⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
Contrastive Cross-Modal Learning for Infusing Chest X-ray Knowledge into ECGs
Authors:Vineet Punyamoorty, Aditya Malusare, Vaneet Aggarwal
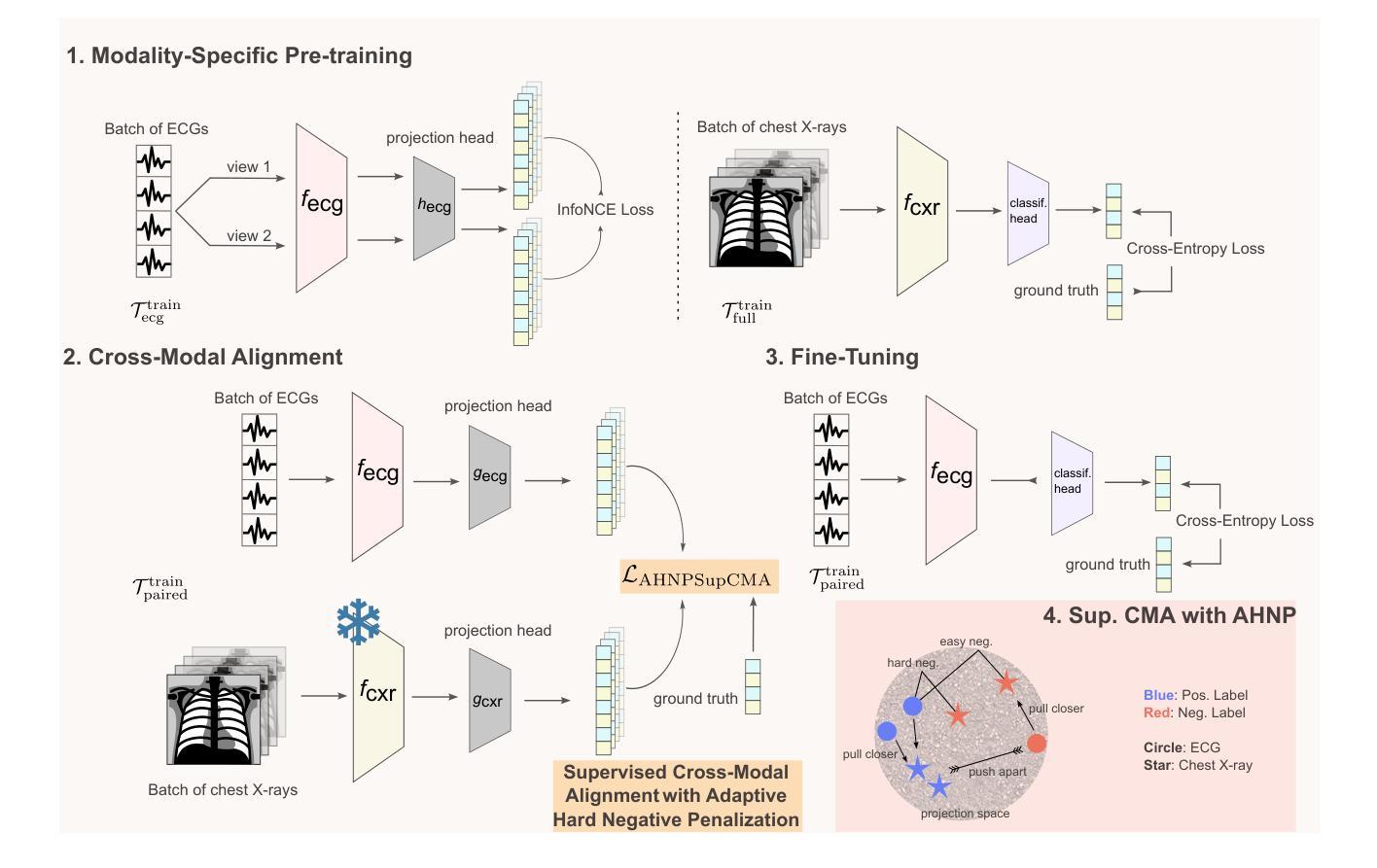
Modern diagnostic workflows are increasingly multimodal, integrating diverse data sources such as medical images, structured records, and physiological time series. Among these, electrocardiograms (ECGs) and chest X-rays (CXRs) are two of the most widely used modalities for cardiac assessment. While CXRs provide rich diagnostic information, ECGs are more accessible and can support scalable early warning systems. In this work, we propose CroMoTEX, a novel contrastive learning-based framework that leverages chest X-rays during training to learn clinically informative ECG representations for multiple cardiac-related pathologies: cardiomegaly, pleural effusion, and edema. Our method aligns ECG and CXR representations using a novel supervised cross-modal contrastive objective with adaptive hard negative weighting, enabling robust and task-relevant feature learning. At test time, CroMoTEX relies solely on ECG input, allowing scalable deployment in real-world settings where CXRs may be unavailable. Evaluated on the large-scale MIMIC-IV-ECG and MIMIC-CXR datasets, CroMoTEX outperforms baselines across all three pathologies, achieving up to 78.31 AUROC on edema. Our code is available at github.com/vineetpmoorty/cromotex.
