⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
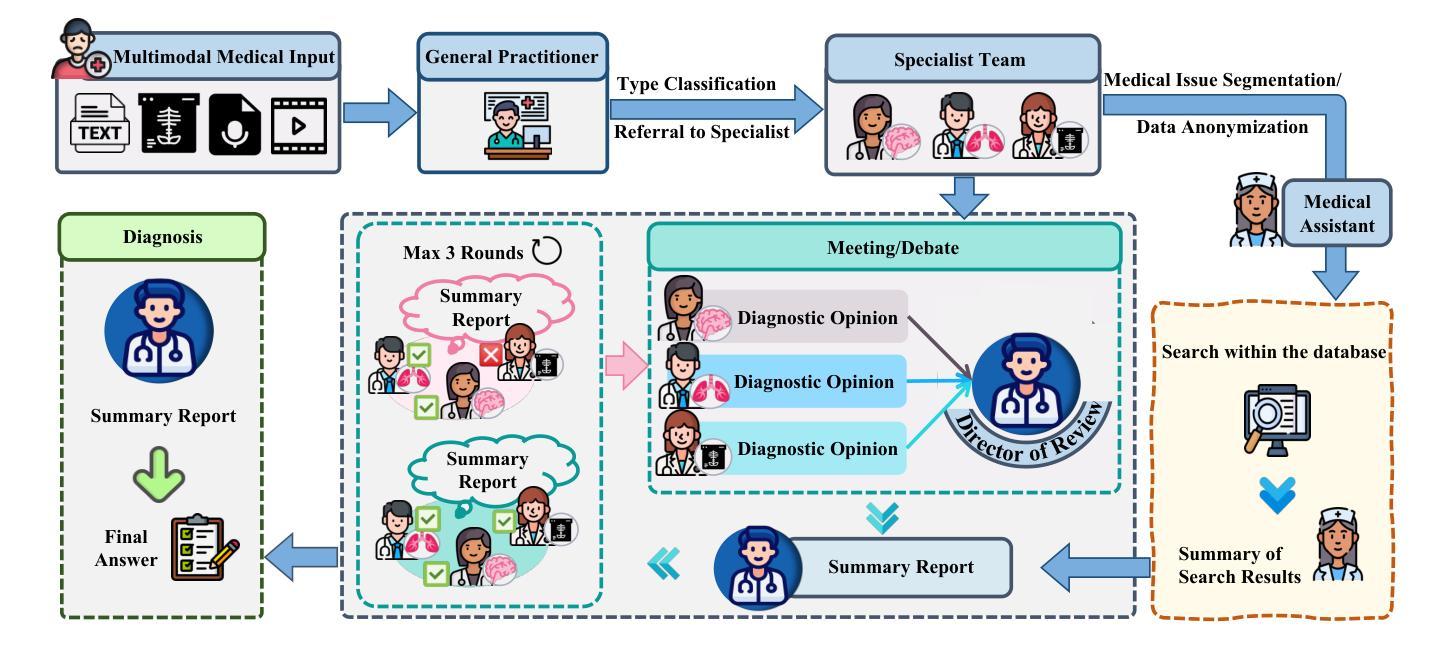
MAM: Modular Multi-Agent Framework for Multi-Modal Medical Diagnosis via Role-Specialized Collaboration
Authors:Yucheng Zhou, Lingran Song, Jianbing Shen
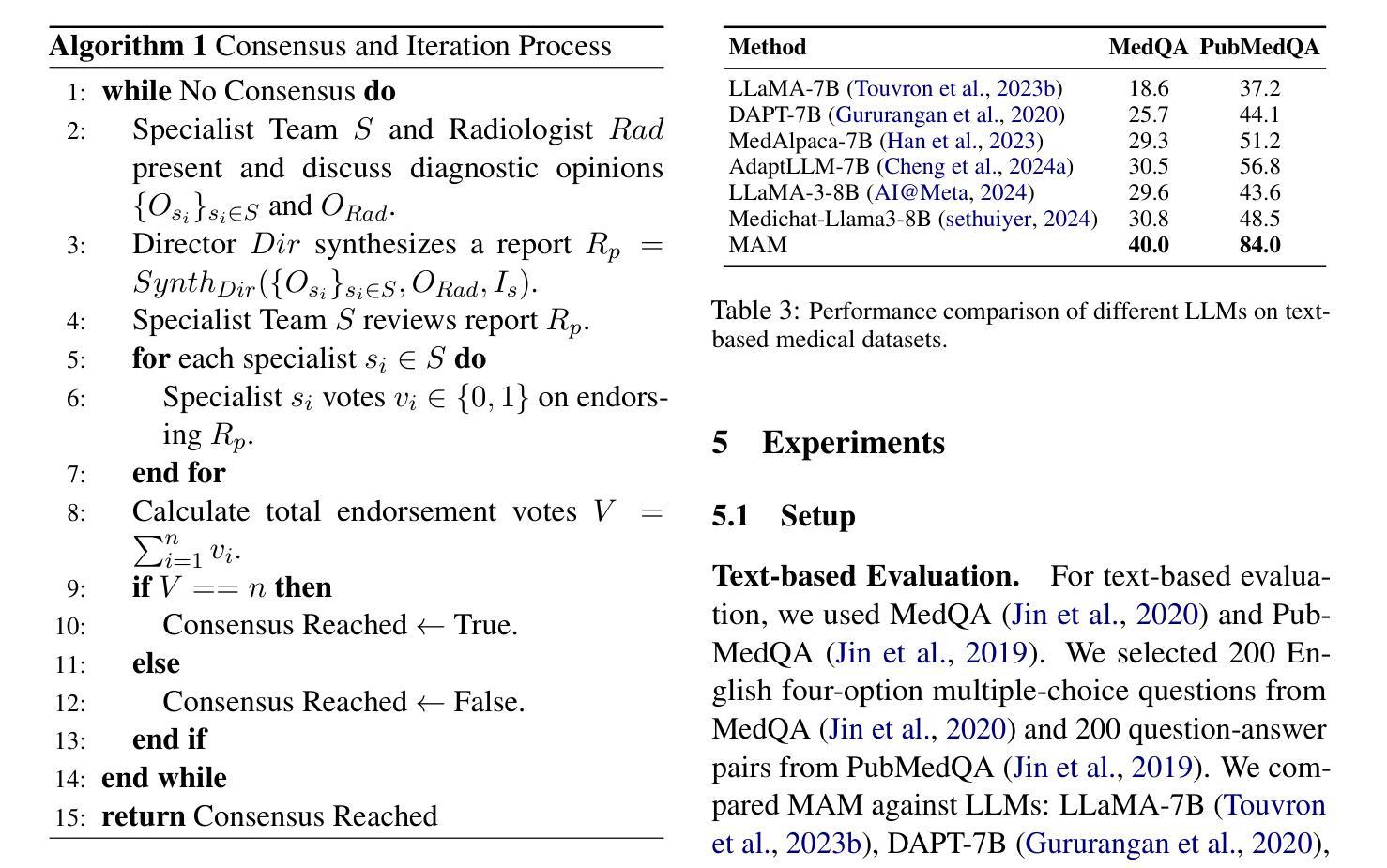
Recent advancements in medical Large Language Models (LLMs) have showcased their powerful reasoning and diagnostic capabilities. Despite their success, current unified multimodal medical LLMs face limitations in knowledge update costs, comprehensiveness, and flexibility. To address these challenges, we introduce the Modular Multi-Agent Framework for Multi-Modal Medical Diagnosis (MAM). Inspired by our empirical findings highlighting the benefits of role assignment and diagnostic discernment in LLMs, MAM decomposes the medical diagnostic process into specialized roles: a General Practitioner, Specialist Team, Radiologist, Medical Assistant, and Director, each embodied by an LLM-based agent. This modular and collaborative framework enables efficient knowledge updates and leverages existing medical LLMs and knowledge bases. Extensive experimental evaluations conducted on a wide range of publicly accessible multimodal medical datasets, incorporating text, image, audio, and video modalities, demonstrate that MAM consistently surpasses the performance of modality-specific LLMs. Notably, MAM achieves significant performance improvements ranging from 18% to 365% compared to baseline models. Our code is released at https://github.com/yczhou001/MAM.
