⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-25 更新
Deep CNN Face Matchers Inherently Support Revocable Biometric Templates
Authors:Aman Bhatta, Michael C. King, Kevin W. Bowyer
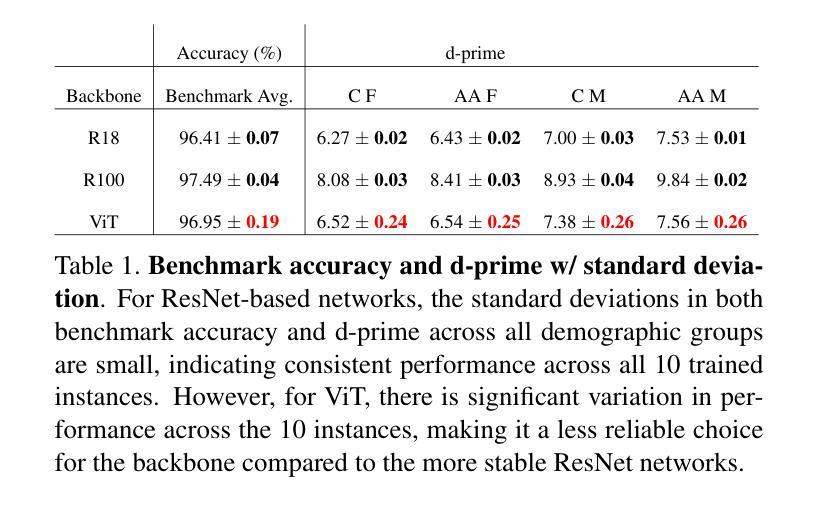
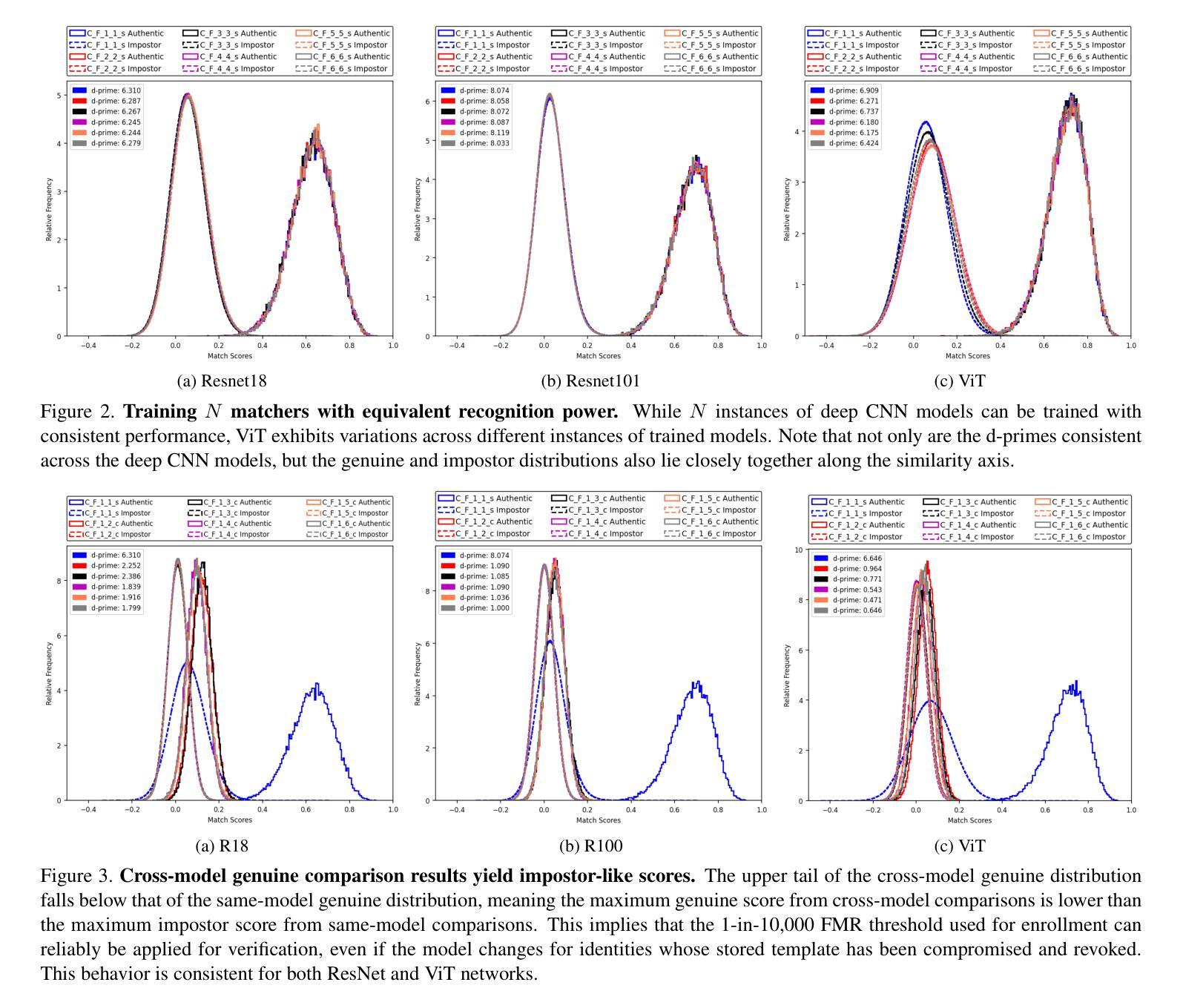
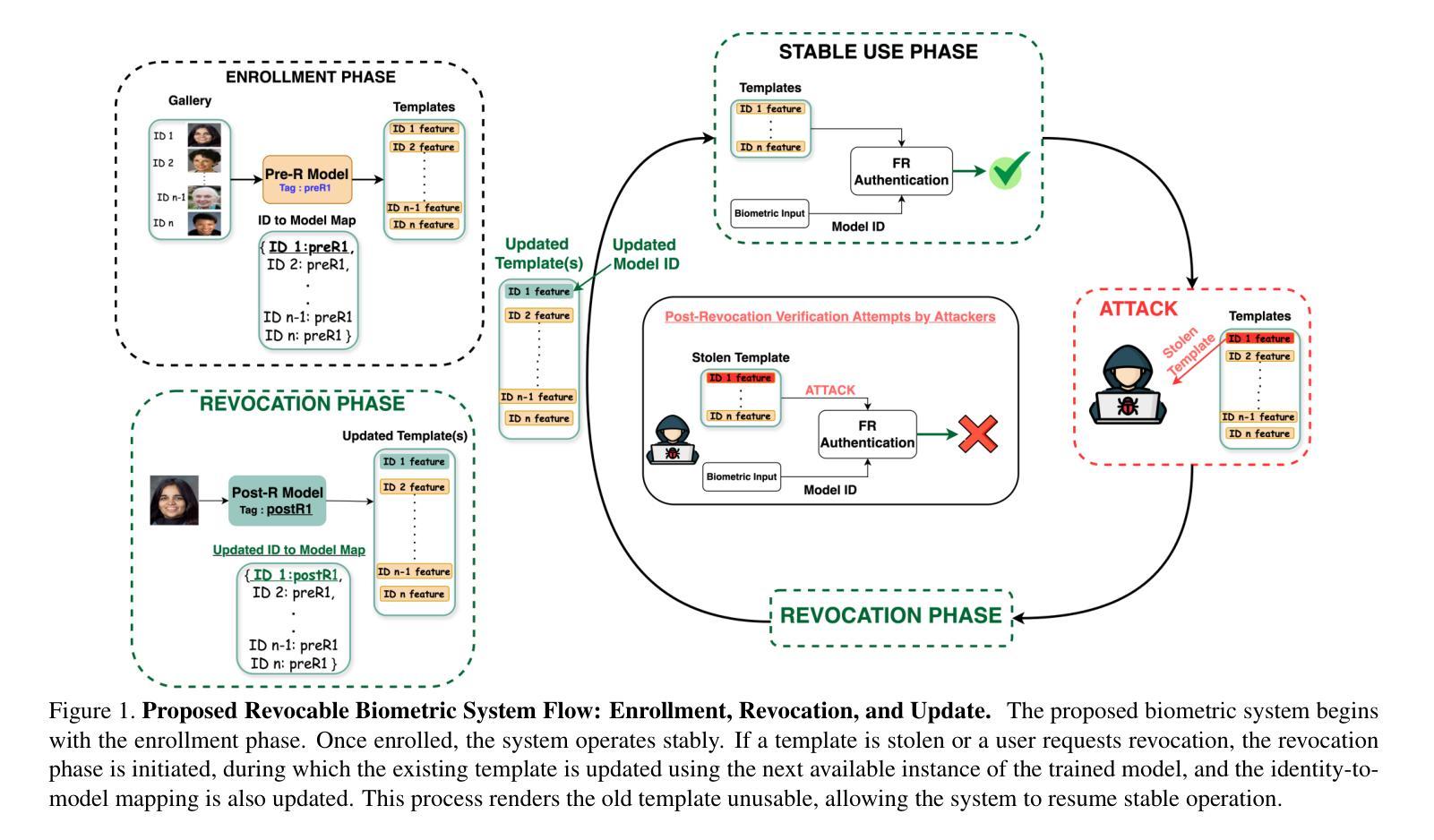
One common critique of biometric authentication is that if an individual’s biometric is compromised, then the individual has no recourse. The concept of revocable biometrics was developed to address this concern. A biometric scheme is revocable if an individual can have their current enrollment in the scheme revoked, so that the compromised biometric template becomes worthless, and the individual can re-enroll with a new template that has similar recognition power. We show that modern deep CNN face matchers inherently allow for a robust revocable biometric scheme. For a given state-of-the-art deep CNN backbone and training set, it is possible to generate an unlimited number of distinct face matcher models that have both (1) equivalent recognition power, and (2) strongly incompatible biometric templates. The equivalent recognition power extends to the point of generating impostor and genuine distributions that have the same shape and placement on the similarity dimension, meaning that the models can share a similarity threshold for a 1-in-10,000 false match rate. The biometric templates from different model instances are so strongly incompatible that the cross-instance similarity score for images of the same person is typically lower than the same-instance similarity score for images of different persons. That is, a stolen biometric template that is revoked is of less value in attempting to match the re-enrolled identity than the average impostor template. We also explore the feasibility of using a Vision Transformer (ViT) backbone-based face matcher in the revocable biometric system proposed in this work and demonstrate that it is less suitable compared to typical ResNet-based deep CNN backbones.
