⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
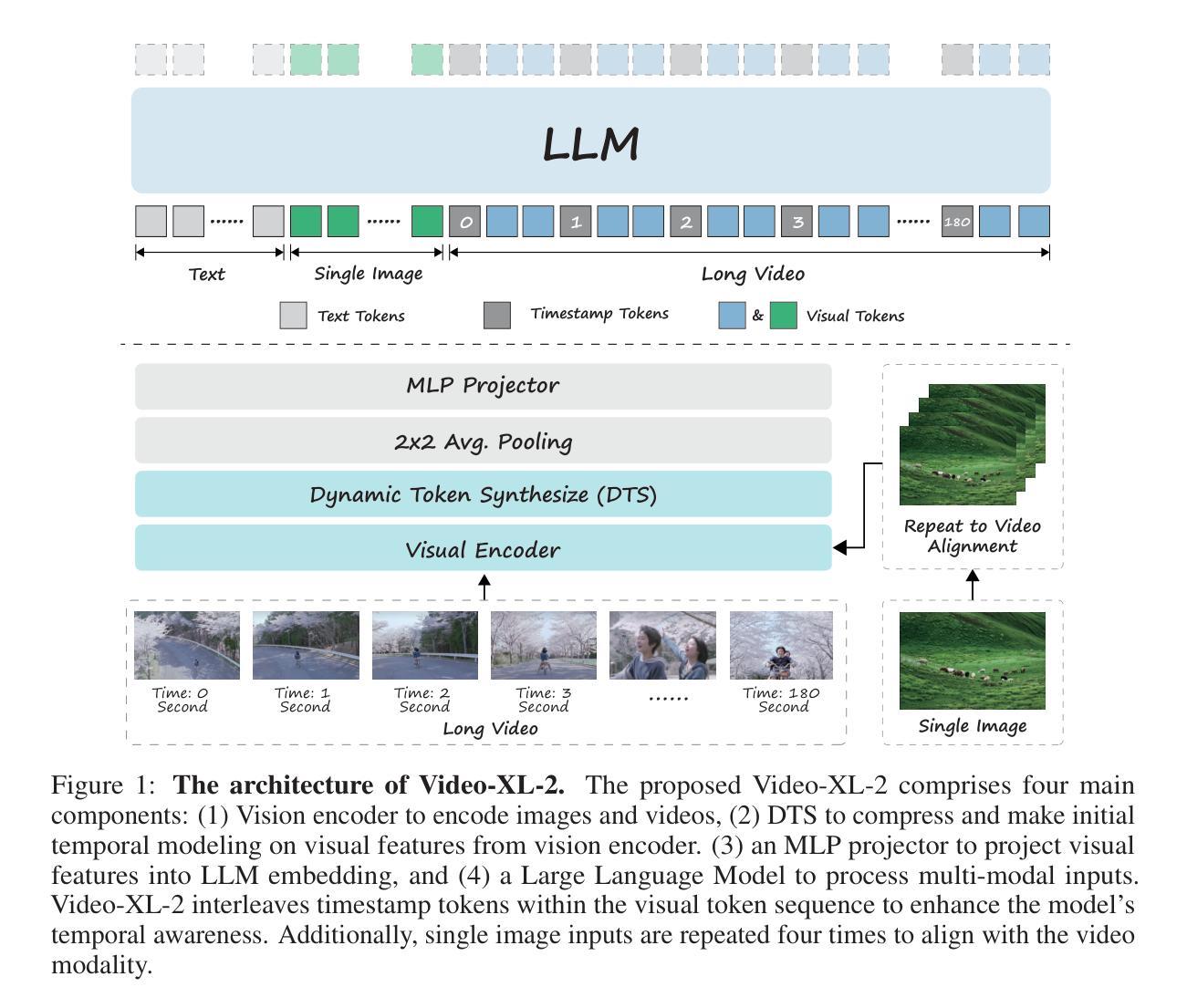
Video-XL-2: Towards Very Long-Video Understanding Through Task-Aware KV Sparsification
Authors:Minghao Qin, Xiangrui Liu, Zhengyang Liang, Yan Shu, Huaying Yuan, Juenjie Zhou, Shitao Xiao, Bo Zhao, Zheng Liu
Multi-modal large language models (MLLMs) models have made significant progress in video understanding over the past few years. However, processing long video inputs remains a major challenge due to high memory and computational costs. This makes it difficult for current models to achieve both strong performance and high efficiency in long video understanding. To address this challenge, we propose Video-XL-2, a novel MLLM that delivers superior cost-effectiveness for long-video understanding based on task-aware KV sparsification. The proposed framework operates with two key steps: chunk-based pre-filling and bi-level key-value decoding. Chunk-based pre-filling divides the visual token sequence into chunks, applying full attention within each chunk and sparse attention across chunks. This significantly reduces computational and memory overhead. During decoding, bi-level key-value decoding selectively reloads either dense or sparse key-values for each chunk based on its relevance to the task. This approach further improves memory efficiency and enhances the model’s ability to capture fine-grained information. Video-XL-2 achieves state-of-the-art performance on various long video understanding