⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
PlanMoGPT: Flow-Enhanced Progressive Planning for Text to Motion Synthesis
Authors:Chuhao Jin, Haosen Li, Bingzi Zhang, Che Liu, Xiting Wang, Ruihua Song, Wenbing Huang, Ying Qin, Fuzheng Zhang, Di Zhang
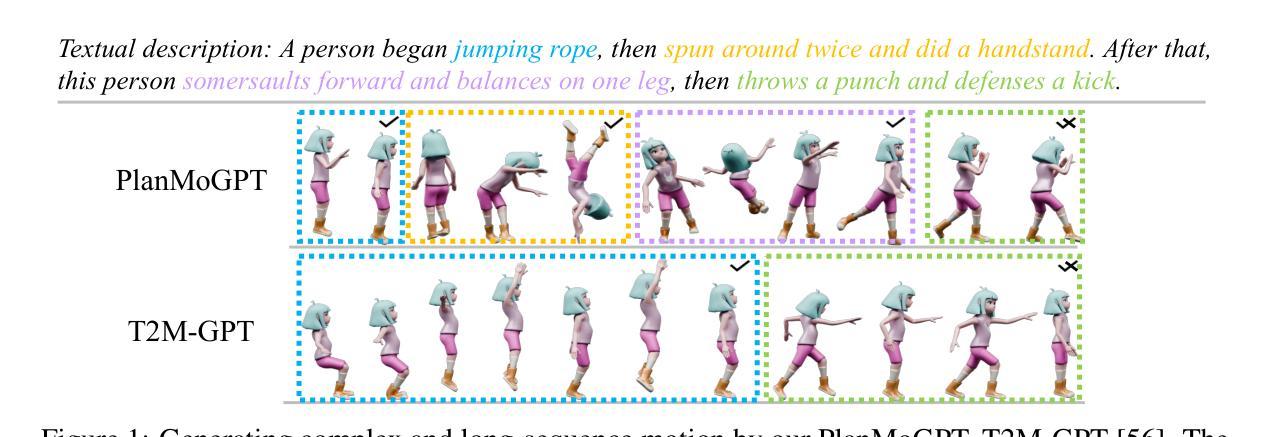
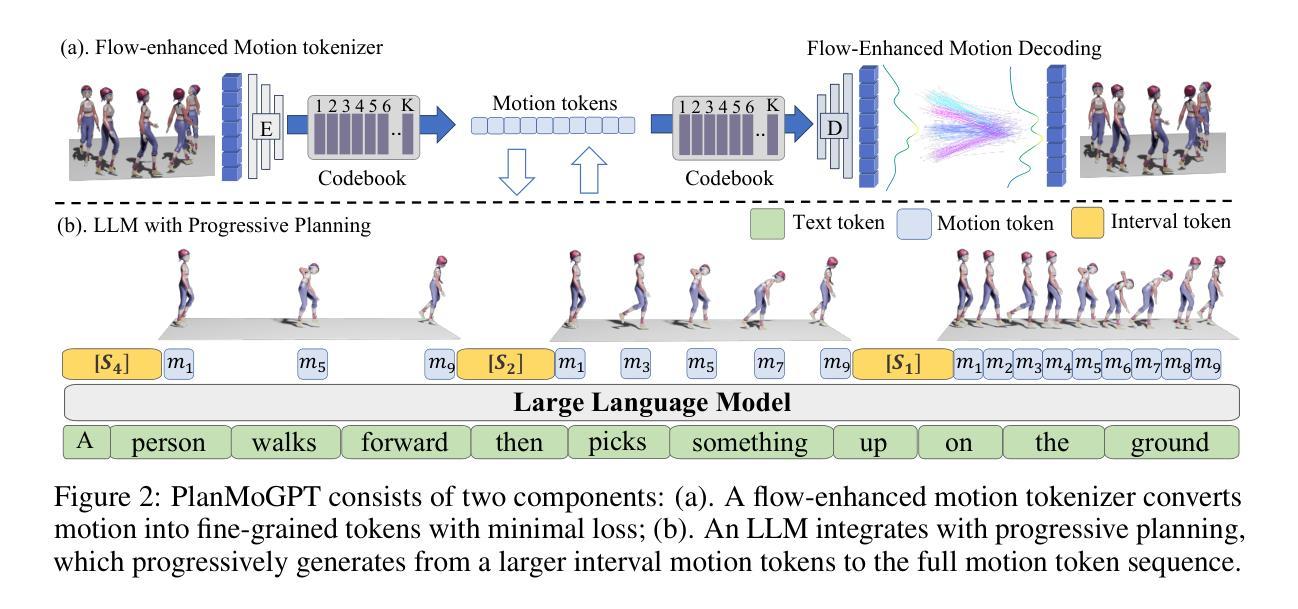
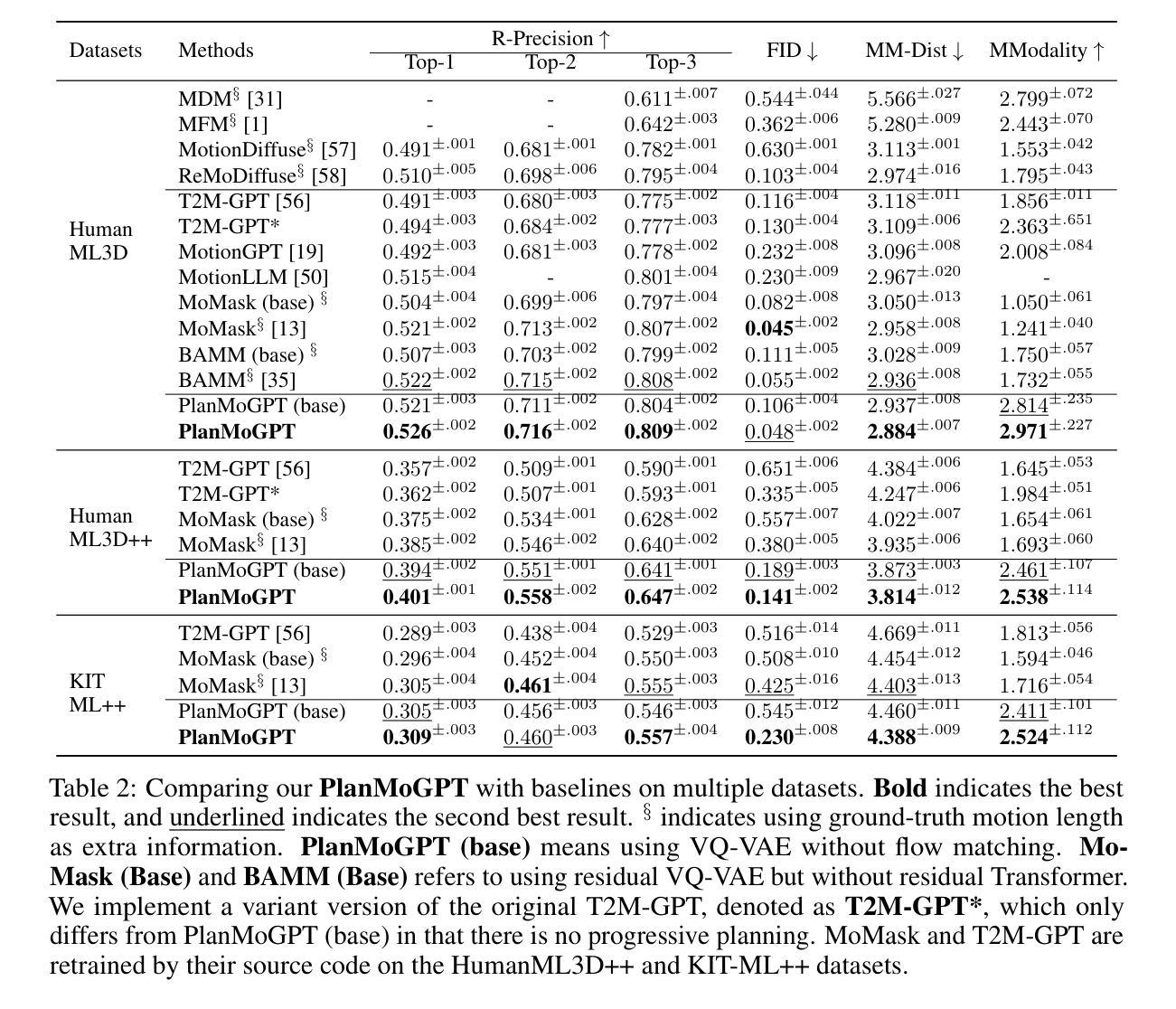
Recent advances in large language models (LLMs) have enabled breakthroughs in many multimodal generation tasks, but a significant performance gap still exists in text-to-motion generation, where LLM-based methods lag far behind non-LLM methods. We identify the granularity of motion tokenization as a critical bottleneck: fine-grained tokenization induces local dependency issues, where LLMs overemphasize short-term coherence at the expense of global semantic alignment, while coarse-grained tokenization sacrifices motion details. To resolve this issue, we propose PlanMoGPT, an LLM-based framework integrating progressive planning and flow-enhanced