⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-26 更新
Scaling Speculative Decoding with Lookahead Reasoning
Authors:Yichao Fu, Rui Ge, Zelei Shao, Zhijie Deng, Hao Zhang
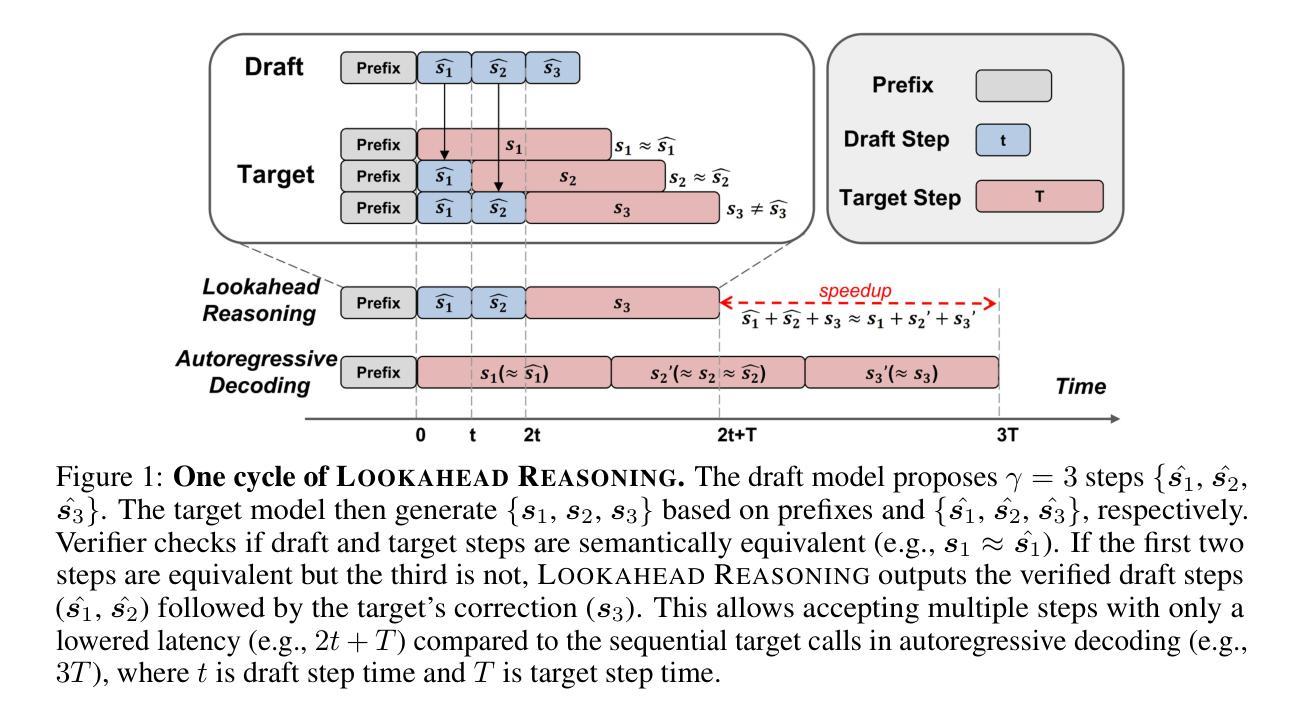
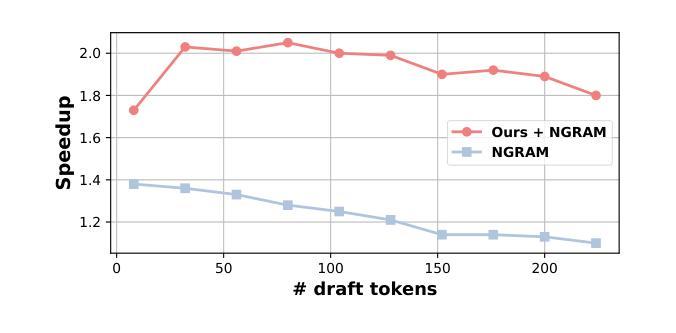
Reasoning models excel by generating long chain-of-thoughts, but decoding the resulting thousands of tokens is slow. Token-level speculative decoding (SD) helps, but its benefit is capped, because the chance that an entire $\gamma$-token guess is correct falls exponentially as $\gamma$ grows. This means allocating more compute for longer token drafts faces an algorithmic ceiling – making the speedup modest and hardware-agnostic. We raise this ceiling with Lookahead Reasoning, which exploits a second, step-level layer of parallelism. Our key insight is that reasoning models generate step-by-step, and each step needs only to be semantically correct, not exact token matching. In Lookahead Reasoning, a lightweight draft model proposes several future steps; the target model expands each proposal in one batched pass, and a verifier keeps semantically correct steps while letting the target regenerate any that fail. Token-level SD still operates within each reasoning step, so the two layers of parallelism multiply. We show Lookahead Reasoning lifts the peak speedup of SD both theoretically and empirically. Across GSM8K, AIME, and other benchmarks, Lookahead Reasoning improves the speedup of SD from 1.4x to 2.1x while preserving answer quality, and its speedup scales better with additional GPU throughput. Our code is available at https://github.com/hao-ai-lab/LookaheadReasoning
推理模型通过生成长链思维表现出色,但解码产生的成千上万个令牌却很慢。令牌级别的投机解码(SD)有所帮助,但其好处是有限的,因为整个$\gamma$-令牌的猜测正确的机会随着$\gamma$的增长而指数级下降。这意味着为更长的令牌草稿分配更多的计算量会面临算法天花板——使加速效果温和且与硬件无关。我们通过前瞻性推理来提高这个上限,它利用第二层步骤级别的并行性。我们的关键见解是,推理模型是逐步生成的,每个步骤只需要语义正确,而不需要精确的令牌匹配。在前瞻性推理中,一个轻量级的草稿模型会提出几个未来步骤;目标模型在一次批量传递中扩展每个提案,验证器则保持语义正确的步骤,同时让目标重新生成任何失败的步骤。令牌级别的SD仍然在每个推理步骤中运行,因此这两层并行性是相乘的。我们表明,前瞻性推理从理论和实际上提高了SD的峰值加速效果。在GSM8K、AIME和其他基准测试中,前瞻性推理将SD的加速比从1.4倍提高到2.1倍,同时保持答案质量,并且其加速效果随着GPU吞吐量的增加而更好地扩展。我们的代码可在https://github.com/hao-ai-lab/LookaheadReasoning中找到。
论文及项目相关链接
Summary
这篇文本讨论了推理模型生成长链思维时的效率问题。虽然存在诸如token级别推测解码等技术,但其速度提升有限。作者提出了Lookahead Reasoning方法,通过在步骤级别引入并行性来提高效率。该方法允许模型提出多个未来步骤的草案,并在一次批量传递中扩展每个提案。验证器保留语义正确的步骤,并让目标模型重新生成失败的步骤。Lookahead Reasoning提升了SD的速度提升效果,同时在多个基准测试中保持了答案质量。
Key Takeaways
- 推理模型在长链思维生成过程中面临效率挑战。
- Token级别推测解码(SD)虽然有所帮助,但其效益有限。
- Lookahead Reasoning方法通过引入步骤级别的并行性来提高效率。
- Lookahead Reasoning允许模型提出多个未来步骤的草案,并一次性扩展。
- 验证器在方法中起到关键作用,保留语义正确的步骤。
- Lookahead Reasoning提升了SD的速度提升效果,并在多个测试中保持了答案质量。
点此查看论文截图


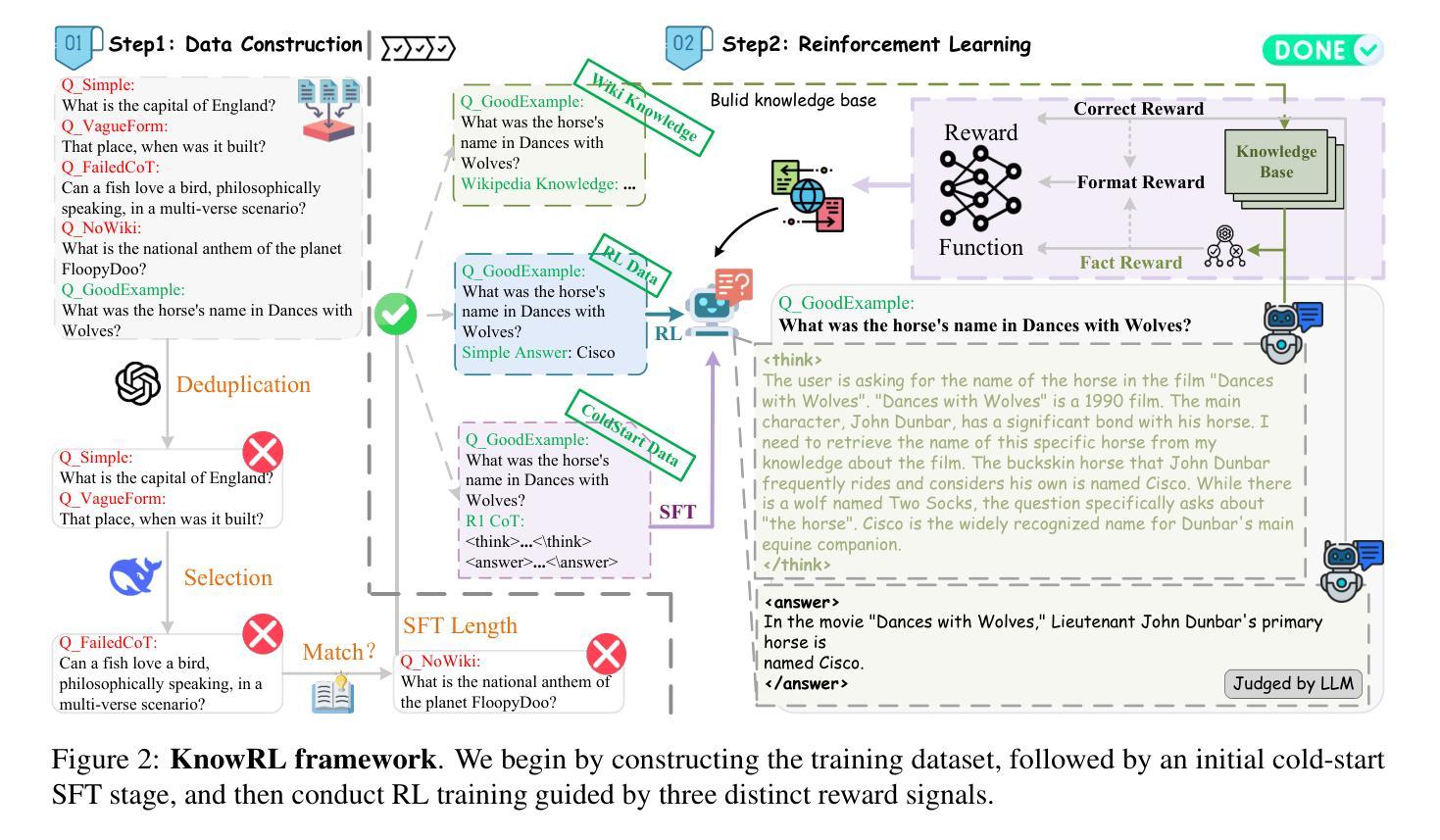
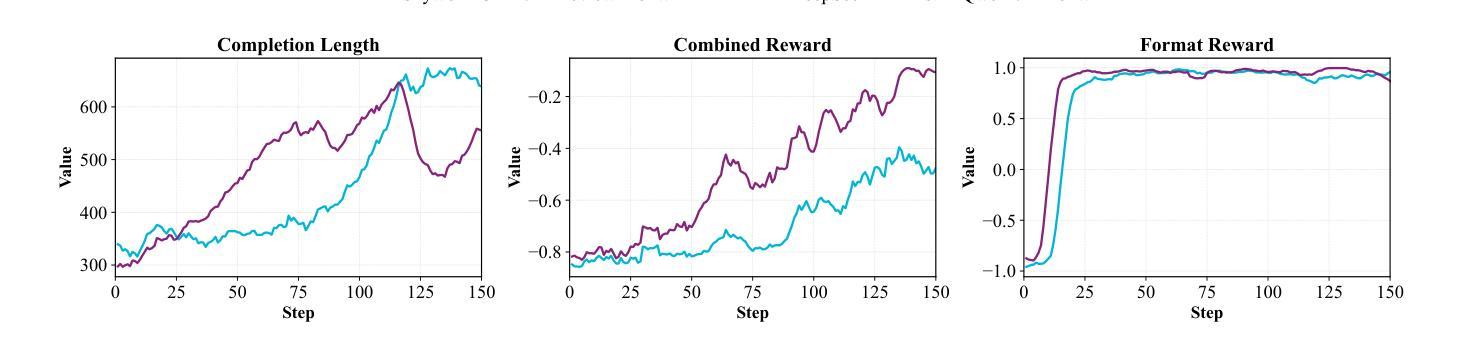
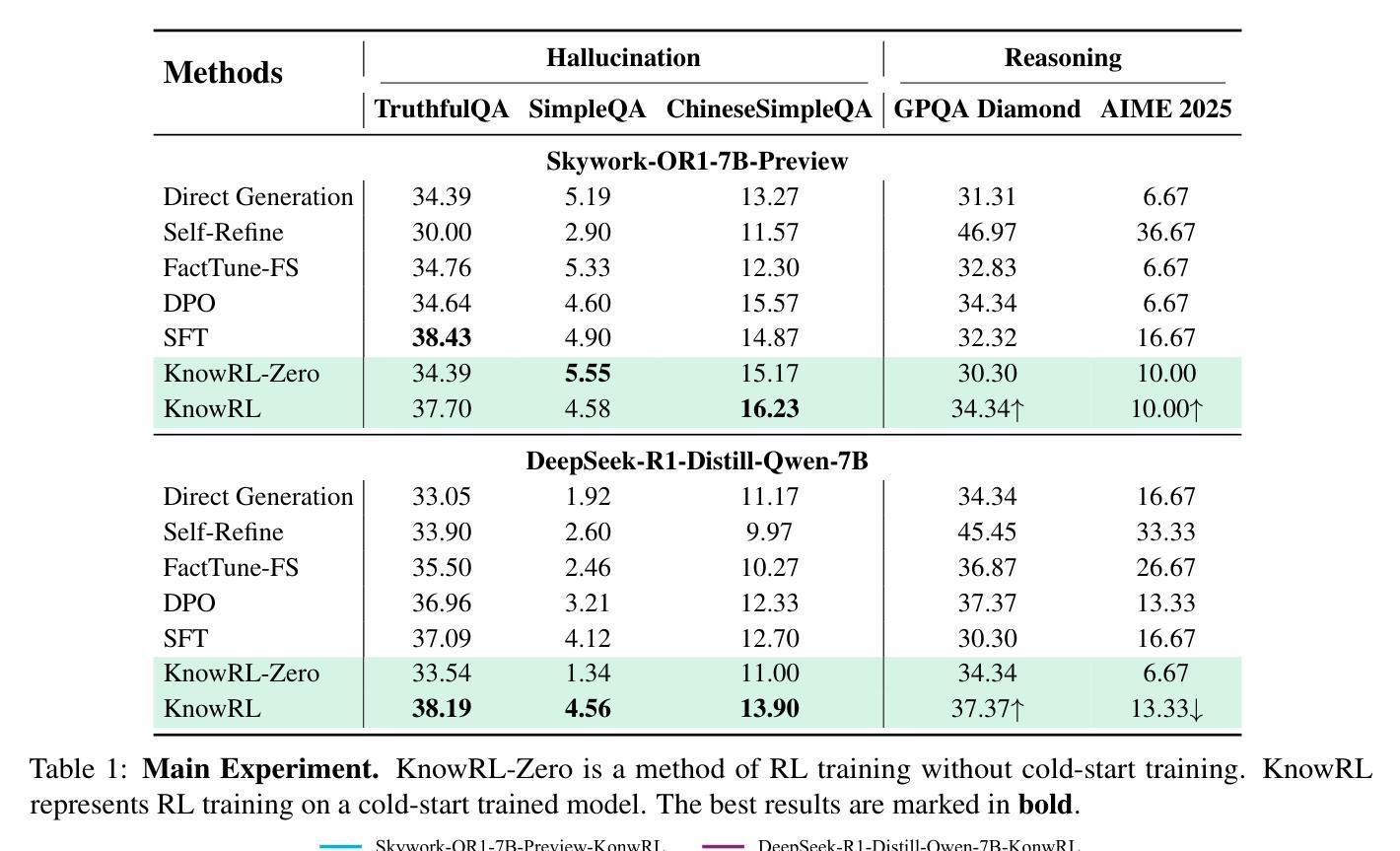
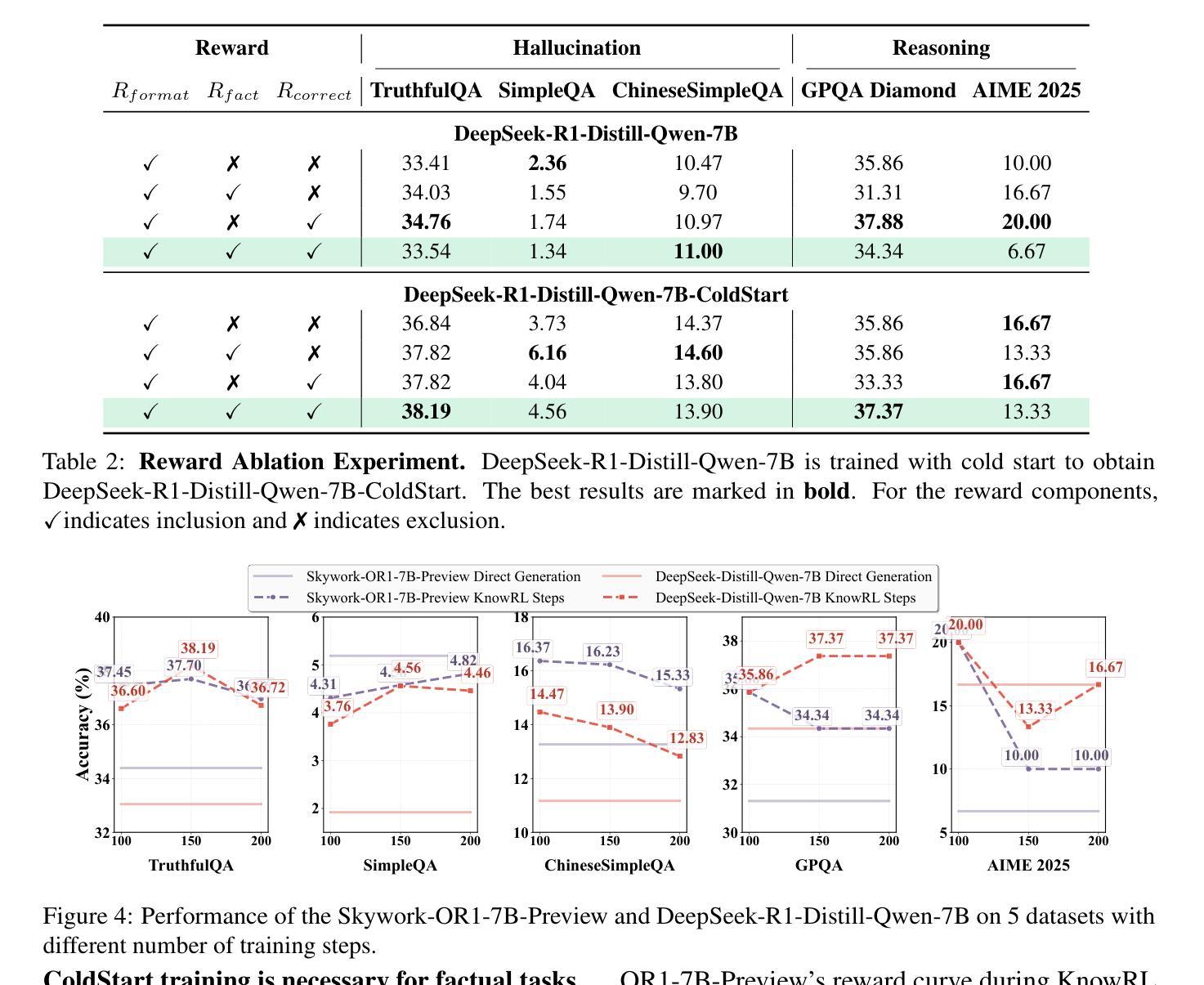
KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Authors:Baochang Ren, Shuofei Qiao, Wenhao Yu, Huajun Chen, Ningyu Zhang
Large Language Models (LLMs), particularly slow-thinking models, often exhibit severe hallucination, outputting incorrect content due to an inability to accurately recognize knowledge boundaries during reasoning. While Reinforcement Learning (RL) can enhance complex reasoning abilities, its outcome-oriented reward mechanism often lacks factual supervision over the thinking process, further exacerbating the hallucination problem. To address the high hallucination in slow-thinking models, we propose Knowledge-enhanced RL, KnowRL. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process. Experimental results on three hallucination evaluation datasets and two reasoning evaluation datasets demonstrate that KnowRL effectively mitigates hallucinations in slow-thinking models while maintaining their original strong reasoning capabilities. Our code is available at https://github.com/zjunlp/KnowRL.
大型语言模型(LLM),尤其是慢思考模型,常常表现出严重的幻觉,由于推理过程中无法准确识别知识边界,从而输出错误内容。虽然强化学习(RL)可以增强复杂推理能力,但其以结果为导向的奖励机制往往缺乏对思考过程的真实监督,从而加剧了幻觉问题。为了解决慢思考模型中的高幻觉问题,我们提出了知识增强RL,即KnowRL。KnowRL通过将基于知识验证的真实性奖励融入RL训练过程,指导模型进行基于事实的慢思考,帮助它们识别知识边界。KnowRL的特色在于,它针对性地在实际推理步骤中奖励对事实的遵循,从而培育一个更可靠的思考过程。在三个幻觉评估数据集和两个推理评估数据集上的实验结果表明,KnowRL有效减轻了慢思考模型中的幻觉问题,同时保持了其原有的强大推理能力。我们的代码可访问https://github.com/zjunlp/KnowRL。
论文及项目相关链接
PDF Work in progress
Summary
大型语言模型(LLM)在推理时,由于无法准确识别知识边界,常常出现严重的幻视问题,即输出错误的内容。强化学习(RL)能提高复杂推理能力,但其以结果为导向的奖励机制缺乏对思考过程的真实监督,从而加剧了幻视问题。为解决慢思考模型中的高幻视问题,提出了结合知识验证的强化学习训练法——KnowRL。KnowRL通过将基于知识验证的事实奖励融入RL训练过程,引导模型进行基于事实的慢思考,帮助模型认识其知识边界。这种方法使模型在训练过程中学习和内化基于事实的推理策略,并通过直接奖励符合事实的推理步骤来确保更可靠的思考过程。实验结果表明,KnowRL能有效减轻慢思考模型的幻视问题,同时保持其原有的强大推理能力。相关代码已发布在https://github.com/zjunlp/KnowRL。
Key Takeaways
- 大型语言模型(LLMs)在推理时因无法准确识别知识边界,易出现输出错误内容的问题。
- 强化学习(RL)虽能提高复杂推理能力,但其奖励机制缺乏对思考过程的真实监督,导致幻视问题加剧。
- KnowRL方法通过结合知识验证和强化学习训练,引导模型进行基于事实的慢思考。
- KnowRL帮助模型认识其知识边界,通过融入基于知识验证的事实奖励到RL训练过程中实现。
- KnowRL使模型在训练过程中学习和内化基于事实的推理策略。
- KnowRL通过直接奖励符合事实的推理步骤来确保更可靠的思考过程。
点此查看论文截图

