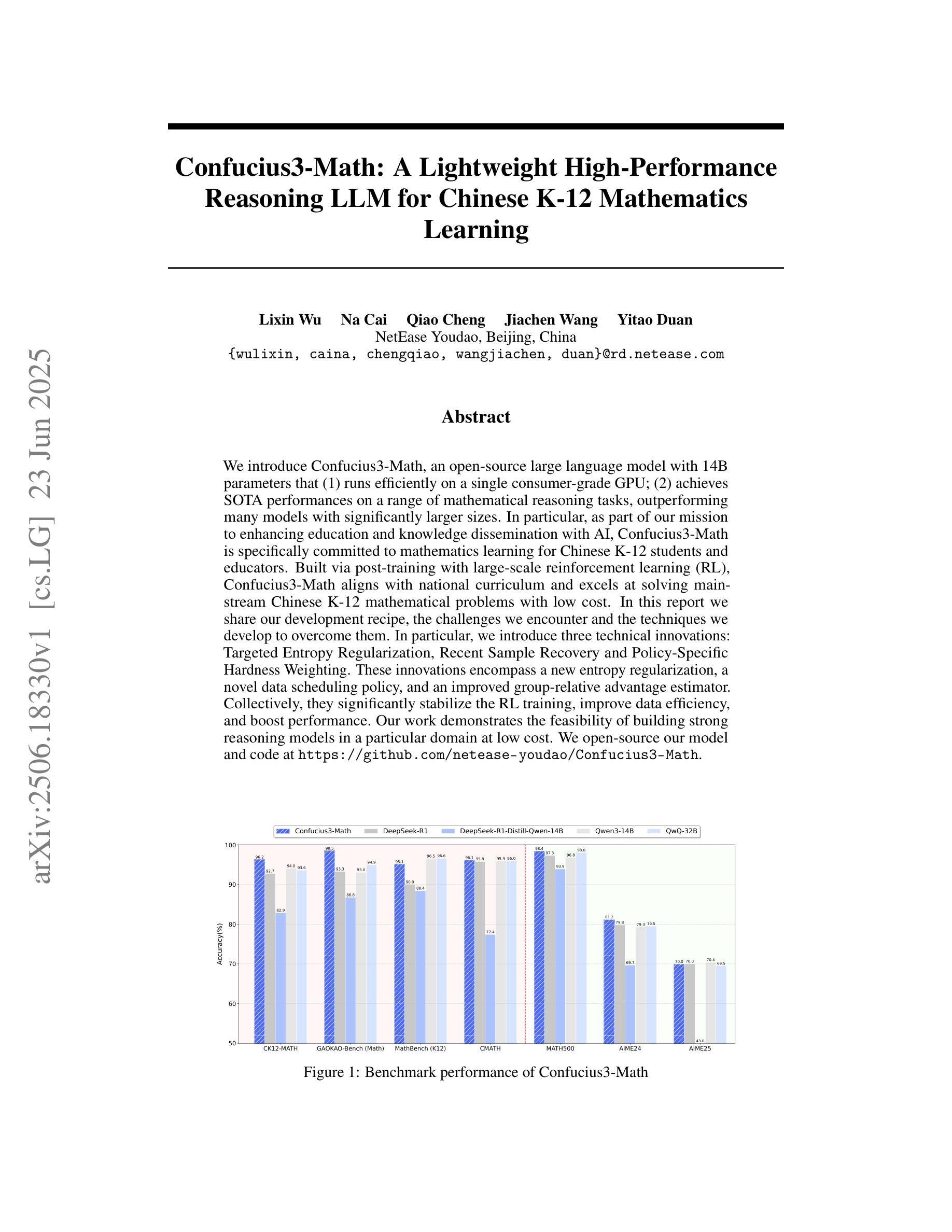
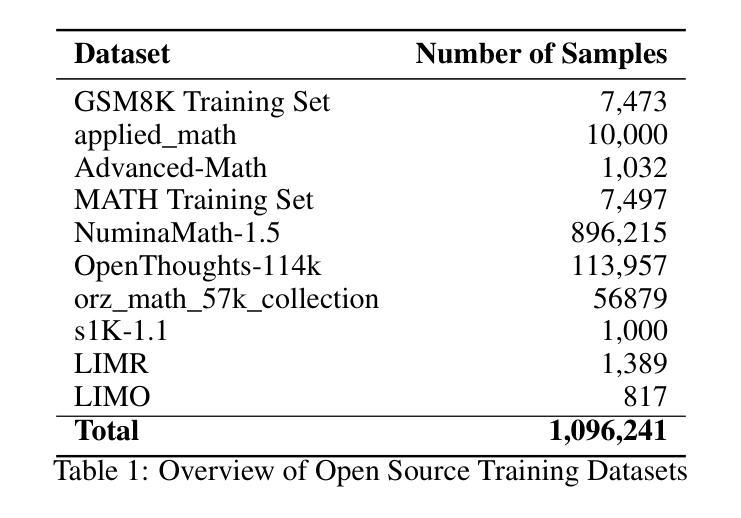
Confucius3-Math: A Lightweight High-Performance Reasoning LLM for Chinese K-12 Mathematics Learning
Authors:Lixin Wu, Na Cai, Qiao Cheng, Jiachen Wang, Yitao Duan
We introduce Confucius3-Math, an open-source large language model with 14B parameters that (1) runs efficiently on a single consumer-grade GPU; (2) achieves SOTA performances on a range of mathematical reasoning tasks, outperforming many models with significantly larger sizes. In particular, as part of our mission to enhancing education and knowledge dissemination with AI, Confucius3-Math is specifically committed to mathematics learning for Chinese K-12 students and educators. Built via post-training with large-scale reinforcement learning (RL), Confucius3-Math aligns with national curriculum and excels at solving main-stream Chinese K-12 mathematical problems with low cost. In this report we share our development recipe, the challenges we encounter and the techniques we develop to overcome them. In particular, we introduce three technical innovations: Targeted Entropy Regularization, Recent Sample Recovery and Policy-Specific Hardness Weighting. These innovations encompass a new entropy regularization, a novel data scheduling policy, and an improved group-relative advantage estimator. Collectively, they significantly stabilize the RL training, improve data efficiency, and boost performance. Our work demonstrates the feasibility of building strong reasoning models in a particular domain at low cost. We open-source our model and code at https://github.com/netease-youdao/Confucius3-Math.
我们推出Confucius3-Math,这是一款拥有14亿参数的开源大型语言模型,它具备以下特点:(1)在单个消费级GPU上运行高效;(2)在各种数学推理任务上达到了最新技术水平,超越了许多规模更大的模型。特别是,作为我们用AI加强教育和知识普及的使命的一部分,Confucius3-Math专注于为中国的K-12学生和教育工作者提供数学学习帮助。通过训练后的大规模强化学习(RL)构建,Confucius3-Math与国家课程相契合,擅长解决主流的中国K-12数学问题且成本低廉。在这份报告中,我们分享了我们的开发配方、遇到的挑战以及为克服这些挑战而开发的技术。特别地,我们介绍了三项技术创新:目标熵正则化、最新样本恢复和策略特定硬度加权。这些创新包括一种新的熵正则化、一种新的数据调度策略以及一个改进的小组相对优势估计器。总体上,它们显著稳定了RL训练,提高了数据效率并提升了性能。我们的工作证明了在特定领域构建强大的推理模型的可行性,并且成本低廉。我们在https://github.com/netease-youdao/Confucius3-Math开源我们的模型和代码。
论文及项目相关链接
Summary
孔子三号数学模型是一个面向中文K-12学生和教育工作者的数学推理大型语言模型。该模型具有开源、运行效率高、性能卓越等特点,能够在单个消费级GPU上运行,并在一系列数学推理任务上取得了最先进的性能。通过大规模强化学习进行训练,该模型符合国家课程标准,擅长解决主流的数学问题,成本低廉。本文介绍了模型的开发过程、面临的挑战以及为克服挑战而开发的技术。该模型的创新技术包括目标熵正则化、最新样本恢复和策略特定硬度加权等。这些创新技术显著稳定强化学习训练,提高数据效率并提升性能。我们公开了模型和代码。
Key Takeaways
- 孔子三号数学是一个面向中文K-12学生和教育工作者的开源大型语言模型。
- 该模型能在单个消费级GPU上高效运行,具有卓越性能。
- 通过大规模强化学习训练,孔子三号数学符合国家课程标准,擅长解决主流数学问题。
- 模型实现三大技术创新:目标熵正则化、最新样本恢复和策略特定硬度加权。
- 这些创新技术显著稳定强化学习训练过程,提高数据效率并提升模型性能。
- 该模型公开源代码供公众使用和学习。
点此查看论文截图

RLPR: Extrapolating RLVR to General Domains without Verifiers
Authors:Tianyu Yu, Bo Ji, Shouli Wang, Shu Yao, Zefan Wang, Ganqu Cui, Lifan Yuan, Ning Ding, Yuan Yao, Zhiyuan Liu, Maosong Sun, Tat-Seng Chua
Reinforcement Learning with Verifiable Rewards (RLVR) demonstrates promising potential in advancing the reasoning capabilities of LLMs. However, its success remains largely confined to mathematical and code domains. This primary limitation stems from the heavy reliance on domain-specific verifiers, which results in prohibitive complexity and limited scalability. To address the challenge, our key observation is that LLM’s intrinsic probability of generating a correct free-form answer directly indicates its own evaluation of the reasoning reward (i.e., how well the reasoning process leads to the correct answer). Building on this insight, we propose RLPR, a simple verifier-free framework that extrapolates RLVR to broader general domains. RLPR uses the LLM’s own token probability scores for reference answers as the reward signal and maximizes the expected reward during training. We find that addressing the high variance of this noisy probability reward is crucial to make it work, and propose prob-to-reward and stabilizing methods to ensure a precise and stable reward from LLM intrinsic probabilities. Comprehensive experiments in four general-domain benchmarks and three mathematical benchmarks show that RLPR consistently improves reasoning capabilities in both areas for Gemma, Llama, and Qwen based models. Notably, RLPR outperforms concurrent VeriFree by 7.6 points on TheoremQA and 7.5 points on Minerva, and even surpasses strong verifier-model-dependent approaches General-Reasoner by 1.6 average points across seven benchmarks.