fine-grained motion tokenization. First, our progressive planning mechanism leverages LLMs’ autoregressive capabilities to hierarchically generate motion tokens by starting from sparse global plans and iteratively refining them into full sequences. Second, our flow-enhanced tokenizer doubles the downsampling resolution and expands the codebook size by eight times, minimizing detail loss during discretization, while a flow-enhanced decoder recovers motion nuances. Extensive experiments on text-to-motion benchmarks demonstrate that it achieves state-of-the-art performance, improving FID scores by 63.8% (from 0.380 to 0.141) on long-sequence generation while enhancing motion diversity by 49.9% compared to existing methods. The proposed framework successfully resolves the diversity-quality trade-off that plagues current non-LLM approaches, establishing new standards for text-to-motion generation.
最近的大型语言模型(LLM)的进步已经在许多多模态生成任务中实现了突破,但在文本到运动生成方面仍存在较大的性能差距,LLM方法远远落后于非LLM方法。我们确定了运动标记的粒度是一个关键的瓶颈:精细的标记会导致局部依赖问题,其中LLM会过分强调短期的一致性而忽略了全局语义对齐,而粗糙的标记则牺牲了运动的细节。为了解决这一问题,我们提出了PlanMoGPT,这是一个基于LLM的框架,融合了渐进式规划和增强流细粒度运动标记化。首先,我们的渐进式规划机制利用LLM的自回归能力,从稀疏的全局规划开始,层次性地生成运动标记,并迭代地将其完善为完整的序列。其次,我们的增强流标记器将下采样分辨率提高了一倍,并将代码本大小扩大了八倍,以在离散化过程中尽量减少细节损失,而增强流解码器则恢复了运动的细微差别。在文本到运动的基准测试上的广泛实验表明,它达到了最先进的性能,在长序列生成方面将FID得分提高了63.8%(从0.380降至0.141),并且与现有方法相比,提高了49.9%的运动多样性。所提出的框架成功地解决了当前非LLM方法所困扰的多样性-质量权衡问题,为文本到运动生成树立了新的标准。
论文及项目相关链接
PDF 14 pages, 7 figures
Summary
近期大型语言模型(LLM)在多模态生成任务中取得突破,但在文本到运动生成方面仍存在性能差距。研究者指出运动令牌化的粒度是关键瓶颈:精细的令牌化会导致局部依赖问题,LLM会过分强调短期连贯性而忽视全局语义对齐,而粗糙的令牌化则牺牲运动细节。为解决这一问题,提出PlanMoGPT框架,结合渐进式规划和流增强精细运动令牌化。首先,通过稀疏全局计划分层生成运动令牌,然后逐步细化。其次,流增强令牌器通过增加下采样分辨率和扩大代码本大小来减少离散化过程中的细节损失,而流增强解码器则能恢复运动细微之处。在文本到运动基准测试上的实验表明,该方法实现了最先进的性能,在长序列生成上FID得分提高了63.8%,同时提高了运动多样性。提出的框架成功解决了当前非LLM方法所面临的多样性-质量权衡问题,为文本到运动生成树立了新标准。
Key Takeaways
- 大型语言模型(LLM)在多模态生成任务中有显著进步,但在文本到运动生成方面存在性能差距。
- 运动令牌化的粒度是文本到运动生成的关键瓶颈。
- 精细的令牌化可能导致局部依赖问题,而粗糙的令牌化则可能牺牲运动细节。
- PlanMoGPT框架结合渐进式规划和流增强精细运动令牌化来解决上述问题。
- PlanMoGPT通过分层生成运动令牌并逐步细化,以提高全局语义对齐和短程连贯性。
- 流增强令牌器和解码器设计旨在减少离散化过程中的细节损失并恢复运动的细微之处。
点此查看论文截图