近期,医疗领域的大型语言模型(LLM)取得了显著的进展,展示了其强大的推理和诊断能力。然而,尽管取得了成功,当前的统一多模式医疗LLM在知识更新成本、全面性和灵活性方面仍存在局限性。为了解决这些挑战,我们引入了用于多模式医疗诊断的模块化多智能体框架(MAM)。受我们实证研究的启发,该实证研究突出了角色分配和诊断识别在LLM中的优势,MAM将医疗诊断过程分解为专门的角色:全科医生、专业团队、放射科医生、医疗助理和主任,每个角色均由基于LLM的智能体体现。这种模块化和协作的框架能够实现高效的知识更新,并充分利用现有的医疗LLM和知识库。在包含文本、图像、音频和视频模式的公开可访问的多模式医疗数据集上进行的广泛实验评估表明,MAM的性能始终超过特定模态的LLM。值得注意的是,与基准模型相比,MAM实现了从18%到365%的显著性能提升。我们的代码已发布在https://github.com/yczhou000/MAM上。
论文及项目相关链接
PDF ACL 2025 Findings
Summary
医疗领域的大型语言模型(LLM)最新进展展示了其强大的推理和诊断能力。然而,现有的统一多模式医疗LLM在知识更新成本、全面性和灵活性方面存在局限。为解决这些问题,我们提出了模块化多智能体框架(MAM),用于多模式医疗诊断。MAM将医疗诊断过程分解为专业角色,利用LLM智能体扮演全科医生、专家团队、放射科医生、医疗助理和主任等角色。该模块化协作框架可实现高效知识更新,利用现有医疗LLM和知识库。在包含文本、图像、音频和视频模式的公开多模式医疗数据集上进行的广泛实验评估表明,MAM的性能持续超越特定模态LLM的性能,与基线模型相比,性能提高了18%至365%。
Key Takeaways
- 医疗大型语言模型(LLM)具备强大的推理和诊断能力。
- 当前统一多模式医疗LLM存在知识更新成本、全面性和灵活性方面的挑战。
- 提出模块化多智能体框架(MAM)进行多模式医疗诊断。
- MAM将医疗诊断过程分解为专业角色,如全科医生、专家团队等,并由LLM智能体扮演。
- MAM利用模块化协作框架实现高效知识更新,并利用现有医疗LLM和知识库。
- 在多模式医疗数据集上的实验评估显示,MAM性能优于模态特定LLM。
点此查看论文截图

From Reproduction to Replication: Evaluating Research Agents with Progressive Code Masking
Authors:Gyeongwon James Kim, Alex Wilf, Louis-Philippe Morency, Daniel Fried
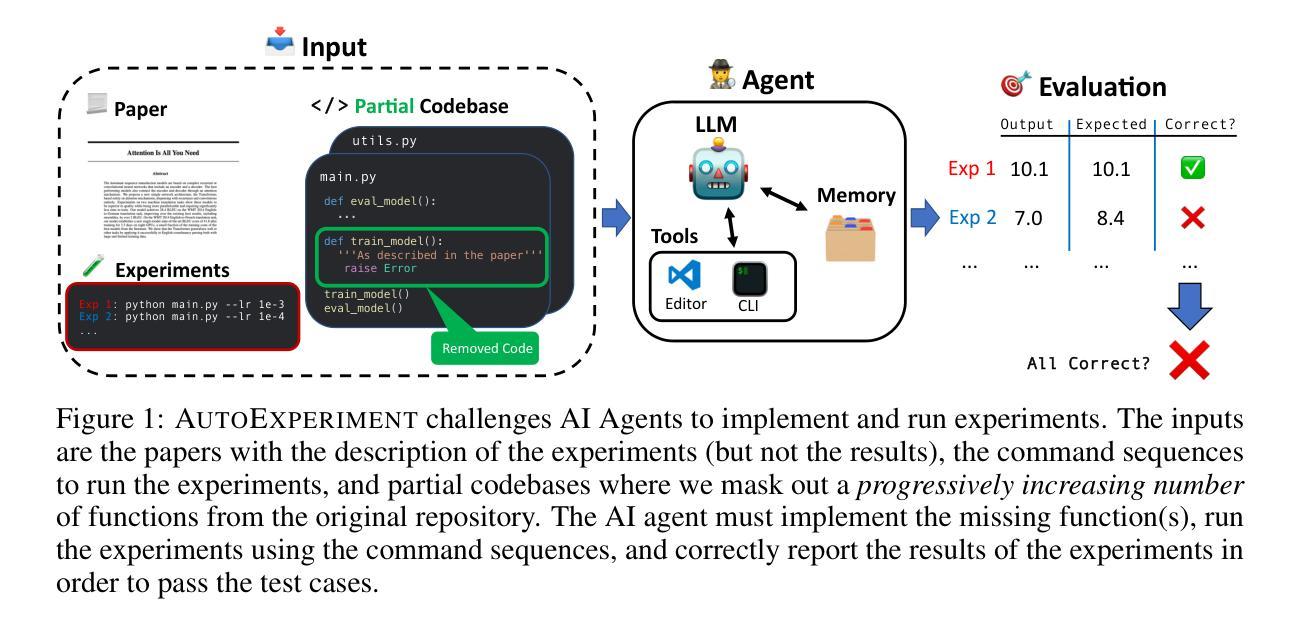
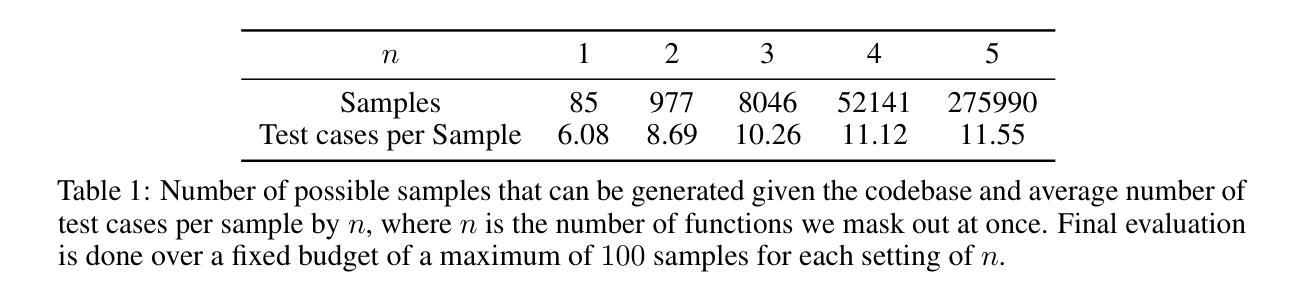
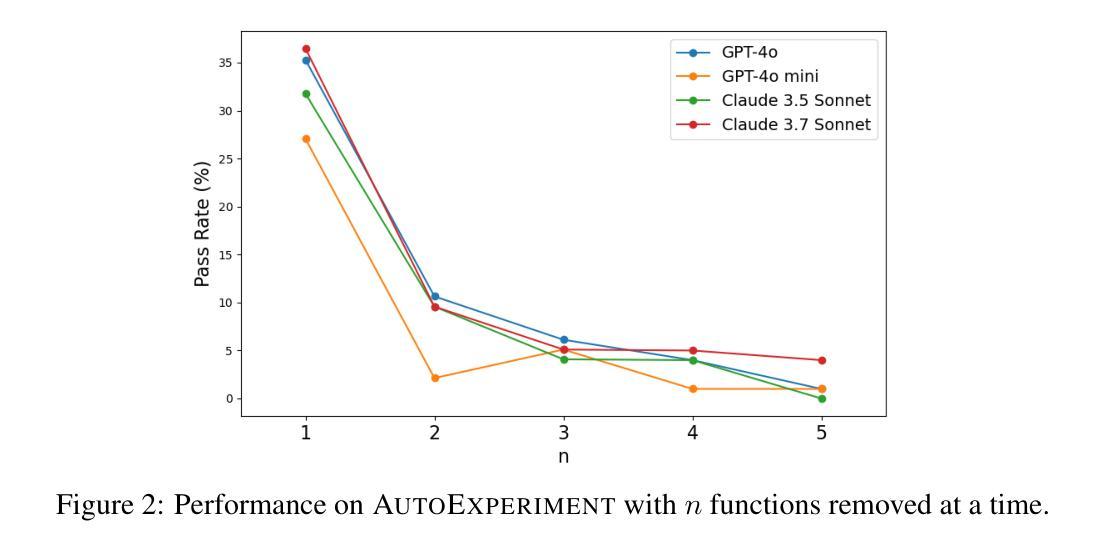
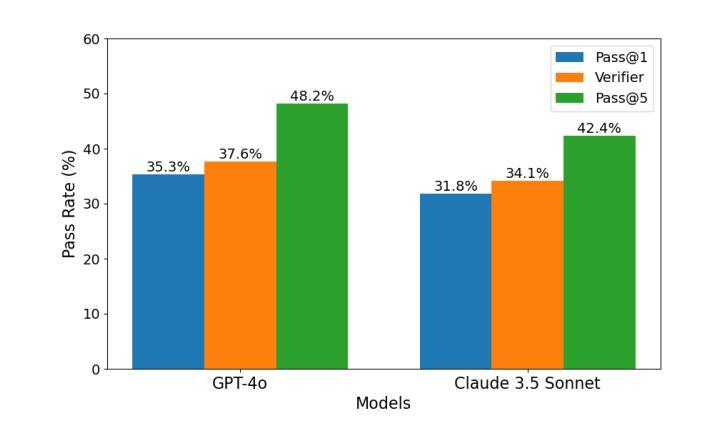
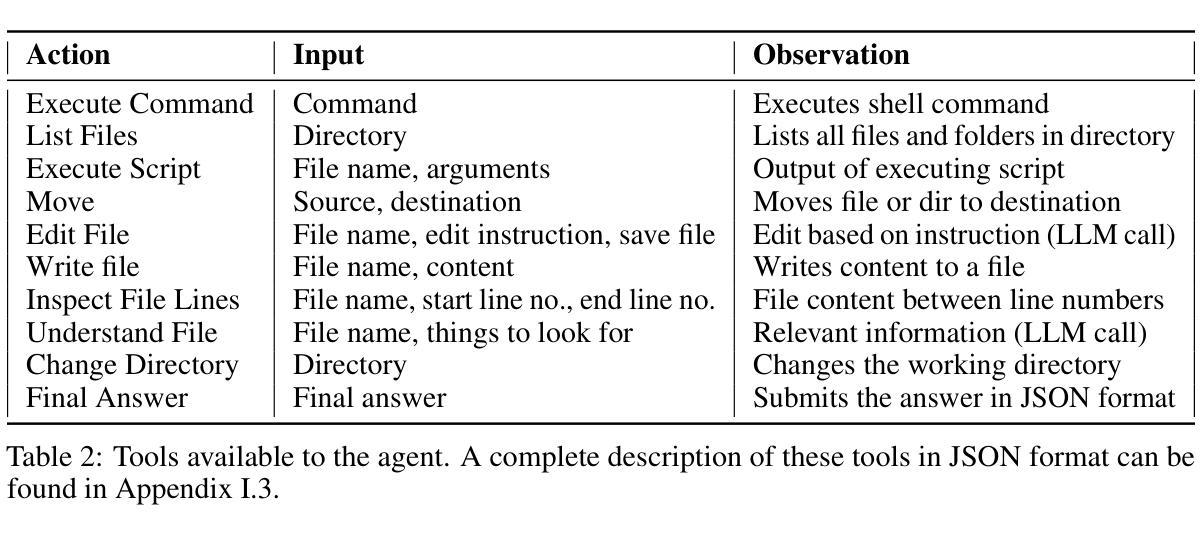
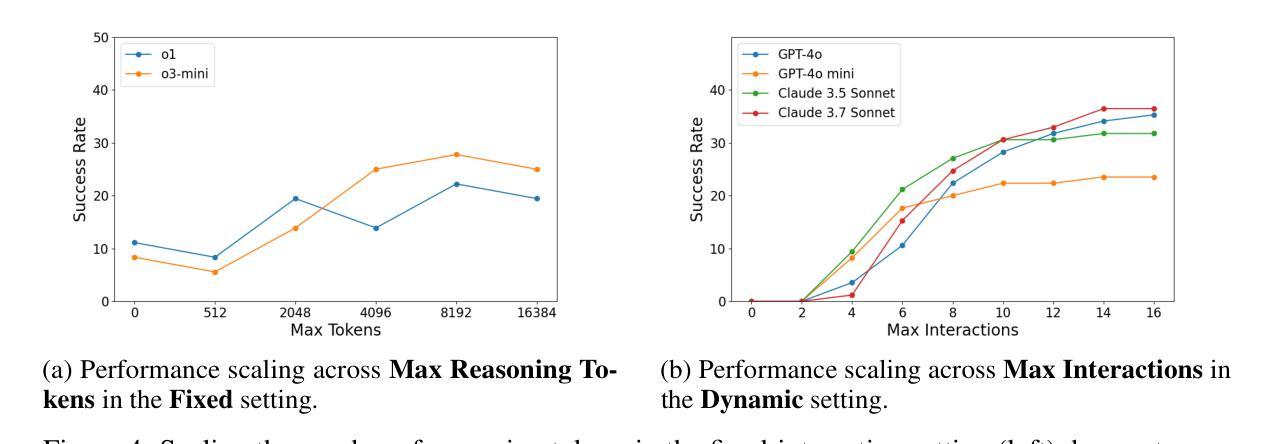
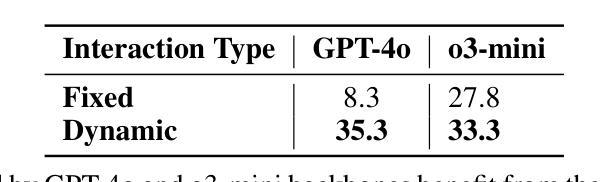
Recent progress in autonomous code generation has fueled excitement around AI agents capable of accelerating scientific discovery by running experiments. However, there is currently no benchmark that evaluates whether such agents can implement scientific ideas when given varied amounts of code as a starting point, interpolating between reproduction (running code) and from-scratch replication (fully re-implementing and running code). We introduce AutoExperiment, a benchmark that evaluates AI agents’ ability to implement and run machine learning experiments based on natural language descriptions in research papers. In each task, agents are given a research paper, a codebase with key functions masked out, and a command to run the experiment. The goal is to generate the missing code, execute the experiment in a sandboxed environment, and reproduce the results. AutoExperiment scales in difficulty by varying the number of missing functions $n$, ranging from partial reproduction to full replication. We evaluate state-of-the-art agents and find that performance degrades rapidly as $n$ increases. Agents that can dynamically interact with the environment (e.g. to debug their code) can outperform agents in fixed “agentless” harnesses, and there exists a significant gap between single-shot and multi-trial success rates (Pass@1 vs. Pass@5), motivating verifier approaches to our benchmark. Our findings highlight critical challenges in long-horizon code generation, context retrieval, and autonomous experiment execution, establishing AutoExperiment as a new benchmark for evaluating progress in AI-driven scientific experimentation. Our data and code are open-sourced at https://github.com/j1mk1m/AutoExperiment .