强化学习与可验证奖励(RLVR)在提升大型语言模型的推理能力方面显示出巨大的潜力。然而,其成功主要局限于数学和代码领域。这种主要局限源于对特定领域验证器的严重依赖,这导致了禁止的复杂性和有限的扩展性。为了应对这一挑战,我们的主要观察结果是,大型语言模型生成正确自由形式答案的内在概率直接指示其对推理奖励的评估(即推理过程如何导致正确答案)。基于这一见解,我们提出了无验证器参与的RLPR框架,该框架将RLVR推广到更广泛的通用领域。RLPR使用大型语言模型对参考答案的自身令牌概率分数作为奖励信号,并在训练过程中最大化预期奖励。我们发现解决这种嘈杂概率奖励的高方差是使其发挥作用的关键,并提出概率到奖励和稳定方法,以确保从大型语言模型内在概率中获得精确稳定的奖励。在四个通用领域基准测试和三个数学基准测试的综合实验表明,RLPR在这两个领域的推理能力均有所提高,适用于Gemma、Llama和Qwen模型。值得注意的是,RLPR在定理问答(TheoremQA)和Minerva上的得分分别比同期验证器VeriFree高出7.6分和7.5分,甚至在七个基准测试中平均高出验证器依赖方法General-Reasoner 1.6分。
论文及项目相关链接
PDF Project Website: https://github.com/openbmb/RLPR
Summary
强化学习与可验证奖励(RLVR)在提升大型语言模型(LLM)的推理能力方面展现出巨大潜力,但其应用主要局限于数学和代码领域。这主要是因为其过于依赖特定领域的验证器,导致复杂性增加和可扩展性有限。基于LLM生成正确自由形式答案的固有概率可以直接反映其对推理奖励的评估这一观察,提出了无需验证器的RLPR框架,将RLVR推广至更广泛的通用领域。RLPR利用LLM对参考答案的自身令牌概率分数作为奖励信号,并在训练过程中最大化预期奖励。研究发现,解决这种概率奖励的高方差至关重要,并提出了prob-to-reward和稳定方法,以确保从LLM内在概率中获得精确稳定的奖励。实验表明,RLPR在通用领域和数学领域的多个基准测试中,均提高了Gemma、Llama和Qwen等模型的推理能力。特别是在定理QA和Minerva上,RLPR分别优于并发验证器VeriFree 7.6点和7.5点,甚至在七个基准测试中平均优于强验证器依赖的方法General-Reasoner 1.6点。
Key Takeaways
- RLVR在提升LLM推理能力方面展现潜力,但主要局限于数学和代码领域。
- 依赖特定领域的验证器导致复杂性和扩展性限制。
- LLM生成正确答案的固有概率可以作为评估推理奖励的指示。
- 提出无需验证器的RLPR框架,适用于更广泛的通用领域。
- RLPR利用LLM的令牌概率分数作为奖励信号,并在训练过程中最大化预期奖励。
- 解决概率奖励的高方差问题对于RLPR的成功至关重要。
点此查看论文截图
Smart-LLaMA-DPO: Reinforced Large Language Model for Explainable Smart Contract Vulnerability Detection
Authors:Lei Yu, Zhirong Huang, Hang Yuan, Shiqi Cheng, Li Yang, Fengjun Zhang, Chenjie Shen, Jiajia Ma, Jingyuan Zhang, Junyi Lu, Chun Zuo
Smart contract vulnerability detection remains a major challenge in blockchain security. Existing vulnerability detection methods face two main issues: (1) Existing datasets lack comprehensive coverage and high-quality explanations for preference learning. (2) Large language models (LLMs) often struggle with accurately interpreting specific concepts in smart contract security. Empirical analysis shows that even after continual pre-training (CPT) and supervised fine-tuning (SFT), LLMs may misinterpret the execution order of state changes, resulting in incorrect explanations despite making correct detection decisions. To address these challenges, we propose Smart-LLaMA-DPO based on LLaMA-3.1-8B. We construct a comprehensive dataset covering four major vulnerability types and machine-unauditable vulnerabilities, including precise labels, explanations, and locations for SFT, as well as high-quality and low-quality output pairs for Direct Preference Optimization (DPO). Second, we perform CPT using large-scale smart contract to enhance the LLM’s understanding of specific security practices in smart contracts. Futhermore, we conduct SFT with our comprehensive dataset. Finally, we apply DPO, leveraging human feedback and a specially designed loss function that increases the probability of preferred explanations while reducing the likelihood of non-preferred outputs. We evaluate Smart-LLaMA-DPO on four major vulnerability types: reentrancy, timestamp dependence, integer overflow/underflow, and delegatecall, as well as machine-unauditable vulnerabilities. Our method significantly outperforms state-of-the-art baselines, with average improvements of 10.43% in F1 score and 7.87% in accuracy. Moreover, both LLM evaluation and human evaluation confirm that our method generates more correct, thorough, and clear explanations.
智能合约漏洞检测仍是区块链安全领域的主要挑战。现有的漏洞检测方法面临两大问题:(1)现有数据集在偏好学习方面缺乏全面覆盖和高质量解释。(2)大型语言模型(LLMs)在准确解释智能合约安全中的特定概念时经常遇到困难。实证分析表明,即使经过持续预训练(CPT)和监督微调(SFT),LLMs仍可能误解状态变更的执行顺序,导致即使做出正确的检测决策,解释也是错误的。为了解决这些挑战,我们基于LLaMA-3.1-8B提出Smart-LLaMA-DPO。我们构建了一个综合数据集,覆盖四种主要漏洞类型和机器无法审核的漏洞,包括精确标签、解释、用于SFT的位置,以及用于直接偏好优化(DPO)的高质量和低质量输出对。其次,我们使用大规模智能合约进行CPT,以增强LLM对智能合约中特定安全实践的理解。此外,我们用我们的综合数据集进行SFT。最后,我们应用DPO,利用人类反馈和专门设计的损失函数,增加首选解释的概率,同时减少非首选输出的可能性。我们在四种主要漏洞类型:重入、时间戳依赖、整数溢出/下溢和delegatecall,以及机器无法审核的漏洞上评估了Smart-LLaMA-DPO。我们的方法显著优于最新基线,F1分数平均提高10.43%,准确率提高7.87%。而且,LLM评估和人类评估都证实,我们的方法生成的解释更加正确、全面和清晰。
论文及项目相关链接
PDF Accepted to ISSTA 2025
Summary
智能合约漏洞检测是区块链安全中的一大挑战。现有方法面临数据集覆盖不全、解释质量不高以及大型语言模型对智能合约安全特定概念解读不精准的问题。为解决这些问题,提出基于LLaMA-3.1-8B的Smart-LLaMA-DPO方法。构建全面数据集,涵盖四大漏洞类型和机器无法审核的漏洞,增强LLM对智能合约安全实践的理解,并进行直接偏好优化。评估显示,该方法在主要漏洞类型上显著优于现有基线,F1分数提高10.43%,准确率提高7.87%,生成的解释更准确、全面、清晰。
Key Takeaways
- 智能合约漏洞检测是区块链安全的重要挑战。
- 现有方法面临数据集覆盖不全和高质量解释缺失的问题。
- 大型语言模型在解读智能合约安全特定概念时存在困难。
- 提出Smart-LLaMA-DPO方法,基于LLaMA-3.1-8B,构建全面数据集以解决上述问题。
- 方法包括构建数据集、增强LLM理解、进行直接偏好优化等步骤。
- 评估显示,Smart-LLaMA-DPO在主要漏洞类型上显著优于现有方法。
点此查看论文截图


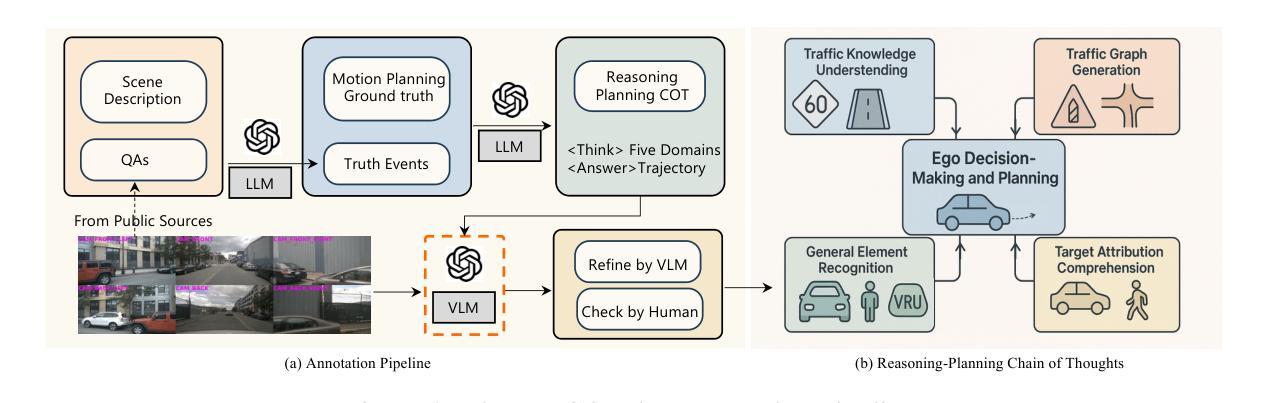
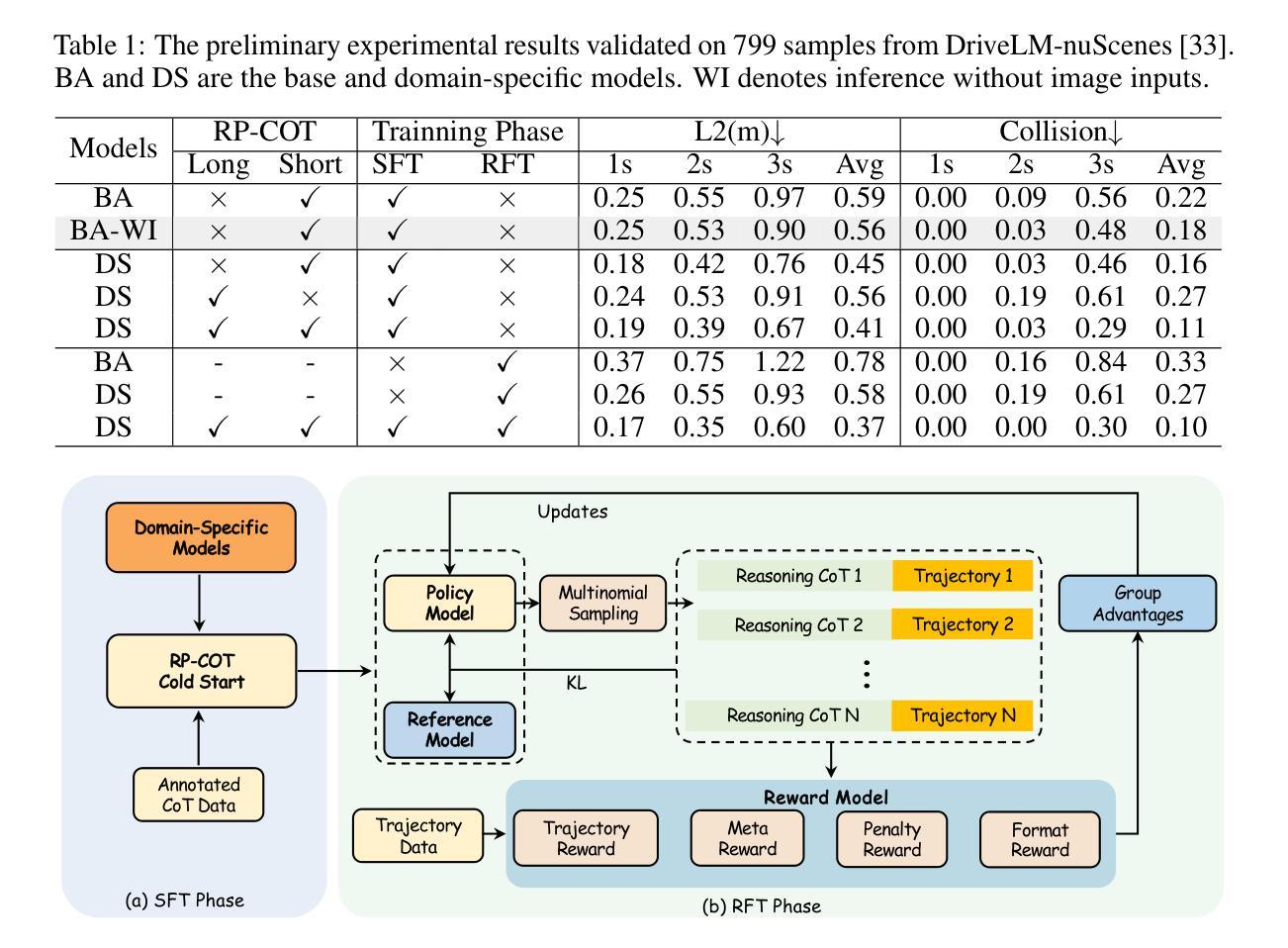
Drive-R1: Bridging Reasoning and Planning in VLMs for Autonomous Driving with Reinforcement Learning
Authors:Yue Li, Meng Tian, Dechang Zhu, Jiangtong Zhu, Zhenyu Lin, Zhiwei Xiong, Xinhai Zhao
Large vision-language models (VLMs) for autonomous driving (AD) are evolving beyond perception and cognition tasks toward motion planning. However, we identify two critical challenges in this direction: (1) VLMs tend to learn shortcuts by relying heavily on history input information, achieving seemingly strong planning results without genuinely understanding the visual inputs; and (2) the chain-ofthought (COT) reasoning processes are always misaligned with the motion planning outcomes, and how to effectively leverage the complex reasoning capability to enhance planning remains largely underexplored. In this paper, we start from a small-scale domain-specific VLM and propose Drive-R1 designed to bridges the scenario reasoning and motion planning for AD. Drive-R1 first undergoes the supervised finetuning on a elaborate dataset containing both long and short COT data. Drive-R1 is encouraged to reason step-by-step from visual input to final planning decisions. Subsequently, Drive-R1 is trained within a reinforcement learning framework that incentivizes the discovery of reasoning paths that are more informative for planning, guided by rewards based on predicted trajectories and meta actions. Experimental evaluations on the nuScenes and DriveLM-nuScenes benchmarks demonstrate that Drive-R1 achieves superior performance compared to existing state-of-the-art VLMs. We believe that Drive-R1 presents a promising direction for bridging reasoning and planning in AD, offering methodological insights for future research and applications.