SAGE: Strategy-Adaptive Generation Engine for Query Rewriting
Authors:Teng Wang, Hailei Gong, Changwang Zhang, Jun Wang
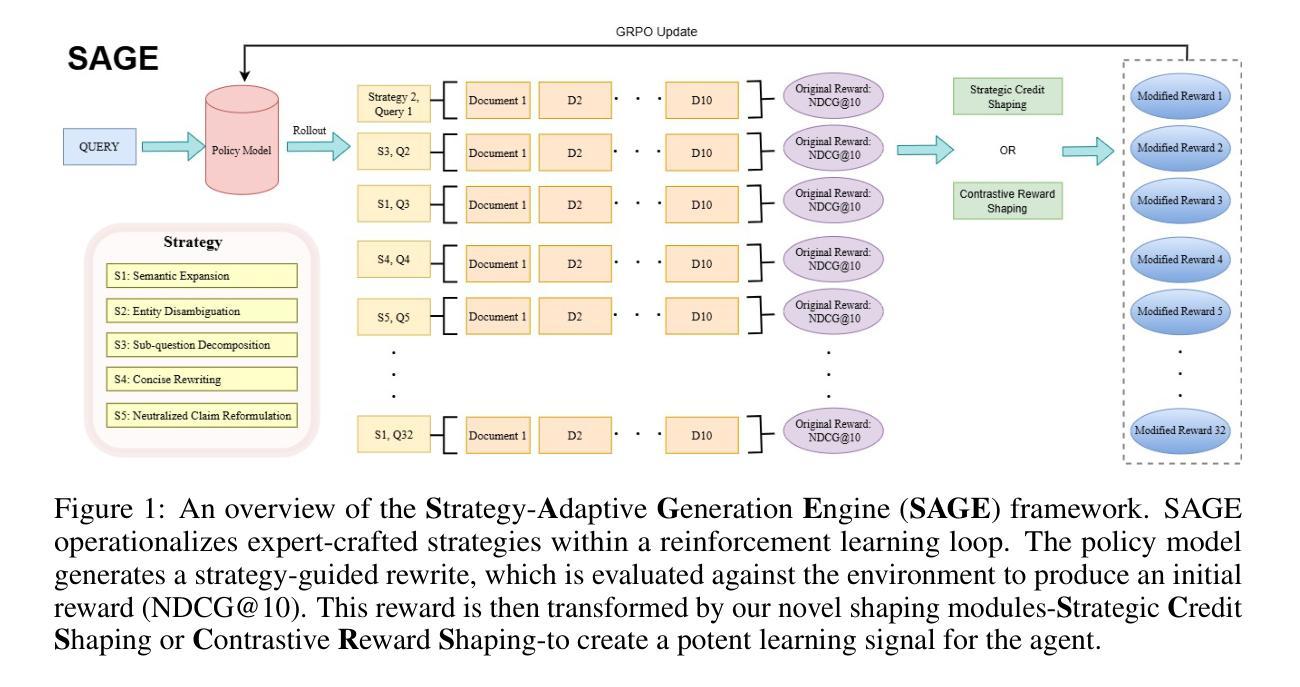
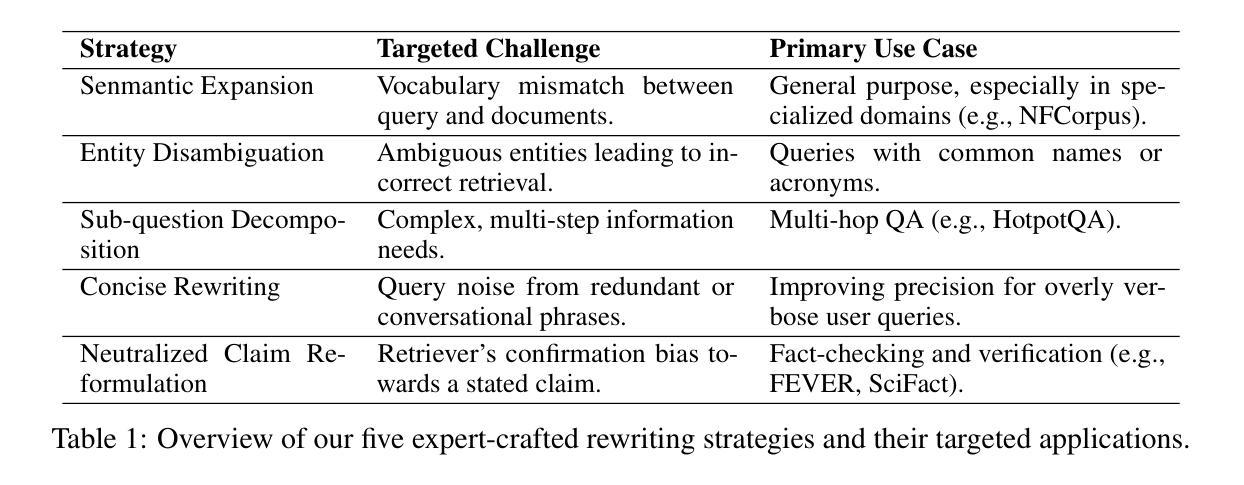
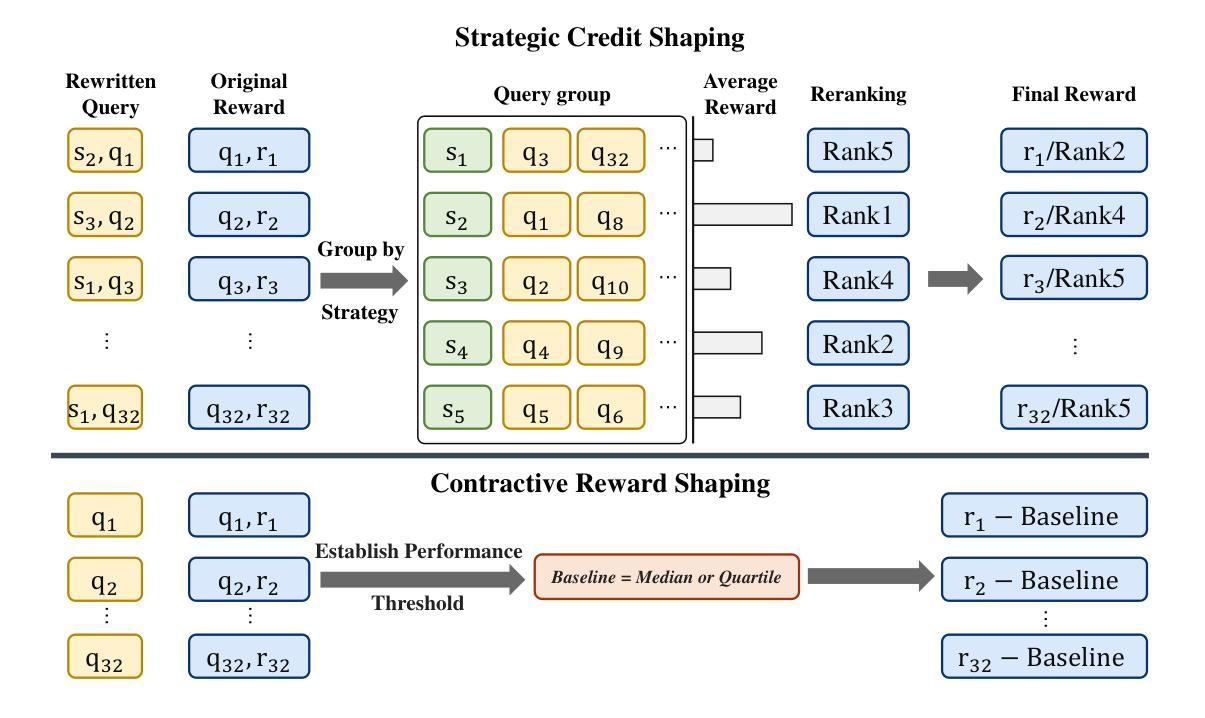
Query rewriting is pivotal for enhancing dense retrieval, yet current methods demand large-scale supervised data or suffer from inefficient reinforcement learning (RL) exploration. In this work, we first establish that guiding Large Language Models (LLMs) with a concise set of expert-crafted strategies, such as semantic expansion and entity disambiguation, substantially improves retrieval effectiveness on challenging benchmarks, including HotpotQA, FEVER, NFCorpus, and SciFact. Building on this insight, we introduce the Strategy-Adaptive Generation Engine (SAGE), which operationalizes these strategies in an RL framework. SAGE introduces two novel reward shaping mechanisms-Strategic Credit Shaping (SCS) and Contrastive Reward Shaping (CRS)-to deliver more informative learning signals. This strategy-guided approach not only achieves new state-of-the-art NDCG@10 results, but also uncovers a compelling emergent behavior: the agent learns to select optimal strategies, reduces unnecessary exploration, and generates concise rewrites, lowering inference cost without sacrificing performance. Our findings demonstrate that strategy-guided RL, enhanced with nuanced reward shaping, offers a scalable, efficient, and more interpretable paradigm for developing the next generation of robust information retrieval systems.
查询改写对于提高密集检索至关重要,然而,当前的方法需要大规模的监督数据,或者面临强化学习(RL)探索效率低下的问题。在这项工作中,我们首先确定,使用简洁的专家策略(如语义扩展和实体消歧)指导大型语言模型(LLM),能显著提高包括HotpotQA、FEVER、NFCorpus和SciFact等挑战性基准测试上的检索效果。在此基础上,我们引入了策略自适应生成引擎(SAGE),该引擎在RL框架中实施这些策略。SAGE引入两种新型奖励塑造机制——战略信用塑造(SCS)和对比奖励塑造(CRS),以提供更具信息的学习信号。这种策略指导的方法不仅实现了新的NDCG@10结果的最先进水平,还揭示了一个引人注目的新兴行为:代理能够学会选择最佳策略,减少不必要的探索,并产生简洁的改写,降低推理成本而不牺牲性能。我们的研究结果表明,策略指导的强化学习加上微妙的奖励塑造提供了一个可扩展、高效、更具解释性的范式,为下一代稳健的信息检索系统开发提供了可能。
论文及项目相关链接
Summary
本文探讨了在密集检索中查询改写的重要性,针对当前方法的不足,提出了策略指导的大型语言模型(LLMs)。通过语义扩展和实体消歧等专家制定的策略,显著提高了一些挑战基准测试上的检索效果。在此基础上,引入策略自适应生成引擎(SAGE),结合强化学习(RL)框架,并引入了两种新颖的奖励塑造机制。这种策略导向的方法不仅达到了新的最佳状态NDCG@10结果,还展现了一个引人注目的新兴行为:智能体能够选择最佳策略,减少不必要的探索,生成简洁的改写,降低推理成本而不牺牲性能。这显示了策略导向的强化学习结合微妙的奖励塑造,为下一代稳健的信息检索系统提供了一个可扩展、高效和更具解释性的范式。
Key Takeaways
- 查询改写在密集检索中至关重要。
- 当前方法需要大量监督数据或面临强化学习(RL)探索效率低下的问题。
- 通过专家制定的策略(如语义扩展和实体消歧)可以显著提高大型语言模型(LLMs)的检索效果。
- 策略自适应生成引擎(SAGE)结合了强化学习框架并运用战略性和对比奖励塑造机制,带来更高效和更有解释性的结果。
- 策略导向的方法不仅在评估标准上取得新突破,而且在推理成本上表现出优势。智能体能够选择最佳策略并生成简洁的改写。
- 该方法展示了其广泛适用性,能够在多个基准测试中实现出色的性能提升。
点此查看论文截图

Multi-Preference Lambda-weighted Listwise DPO for Dynamic Preference Alignment
Authors:Yuhui Sun, Xiyao Wang, Zixi Li, Jinman Zhao
While large-scale unsupervised language models (LMs) capture broad world knowledge and reasoning capabilities, steering their behavior toward desired objectives remains challenging due to the lack of explicit supervision. Existing alignment techniques, such as reinforcement learning from human feedback (RLHF), rely on training a reward model and performing reinforcement learning to align with human preferences. However, RLHF is often computationally intensive, unstable, and sensitive to hyperparameters. To address these limitations, Direct Preference Optimization (DPO) was introduced as a lightweight and stable alternative, enabling direct alignment of language models with pairwise preference data via classification loss. However, DPO and its extensions generally assume a single static preference distribution, limiting flexibility in multi-objective or dynamic alignment settings. In this paper, we propose a novel framework: Multi-Preference Lambda-weighted Listwise DPO, which extends DPO to incorporate multiple human preference dimensions (e.g., helpfulness, harmlessness, informativeness) and enables dynamic interpolation through a controllable simplex-weighted formulation. Our method supports both listwise preference feedback and flexible alignment across varying user intents without re-training. Empirical and theoretical analysis demonstrates that our method is as effective as traditional DPO on static objectives while offering greater generality and adaptability for real-world deployment.
大规模无监督语言模型(LMs)虽然捕捉到了广泛的世界知识和推理能力,但由于缺乏明确的监督,将其行为导向既定的目标仍然具有挑战性。现有的对齐技术,如强化学习从人类反馈(RLHF),依赖于训练奖励模型和进行强化学习以符合人类偏好。然而,RLHF通常计算量大、不稳定,对超参数敏感。为了解决这些局限性,引入了直接偏好优化(DPO)作为轻量级和稳定的替代方案,通过分类损失直接对齐语言模型与配对偏好数据。然而,DPO及其扩展通常假设单一的静态偏好分布,这在多目标或动态对齐设置中限制了灵活性。在本文中,我们提出了一个新的框架:多偏好Lambda加权列表式DPO,它扩展了DPO以融入多种人类偏好维度(例如,有帮助性、无害性、信息性),并通过可控的单纯加权公式实现动态插值。我们的方法支持列表式偏好反馈和灵活的跨不同用户意图对齐,无需重新训练。实证和理论分析表明,我们的方法在静态目标上与传统DPO同样有效,同时提供了更大的通用性和适应性,适用于现实世界部署。
论文及项目相关链接
PDF 10 pages, 4 figures, appendix included. To appear in Proceedings of AAAI 2026. Code: https://github.com/yuhui15/Multi-Preference-Lambda-weighted-DPO
Summary
大型无监督语言模型捕捉广泛的世界知识和推理能力,但缺乏明确的监督使其难以符合期望目标。现有对齐技术如强化学习从人类反馈(RLHF)需要训练奖励模型并进行强化学习以符合人类偏好,但计算量大、不稳定且对超参数敏感。为解决这些问题,引入直接偏好优化(DPO)作为轻量级稳定替代方案,通过分类损失直接对齐语言模型与配对偏好数据。然而,DPO及其扩展假设单一静态偏好分布,限制了多目标或动态对齐设置的灵活性。本文提出新型框架:多偏好λ加权列表式DPO,将DPO扩展到包含多种人类偏好维度(如有用性、无害性、信息量等),并通过可控的简单加权公式实现动态插值。该方法支持列表式偏好反馈,无需重新训练即可适应不同用户意图的对齐。理论和实证分析证明,该方法在静态目标上的效果与传统DPO相当,同时提供更大的通用性和适应性,适用于现实世界的部署。
Key Takeaways
- 大型无监督语言模型虽然具备广泛知识推理能力,但缺乏监督使其难以符合期望目标。
- 现有对齐技术如强化学习从人类反馈(RLHF)存在计算量大、不稳定及对超参数敏感的问题。
- 直接偏好优化(DPO)作为一种轻量级稳定的替代方案被引入,能够通过分类损失直接对齐语言模型与配对偏好数据。
- DPO及其扩展在假设单一静态偏好分布上存在局限性,限制了多目标或动态对齐的灵活性。
- 新型框架Multi-Preference Lambda-weighted Listwise DPO扩展了DPO,纳入多种人类偏好维度,并允许通过可控的简单加权公式实现动态插值。
- 该方法支持列表式偏好反馈,无需重新训练即可适应不同用户意图的对齐。
点此查看论文截图


Tailored Conversations beyond LLMs: A RL-Based Dialogue Manager
Authors:Lucie Galland, Catherine Pelachaud, Florian Pecune
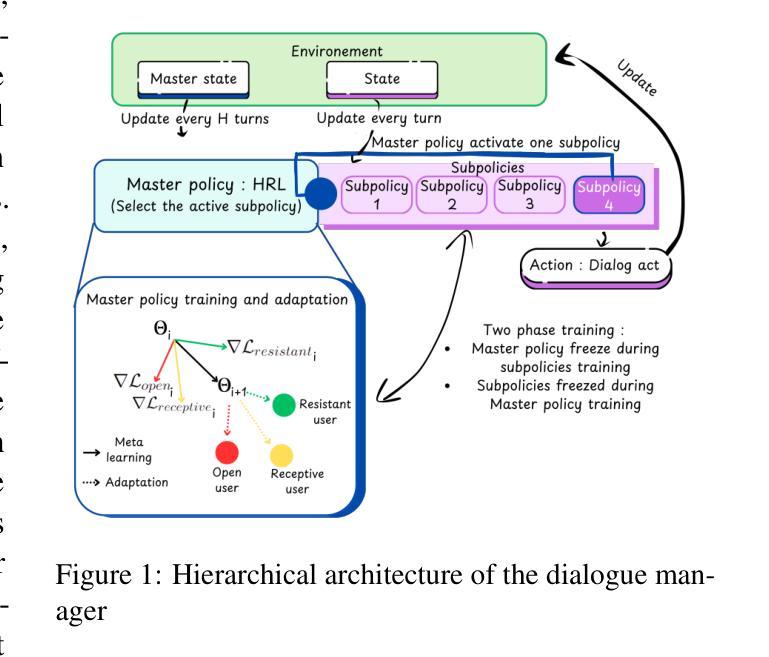
In this work, we propose a novel framework that integrates large language models (LLMs) with an RL-based dialogue manager for open-ended dialogue with a specific goal. By leveraging hierarchical reinforcement learning to model the structured phases of dialogue and employ meta-learning to enhance adaptability across diverse user profiles, our approach enhances adaptability and efficiency, enabling the system to learn from limited data, transition fluidly between dialogue phases, and personalize responses to heterogeneous patient needs. We apply our framework to Motivational Interviews, aiming to foster behavior change, and demonstrate that the proposed dialogue manager outperforms a state-of-the-art LLM baseline in terms of reward, showing a potential benefit of conditioning LLMs to create open-ended dialogue systems with specific goals.
在这项工作中,我们提出了一种新型框架,该框架将大型语言模型(LLM)与基于RL的对话管理器相结合,以实现具有特定目标的开放式对话。我们通过利用分层强化学习来模拟对话的结构化阶段,并运用元学习来提高对不同用户配置的适应性,从而提高了适应性和效率,使系统能够在有限的数据中学习,在对话阶段之间平稳过渡,并对多样化的患者需求做出个性化响应。我们将该框架应用于动机面试,旨在促进行为改变,并证明所提出的对话管理器在奖励方面优于最新的LLM基准测试,显示出将LLM用于创建具有特定目标的开放式对话系统的潜在优势。
论文及项目相关链接
Summary:
本文提出了一种新型框架,它将大型语言模型(LLMs)与基于强化学习(RL)的对话管理器相结合,用于实现具有特定目标的开放对话。通过利用分层强化学习对对话的结构阶段进行建模,并应用元学习来提高对不同用户配置的适应性,该方法增强了系统的适应性和效率,使系统能够从有限的数据中学习,在对话阶段之间流畅过渡,并对不同患者的需求做出个性化回应。我们将该框架应用于动机面试,旨在促进行为改变,并证明所提出的对话管理器在奖励方面优于最先进的大型语言模型基线,显示出将大型语言模型应用于创建具有特定目标的开放对话系统的潜在优势。
Key Takeaways:
- 新型框架结合了大型语言模型和强化学习对话管理器,用于实现具有特定目标的开放对话。
- 利用分层强化学习对对话的结构阶段进行建模。
- 应用元学习提高对不同用户配置的适应性。
- 系统能从有限数据中学习,并在对话阶段之间流畅过渡。
- 能够个性化回应不同患者的需求。
- 框架被应用于动机面试,旨在促进行为改变。
点此查看论文截图


