⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
OmniAvatar: Efficient Audio-Driven Avatar Video Generation with Adaptive Body Animation
Authors:Qijun Gan, Ruizi Yang, Jianke Zhu, Shaofei Xue, Steven Hoi
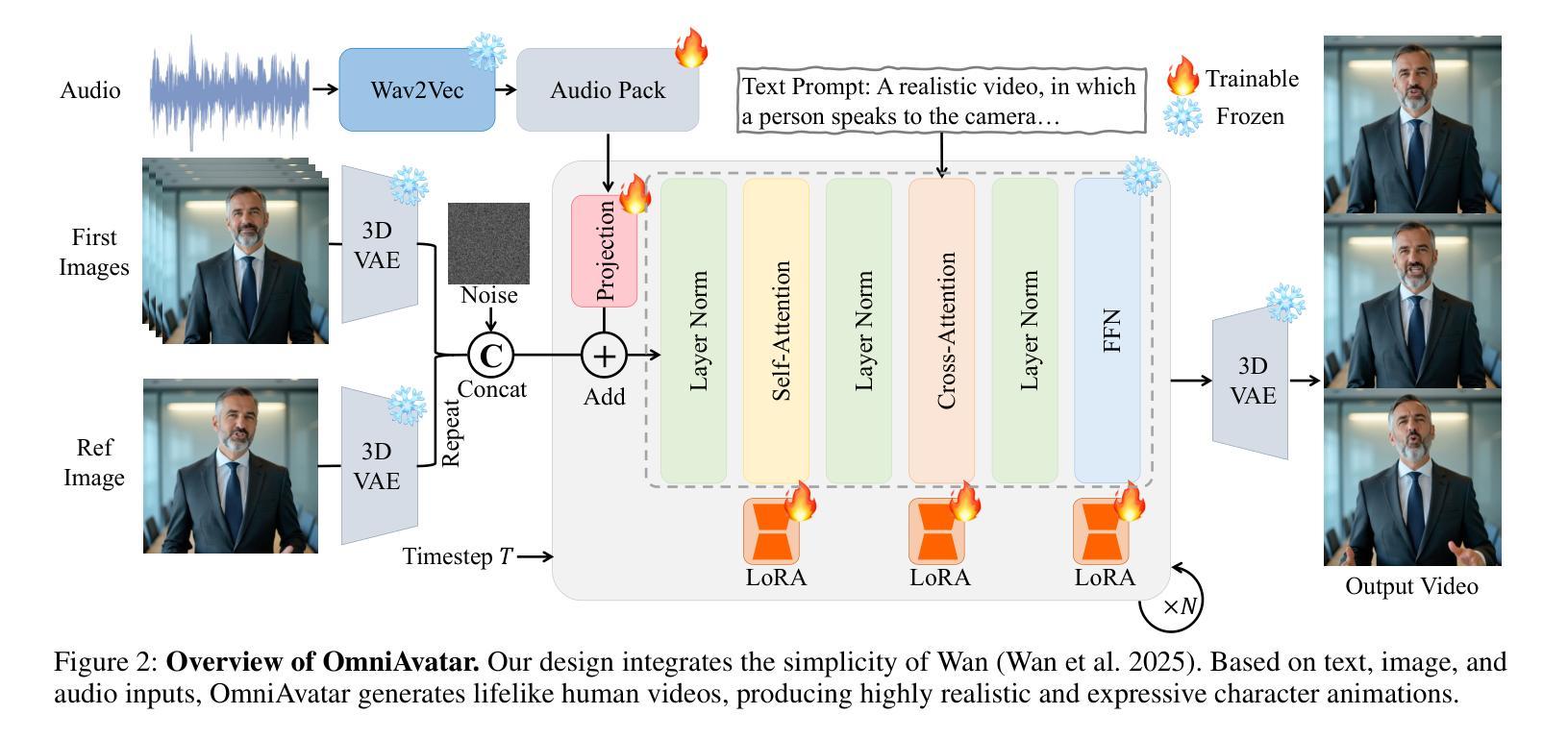
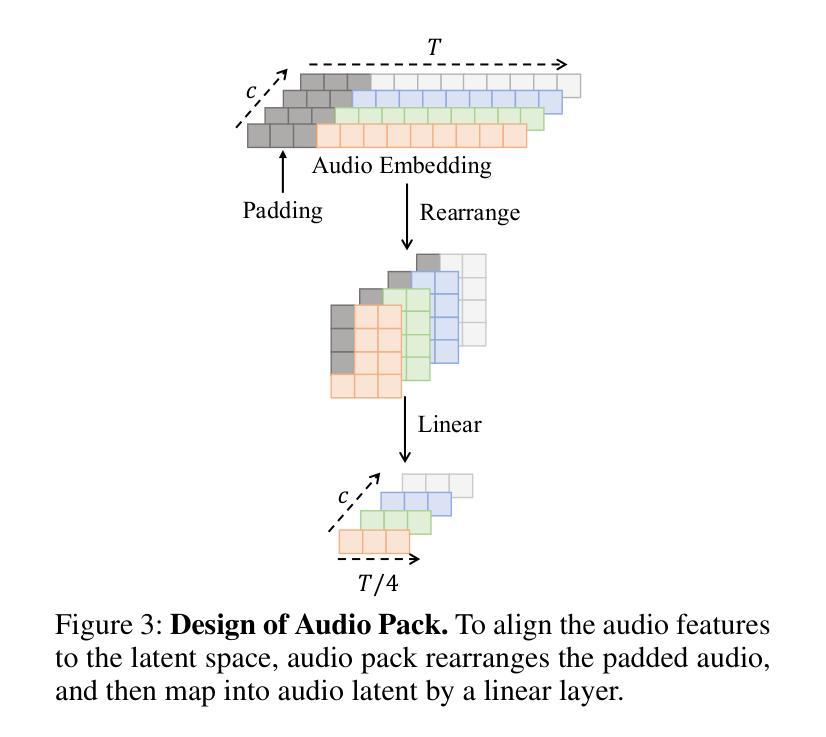
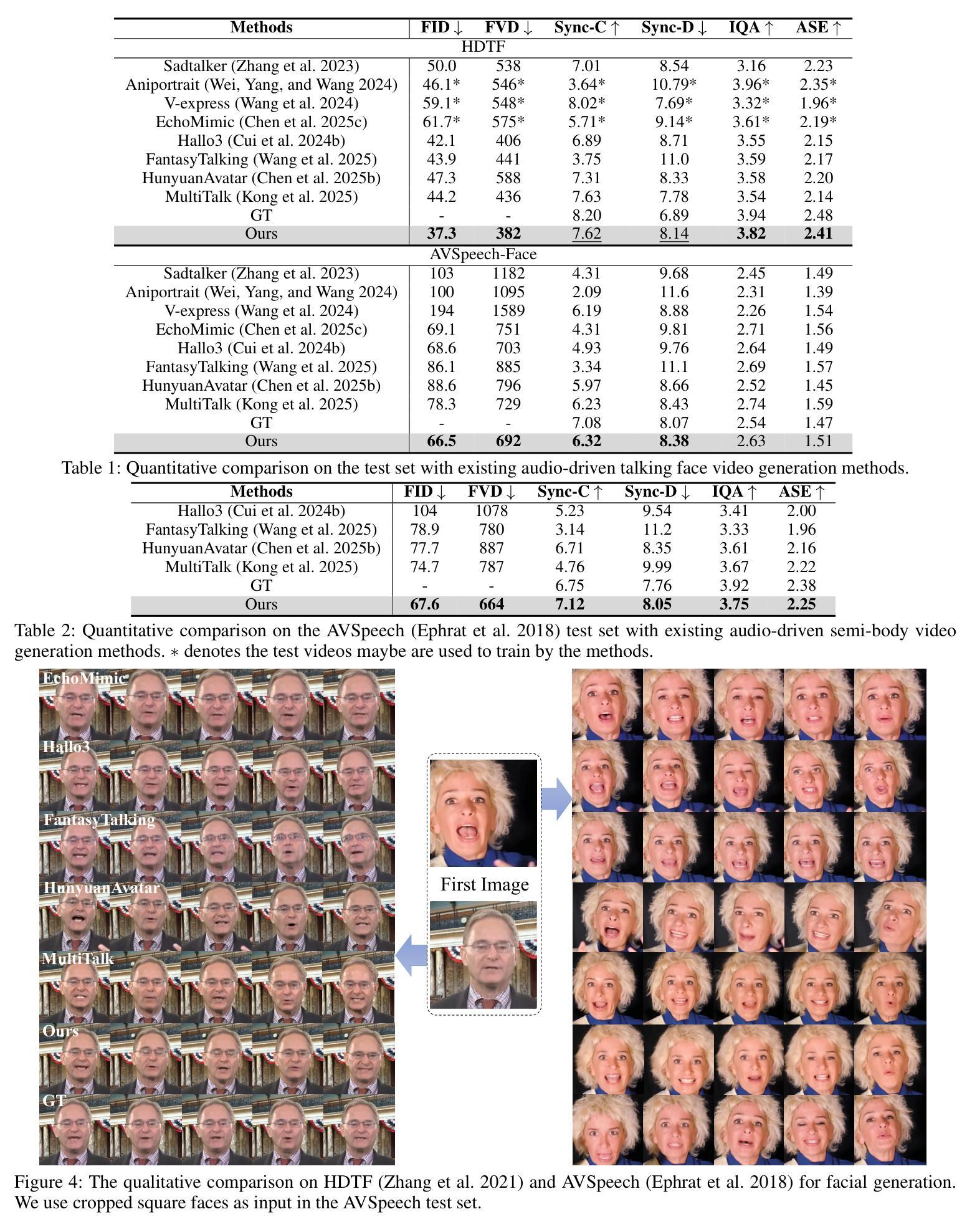
Significant progress has been made in audio-driven human animation, while most existing methods focus mainly on facial movements, limiting their ability to create full-body animations with natural synchronization and fluidity. They also struggle with precise prompt control for fine-grained generation. To tackle these challenges, we introduce OmniAvatar, an innovative audio-driven full-body video generation model that enhances human animation with improved lip-sync accuracy and natural movements. OmniAvatar introduces a pixel-wise multi-hierarchical audio embedding strategy to better capture audio features in the latent space, enhancing lip-syncing across diverse scenes. To preserve the capability for prompt-driven control of foundation models while effectively incorporating audio features, we employ a LoRA-based training approach. Extensive experiments show that OmniAvatar surpasses existing models in both facial and semi-body video generation, offering precise text-based control for creating videos in various domains, such as podcasts, human interactions, dynamic scenes, and singing. Our project page is https://omni-avatar.github.io/.