针对自动驾驶(AD)的大型视觉语言模型(VLM)正在从感知和认知任务向运动规划发展。然而,我们在这个方向上面临两个关键挑战:(1)VLM倾向于通过依赖大量的历史输入信息来学会走捷径,而并非真正理解视觉输入便能够达到看似强大的规划结果;(2)链式思维(COT)推理过程总是与运动规划结果不一致,如何有效利用复杂的推理能力来提升规划仍然是一个未被充分研究的问题。在本文中,我们从一个小规模的特定领域VLM出发,提出了旨在弥合场景推理和自动驾驶运动规划的Drive-R1。Drive-R1首先在包含长短链思维数据的精致数据集上进行监督微调。它鼓励从视觉输入到最终规划决策进行逐步推理。随后,我们在强化学习框架下训练Drive-R1,激励发现更有益于规划的推理路径,并根据预测的轨迹和元动作提供奖励作为指导。在nuScenes和DriveLM-nuScenes基准测试上的实验评估表明,与现有的最先进的VLM相比,Drive-R1实现了卓越的性能。我们相信,Drive-R1为弥合自动驾驶中的推理和规划提供了一个有前景的方向,为未来研究与应用提供了方法论上的启示。
论文及项目相关链接
Summary
本文介绍了大型视觉语言模型(VLMs)在自动驾驶(AD)领域面临的挑战。为解决这些问题,本文提出了一种设计用于连接场景推理和自动驾驶运动规划的特定域小尺度模型Drive-R1。通过采用结合长期和短期思维过程的强化学习训练方法,Drive-R1能够实现从视觉输入到最终规划决策的逐步推理,且在nuScenes和DriveLM-nuScenes基准测试中表现出卓越性能。这为未来的研究和应用提供了方法论上的启示。
Key Takeaways
- 大型视觉语言模型在自动驾驶领域正面临从感知和认知任务向运动规划发展的挑战。
- 存在两个关键挑战:模型依赖历史信息导致的“捷径”学习和思维过程与运动规划结果的不对齐。
- 提出了一种特定域小尺度模型Drive-R1,旨在连接场景推理和自动驾驶运动规划。
- Drive-R1通过结合长期和短期思维过程的强化学习训练,实现从视觉输入到最终规划决策的逐步推理。
- 模型在nuScenes和DriveLM-nuScenes基准测试中表现优越。
- Drive-R1为未来的研究和应用提供了方法论上的启示。
点此查看论文截图


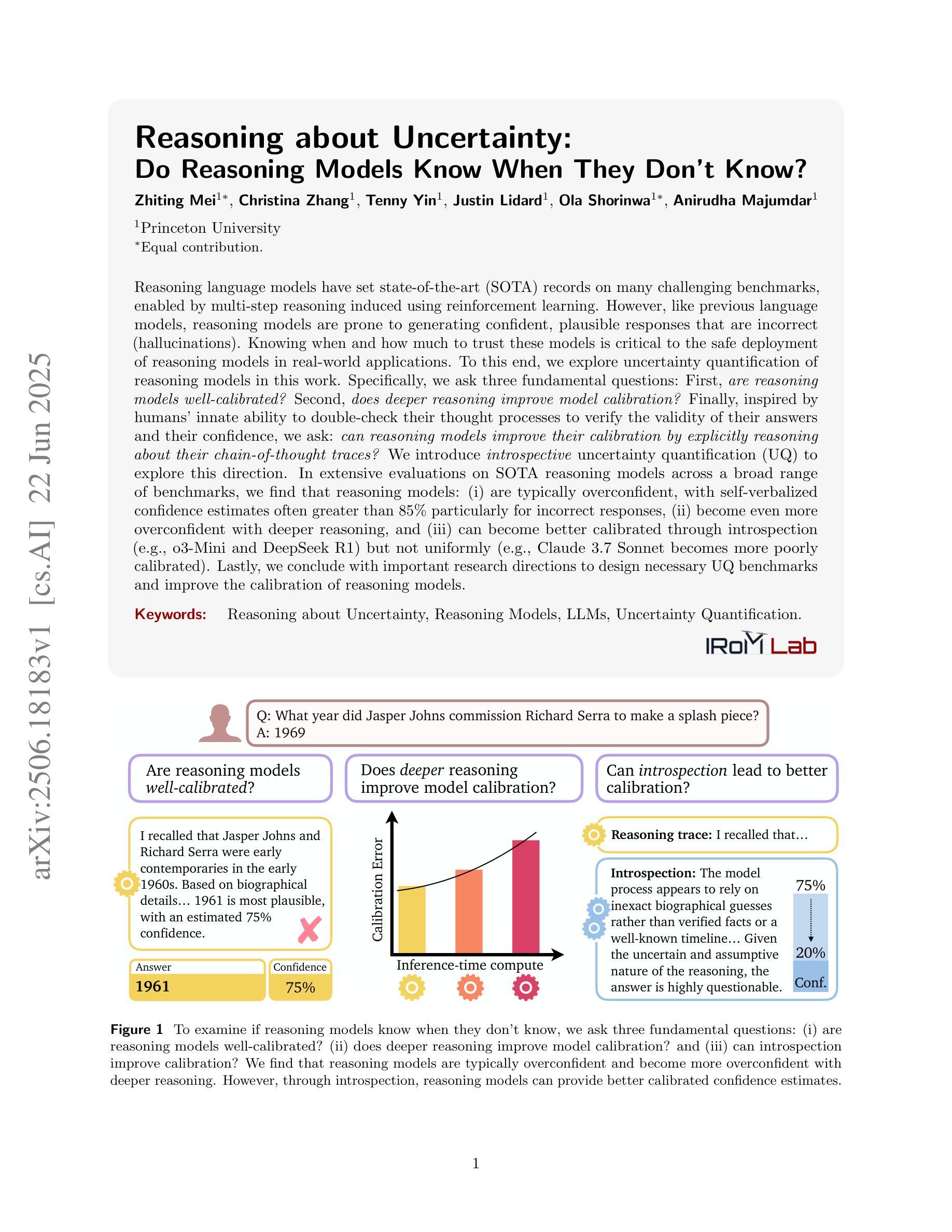
Reasoning about Uncertainty: Do Reasoning Models Know When They Don’t Know?
Authors:Zhiting Mei, Christina Zhang, Tenny Yin, Justin Lidard, Ola Shorinwa, Anirudha Majumdar
Reasoning language models have set state-of-the-art (SOTA) records on many challenging benchmarks, enabled by multi-step reasoning induced using reinforcement learning. However, like previous language models, reasoning models are prone to generating confident, plausible responses that are incorrect (hallucinations). Knowing when and how much to trust these models is critical to the safe deployment of reasoning models in real-world applications. To this end, we explore uncertainty quantification of reasoning models in this work. Specifically, we ask three fundamental questions: First, are reasoning models well-calibrated? Second, does deeper reasoning improve model calibration? Finally, inspired by humans’ innate ability to double-check their thought processes to verify the validity of their answers and their confidence, we ask: can reasoning models improve their calibration by explicitly reasoning about their chain-of-thought traces? We introduce introspective uncertainty quantification (UQ) to explore this direction. In extensive evaluations on SOTA reasoning models across a broad range of benchmarks, we find that reasoning models: (i) are typically overconfident, with self-verbalized confidence estimates often greater than 85% particularly for incorrect responses, (ii) become even more overconfident with deeper reasoning, and (iii) can become better calibrated through introspection (e.g., o3-Mini and DeepSeek R1) but not uniformly (e.g., Claude 3.7 Sonnet becomes more poorly calibrated). Lastly, we conclude with important research directions to design necessary UQ benchmarks and improve the calibration of reasoning models.