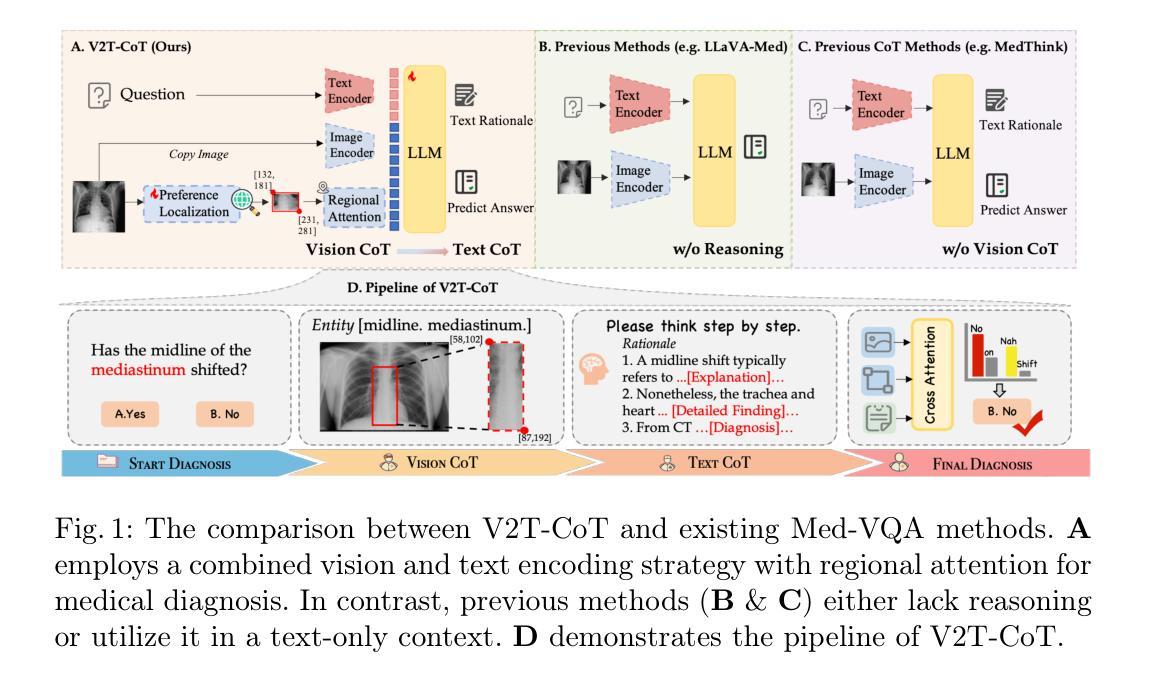
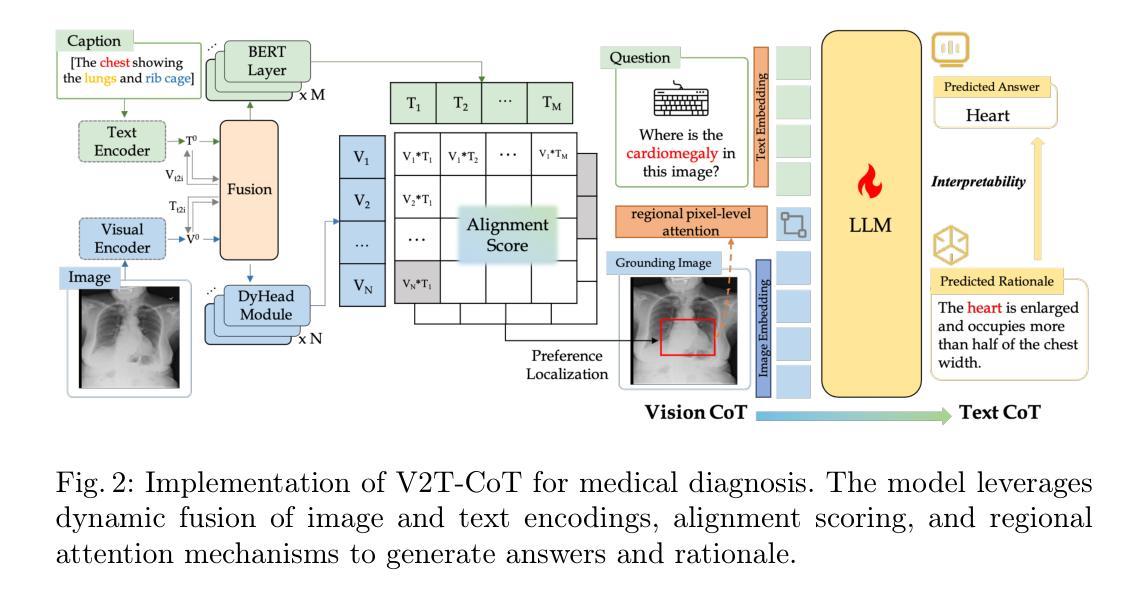
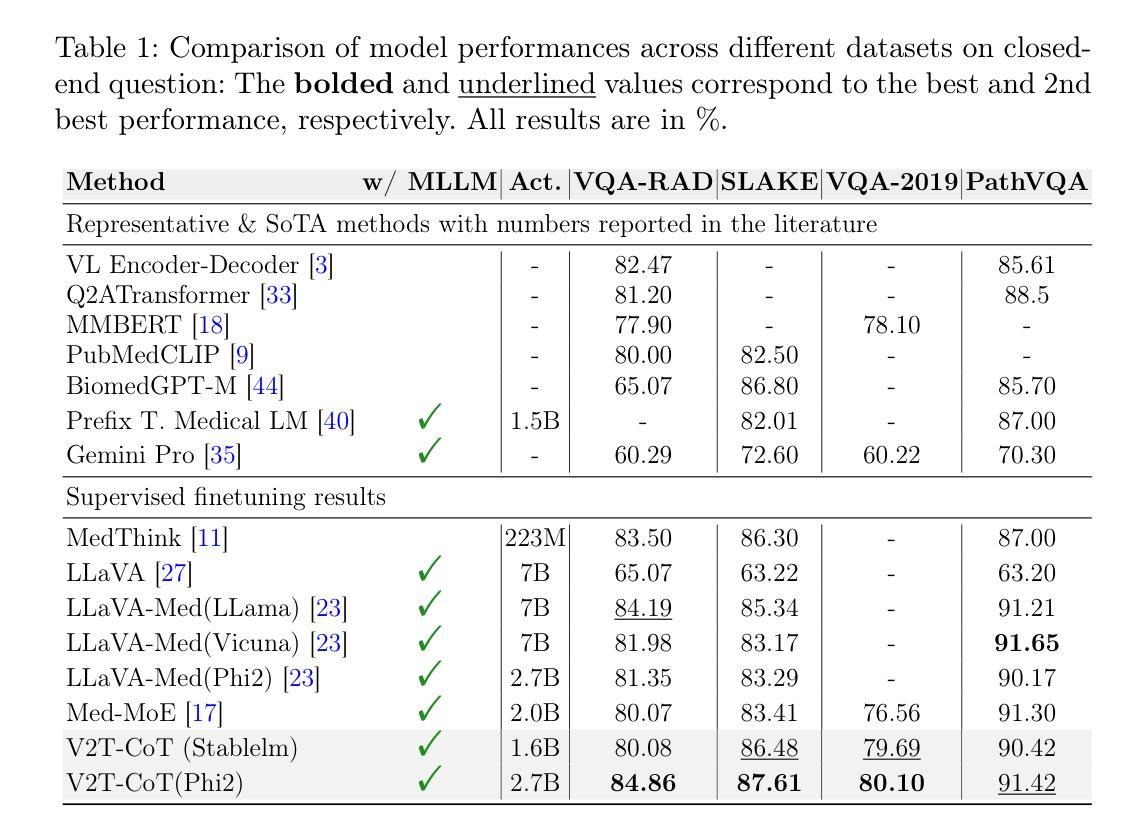
V2T-CoT: From Vision to Text Chain-of-Thought for Medical Reasoning and Diagnosis
Authors:Yuan Wang, Jiaxiang Liu, Shujian Gao, Bin Feng, Zhihang Tang, Xiaotang Gai, Jian Wu, Zuozhu Liu
Recent advances in multimodal techniques have led to significant progress in Medical Visual Question Answering (Med-VQA). However, most existing models focus on global image features rather than localizing disease-specific regions crucial for diagnosis. Additionally, current research tends to emphasize answer accuracy at the expense of the reasoning pathway, yet both are crucial for clinical decision-making. To address these challenges, we propose From Vision to Text Chain-of-Thought (V2T-CoT), a novel approach that automates the localization of preference areas within biomedical images and incorporates this localization into region-level pixel attention as knowledge for Vision CoT. By fine-tuning the vision language model on constructed R-Med 39K dataset, V2T-CoT provides definitive medical reasoning paths. V2T-CoT integrates visual grounding with textual rationale generation to establish precise and explainable diagnostic results. Experimental results across four Med-VQA benchmarks demonstrate state-of-the-art performance, achieving substantial improvements in both performance and interpretability.
近期多模态技术的进展在医疗视觉问答(Med-VQA)领域取得了显著成效。然而,大多数现有模型侧重于全局图像特征,而非定位对诊断至关重要的特定疾病区域。此外,当前研究往往过分强调答案的准确性,而忽视了推理过程的重要性,但这两者对于临床决策都是至关重要的。为了解决这些挑战,我们提出了“从视觉到文本思维链(V2T-CoT)”这一新方法,它会自动定位生物医学图像中的偏好区域,并将这些区域的定位信息纳入区域级像素注意力作为视觉推理的知识。通过在构建的R-Med 39K数据集上对视觉语言模型进行微调,V2T-CoT提供了明确的医疗推理路径。V2T-CoT将视觉定位与文本理由生成相结合,建立精确且可解释的诊断结果。在四个医疗VQA基准测试上的实验结果表明,该方法达到了最先进的性能,在性能和可解释性方面都取得了实质性的改进。
论文及项目相关链接
PDF 12 pages, 4 figures
Summary
近期多模态技术的进展在医疗视觉问答(Med-VQA)领域取得了显著成果。然而,现有模型多关注全局图像特征,忽视了对诊断至关重要的特定疾病区域定位。此外,现有研究往往重视答案准确性,忽视了推理路径的重要性,二者对临床决策均至关重要。为解决这些挑战,我们提出了From Vision to Text Chain-of-Thought(V2T-CoT)方法,该方法可自动定位生物医学图像中的偏好区域,并将这些区域的定位信息融入像素级注意力知识中,形成视觉推理链。通过微调构建的R-Med 39K数据集上的视觉语言模型,V2T-CoT提供了明确的医学推理路径。该方法结合了视觉定位与文本理由生成,为医疗诊断提供了精确且可解释的结果。在四个Med-VQA基准测试上的实验结果显示,V2T-CoT达到了最先进的性能水平,在性能和可解释性方面都取得了显著提高。
Key Takeaways
- 现有医疗视觉问答(Med-VQA)模型忽略了对特定疾病区域定位的重要性。
- V2T-CoT方法能自动定位生物医学图像中的关键区域,并融入像素级注意力知识。
- V2T-CoT通过微调视觉语言模型,在构建的R-Med 39K数据集上提供明确的医学推理路径。
- V2T-CoT结合了视觉定位与文本理由生成,提供精确且可解释的诊断结果。
- V2T-CoT在四个Med-VQA基准测试上表现出卓越性能。
- 该方法在医疗视觉问答的准确性和推理路径的清晰度上均实现了显著提升。
- V2T-CoT为临床决策支持提供了一个有效的工具,有助于提升医疗诊断的精确性和解释性。
点此查看论文截图

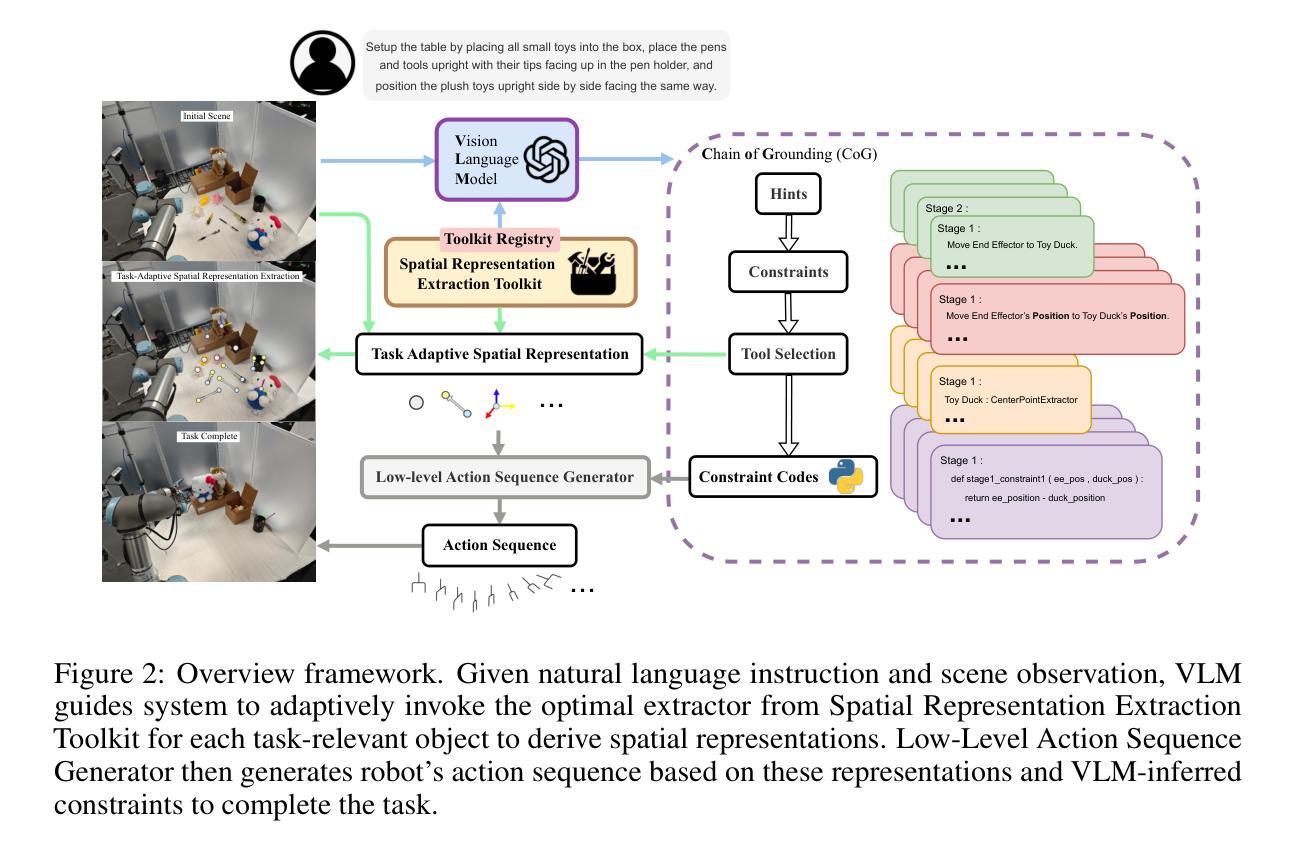
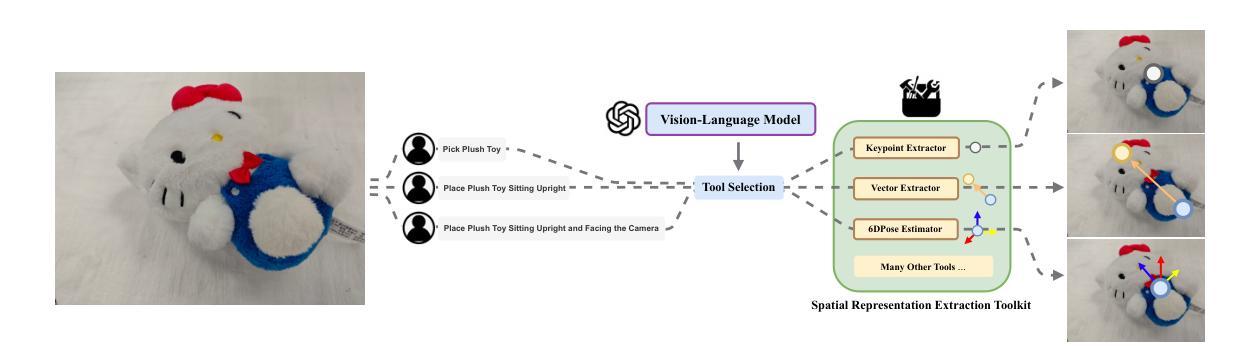
T-Rex: Task-Adaptive Spatial Representation Extraction for Robotic Manipulation with Vision-Language Models
Authors:Yiteng Chen, Wenbo Li, Shiyi Wang, Huiping Zhuang, Qingyao Wu
Building a general robotic manipulation system capable of performing a wide variety of tasks in real-world settings is a challenging task. Vision-Language Models (VLMs) have demonstrated remarkable potential in robotic manipulation tasks, primarily due to the extensive world knowledge they gain from large-scale datasets. In this process, Spatial Representations (such as points representing object positions or vectors representing object orientations) act as a bridge between VLMs and real-world scene, effectively grounding the reasoning abilities of VLMs and applying them to specific task scenarios. However, existing VLM-based robotic approaches often adopt a fixed spatial representation extraction scheme for various tasks, resulting in insufficient representational capability or excessive extraction time. In this work, we introduce T-Rex, a Task-Adaptive Framework for Spatial Representation Extraction, which dynamically selects the most appropriate spatial representation extraction scheme for each entity based on specific task requirements. Our key insight is that task complexity determines the types and granularity of spatial representations, and Stronger representational capabilities are typically associated with Higher overall system operation costs. Through comprehensive experiments in real-world robotic environments, we show that our approach delivers significant advantages in spatial understanding, efficiency, and stability without additional training.
构建能够在真实世界环境中执行多种任务的通用机器人操作系统是一项具有挑战性的任务。视觉语言模型(VLM)在机器人操作任务中表现出了显著潜力,这主要归功于它们从大规模数据中获取的大量世界知识。在此过程中,空间表示(如表示物体位置的点或表示物体方向的向量)充当了VLM和真实世界场景之间的桥梁,有效地将VLM的推理能力应用于特定任务场景。然而,现有的基于VLM的机器人方法往往采用固定的空间表示提取方案来应对各种任务,导致表示能力不足或提取时间过长。在这项工作中,我们引入了T-Rex,一个用于空间表示提取的任务自适应框架,它根据特定任务要求动态选择每个实体的最合适空间表示提取方案。我们的关键见解是,任务复杂性决定了空间表示的类型和粒度,而更强的表示能力通常与更高的整体系统操作成本相关。我们在真实的机器人环境中进行了全面的实验,结果表明,我们的方法在空间理解、效率和稳定性方面取得了显著的优势,且无需额外的训练。
论文及项目相关链接
PDF submitted to NeurIPS 2025
Summary
在真实世界环境中,建立一个能够执行多种任务的通用机器人操纵系统是一项挑战。视觉语言模型(VLMs)在机器人操纵任务中展现出显著潜力,主要由于它们从大规模数据集中获得大量世界知识。空间表征(如表示物体位置的点或表示物体方向的向量)作为VLMs和真实场景之间的桥梁,有效地将VLMs的推理能力应用于特定任务场景。现有基于VLM的机器人方法通常采用固定的空间表征提取方案,导致表征能力不足或提取时间过长。为此,我们引入了T-Rex,一个任务自适应的空间表征提取框架,根据特定任务要求动态选择最适当的空间表征提取方案。实验证明,该方法在真实机器人环境中的空间理解、效率和稳定性方面具有显著优势,无需额外训练。
Key Takeaways
- 机器人操纵系统在真实世界环境中的通用性是一大挑战。
- 视觉语言模型(VLMs)在机器人操纵任务中展现出显著潜力。
- 空间表征是连接VLMs和真实场景的关键桥梁。
- 现有基于VLM的机器人方法存在表征能力不足和提取时间过长的问题。
- 引入T-Rex,一个任务自适应的空间表征提取框架。
- T-Rex能根据任务需求动态选择空间表征提取方案。
点此查看论文截图



Commonsense Generation and Evaluation for Dialogue Systems using Large Language Models
Authors:Marcos Estecha-Garitagoitia, Chen Zhang, Mario Rodríguez-Cantelar, Luis Fernando D’Haro
This paper provides preliminary results on exploring the task of performing turn-level data augmentation for dialogue system based on different types of commonsense relationships, and the automatic evaluation of the generated synthetic turns. The proposed methodology takes advantage of the extended knowledge and zero-shot capabilities of pretrained Large Language Models (LLMs) to follow instructions, understand contextual information, and their commonsense reasoning capabilities. The approach draws inspiration from methodologies like Chain-of-Thought (CoT), applied more explicitly to the task of prompt-based generation for dialogue-based data augmentation conditioned on commonsense attributes, and the automatic evaluation of the generated dialogues. To assess the effectiveness of the proposed approach, first we extracted 200 randomly selected partial dialogues, from 5 different well-known dialogue datasets, and generate alternative responses conditioned on different event commonsense attributes. This novel dataset allows us to measure the proficiency of LLMs in generating contextually relevant commonsense knowledge, particularly up to 12 different specific ATOMIC [10] database relations. Secondly, we propose an evaluation framework to automatically detect the quality of the generated dataset inspired by the ACCENT [26] metric, which offers a nuanced approach to assess event commonsense. However, our method does not follow ACCENT’s complex eventrelation tuple extraction process. Instead, we propose an instruction-based prompt for each commonsense attribute and use state-of-the-art LLMs to automatically detect the original attributes used when creating each augmented turn in the previous step. Preliminary results suggest that our approach effectively harnesses LLMs capabilities for commonsense reasoning and evaluation in dialogue systems.
本文初步探讨了基于不同类型常识关系的对话系统执行回合级别数据增强的任务,以及生成的合成回合的自动评估。所提出的方法利用预训练的大型语言模型(LLM)的扩展知识和零样本能力来执行指令、理解上下文信息以及他们的常识推理能力。该方法受到“思维链”(CoT)等方法的启发,更明确地应用于基于提示的生成任务,用于基于常识属性进行对话数据增强,并对生成的对话进行自动评估。为了评估所提出方法的有效性,我们首先从五个不同的知名对话数据集中随机抽取了200个部分对话,并根据不同的事件常识属性生成了替代响应。这个新数据集允许我们衡量LLM在生成与上下文相关的常识知识方面的熟练程度,特别是多达12种不同的ATOMIC [10]数据库关系。其次,我们提出了一个评估框架,以自动检测生成数据集的质量,该框架受到ACCENT [26]指标的启发,提供了一个微妙的方法来评估事件常识。然而,我们的方法并不遵循ACCENT的复杂事件关系元组提取过程。相反,我们为每个常识属性提出了基于指令的提示,并使用最新的LLM来自动检测在创建每个增强回合时使用的原始属性。初步结果表明,我们的方法有效地利用了LLM在对话系统中的常识推理和评估能力。
论文及项目相关链接
Summary
本文初步探讨了利用预训练的大型语言模型(LLMs)进行对话系统层面的数据增强任务。研究通过基于不同常识关系生成合成对话,并自动评估其质量。研究灵感来源于Chain-of-Thought(CoT)方法,并应用于基于提示的生成式对话数据增强任务中。初步结果表明,该方法有效利用LLMs的常识推理能力,有效评估对话系统的质量。
Key Takeaways
- 利用预训练的大型语言模型(LLMs)进行对话系统的数据增强任务。
- 基于不同常识关系生成合成对话。
- 通过自动评估框架评估生成对话的质量。
- 借鉴Chain-of-Thought(CoT)方法,应用于基于提示的生成式对话数据增强任务。
- 创建一个新数据集来测试LLMs在生成与上下文相关的常识知识方面的熟练程度。
- 提出一个基于指令的提示来自动检测生成数据集的原始属性。
点此查看论文截图