关于生物认证的常见批评之一是,如果个人的生物识别信息被泄露,那么个人便无计可施。为解决这一担忧,开发了可撤销生物识别技术这一概念。如果一个生物识别方案是可撤销的,那么个人就可以撤销其在该方案中的当前注册,这样泄露的生物识别模板就会变得毫无价值,个人可以重新注册一个新的模板,这个新模板具有类似的识别能力。我们展示了现代深度卷积神经网络面部匹配器本质上允许稳健的可撤销生物识别方案。对于给定的先进深度卷积神经网络主干和训练集,可以生成无限数量的独特面部匹配器模型,这些模型既具有(1)相当的识别能力,又拥有(2)高度不兼容的生物识别模板。相当的识别能力扩展到了生成假冒者和真实者的分布,这些分布在相似度维度上具有相同的形状和位置,这意味着这些模型可以共享一个相似度阈值,以达到万分之一的误匹配率。不同模型实例的生物识别模板之间高度不兼容,以至于同一人的不同图像在不同实例之间的相似度分数通常低于不同人的不同图像的相似度分数。也就是说,被撤销的被盗生物识别模板在尝试匹配重新注册的身份时,其价值通常低于假冒者模板的平均值。我们还探讨了在本工作中提出的可撤销生物识别系统中使用基于视觉转换器(ViT)的面部匹配器的可行性,并证明与典型的基于ResNet的深度卷积神经网络主干相比,它不太适合。
论文及项目相关链接
摘要
关于生物识别认证的常见批评之一是,一旦个体的生物识别信息被泄露,个体将束手无策。为解决这一担忧,发展了可撤销生物识别技术。当个体能撤销其在生物识别方案中的当前注册,使得已泄露的生物识别模板失效并重新注册新模板时,该生物识别方案被认为是可撤销的。新模板应具有相似的识别能力。本文展示了现代深度CNN面部识别器天然支持强大的可撤销生物识别方案。对于给定的先进深度CNN主干和训练集,可以生成无限数量的面部识别器模型实例,这些模型实例不仅具有等同的识别能力,而且其生物识别模板之间具有很强的不兼容性和差异性。这意味着,即使某个人的生物识别模板被盗用并撤销后,其重新注册的新模板的匹配价值低于随机假冒者的匹配价值。此外,本文还探讨了将Vision Transformer(ViT)主干应用于本文提出的可撤销生物识别系统的可行性,并证明相较于典型的基于ResNet的深度CNN主干,ViT的应用表现不太理想。
关键见解
- 可撤销生物识别技术解决了生物识别信息泄露后无解决方案的问题。
- 现代深度CNN面部识别器允许生成具有等效识别能力的多种模型实例。
- 这些模型实例的识别模板具有强烈的兼容性和差异性。这意味着撤销的生物识别模板匹配价值较低。
点此查看论文截图

Taming Vision-Language Models for Medical Image Analysis: A Comprehensive Review
Authors:Haoneng Lin, Cheng Xu, Jing Qin
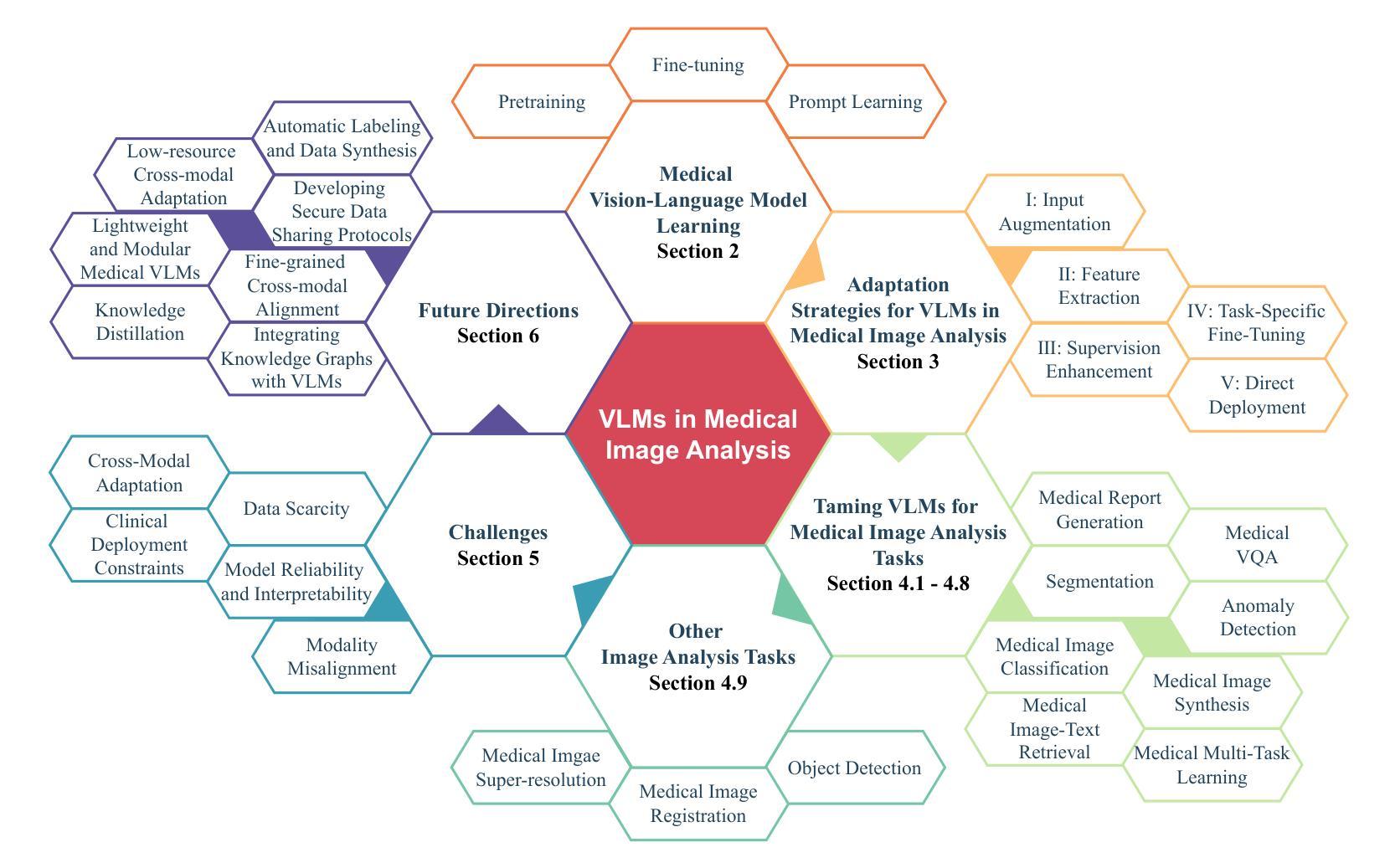
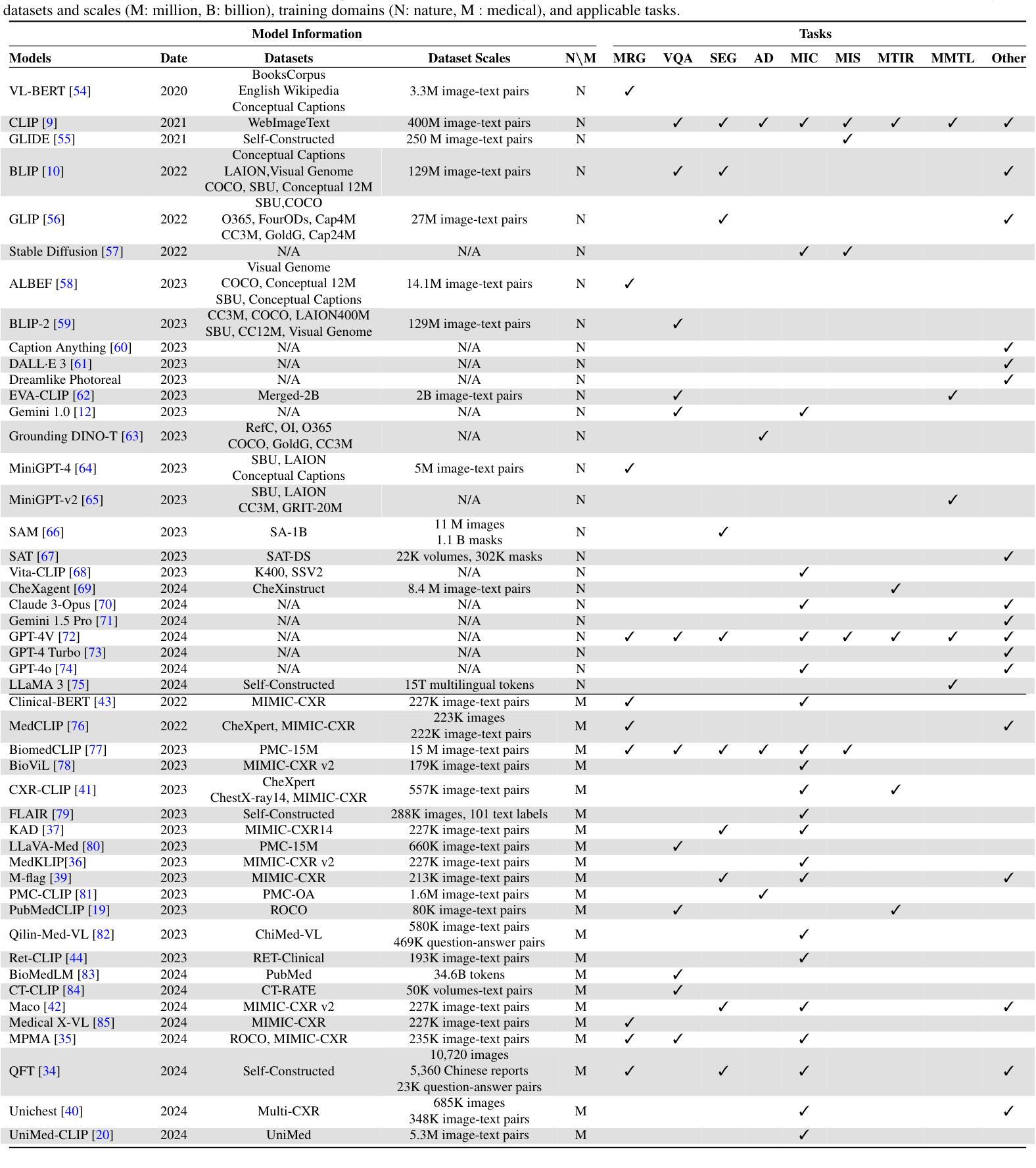
Modern Vision-Language Models (VLMs) exhibit unprecedented capabilities in cross-modal semantic understanding between visual and textual modalities. Given the intrinsic need for multi-modal integration in clinical applications, VLMs have emerged as a promising solution for a wide range of medical image analysis tasks. However, adapting general-purpose VLMs to medical domain poses numerous challenges, such as large domain gaps, complicated pathological variations, and diversity and uniqueness of different tasks. The central purpose of this review is to systematically summarize recent advances in adapting VLMs for medical image analysis, analyzing current challenges, and recommending promising yet urgent directions for further investigations. We begin by introducing core learning strategies for medical VLMs, including pretraining, fine-tuning, and prompt learning. We then categorize five major VLM adaptation strategies for medical image analysis. These strategies are further analyzed across eleven medical imaging tasks to illustrate their current practical implementations. Furthermore, we analyze key challenges that impede the effective adaptation of VLMs to clinical applications and discuss potential directions for future research. We also provide an open-access repository of related literature to facilitate further research, available at https://github.com/haonenglin/Awesome-VLM-for-MIA. It is anticipated that this article can help researchers who are interested in harnessing VLMs in medical image analysis tasks have a better understanding on their capabilities and limitations, as well as current technical barriers, to promote their innovative, robust, and safe application in clinical practice.