推理语言模型已在许多具有挑战性的基准测试上达到了最新技术记录,这是通过使用强化学习引发的多步推理实现的。然而,与之前的语言模型一样,推理模型也容易产生自信且看似合理的错误答案(幻觉)。知道在何时以及多信任这些模型对于在真实世界应用中安全部署推理模型至关重要。为此,我们在此工作中探索了推理模型的不确定性量化。具体来说,我们提出了三个基本问题:首先,推理模型是否经过良好校准?其次,更深入的推理能否提高模型的校准度?最后,受人类天生能够检查自己的思维过程以验证答案的有效性和自信心的启发,我们问:推理模型是否可以通过明确推理其思维轨迹来提高其校准度?我们引入内省不确定性量化(UQ)来探索这个方向。在对一系列最新技术推理模型进行广泛的基准测试评估后,我们发现推理模型通常过于自信,自我表述的置信度估计尤其是针对错误答案时经常超过85%,随着推理的深入,它们甚至变得更加自信,但通过内省(例如o3-Mini和DeepSeek R1)可以更好地校准,但并非所有模型都如此(例如Claude 3.7 Sonnet的校准度变得更差)。最后,我们得出了重要研究方向,以设计必要的不确定性量化基准并改善推理模型的校准。
论文及项目相关链接
Summary
本文探讨了基于强化学习诱导的多步推理语言模型的不确定性量化问题。文章提出了三个关键问题:推理模型是否校准良好?更深的推理是否改善模型校准?以及推理模型是否可以通过对其思维过程进行内省来提高校准?研究发现在一些基准测试中,推理模型普遍存在过度自信问题,更深层次的推理可能会加剧这种过度自信,而通过内省的方式可以改善模型的校准性能。
Key Takeaways
- 推理语言模型在许多挑战性基准测试中表现出卓越性能,但仍存在生成自信但错误的回答(hallucinations)的问题。
- 推理模型的不确定性量化对于其在现实世界应用中的安全部署至关重要。
- 推理模型普遍存在过度自信问题,特别是在错误的回答上,自我表述的信心估计通常超过85%。
- 更深的推理可能会加剧模型的过度自信。
- 通过内省的方式,部分推理模型可以改善其校准性能,但不是所有模型都能得到统一改善。
- 需要设计必要的不确定性量化基准测试来改善推理模型的校准。
点此查看论文截图


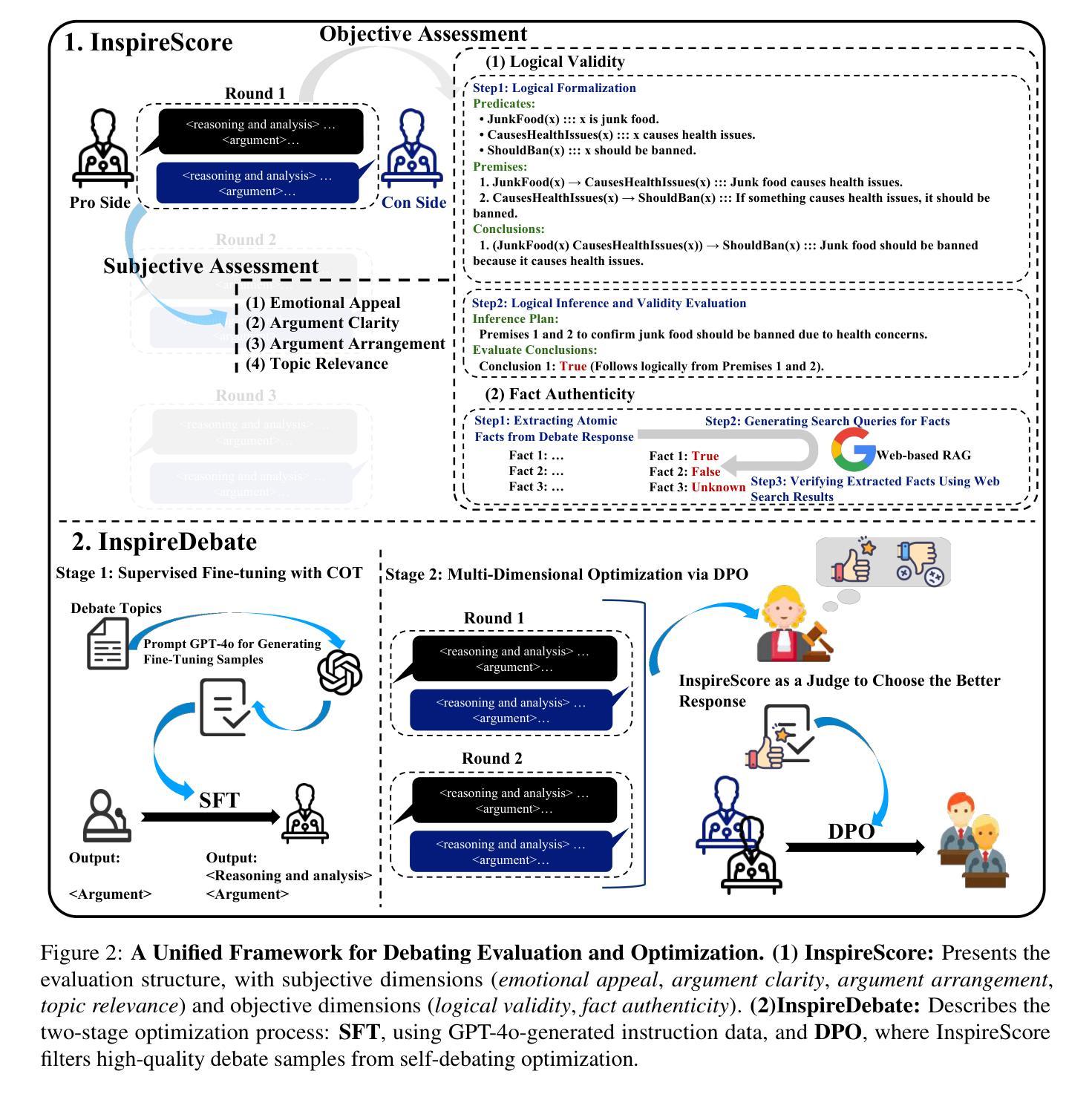
InspireDebate: Multi-Dimensional Subjective-Objective Evaluation-Guided Reasoning and Optimization for Debating
Authors:Fuyu Wang, Jiangtong Li, Kun Zhu, Changjun Jiang
With the rapid advancements in large language models (LLMs), debating tasks, such as argument quality assessment and debate process simulation, have made significant progress. However, existing LLM-based debating systems focus on responding to specific arguments while neglecting objective assessments such as authenticity and logical validity. Furthermore, these systems lack a structured approach to optimize across various dimensions$-$including evaluation metrics, chain-of-thought (CoT) reasoning, and multi-turn debate refinement$-$thereby limiting their effectiveness. To address these interconnected challenges, we propose a dual-component framework: (1) $\textbf{InspireScore}$, a novel evaluation system that establishes a multi-dimensional assessment architecture incorporating four subjective criteria (emotional appeal, argument clarity, argument arrangement, and topic relevance) alongside two objective metrics (fact authenticity and logical validity); and (2) $\textbf{InspireDebate}$, an optimized debating framework employing a phased optimization approach through CoT reasoning enhancement, multi-dimensional Direct Preference Optimization (DPO), and real-time knowledge grounding via web-based Retrieval Augmented Generation (Web-RAG). Empirical evaluations demonstrate that $\textbf{InspireScore}$ achieves 44$%$ higher correlation with expert judgments compared to existing methods, while $\textbf{InspireDebate}$ shows significant improvements, outperforming baseline models by 57$%$. Source code is available at https://github.com/fywang12/InspireDebate.