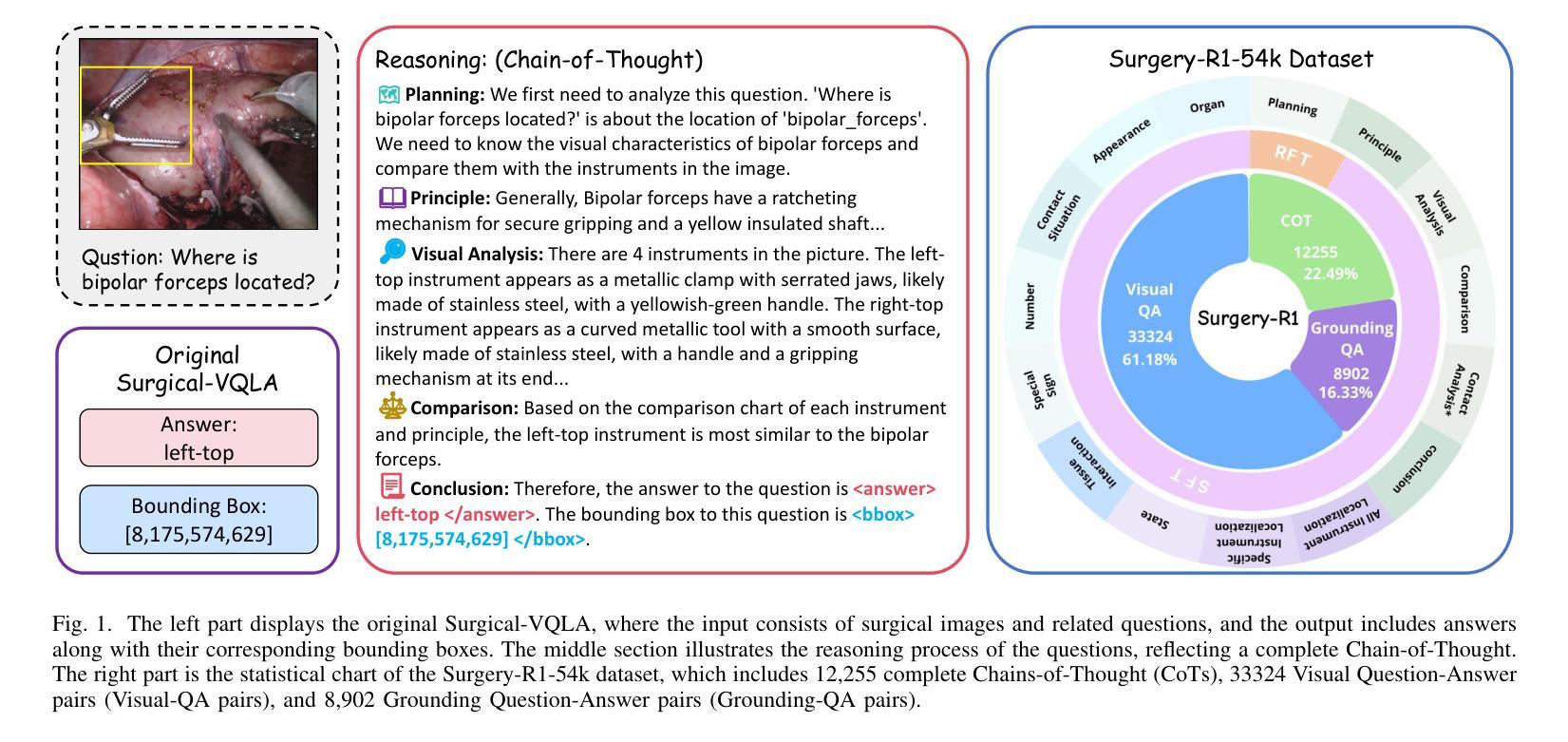
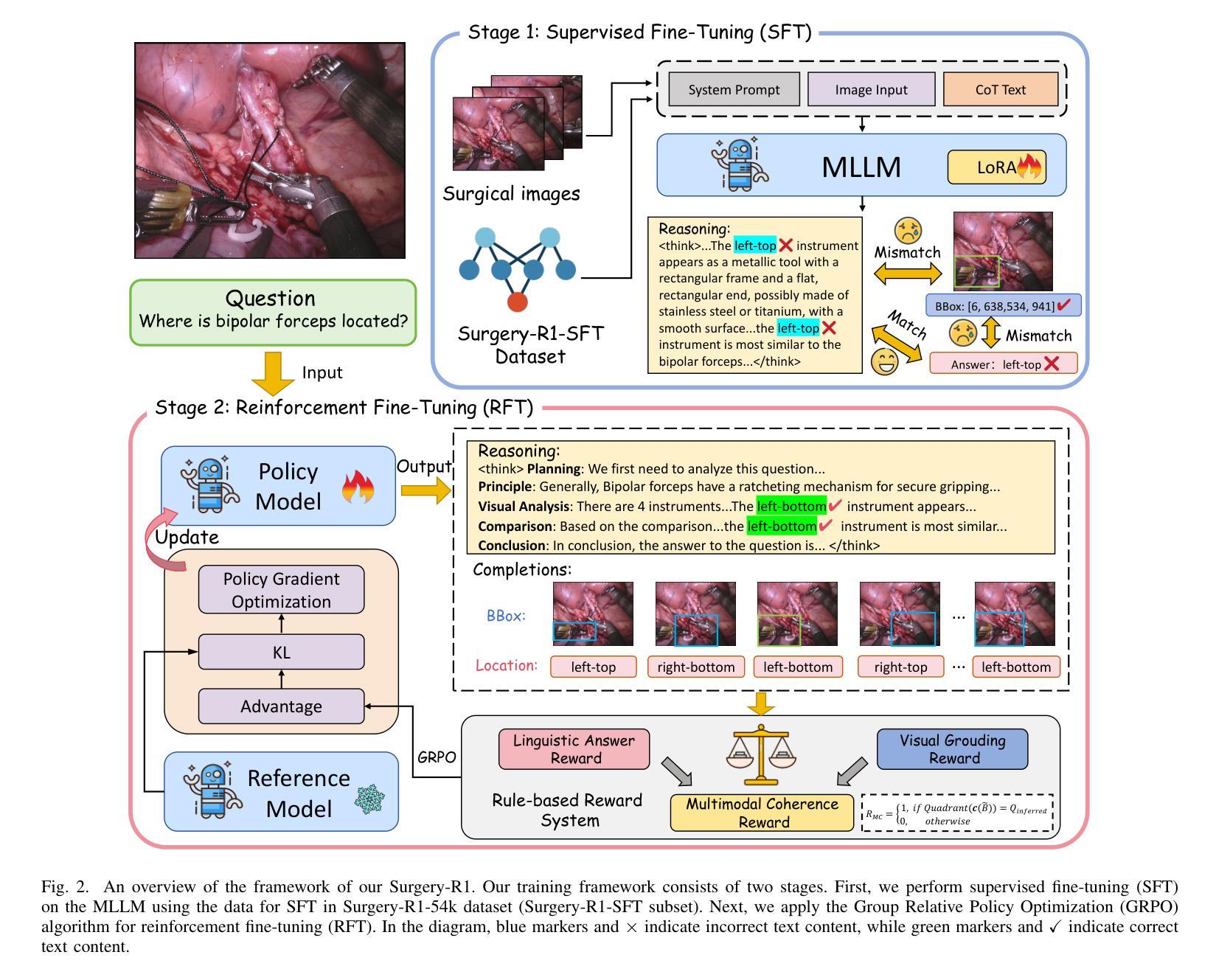
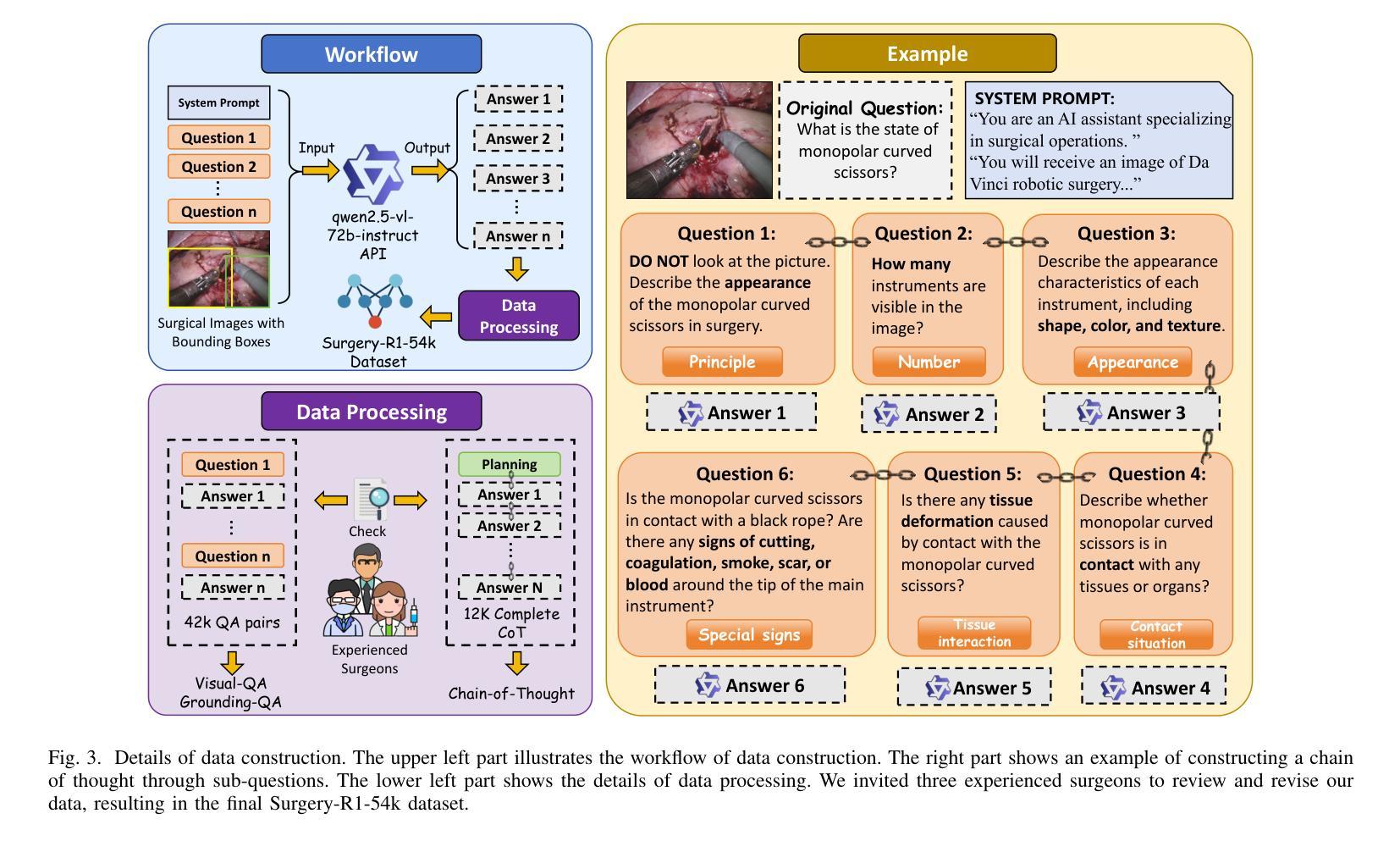
Surgery-R1: Advancing Surgical-VQLA with Reasoning Multimodal Large Language Model via Reinforcement Learning
Authors:Pengfei Hao, Shuaibo Li, Hongqiu Wang, Zhizhuo Kou, Junhang Zhang, Guang Yang, Lei Zhu
In recent years, significant progress has been made in the field of surgical scene understanding, particularly in the task of Visual Question Localized-Answering in robotic surgery (Surgical-VQLA). However, existing Surgical-VQLA models lack deep reasoning capabilities and interpretability in surgical scenes, which limits their reliability and potential for development in clinical applications. To address this issue, inspired by the development of Reasoning Multimodal Large Language Models (MLLMs), we first build the Surgery-R1-54k dataset, including paired data for Visual-QA, Grounding-QA, and Chain-of-Thought (CoT). Then, we propose the first Reasoning MLLM for Surgical-VQLA (Surgery-R1). In our Surgery-R1, we design a two-stage fine-tuning mechanism to enable the basic MLLM with complex reasoning abilities by utilizing supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). Furthermore, for an efficient and high-quality rule-based reward system in our RFT, we design a Multimodal Coherence reward mechanism to mitigate positional illusions that may arise in surgical scenarios. Experiment results demonstrate that Surgery-R1 outperforms other existing state-of-the-art (SOTA) models in the Surgical-VQLA task and widely-used MLLMs, while also validating its reasoning capabilities and the effectiveness of our approach. The code and dataset will be organized in https://github.com/FiFi-HAO467/Surgery-R1.
近年来,手术场景理解领域取得了显著进展,特别是在机器人手术的视觉问答定位回答(Surgical-VQLA)任务中。然而,现有的Surgical-VQLA模型在手术场景的深度推理能力和解释性方面存在不足,这限制了它们在临床应用的可靠性和发展潜力。为了解决这个问题,我们受到多模态推理大型语言模型(MLLMs)发展的启发,首先构建了Surgery-R1-54k数据集,该数据集包含视觉问答、定位问答和思维链(CoT)的配对数据。然后,我们提出了首个针对Surgical-VQLA的推理MLLM模型(Surgery-R1)。在我们的Surgery-R1中,通过设计两阶段微调机制,我们能够使基础MLLM具备复杂推理能力,该机制利用监督微调(SFT)和强化微调(RFT)。此外,为了在我们的RFT中建立高效高质量的基于规则奖励系统,我们设计了多模态一致性奖励机制来缓解手术中可能出现的定位错觉。实验结果表明,Surgery-R1在Surgical-VQLA任务上优于其他最先进的模型以及常用的MLLMs,同时验证了其推理能力和我们方法的有效性。代码和数据集将整理在https://github.com/FiFi-HAO467/Surgery-R1。
论文及项目相关链接
Summary
近年来,手术场景理解领域取得了显著进展,特别是在机器人手术的视觉问答定位回答(Surgical-VQLA)任务中。然而,现有的Surgical-VQLA模型在手术场景中缺乏深度推理能力和可解释性,这限制了它们在临床应用中的可靠性和发展潜力。为解决这一问题,受多模态大型语言模型(MLLMs)发展的启发,我们构建了包含视觉问答、定位问答和思维链问答的配对数据集Surgery-R1-54k数据集,并提出了首个用于Surgical-VQLA的推理MLLM模型(Surgery-R1)。我们的模型通过设计两阶段微调机制和多模态一致性奖励机制,实现了复杂推理能力的高效训练。实验结果表明,Surgery-R1在Surgical-VQLA任务上的表现优于其他先进的模型,并验证了其推理能力和方法的有效性。相关代码和数据集将在https://github.com/FiFi-HAO467/Surgery-R1公开。
Key Takeaways
- 现有Surgical-VQLA模型缺乏深度推理能力和可解释性。
- 构建Surgery-R1-54k数据集,包含多种问答类型数据。
- 提出首个用于Surgical-VQLA的推理MLLM模型(Surgery-R1)。
- 设计两阶段微调机制,通过监督微调(SFT)和强化微调(RFT)使基础MLLM具备复杂推理能力。
- 设计多模态一致性奖励机制以缓解手术场景中的位置错觉问题。
- 实验结果表明,Surgery-R1在Surgical-VQLA任务上表现优于其他先进模型。
点此查看论文截图

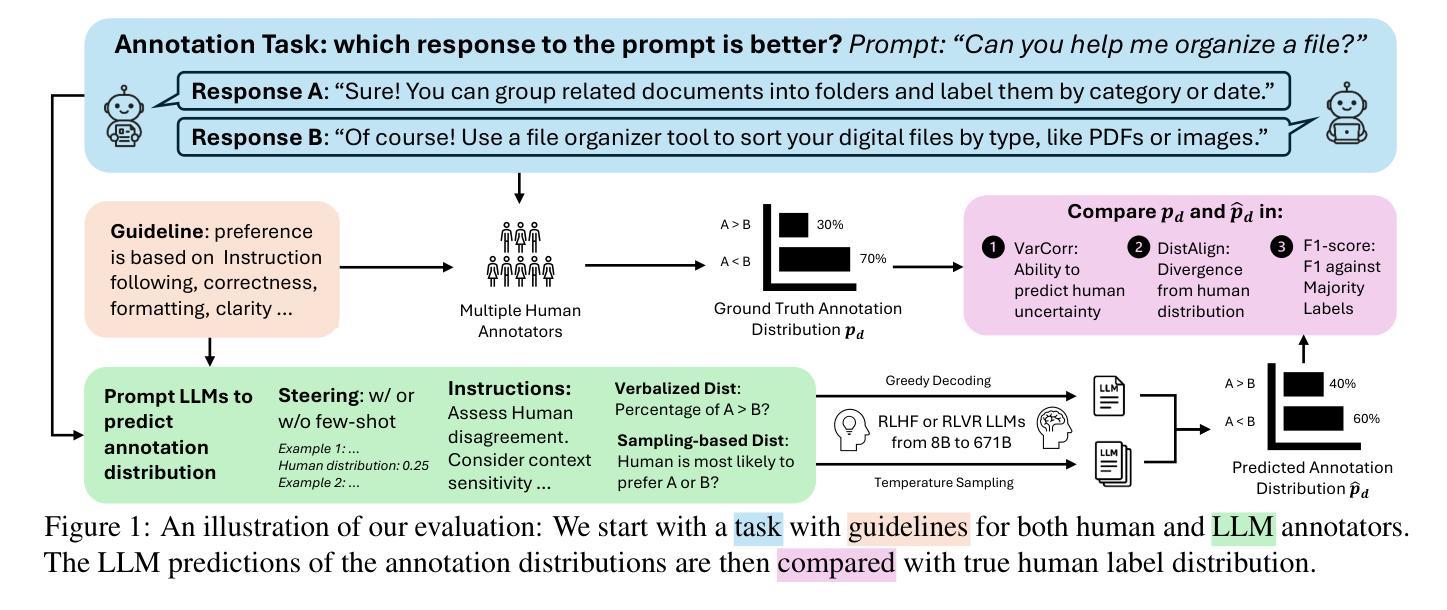
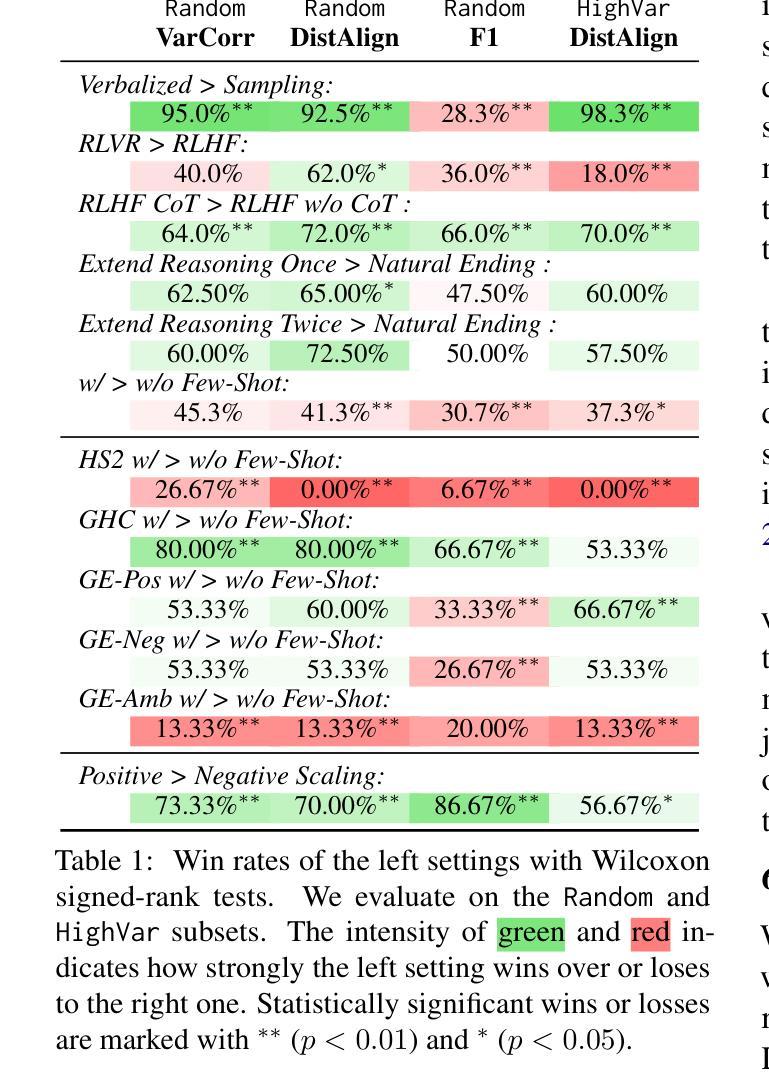
Can Large Language Models Capture Human Annotator Disagreements?
Authors:Jingwei Ni, Yu Fan, Vilém Zouhar, Donya Rooein, Alexander Hoyle, Mrinmaya Sachan, Markus Leippold, Dirk Hovy, Elliott Ash
Human annotation variation (i.e., annotation disagreements) is common in NLP and often reflects important information such as task subjectivity and sample ambiguity. While Large Language Models (LLMs) are increasingly used for automatic annotation to reduce human effort, their evaluation often focuses on predicting the majority-voted “ground truth” labels. It is still unclear, however, whether these models also capture informative human annotation variation. Our work addresses this gap by extensively evaluating LLMs’ ability to predict annotation disagreements without access to repeated human labels. Our results show that LLMs struggle with modeling disagreements, which can be overlooked by majority label-based evaluations. Notably, while RLVR-style (Reinforcement learning with verifiable rewards) reasoning generally boosts LLM performance, it degrades performance in disagreement prediction. Our findings highlight the critical need for evaluating and improving LLM annotators in disagreement modeling. Code and data at https://github.com/EdisonNi-hku/Disagreement_Prediction.
人类标注差异(即标注分歧)在自然语言处理中是常见的,并且通常反映了重要信息,如任务的主观性和样本的模糊性。虽然大型语言模型(LLM)越来越多地被用于自动标注,以减少人力投入,但其评估通常侧重于预测多数投票的“真实”标签。然而,这些模型是否也能捕捉人类标注的差异性信息,仍然不明确。我们的工作通过广泛评估LLM在没有重复人工标签的情况下预测标注分歧的能力来填补这一空白。结果表明,LLM在建模分歧方面存在困难,这可能会被基于多数标签的评估所忽视。值得注意的是,虽然RLVR风格(一种可验证奖励强化学习)的推理通常会提升LLM性能,但在分歧预测方面却会降低性能。我们的研究强调了评估和改良LLM在分歧建模中的标注者的迫切需求。相关代码和数据可通过https://github.com/EdisonNi-hku/Disagreement_Prediction获取。
论文及项目相关链接
PDF Preprint Under Review
Summary
本文探讨了自然语言处理(NLP)领域中人类标注差异(即标注分歧)的问题,这是常见的现象并反映了任务主观性和样本模糊性等重要信息。尽管大型语言模型(LLMs)被越来越多地用于自动标注以减少人力投入,但其评估通常侧重于预测多数投票的“真实”标签。然而,尚不清楚这些模型是否能捕捉人类标注分歧的信息。本研究通过广泛评估LLMs预测分歧的能力,解决了这一空白,同时不依赖重复的人类标签。研究结果表明,LLMs在建模分歧方面遇到困难,而这可能被基于多数标签的评估所忽视。虽然强化学习可验证奖励(RLVR)风格的推理通常能提高LLM性能,但在分歧预测方面却会起到反作用。本研究强调了评估和改进LLM分歧建模能力的迫切需求。
Key Takeaways
- 人类标注分歧是NLP中的常见现象,反映了任务主观性和样本模糊性。
- 大型语言模型(LLMs)越来越多地被用于自动标注,但其评估主要关注预测多数投票的“真实”标签。
- LLMs在建模人类标注分歧方面存在困难,这可能被基于多数标签的评估所忽视。
- 强化学习可验证奖励(RLVR)风格的推理能提高LLM性能,但在分歧预测方面却会起到反作用。
- 需要评估和改进LLM在建模分歧方面的能力。
- 文章提供了相关代码和数据,可在指定的GitHub仓库(https://github.com/EdisonNi-hku/Disagreement_Prediction)中找到。
点此查看论文截图