benchmarks, outperforming existing open-source lightweight models. It also demonstrates exceptional efficiency, capable of processing over 10,000 frames on a single NVIDIA A100 (80GB) GPU and thousands of frames in just a few seconds.
多年来,多模态大型语言模型(MLLMs)在视频理解方面取得了显著进展。然而,由于内存和计算成本高昂,处理长视频输入仍然是一个主要挑战。这使得当前模型在长视频理解中难以实现强劲性能和高效能的平衡。为了应对这一挑战,我们提出了Video-XL-2,这是一种新型的多模态大型语言模型,基于任务感知的KV稀疏化技术,为长视频理解提供了卓越的成本效益。所提出的框架包含两个关键步骤:基于分块的预填充和两级键值解码。基于分块的预填充将视觉令牌序列分成块,在每个块内应用全注意力,并在块间应用稀疏注意力。这显著减少了计算和内存开销。在解码过程中,两级键值解码会根据每个块与任务的关联度,有选择地重新加载密集或稀疏的键值。这种方法进一步提高了内存效率,增强了模型捕获细粒度信息的能力。Video-XL-2在各种长视频理解基准测试中实现了最先进的性能表现,超越了现有的开源轻量级模型。它还展示了出色的效率,能够在单个NVIDIA A100(80GB)GPU上处理超过1万个帧,并在短短几秒内处理数千个帧。
论文及项目相关链接
PDF 12 pages, 5 Figure, 3 Table
Summary
多模态大型语言模型在处理长视频理解任务时面临内存和计算成本高的挑战。针对这一问题,我们提出了Video-XL-2模型,它通过任务感知的KV稀疏化机制,实现了长视频理解的高成本效益。该模型采用基于分块的预填充和两级键值解码技术,有效降低计算和内存开销,同时提高模型捕捉细粒度信息的能力。Video-XL-2在各种长视频理解基准测试中表现优异,优于现有开源轻量级模型,并在单个NVIDIA A100(80GB)GPU上实现了每几秒处理数千帧的高效率。
Key Takeaways
- 多模态大型语言模型在处理长视频理解任务时存在挑战,主要由于高内存和计算成本。
- Video-XL-2模型通过任务感知的KV稀疏化机制解决此问题,实现强性能和高效率。
- Video-XL-2采用基于分块的预填充技术,对视觉令牌序列进行分块处理,降低计算成本。
- 两级键值解码技术可进一步提高内存效率并增强模型捕捉细粒度信息的能力。
- Video-XL-2在各种长视频理解基准测试中表现优异。
- Video-XL-2相比现有开源轻量级模型具有优势。
点此查看论文截图

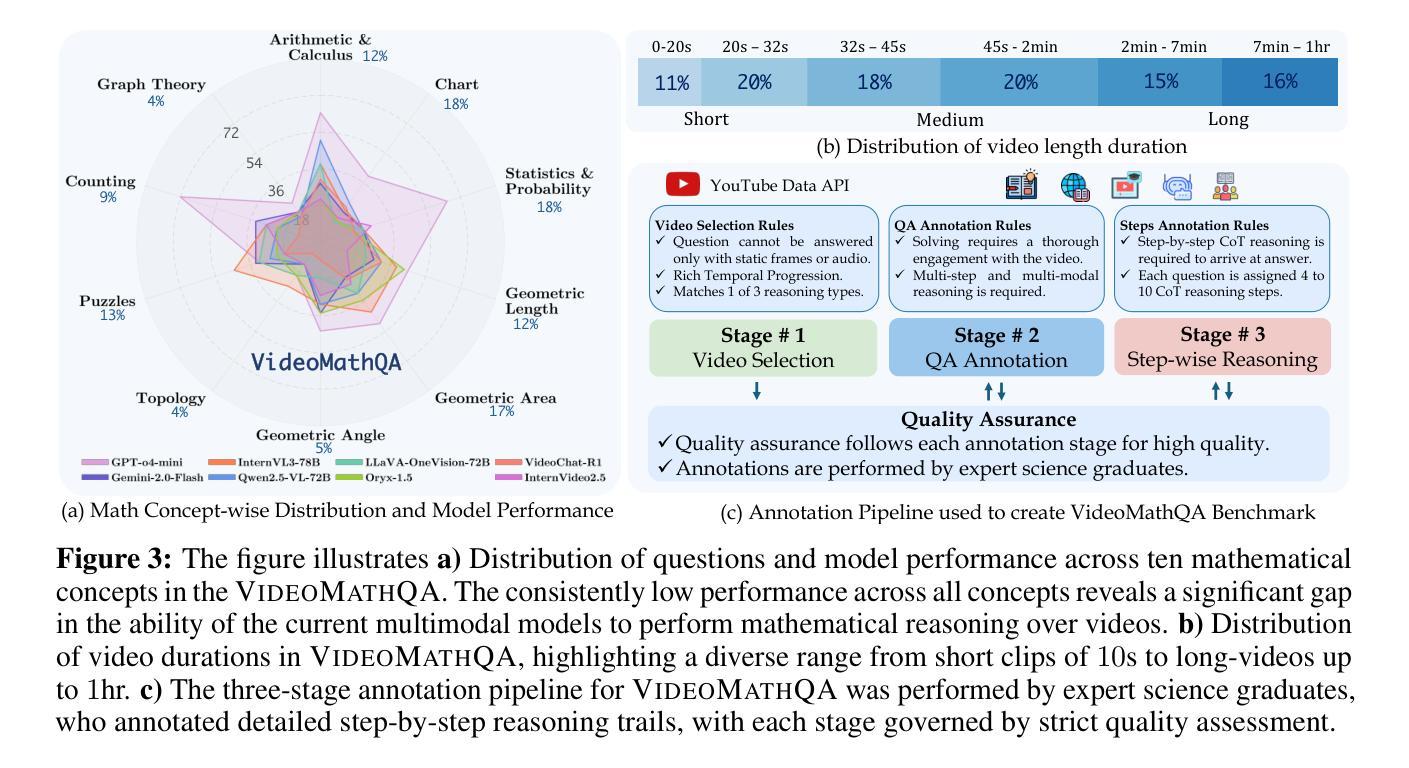
VideoMathQA: Benchmarking Mathematical Reasoning via Multimodal Understanding in Videos
Authors:Hanoona Rasheed, Abdelrahman Shaker, Anqi Tang, Muhammad Maaz, Ming-Hsuan Yang, Salman Khan, Fahad Shahbaz Khan