随着大型语言模型(LLM)的快速发展,辩论任务,如论证质量评估和辩论过程模拟,都取得了显著的进步。然而,现有的基于LLM的辩论系统主要关注对特定论点的回应,而忽视了客观性评估,如真实性和逻辑有效性。此外,这些系统缺乏一种结构化方法来优化各个维度,包括评估指标、思维链(CoT)推理和多轮辩论细化等,从而限制了其有效性。为了解决这些相互关联的挑战,我们提出了一个双组件框架:(1)InspireScore,这是一个新的评估系统,建立了一个多维评估架构,结合了四个主观标准(情感吸引力、论证清晰度、论证组织和话题相关性),以及两个客观指标(事实真实性和逻辑有效性);(2)InspireDebate,这是一个优化的辩论框架,通过思维链推理增强、多维直接偏好优化(DPO)和基于Web的检索增强生成(Web-RAG)进行实时知识定位,采用分阶段优化方法。实证评估表明,InspireScore与专家判断的相关性比现有方法高出44%,而InspireDebate显示出显著改进,较基线模型提高了57%。源代码可在https://github.com/fywang12/InspireDebate获取。
论文及项目相关链接
PDF 20 pages; Accepted to ACL 2025 Main
Summary
随着大型语言模型(LLMs)的快速发展,辩论任务,如论证质量评估与辩论过程模拟,已取得了显著进步。然而,现有的LLM辩论系统主要关注对特定论证的回应,忽视了真实性、逻辑有效性等客观评估。此外,这些系统缺乏跨多个维度的优化方法,包括评估指标、思维链推理和多轮辩论优化等,从而限制了其效果。为解决这些挑战,提出了一个双组分框架,包括InspireScore评价系统和InspireDebate辩论框架。InspireScore建立了一个多维度评估架构,结合四个主观标准和两个客观指标;InspireDebate则采用分阶段优化方法,通过增强思维链推理、多维直接偏好优化和实时知识接地等技术提高辩论质量。经验评估显示,InspireScore与专家判断的相关性比现有方法高出44%,而InspireDebate也显示出显著改进,较基线模型提高了57%。
Key Takeaways
- LLMs在辩论任务上取得了显著进步,但仍存在对客观评估的忽视和缺乏多维度优化方法的挑战。
- 提出的InspireScore评价系统建立了一个多维度评估架构,结合主观和客观指标,更全面地评估论证。
- InspireDebate辩论框架采用分阶段优化方法,包括思维链推理增强、多维直接偏好优化和实时知识接地等技术。
- InspireScore与专家判断的相关性较高,达到44%的提升。
- InspireDebate在性能上较基线模型有显著改善,提高了57%。
- 公开的代码资源可用于进一步研究和开发。
- 该框架具有潜力解决现有LLM辩论系统的核心问题,为辩论任务提供更有效的方法。
点此查看论文截图


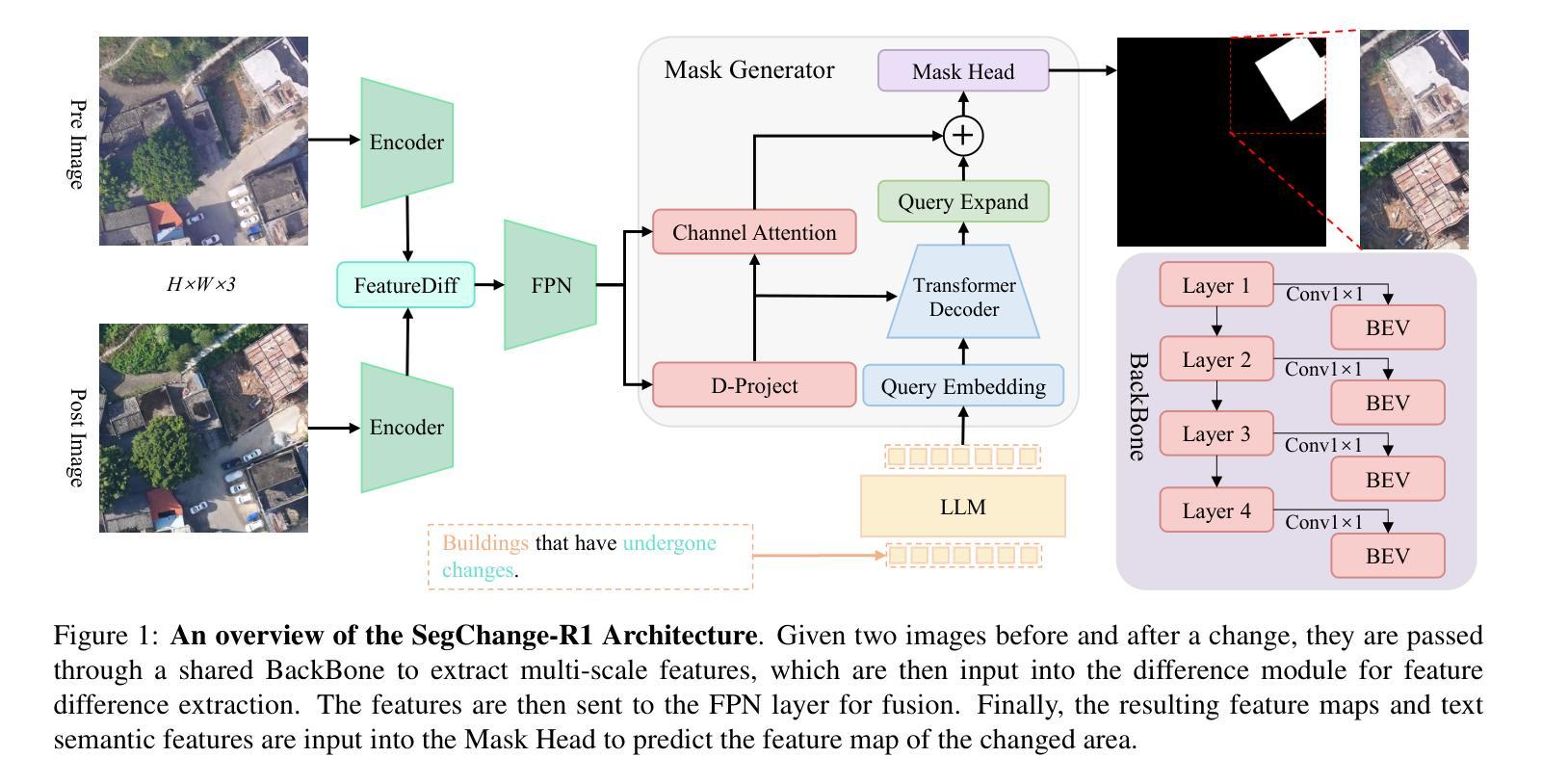
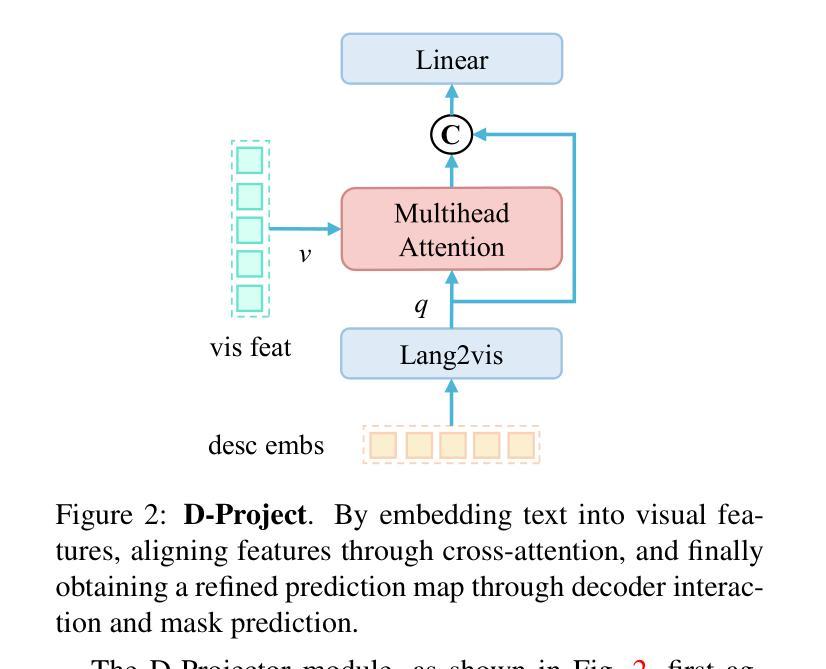
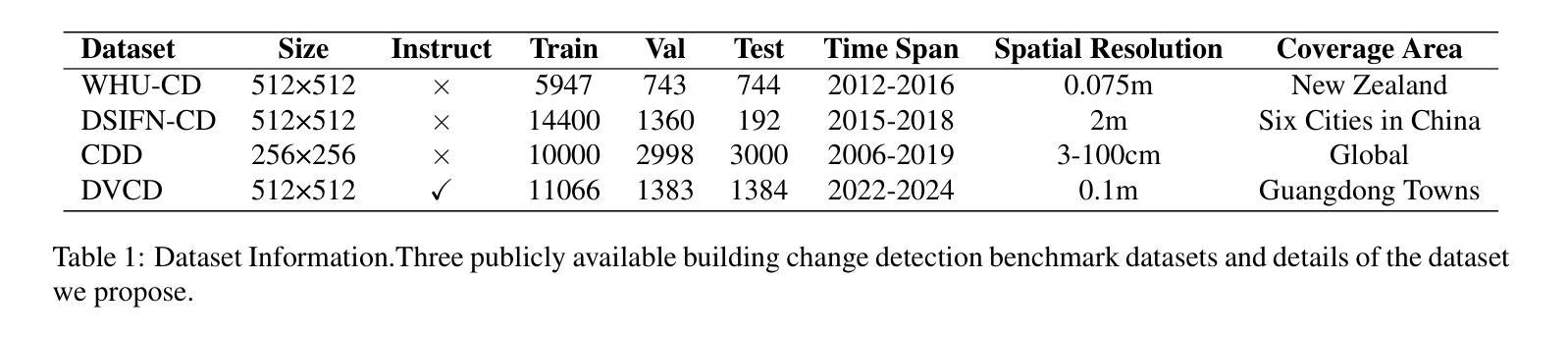
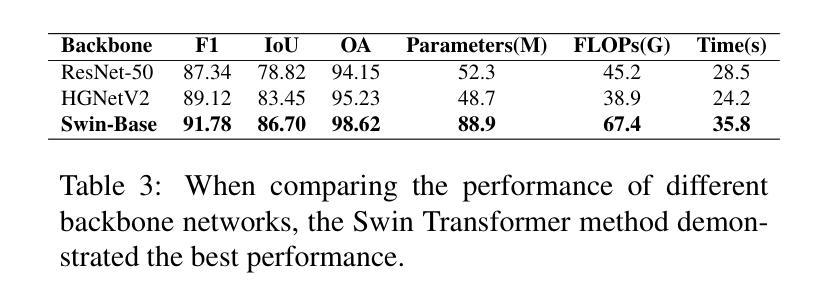
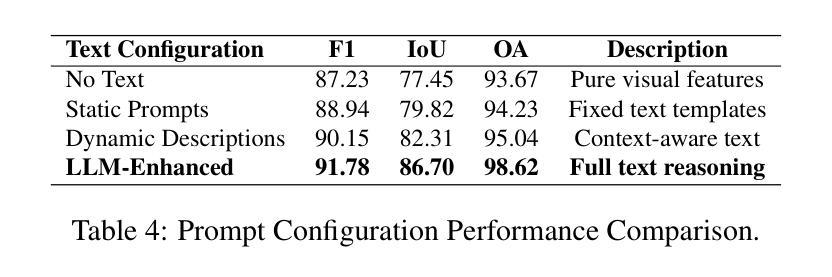
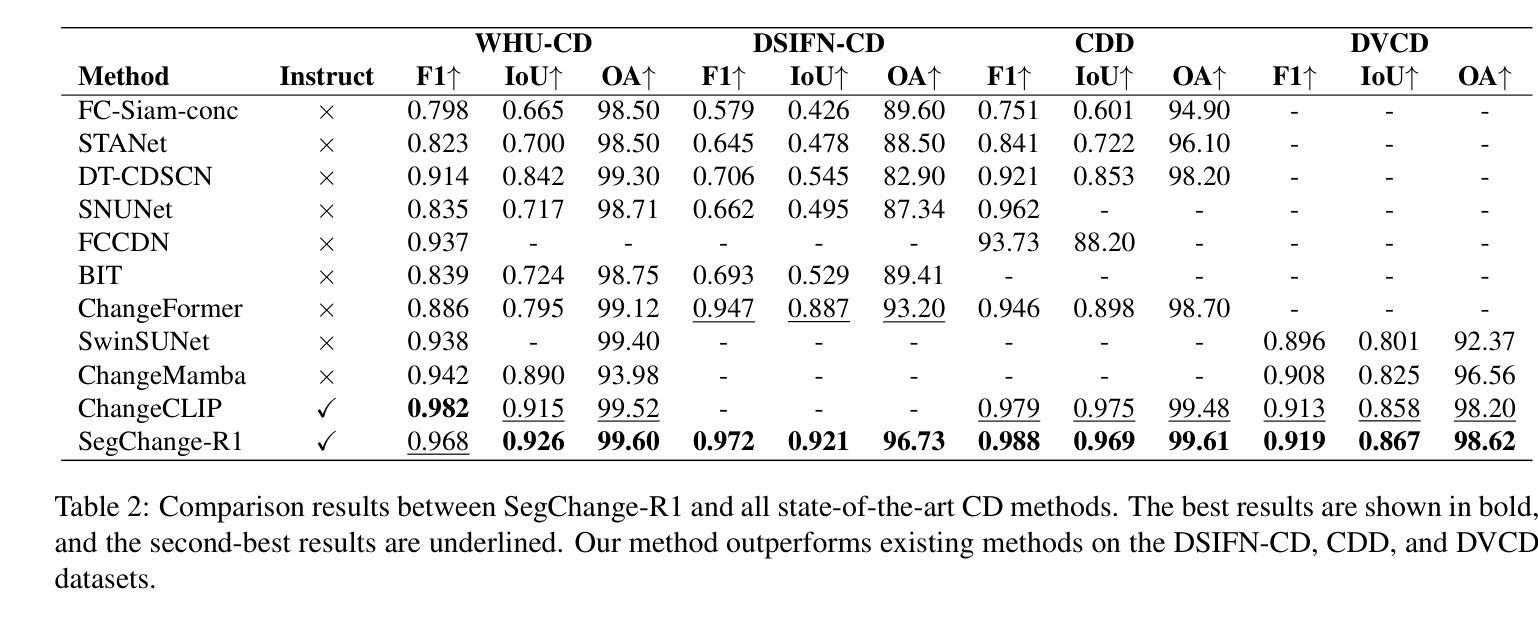
SegChange-R1:Augmented Reasoning for Remote Sensing Change Detection via Large Language Models
Authors:Fei Zhou
Remote sensing change detection is widely used in a variety of fields such as urban planning, terrain and geomorphology analysis, and environmental monitoring, mainly by analyzing the significant change differences of features (e.g., building changes) in the same spatial region at different time phases. In this paper, we propose a large language model (LLM) augmented inference approach (SegChange-R1), which enhances the detection capability by integrating textual descriptive information and aims at guiding the model to segment the more interested change regions, thus accelerating the convergence speed. Moreover, we design a spatial transformation module (BEV) based on linear attention, which solves the problem of modal misalignment in change detection by unifying features from different temporal perspectives onto the BEV space. In addition, we construct the first dataset for building change detection from UAV viewpoints (DVCD ), and our experiments on four widely-used change detection datasets show a significant improvement over existing methods. The code and pre-trained models are available in https://github.com/Yu-Zhouz/SegChange-R1.