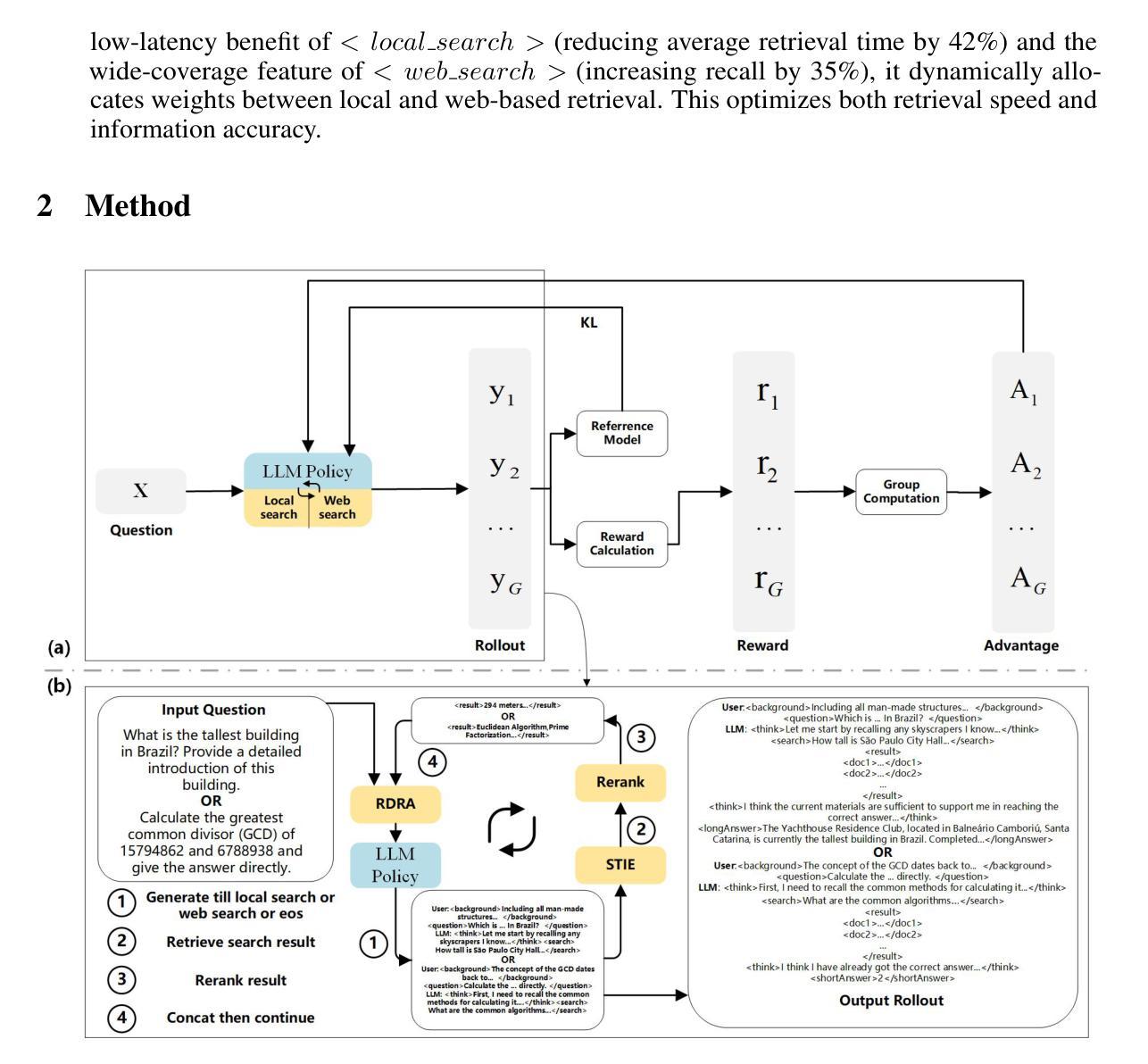
KunLunBaizeRAG: Reinforcement Learning Driven Inference Performance Leap for Large Language Models
Authors:Cheng Li, Jiexiong Liu, Yixuan Chen, Qihang Zhou, KunLun Meta
This paper introduces KunLunBaizeRAG, a reinforcement learning-driven reasoning framework designed to enhance the reasoning capabilities of large language models (LLMs) in complex multi-hop question-answering tasks. The framework addresses key limitations of traditional RAG, such as retrieval drift, information redundancy, and strategy rigidity. Key innovations include the RAG-driven Reasoning Alignment (RDRA) mechanism, the Search-Think Iterative Enhancement (STIE) mechanism, the Network-Local Intelligent Routing (NLR) mechanism, and a progressive hybrid training strategy. Experimental results demonstrate significant improvements in exact match (EM) and LLM-judged score (LJ) across four benchmarks, highlighting the framework’s robustness and effectiveness in complex reasoning scenarios.
本文介绍了昆仑白子RAAG(KunLunBaizeRAG)这一由强化学习驱动(Reinforcement Learning-driven)的推理框架。该框架旨在提高大型语言模型(LLM)在复杂多跳问答任务中的推理能力。该框架解决了传统RAAG的关键局限性,如检索漂移、信息冗余和策略僵化等。主要创新点包括RAAG驱动的推理对齐(RDRA)机制、搜索思考迭代增强(STIE)机制、网络局部智能路由(NLR)机制和一种渐进式混合训练策略。实验结果表明,该框架在四个基准测试上的精确匹配(EM)和LLM判断得分(LJ)均显著提高,凸显其在复杂推理场景中的稳健性和有效性。
论文及项目相关链接
Summary:
本文介绍了KunLunBaizeRAG这一强化学习驱动的推理框架,旨在提升大型语言模型在复杂多跳问答任务中的推理能力。该框架解决了传统RAG的关键局限性,如检索漂移、信息冗余和策略僵化。创新点包括RAG驱动的推理对齐机制(RDRA)、搜索思考迭代增强(STIE)机制、网络本地智能路由(NLR)机制以及渐进式混合训练策略。实验结果显示,该框架在四项基准测试上的精确匹配(EM)和LLM评分(LJ)均有显著提高,证明了其在复杂推理场景中的稳健性和有效性。
Key Takeaways:
- KunLunBaizeRAG是一个强化学习驱动的推理框架,旨在增强大型语言模型的推理能力。
- 框架解决了传统RAG在复杂多跳问答任务中的关键局限性。
- 框架包含多个创新机制,如RAG驱动的推理对齐机制(RDRA)、搜索思考迭代增强(STIE)以及网络本地智能路由(NLR)。
- 采用渐进式混合训练策略,提高框架的稳健性和性能。
- 实验结果显示,在四项基准测试中,KunLunBaizeRAG在精确匹配和LLM评分方面都有显著提高。
- 该框架对于解决复杂推理场景具有显著优势。
点此查看论文截图

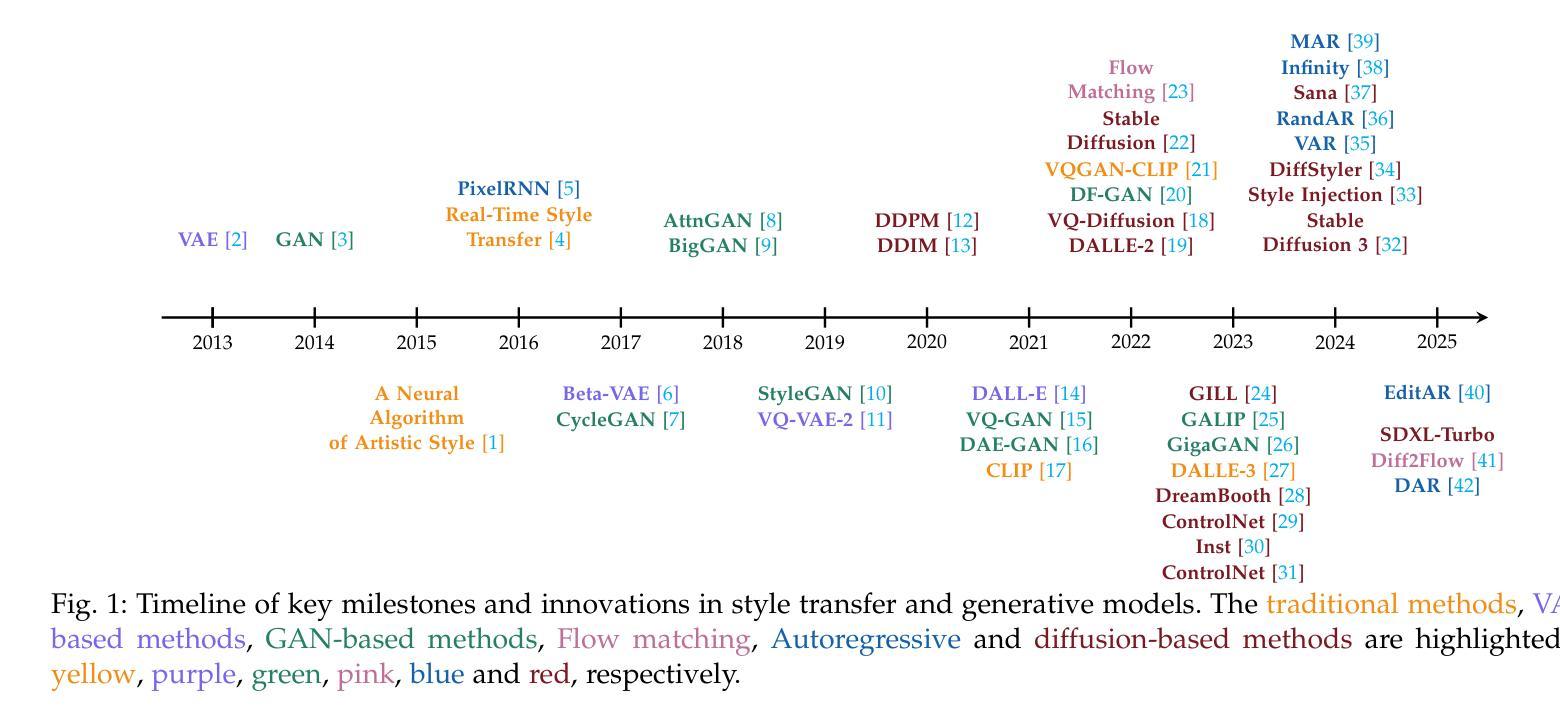
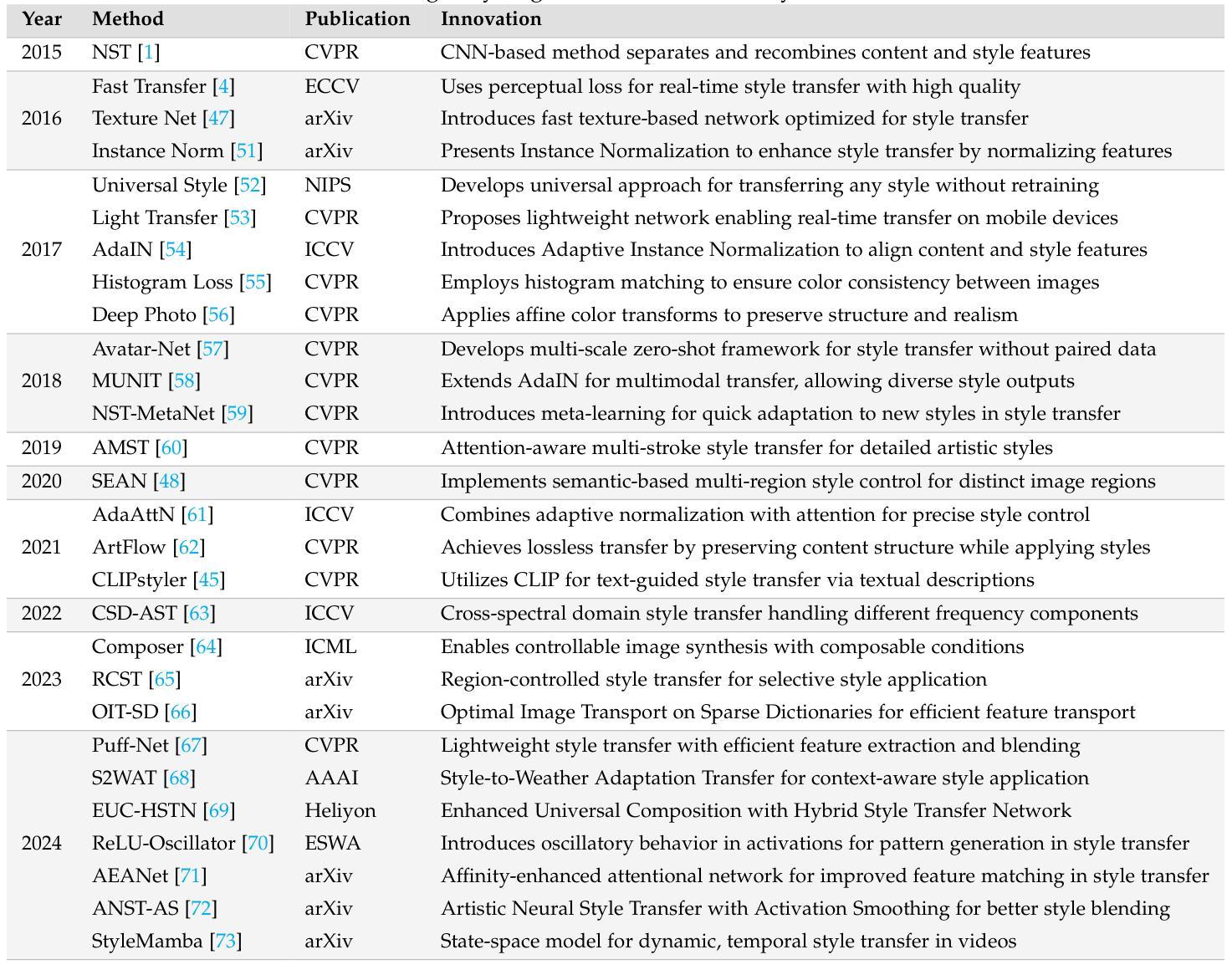
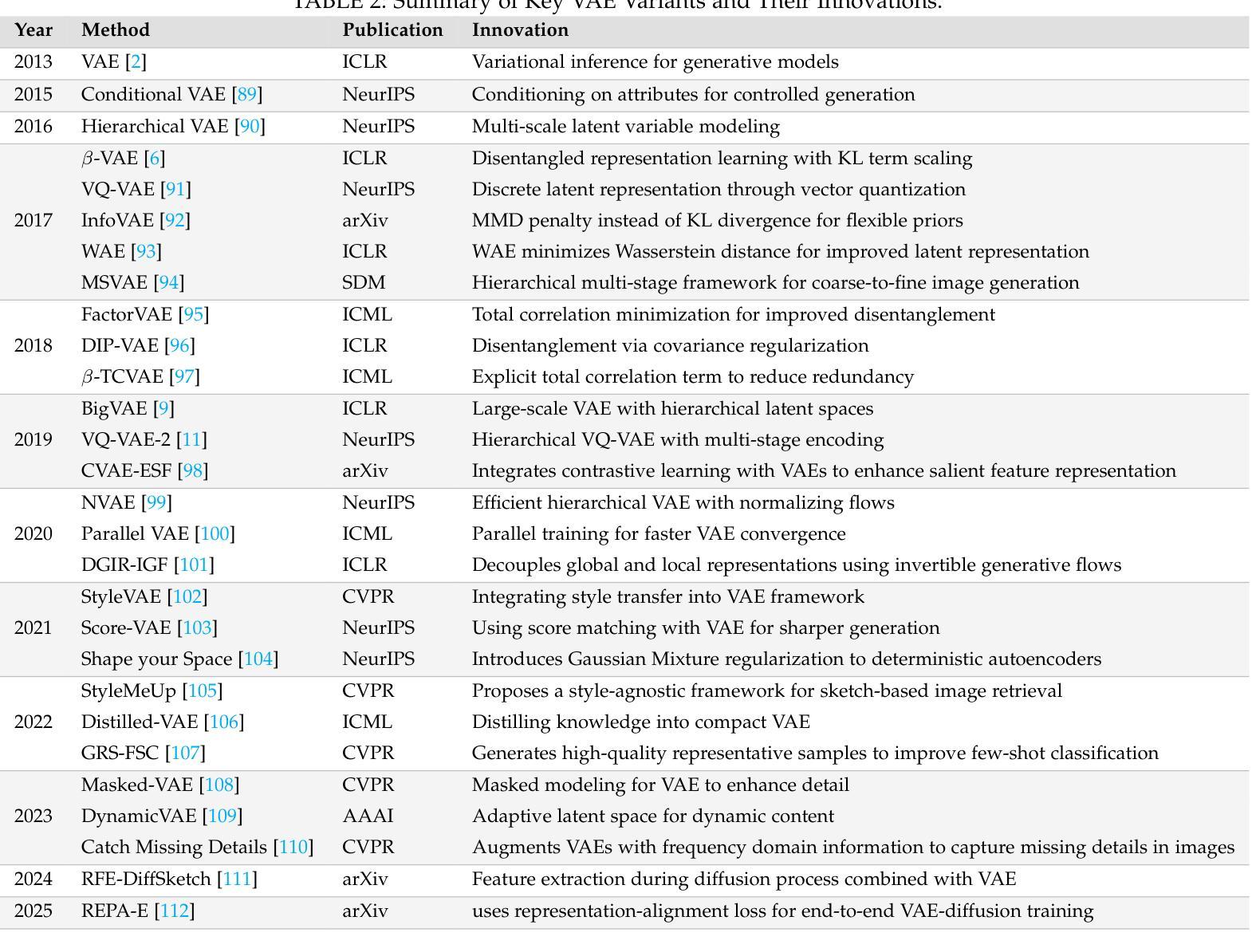
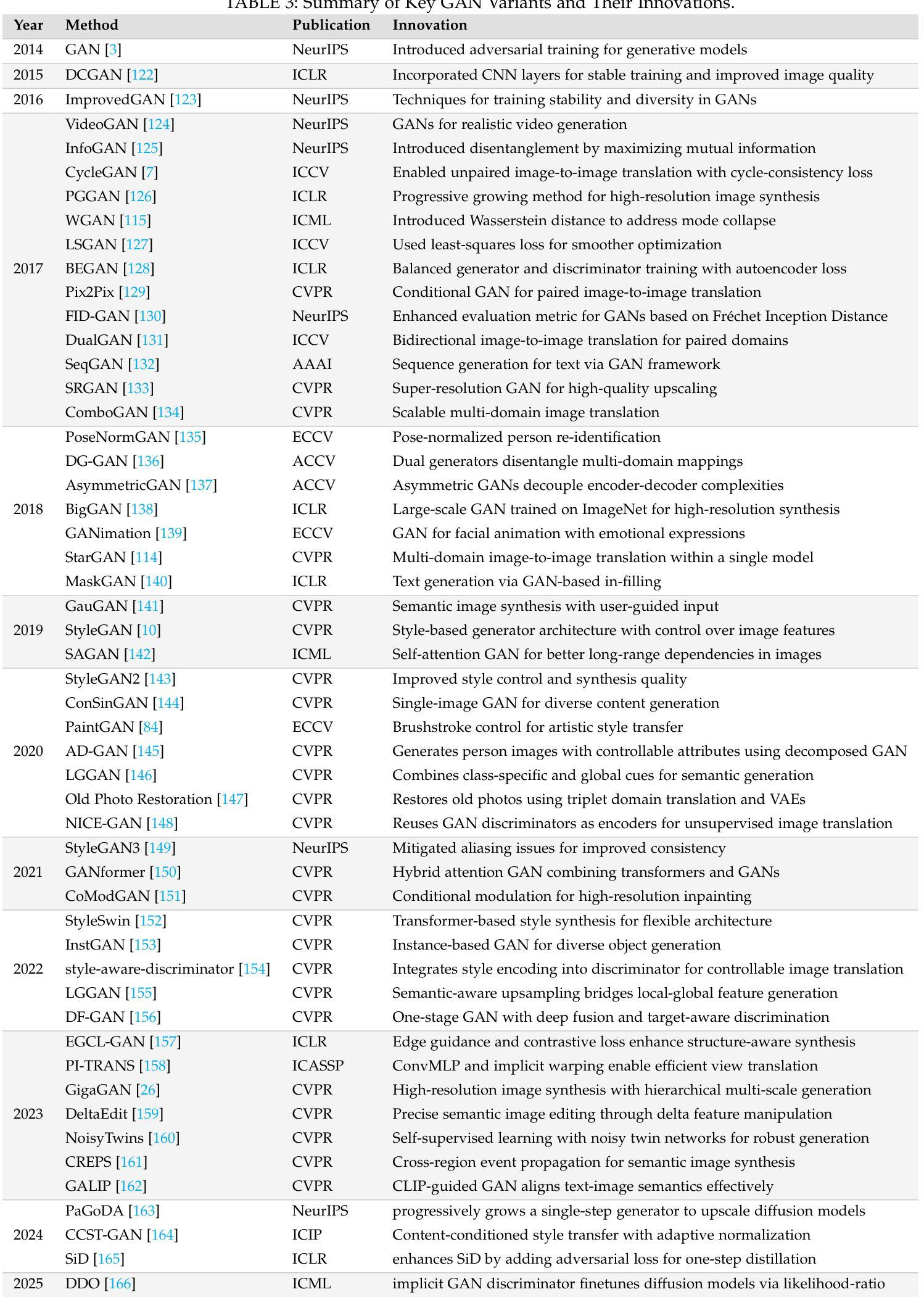
Style Transfer: A Decade Survey
Authors:Tianshan Zhang, Hao Tang
The revolutionary advancement of Artificial Intelligence Generated Content (AIGC) has fundamentally transformed the landscape of visual content creation and artistic expression. While remarkable progress has been made in image generation and style transfer, the underlying mechanisms and aesthetic implications of these technologies remain insufficiently understood. This paper presents a comprehensive survey of AIGC technologies in visual arts, tracing their evolution from early algorithmic frameworks to contemporary deep generative models. We identify three pivotal paradigms: Variational Autoencoders (VAE), Generative Adversarial Networks (GANs), and Diffusion Models, and examine their roles in bridging the gap between human creativity and machine synthesis. To support our analysis, we systematically review over 500 research papers published in the past decade, spanning both foundational developments and state-of-the-art innovations. Furthermore, we propose a multidimensional evaluation framework that incorporates Technical Innovation, Artistic Merit, Visual Quality, Computational Efficiency, and Creative Potential. Our findings reveal both the transformative capacities and current limitations of AIGC systems, emphasizing their profound impact on the future of creative practices. Through this extensive synthesis, we offer a unified perspective on the convergence of artificial intelligence and artistic expression, while outlining key challenges and promising directions for future research in this rapidly evolving field.
人工智能生成内容(AIGC)的革命性进步从根本上改变了视觉内容创作和艺术表达领域的格局。虽然在图像生成和风格转换方面取得了显著进展,但这些技术的基础机制和美学影响尚未得到充分理解。本文对AIGC技术在视觉艺术领域进行了全面综述,追溯了从早期算法框架到当前深度生成模型的演变过程。我们确定了三种关键范式:变分自编码器(VAE)、生成对抗网络(GANs)和扩散模型,并探讨了它们在弥合人类创造力和机器合成之间的差距方面的作用。为了支持我们的分析,我们系统地回顾了过去十年间发表的500多篇研究论文,这些论文涵盖了基础发展和最新创新。此外,我们提出了一个多维评估框架,涵盖了技术创新、艺术价值、视觉质量、计算效率和创意潜力。我们的研究结果揭示了AIGC系统的变革能力和当前局限性,强调了它们对创意实践未来发展的深远影响。通过这一全面的综述,我们对人工智能和艺术表达的融合提供了统一的视角,同时概述了未来在这一快速演变领域进行研究的关键挑战和充满希望的方向。
论文及项目相关链接
PDF 32 pages
Summary
人工智能生成内容(AIGC)的革命性进展从根本上改变了视觉内容创作和艺术表达领域的格局。本文全面综述了AIGC技术在视觉艺术领域的发展,从早期的算法框架到当前的深度生成模型。通过系统回顾过去十年的500多篇研究论文,本文分析了三种关键范式:变分自编码器(VAE)、生成对抗网络(GANs)和扩散模型,它们在弥合人类创造力和机器合成之间的差距方面发挥的作用。本文提出一个多维度评估框架,包括技术创新、艺术价值、视觉质量、计算效率和创意潜力。研究发现揭示了AIGC系统的变革潜力和当前局限性,强调了其对未来创作实践的深远影响。
Key Takeaways
- AIGC技术已经显著改变了视觉内容创作和艺术表达领域的格局。
- 本文综述了AIGC技术在视觉艺术领域的发展,从早期的算法框架到当前的深度生成模型。
- 三种关键范式:变分自编码器(VAE)、生成对抗网络(GANs)和扩散模型在桥梁人类创造力和机器合成方面发挥重要作用。
- 通过系统回顾过去十年的研究论文,本文提供了对AIGC技术的全面理解。
- 提出了一个多维度评估框架,包括技术创新、艺术价值、视觉质量等方面来评估AIGC技术。
- AIGC系统具有显著的变革潜力,但也存在当前局限性。
点此查看论文截图