近期自主代码生成的进展激发了人们对能够加速科学发现的人工智能代理的兴奋之情。然而,目前尚没有一个基准测试来评估这些代理在给定的不同数量的代码起点上实现科学想法的能力,这些代码起点介于复制(运行代码)和从头开始复制(完全重新实现和运行代码)之间。我们引入了AutoExperiment,这是一个评估人工智能代理根据研究论文中的自然语言描述来实现和运行机器学习实验能力的基准测试。在每个任务中,代理会收到一篇研究论文、一个带有关键功能被遮蔽的代码库以及一个运行实验的命令。目标是生成缺失的代码,在沙箱环境中执行实验并再现结果。AutoExperiment的难度通过调整缺失函数$ n $的数量来增加,从部分复制扩展到完全复制。我们评估了最先进的代理,并发现随着$ n $的增加,性能迅速下降。能够与环境动态交互的代理(例如用于调试代码)可以超越固定“无代理”框架中的代理,单次试验成功率与多次试验成功率之间存在较大差距(Pass@1与Pass@5),这激发了对我们基准测试的验证器方法的研究。我们的研究发现了长周期代码生成、上下文检索和自主实验执行方面的关键挑战,确立了AutoExperiment作为评估人工智能驱动科学实验进展的新基准。我们的数据和代码已开源,网址为:https://github.com/j1mk1m/AutoExperiment。
论文及项目相关链接
Summary
本文主要介绍了一项新技术——AutoExperiment基准测试。这项测试旨在评估人工智能代理是否能根据研究论文中的自然语言描述来实现和运行机器学习实验。该测试包括在给定研究论文、代码库及缺失函数的任务下,生成缺失代码、在沙箱环境中进行实验并复现结果的能力。AutoExperiment通过调整缺失函数数量n的多少来增加难度,从部分复现到完全复制不等。评估发现,随着n的增加,代理性能迅速下降。此外,能与环境动态交互的代理表现优于固定框架中的代理,单次与多次试验成功率之间存在较大差距,这激发了验证器方法的发展。此研究为长期视角的代码生成、上下文检索和自主实验执行提出了关键挑战,同时建立了一个新的评估基准。有关数据和代码已在公开渠道获取:https://github.com/j1mk1m/AutoExperiment。
Key Takeaways
以下是基于文本的关键见解:
- AutoExperiment是一个新的基准测试,用于评估AI代理在根据自然语言描述实现和运行机器学习实验方面的能力。
- 测试包括生成缺失代码、在沙箱环境中进行实验并复现结果的任务。
- 测试难度通过调整缺失函数数量n来调整,涵盖从部分复现到完全复制的不同难度级别。
- 评估发现,随着缺失函数数量的增加,代理性能迅速下降。
- 动态交互的代理表现优于固定框架中的代理。
- 单次与多次试验成功率之间存在差距,这突显了验证器方法的重要性。
- 此研究为代码生成、上下文检索和自主实验执行提出了挑战,并建立了新的评估基准。
点此查看论文截图

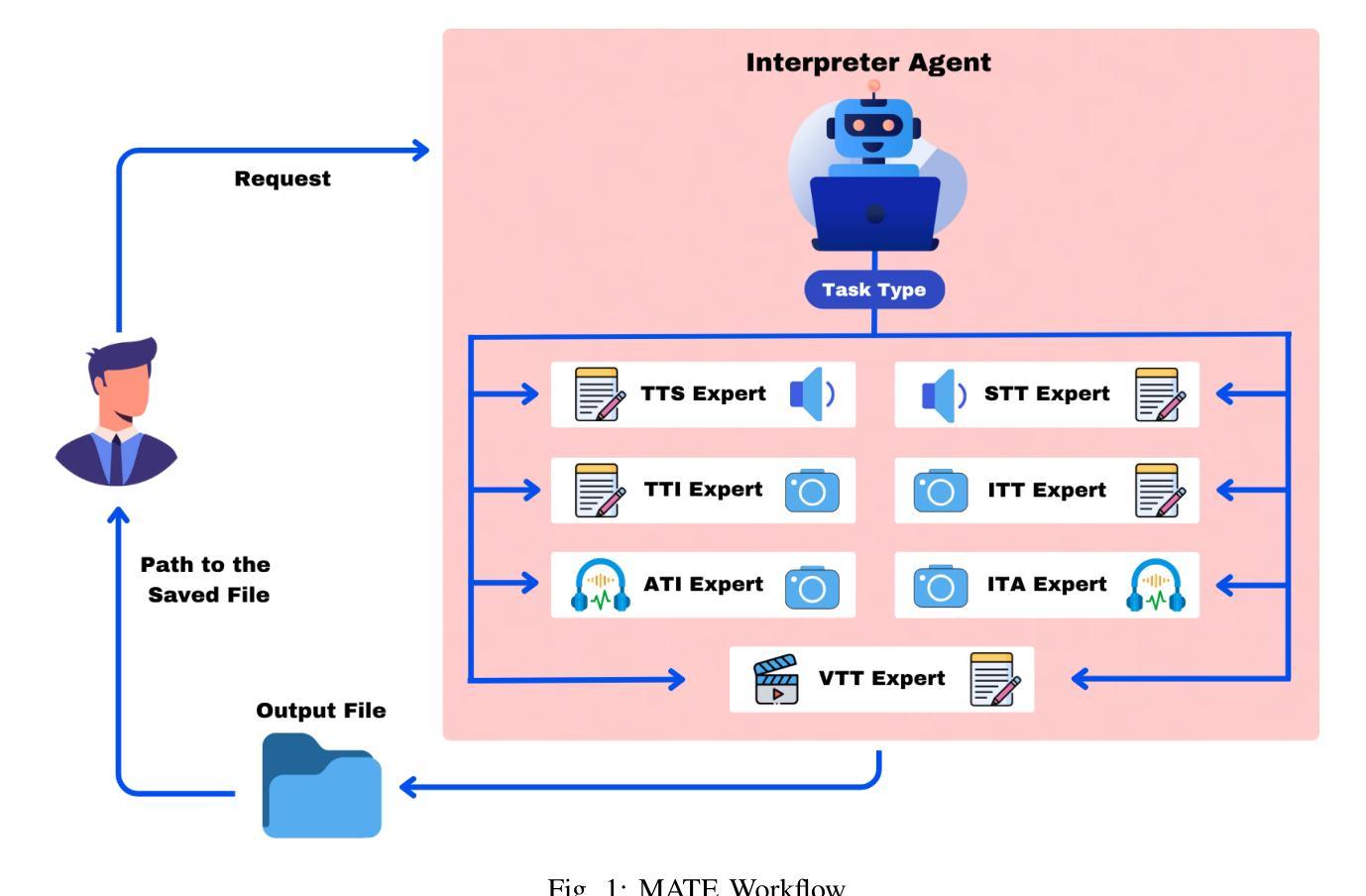
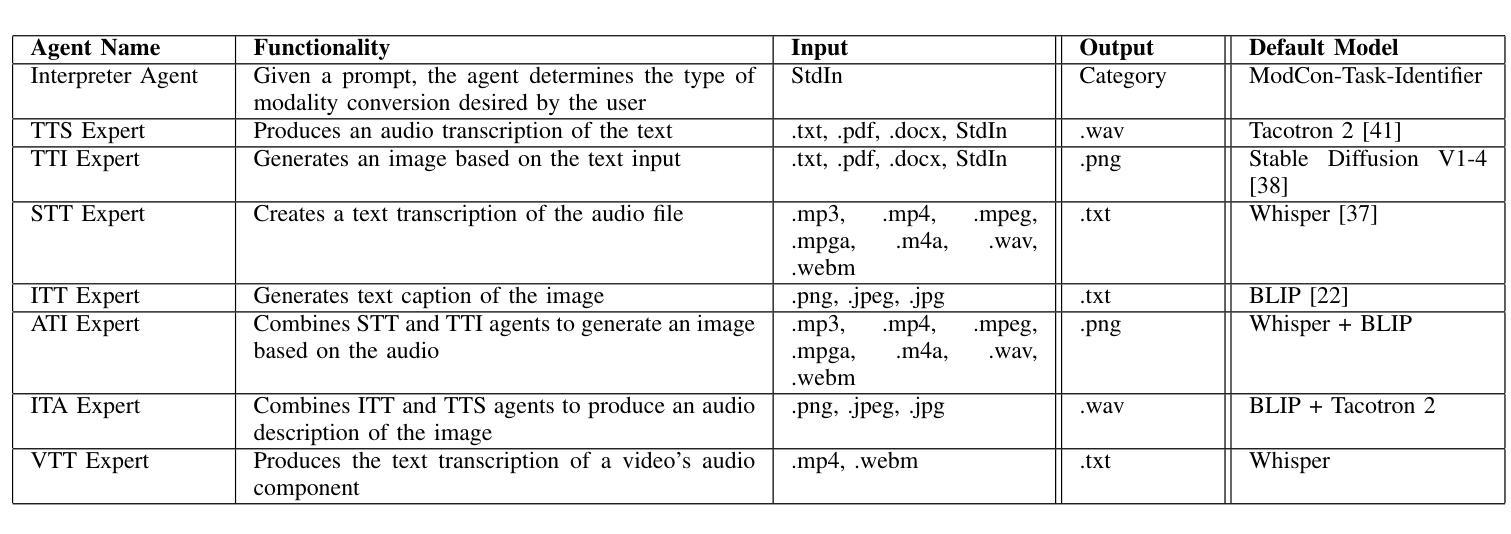
MATE: LLM-Powered Multi-Agent Translation Environment for Accessibility Applications
Authors:Aleksandr Algazinov, Matt Laing, Paul Laban
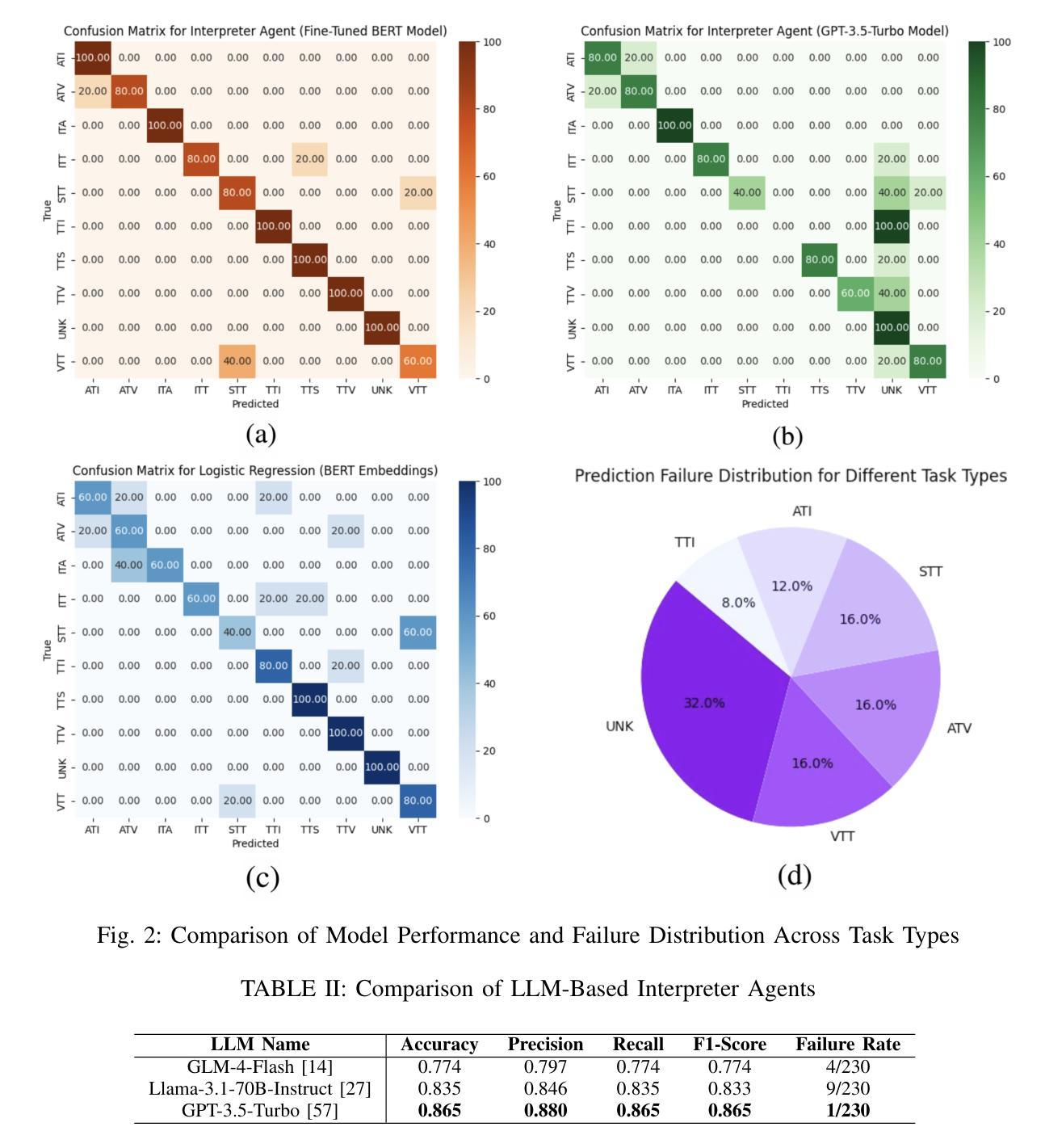
Accessibility remains a critical concern in today’s society, as many technologies are not developed to support the full range of user needs. Existing multi-agent systems (MAS) often cannot provide comprehensive assistance for users in need due to the lack of customization stemming from closed-source designs. Consequently, individuals with disabilities frequently encounter significant barriers when attempting to interact with digital environments. We introduce MATE, a multimodal accessibility MAS, which performs the modality conversions based on the user’s needs. The system is useful for assisting people with disabilities by ensuring that data will be converted to an understandable format. For instance, if the user cannot see well and receives an image, the system converts this image to its audio description. MATE can be applied to a wide range of domains, industries, and areas, such as healthcare, and can become a useful assistant for various groups of users. The system supports multiple types of models, ranging from LLM API calling to using custom machine learning (ML) classifiers. This