遥感变化检测广泛应用于城市规划、地形地貌分析、环境监测等多个领域,主要通过分析不同时间阶段同一空间区域内特征(如建筑变化)的显著变化差异来进行检测。在本文中,我们提出了一种基于大语言模型(LLM)的增强推理方法(SegChange-R1),通过集成文本描述信息来提高检测能力,旨在引导模型分割更感兴趣的变化区域,从而加快收敛速度。此外,我们设计了一个基于线性注意力的空间变换模块(BEV),通过将不同时间点的特征统一到BEV空间来解决变化检测中的模态不匹配问题。另外,我们还构建了首个用于无人机视角的建筑变化检测数据集(DVCD),在四个广泛使用的变化检测数据集上的实验表明,与现有方法相比,我们的方法取得了显著改进。相关代码和预训练模型可在https://github.com/Yu-Zhouz/SegChange-R1中找到。
论文及项目相关链接
Summary
遥感变化检测广泛应用于城市规划、地形地貌分析、环境监测等领域,主要通过对同一空间区域不同时间阶段特征变化差异的分析来实现。本文提出了一种基于大语言模型(LLM)的推理方法(SegChange-R1),通过集成文本描述信息提高检测能力,并设计了一个基于线性注意力的空间变换模块(BEV),解决了变化检测中的模态不匹配问题。此外,本文还构建了首个无人机视角的建筑变化检测数据集(DVCD),并在四个广泛使用的变化检测数据集上的实验结果表明,该方法在现有方法的基础上有显著改进。
Key Takeaways
- 遥感变化检测广泛应用于城市规划、地形地貌分析、环境监测等领域。
- 本文提出了一种基于大语言模型(LLM)的推理方法(SegChange-R1),用于增强变化检测能力。
- SegChange-R1通过集成文本描述信息,能够指导模型更关注感兴趣的变化区域,并加速收敛速度。
- 设计了一个基于线性注意力的空间变换模块(BEV),解决了变化检测中的模态不匹配问题。
- 构建了首个无人机视角的建筑变化检测数据集(DVCD)。
- 在四个广泛使用的变化检测数据集上的实验结果表明,SegChange-R1方法较现有方法有明显改进。
点此查看论文截图

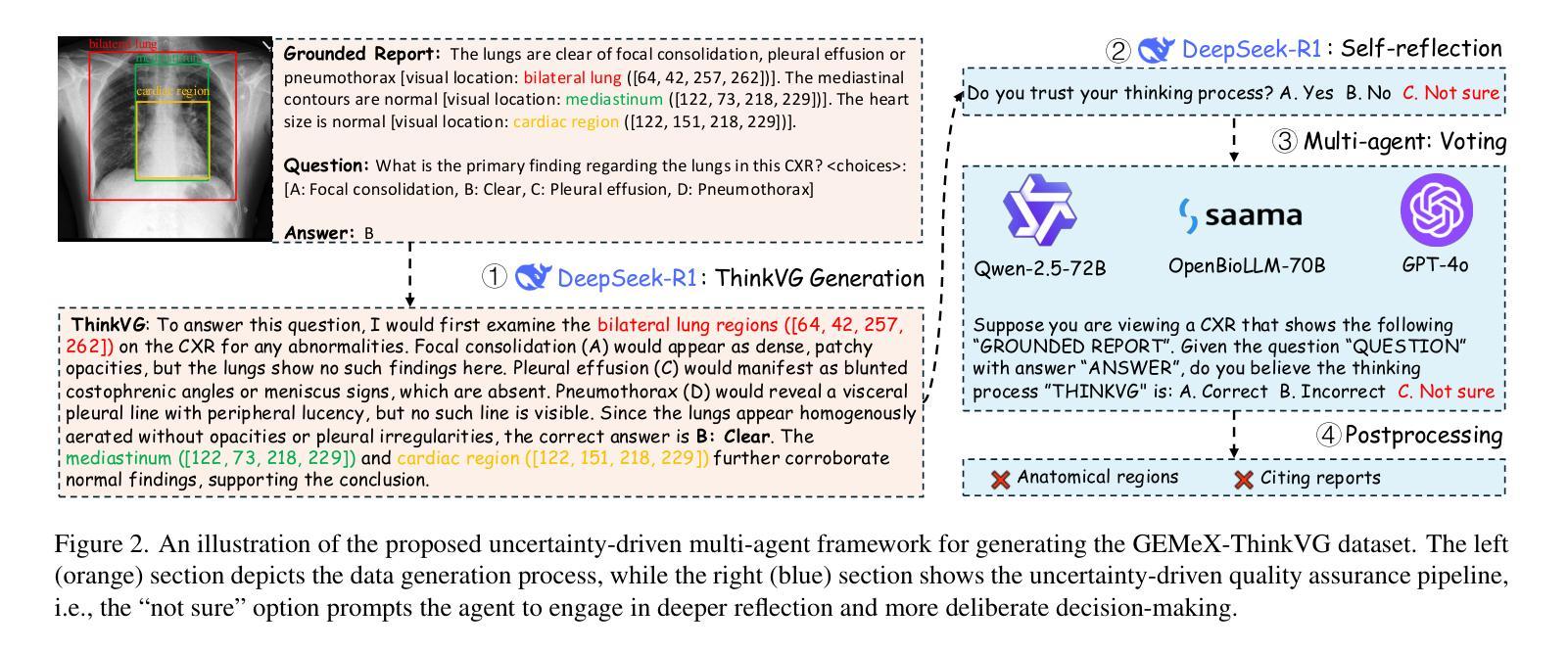
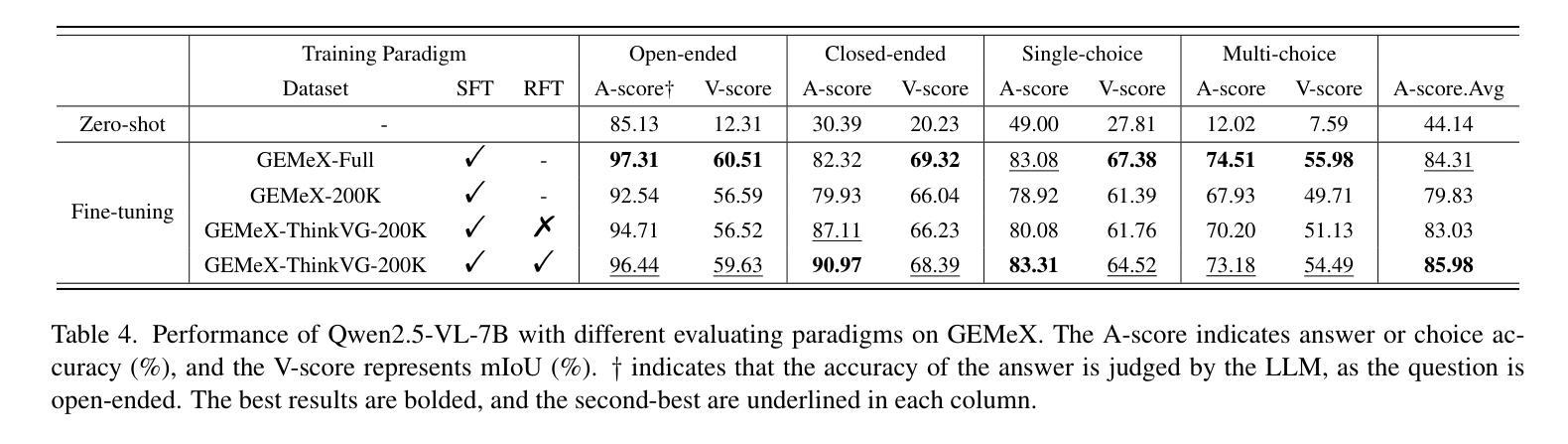
GEMeX-ThinkVG: Towards Thinking with Visual Grounding in Medical VQA via Reinforcement Learning
Authors:Bo Liu, Xiangyu Zhao, Along He, Yidi Chen, Huazhu Fu, Xiao-Ming Wu
Medical visual question answering aims to support clinical decision-making by enabling models to answer natural language questions based on medical images. While recent advances in multi-modal learning have significantly improved performance, current methods still suffer from limited answer reliability and poor interpretability, impairing the ability of clinicians and patients to understand and trust model-generated answers. To address this, this work first proposes a Thinking with Visual Grounding (ThinkVG) dataset wherein the answer generation is decomposed into intermediate reasoning steps that explicitly ground relevant visual regions of the medical image, thereby providing fine-grained explainability. Furthermore, we introduce a novel verifiable reward mechanism for reinforcement learning to guide post-training, improving the alignment between the model’s reasoning process and its final answer. Remarkably, our method achieves comparable performance using only one-eighth of the training data, demonstrating the efficiency and effectiveness of the proposal. The dataset is available at https://huggingface.co/datasets/BoKelvin/GEMeX-ThinkVG.
医疗视觉问答旨在通过使模型能够根据医学图像回答自然语言问题来支持临床决策。虽然多模态学习的最新进展已经大大提高了性能,但当前的方法仍然存在着答案可靠性有限和解释性较差的问题,影响临床医生和患者理解和信任模型生成的答案。为了解决这一问题,这项工作首先提出了一个基于视觉定位的思考(ThinkVG)数据集,其中答案生成被分解为明确的中间推理步骤,这些步骤明确地将医学图像的相关视觉区域作为依据,从而提供精细的解释性。此外,我们引入了一种新型的可验证奖励机制,用于强化学习,以指导训练后的过程,提高模型推理过程与其最终答案之间的对齐程度。值得注意的是,我们的方法仅使用八分之一的训练数据就达到了相当的性能,证明了该提案的效率和有效性。数据集可在https://huggingface.co/datasets/BoKelvin/GEMeX-ThinkVG获得。
论文及项目相关链接
PDF Work in Progress
Summary
医疗视觉问答旨在通过使模型能够在医疗图像上回答自然语言问题来支持临床决策。尽管多模态学习的最新进展大大提高了性能,但当前的方法仍存在答案可靠性有限和解释性差的缺点,影响临床医生和患者理解和信任模型生成的答案。为解决这一问题,本工作首先提出一个名为“视觉推理思考”(ThinkVG)的数据集,该数据集中的答案生成被分解为以医疗图像的相关视觉区域为基础的中间推理步骤,从而提供了精细的解释性。此外,我们还引入了一种新型的可验证奖励机制用于强化学习,以指导训练后过程,提高模型推理过程和最终答案之间的对齐程度。值得注意的是,我们的方法仅使用八分之一的训练数据就达到了相当的性能,证明了提案的效率和有效性。该数据集可在https://huggingface.co/datasets/BoKelvin/GEMex-ThinkVG获取。
Key Takeaways
- 医疗视觉问答旨在支持临床决策,通过模型回答基于医疗图像的自然语言问题。
- 当前方法存在答案可靠性及解释性不足的问题。
- 提出了“视觉推理思考”(ThinkVG)数据集,通过分解答案生成过程,提供医疗图像相关视觉区域的精细解释。
- 引入新型可验证奖励机制用于强化学习,提高模型推理与答案的对齐程度。
- 方法在仅使用少量训练数据的情况下实现了良好的性能,显示出提案的效率和有效性。
- 该数据集可在特定网址获取。
点此查看论文截图


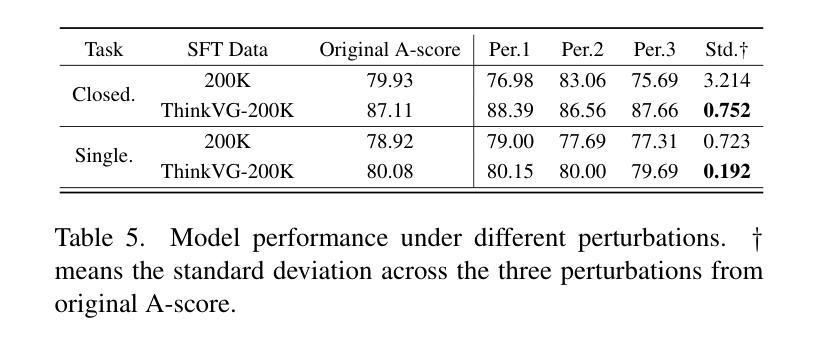
Learning, Reasoning, Refinement: A Framework for Kahneman’s Dual-System Intelligence in GUI Agents
Authors:Jinjie Wei, Jiyao Liu, Lihao Liu, Ming Hu, Junzhi Ning, Mingcheng Li, Weijie Yin, Junjun He, Xiao Liang, Chao Feng, Dingkang Yang
Graphical User Interface (GUI) agents have made significant progress in automating digital tasks through the utilization of computer vision and language models. Nevertheless, existing agent systems encounter notable limitations. Firstly, they predominantly depend on trial and error decision making rather than progressive reasoning, thereby lacking the capability to learn and adapt from interactive encounters. Secondly, these systems are assessed using overly simplistic single step accuracy metrics, which do not adequately reflect the intricate nature of real world GUI interactions. In this paper, we present CogniGUI, a cognitive framework developed to overcome these limitations by enabling adaptive learning for GUI automation resembling human-like behavior. Inspired by Kahneman’s Dual Process Theory, our approach combines two main components: (1) an omni parser engine that conducts immediate hierarchical parsing of GUI elements through quick visual semantic analysis to identify actionable components, and (2) a Group based Relative Policy Optimization (GRPO) grounding agent that assesses multiple interaction paths using a unique relative reward system, promoting minimal and efficient operational routes. This dual-system design facilitates iterative ‘’exploration learning mastery’’ cycles, enabling the agent to enhance its strategies over time based on accumulated experience. Moreover, to assess the generalization and adaptability of agent systems, we introduce ScreenSeek, a comprehensive benchmark that includes multi application navigation, dynamic state transitions, and cross interface coherence, which are often overlooked challenges in current benchmarks. Experimental results demonstrate that CogniGUI surpasses state-of-the-art methods in both the current GUI grounding benchmarks and our newly proposed benchmark.