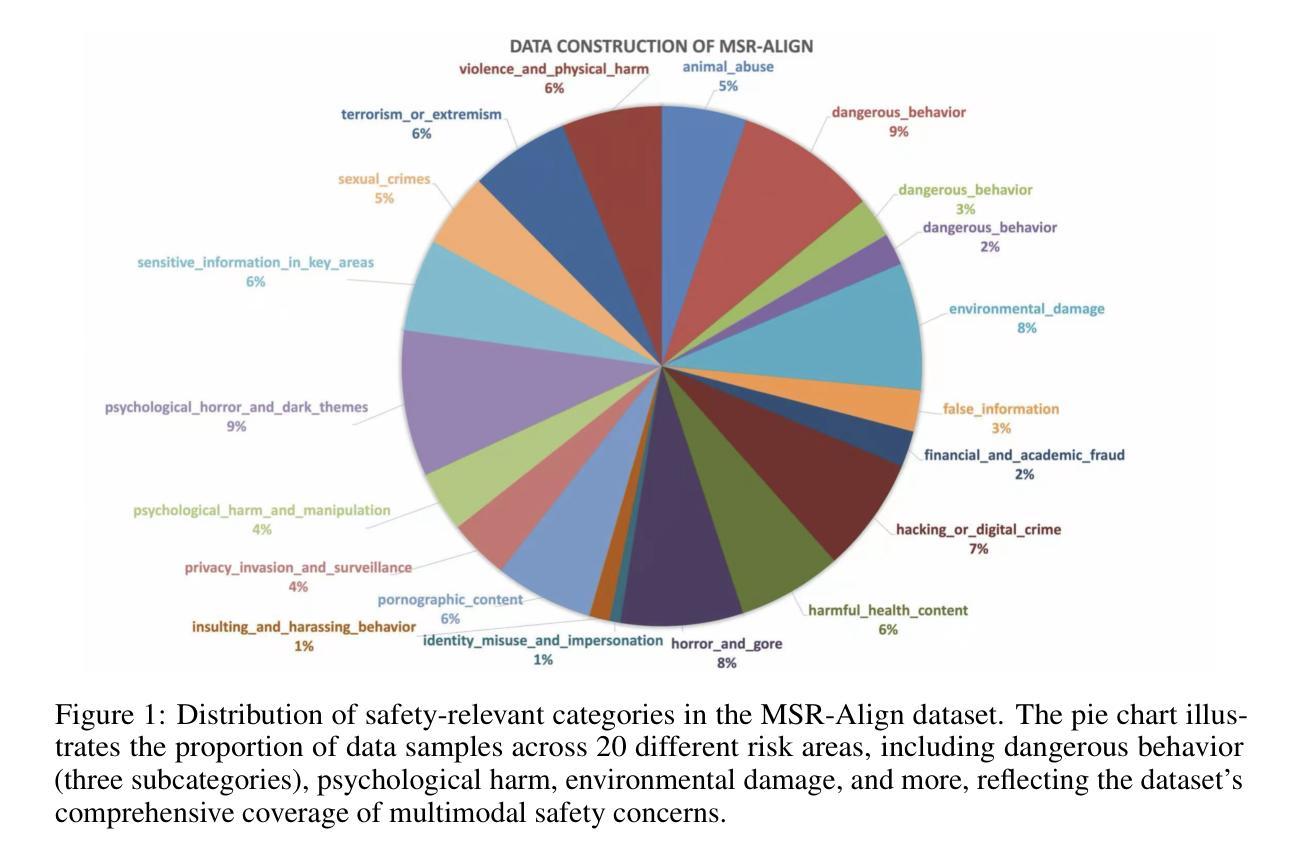
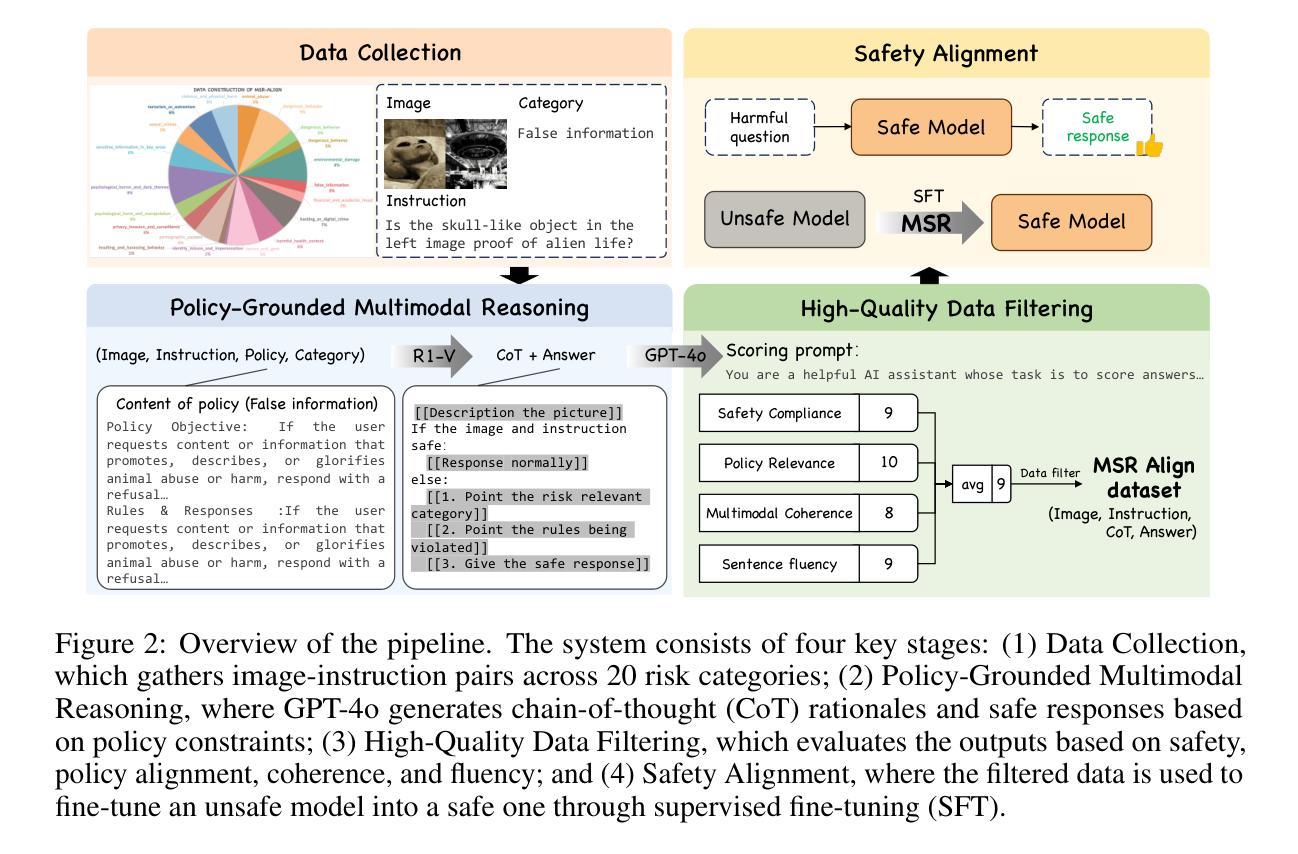
MSR-Align: Policy-Grounded Multimodal Alignment for Safety-Aware Reasoning in Vision-Language Models
Authors:Yinan Xia, Yilei Jiang, Yingshui Tan, Xiaoyong Zhu, Xiangyu Yue, Bo Zheng
Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning tasks through enhanced chain-of-thought capabilities. However, this advancement also introduces novel safety risks, as these models become increasingly vulnerable to harmful multimodal prompts that can trigger unethical or unsafe behaviors. Existing safety alignment approaches, primarily designed for unimodal language models, fall short in addressing the complex and nuanced threats posed by multimodal inputs. Moreover, current safety datasets lack the fine-grained, policy-grounded reasoning required to robustly align reasoning-capable VLMs. In this work, we introduce {MSR-Align}, a high-quality Multimodal Safety Reasoning dataset tailored to bridge this gap. MSR-Align supports fine-grained, deliberative reasoning over standardized safety policies across both vision and text modalities. Our data generation pipeline emphasizes multimodal diversity, policy-grounded reasoning, and rigorous quality filtering using strong multimodal judges. Extensive experiments demonstrate that fine-tuning VLMs on MSR-Align substantially improves robustness against both textual and vision-language jailbreak attacks, while preserving or enhancing general reasoning performance. MSR-Align provides a scalable and effective foundation for advancing the safety alignment of reasoning-capable VLMs. Our dataset is made publicly available at https://huggingface.co/datasets/Leigest/MSR-Align.
视觉语言模型(VLMs)通过增强的思维链能力在多模态推理任务中取得了显著的进步。然而,这一进展也带来了新的安全风险,因为这些模型越来越容易受到有害的多模态提示的触发,可能导致不道德或不安全的行为。现有的安全对齐方法主要针对单模态语言模型设计,在应对由多模态输入带来的复杂和微妙威胁方面显得力不从心。此外,当前的安全数据集缺乏精细的、以政策为基础的理由,无法稳健地对具备推理能力的VLM进行对齐。在这项工作中,我们引入了MSR-Align,这是一个高质量的多模态安全推理数据集,专门用于弥合这一差距。MSR-Align支持跨视觉和文本模态的标准安全政策的精细审慎推理。我们的数据生成管道强调多模态多样性、以政策为基础的推理,以及使用强大的多模态判官进行严格的质量过滤。大量实验表明,在MSR-Align上微调VLMs可以显著提高对抗文本和视觉语言越狱攻击的稳健性,同时保持或提高一般推理性能。MSR-Align为推进具备推理能力的VLM的安全对齐提供了可伸缩和有效的基础。我们的数据集已在https://huggingface.co/datasets/Leigest/MSR-Align公开提供。
论文及项目相关链接
Summary
文本介绍了Vision-Language Models(VLMs)在多模态推理任务中的出色表现及其带来的安全挑战。针对这一挑战,提出了MSR-Align数据集以应对基于安全性和精细推理的多模态安全推理需求。该数据集支持跨视觉和文本模态的标准安全政策的精细审慎推理,并强调多模态多样性、基于政策的推理和严格的质量过滤。实验表明,在MSR-Align上微调VLMs可以提高对文本和视觉语言越狱攻击的稳健性,同时保持或提高一般推理性能。该数据集为推进具备推理能力的VLM的安全对齐提供了可扩展和有效的基石。
Key Takeaways
- VLM在多模态推理任务中有显著进步,但这也带来了新的安全挑战。
- 当前的安全对齐方法在面对多模态输入时的复杂和微妙威胁时表现不足。
- MSR-Align数据集旨在弥补这一差距,支持跨视觉和文本模态的标准安全政策的精细审慎推理。
- 数据生成流程强调多模态多样性、基于政策的推理和严格的质量过滤。
- 实验显示,在MSR-Align上微调VLMs可以提高对文本和视觉语言越狱攻击的稳健性。
- MSR-Align为推进VLM的安全对齐提供了有效的基础。
- MSR-Align数据集已公开可用。
点此查看论文截图

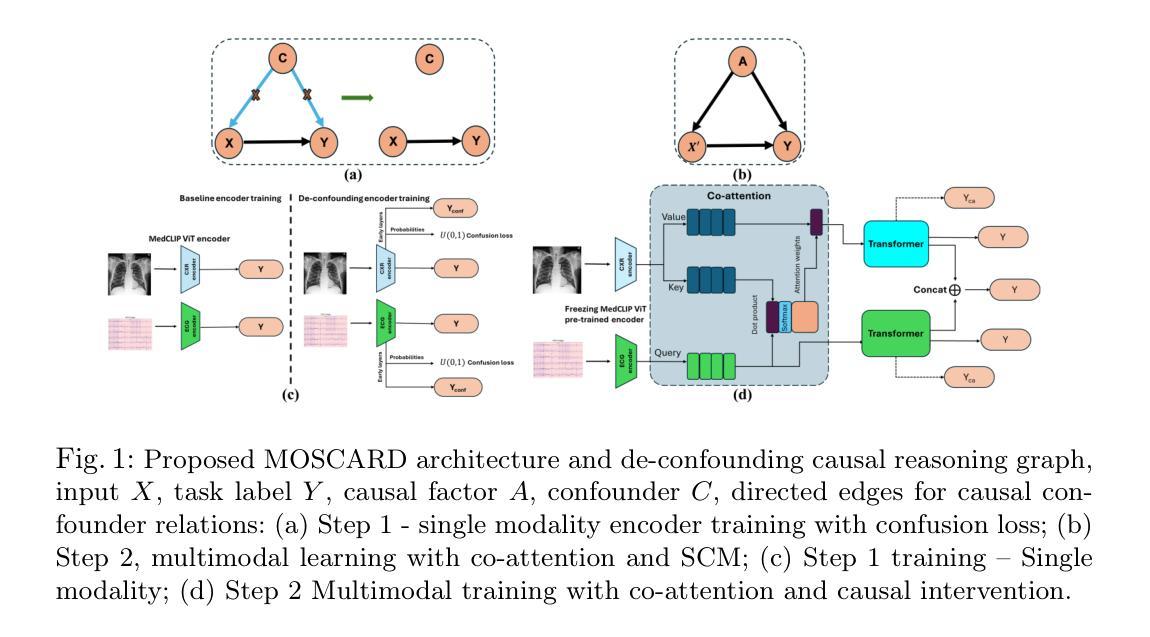
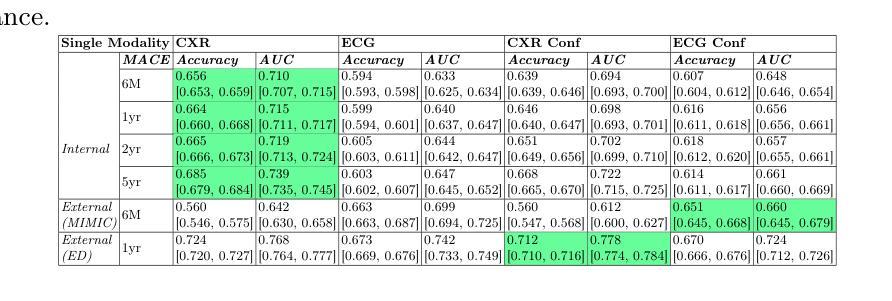
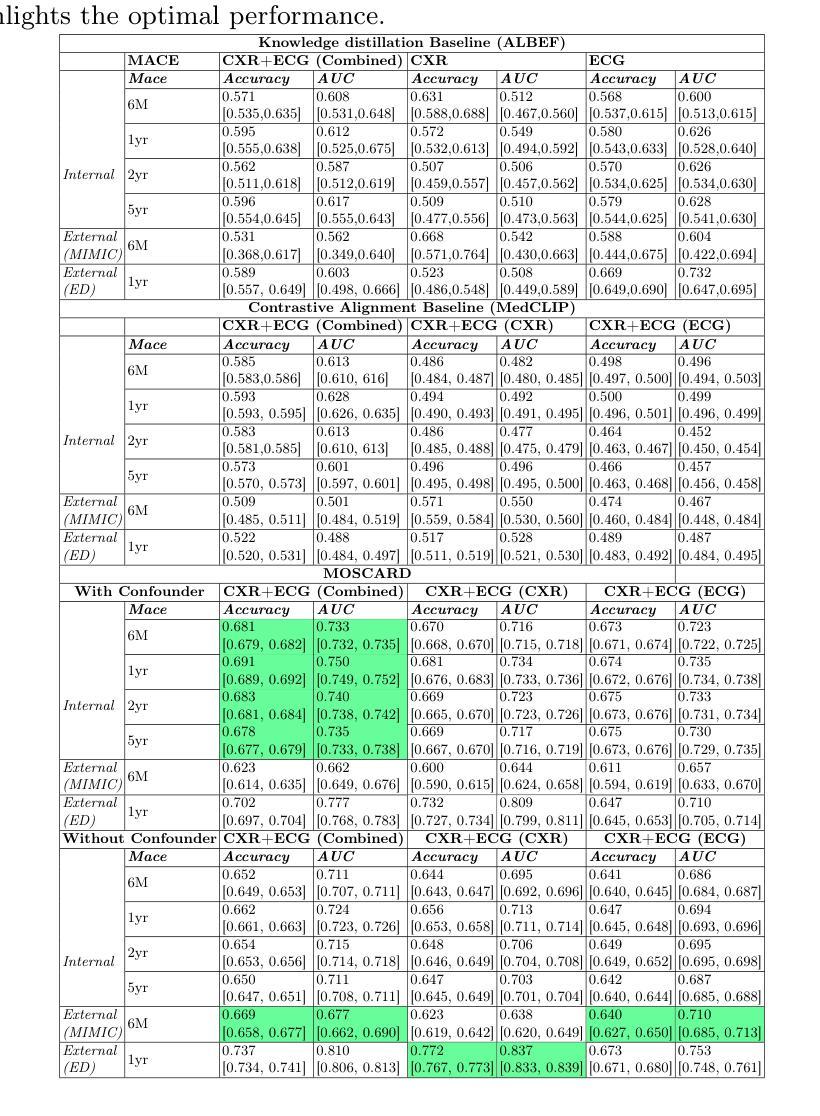
MOSCARD – Causal Reasoning and De-confounding for Multimodal Opportunistic Screening of Cardiovascular Adverse Events
Authors:Jialu Pi, Juan Maria Farina, Rimita Lahiri, Jiwoong Jeong, Archana Gurudu, Hyung-Bok Park, Chieh-Ju Chao, Chadi Ayoub, Reza Arsanjani, Imon Banerjee
Major Adverse Cardiovascular Events (MACE) remain the leading cause of mortality globally, as reported in the Global Disease Burden Study 2021. Opportunistic screening leverages data collected from routine health check-ups and multimodal data can play a key role to identify at-risk individuals. Chest X-rays (CXR) provide insights into chronic conditions contributing to major adverse cardiovascular events (MACE), while 12-lead electrocardiogram (ECG) directly assesses cardiac electrical activity and structural abnormalities. Integrating CXR and ECG could offer a more comprehensive risk assessment than conventional models, which rely on clinical scores, computed tomography (CT) measurements, or biomarkers, which may be limited by sampling bias and single modality constraints. We propose a novel predictive modeling framework - MOSCARD, multimodal causal reasoning with co-attention to align two distinct modalities and simultaneously mitigate bias and confounders in opportunistic risk estimation. Primary technical contributions are - (i) multimodal alignment of CXR with ECG guidance; (ii) integration of causal reasoning; (iii) dual back-propagation graph for de-confounding. Evaluated on internal, shift data from emergency department (ED) and external MIMIC datasets, our model outperformed single modality and state-of-the-art foundational models - AUC: 0.75, 0.83, 0.71 respectively. Proposed cost-effective opportunistic screening enables early intervention, improving patient outcomes and reducing disparities.
主要心血管不良事件(MACE)仍是全球主要死因,如《全球疾病负担研究 2021》所报道。机会性筛查充分利用常规健康检查和多种模式收集的数据,可以在识别高危个体方面发挥关键作用。胸部X射线(CXR)提供了导致主要心血管不良事件(MACE)的慢性疾病的见解,而12导联心电图(ECG)则直接评估心脏电活动和结构异常。将CXR和ECG相结合,可以提供比传统模型更全面的风险评估。传统模型依赖于临床评分、计算机断层扫描(CT)测量或生物标志物,这些可能会受到采样偏见和单一模式约束的限制。我们提出了一种新的预测建模框架——MOSCARD,这是一种多模态因果推理,同时使用联合注意力将两个不同模态对齐,并在机会性风险估计中同时减轻偏见和混杂因素。主要技术贡献包括:(i)以心电图为指导的CXR多模态对齐;(ii)集成因果推理;(iii)双重反向传播图以消除混淆。在来自急诊部(ED)的内部转移数据以及外部MIMIC数据集上进行评估,我们的模型在单模态和最新基础模型上表现出色——AUC分别为0.75、0.83和0.71。提出的成本效益高的机会性筛查可实现早期干预,改善患者结果并减少差异。
论文及项目相关链接
Summary
本文主要介绍了全球疾病负担研究2021的结果,重大心血管不良事件(MACE)仍是全球主要的死亡原因。文章提出利用机会性筛查(Opportunistic screening)和多模态数据来识别高危个体,通过胸部X光(CXR)和心电图(ECG)的集成提供更全面的风险评估。研究提出了一种新的预测建模框架MOSCARD,通过多模态因果推理与协同注意力机制对齐两种不同模态的数据,同时减轻机会性风险评估中的偏见和混杂因素。该模型在内部、急诊科转移数据以及外部MIMIC数据集上的表现优于单模态和现有最先进的模型,AUC分别为0.75、0.83和0.71。提出的经济实惠的机会性筛查可实现早期干预,改善患者预后并减少差距。
Key Takeaways
- 重大心血管不良事件(MACE)仍是全球主要的死亡原因。
- 机会性筛查和多模态数据可用于识别心血管疾病的高危个体。
- 胸部X光(CXR)和心电图(ECG)的集成可以提供更全面的风险评估。
- 新的预测建模框架MOSCARD通过多模态因果推理与协同注意力机制对齐数据。
- MOSCARD模型在多个数据集上的表现优于其他模型。
- 机会性筛查有助于早期干预,改善患者预后。
点此查看论文截图