在音频驱动的人物动画方面已经取得了重大进展,然而大多数现有方法主要关注面部动作,限制了它们创建具有自然同步和流畅度的全身动画的能力。它们对于精细粒度的生成精确提示控制也感到困难。为了应对这些挑战,我们推出了OmniAvatar,这是一个创新的音频驱动全身视频生成模型,通过提高唇同步精度和自然动作来增强人物动画。OmniAvatar引入了一种像素级多层级音频嵌入策略,以更好地在潜在空间中捕获音频特征,增强不同场景的唇同步。为了保留基础模型的提示驱动控制能力,同时有效地融入音频特征,我们采用了基于LoRA的训练方法。大量实验表明,OmniAvatar在面部和半身视频生成方面都超越了现有模型,提供精确的文本基础控制,可创建各种领域的视频,如播客、人物互动、动态场景和歌曲。我们的项目页面是https://omni-avatar.github.io/。
论文及项目相关链接
PDF Project page: https://omni-avatar.github.io/
Summary
OmniAvatar是一项创新的音频驱动全身视频生成模型,能提升人类动画的唇同步精度和自然动作。它采用像素级多层级音频嵌入策略,更好地在潜在空间中捕捉音频特征,并在不同场景中实现唇同步增强。OmniAvatar超越了现有模型在面部和半身视频生成方面的表现,为各种领域如播客、人际互动、动态场景和歌曲创作视频提供了精确的文字控制功能。
Key Takeaways
- OmniAvatar是一个音频驱动全身视频生成模型,提升了人类动画的自然同步和流畅性。
- 该模型采用像素级多层级音频嵌入策略,在潜在空间中更好地捕捉音频特征。
- OmniAvatar增强了唇同步功能,适用于不同场景。
- 该模型在面部和半身视频生成方面表现超越现有模型。
- OmniAvatar支持在各种领域创建视频时提供精确的文字控制功能。
- 使用LoRA基于训练的方法,能在保持基础模型提示驱动控制的同时有效地融入音频特征。
- 该项目的网页地址为https://omni-avatar.github.io/。
点此查看论文截图

Talking to GDELT Through Knowledge Graphs
Authors:Audun Myers, Max Vargas, Sinan G. Aksoy, Cliff Joslyn, Benjamin Wilson, Lee Burke, Tom Grimes
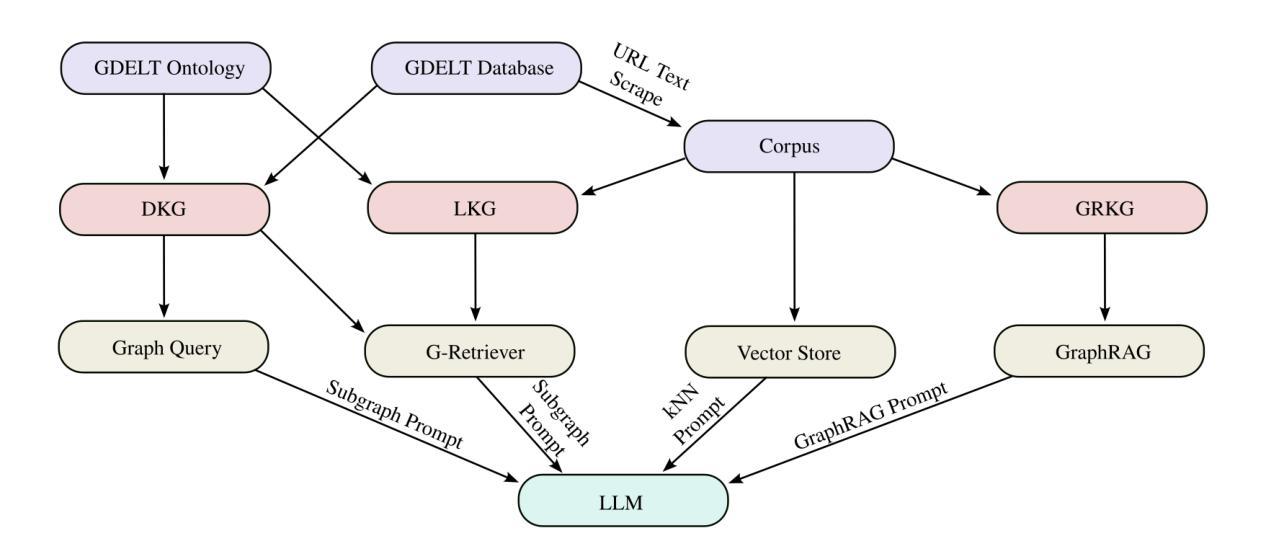
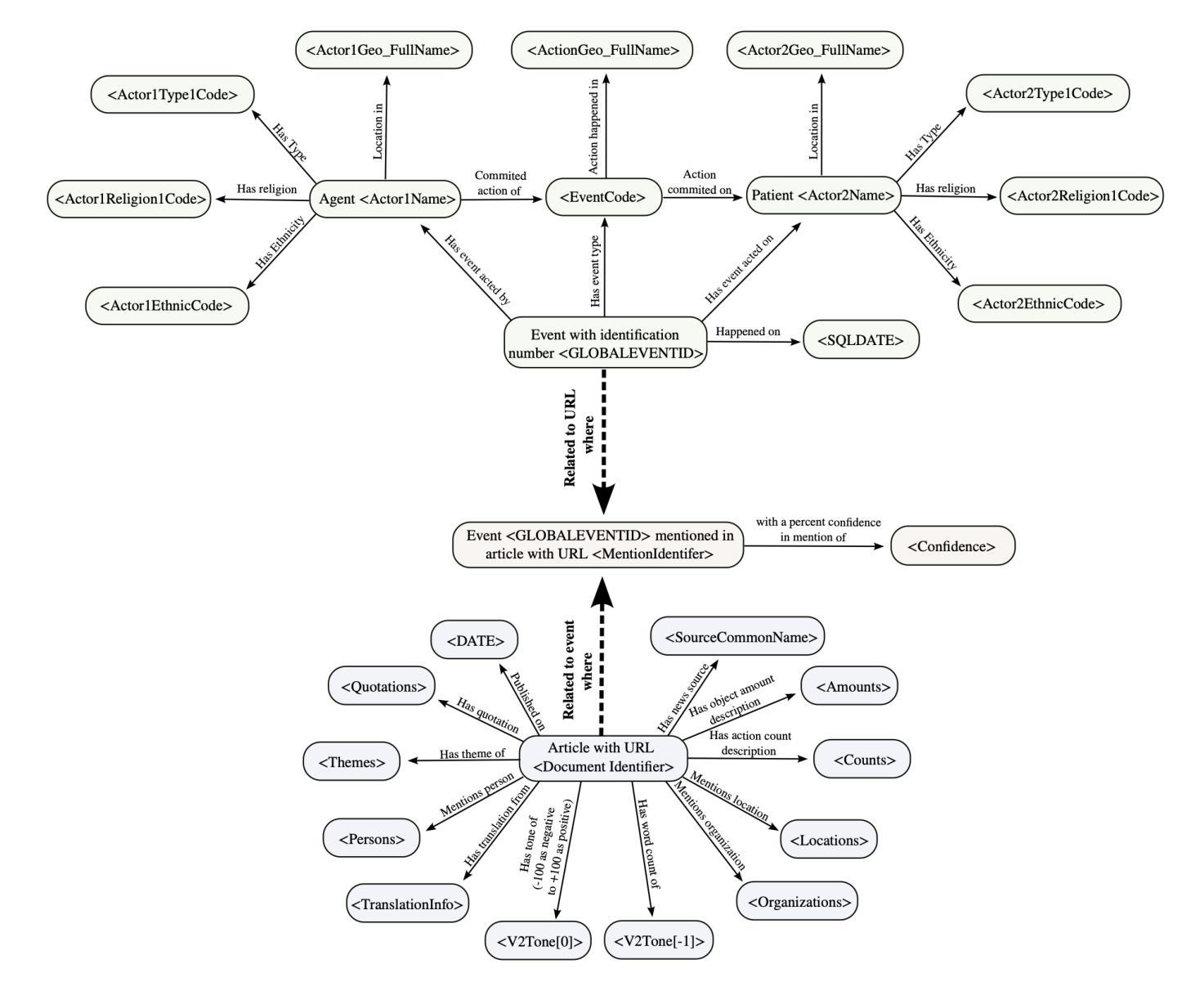
In this work we study various Retrieval Augmented Regeneration (RAG) approaches to gain an understanding of the strengths and weaknesses of each approach in a question-answering analysis. To gain this understanding we use a case-study subset of the Global Database of Events, Language, and Tone (GDELT) dataset as well as a corpus of raw text scraped from the online news articles. To retrieve information from the text corpus we implement a traditional vector store RAG as well as state-of-the-art large language model (LLM) based approaches for automatically constructing KGs and retrieving the relevant subgraphs. In addition to these corpus approaches, we develop a novel ontology-based framework for constructing knowledge graphs (KGs) from GDELT directly which leverages the underlying schema of GDELT to create structured representations of global events. For retrieving relevant information from the ontology-based KGs we implement both direct graph queries and state-of-the-art graph retrieval approaches. We compare the performance of each method in a question-answering task. We find that while our ontology-based KGs are valuable for question-answering, automated extraction of the relevant subgraphs is challenging. Conversely, LLM-generated KGs, while capturing event summaries, often lack consistency and interpretability. Our findings suggest benefits of a synergistic approach between ontology and LLM-based KG construction, with proposed avenues toward that end.
