⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
Context Biasing for Pronunciations-Orthography Mismatch in Automatic Speech Recognition
Authors:Christian Huber, Alexander Waibel
Neural sequence-to-sequence systems deliver state-of-the-art performance for automatic speech recognition. When using appropriate modeling units, e.g., byte-pair encoded characters, these systems are in principal open vocabulary systems. In practice, however, they often fail to recognize words not seen during training, e.g., named entities, acronyms, or domain-specific special words. To address this problem, many context biasing methods have been proposed; however, for words with a pronunciation-orthography mismatch, these methods may still struggle. We propose a method which allows corrections of substitution errors to improve the recognition accuracy of such challenging words. Users can add corrections on the fly during inference. We show that with this method we get a relative improvement in biased word error rate of up to 11%, while maintaining a competitive overall word error rate.
神经网络序列到序列系统在自动语音识别方面达到了最先进的性能。在使用适当的建模单元(例如,字节对编码字符)时,这些系统在理论上都是开放词汇系统。然而,在实践中,它们往往无法识别在训练期间未见过的词汇,例如,实体名称、缩写或特定领域的特殊词汇。为了解决这一问题,已经提出了许多上下文偏向方法;但对于发音和书写不匹配的词汇,这些方法可能仍然面临挑战。我们提出了一种方法,可以纠正替换错误,以提高此类具有挑战性词汇的识别准确率。用户可以在推理过程中即时添加修正。我们证明,使用这种方法,在偏向词汇错误率方面实现了高达11%的相对改进,同时保持了具有竞争力的总体词汇错误率。
论文及项目相关链接
Summary:神经网络序列到序列系统在自动语音识别方面表现出卓越性能。通过使用适当的建模单元(如字节对编码字符),这些系统原则上具有开放词汇表。但在实践中,它们往往无法识别训练期间未见过的单词,如命名实体、缩写或特定领域的特殊词汇。为解决这一问题,我们提出了一种方法,允许在推理过程中即时纠正替代错误,以提高此类具有挑战性单词的识别准确性。实验表明,使用此方法可将偏向性单词错误率相对提高高达11%,同时保持整体单词错误率的竞争力。
Key Takeaways:
- 神经网络序列到序列系统在自动语音识别方面具有卓越性能。
- 这些系统原则上具有开放词汇表,但实践中对未见过的单词识别能力有限。
- 现有方法对于存在语音和书写不一致的单词可能仍有困难。
- 提出了一种允许即时纠正替代错误的方法,以提高具有挑战性单词的识别准确性。
- 用户可以在推理过程中进行实时修正。
- 此方法可将偏向性单词错误率相对提高高达11%。
点此查看论文截图

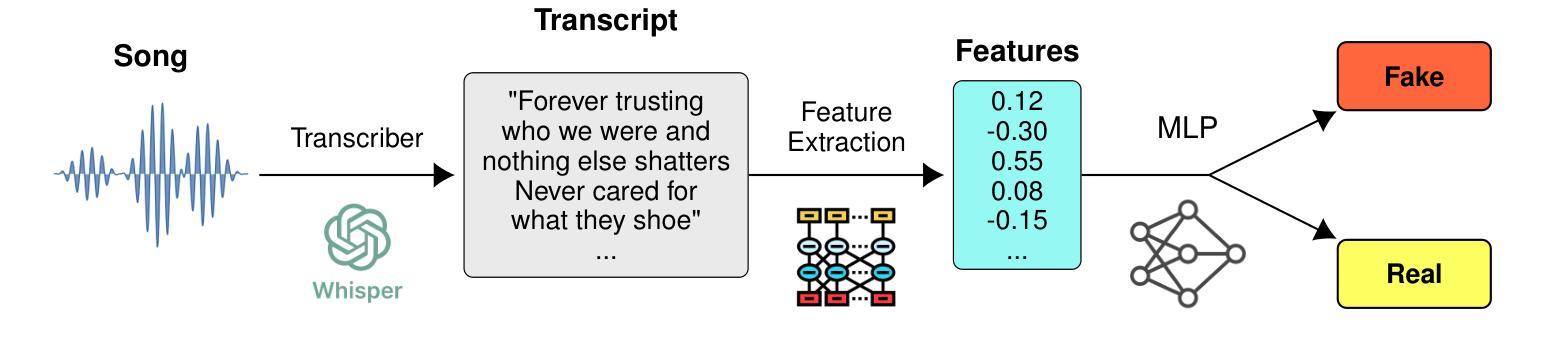
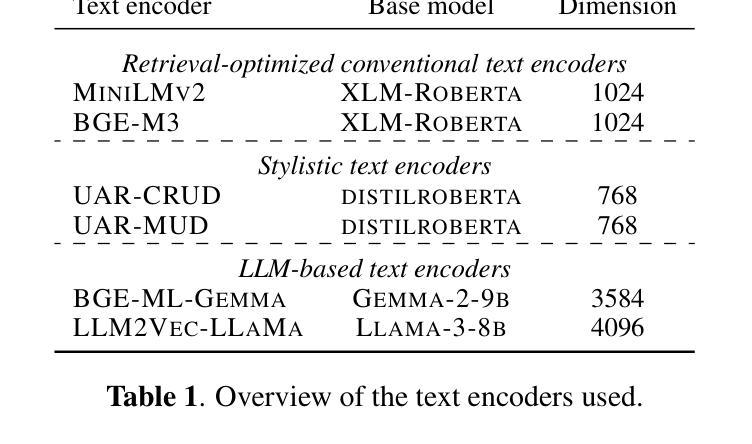
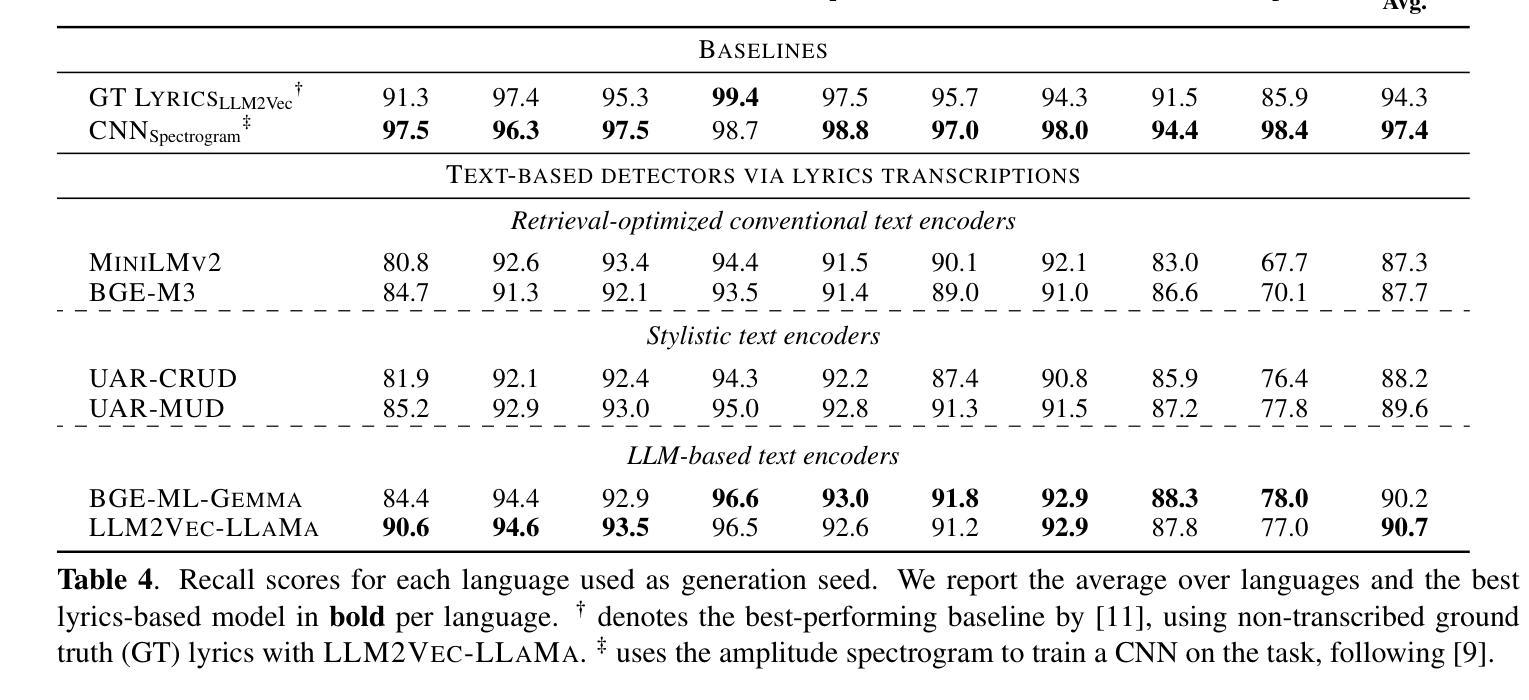
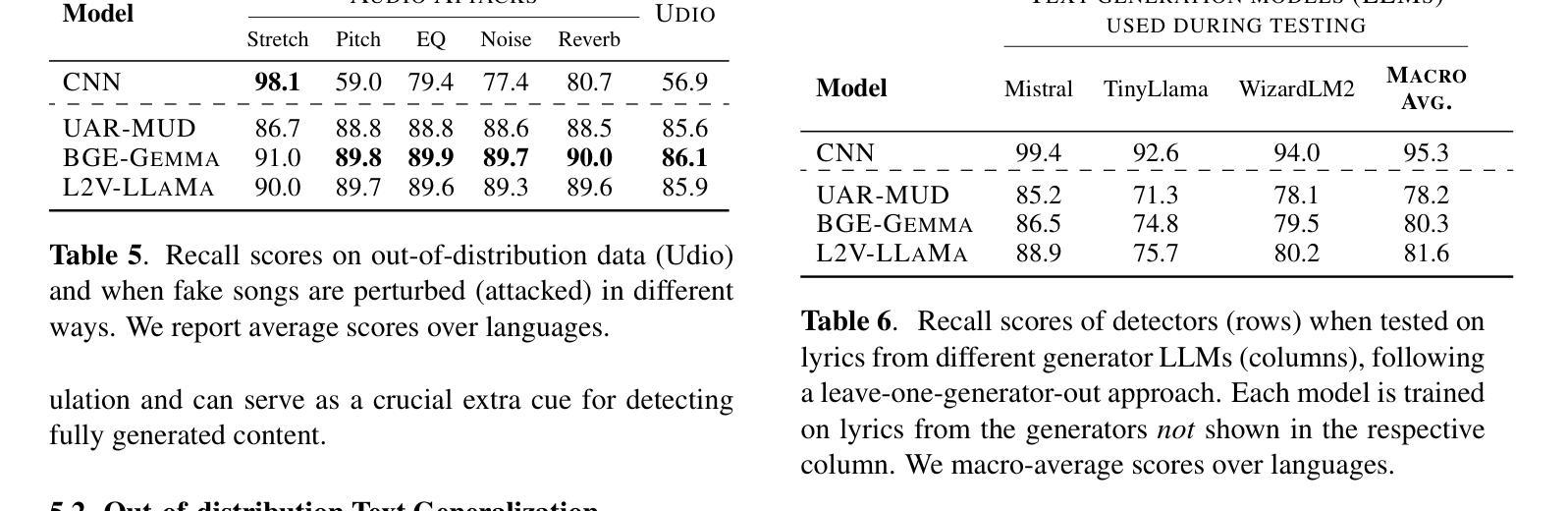
AI-Generated Song Detection via Lyrics Transcripts
Authors:Markus Frohmann, Elena V. Epure, Gabriel Meseguer-Brocal, Markus Schedl, Romain Hennequin
The recent rise in capabilities of AI-based music generation tools has created an upheaval in the music industry, necessitating the creation of accurate methods to detect such AI-generated content. This can be done using audio-based detectors; however, it has been shown that they struggle to generalize to unseen generators or when the audio is perturbed. Furthermore, recent work used accurate and cleanly formatted lyrics sourced from a lyrics provider database to detect AI-generated music. However, in practice, such perfect lyrics are not available (only the audio is); this leaves a substantial gap in applicability in real-life use cases. In this work, we instead propose solving this gap by transcribing songs using general automatic speech recognition (ASR) models. We do this using several detectors. The results on diverse, multi-genre, and multi-lingual lyrics show generally strong detection performance across languages and genres, particularly for our best-performing model using Whisper large-v2 and LLM2Vec embeddings. In addition, we show that our method is more robust than state-of-the-art audio-based ones when the audio is perturbed in different ways and when evaluated on different music generators. Our code is available at https://github.com/deezer/robust-AI-lyrics-detection.