现代视觉语言模型(VLMs)在视觉和文本模态之间的跨模态语义理解方面展现出了前所未有的能力。鉴于临床应用中对多模态集成的内在需求,VLMs已成为广泛应用于医疗图像分析任务的有前途的解决方案。然而,将通用VLMs适应于医学领域带来了许多挑战,例如领域差距大、病理变化复杂以及不同任务的多样性和独特性。本文的中心目的是系统地总结近年来将VLMs适应于医疗图像分析的最新进展,分析当前挑战,并为进一步的调查推荐有前途且紧迫的方向。我们首先介绍医学VLMs的核心学习策略,包括预训练、微调和提示学习。然后我们将五大VLM适应策略分类为医疗图像分析。这些策略进一步在十一个医疗成像任务中进行分析,以说明它们当前的实用实现。此外,我们分析了阻碍VLMs有效适应临床应用的关键挑战,并讨论了未来研究的方向。我们还提供了一个开放访问的相关文献仓库,以促进进一步研究,可在https://github.com/haonenglin/Awesome-VLM-for-MIA获取。预计本文能帮助对在医疗图像分析任务中使用VLMs感兴趣的研究人员更好地了解它们的能力、局限性以及当前的技术障碍,以促进其在临床实践中的创新、稳健和安全应用。
论文及项目相关链接
PDF 34 pages
Summary
视觉语言模型(VLMs)在跨模态语义理解方面展现出前所未有的能力,对于医学影像分析任务具有广泛应用前景。然而,将其应用于医学领域面临诸多挑战。本文综述了近期VLMs在医学影像分析中的进展、五大适应性策略及其在十一种医学影像任务中的应用实例。同时,本文分析了关键挑战并探讨了未来研究方向。提供的相关文献库有助于研究人员了解VLMs在医学影像分析中的能力与局限。
Key Takeaways
- VLMs展现出跨模态语义理解的强大能力,尤其在医学影像分析领域有广泛应用前景。
- VLMs应用于医学领域面临大领域差距、复杂的病理变化和任务多样性等挑战。
- 本文综述了五大VLM适应性策略,包括核心学习策略如预训练、微调、提示学习等。
- 在十一种医学影像任务中,详细阐述了这些策略的实际应用实例。
- 分析了阻碍VLMs有效适应临床应用的挑战,并讨论了未来研究方向。
- 文章提供了一个开放访问的相关文献库,以促进进一步研究。
点此查看论文截图

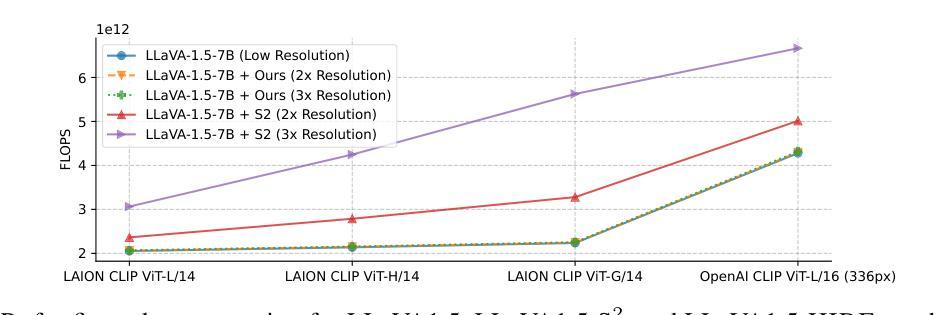
HIRE: Lightweight High-Resolution Image Feature Enrichment for Multimodal LLMs
Authors:Nikitha SR, Aradhya Neeraj Mathur, Tarun Ram Menta, Rishabh Jain, Mausoom Sarkar
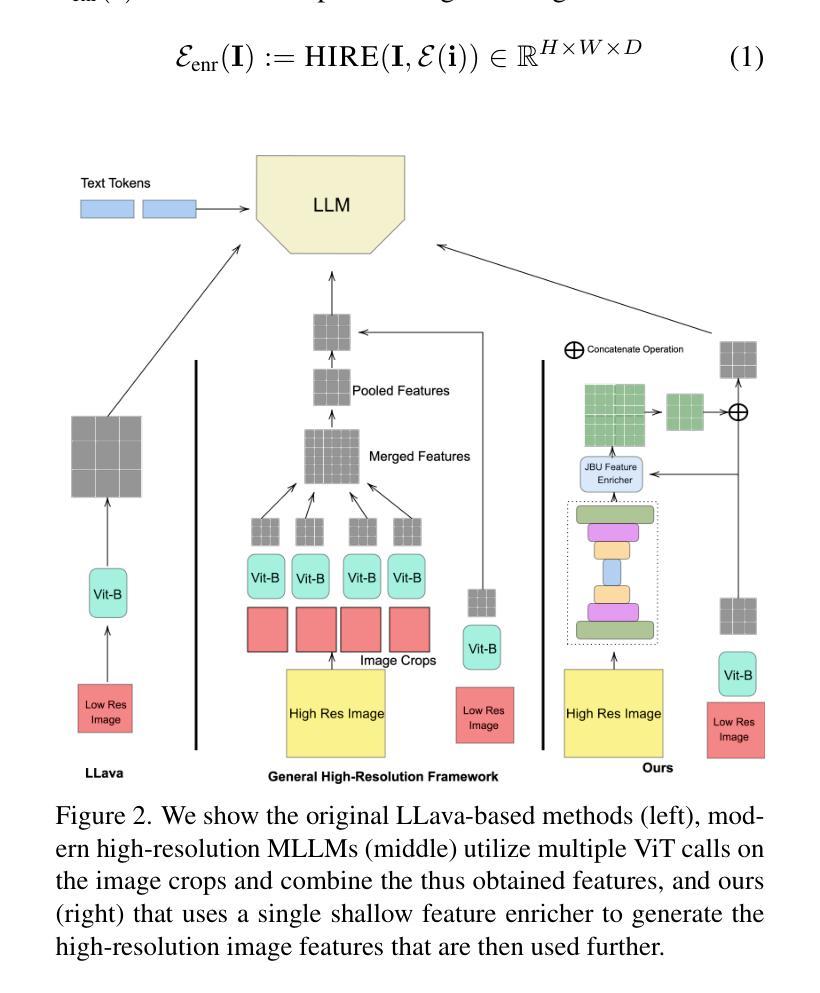
The integration of high-resolution image features in modern multimodal large language models has demonstrated significant improvements in fine-grained visual understanding tasks, achieving high performance across multiple benchmarks. Since these features are obtained from large image encoders like ViT, they come with a significant increase in computational costs due to multiple calls to these encoders. In this work, we first develop an intuition for feature upsampling as a natural extension of high-resolution feature generation. Through extensive experiments and ablations, we demonstrate how a shallow feature enricher can achieve competitive results with tremendous reductions in training and inference time as well as computational cost, with upto 1.5x saving in FLOPs.
将高分辨率图像特征融入现代多模态大型语言模型,已经在细粒度视觉理解任务中显示出重大改进,并在多个基准测试中实现高性能。由于这些特征来自大型图像编码器(如ViT),因此它们需要通过多次调用这些编码器而获得,从而带来计算成本的显著增加。在这项工作中,我们首先发展了一种特征上采样作为高分辨率特征生成的自然扩展的直觉。通过广泛的实验和消融实验,我们展示了浅层特征丰富器如何在训练和推理时间以及计算成本方面实现巨大减少的同时,取得具有竞争力的结果,并且浮点运算量最多可减少1.5倍。
论文及项目相关链接
PDF Accepted in CVPR 2025 Workshop on What’s Next in Multimodal Foundational Models
Summary
现代多模态大型语言模型中集成了高分辨率图像特征,这在精细粒度的视觉理解任务中取得了显著的提升,并在多个基准测试中实现了高性能。然而,由于需要从大型图像编码器(如ViT)获取这些特征,计算成本显著增加。本文首次提出特征上采样作为高分辨率特征生成的自然扩展。通过广泛的实验和消融研究,我们展示了浅层特征丰富器如何在减少训练和推理时间以及计算成本的同时实现具有竞争力的结果,最多可减少1.5倍的FLOPs。
Key Takeaways
- 高分辨率图像特征在现代多模态大型语言模型中的集成显著提高了精细粒度的视觉理解性能。
- 这些特征来自大型图像编码器,如ViT,导致计算成本增加。
- 特征上采样作为高分辨率特征生成的扩展被提出。
- 通过实验和消融研究,证明了浅层特征丰富器在减少训练和推理时间以及计算成本方面的有效性。
- 浅层特征丰富器实现了具有竞争力的结果,最多可减少1.5倍的FLOPs。
- 此方法为提高视觉任务的性能提供了一种新的思路,并可能在未来的研究中得到进一步的应用和发展。
点此查看论文截图

AQUA20: A Benchmark Dataset for Underwater Species Classification under Challenging Conditions
Authors:Taufikur Rahman Fuad, Sabbir Ahmed, Shahriar Ivan
Robust visual recognition in underwater environments remains a significant challenge due to complex distortions such as turbidity, low illumination, and occlusion, which severely degrade the performance of standard vision systems. This paper introduces AQUA20, a comprehensive benchmark dataset comprising 8,171 underwater images across 20 marine species reflecting real-world environmental challenges such as illumination, turbidity, occlusions, etc., providing a valuable resource for underwater visual understanding. Thirteen state-of-the-art deep learning models, including lightweight CNNs (SqueezeNet, MobileNetV2) and transformer-based architectures (ViT, ConvNeXt), were evaluated to benchmark their performance in classifying marine species under challenging conditions. Our experimental results show ConvNeXt achieving the best performance, with a Top-3 accuracy of 98.82% and a Top-1 accuracy of 90.69%, as well as the highest overall F1-score of 88.92% with moderately large parameter size. The results obtained from our other benchmark models also demonstrate trade-offs between complexity and performance. We also provide an extensive explainability analysis using GRAD-CAM and LIME for interpreting the strengths and pitfalls of the models. Our results reveal substantial room for improvement in underwater species recognition and demonstrate the value of AQUA20 as a foundation for future research in this domain. The dataset is publicly available at: https://huggingface.co/datasets/taufiktrf/AQUA20.