在这项工作中,我们研究了各种基于检索的再生(RAG)方法,以了解每种方法在不同问题回答分析中的优势和劣势。为了理解这一点,我们使用了全球事件语言与时态数据库(GDELT)的子集案例研究以及从在线新闻文章中抓取的大量原始文本语料库。我们从文本语料库中检索信息,实现了传统的向量存储RAG以及基于最新大型语言模型(LLM)自动构建知识图谱和检索相关子图的方法。除了这些语料库方法外,我们还开发了一种基于本体构建知识图谱(KGs)的新框架,该框架直接从GDELT中提取信息,并利用GDELT的底层架构创建全球事件的结构化表示。我们从基于本体的知识图谱中检索相关信息时,既采用了直接的图形查询也采用了最新的图形检索方法。我们在问答任务中比较了每种方法的性能。我们发现,虽然我们的基于本体的知识图谱对于问答任务有价值,但自动提取相关子图具有挑战性。相比之下,虽然大型语言模型生成的知识图谱能够捕捉事件摘要,但往往缺乏一致性和可解释性。我们的研究结果表明本体和基于大型语言模型的知识图谱构建的协同方法具有优势,并为此提出了发展方向。
论文及项目相关链接
Summary
该研究探讨了多种基于检索的增强再生(RAG)方法,以了解其在问答分析中的优缺点。研究使用了全球事件、语言和情感数据库的子集及在线新闻文章的文本语料库进行研究。为了从文本语料库中检索信息,该研究实现了传统的向量存储RAG及基于大型语言模型的自动构建知识图谱和检索相关子图的方法。此外,研究还构建了基于本体的知识图谱(KGs),并从GDELT直接利用底层架构创建全球事件的结构化表示。为了从基于本体的知识图谱中检索相关信息,该研究实施了直接图查询和先进的图检索方法。研究比较了每种方法在不同问答任务中的表现。发现本体知识图谱对于问答很有价值,但自动提取相关子图具有挑战性;而基于大型语言模型生成的知识图谱虽然能捕捉事件摘要,但往往缺乏一致性和可解释性。因此,建议采用本体与大型语言模型相结合的方法构建知识图谱。
Key Takeaways
- 研究采用多种RAG方法对问答分析进行了深入探讨。
- 研究使用了GDELT数据集和在线新闻文章的文本语料库。
- 研究实现了传统的向量存储RAG方法以及基于LLM的知识图谱构建方法。
- 提出了一种新颖的基于本体的知识图谱构建框架,直接从GDELT构建全球事件的结构化表示。
- 本体知识图谱对于问答有价值,但自动提取相关子图具有挑战性。
- LLM生成的知识图谱虽然能捕捉事件摘要,但缺乏一致性和可解释性。
点此查看论文截图