近期AI音乐生成工具的能提升对引起了音乐产业的动荡,因此急需创造准确的方法来检测这类AI生成的内容。这可以通过基于音频的检测器来实现;然而,它们在新生成的音乐或者音频发生干扰的情况下通常无法进行有效的检测。另外,最近的研究工作采用了来自歌词提供数据库的准确和格式良好的歌词来检测AI生成的音乐。但在实际应用中,完美的歌词通常无法获取(只有音频),这使得在现实应用场景中的适用性存在很大差距。在这项工作中,我们提议通过采用通用的语音识别(ASR)模型进行歌词转录来解决这一差距。我们使用多种检测器实现这一点。在不同风格和多语言的歌词上的结果表明,我们的模型在不同语言和风格上的检测性能普遍强大,尤其是使用Whisper large-v2和LLM2Vec嵌入的最佳性能模型。此外,我们证明了当音频以不同方式受到干扰以及在不同的音乐生成器上评估时,我们的方法比最新的音频检测方法更为稳健。我们的代码可在https://github.com/deezer/robust-AI-lyrics-detection找到。
论文及项目相关链接
PDF Accepted to ISMIR 2025
Summary
最近人工智能音乐生成工具的进步对音乐产业产生了巨大影响,需要创建准确的方法来检测AI生成的内容。尽管音频检测器可用于此目的,但它们对新生成器或扰动音频的泛化能力有限。为此,本研究提出利用通用语音识别(ASR)模型进行歌词转录来解决实际应用中的问题。通过使用多个检测器,该模型在跨语言和多风格的音乐上表现优异,尤其是使用Whisper large-v2和LLM2Vec嵌入的最佳模型。此外,当音频以不同方式受到干扰或在不同的音乐生成器上评估时,该方法比最新的音频方法更稳健。
Key Takeaways
- AI音乐生成工具的进步对音乐产业产生了深远影响。
- 音频检测器在泛化新生成器和扰动音频方面存在局限性。
- 本研究通过利用通用语音识别(ASR)模型进行歌词转录来解决实际应用中的问题。
- 该模型使用多个检测器在跨语言和多风格的音乐上表现良好。
- 最佳模型使用Whisper large-v2和LLM2Vec嵌入技术。
- 该方法比现有的音频方法更稳健,特别是在处理扰动音频和不同音乐生成器时。
- 研究的代码已公开在GitHub上。
点此查看论文截图



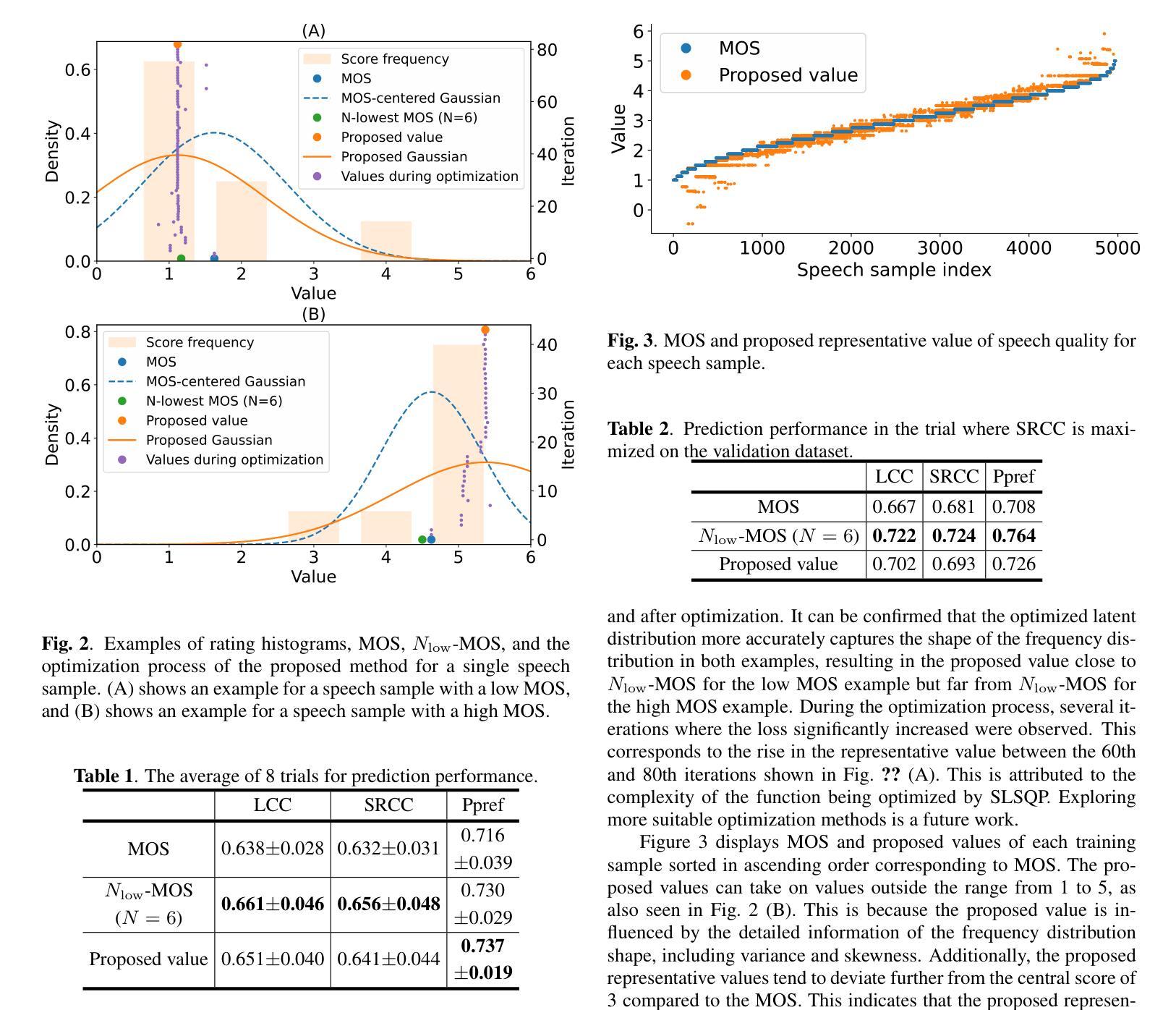
Rethinking Mean Opinion Scores in Speech Quality Assessment: Aggregation through Quantized Distribution Fitting
Authors:Yuto Kondo, Hirokazu Kameoka, Kou Tanaka, Takuhiro Kaneko
Speech quality assessment (SQA) aims to evaluate the quality of speech samples without relying on time-consuming listener questionnaires. Recent efforts have focused on training neural-based SQA models to predict the mean opinion score (MOS) of speech samples produced by text-to-speech or voice conversion systems. This paper targets the enhancement of MOS prediction models’ performance. We propose a novel score aggregation method to address the limitations of conventional annotations for MOS, which typically involve ratings on a scale from 1 to 5. Our method is based on the hypothesis that annotators internally consider continuous scores and then choose the nearest discrete rating. By modeling this process, we approximate the generative distribution of ratings by quantizing the latent continuous distribution. We then use the peak of this latent distribution, estimated through the loss between the quantized distribution and annotated ratings, as a new representative value instead of MOS. Experimental results demonstrate that substituting MOSNet’s predicted target with this proposed value improves prediction performance.