现代诊断工作流程越来越多元化,融合了诸如医学图像、结构化记录和生理时间序列等不同的数据源。其中,心电图(ECG)和胸部X光(CXR)是用于心脏评估的两种最广泛使用的模式。虽然CXRs提供了丰富的诊断信息,但ECGs更容易获取,并支持可扩展的预警系统。在这项工作中,我们提出了CroMoTEX,这是一个基于对比学习的新型框架,它利用训练过程中的胸部X光来学习关于多种心脏相关疾病的临床心电图表示:心脏增大、胸腔积液和水肿。我们的方法通过对齐心电图和CXR的表示,使用一种新型的有监督跨模态对比目标,并带有自适应的硬负权重,从而实现稳健和任务相关的特征学习。在测试阶段,CroMoTEX仅依赖心电图输入,可在现实世界的环境中进行可扩展部署,其中可能没有CXRs可用。在大型MIMIC-IV-ECG和MIMIC-CXR数据集上评估时,CroMoTEX在所有三种疾病上的表现均优于基线,在水肿方面达到了高达78.31的AUROC。我们的代码可在github.com/vineetpmoorty/cromotex找到。
论文及项目相关链接
Summary
本文提出了一种基于对比学习的新框架CroMoTEX,用于利用胸部X射线(CXR)训练心电图(ECG)的临床信息表示。该框架通过一种新型监督跨模态对比目标,结合自适应硬负权重技术,实现稳健和任务相关的特征学习。测试时,CroMoTEX仅依赖心电图输入,可在没有X射线的情况下进行实际应用。在大型MIMIC-IV-ECG和MIMIC-CXR数据集上评估,CroMoTEX在三种心脏相关疾病上的表现均优于基线方法,其中水肿的AUROC达到78.31%。
Key Takeaways
- 现代诊断流程越来越倾向于多模式,融合多种数据来源如医学图像、结构化记录和生理时间序列数据。
- 心电图(ECG)和胸部X射线(CXR)是心脏评估中最常用的两种模式。
- CroMoTEX是一个基于对比学习的新框架,利用CXR训练数据学习ECG的临床信息表示。
- 该框架通过一种新型监督跨模态对比目标,结合自适应硬负权重技术,实现特征学习。
- CroMoTEX在测试时仅依赖心电图输入,适用于没有X射线的实际环境。
- 在大型数据集上评估,CroMoTEX表现优于基线方法,特别是在检测水肿方面。
点此查看论文截图

A Contrastive Learning Foundation Model Based on Perfectly Aligned Sample Pairs for Remote Sensing Images
Authors:Hengtong Shen, Haiyan Gu, Haitao Li, Yi Yang, Agen Qiu
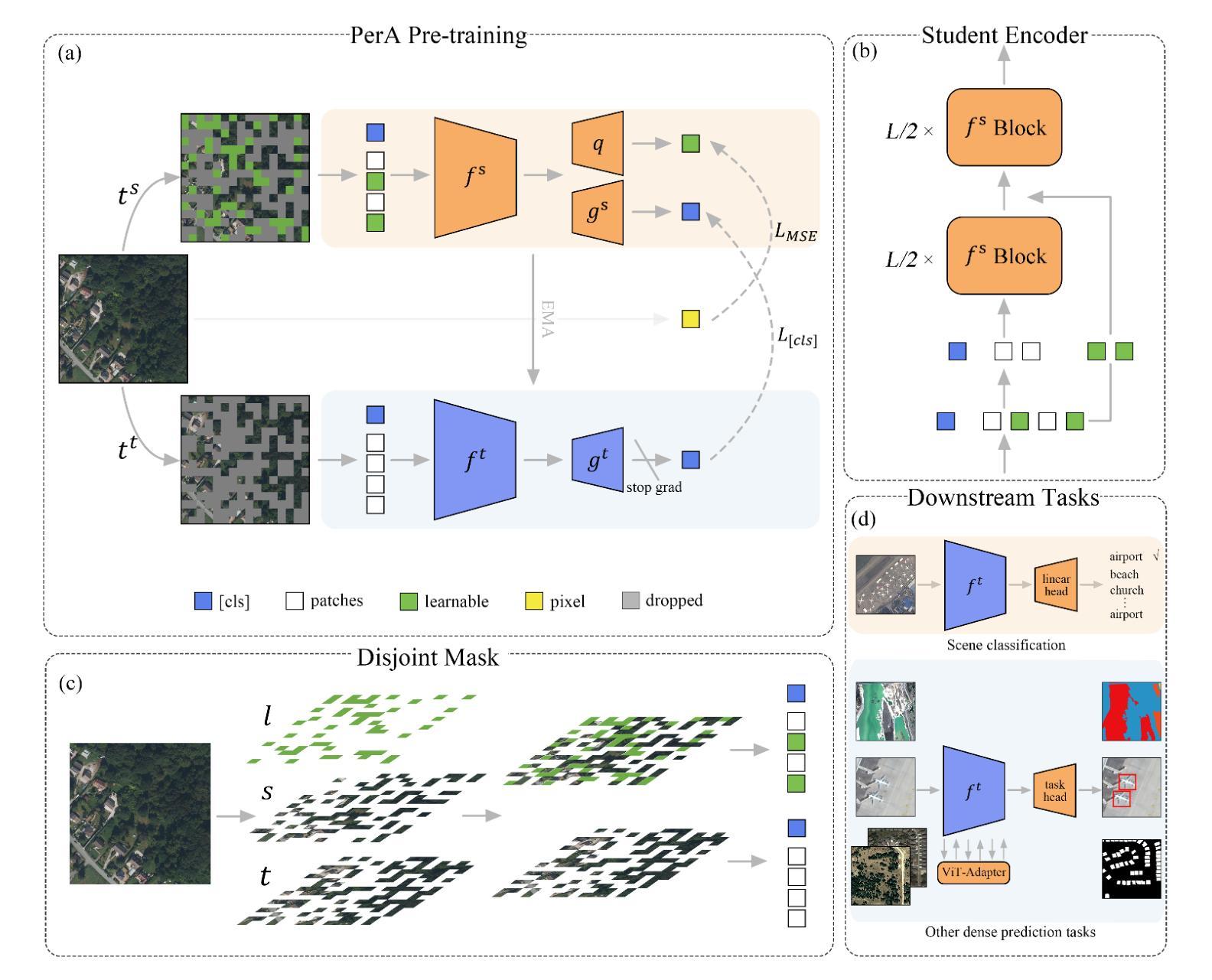
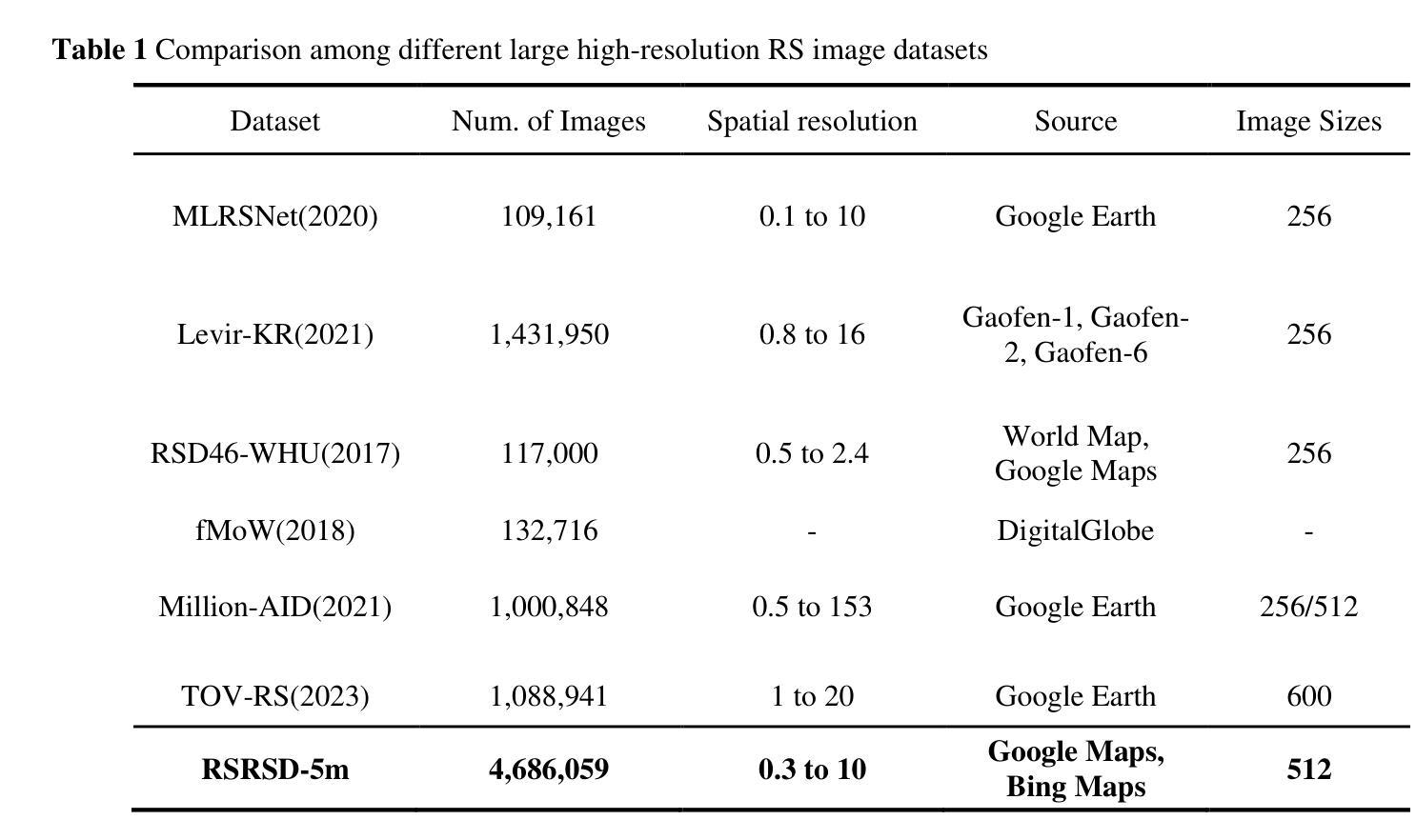