在水下环境中实现稳健的视觉识别仍然是一个重大挑战,因为诸如浑浊、低光照和遮挡之类的复杂失真会严重降低标准视觉系统的性能。本文介绍了AQUA20,这是一个包含8171张水下图像的综合基准数据集,涵盖了20种海洋物种,反映了现实世界中的环境挑战,如光照、浑浊度、遮挡等,为水下视觉理解提供了宝贵的资源。我们评估了13种最先进的深度学习模型,包括轻量级CNN(SqueezeNet、MobileNetV2)和基于transformer的架构(ViT、ConvNeXt),以基准测试它们在具有挑战性的条件下对海洋物种进行分类的性能。实验结果表明,ConvNeXt表现最佳,前三名准确率达到了98.82%,第一名准确率为90.69%,总体F1分数最高,达到了88.92%,且参数规模适中。其他基准模型的结果也显示了复杂性和性能之间的权衡。我们还使用GRAD-CAM和LIME进行了广泛的解释性分析,以解释模型的优点和缺点。我们的结果揭示了水下物种识别方面仍有很大的改进空间,并表明了AQUA20作为未来该领域研究基础的价值。数据集可在https://huggingface.co/datasets/taufiktrf/AQUA20公开获取。
论文及项目相关链接
PDF Submitted to AJSE Springer
Summary
本文介绍了一个名为AQUA20的水下图像数据集,包含8,171张反映真实水下环境挑战(如光照、浊度、遮挡等)的20种海洋生物图像。文章评估了包括轻量化CNN(如SqueezeNet、MobileNetV2)和基于transformer的架构(如ViT、ConvNeXt)在内的13种最先进的深度学习模型在水下物种识别方面的性能。实验结果显示,ConvNeXt表现最佳,前三准确率达到了98.82%,最高准确率达到了90.69%,总体F1分数最高,为88.92%。同时,文章还通过GRAD-CAM和LIME进行了模型的可解释性分析。该数据集公开可用,为未来的水下视觉研究提供了有价值的资源。
Key Takeaways
- AQUA20是一个包含多种水下环境挑战的综合基准数据集,涵盖8,171张水下图像,涉及20种海洋生物。
- 文章评估了13种最先进的深度学习模型在水下物种识别方面的性能。
- ConvNeXt在实验中表现最佳,前三准确率达到了98.82%,最高准确率达到了90.69%,总体F1分数最高。
- 数据集提供了模型可解释性分析,有助于理解模型的优点和缺点。
- 该数据集公开可用,为未来的水下视觉研究提供了重要资源。
- 实验结果显示,在复杂的水下环境下,深度学习模型仍然存在性能上的挑战和提升空间。
点此查看论文截图

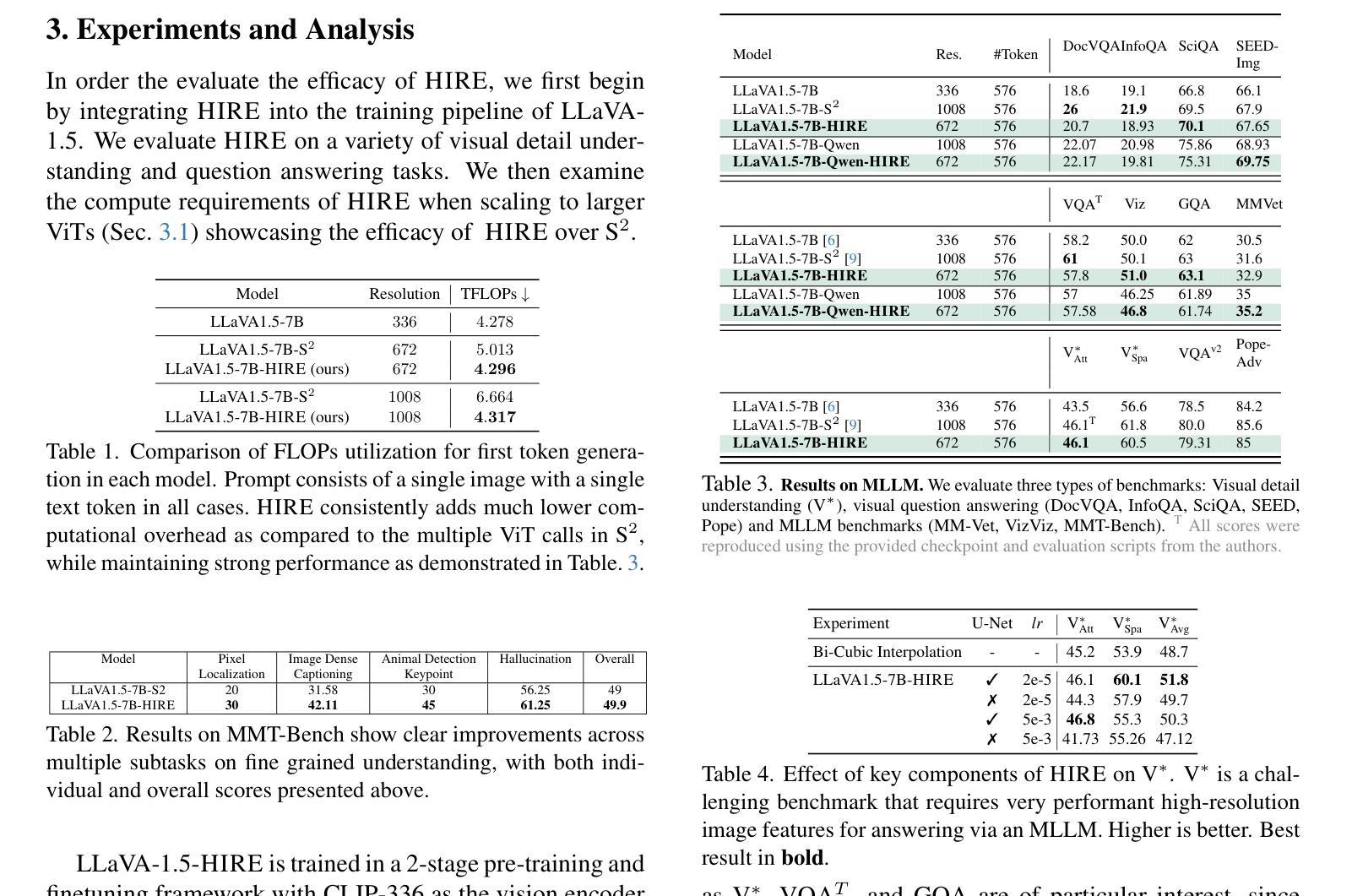
RadarSeq: A Temporal Vision Framework for User Churn Prediction via Radar Chart Sequences
Authors:Sina Najafi, M. Hadi Sepanj, Fahimeh Jafari
Predicting user churn in non-subscription gig platforms, where disengagement is implicit, poses unique challenges due to the absence of explicit labels and the dynamic nature of user behavior. Existing methods often rely on aggregated snapshots or static visual representations, which obscure temporal cues critical for early detection. In this work, we propose a temporally-aware computer vision framework that models user behavioral patterns as a sequence of radar chart images, each encoding day-level behavioral features. By integrating a pretrained CNN encoder with a bidirectional LSTM, our architecture captures both spatial and temporal patterns underlying churn behavior. Extensive experiments on a large real-world dataset demonstrate that our method outperforms classical models and ViT-based radar chart baselines, yielding gains of 17.7 in F1 score, 29.4 in precision, and 16.1 in AUC, along with improved interpretability. The framework’s modular design, explainability tools, and efficient deployment characteristics make it suitable for large-scale churn modeling in dynamic gig-economy platforms.