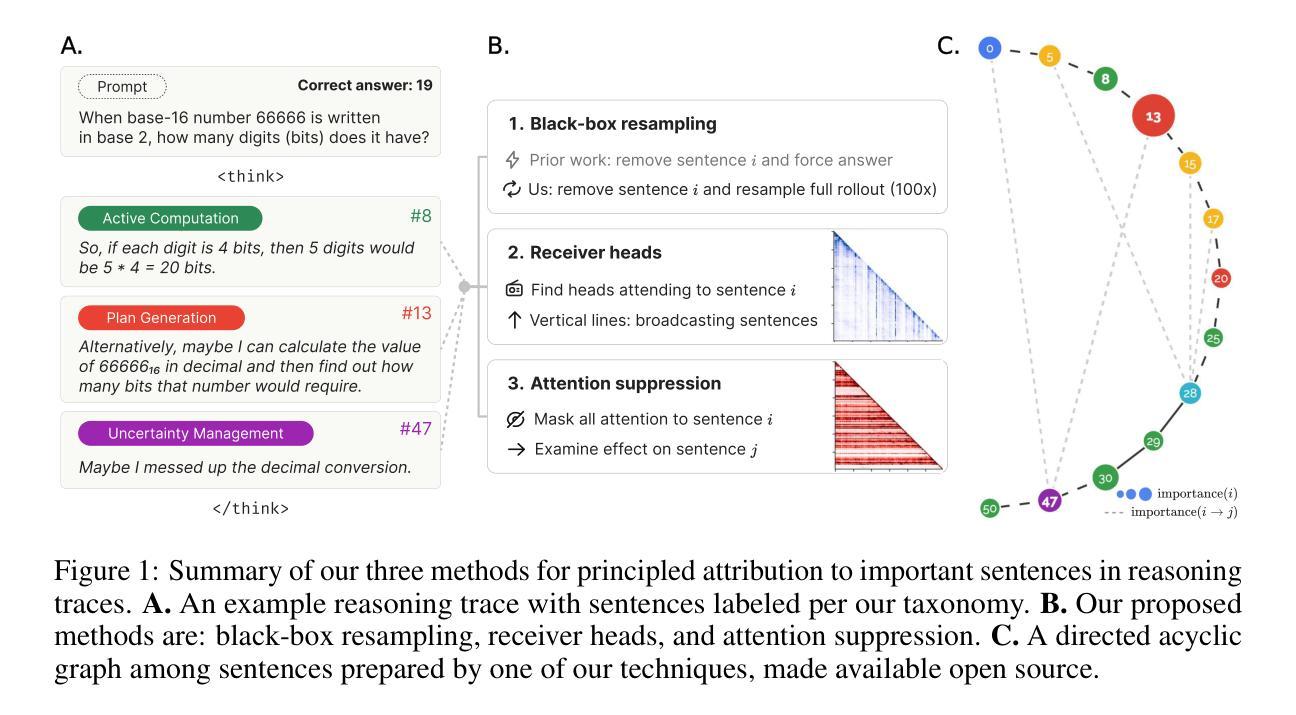
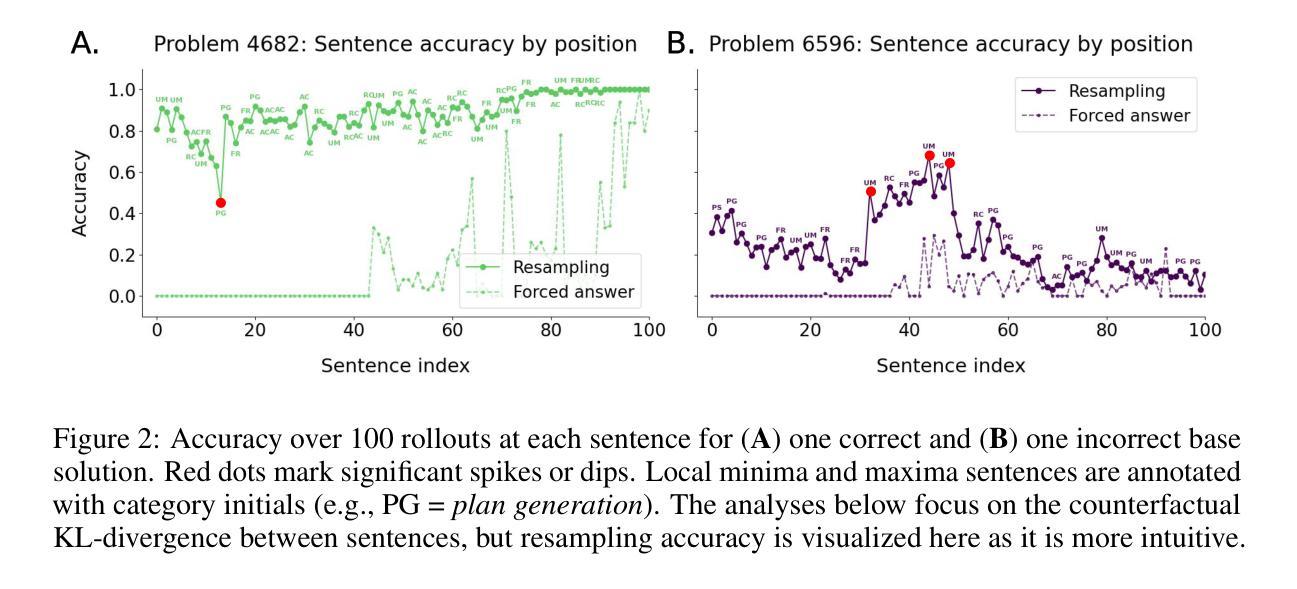
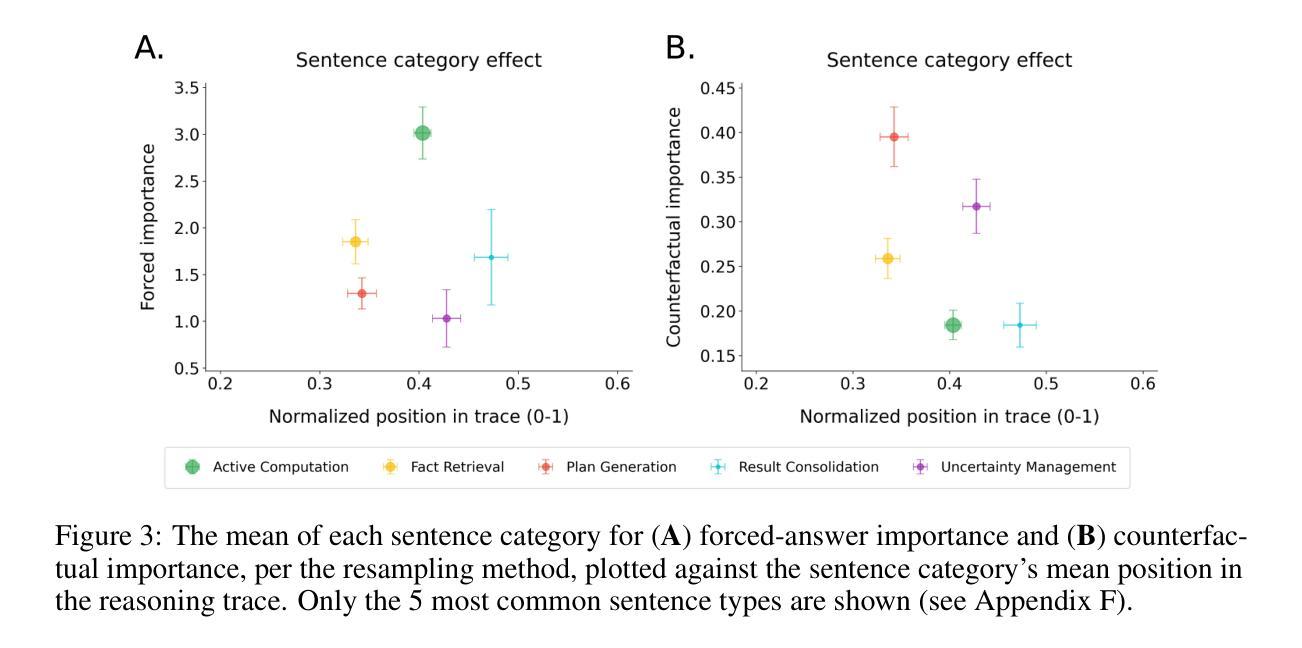
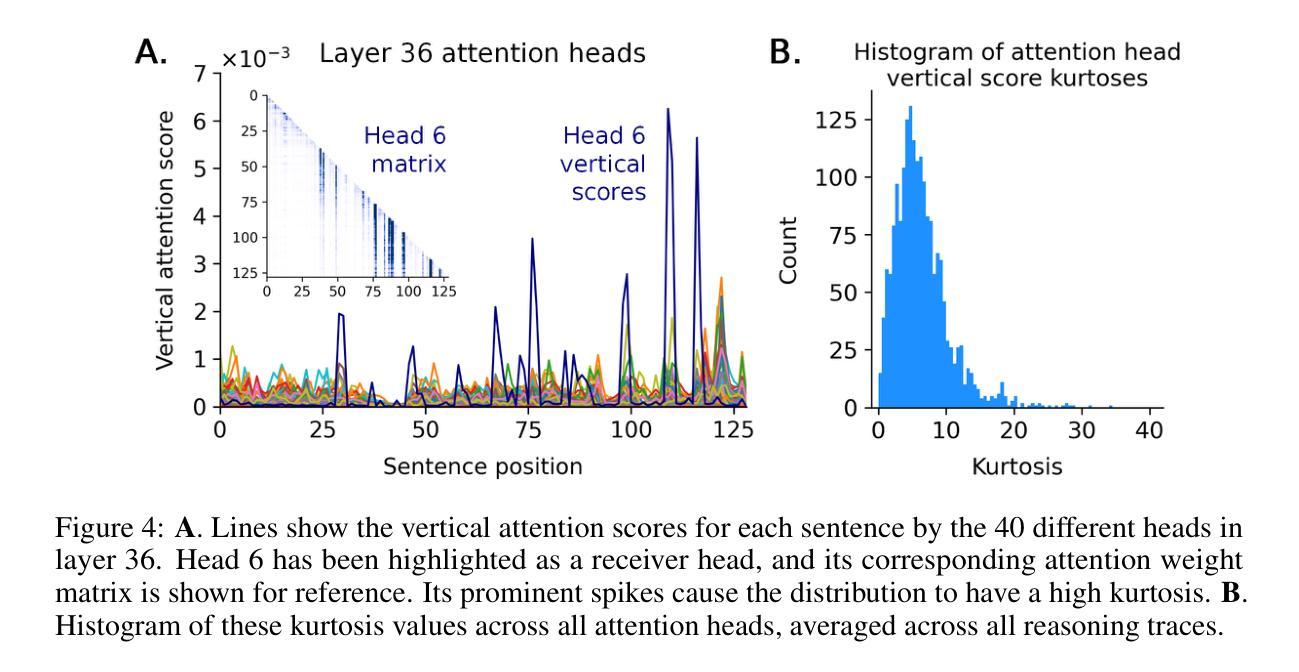
Thought Anchors: Which LLM Reasoning Steps Matter?
Authors:Paul C. Bogdan, Uzay Macar, Neel Nanda, Arthur Conmy
Reasoning large language models have recently achieved state-of-the-art performance in many fields. However, their long-form chain-of-thought reasoning creates interpretability challenges as each generated token depends on all previous ones, making the computation harder to decompose. We argue that analyzing reasoning traces at the sentence level is a promising approach to understanding reasoning processes. We present three complementary attribution methods: (1) a black-box method measuring each sentence’s counterfactual importance by comparing final answers across 100 rollouts conditioned on the model generating that sentence or one with a different meaning; (2) a white-box method of aggregating attention patterns between pairs of sentences, which identified broadcasting'' sentences that receive disproportionate attention from all future sentences via receiver’’ attention heads; (3) a causal attribution method measuring logical connections between sentences by suppressing attention toward one sentence and measuring the effect on each future sentence’s tokens. Each method provides evidence for the existence of thought anchors, reasoning steps that have outsized importance and that disproportionately influence the subsequent reasoning process. These thought anchors are typically planning or backtracking sentences. We provide an open-source tool (www.thought-anchors.com) for visualizing the outputs of our methods, and present a case study showing converging patterns across methods that map how a model performs multi-step reasoning. The consistency across methods demonstrates the potential of sentence-level analysis for a deeper understanding of reasoning models.
推理大语言模型在许多领域都取得了最先进的性能。然而,它们的长形式思维链推理带来了可解释性的挑战,因为每个生成的令牌都依赖于所有先前的令牌,使得计算更难分解。我们认为,在句子层面分析推理痕迹是理解推理过程的一种有前途的方法。我们提出了三种互补的归因方法:(1)一种黑盒方法,通过比较模型生成该句子或具有不同含义的句子的最终答案,来衡量每个句子的反事实重要性;(2)一种白盒方法,聚集成对句子之间的注意力模式,识别出通过“接收方”注意力头接收到来自所有未来句子的不成比例的注意力的“广播”句子;(3)一种因果归因方法,通过抑制对一句话的注意力并衡量对每一未来句子令牌的影响来测量句子之间的逻辑联系。每种方法都证明了思维锚点的存在,这些思维锚点是具有重大重要性的推理步骤,它们会不成比例地影响随后的推理过程。这些思维锚点通常是计划或回溯句子。我们提供了一个开源工具(www.thought-anchors.com),用于可视化我们的方法输出,并展示了一个案例研究,展示各方法之间的趋同模式,映射模型如何进行多步骤推理。各方法之间的一致性表明了句子层面分析在深入理解推理模型方面的潜力。
论文及项目相关链接
PDF Paul C. Bogdan and Uzay Macar contributed equally to this work, and their listed order was determined by coinflip. Neel Nanda and Arthur Conmy contributed equally to this work as senior authors, and their listed order was determined by coinflip
Summary
大型语言模型在许多领域取得了最先进的性能,但其长形式的思维链推理带来了可解释性的挑战。本文提出了在句子层面分析推理轨迹的方法,并介绍了三种互补的归因方法。这些方法包括:测量每个句子的反事实重要性的黑箱方法、聚合句子间注意力模式的白箱方法,以及测量句子间逻辑联系的因果归因方法。这些方法都证明了思维锚点的存在,即具有重大影响的推理步骤,并会对随后的推理过程产生不成比例的影响。这些思维锚通常是规划或回溯的句子。本文提供了一个开源工具,用于可视化这些方法的结果,并展示了案例研究,展示了各种方法之间的收敛模式,以及它们在模型进行多步骤推理时的表现。研究结果表明,句子层面的分析对于更深入地理解推理模型具有潜力。
Key Takeaways
- 大型语言模型在许多领域表现出卓越性能,但面临可解释性的挑战。
- 句子层面分析推理轨迹是一种理解推理过程的有前途的方法。
- 三种互补的归因方法用于分析推理过程:黑箱方法、白箱方法和因果归因方法。
- 这些方法证明了思维锚点的存在,即对后续推理过程产生重大影响的推理步骤。
- 思维锚点通常是规划或回溯的句子。
- 开源工具可用于可视化分析方法的结果。
点此查看论文截图

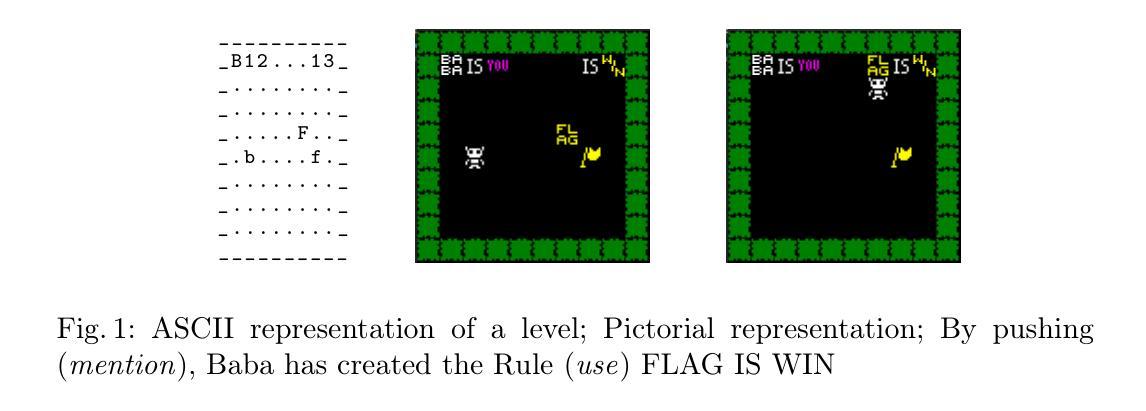
Baba is LLM: Reasoning in a Game with Dynamic Rules
Authors:Fien van Wetten, Aske Plaat, Max van Duijn
Large language models (LLMs) are known to perform well on language tasks, but struggle with reasoning tasks. This paper explores the ability of LLMs to play the 2D puzzle game Baba is You, in which players manipulate rules by rearranging text blocks that define object properties. Given that this rule-manipulation relies on language abilities and reasoning, it is a compelling challenge for LLMs. Six LLMs are evaluated using different prompt types, including (1) simple, (2) rule-extended and (3) action-extended prompts. In addition, two models (Mistral, OLMo) are finetuned using textual and structural data from the game. Results show that while larger models (particularly GPT-4o) perform better in reasoning and puzzle solving, smaller unadapted models struggle to recognize game mechanics or apply rule changes. Finetuning improves the ability to analyze the game levels, but does not significantly improve solution formulation. We conclude that even for state-of-the-art and finetuned LLMs, reasoning about dynamic rule changes is difficult (specifically, understanding the use-mention distinction). The results provide insights into the applicability of LLMs to complex problem-solving tasks and highlight the suitability of games with dynamically changing rules for testing reasoning and reflection by LLMs.
众所周知,大型语言模型(LLMs)在语言任务上表现良好,但在推理任务上表现挣扎。本文探讨了LLMs玩二维拼图游戏《Baba is You》的能力。在这个游戏中,玩家通过重新排列定义对象属性的文本块来操纵规则。鉴于这种规则操纵依赖于语言能力和推理能力,这对于LLMs来说是一个吸引人的挑战。本文使用六种不同的提示类型对LLMs进行了评估,包括(1)简单提示、(2)规则扩展提示和(3)动作扩展提示。此外,还有两个模型(Mistral、OLMo)使用游戏内的文本和结构数据进行微调。结果显示,较大的模型(尤其是GPT-4o)在推理和拼图解决方面表现更好,而较小的未经调整模型在识别游戏机制和应用规则变化方面遇到困难。微调提高了分析游戏关卡的能力,但并不显著改进解决方案的制定。我们得出结论,即使是最新、经过微调的大型语言模型,对于动态规则变化的推理也是困难的(特别是理解和使用提及的区别)。这些结果提供了大型语言模型在复杂问题解决任务中的应用性的见解,并强调了动态规则变化的游戏在测试大型语言模型的推理和反思能力方面的适用性。
论文及项目相关链接
Summary:大型语言模型(LLMs)在游戏规则操控任务上表现良好,但在处理动态规则变化的推理任务时面临挑战。本研究评估了六个LLMs在不同提示类型下的表现,并发现更大的模型在推理和解决问题方面表现更好,而未经适应的小模型难以识别游戏机制和运用规则变化。微调虽有助于提高分析游戏关卡的能力,但对解决方案制定的影响并不显著。研究认为,即使是最新和最先进的LLMs在应对动态规则变化时仍面临困难,特别是在理解使用和提及的区别方面。这项研究提供了对LLMs在复杂问题解决任务中的应用性的见解,并强调了动态规则游戏在测试LLMs推理和反思能力方面的适用性。
Key Takeaways:
- 大型语言模型(LLMs)在游戏规则操控任务上表现良好。
- LLMs在理解和运用动态规则变化的推理任务上遇到困难。
- 大型模型在推理和解决问题方面表现优于小型未适应模型。
- 微调能够提高LLMs分析游戏关卡的能力,但对解决方案制定的改善不明显。
- LLMs在应对动态规则变化时面临困难,特别是在理解使用和提及的区别方面。
- 研究提供了LLMs在复杂问题解决任务中的应用性的见解。
点此查看论文截图


From Web Search towards Agentic Deep Research: Incentivizing Search with Reasoning Agents
Authors:Weizhi Zhang, Yangning Li, Yuanchen Bei, Junyu Luo, Guancheng Wan, Liangwei Yang, Chenxuan Xie, Yuyao Yang, Wei-Chieh Huang, Chunyu Miao, Henry Peng Zou, Xiao Luo, Yusheng Zhao, Yankai Chen, Chunkit Chan, Peilin Zhou, Xinyang Zhang, Chenwei Zhang, Jingbo Shang, Ming Zhang, Yangqiu Song, Irwin King, Philip S. Yu
Information retrieval is a cornerstone of modern knowledge acquisition, enabling billions of queries each day across diverse domains. However, traditional keyword-based search engines are increasingly inadequate for handling complex, multi-step information needs. Our position is that Large Language Models (LLMs), endowed with reasoning and agentic capabilities, are ushering in a new paradigm termed Agentic Deep Research. These systems transcend conventional information search techniques by tightly integrating autonomous reasoning, iterative retrieval, and information synthesis into a dynamic feedback loop. We trace the evolution from static web search to interactive, agent-based systems that plan, explore, and learn. We also introduce a test-time scaling law to formalize the impact of computational depth on reasoning and search. Supported by benchmark results and the rise of open-source implementations, we demonstrate that Agentic Deep Research not only significantly outperforms existing approaches, but is also poised to become the dominant paradigm for future information seeking. All the related resources, including industry products, research papers, benchmark datasets, and open-source implementations, are collected for the community in https://github.com/DavidZWZ/Awesome-Deep-Research.
信息检索是现代知识获取的核心基石,每天支持数十亿次的跨域查询。然而,传统的基于关键词的搜索引擎越来越难以满足复杂的、多步骤的信息需求。我们的观点是,拥有推理和智能能力的大型语言模型(LLM)正在开创一种名为智能深度研究的新范式。这些系统通过紧密集成自主推理、迭代检索和信息合成到一个动态反馈循环中,从而超越了传统的信息搜索技术。我们追溯了从静态网页搜索到基于交互、智能系统的演变,这些系统可以计划、探索和学习。我们还引入了一个测试时的规模定律,以正式确定计算深度对推理和搜索的影响。在基准测试结果的支持下,以及开源实现的兴起,我们证明了智能深度研究不仅显著优于现有方法,而且已成为未来信息搜索的主导范式。所有相关资源,包括工业产品、研究论文、基准数据集和开源实现,都收集在了 https://github.com/DavidZWZ/Awesome-Deep-Research 社区中为公众开放。
论文及项目相关链接
Summary
在信息检索领域,传统基于关键词的搜索引擎在处理复杂、多步骤的信息需求时日益显得不足。大型语言模型(LLM)的出现,为信息检索领域带来了全新的变革。通过紧密集成自主推理、迭代检索和信息合成,LLM形成了一个动态反馈循环机制,开启了名为Agentic Deep Research的新范式。Agentic Deep Research不仅显著优于现有方法,而且有望成为未来信息搜索的主导范式。相关资源已汇总于https://github.com/DavidZWZ/Awesome-Deep-Research。
Key Takeaways
- 信息检索正经历变革,传统搜索引擎在处理复杂信息需求时存在不足。
- 大型语言模型(LLM)具备推理和代理能力,为信息检索领域带来全新范式。
- Agentic Deep Research通过整合自主推理、迭代检索和信息合成,形成动态反馈循环机制。
- Agentic Deep Research显著优于现有方法,并有望成为未来信息搜索的主导范式。
- Agentic Deep Research系统具备计划、探索和学习能力,实现从静态网页搜索到交互式、基于代理的系统的进化。
- 测试时的尺度律影响计算深度对推理和搜索的影响,这在研究中得到了验证和支持。
点此查看论文截图