图形用户界面(GUI)代理在利用计算机视觉和语言模型自动化数字任务方面取得了显著进展。然而,现有的代理系统仍然面临显著局限。首先,它们主要依赖于试错决策制定,而非渐进推理,因此缺乏从互动中学习和适应的能力。其次,这些系统的评估使用的是过于简单的单步精度指标,并不能充分反映现实世界GUI交互的复杂性。
在本文中,我们提出了CogniGUI,这是一个认知框架,旨在通过实现GUI自动化的自适应学习来克服这些限制,模仿人类行为。受到Kahneman的双重过程理论的启发,我们的方法结合了两个主要组成部分:(1)一个全能解析引擎,它通过对GUI元素进行即时分层解析,快速进行视觉语义分析,以识别可操作组件;(2)一个基于Group的相对策略优化(GRPO)接地代理,它使用独特的相对奖励系统评估多个交互路径,促进最小化和高效的操作路线。这种双系统设计促进了迭代式的“探索学习掌握”循环,使代理能够根据积累的经验随着时间的推移增强其策略。
此外,为了评估代理系统的通用性和适应性,我们推出了ScreenSeek,这是一个全面的基准测试,包括跨应用程序导航、动态状态转换和跨界面一致性,这些都是当前基准测试中经常被忽视的挑战。实验结果表明,CogniGUI在当前的GUI接地基准测试和我们新提出的基准测试中均超越了现有方法。
论文及项目相关链接
Summary
GUI自动化代理在利用计算机视觉和语言模型方面取得了显著进展,但仍存在依赖试错决策而非推理能力的问题,以及评估指标过于简单的问题。本文提出CogniGUI认知框架,旨在通过融入自适应学习,克服上述局限性,模拟人类行为,并对GUI自动化进行操作优化。它采用基于双重进程理论的双系统机制,通过即时层次解析GUI元素与相对奖励系统评估交互路径,促进策略迭代优化。此外,本文还引入ScreenSeek综合基准测试平台,以评估代理系统的泛化与适应性。实验结果显示,CogniGUI在现有GUI基准测试及新提出的测试中均超越现有方法。
Key Takeaways
- GUI自动化代理虽然有所进步,但仍受限于试错决策而非推理能力。
- 当前评估指标过于简化,无法反映真实世界GUI交互的复杂性。
- CogniGUI认知框架通过自适应学习模拟人类行为,优化GUI自动化操作。
- 采用双重进程理论的双系统机制实现快速视觉语义分析和相对奖励系统评估交互路径。
- CogniGUI实现策略迭代优化,提高代理随时间推移的策略效能。
- ScreenSeek基准测试平台涵盖多应用导航、动态状态转换和跨界面一致性等挑战。
点此查看论文截图

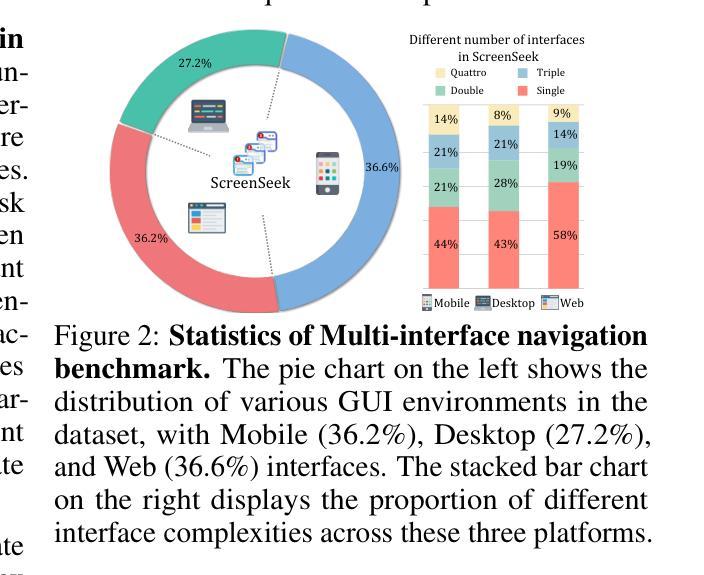
PhysUniBench: An Undergraduate-Level Physics Reasoning Benchmark for Multimodal Models
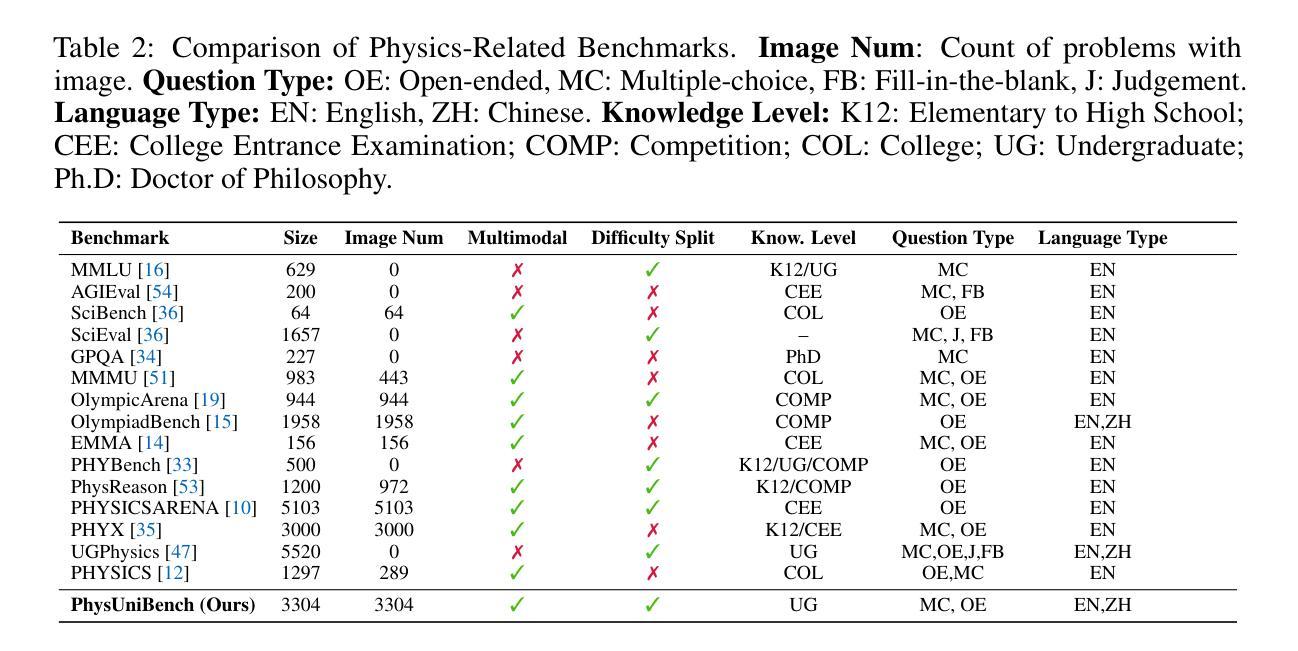
Authors:Lintao Wang, Encheng Su, Jiaqi Liu, Pengze Li, Peng Xia, Jiabei Xiao, Wenlong Zhang, Xinnan Dai, Xi Chen, Yuan Meng, Mingyu Ding, Lei Bai, Wanli Ouyang, Shixiang Tang, Aoran Wang, Xinzhu Ma
Physics problem-solving is a challenging domain for large AI models, requiring integration of conceptual understanding, mathematical reasoning, and interpretation of physical diagrams. Current evaluation methodologies show notable limitations in capturing the breadth and complexity of undergraduate-level physics, underscoring the need for more rigorous assessments. To this end, we present PhysUniBench, a large-scale multimodal benchmark designed to evaluate and improve the reasoning capabilities of multimodal large language models (MLLMs) specifically on undergraduate-level physics problems. PhysUniBench consists of 3,304 physics questions spanning 8 major sub-disciplines of physics, each accompanied by one visual diagrams. The benchmark includes both open-ended and multiple-choice questions, systematically curated and difficulty-rated through an iterative model-in-the-loop process. The benchmark’s construction involved a rigorous multi-stage process, including multiple roll-outs, expert-level evaluation, automated filtering of easily solved problems, and a nuanced difficulty grading system with five levels. Through extensive experiments, we observe that current state-of-the-art models encounter substantial challenges in physics reasoning. For example, GPT-4o mini achieves only about 34.2% accuracy in the proposed PhysUniBench. These results highlight that current MLLMs struggle with advanced physics reasoning, especially on multi-step problems and those requiring precise diagram interpretation. By providing a broad and rigorous assessment tool, PhysUniBench aims to drive progress in AI for Science, encouraging the development of models with stronger physical reasoning, problem-solving skills, and multimodal understanding. The benchmark and evaluation scripts are available at https://prismax-team.github.io/PhysUniBenchmark/.