语音质量评估(SQA)旨在评估语音样本的质量,而不依赖于耗时的听众问卷调查。近期的研究努力集中在训练基于神经网络的SQA模型上,以预测文本到语音或语音转换系统产生的语音样本的平均意见得分(MOS)。本文针对提高MOS预测模型的性能。我们提出了一种新的评分聚合方法,以解决传统MOS标注的局限性,传统标注通常涉及从1到5的评分范围。我们的方法基于这样的假设:注释者在内部考虑连续分数,然后选择最近的离散评分。通过对这一过程进行建模,我们通过量化潜在的连续分布来近似评分的生成分布。然后,我们通过量化分布与注释评分之间的损失来估计潜在分布的峰值,并将其作为新的代表值来代替MOS。实验结果表明,用该提议的值替换MOSNet的预测目标可以提高预测性能。
论文及项目相关链接
PDF Accepted on ICASSP 2025
总结
本文关注语音质量评估(SQA)中均值意见得分(MOS)预测模型的性能提升。针对传统MOS标注方法的局限性,提出了一种新的评分聚合方法。该方法基于标注者实际上考虑的是连续分数,然后选择最接近的离散评分这一假设。通过量化潜在的连续分布来近似评分的生成分布,并使用此潜在分布的峰值(通过量化分布与标注评分之间的损失来估计)作为新的代表性值,以改进MOS预测模型的性能。
关键见解
- 语音质量评估(SQA)旨在评估语音样本的质量,且不依赖耗时的人力调查问卷。
- 近期研究致力于训练基于神经网络的SQA模型,以预测文本到语音或语音转换系统产生的语音样本的均值意见得分(MOS)。
- 本文提出了一种新的评分聚合方法,以解决传统MOS标注方法的局限性。
- 该方法基于标注者实际上在考虑连续分数然后选择最接近的离散评分的假设。
- 通过量化潜在的连续分布来近似评分的生成分布。
- 使用潜在分布的峰值作为新的代表性值,通过损失函数估计这一峰值。
点此查看论文截图


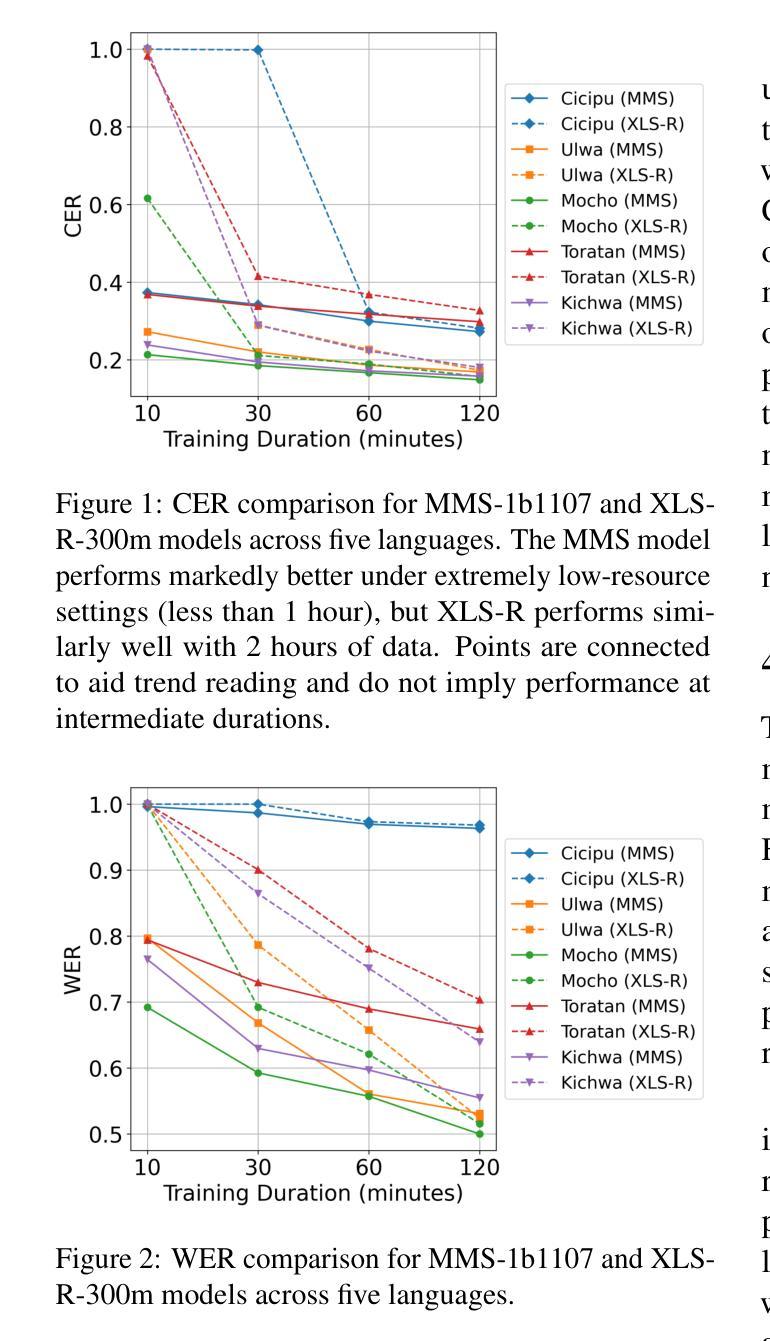
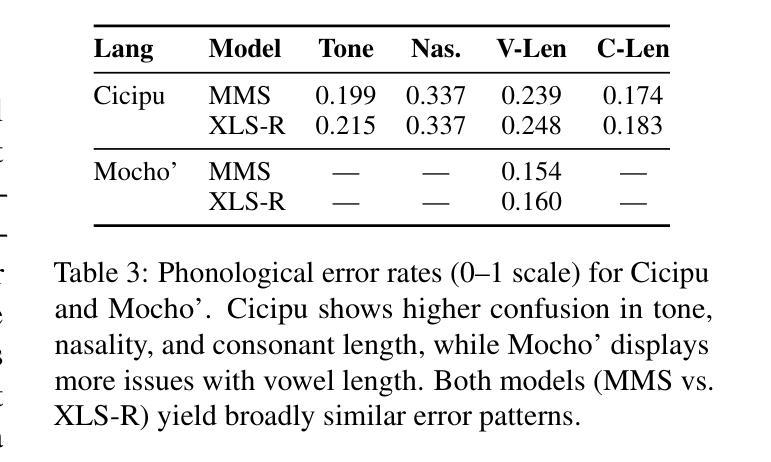
Breaking the Transcription Bottleneck: Fine-tuning ASR Models for Extremely Low-Resource Fieldwork Languages
Authors:Siyu Liang, Gina-Anne Levow
Automatic Speech Recognition (ASR) has reached impressive accuracy for high-resource languages, yet its utility in linguistic fieldwork remains limited. Recordings collected in fieldwork contexts present unique challenges, including spontaneous speech, environmental noise, and severely constrained datasets from under-documented languages. In this paper, we benchmark the performance of two fine-tuned multilingual ASR models, MMS and XLS-R, on five typologically diverse low-resource languages with control of training data duration. Our findings show that MMS is best suited when extremely small amounts of training data are available, whereas XLS-R shows parity performance once training data exceed one hour. We provide linguistically grounded analysis for further provide insights towards practical guidelines for field linguists, highlighting reproducible ASR adaptation approaches to mitigate the transcription bottleneck in language documentation.
自动语音识别(ASR)对于资源丰富的语言已经达到了令人印象深刻的准确性,然而其在语言领域工作中的实用性仍然有限。在现场工作环境中收集的录音呈现出独特的挑战,包括自然口语、环境噪声以及来自记录不全的语言的严重受限数据集。在本文中,我们在控制训练数据时间长度的情况下,对两种经过微调的多语种ASR模型MMS和XLS-R进行了五种类型丰富且资源匮乏的语言的基准测试。我们的研究发现,当可用训练数据量极小的时候,MMS最为合适;而当训练数据超过一个小时时,XLS-R表现出平等的性能。我们提供了基于语言学的分析,为进一步为语言学家提供实际指导的见解,强调可复制的ASR适应方法来减轻语言记录中的转录瓶颈问题。
论文及项目相关链接
Summary:
自动语音识别(ASR)在高资源语言上的准确性令人印象深刻,但在语言领域中的应用仍然有限。特别是在语言田野工作中收集的录音面临诸多挑战,如自发语音、环境噪声以及来自未记录语言的有限数据集。本文对比了两种经过微调的多语种ASR模型MMS和XLS-R,在五种类型多样但资源稀缺的语言环境下的性能。结果表明,当可用训练数据极为有限时,MMS表现最佳,当训练数据超过一小时时,XLS-R表现出同等性能。此外,我们还提供了语言学的见解和实践指南,帮助语言工作者更好地理解如何解决实际应用中的转录瓶颈问题。总体而言,这些建议将极大地促进语言的记录和保护。通过重新建立数据集和其他ASR适应性策略的实施策略的运用有效减少转录的瓶颈问题。我们强调了实际应用中可再生ASR适应性方法的优点,以及它在解决转录瓶颈方面的作用,这将有助于改善未来ASR模型的性能和效率。通过适当的改进和调整策略的运用能够进一步推动ASR技术在语言田野工作中发挥更大的作用。
Key Takeaways:
点此查看论文截图

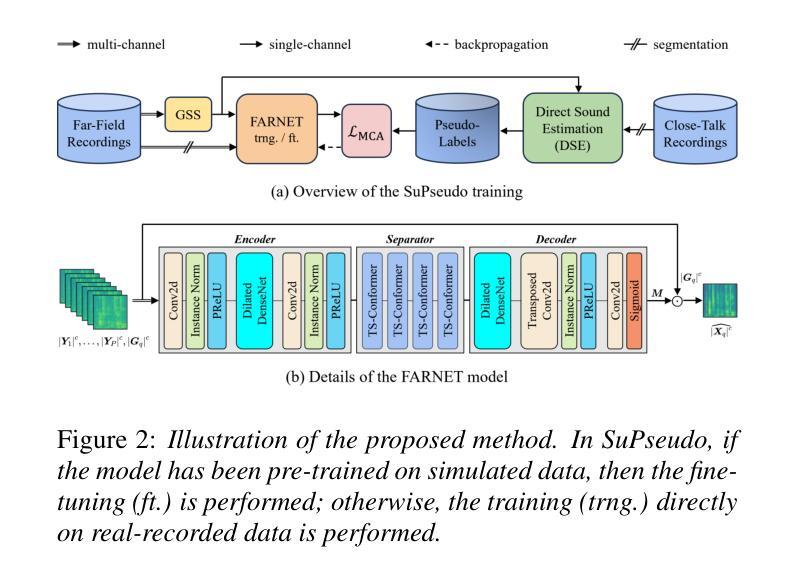
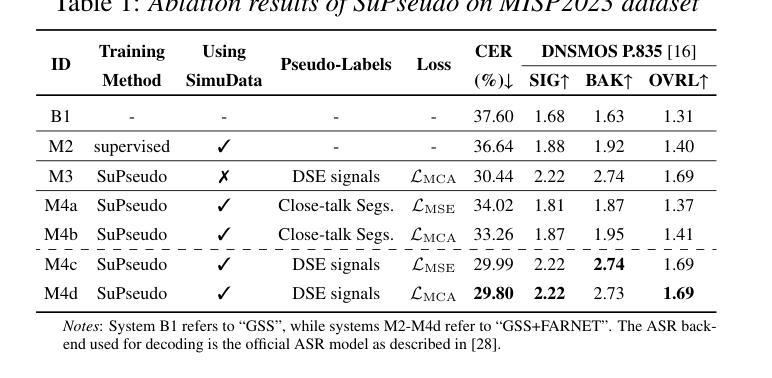
SuPseudo: A Pseudo-supervised Learning Method for Neural Speech Enhancement in Far-field Speech Recognition
Authors:Longjie Luo, Lin Li, Qingyang Hong
Due to the lack of target speech annotations in real-recorded far-field conversational datasets, speech enhancement (SE) models are typically trained on simulated data. However, the trained models often perform poorly in real-world conditions, hindering their application in far-field speech recognition. To address the issue, we (a) propose direct sound estimation (DSE) to estimate the oracle direct sound of real-recorded data for SE; and (b) present a novel pseudo-supervised learning method, SuPseudo, which leverages DSE-estimates as pseudo-labels and enables SE models to directly learn from and adapt to real-recorded data, thereby improving their generalization capability. Furthermore, an SE model called FARNET is designed to fully utilize SuPseudo. Experiments on the MISP2023 corpus demonstrate the effectiveness of SuPseudo, and our system significantly outperforms the previous state-of-the-art. A demo of our method can be found at https://EeLLJ.github.io/SuPseudo/.