在非订阅制的零工平台预测用户流失带来了独特的挑战,因为这里不存在明确的标签和用户行为的动态性导致用户离场行为不明显。现有方法往往依赖于聚合快照或静态视觉表示,这会掩盖早期检测的关键时间线索。在这项工作中,我们提出了一种具有时间感知能力的计算机视觉框架,该框架将用户行为模式建模为雷达图图像序列,每个图像都编码日间行为特征。通过将预训练的CNN编码器与双向LSTM集成在一起,我们的架构捕获了用户流失行为背后的时空模式。在大型真实数据集上进行的广泛实验表明,我们的方法在F1得分、精确度和AUC方面分别提高了17.7分、29.4分和16.1分,超过了经典模型和基于ViT的雷达图基线,同时提高了可解释性。该框架的模块化设计、解释工具以及高效的部署特点使其成为动态零工经济平台大规模流失建模的合适选择。
论文及项目相关链接
Summary
该文本提出了一种针对非订阅制零工平台用户流失预测的计算机视觉框架。该框架通过结合预训练的CNN编码器和双向LSTM,对用户行为模式进行建模,以雷达图序列的形式捕捉空间和时间模式。实验证明,该方法在真实数据集上的表现优于经典模型和基于ViT的雷达图基线,提高了F1分数、精确度和AUC等指标,同时具有较好的可解释性。
Key Takeaways
- 非订阅制零工平台用户流失预测面临独特挑战,如缺乏明确的标签和用户行为的动态性。
- 现有方法常依赖于聚合快照或静态视觉表示,忽略了早期检测所需的时间线索。
- 提出的计算机视觉框架采用雷达图序列建模用户行为模式,编码每日行为特征。
- 结合预训练的CNN编码器和双向LSTM,捕捉用户流失行为的空间和时间模式。
- 在真实数据集上进行的大量实验证明,该方法在F1分数、精确度和AUC等方面表现优异。
- 该框架具有模块化设计、可解释性工具和高效部署特点,适合大规模应用于动态零工经济平台用户流失建模。
点此查看论文截图


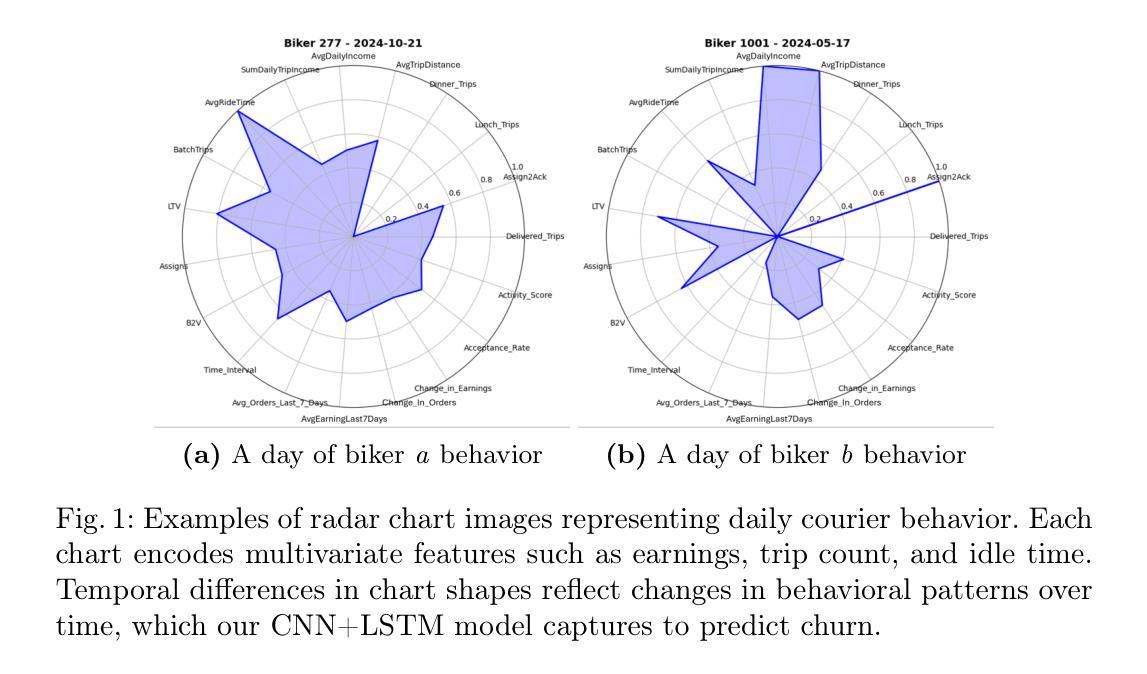
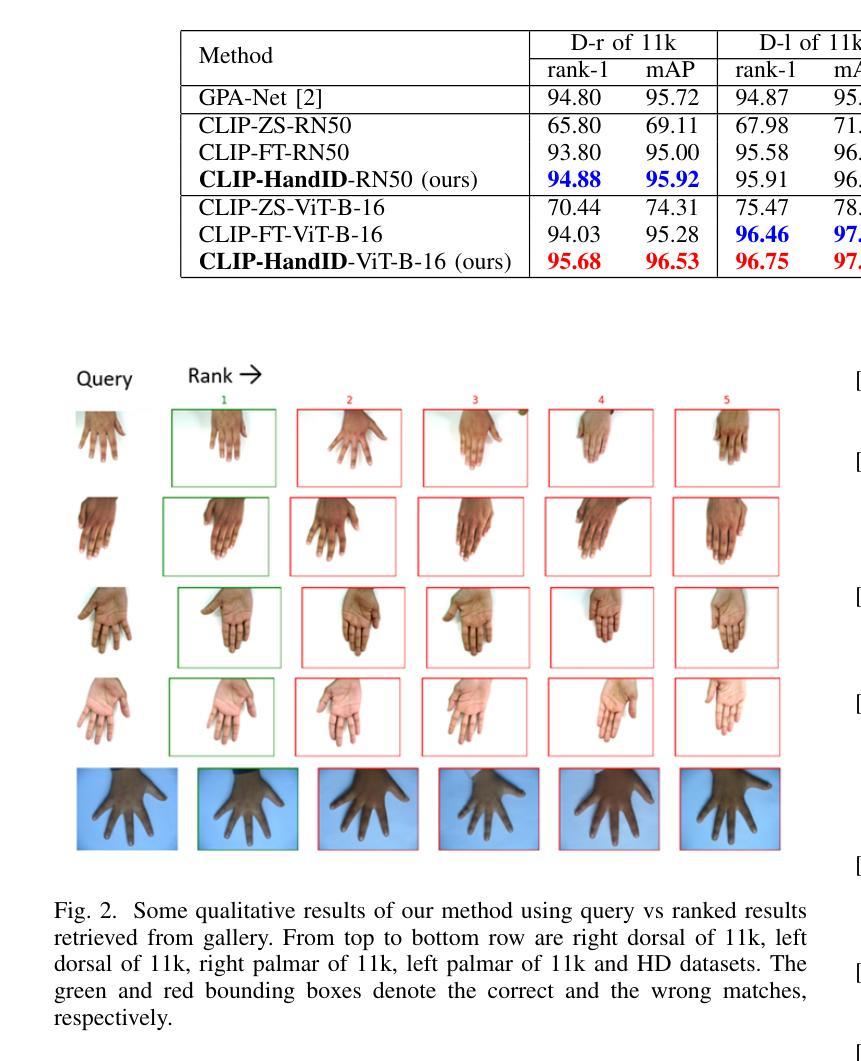
CLIP-HandID: Vision-Language Model for Hand-Based Person Identification
Authors:Nathanael L. Baisa, Babu Pallam, Amudhavel Jayavel
This paper introduces a novel approach to person identification using hand images, designed specifically for criminal investigations. The method is particularly valuable in serious crimes such as sexual abuse, where hand images are often the only identifiable evidence available. Our proposed method, CLIP-HandID, leverages a pre-trained foundational vision-language model - CLIP - to efficiently learn discriminative deep feature representations from hand images (input to CLIP’s image encoder) using textual prompts as semantic guidance. Since hand images are labeled with indexes rather than text descriptions, we employ a textual inversion network to learn pseudo-tokens that encode specific visual contexts or appearance attributes. These learned pseudo-tokens are then incorporated into textual prompts, which are fed into CLIP’s text encoder to leverage its multi-modal reasoning and enhance generalization for identification. Through extensive evaluations on two large, publicly available hand datasets with multi-ethnic representation, we demonstrate that our method significantly outperforms existing approaches.