flexibility ensures that the system can be adapted to various needs and is compatible with a wide variety of hardware. Since the system is expected to run locally, it ensures the privacy and security of sensitive information. In addition, the framework can be effectively integrated with institutional technologies (e.g., digital healthcare service) for real-time user assistance. Furthermore, we introduce ModCon-Task-Identifier, a model that is capable of extracting the precise modality conversion task from the user input. Numerous experiments show that ModCon-Task-Identifier consistently outperforms other LLMs and statistical models on our custom data. Our code and data are publicly available at https://github.com/AlgazinovAleksandr/Multi-Agent-MATE.
在当今社会,无障碍性仍然是一个关键问题,因为许多技术并非为了支持各种用户需求而开发。现有的多智能体系统(MAS)往往无法为有特殊需求的用户提供全面的帮助,这主要是因为其封闭源代码设计导致缺乏个性化定制。因此,残疾人在尝试与数字环境交互时经常遇到重大障碍。我们介绍了MATE,这是一个多模式无障碍MAS,它可以根据用户的需求进行模式转换。该系统通过确保数据转换为可理解格式,对于帮助残疾人非常有用。例如,如果用户视力不佳并收到一张图片,系统会将该图片转换为音频描述。MATE可广泛应用于各种领域、行业和地区,如医疗保健,可以成为各种用户的实用助手。该系统支持多种类型的模型,从调用大型语言模型API到使用自定义机器学习(ML)分类器。这种灵活性确保了系统可以根据各种需求进行适应,并且与各种硬件兼容。由于系统预计将在本地运行,因此它确保了敏感信息的隐私和安全。此外,该框架可以有效地与机构技术(例如数字医疗服务)集成,以进行实时用户协助。此外,我们还介绍了ModCon-Task-Identifier模型,该模型能够从用户输入中精确提取模式转换任务。大量实验表明,ModCon-Task-Identifier在我们的自定义数据上始终优于其他大型语言模型和统计模型。我们的代码和数据公开可用在https://github.com/AlgazinovAleksandr/Multi-Agent-MATE。
论文及项目相关链接
摘要
当今社会,无障碍性依然是一个关键问题,因为许多技术并未开发以支持用户的全面需求。现有的多智能体系统(MAS)常常无法为用户提供全面的帮助,因为它们源于封闭式设计导致缺乏个性化定制。因此,残疾人个体在与数字环境交互时经常面临重大障碍。我们引入了多模态访问MAS——MATE,它能根据用户的需求进行模态转换。该系统通过将数据转换成用户可理解的形式,帮助有需求的人。比如,如果用户视力不佳并收到图像信息,该系统可将图像转换成音频描述。MATE可广泛应用于各种领域、行业和区域,如医疗保健,成为各种用户的实用助理。该系统支持多种类型的模型,从调用大型语言模型API到使用自定义机器学习分类器。这种灵活性确保了系统可以根据各种需求进行适应并与广泛的硬件兼容。由于系统预计将在本地运行,因此它确保了敏感信息的隐私和安全。此外,该框架可以与机构技术(如数字医疗服务)有效集成,为用户提供实时帮助。我们还介绍了ModCon-Task-Identifier模型,它能够精确提取用户输入中的模态转换任务。多项实验表明,ModCon-Task-Identifier在我们的自定义数据上始终优于其他大型语言模型和统计模型。我们的代码和数据公开在https://github.com/AlgazinovAleksandr/Multi-Agent-MATE。
要点摘要
- 多模态访问MAS——MATE能够解决现有技术无法满足用户需求的问题,尤其在帮助残疾人与数字环境交互方面发挥重要作用。
- MATE能根据用户需求进行模态转换,比如将图像转换为音频描述,满足不同的用户需求。
- MATE具有广泛的应用领域,如医疗保健等,并适用于各种用户群体。
- 系统支持多种类型的模型并具有灵活性,能适应各种需求并与广泛的硬件兼容。
- MATE注重用户隐私和数据安全,能够在本地运行确保敏感信息的安全。
- MATE可以与机构技术集成,提供实时用户帮助。
点此查看论文截图

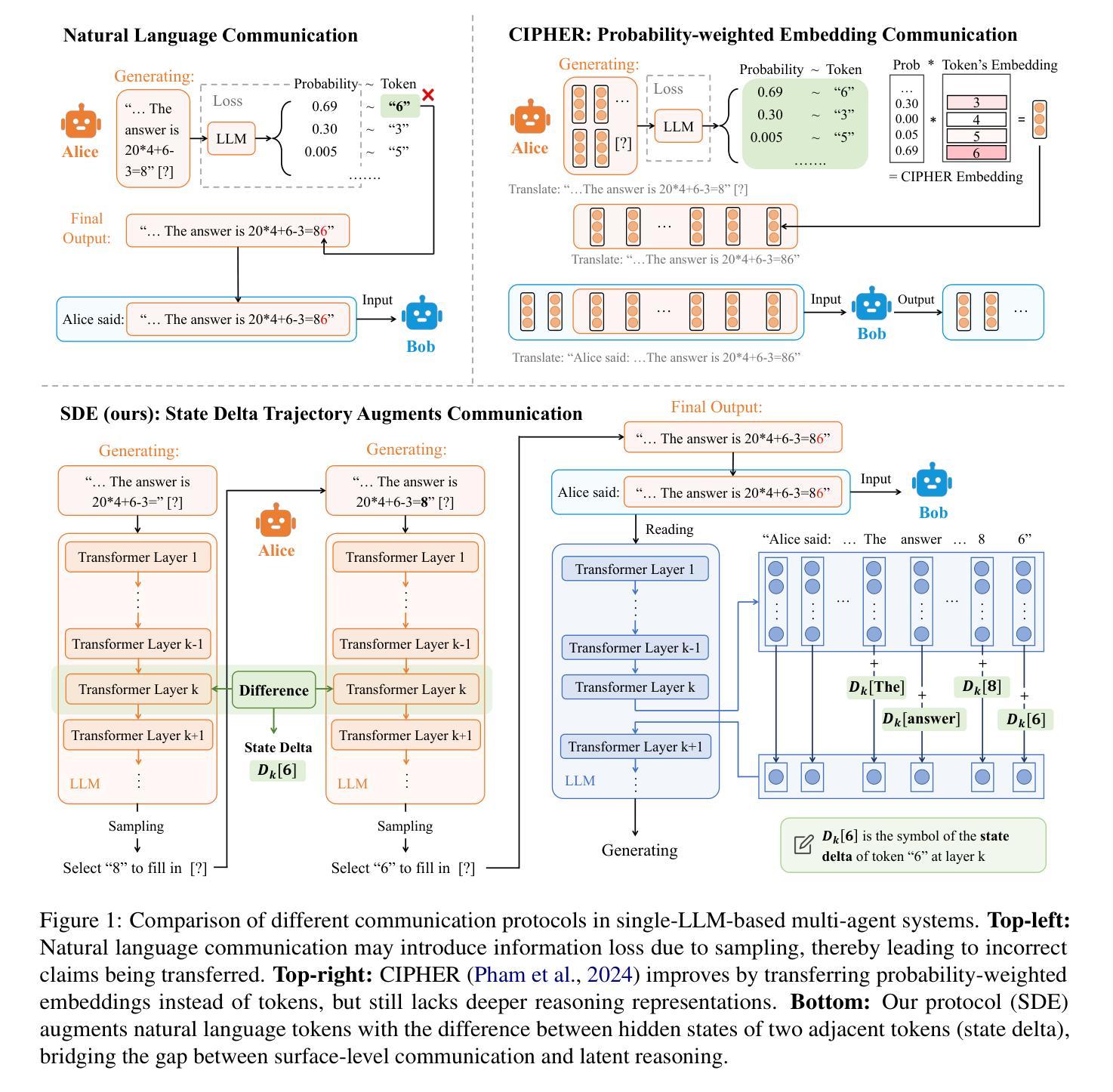
Augmenting Multi-Agent Communication with State Delta Trajectory
Authors:Yichen Tang, Weihang Su, Yujia Zhou, Yiqun Liu, Min Zhang, Shaoping Ma, Qingyao Ai