由于真实录制的远距离对话数据集中缺乏目标语音注释,语音增强(SE)模型通常是在模拟数据上进行训练的。然而,在真实世界条件下,训练好的模型的性能往往不佳,阻碍了它们在远距离语音识别中的应用。为了解决这一问题,我们(a)提出了直接声音估计(DSE),以估计真实录制数据的理想直达声音,用于语音增强;(b)提出了一种新型伪监督学习方法SuPseudo,它利用DSE估计作为伪标签,使SE模型能够直接从真实数据中学习和适应,从而提高其泛化能力。此外,还设计了一个名为FARNET的SE模型,以充分利用SuPseudo。在MISP2023语料库上的实验证明了SuPseudo的有效性,我们的系统显著优于之前的最先进水平。有关我们方法的演示可在https://EeLLJ.github.io/SuPseudo/找到。
论文及项目相关链接
PDF Accepted by InterSpeech 2025
Summary
针对远场语音识别中真实录音数据集目标语音注释缺失的问题,现有的语音增强(SE)模型通常在模拟数据上进行训练,但在现实环境中的表现往往不佳。本文提出了两种解决方案:(a)提出直接声音估计(DSE),用于估计真实录音数据的理想直接声音,用于语音增强;(b)提出了一种新的伪监督学习方法SuPseudo,它利用DSE估计作为伪标签,使SE模型能够直接从真实数据中学习和适应,从而提高其泛化能力。实验表明,SuPseudo方法有效,使用其设计的FARNET模型在MISP2023语料库上的表现优于现有技术。
Key Takeaways
- 真实录音的远场语音识别数据集缺乏目标语音注释,导致语音增强(SE)模型在模拟数据上训练后,现实环境中的表现不佳。
- 提出直接声音估计(DSE)方法,用以估计真实录音数据的理想直接声音,为解决此问题打下基础。
- 介绍了新的伪监督学习方法SuPseudo,它利用DSE的估计结果作为伪标签,使SE模型能够直接从真实数据中学习和适应。
- SuPseudo方法提高了SE模型的泛化能力。
- 设计了名为FARNET的SE模型,以充分利用SuPseudo方法。
- 在MISP2023语料库上的实验证明了SuPseudo方法的有效性,且其表现优于现有技术。
点此查看论文截图
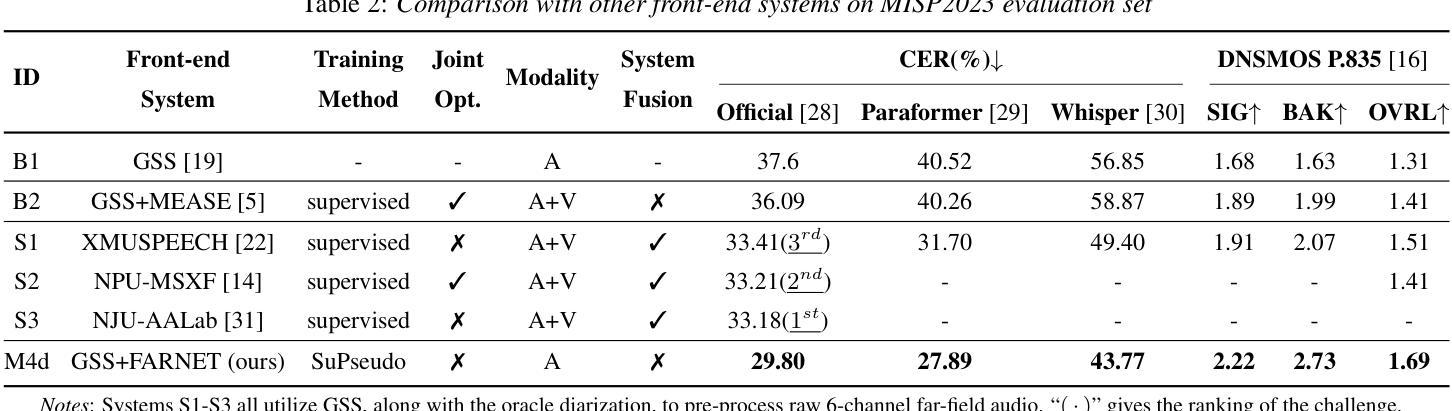
Pseudo Labels-based Neural Speech Enhancement for the AVSR Task in the MISP-Meeting Challenge
Authors:Longjie Luo, Shenghui Lu, Lin Li, Qingyang Hong
This paper presents our system for the MISP-Meeting Challenge Track 2. The primary difficulty lies in the dataset, which contains strong background noise, reverberation, overlapping speech, and diverse meeting topics. To address these issues, we (a) designed G-SpatialNet, a speech enhancement (SE) model to improve Guided Source Separation (GSS) signals; (b) proposed TLS, a framework comprising time alignment, level alignment, and signal-to-noise ratio filtering, to generate signal-level pseudo labels for real-recorded far-field audio data, thereby facilitating SE models’ training; and (c) explored fine-tuning strategies, data augmentation, and multimodal information to enhance the performance of pre-trained Automatic Speech Recognition (ASR) models in meeting scenarios. Finally, our system achieved character error rates (CERs) of 5.44% and 9.52% on the Dev and Eval sets, respectively, with relative improvements of 64.8% and 52.6% over the baseline, securing second place.
本文介绍了我们在MISP-Meeting挑战赛轨道2中的系统。主要难点在于数据集,它包含强烈的背景噪声、回声、语音重叠和多样的会议主题。为了解决这些问题,我们(a)设计了G-SpatialNet,这是一个语音增强(SE)模型,用于改进导向源分离(GSS)信号;(b)提出TLS,一个包含时间对齐、水平对齐和信噪比过滤的框架,用于为真实录制的远距离音频数据生成信号级伪标签,从而帮助训练SE模型;(c)探索了微调策略、数据增强和多模态信息,以提高预训练的自动语音识别(ASR)模型在会议场景中的性能。最终,我们的系统在开发集和评估集上分别实现了5.44%和9.52%的字符错误率(CERs),相对于基线有64.8%和52.6%的相对改进,获得了第二名。
论文及项目相关链接
PDF Accepted by InterSpeech 2025
Summary:
本文介绍了针对MISP-Meeting挑战赛道2的系统。主要难点在于数据集存在强背景噪声、回声、语音重叠以及会议主题多样等问题。为解决这些问题,提出了G-SpatialNet模型以提高引导源分离信号的语音增强效果,并提出了TLS框架以生成信号级伪标签用于真实远距离音频数据的训练,同时探索了微调策略、数据增强和多模态信息以增强会议场景下预训练自动语音识别模型的性能。最终,系统实现了开发集和评估集上的字符错误率分别为5.44%和9.52%,相对于基线有显著改善,获得第二名。
Key Takeaways:
- 系统面临的主要难点在于数据集存在多种语音干扰和多样的会议主题。
- 提出了G-SpatialNet模型,用于提高引导源分离信号的语音增强效果。