本文介绍了一种利用手部图像进行人员识别的新方法,该方法专为刑事侦查设计。该方法在性虐待等严重犯罪中尤其具有价值,在这些情况下,手部图像往往是唯一可用的可识别证据。我们提出的方法CLIP-HandID,利用预训练的通用视觉语言模型CLIP,通过文本提示作为语义指导,有效地从手部图像(输入CLIP图像编码器)中学习判别深度特征表示。由于手部图像用索引而不是文本描述来标记,我们采用文本倒置网络来学习编码特定视觉上下文或外观属性的伪令牌。然后,这些学习到的伪令牌被纳入文本提示中,输入到CLIP的文本编码器中,以利用多模式推理并增强识别推广能力。我们在两个具有多民族代表性的大型公开手部数据集上进行了广泛评估,结果表明我们的方法显著优于现有方法。
论文及项目相关链接
Summary
该研究提出了一种利用手部图像进行人员识别的新方法,尤其适用于刑事调查。该方法在性虐待等严重犯罪中尤其有价值,手部图像往往是唯一可用的可识别证据。提出的CLIP-HandID方法利用预训练的视觉语言模型CLIP,通过文本提示作为语义指导,从手部图像中学习辨别深度特征表示。由于手部图像用索引而非文本描述进行标注,因此采用文本倒置网络学习特定视觉上下文或外观属性的伪标记。这些学习到的伪标记融入文本提示中,并输入CLIP的文本编码器,以利用其多模式推理并增强识别效果的泛化能力。在具有多民族代表性的两个大型公开手部数据集上的广泛评估表明,该方法显著优于现有方法。
Key Takeaways
- 该论文介绍了一种利用手部图像进行人员识别的新方法,特别适用于刑事调查中的严重犯罪。
- 提出了CLIP-HandID方法,利用预训练的视觉语言模型CLIP来学习手部图像的特征表示。
- 文本提示作为语义指导,用于增强模型对手部图像的识别能力。
- 由于手部图像使用索引标注,因此采用文本倒置网络学习特定视觉上下文或外观属性的伪标记。
- 将学习到的伪标记融入文本提示,提高模型的泛化能力。
- 在具有多民族代表性的大型公开手部数据集上进行了广泛评估。
点此查看论文截图

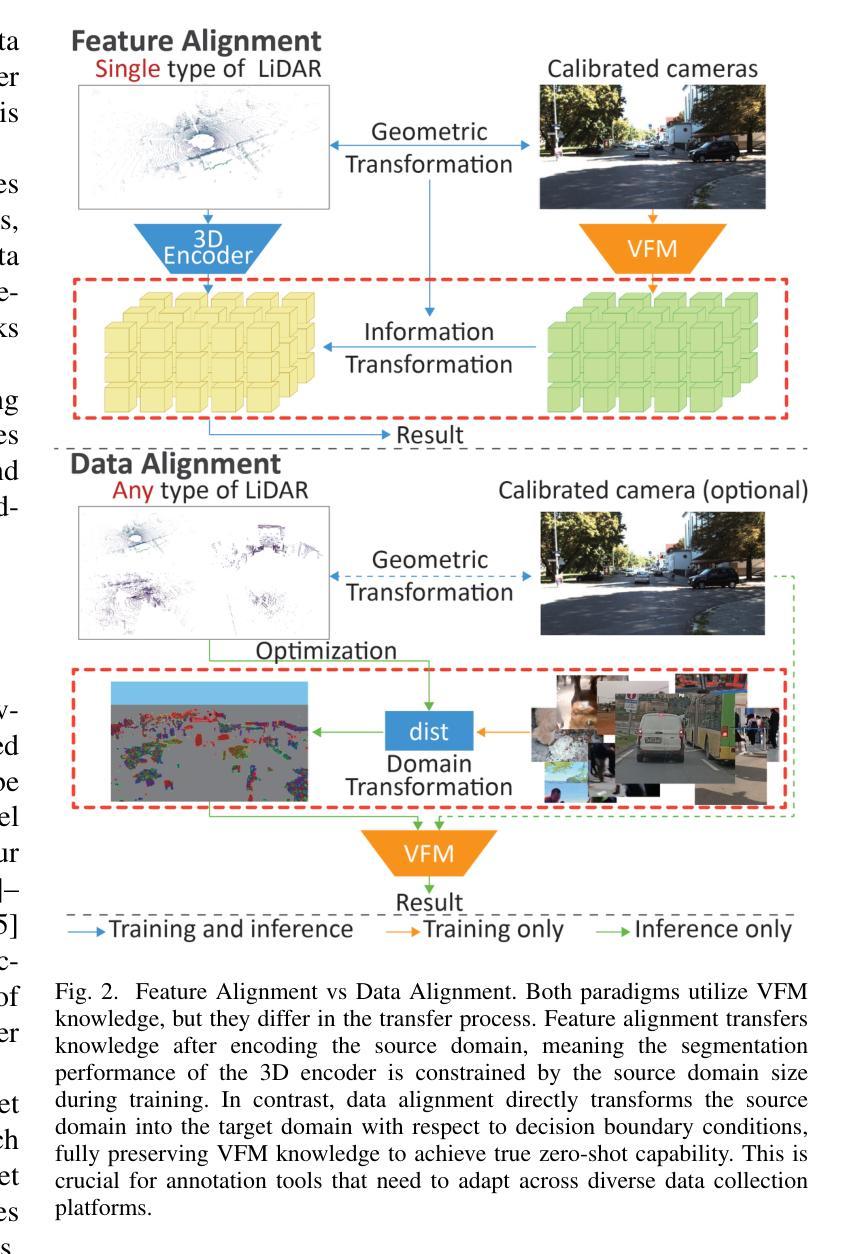
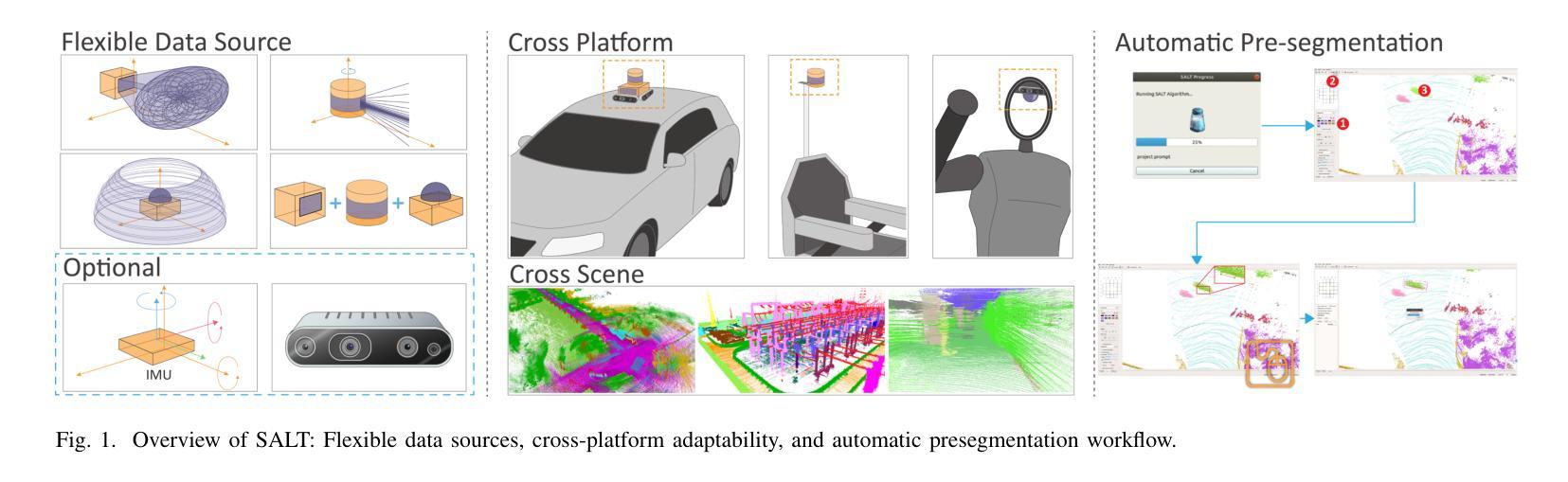
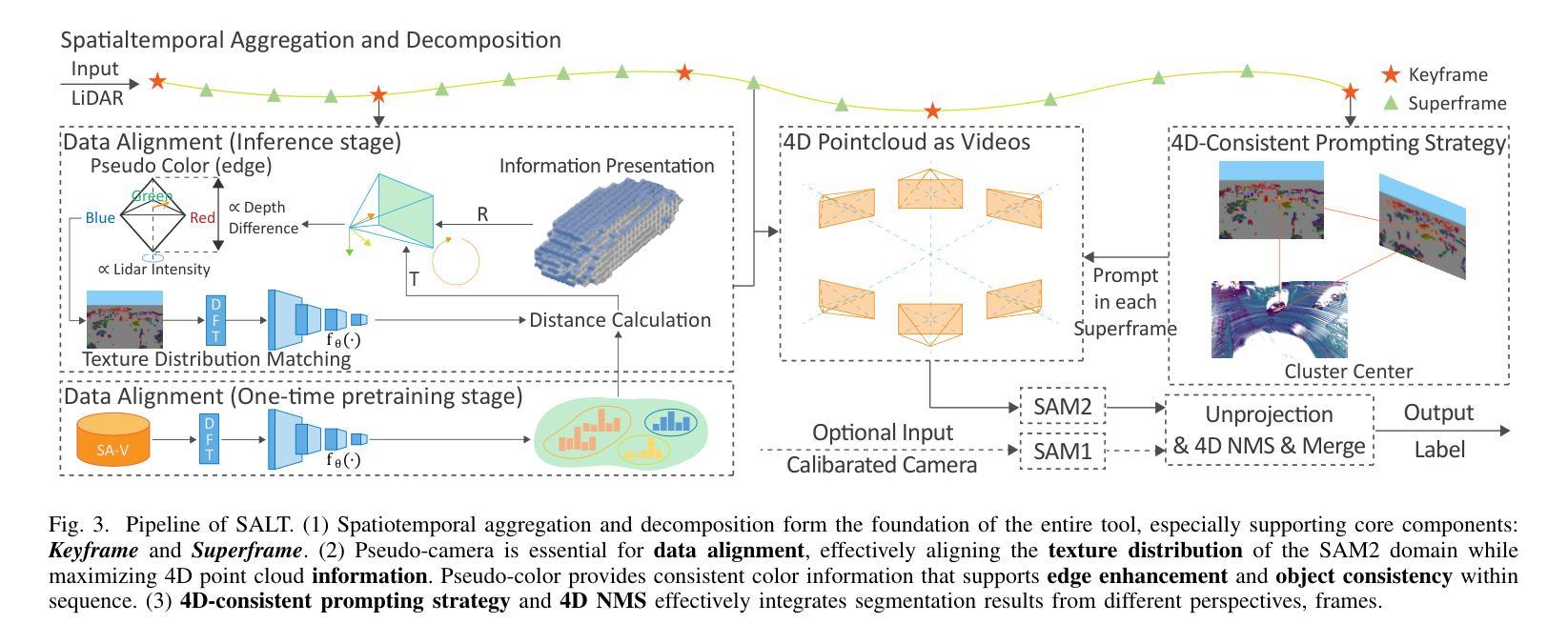
SALT: A Flexible Semi-Automatic Labeling Tool for General LiDAR Point Clouds with Cross-Scene Adaptability and 4D Consistency
Authors:Yanbo Wang, Yongtao Chen, Chuan Cao, Tianchen Deng, Wentao Zhao, Jingchuan Wang, Weidong Chen
We propose a flexible Semi-Automatic Labeling Tool (SALT) for general LiDAR point clouds with cross-scene adaptability and 4D consistency. Unlike recent approaches that rely on camera distillation, SALT operates directly on raw LiDAR data, automatically generating pre-segmentation results. To achieve this, we propose a novel zero-shot learning paradigm, termed data alignment, which transforms LiDAR data into pseudo-images by aligning with the training distribution of vision foundation models. Additionally, we design a 4D-consistent prompting strategy and 4D non-maximum suppression module to enhance SAM2, ensuring high-quality, temporally consistent presegmentation. SALT surpasses the latest zero-shot methods by 18.4% PQ on SemanticKITTI and achieves nearly 40-50% of human annotator performance on our newly collected low-resolution LiDAR data and on combined data from three LiDAR types, significantly boosting annotation efficiency. We anticipate that SALT’s open-sourcing will catalyze substantial expansion of current LiDAR datasets and lay the groundwork for the future development of LiDAR foundation models. Code is available at https://github.com/Cavendish518/SALT.