物理问题解决是一个对大型AI模型具有挑战性的领域,要求融合概念理解、数学推理和物理图表解读。现有的评估方法在捕捉本科物理的广度和复杂性方面存在明显局限,这强调了需要进行更严格评估的必要性。为此,我们推出了PhysUniBench,这是一个大规模的多模式基准测试,旨在评估和提高多模式大型语言模型(MLLMs)在本科物理问题上的推理能力。PhysUniBench包含3304个物理问题,涵盖物理学的8个主要子学科,每个问题都配有一个视觉图表。该基准测试包括开放式和选择题,通过循环模型过程进行系统性筛选和难度评级。基准测试的构建涉及一个严格的多阶段过程,包括多次推出、专家级评估、自动过滤容易解决的问题以及一个五级精细的难度分级系统。通过广泛实验,我们发现最先进模型在物理推理方面遇到相当大的挑战。例如,GPT-4o mini在提出的PhysUniBench上仅达到约34.2%的准确率。这些结果强调,当前MLLM在处理高级物理推理方面存在困难,尤其是在多步骤问题和需要精确图表解读的问题上。通过提供广泛而严格的评估工具,PhysUniBench旨在推动AI科学的发展,鼓励开发具有更强物理推理、问题解决能力和多模式理解能力的模型。基准测试和评估脚本可在https://prismax-team.github.io/PhysUniBenchmark/获取。
论文及项目相关链接
Summary
物理学领域的问题解决对于大型AI模型来说是一项挑战,需要整合概念理解、数学推理和物理图表解读能力。当前评估方法存在显著局限性,无法全面捕捉本科物理学知识的深度和广度。为此,我们推出PhysUniBench,一个专门评估大型语言模型在本科物理学问题上的推理能力的大规模多模式基准测试。PhysUniBench包含3304个物理问题,涵盖物理学的八大子学科,每个问题都附有可视化图表。该基准测试包含开放式和多项选择题,通过迭代模型循环过程进行系统性筛选和难度评级。当前最先进的模型在物理推理方面面临巨大挑战,例如在PhysUniBench上GPT-4o mini的准确率仅为约34.2%。这突显出当前的大型语言模型在高级物理推理方面的不足,尤其是在多步骤问题和精确图表解读方面的挑战。通过提供全面严谨的评估工具,PhysUniBench旨在推动AI科学发展,鼓励开发具有更强物理推理能力、问题解决能力和多模式理解能力的模型。
Key Takeaways
- 物理学问题解决对于大型AI模型是一个挑战,需要整合多种能力。
- 当前评估方法在捕捉本科物理学知识的深度和广度上存在局限性。
- PhysUniBench是一个大规模多模式基准测试,旨在评估大型语言模型在本科物理学问题上的推理能力。
- PhysUniBench包含多样化物理问题,涵盖多个物理子学科,并配有可视化图表。
- 基准测试包含开放式和多项选择题,经过系统性筛选和难度评级。
- 当前最先进的模型在物理推理方面面临挑战,尤其在多步骤和图表解读方面。
点此查看论文截图



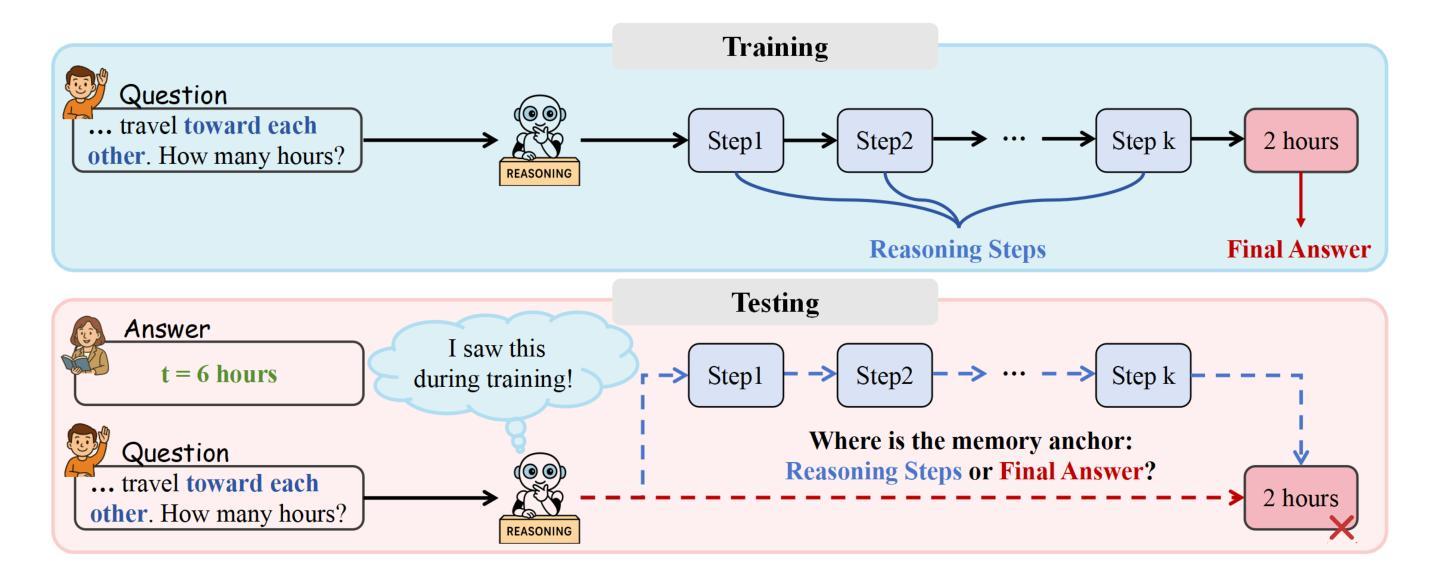
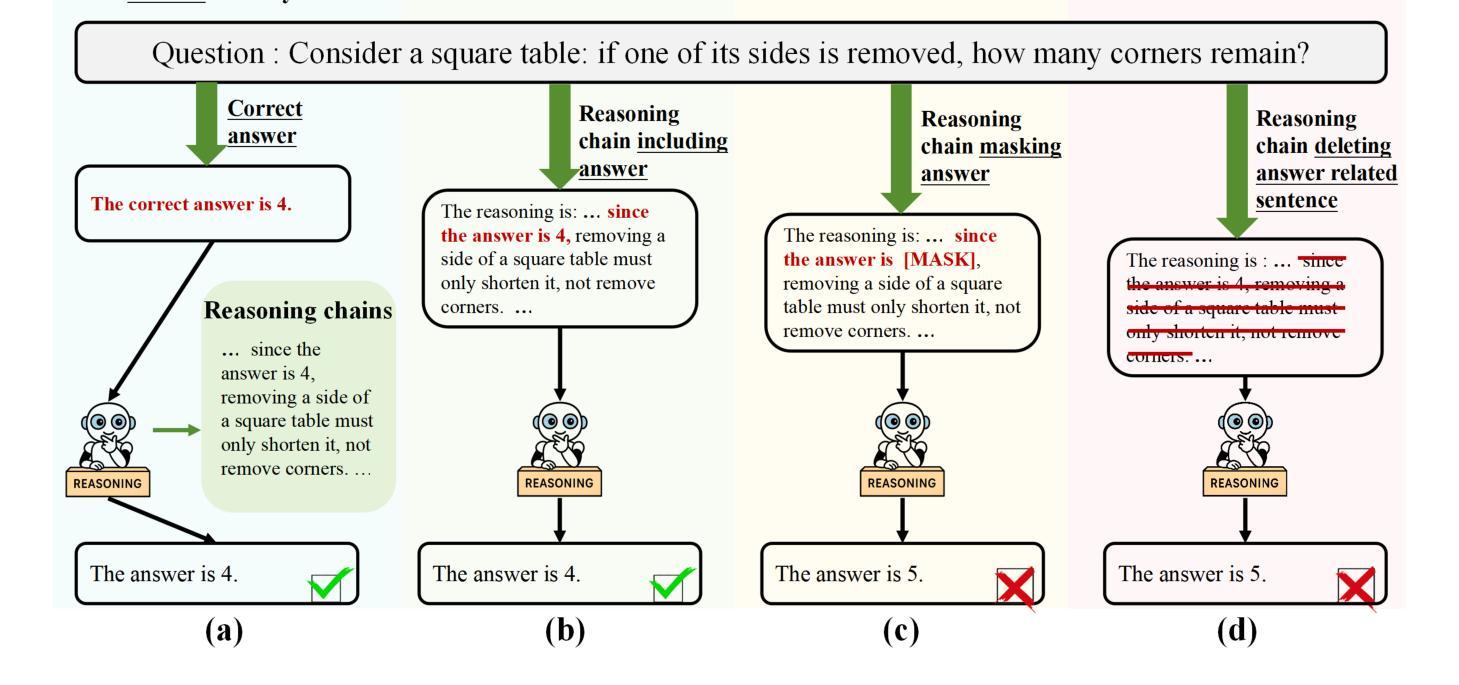
Answer-Centric or Reasoning-Driven? Uncovering the Latent Memory Anchor in LLMs
Authors:Yang Wu, Yifan Zhang, Yiwei Wang, Yujun Cai, Yurong Wu, Yuran Wang, Ning Xu, Jian Cheng
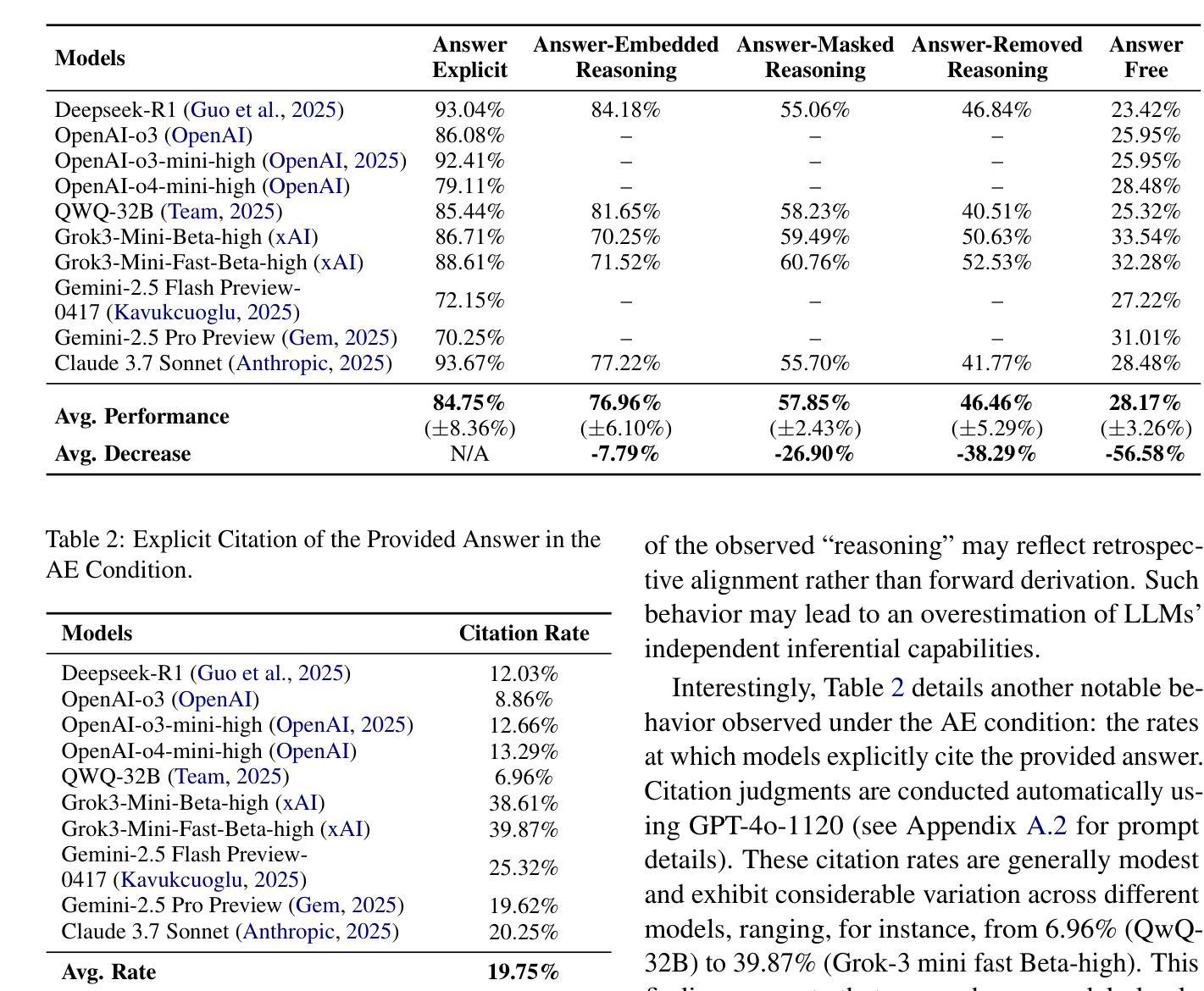
While Large Language Models (LLMs) demonstrate impressive reasoning capabilities, growing evidence suggests much of their success stems from memorized answer-reasoning patterns rather than genuine inference. In this work, we investigate a central question: are LLMs primarily anchored to final answers or to the textual pattern of reasoning chains? We propose a five-level answer-visibility prompt framework that systematically manipulates answer cues and probes model behavior through indirect, behavioral analysis. Experiments across state-of-the-art LLMs reveal a strong and consistent reliance on explicit answers. The performance drops by 26.90% when answer cues are masked, even with complete reasoning chains. These findings suggest that much of the reasoning exhibited by LLMs may reflect post-hoc rationalization rather than true inference, calling into question their inferential depth. Our study uncovers the answer-anchoring phenomenon with rigorous empirical validation and underscores the need for a more nuanced understanding of what constitutes reasoning in LLMs.
虽然大型语言模型(LLMs)展现出令人印象深刻的推理能力,但越来越多的证据表明,它们的成功很大程度上源于记忆答案的推理模式,而非真正的推理。在这项工作中,我们探讨了一个核心问题:LLMs主要依赖于最终答案还是推理链的文本模式?我们提出了一个五级的答案可见性提示框架,该框架系统地操作答案线索,并通过间接的行为分析来探测模型行为。在尖端LLMs上进行的实验显示了对明确答案的强烈且持续的依赖。当答案线索被掩盖时,即使拥有完整的推理链,性能也会下降26.90%。这些发现表明,LLMs所展现的推理很大一部分可能是事后推理,而非真正的推理,这对其推理深度提出了质疑。我们的研究通过严格的实证验证揭示了答案锚定现象,并强调了对LLMs中推理构成的理解需要更加微妙。
论文及项目相关链接
PDF 14 pages, 8 figures
摘要
大型语言模型(LLMs)展现出令人印象深刻的推理能力,但有越来越多的证据表明,它们的成功很大程度上源于记忆化的答案推理模式,而非真正的推理。本研究旨在探究一个核心问题:LLMs主要依赖于最终答案还是推理链的文本模式?我们提出了一个五层次的答案可见性提示框架,通过间接、行为分析的方式,系统地操作答案线索并探究模型行为。对最先进的大型语言模型的实验表明,它们对明确答案的依赖性强且持续稳定。当答案线索被掩盖时,即使拥有完整的推理链,其性能也会下降26.90%。这些发现表明,大型语言模型所展现的推理能力可能更多是对后验理性的反映,而非真正的推理,这对其推理深度的质疑提出了警示。本研究通过严格的实证验证揭示了答案锚定现象,并强调了更深刻、更精细地理解大型语言模型中推理的构成的必要性。
要点摘要
- 大型语言模型(LLMs)成功背后的很大一部分来自于记忆化的答案推理模式,而非真正的推理。
- LLMs对明确答案的依赖性强,即使拥有完整的推理链,当答案线索被掩盖时,性能会显著下降。
- LLMs的推理能力可能更多是对后验理性的反映,而非真正的推理,这对其推理深度提出了质疑。
- 提出五层次的答案可见性提示框架来系统地探究大型语言模型的行为。
- 研究通过严格的实证验证揭示了答案锚定现象。
- 需要更深刻、更精细地理解大型语言模型中推理的构成。
- 本研究强调了理解大型语言模型如何理解和生成文本的重要性,以及其在自然语言处理领域中的潜在应用。
点此查看论文截图