- 提出了TLS框架,包括时间对齐、级别对齐和信噪比过滤,生成信号级伪标签用于训练语音增强模型。
- 通过探索微调策略、数据增强和多模态信息,增强了预训练自动语音识别模型在会议场景下的性能。
- 系统在开发集和评估集上实现了较低的字符错误率。
- 与基线相比,系统性能有显著改善,获得了第二名的好成绩。
- 文中涉及的技术包括语音增强、自动语音识别、信号处理和深度学习等。
点此查看论文截图

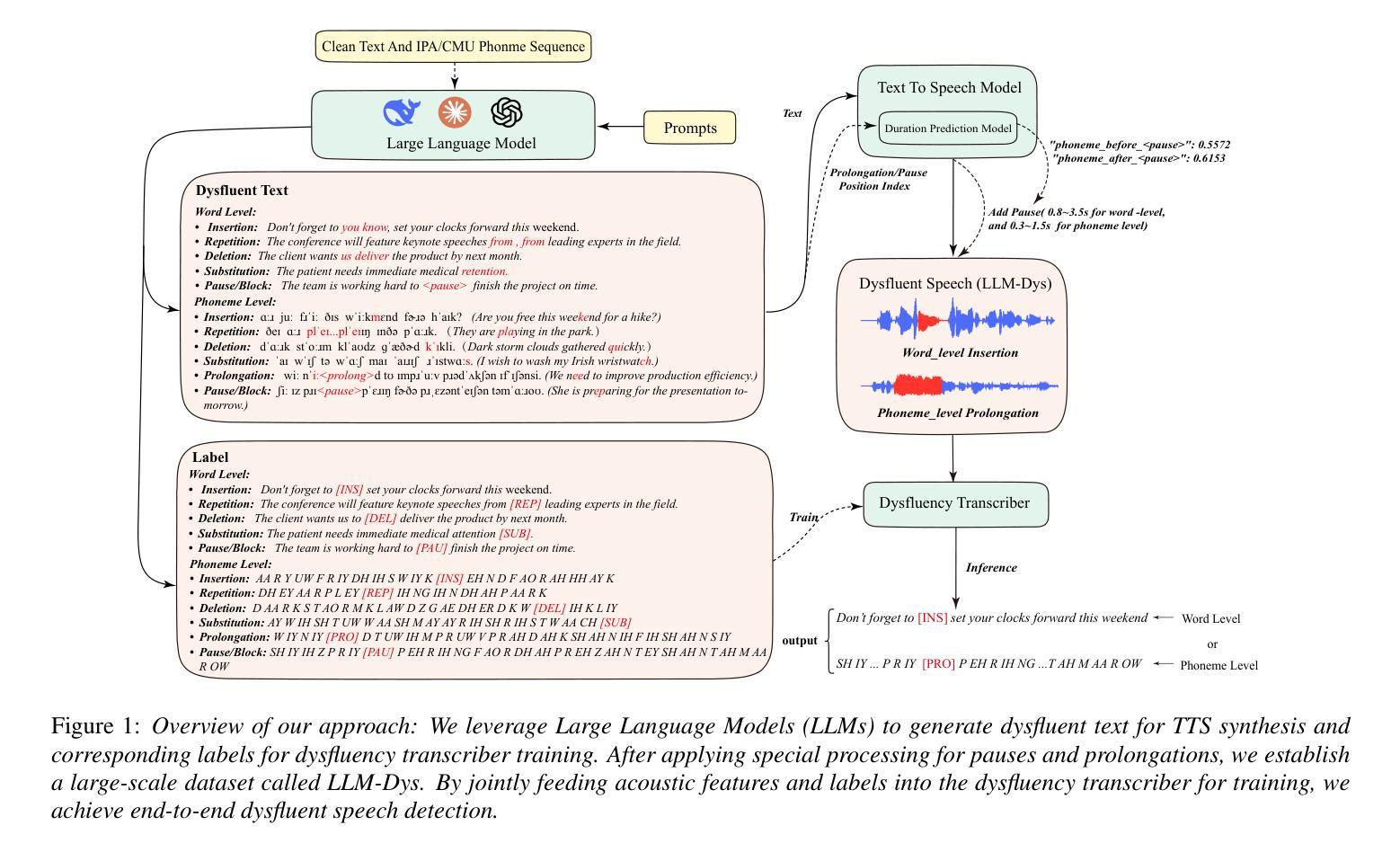
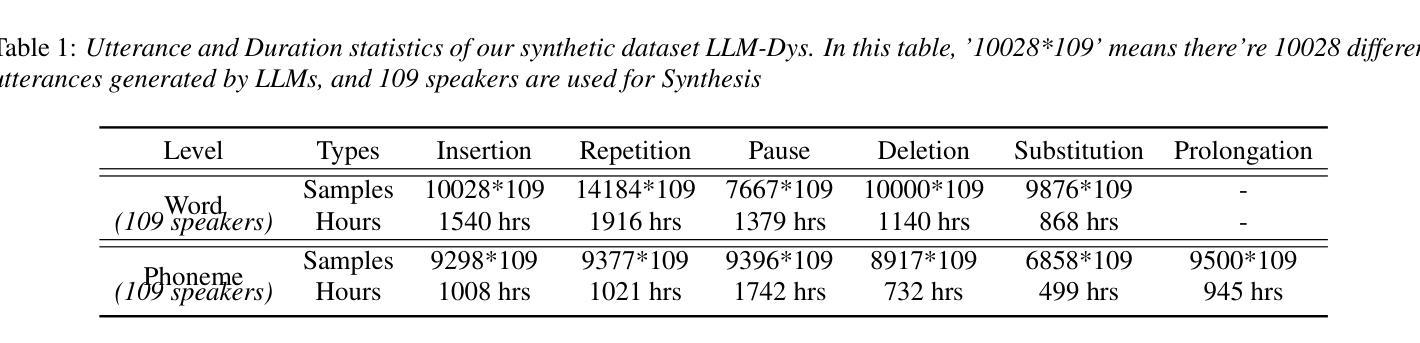
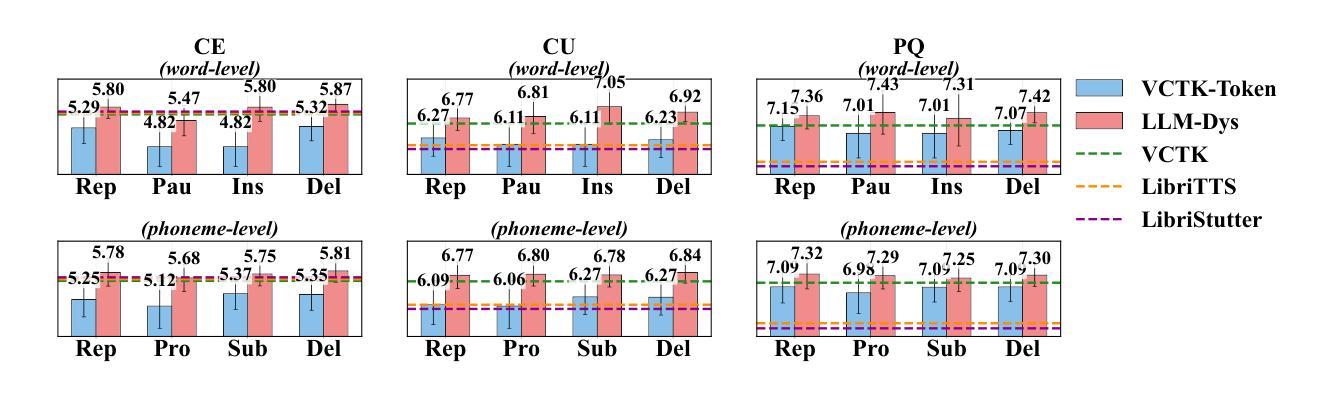
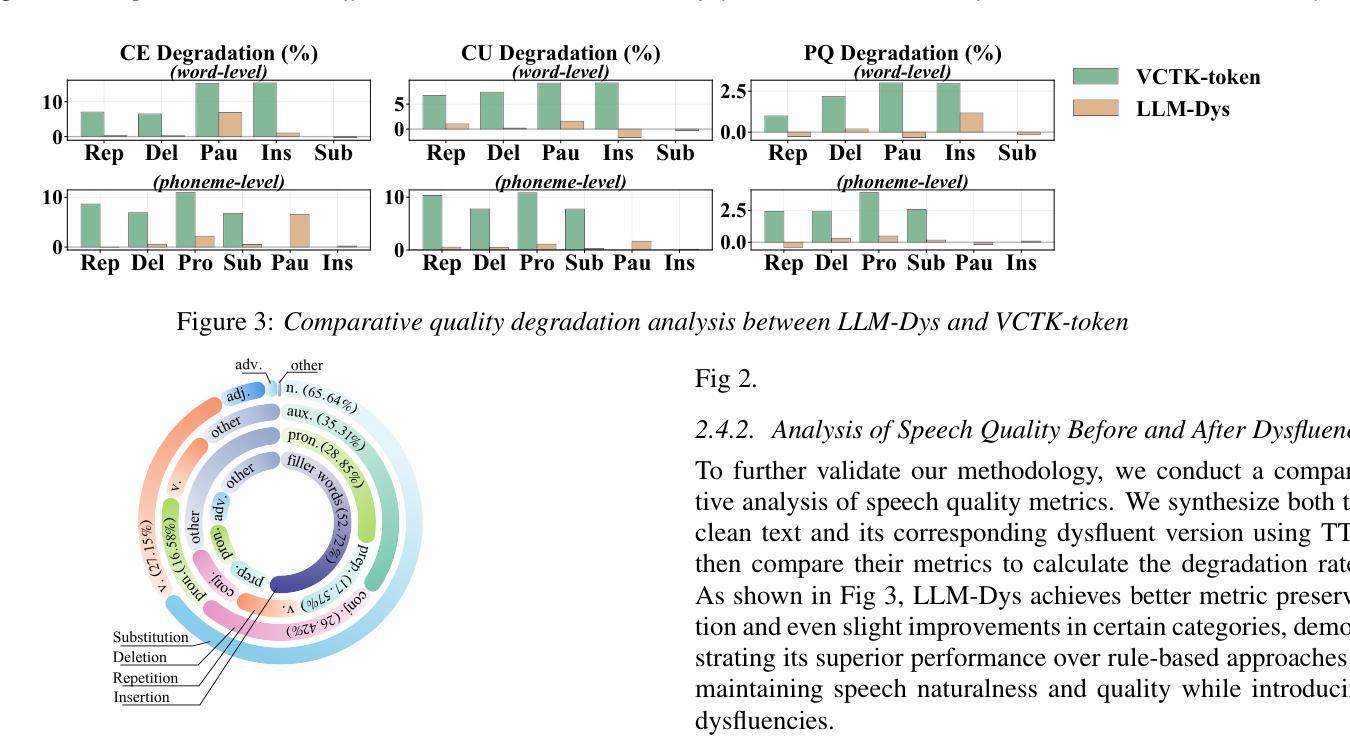
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
Authors:Jinming Zhang, Xuanru Zhou, Jiachen Lian, Shuhe Li, William Li, Zoe Ezzes, Rian Bogley, Lisa Wauters, Zachary Miller, Jet Vonk, Brittany Morin, Maria Gorno-Tempini, Gopala Anumanchipalli
Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys – the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
语音流畅性检测对于临床诊断和治疗语言评估至关重要,但现有方法受到高质量注释数据稀缺的限制。尽管最近文本到语音(TTS)模型的进步已经能够实现合成流畅性生成,但现有合成数据集存在语调不自然和上下文多样性有限的问题。为了解决这些局限性,我们提出了LLM-Dys——一个由大型语言模型增强流畅性模拟的最全面的流畅性语音语料库。该数据集涵盖了跨越单词和音素级别的11个流畅性问题类别。基于这一资源,我们改进了一个端到端的流畅性检测框架。实验验证证明了其卓越的性能。所有数据、模型和代码均公开开源于https://github.com/Berkeley-Speech-Group/LLM-Dys。
论文及项目相关链接
PDF Accepted by Interspeech 2025
Summary
本文介绍了语音流畅性检测在临床诊断和治疗语言评估中的重要性。现有方法受限于高质量标注数据的稀缺性。尽管最近文本转语音模型的进步使得可以生成合成流畅性问题,但现有合成数据集存在韵律不自然和上下文多样性有限的问题。为解决这些问题,我们提出了LLM-Dys——最全面的流畅性语音语料库,通过大型语言模型增强了流畅性模拟。该数据集涵盖了词汇和音素级别的11个流畅性问题类别。基于该资源,我们改进了端到端的流畅性检测框架。实验验证达到了先进水平的效果。所有相关数据、模型和代码已开源分享在:https://github.com/Berkeley-Speech-Group/LLM-Dys。
Key Takeaways
- 现有语音流畅性检测方法受限于高质量标注数据的稀缺性,对于临床诊断和语言评估具有重要意义。
- TTS模型虽可实现合成流畅性的生成,但存在韵律不自然和上下文多样性不足的问题。
- 提出LLM-Dys作为最全面的流畅性语音语料库,通过大型语言模型增强流畅性模拟。
- LLM-Dys涵盖了词汇和音素级别的多种流畅性问题类别。
- 基于LLM-Dys数据集改进了端到端的流畅性检测框架。
- 实验验证显示改进后的框架性能达到先进水平。
点此查看论文截图

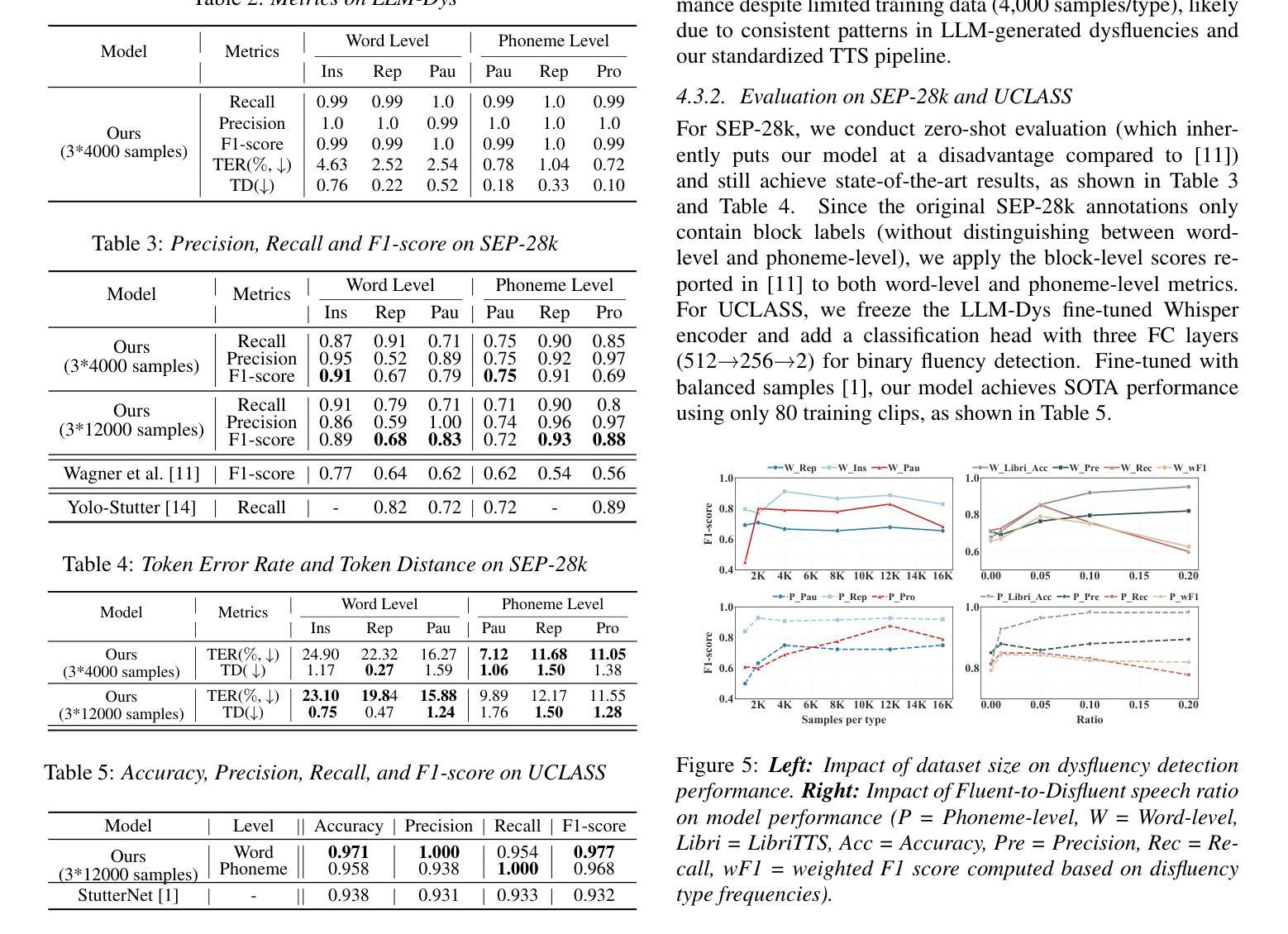
Introducing voice timbre attribute detection
Authors:Jinghao He, Zhengyan Sheng, Liping Chen, Kong Aik Lee, Zhen-Hua Ling
This paper focuses on explaining the timbre conveyed by speech signals and introduces a task termed voice timbre attribute detection (vTAD). In this task, voice timbre is explained with a set of sensory attributes describing its human perception. A pair of speech utterances is processed, and their intensity is compared in a designated timbre descriptor. Moreover, a framework is proposed, which is built upon the speaker embeddings extracted from the speech utterances. The investigation is conducted on the VCTK-RVA dataset. Experimental examinations on the ECAPA-TDNN and FACodec speaker encoders demonstrated that: 1) the ECAPA-TDNN speaker encoder was more capable in the seen scenario, where the testing speakers were included in the training set; 2) the FACodec speaker encoder was superior in the unseen scenario, where the testing speakers were not part of the training, indicating enhanced generalization capability. The VCTK-RVA dataset and open-source code are available on the website https://github.com/vTAD2025-Challenge/vTAD.