我们提出了一种灵活的半自动标注工具(SALT),适用于一般激光雷达点云,具有跨场景适应性和4D一致性。与最近依赖相机蒸馏的方法不同,SALT直接在原始激光雷达数据上运行,自动生成预分割结果。为实现这一点,我们提出了一种新的零样本学习范式,称为数据对齐,通过对齐激光雷达数据与视觉基础模型的训练分布,将激光雷达数据转换为伪图像。此外,我们设计了4D一致提示策略和4D非最大值抑制模块,以增强SAM2,确保高质量、时间一致的预分割。SALT在SemanticKITTI上的PQ得分超过最新零样本方法18.4%,在我们新收集的低分辨率激光雷达数据和三种激光雷达类型组合的数据上,达到人类标注器性能的近40-50%,显著提高了标注效率。我们预计SALT的开源将极大地推动当前激光雷达数据集的发展,并为未来激光雷达基础模型的开发奠定基础。代码可在https://github.com/Cavendish518/SALT处获取。
论文及项目相关链接
Summary
本文提出了一种灵活的半自动标注工具(SALT),适用于一般的激光雷达点云数据,具有跨场景适应性和4D一致性。SALT直接在原始激光雷达数据上操作,自动生成预分割结果,不同于依赖相机蒸馏的现有方法。为实现这一点,本文提出了一种名为数据对齐的新型零样本学习范式,通过将激光雷达数据与视觉基础模型的训练分布对齐,将激光雷达数据转换为伪图像。同时,设计了4D一致的提示策略和4D非最大抑制模块,增强SAM2,确保高质量、时间一致的预分割。SALT在SemanticKITTI上的PQ得分比最新的零样本方法高出18.4%,在新收集的低分辨率激光雷达数据和三种激光雷达类型组合的数据上,达到了人类标注器性能的近40-50%,显著提高了标注效率。
Key Takeaways
- SALT是一种半自动标注工具,适用于一般激光雷达点云数据,具有跨场景适应性和4D一致性。
- SALT直接在原始激光雷达数据上操作,自动生成预分割结果。
- 数据对齐的零样本学习范式将激光雷达数据转换为伪图像,通过与视觉基础模型的训练分布对齐实现。
- 4D一致的提示策略和4D非最大抑制模块增强SAM2,确保高质量、时间一致的预分割。
- SALT在SemanticKITTI数据集上的性能优于其他零样本方法。
- SALT在新收集的低分辨率激光雷达数据和多种激光雷达类型组合的数据上取得了接近人类标注器性能的成果。
点此查看论文截图


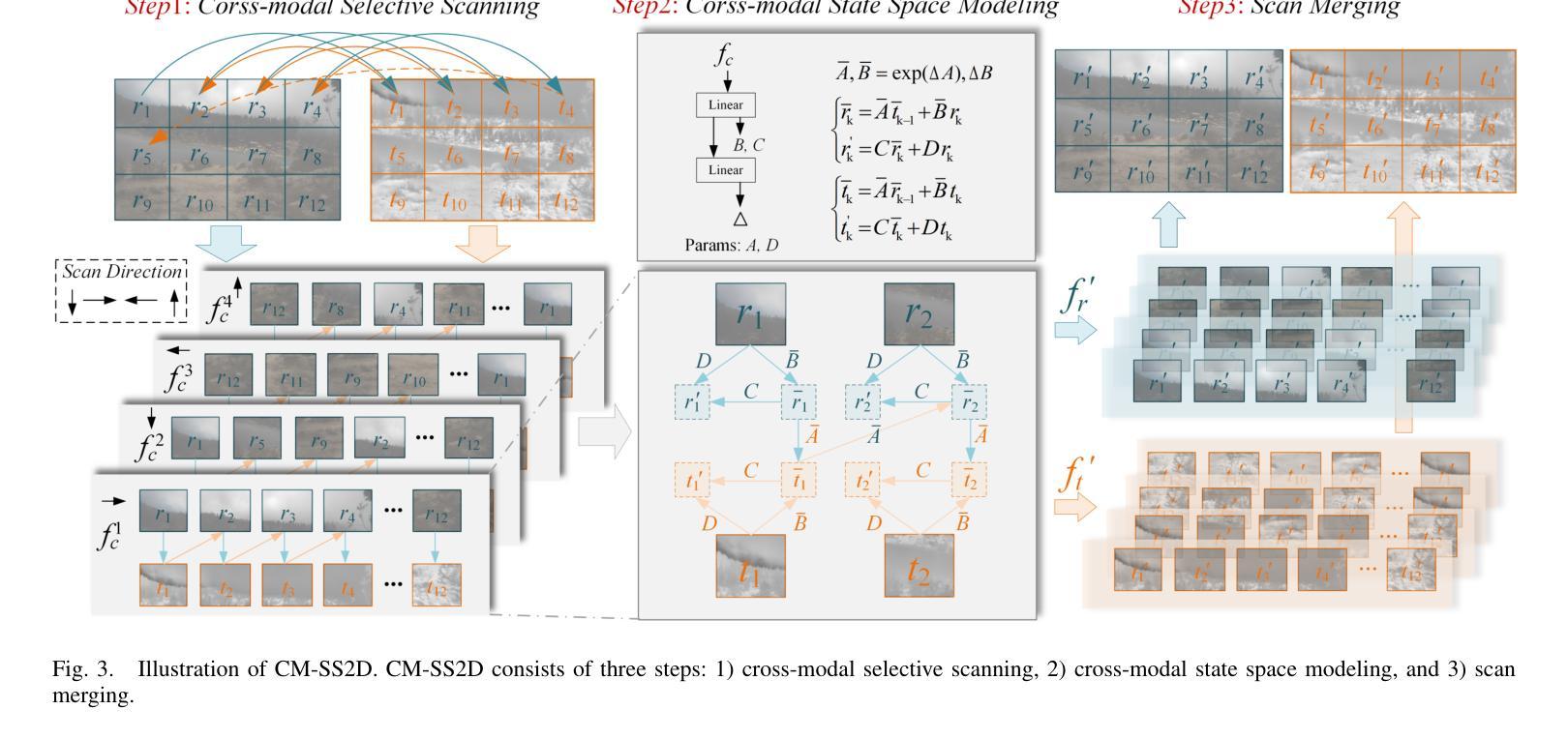
Transformer-based RGB-T Tracking with Channel and Spatial Feature Fusion
Authors:Yunfeng Li, Bo Wang, Ye Li
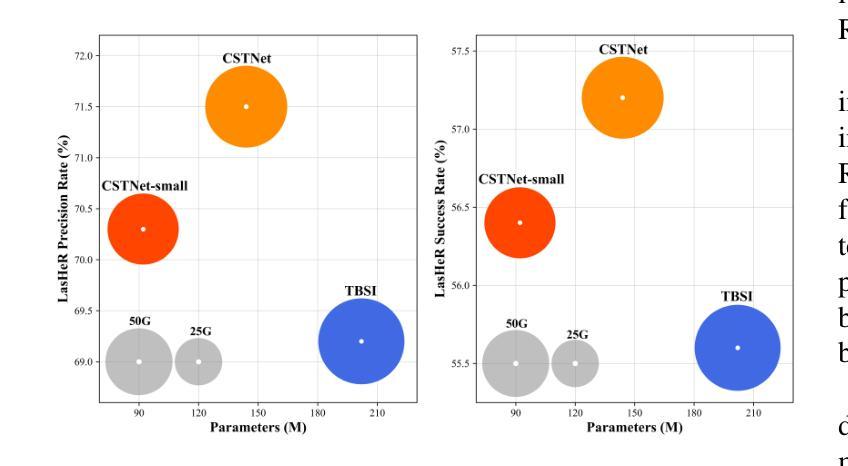
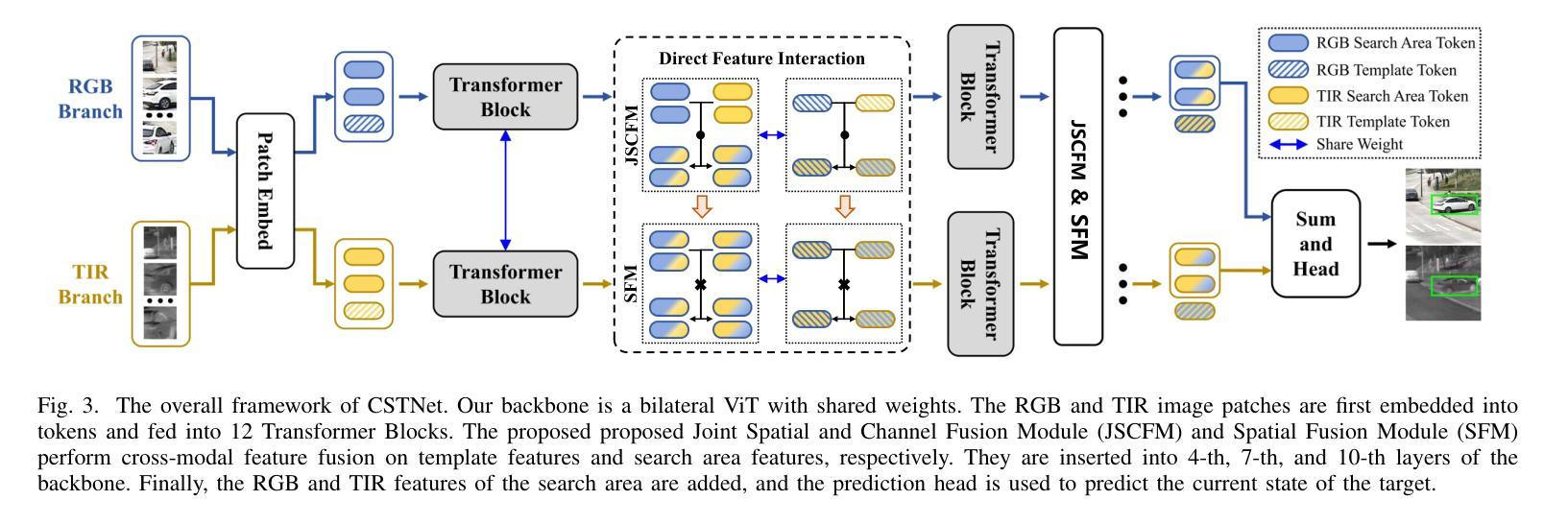
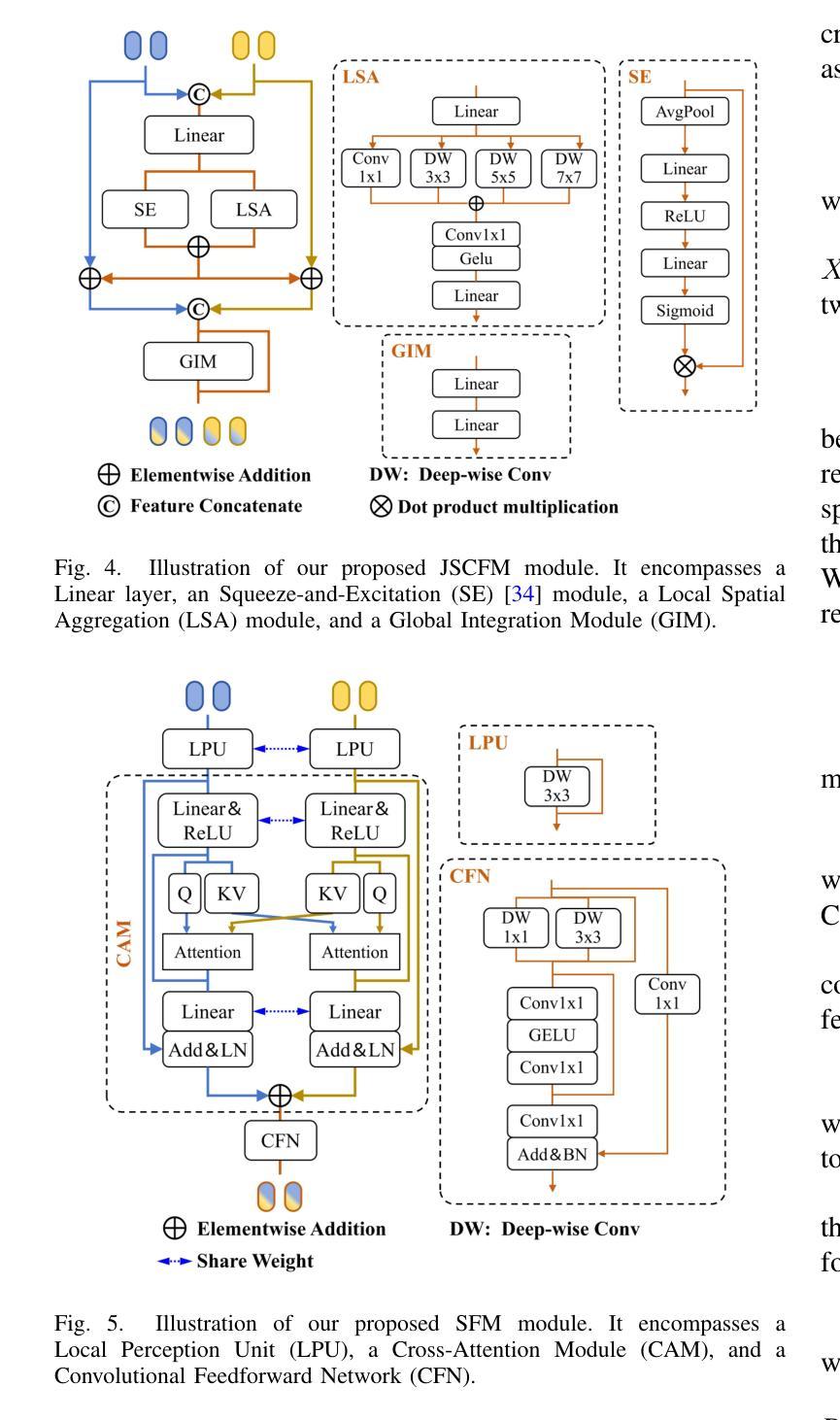
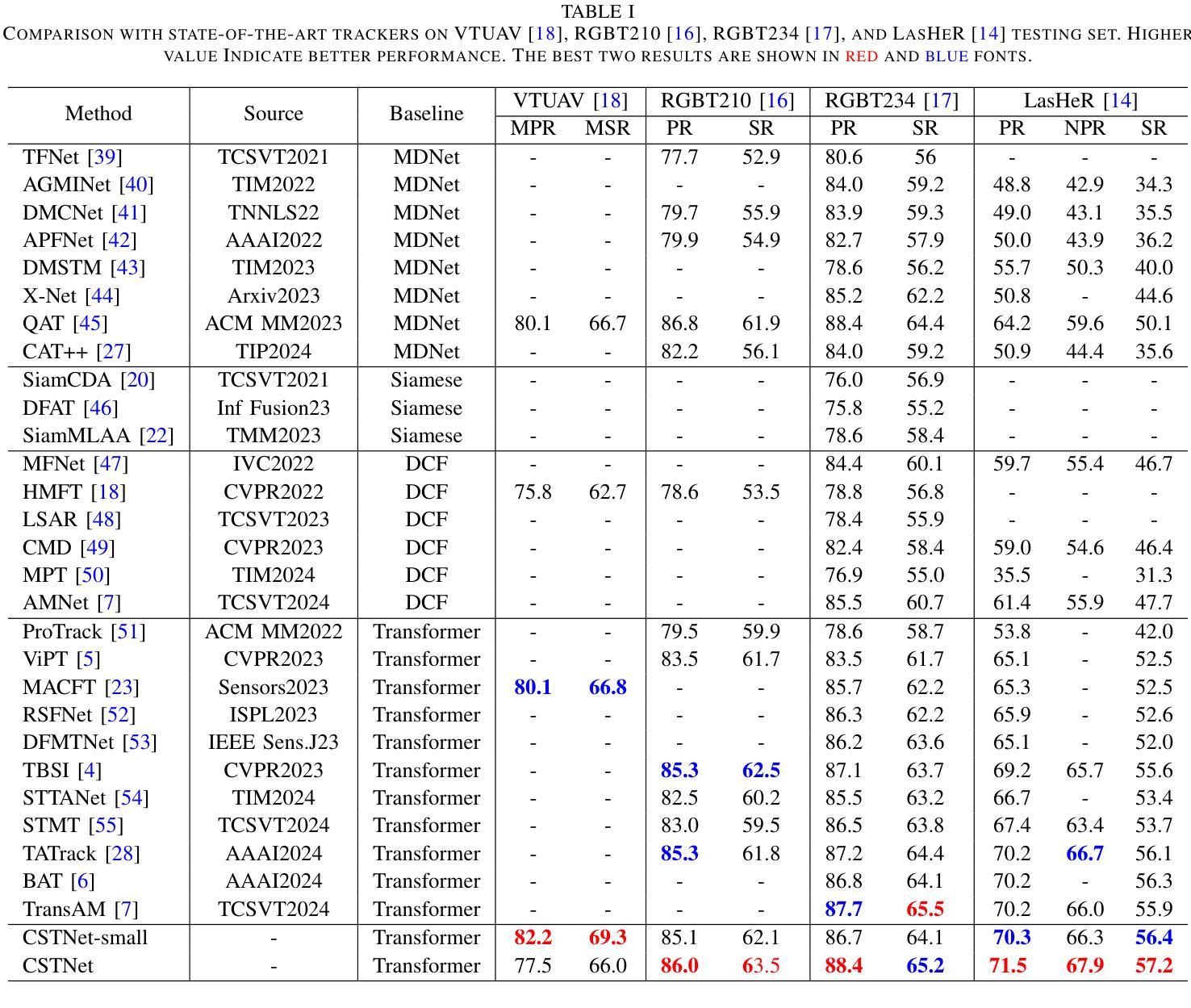
The main problem in RGB-T tracking is the correct and optimal merging of the cross-modal features of visible and thermal images. Some previous methods either do not fully exploit the potential of RGB and TIR information for channel and spatial feature fusion or lack a direct interaction between the template and the search area, which limits the model’s ability to fully utilize the original semantic information of both modalities. To address these limitations, we investigate how to achieve a direct fusion of cross-modal channels and spatial features in RGB-T tracking and propose CSTNet. It uses the Vision Transformer (ViT) as the backbone and adds a Joint Spatial and Channel Fusion Module (JSCFM) and Spatial Fusion Module (SFM) integrated between the transformer blocks to facilitate cross-modal feature interaction. The JSCFM module achieves joint modeling of