Self-Supervised Learning (SSL) enables us to pre-train foundation models without costly labeled data. Among SSL methods, Contrastive Learning (CL) methods are better at obtaining accurate semantic representations in noise interference. However, due to the significant domain gap, while CL methods have achieved great success in many computer vision tasks, they still require specific adaptation for Remote Sensing (RS) images. To this end, we present a novel self-supervised method called PerA, which produces all-purpose RS features through semantically Perfectly Aligned sample pairs. Specifically, PerA obtains features from sampled views by applying spatially disjoint masks to augmented images rather than random cropping. Our framework provides high-quality features by ensuring consistency between teacher and student and predicting learnable mask tokens. Compared to previous contrastive methods, our method demonstrates higher memory efficiency and can be trained with larger batches due to its sparse inputs. Additionally, the proposed method demonstrates remarkable adaptability to uncurated RS data and reduce the impact of the potential semantic inconsistency. We also collect an unlabeled pre-training dataset, which contains about 5 million RS images. We conducted experiments on multiple downstream task datasets and achieved performance comparable to previous state-of-the-art methods with a limited model scale, demonstrating the effectiveness of our approach. We hope this work will contribute to practical remote sensing interpretation works.
自监督学习(SSL)使我们能够在没有昂贵的标记数据的情况下预先训练基础模型。在SSL方法中,对比学习(CL)方法更擅长在噪声干扰中获得准确的语义表示。然而,由于领域差距巨大,虽然CL方法在许多计算机视觉任务中取得了巨大成功,但它们仍然需要对遥感(RS)图像进行特定适应。为此,我们提出了一种新的自监督方法PerA,它通过语义上完全对齐的样本对产生通用的遥感特征。具体来说,PerA通过对增强图像应用空间不连续掩膜来获得样本视图特征,而不是随机裁剪。我们的框架通过确保教师和学生之间的一致性以及预测可学习的掩码令牌,提供了高质量的特征。与之前的对比方法相比,我们的方法具有更高的内存效率,并且由于其稀疏输入,可以使用更大的批次进行训练。此外,所提出的方法对未整理的遥感数据表现出显著的适应性,并减少了潜在语义不一致的影响。我们还收集了一个无标签的预训练数据集,其中包含约500万张遥感图像。我们在多个下游任务数据集上进行了实验,在有限的模型规模下实现了与以前的最先进方法相当的性能,证明了我们的方法的有效性。我们希望这项工作能为实际的遥感解释工作做出贡献。
论文及项目相关链接
Summary
该研究提出了一种名为PerA的新型自监督学习方法,用于遥感图像的无监督学习。通过语义完美对齐的样本对生成通用遥感特征,利用对增强图像应用空间不相邻掩模来获取信息,提高了内存效率和批次训练能力。该方法适用于未处理的遥感数据,减少语义不一致的影响,并在多个下游任务数据集上取得了与最新技术相当的性能。
Key Takeaways
- 研究采用自监督学习(SSL)方法预训练遥感图像模型,无需昂贵的标签数据。
- 对比学习(CL)在噪声干扰中获得准确的语义表示方面表现出优势。
- 针对遥感图像(RS)的特定领域差距,提出了一种新型自监督方法PerA。
- PerA通过应用空间不相邻掩模到增强图像上的采样视图来获取特征,提高了内存效率和批次训练能力。
- PerA具有出色的适应未处理的遥感数据的能力,并降低了潜在语义不一致的影响。
- 使用约5百万遥感图像的无标签预训练数据集进行实验。
点此查看论文截图