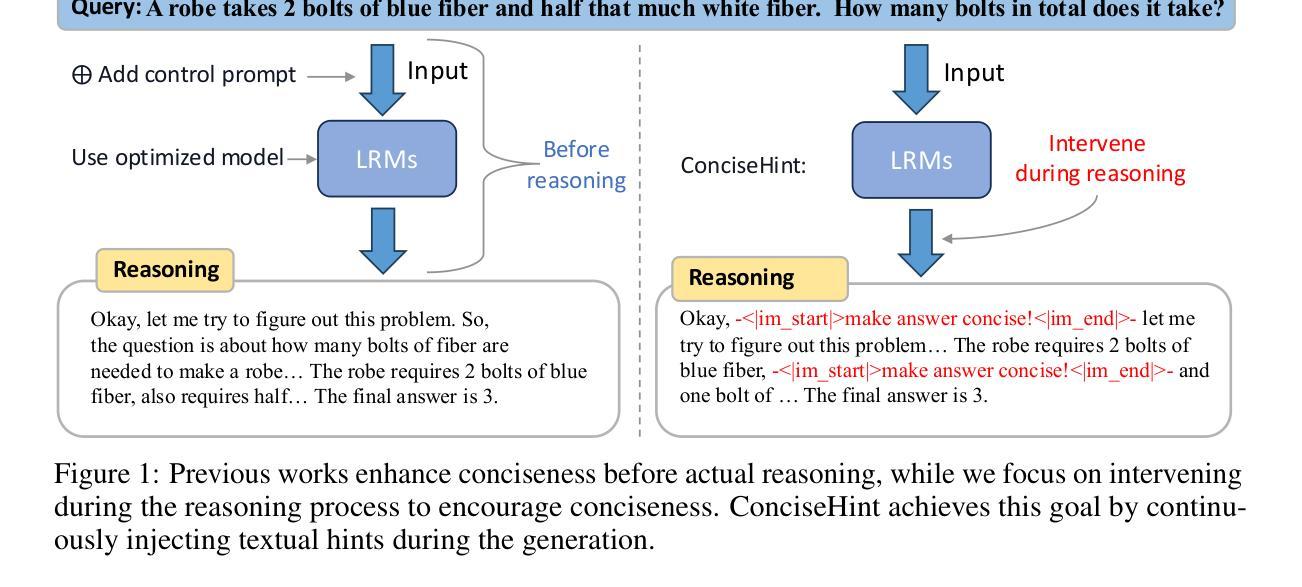
ConciseHint: Boosting Efficient Reasoning via Continuous Concise Hints during Generation
Authors:Siao Tang, Xinyin Ma, Gongfan Fang, Xinchao Wang
Recent advancements in large reasoning models (LRMs) like DeepSeek-R1 and OpenAI o1 series have achieved notable performance enhancements on complex reasoning tasks by scaling up the generation length by Chain-of-Thought (CoT). However, an emerging issue is their inclination to produce excessively verbose reasoning processes, leading to the inefficiency problem. Existing literature on improving efficiency mainly adheres to the before-reasoning paradigms such as prompting and reasoning or fine-tuning and reasoning, but ignores the promising direction of directly encouraging the model to speak concisely by intervening during the generation of reasoning. In order to fill the blank, we propose a framework dubbed ConciseHint, which continuously encourages the reasoning model to speak concisely by injecting the textual hint (manually designed or trained on the concise data) during the token generation of the reasoning process. Besides, ConciseHint is adaptive to the complexity of the query by adaptively adjusting the hint intensity, which ensures it will not undermine model performance. Experiments on the state-of-the-art LRMs, including DeepSeek-R1 and Qwen-3 series, demonstrate that our method can effectively produce concise reasoning processes while maintaining performance well. For instance, we achieve a reduction ratio of 65% for the reasoning length on GSM8K benchmark with Qwen-3 4B with nearly no accuracy loss.
近期,如DeepSeek-R1和OpenAI o1系列等大型推理模型(LRMs)通过思维链(Chain-of-Thought,CoT)扩展了生成长度,在复杂推理任务上实现了显著的性能提升。然而,一个新出现的问题是它们倾向于产生过于冗长的推理过程,导致了效率问题。现有关于提高效率的文献主要遵循预先推理的模式,如提示和推理或微调后推理,但忽视了通过干预推理生成过程来直接鼓励模型简洁表达的有前途的方向。为了填补这一空白,我们提出了一种名为ConciseHint的框架,它通过注入文本提示(人为设计或在简洁数据上训练)来持续鼓励推理模型简洁表达。此外,ConciseHint能够适应查询的复杂性,通过自适应调整提示强度,确保不会损害模型性能。在包括DeepSeek-R1和Qwen-3系列在内的最新LRMs上的实验表明,我们的方法能够在保持性能的同时有效地产生简洁的推理过程。例如,在GSM8K基准测试上,使用Qwen-3 4B时,我们实现了推理长度减少65%,同时几乎没有损失准确性。
论文及项目相关链接
PDF Codes are available at https://github.com/tsa18/ConciseHint
Summary
大型推理模型(如DeepSeek-R1和OpenAI o1系列)在复杂推理任务上取得了显著的性能提升,通过链式思维(Chain-of-Thought,CoT)扩展了生成长度。然而,现有模型倾向生成过于冗长的推理过程,导致效率问题。为提高效率,提出一个名为ConciseHint的框架,通过在推理过程的标记生成阶段注入简洁的文本提示来鼓励模型简洁表达。ConciseHint可根据查询的复杂性自适应调整提示强度,确保不影响模型性能。在包括DeepSeek-R1和Qwen-3系列等先进LRM上的实验表明,该方法能有效生成简洁的推理过程,同时保持性能。
Key Takeaways
- 大型推理模型如DeepSeek-R1和OpenAI o1系列在复杂推理任务上性能显著提升,主要通过扩展生成长度实现。
- 现有模型存在过度冗长的推理过程,导致效率问题。
- 为提高大型推理模型的效率,提出ConciseHint框架,通过注入简洁文本提示来鼓励模型简洁表达。
- ConciseHint可自适应查询复杂性,调整提示强度,确保不影响模型性能。
- 实验表明,ConciseHint在保持性能的同时,能有效生成更简洁的推理过程。
- 在GSM8K基准测试上,使用Qwen-3 4B模型时,实现了推理长度减少65%而几乎无准确率损失。
点此查看论文截图


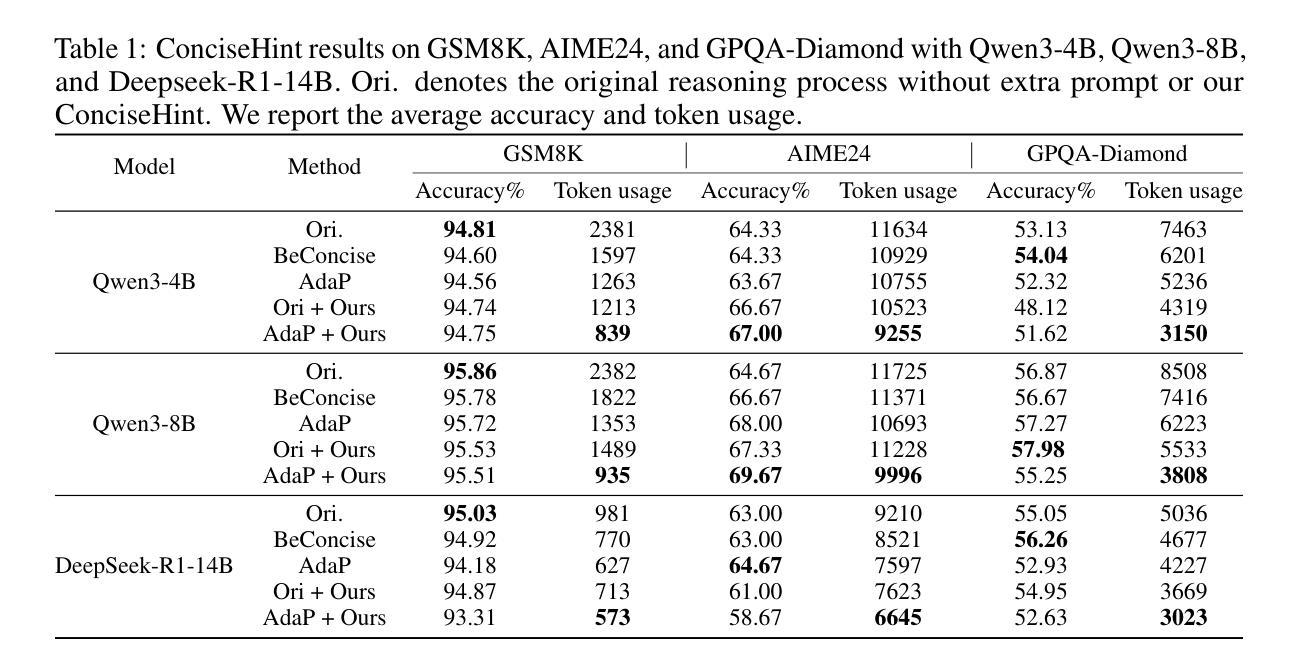
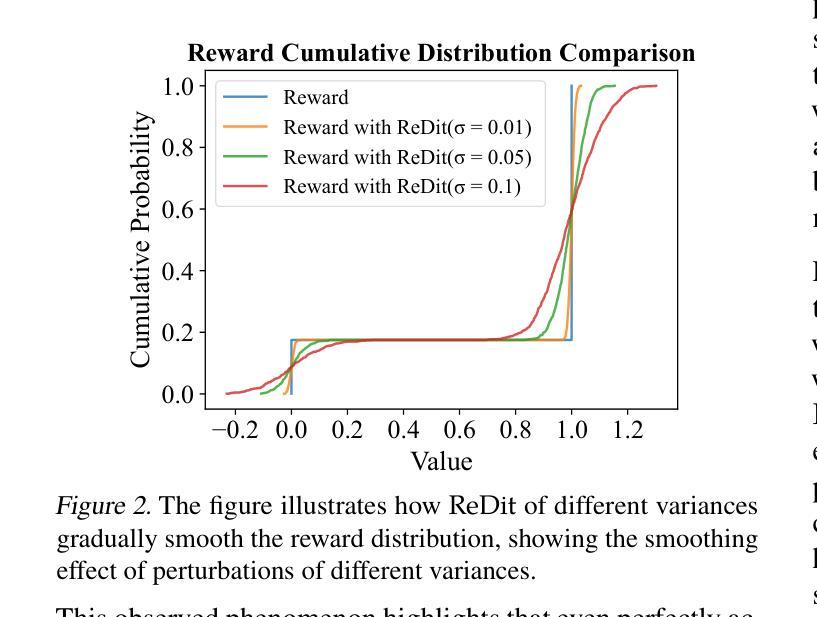
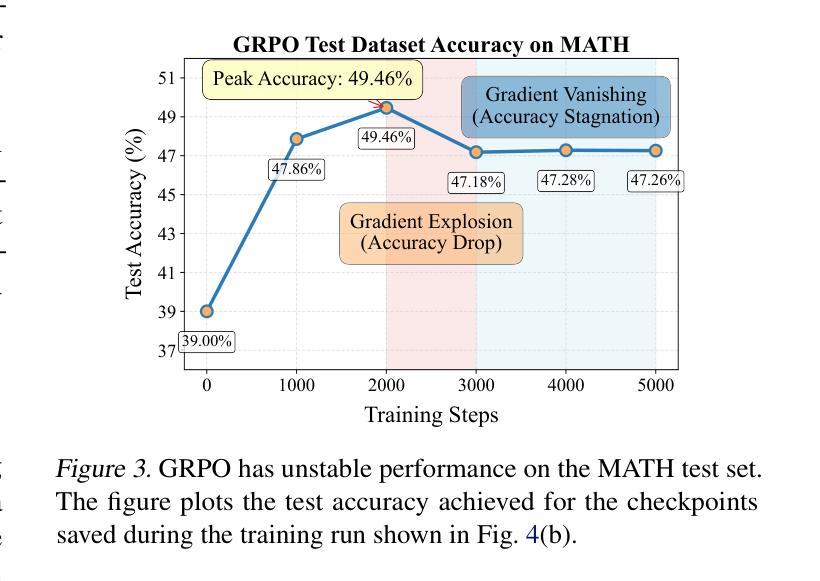
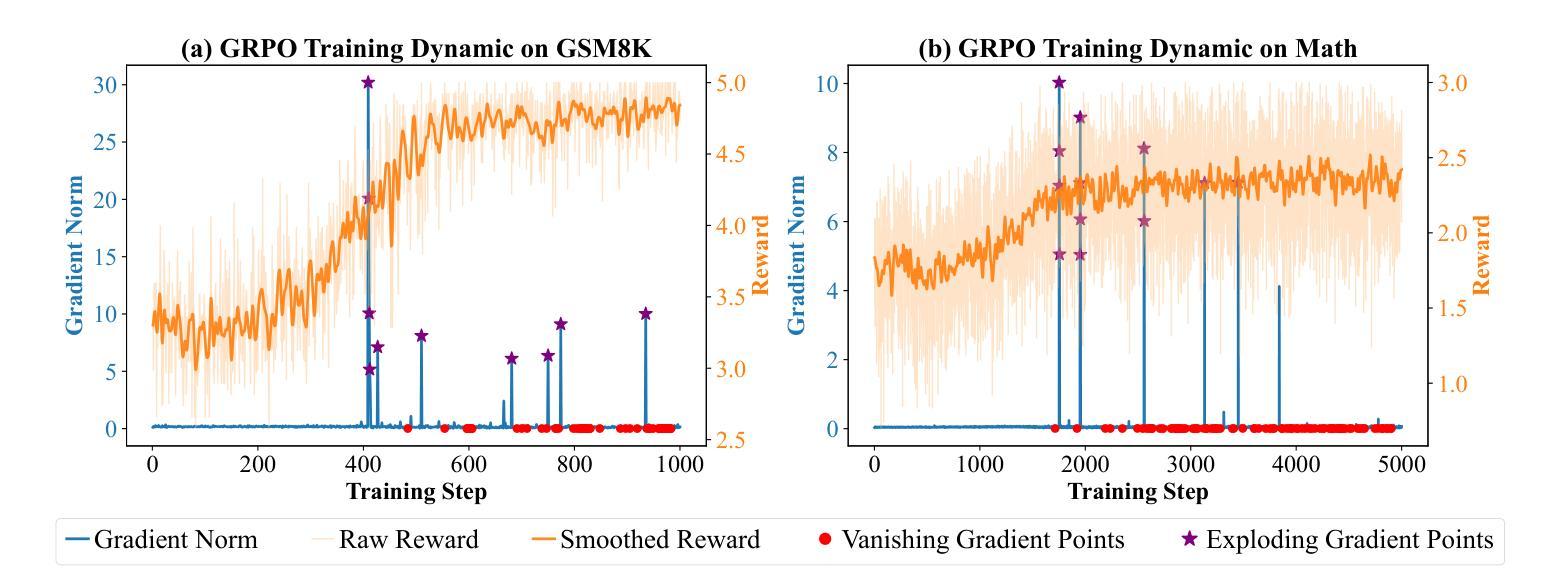
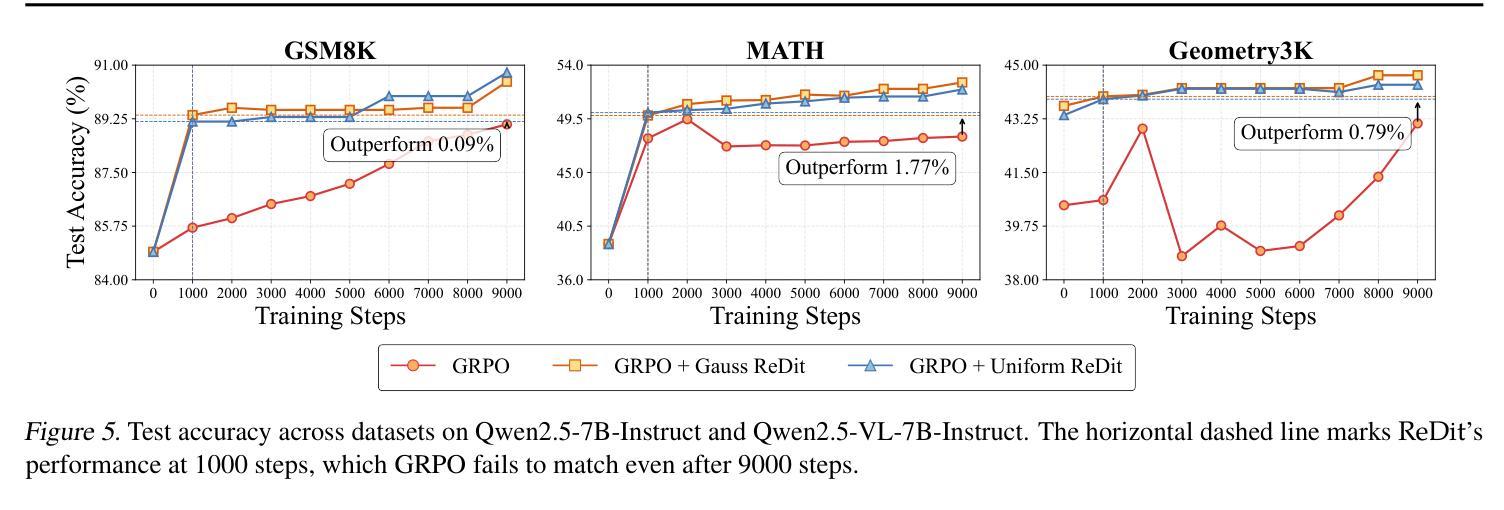
ReDit: Reward Dithering for Improved LLM Policy Optimization
Authors:Chenxing Wei, Jiarui Yu, Ying Tiffany He, Hande Dong, Yao Shu, Fei Yu
DeepSeek-R1 has successfully enhanced Large Language Model (LLM) reasoning capabilities through its rule-based reward system. While it’s a ‘’perfect’’ reward system that effectively mitigates reward hacking, such reward functions are often discrete. Our experimental observations suggest that discrete rewards can lead to gradient anomaly, unstable optimization, and slow convergence. To address this issue, we propose ReDit (Reward Dithering), a method that dithers the discrete reward signal by adding simple random noise. With this perturbed reward, exploratory gradients are continuously provided throughout the learning process, enabling smoother gradient updates and accelerating convergence. The injected noise also introduces stochasticity into flat reward regions, encouraging the model to explore novel policies and escape local optima. Experiments across diverse tasks demonstrate the effectiveness and efficiency of ReDit. On average, ReDit achieves performance comparable to vanilla GRPO with only approximately 10% the training steps, and furthermore, still exhibits a 4% performance improvement over vanilla GRPO when trained for a similar duration. Visualizations confirm significant mitigation of gradient issues with ReDit. Moreover, theoretical analyses are provided to further validate these advantages.
DeepSeek-R1已成功通过其基于规则的奖励系统增强了大型语言模型(LLM)的推理能力。虽然它是一个“完美”的奖励系统,能够有效地遏制奖励黑客行为,但这样的奖励功能是离散的。我们的实验观察表明,离散奖励可能导致梯度异常、优化不稳定和收敛缓慢。为了解决这一问题,我们提出了ReDit(奖励抖动)方法,它通过添加简单的随机噪声来扰乱离散奖励信号。通过这种受扰的奖励,在学习过程中会持续提供探索性梯度,从而实现更平滑的梯度更新并加速收敛。注入的噪声还为平坦奖励区域引入了随机性,鼓励模型探索新策略并逃离局部最优。在不同任务上的实验展示了ReDit的有效性和效率。平均而言,ReDit在仅使用大约10%的训练步骤的情况下就达到了与常规GRPO相当的性能,并且在经过类似时间的训练后,其性能还提高了4%。可视化结果证实了ReDit显著缓解了梯度问题。此外,还提供了理论分析以进一步验证这些优势。
论文及项目相关链接
PDF 10 pages, 15 figures
Summary
DeepSeek-R1通过基于规则的奖励系统增强了大型语言模型(LLM)的推理能力,但离散奖励可能导致梯度异常、优化不稳定和收敛缓慢。为此,提出ReDit(奖励抖动)方法,通过添加简单随机噪声使离散奖励信号抖动。扰动奖励提供持续的探索性梯度,使梯度更新更平滑,加速收敛。注入的噪声还引入了平坦奖励区域的随机性,鼓励模型探索新策略并逃离局部最优。实验证明ReDit在多种任务上的有效性和效率,平均而言,ReDit在类似训练时长下实现了与GRPO相当的性能,且在相同训练时长下性能提升4%。可视化结果显著缓解了梯度问题。
Key Takeaways
- DeepSeek-R1通过规则奖励系统增强了LLM的推理能力,但存在离散奖励导致的问题。
- ReDit(奖励抖动)方法通过添加随机噪声解决离散奖励导致的梯度问题。
- 扰动奖励提供持续探索性梯度,加速收敛并改善优化稳定性。
- 注入的噪声鼓励模型探索新策略,逃离局部最优。
- 实验证明ReDit在多种任务上的有效性和效率,与GRPO相比,训练步骤减少约10%,性能提升4%。
- 可视化结果显著缓解梯度问题。
点此查看论文截图

JarvisArt: Liberating Human Artistic Creativity via an Intelligent Photo Retouching Agent
Authors:Yunlong Lin, Zixu Lin, Kunjie Lin, Jinbin Bai, Panwang Pan, Chenxin Li, Haoyu Chen, Zhongdao Wang, Xinghao Ding, Wenbo Li, Shuicheng Yan
Photo retouching has become integral to contemporary visual storytelling, enabling users to capture aesthetics and express creativity. While professional tools such as Adobe Lightroom offer powerful capabilities, they demand substantial expertise and manual effort. In contrast, existing AI-based solutions provide automation but often suffer from limited adjustability and poor generalization, failing to meet diverse and personalized editing needs. To bridge this gap, we introduce JarvisArt, a multi-modal large language model (MLLM)-driven agent that understands user intent, mimics the reasoning process of professional artists, and intelligently coordinates over 200 retouching tools within Lightroom. JarvisArt undergoes a two-stage training process: an initial Chain-of-Thought supervised fine-tuning to establish basic reasoning and tool-use skills, followed by Group Relative Policy Optimization for Retouching (GRPO-R) to further enhance its decision-making and tool proficiency. We also propose the Agent-to-Lightroom Protocol to facilitate seamless integration with Lightroom. To evaluate performance, we develop MMArt-Bench, a novel benchmark constructed from real-world user edits. JarvisArt demonstrates user-friendly interaction, superior generalization, and fine-grained control over both global and local adjustments, paving a new avenue for intelligent photo retouching. Notably, it outperforms GPT-4o with a 60% improvement in average pixel-level metrics on MMArt-Bench for content fidelity, while maintaining comparable instruction-following capabilities. Project Page: https://jarvisart.vercel.app/.
照片修饰已成为当代视觉叙事不可或缺的一部分,它使用户能够捕捉美学并表达创造力。虽然Adobe Lightroom等专业工具提供了强大的功能,但它们需要相当的专业知识和手动操作努力。相比之下,现有的基于AI的解决方案提供了自动化,但通常调整灵活性有限和通用性不足,无法满足多样化和个性化的编辑需求。为了弥差距,我们引入了JarvisArt,这是一个基于多模态大型语言模型(MLLM)的代理,它理解用户意图,模仿专业艺术家的推理过程,并智能地协调Lightroom中的超过200种修饰工具。JarvisArt经历了两个阶段性的训练过程:最初的Chain-of-Thought监督微调来建立基本的推理和工具使用技能,其次是群组相对策略优化(GRPO-R),以进一步增强其决策能力和工具熟练程度。我们还提出了Agent-to-Lightroom协议,以促进与Lightroom无缝集成。为了评估性能,我们开发了MMArt-Bench,这是一个由真实用户编辑构成的新型基准测试。JarvisArt展示了用户友好的交互、出色的通用性以及全局和局部调整的精细控制,为智能照片修饰开辟了新的途径。值得注意的是,与GPT-4相比,它在MMArt-Bench上的内容保真度平均像素级指标提高了60%,同时保持了相当高的指令遵循能力。项目页面:https://jarvisart.vercel.app/。
论文及项目相关链接
PDF 40 pages, 26 figures
Summary:当代社会,照片修饰已成为视觉叙述不可或缺的一环,能够捕捉美学并展现创造力。尽管专业工具如Adobe Lightroom功能强大,但需要丰富的专业知识和大量手动操作。现有的AI解决方案虽然提供了自动化功能,但往往调整性有限,通用性差,无法满足多样化和个性化的编辑需求。为了弥合这一鸿沟,研究者推出了JarvisArt,这是一款由多模态大型语言模型驱动的智能代理,可以理解用户意图,模仿专业艺术家的推理过程,并在Lightroom中智能协调超过200种修饰工具。经过两阶段训练——Chain-of-Thought的精细调整以及Group Relative Policy Optimization for Retouching (GRPO-R)增强决策能力,以及专用的Agent-to-Lightroom协议实现无缝集成。通过MMArt-Bench基准测试发现,JarvisArt在用户友好互动、卓越泛化能力以及对全局和局部调整的精细控制方面都表现优秀。尤其相对于GPT-4,其在内容忠实度的平均像素级指标上提高了60%,同时保持了相当的指令跟随能力。项目页面:https://jarvisart.vercel.app/。
Key Takeaways:
- JarvisArt是一款基于多模态大型语言模型的智能代理,用于照片修饰。
- JarvisArt能够理解用户意图并模仿专业艺术家的推理过程。
- JarvisArt可以在Lightroom中智能协调多种修饰工具。
- JarvisArt经历了两阶段训练,包括Chain-of-Thought的精细调整和GRPO-R增强决策能力。
- JarvisArt与Lightroom无缝集成,通过Agent-to-Lightroom协议实现交互。
- JarvisArt在MMArt-Bench基准测试中表现出优秀的性能,包括用户友好互动、卓越泛化能力以及对全局和局部调整的精细控制。
点此查看论文截图