Mathematical reasoning in real-world video settings presents a fundamentally different challenge than in static images or text. It requires interpreting fine-grained visual information, accurately reading handwritten or digital text, and integrating spoken cues, often dispersed non-linearly over time. In such multimodal contexts, success hinges not just on perception, but on selectively identifying and integrating the right contextual details from a rich and noisy stream of content. To this end, we introduce VideoMathQA, a benchmark designed to evaluate whether models can perform such temporally extended cross-modal reasoning on videos. The benchmark spans 10 diverse mathematical domains, covering videos ranging from 10 seconds to over 1 hour. It requires models to interpret structured visual content, understand instructional narratives, and jointly ground concepts across visual, audio, and textual modalities. We employ graduate-level experts to ensure high quality, totaling over $920$ man-hours of annotation. To reflect real-world scenarios, questions are designed around three core reasoning challenges: direct problem solving, where answers are grounded in the presented question; conceptual transfer, which requires applying learned methods to new problems; and deep instructional comprehension, involving multi-step reasoning over extended explanations and partially worked-out solutions. Each question includes multi-step reasoning annotations, enabling fine-grained diagnosis of model capabilities. Through this benchmark, we highlight the limitations of existing approaches and establish a systematic evaluation framework for models that must reason, rather than merely perceive, across temporally extended and modality-rich mathematical problem settings. Our benchmark and evaluation code are available at: https://mbzuai-oryx.github.io/VideoMathQA
在真实世界的视频环境中进行数学推理与静态图像或文本中的推理相比,呈现了一个根本性的挑战。它要求解释精细的视觉信息,准确阅读手写或数字文本,并整合口头线索,这些线索通常随时间非线性分布。在这种多模态环境中,成功的关键不仅在于感知,还在于从丰富而嘈杂的内容流中选择性地识别和整合正确的上下文细节。为此,我们引入了VideoMathQA基准测试,旨在评估模型在视频上是否可以进行这样的时间扩展跨模态推理。该基准测试涵盖了10个多样化的数学领域,涵盖从10秒到超过1小时的视频。它要求模型解释结构化的视觉内容,理解指令性叙述,并在视觉、音频和文本模式之间共同建立概念。我们聘请了研究生水平的专家以确保高质量,总标注时间超过920个人小时。为了反映真实世界场景,问题围绕三个核心推理挑战进行设计:直接问题解决,答案基于所提出的问题;概念迁移,要求将所学方法应用于新问题;以及深度指令理解,涉及对扩展解释和部分解决方案的多步骤推理。每个问题都包括多步骤推理注释,能够精细地诊断模型的能力。通过此基准测试,我们突出了现有方法的局限性,并为必须在时间扩展和模态丰富的数学问题环境中进行推理的模型建立了系统的评估框架。我们的基准测试和评估代码可在以下网址找到:https://mbzuai-oryx.github.io/VideoMathQA。
论文及项目相关链接
PDF VideoMathQA Technical Report
摘要
本文介绍了VideoMathQA基准测试,该测试旨在评估模型在视频上进行时间扩展的跨模态推理的能力。该基准测试涵盖了10个不同的数学领域,涉及从10秒到超过1小时的视频。它要求模型解释结构化的视觉内容,理解指令性叙述,并在视觉、音频和文本模式之间共同建立概念。为了确保高质量,我们雇佣了研究生水平的专家进行标注,总计投入了超过920个小时的人力。该基准测试反映了真实场景,问题设计围绕三个核心推理挑战:直接问题解决、概念迁移和深度指令理解。每个问题都包含多步骤推理注释,能够精细地诊断模型的能力。通过此基准测试,我们强调了现有方法的局限性,并为必须在时间延长和模态丰富的数学问题设置中进行推理的模型建立了系统的评估框架。
关键见解
- VideoMathQA是一个评估模型在视频上进行跨模态推理能力的基准测试。
- 该测试涵盖了广泛的数学领域和视频时长,要求模型解释结构化视觉内容、理解指令性叙述,并跨多个模式建立概念。
- 问题设计反映了真实场景,包括直接问题解决、概念迁移和深度指令理解等核心推理挑战。
- 通过精细的标注和多步骤推理注释,该基准测试能够诊断模型的能力。
- 现有方法在VideoMathQA基准测试中存在局限性,需要开发能够在时间延长和模态丰富的数学问题上推理的模型。
- 该基准测试和评估代码已公开发布,可供研究使用。
- 此基准测试强调了跨模态推理在数学领域的实际应用中的挑战性,并为未来的研究提供了方向。
点此查看论文截图