本文重点解释语音信号所传递的音色,并介绍了一项称为音色属性检测(vTAD)的任务。在该任务中,音色通过一系列描述人类感知的感官属性来解释。对一对语音片段进行处理,并在指定的音色描述符中比较它们的强度。此外,提出了一个基于从语音片段中提取的说话者嵌入的框架。该研究在VCTK-RVA数据集上进行。对ECAPA-TDNN和FACodec说话人编码器的实验表明:1)在可见场景下,ECAPA-TDNN说话人编码器更具能力,其中测试说话人包含在训练集中;2)FACodec说话人编码器在未见过的情况下表现更好,其中测试说话人不是训练的一部分,表明其增强了泛化能力。VCTK-RVA数据集和开源代码可在网站https://github.com/vTAD2025-Challenge/vTAD上找到。
论文及项目相关链接
PDF arXiv admin note: substantial text overlap with arXiv:2505.09382
总结
本文介绍了语音信号的音色特征,并定义了一个名为声音音色属性检测(vTAD)的任务。在该任务中,通过一系列描述音色的感知属性来解释音色。处理一段语音信号后,对比两段语音的音色强度在一个特定的音色描述符上。此外,提出了一种基于从语音中提取的说话者嵌入信息的框架,该研究在VCTK-RVA数据集上进行验证。通过ECAPA-TDNN和FACodec两种说话者编码器的实验表明:ECAPA-TDNN在测试说话者包含在训练集中的情况下表现更好;FACodec在测试说话者未参与训练的情况下表现出较强的泛化能力。相关数据集和开源代码可在网站链接上找到。
关键见解
- 文章介绍了语音信号的音色特征,并定义了声音音色属性检测(vTAD)的任务。这是一个新颖的角度来探讨语音信号处理。
- 提出一种对比两段语音信号在特定音色描述符上的音色强度的对比方法。这是vTAD任务的一个重要组成部分。
- 利用基于说话者嵌入信息的框架进行研究,为语音信号的处理和分析提供了新思路。
- 在VCTK-RVA数据集上进行了实验验证,该数据集可用于训练和测试vTAD相关的算法。
- 实验结果显示,ECAPA-TDNN在已知说话者场景下表现较好,而FACodec在未知说话者场景中具有更强的泛化能力。这对于选择适合的编码器提供了参考依据。
- 文章提供的开源代码和数据集有助于推动vTAD领域的研究进展。这对于语音信号处理领域的研究者是一大福音。
点此查看论文截图

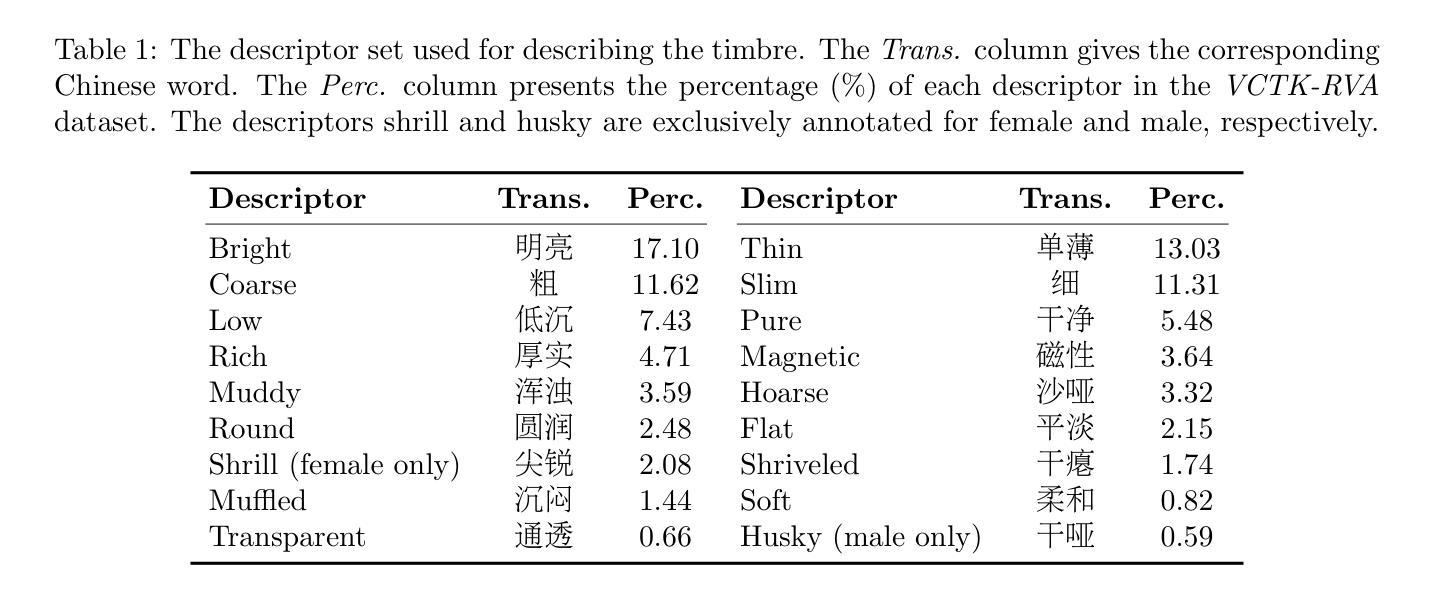
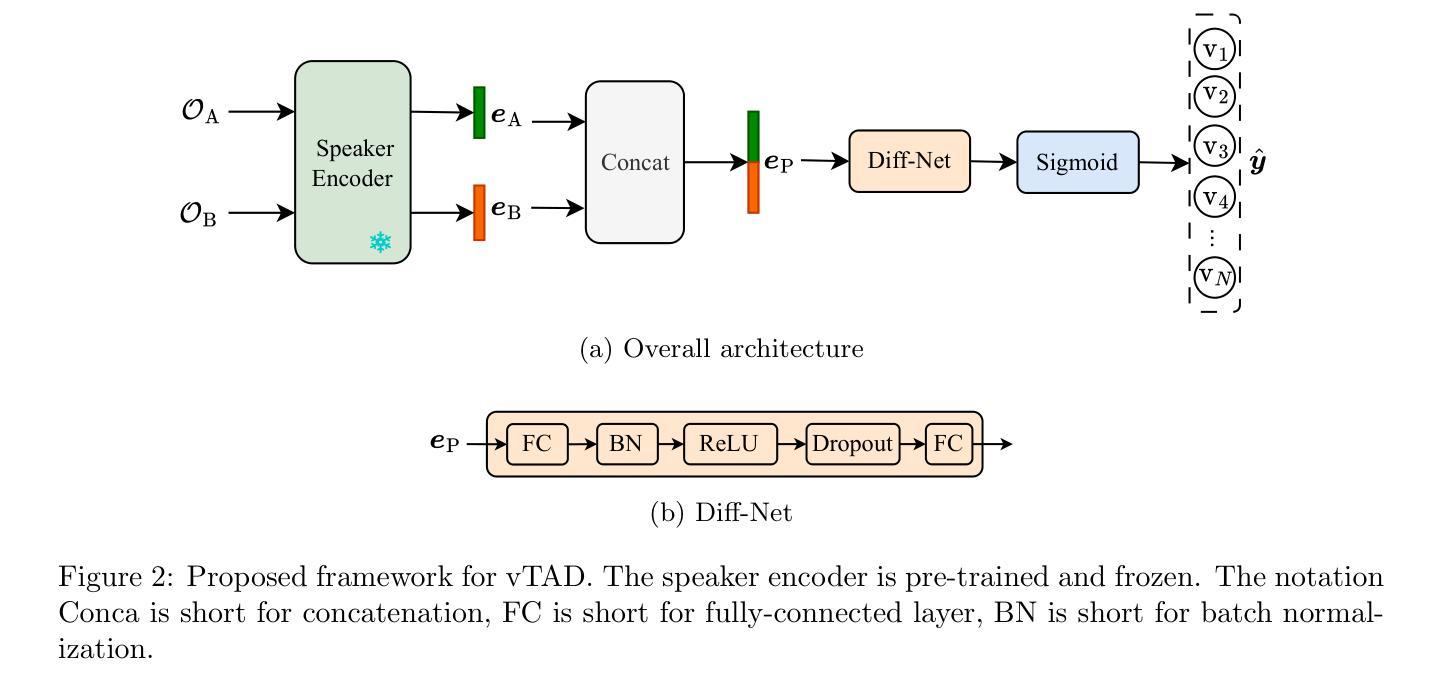
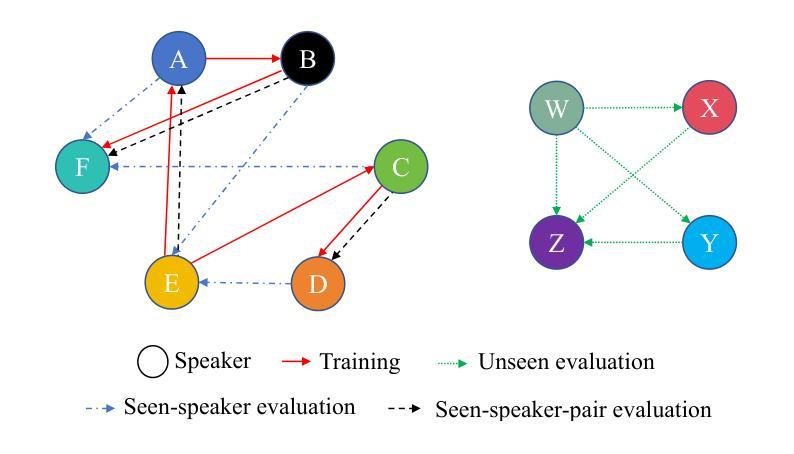
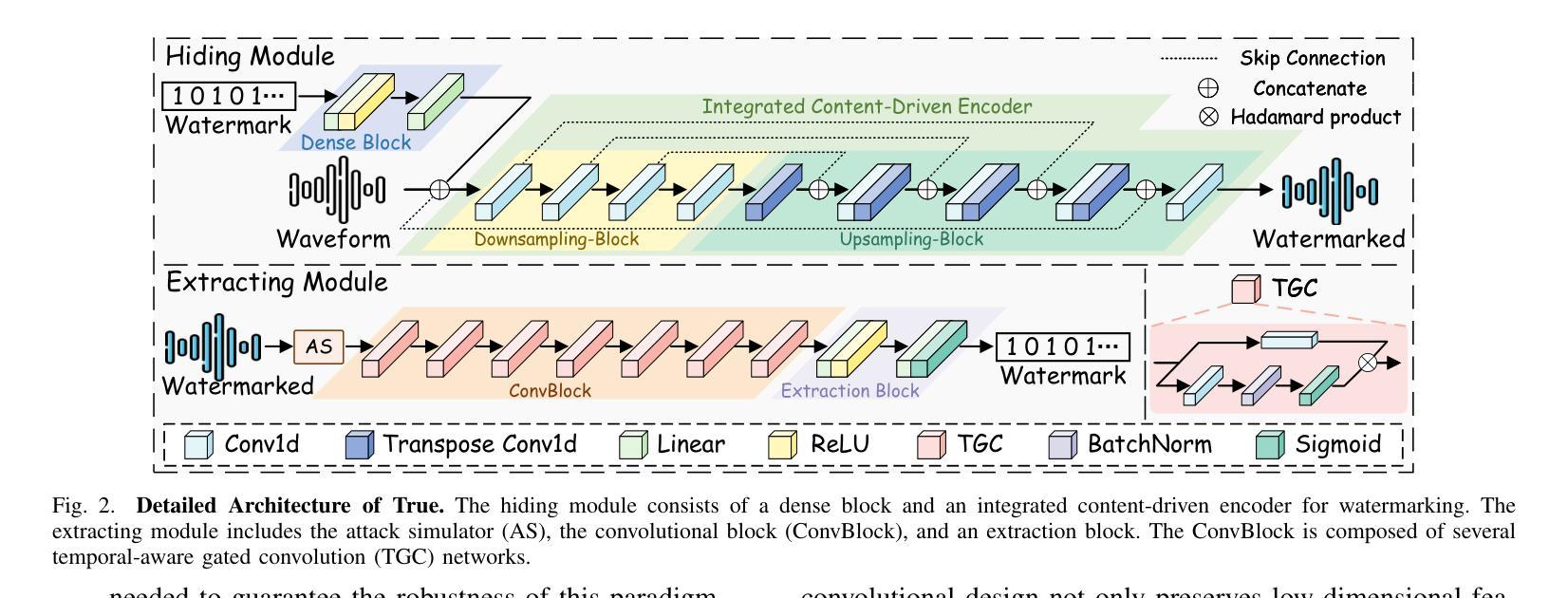
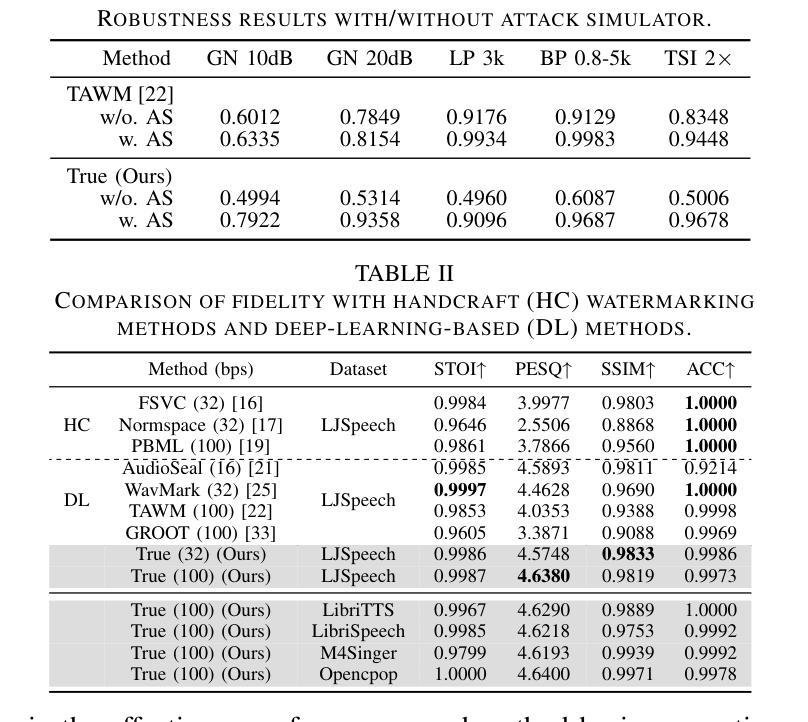
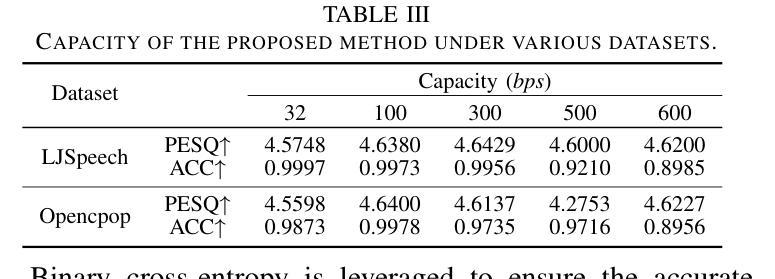
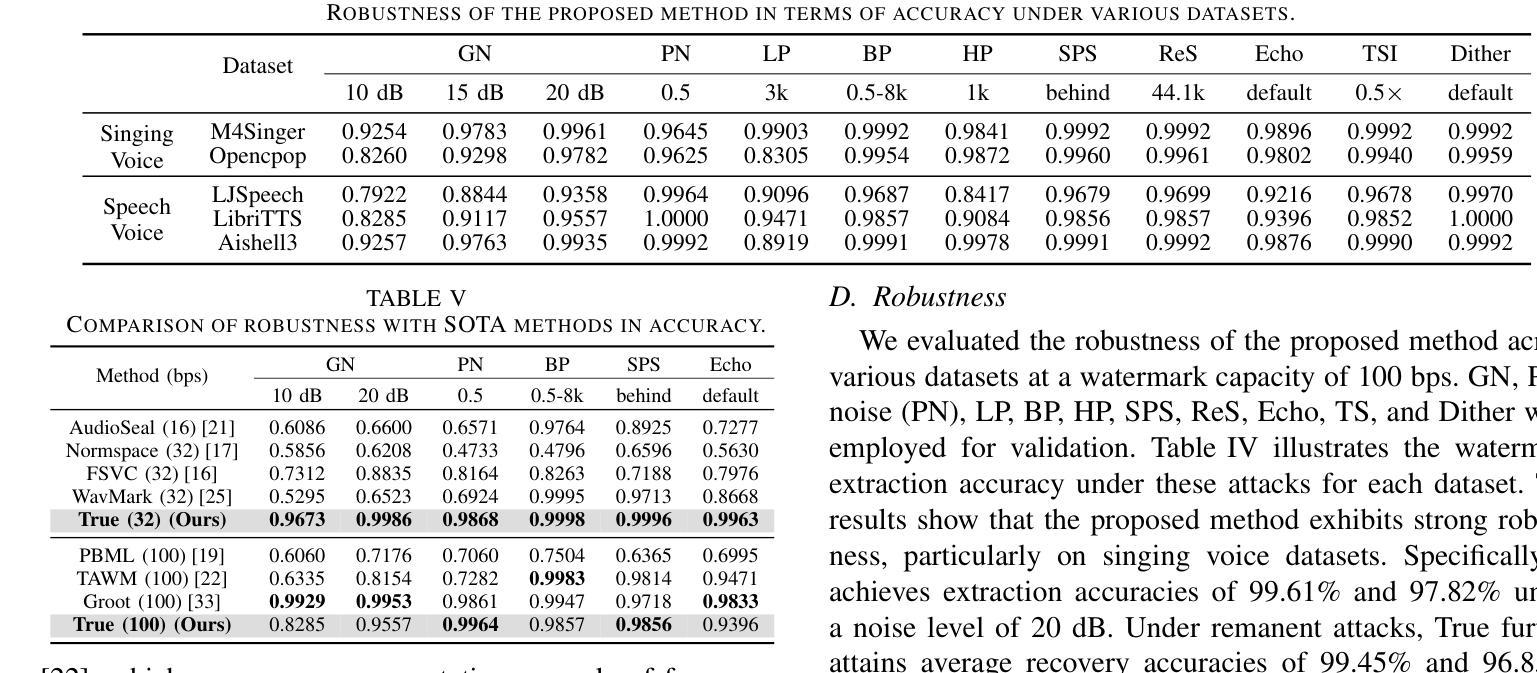
Protecting Your Voice: Temporal-aware Robust Watermarking
Authors:Yue Li, Weizhi Liu, Dongdong Lin, Hui Tian, Hongxia Wang
The rapid advancement of generative models has led to the synthesis of real-fake ambiguous voices. To erase the ambiguity, embedding watermarks into the frequency-domain features of synthesized voices has become a common routine. However, the robustness achieved by choosing the frequency domain often comes at the expense of fine-grained voice features, leading to a loss of fidelity. Maximizing the comprehensive learning of time-domain features to enhance fidelity while maintaining robustness, we pioneer a \textbf{\underline{t}}emporal-aware \textbf{\underline{r}}ob\textbf{\underline{u}}st wat\textbf{\underline{e}}rmarking (\emph{True}) method for protecting the speech and singing voice. For this purpose, the integrated content-driven encoder is designed for watermarked waveform reconstruction, which is structurally lightweight. Additionally, the temporal-aware gated convolutional network is meticulously designed to bit-wise recover the watermark. Comprehensive experiments and comparisons with existing state-of-the-art methods have demonstrated the superior fidelity and vigorous robustness of the proposed \textit{True} achieving an average PESQ score of 4.63.