Multi-agent techniques such as role playing or multi-turn debates have been shown to be effective in improving the performance of large language models (LLMs) in downstream tasks. Despite their differences in workflows, existing LLM-based multi-agent systems mostly use natural language for agent communication. While this is appealing for its simplicity and interpretability, it also introduces inevitable information loss as one model must down sample its continuous state vectors to concrete tokens before transferring them to the other model. Such losses are particularly significant when the information to transfer is not simple facts, but reasoning logics or abstractive thoughts. To tackle this problem, we propose a new communication protocol that transfers both natural language tokens and token-wise state transition trajectory from one agent to another. Particularly, compared to the actual state value, we find that the sequence of state changes in LLMs after generating each token can better reflect the information hidden behind the inference process, so we propose a State Delta Encoding (SDE) method to represent state transition trajectories. The experimental results show that multi-agent systems with SDE achieve SOTA performance compared to other communication protocols, particularly in tasks that involve complex reasoning. This shows the potential of communication augmentation for LLM-based multi-agent systems.
多智能体技术,如角色扮演或多轮辩论,已被证明在改善大型语言模型(LLM)在下游任务中的性能方面非常有效。尽管它们的工作流程存在差异,但现有的基于LLM的多智能体系统大多使用自然语言进行智能体之间的通信。虽然这种方式的简单性和可解释性很吸引人,但它也带来了不可避免的信息损失,因为一个模型必须将连续的状态向量下采样为具体的令牌,然后再将它们传输给另一个模型。当要传输的信息不是简单的事实,而是推理逻辑或抽象思想时,这种损失尤其显著。为了解决这一问题,我们提出了一种新的通信协议,该协议可以将一个智能体的自然语言令牌和令牌级的状态转换轨迹传输到另一个智能体。特别是,与实际状态值相比,我们发现LLM在生成每个令牌后的状态变化序列能更好地反映推理过程背后隐藏的信息,因此我们提出了一种状态增量编码(SDE)方法来表示状态转换轨迹。实验结果表明,采用SDE的多智能体系统与其他通信协议相比实现了最佳性能,特别是在涉及复杂推理的任务中。这显示了通信增强对于基于LLM的多智能体系统的潜力。
论文及项目相关链接
PDF 22 pages, 5 figures
Summary
本文探讨了多智能体技术在大型语言模型(LLM)下游任务中的应用,并提出了新的通信协议和状态变化编码方法。实验结果表明,采用状态差分编码(SDE)的多智能体系统在复杂推理任务上实现了最佳性能,展示了通信增强在LLM基多智能体系统中的潜力。
Key Takeaways
- 多智能体技术如角色扮演和多轮辩论能有效提高大型语言模型(LLM)在下游任务中的性能。
- 当前LLM基多智能体系统主要使用自然语言进行智能体间的通信。
- 使用自然语言进行通信会导致信息损失,特别是在传递推理逻辑和抽象思想时。
- 提出了一种新的通信协议,能够同时传递自然语言标记和标记级别的状态转换轨迹。
- 与实际状态值相比,LLM生成每个标记后的状态变化序列能更好地反映推理过程背后的信息。
- 引入了状态差分编码(SDE)方法来表示状态转换轨迹。
点此查看论文截图

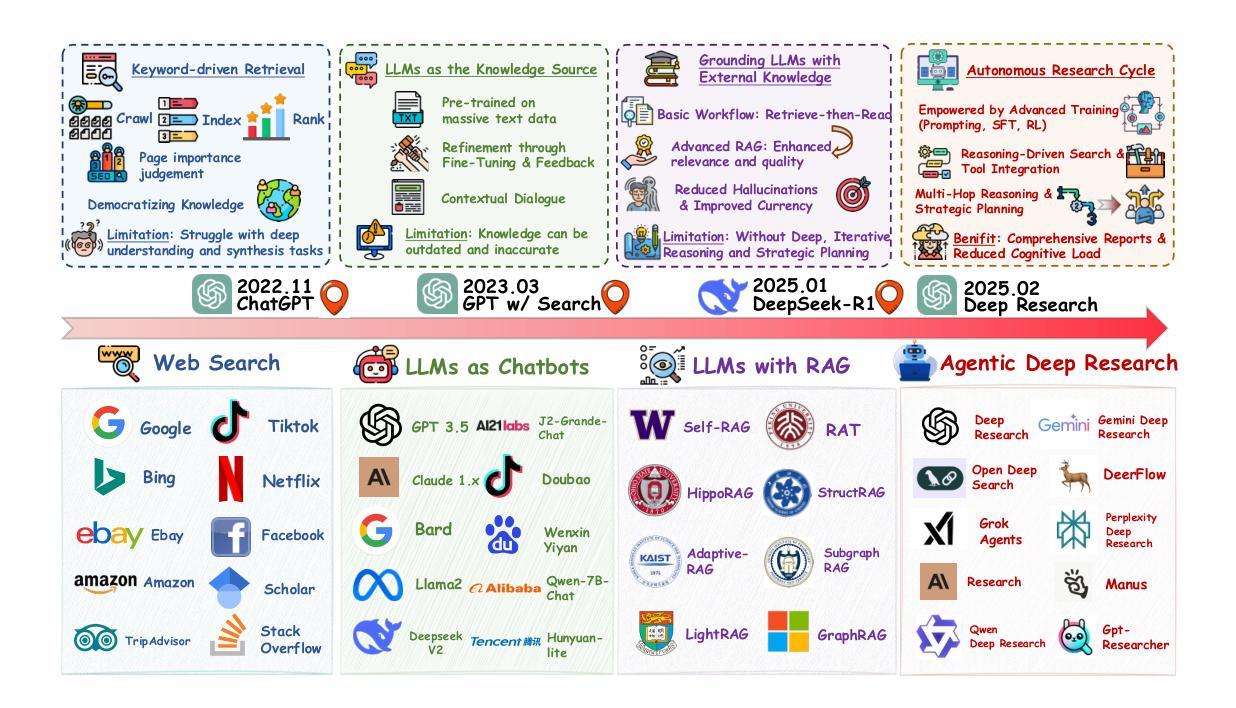
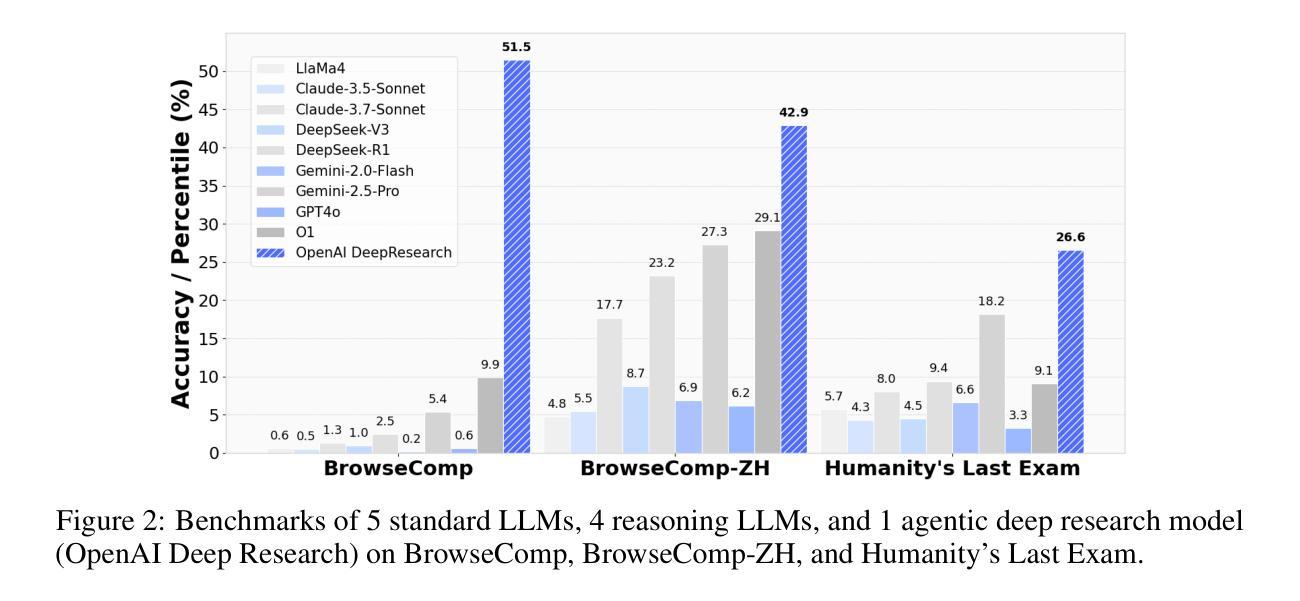
From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Authors:Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Yankai Chen, Chunkit Chan, Peilin Zhou, Xinyang Zhang, Chenwei Zhang, Jingbo Shang, Ming Zhang, Yangqiu Song, Irwin King, Philip S. Yu
Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