channel and multi-level spatial features. The SFM module includes a cross-attention-like architecture for cross modeling and joint learning of RGB and TIR features. Comprehensive experiments show that CSTNet achieves state-of-the-art performance. To enhance practicality, we retrain the model without JSCFM and SFM modules and use CSNet as the pretraining weight, and propose CSTNet-small, which achieves 50% speedup with an average decrease of 1-2% in SR and PR performance. CSTNet and CSTNet-small achieve real-time speeds of 21 fps and 33 fps on the Nvidia Jetson Xavier, meeting actual deployment requirements. Code is available at https://github.com/LiYunfengLYF/CSTNet.
RGB-T跟踪中的主要问题是正确且最优地融合可见光和热图像的跨模态特征。一些之前的方法要么没有充分利用RGB和TIR信息来进行通道和空间特征融合,要么缺乏模板和搜索区域之间的直接交互,这限制了模型充分利用两种模态的原始语义信息的能力。为了解决这些局限性,我们研究了如何在RGB-T跟踪中实现跨模态通道和空间特征的直接融合,并提出了CSTNet。它使用视觉转换器(ViT)作为主干,并添加了联合空间和通道融合模块(JSCFM)和空间融合模块(SFM),这些模块集成在转换器块之间,以促进跨模态特征交互。JSCFM模块实现了通道和多级空间特征的联合建模。SFM模块包括一种类似交叉注意力的架构,用于RGB和TIR特征的交叉建模和联合学习。综合实验表明,CSTNet达到了最先进的性能。为了提高实用性,我们重新训练了不带JSCFM和SFM模块的模型,并使用CSNet作为预训练权重,提出了CSTNet-small,它实现了50%的加速,在SR和PR性能上平均下降1-2%。CSTNet和CSTNet-small在Nvidia Jetson Xavier上实现实时速度分别为21帧和33帧,满足实际部署要求。代码可在https://github.com/LiYunfengLYF/CSTNet找到。
论文及项目相关链接
PDF This work has been submitted to the IEEE for possible publication
摘要
本文解决RGB-T跟踪中的主要难题——可见光和热成像图像的多模态特征正确和最优融合问题。针对现有方法未充分利用RGB和TIR信息的通道和空间特征融合潜力,以及模板和搜索区域之间缺乏直接交互的问题,本文研究了如何实现RGB-T跟踪中的跨模态通道和空间特征的直接融合,并提出了CSTNet。它以Vision Transformer(ViT)为骨干网,并在transformer块之间添加了联合空间和通道融合模块(JSCFM)和空间融合模块(SFM),以促进跨模态特征交互。JSCFM模块实现了通道和多级空间特征的联合建模。SFM模块采用类似交叉注意力的架构,实现RGB和TIR特征的跨建模和联合学习。实验表明,CSTNet达到了最先进的性能。为提高实用性,我们重新训练了不带JSCFM和SFM模块的模型,以CSNet作为预训练权重,并推出了CSTNet-small,其速度提高了50%,在SR和PR性能方面平均降低了1-2%。CSTNet和CSTNet-small在Nvidia Jetson Xavier上实现了实时速度分别为每秒21帧和33帧,满足实际部署要求。相关代码已发布在GitHub上。代码地址:https://github.com/LiYunfengLYF/CSTNet。
要点
- RGB-T跟踪中的主要挑战在于正确并最优地融合可见光和热成像图像的跨模态特征。
- 现有方法在某些方面存在局限,如未充分利用RGB和TIR信息,或在模板和搜索区之间缺乏直接交互。
- CSTNet通过引入Vision Transformer(ViT)作为骨干网来解决这些问题,并添加了联合空间和通道融合模块(JSCFM)以及空间融合模块(SFM)。
- JSCFM模块实现了通道和多级空间特征的联合建模,而SFM模块采用类似交叉注意力的架构进行特征跨建模和联合学习。
- CSTNet在实验中表现出卓越性能,而CSTNet-small版本则更注重实用性,实现了速度的提升并保持了相对的性能。
- CSTNet和CSTNet-small满足实时部署要求,并在Nvidia Jetson Xavier上实现了较高的帧率。
点此查看论文截图