生成模型的快速发展导致了真实与虚假模糊语音的合成。为了消除这种模糊性,将水印嵌入合成语音的频率域特征已成为一种常见做法。然而,通过选择频率域实现的稳健性往往以牺牲精细的语音特征为代价,导致保真度损失。我们最大化对时域特征的全面学习,以提高保真度并保持稳健性,开创了一种保护语音和歌声的时间感知稳健水印方法(True)。为此,设计了一个集成的内容驱动编码器进行水印波形重建,该编码器结构轻巧。此外,精心设计了时间感知门控卷积网络以位恢复水印。综合实验与现有先进方法的比较表明,所提出的True方法的保真度更高、稳健性更强,平均PESQ得分达到4.63。
论文及项目相关链接
Summary
随着生成模型的快速发展,合成语音的真实性和伪造性变得模糊。为了在频率域特征中为合成语音嵌入水印以消除歧义,同时保持稳健性并最大化时间域特征的全面学习以提高保真度,我们首创了一种称为“True”的时间感知稳健水印方法,用于保护语音和歌声。该方法设计了集成的内容驱动编码器和时间感知门控卷积网络,以进行水印嵌入和提取。实验证明,该方法在保真度和稳健性方面均优于现有技术,平均PESQ得分达到4.63。
Key Takeaways
- 生成模型的快速发展导致合成语音的真实性和伪造性变得模糊。
- 在频率域特征中为合成语音嵌入水印是消除歧义的一种常见方法,但可能导致语音特征的损失。
- 为了提高保真度并维持稳健性,需要最大化时间域特征的全面学习。
- 提出了一种新的时间感知稳健水印方法“True”,用于保护语音和歌声。
- “True”方法包括一个集成的内容驱动编码器和一个时间感知门控卷积网络。
- 实验证明,“True”方法在保真度和稳健性方面优于现有技术。
点此查看论文截图

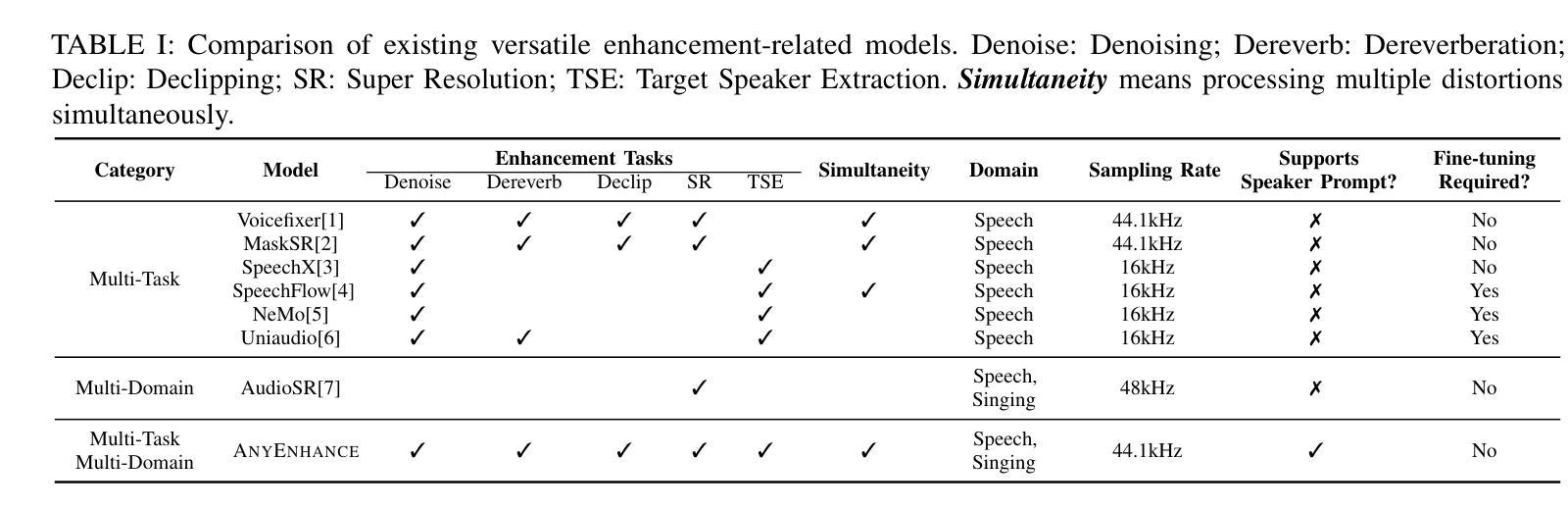
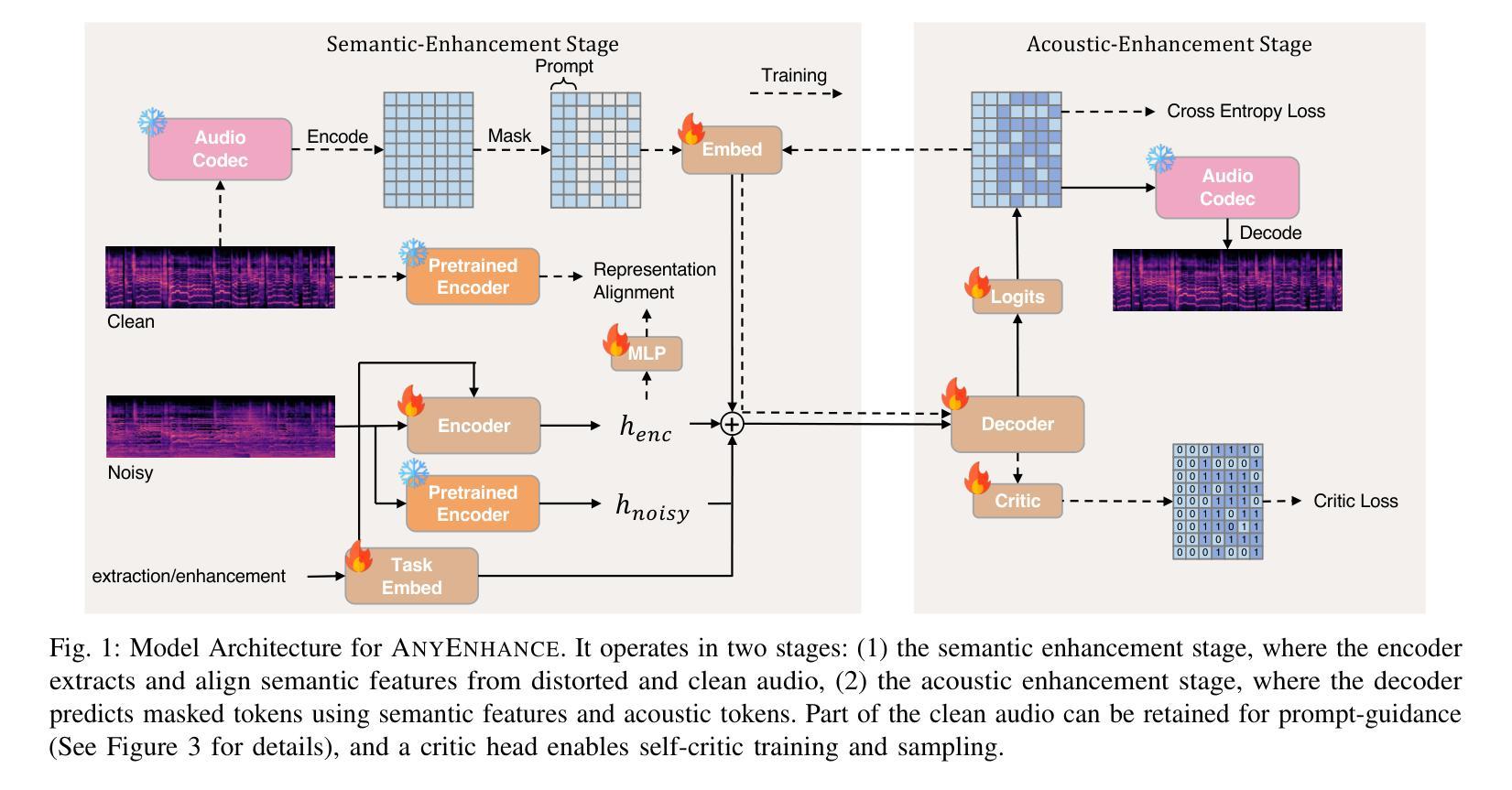
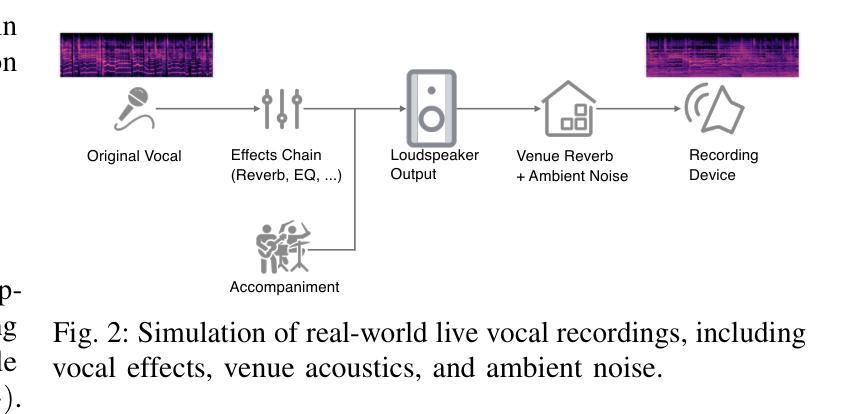
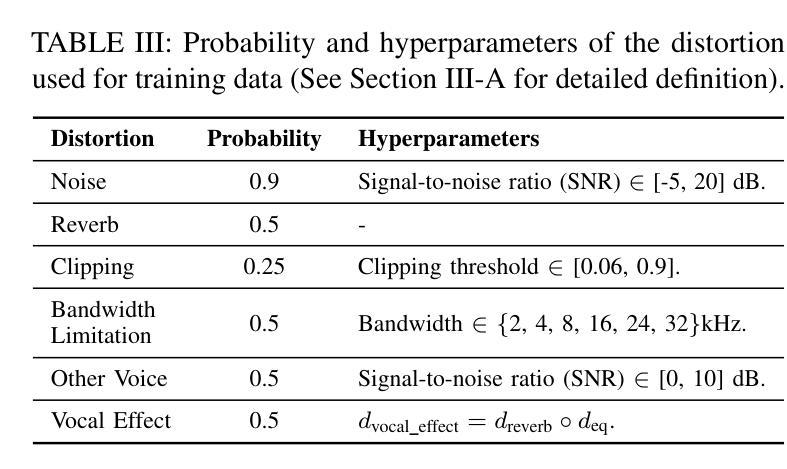
AnyEnhance: A Unified Generative Model with Prompt-Guidance and Self-Critic for Voice Enhancement
Authors:Junan Zhang, Jing Yang, Zihao Fang, Yuancheng Wang, Zehua Zhang, Zhuo Wang, Fan Fan, Zhizheng Wu
We introduce AnyEnhance, a unified generative model for voice enhancement that processes both speech and singing voices. Based on a masked generative model, AnyEnhance is capable of handling both speech and singing voices, supporting a wide range of enhancement tasks including denoising, dereverberation, declipping, super-resolution, and target speaker extraction, all simultaneously and without fine-tuning. AnyEnhance introduces a prompt-guidance mechanism for in-context learning, which allows the model to natively accept a reference speaker’s timbre. In this way, it could boost enhancement performance when a reference audio is available and enable the target speaker extraction task without altering the underlying architecture. Moreover, we also introduce a self-critic mechanism into the generative process for masked generative models, yielding higher-quality outputs through iterative self-assessment and refinement. Extensive experiments on various enhancement tasks demonstrate AnyEnhance outperforms existing methods in terms of both objective metrics and subjective listening tests. Demo audios are publicly available at https://amphionspace.github.io/anyenhance/.
我们介绍了AnyEnhance,这是一个统一的生成模型,用于处理语音和歌唱声音的声音增强。基于掩模生成模型,AnyEnhance能够同时处理语音和歌唱声音,支持广泛的增强任务,包括去噪、去混响、去剪辑、超分辨率和目标说话人提取,而无需微调。AnyEnhance引入了一种上下文学习中的提示引导机制,允许模型直接接受参考说话人的音色。这样,在有参考音频可用的情况下,它可以提高增强性能,并在不改变底层架构的情况下实现目标说话人提取任务。此外,我们还引入了生成过程中的自我批判机制,通过迭代自我评估和修正,产生更高质量的输出。在各种增强任务上的大量实验表明,AnyEnhance在客观指标和主观听觉测试方面优于现有方法。演示音频可在https://amphionspace.github.io/anyenhance/公开访问。
论文及项目相关链接
PDF Accepted by IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP) 2025
Summary
AnyEnhance是一个统一的生成模型,用于增强语音和歌声。它基于掩膜生成模型,能够同时处理各种增强任务,如去噪、去混响、去剪辑、超分辨率和目标语音提取,而无需微调。AnyEnhance引入了一种基于提示的引导机制,用于上下文学习,使模型能够自然地接受参考说话人的音色。此外,还引入了自我批判机制,通过迭代自我评估和细化,产生更高质量的输出。实验表明,AnyEnhance在客观指标和主观听觉测试方面均优于现有方法。
Key Takeaways
- AnyEnhance是一个统一的生成模型,适用于语音和歌声增强。
- 它基于掩膜生成模型,能够处理多种增强任务,包括去噪、去混响、去剪辑、超分辨率和目标语音提取。
- AnyEnhance引入了基于提示的引导机制,允许模型接受参考说话人的音色,提升在有参考音频时的增强性能。
- 模型能够通过自我批判机制产生更高质量的输出,通过迭代自我评估和细化。
- AnyEnhance在客观指标和主观听觉测试方面均表现出优异性能。
- 该模型的应用演示音频可在公众平台获取。
- AnyEnhance的设计使其具有广泛的应用前景,包括语音识别、语音助手、音频编辑等领域。
点此查看论文截图