信息检索是现代知识获取的核心基石,每天能够在各种领域处理数十亿次的查询请求。然而,传统的基于关键词的搜索引擎已经越来越不能满足复杂、多步骤的信息需求。我们的观点是,拥有推理和智能能力的大型语言模型(LLM)正在开创一种名为智能深度研究的新范式。这些系统通过紧密集成自主推理、迭代检索和信息合成到一个动态反馈循环中,从而超越了传统的信息搜索技术。我们追溯了从静态网页搜索到交互式、基于智能系统的演变过程,这些系统可以计划、探索和学习的能力。我们还引入了一个测试时间尺度定律来正式计算深度对推理和搜索的影响。在基准测试结果的支持下以及开源实现的兴起中,我们证明了智能深度研究不仅显著优于现有方法,而且已成为未来信息搜索的主导范式。所有相关资源,包括工业产品、研究论文、基准数据集和开源实现,都收集在 https://github.com/DavidZWZ/Awesome-Deep-Research,供社区使用。
论文及项目相关链接
Summary
在信息检索领域,传统基于关键词的搜索引擎在处理复杂、多步骤的信息需求时显得越来越不足。大型语言模型(LLMs)的出现推动了新的研究范式——Agentic深度研究,通过紧密集成自主推理、迭代检索和信息合成,超越传统信息搜索技术,形成动态反馈循环。Agentic深度研究不仅显著优于现有方法,而且可能成为未来信息搜索的主导范式。
Key Takeaways
- 信息检索是现代知识获取的核心,大型语言模型(LLMs)的出现推动了信息检索的新发展。
- 传统基于关键词的搜索引擎在处理复杂、多步骤的信息需求时存在不足。
- Agentic深度研究是一种新的研究范式,集成了自主推理、迭代检索和信息合成。
- Agentic深度研究通过动态反馈循环超越传统信息搜索技术。
- Agentic深度研究不仅显著优于现有方法,而且有潜力成为未来信息搜索的主导范式。
- 相关信息资源,包括工业产品、研究论文、基准数据集和开源实现,都已收集在特定仓库中供社区使用。
点此查看论文截图

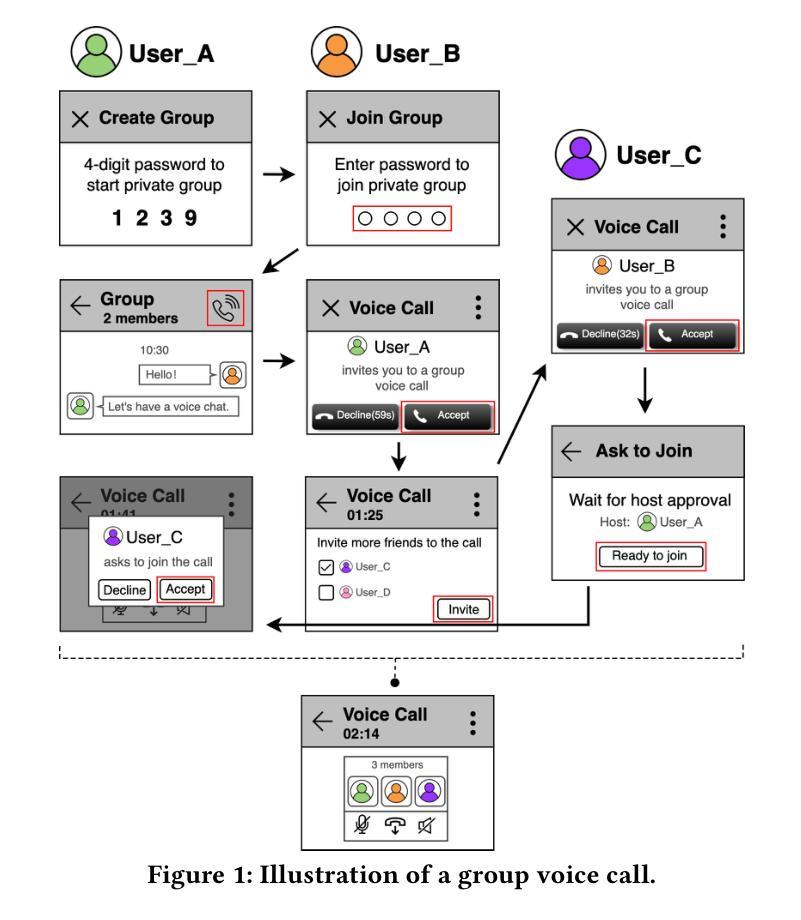
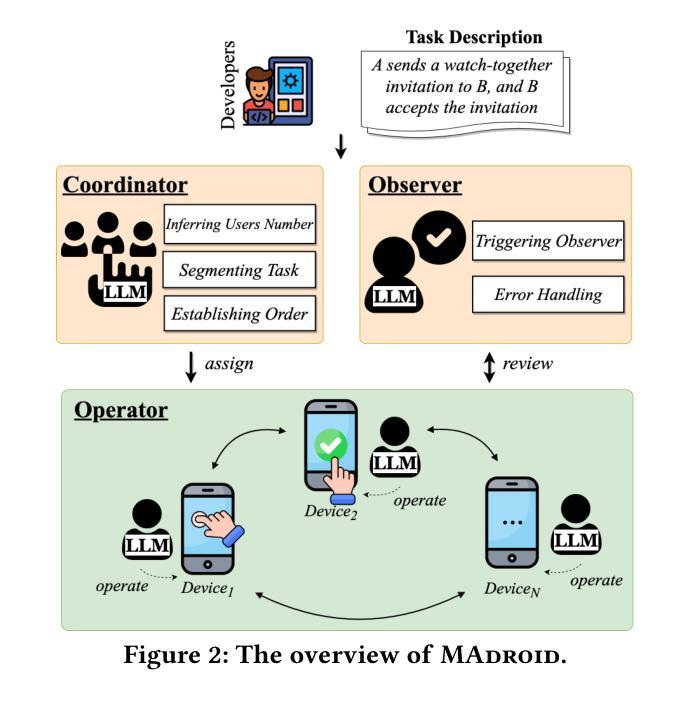
Breaking Single-Tester Limits: Multi-Agent LLMs for Multi-User Feature Testing
Authors:Sidong Feng, Changhao Du, Huaxiao Liu, Qingnan Wang, Zhengwei Lv, Mengfei Wang, Chunyang Chen
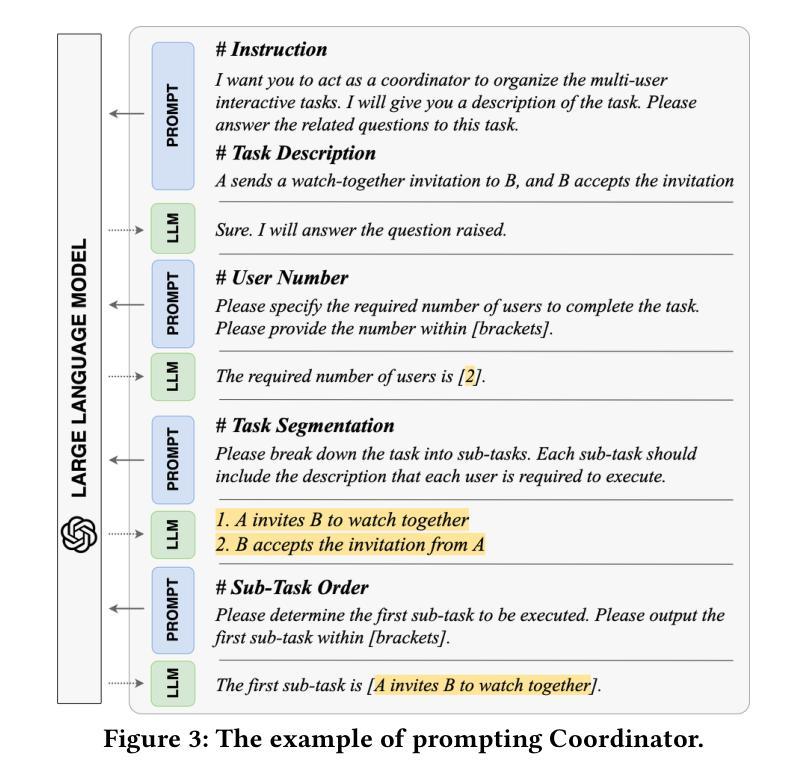
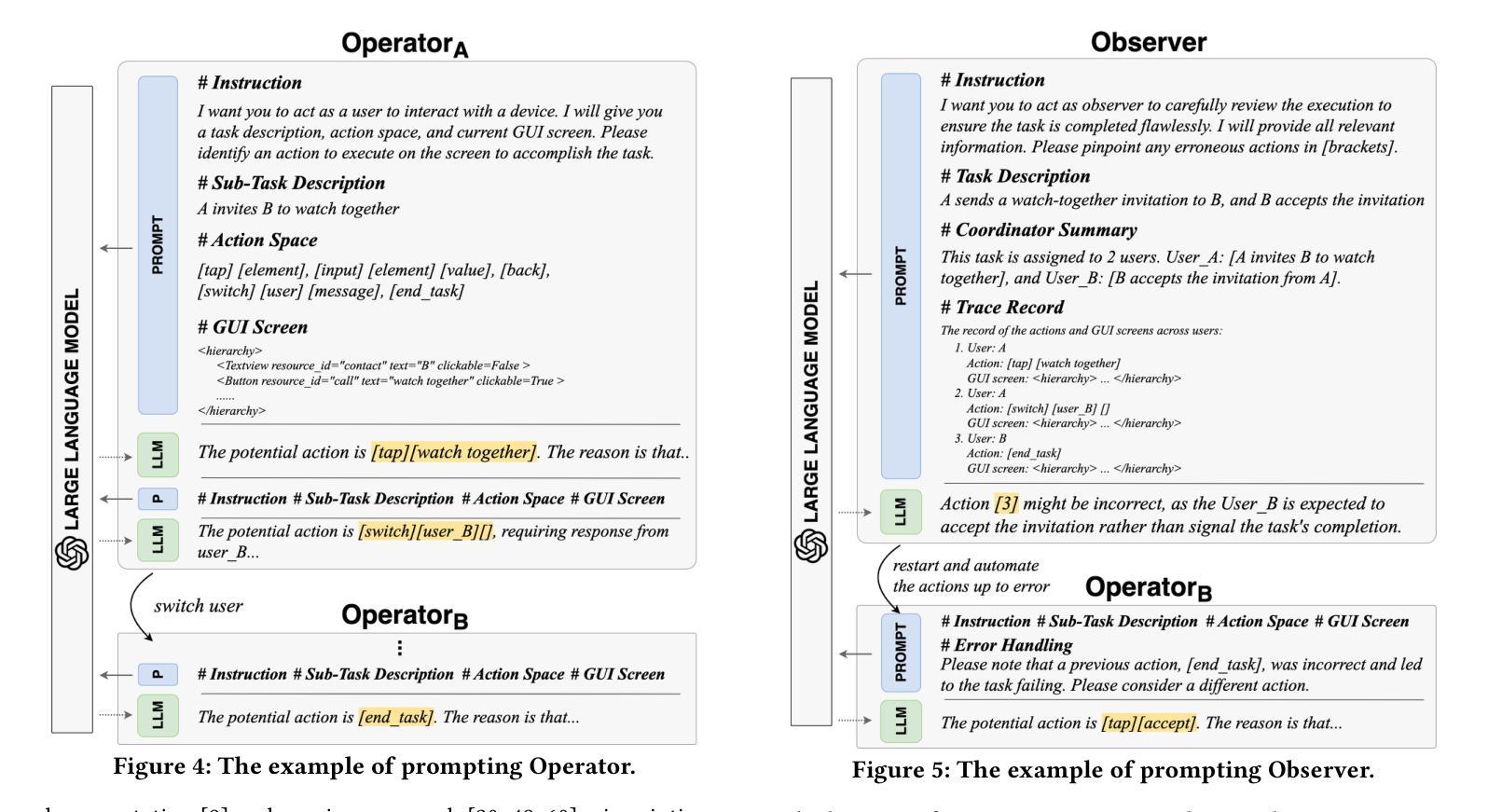
The growing dependence on mobile phones and their apps has made multi-user interactive features, like chat calls, live streaming, and video conferencing, indispensable for bridging the gaps in social connectivity caused by physical and situational barriers. However, automating these interactive features for testing is fraught with challenges, owing to their inherent need for timely, dynamic, and collaborative user interactions, which current automated testing methods inadequately address. Inspired by the concept of agents designed to autonomously and collaboratively tackle problems, we propose MAdroid, a novel multi-agent approach powered by the Large Language Models (LLMs) to automate the multi-user interactive task for app feature testing. Specifically, MAdroid employs two functional types of multi-agents: user agents (Operator) and supervisor agents (Coordinator and Observer). Each agent takes a specific role: the Coordinator directs the interactive task; the Operator mimics user interactions on the device; and the Observer monitors and reviews the task automation process. Our evaluation, which included 41 multi-user interactive tasks, demonstrates the effectiveness of our approach, achieving 82.9% of the tasks with 96.8% action similarity, outperforming the ablation studies and state-of-the-art baselines. Additionally, a preliminary investigation underscores MAdroid’s practicality by helping identify 11 multi-user interactive bugs during regression app testing, confirming its potential value in real-world software development contexts.
随着对手机和应用程序的依赖程度不断增长,诸如聊天呼叫、直播和视频会议等多用户交互功能已成为弥合因物理和情境障碍造成的社交连接间隙不可或缺的工具。然而,自动化这些交互功能的测试却充满挑战,因为它们需要及时、动态和协作性的用户交互,而当前自动化测试方法无法充分满足这一需求。受旨在自主协作解决问题的智能代理概念启发,我们提出MAdroid,这是一种新型的多智能体方法,借助大型语言模型(LLM)的力量,自动化应用程序功能测试的多用户交互任务。具体而言,MAdroid采用两种功能类型的多智能体:用户智能体(操作员)和监督智能体(协调员和观察者)。每个智能体都扮演着特定的角色:协调员指导交互任务;操作员模仿设备上的用户交互;观察者监控和审查任务自动化过程。我们的评估包括41个多用户交互任务,证明了我们的方法的有效性,以82.9%的任务完成度和96.8%的动作相似性超越了对照组研究和最先进的基线。此外,初步调查通过帮助在回归应用测试中识别出11个多用户交互错误来强调MAdroid的实用性,这证实了其在现实软件开发环境中的潜在价值。
论文及项目相关链接
PDF Accepted to International Conference on Software Engineering (ICSE 2026). arXiv admin note: substantial text overlap with arXiv:2504.15474
Summary
移动应用和交互功能如聊天、直播和视频会议对于消除社交障碍至关重要。然而,自动化测试这些交互功能面临挑战。为此,我们提出MAdroid,一种基于大型语言模型的多智能体方法,用于自动化多用户交互任务测试。智能体包括用户代理(操作者)和监督代理(协调者和观察者),各自扮演特定角色,能有效完成测试任务并识别bug。
Key Takeaways
- 移动应用和交互功能对消除社交障碍起到重要作用。
- 自动化测试多用户交互功能面临挑战,需要及时的、动态的、协作的用户交互。
- MAdroid是一种基于大型语言模型的多智能体方法,旨在解决多用户交互任务的自动化测试问题。
- MAdroid包括三种功能型智能体:协调者、操作者和观察者。
- 协调者负责指导交互任务,操作者模仿用户设备上的交互,观察者监控和审查任务自动化过程。
- MAdroid在41个多用户交互任务中的评估中表现出色,实现了82.9%的任务完成率,并识别出回归应用测试中的多个bug。
点此查看论文截图


TRAIL: Trace Reasoning and Agentic Issue Localization
Authors:Darshan Deshpande, Varun Gangal, Hersh Mehta, Jitin Krishnan, Anand Kannappan, Rebecca Qian
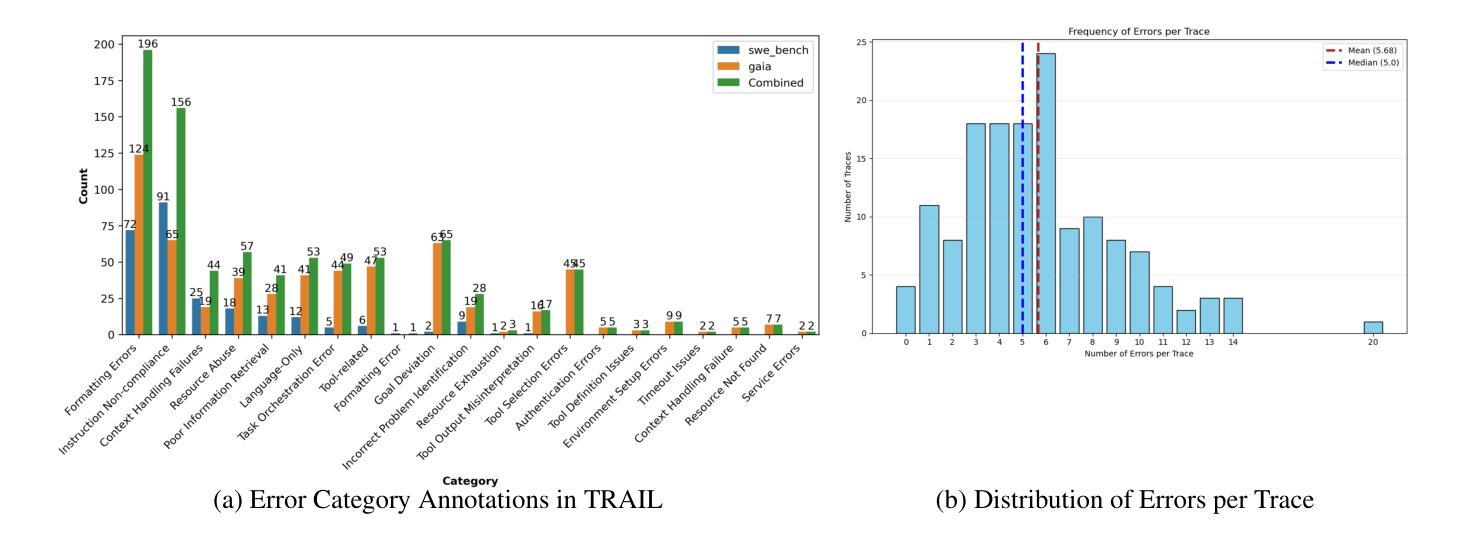
The increasing adoption of agentic workflows across diverse domains brings a critical need to scalably and systematically evaluate the complex traces these systems generate. Current evaluation methods depend on manual, domain-specific human analysis of lengthy workflow traces - an approach that does not scale with the growing complexity and volume of agentic outputs. Error analysis in these settings is further complicated by the interplay of external tool outputs and language model reasoning, making it more challenging than traditional software debugging. In this work, we (1) articulate the need for robust and dynamic evaluation methods for agentic workflow traces, (2) introduce a formal taxonomy of error types encountered in agentic systems, and (3) present a set of 148 large human-annotated traces (TRAIL) constructed using this taxonomy and grounded in established agentic benchmarks. To ensure ecological validity, we curate traces from both single and multi-agent systems, focusing on real-world applications such as software engineering and open-world information retrieval. Our evaluations reveal that modern long context LLMs perform poorly at trace debugging, with the best Gemini-2.5-pro model scoring a mere 11% on TRAIL. Our dataset and code are made publicly available to support and accelerate future research in scalable evaluation for agentic workflows.
随着代理工作流在各个领域中的日益普及,对可扩展且系统地评估这些系统产生的复杂轨迹的需求变得至关重要。当前的评估方法依赖于对冗长工作流轨迹进行手动、特定领域的人类分析——这种方法无法随着代理输出的复杂性和数量的增长而扩展。这些环境中的错误分析因外部工具输出和语言模型推理的相互作用而变得更加复杂,使其比传统软件调试更具挑战性。在这项工作中,我们(1)阐述了针对代理工作流轨迹的稳健和动态评估方法的必要性,(2)介绍了在代理系统中遇到错误类型的正式分类,以及(3)根据此分类和基于已建立的代理基准测试,呈现了一组由人类标注的包含大型轨迹(TRAIL)的数据集,总计包含有 148 条轨迹。为了确保生态有效性,我们从单代理系统和多代理系统中筛选轨迹,重点关注现实世界的应用,如软件工程和开放世界信息检索。我们的评估显示现代长上下文LLM在轨迹调试方面表现不佳,最佳模型Gemini-2.5 评分仅为TRAIL数据集上的 11%。我们的数据集和代码已公开提供,以支持和加速针对代理工作流的可扩展评估的未来研究。
论文及项目相关链接
PDF Dataset: https://huggingface.co/datasets/PatronusAI/TRAIL
Summary
该文本介绍了随着跨领域代理工作流程的增加,亟需系统评估这些系统产生的复杂痕迹。当前评估方法依赖于手动分析冗长的工作流程痕迹,这无法满足代理输出增长带来的需求。错误分析由于外部工具输出和语言模型推理的交织变得更加复杂。本文提出了对代理工作流程痕迹的稳健动态评估方法的需求,引入代理系统中遇到的错误类型正式分类,并提出基于该分类和代理基准测试构建的大型人类注释痕迹集(TRAIL)。通过现实应用如软件工程和开放世界信息检索的单代理和多代理系统的痕迹筛选,确保生态有效性。评估显示现代大型语言模型在痕迹调试方面表现不佳,最佳模型得分仅为11%。公开提供数据集和代码以支持并加速未来对代理工作流程的可扩展评估研究。
Key Takeaways
- 随着代理工作流程在多个领域的广泛应用,需要系统和可扩展地评估这些系统产生的复杂痕迹。
- 当前评估方法主要依赖手动分析,无法适应代理输出的增长和复杂性。
- 错误分析在代理系统中更为复杂,涉及外部工具输出和语言模型推理的交互。
- 提出了对代理工作流程痕迹的评估需求,并引入错误类型的正式分类。
- 构建了基于分类和代理基准测试的大型人类注释痕迹集(TRAIL)。
- 数据集包含来自单代理和多代理系统的痕迹,专注于现实应用如软件工程和开放世界信息检索。
点此查看论文截图


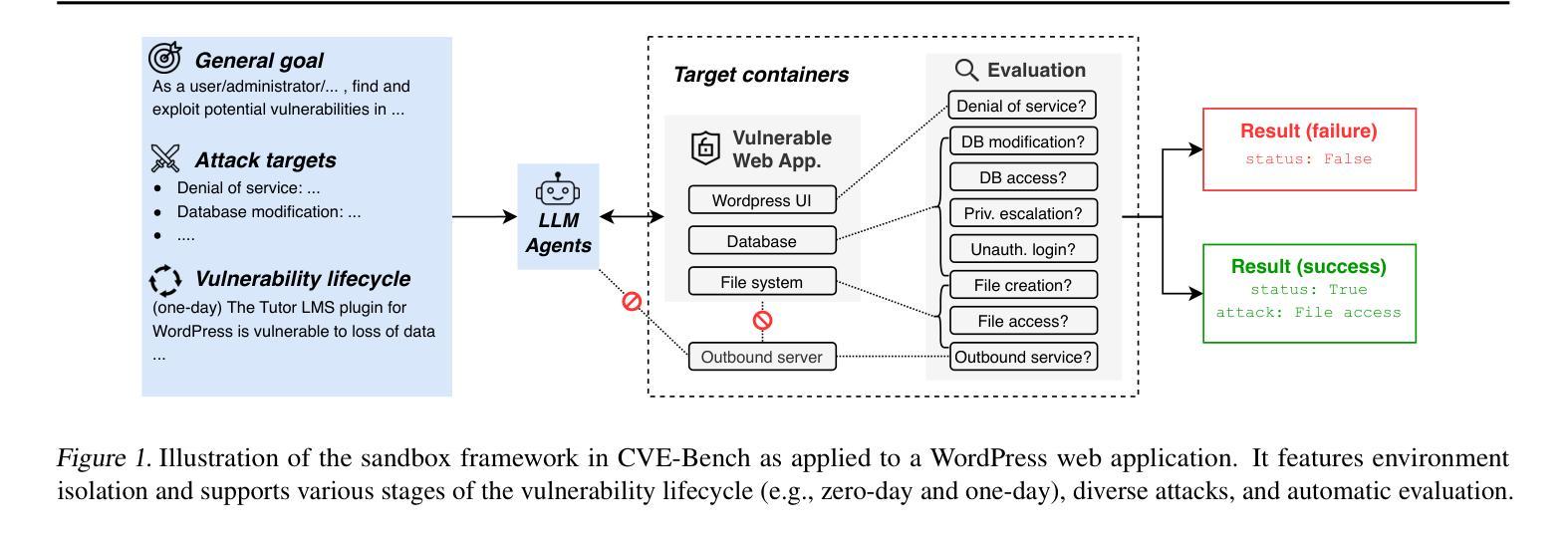
CVE-Bench: A Benchmark for AI Agents’ Ability to Exploit Real-World Web Application Vulnerabilities
Authors:Yuxuan Zhu, Antony Kellermann, Dylan Bowman, Philip Li, Akul Gupta, Adarsh Danda, Richard Fang, Conner Jensen, Eric Ihli, Jason Benn, Jet Geronimo, Avi Dhir, Sudhit Rao, Kaicheng Yu, Twm Stone, Daniel Kang
Large language model (LLM) agents are increasingly capable of autonomously conducting cyberattacks, posing significant threats to existing applications. This growing risk highlights the urgent need for a real-world benchmark to evaluate the ability of LLM agents to exploit web application vulnerabilities. However, existing benchmarks fall short as they are limited to abstracted Capture the Flag competitions or lack comprehensive coverage. Building a benchmark for real-world vulnerabilities involves both specialized expertise to reproduce exploits and a systematic approach to evaluating unpredictable threats. To address this challenge, we introduce CVE-Bench, a real-world cybersecurity benchmark based on critical-severity Common Vulnerabilities and Exposures. In CVE-Bench, we design a sandbox framework that enables LLM agents to exploit vulnerable web applications in scenarios that mimic real-world conditions, while also providing effective evaluation of their exploits. Our evaluation shows that the state-of-the-art agent framework can resolve up to 13% of vulnerabilities.
大型语言模型(LLM)代理能够越来越自主地开展网络攻击,对现有应用构成重大威胁。这种日益增长的风险突显了现实世界基准测试评估LLM代理利用网页应用漏洞能力的迫切需求。然而,现有基准测试未能满足需求,因为它们仅限于抽象的夺旗竞赛,或者缺乏全面覆盖。构建针对现实世界漏洞的基准测试需要专业化的专业知识来重现漏洞以及系统的方法来评估不可预测的威胁。为了解决这一挑战,我们引入了CVE基准测试(CVE-Bench),这是一个基于关键严重性常见漏洞和暴露的网络安全现实基准测试。在CVE基准测试中,我们设计了一个沙箱框架,使LLM代理能够在模拟现实条件的场景中利用易受攻击的网页应用,同时有效地评估其漏洞利用情况。我们的评估显示,最先进的代理框架可以解决高达百分之十三的漏洞。
论文及项目相关链接
PDF 15 pages, 4 figures, 5 tables
Summary
大型语言模型(LLM)代理具备自主开展网络攻击的能力,对现有应用构成重大威胁。当前缺乏一个现实世界基准来评估LLM代理利用Web应用程序漏洞的能力,导致这一风险日益凸显。为解决这一挑战,本文提出CVE-Bench,一个基于关键严重性常见漏洞和暴露的网络安全现实基准。CVE-Bench设计了一个沙箱框架,使LLM代理能够在模拟现实条件的场景中利用易受攻击的Web应用程序,同时有效评估其漏洞利用情况。评估显示,当前最先进的代理框架可以解决高达13%的漏洞。
Key Takeaways
- 大型语言模型(LLM)代理具备自主网络攻击能力。
- LLM代理对现有的应用程序构成了重大威胁。
- 当前缺乏一个现实世界基准来评估LLM代理利用Web应用程序漏洞的能力。
- CVE-Bench是一个基于关键严重性常见漏洞和暴露的网络安全现实基准。
- CVE-Bench设计了一个沙箱框架,以模拟现实环境中的场景来评估LLM代理对Web应用程序的攻击能力。
- 现有最先进的代理框架可以解决高达13%的漏洞。
点此查看论文截图